link管理
链接快照平台
- 输入网页链接,自动生成快照
- 标签化管理网页链接
相关文章推荐

|
不爱学习的高山 · Troubleshoot ...· 2 年前 · |
|
|
绅士的毛衣 · curl (35) tcp ...· 2 年前 · |
|
|
欢乐的打火机 · Matlab绘图 - 知乎· 2 年前 · |

深度学习应用篇-计算机视觉-图像分类[3]:ResNeXt、Res2Net、Swin Transformer、Vision Transformer等模型结构、实现、模型特点详细介绍
深度学习应用篇-计算机视觉-图像分类[3]:ResNeXt、Res2Net、Swin Transformer、Vision Transformer等模型结构、实现、模型特点详细介绍 1.ResNet 相较于VGG的19层和GoogLeNet的22层,ResNet可以提供18、34、50、101、152甚至更多层的网络,同时获得更好的精度。但是为什么要使用更深层次的网络呢?同时,如果只是网络层数的堆叠,那么为什么前人没有获得ResNet一样的成功呢? 1.1. 更深层次的网络? 从理论上来讲,加深深度学习网络可以提升性能。深度网络以端到端的多层方式集成了低/中/高层特征和分类器,且特征的层次可通过加深网络层次的方式来丰富。举一个例子,当深度学习网络只有一层时,要学习的特征会非常复杂,但如果有多层,就可以分层进行学习,如 图1 所示,网络的第一层学习到了边缘和颜色,第二层学习到了纹理,第三层学习到了局部的形状,而第五层已逐渐学习到全局特征。网络的加深,理论上可以提供更好的表达能力,使每一层可以学习到更细化的特征。 1.2. 为什么深度网络不仅仅是层数的堆叠? 1.2.1 梯度消失 or 爆炸 但网络加深真的只有堆叠层数这么简单么?当然不是!首先,最显著的问题就是梯度消失/梯度爆炸。我们都知道神经网络的参数更新依靠梯度反向传播(Back Propagation),那么为什么会出现梯度的消失和爆炸呢?举一个例子解释。如 图2 所示,假设每层只有一个神经元,且激活函数使用Sigmoid函数,则有: $$ z_{i+1} = w_ia_i+b_i\\ a_{i+1} = \sigma(z_{i+1}) $$ 其中,$\sigma(\cdot)$ 为sigmoid函数。 根据链式求导和反向传播,我们可以得到: $$ \frac{\partial y}{\partial a_1} = \frac{\partial y}{\partial a_4}\frac{\partial a_4}{\partial z_4}\frac{\partial z_4}{\partial a_3}\frac{\partial a_3}{\partial z_3}\frac{\partial z_3}{\partial a_2}\frac{\partial a_2}{\partial z_2}\frac{\partial z_2}{\partial a_1} \\ = \frac{\partial y}{\partial a_4}\sigma^{'}(z_4)w_3\sigma^{'}(z_3)w_2\sigma^{'}(z_2)w_1 $$Sigmoid 函数的导数 $\sigma^{'}(x)$ 如 图3 所示: 我们可以看到sigmoid的导数最大值为0.25,那么随着网络层数的增加,小于1的小数不断相乘导致 $\frac{\partial y}{\partial a_1}$ 逐渐趋近于零,从而产生梯度消失。 那么梯度爆炸又是怎么引起的呢?同样的道理,当权重初始化为一个较大值时,虽然和激活函数的导数相乘会减小这个值,但是随着神经网络的加深,梯度呈指数级增长,就会引发梯度爆炸。但是从AlexNet开始,神经网络中就使用ReLU函数替换了Sigmoid,同时BN(Batch Normalization)层的加入,也基本解决了梯度消失/爆炸问题。 1.2.2 网络退化 现在,梯度消失/爆炸的问题解决了是不是就可以通过堆叠层数来加深网络了呢?Still no! 我们来看看ResNet论文中提到的例子(见 图4),很明显,56层的深层网络,在训练集和测试集上的表现都远不如20层的浅层网络,这种随着网络层数加深,accuracy逐渐饱和,然后出现急剧下降,具体表现为深层网络的训练效果反而不如浅层网络好的现象,被称为网络退化(degradation)。 为什么会引起网络退化呢?按照理论上的想法,当浅层网络效果不错的时候,网络层数的增加即使不会引起精度上的提升也不该使模型效果变差。但事实上非线性的激活函数的存在,会造成很多不可逆的信息损失,网络加深到一定程度,过多的信息损失就会造成网络的退化。 而ResNet就是提出一种方法让网络拥有恒等映射能力,即随着网络层数的增加,深层网络至少不会差于浅层网络。 1..3. 残差块 现在我们明白了,为了加深网络结构,使每一次能够学到更细化的特征从而提高网络精度,需要实现的一点是恒等映射。那么残差网络如何能够做到这一点呢? 恒等映射即为 $H(x) = x$,已有的神经网络结构很难做到这一点,但是如果我们将网络设计成 $H(x) = F(x) + x$,即 $F(x) = H(x) - x$,那么只需要使残差函数 $F(x) = 0$,就构成了恒等映射 $H(x) = F(x)$。 残差结构的目的是,随着网络的加深,使 $F(x)$ 逼近于0,使得深度网络的精度在最优浅层网络的基础上不会下降。看到这里你或许会有疑问,既然如此为什么不直接选取最优的浅层网络呢?这是因为最优的浅层网络结构并不易找寻,而ResNet可以通过增加深度,找到最优的浅层网络并保证深层网络不会因为层数的叠加而发生网络退化。 [1] Visualizing and Understanding Convolutional Networks [2] Deep Residual Learning for Image Recognition 2. ResNeXt(2017) ResNeXt是由何凯明团队在2017年CVPR会议上提出来的新型图像分类网络。ResNeXt是ResNet的升级版,在ResNet的基础上,引入了cardinality的概念,类似于ResNet,ResNeXt也有ResNeXt-50,ResNeXt-101的版本。那么相较于ResNet,ResNeXt的创新点在哪里?既然是分类网络,那么在ImageNet数据集上的指标相较于ResNet有何变化?之后的ResNeXt_WSL又是什么东西?下面我和大家一起分享一下这些知识。 2.1 ResNeXt模型结构 在ResNeXt的论文中,作者提出了当时普遍存在的一个问题,如果要提高模型的准确率,往往采取加深网络或者加宽网络的方法。虽然这种方法是有效的,但是随之而来的,是网络设计的难度和计算开销的增加。为了一点精度的提升往往需要付出更大的代价。因此,需要一个更好的策略,在不额外增加计算代价的情况下,提升网络的精度。由此,何等人提出了cardinality的概念。 下图是ResNet(左)与ResNeXt(右)block的差异。在ResNet中,输入的具有256个通道的特征经过1×1卷积压缩4倍到64个通道,之后3×3的卷积核用于处理特征,经1×1卷积扩大通道数与原特征残差连接后输出。ResNeXt也是相同的处理策略,但在ResNeXt中,输入的具有256个通道的特征被分为32个组,每组被压缩64倍到4个通道后进行处理。32个组相加后与原特征残差连接后输出。这里cardinatity指的是一个block中所具有的相同分支的数目。 下图是InceptionNet的两种inception module结构,左边是inception module的naive版本,右边是使用了降维方法的inception module。相较于右边,左边很明显的缺点就是参数大,计算量巨大。使用不同大小的卷积核目的是为了提取不同尺度的特征信息,对于图像而言,多尺度的信息有助于网络更好地对图像信息进行选择,并且使得网络对于不同尺寸的图像输入有更好的适应能力,但多尺度带来的问题就是计算量的增加。因此在右边的模型中,InceptionNet很好地解决了这个问题,首先是1×1的卷积用于特征降维,减小特征的通道数后再采取多尺度的结构提取特征信息,在降低参数量的同时捕获到多尺度的特征信息。 ResNeXt正是借鉴了这种“分割-变换-聚合”的策略,但用相同的拓扑结构组建ResNeXt模块。每个结构都是相同的卷积核,保持了结构的简洁,使得模型在编程上更方便更容易,而InceptionNet则需要更为复杂的设计。 2.2 ResNeXt模型实现 ResNeXt与ResNet的模型结构一致,主要差别在于block的搭建,因此这里用paddle框架来实现block的代码 class ConvBNLayer(nn.Layer): def __init__(self, num_channels, num_filters, filter_size, stride=1, groups=1, act=None, name=None, data_format="NCHW" super(ConvBNLayer, self).__init__() self._conv = Conv2D( in_channels=num_channels, out_channels=num_filters, kernel_size=filter_size, stride=stride, padding=(filter_size - 1) // 2, groups=groups, weight_attr=ParamAttr(name=name + "_weights"), bias_attr=False, data_format=data_format if name == "conv1": bn_name = "bn_" + name else: bn_name = "bn" + name[3:] self._batch_norm = BatchNorm( num_filters, act=act, param_attr=ParamAttr(name=bn_name + '_scale'), bias_attr=ParamAttr(bn_name + '_offset'), moving_mean_name=bn_name + '_mean', moving_variance_name=bn_name + '_variance', data_layout=data_format def forward(self, inputs): y = self._conv(inputs) y = self._batch_norm(y) return y class BottleneckBlock(nn.Layer): def __init__(self, num_channels, num_filters, stride, cardinality, shortcut=True, name=None, data_format="NCHW" super(BottleneckBlock, self).__init__() self.conv0 = ConvBNLayer(num_channels=num_channels, num_filters=num_filters, filter_size=1, act='relu', name=name + "_branch2a", data_format=data_format self.conv1 = ConvBNLayer( num_channels=num_filters, num_filters=num_filters, filter_size=3, groups=cardinality, stride=stride, act='relu', name=name + "_branch2b", data_format=data_format self.conv2 = ConvBNLayer( num_channels=num_filters, num_filters=num_filters * 2 if cardinality == 32 else num_filters, filter_size=1, act=None, name=name + "_branch2c", data_format=data_format if not shortcut: self.short = ConvBNLayer( num_channels=num_channels, num_filters=num_filters * 2 if cardinality == 32 else num_filters, filter_size=1, stride=stride, name=name + "_branch1", data_format=data_format self.shortcut = shortcut def forward(self, inputs): y = self.conv0(inputs) conv1 = self.conv1(y) conv2 = self.conv2(conv1) if self.shortcut: short = inputs else: short = self.short(inputs) y = paddle.add(x=short, y=conv2) y = F.relu(y) return y 2.3 ResNeXt模型特点 ResNeXt通过控制cardinality的数量,使得ResNeXt的参数量和GFLOPs与ResNet几乎相同。 通过cardinality的分支结构,为网络提供更多的非线性,从而获得更精确的分类效果。 2.4 ResNeXt模型指标 上图是ResNet与ResNeXt的参数对比,可以看出,ResNeXt与ResNet几乎是一模一样的参数量和计算量,然而两者在ImageNet上的表现却不一样。 从图中可以看出,ResNeXt除了可以增加block中3×3卷积核的通道数,还可以增加cardinality的分支数来提升模型的精度。ResNeXt-50和ResNeXt-101都大大降低了对应ResNet的错误率。图中,ResNeXt-101从32×4d变为64×4d,虽然增加了两倍的计算量,但也能有效地降低分类错误率。 在2019年何凯明团队开源了ResNeXt_WSL,ResNeXt_WSL是何凯明团队使用弱监督学习训练的ResNeXt,ResNeXt_WSL中的WSL就表示Weakly Supervised Learning(弱监督学习)。 ResNeXt101_32×48d_WSL有8亿+的参数,是通过弱监督学习预训练的方法在Instagram数据集上训练,然后用ImageNet数据集做微调,Instagram有9.4亿张图片,没有经过特别的标注,只带着用户自己加的话题标签。ResNeXt_WSL与ResNeXt是一样的结构,只是训练方式有所改变。下图是ResNeXt_WSL的训练效果。 GoogLeNet 3.Res2Net(2020) 2020年,南开大学程明明组提出了一种面向目标检测任务的新模块Res2Net。并且其论文已被TPAMI2020录用。Res2Net和ResNeXt一样,是ResNet的变体形式,只不过Res2Net不止提高了分类任务的准确率,还提高了检测任务的精度。Res2Net的新模块可以和现有其他优秀模块轻松整合,在不增加计算负载量的情况下,在ImageNet、CIFAR-100等数据集上的测试性能超过了ResNet。因为模型的残差块里又有残差连接,所以取名为Res2Net。 3.1 Res2Net模型结构 模型结构看起来很简单,将输入的特征x,split为k个特征,第i+1(i = 0, 1, 2,...,k-1) 个特征经过3×3卷积后以残差连接的方式融合到第 i+2 个特征中。这就是Res2Net的主要结构。那么这样做的目的是为什么呢?能够有什么好处呢?答案就是多尺度卷积。多尺度特征在检测任务中一直是很重要的,自从空洞卷积提出以来,基于空洞卷积搭建的多尺度金字塔模型在检测任务上取得里程碑式的效果。不同感受野下获取的物体的信息是不同的,小的感受野可能会看到更多的物体细节,对于检测小目标也有很大的好处,而大的感受野可以感受物体的整体结构,方便网络定位物体的位置,细节与位置的结合可以更好地得到具有清晰边界的物体信息,因此,结合了多尺度金字塔的模型往往能获得很好地效果。在Res2Net中,特征k2经过3×3卷积后被送入x3所在的处理流中,k2再次被3×3的卷积优化信息,两个3×3的卷积相当于一个5×5的卷积。那么,k3就想当然与融合了3×3的感受野和5×5的感受野处理后的特征。以此类推,7×7的感受野被应用在k4中。就这样,Res2Net提取多尺度特征用于检测任务,以提高模型的准确率。在这篇论文中,s是比例尺寸的控制参数,也就是可以将输入通道数平均等分为多个特征通道。s越大表明多尺度能力越强,此外一些额外的计算开销也可以忽略。 3.2 Res2Net模型实现 Res2Net与ResNet的模型结构一致,主要差别在于block的搭建,因此这里用paddle框架来实现block的代码 class ConvBNLayer(nn.Layer): def __init__( self, num_channels, num_filters, filter_size, stride=1, groups=1, is_vd_mode=False, act=None, name=None, ): super(ConvBNLayer, self).__init__() self.is_vd_mode = is_vd_mode self._pool2d_avg = AvgPool2D( kernel_size=2, stride=2, padding=0, ceil_mode=True) self._conv = Conv2D( in_channels=num_channels, out_channels=num_filters, kernel_size=filter_size, stride=stride, padding=(filter_size - 1) // 2, groups=groups, weight_attr=ParamAttr(name=name + "_weights"), bias_attr=False) if name == "conv1": bn_name = "bn_" + name else: bn_name = "bn" + name[3:] self._batch_norm = BatchNorm( num_filters, act=act, param_attr=ParamAttr(name=bn_name + '_scale'), bias_attr=ParamAttr(bn_name + '_offset'), moving_mean_name=bn_name + '_mean', moving_variance_name=bn_name + '_variance') def forward(self, inputs): if self.is_vd_mode: inputs = self._pool2d_avg(inputs) y = self._conv(inputs) y = self._batch_norm(y) return y class BottleneckBlock(nn.Layer): def __init__(self, num_channels1, num_channels2, num_filters, stride, scales, shortcut=True, if_first=False, name=None): super(BottleneckBlock, self).__init__() self.stride = stride self.scales = scales self.conv0 = ConvBNLayer( num_channels=num_channels1, num_filters=num_filters, filter_size=1, act='relu', name=name + "_branch2a") self.conv1_list = [] for s in range(scales - 1): conv1 = self.add_sublayer( name + '_branch2b_' + str(s + 1), ConvBNLayer( num_channels=num_filters // scales, num_filters=num_filters // scales, filter_size=3, stride=stride, act='relu', name=name + '_branch2b_' + str(s + 1))) self.conv1_list.append(conv1) self.pool2d_avg = AvgPool2D(kernel_size=3, stride=stride, padding=1) self.conv2 = ConvBNLayer( num_channels=num_filters, num_filters=num_channels2, filter_size=1, act=None, name=name + "_branch2c") if not shortcut: self.short = ConvBNLayer( num_channels=num_channels1, num_filters=num_channels2, filter_size=1, stride=1, is_vd_mode=False if if_first else True, name=name + "_branch1") self.shortcut = shortcut def forward(self, inputs): y = self.conv0(inputs) xs = paddle.split(y, self.scales, 1) ys = [] for s, conv1 in enumerate(self.conv1_list): if s == 0 or self.stride == 2: ys.append(conv1(xs[s])) else: ys.append(conv1(xs[s] + ys[-1])) if self.stride == 1: ys.append(xs[-1]) else: ys.append(self.pool2d_avg(xs[-1])) conv1 = paddle.concat(ys, axis=1) conv2 = self.conv2(conv1) if self.shortcut: short = inputs else: short = self.short(inputs) y = paddle.add(x=short, y=conv2) y = F.relu(y) return y 3.3 模型特点 可与其他结构整合,如SENEt, ResNeXt, DLA等,从而增加准确率。 计算负载不增加,特征提取能力更强大。 3.4 模型指标 ImageNet分类效果如下图 Res2Net-50就是对标ResNet50的版本。 Res2Net-50-299指的是将输入图片裁剪到299×299进行预测的Res2Net-50,因为一般都是裁剪或者resize到224×224。 Res2NeXt-50为融合了ResNeXt的Res2Net-50。 Res2Net-DLA-60指的是融合了DLA-60的Res2Net-50。 Res2NeXt-DLA-60为融合了ResNeXt和DLA-60的Res2Net-50。 SE-Res2Net-50 为融合了SENet的Res2Net-50。 blRes2Net-50为融合了Big-Little Net的Res2Net-50。 Res2Net-v1b-50为采取和ResNet-vd-50一样的处理方法的Res2Net-50。 Res2Net-200-SSLD为Paddle使用简单的半监督标签知识蒸馏(SSLD,Simple Semi-supervised Label Distillation)的方法来提升模型效果得到的。 可见,Res2Net都取得了十分不错的成绩。 COCO数据集效果如下图 Res2Net-50的各种配置都比ResNet-50高。 显著目标检测数据集指标效果如下图 ECSSD、PASCAL-S、DUT-OMRON、HKU-IS都是显著目标检测任务中现在最为常用的测试集,显著目标检测任务的目的就是分割出图片中的显著物体,并用白色像素点表示,其他背景用黑色像素点表示。从图中可以看出来,使用Res2Net作为骨干网络,效果比ResNet有了很大的提升。 参考文献Res2Net 4.Swin Trasnformer(2021) Swin Transformer是由微软亚洲研究院在今年公布的一篇利用transformer架构处理计算机视觉任务的论文。Swin Transformer 在图像分类,图像分割,目标检测等各个领域已经屠榜,在论文中,作者分析表明,Transformer从NLP迁移到CV上没有大放异彩主要有两点原因:1. 两个领域涉及的scale不同,NLP的token是标准固定的大小,而CV的特征尺度变化范围非常大。2. CV比起NLP需要更大的分辨率,而且CV中使用Transformer的计算复杂度是图像尺度的平方,这会导致计算量过于庞大。为了解决这两个问题,Swin Transformer相比之前的ViT做了两个改进:1.引入CNN中常用的层次化构建方式构建层次化Transformer 2.引入locality思想,对无重合的window区域内进行self-attention计算。另外,Swin Transformer可以作为图像分类、目标检测和语义分割等任务的通用骨干网络,可以说,Swin Transformer可能是CNN的完美替代方案。 4.1 Swin Trasnformer模型结构 下图为Swin Transformer与ViT在处理图片方式上的对比,可以看出,Swin Transformer有着ResNet一样的残差结构和CNN具有的多尺度图片结构。 整体概括: 下图为Swin Transformer的网络结构,输入的图像先经过一层卷积进行patch映射,将图像先分割成4 × 4的小块,图片是224×224输入,那么就是56个path块,如果是384×384的尺寸,则是96个path块。这里以224 × 224的输入为例,输入图像经过这一步操作,每个patch的特征维度为4x4x3=48的特征图。因此,输入的图像变成了H/4×W/4×48的特征图。然后,特征图开始输入到stage1,stage1中linear embedding将path特征维度变成C,因此变成了H/4×W/4×C。然后送入Swin Transformer Block,在进入stage2前,接下来先通过Patch Merging操作,Patch Merging和CNN中stride=2的1×1卷积十分相似,Patch Merging在每个Stage开始前做降采样,用于缩小分辨率,调整通道数,当H/4×W/4×C的特征图输送到Patch Merging,将输入按照2x2的相邻patches合并,这样子patch块的数量就变成了H/8 x W/8,特征维度就变成了4C,之后经过一个MLP,将特征维度降为2C。因此变为H/8×W/8×2C。接下来的stage就是重复上面的过程。 每步细说: Linear embedding 下面用Paddle代码逐步讲解Swin Transformer的架构。 以下代码为Linear embedding的操作,整个操作可以看作一个patch大小的卷积核和patch大小的步长的卷积对输入的B,C,H,W的图片进行卷积,得到的自然就是大小为 B,C,H/patch,W/patch的特征图,如果放在第一个Linear embedding中,得到的特征图就为 B,96,56,56的大小。Paddle核心代码如下。 class PatchEmbed(nn.Layer): """ Image to Patch Embedding Args: img_size (int): Image size. Default: 224. patch_size (int): Patch token size. Default: 4. in_chans (int): Number of input image channels. Default: 3. embed_dim (int): Number of linear projection output channels. Default: 96. norm_layer (nn.Layer, optional): Normalization layer. Default: None def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None): super().__init__() img_size = to_2tuple(img_size) patch_size = to_2tuple(patch_size) patches_resolution = [ img_size[0] // patch_size[0], img_size[1] // patch_size[1] self.img_size = img_size self.patch_size = patch_size self.patches_resolution = patches_resolution self.num_patches = patches_resolution[0] * patches_resolution[1] #patch个数 self.in_chans = in_chans self.embed_dim = embed_dim self.proj = nn.Conv2D( in_chans, embed_dim, kernel_size=patch_size, stride=patch_size) #将stride和kernel_size设置为patch_size大小 if norm_layer is not None: self.norm = norm_layer(embed_dim) else: self.norm = None def forward(self, x): B, C, H, W = x.shape x = self.proj(x) # B, 96, H/4, W4 x = x.flatten(2).transpose([0, 2, 1]) # B Ph*Pw 96 if self.norm is not None: x = self.norm(x) return x Patch Merging 以下为PatchMerging的操作。该操作以2为步长,对输入的图片进行采样,总共得到4张下采样的特征图,H和W降低2倍,因此,通道级拼接后得到的是B,4C,H/2,W/2的特征图。然而这样的拼接不能够提取有用的特征信息,于是,一个线性层将4C的通道筛选为2C, 特征图变为了B,2C, H/2, W/2。细细体会可以发现,该操作像极了卷积常用的Pooling操作和步长为2的卷积操作。Poling用于下采样,步长为2的卷积同样可以下采样,另外还起到了特征筛选的效果。总结一下,经过这个操作原本B,C,H,W的特征图就变为了B,2C,H/2,W/2的特征图,完成了下采样操作。 class PatchMerging(nn.Layer): r""" Patch Merging Layer. Args: input_resolution (tuple[int]): Resolution of input feature. dim (int): Number of input channels. norm_layer (nn.Layer, optional): Normalization layer. Default: nn.LayerNorm def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm): super().__init__() self.input_resolution = input_resolution self.dim = dim self.reduction = nn.Linear(4 * dim, 2 * dim, bias_attr=False) self.norm = norm_layer(4 * dim) def forward(self, x): x: B, H*W, C H, W = self.input_resolution B, L, C = x.shape assert L == H * W, "input feature has wrong size" assert H % 2 == 0 and W % 2 == 0, "x size ({}*{}) are not even.".format( H, W) x = x.reshape([B, H, W, C]) # 每次降采样是两倍,因此在行方向和列方向上,间隔2选取元素。 x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C # 拼接在一起作为一整个张量,展开。通道维度会变成原先的4倍(因为H,W各缩小2倍) x = paddle.concat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C x = x.reshape([B, H * W // 4, 4 * C]) # B H/2*W/2 4*C x = self.norm(x) # 通过一个全连接层再调整通道维度为原来的两倍 x = self.reduction(x) return x Swin Transformer Block: 下面的操作是根据window_size划分特征图的操作和还原的操作,原理很简单就是并排划分即可。 def window_partition(x, window_size): Args: x: (B, H, W, C) window_size (int): window size Returns: windows: (num_windows*B, window_size, window_size, C) B, H, W, C = x.shape x = x.reshape([B, H // window_size, window_size, W // window_size, window_size, C]) windows = x.transpose([0, 1, 3, 2, 4, 5]).reshape([-1, window_size, window_size, C]) return windows def window_reverse(windows, window_size, H, W): Args: windows: (num_windows*B, window_size, window_size, C) window_size (int): Window size H (int): Height of image W (int): Width of image Returns: x: (B, H, W, C) B = int(windows.shape[0] / (H * W / window_size / window_size)) x = windows.reshape([B, H // window_size, W // window_size, window_size, window_size, -1]) x = x.transpose([0, 1, 3, 2, 4, 5]).reshape([B, H, W, -1]) return x Swin Transformer中重要的当然是Swin Transformer Block了,下面解释一下Swin Transformer Block的原理。先看一下MLP和LN,MLP和LN为多层感知机和相对于BatchNorm的LayerNorm。原理较为简单,因此直接看paddle代码即可。 class Mlp(nn.Layer): def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.): super().__init__() out_features = out_features or in_features hidden_features = hidden_features or in_features self.fc1 = nn.Linear(in_features, hidden_features) self.act = act_layer() self.fc2 = nn.Linear(hidden_features, out_features) self.drop = nn.Dropout(drop) def forward(self, x): x = self.fc1(x) x = self.act(x) x = self.drop(x) x = self.fc2(x) x = self.drop(x) return x 下图就是Shifted Window based MSA是Swin Transformer的核心部分。Shifted Window based MSA包括了两部分,一个是W-MSA(窗口多头注意力),另一个就是SW-MSA(移位窗口多头自注意力)。这两个是一同出现的。 一开始,Swin Transformer 将一张图片分割为4份,也叫4个Window,然后独立地计算每一部分的MSA。由于每一个Window都是独立的,缺少了信息之间的交流,因此作者又提出了SW-MSA的算法,即采用规则的移动窗口的方法。通过不同窗口的交互,来达到特征的信息交流。注意,这一部分是本论文的精华,想要了解的同学必须要看懂源代码 class WindowAttention(nn.Layer): """ Window based multi-head self attention (W-MSA) module with relative position bias. It supports both of shifted and non-shifted window. Args: dim (int): Number of input channels. window_size (tuple[int]): The height and width of the window. num_heads (int): Number of attention heads. qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0 proj_drop (float, optional): Dropout ratio of output. Default: 0.0 def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.): super().__init__() self.dim = dim self.window_size = window_size # Wh, Ww self.num_heads = num_heads head_dim = dim // num_heads self.scale = qk_scale or head_dim ** -0.5 # define a parameter table of relative position bias relative_position_bias_table = self.create_parameter( shape=((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads), default_initializer=nn.initializer.Constant(value=0)) # 2*Wh-1 * 2*Ww-1, nH self.add_parameter("relative_position_bias_table", relative_position_bias_table) # get pair-wise relative position index for each token inside the window coords_h = paddle.arange(self.window_size[0]) coords_w = paddle.arange(self.window_size[1]) coords = paddle.stack(paddle.meshgrid([coords_h, coords_w])) # 2, Wh, Ww coords_flatten = paddle.flatten(coords, 1) # 2, Wh*Ww relative_coords = coords_flatten.unsqueeze(-1) - coords_flatten.unsqueeze(1) # 2, Wh*Ww, Wh*Ww relative_coords = relative_coords.transpose([1, 2, 0]) # Wh*Ww, Wh*Ww, 2 relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0 relative_coords[:, :, 1] += self.window_size[1] - 1 relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1 self.relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww self.register_buffer("relative_position_index", self.relative_position_index) self.qkv = nn.Linear(dim, dim * 3, bias_attr=qkv_bias) self.attn_drop = nn.Dropout(attn_drop) self.proj = nn.Linear(dim, dim) self.proj_drop = nn.Dropout(proj_drop) self.softmax = nn.Softmax(axis=-1) def forward(self, x, mask=None): Args: x: input features with shape of (num_windows*B, N, C) mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None B_, N, C = x.shape qkv = self.qkv(x).reshape([B_, N, 3, self.num_heads, C // self.num_heads]).transpose([2, 0, 3, 1, 4]) q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple) q = q * self.scale attn = q @ swapdim(k ,-2, -1) relative_position_bias = paddle.index_select(self.relative_position_bias_table, self.relative_position_index.reshape((-1,)),axis=0).reshape((self.window_size[0] * self.window_size[1],self.window_size[0] * self.window_size[1], -1)) relative_position_bias = relative_position_bias.transpose([2, 0, 1]) # nH, Wh*Ww, Wh*Ww attn = attn + relative_position_bias.unsqueeze(0) if mask is not None: nW = mask.shape[0] attn = attn.reshape([B_ // nW, nW, self.num_heads, N, N]) + mask.unsqueeze(1).unsqueeze(0) attn = attn.reshape([-1, self.num_heads, N, N]) attn = self.softmax(attn) else: attn = self.softmax(attn) attn = self.attn_drop(attn) x = swapdim((attn @ v),1, 2).reshape([B_, N, C]) x = self.proj(x) x = self.proj_drop(x) return x 4.2 Swin Trasnformer模型实现 Swin Transformer涉及模型代码较多,所以建议完整的看Swin Transformer的代码,因此推荐一下桨的Swin Transformer实现。 4.3 Swin Trasnformer模型特点 首次在cv领域的transformer模型中采用了分层结构。分层结构因为其不同大小的尺度,使不同层特征有了更加不同的意义,较浅层的特征具有大尺度和细节信息,较深层的特征具有小尺度和物体的整体轮廓信息,在图像分类领域,深层特征具有更加有用的作用,只需要根据这个信息判定物体的类别即可,但是在像素级的分割和检测任务中,则需要更为精细的细节信息,因此,分层结构的模型往往更适用于分割和检测这样的像素级要求的任务中。Swin Transformer 模仿ResNet采取了分层的结构,使其成为了cv领域的通用框架。 引入locality思想,对无重合的window区域内进行self-attention计算。不仅减少了计算量,而且多了不同窗口之间的交互。 4.4 Swin Trasnformer模型效果 第一列为对比的方法,第二列为图片尺寸的大小(尺寸越大浮点运算量越大),第三列为参数量,第四列为浮点运算量,第五列为模型吞吐量。可以看出,Swin-T 在top1准确率上超过了大部分模型EffNet-B3确实是个优秀的网络,在参数量和FLOPs都比Swin-T少的情况下,略优于Swin-T,然而,基于ImageNet1K数据集,Swin-B在这些模型上取得了最优的效果。另外,Swin-L在ImageNet-22K上的top1准确率达到了87.3%的高度,这是以往的模型都没有达到的。并且Swin Transformer的其他配置也取得了优秀的成绩。图中不同配置的Swin Transformer解释如下。 C就是上面提到的类似于通道数的值,layer numbers就是Swin Transformer Block的数量了。这两个都是值越大,效果越好。和ResNet十分相似。 下图为COCO数据集上目标检测与实例分割的表现。都是相同网络在不同骨干网络下的对比。可以看出在不同AP下,Swin Transformer都有大约5%的提升,这已经是很优秀的水平了。怪不得能成为ICCV2021最佳paer。 下图为语义分割数据集ADE20K上的表现。相较于同为transformer的DeiT-S, Swin Transformer-S有了5%的性能提升。相较于ResNeSt-200,Swin Transformer-L也有5%的提升。另外可以看到,在UNet的框架下,Swin Transformer的各个版本都有十分优秀的成绩,这充分说明了Swin Transformer是CV领域的通用骨干网络。 参考文献Swin Transformer 5.ViT( Vision Transformer-2020) 在计算机视觉领域中,多数算法都是保持CNN整体结构不变,在CNN中增加attention模块或者使用attention模块替换CNN中的某些部分。有研究者提出,没有必要总是依赖于CNN。因此,作者提出ViT[1]算法,仅仅使用Transformer结构也能够在图像分类任务中表现很好。 受到NLP领域中Transformer成功应用的启发,ViT算法中尝试将标准的Transformer结构直接应用于图像,并对整个图像分类流程进行最少的修改。具体来讲,ViT算法中,会将整幅图像拆分成小图像块,然后把这些小图像块的线性嵌入序列作为Transformer的输入送入网络,然后使用监督学习的方式进行图像分类的训练。 该算法在中等规模(例如ImageNet)以及大规模(例如ImageNet-21K、JFT-300M)数据集上进行了实验验证,发现: Transformer相较于CNN结构,缺少一定的平移不变性和局部感知性,因此在数据量不充分时,很难达到同等的效果。具体表现为使用中等规模的ImageNet训练的Transformer会比ResNet在精度上低几个百分点。 当有大量的训练样本时,结果则会发生改变。使用大规模数据集进行预训练后,再使用迁移学习的方式应用到其他数据集上,可以达到或超越当前的SOTA水平。 5.1 ViT模型结构与实现 ViT算法的整体结构如 图1 所示。 5.1.1. ViT图像分块嵌入 考虑到在Transformer结构中,输入是一个二维的矩阵,矩阵的形状可以表示为 $(N,D)$,其中 $N$ 是sequence的长度,而 $D$ 是sequence中每个向量的维度。因此,在ViT算法中,首先需要设法将 $H \times W \times C$ 的三维图像转化为 $(N,D)$ 的二维输入。 ViT中的具体实现方式为:将 $H \times W \times C$ 的图像,变为一个 $N \times (P^2 * C)$ 的序列。这个序列可以看作是一系列展平的图像块,也就是将图像切分成小块后,再将其展平。该序列中一共包含了 $N=HW/P^2$ 个图像块,每个图像块的维度则是 $(P^2*C)$。其中 $P$ 是图像块的大小,$C$ 是通道数量。经过如上变换,就可以将 $N$ 视为sequence的长度了。 但是,此时每个图像块的维度是 $(P^2*C)$,而我们实际需要的向量维度是 $D$,因此我们还需要对图像块进行 Embedding。这里 Embedding 的方式非常简单,只需要对每个 $(P^2*C)$ 的图像块做一个线性变换,将维度压缩为 $D$ 即可。 上述对图像进行分块以及 Embedding 的具体方式如 图2 所示。 具体代码实现如下所示。本文中将每个大小为 $P$ 的图像块经过大小为 $P$ 的卷积核来代替原文中将大小为 $P$ 的图像块展平后接全连接运算的操作。 #图像分块、Embedding class PatchEmbed(nn.Layer): def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768): super().__init__() # 原始大小为int,转为tuple,即:img_size原始输入224,变换后为[224,224] img_size = to_2tuple(img_size) patch_size = to_2tuple(patch_size) # 图像块的个数 num_patches = (img_size[1] // patch_size[1]) * \ (img_size[0] // patch_size[0]) self.img_size = img_size self.patch_size = patch_size self.num_patches = num_patches # kernel_size=块大小,即每个块输出一个值,类似每个块展平后使用相同的全连接层进行处理 # 输入维度为3,输出维度为块向量长度 # 与原文中:分块、展平、全连接降维保持一致 # 输出为[B, C, H, W] self.proj = nn.Conv2D( in_chans, embed_dim, kernel_size=patch_size, stride=patch_size) def forward(self, x): B, C, H, W = x.shape assert H == self.img_size[0] and W == self.img_size[1], \ "Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})." # [B, C, H, W] -> [B, C, H*W] ->[B, H*W, C] x = self.proj(x).flatten(2).transpose((0, 2, 1)) return x 5.1.2. ViT多头注意力 将图像转化为 $N \times (P^2 * C)$ 的序列后,就可以将其输入到 Transformer 结构中进行特征提取了,如 图3 所示。 Transformer 结构中最重要的结构就是 Multi-head Attention,即多头注意力结构。具有2个head的 Multi-head Attention 结构如 图4 所示。输入 $a^i$ 经过转移矩阵,并切分生成 $q^{(i,1)}$、$q^{(i,2)}$、$k^{(i,1)}$、$k^{(i,2)}$、$v^{(i,1)}$、$v^{(i,2)}$,然后 $q^{(i,1)}$ 与 $k^{(i,1)}$ 做 attention,得到权重向量 $\alpha$,将 $\alpha$ 与 $v^{(i,1)}$ 进行加权求和,得到最终的 $b^{(i,1)}(i=1,2,…,N)$,同理可以得到 $b^{(i,2)}(i=1,2,…,N)$。接着将它们拼接起来,通过一个线性层进行处理,得到最终的结果。 其中,使用 $q^{(i,j)}$、$k^{(i,j)}$ 与 $v^{(i,j)}$ 计算 $b^{(i,j)}(i=1,2,…,N)$ 的方法是缩放点积注意力 (Scaled Dot-Product Attention)。 结构如 图5 所示。首先使用每个 $q^{(i,j)}$ 去与 $k^{(i,j)}$ 做 attention,这里说的 attention 就是匹配这两个向量有多接近,具体的方式就是计算向量的加权内积,得到 $\alpha_{(i,j)}$。这里的加权内积计算方式如下所示: $$ \alpha_{(1,i)} = q^1 * k^i / \sqrt{d} $$ 其中,$d$ 是 $q$ 和 $k$ 的维度,因为 $q*k$ 的数值会随着维度的增大而增大,因此除以 $\sqrt{d}$ 的值也就相当于归一化的效果。 接下来,把计算得到的 $\alpha_{(i,j)}$ 取 softmax 操作,再将其与 $v^{(i,j)}$ 相乘。 具体代码实现如下所示。 #Multi-head Attention class Attention(nn.Layer): def __init__(self, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.): super().__init__() self.num_heads = num_heads head_dim = dim // num_heads self.scale = qk_scale or head_dim**-0.5 # 计算 q,k,v 的转移矩阵 self.qkv = nn.Linear(dim, dim * 3, bias_attr=qkv_bias) self.attn_drop = nn.Dropout(attn_drop) # 最终的线性层 self.proj = nn.Linear(dim, dim) self.proj_drop = nn.Dropout(proj_drop) def forward(self, x): N, C = x.shape[1:] # 线性变换 qkv = self.qkv(x).reshape((-1, N, 3, self.num_heads, C // self.num_heads)).transpose((2, 0, 3, 1, 4)) # 分割 query key value q, k, v = qkv[0], qkv[1], qkv[2] # Scaled Dot-Product Attention # Matmul + Scale attn = (q.matmul(k.transpose((0, 1, 3, 2)))) * self.scale # SoftMax attn = nn.functional.softmax(attn, axis=-1) attn = self.attn_drop(attn) # Matmul x = (attn.matmul(v)).transpose((0, 2, 1, 3)).reshape((-1, N, C)) # 线性变换 x = self.proj(x) x = self.proj_drop(x) return x 5.1.3. 多层感知机(MLP) Transformer 结构中还有一个重要的结构就是 MLP,即多层感知机,如 图6 所示。 多层感知机由输入层、输出层和至少一层的隐藏层构成。网络中各个隐藏层中神经元可接收相邻前序隐藏层中所有神经元传递而来的信息,经过加工处理后将信息输出给相邻后续隐藏层中所有神经元。在多层感知机中,相邻层所包含的神经元之间通常使用“全连接”方式进行连接。多层感知机可以模拟复杂非线性函数功能,所模拟函数的复杂性取决于网络隐藏层数目和各层中神经元数目。多层感知机的结构如 图7 所示。 具体代码实现如下所示。 class Mlp(nn.Layer): def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.): super().__init__() out_features = out_features or in_features hidden_features = hidden_features or in_features self.fc1 = nn.Linear(in_features, hidden_features) self.act = act_layer() self.fc2 = nn.Linear(hidden_features, out_features) self.drop = nn.Dropout(drop) def forward(self, x): # 输入层:线性变换 x = self.fc1(x) # 应用激活函数 x = self.act(x) # Dropout x = self.drop(x) # 输出层:线性变换 x = self.fc2(x) # Dropout x = self.drop(x) return x 5.1.4. DropPath 除了以上重要模块意外,代码实现过程中还使用了DropPath(Stochastic Depth)来代替传统的Dropout结构,DropPath可以理解为一种特殊的 Dropout。其作用是在训练过程中随机丢弃子图层(randomly drop a subset of layers),而在预测时正常使用完整的 Graph。 具体实现如下: def drop_path(x, drop_prob=0., training=False): if drop_prob == 0. or not training: return x keep_prob = paddle.to_tensor(1 - drop_prob) shape = (paddle.shape(x)[0], ) + (1, ) * (x.ndim - 1) random_tensor = keep_prob + paddle.rand(shape, dtype=x.dtype) random_tensor = paddle.floor(random_tensor) output = x.divide(keep_prob) * random_tensor return output class DropPath(nn.Layer): def __init__(self, drop_prob=None): super(DropPath, self).__init__() self.drop_prob = drop_prob def forward(self, x): return drop_path(x, self.drop_prob, self.training) 5.1.5 基础模块 基于上面实现的 Attention、MLP、DropPath模块就可以组合出 Vision Transformer 模型的一个基础模块,如 图8 所示。 基础模块的具体实现如下: class Block(nn.Layer): def __init__(self, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0., drop_path=0., act_layer=nn.GELU, norm_layer='nn.LayerNorm', epsilon=1e-5): super().__init__() self.norm1 = eval(norm_layer)(dim, epsilon=epsilon) # Multi-head Self-attention self.attn = Attention( num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop) # DropPath self.drop_path = DropPath(drop_path) if drop_path > 0. else Identity() self.norm2 = eval(norm_layer)(dim, epsilon=epsilon) mlp_hidden_dim = int(dim * mlp_ratio) self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop) def forward(self, x): # Multi-head Self-attention, Add, LayerNorm x = x + self.drop_path(self.attn(self.norm1(x))) # Feed Forward, Add, LayerNorm x = x + self.drop_path(self.mlp(self.norm2(x))) return x 5.1.6. 定义ViT网络 基础模块构建好后,就可以构建完整的ViT网络了。在构建完整网络结构之前,还需要给大家介绍几个模块: Class Token 假设我们将原始图像切分成 $3 \times 3$ 共9个小图像块,最终的输入序列长度却是10,也就是说我们这里人为的增加了一个向量进行输入,我们通常将人为增加的这个向量称为 Class Token。那么这个 Class Token 有什么作用呢? 我们可以想象,如果没有这个向量,也就是将 $N=9$ 个向量输入 Transformer 结构中进行编码,我们最终会得到9个编码向量,可对于图像分类任务而言,我们应该选择哪个输出向量进行后续分类呢?因此,ViT算法提出了一个可学习的嵌入向量 Class Token,将它与9个向量一起输入到 Transformer 结构中,输出10个编码向量,然后用这个 Class Token 进行分类预测即可。 其实这里也可以理解为:ViT 其实只用到了 Transformer 中的 Encoder,而并没有用到 Decoder,而 Class Token 的作用就是寻找其他9个输入向量对应的类别。 Positional Encoding 按照 Transformer 结构中的位置编码习惯,这个工作也使用了位置编码。不同的是,ViT 中的位置编码没有采用原版 Transformer 中的 $sincos$ 编码,而是直接设置为可学习的 Positional Encoding。对训练好的 Positional Encoding 进行可视化,如 图9 所示。我们可以看到,位置越接近,往往具有更相似的位置编码。此外,出现了行列结构,同一行/列中的 patch 具有相似的位置编码。 MLP Head 得到输出后,ViT中使用了 MLP Head对输出进行分类处理,这里的 MLP Head 由 LayerNorm 和两层全连接层组成,并且采用了 GELU 激活函数。 具体代码如下所示。 首先构建基础模块部分,包括:参数初始化配置、独立的不进行任何操作的网络层。 #参数初始化配置 trunc_normal_ = nn.initializer.TruncatedNormal(std=.02) zeros_ = nn.initializer.Constant(value=0.) ones_ = nn.initializer.Constant(value=1.) #将输入 x 由 int 类型转为 tuple 类型 def to_2tuple(x): return tuple([x] * 2) #定义一个什么操作都不进行的网络层 class Identity(nn.Layer): def __init__(self): super(Identity, self).__init__() def forward(self, input): return input 完整代码如下所示。 class VisionTransformer(nn.Layer): def __init__(self, img_size=224, patch_size=16, in_chans=3, class_dim=1000, embed_dim=768, depth=12, num_heads=12, mlp_ratio=4, qkv_bias=False, qk_scale=None, drop_rate=0., attn_drop_rate=0., drop_path_rate=0., norm_layer='nn.LayerNorm', epsilon=1e-5, **args): super().__init__() self.class_dim = class_dim self.num_features = self.embed_dim = embed_dim # 图片分块和降维,块大小为patch_size,最终块向量维度为768 self.patch_embed = PatchEmbed( img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim) # 分块数量 num_patches = self.patch_embed.num_patches # 可学习的位置编码 self.pos_embed = self.create_parameter( shape=(1, num_patches + 1, embed_dim), default_initializer=zeros_) self.add_parameter("pos_embed", self.pos_embed) # 人为追加class token,并使用该向量进行分类预测 self.cls_token = self.create_parameter( shape=(1, 1, embed_dim), default_initializer=zeros_) self.add_parameter("cls_token", self.cls_token) self.pos_drop = nn.Dropout(p=drop_rate) dpr = np.linspace(0, drop_path_rate, depth) # transformer self.blocks = nn.LayerList([ Block( dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer, epsilon=epsilon) for i in range(depth) self.norm = eval(norm_layer)(embed_dim, epsilon=epsilon) # Classifier head self.head = nn.Linear(embed_dim, class_dim) if class_dim > 0 else Identity() trunc_normal_(self.pos_embed) trunc_normal_(self.cls_token) self.apply(self._init_weights) # 参数初始化 def _init_weights(self, m): if isinstance(m, nn.Linear): trunc_normal_(m.weight) if isinstance(m, nn.Linear) and m.bias is not None: zeros_(m.bias) elif isinstance(m, nn.LayerNorm): zeros_(m.bias) ones_(m.weight) def forward_features(self, x): B = paddle.shape(x)[0] # 将图片分块,并调整每个块向量的维度 x = self.patch_embed(x) # 将class token与前面的分块进行拼接 cls_tokens = self.cls_token.expand((B, -1, -1)) x = paddle.concat((cls_tokens, x), axis=1) # 将编码向量中加入位置编码 x = x + self.pos_embed x = self.pos_drop(x) # 堆叠 transformer 结构 for blk in self.blocks: x = blk(x) # LayerNorm x = self.norm(x) # 提取分类 tokens 的输出 return x[:, 0] def forward(self, x): # 获取图像特征 x = self.forward_features(x) # 图像分类 x = self.head(x) return x 5.2 ViT模型指标 ViT模型在常用数据集上进行迁移学习,最终指标如 图10 所示。可以看到,在ImageNet上,ViT达到的最高指标为88.55%;在ImageNet ReaL上,ViT达到的最高指标为90.72%;在CIFAR100上,ViT达到的最高指标为94.55%;在VTAB(19 tasks)上,ViT达到的最高指标为88.55%。 5.3 ViT模型特点 作为CV领域最经典的 Transformer 算法之一,不同于传统的CNN算法,ViT尝试将标准的Transformer结构直接应用于图像,并对整个图像分类流程进行最少的修改。 为了满足 Transformer 输入结构的要求,将整幅图像拆分成小图像块,然后把这些小图像块的线性嵌入序列输入到网络。同时,使用了Class Token的方式进行分类预测。 更多文章请关注公重号:汀丶人工智能 [1] An Image is Worth 16x16 Words:Transformers for Image Recognition at Scale
深度学习进阶篇[9]:对抗生成网络GANs综述、代表变体模型、训练策略、GAN在计算机视觉应用和常见数据集介绍,以及前沿问题解决
深度学习进阶篇[9]:对抗生成网络GANs综述、代表变体模型、训练策略、GAN在计算机视觉应用和常见数据集介绍,以及前沿问题解决 对抗生成网络(GANs)综述 1、生成与判别 1.1 生成模型 所谓生成模型,就是指可以描述成一个生成数据的模型,属于一种概率模型。维基百科上对其的定义是:在概率统计理论中, 生成模型是指能够随机生成观测数据的模型,尤其是在给定某些隐含参数的条件下。它给观测值和标注数据序列指定一个联合概率分布。在机器学习中,生成模型可以用来直接对数据建模(例如根据某个变量的概率密度函数进行数据采样),也可以用来建立变量间的条件概率分布。条件概率分布可以由生成模型根据贝叶斯定理形成。通俗的说,通过这个模型我们可以生成不包含在训练数据集中的新的数据。如图1所示,比如我们有很多马的图片通过生成模型学习这些马的图像,从中学习到马的样子,生成模型就可以生成看起来很真实的马的图像并却这个图像是不属于训练图像的。 图1 生成模型处理流程图 而我们常见的模型,一般属于判别模型。如图2所示,判别模型可以简单的理解为分类。例如把一副图像分成猫或者狗或者其他,像图2中我们训练一个判别模型去辨别是否是梵高的画,这个判别模型会对数据集中的画的特征进行提起和分类,从而区分出哪个是梵高大师所作。 因此,生成模型与判别模型的区别在于: 生成模型的数据集是没有和判别模型类似的标签的(即标记信息,生成模型也是可以有标签的,生成模型可以根据标签去生成相应类别的图像),生成模型像是一种非监督学习,而判别模型是一种监督学习。 数学表示: 判别模型: p(y|x) 即给定观测x得到y的概率。 生成模型:p(x) 即观测x出现的概率。如果有标签则表示为: p(x|y) 指定标签y生成x的概率。 图2 判别模型处理流程图 而GAN模型的诞生,就是结合了生成模型的特点与判别模型的特点,通过动态对抗的方式进行训练,在同态平衡中寻找最优解。 2、什么是GAN? 2.1 对抗思想 GAN的主要思想是对抗思想:对抗思想已经成功地应用于许多领域,如机器学习、人工智能、计算机视觉和自然语言处理。最近AlphaGo击败世界顶尖人类玩家的事件引起了公众对人工智能的兴趣。AlphaGo的中间版本使用两个相互竞争的网络。对抗性示例是指与真实示例非常不同,但被非常自信地归入真实类别的示例,或与真实示例略有不同,但被归入错误类别的示例。这是最近一个非常热门的研究课题。 对抗式机器学习是一个极大极小问题。defender构建了我们想要正确工作的分类器,他在参数空间中搜索,以找到尽可能降低分类器成本的参数。同时,攻击者正在搜索模型的输入以使成本最大化。对抗性思想存在于对抗性网络、对抗性学习和对抗性示例中。 对抗思想的理论背景是博弈论。博弈论,又称为对策论(Game Theory)、赛局理论等,既是现代数学的一个新分支,也是运筹学的一个重要学科。博弈论主要研究公式化了的激励结构间的相互作用,是研究具有斗争或竞争性质现象的数学理论和方法。博弈论考虑游戏中的个体的预测行为和实际行为,并研究它们的优化策略。生物学家使用博弈理论来理解和预测进化论的某些结果。(博弈论及其相关概念) 2.2 Generative Adversarial Network(GAN) GAN如其名,是一个生成与对抗并存的神经网络。一般一个GAN网络包括了一个生成器(Generator)和一个判别器(Discriminator)。生成器用来根据要求不断生成越来越接近实际标签的数据,判别器用来不断区分生成器的生成结果和实际标签的区别。例如对于图像超分辨率问题来说,一般神经网络使用损失函数从不同角度(例如像素、特征图等)监督生成图像与真实标签之间的区别,通过优化寻找损失函数的最小值所对应的模型参数。一个GAN网络模型则会通过生成器生成图像,再通过判别器动态的判别生成图像与真实图像的区别。如下图所示,为了具有对比性,左眼展示的是图像原本样子,右眼是通过GAN网络后的样子。很明显, GAN网络将原本模糊的图像变得更加清晰,细节纹理表现的更加突出了。 图4 用于图像超分的GAN模型效果示例 当然,GAN网络也不仅仅用于图像超分任务中,图像转换,图像理解,图像填补等任务都可以使用GAN。 和其他生成算法相比,GANs的提出是为了克服其他生成算法的缺点。对抗式学习背后的基本思想是,生成器试图创建尽可能真实的示例来欺骗鉴别器。鉴别器试图区分假例子和真例子。生成器和鉴别器都通过对抗式学习进行改进。这种对抗性的过程使GANs比其他生成算法具有显著的优势。更具体地说,GANs比其他生成算法具有以下优势: GANs可以并行生成,这对于其他生成算法是不可能的 生成器的设计没有限制。 人们主观上认为GANs比其他方法能产生更好的例子。 下图是一个经典的GAN网络模型。我们先来理解下GAN的两个模型要做什么。首先是判别模型,就是图中右半部分的网络,图中Discriminator部分就是上文到的判别模型,一般使用常见的神经网络结构如VGG、ResNet等作为结构主体。输入一副图像(如$X_{real},X_{fake}$),输出一个概率值,用于判断真假使用(概率值大于0.5为真,小于0.5为假),但真假也不过是人们定义的概率而已。其次是生成模型(Generator部分),生成模型同样也是由经典网络模型为基础构建的,针对不同问题进行卷积层、池化层等的增删修改。Generator的输入为一组随机数Z,输出一个图像。从图中可以看到存在两个数据集,一个是真实数据集,另一个是假的数据集,这个数据集就是有生成网络造出来的数据集。根据这个图我们再来理解一下GAN的目标: 判别网络的目的:能判别出来属于的一张图它是来自真实样本集还是假样本集。假如输入的是真样本,网络输出就接近1,输入的是假样本,网络输出接近0,这就达到了很好判别的目的。 生成网络的目的:生成网络是制作样本的,它的目的就是使得自己制作样本的能力尽可能强,能够达到判别网络没法判断该样本是真样本还是假样本。 GAN网络主要由生成网络与鉴别网络两个部分,隐变量$ z $ (通常为服从高斯分布的随机噪声)通过Generator生成$ X_{fake} $ , 判别器负责判别输入的data是生成的样本$ X_{fake} $ 还是真实样本$ X_{real} $ 。 图5 GAN模型结构示意图 loss如下: $$ {\min _G}{\max _D}V(D,G) = {\min _G}{\max _D}{E_{x \sim {p_{data}}(x)}}[\log D(x)] + {E_{z \sim {p_z}(z)}}[\log (1 - D(G(z)))] $$ 对于判别器D来说,这是一个二分类问题,V(D,G)为二分类问题中常见的交叉熵损失。对于生成器G来说,为了尽可能欺骗D,所以需要最大化生成样本的判别概率D(G(z)),即最小化 $ \log (1 - D(G(z))) $ (注意:$ \log D(x) $ 一项与生成器G无关,所以可以忽略。) 实际训练时,生成器和判别器采取交替训练,即先训练D,然后训练G,不断往复。值得注意的是,对于生成器,其最小化的是$ {\max _D}V(D,G) $ ,即最小化$ V(D,G)$的最大值。为了保证V(D,G)取得最大值,所以我们通常会训练迭代k次判别器,然后再迭代1次生成器(不过在实践当中发现,k通常取1即可)。当生成器G固定时,我们可以对V(D,G)求导,求出最优判别器 $ {D^ * }(x) $: $$ {D^ * }(x) = \frac{ {p_{data}}(x)}}{ {p_g}(x) + {p_{data}}(x)}} $$ 把最优判别器代入上述目标函数,可以进一步求出在最优判别器下,生成器的目标函数等价于优化$ {p_{data}}(x),{p_g}(x) $ 的JS散度(JSD, Jenson Shannon Divergence)。可以证明,当G,D二者的capacity足够时,模型会收敛,二者将达到纳什均衡。此时,$ {p_{data}}(x) = {p_g}(x) $ ,判别器不论是对于$ {p_{data}}(x) $ 还是$ {p_g}(x) $ 中采样的样本,其预测概率均为$ \frac{1}{2} $ ,即生成样本与真实样本达到了难以区分的地步。 3、GAN的发展脉络 伴随着信息技术的革新、硬件设备算力的不断更替,人工智能在信息化社会蓬勃发展,以生成模型为代表的机器学习领域,持续受到研究者关注。它被广泛应用于计算机视觉领域,如图像生成、视频生成等任务;以信息隐写 、文本生成等任务为代表的自然语言处理方向;音频领域的语音合成等方向,并且在这些任务中,生成模型均表现出了惊人的效果。目前,GAN在计算机视觉、医学、自然语言处理等领域的研究一直保持着活跃状态。此外,生成对抗网络模型的研究工作主要集中在以下两个方面:一是聚焦于理论线索尝试提高生成对抗网络的稳定性和解决它的训练问题,或考虑不同的角度(如信息论、模型效率等方面)丰富其结构;二是专注于生成对抗网络在不同应用领域内的变体结构和应用场景 。除了图像合成,生成对抗网络还在其他方向成功应用,如图像的超分辨率 、图像描述 、图像修复 、文本到图像的翻译 、语义分割 、目标检测 、生成性对抗攻击 、机器翻译 、图像融合及去噪 。 2014年,Ian GoodFellow提出了GAN模型。自GAN提出起,生成对抗网络迅速成为了最火的生成式模型。在快速发展的青春期,GAN产生了许多流行的架构,如DCGAN,StyleGAN,BigGAN,StackGAN,Pix2pix,Age-cGAN,CycleGAN等。这个是生成对抗网络家族图。左边部分主要是改进模型解决实际的图片转换,文本转图像,生成图片,视频转换等实际问题;右边部分则是主要解决GAN框架本身存在的一些问题。传统的生成模型最早要追溯到80年代的RBM,以及后来逐渐使用深度神经网络进行包装的AutoEncoder。然后就是现在称得上最火的生成模型GAN。 图6 经典GAN模型发展示意图 4、经典GAN模型介绍 表1 不同种类GANs分类情况 表1是基于算法的GANs方法的整理,从GANs训练策略、结构变化、训练技巧、监督类型等方面对现有GAN方法进行了分类。本文选取经典模型与方法进行说明。 4.1 GAN的代表性变体 4.1.1 InfoGAN 它的原理很简单,在info GAN里面,把输入向量z分成两部分,c 和 z'。c可以理解为可解释的隐变量,而z可以理解为不可压缩的噪声。希望通过约束c与output的关系,使得c的维度对应output的语义特征,以手写数字为例,比如笔画粗细,倾斜度等。为了引入c,作者通过互信息的方式来对c进行约束,也可以理解成自编码的过程。具体的操作是,generator的output,经过一个分类器,看是否能够得到c。其实可以看成一个anto-encoder的反过程。其余的discriminator与常规的GAN是一样的。 图7 InfoGAN结构示意图 在实际过程中,classifier和discriminator会共享参数,只有最后一层是不一样的,classifier输出的是一个vector, discriminator输出的是一个标量。 从损失函数的角度来看,infoGAN的损失函数变为:$$ {\min _G}{\max _D}{V_I}(D,G) = V(D,G) - \lambda I(c;G(z,c)) $$ 相比起原始的GAN,多了一项 $ \lambda I(c;G(z,c)) $,这一项代表的就是c与generator的output的互信息。这一项越大,表示c与output越相关。 为什么info GAN是有效的?直观的理解就是,如果c的每一个维度对Output都有明确的影响,那么classifier就可以根据x返回原来的c。如果c对output没有明显的影响,那么classifier就无法返回原来的c。下面是info GAN的结果。改变categorical变量可以生成不同的数字,改变continuous变量可以改变倾斜度和笔画粗细。 图8 InfoGAN结果 4.1.2 Conditional GANs (cGANs) 如果鉴别器和生成器都依赖于一些额外的信息,则GANs可以扩展为一个条件模型。条件GANs的目标函数是: $$ {\min _G}{\max _D}V(D,G) = {E_{x \sim {p_{data}}(x)}}[\log D(x|y)] + {E_{z \sim {p_z}(z)}}[\log (1 - D(G(z|y)))] $$ 我们可以看到InfoGAN的生成器与CGAN的生成器相似。然而,InfoGAN的潜在编码是未知的,它是通过训练发现的。此外,InfoGAN还有一个额外的网络Qto输出条件变量$ Q(c|x) $。 基于CGAN,我们可以在类标签、文本、边界框和关键点上生成样本条件。使用堆叠生成对抗网络(SGAN)进行文本到照片真实感图像合成。CGAN已用于卷积人脸生成、人脸老化、图像转换、合成具有特定景物属性的户外图像、自然图像描述和3D感知场景操作。Chrysos等人提出了稳健的CGAN。Kumparampil等人讨论了条件GAN对噪声标签的鲁棒性。条件循环根使用具有循环一致性的CGAN。模式搜索GANs(MSGANs)提出了一个简单而有效的正则化项,用于解决CGAN的模式崩溃问题。 对原始信号源[3]的鉴别器进行训练,使其分配给正确信号源的对数可能性最大化: $$ L = E[\log P(S = real|{X_{real}})] + E[\log (P(S = fake|{X_{fake}}))] $$ 辅助分类器GAN(AC-GAN)的目标函数有两部分:正确源的对数似然数LS和正确类标签的对数似然数LC $$ {L_c} = E[\log P(C = c{X_{real}})] + E[\log (P(C = c|{X_{fake}}))] $$ 图9 cGAN结果示意图 pix2pix的插图:训练条件GANs映射灰度→颜色鉴别器学习在真实灰度、颜色元组和伪(由生成器合成)之间进行分类。与原始GANs不同,发生器和鉴别器都观察输入的灰度图像,pix2pix发生器没有噪声输入。 图10 生成器与判别器示意图 整个网络结构如上图所示,其中z为生成网络随机的输入,y为条件,x为真实样本。训练过程仍如GANs,先训练判别器,再训练生成器,交。替进行,直到判别器无法判定真实样本和生成的样本。训练过程中的不同在于,判别器D需要判别三种类型: 条件和与条件相符的真实图片,期望输出为1; 条件和与条件不符的真实图片,期望输出为0; 条件和生成网络生成的输出,期望输出为0 在cGANs的论文中,进行了MNIST数据集的测试。在这个测试中,加入的条件为每个图片的标签。也就是生成器G的输入为随机向量和需要生成的图片的对应标签。判别器D的输入为真实图片和真实图片对应的标签、以及生成图片。下图为生成的一些图片 图11 cGAN生成结果示意图 在训练一个GAN时,只把0这个数字的图片作为真实样本放入GAN训练,GAN能生成一个数字的图片(比如0这个数字的图片),而要想生成0-9所有的对应图片,则需要训练10个不同的GAN,但是加入条件,也就是每个图片样本对应的标签的时候,我们就可以把10个数字的样本和对应的标签都同时放到这个网络中,就可以使用一个GAN网络生成0-9这十个数字的图片了 4.1.3 CycleGAN CycleGAN本质上是两个镜像对称的GAN,构成了一个环形网络。两个GAN共享两个生成器,并各自带一个判别器,即共有两个判别器和两个生成器。一个单向GAN两个loss,两个即共四个loss。 图12 循环一致性损失 论文里最终使用均方误差损失表示: $$ {L_{LSGAN}}(G,{D_Y},X,Y) = { {\rm E}_{y \sim {p_{data}}(y)}}[{({D_Y}(y) - 1)^2}] + { {\rm E}_{x \sim {p_{data}}(x)}}[{(1 - {D_Y}(G(x)))^2}] $$ CycleGAN的网络架构如图所示: 图13 CycleGAN结构示意图 可以实现无配对的两个图片集的训练是CycleGAN与Pixel2Pixel相比的一个典型优点。但是我们仍然需要通过训练创建这个映射来确保输入图像和生成图像间存在有意义的关联,即输入输出共享一些特征。 简而言之,该模型通过从域DA获取输入图像,该输入图像被传递到第一个生成器GeneratorA→B,其任务是将来自域DA的给定图像转换到目标域DB中的图像。然后这个新生成的图像被传递到另一个生成器GeneratorB→A,其任务是在原始域DA转换回图像CyclicA,这里可与自动编码器作对比。这个输出图像必须与原始输入图像相似,用来定义非配对数据集中原来不存在的有意义映射。 4.2 GANs的训练策略 尽管理论上存在唯一的解决方案,但由于多种原因,GANs训练很困难,而且往往不稳定。一个困难是,GANs的最优权重对应于损失函数的鞍点,而不是极小值。具体模型训练可以参考这里。 有许多关于GANs训练的论文。Yadav等人用预测方法稳定了GANs。通过使用独立学习率,为鉴别器和生成器提出了两个时间尺度更新规则(TTUR),以确保模型能够收敛到稳定的局部纳什均衡。Arjovsky为充分理解GANs的训练做了很多理论上的研究,分析了GANs难以训练的原因,严格研究论证了训练中出现的饱和、不稳定等问题,研究了缓解这些问题的实际和理论基础方向,并引入了新的研究工具。Liang等人认为GANs训练是一个持续的学习问题。改进GANs训练的一种方法是评估训练中可能出现的经验性“症状”。这些症状包括:生成模型崩溃,为不同的输入生成非常相似的样本;鉴别器损耗迅速收敛到零,不向发生器提供梯度更新;模型收敛困难。 4.2.1 基于输入输出改进的GAN模型 基于输入输出的改进主要是指从 G 的输入端和 D 的输出端进行改进。在 GAN 的基本模型中, G 的输入为隐空间上的随机变量,因此对其改进主要从隐空间与隐变量这两点展开。改进隐变量的目的是使其更好地控制生成样本的细节,而改进隐空间则是为了更好地区分不同的生成模式。 D 输出的判别结果是真假二分类,可以配合目标函数将其调整为多分类或去除神经网络的 Softmax 层直接输出特征向量,进而优化训练过程、实现半监督学习等效果。 BiCoGAN 模型的提出者认为MIRZA提出的模型的输入 z 与 c 相互纠缠,因此增加了一个编码器(记为 E )用于学习从判别器输出到生成器两个输入的逆映射,从而更精确地编码 c ,以提升模型表现。如图14所示,将 z 与 c 的拼接(记为ˆ z)输入生成器得到输出G(ˆ z) ,将真实样本 x 输入编码器 得 到 输 出 E(x) , 判 别 器 接 收G [(ˆz) ,ˆz] 或[x, E(x)], 作为输入,判定该输入来自生成器或为真实数据的某一类。由于真实样本 x 具有的标签可视为 c ,而 E(x)又可以被拆分为 z'与 c',因此使 c 与 c'尽可能接近,也成为模型训练的目标,从而使编码器学习逆映射。文中提出使用 EFL(extrinsic factor loss)衡量两个分布 p c 与 p c' 的距离,并提出如式(6)所示的目标函数。 图14 BiCoGAN 模型 IcGAN (invertible conditional GAN)以MIRZA的模型为基础,增加了两个预训练的编码器 E z 和E y ,E z 用于生成隐空间中的随机变量 z,E y 用于生成原始条件 y,通过将 y 修改成 y'作为 cGAN的输入条件,从而控制合成图像的细节(如图15所示)。文章提出了 3 种从分布中进行采样获得y'的方法:当 y 为二进制向量时,可通过 KDE(kernel denisity estimation)拟合分布并进行采样;当 y 为实向量时,可选取训练集的标签向量进行直接插值;当某个条件并不是在所有训练集中表现唯一时,可直接对 p data 进行采样。 图15 IcGAN模型 DeLiGAN 适用于训练数据规模小、种类多的场景,DeliGAN 模型如图16所示。Gurumurthy等提出使用 GMM(Gaussian mixture model)对隐空间进行参数化,再随机选择一个高斯分量进行重参数化,从指定的高斯分布中获取样本,但模型使用 GMM 是一种简化假设,限制了其逼近更复杂分布的能力。 图16 DeLiGAN 模型 NEMGAN(noise engineered mode matchingGAN)的提出者提出一种能够在训练集存在数据不均衡情况下表现较好的模式匹配策略,根据生成样本训练出其在隐空间中的对应表示,得到潜在模式的先验分布,从而将生成样本的多种模式进行分离,并且与真实样本的模式进行匹配,保证了生成样本中包含多个真实样本的模式,以缓解模式崩溃问题。 FCGAN(fully conditional GAN)以MIRZA的模型为基础,将额外信息 c 连接到神经网络的每一层,一定限度上提升了有条件生成样本时的生成样本质量,但该模型在 c 较为复杂或大向量的场景中运算效率低。 SGAN(semi-supervised learning GAN) 是一种能够为数据集重建标签信息的半监督模型,其模型如图17 所示。它将 D 改进为分类器与判别器的结合体,D 的输出包含 N 类真实样本和一类生成样本,共有 N+1 类。向模型输入无标签的样本且判别器将其分类为真实样本时,可以将判别器的输出作为该样本的标签。 图17 SGAN 模型 AC-GAN(auxiliary classifier GAN)同时具备MIRZA的模型和ODENA的模型的特点,G 输入随机变量与分类信息 c,D 输出样本为假和分类概率,该方法能够在有条件生成样本时输出生成样本所属的类别。 4.2.2 基于生成器改进的 GAN 模型 基于生成器进行改进的工作,旨在提高生成样本质量与避免模式崩溃问题,使模型能够生成多种类的样本,且同一种类内的样本具有多样性。改进的思路包括:使用集成学习(ensemble learning)的思想综合多个弱生成器所学习到的模式、设计每个生成器专注于学习特定模式多生成器架构,从而使模型整体包含多个模式,使用多智能体系统的思想使多个生成器之间产生竞争与合作的关系等。 AdaGAN模型的提出者提出了一种融入集成学习思想的迭代训练算法。在单步迭代过程中,根据训练样本与混合权值得到一个弱生成器,该弱生成器与上一轮迭代得到的弱生成器加权混合,得到本次迭代结果。若干轮迭代以后,生成器综合了多个弱生成器各自学习到的模式,缓解了模式缺失导致的模式崩溃问题,并能够生成出质量较好的样本。但是,混合多个生成器网络导致输入的隐空间不连续,不能像基本 GAN 模型那样通过插值法得到新的隐变量。 MADGAN(multi-agent diverse GAN)由多个生成器和一个判别器组成,其模型如图16所示。其中,判别器负责判断输入样本是真实样本还是生成样本,若为生成样本则判断它是由哪一个生成器所生成的。每个生成器专注于学习特定模式,模型使多个生成器各自学习,模型最终得到的生成样本来自多个学习到不同模式的生成器,显式地保证了生成样本的多样性,缓解了模式崩溃问题。 图18 MADGAN 模型 MGAN 缓解模式崩溃问题的思路与HOANG等人的思路类似,其模型如图9所示。该模型设计了一种与判别器权值共享但去除掉 Softmax 层的分类器,用于承担判断生成样本所属生成器的功能,判别器仅负责判别样本为真实样本还是生成样本。 图19 MGAN 模型 MPMGAN(message passing multi-agent GAN)模型是一种引入消息传递机制的多生成器,生成器输出作为传递给其他生成器的消息。在消息共享机制的作用下,所有生成器都有合作目标、竞争目标两种目标。合作目标鼓励其他生成器的生成样本优于自身的生成样本;竞争目标促使自身的生成样本优于其他生成器的生成样本。两种目标共同作用使生成样本质量得以优化。 图20 MPMGAN 模型 4.2.3 基于判别器改进的GAN模型 GAN 模型训练过程中,最初的生成样本质量较差,判别器可以简单地区分样本,这导致生成器初始训练速度慢。改进判别器,使其符合生成器当前能力有助于加快训练,使其识别多种模式可以缓解模式崩溃问题。改进思路包括使单一判别器能识别出更多模式,以及使多个判别器中的每个判别器专注于识别特定模式等。 PacGAN 模型如图21所示。PacGAN 将同一类的多个样本“打包”后一起输入判别器,以此保证每次判别器输入的样本都具有多样性。由于判别器每次接受输入时都能感知到样本的多样性,生成器试图欺骗判别器时,需要保证生成样本的多样性,这有助于缓解模式崩溃问题。 图21 PacGAN模型 GMAN ( generative multi-adversarial net-works)模型的提出者认为过度改进判别器会使目标函数过于苛刻,反而抑制生成器学习,因此提出一种结合集成学习的方法,通过设置多个判别器,生成器从多判别器聚合结果中学习,从而使网络加速收敛。GMAN 模型如图22所示。 图22 GMAN模型 DropoutGAN设置了一组判别器,在每批样本训练结束时,以一定概率删除该结果,将剩余结果聚合后反馈到生成器,以此使生成器不局限于欺骗特定判别器。DropoutGAN 模型的提出者认为模式崩溃问题是生成器对特定判别器或静态集成判别器的过度拟合,即生成器学习到了使判别器输出真值的特殊条件而非学习到了样本模式,而该模型的结构中,判别器集合是动态变化的,生成器无法学习到欺骗判别器的特殊条件,从而使生成器学习多种样本模式,有助于缓解模式崩溃问题。DropoutGAN 模型如图23所示。 图23 DropoutGAN模型 D2GAN(dual discriminator GAN)设置了两个判别器 D 1 、D 2 ,分别使用正向 KL 散度及逆向 KL 散度,以充分利用二者互补的统计特性。其中 D 1 通过正确判定样本来自真实样本分布获得奖励,D 2 则通过正确判定样本来自生成样本分布获得奖励。生成器同时欺骗两个判别器,以此来提升生成样本的质量。D2GAN 模型如图24所示。 图24 D2GAN模型 StabilizingGAN 模型的提出者认为真实样本在空间中集中分布,而生成样本初始时在空间中分散分布,导致训练初期判别器能够准确判断出几乎所有生成样本,产生无效梯度,使生成器训练缓慢。因此,他们提出同时训练一组视角受限的判别器,每个判别器都专注于空间中的一部分投影,生成器逐渐满足所有判别器的限制,以此稳定训练,提升生成样本质量。 在 EBGAN(energy-based GAN)模型(如图25所示)中引入了能量函数的方法,事物间差异越大能量越高,故而真实分布附近样本具有较低能量。其研究者设计了一个由编码器和解码器构成的判别器,使用 MSE(mean square error)衡量生成样本与真实样本的差异并作为能量函数,生成器目标为生成最小化能量的生成样本。BEGAN(boundary equilibrium GAN)使用自编码器替代ZHAO等人提出来的模型中的判别器。 图25 EBGAN模型 4.2.4 基于多模块组合改进的 GAN 模型 除了更好地拟合真实样本分布之外,提升网络收敛的速度、提高生成图片的清晰度、将其应用在半监督学习上等同样是 GAN 模型改进的方向。这类研究工作通过调整模块结构,对不同的影响因素加以优化处理,使模型达到特定目的。 GRAN( generative recurrent adversarialnetworks)是一种递归生成模型,它反复生成以上一状态为条件的输出,最终得到更符合人类直觉的生成样本。 StackGAN 以MIRZA的模型为基础构建了一种两阶段模型(如图26所示)。它将文本描述作为额外信息,阶段一生成较低分辨率的图像并输出至阶段二,阶段二输出较高分辨率的图像,从而提高生成图像的分辨率。 图26 StackGAN模型 ProgressGAN 模型的提出者认为小尺度图像能够保证多样性且细节不丢失,他们使用多个且逐渐增大的 WGAN-GP 网络,逐步训练最终生成高清图像。 TripleGAN 通过增加一个分类器网络为真实样本生成标签,生成器为真实标签生成样本,判别器判别接收的样本标签对是否为有真实标签的真实样本,从而同时训练出效果较好的分类器和生成器,将 GAN 的能力扩展到可以为无标签样本打标签。TripleGAN 模型如图 27所示。 图27 TripleGAN模型 ControlGAN 模型的提出者认为MIRZA的模型中的判别器同时承担了真实样本分类与判别真假样本两个任务,因此将其拆分为独立的分类器和判别器,从而在有条件生成样本时更细粒度地控制生成样本的特征。ControlGAN 模型如图28所示。 图28 ControlGAN模型 SGAN(several local pairs GAN)使用若干组局部网络对和一组全局网络对,每组网络对有一个生成器与一个判别器。局部网络对使用固定的配对网络进行训练,不同局部网络对之间没有信息交互,全局网络利用局部网络进行训练。由于每一个局部网络对都可以学到一种模式,在使用局部网络对更新全局网络对后,能够保证全局网络对综合了多种模式,从而缓解模式崩溃问题。SGAN 模型如图29所示。 图29 SGAN模型 MemoryGAN 模型的提出者认为隐空间具有连续的分布,但不同种类的结构却具有不连续性,因此在网络中加入存储网络供生成器和判别器访问,使生成器和判别器学习数据的聚类分布以优化该问题。 4.2.5 基于模型交叉思想改进的GAN模型 结合其他生成模型思想及其他领域思想对GAN 模型进行改进,同样可以起到优化模型表现或拓展模型应用场景的效果。 DCGAN 使 用 去 除 池 化 层 的 CNN(convolutional neural network)替代基本 GAN 模型中的多层感知机(如图 30所示),并使用全局池化层替代全连接层以减少计算量,以提高生成样本的质量,优化训练不稳定的问题。 图30 DCGAN模型中的CNN CapsuleGAN 使用胶囊网络作为判别器的框架(如图31所示)。胶囊网络可以用于替代神经元,将节点输出由一个值转变为一个向量,神经元用于检测某个特定模式,而胶囊网络可以检测某个种类的模式,以此提高判别器的泛化能力,从而提高生成样本质量。 图31 CapsuleGAN的基本原理 VAEGAN 利用GAN来提高VAE生成样本的质量。其观点是:在 VAE 中,编码器将真实分布编码到隐空间,而解码器将隐空间恢复为真实分布。单独解码器即可用作生成模型,但生成样本质量较差,因此再将其输入判别器中。 DEGAN(decoder-encoder GAN)模型的提出者认为输入的随机变量服从高斯分布,因此生成器需将整个高斯分布映射到图像,无法反映真实样本分布。因此借鉴 VAE 的思想,在 GAN中加入预训练的编码器与解码器,将随机变量映射为含有真实样本分布信息的变量,再传递给GAN,从而加速收敛并提高生成质量。 AAE(adversarial auto-encoder)通过在 AE(auto-encoder)的隐藏层中增加对抗的思想来结合 AE 与 GAN。判别器通过判断数据是来自隐藏层还是真实样本,使编码器的分布向真实样本分布靠近。 BiGAN 使用编码器来提取真实样本特征,使用解码器来模仿生成器,并使用判别器来辨别特征样本对来自编码器还是解码器,最终使编码方式和解码方式趋近于互逆,从而使随机变量与真实数据形成映射。ALi和 BiGAN 本质相同,二者仅有细微区别。BiGAN 模型如图32所示。 图32 BiGAN模型 MatAN(matching adversarial network)使用孪生网络替换判别器,以将正确标签考虑在生成器目标函数中。孪生网络用于衡量真实数据与生成数据的相似度。该方法对加快生成器训练有效。 SAGAN(self-attention GAN)模型的提出者认为 GAN 在合成结构约束少的种类上表现较好,但难以捕捉复杂的模式,通过在网络中引入自注意力机制以解决该问题。 KDGAN 运用 KD(knowledge distillation)的思想,模型包含作为学生网络的轻量分类器、大型复杂教师网络及判别器,其中,分类器和教师网络都生成标签,二者通过互相蒸馏输出学习彼此的知识,最终可训练得到表现较好的轻量级分类器。 IRGAN 利用 GAN 将 IR(information re-trieval)领域中的生成式检索模型与判别式检索模型相结合,对于生成器采用基于策略梯度的强化学习来训练,从而在典型的信息检索任务中取得较好的表现。IRGAN 模型如图33所示。 图33 IRGAN模型 LapGAN使用了图像处理领域的思想,同时使用三组 cGAN ,按照高斯金字塔的模式对图像逐级下采样训练网络,按照拉普拉斯金字塔的模式对图像逐级上采样,从而达到从模糊图像中重构高像素图像的目的。 QuGAN 将 GAN的思想与量子计算的思想相结合,将生成器类比生成线路,判别器类比判别线路,生成线路尽可能模仿真实线路的波函数,判别线路尽可能仅通过对辅助比特的测量来确定输入的波函数来自生成线路还是真实线路。 BayesianGAN 模型的提出者认为 GAN 隐式学习分布的方法难以显式建模,因此提出使用随机梯度哈密顿蒙特卡洛方法来边际化两个神经网络的权值,从而使数据表示具有可解释性。 5、GAN的应用 GANs是一个强大的生成模型,它可以使用随机向量生成逼真的样本。我们既不需要知道明确的真实数据分布,也不需要任何数学假设。这些优点使得GANs被广泛应用于图像处理、计算机视觉、序列数据等领域。上图是基于GANs的实际应用场景对不同GAN进行了分类,包括图像超分辨率、图像合成与处理、纹理合成、目标检测、视频合成、音频合成、多模态转变等。 5.1 计算机视觉与图像处理 GANs最成功的应用是图像处理和计算机视觉,如图像超分辨率、图像合成和处理以及视频处理。 5.1.1 超分辨率(SR) 图像超分辨率技术主要解决将低分辨率的图像在不失真的前提下转变为高分辨率的问题,且需要在准确性和速度斱面保持优越性能,此外超分辨率技术可解决例如医学诊断、视频监控、卫星遥感等场景的部分行业痛点问题,应用此技术产生的社会实际价值不可估量。基于深度学习的图像超分辨技术可分为:有监督、无监督、特定应用领域三种类型。SR-GAN 模型将参数化的残差网络代替生成器,而判别器则选用了 VGG 网络,其损失函数通过内容损失和对抗损失的加权组合,相比其他深度卷积网络等模型在超分辨精度和速度上得到了改进,将图像纹理细节的学习表征较好,故而在超分辨领域取得了不俗的效果。 5.1.2 图像合成与处理 姿势相关:提出了用于姿势不变人脸识别的解纠缠表示学习GAN(DR-GAN)。Huang等人通过同时感知局部细节和全局结构,提出了一种用于照片级真实感正面视图合成的双通路GAN(TP-GAN)。Ma等人提出了一种新颖的姿势引导人物生成网络(PG2),该网络基于新颖的姿势和人物的图像,合成任意姿势下的人物图像。Cao等人提出了一种高保真姿态不变模型,用于基于GANs的高分辨率人脸前方化。Siarohin等人提出了用于基于姿势的人体图像生成的可变形人体器官。提出了用于定制化妆转移的姿态鲁棒性SpatialWare GAN(PSGAN)。 肖像相关:APDrawingGAN建议从具有层次性Gan的人脸照片生成艺术肖像画。APDrawingGAN有一个基于微信的软件。GANs还用于其他与人脸相关的应用,如人脸属性更改和肖像编辑。 人脸生成:GANs生成的人脸质量逐年提高,这可以在Sebastian Nowozin的GAN讲座材料1中找到。基于原始GANs生成的人脸视觉质量较低,只能作为概念证明。Radford等人使用了更好的神经网络结构:用于生成人脸的深度卷积神经网络。Roth等人解决了GAN训练的不稳定性问题,允许使用更大的架构,如ResNet。Karras等人利用多尺度训练,以高保真度生成百万像素的人脸图像。面生成的每个对象都是一张脸,且大多数脸数据集往往由直视摄像机的人组成,因此比较简单。 让GAN处理像ImageNet这样的分类数据集有点困难,因为ImageNet有一千个不同的对象类,并且这些图像的质量逐年提高。 虽然大多数论文使用GANs合成二维图像,但Wu等人使用GANs和体积卷积合成了三维(3-D)样本。Wu等人合成了汽车、椅子、沙发和桌子等新奇物品。Im等人利用反复出现的敌对网络生成图像。Yang等人提出了用于图像生成的分层递归GAN(LR-GAN)。 图像补全是一种传统的图像修复处理仸务,其目的是填补图像中内容缺失或被遮盖的部分,在目前的生产生活环境中此类仸务得到广泛的现实应用。大多数补全方法都是基于低级线索,仍图像的邻近区域中寻找小块,幵创建与小块相似的合成内容。王海涌等人借助此原理,实现了局部遮挡情况下的人脸表情识别,识别效率较高。与现有的寻找补全块迚行合成的模型不同,相关研究文献提出的模型基于 CNN 生成缺失区域的内容。该算法采用重构损失函数、两个对抗性损失函数和一个语义解析损失函数迚行训练,以保证像素质量和局部-全局内容的稳定性。 人与图像生成过程之间的交互 有许多应用程序涉及人与图像生成过程之间的交互。真实图像操作很困难,因为它需要以用户控制的方式修改图像,同时使其看起来真实。如果用户没有有效的艺术技巧,编辑时很容易偏离自然图像的多样性。交互式GAN(IGAN)定义了一类图像编辑操作,并将其输出约束为始终位于学习的流形上。 5.1.3 纹理合成 纹理合成是图像领域的经典问题。Markovian GANs(MGAN)是一种基于GANs的纹理合成方法。通过捕获马尔可夫面片的纹理数据,MGAN可以快速生成风格化的视频和图像,从而实现实时纹理合成。空间GAN(SGAN)是第一个将GAN与完全无监督学习应用于纹理合成的人。周期性空间GAN(PSGAN)是SGAN的一个变体,它可以从单个图像或复杂的大数据集中学习周期性纹理。 5.1.4 目标检测 我们如何学习对变形和遮挡保持不变的对象检测器?一种方法是使用数据驱动策略——收集在不同条件下具有对象示例的大规模数据集。我们希望最终的分类器能够使用这些实例来学习不变性。是否可以查看数据集中的所有变形和遮挡?一些变形和遮挡非常罕见,在实际应用中几乎不会发生;然而,我们想学习一种对这种情况不变的方法。Wang等人使用GANs生成具有变形和遮挡的实例。对手的目标是生成对象检测器难以分类的实例。通过使用切割器和GANs,Segan检测到图像中被其他对象遮挡的对象。为了解决小目标检测问题,Li等人提出了感知GAN,Bai等人提出了端到端多任务GAN(MTGAN)。 5.1.5 视频 Villegas等人提出了一种深度神经网络,用于使用GANs预测自然视频序列中的未来帧。Denton和Birodkar提出了一个新模型,名为解纠缠表示网(DRNET),该模型基于GANs从视频中学习解纠缠图像表示。相关研究文献提出了一种新的生成性对抗学习框架下的视频到视频合成方法(video2video)。MoCoGan建议分解运动和内容以生成视频。GAN还被用于其他视频应用,如视频预测和视频重定目标。 视频可通过逐帧分解理解为多张图片的组合,故而在 GAN 生成图像的基础上,实现视频的生成和预测 。视频一般而言是由相对静止的背景色和动态的物体运动组成的,VGAN考虑了这一点,使用双流生成器以 3D CNN 的移动前景生成器预测下一帧,而使用 2D CNN 的静态背景生成器使背景保持静止。Pose-GAN采用混合VAE和GAN斱法,它使用 VAE 斱法在当前的物体姿态和过去姿态隐藏的表示来估计未来的物体运动。 基于视频的 GAN 不仅需要考虑空间建模,还需要考虑时间建模,即视频序列中每个相邻帧之间的运动。MoCoGAN被提出以无监督的斱式学习运动和内容,它将图像的潜在空间划分为内容空间和运动空间。DVD-GAN能够基于 BigGAN 架构生成更长、更高分辨率的视频,同时引入可扩展的、视频专用的生成器和鉴别器架构。 5.1.6 其他图像和视觉应用 GANs已被用于其他图像处理和计算机视觉任务,如对象变形、语义分割、视觉显著性预测、对象跟踪、图像去杂、自然图像抠图、图像修复、图像融合,图像完成,图像分类。 5.2 时序数据 GANs在自然语言、音乐、语音、语音和时间序列等顺序数据方面也取得了成就。 5.2.1 自然语言处理 GAN 在图像上的性能表现,让众多研究者在文本生成领域也提出了基于 GAN 的一些模型。SeqGAN 与强化学习结合,避免了一般 GAN 模型不能生成离散序列,且可在生成离散数据时能够返回模型的梯度值,此类斱法可用于生成语音数据、机器翻译等场景。MaskGAN模型,引入了 Actor-Critic 架构可根据上下文内容填补缺失的文本信息。 除了图像生成文本的应用,文献 StackGAN 可实现通过输入文本信息来产生相应的文本所描述的图像且图像具有高分辨率,此模型实现了文本与图像的交互生成。此外 CookGAN 从图像因果链的角度实现了基于文本生成图像菜单的方法。而TiVGAN 则实现了通过文本来产生连续性视频序列的构想。 5.2.2 音乐 GANs被用于生成音乐,如连续RNN-GAN(C-RNN-GAN)、连续RNN-GAN(风琴)和SeqGAN。 5.2.3 语音和音频 GANs已用于语音和音频分析,如合成、增强和识别。 5.3 其他应用 5.3.1 医学领域 一般来说,在医学成像中使用 GANs 有两种方法:第一种集中在生成阶段,这有助于实现训练数据的基本结构,以创建真实的图像,使得 GANs 能够 更 好 地 处 理 数 据 稀 缺 性 和 患 者 隐 私 问 题。第二种集中在判别阶段,其中判别器可以被认为是未处理图像的先验学习,因此可以作为伪生成图像的检测器。 生成阶段:Sandfort 等人提出了一种基于CycleGAN 的数据增强模型,以提高 CT 分割中的泛化性。Han 等人提出了一种基于 GAN 的两阶段无监督异常检测 MRI 扫描斱法。 判别阶段:Tang 等人提出了一种基于叠加生成对抗网络的 CT 图像分割斱法,网络第一层减少CT 图像中的噪声,第二层创建具有增强边界的更高分辨率图像。Dou 等人提出了用于 MRI 和 CT 的 GANs,通过以无监督斱式支持源域和目标域的特征空间来处理高效的域转移。 5.3.2 三维重构 GAN 在三维空间上对物体的立体形状补全或重构,是对三维重构技术的完善和扩展。Wang 等人提出了一种混合结构,使用递归卷积网络(LRCN)的3D-ED-GAN 模型。Wu 等人提出了 3D-VAE-GAN 模型,该模型利用体积卷积网络和生成对抗网络最新的研究理论仍概率空间生成 3D 对象。相关研究文献介绍了一种新的GAN 训练模型来实现物体详细的三维形状。该模型采用带梯度惩罚的 Wasserstein 归一化训练,提高了图像的真实感,这种架构甚至可以仍 2D 图像中重建3D 形状并完成形状补全。 图34 现实世界物品扫描的 3D 3D-RecGAN 是一个随机深度视图重建指定对象的完整三维结构。该模型在GAN 结构上是一种编码器-解码器 3D 深度神经网络,结合了两个目标损失:用于 3D 物体重建的损失和改迚的 Wasserstein GAN 损失。也有人做出了用于语义部件编辑、形状类比和形状揑值以及三维物体形状补全的代数操作和深度自动编码器 GAN (AE-EMD)。 5.3.3 数据科学 GANs已用于数据生成、神经网络生成、数据增强、空间表示学习、网络嵌入、异构信息网络和移动用户评测。 GANs已经广泛应用于许多其他领域,如恶意软件检测、国际象棋游戏、隐写术、隐私保护、社交机器人和网络修剪。 6、常用数据集 一般来说,基于图像的GANs方法使用的数据集,是基于现有数据图像基础上进行上(下)采样,增加干扰处理。处理后的图像与原图像作为一对图像用于GANs网络的训练。其他方面如视频、文字等,也是在已有的开源(或闭源)数据集上经过预处理后,讲原始数据作为标签进行网络的训练。不过,这样制作的数据集始终不能完全代表实际情况。下面讲介绍五个用于训练GANs的数据集。 6.1 抽象艺术数据集 此数据集包含从 wikiart.org 刮出的 2782 张抽象艺术图像。这些数据可用于构建 GAN,以生成抽象艺术的合成图像。数据集包含梵高、大理、毕加索等真实抽象艺术的图像。 6.2 与 C. 埃莱根斯的高内容筛选 这些数据包含与屏幕对应的图像,以找到使用圆虫C.埃莱甘斯的新抗生素。数据有圆虫感染一种叫做肠球菌的病原体的图像。有些图像是未用抗生素治疗的圆虫,安皮林,而另一些图像是受感染的圆虫,已经用安培素治疗。对于那些有兴趣将GAN应用于一个有趣的药物发现问题的人来说,这是一个很好的开始! 6.3 肺胸X光异常 此数据集包含由放射科医生临床标记的胸部 X 射线图像。有336张胸部X光图像与结核病和326张图像对应健康人。对于那些有兴趣使用 GAN 进行医疗图像数据合成的人来说,这是一个很好的数据源。 6.4 假脸 这些数据实际上包含由 GAN 生成的人类面孔的合成图像。这些图像是从网站这个人不存在获得的。该网站生成一个新的假脸图像,由GAN制作,每次你刷新页面。这是一组伟大的数据,从生成合成图像与 GAN 开始。 6.5 眼镜或没有眼镜 此数据集包含带眼镜的面部图像和无眼镜的面部图像。虽然这些图像是使用 GAN 生成的,但它们也可以作为生成其他合成图像的训练数据。 7、前沿问题 由于GAN在整个深度学习领域都很流行,其局限性最近得到了改进。对于GANs来说,仍然存在一些有待解决的研究问题。 7.1 模式崩溃问题 尽管现有研究在解决模式崩溃问题上进行了很多尝试,也取得了一些进展,但如何解决模式崩溃问题依然是 GAN 面临的主要挑战。 针对 GAN 发生模式崩溃的原因,已有一些研究工作尝试给予解释:将生成器视为一个 N 维流形的参数化描述,当流形上某点的切线空间维数小于 N ,导致在该点沿一些方向进行变化时,数据的变化无效,因此生成器会产生单一的数据; 基于最优传输理论,认为生成器将隐空间的分布映射为流形上的分布是一个传输映射,它具有间断点,是非连续映射,但神经网络目前仅能近似连续映射,从而导致生成无意义结果并引发模式崩溃;当模式崩溃发生时,判别器网络权值矩阵的奇异值急剧减小,可从该问题入手解决模式崩溃问题。 与普通神经网络训练过程相比, GAN 模型中存在生成器 G 与判别器 D 之间的博弈机制,这使得 GAN 模式崩溃问题变得复杂。总而言之, GAN模式崩溃问题研究工作尚处于起步阶段,研究出发的角度多样,未形成一个统一的框架来解释该问题。今后的工作如果能从 GAN 的博弈机制出发,将生成器和判别器两方面的相关因素综合起来,会有助于该问题的解决。 7.2 训练集样本的影响 神经网络的表现主要取决于模型自身的特点,以及训练使用的真实样本集。同样, GAN模型的训练学习的质量也受制于训练样本集的影响。一方面,样本集的自身内在数据分布情况可能会影响 GAN 的训练效率和生成质量。例如,在样本集上定义类内距离集与类间距离集,并依此提出基于距离的可分性指数,用于量化样本可分性,并指出当不同种类样本按相同分布混合时最难以区分,使用这种样本集进行有监督学习时很难使模型有较好表现。这对于 GAN的样本生成质量评价指标设计具有借鉴意义。另一方面, GAN 模型的一大特点是学习真实样本分布,因此需要足够多真实样本进行训练才能有较好表现,研究如何使用小规模训练集得到较好的 GAN 模型是具有挑战和意义的。 GAN 模型对训练集质量也有较高要求,而高质量的数据集往往难以获得,因此研究哪些数据会影响模型表现,如何规避低质量样本带来的负面影响,以降低对训练集质量的高要求,成为今后的研究方向。 此外,在降低训练集样本数量需求方面已有一些研究。通过迁移学习,在预训练的生成器网络和判别器网络上使用适当的样本进行微调,但样本严重不足或样本与预训练数据区别较大时效果不佳。有研究者认为网络权值的奇异值与生成样本的语义有关,因此通过对网络权值进行奇异值分解,微调预训练模型的奇异值来达到使用较少样本训练的目的。在 GAN 上使用元学习,在小样本训练问题上取得了一定的效果。使用重建损失和三元组损失改造GAN 的损失函数,从而将自监督学习的思想引入GAN 中,在小样本训练问题上取得了一些效果。 对于降低训练集样本质量需求的研究已有一些研究。 NRGAN 在模型中设置了图像生成器和噪声生成器,分别用以学习真实样本中的数据分布和噪声分布,从而在无须预知噪声分布的情况下从有噪训练集中生成无噪样本。 目前,有关训练集样本对 GAN 的影响的研究仍处于初期,缩小训练集规模往往导致对复杂模式支持较差,而降低训练集样本质量需求则伴随着过多假设。后续工作应进一步研究产生这些限制的原因,并以此为指导使其应用场景更符合真实情况。 7.3 与模型鲁棒性问题研究的交叉 神经网络鲁棒性反映当输入数据集上出现微小扰动后,模型依然能在输出端表现出抗干扰的能力。 GAN 的研究与人工神经网络鲁棒性的研究相辅相成,密切相关。一方面, GAN 使用对抗样本对网络模型进行训练,有助于提升模型的鲁棒性 。另一方面,神经网络鲁棒性的相关研究与 GAN 的改进存在内在联系,如深度神经网络经过对抗训练后损失在峰值附近更加平滑,以及在 CNN 中使用 Lipschitz 条件可以使模型同时具有较好的鲁棒性与准确性,该领域的相关研究对于 GAN 的改进有一定的参考借鉴价值,特别是在生成对抗样本质量的评价和生成器的目标研究方面。 有研究者从对抗频度和对抗严重程度两方面描述神经网络在数据集上的鲁棒性。其中对抗频度反映数据集上对抗性扰动发生的可能性,对抗严重程度反映扰动发生时导致输出偏离的程度。该方法在 GAN 生成对抗样本数据集质量的评价层面具有借鉴价值,并对生成器的训练具有指导意义。另有研究者提出一种基于符号线性松弛的神经网络安全性分析方法,把对抗性扰动当作安全属性违反的一种约束特例来处理,其框架可以定义 5 种不同的安全属性约束,针对对抗性扰动的结果进行细化。这些工作有助于 GAN 生成器设计目标的分类研究。 本文从不同方面综述了对抗生成网络(GANs)的现有模型方法。首先根据训练策略、结构变化、训练技巧、监督类型等方面对现有GAN方法进行了分类,并以经典网络为例,分别介绍了不同GAN网络的改进点。接着详细介绍了GAN网络的基本结构,并给出了较新的生成对抗网络发展脉络。最后基于实际应用场景对经典常用的GAN模型进行了介绍。我们选取了Kaggle的五个常用的GAN数据集,并分别进行了介绍。数据集链接分别放置于数据集名称处。最后,针对现阶段的生成对抗网络前沿问题进行了介绍。 [1] GAN网络及变体整理 [2] A review on generative adversarial networks: Algorithms, theory, and applications [3] Generative adversarial networks: An overview [4] Generative Adversarial Networks (GANs) in networking: A comprehensive survey & evaluation [5] 生成对抗网络及其应用研究综述 [6] 生成对抗网络研究综述
深度学习进阶篇-国内预训练模型[6]:ERNIE-Doc、THU-ERNIE、K-Encoder融合文本信息和KG知识;原理和模型结构详解。
深度学习进阶篇-国内预训练模型[6]:ERNIE-Doc、THU-ERNIE、K-Encoder融合文本信息和KG知识;原理和模型结构详解。 1.ERNIE-Doc: A Retrospective Long-Document Modeling Transformer 1.1. ERNIE-Doc简介 经典的Transformer在处理数据时,会将文本数据按照固定长度进行截断,这个看起来比较”武断”的操作会造成上下文碎片化以及无法建模更长的序列依赖关系。基于此项考虑,ERNIE-Doc提出了一种文档层级的预训练语言模型方法:ERNIE-Doc在训练某一个Segment时,允许该segment能够获得整个Doc的信息。 如图1所示,假设一篇完整的文档被分割成3个Segment:$S_1, S_2, S_3$,在编码segment $S_2$时,经典的Transformer依赖的只是$S_2$本身:$P(y|S_2)$, Recurrence Transformer (例如 Transformer-XL)依赖的是$S_1, S_2$:$P(y|S_1,S_2)$,这两种方法均没有使Segment $S_2$获得完整的文档信息$S_1, S_2, S_3$。 图1 ERNIE-Doc的建模方式图 但是ERNIE-Doc在建模过程中,使得每个Segment均能获得完整的文档信息:$P(y|S_1, S_2,S_3)$,其中建模长序列的关键点如下: Retrospective feed mechanism: 将文本两次传入模型获得文本序列的representation,第一次将获得完整的文本序列表示,然后该序列的representation继续参与第二次的编码过程,这样该文本序列在第二次编码过程中,每个token位置便能获得序列完整的双向信息。 Enhanced recurrence mechanism: 使用了一种增强的Segment循环机制进行建模。 Segment-reordering objective: 对一篇文档中的各个segment随机打乱,获得多个乱序文档,然后要求模型预测这些文档中哪个是正常语序的文档。 1.2. 经典/Recurrence Transformer的计算 在正式介绍正式ERNIE-DOC之前,我们先来回顾一下经典和Recurrence Transformer模型的计算。假设当前存在一个长文档$D$被划分为这样几个Segment:$D=\{S_1, S_2, ..., S_T\}$,其中每个Segment包含$L$个token:$S_\tau = \{x_{\tau,1}, x_{\tau, 2}, ..., x_{\tau,L}\}$。另外约定$h_\tau^{n} \in \mathbb{R}^{L \times d}$为Transformer第$n$层第$\tau$个Segment的编码向量。对于第$\tau+1$个Segment $S_{\tau+1}$,Transformer第$n$层对其相应的编码计算方式为: $$\begin{split} \begin{align} & \tilde{h}_{\tau+1}^{n-1} = \left\{ \begin{matrix} h_{\tau+1}^{n-1}, \qquad \text{Vanilla Transformers} \\ \left[ \text{SG}(h_{\tau}^{n-1}) \; \circ \;h_{\tau+1}^{n-1} \right], \qquad \text{Recurrence Transformers} \end{matrix} \right. \\ & q_{\tau+1}^{n}, \; k_{\tau+1}^n, \; v_{\tau+1}^n = h_{\tau+1}^{n-1}W_{q}^{\mathrm{ T }}, \; \tilde{h}_{\tau+1}^{n-1}W_{k}^{\mathrm{ T }}, \; \tilde{h}_{\tau+1}^{n-1}W_{v}^{\mathrm{ T }} \\ & h_{\tau+1}^n = \text{Transformer-Layer}(q_{\tau+1}^{n}, \; k_{\tau+1}^n, \; v_{\tau+1}^n) \end{align} \end{split}$$ 如上述讨论,这两种方式均不能使得每个Segment获得Doc的完整信息。 1.3. Retrospective feed mechanism ERNIE-Doc借鉴了人类阅读的行为习惯,在人类阅读时会分为两个阶段:首先会快速略读一下文档内容,然后回过头来仔细阅读。ERNIE-Doc基于此设计了Retrospective feed mechanism,该机制同样包含两个阶段:Skimming phase 和 Retrospective phase。 具体来讲,一篇文档会传入模型两次,第一次被称为Skimming phase,在该阶段将会获得改文档的完整序列表示。第二次被称为 Retrospective phase,在该阶段将会融入Skimming phase获得的完整文档表示,开始进一步的编码计算,从而保证在第二次计算每个Segment编码时能够获得完整的文档信息。Retrospective phase的计算方式如下: $$\begin{split} \begin{align} \hat{H} &= \left[ \hat{H}_{1:T}^{1} \circ \hat{H}_{1:T}^{2} \cdot \cdot \cdot \circ \; \hat{H}_{1:T}^N \right], \quad \text{(skimming phase)} \\ \hat{H}_{1:T}^{i} &= \left[ \hat{h}_1^i \circ \hat{h}_2^i \cdot \cdot \cdot \circ \;\hat{h}_T^i \right] , \quad \text{(skimming phase)} \\ \tilde{h}_{\tau+1}^{n-1} &= \left[{SG}(\hat{H }\circ h_{\tau}^{n-1}) \circ h_{\tau+1}^{n-1} \right], \quad \text{(retrospective phase)} \end{align} \end{split}$$ 其中以上公式各个参数解释如下: $T$:一篇文档的Segment数量; $N$:Transformer模型层的数量;$L$:每个Segment中的最大token数量。 $\hat{H} \in \mathbb{R}^{(L \times T \times N) \times d}$:一篇文档在所有层中输出的编码向量。 $\hat{H}_{1:T}^i \in \mathbb{R}^{(L \times T) \times d}$ : 一篇文档在第$i$层产生的编码向量。 $\hat{h}_\tau^i$:第$\tau$个Segment在第$i$层产生的编码向量。 从以上公式可以看到,在retrospective 阶段,当计算每个Segment时,会引入完整文档的表示$\hat{H}$,这样就保证了编码时,每个token能够获得完整文档的信息。 1.4. Enhanced Recurrence Mechanism ERNIE-Doc通过使用Retrospective feed mechanism和Enhanced Recurrence Mechanism两种方式,增大了计算每个segment时的有效上下文长度。但是第3节引入的公式计算复杂度是很高,因此 Enhanced Recurrence Mechanism期望前一个Segment便能获得完整的文档信息,然后直接融入前一个Segment便能使得当前Segment计算融入完整的文档信息。 如图2所示,ERNIE-Doc通过将前一个Segment的同层编码表示,引入了当前Segment的计算中,这个做法同时也有利于上层信息反补下层的编码表示,具体公式为: $$\tilde{h}_{\tau+1}^{n-1} = \left[{SG}(h_\tau^n) \circ h_{\tau+1}^{n-1} \right]$$ 图2 ERNIE的Segment连接方式 1.5. Segment-Reordering Objective 在预训练阶段,ERNIE-Doc使用了两个预训练任务:MLM和Segment-Reordering Objective。我们先来讨论Segment-Reordering Objective,其旨在帮助模型显式地建模Segment之间的关系,其会将一篇长文档进行划分为若干部分,然后将这些部分进行随机打乱,最后让模型进行预测原始的语序,这是一个$K$分类问题:$K=\sum_{i=1}^m i!$,其中$m$是最大的划分数量。 如图3所示,假设存在一篇文档$D$被划分为3部分:$D=\{C_1, C_2, C_3\}$,ERNIE-Doc通过打乱这些部分得到$\hat{D}=\{C_2, C_3, C_1\}$,然后在最后一个Segment $S_\tau$的位置进行预测原始的文档顺序$C_1, C_2, C_3$。 图3 预训练任务Segment-Reordering Objective 另外,在获得$\hat{D}=\{C_2, C_3, C_1\}$后,ERNIE-Doc会对$\hat{D}$进行划分Segment:$\hat{D} = \{S_1,S_2,...,S_T \}$,并且会对这些Segment中的某些Token 进行Mask,从而构造MLM任务,要求模型根据破坏的Segment $\hat{S}_\tau$恢复成原始的$S_\tau$。结合MLM和Segment-Reordering Objective总的预训练目标为: $$\underset {\theta}{\text{max}} \; \text{log} \; p_\theta(S_\tau|\hat{S}_\tau) + \mathbb{1}_{\tau=T}\; \text{log}\;p_\theta(D|\hat{D})$$ 其中,$\mathbb{1}_{\tau=T}$表示Segment-Reordering Objective仅仅在最后一个Semgnet $S_T$位置被执行,以优化模型。 ERNIE-Doc: A Retrospective Long-Document Modeling Transformer ERNIE-Doc Github 2.ERNIE:Enhanced Language Representation with Informative Entities 2.1. THU-ERNIE简介 当前的预训练模型(比如BERT、GPT等)往往在大规模的语料上进行预训练,学习丰富的语言知识,然后在下游的特定任务上进行微调。但这些模型基本都没有使用知识图谱(KG)这种结构化的知识,而KG本身能提供大量准确的知识信息,通过向预训练语言模型中引入这些外部知识可以帮助模型理解语言知识。基于这样的考虑,作者提出了一种融合知识图谱的语言模型ERNIE,由于该模型是由清华大学提供的,为区别百度的ERNIE,故本文后续将此模型标记为THU-ERNIE。 这个想法很好,但将知识图谱的知识引入到语言模型存在两个挑战: Structured Knowledge Encoding:如何为预训练模型提取和编码知识图谱的信息? Heterogeneous Information Fusion:语言模型和知识图谱对单词的表示(representation)是完全不同的两个向量空间,这种情况下如何将两者进行融合? 对于第一个问题,THU-ERNIE使用TAGME提取文本中的实体,并将这些实体链指到KG中的对应实体对象,然后找出这些实体对象对应的embedding,这些embedding是由一些知识表示方法,例如TransE训练得到的。 对于第二个问题,THU-ERNIE在BERT模型的基础上进行改进,除了MLM、NSP任务外,重新添加了一个和KG相关的预训练目标:Mask掉token和entity (实体) 的对齐关系,并要求模型从图谱的实体中选择合适的entity完成这个对齐。 2.2. THU-ERNIE的模型结构 图1 THU-ERNIE的模型架构 THU-ERNIE在预训练阶段就开始了与KG的融合,如图1a所示,THU-ERNIE是由两种类型的Encoder堆叠而成:T-Encoder和K-Encoder。其中T-Encoder在下边堆叠了$N$层,K-Encoder在上边堆叠了$M$层,所以整个模型共有$N+M$层,T-Encoder的输出和相应的KG实体知识作为K-Encoder的输入。 从功能上来讲,T-Encoder负责从输入序列中捕获词法和句法信息;K-Encoder负责将KG知识和从T-Encoder中提取的文本信息进行融合,其中KG知识在这里主要是实体,这些实体是通过TransE模型训练出来的。 THU-ERNIE中的T-Encoder的结构和BERT结构是一致的,K-Encoder则做了一些改变,K-Encoder对T-Encoder的输出序列和实体输入序列分别进行Multi-Head Self-Attention操作,之后将两者通过Fusion层进行融合。 2.3. K-Encoder融合文本信息和KG知识 本节将详细探讨K-Encoder的内部结构以及K-Encoder是如何融合预训练文本信息和KG知识的。图1b展示了K-Encoder的内部细节信息。 我们可以看到,其对文本序列 (token Input) 和KG知识(Entity Input)分别进行Multi-Head Self-Attention(MH-ATT)操作,假设在第$i$层中,token Input对应的embedding是$\{w_{1}^{(i-1)},w_{2}^{(i-1)},...,w_{n}^{(i-1)}\}$,Entity Input对应的embedding是$\{ e_1^{(i-1)},e_2^{(i-1)},...,e_n^{(i-1)}\}$,则Multi-Head Self-Attention操作的公式可以表示为: $$\begin{split} \{\tilde{w}_{1}^{(i-1)},\tilde{w}_{2}^{(i-1)},...,\tilde{w}_{n}^{(i-1)}\} = \text{MH-ATT}(\{w_{1}^{(i-1)},w_{2}^{(i-1)},...,w_{n}^{(i-1)}\}) \\ \{\tilde{e}_{1}^{(i-1)},\tilde{e}_{2}^{(i-1)},...,\tilde{e}_{m}^{(i-1)}\} = \text{MH-ATT}(\{e_{1}^{(i-1)},e_{2}^{(i-1)},...,e_{m}^{(i-1)}\}) \end{split}$$ 然后Entity序列的输出将被对齐到token序列的第一个token上,例如实体”bob dylan”将被对齐到第一个单词”bob”上。接下里将这些MH-ATT的输入到Fusion层,在这里将进行文本信息和KG知识的信息融合。因为有些token没有对应的entity,有些token有对应的entity,所以这里需要分两种情况讨论。 对于那些有对应entity的token,信息融合的过程是这样的: $$\begin{split} h_j = \sigma(\tilde{W}_t^{(i)}\tilde{w}_j^{(i)}+\tilde{W}_e^{(i)}\tilde{e}_k^{(i)}+\tilde{b}^{(i)}) \\ w_j^{(i)} = \sigma({W}_t^{(i)}{h}_j+b_t^{(i)}) \\ e_k^{(i)} = \sigma({W}_e^{(i)}{h}_j+b_e^{(i)}) \end{split}$$ 对于那些没有对应entity的token,信息融合的过程是这样的: $$\begin{split} h_j = \sigma(\tilde{W}_t^{(i)}\tilde{w}_j^{(i)}+\tilde{b}^{(i)}) \\ w_j^{(i)} = \sigma({W}_t^{(i)}{h}_j+b_t^{(i)}) \end{split}$$ 其中这里的$\sigma(\cdot)$是个非线性的激活函数,通常可以使用GELU函数。最后一层的输出将被视作融合文本信息和KG知识的最终向量。 2.4. THU-ERNIE的预训练任务 在预训练阶段,THU-ERNIE的预训练任务包含3个任务:MLM、NSP和dEA。dEA将随机地Mask掉一些token-entity对,然后要求模型在这些对齐的token上去预测相应的实体分布,其有助于将实体注入到THU-ERNIE模型的语言表示中。 由于KG中实体的数量往往过于庞大,对于要进行这个任务的token来讲,THU-ERNIE将会给定小范围的实体,让该token在这个范围内去计算要输出的实体分布,而不是全部的KG实体。 给定token序列$\{w_{1},w_{2},...,w_{n}\}$和对应的实体序$\{ e_1,e_2,...,e_m\}$,对于要对齐的token $w_i$来讲,相应的对齐公式为: $$p(e_j|w_i) = \frac{exp(\text{linear}(w_i^o) \cdot e_j)}{\sum_{k=1}^{m}exp(\text{linear}(w_i^{o}) \cdot e_k)}$$ 类似与BERT对token的Mask策略,THU-ERNIE在Mask token-entity对齐的时候也采用的一定的策略,如下: 以5%的概率去随机地替换实体,让模型去预测正确的entity。 以15%的概率直接Mask掉token-entity,让模型去预测相应的entity。 以80%的概率保持token-entity的对齐不变,以让模型学到KG知识,提升语言理解能力。 最终,THU-ERNIE的总的预训练损失是由MLM、NSP和dEA三者的加和。 ERNIE:Enhanced Language Representation with Informative Entities ERNIE Githut
深度学习进阶篇-国内预训练模型[5]:ERINE、ERNIE 3.0、ERNIE-的设计思路、模型结构、应用场景等详解
深度学习进阶篇-国内预训练模型[5]:ERINE、ERNIE 3.0、ERNIE-的设计思路、模型结构、应用场景等详解 后预训练模型时代 1.ERINE 1.1 ERINE简介 ERINE是百度发布一个预训练模型,它通过引入三种级别的Knowledge Masking帮助模型学习语言知识,在多项任务上超越了BERT。在模型结构方面,它采用了Transformer的Encoder部分作为模型主干进行训练,如 图1 (图片来自网络)所示。 图1 Transformer的Encoder部分 关于ERNIE网络结构(Transformer Encoder)的工作原理,这里不再展开讨论。接下来,我们将聚焦在ERNIE本身的主要改进点进行讨论,即三个层级的Knowledge Masking 策略。这三种策略都是应用在ERNIE预训练过程中的预训练任务,期望通过这三种级别的任务帮助ERNIE学到更多的语言知识。 1.2 Knowledge Masking Task 训练语料中蕴含着大量的语言知识,例如词法,句法,语义信息,如何让模型有效地学习这些复杂的语言知识是一件有挑战的事情。BERT使用了MLM(masked language-model)和NSP(Next Sentence Prediction)两个预训练任务来进行训练,这两个任务可能并不足以让BERT学到那么多复杂的语言知识,特别是后来多个研究人士提到NSP任务是比较简单的任务,它实际的作用不是很大。 masked language-model(MLM)是指在训练的时候随即从输入预料上mask掉一些单词,然后通过的上下文预测这些单词,该任务非常像我们在中学时期经常做的完形填空。 Next Sentence Prediction(NSP)的任务是判断连个句子是否是具有前后顺承关系的两句话。 考虑到这一点,ERNIE提出了Knowledge Masking的策略,其包含三个级别:ERNIE将Knowledge分成了三个类别:token级别(Basic-Level)、短语级别(Phrase-Level) 和 实体级别(Entity-Level)。通过对这三个级别的对象进行Masking,提高模型对字词、短语的知识理解。 图2展示了这三个级别的Masking策略和BERT Masking的对比,显然,Basic-Level Masking 同BERT的Masking一样,随机地对某些单词(如 written)进行Masking,在预训练过程中,让模型去预测这些被Mask后的单词;Phrase-Level Masking 是对语句中的短语进行masking,如 a series of;Entity-Level Masking是对语句中的实体词进行Masking,如人名 J. K. Rowling。 图2 ERNIE和BERT的Masking策略对比 除了上边的Knowledge Masking外,ERNIE还采用多个异源语料帮助模型训练,例如对话数据,新闻数据,百科数据等等。通过这些改进以保证模型在字词、语句和语义方面更深入地学习到语言知识。当ERINE通过这些预训练任务学习之后,就会变成一个更懂语言知识的预训练模型,接下来,就可以应用ERINE在不同的下游任务进行微调,提高下游任务的效果。例如,文本分类任务。 异源语料 :来自不同源头的数据,比如百度贴吧,百度新闻,维基百科等等 2.ERNIE 3.0: Large-scale Knowledge Enhanced Pre-training for Language Understanding and Generation 2.1. ERNIE 3.0的设计思路 自回归模型(Autoregressive Model, AR),通过估计一串文本序列的生成概率分布进行建模。一般而言,AR模型通过要么从前到后计算文本序列概率,要么从后向前计算文本序列概率,但不论哪种方式的建模,都是单向的。即在预测一个单词的时候无法同时看到该单词位置两边的信息。假设给定的文本序列$x=(x_1, x_2, ..., x_n)$,其从左到右的序列生成概率为: $$p(x)=\prod_{t=1}^n p(x_t|x_{ 自编码模型(Autoencoding Model, AE), 通过从破坏的输入文本序列中重建原始数据进行建模。例如BERT通过预测【mask】位置的词重建原始序列。它的优点在于在预测单词的时候能够同时捕获该单词位置前后双向的信息;它的缺点是预训练过程中采用了mask单词的策略,然而微调阶段并没有,因此导致了预训练阶段和微调阶段的的GAP,另外在训练过程中,对不同mask单词的预测是相互独立的。假设序列中被mask的词为$w\in W_m$,未被mask的词为$w\in W_n$,则其相应的计算概率为: $$p(x) = \prod_{w\in Wm} p(w|W_n)$$ 一般而言,自回归模型在文本生成任务上表现更好,自编码模型在语言理解任务上表现更好。ERNIE 3.0借鉴此想法,在如下方面进行了改进: ERNIE 3.0同时结合了将自回归和自编码网络,从而模型在文本生成和语言理解任务表现均很好。 ERNiE 3.0在预训练阶段中引入了知识图谱数据。 2.2. ERNIE 3.0的模型结构 图1 ERNIE 3.0模型结构 2.2.1 ERNIE 3.0的网络结构 延续ERNIE 2.0的语言学习思路,ERNIE 3.0同样期望通过设置多种预任务的方式辅助模型学习语言的各方面知识,比如词法、句法、和语义信息。这些预训练任务包括自然语言生成、自然语言理解和关系抽取等范畴。ERNIE 3.0期望能够在这三种任务模式(task paradigm)中均能获得比较好的效果,因此提出了一个通用的多模式预训练框架,这就是ERNIE 3.0,如图1所示。 ERNIE 3.0认为不同的任务模式依赖的自然语言的底层特征是相同的,比如词法和句法信息,然而不同的任务模式需要的上层具体的特征是不同的。自然语言理解的任务往往倾向于学习语义连贯性,然而自然语义生成任务却期望能够看见更长的上下文信息。 因此,ERNIE 3.0设计了上下两层网络结构:Universal Representation Module 和 Task-specific Representation Module。其中各个模式的任务共享Universal Representation Module,期望其能够捕获一些通用的基础特征; Task-specific Representation Module将去具体适配不同模式的任务(生成和理解),去抽取不同的特征。 前边提到,自回归模型在文本生成任务上表现更好,自编码模型在语言理解任务上表现更好。因此,ERNIE 3.0在上层使用了两个网络,一个用于聚焦自然语言理解,一个用于聚焦自然语言生成任务。这样做主要有两个好处: 不同任务适配更合适的网络,能够提高模型在相应任务上的表现。 在fune-tuning阶段,可以固定Universal Representation Module,只微调Task-specific Representation Module参数,提高训练效率。 2.2.2 Universal Representation Module 此部分使用Transformer-XL作为骨干网络,Transformer-XL允许模型使用记忆循环机制建模更长的文本序列依赖。在实验中,Universal Representation Module设置了比较多的层数和参数,用以加强捕获期望的词法和句法底层语言特征能力。 这里需要注意的一点是,记忆循环机制只有在自然语言生成任务上会使用。 2.2.3 Task-specific Representation Module 此部分同样使用了Transformer-XL作为骨干网络,Task-specific Representation Module将用于根据不同模式的任务去学习task-specific的高层语义特征。 在ERNIE 3.0的设置中,Universal Representation Module采用了Base版的Transformer-XL,其层数会比Universal Representation Module少。 另外,ERNIE 3.0采用了两种任务模式的Representation Module,一个是NLU-specific Representation Module,另一个是NLG-specific Representation Module,其中前者是一个双向编码网络,后者是个单向编码网络。 2.3. 不同类型的预训练任务 2.3.1 Word-aware Pre-training Task Knowledge Masked Language Modeling Knowledge Masking策略包含三个级别:token级别(Basic-Level)、短语级别(Phrase-Level) 和 实体级别(Entity-Level)。通过对这三个级别的对象进行 Masking,提高模型对字词、短语的知识理解。 图2展示了这三个级别的Masking策略和BERT Masking的对比,显然,Basic-Level Masking 同BERT的Masking一样,随机地对某些单词(如 written)进行Masking,在预训练过程中,让模型去预测这些被Mask后的单词;Phrase-Level Masking 是对语句中的短语进行masking,如 a series of;Entity-Level Masking是对语句中的实体词进行Masking,如人名 J. K. Rowling。 图2 ERNIE和BERT的Masking策略对比 Document Language Modeling ERNIE 3.0 选择使用传统的语言模型作为预训练任务,期望减小模型的语言困惑度。同时采用了ERNIE-Doc中提出的记忆循环机制,以建模更长的序列依赖。 2.3.2 Structure-aware Pre-training Tasks Sentence Reordering Task 将给定的文档依次划分为1-m段,然后打乱这些段,让模型对这些段进行排序,是个k分类问题,这能够帮助模型学习语句之间的关系。 将文档划分为2段,那么排列组合后将有 $2!$ 个可能;将文档划分为3段,那么排列组合后将有 3! 个可能;依次类推,将文档划分为 n 段,那么排列组合后将有 n! 个可能。因此ERNIE将这个任务建模成了一个 k 分类问题,这里 $k=\sum_{n=1}^m n!$。 Sentence Distance Task 预测两个句子之间的距离,是个3分类任务。对应的Label依次是0、1和2。其中0代表两个句子在同一篇文章中,并且他们是相邻的;1代表两个句子在同一篇文章中,但他们不是相邻的;2代表两个句子不在同一篇文章中。 2.3.3 Knowledge-aware Pre-training Tasks 为了向预训练模型中引入知识,ERNIE 3.0 尝试在预训练阶段引入了universal knowledge-text prediction(UKTP)任务,如图3所示。 给定一个三元组和一个句子,ERNIE 3.0会mask掉三元组中的实体关系relation,或者句子中的单词word,然后让模型去预测这些内容。当预测实体关系的时候,模型不仅需要考虑三元组中head和tail实体信息,同时也需要根据句子的上下文信息来决定head和tail的关系,从而帮助模型来理解知识。 这个操作基于远程监督的假设:如果一个句子中同时出现head和tail两个实体,则这个句子能够表达这两个实体的关系。 另外,当预测句子中的单词word时,模型不仅需要考虑句子中的上下文信息,同时还可以参考三元组的实体关系。 图3 universal knowledge-text prediction ERNIE 3.0: LARGE-SCALE KNOWLEDGE ENHANCED PRE-TRAINING FOR LANGUAGE UNDERSTANDING AND GENERATION ERNIE-DOC: A Retrospective Long-Document Modeling Transformer 3.ERNIE-Gram: Pre-training with Explicitly N-Gram Masked language Modeling for Natural Language Understanding 3.1. ERNIE-Gram简介 在经典预训练模型BERT中,主要是通过Masked Language Modeling(MLM)预训练任务学习语言知识。在BERT中MLM会随机Masking一些位置的token,然后让模型去预测这些token。这些Masking的token在中文中便是字,在英文中便是sub-word,这样的预测也许不能让模型获取更加直观的语言知识,所以后续又出现了一些模型,比如ERNIE, SpanBERT等,其从Masking单个字转变成了Masking一系列连续的token,例如Masking实体词,Masking短语等,即从细粒度的Masking转向粗粒度的Masking。 ERNIE-Gram指出一种观点:这种连续的粗粒度Masking策略会忽略信息内部的相互依赖以及不同信息之间的关联。因此,基于这种想法进行改进,提出了一种显式建模n-gram词的方法,即直接去预测一个n-gram词,而不是预测一系列连续的token,从而保证n-gram词的语义完整性。 另外,ERNIE-Gram在预训练阶段借鉴ELECTRA想法,通过引入一个生成器来显式地对不同n-gram词进行建模。具体来讲,其应用生成器模型去采样合理的n-gram词,并用这些词去mask原始的语句,然后让模型去预测这些位置原始的单词。同时还使用了RTD预训练任务,来识别每个token是否是生成的。 3.2. ERNIE和N-Gram的融入方式 上边我们提到了,不同于连续多个token的预测,ERNIE-GRAM采用了一种显式的n-gram方式进行建模,在本节我们将展开讨论ERNIE和显式的n-gram融合建模的方式。ERNIE-Gram主要提出了两种融合方式:Explictly N-gram MLM 和 Comprehensive N-gram Prediction。 在正式介绍之前,我们先回顾一下经典的连续token的建模方式:Contiguously MLM,然后再正式介绍以上ERNIE-Gram提出的两种方式。 3.2.1 Contiguously MLM 给定一串序列$x=\{x_1, x_2, ..., x_{|x|}\}$ 和 n-gram起始边界序列(starting boundaries)$b=\{b_1, b_2, ..., b_{|b|}\}$,根据$x$和$b$进行如下约定: $z=\{z_1, z_2,..., z_{|b|-1}\}$:由$x$转换成的n-gram序列。 $M=\{\}$:从起始边界$b$中随机选择15%的准备Masking的index,组成$M$ $z_M$:由$M$选择出的相应的token集 $z_{\text{\\}M}$: 表示将$x$进行Masking后的序列 图1展示了一个Contiguously MLM的例子,给定的序列为$x=\{x_1,x_2,x_3,x_4,x_5,x_6\}$, 起始边界序列为$b=\{1,2,4,5,6,7\}$, 假设从起始边界序列$b$的随机选择的索引为$M=\{2,4\}$, 则 $z=\{x_1, x_{[2:4)}, x_4, x_5, x_6\}$ $z_M = \{x_{[2:4)}, x_5\}$ $z_{\text{\\}M}=\{x_1,\text{[M]} , \text{[M]}, x_4, \text{[M]}, x_6\}$ Contiguously MLM 可通过如下方式进行优化: $$\begin{split} -\text{log} p_{\theta}(z_M|z_{\text{\\}M}) = -\sum_{z \in z_M} \sum_{x \in z} \text{log}\; p_{\theta}(x|z_{\text{\\}M}) \end{split}$$ 图1 contiguously MLM 在讨论完连续的token Masking策略之后,下面我们将继续讨论ERNIE-Gram中提出的两种显式n-gram的建模方式。 3.2.2 Explicitly N-gram Masked Language Modeling 在连续token预测中, 需要预测多次,每次预测一个token,直到完成这一段连续token的所有预测,才表示完成了一个实体词或者短语。不同于连续token预测, 显式的N-gram预测直接去预测一个n-gram词,即站在一种粗粒度的角度上进行预测。 如图2为所示,假设$y=\{y_1,y_3, ..., y_{|b|-1}\}$为显式的n-gram序列,$y_M=\{y_2, y_4\}$为随机选择的Masking token, 则Masking后的完整序列为$\bar {z}_{\text{\\M}}=\{x_1, \text{[M]}, x_4, \text{[M]}, x_6\}$。 Explicitly N-gram Masked Language Modeling可通过如下方式进行优化: $$\begin{split} -\text{log}p_{\theta}(y_M|z_{\text{\\}M}) = -\sum_{y \in y_M} \text{log} \; p_{\theta}(y|\bar{z}_{\text{\\}M}) \end{split}$$ 图2 Explicitly N-gram MLM 3.2.3 Comprehensive N-gram Prediction 通过以上讨论可知,Contiguously MLM是从细粒度角度进行预测连续token, Explicitly N-gram MLM是从粗粒度角度进行预测n-gram token, 而本节介绍的Comprehensive N-gram是一种融合细粒度和粗粒度的预测方式,其将更加全面地进行建模。其优化的目标函数为以上两种方式的融合,这里需要注意这两种方式是基于统一的上下文$\bar{z}_{\text{\\}M}$进行预测: $$\begin{split} -\text{log} \; p_{\theta}(y_M, z_M|\bar{z}_{\text{\\}M}) = -\sum_{y \in y_M} \text{log} \; p_{\theta}(y|\bar{z}_{\text{\\}M})-\sum_{z \in z_M} \sum_{x \in z} \text{log}\; p_{\theta}(x|\bar{z}_{\text{\\}M}) \end{split}$$ 图3a展示了细粒度和粗粒度预测的详细融合方式,其将细粒度的预测位置直接拼接到了序列的末尾,图中以虚线分割。其中虚线以左是Explictly N-gram的粗粒度预测,虚线以右是Contiguously MLM的细粒度预测。以$y_2$位置为例,由于其包含两个token,所以细粒度预测需要预测2次(论文中这两个位置使用了$M_1$和$M_2$这两个不同的token进行Masking)。 此时,整个文本序列为:$[x_1, \text{[M]}, x_4, \text{[M]}, x_6, \text{[M1]}, \text{[M2]}, \text{[M1]}]$, 为了在Self-Attention时不造成信息的混乱,ERNIE-Gram约定: 虚线以左的 Explicitly N-gram MLM 粗粒度预测,即在预测$y_2$和$y_4$时,只能看见虚线以左的token。 虚线以后的Contiguously MLM细粒度预测,即在预测$x_2,x_3$和$x_5$时,只能看见自己以及虚线以左的token。 图3b展示了其计算时的Attention矩阵,其中红色点表示相互能够看见,在Self-Attention计算时,相互的信息需要融入。 图3 Comprehensive N-gram Prediction 3.3. 使用生成器显式建模N-gram Relation 为了更加显式地建模不同n-gram之间的关系,在预训练阶段,ERNIE-Gram借鉴了Electra的思路,使用一个生成器去生成一个位置的n-gram词,并且用这个n-gram词去mask该位置的n-gram token。 如图4所示,Transformer Encoder ${\theta}^{'}$便是生成器,图4b展示了使用生成的n-gram token去mask原始句子token的一个样例,ERNIE-Gram根据数据Masking位置的词分布采样了public official和completely去替换了原始语句词,即 原始语句:the prime minister proposed nothing less than a overhaul of the tax system. Masking语句:the public official proposed completely a overhaul of the tax system. 然后将Masking语句传入Transformer Encoder $\theta$中进行训练。 图4 Enhanced N-gram Relation Modeling 假设$y_M^{'} = \{ y_2^{'}, y_4^{'}\}$表示生成的n-gram项, $\bar{z}^{'}_{\text{\\}M} = \{x_1, y_2^{'}, x_4, y_4^{'},x_6\}$表示用生成n-gram项Masking后的序列,则联合的预训练目标函数为: $$\begin{split} -\text{log} \; p_{\theta^{'}}(y_M|\bar{z}_{\text{\\}M ^{'}} ) - \text{log}\; p_{\theta}(y_M, z_M|\bar{z}_{\text{\\}M ^{'}} ) \end{split}$$ 另外,ERNIE-Gram融入了the replaced token detection (RTD)任务,用于识别这些token是否是被生成器替换的token。假设$\hat{z}^{'}_{\text{\\}M } = \{x_1, y_2, x_4, y_4,x_6\}$为真实目标n-gram词替换后的序列,则RTD的目标函数为: $$\begin{split} \begin{align} &-\text{log} \; p_{\theta}(\mathbb{1}(\bar{z}^{'}_{\text{\\}M} = \hat{z}_{\text{\\}M} |\bar{z}^{'}_{\text{\\}M}) \\ &= - \sum_{t=1}^{|\hat{z}_{\text{\\}M}|} \text{log}\; p_{\theta}(\mathbb{1}(\bar{z}^{'}_{\text{\\}M,t} = \hat{z}_{\text{\\}M,t} |\bar{z}^{'}_{\text{\\}M,t}) \end{align} \end{split}$$ ERNIE-Gram: Pre-training with Explicitly N-Gram Masked language Modeling for Natural Language Understanding ERNIE-Gram github
深度学习进阶篇-预训练模型[3]:XLNet、BERT、GPT,ELMO的区别优缺点,模型框架、一些Trick、Transformer Encoder等原理详解
深度学习进阶篇-预训练模型[3]:XLNet、BERT、GPT,ELMO的区别优缺点,模型框架、一些Trick、Transformer Encoder等原理详解 1.XLNet:Generalized Autoregressive Pretraining for Language Understanding 1.1. 从AR和AE模型到XLNet模型 自回归模型(Autoregressive Model, AR),通过估计一串文本序列的生成概率分布进行建模。一般而言,AR模型通过要么从前到后计算文本序列概率,要么从后向前计算文本序列概率,但不论哪种方式的建模,都是单向的。即在预测一个单词的时候无法同时看到该单词位置两边的信息。假设给定的文本序列$x=(x_1, x_2, ..., x_n)$,其从左到右的序列生成概率为: $$p(x)=\prod_{t=1}^n p(x_t|x_{ 自编码模型(Autoencoding Model, AE), 通过从破坏的输入文本序列中重建原始数据进行建模。例如BERT通过预测【mask】位置的词重建原始序列。它的优点在于在预测单词的时候能够同时捕获该单词位置前后双向的信息;它的缺点是预训练过程中采用了mask单词的策略,然而微调阶段并没有,因此导致了预训练阶段和微调阶段的的GAP,另外在训练过程中,对不同mask单词的预测是相互独立的。假设序列中被mask的词为$w\in W_m$,未被mask的词为$w\in W_n$,则其相应的计算概率为: $$p(x) = \prod_{w\in Wm} p(w|W_n)$$ 这里对传统的AR和AE模型简单总结一下,AR模型是生成式模型,是单向的;AE模型是判别式模型,是双向的。鉴于传统的AR模型和AE模型自身的优点和缺点,XLNet期望能够融合两者的优点同时又避免两者的缺点,这就是XLNet的设计思路。 整体上XLNet是基于AR模型的建模思路设计的,同时避免了只能单向建模的缺点,因此它是一种能看得见双向信息的广义AR模型。作为一个AR模型,XLNet并没有采用预测mask单词的方式进行建模,因此它不存在上述预训练-微调的GAP,更不存在预测mask的独立性假设。 1.2. Permutation Language Model Permuatation Language Mode (下文将简称为PLM) 是XLNet的核心建模思路,在正式介绍之前,我们再来回顾一下AR模型的建模策略,给定一串文本序列$\text{x}=[x_1,x_2,...,x_n]$,其中每个$x_i$表示一个token,AR模型的通过最大化下边这个似然函数进行建模: $$\begin{split} \begin{align} \mathop{max}\limits_{\theta} \quad log \; P_{\theta}(\text{x}) &= \sum_{t=1}^{n}log\;p_{\theta}(x_t|x_{ 这里,$\text{x}_{ 这种建模方式是单向的,为了在预测某个位置单词的时候,能够让模型看见双向的信息,XLNet采用了全排列的思路,允许模型在不同文本序列排列上进行建模,但模型的参数在不同序列上是共享的,相当于是模型能够看见预测位置单词左右两侧的信息。 举个例子,假设当前有文本序列$\text{x}=[x_1,x_2,x_3]$,这串序列中共有3个token,这三个token共计有6种排列组合方式,其相关的索引序列为: $\text{z}_1 = (1,2,3)$ $\text{z}_2=(1,3,2)$ $\text{z}_3=(2,1,3)$ $\text{z}_4=(2,3,1)$ $\text{z}_5=(3,1,2)$ $\text{z}_6=(3,2,1)$ 采用索引序列$\text{z}_1$的文本序列为$\text{x}=[x_1, x_2, x_3]$,采用索引序列$\text{z}_2$的文本序列为$\text{x}=[x_1, x_3, x_2]$,如果模型在训练过程中能同时看到这样的两个排列,那么在预测$x_2$的时候将可以看到$x_1$,又可以看到$x_3$,因为训练过程中模型的参数是共享的,因此相当于模型能够看到$x_2$前后双向的信息。 下面正式归纳一下XLNet的目标函数,假设给定一串序列$\text{x}=[x_1,x_2,x_3,...,x_n]$,它将有$n!$个不同的排列组合$\mathbb{Z}=[\text{z}_1,\text{z}_2,...,\text{z}_{n!}]$,令$\text{z}\in \mathbb{Z}$表示某一排列方式,$z_{t}$表示为$\text{z}$这个排列的第$t$个位置,$\text{z}_{ XLNet的正式目标函数依据极大似然估计为: $$\begin{split} \begin{align} \mathop{max}_{\theta} \quad L &=\mathbb{E}_{\text{z}∼\mathbb{Z}} \left[ \sum_{t=1}^n log\;p_{\theta}(x_{z_t}|\text{x}_{\text{z}_{ 但是一个长度为$n$的文本序列,其排列组合数为$n!$,数量实在庞大,不便训练,所以在实际训练过程中,XLNet是通过采样的方式逼近目标函数的期望,即: $$\begin{split} \begin{align} \mathop{max}_{\theta} \quad L &=\mathbb{E}_{\text{z}∼\mathbb{Z}} \left[ \sum_{t=1}^n log\;p_{\theta}(x_{z_t}|\text{x}_{z 其中,$z_{it}$表示第$i$个排列的第$t$个位置,$\text{x}_{\text{z}_i注意的是,XLNet只是调整了联合概率$p(\text{x})$的分解顺序,但是原始token之间的顺序是不变的,即token之间还是使用原始顺序的position embedding,$p(\text{x})$的分解顺序的计算主要是通过transformer的mask机制实现的。这样的设定也保证了预训练阶段和微调阶段之间的顺序是一致的,均是正常的自然语序。 图1 不同排列计算第3个单词输出的示意图 图1中$mem^{(0)}$和$mem^{(1)}$代表前一个的segment的缓存信息,另外,输入的序列顺序都是固定的自然语序,position embedding还是按照正常的顺序确定的。只是不同的排列中,参与分解计算的内容不同。具体来讲,对第一个分解次序$3\rightarrow2\rightarrow4\rightarrow1$,因为$x_3$位于最前边,所以在这个分解次序中看不到其他的token内容,只能看到前一个segment的缓存信息;对第一个分解次序$2\rightarrow4\rightarrow3\rightarrow1$,$x_3$前边有$x_2$和$x_4$,所以在计算$x_3$位置输出的时候使用了$x_2$和$x_4$。 这个想法就是PLM的建模思路,看到这里,相信你已经很好地理解了。 1.3. Permutation Language Model如何建模 1.3.1 使用经典的transformer是否能建模PLM 上边看似找到了一个比较好想法去让AR模型在预测一个单词的时候同时能够看到前后双向的信息,但具体怎么来建模实现呢?使用原始的transformer技术直接实现可能会带来一些问题,具体来说,假设当前有两个排列$\text{z}^{1}$和$\text{z}^2$,他们之间具有如下的关系: $$\text{z}_{ 这种情况下,使用经典transformer的方式去预测这两个排列$z_t$位置的输出,将会有: $$\underbrace{p_{\theta}(X_{i}=x|\text{x}_{\text{z}_{ 显然在这种情况下,预测第$i$个位置的单词和预测第$j$个位置的单词的概率分布是相同的,这肯定是不对的,因此使用经典的transformer是无法去做Permutation Language Model建模的。 为了解决这个问题,XLNet在预测目标$z_t$位置的token时,向其引入了位置信息$z_t$,重新定义的预测token概率分布的计算方式为: $$p_{\theta}(x_{z_t}|\text{x}_{\text{z}_{ 从公式中可以看到,其在预测$z_t$位置token的时候,引入了位置信息$z_t$。这样就能解决上述的问题,即经过这个变换后上式将变为: $$\underbrace{p_{\theta}(X_{i}=x|\text{x}_{\text{z}_{ 1.3.2 使用Two-Stream Self-Attention建模PLM 从上边讨论的这些可以看到,当预测$z_t$位置的token时,最多只能使用位置信息$z_t$,而不能使用该$z_t$对应的内容$x_{z_t}$,否则,就相当于使用$x_{z_t}$来预测$x_{z_t}$自己,这没有什么意义;当预测$j>t$后的token $x_{z_j}$时,不仅需要位置信息$z_t$,同时还需要该位置对应的内容$x_{z_t}$。 然而,经典的transformer中是将两者信息在输入层相加融合之后进行后续计算的,因此XLNet提出了一种双流自注意力机制:content-stream 和 query stream,下面我们将来具体探讨一下它们。 content-stream 提供了内容方面的表达 content representation $h_{\theta}(\text{x}_{\text{z}_{\leq t}} )$,简记为$h_{z_t}$,它等同经典的transformer 的状态向量,这个向量中既包含了位置信息$z_t$,又包含了内容信息$x_{z_t}$。 query-stream 提供了查询方面的表达 query representation $g_{\theta}(\text{x}_{\text{z}_{ 图2 双流机制计算图 图2展示了分解顺序为$3 \rightarrow 2 \rightarrow 4 \rightarrow 1$的two-stream计算过程,我们通过这张图来具体聊聊如何去定义$g_{\theta}(\text{x}_{\text{z}_{ 图2a展示了content-stream的自注意力计算,其中$h_i^{(0)}$是由token的embedding进行初始化,可以看到它的计算和经典的transormer是一致的,因为在分解顺序中1位于最后,因此它能看见前边所有的token内容,最终计算得出的$h_1^{(1)}$同时包含了第$1$个位置的内容信息。 图2b展示了query-stream的自注意力计算,其中$g_i^{(0)}$由可学习的参数进行初始化,因为它能看见token 3,2,4的内容信息,所以这里用的是内容信息$h_3^{(0)},h_2^{(0)},h_4^{(0)}$,同时对于第1个位置,只能使用位置信息,而不能使用内容信息,所以这里使用的是$g_1^{(0)}$,它并不包含第1个位置的内容信息。 这样就能比较好地建模$g_{\theta}(\text{x}_{\text{z}_{ 图2c展示了整体的计算流程,最后一层输出的query向量就是我们想要的$g_{\theta}(\text{x}_{\text{z}_{ content-stream和query-stream的mask矩阵内容,就是使用这样的mask矩阵来计算序列分解式的。 关于这两个流的Self-Attention计算公式如下: $$\begin{split} \begin{align} g_{z_t}^{(m)} & \leftarrow \text{Attention}(Q=g_{z_t}^{(m-1)},\, KV=h_{\text{z}_{ 以上是XLNet在预训练阶段的计算过程,这里需要注意的是,在微调阶段,XLNet仅仅使用content respresentation进行fine-tune下游任务。 1.3.3 引入Transformer-XL的想法 由于XLNet本身是个AR模型,它可以完美融入Transformer-XL的思想:相对位置编码和segment循环机制。这两者的原理部分感兴趣的同学可以去阅读Transformer-XL内容,本文重点讨论一下segment循环机制向XLNet的融入过程。 顾名思义,segment循环机制是指长序列切分成$n$个segment (文本片段),然后将每个segment依次传入模型之中,同时传入到模型中,同时传入到模型中还有上一个segment的产生的输出,这个操作有点像RNN,接收上一步的输出和当前步骤的输入,然后根据两者计算产生当前步骤的输出,只不过RNN的循环单位是单词,XLNet的循环单位是segment。 给定一个长序列$\text{s}$,上一个segment为$\tilde{\text{x}}=s_{1:n}$,其对应的排列用$\tilde{\text{z}}$表示;当前的segment为$\text{x}=s_{n+1:2n}$,其对应的排列用$\text{z}$表示。基于排列$\tilde{\text{z}}$处理第1个segment,并将其输出进行缓存,第$m$层的输出用$\tilde{h^{(m)}}$表示。则第2个segment的计算可以按照如下方式进行: $$\begin{split} \begin{align} g_{z_t}^{(m)} & \leftarrow \text{Attention}(Q=g_{z_t}^{(m-1)},\, KV=[\tilde{h}^{(m-1)},h_{\text{z}_{ 即将前一个segment的输出和当前位置$z_t$能看到的内容进行拼接,然后进行Self-Attention融合计算。 这里需要注意的是,由于序列中的position embedding 仅仅依赖于原始序列(输入序列)的位置,而不是排列的顺序,所以一旦前一个segment的输出$\tilde{h}^{(m)}$确定,上述的Attention计算和前一个segment的分解顺序无关。这允许我们去缓存或者复用前一个segment的输出,而不用去管前一个segment的分解顺序。 1.3.4 关于XLNet的一些Trick Partial Prediction 最开始的时候有提到,AR模型通过估计一串文本序列的生成概率分布进行建模:$\sum_{t=1}^n log\;p_{\theta}(x_{z_t}|\text{x}_{\text{z}XLNet收敛会比较慢。 因此XLNet在训练过程中,只选择预测序列最后面的部分位置的token,这里涉及到一个切分点位置$c$,它将指示不预测在$c$前边的位置$\text{z}_{\leq c}$,只预测$c$后边的位置${\text{z}_{>c}}$。XLNet中切分点$c$ 的选择由超参数$K$来确定,$K \approx \frac{n}{n-c}$,其中$n$为序列长度。$K$越大,则需要预测的token数量越少。 这就是Partial Prediction 部分预测,对于切分点$c$之前的token无需计算query representation,这会大大节省内存,加快模型训练速度。加入切分点后,XLNet的目标函数将变为: $$\begin{align} \mathop{max}_{\theta} \quad \mathbb{E}_{\text{z}∼\mathbb{Z}} log \, p_{\theta}(\text{x}_{z_{>c}}|\text{x}_{\leq c}) = \mathop{max}_{\theta}\quad \mathbb{E}_{\text{z}∼\mathbb{Z}} \left[ \sum_{t=c+1}^n log\;p_{\theta}(x_{z_t}|\text{x}_{\text{z}_{ Multiple Segment Input 许多下游任务存在多段输入的情况,比如QA任务中包含query( 简记为A )和answer (简记为B)两个部分,数据的输入形式同BERT一致:$\text{[CLS, A, SEP, B, SEP]}$。 但是在segment循环的时候,每个部分仅仅使用对应上下文的状态缓存。 Relative Segment Encoding Relative Segment Encoding (相对段编码) , 这里的Segment不是上边将的将序列划分为固定的Segment,而是指输入数据的不同部分,例如$\text{[CLS, A, SEP, B, SEP]}$,$\text{A}$和$\text{B}$分别属于不同的Segment。 BERT直接使用了绝对编码,直接给$\text{A}$和$\text{B}$中的token依次设置了0和1,用来指示整个序列中$\text{A}$和$\text{B}$是不同的segment,即是不同的文本段,例如一个是query,另一个是answer。 XLNet与BERT不同,它使用了相对编码,给定序列中的两个位置$i$和$j$,判断这两个位置对应的token是否在同一个segment里面,如果两者在同一个segment里面,$s_{ij}=s_+$,否则$s_{ij}=s_-$。 当预测第$i$个位置token的时候,需要计算用$i$位置的向量向另一位置$j$做attention获取分数,其按照如下公式计算: $$\alpha_{i,j} = (q_i+b)^T s_{ij}$$ 其中$q_i$为第$i$个位置的查询向量,$b$是一个可学习的参数。最终$a_{i,j}$将被加到正常Self-Attention的注意力分数上。 使用相对段编码有这样的优势: 模型的泛化效果会更好; 在微调任务上,它支持超过两个segment输入的下游任务(虽然预训练过程中使用了两个segment); XLNet:Generalized Autoregressive Pretraining for Language Understanding XLNet Github 2.BERT 2.1 BERT介绍 BERT(Bidirectional Encoder Representation from Transformers)是2018年10月由Google AI研究院提出的一种预训练模型,该模型在机器阅读理解顶级水平测试SQuAD1.1中表现出惊人的成绩: 全部两个衡量指标上全面超越人类,并且在11种不同NLP测试中创出SOTA表现,包括将GLUE基准推高至80.4% (绝对改进7.6%),MultiNLI准确度达到86.7% (绝对改进5.6%),成为NLP发展史上的里程碑式的模型成就。 BERT的网络架构使用的是《Attention is all you need》中提出的多层Transformer结构,如 图1 所示。其最大的特点是抛弃了传统的RNN和CNN,通过Attention机制将任意位置的两个单词的距离转换成1,有效的解决了NLP中棘手的长期依赖问题。Transformer的结构在NLP领域中已经得到了广泛应用。 2.2 BERT框架 BERT整体框架包含pre-train和fine-tune两个阶段。pre-train阶段模型是在无标注的标签数据上进行训练,fine-tune阶段,BERT模型首先是被pre-train模型参数初始化,然后所有的参数会用下游的有标注的数据进行训练。 图1 BERT结构 BERT是用了Transformer的encoder侧的网络,encoder中的Self-attention机制在编码一个token的时候同时利用了其上下文的token,其中‘同时利用上下文’即为双向的体现,而并非想Bi-LSTM那样把句子倒序输入一遍。 在它之前是GPT,GPT使用的是Transformer的decoder侧的网络,GPT是一个单向语言模型的预训练过程,更适用于文本生成,通过前文去预测当前的字。 2.2.1Embedding Embedding由三种Embedding求和而成: Token Embeddings是词向量,第一个单词是CLS标志,可以用于之后的分类任务 Segment Embeddings用来区别两种句子,因为预训练不光做LM还要做以两个句子为输入的分类任务 Position Embeddings和之前文章中的Transformer不一样,不是三角函数而是学习出来的 其中[CLS]表示该特征用于分类模型,对非分类模型,该符号可以省去。[SEP]表示分句符号,用于断开输入语料中的两个句子。 BERT在第一句前会加一个[CLS]标志,最后一层该位对应向量可以作为整句话的语义表示,从而用于下游的分类任务等。因为与文本中已有的其它词相比,这个无明显语义信息的符号会更“公平”地融合文本中各个词的语义信息,从而更好的表示整句话的语义。 具体来说,self-attention是用文本中的其它词来增强目标词的语义表示,但是目标词本身的语义还是会占主要部分的,因此,经过BERT的12层(BERT-base为例),每次词的embedding融合了所有词的信息,可以去更好的表示自己的语义。而[CLS]位本身没有语义,经过12层,句子级别的向量,相比其他正常词,可以更好的表征句子语义。 2.2.2Transformer Encoder BERT是用了Transformer的encoder侧的网络,如上图的transformer的Encoder部分,关于transformer的encoder的详细介绍可以参考链接:https://paddlepedia.readthedocs.io/en/latest/tutorials/pretrain_model/transformer.html 在Transformer中,模型的输入会被转换成512维的向量,然后分为8个head,每个head的维度是64维,但是BERT的维度是768维度,然后分成12个head,每个head的维度是64维,这是一个微小的差别。Transformer中position Embedding是用的三角函数,BERT中也有一个Postion Embedding是随机初始化,然后从数据中学出来的。 BERT模型分为24层和12层两种,其差别就是使用transformer encoder的层数的差异,BERT-base使用的是12层的Transformer Encoder结构,BERT-Large使用的是24层的Transformer Encoder结构。 2.2.3 BERT可视化 如上图将注意力看做不同的连线,它们用来连接被更新的位置(左半边)与被注意的位置(右半边)。不同的颜色分别代表相应的注意头,而线条颜色的深浅代表被注意的强度。 2.2.4 注意力六种模式 为了方便演示,这里采用以下例句: 句子A:I went to the store.句子B:At the store, I bought fresh strawberries. BERT 用 WordPiece工具来进行分词,并插入特殊的分离符([CLS],用来分隔样本)和分隔符([SEP],用来分隔样本内的不同句子)。 因此实际输入序列为: [CLS] i went to the store . [SEP] at the store , i bought fresh straw ##berries . [SEP] 模式1:注意下一个词 在这种模式中,每个位置主要注意序列中的下一个词(token)。下面将看到第2层0号头的一个例子。(所选头部由顶部颜色条中突出的显示色块表示。) 模式1:注意下一个词。 左:所有词的注意力。 右:所选词的注意力权重(“i”) 左边显示了所有词的注意力,而右侧图显示一个特定词(“i”)的注意力。在这个例子中,“i”几乎所有的注意力都集中在“went”上,即序列中的下一个词。 在左侧,可以看到 [SEP]符号不符合这种注意力模式,因为[SEP]的大多数注意力被引导到了[CLS]上,而不是下一个词。因此,这种模式似乎主要在每个句子内部出现。 该模式与后向RNN 有关,其状态的更新是从右向左依次进行。模式1出现在模型的多个层中,在某种意义上模拟了RNN 的循环更新。 模式2:注意前一个词 在这种模式中,大部分注意力都集中在句子的前一个词上。例如,下图中“went”的大部分注意力都指向前一个词“i”。 这个模式不像上一个那样显著。有一些注意力也分散到其他词上了,特别是[SEP]符号。与模式1一样,这与RNN 有些类似,只是这种情况下更像前向RNN。 模式2:注意前一个词。 左:所有词的注意力。 右:所选词的注意力权重(“went”) 模式3:注意相同或相关的单词 这种模式注意相同或相关的单词,包括其本身。在下面的例子中,第一次出现的“store”的大部分注意力都是针对自身和第二次出现的“store”。这种模式并不像其他一些模式那样显著,注意力会分散在许多不同的词上。 模式3:注意相同/相关的词。 左:所有词的注意力。 右:所选词的注意权重(“store”) 模式4:注意“其他”句子中相同或相关词 这种模式注意另一个句子中相同或相关的单词。例如,第二句中“store”的大部分注意力都指向第一句中的“store”。可以想象这对于下句预测任务(BERT预训练任务的一部分)特别有用,因为它有助于识别句子之间的关系。 模式4:注意其他句子中相同/相关的单词。 左:所有词的注意力。 右:所选词的注意权重(“store”) 模式5:注意能预测该词的其他单词 这种模式似乎是更注意能预测该词的词,而不包括该词本身。在下面的例子中,“straw”的大部分注意力都集中在“##berries”上(strawberries 草莓,因为WordPiece分开了),而“##berries”的大部分注意力也都集中在“straw”上。 模式5:注意能预测该单词的其他单词。 左:所有词的注意力。 右:所选词的注意力(“## berries”) 这个模式并不像其他模式那样显著。例如,词语的大部分注意力都集中在定界符([CLS])上,而这是下面讨论的模式6的特征。 模式6:注意分隔符 在这种模式中,词语的大部分注意力都集中在分隔符[CLS]或 [SEP]上。在下面的示例中,大部分注意力都集中在两个 [SEP]符号上。这可能是模型将句子级状态传播到单个词语上的一种方式。 模式6:注意分隔符。 左:所有词的注意力。 右:所选词的注意权重(“store”) 2.3 BERT的预训练任务 BERT是一个多任务模型,它的预训练(Pre-training)任务是由两个自监督任务组成,即MLM和NSP,如 图2 所示。 图2 BERT 预训练过程示意图 2.3.1MLM MLM是指在训练的时候随即从输入语料上mask掉一些单词,然后通过的上下文预测该单词,该任务非常像我们在中学时期经常做的完形填空。正如传统的语言模型算法和RNN匹配那样,MLM的这个性质和Transformer的结构是非常匹配的。在BERT的实验中,15%的WordPiece Token会被随机Mask掉。在训练模型时,一个句子会被多次喂到模型中用于参数学习,但是Google并没有在每次都mask掉这些单词,而是在确定要Mask掉的单词之后,做以下处理。 80%的时候会直接替换为[Mask],将句子 “my dog is cute” 转换为句子 “my dog is [Mask]”。 10%的时候将其替换为其它任意单词,将单词 “cute” 替换成另一个随机词,例如 “apple”。将句子 “my dog is cute” 转换为句子 “my dog is apple”。 10%的时候会保留原始Token,例如保持句子为 “my dog is cute” 不变。 这么做的原因是如果句子中的某个Token 100%都会被mask掉,那么在fine-tuning的时候模型就会有一些没有见过的单词。加入随机Token的原因是因为Transformer要保持对每个输入token的分布式表征,否则模型就会记住这个[mask]是token ’cute‘。至于单词带来的负面影响,因为一个单词被随机替换掉的概率只有15%*10% =1.5%,这个负面影响其实是可以忽略不计的。 另外文章指出每次只预测15%的单词,因此模型收敛的比较慢。 1)被随机选择15%的词当中以10%的概率用任意词替换去预测正确的词,相当于文本纠错任务,为BERT模型赋予了一定的文本纠错能力; 2)被随机选择15%的词当中以10%的概率保持不变,缓解了finetune时候与预训练时候输入不匹配的问题(预训练时候输入句子当中有mask,而finetune时候输入是完整无缺的句子,即为输入不匹配问题)。 针对有两个及两个以上连续字组成的词,随机mask字割裂了连续字之间的相关性,使模型不太容易学习到词的语义信息。主要针对这一短板,因此google此后发表了BERT-WWM,国内的哈工大联合讯飞发表了中文版的BERT-WWM。 2.3.2NSP Next Sentence Prediction(NSP)的任务是判断句子B是否是句子A的下文。如果是的话输出’IsNext‘,否则输出’NotNext‘。训练数据的生成方式是从平行语料中随机抽取的连续两句话,其中50%保留抽取的两句话,它们符合IsNext关系,另外50%的第二句话是随机从预料中提取的,它们的关系是NotNext的。这个关系保存在图4中的[CLS]符号中。 在此后的研究(论文《Crosslingual language model pretraining》等)中发现,NSP任务可能并不是必要的,消除NSP损失在下游任务的性能上能够与原始BERT持平或略有提高。这可能是由于Bert以单句子为单位输入,模型无法学习到词之间的远程依赖关系。针对这一点,后续的RoBERTa、ALBERT、spanBERT都移去了NSP任务。 BERT预训练模型最多只能输入512个词,这是因为在BERT中,Token,Position,Segment Embeddings 都是通过学习来得到的。在直接使用Google 的BERT预训练模型时,输入最多512个词(还要除掉[CLS]和[SEP]),最多两个句子合成一句。这之外的词和句子会没有对应的embedding。 如果有足够的硬件资源自己重新训练BERT,可以更改 BERT config,设置更大max_position_embeddings 和 type_vocab_size值去满足自己的需求。 2.4 BERT的微调 在海量的语料上训练完BERT之后,便可以将其应用到NLP的各个任务中了。 微调(Fine-Tuning)的任务包括:基于句子对的分类任务,基于单个句子的分类任务,问答任务,命名实体识别等。 基于句子对的分类任务: MNLI:给定一个前提 (Premise) ,根据这个前提去推断假设 (Hypothesis) 与前提的关系。该任务的关系分为三种,蕴含关系 (Entailment)、矛盾关系 (Contradiction) 以及中立关系 (Neutral)。所以这个问题本质上是一个分类问题,我们需要做的是去发掘前提和假设这两个句子对之间的交互信息。 QQP:基于Quora,判断 Quora 上的两个问题句是否表示的是一样的意思。 QNLI:用于判断文本是否包含问题的答案,类似于我们做阅读理解定位问题所在的段落。 STS-B:预测两个句子的相似性,包括5个级别。 MRPC:也是判断两个句子是否是等价的。 RTE:类似于MNLI,但是只是对蕴含关系的二分类判断,而且数据集更小。 SWAG:从四个句子中选择为可能为前句下文的那个。 基于单个句子的分类任务 SST-2:电影评价的情感分析。 CoLA:句子语义判断,是否是可接受的(Acceptable)。 SQuAD v1.1:给定一个句子(通常是一个问题)和一段描述文本,输出这个问题的答案,类似于做阅读理解的简答题。 命名实体识别 CoNLL-2003 NER:判断一个句子中的单词是不是Person,Organization,Location,Miscellaneous或者other(无命名实体)。 图3 BERT 用于不同的 NLP 任务 2.5 BERT,GPT,ELMO的区别 如上图所示,图中的Trm代表的是Transformer层,E代表的是Token Embedding,即每一个输入的单词映射成的向量,T代表的是模型输出的每个Token的特征向量表示。 BERT使用的是双向的Transformer,OpenAI GPT使用的是从左到右的Transformer。ELMo使用的是单独的从左到右和从右到左的LSTM拼接而成的特征。其中只有BERT在所有的层考虑了左右上下文。除此之外,BERT和OpenAI GPT是微调(fine-tuning)的方法,而ELMo是一个基于特征的方法。 2.5.1 BERT 比 ELMo 效果好的原因 从网络结构以及最后的实验效果来看,BERT 比 ELMo 效果好主要集中在以下几点原因: LSTM 抽取特征的能力远弱于 Transformer 拼接方式双向融合的特征融合能力偏弱 BERT 的训练数据以及模型参数均多于 ELMo 2.5.2 优缺点 BERT 相较于原来的 RNN、LSTM 可以做到并发执行,同时提取词在句子中的关系特征,并且能在多个不同层次提取关系特征,进而更全面反映句子语义。 相较于 word2vec,其又能根据句子上下文获取词义,从而避免歧义出现。 模型参数太多,而且模型太大,少量数据训练时,容易过拟合。 BERT的NSP任务效果不明显,MLM存在和下游任务mismathch的情况。 BERT对生成式任务和长序列建模支持不好。
深度学习进阶篇-预训练模型[2]:Transformer-XL、Longformer、GPT原理、模型结构、应用场景、改进技巧等详细讲解
