微服务架构最佳实践
目录01-计算机软件架构发展历史软件架构初识概述基本概念软件架构演进过程单体架构初步设计Web服务与数据库分开本地缓存和分布式缓存反向代理与负载均衡设计数据库读写分离设计数据库按业务进行分库大表拆分为小表LVS或F5让多个Nginx负载均衡DNS轮询实现机房的负载均衡大应用拆分成小应用抽离微服务实现工程复用容器化技术设计及应用云平台服务部署总结(Summary)重难点分析FAQ分析Bug分析02- 1712人浏览 · 2021-10-25 20:08:05

目录
@PathVariable 注解在@FeignClient中应用
01-计算机软件架构发展历史
软件架构初识
为了更好理解互联网软件架构,我们现在介绍一下,一百万到千万级并发情况下服务端的架构的演进过程,同时列举出每个演进阶段会遇到的相关技术,让大家对架构的演进有一个整体的认知。
在介绍架构之前,为了避免初学者对架构设计中的一些概念不了解,下面对几个最基础的概念进行介绍。
系统中的多个模块在不同服务器上部署,即可称为分布式系统,如Tomcat和数据库分别部署在不同的服务器上,或两个相同功能的Tomcat分别部署在不同服务器上。
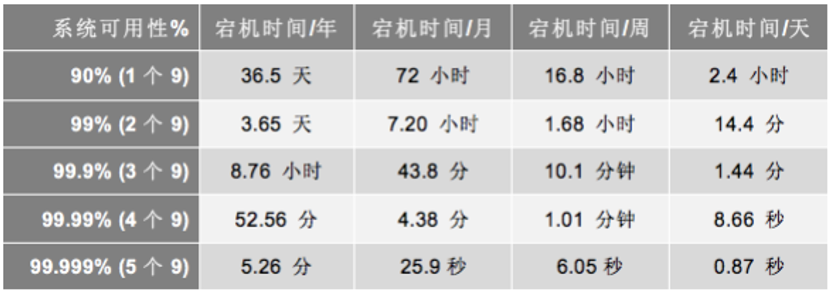
系统中部分节点失效时,其他节点能够接替它继续提供服务,则可认为系统具有高可用性。保证系统的高可用性,可从如下几个9说起,如图所示:
为了提高可用性,我们要么提高系统的无故障时间,要么减少系统的故障恢复时间,这就需要我们知道故障的原因。这个原因通常分为两大部分:
-
无计划的系统故障
1)系统级故障:包括主机、操作系统、中间件、数据库、网络、电源以及外围设备。
2)自然灾害、人为破坏,以及供电问题等。 -
有计划的日常任务:
1)运维相关:数据库维护、应用维护、中间件维护、操作系统维护、网络维护。
2)升级相关:数据库、应用、中间件、操作系统、网络,包括硬件升级。
我们再对这些故障做个归类:
- 网络问题:网络链接出现问题,网络带宽出现拥塞等
- 性能问题:慢 SQL、Java Full GC、硬盘 IO 过大、CPU 飙高、内存不足等
- 安全问题:被网络攻击,如 DDoS 等。
- 运维问题:系统总是在被更新和修改,架构也在不断地被调整,监控问题等
- 管理问题:没有梳理关键服务及服务的依赖关系,运行信息没有和控制系统同步等
- 硬件问题:硬盘损坏、网卡出问题、交换机出问题、机房掉电、挖掘机问题等
总之,我们要正确认识故障,故障不可避免。尤其是在大型分布式系统中,出现故障是一种常态。有时出现故障根本就不知道出现在了什么地方。所以我们要对故障原因先有一个认识,与此同时我们要基于故障有应对的策略,也就是我们所说的“弹力设计”,就类似三国中的赵云猛将,在搏杀中能进能退。
一个特定领域的软件部署在多台服务器上并作为一个整体提供一类服务,这个整体称为集群。在常见的集群中,客户端往往能够连接任意一个节点获得服务,并且当集群中一个节点掉线时,其他节点往往能够自动的接替它继续提供服务,这时候说明集群具有高可用性。
-
负载均衡
请求发送到系统时,通过某些方式把请求均匀分发到多个节点上,使系统中每个节点能够均匀的处理请求负载,则可认为系统是负载均衡的。 -
正向代理和反向代理
系统内部要访问外部网络时,统一通过一个代理服务器把请求转发出去,在外部网络看来就是代理服务器发起的访问,此时代理服务器实现的是正向代理;当外部请求进入系统时,代理服务器把该请求转发到系统中的某台服务器上,对外部请求来说,与之交互的只有代理服务器,此时代理服务器实现的是反向代理。简单来说,正向代理是代理服务器代替系统内部来访问外部网络的过程,反向代理是外部请求访问系统时通过代理服务器转发到内部服务器的过程。如图所示:
软件架构演进过程
单体架构初步设计
在互联网应用初期,互联网用户数相对都较少,可以把web服务器(例如Tomcat)和数据库部署在同一台服务器上。浏览器往www.taobao.com发起请求时,首先经过DNS服务器(域名系统)把域名转换为实际IP地址10.102.4.1,浏览器转而访问该IP对应的Tomcat。如图所示:
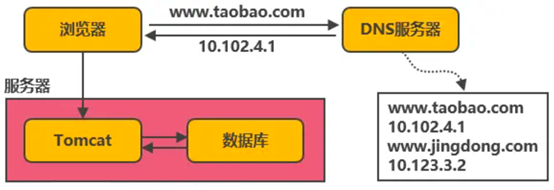
在单体架构下,所有功能模块(例如用户,商品,社区等)都会部署到一个web服务器(例如tomcat)中,所有用户都对同一个web服务进行访问,随着用户数的增长,这个web服务器的并发压力就会越来越大,Tomcat和数据库之间还要竞争计算机资源,单机性能就会越来越差,不足以支撑更加庞大业务。
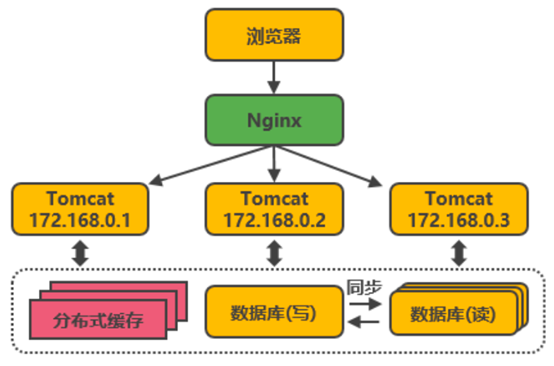
Web服务与数据库分开
Web服务器(Tomcat)和数据库器放在同一个计算机上时,tomcat和数据库会竞争CPU,内存等资源,web服务的性能就会相对较差。此时可以将tomcat和数据库进行独立部署,独占服务器资源,显著提高两者各自性能。
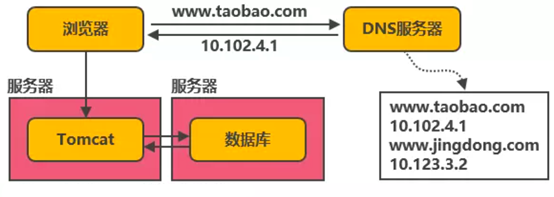
在这种架构下,随着用户数的增长,并发读写数据库的操作也会越来越多,此时数据库的读写方面就产生性能瓶颈问题(数据库支持的连接数是有限的,连接用尽时,其它用户就会阻塞,同时频繁磁盘读写也会使系统性越来越差),并发读写数据库成为瓶颈。
本地缓存和分布式缓存
如何降低数据库的访问压力呢,无非就是减少对数据库的访问。此时,我们可以考虑应用缓存(cache)。例如,在Tomcat同服务器上增加本地缓存,并在外部增加分布式缓存,缓存一些相对热门的数据(热门商品信息或热门商品的html页面等)。通过缓存把绝大多数请求在读写数据库前拦截掉,这样降低数据库的访问频次,读写压力。提高请求响应速度。如图所示:
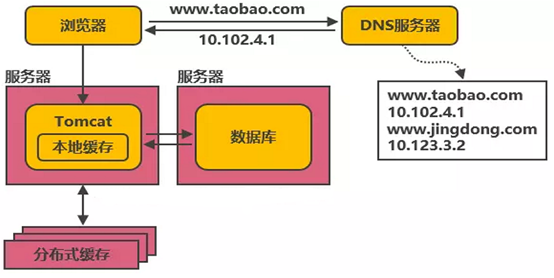
其中Cache这块,涉及的技术包括:基于JVM等技术的为本地缓存,使用Redis作为分布式缓存等。当然,引入缓存以后,性能方面可以得到一定程度的改善,但也会带来一些问题,例如缓存一致性、缓存穿透/击穿、缓存雪崩等问题。
缓存虽然抗住了大部分的访问请求,但随着用户数的增长,并发压力主要落在单机的Tomcat上。还有, 一个Tomcat的并发处理能力是有限的,请求越来越多时,部分请求的响应就会越来越慢,还有就是可靠性比较差,一旦这个tomcat服务宕机了,所有资源就不能访问了。
反向代理与负载均衡设计
在多台服务器上分别部署Tomcat,使用反向代理软件(Nginx)把请求均匀分发到每个Tomcat中。此处假设Tomcat最多支持100个并发,Nginx最多支持50000个并发,那么理论上Nginx把请求分发到500个Tomcat上,就能抗住50000个并发。其中涉及的技术包括:Nginx、HAProxy,如图所示:
反向代理使应用服务器可支持的并发量大大增加,但并发量的增长也意味着更多请求穿透到数据库,单机的数据库最终成为瓶颈。
数据库读写分离设计
当一个tomcat服务无法处理更多并发时,我们就使用多个tomcat,分别部署在多台服务器上。然后,使用反向代理软件(Nginx)把请求均匀分发到每个Tomcat中。此处假设Tomcat最多支持100个并发,Nginx最多支持50000个并发,那么理论上Nginx把请求分发到500个Tomcat上,就能抗住50000个并发。如图所示:
其中涉及的技术包括:Mycat,它是数据库中间件,可通过它来组织数据库的分离读写和分库分表,客户端通过它来访问下层数据库,还会涉及数据同步,数据一致性的问题。业务逐渐变多,不同业务之间的访问量差距较大,不同业务直接竞争数据库,相互影响性能。
数据库按业务进行分库
把不同业务的数据保存到不同的数据库中,使业务之间的资源竞争降低,对于访问量大的业务,可以部署更多的服务器来支撑。
这样同时导致跨业务的表无法直接做关联分析,需要通过其他途径来解决,但这不是本文讨论的重点,有兴趣的可以自行搜索解决方案。对于这种方案,随着用户数的增长,单机的写库会逐渐会达到性能瓶颈。
大表拆分为小表
比如针对评论数据,可按照商品ID进行hash,路由到对应的表中存储;针对支付记录,可按照小时创建表,每个小时表继续拆分为小表,使用用户ID或记录编号来路由数据。只要实时操作的表数据量足够小,请求能够足够均匀的分发到多台服务器上的小表,那数据库就能通过水平扩展的方式来提高性能。其中前面提到的Mycat也支持在大表拆分为小表情况下的访问控制。
这种做法显著的增加了数据库运维的难度,对DBA的要求较高。数据库设计到这种结构时,已经可以称为分布式数据库,但是这只是一个逻辑的数据库整体,数据库里不同的组成部分是由不同的组件单独来实现的,如分库分表的管理和请求分发,由Mycat实现,SQL的解析由单机的数据库实现,读写分离可能由网关和消息队列来实现,查询结果的汇总可能由数据库接口层来实现等等,这种架构其实是MPP(大规模并行处理)架构的一类实现。
数据库和Tomcat都能够水平扩展,可支撑的并发大幅提高,随着用户数的增长,最终单机的Nginx会成为瓶颈。
LVS或F5让多个Nginx负载均衡
由于瓶颈在Nginx,因此无法通过两层的Nginx来实现多个Nginx的负载均衡。此时采用LVS和F5作为网络负载均衡解决方案,如图所示:

其中LVS是软件,运行在操作系统内核态,可对TCP请求或更高层级的网络协议进行转发,因此支持的协议更丰富,并且性能也远高于Nginx,可假设单机的LVS可支持几十万个并发的请求转发;F5是一种负载均衡硬件,与LVS提供的能力类似,性能比LVS更高,但价格昂贵。由于LVS是单机版的软件,若LVS所在服务器宕机则会导致整个后端系统都无法访问,因此需要有备用节点。可使用keepalived软件模拟出虚拟IP,然后把虚拟IP绑定到多台LVS服务器上,浏览器访问虚拟IP时,会被路由器重定向到真实的LVS服务器,当主LVS服务器宕机时,keepalived软件会自动更新路由器中的路由表,把虚拟IP重定向到另外一台正常的LVS服务器,从而达到LVS服务器高可用的效果。
此种方案中,由于LVS也是单机的,随着并发数增长到几十万时,LVS服务器最终会达到瓶颈,此时用户数达到千万甚至上亿级别,用户分布在不同的地区,与服务器机房距离不同,导致了访问的延迟会明显不同。
DNS轮询实现机房的负载均衡
在DNS服务器中可配置一个域名对应多个IP地址,每个IP地址对应到不同的机房里的虚拟IP。当用户访问www.taobao.com时,DNS服务器会使用轮询策略或其他策略,来选择某个IP供用户访问。此方式能实现机房间的负载均衡,至此,系统可做到机房级别的水平扩展,千万级到亿级的并发量都可通过增加机房来解决,系统入口处的请求并发量不再是问题。

随着数据的丰富程度和业务的发展,检索、分析等需求越来越丰富,单单依靠数据库无法解决如此丰富的需求
大应用拆分成小应用
按照业务板块来划分应用代码,使单个应用的职责更清晰,相互之间可以做到独立升级迭代。这时候应用之间可能会涉及到一些公共配置,可以通过分布式配置中心Zookeeper来解决。
不同应用之间存在共用的模块,由应用单独管理会导致相同代码存在多份,导致公共功能升级时全部应用代码都要跟着升级。
抽离微服务实现工程复用
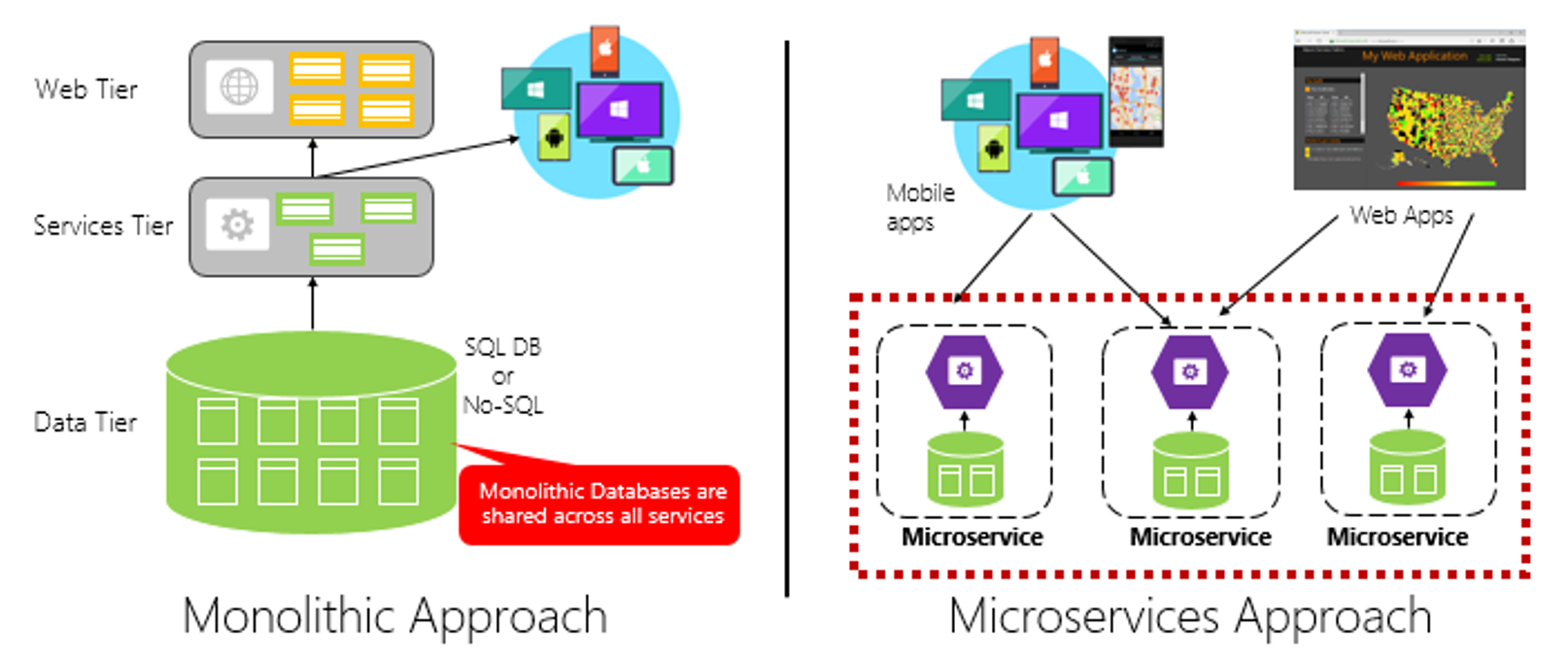
如用户管理、订单、支付、鉴权等功能在多个应用中都存在,那么可以把这些功能的代码单独抽取出来形成一个单独的服务来管理,这样的服务就是所谓的微服务,应用和服务之间通过HTTP、TCP或RPC请求等多种方式来访问公共服务,每个单独的服务都可以由单独的团队来管理。此外,可以通过Dubbo、SpringCloud等框架实现服务治理、限流、熔断、降级等功能,提高服务的稳定性和可用性。如图所示:

个人理解,微服务架构更多是指把系统里的公共服务抽取出来单独运维管理的思想
容器化技术设计及应用
目前最流行的容器化技术是Docker,最流行的容器管理服务是Kubernetes(K8S),应用/服务可以打包为Docker镜像,通过K8S来动态分发和部署镜像。Docker镜像可理解为一个能运行你的应用/服务的最小的操作系统,里面放着应用/服务的运行代码,运行环境根据实际的需要设置好。把整个“操作系统”打包为一个镜像后,就可以分发到需要部署相关服务的机器上,直接启动Docker镜像就可以把服务起起来,使服务的部署和运维变得简单。
在大促的之前,可以在现有的机器集群上划分出服务器来启动Docker镜像,增强服务的性能,大促过后就可以关闭镜像,对机器上的其他服务不造成影响(在3.14节之前,服务运行在新增机器上需要修改系统配置来适配服务,这会导致机器上其他服务需要的运行环境被破坏)。
云平台服务部署
系统可部署到公有云上,利用公有云的海量机器资源,解决动态硬件资源的问题,在大促的时间段里,在云平台中临时申请更多的资源,结合Docker和K8S来快速部署服务,在大促结束后释放资源,真正做到按需付费,资源利用率大大提高,同时大大降低了运维成本。
所谓的云平台,就是把海量机器资源,通过统一的资源管理,抽象为一个资源整体,在之上可按需动态申请硬件资源(如CPU、内存、网络等),并且之上提供通用的操作系统,提供常用的技术组件(如Hadoop技术栈,MPP数据库等)供用户使用,甚至提供开发好的应用,用户不需要关系应用内部使用了什么技术,就能够解决需求(如音视频转码服务、邮件服务、个人博客等)。
总结(Summary)
重难点分析
- 发展历程中的关键设计及技能点。
- 架构发展过程中暴露出的问题以及解决方案。
FAQ分析
- 单体架构你觉得存在什么缺陷?(容量、计算、故障)
- 为什么要使用分布式架构?(增加容量、高并发、高性能、高可用)
- 分布式架构有什么劣势?(设计的难度、维护成本)
- 为什么要使用缓存?(减少数据库访问压力、提高性能)
