link管理
链接快照平台
- 输入网页链接,自动生成快照
- 标签化管理网页链接
相关文章推荐

|
曾深爱过的苦咖啡 · Intel Core i7-13650HX ...· 昨天 · |
|
|
机灵的乌冬面 · K8S的更新、回滚、伸缩_failedget ...· 1 周前 · |
|
|
爱旅游的山楂 · cpu单核性能测试软件,CPU常用跑分软件 ...· 3 周前 · |
|
|
有腹肌的熊猫 · 【6问6答】JAVA 应用 CPU ...· 3 周前 · |
|
|
小眼睛的羊肉串 · InfluxDB使用HTTP的API查询数据 ...· 3 周前 · |
|
|
大鼻子的海龟 · 关中平原城市群扩容?延安、三门峡申请“进群” ...· 1 月前 · |
|
|
耍酷的胡萝卜 · 乌克兰核安全和核安保 | IAEA· 5 月前 · |
|
|
近视的眼镜 · 索菱股份(002766)_股票行情,行情首页 ...· 7 月前 · |
|
|
想出国的乌龙茶 · 持有7代仍忍不住入手小米手环8NFC,到底值 ...· 7 月前 · |
|
|
心软的松鼠 · 关于windows10环境下cmake指令报 ...· 10 月前 · |

【2021-10-13】 OpenAI 研究员最新博客:如何在多GPU上训练真正的大模型? , 原文链接
近几年CPU算力增加已经
远低于
摩尔定律
(Moore’s Law)
摩尔定律
。
为了能够满足机器学习模型发展,只有通过 分布式训练 系统才可以匹配模型不断增长的算力需求。
大语言模型参数量和数据量非常巨大,因此都采用了分布式训练架构完成训练。
OPT
模型训练用了
992块
NVIDIA A100 80G GPU,采用
全分片数据并行
(Fully Sharded Data Parallel)以及Megatron-LM
张量并行
(Tensor Parallelism),整体训练时间将近2个月。
BLOOM
模型在硬件和所采用的系统架构方面的细节。训练一共花费3.5个月,使用48个计算节点。
LLaMA
模型训练采用 NVIDIA A100 80GB GPU
在 pytorch1.7 + cuda10 + TeslaV100的环境下,使用ResNet34,batch_size=16, SGD对花草数据集训练的情况如下:
误差梯度如何在不同设备之间通信?
BN如何在不同设备之间同步?
单GPU、是否使用同步BN训练的三种情况,可以看到
两种GPU训练方法:
DataParallel
和
DistributedDataParallel
:
深度学习任务通用 GPU 进行模型训练。
ALU
),发挥并行计算的优势,特别适合
计算密集型
任务,更高效地完成深度学习模型的训练。
因此,想获得更好的训练性能,需要合理利用 GPU 和 CPU 的优势。
分布式目标
分布式训练总体目标: 提升总训练速度,减少模型训练的总体时间。
总训练速度公式:
CPU + GPU 工作模式
GPU 模式下的模型训练如图所示,分为4步:
分布式训练
【2024-8-23】Github 分布式训练总结 tech_slides , pdf
【2024-5-27】 MIT 助理教授 Song Han 的 分布式训练介绍 ppt:
part1
分布式条件下的多进程、多worker之间的通信技术,常见的主要有:MPI、NCCL,GRPC等。
Pytorch 分布式训练通信依赖
torch.distributed
模块,
torch.distributed
提供了
point-2-point communication
和
collective communication
两种通信方式。
P2P
)提供了send和recv语义,用于任务间的通信。
CC
)提供了 scatter/broadcast/gather/reduce/all_reduce/all_gather 语义,不同的backend在提供的通信语义上具有一定的差异性。
训练大模型主要是CC通信
GPU通信技术
【2024-6-17】 GPU通信技术:GPU Direct、NVLink与RDMA
GPU通信技术是加速计算的关键,其中
GPU Direct
、
NVLink
和
RDMA
是三种主流技术。
RDMA(Remote Direct Memory Access)是一种远程直接内存访问技术,允许一个设备直接访问另一个设备上的内存数据。在GPU通信中,RDMA技术用于加速GPU与CPU、GPU与GPU以及GPU与网络之间的数据传输。
DMA
是“
直接内存读取
”的意思,用来传输数据,它也属于
外设
。只是在传输数据时,无需占用CPU。
比如GPU与CPU之间存在着大量的数据传输.
GPU与CPU集成至同一个处理器芯片时,能够大大减少芯片间的数据搬运,同时因为显存和内存的合并,会大大增加访存压力
DMA传输方向有三个: 外设到内存 , 内存到外设 , 内存到内存 。
外设
到
内存
。即从外设读取数据到内存。例如ADC采集数据到内存,ADC寄存器地址为源地址,内存地址为目标地址。
内存
到
外设
。即从内存读取数据到外设。例如串口向电脑发送数据,内存地址为源地址,串口数据寄存器地址为目标地址。此时内存存储了需要发送的变量数据。
内存
到
内存
。以内部flash向内部sram传输数据为例,此时内部flash地址即为源地址,内部sram地址即为目标地址。同时,需要将DMA_CCRx寄存器的MEM2MEM置位。
一、GPU Direct
GPU Direct 是一种优化GPU之间或GPU与第三方设备之间数据传输的技术。它通过 共享内存访问 和 点对点通信 减少了数据复制和传输延迟。
(1) GPU Direct
Shared Memory
2010年,NVIDIA推出了GPU Direct Shared Memory技术,允许GPU与第三方PCI Express设备通过共享的host memory实现共享内存访问。这使得内存空间得以共享,减少了数据复制,降低了数据交换延迟。
(2) GPU Direct
P2P
(Peer-to-Peer)
2011年,GPU Direct增加了Peer-to-Peer(
P2P
)技术,支持同一PCI Express总线上的GPU之间的直接访问和传输。这种技术绕过了CPU,使得GPU之间通信更加高效。
(3) GPU Direct
RDMA
2013年,GPU Direct增加了
RDMA
(Remote Direct Memory Access)支持。
RDMA允许第三方PCI Express设备绕过CPU host memory,直接访问GPU内存。这种技术大幅提升了数据传输效率,尤其适用于高性能计算和数据中心等场景。
二、NVLink
NVLink是一种专门设计用于连接NVIDIA GPU的高速互联技术。它通过点对点通信方式,绕过传统的PCIe总线,提供了更高的带宽和更低的延迟。
带宽与延迟 NVLink采用串行协议,支持双向数据传输,每个方向都有高达32GB/s的带宽。这使得两个GPU之间能够实现高速数据传输和共享,为多GPU系统提供了更高的性能和效率。与传统的PCIe总线相比,NVLink显著降低了通信延迟。
连接与扩展 NVLink可用于连接两个或多个GPU,以实现多GPU协同工作。这种连接方式简化了系统架构,提高了可扩展性。通过NVLink连接的GPU可以共享数据和计算资源,从而在某些应用中实现性能倍增。
三、RDMA
RDMA(Remote Direct Memory Access)是一种远程直接内存访问技术,允许一个设备直接访问另一个设备上的内存数据。在GPU通信中,RDMA技术用于加速GPU与CPU、GPU与GPU以及GPU与网络之间的数据传输。
DMA原理 在介绍RDMA之前,我们需要理解DMA(Direct Memory Access)原理。DMA是一种技术,允许硬件控制器直接从内存读取或写入数据,而不需要经过CPU。这大大减轻了CPU的负担,提高了数据传输效率。RDMA基于此原理,进一步扩展了其应用范围。
RDMA的优势 RDMA提供了高带宽和低延迟的数据传输能力。它利用网卡等设备的远程直接内存访问功能,允许设备之间快速高效地传输大量数据。在高性能计算、数据中心和云计算等领域,RDMA成为提高系统性能的关键技术之一。
GPU与RDMA的结合 通过将RDMA与GPU相结合,可以实现高性能的GPU通信。在这种配置中,GPU可以借助RDMA直接访问其他设备或网络的内存数据,从而避免了不必要的CPU中介和数据拷贝。这不仅提高了数据传输速率,还降低了CPU负载和功耗。
GPU通信技术在加速计算领域发挥着越来越重要的作用。GPU Direct、NVLink和RDMA是三种主流的GPU通信技术,它们分别通过共享内存访问、高速互联和远程直接内存访问等方式提高了GPU之间的通信效率。在实际应用中,根据不同的场景和需求选择合适的通信技术至关重要。随着技术的不断发展,未来我们有望看到更多创新性的GPU通信解决方案,为高性能计算和数据中心等领域带来更大的性能提升。
PyTorch 支持
torch.distributed 支持 3 种后端,分别为
NCCL
,
Gloo
,
MPI
基本原则:
无限带宽互联的 GPU 集群
无限带宽和 GPU 直连
无限带宽互联的 CPU 集群
以太网互联的 CPU 集群
MPI 后端
MPI 即 消息传递接口 (Message Passing Interface),来自于高性能计算领域的标准的工具。
但是,torch.distributed 对 MPI 并不提供原生支持。
因此,要使用 MPI,必须从源码编译 Pytorch。是否支持 GPU,视安装的 MPI 版本而定。
Gloo 后端
gloo 后端支持 CPU 和 GPU,其支持集体通信(collective Communication),并对其进行了优化。
由于 GPU 之间可以直接进行数据交换,而无需经过 CPU 和内存,因此,在 GPU 上使用 gloo 后端速度更快。
torch.distributed 对 gloo 提供原生支持,无需进行额外操作。
NCCL 通信原语
【2023-7-27】 大模型-LLM分布式训练框架总结
NCCL 的全称为 Nvidia 聚合通信库(NVIDIA Collective Communications Library),是一个可以实现多个 GPU、多个结点间聚合通信的库,在 PCIe、Nvlink、InfiniBand 上可以实现较高的通信速度。
NCCL 高度优化和兼容了 MPI,并且可以感知 GPU 的拓扑,促进多 GPU 多节点的加速,最大化 GPU 内的带宽利用率,所以深度学习框架的研究员可以利用 NCCL 的这个优势,在多个结点内或者跨界点间可以充分利用所有可利用的 GPU。
NCCL 对 CPU 和 GPU 均有较好支持,且 torch.distributed 对其也提供了原生支持。
对于每台主机均使用多进程的情况,使用 NCCL 可以获得最大化的性能。每个进程内,不许对其使用的 GPUs 具有独占权。若进程之间共享 GPUs 资源,则可能导致 deadlocks。
NCCL 英伟达集合通信库专用于多个 GPU 乃至多个节点间通信。
Broadcast
: 一对多的通信原语,一个数据发送者,多个数据接收者,可以在集群内把一个节点自身的数据广播到其他节点上。
Scatter
: 一对多的通信原语,也是一个数据发送者,多个数据接收者,可以在集群内把一个节点自身的数据发散到其他节点上。与Broadcast不同的是,Broadcast把主节点0的数据发送给所有节点,而Scatter则是将数据进行切片再分发给集群内所有的节点。
Gather
: 多对一的通信原语,具有多个数据发送者,一个数据接收者,可以在集群内把多个节点的数据收集到一个节点上。
AllGather
: 多对多的通信原语,具有多个数据发送者,多个数据接收者,可以在集群内把多个节点的数据收集到一个主节点上(Gather),再把这个收集到的数据分发到其他节点上(broadcast),即收集集群内所有的数据到所有的节点上。
Reduce
: 多对一的通信原语,具有多个数据发送者,一个数据接收者,可以在集群内把多个节点的数据规约运算到一个主节点上,常用的规约操作符有:求累加和SUM、求累乘积PROD、求最大值MAX、求最小值MIN、逻辑与LAND、按位与BAND、逻辑或LOR、按位或BOR、逻辑异或LXOR、按位异或BOXR、求最大值和最小大的位置MAXLOC、求最小值和最小值的位置MINLOC等,这些规约运算也需要加速卡支持对应的算子才能生效。
ReduceScatter
: 多对多的通信原语,具有多个数据发送者,多个数据接收者,在集群内的所有节点上都按维度执行相同的Reduce规约运算,再将结果发散到集群内所有的节点上。Reduce-scatter等价于节点个数次的reduce规约运算操作,再后面执行节点个数的scatter次操作。其反向操作是AllGather。
AllReduce
: 多对多的通信原语,具有多个数据发送者,多个数据接收者,在集群内的所有节点上都执行相同的Reduce操作,可以将集群内所有节点的数据规约运算得到的结果发送到所有的节点上。
通信原语汇总
Ring AllReduce:
假设每个worker的数据是一个长度为
S
的向量,那么Ring AllReduce里每个worker发送的数据量是
O(S)
,和worker的数量N无关。避免了
主从架构
中master需要处理
O(S*N)
数据量而成为网络瓶颈的问题。
Ring All-reduce
DistributedDataParallel
Ring All-reduce
=
reduce-scatter
+
all-gather
NCCL 通信行为分析
【2024-5-10】 集合通信行为分析 - 基于NCCL
deepspeed 启动多卡训练时,日志里会打印NCCL通信信息,这些日志都是什么意思?
NCCL 通信阶段
启动
阶段
Bootstrap
Phase: 初始化集合中的所有节点(node)和卡(rank),确保所有卡知道彼此
拓扑
阶段
Topology
Phase: 每隔节点了解机器上各个硬件(CPU/GPU/NIC)映射关系, 创建内部拓扑结构(树/环),通过PCI和NVLink通信
PCIe
or
NVLink
interconnect, and evaluates the graph.
聚合
阶段
Collective
Phase: 用户调用NCCL支持的集合通信原语进行通信
NCCL在getAlgoInfo里面使用ncclTopoGetAlgoTime来遍历计算(algorithm, protocol),最终选择预测会最快做完指定数据量的指定集合通信原语的algorithm和protocol完成该通信原语。
(1) tree
拓扑 log格式
# IP: hostname:pid:tid [cudaDev] NCCL INFO Trees [channel ID] down0 rank/down1 rank/down2 rank->current rank->up rank
10.0.2.11: 2be7fa6883db:57976:58906 [5] NCCL INFO Trees [0] 14/-1/-1->13->12 [1] 14/-1/-1->13->12
# 10.0.2.11上的设备5,其rank为13,有两棵树,分别为channel 0和channel 1: channel 0的子节点只有14, 父节点为12; channel 1一样。
channel log格式
# IP: hostname:pid:tid [cudaDev] NCCL INFO Channel [channel ID] current rank[bus ID]->successor rank[bus ID] via transport type
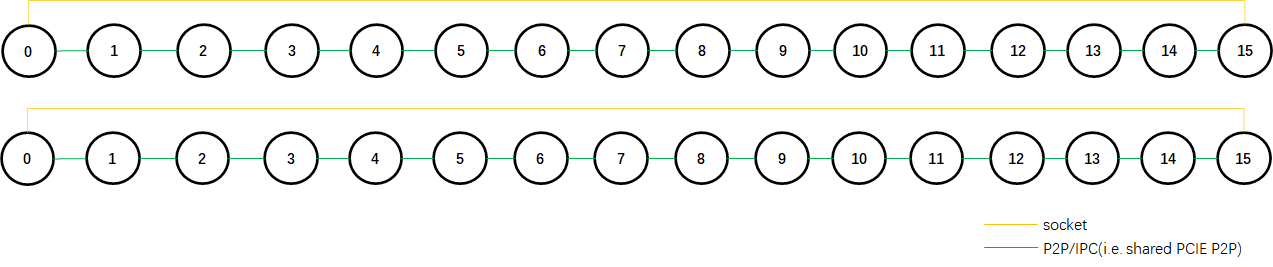
10.0.2.11: 2be7fa6883db:57976:58906 [5] NCCL INFO Channel 00 : 13[3e000] -> 14[40000] via P2P/IPC
# 10.0.2.11上的设备5(rank 为13, bus ID为3e000),其channel 0连接至rank 14,传输方式为P2P/IPC。
依此解析,可得两棵一样的tree,逻辑拓扑如下:img
拓扑log格式
# IP: hostname:pid:tid [cudaDev] NCCL INFO Channel ring_ID/ring_number: rank0 rank1 … last_rank
10.0.2.12: 94f182076445:82261:83141 [0] NCCL INFO Channel 00/02 : 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
# 建成了02个ring,其中第0个ring的成员有:0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15,该ring共由16个rank组成。
channel log格式
与tree拓扑的格式一致。
可得两个一样的ring,逻辑拓扑如下:img
方法1: prune, 【Deep gradient compression】
worker 向 server push 梯度时, 可以对梯度做 prune (sparse gradient) 与 quantization
方法2: Low-Rank 【PowerSGD】,梯度映射到低秩空间,而不是去做细粒度的剪枝和量化
2019年 EPFL 的文章 PowerSGD, 发了 NIPS
方法3: 量化, 1bit SGD
用 one bit 的矩阵作为需要通讯的梯度
方法5: terngrad, ternery
梯度量化到 0, -1, 1
自动并行: 自动搜索并行空间
如:Alpa(自动算子内/算子间并行)), 将并行空间分为 inter-op (pipeline) 与 intra-op (tensor并行),使用NAS搜索这两个空间,考虑整个搜索空间的cost。
优化器相关并行(如:ZeRO(零冗余优化器,在执行的逻辑上是数据并行,但可以达到模型并行的显存优化效果)、PyTorch FSDP)
【2023-12-15】MIT 端侧模型训练课程: TinyML and Efficient Deep Learning Computing, 含 ppt 和 视频
powerful deep learning applications on resource-constrained devices.
