

MaxCompute当前的SQL引擎支持脚本模式SQL(Script Mode SQL)。在脚本模式下编译脚本时,一个多语句的SQL脚本文件将被作为一个整体进行编译,无需对单个语句进行编译。在提交运行时,SQL脚本文件会被整体提交,并生成一个执行计划,保证只需排队一次、执行一次,让您能充分利用MaxCompute的资源。
Script Mode的SQL语句书写便利,您只需要按照业务逻辑,用类似于普通编程语言的方式书写,无需考虑如何组织语句。
语法结构
--set
set odps.sql.type.system.odps2=true;
[set odps.stage.reducer.num=xxx;]
[...]
--ddl
create table table1 xxx;
[create table table2 xxx;]
[...]
--dml
@var1 := SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table3
[WHERE where_condition];
@var2 := SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table4
[WHERE where_condition];
@var3 := SELECT [ALL | DISTINCT] var1.select_expr, var2.select_expr, ...
FROM @var1 join @var2 on ...;
INSERT OVERWRITE|INTO TABLE [PARTITION (partcol1=val1, partcol2=val2 ...)]
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM @var3;
[@var4 := SELECT [ALL | DISTINCT] var1.select_expr, var.select_expr, ... FROM @var1
UNION ALL | UNION
SELECT [ALL | DISTINCT] var1.select_expr, var.select_expr, ... FROM @var2;
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM @var4;]
[...]语法说明
-
脚本模式支持SET语句、部分DDL语句(不支持结果为屏显类型的语句如DESC、SHOW)、DML语句。
-
一个脚本的完整形式是SET、DDL、DML语句按先后顺序排列。每种语句都可以包含0到多个具体的SQL语句,且不同类型的语句不能交错。
-
使用
@声明变量。 -
一个脚本最多支持一个屏显结果的语句(如单独的SELECT语句),否则会发生报错。不建议在脚本中执行屏显的SELECT语句。
-
一个脚本最多支持一个CREATE TABLE AS语句并且必须是最后一句。推荐您将建表语句与INSERT语句分开写。
-
脚本模式下,一旦有一个语句失败,整个脚本的语句都无法执行成功。
-
脚本模式下,只有当所有输入的数据都准备好并插入成功,才会生成一个作业进行数据处理。
-
脚本模式下,如果一个表先被写再被读,则会发生报错,如下。
INSERT OVERWRITE table src2 SELECT * FROM src WHERE key > 0; @a := SELECT * FROM src2; SELECT * FROM @a;所以,为避免因表的先写后读产生的报错,应修改SQL脚本如下。
@a := SELECT * FROM src WHERE key > 0; INSERT OVERWRITE table src2 SELECT * FROM @a; SELECT * FROM @a; -
脚本模式支持IF语句:
-
IF语句可以使程序根据条件,自动选择执行逻辑。MaxCompute的IF语法有如下几种类型。
IF (condition) BEGIN statement 1 statement 2 IF (condition) BEGIN statements END ELSE IF (condition2) BEGIN statements END ELSE BEGIN statements END说明BEGIN和END内部只包含1条语句时,关键字BEGIN、END可以省略。类似于Java中的代码块
{ }。 -
IF语句中的Condition类型分为以下两种:
-
BOOLEAN类型的表达式。这种类型的