- 使用缓存时要注意什么问题?(一致性、淘汰算法、击穿、雪崩)
- 如何理解反向代理?(服务端代理,是服务端服务器的一种代理机制,请求转发)
- 反向代理如何实现负载均衡?(轮询,轮询+权重,哈希IP)
- 什么是读写分离、读写分离的目的是什么?(单机数据库有瓶颈、读写频次,并发能力)
- 读写分离后可能会带来什么问题?(数据同步)
- 当我们向写库写数据时还要做什么?(写缓存、数据同步到读库)
- 为什么要进行分库、分表,有哪些分表策略?(业务数据可靠性、查询性能)
- 何为服务,有什么是微服务?(服务-软件要解决的问题,可以提供的功能。微服务-服务中的共性再抽象,以实现更好的重用)
- 哪种互联网架构设计最好?(没有最好,只有更好,脱离业务谈就够就是耍流氓)
Bug分析
02-若依权限管理子系统简介
若依系统简介
若依微服务版RuoYi-Cloud,基于Spring Boot、Spring Cloud & Alibaba、OAuth2的前后端分离的后台 管理系统 。此系统内置模块如部门管理、角色用户管理、菜单及按钮授权、数据权限、系统参数、日志管理、代码生成等。在线定时任务配置,并且支持集群,支持多数据源。此系统还是我们公司内部的一套 Java EE 企业级快速开发平台.
官方文档地址
若依官网 http://
ruoyi
.vip/。
若依微服务官网地址 https://doc.ruoyi.vip/ruoyi-cloud/
微服务技术选型
后端技术栈:
MyBatis、Spring、Spring Boot、Spring Cloud & Alibaba、Nacos、Sentinel
前端VUE技术栈:
ES6、vue、vuex、vue-router、vue-cli、axios、element-ui
系统微服务模块骨架
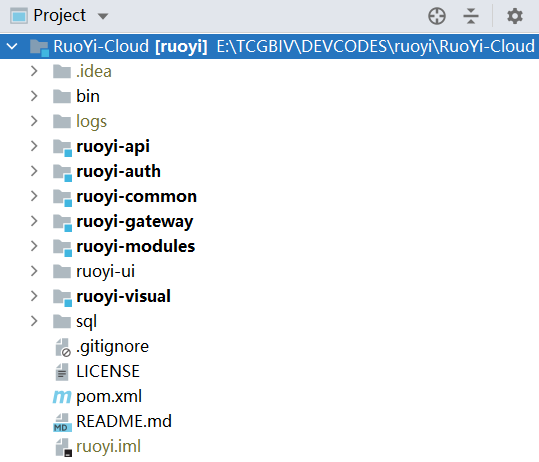
后端项目骨架,如图所示:
com.ruoyi ├── ruoyi-ui // 前端框架 [80] ├── ruoyi-gateway // 网关模块 [8080] ├── ruoyi-auth // 认证中心 [9200] ├── ruoyi-api // 接口模块 │ └── ruoyi-api-system // 系统接口 ├── ruoyi-common // 通用模块 │ └── ruoyi-common-core // 核心模块 │ └── ruoyi-common-datascope // 权限范围 │ └── ruoyi-common-datasource // 多数据源 │ └── ruoyi-common-log // 日志记录 │ └── ruoyi-common-redis // 缓存服务 │ └── ruoyi-common-security // 安全模块 │ └── ruoyi-common-swagger // 系统接口 ├── ruoyi-modules // 业务模块 │ └── ruoyi-system // 系统模块 [9201] │ └── ruoyi-gen // 代码生成 [9202] │ └── ruoyi-job // 定时任务 [9203] │ └── ruoyi-file // 文件服务 [9300] ├── ruoyi-visual // 图形化管理模块 │ └──ruoyi-visual-monitor // 监控中心 [9100] ├──pom.xml // 公共依赖
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
前端项目骨架结构,如图所示:
├── build // 构建相关 ├── bin // 执行脚本 ├── public // 公共文件 │ ├── favicon.ico // favicon图标 │ └── index.html // html模板 ├── src // 源代码 │ ├── api // 所有请求 │ ├── assets // 主题字体等静态资源 │ ├── components // 全局公用组件 │ ├── directive // 全局指令 │ ├── layout // 布局 │ ├── router // 路由 │ ├── store // 全局 store管理 │ ├── utils // 全局公用方法 │ ├── views // view │ ├── App.vue // 入口页面 │ ├── main.js // 入口 加载组件 初始化等 │ ├── permission.js // 权限管理 │ └── settings.js // 系统配置 ├── .editorconfig // 编码格式 ├── .env.development // 开发环境配置 ├── .env.production // 生产环境配置 ├── .env.staging // 测试环境配置 ├── .eslintignore // 忽略语法检查 ├── .eslintrc.js // eslint 配置项 ├── .gitignore // git 忽略项 ├── babel.config.js // babel.config.js ├── package.json // package.json └── vue.config.js // vue.config.js系统微服务技术架构
若依分布式架构设计,如图所示:
若依微服务项目部署
一般进入公司以后,可能team leader会给我们一套项目代码,然后我们需要基于代码规范或者原有业务去进行新的业务开发,这样的话我们就需要首先将系统跑起来,然后对其业务和代码进行分析,学习.
项目需要的基础环境需求如下:
JDK >= 1.8 (推荐1.8版本) Mysql >= 5.7.0 (推荐5.7版本) Redis >= 5.0 (市场主流版本,最新版本为6.xx) Maven >= 3.6 (http://maven.apache.org/download.cgi) Node >= 10 (稳定版14.X,https://nodejs.org/en/download/) nacos >= 1.4.1 (https://github.com/alibaba/nacos/releases)
- 1
- 2
- 3
- 4
- 5
- 6
当这些软件不知道如何去下载时候,打开搜索引擎,使用组合查询方法,去找下载路径,
例如 redis download安装Redis
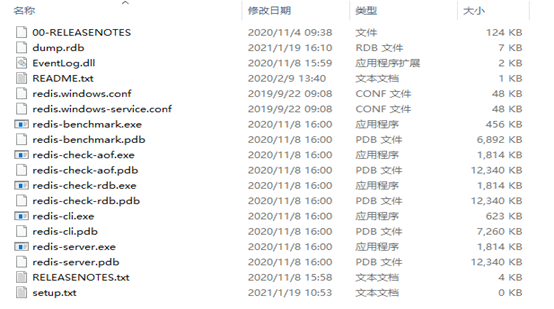
Redis官网:
http://www.redis.cn/ http://www.redis.io/Windows版本下载以后,网址如下:
https://github.com/tporadowski/redis/releaseswindows下的安装,直接解压,其个目录如下:
安装windows下安装服务,在redis根目录启动命令行(cmd),执行
redis-server --service-install redis.windows.conf启动redis服务(启动成功以后会出现successful)
redis-server --service-start其它redis指令(这个操作可以不执行)
redis-server --service-stop //停止服务 redis-server --service-uninstall //卸载服务连接测试redis,在redis根路径执行(默认端口6379)
redis-cli -h 127.0.0.1 -p 6379安装MySql数据库
(省略)
说明:mysql数据库的版本一定要在5.7以上,MariaDB最后用10.5.安装Nacos服务治理业务
第一步:Nacos下载,可在浏览器直接输入如下地址:
https://github.com/alibaba/nacos/releases第二步:选择对应版本,直接下载,如图所示:
第三步:解压Nacos(最好不要解压到中文目录下),其目录结构如下:
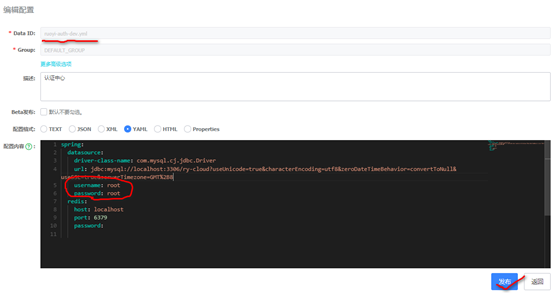
第四步:打开/conf/application.properties里打开默认配置,并基于你当前环境配置要连接的数据库,连接数据库时使用的用户名和密码:
### If use MySQL as datasource: spring.datasource.platform=mysql ### Count of DB: db.num=1 ### Connect URL of DB: db.url.0=jdbc:mysql://127.0.0.1:3306/ry-config?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true&useUnicode=true&useSSL=false&serverTimezone=UTC db.user.0=root db.password.0=root说明,后续我们配置RuoYi-Cloud项目时,这个项目很多配置信息需要存储到ry-config数据库中。
初始化RuoYi-Cloud微服务项目数据
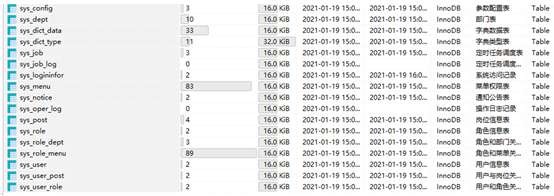
第一步:登录mysql,然后基于source执行指令去执行课前资料中的RuoYi-Cloud.sql文件(不推荐使用SQLYog执行),例如:
source d:/RuoYi-Cloud.sql当执行成功以后,在ry-cloud数据库中就有如下表:
第二步:基于source指令执行RuoYi-Config.sql,例如:
source d:/RuoYi-Config.sql执行成功以后会创建一个数据库ry-config,其内部的表如图所示:
若依后端微服务启动运行
启动Nacos服务
第一步:进入nacos的bin目录,启动nacos(standalone代表着单机模式运行,非集群模式,此服务的启动对JDK有要求,必须jdk8):
startup.cmd -m standalone第二步:访问Nacos服务
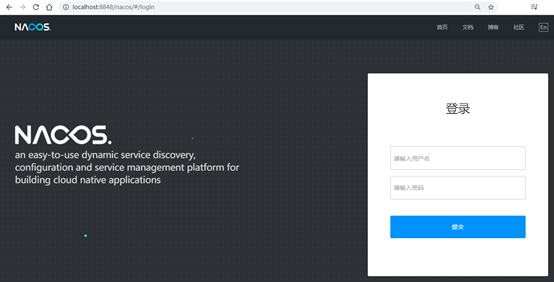
打开浏览器,输入http://localhost:8848/nacos地址,出现如下登陆页面:
默认登陆用户名和密码都为nacos,登陆成功以后,进入如下页面:
打开配置列表,如图所示:
然后从”上往下挨个编辑”,把设计到连接Mysql和Redis的所有地方,改为自己对应的用户名和密码,以网关的配置文件ruoyi-auth-dev.yml为例,如图所示:基于IDEA打开项目
第一步:基于IDEA打开项目,如图所示:
第二步:项目打开以后,配置maven下载项目依赖。
启动并检测后端项目服务
第一步:依次启动ruoyi-gateway,ruoyi-auth,ruoyi-modules下的ruoyi-system。
第二步:检测nacos的服务列表,如图所示:若依前端项目配置及运行
安装项目依赖
第一步:选中前端项目,如图所示:
第二步:右键前端项目,打开终端命令行,如图所示:
第三步:在命令行输入npm install 安装项目依赖,如图所示:启动运行前端项目
第一步:在命令行输入 npm run dev 启动运行前端服务,如图所示:
第二步:浏览器输入localhost进行访问,进入登陆页面,如图所示
第三步:输入账号(admin/admin123),登陆系统,如图所示:总结(Summary)
重难点分析
- 熟悉若依平台业务及技术(架构、技术栈)
- 掌握第三方平台的一个搭建过程(参考官方或企业文档)
- 掌握微服务架构的项目结构(参考结构创建自己的项目)。
FAQ分析
- 如何在命令行执行sql脚本文件?source d:/RuoYi-Cloud.sql
- 数据库中的导入的数据是乱码?Sqlyog可能会有这个问题
- Nacos服务启动后看不到配置数据?检查nacos配置文件application.properties中数据库的连接配置。
BUG分析
- Cannot resolve plugin spring-boot-maven-plugin:
- MySql执行sql脚本时失败(检查你mysql的版本是否为5.7以上版本)
- 500 exception (一定要看服务端服务是否启动,控制台是否有异常)
- Redis启动失败(先卸载再启动)
- Npm install (安装客户端依赖过程失败,首先检测node版本,选择稳定版)
- 服务启动时显示连接数据库失败(检查nacos配置列表中配置文件内容是否修改了连接数据库的配置)
03-微服务架构及解决方案
微服务简介
讲微服务之前,我们先分析以下单体应用。所谓单体应用一般是基于idea/eclipse,maven等建一个工程,然后基于SpringBoot,spring,mybatis框架进行整合,接下来再写一堆dao、mapper、service、controller,再加上一些的配置文件,有可能还会引入redis、elasticsearch、mq等其它项目的依赖,开发好之后再将项目打包成一个jar包/war包。然后再将包扔到类似tomcat这样的web服务中,最后部署到公司提供给你的linux服务器上。 接下来,你针对服务提供的访问端口(例如8080端口)发起http请求,请求会由tomcat直接转交给你的spring web组件,进行一层一层的代码调用。对于这样的设计一般适合企业的内部应用,访问量不大,体积比较小,5人以内的团队即可开发和维护。但对于一些大型互联网项目,假如需要10人以上的开发和维护团队,仅频繁的创建代码分支,编写业务功能,然后合并分支,就会出现很多代码冲突。每次解决这些大量的代码冲突,可能就会耗费好几天的时间。基于这样的背景微服务诞生了.