深度学习进阶篇-预训练模型[2]:Transformer-XL、Longformer、GPT原理、模型结构、应用场景、改进技巧等详细讲解 1.Transformer-XL: Attentive Language Models Beyonds a Fixed-Length Context 1.1. Transformer-XL简介 在正式讨论 Transformer-XL 之前,我们先来看看经典的 Transformer(后文称 Vanilla Transformer)是如何处理数据和训练评估模型的,如图 1 所示。 图 1 Vanilla Transformer 训练和评估阶段 在数据处理方面,给定一串较长的文本串,Vanilla Transformer 会按照固定的长度(比如 512),直接将该文本串进行划分成若干 Segment。这个处理方式不会关注文本串中语句本身的边界(比如标点或段落),这样” 粗暴” 的划分通常会将一句完整的话切分到两个 Segment 里面,导致上下文碎片化(context fragmentation)。另外,Transformer 本身能够维持的依赖长度很有可能会超出这个固定的划分长度,从而导致 Transformer 能够捕获的最大依赖长度不超过这个划分长度,Transformer 本身达不到更好的性能。 在模型训练方面,如图 1a 所示,Vanilla Transformer 每次传给模型一个 Segment 进行训练,第 1 个 Segment 训练完成后,传入第 2 个 Segment 进行训练,然而前后的这两个 Segment 是没有任何联系的,也就是前后的训练是独立的。但事实是前后的 Segment 其实是有关联的。 在模型评估方面,如图 1b 所示,Vanilla Transformer 会采用同训练阶段一致的划分长度,但仅仅预测最后一个位置的 token,完成之后,整个序列向后移动一个位置,预测下一个 token。这个处理方式保证了模型每次预测都能使用足够长的上下文信息,也缓解了训练过程中的 context framentation 问题。但是每次的 Segment 都会重新计算,计算代价很大。 基于上边的这些不足,Transformer-XL 被提出来解决这些问题。它主要提出了两个技术:Segment-Level 循环机制和相对位置编码。Transformer-XL 能够建模更长的序列依赖,比 RNN 长 80%,比 Vanilla Transformer 长 450%。同时具有更快的评估速度,比 Vanilla Transformer 快 1800 + 倍。同时在多项任务上也达到了 SoTA 的效果。 1.2. Transformer-XL 建模更长序列 1.2.1 Segment-Level 循环机制 Transformer-XL 通过引入 Segment-Level recurrence mechanism 来建模更长序列,它通过融合前后两个 Segment 的信息来到这个目的。 这里循环机制和 RNN 循环机制类似,在 RNN 中,每个时刻的 RNN 单元会接收上个时刻的输出和当前时刻的输入,然后将两者融合计算得出当前时刻的输出。Transformer-XL 同样是接收上个时刻的输出和当前时刻的输入,然后将两者融合计算得出当前时刻的输出。但是两者的处理单位并不相同,RNN 的处理单位是一个词,Transformer-XL 的处理单位是一个 Segment。图 2 展示了 Transformer-XL 在训练阶段和评估阶段的 Segment 处理方式。 图 2 Transformer-XL 的训练和评估阶段 在模型训练阶段,如图 2a 所示,Transformer-XL 会缓存前一个 Segment 的输出序列,在计算下一个 Segment 的输出时会使用上一个 Segment 的缓存信息,将前后不同 Segment 的信息进行融合,能够帮助模型看见更远的地方,建模更长的序列依赖能力,同时也避免了 context fragmentation 问题。 在模型评估阶段,如图 2b 所示,Transformer-XL 通过缓存前一个 Segment 的输出序列,当下一个 Segment 需要用这些输出时(前后两个 Segment 具有大部分的重复),不需要重新计算,从而加快了推理速度。 下边我们来具体聊聊这些事情是怎么做的,假设前后的两个 Segment 分别为:$\text{s}_{\tau}=[x_{\tau,1},x_{\tau,2},...,x_{\tau,L}]$和 $\text{s}_{\tau+1}=[x_{\tau+1,1},x_{\tau+1,2},...,x_{\tau+1,L}]$,其中序列长度为 $L$。另外假定 $h_{\tau}^n \in \mathbb{R}^{L \times d}$为由 $\text{s}_{\tau}$计算得出的第 $n$层的状态向量,则下一个 Segment $\text{s}_{\tau+1}$的第 $n$层可按照如下方式计算: $$ \begin{align} & \tilde{h}_{\tau+1}^{n-1} = \left[ \text{SG}(h_{\tau}^{n-1}) \; \circ \;h_{\tau+1}^{n-1} \right] \\ & q_{\tau+1}^{n}, \; k_{\tau+1}^n, \; v_{\tau+1}^n = h_{\tau+1}^{n-1}W_{q}^{\mathrm{ T }}, \; \tilde{h}_{\tau+1}^{n-1}W_{k}^{\mathrm{ T }}, \; \tilde{h}_{\tau+1}^{n-1}W_{v}^{\mathrm{ T }} \\ & h_{\tau+1}^n = \text{Transformer-Layer}(q_{\tau+1}^{n}, \; k_{\tau+1}^n, \; v_{\tau+1}^n) \end{align} $$ 其中,$\text{SG}(h_{\tau}^{n-1})$ 表示不使用梯度,$\left[ \text{SG}(h_{\tau}^{n-1}) \; \circ \;h_{\tau+1}^{n-1} \right]$表示将前后两个 Segment 的输出向量在序列维度上进行拼接。中间的公式表示获取 Self-Attention 计算中相应的 $q,k,v$矩阵,其中在计算 $q$的时候仅仅使用了当前 Segment 的向量,在计算 $k$和 $v$的时候同时使用前一个 Segment 和当前 Segment 的信息。最后通过 Self-Attention 融合计算,得出当前 Segment 的输出向量序列。 1.2.2 相对位置编码 Segment-Level recurrence mechanism 看起来已经做到了长序列建模,但是这里有个问题需要进一步讨论一下。我们知道,在 Vanilla Transformer 使用了绝对位置编码,我们来看看如果将绝对位置编码应用到 Segment-Level recurrence mechanism 中会怎样。 还是假设前后的两个 Segment 分别为:$\text{s}_{\tau}=[x_{\tau,1},x_{\tau,2},...,x_{\tau,L}]$和 $\text{s}_{\tau+1}=[x_{\tau+1,1},x_{\tau+1,2},...,x_{\tau+1,L}]$,其中序列长度为 $L$。每个 Segment 的 Position Embedding 矩阵为 $U_{1:L} \in \mathbb{R}^{L \times d}$, 每个 Segment $\text{s}_{\tau}$的词向量矩阵为 $E_{\text{s}_{\tau}} \in \mathbb{R}^{L \times d}$,在 Vanilla Transformer 中,两者相加输入模型参与计算,如下式所示: $$ h_{\tau+1} = f(h_{\tau},\; E_{\text{s}_{\tau+1}}+U_{1:L}) \\ h_{\tau} = f(h_{\tau-1},\; E_{\text{s}_{\tau}}+U_{1:L}) $$ 很明显,如果按照这个方式计算,前后两个段 $E_{\text{s}_{\tau}}$和 $E_{\text{s}_{\tau+1}}$将具有相同的位置编码,这样两者信息融合的时候肯定会造成位置信息混乱。为了避免这份尴尬的操作,Transformer-XL 使用了相对位置编码。 相对位置是通过计算两个 token 之间的距离定义的,例如第 5 个 token 相对第 2 个 token 之间的距离是 3, 那么位置 $i$相对位置 $j$的距离是 $i-j$,假设序列之中的最大相对距离 $L_{max}$,则我们可以定义这样的一个相对位置矩阵 $R \in \mathbb{R}^{L_{max} \times d}$,其中 $R_k$表示两个 token 之间距离是 $k$的相对位置编码向量。注意在 Transformer-XL 中,相对位置编码向量不是可训练的参数,以 $R_k = [r_{k,1}, r_{k,2},...,r_{k,d}]$为例,每个元素通过如下形式生成: $$r_{b,2j} = \text{sin}(\frac{b}{10000^{2j/d}}), \quad r_{b,2j+1} = \text{cos}(\frac{b}{10000^{(2j)/d}})$$ Transformer-XL 将相对位置编码向量融入了 Self-Attention 机制的计算过程中,这里可能会有些复杂,我们先来看看 Vanilla Transformer 的 Self-Attention 计算过程,如下: $$ \begin{align} A_{i,j}^{\text{abs}} &= (W_q(E_{x_i}+U_i))^{\text{T}}(W_k(E_{x_j}+U_j))) \\ &= \underbrace {E_{x_i}^{\text{T}} W_q^{\text{T}} W_k E_{x_j}}_{(a)} + \underbrace {E_{x_i}^{\text{T}} W_q^{\text{T}} W_k U_j}_{(b)} + \underbrace {U_{i}^{\text{T}} W_q^{\text{T}} W_k E_{x_j}}_{(c)} + \underbrace {U_{i}^{\text{T}} W_q^{\text{T}} W_k U_{j}}_{(d)} \end{align} $$ 其中 $E_{x_i}$表示 token $x_i$的词向量,$U_i$表示其绝对位置编码,根据这个展开公式,Transformer-XL 将相对位置编码信息融入其中,如下: $$\begin{align} A_{i,j}^{\text{rel}} = \underbrace {E_{x_i}^{\text{T}} W_q^{\text{T}} W_{k,E} E_{x_j}}_{(a)} + \underbrace {E_{x_i}^{\text{T}} W_q^{\text{T}} W_{k,R} R_{i-j}}_{(b)} + \underbrace {u^{\text{T}} W_{k,E} E_{x_j}}_{(c)} + \underbrace {v^{\text{T}} W_{k,R} R_{i-j}}_{(d)} \end{align}$$ 这里做了这样几处改变以融入相对位置编码: 在分项 $(b)$和 $(d)$中,使用相对位置编码 $R_{i-j}$取代绝对位置编码 $U_j$。 在分项 $(c)$和 $(d)$中,使用可训练参数 $u$和 $v$取代 $U_{i}^{\text{T}} W_q^{\text{T}}$。因为 $U_{i}^{\text{T}} W_q^{\text{T}}$表示第 $i$个位置的 query 向量,这个 query 向量对于其他要进行 Attention 的位置来说都是一样的,因此可以直接使用统一的可训练参数进行替换。 在所有分项中,使用 $W_{k,E}$和 $W_{k,R}$计算基于内容 (词向量) 的 key 向量和基于位置的 key 向量。 式子中的每个分项分别代表的含义如下: $(a)$描述了基于内容的 Attention $(b)$描述了内容对于每个相对位置的 bias $(c)$描述了内容的全局 bias $(d)$描述了位置的全局 bias 1.2.3 完整的 Self-Attention 计算过程 上边描述了 Transformer-XL 中的两个核心技术:Segment-Level 循环机制和相对位置编码,引入了这两项技术之后,Transformer-XL 中从第 $n-1$层到第 $n$层完整的计算过程是这样的: $$ \begin{align} \tilde{h}_{\tau}^{n-1} &= \left[ \text{SG}(h_{\tau-1}^{n-1}) \; \circ \;h_{\tau}^{n-1} \right] \\ q_{\tau}^{n}, \; k_{\tau}^n, \; v_{\tau}^n &= h_{\tau}^{n-1}{W_{q}^n}^{\mathrm{ T }}, \; \tilde{h}_{\tau}^{n-1}{W_{k,E}^n}^{\mathrm{ T }}, \; \tilde{h}_{\tau}^{n-1}{W_{v}^n}^{\mathrm{ T }} \\ A_{\tau,i,j}^{n} &= {q_{\tau, i}^{n}}^{\text{T}}k_{\tau,j}^{n} + {q_{\tau, i}^{n}}^{\text{T}}W_{k,R}^{n}R_{i-j} + u^{\text{T}}k_{\tau,j} + v^{\text{T}}W_{k,R}^{n}R_{i-j} \\ {\alpha}_{\tau}^n &= \text{Masked-Softmax}(A_{\tau}^n)v_{\tau}^n \\ {\omicron}_{\tau}^n & = \text{LayerNorm}(\text{Linear}({\alpha}_{\tau}^n)+h_{\tau}^{n-1}) \\ h_{\tau}^n &= \text{Positionwise-Feed-Forward}({\omicron}_{\tau}^n) \end{align} $$ 相关资料: Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context Transformer-XL Github 2.Longformer: The Long-Document Transformer 2.1. Longformer简介 目前基于Transformer的预训练模型在各项NLP任务纷纷取得更好的效果,这些成功的部分原因在于Self-Attention机制,它运行模型能够快速便捷地从整个文本序列中捕获重要信息。然而传统的Self-Attention机制的时空复杂度与文本的序列长度呈平方的关系,这在很大程度上限制了模型的输入不能太长,因此需要将过长的文档进行截断传入模型进行处理,例如BERT中能够接受的最大序列长度为512。 基于这些考虑,Longformer被提出来拓展模型在长序列建模的能力,它提出了一种时空复杂度同文本序列长度呈线性关系的Self-Attention,用以保证模型使用更低的时空复杂度建模长文档。 这里需要注意的是Longformer是Transformer的Encoder端。 2.2 Longformer提出的Self-Attention Longformer对长文档建模主要的改进是提出了新的Self-Attention模式,如图1所示,下面我们来详细讨论一下。 图1 经典的Self-Attention和Longformer提出的Self-Attention 图1展示了经典的Self-Attention和Longformer提出的Self-Attention,其中图1a是经典的Self-Attention,它是一种”全看型”的Self-Attention,即每个token都要和序列中的其他所有token进行交互,因此它的时空复杂度均是$O(n^2)$。右边的三种模式是Longformer提出来的Self-Attention模式,分别是Sliding Window Attention(滑窗机制)、Dilated Sliding Window(空洞滑窗机制)和Global+Sliding Window(融合全局信息的滑窗机制)。 2.2.1 Sliding Window Attention 如图1b所示,对于某个token,经典的Self-Attention能够看到并融合所有其他的token,但Sliding window attention设定了一个窗口$w$,它规定序列中的每个token只能看到$w$个token,其左右两侧能看到$\frac{1}{2}w$个token,因此它的时间复杂度是$O(n\times w)$。 你不需要担心这种设定无法建立整个序列的语义信息,因为transformer模型结构本身是层层叠加的结构,模型高层相比底层具有更宽广的感受野,自然能够能够看到更多的信息,因此它有能力去建模融合全部序列信息的全局表示,就行CNN那样。一个拥有$m$层的transformer,它在最上层的感受野尺寸为$m\times w$。 通过这种设定Longformer能够在建模质量和效率之间进行一个比较好的折中。 2.2.2 Dilated Sliding Window 在对一个token进行Self-Attention操作时,普通的Sliding Window Attention只能考虑到长度为$w$的上下文,在不增加计算量的情况下,Longformer提出了Dilated Sliding Window,如图1c所示。在进行Self-Attention的两个相邻token之间会存在大小为$d$的间隙,这样序列中的每个token的感受野范围可扩展到$d\times w$。在第$m$层,感受野的范围将是$m\times d \times w$。 作者在文中提到,在进行Multi-Head Self-Attention时,在某些Head上不设置Dilated Sliding Window以让模型聚焦在局部上下文,在某些Head上设置Dilated Sliding Window以让模型聚焦在更长的上下文序列,这样能够提高模型表现。 2.2.3 Global Attention 以上两种Attention机制还不能完全适应task-specific的任务,因此Global+Sliding Window的Attention机制被提出来,如图1d所示。它设定某些位置的token能够看见全部的token,同时其他的所有token也能看见这些位置的token,相当于是将这些位置的token”暴露”在最外面。 这些位置的确定和具体的任务有关。例如对于分类任务,这个带有全局视角的token是”CLS”;对于QA任务,这些带有全局视角的token是Question对应的这些token。 那么这种融合全局信息的滑窗Attention具体如何实现呢,我们先来回顾一下经典的Self-Attention,公式如下: $$\text{Attention}(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})$$ 即将原始的输入分别映射到了$Q,K,V$三个空间后进行Attention计算,Global+Sliding Window这里涉及到两种Attention,Longformer中分别将这两种Attention映射到了两个独立的空间,即使用$Q_s,K_s,V_s$来计算Sliding Window Attention,使用$Q_g,K_g,V_g$来计算Global Attention。 2.3. Longformer Attention的实现 上述提出的Attention机制在当前的深度学习框架中尚未实现,比如PyTorch/Tensorflow,因此Longformer作者实现了三种方式并进行了对比,如图2所示。 图2 Longformer Attention的不同实现方式 其中Full Self-Attention是经典的自注意力实现;Longformer-loop是一种PyTorch实现,它能够有效节省内存使用并且支持Dilated Sliding Window, 但这种实现方式太慢,因此只能用于测试阶段。Longformer-chunks不支持Dilated Sliding Window,被用于预训练/微调阶段。Longformer-cuda是作者使用TVM实现的CUDA内核方法。可以看到,Longformer能够取得比较好的时空复杂度。 Longformer: The Long-Document Transformer Longformer Github 3.GPT 3.1 简介 2018 年 6 月,OpenAI 发表论文介绍了自己的语言模型 GPT,GPT 是“Generative Pre-Training”的简称,它基于 Transformer 架构,GPT模型先在大规模语料上进行无监督预训练、再在小得多的有监督数据集上为具体任务进行精细调节(fine-tune)的方式。先训练一个通用模型,然后再在各个任务上调节,这种不依赖针对单独任务的模型设计技巧能够一次性在多个任务中取得很好的表现。这中模式也是 2018 年中自然语言处理领域的研究趋势,就像计算机视觉领域流行 ImageNet 预训练模型一样。 NLP 领域中只有小部分标注过的数据,而有大量的数据是未标注,如何只使用标注数据将会大大影响深度学习的性能,所以为了充分利用大量未标注的原始文本数据,需要利用无监督学习来从文本中提取特征,最经典的例子莫过于词嵌入技术。但是词嵌入只能 word-level 级别的任务(同义词等),没法解决句子、句对级别的任务(翻译、推理等)。出现这种问题原因有两个: 不清楚下游任务,所以也就没法针对性的进行优化; 就算知道了下游任务,如果每次都要大改模型也会得不偿失。 为了解决以上问题,作者提出了 GPT 框架,用一种半监督学习的方法来完成语言理解任务,GPT 的训练过程分为两个阶段:无监督Pre-training 和 有监督Fine-tuning。在Pre-training阶段使用单向 Transformer 学习一个语言模型,对句子进行无监督的 Embedding,在fine-tuning阶段,根据具体任务对 Transformer 的参数进行微调,目的是在于学习一种通用的 Representation 方法,针对不同种类的任务只需略作修改便能适应。 3.2. 模型结构 GPT 使用 Transformer 的 Decoder 结构,并对 Transformer Decoder 进行了一些改动,原本的 Decoder 包含了两个 Multi-Head Attention 结构,GPT 只保留了 Mask Multi-Head Attention,如下图所示。 GPT 使用句子序列预测下一个单词,因此要采用 Mask Multi-Head Attention 对单词的下文遮挡,防止信息泄露。例如给定一个句子包含4个单词 [A, B, C, D],GPT 需要利用 A 预测 B,利用 [A, B] 预测 C,利用 [A, B, C] 预测 D。如果利用A 预测B的时候,需要将 [B, C, D] Mask 起来。 Mask 操作是在 Self-Attention 进行 Softmax 之前进行的,具体做法是将要 Mask 的位置用一个无穷小的数替换 -inf,然后再 Softmax,如下图所示。 Softmax 之前需要 Mask GPT Softmax 可以看到,经过 Mask 和 Softmax 之后,当 GPT 根据单词 A 预测单词 B 时,只能使用单词 A 的信息,根据 [A, B] 预测单词 C 时只能使用单词 A, B 的信息。这样就可以防止信息泄露。 下图是 GPT 整体模型图,其中包含了 12 个 Decoder。 GPT只使用了 Transformer 的 Decoder 部分,并且每个子层只有一个 Masked Multi Self-Attention(768 维向量和 12 个 Attention Head)和一个 Feed Forward,共叠加使用了 12 层的 Decoder。 这里简单解释下为什么只用 Decoder 部分:语言模型是利用上文预测下一个单词的,因为 Decoder 使用了 Masked Multi Self-Attention 屏蔽了单词的后面内容,所以 Decoder 是现成的语言模型。又因为没有使用 Encoder,所以也就不需要 encoder-decoder attention 了。 3.3. GPT训练过程 3.3.1 无监督的预训练 无监督的预训练(Pretraining),具体来说,给定一个未标注的预料库$U=\{u_{1},u_{2},...,u_{n}\}$,我们训练一个语言模型,对参数进行最大(对数)似然估计: $$L_{1}(U)=\sum_{i}log P(u_{i}|u_{1},...,u_{k-1};\Theta)$$ 其中,k 是上下文窗口的大小,P 为条件概率,$\Theta$为条件概率的参数,参数更新采用随机梯度下降(GPT实验实现部分具体用的是Adam优化器,并不是原始的随机梯度下降,Adam 优化器的学习率使用了退火策略)。 训练的过程也非常简单,就是将 n 个词的词嵌入$W_{e}$加上位置嵌入$W_{p}$,然后输入到 Transformer 中,n 个输出分别预测该位置的下一个词 可以看到 GPT 是一个单向的模型,GPT 的输入用 $h_{0}$ 表示,0代表的是输入层,$h_{0}$的计算公式如下 $$h_{0}=UW_{e}+W_{p}$$ $W_{e}$是token的Embedding矩阵,$W_{p}$是位置编码的 Embedding 矩阵。用 voc 表示词汇表大小,pos 表示最长的句子长度,dim 表示 Embedding 维度,则$W_{p}$是一个 pos×dim 的矩阵,$W_{e}$是一个 voc×dim 的矩阵。在GPT中,作者对position embedding矩阵进行随机初始化,并让模型自己学习,而不是采用正弦余弦函数进行计算。 得到输入 $h_{0}$ 之后,需要将 $h_{0}$ 依次传入 GPT 的所有 Transformer Decoder 里,最终得到$h_{n}$。 $$h_{l}=transformer\_block(h_{l-1}), \forall l \in [1,n]$$ n 为神经网络的层数。最后得到$h_{n}$再预测下个单词的概率。 $$P(u)=softmax(h_{n}W_{e}^T)$$ 3.3.2 有监督的Fine-Tuning 预训练之后,我们还需要针对特定任务进行 Fine-Tuning。假设监督数据集合$C$的输入$X$是一个序列$x^1,x^2,...,x^m$,输出是一个分类y的标签 ,比如情感分类任务 我们把$x^1,..,x^m$输入 Transformer 模型,得到最上层最后一个时刻的输出$h_{l}^m$,将其通过我们新增的一个 Softmax 层(参数为$W_{y}$)进行分类,最后用交叉熵计算损失,从而根据标准数据调整 Transformer 的参数以及 Softmax 的参数 $W_{y}$。这等价于最大似然估计: $$P(y|x^1,...,x^m)=softmax(h_{l}^mW_{y})$$ $W_{y}$表示预测输出时的参数,微调时候需要最大化以下函数: $$L_{2}(C)=\sum_{x,y}log P(y|x^1,..,x^m)$$ 正常来说,我们应该调整参数使得$L_{2}$最大,但是为了提高训练速度和模型的泛化能力,我们使用 Multi-Task Learning,GPT 在微调的时候也考虑预训练的损失函数,同时让它最大似然$L_{1}$和$L_{2}$ $$L_{3}(C)=L_{2}(C)+\lambda \times L_{1}(C)$$ 这里使用的$L_{1}$还是之前语言模型的损失(似然),但是使用的数据不是前面无监督的数据$U$,而是使用当前任务的数据$C$,而且只使用其中的$X$,而不需要标签y。 3.3.3 其它任务 针对不同任务,需要简单修改下输入数据的格式,例如对于相似度计算或问答,输入是两个序列,为了能够使用 GPT,我们需要一些特殊的技巧把两个输入序列变成一个输入序列 Classification:对于分类问题,不需要做什么修改 Entailment:对于推理问题,可以将先验与假设使用一个分隔符分开 Similarity:对于相似度问题,由于模型是单向的,但相似度与顺序无关,所以要将两个句子顺序颠倒后,把两次输入的结果相加来做最后的推测 Multiple-Choice:对于问答问题,则是将上下文、问题放在一起与答案分隔开,然后进行预测 3.4. GPT优缺点 特征抽取器使用了强大的 Transformer,能够捕捉到更长的记忆信息,且较传统的 RNN 更易于并行化; 方便的两阶段式模型,先预训练一个通用的模型,然后在各个子任务上进行微调,减少了传统方法需要针对各个任务定制设计模型的麻烦。 GPT 最大的问题就是传统的语言模型是单向的;我们根据之前的历史来预测当前词。但是我们不能利用后面的信息。比如句子 The animal didn’t cross the street because it was too tired。我们在编码 it 的语义的时候需要同时利用前后的信息,因为在这个句子中,it 可能指代 animal 也可能指代 street。根据 tired,我们推断它指代的是 animal。但是如果把 tired 改成 wide,那么 it 就是指代 street 了。Transformer 的 Self-Attention 理论上是可以同时关注到这两个词的,但是根据前面的介绍,为了使用 Transformer 学习语言模型,必须用 Mask 来让它看不到未来的信息,所以它也不能解决这个问题。 3.5. GPT 与 ELMo的区别 GPT 与 ELMo 有两个主要的区别: 模型架构不同:ELMo 是浅层的双向 RNN;GPT 是多层的 Transformer encoder 针对下游任务的处理不同:ELMo 将词嵌入添加到特定任务中,作为附加功能;GPT 则针对所有任务微调相同的基本模型 参考文献: Improving Language Understanding by Generative Pre-Training
深度学习进阶篇-预训练模型1:预训练分词Subword、ELMo、Transformer模型原理;结构;技巧以及应用详解
深度学习进阶篇-预训练模型[1]:预训练分词Subword、ELMo、Transformer模型原理;结构;技巧以及应用详解 从字面上看,预训练模型(pre-training model)是先通过一批语料进行训练模型,然后在这个初步训练好的模型基础上,再继续训练或者另作他用。这样的理解基本上是对的,预训练模型的训练和使用分别对应两个阶段:预训练阶段(pre-training)和 微调(fune-tuning)阶段。 预训练阶段一般会在超大规模的语料上,采用无监督(unsupervised)或者弱监督(weak-supervised)的方式训练模型,期望模型能够获得语言相关的知识,比如句法,语法知识等等。经过超大规模语料的”洗礼”,预训练模型往往会是一个Super模型,一方面体现在它具备足够多的语言知识,一方面是因为它的参数规模很大。 微调阶段是利用预训练好的模型,去定制化地训练某些任务,使得预训练模型”更懂”这个任务。例如,利用预训练好的模型继续训练文本分类任务,将会获得比较好的一个分类结果,直观地想,预训练模型已经懂得了语言的知识,在这些知识基础上去学习文本分类任务将会事半功倍。利用预训练模型去微调的一些任务(例如前述文本分类)被称为下游任务(down-stream)。 以BERT为例,BERT是在海量数据中进行训练的,预训练阶段包含两个任务:MLM(Masked Language Model)和NSP (Next Sentence Prediction)。前者类似”完形填空”,在一句中扣出一个单词,然后利用这句话的其他单词去预测被扣出的这个单词;后者是给定两句话,判断这两句话在原文中是否是相邻的关系。 BERT预训练完成之后,后边可以接入多种类型的下游任务,例如文本分类,序列标注,阅读理解等等,通过在这些任务上进行微调,可以获得比较好的实验结果。 1. 预训练分词Subword 1.1Subword介绍 1.1.1分词器是做什么的? 机器无法理解文本。当我们将句子序列送入模型时,模型仅仅能看到一串字节,它无法知道一个词从哪里开始,到哪里结束,所以也不知道一个词是怎么组成的。所以,为了帮助机器理解文本,我们需要 将文本分成一个个小片段 然后将这些片段表示为一个向量作为模型的输入 同时,我们需要将一个个小片段(token) 表示为向量,作为词嵌入矩阵, 通过在语料库上训练来优化token的表示,使其蕴含更多有用的信息,用于之后的任务。 1.1.2为什么需要分词? 在NLP任务中,神经网络模型的训练和预测都需要借助词表来对句子进行表示。 传统构造词表的方法,是先对各个句子进行分词,然后再统计并选出频数最高的前N个词组成词表。通常训练集中包含了大量的词汇,以英语为例,总的单词数量在17万到100万左右。 出于计算效率的考虑,通常N的选取无法包含训练集中的所有词。 因而,这种方法构造的词表存在着如下的问题: 实际应用中,模型预测的词汇是开放的,对于未在词表中出现的词(Out Of Vocabulary, OOV),模型将无法处理及生成; 词表中的低频词/稀疏词在模型训练过程中无法得到充分训练,进而模型不能充分理解这些词的语义; 一个单词因为不同的形态会产生不同的词,如由”look”衍生出的”looks”, “looking”, “looked”,显然这些词具有相近的意思,但是在词表中这些词会被当作不同的词处理,一方面增加了训练冗余,另一方面也造成了大词汇量问题。 一种解决思路是使用字符粒度来表示词表,虽然能够解决OOV问题,但单词被拆分成字符后,一方面丢失了词的语义信息,另一方面,模型输入会变得很长,这使得模型的训练更加复杂难以收敛。 1.1.3分词方法 分词的方法有很多,主要包括基于空格的分词方法,基于字母的分词方法和基于子词的分词方法,也可以自己设定一些分隔符号或者规则进行分词等等。基于子词的分词方法包括Byte Pair Encoding (BPE), WordPiece和Unigram Language Model。下面的章节会详细介绍这几种方法。 基于空格的分词方法 一个句子,使用不同的规则,将有许多种不同的分词结果。我们之前常用的分词方法将空格作为分词的边界。也就是图中的第三种方法。但是,这种方法存在问题,即只有在训练语料中出现的token才能被训练器学习到,而那些没有出现的token将会被$$等特殊标记代替,这样将影响模型的表现。如果我们将词典做得足够大,使其能容纳所有的单词。那么词典将非常庞大,产生很大的开销。同时对于出现次数很少的词,学习其token的向量表示也非常困难。除去这些原因,有很多语言不用空格进行分词,也就无法使用基于空格分词的方法。综上,我们需要新的分词方法来解决这些问题。 基于字母的分词方法 将每个字符看作一个词。 不用担心未知词汇,可以为每一个单词生成词嵌入向量表示。 字母本身就没有任何的内在含义,得到的词嵌入向量缺乏含义。 计算复杂度提升(字母的数目远大于token的数目) 输出序列的长度将变大,对于Bert、CNN等限制最大长度的模型将很容易达到最大值。 基于子词的分词方法 为了改进分词方法,在$$数目和词向量含义丰富性之间达到平衡,提出了Subword Tokenization方法。这种方法的目的是通过一个有限的单词列表来解决所有单词的分词问题,同时将结果中token的数目降到最低。例如,可以用更小的词片段来组成更大的词: “unfortunately” = “un” + “for” + “tun” + “ate” + “ly” 它的划分粒度介于词与字符之间,比如可以将”looking”划分为”look”和”ing”两个子词,而划分出来的”look”,”ing”又能够用来构造其它词,如”look”和”ed”子词可组成单词”looked”,因而Subword方法能够大大降低词典的大小,同时对相近词能更好地处理。 1.2 Byte Pair Encoding (BPE) BPE最早是一种数据压缩算法,由Sennrich等人于2015年引入到NLP领域并很快得到推广。该算法简单有效,因而目前它是最流行的方法。GPT-2和RoBERTa使用的Subword算法都是BPE。在信号压缩领域中BPE过程可视化如下: BPE获得Subword的步骤如下: 准备足够大的训练语料,并确定期望的Subword词表大小; 将单词拆分为成最小单元。比如英文中26个字母加上各种符号,这些作为初始词表; 在语料上统计单词内相邻单元对的频数,选取频数最高的单元对合并成新的Subword单元; 重复第3步直到达到第1步设定的Subword词表大小或下一个最高频数为1。 下面以一个例子来说明。假设有语料集经过统计后表示为: {‘low’:5,’lower’:2,’newest’:6,’widest’:3},其中数字代表的是对应单词在语料中的频数。 1)拆分单词成最小单元,并初始化词表。这里,最小单元为字符,因而,可得到 ‘low</w>’:5 ‘lower</w>’:2 ‘newest</w>’:6 ‘widest</w>’:3 l,o,w,e,r,n,i,d,est</w> 继续上述迭代直到达到预设的Subword词表大小或下一个最高频的字节对出现频率为1。 +1,表明加入合并后的新子词,同时原来的2个子词还保留(2个子词分开出现在语料中)。 +0,表明加入合并后的新子词,同时原来的2个子词中一个保留,一个被消解(一个子词完全随着另一个子词的出现而紧跟着出现)。 -1,表明加入合并后的新子词,同时原来的2个子词都被消解(2个子词同时连续出现)。 实际上,随着合并的次数增加,词表大小通常先增加后减小。 在得到Subword词表后,针对每一个单词,我们可以采用如下的方式来进行编码: 将词典中的所有子词按照长度由大到小进行排序; 对于单词w,依次遍历排好序的词典。查看当前子词是否是该单词的子字符串,如果是,则输出当前子词,并对剩余单词字符串继续匹配。 如果遍历完字典后,仍然有子字符串没有匹配,则将剩余字符串替换为特殊符号输出,如””。 单词的表示即为上述所有输出子词。 解码过程比较简单,如果相邻子词间没有中止符,则将两子词直接拼接,否则两子词之间添加分隔符。 可以很有效地平衡词典尺寸和编码步骤数(将句子编码所需要的token数量) 对于同一个句子, 例如Hello world,如图所示,可能会有不同的Subword序列。不同的Subword序列会产生完全不同的id序列表示,这种歧义可能在解码阶段无法解决。在翻译任务中,不同的id序列可能翻译出不同的句子,这显然是错误的。 在训练任务中,如果能对不同的Subword进行训练的话,将增加模型的健壮性,能够容忍更多的噪声,而BPE的贪心算法无法对随机分布进行学习。 1.3 WordPiece Google的Bert模型在分词的时候使用的是WordPiece算法。与BPE算法类似,WordPiece算法也是每次从词表中选出两个子词合并成新的子词。与BPE的最大区别在于,如何选择两个子词进行合并:BPE选择频数最高的相邻子词合并,而WordPiece选择能够提升语言模型概率最大的相邻子词加入词表。 假设句子$S=(t_{1},t_{2},...,t_{n})$由n个子词组成,$t_{i}$表示子词,且假设各个子词之间是独立存在的,则句子S的语言模型似然值等价于所有子词概率的乘积: $$log P(S)=\sum_{i=1}^n logP(t_{i})$$ 假设把相邻位置的x和y两个子词进行合并,合并后产生的子词记为z,此时句子似然值的变化可表示为: $$logP(t_{z})-(logP(t_{x})+logP(t_{y}))=log(\frac{P(t_{z})}{P(t_{x})P(t_{y})})$$ 从上面的公式,很容易发现,似然值的变化就是两个子词之间的互信息。简而言之,WordPiece每次选择合并的两个子词,他们具有最大的互信息值,也就是两子词在语言模型上具有较强的关联性,它们经常在语料中以相邻方式同时出现。 1.4 Unigram Language Model (ULM) Unigram模型是Kudo.在论文“Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates”中提出的。当时主要是为了解决机器翻译中分词的问题。作者使用一种叫做marginalized likelihood的方法来建模翻译问题,考虑到不同分词结果对最终翻译结果的影响,引入了分词概率。 与WordPiece一样,Unigram Language Model(ULM)同样使用语言模型来挑选子词。不同之处在于,BPE和WordPiece算法的词表大小都是从小到大变化,属于增量法。而Unigram Language Model则是减量法,即先初始化一个大词表,根据评估准则不断丢弃词表,直到满足限定条件。ULM算法考虑了句子的不同分词可能,因而能够输出带概率的多个子词分段。 对于句子S,$\vec x=(x_{1},x_{2},...,x_{m})$为句子的一个分词结果,由m个子词组成。所以,当前分词下句子S的似然值可以表示为: $$P(\vec x)=\prod_{i=1}^m{P(x_{i})}$$ 对于句子S,挑选似然值最大的作为分词结果,则可以表示为 $$x^{*}=arg max_{x \in U(x)} P(\vec x)$$ 其中$U(x)$包含了句子的所有分词结果。在实际应用中,词表大小有上万个,直接罗列所有可能的分词组合不具有操作性。针对这个问题,可通过维特比算法得到$x^*$来解决。 那怎么求解每个子词的概率$P(x_{i})$呢?ULM通过EM算法来估计。假设当前词表V, 则M步最大化的对象是如下似然函数: $$L=\sum_{s=1}^{|D|}log(P(X^{(s)}))=\sum_{s=1}^{|D|}log(\sum_{x \in U(X^{(s)})}P(x))$$ 其中,$|D|$是语料库中语料数量。上述公式的一个直观理解是,将语料库中所有句子的所有分词组合形成的概率相加。 但是,初始时,词表V并不存在。因而,ULM算法采用不断迭代的方法来构造词表以及求解分词概率: 初始时,建立一个足够大的词表。一般,可用语料中的所有字符加上常见的子字符串初始化词表,也可以通过BPE算法初始化。 针对当前词表,用EM算法求解每个子词在语料上的概率。 对于每个子词,计算当该子词被从词表中移除时,总的loss降低了多少,记为该子词的loss。 将子词按照loss大小进行排序,丢弃一定比例loss最小的子词(比如20%),保留下来的子词生成新的词表。这里需要注意的是,单字符不能被丢弃,这是为了避免OOV情况。 重复步骤2到4,直到词表大小减少到设定范围。 可以看出,ULM会保留那些以较高频率出现在很多句子的分词结果中的子词,因为这些子词如果被丢弃,其损失会很大。 使用的训练算法可以利用所有可能的分词结果,这是通过data sampling算法实现的。 提出一种基于语言模型的分词算法,这种语言模型可以给多种分词结果赋予概率,从而可以学到其中的噪声。 1.5 三种子词分词器的关系 2. ELMo 2.1. ELMo简绍 Deep contextualized word representations 获得了 NAACL 2018 的 outstanding paper award,其方法有很大的启发意义。近几年来,预训练的 word representation 在 NLP 任务中表现出了很好的性能,已经是很多 NLP 任务不可或缺的一部分,论文作者认为一个好的 word representation 需要能建模以下两部分信息:单词的特征,如语义,语法;单词在不同语境下的变化,即一词多义。基于这样的动机,作者提出了 ELMo 模型。ELMo 能够训练出来每个词的 embedding,可以作为上下文相关的词的向量。其他几个贡献: 使用字符级别的 CNN 表示。由于单词级别考虑数据可能稀疏,出现 OOV 问题,拆成字符后稀疏性没有那么强了,刻画的会更好。 训练了从左到右或从右到左的语言模型。用这个语言模型输出的结果,直接作为词的向量。 contextualized:这是一个语言模型,其双向 LSTM 产生的词向量会包含左侧上文信息和右侧下文信息,所以称之为 contextualized deep:句子中每个单词都能得到对应的三个 Embedding: 最底层是单词的 Word Embedding,往上走是第一层双向 LSTM 中对应单词位置的 Embedding,这层编码单词的句法信息更多一些;再往上走是第二层 LSTM 中对应单词位置的 Embedding,这层编码单词的语义信息更多一些。 下面的章节会详细介绍 ELMo。 2.1.1 从 Word Embedding 到 ELMo Word Embedding:词嵌入。最简单的理解就是:将词进行向量化表示,实体的抽象成了数学描述,就可以进行建模,应用到很多任务中。之前用语言模型做 Word Embedding 比较火的是 word2vec 和 glove。使用 Word2Vec 或者 Glove,通过做语言模型任务,就可以获得每个单词的 Word Embedding,但是 Word Embedding 无法解决多义词的问题,同一个词在不同的上下文中表示不同的意思,但是在 Word Embedding 中一个词只有一个表示,这导致两种不同的上下文信息都会编码到相同的 word embedding 空间里去。如何根据句子上下文来进行单词的 Word Embedding 表示。ELMO 提供了解决方案。 我们有以下两个句子: I read the book yesterday. Can you read the letter now? 花些时间考虑下这两个句子的区别,第一个句子中的动词 “read” 是过去式,而第二个句子中的 “read” 却是现在式,这是一种一词多义现象。 传统的词嵌入会对两个句子中的词 “read” 生成同样的向量,所以这些架构无法区别多义词,它们无法识别词的上下文。 与之相反,ELMo 的词向量能够很好地解决这种问题。ELMo 模型将整个句子输入方程式中来计算词嵌入。因此,上例中两个句子的 “read” 会有不同的 ELMo 向量。 2.2.ELMo 原理 在此之前的 Word Embedding 本质上是个静态的方式,所谓静态指的是训练好之后每个单词的表达就固定住了,以后使用的时候,不论新句子上下文单词是什么,这个单词的 Word Embedding 不会跟着上下文场景的变化而改变,所以对于比如 Bank 这个词,它事先学好的 Word Embedding 中混合了几种语义 ,在应用中来了个新句子,即使从上下文中(比如句子包含 money 等词)明显可以看出它代表的是 “银行” 的含义,但是对应的 Word Embedding 内容也不会变,它还是混合了多种语义。这是为何说它是静态的,这也是问题所在。 ELMO 的本质思想是:我事先用语言模型学好一个单词的 Word Embedding,此时多义词无法区分,不过这没关系。在我实际使用 Word Embedding 的时候,单词已经具备了特定的上下文了,这个时候我可以根据上下文单词的语义去调整单词的 Word Embedding 表示,这样经过调整后的 Word Embedding 更能表达在这个上下文中的具体含义,自然也就解决了多义词的问题了。所以 ELMO 本身是个根据当前上下文对 Word Embedding 动态调整的思路。 ELMo 表征是 “深” 的,就是说它们是 BiLM 的所有层的内部表征的函数。这样做的好处是能够产生丰富的词语表征。高层的 LSTM 的状态可以捕捉词语以一种和语境相关的特征(比如可以应用在语义消歧),而低层的 LSTM 可以找到语法方面的特征(比如可以做词性标注)。如果把它们结合在一起,会在下游的 NLP 任务中显出优势。 2.2.1 模型结构 ELMO 基于语言模型的,确切的来说是一个 Bidirectional language models,也是一个 Bidirectional LSTM 结构。我们要做的是给定一个含有 N 个 tokens 的序列。分为以下三步: 第一步:得到 word embedding,即上图的 E。所谓 word embedding 就是一个 n*1 维的列向量,其中 n 表示 embedding 向量的大小; 第二步:送入双向 LSTM 模型中,即上图中的 Lstm; 第三步:将 LSTM 的输出 $h_{k}$,与上下文矩阵 $W'$相乘,再将该列向量经过 Softmax 归一化。其中,假定数据集有 V 个单词,$W'$是 $|V|*m$的矩阵,$h_{k}$是 $m*1$的列向量,于是最终结果是 $|V|*1$的归一化后向量,即从输入单词得到的针对每个单词的概率。 2.2.2 双向语言模型 假定一个序列有 N 个 token,即 $(t_{1},t_{2},...,t_{N})$,对于前向语言模型(forward LM),我们基于 $(t_{1},..,t_{k-1})$来预测 $t_{k}$,前向公式表示为: $$p(t_{1},t_{2},...,t_{N})=\prod_{k=1}^{N}p(t_{k}|t_{1},t_{2},...,t_{k-1})$$ 向后语言模型(backword LM)与向前语言模型类似,除了计算的时候倒置输入序列,用后面的上下文预测前面的词: $$p(t_{1},t_{2},...,t_{N})=\prod_{k=1}^{N}p(t_{k}|t_{k+1},t_{k+2},...,t_{N})$$ 一个双向语言模型包含前向和后向语言模型,训练的目标就是联合前向和后向的最大似然: $$\sum_{k=1}^N (log p(t_{k}|t_{1},...,t_{k-1};\Theta_{x},\overrightarrow\Theta_{LSTM},\Theta_{s})+log p(t_{k}|t_{k+1},...,t_{N};\overleftarrow\Theta_{LSTM},\Theta_{s}))$$ 两个网络里都出现了$\Theta_{x}$和$\Theta_{s}$,两个网络共享的参数。 其中$\Theta_{x}$表示映射层的共享,表示第一步中,将单词映射为 word embedding 的共享,就是说同一个单词,映射为同一个 word embedding。 $\Theta_{s}$表示第三步中的上下文矩阵的参数,这个参数在前向和后向 LSTM 中是相同的。 2.2.3 ELMo ELMo 对于每个 token $t_{k}$, 通过一个 L 层的 biLM 计算 2L+1 个表征(representations),这是输入第二阶段的初始值: $$R_{k}=\{ x_{k}^{LM},\overrightarrow h^{LM}_{k,j},\overleftarrow h^{LM}_{k,j}|j=1,...,L\}$$ $$=\{h_{k,j}^{LM}|j=0,...,L\}$$ 其中 k 表示单词位置,j 表示所在层,j=0 表示输入层。故整体可用右侧的 h 表示。$h_{k,0}^{LM}$是对 token 进行直接编码的结果 (这里是字符通过 CNN 编码), $h_{k,j}^{LM}=[\overrightarrow h^{LM}_{k,j};\overleftarrow h^{LM}_{k,j}]$是每个 biLSTM 层输出的结果。在实验中还发现不同层的 biLM 的输出的 token 表示对于不同的任务效果不同. 最上面一层的输出是用 softmax 来预测下面一个单词 应用中将 ELMo 中所有层的输出 R 压缩为单个向量, $ELMo_{k}=E(R_{k};\Theta_{\epsilon})$,最简单的压缩方法是取最上层的结果做为 token 的表示:$E(R_{k})=h_{k,L}^{LM}$, 更通用的做法是通过一些参数来联合所有层的信息: $$ELMo_{k}^{task}=E(R_{k};\Theta^{task})$$ $$=\gamma^{task}\sum_{j=0}^{L}s_{j}^{task}h_{k,j}^{LM}$$ 其中 $s_{j}$是 softmax 标准化权重,$\gamma$是缩放系数,允许任务模型去缩放整个 ELMO 向量。文中提到γ在不同任务中取不同的值效果会有较大的差异, 需要注意, 在 SQuAD 中设置为 0.01 取得的效果要好于设置为 1 时。 文章中提到的 Pre-trained 的 language model 是用了两层的 biLM, 对 token 进行上下文无关的编码是通过 CNN 对字符进行编码, 然后将三层的输出 scale 到 1024 维, 最后对每个 token 输出 3 个 1024 维的向量表示. 2.3.ELMo 训练 2.3.1 第一阶段 语言模型进行预训练 ELMo 采用了典型的两阶段过程,第一个阶段是利用语言模型进行预训练;第二个阶段是在做下游任务时,从预训练网络中提取对应单词的网络各层的 Word Embedding 作为新特征补充到下游任务中。图展示的是其预训练过程: 它的网络结构采用了双层双向 LSTM,目前语言模型训练的任务目标是根据单词 $W_{i}$的上下文去正确预测单词 $W_{i}$,$W_{i}$之前的单词序列 Context-before 称为上文,之后的单词序列 Context-after 称为下文。图中左端的前向双层 LSTM 代表正方向编码器,输入的是从左到右顺序的除了预测单词外 $W_{i}$的上文 Context-before;右端的逆向双层 LSTM 代表反方向编码器,输入的是从右到左的逆序的句子下文 Context-after;每个编码器的深度都是两层 LSTM 叠加。这个网络结构其实在 NLP 中是很常用的。 使用这个网络结构利用大量语料做语言模型任务就能预先训练好这个网络,如果训练好这个网络后,输入一个新句子 $S_{new}$,句子中每个单词都能得到对应的三个 Embedding: 最底层是单词的 Word Embedding,往上走是第一层双向 LSTM 中对应单词位置的 Embedding,这层编码单词的句法信息更多一些;再往上走是第二层 LSTM 中对应单词位置的 Embedding,这层编码单词的语义信息更多一些。也就是说,ELMO 的预训练过程不仅仅学会单词的 Word Embedding,还学会了一个双层双向的 LSTM 网络结构,而这两者后面都有用。 2.3.2 第二阶段 接入下游 NLP 任务 下图展示了下游任务的使用过程,比如我们的下游任务仍然是 QA 问题,此时对于问句 X,我们可以先将句子 X 作为预训练好的 ELMo 网络的输入,这样句子 X 中每个单词在 ELMO 网络中都能获得对应的三个 Embedding,之后给予这三个 Embedding 中的每一个 Embedding 一个权重 a,这个权重可以学习得来,根据各自权重累加求和,将三个 Embedding 整合成一个。然后将整合后的这个 Embedding 作为 X 句在自己任务的那个网络结构中对应单词的输入,以此作为补充的新特征给下游任务使用。 对于上图所示下游任务 QA 中的回答句子 Y 来说也是如此处理。因为 ELMO 给下游提供的是每个单词的特征形式,所以这一类预训练的方法被称为 “Feature-based Pre-Training”。 最后,作者发现给 ELMo 模型增加一定数量的 Dropout,在某些情况下给损失函数加入正则项$\lambda ||w||^2_{2}$,这等于给 ELMo 模型加了一个归纳偏置,使得权重接近 BiLM 所有层的平均权重。 2.4. ELMo 使用步骤 ELMO 的使用主要有三步: 在大的语料库上预训练 biLM 模型。模型由两层 biLSTM 组成,模型之间用残差连接起来。而且作者认为低层的 biLSTM 层能提取语料中的句法信息,高层的 biLSTM 能提取语料中的语义信息。 在我们的训练语料(去除标签),fine-tuning 预训练好的 biLM 模型。这一步可以看作是 biLM 的 domain transfer。 利用 ELMo 产生的 word embedding 来作为任务的输入,有时也可以即在输入时加入,也在输出时加入。 2.4.1优缺点 考虑上下文,针对不同的上下文生成不同的词向量。表达不同的语法或语义信息。如 “活动” 一词,既可以是名词,也可以是动词,既可以做主语,也可以做谓语等。针对这种情况,ELMo 能够根据不同的语法或语义信息生成不同的词向量。 6 个 NLP 任务中性能都有幅度不同的提升,最高的提升达到 25% 左右,而且这 6 个任务的覆盖范围比较广,包含句子语义关系判断,分类任务,阅读理解等多个领域,这说明其适用范围是非常广的,普适性强,这是一个非常好的优点。 使用 LSTM 提取特征,而 LSTM 提取特征的能力弱于 Transformer 使用向量拼接方式融合上下文特征,这种方式获取的上下文信息效果不如想象中好 训练时间长,这也是 RNN 的本质导致的,和上面特征提取缺点差不多; 参考文献: Deep contextualized word representations 3.Transformer 3.1.Transformer 介绍 Transformer 网络架构架构由 Ashish Vaswani 等人在 Attention Is All You Need 一文中提出,并用于机器翻译任务,和以往网络架构有所区别的是,该网络架构中,编码器和解码器没有采用 RNN 或 CNN 等网络架构,而是采用完全依赖于注意力机制的架构。网络架构如下所示: Transformer 改进了 RNN 被人诟病的训练慢的特点,利用 self-attention 可以实现快速并行。下面的章节会详细介绍 Transformer 的各个组成部分。 Transformer 主要由 encoder 和 decoder 两部分组成。在 Transformer 的论文中,encoder 和 decoder 均由 6 个 encoder layer 和 decoder layer 组成,通常我们称之为 encoder block。 transformer 结构 每一个 encoder 和 decoder 的内部简版结构如下图 transformer 的 encoder 或者 decoder 的内部结构 对于 encoder,包含两层,一个 self-attention 层和一个前馈神经网络,self-attention 能帮助当前节点不仅仅只关注当前的词,从而能获取到上下文的语义。 decoder 也包含 encoder 提到的两层网络,但是在这两层中间还有一层 attention 层,帮助当前节点获取到当前需要关注的重点内容。 首先,模型需要对输入的数据进行一个 embedding 操作,enmbedding 结束之后,输入到 encoder 层,self-attention 处理完数据后把数据送给前馈神经网络,前馈神经网络的计算可以并行,得到的输出会输入到下一个 encoder。 embedding 和 self-attention 3.2 Transformer 的结构 Transformer 的结构解析出来如下图表示,包括 Input Embedding, Position Embedding, Encoder, Decoder。 3.2.1 Embedding 字向量与位置编码的公式表示如下: $$X=Embedding Lookup(X)+Position Encoding$$ Input Embedding 可以将 Input Embedding 看作是一个 lookup table,对于每个 word,进行 word embedding 就相当于一个 lookup 操作,查出一个对应结果。 Position Encoding Transformer 模型中还缺少一种解释输入序列中单词顺序的方法。为了处理这个问题,transformer 给 encoder 层和 decoder 层的输入添加了一个额外的向量 Positional Encoding,维度和 embedding 的维度一样,这个向量采用了一种很独特的方法来让模型学习到这个值,这个向量能决定当前词的位置,或者说在一个句子中不同的词之间的距离。这个位置向量的具体计算方法有很多种,论文中的计算方法如下 $$PE(pos,2i)=sin(pos/10000^{2i}/d_{model})$$ $$PE(pos,2i+1)=cos(pos/10000^{2i}/d_{model})$$ 其中 pos 是指当前词在句子中的位置,i 是指向量中每个值的 index,可以看出,在偶数位置,使用正弦编码,在奇数位置,使用余弦编码. 3.2.2 Encoder 用公式把一个 Transformer Encoder block 的计算过程整理一下 自注意力机制 $$Q=XW_{Q}$$ $$K=XW_{K}$$ $$V=XW_{V}$$ $$X_{attention}=selfAttention(Q,K,V)$$ self-attention 残差连接与 Layer Normalization $$X_{attention}=LayerNorm(X_{attention})$$ FeedForward,其实就是两层线性映射并用激活函数激活,比如说 RELU $$X_{hidden}=Linear(RELU(Linear(X_{attention})))$$ FeedForward 残差连接与 Layer Normalization $$X_{hidden}=X_{attention}+X_{hidden}$$ $$X_{hidden}=LayerNorm(X_{hidden})$$ 其中:$X_{hidden} \in R^{batch_size*seq_len*embed_dim}$ 3.2.3自注意力机制 首先,自注意力机制(self-attention)会计算出三个新的向量,在论文中,向量的维度是 512 维,我们把这三个向量分别称为 Query、Key、Value,这三个向量是用 embedding 向量与一个矩阵相乘得到的结果,这个矩阵是随机初始化的,维度为(64,512)注意第二个维度需要和 embedding 的维度一样,其值在反向传播的过程中会一直进行更新,得到的这三个向量的维度是 64 低于 embedding 维度的。 Query Key Value 2、计算 self-attention 的分数值,该分数值决定了当我们在某个位置 encode 一个词时,对输入句子的其他部分的关注程度。这个分数值的计算方法是 Query 与 Key 做点乘,以下图为例,首先我们需要针对 Thinking 这个词,计算出其他词对于该词的一个分数值,首先是针对于自己本身即 q1·k1,然后是针对于第二个词即 q1·k2 Query Key Value 3、接下来,把点乘的结果除以一个常数,这里我们除以 8,这个值一般是采用上文提到的矩阵的第一个维度的开方即 64 的开方 8,当然也可以选择其他的值,然后把得到的结果做一个 softmax 的计算。得到的结果即是每个词对于当前位置的词的相关性大小,当然,当前位置的词相关性肯定会会很大 softmax 4、下一步就是把 Value 和 softmax 得到的值进行相乘,并相加,得到的结果即是 self-attetion 在当前节点的值。 dot product 在实际的应用场景,为了提高计算速度,我们采用的是矩阵的方式,直接计算出 Query, Key, Value 的矩阵,然后把 embedding 的值与三个矩阵直接相乘,把得到的新矩阵 Q 与 K 相乘,乘以一个常数,做 softmax 操作,最后乘上 V 矩阵 scaled dot product attention 这种通过 query 和 key 的相似性程度来确定 value 的权重分布的方法被称为 scaled dot-product attention。 用公式表达如下: $$Q=XW_{Q}$$ $$K=XW_{K}$$ $$V=XW_{V}$$ $$X_{attention}=selfAttention(Q,K,V)$$ 3.2.4 Self-Attention 复杂度 Self-Attention 时间复杂度:$O(n^2 \cdot d)$ ,这里,n 是序列的长度,d 是 embedding 的维度。 Self-Attention 包括三个步骤:相似度计算,softmax 和加权平均,它们分别的时间复杂度是: 相似度计算可以看作大小为 (n,d) 和(d,n)的两个矩阵相乘: $(n,d) *(d,n) =(n^2 \cdot d)$,得到一个 (n,n) 的矩阵 softmax 就是直接计算了,时间复杂度为: $O(n^2)$ 加权平均可以看作大小为 (n,n) 和(n,d)的两个矩阵相乘: $(n,d) *(d,n) =(n^2 \cdot d)$,得到一个 (n,d) 的矩阵 因此,Self-Attention 的时间复杂度是: $O(n^2 \cdot d)$ 3.2.5 Multi-head Attention 不仅仅只初始化一组 Q、K、V 的矩阵,而是初始化多组,tranformer 是使用了 8 组,所以最后得到的结果是 8 个矩阵。 multi-head attention multi-head 注意力的全过程如下,首先输入句子,“Thinking Machines”, 在 embedding 模块把句子中的每个单词变成向量 X,在 encoder 层中,除了第 0 层有 embedding 操作外,其他的层没有 embedding 操作;接着把 X 分成 8 个 head, multi-head attention 总体结构 3.2.6 Multi-Head Attention 复杂度 多头的实现不是循环的计算每个头,而是通过 transposes and reshapes,用矩阵乘法来完成的。 Transformer/BERT 中把 d ,也就是 hidden_size/embedding_size 这个维度做了 reshape 拆分。并将 num_attention_heads 维度 transpose 到前面,使得 Q 和 K 的维度都是 (m,n,a),这里不考虑 batch 维度。 这样点积可以看作大小为 (m,n,a) 和(m,a,n)的两个张量相乘,得到一个 (m,n,n) 的矩阵,其实就相当于 (n,a) 和(a,n)的两个矩阵相乘,做了 m 次,时间复杂度是: $$O(n^2 \cdot m \cdot a)=O(n^2 \cdot d)$$ 因此 Multi-Head Attention 时间复杂度也是 $O(n^2 \cdot d)$,复杂度相较单头并没有变化,主要还是 transposes and reshapes 的操作,相当于把一个大矩阵相乘变成了多个小矩阵的相乘。 3.2.7 残差连接 经过 self-attention 加权之后输出,也就是 Attention(Q,K,V) ,然后把他们加起来做残差连接 $$X_{hidden}=X_{embedding}+self Attention(Q,K,V)$$ 除了 self-attention 这里做残差连接外,feed forward 那个地方也需要残差连接,公式类似: $$X_{hidden}=X_{feed_forward}+X_{hidden}$$ 3.2.8 Layer Normalization Layer Normalization 的作用是把神经网络中隐藏层归一为标准正态分布,也就是独立同分布,以起到加快训练速度,加速收敛的作用 $$X_{hidden}=LayerNorm(X_{hidden})$$ 其中:$X_{hidden} \in R^{batch_size*seq_len*embed_dim}$ LayerNorm 的详细操作如下: $$\mu_{L}=\dfrac{1}{m}\sum_{i=1}^{m}x_{i}$$ 上式以矩阵为单位求均值; $$\delta^{2}=\dfrac{1}{m}\sum_{i=1}^{m}(x_{i}-\mu)^2$$ 上式以矩阵为单位求方差 $$LN(x_{i})=\alpha \dfrac{x_{i}-\mu_{L}}{\sqrt{\delta^{2}+\epsilon}}+\beta$$ 然后用每一列的每一个元素减去这列的均值,再除以这列的标准差,从而得到归一化后的数值,加$\epsilon$是为了防止分母为 0. 此处一般初始化$\alpha$为全 1,而$\beta$为全 0. 3.2.9 Feed Forward 将 Multi-Head Attention 得到的向量再投影到一个更大的空间(论文里将空间放大了 4 倍)在那个大空间里可以更方便地提取需要的信息(使用 Relu 激活函数),最后再投影回 token 向量原来的空间 $$FFN(x)=ReLU(W_{1}x+b_{1})W_{2}+b_{2}$$ 借鉴 SVM 来理解:SVM 对于比较复杂的问题通过将特征其投影到更高维的空间使得问题简单到一个超平面就能解决。这里 token 向量里的信息通过 Feed Forward Layer 被投影到更高维的空间,在高维空间里向量的各类信息彼此之间更容易区别。 3.3 Decoder 和 Encoder 一样,上面三个部分的每一个部分,都有一个残差连接,后接一个 Layer Normalization。Decoder 的中间部件并不复杂,大部分在前面 Encoder 里我们已经介绍过了,但是 Decoder 由于其特殊的功能,因此在训练时会涉及到一些细节,下面会介绍 Decoder 的 Masked Self-Attention 和 Encoder-Decoder Attention 两部分,其结构图如下图所示 decoder self attention 3.2.10 Masked Self-Attention 传统 Seq2Seq 中 Decoder 使用的是 RNN 模型,因此在训练过程中输入因此在训练过程中输入 t 时刻的词,模型无论如何也看不到未来时刻的词,因为循环神经网络是时间驱动的,只有当 t 时刻运算结束了,才能看到 t+1 时刻的词。而 Transformer Decoder 抛弃了 RNN,改为 Self-Attention,由此就产生了一个问题,在训练过程中,整个 ground truth 都暴露在 Decoder 中,这显然是不对的,我们需要对 Decoder 的输入进行一些处理,该处理被称为 Mask。 Mask 非常简单,首先生成一个下三角全 0,上三角全为负无穷的矩阵,然后将其与 Scaled Scores 相加即可,之后再做 softmax,就能将 -inf 变为 0,得到的这个矩阵即为每个字之间的权重。 3.3.2 Masked Encoder-Decoder Attention¶ 其实这一部分的计算流程和前面 Masked Self-Attention 很相似,结构也一摸一样,唯一不同的是这里的 K,V 为 Encoder 的输出,Q 为 Decoder 中 Masked Self-Attention 的输出 Masked Encoder-Decoder Attention 3.2.11 Decoder 的解码 下图展示了 Decoder 的解码过程,Decoder 中的字符预测完之后,会当成输入预测下一个字符,知道遇见终止符号为止。 3.3 Transformer 的最后一层和 Softmax 线性层是一个简单的全连接的神经网络,它将解码器堆栈生成的向量投影到一个更大的向量,称为 logits 向量。如图 linear 的输出 softmax 层将这些分数转换为概率(全部为正值,总和为 1.0)。选择概率最高的单元,并生成与其关联的单词作为此时间步的输出。如图 softmax 的输出。 3.4 Transformer 的权重共享 Transformer 在两个地方进行了权重共享: (1)Encoder 和 Decoder 间的 Embedding 层权重共享; 《Attention is all you need》中 Transformer 被应用在机器翻译任务中,源语言和目标语言是不一样的,但它们可以共用一张大词表,对于两种语言中共同出现的词(比如:数字,标点等等)可以得到更好的表示,而且对于 Encoder 和 Decoder,嵌入时都只有对应语言的 embedding 会被激活,因此是可以共用一张词表做权重共享的。 论文中,Transformer 词表用了 bpe 来处理,所以最小的单元是 subword。英语和德语同属日耳曼语族,有很多相同的 subword,可以共享类似的语义。而像中英这样相差较大的语系,语义共享作用可能不会很大。 但是,共用词表会使得词表数量增大,增加 softmax 的计算时间,因此实际使用中是否共享可能要根据情况权衡。 (2)Decoder 中 Embedding 层和 FC 层权重共享; Embedding 层可以说是通过 onehot 去取到对应的 embedding 向量,FC 层可以说是相反的,通过向量(定义为 x)去得到它可能是某个词的 softmax 概率,取概率最大(贪婪情况下)的作为预测值。 那哪一个会是概率最大的呢?在 FC 层的每一行量级相同的前提下,理论上和 x 相同的那一行对应的点积和 softmax 概率会是最大的(可类比本文问题 1)。 因此,Embedding 层和 FC 层权重共享,Embedding 层中和向量 x 最接近的那一行对应的词,会获得更大的预测概率。实际上,Decoder 中的 Embedding 层和 FC 层有点像互为逆过程。 通过这样的权重共享可以减少参数的数量,加快收敛。 3.4 小结 本文详细介绍了 Transformer 的细节,包括 Encoder,Decoder 部分,输出解码的部分,Transformer 的共享机制等等。 Attention Is All You Need
默认比例是 1:1。 比例数需要是整数,比如 1.3:1 是不行的,但 13:10 可以。 长宽比会影响生成图像的形状和构图。当放大图片时,有些长宽比可能会发生轻微的改变。比如 --ar 16:9(1.75) 最终生成的图片可能是 7:4(1.74)。 ✅ 支持任意比例。但2:1以上的宽高比是实验性的,可能会产生不可预测的结果。 ✅ 1:2 到 2:1 ✅ 5:2 到 2:5 ✅ 1:2 到 2:1 在关键词后加空格,然后带上你不想 AI 生成的内容: --no 或者 —no —no plants 在关键词后加空格,然后带数字: --c 或者 —c --chaos 或者—chaos —c 10 可以输入 0 - 100,默认是 0 风格化程度 在关键词后加空格,然后带数字: --s 或者 —s --stylize 或者—stylize —s 50 默认是 100 细节丰富度 在关键词后加空格带上参数: --q 或者 —q --quality 或者—quality woodcut birch forest --q .25 默认为 1 - 仅支持 .25,.5 ,1 和 2,如果输入大于 2 会被降级到 2 在关键词后加空格带上参数: --seed 或者 —seed --sameseed 或者—sameseed woodcut birch forest --seed 123 输入完全一样的文字 prompt,并且加上 seed 参数,才能生成一样的图。 V1、2、3 还有 test、testp 版本即使加了这个 seed 也没法生成一模一样的图,只能生成近似的图。 ✅ 但只能生成近似图 在关键词后加空格带上参数: --iw 或者 —iw flowers.jpg birthday cake --iw .5 这个参数在不同版本有不同的默认值(就是即使你不输入这个参数,AI 也会自己加这个参数进去)和区间 ✅ 默认为 1,区间是 0.5-2 ✅ 默认为 0.25,区间是 -10000-10000 2.文生图词典合集 Chibi Anime Style Chibi Anime Style 是指卡通迷你风格。是一种独特的绘画风格,特别受到日本动漫迷和卡通迷的喜爱。该风格的特点是将角色绘制成缩小版的样式,更加可爱和卡通化。在这种风格下,一些角色的头比正常比例大得多,人物的描绘也更加简化,并且动画在绘制时常常用短暂时间的快速动作来传递动态效果。 Gakuen Anime Style Gakuen Anime Style是指在日本动漫中常见的一种风格,主要呈现校园生活与高中生活的情境。这种风格的作品通常涉及到学生会、文化节、恋爱、友情、竞争等校园主题,角色也往往是年龄在16-18岁之间的学生。 Gekiga Anime Style Gekiga Anime Style是一种比较沉重、严肃的日本漫画风格,常常涉及社会问题、人生哲理等成人主题。这种风格的特点是以黑色、灰色为主色调,图像表现力较强,人物表情和行为也更加真实。 J Horror Anime Style J Horror Anime Style是指恐怖题材的日本动漫风格,这种风格的作品常常涉及灵异、鬼怪、妖怪等超自然力量。 Jidaimono Anime Style Jidaimono Anime Style是指日本历史剧题材的动漫风格,通常呈现古代日本的历史背景和文化特征。这种风格的作品往往描绘战争、家族斗争、忍者、武士道、神话传说等元素,以及用具有浓重日本特色的艺术表现手法来传递历史文化的内涵。 Kawaii Anime Style Kawaii Anime Style是一种非常可爱和萌的动漫风格,通常呈现出像动物、小孩、角色等可爱的形象。这种风格的作品以颜色鲜明、轮廓粗糙、脸部表情夸张为主要特点。 Mecha Anime Style Mecha Anime Style是以机器人为主题的日本动漫风格,通常呈现出大型机器、机甲战争、铁甲舞者等元素。这种风格的作品常常运用科幻、未来世界设定、大规模战斗等元素,以及动态的战斗场面和机器人设计,塑造出复杂的机器人世界和角色人物关系。 Realistic Anime Style Realistic Anime Style是一种真实主义的日本动漫风格,通常呈现出秉持着更加现实和真实的人物形象和情节。这种风格的作品表现力很强,人物形象、环境场景等具有更多的细节,刻画出更为真实的情感世界。 Semi-Realistic Anime Style Semi-Realistic Anime Style是在Realistic Anime Style和 Anime Style之间的一个中间状态的风格,风格上比较真实,但是仍带有一定的动漫风格。这种风格的作品通常涉及到带有现实性的情节和人物,但是也常常运用到动漫风格的表现手法。 Shoji Anime Style Shoji Anime Style是按照日本漫画家小学馆长生涯逐步形成的一种风格。这种风格的作品,通常以聚焦单个人物或小团体的故事为主线。其特点是画面明亮,颜色和谐,人物表情和行为搞笑夸张,情节简洁易懂。 Kemonomimi Anime Style Kemonomimi Anime Style是一种带有动物耳朵和尾巴等特征的日本动漫风格,通常以人类或近似人类的形象呈现,但却带有不同种类的动物耳朵和尾巴等特征。这种风格的作品与少女漫画(girls' manga)、少年漫画(boys' manga)等风格都有一定的关系。 4.相机和镜头设置列表 Short Exposure 通常用于追拍运动员、表演者或动物等,或者是拍摄需要快速决定瞬间捕捉的场景,例如拍摄火车、汽车、快速移动的车辆等。由于短曝光时间的限制,这种方式可以冻结运动物体并防止出现模糊的情况。 Long Exposure 在长曝光的拍摄中,快速移动的物体会出现轨迹,例如流星、车灯、瀑布等,这种方式会给照片创造出愉悦而神秘的氛围。此外,长曝光可以用于拍摄夜晚的大片景象,例如景色、城市夜景、星空等。 Double Exposure 双重曝光的技术,可以创造出疏密有致和扭曲的、手绘和黑白艺术风格的照片。这种技术在拍摄人像、风景和建筑等领域十分受欢迎,因为它可以创造出独特的环境、浪漫和奇异感觉的图像。 2.8 光圈 在拍摄时,光圈值越大,相应的光线进入相机的量就越大,使得相机所获得的图像更亮。f:2.8 的值是一个比较大的光圈值,因此镜头具有很高的传光能力,适合在低光环境中使用。同时,在大光圈下可以创造出较小的景深效果,突出焦点主题而模糊背景或前景,从而产生轻柔的背景效果,适合拍摄人物肖像或商品照片等类似主题。 Depth of Field 是指在摄影中,被拍摄的画面中被认为是清晰的范围,也称为焦距深度区域,通常用来描述在照片中被认为是清晰的范围。 Soft Focus 指将相机镜头前加入一层特殊的滤镜,使被拍摄的主体轻微模糊以呈现柔和的美感效果。柔焦的视觉效果相较于深景和浅景来说更强调画面的情感主题,把重点集中在逐渐化解结构感的质感效果上,使它在照片上产生一种有点朦胧的妆容,刻画出一幅浪漫的画面。 Deep Focus 将摄像头在一个较大的光圈下设置,保持整个画面都清晰锐利的技术。深景通常需要使用较小的焦距或较远的拍摄距离,以保持整个画面的清晰度,是类似于大景深的一种刻画效果。 Shallow Focus 将相机的光圈调整到一个相对较大的开口,以使摄影师可以根据需要保持相机在平面上的一个特定区域或主体清晰,而照片中的其他区域则变得模糊不清的技术。这种效果常用于摄影肖像,使人物在画面上的清晰度突出,并且画面背景透露轻微的模糊感,带来更具艺术美感的效果。 Vanishing Point 消失点指的是位于无穷远处,用于视觉处理的一点。在透视绘画中,我们可以想象一个位于无穷远处的点,使得所有线条都向它聚拢。消失点可以帮助画家或摄影师达到精致的透视处理效果,从而创造出独特的空间感; Vantage Point 一般呈现的效果是照片中会有一个点是最高点,然后在此最高点斜上方拍摄 5.光线列表设置 Mood Lighting 氛围灯。主要是通过在特定的环境中改变灯光的颜色和亮度等参数来创造一种特定的氛围,以营造舒适、浪漫、放松等感觉。从技术实现上看,Mood lighting则着重于灯光的颜色和亮度控制,注重创造强烈的视觉效果。 Mood lighting通常用于室内设计、酒店、餐厅及居家装饰等领域,旨在创造出一种特定的气氛和体验。 Moody Lighting 情绪灯。它更强调在情感表达和为故事情节服务方面的应用,设计的目的是要把灯光与剧情完美结合起来,以展现角色的个性和情感世界。从技术实现上看,Moody lighting通常采用低亮度和大比例遮挡阴影,强调暗部的扫描,以增加画面的纹理和层次感。 Moody lighting通常用于影视制作、游戏界面、舞台表演等领域,设计的目的是为了增加故事情节的戏剧效果。 Studio Lighting 工作室灯光。是一种专门用于摄影工作室、电视和电影等领域的照明设计。它将光源和灯具放置在一个专用的摄影工作室中,通过精细的照明来创造出各种不同的氛围和场景效果,以满足各种不同的拍摄需求。 Studio lighting 主要应用于商业摄影、时装摄影、艺术摄影、人像摄影、广告拍摄、电影和电视制作等领域,目的是通过精细的照明设计来突出主体的特点,达到最佳的拍摄效果。 Cove Lighting 壁角灯。是一种常用的室内照明设计,其灯具通常安装在墙壁或吊顶壁橱之间的壁角(即“壁橱”)中,从而营造出舒适、柔和、光滑的环境照明效果。 这种照明技术可以为房间提供均匀的光线,同时提高房间的美感和时尚度。 Soft Lighting 柔和照明。是指通过使用柔和、漫射的光线来创造出柔和、温暖的氛围效果。柔和的光线通常是通过使用的漫射灯具来实现的,较为常见的是壁灯、台灯、阅读灯等。 柔和照明效果可以降低照度,减轻视觉疲劳,创造出舒适的氛围和感觉。 Hard Lighting 硬朗照明。是指通过使用聚光灯、筒灯等灯具来聚焦到一个特定的区域中,其光线是相对集中而直接的。 创造出刚硬、明亮的照明效果。硬朗照明常常用于展示场合,如美术馆、商场等环境,以突出展品或商品的特点和质感。 Volumetric Lighting 体积光。是一种创造逼真渲染效果的照明效果技术。它通过在某些场景中添加灯光和各种视觉效果,如扩散、雾、粒子、阴影等,在照明场景中模拟空气中的粒子和尘埃微粒的现象,从而创造出动态、逼真、增强立体感和体积感的照明效果。 适用于多种场景设计中,如电影、电视、视频游戏、动画等领域。它可以让场景更加逼真、立体,增加场景的紧张度和视觉层次感,并带来更具有表现力的视觉效果。 Low-Key Lighting 低键照明。指的是一种特殊的照明效果,该效果通常通过强烈的侧光或背光和阴影来创造高对比度的画面效果。低键照明的特点是明暗分明、阴影浓重、暗调占主导地位,常常构建一种紧张、神秘或黑暗的氛围。 低键照明广泛应用于电影、电视、摄影等领域中,常常用来表现悬疑、恐怖、犯罪等要素。 High-Key Lighting 高键照明。这种照明效果通过使用明亮、均匀的光线来避免明暗对比并压低阴影的出现。这种照明效果特点是亮度高、细节丰富,适用于需要传递愉悦、轻松和开心氛围的场景和环境。 高键照明通常用于广告、情感电影、电视剧等中。 Epic Light 史诗光线。是一种创建极富戏剧性、威严感和视觉效果的照明技术,它可以在场景中添加非常亮烈、盛大、壮观的光线,以吸引观众注意力并增加场景的震撼力。 Epic Light通常用于影视制作、游戏开发、演出等领域中,以营造出一种崇高、壮丽、宏伟的氛围,可以使观众在看到这些效果时,感到非常震撼和难以忘怀。史诗光线的特点是亮度较高、颜色鲜艳,通常用于表现重要的剧情点,如武器的激光、宇宙战争中的太阳和星星、幻想电影和电子游戏中的神秘光芒等。 Rembrandt Lighting 伦勃朗特效是一种起源于荷兰画家伦勃朗的照明效果,其主要特点是在人物脸部形成一个菱形的明暗分界线,嘴巴和下巴的一侧用阴影覆盖,人物的另一侧则被亮光照亮。 能营造出一种柔和而神秘的效果。 Contre-Jour 逆光照明。指的是摄影师将光源放置在被摄物体的背后,令照射效果在镜头前面产生,形成被摄体轮廓明显的负片形态。 于光源位置造成的暗摄影整体的虚化,高对比度和鲜明的轮廓线可以带来文艺和抽象的氛围。 Veiling Flare 透镜毛玻璃。指当光线从透镜或镜头穿过时,透过玻璃或镜头的反光或散射使得图像出现散射光线或最终成像看起来失真的现象。 Crepuscular Rays 黎明、黄昏光线。也称为太阳光柱,是由日光在云层或尘埃中被反射形成的光线束。因为只有在日出和日落时才有足够的光线穿过云层或照射到恰当的夹角,所以Crepuscular Rays通常只出现在日出和日落时刻。 Crepuscular Rays通常会在云层上形成明显的束状光线,给人以美丽的感觉。 Rays of Shimmering Light 闪烁光线。是指在光线散射和折射时出现的光线折射现象。在某些特定的环境下,光线经过不同密度和温度不同的气氛,会出现一种光线折射、散射的效果,从而形成闪烁光束效果。 Godrays 神光。是一种由光线穿过云朵、树枝或其他障碍物时,形成的亮光条纹效果。Godrays通常在光线较强的时分出现,将光线分割成条纹状,形成一种梦幻般的效果,也被称为 "crepuscular rays" 的一种。 参考链接: https://github.com/thinkingjimmy/Learning-Prompt https://github.com/wangxuqi/Prompt-Engineering-Guide-Chinese https://github.com/tonyyuhang/ChatGPT/tree/main https://github.com/f/awesome-chatgpt-prompts
Prompt learning 教学[进阶篇]:简介Prompt框架并给出自然语言处理技术:Few-Shot Prompting、Self-Consistency等;项目实战搭建知识库内容机器人
Prompt learning 教学[进阶篇]:简介Prompt框架并给出自然语言处理技术:Few-Shot Prompting、Self-Consistency等;项目实战搭建知识库内容机器人1.ChatGPT Prompt Framework看完基础篇的各种场景介绍后,你应该对 Prompt 有较深的理解。之前的章节我们讲的都是所谓的「术」,更多地集中讲如何用,但讲「道」的部分不多。高级篇除了会讲更高级的运用外,还会讲更多「道」的部分。高级篇的开篇,我们来讲一下构成 prompt 的框架。1.1Basic Prompt Framework查阅了非常多关于 ChatGPT prompt 的框架资料,我目前觉得写得最清晰的是 Elavis Saravia 总结的框架,他认为一个 prompt 里需包含以下几个元素:Instruction(必须): 指令,即你希望模型执行的具体任务。Context(选填): 背景信息,或者说是上下文信息,这可以引导模型做出更好的反应。Input Data(选填): 输入数据,告知模型需要处理的数据。Output Indicator(选填): 输出指示器,告知模型我们要输出的类型或格式。只要你按照这个框架写 prompt ,模型返回的结果都不会差。当然,你在写 prompt 的时候,并不一定要包含所有4个元素,而是可以根据自己的需求排列组合。比如拿前面的几个场景作为例子:推理:Instruction + Context + Input Data信息提取:Instruction + Context + Input Data + Output Indicator1.2 CRISPE Prompt Framework另一个我觉得很不错的 Framework 是 Matt Nigh 的 CRISPE Framework,这个 framework 更加复杂,但完备性会比较高,比较适合用于编写 prompt 模板。CRISPE 分别代表以下含义:CR: Capacity and Role(能力与角色)。你希望 ChatGPT 扮演怎样的角色。I: Insight(洞察力),背景信息和上下文(坦率说来我觉得用 Context 更好)。S: Statement(指令),你希望 ChatGPT 做什么。P: Personality(个性),你希望 ChatGPT 以什么风格或方式回答你。E: Experiment(尝试),要求 ChatGPT 为你提供多个答案。以下是这几个参数的例子:StepExampleCapacity and RoleAct as an expert on software development on the topic of machine learning frameworks, and an expert blog writer.<br/>把你想象成机器学习框架主题的软件开发专家,以及专业博客作者。InsightThe audience for this blog is technical professionals who are interested in learning about the latest advancements in machine learning.<br/>这个博客的读者主要是有兴趣了解机器学习最新进展技术的专业人士。StatementProvide a comprehensive overview of the most popular machine learning frameworks, including their strengths and weaknesses. Include real-life examples and case studies to illustrate how these frameworks have been successfully used in various industries.<br/>提供最流行的机器学习框架的全面概述,包括它们的优点和缺点。包括现实生活中的例子,和研究案例,以说明这些框架如何在各个行业中成功地被使用。PersonalityWhen responding, use a mix of the writing styles of Andrej Karpathy, Francois Chollet, Jeremy Howard, and Yann LeCun.<br/>在回应时,混合使用 Andrej Karpathy、Francois Chollet、Jeremy Howard 和 Yann LeCun 的写作风格。ExperimentGive me multiple different examples.<br/>给我多个不同的例子。2.Zero-Shot Prompting在基础篇里的推理场景,我提到了 Zero-Shot Prompting 的技术,本章会详细介绍它是什么,以及使用它的技巧。Zero-Shot Prompting 是一种自然语言处理技术,可以让计算机模型根据提示或指令进行任务处理。各位常用的 ChatGPT 就用到这个技术。传统的自然语言处理技术通常需要在大量标注数据上进行有监督的训练,以便模型可以对特定任务或领域进行准确的预测或生成输出。相比之下,Zero-Shot Prompting 的方法更为灵活和通用,因为它不需要针对每个新任务或领域都进行专门的训练。相反,它通过使用预先训练的语言模型和一些示例或提示,来帮助模型进行推理和生成输出。举个例子,我们可以给 ChatGPT 一个简短的 prompt,比如 描述某部电影的故事情节,它就可以生成一个关于该情节的摘要,而不需要进行电影相关的专门训练。2.1 Zero-Shot Prompting 缺点但这个技术并不是没有缺点的:Zero-Shot Prompting 技术依赖于预训练的语言模型,这些模型可能会受到训练数据集的限制和偏见。比如在使用 ChatGPT 的时候,它常常会在一些投资领域,使用男性的「他」,而不是女性的「她」。那是因为训练 ChatGPT 的数据里,提到金融投资领域的内容,多为男性。尽管 Zero-Shot Prompting 技术不需要为每个任务训练单独的模型,但为了获得最佳性能,它需要大量的样本数据进行微调。像 ChatGPT 就是一个例子,它的样本数量是过千亿。由于 Zero-Shot Prompting 技术的灵活性和通用性,它的输出有时可能不够准确,或不符合预期。这可能需要对模型进行进一步的微调或添加更多的提示文本来纠正。2.2 技巧 :Zero-Shot Chain of Thought基于上述的第三点缺点,研究人员就找到了一个叫 Chain of Thought 的技巧。这个技巧使用起来非常简单,只需要在问题的结尾里放一句 Let‘s think step by step (让我们一步步地思考),模型输出的答案会更加准确。这个技巧来自于 Kojima 等人 2022 年的论文 Large Language Models are Zero-Shot Reasoners。在论文里提到,当我们向模型提一个逻辑推理问题时,模型返回了一个错误的答案,但如果我们在问题最后加入 Let‘s think step by step 这句话之后,模型就生成了正确的答案:论文里有讲到原因,感兴趣的朋友可以去看看,我简单解释下为什么( 如果你有更好的解释,不妨反馈给我):首先各位要清楚像 ChatGPT 这类产品,它是一个统计语言模型,本质上是基于过去看到过的所有数据,用统计学意义上的预测结果进行下一步的输出(这也就是为什么你在使用 ChatGPT 的时候,它的答案是一个字一个字地吐出来,而不是直接给你的原因,因为答案是一个字一个字算出来的)。当它拿到的数据里有逻辑,它就会通过统计学的方法将这些逻辑找出来,并将这些逻辑呈现给你,让你感觉到它的回答很有逻辑。在计算的过程中,模型会进行很多假设运算(不过暂时不知道它是怎么算的)。比如解决某个问题是从 A 到 B 再到 C,中间有很多假设。它第一次算出来的答案错误的原因,只是因为它在中间跳过了一些步骤(B)。而让模型一步步地思考,则有助于其按照完整的逻辑链(A > B > C)去运算,而不会跳过某些假设,最后算出正确的答案。按照论文里的解释,零样本思维链涉及两个补全结果,左侧气泡表示基于提示输出的第一次的结果,右侧气泡表示其收到了第一次结果后,将最开始的提示一起拿去运算,最后得出了正确的答案:这个技巧,除了用于解决复杂问题外,还适合生成一些连贯主题的内容,比如写长篇文章、电影剧本等。但需要注意其缺点,连贯不代表,它就一定不会算错,如果其中某一步骤算错了,错误会因为逻辑链,逐步将错误积累,导致生成的文本可能出现与预期不符的内容。另外,根据 Wei 等人在 2022 年的论文表明,它仅在大于等于 100B 参数的模型中使用才会有效。如果你使用的是小样本模型,这个方法不会生效。根据 Yongchao Zhou 等人的最新论文,更好的 prompt 是:Let's work this out in a step by step way to be sure we have the right answer.在吴恩达的 ChatGPT Prompt Engineering 课程中,有提到一个这个技巧的另一种用法,不仅仅只是让 AI 按步骤行事,还会告知 AI 每一步要做什么。比如这个案例(注意这个是 python 代码):prompt_2 = f""" Your task is to perform the following actions: 1 - Summarize the following text delimited by <> with 1 sentence. 2 - Translate the summary into French. 3 - List each name in the French summary. 4 - Output a json object that contains the following keys: french_summary, num_names. Use the following format: Text: <text to summarize> Summary: <summary> Translation: <summary translation> Names: <list of names in Italian summary> Output JSON: <json with summary and num_names> Text: <{text}> """简单解释下这个代码:开头是让 AI 按照 1 ~ 4 步运行然后再让 AI 根据特定格式输出内容最后 AI 的输出是这样的:Summary: Jack and Jill go on a quest to fetch water, but misfortune strikes and they tumble down the hill, returning home slightly battered but with their adventurous spirits undimmed. Translation: Jack et Jill partent en quête d'eau, mais la malchance frappe et ils dégringolent la colline, rentrant chez eux légèrement meurtris mais avec leurs esprits aventureux intacts. Names: Jack, Jill Output JSON: {"french_summary": "Jack et Jill partent en quête d'eau, mais la malchance frappe et ils dégringolent la colline, rentrant chez eux légèrement meurtris mais avec leurs esprits aventureux intacts.", "num_names": 2}上述的案例只是将任务拆解,能让 AI 生成的结果更加符合要求,这个方法同样能提升 AI 的回答准确性,比如这个案例:Determine if the student's solution is correct or not. Question: I'm building a solar power installation and I need help working out the financials. Land costs $100 / square foot I can buy solar panels for $250 / square foot I negotiated a contract for maintenance that will cost \ me a flat $100k per year, and an additional $10 / square foot What is the total cost for the first year of operations as a function of the number of square feet. Student's Solution: Let x be the size of the installation in square feet. Costs: Land cost: 100x Solar panel cost: 250x Maintenance cost: 100,000 + 100x Total cost: 100x + 250x + 100,000 + 100x = 450x + 100,000 AI 的回答是「The student's solution is correct」。但其实学生的答案是错误的,应该 360x + 100,000,我们将 prompt 调整成这样:prompt = f""" Your task is to determine if the student's solution \ is correct or not. To solve the problem do the following: - First, work out your own solution to the problem. - Then compare your solution to the student's solution \ and evaluate if the student's solution is correct or not. Don't decide if the student's solution is correct until you have done the problem yourself. Use the following format: Question: question here Student's solution: student's solution here Actual solution: steps to work out the solution and your solution here Is the student's solution the same as actual solution \ just calculated: yes or no Student grade: correct or incorrect Question: I'm building a solar power installation and I need help \ working out the financials. - Land costs $100 / square foot - I can buy solar panels for $250 / square foot - I negotiated a contract for maintenance that will cost \ me a flat $100k per year, and an additional $10 / square \ What is the total cost for the first year of operations \ as a function of the number of square feet. Student's solution: Let x be the size of the installation in square feet. Costs: 1. Land cost: 100x 2. Solar panel cost: 250x 3. Maintenance cost: 100,000 + 100x Total cost: 100x + 250x + 100,000 + 100x = 450x + 100,000 Actual solution: """本质上,也是将任务分拆成多步,这次 AI 输出的结果是这样的(结果就是正确的了):Let x be the size of the installation in square feet. Costs: 1. Land cost: 100x 2. Solar panel cost: 250x 3. Maintenance cost: 100,000 + 10x Total cost: 100x + 250x + 100,000 + 10x = 360x + 100,000 Is the student's solution the same as actual solution just calculated: Student grade: Incorrect下一章我们会结合 Few-Shot Chain of Thought 来详细讲讲逻辑链的限制。3. Few-Shot Prompting我们在技巧2 中,提到我们可以给模型一些示例,从而让模型返回更符合我们需求的答案。这个技巧其实使用了一个叫 Few-Shot 的方法。这个方法最早是 Brown 等人在 2020 年发现的,论文里有一个这样的例子,非常有意思,通过这个例子你应该更能体会,像 ChatGPT 这类统计语言模型,其实并不懂意思,只是懂概率 Brown 输入的内容是这样的(whatpu 和 farduddle 其实根本不存在):A "whatpu" is a small, furry animal native to Tanzania. An example of a sentence that uses the word whatpu is: We were traveling in Africa and we saw these very cute whatpus. To do a "farduddle" means to jump up and down really fast. An example of a sentence that uses the word farduddle is:Output 是这样的:When we won the game, we all started to farduddle in celebration.不过这并不代表,Few-Shot 就没有缺陷,我们试试下面这个例子:Prompt:The odd numbers in this group add up to an even number: 4, 8, 9, 15, 12, 2, 1. A: The answer is False. The odd numbers in this group add up to an even number: 17, 10, 19, 4, 8, 12, 24. A: The answer is True. The odd numbers in this group add up to an even number: 16, 11, 14, 4, 8, 13, 24. A: The answer is True. The odd numbers in this group add up to an even number: 17, 9, 10, 12, 13, 4, 2. A: The answer is False. The odd numbers in this group add up to an even number: 15, 32, 5, 13, 82, 7, 1. A:Output 是这样的:The answer is True.输出的答案其实是错误的,实际上的答案应该是:Adding all the odd numbers (15, 5, 13, 7, 1) gives 41. The answer is False.那我们有没有什么方法解决?技巧8:Few-Shot Chain of Thought要解决这个缺陷,就要使用到新的技巧,Few-Shot Chain of Thought。根据 Wei 他们团队在 2022 年的研究表明:通过向大语言模型展示一些少量的样例,并在样例中解释推理过程,大语言模型在回答提示时也会显示推理过程。这种推理的解释往往会引导出更准确的结果。下面是论文里的案例,使用方法很简单,在技巧2 的基础上,再将逻辑过程告知给模型即可。从下面这个案例里,你可以看到加入解释后,输出的结果就正确了。那本章开头提的例子就应该是这样的(注:本例子同样来自 Wei 团队论文):The odd numbers in this group add up to an even number: 4, 8, 9, 15, 12, 2, 1. A: Adding all the odd numbers (9, 15, 1) gives 25. The answer is False. The odd numbers in this group add up to an even number: 17, 10, 19, 4, 8, 12, 24. A: Adding all the odd numbers (17, 19) gives 36. The answer is True. The odd numbers in this group add up to an even number: 16, 11, 14, 4, 8, 13, 24. A: Adding all the odd numbers (11, 13) gives 24. The answer is True. The odd numbers in this group add up to an even number: 17, 9, 10, 12, 13, 4, 2. A: Adding all the odd numbers (17, 9, 13) gives 39. The answer is False. The odd numbers in this group add up to an even number: 15, 32, 5, 13, 82, 7, 1. A:聊完技巧,我们再结合前面的 Zero-Shot Chain of Thought,来聊聊 Chain of Thought 的关键知识。根据 Sewon Min 等人在 2022 年的研究 表明,思维链有以下特点:"the label space and the distribution of the input text specified by the demonstrations are both key (regardless of whether the labels are correct for individual inputs)" 标签空间和输入文本的分布都是关键因素(无论这些标签是否正确)。the format you use also plays a key role in performance, even if you just use random labels, this is much better than no labels at all. 即使只是使用随机标签,使用适当的格式也能提高性能。理解起来有点难,我找一个 prompt 案例给大家解释( 如果你有更好的解释,不妨反馈给我)。我给 ChatGPT 一些不一定准确的例子:I loved the new Batman movie! // Negative This is bad // Positive This is good // Negative What a good show! //Output 是这样的:Positive在上述的案例里,每一行,我都写了一句话和一个情感词,并用 // 分开,但我给这些句子都标记了错误的答案,比如第一句其实应该是 Positive 才对。但:即使我给内容打的标签是错误的(比如第一句话,其实应该是 Positive),对于模型来说,它仍然会知道需要输出什么东西。 换句话说,模型知道 // 划线后要输出一个衡量该句子表达何种感情的词(Positive or Negative)。这就是前面论文里 #1 提到的,即使我给的标签是错误的,或者换句话说,是否基于事实,并不重要。标签和输入的文本,以及格式才是关键因素。只要给了示例,即使随机的标签,对于模型生成结果来说,都是有帮助的。这就是前面论文里 #2 提到的内容。最后,需要记住,思维链仅在使用大于等于 100B 参数的模型时,才会生效。BTW,如果你想要了解更多相关信息,可以看看斯坦福大学的讲义:Natural Language Processing with Deep Learning4. Self-Consistencyelf-Consistency 自洽是对 Chain of Thought 的一个补充,它能让模型生成多个思维链,然后取最多数答案的作为最终结果。按照 Xuezhi Wang 等人在 2022 年发表的论文 表明。当我们只用一个逻辑链进行优化时,模型依然有可能会算错,所以 XueZhi Wang 等人提出了一种新的方法,让模型进行多次运算,然后选取最多的答案作为最终结果:就我目前使用下来,在 ChatGPT 上,其自洽性非常高,暂时没有遇到过出现多种答案的情况。查阅多份资料,我发现这个自洽性可能更多的用于评估模型的优劣,好的模型一般自洽性会比较高。在此案例中,考虑如下多步推理问题:Consider a multi-step reasoning problem like the following: Question: If a store has 10 apples and 8 oranges, and it sells 6 apples and 4 oranges, how many fruits are left in the store? Instead of directly answering the question, the chain-of-thought prompting would require the language model to produce a series of short sentences that mimic a human's reasoning process: The store has 10 apples. The store has 8 oranges. 6 apples are sold. 4 oranges are sold. There are 10 - 6 = 4 apples left. There are 8 - 4 = 4 oranges left. The store now has 4 apples + 4 oranges = 8 fruits. Using self-consistency, the language model generates multiple reasoning paths:Reasoning Path A: The store has 10 apples. The store has 8 oranges. 6 apples are sold. 4 oranges are sold. There are 10 - 6 = 4 apples left. There are 8 - 4 = 4 oranges left. The store now has 4 apples + 4 oranges = 8 fruits. Reasoning Path B: The store initially has 10 apples and 8 oranges. It sells 6 apples, so there are 10 - 6 = 4 apples left. It sells 4 oranges, so there are 8 - 4 = 4 oranges left. The store now has 4 apples + 4 oranges = 8 fruits.翻译过来则为:问题:如果一家商店有 10 个苹果和 8 个橙子,此时店里卖出了 6 个苹果和 4 个橙子,那么店里还剩下多少水果? 思维链提示(chain-of-thought prompting)不是直接回答问题,而是要求语言模型生成一系列模仿人类推理过程的短句: 商店有 10 个苹果。 店里有 8 个橙子。 卖了 6 个苹果。 卖了 4 个橙子。 还剩下 10 - 6 = 4 个苹果。 剩下 8 - 4 = 4 个橙子。 商店现在有 4 个苹果 + 4 个橙子 = 8 个水果。使用 Self-consistency,语言模型生成多个推理路径:推理路径A: 商店有 10 个苹果。 店里有 8 个橙子。 卖了 6 个苹果。 卖了 4 个橙子。 还剩下 10 - 6 = 4 个苹果。 剩下 8 - 4 = 4 个橙子。 商店现在有 4 个苹果 + 4 个橙子 = 8 个水果。 推理路径 B: 商店最初有 10 个苹果和 8 个橙子。 商店卖了 6 个苹果,所以还剩下 10 - 6 = 4 个苹果。 商店卖了 4 个橙子,所以还剩下 8 - 4 = 4 个橙子。 商店现在有 4 个苹果 + 4 个橙子 = 8 个水果。Self-consistency 从生成的多个推理路径中选择最一致的答案。在这个例子中,推理路径 A 和 B 都得出相同的答案(8 个水果)。可以看到这种做法增加了模型对最终答案正确的信心。5. Program-Aided Language ModelsPAL Models,全称为 Program-Aided Language Models。需要各位注意,这个方法,真的非常高级,甚至我觉得有点 Hack,而且经过我的多次测试,我觉得以 ChatGPT 目前的能力,已经不再需要使用这个方法。但我在很多 PE 的教程里都有看到这个方法,所以我这里就简单介绍一下,这个方法来自于 2022 年,Luyu Gao 等人的研究,根据他们的研究,在 LLM 模型中,即使使用了前面提到的 Chain of Thought 的方法,也未必能拿到答案,论文中使用的 prompt 是这样的:Q: Roger has 5 tennis balls. He buys 2 more cans of tennis balls. Each can has 3 tennis balls. How many tennis balls does he have now? A: Roger started with 5 tennis balls. 2 cans of 3 tennis balls each is 6 tennis balls. 5 + 6 = 11. The answer is 11. Q: The bakers at the Beverly Hills Bakery baked 200 loaves of bread on Monday morning. They sold 93 loaves in the morning and 39 loaves in the afternoon. A grocery store returned 6 unsold loaves. How many loaves of bread did they have left?论文里提到,当年他们的模型的 Output 是这样的:A: The bakers started with 200 loaves. They sold 93 in the morning and 39 in the afternoon. So they sold 93 + 39 = 132 loaves. The grocery store returned 6 loaves. So they had 200 - 132 - 6 = 62 loaves left. The answer is 62.如果你现在将这个 prompt 输入到最新的 ChatGPT 答案已经是正确的:A: The bakers baked 200 loaves of bread. They sold 93 + 39 = 132 loaves. After the grocery store returned 6 unsold loaves, the bakery had 200 - 132 + 6 = 74 loaves of bread left. The answer is 74.当年 Luyu Gao 的解决方法是在 prompt 里引入代码,并引导模型使用代码来运算和思考,最后答案就是正确的:6.OpenAI Playground 使用方法你会在界面的右侧看到以下几个参数:Mode: 最近更新了第四种 Chat 模式,一般使用 Complete 就好,当然你可以用其他模式,其他模式能通过 GUI 的方式辅助你撰写 prompt。Model: 这里可以切换模型。不同的模型会擅长不同的东西,根据场景选对模型,能让你省很多成本:Ada:这是最便宜,但运算速度最快的模型。官方推荐的使用场景是解析文本,简单分类,地址更正等。Babbage:这个模型能处理比 Ada 复杂的场景。但稍微贵一些,速度也比较快。适合分类,语义搜索等。Curie:这个模型官方解释是「和 Davinci 一样能力很强,且更便宜的模型」。但实际上,这个模型非常擅长文字类的任务,比如写文章、语言翻译、撰写总结等。Davinci:这是 GPT-3 系列模型中能力最强的模型。可以输出更高的质量、更长的回答。每次请求可处理 4000 个 token。适合有复杂意图、因果关系的场景,还有创意生成、搜索、段落总结等。Temperature: 这个主要是控制模型生成结果的随机性。简而言之,温度越低,结果越确定,但也会越平凡或无趣。如果你想要得到一些出人意料的回答,不妨将这个参数调高一些。但如果你的场景是基于事实的场景,比如数据提取、FAQ 场景,此参数就最好调成 0 。Maximum length: 设置单次生成内容的最大长度。Stop Sequence: 该选项设置停止生成文本的特定字符串序列。如果生成文本中包含此序列,则模型将停止生成更多文本。Top P: 该选项是用于 nucleus 采样的一种技术,它可以控制模型生成文本的概率分布,从而影响模型生成文本的多样性和确定性。如果你想要准确的答案,可以将它设定为较低的值。如果你想要更多样化的回复,可以将其设得高一些。Presence Penalty: 该选项控制模型生成文本时是否避免使用特定单词或短语,它可以用于生成文本的敏感话题或特定场景。Best of: 这个选项允许你设置生成多少个文本后,从中选择最优秀的文本作为输出。默认为1,表示只生成一个文本输出。Injection start text: 这个选项可以让你在输入文本的开头添加自定义文本,从而影响模型的生成结果。Injection restart text: 这个选项可以让你在中间某个位置添加自定义文本,从而影响模型继续生成的结果。Show probabilities: 这个选项可以让你查看模型生成每个单词的概率。打开此选项后,你可以看到每个生成的文本单词后面跟着一串数字,表示模型生成该单词的概率大小。配置好参数后,你就可以在左侧输入 prompt 然后测试 prompt 了。7.搭建基于知识库内容的机器人如果你仅想要直接实践,可以看最后一部分实践,以及倒数第二部分限制与注意的地方。最早的时候,我尝试过非常笨的方法,就是在提问的时候,将我的 newsletter 文本传给 AI,它的 prompt 大概是这样的:Please summarize the following sentences to make them easier to understand. Text: """ My newsletter """这个方法能用是能用,但目前 ChatGPT 有个非常大的限制,它限制了最大的 token 数是 4096,大约是 16000 多个字符,注意这个是请求 + 响应,实际请求总数并没那么多。换句话来说,我一次没法导入太多的内容给 ChatGPT(我的一篇 Newsletter 就有将近 5000 字),这个问题就一直卡了我很久,直到我看到了 GPT Index 的库,以及 Lennys Newsletter 的例子。试了下,非常好用,而且步骤也很简单,即使你不懂编程也能轻易地按照步骤实现这个功能。我稍稍优化了下例子的代码,并增加了一些原理介绍。希望大家能喜欢。7.1 原理介绍其实我这个需求,在传统的机器人领域已经有现成方法,比如你应该看到不少电商客服产品,就有类似的功能,你说一句话,机器人就会回复你。这种传统的机器人,通常是基于意图去回答人的问题。举个例子,我们构建了一个客服机器人,它的工作原理简单说来是这样的:当用户问「忘记密码怎么办?」时,它会去找最接近这个意图「密码」,每个意图里会有很多个样本问题,比如「忘记密码如何找回」「忘记密码怎么办」,然后这些样本问题都会有个答案「点击 A 按钮找回密码」,机器人会匹配最接近样本问题的意图,然后返回答案。但这样有个问题,我们需要设置特别多的意图,比如「无法登录」、「忘记密码」、「登录错误」,虽然有可能都在描述一个事情,但我们需要设置三个意图、三组问题和答案。虽然传统的机器人有不少限制,但这种传统方式,给了我们一些灵感。我们好像可以用这个方法来解决限制 token 的问题,我们仅需要传符合某个意图的文档给 AI,然后 AI 仅用该文档来生成答案:比如还是上面的那个客服机器人的例子,当用户提问「忘记密码怎么办?」时,匹配到了「登录」相关的意图,接着匹配知识库中相同或相近意图的文档,比如「登录异常处理解决方案文档」,最后我们将这份文档传给 GPT-3,它再拿这个文档内容生成答案。GPTIndex 这个库简单理解就是做上图左边的那个部分,它的工作原理是这这样的:创建知识库或文档索引找到最相关的索引最后将对应索引的内容给 GPT-3虽然这个方法解决了 token 限制的问题,但也有不少限制:当用户提一些比较模糊的问题时,匹配有可能错误,导致 GPT-3 拿到了错误的内容,最终生成了非常离谱的答案。当用户提问一些没有多少上下文的信息时,机器人有时会生成虚假信息。所以如果你想用这个技术做客服机器人,建议你:通过一些引导问题来先明确用户的意图,就是类似传统客服机器人那样,搞几个按钮,先让用户点击(比如无法登录)。如果相似度太低,建议增加兜底的回答「很抱歉,我无法回答你的问题,你需要转为人工客服吗?」7.2 实践为了让大家更方便使用,我将代码放在了 Google Colab,你无需安装任何环境,只需要用浏览器打开这个:代码文件BTW 你可以将其复制保存到自己的 Google Drive。第一步:导入数据导入的方法有两种,第一种是导入在线数据。导入 GitHub 数据是个相对简单的方式。如果你是第一次使用,我建议你先用这个方法试试。点击下方代码前的播放按钮,就会运行这段代码。运行完成后,会导入我写的几份 newsletter。如果你也想像我那样导入数据,只需要修改 clone 后面的链接地址即可。第二种方法是导入离线数据。点击左侧的文件夹按钮(如果你没有登录,这一步会让你登录),然后点击下图标识 2 的上传按钮,上传文件即可。如果你要传多个文件,建议你先建一个文件夹,然后将文件都上传到该文件夹内。第二 & 三步:安装依赖库直接点击播放按钮即可。不过第三步里,你可以尝试改下参数,你可以改:num_ouputs :这个是设置最大的输出 token 数,越大,回答问题的时候,机器能回答的字就越多。Temperature: 这个主要是控制模型生成结果的随机性。简而言之,温度越低,结果越确定,但也会越平凡或无趣。如果你想要得到一些出人意料的回答,不妨将这个参数调高一些。但如果你的场景是基于事实的场景,比如数据提取、FAQ 场景,此参数就最好调成 0。其他参数不去管它就好,问题不大。第四步:设置 OpenAI API Key这个需要你登录 OpenAI(注意是 OpenAI 不是 ChatGPT),点击右上角的头像,点击 View API Keys,或者你点击这个链接也可以直接访问。然后点击「Create New Secret Key」,然后复制那个 Key 并粘贴到文档里即可。第五步:构建索引这一步程序会将第一步导入的数据都跑一遍,并使用 OpenAI 的 embedings API。如果第一步你上传了自己的数据,只需要将 ' ' 里的 Jimmy-Newsletter-Corpus 修改为你上传的文件夹名称即可。注意:这一步会耗费你的 OpenAI 的 Credit,1000 个 token 的价格是 $0.02,运行以下代码前需要注意你的账号里是否还有钱。如果你用的 OpenAI 账号是个免费账号,你有可能会遇到频率警告,此时可以等一等再运行下方代码(另外你的导入的知识库数据太多,也会触发)。解除这个限制,最好的方式是在你的 OpenAI 账号的 Billing 页面里绑定信用卡。如何绑卡,需要各位自行搜索。第六步:提问这一步你就可以试试提问了,如果你在第一步导入的是我预设的数据,你可以试试问以下问题:Issue 90 主要讲了什么什么内容?推荐一本跟 Issue 90 里提到的书类似的书如果你导入的是自己的资料,也可以问以下几个类型的问题:总结提问信息提取参考链接:https://github.com/thinkingjimmy/Learning-Prompt
带你简单了解Chatgpt背后的秘密:大语言模型所需要条件(数据算法算力)以及其当前阶段的缺点局限性
带你简单了解Chatgpt背后的秘密:大语言模型所需要条件(数据算法算力)以及其当前阶段的缺点局限性1.什么是语言模型?大家或多或少都听过 ChatGPT 是一个 LLMs,那 LLMs 是什么?LLMs 全称是 Large Language Models,中文是大语言模型。那么什么是语言模型?语言模型简单说来,就是对人类的语言建立数学模型,注意,这里的关键是数学模型,语言模型是一个由数学公式构建的模型,并不是什么逻辑框架。这个认知非常重要。最早提出语言模型的概念的是贾里尼克博士。他是世界著名的语音识别和自然语言处理的专家,他在 IBM 实验室工作期间,提出了基于统计的语音识别的框架,这个框架结构对语音和语言处理有着深远的影响,它从根本上使得语音识别有实用的可能。在贾里尼克以前,科学家们把语音识别问题当作人工智能问题和模式匹配问题。而贾里尼克把它当成通信问题。为何是通讯问题?为何转换成通讯问题后,就能实现语音识别?根据香农确定的现代通讯原理,所谓的通讯,也被称为信道的编码和解码,信息源先产生原始信息,然后接收方还原一个和原始信息最接近的信息。比如,你打电话的时候,问对方一句「你吃了晚饭了吗」,在传输前,通讯系统会对这句话进行编码,编成类似「100111101100000…」,但是传输过程中,一定会有信号损失,接收方收到的编码可能是「1001111011000…」,此时我们就没法解码回原来的句子了。那如何解决这个问题?我们可以把与接收到的编码「1001111011000…」类似的句子都罗列出来,可能的情况是:吃了晚饭了吗你吃了饭了吗你吃了晚饭了吗你吃了晚饭了然后通讯系统会计算出哪一种的可能性最大,最后把它选出来。只要噪音不大,并且传输信息有冗余,那我们就能复原出原来的信息。贾里尼克博士认为让计算机理解人类的语言,不是像教人那样教它语法,而是最好能够让计算机计算出哪一种可能的语句概率最大。这种计算自然语言每个句子的概率的数学模型,就是语言模型。2.如何计算概率?第一阶段:最简单的方法,当然就是用统计学的方法去计算了,简单说来,就是靠输入的上下文进行统计,计算出后续词语的概率,比如「你吃了晚饭了吗」,「你吃了」后面按照概率,名词如「饭」或「晚饭」等概率更高,而不太可能是动词,如「睡」「睡觉」。这是语言模型的第一阶段,模型也被称为是统计语言模型(Statistical Language Model,SLM),其基本思想是基于马尔可夫假设建立词语测模型,根据最近的上下文预测下一个词。后续语言模型的发展又迭代了三个版本。第二阶段是神经网络语言模型(Neural Language Model,NLM),是一个用神经网络来训练模型,学习单词之间的关联性和概率关系。它能够利用大量的数据进行深度学习,从而捕捉到词汇之间更加复杂的关系。NLM 模型采用的是分层的结构,把输入的文本数据空间投射到高维的语义空间中并进行学习。通过不断地更新神经网络模型参数,NLM 的神经网络逐渐学会了文本数据的语义并能够生成连贯自然、语义准确的文本。与前面提到的 SLM 相比,由于深度神经网络的学习能力更强,NLM 在学习语言模型时具有更好的泛化能力和适应性。比如能生成更长的文本等。但 NLM 相对来说也比较依赖更大的数据集,并且需要花很多人力在数据标注上。第三阶段是预训练语言模型(Pre-trained Language Model,PLM),是一种使用大量文本数据来训练的自然语言处理模型。相对 NLM 来说,PLM 使用无监督学习方法,因此不需要先标注数据或注明文本类型等信息。各位可能听过的 Transformer 架构就是一种预训练语言模型。第四阶段是大预言模型(Large Language Model),你可以将现在的 LLM 理解为一个训练数据特别大的 PLM,比如 GPT-2 只有 1.5B 参数,GPT-3 则到了惊人 175B,尽管 LLM 只是拓展了模型的大小,但这些大尺寸的预训练语言模型表现出了与较小的预训练语言模型不同的行为,并且在解决一些复杂任务上展现了惊人的能力(俗称涌现能力,注意这个涌现能力目前还存在争议),所以学术界为这些大型预训练语言模型命名为大语言模型 LLM。上面这四个阶段可能比较难理解,你可以简单理解:语言模型本质上都是在计算自然语言每个句子的概率的数学模型。当你输入一个问题给 AI 时,AI 就是用概率算出它的回答。另外,当今的语言模型,并不是一个问题对一个答案,实际上是一个问题,多个答案,然后根据答案的概率进行排序,最后返回一个最可能的答案。3. 开发大语言模型需要什么?了解完大语言模型的原理之后,你可能会好奇 TA 是如何开发的。开发大语言模型的关键是什么。最近看到不少文章为了流量,甚至连 5G 通讯都说成了是开发大语言模型的关键,其实从前面的原理介绍,不难看出,大语言模型的其中一个关键点是数据。关键一:数据训练数据主要是所谓的语料库。今天的很多语言模型的语料库主要有以下几种:Books:BookCorpus 是之前小语言模型如 GPT-2 常用的数据集,包括超过 11000 本电子书。主要包括小说和传记,最近更新时间是 2015 年 12 月。大一点的书籍语料库是 Gutenberg,它有 70000 本书,包括小说、散文、戏剧等作品,是目前最大的开源书籍语料库之一,最近更新时间是 2021 年 12 月。CommonCrawl:这个是目前最大的开源网络爬虫数据库,不过这个数据包含了大量脏数据,所以目前常用的四个数据库是 C4、CC-Stories、CC-News 和 RealNews。另外还有两个基于 CommonCrawl 提取的新闻语料库 REALNEWS 和 CC-News。Reddit Links:简单理解 Reddit 就是外国版本的百度贴吧 + 知乎。目前开源的数据库有 OpenWebText 和 PushShift.io。Wikipedia:维基百科是目前大模型广泛使用的语料库。Code:一般包含 GitHub 上的开源公共代码库,或者是 StackOverflow 的数据,Google 之前发布过一个叫 BigQuery 的数据集。实际上,训练大语言模型会混合使用不同的数据,一般不会只使用单一语料库。比如 GPT-3 用的混合数据集就包括 Books、CommonCrowl、Reddit Links 和 Wikipedia。从数据上看,你需要知道一个事实,中文语料在这上面占比很小。ChatGPT 能用中文回答你的问题,只是因为它的语料里有一些中英文对应的语料,然后模型就像是「懂中文了一样」,所以更可能的情况是,它先生成了英文内容,再翻译成中文。如果你去问 ChatGPT 3.5:请给我几个中文谐音梗,你应该就能理解我说的话了。以下是 ChatGPT 的返回结果:以下是一些中文谐音梗的例子: 我蒸发了,意思是我是 Vaper 了(Vaper发音接近蒸发)。 会有星期天,都得过过来,意思是星期二,星期三,星期四,星期五,星期六,都得过过来。 看到你,我的内心凉了 below zero,意思是凉了半截(below zero与半截音相近)。 蜀道难,难于上青天,赛道难,难于上488(488与“蜀道难”同音)。 洋葱姑娘,想哭却哭不出来,因为洋葱让我流泪了(洋葱和“要哭”在中文中的发音很相似)。 雨纷纷,旧故里草木深,我听闻,你始终在我身边深(“身边深”和“身边寻”谐音)。 你的车开得真快,一开就是“出租”,意思是“出祖宗”(发音类似)。关键二:算法有了数据之后,你还需要有算法去做计算,目前最常用的开发大语言模型的算法库有:Transformers:这是一个使用 Transformer 架构构建的开源 Python 库。DeepSpeed:是由微软开发的深度学习优化库。Megatron-LM:这是由 Nvidia 开发的深度学习库。JAX:它是由 Google 开发的用于高新能机器学习算法的 Python 库。关键三:算力简单理解,算力就是计算资源,或者说硬件,OpenAI 没有说它训练 GPT-3 语言模型花了多少计算资源。但 OpenAI 的 CEO 暗示硬件成本超过一亿美元,如果我们按照 1000 美元一个 GPU 计算,它大约使用了 10 万个 GPU,以 32 位运算为准,它能提供超过 100 PFLOPS 的算力,也就是每秒 10 亿亿次运算以上,这大约是阿里云最大的数据中心的四分之一的算力。注意,这还是 GPT-3 时的花费。另外,我还想分享一个观点,不要以为算力会随时间的前进,就能跨越。算力永远会是制约我们瓶颈,因为我们对人工智能的要求会不断的提高。本文主要内容来自论文 A Survey of Large Language Models。4. 大语言模型有什么缺点?了解完原理后,我觉得有必要跟大家聊聊大语言模型的缺点,这样大家才能知道 AI 的边界在哪里,并在可控的边界内进行创新。缺点一:结果高度依赖训练语料正如我前面提到的,当今的语言模型,即使发展了四个版本,但依然没有脱离「概率计算」,本质上来说它们的核心原理就是「利用已有的信息来预测其他信息」。那这就意味着,大语言模型其实并没有意识,也不知道对错,其生成的结果,高度依赖训练语料。那会导致怎样的后果?如果语料的内容是有偏的(比如带有种族歧视、性别歧视的内容),甚至是错误的,那大语言模型的生成的结果也会是错误的。如果该领域语料很少,大语言模型生成的结果准确率就很低。甚至有可能会出现幻觉(这个是第二个缺点)。当然面对这个缺点,有什么方法规避?第一种方法就是在语料大、且错误率低的领域使用 LLMs。比如语言学领域,像翻译、或者文案生成这种场景。即使语法错误了,但语料里存在大量的相同用法,那某种程度上来说,模型给的答案也算是对的,有点类似古代的通假字,或者现代的很多流行语。第二种就是用人工干预。简单说来就是人工将语料里的内容剔除,或者对其进行人类反馈强化学习。但人工干预并不意味着就没有问题了,这种方法有可能导致新的问题出现,比如将人的主观好恶加入到模型中,或者有可能伪造一些信息,加入到模型中。缺点二:Hallucinations这个可以直译成「幻觉」,简单说来,就是会说胡话。有些问题因为语聊很少,计算概率后,会吐出一些很奇怪的内容,比如这个例子,我让 AI 介绍一个世界上不存在的品牌 Boie 的智能牙刷:Tell me about AeroGlide UltraSlim Smart Toothbrush by BoieAI 的回答是,你可以看到 AI 就是在一本正经地说胡话:The AeroGlide UltraSlim Smart Toothbrush by Boie is a high-tech toothbrush that uses advanced sonic technology to provide a deep and thorough clean. It features a slim and sleek design that makes it easy to hold and maneuver, and it comes with a range of smart features that help you optimize your brushing routine. One of the key features of the AeroGlide UltraSlim Smart Toothbrush is its advanced sonic technology, which uses high-frequency vibrations to break up plaque and bacteria on your teeth and gums. This technology is highly effective at removing even the toughest stains and buildup, leaving your teeth feeling clean and refreshed. In addition to its sonic technology, the AeroGlide UltraSlim Smart Toothbrush also comes with a range of smart features that help you optimize your brushing routine. These include a built-in timer that ensures you brush for the recommended two minutes, as well as a pressure sensor that alerts you if you're brushing too hard. Overall, the AeroGlide UltraSlim Smart Toothbrush by Boie is a highly advanced and effective toothbrush that is perfect for anyone looking to take their oral hygiene to the next level. With its advanced sonic technology and smart features, it provides a deep and thorough clean that leaves your teeth feeling fresh and healthy.缺点三:暂时只能解决数学问题我解释下,这里提到的数学问题,并不仅仅指的是数学运算这种数学问题,而是能通过数学解决的问题。比如我们可以研发无人驾驶汽车,当它遇到行人突然横穿马路时,能自己刹车停下来,这就是一个数学问题,它通过计算识别行人,并进行刹车。但如果这辆无人车在一个单行道的巷子里遇到一辆堵在巷子的汽车,它就没有办法了,只能报警,让司机过来挪车,这就是一个数学无法解决的问题。暂时来看目前大多数的 LLMs 都只能解决数学问题,有些不可计算的问题,暂时都没法解决。特别像是需要自己实操进行实验的问题。当然我这里也只是称其为「暂时」,因为可能未来机器人 + LLMs 有可能会将可计算的范围拓展宽一点。
ChatGPT 中文指令指南,教会你如何使用chatgpt实现中文你想要的答案
ChatGPT 中文指令指南,教会你如何使用chatgpt实现中文你想要的答案1.学习英语--替代词典 App| 场景 | 例子 | Prompts | | ----- | ---- | ---- | | 解释中文英文意思,并解释单词的词根词缀。可以替代词典。 | 告诉我 Egocentric 的词性和音标,并使用中文和英文解释该词的意思,同时告诉我这个词是怎么来的?是如何构造出来的?最后用这个词写 3 句英文例句。 | 告诉我 英文单词 的词性和音标,并使用中文和英文解释该词的意思,同时告诉我这个词是怎么来的?是如何构造出来的?最后用这个词写 3 句英文例句。 || 通过故事帮助记忆单词,并了解单词的用法。| 使用 Egocentric、Egomaniac 写一个能帮助我记忆单词含义的英文故事。 | 使用 英文单词、英文单词 写一个能帮助我记忆单词含义的英文故事。 || 了解近义词或相近词之间的区别。 | Egoist 和 Egotist 的区别在哪里? | 英文单词 和 英文单词 的区别在哪里?|| 通过词根查找相近词,并生成故事方便记忆。 | 请告诉我由 ego 构成的常见英文单词,并解释其中文含义,最后用所有这些词语写成一个能帮助我记忆单词含义的英文故事。 | 请告诉我由 英文单词 构成的常见英文单词,并解释其中文含义,最后用所有这些词语写成一个能帮助我记忆单词含义的英文故事。 || 了解动词短语搭配 | 请告诉我跟 make 搭配使用的常见小品词有哪些,并使用这些短语分别写 1 个英文句子。| 请告诉我跟 英文单词 搭配使用的常见小品词有哪些,并使用这些短语分别写 1 个英文句子。|| 区分正式与口语的表达 | 请告诉我“打电话”用英语如何表达?注意,分别用正式和口语的表达解释。| 请告诉我 “中文” 用英语如何表达?注意,分别用正式和口语的表达解释。|| 询问语法| 请告诉我如何正确使用 the |请告诉我如何正确使用 单词 || 了解完正确用法后,还可以询问常见错误。通过错误学习事半功倍。| 请告诉我使用 the 的常见错误 | 请告诉我使用 单词 的常见错误 || 了解完正确和错误用法,还可以让 ChatGPT 出练习题,通过练习加深印象(这个方法不仅限于学习语法,或者学习英语)| 请提供一些关于如何使用 the 的练习题给我 | 请提供一些关于如何使用 单词 的练习题给我|2.辅助决策人的很多错误的根源都来自于盲点。改变参照系,这是唯一有助于避免认知偏差的事情。人要改变参考系一般比较困难,所以我就想是否有可能让 AI 帮助,试用了下,好像还行。ChatGPT 无法给你确切的答案,但它可以提供一些思考角度。| 场景 | 例子 | Prompts | | ---- | ---- | ---- | | 询问建议和决策关键条件 | 请分析以下问题,并将决策判断所需的条件详细列出来:我是否应该辍学创业?|请分析以下问题,并将决策判断所需的条件详细列出来:问题 || 直接罗列决策点只是基础用法,你还可以在提问的时候,增加一些模型信息,比如让 ChatGPT 使用「六项思考帽」法,分析某个问题。 | 请使用六项思考帽的方法,分析以下问题:我是否应该辍学创业?|请使用 模型,分析以下问题:问题| | 除了模型外,也可以引入某人的经历。只需增加一句请将你想象为 某某某 即可。(不过需要注意:据我测试,其回答的详细程度,取决于对某人的熟悉程度,而且答案只是多了一些背景信息,无法真实模拟。)| 请分别将你想象成为 Steve Jobs 和 Elon Musk , 并从他们的经历和角度回答以下问题,并将决策判断所需的条件详细列出来:我是否应该辍学创业? |请分别将你想象成为 某人 和 某人 , 并从他们的经历和角度回答以下问题,并将决策判断所需的条件详细列出来:问题|2.1购物| 场景 | 例子 | Prompts | | ---- | ---- | ---- | | 购买决策应该是我们最常做的决策。感觉拿 AI 做这种购物决策也不错,不过需要注意,Bing 大多数决策数据来自某乎。| 请告诉我购买玻璃水需要考虑什么?并且推荐我三款能在京东买到的玻璃水,并告诉我推荐他们的原因。 |请告诉我购买 物品 需要考虑什么?并且推荐我三款能在 平台 买到的 物品,并告诉我推荐他们的原因。|2.2旅游| 场景 | 例子 | Prompts | | ---- | ---- | ---- | |规划旅行计划也比较麻烦,在小红书上看了很多攻略,有点眼花缭乱。你可以将你的喜好告诉 AI,它会根据你的要求,搜寻特定结果给你,并且还能进行多轮对话,可以针对某几个要求进行深度沟通。| 我会在云南逗留 1 天,我喜欢名胜古迹和自然风光,请推荐我三个符合我需求的景点,并告诉我推荐他们的原因。 |我会在 某地 逗留 N 天,我喜欢 喜好 ,请推荐我三个符合我需求的景点,并告诉我推荐他们的原因。|2.3健身| 场景 | 例子 | Prompts | | ---- | ---- | ---- | | 将我的个性化需求,比如有哪些器械,或者身体的状况告诉AI,然后问 AI 有没有适合我的健身计划。 | 我有两个 5kg 的哑铃和 两个 2.5kg 的哑铃,和一个弹力带,但没有健身椅。请为我制定一个锻炼肩膀的健身计划。 | 描述条件(如有的器械,身体的状况等)请为我制定一个锻炼 部位 的健身计划。 |
Gradio入门到进阶全网最详细教程[一]:快速搭建AI算法可视化部署演示(侧重项目搭建和案例分享)
Gradio入门到进阶全网最详细教程[一]:快速搭建AI算法可视化部署演示(侧重项目搭建和案例分享)常用的两款AI可视化交互应用比较:GradioGradio的优势在于易用性,代码结构相比Streamlit简单,只需简单定义输入和输出接口即可快速构建简单的交互页面,更轻松部署模型。适合场景相对简单,想要快速部署应用的开发者。便于分享:gradio可以在启动应用时设置share=True参数创建外部分享链接,可以直接在微信中分享给用户使用。方便调试:gradio可以在jupyter中直接展示页面,更加方便调试。StreamlitStreamlit的优势在于可扩展性,相比Gradio复杂,完全熟练使用需要一定时间。可以使用Python编写完整的包含前后端的交互式应用。适合场景相对复杂,想要构建丰富多样交互页面的开发者。Gradio官网链接:https://gradio.app/1. 安装&基本用法Python第三方库Gradio快速上手,当前版本V3.27.0python版本要求3.7及以上pip install gradio #为了更快安装,可以使用清华镜像源 pip install -i https://pypi.tuna.tsinghua.edu.cn/simple gradio安装完直接在IDE上启动快速,1.1 快速入门import gradio as gr #输入文本处理程序 def greet(name): return "Hello " + name + "!" #接口创建函数 #fn设置处理函数,inputs设置输入接口组件,outputs设置输出接口组件 #fn,inputs,outputs都是必填函数 demo = gr.Interface(fn=greet, inputs="text", outputs="text") demo.launch() 运行程序后,打开 http://localhost:7860 即可看到网页效果。左边是文本输入框,右边是结果展示框。Clear按钮用于重置网页状态,Submit按钮用于执行处理程序,Flag按钮用于保存结果到本地。#执行结果 Running on local URL: http://127.0.0.1:7860 To create a public link, set `share=True` in `launch()`.打开浏览器使用即可在本地开发时,如果你想将代码作为Python脚本运行,你可以使用Gradio CLI在重载模式下启动应用程序,这将提供无缝和快速的开发。gradio app.py Note:你也可以做python app.py,但它不会提供自动重新加载机制。2.基本参数|支持的接口2.1 Interface类以及基础模块Gradio 可以包装几乎任何 Python 函数为易于使用的用户界面。从上面例子我们看到,简单的基于文本的函数。但这个函数还可以处理很多类型。Interface类通过以下三个参数进行初始化:fn:包装的函数inputs:输入组件类型,(例如:“text”、"image)ouputs:输出组件类型,(例如:“text”、"image)通过这三个参数,我们可以快速创建一个接口并发布他们。最常用的基础模块构成。应用界面:gr.Interface(简易场景), gr.Blocks(定制化场景)输入输出:gr.Image(图像), gr.Textbox(文本框), gr.DataFrame(数据框), gr.Dropdown(下拉选项), gr.Number(数字), gr.Markdown, gr.Files控制组件:gr.Button(按钮)布局组件:gr.Tab(标签页), gr.Row(行布局), gr.Column(列布局)1.2.1 自定义输入组件import gradio as gr def greet(name): return "Hello " + name + "!" demo = gr.Interface( fn=greet, # 自定义输入框 # 具体设置方法查看官方文档 inputs=gr.Textbox(lines=3, placeholder="Name Here...",label="my input"), outputs="text", demo.launch() Interface.launch()方法返回三个值app,为 Gradio 演示提供支持的 FastAPI 应用程序local_url,本地地址share_url,公共地址,当share=True时生成import gradio as gr def greet(name): return "Hello " + name + "!" iface = gr.Interface( fn=greet, inputs=gr.inputs.Textbox(lines=2, placeholder="Name Here..."), outputs="text", if __name__ == "__main__": app, local_url, share_url = iface.launch() 1.2.2 多个输入和输出对于复杂程序,输入列表中的每个组件按顺序对应于函数的一个参数。输出列表中的每个组件按顺序排列对应于函数返回的一个值。import gradio as gr #该函数有3个输入参数和2个输出参数 def greet(name, is_morning, temperature): salutation = "Good morning" if is_morning else "Good evening" greeting = f"{salutation} {name}. It is {temperature} degrees today" celsius = (temperature - 32) * 5 / 9 return greeting, round(celsius, 2) demo = gr.Interface( fn=greet, #按照处理程序设置输入组件 inputs=["text", "checkbox", gr.Slider(0, 100)], #按照处理程序设置输出组件 outputs=["text", "number"], demo.launch()inputs列表里的每个字段按顺序对应函数的每个参数,outputs同理。1.2.3 图像组件Gradio支持许多类型的组件,如image、dataframe、video。使用示例如下:import numpy as np import gradio as gr def sepia(input_img): #处理图像 sepia_filter = np.array([ [0.393, 0.769, 0.189], [0.349, 0.686, 0.168], [0.272, 0.534, 0.131] sepia_img = input_img.dot(sepia_filter.T) sepia_img /= sepia_img.max() return sepia_img #shape设置输入图像大小 demo = gr.Interface(sepia, gr.Image(shape=(200, 200)), "image") demo.launch()当使用Image组件作为输入时,函数将收到一个维度为(w,h,3)的numpy数组,按照RGB的通道顺序排列。要注意的是,我们的输入图像组件带有一个编辑按钮,可以对图像进行裁剪和放大。以这种方式处理图像可以帮助揭示机器学习模型中的偏差或隐藏的缺陷。此外对于输入组件有个shape参数,指的设置输入图像大小。但是处理方式是保持长宽比的情况下,将图像最短边缩放为指定长度,然后按照中心裁剪方式裁剪最长边到指定长度。当图像不大的情况,一种更好的方式是不设置shape,这样直接传入原图。输入组件Image也可以设置输入类型type,比如type=filepath设置传入处理图像的路径。具体可以查看官方文档,文档写的很清楚。1.2.4 动态界面接口:简单计算器模板实时变化在Interface添加live=True参数,只要输入发生变化,结果马上发生改变。import gradio as gr def calculator(num1, operation, num2): if operation == "add": return num1 + num2 elif operation == "subtract": return num1 - num2 elif operation == "multiply": return num1 * num2 elif operation == "divide": return num1 / num2 iface = gr.Interface( calculator, ["number", gr.inputs.Radio(["add", "subtract", "multiply", "divide"]), "number"], "number", live=True, iface.launch() import gradio as gr #一个简单计算器,含实例说明 def calculator(num1, operation, num2): if operation == "add": return num1 + num2 elif operation == "subtract": return num1 - num2 elif operation == "multiply": return num1 * num2 elif operation == "divide": if num2 == 0: # 设置报错弹窗 raise gr.Error("Cannot divide by zero!") return num1 / num2 demo = gr.Interface( calculator, # 设置输入 "number", gr.Radio(["add", "subtract", "multiply", "divide"]), "number" # 设置输出 "number", # 设置输入参数示例 examples=[ [5, "add", 3], [4, "divide", 2], [-4, "multiply", 2.5], [0, "subtract", 1.2], # 设置网页标题 title="Toy Calculator", # 左上角的描述文字 description="Here's a sample toy calculator. Enjoy!", # 左下角的文字 article = "Check out the examples", demo.launch() 2.2 interface进阶使用2.2.1 interface状态全局变量全局变量的好处就是在调用函数后仍然能够保存,例如在机器学习中通过全局变量从外部加载一个大型模型,并在函数内部使用它,以便每次函数调用都不需要重新加载模型。下面就展示了全局变量使用的好处。import gradio as gr scores = [] def track_score(score): scores.append(score) #返回分数top3 top_scores = sorted(scores, reverse=True)[:3] return top_scores demo = gr.Interface( track_score, gr.Number(label="Score"), gr.JSON(label="Top Scores") demo.launch()会话状态Gradio支持的另一种数据持久性是会话状态,数据在一个页面会话中的多次提交中持久存在。然而,数据不会在你模型的不同用户之间共享。会话状态的典型例子就是聊天机器人,你想访问用户之前提交的信息,但你不能将聊天记录存储在一个全局变量中,因为那样的话,聊天记录会在不同的用户之间乱成一团。注意该状态会在每个页面内的提交中持续存在,但如果您在另一个标签页中加载该演示(或刷新页面),该演示将不会共享聊天历史。要在会话状态下存储数据,你需要做三件事。在你的函数中传入一个额外的参数,它代表界面的状态。在函数的最后,将状态的更新值作为一个额外的返回值返回。在添加输入和输出时添加state组件。import random import gradio as gr def chat(message, history): history = history or [] message = message.lower() if message.startswith("how many"): response = random.randint(1, 10) elif message.startswith("how"): response = random.choice(["Great", "Good", "Okay", "Bad"]) elif message.startswith("where"): response = random.choice(["Here", "There", "Somewhere"]) else: response = "I don't know" history.append((message, response)) return history, history #设置一个对话窗 chatbot = gr.Chatbot().style(color_map=("green", "pink")) demo = gr.Interface( chat, # 添加state组件 ["text", "state"], [chatbot, "state"], # 设置没有保存数据的按钮 allow_flagging="never", demo.launch()2.2.2 interface交互实时变化在Interface中设置live=True,则输出会跟随输入实时变化。这个时候界面不会有submit按钮,因为不需要手动提交输入。同1.2.4流模式在许多情形下,我们的输入是实时视频流或者音频流,那么意味这数据不停地发送到后端,这是可以采用streaming模式处理数据。import gradio as gr import numpy as np def flip(im): return np.flipud(im) demo = gr.Interface( flip, gr.Image(source="webcam", streaming=True), "image", live=True demo.launch() 2.3自定制组件:Blocks构建应用相比Interface,Blocks提供了一个低级别的API,用于设计具有更灵活布局和数据流的网络应用。Blocks允许控制组件在页面上出现的位置,处理复杂的数据流(例如,输出可以作为其他函数的输入),并根据用户交互更新组件的属性可见性。可以定制更多组件,更多详细定制可查看文档2.3.1 简单演示import gradio as gr def greet(name): return "Hello " + name + "!" with gr.Blocks() as demo: #设置输入组件 name = gr.Textbox(label="Name") # 设置输出组件 output = gr.Textbox(label="Output Box") #设置按钮 greet_btn = gr.Button("Greet") #设置按钮点击事件 greet_btn.click(fn=greet, inputs=name, outputs=output) demo.launch()Blocks方式需要with语句添加组件,如果不设置布局方式,那么组件将按照创建的顺序垂直出现在应用程序中,运行界面2.3.2 多模块应用☆import numpy as np import gradio as gr def flip_text(x): return x[::-1] def flip_image(x): return np.fliplr(x) with gr.Blocks() as demo: #用markdown语法编辑输出一段话 gr.Markdown("Flip text or image files using this demo.") # 设置tab选项卡 with gr.Tab("Flip Text"): #Blocks特有组件,设置所有子组件按垂直排列 #垂直排列是默认情况,不加也没关系 with gr.Column(): text_input = gr.Textbox() text_output = gr.Textbox() text_button = gr.Button("Flip") with gr.Tab("Flip Image"): #Blocks特有组件,设置所有子组件按水平排列 with gr.Row(): image_input = gr.Image() image_output = gr.Image() image_button = gr.Button("Flip") #设置折叠内容 with gr.Accordion("Open for More!"): gr.Markdown("Look at me...") text_button.click(flip_text, inputs=text_input, outputs=text_output) image_button.click(flip_image, inputs=image_input, outputs=image_output) demo.launch() 2.3.3 Flagging标记相信有小伙伴已经注意到,输出框下有个Flag按钮。当测试您的模型的用户看到某个输入导致输出错误或意外的模型行为,他们可以标记这个输入让开发者知道。这个文件夹由Interface的flagging_dir参数指定,默认为’flagged’。将这些会导致错误的输入保存到一个csv文件。如果Interface包含文件数据,文件夹也会创建来保存这些标记数据。打开log.csv展示如下:2.3.4 样式、队列、生成器样式在Gradio官方文档,搜索不同的组件加.style(如image.style),可以获取该组件的样式参数设置样例。例如image组件的设置如下:img = gr.Image("lion.jpg").style(height='24', rounded=False)队列如果函数推理时间较长,比如目标检测;或者应用程序处理流量过大,则需要使用queue方法进行排队。queue方法使用websockets,可以防止网络超时。使用方式如下:demo = gr.Interface(...).queue() demo.launch() with gr.Blocks() as demo: demo.queue() demo.launch()生成器在某些情况下,你可能想显示一连串的输出,而不是单一的输出。例如,你可能有一个图像生成模型,如果你想显示在每个步骤中生成的图像,从而得到最终的图像。在这种情况下,你可以向Gradio提供一个生成器函数,而不是一个常规函数。下面是一个生成器的例子,每隔1秒返回1张图片。import gradio as gr import numpy as np import time #生成steps张图片,每隔1秒钟返回 def fake_diffusion(steps): for _ in range(steps): time.sleep(1) image = np.random.randint(255, size=(300, 600, 3)) yield image demo = gr.Interface(fake_diffusion, #设置滑窗,最小值为1,最大值为10,初始值为3,每次改动增减1位 inputs=gr.Slider(1, 10, value=3, step=1), outputs="image") #生成器必须要queue函数 demo.queue() demo.launch()2.4 Blocks进阶使用2.4.1 Blocks事件可交互设置任何输入的组件内容都是可编辑的,而输出组件默认是不能编辑的。如果想要使得输出组件内容可编辑,设置interactive=True即可。import gradio as gr def greet(name): return "Hello " + name + "!" with gr.Blocks() as demo: name = gr.Textbox(label="Name") # 不可交互 # output = gr.Textbox(label="Output Box") # 可交互 output = gr.Textbox(label="Output", interactive=True) greet_btn = gr.Button("Greet") greet_btn.click(fn=greet, inputs=name, outputs=output) demo.launch()事件设置我们可以为不同的组件设置不同事件,如为输入组件添加change事件。可以进一步查看官方文档,看看组件还有哪些事件。import gradio as gr def welcome(name): return f"Welcome to Gradio, {name}!" with gr.Blocks() as demo: gr.Markdown( # Hello World! Start typing below to see the output. inp = gr.Textbox(placeholder="What is your name?") out = gr.Textbox() #设置change事件 inp.change(fn = welcome, inputs = inp, outputs = out) demo.launch()多个数据流如果想处理多个数据流,只要设置相应的输入输出组件即可。import gradio as gr def increase(num): return num + 1 with gr.Blocks() as demo: a = gr.Number(label="a") b = gr.Number(label="b") # 要想b>a,则使得b = a+1 atob = gr.Button("b > a") atob.click(increase, a, b) # 要想a>b,则使得a = b+1 btoa = gr.Button("a > b") btoa.click(increase, b, a) demo.launch()多输出值处理下面的例子展示了输出多个值时,以列表形式表现的处理方式。import gradio as gr with gr.Blocks() as demo: food_box = gr.Number(value=10, label="Food Count") status_box = gr.Textbox() def eat(food): if food > 0: return food - 1, "full" else: return 0, "hungry" gr.Button("EAT").click( fn=eat, inputs=food_box, #根据返回值改变输入组件和输出组件 outputs=[food_box, status_box] demo.launch()下面的例子展示了输出多个值时,以字典形式表现的处理方式。组件配置修改事件监听器函数的返回值通常是相应的输出组件的更新值。有时我们也想更新组件的配置,比如说可见性。在这种情况下,我们可以通过返回update函数更新组件的配置。import gradio as gr def change_textbox(choice): #根据不同输入对输出控件进行更新 if choice == "short": return gr.update(lines=2, visible=True, value="Short story: ") elif choice == "long": return gr.update(lines=8, visible=True, value="Long story...") else: return gr.update(visible=False) with gr.Blocks() as demo: radio = gr.Radio( ["short", "long", "none"], label="Essay Length to Write?" text = gr.Textbox(lines=2, interactive=True) radio.change(fn=change_textbox, inputs=radio, outputs=text) demo.launch() 2.4.2 Blocks布局Blocks应用的是html中的flexbox模型布局,默认情况下组件垂直排列。组件水平排列使用Row函数会将组件按照水平排列,但是在Row函数块里面的组件都会保持同等高度。import gradio as gr with gr.Blocks() as demo: with gr.Row(): img1 = gr.Image() text1 = gr.Text() btn1 = gr.Button("button") demo.launch()组件垂直排列与嵌套组件通常是垂直排列,我们可以通过Row函数和Column函数生成不同复杂的布局。import gradio as gr with gr.Blocks() as demo: with gr.Row(): text1 = gr.Textbox(label="t1") slider2 = gr.Textbox(label="s2") drop3 = gr.Dropdown(["a", "b", "c"], label="d3") with gr.Row(): # scale与相邻列相比的相对宽度。例如,如果列A的比例为2,列B的比例为1,则A的宽度将是B的两倍。 # min_width设置最小宽度,防止列太窄 with gr.Column(scale=2, min_width=600): text1 = gr.Textbox(label="prompt 1") text2 = gr.Textbox(label="prompt 2") inbtw = gr.Button("Between") text4 = gr.Textbox(label="prompt 1") text5 = gr.Textbox(label="prompt 2") with gr.Column(scale=1, min_width=600): img1 = gr.Image("test.jpg") btn = gr.Button("Go") demo.launch()组件可视化:输出可视化从无到有如下所示,我们可以通过visible和update函数构建更为复杂的应用。import gradio as gr with gr.Blocks() as demo: # 出错提示框 error_box = gr.Textbox(label="Error", visible=False) # 输入框 name_box = gr.Textbox(label="Name") age_box = gr.Number(label="Age") symptoms_box = gr.CheckboxGroup(["Cough", "Fever", "Runny Nose"]) submit_btn = gr.Button("Submit") # 输出不可见 with gr.Column(visible=False) as output_col: diagnosis_box = gr.Textbox(label="Diagnosis") patient_summary_box = gr.Textbox(label="Patient Summary") def submit(name, age, symptoms): if len(name) == 0: return {error_box: gr.update(value="Enter name", visible=True)} if age < 0 or age > 200: return {error_box: gr.update(value="Enter valid age", visible=True)} return { output_col: gr.update(visible=True), diagnosis_box: "covid" if "Cough" in symptoms else "flu", patient_summary_box: f"{name}, {age} y/o" submit_btn.click( submit, [name_box, age_box, symptoms_box], [error_box, diagnosis_box, patient_summary_box, output_col], demo.launch()组件渲染:点击作为输入在某些情况下,您可能希望在实际在UI中呈现组件之前定义组件。例如,您可能希望在相应的gr.Textbox输入上方显示使用gr.examples的示例部分。由于gr.Examples需要输入组件对象作为参数,因此您需要先定义输入组件,然后在定义gr.Exmples对象后再进行渲染。解决方法是在gr.Blocks()范围外定义gr.Textbox,并在UI中希望放置的任何位置使用组件的.render()方法。import gradio as gr input_textbox = gr.Textbox() with gr.Blocks() as demo: #提供示例输入给input_textbox,示例输入以嵌套列表形式设置 gr.Examples(["hello", "bonjour", "merhaba"], input_textbox) # render函数渲染input_textbox input_textbox.render() demo.launch()2.4.3 样式修改自定义css要获得额外的样式功能,您可以设置行内css属性将任何样式给应用程序。如下所示。import gradio as gr #修改blocks的背景颜色 with gr.Blocks(css=".gradio-container {background-color: red}") as demo: box1 = gr.Textbox(value="Good Job") box2 = gr.Textbox(value="Failure") demo.launch()元素选择您可以向任何组件添加HTML元素。通过elem_id选择对应的css元素。import gradio as gr # 这里用的是id属性设置 with gr.Blocks(css="#warning {background-color: red}") as demo: box1 = gr.Textbox(value="Good Job", elem_id="warning") box2 = gr.Textbox(value="Failure") box3 = gr.Textbox(value="None", elem_id="warning") demo.launch()3. 应用分享3.1 互联网分享如果运行环境能够连接互联网,在launch函数中设置share参数为True,那么运行程序后。Gradio的服务器会提供XXXXX.gradio.app地址。通过其他设备,比如手机或者笔记本电脑,都可以访问该应用。这种方式下该链接只是本地服务器的代理,不会存储通过本地应用程序发送的任何数据。这个链接在有效期内是免费的,好处就是不需要自己搭建服务器,坏处就是太慢了,毕竟数据经过别人的服务器。demo.launch(share=True)3.2 huggingface托管为了便于向合作伙伴永久展示我们的模型App,可以将gradio的模型部署到 HuggingFace的 Space托管空间中,完全免费的哦。方法如下:1,注册huggingface账号:https://huggingface.co/join2,在space空间中创建项目:https://huggingface.co/spaces3,创建好的项目有一个Readme文档,可以根据说明操作,也可以手工编辑app.py和requirements.txt文件。3.3 局域网分享通过设置server_name=‘0.0.0.0’(表示使用本机ip),server_port(可不改,默认值是7860)。那么可以通过本机ip:端口号在局域网内分享应用。#show_error为True表示在控制台显示错误信息。 demo.launch(server_name='0.0.0.0', server_port=8080, show_error=True)这里host地址可以自行在电脑查询,C:\Windows\System32\drivers\etc\hosts 修改一下即可 127.0.0.1再制定端口号3.4 密码验证在首次打开网页前,可以设置账户密码。比如auth参数为(账户,密码)的元组数据。这种模式下不能够使用queue函数。demo.launch(auth=("admin", "pass1234")) 如果想设置更为复杂的账户密码和密码提示,可以通过函数设置校验规则。#账户和密码相同就可以通过 def same_auth(username, password): return username == password demo.launch(auth=same_auth,auth_message="username and password must be the same") 4.案例升级展示4.1 文本分类#!pip install gradio, ultralytics, transformers, torchkerasimport gradio as gr from transformers import pipeline pipe = pipeline("text-classification") def clf(text): result = pipe(text) label = result[0]['label'] score = result[0]['score'] res = {label:score,'POSITIVE' if label=='NEGATIVE' else 'NEGATIVE': 1-score} return res demo = gr.Interface(fn=clf, inputs="text", outputs="label") gr.close_all() demo.launch(share=True)4.2 图像分类import gradio as gr import pandas as pd from ultralytics import YOLO from skimage import data from PIL import Image model = YOLO('yolov8n-cls.pt') def predict(img): result = model.predict(source=img) df = pd.Series(result[0].names).to_frame() df.columns = ['names'] df['probs'] = result[0].probs df = df.sort_values('probs',ascending=False) res = dict(zip(df['names'],df['probs'])) return res gr.close_all() demo = gr.Interface(fn = predict,inputs = gr.Image(type='pil'), outputs = gr.Label(num_top_classes=5), examples = ['cat.jpeg','people.jpeg','coffee.jpeg']) demo.launch()4.3 目标检测import gradio as gr import pandas as pd from skimage import data from ultralytics.yolo.data import utils model = YOLO('yolov8n.pt') #load class_names yaml_path = str(Path(ultralytics.__file__).parent/'datasets/coco128.yaml') class_names = utils.yaml_load(yaml_path)['names'] def detect(img): if isinstance(img,str): img = get_url_img(img) if img.startswith('http') else Image.open(img).convert('RGB') result = model.predict(source=img) if len(result[0].boxes.boxes)>0: vis = plots.plot_detection(img,boxes=result[0].boxes.boxes, class_names=class_names, min_score=0.2) else: vis = img return vis with gr.Blocks() as demo: gr.Markdown("# yolov8目标检测演示") with gr.Tab("捕捉摄像头喔"): in_img = gr.Image(source='webcam',type='pil') button = gr.Button("执行检测",variant="primary") gr.Markdown("## 预测输出") out_img = gr.Image(type='pil') button.click(detect, inputs=in_img, outputs=out_img) gr.close_all() demo.queue(concurrency_count=5) demo.launch() 4.4 图片筛选器尽管gradio的设计初衷是为了快速创建机器学习用户交互页面。但实际上,通过组合gradio的各种组件,用户可以很方便地实现非常实用的各种应用小工具。例如: 数据分析展示dashboard, 数据标注工具, 制作一个小游戏界面等等。本范例我们将应用 gradio来构建一个图片筛选器,从百度爬取的一堆猫咪表情包中刷选一些我们喜欢的出来。#!pip install -U torchkerasimport torchkeras from torchkeras.data import download_baidu_pictures download_baidu_pictures('猫咪表情包',100) import gradio as gr from PIL import Image import time,os from pathlib import Path base_dir = '猫咪表情包' selected_dir = 'selected' files = [str(x) for x in Path(base_dir).rglob('*.jp*g') if 'checkpoint' not in str(x)] def show_img(path): return Image.open(path) def fn_before(done,todo): return done,todo,path,img def fn_next(done,todo): return done,todo,path,img def save_selected(img_path): return msg def get_default_msg(): return msg with gr.Blocks() as demo: with gr.Row(): total = gr.Number(len(files),label='总数量') with gr.Row(scale = 1): bn_before = gr.Button("上一张") bn_next = gr.Button("下一张") with gr.Row(scale = 2): done = gr.Number(0,label='已完成') todo = gr.Number(len(files),label='待完成') path = gr.Text(files[0],lines=1, label='当前图片路径') feedback_button = gr.Button("选择图片",variant="primary") msg = gr.TextArea(value=get_default_msg,lines=3,max_lines = 5) img = gr.Image(value = show_img(files[0]),type='pil') bn_before.click(fn_before, inputs= [done,todo], outputs=[done,todo,path,img]) bn_next.click(fn_next, inputs= [done,todo], outputs=[done,todo,path,img]) feedback_button.click(save_selected, inputs = path, outputs = msg demo.launch() 参考链接:Gradio官方仓库基于Gradio可视化部署机器学习应用gradio官方文档
深度学习基础入门篇[七]:常用归一化算法、层次归一化算法、归一化和标准化区别于联系、应用案例场景分析。
深度学习基础入门篇[七]:常用归一化算法、层次归一化算法、归一化和标准化区别于联系、应用案例场景分析。1.归一化基础知识点1.1 归一化作用归一化是一种数据处理方式,能将数据经过处理后限制在某个固定范围内。归一化存在两种形式,一种是在通常情况下,将数处理为 [0, 1] 之间的小数,其目的是为了在随后的数据处理过程中更便捷。例如,在图像处理中,就会将图像从 [0, 255] 归一化到 [0, 1]之间,这样既不会改变图像本身的信息储存,又可加速后续的网络处理。其他情况下,也可将数据处理到 [-1, 1] 之间,或其他的固定范围内。另一种是通过归一化将有量纲表达式变成无量纲表达式。那么什么是量纲,又为什么需要将有量纲转化为无量纲呢?具体举一个例子。当我们在做对房价的预测时,收集到的数据中,如房屋的面积、房间的数量、到地铁站的距离、住宅附近的空气质量等,都是量纲,而他们对应的量纲单位分别为平方米、个数、米、AQI等。这些量纲单位的不同,导致数据之间不具有可比性。同时,对于不同的量纲,数据的数量级大小也是不同的,比如房屋到地铁站的距离可以是上千米,而房屋的房间数量一般只有几个。经过归一化处理后,不仅可以消除量纲的影响,也可将各数据归一化至同一量级,从而解决数据间的可比性问题。归一化可以将有量纲转化为无量纲,同时将数据归一化至同一量级,解决数据间的可比性问题。在回归模型中,自变量的量纲不一致会导致回归系数无法解读或错误解读。在KNN、Kmeans等需要进行距离计算的算法中,量纲的量级不同可能会导致拥有较大量级的特征在进行距离计算时占主导地位,从而影响学习结果。数据归一化后,寻求最优解的过程会变得平缓,可以更快速的收敛到最优解。详解请参见3.为什么归一化能提高求解最优解的速度。1.2 归一化提高求解最优解的速度我们提到一个对房价进行预测的例子,假设自变量只有房子到地铁站的距离x1和房子内房间的个数x2,因变量为房价,预测公式和损失函数分别为$$\begin{array}{l}y=\theta_1x_1+\theta_2x_2\\ J=(\theta_1x_1+\theta_2x_2-y_{label})^2\end{array}$$在未归一化时,房子到地铁站的距离的取值在0~5000之间,而房间个数的取值范围仅为0~10。假设x1=1000,x2=3, 那么损失函数的公式可以写为:$$J=\left(1000\theta_1+3\theta_2-y_{label}\right)^2$$可将该损失函数寻求最优解过程可视化为下图:图1: 损失函数的等高线,图1(左)为未归一化时,图1(右)为归一化在图1中,左图的红色椭圆代表归一化前的损失函数等高线,蓝色线段代表梯度的更新,箭头的方向代表梯度更新的方向。寻求最优解的过程就是梯度更新的过程,其更新方向与登高线垂直。由于x1和 x2的量级相差过大,损失函数的等高线呈现为一个瘦窄的椭圆。因此如图1(左)所示,瘦窄的椭圆形会使得梯度下降过程呈之字形呈现,导致梯度下降速度缓慢。当数据经过归一化后,$$x_1^{'}=\frac{1000-0}{5000-0}=0.2,x_2^{'}=\frac{3-0}{10-0}=0.3,$$,那么损失函数的公式可以写为:$$J(x)=\left(0.2\theta_1+0.3\theta_2-y_{label}\right)^2$$我们可以看到,经过归一化后的数据属于同一量级,损失函数的等高线呈现为一个矮胖的椭圆形(如图1(右)所示),求解最优解过程变得更加迅速且平缓,因此可以在通过梯度下降进行求解时获得更快的收敛。1.3 归一化类型1.3.1 Min-max normalization (Rescaling):$$x^{'}=\dfrac{x-min(x)}{max(x)-min(x)}\quad\quad$$归一化后的数据范围为 [0, 1],其中 min(x)、max(x)分别求样本数据的最小值和最大值。1.3.2 Mean normalization:$$x^{'}=\dfrac{x-mean(x)}{max(x)-min(x)}\quad\text{}$$1.3.3 Z-score normalization (Standardization):标准化$$x^{'}=\dfrac{x-\mu}{\sigma}$$归一化后的数据范围为实数集,其中 μ、σ分别为样本数据的均值和标准差。1.3.4 非线性归一化:对数归一化:$$x^{'}=\dfrac{\lg x}{\lg max(x)}$$反正切函数归一化:$$x^{'}=\arctan(x)*\dfrac{2}{\pi}\quad$$归一化后的数据范围为 [-1, 1]小数定标标准化(Demical Point Normalization):$$x^{'}=\dfrac{x}{10^{j}}$$归一化后的数据范围为 [-1, 1],j为使$$max(|x'|)<1$$的最小整数。1.4 不同归一化的使用条件Min-max归一化和mean归一化适合在最大最小值明确不变的情况下使用,比如图像处理时,灰度值限定在 [0, 255] 的范围内,就可以用min-max归一化将其处理到[0, 1]之间。在最大最小值不明确时,每当有新数据加入,都可能会改变最大或最小值,导致归一化结果不稳定,后续使用效果也不稳定。同时,数据需要相对稳定,如果有过大或过小的异常值存在,min-max归一化和mean归一化的效果也不会很好。如果对处理后的数据范围有严格要求,也应使用min-max归一化或mean归一化。Z-score归一化也可称为标准化,经过处理的数据呈均值为0,标准差为1的分布。在数据存在异常值、最大最小值不固定的情况下,可以使用标准化。标准化会改变数据的状态分布,但不会改变分布的种类。特别地,神经网络中经常会使用到z-score归一化,针对这一点,我们将在后续的文章中进行详细的介绍。非线性归一化通常被用在数据分化程度较大的场景,有时需要通过一些数学函数对原始值进行映射,如对数、反正切等。在查找资料的时候,我看到很多文章都提出了:“在分类、聚类算法中,需要使用距离来度量相似性的时候,z-score归一化也就是标准化的效果比归一化要好,但是对于这个观点并没有给出足够的技术支持。因此,我选取了KNN分类网络搜索了相关论文,在论文Comparative Analysis of KNN Algorithm using Various Normalization Techniques [1] 中,在K值不同的情况下,对于相同的数据分别进行min-max归一化和z-score归一化,得到的结果如下图所示:图2: 对于不同的K值,相同数据集不同归一化方式下的预测精确度由此可以看到,至少对于KNN分类问题,z-score归一化和min-max归一化的选择会受到数据集、K值的影响,对于其他的分类和聚类算法,哪一种归一化的方法更好仍有待验证。最好的选择方法就是进行实验,选择在当前实验条件下,能够使模型精度更高的一种。1.5 归一化和标准化的联系与区别谈到归一化和标准化可能会存在一些概念的混淆,我们都知道归一化是指normalization,标准化是指standardization,但根据wiki上对feature scaling方法的定义,standardization其实就是z-score normalization,也就是说标准化其实是归一化的一种,而一般情况下,我们会把z-score归一化称为标准化,把min-max归一化简称为归一化。在下文中,我们也是用标准化指代z-score归一化,并使用归一化指代min-max归一化。其实,归一化和标准化在本质上都是一种线性变换。在4.归一化类型中,我们提到了归一化和标准化的公式,对于归一化的公式,在数据给定的情况下,可以令a=max(x)−min(x)、b=min(x),则归一化的公式可变形为:$$x^{'}=\dfrac{x-b}{a}=\dfrac{x}{a}-\dfrac{b}{a}=\dfrac{x}{a}-c$$标准化的公式与变形后的归一化类似,其中的μ和σ在数据给定的情况下,可以看作常数。因此,标准化的变形与归一化的类似,都可看作对x按比例a进行缩放,再进行c个单位的平移。由此可见,归一化和标准化的本质都是一种线性变换,他们都不会因为对数据的处理而改变数据的原始数值排序。那么归一化和标准化又有什么区别呢?归一化不会改变数据的状态分布,但标准化会改变数据的状态分布;归一化会将数据限定在一个具体的范围内,如 [0, 1],但标准化不会,标准化只会将数据处理为均值为0,标准差为1。References:【1】Comparative Analysis of KNN Algorithm using Various Normalization Techniques;Amit Pandey,Achin Jain.2. 层归一化神经网络的学习过程本质上是在学习数据的分布,如果没有进行归一化的处理,那么每一批次的训练数据的分布是不一样的,从大的方向上来看,神经网络则需要在这多个分布当中找到平衡点,从小的方向上来看 ,由于每层的网络输入数据分布在不断地变化 ,那么会导致每层网络都在找平衡点,显然网络就变得难以收敛 。当然我们可以对输入数据进行归一化处理(例如对输入图像除以255),但这也仅能保证输入层的数据分布是一样的,并不能保证每层网络输入数据分布是一样的,所以在网络的中间我们也是需要加入归一化的处理。归一化定义:数据标准化(Normalization),也称为归一化,归一化就是将需要处理的数据在通过某种算法经过处理后,将其限定在需要的一定的范围内2.1 层归一化产生原因一般的批归一化(Batch Normalization,BN)算法对mini-batch数据集过分依赖,无法应用到在线学习任务中(此时mini-batch数据集包含的样例个数为1),在递归神经网络(Recurrent neural network,RNN)中BN的效果也不明显 ;RNN多用于自然语言处理任务,网络在不同训练周期内输入的句子,句子长度往往不同,在RNN中应用BN时,在不同时间周期使用mini-batch数据集的大小都需要不同,计算复杂,而且如果一个测试句子比训练集中的任何一个句子都长,在测试阶段RNN神经网络预测性能会出现严重偏差。如果更改为使用层归一化,就可以有效的避免这个问题。层归一化:通过计算在一个训练样本上某一层所有的神经元的均值和方差来对神经元进行归一化。$$\mu\leftarrow\dfrac{1}{H}\sum_{i=1}^{H}x_i\\ \sigma\leftarrow\sqrt{\dfrac{1}{H}\sum_{i=1}^{H}(x_i-\mu_D)^2+\epsilon}\\ \vdots\\ y=f(\dfrac{g}{\sigma}(x-\mu)+b)$$相关参数含义:x : 该层神经元的向量表示H : 层中隐藏神经元个数ϵ : 添加较小的值到方差中以防止除零g: 再缩放参数(可训练),新数据以g2为方差b: 再平移参数(可训练),新数据以b为偏差f:激活函数算法作用加快网络的训练收敛速度 在深度神经网络中,如果每层的数据分布都不一样,将会导致网络非常难以收敛和训练(如综述所说难以在多种数据分布中找到平衡点),而每层数据的分布都相同的情况,训练时的收敛速度将会大幅度提升。控制梯度爆炸和防止梯度消失 我们常用的梯度传递的方式是由深层神经元往浅层传播,如果用f′i和O′i分别表示第i层对应的激活层导数和输出导数,那么对于H层的神经网络,第一层的导数$$F_1'=\prod_{i=1}^{H}f_i'*O_i'$$,那么对于$$f_i'*O_i'$$恒大于1的情况,如$$f_i'*O_i'=2$$的情况,使得结果指数上升,发生梯度爆炸,对于$$f_i'*O_i'$$恒小于1,如$$f_i'*O_i'=0.25$$导致结果指数下降,发生梯度消失的现象,底层神经元梯度几乎为0。采用归一化算法后,可以使得f_i'*O_i'$$f_i'*O_i'$$的结果不会太大也不会太小,有利于控制梯度的传播。在飞桨框架案例如下:paddle.nn.LayerNorm(normalized_shape, epsilon=1e-05, weight_attr=None, bias_attr=None, name=None);该接口用于构建 LayerNorm 类的一个可调用对象核心参数的含义:normalized_shape (int|list|tuple) - 期望对哪些维度进行变换。如果是一个整数,会将最后一个维度进行规范化。epsilon (float, 可选) - 对应ϵ-为了数值稳定加在分母上的值。默认值:1e-052.2 应用案例import paddle import numpy as np np.random.seed(123) x_data = np.random.random(size=(2, 2, 2, 3)).astype('float32') x = paddle.to_tensor(x_data) layer_norm = paddle.nn.LayerNorm(x_data.shape[1:]) layer_norm_out = layer_norm(x) print(layer_norm_out) # input # Tensor(shape=[2, 2, 2, 3], dtype=float32, place=CPUPlace, stop_gradient=True, # [[[[0.69646919, 0.28613934, 0.22685145], # [0.55131477, 0.71946895, 0.42310646]], # [[0.98076421, 0.68482971, 0.48093191], # [0.39211753, 0.34317800, 0.72904968]]], # [[[0.43857226, 0.05967790, 0.39804426], # [0.73799539, 0.18249173, 0.17545176]], # [[0.53155136, 0.53182757, 0.63440096], # [0.84943181, 0.72445530, 0.61102349]]]]) # output: # Tensor(shape=[2, 2, 2, 3], dtype=float32, place=CPUPlace, stop_gradient=True, # [[[[ 0.71878898, -1.20117974, -1.47859287], # [ 0.03959895, 0.82640684, -0.56029880]], # [[ 2.04902983, 0.66432685, -0.28972855], # [-0.70529866, -0.93429095, 0.87123591]]], # [[[-0.21512909, -1.81323946, -0.38606915], # [ 1.04778552, -1.29523218, -1.32492554]], # [[ 0.17704056, 0.17820556, 0.61084229], # [ 1.51780486, 0.99067575, 0.51224011]]]])对于一般的图片训练集格式为$$(N,C,H,W)$$的数据,在LN变换中,我们对后三个维度进行归一化。因此实例的输入shape就是后三维x_data.shape[1:]。也就是我们固定了以每张图片为单位,对每张图片的所有通道的像素值统一进行了Z-score归一化。2.3应用场景层归一化在递归神经网络RNN中的效果是受益最大的,它的表现优于批归一化,特别是在动态长序列和小批量的任务当中 。例如在论文Layer Normalization所提到的以下任务当中:图像与语言的顺序嵌入(Order embedding of images and language)教机器阅读和理解(Teaching machines to read and comprehend)Skip-thought向量(Skip-thought vectors)使用DRAW对二值化的MNIST进行建模(Modeling binarized MNIST using DRAW)手写序列生成(Handwriting sequence generation)排列不变MNIST(Permutation invariant MNIST)但是,研究表明,由于在卷积神经网络中,LN会破坏卷积所学习到的特征,致使模型无法收敛,而对于BN算法,基于不同数据的情况,同一特征归一化得到的数据更不容易损失信息,所以在LN和BN都可以应用的场景,BN的表现通常要更好。文献:Ba J L , Kiros J R , Hinton G E . Layer Normalization[J]. 2016.
