|
输入作业的名称。
根据需要输入任意描述(可选)。
选择作业类型:
运行:启动时启动 playbook,在选定的主机上运行 Ansible 任务。
check:执行 playbook 的"dry run"并报告将要进行的更改,而无需实际进行更改。不支持检查模式的任务将丢失,且不会报告潜在的更改。
如需有关作业类型的更多信息,请参阅 Ansible 文档中的
Playbook
部分。
清单(Inventory)
从可供登录的用户可用的清单中选择要用于此作业模板的清单。
系统管理员必须授予您或团队权限,才能在作业模板中使用某些清单。
清单提示会在后续提示窗口中以自己的步骤的形式显示。
从可供登录的用户可用的项目中选择要用于此作业模板的项目。
SCM 分支
只有在您选择了允许分支覆盖的项目时,才会显示此字段。指定要在任务运行中使用的覆盖分支。如果留空,则使用项目中的指定 SCM 分支(或提交散列或标签)。
如需更多信息,请参阅
作业分支覆盖
。
选择要运行此任务的容器镜像。您必须选择一个项目,然后才能选择执行环境。
执行环境提示会在后续提示窗口中以自己的步骤的形式显示。
Playbook
从可用的 playbook 中选择要使用此作业模板启动的 playbook。此字段自动填充所选项目的项目基本路径中找到的 playbook 名称。另外,如果未列出 playbook,则可以输入 playbook 的名称,如您要使用该 playbook 运行的文件的名称(如 foo.yml)。如果您输入无效的文件名,模板会显示一个错误,或者导致作业失败。
图标打开一个单独的窗口。
从用于此作业模板的可用选项中选择凭据。
如果列表太长,请使用下拉菜单列表根据凭证类型过滤。某些凭证类型不会被列出,因为它们不适用于某些作业模板。
如果选择,在启动具有默认凭证的作业模板时,如果相同类型,则提供另一个凭证会替换默认凭证。以下是这个消息的示例:
作业模板默认凭据必须替换为同一类型之一。请为以下类型选择一个凭证,以便继续: Machine。
或者,您可以在看到适合的情况下添加更多凭证。
凭证提示会在后续提示窗口中以自己的步骤的形式显示。
(可选)提供描述此作业模板的标签,如
dev
或
test
。
使用标签对显示中的作业模板和完成的作业进行分组和过滤。
标签在添加到作业模板时创建。标签使用作业模板中提供的项目与单个机构关联。如果机构的成员具有编辑权限(如 admin 角色),则机构的成员可以在作业模板上创建标签。
保存作业模板后,标签会显示在 Expanded 视图中的
作业模板
概述中。
选择标签旁边的
将其删除。删除标签后,它不再与该特定作业或作业模板关联,但它与引用它的任何其他作业关联。
在启动时,作业会继承作业模板中的标签。如果您从作业模板中删除标签,它也会从作业中删除。
如果选择,即使提供了默认值,也会在启动时提示您提供附加标签(如果需要)。
您无法删除现有标签,选择
只删除新添加的标签,而不是现有的默认标签。
向 playbook 传递额外的命令行变量。这是 ansible-playbook 的"-e"或"-extra-vars"命令行参数,记录在 Ansible 文档中
在运行时定义变量的 Ansible 文档中
。
使用 YAML 或 JSON 提供键或值对。这些变量具有最大优先级值,并覆盖其他位置指定的其他变量。以下是一个值:
git_branch: production release_version: 1.5
如果要能够在调度中指定
extra_vars
,您必须在作业模板中为 Variables 选择
Prompt on launch
,或者在作业模板上启用问卷调查。那些回答的问卷调查问题将变为
extra_vars
。
Forks
执行 playbook 时使用的并行或同步进程数量。值为零使用 Ansible 默认设置,即五个并行进程,除非在
/etc/ansible/ansible.cfg
中被覆盖。
用于进一步限制受 playbook 管理或影响的主机列表的主机模式。您可以通过冒号(:)分隔多个模式。与核心 Ansible 一样:
a:b 表示"在组 a 或 b 中"
a:b:&c 表示"在 a 或 b 中,但必须在 c 中"。
答:!b 表示"在 a 中,一定不要在 b 中"
如需更多信息,请参阅 Ansible 文档中的
Patterns:以主机和组为目标
。
如果未选中,则作业模板针对清单中的所有节点,或者仅在
Limit
字段中预定义节点执行。作为工作流的一部分运行时,会使用工作流作业模板限制。
控制 Ansible 在 playbook 执行时生成的输出级别。从 Normal 到各种 Verbose 或 Debug 设置中选择详细程度。这只会出现在
详情
报告视图中。详细日志记录包括所有命令的输出。调试日志记录非常详细,包括对某些支持实例有用的 SSH 操作信息。
详细程度
5
会导致自动化控制器在作业运行时大量阻断,这可能会延迟报告作业已完成(即使它已经完成),并可能导致浏览器标签页锁定。
指定您希望此作业模板运行的分片数量。每个片段针对清单的一部分运行相同的任务。有关作业分片的更多信息,请参阅
作业分片
。
Timeout(超时)
这可让您指定在作业被取消前可以运行的时间长度(以秒为单位)。在设置超时值时请考虑以下几点:
在设置中定义了一个全局超时,默认为 0,表示没有超时。
作业模板上的一个负超时(<0)是作业中的 true "no timeout"。
作业模板上的超时为 0,将作业默认为全局超时(默认为没有超时)。
一个正超时会设置该作业模板的超时时间。
允许您查看 Ansible 任务所做的更改。
选择
Instance 和 Container Groups
来与此作业模板关联。如果列表太长,使用
图标缩小选项范围。作业模板实例组贡献作业调度条件,请参阅
作业运行时 行为 和控制针对规则运行的作业
。系统管理员必须授予您或团队权限,才能在作业模板中使用实例组。使用容器组需要 admin 权限。
如果选择,您将按首选顺序提供作业首选实例组。如果第一个组没有容量,则会考虑列表中的后续组,直到有容量可用为止,该组被选择来运行作业。
如果您提示输入实例组,则输入的内容会替换正常的实例组层次结构,并覆盖所有机构和清单实例组。
实例组提示在后续提示窗口中以自己的步骤的形式显示。
键入 并选择
Create
菜单,以指定应执行 playbook 的哪些部分。有关更多信息和示例,请参阅 Ansible 文档中的
标签
。
键入 并选择
Create
菜单,以指定要跳过的 playbook 的某些任务或部分。有关更多信息和示例,请参阅 Ansible 文档中的
标签
。
如果需要,指定启动此模板的以下选项:
Privilege Escalation
:如果选中,您可以使此 playbook 以管理员身份运行。这等同于将--
become 选项传递给
ansible-playbook
命令。
provisioning Callbacks
:如果选中,您可以启用主机通过 REST API 调用自动化控制器,并从此作业模板启动作业。如需更多信息,请参阅
置备回调
。
启用 Webhook
:如果选中,您可以打开与用于启动作业模板的预定义 SCM 系统 Web 服务进行接口的功能。GitHub 和 GitLab 是支持的 SCM 系统。
如果您启用 Webhook,会显示其他字段,提示输入更多信息:
Webhook Service
:选择要从哪个服务侦听 Webhook。
Webhook URL
:自动填充将 POST 请求发送到的 Webhook 服务的 URL。
Webhook Key
: 生成共享 secret,供 Webhook 服务用来签署发送到自动化控制器的有效负载。您必须在 Webhook 服务上的设置中对此进行配置,以便自动化控制器接受来自该服务的 Webhook。
Webhook 凭证
:(可选)提供 GitHub 或 GitLab 个人访问令牌(PAT)作为凭证,用来向 webhook 服务发回状态更新。在选择它前,凭证必须存在。请参阅
凭证类型
来创建。
有关设置 Webhook 的更多信息,
请参阅使用 Webhook
。
并发作业
:如果选中,则允许队列中的作业如果不依赖于另一个作业,则同时运行。如果要同时运行作业分片,请选中此框。如需更多信息,
请参阅自动控制器容量确定和作业影响
。
启用事实存储
:如果选中,自动化控制器将收集到与作业运行相关的清单中所有主机的事实。
防止实例组 Fallback
: 检查此选项,仅允许
Instance Groups
字段中列出的实例组来运行作业。如果清除,则执行池中的所有可用实例都会根据控制
作业运行中所述的层次结构使用
。
当您完成作业模板详情配置后,点
Save
。
保存模板不会退出作业模板页面,而是提前进入
作业模板详情选项卡
。保存模板后,您可以点
Launch
来启动作业,或者点
Edit
添加或更改模板的属性,如权限、通知、查看完成的作业,并添加问卷调查(如果作业类型不是扫描)。在启动前,您必须首先保存模板,否则
Launch
仍被禁用。
在导航面板中,选择
→
。
验证新创建的模板是否出现在
Templates
列表视图中。
使用以下步骤为团队添加权限。
在导航面板中,选择
→
。
选择一个模板,并在
Access 选项卡中点
Add
。
选择
"用户"
或
"团队",
然后单击下一步
。
点名称旁边的复选框从列表中选择一个或多个用户或团队,将它们添加为成员,然后单击
Next
。
以下示例显示了要添加的两个用户:
选择您希望用户或团队具有的角色。确保向下滚动以获得完整的角色列表。每种资源具有不同的可用选项。
点
Save
将角色应用到所选用户或团队,并将它们添加为成员。
添加用户和团队关闭的窗口,以显示为每个用户和团队分配的更新角色:
要删除特定用户的角色,请点其资源旁的
这会出现确认对话框,要求您确认解除关联。
在删除作业模板前,请确保它不在工作流作业模板中使用。
使用以下方法之一删除作业模板:
选中一个或多个作业模板旁边的复选框,
再单击删除
。
单击所需的作业模板,再单击
Details
页面中的
Delete
。
如果删除由其他工作项目使用的项目,则会打开一个信息,列出受删除影响的项目,并提示您确认删除。有些屏幕包含无效的或之前删除的项目,且无法运行。以下是该消息的示例:
在导航面板中,选择
→
。这可让您查看您设置的任何通知集成及其状态(如果已运行)。
使用切换按钮启用或禁用要与特定模板搭配使用的通知。如需更多信息,请参阅
启用和禁用通知
。
如果没有设置通知,请点击
Add
来创建新通知。有关配置各种通知类型和扩展消息传递的更多信息,请参阅
通知类型
。
Jobs
选项卡提供已运行的作业模板列表。点每个作业旁的展开图标查看以下详情:
Status
ID 和名称
开始和完成的时间
启动了作业,以及使用哪个模板、清单、项目和凭证。
您可以使用任何这些条件过滤已完成的作业列表。
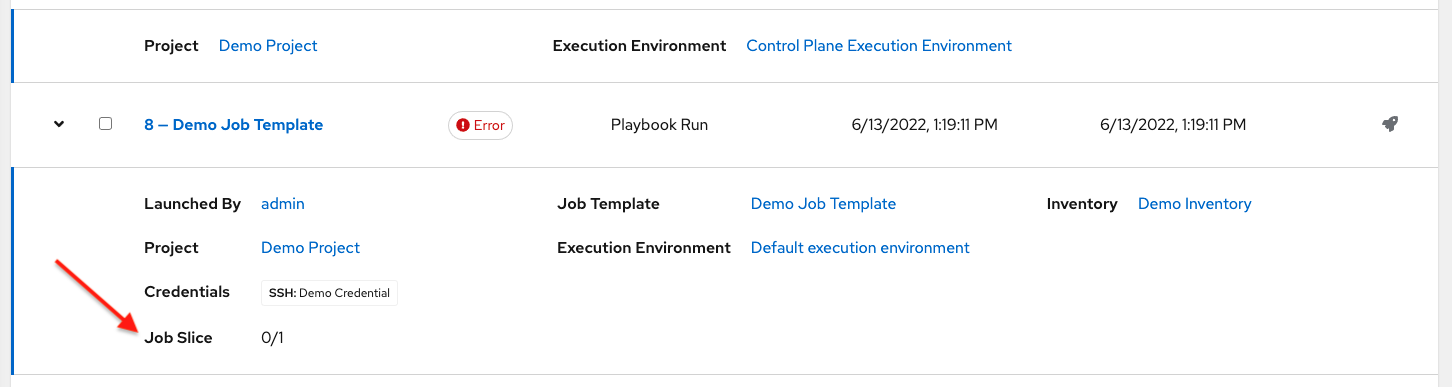
在此列表中显示的切片作业会进行相应标记,包含已运行的分片作业数量:
从
Schedules
选项卡访问特定作业模板的计划。
要调度作业模板,请选择
Schedules
选项卡,然后选择适当的方法:
如果已经设置了调度,请检查、编辑、启用或禁用您的调度首选项。
如果还没有设置调度,请参阅
Schedules
以了解更多信息。
如果您为
Credentials 字段
选择了
Prompt on Launch
,并且您创建或编辑作业模板的调度信息,则会在 Schedules 表单上显示一个
Prompt
选项。
在保存前,您无法在
Prompt
对话框中删除默认机器凭证,而无需将其替换为其他机器凭证。
要在调度上设置
extra_vars
,您必须在作业模板中为
变量
选择
Prompt on Launch
,或者在作业模板上配置和启用问卷调查。
然后,回答的问卷调查问题将变为
extra_vars
。
运行或检查
的作业类型
提供了一种在
作业模板
创建或编辑屏幕中设置问卷调查的方法。问卷调查为 playbook 设置额外变量,类似于
Prompt for Extra Variables
,但采用用户友好的问题和答案方式。调查还允许验证用户输入。选择
Survey
选项卡来创建问卷调查。
Example
调查可用于多种情况。例如,操作希望为开发人员提供一个 "push to stage" 按钮,无需提高 Ansible 知识即可运行。启动后,此任务可以提示输入问题的回答,如"应该如何发布标签?"。
可以询问很多类型的问题,包括多项选择题。
流程
-
从
调查
选项卡中,单击
添加
。
问卷调查可由任意数量的问题组成。对于每个问题,输入以下信息:
问题
:询问用户的问题。
可选:
描述
: 描述用户被要求的内容。
回答变量名称
:用于存储用户响应的 Ansible 变量名称。这是 playbook 要使用的变量。变量名称不能包含空格。
回答类型
:从以下问题类型中选择:
文本
: 单行文本。您可以为此回答设置最小和最大长度(字符数)。
文本域:多行文本字段。
您可以为此回答设置最小和最大长度(字符数)。
密码
:响应被视为敏感信息,就像实际密码一样被处理。您可以为此回答设置最小和最大长度(字符数)。
多项选择(单选
):选项列表,一次只能选择一个。在
Multiple Choice Options
字段中输入选项(每行一个)。
多项选择(多选)
:选项列表,一次可以选择任意数量。在
Multiple Choice Options
字段中输入选项(每行一个)。
整数
:整数。您可以为此回答设置最小和最大长度(字符数)。
浮点
数:十进制数。您可以为此回答设置最小和最大长度(字符数)。
必需
:用户是否需要回答这个问题。
最小长度和最大长度
:指定是否需要回答中的某个长度。
默认回答
:问题的默认回答。这个值在界面中预先填充,并在用户未提供回答时使用。
输入问题信息后,单击
Save
以添加问题。
调查问题显示在
Survey
列表中。对于任何问题,您可以点
来编辑它。
选中每个问题旁边的框,然后单击
Delete
以删除问题,或者使用菜单栏中的切换选项启用或禁用调查提示。
如果您有多个调查问题,点
Edit Order
来通过单击并拖动网格图标来重新安排问题的顺序。
要添加更多问题,请点
添加
。
问卷调查问题中的
Required
设置决定了对于与之交互的用户是否是可选的。
可选的问卷调查变量也可以传递给
extra_vars
中的 playbook。
如果非文本变量(输入类型)标记为可选,且没有填写,则不会将任何问卷调查
extra_var
传递给 playbook。
如果文本输入或文本区域输入标记为可选,未填写,且
最小长度 > 0,
则不会将问卷调查
extra_var
传递给 playbook。
如果文本输入或文本区域输入标记为可选,未填写,并且具有
最小长度 === 0,
则调查
extra_var
将传递给 playbook,并将值设为空字符串("")。
自动化控制器的一个优点是 Ansible playbook 的按钮式部署。您可以配置模板,以存储您通常在命令行上传递给 Ansible playbook 的所有参数。除了 playbook 外,模板还会传递清单、凭证、额外变量以及您可以在命令行上指定的所有选项和设置。
更简单的部署会在每次运行时以相同的方式运行 playbook 来提高一致性,并允许您委派职责。
使用以下方法之一启动作业模板:
在导航面板中,选择
→
,再单击作业模板的
Launch
。
在您要启动的作业模板的作业模板视图中,单击
Launch
。
作业可能需要额外信息才能运行。启动时可以请求以下数据:
设置的凭证
为任意参数选择了
Prompt on Launch
选项
已设置为
Ask
的密码或密码短语
问卷调查(如果已经为作业模板配置了问卷调查)
额外变量(如果作业模板要求提供)
如果作业有用户提供的值,则重启时会考虑这些值。如果用户没有指定值,则作业将使用作业模板中的默认值。作业不会按原样重新启动。它们通过用户提示重新应用到作业模板。
如果您在一个标签页中提供值,返回上一个标签页,请继续下一个标签页会导致在剩余标签页中重新提供值。确保您按照提示出现的顺序填写标签页。
启动后,自动化控制器会在
Jobs
选项卡下自动将 Web 浏览器重定向到此作业的
Job Status
页面。
您可以从列表视图中重新启动最新的作业,以便针对指定清单中的所有主机或仅仅是失败的主机重新运行。如需更多信息,请参阅
作业
部分。
当分片作业正在运行时,作业列表会显示工作流和作业分片,以及用于单独查看其详情的链接。
您可以使用 API 中新添加的端点
/api/v2/bulk/job_launch
来批量启动作业。此端点接受 JSON,您可以指定用于启动的统一作业模板(如作业模板和项目更新)的列表。用户必须具有启动所有作业的适当权限。如果没有启动所有作业,则返回错误,指示操作无法完成的原因。使用
OPTIONS
请求返回相关模式。如需更多信息,请参阅自动化控制器 API 指南中的参考部分中的
Bulk 端点
。
如果您复制作业模板,它不会复制任何关联的调度、通知或权限。用户必须由用户或管理员创建作业模板副本重新创建调度和通知。复制作业模板的用户被授予管理员权限,但没有将权限分配给作业模板。
在导航面板中,选择
→
。
点击与您要复制的模板关联的
在模板列表中会显示带有作为复制来源的新模板的名称和一个时间戳。
