关于如何训练你的BME688传感器的完整指南
各位科技爱好者,大家好!博世发布了
BME688
,一个令人敬畏的新传感器,可以分辨出多达四种不同的气味。本指南将解释教你的BME688如何区分气味的所有细节。如果你是人工智能或Python的新手,请不要担心。本指南适合于初学者。
所以,让我们直接跳到前面。
BME688分线板
或
博世BME688气体传感器开发套件
产生所需气味的标本
一个密闭的容器来放置传感器和标本
博世的BSEC和AI工作室
选择你的应用
1.选择你的应用程序
第一步是选择你的应用。在本指南中,我将使用肉类和奶酪作为例子。但是有无穷无尽的可能性。你可以区分水果和蔬菜,或者清洁剂和香水。你也可以尝试确定食物何时变坏。
在选择应用程序时,有一些事情你应该考虑。你需要为你想区分的每一类提供许多标本,以确保算法变得强大。开始时,你应该选择一些便宜的、可广泛使用的东西。还要记住,最好使用正常空气作为其中一个类别,因为它几乎总是存在的。
为了创建一个强大的算法,你应该对每个标本使用至少半小时的测量数据。因此,能产生恒定香味的标本是一个很好的选择。还要确保使用范围广泛的标本。例如,如果你只用橙子、柠檬和酸橙作为水果类,传感器可能无法将覆盆子归类为水果,因为它与你用于训练的标本差别太大。使用的不同标本越多越好。
一旦你确定了你的选择,就该创建一个新的AI Studio项目了。打开AI Studio并按下
创建项目...
按钮。按下
配置BME板
如果你想用一个特定的配置来记录数据。
2.记录数据
这个过程是不同的,取决于你是否使用了
BME688分线板
或
博世BME688气体传感器开发套件
(进一步的穿梭板)。穿梭板更容易使用,捕获数据的速度将比突破板快八倍,但它的价格要高得多。我将在下面的章节中详细解释这两种方法。
请注意。
BME688传感器需要一些时间来适应环境和烧制。确保在记录训练数据之前让它运行至少24小时。
用BME688梭子板记录数据
BOSCH为穿梭板配备了8个BME688传感器,因此它在相同的时间内产生了8倍的数据。所有的软件都已安装,开箱即用。观看
博世的这个视频教程
以了解测量过程。
如果你在一次会议上记录了许多标本,你可能想记下标本的顺序,以避免混淆。你可以在以后的AI Studio中随时裁剪数据,所以不要害怕捕捉大量的数据。
用BME688分线板记录数据
如果你在使用
BME688分线板
我仍然建议你观看
博世教程
因为它提供了一些关于AI Studio的训练过程的有用信息。但是为了记录训练数据,还需要一些额外的步骤。
我们在
pi3g
为BME68X传感器创建了一个Python库,你可以用它来升级
博世BSEC 2.0
.因此,如果你有一些python的经验是有帮助的,但这不是必须的。
请注意。
请直接在我们的网站上查看安装和使用说明。
GitHub
.
首先克隆我们的
bme68x-python-library
.这可以通过在bash终端执行以下命令来完成。
git clone https://github.com/pi3g/bme68x-python-library.git
现在你需要构建和安装bme68x python模块。该
BSEC 2.0
是专利软件,所以你需要直接从博世下载2.0.6.1版本,并同意他们的许可。将其解压到bme68x-python-library文件夹中,然后执行这些命令。
cd path/to/bme68x-python-library
sudo python3 setup.py install
现在你可以运行
bmerawdata.py
脚本的默认设置。
cd tools/bmerawdata
python3 bmerawdata.py
脚本将在每次测量后显示记录的数据。终止脚本并将数据保存在AI Studio兼容的文件中,按
Ctrl+c
.
