|
PROJECT_NAME
项目的名称。必需。
PROJECT_DISPLAYNAME
项目的显示名称。可以为空。
PROJECT_DESCRIPTION
项目的描述。可以为空。
PROJECT_ADMIN_USER
管理用户的用户名。
PROJECT_REQUESTING_USER
请求用户的用户名。
API 访问权限将授予具有
self-provisioner
角色和
self-provisioners
集群角色绑定的开发人员。默认情况下,所有通过身份验证的开发人员都可获得此角色。
作为集群管理员,您可以修改默认项目模板,以便使用自定义要求创建新项目。
创建自己的自定义项目模板:
以具有
cluster-admin
特权的用户身份登录。
生成默认项目模板:
$ oc adm create-bootstrap-project-template -o yaml > template.yaml
使用文本编辑器,通过添加对象或修改现有对象来修改生成的
template.yaml
文件。
项目模板必须创建在
openshift-config
命名空间中。加载修改后的模板:
$ oc create -f template.yaml -n openshift-config
使用 Web 控制台或 CLI 编辑项目配置资源。
使用 Web 控制台:
导航至
Administration
→
Cluster Settings
页面。
单击
Configuration
以查看所有配置资源。
找到
Project
的条目,并点击
Edit YAML
。
使用 CLI:
编辑
project.config.openshift.io/cluster
资源:
$ oc edit project.config.openshift.io/cluster
更新
spec
部分,使其包含
projectRequestTemplate
和
name
参数,再设置您上传的项目模板的名称。默认名称为
project-request
。
您可以防止经过身份验证的用户组自助置备新项目。
以具有
cluster-admin
特权的用户身份登录。
运行以下命令,以查看
self-provisioners
集群角色绑定用法:
$ oc describe clusterrolebinding.rbac self-provisioners
编辑
self-provisioners
集群角色绑定,以防止自动更新角色。自动更新会使集群角色重置为默认状态。
使用 CLI 更新角色绑定:
运行以下命令:
$ oc edit clusterrolebinding.rbac self-provisioners
在显示的角色绑定中,将
rbac.authorization.kubernetes.io/autoupdate
参数值设置为
false
,如下例所示:
apiVersion: authorization.openshift.io/v1
kind: ClusterRoleBinding
metadata:
annotations:
rbac.authorization.kubernetes.io/autoupdate: "false"
# ...
使用单个命令更新角色绑定:
$ oc patch clusterrolebinding.rbac self-provisioners -p '{ "metadata": { "annotations": { "rbac.authorization.kubernetes.io/autoupdate": "false" } } }'
以通过身份验证的用户身份登陆,验证是否无法再自助置备项目:
$ oc new-project test
当无法自助置备项目的开发人员或服务帐户使用 Web 控制台或 CLI 提出项目创建请求时,默认返回以下错误消息:
You may not request a new project via this API.
集群管理员可以自定义此消息。您可以对这个消息进行自定义,以提供特定于您的组织的关于如何请求新项目的信息。例如:
To request a project, contact your system administrator at
[email protected]
.
To request a new project, fill out the project request form located at
https://internal.example.com/openshift-project-request
.
自定义项目请求消息:
使用 Web 控制台或 CLI 编辑项目配置资源。
使用 Web 控制台:
导航至
Administration
→
Cluster Settings
页面。
单击
Configuration
以查看所有配置资源。
找到
Project
的条目,并点击
Edit YAML
。
使用 CLI:
以具有
cluster-admin
特权的用户身份登录。
编辑
project.config.openshift.io/cluster
资源:
$ oc edit project.config.openshift.io/cluster
更新
spec
部分,使其包含
projectRequestMessage
参数,并将值设为您的自定义消息:
保存更改后,请尝试用无法自助置备项目的开发人员或服务帐户创建一个新项目,以验证是否成功应用了您的更改。
3.1. 使用 Developer 视角创建应用程序
Web 控制台中的
Developer
视角为您提供了下列选项,以便您从
+Add
视图中创建应用程序和相关服务,并将它们部署到 OpenShift Container Platform:
入门资源
:使用这些资源帮助您开始使用开发人员控制台。您可以选择使用
Options
菜单
来隐藏标头。
使用示例创建应用程序
:使用现有代码示例开始在 OpenShift Container Platform 上创建应用程序。
使用引导式练习文档构建
:遵循指导文档构建应用并熟悉关键概念和术语。
探索开发人员新功能
:探索
Developer
视角中的新功能和资源。
Developer Catalog
:浏览 Developer Catalog 以选择所需的应用、服务或源到镜像构建器,然后将它添加到项目中。
所有服务
:浏览目录以在 OpenShift Container Platform 中发现服务。
Database
:选择所需的数据库服务并将其添加到应用程序中。
Operator Backed
:选择和部署所需的 Operator 管理服务。
Helm Chart
:选择所需的 Helm Chart 来简化应用程序和服务部署。
Devfile
: 从
Devfile registry
中选择一个 devfile 来声明性地定义开发环境。
Event Source
:选择一个事件源,从特定系统中注册对一类事件的兴趣。
如果安装了 RHOAS Operator,也可使用 Managed services 选项。
Git 存储库
:使用
From Git
、
From Devfile
或
From Dockerfile
选项分别从您的 Git 存储库中导入一个存在的 codebase、Devfile 或 Dockerfile,以在 OpenShift Container Platform 上构建和部署一个应用程序。
Container Image
:使用镜像流或 registry 中的现有镜像,将其部署到 OpenShift Container Platform 中。
Pipelines
:使用 Tekton 管道为 OpenShift Container Platform 上的软件交付过程创建 CI/CD 管道。
Serverless
:探索
Serverless
选项,在 OpenShift Container Platform 中创建、构建和部署无状态和无服务器应用程序。
Channel
:创建一个 Knative 频道以创建一个事件转发,使用内存的持久性层以及可靠的实现
示例
:探索可用的示例应用程序,以快速创建、构建和部署应用程序。
快速入门
:了解快速启动选项,使用详细的说明和任务创建、导入并运行应用程序。
From Local Machine
:通过
From Local Machine
标题导入或上传在您的本地机器中的文件用于更方便地构建并部署应用程序。
导入 YAML
:上传 YAML 文件,以创建并定义用于构建和部署应用程序的资源。
上传 JAR 文件
:上传 JAR 文件以构建和部署 Java 应用。
共享我的项目
:使用此选项向项目添加或删除用户,并提供可访问性选项。
Helm Chart 仓库
: 使用此选项在命名空间中添加 Helm Chart 仓库。
对资源重新排序
:使用这些资源重新排序添加到导航窗格中的固定资源。当您将鼠标悬停在导航窗格中时,固定资源左侧会显示拖放图标。拖放的资源只能在它所在的部分中丢弃。
请注意,某些选项(如
Pipelines
、
Event Source
和
Import Virtual Machines
)才在安装了
OpenShift Pipelines Operator
、
OpenShift Serverless Operator
和
OpenShift Virtualization Operator
时才会显示。
您可以使用
Developer
视角的
+Add
流中的示例应用程序来快速创建、构建和部署应用程序。
已登陆到 OpenShift Container Platform web 控制台,且处于
Developer
视角。
在
+Add
视图中,点
Samples
标题查看
Samples
页面。
在
Samples
页面中,选择一个可用的示例应用程序来查看
Create Sample Application
表单。
在
Create Sample Application Form
中:
在
Name
字段中,部署名称会被默认显示。您可以根据需要修改此名称。
在
Builder Image Version
中,会默认选择一个构建器镜像。您可以使用
Builder Image Version
下拉列表修改此镜像版本。
默认添加 Git 存储库 URL 示例。
点
Create
创建示例应用程序。示例应用程序的构建状态显示在
Topology
视图中。创建示例应用程序后,您可以看到添加到应用程序的部署。
Quick Starts
页面演示了如何在 OpenShift Container Platform 上创建、导入和运行应用程序,以及逐步说明和任务。
已登陆到 OpenShift Container Platform web 控制台,且处于
Developer
视角。
在
+Add
视图中,点
Getting Started resources
→
Build with guided documentation
→
View all quick start
链接来查看
Quick Starts
页面。
在
Quick Starts
页面中,点您要使用的快速启动的标题。
点
Start
开始快速启动。
执行显示的步骤。
3.1.4. 从 Git 导入代码库来创建应用程序
您可以在
Developer
视角中,使用 GitHub 中的现有代码库,在 OpenShift Container Platform 中创建、构建和部署应用程序。
以下流程逐步指导您在
Developer
视角中使用
Import from Git
选项来创建应用程序。
在
+Add
视图中,点
Git Repository
标题中的
From Git
来查看
Import from git
表单。
在
Git
部分中,输入您要用来创建应用程序的代码库的 Git 存储库 URL。例如,输入此示例 Node.js 应用程序的 URL
https://github.com/sclorg/nodejs-ex
。这个 URL 随后会被验证。
可选:点
Show Advanced Git Options
来添加详情,例如:
git Reference
,指向特定的分支、标签或提交中的代码,以用于构建应用程序。
Context Dir
,指定要用来构建应用程序的应用程序源代码的子目录。
Source Secret
,创建一个具有用来从私有存储库拉取源代码的凭证的
Secret Name
。
可选:您可以通过 Git 存储库导入
Devfile
、
Dockerfile
、
构建器镜像
或
Serverless 函数
,以进一步自定义部署。
如果您的 Git 存储库包含
Devfile
、
Dockerfile
、
构建器镜像
或
func.yaml
,则会自动检测并填充到相应的路径字段中。
如果同一存储库中检测到
Devfile
、
Dockerfile
或
构建器镜像
,则默认选择
Devfile
。
如果在 Git 存储库中检测到
func.yaml
,
Import Strategy
会更改为
Serverless Function
。
另外,您可以使用 Git 存储库 URL 在
+Add
视图中点
Create Serverless function
来创建无服务器函数。
若要编辑文件导入类型并选择不同的策略,请单击
Edit import strategy
选项。
如果检测到多个
Devfiles
、
Dockerfile
或
构建器镜像
,要导入一个特定的实例,请指定相对于上下文目录的对应路径。
在验证 Git URL 后,会选择建议的构建器镜像并标记为星号。如果构建器镜像没有自动探测到,请选择一个构建器镜像。对于
https://github.com/sclorg/nodejs-ex
Git URL,默认选择了 Node.js 构建器镜像。
可选: 使用
Builder Image Version
下拉菜单指定版本。
可选: 使用
Edit import
策略来选择不同的策略。
可选: 对于 Node.js 构建器镜像,请使用
Run command
字段覆盖运行应用程序的命令。
在
General
部分中:
在
Application
字段中输入应用程序组别的唯一名称,例如
myapp
。确保应用程序名称在命名空间中具有唯一性。
系统会基于 Git 存储库的 URL 自动填充
Name
字段,以标识为此应用程序创建的资源(如果没有存在的应用程序)。如果已有应用程序,可以选择将组件部署到现有应用程序中,创建一个新应用程序,或保持该组件没有被分配。
资源名称必须在命名空间中具有唯一性。如果遇到错误,请修改资源名称。
在
Resources
部分,选择:
Deployment
,以纯 Kubernetes 风格方式创建应用程序。
Deployment Config
,创建 OpenShift Container Platform 风格的应用程序。
Serverless Deployment
,创建 Knative 服务。
要设置导入应用程序的默认资源首选项,请转至
User Preferences
→
Applications
→
Resource type
字段。只有集群中安装了 OpenShift Serverless Operator 时,
Import from Git
表单中才会显示
Serverless Deployment
选项。在创建无服务器函数时,
Resources
部分不可用。如需了解更多详细信息,请参阅 OpenShift Serverless 文档。
在
Pipelines
部分,选择
Add Pipeline
,然后点
Show Pipeline Visualization
来查看应用程序的管道。选择了默认管道,但您可以从应用程序的可用管道列表中选择所需的管道。
选中
Add pipeline
复选框,如果满足以下条件,则默认选择
Configure PAC
:
已安装 Pipeline operator
启用了
Pipelines-as-code
在 Git 存储库中检测到
.tekton
目录
在您的存储库中添加 webhook。如果选择了
Configure PAC
并且设置了 GitHub 应用程序,您可以看到
Use GitHub App
和
Setup a webhook
选项。如果没有设置 GitHub App,则只能看到
Setup a webhook
选项:
进入
Settings
→
Webhooks
并点
Add webhook
。
将
Payload URL
设置为 Pipelines as Code 的公共 URL。
将内容类型选为
application/json
。
添加 webhook secret 并在另一个位置记录它。在本地机器上安装
openssl
后,生成一个随机 secret。
点
Let me select individual events
并选择这些事件:
Commit comments
,
Issue comments
,
Pull request
, 和
Pushes
.
点击
Add webhook
。
可选: 在
Advanced Options
部分中,默认选择
Target port
和
Create a route to the application
,以便您可以使用公开的 URL 访问应用程序。
如果您的应用程序没有在默认公共端口(80)上公开其数据,请清除复选框,并设置您想要公开的目标端口号。
可选:可以使用以下高级选项进一步自定义应用程序:
点击
Routing
链接,您可以执行以下操作:
自定义路由的主机名。
指定路由器监控的路径。
从下拉列表中选择流量的目标端口。
选中
Secure Route
复选框来保护您的路由。从相应的下拉列表中,选择所需的 TLS 终止类型,并设置非安全流量的策略。
对于无服务器应用程序,Knative 服务管理上述所有路由选项。但在需要时,您可以自定义流量的目标端口。如果不指定目标端口,则使用默认端口
8080
。
如果要创建
Serverless Deployment
,您可以在创建过程中添加自定义域映射到 Knative 服务。
在
Advanced options
部分中,点
Show advanced Routing options
。
如果要映射到该服务的域映射 CR 已存在,您可以从
Domain mapping
下拉菜单中选择它。
如果要创建新域映射 CR,在框中输入域名,然后选择
Create
选项。例如,如果您在
example.com 中
键入,则
Create
选项为
Create "example.com"
。
点击
Health Checks
链接为您的应用程序添加就绪(Readiness)、存活(Liveness)和启动(Startup)探测。所有探测都预先填充默认数据; 您可以使用默认数据添加探测或根据需要进行自定义。
自定义健康探测:
点
Add Readiness Probe
,在需要的情况下修改参数来检查容器是否准备好处理请求,然后选择要添加的探测。
点
Add Liveness Probe
,在需要的情况下修改参数来检查容器是否仍在运行,选择要添加的探测。
点
Add Startup Probe
,在需要的情况下修改参数来检查容器内的应用程序是否已启动,选择要添加的探测。
对于每个探测,您可以从下拉列表中指定请求类型 -
HTTP GET
、
Container Command
或
TCP Socket
。表单会根据所选请求类型进行更改。然后您可以修改其它参数的默认值,如探测成功和失败的阈值、在容器启动后执行第一个探测前的秒数、探测的频率以及超时值。
构建配置和部署
点
Build Configuration
和
Deployment Configuration
链接来查看对应的配置选项。一些选项会被默认选中;您可以通过添加必要的触发器和环境变量来进一步自定义。
对于无服务器应用程序,
Deployment
选项不会显示,因为 Knative 配置资源为您的部署维护所需的状态,而不是由
DeploymentConfig
资源来维护。
点击
Scaling
链接,以定义您要初始部署的应用程序的 pod 数或实例数。
如果要创建无服务器部署,也可以配置以下设置:
最小 Pod
决定 Knative 服务在任意给定时间运行的 pod 数量较低限制。这也被称为
minScale
设置。
最大 Pod
决定了 Knative 服务可在任意给定时间运行的 pod 数量上限。这也被称为
maxScale
设置。
并发目标
决定了给定时间每个应用程序实例所需的并发请求数。
并发限制
决定了给定时间允许每个应用程序的并发请求数的限值。
并发利用率
决定了在 Knative 扩展额外 pod 前必须满足并发请求限制的百分比,以处理额外的流量。
自动扩展窗口
定义了平均时间窗口,以便在自动扩展器不处于 panic 模式时提供缩放决策的输入。如果在此窗口中没有收到任何请求,服务将缩减为零。autoscale 窗口的默认持续时间为
60s
。这也被称为 stable 窗口。
点击
Resource Limit
链接,设置容器在运行时保证或允许使用的
CPU
和
Memory
资源的数量。
点击
Labels
链接,为您的应用程序添加自定义标签。
单击
Create
以创建应用程序,会显示一个成功通知。您可以在
Topology
视图中查看应用程序的构建状态。
3.1.5. 通过上传 JAR 文件来部署 Java 应用程序