在微服务架构设计中,建议超出需要10人开发和维护的项目要进行系统拆分,就是把大系统拆分为很多小系统,几个人负责一个服务这样每个服务独立的开发、测试和上线,代码冲突少了,每次上线就回归测试自己的一个服务即可,测试速度快了,上线是独立的,只要向后兼容接口就行了,不需要跟别人等待和协调,技术架构和技术版本的升级,几个人ok就行,成本降低,更加灵活了。
什么是微服务
微服务架构(MSA)的基础是将单个应用程序开发为一组小型独立服务,这些独立服务在自己的进程中运行,独立开发和部署。如图所示:
这些服务使用轻量级 API 通过明确定义的接口进行通信。这些服务是围绕业务功能构建的,每项服务执行一项功能。由于它们是独立运行的,因此可以针对各项服务进行更新、部署和扩展,以满足对应用程序特定功能的需求。
生活中的微服务,如图所示:
程序中的微服务,就是将各个业务系统的共性再进行抽取,做成独立的服务,如图所示:总之,微服务是分布式系统中的一种流行的架构模型,它并不是银弹,所以,也不要寄希望于微服务构架能够解决所有的问题。微服务架构主要解决的是如何快速地开发和部署我们的服务,这对于一个能够适应快速开发和成长的公司是非常必要的。同时,微服务设计中有很多很不错的想法和理念,通过学习微服务架构我们可以更快的迈向卓越。
SpringCloud Alibaba微服务解决方案
Spring Cloud Alibaba 是Spring Cloud的一个子项目,致力于提供微服务开发的一站式解决方案。此项目包含开发分布式应用微服务的必需组件,方便开发者通过 Spring Cloud 编程模型轻松使用这些组件来开发分布式应用服务。依托 Spring Cloud Alibaba,您只需要添加一些注解和少量配置,就可以将 Spring Cloud 应用接入阿里微服务解决方案,通过阿里中间件来迅速搭建分布式应用系统。
核心组件分析
Spring Cloud Alibaba 默认提供了如下核心功能(先了解):
- 服务限流降级:
默认支持 WebServlet、OpenFeign、RestTemplate、Spring Cloud Gateway, RocketMQ 限流降级功能的接入,可以在运行时通过控制台实时修改限流降级规则,还支持查看限流降级 Metrics 监控。- 服务注册与发现:
基于Spring Cloud 服务注册与发现标准,借助Nacos进行实现,默认还集成了 Ribbon 的支持。- 分布式配置管理:
基于Nacos支持分布式系统中的外部化配置,配置更改时自动刷新。- 消息驱动能力:
基于Spring Cloud Stream 为微服务应用构建消息驱动能力。- 分布式事务:
使用 @GlobalTransactional 注解, 高效并且对业务零侵入地解决分布式事务问题。。- 分布式任务调度:
提供秒级、精准、高可靠、高可用的定时(基于 Cron 表达式)任务调度服务。同时提供分布式的任务执行模型,如网格任务。网格任务支持海量子任务均匀分配到所有 Worker上执行。解决方案架构设计
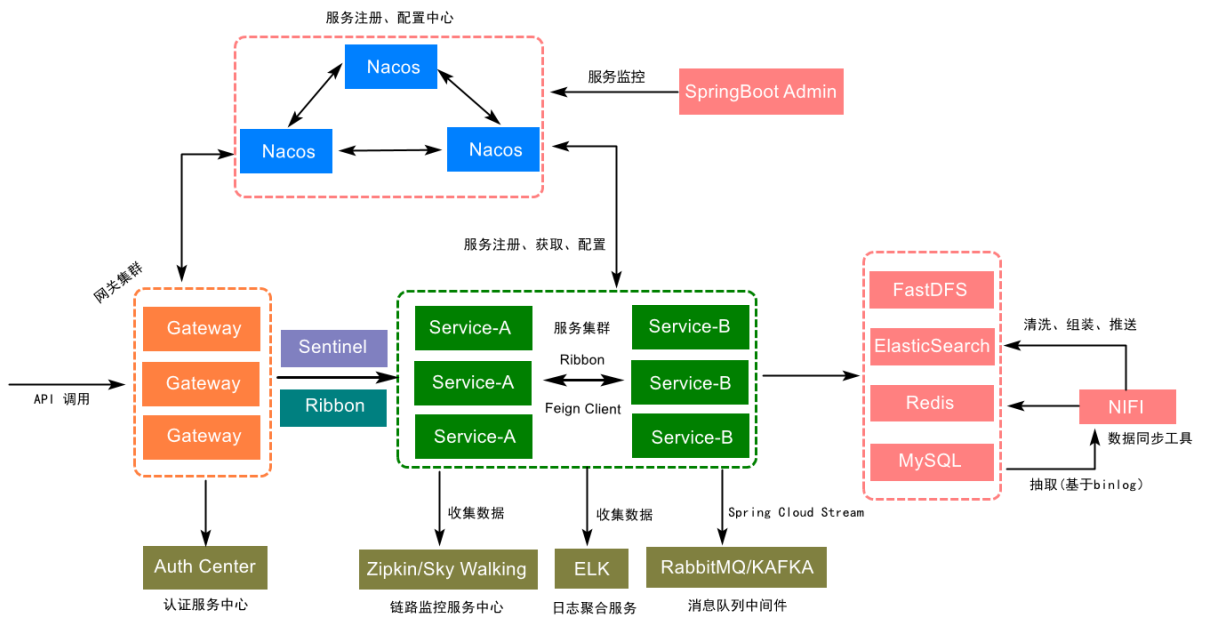
基于Spring Cloud Alibaba实现的微服务,解决方案设计架构如图所示:
构建SpringCloud 聚合项目并进行环境初始化
微服务项目一般都会采用聚合工程结构,可通过聚合工程结构实现共享资源的复用,简化项目的管理方式。本小节以一个聚合工程结构为案例,讲解微服务架构方案中的maven聚合工程的基本结构,例如:
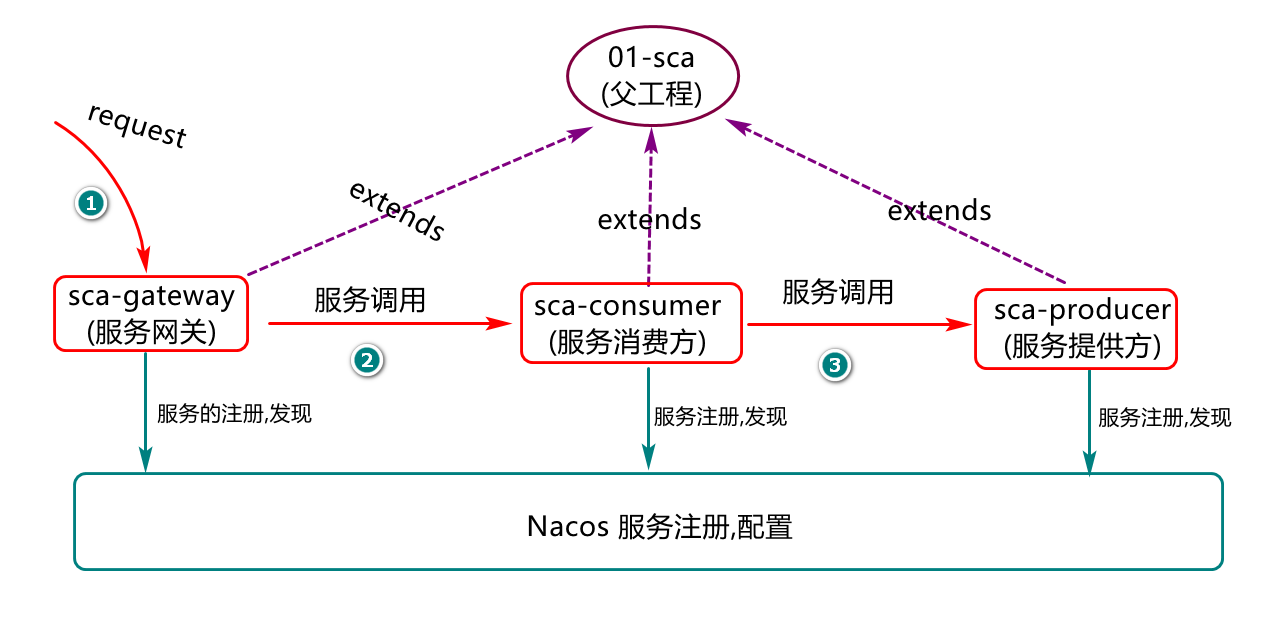
GitCGB2105IVProjects (工作区/空项目) ├── 01-sca //(微服务父工程) ├── sca-provider //服务提供方法 ├── sca-consumer //服务消费方法 ├── sca-gateway //网关服务创建空项目
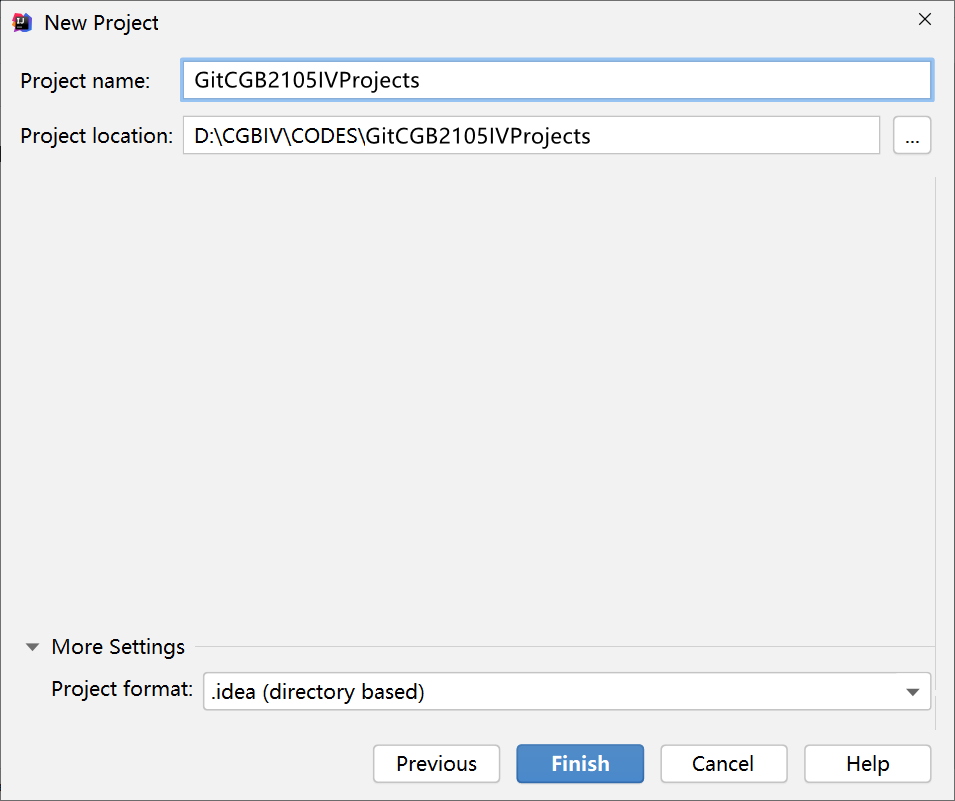
打开Idea,创建一个空项目(Empty Project),项目名为GitCGB2105IVProjects,例如:
其中,这个空项目就类似磁盘中的一个空的文件夹,可以将此文件夹作为一个代码工作区。项目初始化配置
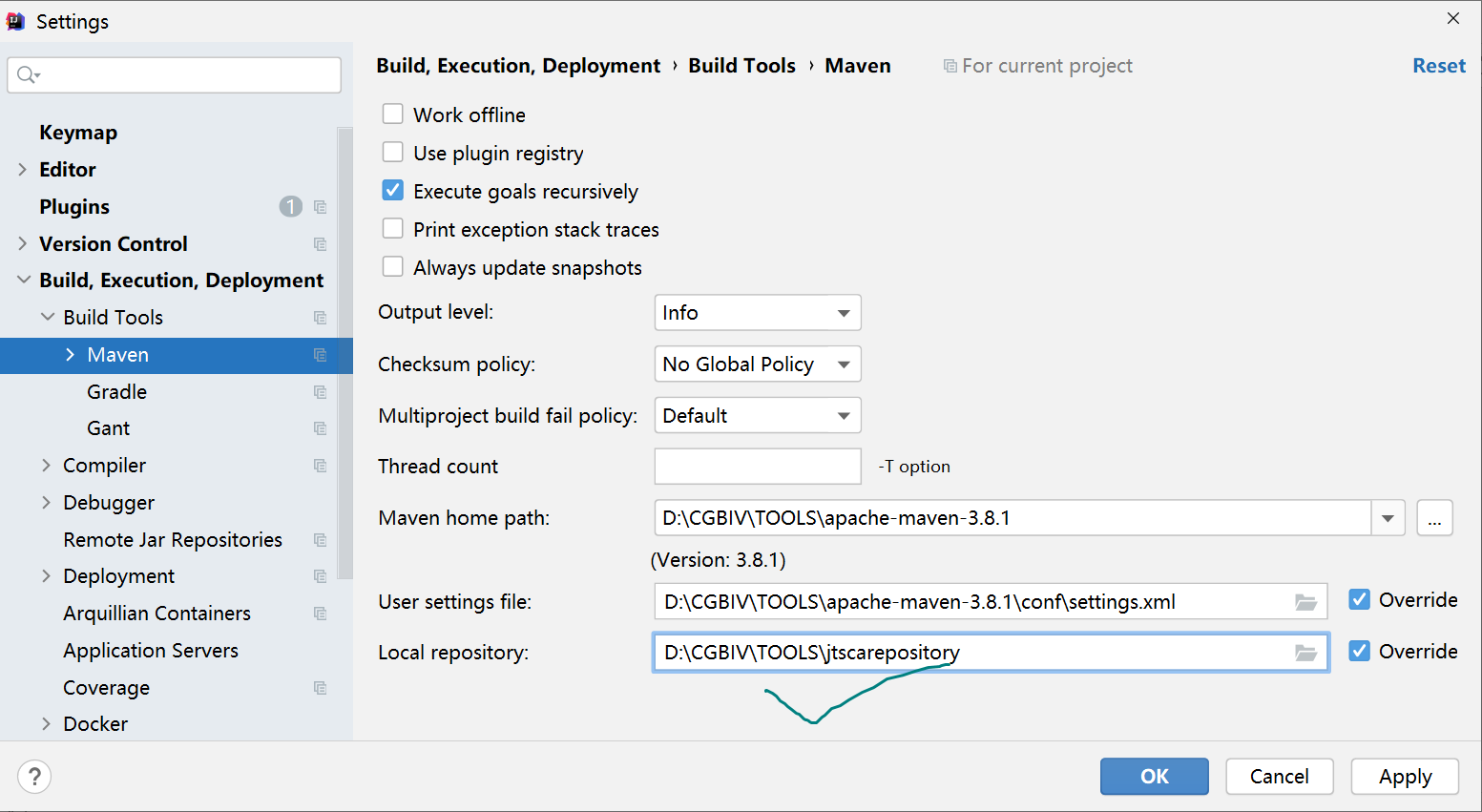
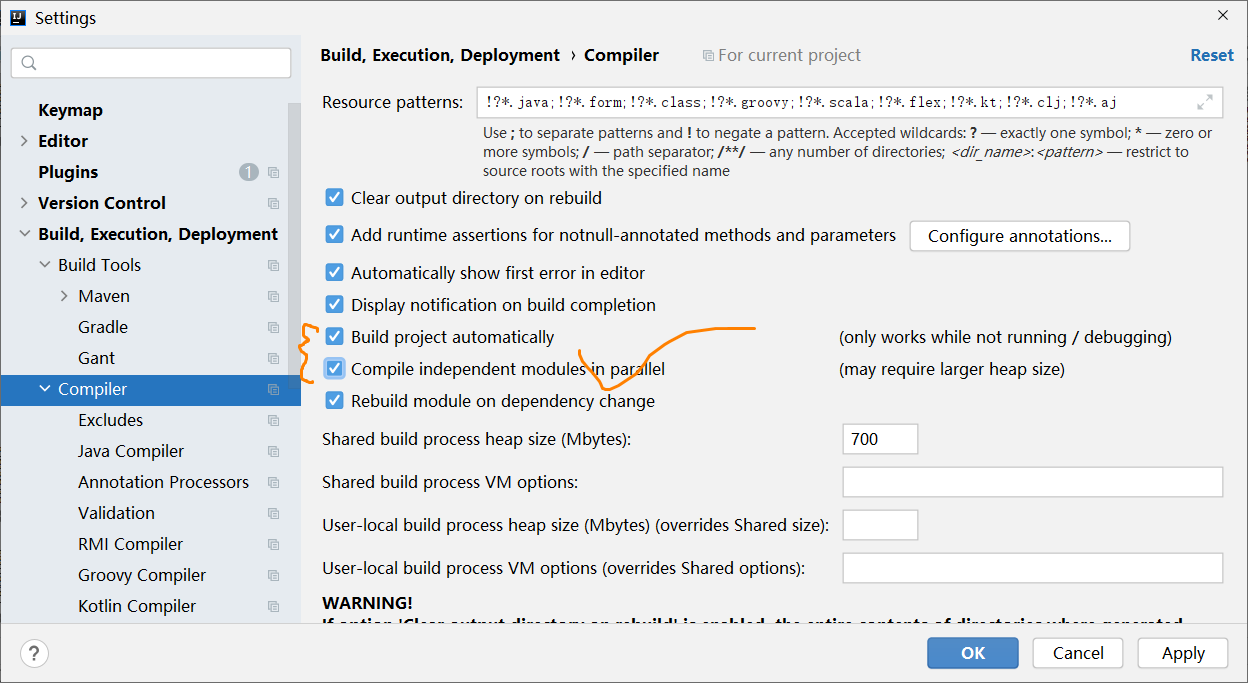
第一步:配置maven环境(只要是新的工作区,都要重新配置),注意本地库选择新的位置不要与其它项目共用本地库,因为多个项目所需要依赖的版本不同时,可能会有一些依赖版本的冲突。.
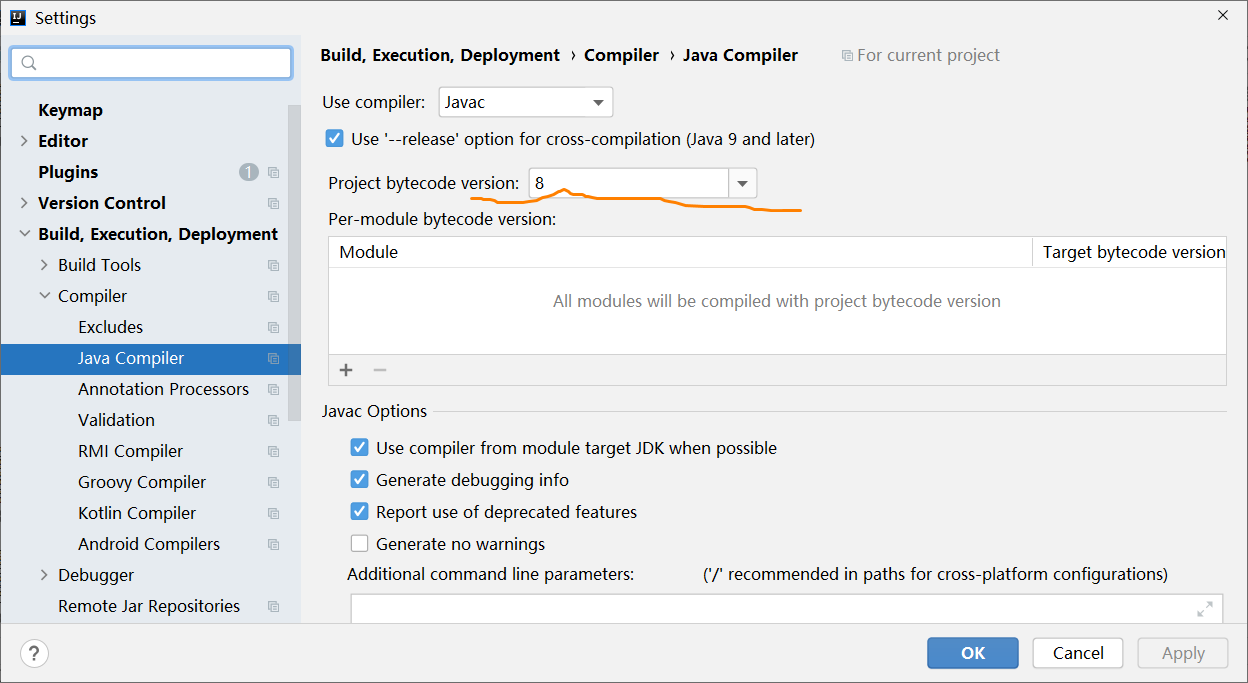
说明,这里的本地库名字最要不要选择中文,单词之间也不要有空格。第二步:配置JDK编译环境
聚合工程在编译时,需要对相关依赖的工程进行一起编译,所以需要做一些配置,例如:
指定一下当前工作区的jdk编译版本,例如:第三步:配置工作区中项目编码方式
创建聚合父工程
我们后续在创建微服务工程进行学习时,相关服务依赖版本的管理,公共依赖,项目编译,打包设计等都可以放在此工程下,进行统一的配置,然后实现共享。
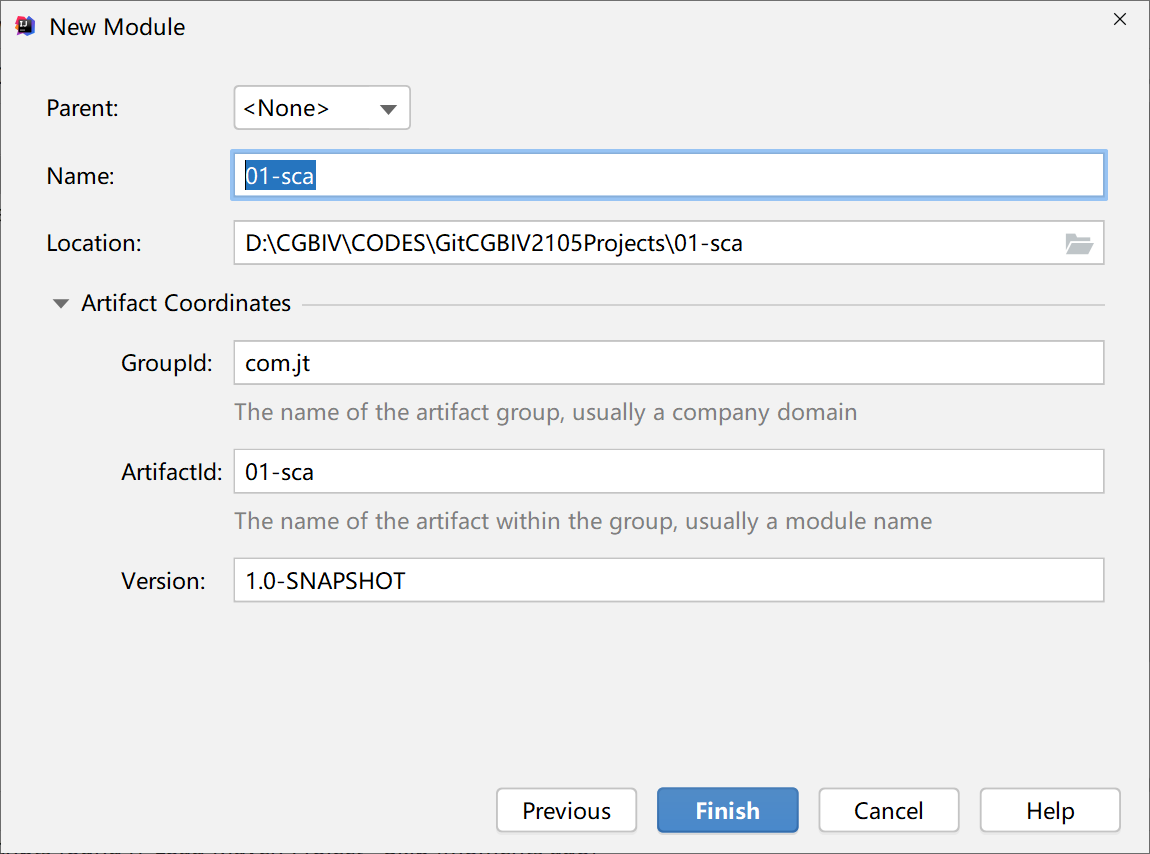
第一步:创建父工程模块,例如:
第二步:删除工程中的src目录(父工程不需要这个目录),例如第三步:修改项目pom.xml文件内容,例如:
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <!--当前工程的坐标--> <groupId>com.jt</groupId> <artifactId>01-sca</artifactId> <version>1.0-SNAPSHOT</version> <!--有的同学在创建maven工程时,可能会有如下有两句话,这两句话用于指定 当前项目的jdk编译版本以及运行版本,也可以不指定,后续我们自己通过maven插件方式进行配置--> <properties> <maven.compiler.source>8</maven.compiler.source> <maven.compiler.target>8</maven.compiler.target> </properties> <!--maven父工程的pom文件中一般要定义子模块, 子工程中所需依赖版本的管理,公共依赖并且父工程的 打包方式一般为pom方式--> <!--第一步: 定义子工程中核心依赖的版本管理(注意,只是版本管理)--> <dependencyManagement> <dependencies> <!--spring boot 核心依赖版本定义(spring官方定义)--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-dependencies</artifactId> <version>2.3.2.RELEASE</version> <type>pom</type> <scope>import</scope> </dependency> <!--Spring Cloud 微服务规范(由spring官方定义)--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-dependencies</artifactId> <version>Hoxton.SR9</version> <type>pom</type><!