3.训练该算法
无论你是否在使用
BME688分线板
或
博世BME688气体传感器开发套件
,下一步是将数据导入AI Studio。按下
进口数据
按钮并选择你的.bmerawdata文件。
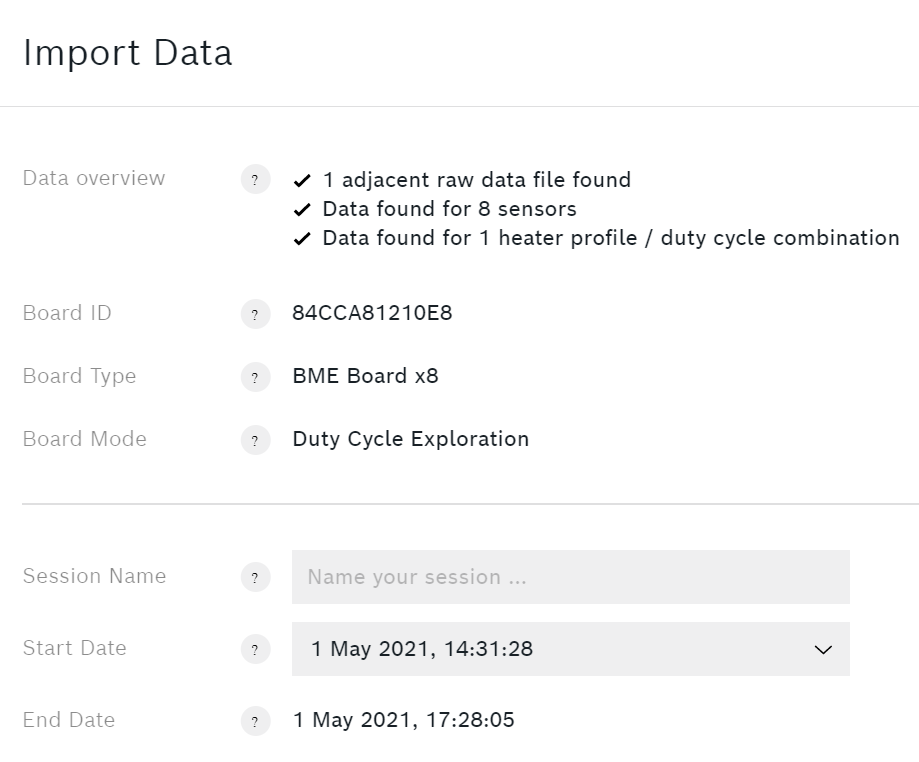 导入数据对话框
导入数据对话框
你的会议需要一个有意义的名字。选择一个列举的标本是合适的。
你可以看到你的数据图表,例如气体数据通道的图表,如下图所示。
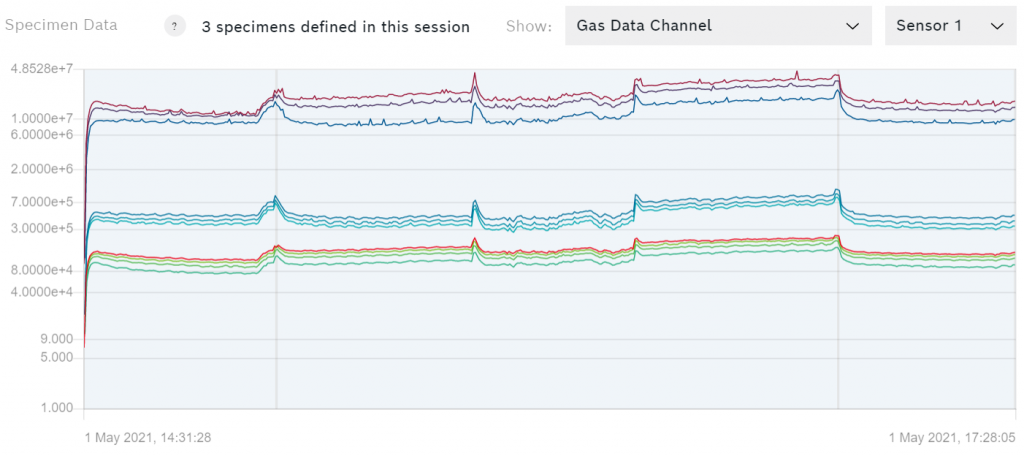 气体数据通道
气体数据通道
如果数据来自梭子板,你可以在八个传感器的数据之间切换。每一条彩色的线代表了用来捕捉数据的加热器曲线的一个步骤。
请注意。
在大多数情况下,你应该只使用气体数据通道进行训练。
现在我们需要给我们的标本贴上标签。如果你用梭子板记录了数据,并使用板上的按钮来标记标本,你已经能够看到每个标本的模板了。你也可以裁剪标本并创建新的标本(例如,如果你用我们的突破板记录了多个标本)。
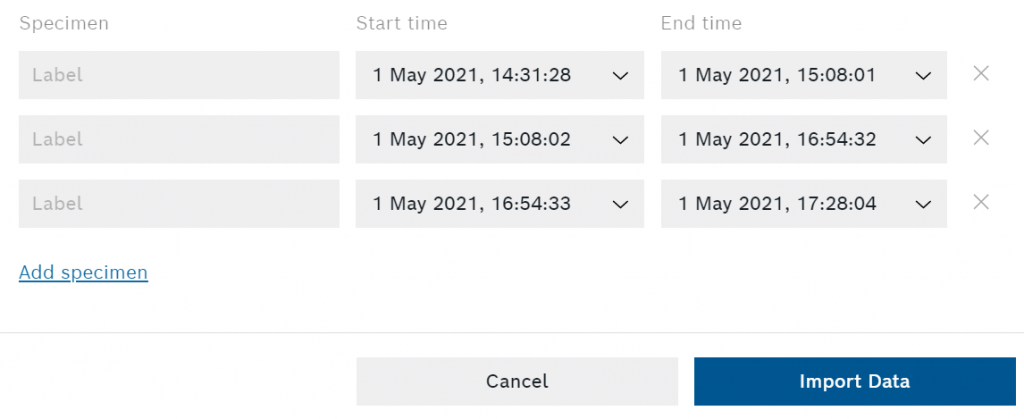 标本标签和时间戳
标本标签和时间戳
在你完成编辑会话后,按
进口数据
按钮,在对话框的右下角。
一旦你导入并标记了所有的标本,就是创建和训练算法的时候了。
选择
我的算法
在顶部点击
+ 新算法
.给你的算法起个名字,代表它应该做什么,在我的例子中
芝士蛋糕(AirMeatCheese
