范例4: 统计bonus表
以上几个操作函数,在表中没有数据的时候,只有count()函数会返回结果,其他都是null
我们知道表bonus是没有任何数据的,可以看到里边有四个字段👇:

那么我们做如下尝试👇:
select count(*) 人数,avg(sal) 员工平均工资,sum(sal) 每月总支出,
max(sal) 最高工资, min(sal) 最低工资
from bonus;

可以清楚的发现,此时只有count()函数会返回最终的结果。即使没有数据也会返回0,而其他的函数统计的结果都是null
实际上针对于count()函数有三种使用形式:
※ count(*): 可以准确的返回表中的全部记录数
※ count(字段): 统计不为null 的所有数据量
※ count(distinct 字段): 消除重复数据之后的结果
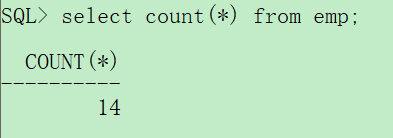
首先来回忆一下emp表中有14条记录

范例5: 统计查询一
select count(*),count(empno)
from emp;

那么comm字段是有null的,同样是可以查询出来的
select count(*),count(empno),count(comm)
from emp;

然后job的值是有相同的职位的,可以用distinct字段👇:
select count(distinct job)
from emp;
什么情况下可能分组?
例如:部门之间进行拔河比赛,那么分组的依据:部门,每个雇员都有相同的部门编号;
例如:上厕所,男女各一边,实际上这也是一个分组。
那么也就证明一点:分组的前提是存在有重复。但是允许单独一行记录进行分组。
如果要想进行分组则应该使用group by子句完成,那么此时的SQL语法结构变为如下形式👇:
【④选出所需要的数据列】select [distinct] * | 分组列 [别名],分组列 [别名],分组列 [别名]…
【①确定数据来源(行与列的集合)】from 表名称 [别名],表名称 [别名]…
【②筛选数据行】[where 限定条件(s)]
【③针对于筛选的行分组】[group by 分组字段,分组字段,分组字段…]
【⑤数据排序】[order by 排序字段 [ASC | DESC],排序字段 [ASC | DESC],…]
范例1: 根据部门编号分组,查询每个部门的编号、人数、平均工资
select deptno,count(*),avg(sal)
from emp
group by deptno;
范例2: 根据职位分组,统计出每个职位的人数,最低工资与最高工资
select job,count(*),min(sal),max(sal)
from emp
group by job;

实际上group by子句之所有麻烦,是因为分组的时候有一些约定条件:
※ 如果查询不使用group by子句,那么select的子句中只允许出现统计函数,其他任何字段不允许出现
| 错误的代码 | 正确的代码 |
|---|
select empno,count(*) from emp;
 | select count(*) from emp;
 |
※如果查询中使用了group by子句,select子句中只允许出现分组字段、统计函数,其他任何字段都不允许出现
| 错误的代码 | 正确的代码 |
|---|
select ename,job,count(*) from emp group by job;
 | select job,count(*) from emp group by job;
 |
※ 统计函数允许嵌套,但是嵌套之后的select子句里面只允许出现嵌套函数,而不允许出现任何字段,包括分组字段。
| 错误的代码 | 正确的代码 |
|---|
select deptno,max(avg(sal)) from emp group by deptno;
 | select max(avg(sal)) from emp group by deptno;
 |
其实第三种方式的原理就是首先如果先用**select deptno,avg(sal) from emp group by deptno;**语句查询出来的是一张表了

然后接着从查询的这张表再次使用统计函数查询出平均工资最高的,即语句select max(avg(sal)) from emp group by deptno; 此时就回到了第一个概念,此时查询平均工资最高的的这个表不需要在进行分组了,直接查就好了,所以是不允许再出现任何字段,包括第一步的分组字段deptno
下一篇👉Oracle-----多表查询与分组统计&having子句&分组案例
本篇博客到这就完啦,非常感谢您的阅读🙏,如果对您有帮助,可以帮忙点个赞或者来波关注鼓励一下喔😬 ,嘿嘿👀
上一篇????:Oracle-----SQL-1999语法&数据集合操作文章目录????大家好!我是近视的脚踏实地,这篇文章主要是来学习Oracle的统计函数 唯有行动 才能解除你所有的不安 ...
当我们刚开始学Oracle时,见到group by,常常会来个三连问:为什么要用group by?group by应该怎么用?为什么写了group by运行时会提示“不是单组分组函数;不符合group by语法”?面对这些问题,我都胆战心惊了(怎么可能)。接下来我将把group by的心经要诀传授给你们,是不是很激动鸭,那就拿起你们的小本本记下来吧(收藏点赞+关注哦)。
何为group by
gr...
(2) 练习标准SQL的数据操作,查询命令及其查询优化。
(3) 学会使用高级SQL命令,排序、分组、自连接查询等。
(4) 学会使用SQL*PLUS命令显示报表,存储到文件等。
【实验内容】
一、 准备使用SQL*PLUS
1. 进入SQL*PLUS
2. 退出SQL*PLUS
3. 显示表结构命令DESCRIBE
SQL>DESCRIBE emp
使用DESCRIBE(缩写DESC)可以列出指定表的基本结构,包括各字段的字段名以及类型、长度、是否非空等信息。
4. 使用SQL*PLUS显示数据库中EMP表的内容
输入下面的查询语句:
SQL>SELECT * FROM emp;
按下回车键执行查询
5. 执行命令文件
START或@命令将指定文件调入SQL缓冲区中,并执行文件内容。
SQL>@ 文件名(文件后缀缺省为.SQL)或
SQL>START 文件名
文件中每条SQL语句顺序装入缓冲区并执行。
二、 数据库命令——有关表、视图等的操作
1. 创建表employee
例1 定义一个人事信息管理系统中存放职工基本信息的一张表。可输入如下命令:
SQL>CREATE TABLE employee
(empno number(6) PRIMARY KEY, /* 职工编号
name varchar2(10) NOT NULL, /* 姓名
deptno number(2) DEFAULT 10, /* 部门号
salary number(7,2) CHECK(salarycreate table emp2 as
select * from emp
where 1=2;
在命令的where子句中给出1=2,表示条件不可能成立,因而只能复制表结构,而不能复制任何数据到新表中去。另外,还可以复制一个表的部分列定义或部分列定义及其数据。
三、 Oracle数据库数据查询
1、单表查询
2、多表查询
四、 SQL*PLUS常用命令
表1 常用报表格式化名命令
命令 定义
Btitle 为报表的每一页设置底端标题
Column 设置列的标题和格式
Compute 让SQL*PLUS计算各种值
Remark 将某些字标记为注释
Set linesize 设置报表的行宽字符数
Set newpage 设置报表各页之间的行数
Spool 使SQL*PLUS将输出写入文件中
Start 使SQL*PLUS执行一个sql文件
Ttitle 设置报表每页的头标题
Break 让SQL*PLUS进行分组操作
例3 建立一个批命令文件对查询到的数据以报表的形式输出并将其保存到指定的文件中。
处理方法:利用SQL*PLUS语言工具(也可以使用其他文本编辑器)建立批命令的.SQL文件。在“SQL>”提示符下,使用EDIT命令在”E:\”中建立SCGB.SQL文件。
SCGB.SQL文件中的命令组如下:
SQL>EDIT E:\ SCGB.SQL
SET echo off
SET pagesize 30
SET linesize 75
TTITLE’2008年4月10号’CE’公司职员基本情况登记表’R’Page:’ FORMAT 99-
>SQL.PNO SKIP 1 CE’===========================’
BTITLE COL 60 ’制标单位’ TAB 3 ‘人事部’
COLUMN empno heading ‘职工|编号’
COLUMN ename format a10 heading ‘姓 名’
COLUMN job heading ‘工 种’
COLUMN sal format $99,990 heading 工 资’
COLUMN comm Like sal heading ‘奖 金’
COLUMN deptno format 9999 heading ‘部门|编号’
COLUMN hiredate heading ‘参加工作时间’
SPOOL e:\sjbb /*在E盘中建立格式报表输出文件,默认属性为LST BREAK on deptno skip 1
COMPUTE sum of sal comm on deptno
SELECT empno,ename,job,hiredate,sal,comm,deptno from emp
ORDER BY deptno,sal;
SPOOL off /*终止SPOOL功能,关闭其文件。注意,此命令不可省,否则将建立空文件。
五、 实验内容
1、以cs+学号为用户名创建用户,并授予用户创建数据对象的权限。
2、复制emp表,复制表名为emp_学号,然后将emp表中工资低于$2000
的职工插入到复制的表中。
3、对复制的emp表插入一行只包含有职工号,职工名,工资与部门号四个数据
项值的记录。
4、在复制的emp表中将雇员ALLEN提升为经理,工资增至$2500,
奖(佣 )金增加40%。
5、删除复制的emp表中工资低于500的记录行。
6、列出10号部门中既不是经理,也不是秘书的职工的所有信息。
7、查找出部门所在地是CHICAGO的部门的职工姓名、工资和工种。
8、统计各部门中各工种的人数、工资总和及奖金总和。
9、查找出工资比其所在部门平均工资高的职工姓名、工种与工资情况。
实验3 Oracle数据库开发环境下PL/SQL编程
【实验目的】
(1)掌握 PL/SQL 的基本使用方法。
(2)在SQL*PLUS环境下运行PL/SQL的简单程序。
(3)应用 PL/SQL 解决实际问题
【实验内容与步骤】
PL/SQL块中的可执行部分是由一系列语句组成的(包括对数据库进行操作的SQL语句,PL/SQL语言的各种流程控制语句等)。在块中对数据库查询,增、删、改等对数据的操作是由SQL命令完成的。在PL/SQL块中,可以使用SQL的数据查询命令,数据操纵命令和事务控制命令。可使用全部SQL函数。PL/SQL中的SQL语句,可使用SQL的比较操作等运算符。但不能使用数据定义语句。
在PL/SQL块中使用SELECT语句时注意几点:
(1)SELECT语句必须含有INTO子句。
(2)INTO子句后的变量个数和位置及数据类型必须和SELECT命令后的字段名表相同。
(3)INTO子句后可以是简单类型变量或组合类型变量。
(4)SELECT语句中的WHERE条件可以包含PL/SQL块中定义的变量及表达式,但变量名不要同数据库表列名相同。
(5)在未使用显式游标的情况下,使用SELECT语句必须保证只有一条记录返回,否则会产生异常情况。
[例3-1] 问题:编写一个过程,求和运算。
SET SERVEROUTPUT ON;
DECLARE
a number:=1;
BEGIN
a:=a+5;
DBMS_OUTPUT.PUT_LINE('和为:'||TO_CHAR(a));
【例3-2】:使用%TYPE声明变量,输出制定表中的相关信息。
DECLARE
my_name student.sname%TYPE;
