原创文章,转载请务必将下面这段话置于文章开头处。
技术世界
,
原文链接
http://www.jasongj.com/kafka/high_throughput/
Kafka设计解析(五)- Kafka性能测试方法及Benchmark报告
》从测试角度说明了Kafka的性能。本文从宏观架构层面和具体实现层面分析了Kafka如何实现高性能。
Kafka设计解析(一)- Kafka背景及架构介绍
》一文所述,Topic只是一个逻辑的概念。每个Topic都包含一个或多个Partition,不同Partition可位于不同节点。同时Partition在物理上对应一个本地文件夹,每个Partition包含一个或多个Segment,每个Segment包含一个数据文件和一个与之对应的索引文件。在逻辑上,可以把一个Partition当作一个非常长的数组,可通过这个“数组”的索引(offset)去访问其数据。
一方面,由于不同Partition可位于不同机器,因此可以充分利用集群优势,实现机器间的并行处理。另一方面,由于Partition在物理上对应一个文件夹,即使多个Partition位于同一个节点,也可通过配置让同一节点上的不同Partition置于不同的disk drive上,从而实现磁盘间的并行处理,充分发挥多磁盘的优势。
利用多磁盘的具体方法是,将不同磁盘mount到不同目录,然后在server.properties中,将
log.dirs
设置为多目录(用逗号分隔)。Kafka会自动将所有Partition尽可能均匀分配到不同目录也即不同目录(也即不同disk)上。
注:虽然物理上最小单位是Segment,但Kafka并不提供同一Partition内不同Segment间的并行处理。因为对于写而言,每次只会写Partition内的一个Segment,而对于读而言,也只会顺序读取同一Partition内的不同Segment。
Kafka设计解析(四)- Kafka Consumer设计解析
》一文所述,多Consumer消费同一个Topic时,同一条消息只会被同一Consumer Group内的一个Consumer所消费。而数据并非按消息为单位分配,而是以Partition为单位分配,也即同一个Partition的数据只会被一个Consumer所消费(在不考虑Rebalance的前提下)。
如果Consumer的个数多于Partition的个数,那么会有部分Consumer无法消费该Topic的任何数据,也即当Consumer个数超过Partition后,增加Consumer并不能增加并行度。
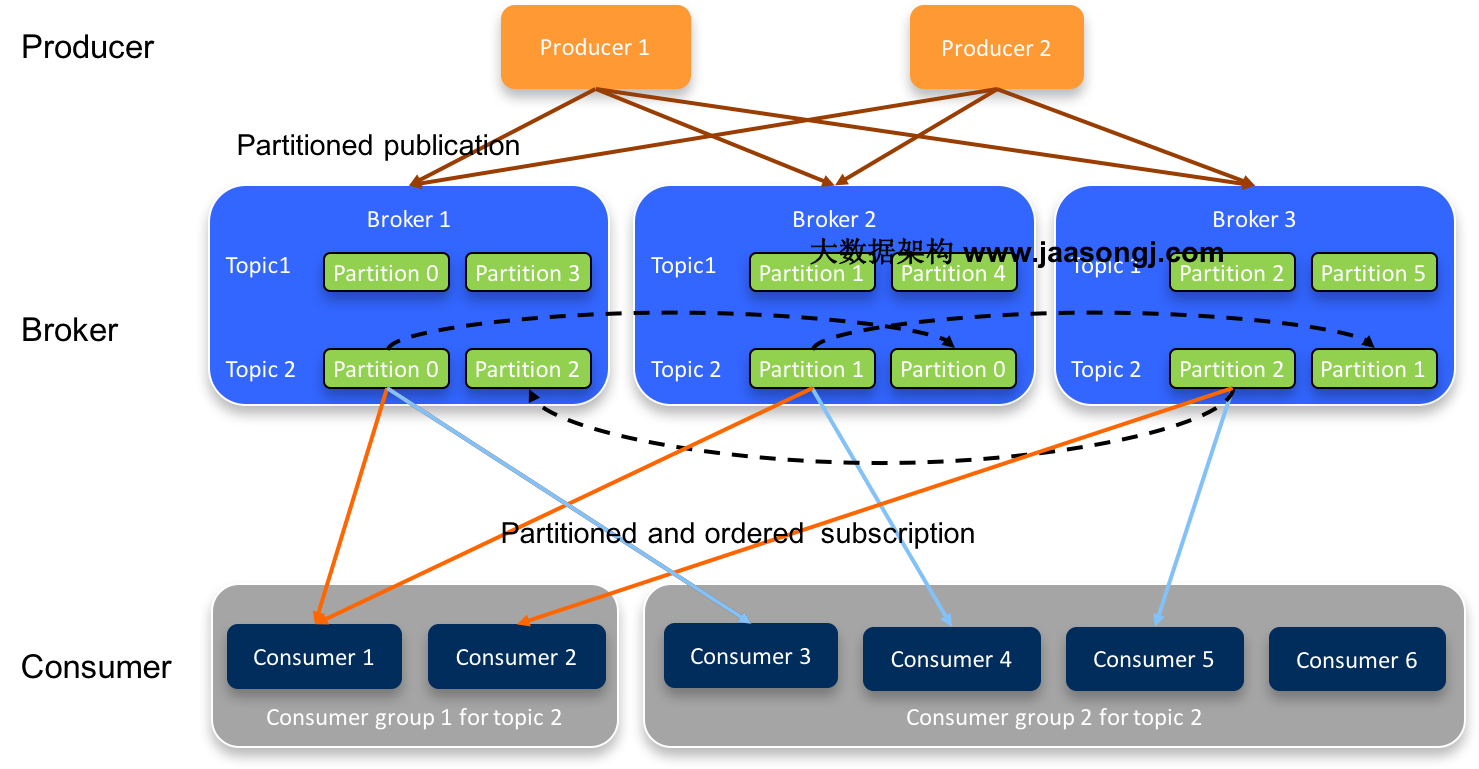
简而言之,Partition个数决定了可能的最大并行度。如下图所示,由于Topic 2只包含3个Partition,故group2中的Consumer 3、Consumer 4、Consumer 5 可分别消费1个Partition的数据,而Consumer 6消费不到Topic 2的任何数据。
