link管理
链接快照平台
- 输入网页链接,自动生成快照
- 标签化管理网页链接
相关文章推荐

|
儒雅的红豆 · mysql 查询 ...· 1 月前 · |
|
|
活泼的棒棒糖 · 南阳市不动产登记服务中心新建商品房买卖合同网 ...· 2 月前 · |
|
|
奔跑的遥控器 · 消息队列 CMQ 词汇表-文档中心-腾讯云· 10 月前 · |
|
|
魁梧的沙发 · BT磁力搜索_磁力狗_CILIMAO磁力猫_ ...· 2 年前 · |
|
|
逼格高的投影仪 · count(): Parameter ...· 2 年前 · |

机器学习算法(一): 基于逻辑回归的分类预测
机器学习算法(一): 基于逻辑回归的分类预测项目链接参考fork一下直接运行:https://www.heywhale.com/home/column/64141d6b1c8c8b518ba97dcc1 逻辑回归的介绍和应用1.1 逻辑回归的介绍逻辑回归(Logistic regression,简称LR)虽然其中带有"回归"两个字,但逻辑回归其实是一个分类模型,并且广泛应用于各个领域之中。虽然现在深度学习相对于这些传统方法更为火热,但实则这些传统方法由于其独特的优势依然广泛应用于各个领域中。而对于逻辑回归而且,最为突出的两点就是其模型简单和模型的可解释性强。逻辑回归模型的优劣势:优点:实现简单,易于理解和实现;计算代价不高,速度很快,存储资源低;缺点:容易欠拟合,分类精度可能不高1.1 逻辑回归的应用逻辑回归模型广泛用于各个领域,包括机器学习,大多数医学领域和社会科学。例如,最初由Boyd 等人开发的创伤和损伤严重度评分(TRISS)被广泛用于预测受伤患者的死亡率,使用逻辑回归 基于观察到的患者特征(年龄,性别,体重指数,各种血液检查的结果等)分析预测发生特定疾病(例如糖尿病,冠心病)的风险。逻辑回归模型也用于预测在给定的过程中,系统或产品的故障的可能性。还用于市场营销应用程序,例如预测客户购买产品或中止订购的倾向等。在经济学中它可以用来预测一个人选择进入劳动力市场的可能性,而商业应用则可以用来预测房主拖欠抵押贷款的可能性。条件随机字段是逻辑回归到顺序数据的扩展,用于自然语言处理。逻辑回归模型现在同样是很多分类算法的基础组件,比如 分类任务中基于GBDT算法+LR逻辑回归实现的信用卡交易反欺诈,CTR(点击通过率)预估等,其好处在于输出值自然地落在0到1之间,并且有概率意义。模型清晰,有对应的概率学理论基础。它拟合出来的参数就代表了每一个特征(feature)对结果的影响。也是一个理解数据的好工具。但同时由于其本质上是一个线性的分类器,所以不能应对较为复杂的数据情况。很多时候我们也会拿逻辑回归模型去做一些任务尝试的基线(基础水平)。说了这些逻辑回归的概念和应用,大家应该已经对其有所期待了吧,那么我们现在开始吧!!!2 学习目标了解 逻辑回归 的理论掌握 逻辑回归 的 sklearn 函数调用使用并将其运用到鸢尾花数据集预测3 代码流程Part1 Demo实践Step1:库函数导入Step2:模型训练Step3:模型参数查看Step4:数据和模型可视化Step5:模型预测Part2 基于鸢尾花(iris)数据集的逻辑回归分类实践Step1:库函数导入Step2:数据读取/载入Step3:数据信息简单查看Step4:可视化描述Step5:利用 逻辑回归模型 在二分类上 进行训练和预测Step5:利用 逻辑回归模型 在三分类(多分类)上 进行训练和预测4 算法实战### 4.1 Demo实践Step1:库函数导入## 基础函数库 import numpy as np ## 导入画图库 import matplotlib.pyplot as plt import seaborn as sns ## 导入逻辑回归模型函数 from sklearn.linear_model import LogisticRegressionStep2:模型训练##Demo演示LogisticRegression分类 ## 构造数据集 x_fearures = np.array([[-1, -2], [-2, -1], [-3, -2], [1, 3], [2, 1], [3, 2]]) y_label = np.array([0, 0, 0, 1, 1, 1]) ## 调用逻辑回归模型 lr_clf = LogisticRegression() ## 用逻辑回归模型拟合构造的数据集 lr_clf = lr_clf.fit(x_fearures, y_label) #其拟合方程为 y=w0+w1*x1+w2*x2Step3:模型参数查看## 查看其对应模型的w print('the weight of Logistic Regression:',lr_clf.coef_) ## 查看其对应模型的w0 print('the intercept(w0) of Logistic Regression:',lr_clf.intercept_) the weight of Logistic Regression: [[0.73455784 0.69539712]] the intercept(w0) of Logistic Regression: [-0.13139986]Step4:数据和模型可视化## 可视化构造的数据样本点 plt.figure() plt.scatter(x_fearures[:,0],x_fearures[:,1], c=y_label, s=50, cmap='viridis') plt.title('Dataset') plt.show()# 可视化决策边界 plt.figure() plt.scatter(x_fearures[:,0],x_fearures[:,1], c=y_label, s=50, cmap='viridis') plt.title('Dataset') nx, ny = 200, 100 x_min, x_max = plt.xlim() y_min, y_max = plt.ylim() x_grid, y_grid = np.meshgrid(np.linspace(x_min, x_max, nx),np.linspace(y_min, y_max, ny)) z_proba = lr_clf.predict_proba(np.c_[x_grid.ravel(), y_grid.ravel()]) z_proba = z_proba[:, 1].reshape(x_grid.shape) plt.contour(x_grid, y_grid, z_proba, [0.5], linewidths=2., colors='blue') plt.show()### 可视化预测新样本 plt.figure() ## new point 1 x_fearures_new1 = np.array([[0, -1]]) plt.scatter(x_fearures_new1[:,0],x_fearures_new1[:,1], s=50, cmap='viridis') plt.annotate(s='New point 1',xy=(0,-1),xytext=(-2,0),color='blue',arrowprops=dict(arrowstyle='-|>',connectionstyle='arc3',color='red')) ## new point 2 x_fearures_new2 = np.array([[1, 2]]) plt.scatter(x_fearures_new2[:,0],x_fearures_new2[:,1], s=50, cmap='viridis') plt.annotate(s='New point 2',xy=(1,2),xytext=(-1.5,2.5),color='red',arrowprops=dict(arrowstyle='-|>',connectionstyle='arc3',color='red')) ## 训练样本 plt.scatter(x_fearures[:,0],x_fearures[:,1], c=y_label, s=50, cmap='viridis') plt.title('Dataset') # 可视化决策边界 plt.contour(x_grid, y_grid, z_proba, [0.5], linewidths=2., colors='blue') plt.show()Step5:模型预测## 在训练集和测试集上分别利用训练好的模型进行预测 y_label_new1_predict = lr_clf.predict(x_fearures_new1) y_label_new2_predict = lr_clf.predict(x_fearures_new2) print('The New point 1 predict class:\n',y_label_new1_predict) print('The New point 2 predict class:\n',y_label_new2_predict) ## 由于逻辑回归模型是概率预测模型(前文介绍的 p = p(y=1|x,\theta)),所以我们可以利用 predict_proba 函数预测其概率 y_label_new1_predict_proba = lr_clf.predict_proba(x_fearures_new1) y_label_new2_predict_proba = lr_clf.predict_proba(x_fearures_new2) print('The New point 1 predict Probability of each class:\n',y_label_new1_predict_proba) print('The New point 2 predict Probability of each class:\n',y_label_new2_predict_proba) The New point 1 predict class: The New point 2 predict class: The New point 1 predict Probability of each class: [[0.69567724 0.30432276]] The New point 2 predict Probability of each class: [[0.11983936 0.88016064]]可以发现训练好的回归模型将X_new1预测为了类别0(判别面左下侧),X_new2预测为了类别1(判别面右上侧)。其训练得到的逻辑回归模型的概率为0.5的判别面为上图中蓝色的线。4.2 基于鸢尾花(iris)数据集的逻辑回归分类实践在实践的最开始,我们首先需要导入一些基础的函数库包括:numpy (Python进行科学计算的基础软件包),pandas(pandas是一种快速,强大,灵活且易于使用的开源数据分析和处理工具),matplotlib和seaborn绘图。Step1:库函数导入## 基础函数库 import numpy as np import pandas as pd ## 绘图函数库 import matplotlib.pyplot as plt import seaborn as sns本次我们选择鸢花数据(iris)进行方法的尝试训练,该数据集一共包含5个变量,其中4个特征变量,1个目标分类变量。共有150个样本,目标变量为 花的类别 其都属于鸢尾属下的三个亚属,分别是山鸢尾 (Iris-setosa),变色鸢尾(Iris-versicolor)和维吉尼亚鸢尾(Iris-virginica)。包含的三种鸢尾花的四个特征,分别是花萼长度(cm)、花萼宽度(cm)、花瓣长度(cm)、花瓣宽度(cm),这些形态特征在过去被用来识别物种。变量描述sepal length花萼长度(cm)sepal width花萼宽度(cm)petal length花瓣长度(cm)petal width花瓣宽度(cm)target鸢尾的三个亚属类别,'setosa'(0), 'versicolor'(1), 'virginica'(2)Step2:数据读取/载入## 我们利用 sklearn 中自带的 iris 数据作为数据载入,并利用Pandas转化为DataFrame格式 from sklearn.datasets import load_iris data = load_iris() #得到数据特征 iris_target = data.target #得到数据对应的标签 iris_features = pd.DataFrame(data=data.data, columns=data.feature_names) #利用Pandas转化为DataFrame格式Step3:数据信息简单查看## 利用.info()查看数据的整体信息 iris_features.info() # Column Non-Null Count Dtype --- ------ -------------- ----- 0 sepal length (cm) 150 non-null float64 1 sepal width (cm) 150 non-null float64 2 petal length (cm) 150 non-null float64 3 petal width (cm) 150 non-null float64 dtypes: float64(4) memory usage: 4.8 KB ## 对于特征进行一些统计描述 iris_features.describe() sepal length (cm) sepal width (cm) petal length (cm) petal width (cm) count 150.000000 150.000000 150.000000 150.000000 mean 5.843333 3.057333 3.758000 1.199333 std 0.828066 0.435866 1.765298 0.762238 min 4.300000 2.000000 1.000000 0.100000 25% 5.100000 2.800000 1.600000 0.300000 50% 5.800000 3.000000 4.350000 1.300000 75% 6.400000 3.300000 5.100000 1.800000 max 7.900000 4.400000 6.900000 2.500000Step4:可视化描述## 合并标签和特征信息 iris_all = iris_features.copy() ##进行浅拷贝,防止对于原始数据的修改 iris_all['target'] = iris_target ## 特征与标签组合的散点可视化 sns.pairplot(data=iris_all,diag_kind='hist', hue= 'target') plt.show() 从上图可以发现,在2D情况下不同的特征组合对于不同类别的花的散点分布,以及大概的区分能力。for col in iris_features.columns: sns.boxplot(x='target', y=col, saturation=0.5,palette='pastel', data=iris_all) plt.title(col) plt.show()利用箱型图我们也可以得到不同类别在不同特征上的分布差异情况。# 选取其前三个特征绘制三维散点图 from mpl_toolkits.mplot3d import Axes3D fig = plt.figure(figsize=(10,8)) ax = fig.add_subplot(111, projection='3d') iris_all_class0 = iris_all[iris_all['target']==0].values iris_all_class1 = iris_all[iris_all['target']==1].values iris_all_class2 = iris_all[iris_all['target']==2].values # 'setosa'(0), 'versicolor'(1), 'virginica'(2) ax.scatter(iris_all_class0[:,0], iris_all_class0[:,1], iris_all_class0[:,2],label='setosa') ax.scatter(iris_all_class1[:,0], iris_all_class1[:,1], iris_all_class1[:,2],label='versicolor') ax.scatter(iris_all_class2[:,0], iris_all_class2[:,1], iris_all_class2[:,2],label='virginica') plt.legend() plt.show()Step5:利用 逻辑回归模型 在二分类上 进行训练和预测## 为了正确评估模型性能,将数据划分为训练集和测试集,并在训练集上训练模型,在测试集上验证模型性能。 from sklearn.model_selection import train_test_split ## 选择其类别为0和1的样本 (不包括类别为2的样本) iris_features_part = iris_features.iloc[:100] iris_target_part = iris_target[:100] ## 测试集大小为20%, 80%/20%分 x_train, x_test, y_train, y_test = train_test_split(iris_features_part, iris_target_part, test_size = 0.2, random_state = 2020) ## 从sklearn中导入逻辑回归模型 from sklearn.linear_model import LogisticRegression ## 定义 逻辑回归模型 clf = LogisticRegression(random_state=0, solver='lbfgs') # 在训练集上训练逻辑回归模型 clf.fit(x_train, y_train) ## 查看其对应的w print('the weight of Logistic Regression:',clf.coef_) ## 查看其对应的w0 print('the intercept(w0) of Logistic Regression:',clf.intercept_) ## 在训练集和测试集上分布利用训练好的模型进行预测 train_predict = clf.predict(x_train) test_predict = clf.predict(x_test) from sklearn import metrics ## 利用accuracy(准确度)【预测正确的样本数目占总预测样本数目的比例】评估模型效果 print('The accuracy of the Logistic Regression is:',metrics.accuracy_score(y_train,train_predict)) print('The accuracy of the Logistic Regression is:',metrics.accuracy_score(y_test,test_predict)) ## 查看混淆矩阵 (预测值和真实值的各类情况统计矩阵) confusion_matrix_result = metrics.confusion_matrix(test_predict,y_test) print('The confusion matrix result:\n',confusion_matrix_result) # 利用热力图对于结果进行可视化 plt.figure(figsize=(8, 6)) sns.heatmap(confusion_matrix_result, annot=True, cmap='Blues') plt.xlabel('Predicted labels') plt.ylabel('True labels') plt.show()The accuracy of the Logistic Regression is: 1.0The accuracy of the Logistic Regression is: 1.0The confusion matrix result: [[ 9 0] [ 0 11]]我们可以发现其准确度为1,代表所有的样本都预测正确了。Step6:利用 逻辑回归模型 在三分类(多分类)上 进行训练和预测## 测试集大小为20%, 80%/20%分 x_train, x_test, y_train, y_test = train_test_split(iris_features, iris_target, test_size = 0.2, random_state = 2020) ## 定义 逻辑回归模型 clf = LogisticRegression(random_state=0, solver='lbfgs') # 在训练集上训练逻辑回归模型 clf.fit(x_train, y_train) ## 查看其对应的w print('the weight of Logistic Regression:\n',clf.coef_) ## 查看其对应的w0 print('the intercept(w0) of Logistic Regression:\n',clf.intercept_) ## 由于这个是3分类,所有我们这里得到了三个逻辑回归模型的参数,其三个逻辑回归组合起来即可实现三分类。 ## 在训练集和测试集上分布利用训练好的模型进行预测 train_predict = clf.predict(x_train) test_predict = clf.predict(x_test) ## 由于逻辑回归模型是概率预测模型(前文介绍的 p = p(y=1|x,\theta)),所有我们可以利用 predict_proba 函数预测其概率 train_predict_proba = clf.predict_proba(x_train) test_predict_proba = clf.predict_proba(x_test) print('The test predict Probability of each class:\n',test_predict_proba) ## 其中第一列代表预测为0类的概率,第二列代表预测为1类的概率,第三列代表预测为2类的概率。 ## 利用accuracy(准确度)【预测正确的样本数目占总预测样本数目的比例】评估模型效果 print('The accuracy of the Logistic Regression is:',metrics.accuracy_score(y_train,train_predict)) print('The accuracy of the Logistic Regression is:',metrics.accuracy_score(y_test,test_predict)) [9.35695863e-01 6.43039513e-02 1.85301359e-07] [9.80621190e-01 1.93787400e-02 7.00125246e-08] [1.68478815e-04 3.30167226e-01 6.69664295e-01] [3.54046163e-03 4.02267805e-01 5.94191734e-01] [9.70617284e-01 2.93824740e-02 2.42443967e-07] [9.64848137e-01 3.51516748e-02 1.87917880e-07] [9.70436779e-01 2.95624025e-02 8.18591606e-07]] The accuracy of the Logistic Regression is: 0.9833333333333333 The accuracy of the Logistic Regression is: 0.8666666666666667## 查看混淆矩阵 confusion_matrix_result = metrics.confusion_matrix(test_predict,y_test) print('The confusion matrix result:\n',confusion_matrix_result) # 利用热力图对于结果进行可视化 plt.figure(figsize=(8, 6)) sns.heatmap(confusion_matrix_result, annot=True, cmap='Blues') plt.xlabel('Predicted labels') plt.ylabel('True labels') plt.show()通过结果我们可以发现,其在三分类的结果的预测准确度上有所下降,其在测试集上的准确度为:$86.67\%$,这是由于'versicolor'(1)和 'virginica'(2)这两个类别的特征,我们从可视化的时候也可以发现,其特征的边界具有一定的模糊性(边界类别混杂,没有明显区分边界),所有在这两类的预测上出现了一定的错误。5 重要知识点逻辑回归 原理简介:Logistic回归虽然名字里带“回归”,但是它实际上是一种分类方法,主要用于两分类问题(即输出只有两种,分别代表两个类别),所以利用了Logistic函数(或称为Sigmoid函数),函数形式为:$$ logi(z)=\frac{1}{1+e^{-z}} $$其对应的函数图像可以表示如下:import numpy as np import matplotlib.pyplot as plt x = np.arange(-5,5,0.01) y = 1/(1+np.exp(-x)) plt.plot(x,y) plt.xlabel('z') plt.ylabel('y') plt.grid() plt.show()通过上图我们可以发现 Logistic 函数是单调递增函数,并且在z=0的时候取值为0.5,并且$logi(\cdot)$函数的取值范围为$(0,1)$。而回归的基本方程为$z=w_0+\sum_i^N w_ix_i$,将回归方程写入其中为:$$ p = p(y=1|x,\theta) = h_\theta(x,\theta)=\frac{1}{1+e^{-(w_0+\sum_i^N w_ix_i)}} $$所以, $p(y=1|x,\theta) = h_\theta(x,\theta)$,$p(y=0|x,\theta) = 1-h_\theta(x,\theta)$逻辑回归从其原理上来说,逻辑回归其实是实现了一个决策边界:对于函数 $y=\frac{1}{1+e^{-z}}$,当 $z=>0$时,$y=>0.5$,分类为1,当 $z<0$时,$y<0.5$,分类为0,其对应的$y$值我们可以视为类别1的概率预测值.对于模型的训练而言:实质上来说就是利用数据求解出对应的模型的特定的$w$。从而得到一个针对于当前数据的特征逻辑回归模型。而对于多分类而言,将多个二分类的逻辑回归组合,即可实现多分类。
2.基于Label studio的训练数据标注指南:(智能文档)文档抽取任务、PDF、表格、图片抽取标注等
文档抽取任务Label Studio使用指南1.基于Label studio的训练数据标注指南:信息抽取(实体关系抽取)、文本分类等2.基于Label studio的训练数据标注指南:(智能文档)文档抽取任务、PDF、表格、图片抽取标注等3.基于Label studio的训练数据标注指南:文本分类任务4.基于Label studio的训练数据标注指南:情感分析任务观点词抽取、属性抽取目录1. 安装2. 文档抽取任务标注2.1 项目创建2.2 数据上传2.3 标签构建2.4 任务标注2.5 数据导出2.6 数据转换2.7 更多配置1. 安装以下标注示例用到的环境配置:Python 3.8+label-studio == 1.7.1paddleocr >= 2.6.0.1在终端(terminal)使用pip安装label-studio:pip install label-studio==1.7.1安装完成后,运行以下命令行:label-studio start在浏览器打开http://localhost:8080/,输入用户名和密码登录,开始使用label-studio进行标注。2. 文档抽取任务标注2.1 项目创建点击创建(Create)开始创建一个新的项目,填写项目名称、描述,然后选择Object Detection with Bounding Boxes。填写项目名称、描述命名实体识别、关系抽取、事件抽取、实体/评价维度分类任务选择Object Detection with Bounding Boxes`文档分类任务选择Image Classification`添加标签(也可跳过后续在Setting/Labeling Interface中添加)图中展示了Span实体类型标签的构建,其他类型标签的构建可参考2.3标签构建2.2 数据上传先从本地或HTTP链接上传图片,然后选择导入本项目。2.3 标签构建Span实体类型标签Relation关系类型标签Relation XML模板: <Relations> <Relation value="单位"/> <Relation value="数量"/> <Relation value="金额"/> </Relations>分类类别标签2.4 任务标注实体抽取标注示例:该标注示例对应的schema为:schema = ['开票日期', '名称', '纳税人识别号', '地址、电话', '开户行及账号', '金 额', '税额', '价税合计', 'No', '税率']关系抽取Step 1. 标注主体(Subject)及客体(Object)Step 2. 关系连线,箭头方向由主体(Subject)指向客体(Object)Step 3. 添加对应关系类型标签Step 4. 完成标注该标注示例对应的schema为:schema = { '名称及规格': [ '金额', '单位', }文档分类标注示例该标注示例对应的schema为:schema = '文档类别[发票,报关单]'2.5 数据导出勾选已标注图片ID,选择导出的文件类型为JSON,导出数据:2.6 数据转换将导出的文件重命名为label_studio.json后,放入./document/data目录下,并将对应的标注图片放入./document/data/images目录下(图片的文件名需与上传到label studio时的命名一致)。通过label\_studio.py脚本可转为UIE的数据格式。路径示例./document/data/ ├── images # 图片目录 │ ├── b0.jpg # 原始图片(文件名需与上传到label studio时的命名一致) │ └── b1.jpg └── label_studio.json # 从label studio导出的标注文件抽取式任务python label_studio.py \ --label_studio_file ./document/data/label_studio.json \ --save_dir ./document/data \ --splits 0.8 0.1 0.1\ --task_type ext文档分类任务python label_studio.py \ --label_studio_file ./document/data/label_studio.json \ --save_dir ./document/data \ --splits 0.8 0.1 0.1 \ --task_type cls \ --prompt_prefix "文档类别" \ --options "发票" "报关单"2.7 更多配置label_studio_file: 从label studio导出的数据标注文件。save_dir: 训练数据的保存目录,默认存储在data目录下。negative_ratio: 最大负例比例,该参数只对抽取类型任务有效,适当构造负例可提升模型效果。负例数量和实际的标签数量有关,最大负例数量 = negative\_ratio * 正例数量。该参数只对训练集有效,默认为5。为了保证评估指标的准确性,验证集和测试集默认构造全负例。splits: 划分数据集时训练集、验证集所占的比例。默认为0.8, 0.1, 0.1表示按照8:1:1的比例将数据划分为训练集、验证集和测试集。task_type: 选择任务类型,可选有抽取和分类两种类型的任务。options: 指定分类任务的类别标签,该参数只对分类类型任务有效。默认为"正向", "负向"。prompt_prefix: 声明分类任务的prompt前缀信息,该参数只对分类类型任务有效。默认为"情感倾向"。is_shuffle: 是否对数据集进行随机打散,默认为True。seed: 随机种子,默认为1000.separator: 实体类别/评价维度与分类标签的分隔符,该参数只对实体/评价维度分类任务有效。默认为"##"。schema_lang:选择schema的语言,将会应该训练数据prompt的构造方式,可选有ch和en。默认为ch。ocr_lang:选择OCR的语言,可选有ch和en。默认为ch。layout_analysis:是否使用PPStructure对文档进行布局分析,该参数只对文档类型标注任务有效。默认为False。备注:默认情况下 label\_studio.py 脚本会按照比例将数据划分为 train/dev/test 数据集每次执行 label\_studio.py 脚本,将会覆盖已有的同名数据文件在模型训练阶段我们推荐构造一些负例以提升模型效果,在数据转换阶段我们内置了这一功能。可通过negative_ratio控制自动构造的负样本比例;负样本数量 = negative\_ratio * 正样本数量。对于从label\_studio导出的文件,默认文件中的每条数据都是经过人工正确标注的。ReferencesLabel Studio
机器学习平台PAI简测:PAI提供包含数据标注、模型构建、模型训练、模型部署、推理优化在内的AI开发全链路服务
1.PAI简介PAI底层支持多种计算框架:流式计算框架Flink。基于开源版本深度优化的深度学习框架TensorFlow。千亿特征样本的大规模并行计算框架Parameter Server。Spark、PySpark、MapReduce等业内主流开源框架。PAI提供的服务:可视化建模和分布式训练PAI-Designer,详情请参见可视化建模(PAI-Designer)。Notebook交互式AI研发PAI-DSW(Data Science Workshop),详情请参见交互式建模(PAI-DSW)。云原生AI基础平台PAI-DLC(Deep Learning Containers),详情请参见训练任务提交(Training)。自动化建模PAI-AutoLearning,详情请参见场景化解决方案。在线预测PAI-EAS(Elastic Algorithm Service),详情请参见模型在线服务(PAI-EAS)。PAI的优势:服务支持单独或组合使用。支持一站式机器学习,您只要准备好训练数据(存放到OSS或MaxCompute中),所有建模工作(包括数据上传、数据预处理、特征工程、模型训练、模型评估和模型发布至离线或在线环境)都可以通过PAI实现。对接DataWorks,支持SQL、UDF、UDAF、MR等多种数据处理方式,灵活性高。生成训练模型的实验流程支持DataWorks周期性调度,且调度任务区分生产环境和开发环境,进而实现数据安全隔离。2.PAI产品架构PAI的业务架构从下至上分别为:1.基础设施层:涵盖硬件设施、基础平台、计算资源及计算框架。PAI支持的硬件设施包括CPU、GPU、FPGA、NPU、容器服务ACK及ECS。云原生AI基础平台和计算引擎层支持云原生AI基础平台PAI-DLC,大数据计算引擎包括MaxCompute、EMR、实时计算等。在PAI上可以使用的计算框架包括PAI-TensorFlow、PAI-PyTorch、Alink、ODL、AliGraph、EasyRL、EasyRec、EasyTransfer及EasyVision等,用于执行分布式计算任务。2.工作空间层:工作空间是PAI的顶层概念,为企业和团队提供统一的计算资源管理及人员权限管理能力,为AI开发者提供支持团队协作的全流程开发工具及AI资产管理能力。PAI工作空间和DataWorks工作空间在概念和实现上互通。3.按照机器学习全流程,PAI分别提供了数据准备、模型开发和训练及模型部署阶段的产品:数据准备:PAI提供了智能标注(iTAG),支持在多种场景下进行数据标注和数据集管理。模型开发和训练:PAI提供了可视化建模PAI-Designer、交互式编程建模PAI-DSW、训练任务提交,满足不同的建模需求。模型部署:PAI提供了云原生在线推理服务平台PAI-EAS,帮助您快速地将模型部署为服务。此外,PAI提供了智能生态市场和AI能力体验中心,您可以获取并体验业务解决方案和模型算法,实现相关业务和技术的高效对接。4.AI服务层:PAI广泛应用于金融、医疗、教育、交通以及安全等各个领域。阿里巴巴集团内部的搜索系统、推荐系统及金融服务系统等,均依赖于PAI进行数据挖掘。2.大数据和AI体验教程测评2.1 图像分类(多分类任务)动物分类:基于亿万个的模型训练数据,能够精准的识别图片中动物的类别,超强的识别效能为您带来快速、高效的类别名称和识别概率。2.2 图像检测能够帮您轻松应对各种图像内容的检测,超强的识别速度和准确率能够识别各种复杂的图像类别,并能精确的定位图像内常见物体的位置,高效返回物体的坐标和类别信息。识别速度很快2.3图像实例分割:强大的识别能力能帮您快速、精准定位图像中每个物体的位置,并能帮助您快速识别图像的类别,提取其像素掩膜,为您提供超强的图像像素级的定位能力。2.4 新闻分类 通过强大的语义理解能力对新闻文本进行智能分析,并快速返回新闻文本的类目信息,如军事、娱乐、美食、体育等。可广泛应用于文本打标场景。2.5 ocr识别为您高效、准确的提取图像中任意角度的文字信息,提取的内容信息可广泛应用于广告、电商、安全、信息电子化等场景。2.6 内容安全审核通过强大的语义理解对新闻文本进行智能分析,并返回文本是否为正常或是恶意文本,包含涉黄、涉政、暴恐、恶意推广识别。可广泛应用于任何文本内容审核场景。3.总结:阿里云PAI+AI开源项目是一个能够快速构建和管理机器学习模型的强大平台,它可以支持多种AI技术,包括机器学习、深度学习、自然语言处理等。它还可以支持多种类型的数据,支持大规模机器学习场景的构建,并且提供全面的数据可视化、模型建模、实验管理和模型部署等功能
阿里云智能语音交互产品测评:基于语音识别、语音合成、自然语言理解等技术
0.智能语音智能语音交互(Intelligent Speech Interaction)是基于语音识别、语音合成、自然语言理解等技术,为企业在多种实际应用场景下,赋予产品“能听、会说、懂你”式的智能人机交互功能。适用于智能问答、智能质检、法庭庭审实时记录、实时演讲字幕、访谈录音转写等场景,在金融、司法、电商等多个领域均有应用。0.1 阿里语音交互的产品核心优势语音识别1.识别准确率高基于SAN-M自研的“识音石”通用端到端语音识别框架,中文识别准确率可达业内领先水平;在输入法、客服、会议等领域,识别字错误率相比上一代系统下降10%~30%,大幅提高了语音识别的精度。2.识别速度快采用“字”级别建模单元及自研模型推理引擎,并发推理速度相比业内主流推理框架提升10倍以上;国内独创的LFR解码技术,在不损失识别精度的情况下,将解码速率提高3倍以上,大幅缩短反馈时间,提升用户体验。3.独创的模型优化工具结合模型优化工具子产品,针对特定的领域定制专属模型,最大限度地提升识别效果。4.丰富的功能支持音字同步、语种识别、说话人识别等丰富功能。5.广泛的领域覆盖适用于智能问答、语音指令、音视频字幕、语音搜索、会议谈话转译、语音质检,公安消防接警、法庭审讯记录等各类场景。语音合成1.技术领先兼顾了多级韵律停顿,达到自然合成韵律的目的,综合利用声学参数和语言学参数,建立基于深度学习的多重自动预测模型。2.效果逼真在本地端实现了基于Knowledge-Aware Neural TTS (KAN-TTS) 语音合成技术,基于深度神经网络和机器学习,将文本转换成真实饱满、抑扬顿挫、富有表现力的语音,使得离线语音合成效果趋近于在线合成效果。同样的语音合成声音定制的合成效果与真人录音相比,几乎可以以假乱真。3.音色个性化支持中英文等多种语言,多种音色,多种场景及多种风格的语音合成声音,并可支持低数据量的离线合成声音定制。4.听感自然经海量音频数据训练,使合成音真实饱满、抑扬顿挫、富有表现力,MOS评分达到业内领先水准。5.深度定制根据用户需求定制音库,满足用户的个性化应用需求,提供标准男女声、温柔甜美女声等多风格选择,支持标记语言(SSML)方式的合成方式,音量、语速、音高等参数也支持动态调整。支持客户指定自有数据合成TTS声音。6.高效稳定接口简单易集成,运行稳定、兼容性强、首包延迟小,内存占用少,CPU占用低,对于低配硬件也有对应的解决方案。7.节省成本离线语音合成无需联网即可完成实时语音合成,按设备数授权,成本可控。声音定制中需要的数据量门槛更低,在中文普通话场景,2000句起即可合成自然流畅效果的声音,加入英文数据后,还可实现中英混读效果,录音和标注的时间成本大幅减少,尽显价格优势。8.多领域覆盖在智能家居、车载、导航、金融、运营商、物流、房地产、教育、有声读物等众多领域积累了大量的词库,使阿里语音合成技术对各领域、各行业的词汇发音更准确。自学习平台1.易用自学习平台颠覆性地提供一键式自助语音优化方案,极大地降低进行语音智能优化所需要的门槛,让不懂技术的业务人员也可以显著提高自身业务识别准确率。2.快速自学习平台能够在数分钟之内完成业务专属定制模型的优化测试上线,更能支持业务相关热词的实时优化,一改传统定制优化长达数周甚至数月的漫长交付弊端。3.准确自学习平台优化效果在很多内外部合作伙伴和项目上得到了充分验证,很多项目最终通过自学习平台不仅解决了可用性问题,还在项目中超过了竞争对手使用传统优化方式所取得的优化效果。0.2 应用场景语音识别1.语音搜索支持各种场景下的语音搜索,如地图导航、浏览器搜索等。可以集成到任何形式的手机应用中,最大限度地解放双手。2.语音指令通过语音命令控制智能设备,实现快捷便利的操作,如控制空调开关、电视换台等。可以集成到智能家居等设备中。3.语音短消息发送或者接收语音短消息时,利用音频转文字能力,实现音频内容快速预览。视频实时直播字幕现场演讲场景、实时直播场景下,将视频中的音频实时转写为字幕,还可以进一步对内容进行管理。4.实时会议记录将会议、法庭庭审中的音频实时转写为文字,辅助会议记录工作,同时适用于电视会议等远距离场景。5.实时客服记录将呼叫中心的语音实时转写为文字,可以实现实时质检等。呼叫中心语音质检上传呼叫中心的录音文件,通过录音文件识别得到文本,进一步通过文本检索,检查有无违规话术、敏感词等信息。6.庭审数据库录入上传庭审记录的录音文件,进行识别后,将识别文本录入数据库。会议记录总结对会议记录的音频文件进行识别,然后通过人工或者自动方法,对会议记录作出总结。7.医院病历录入手术时通过音频记录医生的操作,通过录音文件识别得到文本,提高病例录入效率。语音合成1.智能客服提供多行业多场景的智能客服语音合成能力。提高解答效率,提升客户满意度,降低呼叫中心人工成本。2.智能设备为智能家居、音箱、车载和可穿戴设备等赋予一个最有温度的声音。3.文学有声阅读让富有感染力的声音为您讲故事、读小说、播新闻,满足“懒人”的阅读需求。4.新闻传媒播报释放用户的双手和双眼,提供多种发音风格的新闻播报,打造更极致的传媒体验。5.无障碍播报将文字转成流畅动听的自然语言声音,实现面向各类人群的无障碍播报。6.内容创作自媒体、大V等内容创作方可将个性化定制的声音应用于传播平台。如,资讯播报、视频配音等。7.在线教育“复制”在线课堂老师的声音,增强课堂的交互性。自学习平台1.热词在语音识别服务中,如果在您的业务领域有一些特有的词,默认识别效果较差的情况下可以使用热词功能,将这些词添加到词表,改善识别结果。2.语言模型定制支持上传业务相关的文本语料训练模型,可以在该业务领域中获得更高的识别准确率。如司法、金融等领域。0.3基本概念采样率(sample rate)音频采样率是指录音设备在一秒钟内对声音信号的采样次数,采样频率越高声音的还原就越真实越自然。目前语音识别服务支持16000Hz和8000Hz两种采样率,其中电话业务一般使用8000Hz,其余业务使用16000Hz。调用语音识别服务时,如果语音数据采样率高于16000Hz,需要先把采样率转换为16000Hz才能发送给语音识别服务;如果语音数据采样率是8000Hz,请勿将采样率转换为16000Hz,项目中选用支持8000Hz采样率的模型。采样位数(sample size)采样值或取样值,即是将采样样本幅度量化。用来衡量声音波动变化的参数,或是声卡的分辨率。数值越大、分辨率越高,发出声音的能力越强。目前语音识别中常用的采样位数为16 bit小端序。即每次采样的音频信息用2字节保存,或者说2字节记录1/16000s的音频数据。每个采样数据记录的是振幅,采样精度取决于采样位数的大小:1字节(8 bit)记录256个数,亦即将振幅划分为256个等级。2字节(16 bit)记录65536个数。其中2字节采样位数已经能够达到CD标准。语音编码(format)语音数据存储和传输的方式。注意语音编码和语音文件格式不同,如常见的WAV文件格式,会在其头部定义语音数据的编码,其中的音频数据通常使用PCM、AMR或其他编码。注意 在调用智能语音交互服务之前需确认语音数据编码格式是服务所支持的。声道(sound channel)录制声音时,在不同空间位置采集的相互独立的音频信号。声道数也就是声音录制时的音源数量。常见的音频数据为单声道或双声道(立体声)。说明 除录音文件识别以外的服务只支持单声道(mono)语音数据,如果您的数据是双声道或其他,需要先转换为单声道。逆文本规整(inverse text normalization)语音转换为文本时使用标准化的格式展示数字、金额、日期和地址等对象,以符合阅读习惯。以下是一些示例。更多内容参考官网文档:https://help.aliyun.com/document_detail/72214.html1.智能语音交互实测1.1创建项目1.2 语言模型定制化定制化训练1.3 移动端应用如何安全访问智能语音交互服务为了避免在移动端App或者桌面端工具中保存固定AccessKey ID和AccessKey Secret可能引起的泄漏风险,您可以通过以下两种方案,更加安全地访问智能语音交互服务。方案一:通过App服务端创建Token并下发到移动端使用前提条件已开通智能语音交互服务,并根据产品文档调试成功,具体操作,请参见开通服务。适用场景如果您作为移动App开发者或者桌面端开发者,希望您的用户调用阿里云智能语音交互产品的语音合成、一句话识别、实时识别等服务时,避免在移动端App或者桌面端工具中保存固定AccessKey ID和AccessKey Secret可能引起的泄漏风险,您可以使用App服务端下发语音Token调用服务。1.App端向用户应用服务器请求一个调用智能语音交互接口所依赖的语音Token,此处使用您自有的通信协议即可,比如用户登录时自动请求或服务端自动下发,或定时向应用服务器发起请求。2.用户应用服务器向阿里云智能语音服务发起创建语音Token的真正请求,此处请您使用阿里云SDK或智能语音交互SDK来创建Token,创建Token所需的AccessKey ID和AccessKey Secret保存在您的应用服务器上。由于语音Token具有时效性,您可以在有效期范围内直接返回给App端,无需每次都向智能语音交互服务请求新的Token。3.智能语音交互服务返回给应用服务器一个语音Token信息,包括Token字符串及有效期时间,在有效期内您可以多次复用该Token而无需重新创建,Token的使用不受不同用户、不同设备的限制。4.用户应用服务器将Token返回给App端,此时App端可以缓存并使用该Token,直到Token失效。当Token失效时,App端需要向应用服务器申请新的Token。假设Token凭证有效期为24小时,App端可以在Token过期前1到2小时主动向应用服务器请求更新Token。5.App端使用获取到的Token构建请求,向阿里云智能语音交互公共云发起调用,比如调用实时语音识别、一句话识别、语音合成等接口(不包括录音文件识别、录音文件识别闲时版等离线类接口),更多信息,请参见阿里云智能语音交互相关文档。此方案无需过多额外设置或开发,将AccessKey ID和AccessKey Secret保存到移动端改为保存到用户自己的服务端,并通过服务端创建语音Token再下发给移动端使用,兼容了使用安全性及开发便捷性。方案二:使用STS临时访问凭证调用语音服务您可以通过STS服务给其他用户颁发临时访问凭证,该用户可使用临时访问凭证,在规定时间内调用智能语音交互的录音文件识别服务(含闲时版)。临时访问凭证无需透露您的长期密钥,保障您的账户更加安全。前提条件已确保当前账号为阿里云账号或者被授予AliyunRAMFullAccess权限的RAM用户。关于为RAM用户授权的具体步骤,请参见为RAM用户授权。适用场景如果您作为移动App开发者或者桌面端开发者,希望您的用户调用阿里云智能语音交互产品的语音合成、一句话识别、实时识别等服务时,避免在移动端App或者桌面端工具中保存固定AccessKey ID和AccessKey Secret可能引起的泄漏风险,您可以使用STS授权用户调用服务。交互流程使用STS临时访问凭证授权用户调用阿里云智能语音交互服务(例如录音文件转写)的交互流程如下:1.App端向用户应用服务器请求STS临时访问凭证,此处使用用户自有的通信协议即可,比如用户登录时自动请求或服务端自动下发,或定时向应用服务器发起请求。2.用户应用服务器向阿里云STS服务发起STS请求,此处请使用阿里云SDK,根据应用服务器自身保存的固定AK向STS请求生成一个临时凭证。3.STS返回给应用服务器一个临时访问凭证,包括临时访问密钥(AccessKey ID和AccessKey Secret)、安全令牌(SecurityToken)、该凭证的过期时间等信息。4.用户应用服务器将临时凭证返回给App端,此时App端可以缓存并使用该凭证,直到凭证失效。当凭证失效时,App端需要向应用服务器申请新的临时访问凭证。假设临时访问凭证有效期为1小时,App端可以每30分钟或者每50分钟的频率向应用服务器请求更新临时访问凭证。5.App端使用获取到的临时凭证构建请求,向阿里云智能语音交互公共云发起调用,更多信息,请参见阿里云智能语音交互相关开发文档。本文以录音文件识别为例,为您介绍相关示例代码。2.总结1.音色合成这一块话也是不错的,大部分音色也都能满足,还加上了一些情绪的表达,蛮好的。2.自学平台,可以根据相应的模型,进行学习,帮助语音机器人训练识别模型,让它更懂人类语言,这一点非常的到位。3.不单单可以识别普通话,还可以识别24种中国语言(普通话方言)以及50种外语,这款产品非常的优秀!
Serverless在推进过程中会遇到什么样的挑战?该如何破局?
serverless最大的优势在于资源得到了更合理的利用: 1.快速迭代与部署 2.高并发、高弹性 3.稳定、可靠、安全 4.运维与成本控制 下面进行简单分析: 传统的购买服务器部署应用的方式,在没有使用的时候,服务器就被浪费掉了,对于我这种需要部署一些个人用的小规模应用的情况,买服务器非常的不合算,每天可能实际使用就几分钟,大部分时间都在空置。但是 serverless 是按照实际使用次数/时长来计费的,也就是说,不用的时候真正不花一分钱。所以我越来越多的使用 serverless 部署这些小规模应用,每天实际上使用的 CPU 时间加起来可能还不到一秒,这可以把我的使用成本压缩到几乎忽略不计的程度上。 1.更多人像我这样部署到 serverless 之后,总的服务器消耗就大幅度下降了,原本可能每个人都需要一台独立的服务器,现在上百个人可能实际上就只共享了一台服务器,但每个人都能有良好的用户体验。2.serverless 先天是高并发的,可以无限制的并发请求。当我自己购买服务器部署时,我需要自己在开发应用时解决并发问题,要么就是单线程同时只处理一个请求。3.serverless 开发的时候就不用管并发,我的代码只要能处理一个请求,那么就一定能同时创建无限的运行时来处理更多的请求。4. serverless 的高并发不需要在同一台物理服务器上运行,事实上可以跑在任意位置任意数量的物理服务器上,当我一份代码部署完成之后,用户访问时可以就近选择最近的节点,从而降低延迟,而对于单一物理服务器的传统部署,地球对面的用户访问起来就会非常痛苦。 因为每个请求都是在独立运行时里处理的,错误处理也可以变得很简单,很多不处理就会崩溃的地方真的可以不处理,崩就崩呗,反正就崩单一请求对应的运行时,对其他用户没影响。不像开发传统服务器应用,得尽可能不崩溃否则崩了还得远程上去重启进程。从这个角度来看 serverless 是轻量化应用的最优解决方案,成本更低,复杂度更低,用户体验更好。当然,方便的前提一定是更低的自由度,所以对于复杂的企业项目, serverless 仍然不能成为首选
2023计算机领域顶会(A类)以及ACL 2023自然语言处理(NLP)研究子方向领域汇总
2023年的计算语言学协会年会(ACL 2023)共包含26个领域,代表着当前前计算语言学和自然语言处理研究的不同方面。每个领域都有一组相关联的关键字来描述其潜在的子领域, 这些子领域并非排他性的,它们只描述了最受关注的子领域,并希望能够对该领域包含的相关类型的工作提供一些更好的想法。1.计算机领域顶会(A类)会议简称主要领域会议全称官网截稿时间会议时间CVPR2023计算机视觉The IEEE/CVF Conference on Computer Vision and Pattern Recognition 2023https://cvpr2023.thecvf.com/2022.11.112023.6.18ICCV2023计算机视觉IEEE International Conference on Computer Visionhttps://iccv2023.thecvf.com/2023.3.82023.9.30ECCV2022计算机视觉European Conference on Computer Visionhttps://eccv2022.ecva.net/-------2022.10.23AAAI2023人工智能National Conference of the American Association for Artificial Intelligencehttps://aaai-23.aaai.org/2022.8.82023.2.7IJCAI 2023人工智能National Conference of the American Association for Artificial Intelligencehttps://ijcai-22.org/#2022.8.82023.2.7NIPS2023机器学习International Joint Conference on Artificial Intelligencehttps://neurips.cc/Conferences/20222023.012023.07ICML 2023机器学习International Conference on Machine Learninghttps://icml.cc/2023.012023.06.24ICLR 2023机器学习International Conference on Learning Representationshttps://iclr.cc/Conferences/20232022.09.212023.05.01ICSE 2023软件工程International Conference on Software Engineeringhttps://conf.researchr.org/home/icse-20232022.09.012023.05.14SIGKDD 2023数据挖掘ACM International Conference on Knowledge Discovery and Data Mininghttps://kdd.org/kdd2022/index.html2023.022023.08SIGIR 2023数据挖掘ACM International Conference on Research and Development in Information Retrievalhttps://sigir.org/sigir2022/2023.012023.07ACL 2023计算语言Association of Computational Linguisticshttps://www.2022.aclweb.org/2022.112023.05ACM MM 2023多媒体ACM International Conference on Multimediahttps://2023.acmmmsys.org/participation/important-dates/2022.11.182023.6.7WWW2023网络应用International World Wide Web Conferencehttps://www2023.thewebconf.org/2022.10.62023.05.01SIGGRAPH 2023图形学ACM SIG International Conference on Computer Graphics and Interactive Techniqueshttps://s2022.siggraph.org/2023.012023.08CHI 2023人机交互ACM Conference on Human Factors in Computing Systemshttps://chi2023.acm.org/2022.09.082023.04.23CSCW 2023人机交互ACM Conference on Computer Supported Cooperative Work and Social Computinghttps://cscw.acm.org/2023/2023.01.152023.10.13CCS 2023信息安全ACM Conference on Computer and Communications Securityhttps://www.sigsac.org/ccs/CCS2022/2023.012023.11VLDB 2023数据管理International Conference on Very Large Data Baseshttps://www.vldb.org/2023/?submission-guidelines2023.03.012023.08.28STOC 2023计算机理论ACM Symposium on the Theory of Computinghttp://acm-stoc.org/stoc2022/2022.112023.062.ACL 2023自然语言处理(NLP)研究子方向领域汇总(一)计算社会科学和文化分析 (Computational Social Science and Cultural Analytics)人类行为分析 (Human behavior analysis)态度检测 (Stance detection)框架检测和分析 (Frame detection and analysis)仇恨言论检测 (Hate speech detection)错误信息检测和分析 (Misinformation detection and analysis)人口心理画像预测 (psycho-demographic trait prediction)情绪检测和分析 (emotion detection and analysis)表情符号预测和分析 (emoji prediction and analysis)语言和文化偏见分析 (language/cultural bias analysis)人机交互 (human-computer interaction)社会语言学 (sociolinguistics)用于社会分析的自然语言处理工具 (NLP tools for social analysis)新闻和社交媒体的定量分析 (quantiative analyses of news and/or social media)(二)对话和交互系统 (Dialogue and Interactive Systems)口语对话系统 (Spoken dialogue systems)评价指标 (Evaluation and metrics)任务型 (Task-oriented)人工介入 (Human-in-a-loop)偏见和毒性 (Bias/toxity)事实性 (Factuality)检索 (Retrieval)知识增强 (Knowledge augmented)常识推理 (Commonsense reasoning)互动讲故事 (Interactive storytelling)具象代理人 (Embodied agents)应用 (Applications)多模态对话系统 (Multi-modal dialogue systems)知识驱动对话 (Grounded dialog)多语言和低资源 (Multilingual / low-resource)对话状态追踪 (Dialogue state tracking)对话建模 (Conversational modeling)(三)话语和语用学 (Discourse and Pragmatics)回指消解 (Anaphora resolution)共指消解 (Coreference resolution)桥接消解 (Bridging resolution)连贯 (Coherence)一致 (Cohesion)话语关系 (Discourse relations)话语分析 (Discourse parsing)对话 (Dialogue)会话 (Conversation)话语和多语性 (Dialugue and multilinguality)观点挖掘 (Argument mining)交际 (Communication)(四)自然语言处理和伦理 (Ethics and NLP)数据伦理 (Data ethics)模型偏见和公正性评价 (Model bias/fairness evaluation)减少模型的偏见和不公平性 (Model bias/unfairness mitigation)自然语言处理中的人类因素 (Human factors in NLP)参与式和基于社群的自然语言处理 (Participatory/community-based NLP)自然语言处理应用中的道德考虑 (Ethical considerations in NLP)透明性 (Transparency)政策和治理 (Policy and governance)观点和批评 (Reflections and critiques)(五)语言生成 (Generation)人工评价 (Human evaluation)自动评价 (Automatic evaluation)多语言 (Multilingualism)高效模型 (Efficient models)少样本生成 (Few-shot generation)分析 (Analysis)领域适应 (Domain adaptation)数据到文本生成 (Data-to-text generation)文本到文博生成 (Text-to-text generation)推断方法 (Inference methods)模型结构 (Model architectures)检索增强生成 (Retrieval-augmented generation)交互和合作生成 (Interactive and collaborative generation)(六)信息抽取 (Information Extraction)命名实体识别和关系抽取 (Named entity recognition and relation extraction)事件抽取 (Event extraction)开放信息抽取 (Open information extraction)知识库构建 (Knowledge base construction)实体连接和消歧 (Entity linking and disambiguation)文档级抽取 (Document-level extraction)多语言抽取 (Multilingual extraction)小样本和零样本抽取 (Zero-/few-shot extraction)(七)信息检索和文本挖掘 (Information Retrieval and Text Mining)段落检索 (Passage retrieval)密集检索 (Dense retrieval)文档表征 (Document representation)哈希 (Hashing)重排序 (Re-ranking)预训练 (Pre-training)对比学习 (Constrastive learning)(八)自然语言处理模型的可解释性与分析 (Interpretability and Analysis of Models in NLP)对抗性攻击/例子/训练 (Adversarial attacks/examples/training)校正和不确定性 (Calibration/uncertainty)反事实和对比解释 (Counterfactual/contrastive explanations)数据影响 (Data influence)数据瑕疵 (Data shortcuts/artifacts)解释的忠诚度 (Explantion faithfulness)特征归因 (Feature attribution)自由文本和自然语言解释 (Free-text/natural language explanation)样本硬度 (Hardness of samples)结构和概念解释 (Hierarchical & concept explanations)以人为主体的应用评估 (Human-subject application-grounded evaluations)知识追溯、发现和推导 (Knowledge tracing/discovering/inducing)探究 (Probing)稳健性 (Robustness)话题建模 (Topic modeling)(九)视觉、机器人等领域的语言基础 (Language Grounding to Vision, Robotics and Beyond)视觉语言导航 (Visual Language Navigation)跨模态预训练 (Cross-modal pretraining)图像文本匹配 (Image text macthing)跨模态内容生成 (Cross-modal content generation)视觉问答 (Visual question answering)跨模态应用 (Cross-modal application)跨模态信息抽取 (Cross-modal information extraction)跨模态机器翻译 (Cross-modal machine translation)(十)大模型(Large Language Models)预训练 (Pre-training)提示 (Prompting)规模化 (Scaling)稀疏模型 (Sparse models)检索增强模型 (Retrieval-augmented models)伦理 (Ethics)可解释性和分析 (Interpretability/Analysis)连续学习 (Continual learning)安全和隐私 (Security and privacy)应用 (Applications)稳健性 (Robustness)微调 (Fine-tuning)(十一)语言多样性 (Language Diversity)少资源语言 (Less-resource languages)濒危语言 (Endangered languages)土著语言 (Indigenous languages)少数民族语言 (Minoritized languages)语言记录 (Language documentation)少资源语言的资源 (Resources for less-resourced languages)软件和工具 (Software and tools)(十二)语言学理论、认知建模和心理语言学 (Linguistic Theories, Cognitive Modeling and Psycholinguistics)语言学理论 (Linguistic theories)认知建模 (Cognitive modeling)计算心理语言学 (Computational pyscholinguistics)(十三)自然语言处理中的机器学习 (Machine Learning for NLP)基于图的方法 (Graph-based methods)知识增强的方法 (Knowledge-augmented methods)多任务学习 (Multi-task learning)自监督学习 (Self-supervised learning)对比学习 (Contrastive learning)生成模型 (Generation model)数据增强 (Data augmentation)词嵌入 (Word embedding)结构化预测 (Structured prediction)迁移学习和领域适应 (Transfer learning / domain adaptation)表征学习 (Representation learning)泛化 (Generalization)模型压缩方法 (Model compression methods)参数高效的微调方法 (Parameter-efficient finetuning)少样本学习 (Few-shot learning)强化学习 (Reinforcement learning)优化方法 (Optimization methods)连续学习 (Continual learning)对抗学习 (Adversarial training)元学习 (Meta learning)因果关系 (Causality)图模型 (Graphical models)人参与的学习和主动学习 (Human-in-a-loop / Active learning)(十四)机器翻译 (Machine Translation)自动评价 (Automatic evaluation)偏见 (Biases)领域适应 (Domain adaptation)机器翻译的高效推理方法 (Efficient inference for MT)高效机器翻译训练 (Efficient MT training)少样本和零样本机器翻译 (Few-/Zero-shot MT)人工评价 (Human evaluation)交互机器翻译 (Interactive MT)机器翻译部署和维护 (MT deployment and maintainence)机器翻译理论 (MT theory)建模 (Modeling)多语言机器翻译 (Multilingual MT)多模态 (Multimodality)机器翻译的线上运用 (Online adaptation for MT)并行解码和非自回归的机器翻译 (Parallel decoding/non-autoregressive MT)机器翻译预训练 (Pre-training for MT)规模化 (Scaling)语音翻译 (Speech translation)转码翻译 (Code-switching translation)词表学习 (Vocabulary learning)(十五)多语言和跨语言自然语言处理 (Multilingualism and Cross-Lingual NLP)转码 (Code-switching)混合语言 (Mixed language)多语言 (Multilingualism)语言接触 (Language contact)语言变迁 (Language change)语言变体 (Language variation)跨语言迁移 (Cross-lingual transfer)多语言表征 (Multilingual representation)多语言预训练 (Multilingual pre-training)多语言基线 (Multilingual benchmark)多语言评价 (Multilingual evaluation)方言和语言变种 (Dialects and language varieties)(十六)自然语言处理应用 (NLP Applications)教育应用、语法纠错、文章打分 (Educational applications, GEC, essay scoring)仇恨言论检测 (Hate speech detection)多模态应用 (Multimodal applications)代码生成和理解 (Code generation and understanding)事实检测、谣言和错误信息检测 (Fact checking, rumour/misinformation detection)医疗应用、诊断自然语言处理 (Healthcare applications, clinical NLP)金融和商务自然语言处理 (Financial/business NLP)法律自然语言处理 (Legal NLP)数学自然语言处理 (Mathematical NLP)安全和隐私 (Security/privacy)历史自然语言处理 (Historical NLP)知识图谱 (Knowledge graph)(十七)音系学、形态学和词语分割 (Phonology, Morphology and Word Segmentation)形态变化 (Morphological inflection)范式归纳 (Paradigm induction)形态学分割 (Morphological segementation)子词表征 (Subword representations)中文分割 (Chinese segmentation)词性还原 (Lemmatization)有限元形态学 (Finite-state morphology)形态学分析 (Morphological analysis)音系学 (Phonology)字素音素转换 (Grapheme-to-phoneme conversion)发音建模 (Pronunciation modeling)(十八)问答 (Question Answering)常识问答 (Commonsense QA)阅读理解 (Reading comprehension)逻辑推理 (Logic reasoning)多模态问答 (Multimodal QA)知识库问答 (Knowledge base QA)语义分析 (Semantic parsing)多跳问答 (Multihop QA)生物医学问答 (Biomedical QA)多语言问答 (Multilingual QA)可解释性 (Interpretability)泛化 (Generalization)推理 (Reasoning)对话问答 (Conversational QA)少样本问答 (Few-shot QA)数学问答 (Math QA)表格问答 (Table QA)开放域问答 (Open-domain QA)问题生成 (Question generation)(十九)语言资源及评价 (Resources and Evaluation)语料库构建 (Corpus creation)基线构建 (Benchmarking)语言资源 (Language resources)多语言语料库 (Multilingual corpora)词表构建 (Lexicon creation)语言资源的自动构建与评价 (Automatic creation and evaluation of language resources)自然语言处理数据集 (NLP datasets)数据集自动评价 (Automatic evaluation of datasets)评价方法 (Evaluation methodologies)低资源语言数据集 (Datasets for low resource languages)测量指标 (Metrics)复现性 (Reproducibility)用于评价的统计检验 (Statistical testing for evaluation)(二十)语义学:词汇层面 (Semantics: Lexical)一词多义 (Polysemy)词汇关系 (Lexical relationships)文本蕴含 (Textual entailment)语义合成性 (Compositionality)多词表达 (Multi-word expressions)同义转换 (Paraphrasing)隐喻 (Metaphor)词汇语义变迁 (Lexical semantic change)词嵌入 (Word embeddings)认知 (Cognition)词汇资源 (Lexical resources)情感分析 (Sentiment analysis)多语性 (Multilinguality)可解释性 (Interpretability)探索性研究 (Probing)(二十一)语义学:句级语义、文本推断和其他领域 (Semantics: Sentence-Level Semantics, Textual Inference and Other Areas)同义句识别 (Paraphrase recognition)文本蕴含 (Textual entailment)自然语言推理 (Natural language inference)逻辑推理 (Reasoning)文本语义相似性 (Semantic textual similarity)短语和句子嵌入 (Phrase/sentence embedding)同义句生成 (Paraphrase generation)文本简化 (Text simiplification)词和短语对齐 (Word/phrase alignment)(二十二)情感分析、文本风格分析和论点挖掘 (Sentiment Analysis, Stylistic Analysis and Argument Mining)论点挖掘 (Argument mining)观点检测 (Stance detection)论点质量评价 (Argument quality assessment)修辞和框架 (Rhetoric and framing)论证方案和推理 (Argument schemes and reasoning)论点生成 (Argument generation)风格分析 (Style analysis)风格生成 (Style generation)应用 (Applications)(二十三)语音和多模态 (Speech and Multimodality)自动语音识别 (Automatic speech recognition)口语语言理解 (Spoken language understanding)口语翻译 (Spoken language translation)口语语言基础 (Spoken language grounding)语音和视觉 (Speech and vision)口语查询问答 (QA via spoken queries)口语对话 (Spoken dialog)视频处理 (Video processing)语音基础 (Speech technologies)多模态 (Multimodality)(二十四)文摘 (Summarization)抽取文摘 (Extractive summarization)摘要文摘 (Abstractive summarization)多模态文摘 (Multimodal summarization)多语言文摘 (Multilingual summarization)对话文摘 (Conversational summarization)面向查询的文摘 (Query-focused summarization)多文档文摘 (Multi-document summarization)长格式文摘 (Long-form summarization)句子压缩 (Sentence compression)少样本文摘 (Few-shot summarization)结构 (Architectures)评价 (Evaluation)事实性 (Factuality)(二十五)句法学:标注、组块分析和句法分析 (Syntax: Tagging, Chunking and Parsing)组块分析、浅层分析 (Chunking, shallow-parsing)词性标注 (Part-of-speech tagging)依存句法分析 (Dependency parsing)成分句法分析 (Constituency parsing)深层句法分析 (Deep syntax parsing)语义分析 (Semantic parsing)句法语义接口 (Syntax-semantic inferface)形态句法相关任务的标注和数据集 (Optimized annotations or data set for morpho-syntax related tasks) 句法分析算法 (Parsing algorithms)语法和基于知识的方法 (Grammar and knowledge-based approach)多任务方法 (Multi-task approaches)面向大型多语言的方法 (Massively multilingual oriented approaches)低资源语言词性标注、句法分析和相关任务 (Low-resource languages pos-tagging, parsingand related tasks)形态丰富语言的词性标注、句法分析和相关任务 (Morphologically-rich languages pos tagging,parsing and related tasks) (二十六)主题领域:现实检测 (Theme Track: Reality Check)因为错误的原因而正确 (Right for the wrong reasons)实际运用中的教训 (Lessons from deployment)(非)泛化能力 [(Non-)generalization](非)复现能力 [(Non-)reproducibility)]评价 (Evaluation)方法 (Methodology)负面结果 (Negative results)人工智能噱头和期待 (AI hype and expectations)科学 vs 工程 (Science-vs-engineering)其他领域的结合 (Lessons from other fields)
基于ERNIELayout&pdfplumber-UIE的多方案学术论文信息抽取
本项目链接:https://aistudio.baidu.com/aistudio/projectdetail/5196032?contributionType=1基于ERNIELayout&pdfplumber-UIE的多方案学术论文信息抽取,小样本能力强悍,OCR、版面分析、信息抽取一应俱全。0.问题描述可以参考issue: ERNIE-Layout在(人名和邮箱)信息抽取的诸多问题阐述#4031ERNIE-Layout因为看到功能比较强大就尝试了一下,但遇到信息抽取错误,以及抽取不全等问题使用PDFPlumber库和PaddleNLP UIE模型抽取,遇到问题:无法把姓名和邮箱一一对应。1.基于ERNIE-Layout的DocPrompt开放文档抽取问答模型ERNIE-Layout以文心文本大模型ERNIE为底座,融合文本、图像、布局等信息进行跨模态联合建模,创新性引入布局知识增强,提出阅读顺序预测、细粒度图文匹配等自监督预训练任务,升级空间解偶注意力机制,在各数据集上效果取得大幅度提升,相关工作ERNIE-Layout: Layout-Knowledge Enhanced Multi-modal Pre-training for Document Understanding已被EMNLP 2022 Findings会议收录[1]。考虑到文档智能在多语种上商用广泛,依托PaddleNLP对外开源业界最强的多语言跨模态文档预训练模型ERNIE-Layout。支持:发票抽取问答海报抽取网页抽取表格抽取长文档抽取多语言票据抽取同时提供pipelines流水线搭建更多参考官网,这里就不展开了ERNIE-Layout GitHub地址:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/ernie-layoutHugging Face网页版:https://huggingface.co/spaces/PaddlePaddle/ERNIE-Layout#环境安装 !pip install --upgrade opencv-python !pip install --upgrade paddlenlp !pip install --upgrade paddleocr --user #如果安装失败多试几次 一般都是网络问题 !pip install xlwt # 支持单条、批量预测 from paddlenlp import Taskflow docprompt_en= Taskflow("document_intelligence",lang="en",topn=10) docprompt_en({"doc": "./image/paper_1.jpg", "prompt": ["人名和邮箱" ]}) # batch_size:批处理大小,请结合机器情况进行调整,默认为1。 # lang:选择PaddleOCR的语言,ch可在中英混合的图片中使用,en在英文图片上的效果更好,默认为ch。 # topn: 如果模型识别出多个结果,将返回前n个概率值最高的结果,默认为1。[{'prompt': '人名和邮箱', 'result': [{'value': '[email protected]@yahoo.com', 'prob': 1.0, 'start': 69, 'end': 79}, {'value': '[email protected]', 'prob': 0.98, 'start': 153, 'end': 159}]}] 可以看到效果不好,多个实体不能一同抽取,需要构建成单个问答,比如姓名和邮箱分开抽取,尝试构造合理的开放式prompt。小技巧Prompt设计:在DocPrompt中,Prompt可以是陈述句(例如,文档键值对中的Key),也可以是疑问句。因为是开放域的抽取问答,DocPrompt对Prompt的设计没有特殊限制,只要符合自然语言语义即可。如果对当前的抽取结果不满意,可以多尝试一些不同的Prompt。支持的语言:支持本地路径或者HTTP链接的中英文图片输入,Prompt支持多种不同语言,参考以上不同场景的例子。docprompt_en({"doc": "./image/paper_1.jpg", "prompt": ["人名是什么","邮箱是多少", ]}) #无法罗列全部姓名 [{'prompt': '人名是什么', 'result': [{'value': 'AA.Momtazi-Borojeni', 'prob': 0.74, 'start': 0, 'end': 4}]}, {'prompt': '邮箱是多少', 'result': [{'value': '[email protected]@yahoo.com', 'prob': 1.0, 'start': 69, 'end': 79}]}] [{'prompt': '人名是什么', 'result': [{'value': 'AA.Momtazi-Borojeni', 'prob': 0.74, 'start': 0, 'end': 4}]}, {'prompt': '邮箱是多少', 'result': [{'value': '[email protected]@yahoo.com', 'prob': 1.0, 'start': 69, 'end': 79}]}] [{'prompt': '人名', 'result': [{'value': 'J.Mosafer', 'prob': 0.95, 'start': 80, 'end': 82}, {'value': 'B.Nikfar', 'prob': 0.94, 'start': 111, 'end': 113}, {'value': 'AVaezi', 'prob': 0.94, 'start': 225, 'end': 225}, {'value': 'AA.Momtazi-Borojeni', 'prob': 0.88, 'start': 0, 'end': 4}]}, {'prompt': 'email', 'result': [{'value': '[email protected]@yahoo.com', 'prob': 1.0, 'start': 69, 'end': 79}, {'value': '[email protected]', 'prob': 0.98, 'start': 153, 'end': 159}]}] docprompt_en({"doc": "./image/paper_1.jpg", "prompt": ["人名","邮箱","姓名","名字","email"]}) [{'prompt': '人名', 'result': [{'value': 'J.Mosafer', 'prob': 0.95, 'start': 80, 'end': 82}, {'value': 'B.Nikfar', 'prob': 0.94, 'start': 111, 'end': 113}, {'value': 'AVaezi', 'prob': 0.94, 'start': 225, 'end': 225}, {'value': 'AA.Momtazi-Borojeni', 'prob': 0.88, 'start': 0, 'end': 4}]}, {'prompt': '邮箱', 'result': [{'value': '[email protected]@yahoo.com', 'prob': 1.0, 'start': 69, 'end': 79}, {'value': '[email protected]', 'prob': 0.87, 'start': 153, 'end': 159}]}, {'prompt': '姓名', 'result': [{'value': 'AA.Momtazi-Borojeni', 'prob': 0.76, 'start': 0, 'end': 4}]}, {'prompt': '名字', 'result': [{'value': 'AA.', 'prob': 0.7, 'start': 0, 'end': 1}]}, {'prompt': 'email', 'result': [{'value': '[email protected]@yahoo.com', 'prob': 1.0, 'start': 69, 'end': 79}, {'value': '[email protected]', 'prob': 0.98, 'start': 153, 'end': 159}]}] 可以看出得到的效果不是很好,比较玄学,原因应该就是ocr识别对应姓名人名准确率相对不高,无法全部命中;并且无法一一对应。这块建议看看paddleocr具体实现步骤,研究一下在看看怎么处理。下面讲第二种方法2.基于PDFplumber-UIE信息抽取2.1 PDF文档解析(pdfplumber库)安装PDFPlumber!pip install pdfplumber --user官网链接:https://github.com/jsvine/pdfplumberpdf的文本和表格处理用多种方式可以实现, 本文介绍pdfplumber对文本和表格提取。这个库在GitHub上stars:3.3K多,使用起来很方便, 效果也很好,可以满足对pdf中信息的提取需求。pdfplumber.pdf中包含了.metadata和.pages两个属性。metadata是一个包含pdf信息的字典。pages是一个包含pdfplumber.Page实例的列表,每一个实例代表pdf每一页的信息。每个pdfplumber.Page类:pdfplumber核心功能,对PDF的大部分操作都是基于这个类,类中包含了几个主要的属性:文本、表格、尺寸等page_number 页码width 页面宽度height 页面高度objects/.chars/.lines/.rects 这些属性中每一个都是一个列表,每个列表都包含一个字典,每个字典用于说明页面中的对象信息, 包括直线,字符, 方格等位置信息。一些常用的方法extract_text() 用来提页面中的文本,将页面的所有字符对象整理为的那个字符串extract_words() 返回的是所有的单词及其相关信息extract_tables() 提取页面的表格2.1.1 pdfplumber简单使用# 利用metadata可以获得PDF的基本信息,作者,日期,来源等基本信息。 import pdfplumber import pandas as pd with pdfplumber.open("/home/aistudio/work/input/test_paper.pdf") as pdf: print(pdf.metadata) # print("总页数:"+str(len(pdf.pages))) #总页数 print("pdf文档总页数:", len(pdf.pages)) # 读取第一页的宽度,页高等信息 # 第一页pdfplumber.Page实例 first_page = pdf.pages[0] # 查看页码 print('页码:', first_page.page_number) # 查看页宽 print('页宽:', first_page.width) # 查看页高 print('页高:', first_page.height) {'CreationDate': "D:20180428190534+05'30'", 'Creator': 'Arbortext Advanced Print Publisher 9.0.223/W Unicode', 'ModDate': "D:20180428190653+05'30'", 'Producer': 'Acrobat Distiller 9.4.5 (Windows)', 'Title': '0003617532 1..23 ++', 'rgid': 'PB:324947211_AS:677565220007936@1538555545045'} pdf文档总页数: 24 页码: 1 页宽: 594.95996 页高: 840.95996 # 导入PDFPlumber import pdfplumber #打印第一页信息 with pdfplumber.open("/home/aistudio/work/input/test_paper.pdf") as pdf: first_page = pdf.pages[0] textdata=first_page.extract_text() print(textdata) #打印全部页面 import pdfplumber as ppl pdf_path = "/home/aistudio/work/input/test_paper.pdf" pdf = ppl.open(pdf_path) # 获得 PDFPlumber 的对象,下面查看pdf全部内容 for page in pdf.pages: print(page.extract_text()) !pip install xlwt#读取表格第一页 import pdfplumber import xlwt # 加载pdf path = "/home/aistudio/Scan-1.pdf" with pdfplumber.open(path) as pdf: page_1 = pdf.pages[0] # pdf第一页 table_1 = page_1.extract_table() # 读取表格数据 print(table_1) # 1.创建Excel对象 workbook = xlwt.Workbook(encoding='utf8') # 2.新建sheet表 worksheet = workbook.add_sheet('Sheet1') # 3.自定义列名 clo1 = table_1[0] # 4.将列表元组clo1写入sheet表单中的第一行 for i in range(0, len(clo1)): worksheet.write(0, i, clo1[i]) # 5.将数据写进sheet表单中 for i in range(0, len(table_1[1:])): data = table_1[1:][i] for j in range(0, len(clo1)): worksheet.write(i + 1, j, data[j]) # 保存Excel文件分两种 workbook.save('/home/aistudio/work/input/test_excel.xls') #读取表格全页 import pdfplumber from openpyxl import Workbook class PDF(object): def __init__(self, file_path): self.pdf_path = file_path # 读取pdf文件 self.pdf_info = pdfplumber.open(self.pdf_path) print('读取文件完成!') except Exception as e: print('读取文件失败:', e) # 打印pdf的基本信息、返回字典,作者、创建时间、修改时间/总页数 def get_pdf(self): pdf_info = self.pdf_info.metadata pdf_page = len(self.pdf_info.pages) print('pdf共%s页' % pdf_page) print("pdf文件基本信息:\n", pdf_info) self.close_pdf() # 提取表格数据,并保存到excel中 def get_table(self): wb = Workbook() # 实例化一个工作簿对象 ws = wb.active # 获取第一个sheet con = 0 # 获取每一页的表格中的文字,返回table、row、cell格式:[[[row1],[row2]]] for page in self.pdf_info.pages: for table in page.extract_tables(): for row in table: # 对每个单元格的字符进行简单清洗处理 row_list = [cell.replace('\n', ' ') if cell else '' for cell in row] ws.append(row_list) # 写入数据 con += 1 print('---------------分割线,第%s页---------------' % con) except Exception as e: print('报错:', e) finally: wb.save('\\'.join(self.pdf_path.split('\\')[:-1]) + '\pdf_excel.xlsx') print('写入完成!') self.close_pdf() # 关闭文件 def close_pdf(self): self.pdf_info.close() if __name__ == "__main__": file_path = "/home/aistudio/Scan-1.pdf" pdf_info = PDF(file_path) # pdf_info.get_pdf() # 打印pdf基础信息 # 提取pdf表格数据并保存到excel中,文件保存到跟pdf同一文件路径下 pdf_info.get_table() 更多功能(表格读取,图片提取,可视化界面)可以参考官网或者下面链接:https://blog.csdn.net/fuhanghang/article/details/1225795482.1.2 学术论文特定页面文本提取发表论文作者信息通常放在论文首页的脚末行或参考文献的后面,根据这种情况我们可以进行分类(只要获取作者的邮箱信息即可):第一种国外论文:首页含作者相关信息 or 首页是封面第二页才是作者信息 【获取前n页即可,推荐是2页】第二种国内论文:首页含作者信息(邮箱等)在参考文献之后会有各个做的详细信息,比如是职位,研究领域,科研成果介绍等等 【获取前n页和尾页,推荐是2页+尾页】这样做的好处在于两个方面:节约了存储空间和数据处理时间节约资源消耗,在模型预测时候输入文本数量显著减少,在数据面上加速推理针对1简单阐述:PDF原始大小614.1KB处理方式pdf转文字时延存储占用空间保存指定前n页面文字242ms2.8KB保存指定前n页面文字和尾页328ms5.3KB保存全文2.704s64.1KB针对二:以下6中方案提速不过多赘述,可以参考下面项目模型选择 uie-mini等小模型预测,损失一定精度提升预测效率UIE实现了FastTokenizer进行文本预处理加速fp16半精度推理速度更快UIE INT8 精度推理UIE Slim 数据蒸馏SimpleServing支持支持多卡负载均衡预测UIE Slim满足工业应用场景,解决推理部署耗时问题,提升效能!:https://aistudio.baidu.com/aistudio/projectdetail/4516470?contributionType=1之后有时间重新把paddlenlp技术路线整理一下#第一种写法:保存指定前n页面文字 with pdfplumber.open("/home/aistudio/work/input/test_paper.pdf") as p: for i in range(3): page = p.pages[i] textdata = page.extract_text() # print(textdata) data = open('/home/aistudio/work/input/text.txt',"a") #a表示指定写入模式为追加写入 data.write(textdata) #这里打印出n页文字,因为是追加保存内容是n-1页 #第一种写法:保存指定前n页面文字 with pdfplumber.open("/home/aistudio/work/input/test_paper.pdf") as p: for i in range(3): page = p.pages[i] textdata = page.extract_text() # print(textdata) data = open('/home/aistudio/work/input/text.txt',"a") #a表示指定写入模式为追加写入 data.write(textdata) #这里打印出n页文字,因为是追加保存内容是n-1页 #保存指定前n页面文字和尾页 pdf_path = "/home/aistudio/work/input/test_paper.pdf" pdf = ppl.open(pdf_path) texts = [] # 按页打开,合并所有内容,保留前2页 for i in range(2): text = pdf.pages[i].extract_text() texts.append(text) #保留最后一页,index从0开始 end_num=len(pdf.pages) text_end=pdf.pages[end_num-1].extract_text() texts.append(text_end) txt_string = ''.join(texts) # 保存为和原PDF同名的txt文件 txt_path = pdf_path.split('.')[0]+"_end" + '.txt' with open(txt_path, "w", encoding='utf-8') as f: f.write(txt_string) f.close() #保留全部文章: pdf_path = "/home/aistudio/work/input/test_paper.pdf" pdf = ppl.open(pdf_path) texts = [] # 按页打开,合并所有内容,对于多页或一页PDF都可以使用 for page in pdf.pages: text = page.extract_text() texts.append(text) txt_string = ''.join(texts) # 保存为和原PDF同名的txt文件 txt_path = pdf_path.split('.')[0] +"_all"+'.txt' with open(txt_path, "w", encoding='utf-8') as f: f.write(txt_string) f.close() #从txt中读取文本,作为信息抽取的输入。对于比较长的文本,可能需要人工的设定一些分割关键词,分段输入以提升抽取的效果。 txt_path="/home/aistudio/work/input/test_paper2.txt" with open(txt_path, 'r') as f: file_data = f.readlines() record = '' for data in file_data: record += data print(record) 2.2 UIE信息抽取(论文作者和邮箱)2.2.1 零样本抽取from pprint import pprint import json from paddlenlp import Taskflow def openreadtxt(file_name): data = [] file = open(file_name,'r',encoding='UTF-8') #打开文件 file_data = file.readlines() #读取所有行 for row in file_data: data.append(row) #将每行数据插入data中 return data data_input=openreadtxt('/home/aistudio/work/input/test_paper2.txt') schema = ['人名', 'email'] few_ie = Taskflow('information_extraction', schema=schema, batch_size=16) results=few_ie(data_input) print(results) with open("./output/reslut_2.txt", "w+",encoding='UTF-8') as f: #a : 写入文件,若文件不存在则会先创建再写入,但不会覆盖原文件,而是追加在文件末尾 for result in results: line = json.dumps(result, ensure_ascii=False) #对中文默认使用的ascii编码.想输出真正的中文需要指定ensure_ascii=False f.write(line + "\n") print("数据结果已导出") 2.3长文本的答案获取UIE对于词和句子的抽取效果比较好,但是对应大段的文字结果,还是需要传统的正则方式作为配合,在本次使用的pdf中,还需要获得法院具体的判决结果,使用正则表达式可灵活匹配想要的结果。start_word = '如下' end_word = '特此公告' start = re.search(start_word, record) end = re.search(end_word, record) print(record[start.span()[1]:end.span()[0]]) 海口中院认为:新达公司的住所地在海口市国贸大道 48 号新达商务大厦,该司是由海南省工商行政管理局核准登记 的企业,故海口中院对本案有管辖权。因新达公司不能清偿 到期债务,故深物业股份公司提出对新达公司进行破产清算 的申请符合受理条件。依照《中华人民共和国企业破产法》 第二条第一款、第三条、第七条第二款之规定,裁定如下: 受理申请人深圳市物业发展(集团)股份有限公司对被 申请人海南新达开发总公司破产清算的申请。 本裁定自即日起生效。 二、其他情况 本公司已对海南公司账务进行了全额计提,破产清算对 本公司财务状况无影响。 具体情况请查阅本公司2011年11月28日发布的《董事会 决议公告》。 2.4正则提升效果对于长文本,可以根据关键词进行分割后抽取,但是对于多个实体,比如这篇公告中,通过的多个议案,就无法使用UIE抽取。# 导入正则表达式相关库 import re schema = ['通过议案'] start_word = '通过以下议案' start = re.search(start_word, record) input_data = record[start.span()[0]:] print(input_data) ie = Taskflow('information_extraction', schema=schema) pprint(ie(input_data)) # 正则匹配“一 二 三 四 五 六 七 八 九 十” print(re.findall(r"[\u4e00\u4e8c\u4e09\u56db\u4e94\u516d\u4e03\u516b\u4e5d\u5341]、.*\n", input_data)) ['一、2021 年第三季度报告 \n', '二、关于同意全资子公司收购担保公司 60%股权的议案 详见公司于 2021 年 10 月 29 日刊登在《证券时报》、《中国证券\n', '三、关于同意控股子公司广西新柳邕公司为认购广西新柳邕项\n', '四、关于续聘会计师事务所的议案 \n', '五、关于向银行申请综合授信额度的议案 \n', '一、向中国民生银行股份有限公司深圳分行申请不超过人民币 5\n', '二、向招商银行股份有限公司深圳分行申请不超过人民币 6 亿\n', '六、经理层《岗位聘任协议》 \n', '七、经理层《年度经营业绩责任书》 \n', '八、经理层《任期经营业绩责任书》 \n', '九、关于暂不召开股东大会的议案 \n'] # 3.基于基于UIE-X的信息提取 ## 3.1 跨模态文档信息抽取 跨模态文档信息抽取能力 UIE-X 来了。 信息抽取简单说就是利用计算机从自然语言文本中提取出核心信息,是自然语言处理领域的一项关键任务,包括命名实体识别(也称实体抽取)、关系抽取、事件抽取等。传统信息抽取方案基于序列标注,需要大量标注语料才能获得较好的效果。2022年5月飞桨 PaddleNLP 推出的 UIE,是业界首个开源的面向通用信息抽取的产业级技术方案 ,基于 Prompt 思想,零样本和小样本能力强大,已经成为业界信息抽取任务上的首选方案。 除了纯文本内容外,企业中还存在大量需要从跨模态文档中抽取信息并进行处理的业务场景,例如从合同、收据、报销单、病历等不同类型的文档中抽取所需字段,进行录入、比对、审核校准等操作。为了满足各行业的跨模态文档信息抽取需求,PaddleNLP 基于文心ERNIE-Layout[1]跨模态布局增强预训练模型,集成PaddleOCR的PP-OCR、PP-Structure版面分析等领先能力,基于大量信息抽取标注集,训练并开源了UIE-X–––首个兼具文本及文档抽取能力、多语言、开放域的信息抽取模型。 * 支持实体抽取、关系抽取、跨任务抽取 * 支持跨语言抽取 * 集成PP-OCR,可灵活定制OCR结果 * 使用PP-Structure版面分析功能 * 增加渲染模块,OCR和信息抽取结果可视化 项目链接: [https://aistudio.baidu.com/aistudio/projectdetail/5017442](https://aistudio.baidu.com/aistudio/projectdetail/5017442) ## 3.2 产业实践分享:基于UIE-X的医疗文档信息提取 PaddleNLP全新发布UIE-X ,除已有纯文本抽取的全部功能外,新增文档抽取能力。 UIE-X延续UIE的思路,基于跨模态布局增强预训练模型文心ERNIE-Layout重训模型,融合文本、图像、布局等信息进行联合建模,能够深度理解多模态文档。基于Prompt思想,实现开放域信息抽取,支持零样本抽取,小样本能力领先。 官网链接:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/applications/information_extraction 本案例为UIE-X在医疗领域的实战,通过少量标注+模型微调即可具备定制场景的端到端文档信息提取 目前医疗领域有大量的医学检查报告单,病历,发票,CT影像,眼科等等的医疗图片数据。现阶段,针对这些图片都是靠人工分类,结构化录入系统中,做患者的全生命周期的管理。 耗时耗力,人工成本极大。如果能靠人工智能的技术做到图片的自动分类和结构化,将大大的降低成本,提高系统录入的整体效率。 项目链接: [https://aistudio.baidu.com/aistudio/projectdetail/5261592](https://aistudio.baidu.com/aistudio/projectdetail/5261592) 4.总结本项目提供了基于ERNIELayout&PDFplumber-UIEX多方案学术论文信息抽取,有兴趣同学可以研究一下UIE-X。UIE-X延续UIE的思路,基于跨模态布局增强预训练模型文心ERNIE-Layout重训模型,融合文本、图像、布局等信息进行联合建模,能够深度理解多模态文档。基于Prompt思想,实现开放域信息抽取,支持零样本抽取,小样本能力领先.
