

CVPR2023已经放榜,今年有2360篇,接收率为25.78%。在CVPR2023正式会议召开前,为了让大家更快地获取和学习到计算机视觉前沿技术,极市对CVPR023 最新论文进行追踪,包括分研究方向的论文、代码汇总以及论文技术直播分享。
CVPR 2023 论文分方向整理目前在极市社区持续更新中,已累计更新了 919 篇,项目地址: https://www. cvmart.net/community/de tail/7422
以下是最近更新的 CVPR 2023 论文,涵盖神经网络结构、医学影像、ReId、图像去雾、异常检测等方向。
下载地址: https://www. cvmart.net/community/de tail/7520
2D目标检测(2D Object Detection)
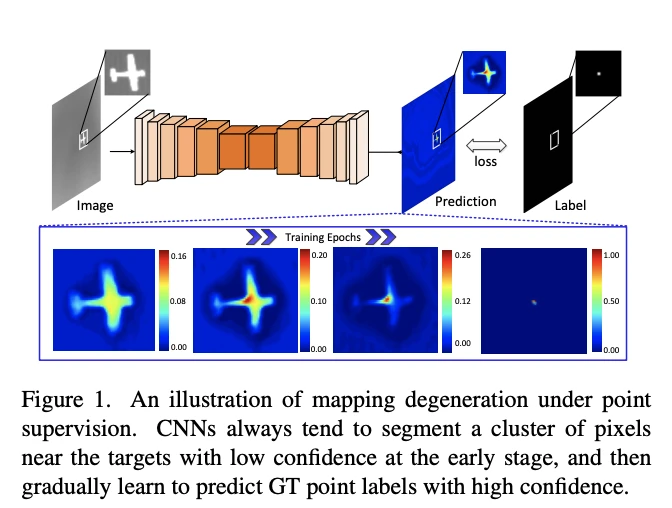
[1]Mapping Degeneration Meets Label Evolution: Learning Infrared Small Target Detection with Single Point Supervision
paper:
https://
arxiv.org/abs/2304.0148
4
code:
https://
github.com/xinyiying/le
sps
[2]Multi-view Adversarial Discriminator: Mine the Non-causal Factors for Object Detection in Unseen Domains
paper:
https://
arxiv.org/abs/2304.0295
0
[3]Continual Detection Transformer for Incremental Object Detection
paper:
https://
arxiv.org/abs/2304.0311
0
[4]DetCLIPv2: Scalable Open-Vocabulary Object Detection Pre-training via Word-Region Alignment
paper:
https://
arxiv.org/abs/2304.0451
4
[5]Benchmarking the Physical-world Adversarial Robustness of Vehicle Detection
paper:
https://
arxiv.org/abs/2304.0509
8
3D目标检测(3D object detection)
[1]Hierarchical Supervision and Shuffle Data Augmentation for 3D Semi-Supervised Object Detection
paper:
https://
arxiv.org/abs/2304.0146
4
code:
https://
github.com/azhuantou/hs
sda
[2]Curricular Object Manipulation in LiDAR-based Object Detection
paper:
https://
arxiv.org/abs/2304.0424
8
code:
https://
github.com/zzy816/com
人物交互检测(HOI Detection)
[1]Instant-NVR: Instant Neural Volumetric Rendering for Human-object Interactions from Monocular RGBD Stream
paper:
https://
arxiv.org/abs/2304.0318
4
[2]Relational Context Learning for Human-Object Interaction Detection
paper:
https://
arxiv.org/abs/2304.0499
7
异常检测(Anomaly Detection)
[1]Robust Outlier Rejection for 3D Registration with Variational Bayes
paper:
https://
arxiv.org/abs/2304.0151
4
code:
https://
github.com/jiang-hb/vbr
eg

[2]Video Event Restoration Based on Keyframes for Video Anomaly Detection