以Spark消费Kafka数据为例,如果所消费的Topic的Partition数为N,则有效的Spark最大并行度也为N。即使将Spark的Executor数设置为N+M,最多也只有N个Executor可同时处理该Topic的数据。
Kafka High Availability(上)
》一文所述,Kafka的数据复制是以Partition为单位的。而多个备份间的数据复制,通过Follower向Leader拉取数据完成。从一这点来讲,Kafka的数据复制方案接近于上文所讲的Master-Slave方案。不同的是,Kafka既不是完全的同步复制,也不是完全的异步复制,而是基于ISR的动态复制方案。
ISR,也即In-sync Replica。每个Partition的Leader都会维护这样一个列表,该列表中,包含了所有与之同步的Replica(包含Leader自己)。每次数据写入时,只有ISR中的所有Replica都复制完,Leader才会将其置为Commit,它才能被Consumer所消费。
这种方案,与同步复制非常接近。但不同的是,这个ISR是由Leader动态维护的。如果Follower不能紧“跟上”Leader,它将被Leader从ISR中移除,待它又重新“跟上”Leader后,会被Leader再次加加ISR中。每次改变ISR后,Leader都会将最新的ISR持久化到Zookeeper中。
至于如何判断某个Follower是否“跟上”Leader,不同版本的Kafka的策略稍微有些区别。
对于0.8.*版本,如果Follower在
replica.lag.time.max.ms
时间内未向Leader发送Fetch请求(也即数据复制请求),则Leader会将其从ISR中移除。如果某Follower持续向Leader发送Fetch请求,但是它与Leader的数据差距在
replica.lag.max.messages
以上,也会被Leader从ISR中移除。
从0.9.0.0版本开始,
replica.lag.max.messages
被移除,故Leader不再考虑Follower落后的消息条数。另外,Leader不仅会判断Follower是否在
replica.lag.time.max.ms
时间内向其发送Fetch请求,同时还会考虑Follower是否在该时间内与之保持同步。
0.10.* 版本的策略与0.9.*版一致
对于0.8.*版本的
replica.lag.max.messages