BEGIN
SELECT sname INTO my_name FROM student
WHERE no=’01203001’;
DBMS_OUTPUT.PUT_LINE(my_name);
【例3-3】问题:编写一个过程,可以输入一个雇员名,如果该雇员的工资低于2000,就给该员工工资增加10%。
declare
v_sal emp.sal%type;
begin
select sal into v_sal from emp where ename=spName;
if v_sal :NEW.sal THEN
DBMS_OUTPUT.PUT_LINE('工资减少');
ELSIF :OLD.sal < :NEW.sal THEN
DBMS_OUTPUT.PUT_LINE('工资增加');
DBMS_OUTPUT.PUT_LINE('工资未作任何变动');
END IF;
DBMS_OUTPUT.PUT_LINE('更新前工资 :' || :OLD.sal);
DBMS_OUTPUT.PUT_LINE('更新后工资 :' || :NEW.sal);
--执行UPDATE查看效果
UPDATE emp SET sal = 3000 WHERE empno = '7788';
6、需要对在表上进行DML操作的用户进行安全检查,看是否具有合适的特权。
Create table foo(a number);
Create trigger biud_foo
Before insert or update or delete
On foo
Begin
If user not in (‘DONNY’) then
Raise_application_error(-20001, ‘You don’t have access to modify this table.’);
End if;
即使SYS,SYSTEM用户也不能修改foo表。
2、 利用PL/SQL编写程序实现下列触发器
1)、编写一个数据库触发器,当任何时候某个部门从dept表中删除时,该触发器将从emp表中删除该部门的所有雇员。(要求:emp表、dept表均为复制后的表)
2)、创建一个触发器,当客户下完订单后,自动统计该订单的所有图书的价格总额。
3)、创建一个触发器,禁止客户在非工作时间(早上8:00前,晚上17:00后)下订单。
五、实验心得
原书名: Pro Oracle SQL
原出版社: Apress
作者: (美)Karen Morton Kerry Osborne Robyn Sands Riyaj Shamsudeen Jared Still
译者: 朱浩波
丛书名: 图灵程序设计丛书
出版社:人民邮电出版社
ISBN:9787115266149
上架时间:2011-11-9
出版日期:2011 年11月
开本:16开
页码:502
版次:1-1
资深Oracle专家力作,OakTable团队推荐
全面、独到、翔实,题材丰富
Oracle开发人员和DBA必备
Oracle 数据库中的SQL是当今市场上功能最强大的SQL实现之一,而本书全面展示了这一工具的威力。如何才能让更多人有效地学习和掌握SQL呢?Karen Morton及其团队在本书中提供了专业的方案:先掌握语言特性,再学习Oracle为提升语言效率而加入的支持特性,进而将两者综合考虑并在工作中加以应用。作者通过总结各自多年的软件开发和教学培训经验,与大家分享了掌握Oracle SQL所独有的丰富功能的技巧所在,内容涵盖SQL执行、联结、集合、分析函数、子句、事务处理等多个方面。读者可以学习到以下几个方面的技巧:
掌握Oracle数据库中独有的SQL强大特征;
读取并理解SQL执行计划;
快速分析并改进表现欠佳的SQL;
通过提示及配置文件等来控制执行计划;
在程序中优化查询而无需改动代码。
作为Oracle SQL经典著作之一,本书为SQL开发人员指明了前行的方向,赋予了他们不断开拓的动力。
KAREN MORTON 研究人员、教育家及顾问,Fidelity信息服务公司的资深数据库管理员和性能调优专家。她从20世纪90年代初就开始使用Oracle,从事 Oracle的教学工作也已经超过10年的时间。她是Oracle ACE,也是OakTable(Oracle社区中著名的“Oracle科学家”的非正式组织)的成员,经常在技术会议上演讲。她的著作还包括 Expert Oracle Practices和Beginning Oracle SQL,博客主页是karenmorton.blogspot.com。
KERRY OSBORNE 专注于Oracle咨询的Enkitec公司的创始人之一。从1982年开始使用Oracle(第2版)。他当过开发人员,也做过DBA,目前是 Oracle ACE总监和OakTable成员。最近几年,他专注于研究Oracle内部原理以及解决性能问题。他的博客主页是 kerryosborne.oracle-guy.com。
ROBYN SANDS 思科公司的软件工程师,为思科的客户设计开发嵌入式Oracle数据库产品。从1996年开始使用Oracle,在应用开发、大型系统实现以及性能评估方面具有丰富的经验。她是OakTable的成员,同时是Expert Oracle Practices (2010年 Apress出版)一书的合著者。
RIYAJ SHAMSUDEEN 专注于性能/数据恢复/电子商务的咨询公司OraInternals的首席数据库管理员和董事长。有近20年使用Oracle技术产品以及Oracle数据库管理员/Oracle数据库应用管理员的经验,是真正应用集群、性能调优以及数据库内部属性方面的专家。同时是一位演讲家及Oracle ACE。
JARED STILL 从1994年就开始使用Oracle。他认为对于SQL的学习是永无止境的,相信每一个查询Oracle数据库的人都需要精通SQL语言,才能写出高效的查询。他参与本书的编写就是为了帮助别人实现这一目标。
封面 -11
封底 -10
扉页 -9
版权 -8
版权声明 -7
致谢 -6
目录 -5
第1章 SQL核心 1
1.1 SQL语言 1
1.2 数据库的接口 2
1.3 SQL*Plus 回顾 3
1.3.1 连接到数据库 3
1.3.2 配置SQL*Plus环境 4
1.3.3 执行命令 6
1.4 5 个核心的SQL语句 8
1.5 SELECT语句 8
1.5.1 FROM子句 9
1.5.2 WHERE子句 11
1.5.3 GROUP BY子句 11
1.5.4 HAVING子句 12
1.5.5 SELECT列表 12
1.5.6 ORDERBY子句 13
1.6 INSERT语句 14
1.6.1 单表插入 14
1.6.2 多表插入 15
1.7 UPDATE语句 17
1.8 DELETE语句 20
1.9 MERGE语句 22
1.10 小结 24
第2章 SQL执行 25
2.1 Oracle架构基础 25
2.2 SGA-共享池 27
2.3 库高速缓存 28
2.4 完全相同的语句 29
2.5 SGA-缓冲区缓存 32
2.6 查询转换 35
2.7 视图合并 36
2.8 子查询解嵌套 39
2.9 谓语前推 42
2.10 使用物化视图进行查询重写 44
2.11 确定执行计划 46
2.12 执行计划并取得数据行 50
2.13 SQL执行——总览 52
2.14 小结 53
第3章 访问和联结方法 55
3.1 全扫描访问方法 55
3.1.1 如何选择全扫描操作 56
3.1.2 全扫描与舍弃 59
3.1.3 全扫描与多块读取 60
3.1.4 全扫描与高水位线 60
3.2 索引扫描访问方法 65
3.2.1 索引结构 66
3.2.2 索引扫描类型 68
3.2.3 索引唯一扫描 71
3.2.4 索引范围扫描 72
3.2.5 索引全扫描 74
3.2.6 索引跳跃扫描 77
3.2.7 索引快速全扫描 79
3.3 联结方法 80
3.3.1 嵌套循环联结 81
3.3.2 排序-合并联结 83
3.3.3 散列联结 84
3.3.4 笛卡儿联结 87
3.3.5 外联结 88
3.4 小结 94
第4章 SQL是关于集合的 95
4.1 以面向集合的思维方式来思考 95
4.1.1 从面向过程转变为基于集合的思维方式 96
4.1.2 面向过程vs.基于集合的思维方式:一个例子 100
4.2 集合运算 102
4.2.1 UNION和UNION ALL 103
4.2.2 MINUS 106
4.2.3 INTERSECT 107
4.3 集合与空值 108
4.3.1 空值与非直观结果 108
4.3.2 集合运算中的空值行为 110
4.3.3 空值与GROUP BY和ORDER BY 112
4.3.4 空值与聚合函数 114
4.4 小结 114
第5章 关于问题 116
5.1 问出好的问题 116
5.2 提问的目的 117
5.3 问题的种类 117
5.4 关于问题的问题 119
5.5 关于数据的问题 121
5.6 建立逻辑表达式 126
5.7 小结 136
第6章 SQL执行计划 137
6.1 解释计划 137
6.1.1 使用解释计划 137
6.1.2 理解解释计划可能达不到目的的方式 143
6.1.3 阅读计划 146
6.2 执行计划 148
6.2.1 查看最近生成的SQL语句 149
6.2.2 查看相关执行计划 149
6.2.3 收集执行计划统计信息 151
6.2.4 标识SQL语句以便以后取回计划 153
6.2.5 深入理解DBMS_XPLAN的细节 156
6.2.6 使用计划信息来解决问题 161
6.3 小结 169
第7章 高级分组 170
7.1 基本的GROUP BY用法 171
7.2 HAVING子句 174
7.3 GROUP BY的“新”功能 175
7.4 GROUP BY的CUBE扩展 175
7.5 CUBE的实际应用 179
7.6 通过GROUPING()函数排除空值 185
7.7 用GROUPING()来扩展报告 186
7.8 使用GROUPING_ID()来扩展报告 187
7.9 GROUPING SETS与ROLLUP() 191
7.10 GROUP BY局限性 193
7.11 小结 196
第8章 分析函数 197
8.1 示例数据 197
8.2 分析函数剖析 198
8.3 函数列表 199
8.4 聚合函数 200
8.4.1 跨越整个分区的聚合函数 201
8.4.2 细粒度窗口声明 201
8.4.3 默认窗口声明 202
8.5 Lead和Lag 202
8.5.1 语法和排序 202
8.5.2 例1:从前一行中返回一个值 203
8.5.3 理解数据行的位移 204
8.5.4 例2:从下一行中返回一个值 204
8.6 First_value和Last_value 205
8.6.1 例子:使用First_value来计算最大值 206
8.6.2 例子:使用Last_value来计算最小值 207
8.7 其他分析函数 207
8.7.1 Nth_value(11gR2) 207
8.7.2 Rank 209
8.7.3 Dense_rank 210
8.7.4 Row_number 211
8.7.5 Ratio_to_report 211
8.7.6 Percent_rank 212
8.7.7 Percentile_cont 213
8.7.8 Percentile_disc 215
8.7.9 NTILE 215
8.7.10 Stddev 216
8.7.11 Listagg 217
8.8 性能调优 218
8.8.1 执行计划 218
8.8.2 谓语 219
8.8.3 索引 220
8.9 高级话题 221
8.9.1 动态SQL 221
8.9.2 嵌套分析函数 222
8.9.3 并行 223
8.9.4 PGA大小 224
8.10 组织行为 224
8.11 小结 224
第9章 Model子句 225
9.1 电子表格 225
9.2 通过Model子句进行跨行引用 226
9.2.1 示例数据 226
9.2.2 剖析Model子句 227
9.2.3 规则 228
9.3 位置和符号引用 229
9.3.1 位置标记 229
9.3.2 符号标记 230
9.3.3 FOR循环 231
9.4 返回更新后的行 232
