|
This profile is intended for use with legacy clients or libraries. The profile is based on the
Old backward compatibility
recommended configuration.
The
Old
profile requires a minimum TLS version of 1.0.
For the Ingress Controller, the minimum TLS version is converted from 1.0 to 1.1.
Intermediate
This profile is the recommended configuration for the majority of clients. It is the default TLS security profile for the Ingress Controller, kubelet, and control plane. The profile is based on the
Intermediate compatibility
recommended configuration.
The
Intermediate
profile requires a minimum TLS version of 1.2.
Modern
This profile is intended for use with modern clients that have no need for backwards compatibility. This profile is based on the
Modern compatibility
recommended configuration.
The
Modern
profile requires a minimum TLS version of 1.3.
Custom
This profile allows you to define the TLS version and ciphers to use.
Use caution when using a
Custom
profile, because invalid configurations can cause problems.
When using one of the predefined profile types, the effective profile configuration is subject to change between releases. For example, given a specification to use the Intermediate profile deployed on release X.Y.Z, an upgrade to release X.Y.Z+1 might cause a new profile configuration to be applied, resulting in a rollout.
3.3.1.2. Configuring the TLS security profile for the Ingress Controller
To configure a TLS security profile for an Ingress Controller, edit the
IngressController
custom resource (CR) to specify a predefined or custom TLS security profile. If a TLS security profile is not configured, the default value is based on the TLS security profile set for the API server.
Prerequisites
-
You have access to the cluster as a user with the
cluster-admin
role.
Procedure
-
Edit the
IngressController
CR in the
openshift-ingress-operator
project to configure the TLS security profile:
$ oc edit IngressController default -n openshift-ingress-operator
-
Add the
spec.tlsSecurityProfile
field:
3.3.1.3. Configuring mutual TLS authentication
You can configure the Ingress Controller to enable mutual TLS (mTLS) authentication by setting a
spec.clientTLS
value. The
clientTLS
value configures the Ingress Controller to verify client certificates. This configuration includes setting a
clientCA
value, which is a reference to a config map. The config map contains the PEM-encoded CA certificate bundle that is used to verify a client’s certificate. Optionally, you can also configure a list of certificate subject filters.
If the
clientCA
value specifies an X509v3 certificate revocation list (CRL) distribution point, the Ingress Operator downloads and manages a CRL config map based on the HTTP URI X509v3
CRL Distribution Point
specified in each provided certificate. The Ingress Controller uses this config map during mTLS/TLS negotiation. Requests that do not provide valid certificates are rejected.
Procedure
-
In the
openshift-config
namespace, create a config map from your CA bundle:
$ oc create configmap \
router-ca-certs-default \
--from-file=ca-bundle.pem=client-ca.crt \1
-n openshift-config
-
1
-
The config map data key must be
ca-bundle.pem
, and the data value must be a CA certificate in PEM format.
Edit the
IngressController
resource in the
openshift-ingress-operator
project:
$ oc edit IngressController default -n openshift-ingress-operator
-
Add the
spec.clientTLS
field and subfields to configure mutual TLS:
$ openssl x509 -in custom-cert.pem -noout -subject
subject= /CN=example.com/ST=NC/C=US/O=Security/OU=OpenShift
3.4. View the default Ingress Controller
The Ingress Operator is a core feature of OpenShift Dedicated and is enabled out of the box.
Every new OpenShift Dedicated installation has an
ingresscontroller
named default. It can be supplemented with additional Ingress Controllers. If the default
ingresscontroller
is deleted, the Ingress Operator will automatically recreate it within a minute.
3.5. View Ingress Operator status
You can view and inspect the status of your Ingress Operator.
3.6. View Ingress Controller logs
You can view your Ingress Controller logs.
3.7. View Ingress Controller status
Your can view the status of a particular Ingress Controller.
3.8. Creating a custom Ingress Controller
As a cluster administrator, you can create a new custom Ingress Controller. Because the default Ingress Controller might change during OpenShift Dedicated updates, creating a custom Ingress Controller can be helpful when maintaining a configuration manually that persists across cluster updates.
This example provides a minimal spec for a custom Ingress Controller. To further customize your custom Ingress Controller, see "Configuring the Ingress Controller".
Prerequisites
-
Install the OpenShift CLI (
oc
).
Log in as a user with
cluster-admin
privileges.
Procedure
-
Create a YAML file that defines the custom
IngressController
object:
3.9. Configuring the Ingress Controller
3.9.1. Setting a custom default certificate
As an administrator, you can configure an Ingress Controller to use a custom certificate by creating a Secret resource and editing the
IngressController
custom resource (CR).
Prerequisites
-
You must have a certificate/key pair in PEM-encoded files, where the certificate is signed by a trusted certificate authority or by a private trusted certificate authority that you configured in a custom PKI.
Your certificate meets the following requirements:
The certificate is valid for the ingress domain.
The certificate uses the
subjectAltName
extension to specify a wildcard domain, such as
*.apps.ocp4.example.com
.
