

ICLR 2022有哪些值得关注的投稿?

51 个回答

ICLR公布了结果,这个回答里大部分文章都录用了!感谢大家关注!
也欢迎大家关注我们的 Oral Paper :
Title: Contrastive Label Disambiguation for Partial Label Learning
突然快600赞了,更新一篇我觉得比较好的工作吧,来自RIKEN的高分工作。
毕竟知乎不是openreview,这个回答里我就不以评审的角度评论这些文章了,大家主要参照文章内容和评审的意见吧。
Sharp Learning Bounds for Contrastive Unsupervised Representation Learning
目标: 解释为什么large batch size能够为对比学习带来性能上的收益。
在先前的工作中(Wang&Isola 2020),我们知道当batch size能够趋近于无穷的时候,无监督对比学习的损失能够使得对比空间中的表征趋近于uniform。但是这没有完全解释为什么batch size增大的时候,学习的效果能够提升,这实际上需要我们找到一个更紧致的泛化误差界。特别的,Arora和Ash的bound中,K增大后泛化误差界会过于松弛。Nozawa & Sato (2021)得到的结果和这篇文章基本一致,关于这个讨论也可以看作者和reviewer的rebuttal。
假设: Data generating process:(i) draw latent positive/negative classes: c^+ , \{c_k^-\}_{k=1}^K\sim\pi^{K+1} (K是负样本数量); (ii) draw an anchor sample x ∼ D_{c^+} ; (iii) draw a positive sample x^+ ∼ D_{c^+} (对应augmentation); (iv) draw K negative samples x^−_k ∼ D_{c^{−}_k} (for each k ∈ [K] ). (这个假设或许有点强?)
定理: 来看一下这篇工作给出的定理:


直接给出了mean classifier误差界关于对比学习损失的上下界。要证明这两个上下界,核心在于求解对 \log\sum\exp(vec) 这个操作符的上下界,由于对比学习中,这里的vec有一些比较好的性质,比如 \exp(-L^2) 和 \exp(L^2) 互为倒数等等,这个上下界可以通过一些简单的代数运算得到。最核心的一步应该是Equation (48),使得 \log\sum\exp 中的运算从“与negative对比”变成了“与类中心”进行对比。
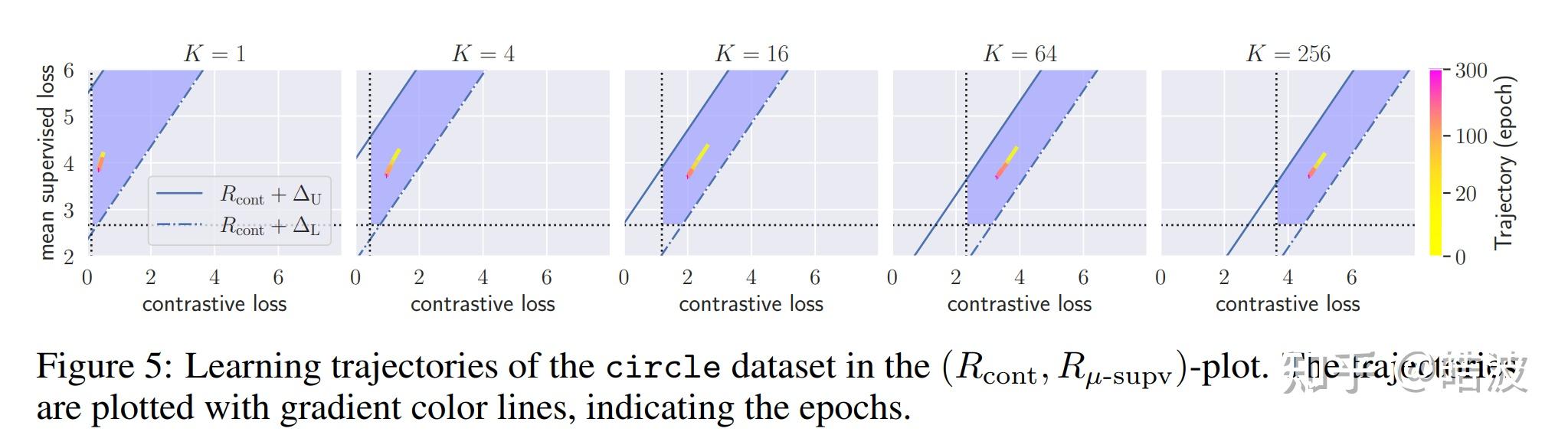
结论: 相比于之前的工作,这篇工作给出了一个更紧致的泛化误差上界(见论文Figure 1),并且给出了一个下界(这个是之前的工作没有讨论的)。这个上界的影响在于,它的阶是 O(\ln 1/K) ,所以随着K的增大,上界能够快速下降(看起来有 \rightarrow -\inf 的问题,不过实际上 R_{cont} 也有一个关于K的项,所以总体来说这个上界不会变成负无穷)。并且上下界的gap能够快速趋近于一个常数,这个上下界的gap收缩可能是影响性能的关键。
如下图,尽管K的大小不会影响,但一个大的K可以让解的可行域能够更窄,则找到一个更优的解可能会更加容易。

看了几篇Contrastive Learning的工作,分析和观点百花齐放,很有意思。
Decoupled Contrastive Learning
(发现Yann的文章凉凉了)Yann组的最新工作,一开始以为是简单的去掉了一项做了个加权,仔细阅读后发现不简单,竟然去掉了分母里Push Away View2后,就能解决对比学习Large Batch-Size的问题。
论文先通过分析了对比学习对各项的梯度,发现batch size影响最大的是一个NPC mulplier的估计,也就下面这一项,它会出现在几个梯度的分项中,过小的batch size会造成该项的distribution shift,从而影响训练,

