一直以来,对内生性的理解都是似懂非懂,就像是蒙着一层黑纱,哈哈~
所以,今天上午把关于内生性的知识认真地看了一遍,梳理了一遍,总结一下,方便后面学习。
内容包括三大块:内生性来源、解决、典型例子
主要学习的内容有:
[1]
计量分析中的内生性问题综述,一篇不得不读的经典作品
[2]
金融学里的内生性和外生性是什么意思?
[3]
内生性的通俗解释
[4]
内生性” 到底是什么鬼? New Yorker告诉你
[5]
内生性问题及其产生原因
以上文章都推荐阅读,本人从[1]、[2]、[3]中学习颇多。
内生性全面介绍
在谈内生性问题前,我们先来聊外生性,或者是严格外生。这个是我们在一个经典的多元回归模型提及到:
计量经济学学习笔记:多元线性模型

基本假定
假定1:线性关系假定,被解释变量与解释变量存在线性随机函数关系。
假定2:严格
外生
假定。(零均值假定、随机扰动项与解释变量不相关)
假定3:球形扰动假定。
假定4:无完全共线假定,解释变量之间无完全共线性。
那么假定2出现了严格外生假定,是什么呢?
外生是指:当所有时期的解释变量X给定时,每一期的随机干扰项均值都为 0。有经验的研究者会讲
X和ε同期外生和跨期外生同时存在,则为严格外生
。表现形式为:
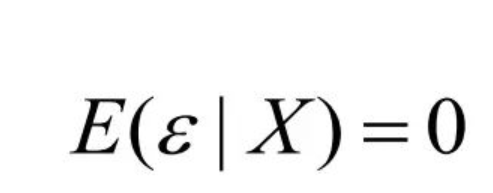
当然要求
解释变量和与过去、现在、未来的扰动项不相关
,通常难以实现,也就是严格外生困难。所以者们退而求其次,
只要求同期外生,这便是弱外生性假定
。我们也可以给出这个假定的条件均值形式

这种情况下,满足假定1、3、4以及弱严格外生假定后,我们能够证明OLS估计量一致、那么渐进正态分布,T检验,F检验以及Wald检验等常用检验都近似有效。
但扰动项与解释变量同期不相关,在现实中也常常不能被满足。

