初识 KEEPFILTERS
我们已经知道,
CALCULATE
的筛选器参数的默认行为是覆盖同一列上已有的筛选器,让我们举一个简单的例子,下面这个
度量值
忽略 Product[Category]上的已有筛选器,只返回 Audio 的销售额。
Audio Sales :=
CALCULATE ( [Sales Amount], 'Product'[Category] = "Audio" )
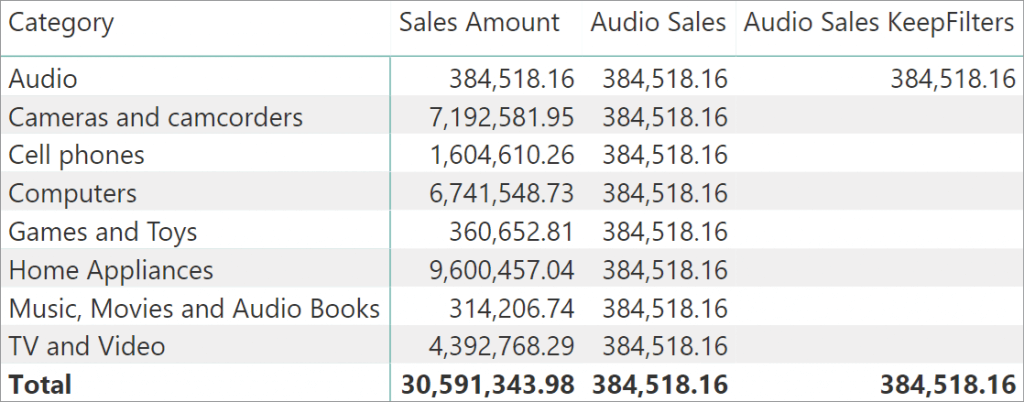
如图所示,对于 Audio Sales 度量值,Audio 对应的 Sales Amount 值在报告的所有行上重复显示。
Audio Sales 始终显示 Audio 产品的销售情况,忽略当前
筛选上下文
CALCULATE
应用新筛选器覆盖当前列上已存在的筛选器,其他列的
筛选上下文
保持不变。
如果不想覆盖现有的筛选器,可以对筛选参数使用
KEEPFILTERS
。例如,如果你只想在外部
筛选上下文
为 Audio 的行显示 Audio 销售额,否则显示空白值,可以定义以下度量值:
Audio Sales KeepFilters :=
CALCULATE ( [Sales Amount], KEEPFILTERS ( 'Product'[Category] = "Audio" ) )
KEEPFILTERS
修改
CALCULATE
将筛选器参数应用于筛选上下文的方式。它不会覆盖同一列上的现有筛选器,而是将新筛选器追加到现有筛选器中。因此,只有包含在筛选上下文中的产品类别才会显示结果。如图所示
Audio Sales KeepFilters 仅在 Audio 行和总计行显示 Audio 产品销售额
正如它名字的含义,
KEEPFILTERS
不覆盖现有筛选,而是保留现有筛选并将新筛选器追加到筛选上下文
。我们可以用下图描述该行为。
KEEPFILTERS 生成一个产品类别同时为 Cell phones 和 Audio 的筛选上下文
KEEPFILTERS 不执行覆盖操作,它将 CALCULATE 筛选参数生成的新筛选器追加到上下文中。如果我们在 Cell Phones 行查看 Audio Sales KeepFilters 度量值,得到的筛选上下文包含两个筛选器:Cell Phones 和 Audio。由于这两个条件的交集是空集,所以结果为空。
理解 KEEPFILTERS
在 DAX 的复杂函数排行榜上,KEEPFILTERS 有一个醒目的位置。某种程度上,它的行为比较容易学习和记忆,但是你很难精确掌握何时使用它以及使用它会产生什么结果。类似于
ALLSELECTED
,KEEPFILTERS 要求你准确地理解它的语义,然后才能安全地使用它。而且,正如对
ALLSELECTED
的介绍那样,我们使用 KEEPFILTERS 来揭示有关筛选上下文内部的更多细节。
KEEPFILTERS 的目的非常简单:它将
新的筛选上下文与之前的筛选上下文进行逻辑上的 AND 运算
。一个例子有助于更好地理解它。在下面的透视表中,公式定义如下:
Sales Amount] :=
SUMX ( Sales, Sales[Quantity] * Sales[Unit Price] )
[RedSalesCalc] :=
CALCULATE ([Sales Amount], Product[Color] = "Red")
[RedSalesValues] :=
CALCULATE ([Sales Amount], Product[Color] = "Red",VALUES ( Product[Color] ))
[RedSalesKeepFilter] :=
CALCULATE ([Sales Amount],KEEPFILTERS ( Product[Color] = "Red" ))