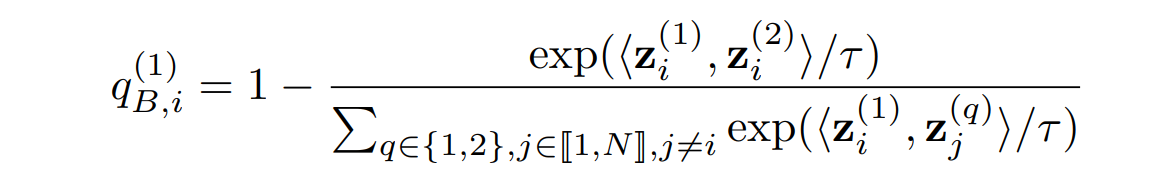
怎么做呢?我们可以在Contrastive Loss中去掉分母中的第二个view就可以了。也就是说,不要push增广得样本即可:

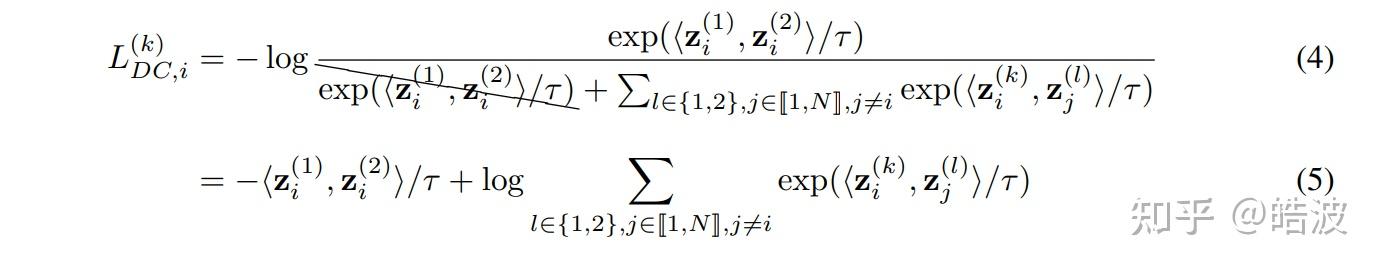
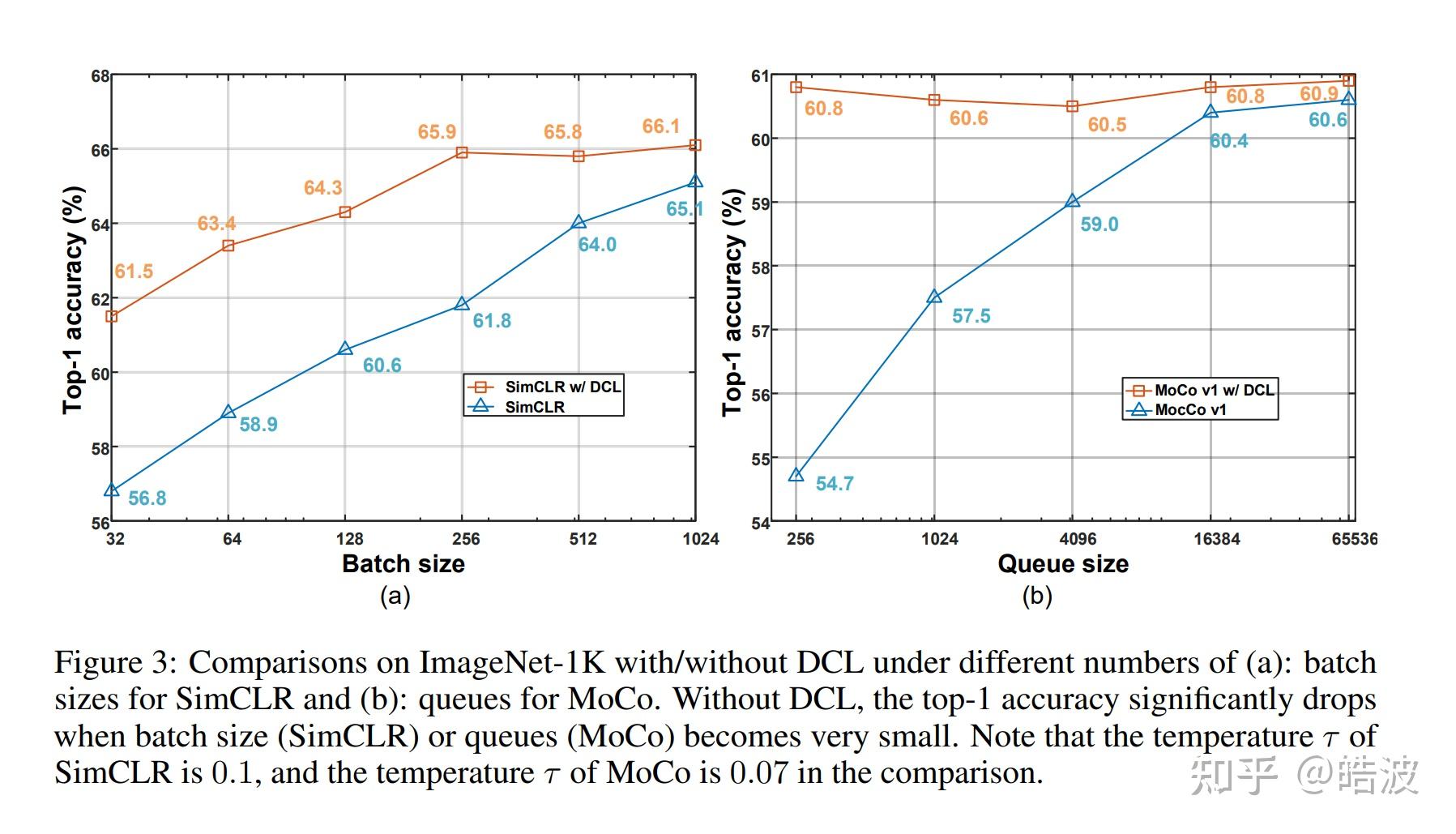
效果有点离谱,基本上比较小的batch-size也有非常大的提升:

Chaos is a Ladder: A New Understanding of Contrastive Learning
这是一篇做理论分析的工作,证明了在Alignment之外,我们还需要引入其他的约束。和这篇比较相关的两篇工作,分别是A theoretical analysis of contrastive unsupervised representation learning和Understanding contrastive representation learning through alignment and uniformity on the hypersphere。前者是证明对比学习情况下,mean classifier的泛化误差界与Intraclass deviation有关。后者则是将损失进行分解,证明了NCE loss的由alignment和uniformity两个性质构成。
具体来说,这篇文章首先分析了alignment和uniformity是不充分的,因为如果我们学习到的表征把每个样本都分的很开,而且完全随机分布,这时候alignment和uniformity不能保证一个紧致的泛化误差上界。所以说,我们需要的是一种Expansion的性质(参考马腾宇组ICLR 2021证明Self-Training的工作),也就是通过augmentation以后,对于(A,A+)和(B,B+)两对样本,如果增广后A+和B+变成非常相似,由于我们进行alignment,这三个样本可能都会变成同一个,那就出现了类似连通图的感觉,所有的样本都能够出于同一个生成集,类似于Spanning tree。由此我们可以得到易于分类的结果。

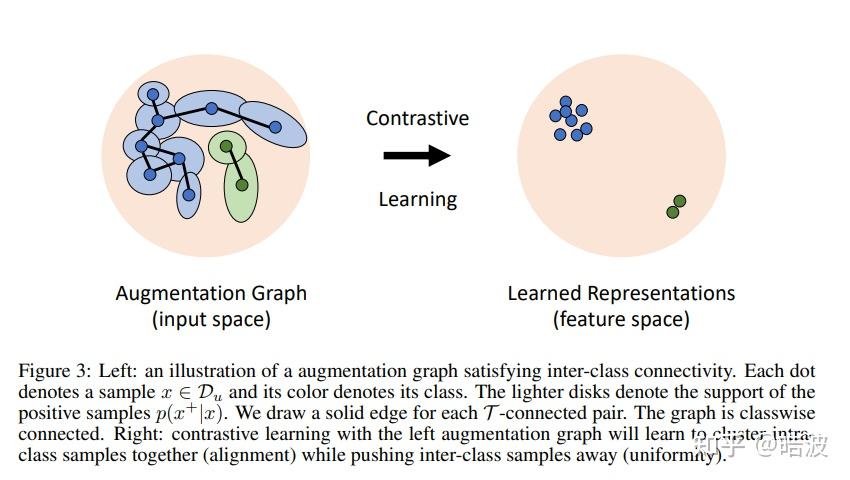
从理论上,作者改进了Sajeev Arora的工作,给出的上界和class conditional variance息息相关。这篇文章和马腾宇组NIPS 2021的工作Provable guarantees for self-supervised deep learning with spectral contrastive loss也有比较强的联系,大家还可以延伸阅读一下。
Contrastive Label Disambiguation for Partial Label Learning
这篇论文把对比学习应用到了弱监督学习问题中,在这个PLL的问题里一个样本的标签是一个候选集合,而不是单个的Ground-truth标签。作者提出的方法同时训练了Classifier和对比学习,然后用Classifier挑选Positive Set,用对比学习的Emebeddings得到一个原型,对弱监督标签进行Disambiguation。近期有多篇对比学习和半监督学习、噪声标签学习的工作,这篇也是在一个新的问题上有很成功的应用。
这篇文章比较有意思的是把方法解释成了EM聚类的过程,推导中把对比学习的Alignment这一项解释成了Class Variance的最小化,这样一来,Alignment这一项可以看作是一个球面上进行von Mises-Fisher聚类的过程。

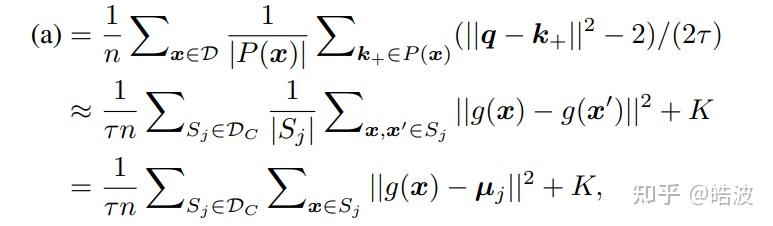
这里聚类的观点是比较有意思的,由于是弱监督学习的工作,所以这篇文章是从Supervised Contrastive Learning的损失出发的,可以证明此时Alignment性质优化的恰巧就是聚类or线性判别分析的目标函数。文章没有显式地在对比学习的目标里加prototype,却推到了和PCL一样的形式——尽管对比学习尝试最小化pairwise点对距离,但其实和直接优化聚类中心(或者说mean classifier)在数学上是等价的。
Contrastive Learning is Just Meta-Learning
这篇文章把对比学习解释成了meta-learning,因为每个instance可以看作不同的任务,而augmented images则是能够看作每个task关联的样本。在Meta-learning中,我们会提供每个任务的support set和query set,但是在对比学习中,我们的样本都是混合在一起的。这种情况更加接近于Prototypical Networks,这时元学习的观点依然十分接近。作者进行了多组实验,发现元学习的效果和SimCLR确实比较接近。基于此,作者提出了一个新的预测旋转损失的目标函数,引入更多的不变性(Invariance)。

