

最近本网站的 HTTPS SSL 证书过期了,于是去域名管理平台重新申请了一下。
无意中通过 dig 发现,网站的 DNS 解析 IP 一直是
198.18.1.xxx
这些。因为域名是 CNAME 映射到 github 的,所以又 dig 了一下 github 对应的 ip,发现也是
198.18.1.xxx
。
从哪个角度来看,至少都有些问题。使用的 DNSPod 域名解析平台,dig 自定义域名和 github page 域名,怎么也不能在同一个网段里。
搜索了一下才知道,原来 ip 198 不是公网 ip,之前以为内网 ip 是 10/192 这些,知识还是有局限。
198.18.0.0/15 198.18.0.0 – 198.19.255.255 131,072 专用网络 用于测试两个不同的子网的网间通信。
https://zh.wikipedia.org/wiki/ 保留 IP 地址
在家庭网络中 dig 互联网的域名,为什么 dns 解析成了 198.x 呢?最后发现是最常使用的网络软件
Surge
引起的。
Surge
这些年给了我很多帮助,很感谢。特意开此文,讲解 Surge 工作原理,以致敬 Surge。
本文会对 Socket、Wireshark、网络系统代理 (http/s、socket5、POSIX)、网络网卡代理 (VIF)、VPN、DNS、DOH (SNI) 等知识点进行描述,以更加全面的讲解 Surge 的工作原理。
致敬 Surge
Surge 只有 iOS 和 Mac 版,是订阅制,简单介绍下订阅制,如下图:
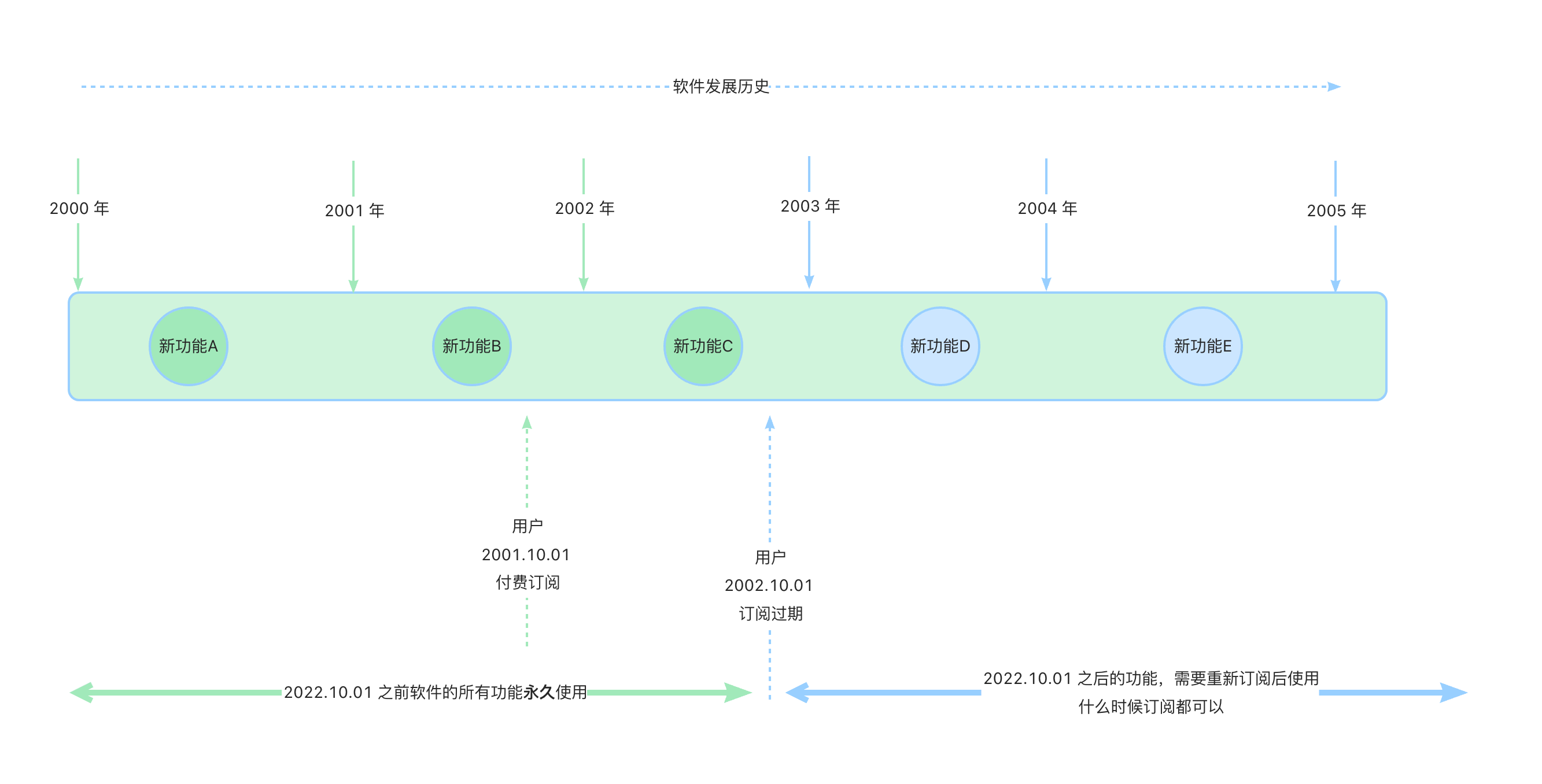
Surge iOS 和 Mac 需要单独购买,iOS 只能在非国区 apple store 下载,Mac 可以在
官网
下载。
价格是有些贵,iOS 和 Mac 差不多都要 $49.9。Mac 版建议拼车,140 元左右,iOS 不建议拼车,比较麻烦。两个平台都可以试用下,效果不错再订阅。
这里有 Surge 的答疑,如:
Mac release notes
、
iOS release notes
、
常见问题
、
订阅说明
。
下面是一些 Surge 的常见使用:
http/https/socks5 代理
、
机场流量转发
(懂的)、
软路由
(相当强悍)、
MitM
&readWrite (比金瓶梅 Charles 好用)、
DNS 代理
、
模块和脚本
(强大功能,非专业人士不常用)。
iOS 和 Mac 可以互联,通过 Mac 连上 iOS 后,可以快速设置 & 查看 iOS 上的网络流量。
如果对于刚需人群,软路由功能就已经让 Surge 的售价低到了尘埃里,懂得已懂。
下面对 Surge 是如何做网络流量劫持代理转发等核心功能,做技术分析。