.然后添加类。我把我的类称为NormalAir、Meat和Cheese。选择哪些标本属于哪个类,并为每个类选择一种颜色。
 命名你的算法
命名你的算法
 编辑你的班级
编辑你的班级
要添加或删除标本,你可以点击其中一个类别。下面是一个例子,说明
肉类
类看起来像。
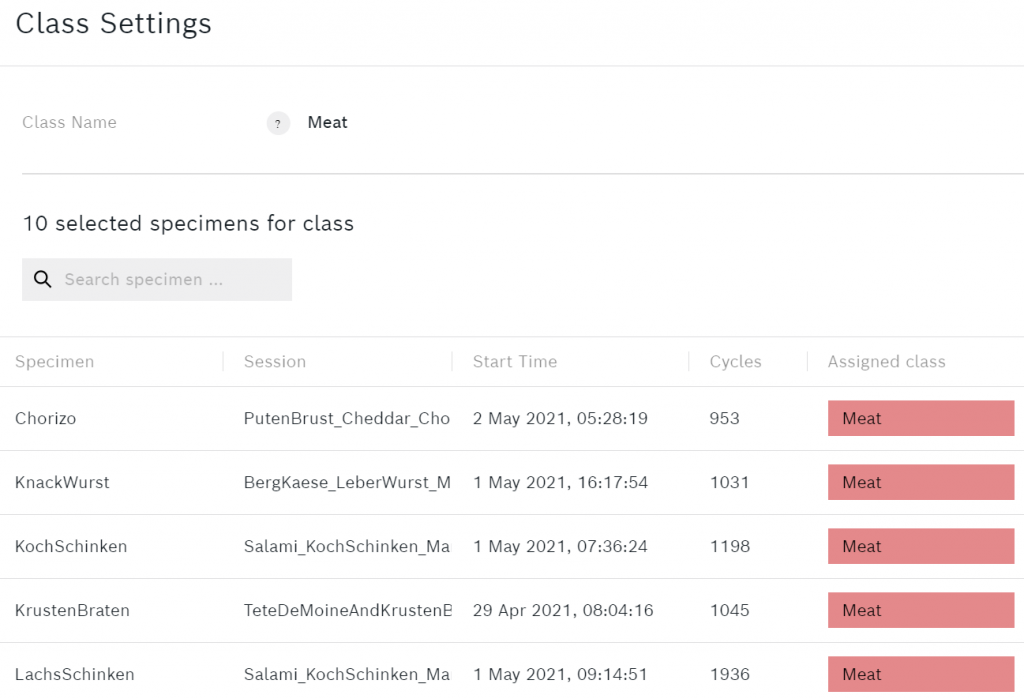 肉类的观点
肉类的观点
在类的下面,你可以看到一些关于算法的额外数据。
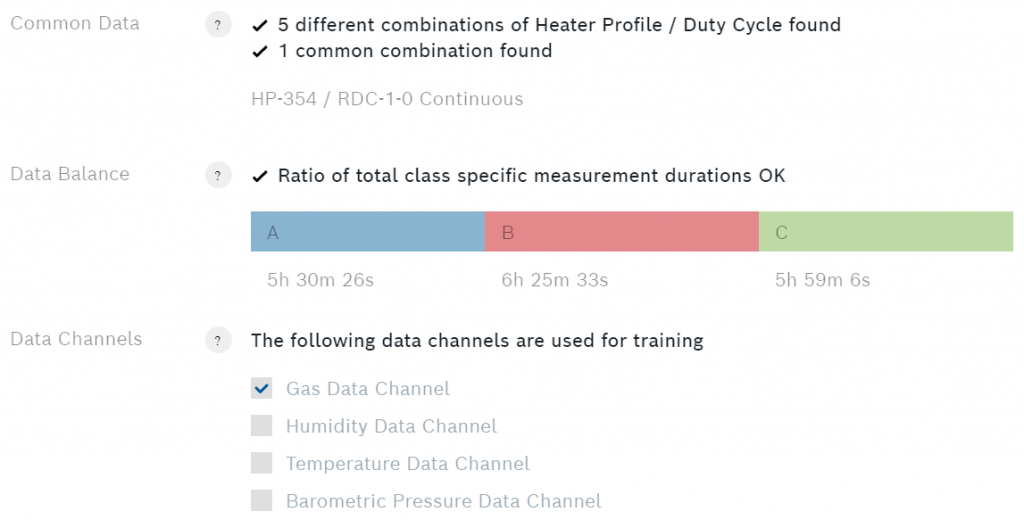 额外的算法数据
额外的算法数据
数据平衡显示了每个类别的总测量时间。为了确保最佳性能,每个类别的测量时间应该是相等的。如果其中一个类的测量时间远远大于此,你可能会遇到算法对该类的偏见。还要注意每个标题前面的问号按钮。按下它可以获得更详细的信息。
请注意。
请务必查看BME688 AI Studio文档以了解更多信息。
在数据通道下,您可以选择四个传感器输出中哪一个用于您的算法。我建议只使用气体数据通道,因为其他通道主要取决于环境而不是样本。一旦你设置好了一切,就可以进行训练了。
培训和出口
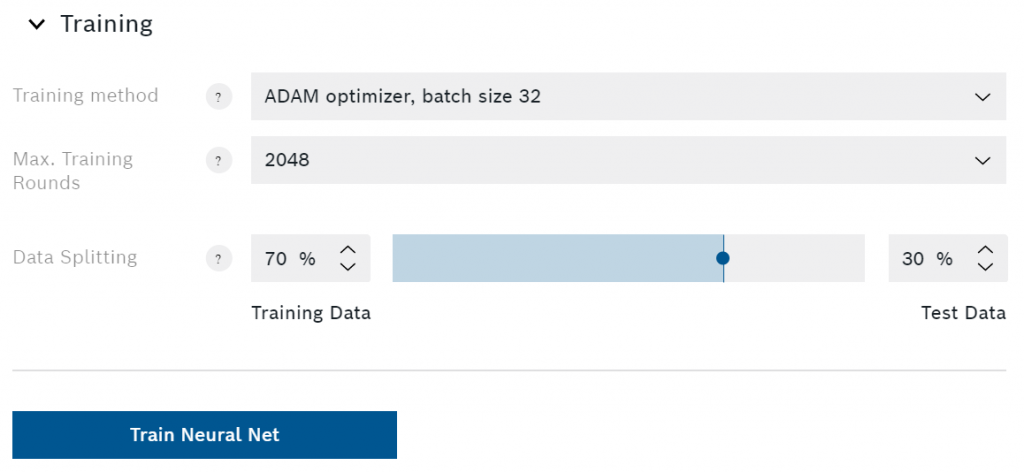 训练你的算法
训练你的算法
在这里你可以选择训练方法、最大轮数和数据分割。如果你是神经网络的新手,你应该把一切都保持在默认设置。不过,我将尝试对这些设置进行简单的解释。