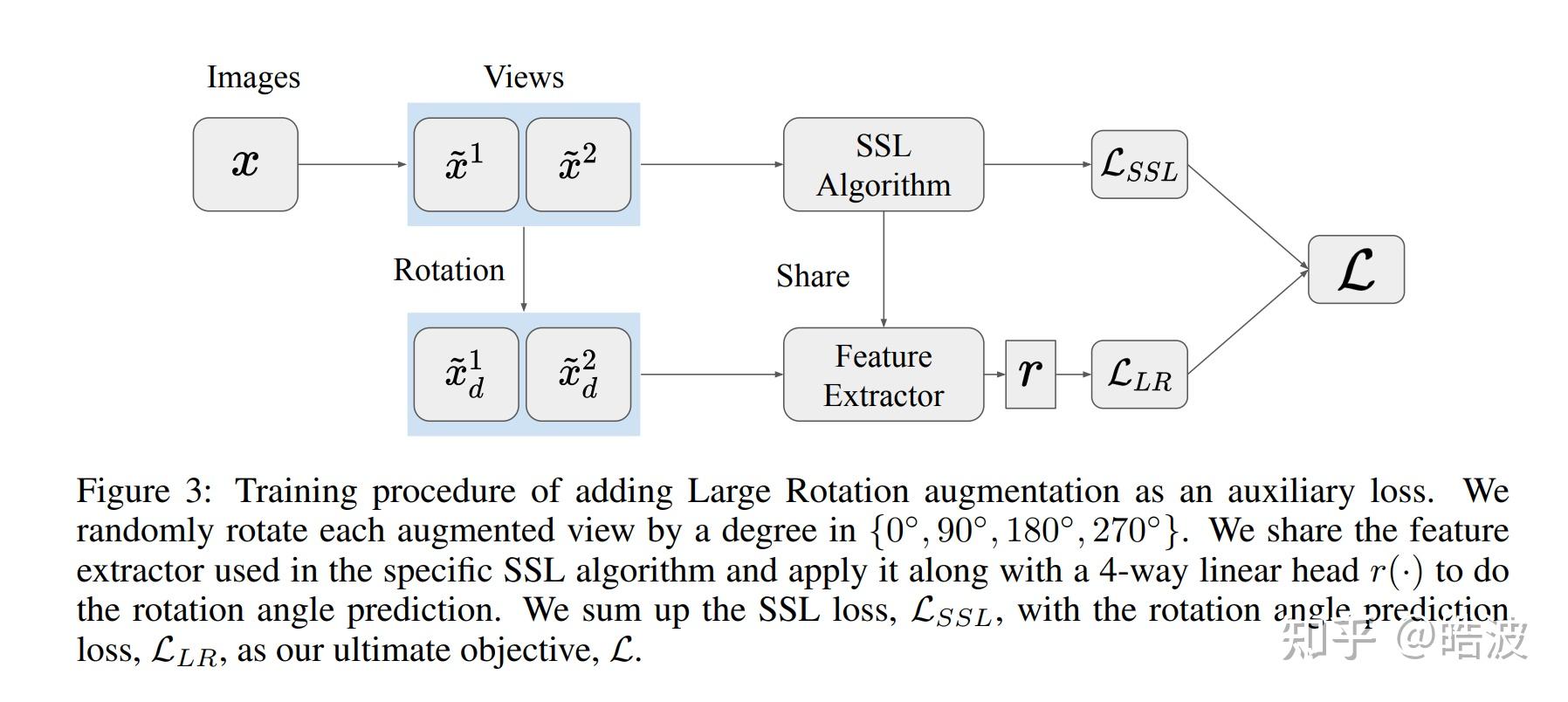
MAML is a Noisy Contrastive Learner
这两篇文章实在是太有意思了,第一篇把对比学习解释成MAML,另一篇则把MAML解释成对比学习。作者推到了MAML的损失的梯度,发现展开以后可以看作某种version的对比学习损失,具体可以直接看论文。
其他论文(没细看or还没看):
- f-Mutual Information Contrastive Learning
- 看起来是把原始的NCE推广到了更广义的divergence
- Self-Contrastive Learning
- multi-exit,在网络的中间层也做对比学习
- Incremental False Negative Detection for Contrastive Learning
- Sharp Learning Bounds for Contrastive Unsupervised Representation Learning
- Rethinking Temperature in Graph Contrastive Learning
- Tackling Oversmoothing of GNNs with Contrastive Learning
- m-mix: Generating hard negatives via multiple samples mixing for contrastive learning
- Semantic-aware Representation Learning Via Probability Contrastive Loss
- What Makes for Good Representations for Contrastive Learning
- ...太多了
看了新的再更
其实很多篇文章都提到了intraclass covariance/deviation,以及mean classifier, prototypes等概念,本质上来说是殊途同归的,原因就是在于alignment这一项其实就是完成了类似线性判别分析的过程,不管有没有prototype,都会把样本往mean classifier上靠,数学上具有一定的等价性。

ICLR 2022一些评分较高比较有意思的,或者偏DG的paper
Oral——A Fine-Grained Analysis on Distribution Shift
文章来自ICLR 2022 Oral: A Fine-Grained Analysis on Distribution Shift
模型对 distribution shifts的鲁棒性在部署时非常重要,域泛化(domain generalization)就是专门研究这个问题的领域。虽然DG已经涌现出了非常多的研究工作,但是绝大多数工作都是将自己的方法在某些常用的benchmark上进行部署,依靠准确度来验证模型的泛化能力。 如何准确的定义distribution shift ,以及 如何系统的测量模型的鲁棒性 这两个问题仍然没有得到解决。本文尝试着对以上两个问题进行解答。
作者主要测试了四类方法
1. 网络结构 ResNet18, ResNet50, ResNet101,ViT以及MLP。
2. Heuristic Data Augmentation。加权重采样会导致样本重复使用多次,导致过拟合。为了减少过拟合,可以用启发式的数据增强来增加训练数据,例如color jitter。这类方法包括AugMix without JSD,RandAugment,AutoAugment 等。
3. Learned Data Augmentation:从源域训练一个一个条件生成模型,从中采样得到新的样本点。这类方法包括CYCLEGAN。
4. Domain generalization方法:包括目前常见的invariant representation。代表方法如IRM,DeepCORAL,DANN,MixUP等。
5. Weighted resampling。也就是说在训练的时候给源域的每个数据点一个权重。这种方法在域泛化,长尾分布中都有不错的效果。代表方法有 JTT,BN-Adapt。
6. Representation learning。 这里主要是选择了β-VAE这类disentanglement的方法。
作者定义了三种不同的分布转移如下图所示