基石
Socket
在之前的
IM 和 Socket 的关系及 Heart 的必要性
文章中,对 Socket 套接字和 Socket 库 有说明。
一定要理解
gethostbyname()
、
socket()
、
bind()
、
connect()
、
listen()
、
accept()
、
send ()/recv () 和 write ()/read ()
这些 socket api,否则无法理解 tcp/udp 的数据包传输,也无法理解下面要说的网络代理。
Wireshark
在之前的
TCP 数据传输过程分析
文章中,有对 Wireshark 如何抓包和数据分析进行过阐述。Wireshark 是网络流量分析的神器,在理解 surge 的过程中,我对 tls、sni、dns、vif、lookback 等场景都进行了抓包分析和验证,非常有帮助。
如果不能对虚拟网卡和物理网卡的数据包进行详细的参数级观测,理解网络代理会有不小的 gap。
网络代理 - 系统代理
网络代理分为两种,分别是 正向代理 和 反向代理 。对于非服务端的 IT 工作者,可能只是听过但是不理解。用图片描述下:
正向代理
:客户端知道有这个代理的存在,并且主动把数据包给到这个代理,希望这个代理能够自行处理数据包,最后给自己一个满意的返回。有些时候希望代理不做任何包的修改,有些时候又希望代理能够主动移除广告等数据包等。anyway,客户端知道代理会干什么,并且知道和真实服务器之间,有这么一个代理的存在。
反向代理
:客户端不知道有这个代理存在,客户端以为在和真实服务器做数据包的流通,实际上数据包已经被反向代理给劫持。反向代理会对数据包做什么处理,客户端也不知道,如监控过滤阻拦有风险的数据包等。反向代理会优化对服务器的访问,会通过数据包的解析,知道客户端的 ip 等信息,做对应服务器节点的访问。反向代理有一个大杀器,就是负载均衡。anyway,反向代理对客户端是透明的。
对于 Surge 来说,对网络流量的劫持属于正向代理,即用户主动配置了 Surge 代理,使得本机流量让 Surge 来做处理。
对于机器的数据包流量,操作系统会给予一定的支持,提供不同层级的 api 开放能力,使得软件层面能够获取到流量。主要有三种途径:
Surge 使用了三种途径里面的前两种,即系统代理和虚拟网卡。
系统代理因为是操作系统层面直接支持,数据包层级较高,数据操作最为简单,因为系统已经做了封装。
系统代理就是三个,分别是 http/https/socks5 代理,相比后面要说的虚拟网卡,代理的数据有限,但也足够用了。下面着重说明这三个系统代理。
http
http 代理最为简单,也是 https 代理的基础。因为是应用层协议,所以操作起来也最方便。简单画图理解下:
提取一下关键点:
着重说一下上面的第 1 点和第 3 点,即 DNS 解析和 Proxy 内部处理的细节。
对于 DNS 解析,因为数据将要被 Proxy 代理,Client 将要和 Proxy 建立 socket 虚拟通道。
这时候,Client 已经和目标服务器之间没有任何关联,而目标域名的 DNS 解析就是为了拿到目标服务器的 IP 然后建立 Socket 套接字。
所以 Client 没有目标域名 DNS 解析的必要。
但是 Client 需要对 Proxy 做域名解析,因为有了 Proxy 的 IP,才能建立 Socket。Proxy 可能是本机的一个服务,也可能是外网服务。如果是本机服务,那就是 127.0.0.1 回路 ip 了。
对于 Proxy 内部处理,因为 HTTP 是明文的,所以 Proxy 可以拿到明文的数据。这样,Proxy 就可以拿到要请求的域名。
此时,Proxy 可以内建域名白名单,匹配上广告,可以直接返回 404。匹配上国内域名,可以直接代请求一下然后将数据返回。匹配上 google,根据自己是否能够直连外网,做直接请求或者二次转发之类的。
Mac http 代理的设置如下:
http proxy python 实现如下,要理解 client_socket 和 server_socket 两个 socket 的生成和处理。
(From ChatGPT - “用 python 写一个 http 代理,处理 get post delete head 等请求。”)
1 |
import socket |
https
https 代理整体流程和 http 没有变化,就是多了一个 http connect 操作,之后的数据包都是加密的转发 (包括 tls 认证过程和之后的对称加密传输)。
大家使用金瓶梅 Charles 的时候,虽然没有设置 MitM 证书,依旧可以看到当前正在进行哪个 https 域名的访问。
按照预期,https 数据是加密的,域名也在加密数据包里面,Charles 不应该看到。
到这里大家应该理解了吧,http connect 操作会将域名给到 proxy,所以 Charles 虽然不知道数据包内容是啥,依旧可以展示在面板上。
https proxy python 实现如下,要注意对 connect 的处理,是返回 client 200 Established,这样 client 才会继续发送后续的数据包。
(From ChatGPT - “用 python 写一个 https 代理,处理 connect 请求。”)
1 |
import socket |
socks5
1 |
SOCKS5请求格式(以字节为单位): |
具体来说,我们还是可以在 proxy 里面拿到数据包,但是需要进行字节级别的偏移计算,才能够拿到我们想要的数据。操作系统会将 socket 数据包,按照 socks5 协议的标准提供到 Proxy。
