简介
两个月前Kaggle上了一个大模型的比赛,这也是Kaggle第一次举办和大模型相关的比赛,作为全程的观察员总结下这个比赛,从中看看大模型时代对NLP的竞赛有啥影响,以及大模型评测有什么参考和借鉴意义。
链接
www.kaggle.com/competitions/kaggle-llm-science-exam
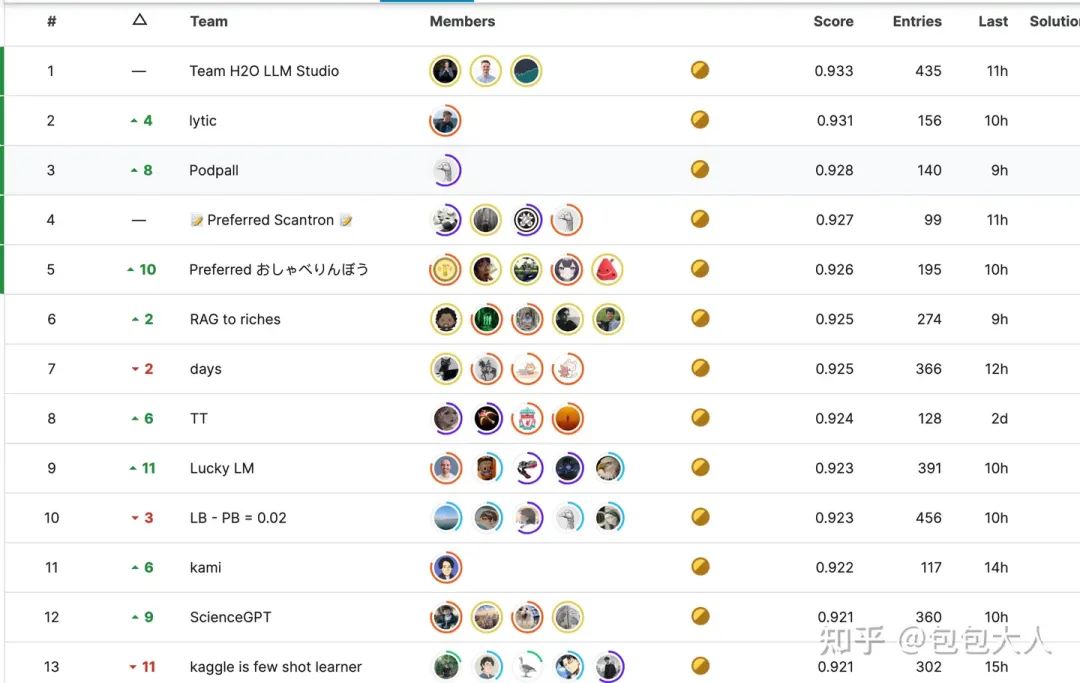
排行榜截图
题目设定:
和传统的大模型评测比较类似,给定的是科学类的题目和5个选项ABCDE,然后选出正确答案的一个。
例如:
Which of the following is an accurate definition of dynamic scaling in self-similar systems?
(以下哪项是自相似系统中动态标度的准确定义?)
A:吧啦吧啦
B:吧啦吧啦
C:吧啦吧啦
D:吧啦吧啦
E:吧啦吧啦
与一般的排行榜不同的是,这个是黑盒测试,给了200条可见的样例数据,真正用来排名的剩下的4000条数据,要提交模型在线推断,属于提交模型的黑盒测试。
注意,Kaggle平台限制了计算资源和断网环境,只有2块T4(16GB显存)的计算资源,并且需要在9小时内推断完毕,因此是一个相对公平的竞争环境,毕竟以往堆模型融合被大家诟病,限制9小时合情合理。
好了,知道题目设定后,经过两个月的激烈角逐,大家各显神通,根据公开方案整理,有用deberta的,有用7B,13B模型的,有用70B模型的。
结论写在前面,就固定场景的答题,限制时间和计算资源的情况进行刷榜而言,可以做如下结论:
1. 现在确实是大模型的天下了,就算大模型用作backbone当作判别模型微调,其效果也比deberta之前的小模型sota好。
2. 大模型本身的zeroshot自己还是不够强,RAG是大模型比较好的解决方案,且大模型zeroshot还是不如deberta进行领域和场景微调。。
3. 在RAG加持下,限制计算资源的情况下,大模型和小模型的差距也没有那么大。
其中,具体按分数高低排排段位的话,
荣耀王者:13B/7B finetune + RAG + model ensemble
星耀:70B finetune + RAG
钻石:derberta finetune + RAG
黄金:70B zeroshot +RAG
白银:deberta finetune
青铜:大模型 zeroshort
所以,小模型场景微调还是要比大模型zeroshot好的,所以大模型时代,小模型也不是一文不值。但是大模型zeroshot拿来就用,且场景宽泛,有不可取代的价值。
无一列外,大家都选择使用了RAG(检索增强生成)。
RAG这具体是个啥呢?