[信息抽取]基于ERNIE3.0的多对多信息抽取算法:属性关系抽取
[信息抽取]基于ERNIE3.0的多对多信息抽取算法:属性关系抽取实体关系,实体属性抽取是信息抽取的关键任务;实体关系抽取是指从一段文本中抽取关系三元组,实体属性抽取是指从一段文本中抽取属性三元组;信息抽取一般分以下几种情况一对一,一对多,多对一,多对多的情况:一对一:“张三男汉族硕士学历”含有一对一的属性三元组(张三,民族,汉族)。一对多:“华扬联众数字技术股份有限公司于2017年8月2日在上海证券交易所上市”,含有一对多的属性三元组(华扬联众数字技术股份有限公司,上市时间,2017年8月2日)和(华扬联众数字技术股份有限公司,上市地点,上海证券交易所上市)多对一:“上海森焱软件有限公司和上海欧提软件有限公司的注册资本均为100万人民币”,含有多对一的属性三元组(上海森焱软件有限公司,注册资本,100万人民币)和(上海欧提软件有限公司,注册资本,100万人民币)多对多:“大华种业稻麦种子加工36.29万吨、销售37.5万吨;苏垦米业大米加工22.02万吨、销售24.86万吨”,含有多对多的属性三元组(大华种业,稻麦种子产量,36.29万吨)和(苏垦米业,大米加工产量,22.02万吨)代码结构如下: ├── data │ ├── entity_attribute_data │ │ ├── dev_data │ │ │ └── dev.json │ │ ├── predict_data │ │ │ └── predict.json │ │ ├── test_data │ │ │ └── test.json │ │ └── train_data │ │ └── train.json │ └── entity_relation_data │ ├── dev_data │ │ └── dev.json │ ├── predict_data │ │ └── predict.json │ ├── test_data │ │ └── test.json │ └── train_data │ └── train.json ├── data_set_reader │ └── ie_data_set_reader.py ├── dict │ ├── entity_attribute_label_map.json │ └── entity_relation_label_map.json ├── examples │ ├── many_to_many_ie_attribute_ernie_fc_ch_infer.json │ ├── many_to_many_ie_attribute_ernie_fc_ch.json │ ├── many_to_many_ie_relation_ernie_fc_ch_infer.json │ └── many_to_many_ie_relation_ernie_fc_ch.json ├── inference │ ├── custom_inference.py │ └── __init__.py ├── model │ ├── ernie_fc_ie_many_to_many.py │ └── __init__.py ├── run_infer.py ├── run_trainer.py └── trainer ├── custom_dynamic_trainer.py ├── custom_trainer.py └── __init__.py1.数据集简介这里提供三份已标注的数据集:属性抽取数据集(demo示例数据集)、关系抽取数据集(demo示例数据集)、DuIE2.0(全量数据集)。属性抽取训练集、测试集、验证集和预测集分别存放在./data/entity_attribute_data目录下的train_data、test_data、dev_data和predict_data文件夹下,对应的示例标签词表存放在./dict目录下。关系抽取训练集、测试集、验证集和预测集分别存放在./data/entity_relation_data目录下的train_data、test_data、dev_data和predict_data文件夹下,对应的示例标签词表存放在./dict目录下。DuIE2.0数据集已经上传到“数据集中”也进行解压注:数据集(包含词表)均为utf-8格式。Demo示例数据集(属性抽取数据集、关系抽取数据集)demo示例数据集中属性抽取数据集与关系抽取数据集的结构一样,他们都只包含少量数据集,可用于快速开始模型的训练与预测。训练集/测试集/的数据格式相同,每个样例分为两个部分文本和对应标签{"text": "倪金德,1916年生,奉天省营口(今辽宁省营口市)人", "spo_list": [{"predicate": "出生日期", "subject": [0, 3], "object": [4, 9]}, {"predicate": "出生地", "subject": [0, 3], "object": [11, 16]}]} {"text": "基本介绍克里斯蒂娜·塞寇丽(Christina Sicoli)身高163cm,在加拿大安大略出生和长大,毕业于伦道夫学院", "spo_list": [{"predicate": "毕业院校", "subject": [4, 13], "object": [55, 60]}]} 预测集只有一个key("text"):{"text": "倪金德,1916年生,奉天省营口(今辽宁省营口市)人"} {"text": "基本介绍克里斯蒂娜·塞寇丽(Christina Sicoli)身高163cm,在加拿大安大略出生和长大,毕业于伦道夫学院"} 标签词表:标签列表是一个json字符串,key是标签值,value是标签对应id,示例词表采用BIO标注,B表示关系,分为主体(S)与客体(O),如下所示:{ "O": 0, "I": 1, "B-毕业院校@S": 2, "B-毕业院校@O": 3, "B-出生地@S": 4, "B-出生地@O": 5, "B-祖籍@S": 6, "B-祖籍@O": 7, "B-国籍@S": 8, "B-国籍@O": 9, "B-出生日期@S": 10, "B-出生日期@O": 11 }注意:O, I对应的ID必须是0, 1,B-XXX@O对应的id需要必须为B-XXX@S对应的id+1(B-XXX@s须为偶数,B-XXX@O须为奇数)DuIE2.0数据集DuIE2.0是业界规模最大的中文关系抽取数据集,其schema在传统简单关系类型基础上添加了多元复杂关系类型,此外其构建语料来自百度百科、百度信息流及百度贴吧文本,全面覆盖书面化表达及口语化表达语料,能充分考察真实业务场景下的关系抽取能力。DuIE2.0数据集的格式与本框架所需要的文本输入格式不一致,需要进行转化成demo示例数据集的格式才能使用,具体转化步骤如下:下载数据集到 ./data/DuIE2.0 文件夹中,并解压进入./data/DuIE2.0目录运行./data/DuIE2.0/convert_data.py 脚本{'text': '《司马迁之人格与风格\u3000道教徒的诗人李白及其痛苦》是李长之代表作品,共收录了两本著作,《司马迁之人格与风格》,是中国第一部透过西方文学批评视角全面审视、评价司马迁及其《史记》的学术专著', 'spo_list': [{'predicate': '作者', 'object_type': {'@value': '人物'}, 'subject_type': '图书作品', 'object': {'@value': '李长之'}, 'subject': '司马迁之人格与风格\u3000道教徒的诗人李白及其痛苦'}, {'predicate': '作者', 'object_type': {'@value': '人物'}, 'subject_type': '图书作品', 'object': {'@value': '李长之'}, 'subject': '司马迁之人格与风格 道教徒的诗人李白及其痛苦'}]} 《司马迁之人格与风格 道教徒的诗人李白及其痛苦》是李长之代表作品,共收录了两本著作,《司马迁之人格与风格》,是中国第一部透过西方文学批评视角全面审视、评价司马迁及其《史记》的学术专著 * 司马迁之人格与风格 道教徒的诗人李白及其痛苦 2.网络模型选择(文心大模型)文心预置的可用于生成任务的模型源文件在/home/aistudio/model/ernie_fc_ie_many_to_many.py网络名称(py文件的类型)简介支持类型ErnieFcIe(ernie_fc_ie_many_to_many.py)ErnieFcIe多对多信息抽取任务模型源文件,可加载ERNIE2.0-Base、ERNIE2.0-large、ERNIE3.0-Base、ERNIE3.0-x-Base、ERNIE3.0-Medium通用信息抽取Finetune任务ERNIE预训练模型下载:文心提供的ERNIE预训练模型的参数文件和配置文件在 /home/aistudio/models_hub目录下,使用对应的sh脚本,即可拉取对应的模型、字典、必要环境等文件。简单罗列可能会用的模型:模型名称下载脚本备注ERNIE1.0-m-BaseTextERNIE-M:通过将跨语言语义与单语语料库对齐来增强多语言表示ERNIE1.0-gen-BaseTextERNIE-GEN:用于自然语言生成的增强型多流预训练和微调框架ERNIE2.0-BaseText ERNIE2.0-largeText ERNIE3.0-BaseText ERNIE3.0-x-BaseText ERNIE3.0-MediumText下载并解压后得到对应模型的参数、字典和配置简单介绍以下几个不常用模型:ERNIE-GEN 是面向生成任务的预训练-微调框架,首次在预训练阶段加入span-by-span 生成任务,让模型每次能够生成一个语义完整的片段。在预训练和微调中通过填充式生成机制和噪声感知机制来缓解曝光偏差问题。此外, ERNIE-GEN 采样多片段-多粒度目标文本采样策略, 增强源文本和目标文本的关联性,加强了编码器和解码器的交互。ERNIE-GEN base 模型和 ERNIE-GEN large 模型。 预训练数据使用英文维基百科和 BookCorpus,总共16GB。此外,我们还发布了基于 430GB 语料(数据描述见ERNIE-GEN Appendix A.1)预训练的ERNIE-GEN large 模型。ERNIE-GEN base (lowercased | 12-layer, 768-hidden, 12-heads, 110M parameters)ERNIE-GEN large (lowercased | 24-layer, 1024-hidden, 16-heads, 340M parameters)ERNIE-GEN large with 430G (lowercased | 24-layer, 1024-hidden, 16-heads, 340M parameters)微调任务:在五个典型生成任务上与当前效果最优的生成预训练模型(UniLM、MASS、PEGASUS、BART、T5等)进行对比, 包括生成式摘要 (Gigaword 和 CNN/DailyMail), 问题生成(SQuAD), 多轮对话(Persona-Chat) 和生成式多轮问答(CoQA)。https://github.com/PaddlePaddle/ERNIE/blob/repro/ernie-gen/README.zh.mdERNIE-M 是面向多语言建模的预训练-微调框架。为了突破双语语料规模对多语言模型的学习效果限制,提升跨语言理解的效果,我们提出基于回译机制,从单语语料中学习语言间的语义对齐关系的预训练模型 ERNIE-M,显著提升包括跨语言自然语言推断、语义检索、语义相似度、命名实体识别、阅读理解在内的 5 种典型跨语言理解任务效果。飞桨发布了 ERNIE-M base 多语言模型和 ERNIE-M large 多语言模型。ERNIE-M base (12-layer, 768-hidden, 12-heads)ERNIE-M large (24-layer, 1024-hidden, 16-heads)下游任务:在自然语言推断,命名实体识别,阅读理解,语义相似度以及跨语言检索等任务上选取了广泛使用的数据集进行模型效果验证,并且与当前效果最优的模型(XLM、Unicoder、XLM-R、INFOXLM、VECO、mBERT等)进行对比。https://github.com/PaddlePaddle/ERNIE/blob/repro/ernie-m/README_zh.md3.训练&预测3.1 属性抽取模型训练&预测以属性抽取数据集的训练为例:训练的配置文件:配置文件:./examples/many_to_many_ie_attribute_ernie_fc_ch.json{ "dataset_reader": { "train_reader": { "name": "train_reader", "type": "IEReader", "fields": [], "config": { "data_path": "./data/entity_attribute_data/train_data/", "shuffle": false, "batch_size": 2, "epoch": 5, "sampling_rate": 1.0, "need_data_distribute": true, "need_generate_examples": false, "extra_params": { "vocab_path": "./models_hub/ernie_3.0_base_ch_dir/vocab.txt", #选择对应预训练模型的词典路径,在models_hub路径下 "label_map_config": "./dict/entity_attribute_label_map.json", "num_labels": 12, "max_seq_len": 512, "do_lower_case":true, "in_tokens":false, "tokenizer": "FullTokenizer" "test_reader": { "name": "test_reader", "type": "IEReader", "fields": [], "config": { "data_path": "./data/entity_attribute_data/test_data/", "shuffle": false, "batch_size": 2, "epoch": 1, "sampling_rate": 1.0, "need_data_distribute": false, "need_generate_examples": false, "extra_params": { "vocab_path": "./models_hub/ernie_3.0_base_ch_dir/vocab.txt", #选择对应预训练模型的词典路径,在models_hub路径下 "label_map_config": "./dict/entity_attribute_label_map.json", "num_labels": 12, "max_seq_len": 512, "do_lower_case":true, "in_tokens":false, "tokenizer": "FullTokenizer" "model": { "type": "ErnieFcIe", "is_dygraph":1, "num_labels":12, "optimization": { "learning_rate": 5e-05, "use_lr_decay": true, "warmup_steps": 0, "warmup_proportion": 0.1, "weight_decay": 0.01, "use_dynamic_loss_scaling": false, "init_loss_scaling": 128, "incr_every_n_steps": 100, "decr_every_n_nan_or_inf": 2, "incr_ratio": 2.0, "decr_ratio": 0.8 "embedding": { "config_path": "./models_hub/ernie_3.0_base_ch_dir/ernie_config.json" #选择对应预训练模型的配置文件路径,在models_hub路径下 "trainer": { "type": "CustomDynamicTrainer", "PADDLE_PLACE_TYPE": "gpu", "PADDLE_IS_FLEET": 0, "train_log_step": 10, "use_amp": true, "is_eval_dev": 0, "is_eval_test": 1, "eval_step": 50, "save_model_step": 100, "load_parameters": "", "load_checkpoint": "", "pre_train_model": [ "name": "ernie_3.0_base_ch", "params_path": "./models_hub/ernie_3.0_base_ch_dir/params" #选择对应预训练模型的参数路径,在models_hub路径下 "output_path": "./output/ie_attribute_ernie_3.0_base_fc_ch", #输出路径 "extra_param": { "meta":{ "job_type": "entity_attribute_extraction" }# 基于示例的数据集,可以运行以下命令在训练集(train.txt)上进行模型训练,并在测试集(test.txt)上进行验证; # 训练属性抽取 %cd /home/aistudio !python run_trainer.py --param_path ./examples/many_to_many_ie_attribute_ernie_fc_ch.json # 训练运行的日志会自动保存在./log/test.log文件中; # 训练中以及结束后产生的模型文件会默认保存在./output/目录下,其中save_inference_model/文件夹会保存用于预测的模型文件,save_checkpoint/文件夹会保存用于热启动的模型文件 部分结果展示:INFO: 11-30 15:19:47: custom_dynamic_trainer.py:85 * 139681516312320 current learning rate: 2e-07 DEBUG: 11-30 15:19:48: ernie_fc_ie_many_to_many.py:234 * 139681516312320 phase = training precision = 1.0 recall = 1.0 f1 = 1.0 step = 2500 time_cost = 0.5210211277008057 loss = [0.00099489] INFO: 11-30 15:19:48: custom_dynamic_trainer.py:85 * 139681516312320 current learning rate: 0.0 DEBUG: 11-30 15:19:48: ernie_fc_ie_many_to_many.py:261 * 139681516312320 phase = test precision = 0.958 recall = 0.976 f1 = 0.967 time_cost = 0.4507319927215576 INFO: 11-30 15:19:48: custom_dynamic_trainer.py:138 * 139681516312320 eval step = 14 INFO: 11-30 15:19:48: custom_dynamic_trainer.py:103 * 139681516312320 Final test result: DEBUG: 11-30 15:19:49: ernie_fc_ie_many_to_many.py:261 * 139681516312320 phase = test precision = 0.958 recall = 0.976 f1 = 0.967 time_cost = 0.44904589653015137 INFO: 11-30 15:19:49: custom_dynamic_trainer.py:138 * 139681516312320 eval step = 14使用预置网络进行预测的方式为使用./run_infer.py入口脚本,通过--param_path参数来传入./examples/目录下的json配置文件。预测分为以下几个步骤:基于示例的数据集,可以运行以下命令在预测集(predict.txt)上进行预测:预测运行的日志会自动保存在./output/predict_result.txt文件中。以属性抽取数据集的预测为例:预测的配置文件配置文件:./examples/many_to_many_ie_attribute_ernie_fc_ch_infer.json在配置文件./examples/many_to_many_ie_attribute_ernie_fc_ch_infer.json中需要更改 inference.inference_model_path 为上面训练过程中所保存的预测模型的路径{ "dataset_reader": { "predict_reader": { "name": "predict_reader", "type": "IEReader", "fields": [], "config": { "data_path": "./data/entity_attribute_data/predict_data/", "shuffle": false, "batch_size": 2, "epoch": 1, "sampling_rate": 1.0, "extra_params": { "vocab_path": "../../models_hub/ernie_3.0_base_ch_dir/vocab.txt", "label_map_config": "./dict/entity_attribute_label_map.json", "num_labels": 12, "max_seq_len": 512, "do_lower_case":true, "in_tokens":false, "tokenizer": "FullTokenizer", "need_data_distribute": false, "need_generate_examples": true "inference": { "output_path": "./output/predict_result.txt", #输出文件路径 "label_map_config": "./dict/entity_attribute_label_map.json", "PADDLE_PLACE_TYPE": "gpu", "inference_model_path": "./output/ie_attribute_ernie_3.0_base_fc_ch/save_inference_model/inference_step_1000", #加载推理模型 "extra_param": { "meta": { "job_type": "information_extraction" }3.2 关系抽取模型训练&预测# 训练关系抽取 !python run_trainer.py --param_path ./examples/many_to_many_ie_relation_ernie_fc_ch.json # 训练运行的日志会自动保存在./log/test.log文件中; # 训练中以及结束后产生的模型文件会默认保存在./output/目录下,其中save_inference_model/文件夹会保存用于预测的模型文件,save_checkpoint/文件夹会保存用于热启动的模型文件 部分结果展示:DEBUG: 11-30 16:09:37: ernie_fc_ie_many_to_many.py:261 * 140264317826816 phase = test precision = 0.953 recall = 0.968 f1 = 0.96 time_cost = 0.7550814151763916 INFO: 11-30 16:09:37: custom_dynamic_trainer.py:138 * 140264317826816 eval step = 50 INFO: 11-30 16:09:41: dynamic_trainer.py:170 * 140264317826816 save path: ./output/ie_relation_ernie_3.0_medium/save_inference_model/inference_step_2500 INFO: 11-30 16:09:42: custom_dynamic_trainer.py:103 * 140264317826816 Final test result: DEBUG: 11-30 16:09:43: ernie_fc_ie_many_to_many.py:261 * 140264317826816 phase = test precision = 0.953 recall = 0.968 f1 = 0.96 time_cost = 0.883291482925415 INFO: 11-30 16:09:43: custom_dynamic_trainer.py:138 * 140264317826816 eval step = 50部分结果:"text": "杨力革,男,汉族,1966年4月生,湖南益阳人,1987年7月参加工作,1992年10月入党,在职研究生学历(2004年7月新疆自治区党委党校领导干部研究生班工商管理专业毕业)", "spo_list": [ "predicate": "出生地", "subject": [ "object": [ "predicate": "出生日期", "subject": [ "object": [ ]4.总结本项目讲解了基于ERNIE信息抽取技术,对属性和关系的抽取涉及多对多抽取,主要是使用可ERNIEKIT组件,整体效果非常不错,当然追求小样本学习的可以参考之前UIE项目或者去官网看看paddlenlp最新的更新,对训练和部署进行了提速。模型任务precisionrecallf1ernie_3.0_medium属性抽取0.9580.9760.967ernie_3.0_medium关系抽取0.9530.9680.96
PGL图学习项目合集&数据集分享&技术归纳业务落地技巧[系列十]
PGL图学习项目合集&数据集分享&技术归纳业务落地技巧[系列十]1.PGL图学习项目合集1.1 关于图计算&图学习的基础知识概览:前置知识点学习(PGL)[系列一] :https://aistudio.baidu.com/aistudio/projectdetail/4982973?contributionType=1本项目对图基本概念、关键技术(表示方法、存储方式、经典算法),应用等都进行详细讲解,并在最后用程序实现各类算法方便大家更好的理解。当然之后所有图计算相关都是为了知识图谱构建的前置条件1.2 图机器学习(GML)&图神经网络(GNN)原理和代码实现(前置学习系列二)https://aistudio.baidu.com/aistudio/projectdetail/4990947?contributionType=1现在已经覆盖了图的介绍,图的主要类型,不同的图算法,在Python中使用Networkx来实现它们,以及用于节点标记,链接预测和图嵌入的图学习技术,最后讲了GNN分类应用以及未来发展方向!1.3 图学习初探Paddle Graph Learning 构建属于自己的图【系列三】 https://aistudio.baidu.com/aistudio/projectdetail/5000517?contributionType=1本项目主要讲解了图学习的基本概念、图的应用场景、以及图算法,最后介绍了PGL图学习框架并给出demo实践,过程中把老项目demo修正版本兼容问题等小坑,并在最新版本运行便于后续同学更有体验感1.4 PGL图学习之图游走类node2vec、deepwalk模型[系列四]https://aistudio.baidu.com/aistudio/projectdetail/5002782?contributionType=1介绍了图嵌入原理以及了图嵌入中的DeepWalk、node2vec算法,利用pgl对DeepWalk、node2vec进行了实现,并给出了多个框架版本的demo满足个性化需求。图学习【参考资料1】词向量word2vec https://aistudio.baidu.com/aistudio/projectdetail/5009409?contributionType=1介绍词向量word2evc概念,及CBOW和Skip-gram的算法实现。图学习【参考资料2】-知识补充与node2vec代码注解https://aistudio.baidu.com/aistudio/projectdetail/5012408?contributionType=1主要引入基本的同构图、异构图知识以及基本概念;同时对deepWalk代码的注解以及node2vec、word2vec的说明总结;(以及作业代码注解)1.5 PGL图学习之图游走类metapath2vec模型[系列五]https://aistudio.baidu.com/aistudio/projectdetail/5009827?contributionType=1介绍了异质图,利用pgl对metapath2vec以及metapath2vec变种算法进行了实现,同时讲解实现图分布式引擎训练,并给出了多个框架版本的demo满足个性化需求。1.6 PGL图学习之图神经网络GNN模型GCN、GAT[系列六] [https://aistudio.baidu.com/aistudio/projectdetail/5054122?contributionType=1](https://aistudio.baidu.com/aistudio/projectdetail/5054122?contributionType=1)本次项目讲解了图神经网络的原理并对GCN、GAT实现方式进行讲解,最后基于PGL实现了两个算法在数据集Cora、Pubmed、Citeseer的表现,在引文网络基准测试中达到了与论文同等水平的指标。1.7 PGL图学习之图神经网络GraphSAGE、GIN图采样算法[系列七] https://aistudio.baidu.com/aistudio/projectdetail/5061984?contributionType=1本项目主要讲解了GraphSage、PinSage、GIN算法的原理和实践,并在多个数据集上进行仿真实验,基于PGl实现原论文复现和对比,也从多个角度探讨当前算法的异同以及在工业落地的技巧等。1.8 PGL图学习之图神经网络ERNIESage、UniMP进阶模型[系列八]https://aistudio.baidu.com/aistudio/projectdetail/5096910?contributionType=1ErnieSage 可以同时建模文本语义与图结构信息,有效提升 Text Graph 的应用效果;UniMP 在概念上统一了特征传播和标签传播, 在OGB取得了优异的半监督分类结果。PGL图学习之ERNIESage算法实现(1.8x版本)【系列八】https://aistudio.baidu.com/aistudio/projectdetail/5097085?contributionType=1ERNIESage运行实例介绍(1.8x版本),提供多个版本pgl代码实现1.9 PGL图学习之项目实践(UniMP算法实现论文节点分类、新冠疫苗项目)[系列九]https://aistudio.baidu.com/aistudio/projectdetail/5100049?contributionType=1本项目借鉴了百度高研黄正杰大佬对图神经网络技术分析以及图算法在业务侧应用落地;实现了论文节点分类和新冠疫苗项目的实践帮助大家更好理解学习图的魅力。PGL图学习之基于GNN模型新冠疫苗任务[系列九]https://aistudio.baidu.com/aistudio/projectdetail/5123296?contributionType=1图神经网络7日打卡营的新冠疫苗项目拔高实战PGL图学习之基于UniMP算法的论文引用网络节点分类任务[系列九]https://aistudio.baidu.com/aistudio/projectdetail/5116458?contributionType=1基于UniMP算法的论文引用网络节点分类,在调通UniMP之后,后续尝试的技巧对于其精度的提升效力微乎其微,所以不得不再次感叹百度PGL团队的强大!༄ℳ持续更新中ꦿོ࿐2.图网络开放数据集按照任务分类,可以把数据集分成以下几类:引文网络生物化学图社交网络知识图谱开源数据集仓库2.1 引文网络1. Pubmed/Cora/Citeseer|这三个数据集均来自于:《Collective classification in network data》引文网络,节点为论文、边为论文间的引用关系。这三个数据集通常用于链路预测或节点分类。数据下载链接:https://aistudio.baidu.com/aistudio/datasetdetail/177587https://aistudio.baidu.com/aistudio/datasetdetail/177589https://aistudio.baidu.com/aistudio/datasetdetail/177591INQS 实验室使用的数据集和所有展示的关系结构,数据集链接:https://linqs.org/datasets/2. DBLPDBLP是大型的计算机类文献索引库。原始的DBLP只是XML格式,清华唐杰教授的一篇论文将其进行处理并获得引文网络数据集。到目前为止已经发展到了第13个版本。DBLP引用网络论文:《ArnetMiner: Extraction and Mining of Academic Social Networks》原始数据可以从这里获得:https://dblp.uni-trier.de/xml/如果是想找处理过的DBLP引文网络数据集,可以从这里获得:https://www.aminer.cn/citation2.2 生物化学图1. PPI蛋白质-蛋白质相互作用(protein-protein interaction, PPI)是指两个或两个以上的蛋白质分子通过非共价键形成 蛋白质复合体(protein complex)的过程。PPI数据集中共有24张图,其中训练用20张,验证/测试分别2张。节点最多可以有121种标签(比如蛋白质的一些性质、所处位置等)。每个节点有50个特征,包含定位基因集合、特征基因集合以及免疫特征。PPI论文:《Predicting multicellular function through multi-layer tissue networks》PPI下载链接:http://snap.stanford.edu/graph2. NCI-1NCI-1是关于化学分子和化合物的数据集,节点代表原子,边代表化学键。NCI-1包含4100个化合物,任务是判断该化合物是否有阻碍癌细胞增长的性质。NCI-1论文:《Comparison of descriptor spaces for chemical compound retrieval and classification》Graph Kernel Datasets提供下载3. MUTAGMUTAG数据集包含188个硝基化合物,标签是判断化合物是芳香族还是杂芳族。MUTAG论文:《Structure-activity relationship of mutagenic aromatic and heteroaromatic nitro compounds. correlation with molecular orbital energies and hydrophobicity》https://aistudio.baidu.com/aistudio/datasetdetail/1775914. D&D/PROTEIND&D在蛋白质数据库的非冗余子集中抽取了了1178个高分辨率蛋白质,使用简单的特征,如二次结构含量、氨基酸倾向、表面性质和配体;其中节点是氨基酸,如果两个节点之间的距离少于6埃(Angstroms),则用一条边连接。PROTEIN则是另一个蛋白质网络。任务是判断这类分子是否酶类。D&D论文:《Distinguishing enzyme structures from non-enzymes without alignments》D&D下载链接:https://github.com/snap-stanford/GraphRNN/tree/master/dataset/DDPROTEIN论文:《Protein function prediction via graph kernels》Graph Kernel Datasets提供下载5. PTCPTC全称是预测毒理学挑战,用来发展先进的SAR技术预测毒理学模型。这个数据集包含了针对啮齿动物的致癌性标记的化合物。根据实验的啮齿动物种类,一共有4个数据集:PTC_FM(雌性小鼠)PTC_FR(雌性大鼠)PTC_MM(雄性小鼠)PTC_MR(雄性大鼠)PTC论文:《Statistical evaluation of the predictive toxicology challenge 2000-2001》Graph Kernel Datasets提供下载6. QM9 这个数据集有133,885个有机分子,包含几何、能量、电子等13个特征,最多有9个非氢原子(重原子)。来自GDB-17数据库。QM9论文:《Quantum chemistry structures and properties of 134 kilo molecules》QM9下载链接:http://quantum-machine.org/datasets/7. AlchemyAlchemy包含119,487个有机分子,其有12个量子力学特征(quantum mechanical properties),最多14个重原子(heavy atoms),从GDB MedChem数据库中取样。扩展了现有分子数据集多样性和容量。Alchemy论文:《Alchemy: A quantum chemistry dataset for benchmarking ai models》Alchemy下载链接:https://alchemy.tencent.com/2.3 社交网络1. RedditReddit数据集是由来自Reddit论坛的帖子组成,如果两个帖子被同一人评论,那么在构图的时候,就认为这两个帖子是相关联的,标签是每个帖子对应的社区分类。Reddit论文:《Inductive representation learning on large graphs》Reddit下载链接:https://aistudio.baidu.com/aistudio/datasetdetail/177810https://github.com/linanqiu/reddit-datasetBlogCatalogBlogCatalog数据集是一个社会关系网络,图是由博主及其社会关系(比如好友)组成,标签是博主的兴趣爱好。2.BlogCatalog论文:《Relational learning via latent social dimensions》BlogCatalog下载链接:http://socialcomputing.asu.edu2.4 知识图谱1.FB13/FB15K/FB15K237这三个数据集是Freebase的子集。其中:FB13:包含13种关系、75043个实体。FB15K:包含1345种关系、14951个实体FB15K237:包含237种关系、14951个实体如果希望找到entity id对应的实体数据,可以通过以下渠道(并不是所有的实体都能找到):https://developers.google.com/freebase/#freebase-wikidata-mappingshttp://sameas.org/2.WN11/WN18/WN18RR这三个是WordNet的子集:WN11:包含11种关系、38696个实体WN18:包含18种关系、40943个实体WN18RR:包含11种关系、40943个实体为了避免在评估模型时出现inverse relation test leakage,建议使用FB15K237/WN18RR来替代FB15K/WN18。更多建议阅读《Convolutional 2D Knowledge Graph Embeddings》FB15K/WN8论文:《Translating Embeddings for Modeling Multi-relational Data》FB13/WN11论文:《Reasoning With Neural Tensor Networks for Knowledge Base Completion》WN18RR论文:《Convolutional 2D Knowledge Graph Embeddings》以上6个知识图谱数据集均可从这里下载:https://github.com/thunlp/OpenKE/tree/master/benchmarks2.5 开源数据仓库1. Network Repository具有交互式可视化和挖掘工具的图数据仓库。具有以下特点:用表格的形式展示每一个图数据集的节点数、遍数、平均度数、最大度数等。可视化对比图数据集之间的参数。在线GraphVis,可视化图结构和详细参数。2. Graph Kernel Datasets图核的基准数据集。提供了一个表格,可以快速得到每个数据集的节点数量、类别数量、是否有节点/边标签、节点/边特征。https://ls11-www.cs.tu-dortmund.de/staff/morris/graphkerneldatasetshttps://chrsmrrs.github.io/datasets/3. Relational Dataset Repository关系机器学习的数据集集合。能够以数据集大小、领域、数据类型等条件来检索数据集。https://relational.fit.cvut.czhttps://relational.fit.cvut.cz/search?domain%5B%5D=Industry4. Stanford Large Network Dataset CollectionSNAP库用于大型社交、信息网络。包括:图分类数据库、社交网络、引用网络、亚马逊网络等等,非常丰富。https://snap.stanford.edu/data/5.Open Graph BenchmarkOGB是真实基准数据集的集合,同时提供数据加载器和评估器(PyTorch)。可以自动下载、处理和切割;完全兼容PyG和DGL。https://ogb.stanford.edu/这个大家就比较熟悉了,基本最先进的图算法都是依赖OGB的数据集验证的。௸持续更新敬请期待~ೄ೨✿3.图学习相关技术归纳3.1 GraphSAGE为例技术归纳GCN和GraphSAGE区别GCN灵活性差、为新节点产生embedding要求 额外的操作 ,比如“对齐”:GCN是 直推式(transductive) 学习,无法直接泛化到新加入(未见过)的节点;GraphSAGE是 归纳式(inductive) 学习,可以为新节点输出节点特征。GCN输出固定:GCN输出的是节点 唯一确定 的embedding;GraphSAGE学习的是节点和邻接节点之间的关系,学习到的是一种映射关系 ,节点的embedding可以随着其邻接节点的变化而变化。GCN很难应用在超大图上:无论是拉普拉斯计算还是图卷积过程,因为GCN其需要对 整张图 进行计算,所以计算量会随着节点数的增加而递增。GraphSAGE通过采样,能够形成 minibatch 来进行批训练,能用在超大图上。2.GraphSAGE等模型优点:采用 归纳学习 的方式,学习邻居节点特征关系,得到泛化性更强的embedding;采样技术,降低空间复杂度,便于构建minibatch用于 批训练 ,还让模型具有更好的泛化性;多样的聚合函数 ,对于不同的数据集/场景可以选用不同的聚合方式,使得模型更加灵活。GraphSAGE的基本思路是:利用一个 聚合函数 ,通过 采样 和学习聚合节点的局部邻居特征,来为节点产生embedding。3.跳数(hops)、搜索深度(search depth)、阶数(order)有啥区别?我们经常听到一阶邻居、二阶邻居,1-hops、2-hops等等,其实他们都是一个概念,就是该节点和目标节点的路径长度,如果路径长度是1,那就是一阶邻接节点、1-hops node。 搜索深度其实和深度搜索的深度的概念相似,也是用路径长度来衡量。 简单来说,这几个概念某种程度上是等价。 在GraphSAGE中,还有聚合层数\迭代次数,比如说只考虑了一阶邻接节点,那就只有一层聚合(迭代了一次),以此类推。4.采样有什么好处于对计算效率的考虑,对每个节点采样一定数量的邻接节点作为待聚合信息的节点。从训练效率考虑:通过采样,可以得到一个 固定大小 的领域集,可以拼成一个batch,送到GPU中进行批训练。从复杂度角度考虑:如果没有采样,单个batch的内存使用和预期运行时间是 不可预测 的;最坏的情况是,即所有的节点都是目标节点的邻接节点。而GraphSAGE的每个batch的空间和时间复杂度都是 固定 的其中K是指层数,也就是要考虑多少阶的邻接节点,是在第i层采样的数量。5.采样数大于邻接节点数怎么办?设采样数量为K:若节点邻居数少于K,则采用 有放回 的抽样方法,直到采样出K个节点。若节点邻居数大于K,则采用 无放回 的抽样。关于邻居的个数,文中提到,即两次扩展的邻居数之积小于500,大约每次只需要扩展20来个邻居时获得较高的性能。实验中也有关于邻居采样数量的对比,如下图,随着邻居抽样数量的递增,边际效益递减,而且计算时间也会增大。6.每一跳采样需要一样吗?不需要,可以分别设置每一跳的采样数量,来进一步缓解因 阶数越高涉及到的节点越多 的问题。原文中,一阶采样数是25,二阶采样数是10。这时候二阶的节点总数是250个节点,计算量大大增加。7.聚合函数的选取有什么要求?由于在图中节点的邻居是 天然无序 的,所以我们希望构造出的聚合函数是 对称 的(即改变输入的顺序,函数的输出结果不变),同时具有 较强的表达能力 (比如可以参数学习)。8.GraphSAGE论文中提供多少种聚合函数?原文中提供三种聚合函数:均值聚合pooling聚合(max-pooling/mean-pooling)LSTM聚合均值聚合的操作:把目标节点和邻居节点的特征 纵向拼接 起来 ;对拼接起来的向量进行 纵向均值化 操作 将得到的结果做一次 非线性变换 产生目标节点的向量表征。pooling聚合的操作:先对邻接节点的特征向量进行一次非线性变换;之后进行一次pooling操作(max-pooling or mean-pooling) ;将得到结果与第k-1层的目标节点的表示向量拼接 ;最后再经过一次非线性变换得到目标节点的第k层表示向量。使用LSTM聚合时需要注意什么?复杂结构的LSTM相比简单的均值操作具有更强的表达能力,然而由于LSTM函数 不是关于输入对称 的,所以在使用时需要对节点的邻居进行 乱序操作 。9.均值聚合和其他聚合函数有啥区别?除了聚合方式,最大的区别在于均值聚合 没有拼接操作 (算法1的第五行),也就是均值聚合不需要把 当前节点上一层的表征 拼接到 已聚合的邻居表征上。这一拼接操作可以简单看成不同“搜索深度”之间的“ skip connection ”(残差结构),并且能够提供显著的性能提升。10 这三种聚合方法,哪种比较好?如果按照其学习参数数量来看,LSTM > Pooling > 均值聚合。而在实验中也发现,在Reddit数据集中,LSTM和max-pooling的效果确实比均值聚合要好一些。11.一般聚合多少层?层数越多越好吗?和GCN一样,一般只需要 1~2层 就能获得比较好的结果;如果聚合3层及以上,其时间复杂度也会随着层数的增加而大幅提升,而且效果并没有什么变化。在GraphSAGE,两层比一层有10-15%的提升;但将层数设置超过2,边际效果上只有0-5%的提升,但是计算时间却变大了10-100倍。12.什么时候和GCN的聚合形式“等价”?聚合函数为 均值聚合 时,其聚合形式与GCN“近似等价”,也就是论文中提到的GraphSAGE-GCN。13.GraphSAGE怎样进行无监督学习?基本思想是:希望 邻近 的节点具有相似的向量表征,同时让 远处 的节点的表示尽可能区分。通过负采样的方法,把邻近节点作为正样本,把远处节点作为负样本,使用类似word2vec的方法进行无监督训练。GraphSAGE远近节点定义:从 节点u 出发,能够通过 随机游走 到达的节点,则是邻近节点v;其他则是远处节点 。13.GraphSAGE是怎么随机游走的?在原文中,为每个节点进行50次步长为5的随机游走,随机游走的实现方式是直接使用DeepWalk的Python代码。至于具体的实现,可以针对数据集来设计你的随机游走算法,比如考虑了权重的有偏游走。GraphSAGE在采样的时候和(带权)随机游走进行负采样的时候,考虑边的权重了。14.如果只有图、没有节点特征,能否使用GraphSAGE?原文里有一段描述:our approach can also make use of structural features that are present in all graphs (e.g., node degrees). Thus, our algorithm can also be applied to graphs without node features.所以就节点没有特征,但也可以根据其结构信息为其构建特征,比如说节点的度数等等15.训练好的GraphSAGE如何得到节点Embedding?假设GraphSAGE已经训练好,我们可以通过以下步骤来获得节点embedding训练过程则只需要将其产生的embedding扔进损失函数计算并反向梯度传播即可。对图中每个节点的邻接节点进行 采样 ,输入节点及其n阶邻接节点的特征向量根据K层的 聚合函数 聚合邻接节点的信息就产生了各节点的embedding16.minibatch的子图是怎么得到的?其实这部分看一下源码就容易理解了。下图的伪代码,就是在其前向传播之前,多了个minibatch的操作。先对所有需要计算的节点进行采样(算法2中的2~7行)。用一个字典来保存节点及其对应的邻接节点。然后训练时随机挑选n个节点作为一个batch,然后通过字典找到对应的一阶节点,进而找到二阶甚至更高阶的节点。这样一阶节点就形成一个batch,K=2时就有三个batch。抽样时的顺序是:k-->k-1--->k-2;训练时,使用迭代的方式来聚合,其顺序是:k-2-->k-1--->k。简单来说,从上到下采样,形成每一层的batch;每一次迭代都从下到上,计算k-1层batch来获得k层的节点embedding,如此类推。每一个minibatch只考虑batch里的节点的计算,不在的不考虑,所以这也是节省计算方法。在算法2的第3行中,k-1<----k,也就是说采样邻居节点时,也考虑了自身节点的信息。相当于GCN中邻接矩阵增加单位矩阵。增加了新的节点来训练,需要为所有“旧”节点重新输出embeding吗?需要。因为GraphSAGE学习到的是节点间的关系,而增加了新节点的训练,这会使得关系参数发生变化,所以旧节点也需要重新输出embedding。GraphSAGE有监督学习有什么不一样的地方吗?没有。监督学习形式根据任务的不同,直接设置目标函数即可,如最常用的节点分类任务使用交叉熵损失函数。17.那和DeepWalk、Node2vec这些有什么不一样?DeepWalk、Node2Vec这些embedding算法直接训练每个节点的embedding,本质上依然是直推式学习,而且需要大量的额外训练才能使他们能预测新的节点。同时,对于embedding的正交变换(orthogonal transformations),这些方法的目标函数是不变的,这意味着生成的向量空间在不同的图之间不是天然泛化的,在再次训练(re-training)时会产生漂移(drift)。与DeepWalk不同的是,GraphSAGE是通过聚合节点的邻接节点特征产生embedding的,而不是简单的进行一个embedding lookup操作得到。3.2 PinSAGE为例技术归纳1.PinSAGE论文中的数据集有多大?论文中涉及到的数据为20亿图片(pins),10亿画板(boards),180亿边(pins与boards连接关系)。用于训练、评估的完整数据集大概有18TB,而完整的输出embedding有4TB。2.PinSAGE使用的是什么图?在论文中,pins集合(用I表示)和boards集合(用C表示)构成了 二分图 ,即pins仅与boards相连接,pins或boards内部无连接。同时,这二分图可以更加通用:I 可以表示为 样本集 (a set of items),C 可以表示为 用户定义的上下文或集合 (a set of user-defined contexts or collections)。3.PinSAGE的任务是什么?利用pin-board 二分图的结构与节点特征 ,为pin生成高质量的embedding用于下游任务,比如pins推荐。4.和GraphSAGE相比,PinSAGE改进了什么?采样 :使用重要性采样替代GraphSAGE的均匀采样;聚合函数 :聚合函数考虑了边的权重;生产者-消费者模式的minibatch构建 :在CPU端采样节点和构建特征,构建计算图;在GPU端在这些子图上进行卷积运算;从而可以低延迟地随机游走构建子图,而不需要把整个图存在显存中。高效的MapReduce推理 :可以分布式地为百万以上的节点生成embedding,最大化地减少重复计算。这里的计算图,指的是用于卷积运算的局部图(或者叫子图),通过采样来形成;与TensorFlow等框架的计算图不是一个概念。4.PinSAGE使用多大的计算资源?训练时,PinSAGE使用32核CPU、16张Tesla K80显卡、500GB内存;推理时,MapReduce运行在378个d2.8xlarge Amazon AWS节点的Hadoop2集群。落地业务真的可怕:PinSAGE和node2vec、DeepWalk这些有啥区别?node2vec,DeepWalk是无监督训练;PinSAGE是有监督训练;node2vec,DeepWalk不能利用节点特征;PinSAGE可以;node2vec,DeepWalk这些模型的参数和节点数呈线性关系,很难应用在超大型的图上;6.PinSAGE的单层聚合过程是怎样的?和GraphSAGE一样,PinSAGE的核心就是一个 局部卷积算子 ,用来学习如何聚合邻居节点信息。PinSAGE的聚合函数叫做CONVOLVE。主要分为3部分:聚合 (第1行):k-1层邻居节点的表征经过一层DNN,然后聚合(可以考虑边的权重),是聚合函数符号,聚合函数可以是max/mean-pooling、加权求和、求平均;更新 (第2行): 拼接 第k-1层目标节点的embedding,然后再经过另一层DNN,形成目标节点新的embedding;归一化 (第3行): 归一化 目标节点新的embedding,使得训练更加稳定;而且归一化后,使用近似最近邻居搜索的效率更高。为什么要将邻居节点的聚合embedding和当前节点的拼接?因为根据T.N Kipf的GCN论文,concat的效果要比直接取平均更好。7.PinSAGE是如何采样的?如何采样这个问题从另一个角度来看就是:如何为目标节点构建邻居节点。和GraphSAGE的均匀采样不一样的是,PinSAGE使用的是重要性采样。PinSAGE对邻居节点的定义是:对目标节点 影响力最大 的T个节点。PinSAGE的邻居节点的重要性其影响力的计算方法有以下步骤:从目标节点开始随机游走;使用 正则 来计算节点的“访问次数”,得到重要性分数;目标节点的邻居节点,则是重要性分数最高的前T个节点。这个重要性分数,其实可以近似看成Personalized PageRank分数。8.重要性采样的好处是什么?和GraphSAGE一样,可以使得 邻居节点的数量固定 ,便于控制内存/显存的使用。在聚合邻居节点时,可以考虑节点的重要性;在PinSAGE实践中,使用的就是 加权平均 (weighted-mean),原文把它称作 importance pooling 。9.采样的大小是多少比较好?从PinSAGE的实验可以看出,随着邻居节点的增加,而收益会递减;并且两层GCN在 邻居数为50 时能够更好的抓取节点的邻居信息,同时保持运算效率。10.PinSAGE的minibatch和GraphSAGE区别:基本一致,但细节上有所区别。比如说:GraphSAGE聚合时就更新了embedding;PinSAGE则在聚合后需要再经过一层DNN才更新目标embedding。batch应该选多大毕竟要在大量的样本上进行训练(有上亿个节点),所以原文里使用的batch比较大,大小为512~4096。从下面表格可以看到, batch的大小为2048 时,能够在每次迭代时间、迭代次数和总训练时间上取得一个不错的综合性能。更多的就不展开了4.业务落地技巧负样本生成 首先是简单采样:在每个minibatch包含节点的范围之外随机采样500个item作为minibatch所有正样本共享的负样本集合。但考虑到实际场景中模型需要从20亿的物品item集合中识别出最相似的1000个,即要从2百万中识别出最相似的那一个,只是简单采样会导致模型分辨的粒度过粗,分辨率只到500分之一,因此增加一种“hard”负样本,即对于每个 对,和物品q有些相似但和物品i不相关的物品集合。这种样本的生成方式是将图中节点根据相对节点q的个性化PageRank分值排序,随机选取排序位置在2000~5000的物品作为“hard”负样本,以此提高模型分辨正负样本的难度。渐进式训练(Curriculum training):如果训练全程都使用hard负样本,会导致模型收敛速度减半,训练时长加倍,因此PinSage采用了一种Curriculum训练的方式,这里我理解是一种渐进式训练方法,即第一轮训练只使用简单负样本,帮助模型参数快速收敛到一个loss比较低的范围;后续训练中逐步加入hard负样本,让模型学会将很相似的物品与些微相似的区分开,方式是第n轮训练时给每个物品的负样本集合中增加n-1个hard负样本。样本的特征信息:Pinterest的业务场景中每个pin通常有一张图片和一系列的文字标注(标题,描述等),因此原始图中每个节点的特征表示由图片Embedding(4096维),文字标注Embedding(256维),以及节点在图中的度的log值拼接而成。其中图片Embedding由6层全连接的VGG-16生成,文字标注Embedding由Word2Vec训练得到。基于random walk的重要性采样:用于邻居节点采样,这一技巧在上面的算法理解部分已经讲解过,此处不再赘述。基于重要性的池化操作:这一技巧用于上一节Convolve算法中的 函数中,聚合经过一层dense层之后的邻居节点Embedding时,基于random walk计算出的节点权重做聚合操作。据论文描述,这一技巧在离线评估指标中提升了46%。on-the-fly convolutions:快速卷积操作,这个技巧主要是相对原始GCN中的卷积操作:特征矩阵与全图拉普拉斯矩阵的幂相乘。涉及到全图的都是计算量超高,这里GraphSage和PinSage都是一致地使用采样邻居节点动态构建局部计算图的方法提升训练效率,只是二者采样的方式不同。生产者消费者模式构建minibatch:这个点主要是为了提高模型训练时GPU的利用率。保存原始图结构的邻居表和数十亿节点的特征矩阵只能放在CPU内存中,GPU执行convolve卷积操作时每次从CPU取数据是很耗时的。为了解决这个问题,PinSage使用re-index技术创建当前minibatch内节点及其邻居组成的子图,同时从数十亿节点的特征矩阵中提取出该子图节点对应的特征矩阵,注意提取后的特征矩阵中的节点索引要与前面子图中的索引保持一致。这个子图的邻接列表和特征矩阵作为一个minibatch送入GPU训练,这样一来,convolve操作过程中就没有GPU与CPU的通信需求了。训练过程中CPU使用OpenMP并设计了一个producer-consumer模式,CPU负责提取特征,re-index,负采样等计算,GPU只负责模型计算。这个技巧降低了一半的训练耗时。多GPU训练超大batch:前向传播过程中,各个GPU等分minibatch,共享一套参数,反向传播时,将每个GPU中的参数梯度都聚合到一起,执行同步SGD。为了适应海量训练数据的需要,增大batchsize从512到4096。为了在超大batchsize下快速收敛保证泛化精度,采用warmup过程:在第一个epoch中将学习率线性提升到最高,后面的epoch中再逐步指数下降。使用MapReduce高效推断:模型训练完成后生成图中各个节点的Embedding过程中,如果直接使用上述PinSage的minibatch算法生成Embedding,会有大量的重复计算,如计算当前target节点的时候,其相当一部分邻居节点已经计算过Embedding了,而当这些邻居节点作为target节点的时候,当前target节点极有可能需要再重新计算一遍,这一部分的重复计算既耗时又浪费。5.总结本项目对PGL图学习系列项目进行整合方便大家后续学习,同时对图学习相关技术和业务落地侧进行归纳总结,以及对图网络开放数据集很多学者和机构发布了许多与图相关的任务。༄ℳ后续将持续更新PGL以及前沿算法和应用,敬请期待! ꦿོ࿐个人主页:https://aistudio.baidu.com/aistudio/usercenter 欢迎关注
PGL图学习之图神经网络GraphSAGE、GIN图采样算法[系列七]
0. PGL图学习之图神经网络GraphSAGE、GIN图采样算法[系列七]本项目链接:https://aistudio.baidu.com/aistudio/projectdetail/5061984?contributionType=1相关项目参考:更多资料见主页关于图计算&图学习的基础知识概览:前置知识点学习(PGL)[系列一] https://aistudio.baidu.com/aistudio/projectdetail/4982973?contributionType=1图机器学习(GML)&图神经网络(GNN)原理和代码实现(前置学习系列二):https://aistudio.baidu.com/aistudio/projectdetail/4990947?contributionType=1在图神经网络中,使用的数据集可能是亿量级的数据,而由于GPU/CPU资源有限无法一次性全图送入计算资源,需要借鉴深度学习中的mini-batch思想。传统的深度学习mini-batch训练每个batch的样本之间无依赖,多层样本计算量固定;而在图神经网络中,每个batch中的节点之间互相依赖,在计算多层时会导致计算量爆炸,因此引入了图采样的概念。GraphSAGE也是图嵌入算法中的一种。在论文Inductive Representation Learning on Large Graphs 在大图上的归纳表示学习中提出。github链接和官方介绍链接。与node2vec相比较而言,node2vec是在图的节点级别上进行嵌入,GraphSAGE则是在整个图的级别上进行嵌入。之前的网络表示学习的transductive,难以从而提出了一个inductive的GraphSAGE算法。GraphSAGE同时利用节点特征信息和结构信息得到Graph Embedding的映射,相比之前的方法,之前都是保存了映射后的结果,而GraphSAGE保存了生成embedding的映射,可扩展性更强,对于节点分类和链接预测问题的表现也比较突出。0.1提出背景现存的方法需要图中所有的顶点在训练embedding的时候都出现;这些前人的方法本质上是transductive,不能自然地泛化到未见过的顶点。文中提出了GraphSAGE,是一个inductive的框架,可以利用顶点特征信息(比如文本属性)来高效地为没有见过的顶点生成embedding。GraphSAGE是为了学习一种节点表示方法,即如何通过从一个顶点的局部邻居采样并聚合顶点特征,而不是为每个顶点训练单独的embedding。这个算法在三个inductive顶点分类benchmark上超越了那些很强的baseline。文中基于citation和Reddit帖子数据的信息图中对未见过的顶点分类,实验表明使用一个PPI(protein-protein interactions)多图数据集,算法可以泛化到完全未见过的图上。0.2 回顾GCN及其问题在大型图中,节点的低维向量embedding被证明了作为各种各样的预测和图分析任务的特征输入是非常有用的。顶点embedding最基本的基本思想是使用降维技术从高维信息中提炼一个顶点的邻居信息,存到低维向量中。这些顶点嵌入之后会作为后续的机器学习系统的输入,解决像顶点分类、聚类、链接预测这样的问题。GCN虽然能提取图中顶点的embedding,但是存在一些问题:GCN的基本思想: 把一个节点在图中的高纬度邻接信息降维到一个低维的向量表示。GCN的优点: 可以捕捉graph的全局信息,从而很好地表示node的特征。GCN的缺点: Transductive learning的方式,需要把所有节点都参与训练才能得到node embedding,无法快速得到新node的embedding。1.图采样算法1.1 GraphSage: Representation Learning on Large Graphs图采样算法:顾名思义,图采样算法就是在一张图中进行采样得到一个子图,这里的采样并不是随机采样,而是采取一些策略。典型的图采样算法包括GraphSAGE、PinSAGE等。文章码源链接:https://cs.stanford.edu/people/jure/pubs/graphsage-nips17.pdfhttps://github.com/williamleif/GraphSAGE前面 GCN 讲解的文章中,我使用的图节点个数非常少,然而在实际问题中,一张图可能节点非常多,因此就没有办法一次性把整张图送入计算资源,所以我们应该使用一种有效的采样算法,从全图中采样出一个子图 ,这样就可以进行训练了。GraphSAGE与GCN对比:既然新增的节点,一定会改变原有节点的表示,那么为什么一定要得到每个节点的一个固定的表示呢?何不直接学习一种节点的表示方法。去学习一个节点的信息是怎么通过其邻居节点的特征聚合而来的。 学习到了这样的“聚合函数”,而我们本身就已知各个节点的特征和邻居关系,我们就可以很方便地得到一个新节点的表示了。GCN等transductive的方法,学到的是每个节点的一个唯一确定的embedding; 而GraphSAGE方法学到的node embedding,是根据node的邻居关系的变化而变化的,也就是说,即使是旧的node,如果建立了一些新的link,那么其对应的embedding也会变化,而且也很方便地学到。在了解图采样算法前,我们至少应该保证采样后的子图是连通的。例如上图图中,左边采样的子图就是连通的,右边的子图不是连通的。GraphSAGE的核心:GraphSAGE不是试图学习一个图上所有node的embedding,而是学习一个为每个node产生embedding的映射。 GraphSage框架中包含两个很重要的操作:Sample采样和Aggregate聚合。这也是其名字GraphSage(Graph SAmple and aggreGatE)的由来。GraphSAGE 主要分两步:采样、聚合。GraphSAGE的采样方式是邻居采样,邻居采样的意思是在某个节点的邻居节点中选择几个节点作为原节点的一阶邻居,之后对在新采样的节点的邻居中继续选择节点作为原节点的二阶节点,以此类推。文中不是对每个顶点都训练一个单独的embeddding向量,而是训练了一组aggregator functions,这些函数学习如何从一个顶点的局部邻居聚合特征信息(见图1)。每个聚合函数从一个顶点的不同的hops或者说不同的搜索深度聚合信息。测试或是推断的时候,使用训练好的系统,通过学习到的聚合函数来对完全未见过的顶点生成embedding。GraphSAGE 是Graph SAmple and aggreGatE的缩写,其运行流程如上图所示,可以分为三个步骤:对图中每个顶点邻居顶点进行采样,因为每个节点的度是不一致的,为了计算高效, 为每个节点采样固定数量的邻居根据聚合函数聚合邻居顶点蕴含的信息得到图中各顶点的向量表示供下游任务使用邻居采样的优点:极大减少计算量允许泛化到新连接关系,个人理解类似dropout的思想,能增强模型的泛化能力采样的阶段首先选取一个点,然后随机选取这个点的一阶邻居,再以这些邻居为起点随机选择它们的一阶邻居。例如下图中,我们要预测 0 号节点,因此首先随机选择 0 号节点的一阶邻居 2、4、5,然后随机选择 2 号节点的一阶邻居 8、9;4 号节点的一阶邻居 11、12;5 号节点的一阶邻居 13、15聚合具体来说就是直接将子图从全图中抽离出来,从最边缘的节点开始,一层一层向里更新节点上图展示了邻居采样的优点,极大减少训练计算量这个是毋庸置疑的,泛化能力增强这个可能不太好理解,因为原本要更新一个节点需要它周围的所有邻居,而通过邻居采样之后,每个节点就不是由所有的邻居来更新它,而是部分邻居节点,所以具有比较强的泛化能力。1.1.1 论文角度看GraphSage聚合函数的选取在图中顶点的邻居是无序的,所以希望构造出的聚合函数是对称的(即也就是对它输入的各种排列,函数的输出结果不变),同时具有较高的表达能力。 聚合函数的对称性(symmetry property)确保了神经网络模型可以被训练且可以应用于任意顺序的顶点邻居特征集合上。a. Mean aggregator :mean aggregator将目标顶点和邻居顶点的第$k−1$层向量拼接起来,然后对向量的每个维度进行求均值的操作,将得到的结果做一次非线性变换产生目标顶点的第$k$层表示向量。卷积聚合器Convolutional aggregator:文中用下面的式子替换算法1中的4行和5行得到GCN的inductive变形:$$ \mathbf{h}_{v}^{k} \leftarrow \sigma\left(\mathbf{W} \cdot \operatorname{MEAN}\left(\left\{\mathbf{h}_{v}^{k-1}\right\} \cup\left\{\mathbf{h}_{u}^{k-1}, \forall u \in \mathcal{N}(v)\right\}\right)\right) $$ 原始算法1中的第4,5行是 $$\begin{array}{l} \mathbf{h}_{\mathcal{N}(v)}^{k} \leftarrow \operatorname{AGGREGATE}_{k}\left(\left\{\mathbf{h}_{u}^{k-1}, \forall u \in \mathcal{N}(v)\right\}\right) \\ \mathbf{h}_{v}^{k} \leftarrow \sigma\left(\mathbf{W}^{k} \cdot \operatorname{CONCAT}\left(\mathbf{h}_{v}^{k-1}, \mathbf{h}_{\mathcal{N}(v)}^{k}\right)\right) \end{array}$$ **论文提出的均值聚合器Mean aggregator:** $$\begin{array}{l} \mathbf{h}_{v}^{k} \leftarrow \sigma\left(\mathbf{W} \cdot \operatorname{MEAN}\left(\left\{\mathbf{h}_{v}^{k-1}\right\} \cup\left\{\mathbf{h}_{u}^{k-1}, \forall u \in \mathcal{N}(v)\right\}\right)\right) \\ \mathbf{h}_{v}^{k} \leftarrow \sigma\left(\mathbf{W}^{k} \cdot \operatorname{CONCAT}\left(\mathbf{h}_{v}^{k-1}, \mathbf{h}_{\mathcal{N}(v)}^{k}\right)\right) \end{array}$$ * 均值聚合近似等价在transducttive GCN框架中的卷积传播规则 * 这个修改后的基于均值的聚合器是convolutional的。但是这个卷积聚合器和文中的其他聚合器的重要不同在于它没有算法1中第5行的CONCAT操作——卷积聚合器没有将顶点前一层的表示$\mathbf{h}^{k-1}_{v}$聚合的邻居向量$\mathbf{h}^k_{\mathcal{N}(v)}$拼接起来 * 拼接操作可以看作一个是GraphSAGE算法在不同的搜索深度或层之间的简单的**skip connection**[Identity mappings in deep residual networks]的形式,它使得模型的表征性能获得了巨大的提升 * 举个简单例子,比如一个节点的3个邻居的embedding分别为[1,2,3,4],[2,3,4,5],[3,4,5,6]按照每一维分别求均值就得到了聚合后的邻居embedding为[2,3,4,5] **b. LSTM aggregator** 文中也测试了一个基于LSTM的复杂的聚合器[Long short-term memory]。和均值聚合器相比,LSTMs有更强的表达能力。但是,LSTMs不是对称的(symmetric),也就是说不具有排列不变性(permutation invariant),因为它们以一个序列的方式处理输入。因此,需要先对邻居节点**随机顺序**,然后将邻居序列的embedding作为LSTM的输入。 * 排列不变性(permutation invariance):指输入的顺序改变不会影响输出的值。 **c. Pooling aggregator** pooling聚合器,它既是对称的,又是可训练的。Pooling aggregator 先对目标顶点的邻居顶点的embedding向量进行一次非线性变换,之后进行一次pooling操作(max pooling or mean pooling),将得到结果与目标顶点的表示向量拼接,最后再经过一次非线性变换得到目标顶点的第k层表示向量。 一个element-wise max pooling操作应用在邻居集合上来聚合信息: $$\begin{aligned} \mathbf{h}_{\mathcal{N}(v)}^{k}=& \mathrm{AGGREGATE}_{k}^{\text {pool}}=\max \left(\left\{\sigma\left(\mathbf{W}_{\text {pool}} \mathbf{h}_{u}^{k-1}+\mathbf{b}\right), \forall u \in \mathcal{N}(v)\right\}\right) \\ &\mathbf{h}_{v}^{k} \leftarrow \sigma\left(\mathbf{W}^{k} \cdot \operatorname{CONCAT}\left(\mathbf{h}_{v}^{k-1}, \mathbf{h}_{\mathcal{N}(v)}^{k}\right)\right) \end{aligned}$$ * $max$表示element-wise最大值操作,取每个特征的最大值 * $\sigma$是非线性激活函数 * 所有相邻节点的向量共享权重,先经过一个非线性全连接层,然后做max-pooling * 按维度应用 max/mean pooling,可以捕获邻居集上在某一个维度的突出的/综合的表现。 #### (有监督和无监督)参数学习 在定义好聚合函数之后,接下来就是对函数中的参数进行学习。文章分别介绍了无监督学习和监督学习两种方式。 **基于图的无监督损失** 基于图的损失函数倾向于使得相邻的顶点有相似的表示,但这会使相互远离的顶点的表示差异变大: $$J \mathcal{G}\left(\mathbf{z}_{u}\right)=-\log \left(\sigma\left(\mathbf{z}_{u}^{T} \mathbf{z}_{v}\right)\right)-Q \cdot \mathbb{E}_{v_{n} \sim P_{n}(v)} \log \left(\sigma\left(-\mathbf{z}_{u}^{T} \mathbf{z}_{v_{n}}\right)\right)$$ * $\mathbf{z}_{u}$为节点$u$通过GraphSAGE生成的embedding * 节点$v$是节点$u$随机游走到达的“邻居” * $\sigma$是sigmoid函数 * $P_{n}$是负采样的概率分布,类似word2vec中的负采样 * $Q$是负样本的数目 * embedding之间相似度通过向量点积计算得到 文中输入到损失函数的表示$\mathbf{z}_u$是从包含一个顶点局部邻居的特征生成出来的,而不像之前的那些方法(如DeepWalk),对每个顶点训练一个独一无二的embedding,然后简单进行一个embedding查找操作得到。 **基于图的有监督损失** 无监督损失函数的设定来学习节点embedding 可以供下游多个任务使用。监督学习形式根据任务的不同直接设置目标函数即可,如最常用的节点分类任务使用交叉熵损失函数。 **参数学习** 通过前向传播得到节点$u$的embedding $z_u$,然后梯度下降(实现使用Adam优化器) 进行反向传播优化参数$\mathbf{W}^{k}$和聚合函数内的参数。 **新节点embedding的生成** 这个$\mathbf{W}^{k}$ 就是所谓的dynamic embedding的核心,因为保存下来了从节点原始的高维特征生成低维embedding的方式。现在,如果想得到一个点的embedding,只需要输入节点的特征向量,经过卷积(利用已经训练好的 $\mathbf{W}^{k}$ 以及特定聚合函数聚合neighbor的属性信息),就产生了节点的embedding。 **有了GCN为啥还要GraphSAGE?** GCN灵活性差、为新节点产生embedding要求 额外的操作 ,比如“对齐”: GCN是 直推式(transductive) 学习,无法直接泛化到新加入(未见过)的节点; GraphSAGE是 归纳式(inductive) 学习,可以为新节点输出节点特征。 GCN输出固定: GCN输出的是节点 唯一确定 的embedding; GraphSAGE学习的是节点和邻接节点之间的关系,学习到的是一种 映射关系 ,节点的embedding可以随着其邻接节点的变化而变化。 GCN很难应用在超大图上: 无论是拉普拉斯计算还是图卷积过程,因为GCN其需要对 整张图 进行计算,所以计算量会随着节点数的增加而递增。 GraphSAGE通过采样,能够形成 minibatch 来进行批训练,能用在超大图上 **GraphSAGE有什么优点?** 采用 归纳学习 的方式,学习邻居节点特征关系,得到泛化性更强的embedding; 采样技术,降低空间复杂度,便于构建minibatch用于 批训练 ,还让模型具有更好的泛化性; 多样的聚合函数 ,对于不同的数据集/场景可以选用不同的聚合方式,使得模型更加灵活。 **采样数大于邻接节点数怎么办?** 设采样数量为K: 若节点邻居数少于K,则采用 有放回 的抽样方法,直到采样出K个节点。 若节点邻居数大于K,则采用 无放回 的抽样。 **训练好的GraphSAGE如何得到节点Embedding?** 假设GraphSAGE已经训练好,我们可以通过以下步骤来获得节点embedding,具体算法请看下图的算法1。 训练过程则只需要将其产生的embedding扔进损失函数计算并反向梯度传播即可。 对图中每个节点的邻接节点进行 采样 ,输入节点及其n阶邻接节点的特征向量 根据K层的 聚合函数 聚合邻接节点的信息 就产生了各节点的embedding  **minibatch的子图是怎么得到的?**  那**和DeepWalk、Node2vec这些有什么不一样?** DeepWalk、Node2Vec这些embedding算法直接训练每个节点的embedding,本质上依然是直推式学习,而且需要大量的额外训练才能使他们能预测新的节点。同时,对于embedding的正交变换(orthogonal transformations),这些方法的目标函数是不变的,这意味着生成的向量空间在不同的图之间不是天然泛化的,在再次训练(re-training)时会产生漂移(drift)。 与DeepWalk不同的是,GraphSAGE是通过聚合节点的邻接节点特征产生embedding的,而不是简单的进行一个embedding lookup操作得到。 论文仿真结果: 实验对比了四个基线:随机分类,基于特征的逻辑回归(忽略图结构),DeepWalk算法,DeepWork+特征;同时还对比了四种GraphSAGE,其中三种在3.3节中已经说明,GraphSAGE-GCN是GCNs的归纳版本。具体超参数为:K=2,s1=25,s2=10。程序使用TensorFlow编写,Adam优化器。 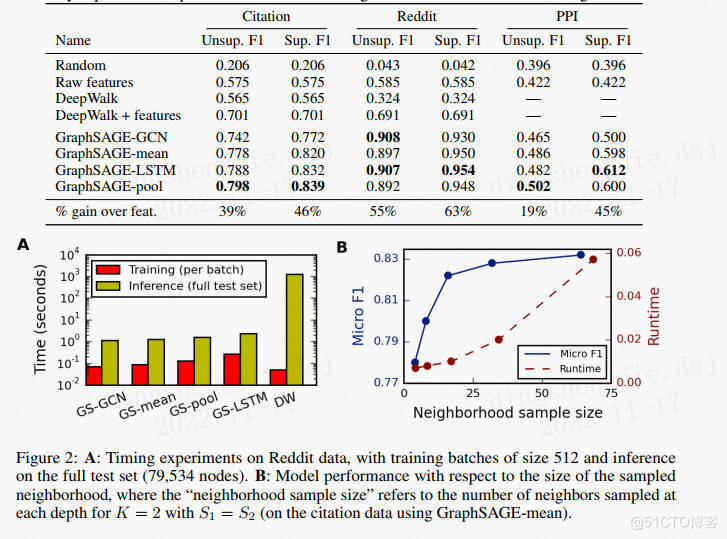 对于跨图泛化的任务,需要学习节点角色而不是训练图的结构。使用跨各种生物蛋白质-蛋白质相互作用(PPI)图,对蛋白质功能进行分类。在20个图表上训练算法,2个图用于测试,2个图用于验证,平均每图包含2373个节点,平均度为28.8。从实验结果可以看出LSTM和池化方法比Mean和GCN效果更好。 对比不同聚合函数: 如表-1所示,LSTM和POOL方法效果最好,与其它方法相比有显著差异,LSTM和POOL之间无显著差异,但LSTM比POOL慢得多(≈2x),使POOL聚合器在总体上略有优势。 ### 1.1.2 更多问题 为什么要采样? 采样数大于邻接节点数怎么办? 采样的邻居节点数应该选取多大? 每一跳采样需要一样吗? 适合有向边吗? 采样是随机的吗? 聚合函数的选取有什么要求? GraphSAGE论文中提供多少种聚合函数? 均值聚合的操作是怎样的? pooling聚合的操作是怎样的? 使用LSTM聚合时需要注意什么? 均值聚合和其他聚合函数有啥区别? max-和mean-pooling有什么区别? 这三种聚合方法,哪种比较好? 一般聚合多少层?层数越多越好吗? 什么时候和GCN的聚合形式“等价”? 参考链接:https://zhuanlan.zhihu.com/p/184991506 https://blog.csdn.net/yyl424525/article/details/100532849 ## 1.2 PinSAGE 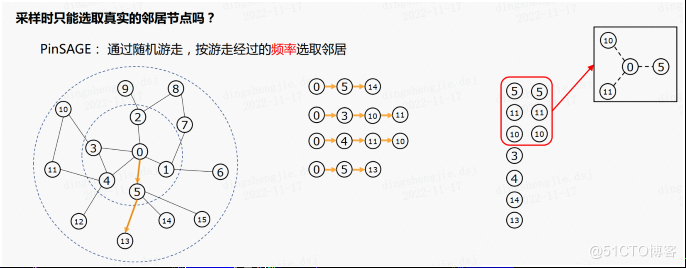 采样时只能选取真实的邻居节点吗?如果构建的是一个与虚拟邻居相连的子图有什么优点?PinSAGE 算法将会给我们解答,PinSAGE 算法通过多次随机游走,按游走经过的频率选取邻居,上图右侧为进行随机游走得到的节点序列,统计序列的频数可以发现节点5,10,11的频数为2,其余为1,当我们希望采样三个节点时,我们选取5,10,11作为0号节点的虚拟邻居。之后如果希望得到0号节点的二阶虚拟邻居则在已采样的节点继续进行随机游走即可。 回到上述问题,采样时选取虚拟邻居有什么好处?**这种采样方式的好处是我们能更快的聚合到远处节点的信息。**。实际上如果是按照 GraphSAGE 算法的方式生成子图,在聚合的过程中,非一阶邻居的信息可以通过消息传递逐渐传到中心,但是随着距离的增大,离中心越远的节点,其信息在传递过程中就越困难,甚至可能无法传递到;如果按照 PinSAGE 算法的方式生成子图,有一定的概率可以将非一阶邻居与中心直接相连,这样就可以快速聚合到多阶邻居的信息 ### 1.2.1论文角度看PinSAGE 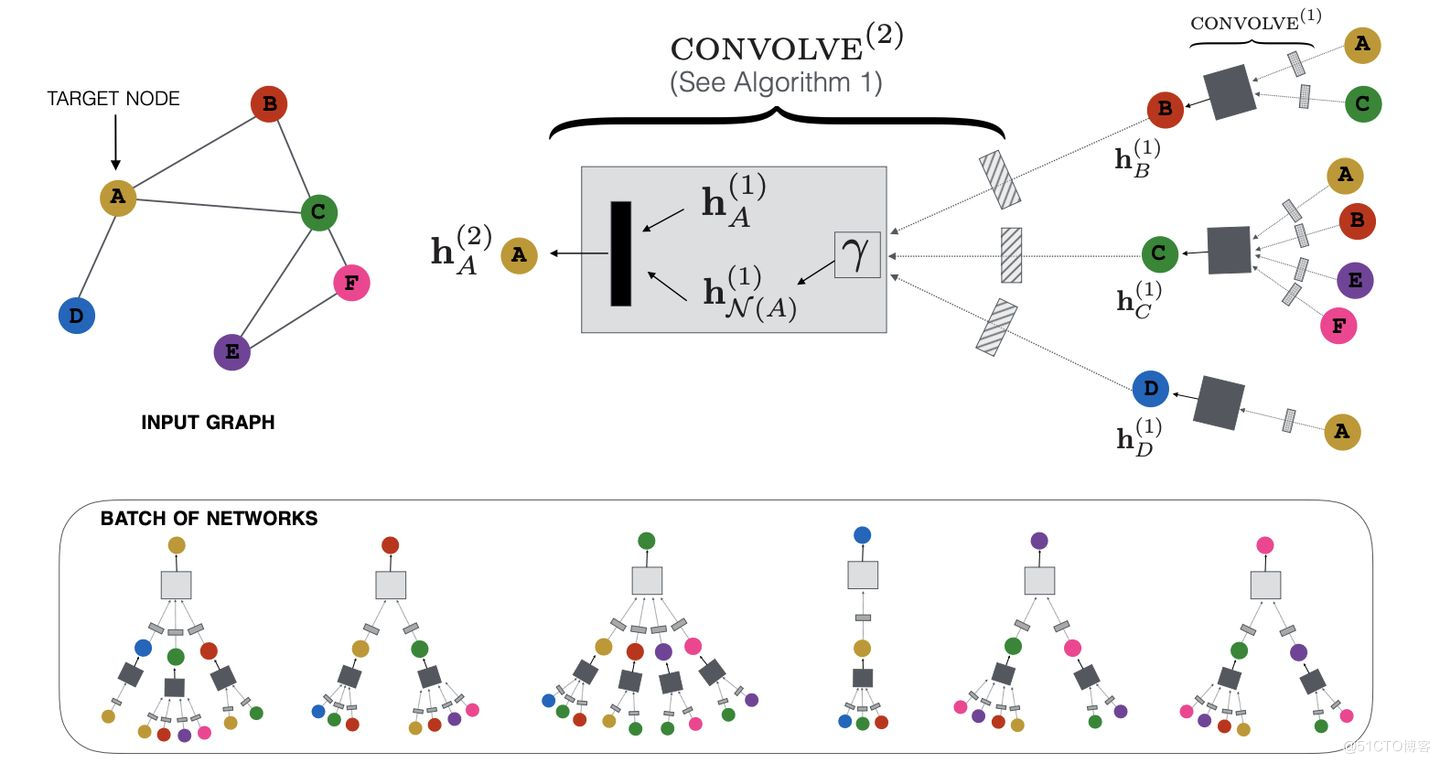 **和GraphSAGE相比,PinSAGE改进了什么?** * 采样 :使用重要性采样替代GraphSAGE的均匀采样; * 聚合函数 :聚合函数考虑了边的权重; * 生产者-消费者模式的minibatch构建 :在CPU端采样节点和构建特征,构建计算图;在GPU端在这些子图上进行卷积运算;从而可以低延迟地随机游走构建子图,而不需要把整个图存在显存中。 * 高效的MapReduce推理 :可以分布式地为百万以上的节点生成embedding,最大化地减少重复计算。 这里的计算图,指的是用于卷积运算的局部图(或者叫子图),通过采样来形成;与TensorFlow等框架的计算图不是一个概念。 **PinSAGE使用多大的计算资源?** 训练时,PinSAGE使用32核CPU、16张Tesla K80显卡、500GB内存; 推理时,MapReduce运行在378个d2.8xlarge Amazon AWS节点的Hadoop2集群。 **PinSAGE和node2vec、DeepWalk这些有啥区别?** node2vec,DeepWalk是无监督训练;PinSAGE是有监督训练; node2vec,DeepWalk不能利用节点特征;PinSAGE可以; node2vec,DeepWalk这些模型的参数和节点数呈线性关系,很难应用在超大型的图上; **PinSAGE的单层聚合过程是怎样的?** 和GraphSAGE一样,PinSAGE的核心就是一个 局部卷积算子 ,用来学习如何聚合邻居节点信息。 如下图算法1所示,PinSAGE的聚合函数叫做CONVOLVE。主要分为3部分: * 聚合 (第1行):k-1层邻居节点的表征经过一层DNN,然后聚合(可以考虑边的权重),是聚合函数符号,聚合函数可以是max/mean-pooling、加权求和、求平均; * 更新 (第2行): 拼接 第k-1层目标节点的embedding,然后再经过另一层DNN,形成目标节点新的embedding; * 归一化 (第3行): 归一化 目标节点新的embedding,使得训练更加稳定;而且归一化后,使用近似最近邻居搜索的效率更高。  **PinSAGE是如何采样的?** 如何采样这个问题从另一个角度来看就是:如何为目标节点构建邻居节点。 和GraphSAGE的均匀采样不一样的是,PinSAGE使用的是重要性采样。 PinSAGE对邻居节点的定义是:对目标节点 影响力最大 的T个节点。 **PinSAGE的邻居节点的重要性是如何计算的?** 其影响力的计算方法有以下步骤: 从目标节点开始随机游走; 使用 正则 来计算节点的“访问次数”,得到重要性分数; 目标节点的邻居节点,则是重要性分数最高的前T个节点。 这个重要性分数,其实可以近似看成Personalized PageRank分数。 关于随机游走,可以阅读《Pixie: A System for Recommending 3+ Billion Items to 200+ Million Users in Real-Time》 **重要性采样的好处是什么?** 和GraphSAGE一样,可以使得 邻居节点的数量固定 ,便于控制内存/显存的使用。 在聚合邻居节点时,可以考虑节点的重要性;在PinSAGE实践中,使用的就是 加权平均 (weighted-mean),原文把它称作 importance pooling 。 **采样的大小是多少比较好?** 从PinSAGE的实验可以看出,随着邻居节点的增加,而收益会递减; 并且两层GCN在 邻居数为50 时能够更好的抓取节点的邻居信息,同时保持运算效率。 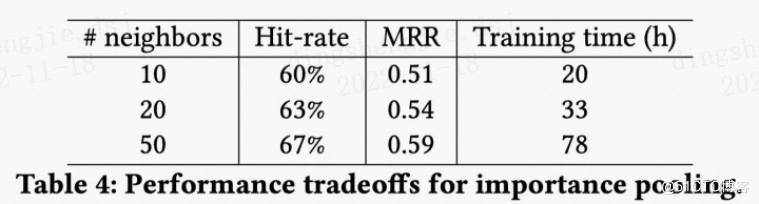 **PinSage论文中还介绍了落地过程中采用的大量工程技巧。** 1. **负样本生成**:首先是简单采样:在每个minibatch包含节点的范围之外随机采样500个item作为minibatch所有正样本共享的负样本集合。但考虑到实际场景中模型需要从20亿的物品item集合中识别出最相似的1000个,即要从2百万中识别出最相似的那一个,只是简单采样会导致模型分辨的粒度过粗,分辨率只到500分之一,因此增加一种“hard”负样本,即对于每个 对,和物品q有些相似但和物品i不相关的物品集合。这种样本的生成方式是将图中节点根据相对节点q的个性化PageRank分值排序,随机选取排序位置在2000~5000的物品作为“hard”负样本,以此提高模型分辨正负样本的难度。 