您可以使用 Web 控制台
Developer
视角使用以下选项上传 JAR 文件:
导航到
Developer 视角
的
+Add
视图,再单击
From Local Machine
标题中的
Upload JAR 文件
。浏览并选择 JAR 文件,或者拖动 JAR 文件以部署应用程序。
进入到
Topology
视图并使用
Upload JAR 文件
选项,或者拖动 JAR 文件以部署应用程序。
使用
Topology
视图中的 in-context 菜单,然后使用
Upload JAR 文件
选项上传 JAR 文件以部署应用程序。
Cluster Samples Operator 必须由集群管理员安装。
您可以访问 OpenShift Container Platform Web 控制台,且处于
Developer
视角。
在
Topology
视图中,右键点任何位置来查看
Add to Project
菜单。
将鼠标悬停在
Add to Project
菜单上,以查看菜单选项,然后选择
Upload JAR 文件
选项以查看
Upload JAR 文件
表单。或者,您可以将 JAR 文件拖到
Topology
视图中。
在
JAR 文件
字段中,浏览本地计算机上所需的 JAR 文件并上传该文件。或者,您可以将 JAR 文件拖到字段。如果将不兼容的文件类型拖到
Topology
视图中,则右上角会显示一个警报。如果上传表单的字段中丢弃了不兼容的文件类型,则会显示字段错误。
默认选择运行时图标和构建器镜像。如果构建器镜像没有自动探测到,请选择一个构建器镜像。如果需要,您可以使用
Builder Image Version
下拉列表来更改版本。
可选:在
Application Name
字段中输入应用程序的唯一名称,用于资源标记。
在
Name
字段中输入相关资源的唯一组件名称。
可选: 使用
Advanced options
→
Resource type
下拉列表,从默认资源类型列表中选择不同的资源类型。
在
Advanced options
菜单中,点
Create a Route to the Application
配置您部署的应用程序的公共 URL。
点
Create
以部署应用。显示有提示通知,以通知您 JAR 文件正在上传。相关通知还包括用于查看构建日志的链接。
如果您在构建运行时尝试关闭浏览器标签页,则会显示 Web 警报。
上传 JAR 文件并部署应用后,您可以在
Topology
视图中查看应用程序。
3.1.6. 使用 Devfile registry 访问 devfile
您可以使用
Developer
视角的
+Add
流中的 devfile 创建应用程序。
+Add
流提供与
devfile 社区 registry
的完整集成。devfile 是一个可移植的 YAML 文件,它描述了您的开发环境,而无需从头开始进行配置。使用
Devfile registry
,您可以使用预配置的 devfile 创建应用程序。
进入
Developer 视角
→
+Add
→
Developer Catalog
→
All Services
。此时会显示
Developer Catalog
中所有可用服务的列表。
在
Type
下,点
Devfiles
浏览支持特定语言或框架的 devfile。另外,您可以使用 keyword 过滤器使用其名称、标签或描述搜索特定 devfile。
点击您要用来创建应用程序的 devfile。devfile 标题显示 devfile 的详情,包括 devfile 的名称、描述、供应商和 devfile 文档。
点
Create
创建一个应用程序,并在
Topology
视图中查看应用程序。
3.1.7. 使用 Developer Catalog 将服务或组件添加到应用程序中
您可以使用 Developer Catalog 根据 Operator 支持的服务(如数据库、构建器镜像和 Helm Charts)部署应用程序和服务。Developer Catalog 包含您可以添加到项目的应用程序组件、服务、事件源或 Source-to-image 构建器的集合。集群管理员可以自定义目录中提供的内容。
在
Developer
视角中,导航到
+Add
视图,从
Developer Catalog
标题中点击
All Services
来查看
Developer Catalog
中的所有可用服务。
在
All Services
下,选择服务类型或您需要添加到项目的组件。在本例中,选择
Databases
以列出所有数据库服务,然后点击
MariaDB
查看该服务的详情。
点
Instantiate Template
查看带有
MariaDB
服务详情的自动填充的模板,然后点
Create
在
Topology
视图中创建并查看 MariaDB 服务的信息。
-
如需有关 OpenShift Serverless 的 Knative 路由设置的更多信息,请参阅
路由
。
如需有关 OpenShift Serverless 的域映射设置的更多信息,请参阅
为 Knative 服务配置自定义域
。
如需有关 OpenShift Serverless 的 Knative 自动扩展设置的更多信息,请参阅
自动扩展
。
有关向项目添加新用户的更多信息,请参阅
使用项目
。
有关创建 Helm Chart 仓库的更多信息,请参阅
创建 Helm Chart 仓库
。
3.2. 从已安装的 Operator 创建应用程序
Operators
是打包、部署和管理 Kubernetes 应用程序的方法。您可以使用集群管理员安装的 Operator 在 OpenShift Container Platform 上创建应用程序。
本指南为开发人员介绍如何使用 OpenShift Container Platform Web 控制台从已安装的 Operator 中创建应用程序。
参阅
Operators
指南来进一步了解 Operator 如何工作以及如何将 Operator Lifecycle Manager 集成到 OpenShift Container Platform 中。
3.2.1. 使用 Operator 创建 etcd 集群
本流程介绍了如何通过由 Operator Lifecycle Manager (OLM) 管理的 etcd Operator 来新建一个 etcd 集群。
访问 OpenShift Container Platform 4.13 集群
管理员已在集群范围内安装了 etcd Operator。
针对此流程在 OpenShift Container Platform Web 控制台中新建一个项目。这个示例使用名为
my-etcd
的项目。
导航至
Operators → Installed Operators
页面。由集群管理员安装到集群且可供使用的 Operator 将以集群服务版本(CSV)列表形式显示在此处。CSV 用于启动和管理由 Operator 提供的软件。
使用以下命令从 CLI 获得该列表:
$ oc get csv
在
Installed Operators
页面中,点 etcd Operator 查看更多详情和可用操作。
正如
Provided API
下所示,该 Operator 提供了三类新资源,包括一种用于
etcd Cluster
的资源(
EtcdCluster
资源)。这些对象的工作方式与内置的原生 Kubernetes 对象(如
Deployment
或
ReplicaSet
)相似,但包含特定于管理 etcd 的逻辑。
新建 etcd 集群:
在
etcd Cluster
API 框中,点
Create instance
。
在下一页中,您可对
EtcdCluster
对象的最小起始模板进行任何修改,比如集群大小。现在,点击
Create
即可完成。点击后即可触发 Operator 启动 pod、服务和新 etcd 集群的其他组件。
点
example
etcd 集群,然后点
Resources
选项卡,您可以看到项目现在包含很多由 Operator 自动创建和配置的资源。
验证已创建了支持您从项目中的其他 pod 访问数据库的 Kubernetes 服务。
给定项目中具有
edit
角色的所有用户均可创建、管理和删除应用程序实例(本例中为 etcd 集群),这些实例由已在项目中创建的 Operator 以自助方式管理,就像云服务一样。如果要赋予其他用户这一权利,项目管理员可使用以下命令添加角色:
$ oc policy add-role-to-user edit <user> -n <target_project>
现在您有了一个 etcd 集群,当 pod 运行不畅,或在集群中的节点之间迁移时,该集群将对故障做出反应并重新平衡数据。最重要的是,具有适当访问权限的集群管理员或开发人员现在可轻松将该数据库用于其应用程序。
您可以使用 OpenShift Container Platform CLI,从包含源代码或二进制代码、镜像和模板的组件创建 OpenShift Container Platform 应用程序。
由
new-app
创建的对象集合取决于作为输入传递的工件,如输入源存储库、镜像或模板。
您可以使用
new-app
命令,从本地或远程 Git 存储库中的源代码创建应用程序。
new-app
命令会创建一个构建配置,其本身会从您的源代码中创建一个新的应用程序镜像。
new-app
命令通常还会创建一个
Deployment
对象来部署新镜像,以及为运行您的镜像的部署提供负载均衡访问的服务。
OpenShift Container Platform 会自动检测要使用管道、源或 docker 构建策略,如果进行源构建,则还检测适当的语言构建器镜像。
从本地目录中的 Git 存储库创建应用程序:
$ oc new-app /<path to source code>
如果使用本地 Git 存储库,该存储库必须具有一个名为
origin
的远程源,指向可由 OpenShift Container Platform 集群访问的 URL。如果没有可识别的远程源,运行
new-app
命令将创建一个二进制构建。
从远程 Git 存储库创建新应用程序:
$ oc new-app https://github.com/sclorg/cakephp-ex
从私有远程 Git 存储库创建应用程序:
$ oc new-app https://github.com/youruser/yourprivaterepo --source-secret=yoursecret
如果使用私有远程 Git 存储库,您可以使用
--source-secret
标志指定一个现有源克隆 secret,此 secret 将注入到构建配置中以访问存储库。
您可以通过指定
--context-dir
标志来使用源代码存储库的子目录。从远程 Git 存储库和上下文子目录创建应用程序:
$ oc new-app https://github.com/sclorg/s2i-ruby-container.git \
--context-dir=2.0/test/puma-test-app
另外,在指定远程 URL 时,您可以通过在 URL 末尾附加
#<branch_name>
来指定要使用的 Git 分支:
$ oc new-app https://github.com/openshift/ruby-hello-world.git#beta4
OpenShift Container Platform 通过检测某些文件自动决定要使用的构建策略:
在创建新应用程序时,如果源存储库的根目录或指定上下文目录中存在 Jenkinsfile 文件,则 OpenShift Container Platform 会生成管道构建策略。
pipeline
构建策略已弃用;请考虑使用 Red Hat OpenShift Pipelines。
在创建新应用程序时,如果源存储库的根目录或指定上下文目录中存在 Dockerfile,则 OpenShift Container Platform 会生成 docker 构建策略。
如果没有检测到 Jenkins 文件或 Dockerfile,OpenShift Container Platform 会生成源构建策略。
通过将
--strategy
标志设置为
docker
、
pipeline
或
source
来覆盖自动检测到的构建策略。
$ oc new-app /home/user/code/myapp --strategy=docker
oc
命令要求包含构建源的文件在远程 Git 存储库中可用。对于所有 Source 构建,您必须使用
git remote -v
。
如果您使用源构建策略,
new-app
会尝试根据存储库根目录或指定上下文目录中是否存在特定文件来确定要使用的语言构建器:
表 3.1. new-app检测到的语言
|
语言
|
文件
|
|
dotnet
project.json
、
*.csproj
pom.xml
nodejs
app.json
、
package.json
cpanfile
、
index.pl
composer.json
、
index.php
python
requirements.txt
、
setup.py
Gemfile
、
Rakefile
、
config.ru
scala
build.sbt
golang
Godeps
、
main.go
检测了语言后,
new-app
会在 OpenShift Container Platform 服务器上搜索具有与所检测语言匹配的
suppors
注解的镜像流标签,或与所检测语言的名称匹配的镜像流。如果找不到匹配项,
new-app
会在
Docker Hub registry
中搜索名称上与所检测语言匹配的镜像。
您可以通过指定镜像(镜像流或容器规格)和存储库(以
~
作为分隔符),来覆盖构建器用于特定源存储库的镜像。请注意,如果进行这一操作,就不会执行构建策略检测和语言检测。
例如,使用
myproject/my-ruby
镜像流以及位于远程存储库中的源:
$ oc new-app myproject/my-ruby~https://github.com/openshift/ruby-hello-world.git
使用
openshift/ruby-20-centos7:latest
容器镜像流以及本地仓库中的源:
$ oc new-app openshift/ruby-20-centos7:latest~/home/user/code/my-ruby-app
语言检测需要在本地安装 Git 客户端,以便克隆并检查您的存储库。如果 Git 不可用,您可以使用
<image>~<repository>
语法指定要与存储库搭配使用的构建器镜像,以避免语言检测步骤。
调用
-i <image> <repository>
需要
new-app
尝试克隆
repository
,从而判断其工件类型;如果 Git 不可用,此操作会失败。
调用
-i <image> --code <repository>
需要
new-app
克隆
repository
,从而能判断
image
应用作源代码的构建器,还是另外部署(使用数据库镜像时)。
您可以从现有镜像部署应用程序。镜像可以来自 OpenShift Container Platform 服务器中的镜像流、特定 registry 中的镜像或本地 Docker 服务器中的镜像。
new-app
命令尝试确定传递给它的参数中指定的镜像类型。但是,您可以使用
--docker-image
参数明确告知
new-app
镜像是一个容器镜像,或使用
-i|--image-stream
参数明确告知镜像是一个镜像流。
如果指定本地 Docker 存储库中的镜像,必须确保同一镜像可供 OpenShift Container Platform 节点使用。
3.3.2.1. Docker Hub MySQL 镜像
从 Dockerhub MySQL 镜像创建应用程序,例如:
$ oc new-app mysql
3.3.2.2. 私有 registry 中的镜像
使用私有 registry 中的镜像创建应用程序时,请指定完整容器镜像规格:
$ oc new-app myregistry:5000/example/myimage
从现有镜像流和可选镜像流标签创建应用程序:
$ oc new-app my-stream:v1
您可以使用之前存储的模板或模板文件创建应用程序,方法是将模板名称指定为参数。例如,您可以存储一个示例应用程序模板,并使用它来创建应用程序。
将应用程序模板上传到当前项目的模板库。以下示例从名为
example/sample-app/application-template-stibuild.json
的文件上传一个应用程序模板:
$ oc create -f examples/sample-app/application-template-stibuild.json
然后,通过引用应用程序模板来创建新应用程序。在本例中,模板名称为
ruby-helloworld-sample
:
$ oc new-app ruby-helloworld-sample
要通过引用本地文件系统中的模板文件创建新应用程序,而无需首先将其保存到 OpenShift Container Platform 中,使用
-f|--file
参数。例如:
$ oc new-app -f examples/sample-app/application-template-stibuild.json
在基于模板创建应用程序时,请使用
-p|--param
参数来设置模板定义的参数值:
$ oc new-app ruby-helloworld-sample \
-p ADMIN_USERNAME=admin -p ADMIN_PASSWORD=mypassword
您可以将参数保存到文件中,然后在实例化模板时通过
--param-file
来使用该文件。如果要从标准输入中读取参数,请使用
--param-file=-
。以下是一个名为
helloworld.params
的示例文件:
ADMIN_USERNAME=admin
ADMIN_PASSWORD=mypassword
在实例化模板时引用文件中的参数:
$ oc new-app ruby-helloworld-sample --param-file=helloworld.params
new-app
命令生成用于构建、部署和运行所创建应用程序的 OpenShift Container Platform 对象。通常情况下,这些对象是在当前项目中创建的,并分配有从输入源存储库或输入镜像中获得的名称。但是,您可以使用
new-app
修改这种行为。
表 3.2. new-app 输出对象
|
对象
|
描述
|
|
BuildConfig
为命令行中指定的每个源存储库创建一个
BuildConfig
对象。
BuildConfig
对象指定要使用的策略、源位置和构建输出位置。
ImageStreams
对于
BuildConfig
对象,通常会创建两个镜像流。其一代表输入镜像。进行源构建时,这是构建器镜像。进行
Docker
构建时,这是
FROM
镜像。其二代表输出镜像。如果容器镜像指定为
new-app
的输入,那么也会为该镜像创建镜像流。
DeploymentConfig
创建一个
DeploymentConfig
对象来部署构建的输出或指定的镜像。
new-app
命令为生成的
DeploymentConfig
对象中包含的容器中指定的所有 Docker 卷创建
emptyDir
卷。
Service
new-app
命令会尝试检测输入镜像中公开的端口。它使用编号最小的已公开端口来生成公开该端口的服务。要公开一个不同的端口,只需在
new-app
完成后使用
oc expose
命令生成额外服务。
根据模板,可在实例化模板时生成其他对象。
|
从模板、源或镜像生成应用程序时,您可以在运行时使用
-e|--env
参数将环境变量传递给应用程序容器:
$ oc new-app openshift/postgresql-92-centos7 \
-e POSTGRESQL_USER=user \
-e POSTGRESQL_DATABASE=db \
-e POSTGRESQL_PASSWORD=password
这些变量可使用
--env-file
参数从文件中读取。以下是一个名为
postgresql.env
的示例文件:
POSTGRESQL_USER=user
POSTGRESQL_DATABASE=db
POSTGRESQL_PASSWORD=password
从文件中读取变量:
$ oc new-app openshift/postgresql-92-centos7 --env-file=postgresql.env
另外,也可使用
--env-file=-
在标准输入上给定环境变量:
$ cat postgresql.env | oc new-app openshift/postgresql-92-centos7 --env-file=-
在
new-app
处理过程中创建的任何
BuildConfig
对象,都不能使用通过
-e|--env
或
--env-file
参数传递的环境变量进行更新。