IF ELSE语句可以在编译阶段决定执行哪个分支,示例如下:@date := '20190101'; @row TABLE(id STRING); --声明变量row,其类型为Table,schema为string. IF ( cast(@date as bigint) % 2 == 0 ) BEGIN @row := SELECT id from src1; END ELSE BEGIN @row := SELECT id from src2; INSERT OVERWRITE TABLE dest SELECT * FROM @row; -
类型为BOOLEAN的Scalar SubQuery。这种类型的
IF ELSE语句在编译阶段无法决定执行哪个分支,在运行时才能决定。因此,需要提交多个作业,示例如下:@i bigint; @t table(id bigint, value bigint); IF ((SELECT count(*) FROM src WHERE a = '5') > 1) BEGIN @i := 1; @t := select @i, @i*2; END ELSE BEGIN @i := 2; @t := select @i, @i*2; select id, value from @t;
-
-
-
脚本模式的适用场景如下:
-
脚本模式适合用来改写本来要用层层嵌套子查询的单个语句,或者因为脚本复杂性而不得不拆成多个语句的脚本。
-
如果多个输入的数据源数据准备完成的时间间隔很长(例如一个01:00可以准备好,一个07:00可以准备好),则不适合通过table variable衔接拼装为一个大的脚本模式SQL。
-
脚本模式下,您可以对一个变量赋常量值,然后执行
SELECT * FROM 变量语句转化为标量与其它列进行计算。常量值也可以存放在一个单行的表中,命令示例如下。转化语法请参见 子查询(SUBQUERY) 。@a := SELECT 10; --对@a赋值常量10,或者赋值存在一个单行表t1中,SELECT col1 FROM t1。 @b := SELECT key,value+(SELECT * FROM @a) FROM t2 WHERE key >10000; --t2表中value值与@a中的值进行计算。 SELECT * FROM @b;
-
示例
脚本模式SQL示例如下。
CREATE TABLE IF NOT EXISTS dest(key STRING, value BIGINT) PARTITIONED BY (d STRING);
CREATE TABLE IF NOT EXISTS dest2(key STRING, value BIGINT) PARTITIONED BY (d STRING);
@a := SELECT * FROM src WHERE value >0;
@b := SELECT * FROM src2 WHERE key is not null;
@c := SELECT * FROM src3 WHERE value is not null;
@d := SELECT a.key,b.value FROM @a LEFT OUTER JOIN @b ON a.key=b.key AND b.value>0;
@e := SELECT a.key,c.value FROM @a INNER JOIN @c ON a.key=c.key;
@f := SELECT * FROM @d UNION SELECT * FROM @e UNION SELECT * FROM @a;
INSERT OVERWRITE table dest PARTITION (d='20171111') SELECT * FROM @f;
@g := SELECT e.key,c.value FROM @e JOIN @c ON e.key=c.key;
INSERT OVERWRITE TABLE dest2 PARTITION (d='20171111') SELECT * FROM @g;工具支持
-
MaxCompute Studio,详情请参见 认识MaxCompute Studio 。
-
MaxCompute客户端(odpscmd),详情请参见 安装并配置MaxCompute客户端 。
-
DataWorks,详情请参见 创建ODPS Script节点 。
使用脚本模式
-
通过MaxCompute Studio使用脚本模式。
使用MaxCompute Studio脚本模式,首先请保证MaxCompute Studio完成安装、添加项目链接、建立MaxCompute SQL脚本文件,详情请参见 安装IntelliJ IDEA 、 管理项目连接 、 创建MaxCompute Script Module 。 编辑脚本页面如下。