单击以打开新模板,然后单击
编辑
。
将
Name
字段的内容替换为新名称,并提供或者修改其他字段中的条目以完成此页面。
点击
Save
。
从自动化控制器 3.2 开始,不再支持扫描作业。此系统跟踪功能用作捕获和存储事实作为历史数据的方法。现在,事实通过事实缓存存储在控制器中。如需更多信息,请参阅
事实缓存
。
在自动化控制器 3.2 之前,系统中的作业模板扫描作业将转换为运行类型,如正常的作业模板。它们保留其相关资源,如清单和凭证。默认情况下,没有相关项目的作业模板扫描作业会被分配一个特殊的 playbook。您还可以使用自己的扫描 playbook 指定项目。为每个指向
awx-facts-playbooks
的机构创建一个项目,并将作业模板设置为 playbook:
https://github.com/ansible/tower-fact-modules/blob/master/scan_facts.yml
。
扫描作业 playbook
scan_facts.yml
包含三种
事实扫描模块
(软件包、服务和文件)的调用,以及 Ansible 的标准事实收集。
scan_facts.yml
playbook 文件类似如下:
- hosts: all
vars:
scan_use_checksum: false
scan_use_recursive: false
tasks:
- scan_packages:
- scan_services:
- scan_files:
paths: '{{ scan_file_paths }}'
get_checksum: '{{ scan_use_checksum }}'
recursive: '{{ scan_use_recursive }}'
when: scan_file_paths is defined
scan_files
事实模块是唯一接受参数的模块,通过扫描作业模板上的
extra_vars
传递:
scan_file_paths
:
/tmp/
scan_use_checksum
: true
scan_use_recursive
: true
scan_file_paths
参数可以有多个设置(如
/tmp/
或
/var/log
)。
scan_use_checksum
和
scan_use_recursive
参数也可以设置为 false 或省略。省略与 false 设置相同。
扫描作业模板应启用
become
,并使用
成为可能
的凭证
。您可以通过从选项列表中检查
Privilege Escalation
来启用
become
:
20.10.2. 支持的 scan_facts.yml OS
如果您使用带有使用事实缓存的
scan_facts.yml
playbook,请确保使用以下支持的操作系统之一:
Red Hat Enterprise Linux 5、6、7、8 和 9
Ubuntu 23.04 (支持 Ubuntu 已被弃用,将在以后的版本中删除)
OEL 6 和 7
SLES 11 和 12
Debian 6、7、9、10、11 和 12
Fedora 22、23 和 24
Amazon Linux 2023.1.20230912
其中一些操作系统需要初始配置来运行 python,或者有权访问 python 软件包,如
python-apt
,扫描模块依赖。
以下是配置某些发行版本的 playbook 示例,以便可以针对它们运行扫描作业:
Bootstrap Ubuntu (16.04)
- name: Get Ubuntu 16, and on ready
hosts: all
sudo: yes
gather_facts: no
tasks:
- name: install python-simplejson
raw: sudo apt-get -y update
raw: sudo apt-get -y install python-simplejson
raw: sudo apt-get install python-apt
Bootstrap Fedora (23, 24)
- name: Get Fedora ready
hosts: all
sudo: yes
gather_facts: no
tasks:
- name: install python-simplejson
raw: sudo dnf -y update
raw: sudo dnf -y install python-simplejson
raw: sudo dnf -y install rpm-python
自定义事实扫描的 playbook 与
Fact 扫描 playbook
部分中的示例类似。例如,只使用自定义
scan_foo
Ansible 事实模块的 playbook 类似如下:
scan_foo.py:
def main():
module = AnsibleModule(
argument_spec = dict())
foo = [
"hello": "world"
"foo": "bar"
results = dict(ansible_facts=dict(foo=foo))
module.exit_json(**results)
main()
要使用自定义事实模块,请确保它位于扫描作业模板中使用的 Ansible 项目的
/library/
子目录中。这个事实扫描模块返回一组硬编码的事实:
"hello": "world"
"foo": "bar"
有关更多信息,请参阅 Ansible 文档中的
开发模块
部分。
自动化控制器可以通过 Ansible 事实缓存插件来基于每个主机存储和检索事实。这个行为可根据每个作业模板进行配置。默认情况下,事实缓存会被关闭,但可以启用来为与作业运行相关的清单中所有主机提供事实请求。这可让您使用带有-
limit
的作业模板,同时仍可访问整个主机事实清单。通过进入
并从
Jobs
选项中选择
作业设置
,可指定插件强制在每个主机的全局超时设置:
在启动使用事实缓存(
use_fact_cache=True
的作业后,每个主机的
ansible_facts
均由控制器存储在作业的清单中。
自动化控制器附带的 Ansible 事实缓存插件在启用了事实缓存的作业上启用(
use_fact_cache=True
)。
当一个启用了事实缓存(
use_fact_cache=True
)的作业正在运行时,自动化控制器会恢复清单中主机的所有记录。任何比每个主机当前存储事实更新时间更新的记录都会在数据库中更新。
新的和更改的事实通过自动化控制器的日志记录功能记录。特别是
system_tracking 命名空间或日志记录
器。日志记录有效负载包括以下字段:
host_name
inventory_id
ansible_facts
Ansible 事实是自动化控制器清单
inventory_id
中
host_name
的所有 Ansible 事实的字典。
如果主机名包含正斜杠(/),事实缓存不适用于该主机。如果您的清单有 100 个主机,且一个主机的名称中有一个 /,则剩余的 99 个主机仍然收集事实。
事实缓存可让您通过运行事实收集来节省时间。如果您在某个作业中有一个针对一千个主机和分叉运行的 playbook,您可以花费 10 分钟在所有这些主机上收集事实。但是,如果您定期运行作业,第一次运行会缓存这些事实,下一次运行会从数据库中拉取它们。这可减少针对大型清单(包括智能清单)的作业运行时。
不要修改 ansible.cfg 文件以应用事实缓存。自定义事实缓存可能会与控制器的事实缓存功能冲突。您必须使用与自动化控制器附带的事实缓存模块。
您可以选择在作业模板窗口的
Options
字段中启用缓存的事实来在作业中使用缓存的事实。
若要清除事实,请运行 Ansible
clear_facts
meta 任务
。以下是使用 Ansible
clear_facts
meta 任务的示例 playbook。
- hosts: all
gather_facts: false
tasks:
- name: Clear gathered facts from all currently targeted hosts
meta: clear_facts
您可以在以下找到事实缓存的 API 端点:
http://<controller server name>/api/v2/hosts/x/ansible_facts
在同步云清单时,可以使用云凭证。它们也可以与作业模板关联,并包含在运行时环境中,供 playbook 使用。支持以下云凭证:
Openstack
Amazon Web Services
Google
Azure
VMware
以下示例 playbook 调用
nova_compute
Ansible OpenStack 云模块并需要凭证:
auth_url
username
password
这些字段通过环境变量
OS_CLIENT_CONFIG_FILE
提供给 playbook,它指向控制器基于云凭证内容的 YAML 文件。以下示例 playbook 将 YAML 文件加载到 Ansible 变量空间中:
OS_CLIENT_CONFIG_FILE 示例:
clouds:
devstack:
auth:
auth_url: http://devstack.yoursite.com:5000/v2.0/
username: admin
password: your_password_here
project_name: demo
- hosts: all
gather_facts: false
vars:
config_file: "{{ lookup('env', 'OS_CLIENT_CONFIG_FILE') }}"
nova_tenant_name: demo
nova_image_name: "cirros-0.3.2-x86_64-uec"
nova_instance_name: autobot
nova_instance_state: 'present'
nova_flavor_name: m1.nano
nova_group:
group_name: antarctica
instance_name: deceptacon
instance_count: 3
tasks:
- debug: msg="{{ config_file }}"
- stat: path="{{ config_file }}"
register: st
- include_vars: "{{ config_file }}"
when: st.stat.exists and st.stat.isreg
- name: "Print out clouds variable"
debug: msg="{{ clouds|default('No clouds found') }}"
- name: "Setting nova instance state to: {{ nova_instance_state }}"
local_action:
module: nova_compute
login_username: "{{ clouds.devstack.auth.username }}"
login_password: "{{ clouds.devstack.auth.password }}"
20.11.2. Amazon Web Services
Amazon Web Services (AWS)云凭证在 playbook 执行过程中作为以下环境变量公开(在作业模板中,选择您的设置所需的云凭证):
AWS_ACCESS_KEY_ID
AWS-SECRET_ACCESS_KEY
每个 AWS 模块在通过控制器运行时都会隐式使用这些凭证,而无需设置
aws_access_key_id
或
aws_secret_access_key
模块选项。
Google 云凭证在 playbook 执行过程中作为以下环境变量公开(在作业模板中,选择您的设置所需的云凭证):
GCE_EMAIL
GCE_PROJECT
GCE_CREDENTIALS_FILE_PATH
每个 Google 模块在通过控制器运行时都会隐式使用这些凭证,而无需设置
service_account_email
、
project_id
或
pem_file
模块选项。
Azure 云凭证在 playbook 执行过程中作为以下环境变量公开(在作业模板中,选择您的设置所需的云凭证):
AZURE_SUBSCRIPTION_ID
AZURE_CERT_PATH
每个 Azure 模块在通过控制器运行时都会隐式使用这些凭证,而无需设置
subscription_id
或
management_cert_path
模块选项。
VMware 云凭证在 playbook 执行过程中作为以下环境变量公开(在作业模板中,选择您的设置所需的云凭证):
VMWARE_USER
VMWARE_PASSWORD
VMWARE_HOST
以下示例 playbook 演示了这些凭证的使用情况:
- vsphere_guest:
vcenter_hostname: "{{ lookup('env', 'VMWARE_HOST') }}"
username: "{{ lookup('env', 'VMWARE_USER') }}"
password: "{{ lookup('env', 'VMWARE_PASSWORD') }}"
guest: newvm001
from_template: yes
template_src: linuxTemplate
cluster: MainCluster
resource_pool: "/Resources"
vm_extra_config:
folder: MyFolder
置备回调是自动化控制器的一项功能,使主机能够启动针对自身运行的 playbook,而不是等待用户从自动化控制器控制台管理主机。
置备回调仅用于在调用主机上运行 playbook,用于云突发。云突发是一种云计算配置,它允许私有云在计算需求激增时通过"突发"进入公共云资源来访问公共云资源。
Example
需要客户端到服务器通信(如传输授权密钥)的新实例,而不是对另一主机运行作业。这为自动配置以下内容提供:
另一个系统置备后的系统(如 AWS 自动扩展,或操作系统置备系统,如 kickstart 或预装)。
以编程方式启动作业,而不直接调用自动化控制器 API。
启动的作业模板仅针对请求调配的主机运行。
这通常通过 firstboot 类型脚本或从
cron
访问。
流程
-
要启用回调,请选中作业模板中的
Provisioning Callbacks
复选框。这将显示作业模板的
Provisioning Callback URL
。
如果要将自动化控制器的置备回调功能与动态清单搭配使用,请为作业模板中使用的清单组设置
Update on Launch
。
回调还需要主机配置密钥,以确保具有 URL 的外部主机无法请求配置。为主机配置密钥提供自定义值。主机密钥可以在多个主机间重复使用,从而将此作业模板应用到多个主机。如果要控制哪些主机可以请求配置,可以随时更改该密钥。
使用 REST 手动回调:
查看 UI 中的回调 URL,格式为: https://<CONTROLLER_SERVER_NAME>/api/v2/job_templates/7/callback/
示例 URL 中的 "7" 是自动化控制器中的作业模板 ID。
确保来自主机的请求是 POST。以下是使用
curl
的示例(全部在一行):
curl -k -f -i -H 'Content-Type:application/json' -XPOST -d '{"host_config_key": "redhat"}' \
https://<CONTROLLER_SERVER_NAME>/api/v2/job_templates/7/callback/
-
确保在清单中定义了请求的主机,以便回调成功。
如果自动化控制器无法按名称或 IP 地址在您定义的一个清单中根据名称或 IP 地址查找主机,则请求将被拒绝。以这种方式运行作业模板时,请确保针对自身启动 playbook 的主机位于清单中。如果清单中缺少主机,则作业模板会失败,并显示
No Hosts Matched
type 错误消息。
如果您的主机不在清单中,并且为清单组自动化控制器设置了
Update on Launch
,则在运行回调前尝试更新基于云的清单源。
成功请求会在
Jobs
标签页中生成一个条目,您可以在其中查看结果和历史记录。您可以使用 REST 访问回调,但推荐的使用回调方法是使用自动化控制器附带的示例脚本之一:
/usr/share/awx/request_tower_configuration.sh
(Linux/UNIX)
/usr/share/awx/request_tower_configuration.ps1
(Windows)
通过传递
-h
标志,其用法在文件的源代码中进行了描述,如下所示:
./request_tower_configuration.sh -h
Usage: ./request_tower_configuration.sh <options>
Request server configuration from Ansible Tower.
