我们知道很多时候爬虫也不是万能的,这个时候就需要我们的自动化测试框架了。
于是Selenium就应运而生了,它可以算的上是自动化测试框架中的佼佼者,因为它解决了大多数用来爬取页面的模块的一个永远的痛,那就是Ajax异步加载 。今天将给大家详解如何用Selenium爬取数据,并最后附上一个真实的案例。
一 、Selenium介绍
Selenium是一个web的自动化测试工具,最初是为网站自动化测试而开发的,Selenium可以直接运行在浏览器上,它支持所有主流的浏览器,可以接收指令,让浏览器自动加载页面,获取需要的数据,甚至页面截屏 。
chromedriver是一个驱动Chrome浏览器的驱动程序,使用他才可以驱动浏览器。当然针对不同的浏览器有不同的driver。以下列出了不同浏览器及其对应的driver:
- Chrome:https://sites.google.com/a/chromium.org/chromedriver/downloads
- Firefox:https://github.com/mozilla/geckodriver/releases
- Edge:https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/
- Safari:https://webkit.org/blog/6900/webdriver-support-in-safari-10/
安装配置chromedriver:https://blog.csdn.net/weixin_43901998/article/details/88087832
安装Selenium:
pip install selenium
安装好浏览器后,将浏览器驱动放在浏览器同级目录下,这样前期工作就算都预备好了。
- 注:不要随便乱下浏览器和驱动,每个浏览器和驱动器的版本都必须是一一对应的,不是通用的。
二、快速入门
1、与浏览器建立连接
# 1.加载网页
from selenium import webdriver
driver = webdriver.PhantomJS(executable_path=r'"安装目录") # 也可以把chrome添加到python文件路径下,就不用写executable_path=r'"安装目录"
driver.get("https://www.baidu.com") # 请求
driver.save_screenshot("baidu.png") # 截图
# 退出
driver.quit()
2、selenium快速入门
from selenium import webdriver
# 实例化浏览器
driver = webdriver.Chrome()
# 发送请求
driver.get('https://www.baidu.com')
# 截图
driver.save_screenshot("baidu.png")
# 最大化窗口
driver.maximize_window()
# 退出浏览器
driver.quit()
三、定位元素
- find_element_by_id:根据id来查找某个元素。
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
- find_element_by_class_name:根据类名查找元素。
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
- find_element_by_name:根据name属性的值来查找元素。
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
- find_element_by_tag_name:根据标签名来查找元素。
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
- find_element_by_xpath:根据xpath语法来获取元素。
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
要注意,find_element是获取第一个满足条件的元素。find_elements是获取所有满足条件的元素。
四、浏览器操作
from selenium import webdriver
# 实例化浏览器
c = webdriver.Chrome()
# 发送请求
c.get('https://www.baidu.com')
1、获取本页面URL
c.current_url
2、获取日志
c.log_types #获取当前日志类型
c.get_log('browser')#浏览器操作日志
c.get_log('driver') #设备日志
c.get_log('client') #客户端日志
c.get_log('server') #服务端日志
##3.窗口操作
c.maximize_window()#最大化
c.fullscreen_window() #全屏
c.minimize_window() #最小化
c.get_window_position() #获取窗口的坐标
c.get_window_rect()#获取窗口的大小和坐标
c.get_window_size()#获取窗口的大小
c.set_window_position(100,200)#设置窗口的坐标
c.set_window_rect(100,200,32,50) #设置窗口的大小和坐标
c.set_window_size(400,600)#设置窗口的大小
c.current_window_handle #返回当前窗口的句柄
c.window_handles #返回当前会话中的所有窗口的句柄
3、设置延时
c.set_script_timeout(5) #设置脚本延时五秒后执行
c.set_page_load_timeout(5)#设置页面读取时间延时五秒
4、关闭
c.close() #关闭当前标签页