You must have an
IngressController
CR. You may use the default one:
$ oc --namespace openshift-ingress-operator get ingresscontrollers
-
Update the IngressController CR to reference the new certificate secret:
$ oc patch --type=merge --namespace openshift-ingress-operator ingresscontrollers/default \
--patch '{"spec":{"defaultCertificate":{"name":"custom-certs-default"}}}'
-
Verify the update was effective:
$ echo Q |\
openssl s_client -connect console-openshift-console.apps.<domain>:443 -showcerts 2>/dev/null |\
openssl x509 -noout -subject -issuer -enddate
where:
-
<domain>
-
Specifies the base domain name for your cluster.
The certificate secret name should match the value used to update the CR.
Once the IngressController CR has been modified, the Ingress Operator updates the Ingress Controller’s deployment to use the custom certificate.
3.9.2. Removing a custom default certificate
As an administrator, you can remove a custom certificate that you configured an Ingress Controller to use.
Prerequisites
-
You have access to the cluster as a user with the
cluster-admin
role.
You have installed the OpenShift CLI (
oc
).
You previously configured a custom default certificate for the Ingress Controller.
Procedure
-
To remove the custom certificate and restore the certificate that ships with OpenShift Dedicated, enter the following command:
$ oc patch -n openshift-ingress-operator ingresscontrollers/default \
--type json -p $'- op: remove\n path: /spec/defaultCertificate'
There can be a delay while the cluster reconciles the new certificate configuration.
Verification
-
To confirm that the original cluster certificate is restored, enter the following command:
$ echo Q | \
openssl s_client -connect console-openshift-console.apps.<domain>:443 -showcerts 2>/dev/null | \
openssl x509 -noout -subject -issuer -enddate
where:
-
<domain>
-
Specifies the base domain name for your cluster.
3.9.3. Autoscaling an Ingress Controller
Automatically scale an Ingress Controller to dynamically meet routing performance or availability requirements such as the requirement to increase throughput. The following procedure provides an example for scaling up the default
IngressController
.
Prerequisites
-
You have the OpenShift CLI (
oc
) installed.
You have access to an OpenShift Dedicated cluster as a user with the
cluster-admin
role.
You have the Custom Metrics Autoscaler Operator installed.
You are in the
openshift-ingress-operator
project namespace.
Procedure
-
Create a service account to authenticate with Thanos by running the following command:
$ oc create serviceaccount thanos && oc describe serviceaccount thanos
-
Create the
TriggerAuthentication
object and pass the value of the
secret
variable to the
TOKEN
parameter:
$ oc process TOKEN="$secret" -f - <<EOF | oc apply -f -
apiVersion: template.openshift.io/v1
kind: Template
parameters:
- name: TOKEN
objects:
- apiVersion: keda.sh/v1alpha1
kind: TriggerAuthentication
metadata:
name: keda-trigger-auth-prometheus
spec:
secretTargetRef:
- parameter: bearerToken
name: \${TOKEN}
key: token
- parameter: ca
name: \${TOKEN}
key: ca.crt
Create and apply a role for reading metrics from Thanos:
Create a new role, thanos-metrics-reader.yaml, that reads metrics from pods and nodes:
Add the new role to the service account by entering the following commands:
$ oc adm policy add-role-to-user thanos-metrics-reader -z thanos --role-namespace=openshift-ingress-operator
$ oc adm policy -n openshift-ingress-operator add-cluster-role-to-user cluster-monitoring-view -z thanos
The argument
add-cluster-role-to-user
is only required if you use cross-namespace queries. The following step uses a query from the
kube-metrics
namespace which requires this argument.
Create a new
ScaledObject
YAML file,
ingress-autoscaler.yaml
, that targets the default Ingress Controller deployment:
If you are using cross-namespace queries, you must target port 9091 and not port 9092 in the
serverAddress
field. You also must have elevated privileges to read metrics from this port.
Apply the custom resource definition by running the following command:
$ oc apply -f ingress-autoscaler.yaml
Verification
-
Verify that the default Ingress Controller is scaled out to match the value returned by the
kube-state-metrics
query by running the following commands:
Use the
grep
command to search the Ingress Controller YAML file for replicas:
$ oc get ingresscontroller/default -o yaml | grep replicas:
3.9.4. Scaling an Ingress Controller
Manually scale an Ingress Controller to meeting routing performance or availability requirements such as the requirement to increase throughput.
oc
commands are used to scale the
IngressController
resource. The following procedure provides an example for scaling up the default
IngressController
.
Scaling is not an immediate action, as it takes time to create the desired number of replicas.
Procedure
-
View the current number of available replicas for the default
IngressController
:
$ oc get -n openshift-ingress-operator ingresscontrollers/default -o jsonpath='{$.status.availableReplicas}'
3.9.6. Setting Ingress Controller thread count
A cluster administrator can set the thread count to increase the amount of incoming connections a cluster can handle. You can patch an existing Ingress Controller to increase the amount of threads.
Prerequisites
-
The following assumes that you already created an Ingress Controller.
3.9.7. Configuring an Ingress Controller to use an internal load balancer
When creating an Ingress Controller on cloud platforms, the Ingress Controller is published by a public cloud load balancer by default. As an administrator, you can create an Ingress Controller that uses an internal cloud load balancer.
If you want to change the
scope
for an
IngressController
, you can change the
.spec.endpointPublishingStrategy.loadBalancer.scope
parameter after the custom resource (CR) is created.
