前记:
预训练语言模型(Pre-trained Language Model,PLM)想必大家应该并不陌生,其旨在使用自监督学习(Self-supervised Learning)或多任务学习(Multi-task Learning)的方法在大规模的文本语料上进行预训练(Pre-training),基于预训练好的模型,对下游的具体任务进行微调(Fine-tuning)。目前市面上知名的以
英文
为主预训练语言模型有EMLo、BERT、RoBERTa、XLNet、GPT、DeBERTa(部分也开源了中文版本)。以
中文
为主的预训练语言模型有ChineseBERT、MacBERT、StructBERT、SpellBERT等。
知识增强预训练语言模型(Knowledge- enhance PLM)旨在在预训练的时候,试图
将显式的事实知识(Factual Knowledge)融入到模型中
。目前知名的知识增强的模型则有ERNIE(清华)、ERNIE(百度)、K-BERT、KnowBERT、WKLM、KEPLER等。有关所有涉及的预训练模型的细节讲解可相见博主的专栏:
预训练语言模型
在众多知识增强预训练的方法中,最基础最简单且最有效的方法是ERNIE(百度)提出的
entity masking
。大致方法如下:
-
首先给定一个文本句子,使用实体链指工具识别出文本中的所有实体;
-
对于所有识别出的实体,随机挑选若干实体,并替换为[MASK],[MASK]的数量取决于实体的长度
具体方法可参见
ERNIE1.0
。虽然其提出是在中文场景下,但该方法依然适用于英文。我们知道目前的预训练语言模型的分词有两种,一种是以BERT系列为代表的word piece,另一种是以RoBERTa系列为代表的BPE,它们的本质都是将英文单词拆分为若干token,例如“learning”可以被分解为两个token,即“learn”和“###ing”。传统的预训练完全基于token的MLM,而基于实体层面的mask策略,则需要确保实体对应的所有分词也被mask。
本文分享基于英文版本Wikipedia语料和英文知识库Wikidata的知识增强预训练的实现。我们采用Pytorch和HuggingFace实现。建议在Linux开发机上完成。
-
数据获取与预处理
-
HuggingFace实现基于Entity Masking的知识增强预训练
-
下游任务微调
(1)Wikipedia Dumps
首先获取英文的大规模无监督语料。我们参照BERT、RoBERTa等市面上绝大多数的工作,挑选的语料来自于
Wikipedia Dumps
。
一般地,我们直接下载原生态的语料,如图所示:
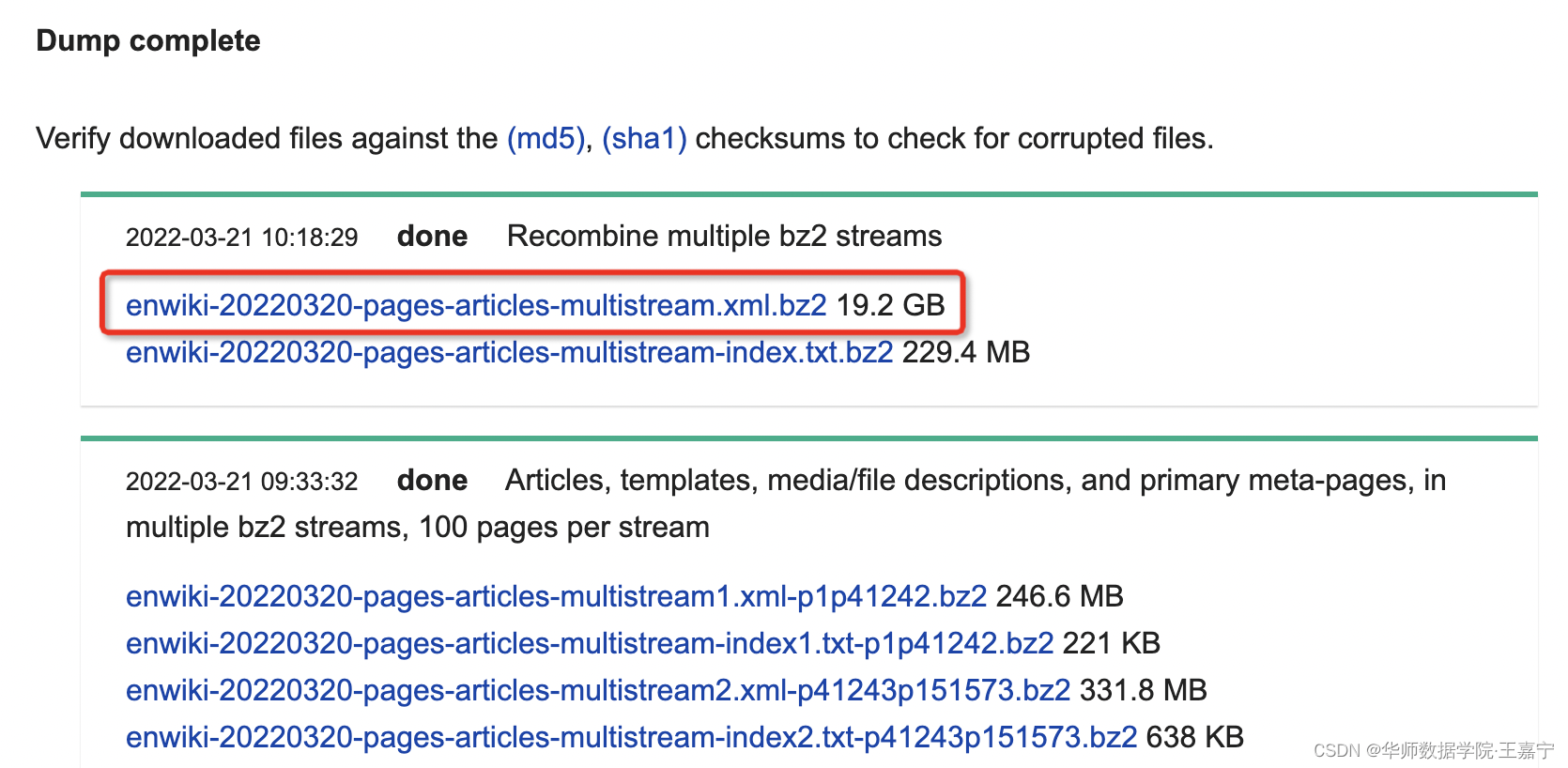
将下载得到的语料放置在项目根目录的data目录下,文件名假设为“xxx.xml.bz”。下载得到的语料
无需自主解压
,通常对应的文本都是格式化的XML文件,并不能直接被使用,因此需要进行预处理。
(2)WikiExtractor
幸运的是,
WikiExtractor
开源工具帮我们解决了预处理的所有环节。具体的说,将WikiExtractor的开源代码下载并放置在data目录下,然后执行命令
python -m wikiextractor.WikiExtractor xxx.xml.bz
,等待数小时后,将会获得全部预处理好的文件。文件目录如下所示:

某个目录下存储的是一堆txt文件:

每个文件存储的是意见处理好的文本:

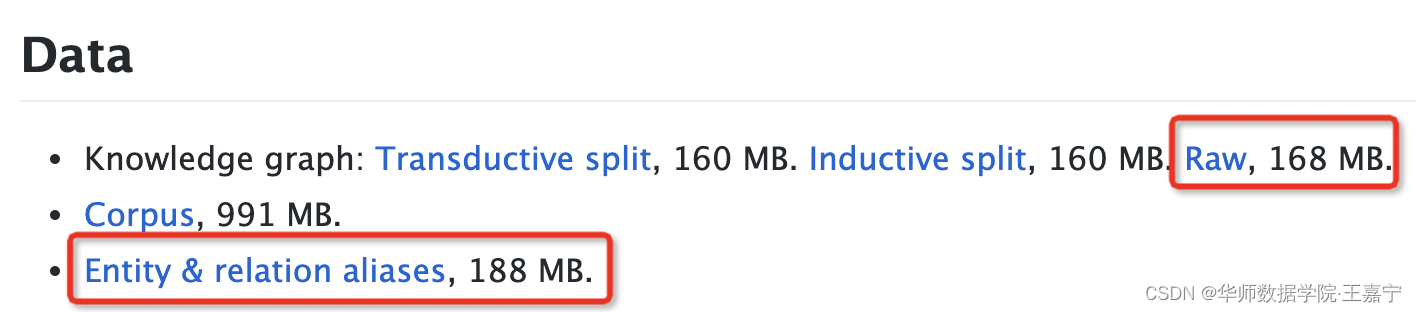
(3)WikiData5M
Wikidata5m是由KEPLER提出的一个基于知识图谱补全的数据集。其下载地址为
https://deepgraphlearning.github.io/project/wikidata5m
可只需下载如图所示的几个文件(下载或比较慢,可以通过VPN渠道下载):
-
Raw:保存着所有三元组。每一行表示一个三元组,即头实体、关系、尾实体,全部使用编号表示;

-
Entity alias(wikidata5m_entity.txt):每一行保存每个实体编号及对应的所有可能的实体名称;实体编号以Q开头;
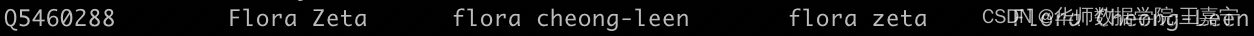
-
Relation alias(wikidata5m_relation.txt):每一行保存每个关系编号及对应的关系名称;关系编号以P开头

因此,我们可以使用python实现一个简单的读取Wikipedia的程序
class KGPrompt:
def __init__(self, tokenizer: PreTrainedTokenizerBase):
self.tokenizer = tokenizer
print('loading wikidata5m knowledge graph ...')
