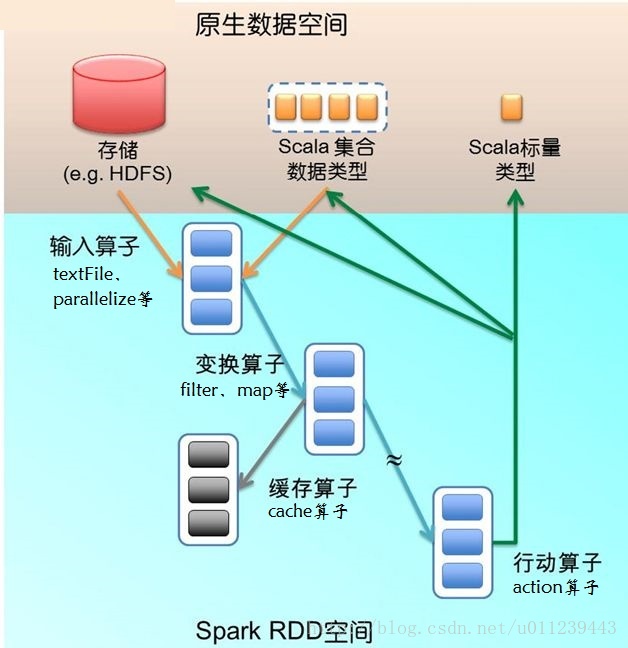
尽管RDD中的Lineage信息可以用来故障恢复,但对于那些Lineage链较长的RDD来说,这种恢复可能很耗时。例如4.3小节中的Pregel任务,每次迭代的顶点状态和消息都跟前一次迭代有关,所以Lineage链很长。如果将Lineage链存到物理存储中,再定期对RDD执行检查点操作就很有效。
一般来说,Lineage链较长、宽依赖的RDD需要采用检查点机制。这种情况下,集群的节点故障可能导致每个父RDD的数据块丢失,因此需要全部重新计算[20]。将窄依赖的RDD数据存到物理存储中可以实现优化,例如前面4.1小节逻辑回归的例子,将数据点和不变的顶点状态存储起来,就不再需要检查点操作。
当前Spark版本提供检查点API,但由用户决定是否需要执行检查点操作。今后我们将实现自动检查点,根据成本效益分析确定RDD Lineage图中的最佳检查点位置。
值得注意的是,因为RDD是只读的,所以不需要任何一致性维护(例如写复制策略,分布式快照或者程序暂停等)带来的开销,后台执行检查点操作。
(注:
我们来阅读下org.apache.spark.rdd.ReliableCheckpointRDD中的def writePartitionToCheckpointFile 和 def writeRDDToCheckpointDirectory:
writePartitionToCheckpointFile:把RDD一个Partition文件里面的数据写到一个Checkpoint文件里面
def writePartitionToCheckpointFile[T: ClassTag](
path: String,
broadcastedConf: Broadcast[SerializableConfiguration],
blockSize: Int = -1)(ctx: TaskContext, iterator: Iterator[T]) {
val env = SparkEnv.get
val outputDir = new Path(path)
val fs = outputDir.getFileSystem(broadcastedConf.value.value)
val finalOutputName = ReliableCheckpointRDD.checkpointFileName(ctx.partitionId())
val finalOutputPath = new Path(outputDir, finalOutputName)
val tempOutputPath =
new Path(outputDir, s".$finalOutputName-attempt-${ctx.attemptNumber()}")
if (fs.exists(tempOutputPath)) {
throw new IOException(s"Checkpoint failed: temporary path $tempOutputPath already exists")
val bufferSize = env.conf.getInt("spark.buffer.size", 65536)
val fileOutputStream = if (blockSize < 0) {
fs.create(tempOutputPath, false, bufferSize)
} else {
fs.create(tempOutputPath, false, bufferSize,
fs.getDefaultReplication(fs.getWorkingDirectory), blockSize)
val serializer = env.serializer.newInstance()
val serializeStream = serializer.serializeStream(fileOutputStream)
Utils.tryWithSafeFinally {
serializeStream.writeAll(iterator)
serializeStream.close()
if (!fs.rename(tempOutputPath, finalOutputPath)) {
if (!fs.exists(finalOutputPath)) {
logInfo(s"Deleting tempOutputPath $tempOutputPath")
fs.delete(tempOutputPath, false)
throw new IOException("Checkpoint failed: failed to save output of task: " +
s"${ctx.attemptNumber()} and final output path does not exist: $finalOutputPath")
} else {
logInfo(s"Final output path $finalOutputPath already exists; not overwriting it")
if (!fs.delete(tempOutputPath, false)) {
logWarning(s"Error deleting ${tempOutputPath}")
writeRDDToCheckpointDirectoryWrite,将一个RDD写入到多个checkpoint文件,并返回一个ReliableCheckpointRDD来代表这个RDD
