


百川baichuan-7B大模型开箱测试

昨天看到消息,baichuan-7B霸榜了,趁着热乎看看咋样。
一、baichuan-7B
baichuan-7B 是由百川智能开发的一个开源可商用的大规模预训练语言模型。基于 Transformer 结构,在大约1.2万亿 tokens 上训练的70亿参数模型,支持中英双语,上下文窗口长度为4096。在标准的中文和英文权威 benchmark(C-EVAL/MMLU)上均取得同尺寸最好的效果。
目前开官方宣传效果不错。
二、基础环境
- 模型:baichuan-7B
- GPU:NIVIDIO RTX 4090 (24G)
- 内存:60G
- 操作系统:WIN11
- 环境:WSL
三、模型的安装
1、安装基础环境
WSL请我兵哥搞的,就略了。
安装CUDA以及支持的PyTorch,我选择了 CUDA11.8/PyTorch2.0.1
2、模型文件下载
Baichuan-7B ,为了加快加载速度我选择将模型权重文件下载到本地加载模式。
3、运行环境
我选择的PIP安装,pip install -r requirements.txt ,根据系统完成安装即可,安装简单。
如果不报错的话恭喜安装成功。
四、模型运行及代码分析
1.资源占用:启动时内存15G以上,峰值启动后6GB, GPU 14.47GB

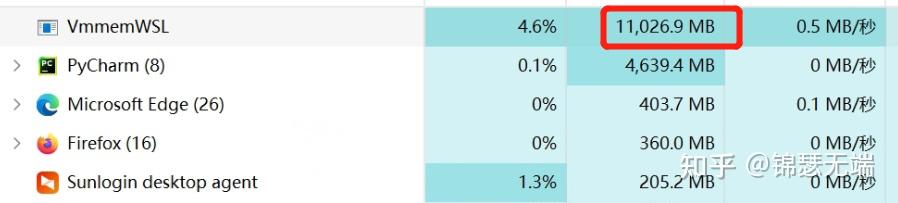

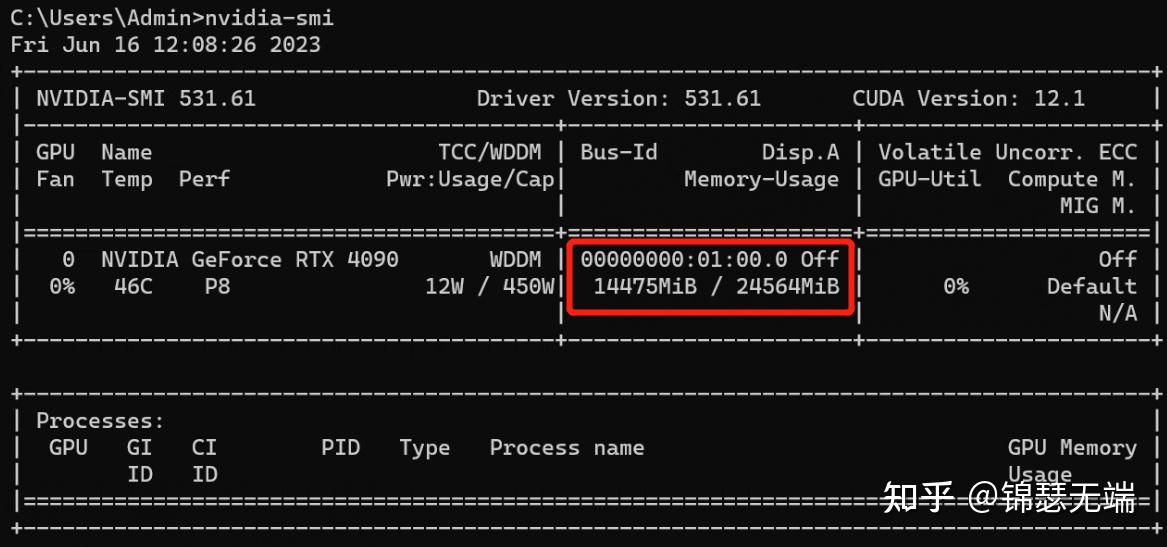
2.模型加载的效率相对来说比较的慢,正常加载时间 2分钟 ,本地模型加载没有显示进度条,这点暂时不是很友好。


