


爬取豆瓣top250电影表单
需求分析
爬虫是获取数据一种方式,能够按照一定规则自动抓取某个网站或者万维网信息的程序;现实环境中很大一部分网络访问都是由爬虫造成的;我们来看一个常见应用场景:
当我们使用百度或者其他搜索引擎搜索某个关键字的时候,搜索结果中会包含对应的内容,比如:搜索Python,搜索结果可能包括Python官网,Python相关文章等,可是这些信息分布在不同的网站,这些搜索引擎是如何知道这些信息与相对应的地址呢?也许是搜索引擎获取网站相关数据及对应的地址;python的官网应该不可能主动把相应数据给这些搜索引擎公司,那么这些数据是如何获取的呢?最可能的答案,搜索引擎公司按照一定的规则将这些网站的信息抓取下来,保存到本地,然后对数据进行清洗处理,这些数据是搜索网站的基础,而获取数据过程就是爬虫所做的事情。
根据爬取方式不同我们可以将爬虫分为两类:
我使用Python完成批量型爬虫的设计与实现,并对抓取数据进行清洗与分析,为什么选择Python?
当前比较火的语言之一,语法简单,容易上手,支持面向对象,丰富的第三方模块:
基于这些模块,快速的构建爬虫,抓取数据,并且对抓取的数据进行分析及可视化。
需求:
1、爬取豆瓣电影top250
2、获取电影名称、年份、评分、导演、编剧、主演、类型、国家、语言、时长等
3、将爬取的数据保存
4、对数据进行清洗,对错误数据在源码或数据中进行处理
5、进行数据分析及可视化
环境搭建
数据爬取
1. 准备工作
url:
https://movie.douban.com/top250
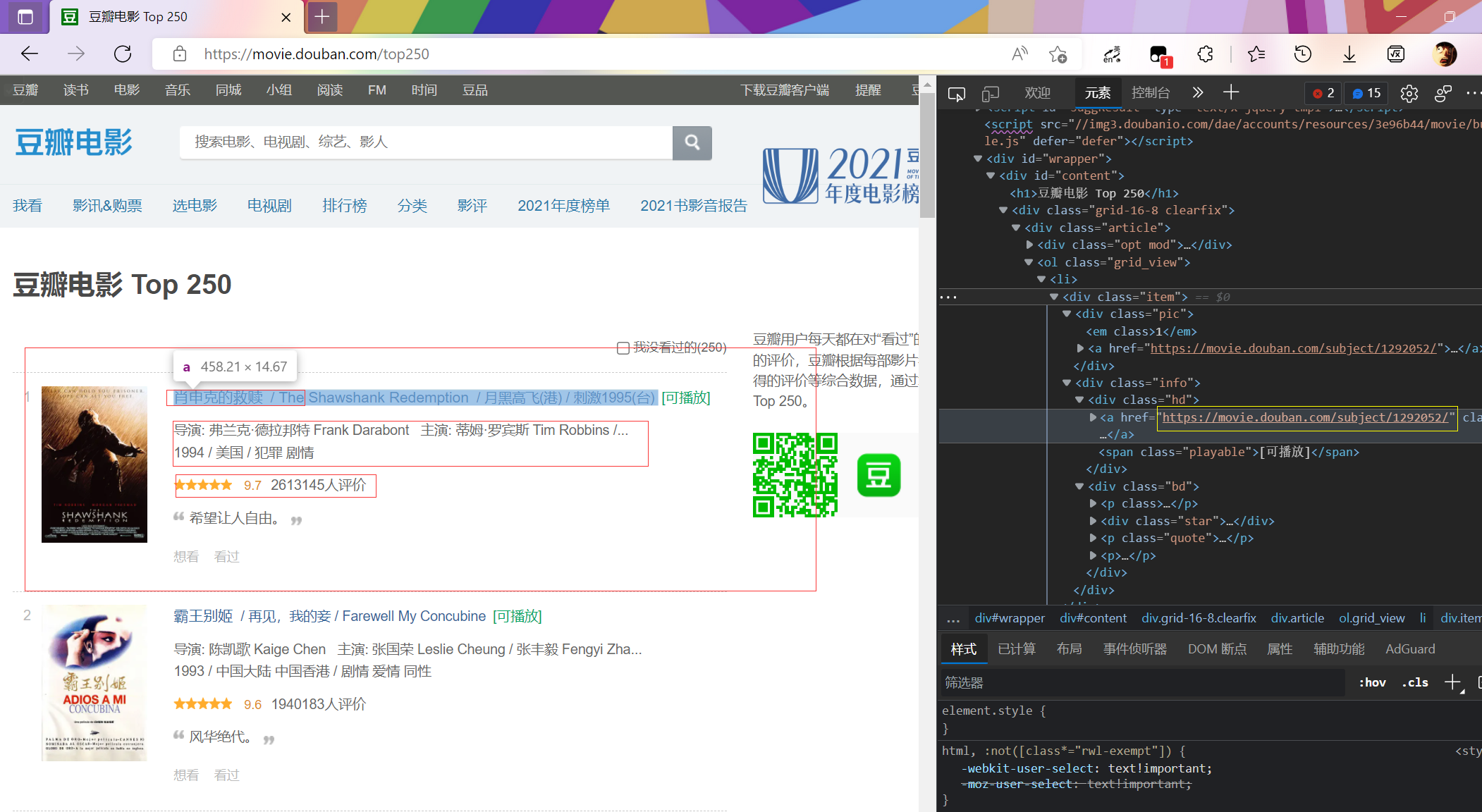
可以看到,在榜单上的信息较少,每个电影详细的信息需要进入链接到详细页面查看。
因此我们需要获取每个电影的详细页url.
