当通过jdbc请求连接至Impalad节点之后,我们提交的SQL会通过BE的JNI调用FE的api进行解析,主要的调用栈如下所示:
query/executeAndWait(impala-beeswax-server.cc)
-Execute(impala-server.cc)
--ExecuteInternal(impala-server.cc)
---InitExecRequest(client-request-state.cc)
----RunFrontendPlanner(query-driver.cc)
-----GetExecRequest(frontend.cc)
------JniFrontendcreateExecRequest()
-------Frontend.createExecRequest()
--------Frontend.getTExecRequest()
---------Frontend.doCreateExecRequest()
在doCreateExecRequest方法中,会通过调用Parse.parse()来对SQL进行解析,解析完成之后,SQL就会变成对应的结构,如下所示:
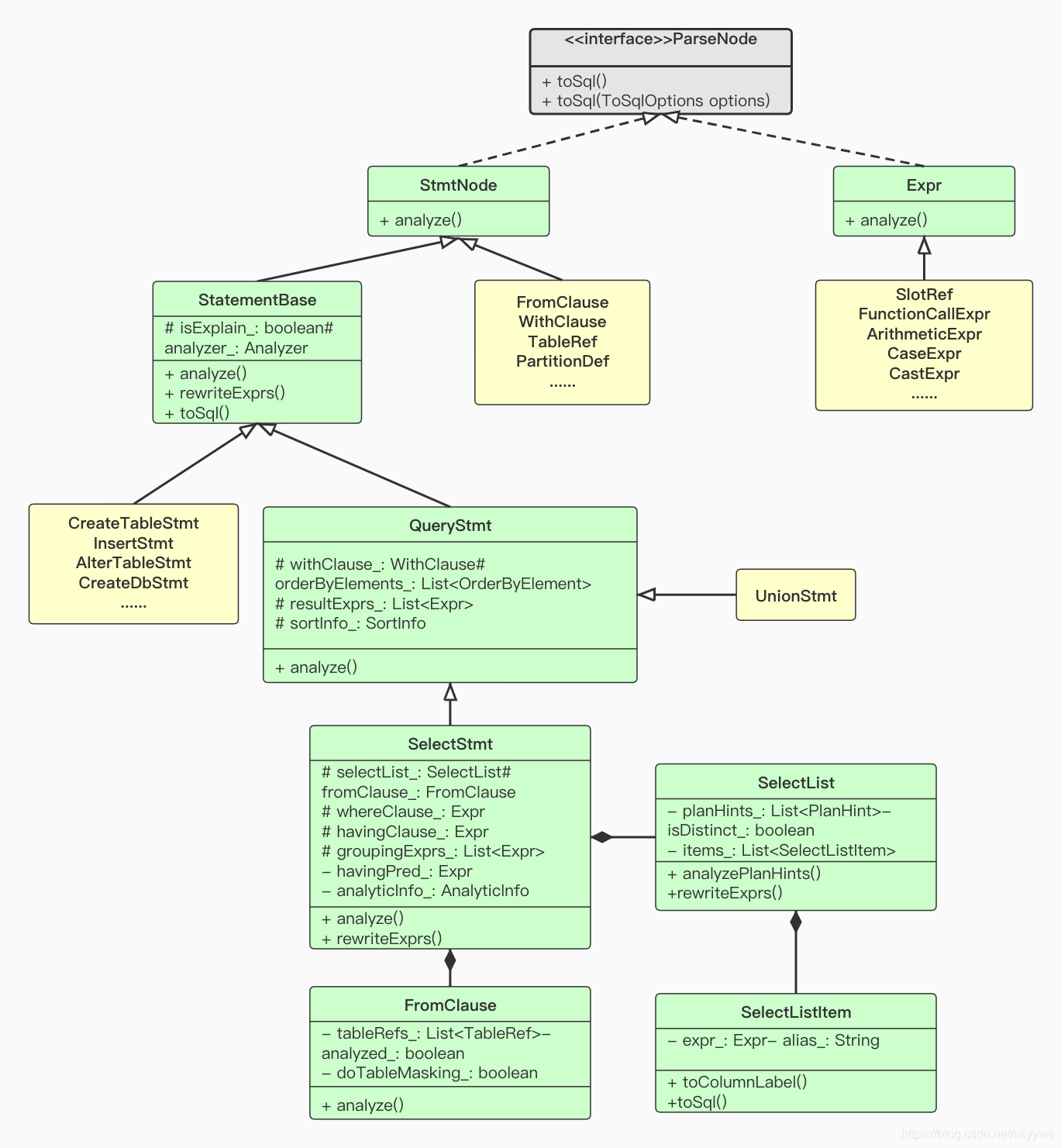
从图中我们可以看到,Impala所有的SQL最终都是继承于StatementBase,包括select、alter、create等。这里我们以简单的select查询为例,最终SQL转换之后会被解析成SelectStmt这个类,而这个类其中又包含SelectList、FromClause等部分。通过Parse.parse()的解析,我们将一条普通的SQL转成了一个Impala的类。目前,Impala在进行SQL解析的时候,采用的是一个开源的框架antlr,关于这个框架不是本文描述的重点,这里就不再展开。
对于图中涉及到的一些接口和类,我们摘取了一部分代码中的注释,供大家参考。
- ParseNode: divide into two broad categories: statement-like nodes and expression nodes;
- StmtNode: Base interface for statements and statement-like nodes such as clauses;
- Expr: Root of the expr node hierarchy;
- StatementBase: Base class for all Impala SQL statements;
- QueryStmt: Abstract base class for any statement that returns results via a list of result expressions;