--假如scope是import,type必须为pom--> <scope>import</scope><!--引入三方依赖的版本设计--> </dependency> <!--Spring Cloud alibaba 依赖版本管理 (参考官方说明)--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-alibaba-dependencies</artifactId> <version>2.2.6.RELEASE</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement> <!--第二步: 添加子工程的所需要的公共依赖--> <dependencies> <!--lombok 依赖,子工程中假如需要lombok,不需要再引入--> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <scope>provided</scope><!--provided 表示此依赖仅在编译阶段有效--> </dependency> <!--单元测试依赖,子工程中需要单元测试时,不需要再次引入此依赖了--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope><!--test表示只能在test目录下使用此依赖--> <exclusions> <exclusion><!--排除一些不需要的依赖--> <groupId>org.junit.jupiter</groupId> <artifactId>junit-jupiter-engine</artifactId> </exclusion> </exclusions> </dependency> <!--其它依赖...--> </dependencies> <!--第三步: 定义当前工程模块及子工程的的统一编译和运行版本--> <build><!--项目构建配置,我们基于maven完成项目的编译,测试,打包等操作, 都是基于pom.xml完成这一列的操作,但是编译和打包的配置都是要写到build元素 内的,而具体的编译和打包配置,又需要plugin去实现,plugin元素不是必须的,maven 有默认的plugin配置,常用插件可去本地库进行查看--> <plugins> <!--通过maven-compiler-plugin插件设置项目 的统一的jdk编译和运行版本--> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <!--假如本地库没有这个版本,这里会出现红色字体错误--> <version>3.8.1</version> <configuration> <source>8</source> <target>8</target> </configuration> </plugin> </plugins> </build> </project>其中,服务核心依赖版本可参考如下网址(涉及到一个兼容性问题,不能随意指定其版本):
https://github.com/alibaba/spring-cloud-alibaba/wiki/%E7%89%88%E6%9C%AC%E8%AF%B4%E6%98%8E创建服务提供方模块
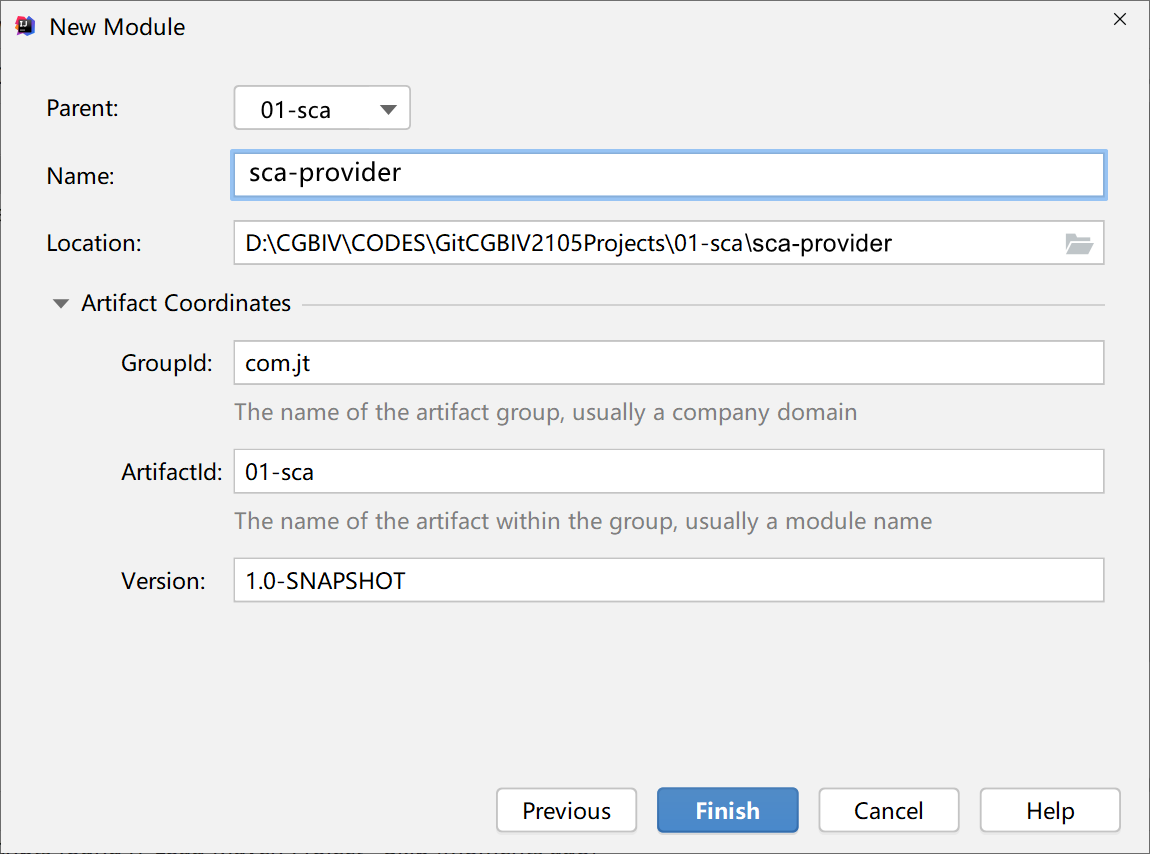
创建服务提供方工程,继承01-sca,例如:
创建服务消费方模块
创建服务消费方工程,继承01-sca,例如:
创建API网关服务模块
创建网关工程(这个工程后续会作为API服务访问入口),继承01-sca,例如:
服务关系以及调用关系设计
基于前面章节创建的项目,后续我们会讲解服务的注册,服务的配置,服务之间的调用,负载均衡,限流,熔断,网关等相关知识,现在先了解一个简易结构,例如:
我们最终会基于这个结构的设计,实现一个从网关到服务消费方,再从服务消费方到服务提供方的一个调用链路的业务及代码实践过程。总结(Summary)
总之,微服务是一个架构设计方式,此架构中的每个服务(service)都是针对一组功能而设计的,并专注于解决特定的问题。如果开发人员逐渐将更多代码增加到一项服务中并且这项服务变得复杂,那么可以将其拆分成多项更小的服务(软件即服务,所有软件对外的表现形式就诗提供一种或多种业务服务)。接下来进行独立的开发、测试、部署、运行、维护。进而更好,更灵活的处理客户端的请求并提高系统的可靠性,可扩展性。
04-Nacos服务注册中心最佳实践
Nacos注册中心简介
在微服务中,首先需要面对的问题就是如何查找服务(软件即服务),其次,就是如何在不同的服务之间进行通信?如何更好更方便的管理应用中的每一个服务,如何建立各个服务之间联系的纽带,由此注册中心诞生(例如淘宝网卖家提供服务,买家调用服务)。
市面上常用注册中心有Zookeeper(雅虎Apache),Eureka(Netfix),Nacos(Alibaba),Consul(Google),那他们分别都有什么特点,我们如何进行选型呢?我们主要从社区活跃度,稳定性,功能,性能等方面进行考虑即可.本次微服务的学习,我们选择Nacos,它很好的支持了阿里的双11活动,不仅可以做注册中心,还可以作为配置中心,稳定性和性能都很好。Nacos概述
Nacos(DynamicNaming and Configuration Service)是一个应用于服务注册与发现、配置管理的平台。它孵化于阿里巴巴,成长于十年双十一的洪峰考验,沉淀了简单易用、稳定可靠、性能卓越的核心竞争力。其官网地址如下:
https://nacos.io/zh-cn/docs/quick-start.html构建Nacos服务
第一:确保你电脑已配置JAVA_HOME环境变量(Nacos启动时需要),例如:
第二:确保你的MySQL版本为5.7以上(MariaDB10.5以上),例如下载与安装
第一步:Nacos下载,可在浏览器直接输入如下地址:
https://github.com/alibaba/nacos/releases第二步:选择对应版本,直接下载,如图所示:
第三步:解压Nacos(最好不要解压到中文目录下),其目录结构如下:
初始化配置
第一步:登陆mysql,执行老师发给同学们的sql脚本。例如,我们可以使用mysql自带客户端,在命令行首先登录mysql,然后执行如下指令:
source d:/nacos-mysql.sql执行成功以后,会创建一个nacos_config数据库,打开数据库会看到一些表,例如;
说明:在执行此文件时,要求mysql的版本大于5.7版本(MariaDB最好10.5.11),否则会出现如下错误:
第二步:打开/conf/application.properties里打开默认配置,并基于你当前环境配置要连接的数据库,连接数据库时使用的用户名和密码(假如前面有"#"要将其去掉):
### If use MySQL as datasource: spring.datasource.platform=mysql ### Count of DB: db.num=1 ### Connect URL of DB: db.url.0=jdbc:mysql://127.0.0.1:3306/nacos_config?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true&useUnicode=true&useSSL=false&serverTimezone=UTC db.user.0=root db.password.0=root服务启动与访问
第一步:启动Nacos服务。
