


浅析CPU高速缓存(cache)

前言
CPU高速缓存是为了解决CPU速率和主存访问速率差距过大问题。本文主要从存储器层次结构和主流cache缓存原理角度,分享解析高速缓存,方便软件编程时写出更加高效的代码!
本文主要资料来源是《深入理解计算机系统》高速缓存章节,补充了一些里面没有提及到的几个重要概念。以读书笔记方式浅析CPU高速缓存原理。
程序员为何需要学习CPU cache?
作为一个程序员,我们需要理解存储器层次结构和CPU cache缓存原理,因为它们对程序性能有着巨大的影响。比如访问CPU寄存器中的数据,只需要一个时钟周期;访问高速缓存中的数据,大概需要几十个时钟周期;如果访问的数据在主存中,需要大概上百个周期;而访问磁盘中的数据则需要大约几千万个周期!因此我们应该了解存储器层次结构,让我们的程序尽可能得高效执行。
存储器层次结构
一种典型的存储器层级结构如下:
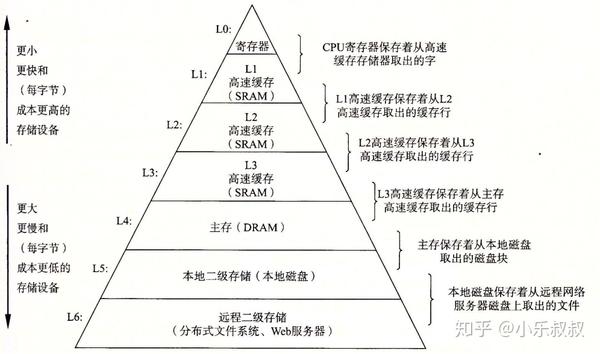

几个关键的层次访问速度:
| 存储器 | 访问速度(clock) | |
|---|---|---|
| CPU寄存器 | 1 | |
| SRAM高速缓存 | n | |
| DRAM主存 | 10n ~ 100n |
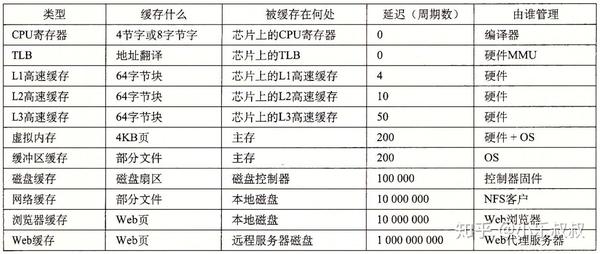
除了本文主角CPU高速缓存外,计算机系统还有很多利用“缓存”的地方:

程序运行的局部性
在了解了存储器层次结构后,我们考虑一个问题:如何用缓存提高程序运行效率?
计算机程序运行遵循局部性原则。局部性原理是指程序在执行时呈现出局部性规律,即在一段时间内,整个程序的执行仅限于程序中的某一部分。相应地,执行所访问的存储空间也局限于某个内存区域。局部性原理又表现为:时间局部性和空间局部性。
- 时间局部性 是指如果程序中的某条指令一旦执行,则不久之后该指令可能再次被执行;如果某数据被访问,则不久之后该数据可能再次被访问。
- 空间局部性 是指一旦程序访问了某个存储单元,则不久之后,其附近的存储单元也将被访问。
具有良好局部性的程序比差的程序更多的倾向于从存储器层次结构较高层次处访问数据,因此运行的更快,尤其是执行大数据量的算术运算。了解局部性原理,有利于提高我们程序的运行效率。
下面引用《深入理解计算机系统》中的一个经典例子,来理解程序局部性对效率的影响。
程序A:
int sum_arry(int a[m][n])
int i, j, sum = 0;
for (i = 0; i < m; i++) {
for (j = 0; j< n; j++)
sum += a[i][j];
return sum;
}程序B
int sum_arry(int a[m][n])
int i, j, sum = 0;