从模板、源或镜像生成应用程序时,您可以在运行时使用
--build-env
参数将环境变量传递给构建容器:
$ oc new-app openshift/ruby-23-centos7 \
--build-env HTTP_PROXY=http://myproxy.net:1337/ \
--build-env GEM_HOME=~/.gem
这些变量可使用
--build-env-file
参数从文件中读取。以下是一个名为
ruby.env
的示例文件:
HTTP_PROXY=http://myproxy.net:1337/
GEM_HOME=~/.gem
从文件中读取变量:
$ oc new-app openshift/ruby-23-centos7 --build-env-file=ruby.env
另外,也可使用
--build-env-file=-
在标准输入上给定环境变量:
$ cat ruby.env | oc new-app openshift/ruby-23-centos7 --build-env-file=-
从源、镜像或模板生成应用程序时,您可以使用
-l|--label
参数为创建的对象添加标签。借助标签,您可以轻松地集中选择、配置和删除与应用程序关联的对象。
$ oc new-app https://github.com/openshift/ruby-hello-world -l name=hello-world
要查看运行
new-app
命令的空运行,您可以使用
-o|--output
参数及
yaml
或
json
值。然后,您可以使用输出结果预览创建的对象,或将其重定向到可以编辑的文件。满意之后,您可以使用
oc create
创建 OpenShift Container Platform 对象。
要将
new-app
工件输出到一个文件,请运行以下命令:
$ oc new-app https://github.com/openshift/ruby-hello-world \
-o yaml > myapp.yaml
编辑该文件:
$ vi myapp.yaml
通过引用该文件来创建新应用程序:
$ oc create -f myapp.yaml
new-app
创建的对象通常命名自用于生成它们的源存储库或镜像。您可以通过在命令中添加
--name
标志来设置生成的对象名称:
$ oc new-app https://github.com/openshift/ruby-hello-world --name=myapp
通常,
new-app
会在当前项目中创建对象。不过,您可以使用
-n|--namespace
参数在另一项目中创建对象:
$ oc new-app https://github.com/openshift/ruby-hello-world -n myproject
new-app
命令允许创建多个应用程序,为
new-app
指定多个参数便可实现。命令行中指定的标签将应用到单一命令创建的所有对象。环境变量应用到从源或镜像创建的所有组件。
从源存储库和 Docker Hub 镜像创建应用程序:
$ oc new-app https://github.com/openshift/ruby-hello-world mysql
如果以独立参数形式指定源代码存储库和构建器镜像,
new-app
会将构建器镜像用作源代码存储库的构建器。如果这不是您的用意,请使用
~
分隔符为源指定所需的构建器镜像。
3.3.4.8. 在单个 pod 中对镜像和源进行分组
new-app
命令允许在一个 pod 中一起部署多个镜像。要指定要将哪些镜像分组在一起,使用
+
分隔符。也可使用
--group
命令行参数来指定应分组在一起的镜像。要将源存储库中构建的镜像与其他镜像一起分组,请在组中指定其构建器镜像:
$ oc new-app ruby+mysql
将通过源构建的镜像和外部镜像一起部署:
$ oc new-app \
ruby~https://github.com/openshift/ruby-hello-world \
mysql \
--group=ruby+mysql
第 4 章 使用 Topology 视图查看应用程序组成
Web 控制台的
Developer
视角中有一个
Topology
视图,它以可视化方式展示项目中的所有应用程序、它们的构建状态,以及关联的组件和服务。
您可以使用
Developer
视角中的左侧导航面板进入
Topology
视图。部署应用程序后,您会自动定向到
Graph view
,从中可查看应用程序 pod 状态,快速访问公共 URL 上的应用程序,访问源代码以进行修改,以及查看上一次构建的状态。您可以缩放视图来查看特定应用程序的更多详情。
Topology
视图为您提供了使用
List
视图监控应用程序的选项。使用
List 视图
图标
查看所有应用程序的列表,并使用
图形视图
图标(
)切回到图形视图。
您可以使用以下命令自定义视图:
使用
Find by name
字段查找所需组件。搜索结果可能会出现在可见区域之外 ; 点击左侧工具栏中的
Fit to Screen
来改变
Topology
视图的大小来显示所有组件。
使用
Display Options
下拉列表配置各种应用程序的
Topology
视图。这些选项取决于项目中部署的组件的类型:
Virtual Machines:显示或隐藏虚拟机。
Application Groupings:通过概述应用程序组和与其关联的警报,将应用程序组压缩到卡中。
Helm Releases:将部署为 Helm Release 的组件整合到卡中,并概述给定的发行版本。
Knative Services:明确将 Knative Service 组件压缩到包含指定组件概述的卡中。
Operator Groupings:清除用于将 Operator 部署的组件整合到卡中,并包含给定组的概述。
Show
项基于
Pod Count
或
Labels
Pod Count:显示组件图标中组件的 pod 数量。
Labels:显示或隐藏组件标签。
Topology
视图也为您提供了
Export application
选项,用于以 ZIP 文件格式下载应用程序。然后,您可以将下载的应用程序导入到另一个项目或集群。如需了解更多详细信息,请参阅
附加资源
部分的
将应用程序导出到另一个项目或集群
。
在 web 控制台的
Developer
视角中的
Topology
视图中,
Graph view
提供了与应用程序和组件交互的选项:
点
Open URL(
 )查看通过公共 URL 上的路由公开的应用程序。
点击
Edit Source code
可访问您的源代码并进行修改。
只有使用
From Git
、
From Catalog
和
From Dockerfile
选项创建了应用程序时,此功能才可用。
光标悬停在 Pod 左下方图标上,可查看最新构建的名称及其状态。应用程序构建的状态显示为
New
(
)、
Pending
(
)、
Running
(
)、
Complemented
(
)、
Failed
(
)和
Canceled(
)查看通过公共 URL 上的路由公开的应用程序。
点击
Edit Source code
可访问您的源代码并进行修改。
只有使用
From Git
、
From Catalog
和
From Dockerfile
选项创建了应用程序时,此功能才可用。
光标悬停在 Pod 左下方图标上,可查看最新构建的名称及其状态。应用程序构建的状态显示为
New
(
)、
Pending
(
)、
Running
(
)、
Complemented
(
)、
Failed
(
)和
Canceled(
 pod 的状态或阶段由不同的颜色和工具提示来表示:
Running
(
):pod 绑定到节点,并创建所有容器。至少一个容器仍在运行,或正在启动或重启过程中。
Not Ready
(
):运行多个容器的 pod,不是所有容器都已就绪。
Warning
(
):pod 中的容器被终止,但终止没有成功。有些容器可能是其他状态。
):pod 中的所有容器都终止,但至少一个容器出现故障而终止。也代表,容器以非零状态退出,或者被系统终止。
Pending
(
):Kubernetes 集群接受 pod,但一个或多个容器尚未设置并准备好运行。这包括 pod 等待调度的时间,以及通过网络下载容器镜像的时间。
Succeeded
(
):pod 中的所有容器都成功终止,且不会被重启。
Terminating
(
):当 pod 被删除时,一些 kubectl 命令会显示
Terminating
。
Terminating
状态不是 pod 的一个阶段。一个 pod 会被赋予一个安全终止期,默认为 30 秒。
Unknown
(
):无法获取 pod 状态。此阶段通常是由于与 pod 应该运行的节点通信时出错造成的。
创建应用程序并部署镜像后,其状态会显示为
Pending
。构建应用程序后,它会显示为
Running
。
pod 的状态或阶段由不同的颜色和工具提示来表示:
Running
(
):pod 绑定到节点,并创建所有容器。至少一个容器仍在运行,或正在启动或重启过程中。
Not Ready
(
):运行多个容器的 pod,不是所有容器都已就绪。
Warning
(
):pod 中的容器被终止,但终止没有成功。有些容器可能是其他状态。
):pod 中的所有容器都终止,但至少一个容器出现故障而终止。也代表,容器以非零状态退出,或者被系统终止。
Pending
(
):Kubernetes 集群接受 pod,但一个或多个容器尚未设置并准备好运行。这包括 pod 等待调度的时间,以及通过网络下载容器镜像的时间。
Succeeded
(
):pod 中的所有容器都成功终止,且不会被重启。
Terminating
(
):当 pod 被删除时,一些 kubectl 命令会显示
Terminating
。
Terminating
状态不是 pod 的一个阶段。一个 pod 会被赋予一个安全终止期,默认为 30 秒。
Unknown
(
):无法获取 pod 状态。此阶段通常是由于与 pod 应该运行的节点通信时出错造成的。
创建应用程序并部署镜像后,其状态会显示为
Pending
。构建应用程序后,它会显示为
Running
。
应用程序资源名称附有代表不同类型资源对象的指示符,如下所示:
CJ
:
CronJob
D
:
Deployment
DC
:
DeploymentConfig
DS
:
DaemonSet
J
:
Job
P
:
Pod
SS
:
StatefulSet
(Knative):无服务器应用程序
无服务器应用程序需要一些时间才能加载并显示在
Graph 视图
中。部署无服务器应用程序时,首先会创建一个服务资源,然后创建一个修订。之后,它会被部署并显示在
Graph 视图
中。如果它是唯一的工作负载,可能会重定向到
Add
页面。部署修订后,无服务器应用程序会显示在
Graph 视图
中。
4.4. 扩展应用程序 Pod 以及检查构建和路由
Topology
视图在
Overview
面板中提供所部署组件的详情。您可以使用
Overview
和
Details
选项卡来扩展应用程序 pod,检查构建状态、服务和路由,如下所示:
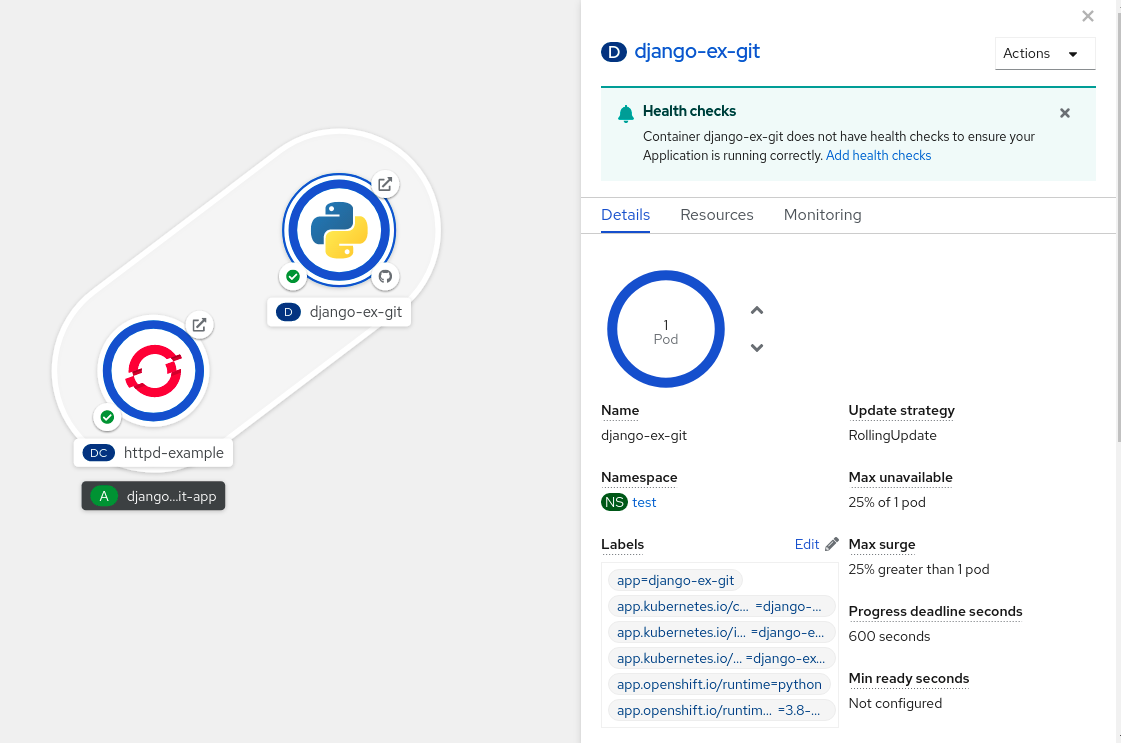
点击组件节点,以查看右侧的
Overview
面板。使用
Details
选项卡进行:
使用向上和向下箭头缩放 pod,手动增加或减少应用程序的实例数。对于无服务器应用程序,pod 数在空闲时会自动缩减为零,而且能根据频道流量扩展。
检查应用程序的
Labels
、
Annotations
和
Status
。
点击
Resources
选项卡可以:
查看所有 pod 列表,查看其状态,访问日志,还能点击 pod 来查看 pod 详情。
查看构建及其状态,访问日志,并在需要时启动新的构建。
查看组件所使用的服务和路由。
对于无服务器应用程序,
Resources
选项卡提供用于该组件的版本、路由和配置的有关信息。
您可以向项目添加组件。
进入
+Add
视图。
点击左侧导航窗格旁的
Add to Project
(
)或按
Ctrl
+
Space
搜索组件并点
Start
/
Create
/
Install
按钮,或者点
Enter
将组件添加到项目中,并在拓扑
Graph 视图
中查看它。
另外,您还可以在上下文菜单中使用可用选项,如
Import from Git
,
Container Image
,
Database
,
From Catalog
,
Operator Backed
,
Helm Charts
,
Samples
, 或
Upload JAR 文件
,方法是在拓扑
图形视图
中添加组件。
您可以使用
+Add
视图在项目中添加多个组件或服务,并使用拓扑
图形视图
对应用程序组中的应用程序和资源进行分组。
您已使用
Developer 视角
在 OpenShift Container Platform 上创建并部署了最少两个或多个组件。
要将服务添加到现有应用程序组中,请按
Shift
+ 将它拖动到现有应用程序组中。拖动组件并将其添加到应用程序组中时,会将所需的标签添加到组件。
另外,您还可以在应用程序中添加组件,如下所示:
点服务 pod 查看右侧的
Overview
面板。
单击
Actions
下拉菜单,再选择
Edit Application Grouping
。
在
Edit Application Grouping
对话框中,单击
Application
下拉列表,然后选择适当的应用程序组。
单击
Save
,将服务添加到应用组中。
要从应用程序组中删除组件,您可以选择组件并使用
Shift
+ 拖动操作将组件从应用程序组中拖出。
要在应用程序中添加服务,请使用使用拓扑
图形视图中
的上下文菜单的
+Add
操作。
除了上下文菜单外,您还可以使用边栏添加服务,或者将鼠标悬停在应用程序组中并拖动悬挂的箭头。
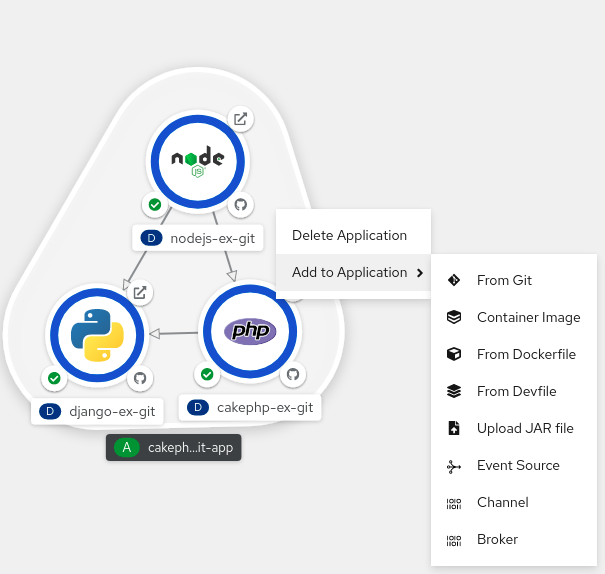
右键单击拓扑
图形视图
中的应用程序组,以显示上下文菜单。
使用
Add to Application
选择将服务添加到应用程序组中的方法,如
From Git
、
Container Image
、
From Dockerfile
、
From Devfile
、
Upload JAR 文件
、
Event Source
、
Channel
或
Broker
。
完成您选择的方法的表单,再单击
Create
。例如,若要根据 Git 存储库中的源代码添加服务,请选择
From Git
方法,填写
Import from Git
表单,然后单击
Create
。
在拓扑
图形视图
中,使用上下文菜单从应用程序中删除服务。
在拓扑
图形视图
中的应用程序组中右键单击应用程序组中的服务,以显示上下文菜单。
选择
Delete Deployment
以删除服务。
4.9. 用于 Topology 视图的标签和注解
Topology
使用下列标签和注解:
-
节点中显示的图标
-
节点中的图标是通过使用
app.openshift.io/runtime
标签(随后是
app.kubernetes.io/name
标签)查找匹配图标来定义的。这种匹配是通过预定义的图标集合来完成的。
-
到源代码编辑器或源的链接
-
app.openshift.io/vcs-uri
注解用于创建源代码编辑器的链接。
-
节点连接器
-
app.openshift.io/connects-to
注解用于连接节点。
-
应用程序分组
-
app.kubernetes.io/part-of=<appname>
标签用于对应用程序、服务和组件进行分组。
如需了解 OpenShift Container Platform 应用程序必须使用的标签和注解,请参阅
OpenShift 应用程序的标签和注解指南
。
作为开发人员,您可以使用 ZIP 文件格式导出应用程序。根据您的需要,使用
+Add
视图中的
Import YAML
选项将导出的应用程序导入到同一集群中的另一个项目或不同的集群。导出应用程序可帮助您重复使用应用程序资源并节省时间。
-
在开发者视角中,执行以下步骤之一:
进入
+Add
视图,在
Application portability
标题中点
Export application
。
进入到
Topology
视图,再点
Export application
。
在
Export Application
对话框中,点
OK
。将打开一个通知,以确认您的项目中的资源导出是否已启动。
在以下情况下可能需要执行的可选步骤:
如果您启动导出不正确的应用程序,点
Export application
→
Cancel Export
。
如果您的导出已经进行,并且要启动一个新的导出,请点
Export application
→
Restart Export
。
如果要查看与导出应用程序关联的日志,请点
Export application
和
View Logs
链接。
成功导出后,点对话框中的
Download
将 ZIP 格式的应用程序资源下载到您的机器中。
6.1. Service Binding Operator 发行注记
Service Binding Operator 由一个控制器和附带的自定义资源定义 (CRD) 组成,用于服务绑定。它管理工作负载的数据平面并提供支持服务。Service Binding Controller 读取由后备服务的 control plane 提供的数据。然后,它会根据通过
ServiceBinding
资源指定的规则将这些数据到工作负载。
使用 Service Binding Operator,您可以:
将工作负载与 Operator 管理的后备服务绑定。
自动配置绑定数据。
为服务提供商提供低接触管理经验,以调配和管理对服务的访问。
通过一致、声明性的服务绑定方法增强开发生命周期,消除群集环境中的差异。
Service Binding Operator 的自定义资源定义 (CRD) 支持以下 API:
使用
binding.operators.coreos.com
API 组的
服务绑定
。
服务绑定 (Spec API)
与
servicebinding.io
API 组。
下表中的一些功能是
技术预览
。它们并不适用于在生产环境中使用。
在下表中,被标记为以下状态的功能:
TP
:
技术预览
GA
:
正式发行
请参阅红帽门户网站中关于对技术预览功能支持范围的信息:
表 6.1. 支持列表
|
Service Binding Operator
|
API 组和支持状态
|
OpenShift 版本
|
|
binding.operators.coreos.com
servicebinding.io
1.3.3
4.9-4.12
1.3.1
4.9-4.11
4.9-4.11
4.7-4.11
1.1.1
4.7-4.10
4.7-4.10
1.0.1
4.7-4.9
4.7-4.9
|
6.1.3. Service Binding Operator 1.3.3 发行注记
Service Binding Operator 1.3.3 现在包括在 OpenShift Container Platform 4.9、4.10、4.11 和 4.12 中。
-
在此次更新之前,为 Service Binding Operator 记录了一个安全漏洞
CVE-2022-41717
。在这个版本中修复了
CVE-2022-41717
错误,并将 v0.0.0-20220906165146-f3363e06e74c 中的
golang.org/x/net
软件包更新为 v0.4.0。
APPSVC-1256
在此次更新之前,只有在相应资源在其他置备服务丢失时设置了 "servicebinding.io/provisioned-service: true" 注解时,才会检测到 Provisioned Services。在这个版本中,检测机制会根据 "status.binding.name" 属性正确识别所有 Provisioned Services。
APPSVC-1204
6.1.4. Service Binding Operator 1.3.1 发行注记
Service Binding Operator 1.3.1 现在包括在 OpenShift Container Platform 4.9、4.10 和 4.11 中。
-
在此次更新之前,为 Service Binding Operator 记录了一个安全漏洞
CVE-2022-32149
。在这个版本中修复了
CVE-2022-32149
错误,并将
golang.org/x/text
软件包从 v0.3.7 更新至 v0.3.8。
APPSVC-1220
6.1.5. Service Binding Operator 1.3 发行注记
Service Binding Operator 1.3 现在包括在 OpenShift Container Platform 4.9、4.10 和 4.11 上。
-
在 Service Binding Operator 1.3 中,Operator Lifecycle Manager (OLM) 描述符功能已被删除,以改进资源利用率。作为 OLM 描述符的替代选择,您可以使用 CRD 注解来声明绑定数据。
