

论文笔记(一)

Multi-label Co-regularization for Semi-supervised Facial Action Unit Recognition
多标记的协同正则化的半监督学习的面部动作单元识别
----NIPS 2019
文章链接:
一、总述:
这篇论文主要针对现有的AU识别方法需要大量的有精确的AU标记的数据的问题,创新了一种新的半监督学习方法用于AU识别,文中叫做multi-label co-regularization。它的数据集中只有小部分的数据具有通过协同训练得到的标记,而更多更大部分的数据是没有标记的。该方法的关键点如下:
1. 首先对整个数据集从两个不同视角生成特征,包括有标记和未标记的数据。
2. 为了保证不同视角生成的特征彼此的独立性,引入一个multi-view loss函数。
3. 为了最小化被预测出的两个视角的分布的差异,让他们具有一致性,引入一个multi-label co-regularization loss函数。
4. 为了能够充分应用之前的经验,即独立AU们之间的关系,作者使用图卷积网络(graph convolutional network——GCN)来将那些未标记的数据的有用信息尽可能地开发出来。
实验证明,作者提出的方法胜过了当前最先进的半监督学习AU识别方法,也更高效地利用了大量的未标记数据进一步提高了AU识别方法的鲁棒性。此外,该方法泛化能力很强,也可以应用于其他相似任务中。
二 、贡献:
1. 提出了一种新颖的半监督AU识别方法——multi-label co-regularization方法,它利用大量的未标记面部图像和相对较少的带有标记的面部图像。
2. 应用了AU之间的关系作为之前的经验嵌入GCN中以便于进一步应用未标记图像中的有效信息。
3. 比起不用大量的未标记的图像的方法和现存最好的半监督AU识别方法,该方法在结果上有更出众的表现。
三、主要内容:
在文章的第一部分,先是介绍了面部运动在各个领域应用广泛,如测谎、心理健康诊断、提高电子学习经验等等。然后提出问题:如何在有标记数据集相对较小的情况下应用大量的未标记数据帮助进行AU识别?事实上,我们可以从两个方向应用未标记数据。
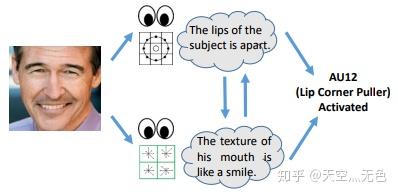
首先,从图1中我们可以看出一张脸可以有很多不同的视角(嘴唇是不是分开的?嘴形是不是像在微笑?)被用于进行AUs分类。由此可知针对不同视角训练的不同模型的多样性存在于标记的和未标记的面部图像中,并且可以进一步用于增强每个模型的泛化能力。这事实上是传统的协同训练方法(co-training methods)提出来的,但遗憾的是,这种方法有很大的限制。近年来,深度神经网络(deep neural networks——DNNs)强大的表征学习能力使生成多视图表示成为可能,可用于基于协同训练的半监督学习。
然后,在不同的AUs之间存在着很强的相关性,如今已经有很多方法利用了它,但它们都是用监督学习的形式去使用的。然而这种AUs间的相关性其实存在于所有的面部图像中,无论是否已经被标记!本文所提出的方法就是从这两个角度下手提高AU识别能力。
文章的第二部分简单介绍了现有的方法和它们存在的问题,这里不再详述。
文章的第三部分具体叙述了传统的协同训练方法和新提出的方法:
(一)传统的协同训练(Traditional Co-training)
训练过程:假设每个训练集中的样本都有两个不同的视角 v_{1} 和 v_{2} ,它们有不同的来源和数据表示,两个模型 M_{1} 和 M_{2} 分别地基于 v_{1} 和 v_{2} 训练得到。每个模型对那些未标记的数据的预测被用于增加另一个模型的训练集。这个过程重复迭代多次直到两个模型都趋于稳定。
协同训练的两个前提:1.两个视角的特征必须彼此条件独立;2.由于重训练的机制,从不同视角训练得到的模型对数据的预测必须趋于相似。
事实上,作者提出的方法也是基于这两个前提的。
(二)Multi-label Co-regularization
作者选用了ResNet-34网络作为特征生成器。
数据集 D 被分成两部分: D=L \cup U ,其中 L 是有标记数据集,而 U 是无标记数据集。对 D 中的每一个图像,都用两个不同的生成器生成两个视角的特征 f_{1},f_{2} 。然后,利用每个视角的特征,学习 C 个分类器来预测 C 个AU的概率,使用第 i 个视角被预测为 j 个AU的概率表示为 p_{ij} : p_{ij}=\sigma(w_{ij}^{T}f_{i}+b_{ij}) 。这里 \sigma 是一个双曲函数, w_{ij} 和 b_{ij} 是分类器的参数。
