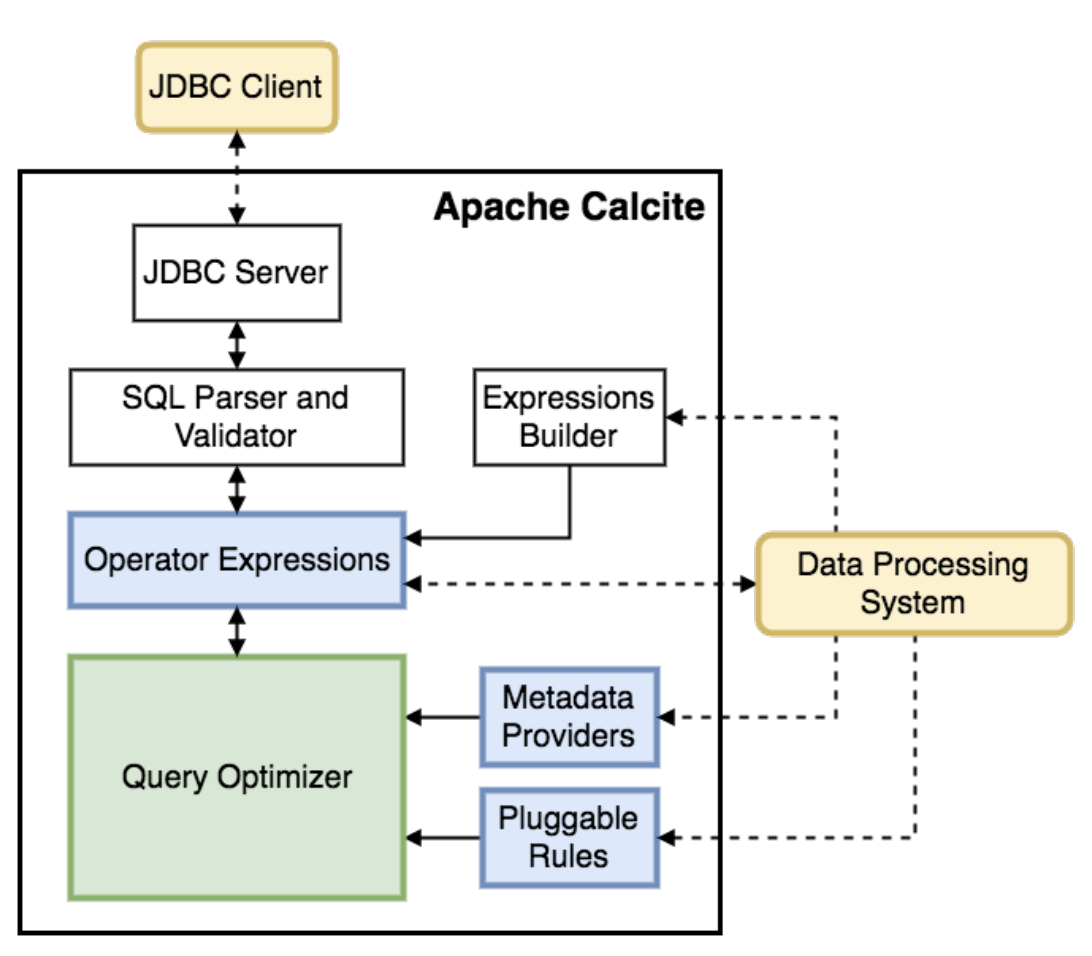
在了解了 Calcite 的基本架构和特点之后,我们以 Calcite 官方经典的 CSV 案例作为入门示例,来展示下 Calcite 强大的功能。首先,从 github 下载 calcite 项目源码,
git clone https://github.com/apache/calcite.git
,然后执行
cd calcite/example/csv
进入 csv 目录。
Calcite 为我们提供了内置的 sqlline 命令,可以通过
./sqlline
快速连接到 Calcite,并使用
!connect
定义数据库连接,
model
属性用于指定 Calcite 的数据模型配置文件。
1
2
3
4
5
6
7
|
./sqlline
Building Apache Calcite 1.31.0-SNAPSHOT
sqlline version 1.12.0
sqlline>
sqlline> !connect jdbc:calcite:model=src/test/resources/model.json admin admin
Transaction isolation level TRANSACTION_REPEATABLE_READ is not supported. Default (TRANSACTION_NONE) will be used instead.