零样本文本分类应用:基于UTC的医疗意图多分类,打通数据标注-模型训练-模型调优-预测部署全流程。
零样本文本分类应用:基于UTC的医疗意图多分类,打通数据标注-模型训练-模型调优-预测部署全流程。1.通用文本分类技术UTC介绍本项目提供基于通用文本分类 UTC(Universal Text Classification) 模型微调的文本分类端到端应用方案,打通数据标注-模型训练-模型调优-预测部署全流程,可快速实现文本分类产品落地。文本分类是一种重要的自然语言处理任务,它可以帮助我们将大量的文本数据进行有效的分类和归纳。实际上,在日常生活中,我们也经常会用到文本分类技术。例如,我们可以使用文本分类来对新闻报道进行分类,对电子邮件进行分类,对社交媒体上的评论进行情感分析等等。但是,文本分类也面临着许多挑战。其中最重要的挑战之一是数据稀缺。由于文本数据往往非常庞大,因此获取足够的训练数据可能非常困难。此外,不同的文本分类任务也可能面临着领域多变和任务多样等挑战。为了应对这些挑战,PaddleNLP推出了一项零样本文本分类应用UTC。该应用通过统一语义匹配方式USM(Unified Semantic Matching)来将标签和文本的语义匹配能力进行统一建模。这种方法可以帮助我们更好地理解文本数据,并从中提取出有用的特征信息。UTC具有低资源迁移能力,可以支持通用分类、评论情感分析、语义相似度计算、蕴含推理、多项式阅读理解等多种“泛分类”任务。这使得开发者可以更加轻松高效地实现多任务文本分类数据标注、训练、调优和上线,从而降低文本分类技术门槛。总之,文本分类是一项重要的自然语言处理任务,它可以帮助我们更好地理解和归纳文本数据。尽管它面临着许多挑战,但是通过使用PaddleNLP的零样本文本分类应用UTC,开发者们可以简单高效实现多任务文本分类数据标注、训练、调优、上线,降低文本分类落地技术门槛。 1.1 分类落地面临难度分类任务看似简单,然而在产业级文本分类落地实践中,面临着诸多挑战:任务多样:单标签、多标签、层次标签、大规模标签等不同的文本分类任务,需要开发不同的分类模型,模型架构往往特化于具体任务,难以使用统一形式建模;数据稀缺:部分领域数据稀缺,难以获取,且领域专业性使得数据标注门槛高;标签迁移:不同领域的标签多样,并且迁移难度大,尤其不同领域间的标签知识很难迁移。1.2 UTC亮点1.2.1 多任务统一建模在传统技术方案中,针对不同的分类任务需要构建多个分类模型,模型需单独训练且数据和知识不共享。而在UTC方案下,单个模型能解决所有分类需求,包括但不限于单标签分类、多标签分类、层次标签分类、大规模事件标签检测、蕴含推理、语义相似度计算等,降低了开发成本和机器成本。 1.2.2 零样本分类和小样本迁移能力强UTC通过大规模多任务预训练后,可以适配不同的行业领域,不同的分类标签,仅标注了几条样本,分类效果就取得大幅提升,大大降低标注门槛和成本。 在医疗、金融、法律等领域中,无需训练数据的零样本情况下UTC效果平均可达到70%+(如下表所示),标注少样本也可带来显著的效果提升:每个标签仅仅标注1条样本后,平均提升了10个点!也就是说,即使在某些场景下表现欠佳,人工标几个样本,丢给模型后就会有大幅的效果提升。1.3 UTC技术思路UTC基于百度最新提出的统一语义匹配框架USM(Unified Semantic Matching)[1],将分类任务统一建模为标签与文本之间的匹配任务,对不同标签的分类任务进行统一建模。具体地说:为了实现任务架构统一,UTC设计了标签与文本之间的词对连接操作(Label–>CLS-Token Linking),这使得模型能够适应不同领域和任务的标签信息,并按需求进行分类,从而实现了开放域场景下的通用文本分类。例如,对于事件检测任务,可将一系列事件标签拼接为[L]上映[L]夺冠[L]下架 ,然后与原文本一起作为整体输入到UTC中,UTC将不同标签标识符[L]与[CLS]进行匹配,可对不同标签类型的分类任务统一建模,直接上图: 为了实现通用能力共享,让不同领域间的标签知识跨域迁移,UTC构建了统一的异质监督学习方法进行多任务预训练,使不同领域任务具备良好的零/少样本迁移性能。统一的异质监督学习方法主要包括三种不同的监督信号:直接监督:分类任务直接相关的数据集,如情感分类、新闻分类、意图识别等。间接监督:分类任务间接相关的数据集,如选项式阅读理解、问题-文章匹配等。远程监督:标签知识库或层级标题与文本对齐后弱标注数据。更多内容参考论文见文末链接 or fork一下项目论文已上传2.文本分类任务Label Studio教程2.1 Label Studio安装以下标注示例用到的环境配置:Python 3.8+label-studio == 1.7.2在终端(terminal)使用pip安装label-studio:pip install label-studio==1.7.2安装完成后,运行以下命令行:label-studio start在浏览器打开http://localhost:8080/,输入用户名和密码登录,开始使用label-studio进行标注。2.2 文本分类任务标注2.2.1 项目创建点击创建(Create)开始创建一个新的项目,填写项目名称、描述,然后在Labeling Setup中选择Text Classification。填写项目名称、描述 数据上传,从本地上传txt格式文件,选择List of tasks,然后选择导入本项目 设置任务,添加标签 数据上传项目创建后,可在Project/文本分类任务中点击Import继续导入数据,同样从本地上传txt格式文件,选择List of tasks 。2.2.2 标签构建项目创建后,可在Setting/Labeling Interface中继续配置标签,默认模式为单标签多分类数据标注。对于多标签多分类数据标注,需要将choice的值由single改为multiple。 2.2.3 任务标注 2.2.4 数据导出勾选已标注文本ID,选择导出的文件类型为JSON,导出数据: 参考链接:Label Studio3.数据转换将导出的文件重命名为label_studio.json后,放入./data目录下。通过label_studio.py脚本可转为UTC的数据格式。在数据转换阶段,还需要提供标签候选信息,放在./data/label.txt文件中,每个标签占一行。例如在医疗意图分类中,标签候选为["病情诊断", "治疗方案", "病因分析", "指标解读", "就医建议", "疾病表述", "后果表述", "注意事项", "功效作用", "医疗费用", "其他"],也可通过options参数直接进行配置。这里提供预先标注好的医疗意图分类数据集的文件,可以运行下面的命令行下载数据集,我们将展示如何使用数据转化脚本生成训练/验证/测试集文件,并使用UTC模型进行微调。#下载医疗意图分类数据集: !wget https://bj.bcebos.com/paddlenlp/datasets/utc-medical.tar.gz !tar -xvf utc-medical.tar.gz !mv utc-medical data !rm utc-medical.tar.gz数据集部分展示[{"id":26092,"annotations":[{"id":59,"completed_by":1,"result":[{"value":{"choices":["注意事项"]},"id":"7iya31L9oc","from_name":"sentiment","to_name":"text","type":"choices","origin":"manual"}],"was_cancelled":false,"ground_truth":false,"created_at":"2023-01-09T07:13:18.982993Z","updated_at":"2023-01-09T07:13:18.983032Z","lead_time":4.022,"prediction":{},"result_count":0,"task":26092,"parent_prediction":null,"parent_annotation":null}],"file_upload":"838fb89a-10-shot.txt","drafts":[],"predictions":[],"data":{"text":"烧氧割要注意那些问题"},"meta":{},"created_at":"2023-01-09T06:48:10.725717Z","updated_at":"2023-01-09T07:13:19.022666Z","inner_id":35,"total_annotations":1,"cancelled_annotations":0,"total_predictions":0,"comment_count":0,"unresolved_comment_count":0,"last_comment_updated_at":null,"project":5,"updated_by":1,"comment_authors":[]}, {"id":26091,"annotations":[{"id":4,"completed_by":1,"result":[{"value":{"choices":["病因分析"]}]# 生成训练/验证集文件: !python label_studio.py \ --label_studio_file ./data/utc-medical/label_studio.json \ --save_dir ./data \ --splits 0.8 0.1 0.1 \ --options ./data/utc-medical/label.txt[32m[2023-04-14 11:28:46,056] [ INFO][0m - Save 45 examples to ./data/train.txt.[0m [32m[2023-04-14 11:28:46,057] [ INFO][0m - Save 6 examples to ./data/dev.txt.[0m [32m[2023-04-14 11:28:46,057] [ INFO][0m - Save 6 examples to ./data/test.txt.[0m [32m[2023-04-14 11:28:46,057] [ INFO][0m - Finished! It takes 0.00 seconds[0m {"text_a": "老年痴呆的症状有哪些", "text_b": "", "question": "", "choices": ["病情诊断", "治疗方案", "病因分析", "指标解读", "就医建议", "疾病表述", "后果表述", "注意事项", "功效作用", "医疗费用", "其他"], "labels": [5]} label_studio_file: 从label studio导出的数据标注文件。save_dir: 训练数据的保存目录,默认存储在data目录下。splits: 划分数据集时训练集、验证集所占的比例。默认为[0.8, 0.1, 0.1]表示按照8:1:1的比例将数据划分为训练集、验证集和测试集。options: 指定分类任务的类别标签。若输入类型为文件,则文件中每行一个标签。is_shuffle: 是否对数据集进行随机打散,默认为True。seed: 随机种子,默认为1000.备注:默认情况下 label_studio.py 脚本会按照比例将数据划分为 train/dev/test 数据集每次执行 label_studio.py 脚本,将会覆盖已有的同名数据文件对于从label_studio导出的文件,默认文件中的每条数据都是经过人工正确标注的。使用Label Studio 数据标注工具进行标注,如果已有标注好的本地数据集,我们需要将数据集整理为文档要求的格式,4.模型训练预测多任务训练场景可分别进行数据转换再进行混合:通用分类、评论情感分析、语义相似度计算、蕴含推理、多项式阅读理解等众多“泛分类”任务##代码结构 ├── deploy/simple_serving/ # 模型部署脚本 ├── utils.py # 数据处理工具 ├── run_train.py # 模型微调脚本 ├── run_eval.py # 模型评估脚本 ├── label_studio.py # 数据格式转换脚本 ├── label_studio_text.md # 数据标注说明文档 └── README.md4.1 模型微调推荐使用 PromptTrainer API 对模型进行微调,该 API 封装了提示定义功能,且继承自 Trainer API 。只需输入模型、数据集等就可以使用 Trainer API 高效快速地进行预训练、微调等任务,可以一键启动多卡训练、混合精度训练、梯度累积、断点重启、日志显示等功能,Trainer API 还针对训练过程的通用训练配置做了封装,比如:优化器、学习率调度等。使用下面的命令,使用 utc-base 作为预训练模型进行模型微调,将微调后的模型保存至output_dir:4.1.1 单卡训练#安装最新版本paddlenlp !pip install --upgrade paddlenlp# 单卡启动: !python run_train.py \ --device gpu \ --logging_steps 10 \ --save_steps 10 \ --eval_steps 10 \ --seed 1000 \ --model_name_or_path utc-base \ --output_dir ./checkpoint/model_best \ --dataset_path ./data/ \ --max_seq_length 512 \ --per_device_train_batch_size 2 \ --per_device_eval_batch_size 2 \ --gradient_accumulation_steps 8 \ --num_train_epochs 20 \ --learning_rate 1e-5 \ --do_train \ --do_eval \ --do_export \ --export_model_dir ./checkpoint/model_best \ --overwrite_output_dir \ --disable_tqdm True \ --metric_for_best_model macro_f1 \ --load_best_model_at_end True \ --save_total_limit 1 \ --save_plmeval_loss: 0.3148668706417084, eval_micro_f1: 0.9848484848484849, eval_macro_f1: 0.9504132231404958, eval_runtime: 0.0757, eval_samples_per_second: 79.286, eval_steps_per_second: 39.643, epoch: 19.6957 [2023-04-13 17:02:45,941] [ INFO] - epoch = 19.6957 [2023-04-13 17:02:45,941] [ INFO] - train_loss = 0.9758 [2023-04-13 17:02:45,942] [ INFO] - train_runtime = 0:00:45.91 [2023-04-13 17:02:45,942] [ INFO] - train_samples_per_second = 19.602 [2023-04-13 17:02:45,942] [ INFO] - train_steps_per_second = 0.871二分类时需要注意的问题ModuleNotFoundError: No module named 'fast_tokenizer'安装一下fast tokenizer pip install --upgrade fast_tokenizer开启single_label时需要将运行脚本中的 metric_for_best_model 参数改为accuracymetric_value = metrics[metric_to_check] KeyError: 'eval_macro_f1'4.1.2 多卡训练如果在GPU环境中使用,可以指定gpus参数进行多卡训练:# !python -u -m paddle.distributed.launch --gpus "0,1,2,3" run_train.py \ # --device gpu \ # --logging_steps 10 \ # --save_steps 10 \ # --eval_steps 10 \ # --seed 1000 \ # --model_name_or_path utc-base \ # --output_dir ./checkpoint/model_best \ # --dataset_path ./data/ \ # --max_seq_length 512 \ # --per_device_train_batch_size 2 \ # --per_device_eval_batch_size 2 \ # --gradient_accumulation_steps 8 \ # --num_train_epochs 20 \ # --learning_rate 1e-5 \ # --do_train \ # --do_eval \ # --do_export \ # --export_model_dir ./checkpoint/model_best \ # --overwrite_output_dir \ # --disable_tqdm True \ # --metric_for_best_model macro_f1 \ # --load_best_model_at_end True \ # --save_total_limit 1 \ # --save_plm该示例代码中由于设置了参数 --do_eval,因此在训练完会自动进行评估。可配置参数说明:single_label: 每条样本是否只预测一个标签。默认为False,表示多标签分类。device: 训练设备,可选择 'cpu'、'gpu' 其中的一种;默认为 GPU 训练。logging_steps: 训练过程中日志打印的间隔 steps 数,默认10。save_steps: 训练过程中保存模型 checkpoint 的间隔 steps 数,默认100。eval_steps: 训练过程中保存模型 checkpoint 的间隔 steps 数,默认100。seed:全局随机种子,默认为 42。model_name_or_path:进行 few shot 训练使用的预训练模型。默认为 "utc-base", 可选"utc-xbase", "utc-base", "utc-medium", "utc-mini", "utc-micro", "utc-nano", "utc-pico"。output_dir:必须,模型训练或压缩后保存的模型目录;默认为 None 。dataset_path:数据集文件所在目录;默认为 ./data/ 。train_file:训练集后缀;默认为 train.txt 。dev_file:开发集后缀;默认为 dev.txt 。max_seq_len:文本最大切分长度,包括标签的输入超过最大长度时会对输入文本进行自动切分,标签部分不可切分,默认为512。per_device_train_batch_size:用于训练的每个 GPU 核心/CPU 的batch大小,默认为8。per_device_eval_batch_size:用于评估的每个 GPU 核心/CPU 的batch大小,默认为8。num_train_epochs: 训练轮次,使用早停法时可以选择 100;默认为10。learning_rate:训练最大学习率,UTC 推荐设置为 1e-5;默认值为3e-5。do_train:是否进行微调训练,设置该参数表示进行微调训练,默认不设置。do_eval:是否进行评估,设置该参数表示进行评估,默认不设置。do_export:是否进行导出,设置该参数表示进行静态图导出,默认不设置。export_model_dir:静态图导出地址,默认为None。overwrite_output_dir: 如果 True,覆盖输出目录的内容。如果 output_dir 指向检查点目录,则使用它继续训练。disable_tqdm: 是否使用tqdm进度条。metric_for_best_model:最优模型指标, UTC 推荐设置为 macro_f1,默认为None。load_best_model_at_end:训练结束后是否加载最优模型,通常与metric_for_best_model配合使用,默认为False。save_total_limit:如果设置次参数,将限制checkpoint的总数。删除旧的checkpoints 输出目录,默认为None。--save_plm:保存模型进行推理部署4.2 模型评估通过运行以下命令进行模型评估预测:!python run_eval.py \ --model_path ./checkpoint/model_best \ --test_path ./data/test.txt \ --per_device_eval_batch_size 16 \ --max_seq_len 512 \ --output_dir ./checkpoint_test测试结果[2023-04-13 17:06:59,413] [ INFO] - test_loss = 1.6392 [2023-04-13 17:06:59,413] [ INFO] - test_macro_f1 = 0.8167 [2023-04-13 17:06:59,413] [ INFO] - test_micro_f1 = 0.9394 [2023-04-13 17:06:59,413] [ INFO] - test_runtime = 0:00:00.87 [2023-04-13 17:06:59,413] [ INFO] - test_samples_per_second = 6.835 [2023-04-13 17:06:59,413] [ INFO] - test_steps_per_second = 1.139可配置参数说明:model_path: 进行评估的模型文件夹路径,路径下需包含模型权重文件model_state.pdparams及配置文件model_config.json。test_path: 进行评估的测试集文件。per_device_eval_batch_size: 批处理大小,请结合机器情况进行调整,默认为16。max_seq_len: 文本最大切分长度,输入超过最大长度时会对输入文本进行自动切分,默认为512。single_label: 每条样本是否只预测一个标签。默认为False,表示多标签分类。4.3模型预测paddlenlp.Taskflow装载定制模型,通过task_path指定模型权重文件的路径,路径下需要包含训练好的模型权重文件model_state.pdparams。!pip install onnxruntime-gpu onnx onnxconverter-common !pip install paddle2onnx #如果出现这个报错 local variable 'paddle2onnx' referenced before assignment ,请安装上述库onnx 的包需要安装 #中途出现一些警告可以忽视 from pprint import pprint from paddlenlp import Taskflow schema = ["病情诊断", "治疗方案", "病因分析", "指标解读", "就医建议", "疾病表述", "后果表述", "注意事项", "功效作用", "医疗费用", "其他"] # my_cls = Taskflow("zero_shot_text_classification", model="utc-base", schema=schema, task_path='/home/aistudio/checkpoint/model_best/plm', precision="fp16") my_cls = Taskflow("zero_shot_text_classification", model="utc-base", schema=schema, task_path='/home/aistudio/checkpoint/model_best/plm') #支持FP16半精度推理加速,需要安装onnx pprint(my_cls(["老年斑为什么都长在面部和手背上","老成都市哪家内痔医院比较好怎么样最好?","中性粒细胞比率偏低"]))[2023-04-14 11:45:11,057] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load 'utc-base'. [2023-04-14 11:45:11,059] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/utc-base/utc_base_vocab.txt [2023-04-14 11:45:11,083] [ INFO] - tokenizer config file saved in /home/aistudio/.paddlenlp/models/utc-base/tokenizer_config.json [2023-04-14 11:45:11,085] [ INFO] - Special tokens file saved in /home/aistudio/.paddlenlp/models/utc-base/special_tokens_map.json [2023-04-14 11:45:11,088] [ INFO] - Assigning ['[O-MASK]'] to the additional_special_tokens key of the tokenizer [{'predictions': [{'label': '病因分析', 'score': 0.7360146263899581}], 'text_a': '老年斑为什么都长在面部和手背上'}, {'predictions': [{'label': '就医建议', 'score': 0.9940570944549809}], 'text_a': '老成都市哪家内痔医院比较好怎么样最好?'}, {'predictions': [{'label': '指标解读', 'score': 0.6683004187689248}], 'text_a': '中性粒细胞比率偏低'}] from pprint import pprint from paddlenlp import Taskflow schema = ["病情诊断", "治疗方案", "病因分析", "指标解读", "就医建议", "疾病表述", "后果表述", "注意事项", "功效作用", "医疗费用", "其他"] my_cls = Taskflow("zero_shot_text_classification", model="utc-base", schema=schema) pprint(my_cls(["老年斑为什么都长在面部和手背上","老成都市哪家内痔医院比较好怎么样最好?","中性粒细胞比率偏低"]))[2023-04-14 11:45:20,869] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load 'utc-base'. [2023-04-14 11:45:20,872] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/utc-base/utc_base_vocab.txt [2023-04-14 11:45:20,897] [ INFO] - tokenizer config file saved in /home/aistudio/.paddlenlp/models/utc-base/tokenizer_config.json [2023-04-14 11:45:20,900] [ INFO] - Special tokens file saved in /home/aistudio/.paddlenlp/models/utc-base/special_tokens_map.json [2023-04-14 11:45:20,903] [ INFO] - Assigning ['[O-MASK]'] to the additional_special_tokens key of the tokenizer [{'predictions': [], 'text_a': '老年斑为什么都长在面部和手背上'}, {'predictions': [{'label': '就医建议', 'score': 0.9283481315032535}, {'label': '其他', 'score': 0.5083715719139965}], 'text_a': '老成都市哪家内痔医院比较好怎么样最好?'}, {'predictions': [{'label': '其他', 'score': 0.9437889944553786}], 'text_a': '中性粒细胞比率偏低'}] 4.3.1 预测结果对比模型文本预测结果评估得分utc-base老年斑为什么都长在面部和手背上空---utc-base老成都市哪家内痔医院比较好怎么样最好?就医建议/其他0.92/0.51utc-base中性粒细胞比率偏低其他0.94utc-base+微调老年斑为什么都长在面部和手背上病因分析0.73utc-base+微调老成都市哪家内痔医院比较好怎么样最好?就医建议0.99utc-base+微调中性粒细胞比率偏低指标解读0.66明显可以看到在通过样本训练后,在test测试的结果小样本本微调的结果显著提升4.3.2 各个模型见对比Micro F1更关注整个数据集的性能,而Macro F1更关注每个类别的性能。医疗意图分类数据集 KUAKE-QIC 验证集 zero-shot 实验指标和小样本下训练对比:| | Macro F1 | Micro F1 | 微调后 Macro F1 |微调后 Micro F1 | | :--------: | :--------: | :--------: | :--------: | :--------: | | utc-xbase | 66.30 | 89.67 | | | | utc-base | 64.13 | 89.06 |81.67(+17.54)|93.94 (+4.88)| | utc-medium | 69.62 | 89.15 || | | utc-micro | 60.31 | 79.14 || | | utc-mini | 65.82 | 89.82 || | | utc-nano | 62.03 | 80.92 || | | utc-pico | 53.63 | 83.57 || |其余模型就不一一验证了,感兴趣同学自行验证。5.模型部署目前 UTC 模型提供基于多种部署方式,包括基于 FastDeploy 的本地 Python 部署以及 PaddleNLP SimpleServing 的服务化部署。5.1 FastDeploy UTC 模型 Python 部署示例以下示例展示如何基于 FastDeploy 库完成 UTC 模型完成通用文本分类任务的 Python 预测部署,可通过命令行参数--device以及--backend指定运行在不同的硬件以及推理引擎后端,并使用--model_dir参数指定运行的模型。模型目录为 application/zero_shot_text_classification/checkpoint/model_best(用户可按实际情况设置)。在部署前,参考 FastDeploy SDK 安装文档安装 FastDeploy Python SDK。本目录下提供 infer.py 快速完成在 CPU/GPU 的通用文本分类任务的 Python 部署示例。依赖安装直接执行以下命令安装部署示例的依赖。# 安装 fast_tokenizer 以及 GPU 版本 fastdeploy pip install fast-tokenizer-python fastdeploy-gpu-python -f https://www.paddlepaddle.org.cn/whl/fastdeploy.html以下示例展示如何基于 FastDeploy 库完成 UTC 模型进行文本分类任务的 Python 预测部署,可通过命令行参数--device以及--backend指定运行在不同的硬件以及推理引擎后端,并使用--model_dir参数指定运行的模型,具体参数设置可查看下面[参数说明])。示例中的模型是按照 [UTC 训练文档]导出得到的部署模型,其模型目录为 application/zero_shot_text_classification/checkpoint/model_best(用户可按实际情况设置)。# CPU 推理 python /home/aistudio/deploy/python/infer.py--model_dir /home/aistudio/checkpoint/model_best --device cpu # GPU 推理 python /home/aistudio/deploy/python/infer.py --model_dir /home/aistudio/checkpoint/model_best --device gpu运行完成后返回的结果如下:参数说明参数参数说明--model_dir指定部署模型的目录,--batch_size输入的batch size,默认为 1--max_length最大序列长度,默认为 128--num_omask_tokens最大标签数量,默认为64--device运行的设备,可选范围: ['cpu', 'gpu'],默认为'cpu'--device_id运行设备的id。默认为0。--cpu_threads当使用cpu推理时,指定推理的cpu线程数,默认为1。--backend支持的推理后端,可选范围: ['onnx_runtime', 'paddle', 'tensorrt', 'paddle_tensorrt'],默认为'paddle'--use_fp16是否使用FP16模式进行推理。使用tensorrt和paddle_tensorrt后端时可开启,默认为FalseFastDeploy 高阶用法FastDeploy 在 Python 端上,提供 fastdeploy.RuntimeOption.use_xxx() 以及 fastdeploy.RuntimeOption.use_xxx_backend() 接口支持开发者选择不同的硬件、不同的推理引擎进行部署。在不同的硬件上部署 UTC 模型,需要选择硬件所支持的推理引擎进行部署,下表展示如何在不同的硬件上选择可用的推理引擎部署 UTC 模型。符号说明: (1) ✅: 已经支持; (2) ❔: 正在进行中; (3) N/A: 暂不支持; 硬件 硬件对应的接口 可用的推理引擎 推理引擎对应的接口 是否支持 Paddle 新格式量化模型 是否支持 FP16 模式 use_cpu() Paddle Inference use_paddle_infer_backend() ONNX Runtime use_ort_backend() use_gpu() Paddle Inference use_paddle_infer_backend() ONNX Runtime use_ort_backend() Paddle TensorRT use_paddle_infer_backend() + paddle_infer_option.enable_trt = True TensorRT use_trt_backend() 昆仑芯 XPU use_kunlunxin() Paddle Lite use_paddle_lite_backend() 华为 昇腾 use_ascend() Paddle Lite use_paddle_lite_backend() Graphcore IPU use_ipu() Paddle Inference use_paddle_infer_backend() # !pip install --user fast-tokenizer-python fastdeploy-gpu-python -f https://www.paddlepaddle.org.cn/whl/fastdeploy.html #比较大1.4G 去终端安装在notebook执行出现问题,可能需要本地对fastdeploy应用调试,或者有小伙伴解决了可以再评论区发表一下,一起解决。在studio 目前显示是安装成功了,但是初始化是失败的 File "/home/aistudio/.data/webide/pip/lib/python3.7/site-packages/fastdeploy/c_lib_wrap.py", line 166, in <module> raise RuntimeError("FastDeploy initalized failed!") RuntimeError: FastDeploy initalized failed!在本地测试模型使用了utc-pico,cpu情况下调试。效果如下:记得修改infer文件对应的预测内容 predictor = Predictor(args, schema=["病情诊断", "治疗方案", "病因分析", "指标解读", "就医建议", "疾病表述", "后果表述", "注意事项", "功效作用", "医疗费用", "其他"]) results = predictor.predict(["月经期间刮痧拔罐会引起身体什么","老年斑为什么都长在面部和手背上","成都市哪家内痔医院比较好怎么样最好?","中性粒细胞比率偏低"]) 推理:模型目录需要包含:model.pdmodel等文件5.2 SimpleServing 的服务化部署在 UTC 的服务化能力中我们提供基于PaddleNLP SimpleServing 来搭建服务化能力,通过几行代码即可搭建服务化部署能力。环境准备使用有SimpleServing功能的PaddleNLP版本(或者最新的develop版本)pip install paddlenlp >= 2.5.0Server服务启动进入文件当前所在路径paddlenlp server server:app --workers 1 --host 0.0.0.0 --port 8190Client请求启动python client.py服务化自定义参数Server 自定义参数schema替换# Default schema schema = ["病情诊断", "治疗方案", "病因分析", "指标解读", "就医建议", "疾病表述", "后果表述", "注意事项", "功效作用", "医疗费用", "其他"]* 设置模型路径 # Default task_path utc = Taskflow("zero_shot_text_classification", model="utc-base", task_path="../../checkpoint/model_best/plm", schema=schema)* 多卡服务化预测PaddleNLP SimpleServing 支持多卡负载均衡预测,主要在服务化注册的时候,注册两个Taskflow的task即可,下面是示例代码utc1 = Taskflow("zero_shot_text_classification", model="utc-base", task_path="../../checkpoint/model_best", schema=schema) utc2 = Taskflow("zero_shot_text_classification", model="utc-base", task_path="../../checkpoint/model_best", schema=schema) service.register_taskflow("taskflow/utc", [utc1, utc2])更多配置from paddlenlp import Taskflow schema = ["病情诊断", "治疗方案", "病因分析", "指标解读", "就医建议", "疾病表述", "后果表述", "注意事项", "功效作用", "医疗费用", "其他"] utc = Taskflow("zero_shot_text_classification", schema=schema, model="utc-base", max_seq_len=512, batch_size=1, pred_threshold=0.5, precision="fp32")schema:定义任务标签候选集合。model:选择任务使用的模型,默认为utc-base, 可选有utc-xbase, utc-base, utc-medium, utc-micro, utc-mini, utc-nano, utc-pico。max_seq_len:最长输入长度,包括所有标签的长度,默认为512。batch_size:批处理大小,请结合机器情况进行调整,默认为1。pred_threshold:模型对标签预测的概率在0~1之间,返回结果去掉小于这个阈值的结果,默认为0.5。precision:选择模型精度,默认为fp32,可选有fp16和fp32。fp16推理速度更快。如果选择fp16,请先确保机器正确安装NVIDIA相关驱动和基础软件,确保CUDA>=11.2,cuDNN>=8.1.1,初次使用需按照提示安装相关依赖。其次,需要确保GPU设备的CUDA计算能力(CUDA Compute Capability)大于7.0,典型的设备包括V100、T4、A10、A100、GTX 20系列和30系列显卡等。更多关于CUDA Compute Capability和精度支持情况请参考NVIDIA文档:GPU硬件与支持精度对照表。Client 自定义参数# Changed to input texts you wanted texts = ["中性粒细胞比率偏低"]%cd /home/aistudio/deploy/simple_serving !paddlenlp server server:app --workers 1 --host 0.0.0.0 --port 8190 #Error loading ASGI app. Could not import module "server". #去终端执行即可/home/aistudio/deploy/simple_serving [2023-04-13 18:26:51,839] [ INFO] - starting to PaddleNLP SimpleServer... [2023-04-13 18:26:51,840] [ INFO] - The PaddleNLP SimpleServer is starting, backend component uvicorn arguments as follows: [2023-04-13 18:26:51,840] [ INFO] - the starting argument [host]=0.0.0.0 [2023-04-13 18:26:51,840] [ INFO] - the starting argument [port]=8190 [2023-04-13 18:26:51,840] [ INFO] - the starting argument [log_level]=None [2023-04-13 18:26:51,840] [ INFO] - the starting argument [workers]=1 [2023-04-13 18:26:51,840] [ INFO] - the starting argument [limit_concurrency]=None [2023-04-13 18:26:51,840] [ INFO] - the starting argument [limit_max_requests]=None [2023-04-13 18:26:51,840] [ INFO] - the starting argument [timeout_keep_alive]=15 [2023-04-13 18:26:51,840] [ INFO] - the starting argument [app_dir]=/home/aistudio/deploy/simple_serving [2023-04-13 18:26:51,840] [ INFO] - the starting argument [reload]=False [2023-04-13 18:26:52,037] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load 'utc-base'. [2023-04-13 18:26:52,038] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/utc-base/utc_base_vocab.txt [2023-04-13 18:26:52,067] [ INFO] - tokenizer config file saved in /home/aistudio/.paddlenlp/models/utc-base/tokenizer_config.json [2023-04-13 18:26:52,067] [ INFO] - Special tokens file saved in /home/aistudio/.paddlenlp/models/utc-base/special_tokens_map.json [2023-04-13 18:26:52,069] [ INFO] - Assigning ['[O-MASK]'] to the additional_special_tokens key of the tokenizer [2023-04-13 18:26:55,628] [ INFO] - Taskflow request [path]=/taskflow/utc is genereated. INFO: Started server process [1718] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8190 (Press CTRL+C to quit) INFO: Shutting down INFO: Waiting for application shutdown. INFO: Application shutdown complete. INFO: Finished server process [1718] 在notebook如果不行,可以直接进入终端进行调试,需要注意的是要在同一个路径下不然会报错# Save at server.py from paddlenlp import SimpleServer, Taskflow schema = ["病情诊断", "治疗方案", "病因分析", "指标解读", "就医建议"] utc = Taskflow("zero_shot_text_classification", model="utc-base", schema=schema, task_path="/home/aistudio/checkpoint/model_best/plm", precision="fp32") app = SimpleServer() app.register_taskflow("taskflow/utc", utc)# %cd /home/aistudio/deploy/simple_serving !python client.py6.总结原项目链接:https://blog.csdn.net/sinat_39620217/article/details/130237035原文文末含码源以及地址 Macro F1和Micro F1都是评估分类模型性能的指标,但是它们计算方式不同。Macro F1是每个类别的F1值的平均值,不考虑类别的样本数。它适用于数据集中各个类别的样本数量相近的情况下,可以更好地反映每个类别的性能。Micro F1是所有类别的F1值的加权平均,其中权重为每个类别的样本数。它将所有类别的预测结果汇总为一个混淆矩阵,并计算出整个数据集的精确率、召回率和F1值。Micro F1适用于多分类问题,尤其是在数据集不平衡的情况下,可以更好地反映整体的性能。总之,Micro F1更关注整个数据集的性能,而Macro F1更关注每个类别的性能。医疗意图分类数据集 KUAKE-QIC 验证集 zero-shot 实验指标和小样本下训练对比:| | Macro F1 | Micro F1 | 微调后 Macro F1 |微调后 Micro F1 | | :--------: | :--------: | :--------: | :--------: | :--------: | | utc-xbase | 66.30 | 89.67 | | | | utc-base | 64.13 | 89.06 |81.67(+17.54)|93.94 (+4.88)| | utc-medium | 69.62 | 89.15 || | | utc-micro | 60.31 | 79.14 || | | utc-mini | 65.82 | 89.82 || | | utc-nano | 62.03 | 80.92 || | | utc-pico | 53.63 | 83.57 || |## 6.1 更多任务适配PaddleNLP结合文心ERNIE,基于UTC技术开源了首个面向通用文本分类的产业级技术方案。对于简单任务,通过调用 paddlenlp.Taskflow API ,仅用三行代码即可实现零样本(Zero-shot)通用文本分类,可支持情感分析、意图识别、语义匹配、蕴含推理等各种可转换为分类问题的NLU任务。仅使用一个模型即可同时支持多个任务,便捷高效!from pprint import pprint from paddlenlp import Taskflow # 情感分析 cls = Taskflow("zero_shot_text_classification", schema=["这是一条好评", "这是一条差评"]) cls("房间干净明亮,非常不错") >>> [{'predictions': [{'label': '这是一条好评', 'score': 0.9695149765679986}], 'text_a': '房间干净明亮,非常不错'}] # 意图识别 schema = ["病情诊断", "治疗方案", "病因分析", "指标解读", "就医建议", "疾病表述", "后果表述", "注意事项", "功效作用", "医疗费用", "其他"] pprint(cls("先天性厚甲症去哪里治")) >>> [{'predictions': [{'label': '就医建议', 'score': 0.9628814210597645}], 'text_a': '先天性厚甲症去哪里治'}] # 语义相似度 cls = Taskflow("zero_shot_text_classification", schema=["不同", "相同"]) pprint(cls([["怎么查看合同", "从哪里可以看到合同"], ["为什么一直没有电话来确认借款信息", "为何我还款了,今天却接到客服电话通知"]])) >>> [{'predictions': [{'label': '相同', 'score': 0.9775065319076257}], 'text_a': '怎么查看合同', 'text_b': '从哪里可以看到合同'}, {'predictions': [{'label': '不同', 'score': 0.9918983379165037}], 'text_a': '为什么一直没有电话来确认借款信息', 'text_b': '为何我还款了,今天却接到客服电话通知'}] # 蕴含推理 cls = Taskflow("zero_shot_text_classification", schema=["中立", "蕴含", "矛盾"]) pprint(cls([["一个骑自行车的人正沿着一条城市街道朝一座有时钟的塔走去。", "骑自行车的人正朝钟楼走去。"], ["一个留着长发和胡须的怪人,在地铁里穿着一件颜色鲜艳的衬衫。", "这件衬衫是新的。"], ["一个穿着绿色衬衫的妈妈和一个穿全黑衣服的男人在跳舞。", "两人都穿着白色裤子。"]])) >>> [{'predictions': [{'label': '蕴含', 'score': 0.9944843058584897}], 'text_a': '一个骑自行车的人正沿着一条城市街道朝一座有时钟的塔走去。', 'text_b': '骑自行车的人正朝钟楼走去。'}, {'predictions': [{'label': '中立', 'score': 0.6659998351201399}], 'text_a': '一个留着长发和胡须的怪人,在地铁里穿着一件颜色鲜艳的衬衫。', 'text_b': '这件衬衫是新的。'}, {'predictions': [{'label': '矛盾', 'score': 0.9270557883904931}], 'text_a': '一个穿着绿色衬衫的妈妈和一个穿全黑衣服的男人在跳舞。', 'text_b': '两人都穿着白色裤子。'}]
DeepSpeed Chat: 一键式RLHF训练,让你的类ChatGPT千亿大模型提速省钱15倍
DeepSpeed Chat: 一键式RLHF训练,让你的类ChatGPT千亿大模型提速省钱15倍1. 概述近日来,ChatGPT及类似模型引发了人工智能(AI)领域的一场风潮。 这场风潮对数字世界产生了革命性影响。ChatGPT类模型具有惊人的泛用性,能够执行归纳、编程、翻译等任务,其结果与人类专家相当甚至更优。为了使ChatGPT等模型的训练和部署更轻松,AI 开源社区进行了各种尝试(例如 ChatLLaMa、Alpaca、Vicuna、Databricks-Dolly等)。然而,尽管开源社区付出了巨大的努力,目前仍缺乏一个支持端到端的基于人工反馈机制的强化学习(RLHF)的规模化系统,这使得训练强大的类ChatGPT模型十分困难。例如,使用现有的开源系统训练一个具有 67 亿参数的类ChatGPT模型通常需要昂贵的多卡至多节点的 GPU 集群,但这些资源对大多数数据科学家或研究者而言难以获取。同时,即使有了这样的计算资源,现有的开源系统的训练效率通常还不到这些机器所能达到的最大效率的5%。简而言之,即使有了昂贵的多GPU集群,现有解决方案也无法轻松、快速、经济的训练具有数千亿参数的最先进的类ChatGPT模型。ChatGPT模型的训练是基于InstructGPT论文中的RLHF方式。这与常见的大语言模型的预训练和微调截然不同。这使得现有深度学习系统在训练类ChatGPT模型时存在种种局限。因此,为了让ChatGPT类型的模型更容易被普通数据科学家和研究者使用,并使RLHF训练真正普及到AI社区,我们发布了 DeepSpeed-Chat。DeepSpeed-Chat具有以下三大核心功能:(i)简化 ChatGPT 类型模型的训练和强化推理体验:只需一个脚本即可实现多个训练步骤,包括使用 Huggingface 预训练的模型、使用 DeepSpeed-RLHF 系统运行 InstructGPT 训练的所有三个步骤、甚至生成你自己的类ChatGPT模型。此外,我们还提供了一个易于使用的推理API,用于用户在模型训练后测试对话式交互。(ii)DeepSpeed-RLHF 模块:DeepSpeed-RLHF 复刻了 InstructGPT 论文中的训练模式,并确保包括a) 监督微调(SFT),b) 奖励模型微调和 c) 基于人类反馈的强化学习(RLHF)在内的三个步骤与其一一对应。此外,我们还提供了数据抽象和混合功能,以支持用户使用多个不同来源的数据源进行训练。(iii)DeepSpeed-RLHF 系统:我们将 DeepSpeed 的训练(training engine)和推理能力(inference engine) 整合到一个统一的混合引擎(DeepSpeed Hybrid Engine or DeepSpeed-HE)中用于 RLHF 训练。DeepSpeed-HE 能够在 RLHF 中无缝地在推理和训练模式之间切换,使其能够利用来自 DeepSpeed-Inference 的各种优化,如张量并行计算和高性能CUDA算子进行语言生成,同时对训练部分还能从 ZeRO- 和 LoRA-based 内存优化策略中受益。DeepSpeed-HE 还能够自动在 RLHF 的不同阶段进行智能的内存管理和数据缓存。DeepSpeed-RLHF 系统在大规模训练中具有无与伦比的效率,使复杂的 RLHF 训练变得快速、经济并且易于大规模推广:高效性和经济性:DeepSpeed-HE 比现有系统快 15 倍以上,使 RLHF 训练快速且经济实惠。例如,DeepSpeed-HE 在 Azure 云上只需 9 小时即可训练一个 OPT-13B模型,只需 18 小时即可训练一个 OPT-30B模型。这两种训练分别花费不到 300 美元和 600 美元。GPUsOPT-6.7BOPT-13BOPT-30BOPT-66B8x A100-40GB5.7 hours10.8 hours1.85 daysNA8x A100-80GB4.1 hours ($132)9 hours ($290)18 hours ($580)2.1 days ($1620)表 1. 单节点 8x A100:训练时长及预估的 Azure 费用。卓越的扩展性:DeepSpeed-HE 能够支持训练拥有数千亿参数的模型,并在多节点多 GPU 系统上展现出卓越的扩展性。因此,即使是一个拥有 130 亿参数的模型,也只需 1.25 小时就能完成训练。而对于庞大的 拥有1750 亿参数的模型,使用 DeepSpeed-HE 进行训练也只需不到一天的时间。GPUsOPT-13BOPT-30BOPT-66BOPT-175B64x A100-80G1.25 hours ($320)4 hours ($1024)7.5 hours ($1920)20 hours ($5120)表 2. 多节点 64x A100-80GB:训练时长及预估的 Azure 费用。非常重要的细节: 上述两个表格(即表一和表二)中的数据均针对 RLHF 训练的第 3 步,基于实际数据集和 DeepSpeed-RLHF 训练吞吐量的测试。该训练在总共 1.35 亿(135M)个字符(token)上进行一个时期(epoch)的训练。我们总共有 6750 万个查询(query)字符(131.9k 个 query,每个序列长度为 256)和 6750 万个生成/回答字符(131.9k 个答案,每个序列长度为 256),每步的最大全局字符批量大小约为 500 万个字符(1024 个查询-答案对)。在与 DeepSpeed-RLHF 进行任何成本和端到端时间比较之前,我们建议读者注意这些设定。想要了解更多详细信息,请参阅我们的页面 benchmark setting。实现 RLHF 训练的普及化:仅凭单个 GPU,DeepSpeed-HE 就能支持训练超过 130 亿参数的模型。这使得那些无法使用多 GPU 系统的数据科学家和研究者不仅能够轻松创建轻量级的 RLHF 模型,还能创建大型且功能强大的模型,以应对不同的使用场景。 V100 32GA6000 48GA100 40GA100 80GModel SizeOPT-2.7BOPT-6.7BOPT-6.7BOPT-13B表 3. DeepSpeed-HE 在不同的 GPU 单卡上支持的最大模型。接下来,我们将深入了解上面介绍的 DeepSpeed-Chat 的三个功能。2. 简洁高效且经济的 ChatGPT 训练与推理体验接下来,我们向你展示如何使用一行命令即可利用 DeepSpeed-RLHF 系统训练 OPT-13B 和 OPT-66B 模型。即使时间有限,你也可以在大约两小时内在单个消费级 GPU 上训练一个 OPT-1.3B 模型。此外,我们还演示了如何利用我们的 DeepSpeed-chat RLHF API 来开发你自己的模型:使用 DeepSpeed-Chat 的 RLHF 示例轻松训练你的第一个 类ChatGPT 模型a) 仅需一个脚本,完成 RLHF 训练的全部三个阶段,生成你的第一个 ChatGPT 模型!以下示例展示了如何使用一个脚本,以预训练的 OPT-13B 作为 actor 模型,OPT-350M 作为 reward 模型,生成一个最终的 130 亿参数的 ChatGPT 类型的模型:pip install deepspeed>=0.9.0 git clone https://github.com/microsoft/DeepSpeedExamples.git cd DeepSpeedExamples/applications/DeepSpeed-Chat/ pip install -r requirements.txt python train.py --actor-model facebook/opt-13b --reward-model facebook/opt-350m --deployment-type single_node大约半天时间,你的 拥有130 亿参数的模型即可完成训练。下表展示了整个过程在三个步骤中所需的时间:Model SizesStep 1Step 2Step 3TotalActor: OPT-13B, Reward: OPT-350M2.5hr0.25hr10.8hr13.6hr表 4. 在单个DGX节点上(8x A100-40G),针对不同的RLHF步骤, 使用DeepSpeed-Chat训练OPT-13b所需的时间。b) 使用 DeepSpeed-Chat 的推理 API 测试训练好的模型将训练好的模型导入提供的简易 API,你不仅可以与模型进行问答互动,还可以进行对话式交流。Human: Do you know Microsoft? Assistant: Yes, I’m a big fan of Microsoft. What about them? Human: Can you explian it to a 6-year old child? I wonder how I should describe it Assistant: Sure, I can try. Microsoft is a company that makes computers, and they make a program called “Windows” which is the operating system that runs on the computer. It’s like the “brain” of the computer. It’s where all the programs and files are stored. It’s also where you’ll find the “start” button, which is where you’ll start to use the computer.想尝试不同的模型大小和配置?轻松实现!我们了解到用户通常喜欢尝试不同的模型大小和配置,以满足他们不同的训练时间、资源和质量的需求。借助 DeepSpeed-Chat,你可以轻松实现这些目标。例如,如果你想在 GPU 集群上训练一个更大、更高质量的模型,用于你的研究或业务,你可以使用相同的脚本,只需输入你期望的模型大小(例如 660 亿参数)和 GPU 数量(例如 64 个 GPU):python train.py --actor-model facebook/opt-66b --reward-model facebook/opt-350m --deployment-type multi_node在 接下来的9 小时内,你将拥有一个 660 亿参数的 ChatGPT 模型,并可以在你喜欢的前端 GUI 中使用:Model SizesStep 1Step 2Step 3TotalActor: OPT-66B, Reward: OPT-350M82 mins5 mins7.5hr9hr表 5. 在8个DGX节点上(64x A100-80G),针对不同的RLHF步骤, 使用DeepSpeed-Chat训练OPT-66b所需的时间。如果你只有大约 1-2 小时的咖啡或午餐休息时间,你也可以尝试使用 DeepSpeed-Chat 训练一个小型模型。例如,我们为单个数据集准备了一个 13 亿参数模型的训练示例,以便在你的消费级 GPU 上测试我们的框架。当你从午餐休息回来时,你的模型已经准备好供你使用!python train.py --actor-model facebook/opt-1.3b --reward-model facebook/opt-350m --deployment-type single_gpuModel SizesStep 1Step 2Step 3TotalActor: OPT-1.3B, Reward: OPT-350M2900 secs670 secs1.2hr2.2hr表 6. 在单个消费级A6000-48G上,针对不同的RLHF步骤, 使用DeepSpeed-Chat训练OPT-1.3b所需的时间。利用 DeepSpeed-Chat 的 RLHF API 自定义你自己的 RLHF 训练流程DeepSpeed-Chat 允许用户使用我们灵活的 API(如下所示)构建自己的 RLHF 训练流程,用户可以使用这些 API 重建自己的 RLHF 训练策略。我们希望这些功能可以为研究探索中创建各种 RLHF 算法提供通用接口和后端。 engine = DeepSpeedRLHFEngine( actor_model_name_or_path=args.actor_model_name_or_path, critic_model_name_or_path=args.critic_model_name_or_path, tokenizer=tokenizer, num_total_iters=num_total_iters, args=args) trainer = DeepSpeedPPOTrainer(engine=engine, args=args) for prompt_batch in prompt_train_dataloader: out = trainer.generate_experience(prompt_batch) actor_loss, critic_loss = trainer.train_rlhf(out)3. 完整的 RLHF 训练流程概述为了实现无缝的训练体验,我们遵循 InstructGPT 论文的方法,并在 DeepSpeed-Chat 中整合了一个端到端的训练流程,如图 1 所示。图 1: DeepSpeed-Chat 的 RLHF 训练流程图示,包含了一些可选择的功能。我们的流程包括三个主要步骤:步骤1:监督微调(SFT) —— 使用精选的人类回答来微调预训练的语言模型以应对各种查询;步骤2:奖励模型微调 —— 使用一个包含人类对同一查询的多个答案打分的数据集来训练一个独立的(通常比 SFT 小的)奖励模型(RW);步骤3:RLHF 训练 —— 利用 Proximal Policy Optimization(PPO)算法,根据 RW 模型的奖励反馈进一步微调 SFT 模型。在步骤3中,我们提供了两个额外的功能,以帮助提高模型质量:指数移动平均(EMA) —— 可以选择基于 EMA 的检查点进行最终评估混合训练 —— 将预训练目标(即下一个单词预测)与 PPO 目标混合,以防止在像 SQuAD2.0 这样的公开基准测试中的性能损失这两个训练功能,EMA 和混合训练,常常被其他的开源框架所忽略,因为它们并不会妨碍训练的进行。然而,根据 InstructGPT,EMA 通常比传统的最终训练模型提供更好的响应质量,而混合训练可以帮助模型保持预训练基准解决能力。因此,我们为用户提供这些功能,以便充分获得 InstructGPT 中描述的训练体验,并争取更高的模型质量。除了与 InstructGPT 论文高度一致外,我们还提供了一项方便的功能,以支持研究人员和从业者使用多个数据资源训练他们自己的 RLHF 模型:数据抽象和混合能力: DeepSpeed-Chat 能够使用多个不同来源的数据集训练模型以获得更好的模型质量。它配备了(1)一个抽象数据集层,以统一不同数据集的格式;以及(2)数据拆分/混合功能,以便多个数据集在 3 个训练阶段中被适当地混合然后拆分。在我们之前的章节中,你可以看到使用整个 DeepSpeed-Chat 训练模型在多轮对话中的表现。4. DeepSpeed Hybrid Engine —— 统一的高效混合引擎,为 RLHF 训练提供动力并进行优化DeepSpeed-Chat流程的前两步与大型模型的常规微调相似,得益于基于ZeRO的内存管理优化和DeepSpeed训练中的并行策略灵活组合,实现了规模和速度的提升。然而,流程的第三步在性能方面是最具挑战性的部分。每次迭代都需要高效处理两个阶段:a) 生成回答的推理阶段,为训练提供输入;b) 更新 actor 和 reward 模型权重的训练阶段,以及它们之间的交互和调度。这引入了两个主要困难:(1)内存成本,因为在第三阶段的整个过程中需要运行多个SFT和RW模型;(2)生成回答阶段的速度较慢,如果没有正确加速,将显著拖慢整个第三阶段。此外,我们在第三阶段中添加的两个重要可选功能,包括指数移动平均(EMA)收集和混合训练,将产生额外的内存和训练成本。为了应对这些挑战,我们将DeepSpeed训练和推理的系统功能整合为一个统一的基础设施,称为混合引擎(Hybrid Engine)。它利用原始DeepSpeed引擎进行高速训练模式,同时轻松应用DeepSpeed推理引擎进行生成/评估模式,为第三阶段的RLHF训练提供了一个明显更快的训练系统。如图2所示,DeepSpeed训练和推理引擎之间的过渡是无缝的:通过为actor模型启用典型的eval和train模式,当运行推理和训练流程时,DeepSpeed选择其不同的优化来运行模型更快并提高整个系统吞吐量。Figure 2. 设计图解:DeepSpeed Hybrid Engine,用于加速 RLHF 流程中最耗时的部分。在RLHF训练的经验生成阶段的推理执行过程中,DeepSpeed混合引擎使用轻量级内存管理系统来处理KV缓存和中间结果,同时使用高度优化的推理CUDA核和张量并行计算。与现有解决方案相比,DeepSpeed-HE显著提高了吞吐量(每秒token数)。在训练执行过程中,混合引擎使用了多种内存优化技术,如DeepSpeed的ZeRO系列技术和现在流行的LoRA方法。这些技术在混合引擎中可以彼此兼容,并可以组合在一起以提供最高训练效率。DeepSpeed-HE可以在训练和推理之间无缝更改模型分区,以支持基于张量并行计算的推理和基于ZeRO的分片机制进行训练。它还会重新配置内存系统以在此期间最大化内存可用性。DeepSpeed-HE还通过规避内存分配瓶颈和支持大批量大小来进一步提高性能。混合引擎集成了DeepSpeed训练和推理的一系列系统技术,突破了现有RLHF训练的极限,并为RLHF工作负载提供了无与伦比的规模和系统效率。5. DeepSpeed RLHF: 通过 Hybrid Engine 实现无与伦比的规模和效率回顾如前所述,DeepSpeed-HE 是一个将强大的用于推理和训练的结合系统,旨在使 DeepSpeed-RLHF 在各种硬件上实现卓越的规模和效率,使 RLHF 训练快速、经济并且易于 AI 社区使用。在效率和经济性方面,如表 1 所示,DeepSpeed-HE 在 Azure 云上只需 9 小时即可训练一个OPT-13B模型,只需 18 小时既可训练 OPT-30B模型,分别花费不到 300 美元和 600 美元。在速度和可扩展性方面,如表 2 所示,即使是 13B 的模型也可以在 1.25 小时内训练,而庞大的 175B 模型可以在不到一天的时间内使用 64 个 GPU 集群进行训练。在 RLHF 的可访问性和普及化方面,DeepSpeed-HE 可以在单个 GPU 上训练超过 130 亿参数的模型,如表 3 所示。与现有 RLHF 系统的吞吐量和模型大小可扩展性比较与其他 RLHF 系统(如 Colossal-AI 或由原生 PyTorch 提供支持的 HuggingFace)相比,DeepSpeed-RLHF 在系统性能和模型可扩展性方面表现出色:就吞吐量而言,DeepSpeed 在单个 GPU 上的 RLHF 训练中实现了 10 倍以上的改进(图 3)。在多 GPU 设置中,它比 Colossal-AI 快 6 - 19 倍,比 HuggingFace DDP 快 1.4 - 10.5 倍(图 4)。就模型可扩展性而言,Colossal-AI 可以在单个 GPU 上运行最大 1.3B 的模型,在单个 A100 40G 节点上运行 6.7B 的模型,而 DeepSpeed-HE 可以在相同的硬件上分别运行 6.5B 和 50B 的模型,实现高达 7.5 倍的提升。因此,凭借超过一个数量级的更高吞吐量,与现有的 RLHF 系统(如 Colossal-AI 或 HuggingFace DDP)相比,DeepSpeed-HE 拥有在相同时间预算下训练更大的 actor 模型的能力,或者以十分之一的成本训练类似大小的模型的能力。图 3. 在单个 NVIDIA A100-40G GPU 上,将 RLHF 训练的吞吐量与另外两个系统框架在步骤 3 进行比较。没有图标表示 OOM(内存不足)的情况图 4. 在单个 DGX 节点上,使用 8 个 NVIDIA A100-40G GPU,对训练流程第 3 步(耗时最长的部分)的不同模型大小进行端到端训练吞吐量比较。没有图标表示 OOM(内存不足)的情况。这种效率的提高是 DeepSpeed-HE 利用 DeepSpeed 推理优化在 RLHF 处理过程中加速 RLHF 生成的结果。图 5 显示了 RLHF 训练迭代中 1.3B 参数模型的时间消耗细节:大部分时间用于生成阶段。通过利用 DeepSpeed 的高性能推理内核,DeepSpeed-HE 在这个阶段可以实现比 HuggingFace 高达 9 倍的吞吐量改进,比 Colossal-AI 高 15 倍,从而实现无与伦比的端到端效率。图 5. DeepSpeed Chat 的混合引擎在生成阶段的优越加速:在单个 DGX 节点上使用 8 个 A100-40G GPU 训练 OPT-1.3B actor 模型 + OPT-350M reward 模型的时间/序列分解。有效吞吐量和可扩展性分析(I) 有效吞吐量分析。 在 RLHF 训练的第 3 阶段,DeepSpeed-HE 的有效吞吐量取决于它在生成和 RL 训练阶段所实现的吞吐量。在我们的 RLHF (详见 benchmarking setting)中,生成阶段占总计算的约 20%,而 RL 训练阶段占剩余的 80%。然而,尽管比例较小,前者可能会占用大部分的端到端时间,因为它需要为每个生成的字符运行一次 actor 模型,使其受到内存带宽限制,难以实现高吞吐量。相比之下,RL 训练阶段是计算密集型的,仅需运行参考 actor 模型进行几次前向和后向传递,每个样本都有来自提示和生成的全部 512 个字符,可以实现良好的吞吐量。图 6. 在最大效率的情况下,DeepSpeed-HE 针对不同模型大小的RLHF生成、训练和有效吞吐量。为了最大化有效吞吐量,DeepSpeed-HE 对两个阶段进行了优化。首先,它使用尽可能大的批量大小以在两个阶段上获得更高的效率。其次,在生成阶段,它利用高性能CUDA内核在模型在单个 GPU 上最大化 GPU 内存带宽利用率,并在其他情况下利用张量并行(Tensor Parallelism, 简写作TP)进行计算。DeepSpeed-HE进一步在生成阶段使用 TP 而不是 ZeRO 以减少 GPU 之间的通信并保持高 GPU 内存带宽利用率。图 6 显示了 DeepSpeed-HE 在 1.3B 到 175B 的模型大小范围内可以实现的最佳有效吞吐量(以 TFlops/GPU 表示)。它还分别显示了在生成和训练阶段实现的吞吐量。DeepSpeed-HE 对 6.7B-66B 范围内的模型最为高效。超出这个范围到 175B 时,由于内存有限,无法支持更大的批量大小,吞吐量下降,但仍比小型 1.3B 模型的效率高 1.2 倍。当我们将这些巨大的模型扩展到更多具有更多内存的 GPU 时,这些模型的每个 GPU 吞吐量可能会进一步提高。此外,我们想指出,如图 2 所示,我们系统的有效性能比现有系统高 19 倍,这表明它们的运行速度低于峰值的 5%。这说明了优化 RLHF 工作负载的挑战以及我们的系统在面对挑战时的有效性。图 7. 在不同数量的DGX (A100-40/80G GPU) 节点上,进行13B(左)和66B(右)actor 模型 和 350M reward 模型的可扩展性训练。(II) 可扩展性分析。 不同模型大小的最佳有效吞吐量取决于不同的 GPU 数量。部分原因是因为一些较大的模型大小需要更多的内存来运行。基于此,我们接下来讨论 DeepSpeed-HE 的可扩展性特性。图 7 显示 DeepSeed-RLHF 在多达 64 个 GPU的集群 上实现了良好的整体扩展。然而,如果我们仔细观察,可以发现 DeepSpeed-RLHF 训练在小规模时实现了超线性扩展,随后在较大规模时实现了接近线性或次线性扩展。这是由于内存可用性和最大全局批量大小之间的相互作用。DeepSpeed-HE 的核心技术基于 ZeRO,用于训练过程中将模型状态分割到每个GPU上。这意味着随着 GPU 数量的增加,每个 GPU 的内存消耗会减少,使得 DeepSpeed-HE 能够在每个 GPU 上支持更大的批量,从而实现超线性扩展。然而,在大规模情况下,尽管可用内存持续增加,但最大全局批量大小仍然限制了每个 GPU 的批量大小,导致接近线性或次线性扩展。因此,在给定的最大全局批量大小(例如,我们设置为 1024 个句子,每个句子长度为 512)下,DeepSpeed-HE 在超线性和次线性可扩展性之间实现了最佳的吞吐量和成本效益。具体的平衡点主要取决于每个 GPU 上可运行的最大批量大小,而这又受到可用内存和全局批量大小的函数所决定。参考链接:https://github.com/microsoft/DeepSpeed/tree/master/blogs/deepspeed-chat
【机器学习入门与实践】数据挖掘-二手车价格交易预测(含EDA探索、特征工程、特征优化、模型融合等)
【机器学习入门与实践】数据挖掘-二手车价格交易预测(含EDA探索、特征工程、特征优化、模型融合等)note:项目链接以及码源见文末1.赛题简介了解赛题赛题概况数据概况预测指标分析赛题数据读取pandas分类指标评价计算示例回归指标评价计算示例EDA探索载入各种数据科学以及可视化库载入数据总览数据概况判断数据缺失和异常了解预测值的分布特征分为类别特征和数字特征,并对类别特征查看unique分布数字特征分析类别特征分析用pandas_profiling生成数据报告特征工程导入数据删除异常值特征构造特征筛选建模调参,相关原理介绍与推荐线性回归模型决策树模型GBDT模型XGBoost模型LightGBM模型推荐教材读取数据线性回归 & 五折交叉验证 & 模拟真实业务情况多种模型对比模型调参模型融合回归\分类概率-融合分类模型融合一些其它方法本赛题示例1.1 数据说明比赛要求参赛选手根据给定的数据集,建立模型,二手汽车的交易价格。来自 Ebay Kleinanzeigen 报废的二手车,数量超过 370,000,包含 20 列变量信息,为了保证比赛的公平性,将会从中抽取 10 万条作为训练集,5 万条作为测试集 A,5 万条作为测试集B。同时会对名称、车辆类型、变速箱、model、燃油类型、品牌、公里数、价格等信息进行脱敏。一般而言,对于数据在比赛界面都有对应的数据概况介绍(匿名特征除外),说明列的性质特征。了解列的性质会有助于我们对于数据的理解和后续分析。Tip:匿名特征,就是未告知数据列所属的性质的特征列。train.csvname - 汽车编码regDate - 汽车注册时间model - 车型编码brand - 品牌bodyType - 车身类型fuelType - 燃油类型gearbox - 变速箱power - 汽车功率kilometer - 汽车行驶公里notRepairedDamage - 汽车有尚未修复的损坏regionCode - 看车地区编码seller - 销售方offerType - 报价类型creatDate - 广告发布时间price - 汽车价格v_0', 'v_1', 'v_2', 'v_3', 'v_4', 'v_5', 'v_6', 'v_7', 'v_8', 'v_9', 'v_10', 'v_11', 'v_12', 'v_13','v_14'(根据汽车的评论、标签等大量信息得到的embedding向量)【人工构造 匿名特征】 数字全都脱敏处理,都为label encoding形式,即数字形式1.2预测指标本赛题的评价标准为MAE(Mean Absolute Error):$$ MAE=\frac{\sum_{i=1}^{n}\left|y_{i}-\hat{y}_{i}\right|}{n} $$其中$y_{i}$代表第$i$个样本的真实值,其中$\hat{y}_{i}$代表第$i$个样本的预测值。一般问题评价指标说明:什么是评估指标:评估指标即是我们对于一个模型效果的数值型量化。(有点类似与对于一个商品评价打分,而这是针对于模型效果和理想效果之间的一个打分)一般来说分类和回归问题的评价指标有如下一些形式:分类算法常见的评估指标如下:对于二类分类器/分类算法,评价指标主要有accuracy, [Precision,Recall,F-score,Pr曲线],ROC-AUC曲线。对于多类分类器/分类算法,评价指标主要有accuracy, [宏平均和微平均,F-score]。对于回归预测类常见的评估指标如下:平均绝对误差(Mean Absolute Error,MAE),均方误差(Mean Squared Error,MSE),平均绝对百分误差(Mean Absolute Percentage Error,MAPE),均方根误差(Root Mean Squared Error), R2(R-Square)平均绝对误差平均绝对误差(Mean Absolute Error,MAE):平均绝对误差,其能更好地反映预测值与真实值误差的实际情况,其计算公式如下:$$ MAE=\frac{1}{N} \sum_{i=1}^{N}\left|y_{i}-\hat{y}_{i}\right| $$均方误差均方误差(Mean Squared Error,MSE),均方误差,其计算公式为:$$ MSE=\frac{1}{N} \sum_{i=1}^{N}\left(y_{i}-\hat{y}_{i}\right)^{2} $$R2(R-Square)的公式为:残差平方和:$$ SS_{res}=\sum\left(y_{i}-\hat{y}_{i}\right)^{2} $$总平均值:$$ SS_{tot}=\sum\left(y_{i}-\overline{y}_{i}\right)^{2} $$其中$\overline{y}$表示$y$的平均值得到$R^2$表达式为:$$ R^{2}=1-\frac{SS_{res}}{SS_{tot}}=1-\frac{\sum\left(y_{i}-\hat{y}_{i}\right)^{2}}{\sum\left(y_{i}-\overline{y}\right)^{2}} $$$R^2$用于度量因变量的变异中可由自变量解释部分所占的比例,取值范围是 0~1,$R^2$越接近1,表明回归平方和占总平方和的比例越大,回归线与各观测点越接近,用x的变化来解释y值变化的部分就越多,回归的拟合程度就越好。所以$R^2$也称为拟合优度(Goodness of Fit)的统计量。$y_{i}$表示真实值,$\hat{y}_{i}$表示预测值,$\overline{y}_{i}$表示样本均值。得分越高拟合效果越好。1.3分析赛题此题为传统的数据挖掘问题,通过数据科学以及机器学习深度学习的办法来进行建模得到结果。此题是一个典型的回归问题。主要应用xgb、lgb、catboost,以及pandas、numpy、matplotlib、seabon、sklearn、keras等等数据挖掘常用库或者框架来进行数据挖掘任务。2.数据探索# 下载数据 !wget http://tianchi-media.oss-cn-beijing.aliyuncs.com/dragonball/DM/data.zip # 解压下载好的数据 !unzip data.zip# 导入函数工具 ## 基础工具 import numpy as np import pandas as pd import warnings import matplotlib import matplotlib.pyplot as plt import seaborn as sns from scipy.special import jn from IPython.display import display, clear_output import time warnings.filterwarnings('ignore') %matplotlib inline ## 模型预测的 from sklearn import linear_model from sklearn import preprocessing from sklearn.svm import SVR from sklearn.ensemble import RandomForestRegressor,GradientBoostingRegressor ## 数据降维处理的 from sklearn.decomposition import PCA,FastICA,FactorAnalysis,SparsePCA import lightgbm as lgb import xgboost as xgb ## 参数搜索和评价的 from sklearn.model_selection import GridSearchCV,cross_val_score,StratifiedKFold,train_test_split from sklearn.metrics import mean_squared_error, mean_absolute_error2.1 数据读取## 通过Pandas对于数据进行读取 (pandas是一个很友好的数据读取函数库) Train_data = pd.read_csv('/home/aistudio/dataset/used_car_train_20200313.csv', sep=' ') TestA_data = pd.read_csv('/home/aistudio/dataset/used_car_testA_20200313.csv', sep=' ') ## 输出数据的大小信息 print('Train data shape:',Train_data.shape) print('TestA data shape:',TestA_data.shape)Train data shape: (150000, 31) TestA data shape: (50000, 30) 2.2 数据简要浏览## 通过.head() 简要浏览读取数据的形式 Train_data.head() SaleID regDate model brand bodyType fuelType gearbox power kilometer 20040402 0.235676 0.101988 0.129549 0.022816 0.097462 -2.881803 2.804097 -2.420821 0.795292 0.914762 20030301 0.264777 0.121004 0.135731 0.026597 0.020582 -4.900482 2.096338 -1.030483 -1.722674 0.245522 14874 20040403 115.0 0.251410 0.114912 0.165147 0.062173 0.027075 -4.846749 1.803559 1.565330 -0.832687 -0.229963 71865 19960908 109.0 0.274293 0.110300 0.121964 0.033395 0.000000 -4.509599 1.285940 -0.501868 -2.438353 -0.478699 111080 20120103 110.0 0.228036 0.073205 0.091880 0.078819 0.121534 -1.896240 0.910783 0.931110 2.834518 1.923482 5 rows × 31 columns 2.3 数据信息查看## 通过 .info() 简要可以看到对应一些数据列名,以及NAN缺失信息 Train_data.info()<class 'pandas.core.frame.DataFrame'> RangeIndex: 150000 entries, 0 to 149999 Data columns (total 31 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 SaleID 150000 non-null int64 1 name 150000 non-null int64 2 regDate 150000 non-null int64 3 model 149999 non-null float64 4 brand 150000 non-null int64 5 bodyType 145494 non-null float64 6 fuelType 141320 non-null float64 7 gearbox 144019 non-null float64 8 power 150000 non-null int64 9 kilometer 150000 non-null float64 10 notRepairedDamage 150000 non-null object 11 regionCode 150000 non-null int64 12 seller 150000 non-null int64 13 offerType 150000 non-null int64 14 creatDate 150000 non-null int64 15 price 150000 non-null int64 16 v_0 150000 non-null float64 17 v_1 150000 non-null float64 18 v_2 150000 non-null float64 19 v_3 150000 non-null float64 20 v_4 150000 non-null float64 21 v_5 150000 non-null float64 22 v_6 150000 non-null float64 23 v_7 150000 non-null float64 24 v_8 150000 non-null float64 25 v_9 150000 non-null float64 26 v_10 150000 non-null float64 27 v_11 150000 non-null float64 28 v_12 150000 non-null float64 29 v_13 150000 non-null float64 30 v_14 150000 non-null float64 dtypes: float64(20), int64(10), object(1) memory usage: 35.5+ MB ## 通过 .columns 查看列名 Train_data.columnsIndex(['SaleID', 'name', 'regDate', 'model', 'brand', 'bodyType', 'fuelType', 'gearbox', 'power', 'kilometer', 'notRepairedDamage', 'regionCode', 'seller', 'offerType', 'creatDate', 'price', 'v_0', 'v_1', 'v_2', 'v_3', 'v_4', 'v_5', 'v_6', 'v_7', 'v_8', 'v_9', 'v_10', 'v_11', 'v_12', 'v_13', 'v_14'], dtype='object') TestA_data.info()<class 'pandas.core.frame.DataFrame'> RangeIndex: 50000 entries, 0 to 49999 Data columns (total 30 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 SaleID 50000 non-null int64 1 name 50000 non-null int64 2 regDate 50000 non-null int64 3 model 50000 non-null float64 4 brand 50000 non-null int64 5 bodyType 48587 non-null float64 6 fuelType 47107 non-null float64 7 gearbox 48090 non-null float64 8 power 50000 non-null int64 9 kilometer 50000 non-null float64 10 notRepairedDamage 50000 non-null object 11 regionCode 50000 non-null int64 12 seller 50000 non-null int64 13 offerType 50000 non-null int64 14 creatDate 50000 non-null int64 15 v_0 50000 non-null float64 16 v_1 50000 non-null float64 17 v_2 50000 non-null float64 18 v_3 50000 non-null float64 19 v_4 50000 non-null float64 20 v_5 50000 non-null float64 21 v_6 50000 non-null float64 22 v_7 50000 non-null float64 23 v_8 50000 non-null float64 24 v_9 50000 non-null float64 25 v_10 50000 non-null float64 26 v_11 50000 non-null float64 27 v_12 50000 non-null float64 28 v_13 50000 non-null float64 29 v_14 50000 non-null float64 dtypes: float64(20), int64(9), object(1) memory usage: 11.4+ MB 2.4 数据统计信息浏览## 通过 .describe() 可以查看数值特征列的一些统计信息 Train_data.describe() SaleID regDate model brand bodyType fuelType gearbox power kilometer count 150000.000000 150000.000000 1.500000e+05 149999.000000 150000.000000 145494.000000 141320.000000 144019.000000 150000.000000 150000.000000 150000.000000 150000.000000 150000.000000 150000.000000 150000.000000 150000.000000 150000.000000 150000.000000 150000.000000 150000.000000 74999.500000 68349.172873 2.003417e+07 47.129021 8.052733 1.792369 0.375842 0.224943 119.316547 12.597160 0.248204 0.044923 0.124692 0.058144 0.061996 -0.001000 0.009035 0.004813 0.000313 -0.000688 43301.414527 61103.875095 5.364988e+04 49.536040 7.864956 1.760640 0.548677 0.417546 177.168419 3.919576 0.045804 0.051743 0.201410 0.029186 0.035692 3.772386 3.286071 2.517478 1.288988 1.038685 0.000000 0.000000 1.991000e+07 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.500000 0.000000 0.000000 0.000000 0.000000 0.000000 -9.168192 -5.558207 -9.639552 -4.153899 -6.546556 37499.750000 11156.000000 1.999091e+07 10.000000 1.000000 0.000000 0.000000 0.000000 75.000000 12.500000 0.243615 0.000038 0.062474 0.035334 0.033930 -3.722303 -1.951543 -1.871846 -1.057789 -0.437034 74999.500000 51638.000000 2.003091e+07 30.000000 6.000000 1.000000 0.000000 0.000000 110.000000 15.000000 0.257798 0.000812 0.095866 0.057014 0.058484 1.624076 -0.358053 -0.130753 -0.036245 0.141246 112499.250000 118841.250000 2.007111e+07 66.000000 13.000000 3.000000 1.000000 0.000000 150.000000 15.000000 0.265297 0.102009 0.125243 0.079382 0.087491 2.844357 1.255022 1.776933 0.942813 0.680378 149999.000000 196812.000000 2.015121e+07 247.000000 39.000000 7.000000 6.000000 1.000000 19312.000000 15.000000 0.291838 0.151420 1.404936 0.160791 0.222787 12.357011 18.819042 13.847792 11.147669 8.658418 8 rows × 30 columns TestA_data.describe() SaleID regDate model brand bodyType fuelType gearbox power kilometer count 50000.000000 50000.000000 5.000000e+04 50000.000000 50000.000000 48587.000000 47107.000000 48090.000000 50000.000000 50000.000000 50000.000000 50000.000000 50000.000000 50000.000000 50000.000000 50000.000000 50000.000000 50000.000000 50000.000000 50000.000000 174999.500000 68542.223280 2.003393e+07 46.844520 8.056240 1.782185 0.373405 0.224350 119.883620 12.595580 0.248669 0.045021 0.122744 0.057997 0.062000 -0.017855 -0.013742 -0.013554 -0.003147 0.001516 14433.901067 61052.808133 5.368870e+04 49.469548 7.819477 1.760736 0.546442 0.417158 185.097387 3.908979 0.044601 0.051766 0.195972 0.029211 0.035653 3.747985 3.231258 2.515962 1.286597 1.027360 150000.000000 0.000000 1.991000e+07 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.500000 0.000000 0.000000 0.000000 0.000000 0.000000 -9.160049 -5.411964 -8.916949 -4.123333 -6.112667 162499.750000 11203.500000 1.999091e+07 10.000000 1.000000 0.000000 0.000000 0.000000 75.000000 12.500000 0.243762 0.000044 0.062644 0.035084 0.033714 -3.700121 -1.971325 -1.876703 -1.060428 -0.437920 174999.500000 52248.500000 2.003091e+07 29.000000 6.000000 1.000000 0.000000 0.000000 109.000000 15.000000 0.257877 0.000815 0.095828 0.057084 0.058764 1.613212 -0.355843 -0.142779 -0.035956 0.138799 187499.250000 118856.500000 2.007110e+07 65.000000 13.000000 3.000000 1.000000 0.000000 150.000000 15.000000 0.265328 0.102025 0.125438 0.079077 0.087489 2.832708 1.262914 1.764335 0.941469 0.681163 199999.000000 196805.000000 2.015121e+07 246.000000 39.000000 7.000000 6.000000 1.000000 20000.000000 15.000000 0.291618 0.153265 1.358813 0.156355 0.214775 12.338872 18.856218 12.950498 5.913273 2.624622 8 rows × 29 columns 3.数据分析#### 1) 提取数值类型特征列名 numerical_cols = Train_data.select_dtypes(exclude = 'object').columns print(numerical_cols)Index(['SaleID', 'name', 'regDate', 'model', 'brand', 'bodyType', 'fuelType', 'gearbox', 'power', 'kilometer', 'regionCode', 'seller', 'offerType', 'creatDate', 'price', 'v_0', 'v_1', 'v_2', 'v_3', 'v_4', 'v_5', 'v_6', 'v_7', 'v_8', 'v_9', 'v_10', 'v_11', 'v_12', 'v_13', 'v_14'], dtype='object') categorical_cols = Train_data.select_dtypes(include = 'object').columns print(categorical_cols)Index(['notRepairedDamage'], dtype='object') #### 2) 构建训练和测试样本 ## 选择特征列 feature_cols = [col for col in numerical_cols if col not in ['SaleID','name','regDate','creatDate','price','model','brand','regionCode','seller']] feature_cols = [col for col in feature_cols if 'Type' not in col] ## 提前特征列,标签列构造训练样本和测试样本 X_data = Train_data[feature_cols] Y_data = Train_data['price'] X_test = TestA_data[feature_cols] print('X train shape:',X_data.shape) print('X test shape:',X_test.shape)X train shape: (150000, 18) X test shape: (50000, 18) ## 定义了一个统计函数,方便后续信息统计 def Sta_inf(data): print('_min',np.min(data)) print('_max:',np.max(data)) print('_mean',np.mean(data)) print('_ptp',np.ptp(data)) print('_std',np.std(data)) print('_var',np.var(data))#### 3) 统计标签的基本分布信息 print('Sta of label:') Sta_inf(Y_data)Sta of label: _min 11 _max: 99999 _mean 5923.327333333334 _ptp 99988 _std 7501.973469876635 _var 56279605.942732885 ## 绘制标签的统计图,查看标签分布 plt.hist(Y_data) plt.show() plt.close()#### 4) 缺省值用-1填补 X_data = X_data.fillna(-1) X_test = X_test.fillna(-1)4. 模型训练与预测(特征工程、模型融合)4.1 利用xgb进行五折交叉验证查看模型的参数效果## xgb-Model xgr = xgb.XGBRegressor(n_estimators=120, learning_rate=0.1, gamma=0, subsample=0.8,\ colsample_bytree=0.9, max_depth=7) #,objective ='reg:squarederror' scores_train = [] scores = [] ## 5折交叉验证方式 sk=StratifiedKFold(n_splits=5,shuffle=True,random_state=0) for train_ind,val_ind in sk.split(X_data,Y_data): train_x=X_data.iloc[train_ind].values train_y=Y_data.iloc[train_ind] val_x=X_data.iloc[val_ind].values val_y=Y_data.iloc[val_ind] xgr.fit(train_x,train_y) pred_train_xgb=xgr.predict(train_x) pred_xgb=xgr.predict(val_x) score_train = mean_absolute_error(train_y,pred_train_xgb) scores_train.append(score_train) score = mean_absolute_error(val_y,pred_xgb) scores.append(score) print('Train mae:',np.mean(score_train)) print('Val mae',np.mean(scores))4.2 定义xgb和lgb模型函数def build_model_xgb(x_train,y_train): model = xgb.XGBRegressor(n_estimators=150, learning_rate=0.1, gamma=0, subsample=0.8,\ colsample_bytree=0.9, max_depth=7) #, objective ='reg:squarederror' model.fit(x_train, y_train) return model def build_model_lgb(x_train,y_train): estimator = lgb.LGBMRegressor(num_leaves=127,n_estimators = 150) param_grid = { 'learning_rate': [0.01, 0.05, 0.1, 0.2], gbm = GridSearchCV(estimator, param_grid) gbm.fit(x_train, y_train) return gbm4.3 切分数据集(Train,Val)进行模型训练,评价和预测## Split data with val x_train,x_val,y_train,y_val = train_test_split(X_data,Y_data,test_size=0.3)print('Train lgb...') model_lgb = build_model_lgb(x_train,y_train) val_lgb = model_lgb.predict(x_val) MAE_lgb = mean_absolute_error(y_val,val_lgb) print('MAE of val with lgb:',MAE_lgb) print('Predict lgb...') model_lgb_pre = build_model_lgb(X_data,Y_data) subA_lgb = model_lgb_pre.predict(X_test) print('Sta of Predict lgb:') Sta_inf(subA_lgb)print('Train xgb...') model_xgb = build_model_xgb(x_train,y_train) val_xgb = model_xgb.predict(x_val) MAE_xgb = mean_absolute_error(y_val,val_xgb) print('MAE of val with xgb:',MAE_xgb) print('Predict xgb...') model_xgb_pre = build_model_xgb(X_data,Y_data) subA_xgb = model_xgb_pre.predict(X_test) print('Sta of Predict xgb:') Sta_inf(subA_xgb)4.4进行两模型的结果加权融合## 这里我们采取了简单的加权融合的方式 val_Weighted = (1-MAE_lgb/(MAE_xgb+MAE_lgb))*val_lgb+(1-MAE_xgb/(MAE_xgb+MAE_lgb))*val_xgb val_Weighted[val_Weighted<0]=10 # 由于我们发现预测的最小值有负数,而真实情况下,price为负是不存在的,由此我们进行对应的后修正 print('MAE of val with Weighted ensemble:',mean_absolute_error(y_val,val_Weighted))sub_Weighted = (1-MAE_lgb/(MAE_xgb+MAE_lgb))*subA_lgb+(1-MAE_xgb/(MAE_xgb+MAE_lgb))*subA_xgb ## 查看预测值的统计进行 plt.hist(Y_data) plt.show() plt.close()4.5.输出结果sub = pd.DataFrame() sub['SaleID'] = TestA_data.SaleID sub['price'] = sub_Weighted sub.to_csv('./sub_Weighted.csv',index=False)sub.head()5. 项目详细展开因篇幅内容限制,将原学习项目拆解成多个notebook方便学习,只需一键fork。5.1 数据分析详解载入各种数据科学以及可视化库:数据科学库 pandas、numpy、scipy;可视化库 matplotlib、seabon;其他;载入数据:载入训练集和测试集;简略观察数据(head()+shape);数据总览:通过describe()来熟悉数据的相关统计量通过info()来熟悉数据类型判断数据缺失和异常查看每列的存在nan情况异常值检测了解预测值的分布总体分布概况(无界约翰逊分布等)查看skewness and kurtosis查看预测值的具体频数特征分为类别特征和数字特征,并对类别特征查看unique分布数字特征分析相关性分析查看几个特征得 偏度和峰值每个数字特征得分布可视化数字特征相互之间的关系可视化多变量互相回归关系可视化类型特征分析unique分布类别特征箱形图可视化类别特征的小提琴图可视化类别特征的柱形图可视化类别特征的每个类别频数可视化(count_plot)用pandas_profiling生成数据报告5.2 特征工程异常处理:通过箱线图(或 3-Sigma)分析删除异常值;BOX-COX 转换(处理有偏分布);长尾截断;特征归一化/标准化:标准化(转换为标准正态分布);归一化(抓换到 [0,1] 区间);针对幂律分布,可以采用公式: $log(\frac{1+x}{1+median})$数据分桶:等频分桶;等距分桶;Best-KS 分桶(类似利用基尼指数进行二分类);卡方分桶;缺失值处理:不处理(针对类似 XGBoost 等树模型);删除(缺失数据太多);插值补全,包括均值/中位数/众数/建模预测/多重插补/压缩感知补全/矩阵补全等;分箱,缺失值一个箱;特征构造:构造统计量特征,报告计数、求和、比例、标准差等;时间特征,包括相对时间和绝对时间,节假日,双休日等;地理信息,包括分箱,分布编码等方法;非线性变换,包括 log/ 平方/ 根号等;特征组合,特征交叉;仁者见仁,智者见智。特征筛选过滤式(filter):先对数据进行特征选择,然后在训练学习器,常见的方法有 Relief/方差选择发/相关系数法/卡方检验法/互信息法;包裹式(wrapper):直接把最终将要使用的学习器的性能作为特征子集的评价准则,常见方法有 LVM(Las Vegas Wrapper) ;嵌入式(embedding):结合过滤式和包裹式,学习器训练过程中自动进行了特征选择,常见的有 lasso 回归;降维PCA/ LDA/ ICA;特征选择也是一种降维。5.3 模型优化线性回归模型:线性回归对于特征的要求;处理长尾分布;理解线性回归模型;模型性能验证:评价函数与目标函数;交叉验证方法;留一验证方法;针对时间序列问题的验证;绘制学习率曲线;绘制验证曲线;嵌入式特征选择:Lasso回归;Ridge回归;决策树;模型对比:常用线性模型;常用非线性模型;模型调参:贪心调参方法;网格调参方法;贝叶斯调参方法;5.4模型融合简单加权融合:回归(分类概率):算术平均融合(Arithmetic mean),几何平均融合(Geometric mean);分类:投票(Voting)综合:排序融合(Rank averaging),log融合stacking/blending:构建多层模型,并利用预测结果再拟合预测。boosting/bagging(在xgboost,Adaboost,GBDT中已经用到):多树的提升方法训练:预测:6.总结二手车预测项目是非常经典项目,数据挖掘实践(二手车价格预测)的内容来自 Datawhale与天池联合发起的,现在通过整理和调整让更多对机器学习感兴趣可以上手实战一下因篇幅内容限制,将原学习项目拆解成多个notebook方便学习,只需一键fork。项目链接:一键fork直接运行,所有项目码源都在里面https://www.heywhale.com/mw/project/64367e0a2a3d6dc93d22054f机器学习数据挖掘专栏:https://www.heywhale.com/home/column/64141d6b1c8c8b518ba97dcc参考链接:https://github.com/datawhalechina/team-learning-data-mining/tree/master/SecondHandCarPriceForecast
深度学习基础入门篇[三]:优化策略梯度下降算法:SGD、MBGD、Momentum、Adam、AdamW
深度学习基础入门篇[三]:优化策略梯度下降算法:SGD、MBGD、Momentum、Adam、AdamW1.梯度下降算法(优化器)1.1 原理解释如果我们定义了一个机器学习模型,比如一个三层的神经网络,那么就需要使得这个模型能够尽可能拟合所提供的训练数据。但是我们如何评价模型对于数据的拟合是否足够呢?那就需要使用相应的指标来评价它的拟合程度,所使用到的函数就称为损失函数(Loss Function),当损失函数值下降,我们就认为模型在拟合的路上又前进了一步。最终模型对训练数据集拟合的最好的情况是在损失函数值最小的时候,在指定数据集上时,为损失函数的平均值最小的时候。由于我们一般情况下很难直接精确地计算得到当模型的参数为何值时,损失函数最小,所以,我们可以通过让参数在损失函数的“场”中,向着损失函数值减小的方向移动,最终在收敛的时候,得到一个极小值的近似解。为了让损失函数的数值下降,那么就需要使用优化算法进行优化,其中,损失函数值下降最快的方向称为负梯度方向,所使用的算法称为梯度下降法,即最速下降法(steepest descent)。当前,几乎所有的机器学习优化算法都是基于梯度下降的算法。总结的来讲优化器(例如梯度下降法)就是在深度学习反向传播过程中,指引损失函数(目标函数)的各个参数往正确的方向更新合适的大小,使得更新后的各个参数让损失函数(目标函数)值不断逼近全局最小。举一个简单例子优化问题可以看做是我们站在山上的某个位置(当前的参数信息),想要以最佳的路线去到山下(最优点)。首先,直观的方法就是环顾四周,找到下山最快的方向走一步,然后再次环顾四周,找到最快的方向,直到下山——这样的方法便是朴素的梯度下降——当前的海拔是我们的目标(损失)函数值,而我们在每一步找到的方向便是函数梯度的反方向(梯度是函数上升最快的方向,所以梯度的反方向就是函数下降最快的方向)。使用梯度下降进行优化,是几乎所有优化器的核心思想。当我们下山时,有两个方面是我们最关心的:首先是优化方向,决定“前进的方向是否正确”,在优化器中反映为梯度或动量。其次是步长,决定“每一步迈多远”,在优化器中反映为学习率。所有优化器都在关注这两个方面,但同时也有一些其他问题,比如应该在哪里出发、路线错误如何处理……这是一些最新的优化器关注的方向。1.2 梯度下降法作用梯度下降是机器学习中常见优化算法之一,梯度下降法有以下几个作用:梯度下降是迭代法的一种,可以用于求解最小二乘问题(线性和非线性都可以),其他的问题,只要损失函数可导也可以使用梯度下降,比如交叉熵损失等等。在求解机器学习算法的模型参数,即无约束优化问题时,主要有梯度下降法,牛顿法等。在求解损失函数的最小值时,可以通过梯度下降法来一步步的迭代求解,得到最小化的损失函数和模型参数值。如果我们需要求解损失函数的最大值,可通过梯度上升法来迭代。梯度下降法和梯度上升法可相互转换。2.深度学习主流模型与梯度下降下表列举了自然语言处理(NLP),计算机视觉(CV),推荐系统(Recommendation System,RS),强化学习(Reinforcement Learning,RL)这四个方向的主流模型使用优化器的情况,可以看出在NLP领域AdamW(AdamWeightDecayOptimizer)使用比较普遍,CV领域SGD和momentum使用比较普遍,推荐领域比较杂,强化学习领域Adam使用比较普遍。依据计算目标函数梯度使用的数据量的不同,有三种梯度下降的变体,即批量梯度下降,随机梯度下降,Mini-batch梯度下降。根据数据量的大小,在参数更新的准确性和执行更新所需时间之间做了一个权衡。2.1 批量梯度下降,BGD标准的梯度下降,即批量梯度下降(batch gradient descent,BGD),在整个训练集上计算损失函数关于参数θ的梯度。$\theta=\theta-\eta\nabla_\theta J(\theta)$其中θ是模型的参数,η是学习率,$∇θJ(θ)$为损失函数对参数θ的导数。由于为了一次参数更新我们需要在整个训练集上计算梯度,导致 BGD 可能会非常慢,而且在训练集太大而不能全部载入内存的时候会很棘手。BGD 也不允许我们在线更新模型参数,即实时增加新的训练样本。BGD 对于凸误差曲面(convex error surface)保证收敛到全局最优点,而对于非凸曲面(non-convex surface)则是局部最优点。2.2 随机梯度下降,SGD随机梯度下降( stotastic gradient descent, SGD )则是每次使用一个训练样本$x_i$和标签$y_i$进行一次参数更新。$\theta=\theta-\eta\cdot\nabla_\theta J(\theta;x^i;y^i)$其中θ是模型的参数,η是学习率,∇θJ(θ)为损失函数对参数θ的导数。BGD 对于大数据集来说执行了很多冗余的计算,因为在每一次参数更新前都要计算很多相似样本的梯度。SGD 通过一次执行一次更解决了这种冗余。因此通常 SGD 的速度会非常快而且可以被用于在线学习。SGD以高方差的特点进行连续参数更新,导致目标函数严重震荡.BGD 能够收敛到(局部)最优点,然而 SGD 的震荡特点导致其可以跳到新的潜在的可能更好的局部最优点。已经有研究显示当我们慢慢的降低学习率时,SGD 拥有和 BGD 一样的收敛性能,对于非凸和凸曲面几乎同样能够达到局部或者全局最优点。2.3 Mini-batch梯度下降,MBGDMini-batch gradient descent( mini-batch gradient descent, MBGD )则是在上面两种方法中采取了一个折中的办法:每次从训练集中取出batchsize个样本作为一个mini-batch,以此来进行一次参数更新$\theta=\theta-\eta\cdot\nabla_\theta J(\theta;x^{(i:i+n);y^{(i:i+n)}})$其中θ是模型的参数,η是学习率,$\nabla_{\theta}J(\theta;x^{(i:i+n);y^{(i:i+n)}}$为损失函数对参数θ的导数,n为Mini-bach的大小(batch size)。 batch size越大,批次越少,训练时间会更快一点,但可能造成数据的很大浪费;而batch size越小,对数据的利用越充分,浪费的数据量越少,但批次会很大,训练会更耗时。2.3.1 优点减小参数更新的方差,这样可以有更稳定的收敛。利用现在最先进的深度学习库对矩阵运算进行了高度优化的特点,这样可以使得计算 mini-batch 的梯度更高效。样本数目较大的话,一般的mini-batch大小为64到512,考虑到电脑内存设置和使用的方式,如果mini-batch大小是2的n次方,代码会运行地快一些,64就是2的6次方,以此类推,128是2的7次方,256是2的8次方,512是2的9次方。所以我经常把mini-batch大小设成2的次方。MBGD 是训练神经网络时的常用方法,而且通常即使实际上使用的是 MBGD,也会使用 SGD 这个词来代替。2.3.2MBGD面临的问题学习率选择选择一个好的学习率是非常困难的。太小的学习率导致收敛非常缓慢,而太大的学习率则会阻碍收敛,导致损失函数在最优点附近震荡甚至发散。相同的学习率被应用到所有参数更新中。如果我们的数据比较稀疏,特征有非常多不同的频率,那么此时我们可能并不想要以相同的程度更新他们,反而是对更少出现的特征给予更大的更新。为了能在学习期间自动调节学习率,根据先前定义好的一个规则来减小学习率,或者两次迭代之间目标函数的改变低于一个阈值的时候。然而这些规则和阈值也是需要在训练前定义好的,所以也不能做到自适应数据的特点上图中,学习率设置过大,导致目标函数值沿着 “山谷” 周围大幅震荡,可能永远都到达不了最小值。鞍点对于神经网络来说,另一个最小化高度非凸误差函数的关键挑战是避免陷入他们大量的次局部最优点(suboptimal)。事实上困难来自于鞍点而不是局部最优点,即损失函数在该点的一个维度上是上坡(slopes up),而在另一个维度上是下坡(slopes down)。这些鞍点通常被一个具有相同误差的平面所包围,这使得对于 SGD 来说非常难于逃脱,因为在各个维度上梯度都趋近于 0 。如图,鞍点得名于它的形状类似于马鞍。尽管它在 x 方向上是一个最小值点,但是它在另一个方向上是局部最大值点,并且,如果它沿着 x 方向变得更平坦的话,梯度下降会在 x 轴振荡并且不能继续根据 y 轴下降,这就会给我们一种已经收敛到最小值点的错觉。3. Momentum为了抑制SGD的震荡,SGDM认为梯度下降过程可以加入惯性。可以简单理解为:当我们将一个小球从山上滚下来时,没有阻力的话,它的动量会越来越大,但是如果遇到了阻力,速度就会变小。SGDM全称是SGD with momentum,在SGD基础上引入了一阶动量:$v_t=\gamma v_{t-1}+\eta\nabla J(\theta)$SGD-M参数更新公式如下,其中η是学习率,∇J(θ)是当前参数的梯度$\theta=\theta-v_t$一阶动量是各个时刻梯度方向的指数移动平均值,也就是说,t时刻的下降方向,不仅由当前点的梯度方向决定,而且由此前累积的下降方向决定。γ的经验值为0.9,这就意味着下降方向主要是此前累积的下降方向,并略微偏向当前时刻的下降方向。想象高速公路上汽车转弯,在高速向前的同时略微偏向,急转弯可是要出事的。 SGD 震荡且缓慢的沿着沟壑的下坡方向朝着局部最优点前进,如下图:momentum能够加速SGD方法,并且能够减少震荡,如下图:特点加入了动量因素,SGD-M缓解了SGD在局部最优点梯度为0,无法持续更新的问题和振荡幅度过大的问题。当局部沟壑比较深,动量加持用完了,依然会困在局部最优里来回振荡4.NAGSGD 还有一个问题是困在局部最优的沟壑里面震荡。想象一下你走到一个盆地,四周都是略高的小山,你觉得没有下坡的方向,那就只能待在这里了。可是如果你爬上高地,就会发现外面的世界还很广阔。因此,我们不能停留在当前位置去观察未来的方向,而要向前一步、多看一步、看远一些。NAG全称Nesterov Accelerated Gradient,是在SGD、SGD-M的基础上的进一步改进,我们知道在时刻t的主要下降方向是由累积动量决定的,自己的梯度方向说了也不算,那与其看当前梯度方向,不如先看看如果跟着累积动量走了一步,那个时候再怎么走。因此,NAG不计算当前位置的梯度方向,而是计算如果按照累积动量走了一步,那个时候的下降方向:$v_t=\gamma v_{t-1}+\eta\nabla_\theta J(\theta-\gamma v_{t-1})$NAG参数更新公式如下,其中η是学习率, $\nabla_\theta J(\theta-\gamma v_{t-1})$是当前参数的梯度$\theta=\theta-v_t$然后用下一个点的梯度方向,与历史累积动量相结合,计算当前时刻的累积动量。如上图,动量法首先计算当前梯度(图中的小蓝色向量),然后在更新累积梯度(updated accumulated gradient)方向上大幅度的跳跃(图中的大蓝色向量)。与此不同的是,NAG 首先在先前的累积梯度(previous accumulated gradient)方向上进行大幅度的跳跃(图中的棕色向量),评估这个梯度并做一下修正(图中的红色向量),这就构成一次完整的 NAG 更新(图中的绿色向量)。这种预期更新防止我们进行的太快,也带来了更高的相应速度,这在一些任务中非常有效的提升了 RNN 的性能。特点有利于跳出当前局部最优的沟壑,寻找新的最优值,但收敛速度慢5.AdaGrad,自适应学习率开启SGD系列的都没有用到二阶动量。二阶动量的出现,才意味着“自适应学习率”优化算法时代的到来。SGD及其变种以同样的学习率更新每个参数,但深度神经网络往往包含大量的参数,这些参数并不是总会用得到。对于经常更新的参数,我们已经积累了大量关于它的知识,不希望被单个样本影响太大,希望学习速率慢一些;对于偶尔更新的参数,我们了解的信息太少,希望能从每个偶然出现的样本身上多学一些,即学习速率大一些。因此,Adagrad 非常适用于稀疏数据。Dean 等人发现 Adagrad 能够大幅提高 SGD 的鲁棒性,并在 Google 用其训练大规模神经网络,这其中就包括 在 YouTube 中学习识别猫。除此之外,Pennington 等人用 Adagrad 来训练 GloVe 词嵌入,因为罕见的词汇需要比常见词更大的更新。AdaGrad算法就是将每一个参数的每一次迭代的梯度取平方累加后在开方,用全局学习率除以这个数,作为学习率的动态更新。对于不同的参数动态的采取不同的学习率,让目标函数更快的收敛。为了简洁,我们用$g_t$来表示t时刻的梯度,$g_{t,i}$就是目标函数的偏导数:$g_{t,i}=\nabla_{\theta}J(\theta_{t,i})$SGD在在每个时刻t对参数$θi$的更新为:$\theta_{t+1,i}=\theta_{t,i}-\eta\cdot g_{t,i}$Adagrad修改了t时刻对于每个参数$θi$的学习率η:$\theta_{t+1,i}=\theta_{t,i}-\dfrac{\eta}{\sqrt{G_{t,ii}+\epsilon}}\cdot g_{t,i}$其中$G_t∈R_d×d$是对角矩阵,其中每一个对角元素i,i是$θi$在时刻t的梯度平方和,一般为了避免分母为0,会在分母上加一个小的平滑项,用符号ϵ表示,通常为10−8 左右。因此$\sqrt{G_{t}+\epsilon}$恒大于0,而且参数更新越频繁,二阶动量越大,学习率就越小。有趣的是,如果去掉开方操作,算法性能会大幅下降优点在稀疏数据场景下表现非常好此前的SGD及其变体的优化器主要聚焦在优化梯度前进的方向上,而AdaGrad首次使用二阶动量来关注学习率(步长),开启了自适应学习率算法的里程。大多数实现使用一个默认值 0.01 。缺点$\sqrt{G_{t}+\epsilon}$是单调递增的,会使得学习率单调递减至0,可能会使得训练过程提前结束,即便后续还有数据也无法学到必要的知识。6. AdaDelta由于AdaGrad单调递减的学习率变化过于激进,考虑一个改变二阶动量计算方法的策略:不累积全部历史梯度,而只关注过去一段时间窗口的下降梯度。这也就是AdaDelta名称中Delta的来历。Adadelta是 Adagrad 的扩展,旨在帮助缓解后者学习率单调下降的问题优点避免了二阶动量持续累积、导致训练过程提前结束的问题了7.RMSProp(2012)RMSProp 算法(Hinton,2012)修改 AdaGrad 以在非凸情况下表现更好,它改变梯度累积为指数加权的移动平均值,从而丢弃距离较远的历史梯度信息。RMSProp 与 Adadelta 的移动均值更新方式十分相似$E[g^2]_{t}=0.9E[g^2]_{t-1}+0.1g_{t}^{2}$RMSProp参数更新公式如下,其中η是学习率, $g_t$是当前参数的梯度$\theta_{t+1}=\theta_t-\dfrac{\eta}{\sqrt{E[g^2]_t+\epsilon}}g_t$RMSprop将学习速率除以梯度平方的指数衰减平均值。Hinton建议γ设置为0.9,默认学习率η为0.0018.AdamAdam最开始是由 OpenAI 的 Diederik Kingma 和多伦多大学的 Jimmy Ba提出的。Adam使用动量和自适应学习率来加快收敛速度。SGD-M在SGD基础上增加了一阶动量,AdaGrad和AdaDelta在SGD基础上增加了二阶动量(二阶矩估计)。把一阶动量和二阶动量都用起来,就是Adam了——Adaptive + Momentum。优点通过一阶动量和二阶动量,有效控制学习率步长和梯度方向,防止梯度的振荡和在鞍点的静止。实现简单,计算高效,对内存需求少参数的更新不受梯度的伸缩变换影响超参数具有很好的解释性,且通常无需调整或仅需很少的微调更新的步长能够被限制在大致的范围内(初始学习率)能自然地实现步长退火过程(自动调整学习率)很适合应用于大规模的数据及参数的场景适用于不稳定目标函数适用于梯度稀疏或梯度存在很大噪声的问题Adam在很多情况下算作默认工作性能比较优秀的优化器。缺点可能不收敛:二阶动量是固定时间窗口内的累积,随着时间窗口的变化,遇到的数据可能发生巨变,使得$V_t$可能会时大时小,不是单调变化。这就可能在训练后期引起学习率的震荡,导致模型无法收敛。$v_t=max(\beta_2\cdot v_{t-1}+(1-\beta_2)g_t^2,v_{t-1})\quad\text{}$修正的方法。由于Adam中的学习率主要是由二阶动量控制的,为了保证算法的收敛,可以对二阶动量的变化进行控制,避免上下波动。可能错过全局最优解:自适应学习率算法可能会对前期出现的特征过拟合,后期才出现的特征很难纠正前期的拟合效果。后期Adam的学习率太低,影响了有效的收敛。9.Adamax10.NadamAdam可以被看作是融合了RMSProp和momentum,RMSprop 贡献了历史平方梯度的指数衰减的平均值$v_t$,而动量则负责历史梯度的指数衰减平均值$m_t$,Nadam在Adam的基础上加入了一阶动量的累积,即Nesterov + Adam = Nadam,为了把NAG融入到Adam中,我们需要修改momentum的项$m_t$11.AMSGrad(2018)AMSGrad在ICLR 2018年被提出来,并获得了最佳论文。AMSGrad是一个随机梯度下降优化方法,它试图解决基于Adam的优化器的收敛问题。AMSGrad使用最大化过去平方梯度vt来更新参数,而不是使用指数平均,这样就降低了指数衰减平均,造成重要历史信息快速丢失的影响。$\begin{array}{c}m_t=\beta_1m_{t-1}+(1-\beta_1)g_t\\ v_t=\beta_2v_{t-1}+(1-\beta_2)g_t^2\end{array}$上面的两个公式跟Adam是一样的,求的是一阶矩和二阶矩,$g_t$是当前参数的梯度,$β1$为一阶矩估计的指数衰减率,$β2$是二阶矩估计的指数衰减率,前者控制一阶矩估计,后者控制二阶矩估计。$\hat{v}_t=max(\hat{v}_{t-1},v_t)$上式求过去最大的平方梯度$v^t$,参数的更新公式如下:$\theta_{t+1}=\theta_t-\dfrac{\eta}{\sqrt{\hat{v}_t}+\epsilon}m_t$从上面的公式可以看出,参数更新公式与Adam没有啥区别,但是求$v^t$有区别。AMSGRAD不增加步长,避免了ADAM和RMSPROP算法的缺陷。12.AdaBoundAdaBound算法训练速度比肩Adam,性能媲美SGD。SGD现在后期调优时还是经常使用到,但SGD的问题是前期收敛速度慢。SGD前期收敛慢的原因: SGD在更新参数时对各个维度上梯度的放缩是一致的,并且在训练数据分布极不均很时训练效果很差。而因为收敛慢的问题应运而生的自适应优化算法Adam、AdaGrad、RMSprop 等,但这些自适应的优化算法虽然可以在训练早期展现出快速的收敛速度,但其在测试集上的表现却会很快陷入停滞,并最终被 SGD 超过。13.AdamWL2 正则化是减少过拟合的经典方法,它会向损失函数添加由模型所有权重的平方和组成的惩罚项,并乘上特定的超参数以控制惩罚力度。加入L2正则以后,损失函数就变为:从上面的公式可以看出,AdamW本质上就是在损失函数里面加入了L2正则项,然后计算梯度和更新参数的时候都需要考虑这个正则项。AdamW使用在hugging face版的transformer中,BERT,XLNET,ELECTRA等主流的NLP模型,都是用了AdamW优化器14.RAdamRAdam(Rectified Adam)是Adam优化器的一个变体,它引入了一项来纠正自适应学习率的方差,试图解决Adam的收敛性差的问题。15.LookaheadLookahead是一种梯度下降优化器,它迭代的更新两个权重集合,”fast”和”slow”。直观地说,该算法通过向前看由另一个优化器生成的快速权值序列来选择搜索方向。 梯度下降的时候,走几步会退回来检查是否方向正确。避免突然掉入局部最低点。Lookahead的算法描述如下:Fast weights它是由内循环优化器(inner-loop)生成的k次序列权重;这里的优化器就是原有的优化器,如SGD,Adam等均可;其优化方法与原优化器并没有区别,例如给定优化器A,目标函数L,当前训练mini-batch样本d,这里会将该轮循环的k次权重,用序列都保存下来。Slow Weights:在每轮内循环结束后,根据本轮的k次权重,计算等到Slow Weights;这里采用的是指数移动平均(exponential moving average, EMA)算法来计算,最终模型使用的参数也是慢更新(Slow Weights)那一套,因此快更新(Fast Weights)相当于做了一系列实验,然后慢更新再根据实验结果选一个比较好的方向,这有点类似 Nesterov Momentum 的思想。
深度学习基础入门篇[二]:机器学习常用评估指标:AUC、mAP、IS、FID、Perplexity、BLEU、ROUGE等详解
A.深度学习基础入门篇[二]:机器学习常用评估指标:AUC、mAP、IS、FID、Perplexity、BLEU、ROUGE等详解1.基础指标简介机器学习的评价指标有精度、精确率、召回率、P-R曲线、F1 值、TPR、FPR、ROC、AUC等指标,还有在生物领域常用的敏感性、特异性等指标。在分类任务中,各指标的计算基础都来自于对正负样本的分类结果,用混淆矩阵表示,如 图1.1 所示:准确率$Accuracy=\dfrac{TP+TN}{TP+FN+FP+TN}$即所有分类正确的样本占全部样本的比例。精确率精准率又叫做:Precision、查准率召回率召回率又叫:Recall、查全率$Recall=\dfrac{TP}{TP+FN}\quad\text{}$即所有正例的样本中,被找出的比例.P-R曲线¶P-R曲线又叫做:PRC图2 PRC曲线图根据预测结果将预测样本排序,最有可能为正样本的在前,最不可能的在后,依次将样本预测为正样本,分别计算当前的精确率和召回率,绘制P-R曲线。F1 值$\quad F1=\dfrac{2*P*R}{P+R}\quad\quad$TPR$TPR=\dfrac{TP}{TP+FN}$真正例率,与召回率相同FPR假正例率$FPR=\dfrac{FP}{TN+FP}\quad$ROC根据预测结果将预测样本排序,最有可能为正样本的在前,最不可能的在后,依次将样本预测为正样本,分别计算当前的TPR和FPR,绘制ROC曲线。AUCArea Under ROC Curve,ROC曲线下的面积:敏感性敏感性或者灵敏度(Sensitivity,也称为真阳性率)是指实际为阳性的样本中,判断为阳性的比例(例如真正有生病的人中,被医院判断为有生病者的比例),计算方式是真阳性除以真阳性+假阴性(实际为阳性,但判断为阴性)的比值(能将实际患病的病例正确地判断为患病的能力,即患者被判为阳性的概率)。公式如下:$sensitivity=\dfrac{TP}{TP+FN}\quad\text{}$即有病(阳性)人群中,检测出阳性的几率。(检测出确实有病的能力)特异性特异性或特异度(Specificity,也称为真阴性率)是指实际为阴性的样本中,判断为阴性的比例(例如真正未生病的人中,被医院判断为未生病者的比例),计算方式是真阴性除以真阴性+假阳性(实际为阴性,但判断为阳性)的比值(能正确判断实际未患病的病例的能力,即试验结果为阴性的比例)。公式如下:$specificity=\dfrac{TN}{TN+FP}\quad\text{}$即无病(阴性)人群中,检测出阴性的几率。(检测出确实没病的能力)2. 目标检测任务重:mAP在目标检测任务中,还有一个非常重要的概念是mAP。mAP是用来衡量目标检测算法精度的一个常用指标。目前各个经典算法都是使用mAP在开源数据集上进行精度对比。在计算mAP之前,还需要使用到两个基础概念:准确率(Precision)和召回率(Recall)2.1准确率和召回率准确率:预测为正的样本中有多少是真正的正样本。召回率:样本中的正例有多少被预测正确。具体计算方式如图2.1所示。如图2.1准确率和召回率计算方式其中,上图还存在以下几个概念:正例:正样本,即该位置存在对应类别的物体。负例:负样本,即该位置不存在对应类别的物体。TP(True Positives):正样本预测为正样本的数量。FP(False Positives):负样本预测为正样本的数量。FN(False Negative):正样本预测为负样本的数量。TN(True Negative):负样本预测为负样本的数量。这里举个例子来说明准确率和召回率是如何进行计算的:假设我们的输入样本中有某个类别的10个目标,我们最终预测得到了8个目标。其中6个目标预测正确(TP),2个目标预测错误(FP),4个目标没有预测到(FN)。则准确率和召回率的计算结果如下所示:准确率:6/(6+2) = 6/8 = 75%召回率:6/(6+4) = 6/10 = 60%2.2 PR曲线上文中,我们学习了如何计算准确率(Precision)和召回率(Recall),得到这两个结果后,我们使用Precision、Recall为纵、横坐标,就可以得到PR曲线,这里同样使用一个例子来演示如何绘制PR曲线。假设我们使用目标检测算法获取了如下的24个目标框,各自的置信度(即网络预测得到的类别得分)按照从上到下进行排序后如 图2 所示。我们通过设置置信度阈值可以控制最终的输出结果。可以预想到的是:如果把阈值设高,则最终输出结果中大部分都会是比较准确的,但也会导致输出结果较少,样本中的正例只有部分被找出,准确率会比较高而召回率会比较低。如果把阈值设低,则最终输出结果会比较多,但是输出的结果中包含了大量负样本,召回率会比较高而准确率率会比较低。图2.2 准确率和召回率列表这里,我们从上往下每次多包含一个点,就可以得到最右边的两列,分别是累加的recall和累加的precision。以recall为自变量、precision为因变量可以得到一系列的坐标点(Recall,Precision)。将这些坐标点进行连线可以得到 图2.3 。图2.3 PR曲线而最终mAP的计算方式其实可以分成如下两步:AP(Average Precision):某一类P-R曲线下的面积。mAP(mean Average Precision):所有类别的AP值取平均。3.GAN评价指标(评价生成图片好坏)生成器G训练好后,我们需要评价生成图片的质量好坏,主要分为主观评价和客观评价,接下来分别介绍这两类方法:主观评价:人眼去观察生成的样本是否与真实样本相似。但是主观评价会存在以下问题:生成图片数量较大时,观察一小部分图片可能无法代表所有图片的质量;生成图片非常真实时,主观认为是一个好的GAN,但可能存在过拟合现象,人眼无法发现。客观评价:因为主观评价存在一些问题,于是就有很多学者提出了GAN的客观评价方法,常用的方法:IS(Inception Score)FID(Fréchet Inception Distance)其他评价方法3.1 ISIS全称是Inception Score,其名字中 Inception 来源于Inception Net,因为计算这个 score 需要用到 Inception Net-V3(第三个版本的 Inception Net)。对于一个在ImageNet训练好的GAN,IS主要从以下两个方面进行评价:清晰度:把生成的图片 x 输入Inception V3模型中,将输出 1000 维(ImageNet有1000类)的向量 y ,向量每个维度的值表示图片属于某类的概率。对于一个清晰的图片,它属于某一类的概率应该非常大。多样性:如果一个模型能生成足够多样的图片,那么它生成的图片在各个类别中的分布应该是平均的,假设生成了 10000 张图片,那么最理想的情况是,1000 类中每类生成了 10 张。IS计算公式为:$IS(G)=exp(E_{x\sim p_g}D_{KL}(p(y|x)||\hat{p}(y)))$其中,$x∼p$:表示从生成器生成的图片;$p(y|x)$:把生成的图片 x 输入到 Inception V3,得到一个 1000 维的向量 y ,即图片x属于各个类别的概率分布;$pˆ(y)$:N 个生成的图片(N 通常取 5000),每个生成图片都输入到 Inception V3 中,各自得到一个的概率分布向量,然后求这些向量的平均,得到生成的图片在所有类别上的边缘分布,具体公式如下:$\hat p(y)=\dfrac1N\sum\limits_{i=1}^N p\left(y|x^{(i)}\right)$$DKL$:表示对$p(y|x)$和$pˆ(y)$ 求KL散度,KL散度公式如下:$D_{KL}\left(P\|Q\right)=\sum\limits_{i}P\left(i\right)\log\dfrac{P\left(i\right)}{Q\left(i\right)}$S不能反映过拟合、且不能在一个数据集上训练分类模型,用来评估另一个数据集上训练的生成模型。3.2 FIDFID全称是Fréchet Inception Distance,计算真实图片和生成图片的Inception特征向量之间的距离。首先将Inception Net-V3模型的输出层替换为最后一个池化层的激活函数的输出值,把生成器生成的图片和真实图片送到模型中,得到2048个激活特征。生成图像的特征均值$μg$和方差$C_g$,以及真实图像的均值$μr$和方差$Cr$,根据均值和方差计算特征向量之间的距离,此距离值即FID:$FID\left(P_r,P_g\right)=||\mu_r-\mu_g||+T_r\left(C_r+C_g-2\left(C_rC_g\right)^{1/2}\right)$其中Tr 指的是被称为「迹」的线性代数运算(即方阵主对角线上的元素之和)。FID方法比较鲁棒,且计算高效。3.3 其他评价方法除了上述介绍的两种GAN客观评价方法 ,更多评价方法:Mode Score、Modifified Inception Score、AM Score、MMD、图像、Image Quality Measures、SSIM、PSNR等4. Perplexity:困惑度Perplexity,中文翻译为困惑度,是信息论中的一个概念,其可以用来衡量一个随机变量的不确定性,也可以用来衡量模型训练的好坏程度。通常情况下,一个随机变量的Perplexity数值越高,代表其不确定性也越高;一个模型推理时的Perplexity数值越高,代表模型表现越差,反之亦然。4.1 随机变量概率分布的困惑度对于离散随机变量X,假设概率分布可以表示为p(x)那么对应的困惑度为:$2^{H(p)}=2^{-\sum_{x\in X}p(x)log_2p(x)}$其中,H(p)为概率分布p的熵。可以看到,一个随机变量熵越大,其对应的困惑度也就越大,随机变量的不确定性也就越大。4.2 模型分布的困惑度困惑度也可以用来衡量模型训练的好坏程度,即衡量模型分布和样本分布之间的差异。一般来讲,在模型的训练过程中,模型分布越接近样本分布,模型训练得也就越好。假设现在有一批数据$x1,x2,x3,...,x_n$,其对应的经验分布为$pr(x)$。现在我们根据这些样本成功训练出了一个模型$pθ(x)$,那么模型分布$pθ(x)$的好坏可以由困惑度进行定义:$2^{H(p_r,p\theta)}=2^{-\sum_i^n p_r(x_i)\log_2p\theta(x_i)}$其中,$H(pr,pθ)$表示样本的经验分布$pr^$和模型分布$pθ$之间的交叉熵。假设每个样本xi的生成概率是相等的,即$p_r(x_i)=1/n$,则模型分布的困惑度可简化为:$2^{H(p_r p\theta)}=2^{-\frac{1}{n}\sum_i^n log_2p\theta(x_i)}$4.3 NLP领域中的困惑度¶在NLP领域,语言模型可以用来计算一个句子的概率,假设现在有这样一句话$s=w1,w2,w3,...,w_n$我们可以这样计算这句话的生成概率:$\begin{aligned}p(s)&=p(w_1,w_2,\ldots,w_n)\\ &=\prod\limits_{i=1}^np(w_i|w_1,w_2,\ldots,w_{i-1})\\ \end{aligned}$在语言模型训练完成之后,如何去评判语言模型的好坏?这时,困惑度就可以发挥作用了。一般来讲,用于评判语言模型的测试集均是合理的、高质量的语料,只要语言模型在测试集上的困惑度越高,则代表语言模型训练地越好,反之亦然。在了解了语句概率的计算后,则对于语句$s=w1,w2,w3,...,w_n$其困惑度可以这样来定义:$\begin{aligned}perplexity&=p(s)^{-\frac{1}{n}}\\ &=p(w_1,w_2,\ldots,w_n)^{-\frac{1}{n}}\\ &=\sqrt[n]{\frac{1}{p(w_1,w_2,\ldots,w_n)}}\\ &=\sqrt[n]{\prod_{i=1}^n\frac{1}{p(w_i|w_1,w_2,\ldots,w_{i-1})}}\\ \end{aligned}$显然,测试集中句子的概率越大,困惑度也就越小。5.BLEU:机器翻译合理性BLEU (BiLingual Evaluation Understudy) 最早用于机器翻译任务上,用于评估机器翻译的语句的合理性。具体来讲,BLEU通过衡量生成序列和参考序列之间的重合度进行计算的。下面我们将以机器翻译为例,进行讨论这个指标。假设当前有一句源文$s$,以及相应的译文参考序列$r1,r2,...,r_n$。机器翻译模型根据源文s生成了一个生成序列x,且W为根据候选序列x生成的N元单词组合,这些N元组合的精度为:$P_N(x)=\dfrac{\sum_{w\in W}min(c_w(x),max_{k=1}^nc_w(r_k))}{\sum_{w\in W}c_w(x)}$其中,$c_w(x)$为N元组合词w在生成序列x中出现的次数,$c_w(r_k)$为N元组合词w在参考序列$r_k$中出现的次数。N元组合的精度$P_N(x)$即为生成序列中的N元组合词在参考序列中出现的比例。从以上公式可以看出,$P_N(x)$的核心思想是衡量生成序列x中的N元组合词是否在参考序列中出现,其计算结果更偏好短的生成序列,即生成序列x越短,精度$P_N(x)$会越高。这种情况下,可以引入长度惩罚因子,如果生成序列x比参考序列$r_k$短,则会对该生成序列x进行惩罚。$b(x)=\left{\begin{matrix}1&\mathrm{if}\quad l_x>l_r\\ \exp(1-l_s/l_r)&\mathrm{if}\quad l_s\leq l_r\end{matrix}\right.$其中,$l_x$表示生成序列x的长度, $l_r$表示参考序列lr的最短长度。前边反复提到一个概念–N元组合词,我们可以根据生成序列x构造不同长度的N元组合词,这样便可以获得不同长度组合词的精度,比如P1(x),P2(x),P3(x)等等。BLEU算法通过计算不同长度的N元组合的精度PN(x),N=1,2,3...,并对其进行几何加权平均得到,如下所示。$\operatorname{BLEU-N}(x)=b(x)\times\exp(\sum\limits_{N=1}^{N'}\alpha_N\log P_N)\quad$其中,$N′$为最长N元组合词的长度, $a_N$为不同N元组合词的权重,一般设置为$\frac{1}{N^{\prime}}$,BLEU算法的值域范围是[0,1],数值越大,表示生成的质量越好。BLEU算法能够比较好地计算生成序列x的字词是否在参考序列中出现过,但是其并没有关注参考序列中的字词是否在生成序列出现过。即BLEU只关心生成的序列精度,而不关心其召回率。6.ROUGE 评估指标:机器翻译模型看过BLEU算法的同学知道,BLEU算法只关心生成序列的字词是否在参考序列中出现,而不关心参考序列中的字词是否在生成序列中出现,这在实际指标评估过程中可能会带来一些影响,从而不能较好评估生成序列的质量。ROUGE (Recall-Oriented Understudy for Gisting Evaluation)算法便是一种解决方案,它能够衡量参考序列中的字词是在生成序列中出现过,即它能够衡量生成序列的召回率。下面还是以机器翻译为例,来探讨一下ROUGE的计算。假设当前有一句源文s,以及相应的译文参考序列$r_1,r_2,...,r_n$。机器翻译模型根据源文s生成了一个生成序列x,且W为根据候选序列x生成的N元单词组合,则ROUGE算法的计算方式为:$\operatorname{ROUGE-N}(x)=\dfrac{\sum_{k=1}^n\sum_{w\in W}\min(c_w(x),c_w(r_k))}{\sum_{k=1}^n\sum_{w\in W}c_w(r_k)}$其中,$c_w(x)$为N元组合词w在生成序列x中出现的次数,$c_w(r_k)$为N元组合词w在参考序列rk中出现的次数。从公式可以看到,ROUGE算法能比较好地计算参考序列中的字词是否在生成序列出现过,但没有关注生成序列的字词是否在参考序列中出现过,即ROUGE算法只关心生成序列的召回率,而不关心准确率。引用[1] 邱锡鹏. 神经网络与深度学习[M]. 北京:机械工业出版社,2021.[2] 吴飞. 人工智能导论:模型与算法[M]. 北京:高等教育出版社,2020.