9.5 求解顺序 233
9.5.1 行求解顺序 233
9.5.2 规则求解顺序 235
9.6 聚合 237
9.7 迭代 237
9.7.1 一个例子 238
9.7.2 PRESENTV与空值 239
9.8 查找表 240
9.9 空值 242
9.10 使用Model子句进行性能调优 243
9.10.1 执行计划 243
9.10.2 谓语前推 246
9.10.3 物化视图 247
9.10.4 并行 249
9.10.5 Model子句执行中的分区 250
9.10.6 索引 251
9.11 子查询因子化 252
9.12 小结 253
第10章 子查询因子化 254
10.1 标准用法 254
10.2 SQL优化 257
10.2.1 测试执行计划 257
10.2.2 跨多个执行的测试 260
10.2.3 测试查询改变的影响 263
10.2.4 寻找其他优化机会 266
10.2.5 将子查询因子化应用到PL/SQL中 270
10.3 递归子查询 273
10.3.1 一个CONNECT BY的例子 274
10.3.2 使用RSF的例子 275
10.3.3 RSF的限制条件 276
10.3.4 与CONNECT BY的不同点 276
10.4 复制CONNECT BY的功能 277
10.4.1 LEVEL伪列 278
10.4.2 SYS_CONNECT_BY_PATH函数 279
10.4.3 CONNECT_BY_ROOT运算符 281
10.4.4 CONNECT_BY_ISCYCLE伪列和NOCYCLE参数 284
10.4.5 CONNECT_BY_ISLEAF伪列 287
10.5 小结 291
第11章 半联结和反联结 292
11.1 半联结 292
11.2 半联结执行计划 300
11.3 控制半联结执行计划 305
11.3.1 使用提示控制半联结执行计划 305
11.3.2 在实例级控制半联结执行计划 308
11.4 半联结限制条件 310
11.5 半联结必要条件 312
11.6 反联结 312
11.7 反联结执行计划 317
11.8 控制反联结执行计划 326
11.8.1 使用提示控制反联结执行计划 326
11.8.2 在实例级控制反联结执行计划 327
11.9 反联结限制条件 330
11.10 反联结必要条件 333
11.11 小结 333
第12章 索引 334
12.1 理解索引 335
12.1.1 什么时候使用索引 335
12.1.2 列的选择 337
12.1.3 空值问题 338
12.2 索引结构类型 339
12.2.1 B-树索引 339
12.2.2 位图索引 340
12.2.3 索引组织表 341
12.3 分区索引 343
12.3.1 局部索引 343
12.3.2 全局索引 345
12.3.3 散列分区与范围分区 346
12.4 与应用特点相匹配的解决方案 348
12.4.1 压缩索引 348
12.4.2 基于函数的索引 350
12.4.3 反转键索引 353
12.4.4 降序索引 354
12.5 管理问题的解决方案 355
12.5.1 不可见索引 355
12.5.2 虚拟索引 356
12.5.3 位图联结索引 357
12.6 小结 359
第13章 SELECT以外的内容 360
13.1 INSERT 360
13.1.1 直接路径插入 360
13.1.2 多表插入 363
13.1.3 条件插入 364
13.1.4 DML错误日志 364
13.2 UPDATE 371
13.3 DELETE 376
13.4 MERGE 380
13.4.1 语法和用法 380
13.4.2 性能比较 383
13.5 小结 385
第14章 事务处理 386
14.1 什么是事务 386
14.2 事务的ACID属性 387
14.3 事务隔离级别 388
14.4 多版本读一致性 390
14.5 事务控制语句 391
14.5.1 Commit(提交) 391
14.5.2 Savepoint(保存点) 391
14.5.3 Rollback(回滚) 391
14.5.4 Set Transaction(设置事务) 391
14.5.5 Set Constraints(设置约束) 392
14.6 将运算分组为事务 392
14.7 订单录入模式 393
14.8 活动事务 399
14.9 使用保存点 400
14.10 序列化事务 403
14.11 隔离事务 406
14.12 自治事务 409
14.13 小结 413
第15章 测试与质量保证 415
15.1 测试用例 416
15.2 测试方法 417
15.3 单元测试 418
15.4 回归测试 422
15.5 模式修改 422
15.6 重复单元测试 425
15.7 执行计划比较 426
15.8 性能测量 432
15.9 在代码中加入性能测量 432
15.10 性能测试 436
15.11 破坏性测试 437
15.12 通过性能测量进行系统检修 439
15.13 小结 442
第16章 计划稳定性与控制 443
16.1 计划不稳定性:理解这个问题 443
16.1.1 统计信息的变化 444
16.1.2 运行环境的改变 446
16.1.3 SQL语句的改变 447
16.1.4 绑定变量窥视 448
16.2 识别执行计划的不稳定性 450
16.2.1 抓取当前所运行查询的数据 451
16.2.2 查看一条语句的性能历史 452
16.2.3 按照执行计划聚合统计信息 454
16.2.4 寻找执行计划的统计方差 454
16.2.5 在一个时间点附近检查偏差 456
16.3 执行计划控制:解决问题 458
16.3.1 调整查询结构 459
16.3.2 适当使用常量 459
16.3.3 给优化器一些提示 459
16.4 执行计划控制:不能直接访问代码 466
16.4.1 选项1:改变统计信息 467
16.4.2 选项2:改变数据库参数 469
16.4.3 选项3:增加或移除访问路径 469
16.4.4 选项4:应用基于提示的执行计划控制机制 470
16.4.5 大纲 470
16.4.6 SQL概要文件 481
16.4.7 SQL执行计划基线 496
16.4.8 基于提示的执行计划控制机制总结 502
16.5 结论 502
本书作者全部是OakTable的成员,且具有15~29年丰富的Oracle开发经验。在研究一些被其他专门讨论Oracle SQL语言的参考书直接忽略的问题时,这种对Oracle数据库的长期钻研无疑是一个巨大的优势。
——亚马逊读者评论
SQL核心
凯伦?莫顿(Karen Morton)
不管你是刚开始写SQL语句还是已经写过很多年了,学会写出“好的”SQL这个过程都需要具有很扎实的SQL核心语法和概念基础知识。本章对SQL语言的核心概念及其性能做了回顾,同时还描述了一些你应该已经很熟悉的常用SQL命令。对于那些以前曾经使用过SQL并且基础知识相当牢靠的读者来说,本章就是一个简要的复习,让你为后面更详细的SQL论述做好准备。如果你是一位SQL新人,你可能想要先阅读Beginning Oracle SQL这本书以确保掌握SQL的基础。不管是哪种情况,第1章的目的就是通过对5个核心SQL语句的快速浏览来衡量一下你的SQL水平,同时还概述了我们用来执行SQL语句的工具:SQL*Plus。
1.1 SQL语言
SQL语言最早是IBM公司于20世纪70年代开发出来的,称为结构化英文查询语言,简称为SEQUEL。该语言是基于E.F.Codd在1969年提出的关系型数据库管理系统(RDBMS)的。后来因为商标的纠纷,其简称又进一步缩写为SQL。1986年和1987年,ANSI(美国国家标准化组织)和ISO(国际标准化组织)先后将SQL语言采纳为标准语言。而人们并不熟悉的是,ANSI官方曾将SQL语言的读音确定为“S-Q-L”。绝大多数人,包括我本人,都还在使用“sequel”的读音,只是因为这样读起来更顺口一些。
SQL的目的就是简单地提供一个到数据库的接口,在本书指的是Oracle数据库。每一条SQL语句对于数据库来说就是一条命令或指令。SQL与其他编程语言(如C或Java)的区别就在于它是要处理数据集合而不是一行一行的数据。语言本身也不需要你提供如何导航到数据的指令——这是在后台透明地进行的。但你将在后面的章节中看到,如果想在Oracle中写出高效的SQL语句,了解数据及其在数据库中的存储方式与存储位置是很重要的。
由于不同的供应商(例如甲骨文、IBM和微软)实现SQL核心功能的机制相差无几,所以基于某一种数据库所学的技巧同样可以应用到其他类型的数据库上。你基本上可以利用同样的SQL语句来进行数据的查询、插入、更新和删除,以及创建、修改和删除对象,而不必管数据库的供应商是哪家。
尽管SQL是各种关系型数据库管理系统的标准语言,但实际上它并不一定是关系型的。在本书后面我将就这一点稍作扩展。如果想要了解更多的细节,我推荐大家阅读C.J.Date的SQL and Relational Theory一书。需要铭记于心的一点是SQL语言并不总是严格遵守关系模型的——它根本就没有实现关系模型的某些要素,同时还不恰当地实现了一些要素。事实上,既然SQL是基于关系模型的,那么要想写出尽可能正确高效的SQL语句,你不仅必须要理解SQL语言,还要理解关系模型。
1.2 数据库的接口
多年以来人们开发出多种途径来传递SQL语句到数据库并获得结果。Oracle数据库的本地接口界面是Oracle调用界面(OCI)。OCI将由Oracle内核传送而来的查询语句发送到数据库。当使用某种Oracle工具如SQL*Plus或者SQL Developer时,你都在使用OCI。其他的Oracle工具如SQL*Loader、数据泵(Data Pump)以及Real Application Testing (RAT)既使用OCI,也可以使用语言特定的接口,如Oracle JDBC-OCI、ODP.Net、Oracle预编译器、Oracle ODBC以及Oracle C++调用接口(OCCI)驱动器。
当使用编程语言(如COBOL或C语言)时,你所写的语句被称为嵌入式的SQL语句并且在应用程序编译之前会由SQL预处理器进行预处理。代码清单1-1是一段可以在C/C++程序块中使用的SQL语句的例子。
代码清单1-1 C/C++程序块中所嵌入的SQL语句
其他工具,例如SQL*Plus和SQL Developer,都是交互式的工具。你输入并执行命令,然后获得相应的输出。交互式工具并不需要在运行代码前先精确编译,你只需要输入想要执行的命令即可。代码清单1-2是一段使用SQL*Plus执行语句的例子。
代码清单1-2 使用SQL*Plus执行SQL语句
在本书中,为了保持一致性我们所用的示例代码清单都使用SQL*Plus工具,但需要记住的是,不管你是用什么方法或工具来输入和执行SQL语句,所有的事情最后都要通过OCI来传递到数据库。这里的主旨就是不管你所使用的是什么工具,其本地接口都是一样的。
1.3 SQL*Plus回顾
SQL*Plus是一个不管采用哪个安装平台(Windows或Unix)都会提供的命令行工具。它是一个用来输入和执行SQL语句并显示输出结果的纯文本环境。用该工具可以直接输入、编辑命令,可以一条条地保存和执行命令或者通过脚本文件来进行,然后将输出结果以很精美格式的报表输出。要启动SQL*Plus你只需要在主机的命令提示符后敲入sqlplus即可。
1.3.1 连接到数据库
有多种方法可以通过SQL*Plus连接数据库。然而在连接之前,你还需要在$ORACLE_HOME/ network/admin/tnsnames.ora这个文件中登记想要连接的数据库。有两种通常使用的方法,或者如代码清单1-3所示那样在启动SQL*Plus时提供连接信息,或者如代码清单1-4所示那样在启动SQL*Plus以后使用connect命令。
代码清单1-3 通过窗口命令提示符连接到SQL*Plus
如果想要启动SQL*Plus而又不显示登录到数据库后的提示,可以在启动SQL*Plus时使用/nolog选项。
代码清单1-4 通过SQL>提示符连接SQL*Plus并登录到数据库
1.3.2 配置SQL*Plus环境
SQL*Plus有很多的命令可以让你来定制工作环境和显示选项。代码清单1-5所示是在SQL>提示符下输入help index命令后显示出来的可用的命令。