外生性假定不满足,这便产生了内生性问题
。严格来说,若扰动项与解释变量不满足弱外生性假定,我们称模型存在内生性问题,与扰动项相关的解释变量被称为内生变量。
前文多元回归模型中,我们提及到随机扰动项和解释变量存在相关,导致了内生性。那么它一般表现在哪里呢,即为何随机扰动项和解释变量存在相关?
首先,回归目的多是为了解释机制或因果推断。那么,简化完美的设计是
划分两个不同组别,他们其他方面都相同,除了关注的研究方面存在差异
,那么我们就能很好地厘清因果关系和解释机制。
然而,总有那些
无法被观察
的,或者学者
未想到的变量
导致两组之间不具有可比性。因此,对于回归方程而言,这就意味着解释变量和遗漏误差项出现了相关(我们无法观察控制到一些点),不能满足高斯马尔可夫定理(Gauss-Markov theorem),估计参数就会有偏误,内生性( endogeneity )问题出现。
并且计量经济学还是定量社会学分析,由于绝大多数实证研究都基于非实验性数据,也即
无法保证实验组和控制组的相似性
,因此内生性问题不可避免。
而,随机扰动项和解释变量存在相关主要源自一般性的遗漏变量偏误(omitted variable bias)、自选择偏误( self-selection bias)、 样本选择偏误( sample selection bias )和联立性偏误( simultaneity bias) 等多个方面。
下面,我就来解释这几种情形的表现,不以公式为例,主要是以例子和个人理解,有错误,请指出。
设解释变量为x,被解释变量为y,遗漏变量为z
(1)一般性的遗漏变量偏误,指的是
遗漏变量(z)会通过解释变量x影响被解释变量(y)
,未将其控制,落入扰动项中,那么
扰动项将与解释变量相关,同时也将导致解释变量x估计系数包括了遗漏变量z的影响效应
,这样就无法区分是x还是z的影响效应。
(2)举例子:
假设研究:“找熟人”和“不找熟人”(x)对于求职结果(y)的因果影响我们遗漏了变量口才(z),那么我们估计出的使用社会关系对工资收入的影响可能就是有偏误的。
原因:口才不仅增加了找关系的成功概率,而且本身也影响工作类型和工资水平。因为较高的语言技能本身就代表了较强的能力。
这种情况下,遗漏变量z就会通过影响x来影响y,导致系数估计偏误。
(1)自选择偏误:可以理解为这个结果是我自己选择而得到的。先进一步理解“选择”,我们可以把所分析的社会现象解析为两个过程。比如,一个过程是
解释变量发挥作用的主体过程,而另外一个则是个人选择的过程
。
自选择偏误问题本质就是
上述两个过程中的非观察到的因素相互关联
。
我们还是举上文找熟人的例子
(2)举例子:
首先,什么人会找熟人?没有很多社会资本、社会地位的会倾向于找熟人、不胆怯、脸皮厚的人会倾向于找熟人等等
其次,不胆怯、脸皮厚的人一定程度上也影响着求职结果
那么,到底是不胆怯、脸皮厚在发挥作用,还是找熟人在发挥作用
在这种情形下,我们就不能笃定说找熟人对求职结果的影响都来自于找熟人,因为样本存在自选择,样本的内在特性也会影响结果。
在这里,我们也可以体验到解释变量发挥作用的主体过程和个人选择的过程的牵扯~
与此相似,根据社会趋同(socialhomophily)理论,社会网在种族、性别、社会阶层、宗教信仰、行为和价值观等方面具有更大的选择性,也即“物以类聚,人以群分”(M cPherson et al. ,2001)1。这也内生性问题的一大来源。
(1)样本选择偏误与自选择偏误是有所不同的。自选择偏误是变量背后附带的群体特性可能影响结果。
而样本选择偏误主要来源于
当因变量的观察仅仅局限于某个有限的非随机样本
。
这种对某些观察值的非随机性排斥(exclusion)不仅源自数据收集程序,而且也来自于研究中社会现象本身所固有的特质。
(2)照常举例子:
照常是以“找熟人”为研究对象,来探讨使用社会资本对求职结果的影响。