在解析出了具体的StatementBase之后(上述例子中就是SelectStmt),Impala接着会构造对应的Analyer,相关的类如下所示:
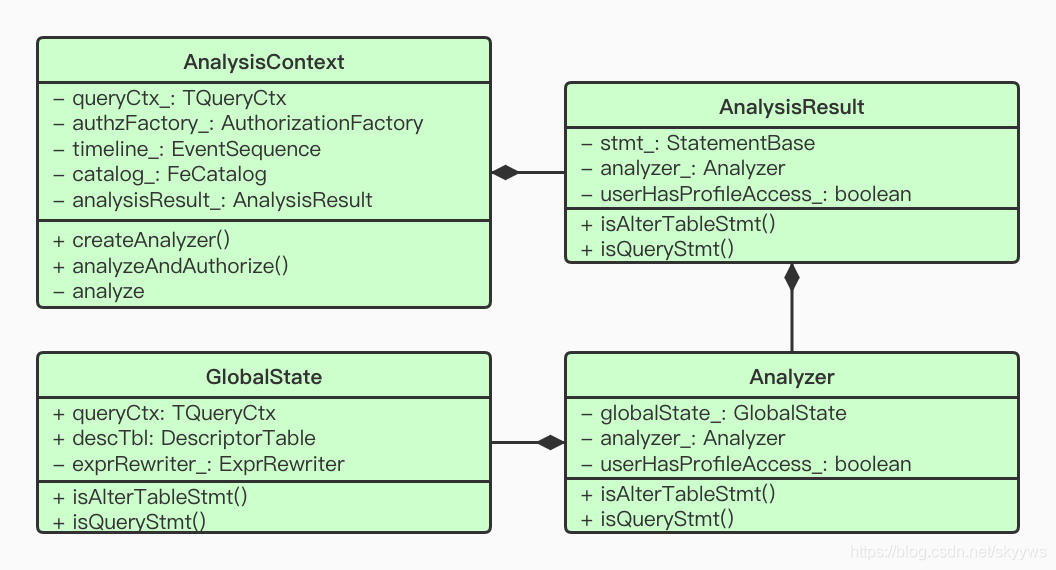
同样,我们截取部分代码中的注释来看一看:
- AnalysisContext: Wrapper class for parsing, analyzing and rewriting a SQL stmt;
- Analyzer: Repository of analysis state for single select block;
- GlobalState: State shared between all objects of an Analyzer tree.
这里最重要的类就是Analyzer,包括了单个select查询块的所有解析之后的状态集合。我们继续以SelectStmt为例来看下生成Analyzer的接口调用流程:
Frontend.doCreateExecRequest()
-AnalysisContext.analyzeAndAuthorize()
--AnalysisContext.analyze()
---SelectStmt.analyze()
----SelectStmt.SelectAnalyzer.analyze()
我们可以看到,主要就是调用各个StatementBase子类的analyze(),来实现对各个查询的解析。这里简单看一下SelectStmt的analyze方法,如下所示:
// SelectStmt.analyze()
public void analyze(Analyzer analyzer) throws AnalysisException {
if (isAnalyzed()) return;
super.analyze(analyzer);
new SelectAnalyzer(analyzer).analyze();
// SelectStmt.SelectAnalyzer.analyze()
private void analyze() throws AnalysisException {
// Start out with table refs to establish aliases.
fromClause_.analyze(analyzer_);
analyzeSelectClause();
verifyResultExprs();
registerViewColumnPrivileges();
analyzeWhereClause();
createSortInfo(analyzer_);
......