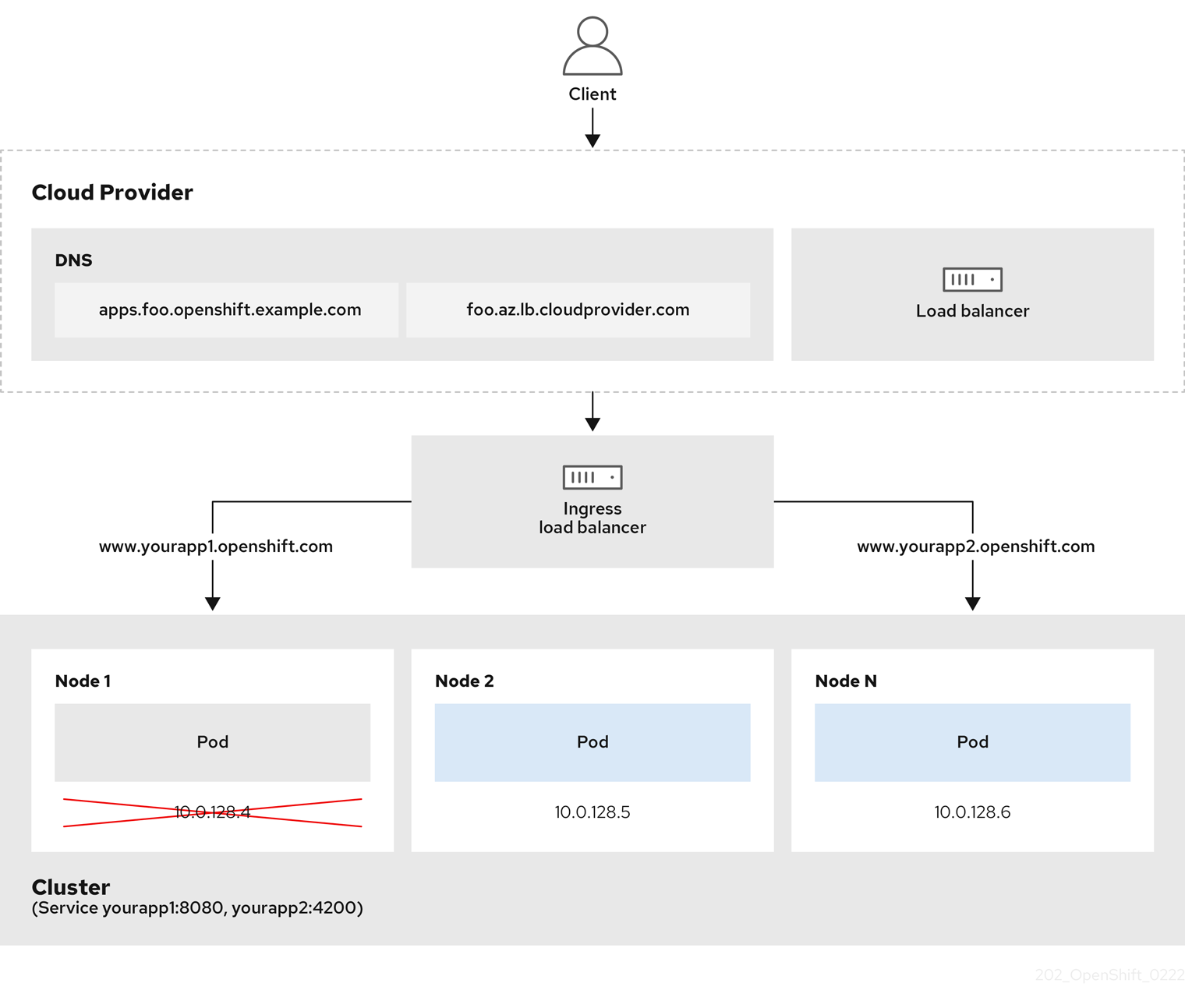
The preceding graphic shows the following concepts pertaining to OpenShift Dedicated Ingress LoadBalancerService endpoint publishing strategy:
You can load balance externally, using the cloud provider load balancer, or internally, using the OpenShift Ingress Controller Load Balancer.
You can use the single IP address of the load balancer and more familiar ports, such as 8080 and 4200 as shown on the cluster depicted in the graphic.
Traffic from the external load balancer is directed at the pods, and managed by the load balancer, as depicted in the instance of a down node. See the
Kubernetes Services documentation
for implementation details.
Prerequisites
-
Install the OpenShift CLI (
oc
).
Log in as a user with
cluster-admin
privileges.
Procedure
-
Create an
IngressController
custom resource (CR) in a file named
<name>-ingress-controller.yaml
, such as in the following example:
apiVersion: operator.openshift.io/v1
kind: IngressController
metadata:
namespace: openshift-ingress-operator
name: <name> 1
spec:
domain: <domain> 2
endpointPublishingStrategy:
type: LoadBalancerService
loadBalancer:
scope: Internal 3
-
1
-
Replace
<name>
with a name for the
IngressController
object.
Specify the
domain
for the application published by the controller.
Specify a value of
Internal
to use an internal load balancer.
Create the Ingress Controller defined in the previous step by running the following command:
$ oc create -f <name>-ingress-controller.yaml 1
-
1
-
Replace
<name>
with the name of the
IngressController
object.
