深度学习编译已经成为当前各个主流深度学习的标配。例如,PyTorch 2.x的
torch.compile
,TensorFlow 2.x 的
tf.function
。深度学习编译的流行主要因为两种原因:
-
深度学习编译可明显提升训练和推理速度:深度学习编译过程进行了大量优化,优化过后的程序能更好地运行在硬件上。
-
深度学习加速器硬件层出不穷,上层软件为每种加速器硬件都进行编程适配的工作量太大,深度学习编译器是一种中间层,尽量减少上层软件开发的成本。
深度学习编译器
在整个深度学习软硬件栈中,深度学习编译器处于深度学习框架和底层硬件之间,它提供了一种中间层,可以覆盖不同的加速器硬件。下图中,Graph Level和Kernel Level都是深度学习编译器所希望做的事情。
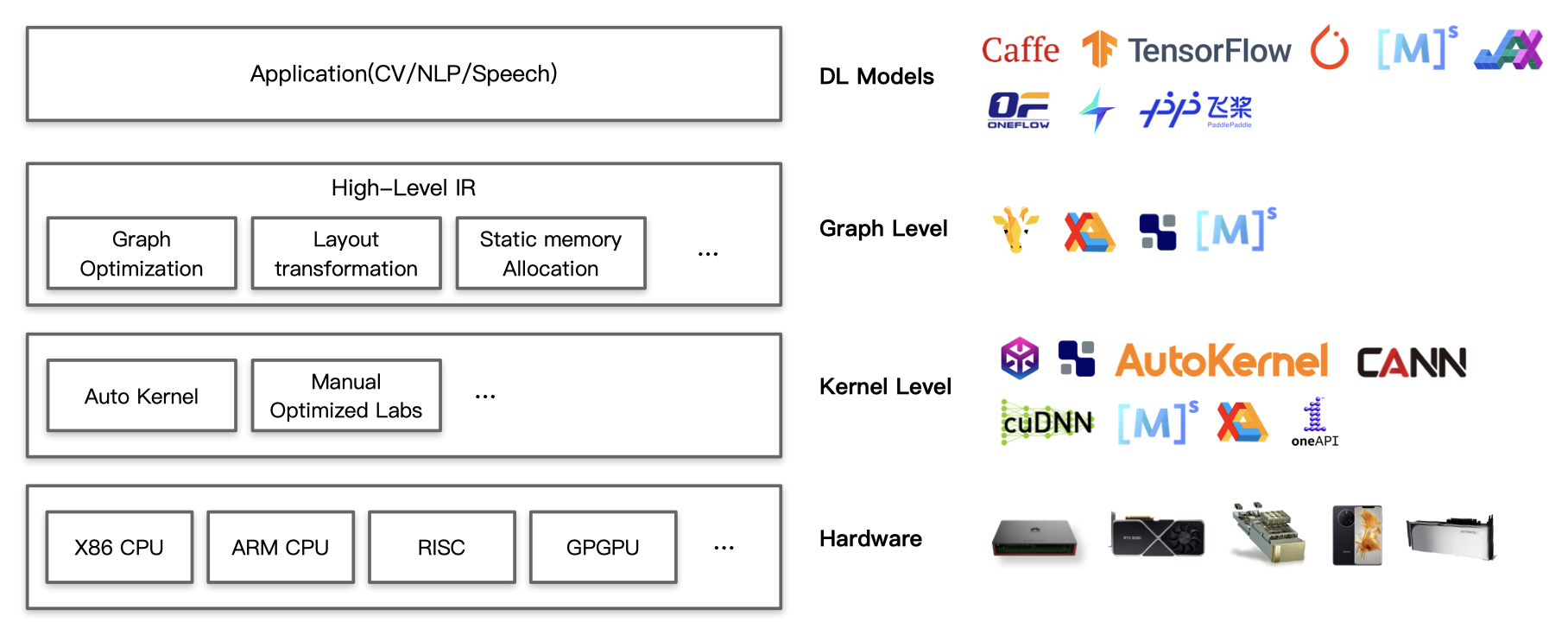 深度学习编译器处于深度学习框架和底层硬件之间
深度学习编译器处于深度学习框架和底层硬件之间
如果对软硬件栈不熟悉,这张图给人感觉比较抽象,我们仍然不是很了解深度学习编译器到底做了什么。这里给出一些具体的例子。
IR:中间表示
深度学习编译器领域出现最多的一个词就是IR,英文全称是Intermediate Representation(中间表示)。IR这个词给人一种高大上的感觉,实际上IR类似下面的代码:
%add_float_.52 (x.53: f32[], y.54: f32[]) -> f32[] {
%x.53 = f32[] parameter(0)
%y.54 = f32[] parameter(1)
ROOT %add.55 = f32[] add(f32[] %x.53, f32[] %y.54)
这是一段Google深度学习编译器XLA编译出来的IR
前端优化:从计算图到IR
在深度学习领域,通常使用计算图来表示计算,深度学习编译器将计算图转化为优化过的IR,并进一步转化为高性能的程序。下图
[3]