2. **渐进式训练(Curriculum training**:如果训练全程都使用hard负样本,会导致模型收敛速度减半,训练时长加倍,因此PinSage采用了一种Curriculum训练的方式,这里我理解是一种渐进式训练方法,即第一轮训练只使用简单负样本,帮助模型参数快速收敛到一个loss比较低的范围;后续训练中逐步加入hard负样本,让模型学会将很相似的物品与些微相似的区分开,方式是第n轮训练时给每个物品的负样本集合中增加n-1个hard负样本。 3. **样本的特征信息**:Pinterest的业务场景中每个pin通常有一张图片和一系列的文字标注(标题,描述等),因此原始图中每个节点的特征表示由图片Embedding(4096维),文字标注Embedding(256维),以及节点在图中的度的log值拼接而成。其中图片Embedding由6层全连接的VGG-16生成,文字标注Embedding由Word2Vec训练得到。 4. **基于random walk的重要性采样**:用于邻居节点采样,这一技巧在上面的算法理解部分已经讲解过,此处不再赘述。 5. **基于重要性的池化操作**:这一技巧用于上一节Convolve算法中的 函数中,聚合经过一层dense层之后的邻居节点Embedding时,基于random walk计算出的节点权重做聚合操作。据论文描述,这一技巧在离线评估指标中提升了46%。 6. **on-the-fly convolutions:快速卷积操作**,这个技巧主要是相对原始GCN中的卷积操作:特征矩阵与全图拉普拉斯矩阵的幂相乘。涉及到全图的都是计算量超高,这里GraphSage和PinSage都是一致地使用采样邻居节点动态构建局部计算图的方法提升训练效率,只是二者采样的方式不同。 7. **生产者消费者模式构建minibatch**:这个点主要是为了提高模型训练时GPU的利用率。保存原始图结构的邻居表和数十亿节点的特征矩阵只能放在CPU内存中,GPU执行convolve卷积操作时每次从CPU取数据是很耗时的。为了解决这个问题,PinSage使用re-index技术创建当前minibatch内节点及其邻居组成的子图,同时从数十亿节点的特征矩阵中提取出该子图节点对应的特征矩阵,注意提取后的特征矩阵中的节点索引要与前面子图中的索引保持一致。这个子图的邻接列表和特征矩阵作为一个minibatch送入GPU训练,这样一来,convolve操作过程中就没有GPU与CPU的通信需求了。训练过程中CPU使用OpenMP并设计了一个producer-consumer模式,CPU负责提取特征,re-index,负采样等计算,GPU只负责模型计算。这个技巧降低了一半的训练耗时。 8. **多GPU训练超大batch**:前向传播过程中,各个GPU等分minibatch,共享一套参数,反向传播时,将每个GPU中的参数梯度都聚合到一起,执行同步SGD。为了适应海量训练数据的需要,增大batchsize从512到4096。为了在超大batchsize下快速收敛保证泛化精度,采用warmup过程:在第一个epoch中将学习率线性提升到最高,后面的epoch中再逐步指数下降。 9. **使用MapReduce高效推断**:模型训练完成后生成图中各个节点的Embedding过程中,如果直接使用上述PinSage的minibatch算法生Embedding,会有大量的重复计算,如计算当前target节点的时候,其相当一部分邻居节点已经计算过Embedding了,而当这些邻居节点作为target节点的时候,当前target节点极有可能需要再重新计算一遍,这一部分的重复计算既耗时又浪费。 ### 1.2.2更多问题 PinSAGE的单层聚合过程是怎样的? 为什么要将邻居节点的聚合embedding和当前节点的拼接? PinSAGE是如何采样的? PinSAGE的邻居节点的重要性是如何计算的? 重要性采样的好处是什么? 采样的大小是多少比较好? MiniBatch PinSAGE的minibatch和GraphSAGE有啥不一样? batch应该选多大? PinSAGE使用什么损失函数? PinSAGE如何定义标签(正例/负例)? PinSAGE用什么方法提高模型训练的鲁棒性和收敛性? PinSAGE如何进行负采样? 训练时简单地负采样,会有什么问题? 如何解决简单负采样带来的问题? 如果只使用“hard”负样本,会有什么问题? 如何解决只使用“hard”负采样带来的问题? 如何区分采样、负采样、”hard“负采样? 直接为使用训练好的模型产生embedding有啥问题? 如何解决推理时重复计算的问题? 下游任务如何应用PinSAGE产生的embedding? 如何为用户进行个性化推荐? 工程性技巧 pin样本的特征如何构建? board样本的特征如何构建? 如何使用多GPU并行训练PinSAGE? PinSAGE为什么要使用生产者-消费者模式? PinSAGE是如何使用生产者-消费者模式? https://zhuanlan.zhihu.com/p/195735468 https://zhuanlan.zhihu.com/p/133739758?utm_source=wechat_session&utm_id=0 ## 1.3 小结 学习大图、不断扩展的图,未见过节点的表征,是一个很常见的应用场景。GraphSAGE通过训练聚合函数,实现优化未知节点的表示方法。之后提出的GAN(图注意力网络)也针对此问题优化。 论文中提出了:传导性问题和归纳性问题,传导性问题是已知全图情况,计算节点表征向量;归纳性问题是在不完全了解全图的情况下,训练节点的表征函数(不是直接计算向量表示)。 图工具的处理过程每轮迭代( 一次propagation)一般都包含:收集信息、聚合、更新,从本文也可以更好地理解,其中聚合的重要性,及优化方法。 GraohSage主要贡献如下: * 针对问题:大图的节点表征 * 结果:训练出的模型可应用于表征没见过的节点 * 核心方法:改进图卷积方法;从邻居节点中采样;考虑了节点特征,加入更复杂的特征聚合方法 一般情况下一个节点的表式通过聚合它k跳之内的邻近节点计算,而全图的表示则通过对所有节点的池化计算。GIN使用了WL-test方法,即图同构测试,它是一个区分网络结构的强效方法,也是通过迭代聚合邻居的方法来更新节点,它的强大在于使用了injective(见后)聚合更新方法。而这里要评测GNN是否能达到类似WL-test的效果。文中还使用了多合集multiset的概念,指可能包含重复元素的集合。 GIN主要贡献如下: * 展示了GNN模型可达到与WL-test类似的图结构区分效果 * 设计了聚合函数和Readout函数,使GNN能达到更好的区分效果 * 发现GCN及GraphSAGE无法很好表达图结构,而GNN可以 * 开发了简单的网络结构GIN(图同构网络),它的区分和表示能力与WL-test类似。 # 2.邻居聚合 在图采样之后,我们需要进行邻居聚合的操作。经典的邻居聚合函数包括取平均、取最大值、求和。 评估聚合表达能力的指标——单射(一对一映射),在上述三种经典聚合函数中,取平均倾向于学习分布,取最大值倾向于忽略重复值,这两个不属于单射,而求和能够保留邻居节点的完整信息,是单射。单射的好处是可以保证对聚合后的结果可区分。  ## 2.1 GIN模型的聚合函数 Graph Isomorphic Net(GIN)的聚合部分是基于单射的。 如上图所示,GIN的聚合函数使用的是求和函数,它特殊的一点是在中心节点加了一个自连边(自环),之后对自连边进行加权。 这样做的好处是即使我们调换了中心节点和邻居节点,得到的聚合结果依旧是不同的。所以带权重的自连边能够保证中心节点和邻居节点可区分。 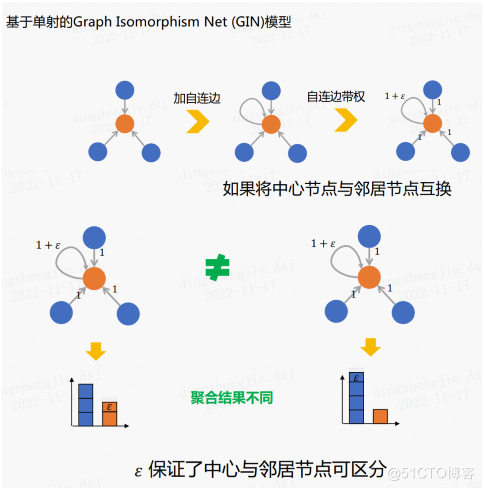 ## 2.2其他复杂的聚合函数 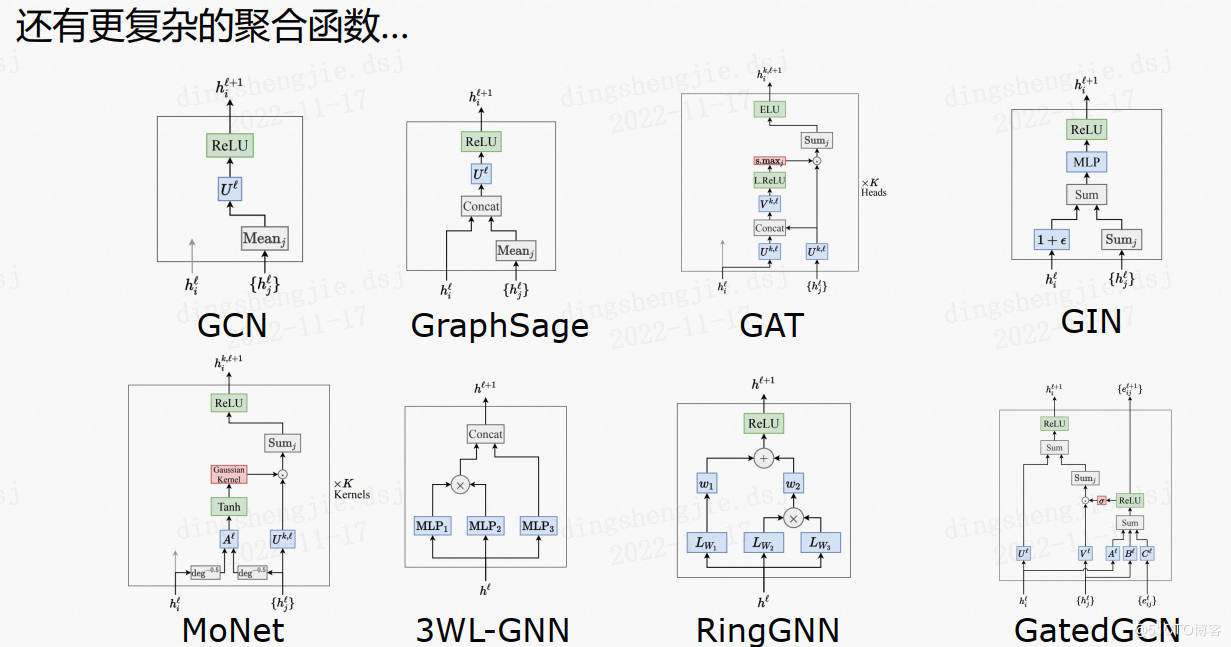 ## 2.3 令居聚合语义场景 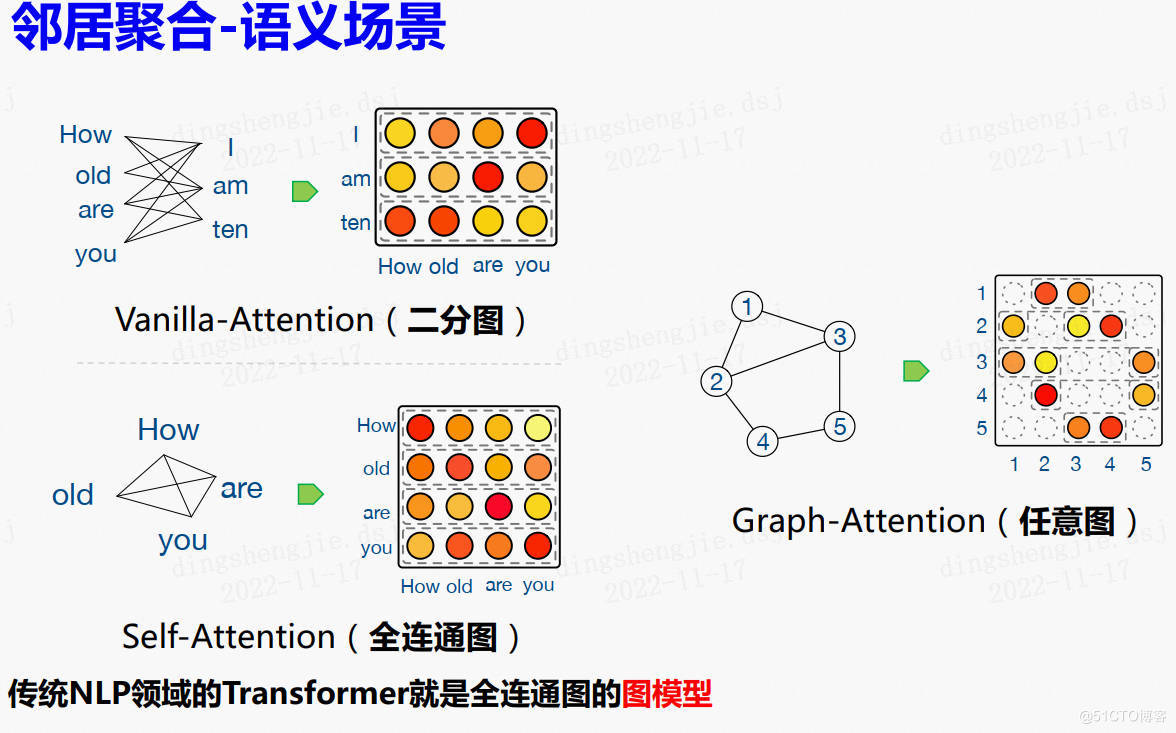 # 3.数据集介绍 数据源:http://snap.stanford.edu/graphsage/ 斯坦福 ## 3.1 Citation数据集 使用科学网引文数据集,将学术论文分类为不同的主题。数据集共包含302424个节点,平均度9.15,使用2000-2004年数据作为训练集,2005年数据作为测试集。使用节点的度以及论文摘要的句嵌入作为特征。 ## 3.2 Reddit数据集 https://aistudio.baidu.com/aistudio/datasetdetail/177810 将Reddit帖子归类为属于不同社区。数据集包含232965个帖子,平均度为492。使用现成的300维GloVe Common Crawl单词向量;对于每个帖子,使用特征包含:(1) 帖子标题的平均嵌入 (2) 帖子所有评论的平均嵌入 (3) 帖子的分数 (4)帖子的评论数量 为了对社区进行抽样,根据 2014 年的评论总数对社区进行了排名,并选择了排名 [11,50](含)的社区。省略了最大的社区,因为它们是大型的通用默认社区,大大扭曲了类分布。选择了在这些社区的联合上定义的图中最大的连通分量。 更多数据资料见: http://files.pushshift.io/reddit/comments/ https://github.com/dingidng/reddit-dataset  最新数据已经更新到2022.10了 ## 3.3 PPI(Protein–protein interactions)蛋白质交互作用 https://aistudio.baidu.com/aistudio/datasetdetail/177807 PPI 网络是蛋白质相互作用(Protein-Protein Interaction,PPI)网络的简称,在GCN中主要用于节点分类任务 PPI是指两种或以上的蛋白质结合的过程,通常旨在执行其生化功能。 一般地,如果两个蛋白质共同参与一个生命过程或者协同完成某一功能,都被看作这两个蛋白质之间存在相互作用。多个蛋白质之间的复杂的相互作用关系可以用PPI网络来描述。 PPI数据集共24张图,每张图对应不同的人体组织,平均每张图有2371个节点,共56944个节点818716条边,每个节点特征长度为50,其中包含位置基因集,基序集和免疫学特征。基因本体基作为label(总共121个),label不是one-hot编码。 * alid_feats.npy文件保存节点的特征,shape为(56944, 50)(节点数目,特征维度),值为0或1,且1的数目稀少 * ppi-class_map.json为节点的label文件,shape为(121, 56944),每个节点的label为121维 * ppi-G.json文件为节点和链接的描述信息,节点:{"test": true, "id": 56708, "val": false}, 表示节点id为56708的节点是否为test集或者val集,链接:"links": [{"source": 0, "target": 372}, {"source": 0, "target": 1101}, 表示节点id为0的节点和为1101的节点之间有links, * ppi-walks.txt文件中为链接信息 * ppi-id_map.json文件为节点id信息 参考链接: https://blog.csdn.net/ziqingnian/article/details/112979175 # 4 基于PGL算法实践 ## 4.1 GraphSAGE GraphSAGE是一个通用的归纳框架,它利用节点特征信息(例如,文本属性)为以前看不见的数据有效地生成节点嵌入。GraphSAGE 不是为每个节点训练单独的嵌入,而是学习一个函数,该函数通过从节点的本地邻域中采样和聚合特征来生成嵌入。基于PGL,我们重现了GraphSAGE算法,在Reddit Dataset中达到了与论文同等水平的指标。此外,这是PGL中子图采样和训练的一个例子。 epoch: Number of epochs default (10) normalize: Normalize the input feature if assign normalize. sample_workers: The number of workers for multiprocessing subgraph sample. lr: Learning rate. symmetry: Make the edges symmetric if assign symmetry. batch_size: Batch size. samples: The max neighbors for each layers hop neighbor sampling. (default: [25, 10]) hidden_size: The hidden size of the GraphSAGE models. parser = argparse.ArgumentParser(description='graphsage') parser.add_argument( "--normalize", action='store_true', help="normalize features") # normalize:归一化节点特征 parser.add_argument( "--symmetry", action='store_true', help="undirect graph") # symmetry:聚合函数的对称性 parser.add_argument("--sample_workers", type=int, default=5) # sample_workers:多线程数据读取器的线程个数 parser.add_argument("--epoch", type=int, default=10) parser.add_argument("--hidden_size", type=int, default=128) parser.add_argument("--batch_size", type=int, default=128) parser.add_argument("--lr", type=float, default=0.01) parser.add_argument('--samples', nargs='+', type=int, default=[25, 10]) # samples_1:第一级邻居采样时候选择的最大邻居个数(默认25)#,samples_2:第而级邻居采样时候选择的最大邻居个数(默认10) 部分结果展示: [INFO] 2022-11-18 16:45:44,177 [ train.py: 63]: Batch 800 train-Loss [0.5213774] train-Acc [0.9140625] [INFO] 2022-11-18 16:45:45,783 [ train.py: 63]: Batch 900 train-Loss [0.65641916] train-Acc [0.875] [INFO] 2022-11-18 16:45:47,385 [ train.py: 63]: Batch 1000 train-Loss [0.57411766] train-Acc [0.921875] [INFO] 2022-11-18 16:45:48,977 [ train.py: 63]: Batch 1100 train-Loss [0.68337256] train-Acc [0.890625] [INFO] 2022-11-18 16:45:50,434 [ train.py: 160]: Runing epoch:9 train_loss:[0.58635516] train_acc:[0.90786038] [INFO] 2022-11-18 16:45:57,836 [ train.py: 165]: Runing epoch:9 val_loss:0.55885834 val_acc:0.9139818 [INFO] 2022-11-18 16:46:05,259 [ train.py: 169]: Runing epoch:9 test_loss:0.5578749 test_acc:0.91468066 100%|███████████████████████████████████████████| 10/10 [06:02<00:00, 36.29s/it] [INFO] 2022-11-18 16:46:05,260 [ train.py: 172]: Runs 0: Model: graphsage Best Test Accuracy: 0.918849 目前官网最佳性能是95.7%,我这里没有调参 | Aggregator | Accuracy_me_10 epochs | Accuracy_200 epochs|Reported in paper_200 epochs| | -------- | -------- | -------- |-------- | | Mean | 91.88% | 95.70% | 95.0% | 其余聚合器下官网和论文性能对比: | Aggregator | Accuracy_200 epochs|Reported in paper_200 epochs| | -------- | -------- |-------- | | Meanpool | 95.60% | 94.8% | | Maxpool | 94.95% | 94.8% | | LSTM | 95.13% | 95.4% | ## 4.2 Graph Isomorphism Network (GIN) 图同构网络(GIN)是一个简单的图神经网络,期望达到Weisfeiler-Lehman图同构测试的能力。基于 PGL重现了 GIN 模型。 * data_path:数据集的根路径 * dataset_name:数据集的名称 * fold_idx:拆分的数据集折叠。这里我们使用10折交叉验证 * train_eps:是否参数是可学习的。 parser.add_argument('--data_path', type=str, default='./gin_data') parser.add_argument('--dataset_name', type=str, default='MUTAG') parser.add_argument('--batch_size', type=int, default=32) parser.add_argument('--fold_idx', type=int, default=0) parser.add_argument('--output_path', type=str, default='./outputs/') parser.add_argument('--use_cuda', action='store_true') parser.add_argument('--num_layers', type=int, default=5) parser.add_argument('--num_mlp_layers', type=int, default=2) parser.add_argument('--feat_size', type=int, default=64) parser.add_argument('--hidden_size', type=int, default=64) parser.add_argument( '--pool_type', type=str, default="sum", choices=["sum", "average", "max"]) parser.add_argument('--train_eps', action='store_true') parser.add_argument('--init_eps', type=float, default=0.0) parser.add_argument('--epochs', type=int, default=350) parser.add_argument('--lr', type=float, default=0.01) parser.add_argument('--dropout_prob', type=float, default=0.5) parser.add_argument('--seed', type=int, default=0) args = parser.parse_args() GIN github代码复现含数据集下载:How Powerful are Graph Neural Networks? [https://github.com/weihua916/powerful-gnns](https://github.com/weihua916/powerful-gnns) https://github.com/weihua916/powerful-gnns/blob/master/dataset.zip 论文使用 9 个图形分类基准:**4 个生物信息学数据集(MUTAG、PTC、NCI1、PROTEINS)** 和 **5 个社交网络数据集(COLLAB、IMDB-BINARY、IMDB-MULTI、REDDITBINARY 和 REDDIT-MULTI5K)(Yanardag & Vishwanathan,2015)**。 重要的是,我目标不是让模型依赖输入节点特征,而是主要从网络结构中学习。因此,在生物信息图中,节点具有分类输入特征,但在社交网络中,它们没有特征。 对于社交网络,按如下方式创建节点特征:对于 REDDIT 数据集,将所有节点特征向量设置为相同(因此,这里的特征是无信息的); 对于其他社交图,我们使用节点度数的 one-hot 编码。 **社交网络数据集。** * IMDB-BINARY 和 IMDB-MULTI 是电影协作数据集。每个图对应于每个演员/女演员的自我网络,其中节点对应于演员/女演员,如果两个演员/女演员出现在同一部电影中,则在两个演员/女演员之间绘制一条边。每个图都是从预先指定的电影类型派生的,任务是对其派生的类型图进行分类。 * REDDIT-BINARY 和 REDDIT-MULTI5K 是平衡数据集,其中每个图表对应一个在线讨论线程,节点对应于用户。如果其中至少一个节点回应了另一个节点的评论,则在两个节点之间绘制一条边。任务是将每个图分类到它所属的社区或子版块。 * COLLAB 是一个科学协作数据集,源自 3 个公共协作数据集,即高能物理、凝聚态物理和天体物理。每个图对应于来自每个领域的不同研究人员的自我网络。任务是将每个图分类到相应研究人员所属的领域。 **生物信息学数据集。** * MUTAG 是一个包含 188 个诱变芳香族和杂芳香族硝基化合物的数据集,具有 7 个离散标签。 * PROTEINS 是一个数据集,其中节点是二级结构元素 (SSE),如果两个节点在氨基酸序列或 3D 空间中是相邻节点,则它们之间存在一条边。 它有 3 个离散标签,代表螺旋、薄片或转弯。 * PTC 是一个包含 344 种化合物的数据集,报告了雄性和雌性大鼠的致癌性,它有 19 个离散标签。 * NCI1 是由美国国家癌症研究所 (NCI) 公开提供的数据集,是经过筛选以抑制或抑制一组人类肿瘤细胞系生长的化学化合物平衡数据集的子集,具有 37 个离散标签。 部分结果展示: [INFO] 2022-11-18 17:12:34,203 [ main.py: 98]: eval: epoch 347 | step 2082 | | loss 0.448468 | acc 0.684211 [INFO] 2022-11-18 17:12:34,297 [ main.py: 98]: eval: epoch 348 | step 2088 | | loss 0.393809 | acc 0.789474 [INFO] 2022-11-18 17:12:34,326 [ main.py: 92]: train: epoch 349 | step 2090 | loss 0.401544 | acc 0.8125 [INFO] 2022-11-18 17:12:34,391 [ main.py: 98]: eval: epoch 349 | step 2094 | | loss 0.441679 | acc 0.736842 [INFO] 2022-11-18 17:12:34,476 [ main.py: 92]: train: epoch 350 | step 2100 | loss 0.573693 | acc 0.7778 [INFO] 2022-11-18 17:12:34,485 [ main.py: 98]: eval: epoch 350 | step 2100 | | loss 0.481966 | acc 0.789474 [INFO] 2022-11-18 17:12:34,485 [ main.py: 103]: best evaluating accuracy: 0.894737 结果整合:(这里就不把数据集一一跑一遍了) | | MUTAG | COLLAB | IMDBBINARY | IMDBMULTI | | -------- | -------- | -------- |-------- | -------- | | PGL result | 90.8 | 78.6 |76.8 |50.8| | paper reuslt | 90.0 | 80.0 | 75.1 | 52.3 | 原论文所有结果: 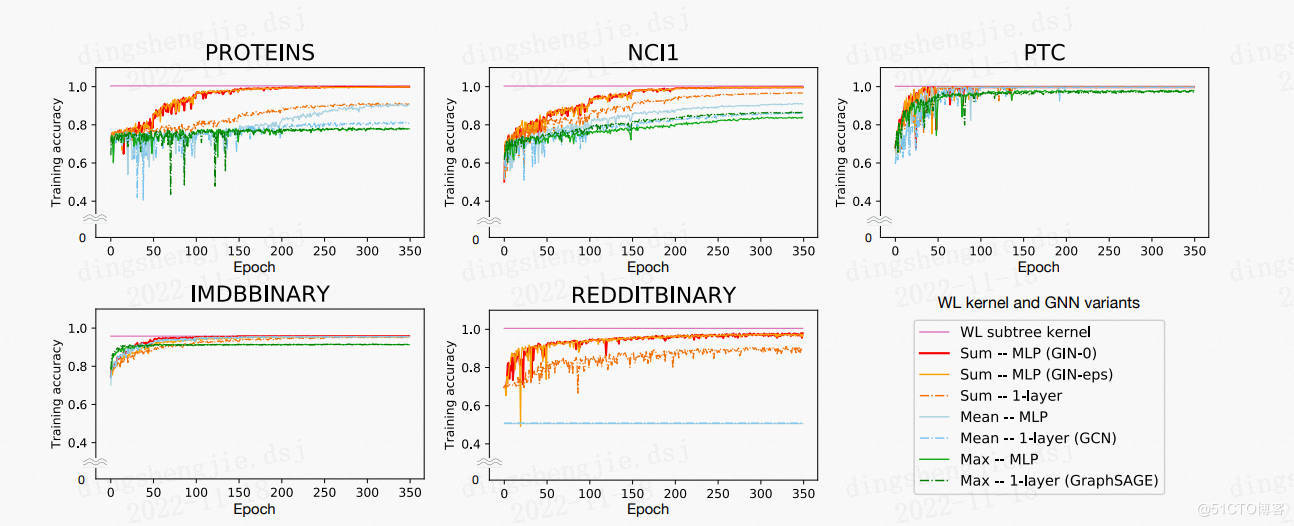 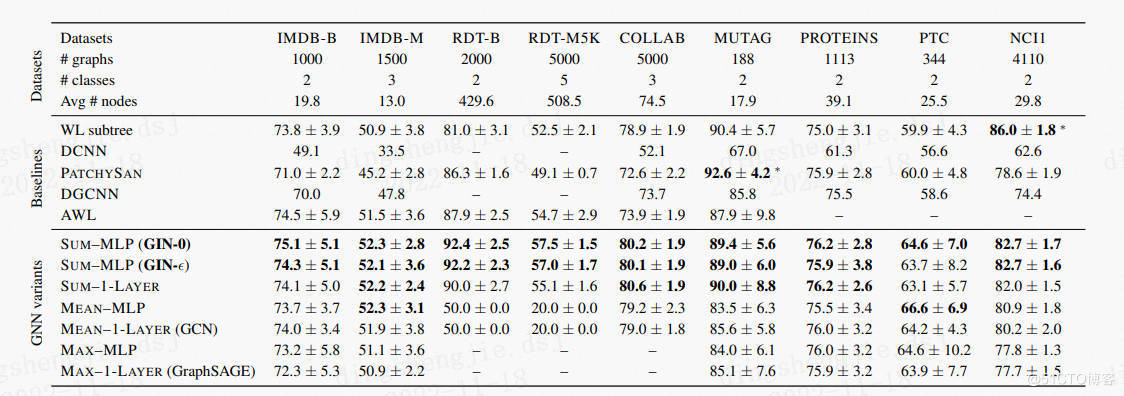
PGL图学习之图神经网络GNN模型GCN、GAT[系列六]
PGL图学习之图神经网络GNN模型GCN、GAT[系列六]项目链接:一键fork直接跑程序 https://aistudio.baidu.com/aistudio/projectdetail/5054122?contributionType=10.前言-学术界业界论文发表情况ICLR2023评审情况:ICLR2023的评审结果已经正式发布!今年的ICLR2023共计提交6300份初始摘要和4922份经过审查的提交,其中经过审查提交相比上一年增加了32.2%。在4922份提交内容中,99%的内容至少有3个评论,总共有超过18500个评论。按照Open Review评审制度,目前ICLR已经进入讨论阶段。官网链接:https://openreview.net/group?id=ICLR.cc/2022/Conference在4922份提交内容中,主要涉及13个研究方向,具体有:1、AI应用应用,例如:语音处理、计算机视觉、自然语言处理等 2、深度学习和表示学习 3、通用机器学习 4、生成模型 5、基础设施,例如:数据集、竞赛、实现、库等 6、科学领域的机器学习,例如:生物学、物理学、健康科学、社会科学、气候/可持续性等 7、神经科学与认知科学,例如:神经编码、脑机接口等 8、优化,例如:凸优化、非凸优化等 9、概率方法,例如:变分推理、因果推理、高斯过程等 10、强化学习,例如:决策和控制,计划,分层RL,机器人等 11、机器学习的社会方面,例如:人工智能安全、公平、隐私、可解释性、人与人工智能交互、伦理等 12、理论,例如:如控制理论、学习理论、算法博弈论。 13、无监督学习和自监督学习ICLR详细介绍:ICLR,全称为「International Conference on Learning Representations」(国际学习表征会议),2013 年5月2日至5月4日在美国亚利桑那州斯科茨代尔顺利举办了第一届ICLR会议。该会议是一年一度的会议,截止到2022年它已经举办了10届,而今年的(2023年)5月1日至5日,将在基加利会议中心完成ICLR的第十一届会议。该会议被学术研究者们广泛认可,被认为是「深度学习的顶级会议」。为什么ICLR为什么会成为深度学习领域的顶会呢? 首先该会议由深度学习三大巨头之二的Yoshua Bengio和Yann LeCun 牵头创办。其中Yoshua Bengio 是蒙特利尔大学教授,深度学习三巨头之一,他领导蒙特利尔大学的人工智能实验室MILA进行 AI 技术的学术研究。MILA 是世界上最大的人工智能研究中心之一,与谷歌也有着密切的合作。 Yann LeCun同为深度学习三巨头之一的他现任 Facebook 人工智能研究院FAIR院长、纽约大学教授。作为卷积神经网络之父,他为深度学习的发展和创新作出了重要贡献。Keywords Frequency 排名前 50 的常用关键字(不区分大小写)及其出现频率: 可有看到图、图神经网络分别排在2、4。1.Graph Convolutional Networks(GCN,图卷积神经网络)GCN的概念首次提出于ICLR2017(成文于2016年):Semi-Supervised Classification with Graph Convolutional Networks:https://arxiv.org/abs/1609.02907图数据中的空间特征具有以下特点:1) 节点特征:每个节点有自己的特征;(体现在点上)2) 结构特征:图数据中的每个节点具有结构特征,即节点与节点存在一定的联系。(体现在边上)总地来说,图数据既要考虑节点信息,也要考虑结构信息,图卷积神经网络就可以自动化地既学习节点特征,又能学习节点与节点之间的关联信息。综上所述,GCN是要为除CV、NLP之外的任务提供一种处理、研究的模型。图卷积的核心思想是利用『边的信息』对『节点信息』进行『聚合』从而生成新的『节点表示』。1.1原理简介假如我们希望做节点相关的任务,就可以通过 Graph Encoder,在图上学习到节点特征,再利用学习到的节点特征做一些相关的任务,比如节点分类、关系预测等等;而同时,我们也可以在得到的节点特征的基础上,做 Graph Pooling 的操作,比如加权求和、取平均等等操作,从而得到整张图的特征,再利用得到的图特征做图相关的任务,比如图匹配、图分类等。图游走类算法主要的目的是在训练得到节点 embedding 之后,再利用其做下游任务,也就是说区分为了两个阶段。对于图卷积网络而言,则可以进行一个端到端的训练,不需要对这个过程进行区分,那么这样其实可以更加针对性地根据具体任务来进行图上的学习和训练。回顾卷积神经网络在图像及文本上的发展在图像上的二维卷积,其实质就是卷积核在二维图像上平移,将卷积核的每个元素与被卷积图像对应位置相乘,再求和,得到一个新的结果。其实它有点类似于将当前像素点和周围的像素点进行某种程度的转换,再得到当前像素点更新后的一个值。它的本质是利用了一维卷积,因为文本是一维数据,在我们已知文本的词表示之后,就在词级别上做一维的卷积。其本质其实和图像上的卷积没有什么差别。(注:卷积核维度和红框维度相同,2 6就是2 6)图像卷积的本质其实非常简单,就是将一个像素点周围的像素,按照不同的权重叠加起来,当然这个权重就是我们通常说的卷积核。其实可以把当前像素点类比做图的节点,而这个节点周围的像素则类比为节点的邻居,从而可以得到图结构卷积的简单的概念:将一个节点周围的邻居按照不同的权重叠加起来而图像上的卷积操作,与图结构上的卷积操作,最大的一个区别就在于:对于图像的像素点来说,它的周围像素点数量其实是固定的;但是对于图而言,节点的邻居数量是不固定的。1.2图卷积网络的两种理解方式GCN的本质目的就是用来提取拓扑图的空间特征。 而图卷积神经网络主要有两类,一类是基于空间域或顶点域vertex domain(spatial domain)的,另一类则是基于频域或谱域spectral domain的。通俗点解释,空域可以类比到直接在图片的像素点上进行卷积,而频域可以类比到对图片进行傅里叶变换后,再进行卷积。所谓的两类其实就是从两个不同的角度理解,关于从空间角度的理解可以看本文的从空间角度理解GCNvertex domain(spatial domain):顶点域(空间域)基于空域卷积的方法直接将卷积操作定义在每个结点的连接关系上,它跟传统的卷积神经网络中的卷积更相似一些。在这个类别中比较有代表性的方法有 Message Passing Neural Networks(MPNN)[1], GraphSage[2], Diffusion Convolution Neural Networks(DCNN)[3], PATCHY-SAN[4]等。spectral domain:频域方法(谱方法这就是谱域图卷积网络的理论基础了。这种思路就是希望借助图谱的理论来实现拓扑图上的卷积操作。从整个研究的时间进程来看:首先研究GSP(graph signal processing)的学者定义了graph上的Fourier Transformation,进而定义了graph上的convolution,最后与深度学习结合提出了Graph Convolutional Network。基于频域卷积的方法则从图信号处理起家,包括 Spectral CNN[5], Cheybyshev Spectral CNN(ChebNet)[6], 和 First order of ChebNet(1stChebNet)[7] 等论文Semi-Supervised Classification with Graph Convolutional Networks就是一阶邻居的ChebNet认真读到这里,脑海中应该会浮现出一系列问题:Q1 什么是Spectral graph theory?Spectral graph theory请参考维基百科的介绍,简单的概括就是借助于图的拉普拉斯矩阵的特征值和特征向量来研究图的性质Q2 GCN为什么要利用Spectral graph theory?这是论文(Semi-Supervised Classification with Graph Convolutional Networks)中的重点和难点,要理解这个问题需要大量的数学定义及推导过程:(1)定义graph上的Fourier Transformation傅里叶变换(利用Spectral graph theory,借助图的拉普拉斯矩阵的特征值和特征向量研究图的性质)(2)定义graph上的convolution卷积1.3 图卷积网络的计算公式H代表每一层的节点表示,第0层即为最开始的节点表示A表示邻接矩阵,如下图所示,两个节点存在邻居关系就将值设为1,对角线默认为1D表示度矩阵,该矩阵除对角线外均为0,对角线的值表示每个节点的度,等价于邻接矩阵对行求和W表示可学习的权重邻接矩阵的对角线上都为1,这是因为添加了自环边,这也是这个公式中使用的定义,其他情况下邻接矩阵是可以不包含自环的。(包含了自环边的邻接矩阵)度矩阵就是将邻接矩阵上的每一行进行求和,作为对角线上的值。而由于我们是要取其-1/2的度矩阵,因此还需要对对角线上求和后的值做一个求倒数和开根号的操作,因此最后可以得到右边的一个矩阵运算结果。为了方便理解,我们可以暂时性地把度矩阵在公式中去掉:为了得到 H^{(l+1)}的第0行,我们需要拿出A的第0行与 H^{(l)}相乘,这是矩阵乘法的概念。接下来就是把计算结果相乘再相加的过程。这个过程其实就是消息传递的过程:对于0号节点来说,将邻居节点的信息传给自身将上式进行拆分,A*H可以理解成将上一层每个节点的节点表示进行聚合,如图,0号节点就是对上一层与其相邻的1号、2号节点和它本身进行聚合。而度矩阵D存在的意义是每个节点的邻居的重要性不同,根据该节点的度来对这些相邻节点的节点表示进行加权,d越大,说明信息量越小。实际情况中,每个节点发送的信息所带的信息量应该是不同的。图卷积网络将邻接矩阵的两边分别乘上了度矩阵,相当于给这个边加了权重。其实就是利用节点度的不同来调整信息量的大小。这个公式其实体现了:一个节点的度越大,那么它所包含的信息量就越小,从而对应的权值也就越小。怎么理解这样的一句话呢,我们可以设想这样的一个场景。假如说在一个社交网络里,一个人认识了几乎所有的人,那么这个人能够给我们的信息量是比较小的。也就是说,每个节点通过边对外发送相同量的信息, 边越多的节点,每条边发送出去的信息量就越小。1.4用多层图网络完成节点分类任务GCN算法主要包括以下几步:第一步是利用上面的核心公式进行节点间特征传递第二步对每个节点过一层DNN重复以上两步得到L层的GCN获得的最终节点表示H送入分类器进行分类更详细的资料参考:图卷积网络 GCN Graph Convolutional Network(谱域GCN)的理解和详细推导1.5 GCN参数解释主要是帮助大家理解消息传递机制的一些参数类型。这里给出一个简化版本的 GCN 模型,帮助理解PGL框架实现消息传递的流程。 def gcn_layer(gw, feature, hidden_size, activation, name, norm=None): 描述:通过GCN层计算新的节点表示 输入:gw - GraphWrapper对象 feature - 节点表示 (num_nodes, feature_size) hidden_size - GCN层的隐藏层维度 int activation - 激活函数 str name - GCN层名称 str norm - 标准化tensor float32 (num_nodes,),None表示不标准化 输出:新的节点表示 (num_nodes, hidden_size) # send函数 def send_func(src_feat, dst_feat, edge_feat): 描述:用于send节点信息。函数名可自定义,参数列表固定 输入:src_feat - 源节点的表示字典 {name:(num_edges, feature_size)} dst_feat - 目标节点表示字典 {name:(num_edges, feature_size)} edge_feat - 与边(src, dst)相关的特征字典 {name:(num_edges, feature_size)} 输出:存储发送信息的张量或字典 (num_edges, feature_size) or {name:(num_edges, feature_size)} return src_feat["h"] # 直接返回源节点表示作为信息 # send和recv函数是搭配实现的,send的输出就是recv函数的输入 # recv函数 def recv_func(msg): 描述:对接收到的msg进行聚合。函数名可自定义,参数列表固定 输出:新的节点表示张量 (num_nodes, feature_size) return L.sequence_pool(msg, pool_type='sum') # 对接收到的消息求和 ### 消息传递机制执行过程 # gw.send函数 msg = gw.send(send_func, nfeat_list=[("h", feature)]) 描述:触发message函数,发送消息并将消息返回 输入:message_func - 自定义的消息函数 nfeat_list - list [name] or tuple (name, tensor) efeat_list - list [name] or tuple (name, tensor) 输出:消息字典 {name:(num_edges, feature_size)} # gw.recv函数 output = gw.recv(msg, recv_func) 描述:触发reduce函数,接收并处理消息 输入:msg - gw.send输出的消息字典 reduce_function - "sum"或自定义的reduce函数 输出:新的节点特征 (num_nodes, feature_size) 如果reduce函数是对消息求和,可以直接用"sum"作为参数,使用内置函数加速训练,上述语句等价于 \ output = gw.recv(msg, "sum") # 通过以activation为激活函数的全连接输出层 output = L.fc(output, size=hidden_size, bias_attr=False, act=activation, name=name) return output 2.Graph Attention Networks(GAT,图注意力机制网络)Graph Attention Networks:https://arxiv.org/abs/1710.10903GCN网络中的一个缺点是边的权重与节点的度度相关而且不可学习,因此有了图注意力算法。在GAT中,边的权重变成节点间的可学习的函数并且与两个节点之间的相关性有关。2.1.计算方法注意力机制的计算方法如下:首先将目标节点和源节点的表示拼接到一起,通过网络计算相关性,之后通过LeakyReLu激活函数和softmax归一化得到注意力分数,最后用得到的α进行聚合,后续步骤和GCN一致。以及多头Attention公式2.2 空间GNN空间GNN(Spatial GNN):基于邻居聚合的图模型称为空间GNN,例如GCN、GAT等等。大部分的空间GNN都可以用消息传递实现,消息传递包括消息的发送和消息的接受。基于消息传递的图神经网络的通用公式:2.3 消息传递demo例子2.4 GAT参数解释其中:在 send 函数中完成 LeakyReLU部分的计算;在 recv 函数中,对接受到的 logits 信息进行 softmax 操作,形成归一化的分数(公式当中的 alpha),再与结果进行加权求和。def single_head_gat(graph_wrapper, node_feature, hidden_size, name): # 实现单头GAT def send_func(src_feat, dst_feat, edge_feat): ################################## # 按照提示一步步理解代码吧,你只需要填###的地方 # 1. 将源节点特征与目标节点特征concat 起来,对应公式当中的 concat 符号,可能用到的 API: fluid.layers.concat Wh = fluid.layers.concat(input=[src_feat["Wh"], dst_feat["Wh"]], axis=1) # 2. 将上述 Wh 结果通过全连接层,也就对应公式中的a^T alpha = fluid.layers.fc(Wh, size=1, name=name + "_alpha", bias_attr=False) # 3. 将计算好的 alpha 利用 LeakyReLU 函数激活,可能用到的 API: fluid.layers.leaky_relu alpha = fluid.layers.leaky_relu(alpha, 0.2) ################################## return {"alpha": alpha, "Wh": src_feat["Wh"]} def recv_func(msg): ################################## # 按照提示一步步理解代码吧,你只需要填###的地方 # 1. 对接收到的 logits 信息进行 softmax 操作,形成归一化分数,可能用到的 API: paddle_helper.sequence_softmax alpha = msg["alpha"] norm_alpha = paddle_helper.sequence_softmax(alpha) # 2. 对 msg["Wh"],也就是节点特征,用上述结果进行加权 output = norm_alpha * msg["Wh"] # 3. 对加权后的结果进行相加的邻居聚合,可能用到的API: fluid.layers.sequence_pool output = fluid.layers.sequence_pool(output, pool_type="sum") ################################## return output # 这一步,其实对应了求解公式当中的Whi, Whj,相当于对node feature加了一个全连接层 Wh = fluid.layers.fc(node_feature, hidden_size, bias_attr=False, name=name + "_hidden") # 消息传递机制执行过程 message = graph_wrapper.send(send_func, nfeat_list=[("Wh", Wh)]) output = graph_wrapper.recv(message, recv_func) output = fluid.layers.elu(output) return output def gat(graph_wrapper, node_feature, hidden_size): # 完整多头GAT # 这里配置多个头,每个头的输出concat在一起,构成多头GAT heads_output = [] # 可以调整头数 (8 head x 8 hidden_size)的效果较好 n_heads = 8 for head_no in range(n_heads): # 请完成单头的GAT的代码 single_output = single_head_gat(graph_wrapper, node_feature, hidden_size, name="head_%s" % (head_no) ) heads_output.append(single_output) output = fluid.layers.concat(heads_output, -1) return output 3.数据集介绍3个常用的图学习数据集,CORA, PUBMED, CITESEER。可以在论文中找到数据集的相关介绍。今天我们来了解一下这几个数据集3.1Cora数据集Cora数据集由机器学习论文组成,是近年来图深度学习很喜欢使用的数据集。在整个语料库中包含2708篇论文,并分为以下七类:基于案例遗传算法神经网络概率方法强化学习规则学习理论论文之间互相引用,在该数据集中,每篇论文都至少引用了一篇其他论文,或者被其他论文引用,也就是样本点之间存在联系,没有任何一个样本点与其他样本点完全没联系。如果将样本点看做图中的点,则这是一个连通的图,不存在孤立点。这样形成的网络有5429条边。在消除停词以及除去文档频率小于10的词汇,最终词汇表中有1433个词汇。每篇论文都由一个1433维的词向量表示,所以,每个样本点具有1433个特征。词向量的每个元素都对应一个词,且该元素只有0或1两个取值。取0表示该元素对应的词不在论文中,取1表示在论文中。数据集有包含两个文件:.content文件包含以下格式的论文描述:<paper_id> <word_attributes>+ <class_label>每行的第一个条目包含纸张的唯一字符串标识,后跟二进制值,指示词汇中的每个单词在文章中是存在(由1表示)还是不存在(由0表示)。最后,该行的最后一个条目包含纸张的类别标签。因此数据集的$feature$应该为$2709×14332709 \times 14332709×1433$维度。第一行为$idx$,最后一行为$label$。那个.cites文件包含语料库的引用’图’。每行以以下格式描述一个链接:<被引论文编号> <引论文编号>每行包含两个纸质id。第一个条目是被引用论文的标识,第二个标识代表包含引用的论文。链接的方向是从右向左。如果一行由“论文1 论文2”表示,则链接是“论文2 - >论文1”。可以通过论文之间的索引关系建立邻接矩阵adj下载链接:https://aistudio.baidu.com/aistudio/datasetdetail/177587相关论文:Qing Lu, and Lise Getoor. "Link-based classification." ICML, 2003.Prithviraj Sen, et al. "Collective classification in network data." AI Magazine, 2008.3.2PubMed数据集PubMed 是一个提供生物医学方面的论文搜寻以及摘要,并且免费搜寻的数据库。它的数据库来源为MEDLINE。其核心主题为医学,但亦包括其他与医学相关的领域,像是护理学或者其他健康学科。PUBMED数据集是基于PubMed 文献数据库生成的。它包含了19717篇糖尿病相关的科学出版物,这些出版物被分成三个类别。这些出版物的互相引用网络包含了44338条边。在消除停词以及除去低频词汇,最终词汇表中有500个词汇。这些出版物用一个TF/IDF加权的词向量来描述是否包含词汇表中的词汇。下载链接:https://aistudio.baidu.com/aistudio/datasetdetail/177591相关论文:Galileo Namata, et. al. "Query-driven Active Surveying for Collective Classification." MLG. 2012.3.3CiteSeer数据集CiteSeer(又名ResearchIndex),是NEC研究院在自动引文索引(Autonomous Citation Indexing, ACI)机制的基础上建设的一个学术论文数字图书馆。这个引文索引系统提供了一种通过引文链接的检索文献的方式,目标是从多个方面促进学术文献的传播和反馈。在整个语料库中包含3312篇论文,并分为以下六类:AgentsAIDBIRMLHCI论文之间互相引用,在该数据集中,每篇论文都至少引用了一篇其他论文,或者被其他论文引用,也就是样本点之间存在联系,没有任何一个样本点与其他样本点完全没联系。如果将样本点看做图中的点,则这是一个连通的图,不存在孤立点。这样形成的网络有4732条边。在消除停词以及除去文档频率小于10的词汇,最终词汇表中有3703个词汇。每篇论文都由一个3703维的词向量表示,所以,每个样本点具有3703个特征。词向量的每个元素都对应一个词,且该元素只有0或1两个取值。取0表示该元素对应的词不在论文中,取1表示在论文中。下载链接:https://aistudio.baidu.com/aistudio/datasetdetail/177589相关论文Qing Lu, and Lise Getoor. "Link-based classification." ICML, 2003.Prithviraj Sen, et al. "Collective classification in network data." AI Magazine, 2008.3.4 小结数据集图数节点数边数特征维度标签数Cora12708542914337Citeseer13327473237036Pubmed119717443385003更多图数据集:https://linqs.org/datasets/GCN常用数据集 KarateClub:数据为无向图,来源于论文An Information Flow Model for Conflict and Fission in Small Groups TUDataset:包括58个基础的分类数据集集合,数据都为无向图,如”IMDB-BINARY”,”PROTEINS”等,来源于TU Dortmund University Planetoid:引用网络数据集,包括“Cora”, “CiteSeer” and “PubMed”,数据都为无向图,来源于论文Revisiting Semi-Supervised Learning with Graph Embeddings。节点代表文档,边代表引用关系。 CoraFull:完整的”Cora”引用网络数据集,数据为无向图,来源于论文Deep Gaussian Embedding of Graphs: Unsupervised Inductive Learning via Ranking。节点代表文档,边代表引用关系。 Coauthor:共同作者网络数据集,包括”CS”和”Physics”,数据都为无向图,来源于论文Pitfalls of Graph Neural Network Evaluation。节点代表作者,若是共同作者则被边相连。学习任务是将作者映射到各自的研究领域中。 Amazon:亚马逊网络数据集,包括”Computers”和”Photo”,数据都为无向图,来源于论文Pitfalls of Graph Neural Network Evaluation。节点代表货物i,边代表两种货物经常被同时购买。学习任务是将货物映射到各自的种类里。 PPI:蛋白质-蛋白质反应网络,数据为无向图,来源于论文Predicting multicellular function through multi-layer tissue networks Entities:关系实体网络,包括“AIFB”, “MUTAG”, “BGS” 和“AM”,数据都为无向图,来源于论文Modeling Relational Data with Graph Convolutional Networks BitcoinOTC:数据为有向图,包括138个”who-trusts-whom”网络,来源于论文EvolveGCN: Evolving Graph Convolutional Networks for Dynamic Graphs,数据链接为Bitcoin OTC trust weighted signed network4.基于PGL的GNN算法实践4.1 GCN图卷积网络 (GCN)是一种功能强大的神经网络,专为图上的机器学习而设计。基于PGL复现了GCN算法,在引文网络基准测试中达到了与论文同等水平的指标。搭建GCN的简单例子:要构建一个 gcn 层,可以使用我们预定义的pgl.nn.GCNConv或者只编写一个带有消息传递接口的 gcn 层。!CUDA_VISIBLE_DEVICES=0 python train.py --dataset cora 仿真结果:| Dataset | Accuracy | | -------- | -------- | | Cora | 81.16% | | Pubmed | 79.34% | |Citeseer | 70.91% |4.2 GAT图注意力网络 (GAT)是一种对图结构数据进行操作的新型架构,它利用掩蔽的自注意层来解决基于图卷积或其近似的先前方法的缺点。基于PGL,我们复现了GAT算法,在引文网络基准测试中达到了与论文同等水平的指标。搭建单头GAT的简单例子:要构建一个 gat 层,可以使用我们的预定义pgl.nn.GATConv或只编写一个带有消息传递接口的 gat 层。GAT仿真结果:| Dataset | Accuracy | | -------- | -------- | | Cora | 82.97% | | Pubmed | 77.99% | |Citeseer | 70.91% | 项目链接:一键fork直接跑程序 https://aistudio.baidu.com/aistudio/projectdetail/5054122?contributionType=15.总结本次项目讲解了图神经网络的原理并对GCN、GAT实现方式进行讲解,最后基于PGL实现了两个算法在数据集Cora、Pubmed、Citeseer的表现,在引文网络基准测试中达到了与论文同等水平的指标。目前的数据集样本节点和边都不是很大,下个项目将会讲解面对亿级别图应该如何去做。参考链接:感兴趣可以看看详细的推到以及涉及有趣的问题
PGL图学习之图游走类metapath2vec模型[系列五]
PGL图学习之图游走类metapath2vec模型[系列五]本项目链接:https://aistudio.baidu.com/aistudio/projectdetail/5009827?contributionType=1有疑问查看原项目相关项目参考:关于图计算&图学习的基础知识概览:前置知识点学习(PGL)[系列一] https://aistudio.baidu.com/aistudio/projectdetail/4982973?contributionType=1图机器学习(GML)&图神经网络(GNN)原理和代码实现(前置学习系列二):https://aistudio.baidu.com/aistudio/projectdetail/4990947?contributionType=1图学习【参考资料2】-知识补充与node2vec代码注解: https://aistudio.baidu.com/aistudio/projectdetail/5012408?forkThirdPart=1图学习【参考资料1】词向量word2vec: [https://aistudio.baidu.com/aistudio/projectdetail/5009409?contributionType=1](https://aistudio.baidu.com/aistudio/projectdetail/5009409?contributionType=11.异质图在图结构中有一个重要概念,同构图和异构图:同构图:节点类型仅有一种的图异构图:节点类型有多种的图,举例如下:异质图介绍在真实世界中,很多的图包含了多种类别节点和边,这类图我们称之为异质图。显然,同构图是异质图中的一个特例,边和节点的种类都是一。异质图比同构图的处理上更为复杂。为了能够处理实际世界中的这大部分异质图,PGL进一步开发了图框架来对异质图模型的支持图神经网络的计算,新增了MetaPath采样支持异质图表示学习。本节:举例异质图数据理解PGL是如何支持异质图的计算使用PGL来实现一个简单的异质图神经网络模型,来对异质图中特定类型节点分类。PGL中引入了异质图的支持,新增MetaPath采样支持异质图表示学习,新增异质图Message Passing机制支持基于消息传递的异质图算法,利用新增的异质图接口,能轻松搭建前沿的异质图学习算法。真实世界中的大部分图都存在着多种类型的边和节点。其中,电子交易网络就是非常常见的异质图。这种类型的图通常包含两种以上类型的节点(商品和用户等),和两以上的边(购买和点击等)。接下来就用图例介绍,图中有多种用户点击或者购买商品。这个图中有两种节点,分别是“用户”和“商品”。同时包含了两种类型的边,“购买”和“点击”。以及学术论文1.1使用PGL创建一个异质图在异质图中,存在着多种边,我们需要对它们进行区分。使用PGL可以用一下形式来表示边: 'click': [(0, 4), (0, 7), (1, 6), (2, 5), (3, 6)], 'buy': [(0, 5), (1, 4), (1, 6), (2, 7), (3, 5)], clicked = [(j, i) for i, j in edges['click']] bought = [(j, i) for i, j in edges['buy']] edges['clicked'] = clicked edges['bought'] = bought # 在异质图中,节点也有不同的类型。因此你需要对每一个节点的类别进行标记,节点的表示格式如下: node_types = [(0, 'user'), (1, 'user'), (2, 'user'), (3, 'user'), (4, 'item'), (5, 'item'),(6, 'item'), (7, 'item')] # 由于边的类型不同,边的特征要根据不同类别来区分。 import numpy as np import paddle import paddle.nn as nn import pgl from pgl import graph # 导入 PGL 中的图模块 import paddle.fluid as fluid # 导入飞桨框架 seed = 0 np.random.seed(0) paddle.seed(0) num_nodes = len(node_types) node_features = {'features': np.random.randn(num_nodes, 8).astype("float32")} labels = np.array([0, 1, 0, 1, 0, 1, 1, 0]) # 在准备好节点和边后,可以利用PGL来构建异质图。 g = pgl.HeterGraph(edges=edges, node_types=node_types, node_feat=node_features) #如果遇到报错显示没有pgl.HeterGraph,重启项目即可 # 在构建了异质图后,我们可以利用PGL很轻松的实现信息传递范式。在这个例子中,我们有两种类型的边,所以我们定义如下的信息传递函数: class HeterMessagePassingLayer(nn.Layer): def __init__(self, in_dim, out_dim, etypes): super(HeterMessagePassingLayer, self).__init__() self.in_dim = in_dim self.out_dim = out_dim self.etypes = etypes self.weight = [] for i in range(len(self.etypes)): self.weight.append( self.create_parameter(shape=[self.in_dim, self.out_dim])) def forward(self, graph, feat): def send_func(src_feat, dst_feat, edge_feat): return src_feat def recv_func(msg): return msg.reduce_mean(msg["h"]) feat_list = [] for idx, etype in enumerate(self.etypes): h = paddle.matmul(feat, self.weight[idx]) msg = graph[etype].send(send_func, src_feat={"h": h}) h = graph[etype].recv(recv_func, msg) feat_list.append(h) h = paddle.stack(feat_list, axis=0) h = paddle.sum(h, axis=0) return h # 通过堆叠两个 HeterMessagePassingLayer 创建一个简单的 GNN。 class HeterGNN(nn.Layer): def __init__(self, in_dim, hidden_size, etypes, num_class): super(HeterGNN, self).__init__() self.in_dim = in_dim self.hidden_size = hidden_size self.etypes = etypes self.num_class = num_class self.layers = nn.LayerList() self.layers.append( HeterMessagePassingLayer(self.in_dim, self.hidden_size, self.etypes)) self.layers.append( HeterMessagePassingLayer(self.hidden_size, self.hidden_size, self.etypes)) self.linear = nn.Linear(self.hidden_size, self.num_class) def forward(self, graph, feat): h = feat for i in range(len(self.layers)): h = self.layers[i](graph, h) logits = self.linear(h) return logits model = HeterGNN(8, 8, g.edge_types, 2) criterion = paddle.nn.loss.CrossEntropyLoss() optim = paddle.optimizer.Adam(learning_rate=0.05, parameters=model.parameters()) g.tensor() labels = paddle.to_tensor(labels) for epoch in range(10): #print(g.node_feat["features"]) logits = model(g, g.node_feat["features"]) loss = criterion(logits, labels) loss.backward() optim.step() optim.clear_grad() print("epoch: %s | loss: %.4f" % (epoch, loss.numpy()[0])) epoch: 1 | loss: 1.1593 epoch: 2 | loss: 0.9971 epoch: 3 | loss: 0.8670 epoch: 4 | loss: 0.7591 epoch: 5 | loss: 0.6629 epoch: 6 | loss: 0.5773 epoch: 7 | loss: 0.5130 epoch: 8 | loss: 0.4782 epoch: 9 | loss: 0.4551 2. methpath2vec及其变种(原理)上篇项目讲的deepwalk、node2vec两种方法都是在同构图中进行游走,如果在异构图中游走,会产生下面的问题:偏向于出现频率高的节点类型偏向于相对集中的节点(度数高的节点)因此在异构图中采用methpath2vec算法。metapath2vec: Scalable Representation Learning for Heterogeneous Networks论文网址项目主页发表时间: KDD 2017论文作者: Yuxiao Dong, Nitesh V. Chawla, Ananthram Swami作者单位: Microsoft ResearchMetapath2vec是Yuxiao Dong等于2017年提出的一种用于异构信息网络(Heterogeneous Information Network, HIN)的顶点嵌入方法。metapath2vec使用基于meta-path的random walks来构建每个顶点的异构邻域,然后用Skip-Gram模型来完成顶点的嵌入。在metapath2vec的基础上,作者还提出了metapath2vec++来同时实现异构网络中的结构和语义关联的建模。methpath2vec中有元路径(meta path)的概念,含义就是在图中选取的节点类型构成的组合路径,这个路径是有实际意义的,例如以上面的异构图为例,A-P-A代表同一篇论文的两个作者,A-P-C-P-A代表两个作者分别在同一个会议上发表了两篇论文。2.1前置重要概念:2.1.1 网络嵌入;异构图/同构图1)网络嵌入Network Embedding针对网络嵌入的相关工作主要有两大部分构成,一部分是图嵌入,一部分是图神经网络。图嵌入方面的相关代表有Deepwalk、LINE、Node2vec以及NetMF,Deepwalk源于NLP(自然语言处理)方面的Word2vec,将Word2vec应用到社交网络体现出了良好的效果,LINE主要是针对大规模网络,Node2vec是在Deepwalk的随机游走上进行了改进,使得游走不再变得那么随机,使得其概率可控,具体就不做过多赘述。对于图神经网络,GCN通过卷积神经网络结合了邻居节点的特征表示融入到节点的表示中,GraphSAGE它就是一个典型的生成式模型,且它结合了节点的结构信息,而且,它不是直接为每个节点生成嵌入,而是生成一个可以表示节点嵌入的函数表示形式,这样的模型,也就是这种生成式模型,有助于它在训练期间对未观察到的节点进行归纳和判断。2)同构Homogeneous与异构HeterogeneousHeterogeneity:表示节点/边的单类还是多类Heterogeneous/Heterogeneous:表示节点是单类还是多类为了区分,论文添加了Multiplex:表示边是单类还是多类Attribute:是否是属性图,图的节点是否具有属性信息根据图结构(同构/异构)以及是否包含节点特征,作者将图分为如下六类(缩写):同构图:HOmogeneous Network (or HON), 属性同构图Attributed HOmogeneous Network (or AHON), 点异构图HEterogeneous Network (orHEN), 属性点异构图Attributed HEterogeneous Network (or AHEN), 边异构图Multiplex HEterogeneous Network (or MHEN), 带节点属性的异构图Attributed Multiplex HEterogeneous Network (or AMHEN)论文归纳了以及每一种网络类型对应的经典的研究方法,如下表:3)节点属性的异构图AMHEN论文给出一个带节点属性的异构图的例子。在左侧原始的图中,用户包含了性别、年龄等属性,商品包含了价格、类目等属性。用户与商品之间包含了4种类型的边,分别对应点击、收藏、加入购物车以及购买行为。传统的 graph embedding 算法比如 DeepWalk 的做法会忽略图中边的类型以及节点的特征,然后转换成一个 HON。如果将边的类型考虑进去,那么就得到一个 MHEN,能够取得非常明显的效果。此外,如果将节点的属性也同时考虑进去,那么就利用了原图的所有信息,可以得到最好的效果。4)AMHEN嵌入难点除了异构性和多样性外,处理 AMHEN 也面临着多重挑战:多路复用的边(Multiplex Edges):每个节点对可能含有多种不同的类型边,如何将不同的关系边进行统一嵌入;局部交互(Partial Observations): 存在大量的长尾客户(可能只与某些产品进行很少的交互);归纳学习(Inductive):如何解决冷启动问题;可扩展性(Scalability),如何拓展到大规模网络中。2.1.2 信息网络(Information Network)信息网络(Information Network)是指一个有向图 G=(V,E), 同时还有一个object类型映射函数 $\phi : V \to \mathcal{A}$,边类型映射函数$\psi : E \to \mathcal{R}$。每一个object $v \in V$, 都有一个特定的object 类型$\phi (v) \in \mathcal{A}$;每一条边$e \in E$ 都有一个特定的relation $\psi(e) \in \mathcal{R}$。异质网络(Heterogeneous Network)指的是object的类型$|\mathcal{A}|>1$或者relation的类型$|\mathcal{R}>1|$。2.1.3 网络模式(Network schema)网络模式(Network schema),定义为:$T_G=(\mathcal{A,R})$,是信息网络 G=(V, E)的一种 meta模板,这个信息网络有一个object类型映射函数$\phi : V \to \mathcal{A}$ 和 link 类型映射函数$\psi: E \to \mathcal{R}$。信息网络G是一个定义在object类型$\mathcal{A}$上的有向图,并且边是$\mathcal{R}$中的relation。2.1.4 元路径(Meta Path)Meta Path 是2011年 Yizhou Sun etc. 在Mining Heterogeneous Information Networks: Principles and Methodologies提出的, 针对异质网络中的相似性搜索。Meta Path 是一条包含relation序列的路径,而这些 relation 定义在不同类型object之间。元路径P是定义在网络模式TG = (A, R)上的,如$A_1→^RA_2→^RA_3...→^RA_{l+1}$表示了从$A_1$ 到$A_{l+1}$的复杂的关系,$R = R_1 ∘ R_2 ∘ R_3 ∘R_l。$元路径P的长度即为关系R的个数.确定元路径的意义在于我们会根据确定的元路径进行随机游走,如果元路径没有意义,会导致后续的训练过程中无法充分体现节点的意义,元路径通常需要人工进行筛选。在基于元路径的游走过程中,只要首尾节点类型相同,就可以继续游走,直到达到最大游走长度或者找不到指定要求的节点。通常来说,元路径是对称的。目前大部分的工作都集中在同构网络中,但真实场景下异构网络才是最常见的。针对同构网络设计的模型很多都没法应用于异构网络,比如说,对于一个学术网络而言:如何高效根据上下文信息表征不同类型的节点?能否用 Deepwalk 或者 Node2Vec 来学习网络中的节点?能否直接将应用于同构网络的 Embedding 模型直接应用于异构网络?解决诸如此类的挑战,有利于更好的在异构网络中应用多种网络挖掘任务:传统的方法都是基于结构特征(如元路径 meta-path)来求相似性,类似的方法有 PathSim、PathSelClus、RankClass 等:但这种方式挖掘出来的元路径(如 “APCPA”)经常会出现相似度为 0 的情况。如果我们能够将 Embedding 的思想应用于异构网络,则不会再出现这种情况。基于这种观察,作者提出了两个可以应用于异构网络的 Graph Embedding 的算法模型——metapath2vec 以及 metapath2vec++。问题定义Problem DefinitionDefinition 1: 异质网络(Heterogeneous Network):$G = (V,E,T)$,其中每个节点和边分别对应一个映射 $\phi(v) : V \rightarrow T_{V}$ 和$\psi(e) : E \rightarrow T_{E}$。 其中$T_V$和$T_E$分别表示节点的类型集合以及关系的类型集合。且$\left|T_{V}\right|+\left|T_{E}\right|>2$。Definition 2: 异质网络表示学习(Heterogeneous Network Representation Learning):给定一个异构网络,学习一个维的潜在表征可以表征网络中顶点之间的结构信息和语义场景关系。异构网络表征学习的输出是一个低维的矩阵,其中行是一个维的向量,表示顶点的表征。这里需要注意的是,虽然顶点的类型不同,但是不同类型的顶点的表征向量映射到同一个维度空间。由于网络异构性的存在,传统的基于同构网络的顶点嵌入表征方法很难有效地直接应用在异构网络上。异质网络中的节点学习一个$d$维的表示 $\mathrm{X} \in \mathbb{R}^{|V| \times d}$,$d \ll|V|$。节点的向量表示可以捕获节点间结构和语义关系。2.2 Metapath2vec框架在正式介绍metapath2vec方法之前,作者首先介绍了同构网络上的基于random walk的graph embedding算法的基本思想,如:Deepwalk和node2vec等。该类方法采用了类似word2vec的思想,即:使用skip-gram模型对每个顶点的局部领域顶点信息进行预测,进而学习到每个顶点的特征表示。通常,对于一个同构网络$G = (V,E)$,目标是从每个顶点的局部领域上最大化网络似然:$$ \arg \max _{\theta} \prod_{v \in V} \prod_{c \in N(v)} p(c \mid v ; \theta) $$其中 $N(v)$ 表示顶点 $v$ 的领域, 如1-hop以内的邻接页点, 2 -hop以内的邻接顶点。 $p(c \mid v ; \theta)$ 表 示给定顶点 $v$ 后, 顶点 $c$ 的条件概率。下面正式给出基于异构网络的metapath2vec嵌入算法。metapath2vec分为两个部分,分别是Meta-Path-Based Random Walks和Heterogeneous Skip-Gram2.2.1 Heterogeneous Skip-Gram在metapath2vec中,作者使用Skip-Gram模型通过在顶点 $v$ 的领域 $N_{t}(v), t \in T_{V}$ 上最大化 条件概率来学习异构网络 $G=(V, E, T)$ 上的顶点表征。$$ \arg \max _{\theta} \sum_{v \in V} \sum_{t \in T_{V}} \sum_{c_{t} \in N_{t}(v)} \log p\left(c_{t} \mid v ; \theta\right) $$其中 $N_{t}(v)$ 表示顶点 $v$ 的类型为 $t$ 的领域顶点集合。 $p\left(c_{t} \mid v ; \theta\right)$ 通常定义为一个softmax函数,即:$$ p\left(c_{t} \mid v ; \theta\right)=\frac{e^{X_{c_{t}} \cdot X_{v}}}{\sum_{u \in V} e^{X_{u} \cdot X_{v}}} $$其中 $X_{v}$ 是矩阵 $X$ 的第 $v$ 行矩阵, 表示页点 $v$ 的嵌入向量。为了提升参数更新效率 metapath2vec采用了Negative Sampling进行参数迭代更新, 给定一个Negative Sampling的大 小 $M,$ 参数更新过程如下:$$ \log \sigma\left(X_{c_{t}} \cdot X_{v}\right)+\sum_{m=1}^{M} \mathbb{E}_{u^{m} \sim P(u)}\left[\log \sigma\left(-X_{u^{m}} \cdot X_{v}\right)\right] $$其中$\sigma(x)=\frac{1} {1+e^{-x}}$, $P(u)是一个negative node $u^m$在M次采样中的预定义分布。metapath2vec通过不考虑顶点的类型进行节点抽取来确定当前顶点的频率。2.2.2Meta-Pathe-Based Random Walks在同构网络中,DeepWalk和node2vec等算法通过随机游走的方式来构建Skip-Gram模型的上下文语料库,受此启发,作者提出了一种异构网络上的随机游走方式。在不考虑顶点类型和边类型的情况下,$p(v^{i+1}|v^i)$表示从顶点$v^i$向其邻居顶点$v^{i+1}$的转移概率。然而Sun等已证明异构网络上的随机游走会偏向于某些高度可见的类型的顶点,这些顶点的路径在网络中具有一定的统治地位,而这些有一定比例的路径指向一小部分节点的集合。鉴于此,作者提出了一种基于meta-path的随机游走方式来生成Skip-Gram模型的邻域上下文。该随机游走方式可以同时捕获不同类型顶点之间语义关系和结构关系,促进了异构网络结构向metapath2vec的Skip-Gram模型的转换。 一个meta-path的scheme可以定义成如下形式:$$ V_{1} \stackrel{R_{1}}{\longrightarrow} V_{2} \stackrel{R_{2}}{\longrightarrow} \ldots V_{t} \stackrel{R_{t}}{\longrightarrow} V_{t+1} \ldots V_{l-1} \stackrel{R_{l-1}}{\longrightarrow} V_{l} $$其中$$ R=R_{1} \circ R_{2} \circ \cdots \circ R_{l-1} $$表示顶点 $V_{1}$ 和顶点 $V_{l}$ 之间的路径组合。例如下图中, "APA"表示一种固定语义的metapath, "APVPA"表示另外一种固定语义的meta-path。并且很多之前的研究成果都表明, meta-path在很多异构网络数据挖掘中很很大作用。因此,在本文中,作者给出了基于meta-path的随机游走方式。给定一个异构网络 $G=(V, E, T)$ 和一个meta-path的scheme $\mathcal{P}$ :$$ V_{1} \stackrel{R_{1}}{\longrightarrow} V_{2} \stackrel{R_{2}}{\longrightarrow} \ldots V_{t} \stackrel{R_{t}}{\longrightarrow} V_{t \pm 1} \ldots V_{l-1} \stackrel{R_{l-1}}{\longrightarrow} V_{l} $$那么在第 $i$ 步的转移概率定义如下:$$ p\left(v^{i+1} \mid v_{t}^{i}, \mathcal{P}\right)=\left\{\begin{array}{ll} \frac{1}{\left|N_{t+1}\left(v_{t}^{i}\right)\right|} & \left(v^{i+1}, v^{i}\right) \in E, \phi\left(v^{i+1}\right)=t+1 \\ 0 & \left(v^{i+1}, v^{i}\right) \in E, \phi\left(v^{i+1}\right) \neq t+1 \\ 0 & \left(v^{i+1}, v^{i}\right) \notin E \end{array}\right. $$其中 $v_{t}^{i} \in V_{t}, \quad N_{t+1}\left(v_{t}^{i}\right)$ 表示页点 $v_{t}^{i}$ 的 $V_{t+1}$ 类型的领域顶点集合。换言之, $v^{i+1} \in V_{t+1},$ 也 就是说随机游走是在预定义的meta-path scheme $\mathcal{P}$ 条件下的有偏游走。初次之外, meta-path 通常是以一种对称的方式来使用, 也就是说在上述路径组合中,顶点 $V_{1}$ 的类型和 $V_{l}$ 的类型相同。即:$$ p\left(v^{i+1} \mid v_{t}^{i}\right)=p\left(v^{i+1} \mid v_{l}^{i}\right), \text { if } \mathbf{t}=1 $$基于meta-path的随机游走保证不同类型顶点之间的语义关系可以适当的融入Skip-Gram模型中。2.3 Metapath2vec++框架methpath2vec的变种:methpath2vec++:在负采样时考虑节点类型multi-methpath2vec++:针对多条元路径进行游走side info+multi-methpath2vec++:在获取元路径的基础上考虑了节点的特征metapath2vec在为每个顶点构建领域时,通过meta-path来指导随机游走过程向指定类型的顶点进行有偏游走。但是在softmax环节中,并没有顶点的类型,而是将所有的顶点认为是同一种类型的顶点。换言之,metapath2vec在Negative Sampling环节采样的negative 样本并没有考虑顶点的类型,也就是说metapath2vec支持任意类型顶点的Negative Sampling。于是作者在metapath2vec的基础上又提出了改进方案metapath2vec++。2.3.1Heterogeneous Negative Sampling在metapath2vec++中, softmax函数根据不同类型的顶点的上下文 $c_{t}$ 进行归一化。也就是说$p\left(c_{t} \mid v ; \theta\right)$ 根据固定类型的页点进行调整。即:$$ p\left(c_{t} \mid v ; \theta\right)=\frac{e^{X_{c_{t}} \cdot X_{v}}}{\sum_{u_{t} \in V_{t}} e^{X_{u_{t}} \cdot X_{v}}} $$其中 $V_{t}$ 是网络中 $t$ 类型顶点集合。在这种情况下, metapath2vec++为Skip-Gram模型的输出层中的每种类型的领域指定了一个多项式分布的集合。而在metapath2vec, DeepWalk和node2vec中, Skip-Gram输出多项式分布的维度等于蜂个网络中顶点的数目,然而对于metapath2vec++的Skip-Gram, 其针对特定类型的输出多项式的维度取决于网络中当前类型顶点的数目。如下图示。最终我们可以得到如下的目标函数:$$ O(X)=\log \sigma\left(X_{c_{t}} \cdot X_{v}\right)+\sum_{m=1}^{M} \mathbb{E}_{u_{t}^{m} \sim P_{t}\left(u_{t}\right)}\left[\log \sigma\left(-X_{u_{t}^{m}} \cdot X_{v}\right)\right] $$可以得出其梯度如下:$$ \begin{array}{c} \frac{\partial O(X)}{\partial X_{u_{t}^{m}}}=\left(\sigma\left(X_{u_{t}^{m}} \cdot X_{v}-\mathbb{I}_{c_{t}}\left[u_{t}^{m}\right]\right)\right) X_{v} \\ \frac{\partial O(X)}{\partial X_{v}}=\sum_{m=0}^{M}\left(\sigma\left(X_{u_{i}^{* n}} \cdot X_{v}-\mathbb{I}_{c_{i}}\left[u_{t}^{m}\right]\right)\right) X_{v_{t}^{m}} \end{array} $$其中 $\mathbb{I}_{c_{t}}\left[u_{t}^{m}\right]$ 是一个指示函数, 用来指示 $u_{t}^{m}$ 在 $m=0, u_{t}^{0}=c_{t}$ 时是否是顶点 $c_{t}$ 的上下文。该 算法使用随机梯度下降进行参数优化。整个metapath2vec++算法如下。3.分布式图引擎(快速入门)因为会存在许多无法在一台机器上加载的巨大图,例如社交网络和引文网络。为了处理这样的图,PGL 开发了一个分布式图引擎框架来支持大规模图网络上的图采样,以进行分布式 GNN 训练。下面将介绍执行分布式图引擎以进行图采样的步骤。如何启动分布式图引擎服务的示例:假设我们有一个下图,它有两种类型的节点(u 和 t)。首先,我们应该创建一个配置文件并指定每台机器的 ip 地址。 这里我们使用两个端口来模拟两台机器。创建配置文件和 ip 地址文件后,我们现在可以启动两个图形服务器。然后我们可以使用客户端从图服务器中采样邻居或采样节点。4 methpath2vec(实践)4.1数据集介绍链接:https://ericdongyx.github.io/metapath2vec/m2v.html将所有数据和代码下载到一个 zip 文件中---metapath2vec.zip 6.7 GB,包括以下 B、C、D、E 和 F 部分(DropBox |百度云)。Bibtex: @inproceedings{dong2017metapath2vec, title={metapath2vec: 异构网络的可扩展表示学习}, author={Dong, Yuxiao and Chawla, Nitesh V and Swami, Ananthram}, booktitle={KDD '17}, pages={135- -144}, 年份={2017}, 组织={ACM} }引用:Yuxiao Dong、Nitesh V. Chawla 和 Ananthram Swami。2017. metapath2vec:异构网络的可扩展表示学习。在 KDD'17 中。135–144。原始网络数据AMiner计算机科学 (CS) 数据: CS 数据集由 1,693,531 名计算机科学家和 3,194,405 篇论文组成,来自 3,883 个计算机科学场所——包括会议和期刊——截至 2016 年。我们构建了一个异构协作网络,其中有是三种类型的节点:作者、论文和地点。Citation: Jie Tang, Jing Zhang, Limin Yao, Juanzi Li, Li Zhang, and Zhong Su. 2008. ArnetMiner: Extraction and Mining of Academic Social Networks. In KDD'08. 990–998. 数据库和信息系统(DBIS)数据: DBIS 数据集由 Sun 等人构建和使用。它涵盖了 464 个场所、其前 5000 位作者以及相应的 72,902 篇出版物。我们还从 DBIS 构建了异构协作网络,其中一个链接可以连接两位作者,一位作者和一篇论文,以及一篇论文和一个地点。Citation: Yizhou Sun, Jiawei Han, Xifeng Yan, Philip S. Yu, and Tianyi Wu. 2011. Pathsim: Meta path-based top-k similarity search in heterogeneous information networks. In VLDB'11. 992–1003.4.2 PGL实现metapath2vec算法利用PGL来复现metapath2vec模型。和前面xxx2vec的方法类似,先做网络嵌入系数矩阵的训练,然后使用训练好的矩阵在做预测。Dataset.py 包含了对图数据进行深度游走生成walks等接口model.py 包含用于训练metapath2vec的skipgram模型定义utils.py 包含了对配置文件config.yaml的读取接口超参数所有超参数都保存在config.yaml文件中,所以在训练之前,你可以打开config.yaml来修改你喜欢的超参数。PGL 图形引擎启动现在我们支持使用PGL Graph Engine分布式加载图数据。我们还开发了一个简单的教程来展示如何启动图形引擎要启动分布式图服务,请按照以下步骤操作。1)IP地址设置第一步是为每个图形服务器设置 IP 列表。每个带有端口的 IP 地址代表一个服务器。在ip_list.txt文件中,我们为演示设置了 4 个 IP 地址如下:127.0.0.1:8553 127.0.0.1:8554 127.0.0.1:8555 127.0.0.1:85562)通过 OpenMPI 启动图形引擎在启动图形引擎之前,您应该在中设置以下超参数config.yaml:etype2files: "p2a:./graph_data/paper2author_edges.txt,p2c:./graph_data/paper2conf_edges.txt" ntype2files: "p:./graph_data/node_types.txt,a:./graph_data/node_types.txt,c:./graph_data/node_types.txt" symmetry: True shard_num: 100然后,我们可以在 OpenMPI 的帮助下启动图形引擎。mpirun -np 4 python -m pgl.distributed.launch --ip_config ./ip_list.txt --conf ./config.yaml --mode mpi --shard_num 100 手动启动图形引擎如果您没有安装 OpenMPI,您可以手动启动图形引擎。Fox 示例,如果我们要使用 4 个服务器,我们应该在 4 个终端上分别运行以下命令。# terminal 3 python -m pgl.distributed.launch --ip_config ./ip_list.txt --conf ./config.yaml --shard_num 100 --server_id 3 # terminal 2 python -m pgl.distributed.launch --ip_config ./ip_list.txt --conf ./config.yaml --shard_num 100 --server_id 2 # terminal 1 python -m pgl.distributed.launch --ip_config ./ip_list.txt --conf ./config.yaml --shard_num 100 --server_id 1 # terminal 0 python -m pgl.distributed.launch --ip_config ./ip_list.txt --conf ./config.yaml --shard_num 100 --server_id 06.总结介绍了异质图,利用pgl对metapath2vec、metapath2vec 进行了实现,并给出了多个框架版本的demo满足个性化需求metapath2vec是一种用于异构网络中表示学习的算法框架,其中包含多种类型的节点和链接。给定异构图,metapath2vec 算法首先生成基于元路径的随机游走,然后使用 skipgram 模型训练语言模型。基于 PGL重现了 metapath2vec 算法,用于可扩展的表示学习。参考资料Meta Path 定义metapath2vec 异构网络表示学习【图网络论文(一)】异构图网络:metapath2vec#16 知识分享:Metapath2vec的前世今生Graph Embedding之metapath2vec【Graph Embedding】: metapath2vec算法
