

Java线程栈分析 - CPU利用率持续升高
异常现象
某日接到业务同学反馈异常如下:
1.业务放量过程中,cpu持续升高,不清楚具体的原因
2.系统代码主要在等待下游返回结果,本地并没有复杂的处理逻辑
线程栈分析
业务同学保留了现场的jstack log(线程栈日志)。上传线程栈日志并通过ATP线程栈分析。打开 方法热度 视图,它会聚合出那一刻Java进程内所有线程调用方法的热度信息:
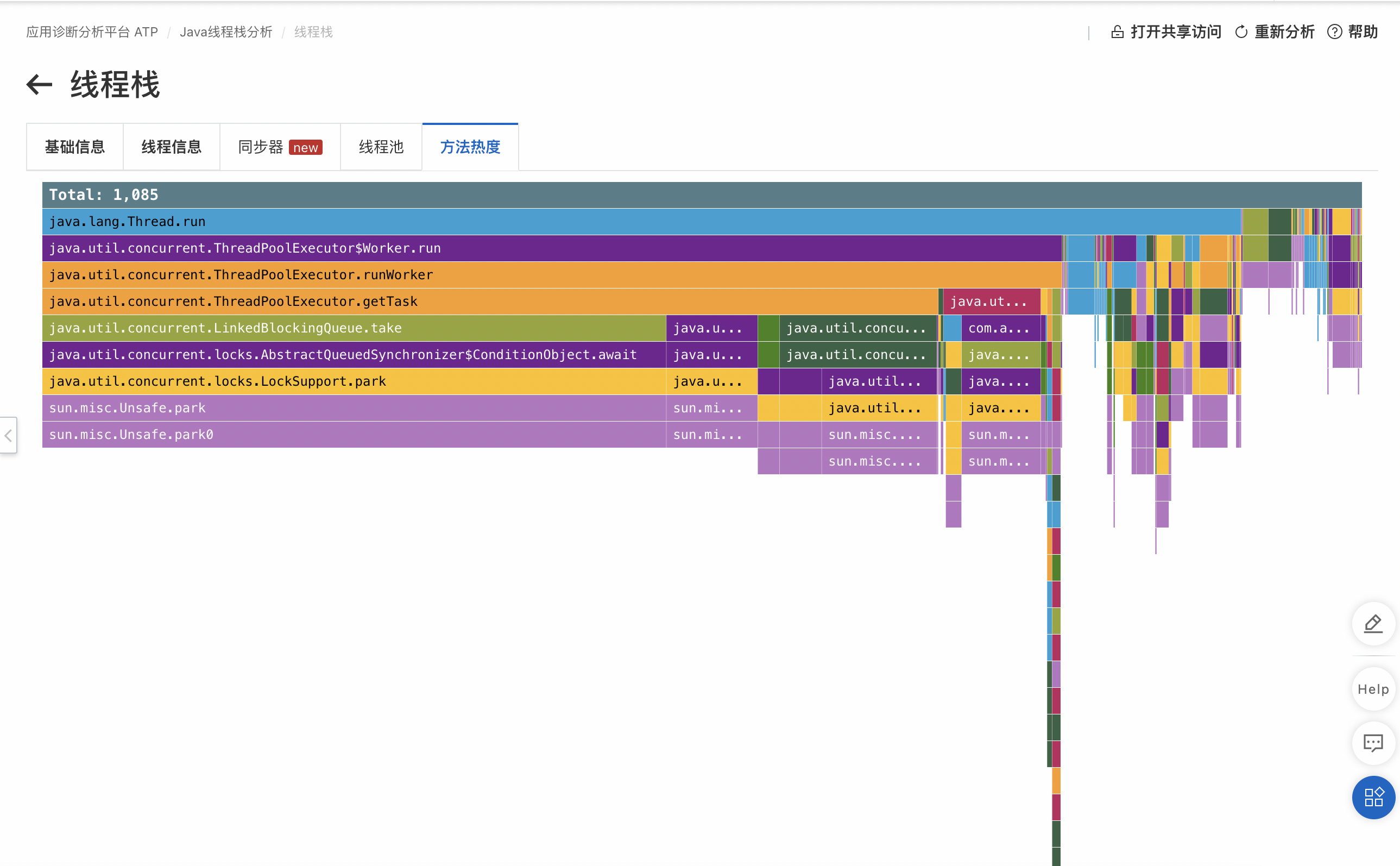 选择最热的方法(即最深的那条柱):