Optional: Confirm that the Ingress Controller was created by running the following command:
$ oc --all-namespaces=true get ingresscontrollers
3.9.8. Setting the Ingress Controller health check interval
A cluster administrator can set the health check interval to define how long the router waits between two consecutive health checks. This value is applied globally as a default for all routes. The default value is 5 seconds.
Prerequisites
-
The following assumes that you already created an Ingress Controller.
Procedure
-
Update the Ingress Controller to change the interval between back end health checks:
$ oc -n openshift-ingress-operator patch ingresscontroller/default --type=merge -p '{"spec":{"tuningOptions": {"healthCheckInterval": "8s"}}}'
To override the
healthCheckInterval
for a single route, use the route annotation
router.openshift.io/haproxy.health.check.interval
3.9.9. Configuring the default Ingress Controller for your cluster to be internal
You can configure the
default
Ingress Controller for your cluster to be internal by deleting and recreating it.
If you want to change the
scope
for an
IngressController
, you can change the
.spec.endpointPublishingStrategy.loadBalancer.scope
parameter after the custom resource (CR) is created.
Prerequisites
-
Install the OpenShift CLI (
oc
).
Log in as a user with
cluster-admin
privileges.
Procedure
-
Configure the
default
Ingress Controller for your cluster to be internal by deleting and recreating it.
$ oc replace --force --wait --filename - <<EOF
apiVersion: operator.openshift.io/v1
kind: IngressController
metadata:
namespace: openshift-ingress-operator
name: default
spec:
endpointPublishingStrategy:
type: LoadBalancerService
loadBalancer:
scope: Internal
EOF
3.9.10. Configuring the route admission policy
Administrators and application developers can run applications in multiple namespaces with the same domain name. This is for organizations where multiple teams develop microservices that are exposed on the same hostname.
Allowing claims across namespaces should only be enabled for clusters with trust between namespaces, otherwise a malicious user could take over a hostname. For this reason, the default admission policy disallows hostname claims across namespaces.
Prerequisites
-
Cluster administrator privileges.
Procedure
-
Edit the
.spec.routeAdmission
field of the
ingresscontroller
resource variable using the following command:
$ oc -n openshift-ingress-operator patch ingresscontroller/default --patch '{"spec":{"routeAdmission":{"namespaceOwnership":"InterNamespaceAllowed"}}}' --type=merge
3.9.11. Using wildcard routes
The HAProxy Ingress Controller has support for wildcard routes. The Ingress Operator uses
wildcardPolicy
to configure the
ROUTER_ALLOW_WILDCARD_ROUTES
environment variable of the Ingress Controller.
The default behavior of the Ingress Controller is to admit routes with a wildcard policy of
None
, which is backwards compatible with existing
IngressController
resources.
Procedure
-
Configure the wildcard policy.
Use the following command to edit the
IngressController
resource:
$ oc edit IngressController
-
Under
spec
, set the
wildcardPolicy
field to
WildcardsDisallowed
or
WildcardsAllowed
:
spec:
routeAdmission:
wildcardPolicy: WildcardsDisallowed # or WildcardsAllowed
3.9.14. Using X-Forwarded headers
You configure the HAProxy Ingress Controller to specify a policy for how to handle HTTP headers including
Forwarded
and
X-Forwarded-For
. The Ingress Operator uses the
HTTPHeaders
field to configure the
ROUTER_SET_FORWARDED_HEADERS
environment variable of the Ingress Controller.
Procedure
-
Configure the
HTTPHeaders
field for the Ingress Controller.
Use the following command to edit the
IngressController
resource:
$ oc edit IngressController
-
Under
spec
, set the
HTTPHeaders
policy field to
Append
,
Replace
,
IfNone
, or
Never
:
apiVersion: operator.openshift.io/v1
kind: IngressController
metadata:
name: default
namespace: openshift-ingress-operator
spec:
httpHeaders:
forwardedHeaderPolicy: Append
Example use cases
As a cluster administrator, you can:
Configure an external proxy that injects the
X-Forwarded-For
header into each request before forwarding it to an Ingress Controller.
To configure the Ingress Controller to pass the header through unmodified, you specify the
never
policy. The Ingress Controller then never sets the headers, and applications receive only the headers that the external proxy provides.
Configure the Ingress Controller to pass the
X-Forwarded-For
header that your external proxy sets on external cluster requests through unmodified.
To configure the Ingress Controller to set the
X-Forwarded-For
header on internal cluster requests, which do not go through the external proxy, specify the
if-none
policy. If an HTTP request already has the header set through the external proxy, then the Ingress Controller preserves it. If the header is absent because the request did not come through the proxy, then the Ingress Controller adds the header.
As an application developer, you can:
Configure an application-specific external proxy that injects the
X-Forwarded-For
header.
To configure an Ingress Controller to pass the header through unmodified for an application’s Route, without affecting the policy for other Routes, add an annotation
haproxy.router.openshift.io/set-forwarded-headers: if-none
or
haproxy.router.openshift.io/set-forwarded-headers: never
on the Route for the application.
You can set the
haproxy.router.openshift.io/set-forwarded-headers
annotation on a per route basis, independent from the globally set value for the Ingress Controller.