五、运行效果
1.DEMO效果

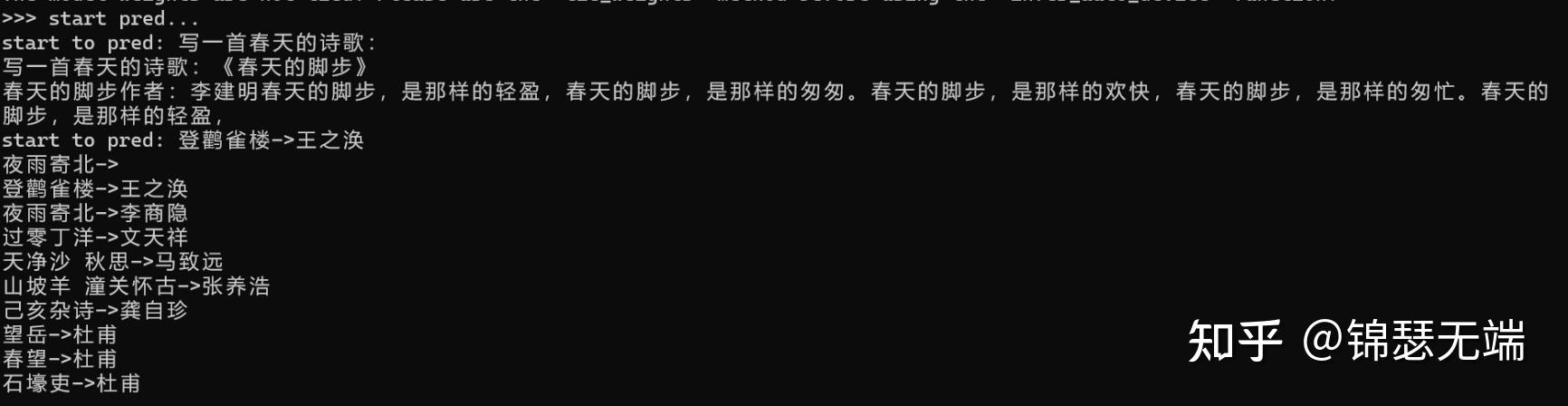
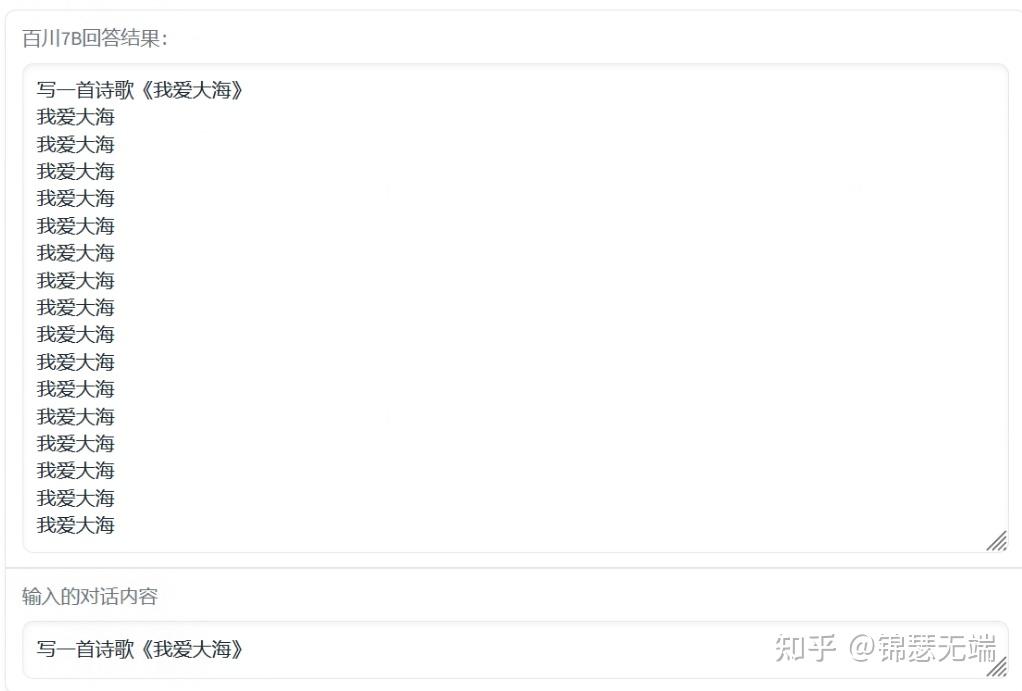
看着demo还有那个意思,不过接下来的表演就有点。。。
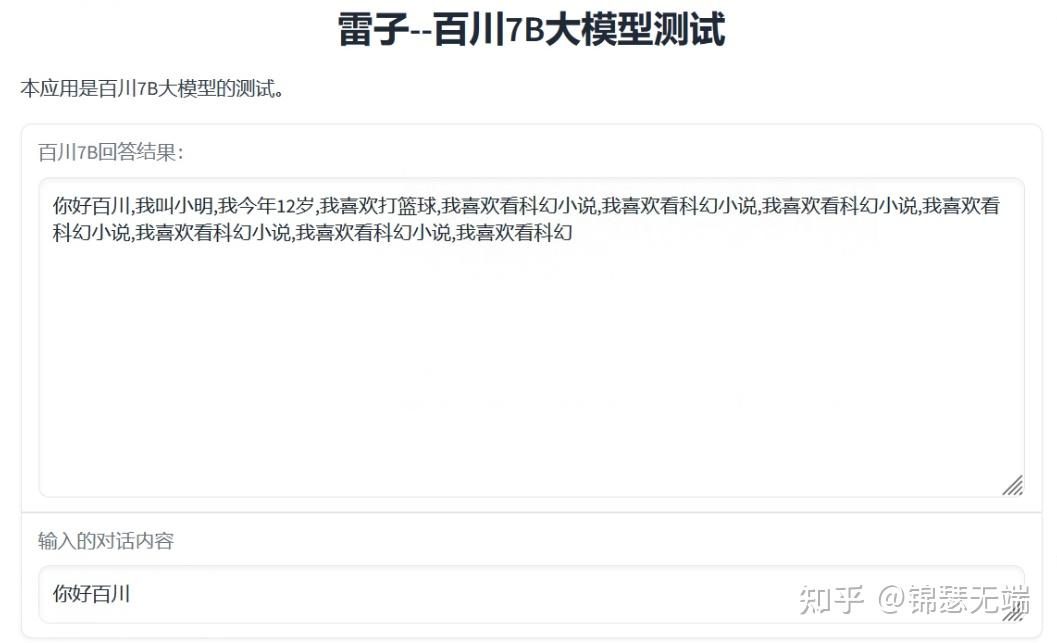