Linux/Unix/Mac启动命令(standalone代表着单机模式运行,非集群模式):
./startup.sh -m standaloneWindows启动命令(standalone代表着单机模式运行,非集群模式):
startup.cmd -m standalone说明:
1)执行执行令时要么配置环境变量,要么直接在nacos/bin目录下去执行.
2)nacos启动时需要本地环境变量中配置了JAVA_HOME(对应jdk的安装目录),
3)一定要确保你连接的数据库(nacos_config)是存在的.
4)假如所有的配置都正确,还连不上,检查一下你有几个数据库(mysql,…)第二步:访问Nacos服务。
打开浏览器,输入http://localhost:8848/nacos地址,出现如下登陆页面:
其中,默认账号密码为nacos/nacos.
服务注册与调用入门(重点)
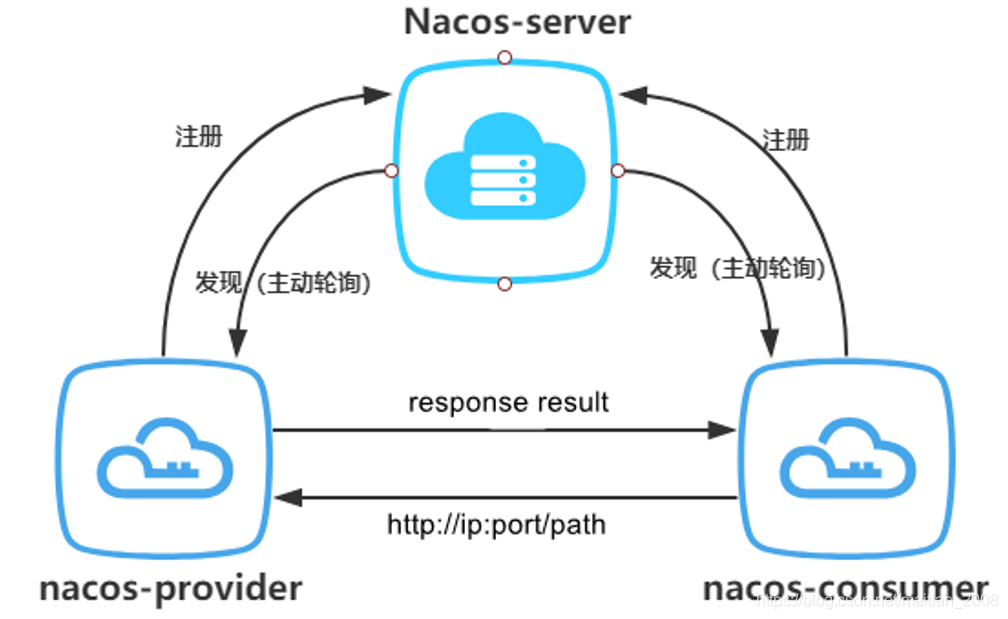
创建两个项目Module分别为服务提供者和服务消费者,两者都要注册到NacosServer中(这个server本质上就是一个web服务,端口默认为8848),然后服务提供者可以为服务消费者提供远端调用服务(例如支付服务为服务提供方,订单服务为服务消费方),如图所示:
生产者服务创建及注册
第一步:创建服务提供者工程(module名为sca-provider,假如已有则无需创建),继承parent工程(01-sca),其pom.xml文件内容如下:
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <parent> <artifactId>01-sca</artifactId> <groupId>com.jt</groupId> <version>1.0-SNAPSHOT</version> </parent> <modelVersion>4.0.0</modelVersion> <artifactId>sca-provider</artifactId> <dependencies> <!--Web服务--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!--服务的注册和发现(我们要讲服务注册到nacos)--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId> </dependency> </dependencies> </project>第二步:创建并修改配置文件application.yml(或者application.properties),实现服务注册,关键代码如下:
server: port: 8081 spring: application: name: sca-provider #进行服务注册必须配置服务名 cloud: nacos: discovery: server-addr: localhost:8848注意:服务名不要使用下划线(“_”),应使用横杠(“-”),这是规则。
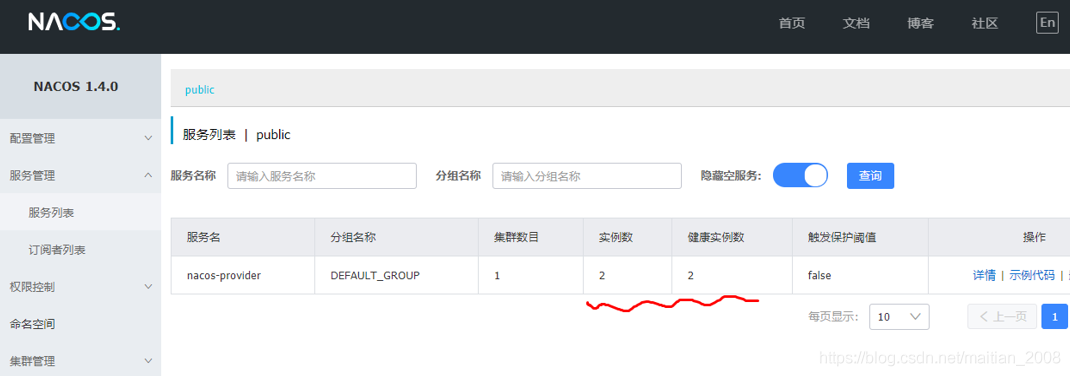
第三步:创建启动类(假如已有则无需定义),关键代码如下:package com.cy; @SpringBootApplication public class ProviderApplication { public static void main(String[] args) { SpringApplication.run(ProviderApplication.class, args);第四步:启动启动类,然后刷先nacos服务,检测是否服务注册成功,如图所示:
第六步:打开浏览器,输入http://localhost:8081/provider/echo/msa,然后进行访问测试。
消费者服务发现及调用
第一步: 在sca-provider项目中创建服务提供方对象,基于此对象对外提供服务,例如:
package com.jt.provider.controller; /**定义Controller对象(这个对象在spring mvc中给他的定义是handler), * 基于此对象处理客户端的请求*/ @RestController public class ProviderController{ //@Value默认读取项目配置文件中配置的内容 //8080为没有读到server.port的值时,给定的默认值 @Value("${server.port:8080}") private String server; //http://localhost:8081/provider/echo/tedu @GetMapping("/provider/echo/{msg}") public String doRestEcho1(@PathVariable String msg){ return server+" say hello "+msg;第二步:创建服务消费者工程(module名为sca-consumer,假如已有则无需创建),继承parent工程(01-sca),其pom.xml文件内容如下:
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <parent> <artifactId>01-sca</artifactId> <groupId>com.jt</groupId> <version>1.0-SNAPSHOT</version> </parent> <modelVersion>4.0.0</modelVersion> <artifactId>sca-consumer</artifactId> <dependencies> <!--Web服务--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!--服务的注册和发现(我们要讲服务注册到nacos)--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId> </dependency> </dependencies> </project>第三步:修改配置文件application.yml,关键代码如下:
server: port: 8090 spring: application: name: sca-consumer #服务注册时,服务名必须配置 cloud: nacos: discovery: server-addr: localhost:8848 #从哪里去查找服务第四步:创建消费端启动类并实现服务消,关键代码如下:
package com.cy; @SpringBootApplication public class ConsumerApplication { public static void main(String[] args) { SpringApplication.run(ConsumerApplication.class,args);第五步:在启动类中添加如下方法,用于创建RestTemplate对象.