对每个视角用二元交叉熵损失函数计算损失,对第 i 个视角的AU识别损失函数 L_{vi} 表示为:
L_{vi}=-\frac{1}{C}\sum_{j=1}^{C}{a_{c}[p_{j}logp_{ij}+(1-p_{j}log(1-p_{ij})]} ,
其中 p_{j} 是第 j 个AU发生的概率,在0到1之间的一个值; a_{c} 是平衡参数,由选择学习策略计算得到的。
这个方法的一个关键点就是不同视角的特征之间必须保证条件独立,本文提出了一个multi-view loss去保证这一要求,即正交化AU不同视角分类器的权值,这个multi-view loss L_{mv} 定义为: L_{mv}=\frac{1}{C}\sum_{j=1}^{C}{\frac{W_{1j}^{T}W_{2j}^{}}{||W_{1j}||||W_{2j}||}} ,
这里 W_{ij}=[w_{ij} b_{ij}] 表示第 i 个视角的第 j 个AU分类器的参数。这样一来,不同视角生成的特征就会不同而互补。
除了条件独立,另一个关键在于不同视角的分类器最终必须得到一致的预测。为此,本文提出了一个co-regularization loss来代替传统的协同训练中的重训练机制。本文用JS散度来表示两个分布情况之间的距离,co-regularization loss L_{cr} 被定义为:
L_{cr}=\frac{1}{C}\sum_{j=1}^{C}{H(\frac{p_{1j}+p_{2j}}{2})-\frac{H(p_{1j})+H(p_{2j})}{2})} ,
这里 H(p)=-(plogp+(1-p)log(1-p)) 是关于 p 的熵。
因此multi-label co-regularization方法最终的损失函数为:
L=\frac{1}{2}\sum_{i=1}^{2}{L_{vi}+\lambda_{mv}L_{mv}+\lambda_{cr}L_{cr}} ,
这里 \lambda_{mv} 和 \lambda_{cr} 是平衡不同损失函数影响的超参数。
上文给出了这个方法的损失函数,接下来描述如何利用不同AU之间的关系作为之前的经验。GCN对于在不同节点之间传递信息是一个非常有效的模型。在本文中用的是双层的GCN。两个不同视角AU分类器的参数 W_{ij} 作为GCN的节点。GCN的输入和输出的形式为:
W_{i}=[W_{i1};W_{i2};...;W_{iC}] ,
这里 W_{i} 的第 j 列是第 j 个AU的分类器的参数。GCN的信息传递机制为:
W_{i}^{t}=\tilde{A}ReLU(\tilde{A}W_{i}^{0}H^{(0)})H^{(1)} ;
这里 W_{i}^{0} 和 W_{i}^{t} 分别为GCN的输入和输出, \tilde{A} 是节点的邻接矩阵,而 H^{(0)} 和 H^{(1)} 是GCN的参数。 ReLU 是GCN的激活函数,本文使用的是Leaky ReLU。
GCN的关键部分在于定义邻接矩阵 \tilde{A} ,文中选择了标记数据计算得到的依赖矩阵作为邻接矩阵。因为正例的数目不够,这里考虑应用正例和反例的样本以减少不平衡产生的影响。首先想到的是平均 C 个AU的依赖矩阵为:
P_{dep}=\frac{1}{2}([P(L_{i}=1|L_{j}=1)]_{C\times C}+[P(L_{i}=-1|L_{j}=-1)]_{C\times C})
由于当依赖概率 P(L_{i}=1|L_{j}=1)=0.5 时意味着第 j 个AU的激活并没有对第 i 个AU提供什么有用的信息,第 i 个AU发不发生的概率相同都是0.5。而且依赖矩阵的所有元素必须为正,对角线元素应该为1。根据以上情况,我们进一步修改 P_{dep} 得到以下最终依赖矩阵:
\tilde{A}=ABS((P_{dep}-0.5)\times 2)
这里 ABS(M) 返回的是 M 中所有元素求绝对值后得到的新矩阵。
四、实验结果:
文章用了EmotioNet和BP4D这两个数据库进行试验,评估的标准为F1值。经过与最新的半监督学习方法(如co-training,mean-teacher和MLCT)和不应用未标记数据的情况相比较,作者提出的方法的明显有更好的表现。
此外,本文还提供ablation study将我们添加的loss函数 L_{mv} , L_{cr} 和GCN逐步地加入只应用标记数据的模型中来检测它们对实验表现的影响。
最后,文章还使用了CelebA数据库估计面部属性,来证明此方法的泛化性能优秀,同样能应用于其他相似的任务中。