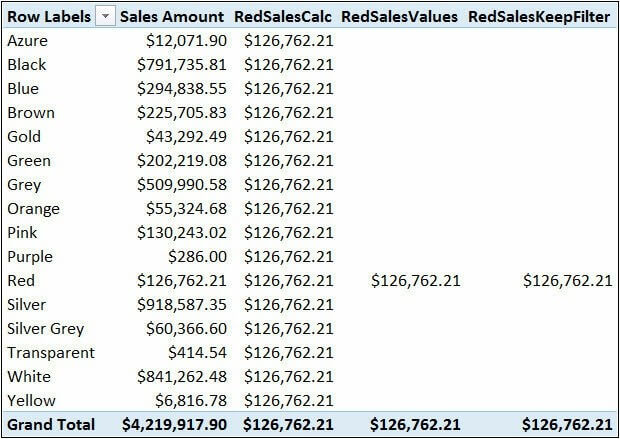
透视表使用的最后两个度量值计值结果相同
正如你所看到的,RedSalesCalc 总是计算红色产品的销售,而 RedSalesValues 和 RedSalesKeepFilter 只在红色已经存在于筛选上下文中时才计算红色产品的销售额。事实上,每个度量值的计值方式都有所不同:
RedSalesValues 显式使用 VALUES 函数检索当前筛选上下文中活动的颜色值,CALCULATE 将其与 Product[Color]上的筛选条件取交集。
RedSalesKeepFilter 使用 KEEPFILTERS 函数。KEEPFILTERS 在计算内部参数之后,将结果与之前的筛选上下文取交集。
虽然两个度量值看起来非常相似,在这个例子中它们也得到相同的结果,但是这是两种不同的实现技术:
KEEPFILTERS 不是表函数:它返回的结果不是表。事实上,你只能在 CALCULATE 中使用 KEEPFILTERS,或者在迭代时用作顶层函数(我们将很快看到这个特性)。
KEEPFILTERS 将其内部条件与之前的整个筛选上下文置于 AND 条件中,而 VALUES 只能与单个列做 AND 计算。这个事实在前面的示例中并不明显;通过下面的例子,它会变得更加清晰。
KEEPFILTERS 与上下文转换
当 KEEPFILTERS 用于
迭代函数
的第一参数时,发生
上下文转换
后,它将保留现有的筛选上下文,使用转换后的筛选上下文与其计算交集。
Average Sales Only Trendy Colors :=
VAR TrendyColors =
TREATAS (
{ "Red", "Blue", "White" },
'Product'[Color]
RETURN
AVERAGEX (
KEEPFILTERS ( TrendyColors ),
[Sales Amount]
Average Sales Only Trendy Colors 度量值只计算 TrendyColors 中所包含颜色的平均销售额,而不考虑那些不在当前 TrendyColors 中的颜色。如果此度量值的外部上下文中有一个包含{Red, Yellow, White}的筛选器,那么结果将仅对红色和白色计值,忽略黄色和蓝色。
不同于一般的
上下文转换 后的计值顺序,KEEPFILTERS 改变了 CALCULATE 的语义,执行一种特殊的计算逻辑
被还原的复杂筛选器
要理解 VALUES 和 KEEPFILTERS 之间的区别,你需要在同一个查询 中混合使用上下文转换 和复杂筛选器。假设你希望计算一个显示月平均销售额的度量值。此度量值将沿着年和月迭代,并为每个月计算总销售额。然后使用标准的 AVERAGEX 函数聚合各部分的结果,如下例所示:
[AvgMonthlySales] :=
AVERAGEX (
CROSSJOIN (
VALUES ( 'Date'[Calendar Year] ),
VALUES ( 'Date'[Month] )
[Sales Amount]
如果在一个简单的报告中使用这个度量值显示各年份的平均销售额,结果是正确的
数据透视表各年份的月均销售额和总销售额计算正确
出于教学目的,为了使这个示例更清晰,我们修改了
日期表 上的日历层级结构,使用月份名称(不包括年份)作为第二级。从技术上讲,这种修改使层级结构变得不合理,导致层级结构的设计背离了最佳实践,但是我们需要通过这种方式来更好地展示 KEEPFILTERS 的效果。
为了说明 KEEPFILTERS 的用处,你需要在日历表上创建一个复杂的筛选器。这样做时,你会看到公式将不再计算正确的值。一个复杂的筛选器 (也称为“固化筛选器(arbitrarily shaped filter)”,我们将在 DAX 高级原理中介绍)是一个包含相互关联筛选列的筛选器 。