paper:
https://
arxiv.org/abs/2304.0511
2
语义分割(Semantic Segmentation)
[1]DiGA: Distil to Generalize and then Adapt for Domain Adaptive Semantic Segmentation
paper:
https://
arxiv.org/abs/2304.0222
2
code:
https://
github.com/fy-vision/di
ga
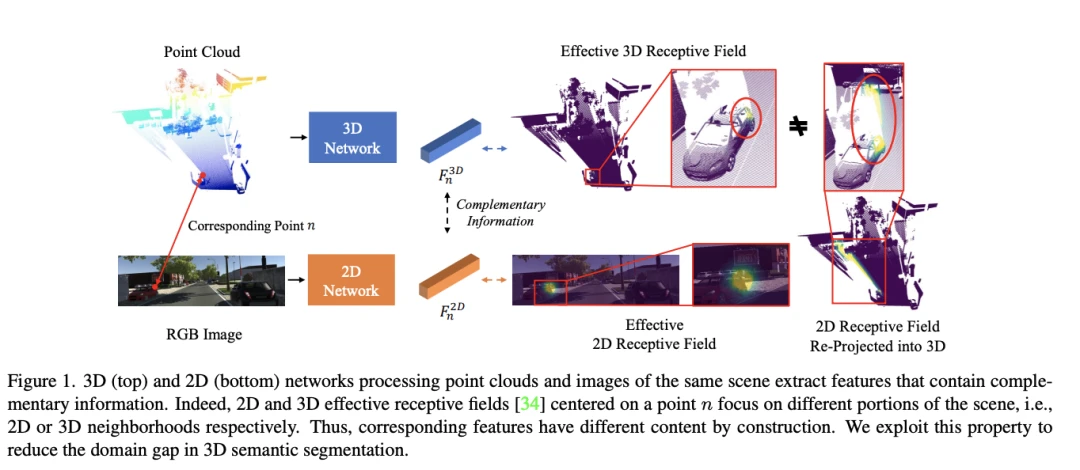
[2]Exploiting the Complementarity of 2D and 3D Networks to Address Domain-Shift in 3D Semantic Segmentation
paper:
https://
arxiv.org/abs/2304.0299
1
code:
https://
github.com/cvlab-unibo/
mm2d3d
[3]Federated Incremental Semantic Segmentation
paper:
https://
arxiv.org/abs/2304.0462
0
code:
https://
github.com/jiahuadong/f
iss
[4]Continual Semantic Segmentation with Automatic Memory Sample Selection
paper:
https://
arxiv.org/abs/2304.0501
5
深度估计(Depth Estimation)
[1]EGA-Depth: Efficient Guided Attention for Self-Supervised Multi-Camera Depth Estimation
paper:
https://
arxiv.org/abs/2304.0336
9
[2]DualRefine: Self-Supervised Depth and Pose Estimation Through Iterative Epipolar Sampling and Refinement Toward Equilibrium
paper:
https://
arxiv.org/abs/2304.0356
0
code:
https://
github.com/antabangun/d
ualrefine
人体解析/人体姿态估计(Human Parsing/Human Pose Estimation)
[1]A2J-Transformer: Anchor-to-Joint Transformer Network for 3D Interacting Hand Pose Estimation from a Single RGB Image
paper:
https://
arxiv.org/abs/2304.0363
5
code:
https://
github.com/changlongjia
nggit/a2j-transformer
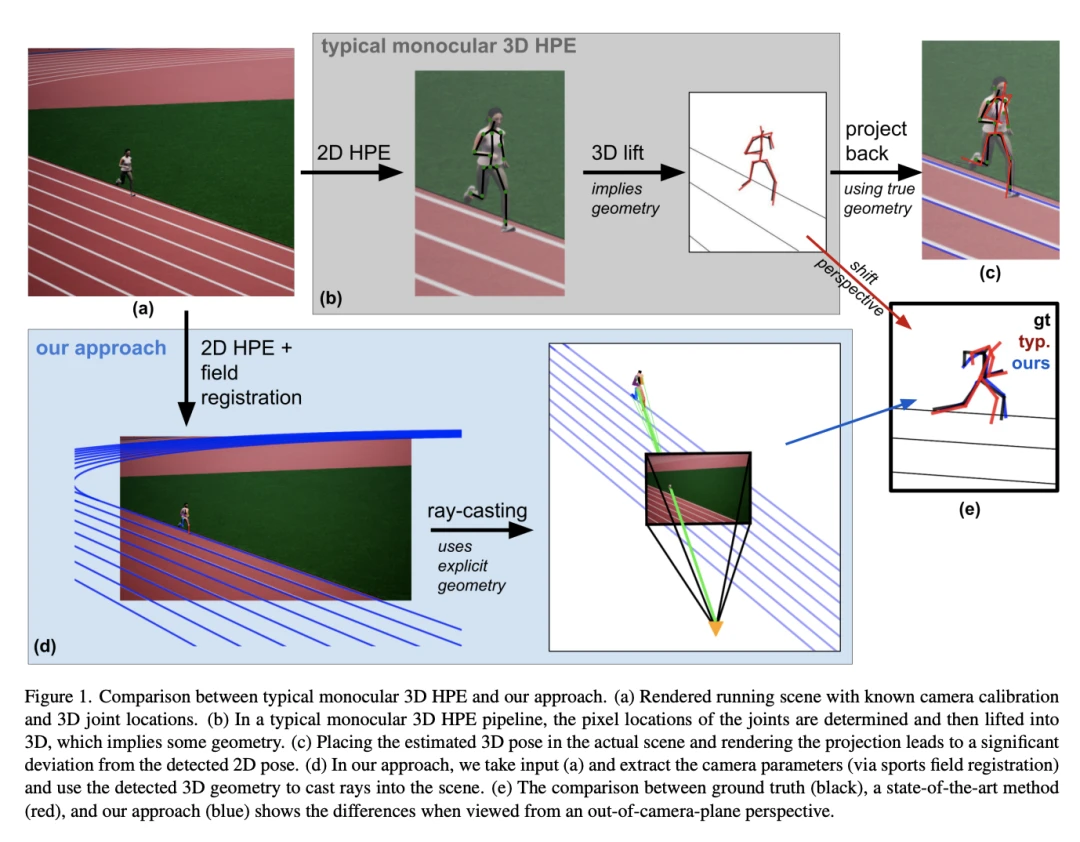
[2]Monocular 3D Human Pose Estimation for Sports Broadcasts using Partial Sports Field Registration
paper:
https://
arxiv.org/abs/2304.0443
7
code:
https://
github.com/tobibaum/par
tialsportsfieldreg_3dhpe
[3]DeFeeNet: Consecutive 3D Human Motion Prediction with Deviation Feedback
paper:
https://
arxiv.org/abs/2304.0449
6
视频处理(Video Processing)
[1]BiFormer: Learning Bilateral Motion Estimation via Bilateral Transformer for 4K Video Frame Interpolation
paper:
https://
arxiv.org/abs/2304.0222
5
code:
https://
github.com/junheum/bifo
rmer
超分辨率(Super Resolution)