0: jdbc:calcite:model=src/test/resources/mode>
|
连接成功后,我们可以执行一些语句来测试 SQL 执行,
!tables
用于查询表相关的元数据,
!columns depts
用于查询列相关的元数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
0: jdbc:calcite:model=src/test/resources/mode> !tables
+
| TABLE_CAT | TABLE_SCHEM | TABLE_NAME | TABLE_TYPE | REMARKS | TYPE_CAT | TYPE_SCHEM | TYPE_NAME | SELF_REFERENCING_COL_NAME | REF_GENERATION |
+
| | SALES | DEPTS | TABLE | | | | | | |
| | SALES | EMPS | TABLE | | | | | | |
| | SALES | SDEPTS | TABLE | | | | | | |
| | metadata | COLUMNS | SYSTEM TABLE | | | | | | |
| | metadata | TABLES | SYSTEM TABLE | | | | | | |
+
0: jdbc:calcite:model=src/test/resources/mode> !columns depts
+
| TABLE_CAT | TABLE_SCHEM | TABLE_NAME | COLUMN_NAME | DATA_TYPE | TYPE_NAME | COLUMN_SIZE | BUFFER_LENGTH | DECIMAL_DIGITS | NUM_PREC_RADIX | NULLABLE | REMARKS | COLUMN_DEF | SQL_DATA_TYPE | SQL_DATETIME_SUB | CHAR_OCTET_LENGTH | ORDINAL_POSI |
+
| | SALES | DEPTS | DEPTNO | 4 | INTEGER | -1 | null | null | 10 | 1 | | | null | null | -1 | 1 |
| | SALES | DEPTS | NAME | 12 | VARCHAR | -1 | null | null | 10 | 1 | | | null | null | -1 | 2 |
+
|
我们再来执行一些复杂的查询语句,看看 Calcite 是否能够真正地提供完善的查询引擎功能。通过下面的查询结果可以看出,Calcite 能够完美支持复杂的 SQL 语句。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
0: jdbc:calcite:model=src/test/resources/mode> SELECT * FROM DEPTS;
+
| DEPTNO | NAME |
+
| 10 | Sales |
| 20 | Marketing |
| 30 | Accounts |
+
3 rows selected (0.01 seconds)
0: jdbc:calcite:model=src/test/resources/mode> SELECT d.name, COUNT(1) AS "count" FROM DEPTS d INNER JOIN EMPS e ON d.deptno = e.deptno GROUP BY d.name;
+
| NAME | count |
+
| Sales | 1 |
| Marketing | 2 |
+
2 rows selected (0.179 seconds)
|
看到这里大家不禁会问,Calcite 是如何基于 CSV 格式的数据存储,来提供完善的 SQL 查询能力呢?下面我们将结合 Calcite 源码,针对一些典型的 SQL 查询语句,初步学习下 Calcite 内部的实现原理。
在 Caclite 集成 CSV 示例中,我们主要关注三个部分:一是 Calcite 元数据的定义,二是优化规则的管理,三是最优计划的执行。这三个部分是 Calcite 执行流程的核心,元数据主要用于对 SqlNode 语法树进行校验,并为 CBO 优化中代价的计算提供统计信息。优化规则被 Calcite 优化器使用,用来对逻辑计划进行改写,并生成最优的执行计划。最终,执行器会基于最优的执行计划,在不同的存储引擎上进行执行。