kg_output = './pretrain_data/kg/'
kg = np.load(
os.path.join(kg_output, 'wiki_kg.npz'), allow_pickle=True
self.wiki5m_alias2qid, self.wiki5m_qid2alias, self.wiki5m_pid2alias, self.head_cluster = \
kg['wiki5m_alias2qid'][()], kg['wiki5m_qid2alias'][()], kg['wiki5m_pid2alias'][()], kg['head_cluster'][()]
print('loading success .')
def sample_entity(self, qid=None, neg_num=0):
positive = None
negative = list()
if not qid and qid in self.wiki5m_qid2alias:
positive = random.sample(self.wiki5m_qid2alias[qid], 1)[0]
if neg_num > 0:
negative_qid = random.sample(self.wiki5m_qid2alias.keys(), neg_num)
for i in negative_qid:
negative.append(random.sample(self.wiki5m_qid2alias[i], 1)[0])
return positive, negative
def sample_relation(self, pid=None, neg_num=0):
positive = None
negative = list()
if not pid and pid in self.wiki5m_pid2alias:
positive = random.sample(self.wiki5m_pid2alias[pid], 1)[0]
if neg_num > 0:
negative_pid = random.sample(self.wiki5m_pid2alias.keys(), neg_num)
for i in negative_pid:
negative.append(random.sample(self.wiki5m_pid2alias[i], 1)[0])
return positive, negative
def encode_kg(self, kg_str_or_list, max_len):
if type(kg_str_or_list) == str:
kg_str_or_list = [kg_str_or_list]
kg_input_ids = list()
for kg_str in kg_str_or_list:
kg_ids = self.tokenizer.encode(kg_str, add_special_tokens=False, max_length=max_len)
kg_ids = [self.tokenizer.cls_token_id] + kg_ids[:max_len - 2] + [self.tokenizer.sep_token_id]
kg_ids.extend([self.tokenizer.pad_token_id] * (max_len - len(kg_ids)))
kg_input_ids.append(kg_ids)
return kg_input_ids
def get_demonstration(self, example: Dict, is_negative=False, start_from_input=True):
data = {
'token_ids': tokens,
'entity_qid': entity_ids,
'entity_pos': mention_spans,
'relation_pid': None,
'relation_pos': None,
input_ids, entity_ids = example['token_ids'], example['entity_qid']
input_ids = [self.tokenizer.cls_token_id] + input_ids + [self.tokenizer.sep_token_id]
type_id = 0
token_type_ids = [type_id] * len(input_ids)
start_length = len(input_ids) if start_from_input else 0
entity_spans, relation_spans = list(), list()
token_type_span = list()
token_type_span.append((0, len(input_ids)))
if is_negative:
entity_ids = random.sample(self.wiki5m_qid2alias.keys(), len(entity_ids))
type_id = 1
for entity_id in entity_ids:
if entity_id in self.wiki5m_qid2alias.keys() and entity_id in self.head_cluster.keys():
entity_name_list = self.wiki5m_qid2alias[entity_id]
cluster_list = self.head_cluster[entity_id]
head_name = random.sample(entity_name_list, 1)[0]
triple = random.sample(cluster_list, 1)[0]
if triple[0] in self.wiki5m_pid2alias.keys() and triple[1] in self.wiki5m_qid2alias.keys():
relation_name = self.wiki5m_pid2alias[triple[0]]
tail_name = random.sample(self.wiki5m_qid2alias[triple[1]], 1)[0]
template_tokens, entity_span, relation_span = self.template(
head=head_name,
relation=relation_name,
tail=tail_name,
type_id=random.randint(0, 2),
start_length=start_length
if len(input_ids) + len(template_tokens) >= self.tokenizer.model_max_length - 2:
break
start = len(input_ids)
input_ids.extend(template_tokens)
end = len(input_ids)
token_type_ids.extend([type_id] * len(template_tokens))
entity_spans.extend(entity_span)
relation_spans.extend(relation_span)
token_type_span.append((start, end))
return {
'input_ids': input_ids,
'token_type_ids': token_type_ids,
'noise_detect_label': 0 if is_negative else 1,
'entity_spans': entity_spans,
'relation_spans': relation_spans,
'token_type_span': token_type_span
def template(self, head, relation, tail, type_id=0, start_length=0):
if type_id == 0:
templates = ["The relation between", head, "and", tail, "is", relation]
flag = [0, 1, 0, 1, 0, 2]
elif type_id == 1:
templates = [head, relation, tail]
flag = [1, 2, 1]
elif type_id == 2:
templates = [head, "is the", relation, "of", tail]
flag = [1, 0, 2, 0, 1]
template_tokens = list()
entity_spans = list()
relation_spans = list()
for ei, string in enumerate(templates):
start = start_length + len(template_tokens)
tokens = self.tokenizer.encode(string, add_special_tokens=False)
template_tokens.extend(tokens)
end = start_length + len(template_tokens)
if flag[ei] == 1:
entity_spans.append((start, end))
elif flag[ei] == 2:
relation_spans.append((start, end))
template_tokens += [self.tokenizer.sep_token_id]
return template_tokens, entity_spans, relation_spans
(4)Curpora构建
接下来则是数据处理的关键,即如何对每个wikipedia的每个句子获得对应的实体。我们使用TagMe工具。
TagMe是一个基于Wikipedia的实体链指工具,其可以快速地从英文的文本中返回所有实体及其置信得分。TagMe的使用细节可参考博客https://blog.csdn.net/qq_43549752/article/details/88912835
Step1: 进入页面注册:https://services.d4science.org/home,并选择Google(Gmail)账户登录;
Step2: 登录后在中间有一个Cannot find the VRE you were looking for? If you are looking for a VRE please remember to identify the proper Gateway to use via the Explore page. The credentials and the identity are the same through all Gateways of the D4Science infrastructure. 点击 all Gateways of the D4Science infrastructure 后 进入 SoBigData Gateway, 19 VREs / VLabs ,然后找到TagMe,点击Access this Ver