基于Labelstudio的UIE半监督智能标注方案(本地版),赶快用起来
基于Labelstudio的UIE半监督智能标注方案(本地版)更多技术细节参考上一篇项目,本篇主要侧重本地端链路走通教学,提速提效:基于Labelstudio的UIE半监督深度学习的智能标注方案(云端版),提效更多内容参考文末码源自然语言处理信息抽取智能标注方案包括以下几种:基于规则的标注方案:通过编写一系列规则来识别文本中的实体、关系等信息,并将其标注。基于规则的标注方案是一种传统的方法,它需要人工编写规则来识别文本中的实体、关系等信息,并将其标注。这种方法的优点是易于理解和实现,但缺点是需要大量的人工工作,并且规则难以覆盖所有情况。基于机器学习的标注方案:通过训练模型来自动识别文本中的实体、关系等信息,并将其标注。基于机器学习的标注方案是一种自动化的方法,它使用已经标注好的数据集训练模型,并使用模型来自动标注文本中的实体、关系等信息。这种方法的优点是可以处理大量的数据,并且可以自适应地调整模型,但缺点是需要大量的标注数据和计算资源,并且模型的性能受到标注数据的质量和数量的限制。基于深度学习的标注方案:通过使用深度学习模型来自动识别文本中的实体、关系等信息,并将其标注。基于深度学习的标注方案是一种最新的方法,它使用深度学习模型来自动从文本中提取实体、关系等信息,并将其标注。这种方法的优点是可以处理大量的数据,并且具有较高的准确性,但缺点是需要大量的标注数据和计算资源,并且模型的训练和调试需要专业的知识和技能。基于半监督学习的标注方案:通过使用少量的手工标注数据和大量的未标注数据来训练模型,从而实现自动标注。基于半监督学习的标注方案是一种利用少量的手工标注数据和大量的未标注数据来训练模型的方法。这种方法的优点是可以利用未标注数据来提高模型的性能,但缺点是需要大量的未标注数据和计算资源,并且模型的性能受到标注数据的质量基于远程监督的标注方案:利用已知的知识库来自动标注文本中的实体、关系等信息,从而减少手工标注的工作量。本次项目主要讲解的是基于半监督深度学习的标注方案。1.智能标注本地版 Machine Learning 集成教学1.1 本地启动 Label Studio安装label-studio:#创建名为label_studio的虚拟环境(示例的Python版本为3.8) conda create -n labelstudio python=3.8 #激活虚拟环境 conda activate labelstudio #pip安装label-studio (version=1.7.2) pip install label-studio==1.7.2 1.2 启动 Machine Learning Backend在终端中依次执行下列命令: #安装label-studio机器学习后端,dirname为放代码的文件夹路径 cd dirname git clone https://github.com/heartexlabs/label-studio-ml-backend #安装label-studio及其依赖 cd label-studio-ml-backend pip install -U -e . #(可选) 安装label-studio中examples运行所需的requirements pip install -r label_studio_ml/examples/requirements.txt 创建与启动模型:定义模型在使用label-studio后端之前,要先定义好自己的训练模型,模型的定义需要继承自label-studio指定的类,具体可参考第四节。创建后端模型:按照要求创建好的模型文件的路径假设为/Users/kyrol/Desktop/my_ml_backend.py,终端中执行以下命令: # 初始化自定义机器学习后端 label-studio-ml init my_ml_backend --script /Users/kyrol/Desktop/my_ml_backend.py #命令执行完毕会在当前文件夹下创建名为 my_ml_backend 的文件夹, 里面放有 my_ml_backend.py, _wsgi.py 等内容。 #其中,_wsgi.py是要运行的python 主文件,可以查看里面内容。注意:同时需要把依赖文件放入my_ml_backend.py文件夹。 # 开启机器学习后端服务 label-studio-ml start my_ml_backend 成功启动后,在终端中可以看到 ML 后端的 URL。1.3 模型配置与训练开启可视化窗口,再开启一个终端窗口,首先,激活conda对应的环境;然后,cd 到label-studio代码所在路径;然后,执行以下终端命令,启动可视化的窗口:在启动自定义机器学习后端之后,就可以将其添加到 Label Studio 项目中。具体步骤如下:配置训练数据文件根据不同的任务配置不同的标签,在settings中点击Labeling Interface, 配置项目标签,具体可参考官网。训练模型创建一个project点击 setting点击 Machine Learning配置模型训练端口,导入模型训练后的模型会保存在 my_ml_backend 文件夹中以数字命名的文件夹内。具体步骤如下所示:点击 Settings - Machine Learning - Add Model填入标题、ML 后端的 URL、描述(可选)等内容选择 Use for interactive preannotations 打开交互式预注释功能(可选)点击 Validate and Save1.3 获取交互式预注释若要使用交互式预注释功能,需在添加 ML Backend 时打开 Use for interactive preannotations 选项。如未打开,可点击 Edit 进行编辑。然后随便点击一个数据,label studio 就会悄悄运行刚才的 ml backend 生成新的标注了。查看预标注好的数据,如有必要,对标注进行修改。本例中,预标注的结果中『NBA』没有被识别出来,手动添加实体将其标注为『组织』。本例中,预标注的结果中将『人名』实体『三月』错标注为『时间』实体,手动进行修改。修改完成后,或预标注的结果已经符合预期,点击 Submit 提交标注结果。1.4 智能标注(自动再训练模型)在标注了至少一项任务之后,就可以开始训练模型了。点击 Settings - Machine Learning - Start Training 开始训练。动态图为引用方便展示这个流程。然后返回启动 label-studio-ml-backend 的窗口可以看到训练的流程启动了。 2.UIE-base预训练模型进行命名实体识别from pprint import pprint from paddlenlp import Taskflow schema = ['地名', '人名', '组织', '时间', '产品', '价格', '天气'] ie = Taskflow('information_extraction', schema=schema) pprint(ie("2K 与 Gearbox Software 宣布,《小缇娜的奇幻之地》将于 6 月 24 日凌晨 1 点登录 Steam,此前 PC 平台为 Epic 限时独占。在限定期间内,Steam 玩家可以在 Steam 入手《小缇娜的奇幻之地》,并在 2022 年 7 月 8 日前享有获得黄金英雄铠甲包。"))[{'产品': [{'end': 35, 'probability': 0.8595664902550801, 'start': 25, 'text': '《小缇娜的奇幻之地》'}], '地名': [{'end': 34, 'probability': 0.30077351606695757, 'start': 26, 'text': '小缇娜的奇幻之地'}, {'end': 117, 'probability': 0.5250433327469182, 'start': 109, 'text': '小缇娜的奇幻之地'}], '时间': [{'end': 52, 'probability': 0.8796518890642702, 'start': 38, 'text': '6 月 24 日凌晨 1 点'}], '组织': [{'end': 2, 'probability': 0.6914450625760651, 'start': 0, 'text': '2K'}, {'end': 93, 'probability': 0.5971815528872604, 'start': 88, 'text': 'Steam'}, {'end': 75, 'probability': 0.5844303540013343, 'start': 71, 'text': 'Epic'}, {'end': 105, 'probability': 0.45620707081511114, 'start': 100, 'text': 'Steam'}, {'end': 60, 'probability': 0.5683007420326334, 'start': 55, 'text': 'Steam'}, {'end': 21, 'probability': 0.6797917390407271, 'start': 5, 'text': 'Gearbox Software'}]}] pprint(ie("近日,量子计算专家、ACM计算奖得主Scott Aaronson通过博客宣布,将于本周离开得克萨斯大学奥斯汀分校(UT Austin)一年,并加盟人工智能研究公司OpenAI。"))[{'人名': [{'end': 23, 'probability': 0.664236391748247, 'start': 18, 'text': 'Scott'}, {'end': 32, 'probability': 0.479811241610971, 'start': 24, 'text': 'Aaronson'}], '时间': [{'end': 43, 'probability': 0.8424644728072508, 'start': 41, 'text': '本周'}], '组织': [{'end': 87, 'probability': 0.5550909248934985, 'start': 81, 'text': 'OpenAI'}]}] 使用默认模型 uie-base 进行命名实体识别,效果还不错,大多数的命名实体被识别出来了,但依然存在部分实体未被识别出,部分文本被误识别等问题。比如 "Scott Aaronson" 被识别为了两个人名,比如 "得克萨斯大学奥斯汀分校" 没有被识别出来。为提升识别效果,将通过标注少量数据对模型进行微调。3.模型微调在终端中执行以下脚本,将 label studio 导出的数据文件格式转换成 doccano 导出的数据文件格式。python labelstudio2doccano.py --labelstudio_file dataset/label-studio.json参数说明:labelstudio_file: label studio 的导出文件路径(仅支持 JSON 格式)。doccano_file: doccano 格式的数据文件保存路径,默认为 "doccano_ext.jsonl"。task_type: 任务类型,可选有抽取("ext")和分类("cls")两种类型的任务,默认为 "ext"。!python doccano.py \ --doccano_file dataset/doccano_ext.jsonl \ --task_type "ext" \ --save_dir ./data \ --splits 0.8 0.2 0参数说明:doccano_file: doccano 格式的数据标注文件路径。task_type: 选择任务类型,可选有抽取("ext")和分类("cls")两种类型的任务。save_dir: 训练数据的保存目录,默认存储在 data 目录下。negative_ratio: 最大负例比例,该参数只对抽取类型任务有效,适当构造负例可提升模型效果。负例数量和实际的标签数量有关,最大负例数量 = negative_ratio * 正例数量。该参数只对训练集有效,默认为 5。为了保证评估指标的准确性,验证集和测试集默认构造全负例。splits: 划分数据集时训练集、验证集、测试集所占的比例。默认为 [0.8, 0.1, 0.1] 。options: 指定分类任务的类别标签,该参数只对分类类型任务有效。默认为 ["正向", "负向"]。prompt_prefix: 声明分类任务的 prompt 前缀信息,该参数只对分类类型任务有效。默认为 "情感倾向"。is_shuffle: 是否对数据集进行随机打散,默认为 True。seed: 随机种子,默认为 1000。separator: 实体类别/评价维度与分类标签的分隔符,该参数只对实体/评价维度级分类任务有效。默认为 "##"。注:每次执行 doccano.py 脚本,将会覆盖已有的同名数据文件。3.1 Finetune在终端中执行以下脚本进行模型微调。# 然后在终端中执行以下脚本,对 doccano 格式的数据文件进行处理,执行后会在 /home/data 目录下生成训练/验证/测试集文件。 !python finetune.py \ --train_path "./data/train.txt" \ --dev_path "./data/dev.txt" \ --save_dir "./checkpoint" \ --learning_rate 1e-5 \ --batch_size 32 \ --max_seq_len 512 \ --num_epochs 100 \ --model "uie-base" \ --seed 1000 \ --logging_steps 100 \ --valid_steps 100 \ --device "gpu"[2023-03-31 16:14:53,465] [ INFO] - global step 600, epoch: 67, loss: 0.00012, speed: 3.76 step/s [2023-03-31 16:14:53,908] [ INFO] - Evaluation precision: 0.93478, recall: 0.79630, F1: 0.86000 [2023-03-31 16:15:20,328] [ INFO] - global step 700, epoch: 78, loss: 0.00010, speed: 3.79 step/s [2023-03-31 16:15:20,777] [ INFO] - Evaluation precision: 0.93750, recall: 0.83333, F1: 0.88235 [2023-03-31 16:15:46,992] [ INFO] - global step 800, epoch: 89, loss: 0.00009, speed: 3.81 step/s [2023-03-31 16:15:47,439] [ INFO] - Evaluation precision: 0.91667, recall: 0.81481, F1: 0.86275 [2023-03-31 16:16:13,316] [ INFO] - global step 900, epoch: 100, loss: 0.00008, speed: 3.86 step/s [2023-03-31 16:16:13,758] [ INFO] - Evaluation precision: 0.95833, recall: 0.85185, F1: 0.90196 结果展示:参数说明:train_path: 训练集文件路径。dev_path: 验证集文件路径。save_dir: 模型存储路径,默认为 "./checkpoint"。learning_rate: 学习率,默认为 1e-5。batch_size: 批处理大小,请结合机器情况进行调整,默认为 16。max_seq_len: 文本最大切分长度,输入超过最大长度时会对输入文本进行自动切分,默认为 512。num_epochs: 训练轮数,默认为 100。model: 选择模型,程序会基于选择的模型进行模型微调,可选有 "uie-base", "uie-medium", "uie-mini", "uie-micro" 和 "uie-nano",默认为 "uie-base"。seed: 随机种子,默认为 1000。logging_steps: 日志打印的间隔 steps 数,默认为 10。valid_steps: evaluate 的间隔 steps 数,默认为 100。device: 选用什么设备进行训练,可选 "cpu" 或 "gpu"。init_from_ckpt: 初始化模型参数的路径,可从断点处继续训练。3.2 模型评估在终端中执行以下脚本进行模型评估。输出示例:参数说明:model_path: 进行评估的模型文件夹路径,路径下需包含模型权重文件 model_state.pdparams 及配置文件 model_config.json。test_path: 进行评估的测试集文件。batch_size: 批处理大小,请结合机器情况进行调整,默认为 16。max_seq_len: 文本最大切分长度,输入超过最大长度时会对输入文本进行自动切分,默认为 512。debug: 是否开启 debug 模式对每个正例类别分别进行评估,该模式仅用于模型调试,默认关闭。debug 模式输出示例:!python evaluate.py \ --model_path ./checkpoint/model_best \ --test_path ./data/dev.txt \ --batch_size 16 \ --max_seq_len 512[2023-03-31 16:16:18,503] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load './checkpoint/model_best'. W0331 16:16:18.530714 1666 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 8.0, Driver API Version: 11.2, Runtime API Version: 11.2 W0331 16:16:18.533171 1666 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2. [2023-03-31 16:16:24,551] [ INFO] - ----------------------------- [2023-03-31 16:16:24,551] [ INFO] - Class Name: all_classes [2023-03-31 16:16:24,551] [ INFO] - Evaluation Precision: 0.95918 | Recall: 0.87037 | F1: 0.91262 !python evaluate.py \ --model_path ./checkpoint/model_best \ --test_path ./data/dev.txt \ --debug[2023-03-31 16:16:29,246] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load './checkpoint/model_best'. W0331 16:16:29.278601 1707 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 8.0, Driver API Version: 11.2, Runtime API Version: 11.2 W0331 16:16:29.281224 1707 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2. [2023-03-31 16:16:34,944] [ INFO] - ----------------------------- [2023-03-31 16:16:34,944] [ INFO] - Class Name: 时间 [2023-03-31 16:16:34,944] [ INFO] - Evaluation Precision: 1.00000 | Recall: 0.90000 | F1: 0.94737 [2023-03-31 16:16:34,998] [ INFO] - ----------------------------- [2023-03-31 16:16:34,998] [ INFO] - Class Name: 地名 [2023-03-31 16:16:34,998] [ INFO] - Evaluation Precision: 0.95833 | Recall: 0.85185 | F1: 0.90196 [2023-03-31 16:16:35,022] [ INFO] - ----------------------------- [2023-03-31 16:16:35,022] [ INFO] - Class Name: 产品 [2023-03-31 16:16:35,022] [ INFO] - Evaluation Precision: 1.00000 | Recall: 1.00000 | F1: 1.00000 [2023-03-31 16:16:35,048] [ INFO] - ----------------------------- [2023-03-31 16:16:35,048] [ INFO] - Class Name: 组织 [2023-03-31 16:16:35,049] [ INFO] - Evaluation Precision: 1.00000 | Recall: 0.50000 | F1: 0.66667 [2023-03-31 16:16:35,071] [ INFO] - ----------------------------- [2023-03-31 16:16:35,071] [ INFO] - Class Name: 人名 [2023-03-31 16:16:35,071] [ INFO] - Evaluation Precision: 1.00000 | Recall: 1.00000 | F1: 1.00000 [2023-03-31 16:16:35,092] [ INFO] - ----------------------------- [2023-03-31 16:16:35,092] [ INFO] - Class Name: 天气 [2023-03-31 16:16:35,092] [ INFO] - Evaluation Precision: 1.00000 | Recall: 1.00000 | F1: 1.00000 [2023-03-31 16:16:35,109] [ INFO] - ----------------------------- [2023-03-31 16:16:35,109] [ INFO] - Class Name: 价格 [2023-03-31 16:16:35,109] [ INFO] - Evaluation Precision: 1.00000 | Recall: 1.00000 | F1: 1.00000 3.3 微调后效果my_ie = Taskflow("information_extraction", schema=schema, task_path='./checkpoint/model_best') # task_path 指定模型权重文件的路径 pprint(my_ie("2K 与 Gearbox Software 宣布,《小缇娜的奇幻之地》将于 6 月 24 日凌晨 1 点登录 Steam,此前 PC 平台为 Epic 限时独占。在限定期间内,Steam 玩家可以在 Steam 入手《小缇娜的奇幻之地》,并在 2022 年 7 月 8 日前享有获得黄金英雄铠甲包。"))[2023-03-31 16:16:39,383] [ INFO] - Converting to the inference model cost a little time. [2023-03-31 16:16:46,661] [ INFO] - The inference model save in the path:./checkpoint/model_best/static/inference [2023-03-31 16:16:48,783] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load './checkpoint/model_best'. [{'产品': [{'end': 118, 'probability': 0.9860396834664122, 'start': 108, 'text': '《小缇娜的奇幻之地》'}, {'end': 35, 'probability': 0.9870830377819004, 'start': 25, 'text': '《小缇娜的奇幻之地》'}, {'end': 148, 'probability': 0.9075236400717301, 'start': 141, 'text': '黄金英雄铠甲包'}], '时间': [{'end': 52, 'probability': 0.9998017644462607, 'start': 38, 'text': '6 月 24 日凌晨 1 点'}, {'end': 137, 'probability': 0.9875673117430104, 'start': 122, 'text': '2022 年 7 月 8 日前'}], '组织': [{'end': 2, 'probability': 0.9888051241547942, 'start': 0, 'text': '2K'}, {'end': 93, 'probability': 0.9503029387182096, 'start': 88, 'text': 'Steam'}, {'end': 75, 'probability': 0.9819544449787045, 'start': 71, 'text': 'Epic'}, {'end': 105, 'probability': 0.7914398215948992, 'start': 100, 'text': 'Steam'}, {'end': 60, 'probability': 0.982935890915897, 'start': 55, 'text': 'Steam'}, {'end': 21, 'probability': 0.9994608274841141, 'start': 5, 'text': 'Gearbox Software'}]}] pprint(my_ie("近日,量子计算专家、ACM计算奖得主Scott Aaronson通过博客宣布,将于本周离开得克萨斯大学奥斯汀分校(UT Austin)一年,并加盟人工智能研究公司OpenAI。"))[{'人名': [{'end': 32, 'probability': 0.9990193078443497, 'start': 18, 'text': 'Scott Aaronson'}], '时间': [{'end': 2, 'probability': 0.9998481327061199, 'start': 0, 'text': '近日'}, {'end': 43, 'probability': 0.9995744486620453, 'start': 41, 'text': '本周'}], '组织': [{'end': 66, 'probability': 0.9900117066000078, 'start': 57, 'text': 'UT Austin'}, {'end': 87, 'probability': 0.9993381402363184, 'start': 81, 'text': 'OpenAI'}, {'end': 56, 'probability': 0.9968616126324434, 'start': 45, 'text': '得克萨斯大学奥斯汀分校'}, {'end': 13, 'probability': 0.8434502340745098, 'start': 10, 'text': 'ACM'}]}] 基于 50 条标注数据进行模型微调后,效果有所提升。4.智能标注:Machine Learning Backend 编写教学在基于UIE的命名实体识别的基础上,进一步通过集成 Label Studio 的 Machine Learning Backend 实现交互式预注释和模型训练等功能。环境安装: pip install label_studio_ml pip uninstall attr完整的 Machine Learning Backend 见 my_ml_backend.py 文件。更多有关自定义机器学习后端编写的内容可参考 Write your own ML backend。简单来讲,my_ml_backend.py 内主要包含一个继承自 LabelStudioMLBase 的类,其内容可以分为以下三个主要部分:init 方法,包含模型的加载和基本配置的初始化predict 方法,用于为标注数据生成新的预测结果,其关键参数 tasks 就是 label studio 传递的原始数据fit 方法,用于模型的训练,当点击页面上的 Train 按钮时,会调用此方法(具体的位置在下文会提到),其关键参数 annotations 就是 label studio 传递的已经标注了的数据4.1 init 初始化方法导入依赖库import numpy as np import os import json from paddlenlp import Taskflow from label_studio_ml.model import LabelStudioMLBase声明并初始化一个类首先创建一个类声明,通过继承 LabelStudioMLBase 创建一个与 Label Studio 兼容的 ML 后端服务器。class MyModel(LabelStudioMLBase):然后,在 __init__ 方法中定义和初始化需要的变量。LabelStudioMLBase 类提供了以下self.label_config: 原始标签配置。self.parsed_label_config: 为项目提供结构化的 Label Studio 标签配置。self.train_output: 包含之前模型训练运行的结果,与训练调用部分中定义的 fit() 方法的输出相同。如本教程的例子中,标签配置为:<View> <Labels name="label" toName="text"> <Label value="地名" background="#FFA39E"/> <Label value="人名" background="#D4380D"/> <Label value="组织" background="#FFC069"/> <Label value="时间" background="#AD8B00"/> <Label value="产品" background="#D3F261"/> <Label value="价格" background="#389E0D"/> <Label value="天气" background="#5CDBD3"/> </Labels> <Text name="text" value="$text"/> </View>相对应的 parsed_label_config 如下所示:{ 'label': { 'type': 'Labels', 'to_name': ['text'], 'inputs': [{ 'type': 'Text', 'value': 'text' 'labels': ['地名', '人名', '组织', '时间', '产品', '价格', '天气'], 'labels_attrs': { '地名': { 'value': '地名', 'background': '#FFA39E' '人名': { 'value': '人名', 'background': '#D4380D' '组织': { 'value': '组织', 'background': '#FFC069' '时间': { 'value': '时间', 'background': '#AD8B00' '产品': { 'value': '产品', 'background': '#D3F261' '价格': { 'value': '价格', 'background': '#389E0D' '天气': { 'value': '天气', 'background': '#5CDBD3' }根据需要从 self.parsed_label_config 变量中提取需要的信息,并通过 PaddleNLP 的 Taskflow 加载用于预标注的模型。def __init__(self, **kwargs): # don't forget to initialize base class... super(MyModel, self).__init__(**kwargs) # print("parsed_label_config:", self.parsed_label_config) self.from_name, self.info = list(self.parsed_label_config.items())[0] assert self.info['type'] == 'Labels' assert self.info['inputs'][0]['type'] == 'Text' self.to_name = self.info['to_name'][0] self.value = self.info['inputs'][0]['value'] self.labels = list(self.info['labels']) self.model = Taskflow("information_extraction", schema=self.labels, task_path= './checkpoint/model_best')4.2 使用ML Backend predict 预测方法(自动标注)编写代码覆盖 predict(tasks, **kwargs) 方法。predict() 方法接受 [JSON 格式的 Label Studio 任务]返回预测。此外,还可以包含和自定义可用于主动学习循环的预测分数。tasks 参数包含了有关要进行预注释的任务的详细信息。具体的 task 格式如下所示:{ 'id': 16, 'data': { 'text': '新华社都柏林6月28日电(记者张琪)第二届“汉语桥”世界小学生中文秀爱尔兰赛区比赛结果日前揭晓,来自都柏林市的小学五年级学生埃拉·戈尔曼获得一等奖。' 'meta': {}, 'created_at': '2022-07-12T07:05:06.793411Z', 'updated_at': '2022-07-12T07:05:06.793424Z', 'is_labeled': False, 'overlap': 1, 'inner_id': 6, 'total_annotations': 0, 'cancelled_annotations': 0, 'total_predictions': 0, 'project': 2, 'updated_by': None, 'file_upload': 2, 'annotations': [], 'predictions': [] }通过 Taskflow 进行预测需要从 ['data']['text'] 字段提取出原始文本,返回的 uie 预测结果格式如下所示:{ '地名': [{ 'text': '爱尔兰', 'start': 34, 'end': 37, 'probability': 0.9999107139090313 'text': '都柏林市', 'start': 50, 'end': 54, 'probability': 0.9997840536235998 'text': '都柏林', 'start': 3, 'end': 6, 'probability': 0.9999684097596173 '人名': [{ 'text': '埃拉·戈尔曼', 'start': 62, 'end': 68, 'probability': 0.9999879598978225 'text': '张琪', 'start': 15, 'end': 17, 'probability': 0.9999905824882092 '组织': [{ 'text': '新华社', 'start': 0, 'end': 3, 'probability': 0.999975681447097 '时间': [{ 'text': '6月28日', 'start': 6, 'end': 11, 'probability': 0.9997071721989244 'text': '日前', 'start': 43, 'end': 45, 'probability': 0.9999804497706464 }从 uie 预测结果中提取相应的字段,构成 Label Studio 接受的预注释格式。命名实体识别任务的具体预注释示例可参考 [Import span pre-annotations for text]更多其他类型任务的具体预注释示例可参考 [Specific examples for pre-annotations]def predict(self, tasks, **kwargs): from_name = self.from_name to_name = self.to_name model = self.model predictions = [] for task in tasks: # print("predict task:", task) text = task['data'][self.value] uie = model(text)[0] # print("uie:", uie) result = [] scores = [] for key in uie: for item in uie[key]: result.append({ 'from_name': from_name, 'to_name': to_name, 'type': 'labels', 'value': { 'start': item['start'], 'end': item['end'], 'score': item['probability'], 'text': item['text'], 'labels': [key] scores.append(item['probability']) result = sorted(result, key=lambda k: k["value"]["start"]) mean_score = np.mean(scores) if len(scores) > 0 else 0 predictions.append({ 'result': result, # optionally you can include prediction scores that you can use to sort the tasks and do active learning 'score': float(mean_score), 'model_version': 'uie-ner' return predictions4.3 使用 ML Backend fit 训练方法(根据标注好的数据再次优化训练模型)基于新注释更新模型。编写代码覆盖 fit() 方法。fit() 方法接受 [JSON 格式的 Label Studio 注释]并返回任意一个可以存储模型相关信息的 JSON 字典。def fit(self, annotations, workdir=None, **kwargs): """ This is where training happens: train your model given list of annotations, then returns dict with created links and resources # print("annotations:", annotations) dataset = convert(annotations) with open("./doccano_ext.jsonl", "w", encoding="utf-8") as outfile: for item in dataset: outline = json.dumps(item, ensure_ascii=False) outfile.write(outline + "\n") os.system('python doccano.py \ --doccano_file ./doccano_ext.jsonl \ --task_type "ext" \ --save_dir ./data \ --splits 0.8 0.2 0') os.system('python finetune.py \ --train_path "./data/train.txt" \ --dev_path "./data/dev.txt" \ --save_dir "./checkpoint" \ --learning_rate 1e-5 \ --batch_size 4 \ --max_seq_len 512 \ --num_epochs 50 \ --model "uie-base" \ --init_from_ckpt "./checkpoint/model_best/model_state.pdparams" \ --seed 1000 \ --logging_steps 10 \ --valid_steps 100 \ --device "gpu"') return { 'path': workdir }6.总结人工标注的缺点主要有以下几点:产能低:人工标注需要大量的人力物力投入,且标注速度慢,产能低,无法满足大规模标注的需求。受限条件多:人工标注受到人力、物力、时间等条件的限制,无法适应所有的标注场景,尤其是一些复杂的标注任务。易受主观因素影响:人工标注受到人为因素的影响,如标注人员的专业素养、标注态度、主观判断等,易受到人为误差的干扰,导致标注结果不准确。难以满足个性化需求:人工标注无法满足所有标注场景和个性化需求,无法精确地标注出所有的关键信息,需要使用者自行选择和判断。相比之下,智能标注的优势主要包括:效率更高:智能标注可以自动化地进行标注,能够快速地生成标注结果,减少了人工标注所需的时间和精力,提高了标注效率。精度更高:智能标注采用了先进的人工智能技术,能够对图像进行深度学习和处理,能够生成更加准确和精细的标注结果,特别是对于一些细节和特征的标注,手动标注往往存在误差较大的问题。自动纠错:智能标注可以自动检测标注结果中的错误,并进行自动修正,能够有效地避免标注错误带来的影响,提高了标注的准确性。灵活性更强:智能标注可以根据不同的应用场景和需求,生成不同类型的标注结果,能够满足用户的多样化需求,提高了标注的适用性。总之,智能标注相对于人工标注有着更高的效率、更高的精度、更强的灵活性和更好的适用性,可以更好地满足用户的需求。6.1 码源智能标注:基于Labelstudio的UIE半监督深度学习的智能标注方案码源更多细节参考:人工智能知识图谱之信息抽取:基于Labelstudio的UIE半监督深度学习的智能标注方案(云端版),提效。
人工智能知识图谱之信息抽取:基于Labelstudio的UIE半监督深度学习的智能标注方案(云端版),提效。
基于Label studio实现UIE信息抽取智能标注方案,提升标注效率!项目链接见文末人工标注的缺点主要有以下几点:产能低:人工标注需要大量的人力物力投入,且标注速度慢,产能低,无法满足大规模标注的需求。受限条件多:人工标注受到人力、物力、时间等条件的限制,无法适应所有的标注场景,尤其是一些复杂的标注任务。易受主观因素影响:人工标注受到人为因素的影响,如标注人员的专业素养、标注态度、主观判断等,易受到人为误差的干扰,导致标注结果不准确。难以满足个性化需求:人工标注无法满足所有标注场景和个性化需求,无法精确地标注出所有的关键信息,需要使用者自行选择和判断。相比之下,智能标注的优势主要包括:效率更高:智能标注可以自动化地进行标注,能够快速地生成标注结果,减少了人工标注所需的时间和精力,提高了标注效率。精度更高:智能标注采用了先进的人工智能技术,能够对图像进行深度学习和处理,能够生成更加准确和精细的标注结果,特别是对于一些细节和特征的标注,手动标注往往存在误差较大的问题。自动纠错:智能标注可以自动检测标注结果中的错误,并进行自动修正,能够有效地避免标注错误带来的影响,提高了标注的准确性。灵活性更强:智能标注可以根据不同的应用场景和需求,生成不同类型的标注结果,能够满足用户的多样化需求,提高了标注的适用性。总之,智能标注相对于人工标注有着更高的效率、更高的精度、更强的灵活性和更好的适用性,可以更好地满足用户的需求。自然语言处理信息抽取智能标注方案包括以下几种:基于规则的标注方案:通过编写一系列规则来识别文本中的实体、关系等信息,并将其标注。基于规则的标注方案是一种传统的方法,它需要人工编写规则来识别文本中的实体、关系等信息,并将其标注。这种方法的优点是易于理解和实现,但缺点是需要大量的人工工作,并且规则难以覆盖所有情况。基于机器学习的标注方案:通过训练模型来自动识别文本中的实体、关系等信息,并将其标注。基于机器学习的标注方案是一种自动化的方法,它使用已经标注好的数据集训练模型,并使用模型来自动标注文本中的实体、关系等信息。这种方法的优点是可以处理大量的数据,并且可以自适应地调整模型,但缺点是需要大量的标注数据和计算资源,并且模型的性能受到标注数据的质量和数量的限制。基于深度学习的标注方案:通过使用深度学习模型来自动识别文本中的实体、关系等信息,并将其标注。基于深度学习的标注方案是一种最新的方法,它使用深度学习模型来自动从文本中提取实体、关系等信息,并将其标注。这种方法的优点是可以处理大量的数据,并且具有较高的准确性,但缺点是需要大量的标注数据和计算资源,并且模型的训练和调试需要专业的知识和技能。基于半监督学习的标注方案:通过使用少量的手工标注数据和大量的未标注数据来训练模型,从而实现自动标注。基于半监督学习的标注方案是一种利用少量的手工标注数据和大量的未标注数据来训练模型的方法。这种方法的优点是可以利用未标注数据来提高模型的性能,但缺点是需要大量的未标注数据和计算资源,并且模型的性能受到标注数据的质量基于远程监督的标注方案:利用已知的知识库来自动标注文本中的实体、关系等信息,从而减少手工标注的工作量。本次项目主要讲解的是基于半监督深度学习的标注方案。1.UIE-base预训练模型进行命名实体识别from pprint import pprint from paddlenlp import Taskflow schema = ['地名', '人名', '组织', '时间', '产品', '价格', '天气'] ie = Taskflow('information_extraction', schema=schema) pprint(ie("2K 与 Gearbox Software 宣布,《小缇娜的奇幻之地》将于 6 月 24 日凌晨 1 点登录 Steam,此前 PC 平台为 Epic 限时独占。在限定期间内,Steam 玩家可以在 Steam 入手《小缇娜的奇幻之地》,并在 2022 年 7 月 8 日前享有获得黄金英雄铠甲包。"))[2023-03-27 16:11:00,527] [ INFO] - Downloading model_state.pdparams from https://bj.bcebos.com/paddlenlp/taskflow/information_extraction/uie_base_v1.0/model_state.pdparams 100%|██████████| 450M/450M [00:45<00:00, 10.4MB/s] [2023-03-27 16:11:46,996] [ INFO] - Downloading model_config.json from https://bj.bcebos.com/paddlenlp/taskflow/information_extraction/uie_base/model_config.json 100%|██████████| 377/377 [00:00<00:00, 309kB/s] [2023-03-27 16:11:47,074] [ INFO] - Downloading vocab.txt from https://bj.bcebos.com/paddlenlp/taskflow/information_extraction/uie_base/vocab.txt 100%|██████████| 182k/182k [00:00<00:00, 1.27MB/s] [2023-03-27 16:11:47,292] [ INFO] - Downloading special_tokens_map.json from https://bj.bcebos.com/paddlenlp/taskflow/information_extraction/uie_base/special_tokens_map.json 100%|██████████| 112/112 [00:00<00:00, 99.6kB/s] [2023-03-27 16:11:47,364] [ INFO] - Downloading tokenizer_config.json from https://bj.bcebos.com/paddlenlp/taskflow/information_extraction/uie_base/tokenizer_config.json 100%|██████████| 172/172 [00:00<00:00, 192kB/s] W0327 16:11:47.478449 273 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 8.0, Driver API Version: 11.2, Runtime API Version: 11.2 W0327 16:11:47.481654 273 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2. [2023-03-27 16:11:50,518] [ INFO] - Converting to the inference model cost a little time. [2023-03-27 16:11:57,379] [ INFO] - The inference model save in the path:/home/aistudio/.paddlenlp/taskflow/information_extraction/uie-base/static/inference [2023-03-27 16:11:59,489] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load '/home/aistudio/.paddlenlp/taskflow/information_extraction/uie-base'. [{'产品': [{'end': 35, 'probability': 0.8595664902550801, 'start': 25, 'text': '《小缇娜的奇幻之地》'}], '地名': [{'end': 34, 'probability': 0.30077351606695757, 'start': 26, 'text': '小缇娜的奇幻之地'}, {'end': 117, 'probability': 0.5250433327469182, 'start': 109, 'text': '小缇娜的奇幻之地'}], '时间': [{'end': 52, 'probability': 0.8796518890642702, 'start': 38, 'text': '6 月 24 日凌晨 1 点'}], '组织': [{'end': 2, 'probability': 0.6914450625760651, 'start': 0, 'text': '2K'}, {'end': 93, 'probability': 0.5971815528872604, 'start': 88, 'text': 'Steam'}, {'end': 75, 'probability': 0.5844303540013343, 'start': 71, 'text': 'Epic'}, {'end': 105, 'probability': 0.45620707081511114, 'start': 100, 'text': 'Steam'}, {'end': 60, 'probability': 0.5683007420326334, 'start': 55, 'text': 'Steam'}, {'end': 21, 'probability': 0.6797917390407271, 'start': 5, 'text': 'Gearbox Software'}]}] pprint(ie("近日,量子计算专家、ACM计算奖得主Scott Aaronson通过博客宣布,将于本周离开得克萨斯大学奥斯汀分校(UT Austin)一年,并加盟人工智能研究公司OpenAI。"))[{'人名': [{'end': 23, 'probability': 0.664236391748247, 'start': 18, 'text': 'Scott'}, {'end': 32, 'probability': 0.479811241610971, 'start': 24, 'text': 'Aaronson'}], '时间': [{'end': 43, 'probability': 0.8424644728072508, 'start': 41, 'text': '本周'}], '组织': [{'end': 87, 'probability': 0.5550909248934985, 'start': 81, 'text': 'OpenAI'}]}] 使用默认模型 uie-base 进行命名实体识别,效果还不错,大多数的命名实体被识别出来了,但依然存在部分实体未被识别出,部分文本被误识别等问题。比如 "Scott Aaronson" 被识别为了两个人名,比如 "得克萨斯大学奥斯汀分校" 没有被识别出来。为提升识别效果,将通过标注少量数据对模型进行微调。2.基于Label Studio的数据标注在将智能标注前,先讲解手动标注,通过手动标注后才会感知到智能标注的提效和交互性。由于AI studio不支持在线标注,这里大家在本地端进行标注,标注完毕后上传数据集即可2.1 Label Studio安装以下标注示例用到的环境配置:Python 3.8+label-studio == 1.7.1paddleocr >= 2.6.0.1在终端(terminal)使用pip安装label-studio:pip install label-studio==1.7.1安装完成后,运行以下命令行:label-studio start在浏览器打开http://localhost:8080/,输入用户名和密码登录,开始使用label-studio进行标注。2.2 实体抽取任务标注项目创建点击创建(Create)开始创建一个新的项目,填写项目名称、描述,然后选择Object Detection with Bounding Boxes。填写项目名称、描述命名实体识别任务选择添加标签(也可跳过后续在Setting/Labeling Interface中配置)数据上传先从本地上传txt格式文件,选择List of tasks,然后选择导入本项目。实体抽取标注数据导出勾选已标注文本ID,选择导出的文件类型为JSON,导出数据:3. 模型微调3.1 数据转换在终端中执行以下脚本,将 label studio 导出的数据文件格式转换成 doccano 导出的数据文件格式。python labelstudio2doccano.py --labelstudio_file dataset/label-studio.json参数说明:labelstudio_file: label studio 的导出文件路径(仅支持 JSON 格式)。doccano_file: doccano 格式的数据文件保存路径,默认为 "doccano_ext.jsonl"。task_type: 任务类型,可选有抽取("ext")和分类("cls")两种类型的任务,默认为 "ext"。!python doccano.py \ --doccano_file dataset/doccano_ext.jsonl \ --task_type "ext" \ --save_dir ./data \ --splits 0.8 0.2 0[2023-03-27 16:43:33,438] [ INFO] - Converting doccano data... 100%|████████████████████████████████████████| 40/40 [00:00<00:00, 29794.38it/s] [2023-03-27 16:43:33,440] [ INFO] - Adding negative samples for first stage prompt... 100%|███████████████████████████████████████| 40/40 [00:00<00:00, 118650.75it/s] [2023-03-27 16:43:33,441] [ INFO] - Converting doccano data... 100%|████████████████████████████████████████| 10/10 [00:00<00:00, 38095.40it/s] [2023-03-27 16:43:33,442] [ INFO] - Adding negative samples for first stage prompt... 100%|███████████████████████████████████████| 10/10 [00:00<00:00, 130257.89it/s] [2023-03-27 16:43:33,442] [ INFO] - Converting doccano data... 0it [00:00, ?it/s] [2023-03-27 16:43:33,442] [ INFO] - Adding negative samples for first stage prompt... 0it [00:00, ?it/s] [2023-03-27 16:43:33,444] [ INFO] - Save 274 examples to ./data/train.txt. [2023-03-27 16:43:33,445] [ INFO] - Save 70 examples to ./data/dev.txt. [2023-03-27 16:43:33,445] [ INFO] - Save 0 examples to ./data/test.txt. [2023-03-27 16:43:33,445] [ INFO] - Finished! It takes 0.01 seconds 参数说明:doccano_file: doccano 格式的数据标注文件路径。task_type: 选择任务类型,可选有抽取("ext")和分类("cls")两种类型的任务。save_dir: 训练数据的保存目录,默认存储在 data 目录下。negative_ratio: 最大负例比例,该参数只对抽取类型任务有效,适当构造负例可提升模型效果。负例数量和实际的标签数量有关,最大负例数量 = negative_ratio * 正例数量。该参数只对训练集有效,默认为 5。为了保证评估指标的准确性,验证集和测试集默认构造全负例。splits: 划分数据集时训练集、验证集、测试集所占的比例。默认为 [0.8, 0.1, 0.1] 。options: 指定分类任务的类别标签,该参数只对分类类型任务有效。默认为 ["正向", "负向"]。prompt_prefix: 声明分类任务的 prompt 前缀信息,该参数只对分类类型任务有效。默认为 "情感倾向"。is_shuffle: 是否对数据集进行随机打散,默认为 True。seed: 随机种子,默认为 1000。separator: 实体类别/评价维度与分类标签的分隔符,该参数只对实体/评价维度级分类任务有效。默认为 "##"。注:每次执行 doccano.py 脚本,将会覆盖已有的同名数据文件。3.2 Finetune在终端中执行以下脚本进行模型微调。# 然后在终端中执行以下脚本,对 doccano 格式的数据文件进行处理,执行后会在 /home/data 目录下生成训练/验证/测试集文件。 !python finetune.py \ --train_path "./data/train.txt" \ --dev_path "./data/dev.txt" \ --save_dir "./checkpoint" \ --learning_rate 1e-5 \ --batch_size 32 \ --max_seq_len 512 \ --num_epochs 100 \ --model "uie-base" \ --seed 1000 \ --logging_steps 100 \ --valid_steps 100 \ --device "gpu"[2023-03-27 16:47:58,806] [ INFO] - Downloading resource files... [2023-03-27 16:47:58,810] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load 'uie-base'. W0327 16:47:58.836591 13399 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 8.0, Driver API Version: 11.2, Runtime API Version: 11.2 W0327 16:47:58.839186 13399 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2. [2023-03-27 16:48:30,349] [ INFO] - global step 100, epoch: 12, loss: 0.00060, speed: 3.46 step/s [2023-03-27 16:48:30,794] [ INFO] - Evaluation precision: 0.93878, recall: 0.85185, F1: 0.89320 [2023-03-27 16:48:30,794] [ INFO] - best F1 performence has been updated: 0.00000 --> 0.89320 [2023-03-27 16:48:58,054] [ INFO] - global step 200, epoch: 23, loss: 0.00032, speed: 3.82 step/s [2023-03-27 16:48:58,500] [ INFO] - Evaluation precision: 0.95918, recall: 0.87037, F1: 0.91262 [2023-03-27 16:48:58,500] [ INFO] - best F1 performence has been updated: 0.89320 --> 0.91262 [2023-03-27 16:49:25,664] [ INFO] - global step 300, epoch: 34, loss: 0.00022, speed: 3.83 step/s [2023-03-27 16:49:26,107] [ INFO] - Evaluation precision: 0.90385, recall: 0.87037, F1: 0.88679 [2023-03-27 16:49:52,155] [ INFO] - global step 400, epoch: 45, loss: 0.00017, speed: 3.84 step/s [2023-03-27 16:49:52,601] [ INFO] - Evaluation precision: 0.93878, recall: 0.85185, F1: 0.89320 [2023-03-27 16:50:18,632] [ INFO] - global step 500, epoch: 56, loss: 0.00014, speed: 3.84 step/s [2023-03-27 16:50:19,075] [ INFO] - Evaluation precision: 0.92157, recall: 0.87037, F1: 0.89524 [2023-03-27 16:50:45,077] [ INFO] - global step 600, epoch: 67, loss: 0.00012, speed: 3.85 step/s [2023-03-27 16:50:45,523] [ INFO] - Evaluation precision: 0.93478, recall: 0.79630, F1: 0.86000 [2023-03-27 16:51:11,546] [ INFO] - global step 700, epoch: 78, loss: 0.00010, speed: 3.84 step/s [2023-03-27 16:51:11,987] [ INFO] - Evaluation precision: 0.93750, recall: 0.83333, F1: 0.88235 [2023-03-27 16:51:38,013] [ INFO] - global step 800, epoch: 89, loss: 0.00009, speed: 3.84 step/s [2023-03-27 16:51:38,457] [ INFO] - Evaluation precision: 0.93617, recall: 0.81481, F1: 0.87129 [2023-03-27 16:52:04,361] [ INFO] - global step 900, epoch: 100, loss: 0.00008, speed: 3.86 step/s [2023-03-27 16:52:04,808] [ INFO] - Evaluation precision: 0.95745, recall: 0.83333, F1: 0.89109 结果展示:参数说明:train_path: 训练集文件路径。dev_path: 验证集文件路径。save_dir: 模型存储路径,默认为 "./checkpoint"。learning_rate: 学习率,默认为 1e-5。batch_size: 批处理大小,请结合机器情况进行调整,默认为 16。max_seq_len: 文本最大切分长度,输入超过最大长度时会对输入文本进行自动切分,默认为 512。num_epochs: 训练轮数,默认为 100。model: 选择模型,程序会基于选择的模型进行模型微调,可选有 "uie-base", "uie-medium", "uie-mini", "uie-micro" 和 "uie-nano",默认为 "uie-base"。seed: 随机种子,默认为 1000。logging_steps: 日志打印的间隔 steps 数,默认为 10。valid_steps: evaluate 的间隔 steps 数,默认为 100。device: 选用什么设备进行训练,可选 "cpu" 或 "gpu"。init_from_ckpt: 初始化模型参数的路径,可从断点处继续训练。3.3 模型评估在终端中执行以下脚本进行模型评估。输出示例:参数说明:model_path: 进行评估的模型文件夹路径,路径下需包含模型权重文件 model_state.pdparams 及配置文件 model_config.json。test_path: 进行评估的测试集文件。batch_size: 批处理大小,请结合机器情况进行调整,默认为 16。max_seq_len: 文本最大切分长度,输入超过最大长度时会对输入文本进行自动切分,默认为 512。debug: 是否开启 debug 模式对每个正例类别分别进行评估,该模式仅用于模型调试,默认关闭。debug 模式输出示例:!python evaluate.py \ --model_path ./checkpoint/model_best \ --test_path ./data/dev.txt \ --batch_size 16 \ --max_seq_len 512[2023-03-27 16:56:21,832] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load './checkpoint/model_best'. W0327 16:56:21.863559 15278 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 8.0, Driver API Version: 11.2, Runtime API Version: 11.2 W0327 16:56:21.866312 15278 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2. [2023-03-27 16:56:27,409] [ INFO] - ----------------------------- [2023-03-27 16:56:27,409] [ INFO] - Class Name: all_classes [2023-03-27 16:56:27,409] [ INFO] - Evaluation Precision: 0.95918 | Recall: 0.87037 | F1: 0.91262 !python evaluate.py \ --model_path ./checkpoint/model_best \ --test_path ./data/dev.txt \ --debug[2023-03-27 16:56:31,824] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load './checkpoint/model_best'. W0327 16:56:31.856709 15361 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 8.0, Driver API Version: 11.2, Runtime API Version: 11.2 W0327 16:56:31.859668 15361 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2. [2023-03-27 16:56:37,039] [ INFO] - ----------------------------- [2023-03-27 16:56:37,039] [ INFO] - Class Name: 时间 [2023-03-27 16:56:37,039] [ INFO] - Evaluation Precision: 1.00000 | Recall: 0.90000 | F1: 0.94737 [2023-03-27 16:56:37,092] [ INFO] - ----------------------------- [2023-03-27 16:56:37,092] [ INFO] - Class Name: 地名 [2023-03-27 16:56:37,092] [ INFO] - Evaluation Precision: 0.95833 | Recall: 0.85185 | F1: 0.90196 [2023-03-27 16:56:37,113] [ INFO] - ----------------------------- [2023-03-27 16:56:37,113] [ INFO] - Class Name: 产品 [2023-03-27 16:56:37,113] [ INFO] - Evaluation Precision: 1.00000 | Recall: 1.00000 | F1: 1.00000 [2023-03-27 16:56:37,139] [ INFO] - ----------------------------- [2023-03-27 16:56:37,139] [ INFO] - Class Name: 组织 [2023-03-27 16:56:37,139] [ INFO] - Evaluation Precision: 1.00000 | Recall: 0.50000 | F1: 0.66667 [2023-03-27 16:56:37,161] [ INFO] - ----------------------------- [2023-03-27 16:56:37,161] [ INFO] - Class Name: 人名 [2023-03-27 16:56:37,161] [ INFO] - Evaluation Precision: 1.00000 | Recall: 1.00000 | F1: 1.00000 [2023-03-27 16:56:37,181] [ INFO] - ----------------------------- [2023-03-27 16:56:37,181] [ INFO] - Class Name: 天气 [2023-03-27 16:56:37,181] [ INFO] - Evaluation Precision: 1.00000 | Recall: 1.00000 | F1: 1.00000 [2023-03-27 16:56:37,198] [ INFO] - ----------------------------- [2023-03-27 16:56:37,198] [ INFO] - Class Name: 价格 [2023-03-27 16:56:37,198] [ INFO] - Evaluation Precision: 1.00000 | Recall: 1.00000 | F1: 1.00000 3.4 微调后效果my_ie = Taskflow("information_extraction", schema=schema, task_path='./checkpoint/model_best') # task_path 指定模型权重文件的路径 pprint(my_ie("2K 与 Gearbox Software 宣布,《小缇娜的奇幻之地》将于 6 月 24 日凌晨 1 点登录 Steam,此前 PC 平台为 Epic 限时独占。在限定期间内,Steam 玩家可以在 Steam 入手《小缇娜的奇幻之地》,并在 2022 年 7 月 8 日前享有获得黄金英雄铠甲包。"))[2023-03-27 16:59:31,064] [ INFO] - Converting to the inference model cost a little time. [2023-03-27 16:59:38,171] [ INFO] - The inference model save in the path:./checkpoint/model_best/static/inference [2023-03-27 16:59:40,364] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load './checkpoint/model_best'. [{'产品': [{'end': 118, 'probability': 0.9860373472963602, 'start': 108, 'text': '《小缇娜的奇幻之地》'}, {'end': 35, 'probability': 0.9870597349192849, 'start': 25, 'text': '《小缇娜的奇幻之地》'}, {'end': 148, 'probability': 0.9075982731610566, 'start': 141, 'text': '黄金英雄铠甲包'}], '时间': [{'end': 52, 'probability': 0.9998029564426645, 'start': 38, 'text': '6 月 24 日凌晨 1 点'}, {'end': 137, 'probability': 0.9876786236837809, 'start': 122, 'text': '2022 年 7 月 8 日前'}], '组织': [{'end': 2, 'probability': 0.988802896329716, 'start': 0, 'text': '2K'}, {'end': 93, 'probability': 0.9500440898664806, 'start': 88, 'text': 'Steam'}, {'end': 75, 'probability': 0.9819772965571794, 'start': 71, 'text': 'Epic'}, {'end': 105, 'probability': 0.7921079762008958, 'start': 100, 'text': 'Steam'}, {'end': 60, 'probability': 0.9829542747088276, 'start': 55, 'text': 'Steam'}, {'end': 21, 'probability': 0.9994613042455924, 'start': 5, 'text': 'Gearbox Software'}]}] pprint(my_ie("近日,量子计算专家、ACM计算奖得主Scott Aaronson通过博客宣布,将于本周离开得克萨斯大学奥斯汀分校(UT Austin)一年,并加盟人工智能研究公司OpenAI。"))[{'人名': [{'end': 32, 'probability': 0.9990170436659866, 'start': 18, 'text': 'Scott Aaronson'}], '时间': [{'end': 2, 'probability': 0.9998477751029782, 'start': 0, 'text': '近日'}, {'end': 43, 'probability': 0.9995671774285029, 'start': 41, 'text': '本周'}], '组织': [{'end': 66, 'probability': 0.9900270615638647, 'start': 57, 'text': 'UT Austin'}, {'end': 87, 'probability': 0.9993388552686611, 'start': 81, 'text': 'OpenAI'}, {'end': 56, 'probability': 0.9968586409231648, 'start': 45, 'text': '得克萨斯大学奥斯汀分校'}, {'end': 13, 'probability': 0.8437228020724348, 'start': 10, 'text': 'ACM'}]}] 基于 50 条标注数据进行模型微调后,效果有所提升。4.基于Label Studio的智能标注(含自动训练)部分效果展示更多详细内容查看链接:人工智能知识图谱之信息抽取:基于Labelstudio的UIE半监督深度学习的智能标注方案(云端版),提效。里面有详细代码实现查看预标注好的数据,如有必要,对标注进行修改。5.模型部署以下是 UIE Python 端的部署流程,包括环境准备、模型导出和使用示例。5.1 UIE Python 端的部署流程模型导出模型训练、压缩时已经自动进行了静态图的导出以及 tokenizer 配置文件保存,保存路径${finetuned_model} 下应该有 .pdimodel、.pdiparams 模型文件可用于推理。模型部署以下示例展示如何基于 FastDeploy 库完成 UIE 模型完成通用信息抽取任务的 Python 预测部署。先参考 UIE 模型部署安装FastDeploy Python 依赖包。 可通过命令行参数--device以及--backend指定运行在不同的硬件以及推理引擎后端,并使用--model_dir参数指定运行的模型。模型目录为 model_zoo/uie/checkpoint/model_best(用户可按实际情况设置)。FastDeploy提供各平台预编译库,供开发者直接下载安装使用。当然FastDeploy编译也非常容易,开发者也可根据自身需求编译FastDeploy。详情参考链接:https://github.com/PaddlePaddle/FastDeploy/blob/develop/docs/cn/build_and_install/download_prebuilt_libraries.mdGPU端为了在GPU上获得最佳的推理性能和稳定性,请先确保机器已正确安装NVIDIA相关驱动和基础软件,确保CUDA >= 11.2,cuDNN >= 8.1.1,并使用以下命令安装所需依赖python部署比较常规就不展开:参考模型部署5.2 Serving 服务编写编写 predictor.py 文件:导入依赖库:除了业务中用到的库之外,需要额外依赖serving。后处理(可选):根据需要对模型返回的结果进行处理,以更好地展示。本教程中通过 format() 函数和 add_o() 函数修改命名实体识别结果的形式。Predictor 类: 不需要继承其他的类,但是至少需要提供 __init__ 和 predict 两个接口。在 __init__ 中定义实体抽取结构,通过 Taskflow 加载模型。在 predict 中进行预测,返回后处理的结果。class Predictor: def __init__(self): self.schema = ['地名', '人名', '组织', '时间', '产品', '价格', '天气'] self.ie = Taskflow("information_extraction", schema=self.schema, task_path='./checkpoint/model_best') def predict(self, json): text = json["input"] uie = self.ie(text)[0] result = format(text, uie) return result运行:启动服务。if __name__ == '__main__': serv.run(Predictor)在项目根目录下已经提供了编写好的 predictor.py 可以直接在后续使用。# !paddlenlp server server:app --workers 1 --host 0.0.0.0 --port 8189 # !pip install --upgrade paddlenlp # import json # import requests # url = "http://0.0.0.0:8189/taskflow/uie" # headers = {"Content-Type": "application/json"} # texts = ["近日,量子计算专家、ACM计算奖得主Scott Aaronson通过博客宣布,将于本周离开得克萨斯大学奥斯汀分校(UT Austin)一年,并加盟人工智能研究公司OpenAI"] # data = { # "data": { # "text": texts, # } # r = requests.post(url=url, headers=headers, data=json.dumps(data)) # datas = json.loads(r.text) # print(datas)note:部署环节请在本地上调试,更多详情参考:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/uie6.总结Label Studio 所提供的 Machine Learning Backend 提供了一个比较灵活的辅助人工标注的框架,我们通过它确实可以加快 nlp 数据的标注Label Studio 的 enterprise 版本提供了 Active Learning 的流程,不过从其描述看这个流程并不完美,尤其是 fit 部分,由于 Label Studio 低估了「Train」所花费的时间,所以每次标注都自动训练的流程可能并不会那么顺滑(会在链接时候等待一段时间)这次项目并没有使用 Label Studio 所提供的「Auto-Annotation」的功能,因为它存在重复标注的问题既然 Label Studio 提供了它的 api 那其实可玩的东西还是很多的,配合 webhook 等内容可能会让这个标注和训练的流程做的更加高效此外目前使用的UIE码源是前几个版本的,最新官网更新了一些训练升级API,后续再重新优化现有项目。本人对容器相关技术不太了解,所以在一些容器化技术操作上更多就是借鉴使用了,如有疑问评论区留言即可。更多详情请参考Label Studio官网:6.1 项目链接部分效果展示更多详细内容查看链接:人工智能知识图谱之信息抽取:基于Labelstudio的UIE半监督深度学习的智能标注方案(云端版),提效。里面有详细代码实现
机器学习实战系列[一]:工业蒸汽量预测(最新版本下篇)含特征优化模型融合等
工业蒸汽量预测(最新版本下篇)原项目链接:https://www.heywhale.com/home/column/64141d6b1c8c8b518ba97dcc5.模型验证5.1模型评估的概念与正则化5.1.1 过拟合与欠拟合### 获取并绘制数据集 import numpy as np import matplotlib.pyplot as plt %matplotlib inline np.random.seed(666) x = np.random.uniform(-3.0, 3.0, size=100) X = x.reshape(-1, 1) y = 0.5 * x**2 + x + 2 + np.random.normal(0, 1, size=100) plt.scatter(x, y) plt.show()使用线性回归拟合数据from sklearn.linear_model import LinearRegression lin_reg = LinearRegression() lin_reg.fit(X, y) lin_reg.score(X, y) # 输出:0.49537078118650090.4953707811865009 准确率为 0.495,比较低,直线拟合数据的程度较低。### 使用均方误差判断拟合程度 from sklearn.metrics import mean_squared_error y_predict = lin_reg.predict(X) mean_squared_error(y, y_predict) # 输出:3.07500257656365773.0750025765636577 ### 绘制拟合结果 y_predict = lin_reg.predict(X) plt.scatter(x, y) plt.plot(np.sort(x), y_predict[np.argsort(x)], color='r') plt.show()5.1.2 回归模型的评估指标和调用方法### 使用多项式回归拟合 # * 封装 Pipeline 管道 from sklearn.pipeline import Pipeline from sklearn.preprocessing import PolynomialFeatures from sklearn.preprocessing import StandardScaler def PolynomialRegression(degree): return Pipeline([ ('poly', PolynomialFeatures(degree=degree)), ('std_scaler', StandardScaler()), ('lin_reg', LinearRegression()) ])使用 Pipeline 拟合数据:degree = 2poly2_reg = PolynomialRegression(degree=2) poly2_reg.fit(X, y) y2_predict = poly2_reg.predict(X) # 比较真值和预测值的均方误差 mean_squared_error(y, y2_predict) # 输出:1.09873921424178561.0987392142417856 绘制拟合结果plt.scatter(x, y) plt.plot(np.sort(x), y2_predict[np.argsort(x)], color='r') plt.show()调整 degree = 10poly10_reg = PolynomialRegression(degree=10) poly10_reg.fit(X, y) y10_predict = poly10_reg.predict(X) mean_squared_error(y, y10_predict) # 输出:1.0508466763764164 plt.scatter(x, y) plt.plot(np.sort(x), y10_predict[np.argsort(x)], color='r') plt.show()调整 degree = 100poly100_reg = PolynomialRegression(degree=100) poly100_reg.fit(X, y) y100_predict = poly100_reg.predict(X) mean_squared_error(y, y100_predict) # 输出:0.6874357783433694 plt.scatter(x, y) plt.plot(np.sort(x), y100_predict[np.argsort(x)], color='r') plt.show()分析degree=2:均方误差为 1.0987392142417856;degree=10:均方误差为 1.0508466763764164;degree=100:均方误差为 0.6874357783433694;degree 越大拟合的效果越好,因为样本点是一定的,我们总能找到一条曲线将所有的样本点拟合,也就是说将所有的样本点都完全落在这根曲线上,使得整体的均方误差为 0;红色曲线并不是所计算出的拟合曲线,而此红色曲线只是原有的数据点对应的 y 的预测值连接出来的结果,而且有的地方没有数据点,因此连接的结果和原来的曲线不一样;5.1.3 交叉验证交叉验证迭代器K折交叉验证: KFold 将所有的样例划分为 k 个组,称为折叠 (fold) (如果 k = n, 这等价于 Leave One Out(留一) 策略),都具有相同的大小(如果可能)。预测函数学习时使用 k - 1 个折叠中的数据,最后一个剩下的折叠会用于测试。K折重复多次: RepeatedKFold 重复 K-Fold n 次。当需要运行时可以使用它 KFold n 次,在每次重复中产生不同的分割。留一交叉验证: LeaveOneOut (或 LOO) 是一个简单的交叉验证。每个学习集都是通过除了一个样本以外的所有样本创建的,测试集是被留下的样本。 因此,对于 n 个样本,我们有 n 个不同的训练集和 n 个不同的测试集。这种交叉验证程序不会浪费太多数据,因为只有一个样本是从训练集中删除掉的:留P交叉验证: LeavePOut 与 LeaveOneOut 非常相似,因为它通过从整个集合中删除 p 个样本来创建所有可能的 训练/测试集。对于 n 个样本,这产生了 {n \choose p} 个 训练-测试 对。与 LeaveOneOut 和 KFold 不同,当 p > 1 时,测试集会重叠。用户自定义数据集划分: ShuffleSplit 迭代器将会生成一个用户给定数量的独立的训练/测试数据划分。样例首先被打散然后划分为一对训练测试集合。设置每次生成的随机数相同: 可以通过设定明确的 random_state ,使得伪随机生成器的结果可以重复。基于类标签、具有分层的交叉验证迭代器如何解决样本不平衡问题? 使用StratifiedKFold和StratifiedShuffleSplit 分层抽样。 一些分类问题在目标类别的分布上可能表现出很大的不平衡性:例如,可能会出现比正样本多数倍的负样本。在这种情况下,建议采用如 StratifiedKFold 和 StratifiedShuffleSplit 中实现的分层抽样方法,确保相对的类别频率在每个训练和验证 折叠 中大致保留。StratifiedKFold是 k-fold 的变种,会返回 stratified(分层) 的折叠:每个小集合中, 各个类别的样例比例大致和完整数据集中相同。StratifiedShuffleSplit是 ShuffleSplit 的一个变种,会返回直接的划分,比如: 创建一个划分,但是划分中每个类的比例和完整数据集中的相同。用于分组数据的交叉验证迭代器如何进一步测试模型的泛化能力? 留出一组特定的不属于测试集和训练集的数据。有时我们想知道在一组特定的 groups 上训练的模型是否能很好地适用于看不见的 group 。为了衡量这一点,我们需要确保验证对象中的所有样本来自配对训练折叠中完全没有表示的组。GroupKFold是 k-fold 的变体,它确保同一个 group 在测试和训练集中都不被表示。 例如,如果数据是从不同的 subjects 获得的,每个 subject 有多个样本,并且如果模型足够灵活以高度人物指定的特征中学习,则可能无法推广到新的 subject 。 GroupKFold 可以检测到这种过拟合的情况。LeaveOneGroupOut是一个交叉验证方案,它根据第三方提供的 array of integer groups (整数组的数组)来提供样本。这个组信息可以用来编码任意域特定的预定义交叉验证折叠。每个训练集都是由除特定组别以外的所有样本构成的。LeavePGroupsOut类似于 LeaveOneGroupOut ,但为每个训练/测试集删除与 P 组有关的样本。GroupShuffleSplit迭代器是 ShuffleSplit 和 LeavePGroupsOut 的组合,它生成一个随机划分分区的序列,其中为每个分组提供了一个组子集。时间序列分割TimeSeriesSplit是 k-fold 的一个变体,它首先返回 k 折作为训练数据集,并且 (k+1) 折作为测试数据集。 请注意,与标准的交叉验证方法不同,连续的训练集是超越前者的超集。 另外,它将所有的剩余数据添加到第一个训练分区,它总是用来训练模型。from sklearn.model_selection import train_test_split,cross_val_score,cross_validate # 交叉验证所需的函数 from sklearn.model_selection import KFold,LeaveOneOut,LeavePOut,ShuffleSplit # 交叉验证所需的子集划分方法 from sklearn.model_selection import StratifiedKFold,StratifiedShuffleSplit # 分层分割 from sklearn.model_selection import GroupKFold,LeaveOneGroupOut,LeavePGroupsOut,GroupShuffleSplit # 分组分割 from sklearn.model_selection import TimeSeriesSplit # 时间序列分割 from sklearn import datasets # 自带数据集 from sklearn import svm # SVM算法 from sklearn import preprocessing # 预处理模块 from sklearn.metrics import recall_score # 模型度量 iris = datasets.load_iris() # 加载数据集 print('样本集大小:',iris.data.shape,iris.target.shape) # ===================================数据集划分,训练模型========================== X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.4, random_state=0) # 交叉验证划分训练集和测试集.test_size为测试集所占的比例 print('训练集大小:',X_train.shape,y_train.shape) # 训练集样本大小 print('测试集大小:',X_test.shape,y_test.shape) # 测试集样本大小 clf = svm.SVC(kernel='linear', C=1).fit(X_train, y_train) # 使用训练集训练模型 print('准确率:',clf.score(X_test, y_test)) # 计算测试集的度量值(准确率) # 如果涉及到归一化,则在测试集上也要使用训练集模型提取的归一化函数。 scaler = preprocessing.StandardScaler().fit(X_train) # 通过训练集获得归一化函数模型。(也就是先减几,再除以几的函数)。在训练集和测试集上都使用这个归一化函数 X_train_transformed = scaler.transform(X_train) clf = svm.SVC(kernel='linear', C=1).fit(X_train_transformed, y_train) # 使用训练集训练模型 X_test_transformed = scaler.transform(X_test) print(clf.score(X_test_transformed, y_test)) # 计算测试集的度量值(准确度) # ===================================直接调用交叉验证评估模型========================== clf = svm.SVC(kernel='linear', C=1) scores = cross_val_score(clf, iris.data, iris.target, cv=5) #cv为迭代次数。 print(scores) # 打印输出每次迭代的度量值(准确度) print("Accuracy: %0.2f (+/- %0.2f)" % (scores.mean(), scores.std() * 2)) # 获取置信区间。(也就是均值和方差) # ===================================多种度量结果====================================== scoring = ['precision_macro', 'recall_macro'] # precision_macro为精度,recall_macro为召回率 scores = cross_validate(clf, iris.data, iris.target, scoring=scoring,cv=5, return_train_score=True) sorted(scores.keys()) print('测试结果:',scores) # scores类型为字典。包含训练得分,拟合次数, score-times (得分次数) # ==================================K折交叉验证、留一交叉验证、留p交叉验证、随机排列交叉验证========================================== # k折划分子集 kf = KFold(n_splits=2) for train, test in kf.split(iris.data): print("k折划分:%s %s" % (train.shape, test.shape)) break # 留一划分子集 loo = LeaveOneOut() for train, test in loo.split(iris.data): print("留一划分:%s %s" % (train.shape, test.shape)) break # 留p划分子集 lpo = LeavePOut(p=2) for train, test in loo.split(iris.data): print("留p划分:%s %s" % (train.shape, test.shape)) break # 随机排列划分子集 ss = ShuffleSplit(n_splits=3, test_size=0.25,random_state=0) for train_index, test_index in ss.split(iris.data): print("随机排列划分:%s %s" % (train.shape, test.shape)) break # ==================================分层K折交叉验证、分层随机交叉验证========================================== skf = StratifiedKFold(n_splits=3) #各个类别的比例大致和完整数据集中相同 for train, test in skf.split(iris.data, iris.target): print("分层K折划分:%s %s" % (train.shape, test.shape)) break skf = StratifiedShuffleSplit(n_splits=3) # 划分中每个类的比例和完整数据集中的相同 for train, test in skf.split(iris.data, iris.target): print("分层随机划分:%s %s" % (train.shape, test.shape)) break # ==================================组 k-fold交叉验证、留一组交叉验证、留 P 组交叉验证、Group Shuffle Split========================================== X = [0.1, 0.2, 2.2, 2.4, 2.3, 4.55, 5.8, 8.8, 9, 10] y = ["a", "b", "b", "b", "c", "c", "c", "d", "d", "d"] groups = [1, 1, 1, 2, 2, 2, 3, 3, 3, 3] # k折分组 gkf = GroupKFold(n_splits=3) # 训练集和测试集属于不同的组 for train, test in gkf.split(X, y, groups=groups): print("组 k-fold分割:%s %s" % (train, test)) # 留一分组 logo = LeaveOneGroupOut() for train, test in logo.split(X, y, groups=groups): print("留一组分割:%s %s" % (train, test)) # 留p分组 lpgo = LeavePGroupsOut(n_groups=2) for train, test in lpgo.split(X, y, groups=groups): print("留 P 组分割:%s %s" % (train, test)) # 随机分组 gss = GroupShuffleSplit(n_splits=4, test_size=0.5, random_state=0) for train, test in gss.split(X, y, groups=groups): print("随机分割:%s %s" % (train, test)) # ==================================时间序列分割========================================== tscv = TimeSeriesSplit(n_splits=3) TimeSeriesSplit(max_train_size=None, n_splits=3) for train, test in tscv.split(iris.data): print("时间序列分割:%s %s" % (train, test))样本集大小: (150, 4) (150,) 训练集大小: (90, 4) (90,) 测试集大小: (60, 4) (60,) 准确率: 0.9666666666666667 0.9333333333333333 [0.96666667 1. 0.96666667 0.96666667 1. ] Accuracy: 0.98 (+/- 0.03) 测试结果: {'fit_time': array([0.000494 , 0.0005343 , 0.00048256, 0.00053048, 0.00047898]), 'score_time': array([0.00132895, 0.00126219, 0.00118518, 0.00140405, 0.00118995]), 'test_precision_macro': array([0.96969697, 1. , 0.96969697, 0.96969697, 1. ]), 'train_precision_macro': array([0.97674419, 0.97674419, 0.99186992, 0.98412698, 0.98333333]), 'test_recall_macro': array([0.96666667, 1. , 0.96666667, 0.96666667, 1. ]), 'train_recall_macro': array([0.975 , 0.975 , 0.99166667, 0.98333333, 0.98333333])} k折划分:(75,) (75,) 留一划分:(149,) (1,) 留p划分:(149,) (1,) 随机排列划分:(149,) (1,) 分层K折划分:(100,) (50,) 分层随机划分:(135,) (15,) 组 k-fold分割:[0 1 2 3 4 5] [6 7 8 9] 组 k-fold分割:[0 1 2 6 7 8 9] [3 4 5] 组 k-fold分割:[3 4 5 6 7 8 9] [0 1 2] 留一组分割:[3 4 5 6 7 8 9] [0 1 2] 留一组分割:[0 1 2 6 7 8 9] [3 4 5] 留一组分割:[0 1 2 3 4 5] [6 7 8 9] 留 P 组分割:[6 7 8 9] [0 1 2 3 4 5] 留 P 组分割:[3 4 5] [0 1 2 6 7 8 9] 留 P 组分割:[0 1 2] [3 4 5 6 7 8 9] 随机分割:[0 1 2] [3 4 5 6 7 8 9] 随机分割:[3 4 5] [0 1 2 6 7 8 9] 随机分割:[3 4 5] [0 1 2 6 7 8 9] 随机分割:[3 4 5] [0 1 2 6 7 8 9] 时间序列分割:[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38] [39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75] 时间序列分割:[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75] [ 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 时间序列分割:[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112] [113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 5.2 网格搜索Grid Search:一种调参手段;穷举搜索:在所有候选的参数选择中,通过循环遍历,尝试每一种可能性,表现最好的参数就是最终的结果。其原理就像是在数组里找最大值。5.2.1 简单的网格搜索from sklearn.datasets import load_iris from sklearn.svm import SVC from sklearn.model_selection import train_test_split iris = load_iris() X_train,X_test,y_train,y_test = train_test_split(iris.data,iris.target,random_state=0) print("Size of training set:{} size of testing set:{}".format(X_train.shape[0],X_test.shape[0])) #### grid search start best_score = 0 for gamma in [0.001,0.01,0.1,1,10,100]: for C in [0.001,0.01,0.1,1,10,100]: svm = SVC(gamma=gamma,C=C)#对于每种参数可能的组合,进行一次训练; svm.fit(X_train,y_train) score = svm.score(X_test,y_test) if score > best_score:#找到表现最好的参数 best_score = score best_parameters = {'gamma':gamma,'C':C} #### grid search end print("Best score:{:.2f}".format(best_score)) print("Best parameters:{}".format(best_parameters))Size of training set:112 size of testing set:38 Best score:0.97 Best parameters:{'gamma': 0.001, 'C': 100} 5.2.2 Grid Search with Cross Validation(具有交叉验证的网格搜索)X_trainval,X_test,y_trainval,y_test = train_test_split(iris.data,iris.target,random_state=0) X_train,X_val,y_train,y_val = train_test_split(X_trainval,y_trainval,random_state=1) print("Size of training set:{} size of validation set:{} size of testing set:{}".format(X_train.shape[0],X_val.shape[0],X_test.shape[0])) best_score = 0.0 for gamma in [0.001,0.01,0.1,1,10,100]: for C in [0.001,0.01,0.1,1,10,100]: svm = SVC(gamma=gamma,C=C) svm.fit(X_train,y_train) score = svm.score(X_val,y_val) if score > best_score: best_score = score best_parameters = {'gamma':gamma,'C':C} svm = SVC(**best_parameters) #使用最佳参数,构建新的模型 svm.fit(X_trainval,y_trainval) #使用训练集和验证集进行训练,more data always results in good performance. test_score = svm.score(X_test,y_test) # evaluation模型评估 print("Best score on validation set:{:.2f}".format(best_score)) print("Best parameters:{}".format(best_parameters)) print("Best score on test set:{:.2f}".format(test_score))Size of training set:84 size of validation set:28 size of testing set:38 Best score on validation set:0.96 Best parameters:{'gamma': 0.001, 'C': 10} Best score on test set:0.92 from sklearn.model_selection import cross_val_score best_score = 0.0 for gamma in [0.001,0.01,0.1,1,10,100]: for C in [0.001,0.01,0.1,1,10,100]: svm = SVC(gamma=gamma,C=C) scores = cross_val_score(svm,X_trainval,y_trainval,cv=5) #5折交叉验证 score = scores.mean() #取平均数 if score > best_score: best_score = score best_parameters = {"gamma":gamma,"C":C} svm = SVC(**best_parameters) svm.fit(X_trainval,y_trainval) test_score = svm.score(X_test,y_test) print("Best score on validation set:{:.2f}".format(best_score)) print("Best parameters:{}".format(best_parameters)) print("Score on testing set:{:.2f}".format(test_score))Best score on validation set:0.97 Best parameters:{'gamma': 0.1, 'C': 10} Score on testing set:0.97 交叉验证经常与网格搜索进行结合,作为参数评价的一种方法,这种方法叫做grid search with cross validation。sklearn因此设计了一个这样的类GridSearchCV,这个类实现了fit,predict,score等方法,被当做了一个estimator,使用fit方法,该过程中:(1)搜索到最佳参数;(2)实例化了一个最佳参数的estimator;from sklearn.model_selection import GridSearchCV #把要调整的参数以及其候选值 列出来; param_grid = {"gamma":[0.001,0.01,0.1,1,10,100], "C":[0.001,0.01,0.1,1,10,100]} print("Parameters:{}".format(param_grid)) grid_search = GridSearchCV(SVC(),param_grid,cv=5) #实例化一个GridSearchCV类 X_train,X_test,y_train,y_test = train_test_split(iris.data,iris.target,random_state=10) grid_search.fit(X_train,y_train) #训练,找到最优的参数,同时使用最优的参数实例化一个新的SVC estimator。 print("Test set score:{:.2f}".format(grid_search.score(X_test,y_test))) print("Best parameters:{}".format(grid_search.best_params_)) print("Best score on train set:{:.2f}".format(grid_search.best_score_))Parameters:{'gamma': [0.001, 0.01, 0.1, 1, 10, 100], 'C': [0.001, 0.01, 0.1, 1, 10, 100]} Test set score:0.97 Best parameters:{'C': 10, 'gamma': 0.1} Best score on train set:0.98 5.2.3 学习曲线import numpy as np import matplotlib.pyplot as plt from sklearn.naive_bayes import GaussianNB from sklearn.svm import SVC from sklearn.datasets import load_digits from sklearn.model_selection import learning_curve from sklearn.model_selection import ShuffleSplitdef plot_learning_curve(estimator, title, X, y, ylim=None, cv=None, n_jobs=1, train_sizes=np.linspace(.1, 1.0, 5)): plt.figure() plt.title(title) if ylim is not None: plt.ylim(*ylim) plt.xlabel("Training examples") plt.ylabel("Score") train_sizes, train_scores, test_scores = learning_curve( estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes) train_scores_mean = np.mean(train_scores, axis=1) train_scores_std = np.std(train_scores, axis=1) test_scores_mean = np.mean(test_scores, axis=1) test_scores_std = np.std(test_scores, axis=1) plt.grid() plt.fill_between(train_sizes, train_scores_mean - train_scores_std, train_scores_mean + train_scores_std, alpha=0.1, color="r") plt.fill_between(train_sizes, test_scores_mean - test_scores_std, test_scores_mean + test_scores_std, alpha=0.1, color="g") plt.plot(train_sizes, train_scores_mean, 'o-', color="r", label="Training score") plt.plot(train_sizes, test_scores_mean, 'o-', color="g", label="Cross-validation score") plt.legend(loc="best") return plt digits = load_digits() X, y = digits.data, digits.target title = "Learning Curves (Naive Bayes)" # Cross validation with 100 iterations to get smoother mean test and train # score curves, each time with 20% data randomly selected as a validation set. cv = ShuffleSplit(n_splits=100, test_size=0.2, random_state=0) estimator = GaussianNB() plot_learning_curve(estimator, title, X, y, ylim=(0.7, 1.01), cv=cv, n_jobs=4)<module 'matplotlib.pyplot' from '/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/pyplot.py'> title = "Learning Curves (SVM, RBF kernel, $\gamma=0.001$)" # SVC is more expensive so we do a lower number of CV iterations: cv = ShuffleSplit(n_splits=10, test_size=0.2, random_state=0) estimator = SVC(gamma=0.001) plot_learning_curve(estimator, title, X, y, (0.7, 1.01), cv=cv, n_jobs=4) <module 'matplotlib.pyplot' from '/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/pyplot.py'> 5.2.4 验证曲线import matplotlib.pyplot as plt import numpy as np from sklearn.datasets import load_digits from sklearn.svm import SVC from sklearn. model_selection import validation_curve digits = load_digits() X, y = digits.data, digits.target param_range = np.logspace(-6, -1, 5) train_scores, test_scores = validation_curve( SVC(), X, y, param_name="gamma", param_range=param_range, cv=10, scoring="accuracy", n_jobs=1) train_scores_mean = np.mean(train_scores, axis=1) train_scores_std = np.std(train_scores, axis=1) test_scores_mean = np.mean(test_scores, axis=1) test_scores_std = np.std(test_scores, axis=1) plt.title("Validation Curve with SVM") plt.xlabel("$\gamma$") plt.ylabel("Score") plt.ylim(0.0, 1.1) plt.semilogx(param_range, train_scores_mean, label="Training score", color="r") plt.fill_between(param_range, train_scores_mean - train_scores_std, train_scores_mean + train_scores_std, alpha=0.2, color="r") plt.semilogx(param_range, test_scores_mean, label="Cross-validation score", color="g") plt.fill_between(param_range, test_scores_mean - test_scores_std, test_scores_mean + test_scores_std, alpha=0.2, color="g") plt.legend(loc="best") plt.show()5.3 工业蒸汽赛题模型验证5.3.1 模型过拟合与欠拟合import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns from scipy import stats import warnings warnings.filterwarnings("ignore") from sklearn.linear_model import LinearRegression #线性回归 from sklearn.neighbors import KNeighborsRegressor #K近邻回归 from sklearn.tree import DecisionTreeRegressor #决策树回归 from sklearn.ensemble import RandomForestRegressor #随机森林回归 from sklearn.svm import SVR #支持向量回归 import lightgbm as lgb #lightGbm模型 from sklearn.model_selection import train_test_split # 切分数据 from sklearn.metrics import mean_squared_error #评价指标 from sklearn.linear_model import SGDRegressor# 下载需要用到的数据集 !wget http://tianchi-media.oss-cn-beijing.aliyuncs.com/DSW/Industrial_Steam_Forecast/zhengqi_test.txt !wget http://tianchi-media.oss-cn-beijing.aliyuncs.com/DSW/Industrial_Steam_Forecast/zhengqi_train.txt--2023-03-24 22:17:50-- http://tianchi-media.oss-cn-beijing.aliyuncs.com/DSW/Industrial_Steam_Forecast/zhengqi_test.txt 正在解析主机 tianchi-media.oss-cn-beijing.aliyuncs.com (tianchi-media.oss-cn-beijing.aliyuncs.com)... 49.7.22.39 正在连接 tianchi-media.oss-cn-beijing.aliyuncs.com (tianchi-media.oss-cn-beijing.aliyuncs.com)|49.7.22.39|:80... 已连接。 已发出 HTTP 请求,正在等待回应... 200 OK 长度: 466959 (456K) [text/plain] 正在保存至: “zhengqi_test.txt.2” zhengqi_test.txt.2 100%[===================>] 456.01K --.-KB/s in 0.03s 2023-03-24 22:17:51 (13.2 MB/s) - 已保存 “zhengqi_test.txt.2” [466959/466959]) --2023-03-24 22:17:51-- http://tianchi-media.oss-cn-beijing.aliyuncs.com/DSW/Industrial_Steam_Forecast/zhengqi_train.txt 正在解析主机 tianchi-media.oss-cn-beijing.aliyuncs.com (tianchi-media.oss-cn-beijing.aliyuncs.com)... 49.7.22.39 正在连接 tianchi-media.oss-cn-beijing.aliyuncs.com (tianchi-media.oss-cn-beijing.aliyuncs.com)|49.7.22.39|:80... 已连接。 已发出 HTTP 请求,正在等待回应... 200 OK 长度: 714370 (698K) [text/plain] 正在保存至: “zhengqi_train.txt.2” zhengqi_train.txt.2 100%[===================>] 697.63K --.-KB/s in 0.04s 2023-03-24 22:17:51 (17.8 MB/s) - 已保存 “zhengqi_train.txt.2” [714370/714370]) train_data_file = "./zhengqi_train.txt" test_data_file = "./zhengqi_test.txt" train_data = pd.read_csv(train_data_file, sep='\t', encoding='utf-8') test_data = pd.read_csv(test_data_file, sep='\t', encoding='utf-8')from sklearn import preprocessing features_columns = [col for col in train_data.columns if col not in ['target']] min_max_scaler = preprocessing.MinMaxScaler() min_max_scaler = min_max_scaler.fit(train_data[features_columns]) train_data_scaler = min_max_scaler.transform(train_data[features_columns]) test_data_scaler = min_max_scaler.transform(test_data[features_columns]) train_data_scaler = pd.DataFrame(train_data_scaler) train_data_scaler.columns = features_columns test_data_scaler = pd.DataFrame(test_data_scaler) test_data_scaler.columns = features_columns train_data_scaler['target'] = train_data['target']from sklearn.decomposition import PCA #主成分分析法 #PCA方法降维 #保留16个主成分 pca = PCA(n_components=16) new_train_pca_16 = pca.fit_transform(train_data_scaler.iloc[:,0:-1]) new_test_pca_16 = pca.transform(test_data_scaler) new_train_pca_16 = pd.DataFrame(new_train_pca_16) new_test_pca_16 = pd.DataFrame(new_test_pca_16) new_train_pca_16['target'] = train_data_scaler['target']#采用 pca 保留16维特征的数据 new_train_pca_16 = new_train_pca_16.fillna(0) train = new_train_pca_16[new_test_pca_16.columns] target = new_train_pca_16['target'] # 切分数据 训练数据80% 验证数据20% train_data,test_data,train_target,test_target=train_test_split(train,target,test_size=0.2,random_state=0)#### 欠拟合 clf = SGDRegressor(max_iter=500, tol=1e-2) clf.fit(train_data, train_target) score_train = mean_squared_error(train_target, clf.predict(train_data)) score_test = mean_squared_error(test_target, clf.predict(test_data)) print("SGDRegressor train MSE: ", score_train) print("SGDRegressor test MSE: ", score_test)SGDRegressor train MSE: 0.15125847407064866 SGDRegressor test MSE: 0.15565698772176442 ### 过拟合 from sklearn.preprocessing import PolynomialFeatures poly = PolynomialFeatures(5) train_data_poly = poly.fit_transform(train_data) test_data_poly = poly.transform(test_data) clf = SGDRegressor(max_iter=1000, tol=1e-3) clf.fit(train_data_poly, train_target) score_train = mean_squared_error(train_target, clf.predict(train_data_poly)) score_test = mean_squared_error(test_target, clf.predict(test_data_poly)) print("SGDRegressor train MSE: ", score_train) print("SGDRegressor test MSE: ", score_test)SGDRegressor train MSE: 0.13230725829556678 SGDRegressor test MSE: 0.14475818228220433 ### 正常拟合 from sklearn.preprocessing import PolynomialFeatures poly = PolynomialFeatures(3) train_data_poly = poly.fit_transform(train_data) test_data_poly = poly.transform(test_data) clf = SGDRegressor(max_iter=1000, tol=1e-3) clf.fit(train_data_poly, train_target) score_train = mean_squared_error(train_target, clf.predict(train_data_poly)) score_test = mean_squared_error(test_target, clf.predict(test_data_poly)) print("SGDRegressor train MSE: ", score_train) print("SGDRegressor test MSE: ", score_test)SGDRegressor train MSE: 0.13399656558429307 SGDRegressor test MSE: 0.14255473176638828 5.3.2 模型正则化L2范数正则化poly = PolynomialFeatures(3) train_data_poly = poly.fit_transform(train_data) test_data_poly = poly.transform(test_data) clf = SGDRegressor(max_iter=1000, tol=1e-3, penalty= 'L2', alpha=0.0001) clf.fit(train_data_poly, train_target) score_train = mean_squared_error(train_target, clf.predict(train_data_poly)) score_test = mean_squared_error(test_target, clf.predict(test_data_poly)) print("SGDRegressor train MSE: ", score_train) print("SGDRegressor test MSE: ", score_test)SGDRegressor train MSE: 0.1344679787727263 SGDRegressor test MSE: 0.14283084627234435 L1范数正则化poly = PolynomialFeatures(3) train_data_poly = poly.fit_transform(train_data) test_data_poly = poly.transform(test_data) clf = SGDRegressor(max_iter=1000, tol=1e-3, penalty= 'L1', alpha=0.00001) clf.fit(train_data_poly, train_target) score_train = mean_squared_error(train_target, clf.predict(train_data_poly)) score_test = mean_squared_error(test_target, clf.predict(test_data_poly)) print("SGDRegressor train MSE: ", score_train) print("SGDRegressor test MSE: ", score_test)SGDRegressor train MSE: 0.13516056789895906 SGDRegressor test MSE: 0.14330444056183564 ElasticNet L1和L2范数加权正则化poly = PolynomialFeatures(3) train_data_poly = poly.fit_transform(train_data) test_data_poly = poly.transform(test_data) clf = SGDRegressor(max_iter=1000, tol=1e-3, penalty= 'elasticnet', l1_ratio=0.9, alpha=0.00001) clf.fit(train_data_poly, train_target) score_train = mean_squared_error(train_target, clf.predict(train_data_poly)) score_test = mean_squared_error(test_target, clf.predict(test_data_poly)) print("SGDRegressor train MSE: ", score_train) print("SGDRegressor test MSE: ", score_test)SGDRegressor train MSE: 0.13409834594770004 SGDRegressor test MSE: 0.14238154901534278 5.3.3 模型交叉验证简单交叉验证 Hold-out-menthod# 简单交叉验证 from sklearn.model_selection import train_test_split # 切分数据 # 切分数据 训练数据80% 验证数据20% train_data,test_data,train_target,test_target=train_test_split(train,target,test_size=0.2,random_state=0) clf = SGDRegressor(max_iter=1000, tol=1e-3) clf.fit(train_data, train_target) score_train = mean_squared_error(train_target, clf.predict(train_data)) score_test = mean_squared_error(test_target, clf.predict(test_data)) print("SGDRegressor train MSE: ", score_train) print("SGDRegressor test MSE: ", score_test)SGDRegressor train MSE: 0.14143759510386256 SGDRegressor test MSE: 0.14691862910491496 K折交叉验证 K-fold CV# 5折交叉验证 from sklearn.model_selection import KFold kf = KFold(n_splits=5) for k, (train_index, test_index) in enumerate(kf.split(train)): train_data,test_data,train_target,test_target = train.values[train_index],train.values[test_index],target[train_index],target[test_index] clf = SGDRegressor(max_iter=1000, tol=1e-3) clf.fit(train_data, train_target) score_train = mean_squared_error(train_target, clf.predict(train_data)) score_test = mean_squared_error(test_target, clf.predict(test_data)) print(k, " 折", "SGDRegressor train MSE: ", score_train) print(k, " 折", "SGDRegressor test MSE: ", score_test, '\n') 0 折 SGDRegressor train MSE: 0.14989313756469505 0 折 SGDRegressor test MSE: 0.10630068590577227 1 折 SGDRegressor train MSE: 0.1335269045335198 1 折 SGDRegressor test MSE: 0.18239988520454367 2 折 SGDRegressor train MSE: 0.14713477627139634 2 折 SGDRegressor test MSE: 0.13314646232843022 3 折 SGDRegressor train MSE: 0.14067731027537836 3 折 SGDRegressor test MSE: 0.16311142798019898 4 折 SGDRegressor train MSE: 0.13809527090941803 4 折 SGDRegressor test MSE: 0.16535259610698216 留一法 LOO CVfrom sklearn.model_selection import LeaveOneOut loo = LeaveOneOut() num = 100 for k, (train_index, test_index) in enumerate(loo.split(train)): train_data,test_data,train_target,test_target = train.values[train_index],train.values[test_index],target[train_index],target[test_index] clf = SGDRegressor(max_iter=1000, tol=1e-3) clf.fit(train_data, train_target) score_train = mean_squared_error(train_target, clf.predict(train_data)) score_test = mean_squared_error(test_target, clf.predict(test_data)) print(k, " 个", "SGDRegressor train MSE: ", score_train) print(k, " 个", "SGDRegressor test MSE: ", score_test, '\n') if k >= 9: break0 个 SGDRegressor train MSE: 0.14167336296809338 0 个 SGDRegressor test MSE: 0.013368856967176993 1 个 SGDRegressor train MSE: 0.14158431010604786 1 个 SGDRegressor test MSE: 0.12481451551630947 2 个 SGDRegressor train MSE: 0.14150252555121376 2 个 SGDRegressor test MSE: 0.03855470133268372 3 个 SGDRegressor train MSE: 0.14164982490586497 3 个 SGDRegressor test MSE: 0.004218299742968551 4 个 SGDRegressor train MSE: 0.1415724024144491 4 个 SGDRegressor test MSE: 0.012171393307787685 5 个 SGDRegressor train MSE: 0.14164330849085816 5 个 SGDRegressor test MSE: 0.13457429896691775 6 个 SGDRegressor train MSE: 0.14162839258823134 6 个 SGDRegressor test MSE: 0.022584321520003964 7 个 SGDRegressor train MSE: 0.14156535630118358 7 个 SGDRegressor test MSE: 0.0007881735114026308 8 个 SGDRegressor train MSE: 0.14161403732956687 8 个 SGDRegressor test MSE: 0.09236755222443295 9 个 SGDRegressor train MSE: 0.1416518678123776 9 个 SGDRegressor test MSE: 0.049938663947863705 留P法 LPO CVfrom sklearn.model_selection import LeavePOut lpo = LeavePOut(p=10) num = 100 for k, (train_index, test_index) in enumerate(lpo.split(train)): train_data,test_data,train_target,test_target = train.values[train_index],train.values[test_index],target[train_index],target[test_index] clf = SGDRegressor(max_iter=1000, tol=1e-3) clf.fit(train_data, train_target) score_train = mean_squared_error(train_target, clf.predict(train_data)) score_test = mean_squared_error(test_target, clf.predict(test_data)) print(k, " 10个", "SGDRegressor train MSE: ", score_train) print(k, " 10个", "SGDRegressor test MSE: ", score_test, '\n') if k >= 9: break0 10个 SGDRegressor train MSE: 0.14188547241073846 0 10个 SGDRegressor test MSE: 0.04919852578302554 1 10个 SGDRegressor train MSE: 0.1419628899970283 1 10个 SGDRegressor test MSE: 0.0452239727984194 2 10个 SGDRegressor train MSE: 0.14213271221606072 2 10个 SGDRegressor test MSE: 0.04699670484045908 3 10个 SGDRegressor train MSE: 0.14197467153253543 3 10个 SGDRegressor test MSE: 0.054453728030175695 4 10个 SGDRegressor train MSE: 0.14187879341894122 4 10个 SGDRegressor test MSE: 0.06924591926518929 5 10个 SGDRegressor train MSE: 0.14201820586737332 5 10个 SGDRegressor test MSE: 0.04544729649569867 6 10个 SGDRegressor train MSE: 0.1420321877668132 6 10个 SGDRegressor test MSE: 0.04932459950875607 7 10个 SGDRegressor train MSE: 0.1419166425781182 7 10个 SGDRegressor test MSE: 0.05328512633699939 8 10个 SGDRegressor train MSE: 0.1413933355339114 8 10个 SGDRegressor test MSE: 0.04634695705557035 9 10个 SGDRegressor train MSE: 0.14188082336683486 9 10个 SGDRegressor test MSE: 0.045133396081342994 5.3.4 模型超参空间及调参穷举网格搜索from sklearn.model_selection import GridSearchCV from sklearn.ensemble import RandomForestRegressor from sklearn.model_selection import train_test_split # 切分数据 # 切分数据 训练数据80% 验证数据20% train_data,test_data,train_target,test_target=train_test_split(train,target,test_size=0.2,random_state=0) randomForestRegressor = RandomForestRegressor() parameters = { 'n_estimators':[50, 100, 200], 'max_depth':[1, 2, 3] clf = GridSearchCV(randomForestRegressor, parameters, cv=5) clf.fit(train_data, train_target) score_test = mean_squared_error(test_target, clf.predict(test_data)) print("RandomForestRegressor GridSearchCV test MSE: ", score_test) sorted(clf.cv_results_.keys())RandomForestRegressor GridSearchCV test MSE: 0.2595696984416692 随机参数优化from sklearn.model_selection import RandomizedSearchCV from sklearn.ensemble import RandomForestRegressor from sklearn.model_selection import train_test_split # 切分数据 # 切分数据 训练数据80% 验证数据20% train_data,test_data,train_target,test_target=train_test_split(train,target,test_size=0.2,random_state=0) randomForestRegressor = RandomForestRegressor() parameters = { 'n_estimators':[10, 50], 'max_depth':[1, 2, 5] clf = RandomizedSearchCV(randomForestRegressor, parameters, cv=5) clf.fit(train_data, train_target) score_test = mean_squared_error(test_target, clf.predict(test_data)) print("RandomForestRegressor RandomizedSearchCV test MSE: ", score_test) sorted(clf.cv_results_.keys())RandomForestRegressor RandomizedSearchCV test MSE: 0.1952974248358807 Lgb 调参!pip install lightgbm Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple Requirement already satisfied: lightgbm in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (3.1.1) Requirement already satisfied: wheel in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from lightgbm) (0.33.6) Requirement already satisfied: numpy in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from lightgbm) (1.19.5) Requirement already satisfied: scikit-learn!=0.22.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from lightgbm) (0.22.1) Requirement already satisfied: scipy in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from lightgbm) (1.3.0) Requirement already satisfied: joblib>=0.11 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-learn!=0.22.0->lightgbm) (0.14.1) [1m[[0m[34;49mnotice[0m[1;39;49m][0m[39;49m A new release of pip available: [0m[31;49m22.1.2[0m[39;49m -> [0m[32;49m23.0.1[0m [1m[[0m[34;49mnotice[0m[1;39;49m][0m[39;49m To update, run: [0m[32;49mpip install --upgrade pip[0m clf = lgb.LGBMRegressor(num_leaves=21)#num_leaves=31 parameters = { 'learning_rate': [0.01, 0.1], 'n_estimators': [20, 40] clf = GridSearchCV(clf, parameters, cv=5) clf.fit(train_data, train_target) print('Best parameters found by grid search are:', clf.best_params_) score_test = mean_squared_error(test_target, clf.predict(test_data)) print("LGBMRegressor RandomizedSearchCV test MSE: ", score_test)Lgb 线下验证train_data2 = pd.read_csv('./zhengqi_train.txt',sep='\t') test_data2 = pd.read_csv('./zhengqi_test.txt',sep='\t') train_data2_f = train_data2[test_data2.columns].values train_data2_target = train_data2['target'].values[报错信息:TypeError: __init__() got an unexpected keyword argument 'n_folds'](https://blog.csdn.net/qq_35781239/article/details/100866176?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522167966851516800211597927%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=167966851516800211597927&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-4-100866176-null-null.142^v76^insert_down38,201^v4^add_ask,239^v2^insert_chatgpt&utm_term=__init__%28%29%20got%20multiple%20values%20for%20argument%20n_splits&spm=1018.2226.3001.4187)# lgb 模型 from sklearn.model_selection import KFold import lightgbm as lgb import numpy as np # 5折交叉验证 Folds=5 kf = KFold(n_splits=Folds, random_state=100, shuffle=True) #注意参数修改 # 导入错误的KFold包 # from sklearn.cross_validation import KFold 已经淘汰,需要改为from sklearn.model_selection import KFold,具体信息参见Sklearn官方文档 # 使用错误的参数 # kf = KFold(titanic.shape[0], n_folds=3, random_state=1)由于sklearn的更新,Kfold的参数已经更改, n_folds更改为n_splits,前文代码更改为kf = KFold(n_splits=3, shuffle=False, random_state=1),如果不更改,会发生报错TypeError: __init__() got multiple values for argument 'n_splits' # 除此之外,for train, test in kf:同时更改为for train, test in kf.split(titanic[predictions]): 此时相当于用predictions来进行折叠交叉划分。 # 记录训练和预测MSE MSE_DICT = { 'train_mse':[], 'test_mse':[] # 线下训练预测 for i, (train_index, test_index) in enumerate (kf.split(train_data2_f)): # lgb树模型 lgb_reg = lgb.LGBMRegressor( learning_rate=0.01, max_depth=-1, n_estimators=100, boosting_type='gbdt', random_state=100, objective='regression', # 切分训练集和预测集 X_train_KFold, X_test_KFold = train_data2_f[train_index], train_data2_f[test_index] y_train_KFold, y_test_KFold = train_data2_target[train_index], train_data2_target[test_index] # 训练模型 # reg.fit(X_train_KFold, y_train_KFold) lgb_reg.fit( X=X_train_KFold,y=y_train_KFold, eval_set=[(X_train_KFold, y_train_KFold),(X_test_KFold, y_test_KFold)], eval_names=['Train','Test'], early_stopping_rounds=10, eval_metric='MSE', verbose=50 # 训练集预测 测试集预测 y_train_KFold_predict = lgb_reg.predict(X_train_KFold,num_iteration=lgb_reg.best_iteration_) y_test_KFold_predict = lgb_reg.predict(X_test_KFold,num_iteration=lgb_reg.best_iteration_) print('第{}折 训练和预测 训练MSE 预测MSE'.format(i)) train_mse = mean_squared_error(y_train_KFold_predict, y_train_KFold) print('------\n', '训练MSE\n', train_mse, '\n------') test_mse = mean_squared_error(y_test_KFold_predict, y_test_KFold) print('------\n', '预测MSE\n', test_mse, '\n------\n') MSE_DICT['train_mse'].append(train_mse) MSE_DICT['test_mse'].append(test_mse) print('------\n', '训练MSE\n', MSE_DICT['train_mse'], '\n', np.mean(MSE_DICT['train_mse']), '\n------') print('------\n', '预测MSE\n', MSE_DICT['test_mse'], '\n', np.mean(MSE_DICT['test_mse']), '\n------')5.3.5 学习曲线和验证曲线### 学习曲线 print(__doc__) import numpy as np import matplotlib.pyplot as plt from sklearn import model_selection from sklearn.linear_model import SGDRegressor from sklearn.model_selection import learning_curve def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None, n_jobs=1, train_sizes=np.linspace(.1, 1.0, 5)): plt.figure() plt.title(title) if ylim is not None: plt.ylim(*ylim) plt.xlabel("Training examples") plt.ylabel("Score") train_sizes, train_scores, test_scores = learning_curve( estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes) train_scores_mean = np.mean(train_scores, axis=1) train_scores_std = np.std(train_scores, axis=1) test_scores_mean = np.mean(test_scores, axis=1) test_scores_std = np.std(test_scores, axis=1) plt.grid() plt.fill_between(train_sizes, train_scores_mean - train_scores_std, train_scores_mean + train_scores_std, alpha=0.1, color="r") plt.fill_between(train_sizes, test_scores_mean - test_scores_std, test_scores_mean + test_scores_std, alpha=0.1, color="g") plt.plot(train_sizes, train_scores_mean, 'o-', color="r", label="Training score") plt.plot(train_sizes, test_scores_mean, 'o-', color="g", label="Cross-validation score") plt.legend(loc="best") return plt X = train_data2[test_data2.columns].values y = train_data2['target'].values title = "LinearRegression" # Cross validation with 100 iterations to get smoother mean test and train # score curves, each time with 20% data randomly selected as a validation set. # cv = model_selection.ShuffleSplit(X.shape[0], n_splits=100, # test_size=0.2, random_state=0) cv = model_selection.ShuffleSplit(n_splits=100, test_size=0.2, random_state=0) estimator = SGDRegressor() plot_learning_curve(estimator, title, X, y, ylim=(0.7, 1.01), cv=cv, n_jobs=-1) Automatically created module for IPython interactive environment import matplotlib.pyplot as plt import numpy as np from sklearn.linear_model import SGDRegressor from sklearn.model_selection import validation_curve X = train_data2[test_data2.columns].values y = train_data2['target'].values # max_iter=1000, tol=1e-3, penalty= 'L1', alpha=0.00001 param_range = [0.1, 0.01, 0.001, 0.0001, 0.00001, 0.000001] train_scores, test_scores = validation_curve( SGDRegressor(max_iter=1000, tol=1e-3, penalty= 'L1'), X, y, param_name="alpha", param_range=param_range, cv=10, scoring='r2', n_jobs=1) train_scores_mean = np.mean(train_scores, axis=1) train_scores_std = np.std(train_scores, axis=1) test_scores_mean = np.mean(test_scores, axis=1) test_scores_std = np.std(test_scores, axis=1) plt.title("Validation Curve with SGDRegressor") plt.xlabel("alpha") plt.ylabel("Score") plt.ylim(0.0, 1.1) plt.semilogx(param_range, train_scores_mean, label="Training score", color="r") plt.fill_between(param_range, train_scores_mean - train_scores_std, train_scores_mean + train_scores_std, alpha=0.2, color="r") plt.semilogx(param_range, test_scores_mean, label="Cross-validation score", color="g") plt.fill_between(param_range, test_scores_mean - test_scores_std, test_scores_mean + test_scores_std, alpha=0.2, color="g") plt.legend(loc="best") plt.show()Automatically created module for IPython interactive environment 6.特征优化6.1 定义特征构造方法,构造特征#导入数据 import pandas as pd train_data_file = "./zhengqi_train.txt" test_data_file = "./zhengqi_test.txt" train_data = pd.read_csv(train_data_file, sep='\t', encoding='utf-8') test_data = pd.read_csv(test_data_file, sep='\t', encoding='utf-8') epsilon=1e-5 #组交叉特征,可以自行定义,如增加: x*x/y, log(x)/y 等等 func_dict = { 'add': lambda x,y: x+y, 'mins': lambda x,y: x-y, 'div': lambda x,y: x/(y+epsilon), 'multi': lambda x,y: x*y ### 定义特征构造的函数 def auto_features_make(train_data,test_data,func_dict,col_list): train_data, test_data = train_data.copy(), test_data.copy() for col_i in col_list: for col_j in col_list: for func_name, func in func_dict.items(): for data in [train_data,test_data]: func_features = func(data[col_i],data[col_j]) col_func_features = '-'.join([col_i,func_name,col_j]) data[col_func_features] = func_features return train_data,test_data ### 对训练集和测试集数据进行特征构造 train_data2, test_data2 = auto_features_make(train_data,test_data,func_dict,col_list=test_data.columns) from sklearn.decomposition import PCA #主成分分析法 #PCA方法降维 pca = PCA(n_components=500) train_data2_pca = pca.fit_transform(train_data2.iloc[:,0:-1]) test_data2_pca = pca.transform(test_data2) train_data2_pca = pd.DataFrame(train_data2_pca) test_data2_pca = pd.DataFrame(test_data2_pca) train_data2_pca['target'] = train_data2['target'] X_train2 = train_data2[test_data2.columns].values y_train = train_data2['target']6.2 基于lightgbm对构造特征进行训练和评估# ls_validation i from sklearn.model_selection import KFold from sklearn.metrics import mean_squared_error import lightgbm as lgb import numpy as np # 5折交叉验证,版本迭代参数更新 Folds=5 kf = KFold(n_splits=Folds, shuffle=True, random_state=2019) # 版本修改导致用法有不同: # 1. n_folds参数修改为n_splits # 2. train_data.shape[0]参数被去除。所以你的这一行修改为kf =KFold(n_splits=3, random_state=1) # 然后在你后面要用到kf的地方,比如原来的: # for i, (train_index, test_index) in enumerate(kf): # 修改成: # for i, (train_index, test_index) in enumerate(kf.split(train)):# train就是你的训练数据 # 记录训练和预测MSE MSE_DICT = { 'train_mse':[], 'test_mse':[] # 线下训练预测 for i, (train_index, test_index) in enumerate(kf.split(X_train2)): # lgb树模型 lgb_reg = lgb.LGBMRegressor( learning_rate=0.01, max_depth=-1, n_estimators=100, #记得修改 boosting_type='gbdt', random_state=2019, objective='regression', # 切分训练集和预测集 X_train_KFold, X_test_KFold = X_train2[train_index], X_train2[test_index] y_train_KFold, y_test_KFold = y_train[train_index], y_train[test_index] # 训练模型 lgb_reg.fit( X=X_train_KFold,y=y_train_KFold, eval_set=[(X_train_KFold, y_train_KFold),(X_test_KFold, y_test_KFold)], eval_names=['Train','Test'], early_stopping_rounds=10, #记得修改 eval_metric='MSE', verbose=50 # 训练集预测 测试集预测 y_train_KFold_predict = lgb_reg.predict(X_train_KFold,num_iteration=lgb_reg.best_iteration_) y_test_KFold_predict = lgb_reg.predict(X_test_KFold,num_iteration=lgb_reg.best_iteration_) print('第{}折 训练和预测 训练MSE 预测MSE'.format(i)) train_mse = mean_squared_error(y_train_KFold_predict, y_train_KFold) print('------\n', '训练MSE\n', train_mse, '\n------') test_mse = mean_squared_error(y_test_KFold_predict, y_test_KFold) print('------\n', '预测MSE\n', test_mse, '\n------\n') MSE_DICT['train_mse'].append(train_mse) MSE_DICT['test_mse'].append(test_mse) print('------\n', '训练MSE\n', MSE_DICT['train_mse'], '\n', np.mean(MSE_DICT['train_mse']), '\n------') print('------\n', '预测MSE\n', MSE_DICT['test_mse'], '\n', np.mean(MSE_DICT['test_mse']), '\n------')Training until validation scores don't improve for 10 rounds --------------------------------------------------------------------------- KeyboardInterrupt Traceback (most recent call last) /tmp/ipykernel_5027/2900171053.py in <module> 49 early_stopping_rounds=10, #记得修改 50 eval_metric='MSE', ---> 51 verbose=50 52 ) /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/lightgbm/sklearn.py in fit(self, X, y, sample_weight, init_score, eval_set, eval_names, eval_sample_weight, eval_init_score, eval_metric, early_stopping_rounds, verbose, feature_name, categorical_feature, callbacks, init_model) 777 verbose=verbose, feature_name=feature_name, 778 categorical_feature=categorical_feature, --> 779 callbacks=callbacks, init_model=init_model) 780 return self /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/lightgbm/sklearn.py in fit(self, X, y, sample_weight, init_score, group, eval_set, eval_names, eval_sample_weight, eval_class_weight, eval_init_score, eval_group, eval_metric, early_stopping_rounds, verbose, feature_name, categorical_feature, callbacks, init_model) 615 evals_result=evals_result, fobj=self._fobj, feval=eval_metrics_callable, 616 verbose_eval=verbose, feature_name=feature_name, --> 617 callbacks=callbacks, init_model=init_model) 619 if evals_result: /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/lightgbm/engine.py in train(params, train_set, num_boost_round, valid_sets, valid_names, fobj, feval, init_model, feature_name, categorical_feature, early_stopping_rounds, evals_result, verbose_eval, learning_rates, keep_training_booster, callbacks) 250 evaluation_result_list=None)) --> 252 booster.update(fobj=fobj) 254 evaluation_result_list = [] /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/lightgbm/basic.py in update(self, train_set, fobj) 2458 _safe_call(_LIB.LGBM_BoosterUpdateOneIter( 2459 self.handle, -> 2460 ctypes.byref(is_finished))) 2461 self.__is_predicted_cur_iter = [False for _ in range_(self.__num_dataset)] 2462 return is_finished.value == 1 KeyboardInterrupt: 7.模型融合下面把上一章关键流程在跑一边# 导入包 import warnings warnings.filterwarnings("ignore") import matplotlib.pyplot as plt plt.rcParams.update({'figure.max_open_warning': 0}) import seaborn as sns # modelling import pandas as pd import numpy as np from scipy import stats from sklearn.model_selection import train_test_split from sklearn.model_selection import GridSearchCV, RepeatedKFold, cross_val_score,cross_val_predict,KFold from sklearn.metrics import make_scorer,mean_squared_error from sklearn.linear_model import LinearRegression, Lasso, Ridge, ElasticNet from sklearn.svm import LinearSVR, SVR from sklearn.neighbors import KNeighborsRegressor from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor,AdaBoostRegressor from xgboost import XGBRegressor from sklearn.preprocessing import PolynomialFeatures,MinMaxScaler,StandardScaler#load_dataset with open("./zhengqi_train.txt") as fr: data_train=pd.read_table(fr,sep="\t") with open("./zhengqi_test.txt") as fr_test: data_test=pd.read_table(fr_test,sep="\t")# 合并数据 #merge train_set and test_set data_train["oringin"]="train" data_test["oringin"]="test" data_all=pd.concat([data_train,data_test],axis=0,ignore_index=True) # 删除相关特征 data_all.drop(["V5","V9","V11","V17","V22","V28"],axis=1,inplace=True)# 数据最大最小归一化 # normalise numeric columns cols_numeric=list(data_all.columns) cols_numeric.remove("oringin") def scale_minmax(col): return (col-col.min())/(col.max()-col.min()) scale_cols = [col for col in cols_numeric if col!='target'] data_all[scale_cols] = data_all[scale_cols].apply(scale_minmax,axis=0)# #Check effect of Box-Cox transforms on distributions of continuous variables # # 画图:探查特征和标签相关信息 # fcols = 6 # frows = len(cols_numeric)-1 # plt.figure(figsize=(4*fcols,4*frows)) # i=0 # for var in cols_numeric: # if var!='target': # dat = data_all[[var, 'target']].dropna() # i+=1 # plt.subplot(frows,fcols,i) # sns.distplot(dat[var] , fit=stats.norm); # plt.title(var+' Original') # plt.xlabel('') # i+=1 # plt.subplot(frows,fcols,i) # _=stats.probplot(dat[var], plot=plt) # plt.title('skew='+'{:.4f}'.format(stats.skew(dat[var]))) # plt.xlabel('') # plt.ylabel('') # i+=1 # plt.subplot(frows,fcols,i) # plt.plot(dat[var], dat['target'],'.',alpha=0.5) # plt.title('corr='+'{:.2f}'.format(np.corrcoef(dat[var], dat['target'])[0][1])) # i+=1 # plt.subplot(frows,fcols,i) # trans_var, lambda_var = stats.boxcox(dat[var].dropna()+1) # trans_var = scale_minmax(trans_var) # sns.distplot(trans_var , fit=stats.norm); # plt.title(var+' Tramsformed') # plt.xlabel('') # i+=1 # plt.subplot(frows,fcols,i) # _=stats.probplot(trans_var, plot=plt) # plt.title('skew='+'{:.4f}'.format(stats.skew(trans_var))) # plt.xlabel('') # plt.ylabel('') # i+=1 # plt.subplot(frows,fcols,i) # plt.plot(trans_var, dat['target'],'.',alpha=0.5) # plt.title('corr='+'{:.2f}'.format(np.corrcoef(trans_var,dat['target'])[0][1]))对特征进行Box-Cox变换,使其满足正态性Box-Cox变换是Box和Cox在1964年提出的一种广义幂变换方法,是统计建模中常用的一种数据变换,用于连续的响应变量不满足正态分布的情况。Box-Cox变换之后,可以一定程度上减小不可观测的误差和预测变量的相关性。Box-Cox变换的主要特点是引入一个参数,通过数据本身估计该参数进而确定应采取的数据变换形式,Box-Cox变换可以明显地改善数据的正态性、对称性和方差相等性,对许多实际数据都是行之有效的cols_transform=data_all.columns[0:-2] for col in cols_transform: # transform column data_all.loc[:,col], _ = stats.boxcox(data_all.loc[:,col]+1)# 标签数据统计转换后的数据,计算分位数画图展示(基于正态分布) print(data_all.target.describe()) plt.figure(figsize=(12,4)) plt.subplot(1,2,1) sns.distplot(data_all.target.dropna() , fit=stats.norm); plt.subplot(1,2,2) _=stats.probplot(data_all.target.dropna(), plot=plt)# 标签数据对数变换数据,使数据更符合正态,并画图展示 #Log Transform SalePrice to improve normality sp = data_train.target data_train.target1 =np.power(1.5,sp) print(data_train.target1.describe()) plt.figure(figsize=(12,4)) plt.subplot(1,2,1) sns.distplot(data_train.target1.dropna(),fit=stats.norm); plt.subplot(1,2,2) _=stats.probplot(data_train.target1.dropna(), plot=plt)# 获取训练和测试数据 # function to get training samples def get_training_data(): # extract training samples from sklearn.model_selection import train_test_split df_train = data_all[data_all["oringin"]=="train"] df_train["label"]=data_train.target1 # split SalePrice and features y = df_train.target X = df_train.drop(["oringin","target","label"],axis=1) X_train,X_valid,y_train,y_valid=train_test_split(X,y,test_size=0.3,random_state=100) return X_train,X_valid,y_train,y_valid # extract test data (without SalePrice) def get_test_data(): df_test = data_all[data_all["oringin"]=="test"].reset_index(drop=True) return df_test.drop(["oringin","target"],axis=1)# 评分函数 from sklearn.metrics import make_scorer # metric for evaluation def rmse(y_true, y_pred): diff = y_pred - y_true sum_sq = sum(diff**2) n = len(y_pred) return np.sqrt(sum_sq/n) def mse(y_ture,y_pred): return mean_squared_error(y_ture,y_pred) # scorer to be used in sklearn model fitting rmse_scorer = make_scorer(rmse, greater_is_better=False) mse_scorer = make_scorer(mse, greater_is_better=False)# 获取异常数据,并画图 # function to detect outliers based on the predictions of a model def find_outliers(model, X, y, sigma=3): # predict y values using model y_pred = pd.Series(model.predict(X), index=y.index) # if predicting fails, try fitting the model first except: model.fit(X,y) y_pred = pd.Series(model.predict(X), index=y.index) # calculate residuals between the model prediction and true y values resid = y - y_pred mean_resid = resid.mean() std_resid = resid.std() # calculate z statistic, define outliers to be where |z|>sigma z = (resid - mean_resid)/std_resid outliers = z[abs(z)>sigma].index # print and plot the results print('R2=',model.score(X,y)) print('rmse=',rmse(y, y_pred)) print("mse=",mean_squared_error(y,y_pred)) print('---------------------------------------') print('mean of residuals:',mean_resid) print('std of residuals:',std_resid) print('---------------------------------------') print(len(outliers),'outliers:') print(outliers.tolist()) plt.figure(figsize=(15,5)) ax_131 = plt.subplot(1,3,1) plt.plot(y,y_pred,'.') plt.plot(y.loc[outliers],y_pred.loc[outliers],'ro') plt.legend(['Accepted','Outlier']) plt.xlabel('y') plt.ylabel('y_pred'); ax_132=plt.subplot(1,3,2) plt.plot(y,y-y_pred,'.') plt.plot(y.loc[outliers],y.loc[outliers]-y_pred.loc[outliers],'ro') plt.legend(['Accepted','Outlier']) plt.xlabel('y') plt.ylabel('y - y_pred'); ax_133=plt.subplot(1,3,3) z.plot.hist(bins=50,ax=ax_133) z.loc[outliers].plot.hist(color='r',bins=50,ax=ax_133) plt.legend(['Accepted','Outlier']) plt.xlabel('z') plt.savefig('outliers.png') return outliers# get training data from sklearn.linear_model import Ridge X_train, X_valid,y_train,y_valid = get_training_data() test=get_test_data() # find and remove outliers using a Ridge model outliers = find_outliers(Ridge(), X_train, y_train) # permanently remove these outliers from the data #df_train = data_all[data_all["oringin"]=="train"] #df_train["label"]=data_train.target1 #df_train=df_train.drop(outliers) X_outliers=X_train.loc[outliers] y_outliers=y_train.loc[outliers] X_t=X_train.drop(outliers) y_t=y_train.drop(outliers)# 使用删除异常的数据进行模型训练 def get_trainning_data_omitoutliers(): y1=y_t.copy() X1=X_t.copy() return X1,y1# 采用网格搜索训练模型 from sklearn.preprocessing import StandardScaler def train_model(model, param_grid=[], X=[], y=[], splits=5, repeats=5): # get unmodified training data, unless data to use already specified if len(y)==0: X,y = get_trainning_data_omitoutliers() #poly_trans=PolynomialFeatures(degree=2) #X=poly_trans.fit_transform(X) #X=MinMaxScaler().fit_transform(X) # create cross-validation method rkfold = RepeatedKFold(n_splits=splits, n_repeats=repeats) # perform a grid search if param_grid given if len(param_grid)>0: # setup grid search parameters gsearch = GridSearchCV(model, param_grid, cv=rkfold, scoring="neg_mean_squared_error", verbose=1, return_train_score=True) # search the grid gsearch.fit(X,y) # extract best model from the grid model = gsearch.best_estimator_ best_idx = gsearch.best_index_ # get cv-scores for best model grid_results = pd.DataFrame(gsearch.cv_results_) cv_mean = abs(grid_results.loc[best_idx,'mean_test_score']) cv_std = grid_results.loc[best_idx,'std_test_score'] # no grid search, just cross-val score for given model else: grid_results = [] cv_results = cross_val_score(model, X, y, scoring="neg_mean_squared_error", cv=rkfold) cv_mean = abs(np.mean(cv_results)) cv_std = np.std(cv_results) # combine mean and std cv-score in to a pandas series cv_score = pd.Series({'mean':cv_mean,'std':cv_std}) # predict y using the fitted model y_pred = model.predict(X) # print stats on model performance print('----------------------') print(model) print('----------------------') print('score=',model.score(X,y)) print('rmse=',rmse(y, y_pred)) print('mse=',mse(y, y_pred)) print('cross_val: mean=',cv_mean,', std=',cv_std) # residual plots y_pred = pd.Series(y_pred,index=y.index) resid = y - y_pred mean_resid = resid.mean() std_resid = resid.std() z = (resid - mean_resid)/std_resid n_outliers = sum(abs(z)>3) plt.figure(figsize=(15,5)) ax_131 = plt.subplot(1,3,1) plt.plot(y,y_pred,'.') plt.xlabel('y') plt.ylabel('y_pred'); plt.title('corr = {:.3f}'.format(np.corrcoef(y,y_pred)[0][1])) ax_132=plt.subplot(1,3,2) plt.plot(y,y-y_pred,'.') plt.xlabel('y') plt.ylabel('y - y_pred'); plt.title('std resid = {:.3f}'.format(std_resid)) ax_133=plt.subplot(1,3,3) z.plot.hist(bins=50,ax=ax_133) plt.xlabel('z') plt.title('{:.0f} samples with z>3'.format(n_outliers)) return model, cv_score, grid_results# places to store optimal models and scores opt_models = dict() score_models = pd.DataFrame(columns=['mean','std']) # no. k-fold splits splits=5 # no. k-fold iterations repeats=57.1 单一模型预测效果7.1.1 岭回归 model = 'Ridge' opt_models[model] = Ridge() alph_range = np.arange(0.25,6,0.25) param_grid = {'alpha': alph_range} opt_models[model],cv_score,grid_results = train_model(opt_models[model], param_grid=param_grid, splits=splits, repeats=repeats) cv_score.name = model score_models = score_models.append(cv_score) plt.figure() plt.errorbar(alph_range, abs(grid_results['mean_test_score']), abs(grid_results['std_test_score'])/np.sqrt(splits*repeats)) plt.xlabel('alpha') plt.ylabel('score')7.1.2 Lasso回归model = 'Lasso' opt_models[model] = Lasso() alph_range = np.arange(1e-4,1e-3,4e-5) param_grid = {'alpha': alph_range} opt_models[model], cv_score, grid_results = train_model(opt_models[model], param_grid=param_grid, splits=splits, repeats=repeats) cv_score.name = model score_models = score_models.append(cv_score) plt.figure() plt.errorbar(alph_range, abs(grid_results['mean_test_score']),abs(grid_results['std_test_score'])/np.sqrt(splits*repeats)) plt.xlabel('alpha') plt.ylabel('score')7.1.3 ElasticNet 回归model ='ElasticNet' opt_models[model] = ElasticNet() param_grid = {'alpha': np.arange(1e-4,1e-3,1e-4), 'l1_ratio': np.arange(0.1,1.0,0.1), 'max_iter':[100000]} opt_models[model], cv_score, grid_results = train_model(opt_models[model], param_grid=param_grid, splits=splits, repeats=1) cv_score.name = model score_models = score_models.append(cv_score)7.1.4 SVR回归model='LinearSVR' opt_models[model] = LinearSVR() crange = np.arange(0.1,1.0,0.1) param_grid = {'C':crange, 'max_iter':[1000]} opt_models[model], cv_score, grid_results = train_model(opt_models[model], param_grid=param_grid, splits=splits, repeats=repeats) cv_score.name = model score_models = score_models.append(cv_score) plt.figure() plt.errorbar(crange, abs(grid_results['mean_test_score']),abs(grid_results['std_test_score'])/np.sqrt(splits*repeats)) plt.xlabel('C') plt.ylabel('score') 7.1.5 KNN最近邻model = 'KNeighbors' opt_models[model] = KNeighborsRegressor() param_grid = {'n_neighbors':np.arange(3,11,1)} opt_models[model], cv_score, grid_results = train_model(opt_models[model], param_grid=param_grid, splits=splits, repeats=1) cv_score.name = model score_models = score_models.append(cv_score) plt.figure() plt.errorbar(np.arange(3,11,1), abs(grid_results['mean_test_score']),abs(grid_results['std_test_score'])/np.sqrt(splits*1)) plt.xlabel('n_neighbors') plt.ylabel('score')7.1.6 GBDT 模型model = 'GradientBoosting' opt_models[model] = GradientBoostingRegressor() param_grid = {'n_estimators':[150,250,350], 'max_depth':[1,2,3], 'min_samples_split':[5,6,7]} opt_models[model], cv_score, grid_results = train_model(opt_models[model], param_grid=param_grid, splits=splits, repeats=1) cv_score.name = model score_models = score_models.append(cv_score)7.1.7XGB模型model = 'XGB' opt_models[model] = XGBRegressor() param_grid = {'n_estimators':[100,200,300,400,500], 'max_depth':[1,2,3], opt_models[model], cv_score,grid_results = train_model(opt_models[model], param_grid=param_grid, splits=splits, repeats=1) cv_score.name = model score_models = score_models.append(cv_score)7.1.8 随机森林模型model = 'RandomForest' opt_models[model] = RandomForestRegressor() param_grid = {'n_estimators':[100,150,200], 'max_features':[8,12,16,20,24], 'min_samples_split':[2,4,6]} opt_models[model], cv_score, grid_results = train_model(opt_models[model], param_grid=param_grid, splits=5, repeats=1) cv_score.name = model score_models = score_models.append(cv_score)7.2 模型预测--多模型Baggingdef model_predict(test_data,test_y=[],stack=False): #poly_trans=PolynomialFeatures(degree=2) #test_data1=poly_trans.fit_transform(test_data) #test_data=MinMaxScaler().fit_transform(test_data) y_predict_total=np.zeros((test_data.shape[0],)) for model in opt_models.keys(): if model!="LinearSVR" and model!="KNeighbors": y_predict=opt_models[model].predict(test_data) y_predict_total+=y_predict if len(test_y)>0: print("{}_mse:".format(model),mean_squared_error(y_predict,test_y)) y_predict_mean=np.round(y_predict_total/i,3) if len(test_y)>0: print("mean_mse:",mean_squared_error(y_predict_mean,test_y)) else: y_predict_mean=pd.Series(y_predict_mean) return y_predict_mean# Bagging预测 model_predict(X_valid,y_valid)7.3 模型融合Stacking7.3.1 模型融合stacking简单示例import numpy as np import matplotlib.pyplot as plt import matplotlib.gridspec as gridspec import itertools from sklearn.linear_model import LogisticRegression from sklearn.svm import SVC from sklearn.ensemble import RandomForestClassifier ##主要使用pip install mlxtend安装mlxtend from mlxtend.classifier import EnsembleVoteClassifier from mlxtend.data import iris_data from mlxtend.plotting import plot_decision_regions %matplotlib inline # Initializing Classifiers clf1 = LogisticRegression(random_state=0) clf2 = RandomForestClassifier(random_state=0) clf3 = SVC(random_state=0, probability=True) eclf = EnsembleVoteClassifier(clfs=[clf1, clf2, clf3], weights=[2, 1, 1], voting='soft') # Loading some example data X, y = iris_data() X = X[:,[0, 2]] # Plotting Decision Regions gs = gridspec.GridSpec(2, 2) fig = plt.figure(figsize=(10, 8)) for clf, lab, grd in zip([clf1, clf2, clf3, eclf], ['Logistic Regression', 'Random Forest', 'RBF kernel SVM', 'Ensemble'], itertools.product([0, 1], repeat=2)): clf.fit(X, y) ax = plt.subplot(gs[grd[0], grd[1]]) fig = plot_decision_regions(X=X, y=y, clf=clf, legend=2) plt.title(lab) plt.show()7.3.2工业蒸汽多模型融合stackingfrom sklearn.model_selection import train_test_split import pandas as pd import numpy as np from scipy import sparse import xgboost import lightgbm from sklearn.ensemble import RandomForestRegressor,AdaBoostRegressor,GradientBoostingRegressor,ExtraTreesRegressor from sklearn.linear_model import LinearRegression from sklearn.metrics import mean_squared_error def stacking_reg(clf,train_x,train_y,test_x,clf_name,kf,label_split=None): train=np.zeros((train_x.shape[0],1)) test=np.zeros((test_x.shape[0],1)) test_pre=np.empty((folds,test_x.shape[0],1)) cv_scores=[] for i,(train_index,test_index) in enumerate(kf.split(train_x,label_split)): tr_x=train_x[train_index] tr_y=train_y[train_index] te_x=train_x[test_index] te_y = train_y[test_index] if clf_name in ["rf","ada","gb","et","lr","lsvc","knn"]: clf.fit(tr_x,tr_y) pre=clf.predict(te_x).reshape(-1,1) train[test_index]=pre test_pre[i,:]=clf.predict(test_x).reshape(-1,1) cv_scores.append(mean_squared_error(te_y, pre)) elif clf_name in ["xgb"]: train_matrix = clf.DMatrix(tr_x, label=tr_y, missing=-1) test_matrix = clf.DMatrix(te_x, label=te_y, missing=-1) z = clf.DMatrix(test_x, label=te_y, missing=-1) params = {'booster': 'gbtree', 'eval_metric': 'rmse', 'gamma': 1, 'min_child_weight': 1.5, 'max_depth': 5, 'lambda': 10, 'subsample': 0.7, 'colsample_bytree': 0.7, 'colsample_bylevel': 0.7, 'eta': 0.03, 'tree_method': 'exact', 'seed': 2017, 'nthread': 12 num_round = 1000 #记得修改 early_stopping_rounds = 10 #修改 watchlist = [(train_matrix, 'train'), (test_matrix, 'eval') if test_matrix: model = clf.train(params, train_matrix, num_boost_round=num_round,evals=watchlist, early_stopping_rounds=early_stopping_rounds pre= model.predict(test_matrix,ntree_limit=model.best_ntree_limit).reshape(-1,1) train[test_index]=pre test_pre[i, :]= model.predict(z, ntree_limit=model.best_ntree_limit).reshape(-1,1) cv_scores.append(mean_squared_error(te_y, pre)) elif clf_name in ["lgb"]: train_matrix = clf.Dataset(tr_x, label=tr_y) test_matrix = clf.Dataset(te_x, label=te_y) #z = clf.Dataset(test_x, label=te_y) #z=test_x params = { 'boosting_type': 'gbdt', 'objective': 'regression_l2', 'metric': 'mse', 'min_child_weight': 1.5, 'num_leaves': 2**5, 'lambda_l2': 10, 'subsample': 0.7, 'colsample_bytree': 0.7, 'colsample_bylevel': 0.7, 'learning_rate': 0.03, 'tree_method': 'exact', 'seed': 2017, 'nthread': 12, 'silent': True, num_round = 10000 early_stopping_rounds = 100 if test_matrix: model = clf.train(params, train_matrix,num_round,valid_sets=test_matrix, early_stopping_rounds=early_stopping_rounds pre= model.predict(te_x,num_iteration=model.best_iteration).reshape(-1,1) train[test_index]=pre test_pre[i, :]= model.predict(test_x, num_iteration=model.best_iteration).reshape(-1,1) cv_scores.append(mean_squared_error(te_y, pre)) else: raise IOError("Please add new clf.") print("%s now score is:"%clf_name,cv_scores) test[:]=test_pre.mean(axis=0) print("%s_score_list:"%clf_name,cv_scores) print("%s_score_mean:"%clf_name,np.mean(cv_scores)) return train.reshape(-1,1),test.reshape(-1,1) 模型融合stacking基学习器 def rf_reg(x_train, y_train, x_valid, kf, label_split=None): randomforest = RandomForestRegressor(n_estimators=100, max_depth=20, n_jobs=-1, random_state=2017, max_features="auto",verbose=1) rf_train, rf_test = stacking_reg(randomforest, x_train, y_train, x_valid, "rf", kf, label_split=label_split) return rf_train, rf_test,"rf_reg" def ada_reg(x_train, y_train, x_valid, kf, label_split=None): adaboost = AdaBoostRegressor(n_estimators=30, random_state=2017, learning_rate=0.01) ada_train, ada_test = stacking_reg(adaboost, x_train, y_train, x_valid, "ada", kf, label_split=label_split) return ada_train, ada_test,"ada_reg" def gb_reg(x_train, y_train, x_valid, kf, label_split=None): gbdt = GradientBoostingRegressor(learning_rate=0.04, n_estimators=100, subsample=0.8, random_state=2017,max_depth=5,verbose=1) gbdt_train, gbdt_test = stacking_reg(gbdt, x_train, y_train, x_valid, "gb", kf, label_split=label_split) return gbdt_train, gbdt_test,"gb_reg" def et_reg(x_train, y_train, x_valid, kf, label_split=None): extratree = ExtraTreesRegressor(n_estimators=100, max_depth=35, max_features="auto", n_jobs=-1, random_state=2017,verbose=1) et_train, et_test = stacking_reg(extratree, x_train, y_train, x_valid, "et", kf, label_split=label_split) return et_train, et_test,"et_reg" def lr_reg(x_train, y_train, x_valid, kf, label_split=None): lr_reg=LinearRegression(n_jobs=-1) lr_train, lr_test = stacking_reg(lr_reg, x_train, y_train, x_valid, "lr", kf, label_split=label_split) return lr_train, lr_test, "lr_reg" def xgb_reg(x_train, y_train, x_valid, kf, label_split=None): xgb_train, xgb_test = stacking_reg(xgboost, x_train, y_train, x_valid, "xgb", kf, label_split=label_split) return xgb_train, xgb_test,"xgb_reg" def lgb_reg(x_train, y_train, x_valid, kf, label_split=None): lgb_train, lgb_test = stacking_reg(lightgbm, x_train, y_train, x_valid, "lgb", kf, label_split=label_split) return lgb_train, lgb_test,"lgb_reg"模型融合stacking预测def stacking_pred(x_train, y_train, x_valid, kf, clf_list, label_split=None, clf_fin="lgb", if_concat_origin=True): for k, clf_list in enumerate(clf_list): clf_list = [clf_list] column_list = [] train_data_list=[] test_data_list=[] for clf in clf_list: train_data,test_data,clf_name=clf(x_train, y_train, x_valid, kf, label_split=label_split) train_data_list.append(train_data) test_data_list.append(test_data) column_list.append("clf_%s" % (clf_name)) train = np.concatenate(train_data_list, axis=1) test = np.concatenate(test_data_list, axis=1) if if_concat_origin: train = np.concatenate([x_train, train], axis=1) test = np.concatenate([x_valid, test], axis=1) print(x_train.shape) print(train.shape) print(clf_name) print(clf_name in ["lgb"]) if clf_fin in ["rf","ada","gb","et","lr","lsvc","knn"]: if clf_fin in ["rf"]: clf = RandomForestRegressor(n_estimators=100, max_depth=20, n_jobs=-1, random_state=2017, max_features="auto",verbose=1) elif clf_fin in ["ada"]: clf = AdaBoostRegressor(n_estimators=30, random_state=2017, learning_rate=0.01) elif clf_fin in ["gb"]: clf = GradientBoostingRegressor(learning_rate=0.04, n_estimators=100, subsample=0.8, random_state=2017,max_depth=5,verbose=1) elif clf_fin in ["et"]: clf = ExtraTreesRegressor(n_estimators=100, max_depth=35, max_features="auto", n_jobs=-1, random_state=2017,verbose=1) elif clf_fin in ["lr"]: clf = LinearRegression(n_jobs=-1) clf.fit(train, y_train) pre = clf.predict(test).reshape(-1,1) return pred elif clf_fin in ["xgb"]: clf = xgboost train_matrix = clf.DMatrix(train, label=y_train, missing=-1) test_matrix = clf.DMatrix(train, label=y_train, missing=-1) params = {'booster': 'gbtree', 'eval_metric': 'rmse', 'gamma': 1, 'min_child_weight': 1.5, 'max_depth': 5, 'lambda': 10, 'subsample': 0.7, 'colsample_bytree': 0.7, 'colsample_bylevel': 0.7, 'eta': 0.03, 'tree_method': 'exact', 'seed': 2017, 'nthread': 12 num_round = 1000 early_stopping_rounds = 10 watchlist = [(train_matrix, 'train'), (test_matrix, 'eval') model = clf.train(params, train_matrix, num_boost_round=num_round,evals=watchlist, early_stopping_rounds=early_stopping_rounds pre = model.predict(test,ntree_limit=model.best_ntree_limit).reshape(-1,1) return pre elif clf_fin in ["lgb"]: print(clf_name) clf = lightgbm train_matrix = clf.Dataset(train, label=y_train) test_matrix = clf.Dataset(train, label=y_train) params = { 'boosting_type': 'gbdt', 'objective': 'regression_l2', 'metric': 'mse', 'min_child_weight': 1.5, 'num_leaves': 2**5, 'lambda_l2': 10, 'subsample': 0.7, 'colsample_bytree': 0.7, 'colsample_bylevel': 0.7, 'learning_rate': 0.03, 'tree_method': 'exact', 'seed': 2017, 'nthread': 12, 'silent': True, num_round = 1000 early_stopping_rounds = 10 model = clf.train(params, train_matrix,num_round,valid_sets=test_matrix, early_stopping_rounds=early_stopping_rounds print('pred') pre = model.predict(test,num_iteration=model.best_iteration).reshape(-1,1) print(pre) return pre# #load_dataset with open("./zhengqi_train.txt") as fr: data_train=pd.read_table(fr,sep="\t") with open("./zhengqi_test.txt") as fr_test: data_test=pd.read_table(fr_test,sep="\t")### K折交叉验证 from sklearn.model_selection import StratifiedKFold, KFold folds = 5 seed = 1 kf = KFold(n_splits=5, shuffle=True, random_state=0)### 训练集和测试集数据 x_train = data_train[data_test.columns].values x_valid = data_test[data_test.columns].values y_train = data_train['target'].values### 使用lr_reg和lgb_reg进行融合预测 clf_list = [lr_reg, lgb_reg] #clf_list = [lr_reg, rf_reg] ##很容易过拟合 pred = stacking_pred(x_train, y_train, x_valid, kf, clf_list, label_split=None, clf_fin="lgb", if_concat_origin=True) print(pred )8.总结本项目主要讲解了数据探索性分析:查看变量间相关性以及找出关键变量;数据特征工程对数据精进:异常值处理、归一化处理以及特征降维;在进行归回模型训练涉及主流ML模型:决策树、随机森林,lightgbm等;在模型验证方面:讲解了相关评估指标以及交叉验证等;同时用lgb对特征进行优化;最后进行基于stacking方式模型融合。原项目链接:https://www.heywhale.com/home/column/64141d6b1c8c8b518ba97dcc参考链接:https://tianchi.aliyun.com/course/278/3427本人最近打算整合ML、DRL、NLP等相关领域的体系化项目课程,方便入门同学快速掌握相关知识。声明:部分项目为网络经典项目方便大家快速学习,后续会不断增添实战环节(比赛、论文、现实应用等)。对于机器学习这块规划为:基础入门机器学习算法--->简单项目实战--->数据建模比赛----->相关现实中应用场景问题解决。一条路线帮助大家学习,快速实战。对于深度强化学习这块规划为:基础单智能算法教学(gym环境为主)---->主流多智能算法教学(gym环境为主)---->单智能多智能题实战(论文复现偏业务如:无人机优化调度、电力资源调度等项目应用)自然语言处理相关规划:除了单点算法技术外,主要围绕知识图谱构建进行:信息抽取相关技术(含智能标注)--->知识融合---->知识推理---->图谱应用上述对于你掌握后的期许:对于ML,希望你后续可以乱杀数学建模相关比赛(参加就获奖保底,top还是难的需要钻研)可以实际解决现实中一些优化调度问题,而非停留在gym环境下的一些游戏demo玩玩。(更深层次可能需要自己钻研了,难度还是很大的)掌握可知识图谱全流程构建其中各个重要环节算法,包含图数据库相关知识。这三块领域耦合情况比较大,后续会通过比如:搜索推荐系统整个项目进行耦合,各项算法都会耦合在其中。举例:知识图谱就会用到(图算法、NLP、ML相关算法),搜索推荐系统(除了该领域召回粗排精排重排混排等算法外,还有强化学习、知识图谱等耦合在其中)。饼画的有点大,后面慢慢实现。
机器学习实战系列[一]:工业蒸汽量预测(最新版本上篇)含数据探索特征工程等
机器学习实战系列[一]:工业蒸汽量预测背景介绍火力发电的基本原理是:燃料在燃烧时加热水生成蒸汽,蒸汽压力推动汽轮机旋转,然后汽轮机带动发电机旋转,产生电能。在这一系列的能量转化中,影响发电效率的核心是锅炉的燃烧效率,即燃料燃烧加热水产生高温高压蒸汽。锅炉的燃烧效率的影响因素很多,包括锅炉的可调参数,如燃烧给量,一二次风,引风,返料风,给水水量;以及锅炉的工况,比如锅炉床温、床压,炉膛温度、压力,过热器的温度等。相关描述经脱敏后的锅炉传感器采集的数据(采集频率是分钟级别),根据锅炉的工况,预测产生的蒸汽量。数据说明数据分成训练数据(train.txt)和测试数据(test.txt),其中字段”V0”-“V37”,这38个字段是作为特征变量,”target”作为目标变量。选手利用训练数据训练出模型,预测测试数据的目标变量,排名结果依据预测结果的MSE(mean square error)。结果评估预测结果以mean square error作为评判标准。1.数据探索性分析import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns from scipy import stats import warnings warnings.filterwarnings("ignore") %matplotlib inline# 下载需要用到的数据集 !wget http://tianchi-media.oss-cn-beijing.aliyuncs.com/DSW/Industrial_Steam_Forecast/zhengqi_test.txt !wget http://tianchi-media.oss-cn-beijing.aliyuncs.com/DSW/Industrial_Steam_Forecast/zhengqi_train.txt--2023-03-23 18:10:23-- http://tianchi-media.oss-cn-beijing.aliyuncs.com/DSW/Industrial_Steam_Forecast/zhengqi_test.txt 正在解析主机 tianchi-media.oss-cn-beijing.aliyuncs.com (tianchi-media.oss-cn-beijing.aliyuncs.com)... 49.7.22.39 正在连接 tianchi-media.oss-cn-beijing.aliyuncs.com (tianchi-media.oss-cn-beijing.aliyuncs.com)|49.7.22.39|:80... 已连接。 已发出 HTTP 请求,正在等待回应... 200 OK 长度: 466959 (456K) [text/plain] 正在保存至: “zhengqi_test.txt.1” zhengqi_test.txt.1 100%[===================>] 456.01K --.-KB/s in 0.04s 2023-03-23 18:10:23 (10.0 MB/s) - 已保存 “zhengqi_test.txt.1” [466959/466959]) --2023-03-23 18:10:23-- http://tianchi-media.oss-cn-beijing.aliyuncs.com/DSW/Industrial_Steam_Forecast/zhengqi_train.txt 正在解析主机 tianchi-media.oss-cn-beijing.aliyuncs.com (tianchi-media.oss-cn-beijing.aliyuncs.com)... 49.7.22.39 正在连接 tianchi-media.oss-cn-beijing.aliyuncs.com (tianchi-media.oss-cn-beijing.aliyuncs.com)|49.7.22.39|:80... 已连接。 已发出 HTTP 请求,正在等待回应... 200 OK 长度: 714370 (698K) [text/plain] 正在保存至: “zhengqi_train.txt.1” zhengqi_train.txt.1 100%[===================>] 697.63K --.-KB/s in 0.04s 2023-03-23 18:10:24 (17.9 MB/s) - 已保存 “zhengqi_train.txt.1” [714370/714370]) # **读取数据文件** # 使用Pandas库`read_csv()`函数进行数据读取,分割符为‘\t’ train_data_file = "./zhengqi_train.txt" test_data_file = "./zhengqi_test.txt" train_data = pd.read_csv(train_data_file, sep='\t', encoding='utf-8') test_data = pd.read_csv(test_data_file, sep='\t', encoding='utf-8')1.1 查看数据信息#查看特征变量信息 train_data.info()<class 'pandas.core.frame.DataFrame'> RangeIndex: 2888 entries, 0 to 2887 Data columns (total 39 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 V0 2888 non-null float64 1 V1 2888 non-null float64 2 V2 2888 non-null float64 3 V3 2888 non-null float64 4 V4 2888 non-null float64 5 V5 2888 non-null float64 6 V6 2888 non-null float64 7 V7 2888 non-null float64 8 V8 2888 non-null float64 9 V9 2888 non-null float64 10 V10 2888 non-null float64 11 V11 2888 non-null float64 12 V12 2888 non-null float64 13 V13 2888 non-null float64 14 V14 2888 non-null float64 15 V15 2888 non-null float64 16 V16 2888 non-null float64 17 V17 2888 non-null float64 18 V18 2888 non-null float64 19 V19 2888 non-null float64 20 V20 2888 non-null float64 21 V21 2888 non-null float64 22 V22 2888 non-null float64 23 V23 2888 non-null float64 24 V24 2888 non-null float64 25 V25 2888 non-null float64 26 V26 2888 non-null float64 27 V27 2888 non-null float64 28 V28 2888 non-null float64 29 V29 2888 non-null float64 30 V30 2888 non-null float64 31 V31 2888 non-null float64 32 V32 2888 non-null float64 33 V33 2888 non-null float64 34 V34 2888 non-null float64 35 V35 2888 non-null float64 36 V36 2888 non-null float64 37 V37 2888 non-null float64 38 target 2888 non-null float64 dtypes: float64(39) memory usage: 880.1 KB 此训练集数据共有2888个样本,数据中有V0-V37共计38个特征变量,变量类型都为数值类型,所有数据特征没有缺失值数据;数据字段由于采用了脱敏处理,删除了特征数据的具体含义;target字段为标签变量test_data.info()<class 'pandas.core.frame.DataFrame'> RangeIndex: 1925 entries, 0 to 1924 Data columns (total 38 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 V0 1925 non-null float64 1 V1 1925 non-null float64 2 V2 1925 non-null float64 3 V3 1925 non-null float64 4 V4 1925 non-null float64 5 V5 1925 non-null float64 6 V6 1925 non-null float64 7 V7 1925 non-null float64 8 V8 1925 non-null float64 9 V9 1925 non-null float64 10 V10 1925 non-null float64 11 V11 1925 non-null float64 12 V12 1925 non-null float64 13 V13 1925 non-null float64 14 V14 1925 non-null float64 15 V15 1925 non-null float64 16 V16 1925 non-null float64 17 V17 1925 non-null float64 18 V18 1925 non-null float64 19 V19 1925 non-null float64 20 V20 1925 non-null float64 21 V21 1925 non-null float64 22 V22 1925 non-null float64 23 V23 1925 non-null float64 24 V24 1925 non-null float64 25 V25 1925 non-null float64 26 V26 1925 non-null float64 27 V27 1925 non-null float64 28 V28 1925 non-null float64 29 V29 1925 non-null float64 30 V30 1925 non-null float64 31 V31 1925 non-null float64 32 V32 1925 non-null float64 33 V33 1925 non-null float64 34 V34 1925 non-null float64 35 V35 1925 non-null float64 36 V36 1925 non-null float64 37 V37 1925 non-null float64 dtypes: float64(38) memory usage: 571.6 KB 测试集数据共有1925个样本,数据中有V0-V37共计38个特征变量,变量类型都为数值类型# 查看数据统计信息 train_data.describe() target count 2888.000000 2888.000000 2888.000000 2888.000000 2888.000000 2888.000000 2888.000000 2888.000000 2888.000000 2888.000000 2888.000000 2888.000000 2888.000000 2888.000000 2888.000000 2888.000000 2888.000000 2888.000000 2888.000000 2888.000000 0.123048 0.056068 0.289720 -0.067790 0.012921 -0.558565 0.182892 0.116155 0.177856 -0.169452 0.097648 0.055477 0.127791 0.020806 0.007801 0.006715 0.197764 0.030658 -0.130330 0.126353 0.928031 0.941515 0.911236 0.970298 0.888377 0.517957 0.918054 0.955116 0.895444 0.953813 1.061200 0.901934 0.873028 0.902584 1.006995 1.003291 0.985675 0.970812 1.017196 0.983966 -4.335000 -5.122000 -3.420000 -3.956000 -4.742000 -2.182000 -4.576000 -5.048000 -4.692000 -12.891000 -2.912000 -4.507000 -5.859000 -4.053000 -4.627000 -4.789000 -5.695000 -2.608000 -3.630000 -3.044000 -0.297000 -0.226250 -0.313000 -0.652250 -0.385000 -0.853000 -0.310000 -0.295000 -0.159000 -0.390000 -0.664000 -0.283000 -0.170250 -0.407250 -0.499000 -0.290000 -0.202500 -0.413000 -0.798250 -0.350250 0.359000 0.272500 0.386000 -0.044500 0.110000 -0.466000 0.388000 0.344000 0.362000 0.042000 -0.023000 0.053500 0.299500 0.039000 -0.040000 0.160000 0.364000 0.137000 -0.185500 0.313000 0.726000 0.599000 0.918250 0.624000 0.550250 -0.154000 0.831250 0.782250 0.726000 0.042000 0.745250 0.488000 0.635000 0.557000 0.462000 0.273000 0.602000 0.644250 0.495250 0.793250 2.121000 1.918000 2.828000 2.457000 2.689000 0.489000 1.895000 1.918000 2.245000 1.335000 4.580000 2.689000 2.013000 2.395000 5.465000 5.110000 2.324000 5.238000 3.000000 2.538000 8 rows × 39 columns test_data.describe() count 1925.000000 1925.000000 1925.000000 1925.000000 1925.000000 1925.000000 1925.000000 1925.000000 1925.000000 1925.000000 1925.000000 1925.000000 1925.000000 1925.000000 1925.000000 1925.000000 1925.000000 1925.000000 1925.000000 1925.000000 -0.184404 -0.083912 -0.434762 0.101671 -0.019172 0.838049 -0.274092 -0.173971 -0.266709 0.255114 -0.206871 -0.146463 -0.083215 -0.191729 -0.030782 -0.011433 -0.009985 -0.296895 -0.046270 0.195735 1.073333 1.076670 0.969541 1.034925 1.147286 0.963043 1.054119 1.040101 1.085916 1.014394 1.064140 0.880593 1.126414 1.138454 1.130228 0.989732 0.995213 0.946896 1.040854 0.940599 -4.814000 -5.488000 -4.283000 -3.276000 -4.921000 -1.168000 -5.649000 -5.625000 -6.059000 -6.784000 -2.435000 -2.413000 -4.507000 -7.698000 -4.057000 -4.627000 -4.789000 -7.477000 -2.608000 -3.346000 -0.664000 -0.451000 -0.978000 -0.644000 -0.497000 0.122000 -0.732000 -0.509000 -0.775000 -0.390000 -0.453000 -0.818000 -0.339000 -0.476000 -0.472000 -0.460000 -0.290000 -0.349000 -0.593000 -0.432000 0.065000 0.195000 -0.267000 0.220000 0.118000 0.437000 -0.082000 0.018000 -0.004000 0.401000 -0.445000 -0.199000 0.010000 0.100000 0.155000 -0.040000 0.160000 -0.270000 0.083000 0.152000 0.549000 0.589000 0.278000 0.793000 0.610000 1.928000 0.457000 0.515000 0.482000 0.904000 -0.434000 0.468000 0.447000 0.471000 0.627000 0.419000 0.273000 0.364000 0.651000 0.797000 2.100000 2.120000 1.946000 2.603000 4.475000 3.176000 1.528000 1.394000 2.408000 1.766000 4.656000 3.022000 3.139000 1.428000 2.299000 5.465000 5.110000 1.671000 2.861000 3.021000 8 rows × 38 columns 上面数据显示了数据的统计信息,例如样本数,数据的均值mean,标准差std,最小值,最大值等# 查看数据字段信息 train_data.head() target 0.566 0.016 -0.143 0.407 0.452 -0.901 -1.812 -2.360 -0.436 -2.114 0.136 0.109 -0.615 0.327 -4.627 -4.789 -5.101 -2.608 -3.508 0.175 0.968 0.437 0.066 0.566 0.194 -0.893 -1.566 -2.360 0.332 -2.114 -0.128 0.124 0.032 0.600 -0.843 0.160 0.364 -0.335 -0.730 0.676 1.013 0.568 0.235 0.370 0.112 -0.797 -1.367 -2.360 0.396 -2.114 -0.009 0.361 0.277 -0.116 -0.843 0.160 0.364 0.765 -0.589 0.633 0.733 0.368 0.283 0.165 0.599 -0.679 -1.200 -2.086 0.403 -2.114 0.015 0.417 0.279 0.603 -0.843 -0.065 0.364 0.333 -0.112 0.206 0.684 0.638 0.260 0.209 0.337 -0.454 -1.073 -2.086 0.314 -2.114 0.183 1.078 0.328 0.418 -0.843 -0.215 0.364 -0.280 -0.028 0.384 5 rows × 39 columns 上面显示训练集前5条数据的基本信息,可以看到数据都是浮点型数据,数据都是数值型连续型特征test_data.head() 0.368 0.380 -0.225 -0.049 0.379 0.092 0.550 0.551 0.244 0.904 -0.449 0.047 0.057 -0.042 0.847 0.534 -0.009 -0.190 -0.567 0.388 0.148 0.489 -0.247 -0.049 0.122 -0.201 0.487 0.493 -0.127 0.904 -0.443 0.047 0.560 0.176 0.551 0.046 -0.220 0.008 -0.294 0.104 -0.166 -0.062 -0.311 0.046 -0.055 0.063 0.485 0.493 -0.227 0.904 -0.458 -0.398 0.101 0.199 0.634 0.017 -0.234 0.008 0.373 0.569 0.102 0.294 -0.259 0.051 -0.183 0.148 0.474 0.504 0.010 0.904 -0.456 -0.398 1.007 0.137 1.042 -0.040 -0.290 0.008 -0.666 0.391 0.300 0.428 0.208 0.051 -0.033 0.116 0.408 0.497 0.155 0.904 -0.458 -0.776 0.291 0.370 0.181 -0.040 -0.290 0.008 -0.140 -0.497 5 rows × 38 columns 1.2 可视化探索数据fig = plt.figure(figsize=(4, 6)) # 指定绘图对象宽度和高度 sns.boxplot(train_data['V0'],orient="v", width=0.5)<matplotlib.axes._subplots.AxesSubplot at 0x7faf89f46950> # 画箱式图 # column = train_data.columns.tolist()[:39] # 列表头 # fig = plt.figure(figsize=(20, 40)) # 指定绘图对象宽度和高度 # for i in range(38): # plt.subplot(13, 3, i + 1) # 13行3列子图 # sns.boxplot(train_data[column[i]], orient="v", width=0.5) # 箱式图 # plt.ylabel(column[i], fontsize=8) # plt.show() #箱图自行打开查看数据分布图查看特征变量‘V0’的数据分布直方图,并绘制Q-Q图查看数据是否近似于正态分布plt.figure(figsize=(10,5)) ax=plt.subplot(1,2,1) sns.distplot(train_data['V0'],fit=stats.norm) ax=plt.subplot(1,2,2) res = stats.probplot(train_data['V0'], plot=plt)查看查看所有数据的直方图和Q-Q图,查看训练集的数据是否近似于正态分布# train_cols = 6 # train_rows = len(train_data.columns) # plt.figure(figsize=(4*train_cols,4*train_rows)) # i=0 # for col in train_data.columns: # i+=1 # ax=plt.subplot(train_rows,train_cols,i) # sns.distplot(train_data[col],fit=stats.norm) # i+=1 # ax=plt.subplot(train_rows,train_cols,i) # res = stats.probplot(train_data[col], plot=plt) # plt.show() #QQ图自行打开由上面的数据分布图信息可以看出,很多特征变量(如'V1','V9','V24','V28'等)的数据分布不是正态的,数据并不跟随对角线,后续可以使用数据变换对数据进行转换。对比同一特征变量‘V0’下,训练集数据和测试集数据的分布情况,查看数据分布是否一致ax = sns.kdeplot(train_data['V0'], color="Red", shade=True) ax = sns.kdeplot(test_data['V0'], color="Blue", shade=True) ax.set_xlabel('V0') ax.set_ylabel("Frequency") ax = ax.legend(["train","test"])查看所有特征变量下,训练集数据和测试集数据的分布情况,分析并寻找出数据分布不一致的特征变量。# dist_cols = 6 # dist_rows = len(test_data.columns) # plt.figure(figsize=(4*dist_cols,4*dist_rows)) # i=1 # for col in test_data.columns: # ax=plt.subplot(dist_rows,dist_cols,i) # ax = sns.kdeplot(train_data[col], color="Red", shade=True) # ax = sns.kdeplot(test_data[col], color="Blue", shade=True) # ax.set_xlabel(col) # ax.set_ylabel("Frequency") # ax = ax.legend(["train","test"]) # i+=1 # plt.show() #自行打开查看特征'V5', 'V17', 'V28', 'V22', 'V11', 'V9'数据的数据分布drop_col = 6 drop_row = 1 plt.figure(figsize=(5*drop_col,5*drop_row)) for col in ["V5","V9","V11","V17","V22","V28"]: ax =plt.subplot(drop_row,drop_col,i) ax = sns.kdeplot(train_data[col], color="Red", shade=True) ax = sns.kdeplot(test_data[col], color="Blue", shade=True) ax.set_xlabel(col) ax.set_ylabel("Frequency") ax = ax.legend(["train","test"]) plt.show()由上图的数据分布可以看到特征'V5','V9','V11','V17','V22','V28' 训练集数据与测试集数据分布不一致,会导致模型泛化能力差,采用删除此类特征方法。drop_columns = ['V5','V9','V11','V17','V22','V28'] # 合并训练集和测试集数据,并可视化训练集和测试集数据特征分布图可视化线性回归关系查看特征变量‘V0’与'target'变量的线性回归关系fcols = 2 frows = 1 plt.figure(figsize=(8,4)) ax=plt.subplot(1,2,1) sns.regplot(x='V0', y='target', data=train_data, ax=ax, scatter_kws={'marker':'.','s':3,'alpha':0.3}, line_kws={'color':'k'}); plt.xlabel('V0') plt.ylabel('target') ax=plt.subplot(1,2,2) sns.distplot(train_data['V0'].dropna()) plt.xlabel('V0') plt.show()1.2.2 查看变量间线性回归关系# fcols = 6 # frows = len(test_data.columns) # plt.figure(figsize=(5*fcols,4*frows)) # i=0 # for col in test_data.columns: # i+=1 # ax=plt.subplot(frows,fcols,i) # sns.regplot(x=col, y='target', data=train_data, ax=ax, # scatter_kws={'marker':'.','s':3,'alpha':0.3}, # line_kws={'color':'k'}); # plt.xlabel(col) # plt.ylabel('target') # i+=1 # ax=plt.subplot(frows,fcols,i) # sns.distplot(train_data[col].dropna()) # plt.xlabel(col) #已注释图片生成,自行打开1.2.2 查看特征变量的相关性 data_train1 = train_data.drop(['V5','V9','V11','V17','V22','V28'],axis=1) train_corr = data_train1.corr() train_corr target 1.000000 0.908607 0.463643 0.409576 0.781212 0.189267 0.141294 0.794013 0.298443 0.751830 0.302145 0.156968 0.675003 0.050951 0.056439 -0.019342 0.138933 0.231417 -0.494076 0.873212 0.908607 1.000000 0.506514 0.383924 0.657790 0.276805 0.205023 0.874650 0.310120 0.656186 0.147096 0.175997 0.769745 0.085604 0.035129 -0.029115 0.146329 0.235299 -0.494043 0.871846 0.463643 0.506514 1.000000 0.410148 0.057697 0.615938 0.477114 0.703431 0.346006 0.059941 -0.275764 0.175943 0.653764 0.033942 0.050309 -0.025620 0.043648 0.316462 -0.734956 0.638878 0.409576 0.383924 0.410148 1.000000 0.315046 0.233896 0.197836 0.411946 0.321262 0.306397 0.117610 0.043966 0.421954 -0.092423 -0.007159 -0.031898 0.080034 0.324475 -0.229613 0.512074 0.781212 0.657790 0.057697 0.315046 1.000000 -0.117529 -0.052370 0.449542 0.141129 0.927685 0.659093 0.022807 0.447016 -0.026186 0.062367 0.028659 0.100010 0.113609 -0.031054 0.603984 0.189267 0.276805 0.615938 0.233896 -0.117529 1.000000 0.917502 0.468233 0.415660 -0.087312 -0.467980 0.188907 0.546535 0.144550 0.054210 -0.002914 0.044992 0.433804 -0.404817 0.370037 0.141294 0.205023 0.477114 0.197836 -0.052370 0.917502 1.000000 0.389987 0.310982 -0.036791 -0.311363 0.170113 0.475254 0.122707 0.034508 -0.019103 0.111166 0.340479 -0.292285 0.287815 0.794013 0.874650 0.703431 0.411946 0.449542 0.468233 0.389987 1.000000 0.419703 0.420557 -0.011091 0.150258 0.878072 0.038430 0.026843 -0.036297 0.179167 0.326586 -0.553121 0.831904 0.298443 0.310120 0.346006 0.321262 0.141129 0.415660 0.310982 0.419703 1.000000 0.140462 -0.105042 -0.036705 0.560213 -0.093213 0.016739 -0.026994 0.026846 0.922190 -0.045851 0.394767 0.751830 0.656186 0.059941 0.306397 0.927685 -0.087312 -0.036791 0.420557 0.140462 1.000000 0.666775 0.028866 0.441963 -0.007658 0.046674 0.010122 0.081963 0.112150 -0.054827 0.594189 0.185144 0.157518 0.204762 -0.003636 0.075993 0.138367 0.110973 0.153299 -0.059553 0.098771 0.008235 0.027328 0.113743 0.130598 0.157513 0.116944 0.219906 -0.024751 -0.379714 0.203373 -0.004144 -0.006268 -0.106282 -0.232677 0.023853 0.072911 0.163931 0.008138 -0.077543 0.020069 0.056814 -0.004057 0.010989 0.106581 0.073535 0.043218 0.233523 -0.086217 0.010553 0.008424 0.314520 0.164702 -0.224573 0.143457 0.615704 -0.431542 -0.291272 0.018366 -0.046737 0.642081 0.951314 -0.111311 0.011768 -0.104618 0.050254 0.048602 0.100817 -0.051861 0.245635 0.154020 0.347357 0.435606 0.782474 0.394517 0.023818 0.847119 0.752683 0.680031 0.546975 0.025736 -0.342210 0.154794 0.778538 0.041474 0.028878 -0.054775 0.082293 0.551880 -0.420053 0.536748 0.148622 0.123862 0.132105 0.022868 0.136022 0.110570 0.098691 0.093682 -0.024693 0.119833 0.053958 0.470341 0.079718 0.411967 0.512139 0.365410 0.152088 0.019603 -0.181937 0.170721 -0.100294 -0.092673 -0.161802 -0.246008 -0.205729 0.215290 0.158371 -0.144693 0.074903 -0.148319 -0.205409 0.100133 -0.131542 0.144018 -0.021517 -0.079753 -0.220737 0.087605 0.012115 -0.114976 0.462493 0.459795 0.298385 0.289594 0.291309 0.136091 0.089399 0.412868 0.207612 0.271559 0.016233 0.086165 0.326863 0.050699 0.009358 -0.000979 0.048981 0.161315 -0.322006 0.444965 -0.029285 -0.012911 -0.030932 0.114373 0.174025 -0.051806 -0.065300 -0.047839 0.082288 0.144371 0.157097 -0.077945 0.053025 -0.159128 -0.087561 -0.053707 -0.199398 0.047340 0.315470 -0.010063 0.231136 0.222574 0.065509 0.081374 0.196530 0.069901 0.125180 0.174124 -0.066537 0.180049 0.116122 0.363963 0.129783 0.367086 0.183666 0.196681 0.635252 -0.035949 -0.187582 0.226331 -0.324959 -0.233556 0.010225 -0.237326 -0.529866 0.072418 -0.030292 -0.136898 -0.029420 -0.550881 -0.642370 0.033532 -0.202097 0.060608 -0.134320 -0.095588 -0.243738 -0.041325 -0.137614 -0.264815 -0.200706 -0.070627 0.481785 -0.100569 -0.444375 0.438610 0.316744 0.173320 0.079805 -0.448877 -0.575154 0.088238 0.201243 0.065501 -0.013312 -0.030747 -0.093948 0.069302 -0.246742 -0.019373 -0.125140 -0.043012 0.035370 -0.027685 -0.080487 0.106055 0.160566 0.015724 0.072366 -0.124111 -0.133694 -0.057247 0.062879 -0.004545 -0.034596 0.051294 0.085576 0.064963 0.010880 -0.046724 0.733198 0.824198 0.726250 0.392006 0.412083 0.474441 0.424185 0.901100 0.246085 0.374380 -0.032772 0.208074 0.790239 0.095127 0.030135 -0.036123 0.159884 0.226713 -0.617771 0.812585 0.302145 0.147096 -0.275764 0.117610 0.659093 -0.467980 -0.311363 -0.011091 -0.105042 0.666775 1.000000 -0.122817 -0.004364 -0.110699 0.035272 0.035392 0.078588 -0.099309 0.285581 0.123329 0.156968 0.175997 0.175943 0.043966 0.022807 0.188907 0.170113 0.150258 -0.036705 0.028866 -0.122817 1.000000 0.114318 0.695725 0.083693 -0.028573 -0.027987 0.006961 -0.256814 0.187311 0.675003 0.769745 0.653764 0.421954 0.447016 0.546535 0.475254 0.878072 0.560213 0.441963 -0.004364 0.114318 1.000000 0.016782 0.016733 -0.047273 0.152314 0.510851 -0.357785 0.750297 0.050951 0.085604 0.033942 -0.092423 -0.026186 0.144550 0.122707 0.038430 -0.093213 -0.007658 -0.110699 0.695725 0.016782 1.000000 0.105255 0.069300 0.016901 -0.054411 -0.162417 0.066606 0.056439 0.035129 0.050309 -0.007159 0.062367 0.054210 0.034508 0.026843 0.016739 0.046674 0.035272 0.083693 0.016733 0.105255 1.000000 0.719126 0.167597 0.031586 -0.062715 0.077273 -0.019342 -0.029115 -0.025620 -0.031898 0.028659 -0.002914 -0.019103 -0.036297 -0.026994 0.010122 0.035392 -0.028573 -0.047273 0.069300 0.719126 1.000000 0.233616 -0.019032 -0.006854 -0.006034 0.138933 0.146329 0.043648 0.080034 0.100010 0.044992 0.111166 0.179167 0.026846 0.081963 0.078588 -0.027987 0.152314 0.016901 0.167597 0.233616 1.000000 0.025401 -0.077991 0.140294 0.231417 0.235299 0.316462 0.324475 0.113609 0.433804 0.340479 0.326586 0.922190 0.112150 -0.099309 0.006961 0.510851 -0.054411 0.031586 -0.019032 0.025401 1.000000 -0.039478 0.319309 -0.494076 -0.494043 -0.734956 -0.229613 -0.031054 -0.404817 -0.292285 -0.553121 -0.045851 -0.054827 0.285581 -0.256814 -0.357785 -0.162417 -0.062715 -0.006854 -0.077991 -0.039478 1.000000 -0.565795 target 0.873212 0.871846 0.638878 0.512074 0.603984 0.370037 0.287815 0.831904 0.394767 0.594189 0.123329 0.187311 0.750297 0.066606 0.077273 -0.006034 0.140294 0.319309 -0.565795 1.000000 33 rows × 33 columns # 画出相关性热力图 ax = plt.subplots(figsize=(20, 16))#调整画布大小 ax = sns.heatmap(train_corr, vmax=.8, square=True, annot=True)#画热力图 annot=True 显示系数# 找出相关程度 data_train1 = train_data.drop(['V5','V9','V11','V17','V22','V28'],axis=1) plt.figure(figsize=(20, 16)) # 指定绘图对象宽度和高度 colnm = data_train1.columns.tolist() # 列表头 mcorr = data_train1[colnm].corr(method="spearman") # 相关系数矩阵,即给出了任意两个变量之间的相关系数 mask = np.zeros_like(mcorr, dtype=np.bool) # 构造与mcorr同维数矩阵 为bool型 mask[np.triu_indices_from(mask)] = True # 角分线右侧为True cmap = sns.diverging_palette(220, 10, as_cmap=True) # 返回matplotlib colormap对象 g = sns.heatmap(mcorr, mask=mask, cmap=cmap, square=True, annot=True, fmt='0.2f') # 热力图(看两两相似度) plt.show()上图为所有特征变量和target变量两两之间的相关系数,由此可以看出各个特征变量V0-V37之间的相关性以及特征变量V0-V37与target的相关性。1.2.3 查找重要变量查找出特征变量和target变量相关系数大于0.5的特征变量#寻找K个最相关的特征信息 k = 10 # number of variables for heatmap cols = train_corr.nlargest(k, 'target')['target'].index cm = np.corrcoef(train_data[cols].values.T) hm = plt.subplots(figsize=(10, 10))#调整画布大小 #hm = sns.heatmap(cm, cbar=True, annot=True, square=True) #g = sns.heatmap(train_data[cols].corr(),annot=True,square=True,cmap="RdYlGn") hm = sns.heatmap(train_data[cols].corr(),annot=True,square=True) plt.show()threshold = 0.5 corrmat = train_data.corr() top_corr_features = corrmat.index[abs(corrmat["target"])>threshold] plt.figure(figsize=(10,10)) g = sns.heatmap(train_data[top_corr_features].corr(),annot=True,cmap="RdYlGn") drop_columns.clear() drop_columns = ['V5','V9','V11','V17','V22','V28']# Threshold for removing correlated variables threshold = 0.5 # Absolute value correlation matrix corr_matrix = data_train1.corr().abs() drop_col=corr_matrix[corr_matrix["target"]<threshold].index #data_all.drop(drop_col, axis=1, inplace=True)由于'V14', 'V21', 'V25', 'V26', 'V32', 'V33', 'V34'特征的相关系数值小于0.5,故认为这些特征与最终的预测target值不相关,删除这些特征变量;#merge train_set and test_set train_x = train_data.drop(['target'], axis=1) #data_all=pd.concat([train_data,test_data],axis=0,ignore_index=True) data_all = pd.concat([train_x,test_data]) data_all.drop(drop_columns,axis=1,inplace=True) #View data data_all.head() 0.566 0.016 -0.143 0.407 0.452 -1.812 -2.360 -0.436 -0.940 -0.073 0.168 0.136 0.109 -0.615 0.327 -4.627 -4.789 -5.101 -2.608 -3.508 0.968 0.437 0.066 0.566 0.194 -1.566 -2.360 0.332 0.188 -0.134 0.338 -0.128 0.124 0.032 0.600 -0.843 0.160 0.364 -0.335 -0.730 1.013 0.568 0.235 0.370 0.112 -1.367 -2.360 0.396 0.874 -0.072 0.326 -0.009 0.361 0.277 -0.116 -0.843 0.160 0.364 0.765 -0.589 0.733 0.368 0.283 0.165 0.599 -1.200 -2.086 0.403 0.011 -0.014 0.277 0.015 0.417 0.279 0.603 -0.843 -0.065 0.364 0.333 -0.112 0.684 0.638 0.260 0.209 0.337 -1.073 -2.086 0.314 -0.251 0.199 0.332 0.183 1.078 0.328 0.418 -0.843 -0.215 0.364 -0.280 -0.028 5 rows × 32 columns # normalise numeric columns cols_numeric=list(data_all.columns) def scale_minmax(col): return (col-col.min())/(col.max()-col.min()) data_all[cols_numeric] = data_all[cols_numeric].apply(scale_minmax,axis=0) data_all[cols_numeric].describe() count 4813.000000 4813.000000 4813.000000 4813.000000 4813.000000 4813.000000 4813.000000 4813.000000 4813.000000 4813.000000 4813.000000 4813.000000 4813.000000 4813.000000 4813.000000 4813.000000 4813.000000 4813.000000 4813.000000 4813.000000 0.694172 0.721357 0.602300 0.603139 0.523743 0.748823 0.745740 0.715607 0.348518 0.578507 0.881401 0.388683 0.589459 0.792709 0.628824 0.458493 0.483790 0.762873 0.332385 0.545795 0.144198 0.131443 0.140628 0.152462 0.106430 0.132560 0.132577 0.118105 0.134882 0.105088 0.128221 0.133475 0.130786 0.102976 0.155003 0.099095 0.101020 0.102037 0.127456 0.150356 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.626676 0.679416 0.514414 0.503888 0.478182 0.683324 0.696938 0.664934 0.284327 0.532892 0.888575 0.292445 0.550092 0.761816 0.562461 0.409037 0.454490 0.727273 0.270584 0.445647 0.729488 0.752497 0.617072 0.614270 0.535866 0.774125 0.771974 0.742884 0.366469 0.591635 0.916015 0.375734 0.594428 0.815055 0.643056 0.454518 0.499949 0.800020 0.347056 0.539317 0.790195 0.799553 0.700464 0.710474 0.585036 0.842259 0.836405 0.790835 0.432965 0.641971 0.932555 0.471837 0.650798 0.852229 0.719777 0.500000 0.511365 0.800020 0.414861 0.643061 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 8 rows × 32 columns #col_data_process = cols_numeric.append('target') train_data_process = train_data[cols_numeric] train_data_process = train_data_process[cols_numeric].apply(scale_minmax,axis=0) test_data_process = test_data[cols_numeric] test_data_process = test_data_process[cols_numeric].apply(scale_minmax,axis=0) cols_numeric_left = cols_numeric[0:13] cols_numeric_right = cols_numeric[13:]## Check effect of Box-Cox transforms on distributions of continuous variables train_data_process = pd.concat([train_data_process, train_data['target']], axis=1) fcols = 6 frows = len(cols_numeric_left) plt.figure(figsize=(4*fcols,4*frows)) for var in cols_numeric_left: dat = train_data_process[[var, 'target']].dropna() plt.subplot(frows,fcols,i) sns.distplot(dat[var] , fit=stats.norm); plt.title(var+' Original') plt.xlabel('') plt.subplot(frows,fcols,i) _=stats.probplot(dat[var], plot=plt) plt.title('skew='+'{:.4f}'.format(stats.skew(dat[var]))) plt.xlabel('') plt.ylabel('') plt.subplot(frows,fcols,i) plt.plot(dat[var], dat['target'],'.',alpha=0.5) plt.title('corr='+'{:.2f}'.format(np.corrcoef(dat[var], dat['target'])[0][1])) plt.subplot(frows,fcols,i) trans_var, lambda_var = stats.boxcox(dat[var].dropna()+1) trans_var = scale_minmax(trans_var) sns.distplot(trans_var , fit=stats.norm); plt.title(var+' Tramsformed') plt.xlabel('') plt.subplot(frows,fcols,i) _=stats.probplot(trans_var, plot=plt) plt.title('skew='+'{:.4f}'.format(stats.skew(trans_var))) plt.xlabel('') plt.ylabel('') plt.subplot(frows,fcols,i) plt.plot(trans_var, dat['target'],'.',alpha=0.5) plt.title('corr='+'{:.2f}'.format(np.corrcoef(trans_var,dat['target'])[0][1]))# ## Check effect of Box-Cox transforms on distributions of continuous variables #已注释图片生成,自行打开 # fcols = 6 # frows = len(cols_numeric_right) # plt.figure(figsize=(4*fcols,4*frows)) # i=0 # for var in cols_numeric_right: # dat = train_data_process[[var, 'target']].dropna() # i+=1 # plt.subplot(frows,fcols,i) # sns.distplot(dat[var] , fit=stats.norm); # plt.title(var+' Original') # plt.xlabel('') # i+=1 # plt.subplot(frows,fcols,i) # _=stats.probplot(dat[var], plot=plt) # plt.title('skew='+'{:.4f}'.format(stats.skew(dat[var]))) # plt.xlabel('') # plt.ylabel('') # i+=1 # plt.subplot(frows,fcols,i) # plt.plot(dat[var], dat['target'],'.',alpha=0.5) # plt.title('corr='+'{:.2f}'.format(np.corrcoef(dat[var], dat['target'])[0][1])) # i+=1 # plt.subplot(frows,fcols,i) # trans_var, lambda_var = stats.boxcox(dat[var].dropna()+1) # trans_var = scale_minmax(trans_var) # sns.distplot(trans_var , fit=stats.norm); # plt.title(var+' Tramsformed') # plt.xlabel('') # i+=1 # plt.subplot(frows,fcols,i) # _=stats.probplot(trans_var, plot=plt) # plt.title('skew='+'{:.4f}'.format(stats.skew(trans_var))) # plt.xlabel('') # plt.ylabel('') # i+=1 # plt.subplot(frows,fcols,i) # plt.plot(trans_var, dat['target'],'.',alpha=0.5) # plt.title('corr='+'{:.2f}'.format(np.corrcoef(trans_var,dat['target'])[0][1]))2.