

ICLR 2023:环境标签平滑,一行代码提升对抗学习稳定性/泛化性

Domain adaptation(DA: 域自适应),Domain generalization(DG: 域泛化)一直以来都是各大顶会的热门研究方向。DA假设我们有有一个带标签的训练集(源域),这时候我们想让模型在另一个数据集上同样表现很好(目标域),利用目标域的无标签数据,提升模型在域间的适应能力是DA所强调的。以此为基础,DG进一步弱化了假设,我们只有多个源域的数据,根本不知道目标域是什么,这个时候如何提升模型泛化性呢?核心在于如何利用多个源域带来的丰富信息。
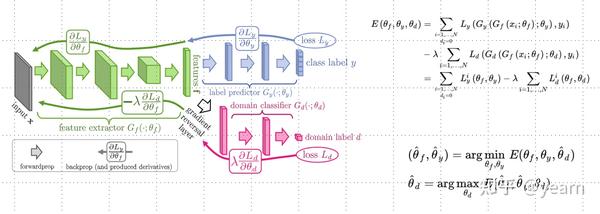
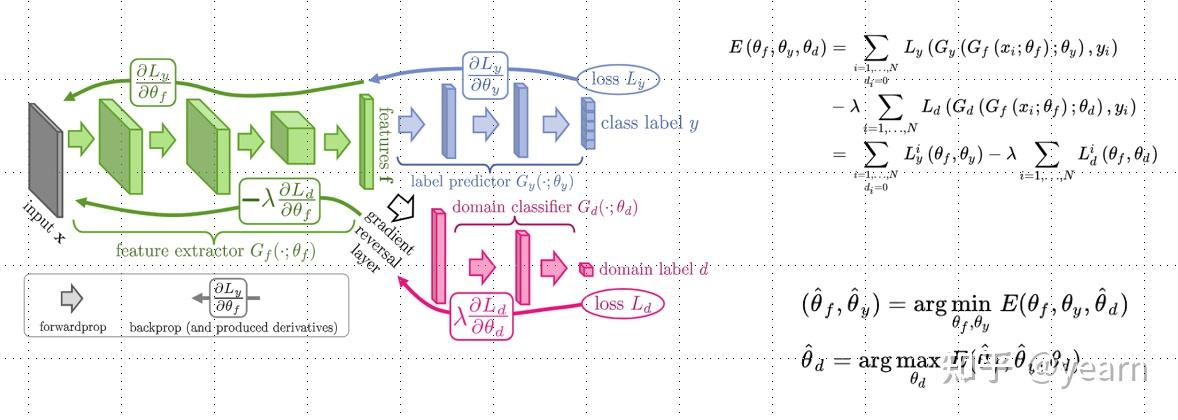
通过域对抗训练( Domain adversarial training : DAT)最小化域分歧(domain divergence),在DA/DG任务中显示出了很好的的泛化性能。如下图所示,我们在backbone+classifier的基础上增加一个域分类器来对特征归属的域进行分类,在梯度反传至backbone时将符号取负,以此训练backbone让他的特征与域信息无关,只与分类信息相关。尽管DAT具有领域适应和领域泛化的能力,但它以难以训练和收敛而闻名。
本文介绍我们发表于ICLR 2023得文章《Free Lunch for Domain Adversarial Training: Environment Label Smoothing 》,只需要对DAT算法的域分类器进行一行代码的修改,就可以在多种任务上取得更好的泛化效果,训练稳定性,以及收敛速度。
论文题目 :
Free Lunch for Domain Adversarial Training: Environment Label Smoothing
论文链接 :
https:// arxiv.org/abs/2302.0019 4
代码链接 :
https:// github.com/yfzhang114/E nvironment-Label-Smoothing


Motivation
本文的motivation主要有两点
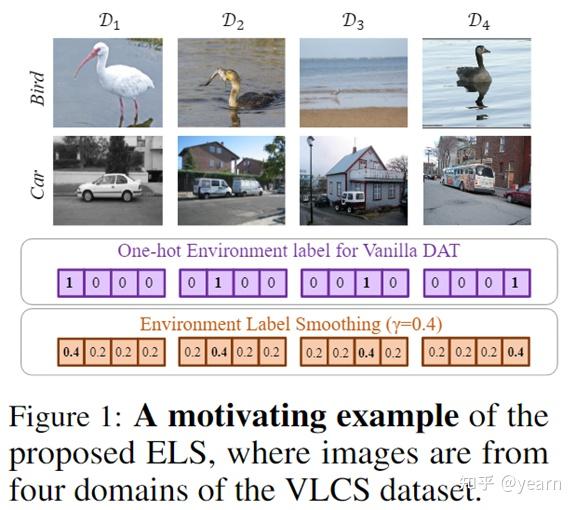
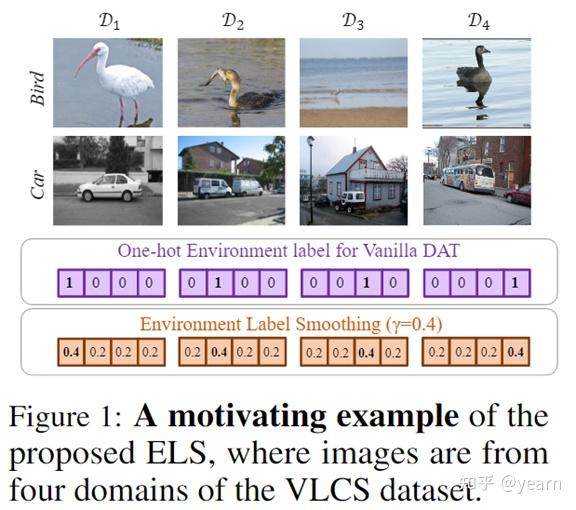
