

查找grep、提取awk、sed、重定向
脚本文件1、
#!/bin/bash
for i in $(grep "辞职" publish_origin.csv | awk -F"," '{print $8}' | sed 's/pdf/txt/' |sed 's,20.*/,,');do
echo $i
cat xsb_top10_txt/$i
done

脚本文件2、
#!/bin/bash
for i in $(grep "txt" key_para_test_set);do
echo $i
cat key_para_test_set/$i
done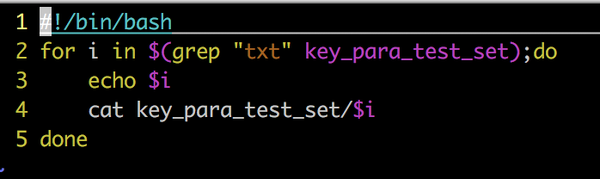
-e :可以换行
echo -e "1\n2\n3\n4\n6\n5" >test4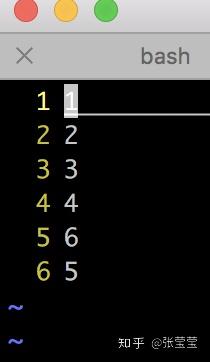
1、grep:文本搜索
grep命令_Linux grep 命令用法详解:强大的文本搜索工具
详解:
linux下grep用法 - CSDN博客 grep命令最经常使用的功能总结 - tlnshuju - 博客园
grep命令最经常使用的功能总结 - tlnshuju - 博客园

1、输出除之外的所有行 -v 选项:
grep -v "match_pattern" file_name2、使用正则表达式 -E 选项:
grep -E "[1-9]+"
egrep "[1-9]+"3、只输出文件中匹配到的部分 -o 选项:
echo this is a. test. | grep -o -E "[a-z]+\."
echo this is a. test. | egrep -o "[a-z]+\."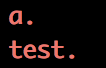
4、统计文件或者文本中包含匹配字符串的行数 -c 选项:
grep -c "text" file_namegrep -c "离职" publish_origin.csv
输出结果:1080
5、输出包含匹配字符串的行数 -n 选项:
grep "text" -n file_name
cat file_name | grep "text" -n例如:
cat publish_origin.csv | grep "离职" -n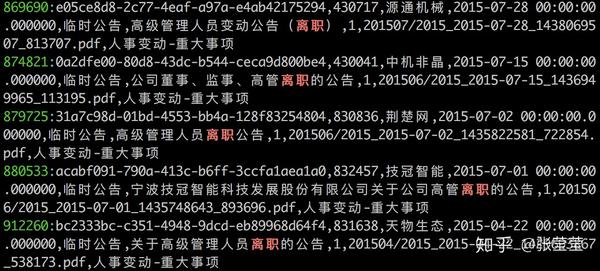

6、打印样式匹配所位于的字符或字节偏移:
echo gunisnotunix | grep -b -o "g"
echo gunisnotunix | grep -b -o "not"输出:0:g
5:not
小案例:
在file文件中过滤掉字符串'str'所在的行
1grep -v "str"file
在file文件中查找时间在2017:22:50~2017:22:59所在的行
1grep -E "2017:22:5[0-9]"file在file文件中查找不包括360的行
1grep -E "^[^360]"file在file文件中查找包括w和t的行
1grep -E "w*t"file
在file文件中查找大于560小于893的行
1grep -E "[5-8][6-9][0-3]"在file文件中查找包含两个9的行
1grep -E "9{2}"file
查找大于两个9的行
1grep -E "9{2,}"file查找file文件中的空行
1grep -E "^$"file查找包括?的行
1grep "?"file查找文件中以w开头的行
1grep -E "^w"file查找文件中不是以w开头的行
1grep -E "^[^w]"file
小案例:
grep "公告" publish_origin.csv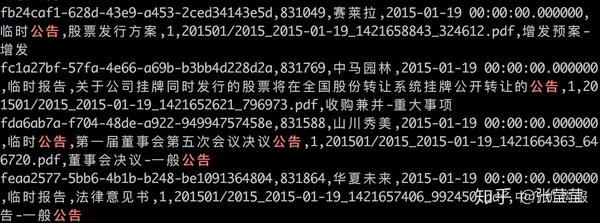