数据特征工程2.1数据预处理和特征处理# 导入数据分析工具包 import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns from scipy import stats import warnings warnings.filterwarnings("ignore") %matplotlib inline # 读取数据 train_data_file = "./zhengqi_train.txt" test_data_file = "./zhengqi_test.txt" train_data = pd.read_csv(train_data_file, sep='\t', encoding='utf-8') test_data = pd.read_csv(test_data_file, sep='\t', encoding='utf-8')train_data.describe() #数据总览 target count 2888.000000 2888.000000 2888.000000 2888.000000 2888.000000 2888.000000 2888.000000 2888.000000 2888.000000 2888.000000 2888.000000 2888.000000 2888.000000 2888.000000 2888.000000 2888.000000 2888.000000 2888.000000 2888.000000 2888.000000 0.123048 0.056068 0.289720 -0.067790 0.012921 -0.558565 0.182892 0.116155 0.177856 -0.169452 0.097648 0.055477 0.127791 0.020806 0.007801 0.006715 0.197764 0.030658 -0.130330 0.126353 0.928031 0.941515 0.911236 0.970298 0.888377 0.517957 0.918054 0.955116 0.895444 0.953813 1.061200 0.901934 0.873028 0.902584 1.006995 1.003291 0.985675 0.970812 1.017196 0.983966 -4.335000 -5.122000 -3.420000 -3.956000 -4.742000 -2.182000 -4.576000 -5.048000 -4.692000 -12.891000 -2.912000 -4.507000 -5.859000 -4.053000 -4.627000 -4.789000 -5.695000 -2.608000 -3.630000 -3.044000 -0.297000 -0.226250 -0.313000 -0.652250 -0.385000 -0.853000 -0.310000 -0.295000 -0.159000 -0.390000 -0.664000 -0.283000 -0.170250 -0.407250 -0.499000 -0.290000 -0.202500 -0.413000 -0.798250 -0.350250 0.359000 0.272500 0.386000 -0.044500 0.110000 -0.466000 0.388000 0.344000 0.362000 0.042000 -0.023000 0.053500 0.299500 0.039000 -0.040000 0.160000 0.364000 0.137000 -0.185500 0.313000 0.726000 0.599000 0.918250 0.624000 0.550250 -0.154000 0.831250 0.782250 0.726000 0.042000 0.745250 0.488000 0.635000 0.557000 0.462000 0.273000 0.602000 0.644250 0.495250 0.793250 2.121000 1.918000 2.828000 2.457000 2.689000 0.489000 1.895000 1.918000 2.245000 1.335000 4.580000 2.689000 2.013000 2.395000 5.465000 5.110000 2.324000 5.238000 3.000000 2.538000 8 rows × 39 columns 2.1.1 异常值分析#异常值分析 plt.figure(figsize=(18, 10)) plt.boxplot(x=train_data.values,labels=train_data.columns) plt.hlines([-7.5, 7.5], 0, 40, colors='r') plt.show()## 删除异常值 train_data = train_data[train_data['V9']>-7.5] train_data.describe() target count 2886.000000 2886.000000 2886.000000 2886.000000 2886.000000 2886.000000 2886.000000 2886.000000 2886.000000 2886.00000 2886.000000 2886.000000 2886.000000 2886.000000 2886.000000 2886.000000 2886.000000 2886.000000 2886.000000 2886.000000 0.123725 0.056856 0.290340 -0.068364 0.012254 -0.558971 0.183273 0.116274 0.178138 -0.16213 0.097019 0.058619 0.127617 0.023626 0.008271 0.006959 0.198513 0.030099 -0.131957 0.127451 0.927984 0.941269 0.911231 0.970357 0.888037 0.517871 0.918211 0.955418 0.895552 0.91089 1.060824 0.894311 0.873300 0.896509 1.007175 1.003411 0.985058 0.970258 1.015666 0.983144 -4.335000 -5.122000 -3.420000 -3.956000 -4.742000 -2.182000 -4.576000 -5.048000 -4.692000 -7.07100 -2.912000 -4.507000 -5.859000 -4.053000 -4.627000 -4.789000 -5.695000 -2.608000 -3.630000 -3.044000 -0.292000 -0.224250 -0.310000 -0.652750 -0.385000 -0.853000 -0.310000 -0.295000 -0.158750 -0.39000 -0.664000 -0.282000 -0.170750 -0.405000 -0.499000 -0.290000 -0.199750 -0.412750 -0.798750 -0.347500 0.359500 0.273000 0.386000 -0.045000 0.109500 -0.466000 0.388500 0.345000 0.362000 0.04200 -0.023000 0.054500 0.299500 0.040000 -0.040000 0.160000 0.364000 0.137000 -0.186000 0.314000 0.726000 0.599000 0.918750 0.623500 0.550000 -0.154000 0.831750 0.782750 0.726000 0.04200 0.745000 0.488000 0.635000 0.557000 0.462000 0.273000 0.602000 0.643750 0.493000 0.793750 2.121000 1.918000 2.828000 2.457000 2.689000 0.489000 1.895000 1.918000 2.245000 1.33500 4.580000 2.689000 2.013000 2.395000 5.465000 5.110000 2.324000 5.238000 3.000000 2.538000 8 rows × 39 columns test_data.describe() count 1925.000000 1925.000000 1925.000000 1925.000000 1925.000000 1925.000000 1925.000000 1925.000000 1925.000000 1925.000000 1925.000000 1925.000000 1925.000000 1925.000000 1925.000000 1925.000000 1925.000000 1925.000000 1925.000000 1925.000000 -0.184404 -0.083912 -0.434762 0.101671 -0.019172 0.838049 -0.274092 -0.173971 -0.266709 0.255114 -0.206871 -0.146463 -0.083215 -0.191729 -0.030782 -0.011433 -0.009985 -0.296895 -0.046270 0.195735 1.073333 1.076670 0.969541 1.034925 1.147286 0.963043 1.054119 1.040101 1.085916 1.014394 1.064140 0.880593 1.126414 1.138454 1.130228 0.989732 0.995213 0.946896 1.040854 0.940599 -4.814000 -5.488000 -4.283000 -3.276000 -4.921000 -1.168000 -5.649000 -5.625000 -6.059000 -6.784000 -2.435000 -2.413000 -4.507000 -7.698000 -4.057000 -4.627000 -4.789000 -7.477000 -2.608000 -3.346000 -0.664000 -0.451000 -0.978000 -0.644000 -0.497000 0.122000 -0.732000 -0.509000 -0.775000 -0.390000 -0.453000 -0.818000 -0.339000 -0.476000 -0.472000 -0.460000 -0.290000 -0.349000 -0.593000 -0.432000 0.065000 0.195000 -0.267000 0.220000 0.118000 0.437000 -0.082000 0.018000 -0.004000 0.401000 -0.445000 -0.199000 0.010000 0.100000 0.155000 -0.040000 0.160000 -0.270000 0.083000 0.152000 0.549000 0.589000 0.278000 0.793000 0.610000 1.928000 0.457000 0.515000 0.482000 0.904000 -0.434000 0.468000 0.447000 0.471000 0.627000 0.419000 0.273000 0.364000 0.651000 0.797000 2.100000 2.120000 1.946000 2.603000 4.475000 3.176000 1.528000 1.394000 2.408000 1.766000 4.656000 3.022000 3.139000 1.428000 2.299000 5.465000 5.110000 1.671000 2.861000 3.021000 8 rows × 38 columns 2.1.2 归一化处理 from sklearn import preprocessing features_columns = [col for col in train_data.columns if col not in ['target']] min_max_scaler = preprocessing.MinMaxScaler() min_max_scaler = min_max_scaler.fit(train_data[features_columns]) train_data_scaler = min_max_scaler.transform(train_data[features_columns]) test_data_scaler = min_max_scaler.transform(test_data[features_columns]) train_data_scaler = pd.DataFrame(train_data_scaler) train_data_scaler.columns = features_columns test_data_scaler = pd.DataFrame(test_data_scaler) test_data_scaler.columns = features_columns train_data_scaler['target'] = train_data['target']train_data_scaler.describe() test_data_scaler.describe() count 1925.000000 1925.000000 1925.000000 1925.000000 1925.000000 1925.000000 1925.000000 1925.000000 1925.000000 1925.000000 1925.000000 1925.000000 1925.000000 1925.000000 1925.000000 1925.000000 1925.000000 1925.000000 1925.000000 1925.000000 0.642905 0.715637 0.477791 0.632726 0.635558 1.130681 0.664798 0.699688 0.637926 0.871534 0.313556 0.369132 0.614756 0.719928 0.623793 0.457349 0.482778 0.673164 0.326501 0.577034 0.166253 0.152936 0.155176 0.161379 0.154392 0.360555 0.162899 0.149311 0.156540 0.120675 0.149752 0.117538 0.156533 0.144621 0.175284 0.098071 0.100537 0.118082 0.132661 0.141870 -0.074195 -0.051989 -0.138124 0.106035 -0.024088 0.379633 -0.165817 -0.082831 -0.197059 0.034142 0.000000 0.066604 0.000000 -0.233613 -0.000620 0.000000 0.000000 -0.222222 0.000000 0.042836 0.568618 0.663494 0.390845 0.516451 0.571256 0.862598 0.594035 0.651593 0.564653 0.794789 0.278919 0.279498 0.579211 0.683816 0.555366 0.412901 0.454490 0.666667 0.256819 0.482353 0.681537 0.755256 0.504641 0.651177 0.654017 0.980532 0.694483 0.727247 0.675796 0.888889 0.280045 0.362120 0.627710 0.756987 0.652605 0.454518 0.499949 0.676518 0.342977 0.570437 0.756506 0.811222 0.591869 0.740527 0.720226 1.538750 0.777778 0.798593 0.745856 0.948727 0.281593 0.451148 0.688438 0.804116 0.725806 0.500000 0.511365 0.755580 0.415371 0.667722 0.996747 1.028693 0.858835 1.022766 1.240345 2.005990 0.943285 0.924777 1.023497 1.051273 0.997889 0.792045 1.062535 0.925686 0.985112 1.000000 1.000000 0.918568 0.697043 1.003167 8 rows × 38 columns #查看数据集情况 dist_cols = 6 dist_rows = len(test_data_scaler.columns) plt.figure(figsize=(4*dist_cols,4*dist_rows)) for i, col in enumerate(test_data_scaler.columns): ax=plt.subplot(dist_rows,dist_cols,i+1) ax = sns.kdeplot(train_data_scaler[col], color="Red", shade=True) ax = sns.kdeplot(test_data_scaler[col], color="Blue", shade=True) ax.set_xlabel(col) ax.set_ylabel("Frequency") ax = ax.legend(["train","test"]) # plt.show() #已注释图片生成,自行打开查看特征'V5', 'V17', 'V28', 'V22', 'V11', 'V9'数据的数据分布drop_col = 6 drop_row = 1 plt.figure(figsize=(5*drop_col,5*drop_row)) for i, col in enumerate(["V5","V9","V11","V17","V22","V28"]): ax =plt.subplot(drop_row,drop_col,i+1) ax = sns.kdeplot(train_data_scaler[col], color="Red", shade=True) ax= sns.kdeplot(test_data_scaler[col], color="Blue", shade=True) ax.set_xlabel(col) ax.set_ylabel("Frequency") ax = ax.legend(["train","test"]) plt.show()这几个特征下,训练集的数据和测试集的数据分布不一致,会影响模型的泛化能力,故删除这些特征3.1.3 特征相关性plt.figure(figsize=(20, 16)) column = train_data_scaler.columns.tolist() mcorr = train_data_scaler[column].corr(method="spearman") mask = np.zeros_like(mcorr, dtype=np.bool) mask[np.triu_indices_from(mask)] = True cmap = sns.diverging_palette(220, 10, as_cmap=True) g = sns.heatmap(mcorr, mask=mask, cmap=cmap, square=True, annot=True, fmt='0.2f') plt.show()2.2 特征降维mcorr=mcorr.abs() numerical_corr=mcorr[mcorr['target']>0.1]['target'] print(numerical_corr.sort_values(ascending=False)) index0 = numerical_corr.sort_values(ascending=False).index print(train_data_scaler[index0].corr('spearman'))target 1.000000 V0 0.712403 V31 0.711636 V1 0.682909 V8 0.679469 V27 0.657398 V2 0.585850 V16 0.545793 V3 0.501622 V4 0.478683 V12 0.460300 V10 0.448682 V36 0.425991 V37 0.376443 V24 0.305526 V5 0.286076 V6 0.280195 V20 0.278381 V11 0.234551 V15 0.221290 V29 0.190109 V7 0.185321 V19 0.180111 V18 0.149741 V13 0.149199 V17 0.126262 V22 0.112743 V30 0.101378 Name: target, dtype: float64 target V0 V31 V1 V8 V27 V2 \ target 1.000000 0.712403 0.711636 0.682909 0.679469 0.657398 0.585850 V0 0.712403 1.000000 0.739116 0.894116 0.832151 0.763128 0.516817 V31 0.711636 0.739116 1.000000 0.807585 0.841469 0.765750 0.589890 V1 0.682909 0.894116 0.807585 1.000000 0.849034 0.807102 0.490239 V8 0.679469 0.832151 0.841469 0.849034 1.000000 0.887119 0.676417 V27 0.657398 0.763128 0.765750 0.807102 0.887119 1.000000 0.709534 V2 0.585850 0.516817 0.589890 0.490239 0.676417 0.709534 1.000000 V16 0.545793 0.388852 0.642309 0.396122 0.642156 0.620981 0.783643 V3 0.501622 0.401150 0.420134 0.363749 0.400915 0.402468 0.417190 V4 0.478683 0.697430 0.521226 0.651615 0.455801 0.424260 0.062134 V12 0.460300 0.640696 0.471528 0.596173 0.368572 0.336190 0.055734 V10 0.448682 0.279350 0.445335 0.255763 0.351127 0.203066 0.292769 V36 0.425991 0.214930 0.390250 0.192985 0.263291 0.186131 0.259475 V37 -0.376443 -0.472200 -0.301906 -0.397080 -0.507057 -0.557098 -0.731786 V24 -0.305526 -0.336325 -0.267968 -0.289742 -0.148323 -0.153834 0.018458 V5 -0.286076 -0.356704 -0.162304 -0.242776 -0.188993 -0.222596 -0.324464 V6 0.280195 0.131507 0.340145 0.147037 0.355064 0.356526 0.546921 V20 0.278381 0.444939 0.349530 0.421987 0.408853 0.361040 0.293635 V11 -0.234551 -0.333101 -0.131425 -0.221910 -0.161792 -0.190952 -0.271868 V15 0.221290 0.334135 0.110674 0.230395 0.054701 0.007156 -0.206499 V29 0.190109 0.334603 0.121833 0.240964 0.050211 0.006048 -0.255559 V7 0.185321 0.075732 0.277283 0.082766 0.278231 0.290620 0.378984 V19 -0.180111 -0.144295 -0.183185 -0.146559 -0.170237 -0.228613 -0.179416 V18 0.149741 0.132143 0.094678 0.093688 0.079592 0.091660 0.114929 V13 0.149199 0.173861 0.071517 0.134595 0.105380 0.126831 0.180477 V17 0.126262 0.055024 0.115056 0.081446 0.102544 0.036520 -0.050935 V22 -0.112743 -0.076698 -0.106450 -0.072848 -0.078333 -0.111196 -0.241206 V30 0.101378 0.099242 0.131453 0.109216 0.165204 0.167073 0.176236 V16 V3 V4 ... V11 V15 V29 \ target 0.545793 0.501622 0.478683 ... -0.234551 0.221290 0.190109 V0 0.388852 0.401150 0.697430 ... -0.333101 0.334135 0.334603 V31 0.642309 0.420134 0.521226 ... -0.131425 0.110674 0.121833 V1 0.396122 0.363749 0.651615 ... -0.221910 0.230395 0.240964 V8 0.642156 0.400915 0.455801 ... -0.161792 0.054701 0.050211 V27 0.620981 0.402468 0.424260 ... -0.190952 0.007156 0.006048 V2 0.783643 0.417190 0.062134 ... -0.271868 -0.206499 -0.255559 V16 1.000000 0.388886 0.009749 ... -0.088716 -0.280952 -0.327558 V3 0.388886 1.000000 0.294049 ... -0.126924 0.145291 0.128079 V4 0.009749 0.294049 1.000000 ... -0.164113 0.641180 0.692626 V12 -0.024541 0.286500 0.897807 ... -0.232228 0.703861 0.732617 V10 0.473009 0.295181 0.123829 ... 0.049969 -0.014449 -0.060440 V36 0.469130 0.299063 0.099359 ... -0.017805 -0.012844 -0.051097 V37 -0.431507 -0.219751 0.040396 ... 0.455998 0.234751 0.273926 V24 0.064523 -0.237022 -0.558334 ... 0.170969 -0.687353 -0.677833 V5 -0.045495 -0.230466 -0.248061 ... 0.797583 -0.250027 -0.233233 V6 0.760362 0.181135 -0.204780 ... -0.170545 -0.443436 -0.486682 V20 0.239572 0.270647 0.257815 ... -0.138684 0.050867 0.035022 V11 -0.088716 -0.126924 -0.164113 ... 1.000000 -0.123004 -0.120982 V15 -0.280952 0.145291 0.641180 ... -0.123004 1.000000 0.947360 V29 -0.327558 0.128079 0.692626 ... -0.120982 0.947360 1.000000 V7 0.651907 0.132564 -0.150577 ... -0.097623 -0.335054 -0.360490 V19 -0.019645 -0.265940 -0.237529 ... -0.094150 -0.215364 -0.212691 V18 0.066147 0.014697 0.135792 ... -0.153625 0.109030 0.098474 V13 0.074214 -0.019453 0.061801 ... -0.436341 0.047845 0.024514 V17 0.172978 0.067720 0.060753 ... 0.192222 -0.004555 -0.006498 V22 -0.091204 -0.305218 0.021174 ... 0.079577 0.069993 0.072070 V30 0.217428 0.055660 -0.053976 ... -0.102750 -0.147541 -0.161966 V7 V19 V18 V13 V17 V22 V30 target 0.185321 -0.180111 0.149741 0.149199 0.126262 -0.112743 0.101378 V0 0.075732 -0.144295 0.132143 0.173861 0.055024 -0.076698 0.099242 V31 0.277283 -0.183185 0.094678 0.071517 0.115056 -0.106450 0.131453 V1 0.082766 -0.146559 0.093688 0.134595 0.081446 -0.072848 0.109216 V8 0.278231 -0.170237 0.079592 0.105380 0.102544 -0.078333 0.165204 V27 0.290620 -0.228613 0.091660 0.126831 0.036520 -0.111196 0.167073 V2 0.378984 -0.179416 0.114929 0.180477 -0.050935 -0.241206 0.176236 V16 0.651907 -0.019645 0.066147 0.074214 0.172978 -0.091204 0.217428 V3 0.132564 -0.265940 0.014697 -0.019453 0.067720 -0.305218 0.055660 V4 -0.150577 -0.237529 0.135792 0.061801 0.060753 0.021174 -0.053976 V12 -0.157087 -0.174034 0.125965 0.102293 0.012429 -0.004863 -0.054432 V10 0.242818 0.089046 0.038237 -0.100776 0.258885 -0.132951 0.027257 V36 0.268044 0.099034 0.066478 -0.068582 0.298962 -0.136943 0.056802 V37 -0.284305 0.025241 -0.097699 -0.344661 0.052673 0.110455 -0.176127 V24 0.076407 0.287262 -0.221117 -0.073906 0.094367 0.081279 0.079363 V5 0.118541 0.247903 -0.191786 -0.408978 0.342555 0.143785 0.020252 V6 0.904614 0.292661 0.061109 0.088866 0.094702 -0.102842 0.201834 V20 0.064205 0.029483 0.050529 0.004600 0.061369 -0.092706 0.035036 V11 -0.097623 -0.094150 -0.153625 -0.436341 0.192222 0.079577 -0.102750 V15 -0.335054 -0.215364 0.109030 0.047845 -0.004555 0.069993 -0.147541 V29 -0.360490 -0.212691 0.098474 0.024514 -0.006498 0.072070 -0.161966 V7 1.000000 0.269472 0.032519 0.059724 0.178034 0.058178 0.196347 V19 0.269472 1.000000 -0.034215 -0.106162 0.250114 0.075582 0.120766 V18 0.032519 -0.034215 1.000000 0.242008 -0.073678 0.016819 0.133708 V13 0.059724 -0.106162 0.242008 1.000000 -0.108020 0.348432 -0.097178 V17 0.178034 0.250114 -0.073678 -0.108020 1.000000 0.363785 0.057480 V22 0.058178 0.075582 0.016819 0.348432 0.363785 1.000000 -0.054570 V30 0.196347 0.120766 0.133708 -0.097178 0.057480 -0.054570 1.000000 [28 rows x 28 columns] 2.2.1 相关性初筛features_corr = numerical_corr.sort_values(ascending=False).reset_index() features_corr.columns = ['features_and_target', 'corr'] features_corr_select = features_corr[features_corr['corr']>0.3] # 筛选出大于相关性大于0.3的特征 print(features_corr_select) select_features = [col for col in features_corr_select['features_and_target'] if col not in ['target']] new_train_data_corr_select = train_data_scaler[select_features+['target']] new_test_data_corr_select = test_data_scaler[select_features] features_and_target corr 0 target 1.000000 1 V0 0.712403 2 V31 0.711636 3 V1 0.682909 4 V8 0.679469 5 V27 0.657398 6 V2 0.585850 7 V16 0.545793 8 V3 0.501622 9 V4 0.478683 10 V12 0.460300 11 V10 0.448682 12 V36 0.425991 13 V37 0.376443 14 V24 0.305526 2.2.2 多重共线性分析!pip install statsmodels -i https://pypi.tuna.tsinghua.edu.cn/simpleLooking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple Requirement already satisfied: statsmodels in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (0.13.5) Requirement already satisfied: scipy>=1.3 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from statsmodels) (1.6.3) Requirement already satisfied: pandas>=0.25 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from statsmodels) (1.1.5) Requirement already satisfied: packaging>=21.3 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from statsmodels) (21.3) Requirement already satisfied: numpy>=1.17 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from statsmodels) (1.19.5) Requirement already satisfied: patsy>=0.5.2 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from statsmodels) (0.5.3) Requirement already satisfied: pyparsing!=3.0.5,>=2.0.2 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from packaging>=21.3->statsmodels) (3.0.9) Requirement already satisfied: pytz>=2017.2 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pandas>=0.25->statsmodels) (2019.3) Requirement already satisfied: python-dateutil>=2.7.3 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pandas>=0.25->statsmodels) (2.8.2) Requirement already satisfied: six in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from patsy>=0.5.2->statsmodels) (1.16.0) [1m[[0m[34;49mnotice[0m[1;39;49m][0m[39;49m A new release of pip available: [0m[31;49m22.1.2[0m[39;49m -> [0m[32;49m23.0.1[0m [1m[[0m[34;49mnotice[0m[1;39;49m][0m[39;49m To update, run: [0m[32;49mpip install --upgrade pip[0m from statsmodels.stats.outliers_influence import variance_inflation_factor #多重共线性方差膨胀因子 #多重共线性 new_numerical=['V0', 'V2', 'V3', 'V4', 'V5', 'V6', 'V10','V11', 'V13', 'V15', 'V16', 'V18', 'V19', 'V20', 'V22','V24','V30', 'V31', 'V37'] X=np.matrix(train_data_scaler[new_numerical]) VIF_list=[variance_inflation_factor(X, i) for i in range(X.shape[1])] VIF_list[216.73387180903222, 114.38118723828812, 27.863778129686356, 201.96436579080174, 78.93722825798903, 151.06983667656212, 14.519604941508451, 82.69750284665385, 28.479378440614585, 27.759176471505945, 526.6483470743831, 23.50166642638334, 19.920315849901424, 24.640481765008683, 11.816055964845381, 4.958208708452915, 37.09877416736591, 298.26442986612767, 47.854002539887034] 2.2.3 PCA处理降维from sklearn.decomposition import PCA #主成分分析法 #PCA方法降维 #保持90%的信息 pca = PCA(n_components=0.9) new_train_pca_90 = pca.fit_transform(train_data_scaler.iloc[:,0:-1]) new_test_pca_90 = pca.transform(test_data_scaler) new_train_pca_90 = pd.DataFrame(new_train_pca_90) new_test_pca_90 = pd.DataFrame(new_test_pca_90) new_train_pca_90['target'] = train_data_scaler['target'] new_train_pca_90.describe() target count 2.886000e+03 2886.000000 2.886000e+03 2.886000e+03 2.886000e+03 2.886000e+03 2.886000e+03 2.886000e+03 2.886000e+03 2.886000e+03 2.886000e+03 2.886000e+03 2886.000000 2.886000e+03 2.886000e+03 2.886000e+03 2884.000000 2.954440e-17 0.000000 3.200643e-17 4.924066e-18 7.139896e-17 -2.585135e-17 7.878506e-17 -5.170269e-17 -9.848132e-17 1.218706e-16 -7.016794e-17 1.181776e-16 0.000000 -3.446846e-17 -3.446846e-17 8.863319e-17 0.127274 3.998976e-01 0.350024 2.938631e-01 2.728023e-01 2.077128e-01 1.951842e-01 1.877104e-01 1.607670e-01 1.512707e-01 1.443772e-01 1.368790e-01 1.286192e-01 0.119330 1.149758e-01 1.133507e-01 1.019259e-01 0.983462 -1.071795e+00 -0.942948 -9.948314e-01 -7.103087e-01 -7.703987e-01 -5.340294e-01 -5.993766e-01 -5.870755e-01 -6.282818e-01 -4.902583e-01 -6.341045e-01 -5.906753e-01 -0.417515 -4.310613e-01 -4.170535e-01 -3.601627e-01 -3.044000 -2.804085e-01 -0.261373 -2.090797e-01 -1.945196e-01 -1.315620e-01 -1.264097e-01 -1.236360e-01 -1.016452e-01 -9.662098e-02 -9.297088e-02 -8.202809e-02 -7.721868e-02 -0.071400 -7.474073e-02 -7.709743e-02 -6.603914e-02 -0.348500 -1.417104e-02 -0.012772 2.112166e-02 -2.337401e-02 -5.122797e-03 -1.355336e-02 -1.747870e-04 -4.656359e-03 2.572054e-03 -1.479172e-03 7.286444e-03 -5.745946e-03 -0.004141 1.054915e-03 -1.758387e-03 -7.533392e-04 0.313000 2.287306e-01 0.231772 2.069571e-01 1.657590e-01 1.281660e-01 9.993122e-02 1.272081e-01 9.657222e-02 1.002626e-01 9.059634e-02 8.833765e-02 7.148033e-02 0.067862 7.574868e-02 7.116829e-02 6.357449e-02 0.794250 1.597730e+00 1.382802 1.010250e+00 1.448007e+00 1.034061e+00 1.358962e+00 6.191589e-01 7.370089e-01 6.449125e-01 5.839586e-01 6.405187e-01 6.780732e-01 0.515612 4.978126e-01 4.673189e-01 4.570870e-01 2.538000 train_data_scaler.describe() target count 2886.000000 2886.000000 2886.000000 2886.000000 2886.000000 2886.000000 2886.000000 2886.000000 2886.000000 2886.000000 2886.000000 2886.000000 2886.000000 2886.000000 2886.000000 2886.000000 2886.000000 2886.000000 2886.000000 2884.000000 0.690633 0.735633 0.593844 0.606212 0.639787 0.607649 0.735477 0.741354 0.702053 0.821897 0.401631 0.634466 0.760495 0.632231 0.459302 0.484489 0.734944 0.336235 0.527608 0.127274 0.143740 0.133703 0.145844 0.151311 0.119504 0.193887 0.141896 0.137154 0.129098 0.108362 0.141594 0.124279 0.110938 0.139037 0.099799 0.101365 0.122840 0.123663 0.153192 0.983462 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 -3.044000 0.626239 0.695703 0.497759 0.515087 0.586328 0.497566 0.659249 0.682314 0.653489 0.794789 0.300053 0.587132 0.722593 0.565757 0.409037 0.454490 0.685279 0.279792 0.427036 -0.348500 0.727153 0.766335 0.609155 0.609855 0.652873 0.642456 0.767192 0.774189 0.728557 0.846181 0.385611 0.633894 0.782330 0.634770 0.454518 0.499949 0.755580 0.349860 0.519457 0.313000 0.783922 0.812642 0.694422 0.714096 0.712152 0.759266 0.835690 0.837030 0.781029 0.846181 0.488121 0.694136 0.824949 0.714950 0.504261 0.511365 0.785260 0.414447 0.621870 0.794250 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 2.538000 8 rows × 39 columns #PCA方法降维 #保留16个主成分 pca = PCA(n_components=0.95) new_train_pca_16 = pca.fit_transform(train_data_scaler.iloc[:,0:-1]) new_test_pca_16 = pca.transform(test_data_scaler) new_train_pca_16 = pd.DataFrame(new_train_pca_16) new_test_pca_16 = pd.DataFrame(new_test_pca_16) new_train_pca_16['target'] = train_data_scaler['target'] new_train_pca_16.describe() target count 2.886000e+03 2886.000000 2.886000e+03 2.886000e+03 2.886000e+03 2.886000e+03 2.886000e+03 2.886000e+03 2.886000e+03 2.886000e+03 2886.000000 2.886000e+03 2.886000e+03 2.886000e+03 2.886000e+03 2.886000e+03 2.886000e+03 2.886000e+03 2.886000e+03 2884.000000 2.954440e-17 0.000000 3.200643e-17 4.924066e-18 7.139896e-17 -2.585135e-17 7.878506e-17 -5.170269e-17 -9.848132e-17 1.218706e-16 0.000000 -3.446846e-17 -3.446846e-17 8.863319e-17 4.493210e-17 1.107915e-17 -1.908076e-17 7.293773e-17 -1.224861e-16 0.127274 3.998976e-01 0.350024 2.938631e-01 2.728023e-01 2.077128e-01 1.951842e-01 1.877104e-01 1.607670e-01 1.512707e-01 1.443772e-01 0.119330 1.149758e-01 1.133507e-01 1.019259e-01 9.617307e-02 9.205940e-02 8.423171e-02 8.295263e-02 7.696785e-02 0.983462 -1.071795e+00 -0.942948 -9.948314e-01 -7.103087e-01 -7.703987e-01 -5.340294e-01 -5.993766e-01 -5.870755e-01 -6.282818e-01 -4.902583e-01 -0.417515 -4.310613e-01 -4.170535e-01 -3.601627e-01 -3.432530e-01 -3.530609e-01 -3.908328e-01 -3.089560e-01 -2.867812e-01 -3.044000 -2.804085e-01 -0.261373 -2.090797e-01 -1.945196e-01 -1.315620e-01 -1.264097e-01 -1.236360e-01 -1.016452e-01 -9.662098e-02 -9.297088e-02 -0.071400 -7.474073e-02 -7.709743e-02 -6.603914e-02 -6.064846e-02 -6.247177e-02 -5.357475e-02 -5.279870e-02 -4.930849e-02 -0.348500 -1.417104e-02 -0.012772 2.112166e-02 -2.337401e-02 -5.122797e-03 -1.355336e-02 -1.747870e-04 -4.656359e-03 2.572054e-03 -1.479172e-03 -0.004141 1.054915e-03 -1.758387e-03 -7.533392e-04 -4.559279e-03 -2.317781e-03 -3.034317e-04 3.391130e-03 -1.703944e-03 0.313000 2.287306e-01 0.231772 2.069571e-01 1.657590e-01 1.281660e-01 9.993122e-02 1.272081e-01 9.657222e-02 1.002626e-01 9.059634e-02 0.067862 7.574868e-02 7.116829e-02 6.357449e-02 5.732624e-02 6.139602e-02 5.068802e-02 5.084688e-02 4.693391e-02 0.794250 1.597730e+00 1.382802 1.010250e+00 1.448007e+00 1.034061e+00 1.358962e+00 6.191589e-01 7.370089e-01 6.449125e-01 5.839586e-01 0.515612 4.978126e-01 4.673189e-01 4.570870e-01 5.153325e-01 3.556862e-01 4.709891e-01 3.677911e-01 3.663361e-01 2.538000 8 rows × 22 columns 3.模型训练3.1 回归及相关模型## 导入相关库 from sklearn.linear_model import LinearRegression #线性回归 from sklearn.neighbors import KNeighborsRegressor #K近邻回归 from sklearn.tree import DecisionTreeRegressor #决策树回归 from sklearn.ensemble import RandomForestRegressor #随机森林回归 from sklearn.svm import SVR #支持向量回归 import lightgbm as lgb #lightGbm模型 from sklearn.ensemble import GradientBoostingRegressor from sklearn.model_selection import train_test_split # 切分数据 from sklearn.metrics import mean_squared_error #评价指标 from sklearn.model_selection import learning_curve from sklearn.model_selection import ShuffleSplit ## 切分训练数据和线下验证数据 #采用 pca 保留16维特征的数据 new_train_pca_16 = new_train_pca_16.fillna(0) train = new_train_pca_16[new_test_pca_16.columns] target = new_train_pca_16['target'] # 切分数据 训练数据80% 验证数据20% train_data,test_data,train_target,test_target=train_test_split(train,target,test_size=0.2,random_state=0)3.1.1 多元线性回归模型clf = LinearRegression() clf.fit(train_data, train_target) score = mean_squared_error(test_target, clf.predict(test_data)) print("LinearRegression: ", score) train_score = [] test_score = [] # 给予不同的数据量,查看模型的学习效果 for i in range(10, len(train_data)+1, 10): lin_reg = LinearRegression() lin_reg.fit(train_data[:i], train_target[:i]) # LinearRegression().fit(X_train[:i], y_train[:i]) # 查看模型的预测情况:两种,模型基于训练数据集预测的情况(可以理解为模型拟合训练数据集的情况),模型基于测试数据集预测的情况 # 此处使用 lin_reg.predict(X_train[:i]),为训练模型的全部数据集 y_train_predict = lin_reg.predict(train_data[:i]) train_score.append(mean_squared_error(train_target[:i], y_train_predict)) y_test_predict = lin_reg.predict(test_data) test_score.append(mean_squared_error(test_target, y_test_predict)) # np.sqrt(train_score):将列表 train_score 中的数开平方 plt.plot([i for i in range(1, len(train_score)+1)], train_score, label='train') plt.plot([i for i in range(1, len(test_score)+1)], test_score, label='test') # plt.legend():显示图例(如图形的 label); plt.legend() plt.show()LinearRegression: 0.2642337917628173 定义绘制模型学习曲线函数def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None, n_jobs=1, train_sizes=np.linspace(.1, 1.0, 5)): plt.figure() plt.title(title) if ylim is not None: plt.ylim(*ylim) plt.xlabel("Training examples") plt.ylabel("Score") train_sizes, train_scores, test_scores = learning_curve( estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes) train_scores_mean = np.mean(train_scores, axis=1) train_scores_std = np.std(train_scores, axis=1) test_scores_mean = np.mean(test_scores, axis=1) test_scores_std = np.std(test_scores, axis=1) print(train_scores_mean) print(test_scores_mean) plt.grid() plt.fill_between(train_sizes, train_scores_mean - train_scores_std, train_scores_mean + train_scores_std, alpha=0.1, color="r") plt.fill_between(train_sizes, test_scores_mean - test_scores_std, test_scores_mean + test_scores_std, alpha=0.1, color="g") plt.plot(train_sizes, train_scores_mean, 'o-', color="r", label="Training score") plt.plot(train_sizes, test_scores_mean, 'o-', color="g", label="Cross-validation score") plt.legend(loc="best") return pltdef plot_learning_curve_old(algo, X_train, X_test, y_train, y_test): """绘制学习曲线:只需要传入算法(或实例对象)、X_train、X_test、y_train、y_test""" """当使用该函数时传入算法,该算法的变量要进行实例化,如:PolynomialRegression(degree=2),变量 degree 要进行实例化""" train_score = [] test_score = [] for i in range(10, len(X_train)+1, 10): algo.fit(X_train[:i], y_train[:i]) y_train_predict = algo.predict(X_train[:i]) train_score.append(mean_squared_error(y_train[:i], y_train_predict)) y_test_predict = algo.predict(X_test) test_score.append(mean_squared_error(y_test, y_test_predict)) plt.plot([i for i in range(1, len(train_score)+1)], train_score, label="train") plt.plot([i for i in range(1, len(test_score)+1)], test_score, label="test") plt.legend() plt.show()# plot_learning_curve_old(LinearRegression(), train_data, test_data, train_target, test_target)# 线性回归模型学习曲线 X = train_data.values y = train_target.values title = r"LinearRegression" cv = ShuffleSplit(n_splits=100, test_size=0.2, random_state=0) estimator = LinearRegression() #建模 plot_learning_curve(estimator, title, X, y, ylim=(0.5, 0.8), cv=cv, n_jobs=1) [0.70183463 0.66761103 0.66101945 0.65732898 0.65360375] [0.57364886 0.61882339 0.62809368 0.63012866 0.63158596] 3.1.2 KNN近邻回归for i in range(3,10): clf = KNeighborsRegressor(n_neighbors=i) # 最近三个 clf.fit(train_data, train_target) score = mean_squared_error(test_target, clf.predict(test_data)) print("KNeighborsRegressor: ", score) KNeighborsRegressor: 0.27619208861976163 KNeighborsRegressor: 0.2597627823313149 KNeighborsRegressor: 0.2628212724567474 KNeighborsRegressor: 0.26670982271241833 KNeighborsRegressor: 0.2659603905091448 KNeighborsRegressor: 0.26353694644788067 KNeighborsRegressor: 0.2673470579477979 # plot_learning_curve_old(KNeighborsRegressor(n_neighbors=5) , train_data, test_data, train_target, test_target)# 绘制K近邻回归学习曲线 X = train_data.values y = train_target.values # K近邻回归 title = r"KNeighborsRegressor" cv = ShuffleSplit(n_splits=100, test_size=0.2, random_state=0) estimator = KNeighborsRegressor(n_neighbors=8) #建模 plot_learning_curve(estimator, title, X, y, ylim=(0.3, 0.9), cv=cv, n_jobs=1)[0.61581146 0.68763995 0.71414969 0.73084172 0.73976273] [0.50369207 0.58753672 0.61969929 0.64062459 0.6560054 ] 3.1.3决策树回归clf = DecisionTreeRegressor() clf.fit(train_data, train_target) score = mean_squared_error(test_target, clf.predict(test_data)) print("DecisionTreeRegressor: ", score)DecisionTreeRegressor: 0.6405298823529413 # plot_learning_curve_old(DecisionTreeRegressor(), train_data, test_data, train_target, test_target)X = train_data.values y = train_target.values # 决策树回归 title = r"DecisionTreeRegressor" cv = ShuffleSplit(n_splits=100, test_size=0.2, random_state=0) estimator = DecisionTreeRegressor() #建模 plot_learning_curve(estimator, title, X, y, ylim=(0.1, 1.3), cv=cv, n_jobs=1)[1. 1. 1. 1. 1.] [0.11833987 0.22982731 0.2797608 0.30950084 0.32628853] 3.1.4 随机森林回归clf = RandomForestRegressor(n_estimators=200) # 200棵树模型 clf.fit(train_data, train_target) score = mean_squared_error(test_target, clf.predict(test_data)) print("RandomForestRegressor: ", score) # plot_learning_curve_old(RandomForestRegressor(n_estimators=200), train_data, test_data, train_target, test_target)RandomForestRegressor: 0.24087959640588236 X = train_data.values y = train_target.values # 随机森林 title = r"RandomForestRegressor" cv = ShuffleSplit(n_splits=100, test_size=0.2, random_state=0) estimator = RandomForestRegressor(n_estimators=200) #建模 plot_learning_curve(estimator, title, X, y, ylim=(0.4, 1.0), cv=cv, n_jobs=1)[0.93619796 0.94798334 0.95197393 0.95415054 0.95570763] [0.53953995 0.61531165 0.64366926 0.65941678 0.67319725] <module 'matplotlib.pyplot' from '/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/pyplot.py'> 3.1.5 Gradient Boostingfrom sklearn.ensemble import GradientBoostingRegressor myGBR = GradientBoostingRegressor(alpha=0.9, criterion='friedman_mse', init=None, learning_rate=0.03, loss='huber', max_depth=14, max_features='sqrt', max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, min_samples_leaf=10, min_samples_split=40, min_weight_fraction_leaf=0.0, n_estimators=10, warm_start=False) # 参数已删除 presort=True, random_state=10, subsample=0.8, verbose=0, myGBR.fit(train_data, train_target) score = mean_squared_error(test_target, clf.predict(test_data)) print("GradientBoostingRegressor: ", score) myGBR = GradientBoostingRegressor(alpha=0.9, criterion='friedman_mse', init=None, learning_rate=0.03, loss='huber', max_depth=14, max_features='sqrt', max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, min_samples_leaf=10, min_samples_split=40, min_weight_fraction_leaf=0.0, n_estimators=10, warm_start=False) #为了快速展示n_estimators设置较小,实战中请按需设置 # plot_learning_curve_old(myGBR, train_data, test_data, train_target, test_target) GradientBoostingRegressor: 0.906640574789251 X = train_data.values y = train_target.values # GradientBoosting title = r"GradientBoostingRegressor" cv = ShuffleSplit(n_splits=10, test_size=0.2, random_state=0) estimator = GradientBoostingRegressor(alpha=0.9, criterion='friedman_mse', init=None, learning_rate=0.03, loss='huber', max_depth=14, max_features='sqrt', max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, min_samples_leaf=10, min_samples_split=40, min_weight_fraction_leaf=0.0, n_estimators=10, warm_start=False) #建模 plot_learning_curve(estimator, title, X, y, ylim=(0.4, 1.0), cv=cv, n_jobs=1) #为了快速展示n_estimators设置较小,实战中请按需设置3.1.6 lightgbm回归# lgb回归模型 clf = lgb.LGBMRegressor( learning_rate=0.01, max_depth=-1, n_estimators=10, boosting_type='gbdt', random_state=2019, objective='regression', # #为了快速展示n_estimators设置较小,实战中请按需设置 # 训练模型 clf.fit( X=train_data, y=train_target, eval_metric='MSE', verbose=50 score = mean_squared_error(test_target, clf.predict(test_data)) print("lightGbm: ", score)lightGbm: 0.906640574789251 X = train_data.values y = train_target.values # LGBM title = r"LGBMRegressor" cv = ShuffleSplit(n_splits=10, test_size=0.2, random_state=0) estimator = lgb.LGBMRegressor( learning_rate=0.01, max_depth=-1, n_estimators=10, boosting_type='gbdt', random_state=2019, objective='regression' ) #建模 plot_learning_curve(estimator, title, X, y, ylim=(0.4, 1.0), cv=cv, n_jobs=1) #为了快速展示n_estimators设置较小,实战中请按需设置4.篇中总结x在工业蒸汽量预测上篇中,主要讲解了数据探索性分析:查看变量间相关性以及找出关键变量;数据特征工程对数据精进:异常值处理、归一化处理以及特征降维;在进行归回模型训练涉及主流ML模型:决策树、随机森林,lightgbm等。下一篇中将着重讲解模型验证、特征优化、模型融合等。参考链接:https://tianchi.aliyun.com/course/278/3427原项目链接:https://www.heywhale.com/home/column/64141d6b1c8c8b518ba97dcc
机器学习算法(八):基于BP神经网络的乳腺癌的分类预测
机器学习算法(八):基于BP神经网络的乳腺癌的分类预测本项目链接:https://www.heywhale.com/home/column/64141d6b1c8c8b518ba97dcc1.算法简介和应用1.1 算法简介BP(Back Propagation)网络是1986年由Rumelhart和McCelland为首的科学家小组提出,是一种按误差逆传播算法训练的多层前馈网络,是目前应用最广泛的神经网络模型之一。BP网络能学习和存贮大量的输入-输出模式映射关系,而无需事前揭示描述这种映射关系的数学方程。它的学习规则是使用最速下降法,通过反向传播来不断调整网络的权值和阈值,使网络的误差平方和最小。BP神经网络模型拓扑结构包括输入层(input)、隐层(hide layer)和输出层(output layer)。在模拟过程中收集系统所产生的误差,通过误差反传,然后调整权值大小,通过该不断迭代更新,最后使得模型趋于整体最优化(这是一个循环,我们在训练神经网络的时候是要不断的去重复这个过程的)。BP神经网络模型要点在于数据的前向传播和误差反向传播,来对参数进行更新,使得损失最小化。 误差反向传播算法简称反向传播算法(即BP算法)。使用反向传播算法的多层感知器又称为BP神经网络。BP算法是一个迭代算法,它的基本思想为: (1)先计算每一层的状态和激活值,直到最后一层(即信号是前向传播的); (2)计算每一层的误差,误差的计算过程是从最后一层向前推进的(这就是反向传播算法名字的由来); (3)更新参数(目标是误差变小)。迭代前面两个步骤,直到满足停止准则(比如相邻两次迭代的误差的差别很小)。 在这个过程,函数的导数链式法则求导很重要,需要手动推导BP神经网络模型的梯度反向传播过程,熟练掌握链式法则进行求导,对参数进行更新。1.2.算法应用BP反映了生物神经系统处理外界事物的基本过程,是在模拟人脑神经组织的基础上发展起来的计算系统,是由大量处理单元通过广泛互联而构成的网络体系,它具有生物神经系统的基本特征,在一定程度上反映了人脑功能的若干反映,是对生物系统的某种模拟,具有大规模并行、分布式处理、自组织、自学习等优点,被广泛应用于语音分析、图像识别、数字水印、计算机视觉等很多领域,取得了许多突出的成果。最近由于人工神经网络的快速发展,它已经成为模式识别的强有力的工具。神经网络的运用展开了新的领域,解决其它模式识别不能解决的问题,其分类功能特别适合于模式识别与分类的应用。2.相关流程掌握BP算法基本原理掌握利用BP进行代码实战Part 1 Demo实践Step1:库函数导入Step2:模型训练Step3:模型参数查看Step4:数据和模型可视化Step5:模型预测Part 2 基于BP神经网络的乳腺癌分类实践Step1:库函数导入Step2:数据读取/载入Step3:数据信息简单查看与可视化Step4:利用BP神经网络在乳腺癌数据上进行训练和预测3.代码实战3.1 Part 1 Demo实践Step1:库函数导入# 基础数组运算库导入 import numpy as np # 画图库导入 import matplotlib.pyplot as plt # 导入三维显示工具 from mpl_toolkits.mplot3d import Axes3D # 导入BP模型 from sklearn.neural_network import MLPClassifier # 导入demo数据制作方法 from sklearn.datasets import make_classification from sklearn.metrics import classification_report, confusion_matrix import seaborn as sns import warnings from sklearn.exceptions import ConvergenceWarning Step2:模型训练# 制作五个类别的数据,每个类别1000个样本 train_samples, train_labels = make_classification(n_samples=1000, n_features=3, n_redundant=0, n_classes=5, n_informative=3, n_clusters_per_class=1, class_sep=3, random_state=10) # 将五个类别的数据进行三维显示 fig = plt.figure() ax = Axes3D(fig, rect=[0, 0, 1, 1], elev=20, azim=20) ax.scatter(train_samples[:, 0], train_samples[:, 1], train_samples[:, 2], marker='o', c=train_labels) plt.title('Demo Data Map')Text(0.5,0.92,'Demo Data Map') # 建立 BP 模型, 采用sgd优化器,relu非线性映射函数 BP = MLPClassifier(solver='sgd',activation = 'relu',max_iter = 500,alpha = 1e-3,hidden_layer_sizes = (32,32),random_state = 1) # 进行模型训练 with warnings.catch_warnings(): warnings.filterwarnings("ignore", category=ConvergenceWarning, module="sklearn") BP.fit(train_samples, train_labels)Step3:模型参数查看# 查看 BP 模型的参数 print(BP)MLPClassifier(alpha=0.001, hidden_layer_sizes=(32, 32), max_iter=500, random_state=1, solver='sgd') Step4:数据和模型可视化# 进行模型预测 predict_labels = BP.predict(train_samples) # 显示预测的散点图 fig = plt.figure() ax = Axes3D(fig, rect=[0, 0, 1, 1], elev=20, azim=20) ax.scatter(train_samples[:, 0], train_samples[:, 1], train_samples[:, 2], marker='o', c=predict_labels) plt.title('Demo Data Predict Map with BP Model') # 显示预测分数 print("预测准确率: {:.4f}".format(BP.score(train_samples, train_labels))) # 可视化预测数据 print("真实类别:", train_labels[:10]) print("预测类别:", predict_labels[:10]) # 准确率等报表 print(classification_report(train_labels, predict_labels)) # 计算混淆矩阵 classes = [0, 1, 2, 3] cofusion_mat = confusion_matrix(train_labels, predict_labels, classes) sns.set() figur, ax = plt.subplots() # 画热力图 sns.heatmap(cofusion_mat, cmap="YlGnBu_r", annot=True, ax=ax) ax.set_title('confusion matrix') # 标题 ax.set_xticklabels([''] + classes, minor=True) ax.set_yticklabels([''] + classes, minor=True) ax.set_xlabel('predict') # x轴 ax.set_ylabel('true') # y轴 plt.show()预测准确率: 0.9950 真实类别: [0 4 2 2 3 2 3 0 1 0] 预测类别: [0 4 2 2 3 2 3 0 1 0] precision recall f1-score support 0 0.98 0.99 0.99 198 1 1.00 0.99 0.99 203 2 1.00 1.00 1.00 200 3 0.99 1.00 1.00 199 4 0.99 0.99 0.99 200 accuracy 0.99 1000 macro avg 0.99 1.00 0.99 1000 weighted avg 1.00 0.99 1.00 1000 /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/sklearn/utils/validation.py:72: FutureWarning: Pass labels=[0, 1, 2, 3] as keyword args. From version 1.0 (renaming of 0.25) passing these as positional arguments will result in an error "will result in an error", FutureWarning) Step5:模型预测# 进行新的测试数据测试 test_sample = np.array([[-1, 0.1, 0.1]]) print(f"{test_sample} 类别是: ", BP.predict(test_sample)) print(f"{test_sample} 类别概率分别是: ", BP.predict_proba(test_sample)) test_sample = np.array([[-1.2, 10, -91]]) print(f"{test_sample} 类别是: ", BP.predict(test_sample)) print(f"{test_sample} 类别概率分别是: ", BP.predict_proba(test_sample)) test_sample = np.array([[-12, -0.1, -0.1]]) print(f"{test_sample} 类别是: ", BP.predict(test_sample)) print(f"{test_sample} 类别概率分别是: ", BP.predict_proba(test_sample)) test_sample = np.array([[100, -90.1, -9.1]]) print(f"{test_sample} 类别是: ", BP.predict(test_sample)) print(f"{test_sample} 类别概率分别是: ", BP.predict_proba(test_sample))[[-1. 0.1 0.1]] 类别是: [4] [[-1. 0.1 0.1]] 类别概率分别是: [[0.08380116 0.1912275 0.17608601 0.16488309 0.38400224]] [[ -1.2 10. -91. ]] 类别是: [1] [[ -1.2 10. -91. ]] 类别概率分别是: [[3.37231505e-30 1.00000000e+00 4.24566351e-51 1.92771500e-57 5.16916174e-17]] [[-12. -0.1 -0.1]] 类别是: [4] [[-12. -0.1 -0.1]] 类别概率分别是: [[1.42696980e-06 5.86057194e-05 2.99819240e-05 3.03896335e-05 9.99879596e-01]] [[100. -90.1 -9.1]] 类别是: [2] [[100. -90.1 -9.1]] 类别概率分别是: [[2.45024178e-02 8.44965777e-67 9.75497582e-01 1.41511057e-66 4.23516105e-50]] 3.2 Part 2 基于BP神经网络的乳腺癌分类实践Step1:库函数导入# 导入乳腺癌数据集 from sklearn.datasets import load_breast_cancer # 导入BP模型 from sklearn.neural_network import MLPClassifier # 导入训练集分割方法 from sklearn.model_selection import train_test_split # 导入预测指标计算函数和混淆矩阵计算函数 from sklearn.metrics import classification_report, confusion_matrix # 导入绘图包 import seaborn as sns import matplotlibStep2:数据读取/载入# 导入乳腺癌数据集 cancer = load_breast_cancer()Step3:数据信息简单查看与可视化# 查看数据集信息 print('breast_cancer数据集的长度为:',len(cancer)) print('breast_cancer数据集的类型为:',type(cancer)) # 分割数据为训练集和测试集 cancer_data = cancer['data'] print('cancer_data数据维度为:',cancer_data.shape) cancer_target = cancer['target'] print('cancer_target标签维度为:',cancer_target.shape) cancer_names = cancer['feature_names'] cancer_desc = cancer['DESCR'] #分为训练集与测试集 cancer_data_train,cancer_data_test = train_test_split(cancer_data,test_size=0.2,random_state=42)#训练集 cancer_target_train,cancer_target_test = train_test_split(cancer_target,test_size=0.2,random_state=42)#测试集breast_cancer数据集的长度为: 7 breast_cancer数据集的类型为: <class 'sklearn.utils.Bunch'> cancer_data数据维度为: (569, 30) cancer_target标签维度为: (569,) Step4:利用BP在乳腺癌数据上进行训练和预测# 建立 BP 模型, 采用Adam优化器,relu非线性映射函数 BP = MLPClassifier(solver='adam',activation = 'relu',max_iter = 1000,alpha = 1e-3,hidden_layer_sizes = (64,32, 32),random_state = 1) # 进行模型训练 BP.fit(cancer_data_train, cancer_target_train)MLPClassifier(alpha=0.001, hidden_layer_sizes=(64, 32, 32), max_iter=1000, random_state=1) # 进行模型预测 predict_train_labels = BP.predict(cancer_data_train) # 可视化真实数据 fig = plt.figure() ax = Axes3D(fig, rect=[0, 0, 1, 1], elev=20, azim=20) ax.scatter(cancer_data_train[:, 0], cancer_data_train[:, 1], cancer_data_train[:, 2], marker='o', c=cancer_target_train) plt.title('True Label Map') plt.show() # 可视化预测数据 fig = plt.figure() ax = Axes3D(fig, rect=[0, 0, 1, 1], elev=20, azim=20) ax.scatter(cancer_data_train[:, 0], cancer_data_train[:, 1], cancer_data_train[:, 2], marker='o', c=predict_train_labels) plt.title('Cancer with BP Model') plt.show()# 显示预测分数 print("预测准确率: {:.4f}".format(BP.score(cancer_data_test, cancer_target_test))) # 进行测试集数据的类别预测 predict_test_labels = BP.predict(cancer_data_test) print("测试集的真实标签:\n", cancer_target_test) print("测试集的预测标签:\n", predict_test_labels)预测准确率: 0.9474 测试集的真实标签: [1 0 0 1 1 0 0 0 1 1 1 0 1 0 1 0 1 1 1 0 0 1 0 1 1 1 1 1 1 0 1 1 1 1 1 1 0 1 0 1 1 0 1 1 1 1 1 1 1 1 0 0 1 1 1 1 1 0 0 1 1 0 0 1 1 1 0 0 1 1 0 0 1 0 1 1 1 0 1 1 0 1 0 0 0 0 0 0 1 1 1 1 1 1 1 1 0 0 1 0 0 1 0 0 1 1 1 0 1 1 0 1 1 0] 测试集的预测标签: [1 0 0 1 1 0 0 0 1 1 1 0 1 0 1 0 1 1 1 0 1 1 0 1 1 1 1 1 1 0 1 1 1 1 1 1 0 1 0 1 1 0 1 1 1 1 1 1 1 1 0 0 1 1 1 1 1 0 1 1 1 0 0 1 1 1 0 0 1 1 0 0 1 1 1 1 1 1 1 1 0 1 1 0 0 1 0 0 1 1 1 1 1 1 1 1 0 0 1 0 0 1 0 0 1 1 1 0 1 1 0 1 1 0] # 进行预测结果指标统计 统计每一类别的预测准确率、召回率、F1分数 print(classification_report(cancer_target_test, predict_test_labels)) precision recall f1-score support 0 1.00 0.86 0.92 43 1 0.92 1.00 0.96 71 accuracy 0.95 114 macro avg 0.96 0.93 0.94 114 weighted avg 0.95 0.95 0.95 114 # 计算混淆矩阵 confusion_mat = confusion_matrix(cancer_target_test, predict_test_labels) # 打混淆矩阵 print(confusion_mat)[[37 6] [ 0 71]] # 将混淆矩阵以热力图的防线显示 sns.set() figure, ax = plt.subplots() # 画热力图 sns.heatmap(confusion_mat, cmap="YlGnBu_r", annot=True, ax=ax) ax.set_title('confusion matrix') # x轴为预测类别 ax.set_xlabel('predict') # y轴实际类别 ax.set_ylabel('true') plt.show()4. 总结BP神经网络具有以下优点:1) 非线性映射能力:BP神经网络实质上实现了一个从输入到输出的映射功能,数学理论证明三层的神经网络就能够以任意精度逼近任何非线性连续函数。这使得其特别适合于求解内部机制复杂的问题,即BP神经网络具有较强的非线性映射能力。2) 自学习和自适应能力:BP神经网络在训练时,能够通过学习自动提取输入、输出数据间的“合理规则”,并自适应地将学习内容记忆于网络的权值中。即BP神经网络具有高度自学习和自适应的能力。3) 泛化能力:所谓泛化能力是指在设计模式分类器时,即要考虑网络在保证对所需分类对象进行正确分类,还要关心网络在经过训练后,能否对未见过的模式或有噪声污染的模式,进行正确的分类。也即BP神经网络具有将学习成果应用于新知识的能力。 BP神经网络具有以下缺点:1) 局部极小化问题:从数学角度看,传统的 BP神经网络为一种局部搜索的优化方法,它要解决的是一个复杂非线性化问题,网络的权值是通过沿局部改善的方向逐渐进行调整的,这样会使算法陷入局部极值,权值收敛到局部极小点,从而导致网络训练失败。加上BP神经网络对初始网络权重非常敏感,以不同的权重初始化网络,其往往会收敛于不同的局部极小,这也是每次训练得到不同结果的根本原因。2) BP 神经网络算法的收敛速度慢:由于BP神经网络算法本质上为梯度下降法,它所要优化的目标函数是非常复杂的,因此,必然会出现“锯齿形现象”,这使得BP算法低效;又由于优化的目标函数很复杂,它必然会在神经元输出接近0或1的情况下,出现一些平坦区,在这些区域内,权值误差改变很小,使训练过程几乎停顿;BP神经网络模型中,为了使网络执行BP算法,不能使用传统的一维搜索法求每次迭代的步长,而必须把步长的更新规则预先赋予网络,这种方法也会引起算法低效。以上种种,导致了BP神经网络算法收敛速度慢的现象。3) BP 神经网络结构选择不一:BP神经网络结构的选择至今尚无一种统一而完整的理论指导,一般只能由经验选定。网络结构选择过大,训练中效率不高,可能出现过拟合现象,造成网络性能低,容错性下降,若选择过小,则又会造成网络可能不收敛。而网络的结构直接影响网络的逼近能力及推广性质。因此,应用中如何选择合适的网络结构是一个重要的问题。 本项目链接:https://www.heywhale.com/home/column/64141d6b1c8c8b518ba97dcc参考链接:https://tianchi.aliyun.com/course/278/3425本人最近打算整合ML、DRL、NLP等相关领域的体系化项目课程,方便入门同学快速掌握相关知识。声明:部分项目为网络经典项目方便大家快速学习,后续会不断增添实战环节(比赛、论文、现实应用等)。对于机器学习这块规划为:基础入门机器学习算法--->简单项目实战--->数据建模比赛----->相关现实中应用场景问题解决。一条路线帮助大家学习,快速实战。对于深度强化学习这块规划为:基础单智能算法教学(gym环境为主)---->主流多智能算法教学(gym环境为主)---->单智能多智能题实战(论文复现偏业务如:无人机优化调度、电力资源调度等项目应用)自然语言处理相关规划:除了单点算法技术外,主要围绕知识图谱构建进行:信息抽取相关技术(含智能标注)--->知识融合---->知识推理---->图谱应用上述对于你掌握后的期许:对于ML,希望你后续可以乱杀数学建模相关比赛(参加就获奖保底,top还是难的需要钻研)可以实际解决现实中一些优化调度问题,而非停留在gym环境下的一些游戏demo玩玩。(更深层次可能需要自己钻研了,难度还是很大的)掌握可知识图谱全流程构建其中各个重要环节算法,包含图数据库相关知识。这三块领域耦合情况比较大,后续会通过比如:搜索推荐系统整个项目进行耦合,各项算法都会耦合在其中。举例:知识图谱就会用到(图算法、NLP、ML相关算法),搜索推荐系统(除了该领域召回粗排精排重排混排等算法外,还有强化学习、知识图谱等耦合在其中)。饼画的有点大,后面慢慢实现。
机器学习系列入门系列[七]:基于英雄联盟数据集的LightGBM的分类预测
1. 机器学习系列入门系列[七]:基于英雄联盟数据集的LightGBM的分类预测本项目链接:https://www.heywhale.com/home/column/64141d6b1c8c8b518ba97dcc1.1 LightGBM原理简介LightGBM是2017年由微软推出的可扩展机器学习系统,是微软旗下DMKT的一个开源项目,它是一款基于GBDT(梯度提升决策树)算法的分布式梯度提升框架,为了满足缩短模型计算时间的需求,LightGBM的设计思路主要集中在减小数据对内存与计算性能的使用,以及减少多机器并行计算时的通讯代价。LightGBM可以看作是XGBoost的升级豪华版,在获得与XGBoost近似精度的同时,又提供了更快的训练速度与更少的内存消耗。正如其名字中的Light所蕴含的那样,LightGBM在大规模数据集上跑起来更加优雅轻盈,一经推出便成为各种数据竞赛中刷榜夺冠的神兵利器。LightGBM底层实现了GBDT算法,并且添加了一系列的新特性:基于直方图算法进行优化,使数据存储更加方便、运算更快、鲁棒性强、模型更加稳定等。提出了带深度限制的 Leaf-wise 算法,抛弃了大多数GBDT工具使用的按层生长 (level-wise) 的决策树生长策略,而使用了带有深度限制的按叶子生长策略,可以降低误差,得到更好的精度。提出了单边梯度采样算法,排除大部分小梯度的样本,仅用剩下的样本计算信息增益,它是一种在减少数据量和保证精度上平衡的算法。提出了互斥特征捆绑算法,高维度的数据往往是稀疏的,这种稀疏性启发我们设计一种无损的方法来减少特征的维度。通常被捆绑的特征都是互斥的(即特征不会同时为非零值,像one-hot),这样两个特征捆绑起来就不会丢失信息。LightGBM是基于CART树的集成模型,它的思想是串联多个决策树模型共同进行决策。那么如何串联呢?LightGBM采用迭代预测误差的方法串联。举个通俗的例子,我们现在需要预测一辆车价值3000元。我们构建决策树1训练后预测为2600元,我们发现有400元的误差,那么决策树2的训练目标为400元,但决策树2的预测结果为350元,还存在50元的误差就交给第三棵树……以此类推,每一颗树用来估计之前所有树的误差,最后所有树预测结果的求和就是最终预测结果!LightGBM的基模型是CART回归树,它有两个特点:(1)CART树,是一颗二叉树。(2)回归树,最后拟合结果是连续值。LightGBM模型可以表示为以下形式,我们约定$f_t(x)$表示前$t$颗树的和,$h_t(x)$表示第$t$颗决策树,模型定义如下:$f_{t}(x)=\sum_{t=1}^{T} h_{t}(x)$由于模型递归生成,第$t$步的模型由第$t-1$步的模型形成,可以写成:$f_{t}(x)=f_{t-1}(x)+h_{t}(x)$每次需要加上的树$h_t(x)$是之前树求和的误差:$r_{t, i}=y_{i}-f_{m-1}\left(x_{i}\right)$我们每一步只要拟合一颗输出为$r_{t,i}$的CART树加到$f_{t-1}(x)$就可以了。1.2 LightGBM的应用LightGBM在机器学习与数据挖掘领域有着极为广泛的应用。据统计LightGBM模型自2016到2019年在Kaggle平台上累积获得数据竞赛前三名三十余次,其中包括CIKM2017 AnalytiCup、IEEE Fraud Detection等知名竞赛。这些竞赛来源于各行各业的真实业务,这些竞赛成绩表明LightGBM具有很好的可扩展性,在各类不同问题上都可以取得非常好的效果。同时,LightGBM还被成功应用在工业界与学术界的各种问题中。例如金融风控、购买行为识别、交通流量预测、环境声音分类、基因分类、生物成分分析等诸多领域。虽然领域相关的数据分析和特性工程在这些解决方案中也发挥了重要作用,但学习者与实践者对LightGBM的一致选择表明了这一软件包的影响力与重要性。2.相关流程了解 LightGBM 的参数与相关知识掌握 LightGBM 的Python调用并将其运用到英雄联盟游戏胜负预测数据集上Part1 基于英雄联盟数据集的LightGBM分类实践Step1: 库函数导入Step2: 数据读取/载入Step3: 数据信息简单查看Step4: 可视化描述Step5: 利用 LightGBM 进行训练与预测Step6: 利用 LightGBM 进行特征选择Step7: 通过调整参数获得更好的效果3.基于英雄联盟数据集的LightGBM分类实战在实践的最开始,我们首先需要导入一些基础的函数库包括:numpy (Python进行科学计算的基础软件包),pandas(pandas是一种快速,强大,灵活且易于使用的开源数据分析和处理工具),matplotlib和seaborn绘图。#下载需要用到的数据集 !wget https://tianchi-media.oss-cn-beijing.aliyuncs.com/DSW/8LightGBM/high_diamond_ranked_10min.csv--2023-03-22 19:33:36-- https://tianchi-media.oss-cn-beijing.aliyuncs.com/DSW/8LightGBM/high_diamond_ranked_10min.csv 正在解析主机 tianchi-media.oss-cn-beijing.aliyuncs.com (tianchi-media.oss-cn-beijing.aliyuncs.com)... 49.7.22.39 正在连接 tianchi-media.oss-cn-beijing.aliyuncs.com (tianchi-media.oss-cn-beijing.aliyuncs.com)|49.7.22.39|:443... 已连接。 已发出 HTTP 请求,正在等待回应... 200 OK 长度: 1446502 (1.4M) [text/csv] 正在保存至: “high_diamond_ranked_10min.csv” high_diamond_ranked 100%[===================>] 1.38M --.-KB/s in 0.04s 2023-03-22 19:33:36 (38.3 MB/s) - 已保存 “high_diamond_ranked_10min.csv” [1446502/1446502]) Step1:函数库导入## 基础函数库 import numpy as np import pandas as pd ## 绘图函数库 import matplotlib.pyplot as plt import seaborn as sns本次我们选择英雄联盟数据集进行LightGBM的场景体验。英雄联盟是2009年美国拳头游戏开发的MOBA竞技网游,在每局比赛中蓝队与红队在同一个地图进行作战,游戏的目标是破坏敌方队伍的防御塔,进而摧毁敌方的水晶枢纽,拿下比赛的胜利。现在共有9881场英雄联盟韩服钻石段位以上的排位比赛数据,数据提供了在十分钟时的游戏状态,包括击杀数、死亡数、金币数量、经验值、等级……等信息。列blueWins是数据的标签,代表了本场比赛是否为蓝队获胜。数据的各个特征描述如下:特征名称特征意义取值范围 WardsPlaced插眼数量整数 WardsDestroyed拆眼数量整数 FirstBlood是否获得首次击杀整数 Kills击杀英雄数量整数 Deaths死亡数量整数 Assists助攻数量整数 EliteMonsters击杀大型野怪数量整数 Dragons击杀史诗野怪数量整数 Heralds击杀峡谷先锋数量整数 TowersDestroyed推塔数量整数 TotalGold总经济整数 AvgLevel平均英雄等级浮点数 TotalExperience英雄总经验整数 TotalMinionsKilled英雄补兵数量整数 TotalJungleMinionsKilled英雄击杀野怪数量整数 GoldDiff经济差距整数 ExperienceDiff经验差距整数 CSPerMin分均补刀浮点数 GoldPerMin分均经济浮点数 Step2:数据读取/载入## 我们利用Pandas自带的read_csv函数读取并转化为DataFrame格式 df = pd.read_csv('./high_diamond_ranked_10min.csv') y = df.blueWinsStep3:数据信息简单查看## 利用.info()查看数据的整体信息 df.info()<class 'pandas.core.frame.DataFrame'> RangeIndex: 9879 entries, 0 to 9878 Data columns (total 40 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 gameId 9879 non-null int64 1 blueWins 9879 non-null int64 2 blueWardsPlaced 9879 non-null int64 3 blueWardsDestroyed 9879 non-null int64 4 blueFirstBlood 9879 non-null int64 5 blueKills 9879 non-null int64 6 blueDeaths 9879 non-null int64 7 blueAssists 9879 non-null int64 8 blueEliteMonsters 9879 non-null int64 9 blueDragons 9879 non-null int64 10 blueHeralds 9879 non-null int64 11 blueTowersDestroyed 9879 non-null int64 12 blueTotalGold 9879 non-null int64 13 blueAvgLevel 9879 non-null float64 14 blueTotalExperience 9879 non-null int64 15 blueTotalMinionsKilled 9879 non-null int64 16 blueTotalJungleMinionsKilled 9879 non-null int64 17 blueGoldDiff 9879 non-null int64 18 blueExperienceDiff 9879 non-null int64 19 blueCSPerMin 9879 non-null float64 20 blueGoldPerMin 9879 non-null float64 21 redWardsPlaced 9879 non-null int64 22 redWardsDestroyed 9879 non-null int64 23 redFirstBlood 9879 non-null int64 24 redKills 9879 non-null int64 25 redDeaths 9879 non-null int64 26 redAssists 9879 non-null int64 27 redEliteMonsters 9879 non-null int64 28 redDragons 9879 non-null int64 29 redHeralds 9879 non-null int64 30 redTowersDestroyed 9879 non-null int64 31 redTotalGold 9879 non-null int64 32 redAvgLevel 9879 non-null float64 33 redTotalExperience 9879 non-null int64 34 redTotalMinionsKilled 9879 non-null int64 35 redTotalJungleMinionsKilled 9879 non-null int64 36 redGoldDiff 9879 non-null int64 37 redExperienceDiff 9879 non-null int64 38 redCSPerMin 9879 non-null float64 39 redGoldPerMin 9879 non-null float64 dtypes: float64(6), int64(34) memory usage: 3.0 MB ## 进行简单的数据查看,我们可以利用 .head() 头部.tail()尾部 df.head() gameId blueWins blueWardsPlaced blueWardsDestroyed blueFirstBlood blueKills blueDeaths blueAssists blueEliteMonsters blueDragons redTowersDestroyed redTotalGold redAvgLevel redTotalExperience redTotalMinionsKilled redTotalJungleMinionsKilled redGoldDiff redExperienceDiff redCSPerMin redGoldPerMin 4519157822 16567 17047 1656.7 4523371949 17620 17438 1762.0 4521474530 17285 17254 1728.5 4524384067 16478 17961 1647.8 4436033771 17404 18313 1740.4 5 rows × 40 columns df.tail() gameId blueWins blueWardsPlaced blueWardsDestroyed blueFirstBlood blueKills blueDeaths blueAssists blueEliteMonsters blueDragons redTowersDestroyed redTotalGold redAvgLevel redTotalExperience redTotalMinionsKilled redTotalJungleMinionsKilled redGoldDiff redExperienceDiff redCSPerMin redGoldPerMin 4527873286 15246 16498 -2519 -2469 1524.6 4527797466 15456 18367 1545.6 4527713716 18319 19909 1831.9 4527628313 15298 18314 1529.8 4523772935 15339 17379 1533.9 5 rows × 40 columns ## 标注标签并利用value_counts函数查看训练集标签的数量 y = df.blueWins y.value_counts()0 4949 1 4930 Name: blueWins, dtype: int64 数据集正负标签数量基本相同,不存在数据不平衡的问题。## 标注特征列 drop_cols = ['gameId','blueWins'] x = df.drop(drop_cols, axis=1)## 对于特征进行一些统计描述 x.describe() blueWardsPlaced blueWardsDestroyed blueFirstBlood blueKills blueDeaths blueAssists blueEliteMonsters blueDragons blueHeralds blueTowersDestroyed redTowersDestroyed redTotalGold redAvgLevel redTotalExperience redTotalMinionsKilled redTotalJungleMinionsKilled redGoldDiff redExperienceDiff redCSPerMin redGoldPerMin count 9879.000000 9879.000000 9879.000000 9879.000000 9879.000000 9879.000000 9879.000000 9879.000000 9879.000000 9879.000000 9879.000000 9879.000000 9879.000000 9879.000000 9879.000000 9879.000000 9879.000000 9879.000000 9879.000000 9879.000000 22.288288 2.824881 0.504808 6.183925 6.137666 6.645106 0.549954 0.361980 0.187974 0.051422 0.043021 16489.041401 6.925316 17961.730438 217.349226 51.313088 -14.414111 33.620306 21.734923 1648.904140 18.019177 2.174998 0.500002 3.011028 2.933818 4.064520 0.625527 0.480597 0.390712 0.244369 0.216900 1490.888406 0.305311 1198.583912 21.911668 10.027885 2453.349179 1920.370438 2.191167 149.088841 5.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 11212.000000 4.800000 10465.000000 107.000000 4.000000 -11467.000000 -8348.000000 10.700000 1121.200000 14.000000 1.000000 0.000000 4.000000 4.000000 4.000000 0.000000 0.000000 0.000000 0.000000 0.000000 15427.500000 6.800000 17209.500000 203.000000 44.000000 -1596.000000 -1212.000000 20.300000 1542.750000 16.000000 3.000000 1.000000 6.000000 6.000000 6.000000 0.000000 0.000000 0.000000 0.000000 0.000000 16378.000000 7.000000 17974.000000 218.000000 51.000000 -14.000000 28.000000 21.800000 1637.800000 20.000000 4.000000 1.000000 8.000000 8.000000 9.000000 1.000000 1.000000 0.000000 0.000000 0.000000 17418.500000 7.200000 18764.500000 233.000000 57.000000 1585.500000 1290.500000 23.300000 1741.850000 250.000000 27.000000 1.000000 22.000000 22.000000 29.000000 2.000000 1.000000 1.000000 4.000000 2.000000 22732.000000 8.200000 22269.000000 289.000000 92.000000 10830.000000 9333.000000 28.900000 2273.200000 8 rows × 38 columns 我们发现不同对局中插眼数和拆眼数的取值范围存在明显差距,甚至有前十分钟插了250个眼的异常值。我们发现EliteMonsters的取值相当于Deagons + Heralds。我们发现TotalGold 等变量在大部分对局中差距不大。我们发现两支队伍的经济差和经验差是相反数。我们发现红队和蓝队拿到首次击杀的概率大概都是50%## 根据上面的描述,我们可以去除一些重复变量,比如只要知道蓝队是否拿到一血,我们就知道红队有没有拿到,可以去除红队的相关冗余数据。 drop_cols = ['redFirstBlood','redKills','redDeaths' ,'redGoldDiff','redExperienceDiff', 'blueCSPerMin', 'blueGoldPerMin','redCSPerMin','redGoldPerMin'] x.drop(drop_cols, axis=1, inplace=True)Step4:可视化描述data = x data_std = (data - data.mean()) / data.std() data = pd.concat([y, data_std.iloc[:, 0:9]], axis=1) data = pd.melt(data, id_vars='blueWins', var_name='Features', value_name='Values') fig, ax = plt.subplots(1,2,figsize=(15,5)) # 绘制小提琴图 sns.violinplot(x='Features', y='Values', hue='blueWins', data=data, split=True, inner='quart', ax=ax[0], palette='Blues') fig.autofmt_xdate(rotation=45) data = x data_std = (data - data.mean()) / data.std() data = pd.concat([y, data_std.iloc[:, 9:18]], axis=1) data = pd.melt(data, id_vars='blueWins', var_name='Features', value_name='Values') # 绘制小提琴图 sns.violinplot(x='Features', y='Values', hue='blueWins', data=data, split=True, inner='quart', ax=ax[1], palette='Blues') fig.autofmt_xdate(rotation=45) plt.show()小提琴图 (Violin Plot)是用来展示多组数据的分布状态以及概率密度。这种图表结合了箱形图和密度图的特征,主要用来显示数据的分布形状。从图中我们可以看出:击杀英雄数量越多更容易赢,死亡数量越多越容易输(bluekills与bluedeaths左右的区别)。助攻数量与击杀英雄数量形成的图形状类似,说明他们对游戏结果的影响差不多。一血的取得情况与获胜有正相关,但是相关性不如击杀英雄数量明显。经济差与经验差对于游戏胜负的影响较小。击杀野怪数量对游戏胜负的影响并不大。plt.figure(figsize=(18,14)) sns.heatmap(round(x.corr(),2), cmap='Blues', annot=True) plt.show()同时我们画出各个特征之间的相关性热力图,颜色越深代表特征之间相关性越强,我们剔除那些相关性较强的冗余特征。# 去除冗余特征 drop_cols = ['redAvgLevel','blueAvgLevel'] x.drop(drop_cols, axis=1, inplace=True)sns.set(style='whitegrid', palette='muted') # 构造两个新特征 x['wardsPlacedDiff'] = x['blueWardsPlaced'] - x['redWardsPlaced'] x['wardsDestroyedDiff'] = x['blueWardsDestroyed'] - x['redWardsDestroyed'] data = x[['blueWardsPlaced','blueWardsDestroyed','wardsPlacedDiff','wardsDestroyedDiff']].sample(1000) data_std = (data - data.mean()) / data.std() data = pd.concat([y, data_std], axis=1) data = pd.melt(data, id_vars='blueWins', var_name='Features', value_name='Values') plt.figure(figsize=(10,6)) sns.swarmplot(x='Features', y='Values', hue='blueWins', data=data) plt.xticks(rotation=45) plt.show()我们画出了插眼数量的散点图,发现不存在插眼数量与游戏胜负间的显著规律。猜测由于钻石分段以上在哪插眼在哪好排眼都是套路,所以数据中前十分钟插眼数拔眼数对游戏的影响不大。所以我们暂时先把这些特征去掉。## 去除和眼位相关的特征 drop_cols = ['blueWardsPlaced','blueWardsDestroyed','wardsPlacedDiff', 'wardsDestroyedDiff','redWardsPlaced','redWardsDestroyed'] x.drop(drop_cols, axis=1, inplace=True)x['killsDiff'] = x['blueKills'] - x['blueDeaths'] x['assistsDiff'] = x['blueAssists'] - x['redAssists'] x[['blueKills','blueDeaths','blueAssists','killsDiff','assistsDiff','redAssists']].hist(figsize=(12,10), bins=20) plt.show()我们发现击杀、死亡与助攻数的数据分布差别不大。但是击杀减去死亡、助攻减去死亡的分布与原分布差别很大,因此我们新构造这么两个特征。 data = x[['blueKills','blueDeaths','blueAssists','killsDiff','assistsDiff','redAssists']].sample(1000) data_std = (data - data.mean()) / data.std() data = pd.concat([y, data_std], axis=1) data = pd.melt(data, id_vars='blueWins', var_name='Features', value_name='Values') plt.figure(figsize=(10,6)) sns.swarmplot(x='Features', y='Values', hue='blueWins', data=data) plt.xticks(rotation=45) plt.show()从上图我们可以发现击杀数与死亡数与助攻数,以及我们构造的特征对数据都有较好的分类能力。data = pd.concat([y, x], axis=1).sample(500) sns.pairplot(data, vars=['blueKills','blueDeaths','blueAssists','killsDiff','assistsDiff','redAssists'], hue='blueWins') plt.show()一些特征两两组合后对于数据的划分能力也有提升。x['dragonsDiff'] = x['blueDragons'] - x['redDragons'] x['heraldsDiff'] = x['blueHeralds'] - x['redHeralds'] x['eliteDiff'] = x['blueEliteMonsters'] - x['redEliteMonsters'] data = pd.concat([y, x], axis=1) eliteGroup = data.groupby(['eliteDiff'])['blueWins'].mean() dragonGroup = data.groupby(['dragonsDiff'])['blueWins'].mean() heraldGroup = data.groupby(['heraldsDiff'])['blueWins'].mean() fig, ax = plt.subplots(1,3, figsize=(15,4)) eliteGroup.plot(kind='bar', ax=ax[0]) dragonGroup.plot(kind='bar', ax=ax[1]) heraldGroup.plot(kind='bar', ax=ax[2]) print(eliteGroup) print(dragonGroup) print(heraldGroup) plt.show()eliteDiff -2 0.286301 -1 0.368772 0 0.500683 1 0.632093 2 0.735211 Name: blueWins, dtype: float64 dragonsDiff -1 0.374173 0 0.500000 1 0.640940 Name: blueWins, dtype: float64 heraldsDiff -1 0.387729 0 0.498680 1 0.595046 Name: blueWins, dtype: float64 我们构造了两队之间是否拿到龙、是否拿到峡谷先锋、击杀大型野怪的数量差值,发现在游戏的前期拿到龙比拿到峡谷先锋更容易获得胜利。拿到大型野怪的数量和胜率也存在着强相关。x['towerDiff'] = x['blueTowersDestroyed'] - x['redTowersDestroyed'] data = pd.concat([y, x], axis=1) towerGroup = data.groupby(['towerDiff'])['blueWins'] print(towerGroup.count()) print(towerGroup.mean()) fig, ax = plt.subplots(1,2,figsize=(15,5)) towerGroup.mean().plot(kind='line', ax=ax[0]) ax[0].set_title('Proportion of Blue Wins') ax[0].set_ylabel('Proportion') towerGroup.count().plot(kind='line', ax=ax[1]) ax[1].set_title('Count of Towers Destroyed') ax[1].set_ylabel('Count')towerDiff -2 27 -1 347 0 9064 1 406 2 28 3 6 4 1 Name: blueWins, dtype: int64 towerDiff -2 0.185185 -1 0.216138 0 0.498124 1 0.741379 2 0.964286 3 1.000000 4 1.000000 Name: blueWins, dtype: float64 推塔是英雄联盟这个游戏的核心,因此推塔数量可能与游戏的胜负有很大关系。我们绘图发现,尽管前十分钟推掉第一座防御塔的概率很低,但是一旦某只队伍推掉第一座防御塔,获得游戏的胜率将大大增加。Step5:利用 LightGBM 进行训练与预测## 为了正确评估模型性能,将数据划分为训练集和测试集,并在训练集上训练模型,在测试集上验证模型性能。 from sklearn.model_selection import train_test_split ## 选择其类别为0和1的样本 (不包括类别为2的样本) data_target_part = y data_features_part = x ## 测试集大小为20%, 80%/20%分 x_train, x_test, y_train, y_test = train_test_split(data_features_part, data_target_part, test_size = 0.2, random_state = 2020)## 导入LightGBM模型 from lightgbm.sklearn import LGBMClassifier ## 定义 LightGBM 模型 clf = LGBMClassifier() # 在训练集上训练LightGBM模型 clf.fit(x_train, y_train)LGBMClassifier() ## 在训练集和测试集上分布利用训练好的模型进行预测 train_predict = clf.predict(x_train) test_predict = clf.predict(x_test) from sklearn import metrics ## 利用accuracy(准确度)【预测正确的样本数目占总预测样本数目的比例】评估模型效果 print('The accuracy of the Logistic Regression is:',metrics.accuracy_score(y_train,train_predict)) print('The accuracy of the Logistic Regression is:',metrics.accuracy_score(y_test,test_predict)) ## 查看混淆矩阵 (预测值和真实值的各类情况统计矩阵) confusion_matrix_result = metrics.confusion_matrix(test_predict,y_test) print('The confusion matrix result:\n',confusion_matrix_result) # 利用热力图对于结果进行可视化 plt.figure(figsize=(8, 6)) sns.heatmap(confusion_matrix_result, annot=True, cmap='Blues') plt.xlabel('Predicted labels') plt.ylabel('True labels') plt.show()The accuracy of the Logistic Regression is: 0.8447425028470201 The accuracy of the Logistic Regression is: 0.722165991902834 The confusion matrix result: [[714 300] [249 713]] 我们可以发现共有718 + 707个样本预测正确,306 + 245个样本预测错误。Step7: 利用 LightGBM 进行特征选择LightGBM的特征选择属于特征选择中的嵌入式方法,在LightGBM中可以用属性feature_importances_去查看特征的重要度。sns.barplot(y=data_features_part.columns, x=clf.feature_importances_)<matplotlib.axes._subplots.AxesSubplot at 0x7fcb1048e350> 总经济差距等特征,助攻数量、击杀死亡数量等特征都具有很大的作用。插眼数、推塔数对模型的影响并不大。初次之外,我们还可以使用LightGBM中的下列重要属性来评估特征的重要性。gain:当利用特征做划分的时候的评价基尼指数split:是以特征用到的次数来评价from sklearn.metrics import accuracy_score from lightgbm import plot_importance def estimate(model,data): #sns.barplot(data.columns,model.feature_importances_) ax1=plot_importance(model,importance_type="gain") ax1.set_title('gain') ax2=plot_importance(model, importance_type="split") ax2.set_title('split') plt.show() def classes(data,label,test): model=LGBMClassifier() model.fit(data,label) ans=model.predict(test) estimate(model, data) return ans ans=classes(x_train,y_train,x_test) pre=accuracy_score(y_test, ans) print('acc=',accuracy_score(y_test,ans)) acc= 0.722165991902834 这些图同样可以帮助我们更好的了解其他重要特征。Step8: 通过调整参数获得更好的效果LightGBM中包括但不限于下列对模型影响较大的参数:learning_rate: 有时也叫作eta,系统默认值为0.3。每一步迭代的步长,很重要。太大了运行准确率不高,太小了运行速度慢。num_leaves:系统默认为32。这个参数控制每棵树中最大叶子节点数量。feature_fraction:系统默认值为1。我们一般设置成0.8左右。用来控制每棵随机采样的列数的占比(每一列是一个特征)。max_depth: 系统默认值为6,我们常用3-10之间的数字。这个值为树的最大深度。这个值是用来控制过拟合的。max_depth越大,模型学习的更加具体。调节模型参数的方法有贪心算法、网格调参、贝叶斯调参等。这里我们采用网格调参,它的基本思想是穷举搜索:在所有候选的参数选择中,通过循环遍历,尝试每一种可能性,表现最好的参数就是最终的结果## 从sklearn库中导入网格调参函数 from sklearn.model_selection import GridSearchCV ## 定义参数取值范围 learning_rate = [0.1, 0.3, 0.6] feature_fraction = [0.5, 0.8, 1] num_leaves = [16, 32, 64] max_depth = [-1,3,5,8] parameters = { 'learning_rate': learning_rate, 'feature_fraction':feature_fraction, 'num_leaves': num_leaves, 'max_depth': max_depth} model = LGBMClassifier(n_estimators = 50) ## 进行网格搜索 clf = GridSearchCV(model, parameters, cv=3, scoring='accuracy',verbose=3, n_jobs=-1) clf = clf.fit(x_train, y_train)[CV 1/3] END feature_fraction=1, learning_rate=0.6, max_depth=8, num_leaves=64;, score=0.672 total time= 0.1s [CV 3/3] END feature_fraction=1, learning_rate=0.6, max_depth=8, num_leaves=64;, score=0.685 total time= 0.1s [LightGBM] [Warning] feature_fraction is set=1, colsample_bytree=1.0 will be ignored. Current value: feature_fraction=1 ## 网格搜索后的最好参数为 clf.best_params_{'feature_fraction': 1, 'learning_rate': 0.1, 'max_depth': 3, 'num_leaves': 16} ## 在训练集和测试集上分布利用最好的模型参数进行预测 ## 定义带参数的 LightGBM模型 clf = LGBMClassifier(feature_fraction = 0.8, learning_rate = 0.1, max_depth= 3, num_leaves = 16) # 在训练集上训练LightGBM模型 clf.fit(x_train, y_train) train_predict = clf.predict(x_train) test_predict = clf.predict(x_test) ## 利用accuracy(准确度)【预测正确的样本数目占总预测样本数目的比例】评估模型效果 print('The accuracy of the Logistic Regression is:',metrics.accuracy_score(y_train,train_predict)) print('The accuracy of the Logistic Regression is:',metrics.accuracy_score(y_test,test_predict)) ## 查看混淆矩阵 (预测值和真实值的各类情况统计矩阵) confusion_matrix_result = metrics.confusion_matrix(test_predict,y_test) print('The confusion matrix result:\n',confusion_matrix_result) # 利用热力图对于结果进行可视化 plt.figure(figsize=(8, 6)) sns.heatmap(confusion_matrix_result, annot=True, cmap='Blues') plt.xlabel('Predicted labels') plt.ylabel('True labels') plt.show()The accuracy of the Logistic Regression is: 0.7440212577502214 The accuracy of the Logistic Regression is: 0.7317813765182186 The confusion matrix result: [[722 289] [241 724]] 原本有306 + 245个错误,现在有 287 + 230个错误,带来了明显的正确率提升。3.1基本参数调整num_leaves参数 这是控制树模型复杂度的主要参数,一般的我们会使num_leaves小于(2的max_depth次方),以防止过拟合。由于LightGBM是leaf-wise建树与XGBoost的depth-wise建树方法不同,num_leaves比depth有更大的作用。、min_data_in_leaf 这是处理过拟合问题中一个非常重要的参数. 它的值取决于训练数据的样本个树和 num_leaves参数. 将其设置的较大可以避免生成一个过深的树, 但有可能导致欠拟合. 实际应用中, 对于大数据集, 设置其为几百或几千就足够了.max_depth 树的深度,depth 的概念在 leaf-wise 树中并没有多大作用, 因为并不存在一个从 leaves 到 depth 的合理映射。3.2针对训练速度的参数调整通过设置 bagging_fraction 和 bagging_freq 参数来使用 bagging 方法。通过设置 feature_fraction 参数来使用特征的子抽样。选择较小的 max_bin 参数。使用 save_binary 在未来的学习过程对数据加载进行加速。3.3针对准确率的参数调整使用较大的 max_bin (学习速度可能变慢)使用较小的 learning_rate 和较大的 num_iterations使用较大的 num_leaves (可能导致过拟合)使用更大的训练数据尝试 dart 模式3.4针对过拟合的参数调整使用较小的 max_bin使用较小的 num_leaves使用 min_data_in_leaf 和 min_sum_hessian_in_leaf通过设置 bagging_fraction 和 bagging_freq 来使用 bagging通过设置 feature_fraction 来使用特征子抽样使用更大的训练数据使用 lambda_l1, lambda_l2 和 min_gain_to_split 来使用正则尝试 max_depth 来避免生成过深的树4.总结LightGBM的主要优点:简单易用。提供了主流的Python\C++\R语言接口,用户可以轻松使用LightGBM建模并获得相当不错的效果。高效可扩展。在处理大规模数据集时高效迅速、高准确度,对内存等硬件资源要求不高。鲁棒性强。相较于深度学习模型不需要精细调参便能取得近似的效果。LightGBM直接支持缺失值与类别特征,无需对数据额外进行特殊处理LightGBM的主要缺点:相对于深度学习模型无法对时空位置建模,不能很好地捕获图像、语音、文本等高维数据。在拥有海量训练数据,并能找到合适的深度学习模型时,深度学习的精度可以遥遥领先LightGBM。本项目链接:https://www.heywhale.com/home/column/64141d6b1c8c8b518ba97dcc参考链接:https://tianchi.aliyun.com/course/278/3424本人最近打算整合ML、DRL、NLP等相关领域的体系化项目课程,方便入门同学快速掌握相关知识。声明:部分项目为网络经典项目方便大家快速学习,后续会不断增添实战环节(比赛、论文、现实应用等)。对于机器学习这块规划为:基础入门机器学习算法--->简单项目实战--->数据建模比赛----->相关现实中应用场景问题解决。一条路线帮助大家学习,快速实战。对于深度强化学习这块规划为:基础单智能算法教学(gym环境为主)---->主流多智能算法教学(gym环境为主)---->单智能多智能题实战(论文复现偏业务如:无人机优化调度、电力资源调度等项目应用)自然语言处理相关规划:除了单点算法技术外,主要围绕知识图谱构建进行:信息抽取相关技术(含智能标注)--->知识融合---->知识推理---->图谱应用上述对于你掌握后的期许:对于ML,希望你后续可以乱杀数学建模相关比赛(参加就获奖保底,top还是难的需要钻研)可以实际解决现实中一些优化调度问题,而非停留在gym环境下的一些游戏demo玩玩。(更深层次可能需要自己钻研了,难度还是很大的)掌握可知识图谱全流程构建其中各个重要环节算法,包含图数据库相关知识。这三块领域耦合情况比较大,后续会通过比如:搜索推荐系统整个项目进行耦合,各项算法都会耦合在其中。举例:知识图谱就会用到(图算法、NLP、ML相关算法),搜索推荐系统(除了该领域召回粗排精排重排混排等算法外,还有强化学习、知识图谱等耦合在其中)。饼画的有点大,后面慢慢实现。
机器学习算法(六)基于天气数据集的XGBoost分类预测
1.机器学习算法(六)基于天气数据集的XGBoost分类预测本项目链接:https://www.heywhale.com/home/column/64141d6b1c8c8b518ba97dcc1.1 XGBoost的介绍与应用XGBoost是2016年由华盛顿大学陈天奇老师带领开发的一个可扩展机器学习系统。严格意义上讲XGBoost并不是一种模型,而是一个可供用户轻松解决分类、回归或排序问题的软件包。它内部实现了梯度提升树(GBDT)模型,并对模型中的算法进行了诸多优化,在取得高精度的同时又保持了极快的速度,在一段时间内成为了国内外数据挖掘、机器学习领域中的大规模杀伤性武器。更重要的是,XGBoost在系统优化和机器学习原理方面都进行了深入的考虑。毫不夸张的讲,XGBoost提供的可扩展性,可移植性与准确性推动了机器学习计算限制的上限,该系统在单台机器上运行速度比当时流行解决方案快十倍以上,甚至在分布式系统中可以处理十亿级的数据。XGBoost在机器学习与数据挖掘领域有着极为广泛的应用。据统计在2015年Kaggle平台上29个获奖方案中,17只队伍使用了XGBoost;在2015年KDD-Cup中,前十名的队伍均使用了XGBoost,且集成其他模型比不上调节XGBoost的参数所带来的提升。这些实实在在的例子都表明,XGBoost在各种问题上都可以取得非常好的效果。同时,XGBoost还被成功应用在工业界与学术界的各种问题中。例如商店销售额预测、高能物理事件分类、web文本分类;用户行为预测、运动检测、广告点击率预测、恶意软件分类、灾害风险预测、在线课程退学率预测。虽然领域相关的数据分析和特性工程在这些解决方案中也发挥了重要作用,但学习者与实践者对XGBoost的一致选择表明了这一软件包的影响力与重要性。1.2 原理介绍XGBoost底层实现了GBDT算法,并对GBDT算法做了一系列优化:对目标函数进行了泰勒展示的二阶展开,可以更加高效拟合误差。提出了一种估计分裂点的算法加速CART树的构建过程,同时可以处理稀疏数据。提出了一种树的并行策略加速迭代。为模型的分布式算法进行了底层优化。XGBoost是基于CART树的集成模型,它的思想是串联多个决策树模型共同进行决策。那么如何串联呢?XGBoost采用迭代预测误差的方法串联。举个通俗的例子,我们现在需要预测一辆车价值3000元。我们构建决策树1训练后预测为2600元,我们发现有400元的误差,那么决策树2的训练目标为400元,但决策树2的预测结果为350元,还存在50元的误差就交给第三棵树……以此类推,每一颗树用来估计之前所有树的误差,最后所有树预测结果的求和就是最终预测结果!XGBoost的基模型是CART回归树,它有两个特点:(1)CART树,是一颗二叉树。(2)回归树,最后拟合结果是连续值。XGBoost模型可以表示为以下形式,我们约定$f_t(x)$表示前$t$颗树的和,$h_t(x)$表示第$t$颗决策树,模型定义如下:$f_{t}(x)=\sum_{t=1}^{T} h_{t}(x)$由于模型递归生成,第$t$步的模型由第$t-1$步的模型形成,可以写成:$f_{t}(x)=f_{t-1}(x)+h_{t}(x)$每次需要加上的树$h_t(x)$是之前树求和的误差:$r_{t, i}=y_{i}-f_{m-1}\left(x_{i}\right)$我们每一步只要拟合一颗输出为$r_{t,i}$的CART树加到$f_{t-1}(x)$就可以了。1.3 相关流程了解 XGBoost 的参数与相关知识掌握 XGBoost 的Python调用并将其运用到天气数据集预测Part1 基于天气数据集的XGBoost分类实践Step1: 库函数导入Step2: 数据读取/载入Step3: 数据信息简单查看Step4: 可视化描述Step5: 对离散变量进行编码Step6: 利用 XGBoost 进行训练与预测Step7: 利用 XGBoost 进行特征选择Step8: 通过调整参数获得更好的效果3.基于天气数据集的XGBoost分类实战3.1 EDA探索性分析在实践的最开始,我们首先需要导入一些基础的函数库包括:numpy (Python进行科学计算的基础软件包),pandas(pandas是一种快速,强大,灵活且易于使用的开源数据分析和处理工具),matplotlib和seaborn绘图。#导入需要用到的数据集 !wget https://tianchi-media.oss-cn-beijing.aliyuncs.com/DSW/7XGBoost/train.csv--2023-03-22 17:33:53-- https://tianchi-media.oss-cn-beijing.aliyuncs.com/DSW/7XGBoost/train.csv 正在解析主机 tianchi-media.oss-cn-beijing.aliyuncs.com (tianchi-media.oss-cn-beijing.aliyuncs.com)... 49.7.22.39 正在连接 tianchi-media.oss-cn-beijing.aliyuncs.com (tianchi-media.oss-cn-beijing.aliyuncs.com)|49.7.22.39|:443... 已连接。 已发出 HTTP 请求,正在等待回应... 200 OK 长度: 11476379 (11M) [text/csv] 正在保存至: “train.csv.2” train.csv.2 100%[===================>] 10.94M 8.82MB/s in 1.2s 2023-03-22 17:33:55 (8.82 MB/s) - 已保存 “train.csv.2” [11476379/11476379]) Step1:函数库导入## 基础函数库 import numpy as np import pandas as pd ## 绘图函数库 import matplotlib.pyplot as plt import seaborn as sns本次我们选择天气数据集进行方法的尝试训练,现在有一些由气象站提供的每日降雨数据,我们需要根据历史降雨数据来预测明天会下雨的概率。样例涉及到的测试集数据test.csv与train.csv的格式完全相同,但其RainTomorrow未给出,为预测变量。数据的各个特征描述如下:特征名称意义取值范围Date日期字符串Location气象站的地址字符串MinTemp最低温度实数MaxTemp最高温度实数Rainfall降雨量实数Evaporation蒸发量实数Sunshine光照时间实数WindGustDir最强的风的方向字符串WindGustSpeed最强的风的速度实数WindDir9am早上9点的风向字符串WindDir3pm下午3点的风向字符串WindSpeed9am早上9点的风速实数WindSpeed3pm下午3点的风速实数Humidity9am早上9点的湿度实数Humidity3pm下午3点的湿度实数Pressure9am早上9点的大气压实数Pressure3pm早上3点的大气压实数Cloud9am早上9点的云指数实数Cloud3pm早上3点的云指数实数Temp9am早上9点的温度实数Temp3pm早上3点的温度实数RainToday今天是否下雨No,YesRainTomorrow明天是否下雨No,YesStep2:数据读取/载入## 我们利用Pandas自带的read_csv函数读取并转化为DataFrame格式 data = pd.read_csv('train.csv')Step3:数据信息简单查看## 利用.info()查看数据的整体信息 data.info()<class 'pandas.core.frame.DataFrame'> RangeIndex: 106644 entries, 0 to 106643 Data columns (total 23 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Date 106644 non-null object 1 Location 106644 non-null object 2 MinTemp 106183 non-null float64 3 MaxTemp 106413 non-null float64 4 Rainfall 105610 non-null float64 5 Evaporation 60974 non-null float64 6 Sunshine 55718 non-null float64 7 WindGustDir 99660 non-null object 8 WindGustSpeed 99702 non-null float64 9 WindDir9am 99166 non-null object 10 WindDir3pm 103788 non-null object 11 WindSpeed9am 105643 non-null float64 12 WindSpeed3pm 104653 non-null float64 13 Humidity9am 105327 non-null float64 14 Humidity3pm 103932 non-null float64 15 Pressure9am 96107 non-null float64 16 Pressure3pm 96123 non-null float64 17 Cloud9am 66303 non-null float64 18 Cloud3pm 63691 non-null float64 19 Temp9am 105983 non-null float64 20 Temp3pm 104599 non-null float64 21 RainToday 105610 non-null object 22 RainTomorrow 106644 non-null object dtypes: float64(16), object(7) memory usage: 18.7+ MB ## 进行简单的数据查看,我们可以利用 .head() 头部.tail()尾部 data.head() Location MinTemp MaxTemp Rainfall Evaporation Sunshine WindGustDir WindGustSpeed WindDir9am Humidity9am Humidity3pm Pressure9am Pressure3pm Cloud9am Cloud3pm Temp9am Temp3pm RainToday RainTomorrow 2012/1/19 MountGinini 2015/4/13 1021.9 1017.9 2010/8/5 Nuriootpa 1025.9 1025.3 2013/3/18 Adelaide 1025.0 1022.2 2011/2/16 1018.0 1014.1 5 rows × 23 columns 这里我们发现数据集中存在NaN,一般的我们认为NaN在数据集中代表了缺失值,可能是数据采集或处理时产生的一种错误。这里我们采用-1将缺失值进行填补,还有其他例如“中位数填补、平均数填补”的缺失值处理方法有兴趣的同学也可以尝试。data = data.fillna(-1)data.tail() Location MinTemp MaxTemp Rainfall Evaporation Sunshine WindGustDir WindGustSpeed WindDir9am Humidity9am Humidity3pm Pressure9am Pressure3pm Cloud9am Cloud3pm Temp9am Temp3pm RainToday RainTomorrow 106639 2011/5/23 Launceston 999.2 995.2 106640 2014/12/9 GoldCoast 1013.8 1010.0 106641 2014/10/7 Wollongong 1008.2 1008.2 106642 2012/1/16 Newcastle 106643 2014/10/21 AliceSprings 1017.9 1014.0 5 rows × 23 columns ## 利用value_counts函数查看训练集标签的数量 pd.Series(data['RainTomorrow']).value_counts()No 82786 Yes 23858 Name: RainTomorrow, dtype: int64 我们发现数据集中的负样本数量远大于正样本数量,这种常见的问题叫做“数据不平衡”问题,在某些情况下需要进行一些特殊处理。## 对于特征进行一些统计描述 data.describe() MinTemp MaxTemp Rainfall Evaporation Sunshine WindGustSpeed WindSpeed9am WindSpeed3pm Humidity9am Humidity3pm Pressure9am Pressure3pm Cloud9am Cloud3pm Temp9am Temp3pm count 106644.000000 106644.000000 106644.000000 106644.000000 106644.000000 106644.000000 106644.000000 106644.000000 106644.000000 106644.000000 106644.000000 106644.000000 106644.000000 106644.000000 106644.000000 106644.000000 12.129147 23.183398 2.313912 2.704798 3.509008 37.305137 13.852200 18.265378 67.940353 50.104657 917.003689 914.995385 2.381231 2.285670 16.877842 21.257600 6.444358 7.208596 8.379145 4.519172 5.105696 16.585310 8.949659 9.118835 20.481579 22.136917 304.042528 303.120731 3.483751 3.419658 6.629811 7.549532 -8.500000 -4.800000 -1.000000 -1.000000 -1.000000 -1.000000 -1.000000 -1.000000 -1.000000 -1.000000 -1.000000 -1.000000 -1.000000 -1.000000 -7.200000 -5.400000 7.500000 17.900000 0.000000 -1.000000 -1.000000 30.000000 7.000000 11.000000 56.000000 35.000000 1011.000000 1008.500000 -1.000000 -1.000000 12.200000 16.300000 12.000000 22.600000 0.000000 1.600000 0.200000 37.000000 13.000000 17.000000 70.000000 51.000000 1016.700000 1014.200000 1.000000 1.000000 16.700000 20.900000 16.800000 28.300000 0.600000 5.400000 8.700000 46.000000 19.000000 24.000000 83.000000 65.000000 1021.800000 1019.400000 6.000000 6.000000 21.500000 26.300000 31.900000 48.100000 268.600000 145.000000 14.500000 135.000000 130.000000 87.000000 100.000000 100.000000 1041.000000 1039.600000 9.000000 9.000000 39.400000 46.200000 Step4:可视化描述为了方便,我们先纪录数字特征与非数字特征:numerical_features = [x for x in data.columns if data[x].dtype == np.float]category_features = [x for x in data.columns if data[x].dtype != np.float and x != 'RainTomorrow']## 选取三个特征与标签组合的散点可视化 sns.pairplot(data=data[['Rainfall', 'Evaporation', 'Sunshine'] + ['RainTomorrow']], diag_kind='hist', hue= 'RainTomorrow') plt.show()从上图可以发现,在2D情况下不同的特征组合对于第二天下雨与不下雨的散点分布,以及大概的区分能力。相对的Sunshine与其他特征的组合更具有区分能力for col in data[numerical_features].columns: if col != 'RainTomorrow': sns.boxplot(x='RainTomorrow', y=col, saturation=0.5, palette='pastel', data=data) plt.title(col) plt.show()利用箱型图我们也可以得到不同类别在不同特征上的分布差异情况。我们可以发现Sunshine,Humidity3pm,Cloud9am,Cloud3pm的区分能力较强tlog = {} for i in category_features: tlog[i] = data[data['RainTomorrow'] == 'Yes'][i].value_counts() flog = {} for i in category_features: flog[i] = data[data['RainTomorrow'] == 'No'][i].value_counts() plt.figure(figsize=(10,10)) plt.subplot(1,2,1) plt.title('RainTomorrow') sns.barplot(x = pd.DataFrame(tlog['Location']).sort_index()['Location'], y = pd.DataFrame(tlog['Location']).sort_index().index, color = "red") plt.subplot(1,2,2) plt.title('Not RainTomorrow') sns.barplot(x = pd.DataFrame(flog['Location']).sort_index()['Location'], y = pd.DataFrame(flog['Location']).sort_index().index, color = "blue") plt.show()从上图可以发现不同地区降雨情况差别很大,有些地方明显更容易降雨plt.figure(figsize=(10,2)) plt.subplot(1,2,1) plt.title('RainTomorrow') sns.barplot(x = pd.DataFrame(tlog['RainToday'][:2]).sort_index()['RainToday'], y = pd.DataFrame(tlog['RainToday'][:2]).sort_index().index, color = "red") plt.subplot(1,2,2) plt.title('Not RainTomorrow') sns.barplot(x = pd.DataFrame(flog['RainToday'][:2]).sort_index()['RainToday'], y = pd.DataFrame(flog['RainToday'][:2]).sort_index().index, color = "blue") plt.show()上图我们可以发现,今天下雨明天不一定下雨,但今天不下雨,第二天大概率也不下雨。3.2 特征向量编码Step5:对离散变量进行编码由于XGBoost无法处理字符串类型的数据,我们需要一些方法讲字符串数据转化为数据。一种最简单的方法是把所有的相同类别的特征编码成同一个值,例如女=0,男=1,狗狗=2,所以最后编码的特征值是在$[0, 特征数量-1]$之间的整数。除此之外,还有独热编码、求和编码、留一法编码等等方法可以获得更好的效果。## 把所有的相同类别的特征编码为同一个值 def get_mapfunction(x): mapp = dict(zip(x.unique().tolist(), range(len(x.unique().tolist())))) def mapfunction(y): if y in mapp: return mapp[y] else: return -1 return mapfunction for i in category_features: data[i] = data[i].apply(get_mapfunction(data[i])) ## 编码后的字符串特征变成了数字 data['Location'].unique()array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48]) 3.3 模型训练预测Step6:利用 XGBoost 进行训练与预测## 为了正确评估模型性能,将数据划分为训练集和测试集,并在训练集上训练模型,在测试集上验证模型性能。 from sklearn.model_selection import train_test_split ## 选择其类别为0和1的样本 (不包括类别为2的样本) data_target_part = data['RainTomorrow'] data_features_part = data[[x for x in data.columns if x != 'RainTomorrow']] ## 测试集大小为20%, 80%/20%分 x_train, x_test, y_train, y_test = train_test_split(data_features_part, data_target_part, test_size = 0.2, random_state = 2020) #查看标签数据 print(y_train[0:2],y_test[0:2]) # 替换Yes为1,No为0 y_train = y_train.replace({'Yes': 1, 'No': 0}) y_test = y_test.replace({'Yes': 1, 'No': 0}) # 打印修改后的结果 print(y_train[0:2],y_test[0:2])98173 No 33154 No Name: RainTomorrow, dtype: object 10273 Yes 90769 No Name: RainTomorrow, dtype: object 98173 0 33154 0 Name: RainTomorrow, dtype: int64 10273 1 90769 0 Name: RainTomorrow, dtype: int64 The label for xgboost must consist of integer labels of the form 0, 1, 2, ..., [num_class - 1]. This means that the labels must be sequential integers starting from 0 up to the total number of classes minus 1. For example, if there are 3 classes, the labels should be 0, 1, and 2. If the labels are not in this format, xgboost may not be able to train the model properly.## 导入XGBoost模型 from xgboost.sklearn import XGBClassifier ## 定义 XGBoost模型 clf = XGBClassifier(use_label_encoder=False) # 在训练集上训练XGBoost模型 clf.fit(x_train, y_train) #https://cloud.tencent.com/developer/ask/sof/913362/answer/1303557[17:34:10] WARNING: ../src/learner.cc:1061: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'binary:logistic' was changed from 'error' to 'logloss'. Explicitly set eval_metric if you'd like to restore the old behavior. XGBClassifier(base_score=0.5, booster='gbtree', colsample_bylevel=1, colsample_bynode=1, colsample_bytree=1, gamma=0, gpu_id=-1, importance_type='gain', interaction_constraints='', learning_rate=0.300000012, max_delta_step=0, max_depth=6, min_child_weight=1, missing=nan, monotone_constraints='()', n_estimators=100, n_jobs=24, num_parallel_tree=1, random_state=0, reg_alpha=0, reg_lambda=1, scale_pos_weight=1, subsample=1, tree_method='exact', use_label_encoder=False, validate_parameters=1, verbosity=None) ## 在训练集和测试集上分布利用训练好的模型进行预测 train_predict = clf.predict(x_train) test_predict = clf.predict(x_test) from sklearn import metrics ## 利用accuracy(准确度)【预测正确的样本数目占总预测样本数目的比例】评估模型效果 print('The accuracy of the Logistic Regression is:',metrics.accuracy_score(y_train,train_predict)) print('The accuracy of the Logistic Regression is:',metrics.accuracy_score(y_test,test_predict)) ## 查看混淆矩阵 (预测值和真实值的各类情况统计矩阵) confusion_matrix_result = metrics.confusion_matrix(test_predict,y_test) print('The confusion matrix result:\n',confusion_matrix_result) # 利用热力图对于结果进行可视化 plt.figure(figsize=(8, 6)) sns.heatmap(confusion_matrix_result, annot=True, cmap='Blues') plt.xlabel('Predicted labels') plt.ylabel('True labels') plt.show()The accuracy of the Logistic Regression is: 0.8982476703979371 The accuracy of the Logistic Regression is: 0.8575179333302076 The confusion matrix result: [[15656 2142] [ 897 2634]] 我们可以发现共有15759 + 2306个样本预测正确,2470 + 794个样本预测错误。3.3.1 特征选择Step7: 利用 XGBoost 进行特征选择XGBoost的特征选择属于特征选择中的嵌入式方法,在XGboost中可以用属性feature_importances_去查看特征的重要度。? sns.barplotsns.barplot(y=data_features_part.columns, x=clf.feature_importances_)从图中我们可以发现下午3点的湿度与今天是否下雨是决定第二天是否下雨最重要的因素初次之外,我们还可以使用XGBoost中的下列重要属性来评估特征的重要性。weight:是以特征用到的次数来评价gain:当利用特征做划分的时候的评价基尼指数cover:利用一个覆盖样本的指标二阶导数(具体原理不清楚有待探究)平均值来划分。total_gain:总基尼指数total_cover:总覆盖from sklearn.metrics import accuracy_score from xgboost import plot_importance def estimate(model,data): #sns.barplot(data.columns,model.feature_importances_) ax1=plot_importance(model,importance_type="gain") ax1.set_title('gain') ax2=plot_importance(model, importance_type="weight") ax2.set_title('weight') ax3 = plot_importance(model, importance_type="cover") ax3.set_title('cover') plt.show() def classes(data,label,test): model=XGBClassifier() model.fit(data,label) ans=model.predict(test) estimate(model, data) return ans ans=classes(x_train,y_train,x_test) pre=accuracy_score(y_test, ans) print('acc=',accuracy_score(y_test,ans)) /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/xgboost/sklearn.py:888: UserWarning: The use of label encoder in XGBClassifier is deprecated and will be removed in a future release. To remove this warning, do the following: 1) Pass option use_label_encoder=False when constructing XGBClassifier object; and 2) Encode your labels (y) as integers starting with 0, i.e. 0, 1, 2, ..., [num_class - 1]. warnings.warn(label_encoder_deprecation_msg, UserWarning) [17:34:28] WARNING: ../src/learner.cc:1061: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'binary:logistic' was changed from 'error' to 'logloss'. Explicitly set eval_metric if you'd like to restore the old behavior. acc= 0.8575179333302076 这些图同样可以帮助我们更好的了解其他重要特征。Step8: 通过调整参数获得更好的效果XGBoost中包括但不限于下列对模型影响较大的参数:1. learning_rate: 有时也叫作eta,系统默认值为0.3。每一步迭代的步长,很重要。太大了运行准确率不高,太小了运行速度慢。 2. subsample:系统默认为1。这个参数控制对于每棵树,随机采样的比例。减小这个参数的值,算法会更加保守,避免过拟合, 取值范围零到一。 3. colsample_bytree:系统默认值为1。我们一般设置成0.8左右。用来控制每棵随机采样的列数的占比(每一列是一个特征)。 4. max_depth: 系统默认值为6,我们常用3-10之间的数字。这个值为树的最大深度。这个值是用来控制过拟合的。max_depth越大,模型学习的更加具体。3.3.2 核心参数调优1.eta[默认0.3] 通过为每一颗树增加权重,提高模型的鲁棒性。 典型值为0.01-0.2。 2.min_child_weight[默认1] 决定最小叶子节点样本权重和。 这个参数可以避免过拟合。当它的值较大时,可以避免模型学习到局部的特殊样本。 但是如果这个值过高,则会导致模型拟合不充分。 3.max_depth[默认6] 这个值也是用来避免过拟合的。max_depth越大,模型会学到更具体更局部的样本。 典型值:3-10 4.max_leaf_nodes 树上最大的节点或叶子的数量。 可以替代max_depth的作用。 这个参数的定义会导致忽略max_depth参数。 5.gamma[默认0] 在节点分裂时,只有分裂后损失函数的值下降了,才会分裂这个节点。Gamma指定了节点分裂所需的最小损失函数下降值。这个参数的值越大,算法越保守。这个参数的值和损失函数息息相关。 6.max_delta_step[默认0] 这参数限制每棵树权重改变的最大步长。如果这个参数的值为0,那就意味着没有约束。如果它被赋予了某个正值,那么它会让这个算法更加保守。 但是当各类别的样本十分不平衡时,它对分类问题是很有帮助的。 7.subsample[默认1] 这个参数控制对于每棵树,随机采样的比例。 减小这个参数的值,算法会更加保守,避免过拟合。但是,如果这个值设置得过小,它可能会导致欠拟合。 典型值:0.5-1 8.colsample_bytree[默认1] 用来控制每棵随机采样的列数的占比(每一列是一个特征)。 典型值:0.5-1 9.colsample_bylevel[默认1] 用来控制树的每一级的每一次分裂,对列数的采样的占比。 subsample参数和colsample_bytree参数可以起到相同的作用,一般用不到。10.lambda[默认1] 权重的L2正则化项。(和Ridge regression类似)。 这个参数是用来控制XGBoost的正则化部分的。虽然大部分数据科学家很少用到这个参数,但是这个参数在减少过拟合上还是可以挖掘出更多用处的。 11.alpha[默认1] 权重的L1正则化项。(和Lasso regression类似)。 可以应用在很高维度的情况下,使得算法的速度更快。 12.scale_pos_weight[默认1] 在各类别样本十分不平衡时,把这个参数设定为一个正值,可以使算法更快收敛。3.3.3 网格调参法调节模型参数的方法有贪心算法、网格调参、贝叶斯调参等。这里我们采用网格调参,它的基本思想是穷举搜索:在所有候选的参数选择中,通过循环遍历,尝试每一种可能性,表现最好的参数就是最终的结果## 从sklearn库中导入网格调参函数 from sklearn.model_selection import GridSearchCV ## 定义参数取值范围 learning_rate = [0.1, 0.3,] subsample = [0.8] colsample_bytree = [0.6, 0.8] max_depth = [3,5] parameters = { 'learning_rate': learning_rate, 'subsample': subsample, 'colsample_bytree':colsample_bytree, 'max_depth': max_depth} model = XGBClassifier(n_estimators = 20) ## 进行网格搜索 clf = GridSearchCV(model, parameters, cv=3, scoring='accuracy',verbose=1,n_jobs=-1) clf = clf.fit(x_train, y_train)## 网格搜索后的最好参数为 clf.best_params_## 在训练集和测试集上分布利用最好的模型参数进行预测 ## 定义带参数的 XGBoost模型 clf = XGBClassifier(colsample_bytree = 0.6, learning_rate = 0.3, max_depth= 8, subsample = 0.9) # 在训练集上训练XGBoost模型 clf.fit(x_train, y_train) train_predict = clf.predict(x_train) test_predict = clf.predict(x_test) ## 利用accuracy(准确度)【预测正确的样本数目占总预测样本数目的比例】评估模型效果 print('The accuracy of the Logistic Regression is:',metrics.accuracy_score(y_train,train_predict)) print('The accuracy of the Logistic Regression is:',metrics.accuracy_score(y_test,test_predict)) ## 查看混淆矩阵 (预测值和真实值的各类情况统计矩阵) confusion_matrix_result = metrics.confusion_matrix(test_predict,y_test) print('The confusion matrix result:\n',confusion_matrix_result) # 利用热力图对于结果进行可视化 plt.figure(figsize=(8, 6)) sns.heatmap(confusion_matrix_result, annot=True, cmap='Blues') plt.xlabel('Predicted labels') plt.ylabel('True labels') plt.show()/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/xgboost/sklearn.py:888: UserWarning: The use of label encoder in XGBClassifier is deprecated and will be removed in a future release. To remove this warning, do the following: 1) Pass option use_label_encoder=False when constructing XGBClassifier object; and 2) Encode your labels (y) as integers starting with 0, i.e. 0, 1, 2, ..., [num_class - 1]. warnings.warn(label_encoder_deprecation_msg, UserWarning) [17:55:25] WARNING: ../src/learner.cc:1061: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'binary:logistic' was changed from 'error' to 'logloss'. Explicitly set eval_metric if you'd like to restore the old behavior. The accuracy of the Logistic Regression is: 0.9382992439781984 The accuracy of the Logistic Regression is: 0.856674011908669 The confusion matrix result: [[15611 2115] [ 942 2661]] 原本有2470 + 790个错误,现在有 2112 + 939个错误,带来了明显的正确率提升。更多调参技巧请参考:https://blog.csdn.net/weixin_62684026/article/details/1268592624. 总结XGBoost的主要优点:简单易用。相对其他机器学习库,用户可以轻松使用XGBoost并获得相当不错的效果。高效可扩展。在处理大规模数据集时速度快效果好,对内存等硬件资源要求不高。鲁棒性强。相对于深度学习模型不需要精细调参便能取得接近的效果。XGBoost内部实现提升树模型,可以自动处理缺失值。XGBoost的主要缺点:相对于深度学习模型无法对时空位置建模,不能很好地捕获图像、语音、文本等高维数据。在拥有海量训练数据,并能找到合适的深度学习模型时,深度学习的精度可以遥遥领先XGBoost。本项目链接:https://www.heywhale.com/home/column/64141d6b1c8c8b518ba97dcc参考链接:https://tianchi.aliyun.com/course/278/3423本人最近打算整合ML、DRL、NLP等相关领域的体系化项目课程,方便入门同学快速掌握相关知识。声明:部分项目为网络经典项目方便大家快速学习,后续会不断增添实战环节(比赛、论文、现实应用等)。对于机器学习这块规划为:基础入门机器学习算法--->简单项目实战--->数据建模比赛----->相关现实中应用场景问题解决。一条路线帮助大家学习,快速实战。对于深度强化学习这块规划为:基础单智能算法教学(gym环境为主)---->主流多智能算法教学(gym环境为主)---->单智能多智能题实战(论文复现偏业务如:无人机优化调度、电力资源调度等项目应用)自然语言处理相关规划:除了单点算法技术外,主要围绕知识图谱构建进行:信息抽取相关技术(含智能标注)--->知识融合---->知识推理---->图谱应用上述对于你掌握后的期许:对于ML,希望你后续可以乱杀数学建模相关比赛(参加就获奖保底,top还是难的需要钻研)可以实际解决现实中一些优化调度问题,而非停留在gym环境下的一些游戏demo玩玩。(更深层次可能需要自己钻研了,难度还是很大的)掌握可知识图谱全流程构建其中各个重要环节算法,包含图数据库相关知识。这三块领域耦合情况比较大,后续会通过比如:搜索推荐系统整个项目进行耦合,各项算法都会耦合在其中。举例:知识图谱就会用到(图算法、NLP、ML相关算法),搜索推荐系统(除了该领域召回粗排精排重排混排等算法外,还有强化学习、知识图谱等耦合在其中)。饼画的有点大,后面慢慢实现。
机器学习算法(二): 基于鸢尾花数据集的朴素贝叶斯(Naive Bayes)预测分类
机器学习算法(二): 基于鸢尾花数据集的朴素贝叶斯(Naive Bayes)预测分类项目链接参考:https://www.heywhale.com/home/column/64141d6b1c8c8b518ba97dcc1. 实验室介绍1.1 实验环境1. python3.7 2. numpy >= '1.16.4' 3. sklearn >= '0.23.1'1.2 朴素贝叶斯的介绍朴素贝叶斯算法(Naive Bayes, NB) 是应用最为广泛的分类算法之一。它是基于贝叶斯定义和特征条件独立假设的分类器方法。由于朴素贝叶斯法基于贝叶斯公式计算得到,有着坚实的数学基础,以及稳定的分类效率。NB模型所需估计的参数很少,对缺失数据不太敏感,算法也比较简单。当年的垃圾邮件分类都是基于朴素贝叶斯分类器识别的。什么是条件概率,我们从一个摸球的例子来理解。我们有两个桶:灰色桶和绿色桶,一共有7个小球,4个蓝色3个紫色,分布如下图:从这7个球中,随机选择1个球是紫色的概率p是多少?选择过程如下:先选择桶再从选择的桶中选择一个球$$ p(球=紫色) \\ =p(选择灰桶) \cdot p(从灰桶中选择紫色) + p(选择绿桶) \cdot p(从灰桶中选择紫色) \\ =\frac{1}{2} \cdot \frac{2}{4} + \frac{1}{2} \cdot \frac{1}{2} $$上述我们选择小球的过程就是条件概率的过程,在选择桶的颜色的情况下是紫色的概率,另一种计算条件概率的方法是贝叶斯准则。贝叶斯公式是英国数学家提出的一个数据公式:$$ p(A|B)=\frac{p(A,B)}{p(B)}=\frac{p(B|A) \cdot p(A)}{\sum_{a \in ℱ_A}p(B|a) \cdot p(a)} $$p(A,B):表示事件A和事件B同时发生的概率。p(B):表示事件B发生的概率,叫做先验概率;p(A):表示事件A发生的概率。p(A|B):表示当事件B发生的条件下,事件A发生的概率叫做后验概率。p(B|A):表示当事件A发生的条件下,事件B发生的概率。我们用一句话理解贝叶斯:世间很多事都存在某种联系,假设事件A和事件B。人们常常使用已经发生的某个事件去推断我们想要知道的之间的概率。例如,医生在确诊的时候,会根据病人的舌苔、心跳等来判断病人得了什么病。对病人来说,只会关注得了什么病,医生会通道已经发生的事件来确诊具体的情况。这里就用到了贝叶斯思想,A是已经发生的病人症状,在A发生的条件下是B_i的概率。1.3 朴素贝叶斯的应用朴素贝叶斯算法假设所有特征的出现相互独立互不影响,每一特征同等重要,又因为其简单,而且具有很好的可解释性一般。相对于其他精心设计的更复杂的分类算法,朴素贝叶斯分类算法是学习效率和分类效果较好的分类器之一。朴素贝叶斯算法一般应用在文本分类,垃圾邮件的分类,信用评估,钓鱼网站检测等。2. 实验室手册2.1 学习目标掌握贝叶斯公式结合两个实例了解贝朴素叶斯的参数估计掌握贝叶斯估计2.2 代码流程Part 1. 莺尾花数据集--贝叶斯分类Step1: 库函数导入Step2: 数据导入&分析Step3: 模型训练Step4: 模型预测Step5: 原理简析Part 2. 模拟离散数据集--贝叶斯分类Step1: 库函数导入Step2: 数据导入&分析Step3: 模型训练&可视化Step4: 原理简析2.3 算法实战莺尾花数据集--贝叶斯分类Step1: 库函数导入import warnings warnings.filterwarnings('ignore') import numpy as np # 加载莺尾花数据集 from sklearn import datasets # 导入高斯朴素贝叶斯分类器 from sklearn.naive_bayes import GaussianNB from sklearn.model_selection import train_test_splitStep2: 数据导入&分析X, y = datasets.load_iris(return_X_y=True) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)我们需要计算两个概率分别是:条件概率:$P(X^{(i)}=x^{(i)}|Y=c_k)$和类目$c_k$的先验概率:$P(Y=c_k)$。通过分析发现训练数据是数值类型的数据,这里假设每个特征服从高斯分布,因此我们选择高斯朴素贝叶斯来进行分类计算。Step3: 模型训练# 使用高斯朴素贝叶斯进行计算 clf = GaussianNB(var_smoothing=1e-8) clf.fit(X_train, y_train)Step4: 模型预测# 评估 y_pred = clf.predict(X_test) acc = np.sum(y_test == y_pred) / X_test.shape[0] print("Test Acc : %.3f" % acc) y_proba = clf.predict_proba(X_test[:1]) print(clf.predict(X_test[:1])) print("预计的概率值:", y_proba)Test Acc : 0.967 [2] 预计的概率值: [[1.63542393e-232 2.18880483e-0069.99997811e-001]]Step5: 原理简析高斯朴素贝叶斯假设每个特征都服从高斯分布,我们把一个随机变量X服从数学期望为μ,方差为σ^2的数据分布称为高斯分布。对于每个特征我们一般使用平均值来估计μ和使用所有特征的方差估计σ^2。$$ P(X^{(i)}=x^{(i)}|Y=c_k) = \frac{1}{\sqrt{2\pi\sigma^2_y}} \exp\left(-\frac{(x^{(i)} - \mu_{c_k})^2}{2\sigma^2_{c_k}}\right) $$从上述例子中的预测结果中,我们可以看到类别2对应的后验概率值最大,所以我们认为类目2是最优的结果。模拟离散数据集--贝叶斯分类Step1: 库函数导入+ Step2: 数据导入&分析 + Step3: 模型训练&可视化 + Step4: 原理简析 import random import numpy as np # 使用基于类目特征的朴素贝叶斯 from sklearn.naive_bayes import CategoricalNB from sklearn.model_selection import train_test_splitStep2: 数据导入&分析# 模拟数据 rng = np.random.RandomState(1) # 随机生成600个100维的数据,每一维的特征都是[0, 4]之前的整数 X = rng.randint(5, size=(600, 100)) y = np.array([1, 2, 3, 4, 5, 6] * 100) data = np.c_[X, y] # X和y进行整体打散 random.shuffle(data) X = data[:,:-1] y = data[:, -1] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)所有的数据特征都是离散特征,我们引入基于离散特征的朴素贝叶斯分类器。Step3: 模型训练&预测clf = CategoricalNB(alpha=1) clf.fit(X_train, y_train) acc = clf.score(X_test, y_test) print("Test Acc : %.3f" % acc)Test Acc : 0.683# 随机数据测试,分析预测结果,贝叶斯会选择概率最大的预测结果 # 比如这里的预测结果是6,6对应的概率最大,由于我们是随机数据 # 读者运行的时候,可能会出现不一样的结果。 x = rng.randint(5, size=(1, 100)) print(clf.predict_proba(x)) print(clf.predict(x))[[3.48859652e-04 4.34747491e-04 2.23077189e-03 9.90226387e-01 5.98248900e-03 7.76745425e-04]]2.4 原理简析2.4.1 结果分析可以看到测试的数据的结果,贝叶斯会选择概率最大的预测结果,比如这里的预测结果是6,6对应的概率最大,由于我们是随机数据,读者运行的时候,可能会出现不一样的结果。这里的测试数据的准确率没有任何意义,因为数据是随机生成的,不一定具有贝叶斯先验性,这里只是作为一个列子引导大家如何使用。alpha=1这个参数表示什么?我们知道贝叶斯法一定要计算两个概率:条件概率:$P(X^{(i)}=x^{(i)}|Y=c_k)$和类目$c_k$的先验概率:$P(Y=c_k)$。对于离散特征:$$ P(X^{(j)}=x^{(j)}|Y=c_k)=\frac{\sum_{i=1}^{N}I(x_i^j=a_{jl},y_i=c_k)+\alpha}{\sum_{i=1}^{N}I(y_i=c_k)+S_j\alpha} $$我们可以看出就是对每一个变量的多加了一个频数alpha。当alphaλ=0时,就是极大似然估计。通常取值alpha=1,这就是拉普拉斯平滑(Laplace smoothing),这有叫做贝叶斯估计,主要是因为如果使用极大似然估计,如果某个特征值在训练数据中没有出现,这时候会出现概率为0的情况,导致整个估计都为0,因为引入贝叶斯估计。其中:$S_j$:表示第j个特征的个数。$x_i^j$:表示第i个样本的第j维元素。$y_i$:第i个样本的label。2.4.2 朴素贝叶斯算法朴素贝叶斯法 = 贝叶斯定理 + 特征条件独立。输入$X \in R^n$空间是n维向量集合,输出空间$y=\{c_1,c_2,...,c_K\}$. 所有的X和y都是对应空间上的随机变量. $P(X,Y)$是X和Y的联合概率分别. 训练数据集(由$P(X,Y)$独立同分布产生):$$T=\{(x_1,y_1),(x_2,y_2),...,(x_N,y_N)\}$$计算测试数据x的列表,我们需要依次计算$P(Y=c_k|X=x)$,取概率最大的值,就是x对应的分类。$P(Y=c_k|X=x)$我们一般这样解释,当给定$(X=x)$的条件下,$Y=c_k$的概率,这就是条件概率. 这就简单了,我们只需要每个的x,计算其对应的$c_k,k \in [1,2,...,K]$的概率,选择最大的概率作为这个x的类别进行了. 通过贝叶斯公式进行变形,得到预测的概率计算公式:$$P(Y=c_k|X=x)=\frac{P(X=x|Y=c_k)P(Y=c_k)}{\sum_{k}P(X=x|Y=c_k)P(Y=c_k)}$$我们只需要计算以下两个概率即可,又由于朴素贝叶斯假设条件独立,我们可以单独计算每个特征的条件概率:$P(X^{(i)}=x^{(i)}|Y=c_k)$和类目$c_k$的先验概率:$P(Y=c_k)$。为了更好的理解这个公式,看下图解释:其中:$$ P(Y=c_k)=\frac{\sum_{i=1}^{N}I(y_i=c_k)}{N}, k=1,2,...,K $$当涉及到多个条件时,朴素贝叶斯有一个提前的假设,我们称之为 条件独立性假设(或者 简单假设:Naive):公式如下$$ P(A,B|Y) = P(A|Y) \cdot P(B|Y) $$这个公式是朴素贝叶斯的基础假设,即各个条件概率是相互独立的,A不影响B,B不影响A。而对这里来说,假设$X = [x_1,x_2,...,x_n]$$$ P(X=x|Y=c_k) \\ =P(X^{(1)}=x^{(1)},X^{(2)}=x^{(2)},...,X^{(n)}=x^{(n)}|Y=c_k) \\ =\prod_{i=1}^{n} P(x_i | y) $$由此原式可以等价为:$$P(Y=c_k|X=x)=\frac{\prod_{i=1}^{n} P(x_i | Y=c_k)P(Y=c_k)}{\sum_{k}\prod_{i=1}^{n} P(x_i | Y=c_k)P(Y=c_k)}$$我们为了选择后验概率最大的结果,进行概率的比较,由于分母一致,这里直接去掉分母,得到最后的计算公式。$$ y=arg max_{c_k}P(Y=c_k)\prod_{j}P(X^{(j)}=x^{(j)}|Y=c_k) $$我们来看一个实例,更好的理解贝叶斯的计算过程,根据天气和是否是周末预测一个人是否会出门。index$X_1:$天气的好坏$X_2:$是否周末$Y:$是否出门1好是出门2好否出门3好是不出门4好否出门5不好是出门6不好否不出门根据上述数据,为了更好的理解计算过程,我们给出几个计算公式:a. 当出门的条件下,X_1是天气不好的概率:$$ p(X_1=不好|Y=出门) =\frac{p(X_1=不好,Y=出门)}{p(Y=出门)}=\frac{1}{4} $$b. 出门的概率$$ p(Y=出门)=\frac{4}{6} $$c. X_1天气不好的概率、$$ p(X_1=不好)=\frac{2}{6} $$d. 在X_1天气不好的情况下,出门的概率:$$ p(Y=出门|X_1=不好)=\frac{p(X_1=不好|Y=出门) \cdot p(Y=出门)}{p(X=不好)} \\ =\frac{\frac{1}{4} \cdot \frac{4}{6}}{\frac{2}{6}}=\frac{1}{2} $$f. 在X_1天气不好的情况下,不出门的概率:$$ p(Y=出门|X_1=不好)=1-p(Y=不出门|X_1=不好)=1-\frac{1}{2}=\frac{1}{2} $$2.4.3 朴素贝叶斯的优缺点优点:朴素贝叶斯算法主要基于经典的贝叶斯公式进行推倒,具有很好的数学原理。而且在数据量很小的时候表现良好,数据量很大的时候也可以进行增量计算。由于朴素贝叶斯使用先验概率估计后验概率具有很好的模型的可解释性。缺点:朴素贝叶斯模型与其他分类方法相比具有最小的理论误差率。但是实际上并非总是如此,这是因为朴素贝叶斯模型给定输出类别的情况下,假设属性之间相互独立,这个假设在实际应用中往往是不成立的,在属性个数比较多或者属性之间相关性较大时,分类效果不好。而在属性相关性较小时,朴素贝叶斯性能最为良好。对于这一点,有半朴素贝叶斯之类的算法通过考虑部分关联性适度改进,例如为了计算量不至于太大,我们假定每个属性只依赖另外的一个。解决特征之间的相关性,我们还可以使用数据降维(PCA)的方法,去除特征相关性,再进行朴素贝叶斯计算。
机器学习算法(一): 基于逻辑回归的分类预测
机器学习算法(一): 基于逻辑回归的分类预测项目链接参考fork一下直接运行:https://www.heywhale.com/home/column/64141d6b1c8c8b518ba97dcc1 逻辑回归的介绍和应用1.1 逻辑回归的介绍逻辑回归(Logistic regression,简称LR)虽然其中带有"回归"两个字,但逻辑回归其实是一个分类模型,并且广泛应用于各个领域之中。虽然现在深度学习相对于这些传统方法更为火热,但实则这些传统方法由于其独特的优势依然广泛应用于各个领域中。而对于逻辑回归而且,最为突出的两点就是其模型简单和模型的可解释性强。逻辑回归模型的优劣势:优点:实现简单,易于理解和实现;计算代价不高,速度很快,存储资源低;缺点:容易欠拟合,分类精度可能不高1.1 逻辑回归的应用逻辑回归模型广泛用于各个领域,包括机器学习,大多数医学领域和社会科学。例如,最初由Boyd 等人开发的创伤和损伤严重度评分(TRISS)被广泛用于预测受伤患者的死亡率,使用逻辑回归 基于观察到的患者特征(年龄,性别,体重指数,各种血液检查的结果等)分析预测发生特定疾病(例如糖尿病,冠心病)的风险。逻辑回归模型也用于预测在给定的过程中,系统或产品的故障的可能性。还用于市场营销应用程序,例如预测客户购买产品或中止订购的倾向等。在经济学中它可以用来预测一个人选择进入劳动力市场的可能性,而商业应用则可以用来预测房主拖欠抵押贷款的可能性。条件随机字段是逻辑回归到顺序数据的扩展,用于自然语言处理。逻辑回归模型现在同样是很多分类算法的基础组件,比如 分类任务中基于GBDT算法+LR逻辑回归实现的信用卡交易反欺诈,CTR(点击通过率)预估等,其好处在于输出值自然地落在0到1之间,并且有概率意义。模型清晰,有对应的概率学理论基础。它拟合出来的参数就代表了每一个特征(feature)对结果的影响。也是一个理解数据的好工具。但同时由于其本质上是一个线性的分类器,所以不能应对较为复杂的数据情况。很多时候我们也会拿逻辑回归模型去做一些任务尝试的基线(基础水平)。说了这些逻辑回归的概念和应用,大家应该已经对其有所期待了吧,那么我们现在开始吧!!!2 学习目标了解 逻辑回归 的理论掌握 逻辑回归 的 sklearn 函数调用使用并将其运用到鸢尾花数据集预测3 代码流程Part1 Demo实践Step1:库函数导入Step2:模型训练Step3:模型参数查看Step4:数据和模型可视化Step5:模型预测Part2 基于鸢尾花(iris)数据集的逻辑回归分类实践Step1:库函数导入Step2:数据读取/载入Step3:数据信息简单查看Step4:可视化描述Step5:利用 逻辑回归模型 在二分类上 进行训练和预测Step5:利用 逻辑回归模型 在三分类(多分类)上 进行训练和预测4 算法实战### 4.1 Demo实践Step1:库函数导入## 基础函数库 import numpy as np ## 导入画图库 import matplotlib.pyplot as plt import seaborn as sns ## 导入逻辑回归模型函数 from sklearn.linear_model import LogisticRegressionStep2:模型训练##Demo演示LogisticRegression分类 ## 构造数据集 x_fearures = np.array([[-1, -2], [-2, -1], [-3, -2], [1, 3], [2, 1], [3, 2]]) y_label = np.array([0, 0, 0, 1, 1, 1]) ## 调用逻辑回归模型 lr_clf = LogisticRegression() ## 用逻辑回归模型拟合构造的数据集 lr_clf = lr_clf.fit(x_fearures, y_label) #其拟合方程为 y=w0+w1*x1+w2*x2Step3:模型参数查看## 查看其对应模型的w print('the weight of Logistic Regression:',lr_clf.coef_) ## 查看其对应模型的w0 print('the intercept(w0) of Logistic Regression:',lr_clf.intercept_) the weight of Logistic Regression: [[0.73455784 0.69539712]] the intercept(w0) of Logistic Regression: [-0.13139986]Step4:数据和模型可视化## 可视化构造的数据样本点 plt.figure() plt.scatter(x_fearures[:,0],x_fearures[:,1], c=y_label, s=50, cmap='viridis') plt.title('Dataset') plt.show()# 可视化决策边界 plt.figure() plt.scatter(x_fearures[:,0],x_fearures[:,1], c=y_label, s=50, cmap='viridis') plt.title('Dataset') nx, ny = 200, 100 x_min, x_max = plt.xlim() y_min, y_max = plt.ylim() x_grid, y_grid = np.meshgrid(np.linspace(x_min, x_max, nx),np.linspace(y_min, y_max, ny)) z_proba = lr_clf.predict_proba(np.c_[x_grid.ravel(), y_grid.ravel()]) z_proba = z_proba[:, 1].reshape(x_grid.shape) plt.contour(x_grid, y_grid, z_proba, [0.5], linewidths=2., colors='blue') plt.show()### 可视化预测新样本 plt.figure() ## new point 1 x_fearures_new1 = np.array([[0, -1]]) plt.scatter(x_fearures_new1[:,0],x_fearures_new1[:,1], s=50, cmap='viridis') plt.annotate(s='New point 1',xy=(0,-1),xytext=(-2,0),color='blue',arrowprops=dict(arrowstyle='-|>',connectionstyle='arc3',color='red')) ## new point 2 x_fearures_new2 = np.array([[1, 2]]) plt.scatter(x_fearures_new2[:,0],x_fearures_new2[:,1], s=50, cmap='viridis') plt.annotate(s='New point 2',xy=(1,2),xytext=(-1.5,2.5),color='red',arrowprops=dict(arrowstyle='-|>',connectionstyle='arc3',color='red')) ## 训练样本 plt.scatter(x_fearures[:,0],x_fearures[:,1], c=y_label, s=50, cmap='viridis') plt.title('Dataset') # 可视化决策边界 plt.contour(x_grid, y_grid, z_proba, [0.5], linewidths=2., colors='blue') plt.show()Step5:模型预测## 在训练集和测试集上分别利用训练好的模型进行预测 y_label_new1_predict = lr_clf.predict(x_fearures_new1) y_label_new2_predict = lr_clf.predict(x_fearures_new2) print('The New point 1 predict class:\n',y_label_new1_predict) print('The New point 2 predict class:\n',y_label_new2_predict) ## 由于逻辑回归模型是概率预测模型(前文介绍的 p = p(y=1|x,\theta)),所以我们可以利用 predict_proba 函数预测其概率 y_label_new1_predict_proba = lr_clf.predict_proba(x_fearures_new1) y_label_new2_predict_proba = lr_clf.predict_proba(x_fearures_new2) print('The New point 1 predict Probability of each class:\n',y_label_new1_predict_proba) print('The New point 2 predict Probability of each class:\n',y_label_new2_predict_proba) The New point 1 predict class: The New point 2 predict class: The New point 1 predict Probability of each class: [[0.69567724 0.30432276]] The New point 2 predict Probability of each class: [[0.11983936 0.88016064]]可以发现训练好的回归模型将X_new1预测为了类别0(判别面左下侧),X_new2预测为了类别1(判别面右上侧)。其训练得到的逻辑回归模型的概率为0.5的判别面为上图中蓝色的线。4.2 基于鸢尾花(iris)数据集的逻辑回归分类实践在实践的最开始,我们首先需要导入一些基础的函数库包括:numpy (Python进行科学计算的基础软件包),pandas(pandas是一种快速,强大,灵活且易于使用的开源数据分析和处理工具),matplotlib和seaborn绘图。Step1:库函数导入## 基础函数库 import numpy as np import pandas as pd ## 绘图函数库 import matplotlib.pyplot as plt import seaborn as sns本次我们选择鸢花数据(iris)进行方法的尝试训练,该数据集一共包含5个变量,其中4个特征变量,1个目标分类变量。共有150个样本,目标变量为 花的类别 其都属于鸢尾属下的三个亚属,分别是山鸢尾 (Iris-setosa),变色鸢尾(Iris-versicolor)和维吉尼亚鸢尾(Iris-virginica)。包含的三种鸢尾花的四个特征,分别是花萼长度(cm)、花萼宽度(cm)、花瓣长度(cm)、花瓣宽度(cm),这些形态特征在过去被用来识别物种。变量描述sepal length花萼长度(cm)sepal width花萼宽度(cm)petal length花瓣长度(cm)petal width花瓣宽度(cm)target鸢尾的三个亚属类别,'setosa'(0), 'versicolor'(1), 'virginica'(2)Step2:数据读取/载入## 我们利用 sklearn 中自带的 iris 数据作为数据载入,并利用Pandas转化为DataFrame格式 from sklearn.datasets import load_iris data = load_iris() #得到数据特征 iris_target = data.target #得到数据对应的标签 iris_features = pd.DataFrame(data=data.data, columns=data.feature_names) #利用Pandas转化为DataFrame格式Step3:数据信息简单查看## 利用.info()查看数据的整体信息 iris_features.info() # Column Non-Null Count Dtype --- ------ -------------- ----- 0 sepal length (cm) 150 non-null float64 1 sepal width (cm) 150 non-null float64 2 petal length (cm) 150 non-null float64 3 petal width (cm) 150 non-null float64 dtypes: float64(4) memory usage: 4.8 KB ## 对于特征进行一些统计描述 iris_features.describe() sepal length (cm) sepal width (cm) petal length (cm) petal width (cm) count 150.000000 150.000000 150.000000 150.000000 mean 5.843333 3.057333 3.758000 1.199333 std 0.828066 0.435866 1.765298 0.762238 min 4.300000 2.000000 1.000000 0.100000 25% 5.100000 2.800000 1.600000 0.300000 50% 5.800000 3.000000 4.350000 1.300000 75% 6.400000 3.300000 5.100000 1.800000 max 7.900000 4.400000 6.900000 2.500000Step4:可视化描述## 合并标签和特征信息 iris_all = iris_features.copy() ##进行浅拷贝,防止对于原始数据的修改 iris_all['target'] = iris_target ## 特征与标签组合的散点可视化 sns.pairplot(data=iris_all,diag_kind='hist', hue= 'target') plt.show() 从上图可以发现,在2D情况下不同的特征组合对于不同类别的花的散点分布,以及大概的区分能力。for col in iris_features.columns: sns.boxplot(x='target', y=col, saturation=0.5,palette='pastel', data=iris_all) plt.title(col) plt.show()利用箱型图我们也可以得到不同类别在不同特征上的分布差异情况。# 选取其前三个特征绘制三维散点图 from mpl_toolkits.mplot3d import Axes3D fig = plt.figure(figsize=(10,8)) ax = fig.add_subplot(111, projection='3d') iris_all_class0 = iris_all[iris_all['target']==0].values iris_all_class1 = iris_all[iris_all['target']==1].values iris_all_class2 = iris_all[iris_all['target']==2].values # 'setosa'(0), 'versicolor'(1), 'virginica'(2) ax.scatter(iris_all_class0[:,0], iris_all_class0[:,1], iris_all_class0[:,2],label='setosa') ax.scatter(iris_all_class1[:,0], iris_all_class1[:,1], iris_all_class1[:,2],label='versicolor') ax.scatter(iris_all_class2[:,0], iris_all_class2[:,1], iris_all_class2[:,2],label='virginica') plt.legend() plt.show()Step5:利用 逻辑回归模型 在二分类上 进行训练和预测## 为了正确评估模型性能,将数据划分为训练集和测试集,并在训练集上训练模型,在测试集上验证模型性能。 from sklearn.model_selection import train_test_split ## 选择其类别为0和1的样本 (不包括类别为2的样本) iris_features_part = iris_features.iloc[:100] iris_target_part = iris_target[:100] ## 测试集大小为20%, 80%/20%分 x_train, x_test, y_train, y_test = train_test_split(iris_features_part, iris_target_part, test_size = 0.2, random_state = 2020) ## 从sklearn中导入逻辑回归模型 from sklearn.linear_model import LogisticRegression ## 定义 逻辑回归模型 clf = LogisticRegression(random_state=0, solver='lbfgs') # 在训练集上训练逻辑回归模型 clf.fit(x_train, y_train) ## 查看其对应的w print('the weight of Logistic Regression:',clf.coef_) ## 查看其对应的w0 print('the intercept(w0) of Logistic Regression:',clf.intercept_) ## 在训练集和测试集上分布利用训练好的模型进行预测 train_predict = clf.predict(x_train) test_predict = clf.predict(x_test) from sklearn import metrics ## 利用accuracy(准确度)【预测正确的样本数目占总预测样本数目的比例】评估模型效果 print('The accuracy of the Logistic Regression is:',metrics.accuracy_score(y_train,train_predict)) print('The accuracy of the Logistic Regression is:',metrics.accuracy_score(y_test,test_predict)) ## 查看混淆矩阵 (预测值和真实值的各类情况统计矩阵) confusion_matrix_result = metrics.confusion_matrix(test_predict,y_test) print('The confusion matrix result:\n',confusion_matrix_result) # 利用热力图对于结果进行可视化 plt.figure(figsize=(8, 6)) sns.heatmap(confusion_matrix_result, annot=True, cmap='Blues') plt.xlabel('Predicted labels') plt.ylabel('True labels') plt.show()The accuracy of the Logistic Regression is: 1.0The accuracy of the Logistic Regression is: 1.0The confusion matrix result: [[ 9 0] [ 0 11]]我们可以发现其准确度为1,代表所有的样本都预测正确了。Step6:利用 逻辑回归模型 在三分类(多分类)上 进行训练和预测## 测试集大小为20%, 80%/20%分 x_train, x_test, y_train, y_test = train_test_split(iris_features, iris_target, test_size = 0.2, random_state = 2020) ## 定义 逻辑回归模型 clf = LogisticRegression(random_state=0, solver='lbfgs') # 在训练集上训练逻辑回归模型 clf.fit(x_train, y_train) ## 查看其对应的w print('the weight of Logistic Regression:\n',clf.coef_) ## 查看其对应的w0 print('the intercept(w0) of Logistic Regression:\n',clf.intercept_) ## 由于这个是3分类,所有我们这里得到了三个逻辑回归模型的参数,其三个逻辑回归组合起来即可实现三分类。 ## 在训练集和测试集上分布利用训练好的模型进行预测 train_predict = clf.predict(x_train) test_predict = clf.predict(x_test) ## 由于逻辑回归模型是概率预测模型(前文介绍的 p = p(y=1|x,\theta)),所有我们可以利用 predict_proba 函数预测其概率 train_predict_proba = clf.predict_proba(x_train) test_predict_proba = clf.predict_proba(x_test) print('The test predict Probability of each class:\n',test_predict_proba) ## 其中第一列代表预测为0类的概率,第二列代表预测为1类的概率,第三列代表预测为2类的概率。 ## 利用accuracy(准确度)【预测正确的样本数目占总预测样本数目的比例】评估模型效果 print('The accuracy of the Logistic Regression is:',metrics.accuracy_score(y_train,train_predict)) print('The accuracy of the Logistic Regression is:',metrics.accuracy_score(y_test,test_predict)) [9.35695863e-01 6.43039513e-02 1.85301359e-07] [9.80621190e-01 1.93787400e-02 7.00125246e-08] [1.68478815e-04 3.30167226e-01 6.69664295e-01] [3.54046163e-03 4.02267805e-01 5.94191734e-01] [9.70617284e-01 2.93824740e-02 2.42443967e-07] [9.64848137e-01 3.51516748e-02 1.87917880e-07] [9.70436779e-01 2.95624025e-02 8.18591606e-07]] The accuracy of the Logistic Regression is: 0.9833333333333333 The accuracy of the Logistic Regression is: 0.8666666666666667## 查看混淆矩阵 confusion_matrix_result = metrics.confusion_matrix(test_predict,y_test) print('The confusion matrix result:\n',confusion_matrix_result) # 利用热力图对于结果进行可视化 plt.figure(figsize=(8, 6)) sns.heatmap(confusion_matrix_result, annot=True, cmap='Blues') plt.xlabel('Predicted labels') plt.ylabel('True labels') plt.show()通过结果我们可以发现,其在三分类的结果的预测准确度上有所下降,其在测试集上的准确度为:$86.67\%$,这是由于'versicolor'(1)和 'virginica'(2)这两个类别的特征,我们从可视化的时候也可以发现,其特征的边界具有一定的模糊性(边界类别混杂,没有明显区分边界),所有在这两类的预测上出现了一定的错误。5 重要知识点逻辑回归 原理简介:Logistic回归虽然名字里带“回归”,但是它实际上是一种分类方法,主要用于两分类问题(即输出只有两种,分别代表两个类别),所以利用了Logistic函数(或称为Sigmoid函数),函数形式为:$$ logi(z)=\frac{1}{1+e^{-z}} $$其对应的函数图像可以表示如下:import numpy as np import matplotlib.pyplot as plt x = np.arange(-5,5,0.01) y = 1/(1+np.exp(-x)) plt.plot(x,y) plt.xlabel('z') plt.ylabel('y') plt.grid() plt.show()通过上图我们可以发现 Logistic 函数是单调递增函数,并且在z=0的时候取值为0.5,并且$logi(\cdot)$函数的取值范围为$(0,1)$。而回归的基本方程为$z=w_0+\sum_i^N w_ix_i$,将回归方程写入其中为:$$ p = p(y=1|x,\theta) = h_\theta(x,\theta)=\frac{1}{1+e^{-(w_0+\sum_i^N w_ix_i)}} $$所以, $p(y=1|x,\theta) = h_\theta(x,\theta)$,$p(y=0|x,\theta) = 1-h_\theta(x,\theta)$逻辑回归从其原理上来说,逻辑回归其实是实现了一个决策边界:对于函数 $y=\frac{1}{1+e^{-z}}$,当 $z=>0$时,$y=>0.5$,分类为1,当 $z<0$时,$y<0.5$,分类为0,其对应的$y$值我们可以视为类别1的概率预测值.对于模型的训练而言:实质上来说就是利用数据求解出对应的模型的特定的$w$。从而得到一个针对于当前数据的特征逻辑回归模型。而对于多分类而言,将多个二分类的逻辑回归组合,即可实现多分类。
2.基于Label studio的训练数据标注指南:(智能文档)文档抽取任务、PDF、表格、图片抽取标注等
文档抽取任务Label Studio使用指南1.基于Label studio的训练数据标注指南:信息抽取(实体关系抽取)、文本分类等2.基于Label studio的训练数据标注指南:(智能文档)文档抽取任务、PDF、表格、图片抽取标注等3.基于Label studio的训练数据标注指南:文本分类任务4.基于Label studio的训练数据标注指南:情感分析任务观点词抽取、属性抽取目录1. 安装2. 文档抽取任务标注2.1 项目创建2.2 数据上传2.3 标签构建2.4 任务标注2.5 数据导出2.6 数据转换2.7 更多配置1. 安装以下标注示例用到的环境配置:Python 3.8+label-studio == 1.7.1paddleocr >= 2.6.0.1在终端(terminal)使用pip安装label-studio:pip install label-studio==1.7.1安装完成后,运行以下命令行:label-studio start在浏览器打开http://localhost:8080/,输入用户名和密码登录,开始使用label-studio进行标注。2. 文档抽取任务标注2.1 项目创建点击创建(Create)开始创建一个新的项目,填写项目名称、描述,然后选择Object Detection with Bounding Boxes。填写项目名称、描述命名实体识别、关系抽取、事件抽取、实体/评价维度分类任务选择Object Detection with Bounding Boxes`文档分类任务选择Image Classification`添加标签(也可跳过后续在Setting/Labeling Interface中添加)图中展示了Span实体类型标签的构建,其他类型标签的构建可参考2.3标签构建2.2 数据上传先从本地或HTTP链接上传图片,然后选择导入本项目。2.3 标签构建Span实体类型标签Relation关系类型标签Relation XML模板: <Relations> <Relation value="单位"/> <Relation value="数量"/> <Relation value="金额"/> </Relations>分类类别标签2.4 任务标注实体抽取标注示例:该标注示例对应的schema为:schema = ['开票日期', '名称', '纳税人识别号', '地址、电话', '开户行及账号', '金 额', '税额', '价税合计', 'No', '税率']关系抽取Step 1. 标注主体(Subject)及客体(Object)Step 2. 关系连线,箭头方向由主体(Subject)指向客体(Object)Step 3. 添加对应关系类型标签Step 4. 完成标注该标注示例对应的schema为:schema = { '名称及规格': [ '金额', '单位', }文档分类标注示例该标注示例对应的schema为:schema = '文档类别[发票,报关单]'2.5 数据导出勾选已标注图片ID,选择导出的文件类型为JSON,导出数据:2.6 数据转换将导出的文件重命名为label_studio.json后,放入./document/data目录下,并将对应的标注图片放入./document/data/images目录下(图片的文件名需与上传到label studio时的命名一致)。通过label\_studio.py脚本可转为UIE的数据格式。路径示例./document/data/ ├── images # 图片目录 │ ├── b0.jpg # 原始图片(文件名需与上传到label studio时的命名一致) │ └── b1.jpg └── label_studio.json # 从label studio导出的标注文件抽取式任务python label_studio.py \ --label_studio_file ./document/data/label_studio.json \ --save_dir ./document/data \ --splits 0.8 0.1 0.1\ --task_type ext文档分类任务python label_studio.py \ --label_studio_file ./document/data/label_studio.json \ --save_dir ./document/data \ --splits 0.8 0.1 0.1 \ --task_type cls \ --prompt_prefix "文档类别" \ --options "发票" "报关单"2.7 更多配置label_studio_file: 从label studio导出的数据标注文件。save_dir: 训练数据的保存目录,默认存储在data目录下。negative_ratio: 最大负例比例,该参数只对抽取类型任务有效,适当构造负例可提升模型效果。负例数量和实际的标签数量有关,最大负例数量 = negative\_ratio * 正例数量。该参数只对训练集有效,默认为5。为了保证评估指标的准确性,验证集和测试集默认构造全负例。splits: 划分数据集时训练集、验证集所占的比例。默认为0.8, 0.1, 0.1表示按照8:1:1的比例将数据划分为训练集、验证集和测试集。task_type: 选择任务类型,可选有抽取和分类两种类型的任务。options: 指定分类任务的类别标签,该参数只对分类类型任务有效。默认为"正向", "负向"。prompt_prefix: 声明分类任务的prompt前缀信息,该参数只对分类类型任务有效。默认为"情感倾向"。is_shuffle: 是否对数据集进行随机打散,默认为True。seed: 随机种子,默认为1000.separator: 实体类别/评价维度与分类标签的分隔符,该参数只对实体/评价维度分类任务有效。默认为"##"。schema_lang:选择schema的语言,将会应该训练数据prompt的构造方式,可选有ch和en。默认为ch。ocr_lang:选择OCR的语言,可选有ch和en。默认为ch。layout_analysis:是否使用PPStructure对文档进行布局分析,该参数只对文档类型标注任务有效。默认为False。备注:默认情况下 label\_studio.py 脚本会按照比例将数据划分为 train/dev/test 数据集每次执行 label\_studio.py 脚本,将会覆盖已有的同名数据文件在模型训练阶段我们推荐构造一些负例以提升模型效果,在数据转换阶段我们内置了这一功能。可通过negative_ratio控制自动构造的负样本比例;负样本数量 = negative\_ratio * 正样本数量。对于从label\_studio导出的文件,默认文件中的每条数据都是经过人工正确标注的。ReferencesLabel Studio
1.基于Label studio的训练数据标注指南:信息抽取(实体关系抽取)、文本分类等
文本抽取任务Label Studio使用指南1.基于Label studio的训练数据标注指南:信息抽取(实体关系抽取)、文本分类等2.基于Label studio的训练数据标注指南:(智能文档)文档抽取任务、PDF、表格、图片抽取标注等3.基于Label studio的训练数据标注指南:文本分类任务4.基于Label studio的训练数据标注指南:情感分析任务观点词抽取、属性抽取目录1. 安装2. 文本抽取任务标注2.1 项目创建2.2 数据上传2.3 标签构建2.4 任务标注2.5 数据导出2.6 数据转换2.7 更多配置1. 安装以下标注示例用到的环境配置:Python 3.8+label-studio == 1.7.1paddleocr >= 2.6.0.1在终端(terminal)使用pip安装label-studio:pip install label-studio==1.7.1 pip install label-studio #安装过程报错ERROR: Could not install packages due to an OSError: [WinError 5] 拒绝访问 #添加管理员权限 pip install --user label-studio#如果途中出现警告:WARNING: Ignoring invalid distribution -sonschema (d:\anaconda\envs\paddlenlp\lib\site-packages) 1.原因可能是之前下载库的时候没有成功或者中途退出,当包出现问题(例如缺少依赖项或与其他包冲突)时,可能会出现此警告消息。如果包与正在使用的 Python 版本不兼容,也可能发生这种情况。 2.到提示的目录site-packages下删除~ip开头的目录。 3.然后pip重新安装库即可。#如果怕环境冲突就新建虚拟环境,单独安装 conda create -n test python=3.8 #test为创建的虚拟环境名称安装完成后,运行以下命令行:label-studio start在浏览器打开http://localhost:8080/,输入用户名和密码登录,开始使用label-studio进行标注。2. 文本抽取任务标注2.1 项目创建点击创建(Create)开始创建一个新的项目,填写项目名称、描述,然后选择Object Detection with Bounding Boxes。填写项目名称、描述命名实体识别、关系抽取、事件抽取、实体/评价维度分类任务选择`Relation Extraction。文本分类、句子级情感倾向分类任务选择Text Classification。添加标签(也可跳过后续在Setting/Labeling Interface中配置)图中展示了实体类型标签的构建,其他类型标签的构建可参考2.3标签构建2.2 数据上传先从本地上传txt格式文件,选择List of tasks,然后选择导入本项目。2.3 标签构建Span类型标签Relation类型标签Relation XML模板: <Relations> <Relation value="歌手"/> <Relation value="发行时间"/> <Relation value="所属专辑"/> </Relations>分类类别标签2.4 任务标注实体抽取标注示例:该标注示例对应的schema为:schema = [ '时间', '选手', '赛事名称', ]关系抽取对于关系抽取,其P的类型设置十分重要,需要遵循以下原则“{S}的{P}为{O}”需要能够构成语义合理的短语。比如对于三元组(S, 父子, O),关系类别为父子是没有问题的。但按照UIE当前关系类型prompt的构造方式,“S的父子为O”这个表达不是很通顺,因此P改成孩子更好,即“S的孩子为O”。合理的P类型设置,将显著提升零样本效果。该标注示例对应的schema为:schema = { '作品名': [ '歌手', '发行时间', '所属专辑' }事件抽取该标注示例对应的schema为:schema = { '地震触发词': [ '时间', }句子级分类该标注示例对应的schema为:schema = '情感倾向[正向,负向]'实体/评价维度分类该标注示例对应的schema为:schema = { '评价维度': [ '观点词', '情感倾向[正向,负向]' }2.5 数据导出勾选已标注文本ID,选择导出的文件类型为JSON,导出数据:2.6 数据转换将导出的文件重命名为label_studio.json后,放入./data目录下。通过label_studio.py脚本可转为UIE的数据格式。抽取式任务python label_studio.py \ --label_studio_file ./data/label_studio.json \ --save_dir ./data \ --splits 0.8 0.1 0.1 \ --task_type ext句子级分类任务在数据转换阶段,我们会自动构造用于模型训练的prompt信息。例如句子级情感分类中,prompt为情感倾向[正向,负向],可以通过prompt_prefix和options参数进行配置。python label_studio.py \ --label_studio_file ./data/label_studio.json \ --task_type cls \ --save_dir ./data \ --splits 0.8 0.1 0.1 \ --prompt_prefix "情感倾向" \ --options "正向" "负向"实体/评价维度分类任务在数据转换阶段,我们会自动构造用于模型训练的prompt信息。例如评价维度情感分类中,prompt为XXX的情感倾向[正向,负向],可以通过prompt_prefix和options参数进行声明。python label_studio.py \ --label_studio_file ./data/label_studio.json \ --task_type ext \ --save_dir ./data \ --splits 0.8 0.1 0.1 \ --prompt_prefix "情感倾向" \ --options "正向" "负向" \ --separator "##"2.7 更多配置label_studio_file: 从label studio导出的数据标注文件。save_dir: 训练数据的保存目录,默认存储在data目录下。negative_ratio: 最大负例比例,该参数只对抽取类型任务有效,适当构造负例可提升模型效果。负例数量和实际的标签数量有关,最大负例数量 = negative_ratio * 正例数量。该参数只对训练集有效,默认为5。为了保证评估指标的准确性,验证集和测试集默认构造全负例。splits: 划分数据集时训练集、验证集所占的比例。默认为[0.8, 0.1, 0.1]表示按照8:1:1的比例将数据划分为训练集、验证集和测试集。task_type: 选择任务类型,可选有抽取和分类两种类型的任务。options: 指定分类任务的类别标签,该参数只对分类类型任务有效。默认为["正向", "负向"]。prompt_prefix: 声明分类任务的prompt前缀信息,该参数只对分类类型任务有效。默认为"情感倾向"。is_shuffle: 是否对数据集进行随机打散,默认为True。seed: 随机种子,默认为1000.schema_lang:选择schema的语言,将会应该训练数据prompt的构造方式,可选有ch和en。默认为ch。separator: 实体类别/评价维度与分类标签的分隔符,该参数只对实体/评价维度分类任务有效。默认为"##"。备注:默认情况下 label_studio.py 脚本会按照比例将数据划分为 train/dev/test 数据集每次执行 label_studio.py 脚本,将会覆盖已有的同名数据文件在模型训练阶段我们推荐构造一些负例以提升模型效果,在数据转换阶段我们内置了这一功能。可通过negative_ratio控制自动构造的负样本比例;负样本数量 = negative_ratio * 正样本数量。对于从label_studio导出的文件,默认文件中的每条数据都是经过人工正确标注的。ReferencesLabel Studiolabel studio标注
机器学习平台PAI简测:PAI提供包含数据标注、模型构建、模型训练、模型部署、推理优化在内的AI开发全链路服务
1.PAI简介PAI底层支持多种计算框架:流式计算框架Flink。基于开源版本深度优化的深度学习框架TensorFlow。千亿特征样本的大规模并行计算框架Parameter Server。Spark、PySpark、MapReduce等业内主流开源框架。PAI提供的服务:可视化建模和分布式训练PAI-Designer,详情请参见可视化建模(PAI-Designer)。Notebook交互式AI研发PAI-DSW(Data Science Workshop),详情请参见交互式建模(PAI-DSW)。云原生AI基础平台PAI-DLC(Deep Learning Containers),详情请参见训练任务提交(Training)。自动化建模PAI-AutoLearning,详情请参见场景化解决方案。在线预测PAI-EAS(Elastic Algorithm Service),详情请参见模型在线服务(PAI-EAS)。PAI的优势:服务支持单独或组合使用。支持一站式机器学习,您只要准备好训练数据(存放到OSS或MaxCompute中),所有建模工作(包括数据上传、数据预处理、特征工程、模型训练、模型评估和模型发布至离线或在线环境)都可以通过PAI实现。对接DataWorks,支持SQL、UDF、UDAF、MR等多种数据处理方式,灵活性高。生成训练模型的实验流程支持DataWorks周期性调度,且调度任务区分生产环境和开发环境,进而实现数据安全隔离。2.PAI产品架构PAI的业务架构从下至上分别为:1.基础设施层:涵盖硬件设施、基础平台、计算资源及计算框架。PAI支持的硬件设施包括CPU、GPU、FPGA、NPU、容器服务ACK及ECS。云原生AI基础平台和计算引擎层支持云原生AI基础平台PAI-DLC,大数据计算引擎包括MaxCompute、EMR、实时计算等。在PAI上可以使用的计算框架包括PAI-TensorFlow、PAI-PyTorch、Alink、ODL、AliGraph、EasyRL、EasyRec、EasyTransfer及EasyVision等,用于执行分布式计算任务。2.工作空间层:工作空间是PAI的顶层概念,为企业和团队提供统一的计算资源管理及人员权限管理能力,为AI开发者提供支持团队协作的全流程开发工具及AI资产管理能力。PAI工作空间和DataWorks工作空间在概念和实现上互通。3.按照机器学习全流程,PAI分别提供了数据准备、模型开发和训练及模型部署阶段的产品:数据准备:PAI提供了智能标注(iTAG),支持在多种场景下进行数据标注和数据集管理。模型开发和训练:PAI提供了可视化建模PAI-Designer、交互式编程建模PAI-DSW、训练任务提交,满足不同的建模需求。模型部署:PAI提供了云原生在线推理服务平台PAI-EAS,帮助您快速地将模型部署为服务。此外,PAI提供了智能生态市场和AI能力体验中心,您可以获取并体验业务解决方案和模型算法,实现相关业务和技术的高效对接。4.AI服务层:PAI广泛应用于金融、医疗、教育、交通以及安全等各个领域。阿里巴巴集团内部的搜索系统、推荐系统及金融服务系统等,均依赖于PAI进行数据挖掘。2.大数据和AI体验教程测评2.1 图像分类(多分类任务)动物分类:基于亿万个的模型训练数据,能够精准的识别图片中动物的类别,超强的识别效能为您带来快速、高效的类别名称和识别概率。2.2 图像检测能够帮您轻松应对各种图像内容的检测,超强的识别速度和准确率能够识别各种复杂的图像类别,并能精确的定位图像内常见物体的位置,高效返回物体的坐标和类别信息。识别速度很快2.3图像实例分割:强大的识别能力能帮您快速、精准定位图像中每个物体的位置,并能帮助您快速识别图像的类别,提取其像素掩膜,为您提供超强的图像像素级的定位能力。2.4 新闻分类 通过强大的语义理解能力对新闻文本进行智能分析,并快速返回新闻文本的类目信息,如军事、娱乐、美食、体育等。可广泛应用于文本打标场景。2.5 ocr识别为您高效、准确的提取图像中任意角度的文字信息,提取的内容信息可广泛应用于广告、电商、安全、信息电子化等场景。2.6 内容安全审核通过强大的语义理解对新闻文本进行智能分析,并返回文本是否为正常或是恶意文本,包含涉黄、涉政、暴恐、恶意推广识别。可广泛应用于任何文本内容审核场景。3.总结:阿里云PAI+AI开源项目是一个能够快速构建和管理机器学习模型的强大平台,它可以支持多种AI技术,包括机器学习、深度学习、自然语言处理等。它还可以支持多种类型的数据,支持大规模机器学习场景的构建,并且提供全面的数据可视化、模型建模、实验管理和模型部署等功能
人机协同翻译平台:Alynx阿里翻译旗下智能协同翻译平台
0.Alynx阿里翻译旗下智能协同翻译平台Alynx是阿里翻译旗下智能协同翻译平台,致力于为有自主人工翻译需求的用户提供高效管理翻译项目的平台,赋能用户快速完成翻译需求。1、专业的在线翻译能力高效的项目管理能力,支持在线实时追踪项目进度,多人实时协同工作专业的语料和术语管理能力,支持在线查询和维护语料术语强大的在线翻译平台,支持MTPE的译后编辑模式,支持自动匹配语料与术语,助力译员提升翻译效率、质量和一致性支持包括word、ppt、excel、txt、json等常用格式在内的43种文档格式的解析和合并支持自动质量检查,自动检查译文的一致性、术语、数字、标点等错误2、更轻量化的流程支持支持创建人自己翻译文档支持通过链接快速分享翻译任务给他人,也可通过平台分发任务给他人进行翻译支持MT+TM模式自动生成译文,一键获取译稿3.应用场景自己翻译文档场景描述:我有若干文档需求翻译,我希望能借助机翻结果和语料术语库进行翻译,这样相比在word或lark上翻译会更高效也更能保证翻译质量。多人协作翻译文档场景描述:我有若干文档需要翻译,我需要别人帮我一起翻译,我希望能够在线给别人指派任务并且可以跟踪翻译项目,这样可以提升我的项目管理效果;并且我希望能借助机翻结果和语料术语库进行翻译,这样相比在word或lark上翻译会更高效也更能保证翻译质量。一键获取自动生成的专属译文场景描述:我有若干文档需要翻译,但我对文档的质量要求不高,我希望能够优先匹配指定语料库结果,如匹配不上则使用机翻结果,这样既能快速获取译文,又能保证质量比机翻结果更好。1.翻译实战1.1 文档翻译功能很丰富支持:文档翻译、图片翻译、视频翻译等。以文档翻译为例:点击“文档翻译”后上传文档页面,可上传一份或多份文档。已学术论文为例进行测评:项目设置,系统默认规则即可,如想修改在点击【下一步】后修改项目设置信息并另存为新模板,下次可选择自定义模板。可以进行定制化:填写项目信息,填写项目设置信息;项目设置可根据项目需求,自定义项目设置信息;可以自定义文件解析、语料库、术语库、机翻引擎、任务自动分配等配置。点击【立即创建】后,项目创建成功,可以点击【编辑】自己去编辑译文,也可以点击【分配】把任务分配给其他人进行翻译。项目创建完成后,可立即进行分配译员进行生产,或稍后在“我的项目”入口进入该项目分配译员。译员用户登录alynx系统,点击【翻译】按钮进行翻译;或可在项目详情页面,点击【进入工作台】进入翻译工作台页面。译员对原文进行翻译,翻译任务完成点击【Save All】保存进度,确认无误后点击【Submit All】提交任务。1.2 智能机翻首页点击智能机翻,切换到文档翻译,设置源语言和目标语言、后上传文档。预览点击查看,可以预览机翻结果。点击去编辑,可以进入编辑工作台,对机翻结果进行调整。调整后,可以在工作台或历史记录中下载最新结果。整体翻译比较准确。图像视频翻译更多参考官方使用手册https://help.aliyun.com/document_detail/463163.html2.总结优点:1.协作式:人机协同翻译能够将专业词汇实时罗列出来,供我们选择合适的去使用,并且可以上下文匹配,不用我们每次去重复翻译和记忆。多人协同翻译,同时人翻加机翻结合,减轻了以前完全靠人工翻译的压力,借助人机协同翻译,事半功倍。2.功能多个性化调试:a.文档翻译、视频翻译模块b.可以根据翻译内容进行个性化搭配,翻译出自己满意的句子3.操作简单:整个产品的操作没有难点,直接进行操作即可4.效果整体不错:大部分优于百度、有道翻译免费版本缺点:也是大部分翻译软件通病,目前提供的是通用领域的,定制化领域效果不太明显,导致部分翻译“语义”漂移了。
推荐系统[四]:精排-详解排序算法LTR (Learning to Rank)_ poitwise, pairwise, listwise相关评价指标,超详细知识指南。
0.前言召回排序流程策略算法简介推荐可分为以下四个流程,分别是召回、粗排、精排以及重排:召回是源头,在某种意义上决定着整个推荐的天花板;粗排是初筛,一般不会上复杂模型;精排是整个推荐环节的重中之重,在特征和模型上都会做的比较复杂;重排,一般是做打散或满足业务运营的特定强插需求,同样不会使用复杂模型;召回层:召回解决的是从海量候选item中召回千级别的item问题统计类,热度,LBS;协同过滤类,UserCF、ItemCF;U2T2I,如基于user tag召回;I2I类,如Embedding(Word2Vec、FastText),GraphEmbedding(Node2Vec、DeepWalk、EGES);U2I类,如DSSM、YouTube DNN、Sentence Bert;模型类:模型类的模式是将用户和item分别映射到一个向量空间,然后用向量召回,这类有itemcf,usercf,embedding(word2vec),Graph embedding(node2vec等),DNN(如DSSM双塔召回,YouTubeDNN等),RNN(预测下一个点击的item得到用户emb和item emb);向量检索可以用Annoy(基于LSH),Faiss(基于矢量量化)。此外还见过用逻辑回归搞个预估模型,把权重大的交叉特征拿出来构建索引做召回排序策略,learning to rank 流程三大模式(pointwise、pairwise、listwise),主要是特征工程和CTR模型预估;粗排层:本质上跟精排类似,只是特征和模型复杂度上会精简,此外也有将精排模型通过蒸馏得到简化版模型来做粗排常见的特征挖掘(user、item、context,以及相互交叉);精排层:精排解决的是从千级别item到几十这个级别的问题CTR预估:lr,gbdt,fm及其变种(fm是一个工程团队不太强又对算法精度有一定要求时比较好的选择),widedeep,deepfm,NCF各种交叉,DIN,BERT,RNN多目标:MOE,MMOE,MTL(多任务学习)打分公式融合: 随机搜索,CEM(性价比比较高的方法),在线贝叶斯优化(高斯过程),带模型CEM,强化学习等重排层:重排层解决的是展示列表总体最优,模型有 MMR,DPP,RNN系列(参考阿里的globalrerank系列)展示层:推荐理由:统计规则、行为规则、抽取式(一般从评论和内容中抽取)、生成式;排序可以用汤普森采样(简单有效),融合到精排模型排等等首图优选:CNN抽特征,汤普森采样探索与利用:随机策略(简单有效),汤普森采样,bandit,强化学习(Q-Learning、DQN)等产品层:交互式推荐、分tab、多种类型物料融合粗排与精排就像级联漏斗,两者目标更多保持同向一致性,粗排就是跟精排保持步调一致。如果粗排排序高的,精排排序也高,那么粗排就很好的完成了“帮助精排缓冲”的目的。而rerank环节类似于排序改判:可能涉及业务调整、打散、强插、增量分等等。1.精排简介Learning to Rank (LTR)是一类技术方法,主要利用机器学习算法解决实际中的排序问题。传统的机器学习主要解决的问题是一个分类或者回归问题,比如对一个样本数据预测对应的类别或者预测一个数值分值。而LTR解决的是一个排序问题,对一个list的item进行一个排序,所以LTR并不太关注这个list的每个item具体得多少分值,更关注所有item的相对顺序。排序通常是信息检索的核心成分,所以LTR最常见的应用是搜索场景,对召回的document进行排序。1.1 精排应用场景排序学习场景:推荐系统,基于历史行为的“猜你喜欢”搜索排序,基于某Query进行的结果排序,期望用户选中的在排序结果中是靠前的 => 有意识的被动推荐排序结果都很重要,猜用户想要点击或者booking的item就在结果列表前面排序学习是个性化结果,用于搜索列表、推荐列表、广告等场景1.2 常用模型排序模型按照结构划分,可以分为线性排序模型、树模型、深度学习模型:从早期的线性模型LR,到引入自动二阶交叉特征的FM和FFM,到非线性树模型GBDT和GBDT+LR,到最近全面迁移至大规模深度学习排序模型。线性排序模型:LR树模型:GBDT,GBDT+LR, LambdaMART深度学习模型: DeepFM,Wide&Deep, ListNet, AdaRank,SoftRank,LambdaRank等2.LTR三大结构:Pointwise, Pairwise, Listwise序模型按照样本生成方法和损失函数loss的不同,可以划分成Pointwise, Pairwise, Listwise三类方法:Pointwise排序学习(单点法):将训练样本转换为多分类问题(样本特征-类别标记)或者回归问题(样本特征-连续值)只考虑单个样本的好坏,没有考虑样本之间的顺序Pairewise排序学习(配对法):比较流行的LTR学习方法,将排序问题转换为二元分类问题接收到用户査询后,返回相关文档列表,确定文档之间的先后顺序关系(多个pair的排序问题),只考虑了两个文档的相对顺序,没有考虑文档在搜索列表中的位置。Listwise排序学习(列表法):它是将每个Query对应的所有搜索结果列表作为一个训练样例根据训练样例训练得到最优评分函数F,对应新的查询,评分F对每个文档打分,然后根据得分由高到低排序,即为最终的排序结果2.1 pointwisepointwise将其转化为多类分类或者回归问题Pointwise 类方法,其 L2R 框架具有以下特征:输入空间中样本是单个 doc(和对应 query)构成的特征向量;输出空间中样本是单个 doc(和对应 query)的相关度;假设空间中样本是打分函数;损失函数评估单个 doc 的预测得分和真实得分之间差异。这里讨论下,关于人工标注标签怎么转换到 pointwise 类方法的输出空间:如果标注直接是相关度 $s_j$,则 $doc x_j$ 的真实标签定义为 $y_j=s_j$如果标注是 pairwise preference $s_{u,v}$,则 $doc x_j$ 的真实标签可以利用该 doc 击败了其他 docs 的频次如果标注是整体排序 π,则 $doc x_j$ 的真实标签可以利用映射函数,如将 doc 的排序位置序号当作真实标签2.1.1 算法简介根据使用的 ML 方法不同,pointwise 类可以进一步分成三类:基于回归的算法、基于分类的算法,基于有序回归的算法。下面详细介绍。基于回归的算法此时,输出空间包含的是实值相关度得分。采用 ML 中传统的回归方法即可。基于分类的算法此时,输出空间包含的是无序类别。对于二分类,SVM、LR 等均可;对于多分类,提升树等均可。基于有序回归的算法此时,输出空间包含的是有序类别。通常是找到一个打分函数,然后用一系列阈值对得分进行分割,得到有序类别。采用 PRanking、基于 margin 的方法都可以。2.1.2 ponitwise 细则pointwise方法损失函数计算只与单个document有关,本质上是训练一个分类模型或者回归模型,判断这个document与当前的这个query相关程度,最后的排序结果就是从模型对这些document的预测的分值进行一个排序。对于pointwise方法,给定一个query的document list,对于每个document的预测与其它document是独立的。所以模型输入和对应的标签label形式如下:输入: 单个document标签label: document所属类型或者分值pointwise方法将排序任务看做对单个文本的回归或者分类任务来做。若文档document的相关性等级有K种,则我们可以建模为一个有K个类别的$\{0,1,2,..., K-1\}$的Multi-class分类任务,则 $y_i \in \R^k$ 一个k维度的one-hot表示, 我们可以用交叉熵loss作为目标损失函数:$\left.\mathrm{L}=-\left(\mathrm{y}_{\mathrm{i}} \log \left(\mathrm{p}_{\mathrm{i}}\right)-\left(1-\mathrm{y}_{\mathrm{i}}\right) \log \left(1-\mathrm{p}_{\mathrm{i}}\right)\right]\right)$参考链接:https://zhuanlan.zhihu.com/p/5285338672.1.3 Pointwise排序学习(单点法)总结:将文档转化为特征向量,每个文档都是独立的对于某一个query,它将每个doc分别判断与这个query的相关程度将docs排序问题转化为了分类(比如相关、不相关)或回归问题(相关程度越大,回归函数的值越大)从训练数据中学习到的分类或者回归函数对doc打分,打分结果即是搜索结果,CTR可以采用Pointwise方式进行学习,对每一个候选item给出一个评分,基于评分进行排序仅仅考虑了query和doc之间的关系,而没有考虑排序列表中docs之间的关系主要算法:转换为回归问题,使用LR,GBDT,Prank, McRank缺陷ranking 追求的是排序结果,并不要求精确打分,只要有相对打分即可。pointwise 类方法并没有考虑同一个 query 对应的 docs 间的内部依赖性。一方面,导致输入空间内的样本不是 IID 的,违反了 ML 的基本假设,另一方面,没有充分利用这种样本间的结构性。其次,当不同 query 对应不同数量的 docs 时,整体 loss 将会被对应 docs 数量大的 query 组所支配,前面说过应该每组 query 都是等价的。损失函数也没有 model 到预测排序中的位置信息。因此,损失函数可能无意的过多强调那些不重要的 docs,即那些排序在后面对用户体验影响小的 doc。改进Pointwise 类算法也可以再改进,比如在 loss 中引入基于 query 的正则化因子的 RankCosine 方法。2.2 pairwisepairwise将其转化为pair分类问题Pairwise 类方法,其 L2R 框架具有以下特征:输入空间中样本是(同一 query 对应的)两个 doc(和对应 query)构成的两个特征向量;输出空间中样本是 pairwise preference;假设空间中样本是二变量函数;损失函数评估 doc pair 的预测 preference 和真实 preference 之间差异。这里讨论下,关于人工标注标签怎么转换到 pairwise 类方法的输出空间:如果标注直接是相关度 $s_j$,则 doc $pair (x_u,x_v)$ 的真实标签定义为 $y_{u,v}=2*I_{s_u>s_v}-1$如果标注是 pairwise preference $s_{u,v}$,则 doc $pair (x_u,x_v)$ 的真实标签定义为$y_{u,v}=s_{u,v}$如果标注是整体排序 π,则 doc $pair (x_u,x_v)$ 的真实标签定义为$y_{u,v}=2*I_{π_u,π_v}-1$2.2.1 算法简介基于二分类的算法pairwise 类方法基本就是使用二分类算法即可。经典的算法有 基于 NN 的 SortNet,基于 NN 的 RankNet,基于 fidelity loss 的 FRank,基于 AdaBoost 的 RankBoost,基于 SVM 的 RankingSVM,基于提升树的 GBRank。2.2.2 pairwise细则基于pairwise的方法,在计算目标损失函数的时候,每一次需要基于一个pair的document的预测结果进行损失函数的计算。比如给定一个pair对的document,优化器需要优化的是两个document的排序关系,与groud truth的排序顺序保持一致。目标是最小化与groud truth不一致的排序对。在实际应用中,pairwise方法比pointwise效果更好,因为预测相对的排序相比预测一个类别或者一个分值,更符合排序的性质。其中模型输入和对应的标签label形式如下:输入: 一个pair对document (A,B)输出标签: 相对顺序label (1, 0.5, 0)其中1表示相关性等级A>B,0.5表示相关性等级A=B,0表示相关性等级A<B。2.2.3 Pairewise排序学习(配对法)总结:比较流行的LTR学习方法,将排序问题转换为二元分类问题接收到用户査询后,返回相关文档列表,确定文档之间的先后顺序关系(多个pair的排序问题)对于同一查询的相关文档集中,对任何两个不同label的文档,都可以得到一个训练实例$(di,dj)$,如果$di>dj$则赋值+1,反之-1没有考虑文档出现在搜索列表中的位置,排在搜索结果前面的文档更为重要,如果靠前的文档出现判断错误,代价会很高1. 缺点:虽然 pairwise 类相较 pointwise 类 model 到一些 doc pair 间的相对顺序信息,但还是存在不少问题,回顾概述中提到的评估指标应该基于 query 和 position,如果人工标注给定的是第一种和第三种,即已包含多有序类别,那么转化成 pairwise preference 时必定会损失掉一些更细粒度的相关度标注信息。doc pair 的数量将是 doc 数量的二次,从而 pointwise 类方法就存在的 query 间 doc 数量的不平衡性将在 pairwise 类方法中进一步放大。pairwise 类方法相对 pointwise 类方法对噪声标注更敏感,即一个错误标注会引起多个 doc pair 标注错误。pairwise 类方法仅考虑了 doc pair 的相对位置,损失函数还是没有 model 到预测排序中的位置信息。pairwise 类方法也没有考虑同一个 query 对应的 doc pair 间的内部依赖性,即输入空间内的样本并不是 IID 的,违反了 ML 的基本假设,并且也没有充分利用这种样本间的结构性。2. 改进pairwise 类方法也有一些尝试,去一定程度解决上述缺陷,比如:Multiple hyperplane ranker,主要针对前述第一个缺陷magnitude-preserving ranking,主要针对前述第一个缺陷IRSVM,主要针对前述第二个缺陷采用 Sigmoid 进行改进的 pairwise 方法,主要针对前述第三个缺陷P-norm push,主要针对前述第四个缺陷Ordered weighted average ranking,主要针对前述第四个缺陷LambdaRank,主要针对前述第四个缺陷Sparse ranker,主要针对前述第四个缺陷2.3 listwiseListwise 类方法,其 L2R 框架具有以下特征:输入空间中样本是(同一 query 对应的)所有 doc(与对应的 query)构成的多个特征向量(列表);输出空间中样本是这些 doc(和对应 query)的相关度排序列表或者排列;假设空间中样本是多变量函数,对于 docs 得到其排列,实践中,通常是一个打分函数,根据打分函数对所有 docs 的打分进行排序得到 docs 相关度的排列;损失函数分成两类,一类是直接和评价指标相关的,还有一类不是直接相关的。具体后面介绍。这里讨论下,关于人工标注标签怎么转换到 listwise 类方法的输出空间:如果标注直接是相关度$s_j$,则 doc set 的真实标签可以利用相关度 $s_j$进行比较构造出排列如果标注是 pairwise preference $s_{u,v}$,则 doc set 的真实标签也可以利用所有 $s_{u,v}$进行比较构造出排列如果标注是整体排序 π,则 doc set 则可以直接得到真实标签2.3.1 算法简介直接基于评价指标的算法直接取优化 ranking 的评价指标,也算是 listwise 中最直观的方法。但这并不简单,因为前面说过评价指标都是离散不可微的,具体处理方式有这么几种:优化基于评价指标的 ranking error 的连续可微的近似,这种方法就可以直接应用已有的优化方法,如SoftRank,ApproximateRank,SmoothRank优化基于评价指标的 ranking error 的连续可微的上界,如 SVM-MAP,SVM-NDCG,PermuRank使用可以优化非平滑目标函数的优化技术,如 AdaRank,RankGP上述方法的优化目标都是直接和 ranking 的评价指标有关。现在来考虑一个概念,informativeness。通常认为一个更有信息量的指标,可以产生更有效的排序模型。而多层评价指标(NDCG)相较二元评价(AP)指标通常更富信息量。因此,有时虽然使用信息量更少的指标来评估模型,但仍然可以使用更富信息量的指标来作为 loss 进行模型训练。通过直接优化排序结果中的评测指标来优化排序任务,但是基于评测指标比如NDCG依赖排序结果,是不连续不可导的。所以优化这些不连续不可导的目标函数面临较大的挑战,目前多数优化技术都是基于函数可导的情况。那么如何解决这个问题?常见的有如下两种方法:通过使用优化技术将目标函数转变成连续可导的函数,然后进行求解,比如SoftRank和 AdaRank等模型通过使用优化技术对非连续的不可导目标函数就行求解,比如 LambdaRankLambdaRankRankNet优化目标是最小化pair对错误,但是在信息检索领域比如NDCG这样的评测指标,这样的优化目标并不能够最大化效果,通常在信息检索中我们更关注的是topN的排序结果,且相关性越大的文本最需要排在最前面。如下图所示:给定一个query,上图为排序结果展示,其中蓝色的线表示的是相关的文档,灰色的线表示不相关的文档,那么在左图,有13个pair对错误,而在右图中,有11个pair对错误,在RankNet,右图的排序结果要比左图好,但是在信息检索指标中,比如NDCG指标,左图的效果比右边更好。我们在上面介绍RankNet中,将上述(1)(2)公式代人到(3)公式中,我们可以得到损失函数如下:$\mathrm{C}=\frac{1}{2}\left(1-\mathrm{S}_{\mathrm{ij}}\right) \sigma\left(\mathrm{s}_{\mathrm{i}}-\mathrm{s}_{\mathrm{j}}\right)+\log \left(1+\mathrm{e}^{-\sigma\left(\mathrm{s}_{\mathrm{i}}-\mathrm{s}_{\mathrm{j}}\right)}\right)$详细内容不展开参考博客:https://blog.csdn.net/BGoodHabit/article/details/1223827504.1.1节LambdaMART参考上述博客4.1.2节非直接基于评价指标的算法(定义损失函数)这里,不再使用和评价指标相关的 loss 来优化模型,而是设计能衡量模型输出与真实排列之间差异的 loss,如此获得的模型在评价指标上也能获得不错的性能。经典的如 ,ListNet,ListMLE,StructRank,BoltzRank。ListNetListNet与RankNet很相似,RankNet是用pair对文本排序顺序进行模型训练,而ListNet用的是整个list文本排序顺序进行模型训练。若训练样本中有m个query,假如对应需要排序的最多文本数量为n ,则RankNet的复杂度为$O(m \cdot n^2)$而ListNet的复杂度为$O(m \cdot n)$,所以整体来说在训练过程中ListNet相比RankNet更高效。ListMLEListMLE也是基于list计算损失函数,论文对learning to rank算法从函数凸性,连续性,鲁棒性等多个维度进行了分析,提出了一种基于最大似然loss的listwise排序算法,取名为ListMLE。上述参考博客:4.2.2节2.3.2 Listwise细则更多内容参考(https://blog.csdn.net/sinat_39620217/article/details/129057635)[https://blog.csdn.net/sinat_39620217/article/details/129057635]2.3.3 Listwise排序学习(列表法)总结:它是将每个Query对应的所有搜索结果列表作为一个训练样例根据训练样例训练得到最优评分函数F,对应新的查询,评分F对每个文档打分,然后根据得分由高到低排序,即为最终的排序结果直接考虑整体序列,针对Ranking评价指标(比如MAP, NDCG)进行优化主要算法:ListNet, AdaRank,SoftRank,LambdaRank, LambdaMART等LambdaMART是对RankNet和LambdaRank的改进,在 Yahoo Learning to Rank Challenge比赛中的冠军模型listwise 类相较 pointwise、pairwise 对 ranking 的 model 更自然,解决了 ranking 应该基于 query 和 position 问题。listwise 类存在的主要缺陷是:一些 ranking 算法需要基于排列来计算 loss,从而使得训练复杂度较高,如 ListNet和 BoltzRank。此外,位置信息并没有在 loss 中得到充分利用,可以考虑在 ListNet 和 ListMLE 的 loss 中引入位置折扣因子。2.4 三类方法代表汇总wiki有很全的三类方法代表:2019 FastAP [30] listwise Optimizes Average Precision to learn deep embeddings 2019 Mulberry listwise & hybrid Learns ranking policies maximizing multiple metrics across the entire dataset 2019 DirectRanker pairwise Generalisation of the RankNet architecture 2019 GSF [31] listwise A permutation-invariant multi-variate ranking function that encodes and ranks items with groupwise scoring functions built with deep neural networks. 2020 RaMBO[32] listwise Optimizes rank-based metrics using blackbox backpropagation[33] 2020 PRM [34] pairwise Transformer network encoding both the dependencies among items and the interactions between the user and items 2020 SetRank [35] listwise A permutation-invariant multi-variate ranking function that encodes and ranks items with self-attention networks. 2021 PiRank [36] listwise Differentiable surrogates for ranking able to exactly recover the desired metrics and scales favourably to large list sizes, significantly improving internet-scale benchmarks. 2022 SAS-Rank listwise Combining Simulated Annealing with Evolutionary Strategy for implicit and explicit learning to rank from relevance labels 2022 VNS-Rank listwise Variable Neighborhood Search in 2 Novel Methodologies in AI for Learning to Rank 2022 VNA-Rank listwise Combining Simulated Annealing with Variable Neighbourhood Search for Learning to Rank2.5 评估指标更多内容参考(https://blog.csdn.net/sinat_39620217/article/details/129057635)[https://blog.csdn.net/sinat_39620217/article/details/129057635]2.5.1 WTA(Winners take all)2.5.2 MRR(Mean Reciprocal Rank)2.5.3 RC(Rank Correlation)2.5.4 MAP(Mean Average Precision)2.5.5 NDCG(Normalized Discounted Cumulative Gain)2.5.6 小结可以发现,这些评估指标具备两大特性:基于 query ,即不管一个 query 对应的 docs 排序有多糟糕,也不会严重影响整体的评价过程,因为每组 query-docs 对平均指标都是相同的贡献。基于 position ,即显式的利用了排序列表中的位置信息,这个特性的副作用就是上述指标是离散不可微的。一方面,这些指标离散不可微,从而没法应用到某些学习算法模型上;另一方面,这些评估指标较为权威,通常用来评估基于各类方式训练出来的 ranking 模型。因此,即使某些模型提出新颖的损失函数构造方式,也要受这些指标启发,符合上述两个特性才可以。3.推荐参考链接
阿里云智能语音交互产品测评:基于语音识别、语音合成、自然语言理解等技术
0.智能语音智能语音交互(Intelligent Speech Interaction)是基于语音识别、语音合成、自然语言理解等技术,为企业在多种实际应用场景下,赋予产品“能听、会说、懂你”式的智能人机交互功能。适用于智能问答、智能质检、法庭庭审实时记录、实时演讲字幕、访谈录音转写等场景,在金融、司法、电商等多个领域均有应用。0.1 阿里语音交互的产品核心优势语音识别1.识别准确率高基于SAN-M自研的“识音石”通用端到端语音识别框架,中文识别准确率可达业内领先水平;在输入法、客服、会议等领域,识别字错误率相比上一代系统下降10%~30%,大幅提高了语音识别的精度。2.识别速度快采用“字”级别建模单元及自研模型推理引擎,并发推理速度相比业内主流推理框架提升10倍以上;国内独创的LFR解码技术,在不损失识别精度的情况下,将解码速率提高3倍以上,大幅缩短反馈时间,提升用户体验。3.独创的模型优化工具结合模型优化工具子产品,针对特定的领域定制专属模型,最大限度地提升识别效果。4.丰富的功能支持音字同步、语种识别、说话人识别等丰富功能。5.广泛的领域覆盖适用于智能问答、语音指令、音视频字幕、语音搜索、会议谈话转译、语音质检,公安消防接警、法庭审讯记录等各类场景。语音合成1.技术领先兼顾了多级韵律停顿,达到自然合成韵律的目的,综合利用声学参数和语言学参数,建立基于深度学习的多重自动预测模型。2.效果逼真在本地端实现了基于Knowledge-Aware Neural TTS (KAN-TTS) 语音合成技术,基于深度神经网络和机器学习,将文本转换成真实饱满、抑扬顿挫、富有表现力的语音,使得离线语音合成效果趋近于在线合成效果。同样的语音合成声音定制的合成效果与真人录音相比,几乎可以以假乱真。3.音色个性化支持中英文等多种语言,多种音色,多种场景及多种风格的语音合成声音,并可支持低数据量的离线合成声音定制。4.听感自然经海量音频数据训练,使合成音真实饱满、抑扬顿挫、富有表现力,MOS评分达到业内领先水准。5.深度定制根据用户需求定制音库,满足用户的个性化应用需求,提供标准男女声、温柔甜美女声等多风格选择,支持标记语言(SSML)方式的合成方式,音量、语速、音高等参数也支持动态调整。支持客户指定自有数据合成TTS声音。6.高效稳定接口简单易集成,运行稳定、兼容性强、首包延迟小,内存占用少,CPU占用低,对于低配硬件也有对应的解决方案。7.节省成本离线语音合成无需联网即可完成实时语音合成,按设备数授权,成本可控。声音定制中需要的数据量门槛更低,在中文普通话场景,2000句起即可合成自然流畅效果的声音,加入英文数据后,还可实现中英混读效果,录音和标注的时间成本大幅减少,尽显价格优势。8.多领域覆盖在智能家居、车载、导航、金融、运营商、物流、房地产、教育、有声读物等众多领域积累了大量的词库,使阿里语音合成技术对各领域、各行业的词汇发音更准确。自学习平台1.易用自学习平台颠覆性地提供一键式自助语音优化方案,极大地降低进行语音智能优化所需要的门槛,让不懂技术的业务人员也可以显著提高自身业务识别准确率。2.快速自学习平台能够在数分钟之内完成业务专属定制模型的优化测试上线,更能支持业务相关热词的实时优化,一改传统定制优化长达数周甚至数月的漫长交付弊端。3.准确自学习平台优化效果在很多内外部合作伙伴和项目上得到了充分验证,很多项目最终通过自学习平台不仅解决了可用性问题,还在项目中超过了竞争对手使用传统优化方式所取得的优化效果。0.2 应用场景语音识别1.语音搜索支持各种场景下的语音搜索,如地图导航、浏览器搜索等。可以集成到任何形式的手机应用中,最大限度地解放双手。2.语音指令通过语音命令控制智能设备,实现快捷便利的操作,如控制空调开关、电视换台等。可以集成到智能家居等设备中。3.语音短消息发送或者接收语音短消息时,利用音频转文字能力,实现音频内容快速预览。视频实时直播字幕现场演讲场景、实时直播场景下,将视频中的音频实时转写为字幕,还可以进一步对内容进行管理。4.实时会议记录将会议、法庭庭审中的音频实时转写为文字,辅助会议记录工作,同时适用于电视会议等远距离场景。5.实时客服记录将呼叫中心的语音实时转写为文字,可以实现实时质检等。呼叫中心语音质检上传呼叫中心的录音文件,通过录音文件识别得到文本,进一步通过文本检索,检查有无违规话术、敏感词等信息。6.庭审数据库录入上传庭审记录的录音文件,进行识别后,将识别文本录入数据库。会议记录总结对会议记录的音频文件进行识别,然后通过人工或者自动方法,对会议记录作出总结。7.医院病历录入手术时通过音频记录医生的操作,通过录音文件识别得到文本,提高病例录入效率。语音合成1.智能客服提供多行业多场景的智能客服语音合成能力。提高解答效率,提升客户满意度,降低呼叫中心人工成本。2.智能设备为智能家居、音箱、车载和可穿戴设备等赋予一个最有温度的声音。3.文学有声阅读让富有感染力的声音为您讲故事、读小说、播新闻,满足“懒人”的阅读需求。4.新闻传媒播报释放用户的双手和双眼,提供多种发音风格的新闻播报,打造更极致的传媒体验。5.无障碍播报将文字转成流畅动听的自然语言声音,实现面向各类人群的无障碍播报。6.内容创作自媒体、大V等内容创作方可将个性化定制的声音应用于传播平台。如,资讯播报、视频配音等。7.在线教育“复制”在线课堂老师的声音,增强课堂的交互性。自学习平台1.热词在语音识别服务中,如果在您的业务领域有一些特有的词,默认识别效果较差的情况下可以使用热词功能,将这些词添加到词表,改善识别结果。2.语言模型定制支持上传业务相关的文本语料训练模型,可以在该业务领域中获得更高的识别准确率。如司法、金融等领域。0.3基本概念采样率(sample rate)音频采样率是指录音设备在一秒钟内对声音信号的采样次数,采样频率越高声音的还原就越真实越自然。目前语音识别服务支持16000Hz和8000Hz两种采样率,其中电话业务一般使用8000Hz,其余业务使用16000Hz。调用语音识别服务时,如果语音数据采样率高于16000Hz,需要先把采样率转换为16000Hz才能发送给语音识别服务;如果语音数据采样率是8000Hz,请勿将采样率转换为16000Hz,项目中选用支持8000Hz采样率的模型。采样位数(sample size)采样值或取样值,即是将采样样本幅度量化。用来衡量声音波动变化的参数,或是声卡的分辨率。数值越大、分辨率越高,发出声音的能力越强。目前语音识别中常用的采样位数为16 bit小端序。即每次采样的音频信息用2字节保存,或者说2字节记录1/16000s的音频数据。每个采样数据记录的是振幅,采样精度取决于采样位数的大小:1字节(8 bit)记录256个数,亦即将振幅划分为256个等级。2字节(16 bit)记录65536个数。其中2字节采样位数已经能够达到CD标准。语音编码(format)语音数据存储和传输的方式。注意语音编码和语音文件格式不同,如常见的WAV文件格式,会在其头部定义语音数据的编码,其中的音频数据通常使用PCM、AMR或其他编码。注意 在调用智能语音交互服务之前需确认语音数据编码格式是服务所支持的。声道(sound channel)录制声音时,在不同空间位置采集的相互独立的音频信号。声道数也就是声音录制时的音源数量。常见的音频数据为单声道或双声道(立体声)。说明 除录音文件识别以外的服务只支持单声道(mono)语音数据,如果您的数据是双声道或其他,需要先转换为单声道。逆文本规整(inverse text normalization)语音转换为文本时使用标准化的格式展示数字、金额、日期和地址等对象,以符合阅读习惯。以下是一些示例。更多内容参考官网文档:https://help.aliyun.com/document_detail/72214.html1.智能语音交互实测1.1创建项目1.2 语言模型定制化定制化训练1.3 移动端应用如何安全访问智能语音交互服务为了避免在移动端App或者桌面端工具中保存固定AccessKey ID和AccessKey Secret可能引起的泄漏风险,您可以通过以下两种方案,更加安全地访问智能语音交互服务。方案一:通过App服务端创建Token并下发到移动端使用前提条件已开通智能语音交互服务,并根据产品文档调试成功,具体操作,请参见开通服务。适用场景如果您作为移动App开发者或者桌面端开发者,希望您的用户调用阿里云智能语音交互产品的语音合成、一句话识别、实时识别等服务时,避免在移动端App或者桌面端工具中保存固定AccessKey ID和AccessKey Secret可能引起的泄漏风险,您可以使用App服务端下发语音Token调用服务。1.App端向用户应用服务器请求一个调用智能语音交互接口所依赖的语音Token,此处使用您自有的通信协议即可,比如用户登录时自动请求或服务端自动下发,或定时向应用服务器发起请求。2.用户应用服务器向阿里云智能语音服务发起创建语音Token的真正请求,此处请您使用阿里云SDK或智能语音交互SDK来创建Token,创建Token所需的AccessKey ID和AccessKey Secret保存在您的应用服务器上。由于语音Token具有时效性,您可以在有效期范围内直接返回给App端,无需每次都向智能语音交互服务请求新的Token。3.智能语音交互服务返回给应用服务器一个语音Token信息,包括Token字符串及有效期时间,在有效期内您可以多次复用该Token而无需重新创建,Token的使用不受不同用户、不同设备的限制。4.用户应用服务器将Token返回给App端,此时App端可以缓存并使用该Token,直到Token失效。当Token失效时,App端需要向应用服务器申请新的Token。假设Token凭证有效期为24小时,App端可以在Token过期前1到2小时主动向应用服务器请求更新Token。5.App端使用获取到的Token构建请求,向阿里云智能语音交互公共云发起调用,比如调用实时语音识别、一句话识别、语音合成等接口(不包括录音文件识别、录音文件识别闲时版等离线类接口),更多信息,请参见阿里云智能语音交互相关文档。此方案无需过多额外设置或开发,将AccessKey ID和AccessKey Secret保存到移动端改为保存到用户自己的服务端,并通过服务端创建语音Token再下发给移动端使用,兼容了使用安全性及开发便捷性。方案二:使用STS临时访问凭证调用语音服务您可以通过STS服务给其他用户颁发临时访问凭证,该用户可使用临时访问凭证,在规定时间内调用智能语音交互的录音文件识别服务(含闲时版)。临时访问凭证无需透露您的长期密钥,保障您的账户更加安全。前提条件已确保当前账号为阿里云账号或者被授予AliyunRAMFullAccess权限的RAM用户。关于为RAM用户授权的具体步骤,请参见为RAM用户授权。适用场景如果您作为移动App开发者或者桌面端开发者,希望您的用户调用阿里云智能语音交互产品的语音合成、一句话识别、实时识别等服务时,避免在移动端App或者桌面端工具中保存固定AccessKey ID和AccessKey Secret可能引起的泄漏风险,您可以使用STS授权用户调用服务。交互流程使用STS临时访问凭证授权用户调用阿里云智能语音交互服务(例如录音文件转写)的交互流程如下:1.App端向用户应用服务器请求STS临时访问凭证,此处使用用户自有的通信协议即可,比如用户登录时自动请求或服务端自动下发,或定时向应用服务器发起请求。2.用户应用服务器向阿里云STS服务发起STS请求,此处请使用阿里云SDK,根据应用服务器自身保存的固定AK向STS请求生成一个临时凭证。3.STS返回给应用服务器一个临时访问凭证,包括临时访问密钥(AccessKey ID和AccessKey Secret)、安全令牌(SecurityToken)、该凭证的过期时间等信息。4.用户应用服务器将临时凭证返回给App端,此时App端可以缓存并使用该凭证,直到凭证失效。当凭证失效时,App端需要向应用服务器申请新的临时访问凭证。假设临时访问凭证有效期为1小时,App端可以每30分钟或者每50分钟的频率向应用服务器请求更新临时访问凭证。5.App端使用获取到的临时凭证构建请求,向阿里云智能语音交互公共云发起调用,更多信息,请参见阿里云智能语音交互相关开发文档。本文以录音文件识别为例,为您介绍相关示例代码。2.总结1.音色合成这一块话也是不错的,大部分音色也都能满足,还加上了一些情绪的表达,蛮好的。2.自学平台,可以根据相应的模型,进行学习,帮助语音机器人训练识别模型,让它更懂人类语言,这一点非常的到位。3.不单单可以识别普通话,还可以识别24种中国语言(普通话方言)以及50种外语,这款产品非常的优秀!