我们先关注 Calcite 元数据的定义,元数据的定义是通过
!connect jdbc:calcite:model=src/test/resources/model.json admin admin
命令,指定 model 属性对应的配置文件
model.json
来注册元数据,具体内容如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
{
"version":"1.0",
"defaultSchema":"SALES",
"schemas":[
{
"name":"SALES",
"type":"custom",
"factory":"org.apache.calcite.adapter.csv.CsvSchemaFactory",
"operand":{
"directory":"sales"
}
}
]
}
|
CsvSchemaFactory 类负责创建 Calcite 元数据 CsvSchema,
operand
用于指定参数,
directory
代表 CSV 文件的路径,
flavor
则代表 Calcite 的表类型,包含了
SCANNABLE
、
FILTERABLE
和
TRANSLATABLE
三种类型。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
@SuppressWarnings("UnusedDeclaration")
public class CsvSchemaFactory implements SchemaFactory {
public static final CsvSchemaFactory INSTANCE = new CsvSchemaFactory();
private CsvSchemaFactory() {
}
@Override
public Schema create(SchemaPlus parentSchema, String name, Map<String, Object> operand) {
final String directory = (String) operand.get("directory");
final File base = (File) operand.get(ModelHandler.ExtraOperand.BASE_DIRECTORY.camelName);
File directoryFile = new File(directory);
if (base != null && !directoryFile.isAbsolute()) {
directoryFile = new File(base, directory);
}
String flavorName = (String) operand.get("flavor");
CsvTable.Flavor flavor;
if (flavorName == null) {
flavor = CsvTable.Flavor.SCANNABLE;
} else {
flavor = CsvTable.Flavor.valueOf(flavorName.toUpperCase(Locale.ROOT));
}
return new CsvSchema(directoryFile, flavor);
}
}
|
CsvSchema 类的定义如下,它继承了 AbstractSchema 并实现了 getTableMap 方法,getTableMap 方法根据 flavor 参数创建不同类型的表。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
|
public class CsvSchema extends AbstractSchema {
private final File directoryFile;
private final CsvTable.Flavor flavor;
private Map<String, Table> tableMap;
public CsvSchema(File directoryFile, CsvTable.Flavor flavor) {