代码清单1-5 SQL*Plus命令列表
set命令是用来定制工作环境的最基本的命令。代码清单1-6为set命令的帮助文本。
代码清单1-6 SQL*Plus的SET命令
有了上面这些可用命令,你就能够很轻松地定制最适合你的运行环境了。但有一点要铭记于心的就是当你退出或关闭SQL*Plus的时候,这些设置命令就不再被保留了。为了避免每次使用SQL*Plus时都重新敲入一遍这些设置命令,你可以创建一个login.sql文件。事实上每次启动SQL*Plus的时候它都会默认去读两个文件。第一个是$ORACLE_HOME/sqlplus/admin目录下的glogin.sql文件。如果找到了这个文件,它就会被读进来,文件中的命令语句也会被执行。这样就可以把那些定制你的会话体验的SQL*Plus命令和SQL语句保存起来。
在读取glogin.sql文件以后,SQL*Plus会进一步寻找login.sql文件。这个文件必须在SQL*Plus的启动文件夹中或者包含在环境变量SQLPATH所指向的文件夹路径中。在login.sql文件中的所有命令优先级都比glogin.sql文件中的命令高。从10g开始,Oracle在每次你启动SQL*Plus或者从SQL*Plus里执行connect命令的时候都会同时去读取glogin.sql和login.sql这两个文件。在Oracle 10g之前,login.sql脚本文件只有在SQL*Plus启动的时候才会被执行。代码清单1-7是一个常见的login.sql文件内容。
代码清单1-7 一个常见的login.sql文件
注意这里在SET SQLPROMPT中使用的变量_user和_connect_identifier。它们是预定义变量的两个示例。你可以在login.sql文件中或者任何你创建的脚本文件中使用下面这些预定义变量:
·_connect_identifier
·_date
·_editor(这个变量指定了当你使用edit命令的时候启动哪个编辑器)
·_o_version
·_o_release
·_privilege
·_sqlplus_release
·_user
1.3.3 执行命令
有两种命令可以在SQL*Plus中执行:SQL语句和SQL*Plus命令。代码清单1-5和代码清单1-6中所列出的SQL*Plus命令对于SQL*Plus来说是特有的命令,可以用来定制运行环境并且可以运行SQL*Plus特有的命令,例如DESCRIBE和CONNECT。要想执行一个SQL*Plus命令,你只需在命令提示符后输入该命令然后敲回车,命令会自动被执行。另一方面,如果要执行SQL语句,就必须使用一个特定字符来表明你想要执行输入的语句,分号(;)或者斜线(/)都可以。使用分号的话可以直接放在输入命令的后面或者放在接下来的空行中,而斜线则必须放在接下来的空行中才可以被识别。代码清单1-8展示了如何使用这两种符号。
代码清单1-8 执行字符的用法
注意第5个在语句最后面加了一个斜线(/)的例子。光标移动到了下一行而不是立即执行语句命令。接下来,如果你再按一下回车键,语句就会被放入SQL*Plus的缓冲器中,但是也不执行。如果想要查看SQL*Plus缓冲器中的内容,可以使用list命令(也可以简写为l)。接下来如果你想在缓冲器中通过使用斜线(/)来执行语句[尽管斜线(/)命令本来就是这样来用的]在这里也将会返回一个错误。这是因为你最初在SQL语句的结尾敲入了一个斜线(/),而斜线(/)并不是一个有效的SQL命令,从而在语句想要执行的时候报错。
另外一种执行命令的方法是把命令放到一个文件中。你可以在SQL*Plus之外直接用文本编辑器生成这些文件,也可以在SQL*Plus中使用EDIT命令来直接调用编辑器。如果已经有了一个文件,EDIT命令可以打开这个文件,如果没有的话就会创建新的文件。文件必须放在默认文件夹中,否则你必须指定文件的全路径。想要设定所选择的编辑器,你只需要利用命令define_ editor='//myeditor.exe'来设置预定义变量_editor。具有.sql扩展名的文件在执行的时候不必敲入扩展名,通过@或START命令都可以执行。代码清单1-9中列出了这两个命令的用法。
代码清单1-9 执行.sql脚本文件
SQL*Plus具有很多特性和选项,以致于多得在这里不能一一列举。就本书需要而言,这种概述就已经足够了。但是,Oracle文档对SQL*Plus的用法给出了指导,而且很多的书,比如Beginning Oracle SQL,都对SQL*Plus作了更为深入的阐述,如果感兴趣你可以参考。
1.4 5个核心的SQL语句
SQL语言有很多不同的语句,但在整个职业生涯中,你可能只会用到其中很少的一部分。不过你所使用的几乎其他任何产品不也是这样的吗?据说有一个统计结果是,绝大多数人都仅使用了他们常用的软件产品或编程语言所有功能的20%甚至更少。我不知道这个统计真实与否,但以我的经验来看,这似乎是很准确的。我发现同样的基本SQL语句格式在大多数应用中使用了将近20年了。极少数的人使用过SQL提供的所有功能——即使对于那些他们确实经常使用的功能也常常用得不是很恰当。显而易见,我们不可能覆盖SQL语言的所有语句以及它们的选项。本书的目的在于让你能够深入理解那些最常用的SQL语句并帮助你更高效地使用它们。
在本书中,我们将重点讨论5个最常用的SQL语句,它们分别为SELECT、INSERT、UPDATE、DELETE以及MERGE。尽管这些核心语句都将逐个讲解,但重中之重还是SELECT语句。将这5个语句用好了将会为你在日常工作中用好SQL语言打下坚实的基础。
1.5 SELECT语句
SELECT语句用来从一个或多个表中或者其他数据库对象中提取数据。你应该已经很熟悉SELECT语句的基础知识了,所以我将不再从一个初学者的角度来介绍SELECT语句,而是首先回顾一下SELECT语句的执行逻辑。对于如何来写一个基本的SELECT语句你应该已经学习过了,但为了培养基本的思维模式,你要一直写出符合语法规则的高效SQL语句,你需要理解SQL语句是如何执行的。
一个查询语句在逻辑上的处理方式可能会与实际物理处理过程大相径庭。Oracle基于查询成本的优化器(cost-based optimizer , CBO)用来产生实际的执行计划。我们在后面的章节中将会讲解优化器是干什么的,如何来实现其功能的以及为什么要进行优化。目前,我们需要关心的是优化器将会决定如何访问表、按照什么样的顺序来处理它们,以及如何将多个表联结起来及如何使用筛选器。查询的处理在逻辑上是按照特定的顺序进行的,但是,优化器所选择的物理执行计划可能会按照完全不同的顺序来实际执行这些步骤。代码清单1-10是一段包含SELECT语句的主要子句的查询片段,在其中标出了每一个子句的逻辑处理顺序。
代码清单1-10 查询语句的逻辑处理顺序
你应该立刻注意到SQL有别于其他编程语言的一点在于首先处理的并不是写在第一行的语句(SELECT语句),而是FROM子句。注意在这个代码清单中我给出了两个不同的FROM子句。标记为1.1的那个FROM子句表示的是当使用ANSI语法时的不同。我们可以把处理过程中的每一个步骤想象为生成一个临时的数据集。随着每个处理步骤的进行,这个数据集被不断地操作直到生成最终的处理结果。查询返回给调用者的就是这个最终结果数据集。
为了更详细地了解SELECT语句的每个部分,你可以参考代码清单1-11所示的查询语句,该语句返回的结果集为下订单超过4次的女顾客的列表。
代码清单1-11 下订单超过4次的女顾客查询语句
1.5.1 FROM子句
FROM子句列出了所查询数据的源对象。这个子句可以包含表、视图、物化视图、分区或子分区,或者你可以建立一个子查询来生成子对象。如果使用了多个源对象,其逻辑处理阶段也将会应用到每一个联结类型以及谓词ON(如步骤1.1所示)。在本书后面的章节中你将会进一步了解联结类型的更多细节,但注意在处理联结语句的时候是按照下面的顺序来进行的:
(1) 交叉联结,也称为笛卡儿乘积;
(2) 内联结;
(3) 外联结。
在代码清单1-11所示的查询例子中,FROM子句列出了两张表:customers和orders,通过customer_id列来联结。因此,当处理这一信息时,FROM子句所生成的初始数据集将会包含这两张表中customer_id相匹配的行。在本例中结果集将会包含105行。为了验证这一点,只要执行例子中的前4行,如代码清单1-12所示。
代码清单1-12 仅通过FROM子句的部分查询语句的执行
注意 为了使之很好地适应页面我手工调整了输出结果,实际输出结果在页面上超过105行。
1.5.2 WHERE子句
WHERE子句提供了一种方法,可以按照条件来限制查询最终返回结果集的行数。每个条件或者谓语都是以两个值或表达式相比较的形式出现的。比较的结果要么是匹配(值为TRUE)要么是不匹配(值为FALSE)。如果比较的结果是FALSE,那么相应的行不会被包含在最终结果集中。
这里我需要稍微偏离一下主题,来谈一谈与这一步相关的SQL中的一个重要方面。事实上,SQL中逻辑比较的可能结果是TRUE、FALSE以及未知。当其中包含空值(null)的时候比较的结果就会是未知。空值与任何值比较或者用在表达式中都会得到空值,或者是未知。一个空值代表一个相应值的缺失,并且可能因为SQL语言中的不同部分对空值的处理不同而令人费解。关于空值是如何影响SQL语句执行的话题将会贯穿本书,但在这里我不得不先提及一下这个话题。我之前所说的还是基本正确的,一个比较的返回值将会是TRUE或者FALSE。你会发现当进行筛选的比较条件中包含空值的时候,将作为FALSE来对待。
在我们的例子中,只有一个将结果限定为下了订单的女性消费者的谓语。如果你查看FROM子句执行之后的中间结果(见代码清单1-12),你会发现105行中仅有31行是由女性消费者所下的订单(gender = 'F')。因此,在应用了WHERE子句以后,中间结果集将从105行减少到31行。
应用WHERE子句以后得到了更精确的结果集。注意,在这里使用的是“精确的结果集”。我的意思是说现在已经得到了能够满足你查询需求的数据行。其他子句(GROUP BY, HAVING)也许可以用来聚合并且进一步限制调用程序会接收到的最终的结果集,但需要注意的很重要的一点是,目前已经得到了查询计算最终结果所需的所有数据。
WHERE子句的目的是限制或者减小结果集。你所使用的限制条件越少,最终返回的结果集中包含的数据就会越多。你需要返回的数据越多,执行查询的时间也就越长。
1.5.3 GROUP BY子句
GROUP BY子句将执行FROM和WHERE子句后得到的经过筛选后的结果集进行聚合。查询出来的结果按照GROUP BY子句中列出的表达式进行分组,来为每一个分组得出一行汇总结果。你可以按照FROM子句中所列出对象的任意字段进行分组,即使你并不想在输出结果列表中显示该列。相反,Select列表中的任何非聚合字段都必须包括在GROUP BY表达式中。
GROUP BY子句中还可以包含两个附加的运算:ROLLUP 和CUBE。ROLLUP运算用来产生部分求和值,CUBE运算用来求得交互分类值。当你使用这两种运算中任意一个的时候,你将会得到不止一行的汇总信息。在第7章中将会对这两个运算进行更详细的讨论。
在示例查询中,需要按照customer_id来进行分组。这就意味着对于每一个唯一的customer_id只会返回一行值。在WHERE子句执行后所得到的代表下订单的女性消费者的31行订单中,有11个独特的customer_id值,如代码清单1-13所示。
代码清单1-13 截至GROUP BY子句的部分查询执行
你会发现查询的结果是经过分组的,但并没有排序。表面上看结果好像是按照order_ct字段排序的,但这仅仅是个巧合而不是确定的行为。需要记住的很重要的一点是:GROUP BY子句并不确定结果数据的排序。如果你需要结果按照特定的顺序排列,则必须指定一个order by子句。
1.5.4 HAVING子句
HAVING子句将分组汇总后的查询结果限定为只有该子句中的条件为真的数据行。除非你使用HAVING子句,否则将返回所有的汇总行。事实上,GROUP BY子句和HAVING子句的位置是可以互换的,谁先谁后都无关紧要。但是,似乎在编码中将GROUP BY子句放在前面更有意义一些,因为GROUP BY子句在逻辑上是先执行的。从本质上来说,HAVING子句是在GROUP BY子句执行后用来筛选汇总值的第二个WHERE子句。
