

RTX 4090 相比于 3090ti 和 3090, 在深度学习性能上提升了多少?
关注者
225
被浏览
656,329
15 个回答

lambda 前阵出了一个 benchmark,可以一起来看下:
还有对应repo:
注意:结论来源于 lambda 博文,笔者只是搬运,并非笔者测试
结论:
相比 RTX3090:
- RTX4090 训练速度更快 , 并更具性价比 (吞吐量/美元) (测试用例包含 视觉、语言、语音和推荐系统)
- RTX4090 的 电力成本 (吞吐量/Watt)与RTX3090 相当 ,尽管它有着450W的功耗。
- 多 GPU 分布式性能更好
Pytorch 训练吞吐量测试
| GPU/Model | ResNet50 | SSD | Bert Base Finetune | TransformerXL Large | Tacotron2 | NCF |
| GeForce RTX 3090 TF32 | 144 | 513 | 85 | 12101 | 25350 | 14714953 |
| GeForce RTX 3090 FP16 | 236 | 905 | 172 | 22863 | 25018 | 25118176 |
| GeForce RTX 4090 TF32 | 224 | 721 | 137 | 22750 | 32910 | 17476573 |
| GeForce RTX 4090 FP16 | 379 | 1301 | 297 | 40427 | 32661 | 32192491 |
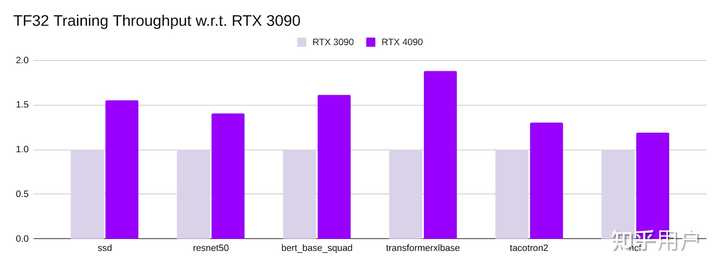

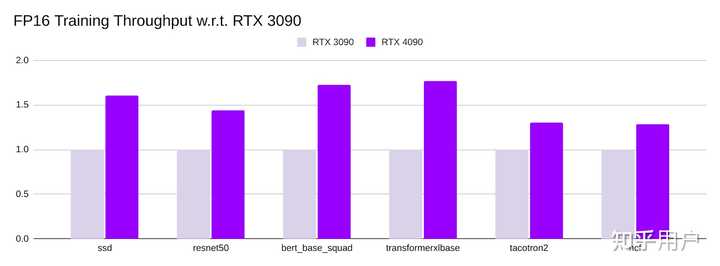

RTX 4090的训练吞吐量明显更高。对于不同的模型的TF32训练吞吐量比RTX 3090高1.3倍至1.9倍,FP16训练吞吐量比RTX 3090高1.3倍至1.8倍。
吞吐量/价格
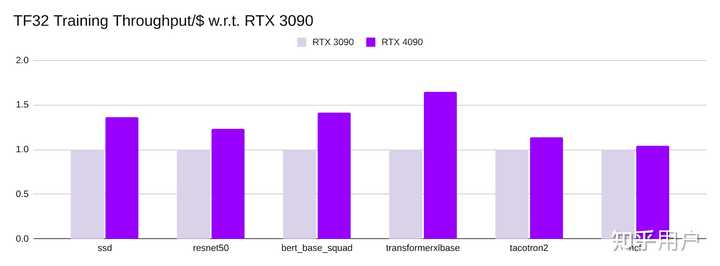

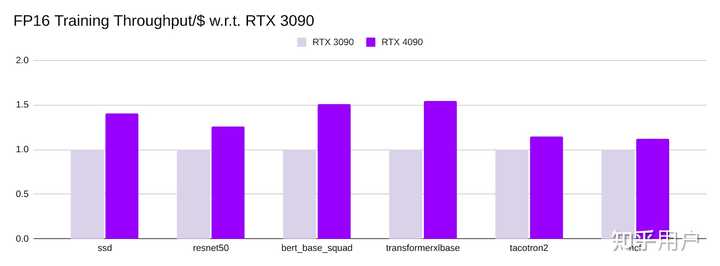

RTX 3090和RTX 4090的参考价格分别为1400美元和1599美元。RTX 4090的性价比很高,其 吞吐量/价格 在不同模型上 与RTX 3090相比 在1.2倍至1.6倍之间。
电力成本
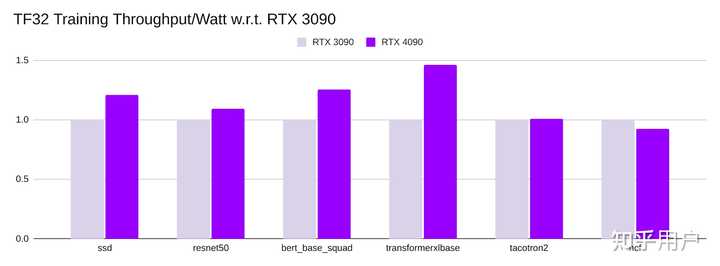