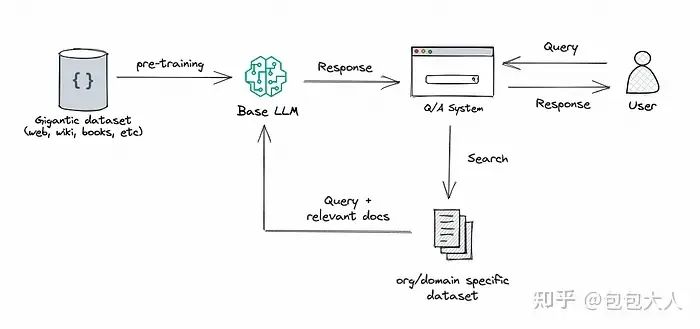
RAG结构
RAG
:R是retrievel,A是augment增强,G是generation生成,将检索(或搜索)的能力集成到LLM文本生成中。它结合了一个检索系统和一个LLM,前者从大型语料库中获取相关文档片段,后者使用这些片段中的信息生成答案。本质上,RAG 帮助模型“查找”外部信息以改进其响应。
与之相对的额是微调,微调的流程大加都比较熟悉了。
关于RAG和微调的选择,通过这个比赛也算完美印证了之前的大家认知里的结论。
在外部知识要求高的情况下,优先RAG,需要模型适配(风格行为词汇)等,就需要微调,两者要求都高的话,需要结合使用。
具体到这个题目来说,就是使用题目和选项去召回维基百科相关的文档,拼接在要回答的题目上。告诉模型:
二分类形式:参考内容{召回文档},请回答题目{qustion},选项{statement}的是否正确?
五分类形式:参考内容{召回文档},请回答题目{qustion},选项{statement[1-5]}中最正确的是ABCDE中的哪一个?
其中召回文档,就是用公开爬取的维基百科相关内容。
关于具体的召回技术,主要有向量+fasiss召回,tfidf相似度矩阵乘法,BM25等。
这里第[19th Privat]给了一个非大模型方案RAG流程比较清楚的图。
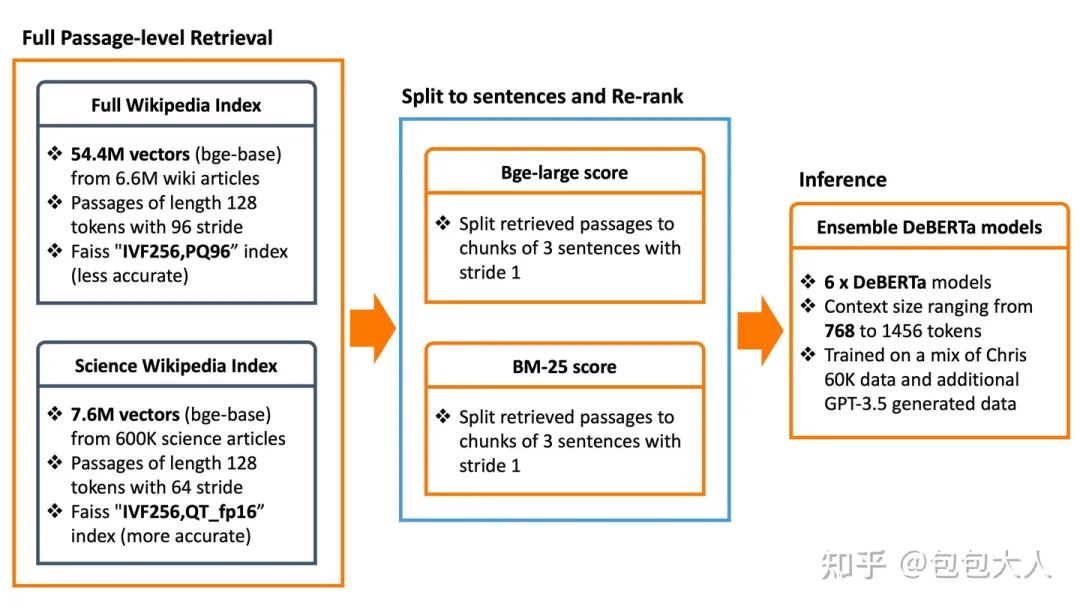
deberta + RAG
注意,这里所有的维基百科文档都是公开爬取的外部数据。大家都使用gpt构造了类似的题目来扩充数据。
第一名很早之前就使用了RAG+微调,一直遥遥领先,其具体的关键点为:
1.RAG+维基百科文档(上TB原始cirrussearch维基百科数据,夸张)
2.e5向量模型,具体是
e5-base-v2
,
e5-large-v2
,
gte-base
,
gte-large和bge-large
3.自己定制pytorch的相似度模型,无需faiss,可以解决GPU显存不够的问题。
4.大多数模型是7B和融合,又一个13B,单更大的模型没起作用。
5. 想让deberta work,但是大模型太强了,甚至融合都没用。
6.所有的LLM都是二分类头+微调的。
7.用了两种典型的分类头结构