6.1.6. Service Binding Operator 1.2 发行注记
Service Binding Operator 1.2 现在包括在 OpenShift Container Platform 4.7、4.8、4.9、4.10 和 4.11 上。
本节重点介绍 Service Binding Operator 1.2 中的新内容:
通过将
optional
标志值设为
true
,启用 Service Binding Operator 以考虑注解中的可选字段。
支持
servicebinding.io/v1beta1
资源。
通过公开相关绑定 secret 而无需存在工作负载,可以改进可绑定服务的可用性。
-
目前,当您在 OpenShift Container Platform 4.11 上安装 Service Binding Operator 时,Service Binding Operator 的内存占用量会高于预期限制。但是,使用低的情况下,内存占用量保留在环境或方案的预期范围内。与 OpenShift Container Platform 4.10 相比,在压力下,平均和最大内存占用率都显著提高。这个问题也会在以前的 Service Binding Operator 版本中识别。当前没有解决此问题的方法。
APPSVC-1200
默认情况下,投射文件的权限设置为 0644。Service Binding Operator 无法因为 Kubernetes 中的一个错误而设置特定权限,这会导致在服务需要特定权限(如
0600
)时出现问题。作为临时解决方案,您可以修改程序代码或正在工作负载资源中运行的应用程序,将文件复制到
/tmp
目录中并设置适当的权限。
APPSVC-1127
在单一命名空间安装模式中安装 Service Binding Operator 当前存在一个已知问题。因为缺少一些命名空间范围的访问控制 (RBAC) 规则,应用程序可能无法成功绑定到 Service Binding Operator 可自动探测和绑定到的、几个已知的 Operator 支持的服务。当发生这种情况时,它会生成类似以下示例的错误消息:
6.1.7. Service Binding Operator 1.1.1 发行注记
Service Binding Operator 1.1.1 现在包括在 OpenShift Container Platform 4.7、4.8、4.9 和 4.10 上。
-
在此次更新之前,在 Service Binding Operator Helm chart 中记录了一个安全漏洞
CVE-2021-38561
。在这个版本中,
CVE-2021-38561
错误,并将
golang.org/x/text
软件包从 v0.3.6 更新至 v0.3.7。
APPSVC-1124
在此次更新之前,Developer Sandbox 用户没有足够权限来读取
ClusterWorkloadResourceMapping
资源。因此,Service Binding Operator 会阻止所有服务绑定成功。在这个版本中,Service Binding Operator 会为任何经过身份验证的主体(包括 Developer Sandbox 用户)包含适当的基于角色的访问控制(RBAC)规则。这些 RBAC 规则允许 Service Binding Operator
get
,
list
, 和
watch
Developer Sandbox 用户的
ClusterWorkloadResourceMapping
资源,并成功处理服务绑定。
APPSVC-1135
6.1.8. Service Binding Operator 1.1 发行注记
Service Binding Operator 现在包括在 OpenShift Container Platform 4.7、4.8、4.9 和 4.10 中。
本节重点介绍 Service Binding Operator 1.1 中的新内容:
服务绑定选项
工作负载资源映射:精确定义需要针对辅助工作负载投射绑定数据的位置。
使用标签选择器绑定新工作负载。
-
在此次更新之前,使用标签选择器提取工作负载的服务绑定不会将数据绑定到与给定标签选择器匹配的新工作负载中。因此,Service Binding Operator 无法定期绑定这些新工作负载。在这个版本中,服务绑定将数据绑定到与给定标签选择器匹配的新工作负载。Service Binding Operator 现在定期尝试查找和绑定这些新工作负载。
APPSVC-1083
6.1.9. Service Binding Operator 1.0.1 发行注记
Service Binding Operator 现在包括在 OpenShift Container Platform 4.7、4.8 和 4.9 中。
Service Binding Operator 1.0.1 支持 OpenShift Container Platform 4.9 及之后的版本运行:
IBM Power 系统
IBM Z 和 LinuxONE
Service Binding Operator 1.0.1 的自定义资源定义(CRD)支持以下 API:
使用
binding.operators.coreos.com
API 组的
服务绑定
。
服务绑定(Spec API 技术预览)
,使用
servicebinding.io
API 组。
带有
servicebinding.io
API 组的
Service Binding (Spec API Tech Preview)
只是一个技术预览功能。技术预览功能不受红帽产品服务等级协议(SLA)支持,且功能可能并不完整。红帽不推荐在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。
有关红帽技术预览功能支持范围的更多信息,请参阅
技术预览功能支持范围
。
这个版本中的一些功能当前还处于技术预览状态。它们并不适用于在生产环境中使用。
技术预览功能支持范围
在下表中,功能被标记为以下状态:
TP
:
技术预览
GA
:
正式发行
请参阅红帽门户网站中关于对技术预览功能支持范围的信息:
表 6.2. 支持列表
|
功能
|
Service Binding Operator 1.0.1
|
|
binding.operators.coreos.com
API 组
ServiceBinding.io
API 组
|
-
在此次更新之前,从 CR 的
postgresql.k8s.enterpriesedb.io/v1
API 的
Cluster
自定义资源(CR)中绑定数据值,从 CR 的
.metadata.name
字段收集
主机
绑定值。收集的绑定值是不正确的主机名,正确的主机名在
.status.writeService
字段中可用。在这个版本中,Service Binding Operator 用来公开后备服务 CR 的绑定数据值的注解现在被修改为从
.status.writeService
字段收集
主机
绑定值。Service Binding Operator 使用这些修改的注解来将正确的主机名注入到
主机
和
供应商
绑定中。
APPSVC-1040
在这个更新之前,当您绑定
postgres-operator.crunchydata.com/v1beta1
API 的
PostgresCluster
CR 时,绑定数据值不包括数据库证书的值。因此,应用程序无法连接到数据库。在这个版本中,对 Service Binding Operator 用来从后备服务 CR 中公开绑定数据的注解的修改现在包含数据库证书。Service Binding Operator 使用以下修改后的注解来生成正确的
ca.crt
、
tls.crt
和
tls.key
证书文件。
APPSVC-1045
在此次更新之前,当绑定
pxc.percona.com
API 的
PerconaXtraDBCluster
自定义资源(CR)时,绑定数据值不包括
端口
和
数据库
值。这些绑定值与其他已注入的绑定值是应用程序成功连接到数据库服务所需的值。在这个版本中,Service Binding Operator 用来公开服务 CR 的绑定数据值的注解现在被修改为项目额外的
端口
和
数据库
绑定值。Service Binding Operator 使用以下修改后的注解来生成完整的、应用程序用于成功连接到数据库服务所需的绑定值。
APPSVC-1073
6.1.10. Service Binding Operator 1.0 发行注记
Service Binding Operator 现在包括在 OpenShift Container Platform 4.7、4.8 和 4.9 中。
Service Binding Operator 1.0 的自定义资源定义 (CRD) 支持以下 API:
使用
binding.operators.coreos.com
API 组的
服务绑定
。
服务绑定(Spec API 技术预览)
,使用
servicebinding.io
API 组。
带有
servicebinding.io
API 组的
Service Binding (Spec API Tech Preview)
只是一个技术预览功能。技术预览功能不受红帽产品服务等级协议(SLA)支持,且功能可能并不完整。红帽不推荐在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。
有关红帽技术预览功能支持范围的更多信息,请参阅
技术预览功能支持范围
。
这个版本中的一些功能当前还处于技术预览状态。它们并不适用于在生产环境中使用。
技术预览功能支持范围
在下表中,功能被标记为以下状态:
TP
:
技术预览
GA
:
正式发行
请参阅红帽门户网站中关于对技术预览功能支持范围的信息:
表 6.3. 支持列表
|
功能
|
Service Binding Operator 1.0
|
|
binding.operators.coreos.com
API 组
ServiceBinding.io
API 组
|
Service Binding Operator 1.0 支持 OpenShift Container Platform 4.9 及之后的版本运行:
IBM Power 系统
IBM Z 和 LinuxONE
本节重点介绍了 Service Binding Operator 1.0 中的新功能:
公开服务的绑定数据
根据 CRD、自定义资源 (CR) 或资源中的注解。
基于 Operator Lifecycle Manager (OLM) 描述符中存在的描述符。
支持置备的服务
工作负载投射
使用卷挂载以文件形式预测绑定数据。
绑定数据作为环境变量的投射。
服务绑定选项
在与工作负载命名空间不同的命名空间中绑定后备服务。
项目绑定数据到特定的容器工作负载。
自动检测来自后备服务 CR 拥有的资源的绑定数据。
编写来自公开绑定数据的自定义绑定数据。
支持非
PodSpec
兼容工作负载资源。
支持基于角色的访问控制 (RBAC)。
6.2. 了解 Service Binding Operator
应用程序开发人员需要访问支持的服务,以构建和连接工作负载。连接工作负载以支持服务始终是一个挑战,因为每个服务提供商建议以不同方式访问其机密并在工作负载中使用它们。此外,手动配置和维护这种工作负载和后备服务组合,使得流程变得繁琐、效率低下且容易出错。
Service Binding Operator 可让应用程序开发人员将工作负载与 Operator 管理的后备服务轻松绑定,而无需任何手动步骤来配置绑定连接。
本节总结了服务绑定中使用的基本术语。
提供向工作负载提供服务的信息的操作表示。例如,在 Java 应用程序和它所需的数据库之间建立凭据交换。
应用在网络上运行的任何服务或软件作为其正常操作的一部分。示例包括数据库、消息代理、带 REST 端点的应用、事件流、应用程序性能监控器 (APM) 或硬件安全模块 (HSM)。
工作负载(应用程序)
容器内运行的任何进程。示例包括 Spring Boot 应用、NodeJS Express 应用或 Ruby on Rails 应用。
有关用于配置集群中其他资源行为的服务的信息。示例包括凭证、连接详情、卷挂载或 secret。
任何在连接的组件(如可绑定后备服务)和需要支持服务的应用程序之间建立交互的连接。
|
6.2.2. 关于 Service Binding Operator
Service Binding Operator 由一个控制器和附带的自定义资源定义 (CRD) 组成,用于服务绑定。它管理工作负载的数据平面并提供支持服务。Service Binding Controller 读取由后备服务的 control plane 提供的数据。然后,它会根据通过
ServiceBinding
资源指定的规则将这些数据到工作负载。
因此,Service Binding Operator 通过自动收集和与工作负载共享绑定数据,使工作负载能够使用后备服务或外部服务。这个过程包括使后备服务绑定,并将工作负载和服务绑定在一起。
6.2.2.1. 使 Operator 管理的后备服务可绑定
要使服务可绑定,作为 Operator 供应商,您需要公开工作负载所需的绑定数据,以便与 Operator 提供的服务绑定。您可以在管理后备服务的 Operator CRD 中以注解或描述符形式提供绑定数据。
通过将 Service Binding Operator 用作应用程序开发人员,您需要声明建立绑定连接的意图。您必须创建一个
ServiceBinding
CR 来引用后端服务。此操作会触发 Service Binding Operator 将公开的绑定数据项目到工作负载中。Service Binding Operator 接收声明的意图,并将工作负载与后备服务绑定。
Service Binding Operator 的 CRD 支持以下 API:
使用
binding.operators.coreos.com
API 组的
服务绑定
。
服务绑定 (Spec API)
与
servicebinding.io
API 组。
使用 Service Binding Operator,您可以:
将工作负载绑定到 Operator 管理的后备服务。
自动配置绑定数据。
为服务提供商提供低接触管理经验,以调配和管理对服务的访问。
通过一致、声明性的服务绑定方法增强开发生命周期,消除群集环境中的差异。
Service Binding Operator 的 CRD 支持以下 API:
使用
binding.operators.coreos.com
API 组的
服务绑定
。
服务绑定 (Spec API)
与
servicebinding.io
API 组。
这两个 API 组都有类似的功能,但它们并不完全一致。以下是这些 API 组之间的区别的完整列表:
|
功能
|
binding.operators.coreos.com
API 组支持
|
由
servicebinding.io
API 组支持
|
备注
|
|
绑定到置备的服务
不适用 (N/A)
直接 secret 投射
不适用 (N/A)
作为文件绑定
servicebinding.io
API 组的服务绑定的默认行为
服务绑定
binding.operators.coreos.com
API 组的参与功能
作为环境变量绑定
服务绑定
binding.operators.coreos.com
API 组的默认行为。
服务绑定
servicebinding.io
API 组的参与功能:环境变量和文件一起创建。
使用标签选择器选择工作负载
不适用 (N/A)
发现绑定资源 (
.spec.detectBindingResources
)
servicebinding.io
API 组没有对应的功能。
servicebinding.io
API 组中没有当前的机制来解释命名策略使用的模板。
因为
binding.operators.coreos.com
API 组中的服务绑定可以在
ServiceBinding
资源中指定映射行为,所以
servicebinding.io
API 组无法完全支持对等的行为,而无需更多与工作负载相关的信息。
容器名称过滤
binding.operators.coreos.com
API 组没有等同的功能。
Secret 路径
servicebinding.io
API 组没有对应的功能。
备用绑定源(例如,从注解中绑定数据)
被 Service Binding Operator 允许
该规范需要支持从置备的服务和 secret 获取数据。但是,对规格的严格读取表示,支持其他绑定数据源。使用这个事实,Service Binding Operator 可以从各种源拉取绑定数据(例如,从注解中拉取绑定数据)。Service Binding Operator 在两个 API 组上支持这些源。
|
6.3. 安装 Service Binding Operator
本指南指导集群管理员完成将 Service Binding Operator 安装到 OpenShift Container Platform 集群的过程。
您可以在 OpenShift Container Platform 4.7 及更新的版本上安装 Service Binding Operator。
可以使用具有
cluster-admin
权限的账户访问 OpenShift Container Platform 集群。
您的集群启用了
Marketplace 功能
,或者手动配置 Red Hat Operator 目录源。
6.3.1. 使用 Web 控制台安装 Service Binding Operator
您可以使用 OpenShift Container Platform OperatorHub 安装 Service Binding Operator。安装 Service Binding Operator 时,服务绑定配置所需的自定义资源 (CR) 将与 Operator 一起自动安装。
在控制台的
Administrator
视角中,导航到
Operators
→
OperatorHub
。
使用
Filter by keyword
复选框在目录中搜索
Service Binding Operator
。点
Service Binding Operator
标题。
阅读
Service Binding Operator
页面中有关 Operator 的简单描述。点
Install
。
在
Install Operator
页面中:
为
Installation Mode
选择
All namespaces on the cluster (default)
。选择该项会将 Operator 安装至默认
openshift-operators
命名空间,这将启用 Operator 以进行监视并在集群中的所有命名空间中可用。
为
Approval Strategy
选择
Automatic
。这样可确保以后对 Operator 的升级由 Operator Lifecycle Manager (OLM) 自动进行。如果您选择
Manual
批准策略,OLM 会创建一个更新请求。作为集群管理员,您必须手动批准 OLM 更新请求,才可将 Operator 更新至新版本。
选择一个
Update Channel
。
默认情况下,
stable
频道启用 Service Binding Operator 最新稳定且受支持的发行版本。
点
Install
。
Operator 会自动安装到
openshift-operators
命名空间中。
在
Installed Operator — ready for use
窗格中,点
View Operator
。您会看到
Installed Operators
页面中列出的 Operator。
验证
Status
是否已设置为
Succeeded
来确认已成功安装 Service Binding Operator。
Service Binding Operator 管理工作负载和后备服务的数据平面。本指南提供了一些示例,可帮助您创建数据库实例、部署应用程序,以及使用 Service Binding Operator 在应用程序和数据库服务间创建绑定连接。
可以使用具有
cluster-admin
权限的账户访问 OpenShift Container Platform 集群。
已安装
oc
CLI。
已从 OperatorHub 安装了 Service Binding Operator。
您已使用
v5
更新频道从 OperatorHub 安装 Crunchy Postgres for Kubernetes Operator 的 5.1.2 版本。安装的 Operator 在适当的命名空间中可用,如
my-petclinic
命名空间。
您可以使用
oc create namespace my-petclinic
命令创建命名空间。
6.4.1. 创建 PostgreSQL 数据库实例
要创建 PostgreSQL 数据库实例,您必须创建一个