super();
this.directoryFile = directoryFile;
this.flavor = flavor;
}
private static String trim(String s, String suffix) {
String trimmed = trimOrNull(s, suffix);
return trimmed != null ? trimmed : s;
}
private static String trimOrNull(String s, String suffix) {
return s.endsWith(suffix) ? s.substring(0, s.length() - suffix.length()) : null;
}
@Override
protected Map<String, Table> getTableMap() {
if (tableMap == null) {
tableMap = createTableMap();
}
return tableMap;
}
private Map<String, Table> createTableMap() {
final Source baseSource = Sources.of(directoryFile);
File[] files = directoryFile.listFiles((dir, name) -> {
final String nameSansGz = trim(name, ".gz");
return nameSansGz.endsWith(".csv") || nameSansGz.endsWith(".json");
});
if (files == null) {
System.out.println("directory " + directoryFile + " not found");
files = new File[0];
}
final ImmutableMap.Builder<String, Table> builder = ImmutableMap.builder();
for (File file : files) {
Source source = Sources.of(file);
Source sourceSansGz = source.trim(".gz");
final Source sourceSansJson = sourceSansGz.trimOrNull(".json");
if (sourceSansJson != null) {
final Table table = new JsonScannableTable(source);
builder.put(sourceSansJson.relative(baseSource).path(), table);
}
final Source sourceSansCsv = sourceSansGz.trimOrNull(".csv");
if (sourceSansCsv != null) {
final Table table = createTable(source);
builder.put(sourceSansCsv.relative(baseSource).path(), table);
}
}
return builder.build();
}
private Table createTable(Source source) {
switch (flavor) {
case TRANSLATABLE:
return new CsvTranslatableTable(source, null);
case SCANNABLE:
return new CsvScannableTable(source, null);
case FILTERABLE:
return new CsvFilterableTable(source, null);
default:
throw new AssertionError("Unknown flavor " + this.flavor);
}
}
}
|
CsvSchema#createTable
方法中定义了三种表类型,让我们来看下这三种类型的区别:
CsvTranslatableTable
:实现了
QueryableTable
