


【机器学习笔记】:从零开始学会逻辑回归(一)

作者:xiaoyu
微信公众号: Python数据科学
知乎: python数据分析师
1. 前言
逻辑回归是一个非常经典,也是很常用的模型。之前和大家分享过它的重要性: 5个原因告诉你:为什么在成为数据科学家之前,“逻辑回归”是第一个需要学习的
关于逻辑回归,可以用一句话来总结: 逻辑回归假设数据服从伯努利分布,通过极大似然函数的方法,运用梯度下降来求解参数,来达到将数据二分类的目的。
本篇我们就开始逻辑回归的介绍。
2. sigmoid函数
首先我们了解一个函数: sigmoid ,逻辑回归就是基于这个函数构建的模型。sigmod函数公式如下:
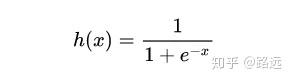
使用Python的numpy,matplotlib对该函数进行可视化,如下:
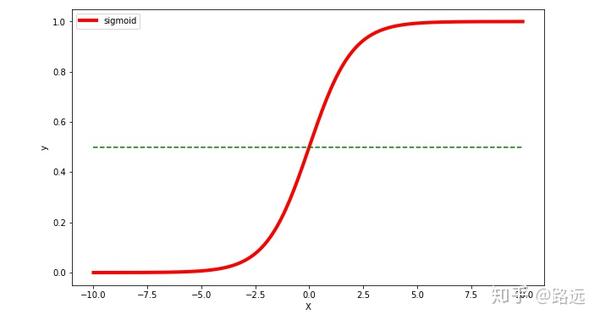

图中我们可以直观地看到这个函数的一些特点:
- 中间范围内函数斜率最大,对应Y的大部分数值变化
- Y轴数值范围在 0~1 之间
- X轴数值范围没有限制,但当X大于一定数值后,Y无限趋近于1,而小于一定数值后,Y无限趋近于0
- 特别地,当 X=0 时,Y=0.5
3. 广义线性模型
前几篇我们详细地介绍了线性回归模型:
【机器学习笔记】:大话线性回归(一)
【机器学习笔记】:大话线性回归(二)
【机器学习笔记】:大话线性回归(三)
其中在残差分析的过程中,如果残差方差不是齐性的,我们一般会对变量 取自然对数 进行变换,以达到残差方差齐性的效果。比如我们这样取对数:
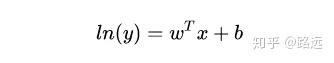
我们一般称这种为 “对数线性回归” ,其形式上是线性回归,但实际上是在求输入空间到输出空间的非线性函数映射。这里的对数函数就起到了将线性回归模型预测值与真实值联系起来的作用。
我们称这样变换后的模型为 “广义线性模型” ,其中对数函数为 “联系函数”, 当然也可以是其他函数。广义线性模型是个宏观概念,上面通过对数函数变换得到的模型只是广义线性模型的其中一种而已。
4. 逻辑回归模型构建
了解了上面的基本内容,我们来看一下逻辑回归模型是如何建立的。其实,逻辑回归模型也是 广义线性模型 的其中一种,只是形式上和上面取对数有些不同。它正是通过开始提到的 sigmoid函数变换 得到的模型。
那么为什么要用sigmoid函数呢?
对于一般的线性回归模型,我们知道:我们的自变量X和因变量Y都是 连续的数值 ,通过X的输入就可以很好的预测Y值。
但现实生活中,我们也有离散的数据类型,比如好和坏,男和女等等。那么我们在想:在线性回归模型的基础上,是否可以实现一个预测因变量是离散数据类型的模型呢?
答案当然是可以的。我们可能会想到阶跃函数:
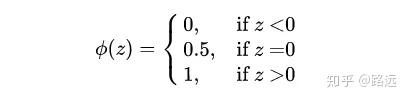
但是它在这里是不合适的,正如我们神经网络激活函数不选择阶跃函数一样,因为它 不连续不可微 。而能满足分类效果,且是连续的函数,sigmoid是再好不过的选择了(返回文章开头看一下sigmoid函数的特点就知道了)。因此,逻辑回归模型就可以通过 在线性回归模型的基础上,套一个sigmoid函数 来实现,这样不管X取什么样的值,Y值都被非线性地映射在 0~1 之间,实现二分类。这也证明一个结论: 逻辑回归不是回归模型,而是分类模型。
我们这里讨论的都是二元分类,因此,一个 二元逻辑回归模型 就建立出来了,其的公式如下:
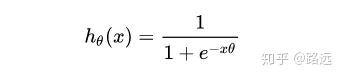
我们简单地把原来的X替换为一个线性模型就得到了上面公式。代替部分可以扩展如下:
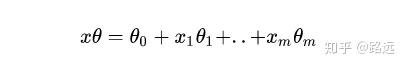
除了上面的表现形式,我们也可以用另外一种形式来表达二元逻辑回归模型。将上面模型简单地进行变化:
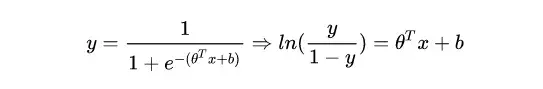