PostgresCluster
自定义资源 (CR) 并配置数据库。
在 shell 中运行以下命令来在
my-petclinic
命名空间中创建
PostgresCluster
CR:
$ oc apply -n my-petclinic -f - << EOD
apiVersion: postgres-operator.crunchydata.com/v1beta1
kind: PostgresCluster
metadata:
name: hippo
spec:
image: registry.developers.crunchydata.com/crunchydata/crunchy-postgres:ubi8-14.4-0
postgresVersion: 14
instances:
- name: instance1
dataVolumeClaimSpec:
accessModes:
- "ReadWriteOnce"
resources:
requests:
storage: 1Gi
backups:
pgbackrest:
image: registry.developers.crunchydata.com/crunchydata/crunchy-pgbackrest:ubi8-2.38-0
repos:
- name: repo1
volume:
volumeClaimSpec:
accessModes:
- "ReadWriteOnce"
resources:
requests:
storage: 1Gi
此 PostgresCluster CR 中的注解启用服务绑定连接并触发 Operator 协调。
输出会验证数据库实例是否已创建:
postgrescluster.postgres-operator.crunchydata.com/hippo created
创建数据库实例后,确保 my-petclinic 命名空间中的所有 pod 都在运行:
$ oc get pods -n my-petclinic
输出(需要几分钟)验证是否创建并配置了数据库:
NAME READY STATUS RESTARTS AGE
hippo-backup-9rxm-88rzq 0/1 Completed 0 2m2s
hippo-instance1-6psd-0 4/4 Running 0 3m28s
hippo-repo-host-0 2/2 Running 0 3m28s
配置了数据库后,您可以部署示例应用程序并将其连接到数据库服务。
6.4.2. 部署 Spring PetClinic 示例应用程序
要在 OpenShift Container Platform 集群上部署 Spring PetClinic 示例应用程序,您必须使用部署配置并配置本地环境才能测试应用程序。
在 shell 中运行以下命令,使用
PostgresCluster
自定义资源(CR)部署
spring-petclinic
应用程序:
$ oc apply -n my-petclinic -f - << EOD
apiVersion: apps/v1
kind: Deployment
metadata:
name: spring-petclinic
labels:
app: spring-petclinic
spec:
replicas: 1
selector:
matchLabels:
app: spring-petclinic
template:
metadata:
labels:
app: spring-petclinic
spec:
containers:
- name: app
image: quay.io/service-binding/spring-petclinic:latest
imagePullPolicy: Always
- name: SPRING_PROFILES_ACTIVE
value: postgres
ports:
- name: http
containerPort: 8080
apiVersion: v1
kind: Service
metadata:
labels:
app: spring-petclinic
name: spring-petclinic
spec:
type: NodePort
ports:
- port: 80
protocol: TCP
targetPort: 8080
selector:
app: spring-petclinic
输出会验证 Spring PetClinic 示例应用是否已创建并部署:
deployment.apps/spring-petclinic created
service/spring-petclinic created
如果要在 web 控制台的 Developer 视角中使用 容器镜像 部署应用程序,则必须在高级选项的 Deployment 部分输入以下环境变量:
名称:SPRING_PROFILES_ACTIVE
值: postgres
运行以下命令,验证应用程序是否还没有连接到数据库服务:
$ oc get pods -n my-petclinic
显示 CrashLoopBackOff 状态需要几分钟时间 :
NAME READY STATUS RESTARTS AGE
spring-petclinic-5b4c7999d4-wzdtz 0/1 CrashLoopBackOff 4 (13s ago) 2m25s
在这个阶段,pod 无法启动。如果您尝试与应用交互,它会返回错误。
公开服务来为应用程序创建路由:
$ oc expose service spring-petclinic -n my-petclinic
检查输出来验证 spring-petclinic 服务是否已公开,同时创建了 Spring PetClinic 示例应用程序的路由:
route.route.openshift.io/spring-petclinic exposed
现在,您可以使用 Service Binding Operator 将应用程序连接到数据库服务。
6.4.3. 将 Spring PetClinic 示例应用程序连接到 PostgreSQL 数据库服务
要将示例应用程序连接到数据库服务,您必须创建一个
ServiceBinding
自定义资源 (CR),该资源会触发 Service Binding Operator 将绑定数据项目到应用程序中。
创建
ServiceBinding
CR 以项目绑定数据:
$ oc apply -n my-petclinic -f - << EOD
apiVersion: binding.operators.coreos.com/v1alpha1
kind: ServiceBinding
metadata:
name: spring-petclinic-pgcluster
spec:
services: 1
- group: postgres-operator.crunchydata.com
version: v1beta1
kind: PostgresCluster 2
name: hippo
application: 3
name: spring-petclinic
group: apps
version: v1
resource: deployments
EOD
-
1
-
指定服务资源列表。
数据库的 CR。
示例应用程序,指向带有嵌入式 PodSpec 的 Deployment 或任何其他类似资源。
输出会验证是否已创建
ServiceBinding
CR 以将绑定数据项目到示例应用程序中。
servicebinding.binding.operators.coreos.com/spring-petclinic created
验证服务绑定的请求是否成功:
$ oc get servicebindings -n my-petclinic
6.5. 在 IBM Power、IBM Z 和 IBM (R) Linux 上使用服务绑定
Service Binding Operator 管理工作负载和后备服务的数据平面。本指南提供了一些示例,可帮助您创建数据库实例、部署应用程序,以及使用 Service Binding Operator 在应用程序和数据库服务间创建绑定连接。
可以使用具有
cluster-admin
权限的账户访问 OpenShift Container Platform 集群。
已安装
oc
CLI。
您已从 OperatorHub 安装 Service Binding Operator。
6.5.1. 部署 PostgreSQL Operator
流程
-
要在
my-petclinic
命名空间中部署 Dev4Devs PostgreSQL Operator,请在 shell 中运行以下命令:
$ oc apply -f - << EOD
apiVersion: v1
kind: Namespace
metadata:
name: my-petclinic
apiVersion: operators.coreos.com/v1
kind: OperatorGroup
metadata:
name: postgres-operator-group
namespace: my-petclinic
apiVersion: operators.coreos.com/v1alpha1
kind: CatalogSource
metadata:
name: ibm-multiarch-catalog
namespace: openshift-marketplace
spec:
sourceType: grpc
image: quay.io/ibm/operator-registry-<architecture> 1
imagePullPolicy: IfNotPresent
displayName: ibm-multiarch-catalog
updateStrategy:
registryPoll:
interval: 30m
apiVersion: operators.coreos.com/v1alpha1
kind: Subscription
metadata:
name: postgresql-operator-dev4devs-com
namespace: openshift-operators
spec:
channel: alpha
installPlanApproval: Automatic
name: postgresql-operator-dev4devs-com
source: ibm-multiarch-catalog
sourceNamespace: openshift-marketplace
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: database-view
labels:
servicebinding.io/controller: "true"
rules:
- apiGroups:
- postgresql.dev4devs.com
resources:
- databases
verbs:
- get
- list
EOD
-
1
-
Operator 镜像。
对于 IBM Power:
quay.io/ibm/operator-registry-ppc64le:release-4.9
对于 IBM Z 和 IBM® LinuxONE:
quay.io/ibm/operator-registry-s390x:release-4.8
安装 Operator 后,列出
openshift-operators
命名空间中的 Operator 订阅:
$ oc get subs -n openshift-operators
6.5.2. 创建 PostgreSQL 数据库实例
要创建 PostgreSQL 数据库实例,您必须创建一个
Database
自定义资源(CR)并配置数据库。
在 shell 中运行以下命令来在
my-petclinic
命名空间中创建
Database
CR:
$ oc apply -f - << EOD
apiVersion: postgresql.dev4devs.com/v1alpha1
kind: Database
metadata:
name: sampledatabase
namespace: my-petclinic
annotations:
host: sampledatabase
type: postgresql
port: "5432"
service.binding/database: 'path={.spec.databaseName}'
service.binding/port: 'path={.metadata.annotations.port}'
service.binding/password: 'path={.spec.databasePassword}'
service.binding/username: 'path={.spec.databaseUser}'
service.binding/type: 'path={.metadata.annotations.type}'
service.binding/host: 'path={.metadata.annotations.host}'
spec:
databaseCpu: 30m
databaseCpuLimit: 60m
databaseMemoryLimit: 512Mi
databaseMemoryRequest: 128Mi
databaseName: "sampledb"
databaseNameKeyEnvVar: POSTGRESQL_DATABASE
databasePassword: "samplepwd"
databasePasswordKeyEnvVar: POSTGRESQL_PASSWORD
databaseStorageRequest: 1Gi
databaseUser: "sampleuser"
databaseUserKeyEnvVar: POSTGRESQL_USER
image: registry.redhat.io/rhel8/postgresql-13:latest
databaseStorageClassName: nfs-storage-provisioner
size: 1
此 Database CR 中添加的注解可启用服务绑定连接并触发 Operator 协调。
输出会验证数据库实例是否已创建:
database.postgresql.dev4devs.com/sampledatabase created
创建数据库实例后,确保 my-petclinic 命名空间中的所有 pod 都在运行:
$ oc get pods -n my-petclinic
输出(需要几分钟)验证是否创建并配置了数据库:
NAME READY STATUS RESTARTS AGE
sampledatabase-cbc655488-74kss 0/1 Running 0 32s
配置了数据库后,您可以部署示例应用程序并将其连接到数据库服务。
6.5.3. 部署 Spring PetClinic 示例应用程序
要在 OpenShift Container Platform 集群上部署 Spring PetClinic 示例应用程序,您必须使用部署配置并配置本地环境才能测试应用程序。
在 shell 中运行以下命令,使用
PostgresCluster
自定义资源(CR)部署
spring-petclinic
应用程序:
$ oc apply -n my-petclinic -f - << EOD
apiVersion: apps/v1
kind: Deployment
metadata:
name: spring-petclinic
labels:
app: spring-petclinic
spec:
replicas: 1
selector:
matchLabels:
app: spring-petclinic
template:
metadata:
labels:
app: spring-petclinic
spec:
containers:
- name: app
image: quay.io/service-binding/spring-petclinic:latest
imagePullPolicy: Always
- name: SPRING_PROFILES_ACTIVE
value: postgres
- name: org.springframework.cloud.bindings.boot.enable
value: "true"
ports:
- name: http
containerPort: 8080
apiVersion: v1
kind: Service
metadata:
labels:
app: spring-petclinic
name: spring-petclinic
spec:
type: NodePort
ports:
- port: 80
protocol: TCP
targetPort: 8080
selector:
app: spring-petclinic
输出会验证 Spring PetClinic 示例应用是否已创建并部署:
deployment.apps/spring-petclinic created
service/spring-petclinic created
如果要在 web 控制台的 Developer 视角中使用 容器镜像 部署应用程序,则必须在高级选项的 Deployment 部分输入以下环境变量:
名称:SPRING_PROFILES_ACTIVE
值: postgres
运行以下命令,验证应用程序是否还没有连接到数据库服务:
$ oc get pods -n my-petclinic
显示 CrashLoopBackOff 状态需要几分钟:
NAME READY STATUS RESTARTS AGE
spring-petclinic-5b4c7999d4-wzdtz 0/1 CrashLoopBackOff 4 (13s ago) 2m25s
在这个阶段,pod 无法启动。如果您尝试与应用交互,它会返回错误。
现在,您可以使用 Service Binding Operator 将应用程序连接到数据库服务。
6.5.4. 将 Spring PetClinic 示例应用程序连接到 PostgreSQL 数据库服务
要将示例应用程序连接到数据库服务,您必须创建一个
ServiceBinding
自定义资源 (CR),该资源会触发 Service Binding Operator 将绑定数据项目到应用程序中。
创建
ServiceBinding
CR 以项目绑定数据:
$ oc apply -n my-petclinic -f - << EOD
apiVersion: binding.operators.coreos.com/v1alpha1
kind: ServiceBinding
metadata:
name: spring-petclinic-pgcluster
spec:
services: 1
- group: postgresql.dev4devs.com
kind: Database 2
name: sampledatabase
version: v1alpha1
application: 3
name: spring-petclinic
group: apps
version: v1
resource: deployments
EOD
-
1
-
指定服务资源列表。
数据库的 CR。
示例应用程序,指向带有嵌入式 PodSpec 的 Deployment 或任何其他类似资源。
输出会验证是否已创建
ServiceBinding
CR 以将绑定数据项目到示例应用程序中。
servicebinding.binding.operators.coreos.com/spring-petclinic created
验证服务绑定的请求是否成功:
$ oc get servicebindings -n my-petclinic
应用程序开发人员需要访问支持的服务,以构建和连接工作负载。连接工作负载以支持服务始终是一个挑战,因为每个服务提供商需要以不同的方式访问其机密并在工作负载中使用它们。
Service Binding Operator 可让应用程序开发人员将工作负载与 Operator 管理的后备服务轻松绑定,而无需任何手动步骤来配置绑定连接。要使 Service Binding Operator 作为 Operator 供应商或创建后备服务的用户提供绑定数据,您必须公开绑定数据,以便 Service Binding Operator 自动检测到绑定数据。然后,Service Binding Operator 会自动从后备服务收集绑定数据,并将其与工作负载共享,以提供一致且可预测的体验。
本节论述了您可以使用什么方法公开绑定数据。
确保您了解并了解您的工作负载要求和环境,以及如何与所提供的服务配合使用。
在以下情况下公开绑定数据:
后备服务作为调配的服务资源提供。
您要连接到的服务符合 Service Binding 规格。您必须创建一个带有所有所需绑定数据值的
Secret