阿里视觉智能开放平台(灵杰AI开放服务)【评测】人脸活体检测、智能美肤、文字识别等功能很多等待你的开发
阿里视觉智能开放平台之DetectLivingFace 人脸活体检测人脸活体检测(DetectLivingFace)能力可以检测图片中的人脸是否为来自认证设备端的近距离裸拍活体人脸对象,可广泛应用在人脸实时采集场景,满足人脸注册认证的真实性和安全性要求。活体判断的前置条件是图像中有人脸。具有针对手机、门禁机、考勤机、PC智能终端认证设备场景下的对翻拍、PS图片、打印图片、高仿模具等作弊攻击的高精度拦截的核心产品优势。广泛适用于系统人脸登录防攻击、门禁闸机刷脸通行、金融远程身份认证等实人认证场景。产品通过标准API被轻量化集成,让所有开发者可一键拥有人脸活体检测能力。1.人体人脸1.1人脸检测与五官定位功能描述人脸检测与五官定位能力可以检测图片中的人脸并给出每张人脸定位和关键点信息。输出人脸数量、人脸矩形坐标、人脸姿态、双瞳孔中心坐标、人脸置信度列表等信息。支持检测含有多张人脸的照片。应用场景人脸关键点检测,是后续识别、分析和特效应用的基础。它为人脸识别、表情分析、疲劳检测、三维人脸重建、人脸美颜、换脸等人脸相关应用提供了人脸精确信息。特色优势1.稠密关键点:提供105个关键点,足以应对人脸识别、姿态矫正、换脸等要求高精度人脸定位的应用。2.适应能力强:适应最大90度侧脸,平面360旋转人脸等情景。适用于各种应用场景。3.支持多人脸:支持在同张图中检测上千个人脸。实战测试快速识别出授权图像中人脸数量和区域,输出数量、矩行坐标、姿态、双瞳孔中心坐标、105关键点等信息,可支持多人场景的检测。更多开源免费模型体验及下载,详见魔搭社区:FLCM人脸关键点置信度模型、RetinaFace人脸检测关键点模型、MogFace人脸检测模型-large、TinyMog人脸检测器-tiny、Mtcnn人脸检测关键点模型、ULFD人脸检测模型-tiny可以看出在多人、单人、跨年龄层都取得不错的效果1.2 人脸活体检测功能描述人脸活体检测能力可以检测图片中的人脸是否为来自认证设备端的近距离裸拍活体人脸对象,可广泛应用在人脸实时采集场景,满足人脸注册认证的真实性和安全性要求。活体判断的前置条件是图像中有人脸。能力范围来看:1. 认证设备端是指借助近距离裸拍活体正面人脸用于认证、通行等服务场景的含RGB摄像头的硬件设备,常见的认证设备端有手机、门禁机、考勤机、PC等智能终端认证设备。2. 裸拍活体正面人脸是指真人未经重度PS、风格化、人工合成等后处理的含正面人脸(非模糊、遮挡、大角度的正面人脸)的照片。常见的非真人有纸张人脸、电子屏人脸等;常见经过重度PS后处理的照片有摆拍街景照、摆拍人物风景照、摆拍证件照等;常见的其他后处理及生成照片有动漫人脸、绘画人脸等。应用场景系统人脸登录防攻击:通过检测上传的图像是否为真人实拍,而非攻击及PS等后处理照片,以防止攻击者登录系统带来安全风险。门禁闸机刷脸通行:面向人脸注册和认证环节设备端实时的活体检测,实现注册与认证过程中的真人校验,防止非法分子盗用、伪造他人身份打卡通行。智慧酒店自助入住:在酒店前台自助办理入住场景中,运用活体检测技术实现无人监管场景下,住客非活体攻击(纸张人脸、电子屏人脸)的高效率拦截。金融远程身份认证:面向投资理财、基金交易、保险理赔等金融业务的活体检测需求,高效率实现对翻拍、PS图片、打印图片、高仿模具等攻击的拦截,确保用户身份真实。 特色优势基于图片中人像目标的高维度特征(风格化、摩尔纹、成像畸形等),判断目标对象是否为活体,有效防止屏幕二次翻拍等作弊攻击,支持单张或多张判断逻辑。灵活支持RGB摄像头设备的实时活体检测,可有效防止翻拍、头模、打印图片等样本攻击。简单易用:可直接调用的API接口,服务简单易用,易被集成,兼容性强。输入限制图像格式:PNG、JPG、JPEG、BMP、GIF、WEBP。图像大小:不超过10 MB。如您有大图需求,请通过钉钉群(23109592)联系我们。图像分辨率:建议大于256×256像素,像素过低可能会影响识别效果。URL地址中不能包含中文字符。检测说明最长检测时间是5秒,如果在该时间内没有完成检测,系统会强制返回超时错误码。图像下载时间限制为3秒,如果下载时间超过3秒,系统会返回下载超时。图像检测接口响应时间依赖图像的下载时间。请保证被检测图像所在的存储服务稳定可靠,建议您使用阿里云OSS存储或者CDN缓存。最多可检测10张图像。实战测试可以看出这个活体检测效果很出众,可以快速把真人直照和翻照(照片、卡通等)识别出来1.高精度防伪、尊重隐私、高灵敏拦截、简单易用2.人脸活体检测功能使用起来非常简单,尤其是api调用方式很简单,而且使用文档写的也很详细1.3 智能美肤功能描述智能美肤功能可实现输入一张人物图像,自动对脸部以及全身皮肤进行美肤,同时尽可能的保留皮肤质感。功能支持情况如下:脸部美肤:脸部区域匀肤、去瑕疵,比如:痘、痘印、雀斑等。全身皮肤:全身皮肤区域美白。多人照片:支持不超过10人的多人图片处理。应用场景专业修图:可用于影楼、电商、图片直播等专业摄影场景,利用智能美肤算法快速进行美肤修图,提高工作效率。美颜拍摄:用于娱乐、生活等场景,提高人物美观度。特色优势保留皮肤质感:使用深度学习算法,实现精准美肤,皮肤光滑有质感。保持背景稳定:仅对裸露的皮肤区域进行修饰,不影响背景区域。支持多人美肤:支持单张图像中多人的美肤。效果展示:可以看出美颜效果很不错!1.4 更多功能简介:人脸属性识别检测授权图像中信息,输出人脸数量,概率、性别、年龄、表情(中性/微笑)、是否戴眼镜、是否佩戴口罩等多种属性,实现高性能的属性识别。动作行为识别判断输入授权图片的人体动作行为,当前可以识别的行为类别包括:举手、吃喝、吸烟、打电话、玩手机、趴桌睡觉、跌倒等动作。更多有趣功能自行尝试2.阿里视觉智能开放平台其他开放能力2.1 概况预览参考文档:https://help.aliyun.com/document_detail/155007.html?spm=a2c4g.11186623.0.0.33a45487V5u43t2.1文字识别2.1.1 表格识别自动识别表格位置、表格内容信息,适用于黑色的,横线、竖线都齐全的表格中内容识别。2.1.2 PDF识别整体看到效果很不错
Serverless在推进过程中会遇到什么样的挑战?该如何破局?
serverless最大的优势在于资源得到了更合理的利用: 1.快速迭代与部署 2.高并发、高弹性 3.稳定、可靠、安全 4.运维与成本控制 下面进行简单分析: 传统的购买服务器部署应用的方式,在没有使用的时候,服务器就被浪费掉了,对于我这种需要部署一些个人用的小规模应用的情况,买服务器非常的不合算,每天可能实际使用就几分钟,大部分时间都在空置。但是 serverless 是按照实际使用次数/时长来计费的,也就是说,不用的时候真正不花一分钱。所以我越来越多的使用 serverless 部署这些小规模应用,每天实际上使用的 CPU 时间加起来可能还不到一秒,这可以把我的使用成本压缩到几乎忽略不计的程度上。 1.更多人像我这样部署到 serverless 之后,总的服务器消耗就大幅度下降了,原本可能每个人都需要一台独立的服务器,现在上百个人可能实际上就只共享了一台服务器,但每个人都能有良好的用户体验。2.serverless 先天是高并发的,可以无限制的并发请求。当我自己购买服务器部署时,我需要自己在开发应用时解决并发问题,要么就是单线程同时只处理一个请求。3.serverless 开发的时候就不用管并发,我的代码只要能处理一个请求,那么就一定能同时创建无限的运行时来处理更多的请求。4. serverless 的高并发不需要在同一台物理服务器上运行,事实上可以跑在任意位置任意数量的物理服务器上,当我一份代码部署完成之后,用户访问时可以就近选择最近的节点,从而降低延迟,而对于单一物理服务器的传统部署,地球对面的用户访问起来就会非常痛苦。 因为每个请求都是在独立运行时里处理的,错误处理也可以变得很简单,很多不处理就会崩溃的地方真的可以不处理,崩就崩呗,反正就崩单一请求对应的运行时,对其他用户没影响。不像开发传统服务器应用,得尽可能不崩溃否则崩了还得远程上去重启进程。从这个角度来看 serverless 是轻量化应用的最优解决方案,成本更低,复杂度更低,用户体验更好。当然,方便的前提一定是更低的自由度,所以对于复杂的企业项目, serverless 仍然不能成为首选
推荐系统[八]算法实践总结V1:淘宝逛逛and阿里飞猪个性化推荐:召回算法实践总结【冷启动召回、复购召回、用户行为召回等算法实战】
0.前言:召回排序流程策略算法简介推荐可分为以下四个流程,分别是召回、粗排、精排以及重排:召回是源头,在某种意义上决定着整个推荐的天花板;粗排是初筛,一般不会上复杂模型;精排是整个推荐环节的重中之重,在特征和模型上都会做的比较复杂;重排,一般是做打散或满足业务运营的特定强插需求,同样不会使用复杂模型;召回层:召回解决的是从海量候选item中召回千级别的item问题统计类,热度,LBS;协同过滤类,UserCF、ItemCF;U2T2I,如基于user tag召回;I2I类,如Embedding(Word2Vec、FastText),GraphEmbedding(Node2Vec、DeepWalk、EGES);U2I类,如DSSM、YouTube DNN、Sentence Bert;模型类:模型类的模式是将用户和item分别映射到一个向量空间,然后用向量召回,这类有itemcf,usercf,embedding(word2vec),Graph embedding(node2vec等),DNN(如DSSM双塔召回,YouTubeDNN等),RNN(预测下一个点击的item得到用户emb和item emb);向量检索可以用Annoy(基于LSH),Faiss(基于矢量量化)。此外还见过用逻辑回归搞个预估模型,把权重大的交叉特征拿出来构建索引做召回排序策略,learning to rank 流程三大模式(pointwise、pairwise、listwise),主要是特征工程和CTR模型预估;粗排层:本质上跟精排类似,只是特征和模型复杂度上会精简,此外也有将精排模型通过蒸馏得到简化版模型来做粗排常见的特征挖掘(user、item、context,以及相互交叉);精排层:精排解决的是从千级别item到几十这个级别的问题CTR预估:lr,gbdt,fm及其变种(fm是一个工程团队不太强又对算法精度有一定要求时比较好的选择),widedeep,deepfm,NCF各种交叉,DIN,BERT,RNN多目标:MOE,MMOE,MTL(多任务学习)打分公式融合: 随机搜索,CEM(性价比比较高的方法),在线贝叶斯优化(高斯过程),带模型CEM,强化学习等重排层:重排层解决的是展示列表总体最优,模型有 MMR,DPP,RNN系列(参考阿里的globalrerank系列)展示层:推荐理由:统计规则、行为规则、抽取式(一般从评论和内容中抽取)、生成式;排序可以用汤普森采样(简单有效),融合到精排模型排等等首图优选:CNN抽特征,汤普森采样探索与利用:随机策略(简单有效),汤普森采样,bandit,强化学习(Q-Learning、DQN)等产品层:交互式推荐、分tab、多种类型物料融合1.淘宝逛逛召回算法实践总结内容化这几年越来越成为电商的重点,用户来到网购的时候越来越不局限在只有明确需求的时候,而更多的是没有明确需求的时候,就像是逛街一样。逛逛就是在这样的背景下诞生的内容化产品,打造出有用、有趣、潮流、奇妙、新鲜的内容,为消费者提供全新的内容消费体验。在这个场景下的内容召回有很多问题需要探索,其中主要的特点和挑战有:强时效性:内容推荐场景下的内容新旧汰换非常快,新内容的用户行为少,很难用用户历史行为去描述新内容,而用户行为正是老内容投放主要的依赖。所以当不能依靠用户行为数据来建模内容之间关系的时候,我们必须要找到其他可以表征内容的方法。多兴趣表征:多兴趣表征,特别是多峰召回是这几年比较主流的一个趋势。但是目前多峰模型中峰的数量是固定的,当用户行为高度集中的时候,强制的将用户行为拆分成多向量,又会影响单个向量的表达能力。如何去平衡不同用户行为特点,特别是收敛和发散的兴趣分布,就成了此类任务的挑战。在设计优化方向的时候,我们重点考虑上面描述问题的解法(召回本身也需要兼顾精准性和多样性,所以单一召回模型显然无法满足这些要求,我们的思路是开发多个互补的召回模型)。详细的介绍在后面的章节以及对应的后续文章中展开:跨域联合召回:除了单纯把多域的信息平等输入到模型中,如何更好利用跨域之间的信息交互就变的尤为重要。目前有很多优秀的工作在讨论这样的问题,比如通过用户语义,通过差异学习和辅助loss等。我们提出了基于异构序列融合的多兴趣深度召回模型CMDM(a cross-domain multi-interest deep matching network),以及双序列融合网络Contextual Gate DAN 2种模型结构来解决这个问题。语义&图谱&多模态:解决时效性,最主要的问题就是怎么去建模新内容,最自然的就是content-based的思想。content-based的关键是真正理解内容本身,而content-based里主要的输入信息就是语义,图像,视频等多模态信息。目前有许多工作在讨论这样的问题,比如通过认知的方式来解决,多模态表征学习,结合bert和高阶张量等方式等等。在语义召回上,我们不仅仅满足于语义信息的融入,还通过Auxiliary Sequence Mask Learning去对行为序列进行高阶语义层面的提纯。更进一步,我们利用内容图谱信息来推荐,并且引入了个性化动态图谱的概念。对于新老内容上表达能力的差异问题,我们通过multi-view learning的思想去将id特征和多模态特征做融合。泛多峰:为了解决多峰强制将兴趣拆分的问题,我们考虑到单峰和多峰的各自特点,特别是在泛化和多样性上各自有不同的建模能力。基于此,我们提出了泛多峰的概念。1.1 跨域联合召回1.1.1 基于异构序列融合的多兴趣深度召回在单一推荐场景下,深度召回模型只需要考虑用户在当前场景下的消费行为,通过序列建模技术提取用户兴趣进而与目标商品或内容进行匹配建模。而在本推荐场景下,深度召回模型需要同时考虑用户内容消费行为和商品消费行为,进行跨场景建模。为此,我们提出了CMDM多兴趣召回模型架构,能够对用户的跨场景异构行为序列进行融合建模。在CMDM中,我们设计了用于异构序列建模的层级注意力模块,通过层级注意力模块提取的多个用户兴趣向量与目标内容向量进行匹配建模。1.1.2 双序列融合网络Contextual Gate DAN除了通过层次注意力的方式,异构序列中还有个特点就是在时间上更接近交叉并存的状态。为了学习到两个序列之间的信息交叉,充分融合商品点击序列和内容点击序列,我们从自然语言处理的VQA任务中得到启发。VQA是用自然语言回答给定图像的问题的任务,常用做法是在图片上应用视觉注意力,在文本上应用文本注意力,再分别将图片、文字多模态向量输入到一个联合的学习空间,通过融合映射到共享语义空间。而DAN结构是VQA任务中一个十分有效的模型结构,DAN通过设计模块化网络,允许视觉和文本注意力在协作期间相互引导并共享语义信息。我们对DAN结构进行了改进,设计了Contextual Gate DAN 双序列融合网络:1.2 语义&图谱&多模态1.2.1 多模态语义召回在内容推荐场景内,存在大量新内容需要冷启动,我们主要通过语义和多模态2种方式。相对于搜索任务,语义匹配是一个从单点到多点,解空间更大更广的问题。首先是用户行为的不确定性,内容推荐场景下用户决策空间更大更广,从而导致用户对推荐系统的反馈信号本身就存在较大的不确定性;再就是语义空间表达的对齐问题,这里的对齐包含两个方面,第一个方面是单个序列里的内容表达的语义标签提取方式差别大(比如cpv、分词、语义标签、多模态表征等等),另外一个方面是多序列(内容和商品等)之间的语义空间对齐问题。多模态的召回方式融合了文本,图像,音频等大量模式跨域信息,由于与内容互动解耦,在缓解内容冷启动上具有一定的优势。多模态召回主要是通过理解内容多模态表征,先后进行了collaborative filtering、聚类中心召回、个性化多模态表征相关的探索工作,在多样性方面取得了一定的效果,深度语义召回方面针对用户行为去噪和更好的表达语义信息角度出发,迭代了cate-aware和query-aware和序列mask 自监督任务的模型。1.2.2 行为稀疏场景下的图模型实践更进一步,我们利用内容图谱信息来推荐。知识图谱构建的出发点就是对用户的深度认知,能够帮助系统以用户需求出发构建概念,从而可以帮助理解用户行为背后的语义和逻辑。这样可以将用户的每次点击行为,都用图谱的形式极大的丰富,图谱带来的可解释的能力还可以大大加快模型的收敛速度。知识图谱有个特点,就是其中的信息是相对固定的,或者说是静态的,因为知识图谱基本是由先验信息构成的。但是从各个用户的角度,知识图谱的数据中的链接重要度并不相同。比如一个电影,有的用户是因为主演看的,有的用户是因为导演看的,那么这个电影连接的主演边和导演边的权重就因人而异了。我们提出了一种新的方法来融合用户动态信息和静态图谱数据。每个行为都用图谱扩展,这样行为序列变成行为图谱序列, 并且加入KnowledgeGraph-guided gating的自适应的生成式门控图注意力,去影响知识图谱融入到模型中的点边的权重。1.2.3 融合多模态信息的跨模态召回针对新内容冷启动的问题,我们提出了跨模态召回模型来兼顾content-based和behaviour-based的召回各自的优点。在跨模态召回模型构建前,我们首先引入了多模态meta信息为主的“语义” deep collaborative filtering召回,两者的显著差别主要在target side的特征组成中相较与behaviour-based的特征,多模态特征构建的模型去除了影响较大的内容id类的特征,将这些特征更换为了来自多模态预训练技术得到的多模态表征输入。除了上面的变化,我们还加入了triplet loss的部分使得embedding空间更具有区分度,效率指标也有了较大幅度的提升。1.3 用户多兴趣表征(多模型簇联合学习):泛多峰多峰召回模型通过对用户侧产生多个表征不同“兴趣”的向量进行多个向量的召回,是对于单峰的一个拓展,将单个用户的表达扩展成了多个兴趣表达, 更精确地刻画了用户, 从而取得更好的效果。我们通过对于单峰模型及多峰模型的观察发现,用户行为高度集中的序列单峰模型的线上效率相对于多峰模型会更有优势,而那些用户序列类目丰富度较高的则多峰模型的效率明显占优。所以这里提出了泛多峰u2i模型的概念,尝试将多峰模型容易拟合行为序列类目丰富度较高的用户,而单峰模型则更容易拟合行为序列类目丰富度较为集中的用户的优势进行结合。使得单一模型能够通过产生不同算法簇的多个不同表征的向量在不同簇的内容向量中进行召回,从而具备这两种召回范式的优点。1.4 提升优化:▐ 认知推荐我们正在尝试,将图谱用于user embedding投影,投影的平面空间就是语义空间,这样做到可控多维度语义可解释embedding。另外,对于召回,采样方式对模型效果影响非常大,结合知识图谱来进行graph-based Learning to sample的优化,对于正负样本的选取更加做到关联可控,加快迭代速度,提升效果。▐ 兴趣破圈在内容化推荐领域,仅仅相似度提高的优化,会导致用户没有新鲜感,对平台粘性变低。如何帮助用户探索他更多的兴趣,是现在内容化推荐亟待解决的另一个问题。一种做法是兴趣近邻,从已有兴趣出发,慢慢通过兴趣之间的相似,扩展用户未知的领域,可以参考MIND,CLR一些思路。另一种做法是对兴趣构建推理引擎,在对已有兴趣推理过程建模之后,加入扰动来探索用户可能新的兴趣。2.阿里飞猪个性化推荐:召回篇常见的有基于user profile的召回,基于协同过滤的召回,还有最近比较流程的基于embedding向量相似度的topN召回等等。方法大家都知道,但具体问题具体分析,对应到旅行场景中这些方法都面临着种种挑战。例如:旅行用户需求周期长,行为稀疏导致训练不足;行为兴趣点发散导致效果相关性较差;冷启动用户多导致整体召回不足,并且热门现象严重;同时,具备旅行特色的召回如何满足,例如:针对有明确行程的用户如何精准召回,差旅用户的周期性复购需求如何识别并召回等。本次分享将介绍在飞猪旅行场景下,是如何针对这些问题进行优化并提升效果的。主要内容包括:⻜猪旅行场景召回问题、冷启动用户的召回、行程的表达与召回、基于用户行为的召回、周期性复购的召回。2.1 飞猪旅行场景召回问题推荐系统流程首先介绍推荐的整体流程。整体上分为5个阶段。从全量的商品池开始,之后依此是召回阶段,粗排/精排阶段,最后的混排模块根据业务实际情况而定,并不是大多数推荐系统必须的。粗排和精排在另外一次分享中已经介绍过了,本次分享主要介绍一下飞猪推荐系统的召回问题,召回可以说决定了推荐系统效果的上限。下面说一下召回和粗排/精排的区别。从召回到粗排再到精排模块,商品的数据量是递减的,模型的复杂度会增高。具体会体现在输入特征数量和模型复杂度的增加,更新往往也会更频繁。对应的训练和上线的方式也会不同,拿召回来讲,出于性能的考虑,往往采用离线训练+打分或者离线训练得到向量表达+向量检索的方式,而排序阶段为了更好的准确率和线上指标,更多的是离线训练+实时打分,甚至在线学习的方式。召回的本质其实就是将用户和商品从不同维度关联起来。常见的方法比如content-base匹配,或者item/user based的协同过滤,还有最近比较流行的向量化召回。向量化召回常用做法是用深度学习将用户和商品都表达成向量,然后基于内积或欧式距离通过向量检索的方式找到和用户最匹配的商品。2.1.1 飞猪推荐场景飞猪的推荐页面有很多,比如首页,支付成功页,订单列表页,订单详情页都有猜你喜欢。不同页面对应了不同的场景,用户在不同场景下需求不同,也有一定的交叉。比如首页偏重逛/种草,但支付完成后推荐一些与订单相关的商品会更好。我们大致可以把用户分为三类:无行为、有行为,还有一种是飞猪场景下特殊的一类"有行程"。2.1.2 主要问题本次分享的主要内容就是针对这三类用户在推荐过程中存在的问题+周期性复购场景 ( 出差/回家 ) 的解决。航旅场景下的召回存在以下问题:冷启动:航旅商品的热门现象严重,user profile缺乏。相关性vs搭配性:航旅场景下要求搭配性比较高,传统的I2I只偏重相关性。但用户的行程需求不是单点的,比如买了飞机票还要看住宿。行程受上下文影响比较多,比如季节、用户近期行为等。相关性不足:航旅用户的行为稀疏又发散,目前的召回结果噪音较多。下面会对我们在优化过程中碰到的相关问题一一介绍。我们知道,召回处于推荐链路的底端,对召回常规的离线评估方式有预测用户未来点击的TopN准确率或者用户未来点击的商品在召回队列中平均位置等等。但是在工业系统中,为了召回的多样性和准确率,都是存在多路召回的,离线指标的提高并不代表线上效果的提升,一种常见的评估某路召回效果的方式就是对比同类召回通道的线上点击率,这种评估更能真实反映线上的召回效果,基于篇幅的考虑,后面的介绍主要展示了线上召回通道点击率的提升效果。2.2 冷启动用户召回2.2.1 User冷启动召回用户冷启动召回主要有以下几种方案:Global Hot、Cross Domain、基于用户属性的召回。全局热门:缺点是和user无关,相关性差。Cross domain:一种做法是基于不同域 ( 例如飞猪和淘宝 ) 共同用户的行为将不同域的用户映射到同一个向量空间,然后借助其他域的丰富行为提升本域冷启动用户的召回效果。基于用户属性:单一属性的缺点是热门现象严重,个性化不足。我们采用了基于多属性组合的方法。2.2.2 UserAttr2I在这里介绍我们的方案UserAttr2I,使用类似排序模型的方法,输入用户+商品的属性,预测用户是否会点击一个商品。开始用线性FTRL模型,效果不是很好。原因是线性模型无法学习高阶特征,并且解释性比较差。针对这两个问题,通过DeepNet提高泛化性,同时用GBDT来做特征筛选。下面对比双塔结构和深度特征交叉两种方案,优缺点如图所示。最终选择了第二种,原因是目标用户是冷启动,能用到的特征比较少。如果放弃挖掘用户和宝贝之间的关系会导致相关性比较差。模型结构如下:通过attention操作以及GBDT的叶子节点即可满足冷启动的可解释性。对比其他冷启动的召回方式,Attribute2I的点击率最高。2.3 行程的表达与召回2.3.1 Order2I在飞猪场景下用户有类似如下的需求:买了去某地的机票,用户很可能需要与之搭配的签证/wifi/酒店等等,而协同过滤通常只能推出同类型商品,比如门票推门票,酒店推酒店。另外飞猪不像淘宝用户可能会经常逛,有比较丰富的历史行为信息可以供我们去分析和计算,飞猪用户通常是"买完即走"。通过数据分析我们发现订单附近的行为数据和订单有较高搭配关系,我们通过Graph Embedding的方式学习订单和宝贝的Embed,以此来学习搭配关系。难点有以下几个:如何挖掘反映搭配关系的数据集合搭配的限制性比较强,如果仅仅基于用户行为构建图,由于用户行为噪音多,会造成较多badcase如果完全基于随机游走学习Embed,最后的召回结果相关性差,因此需要行业知识的约束数据稀疏,覆盖商品少,冷启动效果差**解决方案:利用航旅知识图谱以及用户的行为序列进行加权异构图的构建 ( 机票/火车票节点利用业务线+出发地+目的地唯一标示、宝贝&酒店利用其id唯一标示 )。之后的流程和传统的Graph Embedding类似。**具体过程:① 以订单粒度对用户的行为做拆分和聚合,同时加入点击行为缓解稀疏问题。② 边的权重的计算同时考虑知识图谱和用户行为,这种做法一方面可以增加约束控制效果,另一方面也可以抑制稀疏,解决冷启动的问题。③ 序列采样过程中会基于转移概率进行剪枝操作,用来抑制噪声和缓解热门问题。④ skip-gram+负采样训练。这里有一个具体的case,用户订了一张去曼谷的机票,order2I召回了曼谷的一些自助餐,落地签,热门景点等,体现了较好的搭配性。整体的指标上order2I的点击率也明显高于其他方式。2.3.2 journey2IOrder2I将订单进行向量化表达,从而进行召回。但是它还有一些问题:用户的某次行程可能由多个订单组成,甚至有的订单只是中转的作用,Graph Embedding还是基于单个订单进行搭配的推荐;用户的某次行程不是一个出发地+目的地就能描述的,它不仅与行程本身属性 ( 例如出发/到达时间,目的地,行程意图等 ) 相关,还与用户的属性和偏好 ( 例如年龄,是否是亲子用户 ) 相关。因此行程既是User-Aware又是Context-Aware的。而Order2I学习的还是一种全局的整体偏好,与用户无关,不够个性化。因此我们尝试在行程的粒度做召回,综合考虑用户属性、行程意图、上下文等因素,更个性化的召回与用户这次行程以及用户自身强相关的的宝贝。以行程为粒度,对多个订单做聚合,并且增加行程相关的特征。融入用户的基础属性特征和历史行为序列。丰富行程特征并引入attention机制。采用双塔模型离线存储商品向量,在线做向量化召回。模型结构如下:模型左边主要是利用行程特征对订单序列以及用户的历史行为序列进行attention操作,用于识别关键订单以及用户关键行为。在此基础上融合行程特征和用户属性特征学习用户该段行程的Embed。模型右边是商品特征,经过多层MLP之后学习到的宝贝Embed。两边做内积运算,利用交叉熵损失进行优化,这样保证召回的结果不仅与行程相关还与用户行为相关。两个同样是上海到西安的用户。用户1点击了历史博物馆和小吃,不仅召回了与机票搭配的接送机,还召回了与行为行为相关的小吃街附近的酒店以及历史博物馆相关的宝贝。用户2点击了一个接送机,除了召回接送机还召回了机场附近的酒店和热门的POI景点门票。可以看出基于用户的不同行为,召回结果不仅满足搭配关系还与用户行为强相关。从指标来看Journey2I相对Order2I有进一步明显的提升。2.4 基于用户行为的召回2.4.1 Session-Based I2I航旅用户的行为有稀疏和发散的特点。利用右图一个具体的用户实例来说明这两个特点:用户在第一天点击了两个大理一日游,第20天点击了一些马尔代夫蜜月相关的商品,第21天又点击了大理的一日游。稀疏性体现在一个月只来了3次,点击了8个宝贝。发散性体现在用户大理一日游和出国蜜月游两个topic感兴趣。在用户有行为的情况下进行召回,我们常采用的方法是基于User-Rate矩阵的协同过滤方法 ( 如ItemCF,Swing。ItemCF认为同时点击两个商品的用户越多则这两个商品越相似。Swing是在阿里多个业务被验证过非常有效的一种召回方式,它认为user-item-user的结构比itemCF的单边结构更稳定 ),但是由于航旅用户行为稀疏,基于User-Rate矩阵召回结果的准确率比较低,泛化性差。针对这两个问题我们可以通过扩充历史数据来增加样本覆盖。航旅场景因为用户点击数据比较稀疏,需要比电商 ( 淘宝 ) 扩充更多 ( 时间更长 ) 的数据才够。这又带来了兴趣点转移多的问题。在这里我们采用对行为序列进行session划分,保证相关性。这里以swing为例讲解一下构造约束的方式。我们以用户的行为意图为中心,将表示共同意图的商品聚合在一个序列中,如上图对用户行为序列的切分。在这个case中,上面是传统swing的召回结果,下面是基于session的召回结果。当trigger是沙溪古镇一日游的时候,上面有一个杭州莫干山和玉龙雪山一日游,这两个不相关结果的出现是因为它们是热门商品,也称哈利波特效应。下面的召回结果就都是和沙溪古镇相关的了。从指标来看,session-based召回比swing和itemCF都高。2.4.2 Meta-Path Graph Embedding基于I2I相关矩阵的优点是相关性好,缺点是覆盖率比较低。而Embed的方式虽然新颖性好但是相关性差。右边的case是Embed的召回结果,上海迪士尼乐园召回了一个珠海长隆的企鹅酒店和香港迪士尼。我们期望的应该是在上海具有亲子属性,或者在上海迪士尼附近的景点。解决Embed相关性低的方式借鉴了session-based召回的经验,将航旅知识图谱融合,构建航旅特定的Meta-Path。效果上看meta-path的效果是比deepwalk更好。2.5周期性复购的召回复购场景的需求来自于:飞猪有大量的差旅和回家用户,该部分用户的行为有固定模式,会在特定的时间进行酒店和交通的购买,那么该如何满足这部分用户的需求?2.5.1 Rebuy2I我们的目标是在正确的时间点来给用户推出合适的复购商品,下面以酒店为例具体讲解 ( 其他的品类原理类似 )。输入用户在飞猪的酒店历史购买数据,输出是用户在某个时间点对某个酒店的复购概率。当有多个可复购酒店时,按照概率降序排序。常见做法有以下几种:利用酒店本身的复购概率基于用户购买历史的Retarget利用Poission-Gamma分布的统计建模首先取用户对酒店的购买历史,利用矩估计/参数估计计算酒店的购买频次 ( 参数α和β )。接下来就可以调整每个用户的购买概率,k是购买次数,t是第一次购买距离最近一次购买的时间间隔。最后代入Possion分布计算复购概率,加入用户的平均购买周期来缓解刚刚完成购买的酒店复购概率最大的问题。从左图可以看出在购买一段时间以后,复购概率达到最大值,之后递减。实际使用中复购单独作为一路召回,效果比前面提到的retarget和热门召回更好。2.6 总结最后总结一下做好召回的几个思路:首先要基于业务场景,来发掘用户需求,发现自有场景的特点。接下来通过case和数据分析来发现问题,通过理解模型结构或者特征背后的动机进行针对性的改进。最后在召回和排序之间找到边界,效果和性能之间做好trade-off。2.7 Q&AQ:Journey2i的双塔模型如何负采样,正负比例如何控制?A:关于召回的负采样是一个非常值得研究的问题。我们也做了很多尝试,例如我们曾经尝试过按照排序的套路用曝光样本做负样本,但是效果很差。然后也进行了全局负采样,效果要明显好于曝光的方式,但是负样本如何采也值得一提,采得太随机,你的负样本容易太easy,模型的auc可能虚高,因此也要新增一些hard的样本,在journey2i中就是那些属于本次行程相关城市目的地的商品,但是用户不太可能购买的商品,具体的方式这里不展开介绍了。Facebook在KDD2020中有篇论文也对召回的采样问题做了详细的介绍,推荐阅读。关于正负比例,我们的经验是没有绝对的答案,需要在优化过程中摸索,不过一般只要抽样方式ok,正负比例的变化不会对最终结果有太大的影响。Q:Journey2I无法考虑交互特征,是否会有影响?A:肯定会有影响。理论上讲,没有Journey和target item的交互特征,auc和准确率肯定会打折扣,但是需要针对具体问题具体分析,做召回的优化和排序有个很明显的不同就是需要在性能、准确率、多样性上做trade-off。Q:meta-path,session-base解决问题和出发点是什么?A:session-base解决的是扩充稀疏的数据后会带来兴趣发散的问题。举个极端的例子,有个用户每个月都出差,去到不同的地点。召回结果就会混合多个地点。Meta-path解决的是相关性低的问题。
推荐系统[二]:召回算法超详细讲解[召回模型演化过程、召回模型主流常见算法(DeepMF_TDM_Airbnb Embedding_Item2vec等)、召回路径简介、多路召回融合]
1.前言:召回排序流程策略算法简介推荐可分为以下四个流程,分别是召回、粗排、精排以及重排:召回是源头,在某种意义上决定着整个推荐的天花板;粗排是初筛,一般不会上复杂模型;精排是整个推荐环节的重中之重,在特征和模型上都会做的比较复杂;重排,一般是做打散或满足业务运营的特定强插需求,同样不会使用复杂模型;召回层:召回解决的是从海量候选item中召回千级别的item问题统计类,热度,LBS;协同过滤类,UserCF、ItemCF;U2T2I,如基于user tag召回;I2I类,如Embedding(Word2Vec、FastText),GraphEmbedding(Node2Vec、DeepWalk、EGES);U2I类,如DSSM、YouTube DNN、Sentence Bert;模型类:模型类的模式是将用户和item分别映射到一个向量空间,然后用向量召回,这类有itemcf,usercf,embedding(word2vec),Graph embedding(node2vec等),DNN(如DSSM双塔召回,YouTubeDNN等),RNN(预测下一个点击的item得到用户emb和item emb);向量检索可以用Annoy(基于LSH),Faiss(基于矢量量化)。此外还见过用逻辑回归搞个预估模型,把权重大的交叉特征拿出来构建索引做召回排序策略,learning to rank 流程三大模式(pointwise、pairwise、listwise),主要是特征工程和CTR模型预估;粗排层:本质上跟精排类似,只是特征和模型复杂度上会精简,此外也有将精排模型通过蒸馏得到简化版模型来做粗排常见的特征挖掘(user、item、context,以及相互交叉);精排层:精排解决的是从千级别item到几十这个级别的问题CTR预估:lr,gbdt,fm及其变种(fm是一个工程团队不太强又对算法精度有一定要求时比较好的选择),widedeep,deepfm,NCF各种交叉,DIN,BERT,RNN多目标:MOE,MMOE,MTL(多任务学习)打分公式融合: 随机搜索,CEM(性价比比较高的方法),在线贝叶斯优化(高斯过程),带模型CEM,强化学习等重排层:重排层解决的是展示列表总体最优,模型有 MMR,DPP,RNN系列(参考阿里的globalrerank系列)展示层:推荐理由:统计规则、行为规则、抽取式(一般从评论和内容中抽取)、生成式;排序可以用汤普森采样(简单有效),融合到精排模型排等等首图优选:CNN抽特征,汤普森采样探索与利用:随机策略(简单有效),汤普森采样,bandit,强化学习(Q-Learning、DQN)等产品层:交互式推荐、分tab、多种类型物料融合2.召回算法简介召回区分主路和旁路,主路的作用是个性化+向上管理,而旁路的作用是查缺补漏推荐系统的前几个操作可能就决定了整个系统的走向,在初期一定要三思而后行做自媒体,打广告,漏斗的入口有多大很重要。召回这里稍微有些复杂,因为召回是多路的。首先我们要解释主路和旁路的差别,主路的意义和粗排类似,可以看作是一个入口更大,但模型更加简单的粗排。主路的意义是为粗排分担压力。但是旁路却不是这样的,旁路出现的时机往往是当主路存在某种机制上的问题,而单靠现在的这个模型很难解决的时候。举个例子,主路召回学的不错,但是它可能由于某种原因,特别讨厌影视剧片段这一类内容,导致了这类视频无法上升到粗排上。那这样的话整个系统推不出影视剧片段就是一个问题。从多路召回的角度来讲,我们可能需要单加一路专门召回影视剧的,并且规定:主路召回只能出3000个,这一路新加的固定出500个,两边合并起来进入到粗排中去。这个栗子,是出现旁路的一个动机。2.1 召回路径介绍推荐系统中的i2i、u2i、u2i2i、u2u2i、u2tag2i,都是指推荐系统的召回路径。第一种召回,是非个性化的。比如对于新用户,我们要确保用最高质量的视频把他们留住,那么我们可以划一个“精品池”出来,根据他们的某种热度排序,作为一路召回。做法就是新用户的每次请求我们都把这些精品池的内容当做结果送给粗排。这样的召回做起来最容易,用sql就可以搞定。第二种召回,是i2i,i指的是item,严格意义上应该叫u2i2i。指的是用用户的历史item,来找相似的item。比如说我们把用户过去点过赞的视频拿出来,去找画面上,BGM上,或者用户行为结构上相似的视频。等于说我们就认为用户还会喜欢看同样类型的视频。这种召回,既可以从内容上建立相似关系(利用深度学习),也可以用现在比较火的graph来构建关系。这种召回负担也比较小,图像上谁和谁相似完全可以离线计算,甚至都不会随着时间变化。第三种召回是u2i,即纯粹从user和item的关系出发。我们所说的双塔就是一个典型的u2i。在用户请求过来的时候,计算出user的embedding,然后去一个实现存好的item embedding的空间,寻找最相似的一批拿出来。由于要实时计算user特征,它的负担要大于前面两者,但这种召回个性化程度最高,实践中效果也是非常好的。通过上图理解什么是召回路径:u、i、tag是指图中的节点2是指图中的线(关系)i2i:指从一个物品到达另外一个物品,item 到 item应用:头条,在下方列出相似的、相关的文章;算法:内容相似,eg:文章的相似,取标题的关键字,内容相似协同过滤关联规则挖掘等两个物品被同时看的可能性很大,当一个物品被查看,就给他推荐另一个物品u2i:指从一个用户到达一个物品,user 到item一般指用户的直接行为,比如播放、点击、购买等;用户查看了一个物品,就会再次给它推荐这个物品结合i2i一起使用,就是用户查看以合物品,就会给他推荐另一个相似的物品,就是u2i2i路径;u2i2i:从一个用户,通过一个物品,到达另一个物品用户查看了一个耳机(u2i),找出和这个耳机相似或者相关的产品(i2i)并推荐给用户对路径的使用,已经从一条线变成两条线方法:就是把两种算法结合起来,先得到u2i的数据,再利用i2i的数据进行扩展,就可以从第一个节点,越过一个节点,到达第三个节点,实现推荐中间的桥梁是itemu2u2i:从一个用户,到达另一个用户,到达一个物品先计算u2u:两种方法一是:取用户的性别、年龄、职业等人工属性的信息,计算相似性,得到u2u;一是:从行为数据中进行挖掘,比如看的内容和视频大部分很相似,就可以看作一类人;也可以使用聚类的方法进行u2u计算u2u一般用在社交里,比如微博、Facebook,推荐感兴趣的人userB和UserC相似,如果userB查看了某个商品,就把这个商品推荐给userC;中间的桥梁是useru2tag2i:中间节点是Tag标签,而不是 u 或者 i京东,豆瓣,物品的标签非常丰富、非常详细;比如统计一个用户历史查看过的书籍,就可以计算标签偏好的向量:标签+喜欢的强度。用户就达到了tag的节点,而商品本身带有标签,这就可以互通,进行推荐先算出用户的tag偏好,然后匹配item列表这种方法的泛化性能比较好(推荐的内容不那么狭窄,比如喜欢科幻,那么会推荐科幻的所有内容)今日头条就大量使用标签推荐基于图的算法:u22i*起始于U,结束于I,中间跨越很多的U、很多的I,可以在图中不停的游走例如:PersonalRank,不限制一条还是两条线,在图中到处的游走,游走带着概率,可以达到很多的item;但是相比前面一条、两条边的路径,性能不是很好2.2 多路召回融合排序2.2.1 多路召回推荐服务一般有多个环节(召回、粗排序、精排序),一般会使用多个召回策略,互相弥补不足,效果更好。比如说:实时召回- U2I2I,几秒之内根据行为更新推荐列表。用U2I得到你实时的行为对象列表,再根据I2I得到可能喜欢的其他的物品这个是实时召回,剩下3个是提前算好的基于内容 - U2Tag2I先算好用户的偏好tag,然后对tag计算相似度,获取可能感兴趣的item矩阵分解 - U2I先算好User和Item的tag矩阵,然后叉乘,给每个user推荐item提前存储好进行推荐聚类推荐 - U2U2I根据用户信息对用户进行聚类,然后找到最相似的user,推荐最相似user喜欢的物品;或者找到聚类中大家喜欢的物品,进行推荐写程序时,每个策略之间毫不相关,所以:1、一般可以编写并发多线程同时执行 2、每一种策略输出结果,都有一个顺序,但最后要的结果只有一个列表,这就需要融合排序2.2.2 融合排序多种召回策略的内容,取TOPN合并成一个新的列表。这个新的列表,可以直接返回给前端,进行展示;也可以发给精排,进行排序。精排模型非常耗时,所以召回的内容,会经过粗排之后,把少量的数据给精排进行排序几种多路召回结果融合的方法举个例子:几种召回策略返回的列表(Item-id,权重)分别为:召回策略返回列表 召回策略XA:0.9B:0.8C:0.7召回策略YB:0.6C:0.5D:0.4召回策略ZC:0.3D:0.2E:0.1融合策略:1、按顺序展示比如说实时 > 购买数据召回 > 播放数据召回,则直接展示A、B、C、D、E2、平均法分母为召回策略个数,分子为权重加和C为(0.7+0.5+0.3)/3,B为(0.8+0.6)/33、加权平均比如三种策略自己指定权重为0.4、0.3、0.3,则B的权重为(0.40.8 + 0.60.3 + 0*0.2)/ (0.4+0.3+0.2),这个方法有个问题就是,每个策略的权重是自己设置的,并不准确,所以,有动态加权法4、动态加权法计算XYZ三种召回策略的CTR,作为每天更新的动态加权只考虑了点击率,并不全面每种召回源CTR计算方法:展现日志-带召回源:X,Y,Z,X,Y,Z点击日志-带召回源:点击X则每种召回的CTR = 点击数/展现数5、机器学习权重法逻辑回归LR分类模型预先离线算好各种召回的权重,然后做加权召回考虑更多的特征以及环境因素,会更准确以上融合排序的方法,成本逐渐增大,效果依次变好,按照成本进行选择3.推荐场景中召回模型的演化过程3.1 传统方法:基于协同过滤更多内容参考:https://blog.csdn.net/sinat_39620217/article/details/1291196113.2 单 Embedding 向量召回3.2.1 Youtube DNN 召回3.2.2 双塔模型召回3.2 多 Embedding 向量召回-用户多兴趣表达3.2.1 Multi-Interest Network with Dynamic Routing 模型3.3 Graph Embedding3.3.1 阿里 Graph Embedding with Side information传统的 graph embedding 过程如下图:3.3.2 GraphSAGE:Inductive representation learning on large graphs3.4 结合用户长期和短期兴趣建模### 3.4.2 Next Item Recommendation with Self-Attention更多内容参考:https://blog.csdn.net/sinat_39620217/article/details/1291196113.5 TDM 深度树匹配召回TDM 是为大规模推荐系统设计的、能够承载任意先进模型 ( 也就是可以通过任何深度学习推荐模型来训练树 ) 来高效检索用户兴趣的推荐算法解决方案。TDM 基于树结构,提出了一套对用户兴趣度量进行层次化建模与检索的方法论,使得系统能直接利高级深度学习模型在全库范围内检索用户兴趣。其基本原理是使用树结构对全库 item 进行索引,然后训练深度模型以支持树上的逐层检索,从而将大规模推荐中全库检索的复杂度由 O(n) ( n 为所有 item 的量级 ) 下降至 O(log n)。3.5.1 树结构### 3.5.2 怎么基于树来实现高效的检索?3.5.3 兴趣建模4.当前业界的主流召回算法综述4.1 Youtube DNN当前的主流方法的通用思路就是对于use和item的embedding的学习, 这也被称为表示学习; YoutbeDNN是经典的将深度学习模型引入推荐系统中,可以看到网络模型并不复杂,但是文中有很多工程上的技巧,比如说 word2vec对 video 和 search token做embedding后做为video初始embedding,对模型训练中训练时间和采集日志时间之间“position bias”的处理,以及对大规模多分类问题的负采样softmax。4.2 DeepMF4.3 DSSM更多内容参考:https://blog.csdn.net/sinat_39620217/article/details/1291196114.4.Item2vec4.5.Airbnb Embedding4.6.DeepWalk4.7 Node2Vec4.8.EGES4.9.LINE更多内容参考:https://blog.csdn.net/sinat_39620217/article/details/1291196114.10.SDNE4.11.GraphSAGE4.12 MIND4.13.SDM4.14.DeepFM4.15.NCF4.16.TDM更多内容参考:https://blog.csdn.net/sinat_39620217/article/details/129119611参考推荐:关于图相关学习推荐参考更多内容参考:https://blog.csdn.net/sinat_39620217/article/details/129119611[图学习项目合集&数据集分享&技术归纳业务落地技巧[系列十]](https://blog.csdn.net/sinat_39620217/article/details/128148181)更多内容参考:https://blog.csdn.net/sinat_39620217/article/details/129119611
特定领域知识图谱融合方案:文本匹配算法之预训练Simbert、ERNIE-Gram单塔模型等诸多模型【三】
特定领域知识图谱融合方案:文本匹配算法之预训练模型SimBert、ERNIE-Gram文本匹配任务在自然语言处理中是非常重要的基础任务之一,一般研究两段文本之间的关系。有很多应用场景;如信息检索、问答系统、智能对话、文本鉴别、智能推荐、文本数据去重、文本相似度计算、自然语言推理、问答系统、信息检索等,但文本匹配或者说自然语言处理仍然存在很多难点。这些自然语言处理任务在很大程度上都可以抽象成文本匹配问题,比如信息检索可以归结为搜索词和文档资源的匹配,问答系统可以归结为问题和候选答案的匹配,复述问题可以归结为两个同义句的匹配。0.前言:特定领域知识图谱融合方案本项目主要围绕着特定领域知识图谱(Domain-specific KnowledgeGraph:DKG)融合方案:文本匹配算法、知识融合学术界方案、知识融合业界落地方案、算法测评KG生产质量保障讲解了文本匹配算法的综述,从经典的传统模型到孪生神经网络“双塔模型”再到预训练模型以及有监督无监督联合模型,期间也涉及了近几年前沿的对比学习模型,之后提出了文本匹配技巧提升方案,最终给出了DKG的落地方案。这边主要以原理讲解和技术方案阐述为主,之后会慢慢把项目开源出来,一起共建KG,从知识抽取到知识融合、知识推理、质量评估等争取走通完整的流程。0.1 前置参考项目前置参考项目1.特定领域知识图谱融合方案:技术知识前置【一】-文本匹配算法https://blog.csdn.net/sinat_39620217/article/details/1287185372.特定领域知识图谱融合方案:文本匹配算法Simnet、Simcse、Diffcse【二】https://blog.csdn.net/sinat_39620217/article/details/1288330573.特定领域知识图谱融合方案:文本匹配算法之预训练Simbert、ERNIE-Gram单塔模型等诸多模型【三】https://blog.csdn.net/sinat_39620217/article/details/1290265704.特定领域知识图谱融合方案:学以致用-问题匹配鲁棒性评测比赛验证【四】https://blog.csdn.net/sinat_39620217/article/details/129026193NLP知识图谱项目合集(信息抽取、文本分类、图神经网络、性能优化等)https://blog.csdn.net/sinat_39620217/article/details/1288051542023计算机领域顶会以及ACL自然语言处理(NLP)研究子方向汇总https://blog.csdn.net/sinat_39620217/article/details/1288975390.2 结论先看仿真结果如下:模型dev accSimcse(无监督)58.97%Diffcse(无监督)63.23%bert-base-chinese86.53%bert-wwm-chinese86.33%bert-wwm-ext-chinese86.05%ernie-tiny86.07%roberta-wwm-ext87.53%rbt385.37%rbtl385.17%ERNIE-1.0-Base89.34%ERNIE-1.0-Base89.34%ERNIE-Gram-Base-Pointwise90.58%SimCSE 模型适合缺乏监督数据,但是又有大量无监督数据的匹配和检索场景。相比于 SimCSE 模型,DiffCSE模型会更关注语句之间的差异性,具有精确的向量表示能力。DiffCSE 模型同样适合缺乏监督数据,但是又有大量无监督数据的匹配和检索场景。明显看到有监督模型中ERNIE-Gram比之前所有模型性能的优秀1.SimBERT(UniLM)预训练模型按照训练方式或者网络结构可以分成三类:一是以BERT[2]为代表的自编码(Auto-Encoding)语言模型,Autoencoding Language Modeling,自编码语言模型:通过上下文信息来预测当前被mask的token,代表有BERT、Word2Vec(CBOW)等.它使用MLM做预训练任务,自编码预训模型往往更擅长做判别类任务,或者叫做自然语言理解(Natural Language Understanding,NLU)任务,例如文本分类,NER等。$p(x)=\prod_{x \in \text { Mask }} p(x \mid$ content $)$缺点:由于训练中采用了[MASK]标记,导致预训练与微调阶段不一致的问题,且对于生成式问题的支持能力较差优点:能够很好的编码上下文语义信息,在自然语言理解(NLU)相关的下游任务上表现突出二是以GPT[3]为代表的自回归(Auto-Regressive)语言模型,Aotoregressive Lanuage Modeling,自回归语言模型:根据前面(或后面)出现的token来预测当前时刻的token,代表模型有ELMO、GTP等,它一般采用生成类任务做预训练,类似于我们写一篇文章,自回归语言模型更擅长做生成类任务(Natural Language Generating,NLG),例如文章生成等。$\begin{aligned} & \text { forward: } p(x)=\prod_{t=1}^T p\left(x_t \mid x_{t}\right)\end{aligned}$缺点:只能利用单向语义而不能同时利用上下文信息优点:对自然语言生成任务(NLG)友好,符合生成式任务的生成过程三是以encoder-decoder为基础模型架构的预训练模,例如MASS[4],它通过编码器将输入句子编码成特征向量,然后通过解码器将该特征向量转化成输出文本序列。基于Encoder-Decoder的预训练模型的优点是它能够兼顾自编码语言模型和自回归语言模型:在它的编码器之后接一个分类层便可以制作一个判别类任务,而同时使用编码器和解码器便可以做生成类任务。这里要介绍的统一语言模型(Unified Language Model,UniLM)[1]从网络结构上看,它的结构是和BERT相同的编码器的结构。但是从它的预训练任务上来看,它不仅可以像自编码语言模型那样利用掩码标志的上下文进行训练,还可以像自回归语言模型那样从左向右的进行训练。甚至可以像Encoder-Decoder架构的模型先对输入文本进行编码,再从左向右的生成序列。UniLM是在微软研究院在BERT的基础上提出的预训练语言模型,被称为统一预训练语言模型。使用三种特殊的Mask的预训练目标,从而使得模型可以用于NLG,同时在NLU任务获得和BERT一样的效果它可以完成单向、序列到序列和双向预测任务,可以说是结合了AR和AE两种语言模型的优点,UniLM在文本摘要、生成式问题回答等领域取得了SOTA的成绩[1] Dong, Li, et al. "Unified language model pre-training for natural language understanding and generation." Advances in Neural Information Processing Systems 32 (2019).[2] Devlin J, Chang M W, Lee K, et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding[J]. arXiv preprint arXiv:1810.04805, 2018.[3] Radford, A., Narasimhan, K., Salimans, T. and Sutskever, I., 2018. Improving language understanding by generative pre-training.[4] Song, Kaitao, et al. "Mass: Masked sequence to sequence pre-training for language generation."arXiv preprint arXiv:1905.02450(2019).1.1 UniLM 模型详解原始论文:Unified Language Model Pre-training for Natural Language Understanding and Generation刚介绍的三种不同的类型的预训练架构往往需要使用不同的预训练任务进行训练。但是这些任务都可以归纳为根据已知的内容预测未知的内容,不同的是哪些内容是我们已知的,哪些是需要预测的。UniLM最核心的内容将用来训练不同架构的任务都统一到了一种类似于掩码语言模型的框架上,然后通过一个变量掩码矩阵M(Mask Matrix) 来适配不同的任务。UniLM所有核心的内容可以概括为下图。模型框架如上图所示,在预训练阶段,UniLM模型通过三种不同目标函数的语言模型(包括:双向语言模型,单向语言模型和序列到序列语言模型),去共同学习一个Transformer网络;为了控制对将要预测的token可见到的上下文,使用了不同的self-attention mask来实现。即通过不同的掩码来控制预测单词的可见上下文词语数量,实现不同的模型表征.1.1.1 模型输入首先对于一个输入句子,UniLM采用了WordPiece的方式对其进行了分词。除了分词得到的token嵌入,UniLM中添加了位置嵌入(和BERT相同的方式)和用于区分文本对的两个段的段嵌入(Segment Embedding)。为了得到整句的特征向量,UniLM在句子的开始添加了[SOS]标志。为了分割不同的段,它向其中添加了[EOS]标志。具体例子可以参考图中的蓝色虚线框中的内容。包括token embedding,position embedding,segment embedding,同时segment embedding还可以作为模型采取何种训练方式(单向,双向,序列到序列)的一种标识1.1.2 网络结构如图1红色虚线框中的内容,UniLM使用了 $L$ 层Transformer的架构,为了区分使不同的预训练任务可以共享这个网络,UniLM在其中添加了掩码矩阵的运算符。具体的讲,我们假设输入文本表示为 $\left\{\boldsymbol{x}_i\right\}_{i=1}^{|x|}$,它经过嵌入层后得到第一层的输入 $\boldsymbol{H}^0=\left[\boldsymbol{x}_1, \cdots, \boldsymbol{x}_{|x|}\right]$,然后经过 $L$层Transformer后得到最终的特征向量,表示为 $\boldsymbol{H}^l=\text { Transformer }\left(\boldsymbol{H}^{l-1}\right), l \in[1, L]$,再抽象编码成$\mathbf{H}_1=\left[\mathbf{h}_1^{\mathbf{l}}, \ldots, \mathbf{h}_{|\mathbf{x}|}^{\mathbf{1}}\right]$的不同层次的上下文表示。在每个$\text{Transformer}_l$块中,使用多个self-attention heads来聚合前一层的输出向量。对于第$l$个$\text{Transformer}_l$层,self-attention head $\mathbf A_l$的输出通过以下方。 不同于原始的Transformer,UniLM在其中添加了掩码矩阵,以第$l$层为例,此时Transformer转化为式(1)到式(3)所示的形式。$\begin{gathered}\boldsymbol{Q}_l=\boldsymbol{H}^{l-1} \boldsymbol{W}_l^Q \quad \boldsymbol{K}_l=\boldsymbol{H}^{l-1} \boldsymbol{W}_l^K \quad \boldsymbol{V}_l=\boldsymbol{H}^{l-1} \boldsymbol{W}_l^V \\ \boldsymbol{M}_{i j}= \begin{cases}0, & \text { allow to attend } \\ -\infty & \text { prevent from attending }\end{cases} \\ \boldsymbol{A}_l=\operatorname{softmax}\left(\frac{\boldsymbol{Q}_l \boldsymbol{K}_l^{\top}}{\sqrt{d_k}}+\boldsymbol{M}\right) \boldsymbol{V}_l\end{gathered}$其中 $\mathbf{H}^{l-1} \in \mathbb{R}^{|x| \times d_h}$分别使用参数矩阵$\boldsymbol{W}_l^Q, \boldsymbol{W}_l^K, \boldsymbol{W}_l^V$分别线性地投影到三元组Query,Key,Value中, $M \in \mathbb{R}^{|x| \times |x| }$是我们前面多次提到过的用于控制预训练任务的掩码矩阵。通过根据掩码矩阵$M$确定一对tokens是否可以相互attend,覆盖被编码的特征,让预测时只能关注到与特定任务相关的特征,从而实现了不同的预训练方式.1.1.3 任务统一UniLM共有4个预训练任务,除了图1中所示的三个语言模型外,还有一个经典的NSP任务,下面我们分别介绍它们。双向语言模型:MASK完形填空任务,输入的是一个文本对$[SOS,x_1,x_2,Mask,x_4,EOS,x_5,MASK,x_7,EOS]$双向语言模型是图1的最上面的任务,它和掩码语言模型一样就是利用上下文预测被掩码的部分。,与Bert模型一致,在预测被掩蔽token时,可以观察到所有的token,如上图所示,使用全0矩阵来作为掩码矩阵,模型需要根据所有的上下文分析,所以$M$是一个0矩阵。单向语言模型:MASK完形填空任务,输入的是一个单独的文本$[x_1,x_2,Mask,x_4]$单向语言模型可以使从左向右也可以是从右向左,图1的例子是从左向右的,也就是GPT[3]中使用的掩码方式。在这种预测方式中,模型在预测第t时间片的内容时只能看到第t时间片之前的内容,因此$M$是一个上三角全为 $-\infty$的上三角矩阵(图1中第二个掩码矩阵的阴影部分)。同理,当单向语言模型是从右向左时,$M$是一个下三角矩阵。在这种训练方式中,观测序列分为从左到右和从右向左两种,从左到右,即仅通过被掩蔽token的左侧所有本文来预测被掩蔽的token;从右到左,则是仅通过被掩蔽token的右侧所有本文来预测被掩蔽的token,如上图所示,使用上三角矩阵来作为掩码矩阵,阴影部分为,空白部分为0,Seq-to-Seq语言模型:MASK完形填空任务,输入的是一个文本对$[SOS,x_1,x_2,Mask,x_4,EOS,x_5,MASK,x_7,EOS]$如果被掩蔽token在第一个文本序列中,那么仅可以使用第一个文本序列中所有token,不能使用第二个文本序列的任何信息;如果被掩蔽token在第二个文本序列中,那么使用一个文本序列中所有token和第二个文本序列中被掩蔽token的左侧所有token预测被掩蔽token如上图所示,在训练的时候,一个序列由[SOS]S_1[EOS]S_2[EOS]组成,其中S1是source segments,S2是target segments。随机mask两个segment其中的词,其中如果masked是source segment的词的话,则它可以attend to所有的source segment的tokens,如果masked的是target segment,则模型只能attend to所有的source tokens以及target segment中当前词和该词左边的所有tokens,这样模型可以隐形地学习到一个双向的encoder和单向decoder(类似transformer)在Seq-to-Seq任务中,例如机器翻译,我们通常先通过编码器将输入句子编码成特征向量,然后通过解码器将这个特征向量解码成预测内容。UniLM的结构和传统的Encoder-Decoder模型的差异非常大,它仅有一个多层的Transformer构成。在进行预训练时,UniLM首先将两个句子拼接成一个序列,并通过[EOS]来分割句子,表示为:[SOS]S1[EOS]S2[EOS]。在编码时,我们需要知道输入句子的完整内容,因此不需要对输入文本进行覆盖。但是当进行解码时,解码器的部分便变成一个从左向右的单向语言模型。因此对于句子中的第1个片段(S1部分)对应的块矩阵,它是一个0矩阵(左上块矩阵),对于的句子第2个片段(S2部分)的对应的块矩阵,它是上三角矩阵的一部分(右上块矩阵)。因此我们可以得到图1中最下面的$M$ 。可以看出,UniLM虽然采用了编码器的架构,但是在训练Seq-to-Seq语言模型时它也可以像经典的Encoder-to-Decoder那样关注到输入的全部特征以及输出的已生成的特征。NSP:UniLM也像BERT一样添加了NSP作为预训练任务。对于双向语言模型(Bidirectional LM),与Bert模型一样,也进行下一个句子预测。如果是第一段文本的下一段文本,则预测1;否则预测01.1.4 训练与微调训练:在训练时,1/3的时间用来训练双向语言模型,1/3的时间用来训练单向语言模型,其中从左向右和从右向左各站一半,最后1/3用了训练Encoder-Decoder架构。微调:对于NLU任务来说,我们可以直接将UniLM视作一个编码器,然后通过[SOS]标志得到整句的特征向量,再通过在特征向量后添加分类层得到预测的类别。对于NLG任务来说,我们可以像前面介绍的把句子拼接成序列“[SOS]S1[EOS]S2[EOS]”。其中S1是输入文本的全部内容。为了进行微调,我们会随机掩码掉目标句子S2的部分内容。同时我们可会掩码掉目标句子的[EOS],我们的目的是让模型自己预测何时预测[EOS]从而停止预测,而不是预测一个我们提前设置好的长度。网络设置:24层Transformer,1024个hidden size,16个attention heads参数大小:340M初始化:直接采用Bert-Large的参数初始化激活函数:GELU,与bert一样dropout比例:0.1权重衰减因子:0.01batch_size:330混合训练方式:对于一个batch,1/3时间采用双向语言模型的目标,1/3的时间采用Seq2Seq语言模型目标,最后1/3平均分配给两种单向学习的语言模型,也就是left-to-right和right-to-left方式各占1/6时间MASK方式:总体比例15%,其中80%的情况下直接用[MASK]替代,10%的情况下随机选择一个词替代,最后10%的情况用真实值。还有就是80%的情况是每次只mask一个词,另外20%的情况是mask掉bi-gram或者tri-gram1.1.5 小结UniLM和很多Encoder-Decoder架构的模型一样(例如MASS)像统一NLU和NLG任务,但是无疑UniLM的架构更加优雅。像MASS在做NLU任务时,它只会采用模型的Encoder部分,从而丢弃了Decoder部分的全部特征。UniLM有一个问题是在做机器翻译这样经典的Seq-to-Seq任务时,它的掩码机制导致它并没有使用表示[SOS]标志对应的全句特征,而是使用了输入句子的序列。这个方式可能缺乏了对整句特征的捕获,从而导致生成的内容缺乏对全局信息的把控。此外,UniLM在五个NLG数据集上的表现优于以前的最新模型:CNN/DailyMail和Gigaword文本摘要、SQuAD问题生成、CoQA生成问题回答和DSTC7基于对话生成,其优势总结如下:三种不同的训练目标,网络参数共享网络参数共享,使得模型避免了过拟合于某单一的语言模型,使得学习出来的模型更加具有普适性采用了Seq2Seq语言模型,使得其在能够完成NLU任务的同时,也能够完成NLG任务1.2 SimBert1.2.1 融合检索和生成的SimBERT模型基于UniLM思想、融检索与生成于一体的BERT模型。权重下载:https://github.com/ZhuiyiTechnology/pretrained-modelsUniLM的核心是通过特殊的Attention Mask来赋予模型具有Seq2Seq的能力。假如输入是“你想吃啥”,目标句子是“白切鸡”,那UNILM将这两个句子拼成一个:[CLS] 你 想 吃 啥 [SEP] 白 切 鸡 [SEP],然后接如图的Attention Mask:换句话说,[CLS] 你 想 吃 啥 [SEP]这几个token之间是双向的Attention,而白 切 鸡 [SEP]这几个token则是单向Attention,从而允许递归地预测白 切 鸡 [SEP]这几个token,所以它具备文本生成能力。UNILM做Seq2Seq模型图示。输入部分内部可做双向Attention,输出部分只做单向Attention。Seq2Seq只能说明UniLM具有NLG的能力,那前面为什么说它同时具备NLU和NLG能力呢?因为UniLM特殊的Attention Mask,所以[CLS] 你 想 吃 啥 [SEP]这6个token只在它们之间相互做Attention,而跟白 切 鸡 [SEP]完全没关系,这就意味着,尽管后面拼接了白 切 鸡 [SEP],但这不会影响到前6个编码向量。再说明白一点,那就是前6个编码向量等价于只有[CLS] 你 想 吃 啥 [SEP]时的编码结果,如果[CLS]的向量代表着句向量,那么它就是你 想 吃 啥的句向量,而不是加上白 切 鸡后的句向量。由于这个特性,UniLM在输入的时候也随机加入一些[MASK],这样输入部分就可以做MLM任务,输出部分就可以做Seq2Seq任务,MLM增强了NLU能力,而Seq2Seq增强了NLG能力,一举两得。1.2.2 SimBertSimBERT属于有监督训练,训练语料是自行收集到的相似句对,通过一句来预测另一句的相似句生成任务来构建Seq2Seq部分,然后前面也提到过[CLS]的向量事实上就代表着输入的句向量,所以可以同时用它来训练一个检索任务,如下图假设SENT_a和SENT_b是一组相似句,那么在同一个batch中,把[CLS] SENT_a [SEP] SENT_b [SEP]和[CLS] SENT_b [SEP] SENT_a [SEP]都加入训练,做一个相似句的生成任务,这是Seq2Seq部分。另一方面,把整个batch内的[CLS]向量都拿出来,得到一个bxd的句向量矩阵V(b是batch_size,d是hidden_size),然后对d维度做l2归一化,得到新的V,然后两两做内积,得到bxv的相似度矩阵VV^T,接着乘以一个scale(我们取了30),并mask掉对角线部分,最后每一行进行softmax,作为一个分类任务训练,每个样本的目标标签是它的相似句(至于自身已经被mask掉)。说白了,就是把batch内所有的非相似样本都当作负样本,借助softmax来增加相似样本的相似度,降低其余样本的相似度。详细介绍请看:https://kexue.fm/archives/7427部分结果展示:>>> gen_synonyms(u'微信和支付宝哪个好?') u'微信和支付宝,哪个好?', u'微信和支付宝哪个好', u'支付宝和微信哪个好', u'支付宝和微信哪个好啊', u'微信和支付宝那个好用?', u'微信和支付宝哪个好用', u'支付宝和微信那个更好', u'支付宝和微信哪个好用', u'微信和支付宝用起来哪个好?', u'微信和支付宝选哪个好', u'微信好还是支付宝比较用', u'微信与支付宝哪个', u'支付宝和微信哪个好用一点?', u'支付宝好还是微信', u'微信支付宝究竟哪个好', u'支付宝和微信哪个实用性更好', u'好,支付宝和微信哪个更安全?', u'微信支付宝哪个好用?有什么区别', u'微信和支付宝有什么区别?谁比较好用', u'支付宝和微信哪个好玩' >>> most_similar(u'怎么开初婚未育证明', 20) (u'开初婚未育证明怎么弄?', 0.9728098), (u'初婚未育情况证明怎么开?', 0.9612292), (u'到哪里开初婚未育证明?', 0.94987774), (u'初婚未育证明在哪里开?', 0.9476072), (u'男方也要开初婚证明吗?', 0.7712214), (u'初婚证明除了村里开,单位可以开吗?', 0.63224965), (u'生孩子怎么发', 0.40672967), (u'是需要您到当地公安局开具变更证明的', 0.39978087), (u'淘宝开店认证未通过怎么办', 0.39477515), (u'您好,是需要当地公安局开具的变更证明的', 0.39288986), (u'没有工作证明,怎么办信用卡', 0.37745982), (u'未成年小孩还没办身份证怎么买高铁车票', 0.36504325), (u'烟草证不给办,应该怎么办呢?', 0.35596085), (u'怎么生孩子', 0.3493368), (u'怎么开福利彩票站', 0.34158638), (u'沈阳烟草证怎么办?好办不?', 0.33718678), (u'男性不孕不育有哪些特征', 0.33530876), (u'结婚证丢了一本怎么办离婚', 0.33166665), (u'怎样到地税局开发票?', 0.33079252), (u'男性不孕不育检查要注意什么?', 0.3274408) ]1.2.3 SimBER训练预测SimBERT的模型权重是以Google开源的BERT模型为基础,基于微软的UniLM思想设计了融检索与生成于一体的任务,来进一步微调后得到的模型,所以它同时具备相似问生成和相似句检索能力。数据集使用的是LCQMC相关情况参考:https://aistudio.baidu.com/aistudio/projectdetail/5423713?contributionType=1#数据准备:使用PaddleNLP内置数据集 from paddlenlp.datasets import load_dataset train_ds, dev_ds, test_ds = load_dataset("lcqmc", splits=["train", "dev", "test"]) #保存数据集并查看 import json with open("/home/aistudio/output/test.txt", "w+",encoding='UTF-8') as f: #a : 写入文件,若文件不存在则会先创建再写入,但不会覆盖原文件,而是追加在文件末尾 for result in dev_ds: line = json.dumps(result, ensure_ascii=False) #对中文默认使用的ascii编码.想输出真正的中文需要指定ensure_ascii=False f.write(line + "\n") #数据有上传一份也有内置读取,根据个人喜好自行选择待预测数据集部分展示:开初婚未育证明怎么弄? 初婚未育情况证明怎么开? 1 谁知道她是网络美女吗? 爱情这杯酒谁喝都会醉是什么歌 0 人和畜生的区别是什么? 人与畜生的区别是什么! 1 男孩喝女孩的尿的故事 怎样才知道是生男孩还是女孩 0 这种图片是用什么软件制作的? 这种图片制作是用什么软件呢? 1 这腰带是什么牌子 护腰带什么牌子好 0 什么牌子的空调最好! 什么牌子的空调扇最好 0这里要注意数据格式。没有标签的开初婚未育证明怎么弄? 初婚未育情况证明怎么开? 谁知道她是网络美女吗? 爱情这杯酒谁喝都会醉是什么歌 人和畜生的区别是什么? 人与畜生的区别是什么! 男孩喝女孩的尿的故事 怎样才知道是生男孩还是女孩 这种图片是用什么软件制作的? 这种图片制作是用什么软件呢? 这腰带是什么牌子 护腰带什么牌子好 什么牌子的空调最好! 什么牌子的空调扇最好 #模型预测 # %cd SimBERT !export CUDA_VISIBLE_DEVICES=0 !python predict.py --input_file /home/aistudio/LCQMC/dev.txt按照predict.py.py进行预测得到相似度,部分展示:{'query': '开初婚未育证明怎么弄?', 'title': '初婚未育情况证明怎么开?', 'similarity': 0.9500292} {'query': '谁知道她是网络美女吗?', 'title': '爱情这杯酒谁喝都会醉是什么歌', 'similarity': 0.24593769} {'query': '人和畜生的区别是什么?', 'title': '人与畜生的区别是什么!', 'similarity': 0.9916624} {'query': '男孩喝女孩的尿的故事', 'title': '怎样才知道是生男孩还是女孩', 'similarity': 0.3250241} {'query': '这种图片是用什么软件制作的?', 'title': '这种图片制作是用什么软件呢?', 'similarity': 0.9774641} {'query': '这腰带是什么牌子', 'title': '护腰带什么牌子好', 'similarity': 0.74771273} {'query': '什么牌子的空调最好!', 'title': '什么牌子的空调扇最好', 'similarity': 0.83304036}以阈值0.9以上为相似度判断,得到结果和标注答案一致1010100.2.Sentence Transformers (ERNIE/BERT/RoBERTa/Electra)随着深度学习的发展,模型参数的数量飞速增长。为了训练这些参数,需要更大的数据集来避免过拟合。然而,对于大部分NLP任务来说,构建大规模的标注数据集非常困难(成本过高),特别是对于句法和语义相关的任务。相比之下,大规模的未标注语料库的构建则相对容易。为了利用这些数据,我们可以先从其中学习到一个好的表示,再将这些表示应用到其他任务中。最近的研究表明,基于大规模未标注语料库的预训练模型(Pretrained Models, PTM) 在NLP任务上取得了很好的表现。近年来,大量的研究表明基于大型语料库的预训练模型(Pretrained Models, PTM)可以学习通用的语言表示,有利于下游NLP任务,同时能够避免从零开始训练模型。随着计算能力的发展,深度模型的出现(即 Transformer)和训练技巧的增强使得 PTM 不断发展,由浅变深。百度的预训练模型ERNIE经过海量的数据训练后,其特征抽取的工作已经做的非常好。借鉴迁移学习的思想,我们可以利用其在海量数据中学习的语义信息辅助小数据集(如本示例中的医疗文本数据集)上的任务。以 ERNIE 为代表的模型Fine-tune完成文本匹配任务。使用预训练模型ERNIE完成文本匹配任务,大家可能会想到将query和title文本拼接,之后输入ERNIE中,取CLS特征(pooled_output),之后输出全连接层,进行二分类。如下图ERNIE用于句对分类任务的用法:然而,以上用法的问题在于,ERNIE的模型参数非常庞大,导致计算量非常大,预测的速度也不够理想。从而达不到线上业务的要求。针对该问题,可以使用PaddleNLP工具搭建Sentence Transformer网络。**Sentence Transformer采用了双塔(Siamese)的网络结构。Query和Title分别输入ERNIE,共享一个ERNIE参数,得到各自的token embedding特征。之后对token embedding进行pooling(此处教程使用mean pooling操作),之后输出分别记作u,v。之后将三个表征(u,v,|u-v|)拼接起来,进行二分类。网络结构如上图所示。同时,不仅可以使用ERNIR作为文本语义特征提取器,可以利用BERT/RoBerta/Electra等模型作为文本语义特征提取器**论文参考:Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks https://arxiv.org/abs/1908.10084那么Sentence Transformer采用Siamese的网路结构,是如何提升预测速度呢?Siamese的网络结构好处在于query和title分别输入同一套网络。如在信息搜索任务中,此时就可以将数据库中的title文本提前计算好对应sequence_output特征,保存在数据库中。当用户搜索query时,只需计算query的sequence_output特征与保存在数据库中的title sequence_output特征,通过一个简单的mean_pooling和全连接层进行二分类即可。从而大幅提升预测效率,同时也保障了模型性能。关于匹配任务常用的Siamese网络结构可以参考:https://blog.csdn.net/thriving_fcl/article/details/737305522.1 模型简介针对中文文本匹配问题,开源了一系列模型:BERT(Bidirectional Encoder Representations from Transformers)中文模型,简写bert-base-chinese, 其由12层Transformer网络组成。ERNIE(Enhanced Representation through Knowledge Integration),支持ERNIE 1.0中文模型(简写ernie-1.0)和ERNIE Tiny中文模型(简写ernie-tiny)。 其中ernie由12层Transformer网络组成,ernie-tiny由3层Transformer网络组成。RoBERTa(A Robustly Optimized BERT Pretraining Approach),支持12层Transformer网络的roberta-wwm-ext。在LQCMC数据集下各个模型评估:模型dev acctest accbert-base-chinese0.865370.84440bert-wwm-chinese0.863330.84128bert-wwm-ext-chinese0.860490.83848ernie-1.00.874800.84760ernie-tiny0.860710.83352roberta-wwm-ext0.875260.84904rbt30.853670.83464rbtl30.851740.837442.2 模型训练以中文文本匹配公开数据集LCQMC为示例数据集,可以运行下面的命令,在训练集(train.tsv)上进行模型训练,并在开发集(dev.tsv)验证部分结果展示:global step 7010, epoch: 8, batch: 479, loss: 0.06888, accu: 0.97227, speed: 1.40 step/s global step 7020, epoch: 8, batch: 489, loss: 0.08377, accu: 0.97617, speed: 6.30 step/s global step 7030, epoch: 8, batch: 499, loss: 0.07471, accu: 0.97630, speed: 6.32 step/s global step 7040, epoch: 8, batch: 509, loss: 0.05239, accu: 0.97559, speed: 6.32 step/s global step 7050, epoch: 8, batch: 519, loss: 0.04824, accu: 0.97539, speed: 6.30 step/s global step 7060, epoch: 8, batch: 529, loss: 0.05198, accu: 0.97617, speed: 6.42 step/s global step 7070, epoch: 8, batch: 539, loss: 0.07196, accu: 0.97651, speed: 6.42 step/s global step 7080, epoch: 8, batch: 549, loss: 0.07003, accu: 0.97646, speed: 6.36 step/s global step 7090, epoch: 8, batch: 559, loss: 0.10023, accu: 0.97587, speed: 6.34 step/s global step 7100, epoch: 8, batch: 569, loss: 0.04805, accu: 0.97641, speed: 6.08 step/s eval loss: 0.46545, accu: 0.87264 [2023-02-07 17:31:29,933] [ INFO] - tokenizer config file saved in ./checkpoints_ernie/model_7100/tokenizer_config.json [2023-02-07 17:31:29,933] [ INFO] - Special tokens file saved in ./checkpoints_ernie/model_7100/special_tokens_map.json代码示例中使用的预训练模型是ERNIE,如果想要使用其他预训练模型如BERT,RoBERTa,Electra等,只需更换model 和 tokenizer即可。# 使用 ERNIE 预训练模型 # ernie-3.0-medium-zh model = AutoModel.from_pretrained('ernie-3.0-medium-zh') tokenizer = AutoTokenizer.from_pretrained('ernie-3.0-medium-zh') # ernie-1.0 # model = AutoModel.from_pretrained('ernie-1.0-base-zh') # tokenizer = AutoTokenizer.from_pretrained('ernie-1.0-base-zh') # ernie-tiny # model = AutoModel.Model.from_pretrained('ernie-tiny') # tokenizer = AutoTokenizer.from_pretrained('ernie-tiny') # 使用 BERT 预训练模型 # bert-base-chinese # model = AutoModel.Model.from_pretrained('bert-base-chinese') # tokenizer = AutoTokenizer.from_pretrained('bert-base-chinese') # bert-wwm-chinese # model = AutoModel.from_pretrained('bert-wwm-chinese') # tokenizer = AutoTokenizer.from_pretrained('bert-wwm-chinese') # bert-wwm-ext-chinese # model = AutoModel.from_pretrained('bert-wwm-ext-chinese') # tokenizer = AutoTokenizer.from_pretrained('bert-wwm-ext-chinese') # 使用 RoBERTa 预训练模型 # roberta-wwm-ext # model = AutoModel..from_pretrained('roberta-wwm-ext') # tokenizer = AutoTokenizer.from_pretrained('roberta-wwm-ext') # roberta-wwm-ext # model = AutoModel.from_pretrained('roberta-wwm-ext-large') # tokenizer = AutoTokenizer.from_pretrained('roberta-wwm-ext-large') 更多预训练模型,参考transformers程序运行时将会自动进行训练,评估,测试。同时训练过程中会自动保存模型在指定的save_dir中。 如:checkpoints/ ├── model_100 │ ├── model_config.json │ ├── model_state.pdparams │ ├── tokenizer_config.json │ └── vocab.txt └── ...NOTE:如需恢复模型训练,则可以设置init_from_ckpt, 如init_from_ckpt=checkpoints/model_100/model_state.pdparams。如需使用ernie-tiny模型,则需要提前先安装sentencepiece依赖,如pip install sentencepiece#模型预测 !export CUDA_VISIBLE_DEVICES=0 !python predict.py --device gpu --params_path /home/aistudio/Fine-tune/checkpoints_ernie/model_7100/model_state.pdparams输出结果:Data: ['开初婚未育证明怎么弄?', '初婚未育情况证明怎么开?'] Lable: similar Data: ['谁知道她是网络美女吗?', '爱情这杯酒谁喝都会醉是什么歌'] Lable: dissimilar Data: ['人和畜生的区别是什么?', '人与畜生的区别是什么!'] Lable: similar Data: ['男孩喝女孩的尿的故事', '怎样才知道是生男孩还是女孩'] Lable: dissimilar Data: ['这种图片是用什么软件制作的?', '这种图片制作是用什么软件呢?'] Lable: similar Data: ['这腰带是什么牌子', '护腰带什么牌子好'] Lable: dissimilar Data: ['什么牌子的空调最好!', '什么牌子的空调扇最好'] Lable: dissimilar1010100和Simbert以及标注真实标签一致修改代码api接口参考:https://www.paddlepaddle.org.cn/documentation/docs/zh/api/paddle/argmax_cn.html#argmax2.3小结基于双塔 Point-wise 范式的语义匹配模型 SimNet 和 Sentence Transformers, 这 2 种方案计算效率更高,适合对延时要求高、根据语义相似度进行粗排的应用场景。关于Sentence Transformer更多信息参考www.SBERT.net以及论文:Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks (EMNLP 2019)Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation (EMNLP 2020)Augmented SBERT: Data Augmentation Method for Improving Bi-Encoders for Pairwise Sentence Scoring Tasks (arXiv 2020)3.预训练模型 ERNIE-Gram 的单塔文本匹配文本匹配任务数据每一个样本通常由两个文本组成(query,title)。类别形式为 0 或 1,0 表示 query 与 title 不匹配; 1 表示匹配。基于单塔 Point-wise 范式的语义匹配模型 ernie_matching: 模型精度高、计算复杂度高, 适合直接进行语义匹配 2 分类的应用场景。基于单塔 Pair-wise 范式的语义匹配模型 ernie_matching: 模型精度高、计算复杂度高, 对文本相似度大小的序关系建模能力更强,适合将相似度特征作为上层排序模块输入特征的应用场景。基于双塔 Point-Wise 范式的语义匹配模型 这2 种方案计算效率更高,适合对延时要求高、根据语义相似度进行粗排的应用场景。Pointwise:输入两个文本和一个标签,可看作为一个分类问题,即判断输入的两个文本是否匹配。Pairwise:输入为三个文本,分别为Query以及对应的正样本和负样本,该训练方式考虑到了文本之间的相对顺序。单塔/双塔单塔:先将输入文本合并,然后输入到单一的神经网络模型。双塔:对输入文本分别进行编码成固定长度的向量,通过文本的表示向量进行交互计算得到文本之间的关系。本项目使用语义匹配数据集 LCQMC 作为训练集 , 基于 ERNIE-Gram 预训练模型热启训练并开源了单塔 Point-wise 语义匹配模型, 用户可以直接基于这个模型对文本对进行语义匹配的 2 分类任务代码结构说明ernie_matching/ ├── deply # 部署 | └── python | └── predict.py # python 预测部署示例 ├── export_model.py # 动态图参数导出静态图参数脚本 ├── model.py # Point-wise & Pair-wise 匹配模型组网 ├── data.py # Point-wise & Pair-wise 训练样本的转换逻辑 、Pair-wise 生成随机负例的逻辑 ├── train_pointwise.py # Point-wise 单塔匹配模型训练脚本 ├── train_pairwise.py # Pair-wise 单塔匹配模型训练脚本 ├── predict_pointwise.py # Point-wise 单塔匹配模型预测脚本,输出文本对是否相似: 0、1 分类 ├── predict_pairwise.py # Pair-wise 单塔匹配模型预测脚本,输出文本对的相似度打分 └── train.py # 模型训练评估数据集简介:LCQMC是百度知道领域的中文问题匹配数据集,目的是为了解决在中文领域大规模问题匹配数据集的缺失。该数据集从百度知道不同领域的用户问题中抽取构建数据。3.1模型训练与预测以中文文本匹配公开数据集 LCQMC 为示例数据集,可以运行下面的命令,在训练集(train.tsv)上进行单塔 Point-wise 模型训练,并在开发集(dev.tsv)验证。%cd ERNIE_Gram !unset CUDA_VISIBLE_DEVICES !python -u -m paddle.distributed.launch --gpus "0" train_pointwise.py \ --device gpu \ --save_dir ./checkpoints \ --batch_size 32 \ --learning_rate 2E-5\ --save_step 1000 \ --eval_step 200 \ --epochs 3 # save_dir:可选,保存训练模型的目录;默认保存在当前目录checkpoints文件夹下。 # max_seq_length:可选,ERNIE-Gram 模型使用的最大序列长度,最大不能超过512, 若出现显存不足,请适当调低这一参数;默认为128。 # batch_size:可选,批处理大小,请结合显存情况进行调整,若出现显存不足,请适当调低这一参数;默认为32。 # learning_rate:可选,Fine-tune的最大学习率;默认为5e-5。 # weight_decay:可选,控制正则项力度的参数,用于防止过拟合,默认为0.0。 # epochs: 训练轮次,默认为3。 # warmup_proption:可选,学习率warmup策略的比例,如果0.1,则学习率会在前10%训练step的过程中从0慢慢增长到learning_rate, 而后再缓慢衰减,默认为0.0。 # init_from_ckpt:可选,模型参数路径,热启动模型训练;默认为None。 # seed:可选,随机种子,默认为1000. # device: 选用什么设备进行训练,可选cpu或gpu。如使用gpu训练则参数gpus指定GPU卡号。预测结果部分展示:global step 3810, epoch: 1, batch: 3810, loss: 0.27187, accu: 0.90938, speed: 1.25 step/s global step 3820, epoch: 1, batch: 3820, loss: 0.24648, accu: 0.92188, speed: 21.63 step/s global step 3830, epoch: 1, batch: 3830, loss: 0.23190, accu: 0.92604, speed: 21.38 step/s global step 3840, epoch: 1, batch: 3840, loss: 0.35609, accu: 0.91484, speed: 20.81 step/s global step 3850, epoch: 1, batch: 3850, loss: 0.06531, accu: 0.91687, speed: 19.64 step/s global step 3860, epoch: 1, batch: 3860, loss: 0.16462, accu: 0.91667, speed: 20.57 step/s global step 3870, epoch: 1, batch: 3870, loss: 0.26173, accu: 0.91607, speed: 19.78 step/s global step 3880, epoch: 1, batch: 3880, loss: 0.26429, accu: 0.91602, speed: 19.62 step/s global step 3890, epoch: 1, batch: 3890, loss: 0.09031, accu: 0.91771, speed: 20.49 step/s global step 3900, epoch: 1, batch: 3900, loss: 0.16542, accu: 0.91938, speed: 21.26 step/s global step 3910, epoch: 1, batch: 3910, loss: 0.27632, accu: 0.92074, speed: 21.87 step/s global step 3920, epoch: 1, batch: 3920, loss: 0.13577, accu: 0.92109, speed: 22.31 step/s global step 3930, epoch: 1, batch: 3930, loss: 0.15333, accu: 0.91971, speed: 18.52 step/s global step 3940, epoch: 1, batch: 3940, loss: 0.10362, accu: 0.92031, speed: 21.68 step/s global step 3950, epoch: 1, batch: 3950, loss: 0.14692, accu: 0.92146, speed: 21.74 step/s global step 3960, epoch: 1, batch: 3960, loss: 0.17472, accu: 0.92168, speed: 19.54 step/s global step 3970, epoch: 1, batch: 3970, loss: 0.31994, accu: 0.91967, speed: 21.06 step/s global step 3980, epoch: 1, batch: 3980, loss: 0.17073, accu: 0.91875, speed: 21.22 step/s global step 3990, epoch: 1, batch: 3990, loss: 0.14955, accu: 0.91891, speed: 21.51 step/s global step 4000, epoch: 1, batch: 4000, loss: 0.13987, accu: 0.91922, speed: 21.74 step/s eval dev loss: 0.30795, accu: 0.87253如果想要使用其他预训练模型如 ERNIE, BERT,RoBERTa,Electra等,只需更换model 和 tokenizer即可。 # 使用 ERNIE-3.0-medium-zh 预训练模型 model = AutoModel.from_pretrained('ernie-3.0-medium-zh') tokenizer = AutoTokenizer.from_pretrained('ernie-3.0-medium-zh') # 使用 ERNIE-Gram 预训练模型 model = AutoModel.from_pretrained('ernie-gram-zh') tokenizer = AutoTokenizer.from_pretrained('ernie-gram-zh') # 使用 ERNIE 预训练模型 # ernie-1.0 #model = AutoModel.from_pretrained('ernie-1.0-base-zh')) #tokenizer = AutoTokenizer.from_pretrained('ernie-1.0-base-zh') # ernie-tiny # model = AutoModel.from_pretrained('ernie-tiny')) # tokenizer = AutoTokenizer.from_pretrained('ernie-tiny') # 使用 BERT 预训练模型 # bert-base-chinese # model = AutoModel.from_pretrained('bert-base-chinese') # tokenizer = AutoTokenizer.from_pretrained('bert-base-chinese') # bert-wwm-chinese # model = AutoModel.from_pretrained('bert-wwm-chinese') # tokenizer = AutoTokenizer.from_pretrained('bert-wwm-chinese') # bert-wwm-ext-chinese # model = AutoModel.from_pretrained('bert-wwm-ext-chinese') # tokenizer = AutoTokenizer.from_pretrained('bert-wwm-ext-chinese') # 使用 RoBERTa 预训练模型 # roberta-wwm-ext # model = AutoModel.from_pretrained('roberta-wwm-ext') # tokenizer = AutoTokenizer.from_pretrained('roberta-wwm-ext') # roberta-wwm-ext # model = AutoModel.from_pretrained('roberta-wwm-ext-large') # tokenizer = AutoTokenizer.from_pretrained('roberta-wwm-ext-large') NOTE:如需恢复模型训练,则可以设置init_from_ckpt, 如init_from_ckpt=checkpoints/model_100/model_state.pdparams。如需使用ernie-tiny模型,则需要提前先安装sentencepiece依赖,如pip install sentencepiece!unset CUDA_VISIBLE_DEVICES !python -u -m paddle.distributed.launch --gpus "0" \ predict_pointwise.py \ --device gpu \ --params_path "./checkpoints/model_4000/model_state.pdparams"\ --batch_size 128 \ --max_seq_length 64 \ --input_file '/home/aistudio/LCQMC/test.tsv'预测结果部分展示:{'query': '这张图是哪儿', 'title': '这张图谁有', 'pred_label': 0} {'query': '这是什么水果?', 'title': '这是什么水果。怎么吃?', 'pred_label': 1} {'query': '下巴长痘痘疼是什么原因', 'title': '下巴长痘痘是什么原因?', 'pred_label': 1} {'query': '世界上最痛苦的是什么', 'title': '世界上最痛苦的是什么?', 'pred_label': 1} {'query': '北京的市花是什么?', 'title': '北京的市花是什么花?', 'pred_label': 1} {'query': '这个小男孩叫什么?', 'title': '什么的捡鱼的小男孩', 'pred_label': 0} {'query': '蓝牙耳机什么牌子最好的?', 'title': '什么牌子的蓝牙耳机最好用', 'pred_label': 1} {'query': '湖南卫视我们约会吧中间的歌曲是什么', 'title': '我们约会吧约会成功歌曲是什么', 'pred_label': 0} {'query': '孕妇能吃驴肉吗', 'title': '孕妇可以吃驴肉吗?', 'pred_label': 1} {'query': '什么鞋子比较好', 'title': '配什么鞋子比较好…', 'pred_label': 1} {'query': '怎么把词典下载到手机上啊', 'title': '怎么把牛津高阶英汉双解词典下载到手机词典上啊', 'pred_label': 0} {'query': '话费充值哪里便宜', 'title': '哪里充值(话费)最便宜?', 'pred_label': 1} {'query': '怎样下载歌曲到手机', 'title': '怎么往手机上下载歌曲', 'pred_label': 1} {'query': '苹果手机丢了如何找回?', 'title': '苹果手机掉了怎么找回', 'pred_label': 1} {'query': '考试怎么考高分?', 'title': '考试如何考高分', 'pred_label': 1} {'query': '带凶兆是什么意思', 'title': '主凶兆是什么意思', 'pred_label': 1} {'query': '浅蓝色牛仔裤配什么颜色的帆布鞋好看啊', 'title': '浅蓝色牛仔裤配什么颜色外套和鞋子好看', 'pred_label': 0} {'query': '怎么才能赚大钱', 'title': '怎么样去赚大钱呢', 'pred_label': 1} {'query': '王冕是哪个朝代的', 'title': '王冕是哪个朝代的啊', 'pred_label': 1} {'query': '世界上真的有僵尸吗?', 'title': '这个世界上真的有僵尸吗', 'pred_label': 1} {'query': '梦见小女孩哭', 'title': '梦见小女孩对我笑。', 'pred_label': 0} {'query': '这是神马电影?说什的?', 'title': '这是神马电影?!', 'pred_label': 1} {'query': '李易峰快乐大本营饭拍', 'title': '看李易峰上快乐大本营吻戏', 'pred_label': 0}3.2 基于静态图部署预测模型导出使用动态图训练结束之后,可以使用静态图导出工具 export_model.py 将动态图参数导出成静态图参数。 执行如下命令:!python export_model.py --params_path checkpoints/model_4000/model_state.pdparams --output_path=./output # 其中params_path是指动态图训练保存的参数路径,output_path是指静态图参数导出路径。 # 预测部署 # 导出静态图模型之后,可以基于静态图模型进行预测,deploy/python/predict.py 文件提供了静态图预测示例。执行如下命令: !python deploy/predict.py --model_dir ./output部分结果展示:Data: {'query': '〈我是特种兵之火凤凰〉好看吗', 'title': '特种兵之火凤凰好看吗?'} Label: similar Data: {'query': '现在看电影用什么软件好', 'title': '现在下电影一般用什么软件'} Label: similar Data: {'query': '什么水取之不尽用之不竭是什么生肖', 'title': '什么水取之不尽用之不竭打一生肖'} Label: similar Data: {'query': '愤怒的小鸟哪里下载', 'title': '愤怒的小鸟在哪里下载'} Label: similar Data: {'query': '中国象棋大师网', 'title': '中国象棋大师'} Label: dissimilar Data: {'query': '怎么注册谷歌账号?', 'title': '谷歌账号怎样注册'} Label: similar Data: {'query': '哪里可以看点金胜手', 'title': '点金胜手哪里能看完'} Label: similar Data: {'query': '什么牌子的行车记录仪好,怎么选', 'title': '行车记录仪什么牌子好;选哪个?'} Label: similar Data: {'query': '芭比公主系列总共有哪些QUQ', 'title': '芭比公主系列动漫有哪些'} Label: dissimilar Data: {'query': '新疆省会哪里', 'title': '新疆省会是哪里?'} Label: similar Data: {'query': '今天星期几!', 'title': '今天星期几呢'} Label: similar Data: {'query': '蜂蛹怎么吃', 'title': '蜂蛹怎么养'} Label: dissimilar Data: {'query': '少年老成是什么生肖', 'title': '什么生肖是少年老成'} Label: similar Data: {'query': '有关爱国的歌曲', 'title': '爱国歌曲有哪些'} Label: similar3.3 小结模型dev accSimcse(无监督)58.97%Diffcse(无监督)63.23%bert-base-chinese86.53%bert-wwm-chinese86.33%bert-wwm-ext-chinese86.05%ernie-tiny86.07%roberta-wwm-ext87.53%rbt385.37%rbtl385.17%ERNIE-1.0-Base89.34%ERNIE-1.0-Base89.34%ERNIE-Gram-Base-Pointwise90.58%SimCSE 模型适合缺乏监督数据,但是又有大量无监督数据的匹配和检索场景。相比于 SimCSE 模型,DiffCSE模型会更关注语句之间的差异性,具有精确的向量表示能力。DiffCSE 模型同样适合缺乏监督数据,但是又有大量无监督数据的匹配和检索场景。明显看到有监督模型中ERNIE-Gram比之前所有模型性能的优秀参考文章:https://aistudio.baidu.com/aistudio/projectdetail/5423713?contributionType=14.学以致用--千言问题匹配鲁棒性评测比赛验证特定领域知识图谱融合方案:学以致用-问题匹配鲁棒性评测比赛验证本项目主要讲述文本匹配算法的应用实践、并给出相应的优化方案介绍如:可解释学习等。最后文末介绍了知识融合学术界方案、知识融合业界落地方案、算法测评KG生产质量保障等,涉及对比学习和文本。https://blog.csdn.net/sinat_39620217/article/details/1290261935.特定领域知识图谱(Domain-specific KnowledgeGraph:DKG)融合方案(重点!)在前面技术知识下可以看看后续的实际业务落地方案和学术方案关于图神经网络的知识融合技术学习参考下面链接:[PGL图学习项目合集&数据集分享&技术归纳业务落地技巧[系列十]](https://aistudio.baidu.com/aistudio/projectdetail/5127575?contributionType=1)从入门知识到经典图算法以及进阶图算法等,自行查阅食用!文章篇幅有限请参考专栏按需查阅:NLP知识图谱相关技术业务落地方案和码源5.1特定领域知识图谱知识融合方案(实体对齐):优酷领域知识图谱为例方案链接:https://blog.csdn.net/sinat_39620217/article/details/1286149515.2特定领域知识图谱知识融合方案(实体对齐):文娱知识图谱构建之人物实体对齐方案链接:https://blog.csdn.net/sinat_39620217/article/details/1286739635.3特定领域知识图谱知识融合方案(实体对齐):商品知识图谱技术实战方案链接:https://blog.csdn.net/sinat_39620217/article/details/1286744295.4特定领域知识图谱知识融合方案(实体对齐):基于图神经网络的商品异构实体表征探索方案链接:https://blog.csdn.net/sinat_39620217/article/details/1286749295.5特定领域知识图谱知识融合方案(实体对齐)论文合集方案链接:https://blog.csdn.net/sinat_39620217/article/details/128675199论文资料链接:两份内容不相同,且按照序号从小到大重要性依次递减知识图谱实体对齐资料论文参考(PDF)+实体对齐方案+特定领域知识图谱知识融合方案(实体对齐)知识图谱实体对齐资料论文参考(CAJ)+实体对齐方案+特定领域知识图谱知识融合方案(实体对齐)5.6知识融合算法测试方案(知识生产质量保障)方案链接:https://blog.csdn.net/sinat_39620217/article/details/1286756986. 总结文本匹配任务在自然语言处理中是非常重要的基础任务之一,一般研究两段文本之间的关系。有很多应用场景;如信息检索、问答系统、智能对话、文本鉴别、智能推荐、文本数据去重、文本相似度计算、自然语言推理、问答系统、信息检索等,但文本匹配或者说自然语言处理仍然存在很多难点。这些自然语言处理任务在很大程度上都可以抽象成文本匹配问题,比如信息检索可以归结为搜索词和文档资源的匹配,问答系统可以归结为问题和候选答案的匹配,复述问题可以归结为两个同义句的匹配。本项目主要围绕着特定领域知识图谱(Domain-specific KnowledgeGraph:DKG)融合方案:文本匹配算法、知识融合学术界方案、知识融合业界落地方案、算法测评KG生产质量保障讲解了文本匹配算法的综述,从经典的传统模型到孪生神经网络“双塔模型”再到预训练模型以及有监督无监督联合模型,期间也涉及了近几年前沿的对比学习模型,之后提出了文本匹配技巧提升方案,最终给出了DKG的落地方案。这边主要以原理讲解和技术方案阐述为主,之后会慢慢把项目开源出来,一起共建KG,从知识抽取到知识融合、知识推理、质量评估等争取走通完整的流程。模型dev accSimcse(无监督)58.97%Diffcse(无监督)63.23%bert-base-chinese86.53%bert-wwm-chinese86.33%bert-wwm-ext-chinese86.05%ernie-tiny86.07%roberta-wwm-ext87.53%rbt385.37%rbtl385.17%ERNIE-1.0-Base89.34%ERNIE-1.0-Base89.34%ERNIE-Gram-Base-Pointwise90.58%SimCSE 模型适合缺乏监督数据,但是又有大量无监督数据的匹配和检索场景。相比于 SimCSE 模型,DiffCSE模型会更关注语句之间的差异性,具有精确的向量表示能力。DiffCSE 模型同样适合缺乏监督数据,但是又有大量无监督数据的匹配和检索场景。明显看到有监督模型中ERNIE-Gram比之前所有模型性能的优秀项目参考链接:UniLM详解:https://zhuanlan.zhihu.com/p/584193190原论文:Unified Language Model Pre-training for Natural Language Understanding and Generation:https://arxiv.org/pdf/1905.03197.pdfUniLM 模型详解:https://www.jianshu.com/p/22e3cc4842e1苏神:融合检索和生成的SimBERT模型:https://kexue.fm/archives/7427simbert:https://github.com/PaddlePaddle/PaddleNLP/blob/develop/examples/text_matching/simbert/README.mdsimbert:https://github.com/ZhuiyiTechnology/simbert开源预训练语言模型合集 :https://github.com/ZhuiyiTechnology/pretrained-models
2023计算机领域顶会(A类)以及ACL 2023自然语言处理(NLP)研究子方向领域汇总
2023年的计算语言学协会年会(ACL 2023)共包含26个领域,代表着当前前计算语言学和自然语言处理研究的不同方面。每个领域都有一组相关联的关键字来描述其潜在的子领域, 这些子领域并非排他性的,它们只描述了最受关注的子领域,并希望能够对该领域包含的相关类型的工作提供一些更好的想法。1.计算机领域顶会(A类)会议简称主要领域会议全称官网截稿时间会议时间CVPR2023计算机视觉The IEEE/CVF Conference on Computer Vision and Pattern Recognition 2023https://cvpr2023.thecvf.com/2022.11.112023.6.18ICCV2023计算机视觉IEEE International Conference on Computer Visionhttps://iccv2023.thecvf.com/2023.3.82023.9.30ECCV2022计算机视觉European Conference on Computer Visionhttps://eccv2022.ecva.net/-------2022.10.23AAAI2023人工智能National Conference of the American Association for Artificial Intelligencehttps://aaai-23.aaai.org/2022.8.82023.2.7IJCAI 2023人工智能National Conference of the American Association for Artificial Intelligencehttps://ijcai-22.org/#2022.8.82023.2.7NIPS2023机器学习International Joint Conference on Artificial Intelligencehttps://neurips.cc/Conferences/20222023.012023.07ICML 2023机器学习International Conference on Machine Learninghttps://icml.cc/2023.012023.06.24ICLR 2023机器学习International Conference on Learning Representationshttps://iclr.cc/Conferences/20232022.09.212023.05.01ICSE 2023软件工程International Conference on Software Engineeringhttps://conf.researchr.org/home/icse-20232022.09.012023.05.14SIGKDD 2023数据挖掘ACM International Conference on Knowledge Discovery and Data Mininghttps://kdd.org/kdd2022/index.html2023.022023.08SIGIR 2023数据挖掘ACM International Conference on Research and Development in Information Retrievalhttps://sigir.org/sigir2022/2023.012023.07ACL 2023计算语言Association of Computational Linguisticshttps://www.2022.aclweb.org/2022.112023.05ACM MM 2023多媒体ACM International Conference on Multimediahttps://2023.acmmmsys.org/participation/important-dates/2022.11.182023.6.7WWW2023网络应用International World Wide Web Conferencehttps://www2023.thewebconf.org/2022.10.62023.05.01SIGGRAPH 2023图形学ACM SIG International Conference on Computer Graphics and Interactive Techniqueshttps://s2022.siggraph.org/2023.012023.08CHI 2023人机交互ACM Conference on Human Factors in Computing Systemshttps://chi2023.acm.org/2022.09.082023.04.23CSCW 2023人机交互ACM Conference on Computer Supported Cooperative Work and Social Computinghttps://cscw.acm.org/2023/2023.01.152023.10.13CCS 2023信息安全ACM Conference on Computer and Communications Securityhttps://www.sigsac.org/ccs/CCS2022/2023.012023.11VLDB 2023数据管理International Conference on Very Large Data Baseshttps://www.vldb.org/2023/?submission-guidelines2023.03.012023.08.28STOC 2023计算机理论ACM Symposium on the Theory of Computinghttp://acm-stoc.org/stoc2022/2022.112023.062.ACL 2023自然语言处理(NLP)研究子方向领域汇总(一)计算社会科学和文化分析 (Computational Social Science and Cultural Analytics)人类行为分析 (Human behavior analysis)态度检测 (Stance detection)框架检测和分析 (Frame detection and analysis)仇恨言论检测 (Hate speech detection)错误信息检测和分析 (Misinformation detection and analysis)人口心理画像预测 (psycho-demographic trait prediction)情绪检测和分析 (emotion detection and analysis)表情符号预测和分析 (emoji prediction and analysis)语言和文化偏见分析 (language/cultural bias analysis)人机交互 (human-computer interaction)社会语言学 (sociolinguistics)用于社会分析的自然语言处理工具 (NLP tools for social analysis)新闻和社交媒体的定量分析 (quantiative analyses of news and/or social media)(二)对话和交互系统 (Dialogue and Interactive Systems)口语对话系统 (Spoken dialogue systems)评价指标 (Evaluation and metrics)任务型 (Task-oriented)人工介入 (Human-in-a-loop)偏见和毒性 (Bias/toxity)事实性 (Factuality)检索 (Retrieval)知识增强 (Knowledge augmented)常识推理 (Commonsense reasoning)互动讲故事 (Interactive storytelling)具象代理人 (Embodied agents)应用 (Applications)多模态对话系统 (Multi-modal dialogue systems)知识驱动对话 (Grounded dialog)多语言和低资源 (Multilingual / low-resource)对话状态追踪 (Dialogue state tracking)对话建模 (Conversational modeling)(三)话语和语用学 (Discourse and Pragmatics)回指消解 (Anaphora resolution)共指消解 (Coreference resolution)桥接消解 (Bridging resolution)连贯 (Coherence)一致 (Cohesion)话语关系 (Discourse relations)话语分析 (Discourse parsing)对话 (Dialogue)会话 (Conversation)话语和多语性 (Dialugue and multilinguality)观点挖掘 (Argument mining)交际 (Communication)(四)自然语言处理和伦理 (Ethics and NLP)数据伦理 (Data ethics)模型偏见和公正性评价 (Model bias/fairness evaluation)减少模型的偏见和不公平性 (Model bias/unfairness mitigation)自然语言处理中的人类因素 (Human factors in NLP)参与式和基于社群的自然语言处理 (Participatory/community-based NLP)自然语言处理应用中的道德考虑 (Ethical considerations in NLP)透明性 (Transparency)政策和治理 (Policy and governance)观点和批评 (Reflections and critiques)(五)语言生成 (Generation)人工评价 (Human evaluation)自动评价 (Automatic evaluation)多语言 (Multilingualism)高效模型 (Efficient models)少样本生成 (Few-shot generation)分析 (Analysis)领域适应 (Domain adaptation)数据到文本生成 (Data-to-text generation)文本到文博生成 (Text-to-text generation)推断方法 (Inference methods)模型结构 (Model architectures)检索增强生成 (Retrieval-augmented generation)交互和合作生成 (Interactive and collaborative generation)(六)信息抽取 (Information Extraction)命名实体识别和关系抽取 (Named entity recognition and relation extraction)事件抽取 (Event extraction)开放信息抽取 (Open information extraction)知识库构建 (Knowledge base construction)实体连接和消歧 (Entity linking and disambiguation)文档级抽取 (Document-level extraction)多语言抽取 (Multilingual extraction)小样本和零样本抽取 (Zero-/few-shot extraction)(七)信息检索和文本挖掘 (Information Retrieval and Text Mining)段落检索 (Passage retrieval)密集检索 (Dense retrieval)文档表征 (Document representation)哈希 (Hashing)重排序 (Re-ranking)预训练 (Pre-training)对比学习 (Constrastive learning)(八)自然语言处理模型的可解释性与分析 (Interpretability and Analysis of Models in NLP)对抗性攻击/例子/训练 (Adversarial attacks/examples/training)校正和不确定性 (Calibration/uncertainty)反事实和对比解释 (Counterfactual/contrastive explanations)数据影响 (Data influence)数据瑕疵 (Data shortcuts/artifacts)解释的忠诚度 (Explantion faithfulness)特征归因 (Feature attribution)自由文本和自然语言解释 (Free-text/natural language explanation)样本硬度 (Hardness of samples)结构和概念解释 (Hierarchical & concept explanations)以人为主体的应用评估 (Human-subject application-grounded evaluations)知识追溯、发现和推导 (Knowledge tracing/discovering/inducing)探究 (Probing)稳健性 (Robustness)话题建模 (Topic modeling)(九)视觉、机器人等领域的语言基础 (Language Grounding to Vision, Robotics and Beyond)视觉语言导航 (Visual Language Navigation)跨模态预训练 (Cross-modal pretraining)图像文本匹配 (Image text macthing)跨模态内容生成 (Cross-modal content generation)视觉问答 (Visual question answering)跨模态应用 (Cross-modal application)跨模态信息抽取 (Cross-modal information extraction)跨模态机器翻译 (Cross-modal machine translation)(十)大模型(Large Language Models)预训练 (Pre-training)提示 (Prompting)规模化 (Scaling)稀疏模型 (Sparse models)检索增强模型 (Retrieval-augmented models)伦理 (Ethics)可解释性和分析 (Interpretability/Analysis)连续学习 (Continual learning)安全和隐私 (Security and privacy)应用 (Applications)稳健性 (Robustness)微调 (Fine-tuning)(十一)语言多样性 (Language Diversity)少资源语言 (Less-resource languages)濒危语言 (Endangered languages)土著语言 (Indigenous languages)少数民族语言 (Minoritized languages)语言记录 (Language documentation)少资源语言的资源 (Resources for less-resourced languages)软件和工具 (Software and tools)(十二)语言学理论、认知建模和心理语言学 (Linguistic Theories, Cognitive Modeling and Psycholinguistics)语言学理论 (Linguistic theories)认知建模 (Cognitive modeling)计算心理语言学 (Computational pyscholinguistics)(十三)自然语言处理中的机器学习 (Machine Learning for NLP)基于图的方法 (Graph-based methods)知识增强的方法 (Knowledge-augmented methods)多任务学习 (Multi-task learning)自监督学习 (Self-supervised learning)对比学习 (Contrastive learning)生成模型 (Generation model)数据增强 (Data augmentation)词嵌入 (Word embedding)结构化预测 (Structured prediction)迁移学习和领域适应 (Transfer learning / domain adaptation)表征学习 (Representation learning)泛化 (Generalization)模型压缩方法 (Model compression methods)参数高效的微调方法 (Parameter-efficient finetuning)少样本学习 (Few-shot learning)强化学习 (Reinforcement learning)优化方法 (Optimization methods)连续学习 (Continual learning)对抗学习 (Adversarial training)元学习 (Meta learning)因果关系 (Causality)图模型 (Graphical models)人参与的学习和主动学习 (Human-in-a-loop / Active learning)(十四)机器翻译 (Machine Translation)自动评价 (Automatic evaluation)偏见 (Biases)领域适应 (Domain adaptation)机器翻译的高效推理方法 (Efficient inference for MT)高效机器翻译训练 (Efficient MT training)少样本和零样本机器翻译 (Few-/Zero-shot MT)人工评价 (Human evaluation)交互机器翻译 (Interactive MT)机器翻译部署和维护 (MT deployment and maintainence)机器翻译理论 (MT theory)建模 (Modeling)多语言机器翻译 (Multilingual MT)多模态 (Multimodality)机器翻译的线上运用 (Online adaptation for MT)并行解码和非自回归的机器翻译 (Parallel decoding/non-autoregressive MT)机器翻译预训练 (Pre-training for MT)规模化 (Scaling)语音翻译 (Speech translation)转码翻译 (Code-switching translation)词表学习 (Vocabulary learning)(十五)多语言和跨语言自然语言处理 (Multilingualism and Cross-Lingual NLP)转码 (Code-switching)混合语言 (Mixed language)多语言 (Multilingualism)语言接触 (Language contact)语言变迁 (Language change)语言变体 (Language variation)跨语言迁移 (Cross-lingual transfer)多语言表征 (Multilingual representation)多语言预训练 (Multilingual pre-training)多语言基线 (Multilingual benchmark)多语言评价 (Multilingual evaluation)方言和语言变种 (Dialects and language varieties)(十六)自然语言处理应用 (NLP Applications)教育应用、语法纠错、文章打分 (Educational applications, GEC, essay scoring)仇恨言论检测 (Hate speech detection)多模态应用 (Multimodal applications)代码生成和理解 (Code generation and understanding)事实检测、谣言和错误信息检测 (Fact checking, rumour/misinformation detection)医疗应用、诊断自然语言处理 (Healthcare applications, clinical NLP)金融和商务自然语言处理 (Financial/business NLP)法律自然语言处理 (Legal NLP)数学自然语言处理 (Mathematical NLP)安全和隐私 (Security/privacy)历史自然语言处理 (Historical NLP)知识图谱 (Knowledge graph)(十七)音系学、形态学和词语分割 (Phonology, Morphology and Word Segmentation)形态变化 (Morphological inflection)范式归纳 (Paradigm induction)形态学分割 (Morphological segementation)子词表征 (Subword representations)中文分割 (Chinese segmentation)词性还原 (Lemmatization)有限元形态学 (Finite-state morphology)形态学分析 (Morphological analysis)音系学 (Phonology)字素音素转换 (Grapheme-to-phoneme conversion)发音建模 (Pronunciation modeling)(十八)问答 (Question Answering)常识问答 (Commonsense QA)阅读理解 (Reading comprehension)逻辑推理 (Logic reasoning)多模态问答 (Multimodal QA)知识库问答 (Knowledge base QA)语义分析 (Semantic parsing)多跳问答 (Multihop QA)生物医学问答 (Biomedical QA)多语言问答 (Multilingual QA)可解释性 (Interpretability)泛化 (Generalization)推理 (Reasoning)对话问答 (Conversational QA)少样本问答 (Few-shot QA)数学问答 (Math QA)表格问答 (Table QA)开放域问答 (Open-domain QA)问题生成 (Question generation)(十九)语言资源及评价 (Resources and Evaluation)语料库构建 (Corpus creation)基线构建 (Benchmarking)语言资源 (Language resources)多语言语料库 (Multilingual corpora)词表构建 (Lexicon creation)语言资源的自动构建与评价 (Automatic creation and evaluation of language resources)自然语言处理数据集 (NLP datasets)数据集自动评价 (Automatic evaluation of datasets)评价方法 (Evaluation methodologies)低资源语言数据集 (Datasets for low resource languages)测量指标 (Metrics)复现性 (Reproducibility)用于评价的统计检验 (Statistical testing for evaluation)(二十)语义学:词汇层面 (Semantics: Lexical)一词多义 (Polysemy)词汇关系 (Lexical relationships)文本蕴含 (Textual entailment)语义合成性 (Compositionality)多词表达 (Multi-word expressions)同义转换 (Paraphrasing)隐喻 (Metaphor)词汇语义变迁 (Lexical semantic change)词嵌入 (Word embeddings)认知 (Cognition)词汇资源 (Lexical resources)情感分析 (Sentiment analysis)多语性 (Multilinguality)可解释性 (Interpretability)探索性研究 (Probing)(二十一)语义学:句级语义、文本推断和其他领域 (Semantics: Sentence-Level Semantics, Textual Inference and Other Areas)同义句识别 (Paraphrase recognition)文本蕴含 (Textual entailment)自然语言推理 (Natural language inference)逻辑推理 (Reasoning)文本语义相似性 (Semantic textual similarity)短语和句子嵌入 (Phrase/sentence embedding)同义句生成 (Paraphrase generation)文本简化 (Text simiplification)词和短语对齐 (Word/phrase alignment)(二十二)情感分析、文本风格分析和论点挖掘 (Sentiment Analysis, Stylistic Analysis and Argument Mining)论点挖掘 (Argument mining)观点检测 (Stance detection)论点质量评价 (Argument quality assessment)修辞和框架 (Rhetoric and framing)论证方案和推理 (Argument schemes and reasoning)论点生成 (Argument generation)风格分析 (Style analysis)风格生成 (Style generation)应用 (Applications)(二十三)语音和多模态 (Speech and Multimodality)自动语音识别 (Automatic speech recognition)口语语言理解 (Spoken language understanding)口语翻译 (Spoken language translation)口语语言基础 (Spoken language grounding)语音和视觉 (Speech and vision)口语查询问答 (QA via spoken queries)口语对话 (Spoken dialog)视频处理 (Video processing)语音基础 (Speech technologies)多模态 (Multimodality)(二十四)文摘 (Summarization)抽取文摘 (Extractive summarization)摘要文摘 (Abstractive summarization)多模态文摘 (Multimodal summarization)多语言文摘 (Multilingual summarization)对话文摘 (Conversational summarization)面向查询的文摘 (Query-focused summarization)多文档文摘 (Multi-document summarization)长格式文摘 (Long-form summarization)句子压缩 (Sentence compression)少样本文摘 (Few-shot summarization)结构 (Architectures)评价 (Evaluation)事实性 (Factuality)(二十五)句法学:标注、组块分析和句法分析 (Syntax: Tagging, Chunking and Parsing)组块分析、浅层分析 (Chunking, shallow-parsing)词性标注 (Part-of-speech tagging)依存句法分析 (Dependency parsing)成分句法分析 (Constituency parsing)深层句法分析 (Deep syntax parsing)语义分析 (Semantic parsing)句法语义接口 (Syntax-semantic inferface)形态句法相关任务的标注和数据集 (Optimized annotations or data set for morpho-syntax related tasks) 句法分析算法 (Parsing algorithms)语法和基于知识的方法 (Grammar and knowledge-based approach)多任务方法 (Multi-task approaches)面向大型多语言的方法 (Massively multilingual oriented approaches)低资源语言词性标注、句法分析和相关任务 (Low-resource languages pos-tagging, parsingand related tasks)形态丰富语言的词性标注、句法分析和相关任务 (Morphologically-rich languages pos tagging,parsing and related tasks) (二十六)主题领域:现实检测 (Theme Track: Reality Check)因为错误的原因而正确 (Right for the wrong reasons)实际运用中的教训 (Lessons from deployment)(非)泛化能力 [(Non-)generalization](非)复现能力 [(Non-)reproducibility)]评价 (Evaluation)方法 (Methodology)负面结果 (Negative results)人工智能噱头和期待 (AI hype and expectations)科学 vs 工程 (Science-vs-engineering)其他领域的结合 (Lessons from other fields)
特定领域知识图谱(Domain-specific KnowledgeGraph:DKG)融合方案:技术知识前置【一】-文本匹配算法、知识融合学术界方案、知识融合业界落地方案、算法测评KG生产质量保障
特定领域知识图谱(Domain-specific KnowledgeGraph:DKG)融合方案:技术知识前置【一】-文本匹配算法、知识融合学术界方案、知识融合业界落地方案、算法测评KG生产质量保障0.前言本项目主要围绕着特定领域知识图谱(Domain-specific KnowledgeGraph:DKG)融合方案:技术知识前置【一】-文本匹配算法、知识融合学术界方案、知识融合业界落地方案、算法测评KG生产质量保障讲解了文本匹配算法的综述,从经典的传统模型到孪生神经网络“双塔模型”再到预训练模型以及有监督无监督联合模型,期间也涉及了近几年前沿的对比学习模型,之后提出了文本匹配技巧提升方案,最终给出了DKG的落地方案。这边主要以原理讲解和技术方案阐述为主,之后会慢慢把项目开源出来,一起共建KG,从知识抽取到知识融合、知识推理、质量评估等争取走通完整的流程。1.文本匹配算法综述(短文本匹配)文本匹配任务在自然语言处理中是非常重要的基础任务之一,一般研究两段文本之间的关系。有很多应用场景;如信息检索、问答系统、智能对话、文本鉴别、智能推荐、文本数据去重、文本相似度计算、自然语言推理、问答系统、信息检索等,但文本匹配或者说自然语言处理仍然存在很多难点。这些自然语言处理任务在很大程度上都可以抽象成文本匹配问题,比如信息检索可以归结为搜索词和文档资源的匹配,问答系统可以归结为问题和候选答案的匹配,复述问题可以归结为两个同义句的匹配。如语言不规范,同一句话可以有多种表达方式;如“股市跳水、股市大跌、股市一片绿”歧义,同一个词语或句子在不同语境可能表达不同意思;如“割韭菜”,“领盒饭”,“苹果”“小米”等在不同语境下语义完全不同不规范或错误的输入;如 “ yyds”,“绝绝子”“夺笋”“耗子尾汁”需要知识依赖;如奥运冠军张怡宁绰号“乒乓大魔王”等。短文本匹配即计算两个短文本的相似度,通常分成无监督方式、有监督方式、有监督+无监督方式常见的文本匹配算法如下表(简单罗列),按传统模型和深度模型简单的分为两类:算法类型Jaccord传统模型BM25传统模型VSM传统模型SimHash传统模型Levenshtein传统模型cdssm深度模型arc-ii深度模型match_pyramid深度模型mvlstm深度模型bimpm深度模型drcn深度模型esim深度模型textmatching深度模型bert-base深度模型albert-base深度模型albert-large深度模型raberta深度模型sbert深度模型DiffCSE深度模型ERNIE-Gram深度模型1.1 文本匹配传统模型(无监督方式)文本表征:词袋模型(one-hot 、TF)、词向量预训练(word2vector、fasttext、glove)相似度计算:余弦相似度、曼哈顿距离、欧氏距离、jaccard距离等1.1.1 Jaccord 杰卡德相似系数jaccard相似度是一种非常直观的相似度计算方式,即两句子分词后词语的交集中词语数与并集中词语数之比。$\text { jaccard }=\frac{A \bigcap B}{A \bigcup B}$def jaccard(list1, list2): jaccard相似系数 :param list1:第一句话的词列表 :param list2: 第二句话的词列表 :return:相似度,float值 list1, list2 = set(list1), set(list2) #去重 intersection = list1.intersection(list2) # 交集 union = list1.union(list2) # 并集 Similarity = 1.0 * len(intersection) / len(union) #交集比并集 return Similaritya.分词 内蒙古 锡林郭勒盟 多伦县 县医院 / 多伦县 医院 绵阳市 四 零 四 医院 / 四川 绵阳 404 医院 邓州市 人民 医院 / 南召县 人民 医院 b.去重求交集--并集 多伦县(交集) -- 内蒙古、锡林郭勒盟、多伦县、县医院、医院(并集) 医院(交集) -- 绵阳市、四、零、医院、四川、绵阳、404(并集) 人民、医院(交集) -- 邓州市、人民、医院、南召县(并集)c.相似度文本对相似度真实标签内蒙古 锡林郭勒盟 多伦县 县医院 / 多伦县 医院1/5=0.21绵阳市 四零四医院/四川 绵阳 404 医院1/7 = 0.141邓州市 人民 医院 / 南召县 人民 医院2/4 = 0.501.1.2.Levenshtein编辑距离一个句子转换为另一个句子需要的编辑次数,编辑包括删除、替换、添加,然后使用最长句子的长度归一化得相似度。def Levenshtein(text1, text2): Levenshtein编辑距离 :param text1:字符串1 :param text2:字符串2 :return:相似度,float值 import Levenshtein distance = Levenshtein.distance(text1, text2) Similarity = 1 - distance * 1.0 / max(len(text1), len(text2)) return Similaritya.分词-计字数 内 蒙 古 锡 林 郭 勒 盟 多 伦 县 县 医 院 (14) / 多 伦 县 医 院(5) 绵 阳 市 四 零 四 医 院(8) / 四 川 绵 阳 4 0 4 医 院(9) 邓 州 市 人 民 医 院 (7) / 南 召 县 人 民 医 院(7) b.计算编辑距离 内 蒙 古 锡 林 郭 勒 盟 多 伦 县 县 医 院 ------->删除内、蒙、古、锡、林、郭、勒、盟、县 绵 阳 市 四 零 四 医 院 ------->加 四、川 ------->删除 市 ------->替换 四(4)、零(0)、四(4) 邓 州 市 人 民 医 院 ------->替换邓(南)、 州(召)、 市(县) 文本对距离真实标签内蒙古 锡林郭勒盟 多伦县 县医院 / 多伦县 医院0.3571绵阳市 四零四医院/四川 绵阳 404 医院0.3331邓州市 人民 医院 / 南召县 人民 医院0.57101.1.3 simhash相似度先计算两句子的simhash二进制编码,然后使用海明距离计算,最后使用两句的最大simhash值归一化得相似度。def simhash_(text1, text2): simhash相似度 :param s1: 字符串1 :param s2: 字符串2 :return: 相似度,float值 from simhash import Simhash text1_simhash = Simhash(text1, f=64) #计算simhash向量 text2_simhash = Simhash(text2, f=64) #计算simhash向量 distance = text1_simhash.distance(text2_simhash) #汉明距离 Similarity = 1 - distance / max(len(bin(text1_simhash.value)), len(bin(text2_simhash.value))) #相似度 return Similaritya.分词 内蒙古 锡林郭勒盟 多伦县 县医院 / 多伦县 医院 绵阳市 四 零 四 医院 / 四川 绵阳 404 医院 邓州市 人民 医院 / 南召县 人民 医院 b.计算词权重(此处用tfidf计算,其他方法也可以)| Text | Text | Text |内蒙古5锡林郭勒盟5多伦县2县医院5多伦县7医院1 绵阳市3四6零3四6医院1四川5绵阳54045医院1邓州市7人民4医院1南召县7人民4医院1 c.hash函数映射词向量先将词映射到二进制编码,然后用b步骤中的权重值替换1,b步骤中权重值的负数替换0d.合并(将一段文本内的词向量进行累加)e海明距离判断相似度海明距离可以理解为:两个二进制串之间相同位置不同的个数。举个例子,[1,1,1,0,0,0]和[1,1,1,1,1,1]的海明距离就是3。1.1.4 Bm25相似度一句话概况其主要思想:对Query(待查询语句)进行语素解析,生成语素qi;然后,对于每个搜索结果D,计算每个语素qi与D的相关性得分,最后,将qi相对于D的相关性得分进行加权求和,从而得到Query与D的相关性得分。公式如下:$\operatorname{Score}(Q, d)=\sum_i^n W_i \cdot R\left(q_i, d\right)$Q表示Query,qi即Q分词后的每一个解析语素(对中文而言,我们可以把对Query的分词作为语素分析,每个词看成语素qi)。d表示一个搜索结果文档,Wi表示语素qi的权重,R(qi,d)表示语素qi与文档d的相关性得分。判断一个词与一个文档的相关性的权重定义Wi方法有多种,较常用的是IDF。公式如下:$\operatorname{IDF}\left(q_i\right)=\log \frac{N-n\left(q_i\right)+0.5}{n\left(q_i\right)+0.5}$N为索引中的全部文档数,n(qi)为包含了qi的文档数。根据IDF的定义可以看出当很多文档都包含了qi时,qi的区分度就不高,因此使用qi来判断相关性时的重要度就较低。$\operatorname{Score}(Q, d)=\sum_i^n I D F\left(q_i\right) \cdot \frac{f_i \cdot\left(k_1+1\right)}{f_i+k_1 \cdot\left(1-b+b \cdot \frac{d l}{a v g d l}\right)}$求Score(qi,d)具体的公式可以参考文本相似度-BM25算法其中f(qi, D)为单词在当前候选文档中的词频k1、b为调节因子,通常设为k1=2,b=0.75|D|为当前候选文本数(与目标文本匹配的总条数)avgdl为语料库中所有文档的平均长度。在做文本匹配的时候(如重复问题检测)可以尝试BM25的方法,但在搜索领域中,有时候搜索query和候选文档的长度是不一样甚至差距很大,所以BM25在计算相似性的时候需要对文档长度做一定的处理。文本相似度-BM25算法#Bm25 import math import jieba class BM25(object): def __init__(self, docs):#docs是一个包含所有文本的列表,每个元素是一个文本 self.D = len(docs) #总文本数 self.avgdl = sum([len(doc)+0.0 for doc in docs]) / self.D #平均文本长度 self.docs = docs #文本库列表 self.f = [] # 列表的每一个元素是一个dict,dict存储着一个文档中每个词的出现次数 self.df = {} # 存储每个词及出现了该词的文档数量 self.idf = {} # 存储每个词的idf值 self.k1 = 1.5 self.b = 0.75 self.init() def init(self): for doc in self.docs: #对每个文本 tmp = {} #定义一个字典存储词出现频次 for word in doc: tmp[word] = tmp.get(word, 0) + 1 # 存储每个文档中每个词的出现次数 self.f.append(tmp) for k in tmp.keys(): self.df[k] = self.df.get(k, 0) + 1 for k, v in self.df.items(): self.idf[k] = math.log(self.D-v+0.5)-math.log(v+0.5) #计算idf def sim(self, doc, index): score = 0 for word in doc: if word not in self.f[index]: continue d = len(self.docs[index]) score += (self.idf[word]*self.f[index][word]*(self.k1+1) / (self.f[index][word]+self.k1*(1-self.b+self.b*d / self.avgdl))) return score def simall(self, doc): scores = [] for index in range(self.D): score = self.sim(doc, index) scores.append(score) return scores if __name__ == '__main__': sents1 = ["多伦县医院", #数据库 "四川绵阳404医院", "南召县人民医院"] sents2 = ["内蒙古锡林郭勒盟多伦县县医院","绵阳市四零四医院","邓州市人民医院"]#待匹配文本 doc = [] for sent in sents1: words = list(jieba.cut(sent)) doc.append(words) print(doc) s = BM25(doc) print(s.f) print(s.idf) for k in sents2: print(s.simall(jieba.lcut(k))) #打印相似度匹配结果 1.1.5 VSM(向量空间模型)算法VSM算法的思路主要分为两步:(1) 用向量表示句子,用向量表示句子的方法很多,简单的有onehot,词频法,基于语义的有word2vec/fastText/glove/bert/elmo等,本例中使用基于简单的词频的向量化方式。(2)计算两向量的余弦距离(曼哈顿距离、欧几里得距离、明式距离、切比雪夫距离)得相似度。#tfidf_余弦 def sim_vecidf(self, s1, s2): """词向量通过idf加权平均后计算余弦距离""" v1, v2 = [], [] # 1. 词向量idf加权平均 for s in jieba.cut(s1): idf_v = idf.get(s, 1) if s in voc: v1.append(1.0 * idf_v * voc[s]) v1 = np.array(v1).mean(axis=0) for s in jieba.lcut(s2): idf_v = idf.get(s, 1) if s in voc: v2.append(1.0 * idf_v * voc[s]) v2 = np.array(v2).mean(axis=0) # 2. 计算cosine sim = self.cosine(v1, v2) return sima.句子向量化a1.取句子对的唯一词元组set(内蒙古 锡林郭勒盟 多伦县 县医院 / 多伦县 医院) = (内蒙古 锡林郭勒盟 多伦县 县医院 医院)set(绵阳市 四 零 四 医院 / 四川 绵阳 404 医院) = (绵阳市 四 零 医院 四川 绵阳 404 )set(邓州市 人民 医院 / 南召县 人民 医院) = (邓州市 人民 医院 南召县)a2.根据每个句子在元组中的词频建立向量表示b.计算余弦距离$\operatorname{Cos}(x 1, x 2)=\frac{x 1 \cdot x 2}{|x 1||x 2|}$句子距离内蒙古 锡林郭勒盟 多伦县 县医院 / 多伦县 医院0.3535绵阳市 四零四医院/四川 绵阳 404 医院0.1889邓州市 人民 医院 / 南召县 人民 医院0.66661.1.6 word2vector + 相似度计算(BERT模型+余弦相似度为例)常用做法是通过word2vec等预训练模型得到词向量,然后对文本做分词,通过embedding_lookup得到每个token对应的词向量,然后得到短文本的句向量。对两个文本的句子向量采用相似度计算方法如余弦相似度、曼哈顿距离、欧氏距离等。无监督方式取得的结果取决于预训练词向量的效果。BERT是谷歌在2018年推出的深度语言表示模型,是关于语言理解的深度双向transformers的预训练模型,开启了预训练模型的新篇章。它可以学习文本的语义信息,通过向量形式的输出可以用于下游任务。也就说,它自己已经在大规模预料上训练好的参数,我们在用的时候只需要在这个基础上训练更新参数。bert模型可以解决多种自然语言处理问题,如单文本分类、语句对分类、序列标注等。在解决文本匹配任务时,有两种思路,第一种直接把文本匹配任务作为语句对分类任务,模型输入语句对,输出是否匹配的标签;第二种利用bert模型预训练文本对的上下文嵌入向量,再通过余弦相似度等相似度计算方法验证文本对是否匹配,在此基础上还有很多基于bert模型的变种,篇幅有限不做一一讲述。接下来简单介绍一下bert预训练文本嵌入+余弦相似度的算法框架。a.首先使用大量公域文本数据对BERT模型进行预训练(或直接用谷歌预训练好的模型)b.将文本直接输入模型c.对模型输出的语义向量C,或中间隐层向量,计算余弦相似度,得到匹配结果。基于深度学习的匹配算法种类繁多,如基于CNN网络、RNN网络、LSTM网络等及各种变种层出不穷,在此不一一列举实现。传统的文本匹配方法主要关注文本间字与字,词与词的匹配关系,无法准确识别不同表达方式下不同文本的同一指向关系,即语义关系。因此在这一背景下,要对多源异构的海量地址数据进行匹配,传统的文本匹配方法已不再适用,深度学习方法大行其道。但深度学习方法也有自身的局限性,比如对海量文本和算力的高要求等,都使得深度学习方法的普适性大打折扣,因此没有最好的文本匹配算法,只有当前条件下最适合的文本匹配算法。2.有监督方式2.1 孪生神经网络(Siamese Network)原文:《Learning a Similarity Metric Discriminatively, with Application to Face Verification》要解决什么问题?用于解决类别很多(或者说不确定),然而训练样本的类别数较少的分类任务(比如人脸识别、人脸认证)通常的分类任务中,类别数目固定,且每类下的样本数也较多(比如ImageNet)用了什么方法解决?提出了一种思路:将输入映射为一个特征向量,使用两个向量之间的“距离”(L1 Norm)来表示输入之间的差异(图像语义上的差距)。基于上述思路设计了Siamese Network。每次需要输入两个样本作为一个样本对计算损失函数。[x] 常用的softmax只需要输入一个样本。[x] FaceNet中的Triplet Loss需要输入三个样本。[x] 提出了Contrastive Loss用于训练。效果如何?文中进行了一个衡量两张人脸的相似度的实验,使用了多个数据库,较复杂。siamese network现在依然有很多地方使用,可以取得state-of-the-art的效果。还存在什么问题?contrastive loss的训练样本的选择需要注意,论文中都是尽量保证了50%的正样本对和50%的负样本对。分类问题:第一类,分类数量较少,每一类的数据量较多,比如ImageNet、VOC等。这种分类问题可以使用神经网络或者SVM解决,只要事先知道了所有的类。第二类,分类数量较多(或者说无法确认具体数量),每一类的数据量较少,比如人脸识别、人脸验证任务。文中提出的解决方案:learn a similar metric from data。核心思想是,寻找一个映射函数,能够将输入图像转换到一个特征空间,每幅图像对应一个特征向量,通过一些简单的“距离度量”(比如欧式距离)来表示向量之间的差异,最后通过这个距离来拟合输入图像的相似度差异(语义差异)。2.1.1 简介Siamese Network 是一种神经网络的框架,而不是具体的某种网络,就像seq2seq一样,具体实现上可以使用RNN也可以使用CNN。Siamese network就是“连体的神经网络”,神经网络的“连体”是通过共享权值来实现的。(共享权值即左右两个神经网络的权重一模一样)siamese network的作用是衡量两个输入的相似程度。孪生神经网络有两个输入(Input1 and Input2),将两个输入feed进入两个神经网络(Network1 and Network2),这两个神经网络分别将输入映射到新的空间,形成输入在新的空间中的表示。通过Loss的计算,评价两个输入的相似度。Siamese Network有两个结构相同,且共享权值的子网络。分别接收两个输入X1与X2,将其转换为向量Gw(X1)与Gw(X2),再通过某种距离度量的方式计算两个输出向量的距离Ew。训练Siamese Network采用的训练样本是一个tuple (X1,X2,y)(X1,X2,y),标签y=0表示X1与X2属于不同类型(不相似、不重复、根据应用场景而定)。y=1则表示X2与X2属于相同类型(相似)。LOSS函数的设计应该是当两个输入样本不相似(y=0)时,距离Ew越大,损失越小,即关于Ew的单调递减函数。当两个输入样本相似(y=1)时,距离Ew越大,损失越大,即关于Ew的单调递增函数。用L+(X1,X2)表示y=1时的LOSS,L−(X1,X2)表示y=0时的LOSS,则LOSS函数可以写成如下形式:Lw(X1,X2)=(1−y)L−(X1,X2)+yL+(X1,X2)简单来说:孪生体现在使用相同的编码器(sentence encoder),将文本转为高维向量。具体步骤为,有文本A和文本B分别输入 sentence encoder 进行特征提取和编码,将输入映射到新的空间得到特征向量u和v;最终通过u、v的拼接组合,经过下游网络来计算文本A和B的相似性在训练和测试中,模型的编码器是权重共享的,编码器可以选择CNN、RNN、LSTM等提取到特征u、v后,可以使用余弦距离、欧氏距离等得到两个文本的相似度。缺点是两个文本在编码时候没有交互,缺乏交互的结构没有充分利用到两个文本相互影响的信息2.2 匹配聚合网络(ESIM,BIMPM)在上述孪生网络的基础上,得到特征u、v但是不直接计算向量相似度,而是通过注意力机制将两个文本进行信息交互,最后通过全连接层得到相似度。代表的模型有ESIM,BIMPM等以ESIM为例首先是对两个文本的初期编码,就是对两个文本做分词、文本表征,即对句子进行信息的提取。如果使用LSTM作为encoder,可以得到每个时刻(每个单词)的输出,通常维度为[batch_size, seq_len, embedding_dim]。举例子为,句子A长度10,句子B长度也为10,那么进过编码以后句子A的维度[1,10,300],句子B[1,10,300],这里就得到了上述所提到的u、v接下来是交互操作,为了操作简单忽略batchsize维度,交互即矩阵相乘得到[10,10],矩阵需要对句子A做横向概率归一,对句子B做纵向概率归一。上面这句话其实就是ESIM的核心要点。它是一个两个item之间互相做attention,简单称之为both attention。对attention后得到的向量做拼接后输出编码器,输出再接到全连接层、softmax就可以得到结果,即两个文本相似(label 1)或不相似(label 0)3.预训练语言模型第一阶段,使用通用的预料库训练语言模型,第二阶段预训练的语言模型(BERT相关衍生的模型)做相似度任务,得到信息交互后的向量,连接全连接层,输出概率。即将两个短文本拼接(CLS A1 A2 … A 10 SEP B1 B2 … B10 SEP),然后CLS向量连接全连接层,判断相似与否。这种模型参数多,并且使用了通用的语料库,能够获取到短文本之间隐藏的交互信息,效果较好。简单来说用拼接的方法类似“单塔”,孪生网络的方法类似“双塔”,不完全准确后续会详细说明,预训练模型就不展开讲了,大家去官网或者多看几篇学术论文吧,BERT ERNIE。4.有监督方式 + 无监督方式无监督:直接相加得到句向量,不能很好的表达语义信息,并且词的位置信息没有得到体现,也不包含上下文的语义信息。有监督学习:时间复杂度太高。可以将标准库中的句向量计算完成并存储。新的文本来临时,只需要解决用户问题即可,然后与存储在库中的标准问句进行距离度量。可以使用BERT代替孪生网络的CNN或LSTM结构,获取更多语义信息的句向量,还可以通过蒸馏降低BERT模型的参数,节约时间成本。4.1 Sentence-BERT文章链接:https://arxiv.org/pdf/1908.10084.pdf论文代码:https://github.com/UKPLab/为了让BERT更好地利用文本信息,作者们在论文中提出了如下的SBERT模型。SBERT沿用了孪生网络的结构,文本Encoder部分用同一个BERT来处理。之后,作者分别实验了CLS-token和2种池化策略(Avg-Pooling、Mean-Pooling),对Bert输出的字向量进一步特征提取、压缩,得到u、v。关于u、v整合,作者提供了3种策略:将u、v拼接,接入全连接网络,经过softmax输出,损失函数用交叉熵损失直接计算两个文本的余弦相似度,损失函数用均方根误差如果输入的是三元组SBERT直接用BERT的原始权重初始化,在具体数据集微调,训练过程和传统Siamese Network类似。但是这种训练方式能让Bert更好的捕捉句子之间的关系,生成更优质的句向量。在测试阶段,SBERT直接使用余弦相似度来衡量两个句向量之间的相似度,极大提升了推理速度。使用NLI和STS为代表的匹配数据集,在分类目标函数训练时,作者测试了不同的整合策略,结果显示“(u, v, |u-v|)”的组合效果最好。最重要的部分是元素差:(|u - v|)。句向量之间的差异度量了两个句子嵌入维度间的距离,确保相似的pair更近,不同的pair更远。4.2 对比学习深度学习的本质是做两件事情:①表示学习 ②归纳偏好学习。对比学习(ContrastiveLearning)则是属于表示学习的范畴,它并不需要关注样本的每一个细节,但是学到的特征要使其能够和其他样本区分开。对比学习作为一种无监督表示学习方法,最开始也是在CV领域掀起浪潮,之后NLP跟进,在文本相似度匹配等任务上超过SOTASOTA。该任务主要是对文本进行表征,使相近的文本距离更近,差别大的文本距离更远。NLP的对比学习算法下文将不详细讲述简单展示更多内容参考链接。4.2.1 BERT-Flow 2020.11很多研究发现BERT表示存在问题:未经微调的BERT模型在文本相似度匹配任务上表现不好,甚至不如Glove?作者通过分析BERT的性质,如图:在理论上BERT确实提取到了足够的语义信息,只是这些信息无法通过简单的consine直接利用。主要是因为:①BERT的词向量在空间中不是均匀分布,而是呈锥形。高频词都靠近原点,而低频词远离原点,相当于这两种词处于了空间中不同的区域,那高频词和低频词之间的相似度就不再适用;②低频词的分布很稀疏。低频词表示得到的训练不充分,分布稀疏,导致该区域存在语义定义不完整的地方(poorly defined),这样算出来的相似度存在问题。针对以上问题,提出了BERT-Flow,基于流式生成模型,将BERT的输出空间由一个锥形可逆地映射为标准的高斯分布空间。4.2.2 BERT-Whitening 2021.03BERT-Whitening首先分析了余弦相似度为什么可以衡量向量的相似度:向量A 与B 的乘积等于A AA在B BB所在直线上投影的长度。将两个向量扩展到d维$\cos (A, B)=\frac{\sum_{i=1}^d a_i b_i}{\sqrt{\sum_{i=1}^d a_i^2} \sqrt{\sum_{i=1}^d b_i^2}}$$\text { 模的计算公式: }|A|=\sqrt{a_1^2+a_2^2+\ldots+a_n^2}$上述等式的成立,都是在标准正交基(忘了的同学可以自行复习一下)的条件下,也就是说向量依赖我们选择的坐标基,基底不同,内积对应的坐标公式就不一样,从而余弦值的坐标公式也不一样。所以,BERT的句向量虽然包含了足够的语义,但有可能是因为此时句向量所属的坐标系并非标准正交基,而导致用基于标准正交基的余弦相似度公式计算时效果不好。那么怎么知道具体用了何种基底呢?可以依据统计学去判断,在给向量集合选择基底时,尽量平均地用好每一个基向量,这就体现为每个分量的使用都是独立的、均匀的,如果这组基是标准正交基,那么对应的向量集应该表现出“各向同性”来,如果不是,可以想办法让它变得更加各向同性一写,然后再用余弦公式计算,BERT-Flow正是想到了“flow模型”的办法,而作者则找到了一种更简单的线性变换的方法。标准化协方差矩阵BERT-Whitening还支持降维操作,能达到提速和提效的效果。★PCA和SVD差异分析:PCA可以将方阵分解为特征值和特征向量,SVD则可以分解任意形状的矩阵。4.2.3 ConSERT 2021.05https://arxiv.org/pdf/2105.11741.pdf美团技术团队提出了基于对比学习的句子表示迁移方法——ConSERT,主要证实了以下两点:①BERT对所有的句子都倾向于编码到一个较小的空间区域内,这使得大多数的句子对都具有较高的相似度分数,即使是那些语义上完全无关的句子对。我们将此称为BERT句子表示的“坍缩(Collapse)”现象。②BERT句向量表示的坍缩和句子中的高频词有关。当通过平均词向量的方式计算句向量时,高频词的词向量将会主导句向量,使之难以体现其原本的语义。当计算句向量时去除若干高频词时,坍缩现象可以在一定程度上得到缓解。为了解决BERT存在的坍缩问题,作者提出了句子表示迁移框架:对BERT encoder做了改进,主要包括三个部分:*①数据增强模块,作用于embedding层,为同一文本生成不同的编码。shuffle:更换position id的顺序token cutoff:在某个token维度把embedding置为0feature cutoff:在embedding矩阵中,有768个维度,把某个维度的feature置为0dropout:embedding中每个元素都有一定概率为0,没有行或列的约束数据增强效果:Token Shuffle > Token Cutoff >> Feature Cutoff ≈ Dropout >> None②共享的Bert encoder,生成句向量。③一个对比损失层,在一个Batch内计算损失,拉近同一样本不同句向量的相似度,使不同样本之间相互远离。损失函数:$L_{i, j}=-\log \frac{\exp \left(\operatorname{sim}\left(r_i, r_j\right) / \tau\right)}{\sum_{k=1}^{2 N} 1_{[k \neq i]} \exp \left(\operatorname{sim}\left(r_i, r_k\right) / \tau\right)}$N:Batchsize,2N表示2种数据增强方式,sim():余弦相似度函数,r:句向量,τ:实验0.08−0.12最优除了无监督训练之外,作者还提出了三种进一步融合监督信号的策略:①联合训练(joint):有监督的损失和无监督的损失通过加权联合训练模型。②先有监督再无监督(sup-unsup):先使用有监督损失训练模型,再使用无监督的方法进行表示迁移。③联合训练再无监督(joint-unsup):先使用联合损失训练模型,再使用无监督的方法进行表示迁移。参考链接:https://blog.csdn.net/PX2012007/article/details/1276145654.2.4 SimCSE:2021.04前几节讲述了对比学习的原理和几种基于 Bert 的方式获取句子向量,例如 BERT-flow和 BERT-whitening 等,对预训练 Bert 的输出进行变换从而得到更好的句子向量。后面将通过 ①构造目标函数 ②构建正负例 的对比学习方法训练模型,取得SOTA的效果。SimCSE是有大神陈丹琦发表的《Simple Contrastive Learning of Sentence Embeddings》,简单高效SimCSE包含无监督(图左部分)和有监督(图右部分)两种方法。实线箭头代表正例,虚线代表负例。Unsupervised创新点在于使用Dropout对文本增加噪音。1.正例构造:利用Bert的随机Dropout,同一文本经过两次Bert enconder得到不同的句向量构成相似文本。2.负例构造:同一个Batch中的其他样本作为负例被随机采样。Supervised1.正例:标注数据2.负例:同Batch内的其他样本4.2.5 R-Drop(Supervised):2021.06https://arxiv.org/abs/2106.14448Dropout虽然可以防止模型训练中的过拟合并增强鲁棒性,但是其操作在一定程度上会使训练后的模型成为一种多个子模型的组合约束。SimCSE就是希望Dropout对模型结果不会有太大影响,也就是模型输出对Dropout是鲁棒的。所以,“Dropout两次”这种思想是可以推广到一般任务的,这就是R-Drop(Regularized Dropout),由微软亚洲研究院和苏州大学提出的更加简单有效的正则方法。R-Drop与传统作用于神经元或模型参数的约束方法不同,而是作用于输出层,弥补了Dropout在训练和测试时的不一致性。在每个mini-batch中,每个数据样本过两次带有Dropout的同一个模型,R-Drop再使用KL-divergence(KL散度)约束两次的输出一致。所以,R-Drop约束了由于Dropout带来的两个随机子模型的输出一致性。R-Drop只是简单增加了一个KL-散度损失函数项,并没有其他任何改动。虽然该方法看起来很简单,但在NLP和CV的任务中,都取得了非常不错的SOTA结果。同样的输入,同样的模型,经过两个 Dropout 得到的将是两个不同的分布,近似将这两个路径网络看作两个不同的模型网络。基于此,这两个不同的模型产生的不同分布而这篇文章的主要贡献就是在训练过程中不断拉低这两个分布之间的KL 散度。由于KL 散度本身具有不对称性,作者通过交换这两种分布的位置以间接使用整体对称的KL 散度,称之为双向KL 散度。4.2.6 ESimCSE(Unsupervised):2021.09https://arxiv.org/abs/2109.04380SimCSE构建正负例时存在两个两个缺点:①构造正例长度相等,导致模型预测时存在偏差,长度相等的文本会倾向预测相似度高。②对比学习理论上负例越多,对之间模型学习的越好,但增大Batch会受到性能的限制。ESimCSE针对以上问题做了相应的改进:正例构造:通过引入噪声较小的“单词重复”方式改变正例的长度,设置重复率dup_rate,确定dup_len后利用均匀分布随机选取dup_len子词进行重复。负例构造:为了更有效的扩展负对,同时不降低性能,通过维护一个队列,重用前面紧接的mini-batch的编码嵌入来扩展负对:①将当前mini-batch的句嵌入放入队列,同时将“最老的”句子踢出队列。由于排队句子嵌入来自前面的mini-batch,通过取其参数的移动平均来保持动量更新模型,并利用动量模型生成排队句子嵌入。在使用动量编码器时,关闭了dropout,这可以缩小训练和预测之间的差距。4.2.7 PromptBERT(Unsupervised):2022.01https://arxiv.org/pdf/2201.04337v1.pdfPrompt Learning比较火热,号称NLP的第四范式,作者发现BERT在语义相似度方面表现不好,主要由:static token embeddings biases和ineffective layers,而不是high cosine similarity of the sentence embedding。static token embedding是在bert结构中,输入进block前,通过embedding layer产生的结果,这里强调是静态的embedding,就是embedding metrics中每个token都唯一对应的embedding,是不随句子环境而变化的。至于ineffective layers就很好理解了,就是bert中堆叠的block结构,比如bert-base中的12层。作者认为这些结构,对语义相似度的表征这个方面是无效的。Anisotropy(各向异性):上篇我们已经提到,词向量是有维度的,每个维度上基向量单位向量长度不一样,就是各向异性的。这会造成计算向量相似度的时候产生偏差。如何度量Anisotropy:作者分析了造成embedding bias的原因,除了token frequency是造成bias的原因,作者又提出了:subwords,case sentitive图中不同词频token的分布情况,颜色越深代表词频越高,我们可以看出词频高的token,分布比较紧凑,词频低的token,分布较分散。作者输出这个图像还有一个目的是他提出各向异性(anisotropy)和偏差(bias)是不相关的,各向异性不是导致偏差的原因。Embedding bias意思是映射分布被一些不相关的信息所干扰,是可以用降维的方式去可视化的。更多细节参考原论文,Prompt效果就不赘述了,百度开发的UIE模型在NLP就很强大!4.2.8 SNCSE(Unsupervised):2022.01https://arxiv.org/abs/2201.05979SNCSE同样是由微软团队提出,主要是针对以上方法存在的问题:当前对比学习的数据增强方式,获取的正样本都极为相似,导致模型存在特征抑制,即模型不能区分文本相似度和语义相似度,并更偏向具有相似文本,而不考虑它们之间的实际语义差异。为了减轻特征抑制,该论文提出了通过软负样本结合双向边际损失的无监督句子嵌入对比学习方法。其中,软负样本,即具有高度相似,但与原始样本在语义上存在明显的差异的样本。双向边际损失,即通过扩大原始样本与正例和原始样本与软负例之间的距离,使模型更好地学习到句子之间的语义差别。软负样本构造:为原文本添加显示的否定词。在获取句子表征时,受PromptBERT启发,通过三种模板表示原样本、正样本和软负样本:4.2.9 DiffCSE(Unsupervised):2022.04https://arxiv.org/pdf/2204.10298.pdf结合句子间差异的无监督句子嵌入对比学习方法——DiffCSE主要还是在SimCSE上进行优化(可见SimCSE的重要性),通过ELECTRA模型的生成伪造样本和RTD(Replaced Token Detection)任务,来学习原始句子与伪造句子之间的差异,以提高句向量表征模型的效果。其思想同样来自于CV领域(采用不变对比学习和可变对比学习相结合的方法可以提高图像表征的效果)。作者提出使用基于dropout masks机制的增强作为不敏感转换学习对比学习损失和基于MLM语言模型进行词语替换的方法作为敏感转换学习「原始句子与编辑句子」之间的差异,共同优化句向量表征。在SimCSE模型中,采用pooler层(一个带有tanh激活函数的全连接层)作为句子向量输出。该论文发现,采用带有BN的两层pooler效果更为突出,BN在SimCSE模型上依然有效。①对于掩码概率,经实验发现,在掩码概率为30%时,模型效果最优。②针对两个损失之间的权重值,经实验发现,对比学习损失为RTD损失200倍时,模型效果最优。参考链接:https://blog.csdn.net/PX2012007/article/details/1276964774.2.10 小结SimCSE以来几种比较重要的文本增强式的对比学习算法,按时间顺序,理论上应该是距离越近的算法效果越好,但使用时,还是要结合具体的业务场景,算法没有好坏,还是用看怎么用。对于有些内容,可能叙述的不是很细致或是需要一定的知识铺垫,感兴趣的同学可以针对性的研读论文和辅助其他资料。当然,算法层出不穷,更新很快,后续出现比较重要的对比学习算法。5.文本匹配常见思路(技巧提升)TextCNN/TEXTRNNSiamese-RNN采用多种BERT类预训练模型对单模型进行调参多模型融合BERT后接上RCNN/RNN/CNN/LSTM/Siamese等等5.1方案一特征工程数据清洗:大赛给的数据比较规整,数据清洗部分工作不多,简单做了特殊字符处理等操作。数据增强传递闭包扩充(标签传递)根据IF A=B and A=C THEN B=C的规则,对正样本做了扩充增强。根据IF A=B and A!=C THEN B!=C的规则,对负样本做了扩充增强。在对负样本进行扩充后, 正负样本比例从原始的1.4:1, 变成2.9:1。 所以又对负样本进行了下采样, 是的正负样本比例1:1。同义词替换使用开源包synormise的效果不太好, 后面可以尝试使用公开医学预料训练word2vec模型来做同义词替换(时间问题, 没有尝试)。随机删除,随机替换, 随机交换句式比较短, 随机删除更短。很多query仅仅相差一个单词, 随机替换改变语义。多数属于问句, 随机交换改变了语义。模型选择在预训练模型的基础上通过对抗训练增强模型的泛化性能。BRETBert的一个下游基础任务语句对分类(Sentence Pair Classification Task), [CLS] Bert的输出有一个维度的向量表示BERT+CNN(LSTM)将BERT的输出特征作为文本的表示向量, 然后后面再接上LSTM或者CNN(效果下降)BERT+siamese将大赛提供的category信息利用上, 借用孪生网络的思想与两个Query进行拼接(效果下降)。结果分析单模型线上效果目前所训练的模型中:小模型中BERT-wwm-ext表现是最好的,大模型中RoBERTa-large-pair表现最好。在现有的资源和模型上, 对单模型的参数寻优到达一个天花板,线上最高的分数为0.9603。后面开始探索多模型融合。多模型融合线上效果将不同类型的预训练模型作为基模型进行多模型融合。基模型的挑选准则基于单模型的线上提交效果,从不同类型的单模型中挑选线上表现最好的参数, 重新训练融合。基模型:BERT-wwm-ext + FGMRoBERTa-large-pair + FGMErnie(BaiDu)+ FGM模型融合策略使用的是averaging, 为了降低差别比较小的模型对结果的影响,采用sigmoid反函数的方式进行ensemble。关于对抗训练在NLP中的作用,引用大佬的一句话叫缘,妙不可言~5.2方案二探索分析文本长度:训练集和验证集分布类似,大都集中在10-20个字标签分布总体思路数据划分采用kfold交叉验证(右边的划分方式)•利用全部数据,获得更多信息•降低方差,提高模型性能模型设计二分类交叉熵损失函数:模型融合小模型同时加入CHIP2019数据训练模型特点权重加入外部句对数据BERT-wwm-ext全词Mask1YESErnie-1.0对词、实体及实体关系建模1YESRoBERTa-large-pair面向相似性或句子对任务优化1NO数据预处理对称扩充、传递扩充(注意要保持原来的分布,否则会过拟合)训练三种结构:(实际使用差别不大,第一种又好又简单)对抗训练#代码来自苏剑林bert4keras def adversarial_training(model, embedding_name, epsilon=1): """给模型添加对抗训练 其中model是需要添加对抗训练的keras模型,embedding_name 则是model里边Embedding层的名字。要在模型compile之后使用。 if model.train_function is None: # 如果还没有训练函数 model._make_train_function() # 手动make old_train_function = model.train_function # 备份旧的训练函数 # 查找Embedding层 for output in model.outputs: embedding_layer = search_layer(output, embedding_name) if embedding_layer is not None: break if embedding_layer is None: raise Exception('Embedding layer not found') # 求Embedding梯度 embeddings = embedding_layer.embeddings # Embedding矩阵 gradients = K.gradients(model.total_loss, [embeddings]) # Embedding梯度 gradients = K.zeros_like(embeddings) + gradients[0] # 转为dense tensor # 封装为函数 inputs = (model._feed_inputs + model._feed_targets + model._feed_sample_weights) # 所有输入层 embedding_gradients = K.function( inputs=inputs, outputs=[gradients], name='embedding_gradients', ) # 封装为函数 def train_function(inputs): # 重新定义训练函数 grads = embedding_gradients(inputs)[0] # Embedding梯度 delta = epsilon * grads / (np.sqrt((grads**2).sum()) + 1e-8) # 计算扰动 K.set_value(embeddings, K.eval(embeddings) + delta) # 注入扰动 outputs = old_train_function(inputs) # 梯度下降 K.set_value(embeddings, K.eval(embeddings) - delta) # 删除扰动 return outputs model.train_function = train_function # 覆盖原训练函数 写好函数后,启用对抗训练只需要一行代码 adversarial_training(model, 'Embedding-Token', 0.5)预测算数平均→几何平均→sigmoid平均(用反函数取出sigmoid/softmax归一化之前的状态做平均,信息量更大,提升明显)分类阈值微调(0.47)伪标签5.3 更多方案更多方案就不一一展开了,参考下方链接:https://tianchi.aliyun.com/notebook/101626https://tianchi.aliyun.com/notebook/101648https://tianchi.aliyun.com/notebook/101648参考链接:https://tianchi.aliyun.com/competition/entrance/231776/forumhttps://tianchi.aliyun.com/notebook/1020576.特定领域知识图谱(Domain-specific KnowledgeGraph:DKG)融合方案(重点!)在前面技术知识下可以看看后续的实际业务落地方案和学术方案关于图神经网络的知识融合技术学习参考下面链接:[PGL图学习项目合集&数据集分享&技术归纳业务落地技巧[系列十]](https://aistudio.baidu.com/aistudio/projectdetail/5127575?contributionType=1)从入门知识到经典图算法以及进阶图算法等,自行查阅食用!文章篇幅有限请参考专栏按需查阅:NLP知识图谱相关技术业务落地方案和码源6.1 特定领域知识图谱知识融合方案(实体对齐):优酷领域知识图谱为例方案链接:https://blog.csdn.net/sinat_39620217/article/details/1286149516.2 特定领域知识图谱知识融合方案(实体对齐):文娱知识图谱构建之人物实体对齐方案链接:https://blog.csdn.net/sinat_39620217/article/details/1286739636.3 特定领域知识图谱知识融合方案(实体对齐):商品知识图谱技术实战方案链接:https://blog.csdn.net/sinat_39620217/article/details/1286744296.4 特定领域知识图谱知识融合方案(实体对齐):基于图神经网络的商品异构实体表征探索方案链接:https://blog.csdn.net/sinat_39620217/article/details/1286749296.5 特定领域知识图谱知识融合方案(实体对齐)论文合集方案链接:https://blog.csdn.net/sinat_39620217/article/details/128675199论文资料链接:两份内容不相同,且按照序号从小到大重要性依次递减知识图谱实体对齐资料论文参考(PDF)+实体对齐方案+特定领域知识图谱知识融合方案(实体对齐)知识图谱实体对齐资料论文参考(CAJ)+实体对齐方案+特定领域知识图谱知识融合方案(实体对齐)6.6 知识融合算法测试方案(知识生产质量保障)方案链接:https://blog.csdn.net/sinat_39620217/article/details/1286756987.总结本项目主要围绕着特定领域知识图谱(Domain-specific KnowledgeGraph:DKG)融合方案:技术知识前置【一】-文本匹配算法、知识融合学术界方案、知识融合业界落地方案、算法测评KG生产质量保障讲解了文本匹配算法的综述,从经典的传统模型到孪生神经网络“双塔模型”再到预训练模型以及有监督无监督联合模型,期间也涉及了近几年前沿的对比学习模型,之后提出了文本匹配技巧提升方案,最终给出了DKG的落地方案。这边主要以原理讲解和技术方案阐述为主,之后会慢慢把项目开源出来,一起共建KG,从知识抽取到知识融合、知识推理、质量评估等争取走通完整的流程。
基于ERNIELayout&pdfplumber-UIE的多方案学术论文信息抽取
本项目链接:https://aistudio.baidu.com/aistudio/projectdetail/5196032?contributionType=1基于ERNIELayout&pdfplumber-UIE的多方案学术论文信息抽取,小样本能力强悍,OCR、版面分析、信息抽取一应俱全。0.问题描述可以参考issue: ERNIE-Layout在(人名和邮箱)信息抽取的诸多问题阐述#4031ERNIE-Layout因为看到功能比较强大就尝试了一下,但遇到信息抽取错误,以及抽取不全等问题使用PDFPlumber库和PaddleNLP UIE模型抽取,遇到问题:无法把姓名和邮箱一一对应。1.基于ERNIE-Layout的DocPrompt开放文档抽取问答模型ERNIE-Layout以文心文本大模型ERNIE为底座,融合文本、图像、布局等信息进行跨模态联合建模,创新性引入布局知识增强,提出阅读顺序预测、细粒度图文匹配等自监督预训练任务,升级空间解偶注意力机制,在各数据集上效果取得大幅度提升,相关工作ERNIE-Layout: Layout-Knowledge Enhanced Multi-modal Pre-training for Document Understanding已被EMNLP 2022 Findings会议收录[1]。考虑到文档智能在多语种上商用广泛,依托PaddleNLP对外开源业界最强的多语言跨模态文档预训练模型ERNIE-Layout。支持:发票抽取问答海报抽取网页抽取表格抽取长文档抽取多语言票据抽取同时提供pipelines流水线搭建更多参考官网,这里就不展开了ERNIE-Layout GitHub地址:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/ernie-layoutHugging Face网页版:https://huggingface.co/spaces/PaddlePaddle/ERNIE-Layout#环境安装 !pip install --upgrade opencv-python !pip install --upgrade paddlenlp !pip install --upgrade paddleocr --user #如果安装失败多试几次 一般都是网络问题 !pip install xlwt # 支持单条、批量预测 from paddlenlp import Taskflow docprompt_en= Taskflow("document_intelligence",lang="en",topn=10) docprompt_en({"doc": "./image/paper_1.jpg", "prompt": ["人名和邮箱" ]}) # batch_size:批处理大小,请结合机器情况进行调整,默认为1。 # lang:选择PaddleOCR的语言,ch可在中英混合的图片中使用,en在英文图片上的效果更好,默认为ch。 # topn: 如果模型识别出多个结果,将返回前n个概率值最高的结果,默认为1。[{'prompt': '人名和邮箱', 'result': [{'value': '[email protected]@yahoo.com', 'prob': 1.0, 'start': 69, 'end': 79}, {'value': '[email protected]', 'prob': 0.98, 'start': 153, 'end': 159}]}] 可以看到效果不好,多个实体不能一同抽取,需要构建成单个问答,比如姓名和邮箱分开抽取,尝试构造合理的开放式prompt。小技巧Prompt设计:在DocPrompt中,Prompt可以是陈述句(例如,文档键值对中的Key),也可以是疑问句。因为是开放域的抽取问答,DocPrompt对Prompt的设计没有特殊限制,只要符合自然语言语义即可。如果对当前的抽取结果不满意,可以多尝试一些不同的Prompt。支持的语言:支持本地路径或者HTTP链接的中英文图片输入,Prompt支持多种不同语言,参考以上不同场景的例子。docprompt_en({"doc": "./image/paper_1.jpg", "prompt": ["人名是什么","邮箱是多少", ]}) #无法罗列全部姓名 [{'prompt': '人名是什么', 'result': [{'value': 'AA.Momtazi-Borojeni', 'prob': 0.74, 'start': 0, 'end': 4}]}, {'prompt': '邮箱是多少', 'result': [{'value': '[email protected]@yahoo.com', 'prob': 1.0, 'start': 69, 'end': 79}]}] [{'prompt': '人名是什么', 'result': [{'value': 'AA.Momtazi-Borojeni', 'prob': 0.74, 'start': 0, 'end': 4}]}, {'prompt': '邮箱是多少', 'result': [{'value': '[email protected]@yahoo.com', 'prob': 1.0, 'start': 69, 'end': 79}]}] [{'prompt': '人名', 'result': [{'value': 'J.Mosafer', 'prob': 0.95, 'start': 80, 'end': 82}, {'value': 'B.Nikfar', 'prob': 0.94, 'start': 111, 'end': 113}, {'value': 'AVaezi', 'prob': 0.94, 'start': 225, 'end': 225}, {'value': 'AA.Momtazi-Borojeni', 'prob': 0.88, 'start': 0, 'end': 4}]}, {'prompt': 'email', 'result': [{'value': '[email protected]@yahoo.com', 'prob': 1.0, 'start': 69, 'end': 79}, {'value': '[email protected]', 'prob': 0.98, 'start': 153, 'end': 159}]}] docprompt_en({"doc": "./image/paper_1.jpg", "prompt": ["人名","邮箱","姓名","名字","email"]}) [{'prompt': '人名', 'result': [{'value': 'J.Mosafer', 'prob': 0.95, 'start': 80, 'end': 82}, {'value': 'B.Nikfar', 'prob': 0.94, 'start': 111, 'end': 113}, {'value': 'AVaezi', 'prob': 0.94, 'start': 225, 'end': 225}, {'value': 'AA.Momtazi-Borojeni', 'prob': 0.88, 'start': 0, 'end': 4}]}, {'prompt': '邮箱', 'result': [{'value': '[email protected]@yahoo.com', 'prob': 1.0, 'start': 69, 'end': 79}, {'value': '[email protected]', 'prob': 0.87, 'start': 153, 'end': 159}]}, {'prompt': '姓名', 'result': [{'value': 'AA.Momtazi-Borojeni', 'prob': 0.76, 'start': 0, 'end': 4}]}, {'prompt': '名字', 'result': [{'value': 'AA.', 'prob': 0.7, 'start': 0, 'end': 1}]}, {'prompt': 'email', 'result': [{'value': '[email protected]@yahoo.com', 'prob': 1.0, 'start': 69, 'end': 79}, {'value': '[email protected]', 'prob': 0.98, 'start': 153, 'end': 159}]}] 可以看出得到的效果不是很好,比较玄学,原因应该就是ocr识别对应姓名人名准确率相对不高,无法全部命中;并且无法一一对应。这块建议看看paddleocr具体实现步骤,研究一下在看看怎么处理。下面讲第二种方法2.基于PDFplumber-UIE信息抽取2.1 PDF文档解析(pdfplumber库)安装PDFPlumber!pip install pdfplumber --user官网链接:https://github.com/jsvine/pdfplumberpdf的文本和表格处理用多种方式可以实现, 本文介绍pdfplumber对文本和表格提取。这个库在GitHub上stars:3.3K多,使用起来很方便, 效果也很好,可以满足对pdf中信息的提取需求。pdfplumber.pdf中包含了.metadata和.pages两个属性。metadata是一个包含pdf信息的字典。pages是一个包含pdfplumber.Page实例的列表,每一个实例代表pdf每一页的信息。每个pdfplumber.Page类:pdfplumber核心功能,对PDF的大部分操作都是基于这个类,类中包含了几个主要的属性:文本、表格、尺寸等page_number 页码width 页面宽度height 页面高度objects/.chars/.lines/.rects 这些属性中每一个都是一个列表,每个列表都包含一个字典,每个字典用于说明页面中的对象信息, 包括直线,字符, 方格等位置信息。一些常用的方法extract_text() 用来提页面中的文本,将页面的所有字符对象整理为的那个字符串extract_words() 返回的是所有的单词及其相关信息extract_tables() 提取页面的表格2.1.1 pdfplumber简单使用# 利用metadata可以获得PDF的基本信息,作者,日期,来源等基本信息。 import pdfplumber import pandas as pd with pdfplumber.open("/home/aistudio/work/input/test_paper.pdf") as pdf: print(pdf.metadata) # print("总页数:"+str(len(pdf.pages))) #总页数 print("pdf文档总页数:", len(pdf.pages)) # 读取第一页的宽度,页高等信息 # 第一页pdfplumber.Page实例 first_page = pdf.pages[0] # 查看页码 print('页码:', first_page.page_number) # 查看页宽 print('页宽:', first_page.width) # 查看页高 print('页高:', first_page.height) {'CreationDate': "D:20180428190534+05'30'", 'Creator': 'Arbortext Advanced Print Publisher 9.0.223/W Unicode', 'ModDate': "D:20180428190653+05'30'", 'Producer': 'Acrobat Distiller 9.4.5 (Windows)', 'Title': '0003617532 1..23 ++', 'rgid': 'PB:324947211_AS:677565220007936@1538555545045'} pdf文档总页数: 24 页码: 1 页宽: 594.95996 页高: 840.95996 # 导入PDFPlumber import pdfplumber #打印第一页信息 with pdfplumber.open("/home/aistudio/work/input/test_paper.pdf") as pdf: first_page = pdf.pages[0] textdata=first_page.extract_text() print(textdata) #打印全部页面 import pdfplumber as ppl pdf_path = "/home/aistudio/work/input/test_paper.pdf" pdf = ppl.open(pdf_path) # 获得 PDFPlumber 的对象,下面查看pdf全部内容 for page in pdf.pages: print(page.extract_text()) !pip install xlwt#读取表格第一页 import pdfplumber import xlwt # 加载pdf path = "/home/aistudio/Scan-1.pdf" with pdfplumber.open(path) as pdf: page_1 = pdf.pages[0] # pdf第一页 table_1 = page_1.extract_table() # 读取表格数据 print(table_1) # 1.创建Excel对象 workbook = xlwt.Workbook(encoding='utf8') # 2.新建sheet表 worksheet = workbook.add_sheet('Sheet1') # 3.自定义列名 clo1 = table_1[0] # 4.将列表元组clo1写入sheet表单中的第一行 for i in range(0, len(clo1)): worksheet.write(0, i, clo1[i]) # 5.将数据写进sheet表单中 for i in range(0, len(table_1[1:])): data = table_1[1:][i] for j in range(0, len(clo1)): worksheet.write(i + 1, j, data[j]) # 保存Excel文件分两种 workbook.save('/home/aistudio/work/input/test_excel.xls') #读取表格全页 import pdfplumber from openpyxl import Workbook class PDF(object): def __init__(self, file_path): self.pdf_path = file_path # 读取pdf文件 self.pdf_info = pdfplumber.open(self.pdf_path) print('读取文件完成!') except Exception as e: print('读取文件失败:', e) # 打印pdf的基本信息、返回字典,作者、创建时间、修改时间/总页数 def get_pdf(self): pdf_info = self.pdf_info.metadata pdf_page = len(self.pdf_info.pages) print('pdf共%s页' % pdf_page) print("pdf文件基本信息:\n", pdf_info) self.close_pdf() # 提取表格数据,并保存到excel中 def get_table(self): wb = Workbook() # 实例化一个工作簿对象 ws = wb.active # 获取第一个sheet con = 0 # 获取每一页的表格中的文字,返回table、row、cell格式:[[[row1],[row2]]] for page in self.pdf_info.pages: for table in page.extract_tables(): for row in table: # 对每个单元格的字符进行简单清洗处理 row_list = [cell.replace('\n', ' ') if cell else '' for cell in row] ws.append(row_list) # 写入数据 con += 1 print('---------------分割线,第%s页---------------' % con) except Exception as e: print('报错:', e) finally: wb.save('\\'.join(self.pdf_path.split('\\')[:-1]) + '\pdf_excel.xlsx') print('写入完成!') self.close_pdf() # 关闭文件 def close_pdf(self): self.pdf_info.close() if __name__ == "__main__": file_path = "/home/aistudio/Scan-1.pdf" pdf_info = PDF(file_path) # pdf_info.get_pdf() # 打印pdf基础信息 # 提取pdf表格数据并保存到excel中,文件保存到跟pdf同一文件路径下 pdf_info.get_table() 更多功能(表格读取,图片提取,可视化界面)可以参考官网或者下面链接:https://blog.csdn.net/fuhanghang/article/details/1225795482.1.2 学术论文特定页面文本提取发表论文作者信息通常放在论文首页的脚末行或参考文献的后面,根据这种情况我们可以进行分类(只要获取作者的邮箱信息即可):第一种国外论文:首页含作者相关信息 or 首页是封面第二页才是作者信息 【获取前n页即可,推荐是2页】第二种国内论文:首页含作者信息(邮箱等)在参考文献之后会有各个做的详细信息,比如是职位,研究领域,科研成果介绍等等 【获取前n页和尾页,推荐是2页+尾页】这样做的好处在于两个方面:节约了存储空间和数据处理时间节约资源消耗,在模型预测时候输入文本数量显著减少,在数据面上加速推理针对1简单阐述:PDF原始大小614.1KB处理方式pdf转文字时延存储占用空间保存指定前n页面文字242ms2.8KB保存指定前n页面文字和尾页328ms5.3KB保存全文2.704s64.1KB针对二:以下6中方案提速不过多赘述,可以参考下面项目模型选择 uie-mini等小模型预测,损失一定精度提升预测效率UIE实现了FastTokenizer进行文本预处理加速fp16半精度推理速度更快UIE INT8 精度推理UIE Slim 数据蒸馏SimpleServing支持支持多卡负载均衡预测UIE Slim满足工业应用场景,解决推理部署耗时问题,提升效能!:https://aistudio.baidu.com/aistudio/projectdetail/4516470?contributionType=1之后有时间重新把paddlenlp技术路线整理一下#第一种写法:保存指定前n页面文字 with pdfplumber.open("/home/aistudio/work/input/test_paper.pdf") as p: for i in range(3): page = p.pages[i] textdata = page.extract_text() # print(textdata) data = open('/home/aistudio/work/input/text.txt',"a") #a表示指定写入模式为追加写入 data.write(textdata) #这里打印出n页文字,因为是追加保存内容是n-1页 #第一种写法:保存指定前n页面文字 with pdfplumber.open("/home/aistudio/work/input/test_paper.pdf") as p: for i in range(3): page = p.pages[i] textdata = page.extract_text() # print(textdata) data = open('/home/aistudio/work/input/text.txt',"a") #a表示指定写入模式为追加写入 data.write(textdata) #这里打印出n页文字,因为是追加保存内容是n-1页 #保存指定前n页面文字和尾页 pdf_path = "/home/aistudio/work/input/test_paper.pdf" pdf = ppl.open(pdf_path) texts = [] # 按页打开,合并所有内容,保留前2页 for i in range(2): text = pdf.pages[i].extract_text() texts.append(text) #保留最后一页,index从0开始 end_num=len(pdf.pages) text_end=pdf.pages[end_num-1].extract_text() texts.append(text_end) txt_string = ''.join(texts) # 保存为和原PDF同名的txt文件 txt_path = pdf_path.split('.')[0]+"_end" + '.txt' with open(txt_path, "w", encoding='utf-8') as f: f.write(txt_string) f.close() #保留全部文章: pdf_path = "/home/aistudio/work/input/test_paper.pdf" pdf = ppl.open(pdf_path) texts = [] # 按页打开,合并所有内容,对于多页或一页PDF都可以使用 for page in pdf.pages: text = page.extract_text() texts.append(text) txt_string = ''.join(texts) # 保存为和原PDF同名的txt文件 txt_path = pdf_path.split('.')[0] +"_all"+'.txt' with open(txt_path, "w", encoding='utf-8') as f: f.write(txt_string) f.close() #从txt中读取文本,作为信息抽取的输入。对于比较长的文本,可能需要人工的设定一些分割关键词,分段输入以提升抽取的效果。 txt_path="/home/aistudio/work/input/test_paper2.txt" with open(txt_path, 'r') as f: file_data = f.readlines() record = '' for data in file_data: record += data print(record) 2.2 UIE信息抽取(论文作者和邮箱)2.2.1 零样本抽取from pprint import pprint import json from paddlenlp import Taskflow def openreadtxt(file_name): data = [] file = open(file_name,'r',encoding='UTF-8') #打开文件 file_data = file.readlines() #读取所有行 for row in file_data: data.append(row) #将每行数据插入data中 return data data_input=openreadtxt('/home/aistudio/work/input/test_paper2.txt') schema = ['人名', 'email'] few_ie = Taskflow('information_extraction', schema=schema, batch_size=16) results=few_ie(data_input) print(results) with open("./output/reslut_2.txt", "w+",encoding='UTF-8') as f: #a : 写入文件,若文件不存在则会先创建再写入,但不会覆盖原文件,而是追加在文件末尾 for result in results: line = json.dumps(result, ensure_ascii=False) #对中文默认使用的ascii编码.想输出真正的中文需要指定ensure_ascii=False f.write(line + "\n") print("数据结果已导出") 2.3长文本的答案获取UIE对于词和句子的抽取效果比较好,但是对应大段的文字结果,还是需要传统的正则方式作为配合,在本次使用的pdf中,还需要获得法院具体的判决结果,使用正则表达式可灵活匹配想要的结果。start_word = '如下' end_word = '特此公告' start = re.search(start_word, record) end = re.search(end_word, record) print(record[start.span()[1]:end.span()[0]]) 海口中院认为:新达公司的住所地在海口市国贸大道 48 号新达商务大厦,该司是由海南省工商行政管理局核准登记 的企业,故海口中院对本案有管辖权。因新达公司不能清偿 到期债务,故深物业股份公司提出对新达公司进行破产清算 的申请符合受理条件。依照《中华人民共和国企业破产法》 第二条第一款、第三条、第七条第二款之规定,裁定如下: 受理申请人深圳市物业发展(集团)股份有限公司对被 申请人海南新达开发总公司破产清算的申请。 本裁定自即日起生效。 二、其他情况 本公司已对海南公司账务进行了全额计提,破产清算对 本公司财务状况无影响。 具体情况请查阅本公司2011年11月28日发布的《董事会 决议公告》。 2.4正则提升效果对于长文本,可以根据关键词进行分割后抽取,但是对于多个实体,比如这篇公告中,通过的多个议案,就无法使用UIE抽取。# 导入正则表达式相关库 import re schema = ['通过议案'] start_word = '通过以下议案' start = re.search(start_word, record) input_data = record[start.span()[0]:] print(input_data) ie = Taskflow('information_extraction', schema=schema) pprint(ie(input_data)) # 正则匹配“一 二 三 四 五 六 七 八 九 十” print(re.findall(r"[\u4e00\u4e8c\u4e09\u56db\u4e94\u516d\u4e03\u516b\u4e5d\u5341]、.*\n", input_data)) ['一、2021 年第三季度报告 \n', '二、关于同意全资子公司收购担保公司 60%股权的议案 详见公司于 2021 年 10 月 29 日刊登在《证券时报》、《中国证券\n', '三、关于同意控股子公司广西新柳邕公司为认购广西新柳邕项\n', '四、关于续聘会计师事务所的议案 \n', '五、关于向银行申请综合授信额度的议案 \n', '一、向中国民生银行股份有限公司深圳分行申请不超过人民币 5\n', '二、向招商银行股份有限公司深圳分行申请不超过人民币 6 亿\n', '六、经理层《岗位聘任协议》 \n', '七、经理层《年度经营业绩责任书》 \n', '八、经理层《任期经营业绩责任书》 \n', '九、关于暂不召开股东大会的议案 \n'] # 3.基于基于UIE-X的信息提取 ## 3.1 跨模态文档信息抽取 跨模态文档信息抽取能力 UIE-X 来了。 信息抽取简单说就是利用计算机从自然语言文本中提取出核心信息,是自然语言处理领域的一项关键任务,包括命名实体识别(也称实体抽取)、关系抽取、事件抽取等。传统信息抽取方案基于序列标注,需要大量标注语料才能获得较好的效果。2022年5月飞桨 PaddleNLP 推出的 UIE,是业界首个开源的面向通用信息抽取的产业级技术方案 ,基于 Prompt 思想,零样本和小样本能力强大,已经成为业界信息抽取任务上的首选方案。 除了纯文本内容外,企业中还存在大量需要从跨模态文档中抽取信息并进行处理的业务场景,例如从合同、收据、报销单、病历等不同类型的文档中抽取所需字段,进行录入、比对、审核校准等操作。为了满足各行业的跨模态文档信息抽取需求,PaddleNLP 基于文心ERNIE-Layout[1]跨模态布局增强预训练模型,集成PaddleOCR的PP-OCR、PP-Structure版面分析等领先能力,基于大量信息抽取标注集,训练并开源了UIE-X–––首个兼具文本及文档抽取能力、多语言、开放域的信息抽取模型。 * 支持实体抽取、关系抽取、跨任务抽取 * 支持跨语言抽取 * 集成PP-OCR,可灵活定制OCR结果 * 使用PP-Structure版面分析功能 * 增加渲染模块,OCR和信息抽取结果可视化 项目链接: [https://aistudio.baidu.com/aistudio/projectdetail/5017442](https://aistudio.baidu.com/aistudio/projectdetail/5017442) ## 3.2 产业实践分享:基于UIE-X的医疗文档信息提取 PaddleNLP全新发布UIE-X ,除已有纯文本抽取的全部功能外,新增文档抽取能力。 UIE-X延续UIE的思路,基于跨模态布局增强预训练模型文心ERNIE-Layout重训模型,融合文本、图像、布局等信息进行联合建模,能够深度理解多模态文档。基于Prompt思想,实现开放域信息抽取,支持零样本抽取,小样本能力领先。 官网链接:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/applications/information_extraction 本案例为UIE-X在医疗领域的实战,通过少量标注+模型微调即可具备定制场景的端到端文档信息提取 目前医疗领域有大量的医学检查报告单,病历,发票,CT影像,眼科等等的医疗图片数据。现阶段,针对这些图片都是靠人工分类,结构化录入系统中,做患者的全生命周期的管理。 耗时耗力,人工成本极大。如果能靠人工智能的技术做到图片的自动分类和结构化,将大大的降低成本,提高系统录入的整体效率。 项目链接: [https://aistudio.baidu.com/aistudio/projectdetail/5261592](https://aistudio.baidu.com/aistudio/projectdetail/5261592) 4.总结本项目提供了基于ERNIELayout&PDFplumber-UIEX多方案学术论文信息抽取,有兴趣同学可以研究一下UIE-X。UIE-X延续UIE的思路,基于跨模态布局增强预训练模型文心ERNIE-Layout重训模型,融合文本、图像、布局等信息进行联合建模,能够深度理解多模态文档。基于Prompt思想,实现开放域信息抽取,支持零样本抽取,小样本能力领先.