图机器学习(GML)&图神经网络(GNN)原理和代码实现(前置学习系列二)
项目链接:https://aistudio.baidu.com/aistudio/projectdetail/4990947?contributionType=1欢迎fork欢迎三连!文章篇幅有限,部分程序出图不一一展示,详情进入项目链接即可图机器学习(GML)&图神经网络(GNN)原理和代码实现(PGL)[前置学习系列二]上一个项目对图相关基础知识进行了详细讲述,下面进图GMLnetworkx :NetworkX 是一个 Python 包,用于创建、操作和研究复杂网络的结构、动力学和功能https://networkx.org/documentation/stable/reference/algorithms/index.htmlimport numpy as np import random import networkx as nx from IPython.display import Image import matplotlib.pyplot as plt from sklearn.metrics import accuracy_score from sklearn.metrics import roc_curve from sklearn.metrics import roc_auc_score 1. 图机器学习GML图学习的主要任务图学习中包含三种主要的任务:链接预测(Link prediction)节点标记预测(Node labeling)图嵌入(Graph Embedding)1.1链接预测(Link prediction)在链接预测中,给定图G,我们的目标是预测新边。例如,当图未被完全观察时,或者当新客户加入平台(例如,新的LinkedIn用户)时,预测未来关系或缺失边是很有用的。详细阐述一下就是:GNN链接预测任务,即预测图中两个节点之间的边是否存在。在Social Recommendation,Knowledge Graph Completion等应用中都需要进行链接预测。模型实现上是将链接预测任务看成一个二分类任务:将图中存在的边作为正样本;负采样一些图中不存在的边作为负样本;将正样例和负样例合并划分为训练集和测试集;可以采用二分类模型的评估指标来评估模型的效果,例如:AUC值在一些场景下例如大规模推荐系统或信息检索,模型需要评估top-k预测结果的准确性,因此对于链接预测任务还需要一些其他的评估指标来衡量模型最终效果:MR(MeanRank)MRR(Mean Reciprocal Rank)Hit@nMR, MRR, Hit@n指标含义:假设整个图谱中共n个实体,评估前先进行如下操作:(1)将一个正确的三元组(h,r,t)中的头实体h或者尾实体t,依次替换成整个图谱中的其他所有实体,这样会产生n个三元组;(2)对(1)中产生的n个三元组分别计算其能量值,例如在TransE中计算h+r-t的值,这样n个三元组分别对应自己的能量值;(3)对上述n个三元组按照能量值进行升序排序,记录每个三元组排序后的序号;(4)对所有正确的三元组都进行上述三步操作MR指标:将整个图谱中每个正确三元组的能量值排序后的序号取平均得到的值;MRR指标:将整个图谱每个正确三元组的能量排序后的序号倒数取平均得到的值;Hit@n指标:整个图谱正确三元组的能量排序后序号小于n的三元组所占的比例。因此对于链接预测任务来说,MR指标越小,模型效果越好;MRR和Hit@n指标越大,模型效果越好。接下来本文将在Cora引文数据集上,预测两篇论文之间是否存在引用关系或被引用关系新LinkedIn用户的链接预测只是给出它可能认识的人的建议。在链路预测中,我们只是尝试在节点对之间建立相似性度量,并链接最相似的节点。现在的问题是识别和计算正确的相似性分数!为了说明图中不同链路的相似性差异,让我们通过下面这个图来解释:设$N(i)$是节点$i$的一组邻居。在上图中,节点$i$和$j$的邻居可以表示为:$i$的邻居:1.1.1 相似度分数我们可以根据它们的邻居为这两个节点建立几个相似度分数。公共邻居:$S(i,j) = \mid N(i) \cap N(j) \mid$,即公共邻居的数量。在此示例中,分数将为2,因为它们仅共享2个公共邻居。Jaccard系数:$S(i,j) = \frac { \mid N(i) \cap N(j) \mid } { \mid N(i) \cup N(j) \mid }$,标准化的共同邻居版本。交集是共同的邻居,并集是:因此,Jaccard系数由粉红色与黄色的比率计算出:值是$\frac {1} {6}$。Adamic-Adar指数:$S(i,j) = \sum_{k \in N(i)\cap N(j) } \frac {1} {\log \mid N(k) \mid}$。 对于节点i和j的每个公共邻居(common neighbor),我们将1除以该节点的邻居总数。这个概念是,当预测两个节点之间的连接时,与少量节点之间共享的元素相比,具有非常大的邻域的公共元素不太重要。优先依附(Preferential attachment): $S(i,j) = \mid N(i) \mid * \mid N(j) \mid$当社区信息可用时,我们也可以在社区信息中使用它们。### 1.1.2 性能指标(Performance metrics)我们如何进行链接预测的评估?我们必须隐藏节点对的子集,并根据上面定义的规则预测它们的链接。这相当于监督学习中的train/test的划分。然后,我们评估密集图的正确预测的比例,或者使用稀疏图的标准曲线下的面积(AUC)。参考链接:模型评估指标AUC和ROC:https://cloud.tencent.com/developer/article/15088821.1.3 代码实践这里继续用空手道俱乐部图来举例:使用在前两篇文中提及到的Karate图,并使用python来进行实现n=34 m = 78 G_karate = nx.karate_club_graph() pos = nx.spring_layout(G_karate) nx.draw(G_karate, cmap = plt.get_cmap('rainbow'), with_labels=True, pos=pos) # 我们首先把有关图的信息打印出来: n = G_karate.number_of_nodes() m = G_karate.number_of_edges() print("Number of nodes : %d" % n) print("Number of edges : %d" % m) print("Number of connected components : %d" % nx.number_connected_components(G_karate)) plt.figure(figsize=(12,8)) nx.draw(G_karate, pos=pos) plt.gca().collections[0].set_edgecolor("#000000") # 现在,让删除一些连接,例如25%的边: # Take a random sample of edges edge_subset = random.sample(G_karate.edges(), int(0.25 * G_karate.number_of_edges())) # remove some edges G_karate_train = G_karate.copy() G_karate_train.remove_edges_from(edge_subset) # 绘制部分观察到的图,可以对比上图发现,去掉了一些边 plt.figure(figsize=(12,8)) nx.draw(G_karate_train, pos=pos) # 可以打印我们删除的边数和剩余边数: edge_subset_size = len(list(edge_subset)) print("Deleted : ", str(edge_subset_size)) print("Remaining : ", str((m - edge_subset_size))) # Jaccard Coefficient # 可以先使用Jaccard系数进行预测: pred_jaccard = list(nx.jaccard_coefficient(G_karate_train)) score_jaccard, label_jaccard = zip(*[(s, (u,v) in edge_subset) for (u,v,s) in pred_jaccard]) # 打印前10组结果 print(pred_jaccard[0:10]) # 预测结果如下,其中第一个是节点,第二个是节点,最后一个是Jaccard分数(用来表示两个节点之间边预测的概率)# Compute the ROC AUC Score # 其中,FPR是False Positive Rate, TPR是True Positive Rate fpr_jaccard, tpr_jaccard, _ = roc_curve(label_jaccard, score_jaccard) auc_jaccard = roc_auc_score(label_jaccard, score_jaccard) print(auc_jaccard) # Adamic-Adar # 现在计算Adamic-Adar指数和对应的ROC-AUC分数 # Prediction using Adamic Adar pred_adamic = list(nx.adamic_adar_index(G_karate_train)) score_adamic, label_adamic = zip(*[(s, (u,v) in edge_subset) for (u,v,s) in pred_adamic]) print(pred_adamic[0:10]) # Compute the ROC AUC Score fpr_adamic, tpr_adamic, _ = roc_curve(label_adamic, score_adamic) auc_adamic = roc_auc_score(label_adamic, score_adamic) print(auc_adamic) # Compute the Preferential Attachment # 同样,可以计算Preferential Attachment得分和对应的ROC-AUC分数 pred_pref = list(nx.preferential_attachment(G_karate_train)) score_pref, label_pref = zip(*[(s, (u,v) in edge_subset) for (u,v,s) in pred_pref]) print(pred_pref[0:10]) fpr_pref, tpr_pref, _ = roc_curve(label_pref, score_pref) auc_pref = roc_auc_score(label_pref, score_pref) print(auc_pref)plt.figure(figsize=(12, 8)) plt.plot(fpr_jaccard, tpr_jaccard, label='Jaccard Coefficient - AUC %.2f' % auc_jaccard, linewidth=4) plt.plot(fpr_adamic, tpr_adamic, label='Adamic-Adar - AUC %.2f' % auc_adamic, linewidth=4) plt.plot(fpr_pref, tpr_pref, label='Preferential Attachment - AUC %.2f' % auc_pref, linewidth=4) plt.plot([0, 1], [0, 1], 'k--') plt.xlim([0.0, 1.0]) plt.ylim([0.0, 1.0]) plt.xlabel('False positive rate') plt.ylabel('True positive rate') plt.title("ROC AUC Curve") plt.legend(loc='lower right') plt.show() 1.2 节点标记预测(Node labeling)给定一个未标记某些节点的图,我们希望对这些节点的标签进行预测。这在某种意义上是一种半监督的学习问题。处理这些问题的一种常见方法是假设图上有一定的平滑度。平滑度假设指出通过数据上的高密度区域的路径连接的点可能具有相似的标签。这是标签传播算法背后的主要假设。标签传播算法(Label Propagation Algorithm,LPA)是一种快速算法,仅使用网络结构作为指导来发现图中的社区,而无需任何预定义的目标函数或关于社区的先验信息。单个标签在密集连接的节点组中迅速占据主导地位,但是在穿过稀疏连接区域时会遇到问题。半监督标签传播算法是如何工作?首先,我们有一些数据:$x_1, ..., x_l, x_{l+1}, ..., x_n \in R^p$,,以及前$l$个点的标签:$y_1, ..., y_l \in 1...C$.我们定义初始标签矩阵$Y \in R^{n \times C}$,如果$x_i$具有标签$y_i=j$则$Y_{ij} = 1$,否则为0。该算法将生成预测矩阵$F \in R^{n \times C}$,我们将在下面详述。然后,我们通过查找最可能的标签来预测节点的标签:$\hat{Y_i} = argmax_j F_{i,j}$预测矩阵$F$是什么?预测矩阵是矩阵$F^{\star}$,其最小化平滑度和准确度。因此,我们的结果在平滑性和准确性之间进行权衡。问题的描述非常复杂,所以我将不会详细介绍。但是,解决方案是:$F^{\star} = ( (1-\alpha)I + L_{sym})^{-1} Y$其中:参数$\alpha = \frac {1} {1+\mu}$$Y$是给定的标签$L_{sym}$是图的归一化拉普拉斯矩阵(Laplacian matrix)如果您想进一步了解这个主题,请关注图函数的平滑度和流形正则化的概念。斯坦福有一套很好的标签图可以下载:https://snap.stanford.edu/data/Networkx直接实现标签传播:https://networkx.github.io/documentation/latest/reference/algorithms/generated/networkx.algorithms.community.label_propagation.label_propagation_communities.html接下来我们用python来实现节点标签的预测。 为了给我们使用到的标签添加更多的特征,我们需要使用来自Facebook的真实数据。你可以再这里下载,然后放到facebook路径下。Facebook 数据已通过将每个用户的 Facebook 内部 id 替换为新值来匿名化。此外,虽然已经提供了来自该数据集的特征向量,但对这些特征的解释却很模糊。例如,如果原始数据集可能包含特征“political=Democratic Party”,则新数据将仅包含“political=anonymized feature 1”。因此,使用匿名数据可以确定两个用户是否具有相同的政治派别,但不能确定他们各自的政治派别代表什么。我已经把数据集放在目录里了,就不需要下载了1.2.1 代码实现标签扩散n = G_fb.number_of_nodes() m = G_fb.number_of_edges() print("Number of nodes: %d" % n) print("Number of edges: %d" % m) print("Number of connected components: %d" % nx.number_connected_components(G_fb)) # 我们把图数据显示出来: mapping=dict(zip(G_fb.nodes(), range(n))) nx.relabel_nodes(G_fb, mapping, copy=False) pos = nx.spring_layout(G_fb) plt.figure(figsize=(12,8)) nx.draw(G_fb, node_size=200, pos=pos) plt.gca().collections[0].set_edgecolor("#000000") with open('facebook/3980.featnames') as f: for i, l in enumerate(f): n_feat = i+1 features = np.zeros((n, n_feat)) f = open('facebook/3980.feat', 'r') for line in f: if line.split()[0] in mapping: node_id = mapping[line.split()[0]] features[node_id, :] = list(map(int, line.split()[1:])) features = 2*features-1 feat_id = 6 #特征选择id,自行设置 labels = features[:, feat_id] plt.figure(figsize=(12,8)) nx.draw(G_fb, cmap = plt.get_cmap('bwr'), nodelist=range(n), node_color = labels, node_size=200, pos=pos) plt.gca().collections[0].set_edgecolor("#000000") plt.show() # 这个所选择的特征,在图中相对平滑,因此拥有较好的学习传播性能。 # 为了阐述节点标签预测是如何进行的,我们首先要删掉一些节点的标签,作为要预测的对象。这里我们只保留了30%的节点标签: random.seed(5) proportion_nodes = 0.3 labeled_nodes = random.sample(G_fb.nodes(), int(proportion_nodes * G_fb.number_of_nodes())) known_labels = np.zeros(n) known_labels[labeled_nodes] = labels[labeled_nodes] plt.figure(figsize=(12,8)) nx.draw(G_fb, cmap = plt.get_cmap('bwr'), nodelist=range(n), node_color = known_labels, node_size=200, pos=pos) plt.gca().collections[0].set_edgecolor("#000000") # set node border color to black plt.show()1.3 图嵌入(Graph Embedding)嵌入的学习方式与 word2vec 的 skip-gram 嵌入的学习方式相同,使用的是 skip-gram 模型。问题是,我们如何为 Node2Vec 生成输入语料库?数据要复杂得多,即(非)定向、(非)加权、(a)循环……为了生成语料库,我们使用随机游走采样策略:在处理NLP或计算机视觉问题时,我们习惯在深度神经网络中对图像或文本进行嵌入(embedding)。到目前为止,我们所看到的图的一个局限性是没有向量特征。但是,我们可以学习图的嵌入!图有不同几个级别的嵌入:对图的组件进行嵌入(节点,边,特征…)(Node2Vec) node2vec是一个用于图表示学习的算法框架。给定任何图,它可以学习节点的连续特征表示,然后可以用于各种下游机器学习任务。对图的子图或整个图进行嵌入(Graph2Vec) Learning Distributed Representations of Graphs学习图的分布式表示最近关于图结构化数据的表示学习的工作主要集中在学习图子结构(例如节点和子图)的分布式表示。然而,许多图分析任务(例如图分类和聚类)需要将整个图表示为固定长度的特征向量。虽然上述方法自然不具备学习这种表示的能力,但图内核仍然是获得它们的最有效方法。然而,这些图内核使用手工制作的特征(例如,最短路径、graphlet 等),因此受到泛化性差等问题的阻碍。为了解决这个限制,在这项工作中,我们提出了一个名为 graph2vec 的神经嵌入框架来学习任意大小图的数据驱动的分布式表示。图2vec' s 嵌入是以无监督的方式学习的,并且与任务无关。因此,它们可以用于任何下游任务,例如图分类、聚类甚至播种监督表示学习方法。我们在几个基准和大型现实世界数据集上的实验表明,graph2vec 在分类和聚类精度方面比子结构表示学习方法有显着提高,并且可以与最先进的图内核竞争。### 1.3.1. 节点嵌入(Node Embedding)我们首先关注的是图组件的嵌入。有几种方法可以对节点或边进行嵌入。例如,DeepWalk【http://www.perozzi.net/projects/deepwalk/ 】 使用短随机游走来学习图中边的表示。我们将讨论Node2Vec,这篇论文由2016年斯坦福大学的Aditya Grover和Jure Leskovec发表。作者说:“node2vec是一个用于图表示学习的算法框架。给定任何图,它可以学习节点的连续特征表示,然后可以用于各种下游机器学习任务。“该模型通过使用随机游走,优化邻域保持目标来学习节点的低维表示。Node2Vec的代码可以在GitHub上找到:https://github.com/eliorc/node2vec部分程序出图不一一展示,详情进入项目链接即可2.图神经网络GNN2.1GNN引言图神经网络(Graph Neural Networks,GNN)综述链接:https://zhuanlan.zhihu.com/p/75307407?from_voters_page=true 译文https://arxiv.org/pdf/1901.00596.pdf 原始文章 最新版本V4版本近年来,深度学习彻底改变了许多机器学习任务,从图像分类和视频处理到语音识别和自然语言理解。这些任务中的数据通常在欧几里得空间中表示。然而,越来越多的应用程序将数据从非欧几里德域生成并表示为具有复杂关系和对象之间相互依赖关系的图。图数据的复杂性对现有的机器学习算法提出了重大挑战。最近,出现了许多关于扩展图数据深度学习方法的研究。在本次调查中,我们全面概述了数据挖掘和机器学习领域中的图神经网络 (GNN)。我们提出了一种新的分类法,将最先进的图神经网络分为四类,即循环图神经网络、卷积图神经网络、图自动编码器和时空图神经网络。我们进一步讨论了图神经网络在各个领域的应用,并总结了图神经网络的开源代码、基准数据集和模型评估。最后,我们在这个快速发展的领域提出了潜在的研究方向神经网络最近的成功推动了模式识别和数据挖掘的研究。许多机器学习任务,如对象检测 [1]、[2]、机器翻译 [3]、[4] 和语音识别 [5],曾经严重依赖手工特征工程来提取信息特征集,最近已经由各种端到端深度学习范例彻底改变,例如卷积神经网络 (CNN) [6]、递归神经网络 (RNN) [7] 和自动编码器 [8]。深度学习在许多领域的成功部分归功于快速发展的计算资源(例如 GPU)、大训练数据的可用性以及深度学习从欧几里得数据(例如图像、文本、和视频)。以图像数据为例,我们可以将图像表示为欧几里得空间中的规则网格。卷积神经网络 (CNN) 能够利用图像数据的移位不变性、局部连通性和组合性 [9]。因此,CNN 可以提取与整个数据集共享的局部有意义的特征,用于各种图像分析。虽然深度学习有效地捕获了欧几里得数据的隐藏模式,但越来越多的应用程序将数据以图形的形式表示。例如,在电子商务中,基于图的学习系统可以利用用户和产品之间的交互来做出高度准确的推荐。在化学中,分子被建模为图形,并且需要确定它们的生物活性以进行药物发现。在引文网络中,论文通过引文相互链接,并且需要将它们分类到不同的组中。图数据的复杂性对现有的机器学习算法提出了重大挑战。由于图可能是不规则的,图可能具有可变大小的无序节点,并且来自图中的节点可能具有不同数量的邻居,导致一些重要的操作(例如卷积)在图像域中很容易计算,但是难以应用于图域。此外,现有机器学习算法的一个核心假设是实例相互独立。这个假设不再适用于图数据,因为每个实例(节点)通过各种类型的链接(例如引用、友谊和交互)与其他实例相关联。最近,人们对扩展图形数据的深度学习方法越来越感兴趣。受来自深度学习的 CNN、RNN 和自动编码器的推动,在过去几年中,重要操作的新泛化和定义迅速发展,以处理图数据的复杂性。例如,可以从 2D 卷积推广图卷积。如图 1 所示,可以将图像视为图形的特殊情况,其中像素由相邻像素连接。与 2D 卷积类似,可以通过取节点邻域信息的加权平均值来执行图卷积。二维卷积类似于图,图像中的每个像素都被视为一个节点,其中邻居由过滤器大小确定。 2D 卷积取红色节点及其邻居像素值的加权平均值。 节点的邻居是有序的并且具有固定的大小。图卷积。 为了得到红色节点的隐藏表示,图卷积运算的一个简单解决方案是取红色节点及其邻居节点特征的平均值。 与图像数据不同,节点的邻居是无序且大小可变的。发展:图神经网络 (GNN) Sperduti 等人的简史。 (1997) [13] 首次将神经网络应用于有向无环图,这激发了对 GNN 的早期研究。图神经网络的概念最初是在 Gori 等人中概述的。 (2005) [14] 并在 Scarselli 等人中进一步阐述。 (2009) [15] 和 Gallicchio 等人。 (2010) [16]。这些早期研究属于循环图神经网络(RecGNNs)的范畴。他们通过以迭代方式传播邻居信息来学习目标节点的表示,直到达到一个稳定的固定点。这个过程在计算上是昂贵的,并且最近已经越来越多地努力克服这些挑战[17],[18]。受 CNN 在计算机视觉领域的成功的鼓舞,大量重新定义图数据卷积概念的方法被并行开发。这些方法属于卷积图神经网络 (ConvGNN) 的范畴。 ConvGNN 分为两个主流,基于光谱的方法和基于空间的方法。 Bruna 等人提出了第一个关于基于光谱的 ConvGNN 的杰出研究。 (2013)[19],它开发了一种基于谱图理论的图卷积。从那时起,基于谱的 ConvGNN [20]、[21]、[22]、[23] 的改进、扩展和近似值不断增加。基于空间的 ConvGNN 的研究比基于光谱的 ConvGNN 早得多。 2009 年,Micheli 等人。 [24] 首先通过架构复合非递归层解决了图相互依赖问题,同时继承了 RecGNN 的消息传递思想。然而,这项工作的重要性被忽视了。直到最近,出现了许多基于空间的 ConvGNN(例如,[25]、[26]、[27])。代表性 RecGNNs 和 ConvGNNs 的时间线如表 II 的第一列所示。除了 RecGNNs 和 ConvGNNs,在过去几年中还开发了许多替代 GNN,包括图自动编码器 (GAE) 和时空图神经网络 (STGNN)。这些学习框架可以建立在 RecGNN、ConvGNN 或其他用于图建模的神经架构上。综述总结如下:新分类 我们提出了一种新的图神经网络分类。图神经网络分为四组:循环图神经网络、卷积图神经网络、图自动编码器和时空图神经网络。综合回顾 我们提供了最全面的图数据现代深度学习技术概览。对于每种类型的图神经网络,我们都提供了代表性模型的详细描述,进行了必要的比较,并总结了相应的算法。丰富的资源我们收集了丰富的图神经网络资源,包括最先进的模型、基准数据集、开源代码和实际应用。本调查可用作理解、使用和开发适用于各种现实生活应用的不同深度学习方法的实践指南。未来方向 我们讨论了图神经网络的理论方面,分析了现有方法的局限性,并在模型深度、可扩展性权衡、异质性和动态性方面提出了四个可能的未来研究方向。2.2 神经网络类型在本节中,我们介绍了图神经网络 (GNN) 的分类,如表 II 所示。 我们将图神经网络 (GNN) 分为循环图神经网络 (RecGNN)、卷积图神经网络 (ConvGNN)、图自动编码器 (GAE) 和时空图神经网络 (STGNN)。 图 2 给出了各种模型架构的示例。 下面,我们对每个类别进行简要介绍。2.2.1循环图神经网络(RecGNNs,Recurrent graph neural networks )循环图神经网络(RecGNNs)大多是图神经网络的先驱作品。 RecGNN 旨在学习具有循环神经架构的节点表示。 他们假设图中的一个节点不断地与其邻居交换信息/消息,直到达到稳定的平衡。 RecGNN 在概念上很重要,并启发了后来对卷积图神经网络的研究。 特别是,基于空间的卷积图神经网络继承了消息传递的思想。2.2.2 卷积图神经网络 (ConvGNNs,Convolutional graph neural networks)卷积图神经网络 (ConvGNNs) 将卷积操作从网格数据推广到图数据。 主要思想是通过聚合它自己的特征 xv 和邻居的特征 xu 来生成节点 v 的表示,其中 u ∈ N(v)。 与 RecGNN 不同,ConvGNN 堆叠多个图卷积层以提取高级节点表示。 ConvGNN 在构建许多其他复杂的 GNN 模型中发挥着核心作用。 图 2a 显示了用于节点分类的 ConvGNN。 图 2b 展示了用于图分类的 ConvGNN。2.2.3图自动编码器 (GAE,Graph autoencoders (GAEs))是无监督学习框架,它将节点/图编码到潜在向量空间并从编码信息中重建图数据。 GAE 用于学习网络嵌入和图形生成分布。 对于网络嵌入,GAE 通过重构图结构信息(例如图邻接矩阵)来学习潜在节点表示。 对于图的生成,一些方法逐步生成图的节点和边,而另一些方法一次全部输出图。 图 2c 展示了一个用于网络嵌入的 GAE。2.2.4 时空图神经网络 (STGNN,Spatial-temporal graph neural networks)旨在从时空图中学习隐藏模式,这在各种应用中变得越来越重要,例如交通速度预测 [72]、驾驶员机动预期 [73] 和人类动作识别 [ 75]。 STGNN 的关键思想是同时考虑空间依赖和时间依赖。 许多当前的方法集成了图卷积来捕获空间依赖性,并使用 RNN 或 CNN 对时间依赖性进行建模。 图 2d 说明了用于时空图预测的 STGNN。具体公式推到见论文!2.3图神经网络的应用GNN 在不同的任务和领域中有许多应用。 尽管每个类别的 GNN 都可以直接处理一般任务,包括节点分类、图分类、网络嵌入、图生成和时空图预测,但其他与图相关的一般任务,如节点聚类 [134]、链接预测 [135 ],图分割[136]也可以通过GNN来解决。 我们详细介绍了基于以下研究领域的一些应用。计算机视觉(Computer vision)计算机视觉 GNN 在计算机视觉中的应用包括场景图生成、点云分类和动作识别。识别对象之间的语义关系有助于理解视觉场景背后的含义。 场景图生成模型旨在将图像解析为由对象及其语义关系组成的语义图 [137]、[138]、[139]。另一个应用程序通过在给定场景图的情况下生成逼真的图像来反转该过程 [140]。由于自然语言可以被解析为每个单词代表一个对象的语义图,因此它是一种很有前途的解决方案,可以在给定文本描述的情况下合成图像。 分类和分割点云使 LiDAR 设备能够“看到”周围环境。点云是由 LiDAR 扫描记录的一组 3D 点。 [141]、[142]、[143] 将点云转换为 k-最近邻图或超点图,并使用 ConvGNN 探索拓扑结构。 识别视频中包含的人类行为有助于从机器方面更好地理解视频内容。一些解决方案检测视频剪辑中人体关节的位置。由骨骼连接起来的人体关节自然形成了一个图形。给定人类关节位置的时间序列,[73]、[75] 应用 STGNN 来学习人类动作模式。 此外,GNN 在计算机视觉中的适用方向数量仍在增长。它包括人-物交互[144]、小样本图像分类[145]、[146]、[147]、语义分割[148]、[149]、视觉推理[150]和问答[151]。自然语言处理(Natural language processing )自然语言处理 GNN 在自然语言处理中的一个常见应用是文本分类。 GNN 利用文档或单词的相互关系来推断文档标签 [22]、[42]、[43]。 尽管自然语言数据表现出顺序,但它们也可能包含内部图结构,例如句法依赖树。句法依赖树定义了句子中单词之间的句法关系。 Marcheggiani 等人。 [152] 提出了在 CNN/RNN 句子编码器之上运行的句法 GCN。 Syntactic GCN 基于句子的句法依赖树聚合隐藏的单词表示。巴斯廷斯等人。 [153] 将句法 GCN 应用于神经机器翻译任务。 Marcheggiani 等人。[154] 进一步采用与 Bastings 等人相同的模型。 [153]处理句子的语义依赖图。 图到序列学习学习在给定抽象词的语义图(称为抽象意义表示)的情况下生成具有相同含义的句子。宋等人。 [155] 提出了一种图 LSTM 来编码图级语义信息。贝克等人。 [156] 将 GGNN [17] 应用于图到序列学习和神经机器翻译。逆向任务是序列到图的学习。给定句子生成语义或知识图在知识发现中非常有用交通 Traffic 准确预测交通网络中的交通速度、交通量或道路密度对于智能交通系统至关重要。 [48]、[72]、[74] 使用 STGNN 解决交通预测问题。 他们将交通网络视为一个时空图,其中节点是安装在道路上的传感器,边缘由节点对之间的距离测量,每个节点将窗口内的平均交通速度作为动态输入特征。 另一个工业级应用是出租车需求预测。 鉴于历史出租车需求、位置信息、天气数据和事件特征,Yao 等人。 [159] 结合 LSTM、CNN 和由 LINE [160] 训练的网络嵌入,形成每个位置的联合表示,以预测时间间隔内某个位置所需的出租车数量。推荐系统 Recommender systems基于图的推荐系统将项目和用户作为节点。 通过利用项目与项目、用户与用户、用户与项目之间的关系以及内容信息,基于图的推荐系统能够产生高质量的推荐。 推荐系统的关键是对项目对用户的重要性进行评分。 结果,它可以被转换为链接预测问题。 为了预测用户和项目之间缺失的链接,Van 等人。 [161] 和英等人。 [162] 提出了一种使用 ConvGNN 作为编码器的 GAE。 蒙蒂等人。 [163] 将 RNN 与图卷积相结合,以学习生成已知评级的底层过程化学 Chemistry在化学领域,研究人员应用 GNN 来研究分子/化合物的图形结构。 在分子/化合物图中,原子被视为节点,化学键被视为边缘。 节点分类、图分类和图生成是针对分子/化合物图的三个主要任务,以学习分子指纹 [85]、[86]、预测分子特性 [27]、推断蛋白质界面 [164] 和 合成化合物其他GNN 的应用不仅限于上述领域和任务。 已经探索将 GNN 应用于各种问题,例如程序验证 [17]、程序推理 [166]、社会影响预测 [167]、对抗性攻击预防 [168]、电子健康记录建模 [169]、[170] ]、大脑网络[171]、事件检测[172]和组合优化[173]。2.4未来方向尽管 GNN 已经证明了它们在学习图数据方面的能力,但由于图的复杂性,挑战仍然存在。模型深度 Model depth深度学习的成功在于深度神经架构 [174]。 然而,李等人。 表明随着图卷积层数的增加,ConvGNN 的性能急剧下降 [53]。 随着图卷积将相邻节点的表示推得更近,理论上,在无限数量的图卷积层中,所有节点的表示将收敛到一个点 [53]。 这就提出了一个问题,即深入研究是否仍然是学习图数据的好策略。可扩展性权衡 Scalability trade-offGNN 的可扩展性是以破坏图完整性为代价的。 无论是使用采样还是聚类,模型都会丢失部分图信息。 通过采样,节点可能会错过其有影响力的邻居。 通过聚类,图可能被剥夺了独特的结构模式。 如何权衡算法的可扩展性和图的完整性可能是未来的研究方向。异质性Heterogenity当前的大多数 GNN 都假设图是同质的。 目前的 GNN 很难直接应用于异构图,异构图可能包含不同类型的节点和边,或者不同形式的节点和边输入,例如图像和文本。 因此,应该开发新的方法来处理异构图。动态Dynamicity图本质上是动态的,节点或边可能出现或消失,节点/边输入可能会随时间变化。 需要新的图卷积来适应图的动态性。 虽然图的动态性可以通过 STGNN 部分解决,但很少有人考虑在动态空间关系的情况下如何执行图卷积。总结因为之前一直在研究知识提取相关算法,后续为了构建小型领域知识图谱,会用到知识融合、知识推理等技术,现在开始学习研究图计算相关。现在已经覆盖了图的介绍,图的主要类型,不同的图算法,在Python中使用Networkx来实现它们,以及用于节点标记,链接预测和图嵌入的图学习技术,最后讲了GNN应用。本项目参考了:maelfabien大神、以及自尊心3 在博客 or github上的贡献欢迎大家fork, 后续将开始图计算相关项目以及部分知识提取技术深化!项目参考链接:第一章节:https://maelfabien.github.io/machinelearning/graph_4/#ii-node-labelinghttps://blog.csdn.net/xjxgyc/article/details/100175930https://maelfabien.github.io/machinelearning/graph_5/#node-embeddinghttps://github.com/eliorc/node2vec第二节:https://zhuanlan.zhihu.com/p/75307407?from_voters_page=true 译文https://arxiv.org/pdf/1901.00596.pdf更多参考:https://github.com/maelfabien/Machine_Learning_Tutorials项目链接:https://aistudio.baidu.com/aistudio/projectdetail/4990947?contributionType=1欢迎fork欢迎三连!文章篇幅有限,部分程序出图不一一展示,详情进入项目链接即可
关于图计算&图学习的基础知识概览:前置知识点学习(Paddle Graph L)系列【一】
关于图计算&图学习的基础知识概览:前置知识点学习(Paddle Graph Learning (PGL))欢迎fork本项目原始链接:关于图计算&图学习的基础知识概览:前置知识点学习(Paddle Graph L)https://aistudio.baidu.com/aistudio/projectdetail/4982973?contributionType=1因为篇幅关系就只放了部分程序在第三章,如有需求可自行fork项目原始链接。0.1图计算基本概念首先看到百度百科定义:图计算(Graph Processing)是将数据按照图的方式建模可以获得以往用扁平化的视角很难得到的结果。图(Graph)是用于表示对象之间关联关系的一种抽象数据结构,使用顶点(Vertex)和边(Edge)进行描述:顶点表示对象,边表示对象之间的关系。可抽象成用图描述的数据即为图数据。图计算,便是以图作为数据模型来表达问题并予以解决的这一过程。以高效解决图计算问题为目标的系统软件称为图计算系统。大数据时代,数据之间存在关联关系。由于图是表达事物之间复杂关联关系的组织结构,因此现实生活中的诸多应用场景都需要用到图,例如,淘宝用户好友关系图、道路图、电路图、病毒传播网、国家电网、文献网、社交网和知识图谱。为了从这些数据之间的关联关系中获取有用信息,大量图算法层出不穷。它们通过对大型图数据的迭代处理,获得图数据中隐藏的重要信息。图计算作为下一代人工智能的核心技术,已被广泛应用于医疗、教育、军事、金融等多个领域,并备受各国政府、全球研发机构和巨头公司关注,目前已成为全球科技竞争新的战略制高点。0.1.1图计算图可以将各类数据关联起来:将不同来源、不同类型的数据融合到同一个图里进行分析,得到原本独立分析难以发现的结果;图的表示可以让很多问题处理地更加高效:例如最短路径、连通分量等等,只有用图计算的方式才能予以最高效的解决。然而,图计算具有一些区别于其它类型计算任务的挑战与特点:随机访问多:图计算围绕图的拓扑结构展开,计算过程会访问边以及关联的两个顶点,但由于实际图数据的稀疏性(通常只有几到几百的平均度数),不可避免地产生了大量随机访问;计算不规则:实际图数据具有幂律分布的特性,即绝大多数顶点的度数很小,极少部分顶点的度数却很大(例如在线社交网络中明星用户的粉丝),这使得计算任务的划分较为困难,十分容易导致负载不均衡。0.1.2图计算系统随着图数据规模的不断增长,对图计算能力的要求越来越高,大量专门面向图数据处理的计算系统便是诞生在这样的背景下。Pregel由Google研发是专用图计算系统的开山之作。Pregel提出了以顶点为中心的编程模型,将图分析过程分析为若干轮计算,每一轮各个顶点独立地执行各自的顶点程序,通过消息传递在顶点之间同步状态。Giraph是Pregel的一个开源实现,Facebook基于Giraph使用200台机器分析万亿边级别的图数据,计算一轮PageRank的用时近4分钟。GraphLab出自于CMU的实验室,基于共享内存的机制,允许用户使用异步的方式计算以加快某些算法的收敛速度。PowerGraph在GraphLab基础上做了优化,针对实际图数据中顶点度数的幂律分布特性,提出了顶点分割的思想,可以实现更细粒度的数据划分,从而实现更好的负载均衡。其计算模型也被用在后续的图计算系统上,例如GraphX。尽管上述的这些图计算系统相比MapReduce、Spark等在性能上已经有了显著的性能提升,但是它们的计算效率依然非常低下,甚至不如精心优化的单线程程序。Gemini由清华大学计算机系的团队提出,针对已有系统的局限性,提出了以计算为中心的设计理念,通过降低分布式带来的开销并尽可能优化本地计算部分的实现,使得系统能够在具备扩展性的同时不失高效性 [5] 。针对图计算的各个特性,Gemini在数据压缩存储、图划分、任务调度、通信模式切换等方面都提出了对应的优化措施,比其他知名图计算系统的最快性能还要快一个数量级。ShenTu沿用并扩展了Gemini的编程和计算模型,能够利用神威·太湖之光整机上千万核的计算资源,高效处理70万亿边的超大规模图数据,入围了2018年戈登·贝尔奖的决赛名单。除了使用向外扩展的分布式图计算系统来处理规模超出单机内存的图数据,也有一些解决方案通过在单台机器上高效地使用外存来完成大规模图计算任务,其中的代表有GraphChi、X-Stream、FlashGraph、GridGraph、Mosaic等。0.2 图关键技术0.2.1 图数据的组织由于实际图的稀疏性,图计算系统通常使用稀疏矩阵的存储方法来表示图数据,其中最常用的两种是CSR(Compressed Sparse Row)和CSC(Compressed Sparse Column),分别按行(列)存储每行(列)非零元所在列(行),每一行则(列)对应了一个顶点的出边(入边)。0.2.2图数据的划分将一个大图划分为若干较小的子图,是很多图计算系统都会使用的扩展处理规模的方法;此外,图划分还能增强数据的局部性,从而降低访存的随机性,提升系统效率。对于分布式图计算系统而言,图划分有两个目标:每个子图的规模尽可能相近,获得较为均衡的负载。不同子图之间的依赖(例如跨子图的边)尽可能少,降低机器间的通信开销。图划分有按照顶点划分和按照边划分两种方式,它们各有优劣:顶点划分将每个顶点邻接的边都放在一台机器上,因此计算的局部性更好,但是可能由于度数的幂律分布导致负载不均衡。边划分能够最大程度地改善负载不均衡的问题,但是需要将每个顶点分成若干副本分布于不同机器上,因此会引入额外的同步/空间开销。所有的类Pregel系统采用的均为顶点划分的方式,而PowerGraph/GraphX采用的是边划分的方式。Gemini采用了基于顶点划分的方法来避免引入过大的分布式开销;但是在计算模式上却借鉴了边划分的思想,将每个顶点的计算分布到多台机器上分别进行,并尽可能让每台机器上的计算量接近,从而消解顶点划分可能导致的负载不均衡问题。0.2.3顶点程序的调度在以顶点为中心的图计算模型中,每个顶点程序可以并行地予以调度。大部分图计算系统采用基于BSP模型的同步调度方式,将计算过程分为若干超步(每个超步通常对应一轮迭代),每个超步内所有顶点程序独立并行地执行,结束后进行全局同步。顶点程序可能产生发送给其它顶点的消息,而通信过程通常与计算过程分离。同步调度容易产生的问题是:一旦发生负载不均衡,那么最慢的计算单元会拖慢整体的进度。某些算法可能在同步调度模型下不收敛。为此,部分图计算系统提供了异步调度的选项,让各个顶点程序的执行可以更自由,例如:每个顶点程序可以设定优先级,让优先级高的顶点程序能以更高的频率执行,从而更快地收敛。然而,异步调度在系统设计上引入了更多的复杂度,例如数据一致性的维护,消息的聚合等等,很多情况下的效率并不理想。因此,大多数图计算系统采用的还是同步的调度方式;少数支持异步计算的系统也默认使用同步方式进行调度。0.2.4 计算与通信模式图计算系统使用的通信模式主要分为两种,推动(Push)和拉取(Pull):推动模式下每个顶点沿着边向邻居顶点传递消息,邻居顶点根据收到的消息更新自身的状态。所有的类Pregel系统采用的几乎都是这种计算和通信模式。拉取模式通常将顶点分为主副本和镜像副本,通信发生在每个顶点的两类副本之间而非每条边连接的两个顶点之间。GraphLab、PowerGraph、GraphX等采用的均为这种模式。除了通信的模式有所区别,推动和拉取在计算上也有不同的权衡:推动模式可能产生数据竞争,需要使用锁或原子操作来保证状态的更新是正确的。拉取模式尽管没有竞争的问题,但是可能产生额外的数据访问。Gemini则将两种模式融合起来,根据每一轮迭代参与计算的具体情况,自适应地选择更适合的模式。0.3 图计算应用0.3.1 网页排序将网页作为顶点,网页之间的超链接作为边,整个互联网可以建模成一个非常巨大的图(十万亿级边)。搜索引擎在返回结果时,除了需要考虑网页内容与关键词的相关程度,还需要考虑网页本身的质量。PageRank是最早Google用于对网页进行排序的算法,通过将链接看成投票来指示网页的重要程度。PageRank的计算过程并不复杂:在首轮迭代开始前,所有顶点将自己的PageRank值设为1;每轮迭代中,每个顶点向所有邻居贡献自己当前PageRank值除以出边数作为投票,然后将收到的所有来自邻居的投票累加起来作为新的PageRank值;如此往复,直到所有顶点的PageRank值在相邻两轮之间的变化达到某个阈值为止。0.3.2 社区发现社交网络也是一种典型的图数据:顶点表示人,边表示人际关系;更广义的社交网络可以将与人有关的实体也纳入进来,例如手机、地址、公司等。社区发现是社交网络分析的一个经典应用:将图分成若干社区,每个社区内部的顶点之间具有相比社区外部更紧密的连接关系。社区发现有非常广泛的用途,在金融风控、国家安全、公共卫生等大量场景都有相关的应用。标签传播是一种常用的社区发现算法:每个顶点的标签即为自己的社区,初始化时设置自己的顶点编号;在随后的每一轮迭代中,每个顶点将邻居中出现最频繁的标签设置为自己新的标签;当所有顶点相邻两轮之间的标签变化少于某个阈值时则停止迭代。0.3.3最短路径在图上发现顶点与顶点之间的最短路径是一类很常见的图计算任务,根据起始顶点与目标顶点集合的大小,又可分为单对单(一个顶点到一个顶点)、多对多(多个顶点到多个顶点)、单源(一个顶点到所有其它顶点)、多源(多个顶点到所有其它顶点)、所有点对(所有顶点到其它所有顶点)等。对于无权图,通常使用基于BFS的算法;对于有权图,比较常见的有SPFA算法、Bellman-Ford算法等。最短路径的用途十分广泛:在知识图谱中经常需要寻找两个实体之间的最短关联路径;基于黑名单和实体之间的关联可以发现其它顶点与黑名单之间的距离;而所有点对的最短路径可以帮助衡量各个顶点在整个图的拓扑结构所处的位置(中心程度)。节点级别任务:金融诈骗检测中,节点是用户和商家,边是用户和商家之间的交互,利用图模型预测潜在的金融诈骗分子。在目标检测案例中,将3D点云数据中点与点之间距离作为边,通过图结构可以进行3D目标检测边级别任务:推荐系统中,通过已有的用户-商品数据建立用户图行为关系,得到节点的向量表示,进而进行推荐任务图级别任务:气味识别,利用图神经网络识别分子结构进而识别气味1.图与图学习1.1 图的基本表示方法先简单学习一下图论的基本概念,图论的经典算法,以及近些年来图学习的发展举个例子,一个简单的图可能是这样:节点(node)用红色标出,通过黑色的边(edge)连接。图可用于表示:社交网络网页生物网络…我们可以在图上执行怎样的分析?研究拓扑结构和连接性群体检测识别中心节点预测缺失的节点预测缺失的边…图 G=(V, E) 由下列要素构成:一组节点(也称为 verticle)V=1,…,n一组边 E⊆V×V边 (i,j) ∈ E 连接了节点 i 和 ji 和 j 被称为相邻节点(neighbor)节点的度(degree)是指相邻节点的数量节点、边和度的示意图如果一个图的所有节点都有 n-1 个相邻节点,则该图是完备的(complete)。也就是说所有节点都具备所有可能的连接方式。从 i 到 j 的路径(path)是指从 i 到达 j 的边的序列。该路径的长度(length)等于所经过的边的数量。图的直径(diameter)是指连接任意两个节点的所有最短路径中最长路径的长度。举个例子,在这个案例中,我们可以计算出一些连接任意两个节点的最短路径。该图的直径为 3,因为没有任意两个节点之间的最短路径的长度超过 3。一个直径为 3 的图测地路径(geodesic path)是指两个节点之间的最短路径。如果所有节点都可通过某个路径连接到彼此,则它们构成一个连通分支(connected component)。如果一个图仅有一个连通分支,则该图是连通的(connected)举个例子,下面是一个有两个不同连通分支的图:一个有两个连通分支的图如果一个图的边是有顺序的配对,则该图是有向的(directed)。i 的入度(in-degree)是指向 i 的边的数量,出度(out-degree)是远离 i 的边的数量有向图如果可以回到一个给定节点,则该图是有环的(cyclic)。相对地,如果至少有一个节点无法回到,则该图就是无环的(acyclic)。图可以被加权(weighted),即在节点或关系上施加权重。如果一个图的边数量相比于节点数量较小,则该图是稀疏的(sparse)。相对地,如果节点之间的边非常多,则该图是密集的(dense)Neo4J 的关于图算法的书给出了清晰明了的总结:总结(来自 Neo4J Graph Book & 自尊心3大佬的贡献)1.2 图的存储存储图的方式有三种:相邻矩阵,邻接表,十字链表1.2.1 相邻矩阵有向图的相邻矩阵无向图的相邻矩阵使用邻接矩阵,这通常是在内存中加载的方式:对于图中的每一个可能的配对,如果两个节点有边相连,则设为 1。如果该图是无向图,则 A 是对称的。1.2.2 邻接表对于稀疏图,可以采用邻接表存储法:边较少,相邻矩阵就会出现大量的零元素相邻矩阵的零元素将耗费大量的存储空间和时间无向图的邻接表表示无向图同一条边在邻接表中出现两次上面的图用邻接表可表示为:带权图的邻接表表示有向图的邻接表(出边表)有向图的逆邻接表(入边表)1.2.3 十字链表 (Orthogonal List)可以看成是邻接表和逆邻接表的结合对应于有向图的每一条弧有一个表目,共有5个域:头 headvex尾 tailvex下一条共尾弧 tailnextarc下一条共头弧 headnextarc弧权值等 info 域顶点表目由3个域组成:data 域firstinarc 第一条以该顶点为终点的弧firstoutarc 第一条以该顶点为始点的弧十字链表有两组链表组成:行和列的指针序列每个结点都包含两个指针:同一行的后继同一列的后继这三种表示方式都是等价的,我们可以根据使用场景来选择图的存储方式。1.3 图的类型和性质简单说明图可以根据不同标准进行分类,我们在这里主要讲一种分类方法,同构图与异构图。同构图与异构图同构图:节点类型和边的类型只有一种的图。异构图:节点类型+边类型>2 的图。两个图G和H是同构图(isomorphic graphs),能够通过重新标记图G的顶点而产生图H。如果G和H同构,那么它们的阶是相同的,它们大小是相同的,它们个顶点的度数也对应相同。异构图是一个与同构图相对应的新概念。传统同构图(Homogeneous Graph)数据中只存在一种节点和边,因此在构建图神经网络时所有节点共享同样的模型参数并且拥有同样维度的特征空间。而异构图(Heterogeneous Graph)中可以存在不只一种节点和边,因此允许不同类型的节点拥有不同维度的特征或属性。2.图算法与图分析图分析使用基于图的方法来分析连接的数据。我们可以:查询图数据,使用基本统计信息,可视化地探索图、展示图,或者将图信息预处理后合并到机器学习任务中。图的查询通常用于局部数据分析,而图计算通常涉及整张图和迭代分析。图算法是图分析的工具之一。图算法提供了一种最有效的分析连接数据的方法,它们描述了如何处理图以发现一些定性或者定量的结论。图算法基于图论,利用节点之间的关系来推断复杂系统的结构和变化。我们可以使用这些算法来发现隐藏的信息,验证业务假设,并对行为进行预测2.1 路径搜索算法(Pathfinding and Search)图搜索算法(Pathfinding and Search Algorithms)探索一个图,用于一般发现或显式搜索。这些算法通过从图中找到很多路径,但并不期望这些路径是计算最优的(例如最短的,或者拥有最小的权重和)。图搜索算法包括广度优先搜索和深度优先搜索,它们是遍历图的基础,并且通常是许多其他类型分析的第一步。路径搜索(Pathfinding)算法建立在图搜索算法的基础上,并探索节点之间的路径。这些路径从一个节点开始,遍历关系,直到到达目的地。路径搜索算法识别最优路径,用于物流规划,最低成本呼叫或者叫IP路由问题,以及游戏模拟等。图的遍历 (graph traversal)即给出一个图G和其中任意一个顶点V0,从V0出发系统地访问G中所有的顶点,每个顶点访问而且只访问一次从一个顶点出发,试探性访问其余顶点,同时必须考虑到下列情况从一顶点出发,可能不能到达所有其它的顶点,如:非连通图;也有可能会陷入死循环,如:存在回路的图一般情况下,可以为每个顶点保留一个 标志位 (mark bit):算法开始时,所有顶点的标志位置零在遍历的过程中,当某个顶点被访问时,其标志位就被标记为已访问2.1.1深度优先遍历&广度优先遍历|DFS & BFS图算法中最基础的两个遍历算法:广度优先搜索(Breadth First Search,简称 BFS)和深度优先搜索(Depth First Search,简称 DFS)。BFS 从选定的节点出发,优先访问所有一度关系的节点之后再继续访问二度关系节点,以此类推。DFS 从选定的节点出发,选择任一邻居之后,尽可能的沿着边遍历下去,知道不能前进之后再回溯。深度优先搜索(简称DFS) 类似于树的先根次序遍历,尽可能先对纵深方向进行搜索:选取一个未访问的点 v0 作为源点访问顶点 v0递归地深搜遍历 v0 邻接到的其他顶点重复上述过程直至从 v0 有路径可达的顶点都已被访问过再选取其他未访问顶点作为源点做深搜,直到图的所有顶点都被访问过深度优先搜索的顺序是:a->b->c->f->d->e->g广度优先遍历(breadth-first search)广度优先搜索 (breadth-first search,简称 BFS)。其遍历的过程是:从图中的某个顶点 v0 出发访问并标记了顶点 v0 之后一层层横向搜索 v0 的所有邻接点对这些邻接点一层层横向搜索,直至所有由 v0 有路径可达的顶点都已被访问过再选取其他未访问顶点作为源点做广搜,直到所有点都被访问过广度优先搜索的顺序是:a->b->d->e->f->c->g2.1.2 最短路径最短路径(Shortest Paths)算法计算给定的两个节点之间最短(最小权重和)的路径。算法能够实时地交互和给出结果,可以给出关系传播的度数(degree),可以快速给出两点之间的最短距离,可以计算两点之间成本最低的路线等等。例如:导航:谷歌、百度、高德地图均提供了导航功能,它们就使用了最短路径算法(或者非常接近的变种);社交网络关系:当我们在 LinkedIn、人人(暴露年龄了)等社交平台上查看某人的简介时,平台会展示你们之间有多少共同好友,并列出你们之间的关系。2.1.2.1 单源最短路径(single-source shortest paths)-------迪杰斯特拉(Dijkstra)算法单源最短路径是给定带权图 G = <V,E>,其中每条边 (vi,vj) 上的权W[vi,vj] 是一个 非负实数 。计算从任给的一个源点 s 到所有其他各结点的最短路径迪杰斯特拉(Dijkstra)算法最常见的最短路径算法来自于 1956 年的 Edsger Dijkstra。Dijkstra 的算法首先选择与起点相连的最小权重的节点,也就是 “最临近的” 节点,然后比较 起点到第二临近的节点的权重 与 最临近节点的下一个最临近节点的累计权重和 从而决定下一步该如何行走。可以想象,算法记录的累计权重和 如同地理的 “等高线” 一样,在图上以 “波” 的形式传播,直到到达目的地节点。基本思想把所有结点分成两组:第一组 U 包括已确定最短路径的结点第二组 V–U 包括尚未确定最短路径的结点按最短路径长度递增的顺序逐个把第二组的结点加到第一组中:直至从 s 出发可达结点都包括进第一组中看懂上面的再看一下这个判断自己有没有彻底理解:Dijkstra 算法是贪心法,不适用于负权值的情况。因为权值当作最小取进来后,不会返回去重新计算,即使不存在负的回路,也可能有在后面出现的负权值,从而导致整体计算错误2.1.2.2 每对结点间的最短路径Floyd算法求每对结点之间的最短路径用相邻矩阵 adj 来表示带权有向图基本思想初始化 adj(0) 为相邻矩阵 adj在矩阵 adj(0)上做 n 次迭代,递归地产生一个矩阵序列adj(1),…,adj(k),…,adj(n)其中经过第k次迭代,adj(k)[i,j] 的值等于从结点vi 到结点 vj 路径上所经过的结点序号不大于 k 的最短路径长度其根本思想是动态规划法最短路径算法有两个常用的变种:A (可以念作 A Star)algorithm和 Yen’s K-Shortest Paths。A algorithm 通过提供的额外信息,优化算法下一步探索的方向。Yen’s K-Shortest Paths 不但给出最短路径结果,同时给出了最好的 K 条路径。所有节点对最短路径(All Pairs Shortest Path)也是一个常用的最短路径算法,计算所有节点对的最短路径。相比较一个一个调用单个的最短路径算法,All Pairs Shortest Path 算法会更快。算法并行计算多个节点的信息,并且这些信息在计算中可以被重用。2.1.3 最小生成树最小生成树(Minimum Spanning Tree)算法从一个给定的节点开始,查找其所有可到达的节点,以及将节点与最小可能权重连接在一起,行成的一组关系。它以最小的权重从访问过的节点遍历到下一个未访问的节点,避免了循环。最常用的最小生成树算法来自于 1957 年的 Prim 算法。Prim 算法与Dijkstra 的最短路径类似,所不同的是, Prim 算法每次寻找最小权重访问到下一个节点,而不是累计权重和。并且,Prim 算法允许边的权重为负。上图是最小生成树算法的步骤分解,算法最终用最小的权重将图进行了遍历,并且在遍历的过程中,不产生环。算法可以用于优化连接系统(如水管和电路设计)的路径。它还用于近似一些计算时间未知的问题,如旅行商问题。虽然该算法不一定总能找到绝对最优解,但它使得复杂度极高和计算密集度极大的分析变得更加可能。例如:旅行计划:尽可能降低探索一个国家的旅行成本;追踪流感传播的历史:有人使用最小生成树模型对丙型肝炎病毒感染的医院暴发进行分子流行病学调查2.1.4 随机游走随机游走(Random Walk)算法从图上获得一条随机的路径。随机游走算法从一个节点开始,随机沿着一条边正向或者反向寻找到它的邻居,以此类推,直到达到设置的路径长度。这个过程有点像是一个醉汉在城市闲逛,他可能知道自己大致要去哪儿,但是路径可能极其“迂回”,毕竟,他也无法控制自己~随机游走算法一般用于随机生成一组相关的节点数据,作为后续数据处理或者其他算法使用。例如:作为 node2vec 和 graph2vec 算法的一部分,这些算法可以用于节点向量的生成,从而作为后续深度学习模型的输入;这一点对于了解 NLP (自然语言处理)的朋友来说并不难理解,词是句子的一部分,我们可以通过词的组合(语料)来训练词向量。那么,我们同样可以通过节点的组合(Random Walk)来训练节点向量。这些向量可以表征词或者节点的含义,并且能够做数值计算。这一块的应用很有意思,我们会找机会来详细介绍;作为 Walktrap 和 Infomap 算法的一部分,用于社群发现。如果随机游走总是返回同一组节点,表明这些节点可能在同一个社群;其他机器学习模型的一部分,用于随机产生相关联的节点数据。2.2 中心性算法(Centrality Computation)中心性算法(Centrality Algorithms)用于识别图中特定节点的角色及其对网络的影响。中心性算法能够帮助我们识别最重要的节点,帮助我们了解组动态,例如可信度、可访问性、事物传播的速度以及组与组之间的连接。尽管这些算法中有许多是为社会网络分析而发明的,但它们已经在许多行业和领域中得到了应用。2.2.1 DegreeCentralityDegree Centrality (度中心性,以度作为标准的中心性指标)可能是整篇博文最简单的 “算法” 了。Degree 统计了一个节点直接相连的边的数量,包括出度和入度。Degree 可以简单理解为一个节点的访问机会的大小。例如,在一个社交网络中,一个拥有更多 degree 的人(节点)更容易与人发生直接接触,也更容易获得流感。一个网络的平均度(average degree),是边的数量除以节点的数量。当然,平均度很容易被一些具有极大度的节点 “带跑偏” (skewed)。所以,度的分布(degree distribution)可能是表征网络特征的更好指标。如果你希望通过出度入度来评价节点的中心性,就可以使用 degree centrality。度中心性在关注直接连通时具有很好的效果。应用场景例如,区分在线拍卖的合法用户和欺诈者,欺诈者由于尝尝人为太高拍卖价格,拥有更高的加权中心性(weighted centrality)。2.2.2 ClosenessCentralityCloseness Centrality(紧密性中心性)是一种检测能够通过子图有效传播信息的节点的方法。紧密性中心性计量一个节点到所有其他节点的紧密性(距离的倒数),一个拥有高紧密性中心性的节点拥有着到所有其他节点的距离最小值。对于一个节点来说,紧密性中心性是节点到所有其他节点的最小距离和的倒数:$C(u)=\frac{1}{\sum_{v=1}^{n-1} d(u, v)}$其中 u 是我们要计算紧密性中心性的节点,n 是网络中总的节点数,d(u,v) 代表节点 u 与节点 v 的最短路径距离。更常用的公式是归一化之后的中心性,即计算节点到其他节点的平均距离的倒数,你知道如何修改上面的公式吗?对了,将分子的 1 变成 n-1 即可。理解公式我们就会发现,如果图是一个非连通图,那么我们将无法计算紧密性中心性。那么针对非连通图,调和中心性(Harmonic Centrality)被提了出来(当然它也有归一化的版本,你猜这次n-1应该加在哪里?):$H(u)=\frac{1}{\sum_{v=1}^{n-1} d(u, v)}$Wasserman and Faust 提出过另一种计算紧密性中心性的公式,专门用于包含多个子图并且子图间不相连接的非连通图:$C_{W F}(u)=\frac{n-1}{N-1}\left(\frac{n-1}{\sum_{v=1}^{n-1} d(u, v)}\right)$其中,N 是图中总的节点数量,n 是一个部件(component)中的节点数量。当我们希望关注网络中传播信息最快的节点,我们就可以使用紧密性中心性。2.2.3 BetweennessCentrality中介中心性(Betweenness Centrality)是一种检测节点对图中信息或资源流的影响程度的方法。它通常用于寻找连接图的两个部分的桥梁节点。因为很多时候,一个系统最重要的 “齿轮” 不是那些状态最好的,而是一些看似不起眼的 “媒介”,它们掌握着资源或者信息的流动性。中间中心性算法首先计算连接图中每对节点之间的最短(最小权重和)路径。每个节点都会根据这些通过节点的最短路径的数量得到一个分数。节点所在的路径越短,其得分越高。计算公式:$B(u)=\sum_{s \neq u \neq t} \frac{p(u)}{p}$其中,p 是节点 s 与 t 之间最短路径的数量,p(u) 是其中经过节点 u 的数量。下图给出了对于节点 D 的计算过程:当然,在一张大图上计算中介中心性是十分昂贵的。所以我们需要更快的,成本更小的,并且精度大致相同的算法来计算,例如 Randomized-Approximate Brandes。我们不会对这个算法继续深入,感兴趣的话,可以去了解一下,算法如何通过随机(Random)和度的筛选(Degree)达到近似的效果。中介中心性在现实的网络中有广泛的应用,我们使用它来发现瓶颈、控制点和漏洞。例如,识别不同组织的影响者,他们往往是各个组织的媒介,例如寻找电网的关键点,提高整体鲁棒性。2.2.4 PageRank在所有的中心性算法中,PageRank 是最著名的一个。它测量节点传递影响的能力。PageRank 不但节点的直接影响,也考虑 “邻居” 的影响力。例如,一个节点拥有一个有影响力的 “邻居”,可能比拥有很多不太有影响力的 “邻居” 更有影响力。PageRank 统计到节点的传入关系的数量和质量,从而决定该节点的重要性。PageRank 算法以谷歌联合创始人拉里·佩奇的名字命名,他创建了这个算法来对谷歌搜索结果中的网站进行排名。不同的网页之间相互引用,网页作为节点,引用关系作为边,就可以组成一个网络。被更多网页引用的网页,应该拥有更高的权重;被更高权重引用的网页,也应该拥有更高权重。原始公式:$P R(u)=(1-d)+d\left(\frac{P R(T 1)}{C(T 1)}+\ldots+\frac{P R(T n)}{C(T n)}\right)$其中,u 是我们想要计算 PageRank 的网页,T1 到 Tn 是引用的网页。d 被称为阻尼系数(damping factor),代表一个用户继续点击网页的概率,一般被设置为 0.85,范围 0~1。C(T) 是节点 T 的出度。从理解上来说,PageRank 算法假设一个用户在访问网页时,用户可能随机输入一个网址,也可能通过一些网页的链接访问到别的网页。那么阻尼系数代表用户对当前网页感到无聊,随机选择一个链接访问到新的网页的概率。那么 PageRank 的数值代表这个网页通过其他网页链接过来(入度,in-degree)的可能性。那你能如何解释 PageRank 方程中的 1-d 呢?实际,1-d 代表不通过链接访问,而是随机输入网址访问到网页的概率。PageRank 算法采用迭代方式计算,直到结果收敛或者达到迭代上限。每次迭代都会分两步更新节点权重和边的权重,详细如下图:当然,上图的计算并没有考虑阻尼系数,那为什么一定要阻尼系数呢?除了我们定义的链接访问概率,有没有别的意义呢?从上图的过程中,我们可能会发现一个问题,如果一个节点(或者一组节点),只有边进入,却没有边出去,会怎么样呢?按照上图的迭代,节点会不断抢占 PageRank 分数。这个现象被称为 Rank Sink,如下图:解决 Rank Sink 的方法有两个。第一个,假设这些节点有隐形的边连向了所有的节点,遍历这些隐形的边的过程称为 teleportation。第二个,使用阻尼系数,如果我们设置 d 等于 0.85,我们仍然有 0.15 的概率从这些节点再跳跃出去。尽管阻尼系数的建议值为 0.85,我们仍然可以根据实际需要进行修改。调低阻尼系数,意味着访问网页时,更不可能不断点击链接访问下去,而是更多地随机访问别的网页。那么一个网页的 PageRank 分数会更多地分给他的直接下游网页,而不是下游的下游网页。PageRank 算法已经不仅限于网页排名。例如:寻找最重要的基因:我们要寻找的基因可能不是与生物功能联系最多的基因,而是与最重要功能有紧密联系的基因;who to follow service at twitter:Twitter使用个性化的 PageRank 算法(Personalized PageRank,简称 PPR)向用户推荐他们可能希望关注的其他帐户。该算法通过兴趣和其他的关系连接,为用户展示感兴趣的其他用户;交通流量预测:使用 PageRank 算法计算人们在每条街道上停车或结束行程的可能性;反欺诈:医疗或者保险行业存在异常或者欺诈行为,PageRank 可以作为后续机器学习算法的输入。2.3 社群发现算法(Community Detection)社群的形成在各种类型的网络中都很常见。识别社群对于评估群体行为或突发事件至关重要。对于一个社群来说,内部节点与内部节点的关系(边)比社群外部节点的关系更多。识别这些社群可以揭示节点的分群,找到孤立的社群,发现整体网络结构关系。社群发现算法(Community Detection Algorithms)有助于发现社群中群体行为或者偏好,寻找嵌套关系,或者成为其他分析的前序步骤。社群发现算法也常用于网络可视化。2.3.1 MeasuringAlgorithm三角计数(Triangle Count)和聚类系数(Clustering Coefficient)经常被一起使用。三角计数计算图中由节点组成的三角形的数量,要求任意两个节点间有边(关系)连接。聚类系数算法的目标是测量一个组的聚类紧密程度。该算法计算网络中三角形的数量,与可能的关系的比率。聚类系数为 1 表示这个组内任意两个节点之间有边相连。有两种聚类系数:局部聚类系数(Local Clustering Coefficient)和全局聚类系数(Global Clustering Coefficient)。局部聚类系数计算一个节点的邻居之间的紧密程度,计算时需要三角计数。计算公式:$C C(u)=\frac{2 R_u}{k_u\left(k_u-1\right)}$其中,u 代表我们需要计算聚类系数的节点,R(u) 代表经过节点 u 和它的邻居的三角形个数,k(u) 代表节点 u的度。下图是三三角计数聚类系数计算示意图:全局聚类系数是局部聚类系数的归一化求和。当需要计算一个组的稳定性或者聚类系数时,我们可以使用三角计数。三角计数在社交网络分析中有广泛的应用,通航被用来检测社区。聚类系数可以快速评估特定组或整个网络的内聚性。这些算法可以共同用于特定网络结构的寻找。例如,探索网页的主题结构,基于网页之间的相互联系,检测拥有共同主题的 “网页社群”。2.3.2 ComponentsAlgorithm强关联部件(Strongly Connected Components,简称 SCC)算法寻找有向图内的一组一组节点,每组节点可以通过关系 互相 访问。在 “Community Detection Algorithms” 的图中,我们可以发现,每组节点内部不需要直接相连,只要通过路径访问即可。关联部件(Connected Components)算法,不同于 SCC,组内的节点对只需通过一个方向访问即可。关联类算法作为图分析的早期算法,用以了解图的结构,或确定可能需要独立调查的紧密集群十分有效。对于推荐引擎等应用程序,也可以用来描述组中的类似行为等等。许多时候,算法被用于查找集群并将其折叠成单个节点,以便进一步进行集群间分析。对于我们来说,先运行以下关联类算法查看图是否连通,是一个很好的习惯。2.3.3 LabelPropagation Algorithm标签传播算法(Label Propagation Algorithm,简称 LPA)是一个在图中快速发现社群的算法。在 LPA 算法中,节点的标签完全由它的直接邻居决定。算法非常适合于半监督学习,你可以使用已有标签的节点来种子化传播进程。LPA 是一个较新的算法,由 Raghavan 等人于 2007 年提出。我们可以很形象地理解算法的传播过程,当标签在紧密联系的区域,传播非常快,但到了稀疏连接的区域,传播速度就会下降。当出现一个节点属于多个社群时,算法会使用该节点邻居的标签与权重,决定最终的标签。传播结束后,拥有同样标签的节点被视为在同一群组中。下图展示了算法的两个变种:Push 和 Pull。其中 Pull 算法更为典型,并且可以很好地并行计算:看完上图,你应该已经理解了算法的大概过程。其实,做过图像处理的人很容易明白,所谓的标签传播算法,不过是图像分割算法的变种,Push 算法是区域生长法(Region Growing)的简化版,而 Pull 更像是分割和合并(divide-and-merge,也有人称 split-merge)算法。确实,图像(image)的像素和图(graph)的节点是十分类似的。2.3.4 LouvainModularity AlgorithmLouvain Modularity 算法在给节点分配社群是,会比较社群的密度,而不仅仅是比较节点与社群的紧密程度。算法通过查看节点与社群内关系的密度与平均关系密度的比较,来量化地决定一个节点是否属于社群。算法不但可以发现社群,更可以给出不同尺度不同规模的社群层次,对于理解不同粒度界别的网络结构有极大的帮助。算法在 2008 年被提出以后,迅速成为了最快的模块化算法之一。算法的细节很多,我们无法一一覆盖,下图给出了一个粗略的步骤,帮助我们理解算法如何能够多尺度地构建社群:Louvain Modularity 算法非常适合庞大网络的社群发现,算法采用启发式方式从而能够克服传统 Modularity 类算法的局限。算法应用:检测网络攻击:该算可以应用于大规模网络安全领域中的快速社群发现。一旦这些社群被发现,就可以用来预防网络攻击;主题建模:从 Twitter 和 YouTube 等在线社交平台中提取主题,基于文档中共同出现的术语,作为主题建模过程的一部分。3.算法实践(图分析、图计算)有了前面的前置知识,来一起程序操作一下了3.1创建一个图进行简单分析import numpy as np import random import networkx as nx from IPython.display import Image import matplotlib.pyplot as plt # Load the graph G_karate = nx.karate_club_graph() # Find key-values for the graph pos = nx.spring_layout(G_karate) # Plot the graph nx.draw(G_karate, cmap = plt.get_cmap('rainbow'), with_labels=True, pos=pos)空手道俱乐部图这个「空手道」图表示什么?Wayne W. Zachary 在 1970 到 1972 年这三年中研究的一个空手道俱乐部的社交网络。该网络包含了这个空手道俱乐部的 34 个成员,成员对之间的连接表示他们在俱乐部之外也有联系。在研究期间,管理员 JohnA 与教练 Mr.Hi(化名)之间出现了冲突,导致俱乐部一分为二。一半成员围绕 Mr.Hi 形成了一个新的俱乐部,另一半则找了一个新教练或放弃了空手道。基于收集到的数据,除了其中一个成员,Zachary 正确分配了所有成员在分裂之后所进入的分组。# .degree() 属性会返回该图的每个节点的度(相邻节点的数量)的列表: print(G_karate.degree()) degree_sequence = list(G_karate.degree())# 计算边的数量,但也计算度序列的度量: nb_nodes = n nb_arr = len(G_karate.edges()) avg_degree = np.mean(np.array(degree_sequence)[:,1]) med_degree = np.median(np.array(degree_sequence)[:,1]) max_degree = max(np.array(degree_sequence)[:,1]) min_degree = np.min(np.array(degree_sequence)[:,1]) # 最后,打印所有信息: print("Number of nodes : " + str(nb_nodes)) print("Number of edges : " + str(nb_arr)) print("Maximum degree : " + str(max_degree)) print("Minimum degree : " + str(min_degree)) print("Average degree : " + str(avg_degree)) print("Median degree : " + str(med_degree))# 平均而言,该图中的每个人都连接了 4.6 个人。 # 我们可以绘出这些度的直方图: degree_freq = np.array(nx.degree_histogram(G_karate)).astype('float') plt.figure(figsize=(12, 8)) plt.stem(degree_freq) plt.ylabel("Frequence") plt.xlabel("Degree") plt.show()3.2图类型3.2.1 Erdos-Rényi 模型在 Erdos-Rényi 模型中,我们构建一个带有 n 个节点的随机图模型。这个图是通过以概率 p 独立地在节点 (i,j) 对之间画边来生成的。因此,我们有两个参数:节点数量 n 和概率 p。Erdos-Rényi 图在 Python 中,networkx 软件包有用于生成 Erdos-Rényi 图的内置函数。3.3主要图算法3.3.1路径搜索算法仍以空手道俱乐部图举例# 1.最短路径 # 最短路径计算的是一对节点之间的最短的加权(如果图有加权的话)路径。 # 这可用于确定最优的驾驶方向或社交网络上两个人之间的分离程度。 nx.draw(G_karate, cmap = plt.get_cmap('rainbow'), with_labels=True, pos=pos) # 这会返回图中每个节点之间的最小路径的列表: all_shortest_path = nx.shortest_path(G_karate) # 这里打印了节点0与其余节点的最短路径 print(all_shortest_path[0]) # 例如节点0与节点26的最短路径是[0, 8, 33, 26] {0: [0], 1: [0, 1], 2: [0, 2], 3: [0, 3], 4: [0, 4], 5: [0, 5], 6: [0, 6], 7: [0, 7], 8: [0, 8], 10: [0, 10], 11: [0, 11], 12: [0, 12], 13: [0, 13], 17: [0, 17], 19: [0, 19], 21: [0, 21], 31: [0, 31], 30: [0, 1, 30], 9: [0, 2, 9], 27: [0, 2, 27], 28: [0, 2, 28], 32: [0, 2, 32], 16: [0, 5, 16], 33: [0, 8, 33], 24: [0, 31, 24], 25: [0, 31, 25], 23: [0, 2, 27, 23], 14: [0, 2, 32, 14], 15: [0, 2, 32, 15], 18: [0, 2, 32, 18], 20: [0, 2, 32, 20], 22: [0, 2, 32, 22], 29: [0, 2, 32, 29], 26: [0, 8, 33, 26]} 3.3.2社群检测社群检测是根据给定的质量指标将节点划分为多个分组。这通常可用于识别社交社群、客户行为或网页主题。 社区是指一组相连节点的集合。但是,目前关于社群还没有广泛公认的定义,只是社群内的节点应该要密集地相连。Girvan Newman 算法是一个用于发现社群的常用算法。其通过逐步移除网络内的边来定义社区。我们将居间性称为「边居间性(edge betweenness)」。这是一个正比于穿过该边的节点对之间最短路径的数量的值。该算法的步骤如下:计算网络中所有已有边的居间性。移除居间性最高的边。移除该边后,重新计算所有边的居间性。重复步骤 2 和 3,直到不再剩余边。from networkx.algorithms import community import itertools k = 1 comp = community.girvan_newman(G_karate) for communities in itertools.islice(comp, k): print(tuple(sorted(c) for c in communities)) ([0, 1, 3, 4, 5, 6, 7, 10, 11, 12, 13, 16, 17, 19, 21], [2, 8, 9, 14, 15, 18, 20, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33])import community partition = community.best_partition(G_karate) pos = nx.spring_layout(G_karate) plt.figure(figsize=(8, 8)) plt.axis('off') nx.draw_networkx_nodes(G_karate, pos, node_size=600, cmap=plt.cm.RdYlBu, node_color=list(partition.values())) nx.draw_networkx_edges(G_karate, pos, alpha=0.3) plt.show(G_karate) 3.3.4 中心性算法# Plot the centrality of the nodes plt.figure(figsize=(18, 12)) f, axarr = plt.subplots(2, 2, num=1) plt.sca(axarr[0,0]) nx.draw(G_karate, cmap = plt.get_cmap('inferno'), node_color = c_degree, node_size=300, pos=pos, with_labels=True) axarr[0,0].set_title('Degree Centrality', size=16) plt.sca(axarr[0,1]) nx.draw(G_karate, cmap = plt.get_cmap('inferno'), node_color = c_eigenvector, node_size=300, pos=pos, with_labels=True) axarr[0,1].set_title('Eigenvalue Centrality', size=16) plt.sca(axarr[1,0]) nx.draw(G_karate, cmap = plt.get_cmap('inferno'), node_color = c_closeness, node_size=300, pos=pos, with_labels=True) axarr[1,0].set_title('Proximity Centrality', size=16) plt.sca(axarr[1,1]) nx.draw(G_karate, cmap = plt.get_cmap('inferno'), node_color = c_betweenness, node_size=300, pos=pos, with_labels=True) axarr[1,1].set_title('Betweenness Centrality', size=16) 4.总结因为篇幅关系就只放了部分程序在第三章,如有需求可自行fork项目原始链接。欢迎fork本项目原始链接:关于图计算&图学习的基础知识概览:前置知识点学习(Paddle Graph L)https://aistudio.baidu.com/aistudio/projectdetail/4982973?contributionType=1因为之前一直在研究知识提取相关算法,后续为了构建小型领域知识图谱,会用到知识融合、知识推理等技术,现在开始学习研究图计算相关。本项目主要介绍了主要的图类型以及用于描述图的最基本的属性,以及经典的算法原理作为前置知识点学习(Paddle Graph Learning (PGL)),最后进行程序展示,希望帮助大家更好的理解前置知识。本项目参考了:maelfabien大神、以及自尊心3和Mr.郑 佬们在博客 or github上的贡献 欢迎大家fork, 后续将开始图计算相关项目以及部分知识提取技术深化!
NLP领域任务如何选择合适预训练模型以及选择合适的方案【规范建议】
1.常见NLP任务信息抽取:从给定文本中抽取重要的信息,比如时间、地点、人物、事件、原因、结果、数字、日期、货币、专有名词等等。通俗说来,就是要了解谁在什么时候、什么原因、对谁、做了什么事、有什么结果。文本生成:机器像人一样使用自然语言进行表达和写作。依据输入的不同,文本生成技术主要包括数据到文本生成和文本到文本生成。数据到文本生成是指将包含键值对的数据转化为自然语言文本;文本到文本生成对输入文本进行转化和处理从而产生新的文本问答系统:对一个自然语言表达的问题,由问答系统给出一个精准的答案。需要对自然语言查询语句进行某种程度的语义分析,包括实体链接、关系识别,形成逻辑表达式,然后到知识库中查找可能的候选答案并通过一个排序机制找出最佳的答案。对话系统:系统通过一系列的对话,跟用户进行聊天、回答、完成某一项任务。涉及到用户意图理解、通用聊天引擎、问答引擎、对话管理等技术。此外,为了体现上下文相关,要具备多轮对话能力。语音识别和生成:语音识别是将输入计算机的语音符号识别转换成书面语表示。语音生成又称文语转换、语音合成,它是指将书面文本自动转换成对应的语音表征。信息过滤:通过计算机系统自动识别和过滤符合特定条件的文档信息。通常指网络有害信息的自动识别和过滤,主要用于信息安全和防护,网络内容管理等。舆情分析:是指收集和处理海量信息,自动化地对网络舆情进行分析,以实现及时应对网络舆情的目的。信息检索:对大规模的文档进行索引。可简单对文档中的词汇,赋之以不同的权重来建立索引,也可建立更加深层的索引。在查询的时候,对输入的查询表达式比如一个检索词或者一个句子进行分析,然后在索引里面查找匹配的候选文档,再根据一个排序机制把候选文档排序,最后输出排序得分最高的文档。机器翻译:把输入的源语言文本通过自动翻译获得另外一种语言的文本。机器翻译从最早的基于规则的方法到二十年前的基于统计的方法,再到今天的基于神经网络(编码-解码)的方法,逐渐形成了一套比较严谨的方法体系。文本挖掘:包括文本聚类、分类、情感分析以及对挖掘的信息和知识的可视化、交互式的表达界面。目前主流的技术都是基于统计机器学习的。2.如何将业务问题抽象为已得到很好解决的典型问题2.1 明确业务的输入与输出令输入文本用X表示,输出标签用Y表示,则有以下粗略的分类:2.1.1 如果Y表示某一类的概率,或者是一个定长向量,向量中的每个维度是其属于各个类的概率,且概率之和为1,则可抽象为文本多分类问题。a.一般X只有一段文本。如下所示i.如情感分析等任务。 房间 太 小 。 其他 的 都 一般 0b.如果X是2段文本(X1,X2),则是可以抽象为句对分类问题。如下所示 i:如NLI等任务。 大家觉得她好看吗 大家觉得跑男好看吗? 0c.如果的每个类别的概率相互独立,即各类概率之和不为1,可抽象为文本多标签分类问题。如下所示i:如用户评论分类、黄反识别等任务。 互联网创业就如选秀 需求与服务就是价值 0 1d. 如果X有多段非文本特征输入,如整型、浮点型类型特征。则可抽象为混合特征的分类问题。如下所示i:如CTR预估等任务。CTR预估*CTR预估是推荐中最核心的算法之一。 相关概念: CTR预估:对每次广告的点击情况做出预测,预测用户是点击还是不点击。CTR预估的影响因素:比如历史点击率、广告位置、时间、用户等CTR预估相关介绍推荐算法之4——CTR预估模型2.1.2 如果X是2段文本(X1,X2),Y表示二者的相似度,可抽象为文本匹配问题。如下所示 喜欢 打篮球 的 男生 喜欢 什么样 的 女生 爱 打篮球 的 男生 喜欢 什么样 的 女生 1a.如语义相似度、相似问题匹配等任务。b.文本聚类的问题可以通过文本相似度问题进行处理。2.1.3 如果X有一段文本,Y是一个与X等长的序列,可抽象为序列标注问题。如下所示 海 钓 比 赛 地 点 在 厦 门 与 金 门 之 间 的 海 域 。 O O O O O O O B-LOC I-LOC O B-LOC I-LOC O O O O O Oa.如分词、POS、NER、词槽挖掘等任务。2.1.4 如果X有一段文本,Y是一个不定长的文本,可抽象为文本生成问题。如下所示 Rachel Pike : The science behind a climate headline Khoa học đằng sau một tiêu đề về khí hậua.如机器翻译、文本摘要、标题生成等任务。2.1.5.如果X为一段文本,Y表示文本X作为正常语句出现的概率或者混淆度,则属于语言模型任务。如下所示 <s> but some analysts remain sour on the company but some analysts remain sour on the company <e>a.语言模型任务的子问题是基于上(下)文X预测下(上)一个词出现的概率Y,可以理解为一种特殊的文本分类。2.1.6如果X是2段文本(X1,X2),分别表示正文篇章和问题,Y是篇章中的一小段文本,表示对应问题的答案,则可抽象为阅读理解问题。 "data": [{ "title": "", "paragraphs": [{ "context": "爬行垫根据中间材料的不同可以分为:XPE爬行垫、EPE爬行垫、EVA爬行垫、PVC爬行垫;其中XPE爬行垫、EPE爬行垫都属于PE材料加保鲜膜复合而成,都是无异味的环保材料,但是XPE爬行垫是品质较好的爬行垫,韩国进口爬行垫都是这种爬行垫,而EPE爬行垫是国内厂家为了减低成本,使用EPE(珍珠棉)作为原料生产的一款爬行垫,该材料弹性差,易碎,开孔发泡防水性弱。EVA爬行垫、PVC爬行垫是用EVA或PVC作为原材料与保鲜膜复合的而成的爬行垫,或者把图案转印在原材料上,这两款爬行垫通常有异味,如果是图案转印的爬行垫,油墨外露容易脱落。当时我儿子爬的时候,我们也买了垫子,但是始终有味。最后就没用了,铺的就的薄毯子让他爬。您好,爬行垫一般色彩鲜艳,能吸引宝宝的注意力,当宝宝刚会爬的时候,趴在上面玩,相对比较安全,不存在从床上摔下来的危险。对宝宝的爬行还是很有好处的。还有就是妈妈选择爬行垫时可以选择无害的PE棉,既防潮又隔冷隔热。外有要有一层塑料膜,能隔绝液体进入垫子内部,而且方便清洗。宝宝每次爬行,一定要记得把宝宝的手擦干净。", "qas": [{ "answers": [{ "text": "XPE", "answer_start": 17 "id": "DR-single-pre_and_next_paras-181574", "question": "爬行垫什么材质的好" }2.1.7 如果Y是以上多种任务的组合,则可以抽象为多标签学习、多任务学习任务。a.如实体关系抽取任务,实体抽取本属于序列标注、关系抽取本属于文本多分类。2.2抽象与拆分任务取舍经验2.2.1优先考虑简单的任务,由易到难循序渐进:a.文本分类、文本匹配、序列标注、文本生成、阅读理解、多任务学习、强化学习、对抗学习等。2.2.2 复杂任务可拆分、化简成简单的子任务a.如实体关系抽取任务,可以拆分为实体识别+关系抽取的pipline进行实现。b.如文本纠错任务,可以拆分出语言模型、统计机器翻译等多种不同子任务构造复杂的pipline进行实现。c.如排序任务,输入X为多段文本,输出Y为每段文本的排序位置,可化简成文本分类问题、文本匹配问题进行处理。2.2.3 有监督学习任务优先于无监督学习任务a.因为有监督学习更可控,更易于应用最前沿的研究成果。文心目前只覆盖有监督、自监督任务。b.比如文本关键词抽取,可以有TFIDF之类的无监督解法,但效果控制较困难,不如转换为文本分类问题。2.2.4 能应用深度学习的任务优于不利用深度学习的任务a.因为深度学习算法效果一般更好,而且可以应用到最前沿的预训练模型。文心目前只采用深度学习算法。b.如果文本聚类,可以有LDA之类的解法,但效果一般不如基于深度学习的语义相似度的文本聚类。3. 明确业务目标与限制条件3.1典型业务目标与限制条件1.预测部署性能a.典型指标:qps性能指标:QPS、TPS、系统吞吐量理解2.模型效果a.以文本分类为例,典型指标:精确率、准确率、召回率、F1值b.该评估指标应该在训练开始之前基本确定,否则很容易优化偏。3.硬件采购成本a.典型指标:钱b.GPU远贵于CPU,V100贵于P40。4.训练时间成本(GPU,卡,调参,GPU利用率)a.典型指标:每一轮训练所需要的时间。5.数据大小限制a.由于标注成本较高,很多时候是数据量很少又希望有很好的效果。6.开发迭代成本a.搭建环境成本b.迭代效率:往往是最消耗时间的部分。3.2 可供选择的方案选择平台版还是工具版选择GPU还是CPU训练,哪一款硬件,单机还是多机,单卡还是多卡,本地还是集群选择怎样的预制网络是否需要预训练模型选择哪一版本的预训练模型训练数据要多少batch_size、train_log_step、eval_step、save_model_step选多少4.根据业务目标与限制条件选择合适的方案4.1预测部署性能如果要求qps>1000a.不适合直接部署ERNIE预训练模型。b.但可尝试蒸馏策略,模型效果会存在一定损失。如果要求qps>100a.如果预算允许使用GPU,可尝试直接部署ERNIE相关预训练模型,推荐尝试ERNIE-tiny系列模型。b.如果预算只允许使用CPU,可尝试CPU集群部署ERNIE相关预训练模型。3.如果对部署性能要求不高,可随意尝试各种预训练模型。4.性能细节请参考:模型预测与部署——预测性能4.2 模型效果1.一般来说,复杂的网络优于简单的网络,多样的特征优于单一的特征,有预训练模型的效果优于无预训练模型。a.从模型复杂度来看,LSTM、GRU、CNN、BOW的复杂度与效果依次递减,速度依次提升。2.一般来说,在预训练模型中,large优于base优于tiny,新版本的模型优于旧版本的模型,针对具体任务的预训练模型优于通用版预训练模型。3.一般来说,在不欠拟合的情况下,训练数据越多模型效果越好,标注数据的质量越好效果越好。标注数据的质量优于数据的数量。4.不同任务适合的网络结构并不相同,具体任务具体分析。4.3硬件采购成本1.GPU远贵于CPU,常用训练用GPU型号为V100、P40、K40,价格依次递减。2.具体成本可参考百度云服务器-BCC-价格计算器3.如果缺少训练资源,可通过文心平台版的免费共享队列进行训练,资源紧张,且用且珍惜。4.4训练时间成本1.GPU还是CPUa.对于非ERNIE等复杂网络的模型,CPU的训练速度一般也能接受。 如果训练语料过多,数千万条以上,则建议采用CPU集群进行训练。 b.对于ERNIE模型,尽量采用GPU训练,CPU太慢,训练不起来。2.怎么用好GPU a.GPU并行训练能提升训练速度,建议优先把一个节点(trainer)的卡数用完,再考虑多机训练。因为单机多卡的GPU利用率更高,更快。而多机训练数据通信时间成本较高,时间更慢。 b.大原则:GPU利用率越高训练越快。 c.还有一点需要注意,多卡训练时是将不同的数据文件送给不同的卡,所以数据文件的个数要大于卡的个数。数据文件建议拆分细一些,这可以提升数据读取的速度。 d.熟练的同学可以尝试GPU多进程单机多卡训练、混合精度训练等方法,提升训练速度。3.train_log_step、eval_step、save_model_stepa.分别表示每多少步打印训练日志、每多少步评估一次验证集、每多少步保存一次模型。 b.设置不当也会拖慢训练时间 c.一般建议三者依次放大十倍,如:10、100、10004.batch_sizea.设置过小容易收敛慢,设置过大容易超过显存极限直接挂掉 b.如果使用ERNIE,batch_size建议小一些,使用large版本建议更小一些,如果输入语句并不是很长可以适当增加batch_size。 c.如果不使用ERNIE,可以大一些。 d.建议使用默认配置,如果想优化可以采用二分查找4.5 数据大小限制1.一般建议标注语料越多越好。2.非ERNIE模型一般需要几万至几百万条数据能收敛到较好的效果。3.ERNIE模型一般需要几千至几万条数据即可收敛到较好效果。a.一般不用ERNIE训练数百万条以上的数据,因为这会极大延长训练时间,增大资源消耗,而对效果的提升并不明显。自己有足够GPU资源的用户除外。 b.对于基线模型,建议在几万条数据上验证策略有效后再尝试增加数据量。4.如果用ERNIE模型,最少需要多少样本才能取得效果a.对于文本分类与序列标注,一般来说每个标签覆盖的样本数至少要超过200条才能有一定的效果。也就是说如果要进行50类多分类,就总共至少需要1万条样本。一般分类的类别越多任务越复杂。4.6开发迭代成本1.搭建环境成本a.如果只想训练基线模型验证效果,可以考虑使用文心平台版,免去搭建环境的成本。 b.如果需要不断调试、迭代优化模型,而由于平台版集群资源紧张造成迭代周期过长,可以尝试使用工具版。 i:这会付出搭建环境的成本,但长痛不如短痛。2.迭代效率a.使用工具版本地调试成功后再上集群训练能极大提升迭代效率。 b.使用预训练模型能提升迭代效率。 c.基线模型,建议在几万条数据上验证策略,提升迭代效率。验证有效后再尝试增加数据量5. 如何高效训练NLP任务汇总诸多NLP算法同学的建议,我们把高效训练NLP任务的基本流程总结如下:1.分析业务背景、明确任务输入与输出,将其抽象为已得到很好解决的NLP典型任务。 a.对于复杂任务,需要将其拆分成比较简单的子任务 b.文心已覆盖绝大部分NLP典型任务,可参考文心ERNIE工具版-支持任务。2.准备好几千条格式规范的训练数据,快速实现一个NLP模型基线。 a.最快速的方法是通过文心ERNIE平台版或者工具版,采用预制网络和模型无代码训练一个模型基线。 b.本步骤只需要您知道最基本的机器学习概念,划分好训练集、验证集、测试集进行训练即可。 c.评估训练出模型的效果,看是否满足你的业务需求,如果不满足,可考虑进一步优化模型效果。3.优化模型效果: a.各优化手段按照投入产出比排序如下 i:进一步分析你的业务背景和需求,分析基线模型的不足,进行更细致的技术选型。 ii:采用工具版进行本地小数据调试,极大地提升迭代效率。 iii:基于预制网络进行调参。 iv:自定义组网并进行调参。 v:基于核心接口进行高度自定义开发。 vi:直接修改文心核心源码进行开发。 b.每一种优化手段都都可以申请vip服务进行支持。如何自我判断采用哪种文心开发方式典型的训练方式:无代码训练(不调参),无代码训练(自主调参),自定义组网训练,高阶自定义训练。以上4类训练方式的开发自由度、上手难度、建模的风险、模型效果的上限依次递增,性价比依次递减。本地工具包的调试、迭代效率最高。6总结:需掌握知识6.1 无代码调参建议具备的相关知识1.明确以下概念:有监督学习、标签、特征、训练集、验证集、测试集、逻辑回归、过拟合、欠拟合、激活函数、损失函数、神经网络、学习率、正则化、epoch、batch_size、分词、统计词表。2.知道回归与分类的区别。3.知道如何通过收敛曲线判断过拟合与欠拟合。4.知道准确率、召回率、精确度、F1值、宏平均、微平均的概念与区别。5.知道为什么训练集、验证集、测试集要保证独立同分布。6.知道什么是神经网络.7.知道什么是迁移学习、什么是预训练模型、什么是finetune、迁移学习的优点是什么。6.2 自定义组网建议具备的相关知识1.前提是已经掌握无代码调参建议具备的相关知识2.明确以下概念:Sigmoid函数公式、softmax函数公式、交叉熵公式、前向传播、反向传播、SGD、Adam、词向量、embedding、dropout、BOW、CNN、RNN、GRU、LSTM、迁移学习、3.知道神经网络为什么具有非线性切分能力。4.知道NLP中一维CNN中的卷积核大小、卷积核的个数各指代什么,时序最大池化层如何操作。5.知道NLP中CNN与LSTM的区别,各擅长处理哪类文本问题。6.知道为什么BOW模型无法识别词语顺序关系。7.知道为什么会梯度爆炸,以及如何解决。参考书籍: a.ML特征工程和优化方法 b.周志华《机器学习》前3章 c.迁移学习常见问题 a.CNN常见问题 b.深度学习优化方法 c.花书《深度学习》6-10章 d.《基于深度学习的自然语言处理》整本项目参考链接:https://ai.baidu.com/ai-doc/ERNIE-Ultimate/pl580cszk
主动学习(Active Learning)简介综述汇总以及主流技术方案
主动学习(Active Learning)综述以及在文本分类和序列标注应用项目链接fork一下,含实践程序,因篇幅有限就没放在本博客中,如有需求请自行forkhttps://aistudio.baidu.com/aistudio/projectdetail/4897371?contributionType=10.引言在机器学习(Machine learning)领域,监督学习(Supervised learning)、非监督学习(Unsupervised learning)以及半监督学习(Semi-supervised learning)是三类研究比较多,应用比较广的学习技术,wiki上对这三种学习的简单描述如下:监督学习:通过已有的一部分输入数据与输出数据之间的对应关系,生成一个函数,将输入映射到合适的输出,例如分类。非监督学习:直接对输入数据集进行建模,例如聚类。半监督学习:综合利用有类标的数据和没有类标的数据,来生成合适的分类函数。其实很多机器学习都是在解决类别归属的问题,即给定一些数据,判断每条数据属于哪些类,或者和其他哪些数据属于同一类等等。这样,如果我们上来就对这一堆数据进行某种划分(聚类),通过数据内在的一些属性和联系,将数据自动整理为某几类,这就属于非监督学习。如果我们一开始就知道了这些数据包含的类别,并且有一部分数据(训练数据)已经标上了类标,我们通过对这些已经标好类标的数据进行归纳总结,得出一个“数据-->类别” 的映射函数,来对剩余的数据进行分类,这就属于监督学习。而半监督学习指的是在训练数据十分稀少的情况下,通过利用一些没有类标的数据,提高学习准确率的方法。我们使用一些传统的监督学习方法做分类的时候,往往是训练样本规模越大,分类的效果就越好。但是在现实生活的很多场景中,标记样本的获取是比较困难的,这需要领域内的专家来进行人工标注,所花费的时间成本和经济成本都是很大的。而且,如果训练样本的规模过于庞大,训练的时间花费也会比较多。那么有没有办法,能够使用较少的训练样本来获得性能较好的分类器呢?主动学习(Active Learning)为我们提供了这种可能。主动学习通过一定的算法查询最有用的未标记样本,并交由专家进行标记,然后用查询到的样本训练分类模型来提高模型的精确度。1.主动学习简介主动学习是指对需要标记的数据进行优先排序的过程,这样可以确定哪些数据对训练监督模型产生最大的影响。主动学习是一种学习算法可以交互式查询用户(teacher 或 oracle),用真实标签标注新数据点的策略。主动学习的过程也被称为优化实验设计。主动学习的动机在于认识到并非所有标有标签的样本都同等重要。主动学习是一种策略/算法,是对现有模型的增强。而不是新模型架构。主动学习背后的关键思想是,如果允许机器学习算法选择它学习的数据,这样就可以用更少的训练标签实现更高的准确性。——Active Learning Literature Survey, Burr Settles。通过为专家的标记工作进行优先级排序可以大大减少训练模型所需的标记数据量。降低成本,同时提高准确性。主动学习不是一次为所有的数据收集所有的标签,而是对模型理解最困难的数据进行优先级排序,并仅对那些数据要求标注标签。然后模型对少量已标记的数据进行训练,训练完成后再次要求对最不确定数据进行更多的标记。通过对不确定的样本进行优先排序,模型可以让专家(人工)集中精力提供最有用的信息。这有助于模型更快地学习,并让专家跳过对模型没有太大帮助的数据。这样在某些情况下,可以大大减少需要从专家那里收集的标签数量,并且仍然可以得到一个很好的模型。这样可以为机器学习项目节省时间和金钱!1.1 active learning的基本思想主动学习的模型如下:A=(C,Q,S,L,U),其中 C 为一组或者一个分类器,L是用于训练已标注的样本。Q 是查询函数,用于从未标注样本池U中查询信息量大的信息,S是督导者,可以为U中样本标注正确的标签。学习者通过少量初始标记样本L开始学习,通过一定的查询函数Q选择出一个或一批最有用的样本,并向督导者询问标签,然后利用获得的新知识来训练分类器和进行下一轮查询。主动学习是一个循环的过程,直至达到某一停止准则为止。这个准则可以是迭代次数,也可以是准确率等指标达到设定值在各种主动学习方法中,查询函数的设计最常用的策略是:不确定性准则(uncertainty)和差异性准则(diversity)。 不确定性越大代表信息熵越大,包含的信息越丰富;而差异性越大代表选择的样本能够更全面地代表整个数据集。对于不确定性,我们可以借助信息熵的概念来进行理解。我们知道信息熵是衡量信息量的概念,也是衡量不确定性的概念。信息熵越大,就代表不确定性越大,包含的信息量也就越丰富。事实上,有些基于不确定性的主动学习查询函数就是使用了信息熵来设计的,比如熵值装袋查询(Entropy query-by-bagging)。所以,不确定性策略就是要想方设法地找出不确定性高的样本,因为这些样本所包含的丰富信息量,对我们训练模型来说就是有用的。那么差异性怎么来理解呢?之前说到或查询函数每次迭代中查询一个或者一批样本。我们当然希望所查询的样本提供的信息是全面的,各个样本提供的信息不重复不冗余,即样本之间具有一定的差异性。在每轮迭代抽取单个信息量最大的样本加入训练集的情况下,每一轮迭代中模型都被重新训练,以新获得的知识去参与对样本不确定性的评估可以有效地避免数据冗余。但是如果每次迭代查询一批样本,那么就应该想办法来保证样本的差异性,避免数据冗余。从上图也可以看出来,在相同数目的标注数据中,主动学习算法比监督学习算法的分类误差要低。这里注意横轴是标注数据的数目,对于主动学习而言,相同的标注数据下,主动学习的样本数>监督学习,这个对比主要是为了说明两者对于训练样本的使用效率不同:主动学习训练使用的样本都是经过算法筛选出来对于模型训练有帮助的数据,所以效率高。但是如果是相同样本的数量下去对比两者的误差,那肯定是监督学习占优,这是毋庸置疑的。1.2active learning与半监督学习的不同 很多人认为主动学习也属于半监督学习的范畴了,但实际上是不一样的,半监督学习和直推学习(transductive learning)以及主动学习,都属于利用未标记数据的学习技术,但基本思想还是有区别的。 如上所述,主动学习的“主动”,指的是主动提出标注请求,也就是说,还是需要一个外在的能够对其请求进行标注的实体(通常就是相关领域人员),即主动学习是交互进行的。 而半监督学习,特指的是学习算法不需要人工的干预,基于自身对未标记数据加以利用。2.主动学习基础策略(小试牛刀)2.1常见主动学习策略在未标记的数据集上使用主动学习的步骤是:首先需要做的是需要手动标记该数据的一个非常小的子样本。一旦有少量的标记数据,就需要对其进行训练。该模型当然不会很棒,但是将帮助我们了解参数空间的哪些领域需要首标记。训练模型后,该模型用于预测每个剩余的未标记数据点的类别。根据模型的预测,在每个未标记的数据点上选择分数一旦选择了对标签进行优先排序的最佳方法,这个过程就可以进行迭代重复:在基于优先级分数进行标记的新标签数据集上训练新模型。一旦在数据子集上训练完新模型,未标记的数据点就可以在模型中运行并更新优先级分值,继续标记。通过这种方式,随着模型变得越来越好,我们可以不断优化标签策略。2.1.1基于数据流的主动学习方法基于流(stream-based)的主动学习中,未标记的样例按先后顺序逐个提交给选择引擎,由选择引擎决定是否标注当前提交的样例,如果不标注,则将其丢弃。在基于流的主动学习中,所有训练样本的集合以流的形式呈现给算法。每个样本都被单独发送给算法。算法必须立即决定是否标记这个示例。从这个池中选择的训练样本由oracle(人工的行业专家)标记,在显示下一个样本之前,该标记立即由算法接收。于基于流的算法不能对未标注样例逐一比较,需要对样例的相应评价指标设定阈值,当提交给选择引擎的样例评价指标超过阈值,则进行标注,但这种方法需要针对不同的任务进行调整,所以难以作为一种成熟的方法投入使用。2.1.2基于数据池的主动学习方法基于池(pool-based)的主动学习中则维护一个未标注样例的集合,由选择引擎在该集合中选择当前要标注的样例。在基于池的抽样中,训练样本从一个大的未标记数据池中选择。从这个池中选择的训练样本由oracle标记。2.1.3 基于查询的主动学习方法这种基于委员会查询的方法使用多个模型而不是一个模型。委员会查询(Query by Committee),它维护一个模型集合(集合被称为委员会),通过查询(投票)选择最“有争议”的数据点作为下一个需要标记的数据点。通过这种委员会可的模式以克服一个单一模型所能表达的限制性假设(并且在任务开始时我们也不知道应该使用什么假设)。有两个假设前提:所有模型在已标注数据上结果一致所有模型对于未标注结果样本集存在部分分歧2.2 不确定性度量识别接下来需要标记的最有价值的样本的过程被称为“抽样策略”或“查询策略”。在该过程中的评分函数称为“acquisition function”。该分数的含义是:得分越高的数据点被标记后,对模型训练后的产生价值就越高。有很多中不同的采样策略,例如不确定性抽样,多样性采样等,在本节中,我们将仅关注最常用策略的不确定性度量。不确定性抽样是一组技术,可以用于识别当前机器学习模型中的决策边界附近的未标记样本。这里信息最丰富的例子是分类器最不确定的例子。模型最不确定性的样本可能是在分类边界附近的数据。而我们模型学习的算法将通过观察这些分类最困难的样本来获得有关类边界的更多的信息。让我们以一个具体的例子,假设正在尝试建立一个多类分类,以区分3类猫,狗,马。该模型可能会给我们以下预测:{ "Prediction": { "Label": "Cat", "Prob": { "Cat": 0.9352784428596497, "Horse": 0.05409964170306921, "Dog": 0.038225741147994995, }这个输出很可能来自softmax,它使用指数将对数转换为0-1范围的分数。2.2.1最小置信度:(Least confidence)最小置信度=1(100%置信度)和每个项目的最自信的标签之间的差异。虽然可以单独按置信度的顺序进行排名,但将不确定性得分转换为0-1范围,其中1是最不确定的分数可能很有用。因为在这种情况下,我们必须将分数标准化。我们从1中减去该值,将结果乘以N/(1-N),n为标签数。这时因为最低置信度永远不会小于标签数量(所有标签都具有相同的预测置信度的时候)。让我们将其应用到上面的示例中,不确定性分数将是:(1-0.9352) *(3/2)= 0.0972。最小置信度是最简单,最常用的方法,它提供预测顺序的排名,这样可以以最低的置信度对其预测标签进行采样。2.2.2置信度抽样间距(margin of confidence sampling)不确定性抽样的最直观形式是两个置信度做高的预测之间的差值。也就是说,对于该模型预测的标签对比第二高的标签的差异有多大?这被定义为:不确定性抽样的最直观形式是两个置信度做高的预测之间的差值。也就是说,对于该模型预测的标签对比第二高的标签的差异有多大?这被定义为:同样我们可以将其转换为0-1范围,必须再次使用1减去该值,但是最大可能的分数已经为1了,所以不需要再进行其他操作。让我们将置信度抽样间距应用于上面的示例数据。“猫”和“马”是前两个。使用我们的示例,这种不确定性得分将为1.0 - (0.9352–0.0540)= 0.1188。2.2.3抽样比率 (Ratio sampling)置信度比是置信度边缘的变化,是两个分数之间的差异比率而不是间距的差异的绝对值。2.2.4 熵抽样(Entropy Sampling)应用于概率分布的熵包括将每个概率乘以其自身的对数,然后求和取负数:让我们在示例数据上计算熵:得到 0 - sum(–0.0705,–0.0903,–0.2273)= 0.3881除以标签数的log得到0.3881/ log2(3)= 0.61513.主动学习方法归类3.1 基于不确定性的主动学习方法基于不确定性的主动学习方法将最小化条件熵作为寻找判定函数的依据。Bayesian Active Learning for Classification and Preference Learning(论文 2011年)通过贪婪地找到一个能使当前模型熵最大程度减少的数据点x,但由于模型参数维度很高,直接求解困难,因此在给定数据D和新增数据点x条件下,模型预测和模型参数之间的互信息。Deep Bayesian Active Learning with Image Data(论文,代码 2017年)中实现了这一思路,过程如下:(1)从整体的数据中选一个子集作为初始训练集,来训练任务模型(分类,分割等等)(2)用训好的模型在剩余未标注的图像上以train模式跑多组预测,记录对每个样本的输出。(3)计算对每个样本的熵作为不确定性分数。(4)从大到小依次选择下一组数据标注好后加入训练集,更新训练模型(在上一代模型上fine-tuning),直到满足停止条件。考虑到深度学习中,不能每次选一个数据样本就重新训练一次模型,而是以批数据的形式进行训练,BatchBALD: Efficient and Diverse Batch Acquisition for Deep Bayesian Active Learning(论文 2019年)中,把原来的一个样本变成了一批样本。3.2基于最近邻和支持向量的分类器的方法基于不确定性的主动学习方法依赖模型预测的分类概率来确定模型对该样本的不确定性,但这个概率并不可靠,因为使用softmax分类器的神经网络并不能识别分布外样本,且很容易对OOD样本做出过度自信的预测。OOD(Out of Distribution(OOD) detection指的是模型能够检测出 OOD 样本,而 OOD 样本是相对于 In Distribution(ID) 样本来说的。传统的机器学习方法通常的假设是模型训练和测试的数据是独立同分布的(IID, Independent Identical Distribution),这里训练和测试的数据都可以说是 In Distribution(ID) 。在实际应用当中,模型部署上线后得到的数据往往不能被完全控制的,也就是说模型接收的数据有可能是 OOD样本,也可以叫异常样本(outlier, abnormal)。基于深度模型的Out of Distribution(OOD)检测相关方法介绍在主动学习中,初始阶段使用非常少的标注样本训练模型,意味着大量的未标注样本可能都是OOD样本,若模型过早的给这部分样本一个过度自信的预测概率,就可能使我们错失一些有价值的OOD样本。如图所示,初始训练阶段,模型缺乏虚线框以外的区域的训练数据,但softmax分类器仍然会对这些区域给出很自信的预测,导致选择新的待标注样本时,图中的q点会被忽略,而若q点正好不是class B,则会影响主动学习的性能。3.2.1 NNClassifier针对这个问题NNclassifier中设计了一个基于最近邻和支持向量的分类器来取代softmax, 使模型能对远离已有训练数据的区域产生较高的不确定性。具体而言,每类训练学习N个支持向量,基于样本特征与各类的支持向量之间的距离,就可以定义分类概率为与这N个支持向量的核函数的最大距离:$p_c\left(f_x\right)=\max _n \delta\left(-d\left(f_x, m_{c, n}\right)\right)$定义了新的可以意识到OOD样本的分类器之后,作者给出了对应的主动学习策略:Rejection confidence,用于度量远离所有支持向量的样本,如图(b)所示;confusion confidence,用于度量远离支持向量以及同时靠近多个不同类支持向量的样本,如图©所示。$\begin{aligned} &M_{\text {rejection }}(x)=\sum_c\left(1-p_c\left(f_x\right)\right) \\ &M_{\text {confusion }}(x)=\sum_c\left(1+p_c\left(f_x\right)-\max _c p_c\left(f_x\right)\right) \end{aligned}$3.2.2 RBF network + Gradient PenaltyAmersfoort用RBF神经网络来促使网络具有良好的OOD样本不确定性,同时给出了基于梯度范数的双边正则来削弱特征崩溃(feature collapse)的问题。与NNClassifier相同,本文的作者也定义了一个与各类特征距离的函数K来帮助检测OOD样本,损失函数同样定义成逐类的二值交叉熵。不同于NNClassifier的是,这里的距离是每个样本与该类样本的指数滑动平均得到的。$K_c\left(f_\theta(x), e_c\right)=\exp \left(-\left\|W_c f_\theta(x)-e_c\right\|_2^2 /\left(2 n \sigma^2\right)\right)$另一个不同点在于本文加入了一个双边梯度正则项。$\max \left(0,\left\|\operatorname{grad}_z \sum_c K_{\mathrm{c}}\right\|_F^2-1\right)$这个正则项的作用有两个,一个是保证平滑性,也就是相似的输入有相似的输出,这个是由max()中的梯度部分保证的,而梯度-1则起到避免特征崩溃的作用,也就是相比单纯的使用特征范数正则,-1能够避免模型将很多不同的输入映射到完全相同的特征,也就是feature collapse。3.3基于特征空间覆盖的方法接下来主要介绍基于特征空间覆盖的主动学习代表性工作:coreset。coreset的主要贡献:给出了基于特征空间覆盖的主动学习算法的近似损失上界;证明了新添加的样本在能够缩小标注样本对剩余样本的覆盖半径时,才能提高近似效果。coreset认为主动学习目标就是缩小核心集误差,即主动学习选出的样本损失与全体样本损失之间的差别。我们在主动学习挑选新样本时,并不知道样本的标签,也就没法直接求核心集损失。作者把核心集损失的上界转换做剩余训练样本与挑选出的标注样本间的最大距离。因此,主动学习问题等价于选择添加一组标注样本,使得其他样本对标注样本集的最大距离$\delta_s$ 最小,也就是k-center集覆盖问题。如图所示,蓝色为挑选出的标注样本,红色为其他样本。3.4 基于对抗学习的方法3.4.1VAALVariational Adversarial Active Learning(地址 2019年)描述了一种基于池的半监督主动学习算法,它以对抗的方式(关于对抗学习的详细介绍参见这里)隐式地学习了这种采样机制。与传统的主动学习算法不同,VAAL与任务无关,也就是说,它不依赖于试图获取标注数据的任务的性能。VAAL使用变分自编码器(VAE)和训练好的对抗网络来学习潜在空间,以区分未标注和标注的数据。核心思想本文的出发点可以理解如下:之前很多方法的uncertainty都是基于模型的,也就是说需要有个分割/分类等模型计算预测结果,然后从结果的好坏去分析相应的被预测样本的价值。而本文的uncertainty是基于数据本身的,也就是说并非基于预测结果本身去分析,而是直接基于样本自身的特征去处理。核心思想:利用VAE对已标注的数据和未标注的数据进行编码。因此,对于一个未标注的数据,如果其编码向量与潜在空间中向量的差异足够大,那么我们就认为该样本是有价值的。而对于样本的选择,是通过一个对抗网络来实现的,该对抗网络被用来区分一个样本是已标注还是未标注。因此上文的VAE还有一个额外的任务,即他的编码要让判别器难以区分已经标注还是没有标注。网络结构VAE和对抗网络之间的最大最小博弈是这样进行的:VAE试图欺骗对抗网络去预测,所有的数据点都来自已标注池;对抗网络则学习如何区分潜在空间中的不相似性。其结构如下:VAE和对抗网络之间的最大最小博弈是这样进行的:VAE试图欺骗对抗网络去预测,所有的数据点都来自已标注池;对抗网络则学习如何区分潜在空间中的不相似性。其结构如下:主动学习策略一开始随机选择10%的图像开始训练,此时记训练的网络为版本1。对于版本1,训练会迭代max_iterations次,与一般网络训练过程的差别在于每个iteration除了训练"任务模型"外,还得去训练VAE与判别器。而当迭代结束后,训练得到的"任务模型"其实与直接随机抽取10%的图像训练没有区别,因为VAE与判别器只对下一个网络版本有贡献。利用VAE与判别器内包含的经验,一次性抽取5%的新数据加入训练集,此时开始训练网络版本2。而这里特别关键的一点是,版本2仍然是从预训练VGG开始从头训练的(而非在版本1的基础上继续finetune)。至此一直迭代到选取50%的数据结束。模型特点本文的强化学习有点"离线"的味道,即最后选取出的50%数据可以很轻松的迁移至其他模型中,选择的过程只依赖VAE与判别器,而与具体的任务无关。此外该模型训练十分耗时——从10%逐步提升5%至50%,相当于顺序训练了9个相同的模型,再考虑训练VAE与判别器的耗时,训练该主动学习框架的所需时间可能高达原有基础网络的10倍。3.4.2SRAALSRAAL(论文 https://openaccess.thecvf.com/content_CVPR_2020/html/Zhang_State-Relabeling_Adversarial_Active_Learning_CVPR_2020_paper.html)是VAAL的一个改进版。在VAAL中,判别器的训练的时候只有两种状态,标注/未标注。SRAAL的作者认为这样忽略了一些信息,有时候任务模型已经能很确信的对某个未标注样本做预测了,就应该降低选择这个样本的优先级。为了实现这个思路,作者给出了一个任务模型预测不确定度的计算函数,用这个函数的输出结果作为生成对抗网络的判别器训练过程中,无标注样本的标签,而不用简单的个一个二值变量。3.4.3ARALVAAL有效的一个关键的因素实际上是同时利用标注/无标注的样本共同训练产生特征映射,而不像之前基于特征的coreset等主动学习方法,仅用标注数据训练产生特征。ARAL(https://arxiv.org/abs/1912.09720 2019.11)更进一步,也用这些个无标注样本来训练任务模型(如分类器)本身,整体仍然是在VAAL基础上做的,只是增加了cgan的判别器来实现半监督训练任务模型。整体来说,基于池的主动学习用标注样本来训练任务模型,合成的主动学习标注合成的样本来训练任务模型。相比之下,VAAL用标注数据训练任务模型,用所有数据来训练产生特征;ARAL用所有的训练数据,合成数据来训练任务模型、产生特征映射。相当于使用了半监督的学习方法,与和之前纯基于监督训练的主动学习方法比较自然有所提升。4.融合不确定性和多样性的学习方法☆之前介绍了基于不确定性的方法,以及基于多样性的方法。接下来我们来看看融合两者的方法。就动机而言,如果只用不确定性标准来选样本,在批量选择的场景中,很容易出现选到冗余样本的问题。而在深度学习中,由于训练开销的缘故,通常都采用批主动学习,所以为了提高主动学习的效率,就得考虑批量选择高不确定性样本时的多样性问题。而从多样性样本选择方法的角度来说,单纯的特征空间覆盖算法不能区分模型是否已经能很好预测某部分样本,会限制这类方法所能达到的上限。融合不确定性和多样性的思路主要有三种:完全延续信息论的分析思路,也就是batchBALD,在批量选择的过程中不采取每个样本互信息直接相加,而用求并的方法来避免选到冗余样本;先用不确定性标准选出大于budget size的候选集,再用集覆盖的思路来选择特征差异大的样本;是2的扩展,通过在梯度嵌入空间聚类来选样本,从而避开人工给定候选样本集大小的问题。4.1信息论思路第一种从理论上来看很优雅,从信息论的角度推出怎么在批量选择的场景里选到对模型参数改善最有效的一组样本。但计算复杂度很高,可能并不是很实用,该论文中的实验部分也都是在很小的数据集上完成的。4.2 构建候选集+大差异样本——SA这类方法实现起来最简单,非常启发式。整个主动学习分两步来做,第一步先用不确定性(熵,BALD等)选超出主动学习budget size的候选样本集,在用多样性的方法,选择能最好覆盖这个候选集的一组样本。SA 2017 用Bootstrapping训练若干个模型,用这些模型预测的variance来表示不确定性,之后再用候选集中样本特征相似度来选取与已经选到的样本差异最大的样本,就类似coreset-greedy的做法。CoreLog 2021 基于Proper Scoring Rules给了表示不确定性的度量,先选出不确定性大的前k%个样本,再用kmeans聚类来选择多样的样本。这种结合的方式没毛病,但有个小的问题,很难说清咋确定这个候选集大小,到底多大能算作高不确定性,能丢到候选集里。4.3 梯度嵌入空间——badge☆badge:https://arxiv.org/abs/1906.03671 2020 和第二类方法的思路很像,不确定性的用模型参数就某个样本的梯度大小来表示,多样性用kmeans++来保证。但这个方法很巧妙的地方在于,通过把这个问题丢到梯度嵌入空间来做(而不像第二类方法在样本的特征空间保证多样性),使样本的多样性和不确定性能同时得到保证。梯度范数大小表示不确定性很好理解,和之前用熵之类的指标来表示不确定性类似,模型预测的概率小,意味着熵大,也意味着如果把这样本标了,模型要有较大的变化才能拟合好这个样本,也就是求出来的梯度大。梯度表示多样性,是这类方法的独特之处,用梯度向量来聚类,选到的差异大的样本就变成:让模型参数的更新方向不同的样本,而不是样本特征本身不同。在用梯度表示了不确定性和多样性之后,怎么来选一批既有高不确定性,又不同的样本呢?badge的做法是Kmeans++聚类,第一个样本选梯度范数最大的样本,之后依据每个样本梯度与选到的样本梯度的差的范数来采样新的样本。这里注意这个差是两个向量的差,所以自然的避免了重复的选到梯度方向接近且范数都比较大的一组样本。5. 基于变化最大的方法这一类方法核心的观点是,不管不确定性或多样性,而是希望选出的样本能使模型产生的变化最大。变化最大可以着眼于loss最大,也可以关注梯度的情况,比如梯度范数大小。learning loss 2019 在任务模型上加一个小的附属子网络用来学习预测样本的损失值。训练任务模型的时候,也同时训练这个预测损失模块,之后就用这个模块来预测对哪个未标注样本的损失大,就选他。整个算法的流程图如下损失预测模块的结构和损失计算方法如下:6.总结主动学习(Active Learning)综述以及在文本分类和序列标注应用项目链接fork一下,含实践程序,因篇幅有限就没放在本博客中,如有需求请自行forkhttps://aistudio.baidu.com/aistudio/projectdetail/4897371?contributionType=1 获得有用是标注数据在训练时是非常重要的,但是标注数据可能很非常的费事费力,并且如果标注的质量不佳也会对训练产生很大的影响。主动学习是解决这个问题的一个方向,并且是一个非常好的方向。
基于Ernie-3.0 CAIL2019法研杯要素识别多标签分类任务
相关项目:Paddlenlp之UIE模型实战实体抽取任务【打车数据、快递单】Paddlenlp之UIE分类模型【以情感倾向分析新闻分类为例】含智能标注方案)[应用实践:分类模型大集成者[PaddleHub、Finetune、prompt]](https://aistudio.baidu.com/aistudio/projectdetail/4357474?contributionType=1)Paddlenlp之UIE关系抽取模型【高管关系抽取为例】PaddleNLP基于ERNIR3.0文本分类以中医疗搜索检索词意图分类(KUAKE-QIC)为例【多分类(单标签)】基于ERNIR3.0文本分类:CAIL2018-SMALL罪名预测为例(多标签)本项目链接:基于Ernie-3.0 CAIL2019法研杯要素识别多标签分类任务本项目将介绍如何基于PaddleNLP对ERNIE 3.0预训练模型微调完成法律文本多标签分类预测。本项目主要包括“什么是多标签文本分类预测”、“ERNIE 3.0模型”、“如何使用ERNIE 3.0中文预训练模型进行法律文本多标签分类预测”等三个部分。1. 什么是多标签文本分类预测文本多标签分类是自然语言处理(NLP)中常见的文本分类任务,文本多标签分类在各种现实场景中具有广泛的适用性,例如商品分类、网页标签、新闻标注、蛋白质功能分类、电影分类、语义场景分类等。多标签数据集中样本用来自 n_classes 个可能类别的m个标签类别标记,其中m的取值在0到n_classes之间,这些类别具有不相互排斥的属性。通常,我们将每个样本的标签用One-hot的形式表示,正类用1表示,负类用0表示。例如,数据集中样本可能标签是A、B和C的多标签分类问题,标签为[1,0,1]代表存在标签 A 和 C 而标签 B 不存在的样本。近年来,随着司法改革的全面推进,“以公开为原则,不公开为例外”的政策逐步确立,大量包含了案件事实及其适用法律条文信息的裁判文书逐渐在互联网上公开,海量的数据使自然语言处理技术的应用成为可能。法律条文的组织呈树形层次结构,现实中的案情错综复杂,同一案件可能适用多项法律条文,涉及数罪并罚,需要多标签模型充分学习标签之间的关联性,对文本进行分类预测。2. ERNIE 3.0模型ERNIE 3.0首次在百亿级预训练模型中引入大规模知识图谱,提出了海量无监督文本与大规模知识图谱的平行预训练方法(Universal Knowledge-Text Prediction),通过将知识图谱挖掘算法得到五千万知识图谱三元组与4TB大规模语料同时输入到预训练模型中进行联合掩码训练,促进了结构化知识和无结构文本之间的信息共享,大幅提升了模型对于知识的记忆和推理能力。ERNIE 3.0框架分为两层。第一层是通用语义表示网络,该网络学习数据中的基础和通用的知识。第二层是任务语义表示网络,该网络基于通用语义表示,学习任务相关的知识。在学习过程中,任务语义表示网络只学习对应类别的预训练任务,而通用语义表示网络会学习所有的预训练任务。ERNIE 3.0模型框架3. ERNIE 3.0中文预训练模型进行法律文本多标签分类预测3.1 环境准备AI Studio平台默认安装了Paddle和PaddleNLP,并定期更新版本。 如需手动更新Paddle,可参考飞桨安装说明,安装相应环境下最新版飞桨框架。使用如下命令确保安装最新版PaddleNLP:3.2 加载法律文本多标签数据本数据集(2019年法研杯要素识别任务)来自于“中国裁判文书网”公开的法律文书,每条训练数据由一份法律文书的案情描述片段构成,其中每个句子都被标记了对应的类别标签,数据集一共包含20个标签,标签代表含义如下:DV1 0 婚后有子女 DV2 1 限制行为能力子女抚养 DV3 2 有夫妻共同财产 DV4 3 支付抚养费 DV5 4 不动产分割 DV6 5 婚后分居 DV7 6 二次起诉离婚 DV8 7 按月给付抚养费 DV9 8 准予离婚 DV10 9 有夫妻共同债务 DV11 10 婚前个人财产 DV12 11 法定离婚 DV13 12 不履行家庭义务 DV14 13 存在非婚生子 DV15 14 适当帮助 DV16 15 不履行离婚协议 DV17 16 损害赔偿 DV18 17 感情不和分居满二年 DV19 18 子女随非抚养权人生活 DV20 19 婚后个人财产数据集示例:text labels 所以起诉至法院请求变更两个孩子均由原告抚养,被告承担一个孩子抚养费每月600元。 0,7,3,1 2014年8月原、被告因感情不和分居,2014年10月16日被告文某某向务川自治县人民法院提起离婚诉讼,被法院依法驳回了离婚诉讼请求。 6,5 女儿由原告抚养,被告每月支付小孩抚养费500元; 0,7,3,1使用本地文件创建数据集,自定义read_custom_data()函数读取数据文件,传入load_dataset()创建数据集,返回数据类型为MapDataset。更多数据集自定方法详见如何自定义数据集。# 自定义数据集 import re from paddlenlp.datasets import load_dataset def clean_text(text): text = text.replace("\r", "").replace("\n", "") text = re.sub(r"\\n\n", ".", text) return text # 定义读取数据集函数 def read_custom_data(is_test=False, is_one_hot=True): file_num = 6 if is_test else 48 #文件个数 filepath = 'raw_data/test/' if is_test else 'raw_data/train/' for i in range(file_num): f = open('{}labeled_{}.txt'.format(filepath, i)) while True: line = f.readline() if not line: break data = line.strip().split('\t') # 标签用One-hot表示 if is_one_hot: labels = [float(1) if str(i) in data[1].split(',') else float(0) for i in range(20)] else: labels = [int(d) for d in data[1].split(',')] yield {"text": clean_text(data[0]), "labels": labels} f.close() label_vocab = { 0: "婚后有子女", 1: "限制行为能力子女抚养", 2: "有夫妻共同财产", 3: "支付抚养费", 4: "不动产分割", 5: "婚后分居", 6: "二次起诉离婚", 7: "按月给付抚养费", 8: "准予离婚", 9: "有夫妻共同债务", 10: "婚前个人财产", 11: "法定离婚", 12: "不履行家庭义务", 13: "存在非婚生子", 14: "适当帮助", 15: "不履行离婚协议", 16: "损害赔偿", 17: "感情不和分居满二年", 18: "子女随非抚养权人生活", 19: "婚后个人财产" }# load_dataset()创建数据集 train_ds = load_dataset(read_custom_data, is_test=False, lazy=False) test_ds = load_dataset(read_custom_data, is_test=True, lazy=False) # lazy=False,数据集返回为MapDataset类型 print("数据类型:", type(train_ds)) # labels为One-hot标签 print("训练集样例:", train_ds[0]) print("测试集样例:", test_ds[0])数据类型: <class 'paddlenlp.datasets.dataset.MapDataset'> 训练集样例: {'text': '2013年11月28日原、被告离婚时自愿达成协议,婚生子张某乙由被告李某某抚养,本院以(2013)宝渭法民初字第01848号民事调解书对该协议内容予以了确认,该协议具有法律效力,对原、被告双方均有约束力。', 'labels': [1.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]} 测试集样例: {'text': '综上,原告现要求变更女儿李乙抚养关系的请求,本院应予支持。', 'labels': [1.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]}3.3 加载中文ERNIE 3.0预训练模型和分词器PaddleNLP中Auto模块(包括AutoModel, AutoTokenizer及各种下游任务类)提供了方便易用的接口,无需指定模型类别,即可调用不同网络结构的预训练模型。PaddleNLP的预训练模型可以很容易地通过from_pretrained()方法加载,Transformer预训练模型汇总包含了40多个主流预训练模型,500多个模型权重。AutoModelForSequenceClassification可用于多标签分类,通过预训练模型获取输入文本的表示,之后将文本表示进行分类。PaddleNLP已经实现了ERNIE 3.0预训练模型,可以通过一行代码实现ERNIE 3.0预训练模型和分词器的加载。# 加载中文ERNIE 3.0预训练模型和分词器 from paddlenlp.transformers import AutoModelForSequenceClassification, AutoTokenizer model_name = "ernie-3.0-base-zh" num_classes = 20 model = AutoModelForSequenceClassification.from_pretrained(model_name, num_classes=num_classes) tokenizer = AutoTokenizer.from_pretrained(model_name)3.4 基于预训练模型的数据处理Dataset中通常为原始数据,需要经过一定的数据处理并进行采样组batch。通过Dataset的map函数,使用分词器将数据集从原始文本处理成模型的输入。定义paddle.io.BatchSampler和collate_fn构建 paddle.io.DataLoader。实际训练中,根据显存大小调整批大小batch_size和文本最大长度max_seq_length。import functools import numpy as np from paddle.io import DataLoader, BatchSampler from paddlenlp.data import DataCollatorWithPadding # 数据预处理函数,利用分词器将文本转化为整数序列 def preprocess_function(examples, tokenizer, max_seq_length): result = tokenizer(text=examples["text"], max_seq_len=max_seq_length) result["labels"] = examples["labels"] return result trans_func = functools.partial(preprocess_function, tokenizer=tokenizer, max_seq_length=128) train_ds = train_ds.map(trans_func) test_ds = test_ds.map(trans_func) # collate_fn函数构造,将不同长度序列充到批中数据的最大长度,再将数据堆叠 collate_fn = DataCollatorWithPadding(tokenizer) # 定义BatchSampler,选择批大小和是否随机乱序,进行DataLoader train_batch_sampler = BatchSampler(train_ds, batch_size=64, shuffle=True) test_batch_sampler = BatchSampler(test_ds, batch_size=64, shuffle=False) train_data_loader = DataLoader(dataset=train_ds, batch_sampler=train_batch_sampler, collate_fn=collate_fn) test_data_loader = DataLoader(dataset=test_ds, batch_sampler=test_batch_sampler, collate_fn=collate_fn)3.5 数据训练和评估定义训练所需的优化器、损失函数、评价指标等,就可以开始进行预模型微调任务。import time import paddle.nn.functional as F from metric import MultiLabelReport #文件在根目录下 # Adam优化器、交叉熵损失函数、自定义MultiLabelReport评价指标 optimizer = paddle.optimizer.AdamW(learning_rate=1e-4, parameters=model.parameters()) criterion = paddle.nn.BCEWithLogitsLoss() metric = MultiLabelReport()from eval import evaluate epochs = 5 # 训练轮次 ckpt_dir = "ernie_ckpt" #训练过程中保存模型参数的文件夹 global_step = 0 #迭代次数 tic_train = time.time() best_f1_score = 0 for epoch in range(1, epochs + 1): for step, batch in enumerate(train_data_loader, start=1): input_ids, token_type_ids, labels = batch['input_ids'], batch['token_type_ids'], batch['labels'] # 计算模型输出、损失函数值、分类概率值、准确率、f1分数 logits = model(input_ids, token_type_ids) loss = criterion(logits, labels) probs = F.sigmoid(logits) metric.update(probs, labels) auc, f1_score, _, _ = metric.accumulate() #auc, f1_score, precison, recall # 每迭代10次,打印损失函数值、准确率、f1分数、计算速度 global_step += 1 if global_step % 10 == 0: print( "global step %d, epoch: %d, batch: %d, loss: %.5f, auc: %.5f, f1 score: %.5f, speed: %.2f step/s" % (global_step, epoch, step, loss, auc, f1_score, 10 / (time.time() - tic_train))) tic_train = time.time() # 反向梯度回传,更新参数 loss.backward() optimizer.step() optimizer.clear_grad() # 每迭代40次,评估当前训练的模型、保存当前最佳模型参数和分词器的词表等 if global_step % 40 == 0: save_dir = ckpt_dir if not os.path.exists(save_dir): os.makedirs(save_dir) eval_f1_score = evaluate(model, criterion, metric, test_data_loader, label_vocab, if_return_results=False) if eval_f1_score > best_f1_score: best_f1_score = eval_f1_score model.save_pretrained(save_dir) tokenizer.save_pretrained(save_dir)模型训练过程中会输出如下日志:global step 770, epoch: 4, batch: 95, loss: 0.04217, auc: 0.99446, f1 score: 0.92639, speed: 0.61 step/s global step 780, epoch: 4, batch: 105, loss: 0.03375, auc: 0.99591, f1 score: 0.92674, speed: 0.98 step/s global step 790, epoch: 4, batch: 115, loss: 0.04217, auc: 0.99530, f1 score: 0.92483, speed: 0.80 step/s global step 800, epoch: 4, batch: 125, loss: 0.05338, auc: 0.99534, f1 score: 0.92467, speed: 0.67 step/s eval loss: 0.05298, auc: 0.99185, f1 score: 0.90312, precison: 0.90031, recall: 0.90596 [2022-07-27 16:31:27,917] [ INFO] - tokenizer config file saved in ernie_ckpt/tokenizer_config.json [2022-07-27 16:31:27,920] [ INFO] - Special tokens file saved in ernie_ckpt/special_tokens_map.json global step 810, epoch: 4, batch: 135, loss: 0.04668, auc: 0.99509, f1 score: 0.91319, speed: 0.59 step/s global step 820, epoch: 4, batch: 145, loss: 0.04317, auc: 0.99478, f1 score: 0.91696, speed: 0.98 step/s global step 830, epoch: 4, batch: 155, loss: 0.04573, auc: 0.99488, f1 score: 0.91815, speed: 0.80 step/s global step 840, epoch: 4, batch: 165, loss: 0.05505, auc: 0.99465, f1 score: 0.91753, speed: 0.65 step/s eval loss: 0.05352, auc: 0.99234, f1 score: 0.89713, precison: 0.88058, recall: 0.91432 global step 850, epoch: 4, batch: 175, loss: 0.03971, auc: 0.99626, f1 score: 0.92391, speed: 0.76 step/s global step 860, epoch: 4, batch: 185, loss: 0.04622, auc: 0.99593, f1 score: 0.91806, speed: 0.97 step/s global step 870, epoch: 4, batch: 195, loss: 0.04128, auc: 0.99587, f1 score: 0.91959, speed: 0.77 step/s global step 880, epoch: 4, batch: 205, loss: 0.06053, auc: 0.99566, f1 score: 0.92041, speed: 0.63 step/s eval loss: 0.05234, auc: 0.99220, f1 score: 0.90272, precison: 0.89108, recall: 0.91466 ...3.6 多标签分类预测结果预测加载微调好的模型参数进行情感分析预测,并保存预测结果from eval import evaluate # 模型在测试集中表现 model.set_dict(paddle.load('ernie_ckpt/model_state.pdparams')) # 也可以选择加载预先训练好的模型参数结果查看模型训练结果 # model.set_dict(paddle.load('ernie_ckpt_trained/model_state.pdparams')) print("ERNIE 3.0 在法律文本多标签分类test集表现", end= " ") results = evaluate(model, criterion, metric, test_data_loader, label_vocab)ERNIE 3.0 在法律文本多标签分类test集表现 eval loss: 0.05298, auc: 0.99185, f1 score: 0.90312, precison: 0.90031, recall: 0.90596test_ds = load_dataset(read_custom_data, is_test=True, is_one_hot=False, lazy=False) res_dir = "./results" if not os.path.exists(res_dir): os.makedirs(res_dir) with open(os.path.join(res_dir, "multi_label.tsv"), 'w', encoding="utf8") as f: f.write("text\tprediction\n") for i, pred in enumerate(results): f.write(test_ds[i]['text']+"\t"+pred+"\n")法律多标签文本预测结果示例:4.总结相关项目:Paddlenlp之UIE模型实战实体抽取任务【打车数据、快递单】Paddlenlp之UIE分类模型【以情感倾向分析新闻分类为例】含智能标注方案)[应用实践:分类模型大集成者[PaddleHub、Finetune、prompt]](https://aistudio.baidu.com/aistudio/projectdetail/4357474?contributionType=1)Paddlenlp之UIE关系抽取模型【高管关系抽取为例】PaddleNLP基于ERNIR3.0文本分类以中医疗搜索检索词意图分类(KUAKE-QIC)为例【多分类(单标签)】基于ERNIR3.0文本分类:CAIL2018-SMALL罪名预测为例(多标签)本项目主要讲解了法律任务,和对性能指标的简单探讨,可以看到实际更多问题是关于多标签分类的。China AI & Law Challenge (CAIL)中国法研杯司法人工智能挑战赛本项目数据集:https://github.com/china-ai-law-challenge/CAIL2019/tree/master/%E8%A6%81%E7%B4%A0%E8%AF%86%E5%88%AB数据集自取:欢迎大家关注我的主页:https://aistudio.baidu.com/aistudio/usercenter以及博客:https://blog.csdn.net/sinat_39620217?type=blog
UIE_Slim满足工业应用场景,解决推理部署耗时问题,提升效能。
项目链接:fork一下即可UIE Slim满足工业应用场景,解决推理部署耗时问题,提升效能!如果有图片缺失查看原项目UIE Slim满足工业应用场景,解决推理部署耗时问题,提升效能在UIE强大的抽取能力背后,同样需要较大的算力支持计算。在一些工业应用场景中对性能的要求较高,若不能有效压缩则无法实际应用。因此,基于数据蒸馏技术构建了UIE Slim数据蒸馏系统。其原理是通过数据作为桥梁,将UIE模型的知识迁移到封闭域信息抽取小模型,以达到精度损失较小的情况下却能达到大幅度预测速度提升的效果。FasterTokenizer是一款简单易用、功能强大的跨平台高性能文本预处理库,集成业界多个常用的Tokenizer实现,支持不同NLP场景下的文本预处理功能,如文本分类、阅读理解,序列标注等。结合PaddleNLP Tokenizer模块,为用户在训练、推理阶段提供高效通用的文本预处理能力。use_faster: 使用C++实现的高性能分词算子FasterTokenizer进行文本预处理加速UIE数据蒸馏三步Step 1: 使用UIE模型对标注数据进行finetune,得到Teacher Model。Step 2: 用户提供大规模无标注数据,需与标注数据同源。使用Taskflow UIE对无监督数据进行预测。Step 3: 使用标注数据以及步骤2得到的合成数据训练出封闭域Student Model。效果展示:测试硬件情况:1点算力卡对应的:V100 32GBGPUTesla V100Video Mem32GBCPU4 CoresRAM32GBDisk100GB模型模型计算运行时间precisionrecallF1uie-base68.61049008s0.692770.723270.70769uie-mini28.932519437s0.741380.540880.62545uie-micro26.367019170.747570.484280.58779uie-nano24.89377610.742860.490570.59091蒸馏mini6.839258904s0.77320.750.76142蒸馏micro6.776990s0.782610.720.75蒸馏nano6.6231770s0.79570.740.76684模型计算运行时间:| 模型 | 模型计算运行时间 | 提速x倍|| -------- | -------- | -------- | | UIE base | 203.95947s | 1|| UIE base + FasterTokenizer | 177.1798s | 1.15|| UIE蒸馏mini | 21.97979s |9.28 || UIE蒸馏mini + FasterTokenizer | 20.1557s |10.12 |Archive: data.zipinflating: ./data/unlabeled_data.txtinflating: ./data/doccano_ext.json示例数据包含以下两部分:名称数量doccano格式标注数据(doccano_ext.json)200无标注数据(unlabeled_data.txt)12771. 进行预训练微调,得到Teacher Model具体参数以及doccano标注细节参考文档:Paddlenlp之UIE模型实战实体抽取任务【打车数据、快递单】[PaddleNLP之UIE信息抽取小样本进阶(二)[含doccano详解]](https://aistudio.baidu.com/aistudio/projectdetail/4160689?contributionType=1)Paddlenlp之UIE分类模型【以情感倾向分析新闻分类为例】含智能标注方案)Paddlenlp之UIE关系抽取模型【高管关系抽取为例】UIE:模型模型结构语言大小uie-base (默认)12-layers, 768-hidden, 12-heads中文118Muie-base-en12-layers, 768-hidden, 12-heads英文118Muie-medical-base12-layers, 768-hidden, 12-heads中文uie-medium6-layers, 768-hidden, 12-heads中文75Muie-mini6-layers, 384-hidden, 12-heads中文27Muie-micro4-layers, 384-hidden, 12-heads中文23Muie-nano4-layers, 312-hidden, 12-heads中文18Muie-m-large24-layers, 1024-hidden, 16-heads中、英文实际大小2Guie-m-base12-layers, 768-hidden, 12-heads中、英文实际大小1G实际模型大小解释:base模型118M parameters是指base模型的参数个数,因为同一个模型可以被不同的精度来表示,例如float16,float32,下载下来是450M左右(存储空间大小),是因为下载的模型是float32,118M * 4 大概是存储空间的量级。!python finetune.py \ --train_path "./data/train.txt" \ --dev_path "./data/dev.txt" \ --save_dir "./checkpoint" \ --learning_rate 5e-6 \ --batch_size 16 \ --max_seq_len 512 \ --num_epochs 10 \ --model "uie-base" \ --seed 1000 \ --logging_steps 10 \ --valid_steps 50 \ --device "gpu"base模型部分结果展示:[2022-09-08 17:26:55,701] [ INFO] - Evaluation precision: 0.69375, recall: 0.69811, F1: 0.69592 [2022-09-08 17:27:01,145] [ INFO] - global step 260, epoch: 9, loss: 0.00172, speed: 1.84 step/s [2022-09-08 17:27:06,448] [ INFO] - global step 270, epoch: 9, loss: 0.00168, speed: 1.89 step/s [2022-09-08 17:27:12,102] [ INFO] - global step 280, epoch: 10, loss: 0.00165, speed: 1.77 step/s [2022-09-08 17:27:17,607] [ INFO] - global step 290, epoch: 10, loss: 0.00162, speed: 1.82 step/s [2022-09-08 17:27:22,899] [ INFO] - global step 300, epoch: 10, loss: 0.00159, speed: 1.89 step/s [2022-09-08 17:27:26,577] [ INFO] - Evaluation precision: 0.69277, recall: 0.72327, F1: 0.70769 [2022-09-08 17:27:26,577] [ INFO] - best F1 performence has been updated: 0.69841 --> 0.707692.离线蒸馏2.1 通过训练好的UIE定制模型预测无监督数据的标签用户提供大规模无标注数据,需与标注数据同源。使用Taskflow UIE对无监督数据进行预测。References:GlobalPointer:用统一的方式处理嵌套和非嵌套NER:GPLinker:基于GlobalPointer的实体关系联合抽取GPLinker_pytorchCBLUE%cd /home/aistudio/data_distill !python data_distill.py \ --data_path /home/aistudio/data \ --save_dir student_data \ --task_type relation_extraction \ --synthetic_ratio 10 \ --model_path /home/aistudio/checkpoint/model_best可配置参数说明:data_path: 标注数据(doccano_ext.json)及无监督文本(unlabeled_data.txt)路径。model_path: 训练好的UIE定制模型路径。save_dir: 学生模型训练数据保存路径。synthetic_ratio: 控制合成数据的比例。最大合成数据数量=synthetic_ratio*标注数据数量。task_type: 选择任务类型,可选有entity_extraction,relation_extraction,event_extraction和opinion_extraction。因为是封闭域信息抽取,需指定任务类型。seed: 随机种子,默认为1000。 parser.add_argument("--data_path", default="../data", type=str, help="The directory for labeled data with doccano format and the large scale unlabeled data.") parser.add_argument("--model_path", type=str, default="../checkpoint/model_best", help="The path of saved model that you want to load.") parser.add_argument("--save_dir", default="./distill_task", type=str, help="The path of data that you wanna save.") parser.add_argument("--synthetic_ratio", default=10, type=int, help="The ratio of labeled and synthetic samples.") parser.add_argument("--task_type", choices=['relation_extraction', 'event_extraction', 'entity_extraction', 'opinion_extraction'], default="entity_extraction", type=str, help="Select the training task type.") parser.add_argument("--seed", type=int, default=1000, help="Random seed for initialization")可配置参数说明:model_path: 训练好的UIE定制模型路径。test_path: 测试数据集路径。label_maps_path: 学生模型标签字典。batch_size: 批处理大小,默认为8。max_seq_len: 最大文本长度,默认为256。task_type: 选择任务类型,可选有entity_extraction,relation_extraction,event_extraction和opinion_extraction。因为是封闭域信息抽取的评估,需指定任务类型。parser.add_argument("--model_path", type=str, default=None, help="The path of saved model that you want to load.") parser.add_argument("--test_path", type=str, default=None, help="The path of test set.") parser.add_argument("--encoder", default="ernie-3.0-base-zh", type=str, help="Select the pretrained encoder model for GP.") parser.add_argument("--label_maps_path", default="./ner_data/label_maps.json", type=str, help="The file path of the labels dictionary.") parser.add_argument("--batch_size", type=int, default=16, help="Batch size per GPU/CPU for training.") parser.add_argument("--max_seq_len", type=int, default=128, help="The maximum total input sequence length after tokenization.") parser.add_argument("--task_type", choices=['relation_extraction', 'event_extraction', 'entity_extraction', 'opinion_extraction'], default="entity_extraction",2.3学生模型训练底座模型可以参考下面进行替换!!python train.py \ --task_type relation_extraction \ --train_path student_data/train_data.json \ --dev_path student_data/dev_data.json \ --label_maps_path student_data/label_maps.json \ --num_epochs 200 \ --encoder ernie-3.0-mini-zh# %cd /home/aistudio/data_distill !python train.py \ --task_type relation_extraction \ --train_path student_data/train_data.json \ --dev_path student_data/dev_data.json \ --label_maps_path student_data/label_maps.json \ --num_epochs 100 \ --encoder ernie-3.0-mini-zh\ --device "gpu"\ --valid_steps 100\ --logging_steps 10\ --save_dir './checkpoint2'\ --batch_size 163.Taskflow部署学生模型以及性能测试通过Taskflow一键部署封闭域信息抽取模型,task_path为学生模型路径。demo测试from pprint import pprint from paddlenlp import Taskflow ie = Taskflow("information_extraction", model="uie-data-distill-gp", task_path="checkpoint2/model_best/") # Schema 在闭域信息抽取中是固定的 pprint(ie("登革热@结果 升高 ### 血清白蛋白水平 检查 结果 检查 在资源匮乏地区和富足地区,对有症状患者均应早期检测。")) [{'疾病': [{'end': 3, 'probability': 0.9995957, 'relations': {'实验室检查': [{'end': 21, 'probability': 0.99892455, 'relations': {}, 'start': 14, 'text': '血清白蛋白水平'}], '影像学检查': [{'end': 21, 'probability': 0.99832386, 'relations': {}, 'start': 14, 'text': '血清白蛋白水平'}]}, 'start': 0, 'text': '登革热'}]}]from pprint import pprint import json from paddlenlp.taskflow import Taskflow import pandas as pd #运行时间 import time def openreadtxt(file_name): data = [] file = open(file_name,'r',encoding='UTF-8') #打开文件 file_data = file.readlines() #读取所有行 for row in file_data: data.append(row) #将每行数据插入data中 return data # 时间1 old_time = time.time() data_input=openreadtxt('/home/aistudio/数据集/unlabeled_data.txt') few_ie = Taskflow("information_extraction", model="uie-data-distill-gp", task_path="/home/aistudio/data_distill/checkpoint2/model_best",batch_size=32) # Schema 在闭域信息抽取中是固定的 # 时间1 current_time = time.time() print("数据模型载入运行时间为" + str(current_time - old_time) + "s") old_time1 = time.time() results=few_ie(data_input) current_time1 = time.time() print("模型计算运行时间为" + str(current_time1 - old_time1) + "s") old_time3 = time.time() test = pd.DataFrame(data=results) test.to_csv('/home/aistudio/output/reslut.txt', sep='\t', index=False,header=False) #本地 # with open("/home/aistudio/output/reslut.txt", "w+",encoding='UTF-8') as f: #a : 写入文件,若文件不存在则会先创建再写入,但不会覆盖原文件,而是追加在文件末尾 # for result in results: # line = json.dumps(result, ensure_ascii=False) #对中文默认使用的ascii编码.想输出真正的中文需要指定ensure_ascii=False # f.write(line + "\n") current_time3 = time.time() print("数据导出运行时间为" + str(current_time3 - old_time3) + "s") # for idx, text in enumerate(data): # print('Data: {} \t Lable: {}'.format(text[0], results[idx])) print("数据结果已导出")**mini运行时间:** 数据模型载入运行时间为0.8430757522583008s 模型计算运行时间为6.839258909225464s 数据导出运行时间为0.008304595947265625s **nano运行时间:** 数据模型载入运行时间为0.5164840221405029s 模型计算运行时间为6.6231770515441895s 数据导出运行时间为0.023623943328857422s **micro运行时间:** 数据模型载入运行时间为0.5323500633239746s 模型计算运行时间为6.77699007987976s 数据导出运行时间为0.04320549964904785s4 进行预训练模型UIE-mini并测试推理时间封闭域UIE的schema是固定的,可以在label_maps.json查看0:"手术治疗" 1:"实验室检查" 2:"影像学检查"from pprint import pprint import json from paddlenlp import Taskflow import pandas as pd #运行时间 import time def openreadtxt(file_name): data = [] file = open(file_name,'r',encoding='UTF-8') #打开文件 file_data = file.readlines() #读取所有行 for row in file_data: data.append(row) #将每行数据插入data中 return data # 时间1 old_time = time.time() data_input=openreadtxt('/home/aistudio/数据集/unlabeled_data.txt') schema = {'疾病': ['手术治疗', '实验室检查', '影像学检查']} # few_ie = Taskflow('information_extraction', schema=schema, batch_size=32,task_path='/home/aistudio/checkpoint_mini/model_best') #自行切换 few_ie = Taskflow('information_extraction', schema=schema, batch_size=32,task_path='/home/aistudio/checkpoint_micro/model_best') # 时间1 current_time = time.time() print("数据模型载入运行时间为" + str(current_time - old_time) + "s") old_time1 = time.time() results=few_ie(data_input) current_time1 = time.time() print("模型计算运行时间为" + str(current_time1 - old_time1) + "s") old_time3 = time.time() test = pd.DataFrame(data=results) test.to_csv('/home/aistudio/output/reslut.txt', sep='\t', index=False,header=False) #本地 # with open("/home/aistudio/output/reslut.txt", "w+",encoding='UTF-8') as f: #a : 写入文件,若文件不存在则会先创建再写入,但不会覆盖原文件,而是追加在文件末尾 # for result in results: # line = json.dumps(result, ensure_ascii=False) #对中文默认使用的ascii编码.想输出真正的中文需要指定ensure_ascii=False # f.write(line + "\n") current_time3 = time.time() print("数据导出运行时间为" + str(current_time3 - old_time3) + "s") # for idx, text in enumerate(data): # print('Data: {} \t Lable: {}'.format(text[0], results[idx])) print("数据结果已导出")通过上述程序自行切换:加载对应模型 记录推理时间: **uie-nano** 数据模型载入运行时间为0.3770780563354492s 模型计算运行时间为24.893776178359985s 数据导出运行时间为0.01157689094543457s **uie-micro** 数据模型载入运行时间为0.39632749557495117s 模型计算运行时间为26.367019176483154s 数据导出运行时间为0.012260198593139648s **uie-mini** 数据模型载入运行时间为0.5642790794372559s 模型计算运行时间为28.93251943588257s 数据导出运行时间为0.01435089111328125s **uie-base** 数据模型载入运行时间为1.4756040573120117s 模型计算运行时间为68.61049008369446s 数据导出运行时间为0.02205801010131836s 5.提前尝鲜UIE FasterTokenizer加速,提升推理性能FasterTokenizer是一款简单易用、功能强大的跨平台高性能文本预处理库,集成业界多个常用的Tokenizer实现,支持不同NLP场景下的文本预处理功能,如文本分类、阅读理解,序列标注等。结合PaddleNLP Tokenizer模块,为用户在训练、推理阶段提供高效通用的文本预处理能力。use_faster: 使用C++实现的高性能分词算子FasterTokenizer进行文本预处理加速。需要通过pip install faster_tokenizer安装FasterTokenizer库后方可使用。默认为False。更多使用说明可参考[FasterTokenizer文档]https://github.com/PaddlePaddle/PaddleNLP/blob/develop/faster_tokenizer/README.md特性高性能。由于底层采用C++实现,所以其性能远高于目前常规Python实现的Tokenizer。在文本分类任务上,FasterTokenizer对比Python版本Tokenizer加速比最高可达20倍。跨平台。FasterTokenizer可在不同的系统平台上使用,目前已支持Windows x64,Linux x64以及MacOS 10.14+平台上使用。多编程语言支持。FasterTokenizer提供在C++、Python语言上开发的能力。灵活性强。用户可以通过指定不同的FasterTokenizer组件定制满足需求的Tokenizer。FAQQ:我在AutoTokenizer.from_pretrained接口上已经打开use_faster=True开关,为什么文本预处理阶段性能上好像没有任何变化?A:在有三种情况下,打开use_faster=True开关可能无法提升性能:没有安装faster_tokenizer。若在没有安装faster_tokenizer库的情况下打开use_faster开关,PaddleNLP会给出以下warning:"Can't find the faster_tokenizer package, please ensure install faster_tokenizer correctly. "。加载的Tokenizer类型暂不支持Faster版本。目前支持4种Tokenizer的Faster版本,分别是BERT、ERNIE、TinyBERT以及ERNIE-M Tokenizer。若加载不支持Faster版本的Tokenizer情况下打开use_faster开关,PaddleNLP会给出以下warning:"The tokenizer XXX doesn't have the faster version. Please check the map paddlenlp.transformers.auto.tokenizer.FASTER_TOKENIZER_MAPPING_NAMES to see which faster tokenizers are currently supported."待切词文本长度过短(如文本平均长度小于5)。这种情况下切词开销可能不是整个文本预处理的性能瓶颈,导致在使用FasterTokenizer后仍无法提升整体性能。5.1 方案一把paddlenlp直接装到指定路径然后修改对应文件;详情参考这个PR:Add use_faster flag for uie of taskflow.5.2方案二直接找到pr修改后的版本,从giuhub拉去过来:链接参考https://github.com/joey12300/PaddleNLP/tree/add_ft_requirementsfrom pprint import pprint import json from paddlenlp.taskflow import Taskflow import pandas as pd #运行时间 import time def openreadtxt(file_name): data = [] file = open(file_name,'r',encoding='UTF-8') #打开文件 file_data = file.readlines() #读取所有行 for row in file_data: data.append(row) #将每行数据插入data中 return data # 时间1 old_time = time.time() data_input=openreadtxt('/home/aistudio/数据集/unlabeled_data-Copy1.txt') few_ie = Taskflow("information_extraction", model="uie-data-distill-gp", task_path="/home/aistudio/data_distill/checkpoint2/model_best",use_faster=True,batch_size=32) # Schema 在闭域信息抽取中是固定的 # few_ie = Taskflow("information_extraction", model="uie-data-distill-gp", task_path="/home/aistudio/data_distill/checkpoint2/model_best",batch_size=32) # Schema 在闭域信息抽取中是固定的 # schema = {'疾病': ['手术治疗', '实验室检查', '影像学检查']} # few_ie = Taskflow('information_extraction', schema=schema, batch_size=32,use_faster=True,task_path='/home/aistudio/checkpoint/model_best') # few_ie = Taskflow('information_extraction', schema=schema, batch_size=32,task_path='/home/aistudio/checkpoint/model_best') # 时间1 current_time = time.time() print("数据模型载入运行时间为" + str(current_time - old_time) + "s") old_time1 = time.time() results=few_ie(data_input) current_time1 = time.time() print("模型计算运行时间为" + str(current_time1 - old_time1) + "s") old_time3 = time.time() test = pd.DataFrame(data=results) test.to_csv('/home/aistudio/output/reslut.txt', sep='\t', index=False,header=False) #本地 # with open("/home/aistudio/output/reslut.txt", "w+",encoding='UTF-8') as f: #a : 写入文件,若文件不存在则会先创建再写入,但不会覆盖原文件,而是追加在文件末尾 # for result in results: # line = json.dumps(result, ensure_ascii=False) #对中文默认使用的ascii编码.想输出真正的中文需要指定ensure_ascii=False # f.write(line + "\n") current_time3 = time.time() print("数据导出运行时间为" + str(current_time3 - old_time3) + "s") # for idx, text in enumerate(data): # print('Data: {} \t Lable: {}'.format(text[0], results[idx])) print("数据结果已导出")5.3UIE FasterTokenizer加速,提升推理性能数据样本增大为原来的三倍:unlabeled_data-Copy1.txtUIE base数据模型载入运行时间为1.6006419658660889s模型计算运行时间为203.95947885513306s数据导出运行时间为0.07103896141052246sUIE base + FasterTokenizer 数据模型载入运行时间为1.6196515560150146s模型计算运行时间为177.17986011505127s数据导出运行时间为0.07898902893066406sUIE蒸馏mini数据模型载入运行时间为0.8441095352172852s模型计算运行时间为21.979790925979614s数据导出运行时间为0.02339339256286621sUIE蒸馏mini + FasterTokenizer数据模型载入运行时间为0.7269768714904785s模型计算运行时间为20.155770540237427s数据导出运行时间为0.012202978134155273s6.总结测试硬件情况:1点算力卡对应的:V100 32GBGPUTesla V100Video Mem32GBCPU4 CoresRAM32GBDisk100GB模型模型计算运行时间precisionrecallF1uie-base68.61049008s0.692770.723270.70769uie-mini28.932519437s0.741380.540880.62545uie-micro26.367019170.747570.484280.58779uie-nano24.89377610.742860.490570.59091蒸馏mini6.839258904s0.77320.750.76142蒸馏micro6.776990s0.782610.720.75蒸馏nano6.6231770s0.79570.740.76684模型计算运行时间:| 模型 | 模型计算运行时间 | 提速x倍|| -------- | -------- | -------- | | UIE base | 203.95947s | 1|| UIE base + FasterTokenizer | 177.1798s | 1.15|| UIE蒸馏mini | 21.97979s |9.28 || UIE蒸馏mini + FasterTokenizer | 20.1557s |10.12 |1.可以看出UIE蒸馏在小网络下,性能差不多可以按需选择。可能会在更大任务性能会更好点2.这里uie-base等只简单运行了10个epoch,可以多训练会提升性能3.一般学生模型会选择参数量比较小的,UIE蒸馏版是schema并行推理的,速度会比UIE快很多,特别是schema比较多以及关系抽取等需要多阶段推理的情况1.FasterTokenizer加速,paddlenlp2.4.0版本目前还不支持,只要参考PR改下源码2.封闭域UIE的话schema是固定的,可以在label_maps.json查看,目前支持实体抽取、关系抽取、观点抽取和事件抽取,句子级情感分类目前蒸馏还不支持3.想要更快的推理换下学生模型的backbone就行感谢感谢paddlenlp工作人员@linjieccc的支持,接受了issue并创建了pull request:fix data distill for UIE #3231 https://github.com/PaddlePaddle/PaddleNLP/pull/3231Add use_faster flag for uie of taskflow. #3194展望:后续对FasterTokenizer进行补充;以及研究一下UIE模型的量化、剪枝、NAS项目链接:fork一下即可UIE Slim满足工业应用场景,解决推理部署耗时问题,提升效能!如果有图片缺失查看原项目