公式中, y 可以理解为样本x为正例的概率,而 1-y 则可以理解为样本x为负例时的概率。二者的比值 y/(1-y) 被称为 “odds” ,即 “几率” ,反映了x作为正例的相对可能性,对几率取对数就得到了线性回归模型了。
上式其实是在用 线性回归模型的预测结果去逼近真实标记的对数几率 。所以该模型也被称作 “对数几率回归” 。
5. 二元逻辑回归是如何进行分类的?
通过上面的介绍,我们知道了二元逻辑回归的模型。但我们发现它的Y是在 0~1 之间连续的数值,也即这个范围内的任意小数(百分比)。那么这些小数是如何进行分类的呢?
可以将模型的输出h(x)当作某一分类的概率的大小。 这样来看,小数值越接近1,说明是1分类的概率越大,相反,小数值越接近0,说明是0分类的概率越大。
而实际使用中,我们会对所有输出结果进行排序,然后结合业务来决定出一个 阈值。 假如阈值是0.5,那么我们就可以将大于0.5的输出都视为1分类,而小于0.5的输出都视为0分类。所以, 二元逻辑回归是一种概率类模型,是通过排序并和阈值比较进行分类的。
这个阈值的选择关系到评估标准的结果,其实我们之前也提到过。ROC曲线就是通过遍历所有阈值来实现的,曲线上每一个点对应一对FPR和TPR,而FPR和TPR平衡的点即为F分数 【机器学习笔记】:一文让你彻底记住什么是ROC/AUC(看不懂你来找我)
6. 逻辑回归的假设
正如线性回归模型一样,逻辑回归也有假设条件,主要是两个:
(1)假设数据服从伯努利分布
(2)假设模型的输出值是样本为正例的概率
基于这两个假设,我们可以分别得出类别为1和0的 后验概率估计 :
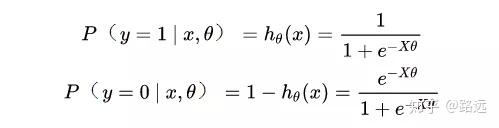

7. 逻辑回归的损失函数
有了模型,我们自然会想到要求策略,也就是损失函数。对于逻辑回归,我们很自然想到:用线性回归的损失函数 “离差平方和” 的形式是否可以?
但事实上,这种形式并不适合,因为所得函数并 非凸函数 ,而是有很多局部的最小值,这样不利于求解。
前面说到逻辑回归其实是概率类模型,因此, 我们通过极大似然估计(MLE)推导逻辑回归损失函数。 下面是具体推导过程。
上面我们通过基本假设得到了1和0两类的后验概率,现在将两个概率合并可得:
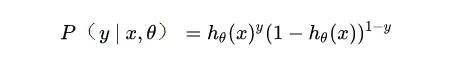

现在我们得到了模型概率的一般形式,接下来就可以使用极大似然估计来根据给定的训练集估计出参数,将n个训练样本的概率相乘得到:
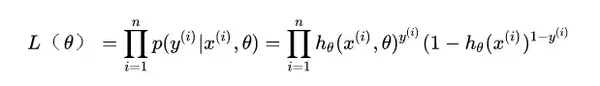

似然函数是相乘的模型,我们可以通过取对数将等式右侧变为相加模型,然后将指数提前,以便于求解。变换后如下:
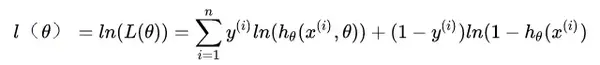

如此就推导出了参数的最大似然估计。我们的目的是将所得似然函数 极大化, 而损失函数是 最小化 ,因此,我们需要在上式前加一个负号便可得到最终的损失函数。
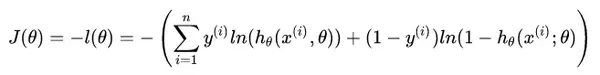