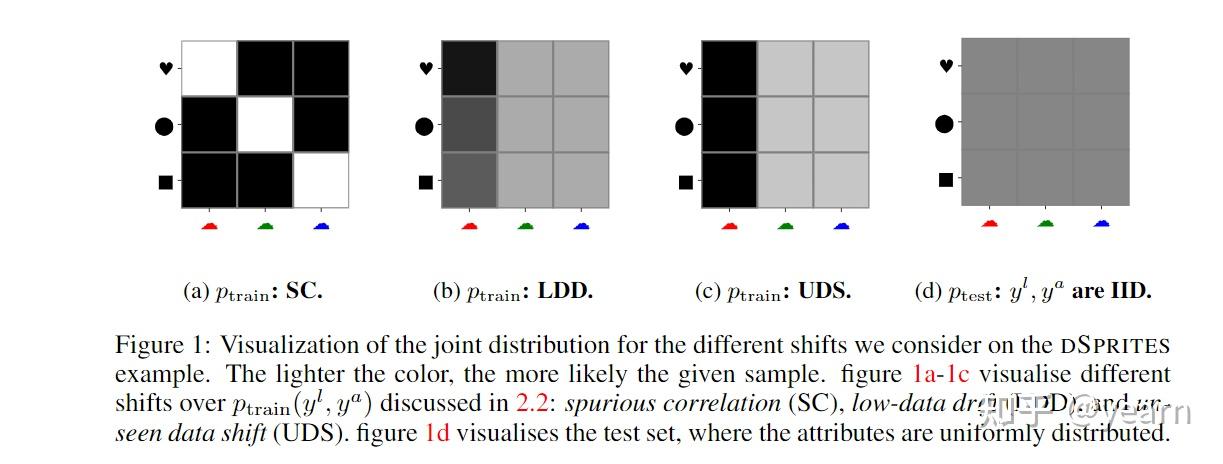
1. Spurious correlation:在训练分布中特征与标签存在一些关系,这些关系在测试集中没有。如上图(a)中的形状与颜色。
2. Low-data drift:属性值在训练过程中分布不均匀,而在测试过程中分布均匀
3. Unseen data shift:有些属性值在训练中不会出现,但在测试过程中会出现。
除此之外还有两种数据集相关的shift即Label noise和数据集的大小。
文章得到的主要结论如下所示
1. 虽然目前的方法可以改进ERM,但没有一种方法总是表现最好。
2. 预训练在各种数据集和distribution shift的情况下都表现得比较好,除非测试数据集非常大而且针对特定领域,比如医学图像类的CAMELYON17数据集。
3. Heuristic augmentation 并不总是对泛化性能有益,这与数据集有关,一个合适的数据增强方法是非常重要的,比如对于rotatedMNIST数据集而言,图像旋转就是最好的增强方法。
4. Learned data augmentation在各种情况下都能稳定带来性能增益。
5. Domain generalization的方法在特定数据集上能带来增益,特别是针对Low-data drift和Unseen data shift两种偏移而言,但是总体来说提升不如启发式的数据增强。
6. 在不同条件下最优的算法不同,也就是说目前没有一个所谓的最厉害的算法。
作者也给出了一些在实际应用中提升泛化性能的tips
1. 启发式的数据增强很简单,可以多次尝试选择不同的组合。
2. 如果启发式的数据增强不work,可以选择使用CYCLE-GAN之类的技术去学习新的数据。
3. 总的来说,预训练被发现对学习健壮表征很有用,
4. 目前的域泛化方法,disentanglement的方法以及重加权的方法带来的提升都很有限而且不是对各个数据集都有用。越复杂的方法越难generalize到其他数据集上。
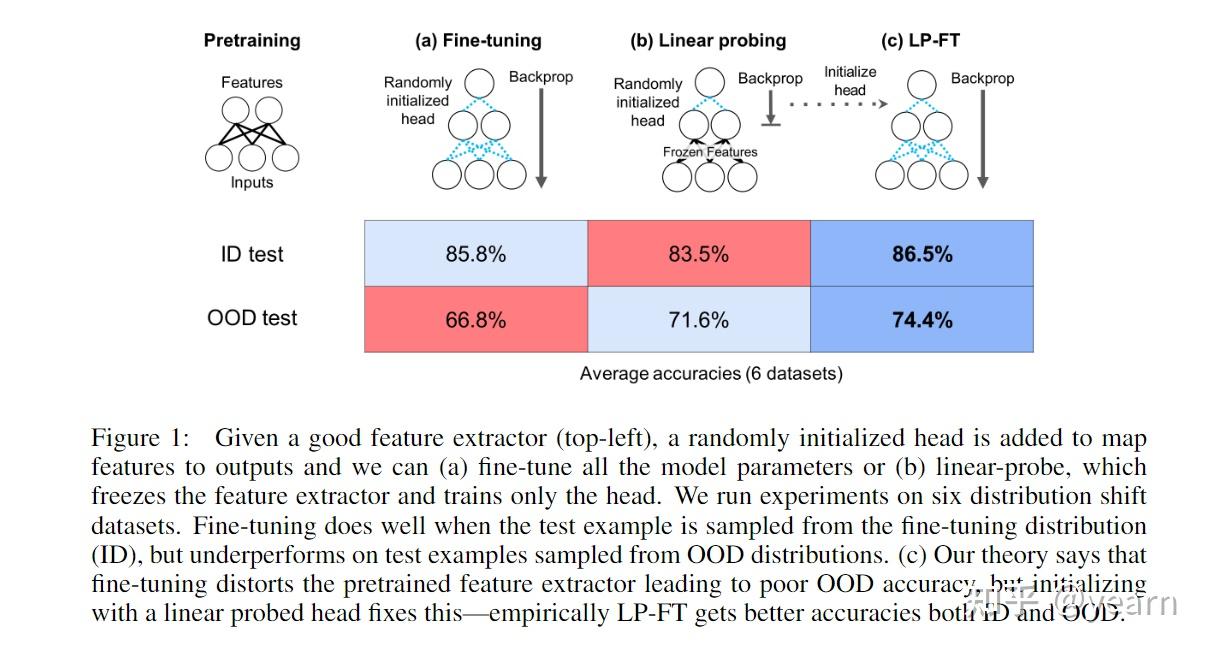
Oral——Fine-Tuning Distorts Pretrained Features and Underperforms Out-of-Distribution
将预训练模型部署到下游任务中一般认为有两种方法,fine-tuning(微调)和linear probing,前者会更新模型的所有参数,后者只更新最后一个线性层。一般认为微调会带来更好的分布内准确度,泛化性更好。比如本文在Breeds-Living17, Breeds-Entity30, DomainNet, CIFAR→STL, CIFAR10.1, FMoW 6个数据集上进行了实验,相比于linear probing,微调一般在分布内平均有2%的性能提升,但是OOD的情况下有6%的性能下降。
本文从理论上分析了微调过参数化的双层线性网络中产生的tradeoff,描述了微调如何扭曲了高质量的预训练特征,从而导致OOD精度较低。 基于这个理论,本文提出了如下图(c)的改进策略。即一个两阶段的训练策略,将linear probing作为微调前的初始化阶段。这样一个简单的改进在ID和OOD的情况都取得了非常不错的性能提升(1% better ID, 8% better OOD)。