Step3: 进入TagMe页面:https://sobigdata.d4science.org/group/tagme
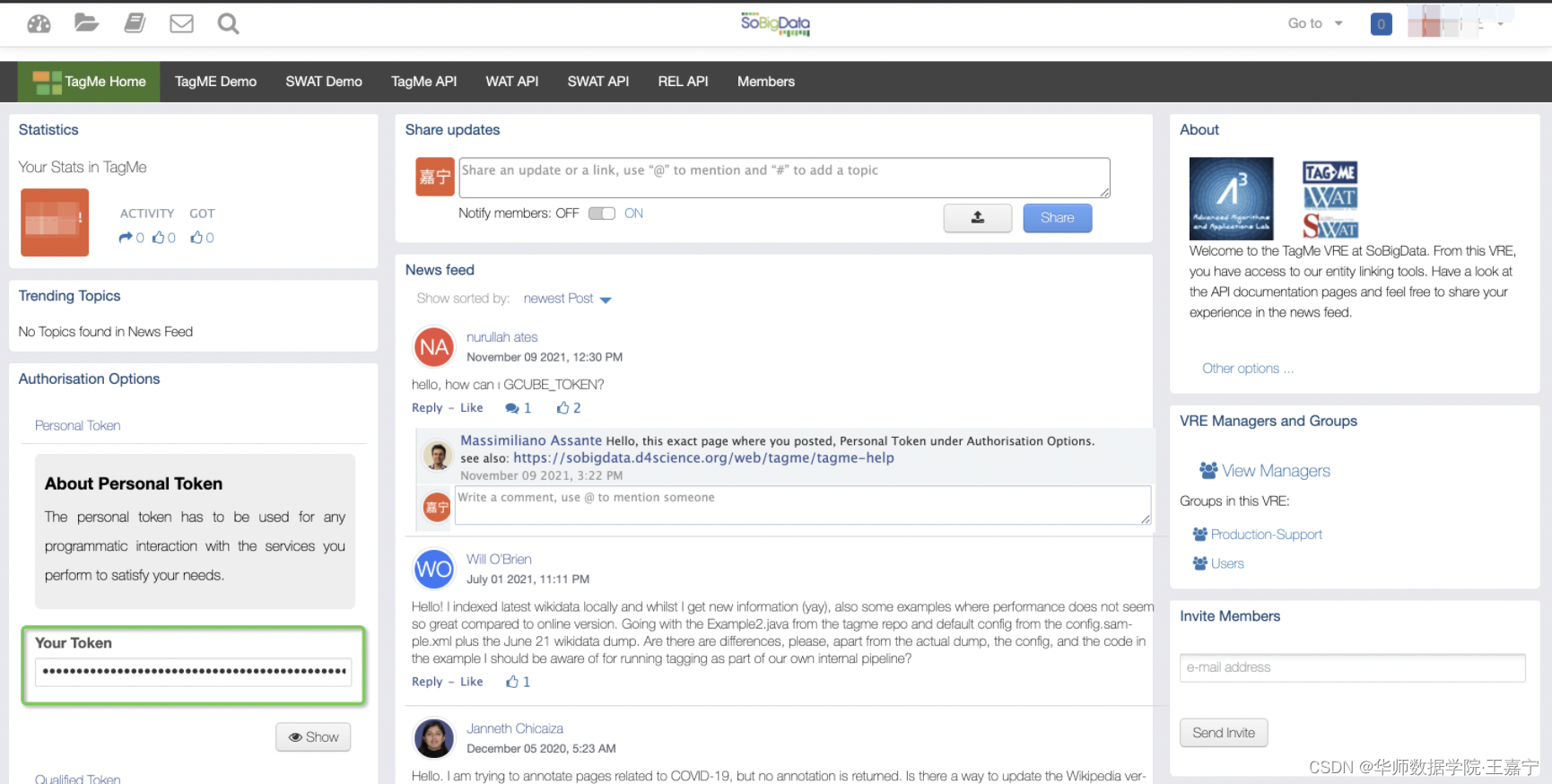 Step4: 获取Your Token(上图绿色区域)
Step4: 获取Your Token(上图绿色区域)
因此,可以基于TagMe,对所有Wikipedia的句子获取相应的实体。TagMe的程序如下所示:
import os
import sys
sys.path.append(os.path.join(os.path.abspath(os.path.dirname(__file__)), '..'))
import random
from tqdm import tqdm
from utils.tagme_test import Annotate
path = '../data_corpus/wiki'
def read_wiki(path):
dirs = os.listdir(path=path)
corpus = list()
for dir in tqdm(dirs):
sub_path = os.path.join(path, dir)
files = os.listdir(sub_path)
for file in files:
file_path = os.path.join(sub_path, file)
with open(file_path, 'r', encoding='utf-8') as fr:
lines = fr.readlines()
for line in lines:
line = line.replace('\n', '')
if 'http' in line:
continue
tokens = line.split(' ')
if len(tokens) < 20:
continue
corpus.append(line)
random.shuffle(corpus)
train_corpus = corpus[: -50000]
validation_corpus = corpus[-50000:]
print('corpus num: {}'.format(len(corpus)))
print('train corpus num: {}'.format(len(train_corpus)))
print('validation corpus num: {}'.format(len(validation_corpus)))
with open('train.txt', 'w', encoding='utf-8') as fw:
for text in tqdm(train_corpus):
fw.write(text + '\n')
with open('validation.txt', 'w', encoding='utf-8') as fw:
for text in tqdm(validation_corpus):
fw.write(text + '\n')
def tag_me(path, file_name):
new_file_name = file_name.split('.')[0] + '_with_entity.' + file_name.split('.')[1]
with open(os.path.join(path, file_name), 'r', encoding='utf-8') as fr:
lines = fr.readlines()
with open(os.path.join(path, new_file_name), 'w', encoding='utf-8') as fw:
for line in tqdm(lines):
txt = line.replace('\n', '')
obj = Annotate(txt, theta=0.2)
entities = list(set([i[1] for i in obj.keys()]))
example = "{}\t{}".format(txt, '\t'.join(entities))
fw.write(example + '\n')
if __name__ == "__main__":
tag_me(path, 'train.txt')
经过预处理,我们期望训练语料的格式如下所示:
"token_ids": [252, 1165, 1731, 13751, 261, 8, 7112, 11, 16359, 9959, 8, 233, 9, 6367, 29, 255, 2753, 11, 9238, 9959, 479, 25244, 263, 16359, 21, 8203, 11, 381, 3677, 1908, 20481, 479, 133, 4996, 9, 5, 16359, 284, 21, 1348, 30, 7393, 16359, 6, 155, 2586, 5893, 9, 18786, 36, 1570, 4718, 2383, 996, 2146, 238, 54, 21, 9390, 13, 27470, 11, 379, 2146, 6, 15, 1060, 744, 22, 627, 13705, 352, 446, 9, 16359, 1064, 7, 1430, 117, 55, 845],
"entity_pos": [[2, 5], [6, 7]
, [13, 17], [18, 20], [27, 31], [41, 49]],
"entity_qid": ["Q2353329", "Q2485216", "Q2730418", "Q23169", "Q2564352", "Q726243"],
"relation_pos": null,
"relation_pid": null
我们暂时只提供10000个预处理好的数据作为demo,可自行前往下载total_pretrain_data_10000.json。
接下来我们简单实用Pytorch和HuggingFace实现基于entity masking的知识增强预训练工作。基本环境涉及如下:
- Python>=3.7
- Pytorch>=1.8
- HuggingFace>=4.19
- Datasets
下面是对应的核心代码,但所有涉及的代码并不能单一运行。博主即将开源本项目的代码,可及时关注GitHub空间:https://github.com/wjn1996
我们直接使用HuggingFace提供的参数
import math
import os
import time
import torch
import numpy as np
from processor import processor_map
from transformers import CONFIG_MAPPING, AutoConfig, AutoTokenizer, HfArgumentParser, set_seed
from HFTrainer import HFTrainer
from transformers.trainer_utils import get_last_checkpoint
from transformers import EarlyStoppingCallback
from config import ModelArguments, DataTrainingArguments, TrainingArguments
from tool.common import init_logger
from models import MODEL_CLASSES, TOKENIZER_CLASSES, build_cls_model
import logging
logger = logging.getLogger(__name__)
torch.set_printoptions(precision=3, edgeitems=5, linewidth=160, sci_mode=False)
def main():
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
training_args.output_dir = os.path.join(training_args.output_dir, list(filter(None, model_args.model_name_or_path.split('/')))[-1])
os.makedirs(training_args.output_dir, exist_ok=True)
log_file = os.path.join(training_args.output_dir,
f'{model_args.model_name_or_path.split(os.sep)[-1]}-{data_args.task_name}-{time.strftime("%Y-%m-%d-%H:%M:%S", time.localtime())}.log')
log_level = training_args.get_process_log_level()
init_logger(log_file, log_level, training_args.local_rank)
logger.warning(
f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}"
+ f"distributed training: {bool(training_args.local_rank != -1)}, 16-bits training: {training_args.fp16}"
logger.info(f"Training/evaluation parameters {training_args}")
last_checkpoint = None
if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
last_checkpoint = get_last_checkpoint(training_args.output_dir)
if last_checkpoint is None and len([i for i in os.listdir(training_args.output_dir) if not i.endswith("log")]) > 0:
raise ValueError(f"Output directory ({training_args.output_dir}) already exists and is not empty. "
"Use --overwrite_output_dir to overcome.")
elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:
logger.info(f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
"the `--output_dir` or add `--overwrite_output_dir` to train from scratch.")
set_seed(training_args.seed)
if data_args.task_name in processor_map:
processor = processor_map[data_args.task_name](data_args, training_args, model_args)
else:
raise ValueError("task name 未指定或不在processor map中")
config_kwargs = {
"cache_dir": model_args.cache_dir,
"revision": model_args.model_revision,
'finetuning_task': data_args.task_name
if hasattr(processor, 'labels'):
config_kwargs['num_labels'] = len(processor.labels)
if model_args.config_name:
config = AutoConfig.from_pretrained(model_args.config_name, **config_kwargs)
elif
model_args.model_name_or_path:
config = AutoConfig.from_pretrained(model_args.model_name_or_path, **config_kwargs)
if 'longformer' in model_args.model_name_or_path:
config.sep_token_id = 102
else:
config = CONFIG_MAPPING[model_args.model_type]()
logger.warning("You are instantiating a new config instance from scratch.")
if model_args.config_overrides is not None:
logger.info(f"Overriding config: {model_args.config_overrides}")
config.update_from_string(model_args.config_overrides)
logger.info(f"New config: {config}")
tokenizer_kwargs = {
"cache_dir": model_args.cache_dir,
"use_fast": model_args.use_fast_tokenizer,
"revision": model_args.model_revision,
tokenizer_class = TOKENIZER_CLASSES.get(model_args.model_type, AutoTokenizer)
if model_args.tokenizer_name:
tokenizer = tokenizer_class.from_pretrained(model_args.tokenizer_name, **tokenizer_kwargs)
elif model_args.model_name_or_path:
tokenizer = tokenizer_class.from_pretrained(model_args.model_name_or_path, **tokenizer_kwargs)
else:
raise ValueError(
"You are instantiating a new tokenizer from scratch. This is not supported by this script."
"You can do it from another script, save it, and load it from here, using --tokenizer_name."
processor.set_tokenizer(tokenizer)
processor.set_config(config)
if data_args.task_type == 'autocls':
model_class = build_cls_model(config)
else:
model_class = MODEL_CLASSES[data_args.task_type]
if model_args.from_scratch:
logger.info("Training new model from scratch")
model = model_class.from_config(config)
else:
model = model_class.from_pretrained(
model_args.model_name_or_path,
from_tf=bool(".ckpt" in model_args.model_name_or_path),
config=config,
cache_dir=model_args.cache_dir,
revision=model_args.model_revision,
use_auth_token=True if model_args.use_auth_token else None,
ignore_mismatched_sizes=True
model.resize_token_embeddings(len(tokenizer))
tokenized_datasets = processor.get_tokenized_datasets()
if training_args.do_train:
if "train" not in tokenized_datasets:
raise ValueError("--do_train requires a train dataset")
train_dataset = tokenized_datasets["train"]
if data_args.max_train_samples is not None:
train_dataset = train_dataset.select(range(data_args.max_train_samples))
if training_args.do_eval:
if "validation" not in tokenized_datasets:
raise ValueError("--do_eval requires a validation dataset")
eval_dataset = tokenized_datasets["validation"]
if data_args.max_eval_samples is not None:
eval_dataset = eval_dataset.select(range(data_args.max_eval_samples))
if training_args.do_predict:
if 'test' not in tokenized_datasets:
raise ValueError("--do_predict requires a test dataset")
test_dataset = tokenized_datasets['test']
if data_args.max_predict_samples is not None:
test_dataset = test_dataset.select(range(data_args.max_predict_samples))
data_collator = processor.get_data_collator()
if hasattr(processor, 'compute_metrics'):
compute_metrics = processor.compute_metrics
else:
compute_metrics = None
if model_args.freeze_epochs:
callbacks.append(FreezeCallback(freeze_epochs=model_args.freeze_epochs, freeze_keyword=model_args.freeze_keyword))
if model_args.ema:
callbacks.append(ExponentialMovingAveragingCallback(model_args.ema_decay))
if training_args.do_predict_during_train:
from callback.evaluate import DoPredictDuringTraining
callbacks.append(DoPredictDuringTraining(test_dataset, processor))
trainer = HFTrainer(
model=model,
args=training_args,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
compute_metrics=compute_metrics,
tokenizer=tokenizer,
data_collator=data_collator,
callbacks=callbacks
if training_args.do_train:
checkpoint = None
if training_args.resume_from_checkpoint is not None:
checkpoint = training_args.resume_from_checkpoint
elif last_checkpoint is not None:
checkpoint = last_checkpoint
train_result = trainer.train(resume_from_checkpoint=checkpoint)
trainer.save_model(
)
metrics = train_result.metrics
max_train_samples = (
data_args.max_train_samples if data_args.max_train_samples is not None else len(train_dataset)
metrics["train_samples"] = min(max_train_samples, len(train_dataset))
trainer.log_metrics("train", metrics)
trainer.save_metrics("train", metrics)
trainer.save_state()
if training_args.do_eval:
logger.info("*** Evaluate ***")
try:
metrics = trainer.evaluate()
max_eval_samples = data_args.max_eval_samples if data_args.max_eval_samples is not None else len(eval_dataset)
metrics["eval_samples"] = min(max_eval_samples, len(eval_dataset))
if data_args.task_type == 'mlm':
try:
perplexity = math.exp(metrics["eval_loss"])
except OverflowError:
perplexity = float("inf")
metrics["perplexity"] = perplexity
trainer.log_metrics("eval", metrics)
trainer.save_metrics("eval", metrics)
except:
logger.info("UNK problems ...")
if training_args.do_predict and not training_args.do_predict_during_train:
logger.info("*** Predict ***")
if not data_args.keep_predict_labels:
for l in ['labels', 'label']:
if l in test_dataset.column_names:
test_dataset = test_dataset.remove_columns(l)
prediction = trainer.predict(test_dataset, metric_key_prefix="predict")
logits = prediction.predictions
if data_args.keep_predict_labels:
label_ids = prediction.label_ids
if hasattr(processor, 'save_result'):
if trainer.is_world_process_zero():
if not data_args.keep_predict_labels:
processor.save_result(logits)
else:
processor.save_result(logits, label_ids)
else:
predictions = np.argmax(logits, axis=1)
output_predict_file = os.path.join(training_args.output_dir, f"predict_results.txt")
if trainer.is_world_process_zero():
with open(output_predict_file, "w") as writer:
logger.info(f"***** Predict results {data_args.task_name} *****")
writer.write("index\tprediction\n")
for index, item in enumerate(predictions):
item = processor.labels[item]
writer.write(f"{index}\t{item}\n")
if __name__ == "__main__":
main()
根据自己的需要,可以重写trainer中的train部分。
from typing import Dict, Union, Any, Optional, Callable, List, Tuple, Iterator
import datasets
from datasets import Dataset
from torch.utils.data import RandomSampler, DistributedSampler
from transformers import PreTrainedModel, DataCollator, PreTrainedTokenizerBase, EvalPrediction, TrainerCallback
from transformers.trainer_pt_utils import DistributedSamplerWithLoop, get_length_grouped_indices
from transformers.trainer_pt_utils import DistributedLengthGroupedSampler as DistributedLengthGroupedSamplerOri
from transformers.trainer_pt_utils import LengthGroupedSampler as LengthGroupedSamplerOri
from transformers.training_args import ParallelMode
from config import TrainingArguments
from transformers.trainer import Trainer, _is_torch_generator_available
import torch
from torch import nn
from transformers.file_utils import is_datasets_available
from models.adversarial import FGM
class LengthGroupedSampler(LengthGroupedSamplerOri):
def __iter__(self):
indices = get_length_grouped_indices(self.lengths, self.batch_size, generator=self.generator, mega_batch_mult=256)
return iter(indices)
class DistributedLengthGroupedSampler(DistributedLengthGroupedSamplerOri):
def __iter__(self) -> Iterator:
g = torch.Generator()
g.manual_seed(self.seed + self.epoch)
indices = get_length_grouped_indices(self.lengths, self.batch_size, generator=g, mega_batch_mult=400)
if not self.drop_last:
indices += indices[: (self.total_size - len(indices))]
else:
indices = indices[: self.total_size]
assert len(indices) == self.total_size
indices = indices[self.rank: self.total_size: self.num_replicas]
assert len(indices) == self.num_samples
return iter(indices)
class HFTrainer(Trainer):
def __init__(
self,
model: Union[PreTrainedModel, nn.Module] = None,
args: TrainingArguments = None,
data_collator: Optional[DataCollator] = None,
train_dataset: Optional[Dataset] = None,
eval_dataset: Optional[Dataset] = None,
tokenizer: Optional[PreTrainedTokenizerBase] = None,
model_init: Callable[[], PreTrainedModel] = None,
compute_metrics: Optional[Callable[[EvalPrediction], Dict]] = None,
callbacks: Optional[List[TrainerCallback]] = None,
optimizers: Tuple[torch.optim.Optimizer, torch.optim.lr_scheduler.LambdaLR] = (None, None),
super(HFTrainer, self).__init__(model, args, data_collator, train_dataset, eval_dataset, tokenizer, model_init, compute_metrics, callbacks, optimizers)
if self.args.do_adv:
self.fgm = FGM(self.model)
for callback in callbacks:
callback.trainer = self
self.global_step_ = 0
def training_step(self, model: nn.Module, inputs: Dict[str, Union[torch.Tensor, Any]]) -> torch.Tensor:
Perform a training step on a batch of inputs.
