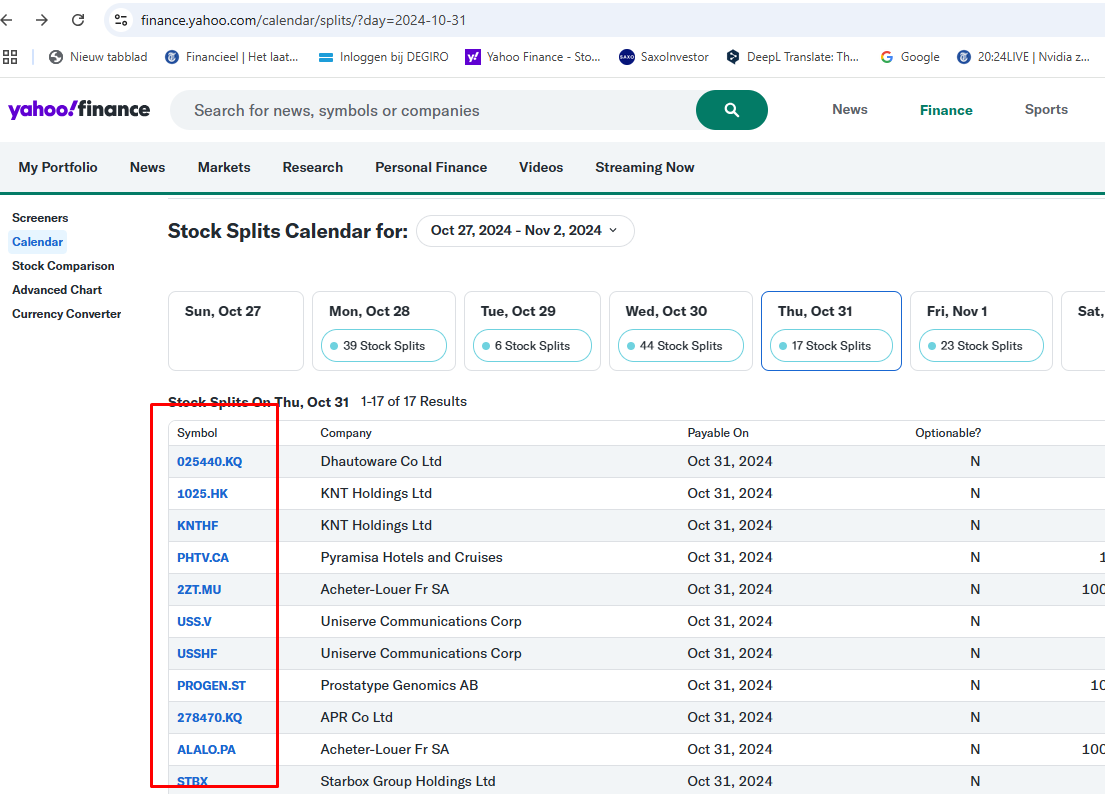
I think there are two issues at play - one minor and probably an oversight and one bigger one…
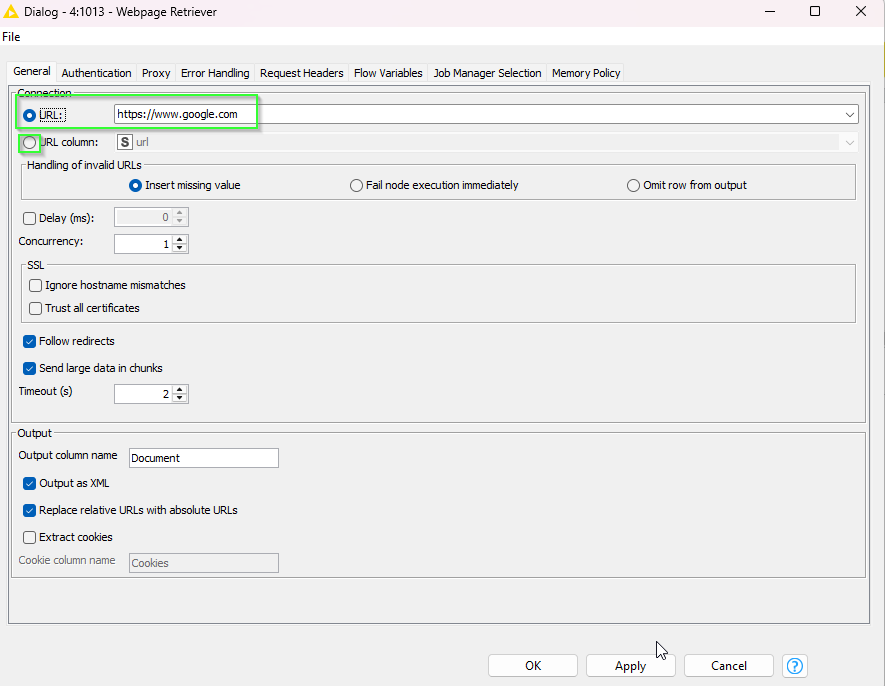
The small one: As far as I can tell from your workflow you are right now getting
google.com
homepage as response - you may want to select your URL column rather than having the default
google.com
address scraped
That said, it looks like yahoo does not like to be pinged this way - the node responds with 503 error.
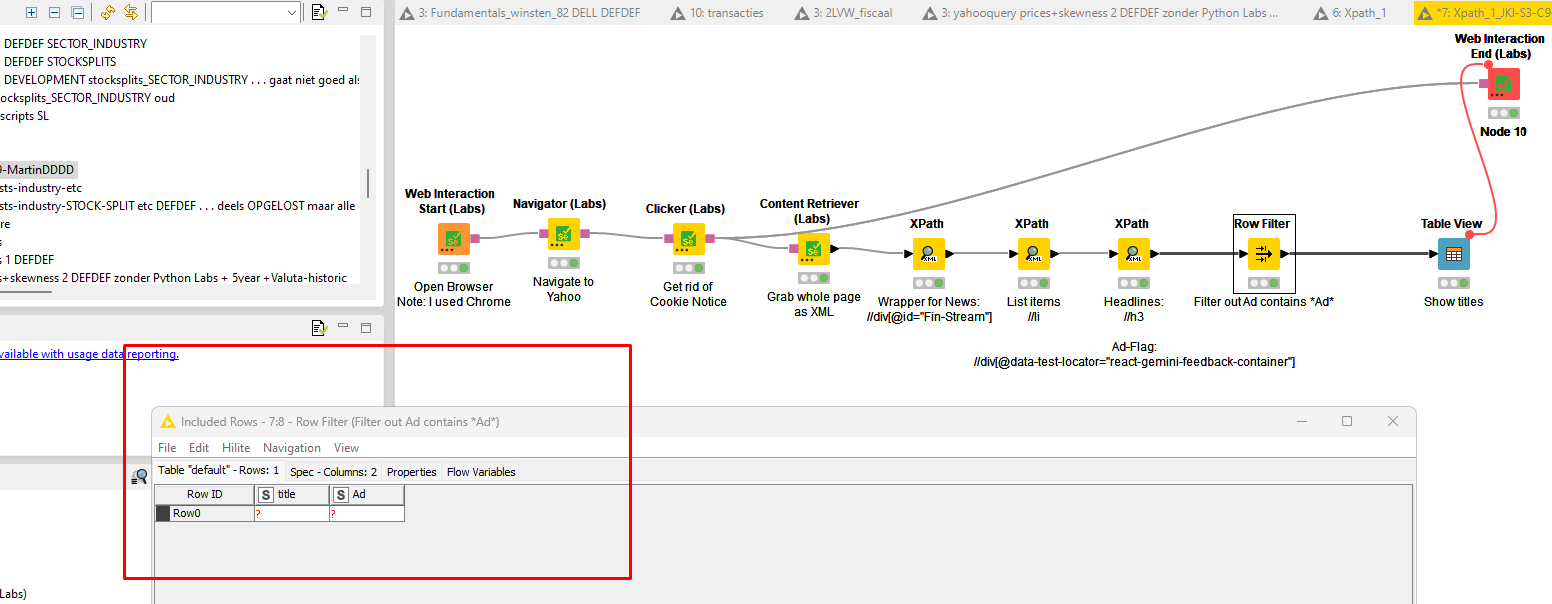
My gut feeling is that you may have to opt for using the KNIME Web Interaction Extension to have KNIME open the website in a browser and then grab the data. There was a just KNIME it challenge to extract economic use from yahoo finance using exactly this extension.
Here’s the solution thread with plenty of options to pick from to see how it can work:
That produces the following error . . .
ERROR Navigator (Labs) 5:2 Execute failed: HTTPConnectionPool(host=‘localhost’, port=30459): Max retries exceeded with url: /session/a72344c9fef2b061b15aa84e3c85a12f/url (Caused by NewConnectionError(‘<urllib3.connection.HTTPConnection object at 0x0000023659746AA0>: Failed to establish a new connection: [WinError 10061] No connection could be made because the target machine actively refused it’))
Strange because the mentioned URL is an existing page. An also tried “Refresh”.
Any idea why it produces this error?
Several years ago I developed a Yahoo Finance URL to use in a GET request. It no longer works due to a variety of changes Yahoo has made. It still may be possible, but frankly after reading a variety of posts on the subject its beyond me. I was able to develop a Python script employing the yfinance package which seems to work fine. I’ve wrapped the workflow in a component so it has interactive inputs. You’ll need a Python environment with the packages highlighted below. You can add a Table write…
I’ve modified the original to include conda propagation for the required Python environment as well as writing an output. You’ll need to change the location of the Excel Writer in the String Manipulation node.