- Environment label noise from domain partition 。众所周知,标签噪音是普遍存在的,环境标签也不例外。首先(1)域标签都是人为规定的,比如如下的VLCS数据集,他们之间并没有非常明显的视觉差异。(2)随着训练的进行,encoder对不同域产生的特征将会越来越相似,然而我们对不同域的特征仍然保持原有的标签。域判别器会过度拟合这些错误标记的例子,从而泛化能力较差。


- Flaws of one-hot environment labels 。使用one-hot标签进行训练,模型输出概率将会高度自信,造成泛化能力差等问题。对于DAT,一个非常自信的域鉴别器会导致梯度消失,不利于训练稳定性。
为了使得DAT算法的训练更加稳定,我们需要1. 让训练过程对噪音标签比较鲁棒,2. 让域分类器的输出不要过于自信。为此我们提出了一个非常简单的算法,environment label smoothing (ELS),将域标签从one-hot形式转化为软标签。
数学上来讲,我们将encoder记作 g ,分类器以及域分类器记作 \hat{h}',\hat{h} ,给定 M 个域 D_1,...,D_M , 分类损失函数 \ell ,smoothing parameter \gamma ,传统的DANN与DANS差别如下


实验效果
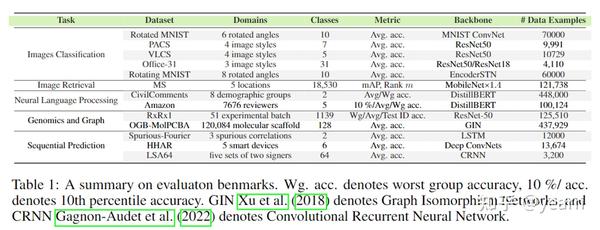
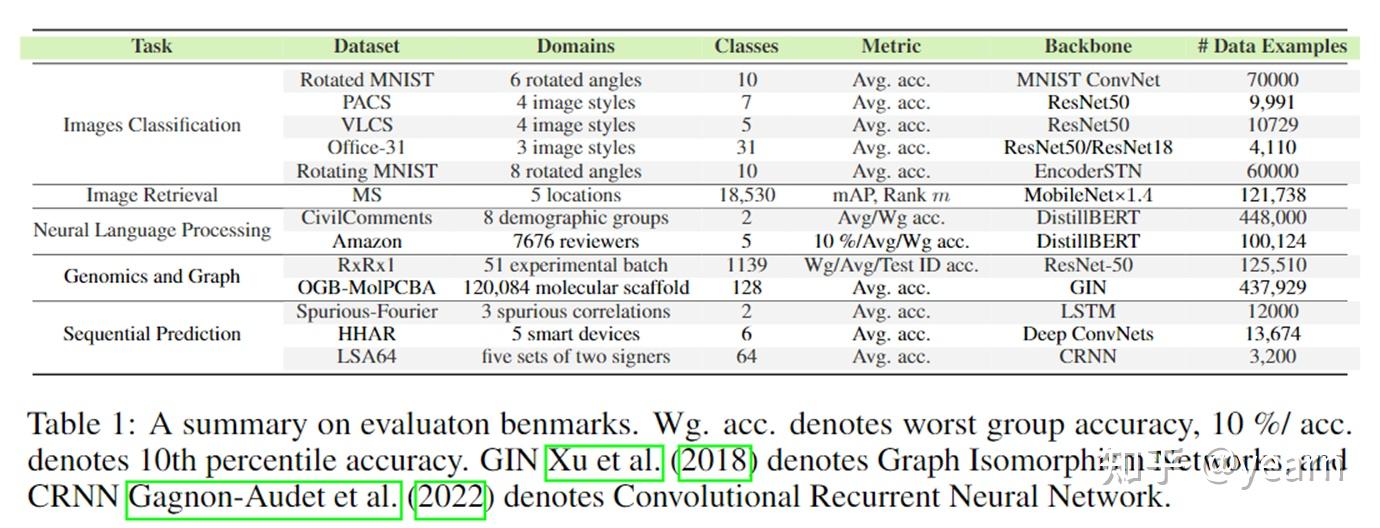
我们在囊括五个任务,十一个数据集,包括十种不同的backbone上验证我们的方法。我们的目标是使得所选择的数据集符合以下条件
- 不同数量的域(从3到120,084);
- 不同数量的类别(从2个到18,530个);
- 不同的数据集大小(从3200到448,000);
- 各种数据维度和backbone(Transformer, ResNet, MobileNet, GIN, RNN)。
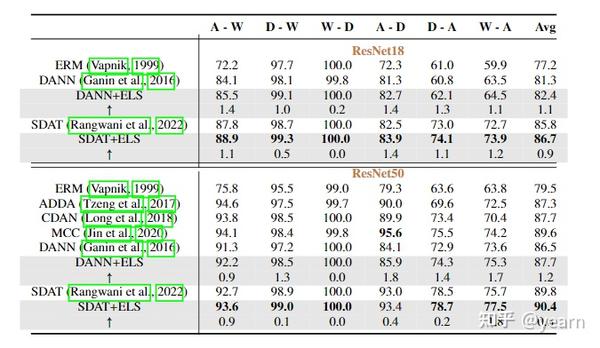
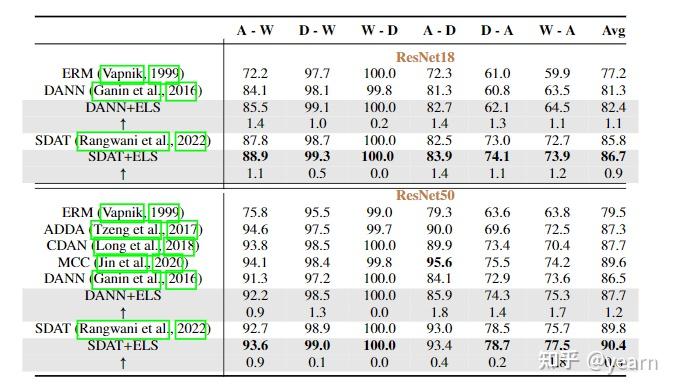
在所有任务上,将我们的ELS与DAT方法结合都取得了明显的性能提升。特别的,在domain adaptation的benchmark上,我们的方法与SDAT结合达到了新的SOTA