报告中的可见数据集显示了 2007 年和 2008 年的所有月份,你可以将其表示为:
FILTER (
CROSSJOIN (
VALUES ( 'Date'[Calendar Year] ),
VALUES ( 'Date'[Month] )
'Date'[Calendar Year] = 2007,
'Date'[Calendar Year] = 2008
唯一的筛选条件是日历年,所以这还不是一个复杂的筛选器。你可以通过层级结构上的筛选器选择 2007 年的最后两个月和 2008 年的前两个月来创建一个复杂的筛选器,如图所示。
通过选择多项,你创建了一个复杂筛选器
这次的筛选条件不再是一个简单筛选器。实际上,你只能在同一表达式中使用同时包含年和月的条件来编写它,如下所示:
EVALUATE
FILTER (
CROSSJOIN (
VALUES ( 'Date'[Calendar Year] ),
VALUES ( 'Date'[Month] )
'Date'[Calendar Year] = "CY 2007"
&& 'Date'[Month] = "November",
'Date'[Calendar Year] = "CY 2007"
&& 'Date'[Month] = "December"
'Date'[Calendar Year] = "CY 2008"
&& 'Date'[Month] = "January",
'Date'[Calendar Year] = "CY 2008"
&& 'Date'[Month] = "February"
换句话说,固化筛选器(arbitrarily shaped filter)是一种特殊的筛选器,它还内含筛选器本身所涉及的列之间的关系 。如果只处理这种筛选器,DAX 能顺利应对。但当你将它们与其他筛选器组合时,问题就出现了,如下图所示,这里我们使用上一幅图的筛选器过滤 AvgMonthlySales。
总数是错误的,显示的值不是正确的月平均值
如你所见,列的总计是错误的(你可以手动计算一下平均值以验证此结论)。在解决这个问题之前,我们需要更好地理解正在发生的事情。
本文隐藏内容查看价格为
5 G币,请先
登录 单独购买的内容长期有效,不受时间限制(购买前先刷新当前页面)。加入VIP会员可享受全站权益,性价比更高。
TOPN 筛选器的潜在风险
需要注意的是,用户可能会以许多不同的方式引入复杂筛选器,而且大多数情况下,他们并不会意识到这个问题。例如,在 Excel 的众多筛选选项中,包括一个“TOP N 筛选器”,该筛选器允许用户从值列表中选择前 N 个元素,并使用度量值对列表进行排序。
在下图中,你可以看到用户在透视表中选择了按 AvgMonthlySales 排序的前三个产品名称。
TOPN 过滤经常带来导致复杂筛选还原的复杂筛选器
因为年份位于行上,用户期望每年看到三个产品(前三个),而透视表显示了四个产品。原因是复杂筛选被还原改变了计算 AvgMonthlySales 的筛选器。
在这种情况下,存储在条件中的关系类似于取 TOPN 的操作(MDX 函数使用 TOPCOUNT,它对应于 DAX 中的 TOPN 函数)。这种操作每年检索一定数量的产品(仅检索给定年份的前三个产品)。它存储了年与产品之间的关系,这种关系被复杂筛选还原所破坏。
对于同一个透视表,如果你使用正确的 AvgMonthlySales 公式(加入 KEEPFILTERS 的公式),得到的就是预期的结果
使用 KEEPFILTERS,报告正确地显示了每年的三种产品
DAX 查询中的 KEEPFILTERS
最后值得注意的是,KEEPFILTERS 不仅在某些度量值中有用(正如我们已经演示的),而且在查询中也很有用。例如,查看以下查询:
EVALUATE
FILTER (
CALCULATETABLE (
ADDCOLUMNS (
CROSSJOIN (