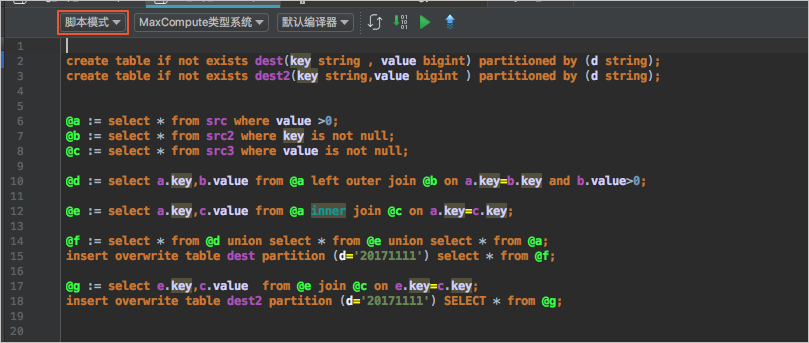
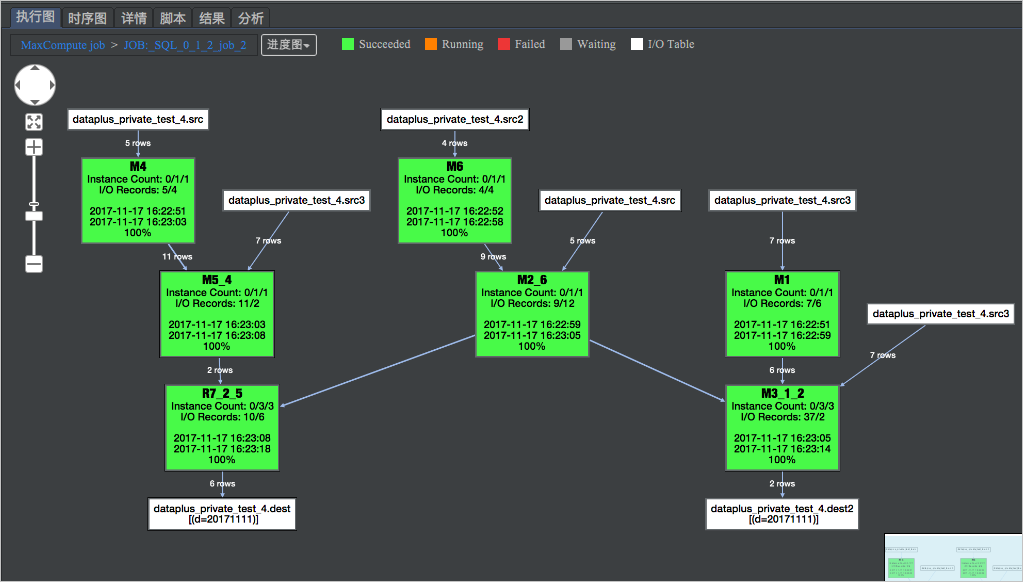
脚本编译后提交运行,查看执行计划图。虽然脚本上是多个语句,但执行计划图是同一个DAG图。
-
通过MaxCompute客户端(odpscmd)使用脚本模式。
您需要使用0.27以上版本的odpscmd提交脚本。建议您安装最新版本 MaxCompute客户端安装包 。安装后,请使用
-s参数提交脚本。编辑脚本模式的源码 myscript.sql 文件,在系统命令行窗口调用odpscmd执行如下命令。更多通过系统命令行窗口运行MaxCompute客户端的操作,请参见 运行MaxCompute客户端 。
..\bin>odpscmd -s myscript.sql说明-s为odpscmd的命令行选项,类似于-f、-e,而非交互环境中的命令。odpscmd的交互环境中暂不支持脚本模式与表变量。 -
通过DataWorks使用脚本模式。
在DataWorks中可以建立脚本模式的节点ODPS Script,示例如下。
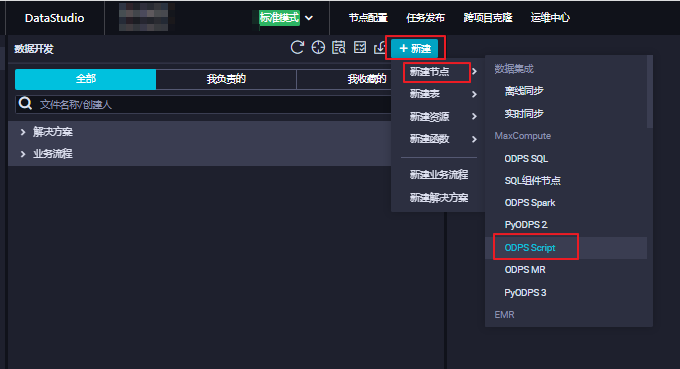
在此节点中进行脚本模式编辑,编辑完成后单击工具栏的 运行 图标,提交脚本到MaxCompute执行。从输出信息的Logview URL中可以查看执行计划图和结果。
-
通过Java SDK使用脚本模式。
在Java SDK中可以直接执行一个SQL脚本,Java SDK详情请参见 Java SDK介绍 ,SQL脚本示例如下。
import java.util.HashMap; import java.util.List; import java.util.Map; import com.aliyun.odps.Instance; import com.aliyun.odps.Odps; import com.aliyun.odps.OdpsException; import com.aliyun.odps.account.Account; import com.aliyun.odps.account.AliyunAccount; import com.aliyun.odps.data.Record; import com.aliyun.odps.task.SQLTask; public class SdkTest { public static void main(String[] args) throws OdpsException { // 阿里云账号AccessKey拥有所有API的访问权限,风险很高。强烈建议您创建并使用RAM用户进行API访问或日常运维,请登录RAM控制台创建RAM用户 // 此处以把AccessKey 和 AccessKeySecret 保存在环境变量为例说明。您也可以根据业务需要,保存到配置文件里 // 强烈建议不要把 AccessKey 和 AccessKeySecret 保存到代码里,会存在密钥泄漏风险 Account account = new AliyunAccount(System.getenv("ALIBABA_CLOUD_ACCESS_KEY_ID"), System.getenv("ALIBABA_CLOUD_ACCESS_KEY_SECRET")); Odps odps = new Odps(account); odps.setDefaultProject("your project_name"); odps.setEndpoint("your end_point"); String sqlScript = "@a := SELECT * FROM jdbc_test;\n" + "SELECT * FROM @a;"; //一定要加这一行配置 Map<String, String> hints = new HashMap<>(); hints.put("odps.sql.submit.mode", "script"); Instance instance = SQLTask.run(odps, "your project_name", sqlScript, hints, null); instance.waitForSuccess(); List<Record> recordList = SQLTask.getResult(instance); for (Record record : recordList) { System.out.println(record.get(0)); System.out.println(record.get(1));