Topics include model compression, pruning, quantization, neural architecture search, distributed training, data/model parallelism, gradient compression, and on-device fine-tuning. application-specific acceleration techniques
模型切分分3个互相正交的维度:[data, model-layer, model-activation(Tensor)]
这3个维度互不影响,可同时实现,即 3D parallelism。
常见多GPU训练方法:
模型并行:如果模型特别大,GPU显存不够,无法将一个显存放在GPU上,需要把网络的不同模块放在不同GPU上,这样可以训练比较大的网络。(下图左半部分)
数据并行:将整个模型放在一块GPU里,再复制到每一块GPU上,同时进行正向传播和反向误差传播。相当于加大了batch_size。(下图右半部分)
模型并行:当单个 GPU无法容纳模型尺寸时,模型并行性变得必要,有必要将模型拆分到多个 GPU 上进行训练。实现模型尺寸超过单个GPU显存的深度学习模型训练。
这种方法的问题是计算使用效率不高,因为在任何时间点只有一个 GPU 正在使用,而其他 GPU 处于空闲状态。
相对于流水线并行和数据并行,模型并行具有以下优点:
支持更大的模型规模:流水线并行和数据并行的限制通常是 GPU 内存大小和 GPU 数量,而模型并行可以支持更大的模型规模,因为模型可以分割成多个子模型,并分配到多个 GPU 上运行。
减少通信开销:流水线并行的模型划分通常会导致模型层之间的通信,而模型并行只需在每个子模型之间进行通信。相对于数据并行,模型并行在执行过程中通信量更少,因为每个 GPU 只需传递模型的一部分而不是全部。
灵活的模型分配:模型并行可以更灵活地将模型分配给不同的 GPU 或计算节点,这意味着可以在不同的 GPU 上运行不同的模型子集,从而实现更好的负载平衡和性能优化。
流水线并行 (PP)
朴素流水线并行(Naive Pipeline Parallelism)是将一组模型层分布在多个 GPU 上,并简单地将数据从 GPU 移动到 GPU,就好像它是一个大型复合 GPU 一样。
流水线并行 (PP) 与上述朴素流水线并行几乎相同,但它解决了 GPU 闲置问题,方法是将传入的 batch 为 micro-batches 并人工创建流水线,从而允许不同的 GPU 同时参与计算过程。
流水并行是将一个大型计算任务拆分成多个小的子任务,并将子任务在多个处理单元上同时执行。不同于数据并行和模型并行,流水并行不是将数据或模型分割成多个部分并在处理单元间并行处理,而是将一系列计算步骤分解成多个流水阶段,并在多个处理单元上同时执行,以减少总体计算时间。
Data Parallelism:模型1台设备装得下,所以同模型用多份数据分开训练Pipeline Parallelism:模型装不下,模型1层或多层1台设备装得下,所以同模型按层拆开训练Tensor Parallelism:模型1层都装不下,所以层内拆开训练数据并行性(Data parallelism (DP))最简单的方法是:将相同的模型权重复制到多个worker中,并将一部分数据分配给每个worker以同时进行处理。
如果模型规模大于单个GPU的内存,Naive DP无法正常工作时。GeePS(Cui 等人,2016 年)之类的方法将暂时未使用的参数卸载回 CPU,以使用有限的 GPU 内存。数据交换传输在后端进行,且不干扰训练计算。
在每个小批量结束时,workers需要同步梯度或权重,以替换旧参数。常见有两种主要的同步方法,它们都有明确的优缺点:
1)大容量同步并行( Bulk synchronous parallels (BSP)):workers在每个小批量结束时同步数据。这种方法可以防止模型权重过时,同时获得良好的学习效率,但每台机器都必须停止并等待其他机器发送梯度。
2)异步并行(Asynchronous parallel (ASP)):每个GPU工作进程异步处理数据,无需等待或暂停。然而,这种方法很容易导致网络使用陈旧的权重参数,从而降低统计学习效率。即使它增加了计算时间,也可能不会加快收敛的训练时间。
中间的某个地方是在每次x迭代时,全局同步梯度(x>1)。自Pytorch v1.5版(Li等人,2021年)以来,该特征在平行分布数据(DDP)中被称为“梯度累积”。Bucket 梯度计算方法避免了梯度的立即AllReduce,而是将多个梯度变化值存储到一个AllReduce中以提高吞吐量,可以基于计算图进行计算和通信调度优化。
模型并行性(Model parallelism: MP)目的是解决模型权重不能适应单个节点的情况,通过将计算和模型参数分布在多台机器上进行训练。
数据并行中,每个worker承载整个模型的完整副本
而模型并行中,每个worker上只分配模型参数的一小部分,从而减少了内存使用和计算。
将单个模型拆分到不同GPU上,而不是在每个GPU上复制整个模型
将模型不同子网放置到不同设备上,并相应地实现该 forward方法以在设备之间移动中间输出。由于模型的一部分只能在任何单个设备上运行,因此一组设备可以共同为更大的模型服务。
模型 m 包含10层:
DataParallel: 每个GPU都具有这10层中每层副本
而在两个GPU上使用模型并行时,每个GPU可以托管5层
由于深度神经网络通常包含一堆垂直层,因此将一个大型模型逐层拆分感觉很简单,其中一组连续的小层被分组到一个工作层上的一个分区中。然而,通过多个具有顺序依赖性的工作线程来运行每个数据批,会导致大量的等待时间和计算资源利用率低下的问题。
模型并行有两种:张量并行 和 流水线并行
张量并行是在一个操作中进行并行计算,如:矩阵-矩阵乘法。
流水线并行是在各层之间进行并行计算。
张量并行是层内并行,流水线并行是层间并行。
流水线并行(综合模型+数据)
通道并行(Pipeline parallelism: PP)将模型并行与数据并行相结合,以减少部分训练过程中出现的空闲时间。
将一个小批量拆分为多个微批次,并使worker在每个阶段中能够同时处理一个微批次。需要注意的是,每个微批次需要两次传递,一次向前,一次向后。worker之间的通信仅传输激活(向前)和梯度(向后)。这些通道的调度方式以及梯度的聚合方式在不同的方法中有所不同。分区(workers)的数量也称为通道深度。
模型按层分割成若干块,每块都交给一个设备。
前向传播: 每个设备将中间激活传递给下一个阶段。
后向传播: 每个设备将输入张量梯度传回给前一个流水线阶段。
这允许设备同时进行计算,从而增加训练的吞吐量。
模型并行和流水线并行都将一个模型垂直分割,可以将一个张量操作的计算水平分割到多个设备上,称为张量并行(tensor parallelism,TP)。
张量并行将张量沿特定维度分成 N 块,每个设备只持有整个张量的 1/N,同时不影响计算图的正确性。
这需要额外的通信来确保结果的正确性。
以当下比较流行的transformer为例,transformer模型主要由多层MLP和自我注意块组成。Megatron-LM(Shoeybi et al.2020)等人采用了一种简单的方法来并行多层计算MLP和自我注意。变压器中的MLP层包含GEMM(通用矩阵乘法)和非线性GeLU传输,按列拆分权重矩阵A
典型的张量并行实现:
Megatron-LM(1D)
Colossal-AI(2D、2.5D、3D)
多维混合并行
多维混合并行指将数据并行、模型并行和流水线并行结合起来进行分布式训练。
超大规模模型的预训练和全参数微调时,都需要用到多维混合并行。
2D 并行
Data 并行+ pipeline 并行
Deepspeed web-link给出了 pipeline 和 data-parallel 的2D并行示意图,其中 rank0 和 rank1 为 data-parallelism, rank0里的 gpu-0 和 gpu-2 进行 pipeline 并行,他们交替进行前向和反向过程,疑问的是(这里没有模型运行的最终的loss,如何进行反向传播呢?)
Tensor 并行 + pipeline
Alpa 将并行空间分为 inter-op (pipeline) 与 intra-op (tensor并行),使用 NAS搜索这两个空间,考虑整个搜索空间的cost。
首先搜索 inter-op 的搜索空间, 制定 pipeline 并行策略
然后搜索 intra-op空间, 指定 data-para 与 operator-para 策略(包括两种)
Data para
Operator parallel (weight 广播,input拆分)
Operator parallel (weight 拆分,input拆分) –> 需要增加 all-reduce cost
UCB博士 郑怜悯 的工作, 他还参加过其他项目 Ansor,TVM, vLLM, FastChat,LMSYS-Chat-1M
HuggingFace Space上的最新火起来工具——Model Memory Calculator,模型内存测量器,在网页端人人可体验。
比如模型bert-base-case Int8估计占用413.18 MB内存,实际占用为413.68MB,相差0.5MB,误差仅有0.1%。
实际推理过程,EleutherAI 发现需要在预测数据基础上,预留20%的内存
【2023-8-30】baichuan-7b (14G) 部署失败,空间不够
GPU: A30, 24G 显存
错误信息:
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 86.00 MiB (GPU 0; 22.20 GiB total capacity; 7.47 GiB already allocated; 51.12 MiB free; 7.48 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
Memory Usage for ‘baichuan-inc/Baichuan-7B’
Linear(M->N): 参数数目:M×N
Conv2d(Cin, Cout, K): 参数数目:Cin × Cout × K × K
BatchNorm(N): 参数数目: 2N
Embedding(N,W): 参数数目: N × W
参数占用显存 = 参数数目 × n
n = 4 :float32
n = 2 : float16
n = 8 : double64
PyTorch中,当执行完 model=MyGreatModel().cuda() 后就会占用相应的显存,占用的显存大小基本与上述分析的显存差不多(会稍大一些,因为其它开销)。
梯度与动量的显存占用
SGD:W_t+1 = W_t - α * ▽ F(W_t)
除了保存权重W, 还要保存对应的梯度 ▽ F(W_t) ,因此, 显存占用等于参数占用显存 x2
带Momentum-SGD:
v_t+1 = ρv_t + ▽ F(W_t)
W_t+1 = W_t - α * v_t+1
还需要保存动量, 因此显存 x3
Adam优化器
动量占用的显存更多,显存x4
神经网络每层输入/输出都需要保存下来,用来反向传播,但是在某些特殊的情况下,不要保存输入。
比如 ReLU,PyTorch中,使用nn.ReLU(inplace = True) 能将激活函数ReLU的输出直接覆盖保存于模型的输入之中,节省不少显存。
这时候是如何反向传播? (提示:y=relu(x) -> dx = dy.copy();dx[ y<=0 ] =0)
去掉 compute_metrics:
有些代码会在输出层后计算rouge分等,这个会输出一个 batch_sizevocab_sizeseq_len 的一个大向量,非常占显存。
采用bf16/fp16进行混合精度训练:
现在大模型基本上都采用 bf16 来进行训练
但是 v100 不支持 bf16,可以采用fp16进行训练。显存占用能够降低1倍。
Flash attention:不仅能够降低显存,更能提高训练速度。batch_size 调小:
batch size 与模型每层激活状态所占显存呈正相关
降低 batch size 能够很大程度上降低这部分显存占用。
采用梯度累积:
global_batch_size = batch_size * 梯度累积如果降低 batch_size 后想保持 global_batch_size 不变,可适当提高梯度累积值。
选择合适的上下文长度:
上下文长度与激活状态所占显存呈正相关
因此可适当降低上下文长度来降低显存占用。
DeepSpeed Zero:
显存占用从高到低为:Zero 1 > Zero 2 > Zero 2 + offload > zero 3 > zero 3 + offload
推荐最多试到 Zero2 + offload。
选择更小的基座模型:在满足需求的情况下,尽量选择更小的基座模型。
慎重选择:
Lora: 能跑全参就别跑 Lora 或 Qlora,一方面是麻烦,另一方面的确是效果差点。Qlora: Qlora 速度比lora慢,但所需显存更少,实在没资源可以试试。Megatron-LM: 可采用流水线并行和张量并行,使用比较麻烦,适合喜欢折腾的同学。Pai-Megatron-LM: Megatron-LM 的衍生,支持 Qwen 的sft和pt,坑比较多,爱折腾可以试试。激活检查点:不推荐,非常耗时。在反向传播时重新计算深度神经网络的中间值。用时间(重新计算这些值两次的时间成本)来换空间(提前存储这些值的内存成本)。
GPU 要存哪些参数
【2023-6-28】参考
模型训练中,GPU 要存储的参数
模型本身的参数、优化器状态、激活函数的输出值、梯度、一些零时的Buffer
模型参数仅占所有数据的小部分
当进行混合精度运算时,模型状态参数(优化器状态 + 梯度+ 模型参数)占大半以上。
因此,要想办法去除模型训练过程中的冗余数据。
LLaMA-6B 占用多大内存
【2023-7-13】LLaMA-6B 占用多大内存?计算过程
精度对所需内存的影响:
fp32精度,一个参数需要 32 bits, 4 bytes.
fp16精度,一个参数需要 16 bits, 2 bytes.
int8精度,一个参数需要 8 bits, 1 byte.