Subclass and override to inject custom behavior.
Args:
model (`nn.Module`):
The model to train.
inputs (`Dict[str, Union[torch.Tensor, Any]]`):
The inputs and targets of the model.
The dictionary will be unpacked before being fed to the model. Most models expect the targets under the
argument `labels`. Check your model's documentation for all accepted arguments.
Return:
`torch.Tensor`: The tensor with training loss on this batch.
self.global_step_ += 1
model.train()
inputs = self._prepare_inputs(inputs)
with self.autocast_smart_context_manager():
loss = self.compute_loss(model, inputs)
if self.args.n_gpu > 1:
loss = loss.mean()
if self.args.gradient_accumulation_steps > 1 and not self.deepspeed:
loss = loss / self.args.gradient_accumulation_steps
if self.global_step_ % 10 == 0:
print('[step={}, loss={}]'.format(self.global_step_, loss))
if self.do_grad_scaling:
self.scaler.scale(loss).backward()
elif self.deepspeed:
loss = self.deepspeed.backward(loss)
else:
loss.backward()
if self.args.do_adv:
self.fgm.attack()
with self.autocast_smart_context_manager():
loss_adv = self.compute_loss(model, inputs)
if self.args.n_gpu > 1:
loss_adv = loss_adv.mean()
if self.args.gradient_accumulation_steps > 1 and not self.deepspeed:
loss_adv = loss_adv / self.args.gradient_accumulation_steps
if self.do_grad_scaling:
self.scaler.scale(loss_adv).backward()
else:
loss_adv.backward()
self.fgm.restore()
return loss.detach()
def _get_train_sampler(self) -> Optional[torch.utils.data.Sampler]:
generator = None
if self.args.world_size <= 1 and _is_torch_generator_available:
generator = torch.Generator()
generator.manual_seed(int(torch.empty((), dtype=torch.int64).random_().item()))
if self.args.group_by_length:
if is_datasets_available() and isinstance(self.train_dataset, datasets.Dataset):
lengths = (
self.train_dataset[self.args.length_column_name]
if self.args.length_column_name in self.train_dataset.column_names
else None
else:
lengths = None
model_input_name = self.tokenizer.model_input_names[0] if self.tokenizer is not None else None
if self.args.world_size <= 1:
return LengthGroupedSampler(
self.args.train_batch_size * self.args.gradient_accumulation_steps,
dataset=self.train_dataset,
lengths=lengths,
model_input_name=model_input_name,
generator=generator,
else:
return DistributedLengthGroupedSampler(
self.args.train_batch_size * self.args.gradient_accumulation_steps,
dataset=self.train_dataset,
num_replicas=self.args.world_size,
rank=self.args.process_index,
lengths=lengths,
model_input_name=model_input_name,
seed=self.args.seed,
else:
if self.args.world_size <= 1:
if _is_torch_generator_available:
return RandomSampler(self.train_dataset, generator=generator)
return RandomSampler(self.train_dataset)
elif (
self.args.parallel_mode in [ParallelMode.TPU, ParallelMode.SAGEMAKER_MODEL_PARALLEL]
and not self.args.dataloader_drop_last
return DistributedSamplerWithLoop(
self.train_dataset,
batch_size=self.args.per_device_train_batch_size,
num_replicas=self.args.world_size,
rank=self.args.process_index,
seed=self.args.seed,
else:
return DistributedSampler(
self.train_dataset,
num_replicas=self.args.world_size,
rank=self.args.process_index,
seed=self.args.seed,
该类用于读取我们保存的预处理语料,例如total_pretrain_data_10000.json,基于该数据,我们需要读取并加载缓存。我们默认使用Datasets的数据集加载方式,需要进行重写:
class WikiKGPLMSupervisedJsonProcessor(DataProcessor):
def __init__(self, data_args, training_args, model_args):
super().__init__(data_args, training_args, model_args)
self.is_only_mlm = False
def get_data_collator(self):
pad_to_multiple_of_8 = self.data_args.line_by_line and self.training_args.fp16 and not self.data_args.pad_to_max_length
if self.is_only_mlm:
print("You set is_only_mlm is True")
return DataCollatorForProcessedWikiKGPLM_OnlyMLM(
tokenizer=self.tokenizer,
mlm_probability=self.data_args.mlm_probability,
pad_to_multiple_of=8 if pad_to_multiple_of_8 else None,
print("You set is_only_mlm is False")
return DataCollatorForProcessedWikiKGPLM(
tokenizer=self.tokenizer,
mlm_probability=self.data_args.mlm_probability,
pad_to_multiple_of=8 if pad_to_multiple_of_8 else None,
def get_examples(self, set_type=None):
data_files = {}
if self.data_args.train_file is not None:
data_files["train"] = self.data_args.train_file
extension = self.data_args.train_file.split(".")[-1]
if self.data_args.validation_file is not None:
data_files["validation"] = self.data_args.validation_file
extension = self.data_args.validation_file.split(".")[-1]
if extension == "json":
extension = "json"
raw_datasets = load_dataset(extension, data_files=data_files, cache_dir=self.model_args.cache_dir)
if "validation" not in raw_datasets.keys():
raw_datasets["validation"] = load_dataset(
extension,
data_files=data_files,
split=f"train[:{self.data_args.validation_split_percentage}%]",
cache_dir=self.model_args.cache_dir,
raw_datasets["train"] = load_dataset(
extension,
data_files=data_files,
split=f"train[{
self.data_args.validation_split_percentage}%:]",
cache_dir=self.model_args.cache_dir,
return raw_datasets
def compute_metrics(self, p: EvalPrediction):
if type(p.predictions) in [tuple, list]:
preds = p.predictions[1]
else:
preds = p.predictions
preds = preds[p.label_ids != -100]
labels = p.label_ids[p.label_ids != -100]
acc = (preds == labels).mean()
return {
'acc': round(acc, 4)
def get_tokenized_datasets(self):
data_files = {}
if self.data_args.train_file is not None:
data_files["train"] = self.data_args.train_file
extension = self.data_args.train_file.split(".")[-1]
if self.data_args.validation_file is not None:
data_files["validation"] = self.data_args.validation_file
extension = self.data_args.validation_file.split(".")[-1]
if extension == "json":
extension = "json"
raw_datasets = load_dataset(extension, data_files=data_files, cache_dir=self.model_args.cache_dir)
if "validation" not in raw_datasets.keys():
raw_datasets["validation"] = load_dataset(
extension,
data_files=data_files,
split=f"train[:{self.data_args.validation_split_percentage}%]",
cache_dir=self.model_args.cache_dir,
raw_datasets["train"] = load_dataset(
extension,
data_files=data_files,
split=f"train[{self.data_args.validation_split_percentage}%:]",
cache_dir=self.model_args.cache_dir,
logger.info(f'validation fingerprint {raw_datasets}')
raw_datasets = DatasetDict({
train: Dataset({
features: ['json'],
num_rows: xxx
validation: Dataset({
features: ['json'],
num_rows: xxx
if self.training_args.do_train:
column_names = raw_datasets["train"].column_names
else:
column_names = raw_datasets["validation"].column_names
text_column_name = "text" if "text" in column_names else column_names[0]
max_seq_length = self.tokenizer.model_max_length if self.data_args.max_seq_length is None else self.data_args.max_seq_length
padding = "max_length" if self.data_args.pad_to_max_length else False
tokenizer = self.tokenizer
def tokenize_function(examples):
examples[text_column_name] = [
line for line in examples[text_column_name] if len(line) > 0 and not line.isspace()
return tokenizer(
examples[text_column_name],
padding=padding,
truncation=True,
max_length=max_seq_length,
return_special_tokens_mask=True,
'text': tokens_str,
'entity_ids': entity_ids,
'mention_spans': mention_spans
