好兄弟们看看是不是这个错:
RuntimeError: CUDA error: device-side assert triggered
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
先在上边儿导入 os 库,把那个环境变量导入:
import os
os.environ['CUDA_LAUNCH_BLOCKING'] = '1'
这样再出错了,打印的信息就比较详细了
这是原来的报错信息,这个报错信息,参考价值不大,好兄弟可以看后面:
torch.Size([4, 1, 96, 96, 96]) torch.Size([4, 1, 96, 96, 96])
Training (0 / 20 Steps) (loss=4.11153): 2%|▏ | 1/58 [00:14<13:44, 14.47s/it]
torch.Size([4, 1, 96, 96, 96]) torch.Size([4, 1, 96, 96, 96])
Training (1 / 20 Steps) (loss=4.06208): 2%|▏ | 1/58 [00:27<13:44, 14.47s/it]
Validate (X / X Steps) (dice=X.X): 0%| | 0/5 [00:00<?, ?it/s]
torch.Size([2, 321, 307, 178]) torch.Size([2, 321, 307, 178])
----------------------------------------
/pytorch/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:312: operator(): block: [189,0,0], thread: [1,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/pytorch/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:312: operator(): block: [63,0,0], thread: [60,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/pytorch/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:312: operator(): block: [149,0,0], thread: [6,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
/pytorch/aten/src/ATen/native/cuda/ScatterGatherKernel.cu:312: operator(): block: [149,0,0], thread: [12,0,0] Assertion `idx_dim >= 0 && idx_dim < index_size && "index out of bounds"` failed.
Validate (X / X Steps) (dice=X.X): 0%| | 0/5 [00:27<?, ?it/s]
Training (1 / 20 Steps) (loss=4.06208): 2%|▏ | 1/58 [00:55<53:07, 55.92s/it]
--------------------------
-------------------------------------------------
RuntimeError Traceback (most recent call last)
Input In [7], in <cell line: 97>()
96 metric_values = []
97 while global_step < max_iterations:
---> 98 global_step, dice_val_best, global_step_best = train(
99 global_step, train_loader, dice_val_best, global_step_best
100 )
101 model.load_state_dict(torch.load(os.path.join(root_dir, "best_metric_model.pth")))
Input In [7], in train(global_step, train_loader, dice_val_best, global_step_best)
56 if (
57 global_step % eval_num == 0 and global_step != 0
58 ) or global_step == max_iterations:
59 epoch_iterator_val = tqdm(
60 val_loader, desc="Validate (X / X Steps) (dice=X.X)", dynamic_ncols=True
61 )
---> 62 dice_val = validation(epoch_iterator_val)
63 epoch_loss /= step
64 epoch_loss_values.append(epoch_loss)
Input In [7], in validation(epoch_iterator_val)
17
18 print("-"*40)
---> 19 print(val_output_convert[0].cpu().numpy().max(),
20 val_labels_convert[0].cpu().numpy().max())
21 print(val_output_convert[0].cpu().numpy().min(),
22 val_labels_convert[0].cpu().numpy().min())
23
RuntimeError: CUDA error: device-side assert triggered
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
这是我错误的地方:
x, y = (batch["image"].cuda(), batch["label"].cuda())
print(x.shape, y.shape)
logit_map = model(x)
print(logit_map.shape, "FUCKCKKCKCKCCK")
torch.Size([4, 1, 96, 96, 96]) torch.Size([4, 1, 96, 96, 96])
torch.Size([4, 14, 96, 96, 96]) FUCKCKKCKCKCCK
稍微看一下程序,x 显然就是输出的图片,而 y 就是对应的label,logit_map 就是对应的预测map
好兄弟们可能猜到了,我这个是3D的分割,所以维度是5,后面的[96, 96, 96] 是输出的shape
那个4是batch_size,1 那一维,是输出的类别
我这个是只有前景和背景,所以只要分两类就可以了,这里应该改成2
话说如果真的就这么简单,我就不氵这篇博客,碰到这个问题的老铁们,一定是拿来改别人代码,没改完整,才遇到这个问题的,今儿咱们就说叨说叨
-
改写自己的数据集,嗯,一般就是新写一个Dataset类,要是他的数据集格式和你的一样,那直接改路径就好了
-
改写输出的模型,一般你的输入都是三通道,输入参数 input_channel 一般不用改,但是输出的类别要改啊,你是输出几类,就是改几类
(分割这里有个问题,有的模型会包括背景,有的会不包括背景,涉及到一个 +1 或者 -1 的问题)
一般来说,模型的输入或者输出通道数,都会在模型的构造函数最开始定义,下边的例子就是改一下out_channels 就行
model = UNETR(
in_channels=1,
out_channels=2,
img_size=(96, 96, 96),
feature_size=16,
hidden_size=768,
mlp_dim=3072,
num_heads=2,
pos_embed="perceptron",
norm_name="instance",
res_block=True,
dropout_rate=0.0,
).to(device)
- 改前处理,这个也可以看做数据增强的一部分,这里一般不涉及通道数或者类别的改动,但是某些域的照片,可能不适合另一个域的数据增强方法,比如医学图像一般只用:
Randomly adjust intensity for data augmentation
而如果你用随机旋转就不是很合适
- 后处理,一般有NMS什么的,不用改
但是在我遇到的问题中,有这个
post_label = AsDiscrete(to_onehot=2)
post_pred = AsDiscrete(argmax=True, to_onehot=2)
官网的解释:
Execute after model forward to transform model output to discrete values.
