tf.keras.callbacks.EarlyStopping
is used to terminate a training if a monitored quantity satisfies some criterion. For example, in the following code snippet, the training will stop before reaching the target epoch (
10000
in this case) if the training loss has not improved for 3 epochs in a roll:
min_delta=1e-3
represents how big a change should be to count as an improvement.
In the above example, some people (I admit I was one of them) may expect that when the training is stopped by the
EarlyStopping
, the last 3 (or 4) epochs have similar values because the loss would not improve further. In other words, people may think the training stopped earlier because the loss
converges
to some value, and continuing the training would not reduce the loss much. An expectation is a situation that the last 4 losses are, for example,
0.01
,
0.0105
,
0.0092
, and
0.0099
. The last 3 losses do not have changes greater than
1e-3
when compared to
0.01
.
But it’s
WRONG
!! Before we look into the source code to understand what
EarlyStopping
does, let’s read the
API documentation
again:
Stop training when a monitored quantity has stopped improving.
It only says “
a monitored quantity
has stopped improving
“. It does not say “
a monitored quantity
has converged
“. So it’s also likely the training is stopped because the loss blew up in 3 epochs in a roll. For example, if the losses of the last 4 epochs are
0.01
,
1.2
,
2.05
, and
3.0
, the
EarlyStopping
also stops the training.
Because training may be stopped due to blowing up, we are not guaranteed to get an optimized model at the last epoch. Even worse, we may get a model with a very huge loss. That’s why
EarlyStopping
has an optional argument called
restore_best_weights
. It helps to recover the model weights that give us the best prediction during the training process.
Now let’s read the source code of
EarlyStopping
. The code of the current version is
here
:
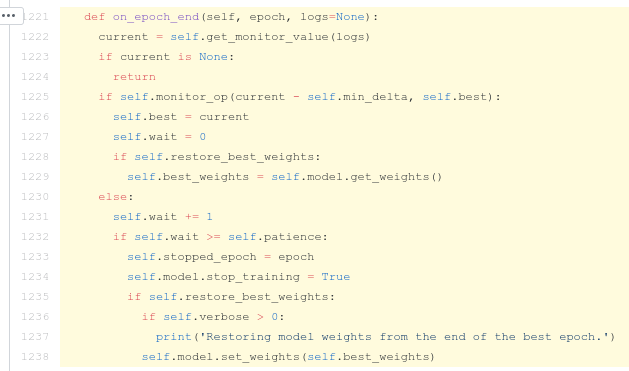
Code of
EarlyStopping.on_epoch_end
(snippet from TensorFlow’s GitHub repo)
self.monitor_op
is
<
(less than) for quantities like loss or root mean squared error and is
>
(greater than) for quantities like accuracy. We can see from line 1225 that if
the current loss + min_delta
(
1e-3
in our case) is less than
the best loss in the training history
, it is deemed as an improvement and updates the best loss record. And any situation that
the current loss + min_delta
is not less than
the best record
(line 1230), it is treated as “not improving” and adds a count to how many epochs in a roll do not improve. This “any situation” of course includes the case when the current loss is greater than the best record. So
EarlyStopping
will stop training if the monitored quantity blows up.
Anyway, as a guy from the area of traditional numerical methods, I expected that an iteration solver stops early only when the residual (i.e., loss) converges to some value and will not have significant changes. If I want to terminate a solver earlier due to blowing-up, I usually have another mechanism that detects whether the solver
diverges
. I rarely put the detection of convergence and divergences in a single detector. And when a solver stops due to divergence, I don’t say it stops. I only use the word “stop” when describing a solver solves something successfully. And apparently, divergence is not a successful solving.
That’s why I didn’t really expect the
tf.keras.callbacks.EarlyStopping
to terminate a training process when the loss blows up.