[1]Better "CMOS" Produces Clearer Images: Learning Space-Variant Blur Estimation for Blind Image Super-Resolution
paper:
https://
arxiv.org/abs/2304.0354
2
图像复原/图像增强/图像重建(Image Restoration/Image Reconstruction)
[1]Generative Diffusion Prior for Unified Image Restoration and Enhancement
paper:
https://
arxiv.org/abs/2304.0124
7
[2]CherryPicker: Semantic Skeletonization and Topological Reconstruction of Cherry Trees
paper:
https://
arxiv.org/abs/2304.0470
8
图像去噪/去模糊/去雨去雾(Image Denoising)
[1]HyperCUT: Video Sequence from a Single Blurry Image using Unsupervised Ordering
paper:
https://
arxiv.org/abs/2304.0168
6
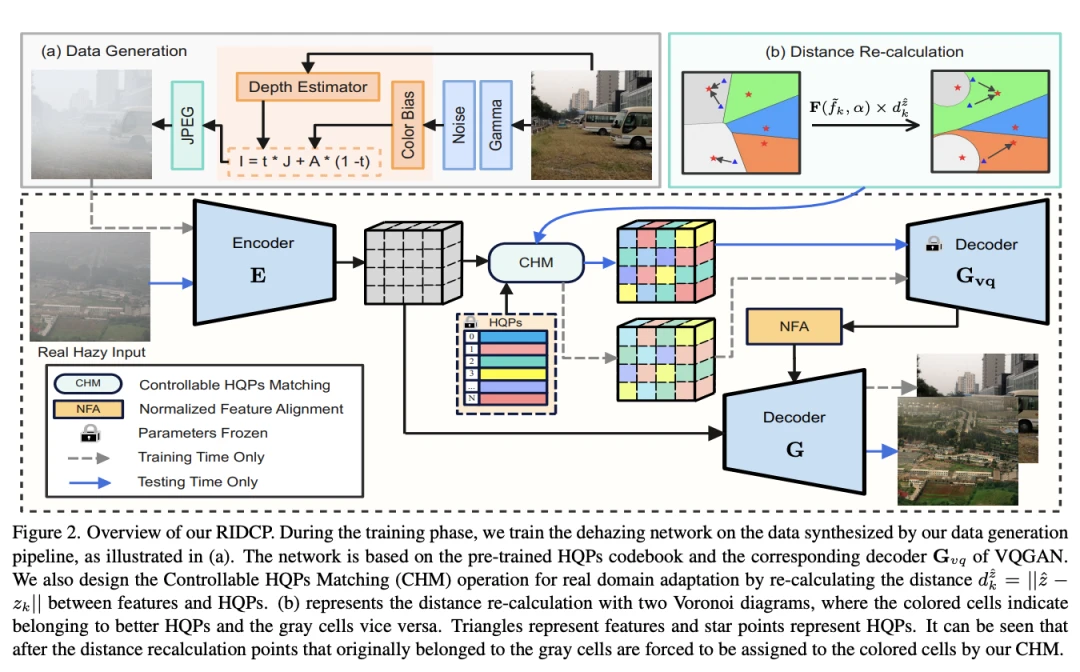
[2]RIDCP: Revitalizing Real Image Dehazing via High-Quality
codebook Priors
paper:
https://
arxiv.org/abs/2304.0399
4
code:
https://
github.com/RQ-Wu/RIDCP_
dehazing
人脸识别/检测(Facial Recognition/Detection)
[1]Gradient Attention Balance Network: Mitigating Face Recognition Racial Bias via Gradient Attention
paper:
https://
arxiv.org/abs/2304.0228
4
[2]Micron-BERT: BERT-based Facial Micro-Expression Recognition
paper:
https://
arxiv.org/abs/2304.0319
5
code:
https://
github.com/uark-cviu/mi
cron-bert
人脸生成/合成/重建/编辑(Face Generation/Face Synthesis/Face Reconstruction/Face Editing)
[1]Learning Personalized High Quality Volumetric Head Avatars from Monocular RGB Videos
paper:
https://
arxiv.org/abs/2304.0143
6
[2]StyleGAN Salon: Multi-View Latent Optimization for Pose-Invariant Hairstyle Transfer
paper:
https://
arxiv.org/abs/2304.0274
4
[3]GANHead: Towards Generative Animatable Neural Head Avatars
paper:
https://
arxiv.org/abs/2304.0395
0
目标跟踪(Object Tracking)
[1]Trace and Pace: Controllable Pedestrian Animation via Guided Trajectory Diffusion
paper:
https://
arxiv.org/abs/2304.0189
3
[2]Unsupervised Sampling Promoting for Stochastic Human Trajectory Prediction
paper:
https://
arxiv.org/abs/2304.0429
8
code:
https://
github.com/viewsetting/
unsupervised_sampling_promoting
图像&视频检索/视频理解(Image&Video Retrieval/Video Understanding)