注意第一名的所有的大模型都是基于lora训练的,这一点是让人比较惊讶的,因为其他队伍有全参数微调的70B模型,其效果不如第一名的几个7B和一个13B的基于lora训练后融合。当然这里存在巨大的召回所用数据的差异。
具体来讲,第一名试了排行榜上https://huggingface.co/spaces/mteb/leaderboard top20的向量模型,最后总结出E5和BGE效果最好,BGE是BAAI中国人搞
的
英文向量模型,效果最好,小小自豪一下。
第一名也尝试了五分类prompt+ABCDE和二分类 prompt+单独的ABCDE方案,最后发现二分类效果更好,这里符合认知,因为大模型存在一个position bias的问题,ABCDE出现的顺序和结果强相关,二分类不存在这个问题。
第一名召回的知识库有两个阶段,第一阶段来自于85GB的维基百科 database,这个wikipedia-22-12-en-embeddings-all-MiniLM-L6-v2模型的训练数据 。第二阶段是自己用原始的维基百科数据不做过滤,https://dumps.wikimedia.org/other/cirrussearch/这个数据应该有几TB,十分夸张。尝试了256, 512 和1024不同的切片检索方式,最后选了512。
推理加速用了kvcache避免prompt重复计算的技巧,具体可以参考这个图。
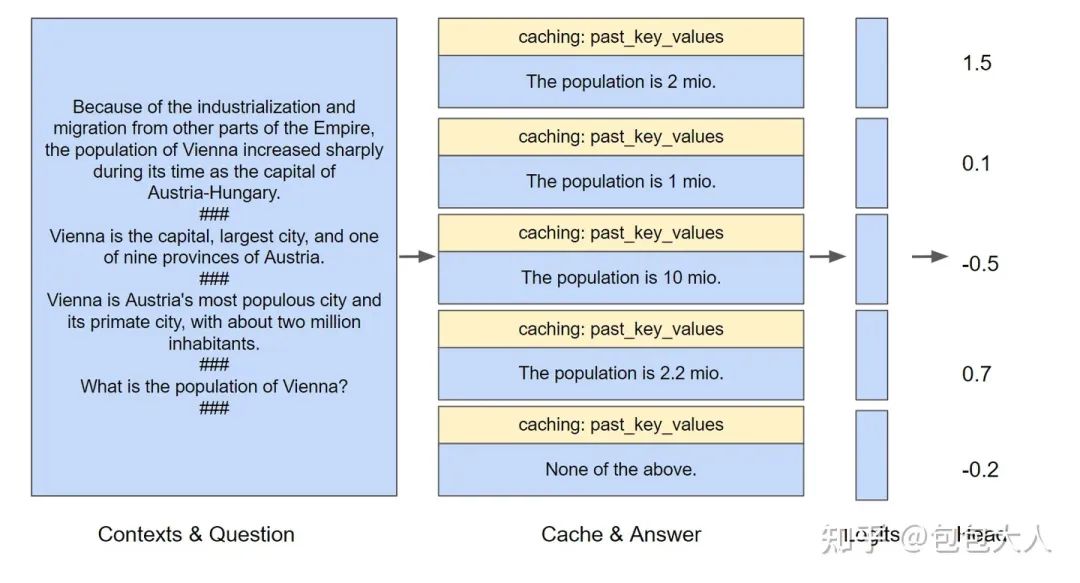
公共部分推一次缓存
链接:Kaggle - LLM Science Exam
总结下第一名:大力出奇迹,主要在数据上。
第三名 融合70B模型替换难题答案
整体的思路图里写的非常完整,值得注意的是,在融合部分,选用了和我们一样的部分融合方案,是用70B去覆盖部分困难问题的答案
。
上分历程为:
第四名 高质量召回+deberta
在kaggle上跑了一个ES,有点离谱。
第四名的方案的亮点是召回。其三路召回为:
v3:根据 Elasticsearch 搜索时的分数对上下文进行排序。
v5:根据与问句的编辑距离对上下文进行排序。
v7:使用语义搜索对上下文进行排序,使用句子转换器实现。