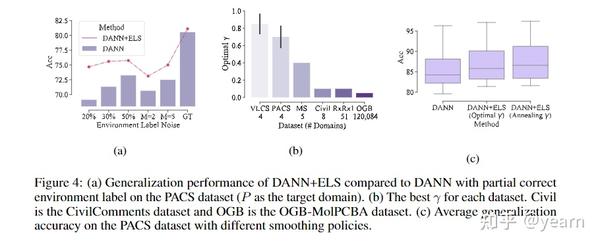
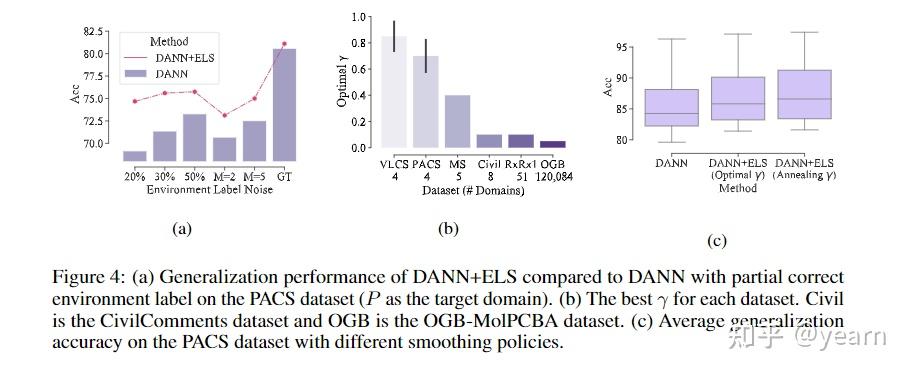
我们也做了一下其他很有意思的实验比如下图(a)我们验证了在标签噪音存在的情况下,ELS+DANN的效果比DANN本身好很多,噪音越大,ELS的好处越明显。(b)我们对如何选择smoothing parameter进行了精细的研究,实验表明,域的数目越多往往需要月小的 \gamma ,域之间的差异越大,域分类器越容易over-confident,因此需要更小的 \gamma 。(c)我们提出了一种smoothing技术,避免繁琐的参数选择,即我们使用 \gamma=1.0-\frac{M-1}{M}\frac{t}{T} , M 是域的数目, t,T 分别是当前训练的iteration以及总共的iteration。
理论验证
这部分是文章的主要贡献之一,我们首先假设鉴别器是无约束优化的,为应用ELS提供了一个理论解释。然后在对梯度的解释和分析的基础上,讨论了ELS如何使训练过程更加稳定。然后,我们从理论上证明,使用ELS,标签噪声的影响可以被消除。最后,为了减轻无约束假设的影响,分别分析了经验间隙、参数化间隙和非渐近收敛性。
Divergence minimization interpretation


我们知道传统DANN的,给定源域和目标域 D_S,D_T ,对抗学习解释为在最小化两个域的JS散度即, 2D_{JS}(D_S||D_T)-2\log 2 ,而我们知道,当这两个域没有overlap的时候,他们离得很远,但是JS散度永远是常数,不会提供任何梯度信息。相比之下,我们的方法可以平滑这两个分布,去优化两个分布的混合分布,使整个训练过程更加稳定。值得注意的是,这与控制 \lambda 来调整损失权重是不一样的,一旦两个域没有overlap, \lambda 的大小makes no difference,但是平滑不一样。我们也在文中联系了GAN的训练过程中为什么需要使用one-side label smoothing而不是传统的label smoothing。
Training stability
在这一小节我们主要有三个理论结果
-
Noise injection for extending distribution supports