在我写这篇文章时,唯一可用的训练方法是ADAM优化器。这是一种寻找误差函数最小值的具体方法(误差越小意味着预测越准确)。你可以选择不同的批次大小来提高训练速度和稳定性。
增加最大的训练轮次是提高算法性能的另一种方法。对于每一轮(通常被称为epoch),AI Studio将整个训练数据集送入神经网络中。这意味着更多的最大回合数将增加训练算法的时间。大多数时候,AI Studio会检测是否达到了最小值,并在达到最大轮数之前完成训练。这就减少了训练时间,避免了过度拟合。
过度拟合意味着神经网络对训练数据进行了过多的调整。如果该算法在训练中的准确率非常高,但在实际测试中的表现却很差,你可能想减少最大训练回合。
数据分割设置允许你选择多少记录的数据被用于训练,多少被用于测试。你应该避免将超过三分之一的数据用于测试。顾名思义,该算法将只使用训练数据进行训练。训练结束后,AI Studio将使用测试数据对算法进行评估,因为它以前从未见过这些数据。
新闻
训练神经网络
来开始训练。你会看到估计的剩余训练时间和准确度和损失的线图。
在每个历时中,准确度和验证准确度应该提高,而损失和验证损失应该减少。等到训练结束。
训练完成后,检查混淆矩阵。它包含关于训练结果的重要信息。最有趣的统计数字是准确率,但如果你的训练数据分布不均,那么F1得分可能是一个更好的指标。
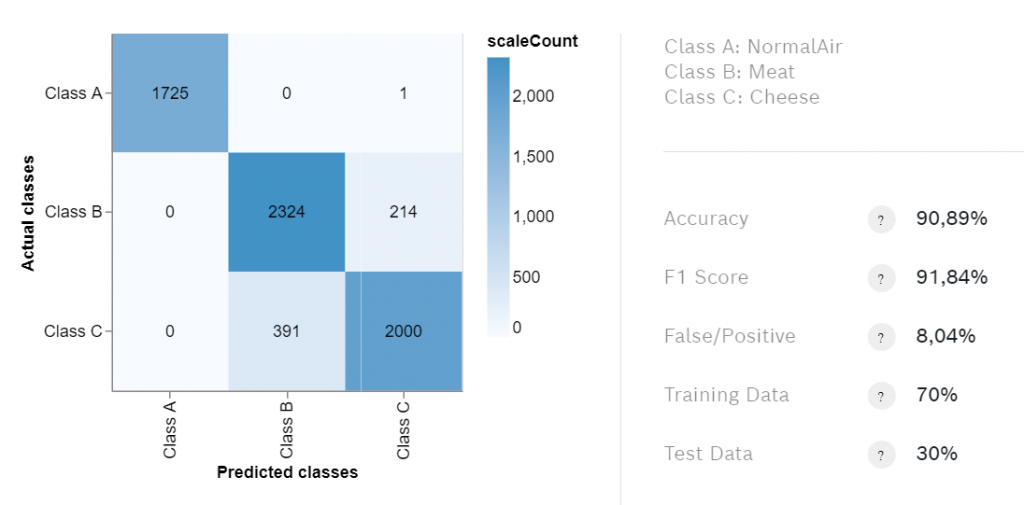 混淆矩阵和训练结果
混淆矩阵和训练结果
你很少会达到超过90%的准确度,所以如果准确度高于80%,你应该导出算法来测试。我们将用我们的检测气味的
