hashCode()
的作用是获取哈希码(
int
整数),也称为散列码。这个哈希码的作用是确定该对象在哈希表中的索引位置。
hashCode()
定义在 JDK 的
Object
类中,这就意味着 Java 中的任何类都包含有
hashCode()
函数。另外需要注意的是:
Object
的
hashCode()
方法是本地方法,也就是用 C 语言或 C++ 实现的。
public native int hashCode();
散列表存储的是键值对(key-value),它的特点是:
能根据“键”快速的检索出对应的“值”。这其中就利用到了散列码!(可以快速找到所需要的对象)
为什么要有 hashCode?
我们以“
HashSet
如何检查重复”为例子来说明为什么要有
hashCode
?
下面这段内容摘自我的 Java 启蒙书《Head First Java》:
当你把对象加入
HashSet
时,
HashSet
会先计算对象的
hashCode
值来判断对象加入的位置,同时也会与其他已经加入的对象的
hashCode
值作比较,如果没有相符的
hashCode
,
HashSet
会假设对象没有重复出现。但是如果发现有相同
hashCode
值的对象,这时会调用
equals()
方法来检查
hashCode
相等的对象是否真的相同。如果两者相同,
HashSet
就不会让其加入操作成功。如果不同的话,就会重新散列到其他位置。这样我们就大大减少了
equals
的次数,相应就大大提高了执行速度。
其实,
hashCode()
和
equals()
都是用于比较两个对象是否相等。
那为什么 JDK 还要同时提供这两个方法呢?
这是因为在一些容器(比如
HashMap
、
HashSet
)中,有了
hashCode()
之后,判断元素是否在对应容器中的效率会更高(参考添加元素进
HashSet
的过程)!
我们在前面也提到了添加元素进
HashSet
的过程,如果
HashSet
在对比的时候,同样的
hashCode
有多个对象,它会继续使用
equals()
来判断是否真的相同。也就是说
hashCode
帮助我们大大缩小了查找成本。
那为什么不只提供
hashCode()
方法呢?
这是因为两个对象的
hashCode
值相等并不代表两个对象就相等。
那为什么两个对象有相同的
hashCode
值,它们也不一定是相等的?
因为
hashCode()
所使用的哈希算法也许刚好会让多个对象传回相同的哈希值。越糟糕的哈希算法越容易碰撞,但这也与数据值域分布的特性有关(所谓哈希碰撞也就是指的是不同的对象得到相同的
hashCode
)。
总结下来就是:
-
如果两个对象的
hashCode
值相等,那这两个对象不一定相等(哈希碰撞)。
-
如果两个对象的
hashCode
值相等并且
equals()
方法也返回
true
,我们才认为这两个对象相等。
-
如果两个对象的
hashCode
值不相等,我们就可以直接认为这两个对象不相等。
相信大家看了我前面对
hashCode()
和
equals()
的介绍之后,下面这个问题已经难不倒你们了。
为什么重写 equals() 时必须重写 hashCode() 方法?
因为两个相等的对象的
hashCode
值必须是相等。也就是说如果
equals
方法判断两个对象是相等的,那这两个对象的
hashCode
值也要相等。
如果重写
equals()
时没有重写
hashCode()
方法的话就可能会导致
equals
方法判断是相等的两个对象,
hashCode
值却不相等。
思考
:重写
equals()
时没有重写
hashCode()
方法的话,使用
HashMap
可能会出现什么问题。
总结
:
-
equals
方法判断两个对象是相等的,那这两个对象的
hashCode
值也要相等。
-
两个对象有相同的
hashCode
值,他们也不一定是相等的(哈希碰撞)。
更多关于
hashCode()
和
equals()
的内容可以查看:
Java hashCode() 和 equals()的若干问题解答
open in new window
String
String、StringBuffer、StringBuilder 的区别?