而我们的目标还是要拿到域名。https 是通过 connect 给的,socks5 就需要字节偏移来获取。
画图理解下:
socks5 proxy python 实现如下,要注意对域名的获取。
(From ChatGPT - “用 python 写一个 socks5 代理。”)
1 |
import socket |
终端默认为什么不走代理
这里说到了 POSIX 标准。但是如果不理解什么是 POSIX 标准,那还是不理解终端流量为什么不过代理。POSIX 其实一敲就懂。
POSIX 是什么
POSIX 可以从 Wiki 上面查,但是大概率看了也不理解。其实它就是一套 API 统一标准,就和 “书同文车同轨统一度量衡” 一样,这里用 C 的运行时库里面的线程来说明:
C 语言有标准库和运行时库,具体可以看一下之前的文章:
从 Core Foundation 看更大世界 -> C 运行时和 C 标准库的关系
。
如果要通过 C 语言来实现多线程操作,就需要使用线程 api。毕竟如果 C 语言本身没有实现,那么我们还要处理各种锁机制和内核线程之间的关系,几乎不可能。关于锁有多么的麻烦,可以看之前文章:
锁 - 共享数据安全指↑
恰巧,C 标准库就是没有制定多线程技术的实现 (最近才制定),所以 Windows 平台的 MCRT 运行时库和 Linux 平台的 glibc 运行时库,都没有一个 C 语言标准的多线程实现。
事实上 MCRT 和 glibc 本身都实现了多线程 api,因为没有 C 标准库制定标准,如果 MCRT 和 glibc 各自为政,两边的 thread api 就会有命名和功能上的差异,开发人员就不能夸平台执行了。
这时候就有了
POSIX 线程
标准,现在 MCRT 和 glibc 都依据 POSIX 线程标准来实现功能和开放 api,两端就统一了。
这就是 C 运行时库里面
<pthread.h>
的标准 api,也是大家一直在使用的,可以在 UNIX、Linux、MacOS、iOS、Android 等各个系统平台上使用。
后面 C 标准库更新,也做了自身线程的标准,就是 <threads.h> ,但它不是 POSIX 标准的,更多用于 C++11 标准中的线程库,主要适用于 C++ 开发。
终端走系统代理
终端要走系统代理,就需要在 zshrc 等配置文件中配置 http_proxy、https_proxy、all_proxy 这些。如果一次窗口周期使用,还可以用 export 来做。
为什么 export 可以使得本次窗口周期内等所有子进程都走代理,可以看之前的文章:
Shell 和进程
而 http_proxy 这些配置可以使得终端网络走系统代理,是因为 POSIX 标准下的网络实现,认 http_proxy 这个流量转发配置。