参数,很多读者曾留言提问,既然只有ISR中的所有Replica复制完后的消息才被认为Commit,那为何会出现Follower与Leader差距过大的情况。原因在于,Leader并不需要等到前一条消息被Commit才接收后一条消息。事实上,Leader可以按顺序接收大量消息,最新的一条消息的Offset被记为LEO(Log end offset)。而只有被ISR中所有Follower都复制过去的消息才会被Commit,Consumer只能消费被Commit的消息,最新被Commit的Offset被记为High watermark。换句话说,LEO 标记的是Leader所保存的最新消息的offset,而High watermark标记的是最新的可被消费的(已同步到ISR中的Follower)消息。而Leader对数据的接收与Follower对数据的复制是异步进行的,因此会出现Hight watermark与LEO存在一定差距的情况。0.8.*版本中
replica.lag.max.messages
限定了Leader允许的该差距的最大值。
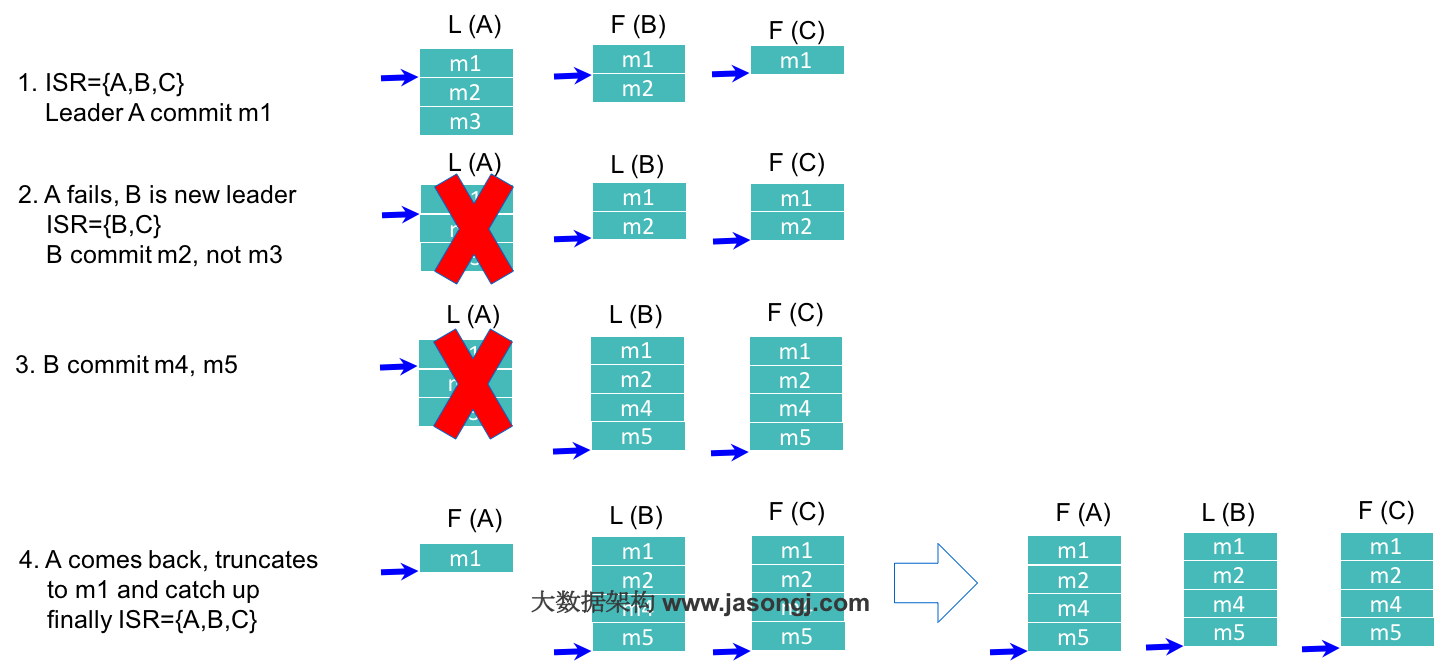
Kafka基于ISR的数据复制方案原理如下图所示。
如上图所示,在第一步中,Leader A总共收到3条消息,故其high watermark为3,但由于ISR中的Follower只同步了第1条消息(m1),故只有m1被Commit,也即只有m1可被Consumer消费。此时Follower B与Leader A的差距是1,而Follower C与Leader A的差距是2,均未超过默认的
replica.lag.max.messages
,故得以保留在ISR中。在第二步中,由于旧的Leader A宕机,新的Leader B在
replica.lag.time.max.ms
时间内未收到来自A的Fetch请求,故将A从ISR中移除,此时ISR={B,C}。同时,由于此时新的Leader B中只有2条消息,并未包含m3(m3从未被任何Leader所Commit),所以m3无法被Consumer消费。第四步中,Follower A恢复正常,它先将宕机前未Commit的所有消息全部删除,然后从最后Commit过的消息的下一条消息开始追赶新的Leader B,直到它“赶上”新的Leader,才被重新加入新的ISR中。
一些场景下顺序写磁盘快于随机写内存
》所述,将写磁盘的过程变为顺序写,可极大提高对磁盘的利用率。
Kafka的整个设计中,Partition相当于一个非常长的数组,而Broker接收到的所有消息顺序写入这个大数组中。同时Consumer通过Offset顺序消费这些数据,并且不删除已经消费的数据,从而避免了随机写磁盘的过程。
由于磁盘有限,不可能保存所有数据,实际上作为消息系统Kafka也没必要保存所有数据,需要删除旧的数据。而这个删除过程,并非通过使用“读-写”模式去修改文件,而是将Partition分为多个Segment,每个Segment对应一个物理文件,通过删除整个文件的方式去删除Partition内的数据。这种方式清除旧数据的方式,也避免了对文件的随机写操作。
