如何修改表的Hash Clustering属性?
增加表的Hash Clustering属性:
alter table table_name [clustered by (col_name [, col_name, ...]) [sorted by (col_name
[asc | desc] [, col_name [asc | desc] ...])] into number_of_buckets buckets];
。
去除表的Hash Clustering属性:
alter table table_name not clustered;
。
如何快速查看项目下哪些表是分区表?
您可以通过
MaxCompute客户端
执行如下命令查看项目下的分区表信息。
select table_name from information_schema.columns where is_partition_key = true group by table_name;
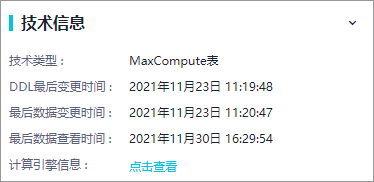
如何查看MaxCompute表的最近访问时间?
您可以在DataWorks
数据地图
中查询表,进入表详情页面获取表的最近访问时间。
如何查看表的数据量?
查看表的数据量包含查看数据条数和占用的物理空间大小:
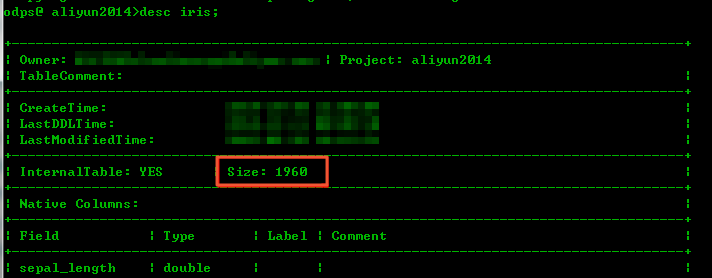
您可以执行
desc
命令查看全量表的物理空间。执行SQL语句
select count() as cnt from table_name;
查看表的数据条数。
 您可以执行
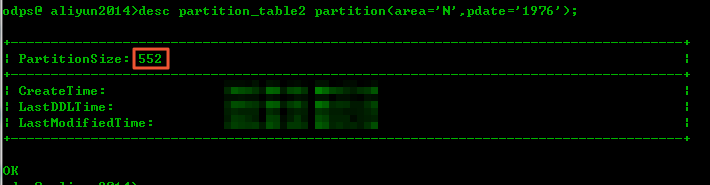
您可以执行
desc
命令和WHERE条件组合方式,查看分区表单个分区占用的物理空间大小。执行SQL语句
select count() as cnt from table_name where ...;
查看分区数据条数。
一张表的分区的数量是否越多越好?
在MaxCompute中,一张表最多允许有60000个分区,同时每个分区的容量没有上限。但是分区数量过多,不便于统计和分析。
MaxCompute限制单个作业中最多不能超过一定数量的Instance,而作业中的Instance数量和输入的数据量以及分区数量是密切相关的,所以您需要根据业务情况,选择合适的分区策略。
如果源表没有分区字段,是否可以增加或更改分区?
MaxCompute不支持在源表上直接增加或修改分区字段,分区字段一旦创建就无法修改。您可以重新创建一张分区表,使用动态分区SQL将源表数据导入至新分区表,详情请参见
插入或覆写动态分区数据(DYNAMIC PARTITION)
。
如何查看指定的分区是否存在?
可以使用函数PARTITION_EXISTS查看指定的分区是否存在,更多函数信息,请参见
PARTITION_EXISTS
。
如何查看分区数量?
您可以通过Information Schema的
PARTITIONS
视图,获取到分区名,进而获取到分区数量。
是否可以添加或删除列?
在MaxCompute中,可以添加列,但不可以删除列。
如何添加列?
添加列的命令示例如下。如果表中已经存在一部分数据,则新添加列的值为NULL。
alter table table_name add columns (col_name1 type1, col_name2 type2…);
更多添加列语法信息,请参见
添加列
。
如何设置自增长列?
MaxCompute不支持自增长列功能,如果您有此需求,且数据量比较小,建议使用
ROW_NUMBER
实现。
MaxCompute单表可以存放的最大列数是多少?
MaxCompute单表可以存放的最大列数为1200列。如果您的列数超过限制,可以参考如下方式处理:
对数据进行降维,缩减到1200列以内。
修改数据的保存方式,例如设备证书、稀疏或稠密矩阵。
MaxCompute不支持删除表的列。如果您有删除列的需求,可以通过如下方法实现:
创建一张新表,命令示例如下。
create table new_table_name as select c1,c2,c3 from old_table_name;
删除旧表,并重命名新表,命令示例如下。
drop table old_table_name;
alter table new_table_name rename to old_table_name;