Paddlenlp之UIE模型实战实体抽取任务【打车数据、快递单】
项目连接:可以直接fork使用Paddlenlp之UIE模型实战实体抽取任务【打车数据、快递单】0.背景介绍本项目将演示如何通过小样本样本进行模型微调,快速且准确抽取快递单中的目的地、出发地、时间、打车费用等内容,形成结构化信息。辅助物流行业从业者进行有效信息的提取,从而降低客户填单的成本。数据集情况:waybill.jsonl文件是快递单信息数据集:{"id": 57, "text": "昌胜远黑龙江省哈尔滨市南岗区宽桥街28号18618391296", "relations": [], "entities": [{"id": 111, "start_offset": 0, "end_offset": 3, "label": "姓名"}, {"id": 112, "start_offset": 3, "end_offset": 7, "label": "省份"}, {"id": 113, "start_offset": 7, "end_offset": 11, "label": "城市"}, {"id": 114, "start_offset": 11, "end_offset": 14, "label": "县区"}, {"id": 115, "start_offset": 14, "end_offset": 20, "label": "详细地址"}, {"id": 116, "start_offset": 20, "end_offset": 31, "label": "电话"}]}{"id": 58, "text": "易颖18500308469山东省烟台市莱阳市富水南路1号", "relations": [], "entities": [{"id": 118, "start_offset": 0, "end_offset": 2, "label": "姓名"}, {"id": 119, "start_offset": 2, "end_offset": 13, "label": "电话"}, {"id": 120, "start_offset": 13, "end_offset": 16, "label": "省份"}, {"id": 121, "start_offset": 16, "end_offset": 19, "label": "城市"}, {"id": 122, "start_offset": 19, "end_offset": 22, "label": "县区"}, {"id": 123, "start_offset": 22, "end_offset": 28, "label": "详细地址"}]}doccano_ext.jsonl是打车数据集:{"id": 1, "text": "昨天晚上十点加班打车回家58元", "relations": [], "entities": [{"id": 0, "start_offset": 0, "end_offset": 6, "label": "时间"}, {"id": 1, "start_offset": 11, "end_offset": 12, "label": "目的地"}, {"id": 2, "start_offset": 12, "end_offset": 14, "label": "费用"}]}{"id": 2, "text": "三月三号早上12点46加班,到公司54", "relations": [], "entities": [{"id": 3, "start_offset": 0, "end_offset": 11, "label": "时间"}, {"id": 4, "start_offset": 15, "end_offset": 17, "label": "目的地"}, {"id": 5, "start_offset": 17, "end_offset": 19, "label": "费用"}]}{"id": 3, "text": "8月31号十一点零四工作加班五十块钱", "relations": [], "entities": [{"id": 6, "start_offset": 0, "end_offset": 10, "label": "时间"}, {"id": 7, "start_offset": 14, "end_offset": 16, "label": "费用"}]}{"id": 4, "text": "5月17号晚上10点35分加班打车回家,36块五", "relations": [], "entities": [{"id": 8, "start_offset": 0, "end_offset": 13, "label": "时间"}, {"id": 1, "start_offset": 18, "end_offset": 19, "label": "目的地"}, {"id": 9, "start_offset": 20, "end_offset": 24, "label": "费用"}]}{"id": 5, "text": "2009年1月份通讯费一百元", "relations": [], "entities": [{"id": 10, "start_offset": 0, "end_offset": 7, "label": "时间"}, {"id": 11, "start_offset": 11, "end_offset": 13, "label": "费用"}]}结果展示预览输入:城市内交通费7月5日金额114广州至佛山 从百度大厦到龙泽苑东区打车费二十元 上海虹桥高铁到杭州时间是9月24日费用是73元 上周末坐动车从北京到上海花费五十块五毛 昨天北京飞上海话费一百元输出:{"出发地": [{"text": "广州", "start": 15, "end": 17, "probability": 0.9073772252165782}], "目的地": [{"text": "佛山", "start": 18, "end": 20, "probability": 0.9927365183877761}], "时间": [{"text": "7月5日", "start": 6, "end": 10, "probability": 0.9978010396512218}]} {"出发地": [{"text": "百度大厦", "start": 1, "end": 5, "probability": 0.968825147409472}], "目的地": [{"text": "龙泽苑东区", "start": 6, "end": 11, "probability": 0.9877913072493669}]} {"目的地": [{"text": "杭州", "start": 7, "end": 9, "probability": 0.9929172180094881}], "时间": [{"text": "9月24日", "start": 12, "end": 17, "probability": 0.9953342057701597}]} {#"出发地": [{"text": "北京", "start": 7, "end": 9, "probability": 0.973048366717471}], "目的地": [{"text": "上海", "start": 10, "end": 12, "probability": 0.988486130309397}], "时间": [{"text": "上周末", "start": 0, "end": 3, "probability": 0.9977407699595275}]} {"出发地": [{"text": "北京", "start": 2, "end": 4, "probability": 0.974188953533556}], "目的地": [{"text": "上海", "start": 5, "end": 7, "probability": 0.9928200521486445}], "时间": [{"text": "昨天", "start": 0, "end": 2, "probability": 0.9731559534465504}]}1.数据集加载(快递单数据、打车数据)doccano_file: 从doccano导出的数据标注文件。save_dir: 训练数据的保存目录,默认存储在data目录下。negative_ratio: 最大负例比例,该参数只对抽取类型任务有效,适当构造负例可提升模型效果。负例数量和实际的标签数量有关,最大负例数量 = negative_ratio * 正例数量。该参数只对训练集有效,默认为5。为了保证评估指标的准确性,验证集和测试集默认构造全负例。splits: 划分数据集时训练集、验证集所占的比例。默认为[0.8, 0.1, 0.1]表示按照8:1:1的比例将数据划分为训练集、验证集和测试集。task_type: 选择任务类型,可选有抽取和分类两种类型的任务。options: 指定分类任务的类别标签,该参数只对分类类型任务有效。默认为["正向", "负向"]。prompt_prefix: 声明分类任务的prompt前缀信息,该参数只对分类类型任务有效。默认为"情感倾向"。is_shuffle: 是否对数据集进行随机打散,默认为True。seed: 随机种子,默认为1000.*separator: 实体类别/评价维度与分类标签的分隔符,该参数只对实体/评价维度级分类任务有效。默认为"##"。!python doccano.py \ --doccano_file ./data/doccano_ext.jsonl \ --task_type 'ext' \ --save_dir ./data \ --splits 0.8 0.1 0.1 \ --negative_ratio 5[2022-07-14 11:34:26,474] [ INFO] - Converting doccano data... 100%|████████████████████████████████████████| 40/40 [00:00<00:00, 42560.16it/s] [2022-07-14 11:34:26,477] [ INFO] - Adding negative samples for first stage prompt... 100%|███████████████████████████████████████| 40/40 [00:00<00:00, 161009.75it/s] [2022-07-14 11:34:26,478] [ INFO] - Converting doccano data... 100%|██████████████████████████████████████████| 5/5 [00:00<00:00, 21754.69it/s] [2022-07-14 11:34:26,479] [ INFO] - Adding negative samples for first stage prompt... 100%|██████████████████████████████████████████| 5/5 [00:00<00:00, 44057.82it/s] [2022-07-14 11:34:26,479] [ INFO] - Converting doccano data... 100%|██████████████████████████████████████████| 5/5 [00:00<00:00, 26181.67it/s] [2022-07-14 11:34:26,480] [ INFO] - Adding negative samples for first stage prompt... 100%|██████████████████████████████████████████| 5/5 [00:00<00:00, 45689.59it/s] [2022-07-14 11:34:26,482] [ INFO] - Save 160 examples to ./data/train.txt. [2022-07-14 11:34:26,482] [ INFO] - Save 20 examples to ./data/dev.txt. [2022-07-14 11:34:26,482] [ INFO] - Save 20 examples to ./data/test.txt. [2022-07-14 11:34:26,482] [ INFO] - Finished! It takes 0.01 seconds输出部分展示:{"content": "上海到北京机票1320元", "result_list": [{"text": "上海", "start": 0, "end": 2}], "prompt": "出发地"} {"content": "上海到北京机票1320元", "result_list": [{"text": "北京", "start": 3, "end": 5}], "prompt": "目的地"} {"content": "上海到北京机票1320元", "result_list": [{"text": "1320", "start": 7, "end": 11}], "prompt": "费用"} {"content": "上海虹桥到杭州东站高铁g7555共73元时间是10月14日", "result_list": [{"text": "上海虹桥", "start": 0, "end": 4}], "prompt": "出发地"} {"content": "上海虹桥到杭州东站高铁g7555共73元时间是10月14日", "result_list": [{"text": "杭州东站", "start": 5, "end": 9}], "prompt": "目的地"} {"content": "上海虹桥到杭州东站高铁g7555共73元时间是10月14日", "result_list": [{"text": "73", "start": 17, "end": 19}], "prompt": "费用"} {"content": "上海虹桥到杭州东站高铁g7555共73元时间是10月14日", "result_list": [{"text": "10月14日", "start": 23, "end": 29}], "prompt": "时间"} {"content": "昨天晚上十点加班打车回家58元", "result_list": [{"text": "昨天晚上十点", "start": 0, "end": 6}], "prompt": "时间"} {"content": "昨天晚上十点加班打车回家58元", "result_list": [{"text": "家", "start": 11, "end": 12}], "prompt": "目的地"} {"content": "昨天晚上十点加班打车回家58元", "result_list": [{"text": "58", "start": 12, "end": 14}], "prompt": "费用"} {"content": "2月20号从南山到光明二十元", "result_list": [{"text": "2月20号", "start": 0, "end": 5}], "prompt": "时间"}2.模型训练!python finetune.py \ --train_path "./data/train.txt" \ --dev_path "./data/dev.txt" \ --save_dir "./checkpoint" \ --learning_rate 1e-5 \ --batch_size 8 \ --max_seq_len 512 \ --num_epochs 100 \ --model "uie-base" \ --seed 1000 \ --logging_steps 10 \ --valid_steps 50 \ --device "gpu"部分训练效果展示:**具体输出已折叠** [2022-07-12 15:09:47,643] [ INFO] - global step 250, epoch: 13, loss: 0.00045, speed: 3.90 step/s [2022-07-12 15:09:47,910] [ INFO] - Evaluation precision: 1.00000, recall: 1.00000, F1: 1.00000 [2022-07-12 15:09:50,399] [ INFO] - global step 260, epoch: 13, loss: 0.00043, speed: 4.02 step/s [2022-07-12 15:09:52,966] [ INFO] - global step 270, epoch: 14, loss: 0.00042, speed: 3.90 step/s [2022-07-12 15:09:55,464] [ INFO] - global step 280, epoch: 14, loss: 0.00040, speed: 4.00 step/s [2022-07-12 15:09:58,028] [ INFO] - global step 290, epoch: 15, loss: 0.00039, speed: 3.90 step/s [2022-07-12 15:10:00,516] [ INFO] - global step 300, epoch: 15, loss: 0.00038, speed: 4.02 step/s [2022-07-12 15:10:00,781] [ INFO] - Evaluation precision: 1.00000, recall: 1.00000, F1: 1.00000 [2022-07-12 15:10:03,348] [ INFO] - global step 310, epoch: 16, loss: 0.00036, speed: 3.90 step/s [2022-07-12 15:10:05,836] [ INFO] - global step 320, epoch: 16, loss: 0.00035, speed: 4.02 step/s [2022-07-12 15:10:08,393] [ INFO] - global step 330, epoch: 17, loss: 0.00034, speed: 3.91 step/s [2022-07-12 15:10:10,888] [ INFO] - global step 340, epoch: 17, loss: 0.00033, speed: 4.01 step/s 推荐使用GPU环境,否则可能会内存溢出。CPU环境下,可以修改model为uie-tiny,适当调下batch_size。 增加准确率的话:--num_epochs 设置大点多训练训练 可配置参数说明: **train_path:** 训练集文件路径。 **dev_path:** 验证集文件路径。 **save_dir:** 模型存储路径,默认为./checkpoint。 **learning_rate:** 学习率,默认为1e-5。 **batch_size:** 批处理大小,请结合显存情况进行调整,若出现显存不足,请适当调低这一参数,默认为16。 **max_seq_len:** 文本最大切分长度,输入超过最大长度时会对输入文本进行自动切分,默认为512。 **num_epochs:** 训练轮数,默认为100。 **model** 选择模型,程序会基于选择的模型进行模型微调,可选有uie-base和uie-tiny,默认为uie-base。 **seed:** 随机种子,默认为1000. **logging_steps:** 日志打印的间隔steps数,默认10。 **valid_steps:** evaluate的间隔steps数,默认100。 **device:** 选用什么设备进行训练,可选cpu或gpu。3模型评估!python evaluate.py \ --model_path ./checkpoint/model_best \ --test_path ./data/test.txt \ --batch_size 16 \ --max_seq_len 512[2022-07-11 13:41:23,831] [ INFO] - ----------------------------- [2022-07-11 13:41:23,831] [ INFO] - Class Name: all_classes [2022-07-11 13:41:23,832] [ INFO] - Evaluation Precision: 1.00000 | Recall: 1.00000 | F1: 1.00000 [2022-07-11 13:41:35,024] [ INFO] - ----------------------------- [2022-07-11 13:41:35,024] [ INFO] - Class Name: 出发地 [2022-07-11 13:41:35,024] [ INFO] - Evaluation Precision: 1.00000 | Recall: 1.00000 | F1: 1.00000 [2022-07-11 13:41:35,139] [ INFO] - ----------------------------- [2022-07-11 13:41:35,139] [ INFO] - Class Name: 目的地 [2022-07-11 13:41:35,139] [ INFO] - Evaluation Precision: 1.00000 | Recall: 1.00000 | F1: 1.00000 [2022-07-11 13:41:35,246] [ INFO] - ----------------------------- [2022-07-11 13:41:35,246] [ INFO] - Class Name: 费用 [2022-07-11 13:41:35,246] [ INFO] - Evaluation Precision: 1.00000 | Recall: 1.00000 | F1: 1.00000 [2022-07-11 13:41:35,313] [ INFO] - ----------------------------- [2022-07-11 13:41:35,313] [ INFO] - Class Name: 时间 [2022-07-11 13:41:35,313] [ INFO] - Evaluation Precision: 1.00000 | Recall: 1.00000 | F1: 1.00000model_path: 进行评估的模型文件夹路径,路径下需包含模型权重文件model_state.pdparams及配置文件model_config.json。test_path: 进行评估的测试集文件。batch_size: 批处理大小,请结合机器情况进行调整,默认为16。max_seq_len: 文本最大切分长度,输入超过最大长度时会对输入文本进行自动切分,默认为512。model: 选择所使用的模型,可选有uie-base, uie-medium, uie-mini, uie-micro和uie-nano,默认为uie-base。debug: 是否开启debug模式对每个正例类别分别进行评估,该模式仅用于模型调试,默认关闭。4 结果预测from pprint import pprint import json from paddlenlp import Taskflow def openreadtxt(file_name): data = [] file = open(file_name,'r',encoding='UTF-8') #打开文件 file_data = file.readlines() #读取所有行 for row in file_data: data.append(row) #将每行数据插入data中 return data data_input=openreadtxt('./input/nlp.txt') schema = ['出发地', '目的地','时间'] few_ie = Taskflow('information_extraction', schema=schema, batch_size=1,task_path='./checkpoint/model_best') results=few_ie(data_input) with open("./output/test.txt", "w+",encoding='UTF-8') as f: #a : 写入文件,若文件不存在则会先创建再写入,但不会覆盖原文件,而是追加在文件末尾 for result in results: line = json.dumps(result, ensure_ascii=False) #对中文默认使用的ascii编码.想输出真正的中文需要指定ensure_ascii=False f.write(line + "\n") print("数据结果已导出")输入文件展示:城市内交通费7月5日金额114广州至佛山 从百度大厦到龙泽苑东区打车费二十元 上海虹桥高铁到杭州时间是9月24日费用是73元 上周末坐动车从北京到上海花费五十块五毛 昨天北京飞上海话费一百元输出展示:{"出发地": [{"text": "广州", "start": 15, "end": 17, "probability": 0.9073772252165782}], "目的地": [{"text": "佛山", "start": 18, "end": 20, "probability": 0.9927365183877761}], "时间": [{"text": "7月5日", "start": 6, "end": 10, "probability": 0.9978010396512218}]} {"出发地": [{"text": "百度大厦", "start": 1, "end": 5, "probability": 0.968825147409472}], "目的地": [{"text": "龙泽苑东区", "start": 6, "end": 11, "probability": 0.9877913072493669}]} {"目的地": [{"text": "杭州", "start": 7, "end": 9, "probability": 0.9929172180094881}], "时间": [{"text": "9月24日", "start": 12, "end": 17, "probability": 0.9953342057701597}]} {"出发地": [{"text": "北京", "start": 7, "end": 9, "probability": 0.973048366717471}], "目的地": [{"text": "上海", "start": 10, "end": 12, "probability": 0.988486130309397}], "时间": [{"text": "上周末", "start": 0, "end": 3, "probability": 0.9977407699595275}]} {"出发地": [{"text": "北京", "start": 2, "end": 4, "probability": 0.974188953533556}], "目的地": [{"text": "上海", "start": 5, "end": 7, "probability": 0.9928200521486445}], "时间": [{"text": "昨天", "start": 0, "end": 2, "probability": 0.9731559534465504}]}5.可视化显示visualDL详细文档可以参考:https://aistudio.baidu.com/aistudio/projectdetail/1739945?contributionType=1有详细讲解,具体实现参考代码,核心是:添加一个初始化记录器下面是结果展示:6.小技巧:获取paddle开源数据集数据集网站:https://paddlenlp.readthedocs.io/zh/latest/data_prepare/dataset_list.html#id2数据集名称 简介 调用方法CoLA 单句分类任务,二分类,判断句子是否合法 paddlenlp.datasets.load_dataset('glue','cola')SST-2 单句分类任务,二分类,判断句子情感极性 paddlenlp.datasets.load_dataset('glue','sst-2')MRPC 句对匹配任务,二分类,判断句子对是否是相同意思 paddlenlp.datasets.load_dataset('glue','mrpc')STSB 计算句子对相似性,分数为1~5 paddlenlp.datasets.load_dataset('glue','sts-b')QQP 判定句子对是否等效,等效、不等效两种情况,二分类任务 paddlenlp.datasets.load_dataset('glue','qqp')MNLI 句子对,一个前提,一个是假设。前提和假设的关系有三种情况:蕴含(entailment),矛盾(contradiction),中立(neutral)。句子对三分类问题 paddlenlp.datasets.load_dataset('glue','mnli')QNLI 判断问题(question)和句子(sentence)是否蕴含,蕴含和不蕴含,二分类 paddlenlp.datasets.load_dataset('glue','qnli')RTE 判断句对是否蕴含,句子1和句子2是否互为蕴含,二分类任务 paddlenlp.datasets.load_dataset('glue','rte')WNLI 判断句子对是否相关,相关或不相关,二分类任务 paddlenlp.datasets.load_dataset('glue','wnli')LCQMC A Large-scale Chinese Question Matching Corpus 语义匹配数据集 paddlenlp.datasets.load_dataset('lcqmc')通过paddlenlp提供的api调用,可以很方便实现数据加载,当然你想要把数据下载到本地,可以参考我下面的输出就可以保存数据了。#加载中文评论情感分析语料数据集ChnSentiCorp from paddlenlp.datasets import load_dataset train_ds, dev_ds, test_ds = load_dataset("chnsenticorp", splits=["train", "dev", "test"]) with open("./output/test2.txt", "w+",encoding='UTF-8') as f: #a : 写入文件,若文件不存在则会先创建再写入,但不会覆盖原文件,而是追加在文件末尾 for result in test_ds: line = json.dumps(result, ensure_ascii=False) #对中文默认使用的ascii编码.想输出真正的中文需要指定ensure_ascii=False f.write(line + "\n")7 总结UIE(Universal Information Extraction):Yaojie Lu等人在ACL-2022中提出了通用信息抽取统一框架UIE。该框架实现了实体抽取、关系抽取、事件抽取、情感分析等任务的统一建模,并使得不同任务间具备良好的迁移和泛化能力。PaddleNLP借鉴该论文的方法,基于ERNIE 3.0知识增强预训练模型,训练并开源了首个中文通用信息抽取模型UIE。该模型可以支持不限定行业领域和抽取目标的关键信息抽取,实现零样本快速冷启动,并具备优秀的小样本微调能力,快速适配特定的抽取目标。UIE的优势使用简单: 用户可以使用自然语言自定义抽取目标,无需训练即可统一抽取输入文本中的对应信息。实现开箱即用,并满足各类信息抽取需求。降本增效: 以往的信息抽取技术需要大量标注数据才能保证信息抽取的效果,为了提高开发过程中的开发效率,减少不必要的重复工作时间,开放域信息抽取可以实现零样本(zero-shot)或者少样本(few-shot)抽取,大幅度降低标注数据依赖,在降低成本的同时,还提升了效果。效果领先: 开放域信息抽取在多种场景,多种任务上,均有不俗的表现。本人本次主要通过实体抽取这个案例分享给大家,主要对开源的paddlenlp的案例进行了细化,比如在结果可视化方面以及结果输入输出的增加,使demo项目更佳完善。当然标注问题是所有问题的痛点,可以参考我的博客来解决这个问题本人博客:https://blog.csdn.net/sinat_39620217?type=blog
PaddleNLP通用信息抽取技术UIE【一】产业应用实例:信息抽取{实体关系抽取、中文分词、精准实体标。情感分析等}、文本纠错、问答系统、闲聊机器人、定制训练
相关文章:1.快递单中抽取关键信息【一】----基于BiGRU+CR+预训练的词向量优化2.快递单信息抽取【二】基于ERNIE1.0至ErnieGram + CRF预训练模型3.快递单信息抽取【三】--五条标注数据提高准确率,仅需五条标注样本,快速完成快递单信息任务1)PaddleNLP通用信息抽取技术UIE【一】产业应用实例:信息抽取{实体关系抽取、中文分词、精准实体标。情感分析等}、文本纠错、问答系统、闲聊机器人、定制训练2)PaddleNLP--UIE(二)--小样本快速提升性能(含doccona标注)!强烈推荐:数据标注平台doccano----简介、安装、使用、踩坑记录项目连接:https://aistudio.baidu.com/aistudio/projectdetail/4180615?contributionType=10. PaddleNLP 一键预测能力 Taskflow API之三大特性功能全面全场景支持:覆盖NLU和NLG领域十一大经典任务。文档级输入:支持文档级输入,解决预训练模型对输入文本的长度限制问题,大大节省用户输入长文本时的代码开发量。定制化训练:支持用户使用自己的数据集进行定制化训练,通过自定义路径一键使用定制化训练好的模型。简捷易用开箱即用,学习成本低,几行代码便可完成调用。产业级效果聚合众多百度自然语言处理领域自研算法以及社区优秀开源模型,模型效果领先。1. 环境准备!pip install --upgrade paddlenlp !pip install pypinyin !pip install LAC2. 基础能力这一章节将会学到的Taskflow技能:利用PaddleNLP Taskflow提取句子中的语言学特征:中文分词、词性识别,依存关系,命名实体识别、关系抽取、事件抽取等。2.0 信息抽取PaddleNLP 5.16新发开放域信息抽取能力,只有你想不到的schema,没有UIE抽取不到的结果哦!详情可参考:信息抽取一键预测能力如需定制化训练,全套代码在此:传送门实体抽取 from pprint import pprint from paddlenlp import Taskflow schema = ['时间', '选手', '赛事名称'] # Define the schema for entity extraction ie = Taskflow('information_extraction', schema=schema) pprint(ie("2月8日上午北京冬奥会自由式滑雪女子大跳台决赛中中国选手谷爱凌以188.25分获得金牌!")) # Better print results using pprint[{'时间': [{'end': 6, 'probability': 0.9857378532473966, 'start': 0, 'text': '2月8日上午'}], '赛事名称': [{'end': 23, 'probability': 0.8503082243989795, 'start': 6, 'text': '北京冬奥会自由式滑雪女子大跳台决赛'}], '选手': [{'end': 31, 'probability': 0.8981535684051067, 'start': 28, 'text': '谷爱凌'}]}]关系抽取# schema = {'歌曲名称': ['歌手', '所属专辑']} # Define the schema for relation extraction ie.set_schema(schema) # Reset schema ie('《告别了》是孙耀威在专辑爱的故事里面的歌曲')[{'歌曲名称': [{'text': '告别了', 'start': 1, 'end': 4, 'probability': 0.6296147448952354, 'relations': {'歌手': [{'text': '孙耀威', 'start': 6, 'end': 9, 'probability': 0.9988380409852198}], '所属专辑': [{'text': '爱的故事', 'start': 12, 'end': 16, 'probability': 0.9968462078543183}]}}, {'text': '爱的故事', 'start': 12, 'end': 16, 'probability': 0.28168534139751955, 'relations': {'歌手': [{'text': '孙耀威', 'start': 6, 'end': 9, 'probability': 0.9951413914998}]}}]}]事件抽取 schema = {'地震触发词': ['地震强度', '时间', '震中位置', '震源深度']} # Define the schema for event extraction ie.set_schema(schema) # Reset schema ie('中国地震台网正式测定:5月16日06时08分在云南临沧市凤庆县(北纬24.34度,东经99.98度)发生3.5级地震,震源深度10千米。')[{'地震触发词': [{'text': '地震', 'start': 56, 'end': 58, 'probability': 0.9977425555988333, 'relations': {'地震强度': [{'text': '3.5级', 'start': 52, 'end': 56, 'probability': 0.998080158269417}], '时间': [{'text': '5月16日06时08分', 'start': 11, 'end': 22, 'probability': 0.9853299181377793}], '震中位置': [{'text': '云南临沧市凤庆县(北纬24.34度,东经99.98度)', 'start': 23, 'end': 50, 'probability': 0.7874013050677604}], '震源深度': [{'text': '10千米', 'start': 63, 'end': 67, 'probability': 0.9937973233053299}]}}]}]句子级情感分类schema = '情感倾向[正向,负向]' # Define the schema for sentence-level sentiment classification ie.set_schema(schema) # Reset schema ie('这个产品用起来真的很流畅,我非常喜欢')[{'情感倾向[正向,负向]': [{'text': '正向', 'probability': 0.9990024058203417}]}]评价维度、观点抽取,对象级情感分析schema = {'评价维度': ['观点词', '情感倾向[正向,负向]']} # Define the schema for opinion extraction ie.set_schema(schema) # Reset schema pprint(ie("地址不错,服务一般,设施陈旧")) # Better print results using pprint[{'评价维度': [{'end': 2, 'probability': 0.9888138676472664, 'relations': {'情感倾向[正向,负向]': [{'probability': 0.998228967796706, 'text': '正向'}], '观点词': [{'end': 4, 'probability': 0.9927846479537372, 'start': 2, 'text': '不错'}]}, 'start': 0, 'text': '地址'}, {'end': 12, 'probability': 0.9588297379365116, 'relations': {'情感倾向[正向,负向]': [{'probability': 0.9949388606013692, 'text': '负向'}], '观点词': [{'end': 14, 'probability': 0.9286749937276362, 'start': 12, 'text': '陈旧'}]}, 'start': 10, 'text': '设施'}, {'end': 7, 'probability': 0.959285414999755, 'relations': {'情感倾向[正向,负向]': [{'probability': 0.9952498258302498, 'text': '负向'}], '观点词': [{'end': 9, 'probability': 0.9949358587838901, 'start': 7, 'text': '一般'}]}, 'start': 5, 'text': '服务'}]}]跨任务跨领域抽取schema = ['寺庙', {'丈夫': '妻子'}] ie.set_schema(schema) pprint(ie('李治即位后,让身在感业寺的武则天续起头发,重新纳入后宫。'))[{'丈夫': [{'end': 2, 'probability': 0.989690572797457, 'relations': {'妻子': [{'end': 16, 'probability': 0.9987625986569526, 'start': 13, 'text': '武则天'}]}, 'start': 0, 'text': '李治'}], '寺庙': [{'end': 12, 'probability': 0.9888578809890554, 'start': 9, 'text': '感业寺'}]}]2.1 中文分词分词作为许多NLP任务的第一道工序,如何在不同场景中『用好』、『用对』尤为重要。Taskflow提供了多种中文分词模式供大家选择,我们列举了几种不同的场景,来示例不同使用方式。2.1.1 文档级输入支持超长文本输入,无需担心『文本截断』问题# 首次调用会有模型下载的额外时间开销 seg = Taskflow("word_segmentation") doc = "苏锦一直记得那个午后,明晃晃的光线穿过教室的窗玻璃洒到自己脸上,有种特别暖和的感觉。那阳光仿佛是能够钻进人的心里,继而延展到身体全部的毛孔中,然后以一种温柔的霸道占据体内各个淋巴细胞。苏锦觉得连自己的每一个气息里都似乎是能流窜出明亮的光。她坐着有些微醉于这份上帝恩赐的福祉当中。是在这样一个午后。她记住了段见城的脸。轮廓俊朗的少年。有着羁傲的眼神和清晰的声线。怎么看这都是少女漫画里必经的情节。教语文的老太太此刻正兀自在讲台上口若悬河的讲解着《孔雀东南飞》,毕竟是已经年过半百的老教师,经历的学生多了,倒也不在乎讲台下那一张张脸上是否挂着的无精打采,昏昏欲睡的表情,按着自己的性子眉飞色舞的描绘着千年前的那段爱情传奇。苏锦一边数着从老太太口里横飞出来的唾沫星子,一边念想着,让理科班这群脑子里已全被物理公式填充了的家伙,去对几千年前焦仲卿和刘兰芝的爱情产生兴趣未免是件太困难的事情了。老太太讲到焦仲卿和刘兰芝双双殉情而死之时咳嗽了一声,提醒底下那群不知已经神游到何方的学生们是时候为文章的主旨做笔记了。苏锦把课文翻到最后,快速扫过大致内容,目光却在那句:府吏闻此事,心知长别离。徘徊庭树下,自挂东南枝上硬生生地停了下来。思绪仿若戛然而止,被某种莫名的感怀而包围,心中有些钝痛,却不知从何而来。“懦弱。”一个略带鄙夷的声音传入苏锦的耳,拦截住了她空白的思绪。苏锦转过头,瞥见后桌的段见城。恍然间有种错觉,这个男生好似是被光线包裹着一般。段见城淡淡说。若他是焦仲卿,定不会让自己和深爱的女子走到这步田地,若是真走到山穷水尽的地步,定是决然赴死。何来徘徊。那清淡口气带着些不屑,却是这般笃定至极。他说,平生最鄙夷懦弱的男子。苏锦静默的注视着这个男生。终究是没有说出话来。苏锦莫名其妙的做了段见城的女友是一年以后的事情。全班在KTV里唱歌,美名曰:升高三前最后的狂欢。包厢里都是拥挤的人,但苏锦却还是能够感受到空调的温度调得异常的低,她躲在冷风吹不到的角落,捧着大杯的雪花啤酒像是喝水一样没有节制,她觉得心里有所郁结并且心思混乱,恍恍惚惚的注视着麦克风被传了一轮又一轮,听着音像里传出或高或低的杂乱音符,而自己却似是置身于别处,与此间的喧嚣起伏无关,只觉得空荡荡。苏锦记得自己与同桌曾谈及过自己这种从暑假开始无法摆脱的混沌状态,同桌是一副了然于胸的模样,义正言辞的对苏锦说,这是高三前期综合症。她说,苏锦你别太看重所谓的高三,高考和大学都只是一个过程而并非最终的意义,我们要以平常心去对待这些。苏锦想,其实自己并非执著什么,而是自幼便对于那些未知的一切充满恐惧。因为无法掌控,所以感到束手无策,身不由己。仿佛有种被命运捏在手里随意摆弄的感觉,特别难受正当苏锦失足于自己庞大的幻觉之时,身边的朋友开始玩起了真心话大冒险之类的游戏。在一边起哄的女生提议游戏从今晚没有唱歌过的人开始,于是因为忙着在沙发上的打牌的段见城那拨人便是首先被开刷的对象,而作为聚众赌博的头子,段见城自然是第一个被逮到。几个暗自对段见城有好感的姑娘早就揣摩好了问题,苏锦被旁边兴奋过头的女生推攘着,神志也渐渐清明起来。不知是谁直白的问出了那句:阿城,你有意中人么?KTV中的嘈杂如同顿时沉淀了一般,纵然空气里似乎还遗留着些噪音过境的痕迹,更多的却是一种屏气凝神的静。段见城沉默的捏着手中那张还没打出去扑克牌,几乎是在所有人的耐心倒塌的前一秒,清晰地说出了苏锦的名字。" print("1. 输入长度:", len(doc)) print("2. 分词结果:", seg(doc))1. 输入长度: 1413 2. 分词结果: ['苏锦', '一直', '记得', '那个', '午后', ',', '明晃晃', '的', '光线', '穿过', '教室', '的', '窗', '玻璃', '洒', '到', '自己', '脸上', ',', '有种', '特别', '暖和', '的', '感觉', '。', '那', '阳光', '仿佛', '是', '能够', '钻进', '人', '的', '心里', ',', '继而', '延展', '到', '身体', '全部', '的', '毛孔', '中', ',', '然后', '以', '一种', '温柔', '的', '霸道', '占据', '体内', '各', '个', '淋巴细胞', '。', '苏锦', '觉得', '连', '自己', '的', '每一个', '气息', '里', '都', '似乎', '是', '能', '流窜', '出', ...........2.1.2 快速模式分词示例如何通过快速模式分词对数据集进行词频统计、构建词表import time from collections import defaultdict from paddlenlp.datasets import load_dataset from paddlenlp import Taskflow seg_fast = Taskflow("word_segmentation", mode="fast") # 加载ChnSentiCorp数据集 train_ds, dev_ds = load_dataset("chnsenticorp", splits=["train", "dev"]) texts = [] for data in train_ds: texts.append(data["text"]) for data in dev_ds: texts.append(data["text"]) inputs_length = len(texts) print("1. 句子数量:", inputs_length) tic_seg = time.time() # 快速分词 results = seg_fast(texts) time_diff = time.time() - tic_seg print("2. 平均速率:%.2f句/s" % (inputs_length/time_diff)) # 词频统计 word_counts = defaultdict(int) for result in results: for word in result: word_counts[word] += 1 # 打印频次最高的前20个单词及其对应词频 print("3. Top 20 Words:", sorted(word_counts.items(), key=lambda d: d[1], reverse=True)[:20])100%|██████████| 1909/1909 [00:00<00:00, 7614.49it/s] 1. 句子数量: 10800 Building prefix dict from the default dictionary ... Dumping model to file cache /tmp/jieba.cache Loading model cost 0.995 seconds. Prefix dict has been built successfully. 2. 平均速率:1429.74句/s 3. Top 20 Words: [(',', 59389), ('的', 41468), ('。', 23207), ('了', 15048), (' ', 11426), ('是', 10479), (',', 9204), ('我', 9167), ('很', 6881), ('!', 6169), ('也', 5793), ('在', 5180), ('酒店', 4829), ('不', 4784), ('都', 4604), ('有', 4589), ('就', 4169), ('.', 4099), ('没有', 3594), ('还', 3455)]2.1.3 精确模式分词使用Taskflow精确模式,实体粒度分词精度最高,语义片段完整,在知识图谱构建等应用中优势明显。实体词容易被切开,例如『陕西省高校管理体制改革实施方案』、『诺戴商务咨询(上海)有限公司』希望能够被完整识别。from paddlenlp import Taskflow # 精确模式模型体积较大,可结合机器情况适当调整batch_size,采用批量样本输入的方式。 seg_accurate = Taskflow("word_segmentation", mode="accurate", batch_size=32) # 批量样本输入,输入为多个句子组成的list,平均速率更快 texts = ["李伟拿出具有科学性、可操作性的《陕西省高校管理体制改革实施方案》", "诺戴商务咨询(上海)有限公司于2016年08月22日成立"] print(seg_accurate(texts))[['李伟', '拿出', '具有', '科学性', '、', '可操作性', '的', '《', '陕西省高校管理体制改革实施方案', '》'], ['诺戴商务咨询(上海)有限公司', '于', '2016年08月22日', '成立']]2.1.4 用户词典快速配置用户词典来对分词结果进行干预from paddlenlp import Taskflow seg = Taskflow("word_segmentation") print(seg("平原上的火焰宣布延期上映"))`['平原', '上', '的', '火焰', '宣布', '延期', '上映']例如我们想把『平原上的火焰』作为一个完整词来识别,而『上映』希望能够被切开,则可以按照如下格式配置自定义词典文件user_dict.txt平原上的火焰 上 映配置后通过user_dict一键装载在这里插入代码片seg = Taskflow("word_segmentation", user_dict="/home/aistudio/user_dict.txt") print(seg("平原上的火焰宣布延期上映"))['平原上的火焰', '宣布', '延期', '上', '映']2.2 词性标注基于百度词法分析工具LAC,训练语料包含近2200万句子,覆盖多种场景from paddlenlp import Taskflow tag = Taskflow("pos_tagging") print(tag("第十四届全运会在西安举办"))[('第十四届', 'm'), ('全运会', 'nz'), ('在', 'p'), ('西安', 'LOC'), ('举办', 'v')]2.3 命名实体识别2.3.1 精确模式基于百度解语的精确模式:最全中文实体标签的命名实体识别工具,不仅适用于通用领域,也适用于生物医疗、教育等垂类领域。包含66种词性及专名类别标签(同类产品的标签数是15个左右) from paddlenlp import Taskflow ner = Taskflow("ner") print(ner(["李伟拿出具有科学性、可操作性的《陕西省高校管理体制改革实施方案》", "诺戴商务咨询(上海)有限公司于2016年08月22日成立"])) [[('李伟', '人物类_实体'), ('拿出', '场景事件'), ('具有', '肯定词'), ('科学性', '修饰词_性质'), ('、', 'w'), ('可操作性', '修饰词_性质'), ('的', '助词'), ('《', 'w'), ('陕西省高校管理体制改革实施方案', '作品类_实体'), ('》', 'w')], [('诺戴商务咨询(上海)有限公司', '组织机构类_企事业单位'), ('于', '介词'), ('2016年08月22日', '时间类_具体时间'), ('成立', '场景事件')]]`在这里插入代码片`精确模式标签集合<table> <tr><td>人物类_实体<td>物体类<td>生物类_动物<td>医学术语类 <tr><td>人物类_概念<td>物体类_兵器<td>品牌名<td>术语类_生物体 <tr><td>作品类_实体<td>物体类_化学物质<td>场所类<td>疾病损伤类 <tr><td>作品类_概念<td>其他角色类<td>场所类_交通场所<td>疾病损伤类_植物病虫害 <tr><td>组织机构类<td>文化类<td>位置方位<td>宇宙类 <tr><td>组织机构类_企事业单位<td>文化类_语言文字<td>世界地区类<td>事件类 <tr><td>组织机构类_医疗卫生机构<td>文化类_奖项赛事活动<td>饮食类<td>时间类 <tr><td>组织机构类_国家机关<td>文化类_制度政策协议<td>饮食类_菜品<td>时间类_特殊日 <tr><td>组织机构类_体育组织机构<td>文化类_姓氏与人名<td>饮食类_饮品<td>术语类 <tr><td>组织机构类_教育组织机构<td>生物类<td>药物类<td>术语类_符号指标类 <tr><td>组织机构类_军事组织机构<td>生物类_植物<td>药物类_中药<td>信息资料 <tr><td>链接地址<td>肯定词<td>个性特征<td>否定词 <tr><td>感官特征<td>数量词<td>场景事件<td>叹词 <tr><td>介词<td>拟声词<td>介词_方位介词<td>修饰词 <tr><td>助词<td>外语单词<td>代词<td>英语单词 <tr><td>连词<td>汉语拼音<td>副词<td>词汇用语 <tr><td>疑问词<td>w(标点)<td><td> </table>精准模式对部分类目(如组织机构等),做了更细的划分识别(如,医疗卫生机构、体育组织机构)。2.3.2 快速模式基于百度词法分析工具LAC,训练语料包含近2200万句子,覆盖多种场景from paddlenlp import Taskflow ner_fast = Taskflow("ner", mode="fast") print(ner_fast("三亚是一个美丽的城市"))[('三亚', 'LOC'), ('是', 'v'), ('一个', 'm'), ('美丽', 'a'), ('的', 'u'), ('城市', 'n')]快速模式标签集合标签含义标签含义标签含义标签含义n普通名词f方位名词s处所名词t时间nr人名ns地名nt机构名nw作品名nz其他专名v普通动词vd动副词vn名动词a形容词ad副形词an名形词d副词m数量词q量词r代词p介词c连词u助词xc其他虚词w标点符号PER人名LOC地名ORG机构名TIME时间2.4 依存句法分析2.4.1 多种使用方式from paddlenlp import Taskflow # 使用BiLSTM作为编码器,速度最快 ddp = Taskflow("dependency_parsing") print(ddp("2月8日谷爱凌夺得北京冬奥会第三金"))[{'word': ['2月8日', '谷爱凌', '夺得', '北京冬奥会', '第三金'], 'head': [3, 3, 0, 5, 3], 'deprel': ['ADV', 'SBV', 'HED', 'ATT', 'VOB']}]# 编码器部分将BiLSTM替换为ERNIE,模型准确率更高! ddp = Taskflow("dependency_parsing", model="ddparser-ernie-1.0") print(ddp("2月8日谷爱凌夺得北京冬奥会第三金"))# 输出概率值和词性标签 ddp = Taskflow("dependency_parsing", prob=True, use_pos=True) print(ddp("2月8日谷爱凌夺得北京冬奥会第三金"))依存句法分析标注关系集合Label关系类型说明示例SBV主谓关系主语与谓词间的关系他送了一本书(他<--送)VOB动宾关系宾语与谓词间的关系他送了一本书(送-->书)POB介宾关系介词与宾语间的关系我把书卖了(把-->书)ADV状中关系状语与中心词间的关系我昨天买书了(昨天<--买)CMP动补关系补语与中心词间的关系我都吃完了(吃-->完)ATT定中关系定语与中心词间的关系他送了一本书(一本<--书)F方位关系方位词与中心词的关系在公园里玩耍(公园-->里)COO并列关系同类型词语间关系叔叔阿姨(叔叔-->阿姨)DBL兼语结构主谓短语做宾语的结构他请我吃饭(请-->我,请-->吃饭)DOB双宾语结构谓语后出现两个宾语他送我一本书(送-->我,送-->书)VV连谓结构同主语的多个谓词间关系他外出吃饭(外出-->吃饭)IC子句结构两个结构独立或关联的单句你好,书店怎么走?(你好<--走)MT虚词成分虚词与中心词间的关系他送了一本书(送-->了)HED核心关系指整个句子的核心 2.4.2 应用示例通过句法分析抽取句子的主谓宾结构信息from paddlenlp import Taskflow ddp = Taskflow("dependency_parsing") print(ddp("9月9日上午纳达尔在亚瑟·阿什球场击败俄罗斯球员梅德韦杰夫"))下图句子中包含了多种结构化信息:from utils import SVOInfo texts = ["9月9日上午纳达尔在亚瑟·阿什球场击败俄罗斯球员梅德韦杰夫", "2月8日谷爱凌夺得北京冬奥会第三金"] results = ddp(texts) # 抽取句子中的SVO(主谓宾)结构化信息 svo_info = [] for result in results: svo_info.append(SVOInfo(result).parse()) for i in range(len(texts)): print("原文本:", texts[i]) print("包含的主谓宾结构:", svo_info[i])3. 『产业』应用这一章节将会学到的Taskflow技能:使用Taskflow来完成情感分析、文本纠错、文本相似度3.1 情感分析3.1.1 BiLSTM默认使用的是BiLSTM。from paddlenlp import Taskflow senta = Taskflow("sentiment_analysis") print(senta("这个产品用起来真的很流畅,我非常喜欢")) [{'text': '这个产品用起来真的很流畅,我非常喜欢', 'label': 'positive', 'score': 0.993867814540863}]3.1.2 SKEP集成百度自研的情感知识增强预训练模型SKEP,利用情感知识构建预训练目标,在海量中文数据上进行预训练,为各类情感分析任务提供统一且强大的情感语义表示能力。在多个公开数据集上模型效果SOTA:任务 句子级情感分类 SST-2 97.60 ChnSentiCorp 96.08 评价对象级的情感分类 SE-ABSA16_PHNS 65.22 COTE_DP 86.30 from paddlenlp import Taskflow senta = Taskflow("sentiment_analysis", model="skep_ernie_1.0_large_ch") print(senta("作为老的四星酒店,房间依然很整洁,相当不错。机场接机服务很好,可以在车上办理入住手续,节省时间。"))[{'text': '作为老的四星酒店,房间依然很整洁,相当不错。机场接机服务很好,可以在车上办理入住手续,节省时间。', 'label': 'positive', 'score': 0.9843240976333618}]3.2 文本纠错ERNIE-CSC在ERNIE预训练模型的基础上,融合了拼音特征的端到端中文拼写纠错模型,整体框架图如下:在中文纠错经典数据集SIGHAN上效果领先:MetricSIGHAN 13SIGHAN 14SIGHAN 15Detection F10.83480.65340.7464Correction F10.82170.63020.7296from paddlenlp import Taskflow corrector = Taskflow("text_correction") print(corrector('遇到逆竟时,我们必须勇于面对,而且要愈挫愈勇。'))[{'source': '遇到逆竟时,我们必须勇于面对,而且要愈挫愈勇。', 'target': '遇到逆境时,我们必须勇于面对,而且要愈挫愈勇。', 'errors': [{'position': 3, 'correction': {'竟': '境'}}]}]3.3 文本相似度基于百度知道2200万对相似句组训练SimBERT达到前沿文本相似效果from paddlenlp import Taskflow similarity = Taskflow("text_similarity") print(similarity([["春天适合种什么花?", "春天适合种什么菜?"], ["小蝌蚪找妈妈怎么样", "小蝌蚪找妈妈是谁画的"]]))[{'text1': '春天适合种什么花?', 'text2': '春天适合种什么菜?', 'similarity': 0.83395267}, {'text1': '小蝌蚪找妈妈怎么样', 'text2': '小蝌蚪找妈妈是谁画的', 'similarity': 0.81923723}]3.4 『解语』-知识标注基于百度解语,首个能够覆盖所有中文词汇的词类知识标注工具,旨在为中文文本解析提供全面、丰富的知识标注结果from paddlenlp import Taskflow wordtag = Taskflow("knowledge_mining") # 结果会与TermTree进行绑定,输出termid print(wordtag("第24届冬季奥林匹克运动会在北京举办"))[{'text': '第24届冬季奥林匹克运动会在北京举办', 'items': [{'item': '第24届冬季奥林匹克运动会', 'offset': 0, 'wordtag_label': '事件类', 'length': 13}, {'item': '在', 'offset': 13, 'wordtag_label': '介词', 'length': 1, 'termid': '介词_cb_在'}, {'item': '北京', 'offset': 14, 'wordtag_label': '世界地区类', 'length': 2, 'termid': '中国地区_cb_北京市'}, {'item': '举办', 'offset': 16, 'wordtag_label': '场景事件', 'length': 2, 'termid': '场景事件_cb_举办'}]}]from termtree import TermTree # 加载百科知识树 termtree = TermTree.from_dir("termtree_type.csv", "TermTree.V1.0") # 通过termid获取别名 print(termtree._nodes["奖项赛事活动_eb_冬季奥林匹克运动会"]._data['alias']) # 通过termid获取百度百科链接 print(termtree._nodes['奖项赛事活动_eb_冬季奥林匹克运动会']._data['links'][0]['bdbkUrl'])['冬奥会', '冬奥', '冬季奥运会']更多TermTree使用方法参考解语:TermTree(百科知识树)4. 『趣味』应用这一章节将会学到的Taskflow技能:感受海量数据训练出来的预训练模型的超强能力利用Taskflow打造一个『能说会道、擅长聊天』的机器人利用Taskflow构建一个问答/写诗系统4.1 交互式闲聊对话基于PLATO-MINI,模型在十亿级别的中文对话数据上进行了预训练,闲聊场景对话效果显著。from paddlenlp import Taskflow dialogue = Taskflow("dialogue") print(dialogue(["你好"]))交互模式(推荐使用终端terminal进入python解释器进行体验):4.2 生成式问答基于开源社区优秀中文预训练模型CPM,参数规模26亿,预训练中文数据达100GB。调用示例:NOTE:由于项目空间有限,这里只列举了调用方法,为了有更好的使用体验,大家可以另外创建一个项目来体验这部分功能~4.3 智能写诗基于开源社区优秀中文预训练模型CPM,参数规模26亿,预训练中文数据达100GB。调用示例:NOTE:由于项目空间有限,这里只列举了调用方法,为了有更好的使用体验,大家可以另外创建一个项目来体验这部分功能~5.定制化训练这一章节将会学到的Taskflow技能:利用自己的数据训练/微调模型,通过Taskflow一键装载并使用5.1 数据准备和训练参考PaddleNLP SKEP情感分析训练示例,完成数据准备和模型训练。# 训练步骤省略,提供了训练好的模型权重文件 # 直接下载并保存到/home/aistudio/custom_model路径 !wget https://bj.bcebos.com/paddlenlp/taskflow/demo/model_state.pdparams -P /home/aistudio/custom_model !wget https://bj.bcebos.com/paddlenlp/taskflow/demo/model_config.json -P /home/aistudio/custom_model5.2 使用定制化模型通过task_path指定自定义模型路径一键加载即可。from paddlenlp import Taskflow my_senta = Taskflow("sentiment_analysis", model="skep_ernie_1.0_large_ch", task_path="/home/aistudio/custom_model") print(my_senta("不错的酒店,服务还可以,下次还会入住的~")) [{'text': '不错的酒店,服务还可以,下次还会入住的~', 'label': 'positive', 'score': 0.9968485236167908}]项目连接:https://aistudio.baidu.com/aistudio/projectdetail/4180615?contributionType=1
PaddleNLP基于ERNIR3.0文本分类以中医疗搜索检索词意图分类(KUAKE-QIC)为例【多分类(单标签)】
相关项目链接:Paddlenlp之UIE模型实战实体抽取任务【打车数据、快递单】Paddlenlp之UIE分类模型【以情感倾向分析新闻分类为例】含智能标注方案)[应用实践:分类模型大集成者[PaddleHub、Finetune、prompt]](https://aistudio.baidu.com/aistudio/projectdetail/4357474?contributionType=1)Paddlenlp之UIE关系抽取模型【高管关系抽取为例】本项目链接:[PaddleNLP基于ERNIR3.0文本分类任务详解【多分类(单标签)】](https://aistudio.baidu.com/aistudio/projectdetail/4362154?contributionType=1)0.前言:文本分类任务介绍文本分类任务是自然语言处理中最常见的任务,文本分类任务简单来说就是对给定的一个句子或一段文本使用文本分类器进行分类。文本分类任务广泛应用于长短文本分类、情感分析、新闻分类、事件类别分类、政务数据分类、商品信息分类、商品类目预测、文章分类、论文类别分类、专利分类、案件描述分类、罪名分类、意图分类、论文专利分类、邮件自动标签、评论正负识别、药物反应分类、对话分类、税种识别、来电信息自动分类、投诉分类、广告检测、敏感违法内容检测、内容安全检测、舆情分析、话题标记等各类日常或专业领域中。文本分类任务可以根据标签类型分为多分类(multi class)、多标签(multi label)、层次分类(hierarchical等三类任务,接下来我们将以下图的新闻文本分类为例介绍三种分类任务的区别。PaddleNLP采用AutoModelForSequenceClassification, AutoTokenizer提供了方便易用的接口,可指定模型名或模型参数文件路径通过from_pretrained() 方法加载不同网络结构的预训练模型,并在输出层上叠加一层线性层,且相应预训练模型权重下载速度快、稳定。Transformer预训练模型汇总包含了如 ERNIE、BERT、RoBERTa等40多个主流预训练模型,500多个模型权重。下面以ERNIE 3.0 中文base模型为例,演示如何加载预训练模型和分词器:from paddlenlp.transformers import AutoModelForSequenceClassification, AutoTokenizer num_classes = 10 model_name = "ernie-3.0-base-zh" model = AutoModelForSequenceClassification.from_pretrained(model_name, num_classes=num_classes) tokenizer = AutoTokenizer.from_pretrained(model_name)1.数据准备1.1加载数据集、自定义数据集通过使用PaddleNLP提供的 load_dataset, MapDataset 和 IterDataset ,可以方便的自定义属于自己的数据集。目前PaddleNLP的通用数据处理流程如下:加载数据集(内置数据集或者自定义数据集,数据集返回 原始数据)。定义 trans_func() ,包括tokenize,token to id等操作,并传入数据集的 map() 方法,将原始数据转为 feature 。根据上一步数据处理的结果定义 batchify 方法和 BatchSampler 。定义 DataLoader , 传入 BatchSampler 和 batchify_fn() 。PaddleNLP Datasets API:供参考PaddleNLP提供了以下数据集的快速读取API,实际使用时请根据需要添加splits信息:加载数据集快速加载内置数据集目前PaddleNLP内置20余个NLP数据集,涵盖阅读理解,文本分类,序列标注,机器翻译等多项任务。目前提供的数据集可以在 数据集列表 中找到。以 msra_ner 数据集为例:load_dataset() 方法会从 paddlenlp.datasets 下找到msra_ner数据集对应的数据读取脚本(默认路径:paddlenlp/datasets/msra_ner.py),并调用脚本中 DatasetBuilder 类的相关方法生成数据集。生成数据集可以以 MapDataset 和 IterDataset 两种类型返回,分别是对 paddle.io.Dataset 和 paddle.io.IterableDataset 的扩展,只需在 load_dataset() 时设置 lazy 参数即可获取相应类型。Flase 对应返回 MapDataset ,True 对应返回 IterDataset,默认值为None,对应返回 DatasetBuilder 默认的数据集类型,大多数为 MapDataset1.1.1以内置数据集格式读取本地数据集有的时候,我们希望使用数据格式与内置数据集相同的本地数据替换某些内置数据集的数据(例如参加SQuAD竞赛,对训练数据进行了数据增强)。 load_dataset() 方法提供的 data_files参数可以实现这个功能。以 SQuAD 为例。 from paddlenlp.datasets import load_dataset train_ds, dev_ds = load_dataset("squad", data_files=("my_train_file.json", "my_dev_file.json")) test_ds = load_dataset("squad", data_files="my_test_file.json")注解对于某些数据集,不同的split的读取方式不同。对于这种情况则需要在 splits 参数中以传入与 data_files 一一对应 的split信息。此时 splits 不再代表选取的内置数据集,而代表以何种格式读取本地数据集。下面以 COLA 数据集为例:from paddlenlp.datasets import load_dataset train_ds, test_ds = load_dataset("glue", "cola", splits=["train", "test"], data_files=["my_train_file.csv", "my_test_file.csv"])另外需要注意数据集的是没有默认加载选项的,splits 和data_files 必须至少指定一个。这个方法还是比较简单的需要注意的是格式要一致!!!!,可以写程序转换一下### 1.1.2 自定义数据集通过使用PaddleNLP提供的 load_dataset() , MapDataset 和 IterDataset 。任何人都可以方便的定义属于自己的数据集。从本地文件创建数据集从本地文件创建数据集时,我们 推荐 根据本地数据集的格式给出读取function并传入 load_dataset() 中创建数据集。以 waybill_ie 快递单信息抽取任务中的数据为例:from paddlenlp.datasets import load_dataset def read(data_path): with open(data_path, 'r', encoding='utf-8') as f: # 跳过列名 next(f) for line in f: words, labels = line.strip('\n').split('\t') words = words.split('\002') labels = labels.split('\002') yield {'tokens': words, 'labels': labels} # data_path为read()方法的参数 map_ds = load_dataset(read, data_path='数据集/data1/dev.txt', lazy=False) iter_ds = load_dataset(read, data_path='数据集/data1/dev.txt', lazy=True) for i in range(3): print(map_ds[i]) {'tokens': ['喻', '晓', '刚', '云', '南', '省', '楚', '雄', '彝', '族', '自', '治', '州', '南', '华', '县', '东', '街', '古', '城', '路', '3', '7', '号', '1', '8', '5', '1', '3', '3', '8', '6', '1', '6', '3'], 'labels': ['P-B', 'P-I', 'P-I', 'A1-B', 'A1-I', 'A1-I', 'A2-B', 'A2-I', 'A2-I', 'A2-I', 'A2-I', 'A2-I', 'A2-I', 'A3-B', 'A3-I', 'A3-I', 'A4-B', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'T-B', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I']} {'tokens': ['1', '3', '4', '2', '6', '3', '3', '8', '1', '3', '5', '寇', '铭', '哲', '黑', '龙', '江', '省', '七', '台', '河', '市', '桃', '山', '区', '风', '采', '路', '朝', '阳', '广', '场'], 'labels': ['T-B', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'P-B', 'P-I', 'P-I', 'A1-B', 'A1-I', 'A1-I', 'A1-I', 'A2-B', 'A2-I', 'A2-I', 'A2-I', 'A3-B', 'A3-I', 'A3-I', 'A4-B', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'A4-I']} {'tokens': ['湖', '南', '省', '长', '沙', '市', '岳', '麓', '区', '银', '杉', '路', '3', '1', '号', '绿', '地', '中', '央', '广', '场', '7', '栋', '2', '1', '楼', '须', '平', '盛', '1', '3', '6', '0', '1', '2', '6', '9', '5', '3', '8'], 'labels': ['A1-B', 'A1-I', 'A1-I', 'A2-B', 'A2-I', 'A2-I', 'A3-B', 'A3-I', 'A3-I', 'A4-B', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'A4-I', 'P-B', 'P-I', 'P-I', 'T-B', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I', 'T-I']}from paddlenlp.datasets import load_dataset def read(data_path): with open(data_path, 'r', encoding='utf-8') as f: # 跳过列名 next(f) for line in f: words, labels = line.strip('\n').split(' ') # words = words.split('\002') # labels = labels.split('') #分类问题内容和标签一般不需要再分割 yield {'connect': words, 'labels': labels} # data_path为read()方法的参数 map_ds = load_dataset(read, data_path='数据集/input.txt', lazy=False) # iter_ds = load_dataset(read, data_path='数据集/dev.txt', lazy=True) # train= load_dataset(read, data_path='数据集/input_train.txt', lazy=False) # dev= load_dataset(read, data_path='数据集/input_dev.txt', lazy=False) #自定义好训练测试集 for i in range(3): print(map_ds[i]){'connect': '出栏一头猪亏损300元,究竟谁能笑到最后!', 'labels': '金融'}{'connect': '区块链投资心得,能做到就不会亏钱', 'labels': '金融'}{'connect': '你家拆迁,要钱还是要房?答案一目了然。', 'labels': '房产'}api接口文档https://paddlenlp.readthedocs.io/zh/latest/source/paddlenlp.datasets.dataset.html推荐将数据读取代码写成生成器(generator)的形式,这样可以更好的构建 MapDataset 和 IterDataset 两种数据集。同时也推荐将单条数据写成字典的格式,这样可以更方便的监测数据流向。事实上,MapDataset 在绝大多数时候都可以满足要求。一般只有在数据集过于庞大无法一次性加载进内存的时候我们才考虑使用 IterDataset 。任何人都可以方便的定义属于自己的数据集。注解:需要注意的是,只有PaddleNLP内置的数据集具有将数据中的label自动转为id的功能(详细条件参见 创建DatasetBuilder)。像上例中的自定义数据集需要在自定义的convert to feature方法中添加label转id的功能。自定义数据读取function中的参数可以直接以关键字参数的的方式传入 load_dataset() 中。而且对于自定义数据集,lazy 参数是必须传入的。2.基于ERNIR3.0文本分类任务模型微调save_dir:保存训练模型的目录;默认保存在当前目录checkpoint文件夹下。dataset:训练数据集;默认为"cblue"。dataset_dir:本地数据集路径,数据集路径中应包含train.txt,dev.txt和label.txt文件;默认为None。task_name:训练数据集;默认为"KUAKE-QIC"。max_seq_length:ERNIE模型使用的最大序列长度,最大不能超过512, 若出现显存不足,请适当调低这一参数;默认为128。model_name:选择预训练模型;默认为"ernie-3.0-base-zh"。device: 选用什么设备进行训练,可选cpu、gpu、xpu、npu。如使用gpu训练,可使用参数gpus指定GPU卡号。batch_size:批处理大小,请结合显存情况进行调整,若出现显存不足,请适当调低这一参数;默认为32。learning_rate:Fine-tune的最大学习率;默认为6e-5。weight_decay:控制正则项力度的参数,用于防止过拟合,默认为0.01。early_stop:选择是否使用早停法(EarlyStopping);默认为False。early_stop_nums:在设定的早停训练轮次内,模型在开发集上表现不再上升,训练终止;默认为4。epochs: 训练轮次,默认为100。warmup:是否使用学习率warmup策略;默认为False。warmup_proportion:学习率warmup策略的比例数,如果设为0.1,则学习率会在前10%steps数从0慢慢增长到learning_rate, 而后再缓慢衰减;默认为0.1。logging_steps: 日志打印的间隔steps数,默认5。init_from_ckpt: 模型初始checkpoint参数地址,默认None。seed:随机种子,默认为3。parser.add_argument("--save_dir", default="./checkpoint", type=str, help="The output directory where the model " "checkpoints will be written.") parser.add_argument("--dataset", default="cblue", type=str, help="Dataset for text classfication.") parser.add_argument("--dataset_dir", default=None, type=str, help="Local dataset directory should include" "train.txt, dev.txt and label.txt") parser.add_argument("--task_name", default="KUAKE-QIC", type=str, help="Task name for text classfication dataset.") parser.add_argument("--max_seq_length", default=128, type=int, help="The maximum total input sequence length" "after tokenization. Sequences longer than this " "will be truncated, sequences shorter will be padded.") parser.add_argument('--model_name', default="ernie-3.0-base-zh", help="Select model to train, defaults " "to ernie-3.0-base-zh.") parser.add_argument('--device', choices=['cpu', 'gpu', 'xpu', 'npu'], default="gpu", help="Select which device to train model, defaults to gpu.") parser.add_argument("--batch_size", default=32, type=int, help="Batch size per GPU/CPU for training.") parser.add_argument("--learning_rate", default=6e-5, type=float, help="The initial learning rate for Adam.") parser.add_argument("--weight_decay", default=0.01, type=float, help="Weight decay if we apply some.") parser.add_argument('--early_stop', action='store_true', help='Epoch before early stop.') parser.add_argument('--early_stop_nums', type=int, default=4, help='Number of epoch before early stop.') parser.add_argument("--epochs", default=100, type=int, help="Total number of training epochs to perform.") parser.add_argument('--warmup', action='store_true', help="whether use warmup strategy") parser.add_argument('--warmup_proportion', default=0.1, type=float, help="Linear warmup proportion of learning " "rate over the training process.") parser.add_argument("--logging_steps", default=5, type=int, help="The interval steps to logging.") parser.add_argument("--init_from_ckpt", type=str, default=None, help="The path of checkpoint to be loaded.") parser.add_argument("--seed", type=int, default=3, help="random seed for initialization")2.1.1 性能指标修改关于性能指标参考手册修改添加:我已经添加进去https://www.paddlepaddle.org.cn/documentation/docs/zh/api/paddle/metric/Overview_cn.html#about-metric-class:import numpy as np import paddle x = np.array([0.1, 0.5, 0.6, 0.7]) y = np.array([0, 1, 1, 1]) m = paddle.metric.Precision() m.update(x, y) res = m.accumulate() print(res) # 1.0 import numpy as np import paddle x = np.array([0.1, 0.5, 0.6, 0.7]) y = np.array([1, 0, 1, 1]) m = paddle.metric.Recall() m.update(x, y) res = m.accumulate() print(res) # 2.0 / 3.0 f1_score = float(2 * precision * recall / (precision + recall)) 修改后文件为:new暂时未解决。吐槽一下最新版本paddlenlp上面py文件已经没了!实际采用这个-----AccuracyAndF1https://paddlenlp.readthedocs.io/zh/latest/source/paddlenlp.metrics.glue.html修改后文件为:new2# !python train.py --warmup --early_stop --epochs 10 --model_name "ernie-3.0-base-zh" --max_seq_length 128 --batch_size 32 --logging_steps 10 --learning_rate 6e-5 !python train.py --warmup --early_stop --epochs 5 --model_name ernie-3.0-medium-zh #修改后的训练文件train_new2.py ,主要使用了paddlenlp.metrics.glue的AccuracyAndF1:准确率及F1-score,可用于GLUE中的MRPC 和QQP任务 #不过吐槽一下: return (acc,precision,recall,f1,(acc + f1) / 2,) 最后一个指标竟然是加权平均..... !python train_new2.py --warmup --early_stop --epochs 5 --save_dir "./checkpoint2" --batch_size 16程序运行时将会自动进行训练,评估,测试。同时训练过程中会自动保存开发集上最佳模型在指定的 save_dir 中,保存模型文件结构如下所示:checkpoint/ ├── model_config.json ├── model_state.pdparams ├── tokenizer_config.json └── vocab.txtNOTE:如需恢复模型训练,则可以设置 init_from_ckpt , 如init_from_ckpt=checkpoint/model_state.pdparams。如需训练中文文本分类任务,只需更换预训练模型参数 model_name 。中文训练任务推荐使用"ernie-3.0-base-zh",更多可选模型可参考Transformer预训练模型。2.1.2 使用文心ERNIE最新大模型进行训练最新开源ERNIE 3.0系列预训练模型:110M参数通用模型ERNIE 3.0 Base280M参数重量级通用模型ERNIE 3.0 XBase74M轻量级通用模型ERNIE 3.0 Medium文档链接:https://github.com/PaddlePaddle/ERNIEERNIE模型汇总ERNIE模型汇总目前直接定义name就可以调用的主要为下面几类:目开源 ERNIE 3.0 Base 、ERNIE 3.0 Medium 、 ERNIE 3.0 Mini 、 ERNIE 3.0 Micro 、 ERNIE 3.0 Nano 五个模型:ERNIE 3.0-Base (12-layer, 768-hidden, 12-heads)ERNIE 3.0-Medium (6-layer, 768-hidden, 12-heads)ERNIE 3.0-Mini (6-layer, 384-hidden, 12-heads)ERNIE 3.0-Micro (4-layer, 384-hidden, 12-heads)ERNIE 3.0-Nano (4-layer, 312-hidden, 12-heads)从本地文件创建数据集使用本地数据集来训练我们的文本分类模型,本项目支持使用固定格式本地数据集文件进行训练如果需要对本地数据集进行数据标注,可以参考文本分类任务doccano数据标注使用指南进行文本分类数据标注。[这个放到下个项目讲解]本项目将以CBLUE数据集中医疗搜索检索词意图分类(KUAKE-QIC)任务为例进行介绍如何加载本地固定格式数据集进行训练:本地数据集目录结构如下:data/ ├── train.txt # 训练数据集文件 ├── dev.txt # 开发数据集文件 ├── label.txt # 分类标签文件 └── data.txt # 可选,待预测数据文件train.txt(训练数据集文件), dev.txt(开发数据集文件),输入文本序列与标签类别名用'\t'分隔开。train.txt/dev.txt 文件格式:<输入序列1>'\t'<标签1>'\n' <输入序列2>'\t'<标签2>'\n' 丙氨酸氨基转移酶和天门冬氨酸氨基转移酶高严重吗 其他 慢性肝炎早期症状有哪些表现 疾病表述 胃不好能吃南瓜吗 注意事项 为什么我的手到夏天就会脱皮而且很严重有什么办法翱4天... 病情诊断 脸上拆线后可以出去玩吗?可以流 其他 西宁青海治不孕不育专科医院 就医建议 冠状沟例外很多肉粒是什么 病情诊断 肛裂治疗用什么方法比较好 治疗方案 包皮过长应该怎么样治疗有效 治疗方案 请问白癜风是一种什么样的疾病 疾病表述 月经过了四天测出怀孕是否可以确定 其他label.txt(分类标签文件)记录数据集中所有标签集合,每一行为一个标签名。label.txt 文件格式:<标签名1>'\n' <标签名2>'\n' ...病情诊断 data.txt(可选,待预测数据文件)。黑苦荞茶的功效与作用及食用方法 交界痣会凸起吗 检查是否能怀孕挂什么科 鱼油怎么吃咬破吃还是直接咽下去 幼儿挑食的生理原因是2.3 GPU多卡训练指定GPU卡号/多卡训练unset CUDA_VISIBLE_DEVICES python -m paddle.distributed.launch --gpus "0" train.py --warmup --early_stopunset CUDA_VISIBLE_DEVICES python -m paddle.distributed.launch --gpus "0" train.py --warmup --dataset_dir data/KUAKE_QIC使用多卡训练可以指定多个GPU卡号,例如 --gpus "0,1"unset CUDA_VISIBLE_DEVICES python -m paddle.distributed.launch --gpus "0,1" train.py --warmup --dataset_dir data/KUAKE_QIC2.4模型预测输入待预测数据和数据标签对照列表,模型预测数据对应的标签使用默认数据进行预测:!python predict.py --params_path ./checkpoint/input data: 黑苦荞茶的功效与作用及食用方法 label: 功效作用 --------------------------------- input data: 交界痣会凸起吗 label: 疾病表述 --------------------------------- input data: 检查是否能怀孕挂什么科 label: 就医建议 --------------------------------- input data: 鱼油怎么吃咬破吃还是直接咽下去 label: 其他 --------------------------------- input data: 幼儿挑食的生理原因是 label: 病因分析 ---------------------------------#也可以选择使用本地数据文件data/data.txt进行预测: !python predict.py --params_path ./checkpoint/ --dataset_dir data/KUAKE_QIClabel: 功效作用 --------------------------------- input data: 交界痣会凸起吗 label: 疾病表述 --------------------------------- input data: 检查是否能怀孕挂什么科 label: 就医建议 --------------------------------- input data: 鱼油怎么吃咬破吃还是直接咽下去 label: 其他 --------------------------------- input data: 幼儿挑食的生理原因是 label: 病因分析 ---------------------------------3.总结最新开源ERNIE 3.0系列预训练模型:110M参数通用模型ERNIE 3.0 Base280M参数重量级通用模型ERNIE 3.0 XBase74M轻量级通用模型ERNIE 3.0 Medium新增语音-语言跨模态模型ERNIE-SAT 正式开源新增ERNIE-Gen(中文)预训练模型,支持多类主流生成任务:主要包括摘要、问题生成、对话、问答动静结合的文心ERNIE开发套件:基于飞桨动态图功能,支持文心ERNIE模型动态图训练。将文本预处理、预训练模型、网络搭建、模型评估、上线部署等NLP开发流程规范封装。支持NLP常用任务:文本分类、文本匹配、序列标注、信息抽取、文本生成、数据蒸馏等。提供数据清洗、数据增强、分词、格式转换、大小写转换等数据预处理工具。文心大模型ERNIE是百度发布的产业级知识增强大模型,涵盖了NLP大模型和跨模态大模型。2019年3月,开源了国内首个开源预训练模型文心ERNIE 1.0,此后在语言与跨模态的理解和生成等领域取得一系列技术突破,并对外开源与开放了系列模型,助力大模型研究与产业化应用发展。这里温馨提示遇到问题多看文档手册后续将对:多标签分类、层次分类进行讲解、以及这块数据集的标注讲解。在空了会对交叉验证,数据增强研究一下本人博客:https://blog.csdn.net/sinat_39620217?type=blog