通过如下代码可知,Kafka删除Segment的方式,是直接删除Segment对应的整个log文件和整个index文件而非删除文件中的部分内容。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
def delete val deletedLog = log.delete() val deletedIndex = index.delete() val deletedTimeIndex = timeIndex.delete() if (!deletedLog && log.file.exists) throw new KafkaStorageException ("Delete of log " + log.file.getName + " failed." ) if (!deletedIndex && index.file.exists) throw new KafkaStorageException ("Delete of index " + index.file.getName + " failed." ) if (!deletedTimeIndex && timeIndex.file.exists) throw new KafkaStorageException ("Delete of time index " + timeIndex.file.getName + " failed." ) }
1 2
buffer = File.read Socket.send(buffer)
Java NIO
的FileChannel的
transferTo
和
transferFrom
方法实现零拷贝,如下所示。
1 2 3 4
@Override public long transferFrom (FileChannel fileChannel, long position, long count) throws IOException return fileChannel.transferTo(position, count, socketChannel); }
注:
transferTo
和
transferFrom
并不保证一定能使用零拷贝。实际上是否能使用零拷贝与操作系统相关,如果操作系统提供
sendfile
这样的零拷贝系统调用,则这两个方法会通过这样的系统调用充分利用零拷贝的优势,否则并不能通过这两个方法本身实现零拷贝。
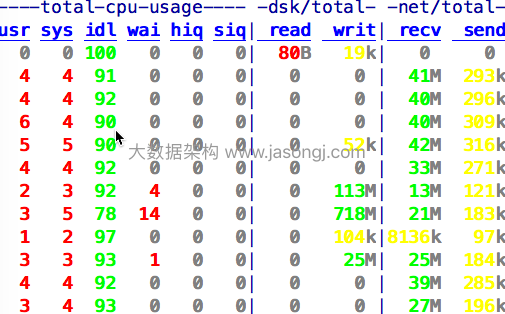
零拷贝章节的图
中可以看到,虽然Broker持续从网络接收数据,但是写磁盘并非每秒都在发生,而是间隔一段时间写一次磁盘,并且每次写磁盘的数据量都非常大(最高达到718MB/S)。


{kind=link}