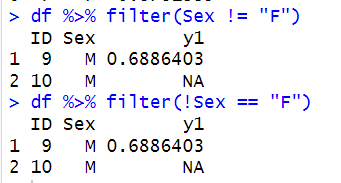
> df2 %>% filter(Sex != "F")
ID Sex y1
1 9 M -1.966617
2 10 M NA
> df2 %>% filter(!Sex == "F")
ID Sex y1
1 9 M -1.966617
2 10 M NA
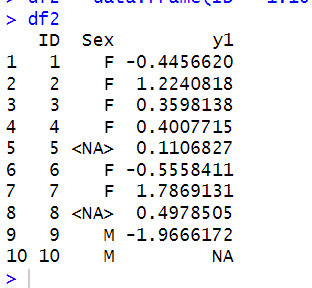
> df2 %>% filter(!Sex %in% "F")
ID Sex y1
1 5 <NA> 0.1106827
2 8 <NA> 0.4978505
3 9 M -1.9666172
4 10 M NA
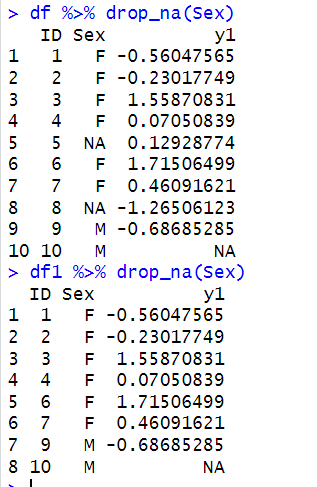
结论:filter过滤时,会自动忽略NA的行,所以,用%in%才是靠谱的!!!
首发于“生信补给站” ,https://mp.weixin.qq.com/s/l9Ci7wREQWpEV5dTvKuoHg,更多的R统计,绘图,生信,请移步????
上篇根据 msleep数据集,介绍了列的操作,盘一盘Tidyverse| 筛行选列之select,玩转列操作
本文盘一盘行的筛选 ????
一 载入R包,数据
#载入R包
#install.packages("tidyverse")
libr...
子集的选取——基于tidyverse准备工作1 选取行子集1.1 slice :根据行特征选取行子集1.2 filter :按条件选取行子集2. 去除重复行3 选取列子集the end
(1)安装tidyverse,用于数据处理
install.packages("tidyverse")
(2)运用R及相关包库及帮助文件进行学习
?filter # 查看filter帮助文件
?slice # 查看slice帮助文件
??select # 查看select帮助文件,
dplyr 包提供了一系列好用的函数,用来进行数据处理和转换,掌握之后可以高效解决数据处理中的绝大多数问题,我们先来看一下 dplyr 包最核心的 5 个函数。
select: 筛选字段
filter: 按条件过滤
arrange: 按字段排序
mutate: 创建新字段
summarize: 数据汇总
这一章需要使用 gapminder 数据集,该数据集记录了 140 多个国家的人口、寿命、国内生产总值(gdp)等,使用前安装一下 install.packages(‘gapminder’)
libra
| 本文首发于 “生信补给站” https://mp.weixin.qq.com/s/tQt0ezYJj3H7x3aWZmKVEQ
使用tidyverse进行简单的数据处理:
盘一盘Tidyverse| 筛行选列之select,玩转列操作
盘一盘Tidyverse| 只要你要只要我有-filter 筛选行
Tidyverse|数据列的分分合合,一分多,多合一
Tidyverse| XX_join :多个数据表(文件)之间的各种连接
本次介绍变量汇总以及分组汇总。
一 summarise 汇总
汇总函数 su