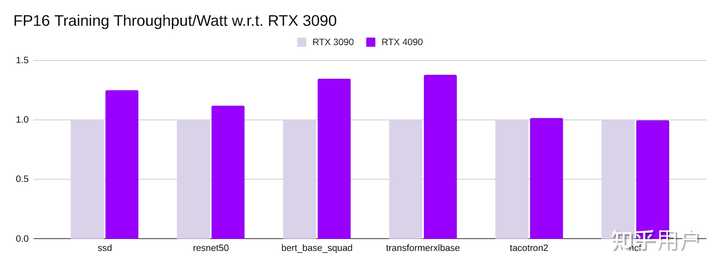

RTX 4090的 训练吞吐量/瓦特 与RTX 3090相当,在RTX 3090的0.92倍到1.5倍之间。
多 GPU 分布式
单 4090 对比 双 4090
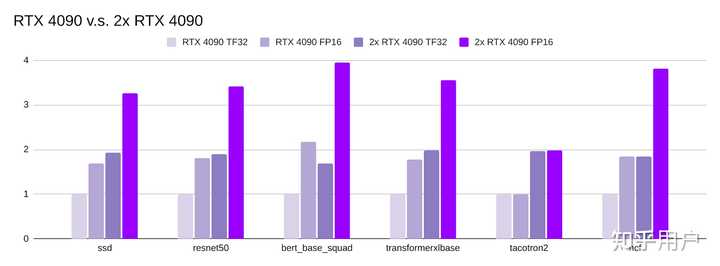

大多数模型在使用两个GPU的情况下获得接近2倍的训练吞吐量;
微调BERT_base的吞吐量增倍小于1.7倍;
在所有测试的GPU中,Tacotron2 FP16并不比TF32快。这与NVIDIA的Tacotron2基准测试的报告一致。
双 4090 对比 双 3090 带 NVlink
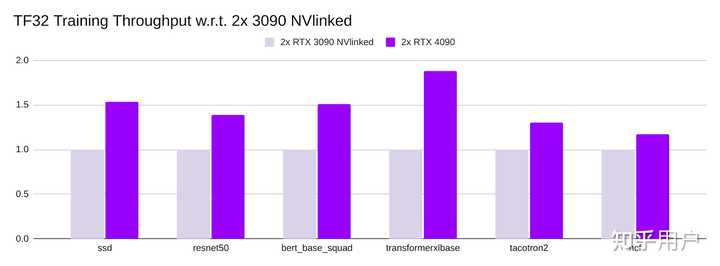

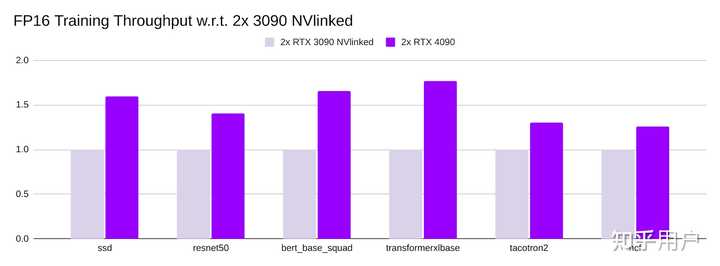

这里也给出了一些很专业的测试:

经典老码农
newest: torch的cu118已经支持了,下面说的基本作废了
刚拿到块4090,简单结论是现在先别买(
之前3090ti出掉了,拿到手光速跑起pytorch训练,网络是私有的cnn,环境windows+torch 1.12.1 cu116,相比3090ti来说训练速度慢了25%左右
对没错,慢了25%(扶额)
查了下cuda11.8才支持40系列的ada架构,奈何11.8前几天才刚发布,torch还没有适配,最高也只有11.6,所以在这上面跑反而是负优化
不过发现了个曲线救国方法,NVIDIA有个自己维护的pytorch的docker镜像,最新版的镜像已经支持cu118了,具体可以自己把玩
NVIDIA Deep Learning Frameworks Documentation
由于不方便用linux,我在windows下用wsl+docker拉取了上面的镜像测试了下训练,性能这回对味儿了,大概比3090ti快个40%-50%左右吧,考虑到wsl和docker是双重性能损耗,实际要是torch出了11.8的适配估计能有3090ti 60%-70%左右提升?(瞎猜的)
上面结果只是个人的实验,在拿到卡之前我也各种搜索看看有没有机器学习方面的benchmark,所以快速测试了下,具体可以等更专业的来测试(
功耗方面3090ti在我机箱里算上其他东西能600多w,现在非满血4090(因为有wsl+docker双重损耗)能跑470多w,注意是算上我机箱其他乱七八糟的加起来470w,看下来4090还是很省电的,目前比3090ti快50%的同时还省了100w的电,建议黄皮子速速发明黑科技电表倒转(
评论有一位测试速度提升了100%多,我觉得靠谱,因为我这个网络forward和loss计算都复杂的一批可能掉很多速度让gpu闲置