选择最热的方法(即最深的那条柱):
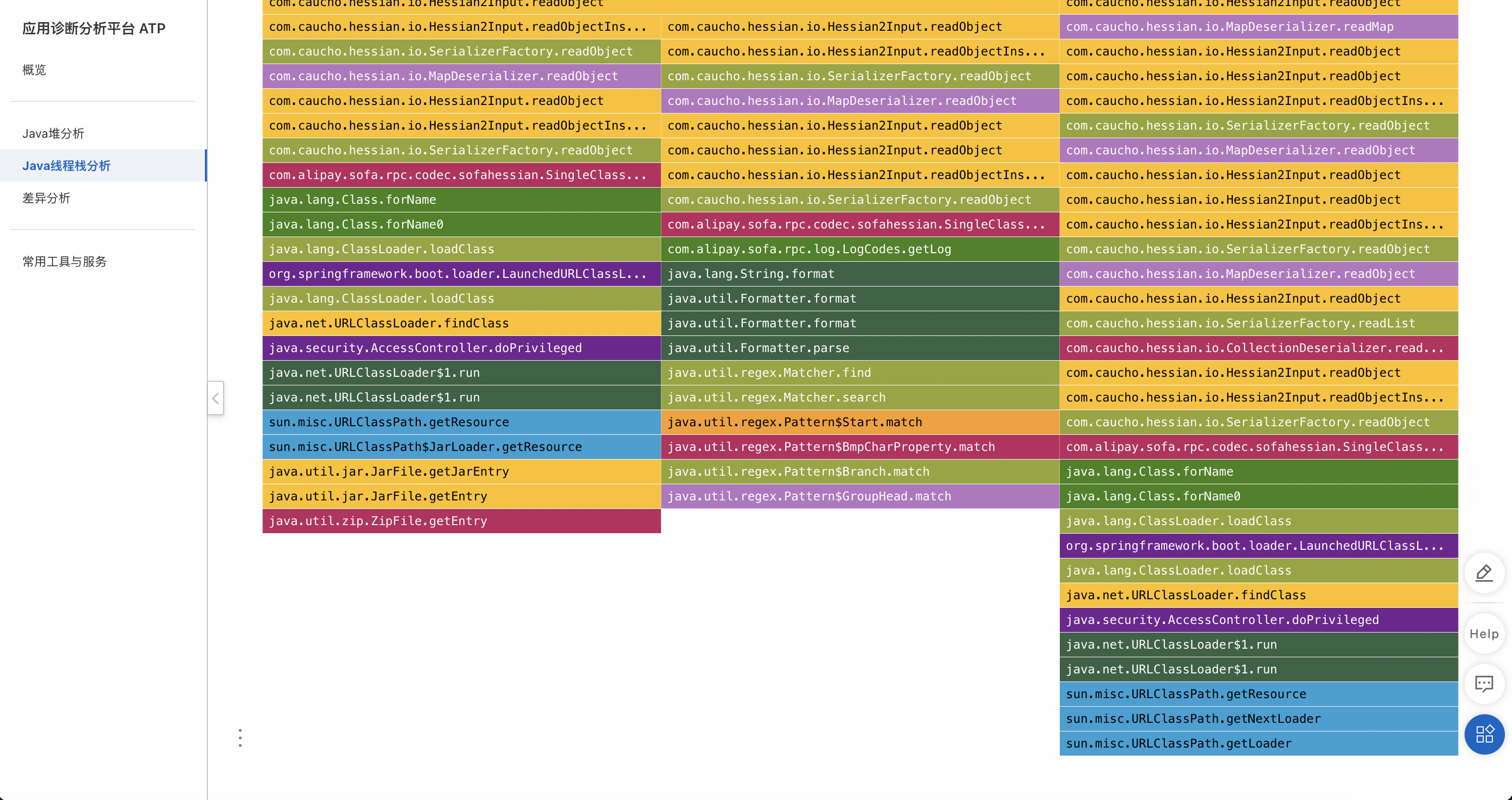
根据方法名可以看出最热的方法是反序列化,序列化过程中会使用URLClassLoader加载类:
Hessian2Input.readObject();
ClassLoader.loadClass();
URLClassLoader.loadClass();
URLClassPath.getResource();
URLClassPath.getNextLoader();