假设我们是采用采访的方式,询问自己的工作是不是通过找熟人获得的,来识别这个人是不是使用社会资本。但值得注意的是,那些具有社会资本,但不想使用,可能是高自尊心,或者是想通过自己努力来获得。我们错过了这些样本,或者说我们只是
圈住了那些不自尊、不努力的样本
,由此我们使用一个不自尊、不努力的样本来研究社会资本的效应,由此是会高估结果的。
需要注意,样本选择偏误和自选择偏误的例子侧重点是不一样的。样本选择偏误是样本选择会强化结果,自选择偏误是样本属性会发挥作用。
(1)联立性问题( simultaneity)也是内生性的一个重要来源。其本质就是解释变量连带地由被解释变量决定,也即双向因果关系。
(2)照常举例:
收入与消费,可以说赚得多,花得也多,但钱花完了,又得想办法去多赚点,这时收入与消费是相互影响的,消费影响收入,收入又变着影响消费。
所以,x已经不是本来的x,
x中混杂了y的信息
。既然x已经不是本来意义上的x,你又如何去估计它对Y的真实影响?这就是我们通常所说的联立性偏误(simultaneity bias),即x与y是同时变动的。
其他举例:金融发展与经济增长 、外商直接投资FDI与经济增长、犯罪率与警备投入。
内生性问题和模型识别(modelidentification)紧密相连。
一般而言,可以把
识别某个模型理解为排除竞争性解释存在的可能,也即控制那些无法观测或者被遗漏的且和解释变量相关的因子
,故解决内生性问题的术语就是模型识别。
本节将针对四种内生性问题来源讨论相应的模型识别策略。
(1)利用非传统数据作为遗漏变量的替代(proxy)以控制潜在
的遗漏变量。通常我们不能穷尽控制变量,所以可以尝试利用
滞后因变量( lagged dependent variable)
作为
未被观察的个体异质性和历史因子的代表
。
(2)依赖于变量在时间维度上的差异,运用
时间固定效应模型
去控制“时间固定的”(time invariant)的非观测因素。但值得注意的是,它无法控制随时间而变化的非观测因素。
(3)利用组内策略( with- group strategy),也即用非时间性(non-time)的组内差异去估计固定效应模型,简而言之就是
个体固定效应
。这尤其适用于处理遗漏变量存在于组别水平( group-level。
(4)使用
工具变量
(若能发现并使读者相信某个外生因素与误差项无关但又和解释变量高度相关,则其或许是-一个好的工具变量)。
在实证研究中解决自选择偏误,最直观的方法就是设法使得选择
行为不存在。因此,
随机分配(Random Assigning to Treatment)是解决问题的最佳途径
。这是因为,随机分配可以确保
主解释变量和未观察因子之间没有任何关联性的出现
。实验和自然实验(natrual experiment)可以设计出随机分配 它们显然是理想的方法。
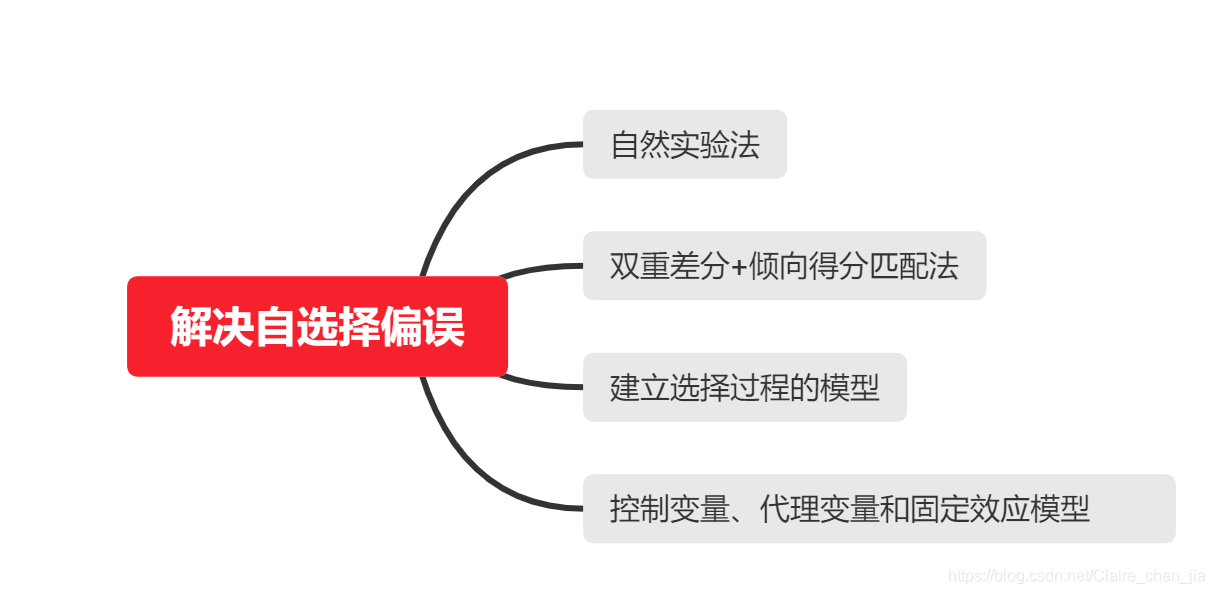
(1)自然实验法:就是发生了某些外部突发事件,使得研究对象仿佛被随机分成了实验组或控制组。
PS 有很多文章声称使用了自然实验,但严格来讲,并没有做到对研究对象进行了随机分组。
(2)双重差分+倾向得分匹配法:DID+PSM,出现一次外部冲击,这次冲击影响了一部分样本,对另一部分样本则无影响,而我们想看一下这次外部冲击到底有何影响。
双重差分法就是用来研究这次冲击的净效应的。其基本思想是,将受冲击的样本视作实验组,再按照一定标准在未受冲击的样本中寻求与实验组匹配的对照组(PSM),而后做差,做差剩下来的便是这次冲击的净效应。
(3)建立选择过程的模型。建立基于选择模型和实质模型的联立方程组是一种校正自选择偏误的简明方法。常用的是
赫克曼二阶段[ two-stage ]法,后面会抽空介绍这种方法的实现
。
(4)纳入更多的控制变量。由于自选择问题也可以被看作是一种遗漏变量偏误的特殊类型,因此我们也可以通过纳入
更多的控制变量、代理变量和固定效应模型等传统方法
来处理这个问题。
(1)被广泛运用来解决样本选择问题的方法是
赫克曼(Heckman,1976)的二阶段法
。