然而这个配置的认证,也是可以由开发人员自定义的,所以安全起见,还是做如下配置,把一些可能的情况都配全。
1 |
export http_proxy=http://127.0.0.1:6152 |
网络代理 - 虚拟网卡
因为虚拟网卡工作在 IP 网络层,对这一层的数据进行代理,为了识别到域名,就需要不少的工作量了。核心在于两点:
在系统代理的时候,操作系统会将域名给到 Proxy,拿到了域名就好办事情了。但是到了 IP 网络层,DNS 域名解析早就完成了,这个时候只能拿到 IP,不可能在拿到域名了 (除非 http 这样的明文,但没有意义)。
所以这个时候,就需要主动对域名进行捕获。Surge 的做法是捕获到 DNS 解析的数据包后,强制返回 198.18 网段的内网 ip,并将内网 ip 和域名做映射(这就是文章开头说到的,dig 本网站 ip 是 198 的困惑)。
这样 client 以为 google 的 ip 是 198.18.x,发送的数据包就会携带这个 ip。在 IP 网络层收到这个 ip 的数据包之后,就知道访问的是 google 了。
这样就完成了
域名捕获
的工作。
但是域名捕获又会带来另一个问题,就是
分片的数据包必须要做重组
。
对于数据包分片,在
TCP 数据传输过程分析
里面有说明,可以查阅下。
概要来说,IP 网络层的数据包,有 icmp/ping 这些不过传输层的数据,也有 tcp/udp 这些传输层过来的数据。tcp 会尽量阻止数据包分片的发生甚至可以强制不分片,而 udp 就完全不会管这个了。
综上,因为 dns 解析过程中分片的数据包标识非目标主机,这里又对数据包强制接管及转发,那么一定要做分片重组,否则目标主机无法完成重组操作。
当然重组逻辑本身可控,主要通过 IP 数据包里面的 16 位包标识 ID 进行重组。
下面还是大图看下具体流程:
整体来说,走虚拟网卡接管网络流量,还是比较费事的。需要多个 socket 的数据中转。
Surge 和 VPN 的差异
Surge 不是 VPN,两者的技术实现有重叠。
我们一直说访问不了 Google,就买个 VPN,其实是泛化的概念。很多时候我们不是在使用 VPN,而是指网络代理。
VPN 的确可以实现翻墙,但不是主要目的,VPN 也不是为了翻墙而做的。
VPN 是虚拟隧道,主要是为了保护数据隐私。VPN 是系统提供的能力,在 系统代理 之外,操作系统还提供了 VPN 的配置,VPN 还有多个配置协议,这些协议工作在不同的网络模型层级上。
最终,VPN 也是通过整合应用层、传输层、IP 网络层、数据链路层的数据包,然后根据不同配置协议进行加密,最后将数据包传输到具体的中转服务器。
鉴于 VPN 的使用场景,中转服务器一般都是企业内部网络,员工用来内部访问企业内网。