Spotlight——Towards a Unified View of Parameter-Efficient Transfer Learning
在下游任务中对大型预训练语言模型进行微调已成为NLP的常见学习范式。传统的微调预训练模型所有参数的方法过于困难,因为参数量实在太大。 最近的工作提出了多种参数高效迁移学习方法,这些方法只调整少量(额外)参数以获得较强的性能,具体有如下几类

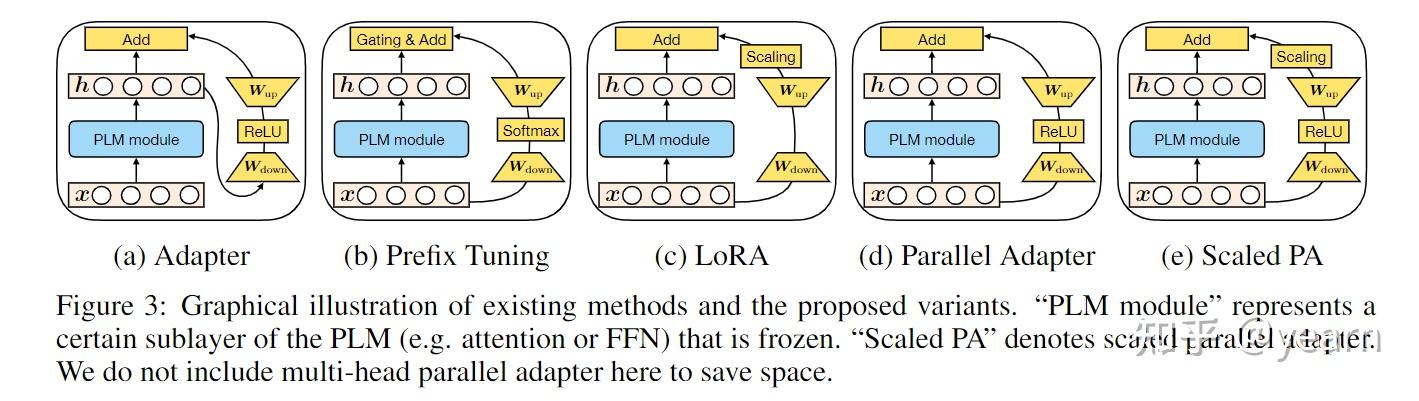
- adapter tuning:将称为adapter的小型神经模块插入到预训练网络的每一层,并且只有adapter在微调时被训练 (上图a)
- prefix tuning与prompt tuning:在输入token中添加额外的多个可训练的token,微调时只训练这些token(上图b)。
- LoRA :在transformer层中注入可训练的低秩矩阵来近似权值更新。 (上图c)
这些方法与对不同的任务集进行全面的微调相比具有相当的性能,通常通过更新不到1%的原始模型参数来实现。 除了节省参数外,参数高效的调优还可以在不出现灾难性遗忘的情况下快速适应新任务,并且通常在OOD评估中显示出卓越的鲁棒性。
然而,目前人们对这些参数高效调优方法成功的重要因素知之甚少,它们之间的联系仍然不清楚。本文旨在回答三个问题: (1)这些方法是如何联系的? (2)这些方法是否共享对其有效性至关重要的设计元素,它们是什么? (3)能否将每种方法的有效成分转移到其他方法中,从而产生更有效的变体?
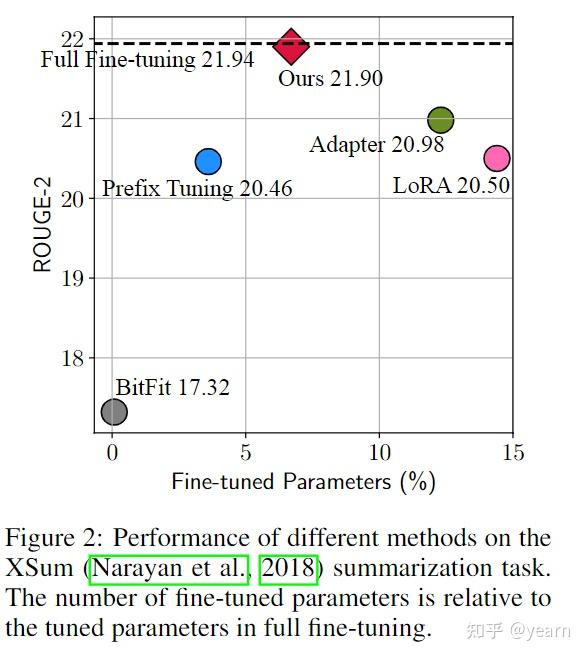
本文首先在公式上找到了adapter和prefix tuning上的联系,在此基础上设计了一个统一的框架,这个统一的框架可以一定程度上揭示目前参数高效调优的成功因素,并以此滋生出了两种变体,在包括文本摘要、机器翻译(MT)、文本分类和一般语言理解的四个NLP基准上进行的实验表明,所提出的方法比现有方法使用的参数更少,同时更有效。