内容/图片来源于:
计量分析中的内生性问题综述,一篇不得不读的经典作品
后面会抽空介绍这种方法的实现~
(2)由于样本选择也可以被视为遗漏变量问题的特殊类型,
工具变量方
法
实际上也可以对它加以处理。
关于联立性偏误的纠正方法。
(1)首先检视一些特殊情况:即人们可以假定由相互因果关系引致的联立性是可以不予考虑的。
(2)另外,人们还可以强加一个时间序列去打破自变量与因变量之间
的联立性,类似于3.1中的法1。

总之,联立性偏误实际亦可看作是一种特殊的遗漏变量偏误。只不过它是由双向因果所导致的。因此,工具变量方法必然是适用的。
换言之,至少要找到一个外生变量,它
不出现在社会学家进行回归的互动效应方程
中,但出现在
代表反向因果的模型中
。

学习自:
金融学里的内生性和外生性是什么意思?
研究:股票的流动性对经理人的激励合约的设计会产生影响。即股票流动性提高时,经理人可能选择现金比重小的激励合约;当股票流动性降低时,经理人可能选择现金比重比较大的激励合约。
内生性:经理人选择现金比重小,股票比重大的激励合约本身可能也会促进股票流动性。
机制1:在薪酬契约设计中更多的股权比例,意味着管理者与投资者利益的绑定,代理问题可能削弱,会吸引更多的投资者交易,这体现为良好的股票流动性;(联立性偏误)
机制2:在薪酬契约设计中更多的股权比例自然会减少现金薪酬的比例,薪酬与股价回报的敏感性也会增强。(样本选择偏误)
此外,文章存在遗漏信息披露质量变量。(假定公司的信息披露质量很高,投资者很放心将资金投放进入该股票,该股票逐渐具有价值贮藏功能,类似可口可乐股票,其交易流动性很高;而高的信息披露质量使得股价在反映经理人行为时成为良好的业绩指标,根据标准的代理理论,这会加强其在薪酬契约中的权重,薪酬敏感性也越强。而信息披露质量似乎并未出现在作者的变量中,这种遗漏变量也会引起内生性问题。)
最后:研究设计很重要,设计越巧妙越好,数据质量也很关键,模型的完善,只是在不断地补缺口~

一直以来,对内生性的理解都是似懂非懂,就像是蒙着一层黑纱,哈哈~所以,今天上午把关于内生性的知识认真地看了一遍,梳理了一遍,总结一下,方便后面学习。内容包括三大块:内生性来源、解决、典型例子主要学习的内容有:[1] 计量分析中的内生性问题综述,一篇不得不读的经典作品[2] 金融学里的内生性和外生性是什么意思?[3] 内生性的通俗解释[4] 内生性” 到底是什么鬼? New Yorker告诉你[5] 内生性问题及其产生原因以上文章都推荐阅读,本人从[1]、[2]、[3]中学习颇多。1 内生
1.
内生性
来源
内生性
问题 (endogeneity issue) 是指模型中的一个或多个解释变量与误差项存在相关关系。换言之,如果 OLS 回归模型中出现,则模型存在
内生性
问题,以致于 OLS 估计量不再是一致估计。进一步,
内生性
问题主要由以下四种原因导致。
1.1 遗漏变量
在实证研究中,研究者通常无法控制所有能影响被解释变量的变量,因此遗漏解释变量 (omitted variables) 是很常见的事情。假设 OLS 模型中解释变量为和,研究者遗漏的解释变量为
如果遗漏的变量...
This chapter discusses how applied researchers in corporate finance can address endogeneity concerns. We begin by reviewing the sources of endogeneity— omitted variables, simultaneity, and measurement error— and their implications for inference. We then discuss in detail a number of econometric techniques aimed at addressing endogeneity problems including: instrumental variables, difference-in-differences estimators, regression discontinuity
design, matching methods, panel data methods, and higher order moments estimators. The unifying themes of our discussion are the emphasis on intuition and the applications to corporate finance.
1. 数值与布尔型2. 字符串2.1 字符串的创建2.2 字符串与数值的相互转换2.3 字符串的连接、复制和转义2.4 字符串的替换、分隔与合并2.5 Python的字符串常用内建函数2.6 字符串截取3. 正则表达式3.1 正则表达式基础知识3.2 正则表达式实例
1. 数值与布尔型
整型int
浮点型float
False
# 查看数据类型用type()
a = 1
b = 1.1
c = True
d = False
print(type(a),type(b),type(c),type(d))
# 判断时返回的是布尔值
print(a == b)
学习
笔记
|| VMware虚拟机下安装Ubuntu18.04
哈罗,这里是Kun的
笔记
空间站,Kun有空的时候呢会在这里记录一些自己的
学习
笔记
、踩坑、爬坑经历。
算是对自己
学习
轨迹的一个记录也希望能帮助到一些跟我有着同样入坑经历的选手吧!
想要用虚拟机玩耍Ubuntu的话首先需要用虚拟机创建一个虚拟环境,然后再安装Ubuntu系统,所以我们分两大步完成:
首先需要做好准备工作:
官网下载Ubuntu18.04_iso文件
官网下载并成功安装VMware
建议可以在已有磁盘里重新压缩一卷至少10G以上(越大越好)的空磁盘来安装系统(虚拟机安装秘钥及压缩新卷操作方法见文尾)
下面就直接开
```python
from appium.webdriver.common.touch_action import TouchAction
from appium.webdriver.common.multi_action import MultiAction
# 找到ScrollView控件
scrollview = driver.find_element_by_xpath('//android.widget.ScrollView')
# 获取屏幕大小
width = driver.get_window_size()['width']
height = driver.get_window_size()['height']
# 计算起始坐标和结束坐标
start_x = width // 2
start_y = height // 4 * 3
end_x = start_x
end_y = height // 4
# 滑动操作
action = TouchAction(driver)
action.press(x=start_x, y=start_y).move_to(x=end_x, y=end_y).release()
action.perform()
通过上述代码可以实现向下滑动屏幕的操作。需要注意的是,滑动的起始坐标和结束坐标需要根据具体场景进行调整,以确保滑动操作的正确性。