在我们的查询例子中,HAVING子句HAVING COUNT(o.order_id) > 4,将分组数据从11行减少到2行。这一点你可以通过查看GROUP BY子句应用后返回的结果行来确认,如代码清单1-13所示。注意仅有146和147号消费者所下的订单数超过4次。这样就产生了组成最终结果集的两行数据。
1.5.5 SELECT列表
SELECT列表列出查询的返回最终结果集中需要显示哪些列。这些列可以是数据表中一个实际的列、一个表达式,或者甚至是一个SELECT语句的结果,如代码清单1-14所示。
代码清单1-14 展现SELECT列表各种可能情况的查询实例
SQL> select.customer_id, c.cust_first_name||''||c.cust_last_name,
当使用另外一个SELECT语句来产生结果中的一列的值的时候,这个查询必须只能返回一行一列的值。这种类型的子查询被称为标量子查询。尽管这可能是一个非常有用的语法,但需要牢记于心的是标量查询在结果集中的每一行结果产生时都要执行一遍。在某些情况下可以进行优化以减少标量子查询的重复执行,但更糟糕的场景是每一行都需要标量子查询执行。你可以想象如果你的结果集中有几千行甚至上百万行数据的时候所需要付出的查询代价!在后面的章节中我们还将回顾标量子查询并讨论如何更好地来使用它们。
在SELECT列表中你还有可能用到的一个选项是DISTINCT子句。在例子中并没有使用它,但我想要简要地提及一下。DISTINCT子句用来在其他子句执行完毕以后从结果集中去除重复的行。
SELECT列表执行完以后,你就得到了最终的查询结果集。所剩的唯一需要做的事情,如果包含了的话,就是将查询结果集按照所需的顺序排序。
1.5.6 ORDER BY子句
ORDER BY子句用来对查询最终返回的结果集进行排序。在本例中,需要按照orders_ct和customer_id进行排序。orders_ct这一列是通过GROUP BY子句中的COUNT聚合函数计算得到的值。如代码清单1-13中所示,有两个消费者的订单超过4个。由于这两个消费者的订单数都是5份,orders_ct这一列的值是相同的,所以要由第二个排序列来确定最终结果的显示顺序。如代码清单1-15中所示,该查询的最终经过排序的输出结果是按照customer_id排序的两行数据集。
代码清单1-15 示例查询的最终输出
当输出结果需要排序的时候,Oracle必须在其他所有子句都执行完之后按照指定的顺序对最终结果集进行排序。需要排序的数据量大小是非常重要的。我这里所说的大小是指结果集中所包含的总字节数。你可以通过用行数乘以每一行的字节数来估计数据集的大小。每行所包含的字节数通过将选择列表中包含的每一列的平均长度相加来确定。
上面的查询实例在选择列表中仅需要列出customer_id 和orders_ct两列的值。我们可以估算每一行输出值的字节数为10。在第6章中我将阐述从哪里能找到优化器所估计的值。因此,如果我们在结果集中只有两行数据,排序的大小实际上是很小的,大约20字节。请记住这仅仅是估算,但这样的估算也是很重要的。
较小的排序会完全在内存中来实现,而较大的排序将不得不使用临时磁盘空间来完成。如你可能推断的那样,在内存中完成的排序比必须使用磁盘的排序要快。因此,当优化器估算排序数据的影响时,它必须要考虑排序数据集的大小,以此来调整如何能够以最有效的方法来获得查询的结果。一般来说,排序是查询过程中开销相当大的一个处理步骤,尤其是当返回结果集很大的时候。
1.6 INSERT语句
INSERT语句用来向表、分区或视图中添加行。可以向单表或者多个表方法中添加数据行。单表插入将会向一个表中插入一行数据,这行数据可以显式地列出插入值也可以通过一个子查询来获取。多表插入将会向一个或多个表中插入行,并且会通过子查询获取值来计算所插入行的值。
1.6.1 单表插入
代码清单1-16中的第一个例子阐明了使用values子句实现的单表插入。每一列的值都显式地输入。如果你要插入表中所定义的所有列的值,那么列的列表是可选的。但是,如果你只想提供部分列的值,则必须在列的列表中指明所需的列名。好的做法是不管是不是需要插入所有列的值,都把所有列的列表列出来。这样做就像该语句的自述文件一样,并且也可以减少将来别人要插入一个新列到表中的时候可能出现的错误。
代码清单1-16 单表插入
第二个例子阐述了通过子查询来实现插入。这是插入数据行的一个非常灵活的选项。所写的子查询可以返回一行或多行数据。返回的每一行都会用来生成需要插入的新行的列值。根据你的需要这个子查询可以很简单也可以很复杂。在本例中,我们使用子查询实现了在现有薪水的基础上为每一位员工发放10%奖金的计算。事实上奖金表包含4列,但在这个插入中我们只列出了3个字段。comm这一列在子查询中并没有占据一列并且我们也没有将它包括在列表中。因为我们没有包含这一列,它的值将会是null。注意如果comm列具有非空约束,那么可能已返回一个约束错误,语句的执行也已失败。
1.6.2 多表插入
代码清单1-17所示的多表插入的例子阐明了一个子查询返回的数据行是如何被用来插入多个表中的。我们从3个表开始:small_customers、medium_customers以及large_customers。我们想要按照每位消费者所下订单的总金额来将数据分别插入这些表。子查询将每一位消费者的order_total列求和来确定该消费者的消费金额是小(所有订单的累加金额小于10 000美元)、中等(介于10 000美元与99 999.99美元之间)还是大(大于等于100 000美元),然后按照条件将这些行插入对应的表中。
代码清单1-17 多表插入
注意INSERT关键字后面ALL子句的使用。当指定了ALL子句的时候,这个语句就会执行无条件的多表插入。也就意味着每一个WHEN子句按照子查询所返回的每一行来确定值而不管前一个条件的输出结果是什么。因此,你需要注意如何来指定每个条件。例如,如果我使用WHEN sum_orders < 100 000这个条件而不是像上面一样列出范围,插入medium_customers表中的行有可能也会插入small_customers表中。
你需要指明FIRST选项来实现每一个WHEN子句按照其出现在语句中的顺序进行评估,并且对于一个给定的子查询行跳过接下来的WHEN子句评估。关键在于要记住哪一个选项能够更好地满足你的需要,ALL还是FIRST,然后使用最适合的选项。
1.7 UPDATE语句
UPDATE语句的作用是改变表中原有行的列值。这个语句的语法由3部分组成:UPDATE、SET和WHERE。UPDATE子句用来指定要更新的表,SET子句用来指明哪些列改变了以及调整的值,WHERE子句用来按条件筛选需要更新的行。WHERE子句是可选的,如果忽略了这个子句的话,更新操作将针对指定表中的所有行进行。
代码清单1-18列出了几种UPDATE语句的不同写法。首先,我建立了一个employees表的副本,名称为employees2,然后我将执行几个完成基本相同任务的不同更新操作:将90部门的员工工资增加10%。在例5中,commission_pct这一列也进行了更新。下面就是采用的不同方法。
例1:使用表达式更新一个单列的值。
例2:通过子查询更新一个单列的值。
例3:通过在WHERE子句中使用子查询确定要更新的数据行来更新单列的值。
例4:通过使用SELECT语句定义表及列的值来更新表。
例5:通过子查询更新多列。
代码清单1-18 UPDATE语句的例子
1.8 DELETE语句
DELETE语句用来从表中移除数据行。该语句的语法结构由3部分组成:DELETE、FROM和WHERE。DELETE关键字是单独列出的。除非你决定使用我们后面将会讨论到的提示(hint),没有其他选项与DELETE关键字相结合。FROM子句用来指定要从哪个表中删除数据行。如代码清单1-19中的例子所示,这个表可以直接指定也可以通过子查询来确定。WHERE子句提供筛选条件有助于确定哪些行是要删除的。如果忽略了WHERE子句,删除操作将删除指定表中的所有数据行。
代码清单1-19展示出了DELETE语句的几种不同写法。注意,在这些例子中我使用了代码清单1-18中创建的employees2表。下面你将看到的就是这些不同的删除方法。
例1:使用WHERE子句中的筛选条件来从指定表中删除行。
例2:使用FROM子句中的子查询来删除行。
例3:使用WHERE子句中的子查询来从指定表中删除行。
代码清单1-19 DELETE语句的例子
1.9 MERGE语句
MERGE语句具有按条件获取要更新或插入到表中的数据行,然后从1个或多个源头对表进行更新或者向表中插入行两方面的能力。它最经常被用在数据仓库中来移动大量的数据,但它的应用不仅限于数据仓库环境下。这个语句提供的一个很大的附加值在于你可以很方便地把多个操作结合成一个。这就使你可以避免使用多个INSERT、UPDATE以及DELETE语句。并且,在本书后面的内容中你将看到,如果你避免去做那些不是必须做的事情,响应时间可能得到相应的改善。
MERGE语句的语法是:
为了说明MERGE语句的用法,代码清单1-20展示出了如何建立一个测试表,然后恰当地利用MERGE条件来向表中插入或更新行。
代码清单1-20 MERGE语句例子
MERGE语句完成了下面这些事情。
·插入了两行(员工id 106和107)。
·更新了一行(员工id 105)。
·删除了一行(员工id 103)。
·一行保持不变(员工id 104)。
如果没有MERGE语句,你必须最少写3条不同的语句来完成同样的事情。
1.10 小结
正如你可以从到目前为止的例子中看出的,SQL语言提供了很多不同的选择来得到同样的结果集。你可能还注意到了一点就是这5个核心的SQL语句都可以使用类似的构造,例如子查询。关键是需要搞清楚在各种不同的使用场景下哪种构造是最高效的。我们将在本书后面的内容中阐述如何做到这一点。
如果你对本章的例子的理解有任何困难,请一定花点时间复习Beginning Oracle SQL或者Oracle文档中的SQL Reference Guide。在本书中接下来的部分我们假设你已经很好地理解了5个核心SQL语句的基本构造:SELECT、INSERT、UPDATE、DELETE和MERGE。
(01) SELECT .................................. ............... .......................................2
查找 SELECT "栏位名" FROM "表格名"
(02) DISTINCT................................. ............... .....................................2
不同值 SELECT DISTINCT "栏位名" FROM "表格名"
(03) WHERE...................................... ............... ....................................2
条件 SELECT "栏位名" FROM "表格名" WHERE "条件"
(04) AND OR ...................................... ............... ..................................3
条件并和或 SELECT "栏位名" FROM "表格名" WHERE "简单条件"
{[AND|OR] "简单条件"}
(05) IN .............................................. ............... ..................................3
包含 SELECT "栏位名" FROM "表格名" WHERE "栏位名" IN ('值一', '值二
', ...)
(06) BETWEEN.............................. ............... ........................................4
范围包含 SELECT "栏位名" FROM " 表格名" WHERE "栏位名" BETWEEN