OPTIONS:
-h Show this message
-s Controller server (e.g. https://ac.example.com) (required)
-k Allow insecure SSL connections and transfers
-c Host config key (required)
-t Job template ID (required)
-e Extra variables
这个脚本可以重试命令,因此比简单的
curl
请求相比,使用回调更为可靠的方法。脚本每分钟重试一次,最多十分钟。
这是示例脚本。如果您在检测到失败情况时需要更多的动态行为,请编辑这个脚本,因为任何非 200 错误代码都可能不是需要重试的临时错误。
您可以在自动化控制器中将回调与动态清单搭配使用。例如,从其中一个受支持的云提供商拉取云清单时。在这些情况下,除了设置
Update On Launch
之外,请确保为清单源配置清单缓存超时,以避免对云的 API 端点造成影响。由于
request_tower_configuration.sh
脚本每分钟轮询一次,因此建议为清单(在清单源本身上配置)的缓存无效时间为一两分钟。
不建议从 cron 任务运行
request_tower_configuration.sh
脚本,但建议每 30 分钟运行推荐的 cron 间隔。重复的配置可以通过调度自动化控制器来处理,以便大多数用户使用回调的主要用途是启用在上线时引导至最新配置的基础镜像。在第一次引导时运行是最佳实践。首次启动脚本是通常自我删除的初始化脚本,因此您设置了一个调用
request_tower_configuration.sh
脚本副本的 init 脚本,并将其设置为自动扩展镜像。
如需更多信息,请参阅
自动化控制器管理指南中的使用
Curl 启动作业
。
分片作业指的是分布式作业的概念。分布式作业用于在大量主机上运行作业,允许您运行多个 ansible-playbooks,各自在清单的子集上运行,它们可以在集群中并行调度。
默认情况下,Ansible 从单个控制实例运行作业。对于不需要跨主机编配的作业,作业分片可以利用自动化控制器将工作分发到集群中的多个节点。
作业分片的工作原理方法是添加一个作业模板字段
job_slice_count
,它指定要将 Ansible 运行分片到的作业数量。当这个数字大于
1
时,自动化控制器会从作业模板而不是作业生成工作流。清单在分片作业之间平均分配。然后,工作流作业启动,并像正常工作流一样继续。
在启动作业时,API 将返回作业资源(如果 job_slice_count = 1)或工作流作业资源。对应的用户界面(UI)重定向到适当的屏幕,以显示运行的状态。
在设置作业分片时,请考虑以下几点:
分片作业会创建一个工作流作业,然后创建作业。
作业分片由作业模板、清单和分片计数组成。
执行后,分片作业会将每个清单分成多个"分片大小"块。然后,它将 ansible-playbook 的作业排队在相应清单的每个块上运行。引入 ansible-playbook 的清单是原始清单的简化版本,仅包含该特定片段中的主机。作业列表中显示的已完成分片作业会相应地标记,以及已运行的分片作业数量:
这些分片作业遵循常规调度行为(fork 数量,根据容量进行排队,根据清单映射分配给实例组)。
作业分片旨在水平扩展作业执行。在作业模板上启用作业分片会将清单划分成在启动时配置的分片数量,然后为每个分片启动作业。
通常,分片的数量等于或小于自动化控制器节点的数量。设置大量作业分片(如数千作业分片)可能会导致性能下降,因为作业调度程序不会同时调度数千个工作流节点,这是分片作业已变得是什么。
带有提示或额外变量的分片作业模板的行为与标准作业模板相同,将所有变量和限制应用到生成的工作流作业集合。但是,当将限制传递给分片作业时,如果限制导致分片没有分配主机,则这些分片将失败,从而导致整个作业失败。
计算分布式作业的作业分片作业状态的方式与工作流作业相同。如果其子作业中存在未处理的失败,则会失败。
任何计划在多个主机间编配(而不是只对单个主机应用更改)的作业都不能配置为分片作业。
任何作业都可能会失败,自动化控制器也不会试图发现或考虑作为分片作业运行时失败的 playbook。
当作业被分片时,它们可以在任何节点上运行。系统中的容量不足可能会导致某些在不同时间运行。当分片作业运行时,作业详情会显示当前运行的工作流和作业分片,以及用于单独查看其详情的链接。
默认情况下,作业模板通常不配置为同时执行(必须在 API 中检查
allow_simultaneous
,或在 UI
中启用 Concurrent 作业
)。分片会覆盖此行为,即使该设置是明确的,也意味着
allow_simultaneous
。如需有关如何指定此功能以及
作业模板
配置中的作业分片数量的信息,请参阅作业模板。
Job templates
部分提供了在 UI 中执行以下操作的更多详情:
使用分片数量大于一的作业模板启动工作流作业。
启动分片作业模板后,取消整个工作流或单独的作业。
在分片完成运行后,重新启动整个工作流或单独的作业。
在启动作业模板后,查看工作流和分片作业的详情。
按照后续部分"搜索作业分片"部分创建后,专门搜索分片作业。
要更轻松地查找分片作业,请使用搜索功能将搜索过滤器应用到:
作业列表仅显示分片作业
作业列表仅显示作业分片的父工作流作业
作业模板列表仅显示生成分片作业的作业模板
使用以下方法之一搜索分片作业:
要只显示作业列表中的分片作业,就像大多数情况一样,您可以根据类型(此处的作业)或
unified_jobs
过滤:
/api/v2/jobs/?job_slice_count__gt=1
仅显示作业分片的父工作流作业:
/api/v2/workflow_jobs/?job_template__isnull=false
仅显示生成分片作业的作业模板:
/api/v2/job_templates/?job_slice_count__gt=1
工作流允许您配置一系列不同的作业模板(或工作流模板),它们可能或不共享清单、playbook 或权限。
工作流具有
管理员
和执行权限,类似于作业模板。工作流完成的任务是将属于发布过程一部分的完整作业集合作为一个单元来跟踪。
作业或工作流模板使用类似图形的结构(称为节点)链接在一起。这些节点可以是作业、项目同步或清单同步。模板可以是不同工作流的一部分,也可以在同一工作流中多次使用。在启动工作流时,图形结构的副本会保存到工作流作业中。
以下示例显示了包含所有三个工作流以及工作流作业模板的工作流:
当工作流运行时,作业会从节点的链接模板生成。链接到具有提示驱动的字段(job_type、job_tags、skip_tags、limit)的节点可以包含这些字段,且不会在启动时提示。提示凭证或清单的作业模板没有默认值,无法包含在工作流中。
在构建工作流时,请考虑以下事项:
根节点默认设置为
ALWAYS
,且无法编辑。
节点可以有多个父项,子项可以链接到任何 success, failure, 或 always 状态。如果为 always,则状态既不会成功,也没有失败。State 在节点级别应用,而不是在工作流作业模板级别应用。工作流作业标记为成功,除非被取消或遇到错误。
如果您删除工作流中的作业或工作流模板,则之前连接到删除的节点会自动连接上游,并保留边缘类型,如下例所示:
您可以有一个聚合的工作流,其中多个作业聚合成一个。在这种情况下,任何作业或所有作业都必须在下一个运行前完成,如下例所示:
在本例中,自动化控制器会并行运行前两个作业模板。当它们都按照指定完成并成功时,第三个下游(聚合节点)会触发。
应用于工作流作业模板中的工作流节点的清单和问卷调查提示。
如果从 API 启动,运行
get
命令会显示一个警告列表并突出显示缺少的组件。下图演示了工作流作业模板的基本工作流:
可以同时启动多个工作流,并为启动它们的时间设置一个调度。您可以在工作流上设置通知,如作业完成时,类似于作业模板的通知。
作业分片旨在水平扩展作业执行。
如果您在作业模板上启用作业分片,它会将清单划分成在启动时配置的分片数量。然后为每个分片启动一个作业。
如需更多信息,请参阅
作业分片
部分。
您可以构建递归工作流,但如果自动化控制器检测到错误,它会在嵌套工作流尝试运行时停止。
在子工作流的作业中收集到的工件会被传递给下游节点。
清单可以在工作流级别设置,或在启动时提示设置清单。
启动后,带有
ask_inventory_on_launch=true
的工作流中的所有作业模板都使用工作流级别清单。
不提示清单的作业模板会忽略工作流清单,并针对自己的清单运行。
如果工作流提示提供清单,调度和其他工作流节点可以提供清单。
在工作流聚合场景中,
set_stats
数据会以未定义的方式合并,因此您必须设置唯一的键。
工作流可以具有以下状态(无“Failed”状态):
Waiting
Running
Success (finished)
Cancel
Failed
在工作流方案中,取消作业会取消分支,而取消工作流作业会取消整个工作流。
要编辑和删除工作流作业模板,您必须具有管理员角色。要创建工作流作业模板,您必须是机构管理员或系统管理员。但是,您可以运行包含您没有权限的作业模板的工作流作业模板。系统管理员可以创建空白工作流,然后将
admin_role
授予低级用户,之后他们可以委派更多访问权限并构建图形。您必须具有对
作业模板的执行
访问权限,才能将其添加到工作流作业模板中。
您还可以执行其他任务,如复制复制或重新启动工作流,具体取决于向用户授予哪些权限。在重新启动或制作副本前,您必须对工作流中使用的所有资源(如作业模板)具有权限。
如需更多信息,
请参阅基于角色的访问控制。
有关执行本节所述任务的更多信息,
请参阅管理指南
。
工作流作业模板将一系列不同资源链接,这些资源将属于发布过程一部分的完整作业集合作为一个单元来跟踪。这些资源包括以下内容:
工作流作业模板
清单源同步
Templates
列表视图显示当前可用的工作流和作业模板。默认视图为折叠状态(Compact),显示模板名称、模板类型和使用该模板运行的作业的状态。您可以单击每个条目旁边的箭头,以展开和查看更多信息。此列表按名称按字母顺序排序,但您可以根据其他条件排序,或者根据模板的不同字段和属性进行搜索。在此屏幕中,您可以启动
工作流作业模板。
只有工作流模板带有工作流可视化工具
图标作为访问工作流编辑器的快捷方式。
工作流模板可用作另一个工作流模板的构建块。您可以通过在工作流模板中设置多个设置来启用
Prompt on Launch
,您可以在工作流作业模板一级编辑该设置。它们不会影响在各个工作流模板级别分配的值。具体步骤请查看
工作流可视化工具
部分。
要创建新工作流作业模板,请完成以下步骤:
如果将限制设置为工作流模板,则不会传递给作业模板,除非您检查了
Prompt on launch
的限制。如果运行的 playbook 是必需的,这可能会导致 playbook 失败。
在
Templates
列表视图中,从
Add
列表中选择
Add workflow template
。
在以下字段中输入相关信息:
如果某个字段选择了
Prompt on launch
复选框,则启动工作流模板,或者在另一个工作流模板中使用工作流模板,则会提示您输入该字段的值。大多数提示的值将覆盖作业模板中设置的任何值。下表中会记录例外情况。
|
字段
|
选项
|
启动时提示
|
|
输入作业的名称。
根据需要输入任意描述(可选)。
机构(Organization)
从可供登录的用户可用的机构中选择用于此模板的组织。
清单(Inventory)
(可选)从登录的用户可用的清单中选择要与此模板搭配使用的清单。
用于进一步限制受 playbook 管理或影响的主机列表的主机模式。您可以通过冒号(:)分隔多个模式。与核心 Ansible 一样:
a:b 表示"在组 a 或 b 中"
a:b:&c 表示"在 a 或 b 中,但必须在 c 中"。
答:!b 表示"在 a 中,一定不要在 b 中"
如需更多信息,请参阅 Ansible 文档中的
Patterns:以主机和组为目标
。
如果选择,即使提供了默认值,也会在启动时提示您选择一个限制。
源控制分支
为工作流选择分支。此分支应用于提示分支的所有工作流作业模板节点。
(可选)提供描述此工作流作业模板的标签,如
dev
或
test
。使用标签对显示中的工作流作业模板和完成的作业进行分组和过滤。
标签在添加到工作流模板时创建。标签使用工作流模板中提供的项目与单个机构关联。如果机构的成员具有编辑权限(如 admin 角色),则机构成员可以在工作流模板上创建标签。
保存作业模板后,标签会显示在工作流作业模板
详情视图中
。
标签仅应用于工作流模板,而不是工作流中使用的作业模板节点。
选择标签旁边的
将其删除。删除标签后,它不再与该特定作业或作业模板关联,但它与引用它的任何其他作业关联。
如果选择,即使提供了默认值,也会在启动时提示您提供附加标签(如果需要)。- 您无法删除现有标签,选择
仅会删除新添加的标签,而不是现有的默认标签。
向 playbook 传递额外的命令行变量。
这是 ansible-playbook 的"-e"或"-extra-vars"命令行参数,记录在 Ansible 文档中,
控制 Ansible 的行为:优先级规则
. - 使用 YAML 或 JSON 提供键或值对。这些变量具有最大优先级值,并覆盖其他位置指定的其他变量。以下是一个值:
git_branch: production release_version: 1.5
如果要能够在调度中指定 extra_vars,您必须在工作流作业模板中为 Variables 选择
Prompt on launch
,或者在作业模板上启用问卷调查。那些回答的问卷调查问题将变为
extra_vars
。有关额外变量的更多信息,请参阅
额外变量
。
键入并选择
Create
下拉菜单来指定应运行 playbook 的哪个部分。有关更多信息和示例,请参阅 Ansible 文档中的
标签
。
键入并选择
Create
下拉菜单来指定要跳过的 playbook 的某些任务或部分。有关更多信息和示例,请参阅 Ansible 文档中的
标签
。
如果需要,指定启动此模板的以下选项:
选中
Enable Webhooks
以打开与用于启动工作流作业模板的预定义 SCM 系统 Web 服务进行接口的功能。GitHub 和 GitLab 是支持的 SCM 系统。
如果您启用 Webhook,会显示其他字段,提示输入更多信息:
Webhook Service
:选择要从哪个服务侦听 Webhook。
Webhook 凭证
:(可选)提供 GitHub 或 GitLab 个人访问令牌(PAT)作为凭证,用来向 webhook 服务发回状态更新。如需更多信息,请参阅
凭证类型
来创建。
当您点
Save
时,会填充其他字段,工作流可视化工具会自动打开。
Webhook URL
:自动填充将 POST 请求发送到的 Webhook 服务的 URL。
Webhook Key
: 生成共享 secret,供 Webhook 服务用来签署发送到自动化控制器的有效负载。您必须在 Webhook 服务上的设置中配置此功能,以便在自动化控制器中接受此服务的 Webhook。有关设置 Webhook 的更多信息,
请参阅使用 Webhook
。
选中
Enable Concurrent Jobs
以允许同时运行此工作流。如需更多信息,
请参阅自动控制器容量确定和作业影响
。
配置完工作流模板后,点
Save
。
保存模板会退出工作流模板页面,并打开工作流可视化工具,以便您构建工作流。如需更多信息,请参阅
工作流可视化工具
部分。否则,请选择以下方法之一:
关闭工作流可视化工具,以返回到新保存的模板的
Details
选项卡。您可以完成以下任务:
查看、编辑、添加权限、通知、计划和调查
查看完成的作业
构建工作流模板
点
Launch
启动工作流。
在启动前保存模板,或者
Launch
仍被禁用。
Notifications
选项卡只有在您保存模板后才会显示。
点
Access
选项卡来查看、获取、编辑和删除用户和团队成员的相关权限。
点
Add
以为此工作流模板创建新权限,按照提示相应地分配它们。
Jobs
选项卡提供已运行的作业模板列表。点每个作业旁的
图标查看每个作业的详情。
从此视图中,您可以点作业 ID,工作流作业的名称并查看其图形表示。以下示例显示了工作流作业的作业详情:
节点使用标签标记,以帮助您识别它们。如需更多信息,请参阅
工作流可视化工具
部分中的图例。
选择
Schedules
选项卡,以访问特定工作流作业模板的计划。
有关调度工作流作业模板运行的更多信息,请参阅
调度作业模板
部分。
如果嵌套工作流中使用的工作流作业模板有问卷调查,或者为 inventory 选项选择了
Prompt on Launch
,则调度表单上的
SAVE
和
CANCEL
选项旁边会显示
PROMPT
选项。单击
PROMPT
以显示可选的
INVENTORY
步骤,您可以在其中提供或删除清单,或者在没有任何更改的情况下跳过这一步。
包含
运行
或检查
的作业类型
的工作流提供了一种在工作流作业模板创建或编辑屏幕中设置问卷调查的方法。
有关作业调查的更多信息,包括如何在工作流作业模板中创建问卷调查和可选问卷调查问题,请参阅
作业模板中的调查
部分。
工作流可视化工具提供了一种图形方式,用于将作业模板、工作流模板、项目同步和清单同步链接到构建工作流模板。在构建工作流模板前,请参阅
工作流
部分,以了解与父、子和同级节点上各种场景相关的注意事项。
您可以设置以下两个或更多节点类型的组合来构建工作流:
模板(作业模板或工作流作业模板)
每个节点都由一个 rectangle 表示,而关系及其关联的边缘类型由连接它们的行(或链接)表示。
要启动工作流可视化工具,请使用以下方法之一:
在导航面板中,选择
→
。
在
Details
选项卡中,选择工作流模板,点
Edit
。
选择
Visualizer
选项卡。
在
Templates
列表中点
单击
Start
以显示要添加到工作流的节点列表。
从
Node Type
列表中,选择要添加的节点类型:
如果选择了
Approval
node,请参阅
Approval nodes
以了解更多信息。
选择节点会提供与其关联的可用的有效选项。
如果您在填充工作流图形时选择了没有默认清单的作业模板,则会使用父工作流的清单。虽然作业模板中不需要凭证,但如果具有需要密码的凭证,则无法为工作流选择作业模板,除非凭证被提示的凭证替代。
当您选择节点类型时,工作流开始构建,且您必须指定要为所选节点执行的操作类型。此操作也称为边缘类型。
如果节点是根节点,则边缘类型默认为
Always
,不可编辑。对于后续节点,您可以选择以下场景(类型)之一以应用到每个节点:
Always
: 无论成功或失败都继续执行。
成功后
:成功完成后,执行下一个模板。
On Failure
: 在失败时执行不同的模板。
如果节点是
Convergence
字段中的聚合节点,请选择节点的行为:
任何
是默认行为,允许任何节点按照指定完成,然后再触发下一个聚合节点。只要一个父状态满足其中一个运行条件,就会
运行任何
子节点。
任何节点都
需要所有节点都完成,但只有一个节点必须以预期结果完成。
选择
All
以确保所有节点都按指定完成,然后再聚合并触发下一个节点。
所有
* 节点的目的是确保每个父节点都满足其预期结果,以运行子节点。工作流检查以确保每个父项都如预期运行子节点。否则,它不会运行子节点。
如果选择,在图形视图中将节点标记为
ALL
:
如果节点是根节点,或者没有与其聚合的节点,设置 Convergence 规则不会应用,因为它的行为是由触发节点的操作决定的。
如果工作流中使用的作业模板为其任何参数选择了
Prompt on Launch
,则会出现
PROMPT
选项,允许您在节点级别更改这些值。使用向导更改每个标签页中的值,然后点击