对于提示和维基百科之间的嵌入,使用了 msmarco-bert-base-dot-v5。对于选项和维基百科之间的嵌入,使用了 all-mpnet-base-v2。
第五名 Mistral 7B 加 Llama-70B Qlora训练
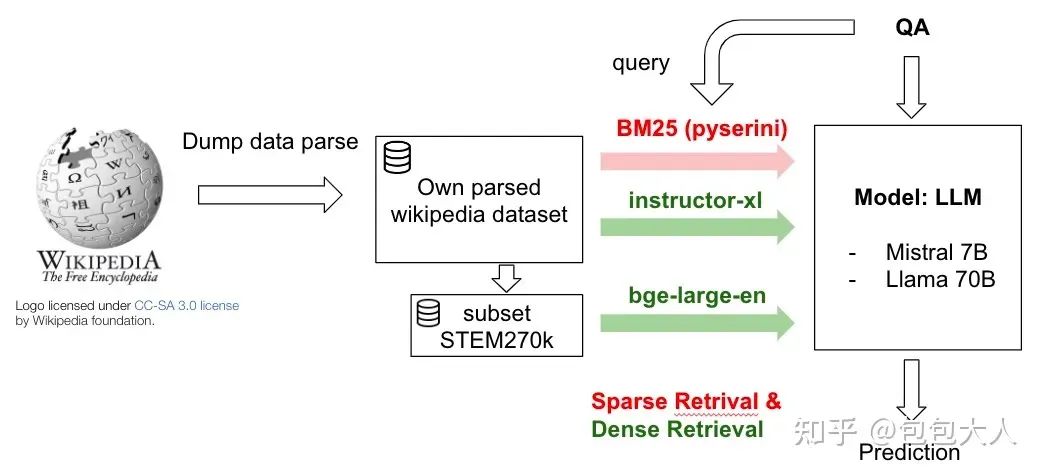
另外他们用了一个比较好的TTA技术,传统的TTA需要打乱顺序多次推断然后平均,他们在输入上构造了{context} {Q} {A B C D E} {B C D E A} … {E A B C D},在关注公共部分{context} {Q} 只需要推断一次并记录kv cache,剩下为了debias 掉position bias的部分,修改attention mask进行5次推断,这样可以节省一定时间。
注:这个70B的低显存+kv cache分层推断方案是法国大哥开源的,算是这个比赛十分有亮点的一个方案,使得70B模型能在两块16GB显寸的卡上推断。链接:https://www.kaggle.com/code/simjeg/platypus2-70b-without-wikipedia-rag
这个黑科技后面展开讲讲。
Continuous Batching:解锁LLM潜力!让LLM推断速度飙升23倍,降低延迟!
如何提供一个可信的AB测试解决方案
一文详解 JDK1.8 的 Lambda、Stream、LocalDateTime
国内外公司开源大语言模型完整列表
开源中国整理的LLM 技术图谱(LLM Tech Map)
1014.AI日报:虚拟创作者出现在宝马新广告中
MPLS静态配置新手必看!案例详解助你快速上手!
开源项目:优化仓储和物流管理的完美解决方案
2023 CCF 中国开源大会丨开源商业化分论坛 即将开幕!
M2 Ultra可并行运行128个Llama 2 7B流
CSS小技巧之单标签loader
用 Python 读取照片的 Exif 信息(顺便说说本人的一些想法)
Git命令只会抄却不理解?看完原理才能事半功倍!
20 个 Java 最佳实践
中国老钱是酱香型的
公司来了位 “新同事”,专门提醒员工接水?
MySQL 5.7废止了?我们暂无计划
《一书解决几乎所有机器学习问题》.PDF下载
将专家知识与深度学习结合,清华团队开发DeepSEED进行高效启动子设计