[1]Improving Image Recognition by Retrieving from Web-Scale Image-Text Data
paper:
https://
arxiv.org/abs/2304.0517
3
行人重识别/检测(Re-Identification/Detection)
[1]PartMix: Regularization Strategy to Learn Part Discovery for Visible-Infrared Person Re-identification
paper:
https://
arxiv.org/abs/2304.0153
7
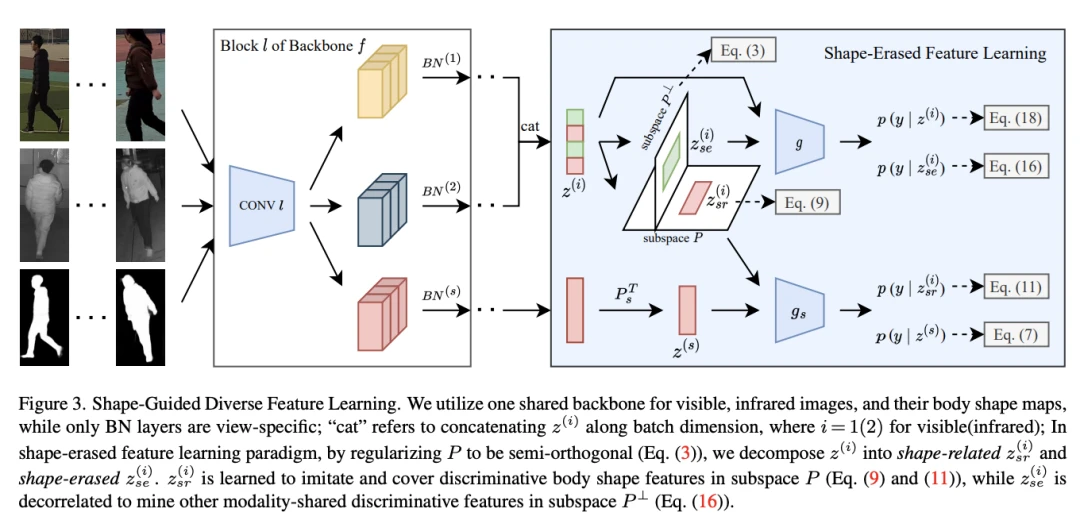
[2]Shape-Erased Feature Learning for Visible-Infrared Person Re-Identification
paper:
https://
arxiv.org/abs/2304.0420
5
code:
https://
github.com/jiawei151/sg
iel_vireid
图像/视频字幕(Image/Video Caption)
[1]Cross-Domain Image Captioning with Discriminative Finetuning
paper:
https://
arxiv.org/abs/2304.0166
2
code:
https://
github.com/facebookrese
arch/EGG
[2]Model-Agnostic Gender Debiased Image Captioning
paper:
https://
arxiv.org/abs/2304.0369
3
医学影像(Medical Imaging)
[1]Topology-Guided Multi-Class Cell Context Generation for Digital Pathology
paper:
https://
arxiv.org/abs/2304.0225
5
[2]Deep Prototypical-Parts Ease Morphological Kidney Stone Identification and are Competitively Robust to Photometric Perturbations
paper:
https://
arxiv.org/abs/2304.0407
7
code:
https://
github.com/danielf29/pr
ototipical_parts
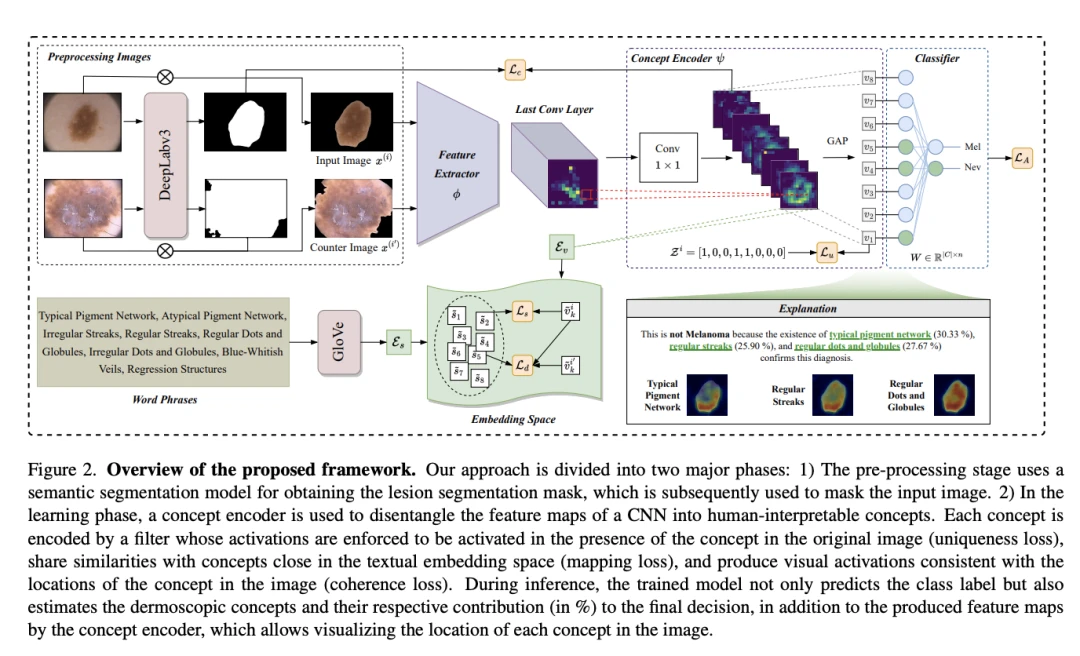
[3]Coherent Concept-based Explanations in Medical Image and Its Application to Skin Lesion Diagnosis
paper:
https://
arxiv.org/abs/2304.0457
9
code:
https://
github.com/cristianopat
ricio/coherent-cbe-skin
图像生成/图像合成(Image Generation/Image Synthesis)
[1]Toward Verifiable and Reproducible Human Evaluation for Text-to-Image Generation
paper:
https://
arxiv.org/abs/2304.0181
6
[2]Few-shot Semantic Image Synthesis with Class Affinity Transfer
paper:
https://
arxiv.org/abs/2304.0232
1
点云(Point Cloud)
[1]MEnsA: Mix-up Ensemble Average for Unsupervised Multi Target Domain Adaptation on 3D Point Clouds
paper:
https://
arxiv.org/abs/2304.0155
4
code:
https://
github.com/sinashish/me
nsa_mtda
场景重建/视图合成/新视角合成(Novel View Synthesis)
[1]Lift3D: Synthesize 3D Training Data by Lifting 2D GAN to 3D Generative Radiance Field