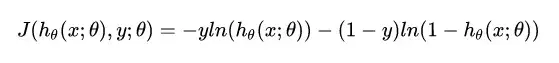

其等价于:
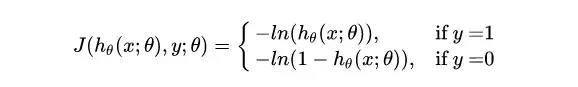

注:逻辑回归的损失函数 “对数似然函数” ,在模型GBDT分类情况下也会用到,又叫作 “交叉熵” 。
8. 逻辑回归损失函数求解
现在我们推导出了逻辑回归的损失函数,而需要求解是模型的参数theta,即线性模型自变量的权重系数。对于线性回归模型而言,可以使用最小二乘法,但对于逻辑回归而言使用传统最小二乘法求解是不合适的。

对于不适合的解释原因有很多,但本质上不能使用经典最小二乘法的原因在于: logistic回归模型的参数估计问题不能“方便地”定义“误差”或者“残差”。
因此,考虑使用迭代类算法优化,常见的就是 ”梯度下降法“ 。当然,还有其它方法比如,坐标轴下降法,牛顿法等。我们本篇介绍使用”梯度下降法“来对损失函数求解。
使用梯度下降法求解逻辑回归损失函数。 梯度下降的迭代公式如下:
\begin{align} \theta_j & =\theta_j+\Delta\theta_j \\ & = \theta_j -\eta\frac{\partial J(\theta)}{\partial \theta_j} \end{align} \\
问题变为如何求损失函数对参数theta的梯度。下面进行详细推导过程:
\begin{align} \frac{\partial J(\theta)}{\partial \theta} & = -\sum_{i=1}^n\left( y^{(i)}\frac{1}{h_\theta(x^{(i)};\theta)}\frac{\partial h_\theta(x^{(i)};\theta)}{\partial \theta}+(1-y^{(i)})\frac{1}{1-h_\theta(x^{(i)};\theta)}\frac{\partial (1-h_\theta(x^{(i)};\theta))}{\partial \theta}\right) \\ & = -\sum_{i=1}^n\frac{1}{h_\theta(x^{(i)};\theta)}\left( \frac{y^{(i)}}{h_\theta(x^{(i)};\theta)}-\frac{1-y^{(i)}}{1-h_\theta(x^{(i)};\theta)} \right) \\ &=-\sum_{i=1}^n x^{(i)}h_\theta(x^{(i)};\theta)(1-h_\theta(x^{(i)};\theta)) \left( \frac{y^{(i)}}{h_\theta(x^{(i)};\theta)}-\frac{1-y^{(i)}}{1-h_\theta(x^{(i)};\theta)} \right) \\ & = -\sum_{i=1}^n x^{(i)}\left(y^{(i)}(1-h_\theta(x^{(i)};\theta))-(1-y^{(i)})h_\theta(x^{(i)};\theta)) \right) \\ &= \sum_{i=1}^n \left( y^{(i)}-h_\theta(x^{(i)};\theta) \right)x^{(i)} \\ \end{align}
推导过程中需要用到的数学知识是: 偏导,对数求导,sigmoid函数求导 。其中,函数求导公式如下:
g^\prime(z)=g(z)(1-g(z)) \\ ln(z)=\frac{1}{z} \\
最后将求得的梯度带入迭代公式中,即为:
\begin{align} \theta_j & =\theta_j+\Delta\theta_j \\ & = \theta_j -\eta\frac{\partial J(\theta)}{\partial \theta_j} \\ & = \theta_j -\eta\sum_{i=1}^n \left( y^{(i)}-h_\theta(x_j^{(i)};\theta) \right)x_j^{(i)} \end{align} \\
注意:公式中,i 代表样本数,j 代表特征数。
其实,常用梯度下降有三个种方法,可以根据需要选择,分别是:批量梯度下降(BGD),随机梯度下降(SGD),small batch梯度下降。具体不进行介绍。
9. 逻辑回归的优缺点
优点:
1. 直接对分类可能性进行建模,无需实现假设数据分布,这样就避免了假设分布不准确所带来的问题。
2. 形式简单,模型的可解释性非常好,特征的权重可以看到不同的特征对最后结果的影响。
3. 除了类别,还能得到近似概率预测,这对许多需利用概率辅助决策的任务很有用。
缺点:
1. 准确率不是很高,因为形势非常的简单,很难去拟合数据的真实分布。
2. 本身无法筛选特征。
以上就是关于逻辑回归模型的一些分享,还有其它正则化,多元逻辑回归等问题,我们将在后续进行介绍。另外,后续也将准备逻辑回归sklearn的使用和实战练习。
如果觉得有帮助,还请给点个赞! 欢迎关注我的个人公众号: Python数据科学
参考:
机器学习,周志华
https:// blog.csdn.net/yinyu1995 0811/article/details/81321944
https://www. cnblogs.com/pinard/p/60 29432.html
