GPT-4,OpenAI的断崖式领先,人类的专属技能不多了?
2023年03月15日 16:57 甲子光年 甲子光年
压力来到百度了。
作者|赵健
人工智能会替代人类吗?在ChatGPT出现之后,人类对于这个问题的答案已经越来越没有信心。
而在昨天夜里,OpenAI低调发布了深度学习新的里程碑:GPT-4,一个比ChatGPT更强大的大模型!OpenAI表示,GPT-4虽然在许多现实世界场景中的能力依旧不如人类,但在各种专业和学术基准上已经和人类表现持平。
GPT-4是一个多模态大模型,具有更强大的创造性、更长的上下文处理能力,可支持图像输入,还可以自定义GPT-4的语言风格。在OpenAI短短24分钟的发布会中,有这样一个场景:在草稿本上用纸笔画出一个非常粗糙的草图,拍照并上传,GPT-4在10秒左右直接生成了网站代码。
著名经济学家朱嘉明表示:GPT-4是OpenAI创造出的又一个重大科技事件,达到了AI历史上前所未有的、不可逆转的新高度。
过去两年,OpenAI重建了整个深度学习堆栈,并与微软Azure一起从头开始共同设计了一台超级计算机。一年前,OpenAI训练GPT-3.5(即ChatGPT)作为系统的第一次“试运行”,发现并修复了一些错误并改进了理论基础。
OpenAI花了6个月的时间来迭代调整GPT-4,取得了有史以来最好的结果,并且成为第一个能够提前准确预测其训练性能的大型模型。这意味着大模型的训练方法将会从过去的纯粹“暴力美学”进化出更高的可控性与预期性。
这次OpenAI并没有公布论文,只有一份技术报告,并且不提供架构(包括模型大小)、硬件、训练计算、数据集构建、训练方法等细节。换句话说,其他AI公司不可能再像过去一样,走一条模仿、复现、超越的道路了。
压力来到了国内公司,尤其是明天即将发布文心一言的百度。
1.比ChatGPT更强大
GPT-4比以往任何时候都更具创造性和协作性。它可以承担文本、音频、图像的生成、编辑任务,并能与用户一起迭代创意和技术写作任务,例如创作歌曲、编写剧本或学习用户的写作风格等。

GPT-4能够处理超过25000个单词的文本,允许使用长格式内容创建、扩展对话以及文档搜索和分析等用例。

在简单的谈话中,ChatGPT与GPT-4可能看不出太大差距。但是,当任务的复杂性达到足够的阈值时,差异就会出现——GPT-4比GPT-3.5更可靠、更有创意,并且能够处理更细微的指令。

左边是ChatGPT,右边是GPT-4
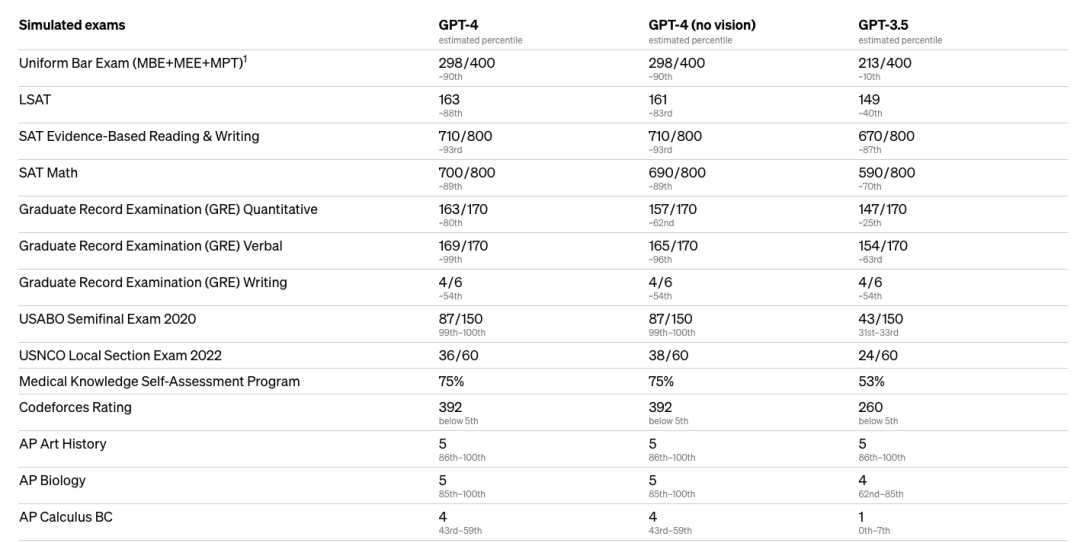
为了解这两种模型之间的区别,OpenAI在各种基准测试中进行了测试,包括人类的模拟考试,比如GRE。OpenAI并没有针对这些考试进行专门培训,但GPT-4的排名依然名列前茅。例如,它通过模拟律师考试,分数在应试者的前10%左右;相比之下,GPT-3.5的得分在倒数10%左右。
GPT-4在语言风格上也迎来了更新。与具有固定冗长语气和风格的经典ChatGPT不同,开发人员(普通用户也将会开放)现在可以在“系统”消息中通过描述来规定他们的AI风格和任务,也就是“自定义”能力。




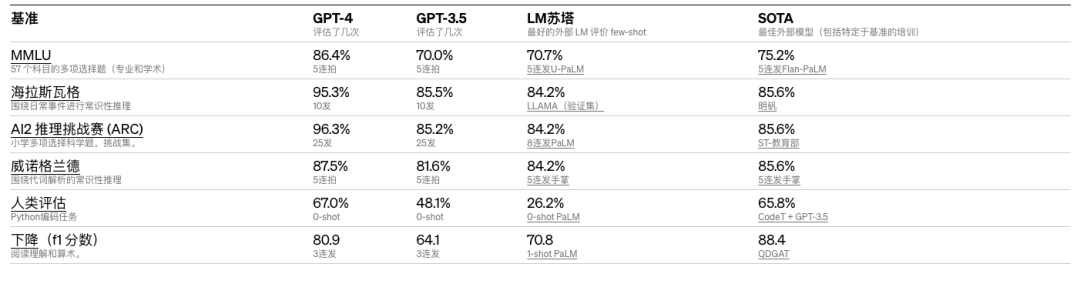
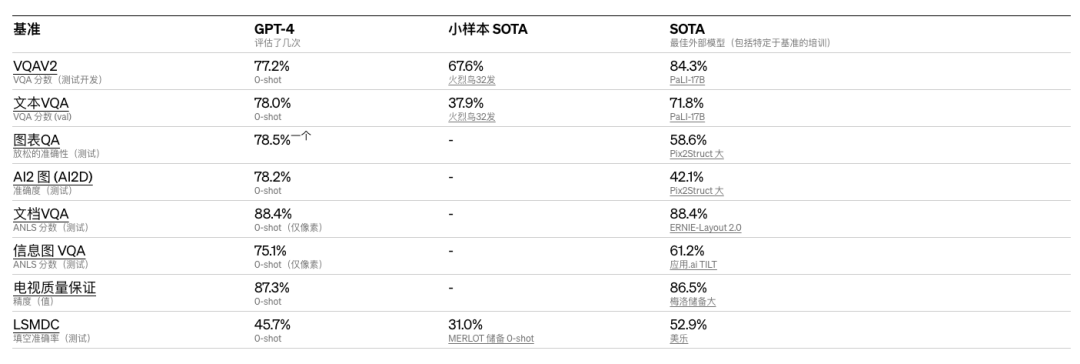
OpenAI在为机器学习模型设计的传统基准上评估了GPT-4,大大优于现有的大型语言模型,以及大多数最先进的 (SOTA) 模型:
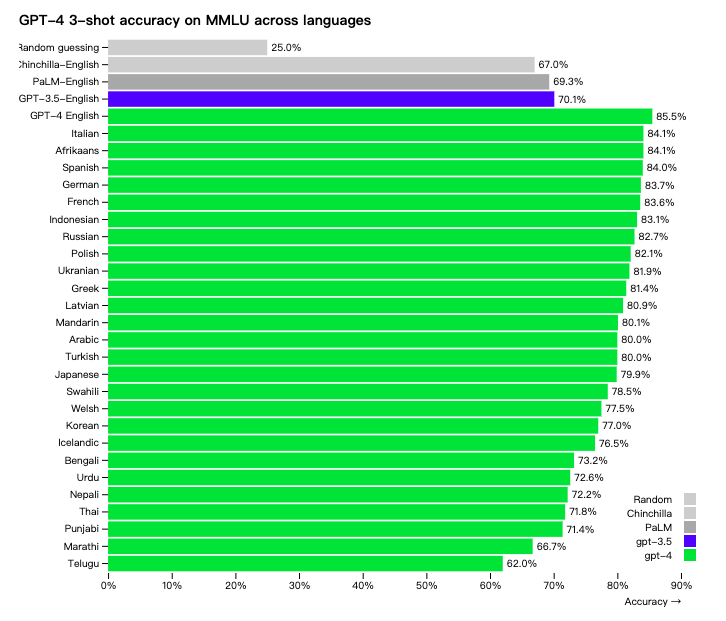
许多现有的ML基准测试都是用英语编写的。OpenAI使用Azure Translate将MMLU基准——一套涵盖57个主题的 14000个多项选择题——翻译成多种语言。在测试的24种语言中,GPT-4优于GPT-3.5和其他LLM(Chinchilla、PaLM)的英语语言性能,包括拉脱维亚语、威尔士语和斯瓦希里语等低资源语言:
OpenAI表示内部也在使用GPT-4,对支持、销售、内容审核和编程等功能产生了巨大影响。
2.多模态大模型,支持图片输入
除了文本能力的增强,GPT-4还带来了新的能力——多模态,它可以接受图像作为输入并生成说明、分类和分析结果。
具体来说,它能在用户输入散布式文本与图像后,自主生成文本输出(自然语言、代码等)。在包括带有文本和照片的文档、图表与屏幕截图中,GPT-4展示了与纯文本输入同样强大的功能。此外,它还可以通过为纯文本语言模型开发的测试时间技术实现进化,能运用少量镜头和思维链提示。
不过,GPT-4的图像输入展示仍然只是研究“样品”预览,真正的成果尚未公开。

GPT-4可以指出被加工图片的“异常”之处

GPT-4还能读懂“梗图”,理解幽默
GPT-4甚至可以直接阅读并分析带有图片的论文:


OpenAI在一组标准的学术视觉基准测试中对GPT-4的表现进行评估,预览了它的性能。然而,OpenAI表示这些数字并不完全代表它的能力范围,因为OpenAI不断发现这个模型能够解决新的、“令人兴奋”的任务。OpenAI计划很快发布更多的分析和评估数据,以及对测试时间技术影响的全面调查。
3.花6个月时间训练,但训练数据只截止到2021年9月
GPT-4是如何训练出来的?
遵循GPT、GPT-2和GPT-3的研究路径,OpenAI的深度学习方法利用更多数据和更多计算来创建越来越复杂和强大的语言模型。
过去两年,OpenAI重建了整个深度学习堆栈,并与微软Azure一起从头开始共同设计了一台超级计算机。一年前,训练GPT-3.5作为系统的第一次“试运行”,OpenAI发现并修复了一些错误并改进了理论基础。结果,GPT-4 训练运行前所未有地稳定,成为能够提前准确预测其训练性能的第一个大型模型。
OpenAI花了6个月的时间使用对抗性测试程序和ChatGPT的经验教训迭代调整 GPT-4,从而在真实性、可操纵性以及拒绝越界和敏感问题方面获得了有史以来最好的结果。在OpenAI的内部评估中,与GPT-3.5相比,GPT-4响应被禁止内容请求的可能性低82%,产生事实响应的可能性高40%。
与以前的GPT模型一样,GPT-4基础模型经过训练可以预测文档中的下一个单词,并且使用公开可用的数据(例如互联网数据)以及已获得许可的数据进行训练。
尽管功能强大,但GPT-4与早期的GPT模型具有相似的局限。最重要的是,它仍然不完全可靠,会“幻觉”事实并出现推理错误。
GPT-4的训练数据截止到2021年9月,因此对之后发生的事件缺乏了解,并且不会从自己的经验中学习。它有时会犯一些简单的推理错误,这些错误似乎与其强大的跨领域功能不符,有时也会过于轻信用户明显错误的陈述;有时,它也会像人类一样在解决难题时失败,例如在生成的代码中引入安全漏洞。
OpenAI提醒,在使用语言模型输出时应格外小心,特别是在高风险上下文中,使用符合特定用例需求的确切协议(例如人工审查、附加上下文的基础或完全避免高风险使用)。
为此,OpenAI纳入了更多的人工反馈,包括ChatGPT用户提交的反馈——这其中可能也包括你与ChatGPT的对话数据。OpenAI还与50多位专家合作,在AI安全和保障等领域获得早期反馈。

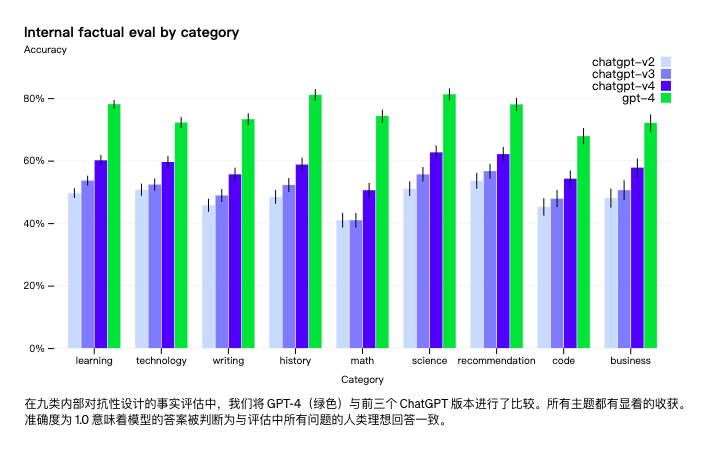
虽然生成内容的可靠性仍是一个真问题,但GPT-4相对于以前的模型显著减少了胡说八道。在OpenAI的内部对抗性真实性评估中,GPT-4的得分比OpenAI最新的GPT-3.5高 40%:
GPT-4项目的主要焦点之一是构建可预测扩展的深度学习框架,主要原因是对于像GPT-4这样非常大的训练任务,进行大量的模型特定调整是不可行的。
OpenAI开发了基础设施和优化方法,能够在多个规模下表现出非常可预测的行为。为了验证这种可扩展性,OpenAI通过对使用相同方法进行训练但计算量少10000倍的模型进行推断,在内部代码库(不是训练集的一部分)上准确预测了GPT-4的最终损失。
现在OpenAI可以准确预测OpenAI在训练期间优化的指标(损失),开始开发方法来预测更多可解释的指标。例如,OpenAI成功预测了HumanEval数据集子集的通过率,从计算量减少 1000 倍的模型推断。
OpenAI认为,准确预测未来的机器学习能力是安全的重要组成部分,但相对于其潜在影响而言,它并没有得到足够的重视。OpenAI正在加大力度开发方法,为社会提供更好的未来系统预期指导,希望这成为该领域的共同目标。
4.如何尝鲜GPT-4?
目前有两种办法可以体验GPT-4。
如果你是普通用户,此前订阅了ChatGPT Plus,将会直接获得GPT-4的访问权限。不过,ChatGPT Plus只能用美国信用卡开通。
OpenAI将根据实践中的需求和系统性能调整使用上限,但预计会受到严重的容量限制。
根据OpenAI看到的流量模式,OpenAI可能会为更高容量的GPT-4使用引入新的订阅级别;OpenAI也希望在某个时候提供一些免费的GPT-4查询,这样那些没有订阅的人也可以尝试一下。
如果你是开发者,要访问GPT-4 API(使用与GPT-3.5-turbo相同的ChatCompletions API),需要像等待New Bing一样加入OpenAI的候补名单。
OpenAI今天将开始邀请一些开发人员,并逐步扩大规模以平衡容量与需求。
OpenAI也公布了定价策略——每1000个prompt tokens0.03美元,每1000个completion tokens 0.06美元。默认速率限制为每分钟4万个token和每分钟200个请求。
GPT-4的上下文长度为8192个token。OpenAI还提供了32768 个tokens上下文(约50页文本)版本的有限访问,该版本也将随着时间自动更新(当前版本GPT-4-32k-0314,支持到6月14日)。定价为每1000个prompt token 0.06美元和每1000个completion token 0.12美元。
此外,OpenAI宣布开源其软件框架OpenAI Evals,用于创建和运行基准测试以评估GPT-4等模型。
OpenAI使用Evals来指导OpenAI模型的开发,OpenAI的用户可以应用它来跟踪模型版本的性能,并不断发展产品集成。例如,Stripe使用Evals来补充他们的人工评估,以衡量其基于GPT的文档工具的准确性。
由于所有代码都是开源的,Evals支持编写新的类来实现自定义评估逻辑。然而,在OpenAI自己的经验中,许多基准测试都遵循几种“模板”的其中之一,因此OpenAI还包括了最有用的模板,包括一个“模型评估模板”——OpenAI发现GPT-4出人意料地能够检查自己的工作。
OpenAI希望Evals成为分享和众包基准测试的工具,代表着最广泛的失败模式和困难任务。作为一个示范,OpenAI创建了一个逻辑谜题评估,其中包含GPT-4失败的十个提示。Evals也与实施现有基准测试兼容;OpenAI包括了几个实施学术基准测试和几个(小的子集)CoQA集成的笔记本作为示例。
GPT-4已经积累了部分商业客户。比如,Stripe使用GPT-4扫描商业网站并向客户支持人员提供摘要,Duolingo将 GPT-4构建到新的语言学习订阅层中。摩根士丹利正在创建一个由GPT-4驱动的系统,该系统将从公司文件中检索信息并将其提供给金融分析师。可汗学院正在利用GPT-4构建某种自动化导师。
GPT-4将大模型推向了一个新的高度,甚至是“断崖式”领先。包括谷歌、百度在内的海内外科技公司,不可避免地将面对自家产品“发布即落后”的尴尬局面,而微软则躺在OpenAI背后“赚麻了”。
返回21经济网首页 >>