模型需要的RAM大致分三个部分:
模型参数: 参数量*每个参数所需内存
对于fp32,LLaMA-6B需要 6B*4 bytes = 24GB 内存
对于int8,LLaMA-6B需要 6B*1 byte = 6GB 内存
梯度: 参数量*每个梯度参数所需内存
优化器参数: 不同的优化器所储存的参数量不同。
对于常用的AdamW,需要储存两倍的模型参数(用来储存一阶和二阶momentum)。
fp32 的 LLaMA-6B,AdamW需要 6B*8 bytes = 48 GB
int8 的 LLaMA-6B,AdamW需要 6B*2 bytes = 12 GB
CUDA kernel也会占据一些RAM,大概1.3GB左右
综上,int8 精度的 LLaMA-6B 模型部分大致需要 6GB + 6GB + 12GB + 1.3GB = 25.3GB 左右。
再根据LLaMA的架构(hidden_size= 4096, intermediate_size= 11008, num_hidden_layers= 32, context_length = 2048)计算中间变量内存。每个instance需要: ( 4096+11008 ) * 2048 * 32 * 1 byte = 990 MB
所以,一张 A100(80GB RAM)大概可以在int8精度,batch_size = 50 的设定下进行全参数训练。
消费级显卡内存和算力查询: 2023 GPU Benchmark and Graphics Card Comparison Chart
7B 占用多大内存
一个7B规模大模型(如LLaMA-2 7B),基于16-bit混合精度训练时
仅考虑模型参数、梯度、优化器情况下,显存占用就有112GB
参数占 GPU 显存近 14GB(每个参数2字节)。
训练时梯度存储占14GB(每个参数对应1个梯度,也是2字节)
优化器Optimizer(假设是主流的AdamW)则是84GB(每个参数对应1个参数copy、一个momentum和一个variance,这三个都是float32)
2byte 模型静态参数权重(以16bit存储) = 14G
2byte 模型更新参数权重 (以16bit存储)= 14G
2byte 梯度(以16bit存储)= 14G
2byte 梯度更新(以16bit存储)= 14G
4byte 一阶动量优化器更新(以32bit存储)= 28G
4byte 二阶方差优化器更新(以32bit存储)= 28G
目前,合计 112GB
还有:前向传播时激活值,各种临时变量
还与sequence length, hidden size、batch size都有关系。
目前A100、H100这样主流显卡单张是放不下,更别提国内中小厂喜欢用的A6000/5000、甚至消费级显卡。
Adam + fp16 混合精度预估
【2023-6-29】LLM Training GPU显存耗用量估计,以Adam + fp16混合精度训练为例,分析其显存占用有以下四个部分
(1) 模型权重 Model
Prameters (FP16) 2 bytes
Gradients (FP16) 2 bytes
(2) 前向激活值 Activations
前向过程中存储, y = w1 * x, 存储x用于计算w1梯度
整体显存占用与batch有关
(3) 优化器 Optimizer:梯度、动量等
Master Weight (FP32) 4 bytes
Adam m (FP32) 4 bytes
Adam v (FP32) 4 bytes
(4) 临时混存 Buffer & Fragmentation
(1) 和 (3) 可以精确估计
显存占用大头是 Adam 优化器,占可计算部分的 12/16=75%
其次是模型参数+梯度,显存容量至少是参数量的16倍
Adam + fp16混合精度训练
不考虑Activation,3090 模型容量上限是 24/16=1.5B,A100 模型容量上限是 80/16=5B
假设训练过程中batchsize恒定为1,也即尽最大可能减少Activation在显存中的占用比例,使得理论计算值16Φ更接近真实的显存占用,那么24G的3090的模型容量上限是1.5B(差不多是GPT-2的水平),80G的A100的模型容量上限是5B
考虑Activation,3090的模型容量上限是 0.75B,A100的容量上限是 2.5B
batchsize为1的训练效率非常低,batchsize大于1才能充分发挥GPU的效率,此时Activation变得不可忽略。经验之谈,一般需要给Activation预留一半的显存空间(比如3090预留12G,A100预留40G),此时3090的模型容量上限是0.75B,A100的容量上限是2.5B,我们实际测试结果接近这个值
[1B, 5B] 是目前市面上大多数GPU卡的分水岭区间
[0, 1B) 市面上绝大多数卡都可以直接硬train一发
[1B, 5B] 大多数卡在这个区间的某个值上触发模型容量上限,具体触发值和显存大小有关
(5B, ~) 目前没有卡能裸训
模型参数量 (P):这个指标反映了你的模型规模。比如,如果你使用的是 LLaMA 模型,它包含 700 亿个参数,那么这个参数量就是 700 亿。
参数内存需求 (4B):通常情况下,每个模型参数需要 4 个字节的存储空间,这是因为浮点数通常需要 4 个字节(即 32 位)来表示。如果你采用的是半精度(16 位)格式,那么所需的内存量会相应减少。
参数位宽 (Q):这个值取决于你是以 16 位还是 32 位的精度来加载模型。16 位精度在许多大型语言模型的应用中较为普遍,因为它在保证足够精度的同时,能够降低内存的消耗。
额外开销 (1.2):乘以 1.2 的系数是为了增加 20% 的额外空间,以应对在模型推理过程中可能需要的额外内存。这不仅仅是为了安全起见,更是为了确保在模型执行过程中,激活操作和其他中间结果的内存需求得到满足。
700亿个参数(以 16位精度加载)的 LLaMA 模型提供服务所需的内存:
M = (P * 4B)/(32/Q) * 1.2 = (70 * 4 bytes)/(32/16) * 1.2 = 168 GB
单块 NVIDIA A100 GPU,尽管配备了 80 GB 显存,但仍然不足以支撑该模型的运行。为了高效地处理内存需求,至少需要两块 A100 GPU,每块都具备 80 GB 的显存容量。
内存/显存优化
显存优化技术:参考
重计算(Recomputation):Activation checkpointing(Gradient checkpointing)本质上是一种用时间换空间的策略。卸载(Offload)技术:一种用通信换显存的方法,简单来说就是让模型参数、激活值等在CPU内存和GPU显存之间左右横跳。如:ZeRO-Offload、ZeRO-Infinity等。混合精度(BF16/FP16):降低训练显存的消耗,还能将训练速度提升2-4倍。
BF16 计算时可避免计算溢出,出现Inf case。
FP16 在输入数据超过65506 时,计算结果溢出,出现Inf case。
CPU卸载
当GPU内存已满时,一种选择是将暂时未使用的数据卸载到CPU,并在以后需要时将其读回(Rhu等人,2016)。数据卸载到CPU 的想法很简单,但由于它会延长训练时间,所以近年来不太流行。
激活重新计算
激活重新计算(Activation recomputation (also known as “activation checkpointing” or “gradient checkpointing”,Chen等人,2016年)是一个以计算时间为代价减少内存占用的聪明而简单的想法
混合精度训练
Narang&Micikevicius等人(2018年)介绍了一种使用半精度浮点(FP16)数字训练模型而不损失模型精度的方法。
三种避免以半精度丢失关键信息的技术:
1)全精度原始权重。维护累积梯度的模型权重的全精度 (FP32) 副本, 对于向前和向后传递,数字四舍五入到半精度。主要是为了防止每个梯度更新(即梯度乘以学习率)可能太小而无法完全包含在 FP16 范围内(即 2-24 在 FP16 中变为零)的情况。
2)损失缩放。扩大损失以更好地处理小幅度的梯度(见图 16), 放大梯度有助于将权重移动到可表示范围的右侧部分(包含较大值)占据更大的部分,从而保留否则会丢失的值。
3)算术精度。对于常见的网络算法(例如向量点积,向量元素相加减少),可以将部分结果累加到 FP32 中,然后将最终输出保存为 FP16,然后再保存到内存中。可以在 FP16 或 FP32 中执行逐点操作。
大模型训练过程中,GPU显存占用主要分成Model States 与 Activation 两部分
混合精度训练流程:通过引入fb16以及bf16精度来减少fb32精度带来的显存消耗。
存储一份fp32的parameter,momentum和variance(统称model states)
在forward开始之前,额外开辟一块存储空间,将fp32 parameter减半到fp16 parameter;
正常做forward和backward,在此之间产生的activation和gradients,都用fp16进行存储;
用fp16 gradients去更新fp32下的model states;
当模型收敛后,fp32的parameter就是最终的参数输出;
混合精度下的显存:
通常模型会使用float32(fp32)精度进行训练,但是随着模型越来越大,训练的硬件成本和时间成本急剧增加。而混合精度训练通过利用float16(fp16)的优点并规避缺点来进行训练。
fp32,fp16,bf16的区别如下图所示
bf16是一种全新的数字格式,更加支持深度学习计算,但需要硬件支持,如NVIDIA A100, NVIDIA A800等
此外,官方文档中提到了AMP(Auto Mixed Precision 自动混合精度训练) ,与ZeRO不能同时使用
Int8 - bitsandbytes
Int8是个很极端的数据类型,最多只能表示-128~127的数字,并且完全没有精度。
为了在训练和inference中使用这个数据类型,bitsandbytes使用了两个方法最大程度地降低了其带来的误差:
vector-wise quantization
mixed precision decompasition
Huggingface 用动图解释了quantization的实现
paper
借助Huggingface PEFT,使用int8训练opt-6.5B的完整流程, notebook
FP 16
Fp16 - mixed precision
混合精度训练大致思路: 在 forward pass 和 gradient computation 时用 fp16 来加速,但是在更新参数时使用 fp32。
Pytorch 官方示例
torch fp16推理:直接使用model.half()将模型转换为fp16.
model.eval()
model.half() # 半精度
Huggingface Transformers:fp16-training
TrainingArguments 里声明 fp16=True
training_args = TrainingArguments(per_device_train_batch_size=4, fp16=True, **default_args)
trainer = Trainer(model=model, args=training_args, train_dataset=ds)
result = trainer.train()
print_summary(result)
中间结果通常会消耗大量内存,尽管它们只在一次向前传递和一次向后传递中需要。这两种使用之间存在明显的时间差距。因此Jain等人(2018年)提出了一种数据编码策略,将第一次使用后的中间结果在第一次传递中进行压缩,然后将其解码回来进行反向传播。
内存高效优化器
优化器内存消耗。以流行的 Adam 优化器为例,它内部需要保持动量和方差,两者都与梯度和模型参数处于同一规模,但是需要节省 4 倍的模型权重内存。
分布式机器学习实现
【2022-6-2】分布式机器学习
流水并行核心优势:
用比较少的 Pipeline Bubble 代价 (当 gradient accumulation step 很大时可以忽略不计),较少的 Tensor Buffer 显存代价,以及非常低的通信开销,将大模型分割在不同的 Group 中。 大幅减少了单张 GPU 上的 weight tensor 大小(数量) 和 Activation tensor 大小(数量)。
跟 Tensor Parallel 相比, Pipeline Parallel 的通信代价很低且可以被 overlap, Tensor Parallel 虽然也能切分模型大小,但是需要全量数据(没有减少 Activation tensor 大小),另外极高的通信频率和通信量使得 Tensor Parallel 只能在机器内 8 张卡用 NVLink 等高速互联来实现,跨机的 TP 会严重拖慢速度。
不仅如此, Pipeline Parallel 还将 Data Parallel 的模型更新限定在一个很小的范围内(比如六台机器), DP 所需的 AllReduce 通信会随着机器数量增多而变慢。 PP 也让 DP 所需同步的模型梯度大小变小了,大大减缓了模型更新对于训练速度的影响。
因此 Pipeline Parallel 是让模型可以达到千亿、集群可以扩充到千卡以上的一个最重要的特性。
流水并行有很重要的约束条件:
需要一个 规整对称的、线性顺序的网络结构。
GPT 就是这样一个典型的网络结构:
完全一样的 Transformer Layer 顺序堆叠,没有分叉和不对称情况,当均匀切分 Layer 时,各个 Stage 的前向/反向计算时间均一致。
作者:成诚
链接:https://www.zhihu.com/question/588325646/answer/3422090041
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
流水并行训练时的 time line 参考如下:
(反向的计算时间是前向的两倍)整个集群最高效的训练时间段是 step 4、5、6、7 的前向 和 step 0、1、2、3 的反向同时在所有 stage 上并行计算的时候,这个时候集群没有空闲,全部都在并行执行。 当我们增加 acc step (比如从 8 增加到 64)时,中间部分完美并行的时间段占比就会更长, bubble time 的占比就会越来越小。
而 T5 的网络结构比 GPT 要复杂很多, T5 是 Encoder-Decoder 架构,整个网络分为两大块,且 Encoder 和 Decoder 的 Transformer Layer 参数大小、Attention 计算量、Context Length 等均不一致,导致 Encoder 的理论计算量要比 Decoder 大很多(整个网络不是均匀对称的)。 更要命的是, T5 Encoder 的输出要发给每个 Decoder Layer,网络结构不是线性而是有大量的分叉,前向反向之间包含了复杂的数据依赖关系, 会导致流水并行中,各个 Stage 之间会产生大量的、非对称的、间隔跨多个 Stage 的数据依赖,更加剧了流水并行的 load balance 问题。
所以直接使用 Megatron 跑 T5 的 Pipeline Parallelism,会从 nsys prof 时间线上看到大量的缝隙,各个 Stage 之间在互相等待,无法真正流水并行起来。
如果不用 Pipeline Parallelism 来训练 T5,那么只能借助: DP、TP 和 ZeRO 来进行并行优化了, 这就约束了 T5 的所有 Layer 都必须放在每一个 GPU 上,这种方式在 13B 量级的模型上是 OK 的,但是再往上扩展到 100B、1T 量级就不 work 了。
同时由于 TP 只能开到 8 (跨机器也会慢几倍), 在千卡 GPU 集群以上,大量的 DP 带来的通信变慢的影响也很严重(ZeRO-2/3 会大幅加剧这种通信开销)。 所以我们才说, 虽然 T5 的理论计算量相较于 GPT 没有增加很多,但是在千亿参数、千卡集群以上规模的时候,T5 的实际训练效率比 GPT 慢很多倍。即使到现在,也没有一个超过 11B 的 T5 模型发布, 而 11B 恰好是一个不借助 PP,仅通过 ZeRO + TP 就可以训练的模型大小,避免了 T5 的模型结构非对称性对于 PP 的灾难性影响。
无论哪种机器学习框架,分布式训练的基本原理都是相同的。可以从并行模式、架构模式、同步范式、物理架构、通信技术等五个不同的角度来分类。
更多信息见优质paper,把 DP(Data Parallel)、MP(Model Parallel)、PP(Pipeline Parallel)各个方面讲的很透彻
ZeRO: Memory Optimizations Toward Training Trillion Parameter Models
分布式训练目的:将原本巨大的训练任务拆解成多个子任务,每个子任务在独立的机器上单独执行。
大规模深度学习任务的难点在于:
1) 训练数据量巨大:将数据拆解成多个小模型分布到不同的node上。→ 数据并行
2) 训练模型的参数巨大:将数据集拆解分布到不同的node上。→ 模型并行
NLP的预训练模型实在太大了
数据并行(DP&DDP)
DP(Data Parallelism):早期数据并行模式,一般采用参数服务器(Parameters Server)编程框架。实际中多用于单机多卡。DDP(Distributed Data Parallelism):分布式数据并行,采用Ring AllReduce 通讯方式,多用于多机多卡场景。DP 单机数据并行
数据并行本质
单进程多线程实现方式,只能实现单机训练, 不算严格意义上的分布式训练
多个GPU 情况下,将模型分发到每个GPU上去,每个GPU都保留完整模型参数。
每个GPU加载全部模型(Parameter、Grad、Optimizer、Activation、Temp buffer)
将每个batch样本平均分配到每个GPU上进行梯度计算