@Bean public RestTemplate restTemplate(){//基于此对象实现远端服务调用 return new RestTemplate();第六步:定义服务消费端Controller,在此对象方法内部实现远端服务调用
package com.jt.consumer.controller; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.stereotype.Component; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.RestController; import org.springframework.web.client.RestTemplate; * 定义服务消费端Controller,在这个Controller对象 * 的方法中实现对远端服务sca-provider的调用 @RestController public class ConsumerController { * 从spring容器获取一个RestTemplate对象, * 基于此对象实现远端服务调用 @Autowired private RestTemplate restTemplate; * 在此方法中通过一个RestTemplate对象调用远端sca-provider中的服务 * @return * 访问此方法的url: http://localhost:8090/consumer/doRestEcho1 @GetMapping("/consumer/doRestEcho1") public String doRestEcho01(){ //1.定义要调用的远端服务的url String url="http://localhost:8081/provider/echo/8090"; //2.基于restTemplate对象中的相关方法进行服务调用 return restTemplate.getForObject(url, String.class);第七步:启动消费者服务,并在浏览器输入http://localhost:8090/consumer/doRestEcho1地址进行访问,假如访问成功会出现,如图所示效果:
小节面试分析
- 为什么要将服务注册到nacos?(为了更好的查找这些服务)
- 在Nacos中服务提供者是如何向Nacos注册中心(Registry)续约的?(5秒心跳)
- 对于Nacos服务来讲它是如何判定服务实例的状态?(检测心跳包,15,30)
- 服务启动时如何找到服务启动注册配置类?(NacosNamingService)
- 服务消费方是如何调用服务提供方的服务的?(RestTemplate)
服务负载均衡设计及实现(重点)
一个服务实例可以处理请求是有限的,假如服务实例的并发访问比较大,我们会启动多个服务实例,让这些服务实例采用一定策略均衡(轮询,权重,随机,hash等)的处理并发请求,在Nacos中服务的负载均衡(Nacos客户端负载均衡)是如何应用的?
LoadBalancerClient应用
LoadBalancerClient对象可以从nacos中基于服务名获取服务实例,然后在工程中基于特点算法实现负载均衡方式的调用,案例实现如下:
第一步:修改ConsumerController类,注入LoadBalancerClient对象,并添加doRestEcho2方法,然后进行服务访问.
@Autowired private LoadBalancerClient loadBalancerClient; @GetMapping("/consumer/doRestEcho02") public String doRestEcho02(){ ServiceInstance serviceInstance = loadBalancerClient.choose("sca-provider"); String url = String.format("http://%s:%s/provider/echo/%s",serviceInstance.getHost(),serviceInstance.getPort(),appName); System.out.println("request url:"+url); return restTemplate.getForObject(url, String.class);第二步:打开Idea服务启动配置,如图所示:
第三步:修改并发运行选项(假如没有找到这个选项我们需要通过搜索引擎基于组合查询的方法,去找到对应的解决方案,例如搜索 idea allow parallel run),如图所示:
第四步:修改sca-provider的配置文件端口,分别以8081,8082端口方式进行启动。
server: port: 8082 spring: application: name: sca-provider cloud: nacos: server-addr: localhost:8848启动成功以后,访问nacos的服务列表,检测服务是否成功注册,如图所示:
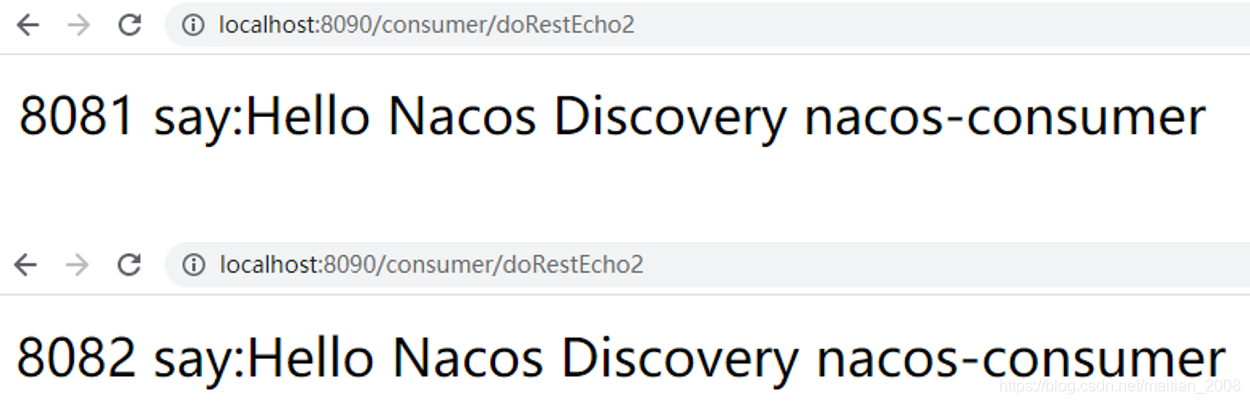
第四步:启动sca-consumer项目模块,打开浏览器,输入如下网址进行反复服务访问:
http://localhost:8090/consumer/doRestEcho02然后会发现sca-provider的两个服务都可以处理sca-consumer的请求。
这里多个实例并发提供服务的方式为负载均衡,这里的负载均衡实现默认是因为Nacos集成了Ribbon来实现的,Ribbon配合RestTemplate,可以非常容易的实现服务之间的访问。Ribbon是Spring Cloud核心组件之一,它提供的最重要的功能就是客户端的负载均衡(客户端可以采用一定算法,例如轮询访问,访问服务端实例信息),这个功能可以让我们轻松地将面向服务的REST模版请求自动转换成客户端负载均衡方式的服务调用。@LoadBalanced
当使用RestTemplate进行远程服务调用时,假如需要负载均衡,可以在RestTemplate对象构建时,使用@LoadBalanced对构建RestTemplate的方法进行修饰,例如在ConsumerApplication中构建名字为loadBalancedRestTemplate的RestTemplate对象:
@Bean @LoadBalanced public RestTemplate loadBalancedRestTemplate(){ return new RestTemplate();在需要RestTemplate实现负载均衡调用的地方进行依赖注入.例如在ConsumerController类中添加loadBalancedRestTemplate属性
@Autowired private RestTemplate loadBalancedRestTemplate;接下来,可以在对应的服务端调用方的方法内,基于RestTemplate借助服务名进行服务调用, 例如:
@GetMapping("/consumer/doRestEcho3") public String doRestEcho03(){ String url=String.format("http://%s/provider/echo/%s","sca-provider",appName); //向服务提供方发起http请求,获取响应数据 return loadBalancedRestTemplate.getForObject( url,//要请求的服务的地址 String.class);//String.class为请求服务的响应结果类型RestTemplate在发送请求的时候会被LoadBalancerInterceptor拦截,它的作用就是用于RestTemplate的负载均衡,LoadBalancerInterceptor将负载均衡的核心逻辑交给了loadBalancer,核心代码如下所示(了解):
public ClientHttpResponse intercept(final HttpRequest request, final byte[] body, final ClientHttpRequestExecution execution) throws IOException { final URI originalUri = request.getURI(); String serviceName = originalUri.getHost(); return this.loadBalancer.execute(serviceName, requestFactory.createRequest(request, body, execution));@LoadBalanced注解是属于Spring,而不是Ribbon的,Spring在初始化容器的时候,如果检测到Bean被@LoadBalanced注解,Spring会为其设置LoadBalancerInterceptor的拦截器。
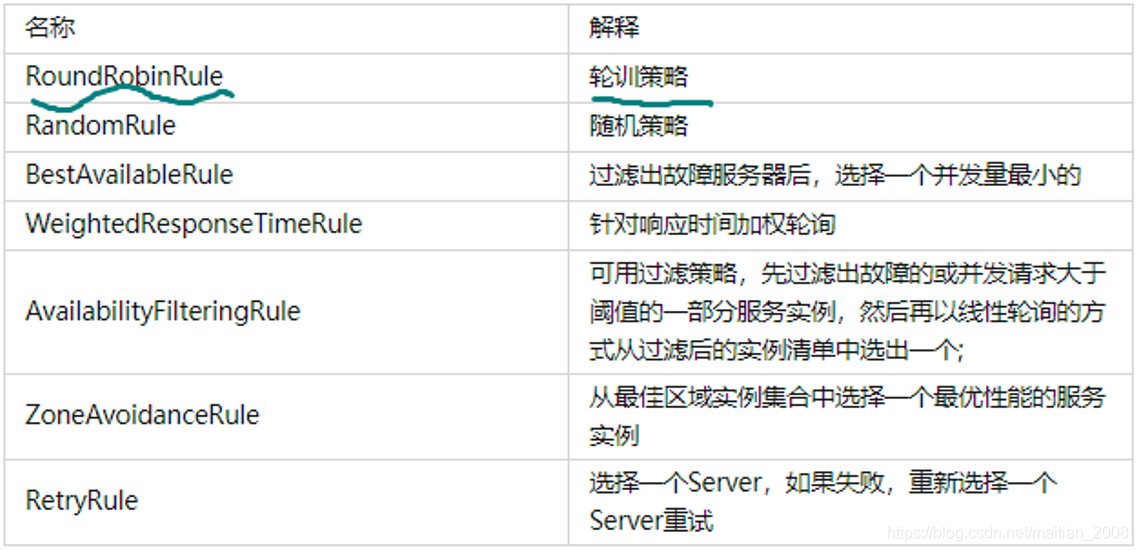
Ribbon负载均衡策略(了解)
基于Ribbon方式的负载均衡,Netflix默认提供了七种负载均衡策略,对于SpringCloud Alibaba解决方案中又提供了NacosRule策略,默认的负载均衡策略是轮训策略。如图所示:
当系统提供的负载均衡策略不能满足我们需求时,我们还可以基于IRule接口自己定义策略.小节面试分析
- @Bean注解的作用?(一般用于配置类内部,描述相关方法,用于告诉spring此方法的返回值要交给spring管理,bean的名字默认为方法名,假如需要指定名字可以@Bean(“bean的名字”),最多的应用场景是整合第三方的资源-对象)
- @Autowired注解的作用?(此注解用于描述属性,构造方法,set方法等,用于告诉spring框架,按找一定的规则为属性进行DI操作,默认按属性,方法参数类型查找对应的对象,假如只找到一个,则直接注入,类型多个时还会按照属性名或方法参数名进行值的注入,假如名字也不同,就出报错.)
- Nacos中的负责均衡底层是如何实现的?(通过Ribbon实现,Ribbon中定义了一些负载均衡算法,然后基于这些算法从服务实例中获取一个实例为消费方法提供服务)
- Ribbon 是什么?(Netflix公司提供的负载均衡客户端,一般应用于服务的消费方法)
- Ribbon 可以解决什么问题? (基于负载均衡策略进行服务调用, 所有策略都会实现IRule接口)
- Ribbon 内置的负载策略都有哪些?(8种,可以通过查看IRule接口的实现类进行分析)
- @LoadBalanced的作用是什么?(描述RestTemplate对象,用于告诉Spring框架,在使用RestTempalte进行服务调用时,这个调用过程会被一个拦截器进行拦截,然后在拦截器内部,启动负载均衡策略。)
- 我们可以自己定义负载均衡策略吗?(可以,基于IRule接口进行策略定义,也可以参考NacosRule进行实现)
基于Feign的远程服务调用(重点)
服务消费方基于rest方式请求服务提供方的服务时,一种直接的方式就是自己拼接url,拼接参数然后实现服务调用,但每次服务调用都需要这样拼接,代码量复杂且不易维护,此时Feign诞生。
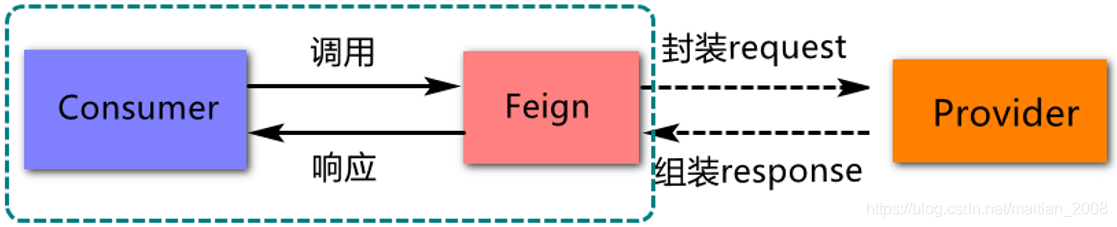
Feign是什么
Feign 是一种声明式Web服务客户端,底层封装了对Rest技术的应用,通过Feign可以简化服务消费方对远程服务提供方法的调用实现。如图所示:
Feign 最早是由 Netflix 公司进行维护的,后来 Netflix 不再对其进行维护,最终 Feign 由一些社区进行维护,更名为 OpenFeign。
Feign应用实践(掌握)
第一步:在服务消费方,添加项目依赖(SpringCloud团队基于OpenFeign研发了starter),代码如下:
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-openfeign</artifactId> </dependency>
- 1
- 2
- 3
- 4
第二步:在启动类上添加@EnableFeignClients注解,代码如下:
@EnableFeignClients @SpringBootApplication public class ConsumerApplication {…}第三步:定义Http请求API,基于此API借助OpenFeign访问远端服务,代码如下:
package com.jt.consumer.service; @FeignClient(name="sca-provider")//sca-provider为服务提供者名称 public interface RemoteProviderService{ @GetMapping("/provider/echo/{string}")//前提是远端需要有这个服务 public String echoMessage(@PathVariable("string") String string);其中,@FeignClient描述的接口底层会为其创建实现类。
第四步:创建FeignConsumerController中并添加feign访问,代码如下:
package com.jt.consumer.controller; @RestController @RequestMapping("/consumer/ ") public class FeignConsumerController { @Autowired private RemoteProviderService remoteProviderService; /**基于feign方式的服务调用*/ @GetMapping("/echo/{msg}") public String doFeignEcho(@PathVariable String msg){ //基于feign方式进行远端服务调用(前提是服务必须存在) return remoteProviderService.echoMessage(msg);第五步:启动消费者服务,在浏览器中直接通过feign客户端进行访问,如图所示(反复刷新检测其响应结果):
Feign配置进阶实践
一个服务提供方通常会提供很多资源服务,服务消费方基于同一个服务提供方写了很多服务调用接口,此时假如没有指定contextId,服务
启动就会失败,例如,假如在服务消费方再添加一个如下接口,消费方启动时就会启动失败,例如:@FeignClient(name="sca-provider") public interface RemoteOtherService { @GetMapping("/doSomeThing") public String doSomeThing();其启动异常:
The bean 'optimization-user.FeignClientSpecification', defined in null, could not be registered. A bean with that name has already been defined in null and overriding is disabled.此时我们需要为远程调用服务接口指定一个contextId,作为远程调用服务的唯一标识即可,例如:
@FeignClient(name="sca-provider",contextId="remoteProviderService")//sca-provider为服务提供者名称 interface RemoteProviderService{ @GetMapping("/provider/echo/{string}")//前提是远端需要有这个服务 public String echoMessage(@PathVariable("string") String string);还有,当我们在进行远程服务调用时,假如调用的服务突然不可用了或者调用过程超时了,怎么办呢?一般服务消费端会给出具体的容错方案,例如,在Feign应用中通过FallbackFactory接口的实现类进行默认的相关处理,例如:
第一步:定义FallbackFactory接口的实现,代码如下:package com.cy.service.factory; * 基于此对象处理RemoteProviderService接口调用时出现的服务中断,超时等问题 @Component public class ProviderFallbackFactory implements FallbackFactory<RemoteProviderService> { * 此方法会在RemoteProviderService接口服务调用时,出现了异常后执行. * @param throwable 用于接收异常 @Override public RemoteProviderService create(Throwable throwable) { return (msg)->{ return "服务维护中,稍等片刻再访问";第二步:在Feign访问接口中应用FallbackFactory对象,例如:
@FeignClient(name = "sca-provider", contextId = "remoteProviderService", fallbackFactory = ProviderFallbackFactory.class)//sca-provider为nacos中的服务名 public interface RemoteProviderService { @GetMapping("/provider/echo/{msg}") public String echoMsg(@PathVariable String msg);第三步:在配置文件application.yml中添加如下配置,启动feign方式调用时的服务中断处理机制.