Preview
选项卡中的
Confirm
。
如果工作流中使用的工作流模板为清单选项选择了
Prompt on Launch
,请使用向导在提示符处提供清单。如果父工作流有自己的清单,它会覆盖此处提供的任何清单。
对于带有提示详情但没有默认值的工作流作业模板,您必须在启用
Select
选项前提供这些值。
以下两个情况会禁用
SELECT
选项,直到
PROMPT
选项提供值前:
当您在工作流作业模板中选择
Prompt on Launch
复选框时,但不提供默认值。
当您创建需要但不提供默认答案的问卷调查问题时。
但是,凭证并不如此。创建工作流节点时不允许在启动时需要密码的凭证,因为在创建节点时必须提供启动该节点所需的所有内容。如果您在工作流作业模板中提示输入凭证,则无法选择在自动化控制器中需要密码的凭证。
当提示向导关闭时,您还必须单击
SELECT
,以在该节点上应用更改。否则,您所做的任何更改都会恢复到作业模板中设置的值。
创建节点时,会使用其作业类型进行标记。与每个工作流节点关联的模板,会根据所选运行场景运行。点 compass (
)图标显示每个运行场景及其作业类型的图例。
将鼠标悬停在节点上以添加另一个节点,查看节点信息、编辑节点详情、编辑现有链接或删除所选节点:
添加或编辑节点后,单击
SELECT
以保存任何修改并将其呈现在图形视图中。有关构建工作流的可能方法,请参阅
构建节点场景
。
构建工作流作业模板后,点
Save
保存整个工作流模板并返回到新的工作流作业模板详情页面。
点
Close
不会保存您的工作,而是关闭整个工作流可视化工具,因此您必须再次启动。
选择
批准节点
需要您的干预才能推进工作流。此功能为在 playbook 间暂停工作流,以便您可以授予继续工作流中的下一个 playbook 的批准。这可让用户指定的时间干预,但也允许您尽快继续,而无需等待其他触发器。
超时的默认值为 none,但您可以指定请求过期前的时间长度,并自动拒绝。选择并提供批准节点的信息后,它会显示在图形视图中,其中包含一个暂停图标。
批准者是满足以下条件的任何人:
可以执行包含批准节点的工作流作业模板的用户。
具有机构管理员或以上特权的用户(用于与该工作流作业模板关联的机构)。
在该特定工作流作业模板中明确为其分配了
Approve
权限的用户。
如果待处理的批准节点没有在指定的时间限制内批准(如果分配了过期时间),或者被拒绝,则它们被标记为 "timed out" 或 "failed",并移到下一个 "on fail node" 或 "always node"。如果批准,则使用 "on success" 路径。如果您试图将 API 中的
POST
发布到已批准、被拒绝或超时的节点,则会显示错误消息通知您此操作冗余,且不会执行进一步的步骤。
下表显示了在批准工作流中允许的各种权限级别:
了解如何在以下场景中管理节点。
点击父节点上的(
)图标添加同级节点:
将鼠标悬停在连接两个节点的行上,并点击加号(
)在节点间插入另一个节点。点击加号(
)图标在两个节点之间自动插入节点:
再次单击
START
,以添加根节点来描述分割场景:
在您要创建分割场景的任何节点上,将鼠标悬停在分割场景开始的节点上,然后点击加号(
)图标。这会从同一父节点添加多个节点,创建同级节点:
在添加新节点时,
PROMPT
选项也适用于工作流模板。工作流模板提示输入清单和问卷调查。
您可以使用以下方法之一撤销最后一个插入的节点:
在不做出选择的情况下点另一个节点。
单击
取消
。
以下示例工作流包含作业模板启动的所有三种类型的作业。如果无法运行,您必须保护同步任务。无论它是否失败还是成功,都继续执行清单同步作业:
点击 compass (
)图标来识别与图形描述相关的符号和颜色的含义,以引用该密钥。
如果您在带有一组具有不同边缘类型的同级节点的工作流中删除附加有后续节点的节点,则附加节点会自动加入同级节点组并保留其边缘类型:
使用自动化控制器,您可以复制工作流作业模板。当您复制工作流作业模板时,它不会复制任何关联的调度、通知或权限。用户必须由用户或系统管理员创建工作流模板副本重新创建调度和通知。复制工作流模板的用户被授予管理员权限,但没有将权限分配给工作流模板。
使用以下方法之一打开您要复制的工作流作业模板:
在导航面板中,选择
→
。
在工作流作业模板
详情视图中
,向下滚动以从模板列表中访问它。
此时会打开一个新模板,其中包含您复制的模板名称和时间戳:
选择复制的模板,并将
Name
字段的内容替换为新名称,并提供或者修改其他字段中的条目以完成此模板。
点击
Save
。
如果资源具有您没有正确权限级别的相关资源,则无法复制该资源。例如,如果项目使用了当前用户仅具有 Read 访问权限的凭据。但是,对于工作流作业模板,如果其任何节点使用未授权的作业模板、清单或凭证,则工作流模板仍然可以复制。但是在复制的工作流作业模板中,工作流模板节点中的对应字段不存在。
实例组可让您在集群环境中对实例进行分组。策略指定实例组的行为方式以及任务的执行方式。以下视图显示基于策略算法的容量级别:
有关与实例组关联的策略或规则的更多信息,请参阅
自动化控制器管理指南中的
实例组
部分。
有关将
实例组连接到容器的更多信息,请参阅容器组
。
使用以下步骤创建新实例组。
在导航面板中,选择
→
。
从
Add
instance group
列表中选择 Add。
在以下字段中输入相关信息:
名称
:名称必须是唯一的,且不能命名为 "controller"。
策略实例最小值
:在新实例上线时,自动分配给此组的最少实例数量。
策略实例百分比
:使用滑块来选择在新实例上线时自动分配给此组的最小实例百分比。
创建新实例组时不需要策略实例字段。如果没有指定值,则
Policy 实例最小值
和
Policy 实例百分比
默认为 0。
最大并发作业
:指定可为任何给定作业运行的最大 fork 数量。
最大 fork
:指定可为任何给定作业运行的最大并发作业数。
Max concurrent jobs
和
Max forks
的默认值 0 表示没有限制。如需更多信息,请参阅
自动化控制器管理指南中的
实例组容量限制
。
点击
Save
。
当您成功创建实例组时,新创建的实例组的
Details
选项卡将保留,允许您查看和编辑您的实例组信息。当您点击
Instance Groups
列表视图中的 Edit
图标时,就会打开这个界面。您还可以编辑
实例,
并查看与此实例组关联的
作业
:
流程
-
选择
Instance Groups
窗口的
Instances
选项卡。
点
关联
。
点击列表中一个或多个可用实例旁边的复选框,以选择要与实例组关联的实例:
在以下示例中,添加到实例组中的实例以及其容量的信息:
流程
-
选择
Instance Group
窗口中的
Jobs
选项卡。
点击作业旁边的箭头
图标展开视图并显示每个作业的详情。
每个作业都显示以下详情:
ID 和名称
它启动和完成的时间
谁启动了作业以及与其关联的可用资源,如模板、清单、项目和执行环境
实例会根据实例组的策略运行。如需更多信息,请参阅
自动化控制器管理指南中的
实例组策略
。
作业是为主机清单启动 Ansible playbook 的一个自动化控制器实例。
Jobs
列表视图显示作业列表及其状态,显示为成功完成、失败或活跃(正在运行)作业。默认视图为折叠状态(Compact),作业名称、状态、作业类型、启动和完成时间。您可以点箭头
图标展开并查看更多信息。您可以根据各种条件对列表进行排序,并执行搜索来过滤感兴趣的作业。
在此屏幕中,您可以完成以下任务:
查看特定作业的详情和标准输出
删除所选作业
重新启动操作只适用于重新启动 playbook 运行,不适用于项目或清单更新、系统作业和工作流作业。当作业重启时,会显示
Jobs Output
视图。选择任何类型的作业也会带您进入该作业的作业输出视图,您可以根据各种条件过滤作业:
Stdout
选项是默认显示,显示作业进程和输出。
Event
选项允许您根据感兴趣的事件进行过滤,如错误、主机失败、主机重试和跳过的项目。您可以根据需要在过滤器中包含多个事件。
Advanced
选项是一个优化的搜索,可让您组合包含或排除条件、按键搜索或查找类型。有关使用搜索的更多信息,请参阅
搜索
部分。
执行清单同步时,结果会显示在
Output
选项卡中。如果使用,Ansible CLI 会显示相同的信息。这对调试非常有用。
ANSIBLE_DISPLAY_ARGS_TO_STDOUT
参数设置为
False
,适用于所有 playbook 运行。此参数与 Ansible 的默认行为匹配,且不会在作业详情界面的任务标头
中显示任务
参数,以避免将某些敏感模块参数泄漏到
stdout
。要恢复之前的行为,请通过
AWX_TASK_ENV
配置设置将
ANSIBLE_DISPLAY_ARGS_TO_STDOUT
设置为
True
。
如需更多信息,请参阅
ANSIBLE_DISPLAY_ARGS_TO_STDOUT
。
使用图标重新启动
作业输出或删除
您可以在相关作业运行时执行清单更新。如果您有大型项目(大约 10 GB),
/tmp
上的磁盘空间可能会出现问题。
访问
Details
选项卡,以查看作业执行的详情:
您可以查看已执行作业的以下详情:
状态
:可以是以下任意一种:
待定
:清单同步已创建,但尚未排队或启动。任何作业(不仅仅是清单源同步)都会处于待处理状态,直到系统准备好运行为止。清单源同步没有就绪的原因包括:
当前正在运行的依赖项(所有依赖项都必须完成才能执行下一个步骤)。
在为其配置的位置运行不足以达到容量。
等待
:清单同步处于等待执行的队列中。
Running
: 清单同步当前正在进行中。
成功
:清单同步作业成功。
失败
:清单同步作业失败。
Inventory
:关联的清单组的名称。
Source
: 云清单的类型。
清单源项目
:用作此清单同步作业源的项目。
执行环境
:使用的执行环境。
执行节点
:用于执行该作业的节点。
实例组
:与此作业使用的实例组的名称(自动化控制器是默认实例组)。
选择这些项目可让您查看对应的作业模板、项目和其他对象。
当执行来自 SCM 的清单(如 git)时,其结果将显示在
Output
选项卡中。如果使用,Ansible CLI 会显示相同的信息。这对调试非常有用。使用导航菜单中的图标重新启动(
)、下载(
)作业输出,或删除(
要查看作业执行及其关联的项目的详细信息,请选择
Access
选项卡。
您可以查看已执行作业的以下详情:
状态
:可以是以下任意一种:
Pending
: SCM 作业已创建,但尚未排队或启动。任何作业(不仅仅是 SCM 作业)会一直处于待处理状态,直到系统准备好运行为止。SCM 作业未准备就绪的原因包括:依赖项当前正在运行(所有依赖项都必须已完成才能执行下一个步骤),或者其配置的位置没有足够的运行容量。
waiting : SCM 作业处于等待执行的队列中。
运行
:SCM 作业当前正在进行中。
成功
:最后一个 SCM 作业成功。
失败
:最后一个 SCM 作业失败。
作业类型
:SCM 作业显示源控制更新。
项目
:项目名称。
项目状态
:指示关联的项目是否已成功更新。
修订
:指示此作业中使用的源项目的修订号。
执行环境
:指定用于运行此作业的执行环境。
执行节点
:指示作业运行的节点。
实例组
:指示作业运行的实例组(如果指定)。
Job Tags
:标签显示执行的各种作业操作。
选择这些项目可让您查看对应的作业模板、项目和其他对象。
执行 playbook 时,结果会显示在
Output
选项卡中。如果使用,Ansible CLI 会显示相同的信息。这对调试非常有用。
事件摘要显示作为此 playbook 一部分运行的以下事件:
此 playbook 运行的次数显示在
Plays
字段中
与此 playbook 关联的任务数量显示在
Tasks
字段中
与此 playbook 关联的主机数量显示在
Hosts
字段中
完成 playbook 运行所需的时间显示在
Elapsed
字段中
使用事件旁边的图标重新启动(
)、下载(
)作业输出,或删除(
将鼠标悬停在
Output
视图中的主机状态栏的部分上,并且显示与该状态关联的主机数量。
在 Job
Templates
页的
Jobs
选项卡中启动作业后,也提供了 playbook 作业的输出。单击输出中的行项目任务,以查看其主机详细信息。
使用
Search
查找特定的事件、主机名及其状态。要只过滤具有特定状态的某些主机,请指定以下有效状态之一:
表示任务成功完成,但没有在主机上执行任何更改。
changed
playbook 任务已执行。由于 Ansible 任务应该具有幂等性,因此任务可能会成功退出,而不必在主机上执行任何内容。在这些情况下,该任务返回
ok
,但未
更改
。
任务失败。此主机停止了进一步的 playbook 执行。
unreachable
主机无法从网络访问,或者具有另一个与之关联的致命错误。
playbook 任务跳过,因为主机不需要更改即可达到目标状态。
rescued
这将显示失败的任务,然后执行 rescue 部分。
这将显示失败的任务,
并且配置了 ignore_errors: yes
。
这些状态也显示在每个
Stdout
窗格中,它们称为主机概述字段的一组"统计数据":
以下示例显示一个只包含无法访问主机的搜索:
有关使用搜索的更多信息,请参阅
搜索
部分。
标准输出视图显示特定作业上发生的事件。默认情况下,所有行都会被扩展,以便显示详情。使用折叠功能(
)图标切换到仅包含 play 和任务的标头的视图。点击加号(
)图标查看标准输出的所有行。
您可以通过单击特定 play 或任务旁的箭头图标来显示特定 play 或任务的所有详情。点侧边的箭头到下键,以展开与该 play 或任务关联的行。点箭头回到侧边位置,以折叠和隐藏行。
在展开或折叠模式中查看详情时,请注意以下几点:
每个没有折叠的显示行都有对应的行号和开始时间。
在 play 或任务完成后,展开或折叠图标位于任何 play 或任务开始时。
如果查询特定的 play 或任务,它会在其完成进程结束时出现折叠状态。
在某些情况下会出现错误消息,表示输出可能太大而无法显示。当存在超过 4000 事件时会出现这种情况。使用搜索和过滤特定事件来绕过错误。
单击
Stdout
窗格中的事件行,并在单独的窗口中显示
Host Events
窗口。此窗口显示受该特定事件影响的主机。
升级到最新版本的 Ansible Automation Platform 涉及逐渐迁移所有历史 playbook 输出和事件。这个迁移过程是逐步的,在安装完成后自动在后台进行。在迁移完成前,带有大量历史作业输出(几十或几百 GB 的输出)的安装可能会缺少作业输出。最新的数据显示在输出的顶部,后跟旧的事件。
Host Details
窗口显示受所选事件及其关联的 play 和任务影响的主机的以下信息:
在
Play
字段中运行的类型。
任务
的类型。
如果适用,Ansible Module 任务以及该模块的任何参数。
若要以 JSON 格式查看结果,请单击
JSON
选项卡。要查看任务的输出,请单击
Standard Out
。要查看输出中的错误,请点
Standard Error
。
访问
Details
选项卡,以查看作业执行的详情:
您可以查看已执行作业的以下详情:
状态
:可以是以下任意一种:
Pending
: playbook 运行已创建,但尚未排队或启动。任何作业(不仅仅是 playbook 运行)会一直处于待处理状态,直到系统准备好运行为止。playbook 运行未准备就绪的原因包括:依赖项当前正在运行(所有依赖项都必须已完成才能执行下一个步骤),或者其配置的位置没有足够的运行容量。
等待
:playbook 运行处于等待执行的队列中。
Running
: playbook 运行当前正在进行中。
成功
:最后一个 playbook 运行成功。
失败
:最后一个 playbook 运行失败。
作业模板
:从中启动此作业的作业模板的名称。
清单
:选择针对此任务运行此清单。
项目
:与启动的作业关联的项目名称。
项目状态
:与启动作业关联的项目的状态。
Playbook
: 用于启动此作业的 playbook。
执行环境
:此作业中使用的执行环境的名称。
容器组
:此作业中使用的容器组的名称。
credentials
:此作业中使用的凭证。
额外变量
:创建作业模板时传递的任何额外变量都会在此处显示。
选择其中一个项目来查看对应的作业模板、项目和其他对象。
自动化控制器容量系统根据实例可用的资源量以及正在运行的作业的大小(称为影响)来确定实例可在实例上运行的作业数量。用于确定这一点的算法基于以下两个方面:
系统可使用多少内存(
mem_capacity
)
系统可使用多少个处理容量(
cpu_capacity
)
容量也会影响实例组。由于组由实例组成,因此实例也可以分配到多个组。这意味着,对一个实例的影响可能会影响其他组的整体容量。
实例组而不是实例本身,可以分配给不同级别的作业使用。如需更多信息,
请参阅
自动化控制器管理指南中的
集群。
当任务管理器准备其图形来确定作业运行的组时,它会将实例组的容量提交到尚未准备好启动的作业。
在较小的配置中,如果只有一个实例可用于某个作业运行,任务管理器可让该作业在实例上运行,即使它会使实例超额。这样可保证作业不会因为置备系统而卡住。
有关
容器组的详情,请参考
自动化控制器管理指南中的
容器容量限制
。
有关分片作业及其对容量的影响的详情,请参考
作业分片执行行为
。
容量算法确定系统可以同时运行多少个 fork。这些算法控制 Ansible 可以同时与多少个系统通信。增加自动化控制器系统运行的 fork 数量,使作业可以更快地运行,方法是并行执行更多工作。但是,这会增加系统的负载,这可能导致工作变慢。
默认
mem_capacity
可让您超额提交处理资源,同时防止系统内存不足。如果您的大多数工作不是处理器密集型,则选择此模式可最大化 fork 数量。
mem_capacity
相对于每个 fork 所需的内存量计算。考虑到内部组件的开销,每个分叉大约需要 100MB。在考虑 Ansible 作业可用的内存量时,容量算法保留 2GB 内存,以考虑存在其他服务。其算法公式是:
(mem - 2048) / mem_per_fork
以下是一个示例:
(4096 - 2048) / 100 == ~20
具有 4GB 内存的系统可以运行 20 个分叉。
mem_per_fork
值通过设置
SYSTEM_TASK_FORKS_MEM
的值来控制,默认值为 100。
Ansible 工作负载通常是处理器密集型。在这种情况下,您可以减少同步工作负载,使更多任务可以更快地运行,并减少这些作业的平均完成时间。
就像
mem_capacity
算法调整每个 fork 所需的内存量一样,
cpu_capacity
算法会调整每个 fork 所需的处理资源量。这个基准值是每个内核的四个 fork。其算法公式是:
cpus * fork_per_cpu
例如,4 核系统类似如下:
4 * 4 == 16
您可以通过将
SYSTEM_TASK_FORKS_CPU
的值设置为 4 来控制
fork_per_cpu
的值。
在选择容量时,了解每个作业类型对容量的影响非常重要。
Ansible 的默认 fork 值为 5。但是,如果您将自动化控制器设置为针对更少的系统运行,则实际的并发值会较低。
当在自动化控制器中运行作业时,所选的 fork 数量会递增 1,以补充 Ansible 父进程。
Example
如果您针对 5 的五个系统运行 playbook,则从作业影响角度来看,实际的 fork 值为 6。
作业和临时作业遵循前面的模型,分叉 +1。如果在作业模板上设置了 fork 值,则您的作业容量值是提供的 forks 值的最小值,以及您拥有的主机数量,再加上 1。+1 是考虑父 Ansible 进程。