可以看到,SelectStmt的解析,主要都在其私有类SelectAnalyzer的analyze中进行处理了,这里包括了对于FromClause的处理、WhereClause的处理等操作。其他的SQL也是类似处理流程,每一个具体的SQL类都有对应的analyze方法。解析完成之后,Impala就会根据解析的结果来生成相应地执行计划:首先是生成一个单机的执行计划,接着会根据单机的执行计划来生成分布式的执行计划。关于执行计划的生成这块,我们会在后续的文章里面陆续提到,这里就不再展开描述。执行计划生成之后,Backend模块就会根据这些执行计划执行实际的扫描、聚合运算等操作,最终返回结果。
我们从第一幅图可以看到,ParseNode主要分为了两个部分:1)StmtNode,这个主要包括查询以及相应的clause实现;2)Expr,我们接下来就看一看这个Expr相应的各个子类都是什么样的,下面就是一个简单的关于UML的类图:
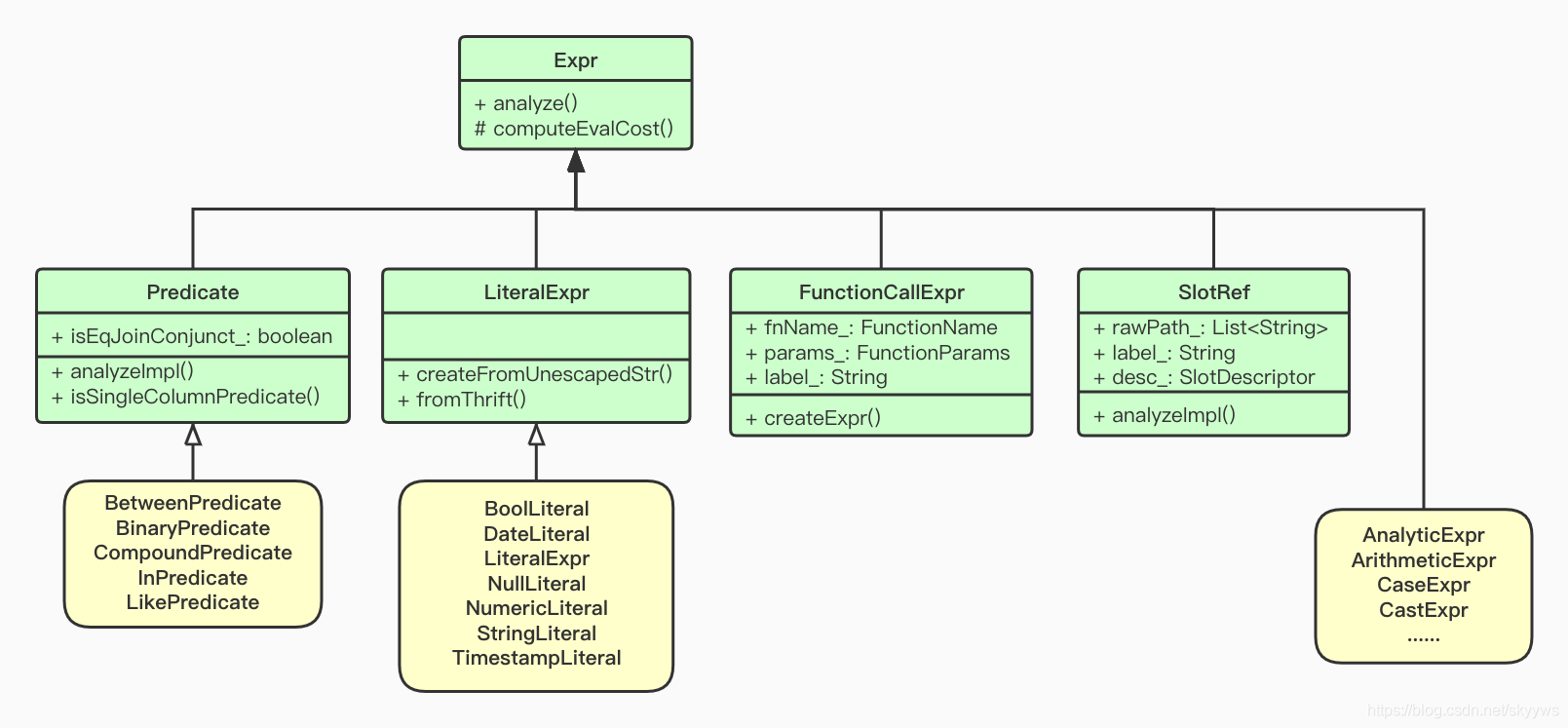
从上图可以看到,有非常多的类都继承了Expr,这里我们看几个比较常见的类:
- Predicate,这个类就是用来保存各种谓词条件的,包括:BetweenPredicate、BinaryPredicate等,我们在上述的SelectStmt中提到的whereClasue_最终就会转换成一个Predicate,根据不同的条件转换成相应的Predicate;
- LiteralExpr,用来保存各种常量的值,例如布尔保存在BoolLiteral中,字符串保存在StringLiteral中等等,目前主要就包括图中的这其中;
- FunctionCallExpr,各种函数调用,最终都会转换成这个对象,例如常见的count、sum等;
- SlotRef,这个可以简单理解为列的描述,SQL中涉及到列都会被转换成一个SlotRef对象,保存着这个列的相关信息;
- 其他还有一些例如AnalyticExpr、CastExpr等这里就不再展开描述,感兴趣的同学可以自行查看相关的源码。
下面我们就从一个具体的SQL出来,来简单看一下上面提到的各个对象是如何解析的,SQL如下:
select id,user,count(1) from table_name
where id>=5 and id<=10
group by id,user order by id desc;
结合上面的几个类图,我们可以看看上述的SQL会被解析成什么样的:
- SelectList包含三个SelectListItem,分别是:id、user和count(1),而这三个item各自包含的Expr分别是:SlotRef、SlotRef和FunctionCallExpr,而这个FunctionCallExpr本身又包含一个NumericLiteral,对应count(1)里面的1;
- fromClause_主要包括了一个表的集合,这里只有一个成员,就是table_name;
- whereClasue_这里转换成了一个CompoundPredicate的谓词,表示组合的谓词,操作符是AND。它本身又包含两个BinaryPredicate,表示包含两个操作数的谓词,分别对应id>=5和id<=10。以第一个为例,它的操作符是>=,本身又包含两个child,分别是id对应的SlotRef以及10对应的NumericLiteral;
- groupingExprs_是一系列的group by成员集合,这里主要就是包括两个SlotRef,分别对应id和user;