和
TranslatableTable
接口,QueryableTable 接口会实现
asQueryable
方法,将表转化成 Queryable 实现类,从而具有
groupBy
、
count
等查询能力,具体可以参考
ExtendedQueryable
。TranslatableTable 则用于将 RelOptTable 对象转换为 RelNode,此案例中为 CsvTableScan,后续可以使用优化规则对 CsvTableScan 进行变换从而实现下推等优化;
CsvScannableTable
:实现了
ScannableTable
接口,用于扫描全部数据记录,Calcite 会调用 scan 获取 csv 文件中的全部数据;
CsvFilterableTable
:实现了
FilterableTable
接口,可以在扫描数据过程中,根据 scan 方法传入的
List<RexNode> filters
参数进行数据过滤。
前面介绍
CsvSchemaFactory
和
CsvSchema
中的元数据初始化逻辑,会在 Calcite JDBC 创建 Connection 进行初始化,具体是调用 ModelHandler 解析 JSON 格式的配置文件,然后调用 CsvSchemaFactory 创建 CsvSchema。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
public void visit(JsonCustomSchema jsonSchema) {
try {
final SchemaPlus parentSchema = currentMutableSchema("sub-schema");
final SchemaFactory schemaFactory =
AvaticaUtils.instantiatePlugin(SchemaFactory.class,
jsonSchema.factory);
final Schema schema =
schemaFactory.create(
parentSchema, jsonSchema.name, operandMap(jsonSchema, jsonSchema.operand));
final SchemaPlus schemaPlus = parentSchema.add(jsonSchema.name, schema);
populateSchema(jsonSchema, schemaPlus);
} catch (Exception e) {
throw new RuntimeException("Error instantiating " + jsonSchema, e);
}
}
|
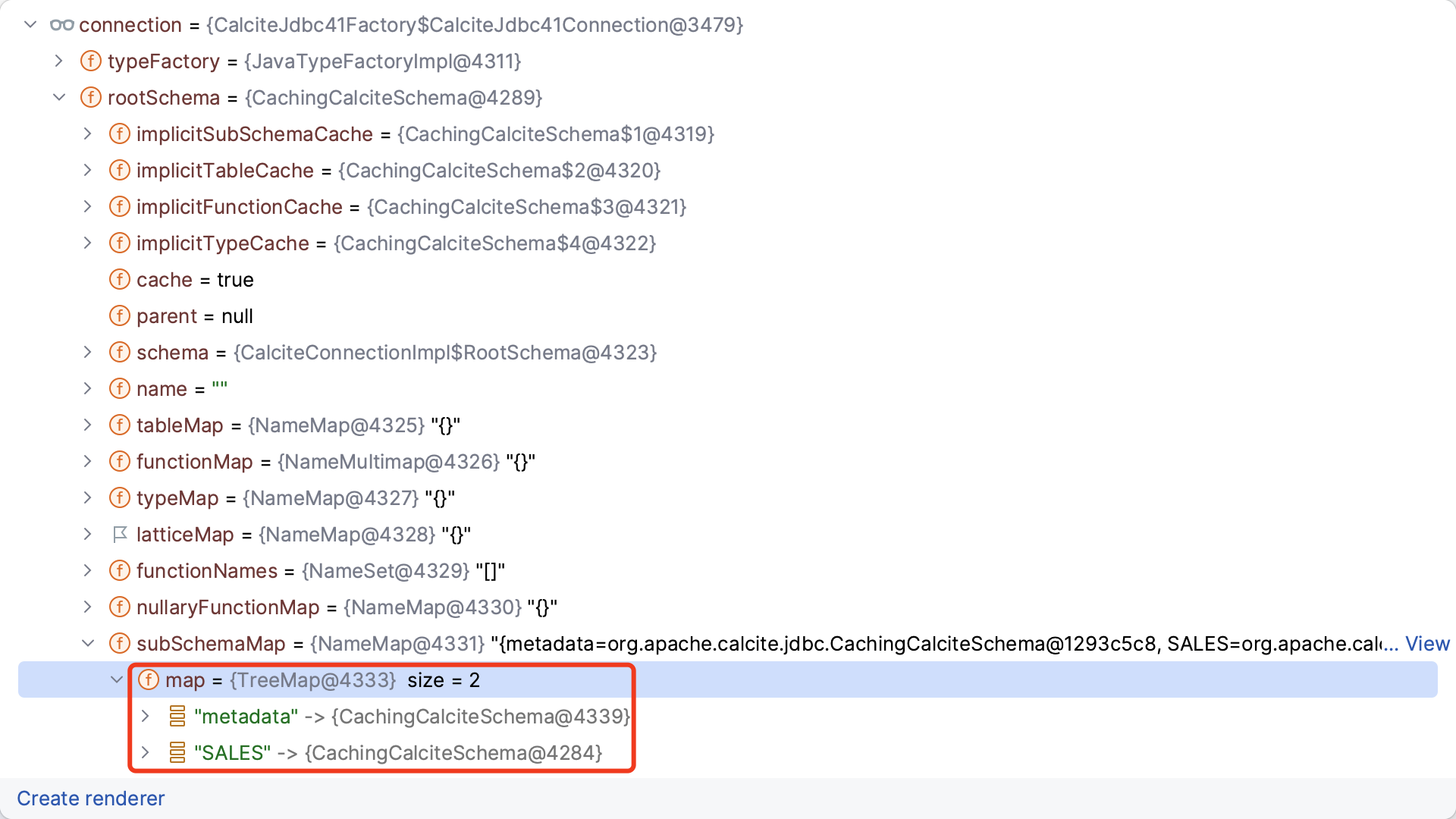
初始化完成后,元数据对象的结构如下,注册了
metadata
和
SALES
两个 schema。
下面我们再来看看 Calcite 是如何管理优化规则的,在 CSV 示例中我们定义了
CsvProjectTableScanRule
,用于匹配在
CsvTableScan
之上的
Project
投影,并将 Project 投影下推到 CsvTableScan 中。刚接触 Calcite 的朋友可能很难理解在
CsvTableScan
之上的
Project
是什么含义?我们通过一条 SQL 来进行理解,假设我们执行的 SQL 为
select name from EMPS
(读者可以使用 CsvTest#testSelectSingleProjectGz 自行测试)。
1
2
3
4
5
|
@Test
void testSelectSingleProjectGz() throws SQLException {
sql("smart", "select name from EMPS").ok();
}
|
Caclite 首先会将 SQL 解析成 SqlNode 语法树,再通过语法校验、逻辑计划生成等阶段得到如下的逻辑计划树。
LogicalProject
代表了逻辑投影,会查询 SQL 中指定的投影字段 name 对应的
数据列
。而 LogicalProject 想要获取投影字段对应的数据,需要向下调用
CsvTableScan
,CsvTableScan 则会对 EMPS 表进行扫描获取
数据行