可变性
String
是不可变的(后面会详细分析原因)。
StringBuilder
与
StringBuffer
都继承自
AbstractStringBuilder
类,在
AbstractStringBuilder
中也是使用字符数组保存字符串,不过没有使用
final
和
private
关键字修饰,最关键的是这个
AbstractStringBuilder
类还提供了很多修改字符串的方法比如
append
方法。
abstract class AbstractStringBuilder implements Appendable, CharSequence {
char[] value;
public AbstractStringBuilder append(String str) {
if (str ==
null)
return appendNull();
int len = str.length();
ensureCapacityInternal(count + len);
str.getChars(0, len, value, count);
count += len;
return this;
线程安全性
String
中的对象是不可变的,也就可以理解为常量,线程安全。
AbstractStringBuilder
是
StringBuilder
与
StringBuffer
的公共父类,定义了一些字符串的基本操作,如
expandCapacity
、
append
、
insert
、
indexOf
等公共方法。
StringBuffer
对方法加了同步锁或者对调用的方法加了同步锁,所以是线程安全的。
StringBuilder
并没有对方法进行加同步锁,所以是非线程安全的。
性能
每次对
String
类型进行改变的时候,都会生成一个新的
String
对象,然后将指针指向新的
String
对象。
StringBuffer
每次都会对
StringBuffer
对象本身进行操作,而不是生成新的对象并改变对象引用。相同情况下使用
StringBuilder
相比使用
StringBuffer
仅能获得 10%~15% 左右的性能提升,但却要冒多线程不安全的风险。
对于三者使用的总结:
-
操作少量的数据: 适用
String
-
单线程操作字符串缓冲区下操作大量数据: 适用
StringBuilder
-
多线程操作字符串缓冲区下操作大量数据: 适用
StringBuffer
String 为什么是不可变的?
String
类中使用
final
关键字修饰字符数组来保存字符串,
所以
String
对象是不可变的。
public final class String implements java.io.Serializable, Comparable<String>, CharSequence {
private final char value[];
🐛 修正:我们知道被
final
关键字修饰的类不能被继承,修饰的方法不能被重写,修饰的变量是基本数据类型则值不能改变,修饰的变量是引用类型则不能再指向其他对象。因此,
final
关键字修饰的数组保存字符串并不是
String
不可变的根本原因,因为这个数组保存的字符串是可变的(
final
修饰引用类型变量的情况)。
String
真正不可变有下面几点原因:
-
保存字符串的数组被
final
修饰且为私有的,并且
String
类没有提供/暴露修改这个字符串的方法。
-
String
类被
final
修饰导致其不能被继承,进而避免了子类破坏
String
不可变。
相关阅读:
如何理解 String 类型值的不可变? - 知乎提问
open in new window
补充(来自
issue 675
open in new window
):在 Java 9 之后,
String
、
StringBuilder
与
StringBuffer
的实现改用
byte
数组存储字符串。
public final class String implements java.io.Serializable,Comparable<String>, CharSequence {
@Stable
private final byte[] value;
abstract class AbstractStringBuilder implements Appendable, CharSequence {
byte[] value;
Java 9 为何要将
String
的底层实现由
char[]
改成了
byte[]
?
新版的 String 其实支持两个编码方案:Latin-1 和 UTF-16。如果字符串中包含的汉字没有超过 Latin-1 可表示范围内的字符,那就会使用 Latin-1 作为编码方案。Latin-1 编码方案下,
byte
占一个字节(8 位),
char
占用 2 个字节(16),
byte
相较
char
节省一半的内存空间。
JDK 官方就说了绝大部分字符串对象只包含 Latin-1 可表示的字符。

如果字符串中包含的汉字超过 Latin-1 可表示范围内的字符,
byte
和
char
所占用的空间是一样的。
这是官方的介绍:https://openjdk.java.net/jeps/254 。
字符串拼接用“+” 还是 StringBuilder?