3.9.15. Enabling HTTP/2 Ingress connectivity
You can enable transparent end-to-end HTTP/2 connectivity in HAProxy. It allows application owners to make use of HTTP/2 protocol capabilities, including single connection, header compression, binary streams, and more.
You can enable HTTP/2 connectivity for an individual Ingress Controller or for the entire cluster.
To enable the use of HTTP/2 for the connection from the client to HAProxy, a route must specify a custom certificate. A route that uses the default certificate cannot use HTTP/2. This restriction is necessary to avoid problems from connection coalescing, where the client re-uses a connection for different routes that use the same certificate.
The connection from HAProxy to the application pod can use HTTP/2 only for re-encrypt routes and not for edge-terminated or insecure routes. This restriction is because HAProxy uses Application-Level Protocol Negotiation (ALPN), which is a TLS extension, to negotiate the use of HTTP/2 with the back-end. The implication is that end-to-end HTTP/2 is possible with passthrough and re-encrypt and not with insecure or edge-terminated routes.
For non-passthrough routes, the Ingress Controller negotiates its connection to the application independently of the connection from the client. This means a client may connect to the Ingress Controller and negotiate HTTP/1.1, and the Ingress Controller may then connect to the application, negotiate HTTP/2, and forward the request from the client HTTP/1.1 connection using the HTTP/2 connection to the application. This poses a problem if the client subsequently tries to upgrade its connection from HTTP/1.1 to the WebSocket protocol, because the Ingress Controller cannot forward WebSocket to HTTP/2 and cannot upgrade its HTTP/2 connection to WebSocket. Consequently, if you have an application that is intended to accept WebSocket connections, it must not allow negotiating the HTTP/2 protocol or else clients will fail to upgrade to the WebSocket protocol.
3.9.16. Configuring the PROXY protocol for an Ingress Controller
A cluster administrator can configure
the PROXY protocol
when an Ingress Controller uses either the
HostNetwork
,
NodePortService
, or
Private
endpoint publishing strategy types. The PROXY protocol enables the load balancer to preserve the original client addresses for connections that the Ingress Controller receives. The original client addresses are useful for logging, filtering, and injecting HTTP headers. In the default configuration, the connections that the Ingress Controller receives only contain the source address that is associated with the load balancer.
The default Ingress Controller with installer-provisioned clusters on non-cloud platforms that use a Keepalived Ingress Virtual IP (VIP) do not support the PROXY protocol.
The PROXY protocol enables the load balancer to preserve the original client addresses for connections that the Ingress Controller receives. The original client addresses are useful for logging, filtering, and injecting HTTP headers. In the default configuration, the connections that the Ingress Controller receives contain only the source IP address that is associated with the load balancer.
For a passthrough route configuration, servers in OpenShift Dedicated clusters cannot observe the original client source IP address. If you need to know the original client source IP address, configure Ingress access logging for your Ingress Controller so that you can view the client source IP addresses.
For re-encrypt and edge routes, the OpenShift Dedicated router sets the
Forwarded
and
X-Forwarded-For
headers so that application workloads check the client source IP address.
For more information about Ingress access logging, see "Configuring Ingress access logging".
Configuring the PROXY protocol for an Ingress Controller is not supported when using the
LoadBalancerService
endpoint publishing strategy type. This restriction is because when OpenShift Dedicated runs in a cloud platform, and an Ingress Controller specifies that a service load balancer should be used, the Ingress Operator configures the load balancer service and enables the PROXY protocol based on the platform requirement for preserving source addresses.
You must configure both OpenShift Dedicated and the external load balancer to use either the PROXY protocol or TCP.
This feature is not supported in cloud deployments. This restriction is because when OpenShift Dedicated runs in a cloud platform, and an Ingress Controller specifies that a service load balancer should be used, the Ingress Operator configures the load balancer service and enables the PROXY protocol based on the platform requirement for preserving source addresses.
You must configure both OpenShift Dedicated and the external load balancer to either use the PROXY protocol or to use Transmission Control Protocol (TCP).
Prerequisites
-
You created an Ingress Controller.
Procedure
-
Edit the Ingress Controller resource by entering the following command in your CLI:
$ oc -n openshift-ingress-operator edit ingresscontroller/default
-
Set the PROXY configuration:
If your Ingress Controller uses the
HostNetwork
endpoint publishing strategy type, set the
spec.endpointPublishingStrategy.hostNetwork.protocol
subfield to
PROXY
:
3.9.17. Specifying an alternative cluster domain using the appsDomain option
As a cluster administrator, you can specify an alternative to the default cluster domain for user-created routes by configuring the
appsDomain
field. The
appsDomain
field is an optional domain for OpenShift Dedicated to use instead of the default, which is specified in the
domain
field. If you specify an alternative domain, it overrides the default cluster domain for the purpose of determining the default host for a new route.
For example, you can use the DNS domain for your company as the default domain for routes and ingresses for applications running on your cluster.
Prerequisites
-
You deployed an OpenShift Dedicated cluster.
You installed the
oc
command line interface.
Procedure
-
Configure the
appsDomain
field by specifying an alternative default domain for user-created routes.
