Python处理大数据,如何提高处理速度?
一、利用大数据分析工具
Dask:
https://dask.org/
Dask简介:Dask支持Pandas的DataFrame和NumpyArray的数据结构,并且既可在本地计算机上运行,也可以扩展到在集群上运行。Dask可支持pandas、Numpy、Sklearn、XGBoost、XArray、RAPIDS等等。
原理及使用方法:
https://blog.csdn.net/sixqingfeng/article/details/125715422
二、加快 Pandas、Numpy 数据处理速度的方法
https://blog.csdn.net/qq_34160248/article/details/124520547
https://pandas.pydata.org/pandas-docs/stable/user_guide/enhancingperf.html
三、对于HDF5数据,可以利用vaex
https://www.zhihu.com/question/19607447
如果利用pandas读取大量数据,导致速度较慢,可以尝试利用vaex。
简介:vaex是一个用处理、展示数据的数据表工具,类似pandas;vaex采取内存映射、惰性计算,不占用内存,适合处理大数据;vaex可以在百亿级数据集上进行秒级的统计分析和可视化展示;
使用方法:
安装:
pip install vaex
四、创建多进程
当遇到处理数据量较大;较多的判断规则等情况时,处理数据往往需要很长的时间。
解决方法:
多进程运算或优化的多进程运算方法
具体例子:
https://zhuanlan.zhihu.com/p/29362983
对于dataframe可以使用
Modin库
;
安装方法:
pip installmodin[ray]
Modin安装前需先安装ray,而ray目前是不支持windows环境的。所以可以先通过WSL进行安装ray后再安装modin。参考:
windows10下安装Modin
安装步骤记录:Modin使用Ray或Dask作为后端,在这里我们使用 dask,命令行输入以下代码同时安装Modin和Dask:
pip install modin[dask]
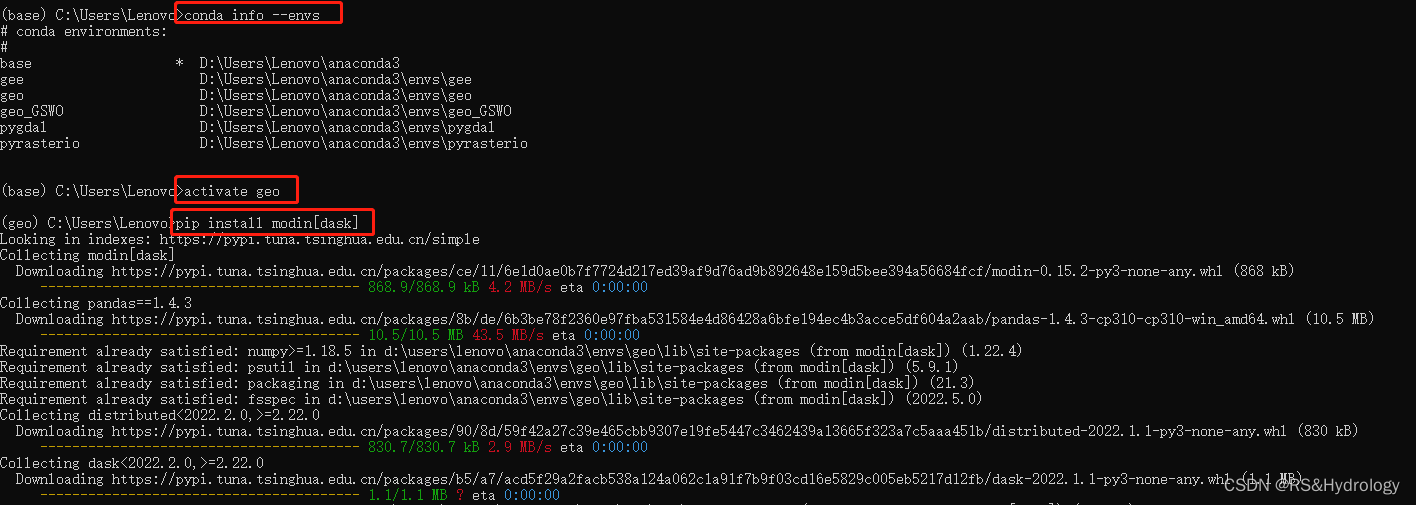
使用:
import modin.pandas as pd
五、大数据技术—Spark
大数据技术spark
Spark简介:
Spark:由美国加州伯克利大学的AMP实验室于2009年开发,基于内存计算的大数据并行计算框架,可用于构建大型的、低延迟的数据分析应用程序。
三大分布式计算系统开源项目:
Hadoop、Spark、Storm
。
六、Dask并行运算
(1)dask简介
dask说明文档:
https://docs.dask.org/en/latest/
Dask安装与使用:
https://blog.csdn.net/bruceoxl/article/details/113092854
Dask是Python中一个用于并行计算的库。
dask工作原理:
参考资料:
https://blog.csdn.net/bruceoxl/article/details/113092854
所有大型的Dask集合变量(例如Dask Array,Dask DataFrame和Dask Bag)以及细粒度的API(例如Delay和Future)都会生成任务图,其中图中的每个节点都是常规的Python函数,而节点之间的边缘是常规的Python对象,由一个任务创建为输出,并在另一任务中用作输入。 在Dask生成这些任务图之后,它需要在并行硬件上执行它们。这就是任务调度。Dask存在不同的任务调度,每个调度程序将使用一个任务图并计算得到相同的结果,但是它们的性能差别很大。