[信息抽取]基于ERNIE3.0的多对多信息抽取算法:属性关系抽取
[信息抽取]基于ERNIE3.0的多对多信息抽取算法:属性关系抽取实体关系,实体属性抽取是信息抽取的关键任务;实体关系抽取是指从一段文本中抽取关系三元组,实体属性抽取是指从一段文本中抽取属性三元组;信息抽取一般分以下几种情况一对一,一对多,多对一,多对多的情况:一对一:“张三男汉族硕士学历”含有一对一的属性三元组(张三,民族,汉族)。一对多:“华扬联众数字技术股份有限公司于2017年8月2日在上海证券交易所上市”,含有一对多的属性三元组(华扬联众数字技术股份有限公司,上市时间,2017年8月2日)和(华扬联众数字技术股份有限公司,上市地点,上海证券交易所上市)多对一:“上海森焱软件有限公司和上海欧提软件有限公司的注册资本均为100万人民币”,含有多对一的属性三元组(上海森焱软件有限公司,注册资本,100万人民币)和(上海欧提软件有限公司,注册资本,100万人民币)多对多:“大华种业稻麦种子加工36.29万吨、销售37.5万吨;苏垦米业大米加工22.02万吨、销售24.86万吨”,含有多对多的属性三元组(大华种业,稻麦种子产量,36.29万吨)和(苏垦米业,大米加工产量,22.02万吨)代码结构如下: ├── data │ ├── entity_attribute_data │ │ ├── dev_data │ │ │ └── dev.json │ │ ├── predict_data │ │ │ └── predict.json │ │ ├── test_data │ │ │ └── test.json │ │ └── train_data │ │ └── train.json │ └── entity_relation_data │ ├── dev_data │ │ └── dev.json │ ├── predict_data │ │ └── predict.json │ ├── test_data │ │ └── test.json │ └── train_data │ └── train.json ├── data_set_reader │ └── ie_data_set_reader.py ├── dict │ ├── entity_attribute_label_map.json │ └── entity_relation_label_map.json ├── examples │ ├── many_to_many_ie_attribute_ernie_fc_ch_infer.json │ ├── many_to_many_ie_attribute_ernie_fc_ch.json │ ├── many_to_many_ie_relation_ernie_fc_ch_infer.json │ └── many_to_many_ie_relation_ernie_fc_ch.json ├── inference │ ├── custom_inference.py │ └── __init__.py ├── model │ ├── ernie_fc_ie_many_to_many.py │ └── __init__.py ├── run_infer.py ├── run_trainer.py └── trainer ├── custom_dynamic_trainer.py ├── custom_trainer.py └── __init__.py1.数据集简介这里提供三份已标注的数据集:属性抽取数据集(demo示例数据集)、关系抽取数据集(demo示例数据集)、DuIE2.0(全量数据集)。属性抽取训练集、测试集、验证集和预测集分别存放在./data/entity_attribute_data目录下的train_data、test_data、dev_data和predict_data文件夹下,对应的示例标签词表存放在./dict目录下。关系抽取训练集、测试集、验证集和预测集分别存放在./data/entity_relation_data目录下的train_data、test_data、dev_data和predict_data文件夹下,对应的示例标签词表存放在./dict目录下。DuIE2.0数据集已经上传到“数据集中”也进行解压注:数据集(包含词表)均为utf-8格式。Demo示例数据集(属性抽取数据集、关系抽取数据集)demo示例数据集中属性抽取数据集与关系抽取数据集的结构一样,他们都只包含少量数据集,可用于快速开始模型的训练与预测。训练集/测试集/的数据格式相同,每个样例分为两个部分文本和对应标签{"text": "倪金德,1916年生,奉天省营口(今辽宁省营口市)人", "spo_list": [{"predicate": "出生日期", "subject": [0, 3], "object": [4, 9]}, {"predicate": "出生地", "subject": [0, 3], "object": [11, 16]}]} {"text": "基本介绍克里斯蒂娜·塞寇丽(Christina Sicoli)身高163cm,在加拿大安大略出生和长大,毕业于伦道夫学院", "spo_list": [{"predicate": "毕业院校", "subject": [4, 13], "object": [55, 60]}]} 预测集只有一个key("text"):{"text": "倪金德,1916年生,奉天省营口(今辽宁省营口市)人"} {"text": "基本介绍克里斯蒂娜·塞寇丽(Christina Sicoli)身高163cm,在加拿大安大略出生和长大,毕业于伦道夫学院"} 标签词表:标签列表是一个json字符串,key是标签值,value是标签对应id,示例词表采用BIO标注,B表示关系,分为主体(S)与客体(O),如下所示:{ "O": 0, "I": 1, "B-毕业院校@S": 2, "B-毕业院校@O": 3, "B-出生地@S": 4, "B-出生地@O": 5, "B-祖籍@S": 6, "B-祖籍@O": 7, "B-国籍@S": 8, "B-国籍@O": 9, "B-出生日期@S": 10, "B-出生日期@O": 11 }注意:O, I对应的ID必须是0, 1,B-XXX@O对应的id需要必须为B-XXX@S对应的id+1(B-XXX@s须为偶数,B-XXX@O须为奇数)DuIE2.0数据集DuIE2.0是业界规模最大的中文关系抽取数据集,其schema在传统简单关系类型基础上添加了多元复杂关系类型,此外其构建语料来自百度百科、百度信息流及百度贴吧文本,全面覆盖书面化表达及口语化表达语料,能充分考察真实业务场景下的关系抽取能力。DuIE2.0数据集的格式与本框架所需要的文本输入格式不一致,需要进行转化成demo示例数据集的格式才能使用,具体转化步骤如下:下载数据集到 ./data/DuIE2.0 文件夹中,并解压进入./data/DuIE2.0目录运行./data/DuIE2.0/convert_data.py 脚本{'text': '《司马迁之人格与风格\u3000道教徒的诗人李白及其痛苦》是李长之代表作品,共收录了两本著作,《司马迁之人格与风格》,是中国第一部透过西方文学批评视角全面审视、评价司马迁及其《史记》的学术专著', 'spo_list': [{'predicate': '作者', 'object_type': {'@value': '人物'}, 'subject_type': '图书作品', 'object': {'@value': '李长之'}, 'subject': '司马迁之人格与风格\u3000道教徒的诗人李白及其痛苦'}, {'predicate': '作者', 'object_type': {'@value': '人物'}, 'subject_type': '图书作品', 'object': {'@value': '李长之'}, 'subject': '司马迁之人格与风格 道教徒的诗人李白及其痛苦'}]} 《司马迁之人格与风格 道教徒的诗人李白及其痛苦》是李长之代表作品,共收录了两本著作,《司马迁之人格与风格》,是中国第一部透过西方文学批评视角全面审视、评价司马迁及其《史记》的学术专著 * 司马迁之人格与风格 道教徒的诗人李白及其痛苦 2.网络模型选择(文心大模型)文心预置的可用于生成任务的模型源文件在/home/aistudio/model/ernie_fc_ie_many_to_many.py网络名称(py文件的类型)简介支持类型ErnieFcIe(ernie_fc_ie_many_to_many.py)ErnieFcIe多对多信息抽取任务模型源文件,可加载ERNIE2.0-Base、ERNIE2.0-large、ERNIE3.0-Base、ERNIE3.0-x-Base、ERNIE3.0-Medium通用信息抽取Finetune任务ERNIE预训练模型下载:文心提供的ERNIE预训练模型的参数文件和配置文件在 /home/aistudio/models_hub目录下,使用对应的sh脚本,即可拉取对应的模型、字典、必要环境等文件。简单罗列可能会用的模型:模型名称下载脚本备注ERNIE1.0-m-BaseTextERNIE-M:通过将跨语言语义与单语语料库对齐来增强多语言表示ERNIE1.0-gen-BaseTextERNIE-GEN:用于自然语言生成的增强型多流预训练和微调框架ERNIE2.0-BaseText ERNIE2.0-largeText ERNIE3.0-BaseText ERNIE3.0-x-BaseText ERNIE3.0-MediumText下载并解压后得到对应模型的参数、字典和配置简单介绍以下几个不常用模型:ERNIE-GEN 是面向生成任务的预训练-微调框架,首次在预训练阶段加入span-by-span 生成任务,让模型每次能够生成一个语义完整的片段。在预训练和微调中通过填充式生成机制和噪声感知机制来缓解曝光偏差问题。此外, ERNIE-GEN 采样多片段-多粒度目标文本采样策略, 增强源文本和目标文本的关联性,加强了编码器和解码器的交互。ERNIE-GEN base 模型和 ERNIE-GEN large 模型。 预训练数据使用英文维基百科和 BookCorpus,总共16GB。此外,我们还发布了基于 430GB 语料(数据描述见ERNIE-GEN Appendix A.1)预训练的ERNIE-GEN large 模型。ERNIE-GEN base (lowercased | 12-layer, 768-hidden, 12-heads, 110M parameters)ERNIE-GEN large (lowercased | 24-layer, 1024-hidden, 16-heads, 340M parameters)ERNIE-GEN large with 430G (lowercased | 24-layer, 1024-hidden, 16-heads, 340M parameters)微调任务:在五个典型生成任务上与当前效果最优的生成预训练模型(UniLM、MASS、PEGASUS、BART、T5等)进行对比, 包括生成式摘要 (Gigaword 和 CNN/DailyMail), 问题生成(SQuAD), 多轮对话(Persona-Chat) 和生成式多轮问答(CoQA)。https://github.com/PaddlePaddle/ERNIE/blob/repro/ernie-gen/README.zh.mdERNIE-M 是面向多语言建模的预训练-微调框架。为了突破双语语料规模对多语言模型的学习效果限制,提升跨语言理解的效果,我们提出基于回译机制,从单语语料中学习语言间的语义对齐关系的预训练模型 ERNIE-M,显著提升包括跨语言自然语言推断、语义检索、语义相似度、命名实体识别、阅读理解在内的 5 种典型跨语言理解任务效果。飞桨发布了 ERNIE-M base 多语言模型和 ERNIE-M large 多语言模型。ERNIE-M base (12-layer, 768-hidden, 12-heads)ERNIE-M large (24-layer, 1024-hidden, 16-heads)下游任务:在自然语言推断,命名实体识别,阅读理解,语义相似度以及跨语言检索等任务上选取了广泛使用的数据集进行模型效果验证,并且与当前效果最优的模型(XLM、Unicoder、XLM-R、INFOXLM、VECO、mBERT等)进行对比。https://github.com/PaddlePaddle/ERNIE/blob/repro/ernie-m/README_zh.md3.训练&预测3.1 属性抽取模型训练&预测以属性抽取数据集的训练为例:训练的配置文件:配置文件:./examples/many_to_many_ie_attribute_ernie_fc_ch.json{ "dataset_reader": { "train_reader": { "name": "train_reader", "type": "IEReader", "fields": [], "config": { "data_path": "./data/entity_attribute_data/train_data/", "shuffle": false, "batch_size": 2, "epoch": 5, "sampling_rate": 1.0, "need_data_distribute": true, "need_generate_examples": false, "extra_params": { "vocab_path": "./models_hub/ernie_3.0_base_ch_dir/vocab.txt", #选择对应预训练模型的词典路径,在models_hub路径下 "label_map_config": "./dict/entity_attribute_label_map.json", "num_labels": 12, "max_seq_len": 512, "do_lower_case":true, "in_tokens":false, "tokenizer": "FullTokenizer" "test_reader": { "name": "test_reader", "type": "IEReader", "fields": [], "config": { "data_path": "./data/entity_attribute_data/test_data/", "shuffle": false, "batch_size": 2, "epoch": 1, "sampling_rate": 1.0, "need_data_distribute": false, "need_generate_examples": false, "extra_params": { "vocab_path": "./models_hub/ernie_3.0_base_ch_dir/vocab.txt", #选择对应预训练模型的词典路径,在models_hub路径下 "label_map_config": "./dict/entity_attribute_label_map.json", "num_labels": 12, "max_seq_len": 512, "do_lower_case":true, "in_tokens":false, "tokenizer": "FullTokenizer" "model": { "type": "ErnieFcIe", "is_dygraph":1, "num_labels":12, "optimization": { "learning_rate": 5e-05, "use_lr_decay": true, "warmup_steps": 0, "warmup_proportion": 0.1, "weight_decay": 0.01, "use_dynamic_loss_scaling": false, "init_loss_scaling": 128, "incr_every_n_steps": 100, "decr_every_n_nan_or_inf": 2, "incr_ratio": 2.0, "decr_ratio": 0.8 "embedding": { "config_path": "./models_hub/ernie_3.0_base_ch_dir/ernie_config.json" #选择对应预训练模型的配置文件路径,在models_hub路径下 "trainer": { "type": "CustomDynamicTrainer", "PADDLE_PLACE_TYPE": "gpu", "PADDLE_IS_FLEET": 0, "train_log_step": 10, "use_amp": true, "is_eval_dev": 0, "is_eval_test": 1, "eval_step": 50, "save_model_step": 100, "load_parameters": "", "load_checkpoint": "", "pre_train_model": [ "name": "ernie_3.0_base_ch", "params_path": "./models_hub/ernie_3.0_base_ch_dir/params" #选择对应预训练模型的参数路径,在models_hub路径下 "output_path": "./output/ie_attribute_ernie_3.0_base_fc_ch", #输出路径 "extra_param": { "meta":{ "job_type": "entity_attribute_extraction" }# 基于示例的数据集,可以运行以下命令在训练集(train.txt)上进行模型训练,并在测试集(test.txt)上进行验证; # 训练属性抽取 %cd /home/aistudio !python run_trainer.py --param_path ./examples/many_to_many_ie_attribute_ernie_fc_ch.json # 训练运行的日志会自动保存在./log/test.log文件中; # 训练中以及结束后产生的模型文件会默认保存在./output/目录下,其中save_inference_model/文件夹会保存用于预测的模型文件,save_checkpoint/文件夹会保存用于热启动的模型文件 部分结果展示:INFO: 11-30 15:19:47: custom_dynamic_trainer.py:85 * 139681516312320 current learning rate: 2e-07 DEBUG: 11-30 15:19:48: ernie_fc_ie_many_to_many.py:234 * 139681516312320 phase = training precision = 1.0 recall = 1.0 f1 = 1.0 step = 2500 time_cost = 0.5210211277008057 loss = [0.00099489] INFO: 11-30 15:19:48: custom_dynamic_trainer.py:85 * 139681516312320 current learning rate: 0.0 DEBUG: 11-30 15:19:48: ernie_fc_ie_many_to_many.py:261 * 139681516312320 phase = test precision = 0.958 recall = 0.976 f1 = 0.967 time_cost = 0.4507319927215576 INFO: 11-30 15:19:48: custom_dynamic_trainer.py:138 * 139681516312320 eval step = 14 INFO: 11-30 15:19:48: custom_dynamic_trainer.py:103 * 139681516312320 Final test result: DEBUG: 11-30 15:19:49: ernie_fc_ie_many_to_many.py:261 * 139681516312320 phase = test precision = 0.958 recall = 0.976 f1 = 0.967 time_cost = 0.44904589653015137 INFO: 11-30 15:19:49: custom_dynamic_trainer.py:138 * 139681516312320 eval step = 14使用预置网络进行预测的方式为使用./run_infer.py入口脚本,通过--param_path参数来传入./examples/目录下的json配置文件。预测分为以下几个步骤:基于示例的数据集,可以运行以下命令在预测集(predict.txt)上进行预测:预测运行的日志会自动保存在./output/predict_result.txt文件中。以属性抽取数据集的预测为例:预测的配置文件配置文件:./examples/many_to_many_ie_attribute_ernie_fc_ch_infer.json在配置文件./examples/many_to_many_ie_attribute_ernie_fc_ch_infer.json中需要更改 inference.inference_model_path 为上面训练过程中所保存的预测模型的路径{ "dataset_reader": { "predict_reader": { "name": "predict_reader", "type": "IEReader", "fields": [], "config": { "data_path": "./data/entity_attribute_data/predict_data/", "shuffle": false, "batch_size": 2, "epoch": 1, "sampling_rate": 1.0, "extra_params": { "vocab_path": "../../models_hub/ernie_3.0_base_ch_dir/vocab.txt", "label_map_config": "./dict/entity_attribute_label_map.json", "num_labels": 12, "max_seq_len": 512, "do_lower_case":true, "in_tokens":false, "tokenizer": "FullTokenizer", "need_data_distribute": false, "need_generate_examples": true "inference": { "output_path": "./output/predict_result.txt", #输出文件路径 "label_map_config": "./dict/entity_attribute_label_map.json", "PADDLE_PLACE_TYPE": "gpu", "inference_model_path": "./output/ie_attribute_ernie_3.0_base_fc_ch/save_inference_model/inference_step_1000", #加载推理模型 "extra_param": { "meta": { "job_type": "information_extraction" }3.2 关系抽取模型训练&预测# 训练关系抽取 !python run_trainer.py --param_path ./examples/many_to_many_ie_relation_ernie_fc_ch.json # 训练运行的日志会自动保存在./log/test.log文件中; # 训练中以及结束后产生的模型文件会默认保存在./output/目录下,其中save_inference_model/文件夹会保存用于预测的模型文件,save_checkpoint/文件夹会保存用于热启动的模型文件 部分结果展示:DEBUG: 11-30 16:09:37: ernie_fc_ie_many_to_many.py:261 * 140264317826816 phase = test precision = 0.953 recall = 0.968 f1 = 0.96 time_cost = 0.7550814151763916 INFO: 11-30 16:09:37: custom_dynamic_trainer.py:138 * 140264317826816 eval step = 50 INFO: 11-30 16:09:41: dynamic_trainer.py:170 * 140264317826816 save path: ./output/ie_relation_ernie_3.0_medium/save_inference_model/inference_step_2500 INFO: 11-30 16:09:42: custom_dynamic_trainer.py:103 * 140264317826816 Final test result: DEBUG: 11-30 16:09:43: ernie_fc_ie_many_to_many.py:261 * 140264317826816 phase = test precision = 0.953 recall = 0.968 f1 = 0.96 time_cost = 0.883291482925415 INFO: 11-30 16:09:43: custom_dynamic_trainer.py:138 * 140264317826816 eval step = 50部分结果:"text": "杨力革,男,汉族,1966年4月生,湖南益阳人,1987年7月参加工作,1992年10月入党,在职研究生学历(2004年7月新疆自治区党委党校领导干部研究生班工商管理专业毕业)", "spo_list": [ "predicate": "出生地", "subject": [ "object": [ "predicate": "出生日期", "subject": [ "object": [ ]4.总结本项目讲解了基于ERNIE信息抽取技术,对属性和关系的抽取涉及多对多抽取,主要是使用可ERNIEKIT组件,整体效果非常不错,当然追求小样本学习的可以参考之前UIE项目或者去官网看看paddlenlp最新的更新,对训练和部署进行了提速。模型任务precisionrecallf1ernie_3.0_medium属性抽取0.9580.9760.967ernie_3.0_medium关系抽取0.9530.9680.96
PGL图学习项目合集&数据集分享&技术归纳业务落地技巧[系列十]
PGL图学习项目合集&数据集分享&技术归纳业务落地技巧[系列十]1.PGL图学习项目合集1.1 关于图计算&图学习的基础知识概览:前置知识点学习(PGL)[系列一] :https://aistudio.baidu.com/aistudio/projectdetail/4982973?contributionType=1本项目对图基本概念、关键技术(表示方法、存储方式、经典算法),应用等都进行详细讲解,并在最后用程序实现各类算法方便大家更好的理解。当然之后所有图计算相关都是为了知识图谱构建的前置条件1.2 图机器学习(GML)&图神经网络(GNN)原理和代码实现(前置学习系列二)https://aistudio.baidu.com/aistudio/projectdetail/4990947?contributionType=1现在已经覆盖了图的介绍,图的主要类型,不同的图算法,在Python中使用Networkx来实现它们,以及用于节点标记,链接预测和图嵌入的图学习技术,最后讲了GNN分类应用以及未来发展方向!1.3 图学习初探Paddle Graph Learning 构建属于自己的图【系列三】 https://aistudio.baidu.com/aistudio/projectdetail/5000517?contributionType=1本项目主要讲解了图学习的基本概念、图的应用场景、以及图算法,最后介绍了PGL图学习框架并给出demo实践,过程中把老项目demo修正版本兼容问题等小坑,并在最新版本运行便于后续同学更有体验感1.4 PGL图学习之图游走类node2vec、deepwalk模型[系列四]https://aistudio.baidu.com/aistudio/projectdetail/5002782?contributionType=1介绍了图嵌入原理以及了图嵌入中的DeepWalk、node2vec算法,利用pgl对DeepWalk、node2vec进行了实现,并给出了多个框架版本的demo满足个性化需求。图学习【参考资料1】词向量word2vec https://aistudio.baidu.com/aistudio/projectdetail/5009409?contributionType=1介绍词向量word2evc概念,及CBOW和Skip-gram的算法实现。图学习【参考资料2】-知识补充与node2vec代码注解https://aistudio.baidu.com/aistudio/projectdetail/5012408?contributionType=1主要引入基本的同构图、异构图知识以及基本概念;同时对deepWalk代码的注解以及node2vec、word2vec的说明总结;(以及作业代码注解)1.5 PGL图学习之图游走类metapath2vec模型[系列五]https://aistudio.baidu.com/aistudio/projectdetail/5009827?contributionType=1介绍了异质图,利用pgl对metapath2vec以及metapath2vec变种算法进行了实现,同时讲解实现图分布式引擎训练,并给出了多个框架版本的demo满足个性化需求。1.6 PGL图学习之图神经网络GNN模型GCN、GAT[系列六] [https://aistudio.baidu.com/aistudio/projectdetail/5054122?contributionType=1](https://aistudio.baidu.com/aistudio/projectdetail/5054122?contributionType=1)本次项目讲解了图神经网络的原理并对GCN、GAT实现方式进行讲解,最后基于PGL实现了两个算法在数据集Cora、Pubmed、Citeseer的表现,在引文网络基准测试中达到了与论文同等水平的指标。1.7 PGL图学习之图神经网络GraphSAGE、GIN图采样算法[系列七] https://aistudio.baidu.com/aistudio/projectdetail/5061984?contributionType=1本项目主要讲解了GraphSage、PinSage、GIN算法的原理和实践,并在多个数据集上进行仿真实验,基于PGl实现原论文复现和对比,也从多个角度探讨当前算法的异同以及在工业落地的技巧等。1.8 PGL图学习之图神经网络ERNIESage、UniMP进阶模型[系列八]https://aistudio.baidu.com/aistudio/projectdetail/5096910?contributionType=1ErnieSage 可以同时建模文本语义与图结构信息,有效提升 Text Graph 的应用效果;UniMP 在概念上统一了特征传播和标签传播, 在OGB取得了优异的半监督分类结果。PGL图学习之ERNIESage算法实现(1.8x版本)【系列八】https://aistudio.baidu.com/aistudio/projectdetail/5097085?contributionType=1ERNIESage运行实例介绍(1.8x版本),提供多个版本pgl代码实现1.9 PGL图学习之项目实践(UniMP算法实现论文节点分类、新冠疫苗项目)[系列九]https://aistudio.baidu.com/aistudio/projectdetail/5100049?contributionType=1本项目借鉴了百度高研黄正杰大佬对图神经网络技术分析以及图算法在业务侧应用落地;实现了论文节点分类和新冠疫苗项目的实践帮助大家更好理解学习图的魅力。PGL图学习之基于GNN模型新冠疫苗任务[系列九]https://aistudio.baidu.com/aistudio/projectdetail/5123296?contributionType=1图神经网络7日打卡营的新冠疫苗项目拔高实战PGL图学习之基于UniMP算法的论文引用网络节点分类任务[系列九]https://aistudio.baidu.com/aistudio/projectdetail/5116458?contributionType=1基于UniMP算法的论文引用网络节点分类,在调通UniMP之后,后续尝试的技巧对于其精度的提升效力微乎其微,所以不得不再次感叹百度PGL团队的强大!༄ℳ持续更新中ꦿོ࿐2.图网络开放数据集按照任务分类,可以把数据集分成以下几类:引文网络生物化学图社交网络知识图谱开源数据集仓库2.1 引文网络1. Pubmed/Cora/Citeseer|这三个数据集均来自于:《Collective classification in network data》引文网络,节点为论文、边为论文间的引用关系。这三个数据集通常用于链路预测或节点分类。数据下载链接:https://aistudio.baidu.com/aistudio/datasetdetail/177587https://aistudio.baidu.com/aistudio/datasetdetail/177589https://aistudio.baidu.com/aistudio/datasetdetail/177591INQS 实验室使用的数据集和所有展示的关系结构,数据集链接:https://linqs.org/datasets/2. DBLPDBLP是大型的计算机类文献索引库。原始的DBLP只是XML格式,清华唐杰教授的一篇论文将其进行处理并获得引文网络数据集。到目前为止已经发展到了第13个版本。DBLP引用网络论文:《ArnetMiner: Extraction and Mining of Academic Social Networks》原始数据可以从这里获得:https://dblp.uni-trier.de/xml/如果是想找处理过的DBLP引文网络数据集,可以从这里获得:https://www.aminer.cn/citation2.2 生物化学图1. PPI蛋白质-蛋白质相互作用(protein-protein interaction, PPI)是指两个或两个以上的蛋白质分子通过非共价键形成 蛋白质复合体(protein complex)的过程。PPI数据集中共有24张图,其中训练用20张,验证/测试分别2张。节点最多可以有121种标签(比如蛋白质的一些性质、所处位置等)。每个节点有50个特征,包含定位基因集合、特征基因集合以及免疫特征。PPI论文:《Predicting multicellular function through multi-layer tissue networks》PPI下载链接:http://snap.stanford.edu/graph2. NCI-1NCI-1是关于化学分子和化合物的数据集,节点代表原子,边代表化学键。NCI-1包含4100个化合物,任务是判断该化合物是否有阻碍癌细胞增长的性质。NCI-1论文:《Comparison of descriptor spaces for chemical compound retrieval and classification》Graph Kernel Datasets提供下载3. MUTAGMUTAG数据集包含188个硝基化合物,标签是判断化合物是芳香族还是杂芳族。MUTAG论文:《Structure-activity relationship of mutagenic aromatic and heteroaromatic nitro compounds. correlation with molecular orbital energies and hydrophobicity》https://aistudio.baidu.com/aistudio/datasetdetail/1775914. D&D/PROTEIND&D在蛋白质数据库的非冗余子集中抽取了了1178个高分辨率蛋白质,使用简单的特征,如二次结构含量、氨基酸倾向、表面性质和配体;其中节点是氨基酸,如果两个节点之间的距离少于6埃(Angstroms),则用一条边连接。PROTEIN则是另一个蛋白质网络。任务是判断这类分子是否酶类。D&D论文:《Distinguishing enzyme structures from non-enzymes without alignments》D&D下载链接:https://github.com/snap-stanford/GraphRNN/tree/master/dataset/DDPROTEIN论文:《Protein function prediction via graph kernels》Graph Kernel Datasets提供下载5. PTCPTC全称是预测毒理学挑战,用来发展先进的SAR技术预测毒理学模型。这个数据集包含了针对啮齿动物的致癌性标记的化合物。根据实验的啮齿动物种类,一共有4个数据集:PTC_FM(雌性小鼠)PTC_FR(雌性大鼠)PTC_MM(雄性小鼠)PTC_MR(雄性大鼠)PTC论文:《Statistical evaluation of the predictive toxicology challenge 2000-2001》Graph Kernel Datasets提供下载6. QM9 这个数据集有133,885个有机分子,包含几何、能量、电子等13个特征,最多有9个非氢原子(重原子)。来自GDB-17数据库。QM9论文:《Quantum chemistry structures and properties of 134 kilo molecules》QM9下载链接:http://quantum-machine.org/datasets/7. AlchemyAlchemy包含119,487个有机分子,其有12个量子力学特征(quantum mechanical properties),最多14个重原子(heavy atoms),从GDB MedChem数据库中取样。扩展了现有分子数据集多样性和容量。Alchemy论文:《Alchemy: A quantum chemistry dataset for benchmarking ai models》Alchemy下载链接:https://alchemy.tencent.com/2.3 社交网络1. RedditReddit数据集是由来自Reddit论坛的帖子组成,如果两个帖子被同一人评论,那么在构图的时候,就认为这两个帖子是相关联的,标签是每个帖子对应的社区分类。Reddit论文:《Inductive representation learning on large graphs》Reddit下载链接:https://aistudio.baidu.com/aistudio/datasetdetail/177810https://github.com/linanqiu/reddit-datasetBlogCatalogBlogCatalog数据集是一个社会关系网络,图是由博主及其社会关系(比如好友)组成,标签是博主的兴趣爱好。2.BlogCatalog论文:《Relational learning via latent social dimensions》BlogCatalog下载链接:http://socialcomputing.asu.edu2.4 知识图谱1.FB13/FB15K/FB15K237这三个数据集是Freebase的子集。其中:FB13:包含13种关系、75043个实体。FB15K:包含1345种关系、14951个实体FB15K237:包含237种关系、14951个实体如果希望找到entity id对应的实体数据,可以通过以下渠道(并不是所有的实体都能找到):https://developers.google.com/freebase/#freebase-wikidata-mappingshttp://sameas.org/2.WN11/WN18/WN18RR这三个是WordNet的子集:WN11:包含11种关系、38696个实体WN18:包含18种关系、40943个实体WN18RR:包含11种关系、40943个实体为了避免在评估模型时出现inverse relation test leakage,建议使用FB15K237/WN18RR来替代FB15K/WN18。更多建议阅读《Convolutional 2D Knowledge Graph Embeddings》FB15K/WN8论文:《Translating Embeddings for Modeling Multi-relational Data》FB13/WN11论文:《Reasoning With Neural Tensor Networks for Knowledge Base Completion》WN18RR论文:《Convolutional 2D Knowledge Graph Embeddings》以上6个知识图谱数据集均可从这里下载:https://github.com/thunlp/OpenKE/tree/master/benchmarks2.5 开源数据仓库1. Network Repository具有交互式可视化和挖掘工具的图数据仓库。具有以下特点:用表格的形式展示每一个图数据集的节点数、遍数、平均度数、最大度数等。可视化对比图数据集之间的参数。在线GraphVis,可视化图结构和详细参数。2. Graph Kernel Datasets图核的基准数据集。提供了一个表格,可以快速得到每个数据集的节点数量、类别数量、是否有节点/边标签、节点/边特征。https://ls11-www.cs.tu-dortmund.de/staff/morris/graphkerneldatasetshttps://chrsmrrs.github.io/datasets/3. Relational Dataset Repository关系机器学习的数据集集合。能够以数据集大小、领域、数据类型等条件来检索数据集。https://relational.fit.cvut.czhttps://relational.fit.cvut.cz/search?domain%5B%5D=Industry4. Stanford Large Network Dataset CollectionSNAP库用于大型社交、信息网络。包括:图分类数据库、社交网络、引用网络、亚马逊网络等等,非常丰富。https://snap.stanford.edu/data/5.Open Graph BenchmarkOGB是真实基准数据集的集合,同时提供数据加载器和评估器(PyTorch)。可以自动下载、处理和切割;完全兼容PyG和DGL。https://ogb.stanford.edu/这个大家就比较熟悉了,基本最先进的图算法都是依赖OGB的数据集验证的。௸持续更新敬请期待~ೄ೨✿3.图学习相关技术归纳3.1 GraphSAGE为例技术归纳GCN和GraphSAGE区别GCN灵活性差、为新节点产生embedding要求 额外的操作 ,比如“对齐”:GCN是 直推式(transductive) 学习,无法直接泛化到新加入(未见过)的节点;GraphSAGE是 归纳式(inductive) 学习,可以为新节点输出节点特征。GCN输出固定:GCN输出的是节点 唯一确定 的embedding;GraphSAGE学习的是节点和邻接节点之间的关系,学习到的是一种映射关系 ,节点的embedding可以随着其邻接节点的变化而变化。GCN很难应用在超大图上:无论是拉普拉斯计算还是图卷积过程,因为GCN其需要对 整张图 进行计算,所以计算量会随着节点数的增加而递增。GraphSAGE通过采样,能够形成 minibatch 来进行批训练,能用在超大图上。2.GraphSAGE等模型优点:采用 归纳学习 的方式,学习邻居节点特征关系,得到泛化性更强的embedding;采样技术,降低空间复杂度,便于构建minibatch用于 批训练 ,还让模型具有更好的泛化性;多样的聚合函数 ,对于不同的数据集/场景可以选用不同的聚合方式,使得模型更加灵活。GraphSAGE的基本思路是:利用一个 聚合函数 ,通过 采样 和学习聚合节点的局部邻居特征,来为节点产生embedding。3.跳数(hops)、搜索深度(search depth)、阶数(order)有啥区别?我们经常听到一阶邻居、二阶邻居,1-hops、2-hops等等,其实他们都是一个概念,就是该节点和目标节点的路径长度,如果路径长度是1,那就是一阶邻接节点、1-hops node。 搜索深度其实和深度搜索的深度的概念相似,也是用路径长度来衡量。 简单来说,这几个概念某种程度上是等价。 在GraphSAGE中,还有聚合层数\迭代次数,比如说只考虑了一阶邻接节点,那就只有一层聚合(迭代了一次),以此类推。4.采样有什么好处于对计算效率的考虑,对每个节点采样一定数量的邻接节点作为待聚合信息的节点。从训练效率考虑:通过采样,可以得到一个 固定大小 的领域集,可以拼成一个batch,送到GPU中进行批训练。从复杂度角度考虑:如果没有采样,单个batch的内存使用和预期运行时间是 不可预测 的;最坏的情况是,即所有的节点都是目标节点的邻接节点。而GraphSAGE的每个batch的空间和时间复杂度都是 固定 的其中K是指层数,也就是要考虑多少阶的邻接节点,是在第i层采样的数量。5.采样数大于邻接节点数怎么办?设采样数量为K:若节点邻居数少于K,则采用 有放回 的抽样方法,直到采样出K个节点。若节点邻居数大于K,则采用 无放回 的抽样。关于邻居的个数,文中提到,即两次扩展的邻居数之积小于500,大约每次只需要扩展20来个邻居时获得较高的性能。实验中也有关于邻居采样数量的对比,如下图,随着邻居抽样数量的递增,边际效益递减,而且计算时间也会增大。6.每一跳采样需要一样吗?不需要,可以分别设置每一跳的采样数量,来进一步缓解因 阶数越高涉及到的节点越多 的问题。原文中,一阶采样数是25,二阶采样数是10。这时候二阶的节点总数是250个节点,计算量大大增加。7.聚合函数的选取有什么要求?由于在图中节点的邻居是 天然无序 的,所以我们希望构造出的聚合函数是 对称 的(即改变输入的顺序,函数的输出结果不变),同时具有 较强的表达能力 (比如可以参数学习)。8.GraphSAGE论文中提供多少种聚合函数?原文中提供三种聚合函数:均值聚合pooling聚合(max-pooling/mean-pooling)LSTM聚合均值聚合的操作:把目标节点和邻居节点的特征 纵向拼接 起来 ;对拼接起来的向量进行 纵向均值化 操作 将得到的结果做一次 非线性变换 产生目标节点的向量表征。pooling聚合的操作:先对邻接节点的特征向量进行一次非线性变换;之后进行一次pooling操作(max-pooling or mean-pooling) ;将得到结果与第k-1层的目标节点的表示向量拼接 ;最后再经过一次非线性变换得到目标节点的第k层表示向量。使用LSTM聚合时需要注意什么?复杂结构的LSTM相比简单的均值操作具有更强的表达能力,然而由于LSTM函数 不是关于输入对称 的,所以在使用时需要对节点的邻居进行 乱序操作 。9.均值聚合和其他聚合函数有啥区别?除了聚合方式,最大的区别在于均值聚合 没有拼接操作 (算法1的第五行),也就是均值聚合不需要把 当前节点上一层的表征 拼接到 已聚合的邻居表征上。这一拼接操作可以简单看成不同“搜索深度”之间的“ skip connection ”(残差结构),并且能够提供显著的性能提升。10 这三种聚合方法,哪种比较好?如果按照其学习参数数量来看,LSTM > Pooling > 均值聚合。而在实验中也发现,在Reddit数据集中,LSTM和max-pooling的效果确实比均值聚合要好一些。11.一般聚合多少层?层数越多越好吗?和GCN一样,一般只需要 1~2层 就能获得比较好的结果;如果聚合3层及以上,其时间复杂度也会随着层数的增加而大幅提升,而且效果并没有什么变化。在GraphSAGE,两层比一层有10-15%的提升;但将层数设置超过2,边际效果上只有0-5%的提升,但是计算时间却变大了10-100倍。12.什么时候和GCN的聚合形式“等价”?聚合函数为 均值聚合 时,其聚合形式与GCN“近似等价”,也就是论文中提到的GraphSAGE-GCN。13.GraphSAGE怎样进行无监督学习?基本思想是:希望 邻近 的节点具有相似的向量表征,同时让 远处 的节点的表示尽可能区分。通过负采样的方法,把邻近节点作为正样本,把远处节点作为负样本,使用类似word2vec的方法进行无监督训练。GraphSAGE远近节点定义:从 节点u 出发,能够通过 随机游走 到达的节点,则是邻近节点v;其他则是远处节点 。13.GraphSAGE是怎么随机游走的?在原文中,为每个节点进行50次步长为5的随机游走,随机游走的实现方式是直接使用DeepWalk的Python代码。至于具体的实现,可以针对数据集来设计你的随机游走算法,比如考虑了权重的有偏游走。GraphSAGE在采样的时候和(带权)随机游走进行负采样的时候,考虑边的权重了。14.如果只有图、没有节点特征,能否使用GraphSAGE?原文里有一段描述:our approach can also make use of structural features that are present in all graphs (e.g., node degrees). Thus, our algorithm can also be applied to graphs without node features.所以就节点没有特征,但也可以根据其结构信息为其构建特征,比如说节点的度数等等15.训练好的GraphSAGE如何得到节点Embedding?假设GraphSAGE已经训练好,我们可以通过以下步骤来获得节点embedding训练过程则只需要将其产生的embedding扔进损失函数计算并反向梯度传播即可。对图中每个节点的邻接节点进行 采样 ,输入节点及其n阶邻接节点的特征向量根据K层的 聚合函数 聚合邻接节点的信息就产生了各节点的embedding16.minibatch的子图是怎么得到的?其实这部分看一下源码就容易理解了。下图的伪代码,就是在其前向传播之前,多了个minibatch的操作。先对所有需要计算的节点进行采样(算法2中的2~7行)。用一个字典来保存节点及其对应的邻接节点。然后训练时随机挑选n个节点作为一个batch,然后通过字典找到对应的一阶节点,进而找到二阶甚至更高阶的节点。这样一阶节点就形成一个batch,K=2时就有三个batch。抽样时的顺序是:k-->k-1--->k-2;训练时,使用迭代的方式来聚合,其顺序是:k-2-->k-1--->k。简单来说,从上到下采样,形成每一层的batch;每一次迭代都从下到上,计算k-1层batch来获得k层的节点embedding,如此类推。每一个minibatch只考虑batch里的节点的计算,不在的不考虑,所以这也是节省计算方法。在算法2的第3行中,k-1<----k,也就是说采样邻居节点时,也考虑了自身节点的信息。相当于GCN中邻接矩阵增加单位矩阵。增加了新的节点来训练,需要为所有“旧”节点重新输出embeding吗?需要。因为GraphSAGE学习到的是节点间的关系,而增加了新节点的训练,这会使得关系参数发生变化,所以旧节点也需要重新输出embedding。GraphSAGE有监督学习有什么不一样的地方吗?没有。监督学习形式根据任务的不同,直接设置目标函数即可,如最常用的节点分类任务使用交叉熵损失函数。17.那和DeepWalk、Node2vec这些有什么不一样?DeepWalk、Node2Vec这些embedding算法直接训练每个节点的embedding,本质上依然是直推式学习,而且需要大量的额外训练才能使他们能预测新的节点。同时,对于embedding的正交变换(orthogonal transformations),这些方法的目标函数是不变的,这意味着生成的向量空间在不同的图之间不是天然泛化的,在再次训练(re-training)时会产生漂移(drift)。与DeepWalk不同的是,GraphSAGE是通过聚合节点的邻接节点特征产生embedding的,而不是简单的进行一个embedding lookup操作得到。3.2 PinSAGE为例技术归纳1.PinSAGE论文中的数据集有多大?论文中涉及到的数据为20亿图片(pins),10亿画板(boards),180亿边(pins与boards连接关系)。用于训练、评估的完整数据集大概有18TB,而完整的输出embedding有4TB。2.PinSAGE使用的是什么图?在论文中,pins集合(用I表示)和boards集合(用C表示)构成了 二分图 ,即pins仅与boards相连接,pins或boards内部无连接。同时,这二分图可以更加通用:I 可以表示为 样本集 (a set of items),C 可以表示为 用户定义的上下文或集合 (a set of user-defined contexts or collections)。3.PinSAGE的任务是什么?利用pin-board 二分图的结构与节点特征 ,为pin生成高质量的embedding用于下游任务,比如pins推荐。4.和GraphSAGE相比,PinSAGE改进了什么?采样 :使用重要性采样替代GraphSAGE的均匀采样;聚合函数 :聚合函数考虑了边的权重;生产者-消费者模式的minibatch构建 :在CPU端采样节点和构建特征,构建计算图;在GPU端在这些子图上进行卷积运算;从而可以低延迟地随机游走构建子图,而不需要把整个图存在显存中。高效的MapReduce推理 :可以分布式地为百万以上的节点生成embedding,最大化地减少重复计算。这里的计算图,指的是用于卷积运算的局部图(或者叫子图),通过采样来形成;与TensorFlow等框架的计算图不是一个概念。4.PinSAGE使用多大的计算资源?训练时,PinSAGE使用32核CPU、16张Tesla K80显卡、500GB内存;推理时,MapReduce运行在378个d2.8xlarge Amazon AWS节点的Hadoop2集群。落地业务真的可怕:PinSAGE和node2vec、DeepWalk这些有啥区别?node2vec,DeepWalk是无监督训练;PinSAGE是有监督训练;node2vec,DeepWalk不能利用节点特征;PinSAGE可以;node2vec,DeepWalk这些模型的参数和节点数呈线性关系,很难应用在超大型的图上;6.PinSAGE的单层聚合过程是怎样的?和GraphSAGE一样,PinSAGE的核心就是一个 局部卷积算子 ,用来学习如何聚合邻居节点信息。PinSAGE的聚合函数叫做CONVOLVE。主要分为3部分:聚合 (第1行):k-1层邻居节点的表征经过一层DNN,然后聚合(可以考虑边的权重),是聚合函数符号,聚合函数可以是max/mean-pooling、加权求和、求平均;更新 (第2行): 拼接 第k-1层目标节点的embedding,然后再经过另一层DNN,形成目标节点新的embedding;归一化 (第3行): 归一化 目标节点新的embedding,使得训练更加稳定;而且归一化后,使用近似最近邻居搜索的效率更高。为什么要将邻居节点的聚合embedding和当前节点的拼接?因为根据T.N Kipf的GCN论文,concat的效果要比直接取平均更好。7.PinSAGE是如何采样的?如何采样这个问题从另一个角度来看就是:如何为目标节点构建邻居节点。和GraphSAGE的均匀采样不一样的是,PinSAGE使用的是重要性采样。PinSAGE对邻居节点的定义是:对目标节点 影响力最大 的T个节点。PinSAGE的邻居节点的重要性其影响力的计算方法有以下步骤:从目标节点开始随机游走;使用 正则 来计算节点的“访问次数”,得到重要性分数;目标节点的邻居节点,则是重要性分数最高的前T个节点。这个重要性分数,其实可以近似看成Personalized PageRank分数。8.重要性采样的好处是什么?和GraphSAGE一样,可以使得 邻居节点的数量固定 ,便于控制内存/显存的使用。在聚合邻居节点时,可以考虑节点的重要性;在PinSAGE实践中,使用的就是 加权平均 (weighted-mean),原文把它称作 importance pooling 。9.采样的大小是多少比较好?从PinSAGE的实验可以看出,随着邻居节点的增加,而收益会递减;并且两层GCN在 邻居数为50 时能够更好的抓取节点的邻居信息,同时保持运算效率。10.PinSAGE的minibatch和GraphSAGE区别:基本一致,但细节上有所区别。比如说:GraphSAGE聚合时就更新了embedding;PinSAGE则在聚合后需要再经过一层DNN才更新目标embedding。batch应该选多大毕竟要在大量的样本上进行训练(有上亿个节点),所以原文里使用的batch比较大,大小为512~4096。从下面表格可以看到, batch的大小为2048 时,能够在每次迭代时间、迭代次数和总训练时间上取得一个不错的综合性能。更多的就不展开了4.业务落地技巧负样本生成 首先是简单采样:在每个minibatch包含节点的范围之外随机采样500个item作为minibatch所有正样本共享的负样本集合。但考虑到实际场景中模型需要从20亿的物品item集合中识别出最相似的1000个,即要从2百万中识别出最相似的那一个,只是简单采样会导致模型分辨的粒度过粗,分辨率只到500分之一,因此增加一种“hard”负样本,即对于每个 对,和物品q有些相似但和物品i不相关的物品集合。这种样本的生成方式是将图中节点根据相对节点q的个性化PageRank分值排序,随机选取排序位置在2000~5000的物品作为“hard”负样本,以此提高模型分辨正负样本的难度。渐进式训练(Curriculum training):如果训练全程都使用hard负样本,会导致模型收敛速度减半,训练时长加倍,因此PinSage采用了一种Curriculum训练的方式,这里我理解是一种渐进式训练方法,即第一轮训练只使用简单负样本,帮助模型参数快速收敛到一个loss比较低的范围;后续训练中逐步加入hard负样本,让模型学会将很相似的物品与些微相似的区分开,方式是第n轮训练时给每个物品的负样本集合中增加n-1个hard负样本。样本的特征信息:Pinterest的业务场景中每个pin通常有一张图片和一系列的文字标注(标题,描述等),因此原始图中每个节点的特征表示由图片Embedding(4096维),文字标注Embedding(256维),以及节点在图中的度的log值拼接而成。其中图片Embedding由6层全连接的VGG-16生成,文字标注Embedding由Word2Vec训练得到。基于random walk的重要性采样:用于邻居节点采样,这一技巧在上面的算法理解部分已经讲解过,此处不再赘述。基于重要性的池化操作:这一技巧用于上一节Convolve算法中的 函数中,聚合经过一层dense层之后的邻居节点Embedding时,基于random walk计算出的节点权重做聚合操作。据论文描述,这一技巧在离线评估指标中提升了46%。on-the-fly convolutions:快速卷积操作,这个技巧主要是相对原始GCN中的卷积操作:特征矩阵与全图拉普拉斯矩阵的幂相乘。涉及到全图的都是计算量超高,这里GraphSage和PinSage都是一致地使用采样邻居节点动态构建局部计算图的方法提升训练效率,只是二者采样的方式不同。生产者消费者模式构建minibatch:这个点主要是为了提高模型训练时GPU的利用率。保存原始图结构的邻居表和数十亿节点的特征矩阵只能放在CPU内存中,GPU执行convolve卷积操作时每次从CPU取数据是很耗时的。为了解决这个问题,PinSage使用re-index技术创建当前minibatch内节点及其邻居组成的子图,同时从数十亿节点的特征矩阵中提取出该子图节点对应的特征矩阵,注意提取后的特征矩阵中的节点索引要与前面子图中的索引保持一致。这个子图的邻接列表和特征矩阵作为一个minibatch送入GPU训练,这样一来,convolve操作过程中就没有GPU与CPU的通信需求了。训练过程中CPU使用OpenMP并设计了一个producer-consumer模式,CPU负责提取特征,re-index,负采样等计算,GPU只负责模型计算。这个技巧降低了一半的训练耗时。多GPU训练超大batch:前向传播过程中,各个GPU等分minibatch,共享一套参数,反向传播时,将每个GPU中的参数梯度都聚合到一起,执行同步SGD。为了适应海量训练数据的需要,增大batchsize从512到4096。为了在超大batchsize下快速收敛保证泛化精度,采用warmup过程:在第一个epoch中将学习率线性提升到最高,后面的epoch中再逐步指数下降。使用MapReduce高效推断:模型训练完成后生成图中各个节点的Embedding过程中,如果直接使用上述PinSage的minibatch算法生成Embedding,会有大量的重复计算,如计算当前target节点的时候,其相当一部分邻居节点已经计算过Embedding了,而当这些邻居节点作为target节点的时候,当前target节点极有可能需要再重新计算一遍,这一部分的重复计算既耗时又浪费。5.总结本项目对PGL图学习系列项目进行整合方便大家后续学习,同时对图学习相关技术和业务落地侧进行归纳总结,以及对图网络开放数据集很多学者和机构发布了许多与图相关的任务。༄ℳ后续将持续更新PGL以及前沿算法和应用,敬请期待! ꦿོ࿐个人主页:https://aistudio.baidu.com/aistudio/usercenter 欢迎关注
PGL图学习之图神经网络GraphSAGE、GIN图采样算法[系列七]
0. PGL图学习之图神经网络GraphSAGE、GIN图采样算法[系列七]本项目链接:https://aistudio.baidu.com/aistudio/projectdetail/5061984?contributionType=1相关项目参考:更多资料见主页关于图计算&图学习的基础知识概览:前置知识点学习(PGL)[系列一] https://aistudio.baidu.com/aistudio/projectdetail/4982973?contributionType=1图机器学习(GML)&图神经网络(GNN)原理和代码实现(前置学习系列二):https://aistudio.baidu.com/aistudio/projectdetail/4990947?contributionType=1在图神经网络中,使用的数据集可能是亿量级的数据,而由于GPU/CPU资源有限无法一次性全图送入计算资源,需要借鉴深度学习中的mini-batch思想。传统的深度学习mini-batch训练每个batch的样本之间无依赖,多层样本计算量固定;而在图神经网络中,每个batch中的节点之间互相依赖,在计算多层时会导致计算量爆炸,因此引入了图采样的概念。GraphSAGE也是图嵌入算法中的一种。在论文Inductive Representation Learning on Large Graphs 在大图上的归纳表示学习中提出。github链接和官方介绍链接。与node2vec相比较而言,node2vec是在图的节点级别上进行嵌入,GraphSAGE则是在整个图的级别上进行嵌入。之前的网络表示学习的transductive,难以从而提出了一个inductive的GraphSAGE算法。GraphSAGE同时利用节点特征信息和结构信息得到Graph Embedding的映射,相比之前的方法,之前都是保存了映射后的结果,而GraphSAGE保存了生成embedding的映射,可扩展性更强,对于节点分类和链接预测问题的表现也比较突出。0.1提出背景现存的方法需要图中所有的顶点在训练embedding的时候都出现;这些前人的方法本质上是transductive,不能自然地泛化到未见过的顶点。文中提出了GraphSAGE,是一个inductive的框架,可以利用顶点特征信息(比如文本属性)来高效地为没有见过的顶点生成embedding。GraphSAGE是为了学习一种节点表示方法,即如何通过从一个顶点的局部邻居采样并聚合顶点特征,而不是为每个顶点训练单独的embedding。这个算法在三个inductive顶点分类benchmark上超越了那些很强的baseline。文中基于citation和Reddit帖子数据的信息图中对未见过的顶点分类,实验表明使用一个PPI(protein-protein interactions)多图数据集,算法可以泛化到完全未见过的图上。0.2 回顾GCN及其问题在大型图中,节点的低维向量embedding被证明了作为各种各样的预测和图分析任务的特征输入是非常有用的。顶点embedding最基本的基本思想是使用降维技术从高维信息中提炼一个顶点的邻居信息,存到低维向量中。这些顶点嵌入之后会作为后续的机器学习系统的输入,解决像顶点分类、聚类、链接预测这样的问题。GCN虽然能提取图中顶点的embedding,但是存在一些问题:GCN的基本思想: 把一个节点在图中的高纬度邻接信息降维到一个低维的向量表示。GCN的优点: 可以捕捉graph的全局信息,从而很好地表示node的特征。GCN的缺点: Transductive learning的方式,需要把所有节点都参与训练才能得到node embedding,无法快速得到新node的embedding。1.图采样算法1.1 GraphSage: Representation Learning on Large Graphs图采样算法:顾名思义,图采样算法就是在一张图中进行采样得到一个子图,这里的采样并不是随机采样,而是采取一些策略。典型的图采样算法包括GraphSAGE、PinSAGE等。文章码源链接:https://cs.stanford.edu/people/jure/pubs/graphsage-nips17.pdfhttps://github.com/williamleif/GraphSAGE前面 GCN 讲解的文章中,我使用的图节点个数非常少,然而在实际问题中,一张图可能节点非常多,因此就没有办法一次性把整张图送入计算资源,所以我们应该使用一种有效的采样算法,从全图中采样出一个子图 ,这样就可以进行训练了。GraphSAGE与GCN对比:既然新增的节点,一定会改变原有节点的表示,那么为什么一定要得到每个节点的一个固定的表示呢?何不直接学习一种节点的表示方法。去学习一个节点的信息是怎么通过其邻居节点的特征聚合而来的。 学习到了这样的“聚合函数”,而我们本身就已知各个节点的特征和邻居关系,我们就可以很方便地得到一个新节点的表示了。GCN等transductive的方法,学到的是每个节点的一个唯一确定的embedding; 而GraphSAGE方法学到的node embedding,是根据node的邻居关系的变化而变化的,也就是说,即使是旧的node,如果建立了一些新的link,那么其对应的embedding也会变化,而且也很方便地学到。在了解图采样算法前,我们至少应该保证采样后的子图是连通的。例如上图图中,左边采样的子图就是连通的,右边的子图不是连通的。GraphSAGE的核心:GraphSAGE不是试图学习一个图上所有node的embedding,而是学习一个为每个node产生embedding的映射。 GraphSage框架中包含两个很重要的操作:Sample采样和Aggregate聚合。这也是其名字GraphSage(Graph SAmple and aggreGatE)的由来。GraphSAGE 主要分两步:采样、聚合。GraphSAGE的采样方式是邻居采样,邻居采样的意思是在某个节点的邻居节点中选择几个节点作为原节点的一阶邻居,之后对在新采样的节点的邻居中继续选择节点作为原节点的二阶节点,以此类推。文中不是对每个顶点都训练一个单独的embeddding向量,而是训练了一组aggregator functions,这些函数学习如何从一个顶点的局部邻居聚合特征信息(见图1)。每个聚合函数从一个顶点的不同的hops或者说不同的搜索深度聚合信息。测试或是推断的时候,使用训练好的系统,通过学习到的聚合函数来对完全未见过的顶点生成embedding。GraphSAGE 是Graph SAmple and aggreGatE的缩写,其运行流程如上图所示,可以分为三个步骤:对图中每个顶点邻居顶点进行采样,因为每个节点的度是不一致的,为了计算高效, 为每个节点采样固定数量的邻居根据聚合函数聚合邻居顶点蕴含的信息得到图中各顶点的向量表示供下游任务使用邻居采样的优点:极大减少计算量允许泛化到新连接关系,个人理解类似dropout的思想,能增强模型的泛化能力采样的阶段首先选取一个点,然后随机选取这个点的一阶邻居,再以这些邻居为起点随机选择它们的一阶邻居。例如下图中,我们要预测 0 号节点,因此首先随机选择 0 号节点的一阶邻居 2、4、5,然后随机选择 2 号节点的一阶邻居 8、9;4 号节点的一阶邻居 11、12;5 号节点的一阶邻居 13、15聚合具体来说就是直接将子图从全图中抽离出来,从最边缘的节点开始,一层一层向里更新节点上图展示了邻居采样的优点,极大减少训练计算量这个是毋庸置疑的,泛化能力增强这个可能不太好理解,因为原本要更新一个节点需要它周围的所有邻居,而通过邻居采样之后,每个节点就不是由所有的邻居来更新它,而是部分邻居节点,所以具有比较强的泛化能力。1.1.1 论文角度看GraphSage聚合函数的选取在图中顶点的邻居是无序的,所以希望构造出的聚合函数是对称的(即也就是对它输入的各种排列,函数的输出结果不变),同时具有较高的表达能力。 聚合函数的对称性(symmetry property)确保了神经网络模型可以被训练且可以应用于任意顺序的顶点邻居特征集合上。a. Mean aggregator :mean aggregator将目标顶点和邻居顶点的第$k−1$层向量拼接起来,然后对向量的每个维度进行求均值的操作,将得到的结果做一次非线性变换产生目标顶点的第$k$层表示向量。卷积聚合器Convolutional aggregator:文中用下面的式子替换算法1中的4行和5行得到GCN的inductive变形:$$ \mathbf{h}_{v}^{k} \leftarrow \sigma\left(\mathbf{W} \cdot \operatorname{MEAN}\left(\left\{\mathbf{h}_{v}^{k-1}\right\} \cup\left\{\mathbf{h}_{u}^{k-1}, \forall u \in \mathcal{N}(v)\right\}\right)\right) $$ 原始算法1中的第4,5行是 $$\begin{array}{l} \mathbf{h}_{\mathcal{N}(v)}^{k} \leftarrow \operatorname{AGGREGATE}_{k}\left(\left\{\mathbf{h}_{u}^{k-1}, \forall u \in \mathcal{N}(v)\right\}\right) \\ \mathbf{h}_{v}^{k} \leftarrow \sigma\left(\mathbf{W}^{k} \cdot \operatorname{CONCAT}\left(\mathbf{h}_{v}^{k-1}, \mathbf{h}_{\mathcal{N}(v)}^{k}\right)\right) \end{array}$$ **论文提出的均值聚合器Mean aggregator:** $$\begin{array}{l} \mathbf{h}_{v}^{k} \leftarrow \sigma\left(\mathbf{W} \cdot \operatorname{MEAN}\left(\left\{\mathbf{h}_{v}^{k-1}\right\} \cup\left\{\mathbf{h}_{u}^{k-1}, \forall u \in \mathcal{N}(v)\right\}\right)\right) \\ \mathbf{h}_{v}^{k} \leftarrow \sigma\left(\mathbf{W}^{k} \cdot \operatorname{CONCAT}\left(\mathbf{h}_{v}^{k-1}, \mathbf{h}_{\mathcal{N}(v)}^{k}\right)\right) \end{array}$$ * 均值聚合近似等价在transducttive GCN框架中的卷积传播规则 * 这个修改后的基于均值的聚合器是convolutional的。但是这个卷积聚合器和文中的其他聚合器的重要不同在于它没有算法1中第5行的CONCAT操作——卷积聚合器没有将顶点前一层的表示$\mathbf{h}^{k-1}_{v}$聚合的邻居向量$\mathbf{h}^k_{\mathcal{N}(v)}$拼接起来 * 拼接操作可以看作一个是GraphSAGE算法在不同的搜索深度或层之间的简单的**skip connection**[Identity mappings in deep residual networks]的形式,它使得模型的表征性能获得了巨大的提升 * 举个简单例子,比如一个节点的3个邻居的embedding分别为[1,2,3,4],[2,3,4,5],[3,4,5,6]按照每一维分别求均值就得到了聚合后的邻居embedding为[2,3,4,5] **b. LSTM aggregator** 文中也测试了一个基于LSTM的复杂的聚合器[Long short-term memory]。和均值聚合器相比,LSTMs有更强的表达能力。但是,LSTMs不是对称的(symmetric),也就是说不具有排列不变性(permutation invariant),因为它们以一个序列的方式处理输入。因此,需要先对邻居节点**随机顺序**,然后将邻居序列的embedding作为LSTM的输入。 * 排列不变性(permutation invariance):指输入的顺序改变不会影响输出的值。 **c. Pooling aggregator** pooling聚合器,它既是对称的,又是可训练的。Pooling aggregator 先对目标顶点的邻居顶点的embedding向量进行一次非线性变换,之后进行一次pooling操作(max pooling or mean pooling),将得到结果与目标顶点的表示向量拼接,最后再经过一次非线性变换得到目标顶点的第k层表示向量。 一个element-wise max pooling操作应用在邻居集合上来聚合信息: $$\begin{aligned} \mathbf{h}_{\mathcal{N}(v)}^{k}=& \mathrm{AGGREGATE}_{k}^{\text {pool}}=\max \left(\left\{\sigma\left(\mathbf{W}_{\text {pool}} \mathbf{h}_{u}^{k-1}+\mathbf{b}\right), \forall u \in \mathcal{N}(v)\right\}\right) \\ &\mathbf{h}_{v}^{k} \leftarrow \sigma\left(\mathbf{W}^{k} \cdot \operatorname{CONCAT}\left(\mathbf{h}_{v}^{k-1}, \mathbf{h}_{\mathcal{N}(v)}^{k}\right)\right) \end{aligned}$$ * $max$表示element-wise最大值操作,取每个特征的最大值 * $\sigma$是非线性激活函数 * 所有相邻节点的向量共享权重,先经过一个非线性全连接层,然后做max-pooling * 按维度应用 max/mean pooling,可以捕获邻居集上在某一个维度的突出的/综合的表现。 #### (有监督和无监督)参数学习 在定义好聚合函数之后,接下来就是对函数中的参数进行学习。文章分别介绍了无监督学习和监督学习两种方式。 **基于图的无监督损失** 基于图的损失函数倾向于使得相邻的顶点有相似的表示,但这会使相互远离的顶点的表示差异变大: $$J \mathcal{G}\left(\mathbf{z}_{u}\right)=-\log \left(\sigma\left(\mathbf{z}_{u}^{T} \mathbf{z}_{v}\right)\right)-Q \cdot \mathbb{E}_{v_{n} \sim P_{n}(v)} \log \left(\sigma\left(-\mathbf{z}_{u}^{T} \mathbf{z}_{v_{n}}\right)\right)$$ * $\mathbf{z}_{u}$为节点$u$通过GraphSAGE生成的embedding * 节点$v$是节点$u$随机游走到达的“邻居” * $\sigma$是sigmoid函数 * $P_{n}$是负采样的概率分布,类似word2vec中的负采样 * $Q$是负样本的数目 * embedding之间相似度通过向量点积计算得到 文中输入到损失函数的表示$\mathbf{z}_u$是从包含一个顶点局部邻居的特征生成出来的,而不像之前的那些方法(如DeepWalk),对每个顶点训练一个独一无二的embedding,然后简单进行一个embedding查找操作得到。 **基于图的有监督损失** 无监督损失函数的设定来学习节点embedding 可以供下游多个任务使用。监督学习形式根据任务的不同直接设置目标函数即可,如最常用的节点分类任务使用交叉熵损失函数。 **参数学习** 通过前向传播得到节点$u$的embedding $z_u$,然后梯度下降(实现使用Adam优化器) 进行反向传播优化参数$\mathbf{W}^{k}$和聚合函数内的参数。 **新节点embedding的生成** 这个$\mathbf{W}^{k}$ 就是所谓的dynamic embedding的核心,因为保存下来了从节点原始的高维特征生成低维embedding的方式。现在,如果想得到一个点的embedding,只需要输入节点的特征向量,经过卷积(利用已经训练好的 $\mathbf{W}^{k}$ 以及特定聚合函数聚合neighbor的属性信息),就产生了节点的embedding。 **有了GCN为啥还要GraphSAGE?** GCN灵活性差、为新节点产生embedding要求 额外的操作 ,比如“对齐”: GCN是 直推式(transductive) 学习,无法直接泛化到新加入(未见过)的节点; GraphSAGE是 归纳式(inductive) 学习,可以为新节点输出节点特征。 GCN输出固定: GCN输出的是节点 唯一确定 的embedding; GraphSAGE学习的是节点和邻接节点之间的关系,学习到的是一种 映射关系 ,节点的embedding可以随着其邻接节点的变化而变化。 GCN很难应用在超大图上: 无论是拉普拉斯计算还是图卷积过程,因为GCN其需要对 整张图 进行计算,所以计算量会随着节点数的增加而递增。 GraphSAGE通过采样,能够形成 minibatch 来进行批训练,能用在超大图上 **GraphSAGE有什么优点?** 采用 归纳学习 的方式,学习邻居节点特征关系,得到泛化性更强的embedding; 采样技术,降低空间复杂度,便于构建minibatch用于 批训练 ,还让模型具有更好的泛化性; 多样的聚合函数 ,对于不同的数据集/场景可以选用不同的聚合方式,使得模型更加灵活。 **采样数大于邻接节点数怎么办?** 设采样数量为K: 若节点邻居数少于K,则采用 有放回 的抽样方法,直到采样出K个节点。 若节点邻居数大于K,则采用 无放回 的抽样。 **训练好的GraphSAGE如何得到节点Embedding?** 假设GraphSAGE已经训练好,我们可以通过以下步骤来获得节点embedding,具体算法请看下图的算法1。 训练过程则只需要将其产生的embedding扔进损失函数计算并反向梯度传播即可。 对图中每个节点的邻接节点进行 采样 ,输入节点及其n阶邻接节点的特征向量 根据K层的 聚合函数 聚合邻接节点的信息 就产生了各节点的embedding  **minibatch的子图是怎么得到的?**  那**和DeepWalk、Node2vec这些有什么不一样?** DeepWalk、Node2Vec这些embedding算法直接训练每个节点的embedding,本质上依然是直推式学习,而且需要大量的额外训练才能使他们能预测新的节点。同时,对于embedding的正交变换(orthogonal transformations),这些方法的目标函数是不变的,这意味着生成的向量空间在不同的图之间不是天然泛化的,在再次训练(re-training)时会产生漂移(drift)。 与DeepWalk不同的是,GraphSAGE是通过聚合节点的邻接节点特征产生embedding的,而不是简单的进行一个embedding lookup操作得到。 论文仿真结果: 实验对比了四个基线:随机分类,基于特征的逻辑回归(忽略图结构),DeepWalk算法,DeepWork+特征;同时还对比了四种GraphSAGE,其中三种在3.3节中已经说明,GraphSAGE-GCN是GCNs的归纳版本。具体超参数为:K=2,s1=25,s2=10。程序使用TensorFlow编写,Adam优化器。 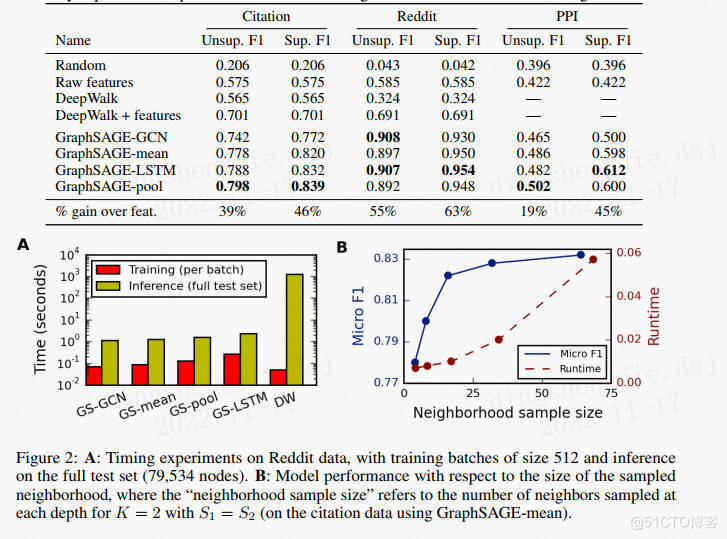 对于跨图泛化的任务,需要学习节点角色而不是训练图的结构。使用跨各种生物蛋白质-蛋白质相互作用(PPI)图,对蛋白质功能进行分类。在20个图表上训练算法,2个图用于测试,2个图用于验证,平均每图包含2373个节点,平均度为28.8。从实验结果可以看出LSTM和池化方法比Mean和GCN效果更好。 对比不同聚合函数: 如表-1所示,LSTM和POOL方法效果最好,与其它方法相比有显著差异,LSTM和POOL之间无显著差异,但LSTM比POOL慢得多(≈2x),使POOL聚合器在总体上略有优势。 ### 1.1.2 更多问题 为什么要采样? 采样数大于邻接节点数怎么办? 采样的邻居节点数应该选取多大? 每一跳采样需要一样吗? 适合有向边吗? 采样是随机的吗? 聚合函数的选取有什么要求? GraphSAGE论文中提供多少种聚合函数? 均值聚合的操作是怎样的? pooling聚合的操作是怎样的? 使用LSTM聚合时需要注意什么? 均值聚合和其他聚合函数有啥区别? max-和mean-pooling有什么区别? 这三种聚合方法,哪种比较好? 一般聚合多少层?层数越多越好吗? 什么时候和GCN的聚合形式“等价”? 参考链接:https://zhuanlan.zhihu.com/p/184991506 https://blog.csdn.net/yyl424525/article/details/100532849 ## 1.2 PinSAGE 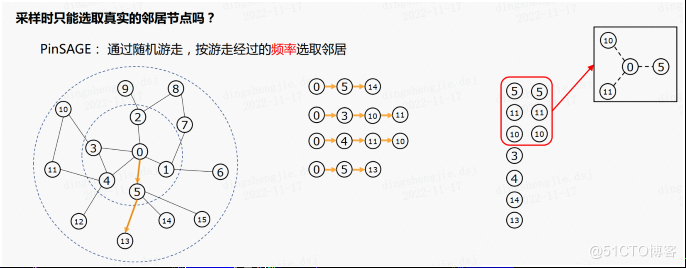 采样时只能选取真实的邻居节点吗?如果构建的是一个与虚拟邻居相连的子图有什么优点?PinSAGE 算法将会给我们解答,PinSAGE 算法通过多次随机游走,按游走经过的频率选取邻居,上图右侧为进行随机游走得到的节点序列,统计序列的频数可以发现节点5,10,11的频数为2,其余为1,当我们希望采样三个节点时,我们选取5,10,11作为0号节点的虚拟邻居。之后如果希望得到0号节点的二阶虚拟邻居则在已采样的节点继续进行随机游走即可。 回到上述问题,采样时选取虚拟邻居有什么好处?**这种采样方式的好处是我们能更快的聚合到远处节点的信息。**。实际上如果是按照 GraphSAGE 算法的方式生成子图,在聚合的过程中,非一阶邻居的信息可以通过消息传递逐渐传到中心,但是随着距离的增大,离中心越远的节点,其信息在传递过程中就越困难,甚至可能无法传递到;如果按照 PinSAGE 算法的方式生成子图,有一定的概率可以将非一阶邻居与中心直接相连,这样就可以快速聚合到多阶邻居的信息 ### 1.2.1论文角度看PinSAGE 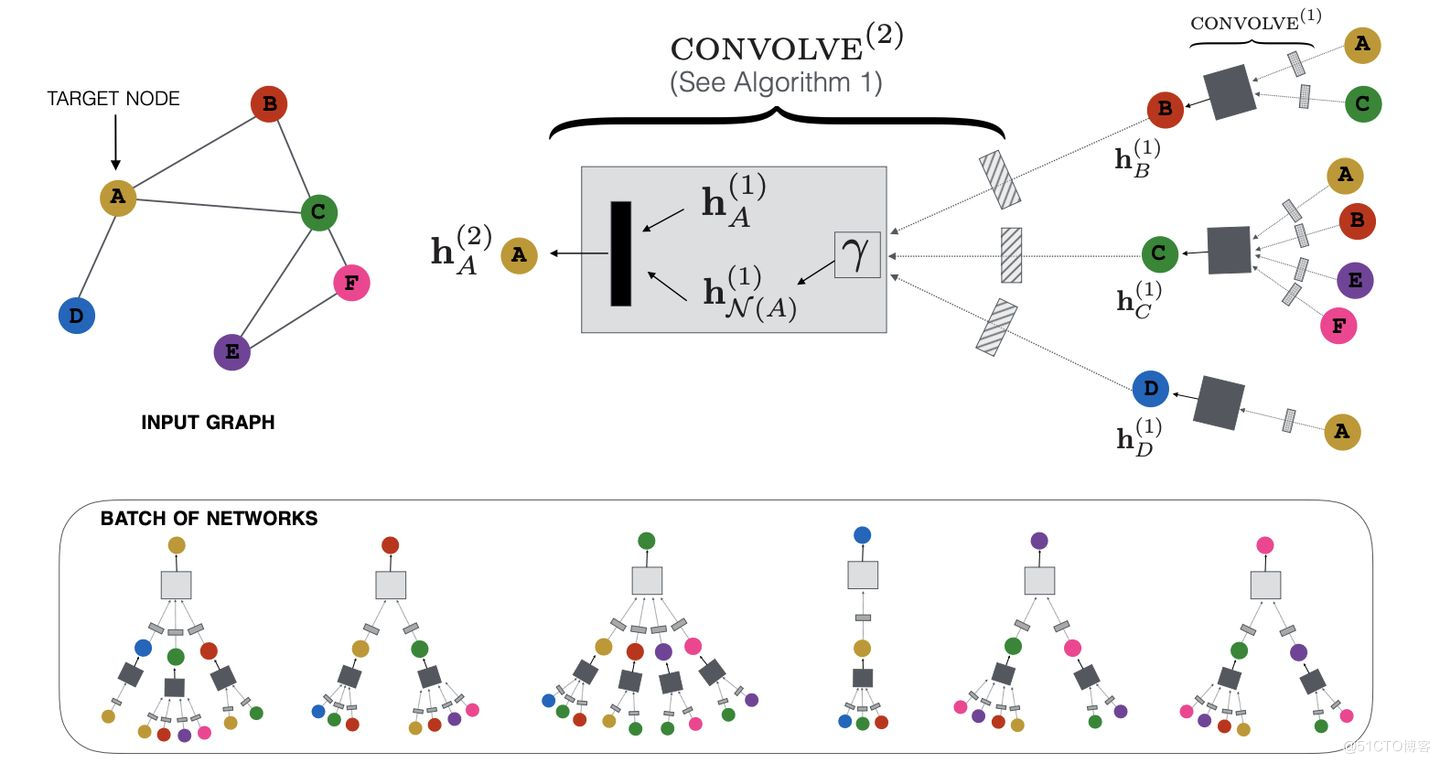 **和GraphSAGE相比,PinSAGE改进了什么?** * 采样 :使用重要性采样替代GraphSAGE的均匀采样; * 聚合函数 :聚合函数考虑了边的权重; * 生产者-消费者模式的minibatch构建 :在CPU端采样节点和构建特征,构建计算图;在GPU端在这些子图上进行卷积运算;从而可以低延迟地随机游走构建子图,而不需要把整个图存在显存中。 * 高效的MapReduce推理 :可以分布式地为百万以上的节点生成embedding,最大化地减少重复计算。 这里的计算图,指的是用于卷积运算的局部图(或者叫子图),通过采样来形成;与TensorFlow等框架的计算图不是一个概念。 **PinSAGE使用多大的计算资源?** 训练时,PinSAGE使用32核CPU、16张Tesla K80显卡、500GB内存; 推理时,MapReduce运行在378个d2.8xlarge Amazon AWS节点的Hadoop2集群。 **PinSAGE和node2vec、DeepWalk这些有啥区别?** node2vec,DeepWalk是无监督训练;PinSAGE是有监督训练; node2vec,DeepWalk不能利用节点特征;PinSAGE可以; node2vec,DeepWalk这些模型的参数和节点数呈线性关系,很难应用在超大型的图上; **PinSAGE的单层聚合过程是怎样的?** 和GraphSAGE一样,PinSAGE的核心就是一个 局部卷积算子 ,用来学习如何聚合邻居节点信息。 如下图算法1所示,PinSAGE的聚合函数叫做CONVOLVE。主要分为3部分: * 聚合 (第1行):k-1层邻居节点的表征经过一层DNN,然后聚合(可以考虑边的权重),是聚合函数符号,聚合函数可以是max/mean-pooling、加权求和、求平均; * 更新 (第2行): 拼接 第k-1层目标节点的embedding,然后再经过另一层DNN,形成目标节点新的embedding; * 归一化 (第3行): 归一化 目标节点新的embedding,使得训练更加稳定;而且归一化后,使用近似最近邻居搜索的效率更高。  **PinSAGE是如何采样的?** 如何采样这个问题从另一个角度来看就是:如何为目标节点构建邻居节点。 和GraphSAGE的均匀采样不一样的是,PinSAGE使用的是重要性采样。 PinSAGE对邻居节点的定义是:对目标节点 影响力最大 的T个节点。 **PinSAGE的邻居节点的重要性是如何计算的?** 其影响力的计算方法有以下步骤: 从目标节点开始随机游走; 使用 正则 来计算节点的“访问次数”,得到重要性分数; 目标节点的邻居节点,则是重要性分数最高的前T个节点。 这个重要性分数,其实可以近似看成Personalized PageRank分数。 关于随机游走,可以阅读《Pixie: A System for Recommending 3+ Billion Items to 200+ Million Users in Real-Time》 **重要性采样的好处是什么?** 和GraphSAGE一样,可以使得 邻居节点的数量固定 ,便于控制内存/显存的使用。 在聚合邻居节点时,可以考虑节点的重要性;在PinSAGE实践中,使用的就是 加权平均 (weighted-mean),原文把它称作 importance pooling 。 **采样的大小是多少比较好?** 从PinSAGE的实验可以看出,随着邻居节点的增加,而收益会递减; 并且两层GCN在 邻居数为50 时能够更好的抓取节点的邻居信息,同时保持运算效率。 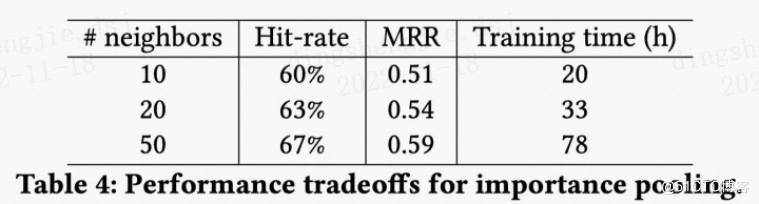 **PinSage论文中还介绍了落地过程中采用的大量工程技巧。** 1. **负样本生成**:首先是简单采样:在每个minibatch包含节点的范围之外随机采样500个item作为minibatch所有正样本共享的负样本集合。但考虑到实际场景中模型需要从20亿的物品item集合中识别出最相似的1000个,即要从2百万中识别出最相似的那一个,只是简单采样会导致模型分辨的粒度过粗,分辨率只到500分之一,因此增加一种“hard”负样本,即对于每个 对,和物品q有些相似但和物品i不相关的物品集合。这种样本的生成方式是将图中节点根据相对节点q的个性化PageRank分值排序,随机选取排序位置在2000~5000的物品作为“hard”负样本,以此提高模型分辨正负样本的难度。 2. **渐进式训练(Curriculum training**:如果训练全程都使用hard负样本,会导致模型收敛速度减半,训练时长加倍,因此PinSage采用了一种Curriculum训练的方式,这里我理解是一种渐进式训练方法,即第一轮训练只使用简单负样本,帮助模型参数快速收敛到一个loss比较低的范围;后续训练中逐步加入hard负样本,让模型学会将很相似的物品与些微相似的区分开,方式是第n轮训练时给每个物品的负样本集合中增加n-1个hard负样本。 3. **样本的特征信息**:Pinterest的业务场景中每个pin通常有一张图片和一系列的文字标注(标题,描述等),因此原始图中每个节点的特征表示由图片Embedding(4096维),文字标注Embedding(256维),以及节点在图中的度的log值拼接而成。其中图片Embedding由6层全连接的VGG-16生成,文字标注Embedding由Word2Vec训练得到。 4. **基于random walk的重要性采样**:用于邻居节点采样,这一技巧在上面的算法理解部分已经讲解过,此处不再赘述。 5. **基于重要性的池化操作**:这一技巧用于上一节Convolve算法中的 函数中,聚合经过一层dense层之后的邻居节点Embedding时,基于random walk计算出的节点权重做聚合操作。据论文描述,这一技巧在离线评估指标中提升了46%。 6. **on-the-fly convolutions:快速卷积操作**,这个技巧主要是相对原始GCN中的卷积操作:特征矩阵与全图拉普拉斯矩阵的幂相乘。涉及到全图的都是计算量超高,这里GraphSage和PinSage都是一致地使用采样邻居节点动态构建局部计算图的方法提升训练效率,只是二者采样的方式不同。 7. **生产者消费者模式构建minibatch**:这个点主要是为了提高模型训练时GPU的利用率。保存原始图结构的邻居表和数十亿节点的特征矩阵只能放在CPU内存中,GPU执行convolve卷积操作时每次从CPU取数据是很耗时的。为了解决这个问题,PinSage使用re-index技术创建当前minibatch内节点及其邻居组成的子图,同时从数十亿节点的特征矩阵中提取出该子图节点对应的特征矩阵,注意提取后的特征矩阵中的节点索引要与前面子图中的索引保持一致。这个子图的邻接列表和特征矩阵作为一个minibatch送入GPU训练,这样一来,convolve操作过程中就没有GPU与CPU的通信需求了。训练过程中CPU使用OpenMP并设计了一个producer-consumer模式,CPU负责提取特征,re-index,负采样等计算,GPU只负责模型计算。这个技巧降低了一半的训练耗时。 8. **多GPU训练超大batch**:前向传播过程中,各个GPU等分minibatch,共享一套参数,反向传播时,将每个GPU中的参数梯度都聚合到一起,执行同步SGD。为了适应海量训练数据的需要,增大batchsize从512到4096。为了在超大batchsize下快速收敛保证泛化精度,采用warmup过程:在第一个epoch中将学习率线性提升到最高,后面的epoch中再逐步指数下降。 9. **使用MapReduce高效推断**:模型训练完成后生成图中各个节点的Embedding过程中,如果直接使用上述PinSage的minibatch算法生Embedding,会有大量的重复计算,如计算当前target节点的时候,其相当一部分邻居节点已经计算过Embedding了,而当这些邻居节点作为target节点的时候,当前target节点极有可能需要再重新计算一遍,这一部分的重复计算既耗时又浪费。 ### 1.2.2更多问题 PinSAGE的单层聚合过程是怎样的? 为什么要将邻居节点的聚合embedding和当前节点的拼接? PinSAGE是如何采样的? PinSAGE的邻居节点的重要性是如何计算的? 重要性采样的好处是什么? 采样的大小是多少比较好? MiniBatch PinSAGE的minibatch和GraphSAGE有啥不一样? batch应该选多大? PinSAGE使用什么损失函数? PinSAGE如何定义标签(正例/负例)? PinSAGE用什么方法提高模型训练的鲁棒性和收敛性? PinSAGE如何进行负采样? 训练时简单地负采样,会有什么问题? 如何解决简单负采样带来的问题? 如果只使用“hard”负样本,会有什么问题? 如何解决只使用“hard”负采样带来的问题? 如何区分采样、负采样、”hard“负采样? 直接为使用训练好的模型产生embedding有啥问题? 如何解决推理时重复计算的问题? 下游任务如何应用PinSAGE产生的embedding? 如何为用户进行个性化推荐? 工程性技巧 pin样本的特征如何构建? board样本的特征如何构建? 如何使用多GPU并行训练PinSAGE? PinSAGE为什么要使用生产者-消费者模式? PinSAGE是如何使用生产者-消费者模式? https://zhuanlan.zhihu.com/p/195735468 https://zhuanlan.zhihu.com/p/133739758?utm_source=wechat_session&utm_id=0 ## 1.3 小结 学习大图、不断扩展的图,未见过节点的表征,是一个很常见的应用场景。GraphSAGE通过训练聚合函数,实现优化未知节点的表示方法。之后提出的GAN(图注意力网络)也针对此问题优化。 论文中提出了:传导性问题和归纳性问题,传导性问题是已知全图情况,计算节点表征向量;归纳性问题是在不完全了解全图的情况下,训练节点的表征函数(不是直接计算向量表示)。 图工具的处理过程每轮迭代( 一次propagation)一般都包含:收集信息、聚合、更新,从本文也可以更好地理解,其中聚合的重要性,及优化方法。 GraohSage主要贡献如下: * 针对问题:大图的节点表征 * 结果:训练出的模型可应用于表征没见过的节点 * 核心方法:改进图卷积方法;从邻居节点中采样;考虑了节点特征,加入更复杂的特征聚合方法 一般情况下一个节点的表式通过聚合它k跳之内的邻近节点计算,而全图的表示则通过对所有节点的池化计算。GIN使用了WL-test方法,即图同构测试,它是一个区分网络结构的强效方法,也是通过迭代聚合邻居的方法来更新节点,它的强大在于使用了injective(见后)聚合更新方法。而这里要评测GNN是否能达到类似WL-test的效果。文中还使用了多合集multiset的概念,指可能包含重复元素的集合。 GIN主要贡献如下: * 展示了GNN模型可达到与WL-test类似的图结构区分效果 * 设计了聚合函数和Readout函数,使GNN能达到更好的区分效果 * 发现GCN及GraphSAGE无法很好表达图结构,而GNN可以 * 开发了简单的网络结构GIN(图同构网络),它的区分和表示能力与WL-test类似。 # 2.邻居聚合 在图采样之后,我们需要进行邻居聚合的操作。经典的邻居聚合函数包括取平均、取最大值、求和。 评估聚合表达能力的指标——单射(一对一映射),在上述三种经典聚合函数中,取平均倾向于学习分布,取最大值倾向于忽略重复值,这两个不属于单射,而求和能够保留邻居节点的完整信息,是单射。单射的好处是可以保证对聚合后的结果可区分。  ## 2.1 GIN模型的聚合函数 Graph Isomorphic Net(GIN)的聚合部分是基于单射的。 如上图所示,GIN的聚合函数使用的是求和函数,它特殊的一点是在中心节点加了一个自连边(自环),之后对自连边进行加权。 这样做的好处是即使我们调换了中心节点和邻居节点,得到的聚合结果依旧是不同的。所以带权重的自连边能够保证中心节点和邻居节点可区分。 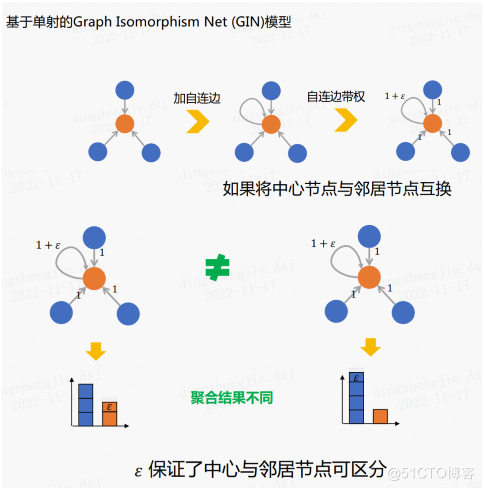 ## 2.2其他复杂的聚合函数 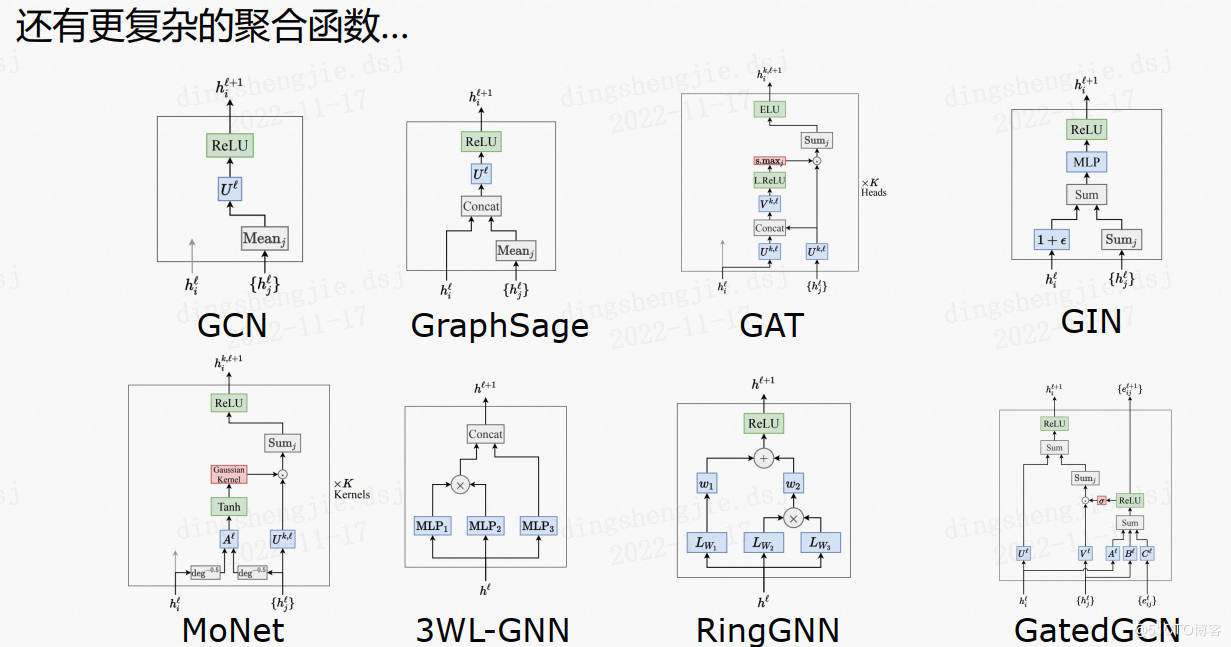 ## 2.3 令居聚合语义场景 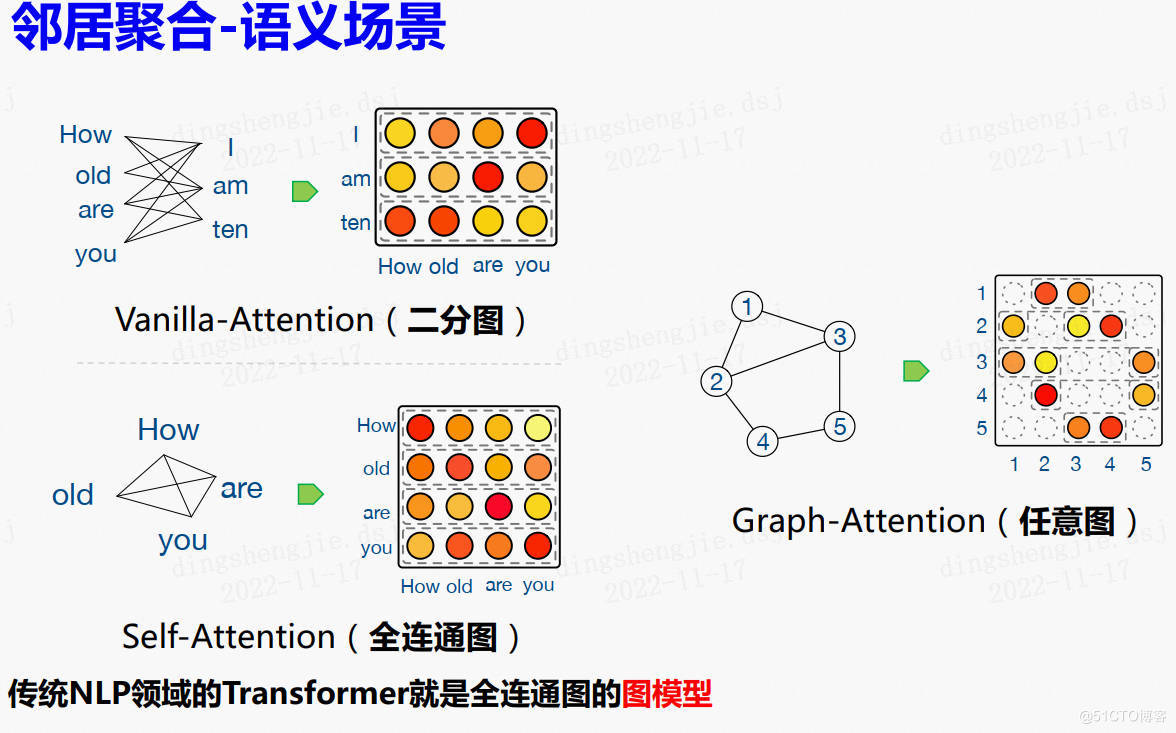 # 3.数据集介绍 数据源:http://snap.stanford.edu/graphsage/ 斯坦福 ## 3.1 Citation数据集 使用科学网引文数据集,将学术论文分类为不同的主题。数据集共包含302424个节点,平均度9.15,使用2000-2004年数据作为训练集,2005年数据作为测试集。使用节点的度以及论文摘要的句嵌入作为特征。 ## 3.2 Reddit数据集 https://aistudio.baidu.com/aistudio/datasetdetail/177810 将Reddit帖子归类为属于不同社区。数据集包含232965个帖子,平均度为492。使用现成的300维GloVe Common Crawl单词向量;对于每个帖子,使用特征包含:(1) 帖子标题的平均嵌入 (2) 帖子所有评论的平均嵌入 (3) 帖子的分数 (4)帖子的评论数量 为了对社区进行抽样,根据 2014 年的评论总数对社区进行了排名,并选择了排名 [11,50](含)的社区。省略了最大的社区,因为它们是大型的通用默认社区,大大扭曲了类分布。选择了在这些社区的联合上定义的图中最大的连通分量。 更多数据资料见: http://files.pushshift.io/reddit/comments/ https://github.com/dingidng/reddit-dataset  最新数据已经更新到2022.10了 ## 3.3 PPI(Protein–protein interactions)蛋白质交互作用 https://aistudio.baidu.com/aistudio/datasetdetail/177807 PPI 网络是蛋白质相互作用(Protein-Protein Interaction,PPI)网络的简称,在GCN中主要用于节点分类任务 PPI是指两种或以上的蛋白质结合的过程,通常旨在执行其生化功能。 一般地,如果两个蛋白质共同参与一个生命过程或者协同完成某一功能,都被看作这两个蛋白质之间存在相互作用。多个蛋白质之间的复杂的相互作用关系可以用PPI网络来描述。 PPI数据集共24张图,每张图对应不同的人体组织,平均每张图有2371个节点,共56944个节点818716条边,每个节点特征长度为50,其中包含位置基因集,基序集和免疫学特征。基因本体基作为label(总共121个),label不是one-hot编码。 * alid_feats.npy文件保存节点的特征,shape为(56944, 50)(节点数目,特征维度),值为0或1,且1的数目稀少 * ppi-class_map.json为节点的label文件,shape为(121, 56944),每个节点的label为121维 * ppi-G.json文件为节点和链接的描述信息,节点:{"test": true, "id": 56708, "val": false}, 表示节点id为56708的节点是否为test集或者val集,链接:"links": [{"source": 0, "target": 372}, {"source": 0, "target": 1101}, 表示节点id为0的节点和为1101的节点之间有links, * ppi-walks.txt文件中为链接信息 * ppi-id_map.json文件为节点id信息 参考链接: https://blog.csdn.net/ziqingnian/article/details/112979175 # 4 基于PGL算法实践 ## 4.1 GraphSAGE GraphSAGE是一个通用的归纳框架,它利用节点特征信息(例如,文本属性)为以前看不见的数据有效地生成节点嵌入。GraphSAGE 不是为每个节点训练单独的嵌入,而是学习一个函数,该函数通过从节点的本地邻域中采样和聚合特征来生成嵌入。基于PGL,我们重现了GraphSAGE算法,在Reddit Dataset中达到了与论文同等水平的指标。此外,这是PGL中子图采样和训练的一个例子。 epoch: Number of epochs default (10) normalize: Normalize the input feature if assign normalize. sample_workers: The number of workers for multiprocessing subgraph sample. lr: Learning rate. symmetry: Make the edges symmetric if assign symmetry. batch_size: Batch size. samples: The max neighbors for each layers hop neighbor sampling. (default: [25, 10]) hidden_size: The hidden size of the GraphSAGE models. parser = argparse.ArgumentParser(description='graphsage') parser.add_argument( "--normalize", action='store_true', help="normalize features") # normalize:归一化节点特征 parser.add_argument( "--symmetry", action='store_true', help="undirect graph") # symmetry:聚合函数的对称性 parser.add_argument("--sample_workers", type=int, default=5) # sample_workers:多线程数据读取器的线程个数 parser.add_argument("--epoch", type=int, default=10) parser.add_argument("--hidden_size", type=int, default=128) parser.add_argument("--batch_size", type=int, default=128) parser.add_argument("--lr", type=float, default=0.01) parser.add_argument('--samples', nargs='+', type=int, default=[25, 10]) # samples_1:第一级邻居采样时候选择的最大邻居个数(默认25)#,samples_2:第而级邻居采样时候选择的最大邻居个数(默认10) 部分结果展示: [INFO] 2022-11-18 16:45:44,177 [ train.py: 63]: Batch 800 train-Loss [0.5213774] train-Acc [0.9140625] [INFO] 2022-11-18 16:45:45,783 [ train.py: 63]: Batch 900 train-Loss [0.65641916] train-Acc [0.875] [INFO] 2022-11-18 16:45:47,385 [ train.py: 63]: Batch 1000 train-Loss [0.57411766] train-Acc [0.921875] [INFO] 2022-11-18 16:45:48,977 [ train.py: 63]: Batch 1100 train-Loss [0.68337256] train-Acc [0.890625] [INFO] 2022-11-18 16:45:50,434 [ train.py: 160]: Runing epoch:9 train_loss:[0.58635516] train_acc:[0.90786038] [INFO] 2022-11-18 16:45:57,836 [ train.py: 165]: Runing epoch:9 val_loss:0.55885834 val_acc:0.9139818 [INFO] 2022-11-18 16:46:05,259 [ train.py: 169]: Runing epoch:9 test_loss:0.5578749 test_acc:0.91468066 100%|███████████████████████████████████████████| 10/10 [06:02<00:00, 36.29s/it] [INFO] 2022-11-18 16:46:05,260 [ train.py: 172]: Runs 0: Model: graphsage Best Test Accuracy: 0.918849 目前官网最佳性能是95.7%,我这里没有调参 | Aggregator | Accuracy_me_10 epochs | Accuracy_200 epochs|Reported in paper_200 epochs| | -------- | -------- | -------- |-------- | | Mean | 91.88% | 95.70% | 95.0% | 其余聚合器下官网和论文性能对比: | Aggregator | Accuracy_200 epochs|Reported in paper_200 epochs| | -------- | -------- |-------- | | Meanpool | 95.60% | 94.8% | | Maxpool | 94.95% | 94.8% | | LSTM | 95.13% | 95.4% | ## 4.2 Graph Isomorphism Network (GIN) 图同构网络(GIN)是一个简单的图神经网络,期望达到Weisfeiler-Lehman图同构测试的能力。基于 PGL重现了 GIN 模型。 * data_path:数据集的根路径 * dataset_name:数据集的名称 * fold_idx:拆分的数据集折叠。这里我们使用10折交叉验证 * train_eps:是否参数是可学习的。 parser.add_argument('--data_path', type=str, default='./gin_data') parser.add_argument('--dataset_name', type=str, default='MUTAG') parser.add_argument('--batch_size', type=int, default=32) parser.add_argument('--fold_idx', type=int, default=0) parser.add_argument('--output_path', type=str, default='./outputs/') parser.add_argument('--use_cuda', action='store_true') parser.add_argument('--num_layers', type=int, default=5) parser.add_argument('--num_mlp_layers', type=int, default=2) parser.add_argument('--feat_size', type=int, default=64) parser.add_argument('--hidden_size', type=int, default=64) parser.add_argument( '--pool_type', type=str, default="sum", choices=["sum", "average", "max"]) parser.add_argument('--train_eps', action='store_true') parser.add_argument('--init_eps', type=float, default=0.0) parser.add_argument('--epochs', type=int, default=350) parser.add_argument('--lr', type=float, default=0.01) parser.add_argument('--dropout_prob', type=float, default=0.5) parser.add_argument('--seed', type=int, default=0) args = parser.parse_args() GIN github代码复现含数据集下载:How Powerful are Graph Neural Networks? [https://github.com/weihua916/powerful-gnns](https://github.com/weihua916/powerful-gnns) https://github.com/weihua916/powerful-gnns/blob/master/dataset.zip 论文使用 9 个图形分类基准:**4 个生物信息学数据集(MUTAG、PTC、NCI1、PROTEINS)** 和 **5 个社交网络数据集(COLLAB、IMDB-BINARY、IMDB-MULTI、REDDITBINARY 和 REDDIT-MULTI5K)(Yanardag & Vishwanathan,2015)**。 重要的是,我目标不是让模型依赖输入节点特征,而是主要从网络结构中学习。因此,在生物信息图中,节点具有分类输入特征,但在社交网络中,它们没有特征。 对于社交网络,按如下方式创建节点特征:对于 REDDIT 数据集,将所有节点特征向量设置为相同(因此,这里的特征是无信息的); 对于其他社交图,我们使用节点度数的 one-hot 编码。 **社交网络数据集。** * IMDB-BINARY 和 IMDB-MULTI 是电影协作数据集。每个图对应于每个演员/女演员的自我网络,其中节点对应于演员/女演员,如果两个演员/女演员出现在同一部电影中,则在两个演员/女演员之间绘制一条边。每个图都是从预先指定的电影类型派生的,任务是对其派生的类型图进行分类。 * REDDIT-BINARY 和 REDDIT-MULTI5K 是平衡数据集,其中每个图表对应一个在线讨论线程,节点对应于用户。如果其中至少一个节点回应了另一个节点的评论,则在两个节点之间绘制一条边。任务是将每个图分类到它所属的社区或子版块。 * COLLAB 是一个科学协作数据集,源自 3 个公共协作数据集,即高能物理、凝聚态物理和天体物理。每个图对应于来自每个领域的不同研究人员的自我网络。任务是将每个图分类到相应研究人员所属的领域。 **生物信息学数据集。** * MUTAG 是一个包含 188 个诱变芳香族和杂芳香族硝基化合物的数据集,具有 7 个离散标签。 * PROTEINS 是一个数据集,其中节点是二级结构元素 (SSE),如果两个节点在氨基酸序列或 3D 空间中是相邻节点,则它们之间存在一条边。 它有 3 个离散标签,代表螺旋、薄片或转弯。 * PTC 是一个包含 344 种化合物的数据集,报告了雄性和雌性大鼠的致癌性,它有 19 个离散标签。 * NCI1 是由美国国家癌症研究所 (NCI) 公开提供的数据集,是经过筛选以抑制或抑制一组人类肿瘤细胞系生长的化学化合物平衡数据集的子集,具有 37 个离散标签。 部分结果展示: [INFO] 2022-11-18 17:12:34,203 [ main.py: 98]: eval: epoch 347 | step 2082 | | loss 0.448468 | acc 0.684211 [INFO] 2022-11-18 17:12:34,297 [ main.py: 98]: eval: epoch 348 | step 2088 | | loss 0.393809 | acc 0.789474 [INFO] 2022-11-18 17:12:34,326 [ main.py: 92]: train: epoch 349 | step 2090 | loss 0.401544 | acc 0.8125 [INFO] 2022-11-18 17:12:34,391 [ main.py: 98]: eval: epoch 349 | step 2094 | | loss 0.441679 | acc 0.736842 [INFO] 2022-11-18 17:12:34,476 [ main.py: 92]: train: epoch 350 | step 2100 | loss 0.573693 | acc 0.7778 [INFO] 2022-11-18 17:12:34,485 [ main.py: 98]: eval: epoch 350 | step 2100 | | loss 0.481966 | acc 0.789474 [INFO] 2022-11-18 17:12:34,485 [ main.py: 103]: best evaluating accuracy: 0.894737 结果整合:(这里就不把数据集一一跑一遍了) | | MUTAG | COLLAB | IMDBBINARY | IMDBMULTI | | -------- | -------- | -------- |-------- | -------- | | PGL result | 90.8 | 78.6 |76.8 |50.8| | paper reuslt | 90.0 | 80.0 | 75.1 | 52.3 | 原论文所有结果: 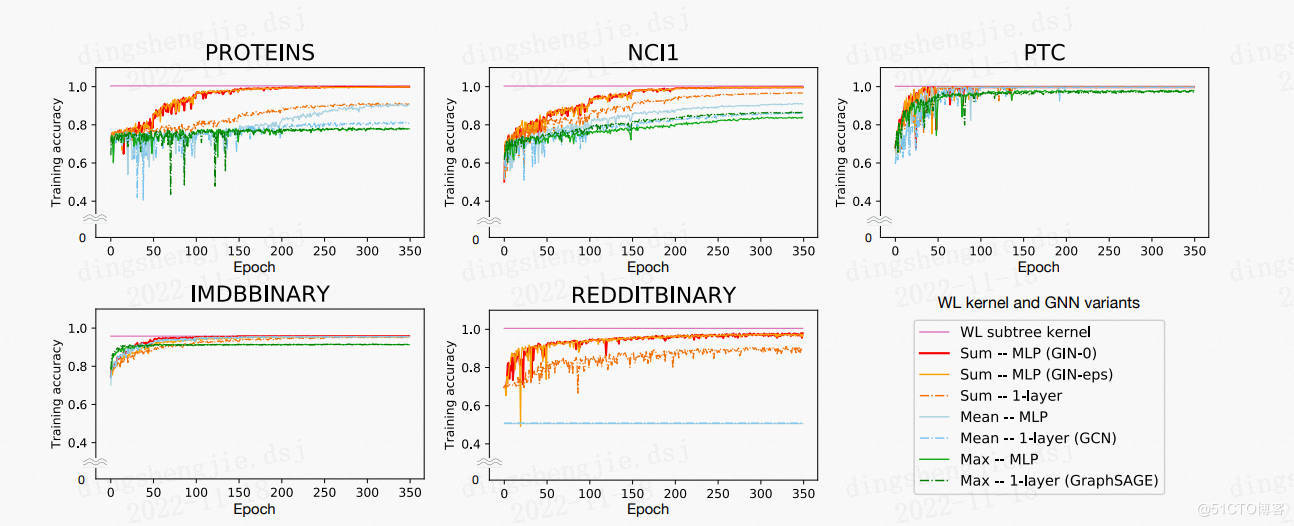 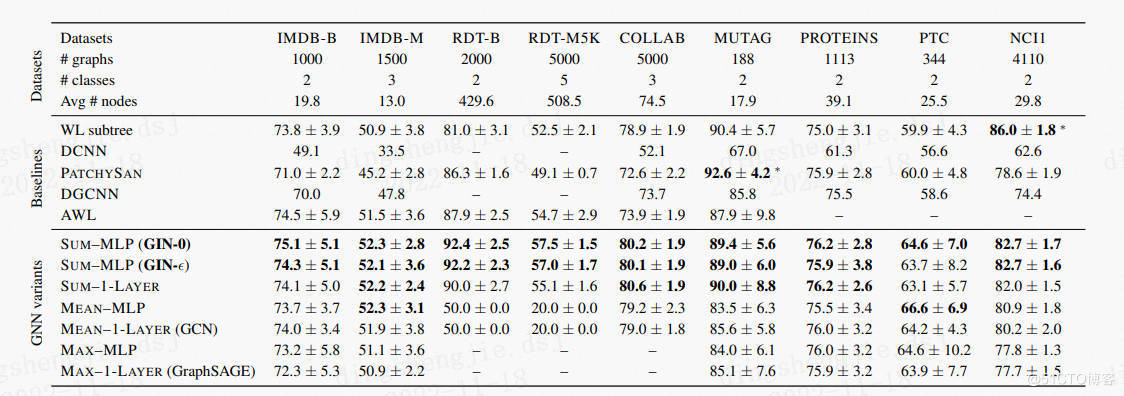
PGL图学习之图神经网络GNN模型GCN、GAT[系列六]
PGL图学习之图神经网络GNN模型GCN、GAT[系列六]项目链接:一键fork直接跑程序 https://aistudio.baidu.com/aistudio/projectdetail/5054122?contributionType=10.前言-学术界业界论文发表情况ICLR2023评审情况:ICLR2023的评审结果已经正式发布!今年的ICLR2023共计提交6300份初始摘要和4922份经过审查的提交,其中经过审查提交相比上一年增加了32.2%。在4922份提交内容中,99%的内容至少有3个评论,总共有超过18500个评论。按照Open Review评审制度,目前ICLR已经进入讨论阶段。官网链接:https://openreview.net/group?id=ICLR.cc/2022/Conference在4922份提交内容中,主要涉及13个研究方向,具体有:1、AI应用应用,例如:语音处理、计算机视觉、自然语言处理等 2、深度学习和表示学习 3、通用机器学习 4、生成模型 5、基础设施,例如:数据集、竞赛、实现、库等 6、科学领域的机器学习,例如:生物学、物理学、健康科学、社会科学、气候/可持续性等 7、神经科学与认知科学,例如:神经编码、脑机接口等 8、优化,例如:凸优化、非凸优化等 9、概率方法,例如:变分推理、因果推理、高斯过程等 10、强化学习,例如:决策和控制,计划,分层RL,机器人等 11、机器学习的社会方面,例如:人工智能安全、公平、隐私、可解释性、人与人工智能交互、伦理等 12、理论,例如:如控制理论、学习理论、算法博弈论。 13、无监督学习和自监督学习ICLR详细介绍:ICLR,全称为「International Conference on Learning Representations」(国际学习表征会议),2013 年5月2日至5月4日在美国亚利桑那州斯科茨代尔顺利举办了第一届ICLR会议。该会议是一年一度的会议,截止到2022年它已经举办了10届,而今年的(2023年)5月1日至5日,将在基加利会议中心完成ICLR的第十一届会议。该会议被学术研究者们广泛认可,被认为是「深度学习的顶级会议」。为什么ICLR为什么会成为深度学习领域的顶会呢? 首先该会议由深度学习三大巨头之二的Yoshua Bengio和Yann LeCun 牵头创办。其中Yoshua Bengio 是蒙特利尔大学教授,深度学习三巨头之一,他领导蒙特利尔大学的人工智能实验室MILA进行 AI 技术的学术研究。MILA 是世界上最大的人工智能研究中心之一,与谷歌也有着密切的合作。 Yann LeCun同为深度学习三巨头之一的他现任 Facebook 人工智能研究院FAIR院长、纽约大学教授。作为卷积神经网络之父,他为深度学习的发展和创新作出了重要贡献。Keywords Frequency 排名前 50 的常用关键字(不区分大小写)及其出现频率: 可有看到图、图神经网络分别排在2、4。1.Graph Convolutional Networks(GCN,图卷积神经网络)GCN的概念首次提出于ICLR2017(成文于2016年):Semi-Supervised Classification with Graph Convolutional Networks:https://arxiv.org/abs/1609.02907图数据中的空间特征具有以下特点:1) 节点特征:每个节点有自己的特征;(体现在点上)2) 结构特征:图数据中的每个节点具有结构特征,即节点与节点存在一定的联系。(体现在边上)总地来说,图数据既要考虑节点信息,也要考虑结构信息,图卷积神经网络就可以自动化地既学习节点特征,又能学习节点与节点之间的关联信息。综上所述,GCN是要为除CV、NLP之外的任务提供一种处理、研究的模型。图卷积的核心思想是利用『边的信息』对『节点信息』进行『聚合』从而生成新的『节点表示』。1.1原理简介假如我们希望做节点相关的任务,就可以通过 Graph Encoder,在图上学习到节点特征,再利用学习到的节点特征做一些相关的任务,比如节点分类、关系预测等等;而同时,我们也可以在得到的节点特征的基础上,做 Graph Pooling 的操作,比如加权求和、取平均等等操作,从而得到整张图的特征,再利用得到的图特征做图相关的任务,比如图匹配、图分类等。图游走类算法主要的目的是在训练得到节点 embedding 之后,再利用其做下游任务,也就是说区分为了两个阶段。对于图卷积网络而言,则可以进行一个端到端的训练,不需要对这个过程进行区分,那么这样其实可以更加针对性地根据具体任务来进行图上的学习和训练。回顾卷积神经网络在图像及文本上的发展在图像上的二维卷积,其实质就是卷积核在二维图像上平移,将卷积核的每个元素与被卷积图像对应位置相乘,再求和,得到一个新的结果。其实它有点类似于将当前像素点和周围的像素点进行某种程度的转换,再得到当前像素点更新后的一个值。它的本质是利用了一维卷积,因为文本是一维数据,在我们已知文本的词表示之后,就在词级别上做一维的卷积。其本质其实和图像上的卷积没有什么差别。(注:卷积核维度和红框维度相同,2 6就是2 6)图像卷积的本质其实非常简单,就是将一个像素点周围的像素,按照不同的权重叠加起来,当然这个权重就是我们通常说的卷积核。其实可以把当前像素点类比做图的节点,而这个节点周围的像素则类比为节点的邻居,从而可以得到图结构卷积的简单的概念:将一个节点周围的邻居按照不同的权重叠加起来而图像上的卷积操作,与图结构上的卷积操作,最大的一个区别就在于:对于图像的像素点来说,它的周围像素点数量其实是固定的;但是对于图而言,节点的邻居数量是不固定的。1.2图卷积网络的两种理解方式GCN的本质目的就是用来提取拓扑图的空间特征。 而图卷积神经网络主要有两类,一类是基于空间域或顶点域vertex domain(spatial domain)的,另一类则是基于频域或谱域spectral domain的。通俗点解释,空域可以类比到直接在图片的像素点上进行卷积,而频域可以类比到对图片进行傅里叶变换后,再进行卷积。所谓的两类其实就是从两个不同的角度理解,关于从空间角度的理解可以看本文的从空间角度理解GCNvertex domain(spatial domain):顶点域(空间域)基于空域卷积的方法直接将卷积操作定义在每个结点的连接关系上,它跟传统的卷积神经网络中的卷积更相似一些。在这个类别中比较有代表性的方法有 Message Passing Neural Networks(MPNN)[1], GraphSage[2], Diffusion Convolution Neural Networks(DCNN)[3], PATCHY-SAN[4]等。spectral domain:频域方法(谱方法这就是谱域图卷积网络的理论基础了。这种思路就是希望借助图谱的理论来实现拓扑图上的卷积操作。从整个研究的时间进程来看:首先研究GSP(graph signal processing)的学者定义了graph上的Fourier Transformation,进而定义了graph上的convolution,最后与深度学习结合提出了Graph Convolutional Network。基于频域卷积的方法则从图信号处理起家,包括 Spectral CNN[5], Cheybyshev Spectral CNN(ChebNet)[6], 和 First order of ChebNet(1stChebNet)[7] 等论文Semi-Supervised Classification with Graph Convolutional Networks就是一阶邻居的ChebNet认真读到这里,脑海中应该会浮现出一系列问题:Q1 什么是Spectral graph theory?Spectral graph theory请参考维基百科的介绍,简单的概括就是借助于图的拉普拉斯矩阵的特征值和特征向量来研究图的性质Q2 GCN为什么要利用Spectral graph theory?这是论文(Semi-Supervised Classification with Graph Convolutional Networks)中的重点和难点,要理解这个问题需要大量的数学定义及推导过程:(1)定义graph上的Fourier Transformation傅里叶变换(利用Spectral graph theory,借助图的拉普拉斯矩阵的特征值和特征向量研究图的性质)(2)定义graph上的convolution卷积1.3 图卷积网络的计算公式H代表每一层的节点表示,第0层即为最开始的节点表示A表示邻接矩阵,如下图所示,两个节点存在邻居关系就将值设为1,对角线默认为1D表示度矩阵,该矩阵除对角线外均为0,对角线的值表示每个节点的度,等价于邻接矩阵对行求和W表示可学习的权重邻接矩阵的对角线上都为1,这是因为添加了自环边,这也是这个公式中使用的定义,其他情况下邻接矩阵是可以不包含自环的。(包含了自环边的邻接矩阵)度矩阵就是将邻接矩阵上的每一行进行求和,作为对角线上的值。而由于我们是要取其-1/2的度矩阵,因此还需要对对角线上求和后的值做一个求倒数和开根号的操作,因此最后可以得到右边的一个矩阵运算结果。为了方便理解,我们可以暂时性地把度矩阵在公式中去掉:为了得到 H^{(l+1)}的第0行,我们需要拿出A的第0行与 H^{(l)}相乘,这是矩阵乘法的概念。接下来就是把计算结果相乘再相加的过程。这个过程其实就是消息传递的过程:对于0号节点来说,将邻居节点的信息传给自身将上式进行拆分,A*H可以理解成将上一层每个节点的节点表示进行聚合,如图,0号节点就是对上一层与其相邻的1号、2号节点和它本身进行聚合。而度矩阵D存在的意义是每个节点的邻居的重要性不同,根据该节点的度来对这些相邻节点的节点表示进行加权,d越大,说明信息量越小。实际情况中,每个节点发送的信息所带的信息量应该是不同的。图卷积网络将邻接矩阵的两边分别乘上了度矩阵,相当于给这个边加了权重。其实就是利用节点度的不同来调整信息量的大小。这个公式其实体现了:一个节点的度越大,那么它所包含的信息量就越小,从而对应的权值也就越小。怎么理解这样的一句话呢,我们可以设想这样的一个场景。假如说在一个社交网络里,一个人认识了几乎所有的人,那么这个人能够给我们的信息量是比较小的。也就是说,每个节点通过边对外发送相同量的信息, 边越多的节点,每条边发送出去的信息量就越小。1.4用多层图网络完成节点分类任务GCN算法主要包括以下几步:第一步是利用上面的核心公式进行节点间特征传递第二步对每个节点过一层DNN重复以上两步得到L层的GCN获得的最终节点表示H送入分类器进行分类更详细的资料参考:图卷积网络 GCN Graph Convolutional Network(谱域GCN)的理解和详细推导1.5 GCN参数解释主要是帮助大家理解消息传递机制的一些参数类型。这里给出一个简化版本的 GCN 模型,帮助理解PGL框架实现消息传递的流程。 def gcn_layer(gw, feature, hidden_size, activation, name, norm=None): 描述:通过GCN层计算新的节点表示 输入:gw - GraphWrapper对象 feature - 节点表示 (num_nodes, feature_size) hidden_size - GCN层的隐藏层维度 int activation - 激活函数 str name - GCN层名称 str norm - 标准化tensor float32 (num_nodes,),None表示不标准化 输出:新的节点表示 (num_nodes, hidden_size) # send函数 def send_func(src_feat, dst_feat, edge_feat): 描述:用于send节点信息。函数名可自定义,参数列表固定 输入:src_feat - 源节点的表示字典 {name:(num_edges, feature_size)} dst_feat - 目标节点表示字典 {name:(num_edges, feature_size)} edge_feat - 与边(src, dst)相关的特征字典 {name:(num_edges, feature_size)} 输出:存储发送信息的张量或字典 (num_edges, feature_size) or {name:(num_edges, feature_size)} return src_feat["h"] # 直接返回源节点表示作为信息 # send和recv函数是搭配实现的,send的输出就是recv函数的输入 # recv函数 def recv_func(msg): 描述:对接收到的msg进行聚合。函数名可自定义,参数列表固定 输出:新的节点表示张量 (num_nodes, feature_size) return L.sequence_pool(msg, pool_type='sum') # 对接收到的消息求和 ### 消息传递机制执行过程 # gw.send函数 msg = gw.send(send_func, nfeat_list=[("h", feature)]) 描述:触发message函数,发送消息并将消息返回 输入:message_func - 自定义的消息函数 nfeat_list - list [name] or tuple (name, tensor) efeat_list - list [name] or tuple (name, tensor) 输出:消息字典 {name:(num_edges, feature_size)} # gw.recv函数 output = gw.recv(msg, recv_func) 描述:触发reduce函数,接收并处理消息 输入:msg - gw.send输出的消息字典 reduce_function - "sum"或自定义的reduce函数 输出:新的节点特征 (num_nodes, feature_size) 如果reduce函数是对消息求和,可以直接用"sum"作为参数,使用内置函数加速训练,上述语句等价于 \ output = gw.recv(msg, "sum") # 通过以activation为激活函数的全连接输出层 output = L.fc(output, size=hidden_size, bias_attr=False, act=activation, name=name) return output 2.Graph Attention Networks(GAT,图注意力机制网络)Graph Attention Networks:https://arxiv.org/abs/1710.10903GCN网络中的一个缺点是边的权重与节点的度度相关而且不可学习,因此有了图注意力算法。在GAT中,边的权重变成节点间的可学习的函数并且与两个节点之间的相关性有关。2.1.计算方法注意力机制的计算方法如下:首先将目标节点和源节点的表示拼接到一起,通过网络计算相关性,之后通过LeakyReLu激活函数和softmax归一化得到注意力分数,最后用得到的α进行聚合,后续步骤和GCN一致。以及多头Attention公式2.2 空间GNN空间GNN(Spatial GNN):基于邻居聚合的图模型称为空间GNN,例如GCN、GAT等等。大部分的空间GNN都可以用消息传递实现,消息传递包括消息的发送和消息的接受。基于消息传递的图神经网络的通用公式:2.3 消息传递demo例子2.4 GAT参数解释其中:在 send 函数中完成 LeakyReLU部分的计算;在 recv 函数中,对接受到的 logits 信息进行 softmax 操作,形成归一化的分数(公式当中的 alpha),再与结果进行加权求和。def single_head_gat(graph_wrapper, node_feature, hidden_size, name): # 实现单头GAT def send_func(src_feat, dst_feat, edge_feat): ################################## # 按照提示一步步理解代码吧,你只需要填###的地方 # 1. 将源节点特征与目标节点特征concat 起来,对应公式当中的 concat 符号,可能用到的 API: fluid.layers.concat Wh = fluid.layers.concat(input=[src_feat["Wh"], dst_feat["Wh"]], axis=1) # 2. 将上述 Wh 结果通过全连接层,也就对应公式中的a^T alpha = fluid.layers.fc(Wh, size=1, name=name + "_alpha", bias_attr=False) # 3. 将计算好的 alpha 利用 LeakyReLU 函数激活,可能用到的 API: fluid.layers.leaky_relu alpha = fluid.layers.leaky_relu(alpha, 0.2) ################################## return {"alpha": alpha, "Wh": src_feat["Wh"]} def recv_func(msg): ################################## # 按照提示一步步理解代码吧,你只需要填###的地方 # 1. 对接收到的 logits 信息进行 softmax 操作,形成归一化分数,可能用到的 API: paddle_helper.sequence_softmax alpha = msg["alpha"] norm_alpha = paddle_helper.sequence_softmax(alpha) # 2. 对 msg["Wh"],也就是节点特征,用上述结果进行加权 output = norm_alpha * msg["Wh"] # 3. 对加权后的结果进行相加的邻居聚合,可能用到的API: fluid.layers.sequence_pool output = fluid.layers.sequence_pool(output, pool_type="sum") ################################## return output # 这一步,其实对应了求解公式当中的Whi, Whj,相当于对node feature加了一个全连接层 Wh = fluid.layers.fc(node_feature, hidden_size, bias_attr=False, name=name + "_hidden") # 消息传递机制执行过程 message = graph_wrapper.send(send_func, nfeat_list=[("Wh", Wh)]) output = graph_wrapper.recv(message, recv_func) output = fluid.layers.elu(output) return output def gat(graph_wrapper, node_feature, hidden_size): # 完整多头GAT # 这里配置多个头,每个头的输出concat在一起,构成多头GAT heads_output = [] # 可以调整头数 (8 head x 8 hidden_size)的效果较好 n_heads = 8 for head_no in range(n_heads): # 请完成单头的GAT的代码 single_output = single_head_gat(graph_wrapper, node_feature, hidden_size, name="head_%s" % (head_no) ) heads_output.append(single_output) output = fluid.layers.concat(heads_output, -1) return output 3.数据集介绍3个常用的图学习数据集,CORA, PUBMED, CITESEER。可以在论文中找到数据集的相关介绍。今天我们来了解一下这几个数据集3.1Cora数据集Cora数据集由机器学习论文组成,是近年来图深度学习很喜欢使用的数据集。在整个语料库中包含2708篇论文,并分为以下七类:基于案例遗传算法神经网络概率方法强化学习规则学习理论论文之间互相引用,在该数据集中,每篇论文都至少引用了一篇其他论文,或者被其他论文引用,也就是样本点之间存在联系,没有任何一个样本点与其他样本点完全没联系。如果将样本点看做图中的点,则这是一个连通的图,不存在孤立点。这样形成的网络有5429条边。在消除停词以及除去文档频率小于10的词汇,最终词汇表中有1433个词汇。每篇论文都由一个1433维的词向量表示,所以,每个样本点具有1433个特征。词向量的每个元素都对应一个词,且该元素只有0或1两个取值。取0表示该元素对应的词不在论文中,取1表示在论文中。数据集有包含两个文件:.content文件包含以下格式的论文描述:<paper_id> <word_attributes>+ <class_label>每行的第一个条目包含纸张的唯一字符串标识,后跟二进制值,指示词汇中的每个单词在文章中是存在(由1表示)还是不存在(由0表示)。最后,该行的最后一个条目包含纸张的类别标签。因此数据集的$feature$应该为$2709×14332709 \times 14332709×1433$维度。第一行为$idx$,最后一行为$label$。那个.cites文件包含语料库的引用’图’。每行以以下格式描述一个链接:<被引论文编号> <引论文编号>每行包含两个纸质id。第一个条目是被引用论文的标识,第二个标识代表包含引用的论文。链接的方向是从右向左。如果一行由“论文1 论文2”表示,则链接是“论文2 - >论文1”。可以通过论文之间的索引关系建立邻接矩阵adj下载链接:https://aistudio.baidu.com/aistudio/datasetdetail/177587相关论文:Qing Lu, and Lise Getoor. "Link-based classification." ICML, 2003.Prithviraj Sen, et al. "Collective classification in network data." AI Magazine, 2008.3.2PubMed数据集PubMed 是一个提供生物医学方面的论文搜寻以及摘要,并且免费搜寻的数据库。它的数据库来源为MEDLINE。其核心主题为医学,但亦包括其他与医学相关的领域,像是护理学或者其他健康学科。PUBMED数据集是基于PubMed 文献数据库生成的。它包含了19717篇糖尿病相关的科学出版物,这些出版物被分成三个类别。这些出版物的互相引用网络包含了44338条边。在消除停词以及除去低频词汇,最终词汇表中有500个词汇。这些出版物用一个TF/IDF加权的词向量来描述是否包含词汇表中的词汇。下载链接:https://aistudio.baidu.com/aistudio/datasetdetail/177591相关论文:Galileo Namata, et. al. "Query-driven Active Surveying for Collective Classification." MLG. 2012.3.3CiteSeer数据集CiteSeer(又名ResearchIndex),是NEC研究院在自动引文索引(Autonomous Citation Indexing, ACI)机制的基础上建设的一个学术论文数字图书馆。这个引文索引系统提供了一种通过引文链接的检索文献的方式,目标是从多个方面促进学术文献的传播和反馈。在整个语料库中包含3312篇论文,并分为以下六类:AgentsAIDBIRMLHCI论文之间互相引用,在该数据集中,每篇论文都至少引用了一篇其他论文,或者被其他论文引用,也就是样本点之间存在联系,没有任何一个样本点与其他样本点完全没联系。如果将样本点看做图中的点,则这是一个连通的图,不存在孤立点。这样形成的网络有4732条边。在消除停词以及除去文档频率小于10的词汇,最终词汇表中有3703个词汇。每篇论文都由一个3703维的词向量表示,所以,每个样本点具有3703个特征。词向量的每个元素都对应一个词,且该元素只有0或1两个取值。取0表示该元素对应的词不在论文中,取1表示在论文中。下载链接:https://aistudio.baidu.com/aistudio/datasetdetail/177589相关论文Qing Lu, and Lise Getoor. "Link-based classification." ICML, 2003.Prithviraj Sen, et al. "Collective classification in network data." AI Magazine, 2008.3.4 小结数据集图数节点数边数特征维度标签数Cora12708542914337Citeseer13327473237036Pubmed119717443385003更多图数据集:https://linqs.org/datasets/GCN常用数据集 KarateClub:数据为无向图,来源于论文An Information Flow Model for Conflict and Fission in Small Groups TUDataset:包括58个基础的分类数据集集合,数据都为无向图,如”IMDB-BINARY”,”PROTEINS”等,来源于TU Dortmund University Planetoid:引用网络数据集,包括“Cora”, “CiteSeer” and “PubMed”,数据都为无向图,来源于论文Revisiting Semi-Supervised Learning with Graph Embeddings。节点代表文档,边代表引用关系。 CoraFull:完整的”Cora”引用网络数据集,数据为无向图,来源于论文Deep Gaussian Embedding of Graphs: Unsupervised Inductive Learning via Ranking。节点代表文档,边代表引用关系。 Coauthor:共同作者网络数据集,包括”CS”和”Physics”,数据都为无向图,来源于论文Pitfalls of Graph Neural Network Evaluation。节点代表作者,若是共同作者则被边相连。学习任务是将作者映射到各自的研究领域中。 Amazon:亚马逊网络数据集,包括”Computers”和”Photo”,数据都为无向图,来源于论文Pitfalls of Graph Neural Network Evaluation。节点代表货物i,边代表两种货物经常被同时购买。学习任务是将货物映射到各自的种类里。 PPI:蛋白质-蛋白质反应网络,数据为无向图,来源于论文Predicting multicellular function through multi-layer tissue networks Entities:关系实体网络,包括“AIFB”, “MUTAG”, “BGS” 和“AM”,数据都为无向图,来源于论文Modeling Relational Data with Graph Convolutional Networks BitcoinOTC:数据为有向图,包括138个”who-trusts-whom”网络,来源于论文EvolveGCN: Evolving Graph Convolutional Networks for Dynamic Graphs,数据链接为Bitcoin OTC trust weighted signed network4.基于PGL的GNN算法实践4.1 GCN图卷积网络 (GCN)是一种功能强大的神经网络,专为图上的机器学习而设计。基于PGL复现了GCN算法,在引文网络基准测试中达到了与论文同等水平的指标。搭建GCN的简单例子:要构建一个 gcn 层,可以使用我们预定义的pgl.nn.GCNConv或者只编写一个带有消息传递接口的 gcn 层。!CUDA_VISIBLE_DEVICES=0 python train.py --dataset cora 仿真结果:| Dataset | Accuracy | | -------- | -------- | | Cora | 81.16% | | Pubmed | 79.34% | |Citeseer | 70.91% |4.2 GAT图注意力网络 (GAT)是一种对图结构数据进行操作的新型架构,它利用掩蔽的自注意层来解决基于图卷积或其近似的先前方法的缺点。基于PGL,我们复现了GAT算法,在引文网络基准测试中达到了与论文同等水平的指标。搭建单头GAT的简单例子:要构建一个 gat 层,可以使用我们的预定义pgl.nn.GATConv或只编写一个带有消息传递接口的 gat 层。GAT仿真结果:| Dataset | Accuracy | | -------- | -------- | | Cora | 82.97% | | Pubmed | 77.99% | |Citeseer | 70.91% | 项目链接:一键fork直接跑程序 https://aistudio.baidu.com/aistudio/projectdetail/5054122?contributionType=15.总结本次项目讲解了图神经网络的原理并对GCN、GAT实现方式进行讲解,最后基于PGL实现了两个算法在数据集Cora、Pubmed、Citeseer的表现,在引文网络基准测试中达到了与论文同等水平的指标。目前的数据集样本节点和边都不是很大,下个项目将会讲解面对亿级别图应该如何去做。参考链接:感兴趣可以看看详细的推到以及涉及有趣的问题
PGL图学习之图游走类metapath2vec模型[系列五]
PGL图学习之图游走类metapath2vec模型[系列五]本项目链接:https://aistudio.baidu.com/aistudio/projectdetail/5009827?contributionType=1有疑问查看原项目相关项目参考:关于图计算&图学习的基础知识概览:前置知识点学习(PGL)[系列一] https://aistudio.baidu.com/aistudio/projectdetail/4982973?contributionType=1图机器学习(GML)&图神经网络(GNN)原理和代码实现(前置学习系列二):https://aistudio.baidu.com/aistudio/projectdetail/4990947?contributionType=1图学习【参考资料2】-知识补充与node2vec代码注解: https://aistudio.baidu.com/aistudio/projectdetail/5012408?forkThirdPart=1图学习【参考资料1】词向量word2vec: [https://aistudio.baidu.com/aistudio/projectdetail/5009409?contributionType=1](https://aistudio.baidu.com/aistudio/projectdetail/5009409?contributionType=11.异质图在图结构中有一个重要概念,同构图和异构图:同构图:节点类型仅有一种的图异构图:节点类型有多种的图,举例如下:异质图介绍在真实世界中,很多的图包含了多种类别节点和边,这类图我们称之为异质图。显然,同构图是异质图中的一个特例,边和节点的种类都是一。异质图比同构图的处理上更为复杂。为了能够处理实际世界中的这大部分异质图,PGL进一步开发了图框架来对异质图模型的支持图神经网络的计算,新增了MetaPath采样支持异质图表示学习。本节:举例异质图数据理解PGL是如何支持异质图的计算使用PGL来实现一个简单的异质图神经网络模型,来对异质图中特定类型节点分类。PGL中引入了异质图的支持,新增MetaPath采样支持异质图表示学习,新增异质图Message Passing机制支持基于消息传递的异质图算法,利用新增的异质图接口,能轻松搭建前沿的异质图学习算法。真实世界中的大部分图都存在着多种类型的边和节点。其中,电子交易网络就是非常常见的异质图。这种类型的图通常包含两种以上类型的节点(商品和用户等),和两以上的边(购买和点击等)。接下来就用图例介绍,图中有多种用户点击或者购买商品。这个图中有两种节点,分别是“用户”和“商品”。同时包含了两种类型的边,“购买”和“点击”。以及学术论文1.1使用PGL创建一个异质图在异质图中,存在着多种边,我们需要对它们进行区分。使用PGL可以用一下形式来表示边: 'click': [(0, 4), (0, 7), (1, 6), (2, 5), (3, 6)], 'buy': [(0, 5), (1, 4), (1, 6), (2, 7), (3, 5)], clicked = [(j, i) for i, j in edges['click']] bought = [(j, i) for i, j in edges['buy']] edges['clicked'] = clicked edges['bought'] = bought # 在异质图中,节点也有不同的类型。因此你需要对每一个节点的类别进行标记,节点的表示格式如下: node_types = [(0, 'user'), (1, 'user'), (2, 'user'), (3, 'user'), (4, 'item'), (5, 'item'),(6, 'item'), (7, 'item')] # 由于边的类型不同,边的特征要根据不同类别来区分。 import numpy as np import paddle import paddle.nn as nn import pgl from pgl import graph # 导入 PGL 中的图模块 import paddle.fluid as fluid # 导入飞桨框架 seed = 0 np.random.seed(0) paddle.seed(0) num_nodes = len(node_types) node_features = {'features': np.random.randn(num_nodes, 8).astype("float32")} labels = np.array([0, 1, 0, 1, 0, 1, 1, 0]) # 在准备好节点和边后,可以利用PGL来构建异质图。 g = pgl.HeterGraph(edges=edges, node_types=node_types, node_feat=node_features) #如果遇到报错显示没有pgl.HeterGraph,重启项目即可 # 在构建了异质图后,我们可以利用PGL很轻松的实现信息传递范式。在这个例子中,我们有两种类型的边,所以我们定义如下的信息传递函数: class HeterMessagePassingLayer(nn.Layer): def __init__(self, in_dim, out_dim, etypes): super(HeterMessagePassingLayer, self).__init__() self.in_dim = in_dim self.out_dim = out_dim self.etypes = etypes self.weight = [] for i in range(len(self.etypes)): self.weight.append( self.create_parameter(shape=[self.in_dim, self.out_dim])) def forward(self, graph, feat): def send_func(src_feat, dst_feat, edge_feat): return src_feat def recv_func(msg): return msg.reduce_mean(msg["h"]) feat_list = [] for idx, etype in enumerate(self.etypes): h = paddle.matmul(feat, self.weight[idx]) msg = graph[etype].send(send_func, src_feat={"h": h}) h = graph[etype].recv(recv_func, msg) feat_list.append(h) h = paddle.stack(feat_list, axis=0) h = paddle.sum(h, axis=0) return h # 通过堆叠两个 HeterMessagePassingLayer 创建一个简单的 GNN。 class HeterGNN(nn.Layer): def __init__(self, in_dim, hidden_size, etypes, num_class): super(HeterGNN, self).__init__() self.in_dim = in_dim self.hidden_size = hidden_size self.etypes = etypes self.num_class = num_class self.layers = nn.LayerList() self.layers.append( HeterMessagePassingLayer(self.in_dim, self.hidden_size, self.etypes)) self.layers.append( HeterMessagePassingLayer(self.hidden_size, self.hidden_size, self.etypes)) self.linear = nn.Linear(self.hidden_size, self.num_class) def forward(self, graph, feat): h = feat for i in range(len(self.layers)): h = self.layers[i](graph, h) logits = self.linear(h) return logits model = HeterGNN(8, 8, g.edge_types, 2) criterion = paddle.nn.loss.CrossEntropyLoss() optim = paddle.optimizer.Adam(learning_rate=0.05, parameters=model.parameters()) g.tensor() labels = paddle.to_tensor(labels) for epoch in range(10): #print(g.node_feat["features"]) logits = model(g, g.node_feat["features"]) loss = criterion(logits, labels) loss.backward() optim.step() optim.clear_grad() print("epoch: %s | loss: %.4f" % (epoch, loss.numpy()[0])) epoch: 1 | loss: 1.1593 epoch: 2 | loss: 0.9971 epoch: 3 | loss: 0.8670 epoch: 4 | loss: 0.7591 epoch: 5 | loss: 0.6629 epoch: 6 | loss: 0.5773 epoch: 7 | loss: 0.5130 epoch: 8 | loss: 0.4782 epoch: 9 | loss: 0.4551 2. methpath2vec及其变种(原理)上篇项目讲的deepwalk、node2vec两种方法都是在同构图中进行游走,如果在异构图中游走,会产生下面的问题:偏向于出现频率高的节点类型偏向于相对集中的节点(度数高的节点)因此在异构图中采用methpath2vec算法。metapath2vec: Scalable Representation Learning for Heterogeneous Networks论文网址项目主页发表时间: KDD 2017论文作者: Yuxiao Dong, Nitesh V. Chawla, Ananthram Swami作者单位: Microsoft ResearchMetapath2vec是Yuxiao Dong等于2017年提出的一种用于异构信息网络(Heterogeneous Information Network, HIN)的顶点嵌入方法。metapath2vec使用基于meta-path的random walks来构建每个顶点的异构邻域,然后用Skip-Gram模型来完成顶点的嵌入。在metapath2vec的基础上,作者还提出了metapath2vec++来同时实现异构网络中的结构和语义关联的建模。methpath2vec中有元路径(meta path)的概念,含义就是在图中选取的节点类型构成的组合路径,这个路径是有实际意义的,例如以上面的异构图为例,A-P-A代表同一篇论文的两个作者,A-P-C-P-A代表两个作者分别在同一个会议上发表了两篇论文。2.1前置重要概念:2.1.1 网络嵌入;异构图/同构图1)网络嵌入Network Embedding针对网络嵌入的相关工作主要有两大部分构成,一部分是图嵌入,一部分是图神经网络。图嵌入方面的相关代表有Deepwalk、LINE、Node2vec以及NetMF,Deepwalk源于NLP(自然语言处理)方面的Word2vec,将Word2vec应用到社交网络体现出了良好的效果,LINE主要是针对大规模网络,Node2vec是在Deepwalk的随机游走上进行了改进,使得游走不再变得那么随机,使得其概率可控,具体就不做过多赘述。对于图神经网络,GCN通过卷积神经网络结合了邻居节点的特征表示融入到节点的表示中,GraphSAGE它就是一个典型的生成式模型,且它结合了节点的结构信息,而且,它不是直接为每个节点生成嵌入,而是生成一个可以表示节点嵌入的函数表示形式,这样的模型,也就是这种生成式模型,有助于它在训练期间对未观察到的节点进行归纳和判断。2)同构Homogeneous与异构HeterogeneousHeterogeneity:表示节点/边的单类还是多类Heterogeneous/Heterogeneous:表示节点是单类还是多类为了区分,论文添加了Multiplex:表示边是单类还是多类Attribute:是否是属性图,图的节点是否具有属性信息根据图结构(同构/异构)以及是否包含节点特征,作者将图分为如下六类(缩写):同构图:HOmogeneous Network (or HON), 属性同构图Attributed HOmogeneous Network (or AHON), 点异构图HEterogeneous Network (orHEN), 属性点异构图Attributed HEterogeneous Network (or AHEN), 边异构图Multiplex HEterogeneous Network (or MHEN), 带节点属性的异构图Attributed Multiplex HEterogeneous Network (or AMHEN)论文归纳了以及每一种网络类型对应的经典的研究方法,如下表:3)节点属性的异构图AMHEN论文给出一个带节点属性的异构图的例子。在左侧原始的图中,用户包含了性别、年龄等属性,商品包含了价格、类目等属性。用户与商品之间包含了4种类型的边,分别对应点击、收藏、加入购物车以及购买行为。传统的 graph embedding 算法比如 DeepWalk 的做法会忽略图中边的类型以及节点的特征,然后转换成一个 HON。如果将边的类型考虑进去,那么就得到一个 MHEN,能够取得非常明显的效果。此外,如果将节点的属性也同时考虑进去,那么就利用了原图的所有信息,可以得到最好的效果。4)AMHEN嵌入难点除了异构性和多样性外,处理 AMHEN 也面临着多重挑战:多路复用的边(Multiplex Edges):每个节点对可能含有多种不同的类型边,如何将不同的关系边进行统一嵌入;局部交互(Partial Observations): 存在大量的长尾客户(可能只与某些产品进行很少的交互);归纳学习(Inductive):如何解决冷启动问题;可扩展性(Scalability),如何拓展到大规模网络中。2.1.2 信息网络(Information Network)信息网络(Information Network)是指一个有向图 G=(V,E), 同时还有一个object类型映射函数 $\phi : V \to \mathcal{A}$,边类型映射函数$\psi : E \to \mathcal{R}$。每一个object $v \in V$, 都有一个特定的object 类型$\phi (v) \in \mathcal{A}$;每一条边$e \in E$ 都有一个特定的relation $\psi(e) \in \mathcal{R}$。异质网络(Heterogeneous Network)指的是object的类型$|\mathcal{A}|>1$或者relation的类型$|\mathcal{R}>1|$。2.1.3 网络模式(Network schema)网络模式(Network schema),定义为:$T_G=(\mathcal{A,R})$,是信息网络 G=(V, E)的一种 meta模板,这个信息网络有一个object类型映射函数$\phi : V \to \mathcal{A}$ 和 link 类型映射函数$\psi: E \to \mathcal{R}$。信息网络G是一个定义在object类型$\mathcal{A}$上的有向图,并且边是$\mathcal{R}$中的relation。2.1.4 元路径(Meta Path)Meta Path 是2011年 Yizhou Sun etc. 在Mining Heterogeneous Information Networks: Principles and Methodologies提出的, 针对异质网络中的相似性搜索。Meta Path 是一条包含relation序列的路径,而这些 relation 定义在不同类型object之间。元路径P是定义在网络模式TG = (A, R)上的,如$A_1→^RA_2→^RA_3...→^RA_{l+1}$表示了从$A_1$ 到$A_{l+1}$的复杂的关系,$R = R_1 ∘ R_2 ∘ R_3 ∘R_l。$元路径P的长度即为关系R的个数.确定元路径的意义在于我们会根据确定的元路径进行随机游走,如果元路径没有意义,会导致后续的训练过程中无法充分体现节点的意义,元路径通常需要人工进行筛选。在基于元路径的游走过程中,只要首尾节点类型相同,就可以继续游走,直到达到最大游走长度或者找不到指定要求的节点。通常来说,元路径是对称的。目前大部分的工作都集中在同构网络中,但真实场景下异构网络才是最常见的。针对同构网络设计的模型很多都没法应用于异构网络,比如说,对于一个学术网络而言:如何高效根据上下文信息表征不同类型的节点?能否用 Deepwalk 或者 Node2Vec 来学习网络中的节点?能否直接将应用于同构网络的 Embedding 模型直接应用于异构网络?解决诸如此类的挑战,有利于更好的在异构网络中应用多种网络挖掘任务:传统的方法都是基于结构特征(如元路径 meta-path)来求相似性,类似的方法有 PathSim、PathSelClus、RankClass 等:但这种方式挖掘出来的元路径(如 “APCPA”)经常会出现相似度为 0 的情况。如果我们能够将 Embedding 的思想应用于异构网络,则不会再出现这种情况。基于这种观察,作者提出了两个可以应用于异构网络的 Graph Embedding 的算法模型——metapath2vec 以及 metapath2vec++。问题定义Problem DefinitionDefinition 1: 异质网络(Heterogeneous Network):$G = (V,E,T)$,其中每个节点和边分别对应一个映射 $\phi(v) : V \rightarrow T_{V}$ 和$\psi(e) : E \rightarrow T_{E}$。 其中$T_V$和$T_E$分别表示节点的类型集合以及关系的类型集合。且$\left|T_{V}\right|+\left|T_{E}\right|>2$。Definition 2: 异质网络表示学习(Heterogeneous Network Representation Learning):给定一个异构网络,学习一个维的潜在表征可以表征网络中顶点之间的结构信息和语义场景关系。异构网络表征学习的输出是一个低维的矩阵,其中行是一个维的向量,表示顶点的表征。这里需要注意的是,虽然顶点的类型不同,但是不同类型的顶点的表征向量映射到同一个维度空间。由于网络异构性的存在,传统的基于同构网络的顶点嵌入表征方法很难有效地直接应用在异构网络上。异质网络中的节点学习一个$d$维的表示 $\mathrm{X} \in \mathbb{R}^{|V| \times d}$,$d \ll|V|$。节点的向量表示可以捕获节点间结构和语义关系。2.2 Metapath2vec框架在正式介绍metapath2vec方法之前,作者首先介绍了同构网络上的基于random walk的graph embedding算法的基本思想,如:Deepwalk和node2vec等。该类方法采用了类似word2vec的思想,即:使用skip-gram模型对每个顶点的局部领域顶点信息进行预测,进而学习到每个顶点的特征表示。通常,对于一个同构网络$G = (V,E)$,目标是从每个顶点的局部领域上最大化网络似然:$$ \arg \max _{\theta} \prod_{v \in V} \prod_{c \in N(v)} p(c \mid v ; \theta) $$其中 $N(v)$ 表示顶点 $v$ 的领域, 如1-hop以内的邻接页点, 2 -hop以内的邻接顶点。 $p(c \mid v ; \theta)$ 表 示给定顶点 $v$ 后, 顶点 $c$ 的条件概率。下面正式给出基于异构网络的metapath2vec嵌入算法。metapath2vec分为两个部分,分别是Meta-Path-Based Random Walks和Heterogeneous Skip-Gram2.2.1 Heterogeneous Skip-Gram在metapath2vec中,作者使用Skip-Gram模型通过在顶点 $v$ 的领域 $N_{t}(v), t \in T_{V}$ 上最大化 条件概率来学习异构网络 $G=(V, E, T)$ 上的顶点表征。$$ \arg \max _{\theta} \sum_{v \in V} \sum_{t \in T_{V}} \sum_{c_{t} \in N_{t}(v)} \log p\left(c_{t} \mid v ; \theta\right) $$其中 $N_{t}(v)$ 表示顶点 $v$ 的类型为 $t$ 的领域顶点集合。 $p\left(c_{t} \mid v ; \theta\right)$ 通常定义为一个softmax函数,即:$$ p\left(c_{t} \mid v ; \theta\right)=\frac{e^{X_{c_{t}} \cdot X_{v}}}{\sum_{u \in V} e^{X_{u} \cdot X_{v}}} $$其中 $X_{v}$ 是矩阵 $X$ 的第 $v$ 行矩阵, 表示页点 $v$ 的嵌入向量。为了提升参数更新效率 metapath2vec采用了Negative Sampling进行参数迭代更新, 给定一个Negative Sampling的大 小 $M,$ 参数更新过程如下:$$ \log \sigma\left(X_{c_{t}} \cdot X_{v}\right)+\sum_{m=1}^{M} \mathbb{E}_{u^{m} \sim P(u)}\left[\log \sigma\left(-X_{u^{m}} \cdot X_{v}\right)\right] $$其中$\sigma(x)=\frac{1} {1+e^{-x}}$, $P(u)是一个negative node $u^m$在M次采样中的预定义分布。metapath2vec通过不考虑顶点的类型进行节点抽取来确定当前顶点的频率。2.2.2Meta-Pathe-Based Random Walks在同构网络中,DeepWalk和node2vec等算法通过随机游走的方式来构建Skip-Gram模型的上下文语料库,受此启发,作者提出了一种异构网络上的随机游走方式。在不考虑顶点类型和边类型的情况下,$p(v^{i+1}|v^i)$表示从顶点$v^i$向其邻居顶点$v^{i+1}$的转移概率。然而Sun等已证明异构网络上的随机游走会偏向于某些高度可见的类型的顶点,这些顶点的路径在网络中具有一定的统治地位,而这些有一定比例的路径指向一小部分节点的集合。鉴于此,作者提出了一种基于meta-path的随机游走方式来生成Skip-Gram模型的邻域上下文。该随机游走方式可以同时捕获不同类型顶点之间语义关系和结构关系,促进了异构网络结构向metapath2vec的Skip-Gram模型的转换。 一个meta-path的scheme可以定义成如下形式:$$ V_{1} \stackrel{R_{1}}{\longrightarrow} V_{2} \stackrel{R_{2}}{\longrightarrow} \ldots V_{t} \stackrel{R_{t}}{\longrightarrow} V_{t+1} \ldots V_{l-1} \stackrel{R_{l-1}}{\longrightarrow} V_{l} $$其中$$ R=R_{1} \circ R_{2} \circ \cdots \circ R_{l-1} $$表示顶点 $V_{1}$ 和顶点 $V_{l}$ 之间的路径组合。例如下图中, "APA"表示一种固定语义的metapath, "APVPA"表示另外一种固定语义的meta-path。并且很多之前的研究成果都表明, meta-path在很多异构网络数据挖掘中很很大作用。因此,在本文中,作者给出了基于meta-path的随机游走方式。给定一个异构网络 $G=(V, E, T)$ 和一个meta-path的scheme $\mathcal{P}$ :$$ V_{1} \stackrel{R_{1}}{\longrightarrow} V_{2} \stackrel{R_{2}}{\longrightarrow} \ldots V_{t} \stackrel{R_{t}}{\longrightarrow} V_{t \pm 1} \ldots V_{l-1} \stackrel{R_{l-1}}{\longrightarrow} V_{l} $$那么在第 $i$ 步的转移概率定义如下:$$ p\left(v^{i+1} \mid v_{t}^{i}, \mathcal{P}\right)=\left\{\begin{array}{ll} \frac{1}{\left|N_{t+1}\left(v_{t}^{i}\right)\right|} & \left(v^{i+1}, v^{i}\right) \in E, \phi\left(v^{i+1}\right)=t+1 \\ 0 & \left(v^{i+1}, v^{i}\right) \in E, \phi\left(v^{i+1}\right) \neq t+1 \\ 0 & \left(v^{i+1}, v^{i}\right) \notin E \end{array}\right. $$其中 $v_{t}^{i} \in V_{t}, \quad N_{t+1}\left(v_{t}^{i}\right)$ 表示页点 $v_{t}^{i}$ 的 $V_{t+1}$ 类型的领域顶点集合。换言之, $v^{i+1} \in V_{t+1},$ 也 就是说随机游走是在预定义的meta-path scheme $\mathcal{P}$ 条件下的有偏游走。初次之外, meta-path 通常是以一种对称的方式来使用, 也就是说在上述路径组合中,顶点 $V_{1}$ 的类型和 $V_{l}$ 的类型相同。即:$$ p\left(v^{i+1} \mid v_{t}^{i}\right)=p\left(v^{i+1} \mid v_{l}^{i}\right), \text { if } \mathbf{t}=1 $$基于meta-path的随机游走保证不同类型顶点之间的语义关系可以适当的融入Skip-Gram模型中。2.3 Metapath2vec++框架methpath2vec的变种:methpath2vec++:在负采样时考虑节点类型multi-methpath2vec++:针对多条元路径进行游走side info+multi-methpath2vec++:在获取元路径的基础上考虑了节点的特征metapath2vec在为每个顶点构建领域时,通过meta-path来指导随机游走过程向指定类型的顶点进行有偏游走。但是在softmax环节中,并没有顶点的类型,而是将所有的顶点认为是同一种类型的顶点。换言之,metapath2vec在Negative Sampling环节采样的negative 样本并没有考虑顶点的类型,也就是说metapath2vec支持任意类型顶点的Negative Sampling。于是作者在metapath2vec的基础上又提出了改进方案metapath2vec++。2.3.1Heterogeneous Negative Sampling在metapath2vec++中, softmax函数根据不同类型的顶点的上下文 $c_{t}$ 进行归一化。也就是说$p\left(c_{t} \mid v ; \theta\right)$ 根据固定类型的页点进行调整。即:$$ p\left(c_{t} \mid v ; \theta\right)=\frac{e^{X_{c_{t}} \cdot X_{v}}}{\sum_{u_{t} \in V_{t}} e^{X_{u_{t}} \cdot X_{v}}} $$其中 $V_{t}$ 是网络中 $t$ 类型顶点集合。在这种情况下, metapath2vec++为Skip-Gram模型的输出层中的每种类型的领域指定了一个多项式分布的集合。而在metapath2vec, DeepWalk和node2vec中, Skip-Gram输出多项式分布的维度等于蜂个网络中顶点的数目,然而对于metapath2vec++的Skip-Gram, 其针对特定类型的输出多项式的维度取决于网络中当前类型顶点的数目。如下图示。最终我们可以得到如下的目标函数:$$ O(X)=\log \sigma\left(X_{c_{t}} \cdot X_{v}\right)+\sum_{m=1}^{M} \mathbb{E}_{u_{t}^{m} \sim P_{t}\left(u_{t}\right)}\left[\log \sigma\left(-X_{u_{t}^{m}} \cdot X_{v}\right)\right] $$可以得出其梯度如下:$$ \begin{array}{c} \frac{\partial O(X)}{\partial X_{u_{t}^{m}}}=\left(\sigma\left(X_{u_{t}^{m}} \cdot X_{v}-\mathbb{I}_{c_{t}}\left[u_{t}^{m}\right]\right)\right) X_{v} \\ \frac{\partial O(X)}{\partial X_{v}}=\sum_{m=0}^{M}\left(\sigma\left(X_{u_{i}^{* n}} \cdot X_{v}-\mathbb{I}_{c_{i}}\left[u_{t}^{m}\right]\right)\right) X_{v_{t}^{m}} \end{array} $$其中 $\mathbb{I}_{c_{t}}\left[u_{t}^{m}\right]$ 是一个指示函数, 用来指示 $u_{t}^{m}$ 在 $m=0, u_{t}^{0}=c_{t}$ 时是否是顶点 $c_{t}$ 的上下文。该 算法使用随机梯度下降进行参数优化。整个metapath2vec++算法如下。3.分布式图引擎(快速入门)因为会存在许多无法在一台机器上加载的巨大图,例如社交网络和引文网络。为了处理这样的图,PGL 开发了一个分布式图引擎框架来支持大规模图网络上的图采样,以进行分布式 GNN 训练。下面将介绍执行分布式图引擎以进行图采样的步骤。如何启动分布式图引擎服务的示例:假设我们有一个下图,它有两种类型的节点(u 和 t)。首先,我们应该创建一个配置文件并指定每台机器的 ip 地址。 这里我们使用两个端口来模拟两台机器。创建配置文件和 ip 地址文件后,我们现在可以启动两个图形服务器。然后我们可以使用客户端从图服务器中采样邻居或采样节点。4 methpath2vec(实践)4.1数据集介绍链接:https://ericdongyx.github.io/metapath2vec/m2v.html将所有数据和代码下载到一个 zip 文件中---metapath2vec.zip 6.7 GB,包括以下 B、C、D、E 和 F 部分(DropBox |百度云)。Bibtex: @inproceedings{dong2017metapath2vec, title={metapath2vec: 异构网络的可扩展表示学习}, author={Dong, Yuxiao and Chawla, Nitesh V and Swami, Ananthram}, booktitle={KDD '17}, pages={135- -144}, 年份={2017}, 组织={ACM} }引用:Yuxiao Dong、Nitesh V. Chawla 和 Ananthram Swami。2017. metapath2vec:异构网络的可扩展表示学习。在 KDD'17 中。135–144。原始网络数据AMiner计算机科学 (CS) 数据: CS 数据集由 1,693,531 名计算机科学家和 3,194,405 篇论文组成,来自 3,883 个计算机科学场所——包括会议和期刊——截至 2016 年。我们构建了一个异构协作网络,其中有是三种类型的节点:作者、论文和地点。Citation: Jie Tang, Jing Zhang, Limin Yao, Juanzi Li, Li Zhang, and Zhong Su. 2008. ArnetMiner: Extraction and Mining of Academic Social Networks. In KDD'08. 990–998. 数据库和信息系统(DBIS)数据: DBIS 数据集由 Sun 等人构建和使用。它涵盖了 464 个场所、其前 5000 位作者以及相应的 72,902 篇出版物。我们还从 DBIS 构建了异构协作网络,其中一个链接可以连接两位作者,一位作者和一篇论文,以及一篇论文和一个地点。Citation: Yizhou Sun, Jiawei Han, Xifeng Yan, Philip S. Yu, and Tianyi Wu. 2011. Pathsim: Meta path-based top-k similarity search in heterogeneous information networks. In VLDB'11. 992–1003.4.2 PGL实现metapath2vec算法利用PGL来复现metapath2vec模型。和前面xxx2vec的方法类似,先做网络嵌入系数矩阵的训练,然后使用训练好的矩阵在做预测。Dataset.py 包含了对图数据进行深度游走生成walks等接口model.py 包含用于训练metapath2vec的skipgram模型定义utils.py 包含了对配置文件config.yaml的读取接口超参数所有超参数都保存在config.yaml文件中,所以在训练之前,你可以打开config.yaml来修改你喜欢的超参数。PGL 图形引擎启动现在我们支持使用PGL Graph Engine分布式加载图数据。我们还开发了一个简单的教程来展示如何启动图形引擎要启动分布式图服务,请按照以下步骤操作。1)IP地址设置第一步是为每个图形服务器设置 IP 列表。每个带有端口的 IP 地址代表一个服务器。在ip_list.txt文件中,我们为演示设置了 4 个 IP 地址如下:127.0.0.1:8553 127.0.0.1:8554 127.0.0.1:8555 127.0.0.1:85562)通过 OpenMPI 启动图形引擎在启动图形引擎之前,您应该在中设置以下超参数config.yaml:etype2files: "p2a:./graph_data/paper2author_edges.txt,p2c:./graph_data/paper2conf_edges.txt" ntype2files: "p:./graph_data/node_types.txt,a:./graph_data/node_types.txt,c:./graph_data/node_types.txt" symmetry: True shard_num: 100然后,我们可以在 OpenMPI 的帮助下启动图形引擎。mpirun -np 4 python -m pgl.distributed.launch --ip_config ./ip_list.txt --conf ./config.yaml --mode mpi --shard_num 100 手动启动图形引擎如果您没有安装 OpenMPI,您可以手动启动图形引擎。Fox 示例,如果我们要使用 4 个服务器,我们应该在 4 个终端上分别运行以下命令。# terminal 3 python -m pgl.distributed.launch --ip_config ./ip_list.txt --conf ./config.yaml --shard_num 100 --server_id 3 # terminal 2 python -m pgl.distributed.launch --ip_config ./ip_list.txt --conf ./config.yaml --shard_num 100 --server_id 2 # terminal 1 python -m pgl.distributed.launch --ip_config ./ip_list.txt --conf ./config.yaml --shard_num 100 --server_id 1 # terminal 0 python -m pgl.distributed.launch --ip_config ./ip_list.txt --conf ./config.yaml --shard_num 100 --server_id 06.总结介绍了异质图,利用pgl对metapath2vec、metapath2vec 进行了实现,并给出了多个框架版本的demo满足个性化需求metapath2vec是一种用于异构网络中表示学习的算法框架,其中包含多种类型的节点和链接。给定异构图,metapath2vec 算法首先生成基于元路径的随机游走,然后使用 skipgram 模型训练语言模型。基于 PGL重现了 metapath2vec 算法,用于可扩展的表示学习。参考资料Meta Path 定义metapath2vec 异构网络表示学习【图网络论文(一)】异构图网络:metapath2vec#16 知识分享:Metapath2vec的前世今生Graph Embedding之metapath2vec【Graph Embedding】: metapath2vec算法