'值一' AND '值二'
(07) LIKE....................................... ............... .......................................4
通配符包含 SELECT "栏位名" FROM "表格名" WHERE "栏位名" LIKE {套
式} -- 支持通配符‘_’ 单个字符 '%' 任意字符
(08) ORDER BY............................... ............... ......................................5
排序 SELECT "栏位名" FROM "表格名" [WHERE "条件"] ORDER BY "栏位
名" [ASC, DESC] -- ASC 小到大 DESC 大到小
(09) 函数........................................ ............... ......................................5
函数 AVG (平均) COUNT (计数) MAX (最大值) MIN (最小值) SUM (总合)
SELECT "函数名"("栏位名") FROM "表格名"
(10) COUNT .................................... .............. ......................................6
计 数 SELECT COUNT(store_name) FROM Store_Information WHERE
store_name is not NULL -- 统计非空
SELECT COUNT(DISTINCT store_name) FROM Store_Information -- 统计多
(11) Group By .................................. .............. .....................................6
字段分组 SELECT "栏位 1", SUM("栏位 2") FROM "表格名" GROUP BY "
栏位 1"
(12) HAVING...................................... .............. ....................................7
函数条件定位 SELECT "栏位 1", SUM("栏位 2") FROM "表格名" GROUP
BY "栏位 1" HAVING (函数条件)
(13) ALIAS........................................... .............. ..................................7
别名 SELECT "表格别名"."栏位 1" "栏位别名" FROM "表格名" "表格别名"
(14) 连接................................................ ..............................................8
SELECT A1.region_name REGION, SUM(A2.Sales) SALES FROM Geography
A1, Store_Information A2 WHERE A1.store_name = A2.store_name GROUP BY
A1.region_name
(15) 外部连接........................................... ............................................9
SELECT A1.store_name, SUM(A2.Sales) SALES FROM Georgraphy A1,
Store_Information A2 WHERE A1.store_name = A2.store_name (+)
GROUP BY A1.store_name
(16) Subquery .............................. .............. .........................................9
嵌套 SELECT "栏位 1" FROM "表格" WHERE "栏位 2" [比较运算素]
(SELECT "栏位 1" FROM "表格" WHERE
(17) UNION.................................... ............... ......................................10
合并不重复结果 [SQL 语句 1] UNION [SQL 语句 2]
(18) UNION ALL....................................... .............. ............................ 11
合并所有结果 [SQL 语句 1] UNION ALL [SQL 语句 2]
(19) INTERSECT..................................................... ............... ............. 11
查找相同值 [SQL 语句 1] INTERSECT [SQL 语句 2]
(20) MINUS............................ ............... ..............................................12
显示第一个语句中不在第二个语句中的项 [SQL 语句 1] MINUS [SQL 语句 2]
(21) Concatenate................................... ............... ...............................12
结果相加(串联)
MySQL/Oracle:
SELECT CONCAT(region_name,store_name) FROM Geography WHERE
store_name = 'Boston';
SQL Server:
SELECT region_name + ' ' + store_name FROM Geography WHERE
store_name = 'Boston';
(22) Substring ...................................................... ............... ...............13
取字符 SUBSTR(str,pos) SUBSTR(str,pos,len)
(23) TRIM ...... .............. .....................................................................14
去空 SELECT TRIM(' Sample '); TRIM()首尾, RTRIM()首, LTRIM()尾
(24) Create Table ........... .............. .....................................................14
建立表格 CREATE TABLE "表格名"("栏位 1" "栏位 1 资料种类","栏位 2"
"栏位 2 资料种类",... )
(25) Create View............................. .............. ......................................15
建立表格视观表 CREATE VIEW "VIEW_NAME" AS "SQL 语句"
(26) Create Index........................................... ............... ......................16
建立索引 CREATE INDEX "INDEX_NAME" ON "TABLE_NAME"
(COLUMN_NAME)
(27) Alter Table.. .............. ..................................................................16
修改表 ALTER TABLE "table_name"[改变方式] -- ADD 增加;DROP 删
除;CHANGE 更名;MODIFY 更改类型
(28) 主键.......................... ..................................................................18
ALTER TABLE Customer ADD PRIMARY KEY (SID)
(29) 外来主键....................................... ............ ..................................18
CREATE TABLE ORDERS(Order_ID integer,Order_Date date,Customer_SID
integer,Amount double,Primary Key (Order_ID),Foreign Key (Customer_SID)
references CUSTOMER(SID));
(30) Drop Table................................................. ............... ...................19
删除表 DROP TABLE "表格名"
(31) Truncate Table ................. ............... ............................................20
清除表内容 TRUNCATE TABLE "表格名"
(32) Insert Into....................................... ............... .............................20
插入内容 INSERT INTO "表格名" ("栏位 1", "栏位 2", ...) VALUES ("值 1",
"值 2", ...)
(33) Update ........................ ................ ................................................20
修改内容 UPDATE "表格名" SET "栏位 1" = [新值] WHERE {条件}
(34) Delete ......................................... .............. .................................21
DELETE FROM "表格名" WHERE {条件}
group by语句中select指定的字段必须是“分组依据字段”。
group by是分组查询,也就是说你前面除了聚合函数外我在group by后面必须要指定,否则就报错。你想想,我按job进行分组,但是ename有很多不同的值,那这样不就是一对多了吗上图来看:
查询的结果不就是一对多吗
右边如何变成一条呢,也就是一对一,那这里
Oracle中的group by到底能干什么
在谈oracle的group by的时候,大多数人的第一印象都是group by不就是用于分组的吗?有什么好说的呢,但是在实际操作中,却经常会出现需要group by但是又不能模范的写出group by,拿到想要的数据的操作。本篇写下自己对于group by的一些见解。
1.对于group by,首先我们什么场景使用?