实例容量决定了哪些作业被分配给任何特定实例。如果作业和临时命令具有更高的 fork 值,则使用更多容量。
作业类型包括以下内容,具有固定影响:
清单更新:1
项目更新:1
系统作业:5
如果您没有在作业模板上设置 fork 值,则您的作业将使用 Ansible 的默认 fork 值 5。但是,如果您的作业少于五个主机,它会使用较少的主机。通常,设置 fork 值高于系统能够使问题出现内存不足或过量提交 CPU 时的问题。您使用的作业模板 fork 值必须适合于系统。如果您有使用 1000 个 fork 的 playbook,但您的系统都没有足够容量,则您的系统会降低,并面临性能或资源问题的风险。
从 CPU 密集型或内存密集型容量限制中选择容量会在最小或最大分叉数量之间进行选择。
在上例中
,CPU 容量最多允许 16 个 fork,而内存容量允许 20 个。对于某些系统,它们之间的差别可能较大,您可能希望在两者之间保持平衡。
instance 字段
capacity_adjustment
允许您选择要考虑多少。它表示为 0.0 到 1.0 之间的值。如果设置为 1.0,则使用最大值。上例涉及内存容量,因此可以选择 20 个 fork。如果设置为 0.0,则使用最小值。值 0.5 是两个算法之间的 50/50 平衡,即 18:
16 + (20 - 16) * 0.5 = 18
流程
查看或编辑容量:
从
Instances Groups
列表视图中,选择所需的实例。
选择
Instances
选项卡,并调整
Capacity Adjustment
滑块。
滑块调整实例容量算法是否产生较少的分叉(在左侧)或产生更多分叉(在右侧)。
项目在
scm_branch
字段中指定要从源控制使用的分支、标签或引用。它们由
Type Details
字段中指定的值表示:
在创建或编辑作业时,您可以选择
Allow Branch Override
。选中此选项时,项目管理员可以将分支选择委托给使用该项目的作业模板,只需要项目
use_role
。
每个作业运行都有自己的私有数据目录。此目录包含作业运行的给定
scm_branch
的项目源树的副本。作业可以自由地更改项目文件夹,并在仍在运行时使用这些更改。此文件夹是临时的,在作业运行结束时被删除。
如果您检查
Clean
选项,则在自动化控制器的本地副本中删除修改后的文件。这可以通过在与 git 或 Subversion 相关的相应 Ansible 模块中使用 force 参数来完成。
有关更多信息,请参阅 Ansible 文档中的
Parameters
部分。
在项目更新过程中,默认分支的修订版本(在项目的
SCM 分支字段中指定
)会在更新时存储。如果在作业中提供非默认
SCM 分支
(而不是提交散列或标签),则在作业启动前会立即从源控制远程拉取最新的修订版本。此修订版本显示在作业的
Source Control Revision
字段中,及其项目更新。
因此,非默认分支无法离线作业运行。为确保作业从源控制运行静态版本,请使用标签或提交哈希。项目更新不会保存所有分支,而只有项目默认分支。
SCM 分支
字段未验证,因此项目必须更新以确保其有效。如果提供或提示了此字段,则不会验证作业模板的
Playbook
字段,您必须启动作业模板以验证预期的 playbook 是否存在。
SCM Refspec
字段指定更新应该从远程下载的额外引用。示例包括以下内容:
refs/
:refs/remotes/origin/
:这将获取所有引用,包括远程的远程
refs/pull/
:refs/remotes/origin/pull/
(GitHub-specific):这将获取所有拉取请求的所有 refs
refs/pull/62/head:refs/remotes/origin/pull/62/head
:这会获取一个 GitHub 拉取请求的 ref
对于大型项目,在使用第一个或第二个示例时请考虑性能影响。
SCM Refspec
参数会影响项目分支的可用性,并可启用对不可用的引用的访问。前面的示例允许您提供 SCM
分支 的拉取请求,在没有
SCM
Refspec
字段的情况下无法实现。
默认情况下,Ansible git 模块获取
refs/heads/
。这意味着,如果
SCM Refspec
为空,项目的分支
、标签和提交散列可用作 SCM 分支。
SCM Refspec
字段中指定的值会影响哪些
SCM 分支
字段可用作覆盖。项目更新(任何类型的)执行额外的
git fetch
命令来从远程拉取该 refspec。
Example
您可以设置使用第一个或第二个 refspec 示例启用分支覆盖的项目。在提示
SCM 分支 的作业模板中使用此选项
。然后,客户端可以在创建新拉取请求时启动作业模板,提供分支
pull/N/head
,并且作业模板可以根据提供的 GitHub 拉取请求引用运行。
有关更多信息,请参阅
Ansible git 模块
。
Webhook 可让您通过 Web 在应用程序间执行指定的命令。自动化控制器目前提供 webhook 与 GitHub 和 GitLab 的集成。
使用以下服务设置 webhook:
设置 GitHub Webhook
设置 GitLab Webhook
查看有效负载输出
webhook 的 GitHub 和 GitLab 的 post-status-back 功能旨在仅在某些 CI 事件下工作。在服务日志中接收其他类型的事件会导致信息类似如下:
awx.main.models.mixins Webhook 事件没有关联状态 API 端点并跳过。
自动化控制器可根据触发的 webhook 事件运行作业。作业状态信息(待定、错误、成功)只能针对拉取请求事件发回。如果您不需要自动化控制器将作业状态回 webhook 服务,请直接转至第 3 步。
生成用于自动化控制器
的个人访问令牌
(PAT):
在 GitHub 帐户的配置集设置中,选择
Settings
。
在导航面板中,选择 <>
。
在
Developer Settings
页面中,选择
Personal access token
。
在
个人访问令牌
屏幕中,单击
Generate a personal access token
。
提示时,请输入您的 GitHub 帐户密码以继续。
在
Note
字段中,输入有关此 PAT 用途的简要描述。
在
Select scopes
字段中,选中
repo:status
、
repo_deployment
和
public_repo
旁边的框。自动化 Webhook 只需要存储库范围访问权限,但邀请除外。如需更多信息,
请参阅 OAuth 应用文档的范围
。
点
Generate token
。
生成令牌时,请确保复制 PAT,因为您在第 2 步中需要它。您无法在 GitHub 中再次访问此令牌。
使用 PAT 创建 GitHub 凭证(可选):
进入您的实例,
并使用生成的令牌为 GitHub PAT 创建新凭证
。
记录此凭据的名称,因为您在回发到 GitHub 的作业模板中使用它。
进入您要启用 webhook 的作业模板,然后选择 webhook 服务和您在上一步中创建的凭证。
点击
Save
。您的作业模板已设置为回 GitHub。
进入您要配置 webhook 的 GitHub 存储库,然后选择
。
在导航面板中,选择
→
。
要完成
Add webhook
页面,您必须检查作业模板或工作流作业模板中的
Enable Webhook
选项。如需更多信息,请参阅创建
作业模板和
创建工作流模板
中的第 3 步。
完成以下字段:
payload URL
:从作业模板中复制
Webhook URL
的内容,并将它粘贴。结果从 GitHub 发送到此地址。
内容类型
:将其设置为
application/json
。
Secret
:从作业模板中复制
Webhook
密钥的内容并将其粘贴到此处。
您要触发此 Webhook 的事件类型?
:选择您要触发 Webhook 的事件类型。任何这样的事件都会触发作业或工作流。要让作业状态(pending, error, success)发送到 GitHub,您必须在
Let me select individual events
部分中选择
Pull requests
部分。
Active
:保留此检查。
点击
Add webhook
。
配置 webhook 时,它会显示在您的仓库活跃的 webhook 列表中,并能够编辑或删除它。单击 webhook,前往
Manage webhook
屏幕。
滚动以查看向 webhook 发出的发送尝试,以及它们是成功还是失败。
如需更多信息,请参阅
Webhooks 文档
。
自动化控制器可根据触发的 webhook 事件运行作业。作业状态信息(待定、错误、成功)只能针对拉取请求事件发回。如果自动化控制器不需要将作业状态回 webhook 服务,请直接转至第 3 步。
生成用于自动化控制器
的个人访问令牌
(PAT):
在 GitLab 中的导航面板中,选择您的 avatar 和
。
在导航面板中,选择
。
完成以下字段:
令牌名称
:输入有关此 PAT 用途的简要描述。
过期日期
:跳过此字段,除非您想为您的 webhook 设置过期日期。
选择范围
:选择适用于您的集成的范围。对于自动化控制器,
api
是唯一需要的选择。
单击
Create personal access token
。
生成令牌时,请确保复制 PAT,因为您在第 2 步中需要它。您无法在 GitLab 中再次访问此令牌。
使用 PAT 创建 GitLab 凭证(可选):
进入您的实例,
并使用生成的令牌为 GitLab PAT 创建新凭证
。
记录此凭据的名称,因为您在回发到 GitLab 的作业模板中使用它。
进入您要启用 webhook 的作业模板,然后选择 webhook 服务和您在上一步中创建的凭证。
点击
Save
。您的作业模板设置为回发到 GitLab。
进入您要配置 webhook 的 GitLab 存储库。
在导航面板中,选择
→
。
要完成
Add webhook
页面,您必须检查作业模板或工作流作业模板中的
Enable Webhook
选项。如需更多信息,请参阅创建
作业模板和
创建工作流模板
中的第 3 步。
完成以下字段:
URL
:从作业模板中复制
Webhook URL
的内容,并将它粘贴。结果从 GitLab 发送到此地址。
Secret Token
:从作业模板中复制
Webhook
密钥的内容并粘贴它。
trigger :选择您要触发 Webhook 的事件类型。
任何这样的事件都会触发作业或工作流。要让作业状态(pending, error, success)发送到 GitLab,您必须在
Trigger
部分中选择
Merge request 事件
。
SSL 验证
:使
启用 SSL 验证
被选择。
点击
Add webhook
。
配置 webhook 后,它会显示在存储库的列表
Project Webhooks
中,并能够测试事件、编辑或删除 webhook。测试 Webhook 事件会显示每个页面的结果是成功还是失败。
如需更多信息,请参阅
Webhooks
。
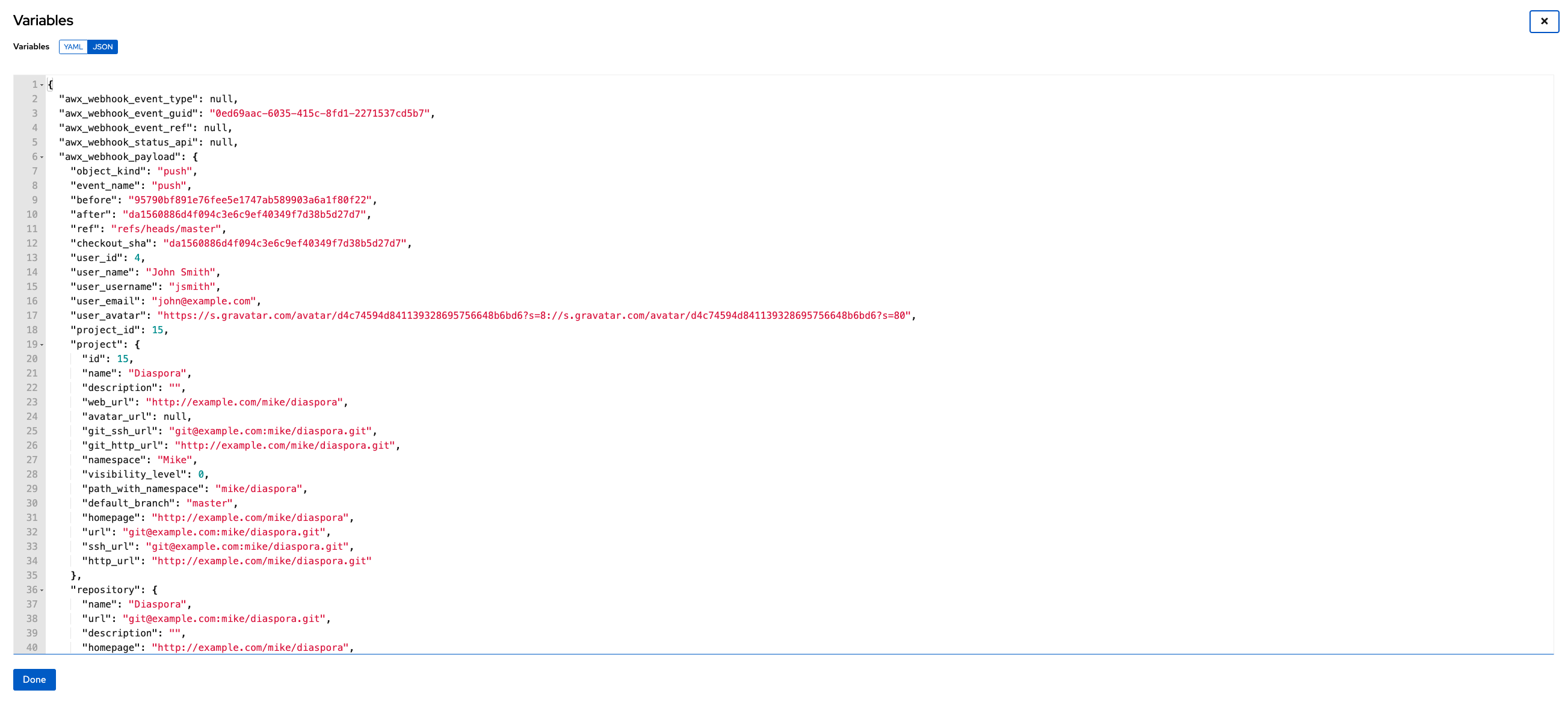
您可以查看作为额外变量公开的整个有效负载。
在导航面板中,选择
→
。
选择启用了 webhook 的作业模板。
选择
Details
选项卡。
在
Extra Variables
字段中,查看
awx_webhook_payload
变量中的有效负载输出,如下例所示:
通知类型
(如 Email、Slack 或 Webhook)是通知模板的实例,具有通知模板中定义的名称、描述和配置。
以下是添加通知模板所需的详情示例:
电子邮件通知模板需要用户名、密码、服务器和收件人
Slack 通知模板需要令牌和频道列表
Webhook 通知模板需要 URL 和标头
当作业失败时,将使用您在通知模板中定义的配置发送通知。
以下显示了通知系统的典型流程:
您可以通过 API 或 UI 创建指向
/api/v2/notification_templates 端点
的
REST API
的通知模板。
您可以将通知模板分配给支持它的各种对象(所有作业模板变体以及机构和项目)以及您想要通知的适当触发器级别(启动、成功或错误)。例如,您可能希望分配特定的通知模板,以便在作业模板 1 失败时触发。在这种情况下,您可以将通知模板与
/api/v2/job_templates/n/notification_templates_error
API 端点的作业模板关联。
您可以在作业启动和作业结束时设置通知。用户和团队也可以定义他们自己的通知,这些通知可以附加到任意作业。
通知模板继承父对象上定义的模板,如下所示:
作业模板使用为它们定义的通知模板。此外,他们可以从作业模板使用的项目中继承通知模板,以及它列在下面列出的机构中。
项目更新使用项目上定义的通知模板,并从与其关联的机构中继承通知模板。
清单更新使用在下面列出的机构上定义的通知模板。
临时命令使用与清单关联的组织上定义的通知模板。
当作业成功或失败时,错误或成功处理程序使用
Notifications
部分中定义的步骤拉取相关通知模板列表。
然后,它会为每个对象创建一个通知对象,其中包含作业的相关详情并将其发送到目的地。这包括电子邮件地址、slack 频道和 SMS 号。
这些通知对象作为作业类型上的相关资源(作业、清单更新、项目更新、项目更新)以及
/api/v2/notifications
提供。您还可以通过检查其相关资源来查看从通知模板发送了哪些通知。
如果通知失败,它不会影响与其关联的作业,或导致它失败。通知的状态可以在其详情端点
/api/v2/notifications/<n>
; 中查看。
使用以下步骤创建通知模板。
在导航面板中,选择
→
。
点
Add
。
完成以下字段:
Name
:输入通知的名称。
描述
:输入通知的描述。此字段是可选的。
Organization
: 指定通知所属的机构。
类型
:从下拉菜单中选择通知类型。如需更多信息,请参阅
通知类型
部分。
点击
Save
。
自动化控制器支持以下通知类型:
Grafana
Mattermost
PagerDuty
Rocket.Chat
Slack
Twilio
Webhook
Webhook 有效负载
每个通知类型都有自己的配置和行为语义。您可能需要以不同的方式进行测试。另外,您可以将每种通知类型自定义为特定的详情,或一组用于触发通知的条件。
有关配置自定义通知的更多信息,
请参阅创建自定义通知
。以下小节详细介绍了每种通知类型。
电子邮件通知类型支持各种 SMTP 服务器,并支持 SSL/TLS 连接。
提供以下详情来设置电子邮件通知:
接收者列表
发件人电子邮件
Timeout
(以秒为单位):使您能够指定最多 120 秒,自动化控制器在失败前尝试连接到电子邮件服务器的时间长度。
要集成 Grafana,您必须首先在
Grafana 系统中创建
API 密钥。这是提供给自动化控制器的令牌。
提供以下详情来设置 Grafana 通知:
Grafana URL
:Grafana API 服务的 URL,例如: http://yourcompany.grafana.com。
Grafana API 密钥
:您必须首先在 Grafana 系统中创建一个 API 密钥。
可选:
仪表板 ID
:当您为 Grafana 帐户创建 API 密钥时,您可以使用自己的唯一 ID 设置仪表板。
可选:
面板 ID
:如果您向 Grafana 界面添加了面板和图形,您可以在这里指定其 ID。
可选:
注解
的标签 : 输入关键字,以帮助识别您要配置的通知类型。
禁用 SSL
验证 :默认情况下 SSL 验证是开启的,但您可以选择关闭验证目标证书真实性的功能。选择这个选项来禁用使用内部或私有 CA 的环境验证。
IRC 通知采用 IRC bot 的形式,它连接,将消息传送到频道或单个用户,然后断开连接。通知 bot 还支持 SSL 身份验证。bot 目前不支持 Nickserv 身份识别。如果频道或用户不存在或者没有在线,通知会失败。故障场景是为连接而保留的。
提供以下详情来设置 IRC 通知:
可选:
IRC 服务器密码
:IRC 服务器可能需要密码才能连接。如果服务器不需要,请将其留空。
IRC 服务器端口
:IRC 服务器端口。
IRC 服务器地址
:IRC 服务器的主机名或地址。
IRC nick
:bot 在连接到服务器后的别名。
目标频道或用户
:发送通知的用户或频道列表。
可选:
禁用 SSL 验证
:检查是否希望 bot 在连接时使用 SSL。
Mattermost 通知类型为 Mattermost 的消息和协作工作区提供了一个简单的接口。
提供以下详情来设置 Mattermost 通知:
目标 URL :发布的完整 URL。
可选:
用户名
:输入通知的用户名。
可选
:
输入通知频道。
Icon URL
: 指定为这个通知显示的图标。
禁用 SSL 验证
:关闭验证目标证书真实性的功能。选择这个选项来禁用使用内部或私有 CA 的环境验证。
Rocket.Chat 通知类型为 Rocket.Chat 的协作和通信平台提供了一个接口。
提供以下详情来设置 Rocket.Chat 通知:
目标 URL
:
POST
到的完整 URL。
可选:
用户名
:输入用户名。
可选:
Icon URL
: 指定为这个通知显示的图标
Disable SSL Verification
:关闭验证目标证书真实性的功能。选择这个选项来禁用使用内部或私有 CA 的环境验证。
Slack 是一个协作团队通信和消息传递工具。
提供以下详情来设置 Slack 通知:
Slack 应用程序。如需更多信息,请参阅 Slack 文档中的
Quickstart
页面。
令牌。如需更多信息,请参阅
Current token
type 文档 页中的
Legacy bots
以及 bot 令牌令牌的特定详情。
当您设置 bot 或应用程序时,您必须完成以下步骤:
导航到
Apps
。
点新创建的应用程序,然后进入
Add features and functionality
,它可让您配置传入的 webhook、bot 和 permissions,
并将您的应用程序安装到工作区中
。
Twilio 是一个语音和 SMS 自动化服务。当您签名后,您必须创建一个从其中发送消息的电话号码。然后,您可以在
Programmable SMS
下定义一个
消息传递服务
,并将之前创建的号码与其相关联。
在被允许使用它发送到任何数字之前,您可能需要验证这个数字或一些其他信息。
消息传递服务
不需要状态回调 URL,不需要处理入站消息。
在您的单独(或子)帐户设置下,您有 API 凭证。Twilio 使用两个凭证来确定来自哪个帐户。
帐户 SID
充当用户名,以及作为密码的
Auth Token
。
提供以下详情来设置 Twilio 通知:
帐户令牌
:输入帐户令牌。
源电话号码
:以"+15556667777"的形式输入与消息传递服务关联的号码。
Destination SMS number (s)
: 输入您要接收 SMS 的数字列表。它必须是 10 位的电话号码。
帐户 SID
:输入帐户 SID。
webhook 通知类型提供了一个简单接口,用于将
POST
发送到预定义的 Web 服务。自动化控制器使用应用程序和 JSON 内容类型以及包含 JSON 格式的相关详情的数据有效负载
POST
到此地址。有些 Web 服务 API 预期 HTTP 请求采用特定格式,带有特定字段。
使用以下命令配置 webhook 通知:
使用
POST
或
PUT
配置 HTTP 方法。
传出请求的正文。
使用基本身份验证配置身份验证。
提供以下详情来设置 Webhook 通知:
可选:
用户名
:输入用户名。
可选:
基本身份验证密码
:
目标 URL
:输入 webhook 通知为