. GANs训练不稳定性的主要来源是实数,生成的分布具有不相交的支撑空间或位于低维流形上。向数据添加来自任意分布的噪声被证明能够扩展两个分布的支持空间,并将保护鉴别器不受测度为0的对抗示例的影响,这将导致稳定且行为良好的训练。环境标签平滑可以看作是一种噪声注入就像我们在上一节的结果中说的那样,其中噪声为γ(DS−DT),两种分布更有可能存在联合支撑。
-
ELS relieves the gradient vanishing phenomenon
. 我们表明,在vanilla DANN中,随着鉴别器变得更好,从鉴别器传递到编码器的梯度会消失。也就是说,要么近似不准确,要么梯度消失,这将使对抗训练极其困难。合并ELS可以缓解这个问题。
-
ELS serves as a data-driven regularization and stabilizes the os-cillatory gradients
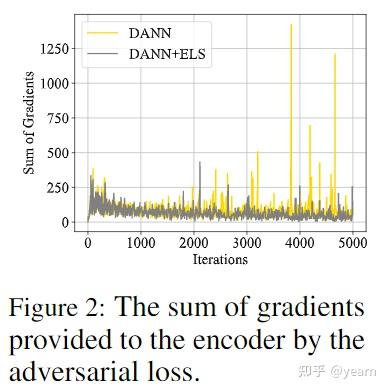
。 编码器相对于对抗损失的梯度在原生DANN中保持高度振荡,这是对抗训练不稳定的重要原因。下图显示了整个训练过程中的梯度动态,其中以PACS数据集为例。使用els,对抗损失带来的梯度更加平滑和稳定。我们从理论上验证了这一观点,其中应用ELS显示为添加了数据依赖的正则化项,与传统对抗损失相比,它稳定了所提供的梯度。
ELS meets noisy labels
在这一节我们推导了当存在环境标签噪音时ELS的表现情况,我们发现,通过调整平滑参数 \gamma ,我们总能缓解甚至于解决噪音数据带来的负面影响。
Empirical gap and parameterization gap
以上的大多数命题基于两个不现实的假设。(i)无限数据样本,(ii)在没有约束的情况下优化判别器,即在无限维空间上优化判别器。在实践中,我们只观察到有限样本的经验分布,判别器总是局限于较小的类,如神经网络或再现核希尔伯特空间(RKHS)。除此之外,JS divergence也有着较大的empirical gap,即经验分布的JS divergence并不能真正意义上代表真实分布的JS divergence。
这一节我们主要回答以下问题,“给定有限维参数化空间上的有限样本,对于ELS算法,经验分布上的期望是否收敛于真实分布上的期望?” 我们严格推导了两个high-probability bound来验证何时以及在什么条件下,上述问题的答案是Yes。