- orderByElements_是从QueryStmt继承而来,成员是一个OrderByElement类,而这个OrderByElement内部也是包含了一个Expr,这里对应的仍旧是一个SlotRef,即id列;
到这里,我们基本对于上述示例中的SQL各个部分的解析都已经完成了。
本文比较浅显地讲述了Impala SQL解析中的两个部分:StmtmentBase和Expr,整个SQL解析的大部分成员对象,最终都会转换成这两个类或者其子类。关于Analyzer类,本身没有过多讲述,只是稍微提了一下,后续有机会再跟大家一起深入分享。
下面给大家介绍怎么理解impala,impala工作原理是什么。
Impala是hadoop上交互式MPP SQL引擎, 也是目前性能最好的开源SQL-on-hadoop方案。 如下图所示, impala性能超过SparkSQL、 Presto、 Hive。
impala与hadoop生态结合紧密
(1) HDFS是impala最主要的数据源。 除此之外, impala也支持HBase,甚至支持...
1、需求:找到每个分组中pv最大的第一条数据,取10万条;
row_number 格式:ROW_NUMBER() OVER (partition BY COLUMN_A ORDER BY COLUMN_B ASC/DESC) rn
rn 是排序的别名执行时每组的编码从1开始
partition by:类似hive的建表,分区的意思;COLUMN_A 是分组字段
Impala由以下组件组成:
Clients-HUE、ODBC clients、JDBC clients和impala shell都可以与impala进行交互,这些接口都可以用在impala的数据查询以及对impala的管理。
Hive Metastore-存储impala可以访问数据的元数据。例如:这些数据可以让impala知道哪些数据库以及数据库的结构是可以访问的,当你创建、删除、修改数据库对象或者加载数据
select t.*, (@indexs:= @indexs+1) index_no from (SELECT @indexs:=0) as indexs, (select 1 from dual ) t
(SELECT @indexs:=0) as indexs
1、查询表中的记录,基本语法:SELECT c1,c2 | * FROM table_name;查询emp表中记录:SELECT * FROM emp;
SELECT name,age FROM emp;执行结果如下:
2、对查询结果进行排序,基本语法如下:SELECT * FROM table_name ORDER BY c1,… [ASC|DESC] [NULLS FIRST|NUL
在使用Impala进行SQL查询的时候,我们经常会使用join来关联多个表进行查询,获取想要的结果。对于表的数量达到千万甚至上亿的时候,不同的join方式所造成的执行速度,可能差距非常大。对于join的实现细节,感兴趣的可以参考:http://hbasefly.com/2017/03/19/sparksql-basic-join/。想直接了解如何加速SQL查询的可以直接跳过这里了。
Impala...
select count(1) from user_table
where day ='2019-03-19'
and url rlike 'http://www.example.com/'
and user_udf(info, 'type') ...

