20世纪50年代中期
乔姆斯基(Chomsky)
提出的
形式语言
句法模式识别用小而简单的基元与语法规则描述和识别大而复杂的模式,通过对基元的识别,进而识别子模式,最终识别复杂模式
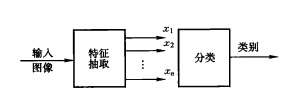
模式识别可以分成两种,一种称为统计方法(或几何法),另一种称为语言方法(或结构法)。统计方法:统计方法重要的是找出能反应图像特点的特征度量,把图像数据进行信息压缩,来抽取图像的特征,如果抽取N个特征能够基本描绘出原来的图像,那么图像就可以应用N维向量来代表。对图像分类就相当于把特征空间划分为若干部分,当输入一个图像时,就根据相应的特征向量属于特征空间的哪一部分而决定属于哪一类。如下图所示:...
各种自然语言处理和信息提取任务,例如问答和命名实体
识别
,都可以受益于有关单词
句法
类别或词性 (POS) 的精确知识(Church,1988 年;Rabiner,1989 年;Stolz,Tannenbaum , & Carstensen, 1965)。 词性标注器被广泛用于为文本数据中的每个单词分配一个最佳词性,随机方法的准确率高达 96% 到 97% (Jurafsky & Martin, 2000)。 在构建 POS 标注器时,人类需要对设计决策做出一系列选择,其中一些选择会显着影响最终引擎的准确性和其他性能方面。 但是,POS 标记器的文档通常会隐含这些选择和决定。 在本文中,我们
概述
了其中一些决策,并根据经验确定了它们对词性标注准确性的影响。 获得的见解对于想要设计、实施、修改、微调、集成或负责任地使用 POS 标记器的人来说可能是宝贵的贡献。 我们在将 POS 标记器构建和集成到 AutoMap(一种促进从文本中提取关系的工具)中考虑了本文中呈现的结果,作为独立特征以及其他任务的辅助特征。
我们有一个技术报告,说明我们的问答发电系统。
架构
概述
我们提出一种方法,该方法通常基于正在进行的工作的框架。 正式地,给了一段 ,问答系统( QAG )检索最重要的句子 从 。 然后, QAG系统生成一组问题-答案对 ,其中每个生成的 可以在 ,及其对 是...的疑问版本 或条款 从一组条款 在 , 没有 在里面。 如下图所示,这是我们的QAG系统中的四个主要模块。
预处理,清理输入通道 从不必要的字符中将其塑造成所需的形式(句子列表)。
句子选择, 最重要的句子 给定 。 可以在TextRank,多词短语提取(MWPE)和潜在语义分析(LSA)之间选择使用的文本摘要方法。 选择的方法将句子排在P中,然后选择顶部的 排名最高的句子作为输出。
间隙选择,用于选择中的短语 可以用作答案 基于
句法
解析器的组成树和命名实体
识别
(NER)。
1 基本概念
结构
模式
识别
: 以
结构
基元为基础,利用
模式
的
结构
信息完成分类的过程,称为
结构
模式
识别
。
基元: 构成
模式
结构
信息的基本单元,本身不包含有意义的
结构
信息。
结构
特征的表达:
(1)串表达:是把任意
结构
,用基元彼此连接形成一个序列进行描述。一维的;
(2)图表达:把
模式
的
结构
看成基元之间的相互连接,基元作为节点,基元与基元之间的链接作为边,
模式
结构
就可以用一个图来表达。图表达能力比串更强(图论),图的缺陷是两个图之间的相似性度量无论从定义上还是从算法上、工程实现上都是一个困难
什么是
模式
? 广义地说,存在于时间和空间中可观察的物体,如果我们可以区别它们是否相同或是否相似,都可以称之为
模式
。
模式
所指的不是事物本身,而是从事物获得的信息,因此,
模式
往往表现为具有时间和空间分布的信息。
模式
的直观特性:
·可观察性
·可区分性
·相似性
模式
识别
的概念
模式
识别
– 直观,无所不在,“人以类聚,物以群分”
·周围物体的认知
模式
和
模式
识别
的概念
模式
识别
的发展简史和应用
模式
识别
的主要方法
模式
识别
的系统和实例几个相关的数学概念
1、
模式
和
模式
识别
的概念
1.1 什么是
模式
(Pattern)?
广义地说,存在于时间和空间中可观察的事物,如果我们可以区别他们是否相同或是否相似,都可以称之为
模式
。
模式
所指的不是事物本身,而是从事物获得的信息,因此,
模式
往往表现为具有时间和空间分布的信息。
1、人工智能之
模式
识别
关于什么是人工智能,至今还缺少一个权威和统一的定义。但究其根本,始终是指机器能够达到人的智能水平,即:能够像人一样,可以感知外在的事物,并通过自主的思维过程做出有目的、有意义的响应。因此,可以说:人工智能包括了感知、决策和行动三个方面的能力,当然这三项能力的运用都是由机器自主完成的,而不受人类的直接控制。而
模式
识别
技术,正是实现人工智能感知能力的重要技术手段。
2、
模式
识别
的发展
模式
识别
与其他技术发展一样,也不是突然出现的,而是有其从初级到高...
前面介绍的所有思想都属于统计
模式
识别
,然而统计
模式
识别
存在2个问题:
1.有的
模式
结构
很复杂,不能用一个矢量来表示。
2.有的
模式
识别
任务中,我们更关心如何描述它的
结构
特征。
因此需要另外一种
模式
识别
:
结构
模式
识别
。
这其中,
句法
模式
识别
主要使用形式语言来描述
模式
结构
,在理论上完备,表1是
句法
模式
识别
与统计
模式
识别
的对应关系,下面做介绍。
串文法就是一种机器能
John-Theo是一个机器翻译服务提供商,他们的主打产品是Google Translate Server(谷歌翻译服务器)。
Google Translate Server是一个强大的在线翻译服务,提供多种语言之间的互译。它的能力和质量得益于谷歌强大的机器学习和人工智能技术。Google Translate Server基于大量的双语语料库,并使用先进的神经网络模型进行训练和优化。通过不断学习和改进,它能够
识别
和理解各种语言的语法、
句法
和语境。
使用Google Translate Server非常简便,用户只需输入待翻译文本,选择源语言和目标语言,点击翻译按钮即可获得快速的翻译结果。这个服务器不仅支持常见的语言如英语、法语、德语、西班牙语等,还覆盖了许多其他语言如中文、阿拉伯语、俄语、日语等。
Google Translate Server的应用非常广泛。它能够帮助人们在国际交流中消除语言障碍,促进不同国家和文化之间的交流与合作。它也是学习外语和翻译工作的有力助手,可以快速准确地翻译大量文本。
然而,尽管Google Translate Server在翻译的速度和准确度上取得了很大进展,但由于机器翻译的局限性,它仍然无法完全替代人工翻译。在某些情况下,特别是涉及到复杂的专业领域、俚语、文化特色等方面,Google Translate Server可能会出现一些错误或不准确的翻译结果。因此,在使用Google Translate Server时,我们仍然需要慎重对待翻译结果,并结合自己的语言能力和实际情况做出判断。
总的来说,John-Theo的Google Translate Server是一个功能强大、易用的在线翻译服务,可以帮助人们迅速获取翻译结果,解决跨语言交流的问题,但在一些特殊场景下仍然需要谨慎使用。