2、awk:数据流处理工具 Linux awk 命令 | 菜鸟教程
AWK用法入门详解 - losbyday - 博客园awk: 文本分析工具;简单来说awk就是 把文件逐行的读入 ,以 空格 为默认分隔符 将每行切片 ,切开的部分再进行各种分析处理。
基本语法:
awk '{[pattern] action}' {filenames} # 行匹配语句 awk '' 只能用单引号1、 其中 pattern 表示 AWK 在数据中查找的内容,而 action 是在找到匹配内容时所执行的一系列命令。
2、 awk语言的最基本功能是在文件或者字符串中 基于指定规则浏览和抽取信息 ,awk抽取信息后,才能进行其他文本操作。完整的awk脚本通常用来格式化文本文件中的信息。
3、 通常, awk是以文件的一行为处理单位的。awk每接收文件的一行,然后执行相应的命令,来处理文本。
小案例:
$ awk '/^(no|so)/' test-----打印所有以模式no或so开头的行。
$ awk '/^[ns]/{print $1}' test-----如果记录以n或s开头,就打印这个记录。
$ awk '$1 ~/[0-9][0-9]$/(print $1}' test-----如果第一个域以两个数字结束就打印这个记录。
$ awk '$1 == 100 || $2 < 50' test-----如果第一个或等于100或者第二个域小于50,则打印该行。
$ awk '$1 != 10' test-----如果第一个域不等于10就打印该行。
$ awk '/test/{print $1 + 10}' test-----如果记录包含正则表达式test,则第一个域加10并打印出来。
$ awk '{print ($1 > 5 ? "ok "$1: "error"$1)}' test-----如果第一个域大于5则打印问号后面的表达式值,否则打印冒号后面的表达式值。
$ awk '/^root/,/^mysql/' test----打印以正则表达式root开头的记录到以正则表达式mysql开头的记录范围内的所有记录。如果找到一个新的正则表达式root开头的记录,则继续打印直到下一个以正则表达式mysql开头的记录为止,或到文件末尾。
1awk '{print $0}' log.log #查找出日志文件中的每一列
$ awk '$1>2' filename #过滤第一列大于2的行
$ awk '$1==2 {print $1,$3}' filename #过滤第一列等于2的行
$ awk '$1>2 && $2=="Are" {print $1,$2,$3}' filename ##过滤第一列大于2,并且第二列为Are的行小案例:
grep "离职" publish_origin.csv | awk -F"," '{print $6, $8}'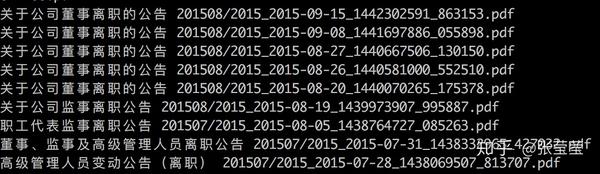

grep "离职" publish_origin.csv | awk -F"," '{print $6, $8}' | sed 's/pdf/txt/'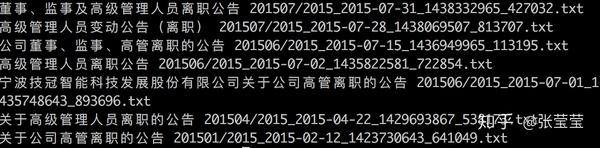

grep "离职" publish_origin.csv | awk -F"," '{print $6, $8}' | sed 's/pdf/txt/' | sed 's,20.*/,,'

如果要文件名前面的/,则形式为:
grep "离职" publish_origin.csv | awk -F"," '{print $6, $8}' | sed 's/pdf/txt/' | sed 's/20.*//'

3、sed:行定位
sed命令_Linux sed 命令用法详解:功能强大的流式文本编辑器
3.1、定界符: 分割正则表达式与替换文本
定界符可以是:/,标点符号字符 替代文本是空时,可以有效地删除匹配的文本;
sed 's,20.*/,,'
= sed 's/20.\{5\}//'1、只打印第二行,不打印其它行的数据
1sed -n '2'p file 2、从第一行到第九行的记录
1sed -n '1,9'p file3、打印匹配php的行
1sed -n '/php/p file4、打印从第九行到匹配php的之间所有行
1sed -n '9,/php/'p file5、把第一行和第二行全部删除(非文件删除)
1sed '1,2'd file sed 小案例:
1、's/被替换者/替换者' :取代第一个匹配的。
echo a b c a d a c> test3.txt
vim test3.txt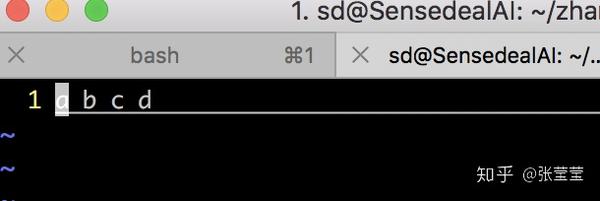

sed 's/a/x/' < test3.txt输出:x b c d
当再次向 test3.txt 中重定向 内容时,会覆盖之前的数据。
echo a b c a d a c> test3.txt
vim test3.txt
2、's/被替换者/替换者/g' :最后加上 g 表示全局替换。
sed 's/a/x/g' < test3.txt输出:x b c x d x c
3、's/被替换者/替换者/n':取代第 n 个匹配到的
4、将多个sed实体以管道串起来时,通过-e选项的方式来完成。
sed -e 's/x/a/g' -e 's/c/y/g' < test3.txt输出:a b y a d a y
当有很多要编辑的项目时,可以将编辑命令全放进一个脚本里,再使用 sed 搭配 -f 选项会更好:
sed删除操作:d命令
删除空白行:
sed '/^$/d' file删除文件的第2行:
sed '2d' file删除文件的第2行到末尾所有行:
sed '2,$d' file sed '2,nd' file 删除第二行到第n行删除文件最后一行:
sed '$d' file删除文件中所有开头是test的行:
sed '/^test/'d file所有以192.168.0.1开头的行都会被替换成它自已加localhost:
sed 's/^192.168.0.1/&localhost/' file