VALUES ( 'Date'[Calendar Year] ),
VALUES ( 'Product'[Product Name] )
"Sales", [Sales Amount]
GENERATE (
VALUES ( 'Date'[Calendar Year] ),
TOPN (
VALUES ( 'Product'[Product Name] ),
[Sales Amount]
NOT (
ISBLANK ( [Sales] )
ORDER BY
'Date'[Calendar Year],
'Product'[Product Name]
你可能不希望编写这么复杂的查询,这里还有一种更好的写法,将 GENERATE 函数作为 ADDCOLUMNS 的参数,如下面的代码所示:
EVALUATE
FILTER (
CALCULATETABLE (
ADDCOLUMNS (
GENERATE (
VALUES ( 'Date'[Calendar Year] ),
TOPN (
VALUES ( 'Product'[Product Name] ),
[Sales Amount]
"Sales", [Sales Amount]
NOT (
ISBLANK ( [Sales] )
ORDER BY
'Date'[Calendar Year],
'Product'[Product Name]
然而,当使用代码生成器和其他自动化工具生成查询时,像之前那种更复杂的查询是非常常见的,因为它们清楚地将投影到行和投影到列上的筛选分开。在这种情况下,你可能会遇到复杂筛选还原 ,因为内层的 ADDCOLUMNS 所迭代的列,被作为 CALCULATE 筛选器参数的 GENERATE 进行了筛选。因此,查询不会检索每年排名前三的产品,而是检索了更多的产品列表。
在本例中,查询的正确写法如下:
EVALUATE
FILTER (
CALCULATETABLE (
ADDCOLUMNS (
KEEPFILTERS (
CROSSJOIN (
VALUES ( 'Date'[Calendar Year] ),
VALUES ( 'Product'[Product Name] )
"Sales", [Sales Amount]
GENERATE (
VALUES ( 'Date'[Calendar Year] ),
TOPN (
VALUES ( 'Product'[Product Name] ),
[Sales Amount]
NOT (
ISBLANK ( [Sales] )
ORDER BY
'Date'[Calendar Year],
'Product'[Product Name]
在这种情况下,KEEPFILTERS 必须在 CROSSJOIN 上操作,以便每年只检索由外层的 GENERATE 选择的前三个产品。需要注意的是,在这种特定的案例中,迭代不是在度量值中发生的,而是在 ADDCOLUMNS 中。
如果你注意观察,会发现使用 Power BI 快速度量值功能生成的公式大都包含 KEEPFILTERS,主要目的就是为了避免发生潜在的复杂筛选还原
本文隐藏内容查看价格为
5 G币,请先
登录 单独购买的内容长期有效,不受时间限制(购买前先刷新当前页面)。加入VIP会员可享受全站权益,性价比更高。









“你可能不希望编写这么复杂的查询,这里还有一种更好的写法,将 GENERATE 函数作为 ADDCOLUMNS 的参数,如下面的代码所示:”
1.老师这个例子的代码是避免固态筛选器被拆开的嘛,也就是不会产生 复杂筛选还原 对嘛?
2.在维度表中来自两个关系表的字段由于CROSSJOIN组合,但是同一个表中会(auto-exists)
如果例子中的:
年份:2007,2008
月份:1 月,2 月,11 月,12 月
来自同一张表,还会产生复杂筛选还原吗?