It can complete below operations:
- execute `argmax` for input logits values.
- threshold input value to 0.0 or 1.0.
- convert input value to One-Hot format.
- round the value to the closest integer.
反正就是把你的结果离散化,你看到 one_hot 眼睛其实就有光了(因为这个东西的长度会随着需求的变化而改变),所以这里也要改
-
后面的 loss 和 optimizer 一般不用改,看心情吧
-
一个没什么用的trick,我还是拿例子说
https://github.com/Project-MONAI/research-contributions/tree/master/UNETR/BTCV

我这个问题是器官分割,一个13个器官,加上一个背景,一共14类
所以要改的地方有:
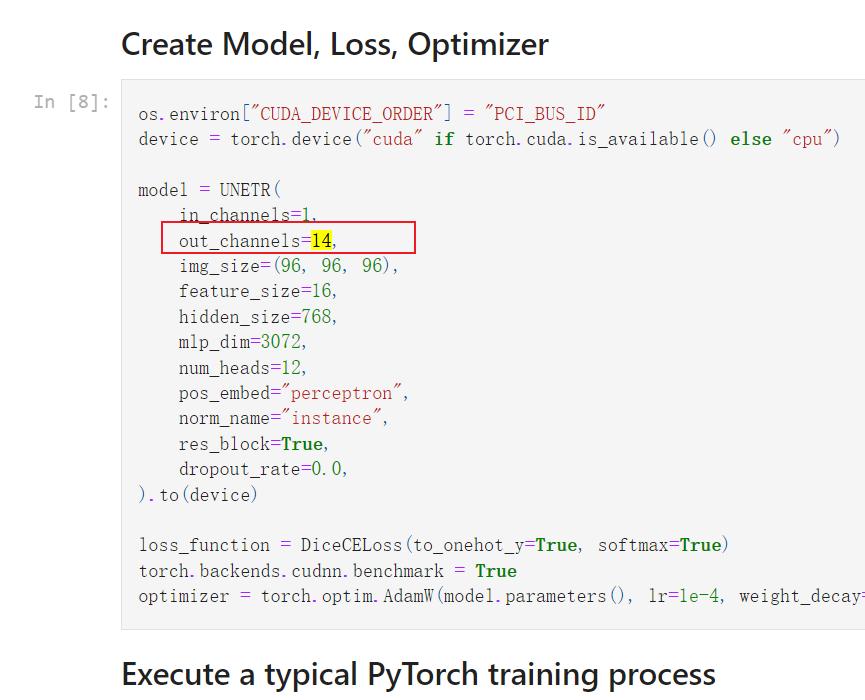
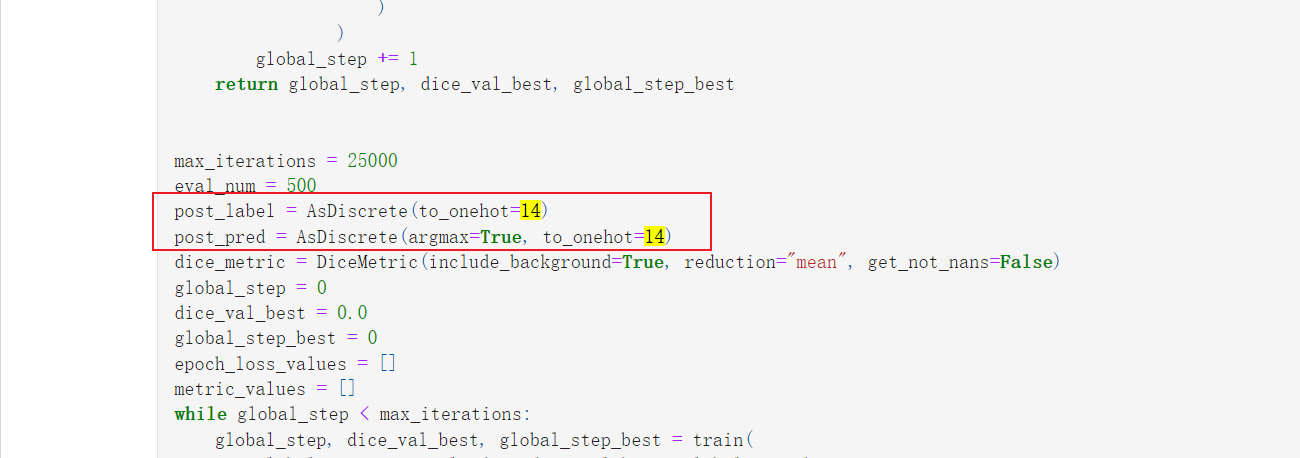
只有这三个,在那个页面,按住 ctrl + F ,输入 14 一个一个看,是不是需要改的
这么憨憨的方法,我最开始咋没想到呢。。。。。。
有参考自:
https://blog.csdn.net/Penta_Kill_5/article/details/118085718
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below m
[每日一氵]好兄弟们看看是不是这个错:RuntimeError: CUDA error: device-side assert triggeredCUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.For debugging consider passing CUDA_LAUNCH_BLOCKING=1.先在上边儿
正在使用的是“cuda:7", 1号机的第7号显卡被拿走了,或者第7号显卡机械位置松动了
3 解决方案
查看目前pytorch可读的显卡有几块(这时候使用nvidia-smi命令同样报错),假设为n, 然后【0,n-1】这些序号的显卡都可以使用:
显卡默认是从0号开始计数的:
已解决BUG:RuntimeError: CUDA error: invalid device ordinal
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
跑模型时出现RuntimeError: CUDA out of memory.错误 查阅了许多相关内容,原因是:GPU显存内存不够
简单总结一下解决方法:
将batch_size改小。
取torch变量标量值时使用item()属性。
可以在测试阶段添加如下代码:
with torch.no_grad(): # 停止自动反向计算梯度
https://wisdomai.xyz/tool/pytorch/archives/2301
https://ptorch.com/news/160.html