c.quit() #关闭浏览器并关闭驱动
5、打印网页源代码
c.page_source
6、屏幕截图操作
c.save_screenshot('1.png')#截图,只支持PNG格式
c.get_screenshot_as_png() #获取当前窗口的截图作为二进制数据
c.get_screenshot_as_base64() #获取当前窗口的截图作为base64编码的字符串
8.前进后退刷新
c.forward() #前进
c.back() #后退
c.refresh()#刷新
7、Cookies操作
c.get_cookie('BAIDUID') #获取指定键的Cookies
c.get_cookies() #获取所有的Cookies
for y in c.get_cookies():
x=y
if x.get('expiry'):
x.pop('expiry')
c.add_cookie(x) #添加Cookies
c.delete_cookie('BAIDUID') #删除指定键的Cookies内容
c.delete_all_cookies() #删除所有cookies
五、操作表单元素
操作输入框:分为两步。
第一步:找到这个元素。
第二步:使用send_keys(value),将数据填充进去
使用clear方法可以清除输入框中的内容
inputTag.clear()
操作checkbox
因为要选中checkbox标签,在网页中是通过鼠标点击的。因此想要选中checkbox标签,那么先选中这个标签,然后执行click事件。
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
操作按钮
操作按钮有很多种方式。比如单击、右击、双击等。这里讲一个最常用的。就是点击。直接调用click函数就可以了。
inputTag = driver.find_element_by_id('su')
inputTag.click()
选择select
select元素不能直接点击。因为点击后还需要选中元素。这时候selenium就专门为select标签提供了一个类selenium.webdriver.support.ui.Select。将获取到的元素当成参数传到这个类中,创建这个对象。以后就可以使用这个对象进行选择了[1]。
切换iframe
我们知道网页中有一种节点叫作 iframe,也就是子 Frame,相当于页面的子页面,它的结构和外部网页的结构完全一致。Selenium打开页面后,默认是在父级 Frame 里面操作,而此时如果页面中还有子 Frame,Selenium是不能获取到子 Frame 里面的节点的。这时就需要使用 switch_to.frame 方法来切换 Frame。
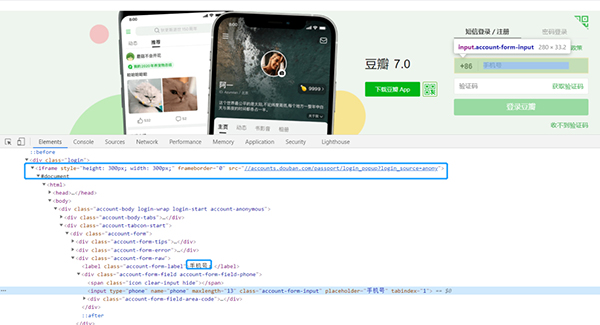
接下来通过豆瓣模拟登录来切换iframe,示例如下:
from selenium import webdriver
import time
url = 'https:www.douban.com'
driver = webdriver.Chrome()
driver.get(self.url)
time.sleep(3)
# 定位iframe标签
login_iframe = self.driver.find_element_by_xpath('//*[@id="anony-reg-new"]/div/div[1]/iframe')
# 切换iframe标签
driver.switch_to.frame(login_iframe)
六、行为链
有时候在页面中的操作可能要有很多步,那么这时候可以使用鼠标行为链类ActionChains来完成。比如现在要将鼠标移动到某个元素上并执行点击事件。
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.context_click()
actions.click(submitTag)
actions.perform()
还有更多的鼠标相关的操作。
- click_and_hold(element):点击但不松开鼠标。
- context_click(element):右键点击。
- double_click(element):双击。
- 更多方法请参考:http://selenium-python.readthedocs.io/api.html
豆瓣模拟登录(定位元素,切换iframe,以及行为链操作)。
from selenium import webdriver
import time
class Douban():
def __init__(self):
self.url = 'https:www.douban.com'
self.driver = webdriver.Chrome()
def login(self):
self.driver.get(self.url)
time.sleep(3)
# 定位iframe标签
login_iframe = self.driver.find_element_by_xpath('//*[@id="anony-reg-new"]/div/div[1]/iframe')
# 切换iframe标签
self.driver.switch_to.frame(login_iframe)
# 第一张截图(登录前)
self.driver.save_screenshot('db1.png')
# 定位密码输入框
self.driver.find_element_by_class_name('account-tab-account').click()
# 输入手机号
self.driver.find_element_by_id('username').send_keys('156xxxxxx26')
# 输入密码
self.driver.find_element_by_id('password').send_keys('.......')