以下为获取子页面url代码:
import requests |
['https://movie.douban.com/subject/1292052/', 'https://movie.douban.com/subject/1291546/', 'https://movie.douban.com/subject/1292720/', 'https://movie.douban.com/subject/1292722/', 'https://movie.douban.com/subject/1295644/', 'https://movie.douban.com/subject/1292063/', 'https://movie.douban.com/subject/1291561/', 'https://movie.douban.com/subject/1295124/', 'https://movie.douban.com/subject/3541415/', 'https://movie.douban.com/subject/3011091/', 'https://movie.douban.com/subject/1889243/', 'https://movie.douban.com/subject/1292064/', 'https://movie.douban.com/subject/1292001/', 'https://movie.douban.com/subject/3793023/', 'https://movie.douban.com/subject/2131459/', 'https://movie.douban.com/subject/1291549/', 'https://movie.douban.com/subject/1307914/', 'https://movie.douban.com/subject/25662329/', 'https://movie.douban.com/subject/1292213/', 'https://movie.douban.com/subject/5912992/', 'https://movie.douban.com/subject/1296141/', 'https://movie.douban.com/subject/1291841/', 'https://movie.douban.com/subject/1849031/', 'https://movie.douban.com/subject/6786002/', 'https://movie.douban.com/subject/3319755/'] |
可以看到我们只获得了一部分
需要修改start的值获取下一页的内容
以下,重构方法类,获取全部url
page_url = [] |