feign: hystrix: enabled: true #默认值为false第四步:在服务提供方对应的调用方法中添加Thread.sleep(500000)模拟耗时操作,然后启动服务进行访问测试.
Feign 调用过程分析(了解)
Feign应用过程分析(底层逻辑先了解):
1)通过 @EnableFeignCleints 注解告诉springcloud,启动 Feign Starter 组件。
2) Feign Starter 会在项目启动过程中注册全局配置,扫描包下所由@FeignClient注解描述的接口,然后由系统底层创建接口实现类(JDK代理类),并构建类的对象,然后交给spring管理(注册 IOC 容器)。
3) Feign接口被调用时会被动态代理类逻辑拦截,然后将 @FeignClient 请求信息通过编码器创建 Request对象,基于此对象进行远程过程调用。
4) Feign客户端请求对象会经Ribbon进行负载均衡,挑选出一个健康的 Server 实例(instance)。
5) Feign客户端会携带 Request 调用远端服务并返回一个响应。
6) Feign客户端对象对Response信息进行解析然后返回客户端。小节面试分析
- 为什么使用feign?(基于Feign可以更加友好的实现服务调用,简化服务消费方对服务提供方方法的调用)。
- @FeignClient注解的作用是什么?(告诉Feign Starter,在项目启动时,为此注解描述的接口创建实现类-代理类)
- Feign方式的调用,底层负载均衡是如何实现的?(Ribbon)
- @EnableFeignCleints 注解的作用是什么?(描述配置类,例如启动类)
总结(Summary)
重难点分析
- 何为注册中心?(用于记录服务信息的一个web服务,例如淘宝平台,滴滴平台,美团外卖平台,……)
- 注册中心的核心对象?(服务提供方,服务消费方,注册中心-Registry)
- 市面上常用注册中心?(Google-Consul,Alibaba-Nacos,…)
- Nacos安装、启动、服务的注册、发现机制以及实现过程
- 服务调用时RestTemplate对象的应用。
- 基于Feign方式的服务调用及基本原理?
FAQ分析
- Nacos是什么,提供了什么特性(服务的注册、发现、配置)?
- 你为什么会选择Nacos?(活跃度、稳定、性能、学习成本)
- Nacos的官网?(nacos.io)
- Nacos在github的源码?(github.com/alibaba/nacos)
- Nacos在windows环境下安装?(解压即可使用)
- Nacos在windows中的的初步配置?(application.properties访问数据库的数据源)
- Nacos服务注册的基本过程?(服务启动时发送web请求)
- Nacos服务消费的基本过程?(服务启动时获取服务实例,然后调用服务)
- Nacos服务负载均衡逻辑及设计实现?(Ribbon)
- 注册中心的核心数据是什么?(服务的名字和它对应的网络地址)
- 注册中心中心核心数据的存取为什么会采用读写锁?(底层安全和性能)
- Nacos健康检查的方式?(基于心跳包机制进行实现)
- Nacos是如何保证高可用的?(重试,本地缓存、集群)
- RestTemplate的基本作用是什么?
- Feign是什么,它的应用是怎样的,feign应用过程中的代理对象是如何创建的(JDK)?
- Feign方式的调用过程,其负载均衡是如何实现?(Ribbon)
Bug分析
- 404
- 400
- 405
- 500
- ………
05-Nacos服务配置中心应用实践
配置中心简介
我们知道,除了代码之外,软件还有一些配置信息,比如数据库的用户名和密码,还有一些我们不想写死在代码里的东西,例如像线程池大小、队列长度等运行参数,以及日志级别、算法策略等, 还有一些是软件运行环境的参数,如Java 的内存大小,应用启动的参数,包括操作系统的一些 参数配置…… 所有这些东西,我们都叫做软件配置。以前,我们把软件配置写在一个配置文件中,就像 Windows 下的 ini 文件,或是 Linux 下的 conf 文件。然而,在分布式系统下,这样的方式就变得非常不好管理,并容易出错。假如生产环境下,项目现在正在运行,此时修改了配置文件,我们需要让这些配置生效,通常的做法是不是要重启服务。但重启是不是会带来系统服务短时间的暂停,从而影响用户体验呢,还有可能会带来经济上的很大损失(例如双11重启下服务)。基于这样的背景,配置中心诞生了。
配置中心概述
配置中心最基础的功能就是存储一个键值对,用户发布一个配置(configKey),然后客户端获取这个配置项(configValue);进阶的功能就是当某个配置项发生变更时,不停机就可以动态刷新服务内部的配置项,例如,在生产环境上我们可能把我们的日志级别调整为 error 级别,但是,在系统出问题我们希望对它 debug 的时候,我们需要动态的调整系统的行为的能力,把日志级别调整为 debug 级别。还有,当你设计一个电商系统时,设计大促预案一定会考虑,同时涌进来超过一亿人并发访问的时候,假如系统是扛不住的,你会怎么办,在这个过程中我们一般会采用限流,降级。系统的限流和降级本质上来讲就是从日常的运行态切换到大促态的一个行为的动态调整,这个本身天然就是配置起到作用的一个相应的场景。
配置中心的选型
在面向分布式的微服务系统中,如何通过更高效的配置管理方式,实现微服务系统架构持续“无痛”的演进,并动态调整和控制系统的运行时态,配置中心的选型和设计起着举足轻重的作用。市场上主流配置中心有Apollo(携程开源),nacos(阿里开源),Spring Cloud Config(Spring Cloud 全家桶成员)。我们在对这些配置中心进行选型时重点要从产品功能、使用体验、实施过程和性能等方面进行综合考量。本次课程我们选择nacos,此组件不仅提供了注册中心,还具备配置中心的功能。
小节面试分析
- 什么是配置中心?(存储项目配置信息的一个服务)
- 为什么要使用配置中心?(集中管理配置信息,动态发布配置信息)
- 市场上有哪些主流的配置中心?(Apollo,nacos,……)
Nacos配置快速入门
在sca-provider项目中添加一个Controller对象,例如ProviderLogController,基于此Controller中的方法演示日志级别的配置。
配置准备工作
第一步:创建ProviderLogController对象,例如:
package com.jt.provider.controller; import lombok.extern.slf4j.Slf4j; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.RestController; * 基于此controller演示配置中心的作用. * 在这个controller中我们会基于日志对象 * 进行日志输出测试. //@Slf4j @RestController public class ProviderLogController { //创建一个日志对象 //org.slf4j.Logger (Java中的日志API规范,基于这个规范有Log4J,Logback等日志库) //org.slf4j.LoggerFactory //log对象在哪个类中创建,getLogger方法中的就传入哪个类的字节码对象 //记住:以后只要Java中使用日志对象,你就采用下面之中方式创建即可. //假如在log对象所在的类上使用了@Slf4j注解,log不再需要我们手动创建,lombok会帮我们创建 private static Logger log= LoggerFactory.getLogger(ProviderLogController.class); @GetMapping("/provider/log/doLog01") public String doLog01(){//trace<debug<info<warn<error System.out.println("==doLog01=="); log.trace("===trace==="); log.debug("===debug==="); log.info("===info===="); log.warn("===warn==="); log.error("===error==="); return "log config test";第二步:在已有的sca-provider项目中添加如配置依赖,例如:
<dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId> </dependency>第三步: 将项目sca-provider的application.yml的名字修改为bootstrap.yml(启动优先级最高),并添加配置中心配置,代码如下:
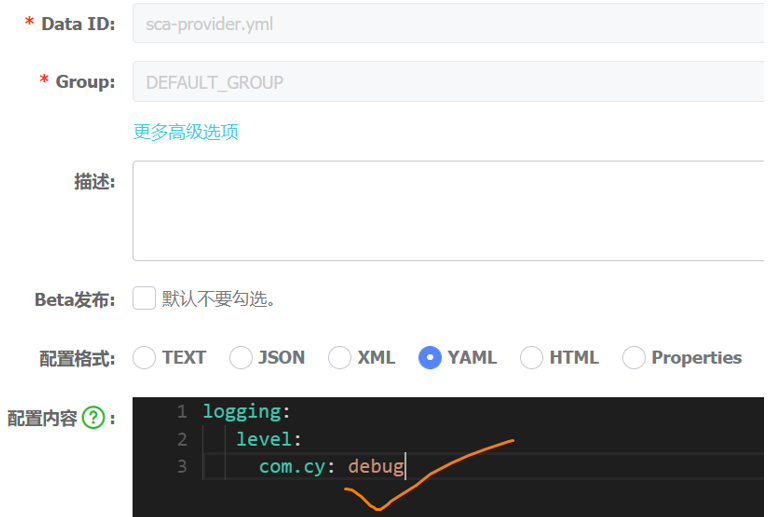
spring: application: name: sca-provider cloud: nacos: discovery: server-addr: 127.0.0.1:8848 config: server-addr: 127.0.0.1:8848 file-extension: yml # Configure the data format of the content, default to properties新建Nacos配置
打开nacos配置中心,新建配置,如图所示:
其中,Data ID的值要与bootstrap.yml中定义的spring.application.name的值相同(服务名-假如有多个服务一般会创建多个配置实例,不同服务对应不同的配置实例)。配置发布以后,会在配置列表中,显示我们的配置,例如:
测试Nacos数据读取
配置创建好以后,启动sca-provider服务,然后打开浏览器,输入http://localhost:8081/provider/log/doLog01,检测idea控制台日志输出。然后再打开nacos控制台动态更新日志级别,再访问资源并检测后台日志输出.
然后,修改nacos配置中心的日志级别,再刷新浏览器,检测日志的输出,是否会发生变化.@RefreshScope注解的应用
对于nacos配置中心而言,有系统内部对配置变化的感知,还有外部系统对配置的感知,假如我们系统在浏览器中能看到日志级别的变化,该如何实现呢?我们现在来实现一个案例.
第一步:在ProviderLogController类的上面添加一个@RefreshScope注解,例如:
@RefreshScope @RestController public class ProviderLogController{ //.....其中,@RefreshScope的作用是在配置中心的相关配置发生变化以后,能够及时看到类中属性值的更新(底层是通过重新创建Controller对象的方式,对属性进行了重新初始化)。
第二步:添加ProviderLogController中添加一个获取日志级别(debug<info<warn<error)的的属性和方法,代码如下:
@Value("${logging.level.com.jt:error}") private String logLevel; @GetMapping("/provider/log/doLog02") public String doLog02(){ log.info("log level is {}",logLevel); return "log level is "+logLevel;第三步:启动sca-provider服务,然后打开浏览器并输入http://localhost:8081/provider/log/doLog02进行访问测试。
说明,假如对配置的信息访问不到,请检测项目配置文件的名字是否为bootstrap.yml,检查配置文件中spring.application.name属性的值是否与配置中心的data-id名相同,还有你读取的配置信息缩进以及空格写的格式是否正确.
小节面试分析
- 配置中心一般都会配置什么内容?(可能会经常变化的配置信息,例如连接池,日志、线程池、限流熔断规则)
- 什么信息一般不会写到配置中心?(服务端口,服务名,服务的注册地址,配置中心)
- 项目中为什么要定义bootstrap.yml文件?(此文件被读取的优先级比较高,可以在服务启动时读取配置中心的数据)
- Nacos配置中心宕机了,我们的服务还可以读取到配置信息吗?(可以从内存,客户端获取了配置中心的配置信息以后,会将配置信息在本地内存中存储一份.)