Spotlight——How Do Vision Transformers Work?
在计算机视觉中,multi-head self-attention(MSAs)已经取得了巨大的成功,但是其中的原因尚不清楚,本文提供了不同解释来帮助我们理解Vision Transformers (ViTs)的优良特性。先将本文发现的优良特性总结如下
- MSAs不仅提高了精度,而且通过使损失的landscape变得平坦,提高了泛化程度。
- MSAs和卷积Convs表现出相反的行为。例如,MSAs是低通滤波器,而Convs是高通滤波器。
- 多层的神经网络的行为就像一系列小的个体模型的串联。此外,最后阶段的MSAs在预测中起着关键作用。
Spotlight——On Predicting Generalization using GANs
对深度网络泛化边界(generalization bounds)的研究旨在提供仅使用训练数据集和网络参数来预测测试误差的方法。虽然泛化界限可以提供许多关于架构设计、训练算法等方面的intuition,但目前的bound很少能对实际测试错误产生良好的预测。当前的论文研究了一个简单的想法: 测试误差能否使用合成数据来进行预测,即使用在相同的训练数据集上训练的生成式对抗网络(GAN)产生的数据? 在研究了几个GAN模型和架构后,本文发现使用在标准数据集上预先训练的GANs,可以预测测试错误,而不需要任何额外的超参数调优。
目前大多数论文对泛化误差的上下界可以概括如下

这里S是训练数据集,C是复杂度的度量,这种类型的bound一般是非常松散的甚至于与泛化性之间的关联并不大。这就激发了对泛化边界有效性的更有原则的实证研究。
本文探索了一个非常简单的baseline来预测泛化效果,在训练数据集上训练生成对抗网络(GAN),并使用生成对抗网络产生的合成数据的性能来预测泛化。虽然说GAN的生成器会呈现模式崩溃(collapse),也就是说,生成的分布只是真实分布的一个很小的子集,而且有理论和实验表明,这可能很难避免。但是本文发现GAN生成的数据允许很好地估计测试误差(和泛化误差)。
本文的算法很简单,就像上面描述的一样。