return raw_datasets
因为HuggingFace默认使用的是Datasets类,因此我们需要为Dataloader设计回调函数,该回调函数的目的是每次加载一个batch的数据时进行一些数据处理,例如生成张量,padding等部分。
由于在真正进行预训练时,语料规模时千万级的,因此我们无法在有限的时间和空间内全部加载所有的数据到内存中,但是我们可以使用Dataloader每次加载一个batch数据,并进行处理。为了提高GPU和CPU的协作效率,可以设置dataloader_num_workers=1
本文的Collator主要为了将读取的数据集进行分词、padding并转化为张量,同时需要根据已知的实体区间,对原始的分词后的序列进行mask操作。
这里有一处细节需要读者注意,BERT分词之后,部分的词会被转换为多个token,所以原始的文本序列和分词后的序列长度是不一致的。本文提供的数据集是已经分词好的,所以读者无需考虑。如若读者自行构建的是原始的文本,则需要考虑分词前后各个词的对应位置映射关系。在HuggingFace中为offset_mapping。
我们提供两种不同的实现方式:
@dataclass
class DataCollatorForPretrainWithKG(DataCollatorMixin):
在使用kg进行预训练
tokenizer: PreTrainedTokenizerBase
mlm: bool = True
mlm_probability: float = 0.15
pad_to_multiple_of: Optional[int] = None
tf_experimental_compile: bool = False
return_tensors: str = "pt"
def __post_init__(self):
self.numerical_tokens = [v for k, v in self.tokenizer.vocab.items() if k.isdigit()]
self.exclude_tokens = self.numerical_tokens + self.tokenizer.all_special_ids
def torch_call(self, examples: List[Union[List[int], Any, Dict[str, Any]]])
-> Dict[str, Any]:
from tool.ner import position_2_bio
for example in examples:
seq_len = len(example['input_ids'])
if 'token_type_ids' not in example:
example['token_type_ids'] = [0] * seq_len
if 'attention_mask' not in example:
example['attention_mask'] = [1] * seq_len
if 'entity_position' in example:
example['ner_labels'] = [position_2_bio(p, seq_len) for p in example['entity_position']]
example.pop('entity_position')
if isinstance(examples[0], (dict, BatchEncoding)):
batch = self.tokenizer.pad(examples, return_tensors="pt", pad_to_multiple_of=self.pad_to_multiple_of)
else:
batch = {
"input_ids": _torch_collate_batch(examples, self.tokenizer, pad_to_multiple_of=self.pad_to_multiple_of)
special_tokens_mask = batch.pop("special_tokens_mask", None)
if self.mlm:
batch["input_ids"], batch["labels"] = self.torch_mask_tokens(
batch["input_ids"], special_tokens_mask=special_tokens_mask
return batch
def torch_mask_tokens(self, inputs: Any, special_tokens_mask: Optional[Any] = None) -> Tuple[Any, Any]:
Prepare masked tokens inputs/labels for masked language modeling: 80% MASK, 10% random, 10% original.
import torch
labels = inputs.clone()
probability_matrix = torch.full(labels.shape, self.mlm_probability)
special_tokens_mask = [
[1 if token in self.exclude_tokens else 0 for token in val] for val in labels.tolist()
special_tokens_mask = torch.tensor(special_tokens_mask, dtype=torch.bool)
probability_matrix.masked_fill_(special_tokens_mask, value=0.0)
masked_indices = torch.bernoulli(probability_matrix).bool()
labels[~masked_indices] = -100
indices_replaced = torch.bernoulli(torch.full(labels.shape, 0.8)).bool() & masked_indices
inputs[indices_replaced] = self.tokenizer.convert_tokens_to_ids(self.tokenizer.mask_token)
indices_random = torch.bernoulli(torch.full(labels.shape, 0.5)).bool() & masked_indices & ~indices_replaced
random_words = torch.randint(len(self.tokenizer), labels.shape, dtype=torch.long)
inputs[indices_random] = random_words[indices_random]
return inputs, labels
class DataCollatorForProcessedWikiKGPLM_OnlyMLM(DataCollatorForLanguageModeling):
Data collator used for language modeling that masks entire words.
Only MLM
- collates batches of tensors, honoring their tokenizer's pad_token
- preprocesses batches for masked language modeling
This collator relies on details of the implementation of subword tokenization by [`BertTokenizer`], specifically
that subword tokens are prefixed with *##*. For tokenizers that do not adhere to this scheme, this collator will
produce an output that is roughly equivalent to [`.DataCollatorForLanguageModeling`].
</Tip>"""
def __post_init__(self):
if self.mlm and self.tokenizer.mask_token is None:
raise ValueError(
"This tokenizer does not have a mask token which is necessary for masked language modeling. "
"You should pass `mlm=False` to train on causal language modeling instead."
self.numerical_tokens = [v for k, v in self.tokenizer.vocab.items() if k.isdigit()]
self.exclude_tokens = self.numerical_tokens + self.tokenizer.all_special_ids
self.kg_prompt = KGPrompt(tokenizer=self.tokenizer)
random.seed(42)
def torch_call(self, features: List[Union[List[int], Any, Dict[str, Any]]]) -> Dict[str, Any]:
assert isinstance(features[0], (dict, BatchEncoding))
input_features = list()
for ei, feature in enumerate(features):
input_ids, kg_prompt_ids,
task_id = feature['input_ids'], feature['kg_prompt_ids'], feature['task_id']
text_len = len(input_ids)
kg_len = len(kg_prompt_ids)
input_ids = input_ids + kg_prompt_ids
input_ids = input_ids[: self.tokenizer.model_max_length]
token_len = len(input_ids)
input_ids.extend([self.tokenizer.pad_token_id] * (self.tokenizer.model_max_length - len(input_ids)))
token_type_ids = [0] * text_len + [0] * kg_len + [0] * (self.tokenizer.model_max_length - text_len - kg_len)
attention_mask = np.zeros([self.tokenizer.model_max_length, self.tokenizer.model_max_length])
token_type_span = [(0, text_len)]
st, ed = text_len, text_len
for ei, token in enumerate(kg_prompt_ids):
if token == self.tokenizer.sep_token_id:
ed = text_len + ei
token_type_span.append((st, ed))
st = ei
context_start, context_end = token_type_span[0]
attention_mask[context_start: context_end, : token_len] = 1
attention_mask[: token_len, context_start: context_end] = 1
for ei, (start, end) in enumerate(token_type_span):
attention_mask[start: end, start: end] = 1
attention_mask = attention_mask.tolist()
entity_candidate = [[0] * 20] * 6
relation_candidate = [[0] * 5] * 6
input_ids = torch.Tensor(input_ids).long()
mlm_labels = input_ids.clone()
probability_matrix = torch.full([text_len], self.mlm_probability)
probability_matrix = torch.cat(
[probability_matrix, torch.zeros([self.tokenizer.model_max_length - text_len])], -1)
masked_indices = torch.bernoulli(probability_matrix).bool()
mlm_labels[~masked_indices] = -100
indices_replaced = torch.bernoulli(torch.full(mlm_labels.shape, 0.8)).bool() & masked_indices
input_ids[indices_replaced] = self.tokenizer.convert_tokens_to_ids(self.tokenizer.mask_token)
indices_random = torch.bernoulli(
torch.full(mlm_labels.shape, 0.5)).bool() & masked_indices & ~indices_replaced
random_words = torch.randint(len(self.tokenizer.get_vocab()), mlm_labels.shape, dtype=torch.long)
input_ids[indices_random] = random_words[indices_random]
input_features.append({
'input_ids': input_ids.numpy().tolist(),
'token_type_ids': token_type_ids,
'attention_mask': attention_mask,
'labels': mlm_labels.numpy().tolist(),
'entity_candidate': entity_candidate,
'relation_candidate': relation_candidate,
'task_id': task_id,
'mask_id': self.tokenizer.mask_token_id
del features
input_features = {key: torch.tensor([feature[key] for feature in input_features], dtype=torch.long) for key in
input_features[0].keys()}
return input_features
def _whole_word_mask(self, input_tokens: List[str], max_predictions=512):
Get 0/1 labels for masked tokens with whole word mask proxy
if not isinstance(self.tokenizer, (BertTokenizer, BertTokenizerFast)):
warnings.warn(
"DataCollatorForWholeWordMask is only suitable for BertTokenizer-like tokenizers. "
"Please refer to the documentation for more information."