Non-asymptotic convergence
如上一节所述,上述分析特别是JS divergence相关的分析都需要假设可以得到最优鉴别器,这意味着假设集具有无限的建模能力,并且训练过程可以收敛到最优结果。如果DAT的目标是凹凸的,那么许多工作可以支持全局收敛行为。然而,凹凸假设过于不切实际,即DAT的更新不再保证收敛。在本节中,我们重点讨论了平衡点附近点的DAT的局部收敛行为。具体来说,我们关注的是非渐近收敛性,它比渐近分析能更精确地揭示动态系统的收敛性.
我们构建一个toy example来帮助理解DAT的收敛。η为学习速率,γ为ELS参数,ca常数。我们在这里总结了我们的理论结果:(1)同时梯度下降(GD) DANN,它同时训练鉴别器和编码器,不能保证非渐近收敛。(2)当 \eta\leq\frac{4}{\sqrt{n_dn_e}c} 时,在训练编码器 n_e 次然后训练判别器 n_d ,得到的交替梯度下降(GD) DANN能以次线性收敛速度收敛。这些结果支持了交替GD训练的重要性,这是在dann实施期间常用的trick。(3)将ELS加入交替GD DANN中,使模型的收敛速度提高了一个因子 \frac{1}{2\gamma-1} ,即当 \eta\leq\frac{4}{\sqrt{n_dn_e}c}\frac{1}{2\gamma-1} 时,模型可以收敛。
截至目前为止,我们仍然有以下假设不能够完全保证。在收敛性分析中,我们假设算法初始化在一个唯一平衡点的邻域,在分析参数空间时,我们假设神经网络为L-Lipschitz。这些假设可能在实践中并不成立,而且它们在计算上很难验证。为此,我们也在实验部分对理论结果进行了验证,从经验上支持我们的理论结果。
总结
在这项工作中,我们提出了一个简单的方法,即。ELS,从环境标签设计的角度优化数据方法的训练过程,这与大多数现有的数据方法是正交的。实验和理论表明,将ELS方法与DAT方法结合可以提高对噪声环境标签的鲁棒性,收敛速度更快,训练更稳定,泛化性能更好。据我们所知,我们的工作迈出了利用和理解环境标签平滑的第一步。虽然ELS是为DAT方法设计的,但减少环境标签噪声的影响和软环境分区可能使所有DG/DA 方法都受益,这是一个很有前途的发展方向。
最后,欢迎大家关注github,聚合了OOD,causality,robustness,optimization以及一些前沿研究方向的一些阅读笔记,非常欢迎大家补充完善