# 点击登录按钮
self.driver.find_element_by_class_name('btn-account').click()
time.sleep(3)
# 第二张截图(登陆后)
self.driver.save_screenshot('db2.png')
def out(self):
'''调用内建的稀构方法,在程序退出的时候自动调用
类似的还可以在文件打开的时候调用close,数据库链接的断开
'''
self.driver.quit()
if __name__ == '__main__':
db = Douban() # 实例化
db.login() # 之后调用登陆方法
七、Selenium页面等待
Cookie操作
获取所有的cookie
cookies = driver.get_cookies()
根据cookie的name获取cookie
value = driver.get_cookie(key)
删除某个cookie
driver.delete_cookie('key')
页面等待
现在的网页越来越多采用了 Ajax 技术,这样程序便不能确定何时某个元素完全加载出来了。如果实际页面等待时间过长导致某个dom元素还没出来,但是你的代码直接使用了这个WebElement,那么就会抛出NullPointer的异常。为了解决这个问题。所以 Selenium 提供了两种等待方式:一种是隐式等待、一种是显式等待。
- 隐式等待:调用driver.implicitly_wait。那么在获取不可用的元素之前,会先等待10秒中的时间。
driver.implicitly_wait(10)
- 显示等待:显示等待是表明某个条件成立后才执行获取元素的操作。也可以在等待的时候指定一个最大的时间,如果超过这个时间那么就抛出一个异常。显示等待应该使用selenium.webdriver.support.excepted_conditions期望的条件和selenium.webdriver.support.ui.WebDriverWait来配合完成。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
driver.get("https://www.baidu.com/")
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
一些其他的等待条件
- presence_of_element_located:某个元素已经加载完毕了。
- presence_of_all_elements_located:网页中所有满足条件的元素都加载完毕了。
- element_to_be_clickable:某个元素是可以点击了。
更多条件请参考:http://selenium-python.readthedocs.io/waits.html
八、打开多窗口和切换页面
有时候窗口中有很多子tab页面。这时候肯定是需要进行切换的。selenium提供了一个叫做switch_to_window来进行切换,具体切换到哪个页面,可以从driver.window_handles中找到。
# 打开一个新的页面
driver.execute_script("window.open('url')")
print(driver.current_url)
# 切换到这个新的页面中
driver.switch_to_window(self.driver.window_handles[1])
九、企鹅电竞案例
下面我们用企鹅电竞为案例,演示一下如何使用Selenium爬取数据。
1、打开官网首页:通过分析页面知道全部直播的信息储存在ul(class='livelist-mod resize-list-container-280-livelist-live)下面的li里面。
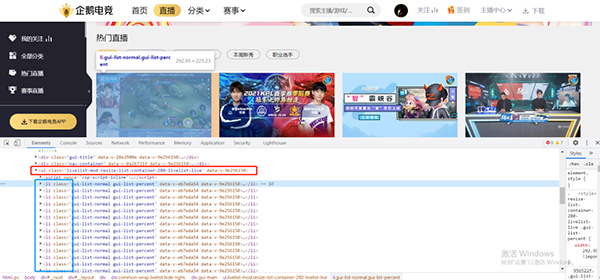
但是通过测试可以发现这个页面瀑布流布局,他不需要翻页,需要滚到页面底部加载更多数据。所以:
dataNum = int(input('请输入目标直播间数量:')) # 用户决定爬取多少个直播间信息
_single = True
# 做一个死循环
while _single:
items = driver.find_elements_by_xpath("//ul[@class='livelist-mod resize-list-container-280-livelist-live']/li") # 页面的li标签(也就是一个直播间数据)
print(len(items))
if len(items) < dataNum:
# 拖动滚动条至底部
js1 = "document.documentElement.scrollTop=100000"
driver.execute_script(js1)
time.sleep(3) # 因为滚动到页面底部只需要一瞬间,休息3s是为了数据加载完全
else:
_single = False
2、我们要获取的是主题(title),界面图片链接(pic),主播名(name),人气(popu),类型(types)。
- 这里我们只爬取了600条数据,但是让页面加载800条数据,因为这个页面加载不完全,也就是他最后面展示的数据不会显示出来(只要使用滚轮滚到底部,由于数据加载,滚轮就会往上一点,这样页面显示的数据是没有完全加载出来)。
items = driver.find_elements_by_xpath("//ul[@class='livelist-mod resize-list-container-280-livelist-live']/li")
print(len(items))
info_list = []
for item in items[:600]:
dic = {}
name = item.find_element_by_xpath("./a/div[2]/p").text # 主播名字
popularity = item.find_element_by_xpath("./a/div[2]/span").text # 人气
title = item.find_element_by_xpath('./a/h4/span[1]').text # 主题
types = item.find_element_by_xpath('./a/h4/span[2]').text # 类型
pic = item.find_element_by_xpath('./a/div[1]/img').get_attribute('src') # 图片链接
picLink = 'https:' + pic
dic['name'] = name
dic['popu'] = popularity
dic['title'] = title
dic['type'] = types
dic['pic'] = picLink
print(dic)
info_list.append(dic)
3、数据提取
这里我们把数据保存到一个csv文件中。
head = ['name','popu','title','type','pic']
with open('qiee.csv', 'w', encoding='utf-8', newline='') as f:
writer = csv.DictWriter(f, head)
writer.writeheader()
writer.writerows(info_list)
print('写入成功')
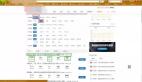
4、运行程序
开始:

结尾:
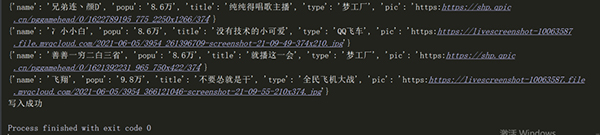
然后我们看下csv文件:

成功爬取到了想要的数据。