Edit the ingress
cluster
resource:
$ oc edit ingresses.config/cluster -o yaml
-
Edit the YAML file:
3.9.19. Using router compression
You configure the HAProxy Ingress Controller to specify router compression globally for specific MIME types. You can use the
mimeTypes
variable to define the formats of MIME types to which compression is applied. The types are: application, image, message, multipart, text, video, or a custom type prefaced by "X-". To see the full notation for MIME types and subtypes, see
RFC1341
.
Memory allocated for compression can affect the max connections. Additionally, compression of large buffers can cause latency, like heavy regex or long lists of regex.
Not all MIME types benefit from compression, but HAProxy still uses resources to try to compress if instructed to. Generally, text formats, such as html, css, and js, formats benefit from compression, but formats that are already compressed, such as image, audio, and video, benefit little in exchange for the time and resources spent on compression.
Procedure
-
Configure the
httpCompression
field for the Ingress Controller.
Use the following command to edit the
IngressController
resource:
$ oc edit -n openshift-ingress-operator ingresscontrollers/default
-
Under
spec
, set the
httpCompression
policy field to
mimeTypes
and specify a list of MIME types that should have compression applied:
apiVersion: operator.openshift.io/v1
kind: IngressController
metadata:
name: default
namespace: openshift-ingress-operator
spec:
httpCompression:
mimeTypes:
- "text/html"
- "text/css; charset=utf-8"
- "application/json"
...
3.9.20. Exposing router metrics
You can expose the HAProxy router metrics by default in Prometheus format on the default stats port, 1936. The external metrics collection and aggregation systems such as Prometheus can access the HAProxy router metrics. You can view the HAProxy router metrics in a browser in the HTML and comma separated values (CSV) format.
Prerequisites
-
You configured your firewall to access the default stats port, 1936.
Procedure
-
Get the router pod name by running the following command:
$ oc get pods -n openshift-ingress
-
Get the password by running the following command:
$ oc rsh <router_pod_name> cat metrics-auth/statsPassword
Get the router IP and metrics certificates by running the following command:
$ oc describe pod <router_pod>
Get the raw statistics in Prometheus format by running the following command:
$ curl -u <user>:<password> http://<router_IP>:<stats_port>/metrics
Access the metrics securely by running the following command:
$ curl -u user:password https://<router_IP>:<stats_port>/metrics -k
Access the default stats port, 1936, by running the following command:
$ curl -u <user>:<password> http://<router_IP>:<stats_port>/metrics
Example 3.1. Example output
...
# HELP haproxy_backend_connections_total Total number of connections.
# TYPE haproxy_backend_connections_total gauge
haproxy_backend_connections_total{backend="http",namespace="default",route="hello-route"} 0
haproxy_backend_connections_total{backend="http",namespace="default",route="hello-route-alt"} 0
haproxy_backend_connections_total{backend="http",namespace="default",route="hello-route01"} 0
# HELP haproxy_exporter_server_threshold Number of servers tracked and the current threshold value.
# TYPE haproxy_exporter_server_threshold gauge
haproxy_exporter_server_threshold{type="current"} 11
haproxy_exporter_server_threshold{type="limit"} 500
# HELP haproxy_frontend_bytes_in_total Current total of incoming bytes.
# TYPE haproxy_frontend_bytes_in_total gauge
haproxy_frontend_bytes_in_total{frontend="fe_no_sni"} 0
haproxy_frontend_bytes_in_total{frontend="fe_sni"} 0
haproxy_frontend_bytes_in_total{frontend="public"} 119070
# HELP haproxy_server_bytes_in_total Current total of incoming bytes.
# TYPE haproxy_server_bytes_in_total gauge
haproxy_server_bytes_in_total{namespace="",pod="",route="",server="fe_no_sni",service=""} 0
haproxy_server_bytes_in_total{namespace="",pod="",route="",server="fe_sni",service=""} 0
haproxy_server_bytes_in_total{namespace="default",pod="docker-registry-5-nk5fz",route="docker-registry",server="10.130.0.89:5000",service="docker-registry"} 0
haproxy_server_bytes_in_total{namespace="default",pod="hello-rc-vkjqx",route="hello-route",server="10.130.0.90:8080",service="hello-svc-1"} 0
Launch the stats window by entering the following URL in a browser:
http://<user>:<password>@<router_IP>:<stats_port>
Optional: Get the stats in CSV format by entering the following URL in a browser:
http://<user>:<password>@<router_ip>:1936/metrics;csv
3.9.21. Customizing HAProxy error code response pages
As a cluster administrator, you can specify a custom error code response page for either 503, 404, or both error pages. The HAProxy router serves a 503 error page when the application pod is not running or a 404 error page when the requested URL does not exist. For example, if you customize the 503 error code response page, then the page is served when the application pod is not running, and the default 404 error code HTTP response page is served by the HAProxy router for an incorrect route or a non-existing route.
Custom error code response pages are specified in a config map then patched to the Ingress Controller. The config map keys have two available file names as follows:
error-page-503.http
and
error-page-404.http
.
Custom HTTP error code response pages must follow the
HAProxy HTTP error page configuration guidelines
. Here is an example of the default OpenShift Dedicated HAProxy router
http 503 error code response page
. You can use the default content as a template for creating your own custom page.
By default, the HAProxy router serves only a 503 error page when the application is not running or when the route is incorrect or non-existent. This default behavior is the same as the behavior on OpenShift Dedicated 4.8 and earlier. If a config map for the customization of an HTTP error code response is not provided, and you are using a custom HTTP error code response page, the router serves a default 404 or 503 error code response page.