资源,并在后备服务自定义资源 (CR) 中引用它。所有绑定数据值的检测都是自动的。
后备服务不能作为调配的服务资源使用。
您必须从后备服务公开绑定数据。根据工作负载要求和环境,您可以选择以下任一方法公开绑定数据:
直接 secret 引用
通过自定义资源定义(CRD)或 CR 注解声明绑定数据
通过拥有的资源检测绑定数据
置备的服务代表后端服务 CR,引用了放置在后备服务 CR 的
.status.binding.name
字段中的
Secret
资源。
作为 Operator 供应商或创建后备服务的用户,您可以通过创建
Secret
资源并在后备服务 CR 的
.status.binding.name
部分中引用它,使用此方法符合 Service Binding 规格。此
Secret
资源必须提供工作负载连接到后备服务所需的所有绑定数据值。
以下示例显示一个
AccountService
CR,它代表一个后备服务和从 CR 引用的
Secret
资源。
如果所有必需的绑定数据值都位于 Service Binding 定义中可以引用的
Secret
资源中,您可以使用此方法。在这个方法中,
ServiceBinding
资源直接引用
Secret
资源来连接服务。
Secret
资源中的所有键都公开为绑定数据。
6.6.1.3. 通过 CRD 或 CR 注解声明绑定数据
您可以使用此方法注解后备服务的资源,以使用特定注解公开绑定数据。在
metadata
部分下添加注解会改变后备服务的 CR 和 CRD。Service Binding Operator 会检测添加到 CR 和 CRD 的注解,然后使用基于注解提取的值创建一个
Secret
资源。
以下示例显示了在
metadata
部分添加的注解以及从资源引用的
ConfigMap
对象:
如果您的后备服务拥有一个或多个 Kubernetes 资源,如路由、服务、配置映射或 secret,您可以使用此方法检测绑定数据。在这个方法中,Service Binding Operator 会检测来自后备服务 CR 拥有的资源的绑定数据。
以下示例显示
ServiceBinding
CR 中的
detectBindingResources
API 选项设置为
true
:
注释中使用的数据模型遵循特定的惯例。
服务绑定注解必须使用以下约定:
service.binding(/<NAME>)?:
"<VALUE>|(path=<JSONPATH_TEMPLATE>(,objectType=<OBJECT_TYPE>)?(,elementType=<ELEMENT_TYPE>)?(,sourceKey=<SOURCE_KEY>)?(,sourceValue=<SOURCE_VALUE>)?)"
指定要公开的绑定值的名称。只有在将
objectType
参数设置为
Secret
或
ConfigMap
时,才能将其排除。
<VALUE>
指定没有设置
path
时公开的常量值。
数据模型详细介绍了
路径
、
elementType
、
objectType
、
sourceKey
和
sourceValue
参数允许的值和语义。
表 6.4. 参数及其描述
|
参数
|
描述
|
默认值
|
|
包含以大括号 {} 括起的 JSONPath 表达式的 jsonpath 模板。
elementType
指定
path
参数中引用的元素值是否满足以下类型之一:
string
sliceOfStrings
sliceOfMaps
string
objectType
指定
path
参数中指示的元素值是否为当前命名空间中的
ConfigMap
、
Secret
或纯文本。
Secret
,如果
elementType
为非字符串。
sourceKey
指定在收集绑定数据时要添加到绑定 secret 的
ConfigMap
或
Secret
中的键。
当与
elementType
=
sliceOfMaps
一同使用时,
sourceKey
参数指定映射中的键,其值为在绑定 secret 中用作键的片段。
使用此可选参数在引用的
Secret
或
ConfigMap
资源中公开特定条目,作为绑定数据。
如果没有指定,则公开来自
Secret
或
ConfigMap
资源的所有键和值,并添加到绑定 secret 中。
sourceValue
指定映射片段中的键。
此键的值用作基础,用于生成添加到绑定 secret 的键值对条目值。
另外,
sourceKey
的值被用作添加到绑定 secret 的 key-value 对条目的键。
只有在
elementType
=
sliceOfMaps
时才必须。
只有在
path
参数中指示的元素引用
ConfigMap
或
Secret
资源时,
sourceKey
和
sourceValue
参数才适用。
您可以在注解中带有可选字段。例如,如果服务端点不需要身份验证,则凭证的路径可能不存在。在这种情况下,注解的目标路径中会出现一个字段。因此,Service Binding Operator 默认会生成一个错误。
作为服务提供商,要指明是否需要注解映射,您可以在启用服务时为注解中的
optional
标记设置值。只有在目标路径可用时,Service Binding Operator 才会提供注解映射。当目标路径不可用时,Service Binding Operator 会跳过可选映射,并继续进行现有映射的预测,而不会抛出任何错误。
要在注解中创建一个字段,将
optional
标志值设置为
true
:
要使用 Service Binding Operator 来公开后备服务绑定数据,您需要特定的基于角色的访问控制(RBAC)权限。在
ClusterRole
资源的
rules
字段下指定特定的操作动词,以便为后备服务资源授予 RBAC 权限。在定义这些
规则
时,允许 Service Binding Operator 在整个集群中读取后备服务资源的绑定数据。如果用户没有读取绑定数据或修改应用程序资源的权限,Service Binding Operator 会阻止这样的用户将服务绑定到应用程序。遵循 RBAC 要求避免用户不必要的权限,并防止访问未经授权的服务或应用程序。
Service Binding Operator 使用专用服务帐户对 Kubernetes API 执行请求。默认情况下,此帐户具有将服务绑定到工作负载的权限,它们都由以下标准 Kubernetes 或 OpenShift 对象表示:
DaemonSets
ReplicaSet
StatefulSets
DeploymentConfig
Operator 服务帐户绑定到一个聚合的集群角色,允许 Operator 供应商或集群管理员启用将自定义服务资源绑定到工作负载。要在
ClusterRole
中授予所需的权限,请为它标上
servicebinding.io/controller
标志,并将标志值设为
true
。以下示例演示了如何允许 Service Binding Operator
get
、
watch
、
list
Crunchy PostgreSQL Operator 的自定义资源(CR):
Service Binding Operator 可让您从后备服务资源和自定义资源定义 (CRD) 中公开绑定数据值。
本节提供了示例,以演示如何使用各种可混合绑定数据类别。您必须修改这些示例,以符合您的工作环境和要求。
以下示例演示了如何将
PostgresCluster
自定义资源 (CR) 的
metadata.name
字段中的字符串公开为用户名:
以下示例演示了如何从
PostgresCluster
自定义资源(CR)公开一个常量值:
6.6.5.3. 公开从资源引用的整个配置映射或 secret
以下示例演示了如何通过注解公开整个 secret:
6.6.5.4. 从一个配置映射或 secret(从一个资源指代) 中公开一个特定条目
以下示例演示了如何通过注解从配置映射中公开特定条目:
apiVersion: v1
kind: ConfigMap
metadata:
name: hippo-config
data:
db_timeout: "10s"
user: "hippo"
6.6.5.6. 使用每个条目的键和值公开集合条目
以下示例演示了如何通过注解使用每个条目的键和值公开集合条目:
6.6.5.7. 使用每个项目一个键公开集合的项目
以下示例演示了如何通过注解在各个项目中使用一个键来公开集合项目:
6.6.5.8. 每个条目使用一个键公开集合条目的值
以下示例演示了如何通过注解使用每个条目值的一个键公开集合条目的值:
本节提供有关如何使用绑定数据的信息。
在后备服务公开绑定数据后,如果工作负载要访问和使用这个数据,您必须将其从后备服务中项目到工作负载中。Service Binding Operator 会自动以以下方法将这一数据集项目到工作负载中:
默认情况下,作为文件。
作为环境变量,在从
ServiceBinding
资源配置
.spec.bindAsFiles
参数后。
6.7.2. 配置目录路径来项目工作负载容器内绑定数据
默认情况下,Service Binding Operator 将绑定数据作为文件挂载到工作负载资源的特定目录中。您可以使用运行工作负载的容器中的
SERVICE_BINDING_ROOT
环境变量设置来配置目录路径。
6.9. 使用 Developer 视角将应用程序连接到服务
使用
Topology
视图用于以下目的:
对应用程序中的多个组件进行分组。
相互连接组件。
使用标签将多个资源连接到服务。
您可以使用绑定或可视连接器来连接组件。
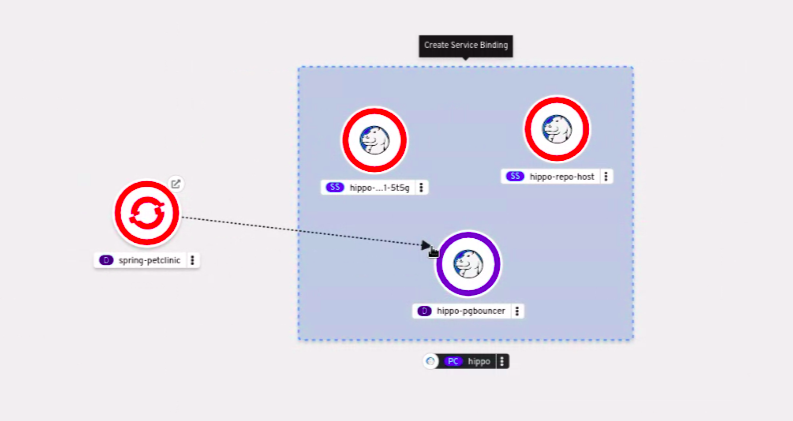
只有当目标节点是 Operator 支持的服务时,才可以在组件之间建立绑定连接。为了表示这种情况,当您将箭头拖到这样的目标节点上时,会出现
Create a binding connector
工具提示。当应用程序使用绑定连接器连接到服务时,会创建一个
ServiceBinding
资源。然后,Service Binding Operator 控制器会将必要的绑定数据项目到应用程序部署中。请求成功后,会重新部署应用程序以在连接的组件间建立交互。
视觉连接器只在组件之间建立视觉连接,描述连接意图。没有建立组件之间的交互。如果目标节点不是一个 Operator 支持的服务,当您将箭头拖到目标节点上时,将会显示
Create a visual connector
工具提示。
6.9.1. 发现并识别 Operator 支持的可绑定服务
作为用户,如果要创建可绑定的服务,您必须知道哪些服务可以绑定。可绑定服务是应用程序可轻松使用的服务,因为它们以标准的方式公开其绑定数据,如凭证、连接详情、卷挂载、secret 和其他绑定数据。
Developer
视角可帮助您发现和识别此类可绑定的服务。
要发现并确定由 Operator 支持的可绑定服务,请考虑以下替代方法:
点
+Add
→
Developer Catalog
→
Operator Backed
查看 Operator 支持的标题。支持服务绑定功能的 Operator 支持的服务在标题上具有
可绑定
的徽标。
在
Operator Backed
页面左侧窗格中,选择
Bindable
。
点
Service binding
旁边的 help 图标查看与可绑定服务相关的信息。
点
+Add
→
Add
并搜索 Operator 支持的服务。当您点可绑定服务时,您可以在侧面面板中查看
Bindable
徽标。
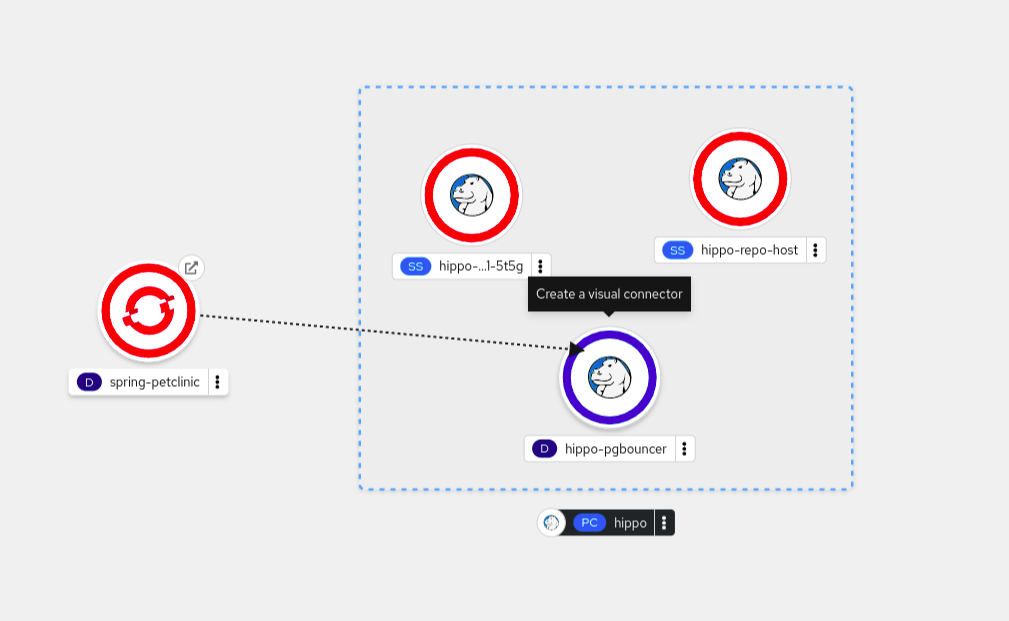
您可以使用可视连接器来描述连接应用程序组件的意图。
此流程介绍了在 PostgreSQL 数据库服务和 Spring PetClinic 示例应用程序之间创建可视连接的示例。
您已使用
Developer
视角创建并部署了 Spring PetClinic 示例应用程序。
已使用
Developer
视角创建并部署了 Crunchy PostgreSQL 数据库实例。此实例具有以下组件:
hippo-backup
、
hippo-instance
、
hippo-repo-host
和
hippo-pgbouncer
。
在
Developer
视角中,切换到相关项目,如
my-petclinic
。
将鼠标悬停在 Spring PetClinic 示例应用上,以查看节点上的悬挂箭头。
单击箭头并将它拖向
hippo-pgbouncer
部署,以将 Spring PetClinic 示例应用与其连接。
点
spring-petclinic
部署来查看
Overview
面板。在
Details
选项卡下,点
Annotations
部分中的编辑图标,查看
Key =
app.openshift.io/connects-to
和
Value =
[{"apiVersion":"apps/v1","kind":"Deployment","name":"hippo-pgbouncer"}]
注解添加到部署。
可选:您可以重复这些步骤,以在其他应用程序和组件之间建立视觉连接。
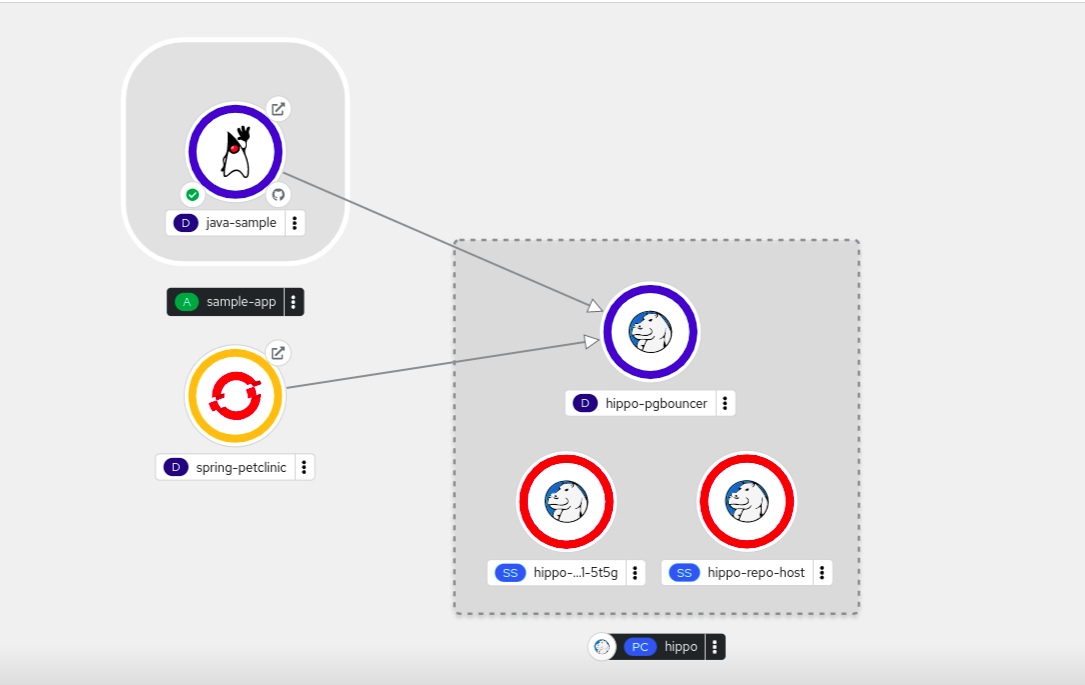
您可以创建一个与 Operator 支持的组件的绑定连接,如下例所示,它使用 PostgreSQL Database 服务和 Spring PetClinic 示例应用程序。要创建与 PostgreSQL Database Operator 支持的服务的绑定连接,您必须首先将红帽提供的 PostgreSQL Database Operator 添加到
OperatorHub
,然后安装 Operator。然后,PostSQL Database Operator 会创建和管理 Database 资源,这会在 secret、配置映射、状态和 spec 属性中公开绑定数据。
您在
Developer
视角中创建并部署了 Spring PetClinic 示例应用程序。
您从
OperatorHub
安装 Service Binding Operator。
您已使用
v5
Update
频道从 OperatorHub 安装了
Crunchy Postgres for Kubernetes
Operator。
您在
Developer
视角中创建了一个
PostgresCluster
资源,这会导致一个含有以下组件的 Crunchy PostgreSQL 数据库实例:
hippo-backup
、
hippo-instance
、
hippo-repo-host
、
hippo-pgbouncer
。
在
Developer
视角中,切换到相关项目,如
my-petclinic
。
在
Topology
视图中,把鼠标移到 Spring PetClinic 示例应用程序上,以查看节点上的悬挂箭头。
将箭头拖放到 Postgres Cluster 的
hippo
数据库图标,以使用 Spring PetClinic 示例应用程序进行绑定连接。
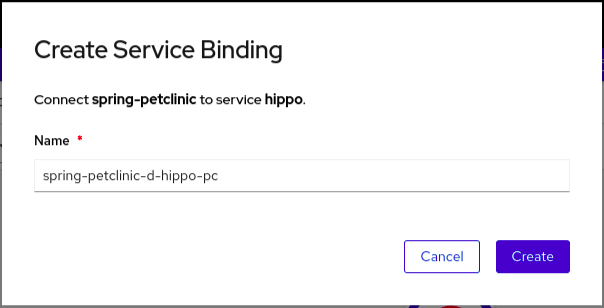
在
Create Service Binding
对话框中,保留默认名称或为服务绑定添加其他名称,然后点
Create
。
可选:如果使用 Topology 视图进行绑定连接,进入
+Add
→
YAML
→
Import YAML
。
可选:在 YAML 编辑器中,添加
ServiceBinding
资源:
apiVersion: binding.operators.coreos.com/v1alpha1
kind: ServiceBinding
metadata:
name: spring-petclinic-pgcluster
namespace: my-petclinic
spec:
services:
- group: postgres-operator.crunchydata.com
version: v1beta1
kind: PostgresCluster
name: hippo
application:
name: spring-petclinic
group: apps
version: v1
resource: deployments
服务绑定请求被创建,并通过
ServiceBinding
资源创建绑定连接。当数据库服务连接请求成功后,会重新部署应用程序并建立连接。
您还可以通过拖动悬挂箭头以添加和创建与 Operator 支持的服务的绑定连接来使用上下文菜单。
在导航菜单中点
Topology
。Topology 视图中的 spring-petclinic 部署包括 Open URL 链接来查看其网页。
点
Open URL
链接。
现在,您可以远程查看 Spring PetClinic 示例应用程序,以确认应用程序现在连接到数据库服务,并且数据已成功投入 Crunchy PostgreSQL 数据库服务中的应用程序。
Service Binding Operator 在应用程序和数据库服务之间成功创建了可正常工作的连接。
6.9.4. 从 Topology 视图验证服务绑定的状态
Developer
视角可帮助您通过
Topology
视图验证服务绑定的状态。
如果服务绑定成功,点绑定连接器。侧面板会出现在
Details
标签页中显示
Connected
状态。
另外,您可以从
Developer
视角在以下页面中查看
Connected
状态:
ServiceBindings
页面。
ServiceBinding 详情
页面。另外,页面标题显示
Connected
图标。
如果服务绑定失败,绑定连接器会显示红色的箭头,并在连接中间有一个红线。点这个连接器,在
Details
选项卡的侧面板中查看
Error
状态。(可选)点
Error
状态查看有关底层问题的特定信息。
您还可以从
Developer
视角查看以下页面中的
错误
状态和提示信息:
ServiceBindings
页面。
ServiceBinding 详情
页面。另外,页面标题会显示
错误
徽标。
在
ServiceBindings
页面中,使用
Filter
下拉菜单根据服务的状态列出服务绑定。
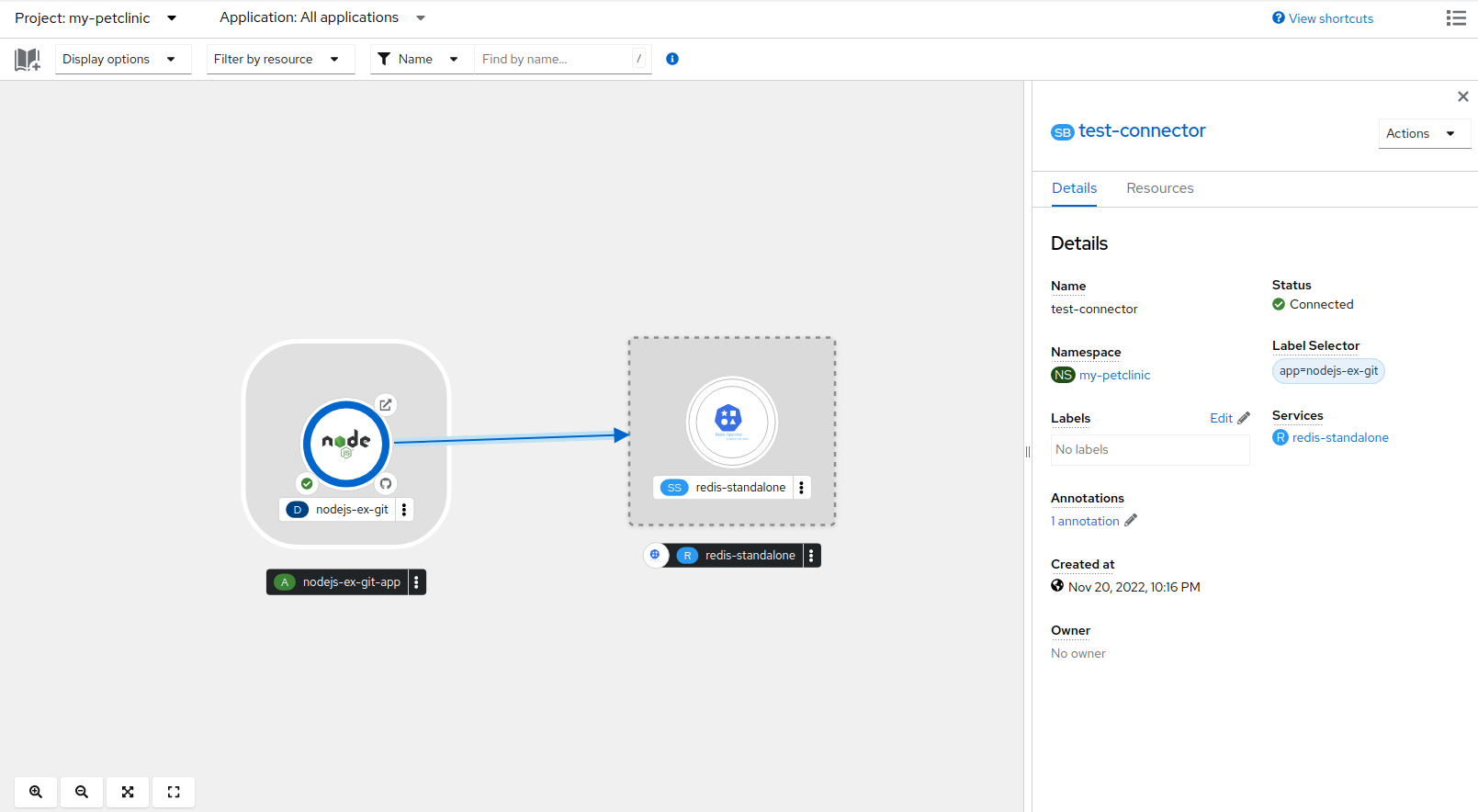
作为用户,使用
Topology
视图中的
Label Selector
来视觉化服务绑定,并简化将应用程序绑定到后备服务的过程。在创建
ServiceBinding
资源时,使用
Label Selector
指定标签来查找和连接应用程序,而不使用应用程序的名称。然后,Service Binding Operator 会消耗这些
ServiceBinding
资源并指定标签,以查找要创建服务绑定的应用程序。
要进入到所有连接的资源列表,请点与
ServiceBinding
资源关联的标签选择器。
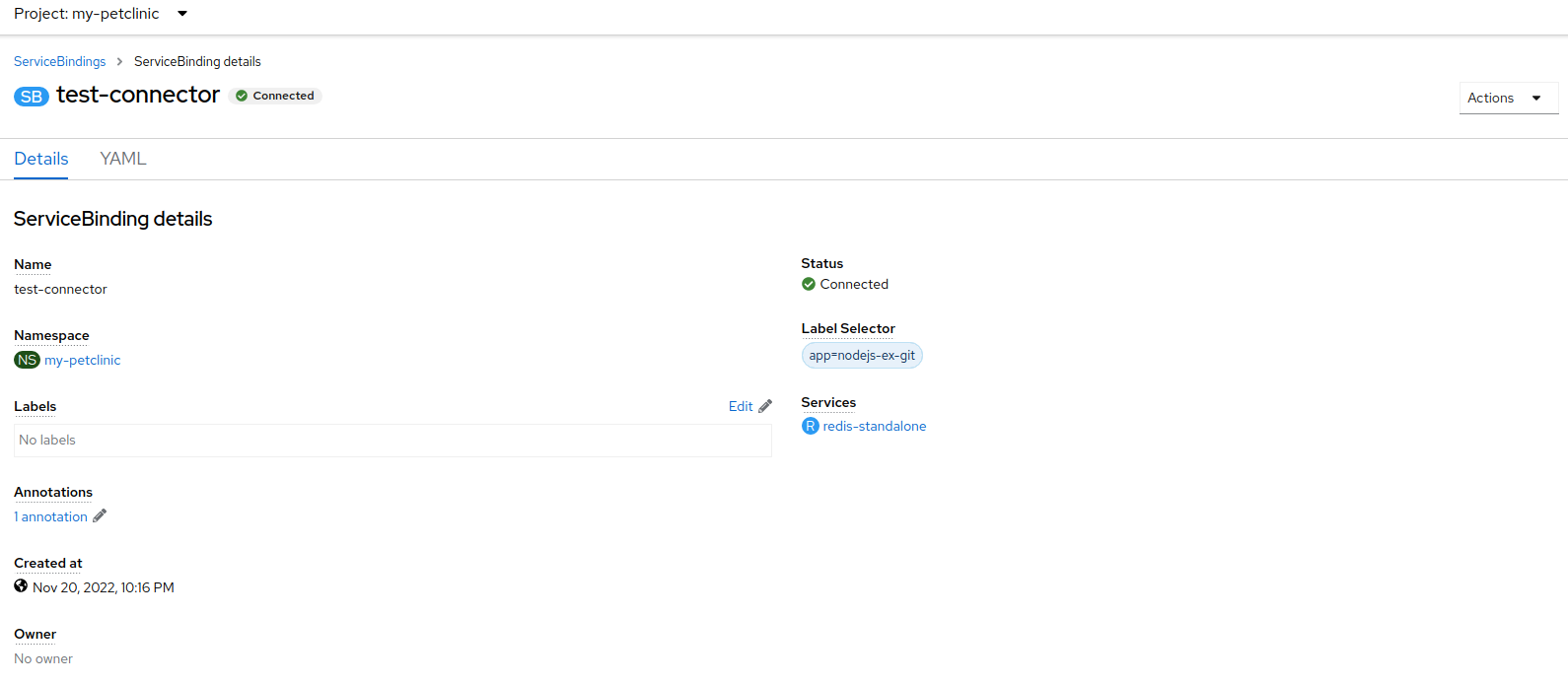
要查看
Label Selector
,请考虑以下方法:
导入
ServiceBinding
资源后,查看
ServiceBinding 详情
页中与服务绑定关联的
Label Selector
。
要使用
Label Selector
并一次性创建一个或多个连接,您必须导入
ServiceBinding
资源的 YAML 文件。
建立连接并点绑定连接器后,服务绑定连接器
详情
侧面板会出现。您可以在此面板中查看与服务绑定关联的
Label Selector
。
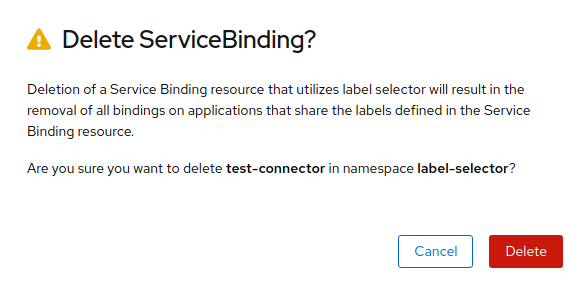
当您删除绑定连接器 (
Topology
中的单个连接与服务绑定) 时,操作会删除与已删除服务绑定关联的所有连接。在删除绑定连接器时,会出现一个确认对话框,它会通知所有连接器都会被删除。
Helm 是一个软件包管理程序,它简化了应用程序和服务部署到 OpenShift Container Platform 集群的过程。
Helm 使用名为
charts
的打包格式。Helm chart 是描述 OpenShift Container Platform 资源的一个文件集合。
在集群中创建 chart 会创建一个 chart 实例,称为
发布(release)
。
每次创建 chart 时,或一个版本被升级或回滚,都会创建一个增量修订版本。
Helm 提供以下功能:
搜索存储在 chart 存储库中的一个大型 chart 集合。
修改现有 chart。
使用 OpenShift Container Platform 或 Kubernetes 资源创建自己的 chart。
将应用程序打包为 chart 并共享。
7.1.2. 红帽 OpenShift Helm chart 认证
您可以选择由红帽为要在 Red Hat OpenShift Container Platform 上部署的所有组件验证并认证 Helm chart。图表采用自动化红帽 OpenShift 认证工作流,确保安全合规,以及与平台的最佳集成和经验。认证可确保 chart 的完整性,并确保 Helm Chart 在 Red Hat OpenShift 集群上无缝工作。
下面的部分论述了如何使用 CLI 在不同的平台中安装 Helm。
在 OpenShift Container Platform web 控制台中,点右上角的
?