常见的场景有:
1.分组求聚合,使用聚合函数做一些操作,比如max,min,sum等等
思考下:在使用group by之前,先弄清楚为什么有些字
Oracle中group by用法
在select 语句中可以使用group by 子句将行划分成较小的组,一旦使用分组后select操作的对象变为各个分组后的数据,在用分组时使用聚组函数返回的是每一个组的汇总信息。列 :select o.customer_no customer_no,count(o.customer_no) as total
,sum(o.amount) as tot
1.ASCII
返回与指定的字符对应的十进制数;
SQL> select ascii('A') A,ascii('a') a,ascii('0') zero,ascii(' ') space from dual;
A A ZERO SPACE
--------- --------- --------- ---------
65 97 48 32
2.CHR
给出整数,返回对应的字符;
SQL> select chr(54740) zhao,chr(65) chr65 from dual;
3.CONCAT
连接两个字符串;
SQL> select concat('010-','88888888')||'转23' 高乾竞电话 from dual;
高乾竞电话
----------------
010-88888888转23
4.INITCAP
返回字符串并将字符串的第一个字母变为大写;
SQL> select initcap('smith') upp from dual;
-----
Smith
5.INSTR(C1,C2,I,J)
在一个字符串中搜索指定的字符,返回发现指定的字符的位置;
C1 被搜索的字符串
C2 希望搜索的字符串
I 搜索的开始位置,默认为1
J 出现的位置,默认为1
SQL> select instr('oracle traning','ra',1,2) instring from dual;
INSTRING
---------
6.LENGTH
返回字符串的长度;
SQL> select name,length(name),addr,length(addr),sal,length(to_char(sal)) from .nchar_tst;
NAME LENGTH(NAME) ADDR LENGTH(ADDR) SAL LENGTH(TO_CHAR(SAL))
------ ------------ ---------------- ------------ --------- --------------------
高乾竞 3 北京市海锭区 6 9999.99 7
7.LOWER
返回字符串,并将所有的字符小写
SQL> select lower('AaBbCcDd')AaBbCcDd from dual;
AABBCCDD
--------
aabbccdd
8.UPPER
返回字符串,并将所有的字符大写
SQL> select upper('AaBbCcDd') upper from dual;
UPPER
--------
AABBCCDD
9.RPAD和LPAD(粘贴字符)
RPAD 在列的右边粘贴字符
LPAD 在列的左边粘贴字符
SQL> select lpad(rpad('gao',10,'*'),17,'*')from dual;
LPAD(RPAD('GAO',1
-----------------
*******gao*******
不够字符则用*来填满
10.LTRIM和RTRIM
LTRIM 删除左边出现的字符串
RTRIM 删除右边出现的字符串
SQL> select ltrim(rtrim(' gao qian jing ',' '),' ') from dual;
LTRIM(RTRIM('
-------------
gao qian jing
11.SUBSTR(string,start,count)
取子字符串,从start开始,取count个
SQL> select substr('13088888888',3,8) from dual;
SUBSTR('
--------
08888888
12.REPLACE('string','s1','s2')
string 希望被替换的字符或变量
s1 被替换的字符串
s2 要替换的字符串
SQL> select replace('he love you','he','i') from dual;
REPLACE('HELOVEYOU','HE','I')
------------------------------
i love you
13.SOUNDEX
返回一个与给定的字符串读音相同的字符串
SQL> create table table1(xm varchar(8));
SQL> insert into table1 values('weather');
SQL> insert into table1 values('wether');
SQL> insert into table1 values('gao');
SQL> select xm from table1 where soundex(xm)=soundex('weather');
--------
weather
wether
14.TRIM('s' from 'string')
LEADING 剪掉前面的字符
TRAILING 剪掉后面的字符
如果不指定,默认为空格符
15.ABS
返回指定值的绝对值
SQL> select abs(100),abs(-100) from dual;
ABS(100) ABS(-100)
--------- ---------
100 100
16.ACOS
给出反余弦的值
SQL> select acos(-1) from dual;
ACOS(-1)
---------
3.1415927
17.ASIN
给出反正弦的值
SQL> select asin(0.5) from dual;
ASIN(0.5)
---------
.52359878
18.ATAN
返回一个数字的反正切值
SQL> select atan(1) from dual;
ATAN(1)
---------
.78539816
19.CEIL
返回大于或等于给出数字的最小整数
SQL> select ceil(3.1415927) from dual;
CEIL(3.1415927)
---------------
20.COS
返回一个给定数字的余弦
SQL> select cos(-3.1415927) from dual;
COS(-3.1415927)
---------------
21.COSH
返回一个数字反余弦值
SQL> select cosh(20) from dual;
COSH(20)
---------
242582598
22.EXP
返回一个数字e的n次方根
SQL> select exp(2),exp(1) from dual;
EXP(2) EXP(1)
-------- ---------
7.3890561 2.7182818
23.FLOOR
对给定的数字取整数
SQL> select floor(2345.67) from dual;
FLOOR(2345.67)
--------------
24.LN
返回一个数字的对数值
SQL> select ln(1),ln(2),ln(2.7182818) from dual;
LN(1) LN(2) LN(2.7182818)
--------- --------- -------------
0 .69314718 .99999999
25.LOG(n1,n2)
返回一个以n1为底n2的对数
SQL> select log(2,1),log(2,4) from dual;
LOG(2,1) LOG(2,4)
--------- ---------
0 2
26.MOD(n1,n2)
返回一个n1除以n2的余数
SQL> select mod(10,3),mod(3,3),mod(2,3) from dual;
MOD(10,3) MOD(3,3) MOD(2,3)
--------- --------- ---------
1 0 2
27.POWER
返回n1的n2次方根
SQL> select power(2,10),power(3,3) from dual;
POWER(2,10) POWER(3,3)
----------- ----------
1024 27
28.ROUND和TRUNC
按照指定的精度进行舍入
SQL> select round(55.5),round(-55.4),trunc(55.5),trunc(-55.5) from dual;
ROUND(55.5) ROUND(-55.4) TRUNC(55.5) TRUNC(-55.5)
----------- ------------ ----------- ------------
56 -55 55 -55
29.SIGN
取数字n的符号,大于0返回1,小于0返回-1,等于0返回0
SQL> select sign(123),sign(-100),sign(0) from dual;
SIGN(123) SIGN(-100) SIGN(0)
--------- ---------- ---------
1 -1 0
30.SIN
返回一个数字的正弦值
SQL> select sin(1.57079) from dual;
SIN(1.57079)
------------
31.SIGH
返回双曲正弦的值
SQL> select sin(20),sinh(20) from dual;
SIN(20) SINH(20)
--------- ---------
.91294525 242582598
32.SQRT
返回数字n的根
SQL> select sqrt(64),sqrt(10) from dual;
SQRT(64) SQRT(10)
--------- ---------
8 3.1622777
33.TAN
返回数字的正切值
SQL> select tan(20),tan(10) from dual;
TAN(20) TAN(10)
--------- ---------
2.2371609 .64836083
34.TANH
返回数字n的双曲正切值
SQL> select tanh(20),tan(20) from dual;
TANH(20) TAN(20)
--------- ---------
1 2.2371609
35.TRUNC
按照指定的精度截取一个数
SQL> select trunc(124.1666,-2) trunc1,trunc(124.16666,2) from dual;
TRUNC1 TRUNC(124.16666,2)
--------- ------------------
100 124.16
36.ADD_MONTHS
增加或减去月份
SQL> select to_char(add_months(to_date('199912','yyyymm'),2),'yyyymm') from dual;
TO_CHA
------
200002
SQL> select to_char(add_months(to_date('199912','yyyymm'),-2),'yyyymm') from dual;
TO_CHA
------
199910
37.LAST_DAY
返回日期的最后一天
SQL> select to_char(sysdate,'yyyy.mm.dd'),to_char((sysdate)+1,'yyyy.mm.dd') from dual;
TO_CHAR(SY TO_CHAR((S
---------- ----------
2004.05.09 2004.05.10
SQL> select last_day(sysdate) from dual;
LAST_DAY(S
----------
31-5月 -04
38.MONTHS_BETWEEN(date2,date1)
给出date2-date1的月份
SQL> select months_between('19-12月-1999','19-3月-1999') mon_between from dual;
MON_BETWEEN
-----------
SQL>selectmonths_between(to_date('2000.05.20','yyyy.mm.dd'),to_date('2005.05.20','yyyy.dd')) mon_betw from dual;
MON_BETW
---------
39.NEW_TIME(date,'this','that')
给出在this时区=other时区的日期和时间
SQL> select to_char(sysdate,'yyyy.mm.dd hh24:mi:ss') bj_time,to_char(new_time
2 (sysdate,'PDT','GMT'),'yyyy.mm.dd hh24:mi:ss') los_angles from dual;
BJ_TIME LOS_ANGLES
------------------- -------------------
2004.05.09 11:05:32 2004.05.09 18:05:32
40.NEXT_DAY(date,'day')
给出日期date和星期x之后计算下一个星期的日期
SQL> select next_day('18-5月-2001','星期五') next_day from dual;
NEXT_DAY
----------
25-5月 -01
41.SYSDATE
用来得到系统的当前日期
SQL> select to_char(sysdate,'dd-mm-yyyy day') from dual;
TO_CHAR(SYSDATE,'
-----------------
09-05-2004 星期日
trunc(date,fmt)按照给出的要求将日期截断,如果fmt='mi'表示保留分,截断秒
SQL> select to_char(trunc(sysdate,'hh'),'yyyy.mm.dd hh24:mi:ss') hh,
2 to_char(trunc(sysdate,'mi'),'yyyy.mm.dd hh24:mi:ss') hhmm from dual;
HH HHMM
------------------- -------------------
2004.05.09 11:00:00 2004.05.09 11:17:00
42.CHARTOROWID
将字符数据类型转换为ROWID类型
SQL> select rowid,rowidtochar(rowid),ename from scott.emp;
ROWID ROWIDTOCHAR(ROWID) ENAME
------------------ ------------------ ----------
AAAAfKAACAAAAEqAAA AAAAfKAACAAAAEqAAA SMITH
AAAAfKAACAAAAEqAAB AAAAfKAACAAAAEqAAB ALLEN
AAAAfKAACAAAAEqAAC AAAAfKAACAAAAEqAAC WARD
AAAAfKAACAAAAEqAAD AAAAfKAACAAAAEqAAD JONES
43.CONVERT(c,dset,sset)
将源字符串 sset从一个语言字符集转换到另一个目的dset字符集
SQL> select convert('strutz','we8hp','f7dec') "conversion" from dual;
conver
------
strutz
44.HEXTORAW
将一个十六进制构成的字符串转换为二进制
45.RAWTOHEXT
将一个二进制构成的字符串转换为十六进制
46.ROWIDTOCHAR
将ROWID数据类型转换为字符类型
47.TO_CHAR(date,'format')
SQL> select to_char(sysdate,'yyyy/mm/dd hh24:mi:ss') from dual;
TO_CHAR(SYSDATE,'YY
-------------------
2004/05/09 21:14:41
48.TO_DATE(string,'format')
将字符串转化为ORACLE中的一个日期
49.TO_MULTI_BYTE
将字符串中的单字节字符转化为多字节字符
SQL> select to_multi_byte('高') from dual;
50.TO_NUMBER
将给出的字符转换为数字
SQL> select to_number('1999') year from dual;
---------
51.BFILENAME(dir,file)
指定一个外部二进制文件
SQL>insert into file_tb1 values(bfilename('lob_dir1','image1.gif'));
52.CONVERT('x','desc','source')
将x字段或变量的源source转换为desc
SQL> select sid,serial#,username,decode(command,
2 0,'none',
3 2,'insert',
4 3,
5 'select',
6 6,'update',
7 7,'delete',
8 8,'drop',
9 'other') cmd from v$session where type!='background';
SID SERIAL# USERNAME CMD
--------- --------- ------------------------------ ------
1 1 none
2 1 none
3 1 none
4 1 none
5 1 none
6 1 none
7 1275 none
8 1275 none
9 20 GAO select
10 40 GAO none
53.DUMP(s,fmt,start,length)
DUMP函数以fmt指定的内部数字格式返回一个VARCHAR2类型的值
SQL> col global_name for a30
SQL> col dump_string for a50
SQL> set lin 200
SQL> select global_name,dump(global_name,1017,8,5) dump_string from global_name;
GLOBAL_NAME DUMP_STRING
------------------------------ --------------------------------------------------
ORACLE.WORLD Typ=1 Len=12 CharacterSet=ZHS16GBK: W,O,R,L,D
54.EMPTY_BLOB()和EMPTY_CLOB()
这两个函数都是用来对大数据类型字段进行初始化操作的函数
55.GREATEST
返回一组表达式中的最大值,即比较字符的编码大小.