图机器学习(GML)&图神经网络(GNN)原理和代码实现(前置学习系列二)
项目链接:https://aistudio.baidu.com/aistudio/projectdetail/4990947?contributionType=1欢迎fork欢迎三连!文章篇幅有限,部分程序出图不一一展示,详情进入项目链接即可图机器学习(GML)&图神经网络(GNN)原理和代码实现(PGL)[前置学习系列二]上一个项目对图相关基础知识进行了详细讲述,下面进图GMLnetworkx :NetworkX 是一个 Python 包,用于创建、操作和研究复杂网络的结构、动力学和功能https://networkx.org/documentation/stable/reference/algorithms/index.htmlimport numpy as np import random import networkx as nx from IPython.display import Image import matplotlib.pyplot as plt from sklearn.metrics import accuracy_score from sklearn.metrics import roc_curve from sklearn.metrics import roc_auc_score 1. 图机器学习GML图学习的主要任务图学习中包含三种主要的任务:链接预测(Link prediction)节点标记预测(Node labeling)图嵌入(Graph Embedding)1.1链接预测(Link prediction)在链接预测中,给定图G,我们的目标是预测新边。例如,当图未被完全观察时,或者当新客户加入平台(例如,新的LinkedIn用户)时,预测未来关系或缺失边是很有用的。详细阐述一下就是:GNN链接预测任务,即预测图中两个节点之间的边是否存在。在Social Recommendation,Knowledge Graph Completion等应用中都需要进行链接预测。模型实现上是将链接预测任务看成一个二分类任务:将图中存在的边作为正样本;负采样一些图中不存在的边作为负样本;将正样例和负样例合并划分为训练集和测试集;可以采用二分类模型的评估指标来评估模型的效果,例如:AUC值在一些场景下例如大规模推荐系统或信息检索,模型需要评估top-k预测结果的准确性,因此对于链接预测任务还需要一些其他的评估指标来衡量模型最终效果:MR(MeanRank)MRR(Mean Reciprocal Rank)Hit@nMR, MRR, Hit@n指标含义:假设整个图谱中共n个实体,评估前先进行如下操作:(1)将一个正确的三元组(h,r,t)中的头实体h或者尾实体t,依次替换成整个图谱中的其他所有实体,这样会产生n个三元组;(2)对(1)中产生的n个三元组分别计算其能量值,例如在TransE中计算h+r-t的值,这样n个三元组分别对应自己的能量值;(3)对上述n个三元组按照能量值进行升序排序,记录每个三元组排序后的序号;(4)对所有正确的三元组都进行上述三步操作MR指标:将整个图谱中每个正确三元组的能量值排序后的序号取平均得到的值;MRR指标:将整个图谱每个正确三元组的能量排序后的序号倒数取平均得到的值;Hit@n指标:整个图谱正确三元组的能量排序后序号小于n的三元组所占的比例。因此对于链接预测任务来说,MR指标越小,模型效果越好;MRR和Hit@n指标越大,模型效果越好。接下来本文将在Cora引文数据集上,预测两篇论文之间是否存在引用关系或被引用关系新LinkedIn用户的链接预测只是给出它可能认识的人的建议。在链路预测中,我们只是尝试在节点对之间建立相似性度量,并链接最相似的节点。现在的问题是识别和计算正确的相似性分数!为了说明图中不同链路的相似性差异,让我们通过下面这个图来解释:设$N(i)$是节点$i$的一组邻居。在上图中,节点$i$和$j$的邻居可以表示为:$i$的邻居:1.1.1 相似度分数我们可以根据它们的邻居为这两个节点建立几个相似度分数。公共邻居:$S(i,j) = \mid N(i) \cap N(j) \mid$,即公共邻居的数量。在此示例中,分数将为2,因为它们仅共享2个公共邻居。Jaccard系数:$S(i,j) = \frac { \mid N(i) \cap N(j) \mid } { \mid N(i) \cup N(j) \mid }$,标准化的共同邻居版本。交集是共同的邻居,并集是:因此,Jaccard系数由粉红色与黄色的比率计算出:值是$\frac {1} {6}$。Adamic-Adar指数:$S(i,j) = \sum_{k \in N(i)\cap N(j) } \frac {1} {\log \mid N(k) \mid}$。 对于节点i和j的每个公共邻居(common neighbor),我们将1除以该节点的邻居总数。这个概念是,当预测两个节点之间的连接时,与少量节点之间共享的元素相比,具有非常大的邻域的公共元素不太重要。优先依附(Preferential attachment): $S(i,j) = \mid N(i) \mid * \mid N(j) \mid$当社区信息可用时,我们也可以在社区信息中使用它们。### 1.1.2 性能指标(Performance metrics)我们如何进行链接预测的评估?我们必须隐藏节点对的子集,并根据上面定义的规则预测它们的链接。这相当于监督学习中的train/test的划分。然后,我们评估密集图的正确预测的比例,或者使用稀疏图的标准曲线下的面积(AUC)。参考链接:模型评估指标AUC和ROC:https://cloud.tencent.com/developer/article/15088821.1.3 代码实践这里继续用空手道俱乐部图来举例:使用在前两篇文中提及到的Karate图,并使用python来进行实现n=34 m = 78 G_karate = nx.karate_club_graph() pos = nx.spring_layout(G_karate) nx.draw(G_karate, cmap = plt.get_cmap('rainbow'), with_labels=True, pos=pos) # 我们首先把有关图的信息打印出来: n = G_karate.number_of_nodes() m = G_karate.number_of_edges() print("Number of nodes : %d" % n) print("Number of edges : %d" % m) print("Number of connected components : %d" % nx.number_connected_components(G_karate)) plt.figure(figsize=(12,8)) nx.draw(G_karate, pos=pos) plt.gca().collections[0].set_edgecolor("#000000") # 现在,让删除一些连接,例如25%的边: # Take a random sample of edges edge_subset = random.sample(G_karate.edges(), int(0.25 * G_karate.number_of_edges())) # remove some edges G_karate_train = G_karate.copy() G_karate_train.remove_edges_from(edge_subset) # 绘制部分观察到的图,可以对比上图发现,去掉了一些边 plt.figure(figsize=(12,8)) nx.draw(G_karate_train, pos=pos) # 可以打印我们删除的边数和剩余边数: edge_subset_size = len(list(edge_subset)) print("Deleted : ", str(edge_subset_size)) print("Remaining : ", str((m - edge_subset_size))) # Jaccard Coefficient # 可以先使用Jaccard系数进行预测: pred_jaccard = list(nx.jaccard_coefficient(G_karate_train)) score_jaccard, label_jaccard = zip(*[(s, (u,v) in edge_subset) for (u,v,s) in pred_jaccard]) # 打印前10组结果 print(pred_jaccard[0:10]) # 预测结果如下,其中第一个是节点,第二个是节点,最后一个是Jaccard分数(用来表示两个节点之间边预测的概率)# Compute the ROC AUC Score # 其中,FPR是False Positive Rate, TPR是True Positive Rate fpr_jaccard, tpr_jaccard, _ = roc_curve(label_jaccard, score_jaccard) auc_jaccard = roc_auc_score(label_jaccard, score_jaccard) print(auc_jaccard) # Adamic-Adar # 现在计算Adamic-Adar指数和对应的ROC-AUC分数 # Prediction using Adamic Adar pred_adamic = list(nx.adamic_adar_index(G_karate_train)) score_adamic, label_adamic = zip(*[(s, (u,v) in edge_subset) for (u,v,s) in pred_adamic]) print(pred_adamic[0:10]) # Compute the ROC AUC Score fpr_adamic, tpr_adamic, _ = roc_curve(label_adamic, score_adamic) auc_adamic = roc_auc_score(label_adamic, score_adamic) print(auc_adamic) # Compute the Preferential Attachment # 同样,可以计算Preferential Attachment得分和对应的ROC-AUC分数 pred_pref = list(nx.preferential_attachment(G_karate_train)) score_pref, label_pref = zip(*[(s, (u,v) in edge_subset) for (u,v,s) in pred_pref]) print(pred_pref[0:10]) fpr_pref, tpr_pref, _ = roc_curve(label_pref, score_pref) auc_pref = roc_auc_score(label_pref, score_pref) print(auc_pref)plt.figure(figsize=(12, 8)) plt.plot(fpr_jaccard, tpr_jaccard, label='Jaccard Coefficient - AUC %.2f' % auc_jaccard, linewidth=4) plt.plot(fpr_adamic, tpr_adamic, label='Adamic-Adar - AUC %.2f' % auc_adamic, linewidth=4) plt.plot(fpr_pref, tpr_pref, label='Preferential Attachment - AUC %.2f' % auc_pref, linewidth=4) plt.plot([0, 1], [0, 1], 'k--') plt.xlim([0.0, 1.0]) plt.ylim([0.0, 1.0]) plt.xlabel('False positive rate') plt.ylabel('True positive rate') plt.title("ROC AUC Curve") plt.legend(loc='lower right') plt.show() 1.2 节点标记预测(Node labeling)给定一个未标记某些节点的图,我们希望对这些节点的标签进行预测。这在某种意义上是一种半监督的学习问题。处理这些问题的一种常见方法是假设图上有一定的平滑度。平滑度假设指出通过数据上的高密度区域的路径连接的点可能具有相似的标签。这是标签传播算法背后的主要假设。标签传播算法(Label Propagation Algorithm,LPA)是一种快速算法,仅使用网络结构作为指导来发现图中的社区,而无需任何预定义的目标函数或关于社区的先验信息。单个标签在密集连接的节点组中迅速占据主导地位,但是在穿过稀疏连接区域时会遇到问题。半监督标签传播算法是如何工作?首先,我们有一些数据:$x_1, ..., x_l, x_{l+1}, ..., x_n \in R^p$,,以及前$l$个点的标签:$y_1, ..., y_l \in 1...C$.我们定义初始标签矩阵$Y \in R^{n \times C}$,如果$x_i$具有标签$y_i=j$则$Y_{ij} = 1$,否则为0。该算法将生成预测矩阵$F \in R^{n \times C}$,我们将在下面详述。然后,我们通过查找最可能的标签来预测节点的标签:$\hat{Y_i} = argmax_j F_{i,j}$预测矩阵$F$是什么?预测矩阵是矩阵$F^{\star}$,其最小化平滑度和准确度。因此,我们的结果在平滑性和准确性之间进行权衡。问题的描述非常复杂,所以我将不会详细介绍。但是,解决方案是:$F^{\star} = ( (1-\alpha)I + L_{sym})^{-1} Y$其中:参数$\alpha = \frac {1} {1+\mu}$$Y$是给定的标签$L_{sym}$是图的归一化拉普拉斯矩阵(Laplacian matrix)如果您想进一步了解这个主题,请关注图函数的平滑度和流形正则化的概念。斯坦福有一套很好的标签图可以下载:https://snap.stanford.edu/data/Networkx直接实现标签传播:https://networkx.github.io/documentation/latest/reference/algorithms/generated/networkx.algorithms.community.label_propagation.label_propagation_communities.html接下来我们用python来实现节点标签的预测。 为了给我们使用到的标签添加更多的特征,我们需要使用来自Facebook的真实数据。你可以再这里下载,然后放到facebook路径下。Facebook 数据已通过将每个用户的 Facebook 内部 id 替换为新值来匿名化。此外,虽然已经提供了来自该数据集的特征向量,但对这些特征的解释却很模糊。例如,如果原始数据集可能包含特征“political=Democratic Party”,则新数据将仅包含“political=anonymized feature 1”。因此,使用匿名数据可以确定两个用户是否具有相同的政治派别,但不能确定他们各自的政治派别代表什么。我已经把数据集放在目录里了,就不需要下载了1.2.1 代码实现标签扩散n = G_fb.number_of_nodes() m = G_fb.number_of_edges() print("Number of nodes: %d" % n) print("Number of edges: %d" % m) print("Number of connected components: %d" % nx.number_connected_components(G_fb)) # 我们把图数据显示出来: mapping=dict(zip(G_fb.nodes(), range(n))) nx.relabel_nodes(G_fb, mapping, copy=False) pos = nx.spring_layout(G_fb) plt.figure(figsize=(12,8)) nx.draw(G_fb, node_size=200, pos=pos) plt.gca().collections[0].set_edgecolor("#000000") with open('facebook/3980.featnames') as f: for i, l in enumerate(f): n_feat = i+1 features = np.zeros((n, n_feat)) f = open('facebook/3980.feat', 'r') for line in f: if line.split()[0] in mapping: node_id = mapping[line.split()[0]] features[node_id, :] = list(map(int, line.split()[1:])) features = 2*features-1 feat_id = 6 #特征选择id,自行设置 labels = features[:, feat_id] plt.figure(figsize=(12,8)) nx.draw(G_fb, cmap = plt.get_cmap('bwr'), nodelist=range(n), node_color = labels, node_size=200, pos=pos) plt.gca().collections[0].set_edgecolor("#000000") plt.show() # 这个所选择的特征,在图中相对平滑,因此拥有较好的学习传播性能。 # 为了阐述节点标签预测是如何进行的,我们首先要删掉一些节点的标签,作为要预测的对象。这里我们只保留了30%的节点标签: random.seed(5) proportion_nodes = 0.3 labeled_nodes = random.sample(G_fb.nodes(), int(proportion_nodes * G_fb.number_of_nodes())) known_labels = np.zeros(n) known_labels[labeled_nodes] = labels[labeled_nodes] plt.figure(figsize=(12,8)) nx.draw(G_fb, cmap = plt.get_cmap('bwr'), nodelist=range(n), node_color = known_labels, node_size=200, pos=pos) plt.gca().collections[0].set_edgecolor("#000000") # set node border color to black plt.show()1.3 图嵌入(Graph Embedding)嵌入的学习方式与 word2vec 的 skip-gram 嵌入的学习方式相同,使用的是 skip-gram 模型。问题是,我们如何为 Node2Vec 生成输入语料库?数据要复杂得多,即(非)定向、(非)加权、(a)循环……为了生成语料库,我们使用随机游走采样策略:在处理NLP或计算机视觉问题时,我们习惯在深度神经网络中对图像或文本进行嵌入(embedding)。到目前为止,我们所看到的图的一个局限性是没有向量特征。但是,我们可以学习图的嵌入!图有不同几个级别的嵌入:对图的组件进行嵌入(节点,边,特征…)(Node2Vec) node2vec是一个用于图表示学习的算法框架。给定任何图,它可以学习节点的连续特征表示,然后可以用于各种下游机器学习任务。对图的子图或整个图进行嵌入(Graph2Vec) Learning Distributed Representations of Graphs学习图的分布式表示最近关于图结构化数据的表示学习的工作主要集中在学习图子结构(例如节点和子图)的分布式表示。然而,许多图分析任务(例如图分类和聚类)需要将整个图表示为固定长度的特征向量。虽然上述方法自然不具备学习这种表示的能力,但图内核仍然是获得它们的最有效方法。然而,这些图内核使用手工制作的特征(例如,最短路径、graphlet 等),因此受到泛化性差等问题的阻碍。为了解决这个限制,在这项工作中,我们提出了一个名为 graph2vec 的神经嵌入框架来学习任意大小图的数据驱动的分布式表示。图2vec' s 嵌入是以无监督的方式学习的,并且与任务无关。因此,它们可以用于任何下游任务,例如图分类、聚类甚至播种监督表示学习方法。我们在几个基准和大型现实世界数据集上的实验表明,graph2vec 在分类和聚类精度方面比子结构表示学习方法有显着提高,并且可以与最先进的图内核竞争。### 1.3.1. 节点嵌入(Node Embedding)我们首先关注的是图组件的嵌入。有几种方法可以对节点或边进行嵌入。例如,DeepWalk【http://www.perozzi.net/projects/deepwalk/ 】 使用短随机游走来学习图中边的表示。我们将讨论Node2Vec,这篇论文由2016年斯坦福大学的Aditya Grover和Jure Leskovec发表。作者说:“node2vec是一个用于图表示学习的算法框架。给定任何图,它可以学习节点的连续特征表示,然后可以用于各种下游机器学习任务。“该模型通过使用随机游走,优化邻域保持目标来学习节点的低维表示。Node2Vec的代码可以在GitHub上找到:https://github.com/eliorc/node2vec部分程序出图不一一展示,详情进入项目链接即可2.图神经网络GNN2.1GNN引言图神经网络(Graph Neural Networks,GNN)综述链接:https://zhuanlan.zhihu.com/p/75307407?from_voters_page=true 译文https://arxiv.org/pdf/1901.00596.pdf 原始文章 最新版本V4版本近年来,深度学习彻底改变了许多机器学习任务,从图像分类和视频处理到语音识别和自然语言理解。这些任务中的数据通常在欧几里得空间中表示。然而,越来越多的应用程序将数据从非欧几里德域生成并表示为具有复杂关系和对象之间相互依赖关系的图。图数据的复杂性对现有的机器学习算法提出了重大挑战。最近,出现了许多关于扩展图数据深度学习方法的研究。在本次调查中,我们全面概述了数据挖掘和机器学习领域中的图神经网络 (GNN)。我们提出了一种新的分类法,将最先进的图神经网络分为四类,即循环图神经网络、卷积图神经网络、图自动编码器和时空图神经网络。我们进一步讨论了图神经网络在各个领域的应用,并总结了图神经网络的开源代码、基准数据集和模型评估。最后,我们在这个快速发展的领域提出了潜在的研究方向神经网络最近的成功推动了模式识别和数据挖掘的研究。许多机器学习任务,如对象检测 [1]、[2]、机器翻译 [3]、[4] 和语音识别 [5],曾经严重依赖手工特征工程来提取信息特征集,最近已经由各种端到端深度学习范例彻底改变,例如卷积神经网络 (CNN) [6]、递归神经网络 (RNN) [7] 和自动编码器 [8]。深度学习在许多领域的成功部分归功于快速发展的计算资源(例如 GPU)、大训练数据的可用性以及深度学习从欧几里得数据(例如图像、文本、和视频)。以图像数据为例,我们可以将图像表示为欧几里得空间中的规则网格。卷积神经网络 (CNN) 能够利用图像数据的移位不变性、局部连通性和组合性 [9]。因此,CNN 可以提取与整个数据集共享的局部有意义的特征,用于各种图像分析。虽然深度学习有效地捕获了欧几里得数据的隐藏模式,但越来越多的应用程序将数据以图形的形式表示。例如,在电子商务中,基于图的学习系统可以利用用户和产品之间的交互来做出高度准确的推荐。在化学中,分子被建模为图形,并且需要确定它们的生物活性以进行药物发现。在引文网络中,论文通过引文相互链接,并且需要将它们分类到不同的组中。图数据的复杂性对现有的机器学习算法提出了重大挑战。由于图可能是不规则的,图可能具有可变大小的无序节点,并且来自图中的节点可能具有不同数量的邻居,导致一些重要的操作(例如卷积)在图像域中很容易计算,但是难以应用于图域。此外,现有机器学习算法的一个核心假设是实例相互独立。这个假设不再适用于图数据,因为每个实例(节点)通过各种类型的链接(例如引用、友谊和交互)与其他实例相关联。最近,人们对扩展图形数据的深度学习方法越来越感兴趣。受来自深度学习的 CNN、RNN 和自动编码器的推动,在过去几年中,重要操作的新泛化和定义迅速发展,以处理图数据的复杂性。例如,可以从 2D 卷积推广图卷积。如图 1 所示,可以将图像视为图形的特殊情况,其中像素由相邻像素连接。与 2D 卷积类似,可以通过取节点邻域信息的加权平均值来执行图卷积。二维卷积类似于图,图像中的每个像素都被视为一个节点,其中邻居由过滤器大小确定。 2D 卷积取红色节点及其邻居像素值的加权平均值。 节点的邻居是有序的并且具有固定的大小。图卷积。 为了得到红色节点的隐藏表示,图卷积运算的一个简单解决方案是取红色节点及其邻居节点特征的平均值。 与图像数据不同,节点的邻居是无序且大小可变的。发展:图神经网络 (GNN) Sperduti 等人的简史。 (1997) [13] 首次将神经网络应用于有向无环图,这激发了对 GNN 的早期研究。图神经网络的概念最初是在 Gori 等人中概述的。 (2005) [14] 并在 Scarselli 等人中进一步阐述。 (2009) [15] 和 Gallicchio 等人。 (2010) [16]。这些早期研究属于循环图神经网络(RecGNNs)的范畴。他们通过以迭代方式传播邻居信息来学习目标节点的表示,直到达到一个稳定的固定点。这个过程在计算上是昂贵的,并且最近已经越来越多地努力克服这些挑战[17],[18]。受 CNN 在计算机视觉领域的成功的鼓舞,大量重新定义图数据卷积概念的方法被并行开发。这些方法属于卷积图神经网络 (ConvGNN) 的范畴。 ConvGNN 分为两个主流,基于光谱的方法和基于空间的方法。 Bruna 等人提出了第一个关于基于光谱的 ConvGNN 的杰出研究。 (2013)[19],它开发了一种基于谱图理论的图卷积。从那时起,基于谱的 ConvGNN [20]、[21]、[22]、[23] 的改进、扩展和近似值不断增加。基于空间的 ConvGNN 的研究比基于光谱的 ConvGNN 早得多。 2009 年,Micheli 等人。 [24] 首先通过架构复合非递归层解决了图相互依赖问题,同时继承了 RecGNN 的消息传递思想。然而,这项工作的重要性被忽视了。直到最近,出现了许多基于空间的 ConvGNN(例如,[25]、[26]、[27])。代表性 RecGNNs 和 ConvGNNs 的时间线如表 II 的第一列所示。除了 RecGNNs 和 ConvGNNs,在过去几年中还开发了许多替代 GNN,包括图自动编码器 (GAE) 和时空图神经网络 (STGNN)。这些学习框架可以建立在 RecGNN、ConvGNN 或其他用于图建模的神经架构上。综述总结如下:新分类 我们提出了一种新的图神经网络分类。图神经网络分为四组:循环图神经网络、卷积图神经网络、图自动编码器和时空图神经网络。综合回顾 我们提供了最全面的图数据现代深度学习技术概览。对于每种类型的图神经网络,我们都提供了代表性模型的详细描述,进行了必要的比较,并总结了相应的算法。丰富的资源我们收集了丰富的图神经网络资源,包括最先进的模型、基准数据集、开源代码和实际应用。本调查可用作理解、使用和开发适用于各种现实生活应用的不同深度学习方法的实践指南。未来方向 我们讨论了图神经网络的理论方面,分析了现有方法的局限性,并在模型深度、可扩展性权衡、异质性和动态性方面提出了四个可能的未来研究方向。2.2 神经网络类型在本节中,我们介绍了图神经网络 (GNN) 的分类,如表 II 所示。 我们将图神经网络 (GNN) 分为循环图神经网络 (RecGNN)、卷积图神经网络 (ConvGNN)、图自动编码器 (GAE) 和时空图神经网络 (STGNN)。 图 2 给出了各种模型架构的示例。 下面,我们对每个类别进行简要介绍。2.2.1循环图神经网络(RecGNNs,Recurrent graph neural networks )循环图神经网络(RecGNNs)大多是图神经网络的先驱作品。 RecGNN 旨在学习具有循环神经架构的节点表示。 他们假设图中的一个节点不断地与其邻居交换信息/消息,直到达到稳定的平衡。 RecGNN 在概念上很重要,并启发了后来对卷积图神经网络的研究。 特别是,基于空间的卷积图神经网络继承了消息传递的思想。2.2.2 卷积图神经网络 (ConvGNNs,Convolutional graph neural networks)卷积图神经网络 (ConvGNNs) 将卷积操作从网格数据推广到图数据。 主要思想是通过聚合它自己的特征 xv 和邻居的特征 xu 来生成节点 v 的表示,其中 u ∈ N(v)。 与 RecGNN 不同,ConvGNN 堆叠多个图卷积层以提取高级节点表示。 ConvGNN 在构建许多其他复杂的 GNN 模型中发挥着核心作用。 图 2a 显示了用于节点分类的 ConvGNN。 图 2b 展示了用于图分类的 ConvGNN。2.2.3图自动编码器 (GAE,Graph autoencoders (GAEs))是无监督学习框架,它将节点/图编码到潜在向量空间并从编码信息中重建图数据。 GAE 用于学习网络嵌入和图形生成分布。 对于网络嵌入,GAE 通过重构图结构信息(例如图邻接矩阵)来学习潜在节点表示。 对于图的生成,一些方法逐步生成图的节点和边,而另一些方法一次全部输出图。 图 2c 展示了一个用于网络嵌入的 GAE。2.2.4 时空图神经网络 (STGNN,Spatial-temporal graph neural networks)旨在从时空图中学习隐藏模式,这在各种应用中变得越来越重要,例如交通速度预测 [72]、驾驶员机动预期 [73] 和人类动作识别 [ 75]。 STGNN 的关键思想是同时考虑空间依赖和时间依赖。 许多当前的方法集成了图卷积来捕获空间依赖性,并使用 RNN 或 CNN 对时间依赖性进行建模。 图 2d 说明了用于时空图预测的 STGNN。具体公式推到见论文!2.3图神经网络的应用GNN 在不同的任务和领域中有许多应用。 尽管每个类别的 GNN 都可以直接处理一般任务,包括节点分类、图分类、网络嵌入、图生成和时空图预测,但其他与图相关的一般任务,如节点聚类 [134]、链接预测 [135 ],图分割[136]也可以通过GNN来解决。 我们详细介绍了基于以下研究领域的一些应用。计算机视觉(Computer vision)计算机视觉 GNN 在计算机视觉中的应用包括场景图生成、点云分类和动作识别。识别对象之间的语义关系有助于理解视觉场景背后的含义。 场景图生成模型旨在将图像解析为由对象及其语义关系组成的语义图 [137]、[138]、[139]。另一个应用程序通过在给定场景图的情况下生成逼真的图像来反转该过程 [140]。由于自然语言可以被解析为每个单词代表一个对象的语义图,因此它是一种很有前途的解决方案,可以在给定文本描述的情况下合成图像。 分类和分割点云使 LiDAR 设备能够“看到”周围环境。点云是由 LiDAR 扫描记录的一组 3D 点。 [141]、[142]、[143] 将点云转换为 k-最近邻图或超点图,并使用 ConvGNN 探索拓扑结构。 识别视频中包含的人类行为有助于从机器方面更好地理解视频内容。一些解决方案检测视频剪辑中人体关节的位置。由骨骼连接起来的人体关节自然形成了一个图形。给定人类关节位置的时间序列,[73]、[75] 应用 STGNN 来学习人类动作模式。 此外,GNN 在计算机视觉中的适用方向数量仍在增长。它包括人-物交互[144]、小样本图像分类[145]、[146]、[147]、语义分割[148]、[149]、视觉推理[150]和问答[151]。自然语言处理(Natural language processing )自然语言处理 GNN 在自然语言处理中的一个常见应用是文本分类。 GNN 利用文档或单词的相互关系来推断文档标签 [22]、[42]、[43]。 尽管自然语言数据表现出顺序,但它们也可能包含内部图结构,例如句法依赖树。句法依赖树定义了句子中单词之间的句法关系。 Marcheggiani 等人。 [152] 提出了在 CNN/RNN 句子编码器之上运行的句法 GCN。 Syntactic GCN 基于句子的句法依赖树聚合隐藏的单词表示。巴斯廷斯等人。 [153] 将句法 GCN 应用于神经机器翻译任务。 Marcheggiani 等人。[154] 进一步采用与 Bastings 等人相同的模型。 [153]处理句子的语义依赖图。 图到序列学习学习在给定抽象词的语义图(称为抽象意义表示)的情况下生成具有相同含义的句子。宋等人。 [155] 提出了一种图 LSTM 来编码图级语义信息。贝克等人。 [156] 将 GGNN [17] 应用于图到序列学习和神经机器翻译。逆向任务是序列到图的学习。给定句子生成语义或知识图在知识发现中非常有用交通 Traffic 准确预测交通网络中的交通速度、交通量或道路密度对于智能交通系统至关重要。 [48]、[72]、[74] 使用 STGNN 解决交通预测问题。 他们将交通网络视为一个时空图,其中节点是安装在道路上的传感器,边缘由节点对之间的距离测量,每个节点将窗口内的平均交通速度作为动态输入特征。 另一个工业级应用是出租车需求预测。 鉴于历史出租车需求、位置信息、天气数据和事件特征,Yao 等人。 [159] 结合 LSTM、CNN 和由 LINE [160] 训练的网络嵌入,形成每个位置的联合表示,以预测时间间隔内某个位置所需的出租车数量。推荐系统 Recommender systems基于图的推荐系统将项目和用户作为节点。 通过利用项目与项目、用户与用户、用户与项目之间的关系以及内容信息,基于图的推荐系统能够产生高质量的推荐。 推荐系统的关键是对项目对用户的重要性进行评分。 结果,它可以被转换为链接预测问题。 为了预测用户和项目之间缺失的链接,Van 等人。 [161] 和英等人。 [162] 提出了一种使用 ConvGNN 作为编码器的 GAE。 蒙蒂等人。 [163] 将 RNN 与图卷积相结合,以学习生成已知评级的底层过程化学 Chemistry在化学领域,研究人员应用 GNN 来研究分子/化合物的图形结构。 在分子/化合物图中,原子被视为节点,化学键被视为边缘。 节点分类、图分类和图生成是针对分子/化合物图的三个主要任务,以学习分子指纹 [85]、[86]、预测分子特性 [27]、推断蛋白质界面 [164] 和 合成化合物其他GNN 的应用不仅限于上述领域和任务。 已经探索将 GNN 应用于各种问题,例如程序验证 [17]、程序推理 [166]、社会影响预测 [167]、对抗性攻击预防 [168]、电子健康记录建模 [169]、[170] ]、大脑网络[171]、事件检测[172]和组合优化[173]。2.4未来方向尽管 GNN 已经证明了它们在学习图数据方面的能力,但由于图的复杂性,挑战仍然存在。模型深度 Model depth深度学习的成功在于深度神经架构 [174]。 然而,李等人。 表明随着图卷积层数的增加,ConvGNN 的性能急剧下降 [53]。 随着图卷积将相邻节点的表示推得更近,理论上,在无限数量的图卷积层中,所有节点的表示将收敛到一个点 [53]。 这就提出了一个问题,即深入研究是否仍然是学习图数据的好策略。可扩展性权衡 Scalability trade-offGNN 的可扩展性是以破坏图完整性为代价的。 无论是使用采样还是聚类,模型都会丢失部分图信息。 通过采样,节点可能会错过其有影响力的邻居。 通过聚类,图可能被剥夺了独特的结构模式。 如何权衡算法的可扩展性和图的完整性可能是未来的研究方向。异质性Heterogenity当前的大多数 GNN 都假设图是同质的。 目前的 GNN 很难直接应用于异构图,异构图可能包含不同类型的节点和边,或者不同形式的节点和边输入,例如图像和文本。 因此,应该开发新的方法来处理异构图。动态Dynamicity图本质上是动态的,节点或边可能出现或消失,节点/边输入可能会随时间变化。 需要新的图卷积来适应图的动态性。 虽然图的动态性可以通过 STGNN 部分解决,但很少有人考虑在动态空间关系的情况下如何执行图卷积。总结因为之前一直在研究知识提取相关算法,后续为了构建小型领域知识图谱,会用到知识融合、知识推理等技术,现在开始学习研究图计算相关。现在已经覆盖了图的介绍,图的主要类型,不同的图算法,在Python中使用Networkx来实现它们,以及用于节点标记,链接预测和图嵌入的图学习技术,最后讲了GNN应用。本项目参考了:maelfabien大神、以及自尊心3 在博客 or github上的贡献欢迎大家fork, 后续将开始图计算相关项目以及部分知识提取技术深化!项目参考链接:第一章节:https://maelfabien.github.io/machinelearning/graph_4/#ii-node-labelinghttps://blog.csdn.net/xjxgyc/article/details/100175930https://maelfabien.github.io/machinelearning/graph_5/#node-embeddinghttps://github.com/eliorc/node2vec第二节:https://zhuanlan.zhihu.com/p/75307407?from_voters_page=true 译文https://arxiv.org/pdf/1901.00596.pdf更多参考:https://github.com/maelfabien/Machine_Learning_Tutorials项目链接:https://aistudio.baidu.com/aistudio/projectdetail/4990947?contributionType=1欢迎fork欢迎三连!文章篇幅有限,部分程序出图不一一展示,详情进入项目链接即可
关于图计算&图学习的基础知识概览:前置知识点学习(Paddle Graph L)系列【一】
关于图计算&图学习的基础知识概览:前置知识点学习(Paddle Graph Learning (PGL))欢迎fork本项目原始链接:关于图计算&图学习的基础知识概览:前置知识点学习(Paddle Graph L)https://aistudio.baidu.com/aistudio/projectdetail/4982973?contributionType=1因为篇幅关系就只放了部分程序在第三章,如有需求可自行fork项目原始链接。0.1图计算基本概念首先看到百度百科定义:图计算(Graph Processing)是将数据按照图的方式建模可以获得以往用扁平化的视角很难得到的结果。图(Graph)是用于表示对象之间关联关系的一种抽象数据结构,使用顶点(Vertex)和边(Edge)进行描述:顶点表示对象,边表示对象之间的关系。可抽象成用图描述的数据即为图数据。图计算,便是以图作为数据模型来表达问题并予以解决的这一过程。以高效解决图计算问题为目标的系统软件称为图计算系统。大数据时代,数据之间存在关联关系。由于图是表达事物之间复杂关联关系的组织结构,因此现实生活中的诸多应用场景都需要用到图,例如,淘宝用户好友关系图、道路图、电路图、病毒传播网、国家电网、文献网、社交网和知识图谱。为了从这些数据之间的关联关系中获取有用信息,大量图算法层出不穷。它们通过对大型图数据的迭代处理,获得图数据中隐藏的重要信息。图计算作为下一代人工智能的核心技术,已被广泛应用于医疗、教育、军事、金融等多个领域,并备受各国政府、全球研发机构和巨头公司关注,目前已成为全球科技竞争新的战略制高点。0.1.1图计算图可以将各类数据关联起来:将不同来源、不同类型的数据融合到同一个图里进行分析,得到原本独立分析难以发现的结果;图的表示可以让很多问题处理地更加高效:例如最短路径、连通分量等等,只有用图计算的方式才能予以最高效的解决。然而,图计算具有一些区别于其它类型计算任务的挑战与特点:随机访问多:图计算围绕图的拓扑结构展开,计算过程会访问边以及关联的两个顶点,但由于实际图数据的稀疏性(通常只有几到几百的平均度数),不可避免地产生了大量随机访问;计算不规则:实际图数据具有幂律分布的特性,即绝大多数顶点的度数很小,极少部分顶点的度数却很大(例如在线社交网络中明星用户的粉丝),这使得计算任务的划分较为困难,十分容易导致负载不均衡。0.1.2图计算系统随着图数据规模的不断增长,对图计算能力的要求越来越高,大量专门面向图数据处理的计算系统便是诞生在这样的背景下。Pregel由Google研发是专用图计算系统的开山之作。Pregel提出了以顶点为中心的编程模型,将图分析过程分析为若干轮计算,每一轮各个顶点独立地执行各自的顶点程序,通过消息传递在顶点之间同步状态。Giraph是Pregel的一个开源实现,Facebook基于Giraph使用200台机器分析万亿边级别的图数据,计算一轮PageRank的用时近4分钟。GraphLab出自于CMU的实验室,基于共享内存的机制,允许用户使用异步的方式计算以加快某些算法的收敛速度。PowerGraph在GraphLab基础上做了优化,针对实际图数据中顶点度数的幂律分布特性,提出了顶点分割的思想,可以实现更细粒度的数据划分,从而实现更好的负载均衡。其计算模型也被用在后续的图计算系统上,例如GraphX。尽管上述的这些图计算系统相比MapReduce、Spark等在性能上已经有了显著的性能提升,但是它们的计算效率依然非常低下,甚至不如精心优化的单线程程序。Gemini由清华大学计算机系的团队提出,针对已有系统的局限性,提出了以计算为中心的设计理念,通过降低分布式带来的开销并尽可能优化本地计算部分的实现,使得系统能够在具备扩展性的同时不失高效性 [5] 。针对图计算的各个特性,Gemini在数据压缩存储、图划分、任务调度、通信模式切换等方面都提出了对应的优化措施,比其他知名图计算系统的最快性能还要快一个数量级。ShenTu沿用并扩展了Gemini的编程和计算模型,能够利用神威·太湖之光整机上千万核的计算资源,高效处理70万亿边的超大规模图数据,入围了2018年戈登·贝尔奖的决赛名单。除了使用向外扩展的分布式图计算系统来处理规模超出单机内存的图数据,也有一些解决方案通过在单台机器上高效地使用外存来完成大规模图计算任务,其中的代表有GraphChi、X-Stream、FlashGraph、GridGraph、Mosaic等。0.2 图关键技术0.2.1 图数据的组织由于实际图的稀疏性,图计算系统通常使用稀疏矩阵的存储方法来表示图数据,其中最常用的两种是CSR(Compressed Sparse Row)和CSC(Compressed Sparse Column),分别按行(列)存储每行(列)非零元所在列(行),每一行则(列)对应了一个顶点的出边(入边)。0.2.2图数据的划分将一个大图划分为若干较小的子图,是很多图计算系统都会使用的扩展处理规模的方法;此外,图划分还能增强数据的局部性,从而降低访存的随机性,提升系统效率。对于分布式图计算系统而言,图划分有两个目标:每个子图的规模尽可能相近,获得较为均衡的负载。不同子图之间的依赖(例如跨子图的边)尽可能少,降低机器间的通信开销。图划分有按照顶点划分和按照边划分两种方式,它们各有优劣:顶点划分将每个顶点邻接的边都放在一台机器上,因此计算的局部性更好,但是可能由于度数的幂律分布导致负载不均衡。边划分能够最大程度地改善负载不均衡的问题,但是需要将每个顶点分成若干副本分布于不同机器上,因此会引入额外的同步/空间开销。所有的类Pregel系统采用的均为顶点划分的方式,而PowerGraph/GraphX采用的是边划分的方式。Gemini采用了基于顶点划分的方法来避免引入过大的分布式开销;但是在计算模式上却借鉴了边划分的思想,将每个顶点的计算分布到多台机器上分别进行,并尽可能让每台机器上的计算量接近,从而消解顶点划分可能导致的负载不均衡问题。0.2.3顶点程序的调度在以顶点为中心的图计算模型中,每个顶点程序可以并行地予以调度。大部分图计算系统采用基于BSP模型的同步调度方式,将计算过程分为若干超步(每个超步通常对应一轮迭代),每个超步内所有顶点程序独立并行地执行,结束后进行全局同步。顶点程序可能产生发送给其它顶点的消息,而通信过程通常与计算过程分离。同步调度容易产生的问题是:一旦发生负载不均衡,那么最慢的计算单元会拖慢整体的进度。某些算法可能在同步调度模型下不收敛。为此,部分图计算系统提供了异步调度的选项,让各个顶点程序的执行可以更自由,例如:每个顶点程序可以设定优先级,让优先级高的顶点程序能以更高的频率执行,从而更快地收敛。然而,异步调度在系统设计上引入了更多的复杂度,例如数据一致性的维护,消息的聚合等等,很多情况下的效率并不理想。因此,大多数图计算系统采用的还是同步的调度方式;少数支持异步计算的系统也默认使用同步方式进行调度。0.2.4 计算与通信模式图计算系统使用的通信模式主要分为两种,推动(Push)和拉取(Pull):推动模式下每个顶点沿着边向邻居顶点传递消息,邻居顶点根据收到的消息更新自身的状态。所有的类Pregel系统采用的几乎都是这种计算和通信模式。拉取模式通常将顶点分为主副本和镜像副本,通信发生在每个顶点的两类副本之间而非每条边连接的两个顶点之间。GraphLab、PowerGraph、GraphX等采用的均为这种模式。除了通信的模式有所区别,推动和拉取在计算上也有不同的权衡:推动模式可能产生数据竞争,需要使用锁或原子操作来保证状态的更新是正确的。拉取模式尽管没有竞争的问题,但是可能产生额外的数据访问。Gemini则将两种模式融合起来,根据每一轮迭代参与计算的具体情况,自适应地选择更适合的模式。0.3 图计算应用0.3.1 网页排序将网页作为顶点,网页之间的超链接作为边,整个互联网可以建模成一个非常巨大的图(十万亿级边)。搜索引擎在返回结果时,除了需要考虑网页内容与关键词的相关程度,还需要考虑网页本身的质量。PageRank是最早Google用于对网页进行排序的算法,通过将链接看成投票来指示网页的重要程度。PageRank的计算过程并不复杂:在首轮迭代开始前,所有顶点将自己的PageRank值设为1;每轮迭代中,每个顶点向所有邻居贡献自己当前PageRank值除以出边数作为投票,然后将收到的所有来自邻居的投票累加起来作为新的PageRank值;如此往复,直到所有顶点的PageRank值在相邻两轮之间的变化达到某个阈值为止。0.3.2 社区发现社交网络也是一种典型的图数据:顶点表示人,边表示人际关系;更广义的社交网络可以将与人有关的实体也纳入进来,例如手机、地址、公司等。社区发现是社交网络分析的一个经典应用:将图分成若干社区,每个社区内部的顶点之间具有相比社区外部更紧密的连接关系。社区发现有非常广泛的用途,在金融风控、国家安全、公共卫生等大量场景都有相关的应用。标签传播是一种常用的社区发现算法:每个顶点的标签即为自己的社区,初始化时设置自己的顶点编号;在随后的每一轮迭代中,每个顶点将邻居中出现最频繁的标签设置为自己新的标签;当所有顶点相邻两轮之间的标签变化少于某个阈值时则停止迭代。0.3.3最短路径在图上发现顶点与顶点之间的最短路径是一类很常见的图计算任务,根据起始顶点与目标顶点集合的大小,又可分为单对单(一个顶点到一个顶点)、多对多(多个顶点到多个顶点)、单源(一个顶点到所有其它顶点)、多源(多个顶点到所有其它顶点)、所有点对(所有顶点到其它所有顶点)等。对于无权图,通常使用基于BFS的算法;对于有权图,比较常见的有SPFA算法、Bellman-Ford算法等。最短路径的用途十分广泛:在知识图谱中经常需要寻找两个实体之间的最短关联路径;基于黑名单和实体之间的关联可以发现其它顶点与黑名单之间的距离;而所有点对的最短路径可以帮助衡量各个顶点在整个图的拓扑结构所处的位置(中心程度)。节点级别任务:金融诈骗检测中,节点是用户和商家,边是用户和商家之间的交互,利用图模型预测潜在的金融诈骗分子。在目标检测案例中,将3D点云数据中点与点之间距离作为边,通过图结构可以进行3D目标检测边级别任务:推荐系统中,通过已有的用户-商品数据建立用户图行为关系,得到节点的向量表示,进而进行推荐任务图级别任务:气味识别,利用图神经网络识别分子结构进而识别气味1.图与图学习1.1 图的基本表示方法先简单学习一下图论的基本概念,图论的经典算法,以及近些年来图学习的发展举个例子,一个简单的图可能是这样:节点(node)用红色标出,通过黑色的边(edge)连接。图可用于表示:社交网络网页生物网络…我们可以在图上执行怎样的分析?研究拓扑结构和连接性群体检测识别中心节点预测缺失的节点预测缺失的边…图 G=(V, E) 由下列要素构成:一组节点(也称为 verticle)V=1,…,n一组边 E⊆V×V边 (i,j) ∈ E 连接了节点 i 和 ji 和 j 被称为相邻节点(neighbor)节点的度(degree)是指相邻节点的数量节点、边和度的示意图如果一个图的所有节点都有 n-1 个相邻节点,则该图是完备的(complete)。也就是说所有节点都具备所有可能的连接方式。从 i 到 j 的路径(path)是指从 i 到达 j 的边的序列。该路径的长度(length)等于所经过的边的数量。图的直径(diameter)是指连接任意两个节点的所有最短路径中最长路径的长度。举个例子,在这个案例中,我们可以计算出一些连接任意两个节点的最短路径。该图的直径为 3,因为没有任意两个节点之间的最短路径的长度超过 3。一个直径为 3 的图测地路径(geodesic path)是指两个节点之间的最短路径。如果所有节点都可通过某个路径连接到彼此,则它们构成一个连通分支(connected component)。如果一个图仅有一个连通分支,则该图是连通的(connected)举个例子,下面是一个有两个不同连通分支的图:一个有两个连通分支的图如果一个图的边是有顺序的配对,则该图是有向的(directed)。i 的入度(in-degree)是指向 i 的边的数量,出度(out-degree)是远离 i 的边的数量有向图如果可以回到一个给定节点,则该图是有环的(cyclic)。相对地,如果至少有一个节点无法回到,则该图就是无环的(acyclic)。图可以被加权(weighted),即在节点或关系上施加权重。如果一个图的边数量相比于节点数量较小,则该图是稀疏的(sparse)。相对地,如果节点之间的边非常多,则该图是密集的(dense)Neo4J 的关于图算法的书给出了清晰明了的总结:总结(来自 Neo4J Graph Book & 自尊心3大佬的贡献)1.2 图的存储存储图的方式有三种:相邻矩阵,邻接表,十字链表1.2.1 相邻矩阵有向图的相邻矩阵无向图的相邻矩阵使用邻接矩阵,这通常是在内存中加载的方式:对于图中的每一个可能的配对,如果两个节点有边相连,则设为 1。如果该图是无向图,则 A 是对称的。1.2.2 邻接表对于稀疏图,可以采用邻接表存储法:边较少,相邻矩阵就会出现大量的零元素相邻矩阵的零元素将耗费大量的存储空间和时间无向图的邻接表表示无向图同一条边在邻接表中出现两次上面的图用邻接表可表示为:带权图的邻接表表示有向图的邻接表(出边表)有向图的逆邻接表(入边表)1.2.3 十字链表 (Orthogonal List)可以看成是邻接表和逆邻接表的结合对应于有向图的每一条弧有一个表目,共有5个域:头 headvex尾 tailvex下一条共尾弧 tailnextarc下一条共头弧 headnextarc弧权值等 info 域顶点表目由3个域组成:data 域firstinarc 第一条以该顶点为终点的弧firstoutarc 第一条以该顶点为始点的弧十字链表有两组链表组成:行和列的指针序列每个结点都包含两个指针:同一行的后继同一列的后继这三种表示方式都是等价的,我们可以根据使用场景来选择图的存储方式。1.3 图的类型和性质简单说明图可以根据不同标准进行分类,我们在这里主要讲一种分类方法,同构图与异构图。同构图与异构图同构图:节点类型和边的类型只有一种的图。异构图:节点类型+边类型>2 的图。两个图G和H是同构图(isomorphic graphs),能够通过重新标记图G的顶点而产生图H。如果G和H同构,那么它们的阶是相同的,它们大小是相同的,它们个顶点的度数也对应相同。异构图是一个与同构图相对应的新概念。传统同构图(Homogeneous Graph)数据中只存在一种节点和边,因此在构建图神经网络时所有节点共享同样的模型参数并且拥有同样维度的特征空间。而异构图(Heterogeneous Graph)中可以存在不只一种节点和边,因此允许不同类型的节点拥有不同维度的特征或属性。2.图算法与图分析图分析使用基于图的方法来分析连接的数据。我们可以:查询图数据,使用基本统计信息,可视化地探索图、展示图,或者将图信息预处理后合并到机器学习任务中。图的查询通常用于局部数据分析,而图计算通常涉及整张图和迭代分析。图算法是图分析的工具之一。图算法提供了一种最有效的分析连接数据的方法,它们描述了如何处理图以发现一些定性或者定量的结论。图算法基于图论,利用节点之间的关系来推断复杂系统的结构和变化。我们可以使用这些算法来发现隐藏的信息,验证业务假设,并对行为进行预测2.1 路径搜索算法(Pathfinding and Search)图搜索算法(Pathfinding and Search Algorithms)探索一个图,用于一般发现或显式搜索。这些算法通过从图中找到很多路径,但并不期望这些路径是计算最优的(例如最短的,或者拥有最小的权重和)。图搜索算法包括广度优先搜索和深度优先搜索,它们是遍历图的基础,并且通常是许多其他类型分析的第一步。路径搜索(Pathfinding)算法建立在图搜索算法的基础上,并探索节点之间的路径。这些路径从一个节点开始,遍历关系,直到到达目的地。路径搜索算法识别最优路径,用于物流规划,最低成本呼叫或者叫IP路由问题,以及游戏模拟等。图的遍历 (graph traversal)即给出一个图G和其中任意一个顶点V0,从V0出发系统地访问G中所有的顶点,每个顶点访问而且只访问一次从一个顶点出发,试探性访问其余顶点,同时必须考虑到下列情况从一顶点出发,可能不能到达所有其它的顶点,如:非连通图;也有可能会陷入死循环,如:存在回路的图一般情况下,可以为每个顶点保留一个 标志位 (mark bit):算法开始时,所有顶点的标志位置零在遍历的过程中,当某个顶点被访问时,其标志位就被标记为已访问2.1.1深度优先遍历&广度优先遍历|DFS & BFS图算法中最基础的两个遍历算法:广度优先搜索(Breadth First Search,简称 BFS)和深度优先搜索(Depth First Search,简称 DFS)。BFS 从选定的节点出发,优先访问所有一度关系的节点之后再继续访问二度关系节点,以此类推。DFS 从选定的节点出发,选择任一邻居之后,尽可能的沿着边遍历下去,知道不能前进之后再回溯。深度优先搜索(简称DFS) 类似于树的先根次序遍历,尽可能先对纵深方向进行搜索:选取一个未访问的点 v0 作为源点访问顶点 v0递归地深搜遍历 v0 邻接到的其他顶点重复上述过程直至从 v0 有路径可达的顶点都已被访问过再选取其他未访问顶点作为源点做深搜,直到图的所有顶点都被访问过深度优先搜索的顺序是:a->b->c->f->d->e->g广度优先遍历(breadth-first search)广度优先搜索 (breadth-first search,简称 BFS)。其遍历的过程是:从图中的某个顶点 v0 出发访问并标记了顶点 v0 之后一层层横向搜索 v0 的所有邻接点对这些邻接点一层层横向搜索,直至所有由 v0 有路径可达的顶点都已被访问过再选取其他未访问顶点作为源点做广搜,直到所有点都被访问过广度优先搜索的顺序是:a->b->d->e->f->c->g2.1.2 最短路径最短路径(Shortest Paths)算法计算给定的两个节点之间最短(最小权重和)的路径。算法能够实时地交互和给出结果,可以给出关系传播的度数(degree),可以快速给出两点之间的最短距离,可以计算两点之间成本最低的路线等等。例如:导航:谷歌、百度、高德地图均提供了导航功能,它们就使用了最短路径算法(或者非常接近的变种);社交网络关系:当我们在 LinkedIn、人人(暴露年龄了)等社交平台上查看某人的简介时,平台会展示你们之间有多少共同好友,并列出你们之间的关系。2.1.2.1 单源最短路径(single-source shortest paths)-------迪杰斯特拉(Dijkstra)算法单源最短路径是给定带权图 G = <V,E>,其中每条边 (vi,vj) 上的权W[vi,vj] 是一个 非负实数 。计算从任给的一个源点 s 到所有其他各结点的最短路径迪杰斯特拉(Dijkstra)算法最常见的最短路径算法来自于 1956 年的 Edsger Dijkstra。Dijkstra 的算法首先选择与起点相连的最小权重的节点,也就是 “最临近的” 节点,然后比较 起点到第二临近的节点的权重 与 最临近节点的下一个最临近节点的累计权重和 从而决定下一步该如何行走。可以想象,算法记录的累计权重和 如同地理的 “等高线” 一样,在图上以 “波” 的形式传播,直到到达目的地节点。基本思想把所有结点分成两组:第一组 U 包括已确定最短路径的结点第二组 V–U 包括尚未确定最短路径的结点按最短路径长度递增的顺序逐个把第二组的结点加到第一组中:直至从 s 出发可达结点都包括进第一组中看懂上面的再看一下这个判断自己有没有彻底理解:Dijkstra 算法是贪心法,不适用于负权值的情况。因为权值当作最小取进来后,不会返回去重新计算,即使不存在负的回路,也可能有在后面出现的负权值,从而导致整体计算错误2.1.2.2 每对结点间的最短路径Floyd算法求每对结点之间的最短路径用相邻矩阵 adj 来表示带权有向图基本思想初始化 adj(0) 为相邻矩阵 adj在矩阵 adj(0)上做 n 次迭代,递归地产生一个矩阵序列adj(1),…,adj(k),…,adj(n)其中经过第k次迭代,adj(k)[i,j] 的值等于从结点vi 到结点 vj 路径上所经过的结点序号不大于 k 的最短路径长度其根本思想是动态规划法最短路径算法有两个常用的变种:A (可以念作 A Star)algorithm和 Yen’s K-Shortest Paths。A algorithm 通过提供的额外信息,优化算法下一步探索的方向。Yen’s K-Shortest Paths 不但给出最短路径结果,同时给出了最好的 K 条路径。所有节点对最短路径(All Pairs Shortest Path)也是一个常用的最短路径算法,计算所有节点对的最短路径。相比较一个一个调用单个的最短路径算法,All Pairs Shortest Path 算法会更快。算法并行计算多个节点的信息,并且这些信息在计算中可以被重用。2.1.3 最小生成树最小生成树(Minimum Spanning Tree)算法从一个给定的节点开始,查找其所有可到达的节点,以及将节点与最小可能权重连接在一起,行成的一组关系。它以最小的权重从访问过的节点遍历到下一个未访问的节点,避免了循环。最常用的最小生成树算法来自于 1957 年的 Prim 算法。Prim 算法与Dijkstra 的最短路径类似,所不同的是, Prim 算法每次寻找最小权重访问到下一个节点,而不是累计权重和。并且,Prim 算法允许边的权重为负。上图是最小生成树算法的步骤分解,算法最终用最小的权重将图进行了遍历,并且在遍历的过程中,不产生环。算法可以用于优化连接系统(如水管和电路设计)的路径。它还用于近似一些计算时间未知的问题,如旅行商问题。虽然该算法不一定总能找到绝对最优解,但它使得复杂度极高和计算密集度极大的分析变得更加可能。例如:旅行计划:尽可能降低探索一个国家的旅行成本;追踪流感传播的历史:有人使用最小生成树模型对丙型肝炎病毒感染的医院暴发进行分子流行病学调查2.1.4 随机游走随机游走(Random Walk)算法从图上获得一条随机的路径。随机游走算法从一个节点开始,随机沿着一条边正向或者反向寻找到它的邻居,以此类推,直到达到设置的路径长度。这个过程有点像是一个醉汉在城市闲逛,他可能知道自己大致要去哪儿,但是路径可能极其“迂回”,毕竟,他也无法控制自己~随机游走算法一般用于随机生成一组相关的节点数据,作为后续数据处理或者其他算法使用。例如:作为 node2vec 和 graph2vec 算法的一部分,这些算法可以用于节点向量的生成,从而作为后续深度学习模型的输入;这一点对于了解 NLP (自然语言处理)的朋友来说并不难理解,词是句子的一部分,我们可以通过词的组合(语料)来训练词向量。那么,我们同样可以通过节点的组合(Random Walk)来训练节点向量。这些向量可以表征词或者节点的含义,并且能够做数值计算。这一块的应用很有意思,我们会找机会来详细介绍;作为 Walktrap 和 Infomap 算法的一部分,用于社群发现。如果随机游走总是返回同一组节点,表明这些节点可能在同一个社群;其他机器学习模型的一部分,用于随机产生相关联的节点数据。2.2 中心性算法(Centrality Computation)中心性算法(Centrality Algorithms)用于识别图中特定节点的角色及其对网络的影响。中心性算法能够帮助我们识别最重要的节点,帮助我们了解组动态,例如可信度、可访问性、事物传播的速度以及组与组之间的连接。尽管这些算法中有许多是为社会网络分析而发明的,但它们已经在许多行业和领域中得到了应用。2.2.1 DegreeCentralityDegree Centrality (度中心性,以度作为标准的中心性指标)可能是整篇博文最简单的 “算法” 了。Degree 统计了一个节点直接相连的边的数量,包括出度和入度。Degree 可以简单理解为一个节点的访问机会的大小。例如,在一个社交网络中,一个拥有更多 degree 的人(节点)更容易与人发生直接接触,也更容易获得流感。一个网络的平均度(average degree),是边的数量除以节点的数量。当然,平均度很容易被一些具有极大度的节点 “带跑偏” (skewed)。所以,度的分布(degree distribution)可能是表征网络特征的更好指标。如果你希望通过出度入度来评价节点的中心性,就可以使用 degree centrality。度中心性在关注直接连通时具有很好的效果。应用场景例如,区分在线拍卖的合法用户和欺诈者,欺诈者由于尝尝人为太高拍卖价格,拥有更高的加权中心性(weighted centrality)。2.2.2 ClosenessCentralityCloseness Centrality(紧密性中心性)是一种检测能够通过子图有效传播信息的节点的方法。紧密性中心性计量一个节点到所有其他节点的紧密性(距离的倒数),一个拥有高紧密性中心性的节点拥有着到所有其他节点的距离最小值。对于一个节点来说,紧密性中心性是节点到所有其他节点的最小距离和的倒数:$C(u)=\frac{1}{\sum_{v=1}^{n-1} d(u, v)}$其中 u 是我们要计算紧密性中心性的节点,n 是网络中总的节点数,d(u,v) 代表节点 u 与节点 v 的最短路径距离。更常用的公式是归一化之后的中心性,即计算节点到其他节点的平均距离的倒数,你知道如何修改上面的公式吗?对了,将分子的 1 变成 n-1 即可。理解公式我们就会发现,如果图是一个非连通图,那么我们将无法计算紧密性中心性。那么针对非连通图,调和中心性(Harmonic Centrality)被提了出来(当然它也有归一化的版本,你猜这次n-1应该加在哪里?):$H(u)=\frac{1}{\sum_{v=1}^{n-1} d(u, v)}$Wasserman and Faust 提出过另一种计算紧密性中心性的公式,专门用于包含多个子图并且子图间不相连接的非连通图:$C_{W F}(u)=\frac{n-1}{N-1}\left(\frac{n-1}{\sum_{v=1}^{n-1} d(u, v)}\right)$其中,N 是图中总的节点数量,n 是一个部件(component)中的节点数量。当我们希望关注网络中传播信息最快的节点,我们就可以使用紧密性中心性。2.2.3 BetweennessCentrality中介中心性(Betweenness Centrality)是一种检测节点对图中信息或资源流的影响程度的方法。它通常用于寻找连接图的两个部分的桥梁节点。因为很多时候,一个系统最重要的 “齿轮” 不是那些状态最好的,而是一些看似不起眼的 “媒介”,它们掌握着资源或者信息的流动性。中间中心性算法首先计算连接图中每对节点之间的最短(最小权重和)路径。每个节点都会根据这些通过节点的最短路径的数量得到一个分数。节点所在的路径越短,其得分越高。计算公式:$B(u)=\sum_{s \neq u \neq t} \frac{p(u)}{p}$其中,p 是节点 s 与 t 之间最短路径的数量,p(u) 是其中经过节点 u 的数量。下图给出了对于节点 D 的计算过程:当然,在一张大图上计算中介中心性是十分昂贵的。所以我们需要更快的,成本更小的,并且精度大致相同的算法来计算,例如 Randomized-Approximate Brandes。我们不会对这个算法继续深入,感兴趣的话,可以去了解一下,算法如何通过随机(Random)和度的筛选(Degree)达到近似的效果。中介中心性在现实的网络中有广泛的应用,我们使用它来发现瓶颈、控制点和漏洞。例如,识别不同组织的影响者,他们往往是各个组织的媒介,例如寻找电网的关键点,提高整体鲁棒性。2.2.4 PageRank在所有的中心性算法中,PageRank 是最著名的一个。它测量节点传递影响的能力。PageRank 不但节点的直接影响,也考虑 “邻居” 的影响力。例如,一个节点拥有一个有影响力的 “邻居”,可能比拥有很多不太有影响力的 “邻居” 更有影响力。PageRank 统计到节点的传入关系的数量和质量,从而决定该节点的重要性。PageRank 算法以谷歌联合创始人拉里·佩奇的名字命名,他创建了这个算法来对谷歌搜索结果中的网站进行排名。不同的网页之间相互引用,网页作为节点,引用关系作为边,就可以组成一个网络。被更多网页引用的网页,应该拥有更高的权重;被更高权重引用的网页,也应该拥有更高权重。原始公式:$P R(u)=(1-d)+d\left(\frac{P R(T 1)}{C(T 1)}+\ldots+\frac{P R(T n)}{C(T n)}\right)$其中,u 是我们想要计算 PageRank 的网页,T1 到 Tn 是引用的网页。d 被称为阻尼系数(damping factor),代表一个用户继续点击网页的概率,一般被设置为 0.85,范围 0~1。C(T) 是节点 T 的出度。从理解上来说,PageRank 算法假设一个用户在访问网页时,用户可能随机输入一个网址,也可能通过一些网页的链接访问到别的网页。那么阻尼系数代表用户对当前网页感到无聊,随机选择一个链接访问到新的网页的概率。那么 PageRank 的数值代表这个网页通过其他网页链接过来(入度,in-degree)的可能性。那你能如何解释 PageRank 方程中的 1-d 呢?实际,1-d 代表不通过链接访问,而是随机输入网址访问到网页的概率。PageRank 算法采用迭代方式计算,直到结果收敛或者达到迭代上限。每次迭代都会分两步更新节点权重和边的权重,详细如下图:当然,上图的计算并没有考虑阻尼系数,那为什么一定要阻尼系数呢?除了我们定义的链接访问概率,有没有别的意义呢?从上图的过程中,我们可能会发现一个问题,如果一个节点(或者一组节点),只有边进入,却没有边出去,会怎么样呢?按照上图的迭代,节点会不断抢占 PageRank 分数。这个现象被称为 Rank Sink,如下图:解决 Rank Sink 的方法有两个。第一个,假设这些节点有隐形的边连向了所有的节点,遍历这些隐形的边的过程称为 teleportation。第二个,使用阻尼系数,如果我们设置 d 等于 0.85,我们仍然有 0.15 的概率从这些节点再跳跃出去。尽管阻尼系数的建议值为 0.85,我们仍然可以根据实际需要进行修改。调低阻尼系数,意味着访问网页时,更不可能不断点击链接访问下去,而是更多地随机访问别的网页。那么一个网页的 PageRank 分数会更多地分给他的直接下游网页,而不是下游的下游网页。PageRank 算法已经不仅限于网页排名。例如:寻找最重要的基因:我们要寻找的基因可能不是与生物功能联系最多的基因,而是与最重要功能有紧密联系的基因;who to follow service at twitter:Twitter使用个性化的 PageRank 算法(Personalized PageRank,简称 PPR)向用户推荐他们可能希望关注的其他帐户。该算法通过兴趣和其他的关系连接,为用户展示感兴趣的其他用户;交通流量预测:使用 PageRank 算法计算人们在每条街道上停车或结束行程的可能性;反欺诈:医疗或者保险行业存在异常或者欺诈行为,PageRank 可以作为后续机器学习算法的输入。2.3 社群发现算法(Community Detection)社群的形成在各种类型的网络中都很常见。识别社群对于评估群体行为或突发事件至关重要。对于一个社群来说,内部节点与内部节点的关系(边)比社群外部节点的关系更多。识别这些社群可以揭示节点的分群,找到孤立的社群,发现整体网络结构关系。社群发现算法(Community Detection Algorithms)有助于发现社群中群体行为或者偏好,寻找嵌套关系,或者成为其他分析的前序步骤。社群发现算法也常用于网络可视化。2.3.1 MeasuringAlgorithm三角计数(Triangle Count)和聚类系数(Clustering Coefficient)经常被一起使用。三角计数计算图中由节点组成的三角形的数量,要求任意两个节点间有边(关系)连接。聚类系数算法的目标是测量一个组的聚类紧密程度。该算法计算网络中三角形的数量,与可能的关系的比率。聚类系数为 1 表示这个组内任意两个节点之间有边相连。有两种聚类系数:局部聚类系数(Local Clustering Coefficient)和全局聚类系数(Global Clustering Coefficient)。局部聚类系数计算一个节点的邻居之间的紧密程度,计算时需要三角计数。计算公式:$C C(u)=\frac{2 R_u}{k_u\left(k_u-1\right)}$其中,u 代表我们需要计算聚类系数的节点,R(u) 代表经过节点 u 和它的邻居的三角形个数,k(u) 代表节点 u的度。下图是三三角计数聚类系数计算示意图:全局聚类系数是局部聚类系数的归一化求和。当需要计算一个组的稳定性或者聚类系数时,我们可以使用三角计数。三角计数在社交网络分析中有广泛的应用,通航被用来检测社区。聚类系数可以快速评估特定组或整个网络的内聚性。这些算法可以共同用于特定网络结构的寻找。例如,探索网页的主题结构,基于网页之间的相互联系,检测拥有共同主题的 “网页社群”。2.3.2 ComponentsAlgorithm强关联部件(Strongly Connected Components,简称 SCC)算法寻找有向图内的一组一组节点,每组节点可以通过关系 互相 访问。在 “Community Detection Algorithms” 的图中,我们可以发现,每组节点内部不需要直接相连,只要通过路径访问即可。关联部件(Connected Components)算法,不同于 SCC,组内的节点对只需通过一个方向访问即可。关联类算法作为图分析的早期算法,用以了解图的结构,或确定可能需要独立调查的紧密集群十分有效。对于推荐引擎等应用程序,也可以用来描述组中的类似行为等等。许多时候,算法被用于查找集群并将其折叠成单个节点,以便进一步进行集群间分析。对于我们来说,先运行以下关联类算法查看图是否连通,是一个很好的习惯。2.3.3 LabelPropagation Algorithm标签传播算法(Label Propagation Algorithm,简称 LPA)是一个在图中快速发现社群的算法。在 LPA 算法中,节点的标签完全由它的直接邻居决定。算法非常适合于半监督学习,你可以使用已有标签的节点来种子化传播进程。LPA 是一个较新的算法,由 Raghavan 等人于 2007 年提出。我们可以很形象地理解算法的传播过程,当标签在紧密联系的区域,传播非常快,但到了稀疏连接的区域,传播速度就会下降。当出现一个节点属于多个社群时,算法会使用该节点邻居的标签与权重,决定最终的标签。传播结束后,拥有同样标签的节点被视为在同一群组中。下图展示了算法的两个变种:Push 和 Pull。其中 Pull 算法更为典型,并且可以很好地并行计算:看完上图,你应该已经理解了算法的大概过程。其实,做过图像处理的人很容易明白,所谓的标签传播算法,不过是图像分割算法的变种,Push 算法是区域生长法(Region Growing)的简化版,而 Pull 更像是分割和合并(divide-and-merge,也有人称 split-merge)算法。确实,图像(image)的像素和图(graph)的节点是十分类似的。2.3.4 LouvainModularity AlgorithmLouvain Modularity 算法在给节点分配社群是,会比较社群的密度,而不仅仅是比较节点与社群的紧密程度。算法通过查看节点与社群内关系的密度与平均关系密度的比较,来量化地决定一个节点是否属于社群。算法不但可以发现社群,更可以给出不同尺度不同规模的社群层次,对于理解不同粒度界别的网络结构有极大的帮助。算法在 2008 年被提出以后,迅速成为了最快的模块化算法之一。算法的细节很多,我们无法一一覆盖,下图给出了一个粗略的步骤,帮助我们理解算法如何能够多尺度地构建社群:Louvain Modularity 算法非常适合庞大网络的社群发现,算法采用启发式方式从而能够克服传统 Modularity 类算法的局限。算法应用:检测网络攻击:该算可以应用于大规模网络安全领域中的快速社群发现。一旦这些社群被发现,就可以用来预防网络攻击;主题建模:从 Twitter 和 YouTube 等在线社交平台中提取主题,基于文档中共同出现的术语,作为主题建模过程的一部分。3.算法实践(图分析、图计算)有了前面的前置知识,来一起程序操作一下了3.1创建一个图进行简单分析import numpy as np import random import networkx as nx from IPython.display import Image import matplotlib.pyplot as plt # Load the graph G_karate = nx.karate_club_graph() # Find key-values for the graph pos = nx.spring_layout(G_karate) # Plot the graph nx.draw(G_karate, cmap = plt.get_cmap('rainbow'), with_labels=True, pos=pos)空手道俱乐部图这个「空手道」图表示什么?Wayne W. Zachary 在 1970 到 1972 年这三年中研究的一个空手道俱乐部的社交网络。该网络包含了这个空手道俱乐部的 34 个成员,成员对之间的连接表示他们在俱乐部之外也有联系。在研究期间,管理员 JohnA 与教练 Mr.Hi(化名)之间出现了冲突,导致俱乐部一分为二。一半成员围绕 Mr.Hi 形成了一个新的俱乐部,另一半则找了一个新教练或放弃了空手道。基于收集到的数据,除了其中一个成员,Zachary 正确分配了所有成员在分裂之后所进入的分组。# .degree() 属性会返回该图的每个节点的度(相邻节点的数量)的列表: print(G_karate.degree()) degree_sequence = list(G_karate.degree())# 计算边的数量,但也计算度序列的度量: nb_nodes = n nb_arr = len(G_karate.edges()) avg_degree = np.mean(np.array(degree_sequence)[:,1]) med_degree = np.median(np.array(degree_sequence)[:,1]) max_degree = max(np.array(degree_sequence)[:,1]) min_degree = np.min(np.array(degree_sequence)[:,1]) # 最后,打印所有信息: print("Number of nodes : " + str(nb_nodes)) print("Number of edges : " + str(nb_arr)) print("Maximum degree : " + str(max_degree)) print("Minimum degree : " + str(min_degree)) print("Average degree : " + str(avg_degree)) print("Median degree : " + str(med_degree))# 平均而言,该图中的每个人都连接了 4.6 个人。 # 我们可以绘出这些度的直方图: degree_freq = np.array(nx.degree_histogram(G_karate)).astype('float') plt.figure(figsize=(12, 8)) plt.stem(degree_freq) plt.ylabel("Frequence") plt.xlabel("Degree") plt.show()3.2图类型3.2.1 Erdos-Rényi 模型在 Erdos-Rényi 模型中,我们构建一个带有 n 个节点的随机图模型。这个图是通过以概率 p 独立地在节点 (i,j) 对之间画边来生成的。因此,我们有两个参数:节点数量 n 和概率 p。Erdos-Rényi 图在 Python 中,networkx 软件包有用于生成 Erdos-Rényi 图的内置函数。3.3主要图算法3.3.1路径搜索算法仍以空手道俱乐部图举例# 1.最短路径 # 最短路径计算的是一对节点之间的最短的加权(如果图有加权的话)路径。 # 这可用于确定最优的驾驶方向或社交网络上两个人之间的分离程度。 nx.draw(G_karate, cmap = plt.get_cmap('rainbow'), with_labels=True, pos=pos) # 这会返回图中每个节点之间的最小路径的列表: all_shortest_path = nx.shortest_path(G_karate) # 这里打印了节点0与其余节点的最短路径 print(all_shortest_path[0]) # 例如节点0与节点26的最短路径是[0, 8, 33, 26] {0: [0], 1: [0, 1], 2: [0, 2], 3: [0, 3], 4: [0, 4], 5: [0, 5], 6: [0, 6], 7: [0, 7], 8: [0, 8], 10: [0, 10], 11: [0, 11], 12: [0, 12], 13: [0, 13], 17: [0, 17], 19: [0, 19], 21: [0, 21], 31: [0, 31], 30: [0, 1, 30], 9: [0, 2, 9], 27: [0, 2, 27], 28: [0, 2, 28], 32: [0, 2, 32], 16: [0, 5, 16], 33: [0, 8, 33], 24: [0, 31, 24], 25: [0, 31, 25], 23: [0, 2, 27, 23], 14: [0, 2, 32, 14], 15: [0, 2, 32, 15], 18: [0, 2, 32, 18], 20: [0, 2, 32, 20], 22: [0, 2, 32, 22], 29: [0, 2, 32, 29], 26: [0, 8, 33, 26]} 3.3.2社群检测社群检测是根据给定的质量指标将节点划分为多个分组。这通常可用于识别社交社群、客户行为或网页主题。 社区是指一组相连节点的集合。但是,目前关于社群还没有广泛公认的定义,只是社群内的节点应该要密集地相连。Girvan Newman 算法是一个用于发现社群的常用算法。其通过逐步移除网络内的边来定义社区。我们将居间性称为「边居间性(edge betweenness)」。这是一个正比于穿过该边的节点对之间最短路径的数量的值。该算法的步骤如下:计算网络中所有已有边的居间性。移除居间性最高的边。移除该边后,重新计算所有边的居间性。重复步骤 2 和 3,直到不再剩余边。from networkx.algorithms import community import itertools k = 1 comp = community.girvan_newman(G_karate) for communities in itertools.islice(comp, k): print(tuple(sorted(c) for c in communities)) ([0, 1, 3, 4, 5, 6, 7, 10, 11, 12, 13, 16, 17, 19, 21], [2, 8, 9, 14, 15, 18, 20, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33])import community partition = community.best_partition(G_karate) pos = nx.spring_layout(G_karate) plt.figure(figsize=(8, 8)) plt.axis('off') nx.draw_networkx_nodes(G_karate, pos, node_size=600, cmap=plt.cm.RdYlBu, node_color=list(partition.values())) nx.draw_networkx_edges(G_karate, pos, alpha=0.3) plt.show(G_karate) 3.3.4 中心性算法# Plot the centrality of the nodes plt.figure(figsize=(18, 12)) f, axarr = plt.subplots(2, 2, num=1) plt.sca(axarr[0,0]) nx.draw(G_karate, cmap = plt.get_cmap('inferno'), node_color = c_degree, node_size=300, pos=pos, with_labels=True) axarr[0,0].set_title('Degree Centrality', size=16) plt.sca(axarr[0,1]) nx.draw(G_karate, cmap = plt.get_cmap('inferno'), node_color = c_eigenvector, node_size=300, pos=pos, with_labels=True) axarr[0,1].set_title('Eigenvalue Centrality', size=16) plt.sca(axarr[1,0]) nx.draw(G_karate, cmap = plt.get_cmap('inferno'), node_color = c_closeness, node_size=300, pos=pos, with_labels=True) axarr[1,0].set_title('Proximity Centrality', size=16) plt.sca(axarr[1,1]) nx.draw(G_karate, cmap = plt.get_cmap('inferno'), node_color = c_betweenness, node_size=300, pos=pos, with_labels=True) axarr[1,1].set_title('Betweenness Centrality', size=16) 4.总结因为篇幅关系就只放了部分程序在第三章,如有需求可自行fork项目原始链接。欢迎fork本项目原始链接:关于图计算&图学习的基础知识概览:前置知识点学习(Paddle Graph L)https://aistudio.baidu.com/aistudio/projectdetail/4982973?contributionType=1因为之前一直在研究知识提取相关算法,后续为了构建小型领域知识图谱,会用到知识融合、知识推理等技术,现在开始学习研究图计算相关。本项目主要介绍了主要的图类型以及用于描述图的最基本的属性,以及经典的算法原理作为前置知识点学习(Paddle Graph Learning (PGL)),最后进行程序展示,希望帮助大家更好的理解前置知识。本项目参考了:maelfabien大神、以及自尊心3和Mr.郑 佬们在博客 or github上的贡献 欢迎大家fork, 后续将开始图计算相关项目以及部分知识提取技术深化!
NLP领域任务如何选择合适预训练模型以及选择合适的方案【规范建议】
1.常见NLP任务信息抽取:从给定文本中抽取重要的信息,比如时间、地点、人物、事件、原因、结果、数字、日期、货币、专有名词等等。通俗说来,就是要了解谁在什么时候、什么原因、对谁、做了什么事、有什么结果。文本生成:机器像人一样使用自然语言进行表达和写作。依据输入的不同,文本生成技术主要包括数据到文本生成和文本到文本生成。数据到文本生成是指将包含键值对的数据转化为自然语言文本;文本到文本生成对输入文本进行转化和处理从而产生新的文本问答系统:对一个自然语言表达的问题,由问答系统给出一个精准的答案。需要对自然语言查询语句进行某种程度的语义分析,包括实体链接、关系识别,形成逻辑表达式,然后到知识库中查找可能的候选答案并通过一个排序机制找出最佳的答案。对话系统:系统通过一系列的对话,跟用户进行聊天、回答、完成某一项任务。涉及到用户意图理解、通用聊天引擎、问答引擎、对话管理等技术。此外,为了体现上下文相关,要具备多轮对话能力。语音识别和生成:语音识别是将输入计算机的语音符号识别转换成书面语表示。语音生成又称文语转换、语音合成,它是指将书面文本自动转换成对应的语音表征。信息过滤:通过计算机系统自动识别和过滤符合特定条件的文档信息。通常指网络有害信息的自动识别和过滤,主要用于信息安全和防护,网络内容管理等。舆情分析:是指收集和处理海量信息,自动化地对网络舆情进行分析,以实现及时应对网络舆情的目的。信息检索:对大规模的文档进行索引。可简单对文档中的词汇,赋之以不同的权重来建立索引,也可建立更加深层的索引。在查询的时候,对输入的查询表达式比如一个检索词或者一个句子进行分析,然后在索引里面查找匹配的候选文档,再根据一个排序机制把候选文档排序,最后输出排序得分最高的文档。机器翻译:把输入的源语言文本通过自动翻译获得另外一种语言的文本。机器翻译从最早的基于规则的方法到二十年前的基于统计的方法,再到今天的基于神经网络(编码-解码)的方法,逐渐形成了一套比较严谨的方法体系。文本挖掘:包括文本聚类、分类、情感分析以及对挖掘的信息和知识的可视化、交互式的表达界面。目前主流的技术都是基于统计机器学习的。2.如何将业务问题抽象为已得到很好解决的典型问题2.1 明确业务的输入与输出令输入文本用X表示,输出标签用Y表示,则有以下粗略的分类:2.1.1 如果Y表示某一类的概率,或者是一个定长向量,向量中的每个维度是其属于各个类的概率,且概率之和为1,则可抽象为文本多分类问题。a.一般X只有一段文本。如下所示i.如情感分析等任务。 房间 太 小 。 其他 的 都 一般 0b.如果X是2段文本(X1,X2),则是可以抽象为句对分类问题。如下所示 i:如NLI等任务。 大家觉得她好看吗 大家觉得跑男好看吗? 0c.如果的每个类别的概率相互独立,即各类概率之和不为1,可抽象为文本多标签分类问题。如下所示i:如用户评论分类、黄反识别等任务。 互联网创业就如选秀 需求与服务就是价值 0 1d. 如果X有多段非文本特征输入,如整型、浮点型类型特征。则可抽象为混合特征的分类问题。如下所示i:如CTR预估等任务。CTR预估*CTR预估是推荐中最核心的算法之一。 相关概念: CTR预估:对每次广告的点击情况做出预测,预测用户是点击还是不点击。CTR预估的影响因素:比如历史点击率、广告位置、时间、用户等CTR预估相关介绍推荐算法之4——CTR预估模型2.1.2 如果X是2段文本(X1,X2),Y表示二者的相似度,可抽象为文本匹配问题。如下所示 喜欢 打篮球 的 男生 喜欢 什么样 的 女生 爱 打篮球 的 男生 喜欢 什么样 的 女生 1a.如语义相似度、相似问题匹配等任务。b.文本聚类的问题可以通过文本相似度问题进行处理。2.1.3 如果X有一段文本,Y是一个与X等长的序列,可抽象为序列标注问题。如下所示 海 钓 比 赛 地 点 在 厦 门 与 金 门 之 间 的 海 域 。 O O O O O O O B-LOC I-LOC O B-LOC I-LOC O O O O O Oa.如分词、POS、NER、词槽挖掘等任务。2.1.4 如果X有一段文本,Y是一个不定长的文本,可抽象为文本生成问题。如下所示 Rachel Pike : The science behind a climate headline Khoa học đằng sau một tiêu đề về khí hậua.如机器翻译、文本摘要、标题生成等任务。2.1.5.如果X为一段文本,Y表示文本X作为正常语句出现的概率或者混淆度,则属于语言模型任务。如下所示 <s> but some analysts remain sour on the company but some analysts remain sour on the company <e>a.语言模型任务的子问题是基于上(下)文X预测下(上)一个词出现的概率Y,可以理解为一种特殊的文本分类。2.1.6如果X是2段文本(X1,X2),分别表示正文篇章和问题,Y是篇章中的一小段文本,表示对应问题的答案,则可抽象为阅读理解问题。 "data": [{ "title": "", "paragraphs": [{ "context": "爬行垫根据中间材料的不同可以分为:XPE爬行垫、EPE爬行垫、EVA爬行垫、PVC爬行垫;其中XPE爬行垫、EPE爬行垫都属于PE材料加保鲜膜复合而成,都是无异味的环保材料,但是XPE爬行垫是品质较好的爬行垫,韩国进口爬行垫都是这种爬行垫,而EPE爬行垫是国内厂家为了减低成本,使用EPE(珍珠棉)作为原料生产的一款爬行垫,该材料弹性差,易碎,开孔发泡防水性弱。EVA爬行垫、PVC爬行垫是用EVA或PVC作为原材料与保鲜膜复合的而成的爬行垫,或者把图案转印在原材料上,这两款爬行垫通常有异味,如果是图案转印的爬行垫,油墨外露容易脱落。当时我儿子爬的时候,我们也买了垫子,但是始终有味。最后就没用了,铺的就的薄毯子让他爬。您好,爬行垫一般色彩鲜艳,能吸引宝宝的注意力,当宝宝刚会爬的时候,趴在上面玩,相对比较安全,不存在从床上摔下来的危险。对宝宝的爬行还是很有好处的。还有就是妈妈选择爬行垫时可以选择无害的PE棉,既防潮又隔冷隔热。外有要有一层塑料膜,能隔绝液体进入垫子内部,而且方便清洗。宝宝每次爬行,一定要记得把宝宝的手擦干净。", "qas": [{ "answers": [{ "text": "XPE", "answer_start": 17 "id": "DR-single-pre_and_next_paras-181574", "question": "爬行垫什么材质的好" }2.1.7 如果Y是以上多种任务的组合,则可以抽象为多标签学习、多任务学习任务。a.如实体关系抽取任务,实体抽取本属于序列标注、关系抽取本属于文本多分类。2.2抽象与拆分任务取舍经验2.2.1优先考虑简单的任务,由易到难循序渐进:a.文本分类、文本匹配、序列标注、文本生成、阅读理解、多任务学习、强化学习、对抗学习等。2.2.2 复杂任务可拆分、化简成简单的子任务a.如实体关系抽取任务,可以拆分为实体识别+关系抽取的pipline进行实现。b.如文本纠错任务,可以拆分出语言模型、统计机器翻译等多种不同子任务构造复杂的pipline进行实现。c.如排序任务,输入X为多段文本,输出Y为每段文本的排序位置,可化简成文本分类问题、文本匹配问题进行处理。2.2.3 有监督学习任务优先于无监督学习任务a.因为有监督学习更可控,更易于应用最前沿的研究成果。文心目前只覆盖有监督、自监督任务。b.比如文本关键词抽取,可以有TFIDF之类的无监督解法,但效果控制较困难,不如转换为文本分类问题。2.2.4 能应用深度学习的任务优于不利用深度学习的任务a.因为深度学习算法效果一般更好,而且可以应用到最前沿的预训练模型。文心目前只采用深度学习算法。b.如果文本聚类,可以有LDA之类的解法,但效果一般不如基于深度学习的语义相似度的文本聚类。3. 明确业务目标与限制条件3.1典型业务目标与限制条件1.预测部署性能a.典型指标:qps性能指标:QPS、TPS、系统吞吐量理解2.模型效果a.以文本分类为例,典型指标:精确率、准确率、召回率、F1值b.该评估指标应该在训练开始之前基本确定,否则很容易优化偏。3.硬件采购成本a.典型指标:钱b.GPU远贵于CPU,V100贵于P40。4.训练时间成本(GPU,卡,调参,GPU利用率)a.典型指标:每一轮训练所需要的时间。5.数据大小限制a.由于标注成本较高,很多时候是数据量很少又希望有很好的效果。6.开发迭代成本a.搭建环境成本b.迭代效率:往往是最消耗时间的部分。3.2 可供选择的方案选择平台版还是工具版选择GPU还是CPU训练,哪一款硬件,单机还是多机,单卡还是多卡,本地还是集群选择怎样的预制网络是否需要预训练模型选择哪一版本的预训练模型训练数据要多少batch_size、train_log_step、eval_step、save_model_step选多少4.根据业务目标与限制条件选择合适的方案4.1预测部署性能如果要求qps>1000a.不适合直接部署ERNIE预训练模型。b.但可尝试蒸馏策略,模型效果会存在一定损失。如果要求qps>100a.如果预算允许使用GPU,可尝试直接部署ERNIE相关预训练模型,推荐尝试ERNIE-tiny系列模型。b.如果预算只允许使用CPU,可尝试CPU集群部署ERNIE相关预训练模型。3.如果对部署性能要求不高,可随意尝试各种预训练模型。4.性能细节请参考:模型预测与部署——预测性能4.2 模型效果1.一般来说,复杂的网络优于简单的网络,多样的特征优于单一的特征,有预训练模型的效果优于无预训练模型。a.从模型复杂度来看,LSTM、GRU、CNN、BOW的复杂度与效果依次递减,速度依次提升。2.一般来说,在预训练模型中,large优于base优于tiny,新版本的模型优于旧版本的模型,针对具体任务的预训练模型优于通用版预训练模型。3.一般来说,在不欠拟合的情况下,训练数据越多模型效果越好,标注数据的质量越好效果越好。标注数据的质量优于数据的数量。4.不同任务适合的网络结构并不相同,具体任务具体分析。4.3硬件采购成本1.GPU远贵于CPU,常用训练用GPU型号为V100、P40、K40,价格依次递减。2.具体成本可参考百度云服务器-BCC-价格计算器3.如果缺少训练资源,可通过文心平台版的免费共享队列进行训练,资源紧张,且用且珍惜。4.4训练时间成本1.GPU还是CPUa.对于非ERNIE等复杂网络的模型,CPU的训练速度一般也能接受。 如果训练语料过多,数千万条以上,则建议采用CPU集群进行训练。 b.对于ERNIE模型,尽量采用GPU训练,CPU太慢,训练不起来。2.怎么用好GPU a.GPU并行训练能提升训练速度,建议优先把一个节点(trainer)的卡数用完,再考虑多机训练。因为单机多卡的GPU利用率更高,更快。而多机训练数据通信时间成本较高,时间更慢。 b.大原则:GPU利用率越高训练越快。 c.还有一点需要注意,多卡训练时是将不同的数据文件送给不同的卡,所以数据文件的个数要大于卡的个数。数据文件建议拆分细一些,这可以提升数据读取的速度。 d.熟练的同学可以尝试GPU多进程单机多卡训练、混合精度训练等方法,提升训练速度。3.train_log_step、eval_step、save_model_stepa.分别表示每多少步打印训练日志、每多少步评估一次验证集、每多少步保存一次模型。 b.设置不当也会拖慢训练时间 c.一般建议三者依次放大十倍,如:10、100、10004.batch_sizea.设置过小容易收敛慢,设置过大容易超过显存极限直接挂掉 b.如果使用ERNIE,batch_size建议小一些,使用large版本建议更小一些,如果输入语句并不是很长可以适当增加batch_size。 c.如果不使用ERNIE,可以大一些。 d.建议使用默认配置,如果想优化可以采用二分查找4.5 数据大小限制1.一般建议标注语料越多越好。2.非ERNIE模型一般需要几万至几百万条数据能收敛到较好的效果。3.ERNIE模型一般需要几千至几万条数据即可收敛到较好效果。a.一般不用ERNIE训练数百万条以上的数据,因为这会极大延长训练时间,增大资源消耗,而对效果的提升并不明显。自己有足够GPU资源的用户除外。 b.对于基线模型,建议在几万条数据上验证策略有效后再尝试增加数据量。4.如果用ERNIE模型,最少需要多少样本才能取得效果a.对于文本分类与序列标注,一般来说每个标签覆盖的样本数至少要超过200条才能有一定的效果。也就是说如果要进行50类多分类,就总共至少需要1万条样本。一般分类的类别越多任务越复杂。4.6开发迭代成本1.搭建环境成本a.如果只想训练基线模型验证效果,可以考虑使用文心平台版,免去搭建环境的成本。 b.如果需要不断调试、迭代优化模型,而由于平台版集群资源紧张造成迭代周期过长,可以尝试使用工具版。 i:这会付出搭建环境的成本,但长痛不如短痛。2.迭代效率a.使用工具版本地调试成功后再上集群训练能极大提升迭代效率。 b.使用预训练模型能提升迭代效率。 c.基线模型,建议在几万条数据上验证策略,提升迭代效率。验证有效后再尝试增加数据量5. 如何高效训练NLP任务汇总诸多NLP算法同学的建议,我们把高效训练NLP任务的基本流程总结如下:1.分析业务背景、明确任务输入与输出,将其抽象为已得到很好解决的NLP典型任务。 a.对于复杂任务,需要将其拆分成比较简单的子任务 b.文心已覆盖绝大部分NLP典型任务,可参考文心ERNIE工具版-支持任务。2.准备好几千条格式规范的训练数据,快速实现一个NLP模型基线。 a.最快速的方法是通过文心ERNIE平台版或者工具版,采用预制网络和模型无代码训练一个模型基线。 b.本步骤只需要您知道最基本的机器学习概念,划分好训练集、验证集、测试集进行训练即可。 c.评估训练出模型的效果,看是否满足你的业务需求,如果不满足,可考虑进一步优化模型效果。3.优化模型效果: a.各优化手段按照投入产出比排序如下 i:进一步分析你的业务背景和需求,分析基线模型的不足,进行更细致的技术选型。 ii:采用工具版进行本地小数据调试,极大地提升迭代效率。 iii:基于预制网络进行调参。 iv:自定义组网并进行调参。 v:基于核心接口进行高度自定义开发。 vi:直接修改文心核心源码进行开发。 b.每一种优化手段都都可以申请vip服务进行支持。如何自我判断采用哪种文心开发方式典型的训练方式:无代码训练(不调参),无代码训练(自主调参),自定义组网训练,高阶自定义训练。以上4类训练方式的开发自由度、上手难度、建模的风险、模型效果的上限依次递增,性价比依次递减。本地工具包的调试、迭代效率最高。6总结:需掌握知识6.1 无代码调参建议具备的相关知识1.明确以下概念:有监督学习、标签、特征、训练集、验证集、测试集、逻辑回归、过拟合、欠拟合、激活函数、损失函数、神经网络、学习率、正则化、epoch、batch_size、分词、统计词表。2.知道回归与分类的区别。3.知道如何通过收敛曲线判断过拟合与欠拟合。4.知道准确率、召回率、精确度、F1值、宏平均、微平均的概念与区别。5.知道为什么训练集、验证集、测试集要保证独立同分布。6.知道什么是神经网络.7.知道什么是迁移学习、什么是预训练模型、什么是finetune、迁移学习的优点是什么。6.2 自定义组网建议具备的相关知识1.前提是已经掌握无代码调参建议具备的相关知识2.明确以下概念:Sigmoid函数公式、softmax函数公式、交叉熵公式、前向传播、反向传播、SGD、Adam、词向量、embedding、dropout、BOW、CNN、RNN、GRU、LSTM、迁移学习、3.知道神经网络为什么具有非线性切分能力。4.知道NLP中一维CNN中的卷积核大小、卷积核的个数各指代什么,时序最大池化层如何操作。5.知道NLP中CNN与LSTM的区别,各擅长处理哪类文本问题。6.知道为什么BOW模型无法识别词语顺序关系。7.知道为什么会梯度爆炸,以及如何解决。参考书籍: a.ML特征工程和优化方法 b.周志华《机器学习》前3章 c.迁移学习常见问题 a.CNN常见问题 b.深度学习优化方法 c.花书《深度学习》6-10章 d.《基于深度学习的自然语言处理》整本项目参考链接:https://ai.baidu.com/ai-doc/ERNIE-Ultimate/pl580cszk
主动学习(Active Learning)简介综述汇总以及主流技术方案
主动学习(Active Learning)综述以及在文本分类和序列标注应用项目链接fork一下,含实践程序,因篇幅有限就没放在本博客中,如有需求请自行forkhttps://aistudio.baidu.com/aistudio/projectdetail/4897371?contributionType=10.引言在机器学习(Machine learning)领域,监督学习(Supervised learning)、非监督学习(Unsupervised learning)以及半监督学习(Semi-supervised learning)是三类研究比较多,应用比较广的学习技术,wiki上对这三种学习的简单描述如下:监督学习:通过已有的一部分输入数据与输出数据之间的对应关系,生成一个函数,将输入映射到合适的输出,例如分类。非监督学习:直接对输入数据集进行建模,例如聚类。半监督学习:综合利用有类标的数据和没有类标的数据,来生成合适的分类函数。其实很多机器学习都是在解决类别归属的问题,即给定一些数据,判断每条数据属于哪些类,或者和其他哪些数据属于同一类等等。这样,如果我们上来就对这一堆数据进行某种划分(聚类),通过数据内在的一些属性和联系,将数据自动整理为某几类,这就属于非监督学习。如果我们一开始就知道了这些数据包含的类别,并且有一部分数据(训练数据)已经标上了类标,我们通过对这些已经标好类标的数据进行归纳总结,得出一个“数据-->类别” 的映射函数,来对剩余的数据进行分类,这就属于监督学习。而半监督学习指的是在训练数据十分稀少的情况下,通过利用一些没有类标的数据,提高学习准确率的方法。我们使用一些传统的监督学习方法做分类的时候,往往是训练样本规模越大,分类的效果就越好。但是在现实生活的很多场景中,标记样本的获取是比较困难的,这需要领域内的专家来进行人工标注,所花费的时间成本和经济成本都是很大的。而且,如果训练样本的规模过于庞大,训练的时间花费也会比较多。那么有没有办法,能够使用较少的训练样本来获得性能较好的分类器呢?主动学习(Active Learning)为我们提供了这种可能。主动学习通过一定的算法查询最有用的未标记样本,并交由专家进行标记,然后用查询到的样本训练分类模型来提高模型的精确度。1.主动学习简介主动学习是指对需要标记的数据进行优先排序的过程,这样可以确定哪些数据对训练监督模型产生最大的影响。主动学习是一种学习算法可以交互式查询用户(teacher 或 oracle),用真实标签标注新数据点的策略。主动学习的过程也被称为优化实验设计。主动学习的动机在于认识到并非所有标有标签的样本都同等重要。主动学习是一种策略/算法,是对现有模型的增强。而不是新模型架构。主动学习背后的关键思想是,如果允许机器学习算法选择它学习的数据,这样就可以用更少的训练标签实现更高的准确性。——Active Learning Literature Survey, Burr Settles。通过为专家的标记工作进行优先级排序可以大大减少训练模型所需的标记数据量。降低成本,同时提高准确性。主动学习不是一次为所有的数据收集所有的标签,而是对模型理解最困难的数据进行优先级排序,并仅对那些数据要求标注标签。然后模型对少量已标记的数据进行训练,训练完成后再次要求对最不确定数据进行更多的标记。通过对不确定的样本进行优先排序,模型可以让专家(人工)集中精力提供最有用的信息。这有助于模型更快地学习,并让专家跳过对模型没有太大帮助的数据。这样在某些情况下,可以大大减少需要从专家那里收集的标签数量,并且仍然可以得到一个很好的模型。这样可以为机器学习项目节省时间和金钱!1.1 active learning的基本思想主动学习的模型如下:A=(C,Q,S,L,U),其中 C 为一组或者一个分类器,L是用于训练已标注的样本。Q 是查询函数,用于从未标注样本池U中查询信息量大的信息,S是督导者,可以为U中样本标注正确的标签。学习者通过少量初始标记样本L开始学习,通过一定的查询函数Q选择出一个或一批最有用的样本,并向督导者询问标签,然后利用获得的新知识来训练分类器和进行下一轮查询。主动学习是一个循环的过程,直至达到某一停止准则为止。这个准则可以是迭代次数,也可以是准确率等指标达到设定值在各种主动学习方法中,查询函数的设计最常用的策略是:不确定性准则(uncertainty)和差异性准则(diversity)。 不确定性越大代表信息熵越大,包含的信息越丰富;而差异性越大代表选择的样本能够更全面地代表整个数据集。对于不确定性,我们可以借助信息熵的概念来进行理解。我们知道信息熵是衡量信息量的概念,也是衡量不确定性的概念。信息熵越大,就代表不确定性越大,包含的信息量也就越丰富。事实上,有些基于不确定性的主动学习查询函数就是使用了信息熵来设计的,比如熵值装袋查询(Entropy query-by-bagging)。所以,不确定性策略就是要想方设法地找出不确定性高的样本,因为这些样本所包含的丰富信息量,对我们训练模型来说就是有用的。那么差异性怎么来理解呢?之前说到或查询函数每次迭代中查询一个或者一批样本。我们当然希望所查询的样本提供的信息是全面的,各个样本提供的信息不重复不冗余,即样本之间具有一定的差异性。在每轮迭代抽取单个信息量最大的样本加入训练集的情况下,每一轮迭代中模型都被重新训练,以新获得的知识去参与对样本不确定性的评估可以有效地避免数据冗余。但是如果每次迭代查询一批样本,那么就应该想办法来保证样本的差异性,避免数据冗余。从上图也可以看出来,在相同数目的标注数据中,主动学习算法比监督学习算法的分类误差要低。这里注意横轴是标注数据的数目,对于主动学习而言,相同的标注数据下,主动学习的样本数>监督学习,这个对比主要是为了说明两者对于训练样本的使用效率不同:主动学习训练使用的样本都是经过算法筛选出来对于模型训练有帮助的数据,所以效率高。但是如果是相同样本的数量下去对比两者的误差,那肯定是监督学习占优,这是毋庸置疑的。1.2active learning与半监督学习的不同 很多人认为主动学习也属于半监督学习的范畴了,但实际上是不一样的,半监督学习和直推学习(transductive learning)以及主动学习,都属于利用未标记数据的学习技术,但基本思想还是有区别的。 如上所述,主动学习的“主动”,指的是主动提出标注请求,也就是说,还是需要一个外在的能够对其请求进行标注的实体(通常就是相关领域人员),即主动学习是交互进行的。 而半监督学习,特指的是学习算法不需要人工的干预,基于自身对未标记数据加以利用。2.主动学习基础策略(小试牛刀)2.1常见主动学习策略在未标记的数据集上使用主动学习的步骤是:首先需要做的是需要手动标记该数据的一个非常小的子样本。一旦有少量的标记数据,就需要对其进行训练。该模型当然不会很棒,但是将帮助我们了解参数空间的哪些领域需要首标记。训练模型后,该模型用于预测每个剩余的未标记数据点的类别。根据模型的预测,在每个未标记的数据点上选择分数一旦选择了对标签进行优先排序的最佳方法,这个过程就可以进行迭代重复:在基于优先级分数进行标记的新标签数据集上训练新模型。一旦在数据子集上训练完新模型,未标记的数据点就可以在模型中运行并更新优先级分值,继续标记。通过这种方式,随着模型变得越来越好,我们可以不断优化标签策略。2.1.1基于数据流的主动学习方法基于流(stream-based)的主动学习中,未标记的样例按先后顺序逐个提交给选择引擎,由选择引擎决定是否标注当前提交的样例,如果不标注,则将其丢弃。在基于流的主动学习中,所有训练样本的集合以流的形式呈现给算法。每个样本都被单独发送给算法。算法必须立即决定是否标记这个示例。从这个池中选择的训练样本由oracle(人工的行业专家)标记,在显示下一个样本之前,该标记立即由算法接收。于基于流的算法不能对未标注样例逐一比较,需要对样例的相应评价指标设定阈值,当提交给选择引擎的样例评价指标超过阈值,则进行标注,但这种方法需要针对不同的任务进行调整,所以难以作为一种成熟的方法投入使用。2.1.2基于数据池的主动学习方法基于池(pool-based)的主动学习中则维护一个未标注样例的集合,由选择引擎在该集合中选择当前要标注的样例。在基于池的抽样中,训练样本从一个大的未标记数据池中选择。从这个池中选择的训练样本由oracle标记。2.1.3 基于查询的主动学习方法这种基于委员会查询的方法使用多个模型而不是一个模型。委员会查询(Query by Committee),它维护一个模型集合(集合被称为委员会),通过查询(投票)选择最“有争议”的数据点作为下一个需要标记的数据点。通过这种委员会可的模式以克服一个单一模型所能表达的限制性假设(并且在任务开始时我们也不知道应该使用什么假设)。有两个假设前提:所有模型在已标注数据上结果一致所有模型对于未标注结果样本集存在部分分歧2.2 不确定性度量识别接下来需要标记的最有价值的样本的过程被称为“抽样策略”或“查询策略”。在该过程中的评分函数称为“acquisition function”。该分数的含义是:得分越高的数据点被标记后,对模型训练后的产生价值就越高。有很多中不同的采样策略,例如不确定性抽样,多样性采样等,在本节中,我们将仅关注最常用策略的不确定性度量。不确定性抽样是一组技术,可以用于识别当前机器学习模型中的决策边界附近的未标记样本。这里信息最丰富的例子是分类器最不确定的例子。模型最不确定性的样本可能是在分类边界附近的数据。而我们模型学习的算法将通过观察这些分类最困难的样本来获得有关类边界的更多的信息。让我们以一个具体的例子,假设正在尝试建立一个多类分类,以区分3类猫,狗,马。该模型可能会给我们以下预测:{ "Prediction": { "Label": "Cat", "Prob": { "Cat": 0.9352784428596497, "Horse": 0.05409964170306921, "Dog": 0.038225741147994995, }这个输出很可能来自softmax,它使用指数将对数转换为0-1范围的分数。2.2.1最小置信度:(Least confidence)最小置信度=1(100%置信度)和每个项目的最自信的标签之间的差异。虽然可以单独按置信度的顺序进行排名,但将不确定性得分转换为0-1范围,其中1是最不确定的分数可能很有用。因为在这种情况下,我们必须将分数标准化。我们从1中减去该值,将结果乘以N/(1-N),n为标签数。这时因为最低置信度永远不会小于标签数量(所有标签都具有相同的预测置信度的时候)。让我们将其应用到上面的示例中,不确定性分数将是:(1-0.9352) *(3/2)= 0.0972。最小置信度是最简单,最常用的方法,它提供预测顺序的排名,这样可以以最低的置信度对其预测标签进行采样。2.2.2置信度抽样间距(margin of confidence sampling)不确定性抽样的最直观形式是两个置信度做高的预测之间的差值。也就是说,对于该模型预测的标签对比第二高的标签的差异有多大?这被定义为:不确定性抽样的最直观形式是两个置信度做高的预测之间的差值。也就是说,对于该模型预测的标签对比第二高的标签的差异有多大?这被定义为:同样我们可以将其转换为0-1范围,必须再次使用1减去该值,但是最大可能的分数已经为1了,所以不需要再进行其他操作。让我们将置信度抽样间距应用于上面的示例数据。“猫”和“马”是前两个。使用我们的示例,这种不确定性得分将为1.0 - (0.9352–0.0540)= 0.1188。2.2.3抽样比率 (Ratio sampling)置信度比是置信度边缘的变化,是两个分数之间的差异比率而不是间距的差异的绝对值。2.2.4 熵抽样(Entropy Sampling)应用于概率分布的熵包括将每个概率乘以其自身的对数,然后求和取负数:让我们在示例数据上计算熵:得到 0 - sum(–0.0705,–0.0903,–0.2273)= 0.3881除以标签数的log得到0.3881/ log2(3)= 0.61513.主动学习方法归类3.1 基于不确定性的主动学习方法基于不确定性的主动学习方法将最小化条件熵作为寻找判定函数的依据。Bayesian Active Learning for Classification and Preference Learning(论文 2011年)通过贪婪地找到一个能使当前模型熵最大程度减少的数据点x,但由于模型参数维度很高,直接求解困难,因此在给定数据D和新增数据点x条件下,模型预测和模型参数之间的互信息。Deep Bayesian Active Learning with Image Data(论文,代码 2017年)中实现了这一思路,过程如下:(1)从整体的数据中选一个子集作为初始训练集,来训练任务模型(分类,分割等等)(2)用训好的模型在剩余未标注的图像上以train模式跑多组预测,记录对每个样本的输出。(3)计算对每个样本的熵作为不确定性分数。(4)从大到小依次选择下一组数据标注好后加入训练集,更新训练模型(在上一代模型上fine-tuning),直到满足停止条件。考虑到深度学习中,不能每次选一个数据样本就重新训练一次模型,而是以批数据的形式进行训练,BatchBALD: Efficient and Diverse Batch Acquisition for Deep Bayesian Active Learning(论文 2019年)中,把原来的一个样本变成了一批样本。3.2基于最近邻和支持向量的分类器的方法基于不确定性的主动学习方法依赖模型预测的分类概率来确定模型对该样本的不确定性,但这个概率并不可靠,因为使用softmax分类器的神经网络并不能识别分布外样本,且很容易对OOD样本做出过度自信的预测。OOD(Out of Distribution(OOD) detection指的是模型能够检测出 OOD 样本,而 OOD 样本是相对于 In Distribution(ID) 样本来说的。传统的机器学习方法通常的假设是模型训练和测试的数据是独立同分布的(IID, Independent Identical Distribution),这里训练和测试的数据都可以说是 In Distribution(ID) 。在实际应用当中,模型部署上线后得到的数据往往不能被完全控制的,也就是说模型接收的数据有可能是 OOD样本,也可以叫异常样本(outlier, abnormal)。基于深度模型的Out of Distribution(OOD)检测相关方法介绍在主动学习中,初始阶段使用非常少的标注样本训练模型,意味着大量的未标注样本可能都是OOD样本,若模型过早的给这部分样本一个过度自信的预测概率,就可能使我们错失一些有价值的OOD样本。如图所示,初始训练阶段,模型缺乏虚线框以外的区域的训练数据,但softmax分类器仍然会对这些区域给出很自信的预测,导致选择新的待标注样本时,图中的q点会被忽略,而若q点正好不是class B,则会影响主动学习的性能。3.2.1 NNClassifier针对这个问题NNclassifier中设计了一个基于最近邻和支持向量的分类器来取代softmax, 使模型能对远离已有训练数据的区域产生较高的不确定性。具体而言,每类训练学习N个支持向量,基于样本特征与各类的支持向量之间的距离,就可以定义分类概率为与这N个支持向量的核函数的最大距离:$p_c\left(f_x\right)=\max _n \delta\left(-d\left(f_x, m_{c, n}\right)\right)$定义了新的可以意识到OOD样本的分类器之后,作者给出了对应的主动学习策略:Rejection confidence,用于度量远离所有支持向量的样本,如图(b)所示;confusion confidence,用于度量远离支持向量以及同时靠近多个不同类支持向量的样本,如图©所示。$\begin{aligned} &M_{\text {rejection }}(x)=\sum_c\left(1-p_c\left(f_x\right)\right) \\ &M_{\text {confusion }}(x)=\sum_c\left(1+p_c\left(f_x\right)-\max _c p_c\left(f_x\right)\right) \end{aligned}$3.2.2 RBF network + Gradient PenaltyAmersfoort用RBF神经网络来促使网络具有良好的OOD样本不确定性,同时给出了基于梯度范数的双边正则来削弱特征崩溃(feature collapse)的问题。与NNClassifier相同,本文的作者也定义了一个与各类特征距离的函数K来帮助检测OOD样本,损失函数同样定义成逐类的二值交叉熵。不同于NNClassifier的是,这里的距离是每个样本与该类样本的指数滑动平均得到的。$K_c\left(f_\theta(x), e_c\right)=\exp \left(-\left\|W_c f_\theta(x)-e_c\right\|_2^2 /\left(2 n \sigma^2\right)\right)$另一个不同点在于本文加入了一个双边梯度正则项。$\max \left(0,\left\|\operatorname{grad}_z \sum_c K_{\mathrm{c}}\right\|_F^2-1\right)$这个正则项的作用有两个,一个是保证平滑性,也就是相似的输入有相似的输出,这个是由max()中的梯度部分保证的,而梯度-1则起到避免特征崩溃的作用,也就是相比单纯的使用特征范数正则,-1能够避免模型将很多不同的输入映射到完全相同的特征,也就是feature collapse。3.3基于特征空间覆盖的方法接下来主要介绍基于特征空间覆盖的主动学习代表性工作:coreset。coreset的主要贡献:给出了基于特征空间覆盖的主动学习算法的近似损失上界;证明了新添加的样本在能够缩小标注样本对剩余样本的覆盖半径时,才能提高近似效果。coreset认为主动学习目标就是缩小核心集误差,即主动学习选出的样本损失与全体样本损失之间的差别。我们在主动学习挑选新样本时,并不知道样本的标签,也就没法直接求核心集损失。作者把核心集损失的上界转换做剩余训练样本与挑选出的标注样本间的最大距离。因此,主动学习问题等价于选择添加一组标注样本,使得其他样本对标注样本集的最大距离$\delta_s$ 最小,也就是k-center集覆盖问题。如图所示,蓝色为挑选出的标注样本,红色为其他样本。3.4 基于对抗学习的方法3.4.1VAALVariational Adversarial Active Learning(地址 2019年)描述了一种基于池的半监督主动学习算法,它以对抗的方式(关于对抗学习的详细介绍参见这里)隐式地学习了这种采样机制。与传统的主动学习算法不同,VAAL与任务无关,也就是说,它不依赖于试图获取标注数据的任务的性能。VAAL使用变分自编码器(VAE)和训练好的对抗网络来学习潜在空间,以区分未标注和标注的数据。核心思想本文的出发点可以理解如下:之前很多方法的uncertainty都是基于模型的,也就是说需要有个分割/分类等模型计算预测结果,然后从结果的好坏去分析相应的被预测样本的价值。而本文的uncertainty是基于数据本身的,也就是说并非基于预测结果本身去分析,而是直接基于样本自身的特征去处理。核心思想:利用VAE对已标注的数据和未标注的数据进行编码。因此,对于一个未标注的数据,如果其编码向量与潜在空间中向量的差异足够大,那么我们就认为该样本是有价值的。而对于样本的选择,是通过一个对抗网络来实现的,该对抗网络被用来区分一个样本是已标注还是未标注。因此上文的VAE还有一个额外的任务,即他的编码要让判别器难以区分已经标注还是没有标注。网络结构VAE和对抗网络之间的最大最小博弈是这样进行的:VAE试图欺骗对抗网络去预测,所有的数据点都来自已标注池;对抗网络则学习如何区分潜在空间中的不相似性。其结构如下:VAE和对抗网络之间的最大最小博弈是这样进行的:VAE试图欺骗对抗网络去预测,所有的数据点都来自已标注池;对抗网络则学习如何区分潜在空间中的不相似性。其结构如下:主动学习策略一开始随机选择10%的图像开始训练,此时记训练的网络为版本1。对于版本1,训练会迭代max_iterations次,与一般网络训练过程的差别在于每个iteration除了训练"任务模型"外,还得去训练VAE与判别器。而当迭代结束后,训练得到的"任务模型"其实与直接随机抽取10%的图像训练没有区别,因为VAE与判别器只对下一个网络版本有贡献。利用VAE与判别器内包含的经验,一次性抽取5%的新数据加入训练集,此时开始训练网络版本2。而这里特别关键的一点是,版本2仍然是从预训练VGG开始从头训练的(而非在版本1的基础上继续finetune)。至此一直迭代到选取50%的数据结束。模型特点本文的强化学习有点"离线"的味道,即最后选取出的50%数据可以很轻松的迁移至其他模型中,选择的过程只依赖VAE与判别器,而与具体的任务无关。此外该模型训练十分耗时——从10%逐步提升5%至50%,相当于顺序训练了9个相同的模型,再考虑训练VAE与判别器的耗时,训练该主动学习框架的所需时间可能高达原有基础网络的10倍。3.4.2SRAALSRAAL(论文 https://openaccess.thecvf.com/content_CVPR_2020/html/Zhang_State-Relabeling_Adversarial_Active_Learning_CVPR_2020_paper.html)是VAAL的一个改进版。在VAAL中,判别器的训练的时候只有两种状态,标注/未标注。SRAAL的作者认为这样忽略了一些信息,有时候任务模型已经能很确信的对某个未标注样本做预测了,就应该降低选择这个样本的优先级。为了实现这个思路,作者给出了一个任务模型预测不确定度的计算函数,用这个函数的输出结果作为生成对抗网络的判别器训练过程中,无标注样本的标签,而不用简单的个一个二值变量。3.4.3ARALVAAL有效的一个关键的因素实际上是同时利用标注/无标注的样本共同训练产生特征映射,而不像之前基于特征的coreset等主动学习方法,仅用标注数据训练产生特征。ARAL(https://arxiv.org/abs/1912.09720 2019.11)更进一步,也用这些个无标注样本来训练任务模型(如分类器)本身,整体仍然是在VAAL基础上做的,只是增加了cgan的判别器来实现半监督训练任务模型。整体来说,基于池的主动学习用标注样本来训练任务模型,合成的主动学习标注合成的样本来训练任务模型。相比之下,VAAL用标注数据训练任务模型,用所有数据来训练产生特征;ARAL用所有的训练数据,合成数据来训练任务模型、产生特征映射。相当于使用了半监督的学习方法,与和之前纯基于监督训练的主动学习方法比较自然有所提升。4.融合不确定性和多样性的学习方法☆之前介绍了基于不确定性的方法,以及基于多样性的方法。接下来我们来看看融合两者的方法。就动机而言,如果只用不确定性标准来选样本,在批量选择的场景中,很容易出现选到冗余样本的问题。而在深度学习中,由于训练开销的缘故,通常都采用批主动学习,所以为了提高主动学习的效率,就得考虑批量选择高不确定性样本时的多样性问题。而从多样性样本选择方法的角度来说,单纯的特征空间覆盖算法不能区分模型是否已经能很好预测某部分样本,会限制这类方法所能达到的上限。融合不确定性和多样性的思路主要有三种:完全延续信息论的分析思路,也就是batchBALD,在批量选择的过程中不采取每个样本互信息直接相加,而用求并的方法来避免选到冗余样本;先用不确定性标准选出大于budget size的候选集,再用集覆盖的思路来选择特征差异大的样本;是2的扩展,通过在梯度嵌入空间聚类来选样本,从而避开人工给定候选样本集大小的问题。4.1信息论思路第一种从理论上来看很优雅,从信息论的角度推出怎么在批量选择的场景里选到对模型参数改善最有效的一组样本。但计算复杂度很高,可能并不是很实用,该论文中的实验部分也都是在很小的数据集上完成的。4.2 构建候选集+大差异样本——SA这类方法实现起来最简单,非常启发式。整个主动学习分两步来做,第一步先用不确定性(熵,BALD等)选超出主动学习budget size的候选样本集,在用多样性的方法,选择能最好覆盖这个候选集的一组样本。SA 2017 用Bootstrapping训练若干个模型,用这些模型预测的variance来表示不确定性,之后再用候选集中样本特征相似度来选取与已经选到的样本差异最大的样本,就类似coreset-greedy的做法。CoreLog 2021 基于Proper Scoring Rules给了表示不确定性的度量,先选出不确定性大的前k%个样本,再用kmeans聚类来选择多样的样本。这种结合的方式没毛病,但有个小的问题,很难说清咋确定这个候选集大小,到底多大能算作高不确定性,能丢到候选集里。4.3 梯度嵌入空间——badge☆badge:https://arxiv.org/abs/1906.03671 2020 和第二类方法的思路很像,不确定性的用模型参数就某个样本的梯度大小来表示,多样性用kmeans++来保证。但这个方法很巧妙的地方在于,通过把这个问题丢到梯度嵌入空间来做(而不像第二类方法在样本的特征空间保证多样性),使样本的多样性和不确定性能同时得到保证。梯度范数大小表示不确定性很好理解,和之前用熵之类的指标来表示不确定性类似,模型预测的概率小,意味着熵大,也意味着如果把这样本标了,模型要有较大的变化才能拟合好这个样本,也就是求出来的梯度大。梯度表示多样性,是这类方法的独特之处,用梯度向量来聚类,选到的差异大的样本就变成:让模型参数的更新方向不同的样本,而不是样本特征本身不同。在用梯度表示了不确定性和多样性之后,怎么来选一批既有高不确定性,又不同的样本呢?badge的做法是Kmeans++聚类,第一个样本选梯度范数最大的样本,之后依据每个样本梯度与选到的样本梯度的差的范数来采样新的样本。这里注意这个差是两个向量的差,所以自然的避免了重复的选到梯度方向接近且范数都比较大的一组样本。5. 基于变化最大的方法这一类方法核心的观点是,不管不确定性或多样性,而是希望选出的样本能使模型产生的变化最大。变化最大可以着眼于loss最大,也可以关注梯度的情况,比如梯度范数大小。learning loss 2019 在任务模型上加一个小的附属子网络用来学习预测样本的损失值。训练任务模型的时候,也同时训练这个预测损失模块,之后就用这个模块来预测对哪个未标注样本的损失大,就选他。整个算法的流程图如下损失预测模块的结构和损失计算方法如下:6.总结主动学习(Active Learning)综述以及在文本分类和序列标注应用项目链接fork一下,含实践程序,因篇幅有限就没放在本博客中,如有需求请自行forkhttps://aistudio.baidu.com/aistudio/projectdetail/4897371?contributionType=1 获得有用是标注数据在训练时是非常重要的,但是标注数据可能很非常的费事费力,并且如果标注的质量不佳也会对训练产生很大的影响。主动学习是解决这个问题的一个方向,并且是一个非常好的方向。
深度学习应用篇-计算机视觉-图像分类[3]:ResNeXt、Res2Net、Swin Transformer、Vision Transformer等模型结构、实现、模型特点详细介绍
深度学习应用篇-计算机视觉-图像分类[3]:ResNeXt、Res2Net、Swin Transformer、Vision Transformer等模型结构、实现、模型特点详细介绍
全栈工程师的优点与价值 其实在我们了解了全栈工程师的概念后,就很容易联想到其优点:
减少了沟通时间,降低了沟通成本,提高了开发效率。
由于前后端,甚至产品的业务,都有一个人来负责完成,不需要沟通,各个端的配合是100%的默契配合,这从很大程度上提高了开发效率。
虽然全栈工程师的知识面较广,能够完成一些前端及后端的开发工作,但全栈开发师的厉害之处并不是他掌握很多知识,可以一个人干多份工作。
而他真正的价值在于处理问题的时候拥有全局性思维。
现在科技日新月异,web前端不再是从前切个图用个jQuery上个AJAX兼容各种浏览器那么简单。现代的Web前端,你需要用到模块化开发、多屏兼容、MVC,各种复杂的交互与优化,甚至你需要用到Node.js来协助前端的开发。一个现代化的项目,是一个非常复杂的构成,我们需要一个人来掌控全局,他不需要是各种技术的资深专家,但他需要熟悉到各种技术。对于一个团队特别是互联网企业来说,有一个全局性思维的人显得尤其重要,这个时候也就彰显了全栈开发工程师的价值。
开源社区该如何建立“可控开源”体系?
1.可控开源体系
开源软件相比于闭源软件,能够获得更多的开发者和关注,社区可以向开源项目提交代码,从而针对所遇见的问题提供相应的解决方案。相比于商业公司,这样能够找到的 Bug 更多,更好。这样的认知,我将其称之为「开源的机制安全」,也就是说,这个机制是可以让整个软件更加的安全。
但是,机制安全并不能够保证软件足够的安全。机制安全能够成立的前提有很多,比如:
开源项目的团队会接受来自社区的贡献:虽然不少项目都开源了,但是很少合并来自社区的贡献,这使得该软件虽然开源了,但是实际上并没有享受到开源软件所带来的机制安全。
开源项目的团队获取到足够多的社区贡献:相比于一些知名的开源项目,你所使用、贡献的项目可能并没有足够多的开发者来为其贡献代码,在发现 Bug 的方面,因为没有足够多的人,也就导致了相对来说,不够安全。
此外,开源这件事在安全层面来看,就是一把双刃剑。固然你通过开源获取到了更多的贡献,但同时因为你将测试从黑盒测试转为了白盒测试。 开发者只需要阅读已经开源的代码,就可以从中发现漏洞并使用漏洞。
那么: 开源社区需要为开源软件的安全负责吗?
为了开源生态能更好的发展,应该如何保证“开源可控”?
举个简单例子:
这段代码单独来看是没有任何问题的,因为它在清理完磁盘队列后会设置pf->disk->queue=null,如果作为一个静态代码审核者,从中肯定看不出任何问题。作为OS内核核心代码,做完整的动态测试是不可能的,因此这段代码是否有问题只能是在开源软件使用者报错的时候才能被发现。但是pf_detect()和另外一个函数pf_uexit()这两个函数,在queue指针为空后的时候被调用,它们将在不检查指针状态的情况下对pf->disk->queue进行操作,从而导致空指针取消引用,导致系统中的相关核心进程崩溃,甚至引起CORE PANIC。原本只有pf_uexit中会做清理,因此不会存在空指针操作的问题。当引入这个补丁后,出现了多次调用清理的可能,因此就可能触发空指针问题。
根据上面的例子,只要提交一个可以触发在该指针为空的时候调用这两个函数的补丁,就很容易会激活这个原本不会造成太大影响的代码缺陷,导致大的故障。别有用心的伪代码贡献者就可以利用这个以前并不会对系统造成多大影响的隐患,通过自己添加的看似无害的代码去主动激活这个隐患,从而造成很大的安全事故。此类的恶意代码攻击手段还有很多。
另外一个开源社区难以防范此类恶意代码攻击的原因是开源社区无法很好的对代码贡献者进行管控,因为理论上任何一个人都可以成为代码贡献者。而在开源社区里,实名制是十分困难的,建立代码贡献者溯源也十分困难。上面是论文中对于伪代码贡献者通过linux开源社区对于代码管理方面的漏洞进行的恶意攻击的示意图。其实我们讨论开源代码的不安全问题并不是为了因噎废食,而是需要找到解决这些问题的方法。中国的基础软件产业需要快速发展,依靠开源社区是一条必须走的捷径,这一点是毋庸置疑的。购买成熟的商业软件公司和直接使用开源代码进行二次开发,从本质上并无优劣之分,都是快速构建信创软件生态的好办法。
一方面是选择开源协议的问题,一方面是代码本身的安全问题。从代码安全方面我们有几条路可走,一条路是基于某个开源代码进行魔改,最终放弃开源代码,完全走向自主的闭源代码。这条路国内的一些大型企业在走。包括腾讯QQ的前身OICQ当年也是使用了大量的ICQ的代码的。华为的OPENGAUSS是基于PostgreSQL 9.2.4的,不过OPENGAUSS已经对代码进行了魔改,连PG的多进程架构都被改成了多线程架构。这种脱离社区代码的完全自主改造,是有成本和代价的,只有具有极强研发能力的企业才能在这条路上走的比较成功。目前我无法说华为的做法是正确的还是错误的,也许等OPENGAUSS 3.0出来后和PG 14比较一下,才能看出来这条路走的是否正确。当然这个正确也是基于时间的,如果华为能坚持走上数年,我想OPENGAUSS全面超过社区版的PG并非不可能。
除了魔改外,还有一条路就像红帽一样,依靠上游的开源社区来发展自己的软件。如果是这样,那么我们就要加强对开源代码的管控,通过自动化工具与人工核查的方法,对代码进行静态与动态分析,从而构建强大的开源代码安全管控能力。成为一家像红帽一样伟大的基于开源生态的软件公司。
可能有朋友要说了,我们既不是华为阿里这样的大厂,又没有强大的代码安全管控能力,我们只是一个开源软件产品的使用者。我们该怎么办呢?难道我们就不能使用开源软件了吗?答案当然是否定的,如果我们的羊圈不够牢固,那么我们就把羊圈修在城里吧,把自己的网络环境的安全搞搞好,增加通用安全防护的投入,启用更为严格的安全防护规章制度等,都是有效提升企业信息系统安全的好方法。作为最终用户,守住安全底线总还是需要的。一个连勒索病毒都会中的企业,其安全管控恐怕基本上等于空白了。
文章最后:上云能从一定程度上解决开源带来的安全性问题吗?,是可以一定程度缓解上述问题,这也是阿里做的好的地方,也是值得大家关注的点。
你使用过哪些云产品组合进行开发?
目前国内的云服务商中,阿里云、腾讯云、华为云是受关注最高的服务商,也是大量的中小型企业由原来的物理服务器转向了云服务器的首选云服务商。和传统的物理物理服务器相比,云服务器具有更安全、业务配置更快、选择更灵活、使用成本更低等优点。不管是用来建网站还搭建电子商务\游戏平台、各类APP\办公系统应用以及测试技术代码等都是非常方便的。
阿里云 一、阿里云服务器 阿里云服务器ECS(Elastic Compute Service)是阿里云提供的性能卓越、稳定可靠、弹性扩展的IaaS(Infrastructure as a Service)级别云计算服务。
二:阿里云服务器可以用来 1、企业官网或轻量的Web应用 网站初始阶段访问量小,只需要一台低配置的云服务器ECS实例即可运行Apache或Nginx等Web应用程序、数据库、存储文件等。随着网站发展,您可以随时升级ECS实例的配置,或者增加ECS实例数量,无需担心低配计算单元在业务突增时带来的资源不足。
2、多媒体以及高并发应用或网站 云服务器ECS与对象存储OSS搭配,对象存储OSS承载静态图片、视频或者下载包,进而降低存储费用。同时配合内容分发网络CDN和负载均衡SLB,可大幅减少用户访问等待时间、降低网络带宽费用以及提高可用性。
3、高I/O要求数据库 支持承载高I/O要求的数据库,如OLTP类型数据库以及NoSQL类型数据库。您可以使用较高配置的I/O优化型云服务器ECS,同时采用ESSD云盘,可实现高I/O并发响应和更高的数据可靠性。您也可以使用多台中等偏下配置的I/O优化型ECS实例,搭配负载均衡SLB,建设高可用底层架构。
4、访问量波动剧烈的应用或网站 某些应用,如抢红包应用、优惠券发放应用、电商网站和票务网站,访问量可能会在短时间内产生巨大的波动。您可以配合使用弹性伸缩,自动化实现在请求高峰来临前增加ECS实例,并在进入请求低谷时减少ECS实例。满足访问量达到峰值时对资源的要求,同时降低了成本。如果搭配负载均衡SLB,您还可以实现高可用应用架构。
5、大数据及实时在线或离线分析 云服务器ECS提供了大数据类型实例规格族,支持Hadoop分布式计算、日志处理和大型数据仓库等业务场景。由于大数据类型实例规格采用了本地存储的架构,云服务器ECS在保证海量存储空间、高存储性能的前提下,可以为云端的Hadoop集群、Spark集群提供更高的网络性能。
6、机器学习和深度学习等AI应用 通过采用GPU计算型实例,您可以搭建基于TensorFlow框架等的AI应用。此外,GPU计算型还可以降低客户端的计算能力要求,适用于图形处理、云游戏云端实时渲染、AR/VR的云端实时渲染等瘦终端场景。
二、腾讯云服务器 腾讯云服务器(Cloud Virtual Machine,CVM)为您提供安全可靠的弹性计算服务。 只需几分钟,您就可以在云端获取和启用 CVM,用于实现您的计算需求。随着业务需求的变化,您可以实时扩展或缩减计算资源。
参考链接:https://zhuanlan.zhihu.com/p/536187643
三、华为云 华为云服务器 弹性云服务器(Elastic Cloud Server,ECS)是由CPU、内存、操作系统、云硬盘组成的基础的计算组件。弹性云服务器创建成功后,您就可以像使用自己的本地PC或物理服务器一样,在云上使用弹性云服务器。
华为云服务器使用场景 1、网站应用 对CPU、内存、硬盘空间和带宽无特殊要求,对安全性、可靠性要求高,服务一般只需要部署在一台或少量的服务器上,一次投入成本少,后期维护成本低的场景。例如网站开发测试环境、小型数据库应用。 推荐使用通用型弹性云服务器,主要提供均衡的计算、内存和网络资源,适用于业务负载压力适中的应用场景,满足企业或个人普通业务搬迁上云需求。
2、企业电商 对内存要求高、数据量大并且数据访问量大、要求快速的数据交换和处理的场景。例如广告精准营销、电商、移动APP。 推荐使用内存优化型弹性云服务器,主要提供高内存实例,同时可以配置超高IO的云硬盘和合适的带宽。
3、图形渲染 对图像视频质量要求高、大内存,大量数据处理,I/O并发能力。可以完成快速的数据处理交换以及大量的GPU计算能力的场景。例如图形渲染、工程制图。 推荐使用GPU图形加速型弹性云服务器,G1型弹性云服务器基于NVIDIA Tesla M60硬件虚拟化技术,提供较为经济的图形加速能力。能够支持DirectX、OpenGL,可以提供最大显存1GiB、分辩率为4096×2160的图形图像处理能力。
4、数据分析 处理大容量数据,需要高I/O能力和快速的数据交换处理能力的场景。例如MapReduce 、Hadoop计算密集型。 推荐使用磁盘增强型弹性云服务器,主要适用于需要对本地存储上的极大型数据集进行高性能顺序读写访问的工作负载,例如:Hadoop分布式计算,大规模的并行数据处理和日志处理应用。主要的数据存储是基于HDD的存储实例,默认配置最高10GE网络能力,提供较高的PPS性能和网络低延迟。最大可支持24个本地磁盘、48个vCPU和384GiB内存。
5、高性能计算 高计算能力、高吞吐量的场景。例如科学计算、基因工程、游戏动画、生物制药计算和存储系统。 推荐使用高性能计算型弹性云服务器,主要使用在受计算限制的高性能处理器的应用程序上,适合要求提供海量并行计算资源、高性能的基础设施服务,需要达到高性能计算和海量存储,对渲染的效率有一定保障的场景。
Serverless在推进过程中会遇到什么样的挑战?该如何破局?
serverless最大的优势在于资源得到了更合理的利用: 1.快速迭代与部署 2.高并发、高弹性 3.稳定、可靠、安全 4.运维与成本控制
下面进行简单分析:
传统的购买服务器部署应用的方式,在没有使用的时候,服务器就被浪费掉了,对于我这种需要部署一些个人用的小规模应用的情况,买服务器非常的不合算,每天可能实际使用就几分钟,大部分时间都在空置。但是 serverless 是按照实际使用次数/时长来计费的,也就是说,不用的时候真正不花一分钱。所以我越来越多的使用 serverless 部署这些小规模应用,每天实际上使用的 CPU 时间加起来可能还不到一秒,这可以把我的使用成本压缩到几乎忽略不计的程度上。
1.更多人像我这样部署到 serverless 之后,总的服务器消耗就大幅度下降了,原本可能每个人都需要一台独立的服务器,现在上百个人可能实际上就只共享了一台服务器,但每个人都能有良好的用户体验。2.serverless 先天是高并发的,可以无限制的并发请求。当我自己购买服务器部署时,我需要自己在开发应用时解决并发问题,要么就是单线程同时只处理一个请求。3.serverless 开发的时候就不用管并发,我的代码只要能处理一个请求,那么就一定能同时创建无限的运行时来处理更多的请求。4. serverless 的高并发不需要在同一台物理服务器上运行,事实上可以跑在任意位置任意数量的物理服务器上,当我一份代码部署完成之后,用户访问时可以就近选择最近的节点,从而降低延迟,而对于单一物理服务器的传统部署,地球对面的用户访问起来就会非常痛苦。
因为每个请求都是在独立运行时里处理的,错误处理也可以变得很简单,很多不处理就会崩溃的地方真的可以不处理,崩就崩呗,反正就崩单一请求对应的运行时,对其他用户没影响。不像开发传统服务器应用,得尽可能不崩溃否则崩了还得远程上去重启进程。从这个角度来看 serverless 是轻量化应用的最优解决方案,成本更低,复杂度更低,用户体验更好。当然,方便的前提一定是更低的自由度,所以对于复杂的企业项目, serverless 仍然不能成为首选
ModelScope社区上线,怎么看待它在AIGC发展中起到的作用?
2022至今,从DALL-E2、 StableDiffusion等人工智能技术,到 ChatGPT等人工智能技术, AIGC领域在互联网上掀起了轩然大波,它那惊人的创作速度,让所有人都为之惊叹。业界曾经也有一个普遍的看法: AIGC绝不会是一种短暂的热点,它的基础技术和工业生态都在不断地迭代进步着。
首先是基本的算法建模,持续地进行突破和革新。例如 GAN、 Transformer、扩散模型等,其性能、稳定性和生成内容质量都在逐步提高。由于生成算法的不断发展, AIGC可以生成不同种类的内容和资料,如文字,代码,图像,语音,视频,三维物体等。
然后是预习模型,即基础模型,大模型,使 AIGC的技术实力发生了质的变化。以往各种生成模式都有,但由于使用门槛高、训练成本高、内容生成简单、质量差等原因,很难适应现实内容的要求。而该系统的前培训模式可以满足多任务、多场景和多功能需求,可以有效地克服上述问题。该技术还使 AIGC的应用和产业化程度得到了明显的提高, AIGC模式能够实现高品质的内容产出,从而使 AIGC模式既是“工厂”,又是“流水线”。因此,诸如谷歌,微软, OpenAI等公司都在积极地推进 AI技术的发展,将其推向了预先培训的模式。
另外多模态技术促进了 AIGC的内容多元化,使 AIGC的通用性能得到了提高。多模式技术实现了语言文字、图像、音视频等不同的信息之间的转换和产生。例如 CLIP,可以将文本与图片进行联系,例如把“狗”与“狗狗”相联系,同时具有大量的相关特性。这为文生图、文生视频等 AIGC技术的发展打下了良好的基础。
AIGC在消费互联网,工业互联网和社交价值等方面的不断升级迭代。当前 AIGC领域的内容类型不断丰富,内容质量不断提高,技术通用化和产业化程度不断提高, AIGC逐渐成为消费者网络领域的主流,出现了写作助手、 AI绘画、对话机器人、数字人等爆款级应用,支撑着传媒、电商、娱乐、影视等领域的内容需求。现在 AIGC也将其扩展到工业互联网,社会价值领域。
未来已经来临,让我们一起迎接 AIGC,迎接下一个新世纪的人工智能,未来一段时间,国产AIGC的产品更多的涌现出来,为中国的人工智能产业创造辉煌。
ChatGPT给国内外科技公司带来了怎样的机遇和威胁?
简单说一下,从NLP中的ChatGPT,以及AI绘画,在这个过程中AI绘画也得到了升级,从原来的二次元绘画到达了真人照片绘画。

在ChatGPT的光芒掩盖一切的这段时间,图像生成AI已经从从画画悄悄进化到了“画照片”。
回归上题“ChatGPT给国内外科技公司带来了怎样的机遇和威胁?” 我认为威胁便是国外先遣者“谷歌微软”的冲击,第一个吃螃蟹;机遇便是新兴技术发展和耦合,,就像有网友表示:AI聊天+AI照片,快进到AI网恋诈骗。应该图+文结合发挥新的商业模式别单独停留在一个点上,乃至后面的视频生成,可发展领域很多。或者说是革新原有很多领域!

动态环境下机器人运动规划与控制以及带有移动障碍物的无人机动画是机器人技术领域的研究热点之一。在这种环境下,机器人需要根据传感器的数据进行实时控制,以避免与运动中的障碍物发生碰撞。对于运动规划和控制,传统的方法是使用PID控制器或者其他控制算法来实现机器人的路径规划和控制。然而,在复杂的环境中,机器人需要考虑移动障碍物的影响,并且需要实时调整路径。近年来,深度学习技术的发展为机器人的运动规划和控制提供了新的解决方案。使用深度学习模型,机器人可以通过学习复杂的环境和障碍物的运动模式来实现更加智能化的运动规划和控制。对于带有移动障碍物的无人机动画,需要考虑无人机的飞行轨迹和障碍物的位置和运动状态。传感器数据的分析和控制算法的设计可以让无人机在复杂的环境中实现安全和高效的飞行。总之,动态环境下机器人运动规划与控制以及带有移动障碍物的无人机动画是机器人领域的重要研究课题,可以应用于未来的智能制造、自动驾驶等领域。
播放量:24
动态环境下机器人运动规划与控制以及带有移动障碍物的无人机动画是机器人技术领域的研究热点之一。在这种环境下,机器人需要根据传感器的数据进行实时控制,以避免与运动中的障碍物发生碰撞。对于运动规划和控制,传统的方法是使用PID控制器或者其他控制算法来实现机器人的路径规划和控制。然而,在复杂的环境中,机器人需要考虑移动障碍物的影响,并且需要实时调整路径。近年来,深度学习技术的发展为机器人的运动规划和控制提供了新的解决方案。使用深度学习模型,机器人可以通过学习复杂的环境和障碍物的运动模式来实现更加智能化的运动规划和控制。对于带有移动障碍物的无人机动画,需要考虑无人机的飞行轨迹和障碍物的位置和运动状态。传感器数据的分析和控制算法的设计可以让无人机在复杂的环境中实现安全和高效的飞行。总之,动态环境下机器人运动规划与控制以及带有移动障碍物的无人机动画是机器人领域的重要研究课题,可以应用于未来的智能制造、自动驾驶等领域。
播放量:35
实时模型强化学习是一种机器学习技术,它可以在无人机的实时环境中学习,并且可以根据环境的变化做出相应的调整。在无人机自主导航中,实时模型强化学习可以用于训练无人机的导航模型,以使其能够在复杂环境中自主导航。具体来说,实时模型强化学习可以通过以下步骤实现:环境建模:建立无人机周围环境的模型,包括地形、障碍物、气象等信息。状态估计:根据环境模型,估计无人机当前的位置和姿态。动作选择:根据估计的位置和姿态,选择最优的动作来控制无人机。动作执行:根据选择的动作,控制无人机执行相应的操作。反馈调整:根据无人机的实际表现,不断调整动作执行的参数,以提高导航的精度和鲁棒性。细化一下:建立状态空间:将无人机所处的环境抽象成一个状态空间,其中每个状态都对应着无人机所处的位置、速度、加速度等信息。定义动作空间:定义无人机可执行的动作集合,例如上升、下降、前进、后退等。设计奖励函数:根据任务需求和目标设定,设计一个奖励函数,用于评估每个状态和执行的动作所获得的收益。该函数应该能够激励无人机朝着预期的目标方向移动,并避免不良行为。进行强化学习训练:利用在线学习等方法,让无人机通过与环境交互来调整策略并优化奖励函数。这样可以使无人机逐渐学会最佳的决策方案,以满足不同的飞行任务。实时执行导航任务:一旦训练完成,无人机就可以在实时环境中根据感知到的状态信息做出决策,并按照最优策略执行自主导航任务。基于实时模型强化学习的无人机自主导航可以通过以下方式实现:实时模型强化学习算法:使用深度学习、神经网络等技术,训练无人机的导航模型,以实现自主导航。无人机传感器数据:无人机需要配备多种传感器,如GPS、IMU、LiDAR等,以获取周围环境的信息。实时数据处理:无人机需要实时获取传感器数据,并对数据进行处理,以实现实时模型强化学习。控制器设计:无人机需要设计相应的控制器,以实现实时模型强化学习的控制。实时模型强化学习控制器:使用实时模型强化学习算法,设计无人机的控制器,以实现实时模型强化学习的控制。总之,基于实时模型强化学习的无人机自主导航是一种具有广泛应用前景的技术,可以提高无人机在复杂环境中的导航精度和鲁棒性。
播放量:25
无人机强化学习是一种利用无人机作为学习对象的强化学习方法,可以用于训练无人机在复杂环境中的决策和行为。GAZEBO 3D动态模拟器是一种常用的无人机强化学习平台,可以模拟各种复杂的环境和任务。在GAZEBO 3D动态模拟器下进行无人机强化学习,需要遵循以下步骤:准备数据集:首先需要准备一个包含无人机在各种复杂环境中的行为数据的数据集。这些数据可以来自于真实的无人机任务,也可以来自于模拟器的仿真数据。搭建模拟器:使用GAZEBO 3D动态模拟器来模拟无人机在各种复杂环境中的行为。可以使用模拟器提供的各种传感器和控制器来实现这一点。定义环境:定义无人机需要面对的各种环境,例如障碍物、地形、气象等。可以使用模拟器提供的各种环境元素来实现这一点。定义策略:定义无人机在不同环境下的决策规则和行为模式。可以使用模拟器提供的各种决策算法和行为模式来实现这一点。训练模型:使用训练数据来训练无人机的决策和行为模型。可以使用GAZEBO 3D动态模拟器提供的各种训练算法和数据集来实现这一点。测试模型:使用测试数据来测试无人机的决策和行为模型。可以使用GAZEBO 3D动态模拟器提供的各种测试算法和数据集来实现这一点。部署模型:将训练好的无人机模型部署到实际环境中,以实现无人机在实际任务中的决策和行为。
播放量:26
基于深度强化学习的机器人避障实验是一种机器人学习方法,通过在多个行人环境中训练机器人,让它学会如何避免障碍物,从而实现自主导航。该方法利用深度强化学习算法,通过学习机器人在环境中的行为,建立机器人与环境之间的映射关系,从而使机器人能够自主避开障碍物。该实验的主要步骤如下:首先,需要配置ROS环境,包括ROS版本和Ubuntu版本的对应关系。安装turtlebot3软件包,这是一个基于ROS的机器人操作库,可以用于编写机器人的控制程序。使用turtlebot3的软件包做仿真,可以通过ROS的机器人仿真器来实现。自己编写ROS package并编译执行,可以通过ROS的包管理器来实现。关于获取机器人scan和camera数据的方法,需要使用ROS的摄像头和深度相机来获取环境信息,并将其传输到机器人中进行处理。配置深度强化学习环境,包括显卡驱动安装注意事项、python2.7和3.7版本兼容问题、OpenCV安装注意事项和GPU加速深度强化学习训练的方法等。神经网络GPU训练过程,包括GPU加速深度强化学习训练的方法和其他小问题。源码,包括基于深度强化学习的机器人避障实验的源代码和其他机器学习算法的源代码。
播放量:21
基于强化学习的斗地主游戏。首先,斗地主是一种经典的纸牌游戏,它的规则非常简单,玩家需要通过出牌组成各种牌型,最终以出牌最快的方式获胜。强化学习是一种机器学习方法,它通过对环境中的输入数据进行学习,从而得到最优的输出结果。在斗地主游戏中,强化学习算法可以通过对游戏规则、玩家出牌策略等数据的学习,来预测玩家的出牌策略,从而提高自己的胜率。具体来说,强化学习算法可以通过以下步骤来实现:收集游戏数据:首先,需要收集斗地主游戏的数据,包括游戏规则、玩家出牌策略等。建立神经网络模型:然后,需要建立一个神经网络模型,用于对游戏数据进行学习。神经网络模型可以使用深度学习框架来实现。训练神经网络模型:接下来,需要使用训练数据对神经网络模型进行训练。训练数据可以是游戏中的真实数据,也可以是模拟数据。预测玩家出牌策略:最后,使用训练好的神经网络模型来预测玩家的出牌策略。预测结果可以是一个概率值,也可以是一个具体的牌型。通过以上步骤,强化学习算法可以在斗地主游戏中获得更好的表现。
播放量:30
强化学习在实际环境下使用时,需要考虑到多种因素,例如游戏难度、环境状况、用户行为等。以下是一些实际应用中强化学习的常见问题和解决方案: 数据质量和数据集选择:强化学习需要大量的训练数据,以便学习到智能体的行为和策略。选择高质量的数据集对于训练效果至关重要。此外,数据集应该包含不同的环境和状况,以便智能体可以在不同的场景下学习和适应。 神经网络结构选择:不同的神经网络结构适用于不同的强化学习任务。在选择神经网络结构时,需要考虑任务的特点、计算资源、训练时间等因素。 策略选择和优化:智能体需要选择最优的策略来达到最大化收益的目标。可以通过尝试不同的策略来选择最佳策略,或者通过反向传播来寻找最优策略。 动态环境和状态估计:强化学习中的智能体需要处理动态环境和状态,例如位置、方向、速度等。可以通过使用卡尔曼滤波器、粒子滤波器等方法来估计智能体的状态。 异常检测和处理:强化学习过程中可能会出现异常情况,例如智能体被卡住、掉入悬崖等。需要设计合适的异常检测和处理机制,以便智能体能够及时停止学习并恢复正常状态。 负面行为和损失函数设计:智能体可能会出现负面行为,例如攻击其他智能体、浪费资源等。需要设计合适的负面行为和损失函数,以便智能体能够在负面行为发生时及时停止学习。 学习率和折扣因子:智能体学习的速度和效果受到学习率和折扣因子的影响。需要根据任务和智能体的特点来选择合适的学习率和折扣因子。 实验设计和评估:在实际应用中,需要设计合适的实验来评估智能体的性能和策略选择。可以通过计算收益、成本、指标等来评估策略的有效性和优化方案。
播放量:55
基于深度强化学习的机械臂位置感知抓取任务深度强化学习控制机械臂的抓取可以通过以下几个步骤实现:环境建模和定义。首先需要建立一个包含多个物体的三维空间,并为每个物体定义它们的位置、姿势、重量和其他属性。这可以通过使用传感器或者计算机视觉技术来实现。策略制定。策略是机器人如何在环境中移动和抓取物体的规则。深度强化学习控制机械臂的抓取可以使用TD3、SAC等算法。初始化和训练。在策略制定之后,需要初始化机械臂和抓取装置。可以使用PyBullet或类似的库来实现这些部件。然后,可以使用反向传播算法来训练机械臂,以便在给定输入时执行预期的动作。测试和评估。一旦机械臂已经被训练,可以使用测试集来评估它的性能。可以使用交叉验证等方法来确定最佳的参数设置。部署和应用。一旦机械臂被训练并准备就绪,可以将其部署到实际环境中。可以使用Python脚本或者图形用户界面来控制机械臂。总之,深度强化学习控制机械臂的抓取需要对环境建模、策略制定、初始化和训练、测试和评估以及部署和应用等方面进行全面考虑。
播放量:25
强化学习在求解迷宫游戏最短路径方面有着很好的应用价值。以下是基于强化学习的迷宫游戏最短路径算法实现:定义状态和行动规则:首先,需要定义迷宫游戏中的状态和行动规则,如起点、终点、可行区域、道具等。然后,定义一个损失函数来描述玩家在行动过程中可能遇到的障碍物和道具对其移动路径的影响。构建模型:使用深度强化学习框架训练神经网络模型,该模型应包含传感器节点、决策树节点、优化器节点和主控节点等。其中,传感器节点用于采集迷宫游戏中的状态信息,决策树节点用于生成行动规则,优化器节点用于调整权重参数以提高寻找最短路径的效率,而主控节点用于监视和管理整个强化学习过程。进行测试和评估:将模型输入到真实的迷宫游戏数据集上进行测试和评估,以验证模型的准确性和鲁棒性。具体方法包括设置不同的难度级别、种类和大小的迷宫游戏数据集,并记录模型的表现和结果。优化和调参:根据测试和评估的结果,对模型的损失函数、优化器参数等进行调整和优化,以提高算法的精度和效率。应用于实际问题:将基于强化学习的迷宫游戏最短路径算法应用于实际的迷宫游戏数据集上,以寻找最短路径并获得更好的结果。例如,可以使用遗传算法优化路径搜索的速度和精度,或者通过禁止某些道具的使用来减少阻碍因素的影响。总之,基于强化学习的迷宫游戏最短路径算法需要进行大量的实验和优化,以达到较好的性能和效率。
推荐文章
|
|
欢乐的打火机 · Matlab绘图 - 知乎 2 年前 |