def writeRDDToCheckpointDirectory[T: ClassTag](
originalRDD: RDD[T],
checkpointDir: String,
blockSize: Int = -1): ReliableCheckpointRDD[T] = {
val sc = originalRDD.sparkContext
val checkpointDirPath = new Path(checkpointDir)
val fs = checkpointDirPath.getFileSystem(sc.hadoopConfiguration)
if (!fs.mkdirs(checkpointDirPath)) {
throw new SparkException(s"Failed to create checkpoint path $checkpointDirPath")
val broadcastedConf = sc.broadcast(
new SerializableConfiguration(sc.hadoopConfiguration))
sc.runJob(originalRDD,
writePartitionToCheckpointFile[T](checkpointDirPath.toString, broadcastedConf) _)
if (originalRDD.partitioner.nonEmpty) {
writePartitionerToCheckpointDir(sc, originalRDD.partitioner.get, checkpointDirPath)
val newRDD = new ReliableCheckpointRDD[T](
sc, checkpointDirPath.toString, originalRDD.partitioner)
if (newRDD.partitions.length != originalRDD.partitions.length) {
throw new SparkException(
s"Checkpoint RDD $newRDD(${newRDD.partitions.length}) has different " +
s"number of partitions from original RDD $originalRDD(${originalRDD.partitions.length})")
newRDD
以上源码有可以改进的地方,因为重新计算RDD其实是没有必要的。
RDD checkpoint之后得到了一个新的RDD,那么child RDD 如何知道 parent RDD 有没有被checkpoint过呢? 看 RDD的源码,我们可以发现:
private var dependencies_ : Seq[Dependency[_]] = null
dependencies_ 用来存放checkpoint后的结果的,如为null,则就判断没checkpoint:
final def dependencies: Seq[Dependency[_]] = {
checkpointRDD.map(r => List(new OneToOneDependency(r))).getOrElse {
if (dependencies_ == null) {
dependencies_ = getDependencies
dependencies_
摘要本文提出了分布式内存抽象的概念——弹性分布式数据集(RDD,Resilient Distributed Datasets),它具备像MapReduce等数据流模型的容错特性,并且允许开发人员在大型集群上执行基于内存的计算。现有的数据流系统对两种应用的处理并不高效:一是迭代式算法,这在图应用和机器学习领域很常见;二是交互式数据挖掘工具。这两种情况下,将数据保存在内存中能够极大地提高性能。为了
Spark简介
Apache Spark是用于大规模数据处理的统一分析引擎,基于内存计算,提高了在大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性,允许用户将Spark部署在大量硬件之上,形成集群。
Spark源码从1.x的40w行发展到现在的超过100w行,有1400多位大牛贡献了代码。整个Spark框架源码是一个巨大的工程。下面我们一起来看下spark的底层执行原理。
Spark运行流程
具体运行流程如下:
SparkContext 向资源管理器注册并向资源管理器申请运行Executo
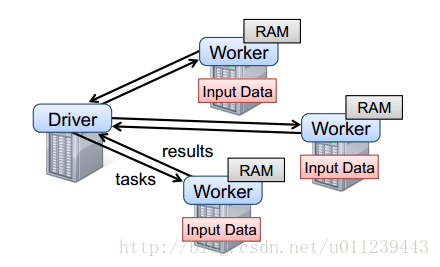
Spark应用程序以进程集合为单位在分布式集群上运行,通过driver程序的main方法创建的SparkContext对象与集群交互。
1、Spark通过SparkContext向Cluster manager(资源管理器)申请所需执行的资源(cpu、内存等)
2、Cluster manager分配应用程序执行需要的资源,在Worker节点上创建Executor
3、SparkContext...
Apache Spark是一个围绕速度、易用性和复杂分析构建的大数据处理框架,最初在2009年由加州大学伯克利分校的AMPLab开发,并于2010年成为Apache的开源项目之一,与Hadoop和Storm等其他大数据和MapReduce技术相比,Spark有如下优势:
1.运行速度快,Spark拥有DAG执行引擎,支持在内存中对数据进行迭代计算。官方提供的数据表明,如果数据由磁盘读取,速度是H...