图标并选
Command Line Tools
。
已安装了 Go 版本 1.13 或更高版本。
-
下载 Helm 二进制文件并将其添加到您的路径中:
Linux (x86_64, amd64)
# curl -L https://mirror.openshift.com/pub/openshift-v4/clients/helm/latest/helm-linux-amd64 -o /usr/local/bin/helm
-
Linux on IBM Z 和 IBM® LinuxONE (s390x)
# curl -L https://mirror.openshift.com/pub/openshift-v4/clients/helm/latest/helm-linux-s390x -o /usr/local/bin/helm
-
Linux on IBM Power (ppc64le)
# curl -L https://mirror.openshift.com/pub/openshift-v4/clients/helm/latest/helm-linux-ppc64le -o /usr/local/bin/helm
使二进制文件可执行:
# chmod +x /usr/local/bin/helm
检查已安装的版本:
$ helm version
-
下载最新的
.exe
文件
并放入您自己选择的目录 。
右键点击
Start
并点击
Control Panel
。
选择
系统和安全性
,然后点击
系统
。
在左侧的菜单中选择
高级系统设置
并点击底部的
环境变量
按钮。
在
变量
部分选择
路径
并点
编辑
。
点
新建
并输入到
.exe
文件的路径,或者点击
浏览
并选择目录,然后点
确定
。
-
下载最新的
.exe
文件
并放入您自己选择的目录 。
点击
搜索
并输入
env
或者
environment
。
选择
为您的帐户编辑环境变量
。
在
变量
部分选择
路径
并点
编辑
。
点
新建
并输入到 exe 文件所在目录的路径,或者点击
浏览
并选择目录,然后点击
确定
。
-
下载 Helm 二进制文件并将其添加到您的路径中:
# curl -L https://mirror.openshift.com/pub/openshift-v4/clients/helm/latest/helm-darwin-amd64 -o /usr/local/bin/helm
-
使二进制文件可执行:
# chmod +x /usr/local/bin/helm
-
检查已安装的版本:
$ helm version
您可以使用以下方法在 OpenShift Container Platform 集群中创建 Helm 发行版本:
Web 控制台的
Developer
视角。
在 web 控制台的
Developer
视角中,
Developer Catalog
显示集群中可用的 Helm chart。默认情况下,它会从 Red Hat OpenShift Helm Chart 仓库中列出 Helm chart。如需 chart 列表,请参阅
Red Hat
Helm index
文件
。
作为集群管理员,您可以添加多个集群范围的 Helm Chart 仓库,与默认的集群范围 Helm 仓库分开,并在
Developer Catalog
中显示这些仓库中的 Helm chart。
作为具有适当基于角色的访问控制(RBAC)权限的普通用户或项目成员,您可以添加多个命名空间范围的 Helm Chart 仓库,除了默认的集群范围的 Helm 仓库,并在
Developer Catalog
中显示这些仓库中的 Helm chart。
在 web 控制台的
Developer
视角中,您可以使用
Helm
页面:
使用
Create
按钮创建 Helm Releases 和 Repositories。
创建、更新或删除集群范围的 Helm Chart 仓库。
在 Repositories 选项卡中查看现有 Helm Chart 仓库列表,它也可以作为集群范围或命名空间范围轻松区分。
7.3.1. 在 OpenShift Container Platform 集群中安装 Helm chart
先决条件
-
您有一个正在运行的 OpenShift Container Platform 集群,并已登录该集群。
您已安装 Helm。
创建一个新项目:
$ oc new-project vault
-
将一个 Helm chart 存储库添加到本地 Helm 客户端:
$ helm repo add openshift-helm-charts https://charts.openshift.io/
-
安装 HashiCorp Vault 示例:
$ helm install example-vault openshift-helm-charts/hashicorp-vault
7.3.2. 使用 Developer 视角创建 Helm 发行版本
您可以使用 web 控制台中的
Developer
视角,或 CLI 从
Developer Catalog
中列出的 Helm chart 中选择并创建发行版本。您可以通过安装 Helm chart 来创建 Helm 发行版本,并在 web 控制台的
Developer
视角中查看它们。
已登陆到 web 控制台并切换到
Developer
视角
。
通过
Developer Catalog
提供的 Helm chart 来创建 Helm 发行版本:
在
Developer
视角中,进入
+Add
视图并选择一个项目。然后点击
Helm Chart
选项来查看
Developer Catalog
中的所有 Helm Chart。
选择一个 chart,查看它的描述信息、README 和其他与之相关的信息。
点
Create
。
在
Create Helm Release
页面中:
在
Release Name
项中输入 release 的唯一名称。
从
Chart Version
下拉列表中选择所需的 chart 版本。
使用
Form View
或
YAML View
配置 Helm Chart。
在可用情况下,您可以在
YAML View
和
Form View
间切换。在不同视图间切换时数据会被保留。
点
Create
来创建 Helm 发行版本。Web 控制台在
Topology
视图中显示新版本。
如果 Helm Chart 带有发行注记,Web 控制台会显示它们。
如果 Helm Chart 创建工作负载,Web 控制台会在
Topology
或
Helm 发行版本详情
页中显示它们。工作负载为
DaemonSet
,
CronJob
,
Pod
,
Deployment
, 和
DeploymentConfig
。
在
Helm Releases
页面中查看新创建的 Helm 发行版本。
您可以使用侧面面板上的
Actions
按钮或右键点击 Helm 发行版本来升级、回滚或删除 Helm 发行版本。
您可以通过在 web 控制台的
Developer
视角中
访问 web 终端
来使用 Helm。
7.3.4. 在 OpenShift Container Platform 上创建自定义 Helm chart
流程
-
创建一个新项目:
$ oc new-project nodejs-ex-k
-
下载包含 OpenShift Container Platform 对象的示例 Node.js chart:
$ git clone https://github.com/redhat-developer/redhat-helm-charts
-
进入包含 chart 示例的目录:
$ cd redhat-helm-charts/alpha/nodejs-ex-k/
-
编辑
Chart.yaml
文件并添加 chart 描述:
apiVersion: v2 1
name: nodejs-ex-k 2
description: A Helm chart for OpenShift 3
icon: https://static.redhat.com/libs/redhat/brand-assets/latest/corp/logo.svg 4
version: 0.2.1 5
-
1
-
Chart API 版本。对于至少需要 Helm 3 的 Helm Chart,它应该是
v2
。
chart 的名称。
chart 的描述。
用作图标的图形的 URL。
根据 Semantic Versioning(SemVer)2.0.0 规范,您的 chart 的版本。
验证 chart 格式是否正确:
$ helm lint
-
安装 chart:
$ helm install nodejs-chart nodejs-ex-k
-
验证 chart 是否已成功安装:
$ helm list
7.3.5. 添加自定义 Helm Chart 仓库
作为集群管理员,您可以将自定义 Helm Chart 存储库添加到集群中,并在
Developer Catalog
中启用从这些仓库中获得 Helm chart 的访问权限。
要添加新的 Helm Chart 仓库,您必须将 Helm Chart 仓库自定义资源(CR)添加到集群中。
7.3.6. 添加命名空间范围的自定义 Helm Chart 仓库
Helm 仓库的集群范围的
HelmChartRepository
自定义资源定义(CRD)可帮助管理员将 Helm 仓库添加为自定义资源。命名空间范围的
ProjectHelmChartRepository
CRD 允许具有适当基于角色的访问控制(RBAC)权限的项目成员创建其所选 Helm 仓库资源,但仅限于其命名空间。此项目成员可从集群范围和命名空间范围 Helm 仓库资源中看到 chart。
管理员可以限制用户创建命名空间范围的 Helm 仓库资源。通过限制用户,管理员具有通过命名空间角色而不是集群角色来控制 RBAC 的灵活性。这可避免用户不必要的权限,并防止访问未经授权的服务或应用程序。
添加命名空间范围的 Helm 仓库不会影响现有集群范围的 Helm 仓库的行为。
作为具有适当 RBAC 权限的普通用户或项目成员,您可以在集群中添加自定义命名空间范围的 Helm Chart 仓库,并在
Developer Catalog
中启用这些仓库中的 Helm chart 访问 Helm chart。
要添加新的命名空间范围的 Helm Chart 仓库,您必须将 Helm Chart 仓库自定义资源(CR)添加到命名空间中。
7.3.7. 创建凭证和 CA 证书以添加 Helm Chart 仓库
有些 Helm Chart 仓库需要凭证和自定义证书颁发机构(CA)证书才能与其连接。您可以使用 Web 控制台和 CLI 添加凭证和证书。
配置凭证和证书,然后使用 CLI 添加 Helm Chart 仓库:
在
openshift-config
命名空间中,使用 PEM 编码格式的自定义 CA 证书创建一个
configmap
,并将它存储在配置映射中的
ca-bundle.crt
键下:
$ oc create configmap helm-ca-cert \
--from-file=ca-bundle.crt=/path/to/certs/ca.crt \
-n openshift-config
在
openshift-config
命名空间中,创建一个
Secret
对象来添加客户端 TLS 配置:
$ oc create secret tls helm-tls-configs \
--cert=/path/to/certs/client.crt \
--key=/path/to/certs/client.key \
-n openshift-config
请注意:客户端证书和密钥必须采用 PEM 编码格式,并分别保存在
tls.crt
和
tls.key
密钥中。
按如下所示添加 Helm 仓库:
$ cat <<EOF | oc apply -f -
apiVersion: helm.openshift.io/v1beta1
kind: HelmChartRepository
metadata:
name: <helm-repository>
spec:
name: <helm-repository>
connectionConfig:
url: <URL for the Helm repository>
tlsConfig:
name: helm-tls-configs
name: helm-ca-cert
ConfigMap 和 Secret 使用 tlsConfig 和 ca 字段在 HelmChartRepository CR 中消耗。这些证书用于连接 Helm 仓库 URL。
默认情况下,所有经过身份验证的用户都可以访问所有配置的 chart。但是,对于需要证书的 Chart 仓库,您必须为用户提供对 openshift-config 命名空间中 helm-ca-cert 配置映射和 helm-tls-configs secret 的读取访问权限,如下所示:
$ cat <<EOF | kubectl apply -f -
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: openshift-config
name: helm-chartrepos-tls-conf-viewer
rules:
- apiGroups: [""]
resources: ["configmaps"]
resourceNames: ["helm-ca-cert"]
verbs: ["get"]
- apiGroups: [""]
resources: ["secrets"]
resourceNames: ["helm-tls-configs"]
verbs: ["get"]
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
namespace: openshift-config
name: helm-chartrepos-tls-conf-viewer
subjects:
- kind: Group
apiGroup: rbac.authorization.k8s.io
name: 'system:authenticated'
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: helm-chartrepos-tls-conf-viewer
EOF
7.3.8. 根据它们的认证级别过滤 Helm Chart
您可以在
Developer Catalog
中根据它们的认证级别过滤 Helm chart。
在
Developer
视角中,进入
+Add
视图并选择一个项目。
在
Developer Catalog
标题中,选择
Helm Chart
选项来查看
Developer Catalog
中的所有 Helm chart。
使用 Helm chart 列表左侧的过滤器过滤所需的 chart:
使用
Chart Repositories
过滤器过滤由
Red Hat Certification Charts
或
OpenShift Helm Charts
提供的 chart。
使用
Source
过滤器过滤来自
合作伙伴、
社区
或
红帽
的 chart。认证图表显示为(
如果只有一个供应商类型,则
Source
过滤器不可见。
现在,您可以选择所需的 chart 并安装它。
您可以通过将
HelmChartRepository
自定义资源中的
disabled
属性设置为
true
,从目录中的特定 Helm Chart 仓库禁用 Helm Charts。
要通过 CLI 禁用 Helm Chart 仓库,将
disabled: true
标志添加到自定义资源中。例如,要删除 Azure 示例 chart 存储库,请运行:
$ cat <<EOF | oc apply -f -
apiVersion: helm.openshift.io/v1beta1
kind: HelmChartRepository
metadata:
name: azure-sample-repo
spec:
connectionConfig:
url:https://raw.githubusercontent.com/Azure-Samples/helm-charts/master/docs
disabled: true
使用 Web 控制台禁用最近添加的 Helm Chart 仓库:
进入 自定义资源定义 并搜索 HelmChartRepository 自定义资源。
进入 实例,找到您要禁用的存储库,并点击其名称。
进入 YAML 选项卡,在 spec 部分添加 disabled: true 标志,点 Save。
您可以使用 web 控制台中的
Developer
视角来更新、回滚或删除 Helm 发行版本。
您可以把一个 Helm 发行版本升级到新的 chart 版本,或更发行版本的配置。
在
Topology
视图中,选择 Helm 发行本来查看侧面面板。
点
Actions
→
Upgrade Helm Release
。
在
Upgrade Helm Release
页面中,选择您要升级到的
Chart Version
,然后点
Upgrade
以创建另一个 Helm 发行版本。
Helm Releases
页面会显示两个修订版本。
如果一个发行版本有问题,您可以将 Helm 发行版本恢复到上一个版本。
使用
Helm
视图回滚发行版本:
在
Developer
视角中,导航到
Helm
视图以查看命名空间中的
Helm Release
版本。
点击列出的发行版本
旁边的
Options
菜单,然后选择
Rollback
。
在
Rollback Helm Release
页中,选择要回滚到的
Revision
,点
Rollback
。
在
Helm Releases
页面中,点 chart 查看该发行版本的详情和资源。
进入
Revision History
标签页来查看这个 chart 的所有修订版本。
如果需要,您可以进一步使用一个特定修订版本旁的
Options
选项
并选择回滚到的修订版本。
流程
-
在
Topology
视图中,右键点击 Helm 发行版本并选择
Delete Helm Release
。
在确认提示中,输入 chart 的名称并点
Delete
。
8.1. 了解 Deployment 和 DeploymentConfig 对象
OpenShift Container Platform 中的
Deployment
和
DeploymentConfig
API 对象提供了两个类似但不同的方法来对常见用户应用程序进行精细管理。由以下独立 API 对象组成:
一个
Deployment
或
DeploymentConfig
对象,用于将应用程序特定组件的所需状态描述为 pod 模板。
Deployment
对象涉及一个或多个
replica sets(复制集)
,其中包含部署状态的一个时间点的记录,作为 pod 模板。同样,
DeploymentConfig
对象涉及一个或多个
replication controllers(复制控制器)
,它在副本集之前。
一个或多个 pod,,表应用程序某一特定版本的实例。
使用
Deployment
对象,除非需要由
DeploymentConfig
对象提供的特定功能或行为。
Deployment 和部署配置分别通过使用原生 Kubernetes API 对象
ReplicaSet
和
ReplicationController
来启用,作为构建块。
用户不必操作由
Deployment
或
DeploymentConfig
对象拥有的副本集、复制控制器或 pod。部署系统可确保正确传播更改。
如果现有部署策略不适用于您的用例,而且必须在部署的生命周期内执行手动步骤,那么应考虑创建自定义部署策略。
以下部分详细介绍了这些对象。
8.1.1.1. 副本集(Replica set)
ReplicaSet
是一个原生 Kubernetes API 对象,可以确保在任意给定时间运行指定数量的 Pod 副本。
只有您需要自定义更新编配,或根本不需要更新时,才使用副本集。否则,使用部署。副本集可以独立使用,但由部署使用用来编配 pod 创建、删除和更新。部署会自动管理其副本集,为 pod 提供声明性更新,且不需要手动管理它们创建的副本集。
以下是
ReplicaSet
定义示例:
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: frontend-1
labels:
tier: frontend
spec:
replicas: 3
selector: 1
matchLabels: 2
tier: frontend
matchExpressions: 3
- {key: tier, operator: In, values: [frontend]}
template:
metadata:
labels:
tier: frontend
spec:
containers:
- image: openshift/hello-openshift
name: helloworld
ports:
- containerPort: 8080
protocol: TCP
restartPolicy: Always
-
1
-
对一组资源进行的标签查询。
matchLabels
和
matchExpressions
的结果在逻辑上是组合在一起的。
基于相等的选择器,使用与选择器匹配的标签指定资源。
基于集合的选择器,用于过滤键。这将选择键等于
tier
并且值等于
frontend
的所有资源。
与副本集类似,复制控制器确保始终运行指定数量的 pod 副本。如果 pod 退出或被删除,复制控制器会做出反应,实例化更多 pod 来达到定义的数量。同样,如果运行中的数量超过所需的数目,它会根据需要删除相应数量的 Pod,使其与定义的数量相符。副本集与复制控制器之间的区别在于,副本集支持基于集合的选择器要求,而复制控制器只支持基于相等的选择器要求。
复制控制器配置包括:
需要的副本数量,可在运行时调整。
创建复制
Pod
时要使用的 Pod 定义。
用于标识受管 pod 的选择器。
选择器是分配给由复制控制器管理的 pod 的一组标签。这些标签包含在复制控制器实例化的
Pod
定义中。复制控制器使用选择器来决定已在运行的 pod 实例数量,以便根据需要进行调整。
复制控制器不会基于负载或流量执行自动扩展,因为复制控制器不会跟踪它们。相反,这需要由外部自动缩放器调整其副本数。
使用
DeploymentConfig
创建复制控制器,而不是直接创建复制控制器。
如果您需要自定义编配或不需要更新,请使用副本集而不是复制控制器。
以下是复制控制器的示例定义:
apiVersion: v1
kind: ReplicationController
metadata:
name: frontend-1
spec:
replicas: 1 1
selector: 2
name: frontend
template: 3
metadata:
labels: 4
name: frontend 5
spec:
containers:
- image: openshift/hello-openshift
name: helloworld
ports:
- containerPort: 8080
protocol: TCP
restartPolicy: Always
-
1
-
要运行的 pod 的副本数。
要运行的 pod 的标签选择器。
控制器创建的 pod 模板。
pod 上的标签应该包括标签选择器中的标签。
扩展任何参数后的最大名称长度为 63 个字符。
Kubernetes 在 OpenShift Container Platform 中提供了一流的原生 API 对象类型,名为
Deployment
。
Deployment
对象用于描述应用程序特定组件的所需状态作为一个 pod 模板。Deployment 创建副本集,用于编配 pod 生命周期。