cand_indexes = []
for (i, token) in enumerate(input_tokens):
if token == "[CLS]" or token == "[SEP]":
continue
if len(cand_indexes) >= 1 and token.startswith("##"):
cand_indexes[-1].append(i)
else:
cand_indexes.append([i])
random.shuffle(cand_indexes)
num_to_predict = min(max_predictions, max(1, int(round(len(input_tokens) * self.mlm_probability))))
masked_lms = []
covered_indexes = set()
for index_set in cand_indexes:
if len(masked_lms) >= num_to_predict:
break
if len(masked_lms) + len(index_set) > num_to_predict:
continue
is_any_index_covered = False
for index in index_set:
if index in covered_indexes:
is_any_index_covered = True
break
if is_any_index_covered:
continue
for index in index_set:
covered_indexes.add(index)
masked_lms.append(index)
if len(covered_indexes) != len(masked_lms):
raise ValueError("Length of covered_indexes is not equal to length of masked_lms.")
mask_labels = [1 if i in covered_indexes else 0 for i in range(len(input_tokens))]
return mask_labels
def torch_mask_tokens(self, inputs: Any, special_tokens_mask: Optional[Any] = None) -> Tuple[Any, Any]:
Prepare masked tokens inputs/labels for masked language modeling: 80% MASK, 10% random, 10% original.
import torch
labels = inputs.clone()
probability_matrix = torch.full(labels.shape, self.mlm_probability)
special_tokens_mask = [
[1 if token in self.exclude_tokens else 0 for token in val] for val in labels.tolist()
special_tokens_mask = torch.tensor(special_tokens_mask, dtype=torch.bool)
probability_matrix.masked_fill_(special_tokens_mask, value=0.0)
masked_indices = torch.bernoulli(probability_matrix).bool()
labels[~masked_indices] = -100
indices_replaced = torch.bernoulli(torch.full(labels.shape, 0.8)).bool() & masked_indices
inputs[indices_replaced] = self.tokenizer.convert_tokens_to_ids(self.tokenizer.mask_token)
indices_random = torch.bernoulli(torch.full(labels.shape, 0.5)).bool() & masked_indices & ~indices_replaced
random_words = torch.randint(len(self.tokenizer), labels.shape, dtype=torch.long)
inputs[indices_random] = random_words[indices_random]
return inputs, labels
由于我们是最原始的MLM任务,因此可模型部分无需自己实现。当然也可以自行重写相关类实现其他自研功能。
import torch
from torch import nn
from torch.nn import CrossEntropyLoss
from collections import OrderedDict
from transformers.models.bert import BertPreTrainedModel, BertModel
from transformers.models.bert.modeling_bert import BertOnlyMLMHead
class BertForPretrainWithKG(BertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.config = config
self.bert = BertModel(config)
classifier_dropout = (
config.classifier_dropout if config.classifier_dropout is not None else config.hidden_dropout_prob
self.dropout = nn.Dropout(classifier_dropout)
self.cls = BertOnlyMLMHead(config)
self.classifiers = nn.ModuleList([nn.Linear(config.
hidden_size, config.num_ner_labels) for _ in range(config.entity_type_num)])
self.post_init()
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
labels=None,
ner_labels=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.bert(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
sequence_output = outputs[0]
prediction_scores = self.cls(sequence_output)
sequence_output = self.dropout(sequence_output)
ner_logits = torch.stack([classifier(sequence_output) for classifier in self.classifiers]).movedim(1, 0)
masked_lm_loss, ner_loss, total_loss = None, None, None
if labels is not None:
loss_fct = CrossEntropyLoss()
masked_lm_loss = loss_fct(prediction_scores.view(-1, self.config.vocab_size), labels.view(-1))
if ner_labels is not None:
loss_fct = CrossEntropyLoss()
active_loss = attention_mask.repeat(self.config.entity_type_num, 1, 1).view(-1) == 1
active_logits = ner_logits.reshape(-1, self.config.num_ner_labels)
active_labels = torch.where(
active_loss, ner_labels.view(-1), torch.tensor(loss_fct.ignore_index).type_as(ner_labels)
ner_loss = loss_fct(active_logits, active_labels)
if masked_lm_loss:
total_loss = masked_lm_loss + ner_loss * 4
return OrderedDict([
('loss', total_loss),
('mlm_loss', masked_lm_loss.unsqueeze(0)),
('ner_loss', ner_loss.unsqueeze(0)),