然后汇总每个GPU上的梯度
将汇总梯度重新分发到每个GPU上,每个GPU模型根据汇总的梯度进行模型参数更细。
K个GPU并数据并行训练过程如下:
任何一次训练迭代中,给定的随机的小批量样本都将被分成K个部分,并均匀地分配到GPU上;
每个GPU根据分配给它的小批量子集,计算模型参数的损失和梯度;
将个GPU中的局部梯度聚合,以获得当前小批量的随机梯度;
聚合梯度被重新分发到每个GPU中;
每个GPU使用这个小批量随机梯度,来更新所维护的完整的模型参数集。
数据并行是在每个worker上存储一个模型的备份,在各个worker 上处理不同的数据子集。然后需要规约(reduce)每个worker的结果,在各节点之间同步模型参数。
这一步会成为数据并行的瓶颈,因为如果worker很多的情况下,worker之间的数据传输会有很大的时间成本。
参数同步后,需要采用不同的方法进行参数更新:
参数平均法:最简单的一种数据平均化
更新式方法
若采用参数平均法,训练的过程如下所示:基于模型的配置随机初始化网络模型参数
将当前这组参数分发到各个工作节点
在每个工作节点,用数据集的一部分数据进行训练
将各个工作节点的参数的均值作为全局参数值
若还有训练数据没有参与训练,则继续从第二步开始
更新式方法与参数平均化类似,主要区别在于,在参数服务器和工作服务器之间传递参数时,更新式方法只传递更新信息(梯度和张量)。
负载不均衡,主GPU负载大
PS 架构通信开销大
DDP 分布式数据并行
DDP (Distribution Data Parallel)
AllReduce 架构,在单机和多机上都可以使用。
负载分散在每个gpu节点上,通信成本是恒定的,与 GPU 数量无关。
模型并行(model parallesim)
当模型参数过大,单个 GPU无法容纳模型参数时,就需要模型并行, 将模型拆分到多个 GPU 训练。
模型并行相对复杂
原理:分布式系统中的不同worker负责网络模型的不同部分
例如,神经网络的不同层被分布到不同worker或者同一层的不同参数被分配到不同worker上。
对于TF这种框架,可以拆分计算图成多个最小依赖子图到不同的worker上。同时在多个子图之间通过通信算子来实现模型并行。
但是模型并行实现起来比较复杂。工业界还是以数据并行为主。
层间 & 层内
Model Parallel主要分两种:intra-layer拆分 和 inter-layer拆分
inter-layer拆分:对模型做网络上的拆分,将每一层或者某几层放在一个worker上单独训练。
缺点:模型训练串行,整个模型的效率取决于最慢的那一层,存在资源浪费
intranet-layer拆分:深度学习的网络结构基本都是一层层的。常规的卷积、池化、BN等等。如果对某一层进行了拆分,那么就是intra-layer拆分。对单层的拆分其实就是拆分这一层的matrix运算。
参考论文:Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
改进: 谷歌提出了GPipe 流水线并行(Pipeline model parallesim ), 引入micro-batches (MBS)的概念,会提升GPU利用率
问题: 流水线最大的问题, 无法充分利用GPU资源,training过程中会出现非预期的Bubble
张量并行(Tensor Model Parallelism)
张量并行(TP)是模型并行一种形式,流水线并行按网络层切分,张量并行按矩阵切分。
2019年,NVIDIA发布《Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM》论文,提出了张量并行方法
核心思想: 每个GPU仅处理矩阵一部分,当算子需要整个矩阵的时候再进行矩阵聚合。无论是横向切分还是竖向切分,都可以将切分后的矩阵放到不同GPU上进行计算,最后将计算的结果再合并。
大模型主要结构都是Transformer模型,Transformer核心模块网路结构:anttention层+残差连接,MLP层+残差连接。
MLP层: 数学表达如下:Y = GeLU(XA) ,Z = Dropout(YB)
Attention层: 数学表达如下:Y = Self-Attention(X) ,Z = Dropout(YB), 多头注意力每个头都是独立的,因此张量切分更方便
大模型训练时,ZeRO支持将模型显存内存占用划分到多张卡或者多个节点。
【2023-8-28】模型并行最佳实践(PyTorch)
两个GPU上运行此模型,只需将每个线性层放在不同的GPU上,然后移动输入(input)和中间输出(intermediate outputs)以匹配层设备(layer devices)。
import torch
import torch.nn as nn
import torch.optim as optim
class ToyModel(nn.Module):
模型并行示例
def __init__(self):
# 模型定义修改: 只需增加 to(device)
super(ToyModel, self).__init__()
self.net1 = torch.nn.Linear(10, 10).to('cuda:0') # 将net1放置在第1个GPU上
self.relu = torch.nn.ReLU()
self.net2 = torch.nn.Linear(10, 5).to('cuda:1') # 将net2放置在第2个GPU上
def forward(self, x):
x = self.relu(self.net1(x.to('cuda:0')))
return self.net2(x.to('cuda:1'))
注意 ToyModel
除了5个用于将线性层(linear layers)和张量(tensors)放置在适当设备上的to(device)调用之外,以上内容与在单个GPU上实现该功能非常相似。那是模型中唯一更改地方(即to(device) )。
在 backward()和 torch.optim 会自动关注梯度(gradients),模型如同一个GPU。
调用损失函数时,只需确保标签(label)与输出(output)在同一设备(on the same device)上。
model = ToyModel()
loss_fn = nn.MSELoss()
optimizer = optim.SGD(model.paraeters(), lr=0.001)
optimizer.zero_grad()
outputs = model(torch.randn(20, 10))
labels = torch.randn(20, 5).to('cuda:1') # ToyMode 的 output 是在 'cuda:1' 上,此处的 label 也应该置于 'cuda:1' 上
loss_fn(outputs,labels).backward()
optimizer.step()
只需更改几行,就可以在多个GPU上运行现有的单GPU模块。
如何分解 torchvision.models.reset50() 为两个GPU。
从现有 ResNet模块继承,并在构建过程中将层拆分为两个GPU。
然后覆盖 forward方法来缝合两个子网,通过相应地移动中间输出。
from torchvision.models.resnet import ResNet, Bottleneck
num_classes = 1000
class ModelParallelResNet50(ResNet):
def __init__(self, *args, **kwargs):
super(ModelParallelResNet50, self).__init__(Bottleneck, [3, 4, 6, 3], num_classes=num_classes, *args, **kwargs)
self.seq1 = nn.Sequential(
self.conv1,
self.bn1,
self.relu,
self.maxpool,
# 模型拆分
self.layer1,
self.layer2
).to('cuda:0') # 放置在第1个GPU上
self.seq2 = nn.Sequential(
self.layer3,
self.layer4,
self.avgpool,
).to('cuda:1') # 放置在第2个GPU上
self.fc.to('cuda:1')
def forward(self, x):
x = self.seq2(self.seq1(x).to('cuda:1'))
return self.fc(x.view(x.size(0), -1))
对于模型太大而无法放入单个GPU的情况,上述实现解决了该问题。但是,如果模型合适,model parallel 将比在单个GPU上运行要慢。
因为在任何时间点,两个GPU中只有1个在工作,而另一个在那儿什么也没做。
在 layer2 和 layer3之间,中间输出需要从 cuda:0 复制到 cuda:1,这使得性能进一步恶化。
import torchvision.models as models
num_batches = 3
batch_size = 120
image_w = 128
image_h = 128
def train(model):
model.train(True)
loss_fn = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.001)
one_hot_indices = torch.LongTensor(batch_size) \
.random_(0, num_classes) \
.view(batch_size, 1)
for _ in range(num_batches):
# generate random inputs and labels
inputs = torch.randn(batch_size, 3, image_w, image_h)
labels = torch.zeros(batch_size, num_classes) \
.scatter_(1, one_hot_indices, 1)
# run forward pass
optimizer.zero_grad()
outputs = model(inputs.to('cuda:0'))
# run backward pass
labels = labels.to(outputs.device)
loss_fn(outputs, labels).backward()
optimizer.step()
两个GPU中的一个会处于空闲状态。怎么优化?
将每个批次进一步划分为拆分流水线,当1个拆分到达第2子网时,可以将下一个拆分馈入第一子网。这样,两个连续的拆分可以在两个GPU上同时运行。
流水线输入(Pipelining Inputs)加速
将每批次 120-image 进一步划分为 20-image 。当PyTorch异步启动CUDA操作时,该实现无需生成多个线程即可实现并发。
class PipelineParallelResNet50(ModelParallelResNet50):
def __init__(self, split_size=20, *args, **kwargs):
super(PipelineParallelResNet50, self).__init__(*args, **kwargs)
self.split_size = split_size
def forward(self, x):
splits = iter(x.split(self.split_size, dim=0))
s_next = next(splits)
s_prev = self.seq1(s_next).to('cuda:1')
ret = []
for s_next in splits:
# A. s_prev runs on cuda:1
s_prev = self.seq2(s_prev)
ret.append(self.fc(s_prev.view(s_prev.size(0), -1)))
# B. s_next runs on cuda:0, which can run concurrently with A
s_prev = self.seq1(s_next).to('cuda:1')
s_prev = self.seq2(s_prev)
ret.append(self.fc(s_prev.view(s_prev.size(0), -1)))
return torch.cat(ret)
setup = "model = PipelineParallelResNet50()"
pp_run_times = timeit.repeat(
stmt, setup, number=1, repeat=num_repeat, globals=globals())
pp_mean, pp_std = np.mean(pp_run_times), np.std(pp_run_times)
plot([mp_mean, rn_mean, pp_mean],
[mp_std, rn_std, pp_std],
['Model Parallel', 'Single GPU', 'Pipelining Model Parallel'],
'mp_vs_rn_vs_pp.png')
设备到设备的张量复制操作在源设备和目标设备上的当前流(current streams)上同步。如果创建多个流,则必须确保复制操作正确同步。在完成复制操作之前写入源张量或读取/写入目标张量可能导致不确定的行为。上面的实现仅在源设备和目标设备上都使用默认流,因此没有必要强制执行其他同步。
流水线并行
数据并行还是模型并行都会在相应机器之间全连接通信,当机器数量增大时,通信开销和时延会大到难以忍受
流水线(管道)并行既解决了超大模型无法在单设备装下的难题,又解决了机器之间的通信开销的问题
每个阶段(stage) 和下一个阶段之间仅有相邻的某一个 Tensor 数据需要传输
每台机器的数据传输量跟总的网络大小、机器总数、并行规模无关。
G-pipe
谷歌提出 G-pipe 流水线并行(Pipeline model parallesim ), 引入micro-batches (MBS)的概念,会提升GPU利用率
F-then-B 调度方式: 原 mini-batch(数据并行切分后的batch)划分成多个 micro-batch(mini-batch再切分后的batch),每个 pipeline stage (流水线并行的计算单元)先整体进行前向计算,再进行反向计算。同一时刻分别计算模型的不同部分,F-then-B 可以显著提升设备资源利用率。F-then-B 模式由于缓存了多个 micro-batch 的中间变量和梯度,显存的实际利用率并不高。
解决: 1F1B (在流水线并行中,pipeline stage 前向计算和反向计算交叉进行的方式)流水线并行方式。1F1B 模式下,前向计算和反向计算交叉进行,可以及时释放不必要的中间变量。
PipeDream
PipeDream 在单个 GPU 上短暂运行性能分析后,自动决定怎样分割这些 DNN 算子,如何平衡不同 stage 之间的计算负载,而同时尽可能减少目标平台上的通信量。
PipeDream将DNN 层划分为多个阶段 —— 每个阶段(stage)由模型中的一组连续层组成。
PipeDream把模型的不同的阶段部署在不同的机器上,每个阶段可能有不同的replication。该阶段对本阶段中所有层执行向前和向后传递。
PipeDream将包含输入层的阶段称为输入阶段,将包含输出层的阶段称为输出阶段。
virtual pipeline
virtual pipeline 是 Megatron-2 论文中最主要的一个创新点。
传统的 pipeline 并行通常会在一个 Device 上放置几个 block,为了扩展效率,在计算强度和通信强度中间取一个平衡。
但 virtual pipeline 在 device 数量不变的情况下,分出更多的 pipeline stage,以更多的通信量,换取空泡比率降低,减小了 step e2e 用时。
张量并行(Tensor Parallelism)
流水线并行主要集中在多层神经网络架构训练上,对于Transformer架构的模型(如BERT,GPT等),MultiHead Attention Layer和MLP的计算量翻了几倍,如果继续按管线切分模型, 可能单层参数都无法被显存装载,因此需要横着把同一层的模型切分开来,这便是张量并行
层间并行: 流水线并行
层内并行: 张量并行
分布式张量计算正交且更通用,将张量操作划分到多个设备上,以加速计算或增加模型大小。
把 Masked Multi Self Attention 和 Feed Forward 都进行切分以并行化,利用Transformers网络的结构,通过添加一些同步原语来创建一个简单的模型并行实现。
张量并行(Tensor Model Parallelism)
张量并行(TP)是模型并行一种形式,流水线并行按网络层切分,张量并行按矩阵切分。
2019年,NVIDIA发布《Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM》论文,提出了张量并行方法
核心思想: 每个GPU仅处理矩阵一部分,当算子需要整个矩阵的时候再进行矩阵聚合。无论是横向切分还是竖向切分,都可以将切分后的矩阵放到不同GPU上进行计算,最后将计算的结果再合并。
张量并行最有名的是: Megatron 和 Deepspeed
随着训练设备的增加,多个worker之间的通信成本增加,模型Reduce的成本也越来越大,数据并行的瓶颈也随之出现。故有学者提出混合并行(数据并行+模型并行)
分布式训练上会频繁用到规约(AllReduce)操作。
all-reduce 操作有多种方式实现:
树状结构:数据在进程间以树状结构进行归约,每个非叶子节点负责将其子节点的数据归约后再传递给其父节点。
环形结构:进程之间形成一个环,数据在环中按顺序传递并归约。
直接归约:所有进程直接将数据发送给一个中心节点,该节点完成归约后将结果发送回所有进程。