,逻辑计划树中 CsvTableScan 会获取数据行中的所有行、所有列,再将数据传递给上层的 LogicalProject 按投影列进行过滤。
细心的读者可能已经发现,为什么我们指定的 SQL 中只需要查询 name 列,而逻辑计划树中的 CsvTableScan 却要扫描所有列?为了避免 CsvTableScan 扫描无用的数据列,CSV 案例中定义了 CsvProjectTableScanRule 优化规则,
主要用于将 Projection 下推到 TableScan 中,在数据扫描阶段就过滤无用的数据列,从而达到减少数据传输,降低计算时占用内存的目的
。可以看到,经过 CsvProjectTableScanRule 优化后,逻辑计划树中只有一个 CsvTableScan 算子,内部包含了 table 和 fields,可以在数据扫描时过滤投影列(和 Projection 下推类似,我们也可以将 Filter 下推到 TableScan 中,减少加载到内存的数据行,Filter 下推读者可以自行尝试下)。
下面展示的是 CsvProjectTableScanRule 规则的实现,它继承了 RelRule 抽象类,CsvProjectTableScanRule 构造方法会将 config 传给父类进行初始化。config 类则是由 CsvProjectTableScanRule 类的内部
Config
接口,通过
@Value.Immutable
注解动态生成的实现类,其核心逻辑定义了优化规则需要匹配的逻辑计划树结构,
此处的结构为 LogicalProject 节点,下方包含一个 CsvTableScan 输入节点,而 CsvTableScan 节点则没有输入节点
。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
|
@Value.Enclosing
public class CsvProjectTableScanRule extends RelRule<CsvProjectTableScanRule.Config> {
protected CsvProjectTableScanRule(Config config) {
super(config);
}
@Override
public void onMatch(RelOptRuleCall call) {
final LogicalProject project = call.rel(0);
final CsvTableScan scan = call.rel(1);
int[] fields = getProjectFields(project.getProjects());
if (fields == null) {
return;
}
call.transformTo(new CsvTableScan(scan.getCluster(), scan.getTable(), scan.csvTable, fields));
}
private static int[] getProjectFields(List<RexNode> exps) {
final int[] fields = new int[exps.size()];
for (int i = 0; i < exps.size(); i++) {
final RexNode exp = exps.get(i);
if (exp instanceof RexInputRef) {
fields[i] = ((RexInputRef) exp).getIndex();
} else {
return null;
}
}
return fields;
}
@Value.Immutable(singleton = false)
public interface Config extends RelRule.Config {
Config DEFAULT = ImmutableCsvProjectTableScanRule.Config.builder()
.withOperandSupplier(b0 ->
b0.operand(LogicalProject.class).oneInput(b1 ->
b1.operand(CsvTableScan.class).noInputs())).build();
@Override
default CsvProjectTableScanRule toRule() {