在RDD中dependencies_是专门用来存储当前RDD的父dependency序列。
dependencies方法,用于获取当前RDD的所有依赖的序列,源码如下:
本套大数据热门技术Spark+机器学习+贝叶斯算法系列课程,历经5年沉淀,调研企业上百家,通过上万学员汇总,保留较为完整的知识体系的同时,让每个模块看起来小而精,碎而不散。在本课程中基于大量案例实战,深度剖析和讲解Spark2.4原理和新特性,且会包含完全从企业真实业务需求中抽取出的案例实战。内容涵盖Spark核心编程、Spark SQL和Spark Streaming、Spark内核以及源码剖析、推荐系统、Kafka消费机制、Spark机器学习、朴素贝叶斯算法、企业级实战案例等。通过理论和实际的紧密结合,可以使学员对大数据Spark技术栈有充分的认识和理解,在项目实战中对Spark和流式处理应用的场景、以及大数据开发有更深刻的认识;并且通过对流处理原理的学习和与批处理架构的对比,可以对大数据处理架构有更全面的了解,为日后成长为架构师打下基础。本套教程可以让学员熟练掌握Spark技术栈,提升自己的职场竞争力,实现更好的升职或者跳槽,或者从J2EE等传统软件开发工程师转型为Spark大数据开发工程师,或是对于正在从事Hadoop大数据开发的朋友可以拓宽自己的技术能力栈,提升自己的价值。Spark应用场景Yahoo将Spark用在Audience Expansion中的应用,进行点击预测和即席查询等。淘宝技术团队使用了Spark来解决多次迭代的机器学习算法、高计算复杂度的算法等。应用于内容推荐、社区发现等。腾讯大数据精准推荐借助Spark快速迭代的优势,实现了在“数据实时采集、算法实时训练、系统实时预测”的全流程实时并行高维算法,最终成功应用于广点通pCTR投放系统上。优酷土豆将Spark应用于视频推荐(图计算)、广告业务,主要实现机器学习、图计算等迭代计算。本套大数据热门技术Spark+机器学习+贝叶斯算法共计13季,本套为第6季。
Spark RDD(弹性分布式数据集)是Spark中最基本的数据结构之一,它是一个不可变的分布式对象集合,可以在集群中进行并行处理。RDD可以从Hadoop文件系统中读取数据,也可以从内存中的数据集创建。RDD支持两种类型的操作:转换操作和行动操作。转换操作是指对RDD进行转换,生成一个新的RDD,而行动操作是指对RDD进行计算并返回结果。RDD具有容错性,因为它们可以在节点之间进行复制,以便在节点故障时恢复数据。
Spark RDD的特点包括:
1. 分布式:RDD可以在集群中进行并行处理,可以在多个节点上进行计算。
2. 不可变性:RDD是不可变的,一旦创建就不能修改,只能通过转换操作生成新的RDD。
3. 容错性:RDD具有容错性,因为它们可以在节点之间进行复制,以便在节点故障时恢复数据。
4. 惰性计算:RDD的计算是惰性的,只有在行动操作时才会进行计算。
5. 缓存:RDD可以缓存到内存中,以便在后续操作中快速访问。
Spark RDD的转换操作包括:
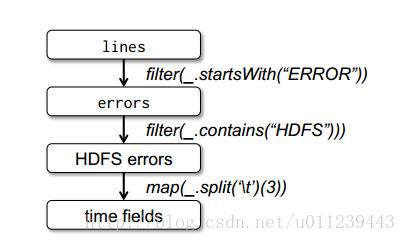
1. map:对RDD中的每个元素应用一个函数,生成一个新的RDD。
2. filter:对RDD中的每个元素应用一个函数,返回一个布尔值,将返回值为true的元素生成一个新的RDD。
3. flatMap:对RDD中的每个元素应用一个函数,生成一个新的RDD,该函数返回一个序列,将所有序列中的元素合并成一个新的RDD。
4. groupByKey:将RDD中的元素按照key进行分组,生成一个新的RDD。
5. reduceByKey:将RDD中的元素按照key进行分组,并对每个分组中的元素进行reduce操作,生成一个新的RDD。
Spark RDD的行动操作包括:
1. count:返回RDD中元素的个数。
2. collect:将RDD中的所有元素收集到一个数组中。
3. reduce:对RDD中的所有元素进行reduce操作,返回一个结果。
4. foreach:对RDD中的每个元素应用一个函数。
5. saveAsTextFile:将RDD中的元素保存到文本文件中。
以上就是Spark RDD的详细介绍。