all-reduce 操作性能对分布式计算的效率至关重要,因此优化这一操作是分布式系统设计中的一个研究热点。使用最多的实现方式是百度提出的 Ring AllReduce 算法,该方法属于环状结构实现的一种。
主流的分布式架构主要分为参数服务器(ParameterServer) 和基于规约(Reduce)两种模式。早期还有基于MPI的方式,不过现在已经很少用了。
传统 parameter server: server和client方式
client通过计算分配给自己的数据,产生梯度,传给server
server 聚合,然后把参数再传给client
这个方式的弊端: server容易成为瓶颈
server通信量太大。
一个client失败,会导致其他client等待。
Ring all reduce 一种分布式方式
各个节点分配通信量。
总的通信量和ps没啥变化,但是通信的压力平摊到各个GPU上了,GPU之间的通信可以并行进行。
假如,GPU数量是N,把模型参数分成N份,每个GPU要存放整个参数。每个GPU也要分配训练数据。
当一次迭代,N个GPU之间要经过一个scatter和gather操作,reduce-scatter是将不同gpu上对应的参数的gradient相加,一共需要通讯(N-1)次。
All-gather 将合并完整的参数,传到其他gpu上,需要通讯(N-1)次。
一次all reduce,单卡通信量为2*sita。
PS:参数服务器
ParameterServer模式是一种基于reduce和broadcat算法的经典架构。
其中一个/一组机器作为PS架构的中心节点,用来存储参数和梯度。
在更新梯度的时候,先全局reduce接受其他worker节点的数据,经过本地计算后(比如参数平均法),再broadcast回所有其他worker。
论文: Parameter Server for Distributed Machine Learning
PS架构的问题在于多个worker与ps通信,PS本身可能存在瓶颈。
随着worker数量的增加,整体通信量也线性增加,加速比也可能停滞在某个点位上。
基于规约 Reduce模式
基于规约的模式解决了上述的问题,最典型的是百度提出的 Ring-AllRuduce。
多个Worker节点连接成一个环,每个Worker依次把自己的梯度同步给下一个Worker,经过至多 2*(N-1) 轮同步,就可以完成所有Worker的梯度更新。
这种方式下所有节点的地位是平等的,因此不存在某个节点的负载瓶颈,随着Worker的增加,整体的通信量并不随着增加。加速比几乎可以跟机器数量成线性关系且不存在明显瓶颈。
目前,越来越多的分布式训练采用Reduce这种模式。Horovod中主要就是用的这种分布式架构。
更多资料参考: 兰瑞Frank:腾讯机智团队分享–AllReduce算法的前世今生
实际训练过程中可能遇到各种问题,比如:部分节点资源受限、卡顿、网络延时等等
因此梯度同步时就存在“木桶“效应,即集群中的某些worker比其他worker更慢,导致整个训练pipeline需要等待慢的worker,整个集群的训练速度受限于最慢机器的速度。
因此梯度同步有“同步”(sync)、“异步”(Async)和混合三种范式。
同步范式:只有所有worker完成当前的计算任务,整个集群才会开始下一次迭代。
TF中同步范式使用SyncReplicasOptimizer优化器
异步模式刚好相反,每个worker只关心知己的进程,完成计算后就尝试更新,能与其他多个worker同步梯度完成取决于各worker当前时刻的状态。其过程不可控,有可能出现模型正确性问题。(可在训练时logging对比)
混合范式结合以上两种情况,各个worker都会等待其他worker的完成,但不是永久等待,有timeout的机制。如果超时了,则此情况下相当于异步机制。并且没来得及完成计算的worker,其梯度则被标记为“stale”而抛弃或另做处理。
Gradient Accumulation 把一个大 Batch 拆分成多个 micro-batch, 每个 micro-batch 前后向计算后的梯度累加,在最后一个micro-batch累加结束后,统一更新模型。
micro-batch 跟数据并行高度相似性:
数据并行是空间上,数据被拆分成多个 tensor,同时喂给多个设备并行计算,然后将梯度累加在一起更新;
而 micro-batch 是时间上的数据并行,数据被拆分成多个 tensor, 按照时序依次进入同一个设备串行计算,然后将梯度累加在一起更新。当总的 batch size 一致,且数据并行的并行度和 micro-batch 的累加次数相等时,数据并行和 Gradient Accumulation 在数学上完全等价。
Gradient Accumulation 通过多个 micro-batch的梯度累加, 使下一个 micro-batch 的前向计算不需要依赖上一个 micro-batch 的反向计算,因此可以畅通无阻的进行下去(当然在一个大 batch 的最后一次 micro-batch 还是会触发这个依赖)。
Gradient Accumulation 解决了很多问题:
单卡下,Gradient Accumulation 将一个大 batch size 拆分成等价的多个小 micro-batch ,从而达到节省显存的目的。
数据并行下,Gradient Accumulation 解决了反向梯度同步开销占比过大的问题(随着机器数和设备数的增加,梯度的 AllReduce 同步开销也加大),因为梯度同步变成了一个稀疏操作,因此可以提升数据并行的加速比。
流水并行下, Gradient Accumulation 使得不同 stage 之间可以并行执行不同的 micro-batch, 从而让各个阶段的计算不阻塞,达到流水的目的。如果每个 micro-batch 前向计算的中间结果(activation)被后向计算所消费,则需要在显存中缓存 8多份(梯度累加的次数)完整的前向 activation。这时就不得不用另一项重要的技术:激活检查点(activation checkpointing)。
物理架构主要是 GPU架构,即:单机单卡、单机多卡、多机单卡、多机多卡(最典型)
单机单卡:常规操作
单机多卡:利用一台GPU上的多块GPU进行分布式训练。数据并行和模型并行皆可。整个训练过程一般只有一个进程,多GPU之间的通信通过多线程的方式,模型参数和梯度在进程内是共享的(基于NCCL的可能不大一样)。这种情况下基于Reduce的架构比PS架构更合适一些,因为不需要一个显式的PS,通过进程内的Reduce即可完成梯度同步。
多机单卡:操作上与多机多卡基本一致
多机多卡:多机多卡是最典型的分布式架构,所以它需要较好的进程间的通讯机制(多worker之间的通信)。
分布式训练的基本原理
TensorFlow的分布式训练
PyTorch的分布式训练框架
Horovod分布式训练
分布式实现
超大规模语言模型主要有两条技术路线:
(1) TPU + XLA + TensorFlow/JAX : Google主导,由于TPU和自家云平台GCP深度绑定
(2) GPU + PyTorch + Megatron-LM + DeepSpeed: NVIDIA、Meta、MS大厂加持,社区氛围活跃
(1) 对于非Googler 只可远观而不可把玩,(2) 更受到群众欢迎。
TF分布式训练方法
黄文坚的Tensorflow分布式实战
TensorFlow主要的分布式训练的方法有三种:
Customer Train Loop:最原始,由框架工程师自己开发
Estimator + Strategy:高级API,不用关心底层硬件
Keras + Strategy:最新出的keras的高级API
第一种方式太过原生,整个分布式的训练过程完全交给工程师来处理,代码模块比较复杂,这里不做赘述。
第二种方式,Estimator是TF的一个高级API,在分布式场景下,其最大的特点是单机和分布式代码一致,且不需要考虑底层的硬件设施。Strategy是tensorflow根据分布式训练的复杂性,抽象出的多种分布式训练策略。TF1.x和TF2.x接口变化较大,不同版本名字可能不一样,以实际使用版本为准。用的比较多的是:
MirroredStrategy:适用于单机多卡、数据并行、同步更新的分布式训练,采用Reduce的更新范式,worker之间采用NCCL进行通信。
MultiWorkerMirroredStrategy:与上面的类似,不同的是这种策略支持多机多卡、数据并行、同步更新的分布式策略、Reduce范式。在TF 1.15版本里,这个策略叫CollectiveAllReduceStrategy。
ParameterServerStrategy:经典的PS架构,多机多卡、数据并行、同步/异步更新
使用Estimator+Strategy 实现分布式训练,参考代码
第三种方式 Keras + Strategy 是Tensorflow最新官方推荐的方案。主要是利用keras的高级API,配合Strategy实现多模式的分布式训练。
#coding=utf-8
#单机单卡,对于单机单卡,可以把参数和计算都定义再gpu上,不过如果参数模型比较大,显存不足等情况,就得放在cpu上
import tensorflow as tf
with tf.device('/cpu:0'):#也可以放在gpu上
w=tf.get_variable('w',(2,2),tf.float32,initializer=tf.constant_initializer(2))
b=tf.get_variable('b',(2,2),tf.float32,initializer=tf.constant_initializer(5))
with tf.device('/gpu:0'):
addwb=w+b
mutwb=w*b
init=tf.initialize_all_variables()
with tf.Session() as sess:
sess.run(init)
np1,np2=sess.run([addwb,mutwb])
print np1,np2
PyTorch
pytorch实现
封装程度非常高,只需保证即将被推到 GPU 的数据是张量(Tensor)或者模型(Module),就可以用 to() 函数快速进行实现。
import torch
from torch import nn
data = torch.ones((3, 3)) # 定义数据(张量)
print(data.device)
net = nn.Sequential(nn.Linear(3, 3)) # 定义模型
print(torch.cuda.is_available()) # 判断当前的机器是否有可用的 GPU
print(torch.cuda.device_count()) # 目前可用的 GPU 的数量。
# 使用第一块GPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # cuda: 0 表示使用的是第一块 GPU。当然可以不用声明“:0”,默认就从第一块开始
print(device) # cpu 或 0
# 数据迁移:将data推到(迁移)gpu上
data_gpu = data.to(device)
print(data_gpu.device)
# 模型迁移:model推到gpu
net.to(device)
单机多卡,只要用device直接指定设备,就可以进行训练,SGD采用各个卡的平均值
问题:除了取均值,还有别的方式吗?
#coding=utf-8
#单机多卡:一般采用共享操作定义在cpu上,然后并行操作定义在各自的gpu上,比如对于深度学习来说,我们一般把参数定义、参数梯度更新统一放在cpu上,各个gpu通过各自计算各自batch数据的梯度值,然后统一传到cpu上,由cpu计算求取平均值,cpu更新参数。具体的深度学习多卡训练代码,请参考:https://github.com/tensorflow/models/blob/master/inception/inception/inception_train.py
import tensorflow as tf
with tf.device('/cpu:0'):
w=tf.get_variable('w',(2,2),tf.float32,initializer=tf.constant_initializer(2))
b=tf.get_variable('b',(2,2),tf.float32,initializer=tf.constant_initializer(5))
with tf.device('/gpu:0'):
addwb=w+b
with tf.device('/gpu:1'):
mutwb=w*b
ini=tf.initialize_all_variables()
with tf.Session() as sess:
sess.run(ini)
while 1:
print sess.run([addwb,mutwb])
多个 GPU 上运行 TensorFlow,则可以采用多塔式方式构建模型,其中每个塔都会分配给不同 GPU。例如:
# Creates a graph.
c = []
for d in ['/device:GPU:2', '/device:GPU:3']:
with tf.device(d):
a = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[2, 3])
b = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[3, 2])
c.append(tf.matmul(a, b))
with tf.device('/cpu:0'):
sum = tf.add_n(c)
# Creates a session with log_device_placement set to True.
sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
# Runs the op.
print(sess.run(sum))
【2020-5-20】每个gpu的梯度要累加起来,单独计算
# train op def
tower_grads = []
for i in xrange(FLAGS.num_gpus):
with tf.device('/gpu:{}'.format(i)):
with tf.name_scope('tower_{}'.format(i)):
next_batch = dhs.get_next_batch()
cnn.inference(
next_batch[0], next_batch[1], next_batch[2],
dropout_keep_prob=FLAGS.dropout_keep_prob,
input_dropout_keep_prob=FLAGS.input_dropout_keep_prob,
phase_train=True)
grads = optimizer.compute_gradients(cnn.loss)
tower_grads.append(grads)
grads = average_gradients(tower_grads)
train_op = optimizer.apply_gradients(grads, global_step=global_step)
def average_gradients(tower_grads):
Calculate the average gradient for each shared variable across all towers.
Note that this function provides a synchronization point across all towers.
NOTE: This function is copied from cifar codes in tensorflow tutorial with minor
modification.
Args:
tower_grads: List of lists of (gradient, variable) tuples. The outer list
is over individual gradients. The inner list is over the gradient
calculation for each tower.
Returns:
List of pairs of (gradient, variable) where the gradient has been averaged
across all towers.
average_grads = []
for grad_and_vars in zip(*tower_grads):
# Note that each grad_and_vars looks like the following:
# ((grad0_gpu0, var0_gpu0), ... , (grad0_gpuN, var0_gpuN))
grads = []
for g, _ in grad_and_vars:
# Add 0 dimension to the gradients to represent the tower.
# NOTE: if batch norm applied, the grad of conv-maxpool-n/b will be
# None
if g is None:
continue
expanded_g = tf.expand_dims(g, 0)
# Append on a 'tower' dimension which we will average over below.
grads.append(expanded_g)
# Average over the 'tower' dimension.
if grads:
grad = tf.concat(axis=0, values=grads)
grad = tf.reduce_mean(grad, 0)
else:
grad = None
# Keep in mind that the Variables are redundant because they are shared
# across towers. So .. we will just return the first tower's pointer to
# the Variable.
v = grad_and_vars[0][1]
grad_and_var = (grad, v)
average_grads.append(grad_and_var)
return average_grads
参考官网:TensorFlow with multiple GPUs
PyTorch
PyTorch 多种解决方案,最简单常用:nn.DataParallel()
module :定义的模型
device_ids 即为训练模型时用到的 GPU 设备号,
output_device 表示输出结果的 device,默认为 0 也就是第一块卡。
在每个迭代训练的Forward过程中:nn.DataParallel都自动将输入按照GUP数量进行split;然后复制模型参数到各个GPU上;分别进行正向计算后将得到网络输出output_x;最后将结果concat拼接到一起送往0号卡中。
在Backward过程中:先由0号卡计算loss函数,通过loss.backward()得到损失函数相于各个gpu输出结果的梯度grad_l1 … gradln;接下来0号卡将所有的grad_i送回对应的GPU_i中;然后GPU们分别进行backward得到各个GPU上面的模型参数梯度值gradm1 … gradmn;最后所有参数的梯度汇总到GPU0卡进行update。
多卡训练时,output_device 的卡所占的显存明显大一些。
因为使用 DataParallel 时,数据并行,每张卡获得的数据都一样多,但是所有卡的 loss 都会在第 output_device 块 GPU 进行计算,这导致了 output_device 卡的负载进一步增加。
只需要一个 DataParallel 函数就可以将模型和数据分发到多个 GPU 上。
但是还是需要了解这内部的运行逻辑, 遇到了诸如时间计算、资源预估、优化调试问题的时候,可以更好地运用 GPU
import os
from torch import nn
import torch
class ASimpleNet(nn.Module):
def __init__(self, layers=3):
super(ASimpleNet, self).__init__()
self.linears = nn.ModuleList([nn.Linear(3, 3, bias=False) for i in range(layers)]) # 设备有几个,就创建几个模型分支,
def forward(self, x): # 模型前馈实际处理过程
print("forward batchsize is: {}".format(x.size()[0]))
x = self.linears(x)
x = torch.relu(x)
return x
device=os.environ['CUDA_VISIBLE_DEVICES']
# os.environ['CUDA_VISIBLE_DEVICES']="0,2" 指定具体的设备
# print("CUDA_VISIBLE_DEVICES :{}".format(os.environ["CUDA_VISIBLE_DEVICES"]))
batch_size = 16
inputs = torch.randn(batch_size, 3) # 创建16个数据
labels = torch.randn(batch_size, 3) # 创建16个数据标签
inputs, labels = inputs.to(device), labels.to(device) # 数据迁移到设备上,返回数据总接口(应该是一个列表/字典,数据片段-GPU对应关系)
net = ASimpleNet() # 模型实例化
net = nn.DataParallel(net) # 模型分布结构化
net.to(device) # 模型迁移到设备上,返回一个模型总接口(应该是一个列表/字典,子模型-GPU对应关系)
for epoch in range(1): # 训练次数自行决定
outputs = net(inputs) # 数据统一入口;数据怎么分配,模型参数怎么同步,内部机制自行来处理
# 输出:
# CUDA_VISIBLE_DEVICES : 3, 2, 1, 0
# forward batchsize is: 4
# forward batchsize is: 4
# forward batchsize is: 4
# forward batchsize is: 4
注意:有几个GPU,建几个分支(同结构模型),这样就可以分散到各个GPU上。
CUDA_VISIBLE_DEVICES 得知了当前程序可见的 GPU 数量为 4,而创建的 batch size 为 16,输出每个 GPU 上模型 forward 函数内部的 print 内容,验证了每个 GPU 获得的数据量都是 4 个。
DataParallel 会自动将数据切分、加载到相应 GPU,将模型复制到相应 GPU,进行正向传播计算梯度并汇总。
DataParallel的整个并行训练过程利用python多线程实现
由以上工作过程分析可知,nn.DataParallel 无法避免的问题:
负载不均衡问题。gpu_0所承担的任务明显要重于其他gpu
速度问题。每个iteration都需要复制模型且均从GPU0卡向其他GPU复制,通讯任务重且效率低;python多线程GIL锁导致的线程颠簸(thrashing)问题。
只能单机运行。由于单进程的约束导致。
只能切分batch到多GPU,而无法让一个model分布在多个GPU上。当一个模型过大,设置batchsize=1时其显存占用仍然大于单张显卡显存,此时就无法使用DataParallel类进行训练。
因此官方推荐使用 torch.nn.DistributedDataParallel 替代 nn.DataParallel
一、基本概念
Cluster、Job、task概念:三者可以简单的看成是层次关系
task相当于每台机器上的一个进程,多个task组成job;
job又有两种:ps参数服务、worker计算服务,组成cluster。
二、同步SGD与异步SGD
1、同步更新:各个用于并行计算的电脑,计算完各自的batch 后,求取梯度值,把梯度值统一送到ps服务机器中,由ps服务机器求取梯度平均值,更新ps服务器上的参数。
如下图所示,可以看成有四台电脑,第一台电脑用于存储参数、共享参数、共享计算,可以简单的理解成内存、计算共享专用的区域,也就是ps job;另外三台电脑用于并行计算的,也就是worker task。
这种计算方法存在的缺陷是:每一轮的梯度更新,都要等到A、B、C三台电脑都计算完毕后,才能更新参数,也就是迭代更新速度取决与A、B、C三台中,最慢的那一台电脑,所以采用同步更新的方法,建议A、B、C三台的计算能力都不想。
2、异步更新:ps服务器收到只要收到一台机器的梯度值,就直接进行参数更新,无需等待其它机器。这种迭代方法比较不稳定,收敛曲线震动比较厉害,因为当A机器计算完更新了ps中的参数,可能B机器还是在用上一次迭代的旧版参数值。
多机多卡讲解
【2024-4-18】大模型多机多卡训练经验总结
LLM多机多卡训练教程好少,有些还拿 torch.distributed.launch 来做,殊不知早就改用 torchrun 了。
环境准备: 以2台机器为例
首先, 2台机器要能免密登录,编辑/etc/hosts文件,加入node信息:
# vi /etc/hosts
ip1 node01
ip2 node02
然后, 两个node分别执行以下操作, 生成私钥和公钥:
ssh-keygen -t rsa
然后, 全部回车,采用默认值。再互相拷贝秘钥:
ssh-copy-id root@ip1
ssh-copy-id root@ip2
分别在2台机器上试试互相ssh,如果无密码输入要求直接登录到另一台服务器则说明配置成功。
2台机器环境必须保持一致,包括python版本,训练所需依赖包等。
还需确保安装了pdsh:
apt-get install pdsh
使用 torchrun,毕竟单张GPU有80G显存,7B模型单卡完全放得下。
假设node01为master,node02需要有相同的模型权重和代码,可以直接在master用scp拷贝过去。
准备工作完成后, 可以启动训练命令
首先在node01(master)执行如下命令(非完整,仅供参考,使用deepspeed ZeRO-2):
torchrun --nproc_per_node 8 --nnodes 2 --master_addr ${MASTER_ADDR} --master_port 14545 --node_rank 0 train.py \
--deepspeed ${deepspeed_config_file} \
nproc_per_node表示每个节点的进程数,可以理解为每个节点所需GPU数
nnode表示节点数,2台机器就是2个节点数
master_add为master的ip
node_rank表示当前启动的是第几个节点
在node02执行同样命令,但需将node_rank指定为1,不出意外的话可以成功跑通,即便报错可能也是依赖包版本两台机器不一致导致。很快就会在控制台看到transformers打印的日志,但发现save_total_limit只在master上管用。
1、定义集群
比如假设上面的图所示,我们有四台电脑,名字假设为:A、B、C、D,那么集群可以定义如下
#coding=utf-8
#多台机器,每台机器有一个显卡、或者多个显卡,这种训练叫做分布式训练
import tensorflow as tf
#现在假设我们有A、B、C、D四台机器,首先需要在各台机器上写一份代码,并跑起来,各机器上的代码内容大部分相同
# ,除了开始定义的时候,需要各自指定该台机器的task之外。以机器A为例子,A机器上的代码如下:
cluster=tf.train.ClusterSpec({
"worker": [
"A_IP:2222",#格式 IP地址:端口号,第一台机器A的IP地址 ,在代码中需要用这台机器计算的时候,就要定义:/job:worker/task:0
"B_IP:1234"#第二台机器的IP地址 /job:worker/task:1
"C_IP:2222"#第三台机器的IP地址 /job:worker/task:2
"ps": [
"D_IP:2222",#第四台机器的IP地址 对应到代码块:/job:ps/task:0
然后需要写四分代码,这四分代码文件大部分相同,但是有几行代码是各不相同的。
2、在各台机器上,定义server
比如A机器上的代码server要定义如下:
server=tf.train.Server(cluster,job_name='worker',task_index=0)#找到‘worker’名字下的,task0,也就是机器A
3、在代码中,指定device
with tf.device('/job:ps/task:0'):#参数定义在机器D上
w=tf.get_variable('w',(2,2),tf.float32,initializer=tf.constant_initializer(2))
b=tf.get_variable('b',(2,2),tf.float32,initializer=tf.constant_initializer(5))
with tf.device('/job:worker/task:0/cpu:0'):#在机器A cpu上运行
addwb=w+b
with tf.device('/job:worker/task:1/cpu:0'):#在机器B cpu上运行
mutwb=w*b
with tf.device('/job:worker/task:2/cpu:0'):#在机器C cpu上运行
divwb=w/b
在深度学习训练中,一般图的计算,对于每个worker task来说,都是相同的,所以我们会把所有图计算、变量定义等代码,都写到下面这个语句下:
with tf.device(tf.train.replica_device_setter(worker_device='/job:worker/task:indexi',cluster=cluster))
函数replica_deviec_setter会自动把变量参数定义部分定义到ps服务中(如果ps有多个任务,那么自动分配)。下面举个例子,假设现在有两台机器A、B,A用于计算服务,B用于参数服务,那么代码如下:
#coding=utf-8
#上面是因为worker计算内容各不相同,不过再深度学习中,一般每个worker的计算内容是一样的,
# 以为都是计算神经网络的每个batch 前向传导,所以一般代码是重用的
import tensorflow as tf
#现在假设我们有A、B台机器,首先需要在各台机器上写一份代码,并跑起来,各机器上的代码内容大部分相同
# ,除了开始定义的时候,需要各自指定该台机器的task之外。以机器A为例子,A机器上的代码如下:
cluster=tf.train.ClusterSpec({
"worker": [
"192.168.11.105:1234",#格式 IP地址:端口号,第一台机器A的IP地址 ,在代码中需要用这台机器计算的时候,就要定义:/job:worker/task:0
"ps": [
"192.168.11.130:2223"#第四台机器的IP地址 对应到代码块:/job:ps/task:0
#不同的机器,下面这一行代码各不相同,server可以根据job_name、task_index两个参数,查找到集群cluster中对应的机器
isps=False
if isps:
server=tf.train.Server(cluster,job_name='ps',task_index=0)#找到‘worker’名字下的,task0,也就是机器A
server.join()
else:
server=tf.train.Server(cluster,job_name='worker',task_index=0)#找到‘worker’名字下的,task0,也就是机器A
with tf.device(tf.train.replica_device_setter(worker_device='/job:worker/task:0',cluster=cluster)):
w=tf.get_variable('w',(2,2),tf.float32,initializer=tf.constant_initializer(2))
b=tf.get_variable('b',(2,2),tf.float32,initializer=tf.constant_initializer(5))
addwb=w+b
mutwb=w*b
divwb=w/b
saver = tf.train.Saver()
summary_op = tf.merge_all_summaries()
init_op = tf.initialize_all_variables()
sv = tf.train.Supervisor(init_op=init_op, summary_op=summary_op, saver=saver)
with sv.managed_session(server.target) as sess:
while 1:
print sess.run([addwb,mutwb,divwb])
把该代码在机器A上运行,你会发现,程序会进入等候状态,等候用于ps参数服务的机器启动,才会运行。
因此接着我们在机器B上运行如下代码:
#coding=utf-8
#上面是因为worker计算内容各不相同,不过再深度学习中,一般每个worker的计算内容是一样的,
# 以为都是计算神经网络的每个batch 前向传导,所以一般代码是重用的
#coding=utf-8
#多台机器,每台机器有一个显卡、或者多个显卡,这种训练叫做分布式训练
import tensorflow as tf
#现在假设我们有A、B、C、D四台机器,首先需要在各台机器上写一份代码,并跑起来,各机器上的代码内容大部分相同
# ,除了开始定义的时候,需要各自指定该台机器的task之外。以机器A为例子,A机器上的代码如下:
cluster=tf.train.ClusterSpec({
"worker": [
"192.168.11.105:1234",#格式 IP地址:端口号,第一台机器A的IP地址 ,在代码中需要用这台机器计算的时候,就要定义:/job:worker/task:0
"ps": [
"192.168.11.130:2223"#第四台机器的IP地址 对应到代码块:/job:ps/task:0
#不同的机器,下面这一行代码各不相同,server可以根据job_name、task_index两个参数,查找到集群cluster中对应的机器
isps=True
if isps:
server=tf.train.Server(cluster,job_name='ps',task_index=0)#找到‘worker’名字下的,task0,也就是机器A
server.join()
else:
server=tf.train.Server(cluster,job_name='worker',task_index=0)#找到‘worker’名字下的,task0,也就是机器A
with tf.device(tf.train.replica_device_setter(worker_device='/job:worker/task:0',cluster=cluster)):
w=tf.get_variable('w',(2,2),tf.float32,initializer=tf.constant_initializer(2))
b=tf.get_variable('b',(2,2),tf.float32,initializer=tf.constant_initializer(5))
addwb=w+b
mutwb=w*b
divwb=w/b
saver = tf.train.Saver()
summary_op = tf.merge_all_summaries()
init_op = tf.initialize_all_variables()
sv = tf.train.Supervisor(init_op=init_op, summary_op=summary_op, saver=saver)
with sv.managed_session(server.target) as sess:
while 1:
print sess.run([addwb,mutwb,divwb])
Tensorflow官方指南
分布式训练需要熟悉的函数:
tf.train.Server
tf.train.Supervisor
tf.train.SessionManager
tf.train.ClusterSpec
tf.train.replica_device_setter
tf.train.MonitoredTrainingSession
tf.train.MonitoredSession
tf.train.SingularMonitoredSession
tf.train.Scaffold
tf.train.SessionCreator
tf.train.ChiefSessionCreator
tf.train.WorkerSessionCreator
PyTorch
DP就是 DataParallel。DP 是单进程控制多 GPU。
DP 将输入的一个 batch 数据分成了 n 份(n 为实际使用的 GPU 数量),分别送到对应的 GPU 进行计算。
在网络前向传播时,模型会从主 GPU 复制到其它 GPU 上;
在反向传播时,每个 GPU 上的梯度汇总到主 GPU 上,求得梯度均值更新模型参数后,再复制到其它 GPU,以此来实现并行。
由于主 GPU 要进行梯度汇总和模型更新,并将计算任务下发给其它 GPU,所以主 GPU 的负载与使用率会比其它 GPU 高,这就导致了 GPU 负载不均衡的现象。
系统会为每个 GPU 创建一个进程,不再有主 GPU,每个 GPU 执行相同的任务。
DDP 使用分布式数据采样器(DistributedSampler)加载数据,确保数据在各个进程之间没有重叠。
在反向传播时,各 GPU 梯度计算完成后,各进程以广播的方式将梯度进行汇总平均,然后每个进程在各自的 GPU 上进行梯度更新,从而确保每个 GPU 上的模型参数始终保持一致。由于无需在不同 GPU 之间复制模型,DDP 的传输数据量更少,因此速度更快。
DDP 既可用于单机多卡也可用于多机多卡,它能解决 DataParallel 速度慢、GPU 负载不均衡等问题。因此,官方更推荐使用 DistributedDataParallel 来进行分布式训练
group:进程组。默认情况下,只有一个组,即一个 world。(DDP 多进程控制多 GPU)
world_size :表示全局进程个数。
rank:表示进程序号,用于进程间通讯,表示进程优先级。rank=0 的主机为主节点。
训练基本流程
(1)初始化进程组:用 init_process_group 函数
backend:是通信所用的后端,可以是“nccl”或“gloo”。一般来说,nccl 用于 GPU 分布式训练,gloo 用于 CPU 进行分布式训练。
init_method:字符串类型,是一个 url,进程初始化方式,默认是 “env://”,表示从环境变量初始化,还可以使用 TCP 的方式或共享文件系统 。
world_size:执行训练的所有的进程数,表示一共有多少个节点(机器)。
rank:进程的编号,也是其优先级,表示当前节点(机器)的编号。group_name:进程组的名字。