paper:
https://
arxiv.org/abs/2304.0352
6
[2]POEM: Reconstructing Hand in a Point Embedded Multi-view Stereo
paper:
https://
arxiv.org/abs/2304.0403
8
code:
https://
github.com/lixiny/poem
[3]Neural Residual Radiance Fields for Streamably Free-Viewpoint Videos
paper:
https://
arxiv.org/abs/2304.0445
2
[4]Neural Lens Modeling
paper:
https://
arxiv.org/abs/2304.0484
8
[5]One-Shot High-Fidelity Talking-Head Synthesis with Deformable Neural Radiance Field
paper:
https://
arxiv.org/abs/2304.0509
7
[6]MonoHuman: Animatable Human Neural Field from Monocular Video
paper:
https://
arxiv.org/abs/2304.0200
1
[7]GINA-3D: Learning to Generate Implicit Neural Assets in the Wild
paper:
https://
arxiv.org/abs/2304.0216
3
[8]Neural Fields meet Explicit Geometric Representation for Inverse Rendering of Urban Scenes
paper:
https://
arxiv.org/abs/2304.0326
6
文本检测/识别/理解(Text Detection/Recognition/Understanding)
[1]Towards Unified Scene Text Spotting based on Sequence Generation
paper:
https://
arxiv.org/abs/2304.0343
5
神经网络结构设计(Neural Network Structure Design)
[1]SMPConv: Self-moving Point Representations for Continuous Convolution
paper:
https://
arxiv.org/abs/2304.0233
0
code:
https://
github.com/sangnekim/sm
pconv
CNN
[1]VNE: An Effective Method for Improving Deep Representation by Manipulating Eigenvalue Distribution
paper:
https://
arxiv.org/abs/2304.0143
4
code:
https://
github.com/jaeill/CVPR2
3-VNE
Transformer
[1]METransformer: Radiology Report Generation by Transformer with Multiple Learnable Expert Tokens
paper:
https://
arxiv.org/abs/2304.0221
1
[2]MethaneMapper: Spectral Absorption aware Hyperspectral Transformer for Methane Detection
paper:
https://
arxiv.org/abs/2304.0276
7
[3]Visual Dependency Transformers: Dependency Tree Emerges from Reversed Attention
paper:
https://
arxiv.org/abs/2304.0328
2
code:
https://
github.com/dingmyu/depe
ndencyvit
[4]Slide-Transformer: Hierarchical Vision Transformer with Local Self-Attention
paper:
https://
arxiv.org/abs/2304.0423
7
code:
https://
github.com/leaplabthu/s
lide-transformer
图神经网络(GNN)
[1]Adversarially Robust Neural Architecture Search for Graph Neural Networks
paper:
https://
arxiv.org/abs/2304.0416
8
归一化/正则化(Batch Normalization)
[1]Delving into Discrete Normalizing Flows on SO(3) Manifold for Probabilistic Rotation Modeling
paper:
https://
arxiv.org/abs/2304.0393
7
模型训练/泛化(Model Training/Generalization)
[1]Re-thinking Model Inversion Attacks Against Deep Neural Networks
paper:
https://
arxiv.org/abs/2304.0166
9
[2]Improved Test-Time Adaptation for Domain Generalization
paper:
https://
arxiv.org/abs/2304.0449
4
长尾分布(Long-Tailed Distribution)
[1]Long-Tailed Visual Recognition via Self-Heterogeneous Integration with Knowledge Excavation
paper:
https://
arxiv.org/abs/2304.0127
9
code:
https://
github.com/jinyan-06/sh
ike
视觉表征学习(Visual Representation Learning)
[1]HNeRV: A Hybrid Neural Representation for Videos
paper:
https://
arxiv.org/abs/2304.0263
3
code:
https://
github.com/haochen-rye/
hnerv
多模态学习(Multi-Modal Learning)
[1]Detecting and Grounding Multi-Modal Media Manipulation
paper:
https://
arxiv.org/abs/2304.0255
6
code:
https://
github.com/rshaojimmy/m
ultimodal-deepfake
[2]Learning Instance-Level Representation for Large-Scale Multi-Modal Pretraining in E-commerce
paper:
https://
arxiv.org/abs/2304.0285
3
[3]Vita-CLIP: Video and text adaptive CLIP via Multimodal Prompting
paper:
https://
arxiv.org/abs/2304.0330
7
code:
https://
github.com/talalwasim/v
ita-clip
视觉-语言(Vision-language)
[1]Learning to Name Classes for Vision and Language Models
paper:
https://
arxiv.org/abs/2304.0183
0
[2]VLPD: Context-Aware Pedestrian Detection via Vision-Language Semantic Self-Supervision
paper:
https://
arxiv.org/abs/2304.0313
5
code:
https://
github.com/lmy98129/vlp
d
[3]CrowdCLIP: Unsupervised Crowd Counting via Vision-Language Model
paper:
https://
arxiv.org/abs/2304.0423
1
code:
https://
github.com/dk-liang/cro
wdclip
[4]Improving Vision-and-Language Navigation by Generating Future-View Image Semantics