PaddleNLP基于ERNIR3.0文本分类以CAIL2018-SMALL数据集罪名预测任务为例【多标签】
相关项目链接:Paddlenlp之UIE模型实战实体抽取任务【打车数据、快递单】Paddlenlp之UIE分类模型【以情感倾向分析新闻分类为例】含智能标注方案)[应用实践:分类模型大集成者[PaddleHub、Finetune、prompt]](https://aistudio.baidu.com/aistudio/projectdetail/4357474?contributionType=1)Paddlenlp之UIE关系抽取模型【高管关系抽取为例】PaddleNLP基于ERNIR3.0文本分类以中医疗搜索检索词意图分类(KUAKE-QIC)为例【多分类(单标签)】基于Ernie-3.0 CAIL2019法研杯要素识别多标签分类任务本项目链接:基于ERNIR3.0文本分类:CAIL2018-SMALL罪名预测为例(多标签)0.前言:文本分类任务介绍文本分类任务是自然语言处理中最常见的任务,文本分类任务简单来说就是对给定的一个句子或一段文本使用文本分类器进行分类。文本分类任务广泛应用于长短文本分类、情感分析、新闻分类、事件类别分类、政务数据分类、商品信息分类、商品类目预测、文章分类、论文类别分类、专利分类、案件描述分类、罪名分类、意图分类、论文专利分类、邮件自动标签、评论正负识别、药物反应分类、对话分类、税种识别、来电信息自动分类、投诉分类、广告检测、敏感违法内容检测、内容安全检测、舆情分析、话题标记等各类日常或专业领域中。文本分类任务可以根据标签类型分为多分类(multi class)、多标签(multi label)、层次分类(hierarchical等三类任务,接下来我们将以下图的新闻文本分类为例介绍三种分类任务的区别。PaddleNLP采用AutoModelForSequenceClassification, AutoTokenizer提供了方便易用的接口,可指定模型名或模型参数文件路径通过from_pretrained() 方法加载不同网络结构的预训练模型,并在输出层上叠加一层线性层,且相应预训练模型权重下载速度快、稳定。Transformer预训练模型汇总包含了如 ERNIE、BERT、RoBERTa等40多个主流预训练模型,500多个模型权重。下面以ERNIE 3.0 中文base模型为例,演示如何加载预训练模型和分词器:from paddlenlp.transformers import AutoModelForSequenceClassification, AutoTokenizer num_classes = 10 model_name = "ernie-3.0-base-zh" model = AutoModelForSequenceClassification.from_pretrained(model_name, num_classes=num_classes) tokenizer = AutoTokenizer.from_pretrained(model_name)0.1 多标签任务介绍文本多标签分类是自然语言处理(NLP)中常见的文本分类任务,文本多标签分类在各种现实场景中具有广泛的适用性,例如商品分类、网页标签、新闻标注、蛋白质功能分类、电影分类、语义场景分类等。多标签数据集中样本用来自 n_classes 个可能类别的 m 个标签类别标记,其中 m 的取值在 0 到 n_classes 之间,这些类别具有不相互排斥的属性。通常,我们将每个样本的标签用One-hot的形式表示,正类用 1 表示,负类用 0 表示。例如,数据集中样本可能标签是A、B和C的多标签分类问题,标签为 [1,0,1] 代表存在标签 A 和 C 而标签 B 不存在的样本。在现实中的案情错综复杂,同一案件可能适用多项法律条文,涉及数罪并罚,需要多标签模型充分学习标签之间的关联性,对文本进行分类预测。CAIL2018—SMALL数据集中罪名预测任务数据来自“中国裁判文书网”公开的刑事法律文书,包括19.6万份文书样例,其中每份数据由法律文书中的案情描述和事实部分组成,包括每个案件被告人被判的罪名,数据集共包含202项罪名,被告人罪名通常涉及一项至多项。以数据集中某一法律文书为例:"公诉机关指控,2009年12月18日22时许,被告人李某(已判刑)伙同被告人丁某、李某乙、李某甲、杨某某在永吉县岔路河镇夜宴歌厅唱完歌后离开,因之前对该歌厅服务生刘某某心怀不满,遂手持事先准备好的镐把、扎枪再次返回夜宴歌厅,在追赶殴打刘某某过程中,任意损毁歌厅内的笔记本电脑、调音台、麦克接收机等物品。被告人丁某用镐把随意将服务员齐某某头部打伤。经物价部门鉴定,笔记本电脑、调音台、麦克接收机总价值人民币7120.00元;经法医鉴定,齐某某左额部硬膜外血肿,构成重伤。被告人丁某、李某乙、李某甲、杨某某案发后外逃,后主动到公安机关投案。并认为,被告人丁某随意殴打他人,致人重伤,其行为已构成××罪。被告人李某乙、李某甲、杨某某在公共场所持械随意殴打他人,情节恶劣,任意毁损他人财物,情节严重,其行为均已构成××罪,应予惩处。"该案件中被告人涉及故意伤害,寻衅滋事两项罪名。接下来我们将讲解如何利用多标签模型,根据输入文本预测案件所涉及的一个或多个罪名。0.2 文本分类应用全流程介绍接下来,我们将按数据准备、训练、性能优化部署等三个阶段对文本分类应用的全流程进行介绍。数据准备如果没有已标注的数据集,推荐doccano数据标注工具,如何使用doccano进行数据标注并转化成指定格式本地数据集详见文本分类任务doccano使用指南。如果已有标注好的本地数据集,我们需要根据不同任务要求将数据集整理为文档要求的格式:多分类数据集格式要求、多标签数据集格式要求、层次分类数据集格式要求。准备好数据集后,我们可以根据现有的数据集规模或训练后模型表现选择是否使用数据增强策略进行数据集扩充。模型训练数据准备完成后,可以开始使用我们的数据集对预训练模型进行微调训练。我们可以根据任务需求,调整可配置参数,选择使用GPU或CPU进行模型训练,脚本默认保存在开发集最佳表现模型。中文任务默认使用"ernie-3.0-base-zh"模型,英文任务默认使用"ernie-2.0-base-en"模型,ERNIE 3.0还支持多个轻量级中文模型,详见ERNIE模型汇总,可以根据任务和设备需求进行选择。首先我们需要根据场景选择不同的任务目录,具体可以见 多分类任务点击这里 多标签任务点击这里 层次分类任务点击这里训练结束后,我们可以加载保存的最佳模型进行模型测试,打印模型预测结果。模型预测在现实部署场景中,我们通常不仅对模型的精度表现有要求,也需要考虑模型性能上的表现。我们可以使用模型裁剪进一步压缩模型体积,文本分类应用已提供裁剪API对上一步微调后的模型进行裁剪,模型裁剪之后会默认导出静态图模型。模型部署需要将保存的最佳模型参数(动态图)导出成静态图参数,用于后续的推理部署。文本分类应用提供了基于ONNXRuntime的本地部署predictor,并且支持在GPU设备使用FP16,在CPU设备使用动态量化的低精度加速推理。文本分类应用同时基于Paddle Serving的服务端部署方案。本项目主要讲解:数据准备、模型训练、模型预测部分,对于部署部分篇幅有限,感兴趣同学可以跑一跑试一试。参考链接:[https://github.com/PaddlePaddle/PaddleNLP/tree/develop/applications/text_classification](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/applications/text_classification1.文本分类任务doccano使用指南【多分类、多标签、层次分类】安装详细事宜参考项目:Paddlenlp之UIE分类模型【以情感倾向分析新闻分类为例】含智能标注方案)强烈推荐:数据标注平台doccano----简介、安装、使用、踩坑记录这里就不对安装等进行重复讲解,默认都会。具体参考项目链接:本项目链接:基于ERNIR3.0文本分类:CAIL2018-SMALL罪名预测为例(多标签)2.基于ERNIR3.0文本分类任务模型微调以下是本项目主要代码结构及说明: ├── train.py # 训练评估脚本 ├── predict.py # 预测脚本 ├── export_model.py # 动态图参数导出静态图参数脚本 ├── utils.py # 工具函数脚本 ├── metric.py # metric脚本 ├── prune.py # 裁剪脚本 ├── prune_trainer.py # 裁剪trainer脚本 ├── prune_config.py # 裁剪训练参数配置 ├── requirements.txt # 环境依赖 └── README.md # 使用说明以公开数据集CAIL2018—SMALL中罪名预测任务为示例,在训练集上进行模型微调,并在开发集上验证。程序运行时将会自动进行训练,评估,测试。同时训练过程中会自动保存开发集上最佳模型在指定的 save_dir 中,保存模型文件结构如下所示:checkpoint/ ├── model_config.json ├── model_state.pdparams ├── tokenizer_config.json └── vocab.txtNOTE:如需恢复模型训练,则可以设置 init_from_ckpt , 如 init_from_ckpt=checkpoint/model_state.pdparams 。如需训练中文文本分类任务,只需更换预训练模型参数 model_name 。中文训练任务推荐使用"ernie-3.0-base-zh",更多可选模型可参考Transformer预训练模型。2.1.加载本地数据集在许多情况,我们需要使用本地数据集来训练我们的文本分类模型,本项目支持使用固定格式本地数据集文件进行训练。如果需要对本地数据集进行数据标注,可以参考文本分类任务doccano数据标注使用指南进行文本分类数据标注。本项目将以CAIL2018-SMALL数据集罪名预测任务为例进行介绍如何加载本地固定格式数据集进行训练:# !wget https://paddlenlp.bj.bcebos.com/datasets/cail2018_small_charges.tar.gz !tar -zxvf cail2018_small_charges.tar.gz !mv cail2018_small_charges data本地数据集目录结构如下:data/ ├── train.txt # 训练数据集文件 ├── dev.txt # 开发数据集文件 ├── test.txt # 可选,测试训练集文件 ├── label.txt # 分类标签文件 └── data.txt # 可选,待预测数据文件train.txt(训练数据集文件), dev.txt(开发数据集文件), test.txt(可选,测试训练集文件)中输入文本序列与标签数据用 '\t' 分隔开,标签中多个标签之间用 ',' 逗号 分隔开。train.txt/dev.txt/test.txt 文件格式:<输入序列1>'\t'<标签1>','<标签2> <输入序列2>'\t'<标签1> ...train.txt/dev.txt/test.txt 文件样例:灵璧县人民检察院指控:××事实2014年11月29日1时许,被告人彭某甲驾驶辽A×××××小型轿车行驶至辽宁省沈阳市于洪区太湖街红色根据地酒店门口路段时,与前方被害人闻某驾驶的辽A×××××号轿车发生追尾的交通事故。事故发生后,被告人彭某甲与乘坐人韩某下车与闻某发生口角争执,并在一起互相厮打。在厮打过程中,彭某甲与韩某用拳头将闻某面部打伤。经鉴定,闻某的损伤程度为轻伤二级。××事实2015年6月至2015年9月,被告人彭某甲通过其建立的“比特战斗”微信群,将47部淫秽视频文件上传至该微信群供群成员观看。公诉机关针对指控提供了相关书证,证人证言,被害人陈述,被告人供述,鉴定意见,现场勘验检查笔录等证据,公诉机关认为,被告人彭某甲伙同他人故意非法损害公民身体健康,致人轻伤;利用移动通讯终端传播淫秽电子信息,情节严重,其行为已触犯《中华人民共和国刑法》××××、××××、××××之规定,构成××罪、××罪,提请法院依法判处。 故意伤害,[制造、贩卖、传播]淫秽物品,传播淫秽物品 酉阳县人民检察院指控,2014年1月17日1时许,被告人周某某在酉阳县桃花源美食街万州烤鱼店外与田某甲发生口角,随后周某某持刀将在店内的被害人田某某砍伤。经重庆市酉阳县公安局物证鉴定室鉴定,田某某所受伤为轻伤二级。指控的证据有被告人立案决定书,户籍信息,鉴定意见,辨认笔录,被害人田某某的陈述,证人冉某、陈某某等人的证言,周某某的供述与辩解等。公诉机关认为,被告人周某某××他人身体,致人轻伤,其行为触犯了《中华人民共和国刑法》第二百三十四××的规定,犯罪事实清楚,证据确实、充分,应当以××罪追究其刑事责任。周某某在××考验期内发现有其他罪没有判决的,适用《中华人民共和国刑法》××、六十九条。提请依法判决。 故意伤害,[组织、强迫、引诱、容留、介绍]卖淫,[引诱、容留、介绍]卖淫 ...label.txt(分类标签文件)记录数据集中所有标签集合,每一行为一个标签名。label.txt 文件格式:故意伤害 非法[持有、私藏][枪支、弹药] ...label.txt 文件样例:故意伤害 非法[持有、私藏][枪支、弹药] ...data.txt(可选,待预测数据文件)data.txt 文件格式:<输入序列1> <输入序列2> ...data.txt 文件样例:经审理查明,2012年4月5日19时许,被告人王某在杭州市下城区朝晖路农贸市场门口贩卖盗版光碟、淫秽光碟时被民警当场抓获,并当场查获其贩卖的各类光碟5515张,其中5280张某属非法出版物、235张某属淫秽物品。上述事实,被告人王某在庭审中亦无异议,且有经庭审举证、质证的扣押物品清单、赃物照片、公安行政处罚决定书、抓获经过及户籍证明等书证;证人胡某、徐某的证言;出版物鉴定书、淫秽物品审查鉴定书及检查笔录等证据证实,足以认定。 榆林市榆阳区人民检察院指控:2015年11月22日2时许,被告人王某某在自己经营的榆阳区长城福源招待所内,介绍并容留杨某向刘某某、白某向乔某某提供性服务各一次 ...2.2 模型预测#单卡训练 !python train.py --early_stop --epochs 10 --warmup --save_dir "./checkpoint" --batch_size 32 --dataset_dir "data/cail2018_small_charges" [2022-07-27 15:03:55,267] [ INFO] - global step 530, epoch: 1, batch: 530, loss: 0.19550, micro f1 score: 0.01304, macro f1 score: 0.01056, speed: 0.60 step/s [2022-07-27 15:04:12,334] [ INFO] - global step 540, epoch: 1, batch: 540, loss: 0.18821, micro f1 score: 0.01303, macro f1 score: 0.01053, speed: 0.60 step/s [2022-07-27 15:04:29,497] [ INFO] - global step 550, epoch: 1, batch: 550, loss: 0.18063, micro f1 score: 0.01302, macro f1 score: 0.01051, speed: 0.59 step/s [2022-07-27 15:04:46,820] [ INFO] - global step 560, epoch: 1, batch: 560, loss: 0.17561, micro f1 score: 0.01301, macro f1 score: 0.01049, speed: 0.59 step/s [2022-07-27 15:05:04,307] [ INFO] - global step 570, epoch: 1, batch: 570, loss: 0.17048, micro f1 score: 0.01300, macro f1 score: 0.01046, speed: 0.58 step/s [2022-07-27 15:05:22,099] [ INFO] - global step 580, epoch: 1, batch: 580, loss: 0.16223, micro f1 score: 0.01299, macro f1 score: 0.01044, speed: 0.57 step/s [2022-07-27 15:05:39,808] [ INFO] - global step 590, epoch: 1, batch: 590, loss: 0.15865, micro f1 score: 0.01298, macro f1 score: 0.01041, speed: 0.58 step/s [2022-07-27 15:05:57,613] [ INFO] - global step 600, epoch: 1, batch: 600, loss: 0.15361, micro f1 score: 0.01297, macro f1 score: 0.01039, speed: 0.57 step/s [2022-07-27 15:06:15,583] [ INFO] - global step 610, epoch: 1, batch: 610, loss: 0.14710, micro f1 score: 0.01296, macro f1 score: 0.01037, speed: 0.57 step/s [2022-07-27 15:06:33,658] [ INFO] - global step 620, epoch: 1, batch: 620, loss: 0.14317, micro f1 score: 0.01295, macro f1 score: 0.01034, speed: 0.56 step/s [2022-07-27 15:06:51,894] [ INFO] - global step 630, epoch: 1, batch: 630, loss: 0.13964, micro f1 score: 0.01294, macro f1 score: 0.01032, speed: 0.56 step/s [2022-07-27 15:07:10,206] [ INFO] - global step 640, epoch: 1, batch: 640, loss: 0.13328, micro f1 score: 0.01293, macro f1 score: 0.01030, speed: 0.56 step/s [2022-07-27 15:07:28,673] [ INFO] - global step 650, epoch: 1, batch: 650, loss: 0.12832, micro f1 score: 0.01292, macro f1 score: 0.01028, speed: 0.55 step/s [2022-07-27 15:07:47,244] [ INFO] - global step 660, epoch: 1, batch: 660, loss: 0.12585, micro f1 score: 0.01292, macro f1 score: 0.01026, speed: 0.55 step/s [2022-07-27 15:08:05,915] [ INFO] - global step 670, epoch: 1, batch: 670, loss: 0.12514, micro f1 score: 0.01291, macro f1 score: 0.01024, speed: 0.55 step/s [2022-07-27 15:08:24,775] [ INFO] - global step 680, epoch: 1, batch: 680, loss: 0.11939, micro f1 score: 0.01290, macro f1 score: 0.01021, speed: 0.54 step/s [2022-07-27 15:08:43,779] [ INFO] - global step 690, epoch: 1, batch: 690, loss: 0.11547, micro f1 score: 0.01289, macro f1 score: 0.01019, speed: 0.54 step/s [2022-07-27 15:09:02,844] [ INFO] - global step 700, epoch: 1, batch: 700, loss: 0.11291, micro f1 score: 0.01288, macro f1 score: 0.01017, speed: 0.53 step/s [2022-07-27 15:09:22,234] [ INFO] - global step 710, epoch: 1, batch: 710, loss: 0.10988, micro f1 score: 0.01287, macro f1 score: 0.01015, speed: 0.53 step/s [2022-07-27 15:09:41,752] [ INFO] - global step 720, epoch: 1, batch: 720, loss: 0.10556, micro f1 score: 0.01286, macro f1 score: 0.01013, speed: 0.52 step/s [2022-07-27 15:10:01,621] [ INFO] - global step 730, epoch: 1, batch: 730, loss: 0.10424, micro f1 score: 0.01285, macro f1 score: 0.01011, speed: 0.51 step/s [2022-07-27 15:10:21,675] [ INFO] - global step 740, epoch: 1, batch: 740, loss: 0.09951, micro f1 score: 0.01284, macro f1 score: 0.01009, speed: 0.51 step/s [2022-07-27 15:10:41,949] [ INFO] - global step 750, epoch: 1, batch: 750, loss: 0.09677, micro f1 score: 0.01283, macro f1 score: 0.01007, speed: 0.50 step/s [2022-07-27 15:11:02,267] [ INFO] - global step 760, epoch: 1, batch: 760, loss: 0.10009, micro f1 score: 0.01282, macro f1 score: 0.01005, speed: 0.50 step/s [2022-07-27 15:11:22,657] [ INFO] - global step 770, epoch: 1, batch: 770, loss: 0.09277, micro f1 score: 0.01281, macro f1 score: 0.01003, speed: 0.50 step/s样本集过大这边就部继续演示了,可支持配置的参数:save_dir保存训练模型的目录;默认保存在当前目录checkpoint文件夹下。dataset:训练数据集;默认为"cail2018_small"。dataset_dir:本地数据集路径,数据集路径中应包含train.txt,dev.txt和label.txt文件;默认为None。task_name:训练数据集;默认为"charges"。max_seq_length:ERNIE模型使用的最大序列长度,最大不能超过512, 若出现显存不足,请适当调低这一参数;默认为512。model_name:选择预训练模型;默认为"ernie-3.0-base-zh"。device: 选用什么设备进行训练,可选cpu、gpu、xpu、npu。如使用gpu训练,择使用参数gpus指定GPU卡号。batch_size:批处理大小,请结合显存情况进行调整,若出现显存不足,请适当调低这一参数;默认为32。learning_rate:Fine-tune的最大学习率;默认为3e-5。weight_decay:控制正则项力度的参数,用于防止过拟合,默认为0.00。early_stop:选择是否使用早停法(EarlyStopping);默认为False。early_stop_nums:在设定的早停训练轮次内,模型在开发集上表现不再上升,训练终止;默认为6。epochs: 训练轮次,默认为1000。warmup:是否使用学习率warmup策略;默认为False。warmup_steps:学习率warmup策略的steps数,如果设为2000,则学习率会在前2000 steps数从0慢慢增长到learning_rate, 而后再缓慢衰减;默认为2000。logging_steps: 日志打印的间隔steps数,默认5。seed:随机种子,默认为3。2.2.1 评价指标定义对评价指标进行阐述一下: criterion = paddle.nn.BCEWithLogitsLoss() metric = MetricReport() #得到F1 值 如果需要修改参考多分类文章 micro_f1_score, macro_f1_score = evaluate(model, criterion, metric, dev_data_loader)可以看到性能指标主要关于F1值,具体大家可以参考文档本次使用的是metrics.py文件从sklearn库导入的:from sklearn.metrics import f1_score, classification_report如有额外需求可以,使用metrics1.py文件从sklearn库导入的:from sklearn.metrics import roc_auc_score, f1_score, precision_score, recall_score import numpy as np from sklearn.metrics import roc_auc_score, f1_score, precision_score, recall_score from paddle.metric import Metric class MultiLabelReport(Metric): AUC and F1 Score for multi-label text classification task. def __init__(self, name='MultiLabelReport', average='micro'): super(MultiLabelReport, self).__init__() self.average = average self._name = name self.reset() def f1_score(self, y_prob): Returns the f1 score by searching the best threshhold best_score = 0 for threshold in [i * 0.01 for i in range(100)]: self.y_pred = y_prob > threshold score = f1_score(y_pred=self.y_pred, y_true=self.y_true, average=self.average) if score > best_score: best_score = score precison = precision_score(y_pred=self.y_pred, y_true=self.y_true, average=self.average) recall = recall_score(y_pred=self.y_pred, y_true=self.y_true, average=self.average) return best_score, precison, recall def reset(self): Resets all of the metric state. self.y_prob = None self.y_true = None def update(self, probs, labels): if self.y_prob is not None: self.y_prob = np.append(self.y_prob, probs.numpy(), axis=0) else: self.y_prob = probs.numpy() if self.y_true is not None: self.y_true = np.append(self.y_true, labels.numpy(), axis=0) else: self.y_true = labels.numpy() def accumulate(self): auc = roc_auc_score( y_score=self.y_prob, y_true=self.y_true, average=self.average) f1_score, precison, recall = self.f1_score(y_prob=self.y_prob) return auc, f1_score, precison, recall def name(self): Returns metric name return self._name详细细节参考项目:#多卡训练: #unset CUDA_VISIBLE_DEVICES #!python -m paddle.distributed.launch --gpus "0" train.py --early_stop --dataset_dir data #使用多卡训练可以指定多个GPU卡号,例如 --gpus "0,1"2.3 模型预测输入待预测数据和数据标签对照列表,模型预测数据对应的标签使用默认数据进行预测:python predict.py --params_path ./checkpoint/也可以选择使用本地数据文件data/data.txt进行预测:!python predict.py --params_path ./checkpoint/ --dataset_dir data/cail2018_small_charges输入样本:经审理查明,2012年4月5日19时许,被告人王某在杭州市下城区朝晖路农贸市场门口贩卖盗版光碟、淫秽光碟时被民警当场抓获,并当场查获其贩卖的各类光碟5515张,其中5280张某属非法出版物、235张某属淫秽物品。上述事实,被告人王某在庭审中亦无异议,且有经庭审举证、质证的扣押物品清单、赃物照片、公安行政处罚决定书、抓获经过及户籍证明等书证;证人胡某、徐某的证言;出版物鉴定书、淫秽物品审查鉴定书及检查笔录等证据证实,足以认定。 榆林市榆阳区人民检察院指控:2015年11月22日2时许,被告人王某某在自己经营的榆阳区长城福源招待所内,介绍并容留杨某向刘某某、白某向乔某某提供性服务各一次。 静乐县人民检察院指控,2014年8月30日15时许,静乐县苏坊村村民张某某因占地问题去苏坊村半切沟静静铁路第五标施工地点阻拦施工时,遭被告人王某某阻止,张某某打电话叫来儿子李某某,李某某看到张某某躺在地上,打了王某某一耳光。于是王某某指使工人殴打李某某,致李某某受伤。经忻州市公安司法鉴定中心鉴定,李某某的损伤评定为轻伤一级。李某某被打伤后,被告人王某某为逃避法律追究,找到任某某,指使任某某作实施××的伪证,并承诺每月给1万元。同时王某某指使工人王某甲、韩某某去丰润派出所作由任某某打伤李某某的伪证,导致任某某被静乐县公安局以涉嫌××罪刑事拘留。公诉机关认为,被告人王某某的行为触犯了《中华人民共和国刑法》××、《中华人民共和国刑法》××××之规定,应以××罪和××罪追究其刑事责任,数罪并罚。 输出结果:自行运行一下3. 结论相关项目链接:Paddlenlp之UIE模型实战实体抽取任务【打车数据、快递单】Paddlenlp之UIE分类模型【以情感倾向分析新闻分类为例】含智能标注方案)[应用实践:分类模型大集成者[PaddleHub、Finetune、prompt]](https://aistudio.baidu.com/aistudio/projectdetail/4357474?contributionType=1)Paddlenlp之UIE关系抽取模型【高管关系抽取为例】PaddleNLP基于ERNIR3.0文本分类以中医疗搜索检索词意图分类(KUAKE-QIC)为例【多分类(单标签)】基于Ernie-3.0 CAIL2019法研杯要素识别多标签分类任务本项目主要讲解了犯罪名预测任务、以及doccano标注指南(对于多分类多标签问题),和对性能指标的简单探讨,可以看到实际更多问题是关于多标签分类的。欢迎大家关注我的主页:https://aistudio.baidu.com/aistudio/usercenter以及博客:https://blog.csdn.net/sinat_39620217?type=blog
PaddleNLP基于ERNIR3.0文本分类:WOS数据集为例(层次分类)
相关项目链接:Paddlenlp之UIE模型实战实体抽取任务【打车数据、快递单】Paddlenlp之UIE分类模型【以情感倾向分析新闻分类为例】含智能标注方案)[应用实践:分类模型大集成者[PaddleHub、Finetune、prompt]](https://aistudio.baidu.com/aistudio/projectdetail/4357474?contributionType=1)Paddlenlp之UIE关系抽取模型【高管关系抽取为例】PaddleNLP基于ERNIR3.0文本分类以中医疗搜索检索词意图分类(KUAKE-QIC)为例【多分类(单标签)】基于Ernie-3.0 CAIL2019法研杯要素识别多标签分类任务本项目链接:基于ERNIR3.0文本分类:WOS数据集为例(层次分类)0.前言:文本分类任务介绍文本分类任务是自然语言处理中最常见的任务,文本分类任务简单来说就是对给定的一个句子或一段文本使用文本分类器进行分类。文本分类任务广泛应用于长短文本分类、情感分析、新闻分类、事件类别分类、政务数据分类、商品信息分类、商品类目预测、文章分类、论文类别分类、专利分类、案件描述分类、罪名分类、意图分类、论文专利分类、邮件自动标签、评论正负识别、药物反应分类、对话分类、税种识别、来电信息自动分类、投诉分类、广告检测、敏感违法内容检测、内容安全检测、舆情分析、话题标记等各类日常或专业领域中。文本分类任务可以根据标签类型分为多分类(multi class)、多标签(multi label)、层次分类(hierarchical等三类任务,接下来我们将以下图的新闻文本分类为例介绍三种分类任务的区别。PaddleNLP采用AutoModelForSequenceClassification, AutoTokenizer提供了方便易用的接口,可指定模型名或模型参数文件路径通过from_pretrained() 方法加载不同网络结构的预训练模型,并在输出层上叠加一层线性层,且相应预训练模型权重下载速度快、稳定。Transformer预训练模型汇总包含了如 ERNIE、BERT、RoBERTa等40多个主流预训练模型,500多个模型权重。下面以ERNIE 3.0 中文base模型为例,演示如何加载预训练模型和分词器:from paddlenlp.transformers import AutoModelForSequenceClassification, AutoTokenizer num_classes = 10 model_name = "ernie-3.0-base-zh" model = AutoModelForSequenceClassification.from_pretrained(model_name, num_classes=num_classes) tokenizer = AutoTokenizer.from_pretrained(model_name)0.1 层次分类任务介绍多标签层次分类任务指自然语言处理任务中,每个样本具有多个标签标记,并且标签集合中标签之间存在预定义的层次结构,多标签层次分类需要充分考虑标签集之间的层次结构关系来预测层次化预测结果。层次分类任务中标签层次结构分为两类,一类为树状结构,另一类为有向无环图(DAG)结构。有向无环图结构与树状结构区别在于,有向无环图中的节点可能存在不止一个父节点。在现实场景中,大量的数据如新闻分类、专利分类、学术论文分类等标签集合存在层次化结构,需要利用算法为文本自动标注更细粒度和更准确的标签。层次分类问题可以被视为一个多标签问题,以下图一个树状标签结构(宠物为根节点)为例,如果一个样本属于美短虎斑,样本也天然地同时属于类别美国短毛猫和类别猫两个样本标签。本项目采用通用多标签层次分类算法,将每个结点的标签路径视为一个多分类标签,使用单个多标签分类器进行决策,以上面美短虎斑的例子为例,该样本包含三个标签:猫、猫##美国短毛猫、猫##美国短毛猫##美短虎斑(不同层的标签之间使用##作为分割符)。下图的标签结构标签集合为猫、猫##波斯猫、猫##缅因猫、猫##美国短毛猫、猫##美国短毛猫##美短加白、猫##美国短毛猫##美短虎斑、猫##美国短毛猫##美短起司、兔、兔##侏儒兔、兔##垂耳兔总共10个标签。0.2 文本分类应用全流程介绍接下来,我们将按数据准备、训练、性能优化部署等三个阶段对文本分类应用的全流程进行介绍。数据准备如果没有已标注的数据集,推荐doccano数据标注工具,如何使用doccano进行数据标注并转化成指定格式本地数据集详见文本分类任务doccano使用指南。如果已有标注好的本地数据集,我们需要根据不同任务要求将数据集整理为文档要求的格式:多分类数据集格式要求、多标签数据集格式要求、层次分类数据集格式要求。准备好数据集后,我们可以根据现有的数据集规模或训练后模型表现选择是否使用数据增强策略进行数据集扩充。模型训练数据准备完成后,可以开始使用我们的数据集对预训练模型进行微调训练。我们可以根据任务需求,调整可配置参数,选择使用GPU或CPU进行模型训练,脚本默认保存在开发集最佳表现模型。中文任务默认使用"ernie-3.0-base-zh"模型,英文任务默认使用"ernie-2.0-base-en"模型,ERNIE 3.0还支持多个轻量级中文模型,详见ERNIE模型汇总,可以根据任务和设备需求进行选择。首先我们需要根据场景选择不同的任务目录,具体可以见 多分类任务点击这里 多标签任务点击这里 层次分类任务点击这里训练结束后,我们可以加载保存的最佳模型进行模型测试,打印模型预测结果。模型预测在现实部署场景中,我们通常不仅对模型的精度表现有要求,也需要考虑模型性能上的表现。我们可以使用模型裁剪进一步压缩模型体积,文本分类应用已提供裁剪API对上一步微调后的模型进行裁剪,模型裁剪之后会默认导出静态图模型。模型部署需要将保存的最佳模型参数(动态图)导出成静态图参数,用于后续的推理部署。文本分类应用提供了基于ONNXRuntime的本地部署predictor,并且支持在GPU设备使用FP16,在CPU设备使用动态量化的低精度加速推理。文本分类应用同时基于Paddle Serving的服务端部署方案。本项目主要讲解:数据准备、模型训练、模型预测部分,对于部署部分篇幅有限,感兴趣同学可以跑一跑试一试。参考链接:[https://github.com/PaddlePaddle/PaddleNLP/tree/develop/applications/text_classification](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/applications/text_classification1.文本分类任务doccano使用指南【多分类、多标签、层次分类】安装详细事宜参考项目:Paddlenlp之UIE分类模型【以情感倾向分析新闻分类为例】含智能标注方案)强烈推荐:数据标注平台doccano----简介、安装、使用、踩坑记录这里就不对安装等进行重复讲解,默认都会。具体参考项目:PaddleNLP基于ERNIR3.0文本分类以中医疗搜索检索词意图分类(KUAKE-QIC)为例【多分类(单标签)】2.基于ERNIR3.0层次分类模型微调以下是本项目主要代码结构及说明: ├── train.py # 训练评估脚本 ├── predict.py # 预测脚本 ├── export_model.py # 动态图参数导出静态图参数脚本 ├── utils.py # 工具函数脚本 ├── metric.py # metric脚本 ├── prune.py # 裁剪脚本 ├── prune_trainer.py # 裁剪trainer脚本 ├── prune_config.py # 裁剪训练参数配置 ├── requirements.txt # 环境依赖 └── README.md # 使用说明以层次分类公开数据集WOS(Web of Science)为示例,在训练集上进行模型微调,并在开发集上验证。WOS数据集是一个两层的层次文本分类数据集,包含7个父类和134子类,每个样本对应一个父类标签和子类标签,父类标签和子类标签间具有树状层次结构关系。程序运行时将会自动进行训练,评估,测试。同时训练过程中会自动保存开发集上最佳模型在指定的 save_dir 中,保存模型文件结构如下所示:checkpoint/ ├── model_config.json ├── model_state.pdparams ├── tokenizer_config.json └── vocab.txtNOTE:如需恢复模型训练,则可以设置 init_from_ckpt , 如 init_from_ckpt=checkpoint/model_state.pdparams 。如需训练中文文本分类任务,只需更换预训练模型参数 model_name 。中文训练任务推荐使用"ernie-3.0-base-zh",更多可选模型可参考Transformer预训练模型。2.1.加载本地数据集在许多情况,我们需要使用本地数据集来训练我们的文本分类模型,本项目支持使用固定格式本地数据集文件进行训练。如果需要对本地数据集进行数据标注,可以参考文本分类任务doccano数据标注使用指南进行文本分类数据标注。本项目将以CAIL2018-SMALL数据集罪名预测任务为例进行介绍如何加载本地固定格式数据集进行训练:!wget https://paddlenlp.bj.bcebos.com/datasets/wos_data.tar.gz !tar -zxvf wos_data.tar.gz !mv wos_data data本地数据集目录结构如下:data/ ├── train.txt # 训练数据集文件 ├── dev.txt # 开发数据集文件 ├── test.txt # 可选,测试训练集文件 ├── label.txt # 分类标签文件 └── data.txt # 可选,待预测数据文件train.txt(训练数据集文件), dev.txt(开发数据集文件), test.txt(可选,测试训练集文件)中 n 表示标签层次结构中最大层数, 代表数据的第i层标签。输入文本序列及不同层的标签数据用'\t'分隔开,每一层标签中多个标签之间用','逗号分隔开。注意,对于第i层数据没有标签的,使用空字符''来表示。train.txt/dev.txt/test.txt 文件格式:<输入序列1>'\t'<level 1 标签1>','<level 1 标签2>'\t'<level 2 标签1>','<level 2 标签2>'\t'...'\t'<level n 标签1>','<level n 标签2> <输入序列2>'\t'<level 1 标签>'\t'<level 2 标签>'\t'...'\t'<level n 标签> ...train.txt/dev.txt/test.txt 文件样例:unintended pregnancy continues to be a substantial public health problem. emergency contraception (ec) provides a last chance at pregnancy prevention. several safe and effective options for emergency contraception are currently available. the yuzpe method, a combined hormonal regimen, was essentially replaced by other oral medications including levonorgestrel and the antiprogestin ulipristal. the antiprogestin mifepristone has been studied for use as emergency contraception. the most effective postcoital method of contraception is the copper intrauterine device (iud). obesity and the simultaneous initiation of progestin-containing contraception may decrease the effectiveness of some emergency contraception. Medical Emergency Contraception the objective of this paper is to present an example in which matrix functions are used to solve a modern control exercise. specifically, the solution for the equation of state, which is a matrix differential equation is calculated. to resolve this, two different methods are presented, first using the properties of the matrix functions and by other side, using the classical method of laplace transform. ECE Control engineering ...label.txt(层次分类标签文件)记录数据集中所有标签路径集合,在标签路径中,高层的标签指向底层标签,标签之间用'##'连接,本项目选择为标签层次结构中的每一个节点生成对应的标签路径。label.txt 文件格式:<level 1: 标签> <level 1: 标签>'##'<level 2: 标签> <level 1: 标签>'##'<level 2: 标签>'##'<level 3: 标签> ...label.txt 文件样例:CS CS##Computer vision CS##Machine learning ECE##Electricity ECE##Lorentz force law ...data.txt(可选,待预测数据文件)data.txt 文件格式:<输入序列1> <输入序列2> ...data.txt 文件样例:<输入序列1> <输入序列2> ...previous research exploring cognitive biases in bulimia nervosa suggests that attentional biases occur for both food-related and body-related cues. individuals with bulimia were compared to non-bulimic controls on an emotional-stroop task which contained both food-related and body-related cues. results indicated that bulimics (but not controls) demonstrated a cognitive bias for both food-related and body related cues. however, a discrepancy between the two cue-types was observed with body-related cognitive biases showing the most robust effects and food-related cognitive biases being the most strongly associated with the severity of the disorder. the results may have implications for clinical practice as bulimics with an increased cognitive bias for food-related cues indicated increased bulimic disorder severity. (c) 2016 elsevier ltd. all rights reserved. posterior reversible encephalopathy syndrome (pres) is a reversible clinical and neuroradiological syndrome which may appear at any age and characterized by headache, altered consciousness, seizures, and cortical blindness. the exact incidence is still unknown. the most commonly identified causes include hypertensive encephalopathy, eclampsia, and some cytotoxic drugs. vasogenic edema related subcortical white matter lesions, hyperintense on t2a and flair sequences, in a relatively symmetrical pattern especially in the occipital and parietal lobes can be detected on cranial mr imaging. these findings tend to resolve partially or completely with early diagnosis and appropriate treatment. here in, we present a rare case of unilateral pres developed following the treatment with pazopanib, a testicular tumor vascular endothelial growth factor (vegf) inhibitory agent. ...2.2模型预测#单卡训练 !python train.py --early_stop --epochs 5 --warmup --save_dir "./checkpoint" --batch_size 32 --dataset_dir "data/wos_data"输出结果部分展示:[2022-07-27 17:54:18,773] [ INFO] - global step 1870, epoch: 2, batch: 930, loss: 0.04018, micro f1 score: 0.56644, macro f1 score: 0.04182, speed: 1.79 step/s [2022-07-27 17:54:24,434] [ INFO] - global step 1875, epoch: 2, batch: 935, loss: 0.03838, micro f1 score: 0.56670, macro f1 score: 0.04185, speed: 1.79 step/s [2022-07-27 17:54:29,539] [ INFO] - global step 1880, epoch: 2, batch: 940, loss: 0.03892, micro f1 score: 0.56682, macro f1 score: 0.04187, speed: 1.98 step/s [2022-07-27 17:55:27,020] [ INFO] - eval loss: 0.03925, micro f1 score: 0.59396, macro f1 score: 0.04428 [2022-07-27 17:55:27,021] [ INFO] - Current best macro f1 score: 0.04428 [2022-07-27 17:55:28,033] [ INFO] - tokenizer config file saved in ./checkpoint/tokenizer_config.json [2022-07-27 17:55:28,034] [ INFO] - Special tokens file saved in ./checkpoint/special_tokens_map.json [2022-07-27 17:55:30,385] [ INFO] - global step 1885, epoch: 3, batch: 5, loss: 0.03854, micro f1 score: 0.64000, macro f1 score: 0.04778, speed: 0.16 step/s [2022-07-27 17:55:31,980] [ INFO] - global step 1890, epoch: 3, batch: 10, loss: 0.03603, micro f1 score: 0.63455, macro f1 score: 0.04747, speed: 6.57 step/s [2022-07-27 17:55:33,539] [ INFO] - global step 1895, epoch: 3, batch: 15, loss: 0.03707, micro f1 score: 0.62945, macro f1 score: 0.04679, speed: 6.73 step/s [2022-07-27 17:55:35,138] [ INFO] - global step 1900, epoch: 3, batch: 20, loss: 0.03549, micro f1 score: 0.62788, macro f1 score: 0.04674, speed: 6.56 step/s [2022-07-27 17:55:36,823] [ INFO] - global step 1905, epoch: 3, batch: 25, loss: 0.03838, micro f1 score: 0.62448, macro f1 score: 0.04646, speed: 6.20 step/s [2022-07-27 17:55:38,457] [ INFO] - global step 1910, epoch: 3, batch: 30, loss: 0.03717, micro f1 score: 0.62339, macro f1 score: 0.04635, speed: 6.42 step/s [2022-07-27 17:55:40,075] [ INFO] - global step 1915, epoch: 3, batch: 35, loss: 0.04115, micro f1 score: 0.62302, macro f1 score: 0.04632, speed: 6.48 step/s [2022-07-27 17:55:41,742] [ INFO] - global step 1920, epoch: 3, batch: 40, loss: 0.03842, micro f1 score: 0.61973, macro f1 score: 0.04607, speed: 6.29 step/s [2022-07-27 17:55:43,423] [ INFO] - global step 1925, epoch: 3, batch: 45, loss: 0.03772, micro f1 score: 0.61950, macro f1 score: 0.04606, speed: 6.22 step/s [2022-07-27 17:55:45,118] [ INFO] - global step 1930, epoch: 3, batch: 50, loss: 0.04074, micro f1 score: 0.61848, macro f1 score: 0.04602, speed: 6.17 step/s样本集过大这边就部继续演示了,可支持配置的参数:save_dir保存训练模型的目录;默认保存在当前目录checkpoint文件夹下。dataset:训练数据集;默认为"cail2018_small"。dataset_dir:本地数据集路径,数据集路径中应包含train.txt,dev.txt和label.txt文件;默认为None。task_name:训练数据集;默认为wos数据集。max_seq_length:ERNIE模型使用的最大序列长度,最大不能超过512, 若出现显存不足,请适当调低这一参数;默认为512。model_name:选择预训练模型;默认为"ernie-2.0-base-en",中文数据集推荐使用"ernie-3.0-base-zh"。device: 选用什么设备进行训练,可选cpu、gpu、xpu、npu。如使用gpu训练,择使用参数gpus指定GPU卡号。batch_size:批处理大小,请结合显存情况进行调整,若出现显存不足,请适当调低这一参数;默认为32。learning_rate:Fine-tune的最大学习率;默认为3e-5。weight_decay:控制正则项力度的参数,用于防止过拟合,默认为0.00。early_stop:选择是否使用早停法(EarlyStopping);默认为False。early_stop_nums:在设定的早停训练轮次内,模型在开发集上表现不再上升,训练终止;默认为6。epochs: 训练轮次,默认为1000。warmup:是否使用学习率warmup策略;默认为False。warmup_steps:学习率warmup策略的steps数,如果设为2000,则学习率会在前2000 steps数从0慢慢增长到learning_rate, 而后再缓慢衰减;默认为2000。logging_steps: 日志打印的间隔steps数,默认5。seed:随机种子,默认为3。depth:层次结构最大深度,默认为2。2.2.1 评价指标定义对评价指标进行阐述一下: criterion = paddle.nn.BCEWithLogitsLoss() metric = MetricReport() #得到F1 值 如果需要修改参考多分类文章 micro_f1_score, macro_f1_score = evaluate(model, criterion, metric, dev_data_loader)可以看到性能指标主要关于F1值,具体大家可以参考文档本次使用的是metrics.py文件从sklearn库导入的:from sklearn.metrics import f1_score, classification_report如有额外需求可以,使用metrics1.py文件从sklearn库导入的:from sklearn.metrics import roc_auc_score, f1_score, precision_score, recall_score import numpy as np from sklearn.metrics import roc_auc_score, f1_score, precision_score, recall_score from paddle.metric import Metric class MultiLabelReport(Metric): AUC and F1 Score for multi-label text classification task. def __init__(self, name='MultiLabelReport', average='micro'): super(MultiLabelReport, self).__init__() self.average = average self._name = name self.reset() def f1_score(self, y_prob): Returns the f1 score by searching the best threshhold best_score = 0 for threshold in [i * 0.01 for i in range(100)]: self.y_pred = y_prob > threshold score = f1_score(y_pred=self.y_pred, y_true=self.y_true, average=self.average) if score > best_score: best_score = score precison = precision_score(y_pred=self.y_pred, y_true=self.y_true, average=self.average) recall = recall_score(y_pred=self.y_pred, y_true=self.y_true, average=self.average) return best_score, precison, recall def reset(self): Resets all of the metric state. self.y_prob = None self.y_true = None def update(self, probs, labels): if self.y_prob is not None: self.y_prob = np.append(self.y_prob, probs.numpy(), axis=0) else: self.y_prob = probs.numpy() if self.y_true is not None: self.y_true = np.append(self.y_true, labels.numpy(), axis=0) else: self.y_true = labels.numpy() def accumulate(self): auc = roc_auc_score( y_score=self.y_prob, y_true=self.y_true, average=self.average) f1_score, precison, recall = self.f1_score(y_prob=self.y_prob) return auc, f1_score, precison, recall def name(self): Returns metric name return self._name详细细节参考项目:#多卡训练: #unset CUDA_VISIBLE_DEVICES #!python -m paddle.distributed.launch --gpus "0" train.py --early_stop --dataset_dir data #使用多卡训练可以指定多个GPU卡号,例如 --gpus "0,1"2.3 模型预测输入待预测数据和数据标签对照列表,模型预测数据对应的标签使用默认数据进行预测:python predict.py --params_path ./checkpoint/也可以选择使用本地数据文件data/data.txt进行预测:!python predict.py --params_path ./checkpoint/ --dataset_dir data/wos_data输出结果:input data: a high degree of uncertainty associated with the emission inventory for china tends to degrade the performance of chemical transport models in predicting pm2.5 concentrations especially on a daily basis. in this study a novel machine learning algorithm, geographically -weighted gradient boosting machine (gw-gbm), was developed by improving gbm through building spatial smoothing kernels to weigh the loss function. this modification addressed the spatial nonstationarity of the relationships between pm2.5 concentrations and predictor variables such as aerosol optical depth (aod) and meteorological conditions. gw-gbm also overcame the estimation bias of pm2.5 concentrations due to missing aod retrievals, and thus potentially improved subsequent exposure analyses. gw-gbm showed good performance in predicting daily pm2.5 concentrations (r-2 = 0.76, rmse = 23.0 g/m(3)) even with partially missing aod data, which was better than the original gbm model (r-2 = 0.71, rmse = 25.3 g/m(3)). on the basis of the continuous spatiotemporal prediction of pm2.5 concentrations, it was predicted that 95% of the population lived in areas where the estimated annual mean pm2.5 concentration was higher than 35 g/m(3), and 45% of the population was exposed to pm2.5 >75 g/m(3) for over 100 days in 2014. gw-gbm accurately predicted continuous daily pm2.5 concentrations in china for assessing acute human health effects. (c) 2017 elsevier ltd. all rights reserved. predicted result: level 1: CS level 2: ---------------------------- input data: previous research exploring cognitive biases in bulimia nervosa suggests that attentional biases occur for both food-related and body-related cues. individuals with bulimia were compared to non-bulimic controls on an emotional-stroop task which contained both food-related and body-related cues. results indicated that bulimics (but not controls) demonstrated a cognitive bias for both food-related and body related cues. however, a discrepancy between the two cue-types was observed with body-related cognitive biases showing the most robust effects and food-related cognitive biases being the most strongly associated with the severity of the disorder. the results may have implications for clinical practice as bulimics with an increased cognitive bias for food-related cues indicated increased bulimic disorder severity. (c) 2016 elsevier ltd. all rights reserved. predicted result: level 1: Psychology level 2: ---------------------------- input data: posterior reversible encephalopathy syndrome (pres) is a reversible clinical and neuroradiological syndrome which may appear at any age and characterized by headache, altered consciousness, seizures, and cortical blindness. the exact incidence is still unknown. the most commonly identified causes include hypertensive encephalopathy, eclampsia, and some cytotoxic drugs. vasogenic edema related subcortical white matter lesions, hyperintense on t2a and flair sequences, in a relatively symmetrical pattern especially in the occipital and parietal lobes can be detected on cranial mr imaging. these findings tend to resolve partially or completely with early diagnosis and appropriate treatment. here in, we present a rare case of unilateral pres developed following the treatment with pazopanib, a testicular tumor vascular endothelial growth factor (vegf) inhibitory agent. predicted result: level 1: Medical level 2: 3.结论相关项目链接:Paddlenlp之UIE模型实战实体抽取任务【打车数据、快递单】Paddlenlp之UIE分类模型【以情感倾向分析新闻分类为例】含智能标注方案)[应用实践:分类模型大集成者[PaddleHub、Finetune、prompt]](https://aistudio.baidu.com/aistudio/projectdetail/4357474?contributionType=1)Paddlenlp之UIE关系抽取模型【高管关系抽取为例】PaddleNLP基于ERNIR3.0文本分类以中医疗搜索检索词意图分类(KUAKE-QIC)为例【多分类(单标签)】基于Ernie-3.0 CAIL2019法研杯要素识别多标签分类任务本项目主要讲解了层次分类任务、以及doccano标注指南(对于多分类多标签问题),和对性能指标的简单探讨,由于需要训练很久暂时就没长时间跑程序,从预测结果看来模型还能更佳精准,就交给后续的你了!欢迎大家关注我的主页:https://aistudio.baidu.com/aistudio/usercenter以及博客:https://blog.csdn.net/sinat_39620217?type=blog
PaddleNLP--UIE--小样本快速提升性能(含doccona标注
相关文章:1.快递单中抽取关键信息【一】----基于BiGRU+CR+预训练的词向量优化2.快递单信息抽取【二】基于ERNIE1.0至ErnieGram + CRF预训练模型3.快递单信息抽取【三】--五条标注数据提高准确率,仅需五条标注样本,快速完成快递单信息任务1)PaddleNLP通用信息抽取技术UIE【一】产业应用实例:信息抽取{实体关系抽取、中文分词、精准实体标。情感分析等}、文本纠错、问答系统、闲聊机器人、定制训练2)PaddleNLP--UIE(二)--小样本快速提升性能(含doccona标注)!强烈推荐:数据标注平台doccano----简介、安装、使用、踩坑记录本项目链接:https://aistudio.baidu.com/aistudio/projectdetail/4160689?contributionType=1项目主页:https://aistudio.baidu.com/aistudio/usercenter0.信息抽取定义以及难点自动从无结构或半结构的文本中抽取出结构化信息的任务, 主要包含的任务包含了实体识别、关系抽取、事件抽取、情感分析、评论抽取等任务; 同时信息抽取涉及的领域非常广泛,信息抽取的技术需求高,下面具体展现一些示例需求跨领域跨任务:领域之间知识迁移难度高,如通用领域知识很难迁移到垂类领域,垂类领域之间的知识很难相互迁移;存在实体、关系、事件等不同的信息抽取任务需求。定制化程度高:针对实体、关系、事件等不同的信息抽取任务,需要开发不同的模型,开发成本和机器资源消耗都很大。训练数据无或很少:部分领域数据稀缺,难以获取,且领域专业性使得数据标注门槛高。针对以上难题,中科院软件所和百度共同提出了一个大一统诸多任务的通用信息抽取技术 UIE(Unified Structure Generation for Universal Information Extraction),发表在ACL‘22。UIE在实体、关系、事件和情感等4个信息抽取任务、13个数据集的全监督、低资源和少样本设置下,UIE均取得了SOTA性能。PaddleNLP结合文心大模型中的知识增强NLP大模型ERNIE 3.0,发挥了UIE在中文任务上的强大潜力,开源了首个面向通用信息抽取的产业级技术方案,不需要标注数据(或仅需少量标注数据),即可快速完成各类信息抽取任务。**链接指路:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/uie )1.使用PaddleNLP Taskflow工具解决信息抽取难点(中文版本)1.1安装PaddleNLP! pip install --upgrade paddlenlp ! pip show paddlenlp1.2 使用Taskflow UIE任务看看效果人力资源入职证明信息抽取from paddlenlp import Taskflow schema = ['姓名', '毕业院校', '职位', '月收入', '身体状况'] ie = Taskflow('information_extraction', schema=schema)schema = ['姓名', '毕业院校', '职位', '月收入', '身体状况'] ie.set_schema(schema) ie('兹证明凌霄为本单位职工,已连续在我单位工作5 年。学历为嘉利顿大学毕业,目前在我单位担任总经理助理 职位。近一年内该员工在我单位平均月收入(税后)为 12000 元。该职工身体状况良好。本单位仅此承诺上述表述是正确的,真实的。')[{'姓名': [{'text': '凌霄', 'start': 3, 'end': 5, 'probability': 0.9042383385504706}], '毕业院校': [{'text': '嘉利顿大学', 'start': 28, 'end': 33, 'probability': 0.9927952662605009}], '职位': [{'text': '总经理助理', 'start': 44, 'end': 49, 'probability': 0.9922470268350594}], '月收入': [{'text': '12000 元', 'start': 77, 'end': 84, 'probability': 0.9788556518998917}], '身体状况': [{'text': '良好', 'start': 92, 'end': 94, 'probability': 0.9939678710475306}]}]# Jupyter Notebook默认做了格式化输出,如果使用其他代码编辑器,可以使用Python原生包pprint进行格式化输出 from pprint import pprint pprint(ie('兹证明凌霄为本单位职工,已连续在我单位工作5 年。学历为嘉利顿大学毕业,目前在我单位担任总经理助理 职位。近一年内该员工在我单位平均月收入(税后)为 12000 元。该职工身体状况良好。本单位仅此承诺上述表述是正确的,真实的。'))医疗病理分析schema = ['肿瘤部位', '肿瘤大小'] ie.set_schema(schema) ie('胃印戒细胞癌,肿瘤主要位于胃窦体部,大小6*2cm,癌组织侵及胃壁浆膜层,并侵犯血管和神经。')[{'肿瘤部位': [{'text': '胃窦体部', 'start': 13, 'end': 17, 'probability': 0.9601818899487213}], '肿瘤大小': [{'text': '6*2cm', 'start': 20, 'end': 25, 'probability': 0.9670914301489972}]}]1.3使用Taskflow UIE进行实体抽取、关系抽取、事件抽取、情感分类、观点抽取# 实体抽取 schema = ['时间', '赛手', '赛事名称'] ie.set_schema(schema) ie('2月8日上午北京冬奥会自由式滑雪女子大跳台决赛中中国选手谷爱凌以188.25分获得金牌!')[{'时间': [{'text': '2月8日上午', 'start': 0, 'end': 6, 'probability': 0.9857379716035553}], '赛手': [{'text': '中国选手谷爱凌', 'start': 24, 'end': 31, 'probability': 0.7232891682586384}], '赛事名称': [{'text': '北京冬奥会自由式滑雪女子大跳台决赛', 'start': 6, 'end': 23, 'probability': 0.8503080086948529}]}]# 关系抽取 schema = {'歌曲名称': ['歌手', '所属专辑']} ie.set_schema(schema) ie('《告别了》是孙耀威在专辑爱的故事里面的歌曲')[{'歌曲名称': [{'text': '告别了', 'start': 1, 'end': 4, 'probability': 0.629614912348881, 'relations': {'歌手': [{'text': '孙耀威', 'start': 6, 'end': 9, 'probability': 0.9988381005599081}], '所属专辑': [{'text': '爱的故事', 'start': 12, 'end': 16, 'probability': 0.9968462078543183}]}}, {'text': '爱的故事', 'start': 12, 'end': 16, 'probability': 0.28168707817316374, 'relations': {'歌手': [{'text': '孙耀威', 'start': 6, 'end': 9, 'probability': 0.9951415104192272}]}}]}]# 事件抽取 schema = {'地震触发词': ['地震强度', '时间', '震中位置', '震源深度']} # 事件需要通过xxx触发词来选择触发词 ie.set_schema(schema) ie('中国地震台网正式测定:5月16日06时08分在云南临沧市凤庆县(北纬24.34度,东经99.98度)发生3.5级地震,震源深度10千米。')[{'地震触发词': [{'text': '地震', 'start': 56, 'end': 58, 'probability': 0.9977425555988333, 'relations': {'地震强度': [{'text': '3.5级', 'start': 52, 'end': 56, 'probability': 0.998080217831891}], '时间': [{'text': '5月16日06时08分', 'start': 11, 'end': 22, 'probability': 0.9853299772936026}], '震中位置': [{'text': '云南临沧市凤庆县(北纬24.34度,东经99.98度)', 'start': 23, 'end': 50, 'probability': 0.7874014521275967}], '震源深度': [{'text': '10千米', 'start': 63, 'end': 67, 'probability': 0.9937974422968665}]}}]}]# 情感倾向分类 schema = '情感倾向[正向,负向]' # 分类任务需要[]来设置分类的label ie.set_schema(schema) ie('这个产品用起来真的很流畅,我非常喜欢')[{'情感倾向[正向,负向]': [{'text': '正向', 'probability': 0.9990024058203417}]}]# 评价抽取 schema = {'评价维度': ['观点词', '情感倾向[正向,负向]']} # 评价抽取的schema是固定的,后续直接按照这个schema进行观点抽取 ie.set_schema(schema) # Reset schema ie('地址不错,服务一般,设施陈旧')[{'评价维度': [{'text': '地址', 'start': 0, 'end': 2, 'probability': 0.9888139270606509, 'relations': {'观点词': [{'text': '不错', 'start': 2, 'end': 4, 'probability': 0.9927845886615216}], '情感倾向[正向,负向]': [{'text': '正向', 'probability': 0.998228967796706}]}}, {'text': '设施', 'start': 10, 'end': 12, 'probability': 0.9588298547520608, 'relations': {'观点词': [{'text': '陈旧', 'start': 12, 'end': 14, 'probability': 0.928675281256794}], '情感倾向[正向,负向]': [{'text': '负向', 'probability': 0.9949388606013692}]}}, {'text': '服务', 'start': 5, 'end': 7, 'probability': 0.9592857070501211, 'relations': {'观点词': [{'text': '一般', 'start': 7, 'end': 9, 'probability': 0.9949359182521675}], '情感倾向[正向,负向]': [{'text': '负向', 'probability': 0.9952498258302498}]}}]}]# 跨任务跨领域抽取 schema = ['寺庙', {'丈夫': '妻子'}] # 抽取的任务中包含了实体抽取和关系抽取 ie.set_schema(schema) ie('李治即位后,让身在感业寺的武则天续起头发,重新纳入后宫。')[{'寺庙': [{'text': '感业寺', 'start': 9, 'end': 12, 'probability': 0.9888581774497425}], '丈夫': [{'text': '李治', 'start': 0, 'end': 2, 'probability': 0.989690572797457, 'relations': {'妻子': [{'text': '武则天', 'start': 13, 'end': 16, 'probability': 0.9987625986790256}]}}]}]1.4使用Taskflow UIE一些技巧1.4.1. 调整batch_size提升预测效率from paddlenlp import Taskflow schema = ['费用'] ie.set_schema(schema) ie = Taskflow('information_extraction', schema=schema, batch_size=2) #资源不充裕情况,batch_size设置小点,利用率增加。。 ie(['二十号21点49分打车回家46块钱', '8月3号往返机场交通费110元', '2019年10月17日22点18分回家打车46元', '三月三0号23点10分加班打车21元'])[{'费用': [{'text': '46块钱', 'start': 13, 'end': 17, 'probability': 0.9781786110574338}]}, {'费用': [{'text': '110元', 'start': 11, 'end': 15, 'probability': 0.9504088995163151}]}, {'费用': [{'text': '46元', 'start': 21, 'end': 24, 'probability': 0.9753814247531167}]}, {'费用': [{'text': '21元', 'start': 15, 'end': 18, 'probability': 0.9761294626311425}]}]1.4.2. 使用UIE-Tiny模型来加快模型预测速度from paddlenlp import Taskflow schema = ['费用'] ie.set_schema(schema) ie = Taskflow('information_extraction', schema=schema, batch_size=2, model='uie-tiny') # ie(['二十号21点49分打车回家46块钱', '8月3号往返机场交通费110元', '2019年10月17日22点18分回家打车46元', '三月三0号23点10分加班打车21元'])[{'费用': [{'text': '46块钱', 'start': 13, 'end': 17, 'probability': 0.8945340489542026}]}, {'费用': [{'text': '110元', 'start': 11, 'end': 15, 'probability': 0.9757676375014448}]}, {'费用': [{'text': '46元', 'start': 21, 'end': 24, 'probability': 0.860397941604333}]}, {'费用': [{'text': '21元', 'start': 15, 'end': 18, 'probability': 0.8595131018474689}]}]2.小样本提升UIE效果Taskflow中的UIE基线版本我们是通过大量的有标签样本进行训练,但是UIE抽取的效果面对部分子领域的效果也不是令人满意,UIE可以通过小样本就可以快速提升效果。为什么UIE可以通过小样本来提升效果呢?UIE的建模方式主要是通过 Prompt 方式来建模, Prompt 在小样本上进行微调效果非常有效,下面我们通过一个具体的case来展示UIE微调的效果。2.1语音报销工单信息抽取1. 背景在某公司内部可以通过语音输入来报销打车费用,通过语音ASR模型可以将语音识别为文字,同时对文字信息进行信息抽取,抽取的信息主要是包括了4个方面,时间、出发地、目的地、费用,通过对文字4个方面的信息进行抽取就可以完成一个报销工单的填写。2. 挑战目前Taskflow UIE任务对于这种非常垂类的任务效果没有完全达到工业使用水平,因此需要一定的微调手段来完成UIE模型的微调来提升模型的效果,下面是一些case的展现ie.set_schema(['时间', '出发地', '目的地', '费用']) ie('10月16日高铁从杭州到上海南站车次d5414共48元') # 无法准确抽取出发地、目的地[{'时间': [{'text': '10月16日', 'start': 0, 'end': 6, 'probability': 0.9552445817793149}], '出发地': [{'text': '杭州', 'start': 9, 'end': 11, 'probability': 0.5713024802221334}], '费用': [{'text': '48元', 'start': 24, 'end': 27, 'probability': 0.8932524634666485}]}]2.2 标注数据参考链接详细版本---doccano标注过程我们推荐使用数据标注平台doccano 进行数据标注,本案例也打通了从标注到训练的通道,即doccano导出数据后可通过doccano.py脚本轻松将数据转换为输入模型时需要的形式,实现无缝衔接。为达到这个目的,您需要按以下标注规则在doccano平台上标注数据:Step 1. 本地安装doccano(请勿在AI Studio内部运行,本地测试环境python=3.8)$ pip install doccanoStep 2. 初始化数据库和账户(用户名和密码可替换为自定义值)$ doccano init``$ doccano createuser --username my_admin_name --password my_password``Step 3. 启动doccano在一个窗口启动doccano的WebServer,保持窗口``$ doccano webserver --port 8000``在另一个窗口启动doccano的任务队列``$ doccano task``Step 4. 运行doccano来标注实体和关系打开浏览器(推荐Chrome),在地址栏中输入http://127.0.0.1:8000/后回车即得以下界面。登陆账户。点击右上角的LOGIN,输入Step 2中设置的用户名和密码登陆。创建项目。点击左上角的CREATE,跳转至以下界面。勾选序列标注(Sequence Labeling)填写项目名称(Project name)等必要信息勾选允许实体重叠(Allow overlapping entity)、使用关系标注(Use relation labeling)创建完成后,项目首页视频提供了从数据导入到导出的七个步骤的详细说明。设置标签。在Labels一栏点击Actions,Create Label手动设置或者Import Labels从文件导入。最上边Span表示实体标签,Relation表示关系标签,需要分别设置。导入数据。在Datasets一栏点击Actions、Import Dataset从文件导入文本数据。根据文件格式(File format)给出的示例,选择适合的格式导入自定义数据文件。导入成功后即跳转至数据列表。标注数据。点击每条数据最右边的Annotate按钮开始标记。标记页面右侧的标签类型(Label Types)开关可在实体标签和关系标签之间切换。实体标注:直接用鼠标选取文本即可标注实体。关系标注:首先点击待标注的关系标签,接着依次点击相应的头尾实体可完成关系标注。导出数据。在Datasets一栏点击Actions、Export Dataset导出已标注的数据。将标注数据转化成UIE训练所需数据将doccano平台的标注数据保存在./data/目录。对于语音报销工单信息抽取的场景,可以直接下载标注好的数据。各个任务标注文档https://github.com/PaddlePaddle/PaddleNLP/blob/develop/model_zoo/uie/doccano.md! wget https://paddlenlp.bj.bcebos.com/datasets/erniekit/speech-cmd-analysis/audio-expense-account.jsonl ! mv audio-expense-account.jsonl ./data/运行以下代码将标注数据转换为UIE训练所需要的数据 splits 0.2 0.8 0.0 训练集 测试集 验证集可配置参数说明doccano_file: 从doccano导出的数据标注文件。save_dir: 训练数据的保存目录,默认存储在data目录下。negative_ratio: 最大负例比例,该参数只对抽取类型任务有效,适当构造负例可提升模型效果。负例数量和实际的标签数量有关,最大负例数量 = negative_ratio * 正例数量。该参数只对训练集有效,默认为5。为了保证评估指标的准确性,验证集和测试集默认构造全负例。splits: 划分数据集时训练集、验证集所占的比例。默认为[0.8, 0.1, 0.1]表示按照8:1:1的比例将数据划分为训练集、验证集和测试集。task_type: 选择任务类型,可选有抽取和分类两种类型的任务。options: 指定分类任务的类别标签,该参数只对分类类型任务有效。prompt_prefix: 声明分类任务的prompt前缀信息,该参数只对分类类型任务有效。is_shuffle: 是否对数据集进行随机打散,默认为True。seed: 随机种子,默认为1000.! python preprocess.py --input_file ./data/audio-expense-account.jsonl --save_dir ./data/ --negative_ratio 5 --splits 0.2 0.8 0.0 --seed 10002.3 训练UIE模型使用标注数据进行小样本训练,模型参数保存在./checkpoint/目录。tips: 推荐使用GPU环境,否则可能会内存溢出。CPU环境下,可以修改model为uie-tiny,适当调下batch_size。增加准确率的话:--num_epochs 设置大点多训练训练可配置参数说明:train_path: 训练集文件路径。dev_path: 验证集文件路径。save_dir: 模型存储路径,默认为./checkpoint。learning_rate: 学习率,默认为1e-5。batch_size: 批处理大小,请结合显存情况进行调整,若出现显存不足,请适当调低这一参数,默认为16。max_seq_len: 文本最大切分长度,输入超过最大长度时会对输入文本进行自动切分,默认为512。num_epochs: 训练轮数,默认为100。model: 选择模型,程序会基于选择的模型进行模型微调,可选有uie-base和uie-tiny,默认为uie-base。seed: 随机种子,默认为1000.logging_steps: 日志打印的间隔steps数,默认10。valid_steps: evaluate的间隔steps数,默认100。device: 选用什么设备进行训练,可选cpu或gpu。! python finetune.py --train_path ./data/train.txt --dev_path ./data/dev.txt --save_dir ./checkpoint --model uie-tiny --learning_rate 1e-5 --batch_size 2 --max_seq_len 512 --num_epochs 50 --seed 1000 --logging_steps 10 --valid_steps 10#! python finetune.py --train_path ./data/train.txt --dev_path ./data/dev.txt --save_dir ./checkpoint --model uie-base --learning_rate 1e-5 --batch_size 16 --max_seq_len 512 --num_epochs 50 --seed 1000 --logging_steps 10 --valid_steps 10使用小样本训练后的模型参数再次测试无法正确抽取的case。from paddlenlp import Taskflow schema = ['时间', '出发地', '目的地', '费用'] few_ie = Taskflow('information_extraction', schema=schema, task_path='./checkpoint/model_best') few_ie(['10月16日高铁从杭州到上海南站车次d5414共48元', '10月22日从公司到首都机场38元过路费'])[{'时间': [{'text': '10月16日', 'start': 0, 'end': 6, 'probability': 0.9998620769863464}], '出发地': [{'text': '杭州', 'start': 9, 'end': 11, 'probability': 0.997861665709749}], '目的地': [{'text': '上海南站', 'start': 12, 'end': 16, 'probability': 0.9974161074329579}], '费用': [{'text': '48', 'start': 24, 'end': 26, 'probability': 0.950222029031579}]}, {'时间': [{'text': '10月22日', 'start': 0, 'end': 6, 'probability': 0.9995716364718135}], '目的地': [{'text': '首都机场', 'start': 10, 'end': 14, 'probability': 0.9984550308953608}], '费用': [{'text': '38', 'start': 14, 'end': 16, 'probability': 0.9465688451171062}]}]