['https://movie.douban.com/subject/1292052/', ......, 'https://movie.douban.com/subject/2297265/'] |
可以看到所以子页面url都爬取出来了
2.子页面信息提取
子页面分析
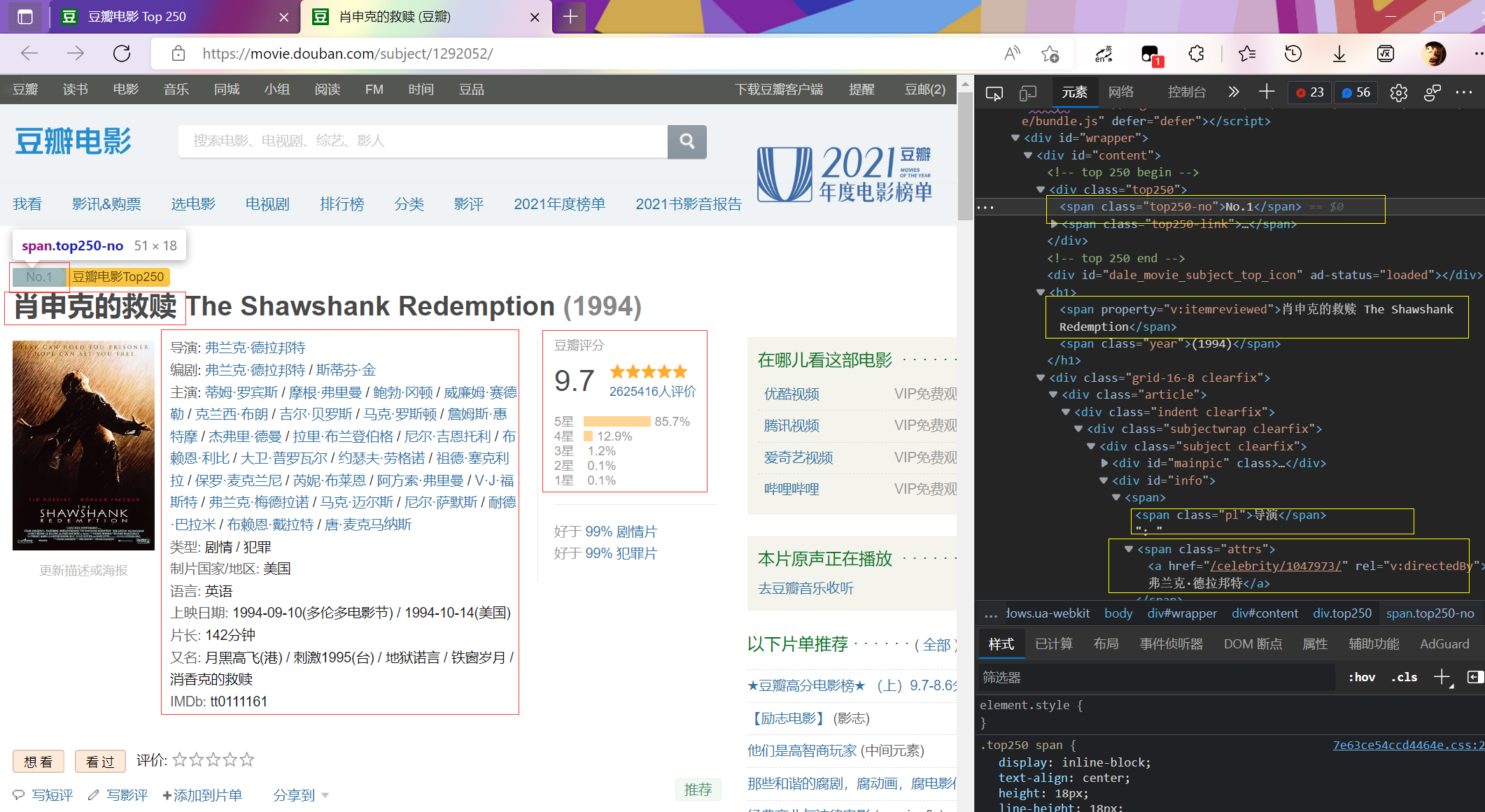
为了方便后面采用的是jupyter实时输出方便修改代码。
from bs4 import BeautifulSoup |
清洗和预处理
有的电影子页面的索引项不同,比如7.千与千寻中出现了官方网站,导致数据出现错位。
同样的问题还存在于216.二十二中,此部为纪录片,没有演员等内容。
修改代码加上循环
两页面的与普通页面不同点:
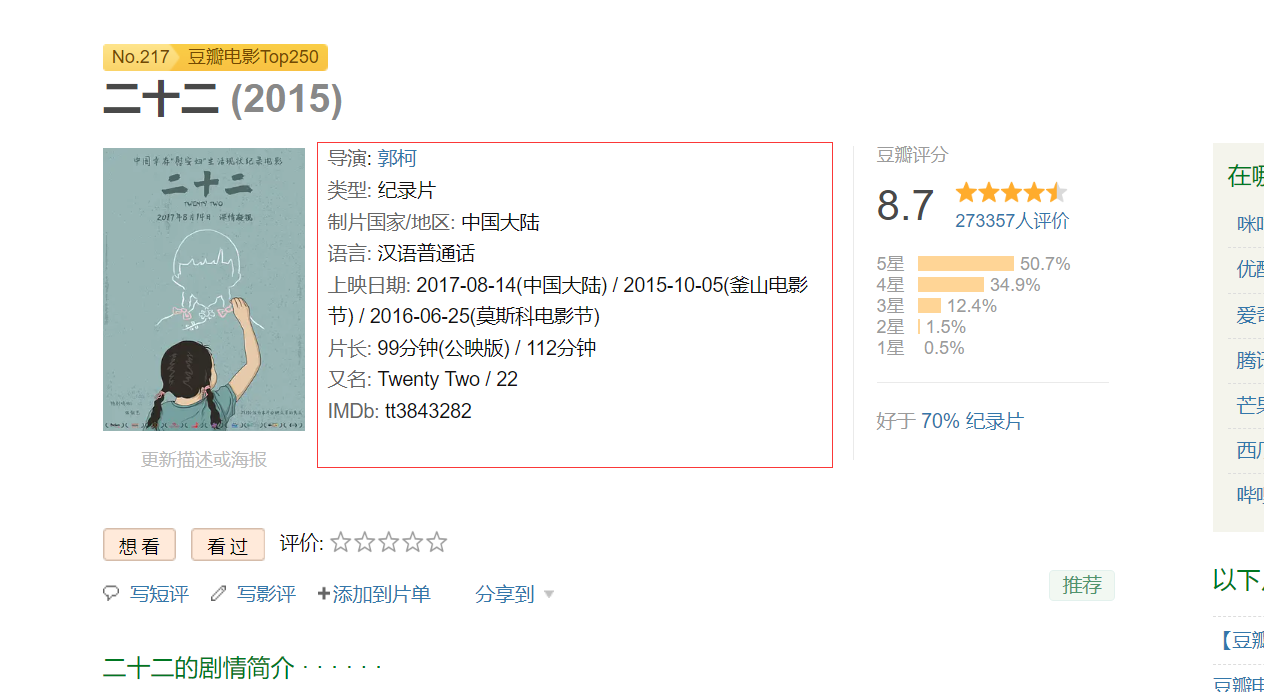
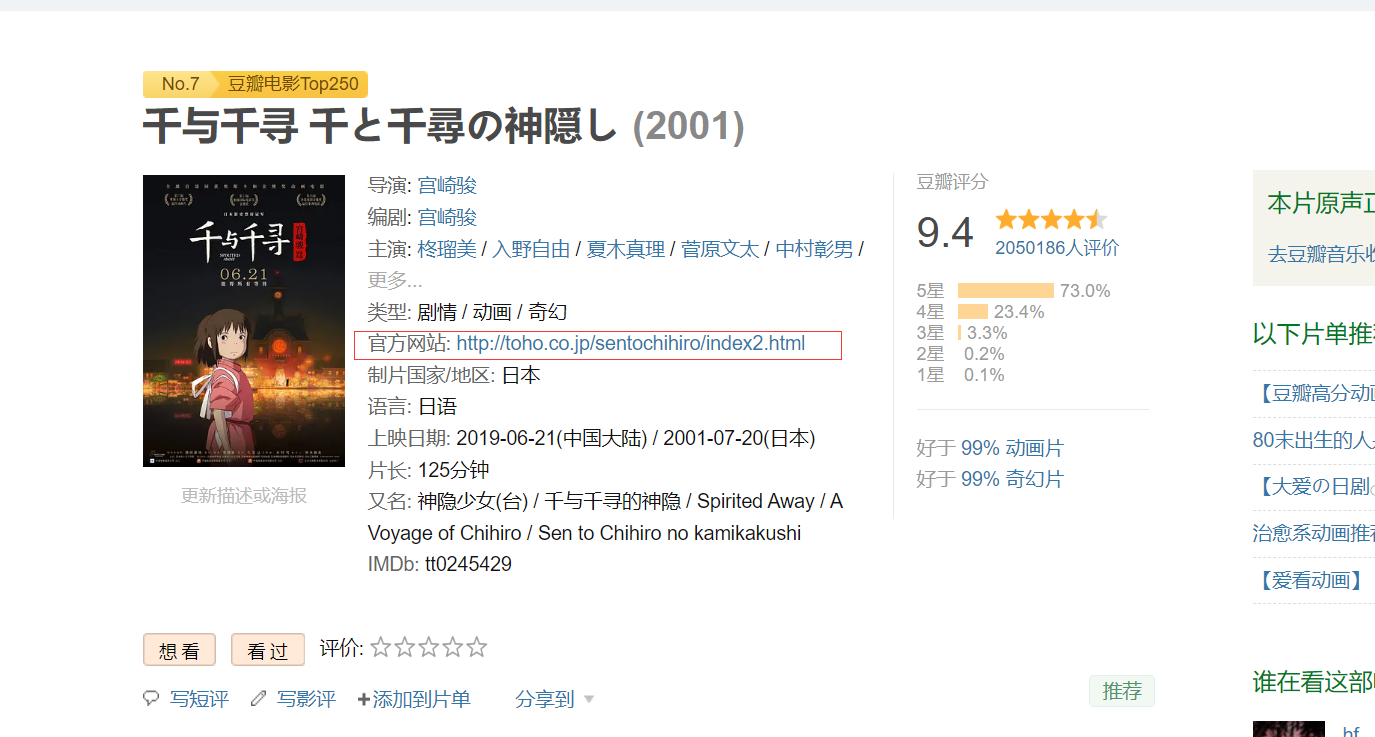
head=['rank','film_name','director','scriptwriter','actor','filmtype','area','language','initialReleaseDate','runtime','rating_num','stars5_rating_per','rating_people'] |
加入线程池加快爬取速度
if __name__ == '__main__': |