paper:
https://
arxiv.org/abs/2304.0490
7
场景图生成(Scene Graph Generation)
[1]Devil's on the Edges: Selective Quad Attention for Scene Graph Generation
paper:
https://
arxiv.org/abs/2304.0349
5
视觉推理/视觉问答(Visual Reasoning/VQA)
[1]Language Models are Causal Knowledge Extractors for Zero-shot Video Question Answering
paper:
https://
arxiv.org/abs/2304.0375
4
数据集(Dataset)
[1]Uncurated Image-Text Datasets: Shedding Light on Demographic Bias
paper:
https://
arxiv.org/abs/2304.0282
8
code:
https://
github.com/noagarcia/ph
ase
小样本学习/零样本学习(Few-shot Learning/Zero-shot Learning)
[1]Zero-shot Generative Model Adaptation via Image-specific Prompt Learning
paper:
https://
arxiv.org/abs/2304.0311
9
迁移学习/domain/自适应(Transfer Learning/Domain Adaptation)
[1]DATE: Domain Adaptive Product Seeker for E-commerce
paper:
https://
arxiv.org/abs/2304.0366
9
[2]Modernizing Old Photos Using Multiple References via Photorealistic Style Transfer
paper:
https://
arxiv.org/abs/2304.0446
1
持续学习(Continual Learning/Life-long Learning)
[1]Asynchronous Federated Continual Learning
paper:
https://
arxiv.org/abs/2304.0362
6
code:
https://
github.com/lttm/fedspac
e
[2]Exploring Data Geometry for Continual Learning
paper:
https://
arxiv.org/abs/2304.0393
1
[3]Task Difficulty Aware Parameter Allocation & Regularization for Lifelong Learning
paper:
https://
arxiv.org/abs/2304.0528
8
code:
https://
github.com/wenjinw/par
[4]Online Distillation with Continual Learning for Cyclic Domain Shifts
paper:
https://
arxiv.org/abs/2304.0123
9
视觉定位/位姿估计(Visual Localization/Pose Estimation)
[1]OrienterNet: Visual Localization in 2D Public Maps with Neural Matching
paper:
https://
arxiv.org/abs/2304.0200
9
增量学习(Incremental Learning)
[1]On the Stability-Plasticity Dilemma of Class-Incremental Learning
paper:
https://
arxiv.org/abs/2304.0166
3
[2]PCR: Proxy-based Contrastive Replay for Online Class-Incremental Continual Learning
paper:
https://
arxiv.org/abs/2304.0440
8
强化学习(Reinforcement Learning)