部分实验效果如下图所示,这个简单的方法在大多数benchmark上都取得了非常不错的效果

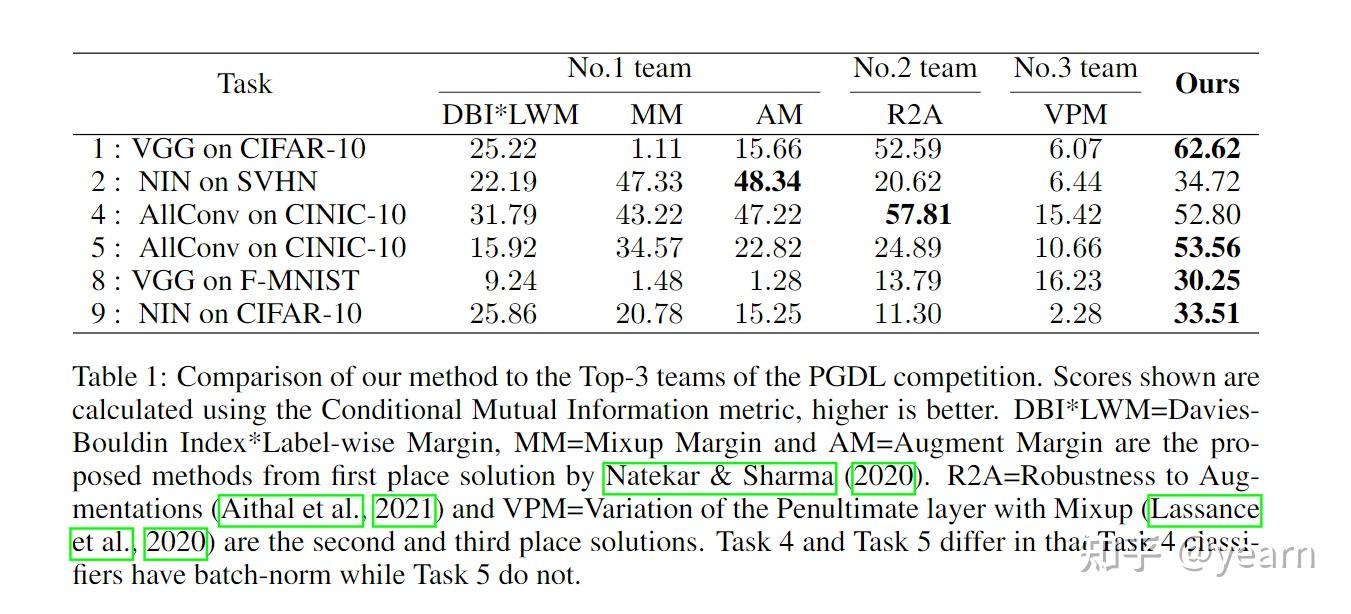
但是GAN本身生成的数据分布并不见得有很大的多样性,而且像前文提到的一样很容易发生model collapse,因此理论上为什么它能这么用来进行预测泛化性尚不可知。
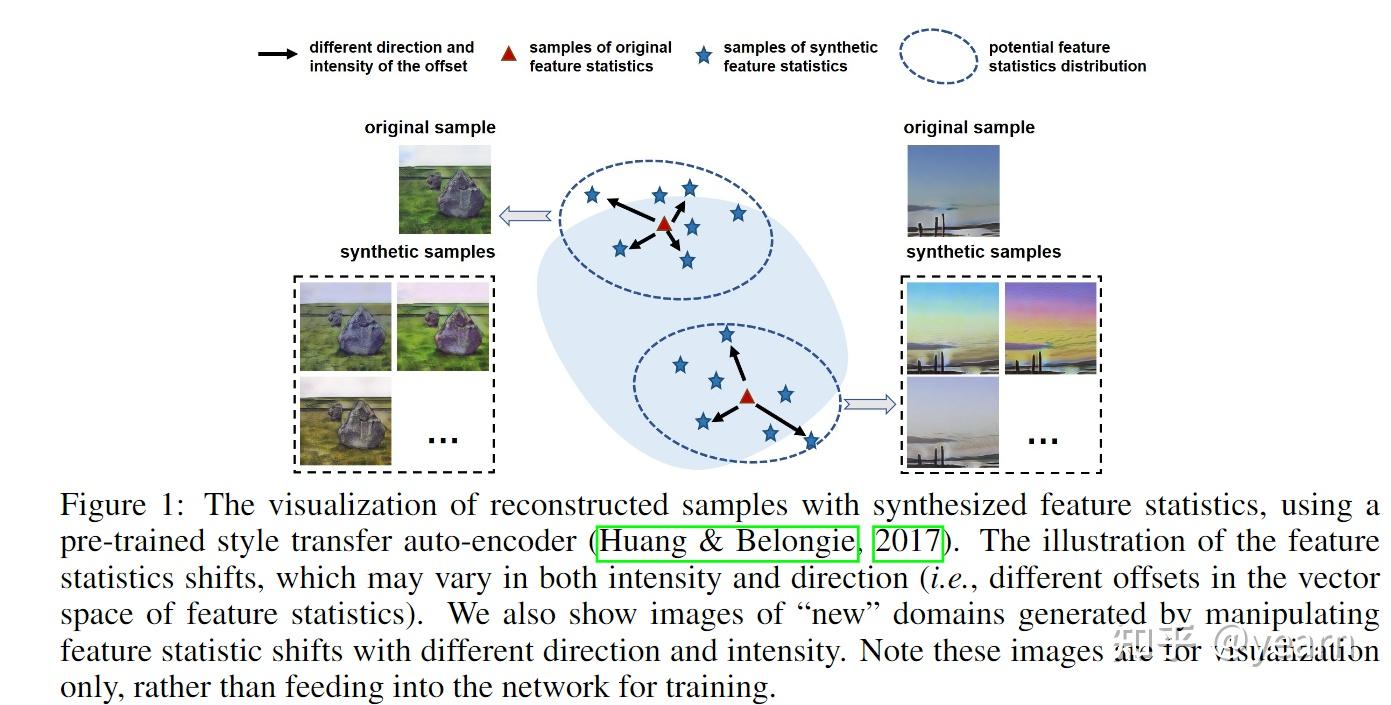
Poster——Uncertainty Modeling for Out-of-Distribution Generalization
域泛化(domain generlaization)是目前一个非常火热的研究课题,认为在训练数据与测试数据间存在分布差异,目前常用的方法都是将特征当作是确定的值,而不考虑他们的不确定性。 本文假设特征考虑潜在的不确定性并遵循多元高斯分布。因此,每个特征统计不再是一个确定性值,而是具有不同分布可能性的概率点。通过不确定的特征统计,可以培训模型以减轻域扰动并实现对潜在域移位的更好的鲁棒性。实现上来说算法类似于数据增强,会确定一个协方差矩阵,特征向量本身作为均值,在范围内进行采样。

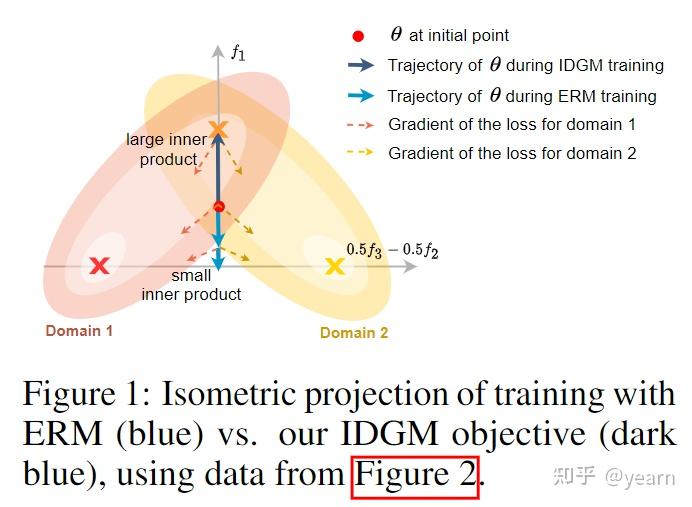
Poster——Gradient Matching for Domain Generalization
本文提出了一种新方法促进域泛化。主要思想是鼓励来自不同域的梯度之间的内积更大。作者提出了一种称为FISH的优化算法,而不是添加一个明确的规范器来完成这一目标。作者进一步显示了他们所提出的方法对WILDS和DomainBED这些benchmark都竞争力。

最后,欢迎大家关注github,聚合了OOD,causality,robustness,optimization以及一些前沿研究方向的一些阅读笔记