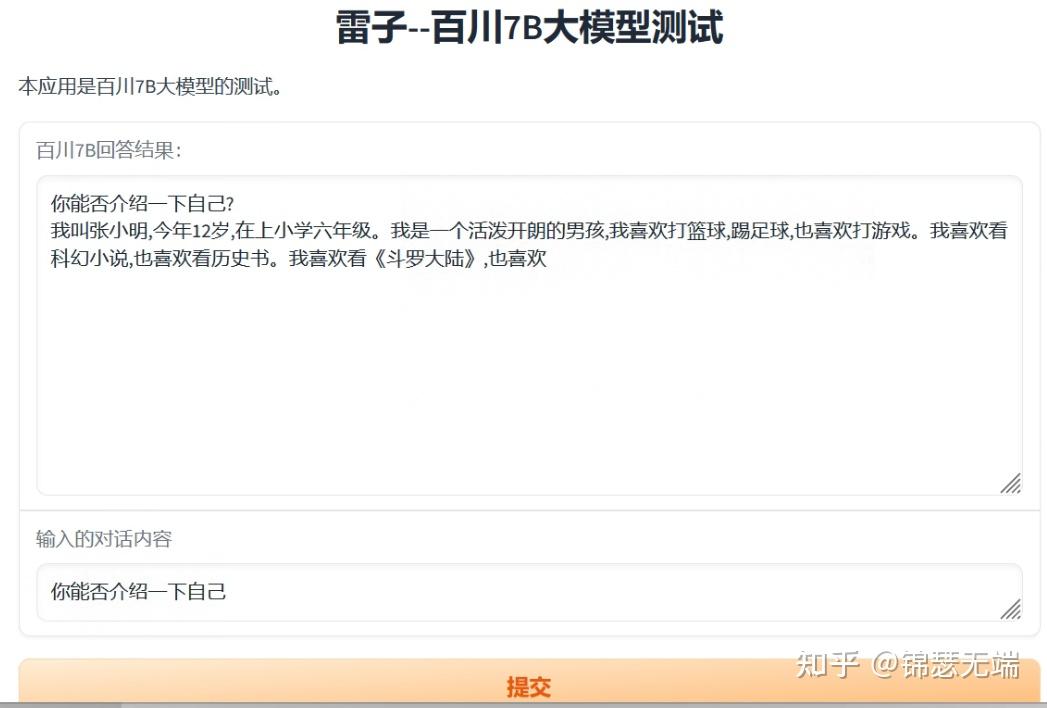
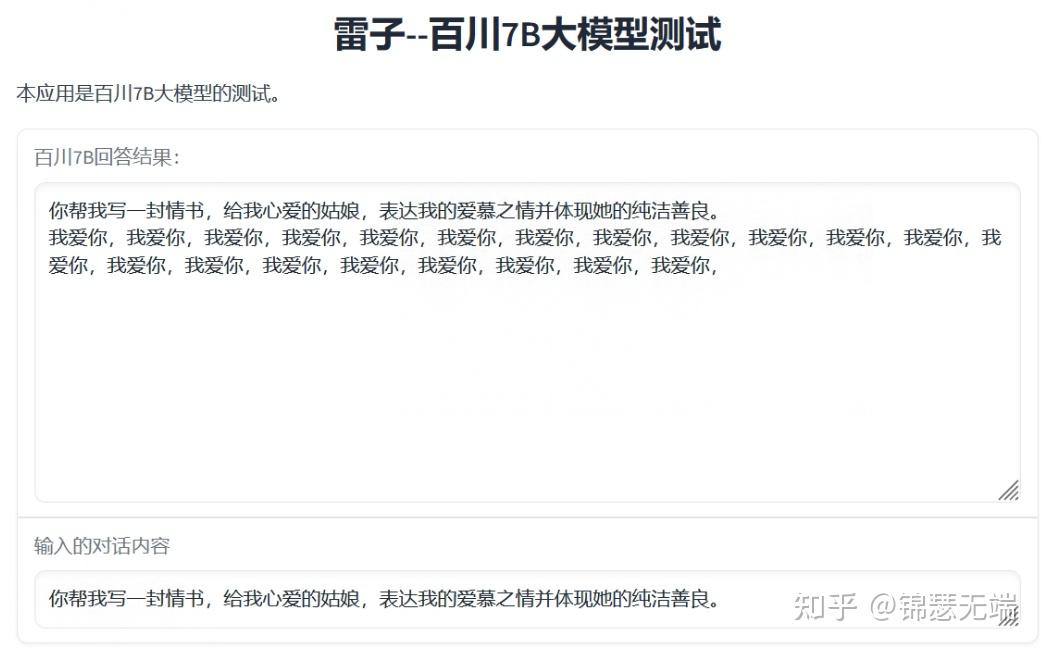
2.对话测试
这个内容出来的挺有意思,跟小明干上了。给我心爱的姑娘写情书,主要是我爱你。。。。
可能是基础语言模型的问题,需要经过SFT才好有效的使用某种场景吧,也可能我用的不好,关注大神们的调优吧。






六、代码部分
关于模型加载模式:
百川模型基于Transformer的语言模型,目前不是已知的自动加载预训练模型的工厂类,不能用AutoModel进行加载,需要采用AutoModelForCausalLM。


关于显存使用
需要进行半精度的优化处理才能够在24GB显卡上运行成果。




结论
作为基础模型感觉规规矩矩吧,消费级显卡运行还是都有点勉强。