return new CsvProjectTableScanRule(this);
}
}
}
|
CsvProjectTableScanRule 继承了 RelRule 抽象类,而 RelRule 抽象类又继承 RelOptRule 抽象类,继承关系如下图所示。Calcite 优化器会调用
matches
方法判断当前优化规则是否匹配,匹配则继续调用
onMatch
方法对逻辑计划树进行变换,通过代码可以看出,CSV 示例中会将投影列 fields 下推到 CsvTableScan 中。
了解了 CsvProjectTableScanRule 大致的优化逻辑后,我们再来看下 Calcite 是如何注册和执行优化规则的。在 CsvTableScan 中定义了一个
register
方法,用于注册和当前关系代数节点相关的优化规则,
CsvRules.PROJECT_SCAN
是调用
toRule
方法得到的优化规则对象。入参
RelOptPlanner
是 Calcite 中的优化器对象,目前提供了
HepPlanner
和
VolcanoPlanner
两种优化器,HepPlanner 采用 RBO 模型,基于已知的优化规则进行优化,而 VolcanoPlanner 则采用 CBO 模型,基于执行计划的代价进行选择。本文由于篇幅原因,先从优化器的外部接口了解其功能,暂时不做过多的探究,在后续的文章中,我们将深入学习这两种优化器的内部实现。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
@Override
public void register(RelOptPlanner planner) {
planner.addRule(CsvRules.PROJECT_SCAN);
}
public abstract class CsvRules {
private CsvRules() {
}
public static final CsvProjectTableScanRule PROJECT_SCAN = CsvProjectTableScanRule.Config.DEFAULT.toRule();
}
|
在注册完成优化规则后,Calcite JDBC 程序会在 SQL 执行阶段,封装多个 Program 实现类,Program 接口提供了如下的
run
方法,用于对关系代数表达式 RelNode 进行变换。
1
2
3
4
5
6
7
8
9
10
11
12
|
public interface Program {
RelNode run(RelOptPlanner planner, RelNode rel, RelTraitSet requiredOutputTraits, List<RelOptMaterialization> materializations, List<RelOptLattice> lattices);
}
|
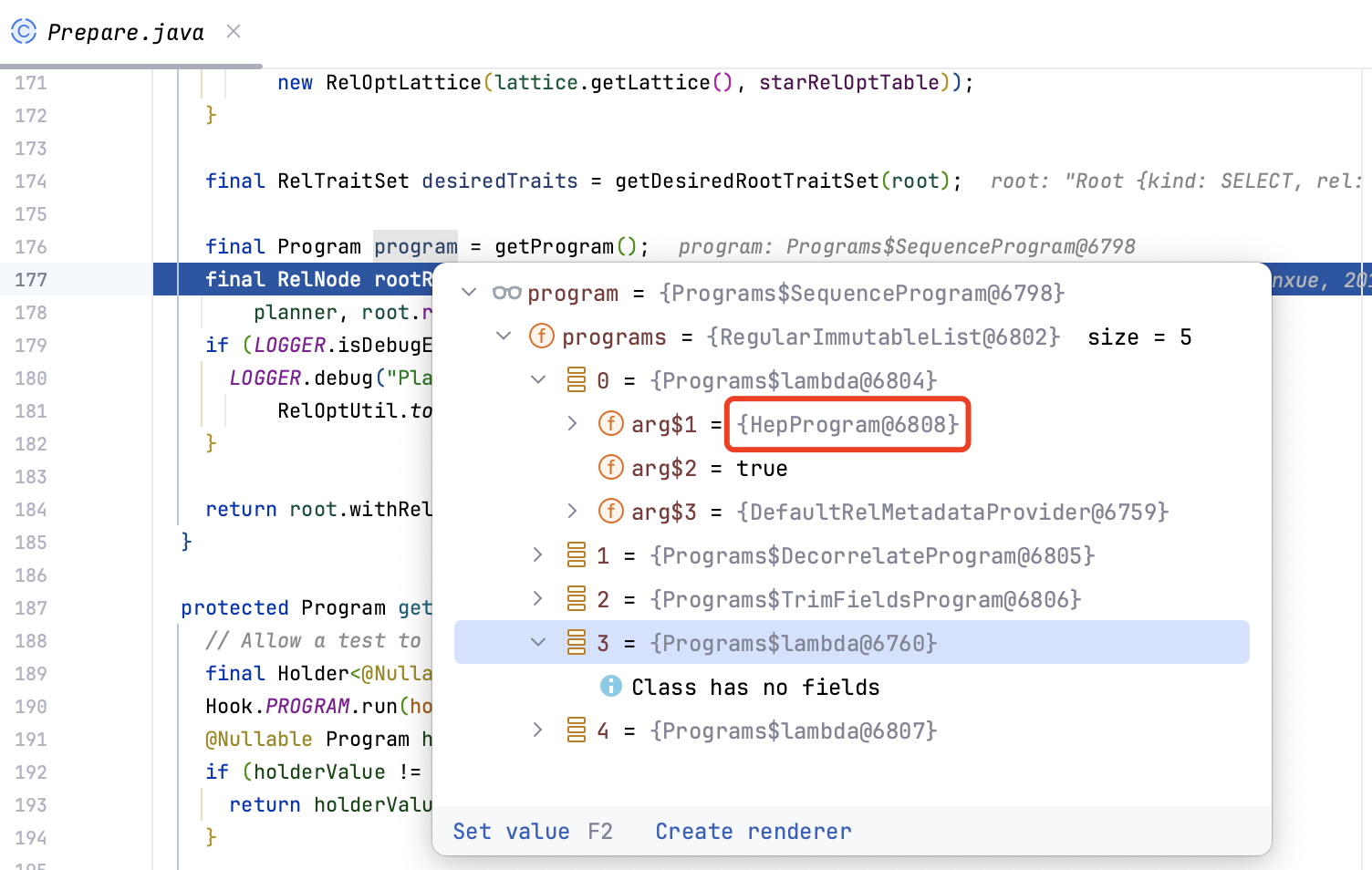
如下图所示,Calcite Prepare 类中默认注册了 5 个 Program,内部封装了
HepPlanner
和
VolcanoPlanner
两种优化器,以及相关子查询消除等改写逻辑,可以对查询 SQL 进行比较全面的查询优化。
Calcite JDBC 默认提供的 Program
调用
program.run
方法会触发
SequenceProgram
内部逻辑, 依次触发 programs 对象的 run 方法。我们以第一个 Program 为例,内部会调用 HepPlanner 优化器的
setRoot
和
findBestExp
方法,setRoot 方法用于将关系代数设置到 planner 中,而 findBestExp 方法则会调用优化器的逻辑,根据优化规则或者代价选择最优的执行计划。
1
2
3
|
planner.setRoot(rel);
planner.findBestExp();
|
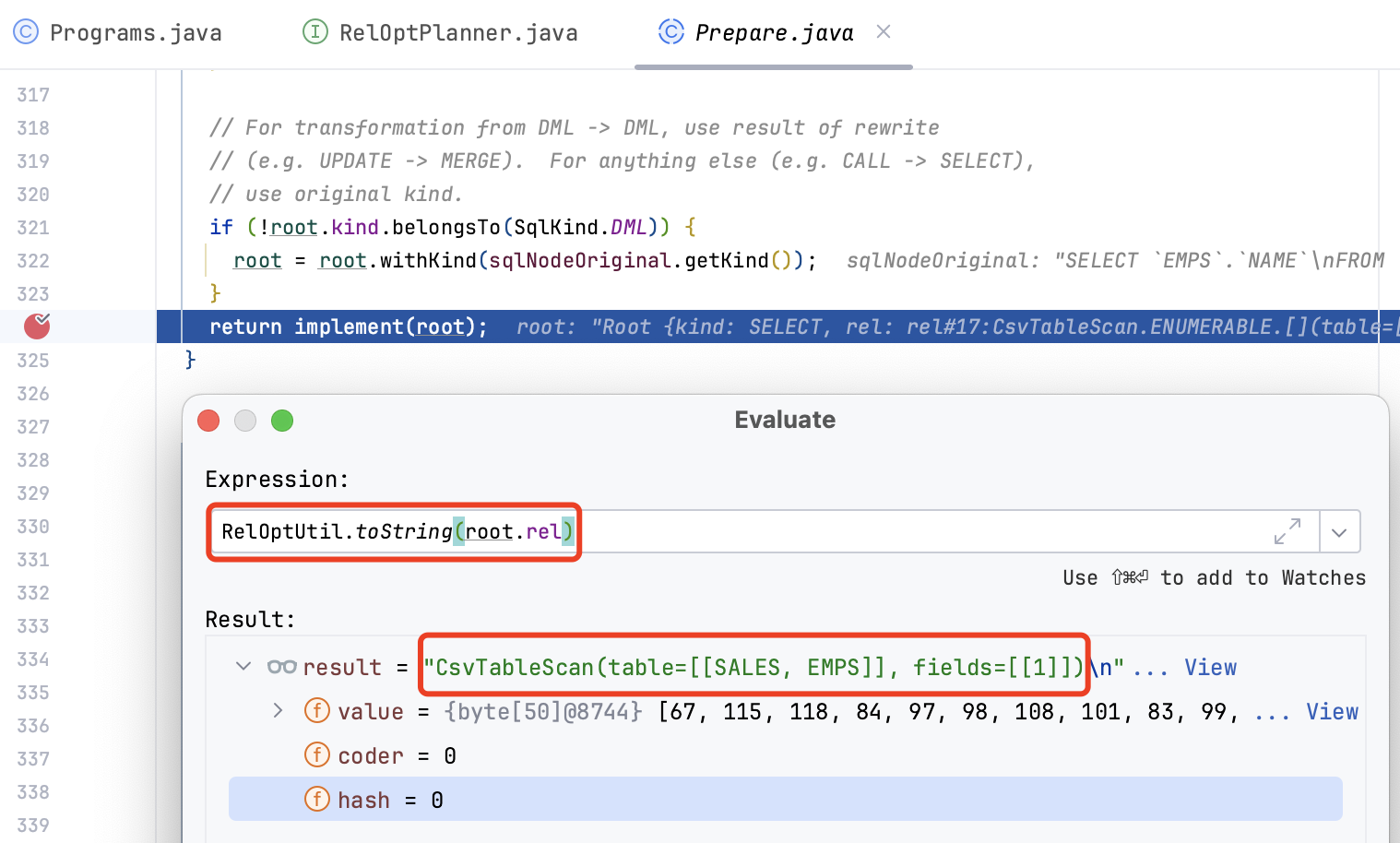
优化完成后我们就得到了最优的执行计划,使用
RelOptUtil.toString(root.rel)
查看其结果为
CsvTableScan(table=[[SALES, EMPS]], fields=[[1]])
,下一步我们将看看最优执行计划是如何执行得到结果的。