SQL> select greatest('AA','AB','AC') from dual;
SQL> select greatest('啊','安','天') from dual;
56.LEAST
返回一组表达式中的最小值
SQL> select least('啊','安','天') from dual;
57.UID
返回标识当前用户的唯一整数
SQL> show user
USER 为"GAO"
SQL> select username,user_id from dba_users where user_id=uid;
USERNAME USER_ID
------------------------------ ---------
GAO 25
58.USER
返回当前用户的名字
SQL> select user from dual;
------------------------------
59.USEREVN
返回当前用户环境的信息,opt可以是:
ENTRYID,SESSIONID,TERMINAL,ISDBA,LABLE,LANGUAGE,CLIENT_INFO,LANG,VSIZE
ISDBA 查看当前用户是否是DBA如果是则返回true
SQL> select userenv('isdba') from dual;
USEREN
------
FALSE
SQL> select userenv('isdba') from dual;
USEREN
------
SESSION
返回会话标志
SQL> select userenv('sessionid') from dual;
USERENV('SESSIONID')
--------------------
ENTRYID
返回会话人口标志
SQL> select userenv('entryid') from dual;
USERENV('ENTRYID')
------------------
INSTANCE
返回当前INSTANCE的标志
SQL> select userenv('instance') from dual;
USERENV('INSTANCE')
-------------------
LANGUAGE
返回当前环境变量
SQL> select userenv('language') from dual;
USERENV('LANGUAGE')
----------------------------------------------------
SIMPLIFIED CHINESE_CHINA.ZHS16GBK
返回当前环境的语言的缩写
SQL> select userenv('lang') from dual;
USERENV('LANG')
----------------------------------------------------
TERMINAL
返回用户的终端或机器的标志
SQL> select userenv('terminal') from dual;
USERENV('TERMINA
----------------
VSIZE(X)
返回X的大小(字节)数
SQL> select vsize(user),user from dual;
VSIZE(USER) USER
----------- ------------------------------
6 SYSTEM
60.AVG(DISTINCT|ALL)
all表示对所有的值求平均值,distinct只对不同的值求平均值
SQLWKS> create table table3(xm varchar(8),sal number(7,2));
语句已处理。
SQLWKS> insert into table3 values('gao',1111.11);
SQLWKS> insert into table3 values('gao',1111.11);
SQLWKS> insert into table3 values('zhu',5555.55);
SQLWKS> commit;
SQL> select avg(distinct sal) from gao.table3;
AVG(DISTINCTSAL)
----------------
3333.33
SQL> select avg(all sal) from gao.table3;
AVG(ALLSAL)
-----------
2592.59
61.MAX(DISTINCT|ALL)
求最大值,ALL表示对所有的值求最大值,DISTINCT表示对不同的值求最大值,相同的只取一次
SQL> select max(distinct sal) from scott.emp;
MAX(DISTINCTSAL)
----------------
62.MIN(DISTINCT|ALL)
求最小值,ALL表示对所有的值求最小值,DISTINCT表示对不同的值求最小值,相同的只取一次
SQL> select min(all sal) from gao.table3;
MIN(ALLSAL)
-----------
1111.11
63.STDDEV(distinct|all)
求标准差,ALL表示对所有的值求标准差,DISTINCT表示只对不同的值求标准差
SQL> select stddev(sal) from scott.emp;
STDDEV(SAL)
-----------
1182.5032
SQL> select stddev(distinct sal) from scott.emp;
STDDEV(DISTINCTSAL)
-------------------
1229.951
64.VARIANCE(DISTINCT|ALL)
SQL> select variance(sal) from scott.emp;
VARIANCE(SAL)
-------------
1398313.9
65.GROUP BY
主要用来对一组数进行统计
SQL> select deptno,count(*),sum(sal) from scott.emp group by deptno;
DEPTNO COUNT(*) SUM(SAL)
--------- --------- ---------
10 3 8750
20 5 10875
30 6 9400
66.HAVING
对分组统计再加限制条件
SQL> select deptno,count(*),sum(sal) from scott.emp group by deptno having nt(*)>=5;
DEPTNO COUNT(*) SUM(SAL)
--------- --------- ---------
20 5 10875
30 6 9400
SQL> select deptno,count(*),sum(sal) from scott.emp having count(*)>=5 group by tno ;
DEPTNO COUNT(*) SUM(SAL)
--------- --------- ---------
20 5 10875
30 6 9400
67.ORDER BY
用于对查询到的结果进行排序输出
SQL> select deptno,ename,sal from scott.emp order by deptno,sal desc;
DEPTNO ENAME SAL
--------- ---------- ---------
10 KING 5000
10 CLARK 2450
10 MILLER 1300
20 SCOTT 3000
20 FORD 3000
20 JONES 2975
20 ADAMS 1100
20 SMITH 800
30 BLAKE 2850
30 ALLEN 1600
30 TURNER 1500
30 WARD 1250
30 MARTIN 1250
30 JAMES 950
1.ASCII
返回与指定的字符对应的十进制数;
SQL> select ascii('A') A,ascii('a') a,ascii('0') zero,ascii(' ') space from dual;
A A ZERO SPACE
--------- --------- --------- ---------
65 97 48 32
2.CHR
给出整数,返回对应的字符;
SQL> select chr(54740) zhao,chr(65) chr65 from dual;
3.CONCAT
连接两个字符串;
SQL> select concat('010-','88888888')||'转23' 高乾竞电话 from dual;
高乾竞电话
----------------
010-88888888转23
4.INITCAP
返回字符串并将字符串的第一个字母变为大写;
SQL> select initcap('smith') upp from dual;
-----
Smith
5.INSTR(C1,C2,I,J)
在一个字符串中搜索指定的字符,返回发现指定的字符的位置;
C1 被搜索的字符串
C2 希望搜索的字符串
I 搜索的开始位置,默认为1
J 出现的位置,默认为1
SQL> select instr('oracle traning','ra',1,2) instring from dual;
INSTRING
---------
6.LENGTH
返回字符串的长度;
SQL> select name,length(name),addr,length(addr),sal,length(to_char(sal)) from gao.nchar_tst;
NAME LENGTH(NAME) ADDR LENGTH(ADDR) SAL LENGTH(TO_CHAR(SAL))
------ ------------ ---------------- ------------ --------- --------------------
高乾竞 3 北京市海锭区 6 9999.99 7
7.LOWER
返回字符串,并将所有的字符小写
SQL> select lower('AaBbCcDd')AaBbCcDd from dual;
AABBCCDD
--------
aabbccdd
8.UPPER
返回字符串,并将所有的字符大写
SQL> select upper('AaBbCcDd') upper from dual;
UPPER
--------
AABBCCDD
9.RPAD和LPAD(粘贴字符)
RPAD 在列的右边粘贴字符
LPAD 在列的左边粘贴字符
SQL> select lpad(rpad('gao',10,'*'),17,'*')from dual;
LPAD(RPAD('GAO',1
-----------------
*******gao*******
不够字符则用*来填满
10.LTRIM和RTRIM
LTRIM 删除左边出现的字符串
RTRIM 删除右边出现的字符串
SQL> select ltrim(rtrim(' gao qian jing ',' '),' ') from dual;
LTRIM(RTRIM('
-------------
gao qian jing
11.SUBSTR(string,start,count)
取子字符串,从start开始,取count个
SQL> select substr('13088888888',3,8) from dual;
SUBSTR('
--------
08888888
12.REPLACE('string','s1','s2')
string 希望被替换的字符或变量
s1 被替换的字符串
s2 要替换的字符串
SQL> select replace('he love you','he','i') from dual;
REPLACE('H
----------
i love you
13.SOUNDEX
返回一个与给定的字符串读音相同的字符串
SQL> create table table1(xm varchar(8));
SQL> insert into table1 values('weather');
SQL> insert into table1 values('wether');
在Oracle中,可以使用GROUP BY子句来统计某年纪某班的人数。假设我们有一个名为"students"的表,其中包含了学生的信息,包括年纪和班级。我们可以使用以下SQL语句来实现这个统计:
SELECT 年纪, 班级, COUNT(*) AS 人数
FROM students
GROUP BY 年纪, 班级;
这个查询将按照年纪和班级进行分组,并计算每个组中的学生人数。结果将包含年纪、班级和对应的人数。请注意,"年纪"和"班级"是根据你的实际表结构来替换的字段名。
#### 引用[.reference_title]
- *1* *2* *3* [Oracle-----统计函数&分组统计(group by)](https://blog.csdn.net/w15977858408/article/details/105091499)[target="_blank" data-report-click={"spm":"1018.2226.3001.9630","extra":{"utm_source":"vip_chatgpt_common_search_pc_result","utm_medium":"distribute.pc_search_result.none-task-cask-2~all~insert_cask~default-1-null.142^v91^insertT0,239^v3^insert_chatgpt"}} ] [.reference_item]
[ .reference_list ]
定义并实现一个复数类(Complex),包含实部(real)及虚部(image)两个属性,包含计算两个复数的和(add)、积(multiply)以及打印复数(print)等三个方法,类的属由构造函数进
41131