Java 语言本身并不支持运算符重载,“+”和“+=”是专门为 String 类重载过的运算符,也是 Java 中仅有的两个重载过的运算符。
String str1 = "he";
String str2 = "llo";
String str3 = "world";
String str4 = str1 + str2 + str3;
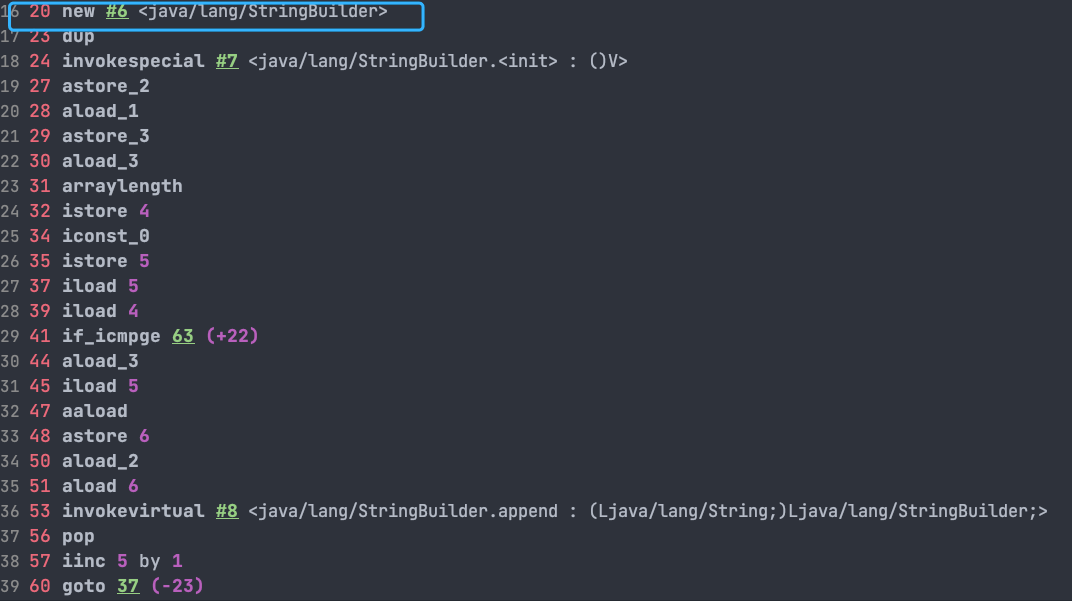
上面的代码对应的字节码如下:

可以看出,字符串对象通过“+”的字符串拼接方式,实际上是通过
StringBuilder
调用
append()
方法实现的,拼接完成之后调用
toString()
得到一个
String
对象 。
不过,在循环内使用“+”进行字符串的拼接的话,存在比较明显的缺陷:
编译器不会创建单个
StringBuilder
以复用,会导致创建过多的
StringBuilder
对象
。
String[] arr = {"he", "llo", "world"};
String s = "";
for (int i = 0; i < arr.length; i++) {
s += arr[i];
System.out.println(s);
StringBuilder
对象是在循环内部被创建的,这意味着每循环一次就会创建一个
StringBuilder
对象。

如果直接使用
StringBuilder
对象进行字符串拼接的话,就不会存在这个问题了。
String[] arr = {"he", "llo", "world"};
StringBuilder s = new StringBuilder();
for (String value : arr) {
s.append(value);
System.out.println(s);
如果你使用 IDEA 的话,IDEA 自带的代码检查机制也会提示你修改代码。
不过,使用 “+” 进行字符串拼接会产生大量的临时对象的问题在 JDK9 中得到了解决。在 JDK9 当中,字符串相加 “+” 改为了用动态方法
makeConcatWithConstants()
来实现,而不是大量的
StringBuilder
了。这个改进是 JDK9 的
JEP 280
open in new window
提出的,这也意味着 JDK 9 之后,你可以放心使用“+” 进行字符串拼接了。关于这部分改进的详细介绍,推荐阅读这篇文章:还在无脑用
StringBuilder?来重温一下字符串拼接吧
open in new window
。
String#equals() 和 Object#equals() 有何区别?
String
中的
equals
方法是被重写过的,比较的是 String 字符串的值是否相等。
Object
的
equals
方法是比较的对象的内存地址。
字符串常量池的作用了解吗?
字符串常量池
是 JVM 为了提升性能和减少内存消耗针对字符串(String 类)专门开辟的一块区域,主要目的是为了避免字符串的重复创建。
String aa = "ab";
String bb = "ab";
System.out.println(aa==bb);