[1]Reinforcement Learning-Based Black-Box Model Inversion Attacks
paper:
https://
arxiv.org/abs/2304.0462
5
元学习(Meta Learning)
[1]Meta-causal Learning for Single Domain Generalization
paper:
https://
arxiv.org/abs/2304.0370
9
[2]Meta Compositional Referring Expression Segmentation
paper:
https://
arxiv.org/abs/2304.0441
5
[3]Meta-Learning with a Geometry-Adaptive Preconditioner
paper:
https://
arxiv.org/abs/2304.0155
2
code:
https://
github.com/suhyun777/cv
pr23-gap
半监督学习/弱监督学习/无监督学习/自监督学习(Self-supervised Learning/Semi-supervised Learning)
[1]Weakly supervised segmentation with point annotations for histopathology images via contrast-based variational model
paper:
https://
arxiv.org/abs/2304.0357
2
[2]Token Boosting for Robust Self-Supervised Visual Transformer Pre-training
paper:
https://
arxiv.org/abs/2304.0417
5
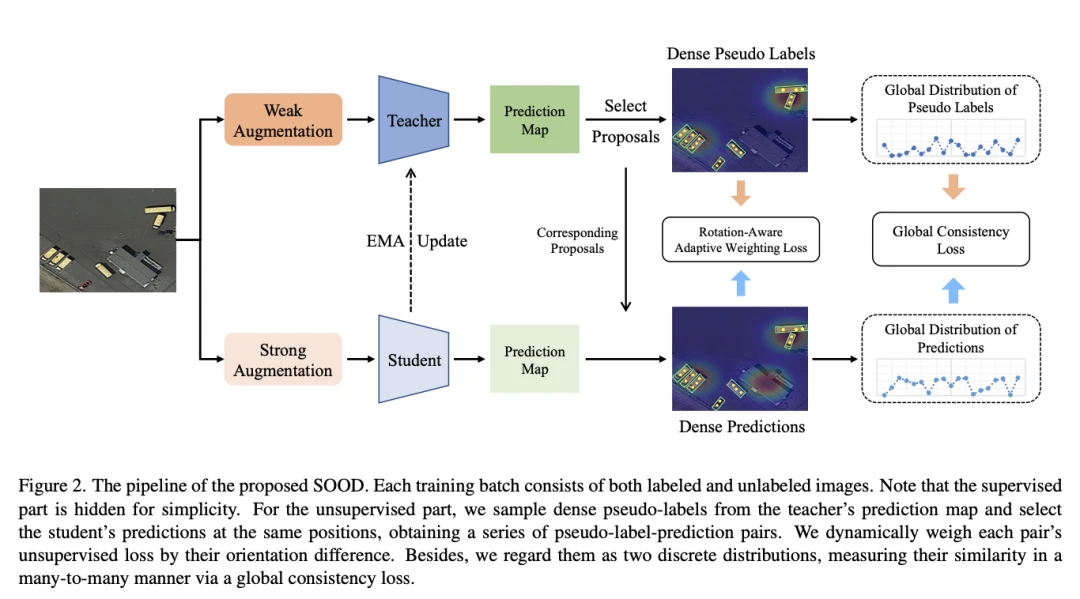
[3]SOOD: Towards Semi-Supervised Oriented Object Detection
paper:
https://
arxiv.org/abs/2304.0451
5
code:
https://
github.com/hamperdredes
/sood
[4]Defending Against Patch-based Backdoor Attacks on Self-Supervised Learning
paper:
https://
arxiv.org/abs/2304.0148
2
code:
https://
github.com/ucdvision/pa
tchsearch
神经网络可解释性(Neural Network Interpretability)
[1]Gradient-based Uncertainty Attribution for Explainable Bayesian Deep Learning
paper:
https://
arxiv.org/abs/2304.0482
4
图像计数(Image Counting)
[1]Density Map Distillation for Incremental Object Counting
paper:
https://
arxiv.org/abs/2304.0525
5
其他
[1]Bridging the Gap between Model Explanations in Partially Annotated Multi-label Classification
paper:
https://
arxiv.org/abs/2304.0180
4
code:
https://
github.com/youngwk/brid
gegapexplanationpamc
[2]Knowledge Combination to Learn Rotated Detection Without Rotated Annotation
paper:
https://
arxiv.org/abs/2304.0219
9
[3]CloSET: Modeling Clothed Humans on Continuous Surface with Explicit Template Decomposition
paper:
https://
arxiv.org/abs/2304.0316
7
[4]DC2: Dual-Camera Defocus Control by Learning to Refocus
paper:
https://
arxiv.org/abs/2304.0328