而我们使用 VPN 翻墙,主要是这个中转服务器,变成了机场,相当于 VPN 帮我们通过机场转发了本机流量。
VPN 是操作系统层面提供的数据代理,支持的协议也比较有限,如 IPSec、L2TP 等。
对于过墙用户来说,VPN 的网络数据包具有明显的特征 (操作系统提供的嘛,具有一定规律),根据这些特征可以很明显的知道这些数据是过墙的敏感数据,从而予以拦截(虽然看不到数据包内容,但是根据特征分析大概率是过墙敏感数据)。
我们将机场给的配置,配置在特定的软件上,实现网络代理。
虽然一样能访问 Google,但这不是 VPN。
虽然不是 VPN,但和 VPN 技术方案有一致。
上面 Surge 实现的系统代理和虚拟网卡,本身不是 VPN,但是可以为本机流量实现中继代理 (机场),从而过墙。
Surge 这些软件,主要就是走特定协议,抹平数据包的特征,使得数据包不具有明显特征,骗过墙。
没有特征本身就是特征。没有墙过滤不了的数据,只是相互博弈的一个过程。
还有一个点,
VPN 本身不是为了过墙而做的,所以对于所有流量,都会发往中继代理
。而 Surge 这些代理软件,可以根据域名来做规则引擎验证,从而实现流量分流。
这也是前面一直在说的,Surge 希望拿到域名的原因。系统代理的时候,操作系统主动提供了域名。虚拟网卡的情况下,Surge 捕获了域名。
看大图吧:
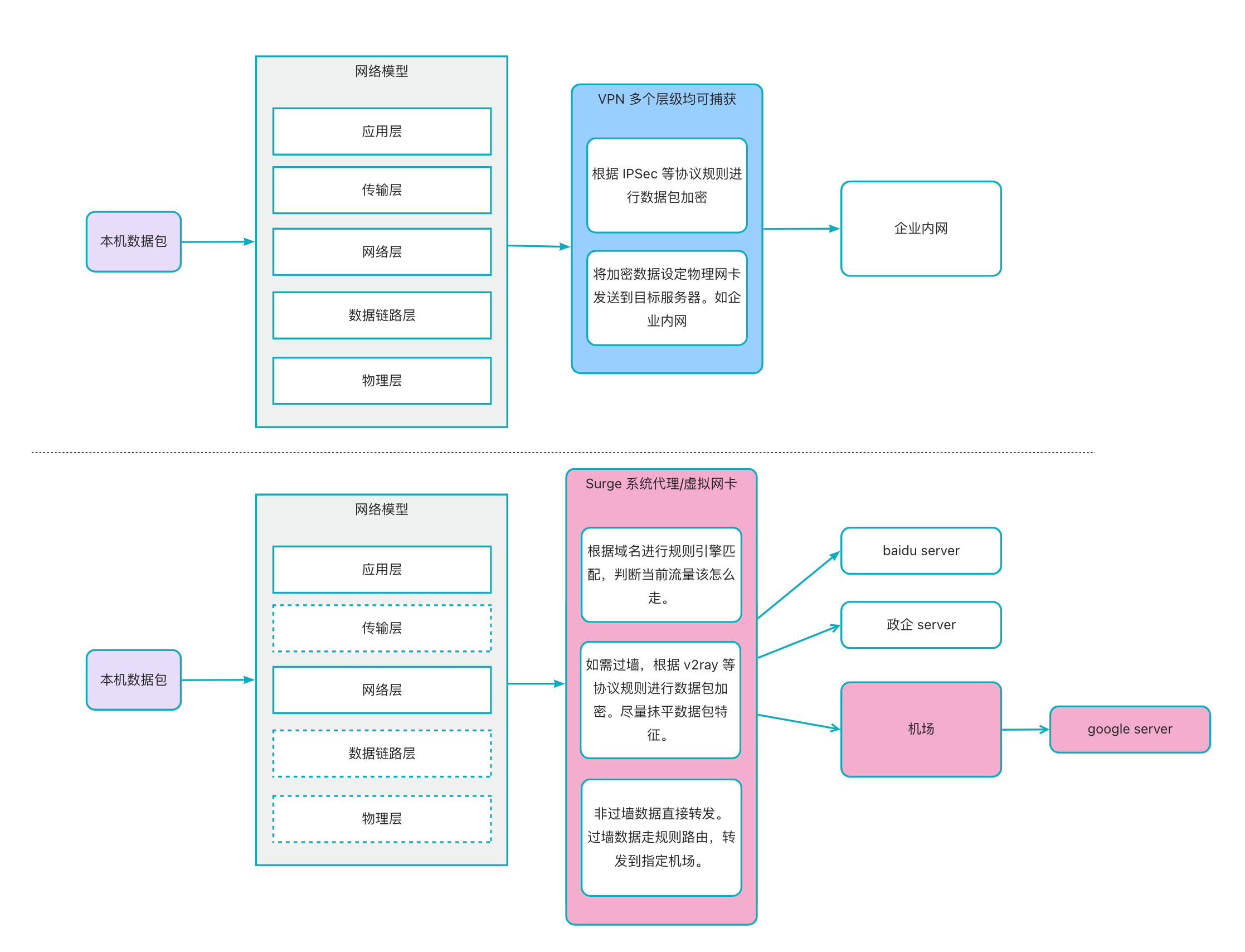
这里还有一个补充,也是大家认为过墙专指 VPN 的原因。
在 iOS 系统上,是没法像 Mac 上面进行 http/https/socks5 配置的。也就是没法直接进行系统代理。
iOS 系统开放了 Network Extension,通过 Extension 可以在应用内部进行系统全局配置,可以做系统代理和虚拟网卡等开发工作。
但是如果使用 Extension,就需要开启 iOS 系统的 VPN,这是唯一接管 iOS 系统网络流量的方式。
所以很多人有过墙就是 VPN 的误区。
MitM
很多成熟的大型应用,也都对 MitM 有校验。比如在进行证书验证的时候,判断证书是否符合预期,不符合预先设置的,则不予通过,这时候 MitM 就会失败了。
了解 MitM 的原理,防护也都会有相应的办法。
这里也顺带批评一下国内银行 app。在开启 VPN 的时候,有些 app 给弹窗提示,有些直接不给使用,挺恶心。
它们应该防护 MitM 和 数据加密,而不是 VPN。MitM 防止应用层截包,数据加密防止应用层以下截包如 Wireshark。
DNS
Surge 对 DNS 解析的处理方案,是:完全抛弃了系统的 DNS 解析,全部自行实现。
Surge 之所以能做到这一点,是因为:
所以,Surge 完全有时机来自行完成 DNS 解析工作。Surge 是怎么做 DNS 解析的呢?
实际上,Surge 虽然抛弃了系统的 DNS 解析,但也没有完全重写。Surge 采用了两个策略来优化 DNS 解析:
Surge 默认对 DNS 的解析操作,的确有效减少了解析耗时。但并没有解决 DNS 劫持等问题。这里推荐看一下网红 IM 网站: 全面了解移动端 DNS 域名劫持等杂症:原理、根源、HttpDNS 解决方案等 ,对于 DNS 带来的问题,说的非常详细。
大家如果对 DNS 解析有疑惑,最好的方式是实战,非常简单的验证即可。这里推荐两个捷径:
这样,后面在看到 wireshark DNS 过滤结果里面的 A/AAAA,就不会迷惑茫然失措了。
实践是最好的理解,1 小时,就对 DNS 的递归解析、迭代查询掌握清楚了。
anyway,DNS 也是 socket 遍历里面的一环,即 gethostbyname () 函数。对于这个函数,其实有一个重要的杀器,用于解决 DNS 劫持的问题,那就是 DOH。
DOH(httpdns)
SNI,就是上面截图里面的:Server Name Indication。
如果服务器 Nginx 配置来 N 个域名的解析,那么 Nginx 就会根据 SNI,知道当前请求的域名是什么,然后返回对应的 ssl/tls CA 证书(如果 Nginx 只配置一个域名,那其实有没有 SNI 都没有关系了)。
Surge 默认已经对 DOH 做支持,在软件的控制面板里面有 DNS over https/https/3/QUIC 的配置。
DOH 的支持需要一定的条件,准确来说,需要 client 支持,因为 DOH 的实现,会带来跨域、http 请求头 host 变为 ip 的预准备工作等:
这些在 Mac 端并没有什么问题,上面的系统代理和网卡代理都可以看到,并不需要 client 主动的感知 DNS,Surge 完全可以全部劫持。目前 Chrome 等浏览器都都做了 DOH 的支持。
但是在 app 上还没法完美支持,这里说的就是 Android 和 iOS。
Android 基于常用的 OKHttp 还比较方便实现,因为 OKHttp 提供 gethostbyname () 接口的实现,这样在 DNS 阶段就可以做 DNS 的 hook。然后对 SNI 做一个反射,就可以完成。
iOS 就相当麻烦了,主要原因是系统没有提供 SNI 的 hook 方式,即使通过 fishhook 完成了 gethostbyname () 的 hook,也没法顺利实现 SNI 的 hook。当然也有解,但是难度很大,很容易出错。这里还是期待系统级别的支持。
其实国内对于 DOH 的支持还不足,几个大的互联网公司的确有支持,但是比较黑盒,更多是解决企业问题。
但 DNS 的劫持问题,确实极为恶劣。大企业即使不用担心墙,也实实在在被 DNS 劫持伤害很大。普通用户更是大千世界一个跨不过去的坎。
尾
谨以此文,致敬 Surge。
感谢互联网带来的繁荣与进步,也感谢窃火者,给岁月以文明。
Surge 官网技术说明
为众人抱薪者,不可使其冻毙于风雪。
为大众谋福利者,不可使其孤军奋战。
为自由开路者,不可使其困顿于荆棘。
- from 窃火者