————————————————
版权声明:本文为CSDN博主「Bruceoxl」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/bruceoxl/article/details/113092854
(2)dask安装
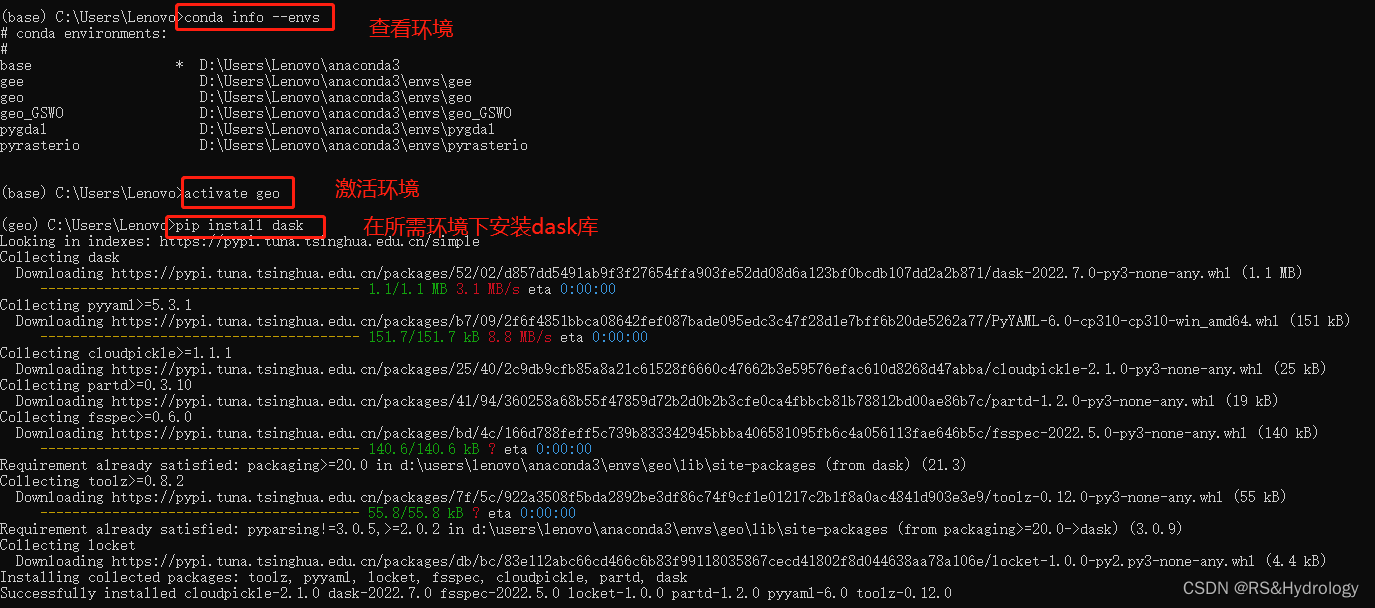
利用anaconda安装:
conda info --envs
activate xx
pip install dask
(3)pandas使用dask并行计算
import dask.dataframe as dd
df = dd.read_csv('1.csv')
参考资料:
1.(强推,总结很全且详细)Python 中处理大型数据工具(dask)https://blog.csdn.net/qq_42374697/article/details/121010300
2.Dask官方教程:
import dask.dataframe as dd
df = dd.read_csv(filename)
df.head()
len(df)
3.Dask DataFrame
https://docs.dask.org/en/stable/dataframe.html
如果你有个5、6 G 大小的文件,想把文件内容读出来做一些处理然后存到另外的文件去,你会使用什么进行处理呢?不用在线等,给几个错误示范:有人用multiprocessing 处理,但是效率非常低。于是,有人用python处理大文件还是会存在效率上的问题。因为效率只是和预期的时间有关,不会报错,报错代表程序本身出现问题了~
所以,为什么用python处理大文件总有效率问题?
如果工作需要,立刻处理一个大文件,你需要注意两点:
01、大型文件的读取效率
面对100w行的大型数据,经过测试各种文件读取方式,得出结论:
with open(filename,rb) as f:
for fLi
1 文本查看
拿到新数据,总是想先打开数据,看看字段和数据情况。然而,我的电脑运存只有16G,超过4G的文本数据如果用记事本或notepad++等文本编辑器直接打开,会一下子涌入运存中,打开很慢或者直接打不开。
EmEditor软件读取大文件很方便。不是免费的,需要注册:EmEditor (Text Editor) – Text Editor for Windows supporting large files and U
在Python中,使用NumPy库来计算大数据的百分比是最快的方法之一。NumPy库是一个高性能科学计算库,专门为数组运算和向量化操作而设计,因此在处理大量数据时非常快速。以下是一个使用NumPy的示例代码:
```python
import numpy as np
data = np.array([10, 20, 30, 40, 50])
total = np.sum(data)
percentages = 100 * data / total
print(percentages)
在这个例子中,我们使用NumPy的数组和向量化操作,将数据数组除以总和,并将结果乘以100,以计算每个元素的百分比。这种方法非常快速,因为它避免了Python中循环的低效性能。如果你有更多的数据需要处理,可以使用NumPy的并行计算功能来进一步提高计算速度。