Calcite JDBC 执行的入口是在
Prepare#implement
方法,入参是最优的执行计划 RelRoot 类(该类对 RelNode 进行了一些包装,可以用于记录排序字段,以及投影别名处理,具体可以参考 RelRoot 类的 JavaDoc 文档),返回的结果是 PreparedResult 接口的实现类。
1
2
3
4
5
6
7
|
protected abstract PreparedResult implement(RelRoot root);
|
PreparedResult 接口具有如下公有方法,
getFieldOrigins
方法用于返回每一个投影列的完整属性
database, schema, table, column
,
getParameterRowType
方法则返回行记录的类型信息,
getBindable
是整个接口的核心,它返回一个可执行的类,调用
bind
方法可以获取一个 Enumerable 迭代器,从而遍历获取最终的结果。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
public interface PreparedResult {
String getCode();
boolean isDml();
TableModify.@Nullable Operation getTableModOp();
List<? extends @Nullable List<String>> getFieldOrigins();
RelDataType getParameterRowType();
Bindable getBindable(Meta.CursorFactory cursorFactory);
}
|
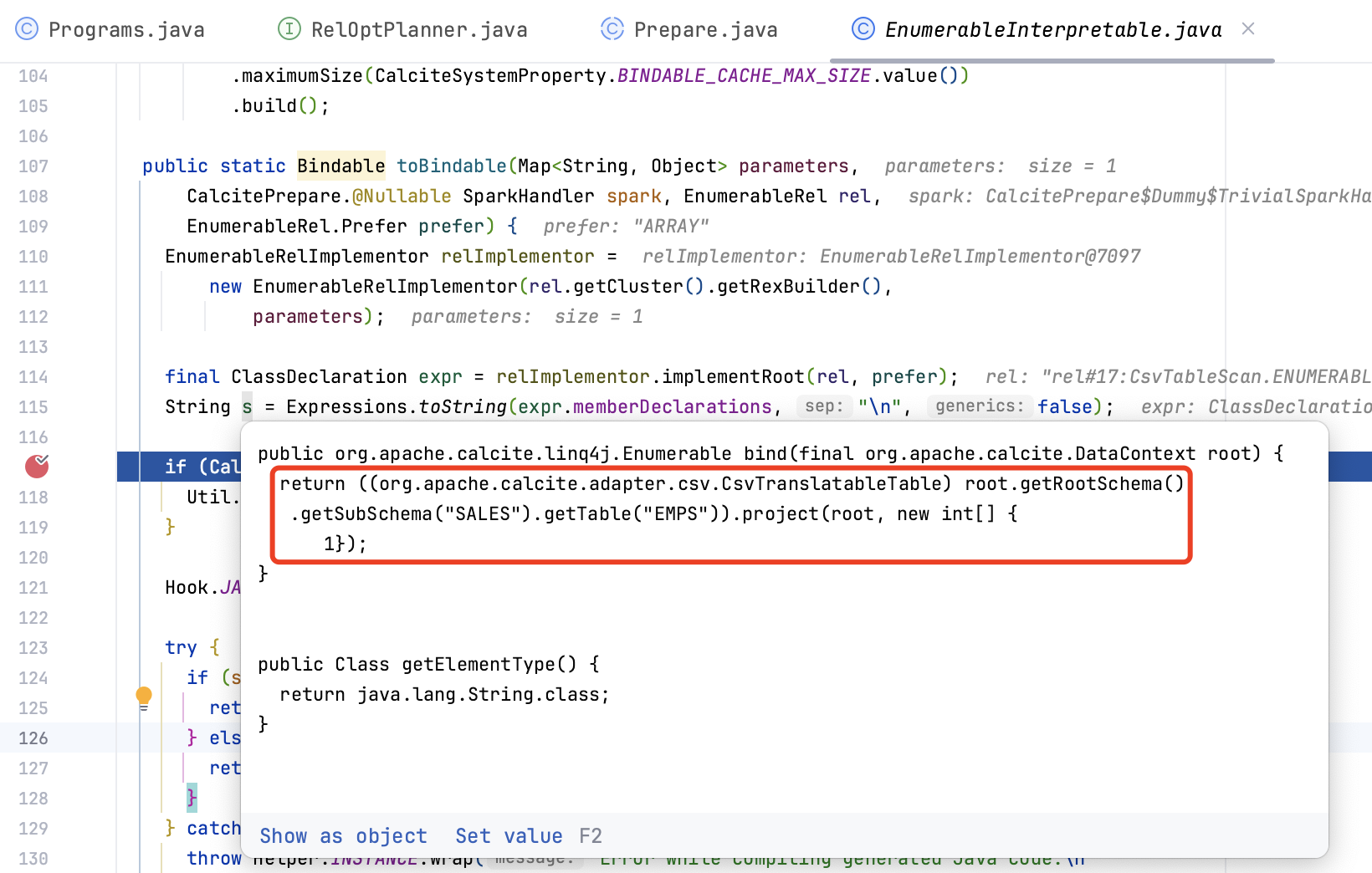
在生成 Bindable 接口的实现类时,会调用 EnumerableInterpretable 生成代码逻辑,并使用 Janino 将代码编译为 Java 类并创建对象。
最终返回的 PreparedResultImpl 实现类如下,getBindable 接口会返回 Janino 动态生成的 Java 对象,而 Bindable 接口调用 bind 方法即可返回 Enumerable 迭代器,Calcite JDBC 从迭代器中遍历出记录,再通过 JDBC 接口封装返回给应用程序。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
return new PreparedResultImpl(resultType, requireNonNull(parameterRowType, "parameterRowType"),
requireNonNull(fieldOrigins, "fieldOrigins"), root.collation.getFieldCollations().isEmpty()
? ImmutableList.of() : ImmutableList.of(root.collation), root.rel, mapTableModOp(isDml, root.kind), isDml) {
@Override
public String getCode() {
throw new UnsupportedOperationException();
}
@Override
public Bindable getBindable(Meta.CursorFactory cursorFactory) {
return bindable;
}
@Override
public Type getElementType() {
return ((Typed) bindable).getElementType();
}
};
public interface Bindable<T> {
Enumerable<T> bind(DataContext dataContext);
}
|
以上就是 Calcite 最优计划执行的大致流程,后面的文章中我将深入分析 Calcite 执行器代码生成的逻辑和 Enumerable 接口的具体实现。此外,我还将和大家一起探究 Presto、Drill、PolarDB-X 等框架的执行引擎逻辑,看看生产级别的执行引擎是如何高效实现的。