码头
网络界面。请确保导出BSEC 2.0.6.1版本的算法,因为
码头
到目前为止只支持这个版本。
请注意。
在大多数情况下,培训将在达到预计期限之前完成。
4.检测气味
要检测气味,只需安装
码头
客户端,并将其连接到你的账户。如果你没有
码头
然而,只需免费注册,并按照那里的指示进行操作。我们的数字鼻子应用程序允许你上传你训练的算法,并通过网络界面看到实时预测。请看
数字鼻帮助
以获得关于如何使用该应用程序的完整解释。
另一种检测气味的方法是通过使用我们的
BME68X Python扩展
.这需要一些python编码,但提供更多的控制,并允许你使用你的算法创建自己的应用程序。请参考
README.md
,在
文档.md
和
例子
文件夹,以了解如何安装和使用该扩展。
所以你有了它。你现在应该能够记录数据,训练你的算法并检测气味。如果你觉得本指南有用,或者在遵循本指南时遇到任何麻烦,请让我知道。
请与我联系:
[email protected]
对我来说,训练算法并不奏效。相反,软件显示错误 "算法不能被训练。训练数据或测试数据似乎都丢失了。"。然而,我已经用BME688分线板为我的每个班级采集了大约一小时的数据。你知道我可能做错了什么吗?
。
[......]上,例如温湿度传感器,或者也许是使用 DHT22 或 BME688 的空气质量项目,或者是使用光[......]的亮度传感器。
。
[...]教您的 BME688 如何闻气味[...]

