zlib
是一个常用的压缩、解压库,使用了 deflate 算法。
zip
和
unzip
工具背后其实用的就是
zlib
。Python 内置了
zlib
标准库,提供的接口也很简洁易用(
zlib.compress
和
zlib.decompress
)。
1
2
3
4
5
|
import zlib
raw = b'abc' * 100
compressed = zlib.compress(raw)
print(f'compress ratio = {len(compressed)/len(raw):.2}')
assert zlib.decompress(compressed) == raw
|
zlib
可以显著压缩数据规模。当然这个例子比较极端,重复了一百遍’abc’,能达到 5%的压缩率。在真实场景下,
zlib
大概能将原始数据压缩到 40%到 50%的大小。

zlib.compress
函数的第二个参数
level
表示压缩级别,范围从 0 到 9,数值越低表示压缩速度越快但压缩率也越高(0 表示只编码而不进行压缩),默认值是-1,在 Python 中一般会使用级别 6。我们可以对比一下不同级别的速度和压缩率。


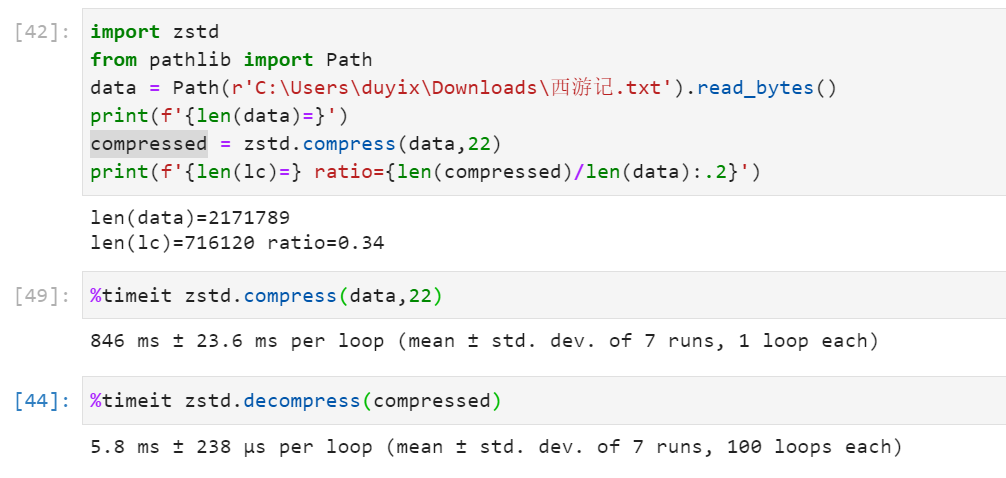
可以看到,在压缩《西游记》小说原文的场景中,级别 1 和级别 9 的压缩率从 50%提高到了 44%,但级别 1 的耗时只有级别 9 的 20%。在数据大小敏感的场景下下,1%的压缩率的提高也是很可观的。
我遇到的这个场景数据是要存在 Redis 里的,并且每个店铺的数据规模有限,倾向于使用更高的压缩率的方案。