('logits', prediction_scores.argmax(2)),
('ner_logits', ner_logits.argmax(3))
模型部分也可以选择RoBERTa、RoFormer或MegatronBert。
在实验中,我们使用单机多卡V100-32G的GPU进行实验,为了加快实验速度,使用FP16混合精度方法。相关超参数为:
- batch size:单卡16,梯度累积step为2;
- learning rate:1e-5;
- 优化器:AdamW;
- warm up rate:0.1(在总的训练step数量的10%的位置之前,学习率默认线性增长,之后则进行指数衰减);
以4卡为例,实验的loss变化情况如图所示(不同颜色代表不同的卡):
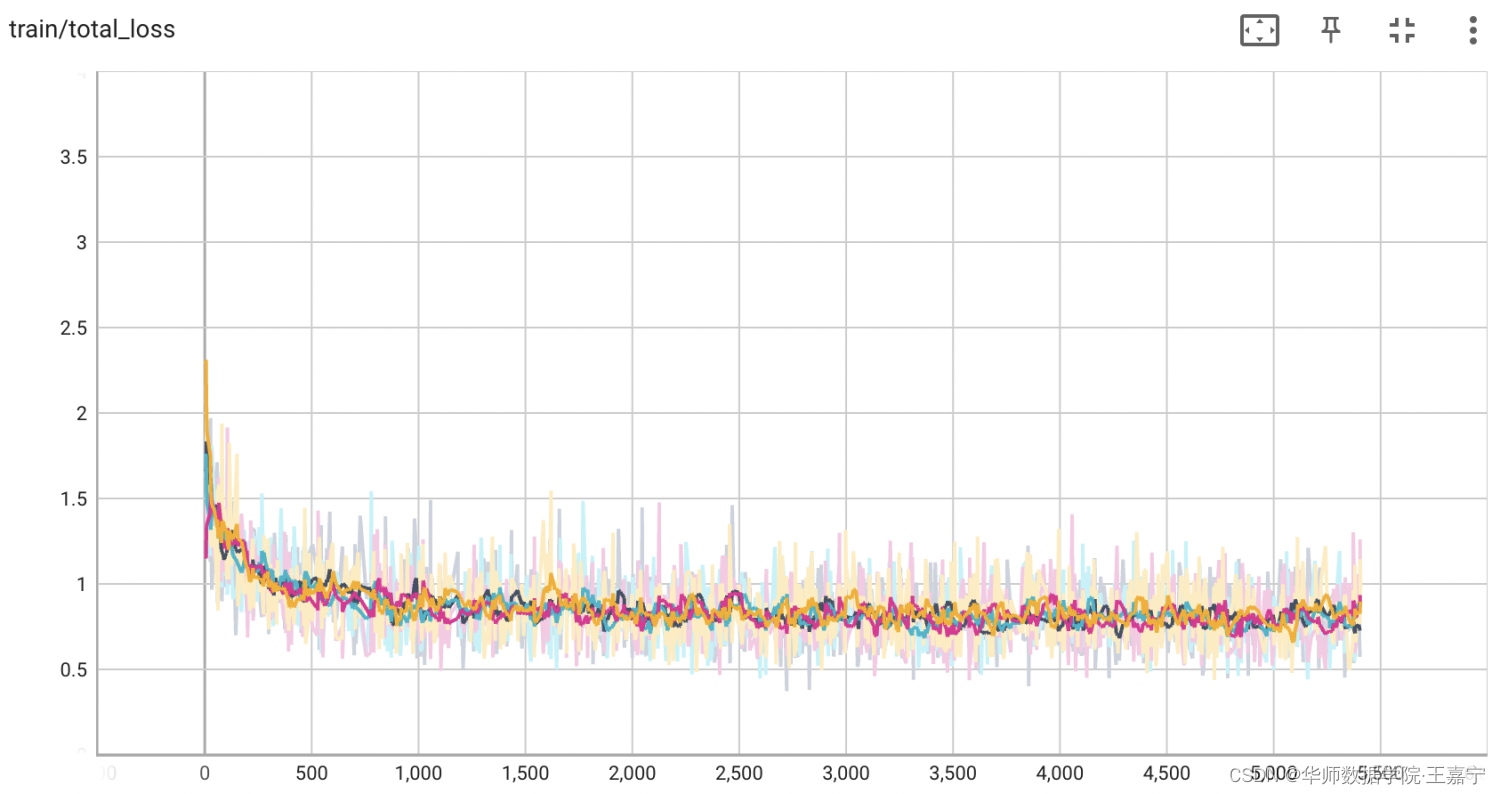
正常情况下,MLM的loss会收敛至0.4~0.7之间,训练5000step大约耗时12~18小时。
为了验证我们的知识增强预训练语言模型是否有效,我们需要与原生态的BERT、RoBERTa进行比较,同时也需要和其他知识增强模型进行对比。我们在此只介绍几个下游任务及其实现。
- Entity Typing:主要为Open Entity数据集;
- Relation Extraction:包括TACRED和FewRel数据集;
- Knowledge Probing:包括LAMA
所有数据可直接由此下载:https://cloud.tsinghua.edu.cn/f/a763616323f946fd8ff6/
我们开源了所有微调任务的脚本,详见:https://github.com/wjn1996/KP-PLM/tree/main/finetune_task
给定一个文本,以及标注的一个实体,Entity Typing的任务目标是预测这个指定实体的类型。通常情况下,我们可以为每个实体前后添加标记(例如[ENT] 和 [/ENT]),并喂入预训练模型中进行分类。
我们挑选了OpenEntity数据集作为评测任务,数据下载地址为:https://www.cs.utexas.edu/~eunsol/html_pages/open_entity.html
Knowledge Probing的任务目的:
- 原始数据中,每个文件表示一个关系,每个样本中有sub_label和obj_label,以及这两个实体远程监督的句子。句子中对obj替换为[MASK]。因此任务目标是知道关系、知道sub以及对应句子,来预测[MASK]对应的obj;
- 我们挑选LAMA数据集。LAMA还给予了模板——如果提供模板,则不用原始给的文本句子,只用对应的模板来预测,例如:[X] is born in [Y],sub为obama替换至[X],[Y]部分为[MASK],用于预测。
LAMA官网:https://github.com/facebookresearch/LAMA
LAMA涉及的环境过低,需要单独创建一个docker,安装对应的requirements,相对比较麻烦,因此我们直接参考CoLAKE提供的LAMA的代码和数据:CoLAKE
实验对比情况如图所示:
- CoLAKE:https://github.com/txsun1997/CoLAKE
- ERNIE(清华):https://github.com/thunlp/ERNIE
自研EasyNLP工具包发布——EasyNLP,Easy-to-use!
亮点包括:
- 更全面的知识模型——知识增强预训练语言模型 + 知识增强多模态模型;
- “三部曲”一键CLUE刷榜工具,成为CLUE官方代码;
- 轻松上手Few-shot Learning,Prompt-tuning
GitHub:https://github.com/alibaba/EasyNLP
Paper:EasyNLP: A Comprehensive and Easy-to-use Toolkit for Natural Language Processing
Cite:
@article{DBLP:journals/corr/abs-2205-00258,
author = {Chengyu Wang and
Minghui Qiu and
Taolin Zhang and
Tingting Liu and
Lei Li and
Jianing Wang and
Ming Wang and
Jun Huang and
Wei Lin},
title = {EasyNLP: {A} Comprehensive and Easy-to-use Toolkit for Natural Language
Processing},
journal = {CoRR},
volume = {abs/2205.00258},
year = {2022},
url = {https://doi.org/10.48550/arXiv.2205.00258},
doi = {10.48550/arXiv.2205.00258},
eprinttype = {arXiv},
eprint = {2205.00258},
timestamp = {Tue, 03 May 2022 15:52:06 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2205-00258.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
前端程序员开发一个自己的小程序,比起学习小程序开发,更大的难点在于搭建小程序的后台。
本文从一个初学者的角度,简单介绍一下腾讯云推出的小程序解决方案 wafer2,让没有后台开发经验的程序员,也能搭建起自己的小程序后台。
wafer
后台的搭建涉及到购买服务器、购买数据库,然后要在服务器上安装运行环境等。说实话,我连要在服务器上装什么都不知道。所以希望能有一个东西,帮我把这些都做好,要是再提供一些登录之类的常用接口就更好了。这就是 wafer 所做的。
其实在小程序后台配置域名的地方,就有跳转到腾讯云的链接:
(此图片来源于网络,如有侵权,请联系删除! )
进入后按照指引购买,就可以拥有
该存储库提供了映射到Wikidata的数据集的版本。
数据组织在 6 个文件中: annotated_wd_data_{train, valid, test}{_full}.txt 。 每个文件每行包含一个示例,格式如下: subject [tab] property [tab] object [tab] question ,其中subject 、 property和object是维基数据项目或属性的标识符。 Rxxx属性标识符对维基数据属性Pxxx的逆属性进行编码。 例如, R19编码属性“出生地”,即P19 (“出生地”)的倒数。 请注意,并非每个翻译的三元组都必须存在于维基数据中。 从 Freebase 迁移到 Wikidata 时的部分信息丢失了。 以“_answerable”结尾的文件只包含维基数据中的三元组。
映射代码在build.ipynb文件中。
Wikidata(维基数据)是一个自由开放的知识库,可以同时被人和机器阅读、编辑[1]。根据官网介绍,Wikidata作为一种结构化数据的集中存储,为其他维基媒体(Wikimedia)项目[2]提供支撑,包括Wikipedia(维基百科)、Wikivoyage(维基导游)、Wiktionary(维基字典)、Wikisource(维基文库)等。
就像维基百科一样,Wikidata 支持自由协作编辑,支持多语言。与维基百科不同的是,Wikidata作为知识库,其内容都是结构化
自从从深度学习框架caffe转到Pytorch之后,感觉Pytorch的优点妙不可言,各种设计简洁,方便研究网络结构修改,容易上手,比TensorFlow的臃肿好多了。对于深度学习的初学者,Pytorch值得推荐。今天主要主要谈谈Pytorch是如何加载预训练模型的参数以及代码的实现过程。
直接加载预选脸模型
如果我们使用的模型和预训练模型完全一样,那么我们就可以直接加载别人的模型,还有一种情况,我们在训练自己模型的过程中,突然中断了,但只要我们保存了之前的模型的参数也可以使用下面的代码直接加载我们保存的模型继续训练,不用从头开始。
model=DPN(*args, **kwargs)
利用大规模知识库的实体嵌入为plm提供外部知识
他们使用了通过单独的知识嵌入(KE)算法学习的固定实体嵌入,这种算法不能很容易地与语言表示对齐,因为它们本质上是在两个不同的向量空间中。
它们需要一个实体链接器将上下文中的单词链接到相应的实体上,从而受益于实体嵌入,这使得它们存在错误传播问题。
与普通的plm相比,它们检索和使用实体嵌入的复杂机制导致
分享一个模型
最后两个教程展示了如何使用 PyTorch、 Keras 和 Accelerate 优化分布式设置的模型。下一步就是把你的模型公之于众!我们相信公开分享知识和资源,使人工智能大众化。我们鼓励你考虑与社区分享你的模式,以帮助其他人节省时间和资源。
在本教程中,您将学习在 Model Hub 上共享经过训练或调优的模型的两种方法:
以编程方式将文件推送到Hub。
通过 web 界面将文件拖放到 Hub。
要与社区共享一个模型,您需要在 huggingface.co 上注册一个帐户。您还可以加