PUT
或
POSTed
的完整 URL。
Disable SSL Verification
:默认情况下 SSL 验证是开启的,但您可以选择关闭验证目标证书真实性的功能。选择这个选项来禁用使用内部或私有 CA 的环境验证。
HTTP Headers
:以 JSON 格式输入标头,其中键和值是字符串。例如:
{"Authentication": "988881adc9fc3655077dc2d4d757d480b5ea0e11", "MessageType": "Test"}`.
-
HTTP 方法
:选择 Webhook 的方法:
POST
:创建新资源。它还作为操作的一个捕获全部,它们不适合于其他类别。除非您知道 Webhook 服务需要
PUT
,否则您可能需要
POST
。
PUT
:更新特定资源(按标识符)或资源集合。如果事先知道资源标识符,也可以使用
PUT
来创建特定资源。
自动化控制器在 Webhook 端点发送以下数据:
job id
created_by
started
finished
status
traceback
inventory
project
playbook
credential
limit
extra_vars
hosts
http method
以下是通过自动化控制器返回的 webhook 消息的
启动
通知示例:
{"id": 38, "name": "Demo Job Template", "url": "https://host/#/jobs/playbook/38", "created_by": "bianca", "started":
"2020-07-28T19:57:07.888193+00:00", "finished": null, "status": "running", "traceback": "", "inventory": "Demo Inventory",
"project": "Demo Project", "playbook": "hello_world.yml", "credential": "Demo Credential", "limit": "", "extra_vars": "{}",
"hosts": {}}POST / HTTP/1.1
自动化控制器会在 Webhook 端点中
返回成功/失败状态
的数据:
job id
created_by
started
finished
status
traceback
inventory
project
playbook
credential
limit
extra_vars
hosts
以下是自动化控制器通过 Webhook 消息返回的
成功/失败
通知示例:
{"id": 46, "name": "AWX-Collection-tests-awx_job_wait-long_running-XVFBGRSAvUUIrYKn", "url": "https://host/#/jobs/playbook/46",
"created_by": "bianca", "started": "2020-07-28T20:43:36.966686+00:00", "finished": "2020-07-28T20:43:44.936072+00:00", "status": "failed",
"traceback": "", "inventory": "Demo Inventory", "project": "AWX-Collection-tests-awx_job_wait-long_running-JJSlglnwtsRJyQmw", "playbook":
"fail.yml", "credential": null, "limit": "", "extra_vars": "{\"sleep_interval\": 300}", "hosts": {"localhost": {"failed": true, "changed": 0,
"dark": 0, "failures": 1, "ok": 1, "processed": 1, "skipped": 0, "rescued": 0, "ignored": 0}}}
您可以在通知表单上
自定义每个 通知类型 的文本内容
。
在
Notification Templates
列表视图中,单击
Add
。
从
Type
列表中选择通知类型。
使用切换启用
自定义消息
。
您可以为各种作业事件提供自定义消息,如下所示:
成功消息正文
工作流已批准消息
工作流拒绝消息
工作流运行消息
工作流待处理消息
工作流超时消息
消息表单因您要配置的通知类型而异。例如,电子邮件和 PagerDuty 通知的消息显示为典型的电子邮件,其中包含正文和主题,在这种情况下,自动化控制器会将字段显示为
Message
和
Message Body
。其他通知类型仅针对每种事件要求
消息
。
Message
字段预先填充一个模板,其中包含顶层变量,并与属性合并,如
id
或
name
。
模板用大括号括起,可以从自动化控制器提供的固定字段集合中提取,如预先填充的消息字段所示:
这个预先填充的字段建议通常向接收事件通知的接收者显示信息。您可以根据需要为作业添加自己的属性来自定义这些消息。自定义通知消息使用 Jinja 呈现;Ansible playbook 使用的同一模板引擎。
消息和消息正文具有不同的内容类型,如下所示:
信息始终只是字符串,仅一行。不支持新行。
消息正文可以是字典或文本块:
Webhooks 和 PagerDuty 的消息正文使用字典定义。这些的默认消息正文是
{{ job_metadata }}
,您可以保留原样的值,或者提供自己的字典。
电子邮件的消息正文使用文本块或多行字符串。默认消息正文为:
{{ job_friendly_name }} #{{ job.id }} had status {{ job.status }}, view details at {{ url }} {{ job_metadata }}
您可以编辑此文本,使
{{ job_metadata }}
留在,或者丢弃
{{ job_metadata }}
。由于正文是文本块,它可以是您想要的任何字符串。
{{ job_metadata }}
呈现为包含描述正在执行作业的字段的字典。在所有情况下,
{{ job_metadata }}
包括以下字段:
created_by
started
finished
status
您无法查询
{{ job_metadata }}
中的各个字段。当您在通知模板中使用
{{ job_metadata }}
时,所有数据都会被返回。
生成的字典类似如下:
{"id": 18,
"name": "Project - Space Procedures",
"url": "https://host/#/jobs/project/18",
"created_by": "admin",
"started": "2019-10-26T00:20:45.139356+00:00",
"finished": "2019-10-26T00:20:55.769713+00:00",
"status": "successful",
"traceback": ""
如果 {{ job_metadata }} 在作业中呈现,它将包括以下附加字段:
清单(inventory)
project
playbook
credential
limit
extra_vars
生成的字典类似如下:
{"id": 12,
"name": "JobTemplate - Launch Rockets",
"url": "https://host/#/jobs/playbook/12",
"created_by": "admin",
"started": "2019-10-26T00:02:07.943774+00:00",
"finished": null,
"status": "running",
"traceback": "",
"inventory": "Inventory - Fleet",
"project": "Project - Space Procedures",
"playbook": "launch.yml",
"credential": "Credential - Mission Control",
"limit": "",
"extra_vars": "{}",
"hosts": {}
如果 {{ job_metadata }} 在工作流作业中呈现,它将包括以下附加字段:
body (此枚举工作流作业中的节点,并包含与每个节点关联的作业描述)
生成的字典类似如下:
{"id": 14,
"name": "Workflow Job Template - Launch Mars Mission",
"url": "https://host/#/workflows/14",
"created_by": "admin",
"started": "2019-10-26T00:11:04.554468+00:00",
"finished": "2019-10-26T00:11:24.249899+00:00",
"status": "successful",
"traceback": "",
"body": "Workflow job summary:
node #1 spawns job #15, \"Assemble Fleet JT\", which finished with status successful.
node #2 spawns job #16, \"Mission Start approval node\", which finished with status successful.\n
node #3 spawns job #17, \"Deploy Fleet\", which finished with status successful."
如果您创建使用无效语法或引用不可用字段的通知模板,则会显示一条错误消息,指出错误的性质。如果您删除通知的自定义消息,则会在其位置显示默认消息。
如果您在不编辑自定义消息(或编辑并恢复到默认值)的情况下保存通知模板,Details 屏幕会假定默认值,且不会显示自定义消息表。如果您编辑并保存任何值,则整个表会显示在 Details 屏幕中。
如需更多信息,请参阅使用带有 Jinja2 的变量。
自动化控制器需要有效的语法来检索正确的数据来显示消息。有关支持的属性和正确的语法构建列表,请参阅 Custom Notifications 支持的属性 部分。
您可以将通知设置为在特定作业启动时通知您,并在作业运行结束时出现成功或失败。请注意以下行为:
如果工作流作业模板启动时启用了通知,并且该工作流中的作业模板也启用了启动时通知,您会收到这两者的通知。
您可以启用在工作流作业模板中的多个作业模板上运行通知。
您可以启用在分片作业模板启动中运行的通知,每个分片都会生成通知。
当您启用在作业启动时运行通知并且通知被删除时,作业模板将继续运行,但会生成错误消息。
您可以从以下资源的
Notifications
选项卡中启用作业启动、作业成功和作业失败时通知,或者它们的组合:
工作流模板
项目(如下例所示)
对于具有批准节点的工作流模板,除了
启动
、
成功
和
Failure
外,您还可以启用或禁用某些与批准相关的事件:
有关使用这些节点类型的更多信息,请参阅
批准节点
。
使用已启动的
、
success
或
error
端点:
/api/v2/organizations/N/notification_templates_started/
/api/v2/organizations/N/notification_templates_success/
/api/v2/organizations/N/notification_templates_error/
另外,../
.././N/notification_templates_started
端点具有
GET
和
POST
操作:
系统作业模板
工作流任务模板
了解支持的作业属性列表以及构建通知消息文本的正确语法。
以下是支持的作业属性:
allow_simultaneous
- (布尔值)指示多个作业是否可以从与此作业关联的作业模板同时运行。
controller_node
- (字符串)管理隔离执行环境的实例。
created
- (日期时间)创建此作业时的时间戳。
custom_virtualenv
- (字符串)用于执行作业的自定义虚拟环境。
description
- (字符串)作业的可选描述。
diff_mode
- (布尔值)如果启用,标准输出中会显示对主机上任何模板文件进行的文本更改。
elapsed
-(decimal)作业运行经过的时间(以秒为单位)。
execution_node
- (字符串)作业执行的节点。
failed
- (布尔值)如果作业失败,则为 True。
finished
- (日期时间)作业完成执行的日期和时间。
force_handlers
- (布尔值)当处理程序被强制运行时,它们也会在通知时运行,即使该主机上的任务失败也是如此。请注意,一些条件(如不可访问的主机)仍然可以阻止处理程序运行。
forks
- (整数)此作业请求的 fork 数量。
id
- (整数)此作业的数据库 ID。
job_explanation
- (字符串)在无法运行和捕获
stdout
时指示作业状态的 status 字段。
job_slice_count
- (整数)如果作为分片作业的一部分运行,则这是分片(如果为 1,则作业不是分片作业的一部分)的总数。
job_slice_number
- (整数)如果作为分片作业的一部分运行,这是在其上操作的清单分片的 ID (如果不是分片作业的一部分,则不使用属性)。
job_tags
- (字符串)仅执行具有指定标签的任务。
job_TYPE
-(选择)这可以
可以运行
、
检查
或
scan
。
launch_type
- (选择)这可以是
手动
、
重新启动
、
回调
、
计划
、
依赖项
、
工作流
、
同步
或
scm
。
limit
- (字符串)如果指定,则 playbook 执行仅限于这组主机。
modified
- (日期时间)最后一次修改此作业的时间戳。
name
- (字符串)此作业的名称。
playbook
-(字符串)执行的 playbook。
scm_revision
- (字符串)用于此作业的项目中的 scm 修订(如果可用)。
skip_tags
- (字符串)如果指定,playbook 执行将跳过此组标签。
start_at_task
- (字符串)如果指定,playbook 执行从与此名称匹配的任务开始。
started
- (日期时间)作业加入启动队列的日期和时间。
状态
-(选择)可以是
新的
、
pending
、
waiting
、
running
、
successful
、
failed
、
error
或
Canceled
。
timeout
- (整数)取消任务前运行的时间(以秒为单位)。
type
- (选择)此作业的数据类型。
url
- (字符串)此作业的 URL。
use_fact_cache
- (布尔值)如果已为作业启用,自动化控制器会在 playbook 运行到数据库和缓存事实的末尾充当 Ansible 事实缓存插件。
verbosity
- (选择)0 到 5 (与 Normal 到 WinRM Debug 相对应)。
host_status_counts
(分配给每个状态的唯一主机数量)
skipped
(整数)
ok
(整数)
changed
(整数)
failures
(整数)
dark
(整数)
processed
(整数)
rescued
(整数)
ignored
(整数)
failed
(布尔值)
summary_fields
:
清单(inventory)
id
- (整数)清单的数据库 ID。
name
- (字符串)清单的名称。
description
- (字符串)清单的可选描述。
has_active_failures
- (布尔值)(已弃用)指示此清单中是否有主机失败的标记。
total_hosts
- (已弃用)(整数)此清单中的主机总数。
hosts_with_active_failures
- (已弃用)(整数)此清单中有活跃故障的主机数量。
total_groups
- (已弃用)(整数)此清单中的组总数。
groups_with_active_failures
- (已弃用)(整数)此清单中有活跃故障的主机数量。
has_inventory_sources
- (已弃用)(布尔值)指明此清单是否具有外部清单源的标记。
total_inventory_sources
-(整数)在此清单中配置的外部清单源总数。
inventory_sources_with_failures
-(整数)此清单中有故障的外部清单源数量。
organization_id
-(id)包含此清单的机构。
kind
-(选择)(空字符串)(代表主机与清单有直接链接)或
smart
project
id
- (整数)项目的数据库 ID。
name
- (字符串)项目名称。
description
(字符串)项目的可选描述。
status
- (选择)
新
、
pending
、
waiting
、
running
、
successful
、
failed
、
error
、
canceled
、
never updated
、
ok
或
missing
之一。
scm_type
(选择) 其中一个(空字符串)、
git
、
hg
、
svn
、
insights
.
job_template
id
- (整数)作业模板的数据库 ID。
description
- (字符串)项目的可选描述。
status
- (选择)
新
、
pending
、
waiting
、
running
、
successful
、
failed
、
error
、
canceled
、
never updated
、
ok
或
missing
之一。
job_template
id
- (整数)作业模板的数据库 ID。
name
- (字符串)作业模板的名称。
description
- (字符串)作业模板的可选描述。
unified_job_template
id
-(整数)统一的作业模板的数据库 ID。
name
- (字符串)统一的作业模板的名称。
description
- (字符串)统一的作业模板的可选描述。
unified_job_type
-(choice)统一作业类型,如
作业
、
workflow_job
或
project_update
。
instance_group
id
- (整数)实例组的数据库 ID。
name
- (字符串)实例组的名称。
created_by
id
-(int)启动操作的用户的数据库 ID。
username
- (字符串)启动操作的用户名。
first_name
- (字符串)名。
last_name
-(string)姓氏。
labels
count
-(int)标签数。
results
- 代表标签的字典列表。例如: {"id": 5, "name": "database jobs"}。
您可以使用分组大括号 {{ }} 在自定义通知消息中引用有关作业的信息。使用点表示法访问特定作业属性,如 {{ job.summary_fields.inventory.name }}。您可以添加在大括号或周围使用的任何字符,或纯文本,如 ":" 用于作业 ID,单引号用于表示某些描述符。自定义消息可在整个消息中包含多个变量:
{{ job_friendly_name }} {{ job.id }} ran on {{ job.execution_node }} in {{ job.elapsed }} seconds.