(2)模型并行化:用 DistributedDataParallel,将模型分发至多 GPU 上
DistributedDataParallel 的参数与 DataParallel 基本相同
(3)创建分布式数据采样器
DP 是直接将一个 batch 的数据划分到不同的卡,但是多机多卡间频繁数据传输会严重影响效率,这时就要用到分布式数据采样器 DistributedSampler,它会为每个子进程划分出一部分数据集,从而使 DataLoader 只会加载特定的一个子数据集,以避免不同进程之间有数据重复。
先将 train_dataset 送到了 DistributedSampler 中,并创建了一个分布式数据采样器 train_sampler。
再构造 DataLoader ,, 参数中传入了一个 sampler=train_sampler,即可让不同的进程节点加载属于自己的那份子数据集。也就是说,使用 DDP 时,不再是从主 GPU 分发数据到其他 GPU 上,而是各 GPU 从自己的硬盘上读取属于自己的那份数据。
具体逻辑:
加载模型阶段。每个GPU都拥有模型的一个副本,所以不需要拷贝模型。rank为0的进程会将网络初始化参数broadcast到其它每个进程中,确保每个进程中的模型都拥有一样的初始化值。
加载数据阶段。DDP 不需要广播数据,而是使用多进程并行加载数据。在 host 之上,每个worker进程都会把自己负责的数据从硬盘加载到 page-locked memory。DistributedSampler 保证每个进程加载到的数据是彼此不重叠的。
前向传播阶段。在每个GPU之上运行前向传播,计算输出。每个GPU都执行同样的训练,所以不需要有主 GPU。
计算损失。在每个GPU之上计算损失。
反向传播阶段。运行后向传播来计算梯度,在计算梯度同时也对梯度执行all-reduce操作。
更新模型参数阶段。因为每个GPU都从完全相同的模型开始训练,并且梯度被all-reduced,因此每个GPU在反向传播结束时最终得到平均梯度的相同副本,所有GPU上的权重更新都相同,也就不需要模型同步了。注意,在每次迭代中,模型中的Buffers 需要从rank为0的进程广播到进程组的其它进程上。
代码略,见原文
使用 DDP 意味着使用多进程,如果直接保存模型,每个进程都会执行一次保存操作,此时只使用主进程中的一个 GPU 来保存即可。
Pytorch 分布式训练
分布式基础
分布式模式
PyTorch 原生支持的并行模式:
完全分片数据并行(full sharded data parallel,FSDP)
混合分片数据并行(hybrid sharding data parallel,HSDP)
张量并行(tensor parallel,TP)
流水线并行(pipeline parallel,PP)
序列并行(sequence parallel,SP)
上下文并行(context parallel,CP)
【2023-3-2】PyTorch 分布式训练实现(DP/DDP/torchrun/多机多卡)
相对 Tensorflow,Pytorch 简单的多。分布式训练主要有两个API:
DataParallel(DP): PS模式,1张卡为reduce(parame server),实现就1行代码
单进程多线程,仅仅能工作在单机中
将数据分割到多个GPU上。典型的数据并行,将模型复制到每个GPU上,一旦GPU0计算出梯度,就同步梯度到各个节点,这需要大量的GPU数据传输(类似PS模式)
DistributedDataParallel(DDP): All-Reduce模式,单机多卡/多级多卡皆可。官方建议API
多进程,单机或多机
每个GPU进程中创建模型副本,并只让数据的一部分对改GPU可用。因为每个GPU中的模型是独立运行的,所以在所有的模型都计算出梯度后,才会在模型之间同步梯度(类似All-reduce)
DDP每个batch只需要一次数据传输;DP可能存在多次数据同步(不用worker之间可能快慢不一样)。DataParallel 通常慢于 DistributedDataParallel
【2024-7-24】PyTorch 为数据分布式训练提供了多种选择。
随着应用从简单到复杂,从原型到产品,常见的开发轨迹可以是:
数据和模型能放入单个GPU,单设备训练,此时不用担心训练速度;
服务器上有多个GPU,且代码修改量最小,加速训练用单个机器多GPU DataParallel;
进一步加速训练,且愿意写点代码,用单个机器多个GPU DistributedDataParallel;
应用程序跨机器边界扩展,用多机器DistributedDataParallel和启动脚本;
预期有错误(比如OOM)或资源可动态连接和分离,使用torchelastic来启动分布式训练。
分布式训练的场景很多,单机多卡,多机多卡,模型并行,数据并行等等。接下来就以常见的单机多卡的情况进行记录。
PyTorch 使用 DDP(Distributed Data Parallel) 实现了真正的分布式数据并行,两个场景下都可使用 DDP 实现模型的分布式训练:
(1) 单机、多 GPU(单进程多线程的伪分布式)
(2) 多机、多 GPU(多机多进程的真正分布式)
方法(1)类似简单 DP 数据并行模式
DP 使用单进程、多线程范式来实现;
而 DDP 完全使用多进程方式,包括单机多进程、多机多进程
即使单机、多 GPU,也建议使用 DDP 模式,实现基于数据并行的模型训练,使用单机 DDP 模式训练模型的性能要比 DP 模式好很多。
DDP 基于集合通信(Collective Communications)实现分布式训练过程中的梯度同步。
反向传播过程中,DDP 使用 AllReduce 来实现分布式梯度计算和同步。
1、DataParallel
模型与变量必须在同一个设备上(CPU or GPU)
pytorch 使用to函数实现变量或模型的存储转移
to函数的对象: 数据Tensor,或 模型Module
张量不执行inplace(即 执行之后重新构建一个新的张量)
模型执行inplace(执行之后不重新构建一个新的模型)
当给定model时,主要实现功能是将input数据依据batch的这个维度,将数据划分到指定的设备上。其他的对象(objects)复制到每个设备上。在前向传播的过程中,module被复制到每个设备上,每个复制的副本处理一部分输入数据。
在反向传播过程中,每个副本module的梯度被汇聚到原始的module上计算(一般为第0块GPU)。
如果当前有4个GPU,batch_size=16,那么模型将被复制到每一个GPU上,在前向传播时,每一个gpu将分到4个batch,每个gpu独立计算依据分到的batch计算出结果的梯度,然后将梯度返回到第一个GPU上,第一个GPU再进行梯度融合、模型更新。在下一次前向传播的时候,将更新后的模型再复制给每一个GPU。
### 第一步:构建模型
# module 需要分发的模型
# device_ids 可分发的gpu,默认分发到所有看见GPU(环境变量设置的)
# output_device 结果输出设备 通常设置成逻辑gpu的第一个
module = your_simple_net() #你的模型
Your_Parallel_Net = torch.nn.DataParallel(module, device_ids=None, output_device=None)
### 第二步:数据迁移
inputs=inputs.to(device)
labels=labels.to(device)
# device通常应为模型输出的output_device,否则无法计算loss
import torch
import torch.nn as nn
from torch.autograd import Variable
from torch.utils.data import Dataset, DataLoader
import os
input_size = 5
output_size = 2
batch_size = 30
data_size = 30
class RandomDataset(Dataset):
def __init__(self, size, length):
self.len = length
self.data = torch.randn(length, size)
def __getitem__(self, index):
return self.data[index]
def __len__(self):
return self.len
rand_loader = DataLoader(dataset=RandomDataset(input_size, data_size), batch_size=batch_size, shuffle=True)
class Model(nn.Module):
# Our model
def __init__(self, input_size, output_size):
super(Model, self).__init__()
self.fc = nn.Linear(input_size, output_size)
def forward(self, input):
output = self.fc(input)
print(" In Model: input size", input.size(),
"output size", output.size())
return output
model = Model(input_size, output_size)
if torch.cuda.is_available():
model.cuda()
if torch.cuda.device_count() > 1:
print("Let's use", torch.cuda.device_count(), "GPUs!")
# 就这一行!将模型整体复制到每个GPU上,计算完成后各自汇总到ps节点
model = nn.DataParallel(model)
for data in rand_loader:
if torch.cuda.is_available():
input_var = Variable(data.cuda())
else:
input_var = Variable(data)
output = model(input_var)
print("Outside: input size", input_var.size(), "output_size", output.size())
2、DDP(官方建议)
DP 问题
为什么要引入DDP(DistributedDataParallel)?DP 存在问题
1、DP 每个训练批次(batch)中,一个进程上先算出模型权重, 然后再分发到每个GPU上
网络通信就成为了瓶颈,而GPU使用率也通常很低。
显存浪费, 多存储了 n-1 份 模型副本
2、每次前向传播时把模型也复制了(即每次更新都复制一遍模型),并且单进程多线程会造成GIL contention (全局解释器锁争用) 这里进程计算权重使通信成为瓶颈造成了大量的时间浪费,因此引入了DDP。
dp 两个问题:
1️⃣ 显存浪费严重。
以单机八卡为例,把模型复制8份放在8张卡上同时推理,因此多付出了7个模型(副本)的显存开销;
2️⃣ 大模型不适用。
以最新提出的Llama 3.1为例,不经量化(FP16数据类型)的情况下,容纳70B的模型需要140GB的显存,即使是40G一张的A100也无法承受。
而这才仅仅是容纳模型,还没有考虑存放数据,以及训练的话存放梯度数据等。因此数据并行并不适用于70B级别大模型的推理和训练。
DDP采用多进程控制多GPU,共同训练模型,一份代码会被pytorch自动分配到n个进程并在n个GPU上运行。
DDP运用 Ring-Reduce通信算法在每个GPU间对梯度进行通讯,交换彼此的梯度,从而获得所有GPU的梯度。
对比DP,不需要在进行模型本体的通信,因此可以加速训练。
torch.nn.DataParallel
DataParallel 全程维护一个 optimizer,对各 GPU 上梯度进行求和,而在主 GPU 进行参数更新,之后再将模型参数 broadcast 到其他 GPU
1、设置 DistributedSampler 来打乱数据,因为一个batch被分配到了好几个进程中,要确保不同的GPU拿到的不是同一份数据。
2、要告诉每个进程自己的id,即使用哪一块GPU。
3、如果需要做BatchNormalization,需要对数据进行同步(还待研究,挖坑)
DDP采用All-Reduce架构,单机多卡、多机多卡都能用。
注意:DDP并不会自动shard数据
如果自己写数据流,得根据torch.distributed.get_rank()去shard数据,获取自己应用的一份
如果用 Dataset API,则需要在定义Dataloader的时候用 DistributedSampler 去shard
torch.distributed 介绍
torch.nn.DataParallel 支持数据并行,但不支持多机分布式训练,且底层实现相较于 distributed 的接口,有些许不足。
Pytorch 通过 torch.distributed 包提供分布式支持,包括 GPU 和 CPU 的分布式训练支持。
Pytorch 分布式目前只支持 Linux。
torch.distributed 优势:
每个进程对应一个独立的训练过程,且只对梯度等少量数据进行信息交换。
迭代中,每个进程具有自己的 optimizer ,独立完成所有优化步骤,进程内与一般的训练无异。
各进程梯度计算完成之后,先将梯度进行汇总平均,再由 rank=0 的进程,将其 broadcast 到所有进程。最后,各进程用该梯度来更新参数。
各进程的模型参数始终保持一致: 各进程初始参数、更新参数都一致
相比 DataParallel, torch.distributed 传输的数据量更少,因此速度更快,效率更高
每个进程包含独立的解释器和 GIL
每个进程拥有独立的解释器和 GIL,消除了单个 Python 进程中的多个执行线程,模型副本或 GPU 的额外解释器开销和 GIL-thrashing ,因此可以减少解释器和 GIL 使用冲突
group:即进程组。默认只有1个组,1个 job 即为1个组,即 1个 world。
当需要进行更加精细的通信时,通过 new_group 接口,使用 word 的子集,创建新组,用于集体通信等。
world_size :表示全局进程数。一个进程可对应多个GPU
world_size ≠ GPU数: 1个进程用多个GPUworld_size = GPU数: 1个进程用1个GPUlocal_word_size: 某个节点上进程数 (相对比较少见)rank:全局进程id, 表示进程序号,用于进程间通讯,表征进程优先级。取值范围: 0~world_size
rank = 0 主机为 master 节点。local_rank:某个节点上进程id, 进程内GPU 编号,非显式参数,由 torch.distributed.launch 内部指定。
rank = 3,local_rank = 0 表示第 3 个进程内的第 1 块 GPU。global_rank: 全局 gpu编号如果 所有进程数(world_size)为W,每个节点上的进程数(local_world_size)为L, 则每个进程上的两个ID:
rank 取值范围:[0, W-1]
rank=0 进程为主进程,负责同步分发工作rank>0 进程为从进程rank=-1, 默认值,非GPU进程?local_rank 取值:[0, L-1]2机8卡的分布式训练示例
gpu 编号: 0~3
local rank: gpu 本地编号, 0~3
global rank: gpu 全局编号, 0~7
Pytorch 分布式基本流程:
使用 distributed 包任何函数前,用 init_process_group 初始化进程组,同时初始化 distributed 包。
如进行小组内集体通信,用 new_group 创建子分组
创建分布式并行模型 DDP(model, device_ids=device_ids)
为数据集创建 Sampler
使用启动工具 torch.distributed.launch 在每个主机上执行一次脚本,开始训练
使用 destory_process_group() 销毁进程组
torch.distributed 提供了 3 种初始化方式:tcp、共享文件 和 环境变量初始化 等。
TCP: 指定进程 0 的 ip 和 port, 手动为每个进程指定进程号。
共享文件: 共享文件对于组内所有进程可见
环境变量:
import torch.distributed as dist
import argparse, os
parser = argparse.ArgumentParser()
parser.add_argument("--local_rank", type=ine, default=0)
args = parser.parse_args()
# 分布式初始化, 读取环境变量 RANK=1 WORLD_SIZE=3 MASTER_ADDR=127.0.0.1 MASTER_PORT=8000
dist.init_process_group("nccl") # 进程组初始化
rank = dist.get_rank()
local_rank_arg = args.local_rank # 命令行形式ARGS形式
local_rank_env = int(os.environ['LOCAL_RANK']) # 用env初始ENV环境变量形式
local_world_size = int(os.environ['LOCAL_WORLD_SIZE'])
# local_rank_env = int(os.environ.get('LOCAL_RANK', 0)) # 在利用env初始ENV环境变量形式
# local_world_size = int(os.environ.get('LOCAL_WORLD_SIZE', 3))
print(f"{rank=}; {local_rank_arg=}; {local_rank_env=}; {local_world_size=}")
python3 -m torch.distributed.launch --nproc_per_node=4 test.py
在一台4卡机器上执行, 样例输出:
# WARNING:torch.distributed.run:
# *****************************************
# Setting OMP_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variable for optimal performance in your application as needed.
# *****************************************
rank=2; local_rank_arg=2; local_rank_env=2, local_world_size=4
rank=0; local_rank_arg=0; local_rank_env=0, local_world_size=4
rank=3; local_rank_arg=3; local_rank_env=3, local_world_size=4
rank=1; local_rank_arg=1; local_rank_env=1, local_world_size=4
一般分布式训练都是为每个进程赋予一块GPU,这样比较简单而且容易调试。 这种情况下,可以通过 local_rank 作为当前进程GPU的id。
pytorch 分布式训练,数据读取采用主进程预读取并缓存,其它进程从缓存中读取,不同进程之间的数据同步具体通过torch.distributed.barrier()实现。参考
分布式数据读取: 主进程读取数据 → 主进程缓存 → 从进程读取缓存
进程号rank
多进程上下文中,通常假定rank 0是第一个进程/主进程,其它进程分别具有 0,1,2 不同rank号,这样总共具有4个进程。
(2)单一进程数据处理
通有些操作没必要并行处理,如: 数据读取与处理操作,只需要一个进程进行处理并缓存,然后与其它进程共享缓存处理数据
但由于不同进程同步执行,单一进程处理数据必然会导致进程间不同步现象(数据读取操作处理时间较长)对于较短时间的单一进程程序运行不会影响线程不同步的情况
为此,torch中采用了barrier()函数对其它非主进程进行阻塞,达到同步目的
(3)barrier()具体原理
如果执行 create_dataloader()函数的进程
不是主进程: 即rank不等于0或者-1
上下文管理器会执行相应的 torch.distributed.barrier(),设置一个阻塞栅栏,让此进程处于等待状态,等待所有进程到达栅栏处(包括主进程数据处理完毕);
是主进程: 其会直接读取数据,然后处理结束之后会遇到 torch.distributed.barrier()
此时,所有进程都到达了当前的栅栏处,这样所有进程就达到了同步,并同时得到释放。
def create_dataloader():
#使用上下文管理器中实现的barrier函数确保分布式中的主进程首先处理数据,然后其它进程直接从缓存中读取
with torch_distributed_zero_first(rank):
dataset = LoadImagesAndLabels()
from contextlib import contextmanager
#定义的用于同步不同进程对数据读取的上下文管理器
@contextmanager
def torch_distributed_zero_first(local_rank: int):
Decorator to make all processes in distributed training wait for each local_master to do something.