信息抽取UIE(二)--小样本快速提升性能(含doccona标注
相关文章:1.快递单中抽取关键信息【一】----基于BiGRU+CR+预训练的词向量优化2.快递单信息抽取【二】基于ERNIE1.0至ErnieGram + CRF预训练模型3.快递单信息抽取【三】--五条标注数据提高准确率,仅需五条标注样本,快速完成快递单信息任务1)PaddleNLP通用信息抽取技术UIE【一】产业应用实例:信息抽取{实体关系抽取、中文分词、精准实体标。情感分析等}、文本纠错、问答系统、闲聊机器人、定制训练2)PaddleNLP--UIE(二)--小样本快速提升性能(含doccona标注)!强烈推荐:数据标注平台doccano----简介、安装、使用、踩坑记录本项目链接:https://aistudio.baidu.com/aistudio/projectdetail/4160689?contributionType=1项目主页:https://aistudio.baidu.com/aistudio/usercenter0.信息抽取定义以及难点自动从无结构或半结构的文本中抽取出结构化信息的任务, 主要包含的任务包含了实体识别、关系抽取、事件抽取、情感分析、评论抽取等任务; 同时信息抽取涉及的领域非常广泛,信息抽取的技术需求高,下面具体展现一些示例需求跨领域跨任务:领域之间知识迁移难度高,如通用领域知识很难迁移到垂类领域,垂类领域之间的知识很难相互迁移;存在实体、关系、事件等不同的信息抽取任务需求。定制化程度高:针对实体、关系、事件等不同的信息抽取任务,需要开发不同的模型,开发成本和机器资源消耗都很大。训练数据无或很少:部分领域数据稀缺,难以获取,且领域专业性使得数据标注门槛高。针对以上难题,中科院软件所和百度共同提出了一个大一统诸多任务的通用信息抽取技术 UIE(Unified Structure Generation for Universal Information Extraction),发表在ACL‘22。UIE在实体、关系、事件和情感等4个信息抽取任务、13个数据集的全监督、低资源和少样本设置下,UIE均取得了SOTA性能。PaddleNLP结合文心大模型中的知识增强NLP大模型ERNIE 3.0,发挥了UIE在中文任务上的强大潜力,开源了首个面向通用信息抽取的产业级技术方案,不需要标注数据(或仅需少量标注数据),即可快速完成各类信息抽取任务。**链接指路:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/uie )1.使用PaddleNLP Taskflow工具解决信息抽取难点(中文版本)1.1安装PaddleNLP! pip install --upgrade paddlenlp ! pip show paddlenlp1.2 使用Taskflow UIE任务看看效果人力资源入职证明信息抽取from paddlenlp import Taskflow schema = ['姓名', '毕业院校', '职位', '月收入', '身体状况'] ie = Taskflow('information_extraction', schema=schema)schema = ['姓名', '毕业院校', '职位', '月收入', '身体状况'] ie.set_schema(schema) ie('兹证明凌霄为本单位职工,已连续在我单位工作5 年。学历为嘉利顿大学毕业,目前在我单位担任总经理助理 职位。近一年内该员工在我单位平均月收入(税后)为 12000 元。该职工身体状况良好。本单位仅此承诺上述表述是正确的,真实的。')[{'姓名': [{'text': '凌霄', 'start': 3, 'end': 5, 'probability': 0.9042383385504706}], '毕业院校': [{'text': '嘉利顿大学', 'start': 28, 'end': 33, 'probability': 0.9927952662605009}], '职位': [{'text': '总经理助理', 'start': 44, 'end': 49, 'probability': 0.9922470268350594}], '月收入': [{'text': '12000 元', 'start': 77, 'end': 84, 'probability': 0.9788556518998917}], '身体状况': [{'text': '良好', 'start': 92, 'end': 94, 'probability': 0.9939678710475306}]}]# Jupyter Notebook默认做了格式化输出,如果使用其他代码编辑器,可以使用Python原生包pprint进行格式化输出 from pprint import pprint pprint(ie('兹证明凌霄为本单位职工,已连续在我单位工作5 年。学历为嘉利顿大学毕业,目前在我单位担任总经理助理 职位。近一年内该员工在我单位平均月收入(税后)为 12000 元。该职工身体状况良好。本单位仅此承诺上述表述是正确的,真实的。'))医疗病理分析schema = ['肿瘤部位', '肿瘤大小'] ie.set_schema(schema) ie('胃印戒细胞癌,肿瘤主要位于胃窦体部,大小6*2cm,癌组织侵及胃壁浆膜层,并侵犯血管和神经。')[{'肿瘤部位': [{'text': '胃窦体部', 'start': 13, 'end': 17, 'probability': 0.9601818899487213}], '肿瘤大小': [{'text': '6*2cm', 'start': 20, 'end': 25, 'probability': 0.9670914301489972}]}]1.3使用Taskflow UIE进行实体抽取、关系抽取、事件抽取、情感分类、观点抽取# 实体抽取 schema = ['时间', '赛手', '赛事名称'] ie.set_schema(schema) ie('2月8日上午北京冬奥会自由式滑雪女子大跳台决赛中中国选手谷爱凌以188.25分获得金牌!')[{'时间': [{'text': '2月8日上午', 'start': 0, 'end': 6, 'probability': 0.9857379716035553}], '赛手': [{'text': '中国选手谷爱凌', 'start': 24, 'end': 31, 'probability': 0.7232891682586384}], '赛事名称': [{'text': '北京冬奥会自由式滑雪女子大跳台决赛', 'start': 6, 'end': 23, 'probability': 0.8503080086948529}]}]# 关系抽取 schema = {'歌曲名称': ['歌手', '所属专辑']} ie.set_schema(schema) ie('《告别了》是孙耀威在专辑爱的故事里面的歌曲')[{'歌曲名称': [{'text': '告别了', 'start': 1, 'end': 4, 'probability': 0.629614912348881, 'relations': {'歌手': [{'text': '孙耀威', 'start': 6, 'end': 9, 'probability': 0.9988381005599081}], '所属专辑': [{'text': '爱的故事', 'start': 12, 'end': 16, 'probability': 0.9968462078543183}]}}, {'text': '爱的故事', 'start': 12, 'end': 16, 'probability': 0.28168707817316374, 'relations': {'歌手': [{'text': '孙耀威', 'start': 6, 'end': 9, 'probability': 0.9951415104192272}]}}]}]# 事件抽取 schema = {'地震触发词': ['地震强度', '时间', '震中位置', '震源深度']} # 事件需要通过xxx触发词来选择触发词 ie.set_schema(schema) ie('中国地震台网正式测定:5月16日06时08分在云南临沧市凤庆县(北纬24.34度,东经99.98度)发生3.5级地震,震源深度10千米。')[{'地震触发词': [{'text': '地震', 'start': 56, 'end': 58, 'probability': 0.9977425555988333, 'relations': {'地震强度': [{'text': '3.5级', 'start': 52, 'end': 56, 'probability': 0.998080217831891}], '时间': [{'text': '5月16日06时08分', 'start': 11, 'end': 22, 'probability': 0.9853299772936026}], '震中位置': [{'text': '云南临沧市凤庆县(北纬24.34度,东经99.98度)', 'start': 23, 'end': 50, 'probability': 0.7874014521275967}], '震源深度': [{'text': '10千米', 'start': 63, 'end': 67, 'probability': 0.9937974422968665}]}}]}]# 情感倾向分类 schema = '情感倾向[正向,负向]' # 分类任务需要[]来设置分类的label ie.set_schema(schema) ie('这个产品用起来真的很流畅,我非常喜欢')[{'情感倾向[正向,负向]': [{'text': '正向', 'probability': 0.9990024058203417}]}]# 评价抽取 schema = {'评价维度': ['观点词', '情感倾向[正向,负向]']} # 评价抽取的schema是固定的,后续直接按照这个schema进行观点抽取 ie.set_schema(schema) # Reset schema ie('地址不错,服务一般,设施陈旧')[{'评价维度': [{'text': '地址', 'start': 0, 'end': 2, 'probability': 0.9888139270606509, 'relations': {'观点词': [{'text': '不错', 'start': 2, 'end': 4, 'probability': 0.9927845886615216}], '情感倾向[正向,负向]': [{'text': '正向', 'probability': 0.998228967796706}]}}, {'text': '设施', 'start': 10, 'end': 12, 'probability': 0.9588298547520608, 'relations': {'观点词': [{'text': '陈旧', 'start': 12, 'end': 14, 'probability': 0.928675281256794}], '情感倾向[正向,负向]': [{'text': '负向', 'probability': 0.9949388606013692}]}}, {'text': '服务', 'start': 5, 'end': 7, 'probability': 0.9592857070501211, 'relations': {'观点词': [{'text': '一般', 'start': 7, 'end': 9, 'probability': 0.9949359182521675}], '情感倾向[正向,负向]': [{'text': '负向', 'probability': 0.9952498258302498}]}}]}]# 跨任务跨领域抽取 schema = ['寺庙', {'丈夫': '妻子'}] # 抽取的任务中包含了实体抽取和关系抽取 ie.set_schema(schema) ie('李治即位后,让身在感业寺的武则天续起头发,重新纳入后宫。')[{'寺庙': [{'text': '感业寺', 'start': 9, 'end': 12, 'probability': 0.9888581774497425}], '丈夫': [{'text': '李治', 'start': 0, 'end': 2, 'probability': 0.989690572797457, 'relations': {'妻子': [{'text': '武则天', 'start': 13, 'end': 16, 'probability': 0.9987625986790256}]}}]}]1.4使用Taskflow UIE一些技巧1.4.1. 调整batch_size提升预测效率from paddlenlp import Taskflow schema = ['费用'] ie.set_schema(schema) ie = Taskflow('information_extraction', schema=schema, batch_size=2) #资源不充裕情况,batch_size设置小点,利用率增加。。 ie(['二十号21点49分打车回家46块钱', '8月3号往返机场交通费110元', '2019年10月17日22点18分回家打车46元', '三月三0号23点10分加班打车21元'])[{'费用': [{'text': '46块钱', 'start': 13, 'end': 17, 'probability': 0.9781786110574338}]}, {'费用': [{'text': '110元', 'start': 11, 'end': 15, 'probability': 0.9504088995163151}]}, {'费用': [{'text': '46元', 'start': 21, 'end': 24, 'probability': 0.9753814247531167}]}, {'费用': [{'text': '21元', 'start': 15, 'end': 18, 'probability': 0.9761294626311425}]}]1.4.2. 使用UIE-Tiny模型来加快模型预测速度from paddlenlp import Taskflow schema = ['费用'] ie.set_schema(schema) ie = Taskflow('information_extraction', schema=schema, batch_size=2, model='uie-tiny') # ie(['二十号21点49分打车回家46块钱', '8月3号往返机场交通费110元', '2019年10月17日22点18分回家打车46元', '三月三0号23点10分加班打车21元'])[{'费用': [{'text': '46块钱', 'start': 13, 'end': 17, 'probability': 0.8945340489542026}]}, {'费用': [{'text': '110元', 'start': 11, 'end': 15, 'probability': 0.9757676375014448}]}, {'费用': [{'text': '46元', 'start': 21, 'end': 24, 'probability': 0.860397941604333}]}, {'费用': [{'text': '21元', 'start': 15, 'end': 18, 'probability': 0.8595131018474689}]}]2.小样本提升UIE效果Taskflow中的UIE基线版本我们是通过大量的有标签样本进行训练,但是UIE抽取的效果面对部分子领域的效果也不是令人满意,UIE可以通过小样本就可以快速提升效果。为什么UIE可以通过小样本来提升效果呢?UIE的建模方式主要是通过 Prompt 方式来建模, Prompt 在小样本上进行微调效果非常有效,下面我们通过一个具体的case来展示UIE微调的效果。2.1语音报销工单信息抽取1. 背景在某公司内部可以通过语音输入来报销打车费用,通过语音ASR模型可以将语音识别为文字,同时对文字信息进行信息抽取,抽取的信息主要是包括了4个方面,时间、出发地、目的地、费用,通过对文字4个方面的信息进行抽取就可以完成一个报销工单的填写。2. 挑战目前Taskflow UIE任务对于这种非常垂类的任务效果没有完全达到工业使用水平,因此需要一定的微调手段来完成UIE模型的微调来提升模型的效果,下面是一些case的展现ie.set_schema(['时间', '出发地', '目的地', '费用']) ie('10月16日高铁从杭州到上海南站车次d5414共48元') # 无法准确抽取出发地、目的地[{'时间': [{'text': '10月16日', 'start': 0, 'end': 6, 'probability': 0.9552445817793149}], '出发地': [{'text': '杭州', 'start': 9, 'end': 11, 'probability': 0.5713024802221334}], '费用': [{'text': '48元', 'start': 24, 'end': 27, 'probability': 0.8932524634666485}]}]2.2 标注数据参考链接详细版本---doccano标注过程我们推荐使用数据标注平台doccano 进行数据标注,本案例也打通了从标注到训练的通道,即doccano导出数据后可通过doccano.py脚本轻松将数据转换为输入模型时需要的形式,实现无缝衔接。为达到这个目的,您需要按以下标注规则在doccano平台上标注数据:Step 1. 本地安装doccano(请勿在AI Studio内部运行,本地测试环境python=3.8)$ pip install doccanoStep 2. 初始化数据库和账户(用户名和密码可替换为自定义值)$ doccano init``$ doccano createuser --username my_admin_name --password my_password``Step 3. 启动doccano在一个窗口启动doccano的WebServer,保持窗口``$ doccano webserver --port 8000``在另一个窗口启动doccano的任务队列``$ doccano task``Step 4. 运行doccano来标注实体和关系打开浏览器(推荐Chrome),在地址栏中输入http://127.0.0.1:8000/后回车即得以下界面。登陆账户。点击右上角的LOGIN,输入Step 2中设置的用户名和密码登陆。创建项目。点击左上角的CREATE,跳转至以下界面。勾选序列标注(Sequence Labeling)填写项目名称(Project name)等必要信息勾选允许实体重叠(Allow overlapping entity)、使用关系标注(Use relation labeling)创建完成后,项目首页视频提供了从数据导入到导出的七个步骤的详细说明。设置标签。在Labels一栏点击Actions,Create Label手动设置或者Import Labels从文件导入。最上边Span表示实体标签,Relation表示关系标签,需要分别设置。导入数据。在Datasets一栏点击Actions、Import Dataset从文件导入文本数据。根据文件格式(File format)给出的示例,选择适合的格式导入自定义数据文件。导入成功后即跳转至数据列表。标注数据。点击每条数据最右边的Annotate按钮开始标记。标记页面右侧的标签类型(Label Types)开关可在实体标签和关系标签之间切换。实体标注:直接用鼠标选取文本即可标注实体。关系标注:首先点击待标注的关系标签,接着依次点击相应的头尾实体可完成关系标注。导出数据。在Datasets一栏点击Actions、Export Dataset导出已标注的数据。将标注数据转化成UIE训练所需数据将doccano平台的标注数据保存在./data/目录。对于语音报销工单信息抽取的场景,可以直接下载标注好的数据。各个任务标注文档https://github.com/PaddlePaddle/PaddleNLP/blob/develop/model_zoo/uie/doccano.md! wget https://paddlenlp.bj.bcebos.com/datasets/erniekit/speech-cmd-analysis/audio-expense-account.jsonl ! mv audio-expense-account.jsonl ./data/运行以下代码将标注数据转换为UIE训练所需要的数据 splits 0.2 0.8 0.0 训练集 测试集 验证集可配置参数说明doccano_file: 从doccano导出的数据标注文件。save_dir: 训练数据的保存目录,默认存储在data目录下。negative_ratio: 最大负例比例,该参数只对抽取类型任务有效,适当构造负例可提升模型效果。负例数量和实际的标签数量有关,最大负例数量 = negative_ratio * 正例数量。该参数只对训练集有效,默认为5。为了保证评估指标的准确性,验证集和测试集默认构造全负例。splits: 划分数据集时训练集、验证集所占的比例。默认为[0.8, 0.1, 0.1]表示按照8:1:1的比例将数据划分为训练集、验证集和测试集。task_type: 选择任务类型,可选有抽取和分类两种类型的任务。options: 指定分类任务的类别标签,该参数只对分类类型任务有效。prompt_prefix: 声明分类任务的prompt前缀信息,该参数只对分类类型任务有效。is_shuffle: 是否对数据集进行随机打散,默认为True。seed: 随机种子,默认为1000.! python preprocess.py --input_file ./data/audio-expense-account.jsonl --save_dir ./data/ --negative_ratio 5 --splits 0.2 0.8 0.0 --seed 10002.3 训练UIE模型使用标注数据进行小样本训练,模型参数保存在./checkpoint/目录。tips: 推荐使用GPU环境,否则可能会内存溢出。CPU环境下,可以修改model为uie-tiny,适当调下batch_size。增加准确率的话:--num_epochs 设置大点多训练训练可配置参数说明:train_path: 训练集文件路径。dev_path: 验证集文件路径。save_dir: 模型存储路径,默认为./checkpoint。learning_rate: 学习率,默认为1e-5。batch_size: 批处理大小,请结合显存情况进行调整,若出现显存不足,请适当调低这一参数,默认为16。max_seq_len: 文本最大切分长度,输入超过最大长度时会对输入文本进行自动切分,默认为512。num_epochs: 训练轮数,默认为100。model: 选择模型,程序会基于选择的模型进行模型微调,可选有uie-base和uie-tiny,默认为uie-base。seed: 随机种子,默认为1000.logging_steps: 日志打印的间隔steps数,默认10。valid_steps: evaluate的间隔steps数,默认100。device: 选用什么设备进行训练,可选cpu或gpu。! python finetune.py --train_path ./data/train.txt --dev_path ./data/dev.txt --save_dir ./checkpoint --model uie-tiny --learning_rate 1e-5 --batch_size 2 --max_seq_len 512 --num_epochs 50 --seed 1000 --logging_steps 10 --valid_steps 10#! python finetune.py --train_path ./data/train.txt --dev_path ./data/dev.txt --save_dir ./checkpoint --model uie-base --learning_rate 1e-5 --batch_size 16 --max_seq_len 512 --num_epochs 50 --seed 1000 --logging_steps 10 --valid_steps 10使用小样本训练后的模型参数再次测试无法正确抽取的case。from paddlenlp import Taskflow schema = ['时间', '出发地', '目的地', '费用'] few_ie = Taskflow('information_extraction', schema=schema, task_path='./checkpoint/model_best') few_ie(['10月16日高铁从杭州到上海南站车次d5414共48元', '10月22日从公司到首都机场38元过路费'])[{'时间': [{'text': '10月16日', 'start': 0, 'end': 6, 'probability': 0.9998620769863464}], '出发地': [{'text': '杭州', 'start': 9, 'end': 11, 'probability': 0.997861665709749}], '目的地': [{'text': '上海南站', 'start': 12, 'end': 16, 'probability': 0.9974161074329579}], '费用': [{'text': '48', 'start': 24, 'end': 26, 'probability': 0.950222029031579}]}, {'时间': [{'text': '10月22日', 'start': 0, 'end': 6, 'probability': 0.9995716364718135}], '目的地': [{'text': '首都机场', 'start': 10, 'end': 14, 'probability': 0.9984550308953608}], '费用': [{'text': '38', 'start': 14, 'end': 16, 'probability': 0.9465688451171062}]}]
AiTrust下预训练和小样本学习在中文医疗信息处理挑战榜CBLUE表现
项目链接:https://aistudio.baidu.com/aistudio/projectdetail/4592515?contributionType=1如果有图片缺失参考项目链接0.项目背景CBLUE又是一个CLUE榜单,大家都知道近年来NLP领域随着预训练语言模型(下面简称PTLM)的兴起又迎来了一波迅猛发展,得益于PTLM技术的推动,催生出一批多任务的benchmark榜单,代表性的工作是GLUE,在中文领域也有CLUE。CBLUE的全名是Chinese Biomedical Language Understanding Evaluation,是目前国内首个医疗AI方向的多任务榜单,相信这个榜单的推出会促进医疗语言模型的发展和医疗NLP领域的发展。榜单的官网介绍如下:中文医疗信息处理评测基准CBLUE(Chinese Biomedical Language Understanding Evaluation)是中国中文信息学会医疗健康与生物信息处理专业委员会在合法开放共享的理念下发起,由阿里云天池平台承办,并由医渡云(北京)技术有限公司、平安医疗科技、阿里夸克、腾讯天衍实验室、北京大学、鹏城实验室、哈尔滨工业大学(深圳)、郑州大学、同济大学、中山大学、复旦大学等开展智慧医疗研究的单位共同协办,旨在推动中文医学NLP技术和社区的发展。 榜单在设计上综合考虑了任务类型和任务难度两个维度,目标是建设一个任务类型覆盖广、同时也要保证任务的难度的benchmark,因此榜单在吸收往届CHIP/CCKS/CCL等学术评测任务的同时也适当增加了业界数据集,业务数据集的特点是数据真实且有噪音,对模型的鲁棒性提出了更高的要求。CBLUE评测基准2.0包括医学文本信息抽取(实体识别、关系抽取、事件抽取)、医学术语归一化、医学文本分类、医学句子关系判定和医疗对话理解与生成共5大类任务14个子任务。blog.csdnimg.cn/ef2cb516bcfa481ab30b0f345c4bf11a.png)中文领域也有CLUE:https://www.cluebenchmarks.com/index.html英文https://gluebenchmark.com/官网介绍榜单一共包含了4大类8细类任务,下面分别介绍:医学信息抽取:主要包含了实体识别NER任务和关系抽取RE两个数据集:CMeEE(Chinese Medical Entity Extraction):是由“北京大学”、“郑州大学”、“鹏城实验室”和“哈尔滨工业大学(深圳)”联合提供。共包括9大类实体:疾病(dis),临床表现(sym),药物(dru),医疗设备(equ),医疗程序(pro),身体(bod),医学检验项目(ite),微生物类(mic)和科室(dep),其中“临床表现”实体类别中允许嵌套,该实体内部允许存在其他八类实体。嵌套实体一向是NER任务中一个难点。CMeIE(Chinese Medical Information Extraction):和CMeEE任务一样,也是由“北京大学”、“郑州大学”、“鹏城实验室”和“哈尔滨工业大学(深圳)”联合提供的。共包括53类关系类型(具体类型参见官网介绍),这个任务需要打榜选手完成端对端的模型预测,即输入是原始的句子,选手需要完成实体识别和关系抽取两个任务。从关系种类的数量53类来看,且标注规范中有提及到关系可能是跨句子分布的(“Combined”字段为false),这是一个比较难的任务。医学术语归一化:这个任务按照我的理解是应该归属到信息抽取这个大类的,都属于知识图谱构造的关键技术,不知道官方为什么单独划分为一类,可能是有其他考虑。包括了一个数据集:CHIP-CDN(CHIP - Clinical Diagnosis Normalization dataset):CHIP这个名字一开始比较困惑,Google上查找了半天也没有找到是什么,后来仔细看官方文档才发现CHIP就是这个榜单的发起单位组织的专业会议(历史经验告诉我们任何时候都要认真读文档),CHIP表示中国健康信息处理会议,全称是China Health Information Processing Conference,是中国中文信息学会医疗健康与生物信息处理专业委员会主办的关于医疗、健康和生物信息处理和数据挖掘等技术的年度会议,是中国健康信息处理领域最重要的学术会议之一,这个会议已经连续举办了六届,最近几届都发布了医疗方向的学术评测任务,这个榜单很多以CHIP开头的数据集就是来源于大会上发布的评测任务。言归正传,CHIP-CDN数据集是由北京医渡云公司提供的,这是一个标准的实体标准化/归一化任务,将给定的医学症状实体映射到医学标准字典(ICD-10)上。这是一个很有实际意义的任务,医生在书写病历的时候,同一个术语往往有多种不同的写法,甚至一个症状可能是多个标准症状的叠加(如官网中的例子:“右肺结节转移可能大” -> “肺占位性病变##肺继发恶性肿瘤##转移性肿瘤”),非常的复杂。这类任务一般不能只靠模型来解决,需要结合具体的行业知识来做判定。医学文本分类:包括两个任务:CHIP-CTC(CHiP - Clinical Trial Criterion dataset):是由同济大学生命科学与技术学院提供,主要针对临床试验筛选标准进行分类,所有文本数据均来自于真实临床试验,也是一个有真实意义的任务。 从技术上看,这是一个典型的短文本多分类问题,共有44个类别(具体类别请参照官网),分类任务研究相对较多,一般需要注意的是类别比例的分布。KUAKE-QIC(KUAKE-Query Intention Classification dataset),是由夸克浏览器提供。这也是一个文本分类问题,共有11种分类(具体分类请查看官网),和CHIP-CTC数据集的区别是这个任务的输入均来自于真实的用户query,数据存在大量的噪音。医学句子关系判定/医学QA:包括3个数据集:CHIP-STS(CHIP - Semantic Textual Similarity dataset):是由平安医疗科技公司提供。是一个典型的语义相似度判断问题,数据集共包含5大类疾病,输出结果是0/1两类标签。这个任务应该不算太难,其中疾病的类别信息也是一个输入,模型在设计的时候要把这个feature考虑进去。KUAKE-QTR(KUAKE-Query Title Relevance dataset):也是由夸克公司提供,搞搜索推荐算法的小伙伴们一看就知道是一个QT match的问题,相比CHIP-STS,这个数据集是一个4分类问题(共0~3分 4档)。官网给的例子还是挺有难度区分的,感觉模型不太容易跑出高性能。KUAKE-QQR(KUAKE-Query Query Relevance dataset):也是由夸克公司提供。和KUAKE-QTR类似,是一个典型的Query-Query match问题,是一个3分类问题(共0~2分 3档)。难点同QTR。1.数据集加载&安装环境KUAKE-QIC(KUAKE-Query Intention Classification dataset),是由夸克浏览器提供。这也是一个文本分类问题,共有11种分类(具体分类请查看官网),和CHIP-CTC数据集的区别是这个任务的输入均来自于真实的用户query,数据存在大量的噪音。!wget https://paddlenlp.bj.bcebos.com/datasets/KUAKE_QIC.tar.gz !tar -zxvf KUAKE_QIC.tar.gz !mv KUAKE_QIC data !rm KUAKE_QIC.tar.gz !pip install --upgrade paddlenlp !pip install scikit-learn数据集展示心肌缺血如何治疗与调养呢? 治疗方案 19号来的月经,25号服用了紧急避孕药本月5号,怎么办? 治疗方案 什么叫痔核脱出?什么叫外痔? 疾病表述 您好,请问一岁三个月的孩子可以服用复方锌布颗粒吗? 其他 多发乳腺结节中药能治愈吗 疾病表述 有了中风怎么样治最好 治疗方案 输卵管粘连的基本检查 其他 尖锐湿疣吃什么中草药好 治疗方案 细胞病理学诊断非典型鳞状细胞,意义不明确。什么意思 指标解读 性生活后白带有酸味是怎么回事? 病情诊断 会是胎动么? 其他 经常干呕恶心,这是生病了吗 其他标签合集:病情诊断 2 预训练模型微调2.1 知识点:学习率warm-up由于神经网络在刚开始训练的时候是非常不稳定的,因此刚开始的学习率应当设置得很低很低,这样可以保证网络能够具有良好的收敛性。但是较低的学习率会使得训练过程变得非常缓慢,因此这里会采用以较低学习率逐渐增大至较高学习率的方式实现网络训练的“热身”阶段,称为 warmup stage。但是如果我们使得网络训练的 loss 最小,那么一直使用较高学习率是不合适的,因为它会使得权重的梯度一直来回震荡,很难使训练的损失值达到全局最低谷。在实际中,由于训练刚开始时,训练数据计算出的梯度 grad 可能与期望方向相反,所以此时采用较小的学习率 learning rate,随着迭代次数增加,学习率 lr 线性增大,增长率为 1/warmup_steps;迭代次数等于 warmup_steps 时,学习率为初始设定的学习率;另一种原因是由于刚开始训练时,模型的权重(weights)是随机初始化的,此时若选择一个较大的学习率,可能带来模型的不稳定(振荡),选择Warmup预热学习率的方式,可以使得开始训练的几个epoches内学习率较小,在预热的小学习率下,模型可以慢慢趋于稳定,等模型相对稳定后再选择预先设置的学习率进行训练,使得模型收敛速度变得更快,模型效果更佳。迭代次数超过warmup_steps时,学习率逐步衰减,衰减率为1/(total-warmup_steps),再进行微调。常见的warmup方式有三种:constant,linear和exponentconstant:在warmup期间,学习率 。ResNet论文中就使用了这种方式,在cifar10上训练ResNet 101时,先用0.01的学习率训练直到训练误差低于80%(大概训练了400个steps),然后使用0.1的学习率进行训练。 * linear:constant的不足之处在于从一个很小的学习率一下变为比较大的学习率可能会导致训练误差突然增大。linear方式可以避免这种问题,在warmup期间,学习率从 线性增长到 。 - **save_dir**:保存训练模型的目录;默认保存在当前目录checkpoint文件夹下。 - * train_file:本地数据集中训练集文件名;默认为"train.txt"。 - * dev_file:本地数据集中开发集文件名;默认为"dev.txt"。 - * label_file:本地数据集中标签集文件名;默认为"label.txt"。 - **device**: 选用什么设备进行训练,选择cpu、gpu、xpu、npu。如使用gpu训练,可使用参数--gpus指定GPU卡号;默认为"gpu"。 - **dataset_dir**::本地数据集路径,数据集路径中应包含train.txt,dev.txt和label.txt文件;默认为None。 - **dataset_dir**:本地数据集路径,数据集路径中应包含train.txt,dev.txt和label.txt文件;默认为None。 - max_seq_length:分词器tokenizer使用的最大序列长度,ERNIE模型最大不能超过2048。请根据文本长度选择,通常推荐128、256或512,若出现显存不足,请适当调低这一参数;默认为128。 **model_name**:选择预训练模型,可选"ernie-1.0-large-zh-cw","ernie-3.0-xbase-zh", "ernie-3.0-base-zh", "ernie-3.0-medium-zh", "ernie-3.0-micro-zh", "ernie-3.0-mini-zh", "ernie-3.0-nano-zh", "ernie-2.0-base-en", "ernie-2.0-large-en","ernie-m-base","ernie-m-large";默认为"ernie-3.0-medium-zh"。 - **batch_size**:批处理大小,请结合显存情况进行调整,若出现显存不足,请适当调低这一参数;默认为32。 - **learning_rate**:Fine-tune的最大学习率;默认为3e-5。 - **weight_decay**:控制正则项力度的参数,用于防止过拟合,默认为0.0。可以设置小点 如0.01等 - ** epochs:** 训练轮次,使用早停法时可以选择100;默认为10。 **early_stop**:选择是否使用早停法(EarlyStopping);模型在开发集经过一定epoch后精度表现不再上升,训练终止;默认为False。 - **early_stop_nums**:在设定的早停训练轮次内,模型在开发集上表现不再上升,训练终止;默认为4。 - **warmup**:是否使用学习率warmup策略,使用时应设置适当的训练轮次(epochs);默认为False。 - **warmup_proportion**:学习率warmup策略的比例数,如果设为0.1,则学习率会在前10%steps数从0慢慢增长到learning_rate, 而后再缓慢衰减;默认为0.1。 - **warmup_steps:**学习率warmup策略的比例数,如果设为1000,则学习率会在1000steps数从0慢慢增长到learning_rate, 而后再缓慢衰减;默认为0。 **logging_steps**: 日志打印的间隔steps数,默认5。 **init_from_ckpt**: 模型初始checkpoint参数地址,默认None。 **seed**:随机种子,默认为3。 训练结果: ```python [2022-09-24 23:46:42,282] [ INFO] - global step 2900, epoch: 14, batch: 79, loss: 0.08345, speed: 4.60 step/s [2022-09-24 23:46:47,353] [ INFO] - eval loss: 1.06234, acc: 0.80102 [2022-09-24 23:46:47,355] [ INFO] - Current best accuracy: 0.81330 [2022-09-24 23:46:58,502] [ INFO] - global step 2950, epoch: 14, batch: 129, loss: 0.00550, speed: 3.09 step/s [2022-09-24 23:47:10,650] [ INFO] - global step 3000, epoch: 14, batch: 179, loss: 0.00378, speed: 4.12 step/s [2022-09-24 23:47:15,735] [ INFO] - eval loss: 1.13159, acc: 0.80767 [2022-09-24 23:47:15,737] [ INFO] - Current best accuracy: 0.81330 [2022-09-24 23:47:23,969] [ INFO] - Early stop! [2022-09-24 23:47:23,969] [ INFO] - Final best accuracy: 0.81330 --dataset_dir "data/KUAKE_QIC" \ --params_path "./checkpoint/" \ --output_file "output.txt" text label 黑苦荞茶的功效与作用及食用方法 功效作用 交界痣会凸起吗 疾病表述 检查是否能怀孕挂什么科 就医建议 鱼油怎么吃咬破吃还是直接咽下去 其他 幼儿挑食的生理原因是 病因分析 # 3.小样本学习 提示学习(Prompt Learning)适用于标注成本高、标注样本较少的文本分类场景。在小样本场景中,相比于预训练模型微调学习,提示学习能取得更好的效果。 提示学习的主要思想是将文本分类任务转换为构造提示中掩码 [MASK] 的分类预测任务,也即在掩码 [MASK]向量后接入线性层分类器预测掩码位置可能的字或词。提示学习使用待预测字的预训练向量来初始化分类器参数(如果待预测的是词,则为词中所有字的预训练向量平均值),充分利用预训练语言模型学习到的特征和标签文本,从而降低样本需求。提示学习同时提供 R-Drop 和 RGL 策略,帮助提升模型效果。 ├── train.py # 模型组网训练脚本 ├── utils.py # 数据处理工具 ├── infer.py # 模型部署脚本 └── README.md ## 3.1 知识点:Rdrop技术(Regularized Dropout) 对比学习 RDrop: Regularized Dropout for Neural Networks 每个数据样本重复经过带有Dropout的同一个模型,再使用KL散度约束两次的输出,使得尽可能一致,而由于 Dropout的随机性,可以近似把输入X走过两次的路径网络当作两个略有不同的模型,如下图所示:  **R-Dropout的原理** 简单地说,就是模型中加入dropout,训练阶段的预测预测两次,要求两次的结果尽可能接近,这种接近体现在损失函数上。 那么,这个“接近”用的是什么呢?作者用的是KL散度。数学上的KL散度是用来对比两个分布是否相同,其连续型和离散型的公式分别是: OK,有这个基础,来继续看R-Dropout就更清晰了,我们要让两次预测结果的KL散度尽可能小,那么这部分的损失函数就可以构造出来了: KL散度本身是不具有自反性的,所以要用第一次预测对第二次的KL散度和第二次预测对第一次预测的KL散度的均值来进行计算。 这部分损失可以加入到整体损失里面作为最终优化的一部分,例如是log loss(当然,其他任务可以用其他的损失): **为什么R-Dropout会有用** 其实dropout的本质就是给模型加一些扰动,而R-dropout就是要扰动,更要保证这种扰动对结果尽可能小,毕竟这里还优化了两次预测的KL散度,所以其实这种训练就让模型的稳定性大幅提升。最近是遇到一些问题,一句话改一两个字意思还一样但是结果差距很大,这个r-dropout应该可以缓解这个问题,甚至说解决。 但是注意,这里是稳定性提升,我的感觉是并没有拉高模型本身的上限,甚至可能拉低上限。我们知道模型是存在不稳定性的,同一套数据的不同顺序,参数的不同初始化,不同的dropout都会导致模型效果存在波动,而且这个波动还不小,R-dropout本质上即使控制这种波动对结果的影响,从而保证了稳定性。而有关拉低上限,我的解释是最终的参数估计预测,相比不带有新的loss子项,这应该是一个有偏估计,还是可能一定程度拉低上限的。 **为什么用KL散度** KL散度本质上是一个对比分布的函数,这与R-Dropout的初衷一致的,要求两次预测尽可能相同,这里是指完全相同,例如多分类下要求的是所有预测的对应概率也是一致的,相比于交叉熵的只针对最优值的prob,这个对比会更加全面和完整。 知识点参考链接: https://blog.csdn.net/Jiana_Feng/article/details/123573686 https://blog.csdn.net/baidu_25854831/article/details/120136660?spm=1001.2101.3001.6650.4&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-4-120136660-blog-123573686.t0_edu_mlt&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-4-120136660-blog-123573686.t0_edu_mlt&utm_relevant_index=5 https://zhuanlan.zhihu.com/p/391881979 ## 3.2 模型训练与预测 ```python !python few-shot/train.py \ --device gpu \ --data_dir ./data/KUAKE_QIC \ --output_dir ./checkpoints_shot/ \ --prompt "这个分类是" \ --max_seq_length 128 \ --learning_rate 3e-5 \ --ppt_learning_rate 3e-4 \ --do_train \ --do_eval \ --use_rdrop \ --num_train_epochs 20 \ --eval_steps 200 \ --logging_steps 50 \ --per_device_eval_batch_size 32 \ --per_device_train_batch_size 32 \ --load_best_model_at_end \ --weight_decay 0.01 \ --save_steps 600 \ --warmup_ratio 0.15 # --warmup_steps 1000 \ #warm_up_ratio = 0.1 # 定义要预热的step #num_warmup_steps = warm_up_ratio * total_steps, num_training_steps = total_steps # --max_steps 5000 \ 可以选择epochs or steps # --do_predict \ # --do_export # --save_steps 500 #默认500 #--warmup_ratio #--warmup_steps #--weight_decay **model_name_or_path**: 内置模型名,或者模型参数配置目录路径。默认为ernie-3.0-base-zh。 **data_dir**: 训练数据集路径,数据格式要求详见数据准备。 **output_dir:** 模型参数、训练日志和静态图导出的保存目录。 **prompt**: 提示模板。定义了如何将文本和提示拼接结合。 **soft_encoder:** 提示向量的编码器,lstm表示双向LSTM, mlp表示双层线性层, None表示直接使用提示向量。默认为lstm。 **use_rdrop:** 使用 R-Drop 策略。 **use_rgl:** 使用 RGL 策略。 **encoder_hidden_size**: 提示向量的维度。若为None,则使用预训练模型字向量维度。默认为200。 **max_seq_length**: 最大句子长度,超过该长度的文本将被截断,不足的以Pad补全。提示文本不会被截断。 **learning_rate:** 预训练语言模型参数基础学习率大小,将与learning rate scheduler产生的值相乘作为当前学习率。 **ppt_learning_rate:** 提示相关参数的基础学习率大小,当预训练参数不固定时,与其共用learning rate scheduler。一般设为**learning_rate的十倍**。 **do_train:** 是否进行训练。 **do_eval:** 是否进行评估。 do_predict: 是否进行预测。 do_export: 是否在运行结束时将模型导出为静态图,保存路径为output_dir/export。 max_steps: 训练的最大步数。此设置将会覆盖num_train_epochs。 eval_steps: 评估模型的间隔步数。 device: 使用的设备,默认为gpu。 logging_steps: 打印日志的间隔步数。 **per_device_train_batch_size:** 每次训练每张卡上的样本数量。可根据实际GPU显存适当调小/调大此配置。 **per_device_eval_batch_size:** 每次评估每张卡上的样本数量。可根据实际GPU显存适当调小/调大此配置。 部分训练结果展示: 跑了两次:最优acc为0.81279-3400steps # 4. 模型优化:TrustAI、数据增强 训练后的模型我们可以使用 模型分析模块 对每个类别分别进行评估,并输出预测错误样本(bad case),默认在GPU环境下使用,在CPU环境下修改参数配置为--device "cpu": 模型表现常常受限于数据质量,在analysis模块中**基于TrustAI的稀疏数据筛选、脏数据清洗、数据增强**三种优化方案助力开发者提升模型效果,更多模型评估和优化方案细节详见训练评估与模型优化指南。 多分类训练评估与模型优化指南: https://github.com/PaddlePaddle/PaddleNLP/blob/develop/applications/text_classification/multi_class/analysis/README.md Data Augmentation API: https://github.com/PaddlePaddle/PaddleNLP/blob/develop/docs/dataaug.md TrustAI: https://github.com/PaddlePaddle/TrustAI ## 4.1 模型评估 使用训练好的模型计算模型的在开发集的准确率,同时打印每个类别数据量及表现: ```python !python analysis/evaluate.py \ --device "gpu" \ --max_seq_length 128 \ --batch_size 32 \ --bad_case_path "./bad_case.txt" \ --dataset_dir "data/KUAKE_QIC" \ --params_path "./checkpoint" 验证结果部分展示: ```python [2022-09-24 23:54:13,923] [ INFO] - -----Evaluate model------- [2022-09-24 23:54:13,923] [ INFO] - Train dataset size: 6931 [2022-09-24 23:54:13,923] [ INFO] - Dev dataset size: 1955 [2022-09-24 23:54:13,923] [ INFO] - Accuracy in dev dataset: 81.38% [2022-09-24 23:54:13,924] [ INFO] - Top-2 accuracy in dev dataset: 92.02% [2022-09-24 23:54:13,925] [ INFO] - Top-3 accuracy in dev dataset: 97.19% [2022-09-24 23:54:13,925] [ INFO] - Class name: 病情诊断 [2022-09-24 23:54:13,925] [ INFO] - Evaluation examples in train dataset: 877(12.7%) | precision: 97.65 | recall: 99.43 | F1 score 98.53 [2022-09-24 23:54:13,925] [ INFO] - Evaluation examples in dev dataset: 288(14.7%) | precision: 82.26 | recall: 88.54 | F1 score 85.28 [2022-09-24 23:54:13,925] [ INFO] - ---------------------------- [2022-09-24 23:54:13,925] [ INFO] - Class name: 治疗方案 [2022-09-24 23:54:13,926] [ INFO] - Evaluation examples in train dataset: 1750(25.2%) | precision: 98.48 | recall: 99.77 | F1 score 99.12 [2022-09-24 23:54:13,926] [ INFO] - Evaluation examples in dev dataset: 676(34.6%) | precision: 88.86 | recall: 93.20 | F1 score 90.97 [2022-09-24 23:54:13,926] [ INFO] - ---------------------------- .............. 可以看出不同类别识别难度不一: 预测错误的样本保存在bad_case.txt文件中: ```python 0.98 病情诊断 其他 最近好像有感冒,身上感觉不定位不定时的痛特别的左边背上还长了一个大包,右眼酸胀。我这样严重吗 0.98 注意事项 其他 月经来后能否继续用月经前用的药 0.97 治疗方案 其他 外阴骚痒,每次跟老公做完事后就有点痒,后来老公说是以前大腿内侧得过皮炎,请问是不是这个造成的,该如何.. 0.99 后果表述 其他 雌二醇在排卵期会怎样? 1.00 病情诊断 其他 白带变黄异味重,怎么会事 0.76 病情诊断 指标解读 孕酮低是不是更年期到了要绝经了 0.98 疾病表述 其他 喉癌的高发人群与先兆 0.99 疾病表述 注意事项 忧郁症的表现及注意点 0.79 功效作用 其他 医师您好:VE是什么,VE真的可以除去黑... 0.53 注意事项 治疗方案 如何预防春天感冒 0.92 病情诊断 其他 四个月大的宝宝喜欢反手抓人正常吗? 可以看到有364条预测错误,占比不少有待改进 ## 4.2 TrustAI:稀疏数据筛选方案 **总结为样本多样性丰富度不够!** 稀疏数据:**指缺乏足够训练数据支持导致低置信度的待预测数据**,简单来说,由于模型在训练过程中没有学习到足够与待预测样本相似的数据,模型难以正确预测样本所属类别。 本项目中稀疏数据筛选基于TrustAI(可信AI)工具集,利用基**于特征相似度的实例级证据分析方法,抽取开发集中样本的支持训练证据,并计算支持证据平均分(通常为得分前三的支持训练证据均分)。分数较低的样本表明其训练证据不足**,在训练集中较为稀疏,实验表明模型在这些样本上表现也相对较差。 稀疏数据筛选旨在开发集中挖掘缺乏训练证据支持的稀疏数据,**通常可以采用数据增强或少量数据标注的两种低成本方式,提升模型预测效果。** 实例级证据分析: https://github.com/PaddlePaddle/TrustAI/blob/main/trustai/interpretation/example_level/README.md 实例级证据分析旨在从训练数据中找出对当前预测起重要作用的若干条实例数据。开发者基于实例级证据可对训练数据中的问题进行分析,如识别训练集中的脏数据、识别数据稀疏等。 本工具包含多种实例级证据分析方法,如表示点方法、基于梯度的相似度方法、基于特征的相似度方法等。 * 表示点方法 * 基于梯度的相似度方法 * 基于特征的相似度方法 **表示点方法** 【脏数据清洗】 表示点方法(Representer Point)将训练数据对当前预测数据的重要度影响(即表征值),分解为训练数据对模型的影响和训练数据与预测数据的语义相关度。对于一条给定的测试数据和测试结果,表征值为正的训练数据表示支持该预测结果,相反,表征值为负的训练数据表示不支持该预测结果。同时,表征值的大小表示了训练数据对测试数据的影响程度。 在真实情况下,众包标注的语料通常掺杂噪音(标注错误),易干扰模型预测。表示点方法倾向于召回梯度较大的训练数据,因此开发者不仅可以使用实例级证据分析方法了解模型行为,也可以通过人工检测标注数据错误,提升模型效果。 **基于梯度的相似度方法** 基于梯度的相似度方法(Grad-Cosin, Grad-Dot)通过模型的梯度挑选对当前测试数据产生正影响和负影响的数据。 基于梯度的相似度方法召回了在梯度意义上对测试数据有正影响和负影响的实例数据。召回的正影响数据往往是与测试数据语义上比较相似且标签一致的数据,负影响数据通常可能是标注错误的、类别模糊的甚至是存在冲突的数据。 **基于特征的相似度方法** 【稀疏数据识别】 基于特征的相似度方法(Feature-Cosin, Feature-Dot, Feature-Euc)通过模型的特征挑选对当前测试数据有正影响和负影响的数据。 基于特征的相似度方法召回了在特征意义上对测试数据有正影响和负影响的实例数据。召回的正影响数据与GC方法相似,负影响数据更倾向于召回和测试数据字面不相似的数据。 详细demo见参考文档 ### 4.2.1稀疏数据识别--数据增强 这里我们将介绍稀疏数据识别--数据增强流程, 1. 首先使用数据增强脚本挖掘开发集中的稀疏数据 2. 然后筛选训练集中对稀疏数据的支持数据进行数据增强, 3. 最后将得到的数据增强后的支持数据加入到训练集中进行训练。 现在我们进行稀疏数据识别--数据增强,得到新增训练数据: ### 4.2.2稀疏数据识别--数据标注 这里我们将介绍稀疏数据识别--数据标注流程, 1. 首先使用数据增强脚本挖掘开发集中的稀疏数据, 2. 然后筛选对稀疏数据支持的未标注数据, 3. 最后将得到支持数据进行标注后加入到训练集中进行训练。 现在我们进行稀疏数据识别--数据标注,得到待标注数据: **annotate**:选择稀疏数据识别--数据标注模式;默认为False。 **unlabeled_file:** 本地数据集中未标注数据文件名;默认为"data.txt"。 ```python [2022-09-25 20:52:35,898] [ INFO] - Sparse data saved in ./data/KUAKE_QIC/sparse.txt [2022-09-25 20:52:35,898] [ INFO] - Accuracy in sparse data: 41.00% [2022-09-25 20:52:35,898] [ INFO] - Average score in sparse data: 0.7830 [2022-09-25 20:52:35,902] [ INFO] - We are using to load './checkpoint/'. [2022-09-25 20:52:40,282] [ INFO] - We are using to load './checkpoint/'. Extracting feature from given dataloader, it will take some time... [2022-09-25 20:52:40,878] [ ERROR] - The index is out of range, please reduce support_num or increase support_threshold. Got 1 now. [2022-09-25 20:52:40,879] [ INFO] - support data saved in ./data/KUAKE_QIC/support.txt [2022-09-25 20:52:40,879] [ INFO] - support average scores: 0.7153 **简单来讲就是标注一些困哪样本** ## 4.3 脏数据清洗方案 训练数据标注质量对模型效果有较大影响,但受限于标注人员水平、标注任务难易程度等影响,训练数据中都存在一定比例的标注较差的数据(脏数据)。当标注数据规模较大时,数据标注检查就成为一个难题。 本项目中脏数据清洗基于TrustAI(可信AI)工具集,**利用基于表示点方法的实例级证据分析方法**,计算训练数据对模型的影响分数,分数高的训练数据表明对模型影响大,这些数据有较大概率为脏数据(标注错误样本)。 现在我们进行脏数据识别,脏数据保存在"train_dirty.txt",剩余训练数据保存在"train_dirty_rest.txt": ## 4.4 数据增强策略方案 在数据量较少或某些类别样本量较少时,也可以通过数据增强策略的方式,生成更多的训练数据,提升模型效果。 Data Augmentation API:https://github.com/PaddlePaddle/PaddleNLP/blob/develop/docs/dataaug.md 词级别数据增强策略 * 词替换 * 词插入 * 词删除 * 词交换 采取替换就好: 同义词替换、同音词替换、本地词表替换、随机词替换 **上下文替换**:上下文替换是随机将句子中单词进行掩码,利用中文预训练模型ERNIE 1.0,根据句子中的上下文预测被掩码的单词。相比于根据词表进行词替换,上下文替换预测出的单词更匹配句子内容,数据增强所需的时间也更长。 **基于TF-IDF的词替换**:TF-IDF算法认为如果一个词在同一个句子中出现的次数多,词对句子的重要性就会增加;如果它在语料库中出现频率越高,它的重要性将被降低。我们将计算每个词的TF-IDF分数,低的TF-IDF得分将有很高的概率被替换。 train_path:待增强训练数据集文件路径;默认为"../data/train.txt"。 aug_path:增强生成的训练数据集文件路径;默认为"../data/train_aug.txt" **aug_strategy**:数据增强策略,可选"mix", "substitute", "insert", "delete", "swap","mix"为多种数据策略混合使用;默认为"**substitute**"。 **aug_type**:词替换/词插入增强类型,可选"synonym", "homonym", "mlm",建议在GPU环境下使用mlm类型;默认为"synonym"。同义词、同音词、mlm:上下文替换 **create_n**:生成的句子数量,默认为2。 **aug_percent**:生成词替换百分比,默认为0.1。 device: 选用什么设备进行增强,选择cpu、gpu、xpu、npu,仅在使用mlm类型有影响;默认为"gpu"。 WordSubstitute 参数介绍: aug_type(str or list(str)): 词替换增强策略类别。可以选择"synonym"、"homonym"、"custom"、"random"、"mlm"或者 前三种词替换增强策略组合。 custom_file_path (str,*可选*): 本地数据增强词表路径。如果词替换增强策略选择"custom",本地数据增强词表路径不能为None。默认为None。 create_n(int): 数据增强句子数量。默认为1。 aug_n(int): 数据增强句子中被替换词数量。默认为None aug_percent(int): 数据增强句子中被替换词数量占全句词比例。如果aug_n不为None,则被替换词数量为aug_n。默认为0.02。 aug_min (int): 数据增强句子中被替换词数量最小值。默认为1。 aug_max (int): 数据增强句子中被替换词数量最大值。默认为10。 tf_idf (bool): 使用TF-IDF分数确定哪些词进行增强。默认为False。 tf_idf_file (str,*可选*): 用于计算TF-IDF分数的文件。如果tf_idf为True,本地数据增强词表路径不能为None。默认为None。 ## 4.5数据增强后进行预训练+小样本训练 把final_data放回到data进行训练 # 5.总结 本项目主要讲解了再主流中文医疗信息处理评测基准CBLUE榜单的一个多分类任务,并对warmup、Rdrop等技术进行简单介绍,使用预训练,小样本学习并通过AITrust可信分析提升模型性能,结果如下: | 模型 | acc | | -------- | -------- | | 预训练 ernie3.0 | 0.81330 | | 小样本 ernie3.0 | 0.81279 | | 预训练 ernie3.0 +数据增强(aitrust) | 0.81688 | | 小样本 ernie3.0+数据增强(aitrust) | 0.81764 | 可以看出在样本量还算大的情况下,预训练方式更有优势(准确率略高一点且训练更快一些),通过AITrust可信分析:稀疏数据筛选、脏数据清洗、数据增强等方案看到模型性能都有提升; 这里提升不显著的原因是,这边没有对筛选出来数据集进行标注:因为没有特定背景知识就不花时间操作了,会导致仍会有噪声存在。相信标注完后能提升3-5%点 1. 对于大多数任务,我们使用预训练模型微调作为首选的文本分类方案:准确率较高,训练较快 2. 提示学习(Prompt Learning)适用于标注成本高、标注样本较少的文本分类场景。在小样本场景中,相比于预训练模型微调学习,提示学习能取得更好的效果。对于标注样本充足、标注成本较低的场景,推荐使用充足的标注样本进行文本分类预训练模型微调 **为了增加性能---可以做成持续学习:** 参考如下图 项目链接: [https://aistudio.baidu.com/aistudio/projectdetail/4592515?contributionType=1](https://aistudio.baidu.com/aistudio/projectdetail/4592515?contributionType=1) 如果有图片缺失参考项目链接 **具体代码fork项目即可**
阿里云智能语音交互产品测评:基于语音识别、语音合成、自然语言理解等技术
智能语音交互基于语音识别、语音合成、自然语言理解等技术,实现“能听、会说、懂你”式的智能人机交互体验,适用于智能客服、质检、会议纪要、实时字幕等多个企业应用场景。
目前已上线实时语音识别、一句话识别、录音文件识别、语音合成等多款产品,您可以在控制台页面进行试用,也可以通过API调用相关能力。
全栈工程师的优点与价值 其实在我们了解了全栈工程师的概念后,就很容易联想到其优点:
减少了沟通时间,降低了沟通成本,提高了开发效率。
由于前后端,甚至产品的业务,都有一个人来负责完成,不需要沟通,各个端的配合是100%的默契配合,这从很大程度上提高了开发效率。
虽然全栈工程师的知识面较广,能够完成一些前端及后端的开发工作,但全栈开发师的厉害之处并不是他掌握很多知识,可以一个人干多份工作。
而他真正的价值在于处理问题的时候拥有全局性思维。
现在科技日新月异,web前端不再是从前切个图用个jQuery上个AJAX兼容各种浏览器那么简单。现代的Web前端,你需要用到模块化开发、多屏兼容、MVC,各种复杂的交互与优化,甚至你需要用到Node.js来协助前端的开发。一个现代化的项目,是一个非常复杂的构成,我们需要一个人来掌控全局,他不需要是各种技术的资深专家,但他需要熟悉到各种技术。对于一个团队特别是互联网企业来说,有一个全局性思维的人显得尤其重要,这个时候也就彰显了全栈开发工程师的价值。
开源社区该如何建立“可控开源”体系?
1.可控开源体系
开源软件相比于闭源软件,能够获得更多的开发者和关注,社区可以向开源项目提交代码,从而针对所遇见的问题提供相应的解决方案。相比于商业公司,这样能够找到的 Bug 更多,更好。这样的认知,我将其称之为「开源的机制安全」,也就是说,这个机制是可以让整个软件更加的安全。
但是,机制安全并不能够保证软件足够的安全。机制安全能够成立的前提有很多,比如:
开源项目的团队会接受来自社区的贡献:虽然不少项目都开源了,但是很少合并来自社区的贡献,这使得该软件虽然开源了,但是实际上并没有享受到开源软件所带来的机制安全。
开源项目的团队获取到足够多的社区贡献:相比于一些知名的开源项目,你所使用、贡献的项目可能并没有足够多的开发者来为其贡献代码,在发现 Bug 的方面,因为没有足够多的人,也就导致了相对来说,不够安全。
此外,开源这件事在安全层面来看,就是一把双刃剑。固然你通过开源获取到了更多的贡献,但同时因为你将测试从黑盒测试转为了白盒测试。 开发者只需要阅读已经开源的代码,就可以从中发现漏洞并使用漏洞。
那么: 开源社区需要为开源软件的安全负责吗?
为了开源生态能更好的发展,应该如何保证“开源可控”?
举个简单例子:
这段代码单独来看是没有任何问题的,因为它在清理完磁盘队列后会设置pf->disk->queue=null,如果作为一个静态代码审核者,从中肯定看不出任何问题。作为OS内核核心代码,做完整的动态测试是不可能的,因此这段代码是否有问题只能是在开源软件使用者报错的时候才能被发现。但是pf_detect()和另外一个函数pf_uexit()这两个函数,在queue指针为空后的时候被调用,它们将在不检查指针状态的情况下对pf->disk->queue进行操作,从而导致空指针取消引用,导致系统中的相关核心进程崩溃,甚至引起CORE PANIC。原本只有pf_uexit中会做清理,因此不会存在空指针操作的问题。当引入这个补丁后,出现了多次调用清理的可能,因此就可能触发空指针问题。
根据上面的例子,只要提交一个可以触发在该指针为空的时候调用这两个函数的补丁,就很容易会激活这个原本不会造成太大影响的代码缺陷,导致大的故障。别有用心的伪代码贡献者就可以利用这个以前并不会对系统造成多大影响的隐患,通过自己添加的看似无害的代码去主动激活这个隐患,从而造成很大的安全事故。此类的恶意代码攻击手段还有很多。
另外一个开源社区难以防范此类恶意代码攻击的原因是开源社区无法很好的对代码贡献者进行管控,因为理论上任何一个人都可以成为代码贡献者。而在开源社区里,实名制是十分困难的,建立代码贡献者溯源也十分困难。上面是论文中对于伪代码贡献者通过linux开源社区对于代码管理方面的漏洞进行的恶意攻击的示意图。其实我们讨论开源代码的不安全问题并不是为了因噎废食,而是需要找到解决这些问题的方法。中国的基础软件产业需要快速发展,依靠开源社区是一条必须走的捷径,这一点是毋庸置疑的。购买成熟的商业软件公司和直接使用开源代码进行二次开发,从本质上并无优劣之分,都是快速构建信创软件生态的好办法。
一方面是选择开源协议的问题,一方面是代码本身的安全问题。从代码安全方面我们有几条路可走,一条路是基于某个开源代码进行魔改,最终放弃开源代码,完全走向自主的闭源代码。这条路国内的一些大型企业在走。包括腾讯QQ的前身OICQ当年也是使用了大量的ICQ的代码的。华为的OPENGAUSS是基于PostgreSQL 9.2.4的,不过OPENGAUSS已经对代码进行了魔改,连PG的多进程架构都被改成了多线程架构。这种脱离社区代码的完全自主改造,是有成本和代价的,只有具有极强研发能力的企业才能在这条路上走的比较成功。目前我无法说华为的做法是正确的还是错误的,也许等OPENGAUSS 3.0出来后和PG 14比较一下,才能看出来这条路走的是否正确。当然这个正确也是基于时间的,如果华为能坚持走上数年,我想OPENGAUSS全面超过社区版的PG并非不可能。
除了魔改外,还有一条路就像红帽一样,依靠上游的开源社区来发展自己的软件。如果是这样,那么我们就要加强对开源代码的管控,通过自动化工具与人工核查的方法,对代码进行静态与动态分析,从而构建强大的开源代码安全管控能力。成为一家像红帽一样伟大的基于开源生态的软件公司。
可能有朋友要说了,我们既不是华为阿里这样的大厂,又没有强大的代码安全管控能力,我们只是一个开源软件产品的使用者。我们该怎么办呢?难道我们就不能使用开源软件了吗?答案当然是否定的,如果我们的羊圈不够牢固,那么我们就把羊圈修在城里吧,把自己的网络环境的安全搞搞好,增加通用安全防护的投入,启用更为严格的安全防护规章制度等,都是有效提升企业信息系统安全的好方法。作为最终用户,守住安全底线总还是需要的。一个连勒索病毒都会中的企业,其安全管控恐怕基本上等于空白了。
文章最后:上云能从一定程度上解决开源带来的安全性问题吗?,是可以一定程度缓解上述问题,这也是阿里做的好的地方,也是值得大家关注的点。
你使用过哪些云产品组合进行开发?
目前国内的云服务商中,阿里云、腾讯云、华为云是受关注最高的服务商,也是大量的中小型企业由原来的物理服务器转向了云服务器的首选云服务商。和传统的物理物理服务器相比,云服务器具有更安全、业务配置更快、选择更灵活、使用成本更低等优点。不管是用来建网站还搭建电子商务\游戏平台、各类APP\办公系统应用以及测试技术代码等都是非常方便的。
阿里云 一、阿里云服务器 阿里云服务器ECS(Elastic Compute Service)是阿里云提供的性能卓越、稳定可靠、弹性扩展的IaaS(Infrastructure as a Service)级别云计算服务。
二:阿里云服务器可以用来 1、企业官网或轻量的Web应用 网站初始阶段访问量小,只需要一台低配置的云服务器ECS实例即可运行Apache或Nginx等Web应用程序、数据库、存储文件等。随着网站发展,您可以随时升级ECS实例的配置,或者增加ECS实例数量,无需担心低配计算单元在业务突增时带来的资源不足。
2、多媒体以及高并发应用或网站 云服务器ECS与对象存储OSS搭配,对象存储OSS承载静态图片、视频或者下载包,进而降低存储费用。同时配合内容分发网络CDN和负载均衡SLB,可大幅减少用户访问等待时间、降低网络带宽费用以及提高可用性。
3、高I/O要求数据库 支持承载高I/O要求的数据库,如OLTP类型数据库以及NoSQL类型数据库。您可以使用较高配置的I/O优化型云服务器ECS,同时采用ESSD云盘,可实现高I/O并发响应和更高的数据可靠性。您也可以使用多台中等偏下配置的I/O优化型ECS实例,搭配负载均衡SLB,建设高可用底层架构。
4、访问量波动剧烈的应用或网站 某些应用,如抢红包应用、优惠券发放应用、电商网站和票务网站,访问量可能会在短时间内产生巨大的波动。您可以配合使用弹性伸缩,自动化实现在请求高峰来临前增加ECS实例,并在进入请求低谷时减少ECS实例。满足访问量达到峰值时对资源的要求,同时降低了成本。如果搭配负载均衡SLB,您还可以实现高可用应用架构。
5、大数据及实时在线或离线分析 云服务器ECS提供了大数据类型实例规格族,支持Hadoop分布式计算、日志处理和大型数据仓库等业务场景。由于大数据类型实例规格采用了本地存储的架构,云服务器ECS在保证海量存储空间、高存储性能的前提下,可以为云端的Hadoop集群、Spark集群提供更高的网络性能。
6、机器学习和深度学习等AI应用 通过采用GPU计算型实例,您可以搭建基于TensorFlow框架等的AI应用。此外,GPU计算型还可以降低客户端的计算能力要求,适用于图形处理、云游戏云端实时渲染、AR/VR的云端实时渲染等瘦终端场景。
二、腾讯云服务器 腾讯云服务器(Cloud Virtual Machine,CVM)为您提供安全可靠的弹性计算服务。 只需几分钟,您就可以在云端获取和启用 CVM,用于实现您的计算需求。随着业务需求的变化,您可以实时扩展或缩减计算资源。
参考链接:https://zhuanlan.zhihu.com/p/536187643
三、华为云 华为云服务器 弹性云服务器(Elastic Cloud Server,ECS)是由CPU、内存、操作系统、云硬盘组成的基础的计算组件。弹性云服务器创建成功后,您就可以像使用自己的本地PC或物理服务器一样,在云上使用弹性云服务器。
华为云服务器使用场景 1、网站应用 对CPU、内存、硬盘空间和带宽无特殊要求,对安全性、可靠性要求高,服务一般只需要部署在一台或少量的服务器上,一次投入成本少,后期维护成本低的场景。例如网站开发测试环境、小型数据库应用。 推荐使用通用型弹性云服务器,主要提供均衡的计算、内存和网络资源,适用于业务负载压力适中的应用场景,满足企业或个人普通业务搬迁上云需求。
2、企业电商 对内存要求高、数据量大并且数据访问量大、要求快速的数据交换和处理的场景。例如广告精准营销、电商、移动APP。 推荐使用内存优化型弹性云服务器,主要提供高内存实例,同时可以配置超高IO的云硬盘和合适的带宽。
3、图形渲染 对图像视频质量要求高、大内存,大量数据处理,I/O并发能力。可以完成快速的数据处理交换以及大量的GPU计算能力的场景。例如图形渲染、工程制图。 推荐使用GPU图形加速型弹性云服务器,G1型弹性云服务器基于NVIDIA Tesla M60硬件虚拟化技术,提供较为经济的图形加速能力。能够支持DirectX、OpenGL,可以提供最大显存1GiB、分辩率为4096×2160的图形图像处理能力。
4、数据分析 处理大容量数据,需要高I/O能力和快速的数据交换处理能力的场景。例如MapReduce 、Hadoop计算密集型。 推荐使用磁盘增强型弹性云服务器,主要适用于需要对本地存储上的极大型数据集进行高性能顺序读写访问的工作负载,例如:Hadoop分布式计算,大规模的并行数据处理和日志处理应用。主要的数据存储是基于HDD的存储实例,默认配置最高10GE网络能力,提供较高的PPS性能和网络低延迟。最大可支持24个本地磁盘、48个vCPU和384GiB内存。
5、高性能计算 高计算能力、高吞吐量的场景。例如科学计算、基因工程、游戏动画、生物制药计算和存储系统。 推荐使用高性能计算型弹性云服务器,主要使用在受计算限制的高性能处理器的应用程序上,适合要求提供海量并行计算资源、高性能的基础设施服务,需要达到高性能计算和海量存储,对渲染的效率有一定保障的场景。
Serverless在推进过程中会遇到什么样的挑战?该如何破局?
serverless最大的优势在于资源得到了更合理的利用: 1.快速迭代与部署 2.高并发、高弹性 3.稳定、可靠、安全 4.运维与成本控制
下面进行简单分析:
传统的购买服务器部署应用的方式,在没有使用的时候,服务器就被浪费掉了,对于我这种需要部署一些个人用的小规模应用的情况,买服务器非常的不合算,每天可能实际使用就几分钟,大部分时间都在空置。但是 serverless 是按照实际使用次数/时长来计费的,也就是说,不用的时候真正不花一分钱。所以我越来越多的使用 serverless 部署这些小规模应用,每天实际上使用的 CPU 时间加起来可能还不到一秒,这可以把我的使用成本压缩到几乎忽略不计的程度上。
1.更多人像我这样部署到 serverless 之后,总的服务器消耗就大幅度下降了,原本可能每个人都需要一台独立的服务器,现在上百个人可能实际上就只共享了一台服务器,但每个人都能有良好的用户体验。2.serverless 先天是高并发的,可以无限制的并发请求。当我自己购买服务器部署时,我需要自己在开发应用时解决并发问题,要么就是单线程同时只处理一个请求。3.serverless 开发的时候就不用管并发,我的代码只要能处理一个请求,那么就一定能同时创建无限的运行时来处理更多的请求。4. serverless 的高并发不需要在同一台物理服务器上运行,事实上可以跑在任意位置任意数量的物理服务器上,当我一份代码部署完成之后,用户访问时可以就近选择最近的节点,从而降低延迟,而对于单一物理服务器的传统部署,地球对面的用户访问起来就会非常痛苦。
因为每个请求都是在独立运行时里处理的,错误处理也可以变得很简单,很多不处理就会崩溃的地方真的可以不处理,崩就崩呗,反正就崩单一请求对应的运行时,对其他用户没影响。不像开发传统服务器应用,得尽可能不崩溃否则崩了还得远程上去重启进程。从这个角度来看 serverless 是轻量化应用的最优解决方案,成本更低,复杂度更低,用户体验更好。当然,方便的前提一定是更低的自由度,所以对于复杂的企业项目, serverless 仍然不能成为首选
ModelScope社区上线,怎么看待它在AIGC发展中起到的作用?
2022至今,从DALL-E2、 StableDiffusion等人工智能技术,到 ChatGPT等人工智能技术, AIGC领域在互联网上掀起了轩然大波,它那惊人的创作速度,让所有人都为之惊叹。业界曾经也有一个普遍的看法: AIGC绝不会是一种短暂的热点,它的基础技术和工业生态都在不断地迭代进步着。
首先是基本的算法建模,持续地进行突破和革新。例如 GAN、 Transformer、扩散模型等,其性能、稳定性和生成内容质量都在逐步提高。由于生成算法的不断发展, AIGC可以生成不同种类的内容和资料,如文字,代码,图像,语音,视频,三维物体等。
然后是预习模型,即基础模型,大模型,使 AIGC的技术实力发生了质的变化。以往各种生成模式都有,但由于使用门槛高、训练成本高、内容生成简单、质量差等原因,很难适应现实内容的要求。而该系统的前培训模式可以满足多任务、多场景和多功能需求,可以有效地克服上述问题。该技术还使 AIGC的应用和产业化程度得到了明显的提高, AIGC模式能够实现高品质的内容产出,从而使 AIGC模式既是“工厂”,又是“流水线”。因此,诸如谷歌,微软, OpenAI等公司都在积极地推进 AI技术的发展,将其推向了预先培训的模式。
另外多模态技术促进了 AIGC的内容多元化,使 AIGC的通用性能得到了提高。多模式技术实现了语言文字、图像、音视频等不同的信息之间的转换和产生。例如 CLIP,可以将文本与图片进行联系,例如把“狗”与“狗狗”相联系,同时具有大量的相关特性。这为文生图、文生视频等 AIGC技术的发展打下了良好的基础。
AIGC在消费互联网,工业互联网和社交价值等方面的不断升级迭代。当前 AIGC领域的内容类型不断丰富,内容质量不断提高,技术通用化和产业化程度不断提高, AIGC逐渐成为消费者网络领域的主流,出现了写作助手、 AI绘画、对话机器人、数字人等爆款级应用,支撑着传媒、电商、娱乐、影视等领域的内容需求。现在 AIGC也将其扩展到工业互联网,社会价值领域。
未来已经来临,让我们一起迎接 AIGC,迎接下一个新世纪的人工智能,未来一段时间,国产AIGC的产品更多的涌现出来,为中国的人工智能产业创造辉煌。
ChatGPT给国内外科技公司带来了怎样的机遇和威胁?
简单说一下,从NLP中的ChatGPT,以及AI绘画,在这个过程中AI绘画也得到了升级,从原来的二次元绘画到达了真人照片绘画。

在ChatGPT的光芒掩盖一切的这段时间,图像生成AI已经从从画画悄悄进化到了“画照片”。
回归上题“ChatGPT给国内外科技公司带来了怎样的机遇和威胁?” 我认为威胁便是国外先遣者“谷歌微软”的冲击,第一个吃螃蟹;机遇便是新兴技术发展和耦合,,就像有网友表示:AI聊天+AI照片,快进到AI网恋诈骗。应该图+文结合发挥新的商业模式别单独停留在一个点上,乃至后面的视频生成,可发展领域很多。或者说是革新原有很多领域!

基于强化学习的斗地主游戏。首先,斗地主是一种经典的纸牌游戏,它的规则非常简单,玩家需要通过出牌组成各种牌型,最终以出牌最快的方式获胜。强化学习是一种机器学习方法,它通过对环境中的输入数据进行学习,从而得到最优的输出结果。在斗地主游戏中,强化学习算法可以通过对游戏规则、玩家出牌策略等数据的学习,来预测玩家的出牌策略,从而提高自己的胜率。具体来说,强化学习算法可以通过以下步骤来实现:收集游戏数据:首先,需要收集斗地主游戏的数据,包括游戏规则、玩家出牌策略等。建立神经网络模型:然后,需要建立一个神经网络模型,用于对游戏数据进行学习。神经网络模型可以使用深度学习框架来实现。训练神经网络模型:接下来,需要使用训练数据对神经网络模型进行训练。训练数据可以是游戏中的真实数据,也可以是模拟数据。预测玩家出牌策略:最后,使用训练好的神经网络模型来预测玩家的出牌策略。预测结果可以是一个概率值,也可以是一个具体的牌型。通过以上步骤,强化学习算法可以在斗地主游戏中获得更好的表现。
播放量:16
强化学习在实际环境下使用时,需要考虑到多种因素,例如游戏难度、环境状况、用户行为等。以下是一些实际应用中强化学习的常见问题和解决方案: 数据质量和数据集选择:强化学习需要大量的训练数据,以便学习到智能体的行为和策略。选择高质量的数据集对于训练效果至关重要。此外,数据集应该包含不同的环境和状况,以便智能体可以在不同的场景下学习和适应。 神经网络结构选择:不同的神经网络结构适用于不同的强化学习任务。在选择神经网络结构时,需要考虑任务的特点、计算资源、训练时间等因素。 策略选择和优化:智能体需要选择最优的策略来达到最大化收益的目标。可以通过尝试不同的策略来选择最佳策略,或者通过反向传播来寻找最优策略。 动态环境和状态估计:强化学习中的智能体需要处理动态环境和状态,例如位置、方向、速度等。可以通过使用卡尔曼滤波器、粒子滤波器等方法来估计智能体的状态。 异常检测和处理:强化学习过程中可能会出现异常情况,例如智能体被卡住、掉入悬崖等。需要设计合适的异常检测和处理机制,以便智能体能够及时停止学习并恢复正常状态。 负面行为和损失函数设计:智能体可能会出现负面行为,例如攻击其他智能体、浪费资源等。需要设计合适的负面行为和损失函数,以便智能体能够在负面行为发生时及时停止学习。 学习率和折扣因子:智能体学习的速度和效果受到学习率和折扣因子的影响。需要根据任务和智能体的特点来选择合适的学习率和折扣因子。 实验设计和评估:在实际应用中,需要设计合适的实验来评估智能体的性能和策略选择。可以通过计算收益、成本、指标等来评估策略的有效性和优化方案。
播放量:32
基于深度强化学习的机械臂位置感知抓取任务深度强化学习控制机械臂的抓取可以通过以下几个步骤实现:环境建模和定义。首先需要建立一个包含多个物体的三维空间,并为每个物体定义它们的位置、姿势、重量和其他属性。这可以通过使用传感器或者计算机视觉技术来实现。策略制定。策略是机器人如何在环境中移动和抓取物体的规则。深度强化学习控制机械臂的抓取可以使用TD3、SAC等算法。初始化和训练。在策略制定之后,需要初始化机械臂和抓取装置。可以使用PyBullet或类似的库来实现这些部件。然后,可以使用反向传播算法来训练机械臂,以便在给定输入时执行预期的动作。测试和评估。一旦机械臂已经被训练,可以使用测试集来评估它的性能。可以使用交叉验证等方法来确定最佳的参数设置。部署和应用。一旦机械臂被训练并准备就绪,可以将其部署到实际环境中。可以使用Python脚本或者图形用户界面来控制机械臂。总之,深度强化学习控制机械臂的抓取需要对环境建模、策略制定、初始化和训练、测试和评估以及部署和应用等方面进行全面考虑。
播放量:15
强化学习在求解迷宫游戏最短路径方面有着很好的应用价值。以下是基于强化学习的迷宫游戏最短路径算法实现:定义状态和行动规则:首先,需要定义迷宫游戏中的状态和行动规则,如起点、终点、可行区域、道具等。然后,定义一个损失函数来描述玩家在行动过程中可能遇到的障碍物和道具对其移动路径的影响。构建模型:使用深度强化学习框架训练神经网络模型,该模型应包含传感器节点、决策树节点、优化器节点和主控节点等。其中,传感器节点用于采集迷宫游戏中的状态信息,决策树节点用于生成行动规则,优化器节点用于调整权重参数以提高寻找最短路径的效率,而主控节点用于监视和管理整个强化学习过程。进行测试和评估:将模型输入到真实的迷宫游戏数据集上进行测试和评估,以验证模型的准确性和鲁棒性。具体方法包括设置不同的难度级别、种类和大小的迷宫游戏数据集,并记录模型的表现和结果。优化和调参:根据测试和评估的结果,对模型的损失函数、优化器参数等进行调整和优化,以提高算法的精度和效率。应用于实际问题:将基于强化学习的迷宫游戏最短路径算法应用于实际的迷宫游戏数据集上,以寻找最短路径并获得更好的结果。例如,可以使用遗传算法优化路径搜索的速度和精度,或者通过禁止某些道具的使用来减少阻碍因素的影响。总之,基于强化学习的迷宫游戏最短路径算法需要进行大量的实验和优化,以达到较好的性能和效率。
播放量:78
谷歌准备发布一个人工智能聊天机器人,与OpenAI的ChatGPT竞争,Deepmind Sparrow是根据人类的反馈进行训练的,使用谷歌搜索来回答关于当前的信息,这可能是他们的答案,因为其很可能在今年进入测试阶段。谷歌Deepmind发布其DreamerV3强化学习通用人工智能,其训练时间仅为OpenAIs类似项目所需时间的一小部分,但也不需要人类输入就能完成minecraft的各种任务。德国Bionic公司在2023年CES上展示了其人工智能驱动的机器人外骨骼,可以帮助工人举起高达30公斤的物体。0:00 新的谷歌人工智能与OpenAI ChatGPT4:28 谷歌Deepmind DreamerV37:06 AI驱动的机器人外骨骼
推荐文章
|
|
奔跑的遥控器 · 消息队列 CMQ 词汇表-文档中心-腾讯云 10 月前 |