以下是可添加到模板中的额外变量:
approval_node_name
- (字符串)批准节点名称。
approval_status
-(选择)
批准的
、
denied
和
timed_out
之一。
URL- (字符串)发出通知的作业 URL (这适用于
启动
、
成功
、
失败
和
批准通知
)。
workflow_url
- (字符串)相关批准节点的 URL。这允许通知接收者进入相关的工作流作业页面来检查这种情况。例如,
可在以下位置查看此节点:{{workflow_url }}
。在与批准相关的通知中,
url
和
workflow_url
都相同。
job_friendly_name
- (字符串)作业的友好名称。
job_metadata
-(string)作业元数据作为 JSON 字符串,例如:
{'url': 'https://towerhost/$/jobs/playbook/13',
'traceback': '',
'status': 'running',
'started': '2019-08-07T21:46:38.362630+00:00',
'project': 'Stub project',
'playbook': 'ping.yml',
'name': 'Stub Job Template',
'limit': '',
'inventory': 'Stub Inventory',
'id': 42,
'hosts': {},
'friendly_name': 'Job',
'finished': False,
'credential': 'Stub credential',
'created_by': 'admin'}
在导航面板中,单击
→
以访问您配置的计划。调度列表可以根据每个列中的任何属性使用方向箭头进行排序。您还可以按名称、日期或调度运行的月份名称进行搜索。
每个调度都有对应的
Actions
列,具有使用调度名称旁边的
On
或
Off
切换来启用或禁用该调度的选项。点 Edit
图标编辑调度。
如果要设置模板、项目或清单源,请点击
Schedules
选项卡来为这些资源配置调度。当您创建调度时,会通过以下方法列出它们:
点计划名称打开其详情。
这标识调度是否与源控制更新关联或系统管理的作业调度。
此任务的下一次调度运行。
您只能从模板、项目或清单源创建调度,而不直接在主
Schedules
屏幕上创建。
创建新时调度:
单击您要配置的资源的
Schedules
选项卡。这可以是模板、项目或清单源。
点
Add
。这将打开
Create New Schedule
窗口。
在以下字段中输入相关信息:
名称 :输入名称
。
可选:
描述
:输入描述。
开始日期/时间
:输入开始计划的日期和时间。
本地时区
:您输入的开始时间必须在此时区中。
重复频率
:根据您选择的频率显示适当的调度选项。
Schedule Details
在建立调度时显示,供您查看调度设置以及所选本地时区中调度的发生次数列表。
作业以 UTC 的形式调度。当夏时制发生时,在一天的特定时间运行的重复作业可能会针对本地时区有相应变化。在保存调度时,系统会将基于本地时区的时间解析为 UTC。要确保正确创建了您的调度,以 UTC 时间设置调度。
点击
Save
。
使用
On
或
Off
切换停止活跃的调度或激活已停止的调度。
第 30 章 为 Red Hat Ansible Automation Platform 修复设置 Red Hat Insights
自动化控制器支持与 Red Hat Insights 集成。
当使用 Red Hat Insights 注册主机时,它会持续扫描漏洞和已知的配置冲突。识别的每个问题都可以以 Ansible playbook 的形式有一个关联的修复。
Red Hat Insights 用户创建一个维护计划来对修复进行分组,并您可以创建一个 playbook 来缓解问题。自动化控制器通过 Red Hat Insights 项目跟踪维护计划 playbook。
通过基本授权向 Red Hat Insights 进行身份验证由特殊凭证支持,它必须首先在自动化控制器中建立。要运行 Red Hat Insights 维护计划,您需要一个 Red Hat Insights 项目和清单。
30.1. 创建 Red Hat Insights 凭证
使用以下步骤创建新凭证以用于 Red Hat Insights:
在导航面板中,选择
→
。
点
Add
。
在以下字段中输入相关信息:
名称
:输入凭证的名称。
可选:
描述
:输入凭证的描述。
可选:
机构
:输入与凭证关联的机构名称,或者点击搜索
图标并从
Select organization
窗口中选择它。
凭证类型
:输入
Insights
或从列表中选择它。
用户名
:输入有效的 Red Hat Insights 凭证。
Password
: 输入有效的 Red Hat Insights 凭证。Red Hat Insights 凭证是用户的
红帽客户门户网站帐户
用户名和密码。
点击
Save
。
30.2. 创建 Red Hat Insights 项目
使用以下步骤创建新项目以用于 Red Hat Insights:
在导航面板中,选择
→
。
点
Add
。
在以下字段中输入相关详情。请注意,以下字段需要特定的 Red Hat Insights 相关条目:
名称
:输入 Red Hat Insights 项目的名称。
可选:
描述
:输入项目的描述。
机构
:输入与凭证关联的机构名称,或者点击搜索(
)图标并从
Select organization
窗口中选择它。
可选:
执行环境
:用于使用这个项目的作业的执行环境。
源控制类型
:选择
Red Hat Insights
。
可选:
Content Signature Validation Credential
: 启用内容签名以验证内容在项目同步时是否保持安全。
Insights 凭证
:这会预先填充您之前创建的 Red Hat Insights 凭证。如果没有,输入凭证,或者点击搜索
图标并从
Select Insights Credential
窗口中选择它。
从
Options
字段中选择此项目的更新选项,并提供任何其他值(如果适用)。有关每个选项的更多信息,请点每个选项旁的工具提示
点击
Save
。
您第一次保存新项目时,所有 SCM 和项目同步会自动进行。如果您希望它们被更新为 Red Hat Insights 中的当前内容,点项目可用操作下的更新
图标手动更新基于 SCM 的项目。
此过程会将 Red Hat Insights 项目与 Red Hat Insights 帐户解决方案同步。请注意,当同步运行后,项目名称旁的状态点会更新。
Insights playbook 包含一个
hosts:
行,其中值是提供给红帽 insights 的主机名,它与提供给自动化控制器的主机名不同。
要创建用于 Red Hat Insights 的新清单,
请参阅创建 Insights 凭证
。
下面描述了使用自动化控制器的最佳实践:
自动化控制器支持直接存储在服务器上的 playbook。因此,您必须将 playbook、角色和任何关联的详情存储在源控制中。这样,您就能获得一个审计跟踪,用于描述您何时和为什么更改了自动化基础架构的规则。另外,它允许与基础架构或团队的其他部分共享 playbook。
如果您要创建跨项目使用的通用角色集合,则应该通过源控制子模块或一个通用位置(如
/opt
)访问它们。项目不应预期从其他项目导入角色或内容。
有关更多信息,请参阅 Ansible 文档中的链接
常规提示
。
避免使用 playbooks
vars_prompt
功能,因为自动化控制器不以交互方式允许
vars_prompt
问题。如果您无法使用
vars_prompt
,请参阅
调查
功能。
避免使用 playbook
暂停
功能时没有超时,因为自动化控制器不允许以交互方式取消暂停。如果无法使用
pause
,则必须设置超时。
作业使用 playbook 目录作为当前工作目录,尽管必须编写作业来使用
playbook_dir
变量,而不必依赖于此操作。
31.3. 使用动态清单源(Dynamic Inventory Sources)
如果您的基础架构有外部的数据源,无论是云供应商还是本地 CMDB,最好定义一个清单同步过程,并使用对动态清单(包括云清单源)的支持。这样可确保您的清单始终为最新版本。
只要
未设置
-
overwrite_vars
,在清单同步后编辑和添加清单主机变量仍然有效。
使用主机和组定义保留变量数据(请参阅清单编辑器),而不是使用
group_vars/
和
host_vars/
。如果使用动态清单源,只要未设置
Overwrite Variables
选项,自动化控制器就可以将这些变量与数据库同步。
使用 "callback" 功能允许新引导实例请求配置自动扩展或置备集成。
将作业模板上的 "forks" 设置为较大的值,以增加执行运行的并行性。有关调整 Ansible 的更多信息,请参阅
Ansible 博客
。
对于持续集成系统(如 Jenkins)来生成作业,它必须向作业模板发出
curl
请求。作业模板的凭证不需要提示输入任何特定密码。有关配置和使用说明,
请参阅
Ansible 文档中的安装。
以下小节描述了自动化控制器如何处理并可让您控制文件系统安全性。
所有 playbook 都是通过
awx
文件系统用户执行的。对于运行作业,自动化控制器通过使用 Linux 容器提供作业隔离。这种保护可确保作业只能从该作业模板的项目目录访问 playbook、角色和数据。
为了获得凭证安全性,您可以选择上传锁定的 SSH 密钥,并将解锁密码设置为"ask"。您还可以选择让系统提示输入 SSH 凭证或 sudo 密码,而不是让系统将其存储在数据库中。
自动化控制器使用自动化执行环境和 Linux 容器可防止 playbook 读取其项目目录之外的文件。
默认情况下,公开给容器内 ansible-playbook 进程的唯一数据是当前使用的项目。
您可以在 Job Settings 中自定义此功能,并将主机中的其他目录公开给容器中。
自动化控制器使用容器技术将作业相互隔离。默认情况下,只有当前项目公开给运行作业模板的容器。
如果需要公开其他目录,您必须自定义 playbook 运行。要配置作业隔离,您可以设置变量。
默认情况下,自动化控制器使用系统的
tmp
目录(默认为
/tmp
)作为其暂存区域。这可以在
Jobs 设置
页面的
Job Execution Path
字段中更改,也可以在位于
/api/v2/settings/jobs
的 REST API 中进行更改:
AWX_ISOLATION_BASE_PATH = "/opt/tmp"
如果应该从主机向运行 playbook 的容器公开任何其他目录,您可以在 Jobs
设置页面的
Paths to Expose to Isolated Jobs
字段中指定,或者在位于
/api/v2/settings
/jobs
的 REST API 中指定它们:
AWX_ISOLATION_SHOW_PATHS = ['/list/of/', '/paths']
如果您的 playbook 需要使用
AWX_ISOLATION_SHOW_PATHS
中定义的密钥或设置,请将此文件添加到
/var/lib/awx/.ssh
中。
此处描述的字段可在
Jobs 设置
页面中找到:
基于角色的访问控制
(RBAC)内置在自动化控制器中,并允许管理员委托对服务器清单、机构等的访问权限。管理员也可以集中管理各种凭据,允许用户在不向用户公开该机密的情况下使用所需的机密。您可以使用 RBAC 启用自动化控制器来提高安全性和简化管理。
RBAC 是向用户或团队授予角色的方法。RBAC 可以被认为是角色,它精确定义了谁或什么可以看到、更改或删除要为其设置特定功能的"对象"。
自动化控制器的 RBAC 设计角色、资源和用户的主要概念如下:
用户可以是一个角色的成员,授予他们对与该角色关联的任何资源或与"子代"角色关联的任何资源的访问权限。
角色是能力的集合。
用户通过为其分配的角色或通过从角色层次结构继承的角色获得对这些权限和自动化控制器资源的访问权限。
角色将一组能力与一组用户相关联。所有功能都源自角色内的成员资格。用户仅通过为其分配的角色或通过角色层次结构继承的角色获得权限。角色的所有成员都具有授予该角色的所有权限。在一个机构中,角色相对稳定,而用户和能力有很多且可能会快速变化。
用户可以有许多角色。
假设您有一个名为"SomeCompany"的机构,并想给两个人"Josie"和"Carter",以管理与该机构关联的所有设置。为此,您必须使两个人都成为 组织的
admin_role
的成员。
系统中通常会有许多角色,其中一些您要包含其他角色的所有功能。例如,您可能希望系统管理员可以访问机构管理员可访问的所有内容,而机构管理员具有项目管理员可访问的所有内容。
这个概念被称为 "Role Hierarchy":
父角色获取与任何子角色相关的所有功能。
角色的成员可以自动获取他们所属角色以及任何子角色的所有权限。
角色层次结构通过允许角色具有"父角色"来表示。角色具有的任何权限都会被隐式授予任何父角色(或那些父角色的父级)。
RBAC 还允许您明确允许用户和用户团队针对特定主机组运行 playbook。用户和团队仅限于被授予了能力的 playbook 和主机组。使用自动化控制器,您可以根据需要创建多个用户和团队,手动创建用户和团队,或者从 LDAP 或 Active Directory 导入它们。
下面介绍如何在您的环境中应用自动化控制器的 RBAC 系统。
在编辑用户时,自动化控制器系统管理员可以将用户指定为
系统管理员
(也称超级用户)或
System Auditor
:
系统管理员会隐式地继承环境中所有对象的所有权限(读取/写入/执行)。
系统审核员隐式继承环境中所有对象的只读权限。
在编辑机构时,系统管理员可以指定以下角色:
一个或多个用户作为机构管理员
一个或多个用户作为机构审核员
一个或多个用户(或团队)作为机构成员
作为机构成员的用户和团队可以查看其机构管理员。
作为机构管理员的用户隐式继承了该机构内所有对象的所有权限。
作为机构审核员的用户隐式继承了该机构内所有对象的只读权限。
在编辑机构中的项目时,系统管理员和机构管理员可指定:
一个或多个作为项目管理员的用户或团队
一个或多个作为项目成员的用户或团队
一个或多个可从 SCM 更新项目的用户或团队(来自属于该机构成员的用户和团队)。
作为项目成员的用户可以查看其项目管理员。
项目管理员隐式继承了从 SCM 更新项目的权限。
管理员也可以指定一个或多个可在作业模板中使用该项目的用户或团队(来自属于该项目成员的用户或团队)。
授予使用、读取或写入凭证的所有访问权限都通过角色处理,该角色使用自动化控制器的 RBAC 系统授予所有权、审核员或使用角色。
系统管理员和机构管理员可根据其管理功能在机构内创建清单和凭证。
无论是编辑清单还是凭证,系统管理员和机构管理员都可以指定一个或多个用户或团队(来自属于该机构成员的用户或团队)来授予该清单或凭证的用量权限。
系统管理员和机构管理员可以指定一个或多个用户或团队(来自属于该机构成员的用户或团队),以便具有(动态或手动)清单更新(动态或手动)。管理员也可以为清单执行临时命令。
系统管理员、机构管理员和项目管理员在其管理功能下的项目中可以创建和修改该项目的新作业模板。
在编辑作业模板时,管理员(自动化控制器、机构和项目)可以在他们具有使用权限的机构中选择清单和凭证,或者他们可以将这些字段留空以便在运行时选择。
另外,他们可以指定具有该作业模板的执行权限的一个或多个用户或团队(来自属于该项目成员的用户或团队)。无论用户或团队针对清单或作业模板中指定的凭证授予了任何显式功能,执行能力都是有效的。
用户可以:
查看他们所属的任何机构或项目
创建只属于他们自己的凭证对象
查看并执行他们被授予执行权限的任何作业模板
如果赋予了执行功能的作业模板没有指定清单或凭证,则在运行时会提示用户在运行时选择他们拥有的机构中的清单和凭证,或被授予了使用能力。
作为作业模板管理员的用户可以对作业模板进行更改。但是,若要更改作业模板中使用的清单、项目、playbook、凭证或实例组,用户还必须具有当前使用或正在设置的项目和清单的"使用"角色。
授予使用、读取或写入凭证的所有访问权限都通过角色处理,并且为资源定义角色。
下表列出了 RBAC 系统角色,它包括了如何根据自动化控制器中的权限定义角色的定义描述:
|
系统角色
|
它可以执行什么操作
|
|
系统管理员 (System Administrator) - 系统范围单例
管理系统的所有方面
系统审核员 (System Auditor) - 系统范围单例
查看系统的所有方面
临时角色 (Ad Hoc Role) - 清单
对清单运行临时命令
管理员角色 (Admin Role) - 机构、团队、清单、项目、作业模板
管理定义的机构、团队、清单、项目或作业模板的所有方面
审核员角色 (Auditor Role) - 所有
查看定义的机构、项目、清单或作业模板的所有方面
执行角色 (Execute Role) - 作业模板
运行分配的作业模板
成员角色 (Member Role) - 机构、团队
用户 是定义的机构或团队的成员。
读取角色 (Read Role) - 机构、团队、清单、项目、作业模板
查看定义的机构、团队、清单、项目或作业模板的所有方面
更新角色 (Update Role) - 项目
从配置的源控制管理系统更新项目
更新角色 (Update Role) - 清单
使用云源更新系统更新清单
所有者角色 (Owner Role) - 凭证
拥有并管理此凭证的所有方面
Use Role - Credential, Inventory, Project, IGs, CGs
在作业模板中使用凭证、清单、项目、IG 或 CG