作者:菜叶儿掉啦
就是当网络参数什么都没有问题了,而且batch_size已经是最小了,还是出现以了问题
但据我遇到的RuntimeError: CUDA error: out of memoryCUDA,其实有两种,
第一种就是如下
RuntimeError: CUDA out of memory. Tried to allocate 338.00 MiB (GPU 0; 2.00 GiB total capacity; 842.86 MiB already allocated; 215.67 MiB free;
Boss之前因工作推荐了一个道路识别的模型,这个模型赢得了GRDDC’2020大赛的冠军。
GRDDC’2020大赛的冠军模型
该模型以YOLOv5为基础,所以在使用的时候,出现了一些YOLOv5一样的问题。
首先,YOLOv5的request.txt中是要求torch>=1.6.0,结果我在运行的时候就给我安装了1.9.0版本的torch。这就是悲剧的开端。
在train.py加载模型的时候:
python3 train.py --data data/road.yaml --cfg models/y
看了多篇文章,基本上这个问题就是计算损失函数的时候,label出了问题。
有时候报的错比较简单,就是这一句话:RuntimeError: cuda runtime error (59) : device-side assert triggered at /opt/conda/conda-bld/…,为了更明确可以打印细节,就是在导入模块之前输入
import os
os.environ['CUDA_LAUNCH_BLOCKING'] = "1"
cunn_ClassNLLCriterion_up
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect. For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
这个错误提示意味着 CUDA kernel 错误可能在其他 API 调用时异步报告,因此下面的堆栈跟踪可能不正确。如果要进行调试,请考虑传递 CUDA_LAUNCH_BLOCKING=1。
这个错误通常出现在 CUDA 的异步执行模式下,当 CUDA kernel 发生错误时,错误信息并不会立即返回。相反,CUDA 会在后续的 API 调用中返回错误信息。如果您想要在 CUDA kernel 出错时立即返回错误信息,可以将 CUDA_LAUNCH_BLOCKING 环境变量设置为 1。这会使 CUDA 在执行 kernel 时阻塞,直到 kernel 执行完成并返回错误信息。这样可以更容易地调试 CUDA kernel 错误。
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below m
100081
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below m
[转载]黑客帝国动态字幕雨效果
氵文大师:
[转载]黑客帝国动态字幕雨效果
匿名的魔术师:


