


手撕resnet50+FPN

FPN原理及伪代码讲解
FPN结构如图所示。这里只画到layer3,实际上layer4也进行了相似的链接。
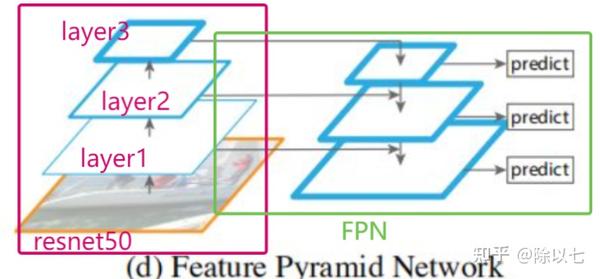
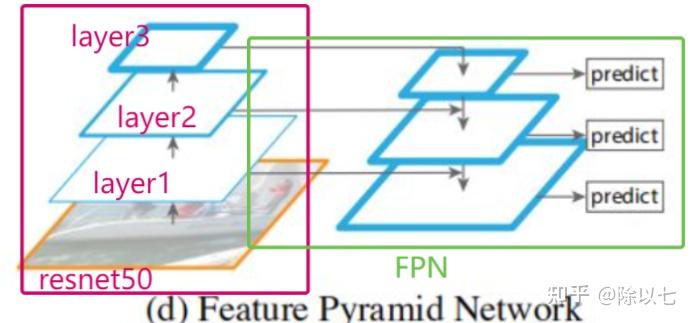
resnet50:
conv1->bn1->relu->maxpool->layer1->layer2->layer3->layer4->avgpool->fc
由 resnet50 可知当输入为[B,C=3,H,W]时,layer1、layer2、layer3、layer4层时的输出分别为:
[B, 256, H/4, W/4 ] (resnet的layer1输出和输入维度相同,在所有的resnet中layer1都不进行W和H的下采样,只针对通道调整)
[B, 512, H/8, W/8 ] (layer2~4结构相同,仅改变输入输出通道数)
[B, 1024, H/16, W/16 ]
[B, 2048, H/32, W/32 ]
layer1~layer4的通道分别[64,128,256,512]*Bottleneck.expansion,即[256,512,1024,2048]
H和W在layer1层之前的Conv1层和MaxPool层分别缩小两倍,所以在layer1处的高和宽为缩小4倍。layer1不对高宽修改,layer2~layer4每层对高宽缩小两倍。
FPN:
使用 torchvision.models._utils. IntermediateLayerGetter 能够利用输入的模型和指定返回层,得到一个新模型。如
body = IntermediateLayerGetter(
model = resnet50(pretrained),
return_layers = {'layer1':'out1','layer2':'out2','layer3':'out3','layer4':'out4'}
# 即:y1 = body(image_shape_B_3_H_W) = OrderedDict(
# {'out1':'layer1处的输出,tensor形状为[B, 256, H/4, W/4 ] ',
# 'out2':'layer2处的输出,tensor形状为[B, 512, H/8, W/8 ] ',
# 'out3':'layer3处的输出,tensor形状为[B, 1024, H/16, W/16 ] ',
# 'out4':'layer4处的输出,tensor形状为[B, 2048, H/32, W/32 ] ' }
# )就能得到一个新的模型(模型记为body),这个模型的输出为一个有序字典,keys分别为out1~out4,values分别为resnet50的layer1~layer4层的输出。
假设layer1~layer4的输出分别为
[B, 256, H/4, W/4 ] [B, 512, H/8, W/8 ] [B, 1024, H/16, W/16 ] [B, 2048, H/32, W/32 ]
使用 torchvision.ops. FeaturePyramidNetwork 模型(模型记为fpn),将layer1~layer4的输出作为该模型的输入,能得到图中的4个predict特征图。
from torchvision.ops.feature_pyramid_network import LastLevelMaxPool
fpn = FeaturePyramidNetwork(in_channels_list = [256, 512, 1024, 2048], out_channels = 256, extra_blocks=LastLevelMaxPool())
# 如使用IntermediateLayerGetter得到的body模型输出y1作为fpn的输入:
# y = fpn(y1)= OrderedDict(
# {'out1':'形状为[B, 256, H/4, W/4 ]的tensor ',
# 'out2':'形状为[B, 256, H/8, W/8 ]的tensor ',
# 'out3':'形状为[B, 256, H/16, W/16 ]的tensor ',
# 'out4':'形状为[B, 256, H/32, W/32 ]的tensor ',
# 'pool':'形状为[B, 256, H/64, W/64 ]的tensor ' } }
# )
#注:若实例化FeaturePyramidNetwork类时参数extra_blocks为默认值None时,输出的y在字典中没有最后一个pool键和对应的值。上面提到的body模型和fpn模型串连,就是resnet_fpn_backbone
视频10分钟讲解resnet50_fpn_backbone的流程:
详细代码实现:
resnet_fpn_backbone
def resnet_fpn_backbone(
backbone_name,
pretrained,
norm_layer=misc_nn_ops.FrozenBatchNorm2d,
trainable_layers=3,
returned_layers=None,
extra_blocks=None
搭建Resnet+FPN,冻结指定层
Args:
backbone_name (string): resnet architecture. Possible values are 'ResNet', 'resnet18', 'resnet34', 'resnet50',
'resnet101', 'resnet152', 'resnext50_32x4d', 'resnext101_32x8d', 'wide_resnet50_2', 'wide_resnet101_2'
pretrained (bool): If True, returns a model with backbone pre-trained on Imagenet
norm_layer (torchvision.ops): it is recommended to use the default value. For details visit:
(https://github.com/facebookresearch/maskrcnn-benchmark/issues/267)
trainable_layers (int): number of trainable (not frozen) resnet layers starting from final block.
Valid values are between 0 and 5, with 5 meaning all backbone layers are trainable.
说人话就是训练最后的多少层,可以选择训练最后0-5层,总共有5层。
returned_layers (list of int): The layers of the network to return. Each entry must be in ``[1, 4]``.
By default all layers are returned.
默认值:returned_layers = [1, 2, 3, 4]
extra_blocks (ExtraFPNBlock or None): if provided, extra operations will
be performed. It is expected to take the fpn features, the original
features and the names of the original features as input, and returns
a new list of feature maps and their corresponding names. By
default a ``LastLevelMaxPool`` is used.
默认值:extra_blocks = LastLevelMaxPool()
#______________________________________________________________________________________________________________________
# 看起来很高级的写法,其实就是torchvision.models.resnet.xxxxx,例如torchvision.models.resnet.resnet50
backbone = resnet.__dict__[backbone_name](
pretrained=pretrained,
norm_layer=norm_layer)
# print(torchvision.models.resnet.__dict__)
# backbone = torchvision.models.resnet.__dict__['resnet50'](
# pretrained=False) # __dict__是python的内置类和实例属性,torchvision.models.resnet.__dict__['resnet50']本质上就是torchvision.models.resnet.resnet50
#______________________________________________________________________________________________________________________
# select layers that wont be frozen
# 根据要求选择训练最后的几层,冻结掉不训练的层
assert 0 <= trainable_layers <= 5
layers_to_train = ['layer4', 'layer3', 'layer2', 'layer1', 'conv1'][:trainable_layers]
if trainable_layers == 5:
layers_to_train.append('bn1') # 如果全部训练:layers_to_train = ['layer4', 'layer3', 'layer2', 'layer1', 'conv1', 'bn1']
for name, parameter in backbone.named_parameters():
if all([not name.startswith(layer) for layer in layers_to_train]):
parameter.requires_grad_(False) # 冻结掉不训练的层
#______________________________________________________________________________________________________________________
if extra_blocks is None:
extra_blocks = LastLevelMaxPool() # Applies a max_pool2d on top of the last feature map
#______________________________________________________________________________________________________________________
if returned_layers is None:
returned_layers = [1, 2, 3, 4]
#______________________________________________________________________________________________________________________
assert min(returned_layers) > 0 and max(returned_layers) < 5
# 将list转为字典:{'layer1': '0', 'layer2': '1', 'layer3': '2', 'layer4': '3'}
return_layers = {f'layer{k}': str(v) for v, k in enumerate(returned_layers)}
#______________________________________________________________________________________________________________________
in_channels_stage2 = backbone.inplanes // 8 # inplane是输入的通道数,2048//8=256
in_channels_list = [in_channels_stage2 * 2 ** (i - 1) for i in returned_layers] # [256, 512, 1024, 2048]
out_channels = 256
return BackboneWithFPN(backbone, return_layers, in_channels_list, out_channels, extra_blocks=extra_blocks)即:
resnet50_fpn = resnet_fpn_backbone('resnet50', pretrained=True, trainable_layers=3)
# resnet50_fpn = BackboneWithFPN(
# backbone = resnet = torchvision.models.resnet50(),
# return_layers = {'layer1': '0', 'layer2': '1', 'layer3': '2', 'layer4': '3'},
# in_channels_list = [256, 512, 1024, 2048],
# out_channels = 256,
# extra_blocks= LastLevelMaxPool()
# )BackboneWithFPN:
class BackboneWithFPN(nn.Module):
def __init__(self, backbone, return_layers, in_channels_list, out_channels, extra_blocks=None):
super(BackboneWithFPN, self).__init__()
if extra_blocks is None:
extra_blocks = LastLevelMaxPool()
self.body = IntermediateLayerGetter(backbone, return_layers=return_layers)
#IntermediateLayerGetter:获取backbone在return_layers字典中keys名字的模型作为输出,输出也为字典格式。
# backbone = resnet = torchvision.models.resnet50()
# return_layers = {'layer1': '0', 'layer2': '1', 'layer3': '2', 'layer4': '3'}
self.fpn = FeaturePyramidNetwork(
in_channels_list=in_channels_list,
out_channels=out_channels,
extra_blocks=extra_blocks,
# in_channels_list = [256, 512, 1024, 2048]
# out_channels = 256
# extra_blocks= LastLevelMaxPool()
self.out_channels = out_channels
def forward(self, x):
x = self.body(x)
x = self.fpn(x)
return xIntermediateLayerGetter
核心为两个部分,第一部分找到return_layers里写的几个层里哪个是在resnet50中最靠后的,找到这个层,写一个新的模型,模型为conv1->bn1->...->找到的这个最后一层,用layers封装成一个有序字典,再用self把这个有序字典转化为ModuleDict,说白了就是获取从开头到某一个(如layer4)层的resnet50,然后
# IntermediateLayerGetter位于torchvision.models._utils
class IntermediateLayerGetter(nn.ModuleDict):
Module wrapper that returns intermediate layers from a model
从模型返回中间层的模块包装器
It has a strong assumption that the modules have been registered into the model in the same order as they are used.
它有一个强烈的假设,即模块已按照与使用时相同的顺序注册到模型中。
This means that one should **not** reuse the same nn.Module twice in the forward if you want this to work.
不能在前向通道中重复使用相同的 nn.Module 两次。
Additionally, it is only able to query submodules that are directly assigned to the model. So if `model` is passed, `model.feature1` can
be returned, but not `model.feature1.layer2`.
此外,它只能查询直接分配给模型的子模块。因此,如果传递了 `model`,则可以返回 `model.feature1`,但不能返回 `model.feature1.layer2`。
即只能调用一级子模块,不能调用二级以下的模块。
Args:
model (nn.Module): model on which we will extract the features
我们将在其上提取特征的模型
return_layers (Dict[name, new_name]): a dict containing the names
of the modules for which the activations will be returned as
the key of the dict, and the value of the dict is the name
of the returned activation (which the user can specify).
一个字典,其中包含模块的名称,其激活将作为字典的键返回,字典的值是返回的激活的名称(用户可以指定)。
Examples::
>>> m = torchvision.models.resnet18(pretrained=True)
>>> # extract layer1 and layer3, giving as names `feat1` and feat2`
>>> new_m = torchvision.models._utils.IntermediateLayerGetter(m,
>>> {'layer1': 'feat1', 'layer3': 'feat2'})
>>> out = new_m(torch.rand(1, 3, 224, 224))
>>> print([(k, v.shape) for k, v in out.items()])
>>> [('feat1', torch.Size([1, 64, 56, 56])),
>>> ('feat2', torch.Size([1, 256, 14, 14]))]
_version = 2
__annotations__ = {
"return_layers": Dict[str, str],
def __init__(self, model: nn.Module, return_layers: Dict[str, str]) -> None:
#如果return_layers中的元素不在model.named_children()中的模型的名字中
if not set(return_layers).issubset([name for name, _ in model.named_children()]):
raise ValueError("return_layers are not present in model")
orig_return_layers = return_layers
return_layers = {str(k): str(v) for k, v in return_layers.items()} # 大概是确保return_layers中的内容全为字符串吧,并没有修改内容
#------------------------------------------------------------------------------------------------------------------
#-------建立一个新的有序字典layers,把模型(resnet50)所有层的名字作为keys,层的内容为values添加到layers中,-------
#-------如果添加的层名字在return_layers中,则删除return_layers中对应的keys和values。可以视为把return_layers删光,---
#-------并生成一个layers,为“不”完整的resnet50模型的OrderedDict。如return_layers中只有一项layer3,那么这里的-----
#-------layers为resnet50从开始到layer3,并不是一直到最后。———————————————————————————---
layers = OrderedDict()
for name, module in model.named_children():
layers[name] = module
if name in return_layers:
del return_layers[name]
if not return_layers: # 如果return_layers为空字典,跳出循环,layers中不再添加层信息
break
#------------------------------------------------------------------------------------------------------------------
super(IntermediateLayerGetter, self).__init__(layers) # layers为resnet50的OrderedDict
self
.return_layers = orig_return_layers
# return_layers = {'layer1': '0', 'layer2': '1', 'layer3': '2', 'layer4': '3'}
def forward(self, x):
out = OrderedDict()
for name, module in self.items(): # 这里的self为nn.ModuleDict,在上面4行处为这个ModuleDict实例化并赋值,即这里是resnet50的ModuleDict
# 但要注意,self不一定是完整的resnet50,而是returun_layers中最后一层为止。如return_layers中只有一项layer3,那么这里的self
#为resnet50从开始到layer3,并不是一直到最后。详细看上方的layers这个OrderedDict
x = module(x)
if name in self.return_layers:
out_name = self.return_layers[name]
out[out_name] = x
return out参考如下:


FeaturePyramidNetwork
本质是对layer1~layer4的输出分别经过一个1×1和3×3的卷积,改变其通道和做特征提取。
实现:
layer1层的输出 : keys = 0 , values.shape = torch.Size([1, 256, 32, 32])
layer2层的输出 : keys = 1 , values.shape = torch.Size([1, 512, 16, 16])
layer3层的输出 : keys = 2 , values.shape = torch.Size([1, 1024, 8, 8])
layer4层的输出 : keys = 3 , values.shape = torch.Size([1, 2048, 4, 4])
经过FeaturePyramidNetwork后得到一个新OrderedDict:
keys = 0 , values.shape = torch.Size([1, 256, 32, 32])
keys = 1 , values.shape = torch.Size([1, 256, 16, 16])
keys = 2 , values.shape = torch.Size([1, 256, 8, 8])
keys = 3 , values.shape = torch.Size([1, 256, 4, 4])
keys = "pool", values.shape = torch.Size([1, 256, 2, 2])
from torchvision.ops.feature_pyramid_network import ExtraFPNBlock
from torch import Tensor
import torch.nn.functional as F
class FeaturePyramidNetwork(nn.Module):
Module that adds a FPN from on top of a set of feature maps. This is based on
`"Feature Pyramid Network for Object Detection" <https://arxiv.org/abs/1612.03144>`_.
The feature maps are currently supposed to be in increasing depth
order.
The input to the model is expected to be an OrderedDict[Tensor], containing
the feature maps on top of which the FPN will be added.
Args:
in_channels_list (list[int]): number of channels for each feature map that
is passed to the module
out_channels (int): number of channels of the FPN representation
extra_blocks (ExtraFPNBlock or None): if provided, extra operations will
be performed. It is expected to take the fpn features, the original
features and the names of the original features as input, and returns
a new list of feature maps and their corresponding names
Examples::
>>> m = torchvision.ops.FeaturePyramidNetwork([10, 20, 30], 5)# 注意这里没有加extra_blocks,实际FPN中有LastLevelMaxPool
>>> # get some dummy data
>>> x = OrderedDict() # 形如{'feat0':Tensor0,'feat1':Tensor1,'feat2':Tensor2},其中tensor0、1、2如下所示
>>> x['feat0'] = torch.rand(1, 10, 64, 64)
>>> x['feat2'] = torch.rand(1, 20, 16, 16)
>>> x['feat3'] = torch.rand(1, 30, 8, 8)
>>> # compute the FPN on top of x
>>> output = m(x)
>>> print([(k, v.shape) for k, v in output.items()])
>>> # returns
>>> [('feat0', torch.Size([1, 5, 64, 64])),
>>> ('feat2', torch.Size([1, 5, 16, 16])),
>>> ('feat3', torch.Size([1, 5, 8, 8]))]
def __init__(
self,
in_channels_list: List[int],
out_channels: int,
extra_blocks: Optional[ExtraFPNBlock] = None, # extra_blocks = LastLevelMaxPool
super(FeaturePyramidNetwork, self).__init__()
self.inner_blocks = nn.ModuleList()
self.layer_blocks = nn.ModuleList()
for in_channels in in_channels_list: # in_channels_list=[256,512,1024,2048], out_channels=256
if in_channels == 0:
raise ValueError("in_channels=0 is currently not supported")
inner_block_module = nn.Conv2d(in_channels, out_channels, kernel_size=1)
layer_block_module = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)
self.inner_blocks.append(inner_block_module)
self.layer_blocks.append(layer_block_module)
# initialize parameters now to avoid modifying the initialization of top_blocks
# 现在初始化参数以避免修改top_blocks的初始化
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_uniform_(m.weight, a=1)
nn.init.constant_(m.bias, 0)
if extra_blocks is not None:
assert isinstance(extra_blocks, ExtraFPNBlock)
self.extra_blocks = extra_blocks
def get_inner_blocks(self):
return self.inner_blocks # 自己写的函数,源代码中没有此项,查看inner_blocks
# (inner_blocks): ModuleList(
# (0): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
# (1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1))
# (2): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))
# (3): Conv2d(2048, 256, kernel_size=(1, 1), stride=(1, 1))
# )
def get_layer_blocks(self):
return self.layer_blocks # 自己写的函数,源代码中没有此项,查看layer_blocks
# (layer_blocks): ModuleList(
# (0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# )
def get_result_from_inner_blocks(self, x: Tensor, idx: int) -> Tensor:
This is equivalent to self.inner_blocks[idx](x),but torchscript doesn't support this yet
inner_blocks = ModuleList([Conv2d(256,256,1),Conv2d(512,256,1),Conv2d(1024,256,1),Conv2d(2048,256,1)])
get_result_from_inner_blocks(x[-1],-1)
# 这里的x为{'feat0':Tensor0,'feat1':Tensor1,'feat2':Tensor2,'feat3':Tensor3}中values转化成的list
# 如这里x[-1]就是Tensor3(Tensor3是resnet50在layer4处经过body模型的输出,shape=[B, 2048, H/32, W/32 ])
# 执行的就是Conv2d(2048,256,1)的1×1卷积
num_blocks = len(self.inner_blocks) # 4
if idx < 0:
idx += num_blocks #idx=3
i = 0
out = x
for module in self.inner_blocks:
if i == idx:
out = module(x)
i += 1
return out
def get_result_from_layer_blocks(self, x: Tensor, idx: int) -> Tensor:
This is equivalent to self.layer_blocks[idx](x),
but torchscript doesn't support this yet
# 执行输入和输出层相同的3×3卷积
num_blocks = len(self.layer_blocks) # 4
if idx < 0:
idx += num_blocks
i = 0
out = x
for module in self.layer_blocks:
if i == idx:
out = module(x)
i += 1
return out
def forward(self, x: Dict[str, Tensor]) -> Dict[str, Tensor]:
Computes the FPN for a set of feature maps.
Args:
x (OrderedDict[Tensor]): feature maps for each feature level.
Returns:
results (OrderedDict[Tensor]): feature maps after FPN layers.
They are ordered from highest resolution first.
# unpack OrderedDict into two lists for easier handling
names = list(x.keys()) # names = ["feat0","feat1","feat2","feat3"]
x = list(x.values()) # x = [tensor0,tensor1,tensor2,tensor3]
last_inner = self.get_result_from_inner_blocks(x[-1], -1) # 对x最后一项Conv2d(2048,256,1),shape=[B, 2048, H/32, W/32 ] ->[B, 256, H/32, W/32 ]
results = []
results.append(self.get_result_from_layer_blocks(last_inner, -1)) # last_inner再Conv2d(256,256,3,padding=1),形状不变
# 这里results就保存了一个layer4的输出经过Conv1×1压缩通道,Conv3×3,得到的结果。
for idx in range(len(x) - 2, -1, -1):
# 从len(x)-2=2,逆序到0,即idx=2,idx=1,idx=0
# 下面的注释以idx=2为例:
inner_lateral = self.get_result_from_inner_blocks(x[idx], idx) # idx=2,对layer3输出进行1×1卷积
feat_shape = inner_lateral.shape[-2:] # 获取高和宽
inner_top_down = F.interpolate(last_inner, size=feat_shape, mode="nearest") # 对layer4改变通道后的结果(以下称fpn后的结果)进行最近邻插值,形状为layer3改变通道后的形状,即高宽×2
last_inner = inner_lateral + inner_top_down # (将layer4处1×1卷积再3×3卷积的结果)插值后与(layer3输出经过1×1卷积改变通道的结果)相加,记为last_inner
results.insert(0, self.get_result_from_layer_blocks(last_inner, idx)) # last_inner经过3×3卷积,结果保存在result中第一个位置
# 最终循环后结果:results = [layer1_fpn,layer2_fpn,layer3_fpn,layer4_fpn]
if self.extra_blocks is not None:
results, names = self.extra_blocks(results, x, names) # extra_blocks = LastLevelMaxPool(),该class在下文提到