if local_rank not in [-1, 0]:
torch.distributed.barrier()
yield #中断后执行上下文代码,然后返回到此处继续往下执行
if local_rank == 0:
torch.distributed.barrier()
初始化进程组 init_process_group
init_process_group 函数原型
torch.distributed.init_process_group(backend, init_method=None, timeout=datetime.timedelta(0, 1800),
world_size=-1, rank=-1, store=None)
每个进程中进行调用,用于初始化该进程。
使用分布式时,该函数必须在 distributed 内所有相关函数之前使用。
backend :指定当前进程要使用的通信后端
小写字符串,支持的通信后端有 gloo, mpi, nccl, 建议用 nccl。
cpu 分布式选 gloo
gpu 分布式选 nccl
init_method :当前进程组初始化方式
可选参数,字符串形式。两种方式: init_method + store, init_method是store的高层封装, 二者互斥
init_method: TCP连接、File共享文件系统、ENV环境变量三种方式store: 同时指定world_size 和 rank参数。store 是一种分布式中核心的key-value存储,用于不同进程间共享信息如果未指定, 默认为 env,表示使用读取环境变量方式初始化。该参数与 store 互斥。
rank :指定当前进程的优先级int 值。表示当前进程的编号,即优先级。如果指定 store 参数,则必须指定该参数。
rank=0 的为主进程,即 master 节点。
world_size :该 job 中的总进程数。如果指定 store 参数,则需要指定该参数。timeout : 指定每个进程的超时时间
可选参数,datetime.timedelta 对象,默认为 30 分钟。该参数仅用于 Gloo 后端。
store
所有 worker 可访问的 key / value,用于交换连接 / 地址信息。与 init_method 互斥。
三种init_method:
init_method=’tcp://ip:port‘: 通过指定rank 0(MASTER进程)的IP和端口,各个进程tcp进行信息交换。需指定 rank 和 world_size 这两个参数。init_method=’file://path‘:通过所有进程都可以访问共享文件系统来进行信息共享。需要指定rank和world_size参数。init_method=env://:从环境变量中读取分布式信息(os.environ),主要包括 MASTER_ADDR, MASTER_PORT, RANK, WORLD_SIZE。 其中,rank和world_size可手动指定,否则从环境变量读取。tcp 和 env 两种方式比较类似, 其实 env就是对tcp 一层封装),都是通过网络地址方式进行通信,最常用的初始化方法。
import os, argparse
import torch
import torch.distributed as dist
parse = argparse.ArgumentParser()
parse.add_argument('--init_method', type=str)
parse.add_argument('--rank', type=int)
parse.add_argument('--ws', type=int)
args = parse.parse_args()
if args.init_method == 'TCP':
dist.init_process_group('nccl', init_method='tcp://127.0.0.1:28765', rank=args.rank, world_size=args.ws)
elif args.init_method == 'ENV':
dist.init_process_group('nccl', init_method='env://')
rank = dist.get_rank()
print(f"rank = {rank} is initialized")
# 单机多卡情况下,localrank = rank. 严谨应该是local_rank来设置device
torch.cuda.set_device(rank)
tensor = torch.tensor([1, 2, 3, 4]).cuda()
print(tensor)
单机双卡机器上,开两个终端,同时运行命令
# TCP方法
python3 test_ddp.py --init_method=TCP --rank=0 --ws=2
python3 test_ddp.py --init_method=TCP --rank=1 --ws=2
# ENV方法
MASTER_ADDR='localhost' MASTER_PORT=28765 RANK=0 WORLD_SIZE=2 python3 test_gpu.py --init_method=ENV
MASTER_ADDR='localhost' MASTER_PORT=28765 RANK=1 WORLD_SIZE=2 python3 test_gpu.py --init_method=ENV
如果开启的进程未达到 word_size 的数量,则所有进程会一直等待,直到都开始运行,可以得到输出如下:
# rank0 的终端:
rank 0 is initialized
tensor([1, 2, 3, 4], device='cuda:0')
# rank1的终端
rank 1 is initialized
tensor([1, 2, 3, 4], device='cuda:1')
初始化DDP时,给后端提供主进程的地址端口、本身RANK,以及进程数量即可。
初始化完成后,可以执行很多分布式的函数,比如 dist.get_rank, dist.all_gather 等等。
new_group
torch.distributed.new_group(ranks=None, timeout=datetime.timedelta(0, 1800), backend=None)
new_group() 函数可用于使用所有进程的任意子集来创建新组。其返回一个分组句柄,可作为 collectives 相关函数的 group 参数 。collectives 是分布式函数,用于特定编程模式中的信息交换。ranks:指定新分组内的成员的 ranks 列表list ,其中每个元素为 int 型
timeout:指定该分组进程组内的操作的超时时间
可选参数,datetime.timedelta 对象,默认为 30 分钟。该参数仅用于 Gloo 后端。
backend:指定要使用的通信后端
小写字符串,支持的通信后端有 gloo,nccl ,必须与 init_process_group() 中一致。
is_initialized 检查默认进程组是否被初始化
is_mpi_available 检查 MPI 后端是否可用
is_nccl_available 检查 NCCL 后端是否可用
(1) TCP 初始化
import torch.distributed as dist
# Use address of one of the machines
dist.init_process_group(backend, init_method='tcp://10.1.1.20:23456',rank=args.rank, world_size=4)
不同进程内,均使用主进程的 ip 地址和 port,确保每个进程能够通过一个 master 进行协作。该 ip 一般为主进程所在的主机的 ip,端口号应该未被其他应用占用。
实际使用时,在每个进程内运行代码,并需要为每一个进程手动指定一个 rank,进程可以分布与相同或不同主机上。
多个进程之间,同步进行。若其中一个出现问题,其他的也马上停止。
# Node 1
python mnsit.py --init-method tcp://192.168.54.179:22225 --rank 0 --world-size 2
# Node 2
python mnsit.py --init-method tcp://192.168.54.179:22225 --rank 1 --world-size 2
初始化示例
tcp_init.pyimport torch.distributed as dist
import torch.utils.data.distributed
# ......
parser = argparse.ArgumentParser(description='PyTorch distributed training on cifar-10')
parser.add_argument('--rank', default=0, help='rank of current process')
parser.add_argument('--word_size', default=2,help="word size")
parser.add_argument('--init_method', default='tcp://127.0.0.1:23456', help="init-method")
args = parser.parse_args()
# ......
dist.init_process_group(backend='nccl', init_method=args.init_method, rank=args.rank, world_size=args.word_size)
# ......
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=download, transform=transform)
train_sampler = torch.utils.data.distributed.DistributedSampler(trainset)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size, sampler=train_sampler)
# ......
net = Net()
net = net.cuda()
net = torch.nn.parallel.DistributedDataParallel(net)
init_method# Node 1 : ip 192.168.1.201 port : 12345
python tcp_init.py --init_method tcp://192.168.1.201:12345 --rank 0 --word_size 3
# Node 2 :
python tcp_init.py --init_method tcp://192.168.1.201:12345 --rank 1 --word_size 3
# Node 3 :
python tcp_init.py --init_method tcp://192.168.1.201:12345 --rank 2 --word_size 3
TCP 方式中,init_process_group 中必须手动指定以下参数
rank 为当前进程的进程号word_size 为当前 job 总进程数init_method 内指定 tcp 模式,且所有进程的 ip:port 必须一致,设定为主进程的 ip:port必须在 rank==0 的进程内保存参数。
若程序内未根据 rank 设定当前进程使用的 GPUs,则默认使用全部 GPU,且以数据并行方式使用。
每条命令表示一个进程。若已开启的进程未达到 word_size 的数量,则所有进程会一直等待
每台主机上可以开启多个进程。但是,若未为每个进程分配合适的 GPU,则同机不同进程可能会共用 GPU,应该坚决避免这种情况。
使用 gloo 后端进行 GPU 训练时,会报错。
若每个进程负责多块 GPU,可以利用多 GPU 进行模型并行。
class ToyMpModel(nn.Module):
def init(self, dev0, dev1):
super(ToyMpModel, self).init()
self.dev0 = dev0
self.dev1 = dev1
self.net1 = torch.nn.Linear(10, 10).to(dev0)
self.relu = torch.nn.ReLU()
self.net2 = torch.nn.Linear(10, 5).to(dev1)
def forward(self, x):
x = x.to(self.dev0)
x = self.relu(self.net1(x))
x = x.to(self.dev1)
return self.net2(x)
# ......
dev0 = rank * 2
dev1 = rank * 2 + 1
mp_model = ToyMpModel(dev0, dev1)
ddp_mp_model = DDP(mp_model)
# ......
(2) 共享文件初始化
共享的文件对于组内所有进程可见
设置方式如下:
import torch.distributed as dist
# rank should always be specified
dist.init_process_group(backend, init_method='file:///mnt/nfs/sharedfile',
world_size=4, rank=args.rank)
file://前缀表示文件系统各式初始化。/mnt/nfs/sharedfile 表示共享文件,各个进程在共享文件系统中通过该文件进行同步或异步。因此,所有进程必须对该文件具有读写权限。
每一个进程将会打开这个文件,写入自己的信息,并等待直到其他所有进程完成该操作
在此之后,所有的请求信息将会被所有的进程可访问,为了避免 race conditions,文件系统必须支持通过 fcntl 锁定(大多数的 local 系统和 NFS 均支持该特性)。
若指定为同一文件,则每次训练开始之前,该文件必须手动删除,但是文件所在路径必须存在!
与 tcp 初始化方式一样,也需要为每一个进程手动指定 rank。
# 主机 01 上:
python mnsit.py --init-method file://PathToShareFile/MultiNode --rank 0 --world-size 2
# 主机 02 上:
python mnsit.py --init-method file://PathToShareFile/MultiNode --rank 1 --world-size 2
相比于 TCP 方式, 麻烦一点的是运行完一次必须更换共享的文件名,或者删除之前的共享文件,不然第二次运行会报错。
(3) Env 初始化(默认)
默认情况下都是环境变量来进行分布式通信,指定 init_method="env://"。
通过在所有机器上设置如下四个环境变量,所有进程将会适当的连接到 master,获取其他进程的信息,并最终与它们握手(信号)。
MASTER_PORT: 必须指定,表示 rank0上机器的一个空闲端口(必须设置)MASTER_ADDR: 必须指定,除了 rank0 主机,表示主进程 rank0 机器的地址(必须设置)WORLD_SIZE: 可选,总进程数,可以这里指定,在 init 函数中也可以指定RANK: 可选,当前进程的 rank,也可以在 init 函数中指定配合 torch.distribution.launch 使用。
# Node 1: (IP: 192.168.1.1, and has a free port: 1234)
python -m torch.distributed.launch --nproc_per_node=NUM_GPUS_YOU_HAVE
--nnodes=2 --node_rank=0 --master_addr="192.168.1.1"
--master_port=1234 YOUR_TRAINING_SCRIPT.py (--arg1 --arg2 --arg3
and all other arguments of your training script)
# Node 2
python -m torch.distributed.launch --nproc_per_node=NUM_GPUS_YOU_HAVE
--nnodes=2 --node_rank=1 --master_addr="192.168.1.1"
--master_port=1234 YOUR_TRAINING_SCRIPT.py (--arg1 --arg2 --arg3
and all other arguments of your training script)
代码 env_init.py
import torch.distributed as dist
import torch.utils.data.distributed
# ......
import argparse
parser = argparse.ArgumentParser()
# 注意这个参数,必须要以这种形式指定,即使代码中不使用。因为 launch 工具默认传递该参数
parser.add_argument("--local_rank", type=int)
args = parser.parse_args()
# ......
dist.init_process_group(backend='nccl', init_method='env://')
# ......
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=download, transform=transform)
train_sampler = torch.utils.data.distributed.DistributedSampler(trainset)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size, sampler=train_sampler)
# ......
# 根据 local_rank,配置当前进程使用的 GPU
net = Net()
device = torch.device('cuda', args.local_rank)
net = net.to(device)
net = torch.nn.parallel.DistributedDataParallel(net, device_ids=[args.local_rank], output_device=args.local_rank)
# 节点0
python -m torch.distributed.launch --nproc_per_node=2 --nnodes=3 --node_rank=0 --master_addr="192.168.1.201" --master_port=23456 env_init.py
# 节点1
python -m torch.distributed.launch --nproc_per_node=2 --nnodes=3 --node_rank=1 --master_addr="192.168.1.201" --master_port=23456 env_init.py
# 节点2
python -m torch.distributed.launch --nproc_per_node=2 --nnodes=3 --node_rank=2 --master_addr="192.168.1.201" --master_port=23456 env_init.py
Env 方式中,init_process_group 无需指定任何参数
必须在 rank==0 的进程内保存参数。
该方式使用 torch.distributed.launch 在每台主机上创建多进程,其中:
nproc_per_node 参数指定为当前主机创建的进程数。一般设定为当前主机的 GPU 数量nnodes 参数指定当前 job 包含多少个节点node_rank 指定当前节点的优先级master_addr 和 master_port 分别指定 master 节点的 ip:port若没有为每个进程合理分配 GPU,则默认使用当前主机上所有的 GPU。即使一台主机上有多个进程,也会共用 GPU。
使用 torch.distributed.launch 工具时,为当前主机创建 nproc_per_node 个进程,每个进程独立执行训练脚本。同时,它还会为每个进程分配一个 local_rank 参数,表示当前进程在当前主机上的编号。
例如:rank=2, local_rank=0 表示第 3 个节点上的第 1 个进程。
需要合理利用 local_rank 参数,来合理分配本地的 GPU 资源
每条命令表示一个进程。若已开启的进程未达到 word_size 数量,则所有进程会一直等待
详见: Pytorch 分布式训练
GPU 启动方式
常见的GPU 启动方式
torch.multiprocessing: 容易控制, 更加灵活
torch.distributed.launch: 代码量少, 启动速度快
torchrun: distributed.launch 的进化版, 代码量更少Slurm Workload Manager: slurm 启动近期更新掉
DDP 本身是一个 python 多进程,完全可以直接通过多进程方式来启动分布式程序。
torch 提供两种启动工具运行torch DDP程序。
torch.multiprocessing
launch/run
(1) mp.spawn
用 torch.multiprocessing(python multiprocessing的封装类) 自动生成多个进程
基本的调用函数 spawn:
mp.spawn(fn, args=(), nprocs=1, join=True, daemon=False)
fn: 进程入口函数,第一个参数会被默认自动加入当前进程的rank, 即实际调用: fn(rank, *args)nprocs: 进程数量,即:world_sizeargs: 函数fn的其他常规参数以tuple形式传递import torch
import torch.distributed as dist
import torch.multiprocessing as mp
def fn(rank, ws, nums):
dist.init_process_group('nccl', init_method='tcp://127.0.0.1:28765', rank=rank, world_size=ws)
rank = dist.get_rank()
print(f"rank = {rank} is initialized")
torch.cuda.set_device(rank)
tensor = torch.tensor(nums).cuda()
print(tensor)
if __name__ == "__main__":
ws = 2
mp.spawn(fn, nprocs=ws, args=(ws, [1, 2, 3, 4]))
python3 test_ddp.py
输出如下:
rank = 0 is initialized
rank = 1 is initialized
tensor([1, 2, 3, 4], device='cuda:1')
tensor([1, 2, 3, 4], device='cuda:0')
这种方式同时适用于 TCP 和 ENV 初始化。
(2) launch/run
torch 提供的 torch.distributed.launch 工具,以模块形式直接执行:
python3 -m torch.distributed.launch --配置 train.py --args参数
常用配置有:
–nnodes: 使用的机器数量,单机的话,就默认是1了
–nproc_per_node: 单机的进程数,即单机的worldsize
–master_addr/port: 使用的主进程rank0的地址和端口
–node_rank: 当前的进程rank
单机情况下
只有 –nproc_per_node 是必须指定
–master_addr/port 和 node_rank 都是可以由launch通过环境自动配置
mport torch
import torch.distributed as dist
import torch.multiprocessing as mp
import os
dist.init_process_group('nccl', init_method='env://')
rank = dist.get_rank()
local_rank = os.environ['LOCAL_RANK']
master_addr = os.environ['MASTER_ADDR']
master_port = os.environ['MASTER_PORT']
print(f"rank = {rank} is initialized in {master_addr}:{master_port}; local_rank = {local_rank}")
torch.cuda.set_device(rank)
tensor = torch.tensor([1, 2, 3, 4]).cuda()
print(tensor)
python3 -m torch.distribued.launch --nproc_per_node=2 test_ddp.py
输出如下:
{kind=link}
{kind=link}