If you use the OpenShift Dedicated default 503 error code page as a template for your customizations, the headers in the file require an editor that can use CRLF line endings.
Procedure
-
Create a config map named
my-custom-error-code-pages
in the
openshift-config
namespace:
$ oc -n openshift-config create configmap my-custom-error-code-pages \
--from-file=error-page-503.http \
--from-file=error-page-404.http
If you do not specify the correct format for the custom error code response page, a router pod outage occurs. To resolve this outage, you must delete or correct the config map and delete the affected router pods so they can be recreated with the correct information.
Patch the Ingress Controller to reference the
my-custom-error-code-pages
config map by name:
$ oc patch -n openshift-ingress-operator ingresscontroller/default --patch '{"spec":{"httpErrorCodePages":{"name":"my-custom-error-code-pages"}}}' --type=merge
The Ingress Operator copies the
my-custom-error-code-pages
config map from the
openshift-config
namespace to the
openshift-ingress
namespace. The Operator names the config map according to the pattern,
<your_ingresscontroller_name>-errorpages
, in the
openshift-ingress
namespace.
Display the copy:
$ oc get cm default-errorpages -n openshift-ingress
-
For 404 custom HTTP custom error code response:
$ oc -n openshift-ingress rsh <router_pod> cat /var/lib/haproxy/conf/error_code_pages/error-page-404.http
For 404 custom http error code response:
Visit a non-existent route or an incorrect route.
Run the following curl command or visit the route hostname in the browser:
$ curl -vk <route_hostname>
Check if the
errorfile
attribute is properly in the
haproxy.config
file:
$ oc -n openshift-ingress rsh <router> cat /var/lib/haproxy/conf/haproxy.config | grep errorfile
3.9.22. Setting the Ingress Controller maximum connections
A cluster administrator can set the maximum number of simultaneous connections for OpenShift router deployments. You can patch an existing Ingress Controller to increase the maximum number of connections.
Prerequisites
-
The following assumes that you already created an Ingress Controller
Procedure
-
Update the Ingress Controller to change the maximum number of connections for HAProxy:
$ oc -n openshift-ingress-operator patch ingresscontroller/default --type=merge -p '{"spec":{"tuningOptions": {"maxConnections": 7500}}}'
If you set the
spec.tuningOptions.maxConnections
value greater than the current operating system limit, the HAProxy process will not start. See the table in the "Ingress Controller configuration parameters" section for more information about this parameter.
3.10. OpenShift Dedicated Ingress Operator configurations
The following table details the components of the Ingress Operator and if Red Hat Site Reliability Engineers (SRE) maintains this component on OpenShift Dedicated clusters.
Table 3.3. Ingress Operator Responsibility Chart
|
Ingress component
|
Managed by
|
Default configuration?
|
|
Scaling Ingress Controller
Ingress Operator thread count
Ingress Controller access logging
Ingress Controller sharding
Ingress Controller route admission policy
Ingress Controller wildcard routes
Ingress Controller X-Forwarded headers
Ingress Controller route compression
|
Chapter 4. OpenShift SDN default CNI network provider
4.1. Enabling multicast for a project
OpenShift SDN CNI is deprecated as of OpenShift Dedicated 4.14. As of OpenShift Dedicated 4.15, the network plugin is not an option for new installations. In a subsequent future release, the OpenShift SDN network plugin is planned to be removed and no longer supported. Red Hat will provide bug fixes and support for this feature until it is removed, but this feature will no longer receive enhancements. As an alternative to OpenShift SDN CNI, you can use OVN Kubernetes CNI instead.
With IP multicast, data is broadcast to many IP addresses simultaneously.
-
At this time, multicast is best used for low-bandwidth coordination or service discovery and not a high-bandwidth solution.
By default, network policies affect all connections in a namespace. However, multicast is unaffected by network policies. If multicast is enabled in the same namespace as your network policies, it is always allowed, even if there is a
deny-all
network policy. Cluster administrators should consider the implications to the exemption of multicast from network policies before enabling it.
Multicast traffic between OpenShift Dedicated pods is disabled by default. If you are using the OpenShift SDN network plugin, you can enable multicast on a per-project basis.
When using the OpenShift SDN network plugin in
networkpolicy
isolation mode:
Multicast packets sent by a pod will be delivered to all other pods in the project, regardless of
NetworkPolicy
objects. Pods might be able to communicate over multicast even when they cannot communicate over unicast.
Multicast packets sent by a pod in one project will never be delivered to pods in any other project, even if there are
NetworkPolicy
objects that allow communication between the projects.
When using the OpenShift SDN network plugin in
multitenant
isolation mode:
Multicast packets sent by a pod will be delivered to all other pods in the project.
Multicast packets sent by a pod in one project will be delivered to pods in other projects only if each project is joined together and multicast is enabled in each joined project.
4.1.2. Enabling multicast between pods
You can enable multicast between pods for your project.
Prerequisites
-
Install the OpenShift CLI (
oc
).
You must log in to the cluster with a user that has the
cluster-admin
or the
dedicated-admin
role.
Procedure
-
Run the following command to enable multicast for a project. Replace
<namespace>
with the namespace for the project you want to enable multicast for.