例如,以下部署定义会创建一个副本集来启动一个
hello-openshift
pod:
8.1.3. DeploymentConfig 对象
在复制控制器的基础上,OpenShift Container Platform 增加了对软件开发和部署生命周期的支持,,及
DeploymentConfig
对象的概念。在最简单的情形中,
DeploymentConfig
对象会创建一个新的复制控制器,并允许它启动 pod。
但是,从
DeploymentConfig
对象部署的 OpenShift Container Platform 也支持从镜像的现有部署过渡到新部署,同时还可以定义在创建复制控制器之前或之后运行的 hook。
DeploymentConfig
部署系统提供以下功能:
DeploymentConfig
对象,这是运行应用程序的模板。
为响应事件而触发自动化部署的触发器。
用户可自定义的部署策略,用于从上一版本过渡到新版本。在 pod 内运行的策略,通常称为部署过程。
一组 hook(生命周期 hook),用于在部署生命周期的不同点上执行自定义行为。
应用程序的版本控制,以便在部署失败时支持手动或自动的回滚。
复制的手动扩展和自动扩展。
在创建
DeploymentConfig
对象时,会创建一个复制控制器来代表
DeploymentConfig
对象的 pod 模板。如果部署被改变,则会使用最新的 pod 模板创建一个新的复制控制器,并运行部署过程来缩减旧复制控制器并扩展新的复制控制器。
在创建时,自动从服务负载均衡器和路由器中添加和移除应用程序的实例。只要应用程序支持接收
TERM
信号时安全关机,您可以确保运行的用户连接拥有正常完成的机会。
OpenShift Container Platform
DeploymentConfig
对象定义以下详细信息:
ReplicationController
定义的元素。
自动创建新部署的触发器。
在部署之间过渡的策略。
生命周期 hook。
每次触发部署时,无论是手动还是自动,部署器 Pod 均管理部署(包括缩减旧复制控制器、扩展新复制控制器以及运行 hook)。部署 pod 在完成部署后会无限期保留,以便保留其部署日志。当部署被另一个部署替换时,以前的复制控制器会被保留,以便在需要时轻松回滚。
8.1.4. Deployment 和 DeploymentConfig 对象的比较
OpenShift Container Platform 支持 Kubernetes
Deployment
对象和 OpenShift Container Platform 提供的
DeploymentConfig
对象,但建议您使用
Deployment
对象,除非您需要
DeploymentConfig
对象提供的特定功能或行为。
以下部分详细阐述两种对象之间的区别,以进一步协助您决定使用哪一种类型。
Deployment
和
DeploymentConfig
对象之间的一个重要区别是为推出(rollout)过程所选择的
CAP theorem
属性。
DeploymentConfig
对象以一致性为先,而
Deployments
对象优先于可用性。
对于
DeploymentConfig
对象,如果运行一个部署器 pod 的节点停机,它不会被替换掉。流程会等待节点重新在线或被手动删除。手动删除节点也会删除对应的 pod。这意味着您无法删除 pod 来取消推出部署,因为 kubelet 负责删除相关联的 pod。
但是,部署推出由控制器管理器驱动。控制器管理器在 master 上运行高可用性模式,并使用群首选举算法提高可用性与一致性相比的价值。在故障期间,其他 master 有可能同时对同一部署做出反应,但这个问题会在故障发生后很快进行调节。
滚动
Deployment
的部署过程是由控制器循环推动的,这与使用部署器 Pod 进行每次新推出部署的
DeploymentConfig
相反。这意味着
Deployment
对象可以拥有尽可能多的活跃副本集,最终部署控制器将缩减所有旧副本集,并扩展最新的副本集。
DeploymentConfig
对象最多可以有一个部署器 pod 运行,否则多个部署器在试图扩展其认为是最新的复制控制器时会导致冲突。因此,任何时间点上只能有两个复制控制器处于活跃状态。最终,这可以更快地为
Deployment
对象推出部署。
按比例扩展
因为部署控制器是适合由
Deployment
对象拥有的新和旧副本集的大小的唯一来源,所以它能够扩展持续推出部署。额外副本会根据每个副本集的大小按比例分发。
当推出(rollout)进行的过程中,
DeploymentConfig
对象无法被扩展,因为控制器会遇到部署器进程中有关新 ReplicationController 大小的问题。
中途暂停推出部署
Deployment 可以在任何时间暂停,这意味着可以暂停正在进行的推出部署。但是,当前还无法暂停部署器 Pod。因此,如果您尝试在推出部署进行期间暂停部署,则部署器进程不受影响,它会继续运行直到完成为止。
8.1.4.3. deploymentConfig 对象相关的功能
自动回滚
目前,在出现故障时,部署不支持自动回滚到上次成功部署的副本集。
部署有一个隐式配置更改触发器,每次更改部署的 Pod 模板都会自动触发新的推出部署。如果您不想在 Pod 模板更改时进行新的推出部署,请暂停部署:
$ oc rollout pause deployments/<name>
生命周期 hook
Deployment 尚不支持任何生命周期 hook。
自定义策略
部署不支持用户指定的自定义部署策略。
8.2.1. 管理 DeploymentConfig 对象
DeploymentConfig
对象可以通过 OpenShift Container Platform Web 控制台的
Workloads
页面或使用
oc
CLI 管理。以下流程演示了 CLI 的用法(除非另有说明)。
您可以启动一个部署推出(rollout)来开始应用程序的部署过程。
要从现有的
DeploymentConfig
对象启动新的部署过程,请运行以下命令:
$ oc rollout latest dc/<name>
如果部署过程已在进行中,此命令会显示一条消息,不会部署新的复制控制器。
您可以查看部署来获取应用程序所有可用修订的基本信息。
要显示所有最近为提供的
DeploymentConfig
对象创建的复制控制器的详细信息,包括任何当前运行的部署过程,请运行以下命令:
$ oc rollout history dc/<name>
要查看修订的相关细节,请使用
--revision
标志:
$ oc rollout history dc/<name> --revision=1
如需有关
DeploymentConfig
对象和最新修订的详细信息,请使用
oc describe
命令:
$ oc describe dc <name>
如果
DeploymentConfig
对象的当前修订无法部署,您可以重启部署过程。
重启已经失败的部署过程:
$ oc rollout retry dc/<name>
如果成功部署了最新的修订,该命令会显示一条消息,且不会重试部署过程。
重试部署会重启部署过程,且不创建新的部署修订。重启的复制控制器具有与失败时相同的配置。
回滚将应用恢复到上一修订,可通过 REST API、命令行或 Web 控制台进行。
回滚到配置的最近一次部署成功的修订:
$ oc rollout undo dc/<name>
恢复
DeploymentConfig
对象的模板以匹配 undo 命令中指定的部署修订,并且会启动新的复制控制器。如果没有通过
--to-revision
指定修订,则使用最近一次成功部署的修订。
部署过程中会禁用
DeploymentConfig
对象中的镜像更改触发器,以防止在回滚完成不久后意外启动新的部署过程。
重新启用镜像更改触发器:
$ oc set triggers dc/<name> --auto
部署配置也支持最新部署过程失败时自动回滚到配置的最近一次成功修订。这时,系统会原样保留部署失败的最新模板,由用户来修复其配置。
您可以为容器添加命令,用来覆盖决镜像的
ENTRYPOINT
设置来改变容器的启动行为。这与生命周期 hook 不同,后者在每个部署的指定时间点上运行一次。
在
DeploymentConfig
对象的
spec
字段中添加
command
参数。您也可以添加
args
字段来修改
command
(如果
command
不存在,则修改
ENTRYPOINT
)。
kind: DeploymentConfig
apiVersion: apps.openshift.io/v1
metadata:
name: example-dc
# ...
spec:
template:
# ...
spec:
containers:
- name: <container_name>
image: 'image'
command:
- '<command>'
args:
- '<argument_1>'
- '<argument_2>'
- '<argument_3>'
例如,使用
-jar
和
/opt/app-root/springboots2idemo.jar
参数来执行
java
命令:
kind: DeploymentConfig
apiVersion: apps.openshift.io/v1
metadata:
name: example-dc
# ...
spec:
template:
# ...
spec:
containers:
- name: example-spring-boot
image: 'image'
command:
- java
args:
- '-jar'
- /opt/app-root/springboots2idemo.jar
# ...
流程
-
输出给定
DeploymentConfig
对象的最新修订的日志:
$ oc logs -f dc/<name>
如果最新的修订正在运行或已失败,命令会返回负责部署 Pod 的进程的日志。如果成功,它将从应用程序的 pod 返回日志。
您还可以查看来自旧的失败部署进程的日志,只要存在这些进程(旧的复制控制器及其部署器 pod)并且没有手动清理或删除:
$ oc logs --version=1 dc/<name>
DeploymentConfig
对象可以包含触发器,推动创建新部署过程以响应集群中的事件。
如果
DeploymentConfig
对象上没有定义任何触发器,则默认添加配置更改触发器。如果触发器定义为空白字段,则必须手动启动部署。
配置更改部署触发器
当在
DeploymentConfig
对象的 pod 模板中发现配置改变时,配置更改触发器会生成一个新的复制控制器。
如果在
DeploymentConfig
对象上定义了配置更改触发器,则在
DeploymentConfig
对象本身创建后会自动创建第一个复制控制器,且不会暂停。
镜像更改部署触发器
镜像更改触发器会在镜像流标签内容更改时(推送镜像的新版本时)产生新的复制控制器。
流程
-
您可以使用
oc set triggers
命令为
DeploymentConfig
对象设置部署触发器。例如,要设置镜像更改触发器,请使用以下命令:
$ oc set triggers dc/<dc_name> \
--from-image=<project>/<image>:<tag> -c <container_name>
部署由节点上消耗资源(内存、CPU 和临时存储)的 pod 完成。默认情况下,pod 消耗无限的节点资源。但是,如果某个项目指定了默认容器限值,则 pod 消耗的资源会被限制在这些限值范围内。
部署的最小内存限值为 12MB。如果容器因为一个
Cannot allocate memory
pod 事件启动失败,这代表内存限制太低。增加或删除内存限制。删除限制可让 pod 消耗无限的节点资源。
您还可以在部署策略中指定资源限值来限制资源使用。部署资源可用于 recreate、rolling 或 custom 部署策略。
在以下示例中,
resources
、
cpu
、
memory
和
ephemeral-storage
中每一个都是可选的:
kind: Deployment
apiVersion: apps/v1
metadata:
name: hello-openshift
# ...
spec:
# ...
type: "Recreate"
resources:
limits:
cpu: "100m" 1
memory: "256Mi" 2
ephemeral-storage: "1Gi" 3
-
1
-
cpu
以 CPU 单元数为单位:
100m
表示 0.1 个 CPU 单元(100 * 1e-3)。
memory
以字节为单位:
256Mi
表示 268435456 字节 (256 * 2 ^ 20)。
ephemeral-storage
以字节为单位:
1Gi
表示 1073741824 字节 (2 ^ 30)。
不过,如果您的项目定义了配额,则需要以下两项之一:
设定了显式
requests
的
resources
部分:
kind: Deployment
apiVersion: apps/v1
metadata:
name: hello-openshift
# ...
spec:
# ...
type: "Recreate"
resources:
requests: 1
cpu: "100m"
memory: "256Mi"
ephemeral-storage: "1Gi"
-
1
-
requests
对象包含与配额中资源列表对应的资源列表。
您项目中定义的限值范围,其中
LimitRange
对象中的默认值应用到部署过程中创建的 pod。
要设置部署资源,请选择以上选项之一。否则,部署 pod 创建失败,显示无法满足配额要求。
如需有关资源限值和请求的更多信息,请参阅
了解管理应用程序内存
。
除了回滚外,您还可以通过手动缩放来对副本数量进行细致的控制。
也可以使用
oc autoscale
命令自动扩展 Pod。
要手动扩展
DeploymentConfig
对象,请使用
oc scale
命令。例如,以下命令将
frontend
DeploymentConfig
对象中的副本设置为
3
。
$ oc scale dc frontend --replicas=3
副本数量最终会传播到
DeploymentConfig
对象
frontend
配置的部署的预期和当前状态。
8.2.1.10. 从 DeploymentConfig 对象访问私有存储库
您可以在
DeploymentConfig
对象中添加 secret,以便它可以从私有存储库访问镜像。此流程演示了 OpenShift Container Platform Web 控制台方法。
创建一个新项目。
导航到
Workloads
→
Secrets
。
创建一个包含用于访问私有镜像存储库的凭证的 secret。
进入到
Workloads
→
DeploymentConfigs
。
创建
DeploymentConfig
对象。
在
DeploymentConfig
对象编辑器页面中,设置
Pull Secret
并保存您的更改。
您可以结合使用节点选择器和带标签的节点来控制 pod 的放置。
集群管理员可为项目设置默认的节点选择器,以便将 pod 放置限制到特定的节点。作为开发人员,您可以设置
Pod
配置的节点选择器来进一步限制节点。
要在创建 Pod 时添加节点选择器,请编辑
Pod
配置并添加
nodeSelector
值。这可添加到单个
Pod
配置中,也可以添加到
Pod
模板中:
apiVersion: v1
kind: Pod
metadata:
name: my-pod
# ...
spec:
nodeSelector:
disktype: ssd
# ...
具有节点选择器时创建的 Pod 会分配给带有指定标签的节点。这里指定的标签将与集群管理员添加的标签结合使用。
例如,如果项目中包含由集群管理员添加的
type=user-node
和
region=east
标签,并且您将上述
disktype: ssd
标签添加到某一 pod,那么该 pod 仅会调度到具有所有这三个标签的节点上。
标签只能设置为一个值;因此,如果在具有管理员设置的默认值
region=east
的
Pod
配置中设置节点选择器
region=west
,这会导致 pod 永不会被调度。
您可以使用非默认服务帐户运行 pod。
编辑
DeploymentConfig
对象:
$ oc edit dc/<deployment_config>
将
serviceAccount
和
serviceAccountName
参数添加到
spec
字段,再指定您要使用的服务帐户:
apiVersion: apps.openshift.io/v1
kind: DeploymentConfig
metadata:
name: example-dc
# ...
spec:
# ...
securityContext: {}
serviceAccount: <service_account>
serviceAccountName: <service_account>
部署策略
用于在不停机的情况下更改或升级应用程序,以便用户不会注意到更改。
由于用户通常通过由路由器处理的路由访问应用程序,因此部署策略侧重于
DeploymentConfig
对象功能或路由功能。侧重于
DeploymentConfig
对象的策略会影响所有使用应用程序的路由。侧重于路由功能的策略则会影响到单个的路由。
多数部署策略通过
DeploymentConfig
对象支持,一些额外的策略则通过路由器功能支持。
选择部署策略时请考虑以下几点:
长时间运行的连接必须被恰当处理。
数据库转换可能比较复杂,且必须和应用程序一同执行并回滚。
如果应用程序由微服务和传统组件构成,则可能需要停机才能完成转换。
您必须拥有进行此操作的基础架构。
如果您的测试环境没有被隔离,则可能会破坏到新版本和旧版本。
部署策略使用就绪度检查来确定新 pod 是否准备就绪。如果就绪度检查失败,
DeploymentConfig
对象会重新尝试运行 pod,直到超时为止。默认超时为
10m
,其值在
dc.spec.strategy.*params
的
TimeoutSeconds
中设置。
滚动部署会逐渐将应用程序旧版本实例替换为应用程序的新版本实例。如果
DeploymentConfig
对象上没有指定任何策略,则滚动策略是默认的部署策略。
在缩减旧组件前,滚动部署通常会 等待新 pod 变为
ready
。如果发生严重问题,可以中止 Rolling 部署。
使用滚动部署:
希望在应用程序更新过程中不需要停机时。
应用程序同时支持运行旧代码和新代码时。
滚动部署意味着您同时运行旧版和新版本的代码。这通常需要您的应用程序可以处理 N-1 兼容性。
OpenShift Container Platform 中的所有滚动部署都属于
Canary 部署
;在替换所有旧实例前测试新的版本(Canary)。如果就绪度检查永不成功,则移除 Canary 实例,并且自动回滚
DeploymentConfig
对象。
就绪度检查是应用程序代码的一部分,并且可以尽可能的精密,确保新实例就绪可用。如果您必须对应用程序进行更复杂的检查(比如向新实例发送真实用户负载),请考虑实施自定义部署或使用蓝绿部署策略。
在 OpenShift Container Platform 中,Rolling 部署是默认类型。您可以使用 CLI 创建滚动部署。
根据
Quay.io
中找到的示例部署镜像创建一个应用程序:
$ oc new-app quay.io/openshifttest/deployment-example:latest
此镜像不会公开任何端口。如果要通过外部 LoadBalancer 服务公开应用程序,或通过公共互联网访问应用程序,请在完成此步骤后使用
oc expose dc/deployment-example --port=<port>
命令创建服务。
如果您安装了路由器,请通过路由(或直接使用服务 IP)提供应用程序。
$ oc expose svc/deployment-example
通过
deployment-example.<project>.<router_domain>
访问应用程序,验证您能否看到
v1
镜像。
将
DeploymentConfig
对象扩展至三个副本:
$ oc scale dc/deployment-example --replicas=3
通过为示例的新版本标上
latest
标签(tag),自动触发新部署:
$ oc tag deployment-example:v2 deployment-example:latest
在浏览器中刷新页面,直到您看到
v2
镜像。
在使用 CLI 时,以下命令显示版本 1 上的 pod 数以及版本 2 上的数量。在 Web 控制台中,pod 逐渐添加到 v2 中并从 v1 中移除:
$ oc describe dc deployment-example
在部署过程中,新复制控制器以递增方式扩展。新 pod 标记为
ready
(通过就绪度检查)后,部署过程将继续。
如果 pod 尚未就绪,该过程会中止,部署回滚到之前的版本。
8.3.2.3. 使用 Developer 视角编辑部署
您可以使用
Developer
视角编辑部署的部署策略、镜像设置、环境变量和高级选项。
处于 web 控制台的
Developer
视角。
您已创建了应用程序。
导航到
Topology
视图。
点您的应用程序查看
Details
面板。
在
Actions
下拉菜单中,选择
Edit Deployment
以查看
Edit Deployment
页面。
您可以为部署编辑以下
高级选项
:
可选:您可以通过点
Pause rollouts
暂停推出部署,然后选择
Pause rollouts for this deployment
复选框。
通过暂停推出部署,您可以在不触发推出部署的情况下对应用程序进行更改。您可以随时恢复推出部署。
可选:通过修改
Replicas
的数量,点
Scaling
以更改您的镜像实例数量。
点击
Save
。
8.3.2.4. 使用 Developer 视角启动滚动部署
您可以通过启动滚动部署来升级应用程序。
处于 web 控制台的
Developer
视角。
您已创建了应用程序。
在
Topology
视图中,点应用程序节点查看侧面面板中的
Overview
选项卡。请注意,
Update Strategy
被设置为默认的
Rolling
策略 。
在
Actions
下拉菜单中,选择
Start Rollout
来启动滚动更新。滚动部署将应用程序更新到新版本,然后终止旧版本。
Recreate(重新创建)策略具有基本的推出部署行为,并支持使用生命周期 hook 将代码注入到部署过程中。
8.3.3.2. 使用 Developer 视角启动重新创建的部署
您可以使用 web 控制台中的
Developer
视角将部署策略从默认的滚动模式切换到重新创建模式。
确认您使用 web 控制台的
Developer
视角。
确保您已使用
Add
视图创建了一个应用程序,并可以在
Topology
视图中查看它。
切换到重新创建的更新策略并升级应用程序:
点您的应用程序查看
Details
面板。
在
Actions
下拉菜单中,选择
Edit Deployment Config
来查看应用程序的部署配置详情。
在 YAML 编辑器中,将
spec.strategy.type
更改为
Recreate
,然后点
Save
。
在
Topology
视图中,选择节点即可看到侧面板中的
Overview
选项卡。
Update Strategy
现在设为
Recreate
。
使用
Actions
下拉菜单选择
Start Rollout
以使用 recreate 策略启动更新。recreate 策略首先会终止旧版本应用程序的 pod,然后为新版本启动 pod。
自定义(Custom)策略允许您提供自己的部署行为。
|
|