URLClassPath.getLoader();URLClassLoader里面有个ucp(URLClassPath),它记录了当前URLClassLoader类加载器加载了哪些jar包,在类加载过程中,它会遍历所有jar包,然后逐个打开jar包并查找里面是否存在期望的类。再结合业务同学的反馈,大概有500多个jar包,所以根据线程栈分析得出的初步猜测是: 在反序列化过程中遇到未加载的类,然后触发URLClassLoader从500多个jar包中遍历查找类,这个查找过程导致了CPU利用率持续升高。
根据上述的栈名称,我们从jstack log中找到对应线程:
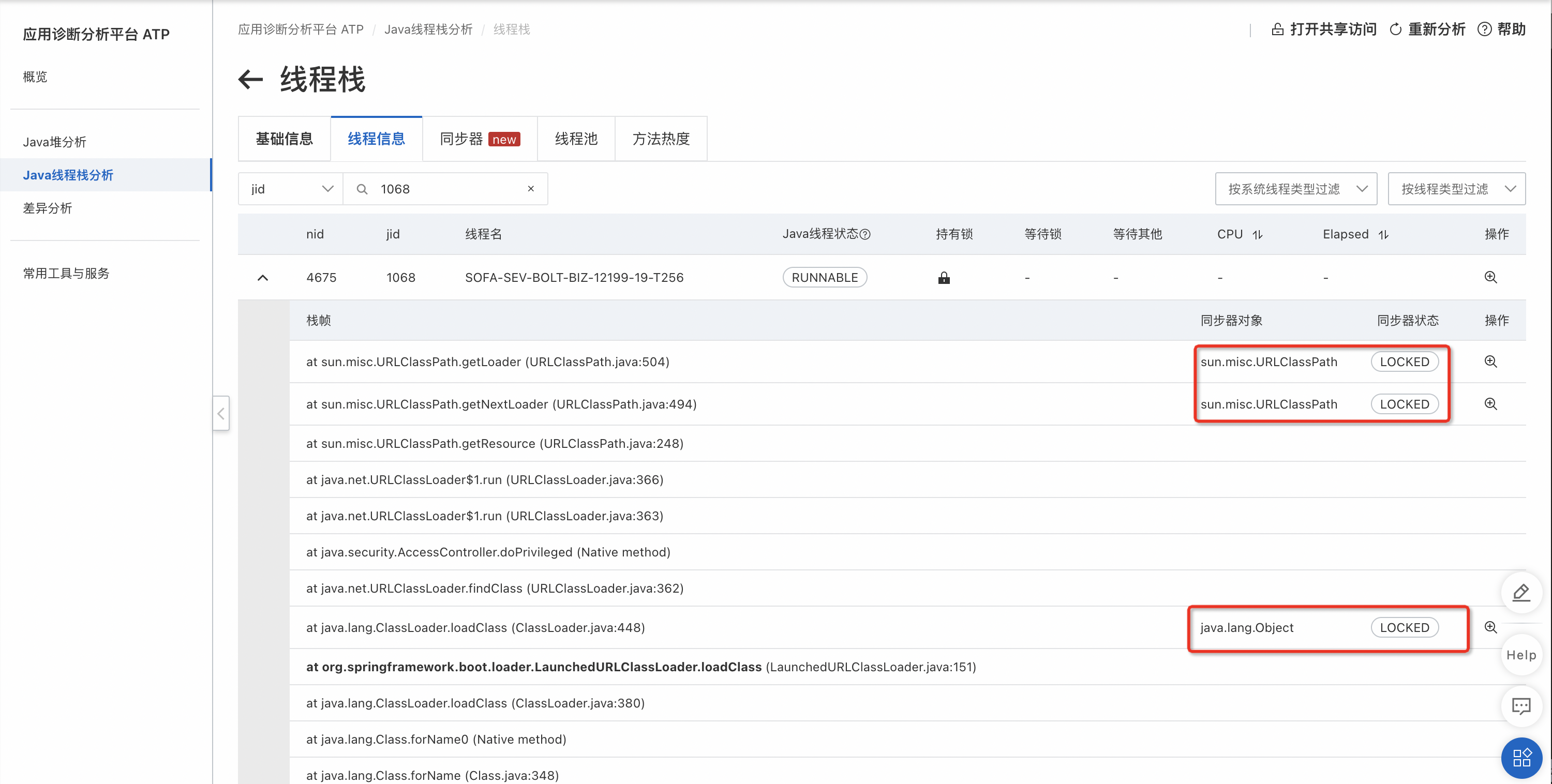
可以看到类加载过程中有三个地方加锁了,查看这些锁:
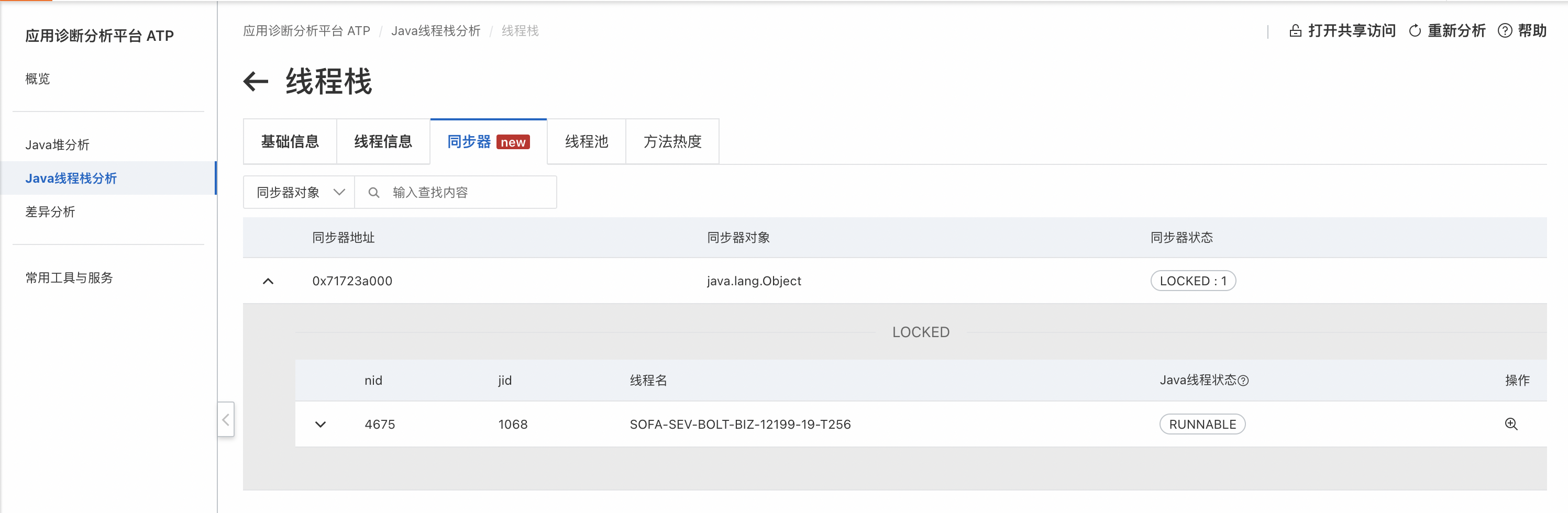
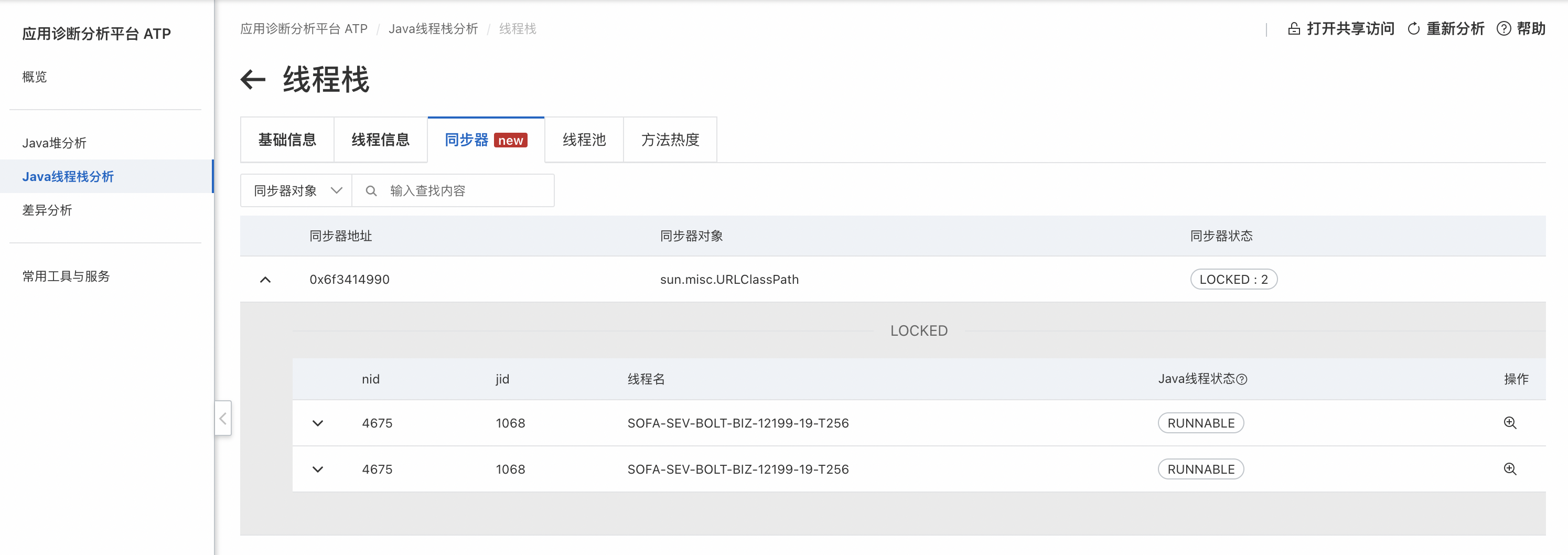
会发现实际上有两把锁,其中一个被递归加锁,更重要的是锁的持有者都是1068线程,另外没有其他线程在等待该锁,说明锁没有竞争,类查找过程仅1068一个线程在进行。
分析结论
所以我们可以更进一步得知,只有一个线程在执行高频的jar包遍历寻找类操作。根据这个猜测的结论,只要类找到,或者说反序列化结束,CPU利用率就应该会下降。和业务同学反馈后得知,序列化在持续进行。这也顺便验证了我们的猜测,因为只有反序列化在持续进行,CPU利用率才会持续上涨。
将这个猜测反馈给业务同学,他们从日志中发现,确实是因为有个类一直找不到,然后每次都在反序列化的时候再重新找,找不到也只会打个日志。到此,分析基本就结束了,剩下的工作是业务同学优化代码,解决该类找不到的问题。