单例角色是授予系统范围权限的特殊角色。自动化控制器目前提供两个内置单例角色,但目前不支持创建或自定义单例角色。
32.2.1.3. 常见团队角色 -“Personas”
自动化控制器支持人员通常能够确保自动化控制器可用,并以平衡可支持性和用户易于使用的方式进行管理。自动化控制器支持人员通常会向用户分配
机构所有者
或
管理员角色
,以便他们能够创建新机构或添加其团队中所需的成员。这可最小化支持人员的数量,并专注于保持服务的正常运行时间,并协助用户使用自动化控制器的用户。
下表列出了自动化控制器机构管理的一些常见角色:
|
系统角色(用于机构)
|
常见用户角色
|
描述
|
|
团队领导 - 技术领导
此用户可控制其机构中其他用户的访问权限。他们可以添加、删除和授予用户对项目、清单和作业模板的特定访问权限。这种类型的用户也可以创建、删除或修改机构项目、模板、清单、团队和凭证的任何方面。
审核员 (Auditor)
安全工程师 - 项目管理器
这个帐户可以在只读模式下查看机构的所有方面。对于检查和维护合规性的用户,这可能是一个不错的角色。对于管理或将自动化控制器的作业数据发送到其他数据收集器的服务帐户,这可能是一个很好的角色。
成员 - 团队
所有其他用户
默认情况下,作为机构成员的这些用户不会收到对机构任何方面的任何访问权限。要授予他们访问对应的机构所有者,必须将它们添加到其各自团队中,并为机构的项目、清单和作业模板的每个组件授予管理员、执行、使用、更新和临时权限。
成员 - 团队"所有者"
超级用户 - 领导开发人员
机构所有者可以通过组接口(包括项目、清单和作业模板)的团队接口提供"admin"。这些用户能够修改和使用所给访问权限的相应组件。
成员 - 团队"执行"
开发人员 - 工程师
这是最常见的角色,使机构成员能够执行作业模板和对特定组件的读取权限。此权限适用于模板。
成员 - 团队"使用"
开发人员 - 工程师
此权限适用于机构的凭证、清单和项目。此权限可让用户使用其作业模板中的相应组件。
成员 - 团队"更新"
开发人员 - 工程师
此权限适用于项目。允许用户在项目上运行 SCM 更新。
|
机构"资源角色"功能特定于特定资源类型,如工作流。作为此类角色的成员通常提供两种类型的权限:如果用户被授予机构 "Default" 的 "workflow admin role",则具有以下权限:
此用户可以在机构 "Default" 中创建新工作流
此用户可编辑 "Default" 机构中的所有工作流
一个例外是作业模板,其中拥有角色独立于创建权限。如需更多信息,请参阅
作业模板
。
32.3.1. 资源角色和机构成员资格角色的独立性
特定于资源的机构角色独立于管理员和成员的组织角色。拥有"Default"机构的"workflow 管理员角色"不允许用户查看机构中所有用户,但"Default"机构中具有 "member" 角色。两种角色互相独立委托。
用户可以仅使用作业模板管理员角色单独编辑不会影响作业运行的字段(非敏感字段)。但是,要编辑影响作业模板中运行的字段,用户必须具有以下内容:
作业模板和容器组的
admin
角色
相关项目的
使用
角色
相关清单的
使用
角色
相关实例组的
使用
角色
引入了"organization job template admin"角色,但如果用户没有项目、清单或
实例组使用
角色,则此角色本身不足以编辑该机构内的作业模板。
要将
完整的
作业模板控制(位于机构中)委派给用户或团队,您必须授予团队或用户所有三个机构级角色:
作业模板管理员
项目管理员
清单管理员
这样可确保用户(或属于具有这些角色的团队成员的所有用户)具有修改机构中作业模板的完整访问权限。如果作业模板使用另一个机构的清单或项目,则具有这些机构角色的用户仍然可以具有修改该作业模板的权限。为了清晰起见,请不要混合来自不同机构的项目或清单。
每个角色都必须有一个内容对象,例如,机构管理员角色具有机构的内容对象。要委派角色,您必须具有内容对象的管理员权限,但有些例外情况会导致您可以重置用户的密码。
parent
是组织。
allow 是这个新权限将明确允许的内容。
范围
是创建此新角色的父资源。例如:
Organization.project_create_role
。
假设资源的创建者被授予该资源的管理员角色。资源创建并不意味着明确指定资源管理的实例。
与每种管理员类型关联的规则如下:
项目管理员
Allow:创建、读取、更新、删除任何项目
Scope:机构
User Interface:
项目添加屏幕 - 机构
清单管理员
Parent:机构管理员
Allow:创建、读取、更新、删除任何清单
Scope:机构
User Interface:
清单添加屏幕 - 机构
与
Use
角色一样,如果您为用户分配了 Project Administrator 和 Inventory Administrator 角色,它允许他们为您的机构创建作业模板(而非工作流)。
凭证管理员
Parent:机构管理员
Allow:创建、读取、更新、删除共享凭证
Scope:机构
User Interface:
凭证添加屏幕 - 机构
通知管理员
Parent:机构管理员
Allow:通知的分配
Scope:机构
工作流管理员
Parent:机构管理员
Allow:创建工作流
Scope:机构
Parent:机构管理员
Allow:执行作业模板和工作流作业模板
Scope:机构
以下是一个示例场景,显示了一个机构及其角色,以及每个角色可以访问哪些资源:
临时(Ad Hoc)
临时命令
使用 Ansible 执行快速命令,使用 /usr/bin/ansible,而不是编配语言,即
/usr/bin/ansible-playbook
。一个临时命令的示例可能会在您的基础架构中重新引导 50 个机器。您可以编写 Playbook 来完成任何操作。playbook 也可以将许多其他操作组合在一起。
回调插件(Callback Plugin)
是指用户编写的代码,这些代码可以从 Ansible 截获结果并对其执行操作。GitHub 项目中的一些示例执行自定义日志记录、发送电子邮件或播放声音效果。
也称为 '
cgroups
',控制组是 Linux 内核中的一个功能,使资源可以被分组并分配以运行进程。除了将资源分配给进程外,cgroups 还可以报告 cgroup 内运行的所有进程使用资源。
使用-
check
选项运行 Ansible,该选项不会在远程系统上进行任何更改,而是仅输出命令在没有此标志的情况下运行时可能发生的更改。这与其它系统中所谓的"dry run"模式类似。但是,这不会考虑意外的命令故障或级联效果(在其它系统中有类似模式)。使用 Check 模式了解可能发生的情况,但它并不是一个好的暂存环境的替代品。
容器组是实例组的一种类型,用于指定在运行任务的 Kubernetes 或 OpenShift 集群中置备 pod 的配置。这些 pod 按需置备,且仅在 playbook 运行期间存在。
身份验证详情,供自动化控制器用于针对机器启动作业、与清单源同步以及从版本控制系统中导入项目内容。如需更多信息,请参阅
凭证
。
Python 代码,包含外部凭证类型、其元数据字段以及与 secret 管理系统交互所需代码的定义。
分布式作业
由作业模板、清单和分片大小组成的作业。执行后,分布式作业会将每个清单划分为多个"分片大小"块,然后用于运行较小的作业分片。
外部凭证类型
用于与 secret 管理系统进行身份验证的受管凭证类型。
事实是发现与远程节点相关的内容。虽然它们可以像变量一样在 playbook 和模板中使用,但事实是推断出来的,而不是设置。通过在远程节点上执行内部设置模块,在运行 play 时自动发现事实。您不必显式调用 setup 模块:只需要运行。如果不需要,可以禁用它来节省时间。为方便从其他配置管理系统切换的用户,事实模块也会从
ohai
和
facter
工具中提取事实(如果分别安装了事实库)和 Puppet。
Forks
Ansible 和自动化控制器并行与远程节点通信。可以在创建或编辑作业模板的过程中通过传递-
forks
或编辑配置文件中的默认设置,以多种方式设置并行级别。默认值为非常保守的五个 fork,但如果您有大量 RAM,您可以将它设置为更高的值,如 50,以增加并行性。
Group
Ansible 中的一组主机,可以作为集合进行寻址,其中很多主机可以存在于单个清单中。
group_vars/
文件是存储在具有清单文件的目录中的文件,具有以每个组命名的可选文件名。这是放置为给定组提供的变量(特别是复杂的数据结构)的便捷位置,因此这些变量不必嵌入到清单文件或 playbook 中。
处理程序(handler)
处理程序类似于 Ansible playbook 中的常规任务(请参阅
任务
),但只有任务包含"notify"指令并且指示它更改了内容时才运行。例如,如果更改了配置文件,则引用配置文件模板操作的任务可能会通知服务重启处理程序。这意味着,只有在需要重启服务时,才能退回服务。处理程序可用于服务重启以外的内容,但服务重启是最常见的用途。
由自动化控制器管理的系统,可能包含物理、虚拟或基于云的服务器,或其他设备(通常是操作系统实例)。主机包含在清单中。有时被称为"节点"。
主机指定符
Ansible 中的每个 Play 将一系列任务(定义系统的角色、目的或顺序)映射到一组系统。每个 play 中的这个"hosts:"指令通常称为主机指定符。它可以选择一个系统、多个系统、一个或多个组,或者一个组中的主机,并且明确不在另一个组中。
包含用于在集群环境中使用的实例的组。实例组提供根据策略对实例进行分组的功能。
清单(Inventory)
可对其启动任务的主机集合。
查找主机、组成员资格以及来自外部资源的变量信息的程序,无论是 SQL 数据库、CMDB 解决方案还是 LDAP。这个概念由 Puppet (其中称为"外部节点分类器")调整,并以类似的方式工作。
有关要合并到当前清单组中的云或其他脚本的信息,从而自动填充组、主机以及有关这些组和主机的变量。
自动化控制器启动的许多后台任务之一,这通常是实例化作业模板来启动 Ansible playbook。其他类型的作业包括清单导入、从源控制进行项目同步或管理清理操作。
运行特定作业的历史记录,包括其输出和成功/失败状态。
请参阅
分布式作业
。
Ansible playbook 以及启动它所需的一组参数的组合。如需更多信息,请参阅
作业模板
。
JSON 是基于文本的格式,用于根据 JavaScript 对象语法表示结构化数据。Ansible 和自动化控制器使用 JSON 从远程模块返回数据。这可让使用任何语言编写的模块,而不只是 Python 编写的模块。
Mesh(网格)
描述由节点组成的网络。节点之间的通信通过 TCP、UDP 或 Unix 套接字等协议在传输层建立。
另请参阅
节点
。
身份验证后,用于在外部系统中查找 secret 的信息。用户在将外部凭证链接到目标凭证字段时提供此信息。
节点对应于实例数据库模型或
/api/v2/instances/
端点中的条目,是参与集群或网格的机器。统一作业 API 报告
controller_node
和
execution_node
字段。执行节点是作业运行的位置,以及作业和服务器功能之间的控制器节点接口。
|
节点类型
|
描述
|
|
运行持久服务的节点,并将作业委托给混合节点和执行节点。
运行持久服务和执行作业的节点。
仅用于跨网格转发。
执行
用于运行从控制节点交付的作业的节点(从用户的 Ansible 自动化提交的作业)
通知类型的实例(电子邮件、Slack 、Webhook 等),其名称、描述和定义的配置。
通知(如 Email、Slack 或 Webhook)在通知模板中定义名称、描述和配置。例如,当作业失败时,将使用通知模板定义的配置发送通知。
任务注册更改事件并通知处理器任务在 play 结束时需要运行另一个操作。如果处理程序由多个任务通知,它仍然仅运行一次。处理程序按照列出的顺序运行,而不是按照通知的顺序运行。
机构(Organization)
用户、团队、项目和清单的逻辑集合。机构是对象层次结构中的最高级别。
Organization Administrator(机构管理员)
具有修改机构成员资格和设置权限的用户,包括在该机构中创建新用户和项目。机构管理员也可以向该机构内的其他用户授予权限。
分配给用户和团队的权限集,它提供读取、修改和管理项目、清单和其他对象的能力。
一个 play 在由主机指定符选择的一组主机(通常由组选择,但有时由主机名 glob 选择)与那些主机上运行的任务之间的映射最小,以定义这些系统执行的角色。playbook 是 play 的列表。playbook 中可以有一个或多个 play。
Playbook
一个 Ansible playbook。有关更多信息,请参阅
Ansible playbook
。
policy
策略指定实例组的行为方式以及任务的执行方式。
自动化控制器中代表 Ansible playbook 的逻辑集合。
角色是 Ansible 和自动化控制器中的机构单元。将角色分配给一组主机(或一组组或主机模式等)意味着它们实施特定的行为。角色可以包含应用变量值、任务和处理程序,或者这些因素的组合。由于与角色关联的文件结构,角色成为可重新分发的单元,允许您在 playbook 或其他用户之间共享行为。
Secret 管理系统
用于安全存储并控制对令牌、密码、证书、加密密钥和其他敏感数据的访问的服务器或服务。
作业应自动运行的日期和时间日历。
请参阅
分布式作业
。
链接到目标凭证字段的外部凭证。
Ansible 不需要 root 登录,因为它是无守护进程的,因此不需要 root 级别守护进程(可能是敏感环境中的安全问题)。Ansible 可以登录并执行嵌套在
sudo
命令中的许多操作,并可处理无密码和基于密码的 sudo。在以
sudo
模式运行时,可以使用 Ansible
复制
、
模板
和
获取
模块来实现一些通常无法使用
sudo
的操作(如
scp
文件传输)。
具有编辑系统中任何对象权限的服务器的管理员,无论它是否与任何机构相关联。超级用户可以创建机构和其他超级用户。
在作业启动时由作业模板询问的问题,可在作业模板上配置。
一个非外部的凭证,它带有一个输入字段,用来链接到外部凭证。
具有关联用户、项目、凭证和权限的机构子部门。团队提供了一种方式来实现基于角色的访问控制方案,并跨机构委派职责。
具有相关权限和凭证的操作器。
Webhook
Webhook 支持应用程序之间的通信和信息共享。它们用于响应推送到 SCM 的提交以及启动作业模板或工作流模板。
工作流作业模板
由任何作业模板组合、项目同步和清单同步组成的集合,将它们链接在一起,以便以单个单元的形式执行。
人类可读的语言,通常用于编写配置文件。Ansible 和自动化控制器使用 YAML 定义 playbook 配置语言和变量文件。YAML 具有最小的语法,非常干净,用户可以轻松地。它是配置文件和人类的数据格式,但也是机器可读。YAML 在动态语言社区中很常见,格式具有可用于多种语言序列化的库。示例包括 Python、Perl 或 Ruby。
The text of and illustrations in this document are licensed by Red Hat under a Creative Commons Attribution–Share Alike 3.0 Unported license ("CC-BY-SA"). An explanation of CC-BY-SA is available at
http://creativecommons.org/licenses/by-sa/3.0/
. In accordance with CC-BY-SA, if you distribute this document or an adaptation of it, you must provide the URL for the original version.
Red Hat, as the licensor of this document, waives the right to enforce, and agrees not to assert, Section 4d of CC-BY-SA to the fullest extent permitted by applicable law.
Red Hat, Red Hat Enterprise Linux, the Shadowman logo, the Red Hat logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries.
Linux
® is the registered trademark of Linus Torvalds in the United States and other countries.
Java
® is a registered trademark of Oracle and/or its affiliates.
XFS
® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries.
MySQL
® is a registered trademark of MySQL AB in the United States, the European Union and other countries.
Node.js
® is an official trademark of Joyent. Red Hat is not formally related to or endorsed by the official Joyent Node.js open source or commercial project.
|
|
|
|