$ oc annotate netnamespace <namespace> \
netnamespace.network.openshift.io/multicast-enabled=true
Start the multicast transmitter.
Get the pod network IP address range:
$ CIDR=$(oc get Network.config.openshift.io cluster \
-o jsonpath='{.status.clusterNetwork[0].cidr}')
To send a multicast message, enter the following command:
$ oc exec msender -i -t -- \
/bin/bash -c "echo | socat STDIO UDP4-DATAGRAM:224.1.0.1:30102,range=$CIDR,ip-multicast-ttl=64"
If multicast is working, the previous command returns the following output:
mlistener
Chapter 5. Network verification for OpenShift Dedicated clusters
Network verification checks run automatically when you deploy an OpenShift Dedicated cluster into an existing Virtual Private Cloud (VPC) or create an additional machine pool with a subnet that is new to your cluster. The checks validate your network configuration and highlight errors, enabling you to resolve configuration issues prior to deployment.
You can also run the network verification checks manually to validate the configuration for an existing cluster.
5.1. Understanding network verification for OpenShift Dedicated clusters
When you deploy an OpenShift Dedicated cluster into an existing Virtual Private Cloud (VPC) or create an additional machine pool with a subnet that is new to your cluster, network verification runs automatically. This helps you identify and resolve configuration issues prior to deployment.
When you prepare to install your cluster by using Red Hat OpenShift Cluster Manager, the automatic checks run after you input a subnet into a subnet ID field on the
Virtual Private Cloud (VPC) subnet settings
page.
When you add a machine pool with a subnet that is new to your cluster, the automatic network verification checks the subnet to ensure that network connectivity is available before the machine pool is provisioned.
After automatic network verification completes, a record is sent to the service log. The record provides the results of the verification check, including any network configuration errors. You can resolve the identified issues before a deployment and the deployment has a greater chance of success.
You can also run the network verification manually for an existing cluster. This enables you to verify the network configuration for your cluster after making configuration changes. For steps to run the network verification checks manually, see
Running the network verification manually
.
5.2. Scope of the network verification checks
The network verification includes checks for each of the following requirements:
The parent Virtual Private Cloud (VPC) exists.
All specified subnets belong to the VPC.
The VPC has
enableDnsSupport
enabled.
The VPC has
enableDnsHostnames
enabled.
Egress is available to the required domain and port combinations that are specified in the
AWS firewall prerequisites
section.
5.3. Automatic network verification bypassing
You can bypass the automatic network verification if you want to deploy an OpenShift Dedicated cluster with known network configuration issues into an existing Virtual Private Cloud (VPC).
If you bypass the network verification when you create a cluster, the cluster has a limited support status. After installation, you can resolve the issues and then manually run the network verification. The limited support status is removed after the verification succeeds.
When you install a cluster into an existing VPC by using Red Hat OpenShift Cluster Manager, you can bypass the automatic verification by selecting
Bypass network verification
on the
Virtual Private Cloud (VPC) subnet settings
page.
5.4. Running the network verification manually
You can manually run the network verification checks for an existing OpenShift Dedicated cluster by using Red Hat OpenShift Cluster Manager.
Prerequisites
-
You have an existing OpenShift Dedicated cluster.
You are the cluster owner or you have the cluster editor role.
Procedure
-
Navigate to
OpenShift Cluster Manager
and select your cluster.
Select
Verify networking
from the
Actions
drop-down menu.
Chapter 6. Configuring a cluster-wide proxy
If you are using an existing Virtual Private Cloud (VPC), you can configure a cluster-wide proxy during an OpenShift Dedicated cluster installation or after the cluster is installed. When you enable a proxy, the core cluster components are denied direct access to the internet, but the proxy does not affect user workloads.
Only cluster system egress traffic is proxied, including calls to the cloud provider API.
You can enable a proxy only for OpenShift Dedicated clusters that use the Customer Cloud Subscription (CCS) model.
If you use a cluster-wide proxy, you are responsible for maintaining the availability of the proxy to the cluster. If the proxy becomes unavailable, then it might impact the health and supportability of the cluster.
6.1. Prerequisites for configuring a cluster-wide proxy
To configure a cluster-wide proxy, you must meet the following requirements. These requirements are valid when you configure a proxy during installation or postinstallation.
General requirements
-
You are the cluster owner.
Your account has sufficient privileges.
You have an existing Virtual Private Cloud (VPC) for your cluster.
You are using the Customer Cloud Subscription (CCS) model for your cluster.
The proxy can access the VPC for the cluster and the private subnets of the VPC. The proxy is also accessible from the VPC for the cluster and from the private subnets of the VPC.
You have added the following endpoints to your VPC endpoint:
ec2.<aws_region>.amazonaws.com
elasticloadbalancing.<aws_region>.amazonaws.com
s3.<aws_region>.amazonaws.com
These endpoints are required to complete requests from the nodes to the AWS EC2 API. Because the proxy works at the container level and not at the node level, you must route these requests to the AWS EC2 API through the AWS private network. Adding the public IP address of the EC2 API to your allowlist in your proxy server is not enough.
When using a cluster-wide proxy, you must configure the
s3.<aws_region>.amazonaws.com
endpoint as type
Gateway
.
Network requirements
|