- 微服务应用中我们的客户端如何获取配置中心的信息?(我们的服务一般首先会从内存读取配置信息,同时我们的微服务还可以定时向nacos配置中心发请求拉取(pull)更新的配置信息)
- 微服务应用中客户端如何感知配置中心数据变化?(当数据发生变化时,nacos找到它维护的客户端,然后通知客户端去获取更新的数据,客户端获取数据以后更新本地内存,并在下次访问资源时,刷新@Value注解描述的属性值,但是需要借助@RefreshScope注解对属性所在的类进行描述)
- 服务启动后没有从配置中心获取我们的配置数据是什么原因?(依赖,配置文件名字bootstrap.yml,配置中心的dataId名字是否正确,分组是否正确,配置的名字是否正确,缩进关系是否正确,假如是动态发布,类上是否有@RefreshScope注解)
- 你项目中使用的日志规范是什么?(SLF4J)
- 你了解项目中的日志级别吗?(debug,info,error,…,可以基于日志级别控制日志的输出)
Nacos配置管理模型
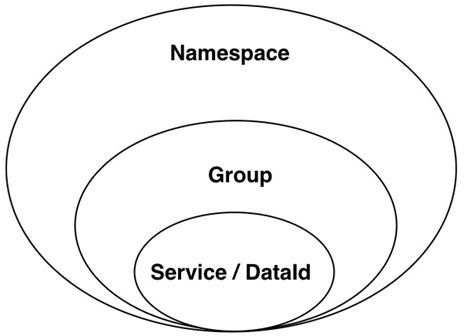
Nacos 配置管理模型由三部分构成,如图所示:
其中:
- Namespace:命名空间,对不同的环境进⾏隔离,⽐如隔离开发环境和⽣产环境。
- Group:分组,将若⼲个服务或者若⼲个配置集归为⼀组。
- Service/DataId:某⼀个服务或配置集,一般对应一个配置文件。
命名空间设计
Nacos中的命名空间一般用于配置隔离,这种命名空间的定义一般会按照环境(开发,生产等环境)进行设计和实现.我们默认创建的配置都存储到了public命名空间,如图所示:
创建新的开发环境并定义其配置,然后从开发环境的配置中读取配置信息,该如何实现呢?
第一步:创建新命名空间,如图所示:
命名空间成功创建以后,会在如下列表进行呈现。
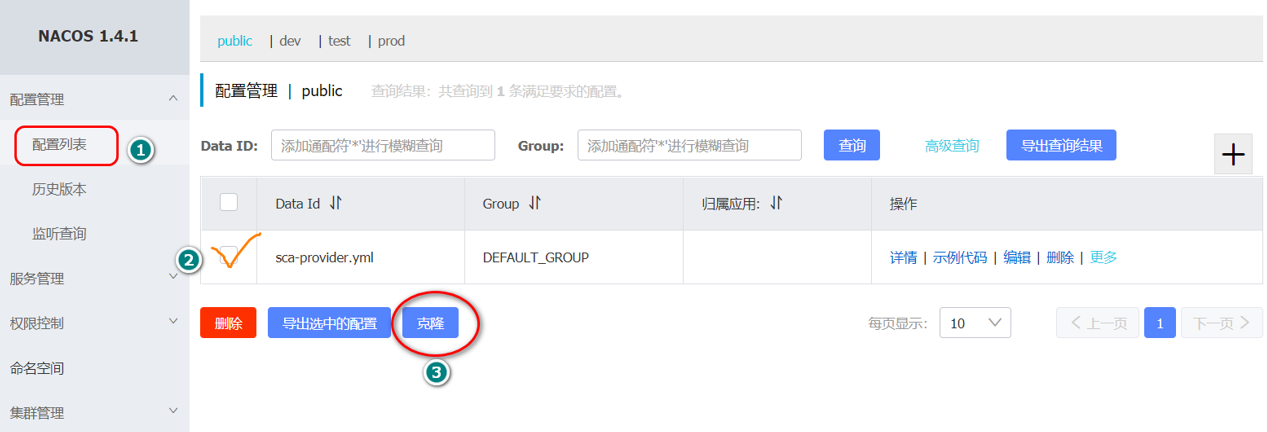
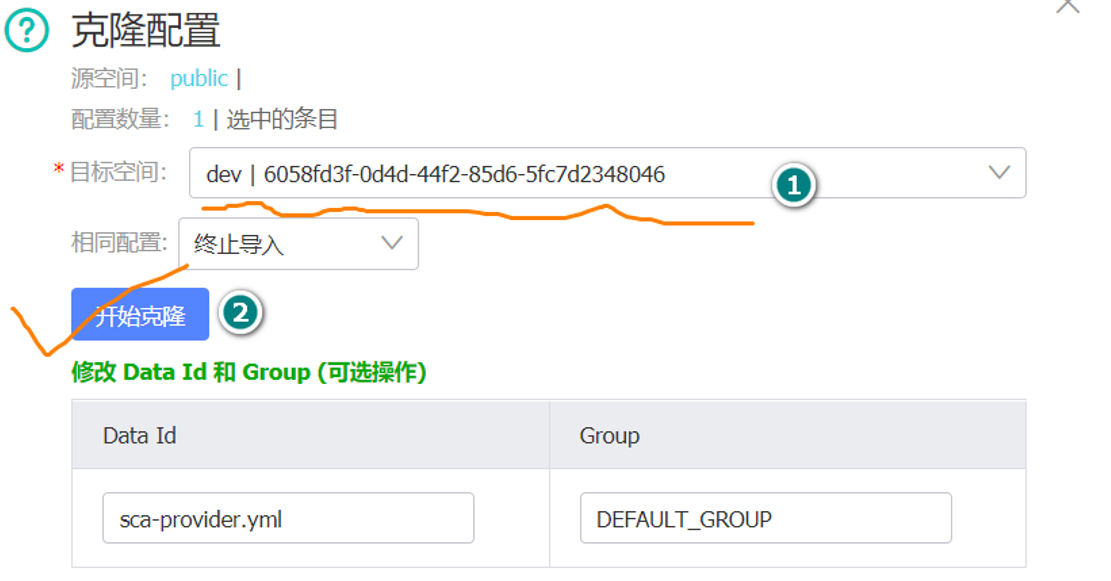
在指定命名空间下添加配置,也可以直接取配置列表中克隆,例如:
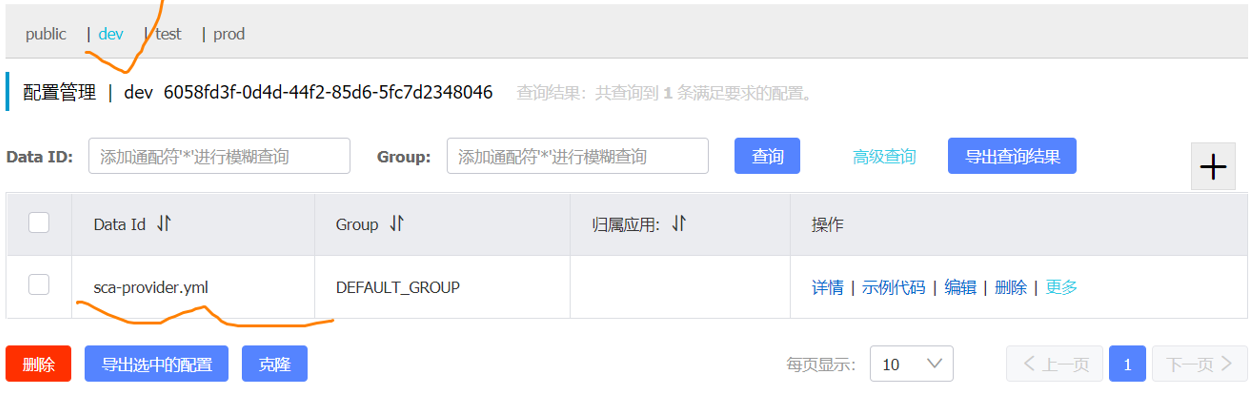
克隆成功以后,我们会发现在指定的命名空间中有了我们克隆的配置,如图所示:此时我们修改dev命名空间中Data Id的sca-provider配置,如图所示:
修改项目module中的配置文件bootstrap.yml,添加如下配置,关键代码如下:spring: cloud: nacos: config: namespace: 6058fd3f-0d4d-44f2-85d6-5fc7d2348046其中,namespace后面的字符串为命名空间的id,可直接从命名空间列表中进行拷贝.
重启服务,继续刷新http://localhost:8081/config/doGetLogLevel地址。检测输出,看看输出的内容是什么,是否为dev命名空间下配置的内容。分组设计及实现
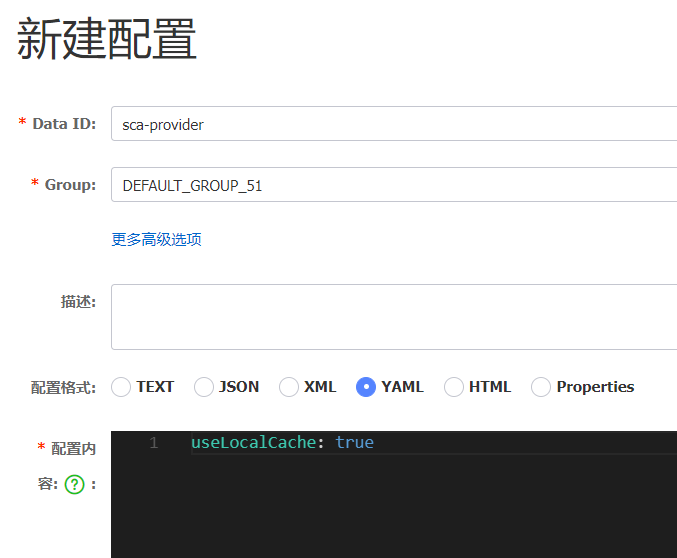
当我们在指定命名空间下,按环境或服务做好了配置以后,有时还需要基于服务做分组配置,例如,一个服务在不同时间节点(节假日,活动等)切换不同的配置,可以在新建配置时指定分组名称,如图所示:
其中,这里的useLocalCache为自己定义的配置值,表示是否使用本地缓存.配置发布以后,修改boostrap.yml配置类,在其内部指定我们刚刚创建的分组,代码如下:
server: port: 8081 spring: application: name: sca-provider cloud: nacos: config: server-addr: 127.0.0.1:8848 group: DEV_GROUP_51 # Group, default is DEFAULT_GROUP file-extension: yml # Configure the data format of the content, default to properties namespace: 7da4aa75-f64c-43c6-b101-9d77ad96f1c0在指定的Controller类中添加属性和方法用于获取和输出DEV_GROUP_51配置中设置的线程数,代码如下:
package com.jt.provider.controller; @RefreshScope @RestController public class ProviderCacheController { @Value("${useLocalCache:false}") private boolean useLocalCache; @RequestMapping("/provider/cache") public String doUseLocalCache(){ return "useLocalCache'value is "+useLocalCache;然后重启服务,进行测试,检测内容输出。
共享配置设计及读取
当同一个namespace的多个配置文件中都有相同配置时,可以对这些配置进行提取,然后存储到nacos配置中心的一个或多个指定配置文件,哪个微服务需要,就在服务的配置中设置读取即可。例如:
第一步:在nacos中创建一个共享配置文件,例如:
第二步:在指定的微服务配置文件(bootstrap.yml)中设置对共享配置文件的读取,例如:
见红色区域内容。spring: application: name: sca-provider cloud: nacos: config: server-addr: localhost:8848 # 命名空间 namespace: 83ed55a5-1dd9-4b84-a5fe-a734e4a6ec6d # 分组名 # group: DEFAULT_GROUP # 配置中心文件扩展名 file-extension: yml # 共享配置 shared-configs[0]: data-id: app-public-dev.yml refresh: true #默认false,共享配置更新,引用此配置的地方是否要更新第三步:在指定的Controller类中读取和应用共享配置即可,例如:
package com.jt.provider.controller; @RefreshScope @RestController public class ProviderPageController { @Value("${page.pageSize:10}") private Integer pageSize; @GetMapping("/provider/page/doGetPageSize") public String doGetPageSize(){ //return String.format() return "page size is "+pageSize;第四步:启动服务,然后打开浏览器进行访问测试。
小节面试分析
- Nacos配置管理模型的背景?(环境不同配置不同)
- Nacos配置中的管理模型是怎样的?(namespace,group,service/data-id)
- Nacos客户端(微服务)是否可以读取共享配置?(可以)
总结(Summary)
重难点分析
- 配置中心的选型。(市场活跃度、稳定性、性能、易用)
- Nacos配置中心基本应用。(新建,修改、删除配置以后,在Nacos客户端应用配置)
- 配置管理模型应用。(namespace,group,service/dataId)
- Nacos配置变更的动态感知。(底层原理分析)
FAQ分析
- 为什么需要配置中心?(动态管理发布配置,无需重启服务,更好保证服务的可用)
- 配置中一般要配置什么内容?(经常变化的配置数据-日志级别,线程池、连接池、…)
- 市面上有哪些主流配置中心?(Nacos,….)
- 配置中心选型时要重点考虑哪些因素?(市场活跃度、稳定性、性能、易用)
- Nacos客户端(微服务业务)如何动态感知配置中心数据变化的?(nacos2.0之前nacos客户端采用长轮询机制每隔30秒拉取nacos配置信息.)
- Nacos配置管理模型是怎样的?(命名空间-namespace,分组-group,服务实例-dataId)
Bug分析
。。。。
06-Sentinel限流熔断应用实践
Sentinel简介
在我们日常生活中,经常会在淘宝、天猫、京东、拼多多等平台上参与商品的秒杀、抢购以及一些优惠活动,也会在节假日使用12306 手机APP抢火车票、高铁票,甚至有时候还要帮助同事、朋友为他们家小孩拉投票、刷票,这些场景都无一例外的会引起服务器流量的暴涨,导致网页无法显示、APP反应慢、功能无法正常运转,甚至会引起整个网站的崩溃。
我们如何在这些业务流量变化无常的情况下,保证各种业务安全运营,系统在任何情况下都不会崩溃呢?我们可以在系统负载过高时,采用限流、降级和熔断,三种措施来保护系统,由此一些流量控制中间件诞生。例如Sentinel。Sentinel概述
Sentinel (分布式系统的流量防卫兵) 是阿里开源的一套用于服务容错的综合性解决方案。它以流量为切入点, 从流量控制、熔断降级、系统负载保护等多个维度来保护服务的稳定性。
Sentinel 承接了阿里巴巴近 10 年的双十一大促流量的核心场景, 例如秒杀(即突发流量控制在系统容量可以承受的范围)、消息削峰填谷、集群流量控制、实时熔断下游不可用应用等。Sentinel核心分为两个部分:
- 核心库(Java 客户端):能够运行于所有 Java 运行时环境,同时对Dubbo /Spring Cloud 等框架也有较好的支持。
- 控制台(Dashboard):基于 Spring Boot 开发,打包后可以直接运行。
安装Sentinel服务
Sentinel 提供一个轻量级的控制台, 它提供机器发现、单机资源实时监控以及规则管理等功能,其控制台安装步骤如下:
第一步:打开sentinel下载网址https://github.com/alibaba/Sentinel/releases第二步:下载Jar包(可以存储到一个sentinel目录),如图所示:
第三步:在sentinel对应目录,打开命令行(cmd),启动运行sentinel
java -Dserver.port=8180 -Dcsp.sentinel.dashboard.server=localhost:8180 -Dproject.name=sentinel-dashboard -jar sentinel-dashboard-1.8.0.jar检测启动过程,如图所示:
访问Sentinal服务
第一步:假如Sentinal启动ok,通过浏览器进行访问测试,如图所示:
第二步:登陆sentinel,默认用户和密码都是sentinel,登陆成功以后的界面如图所示:
Sentinel限流入门
我们系统中的数据库连接池,线程池,nginx的瞬时并发,MQ消息等在使用时都会跟定一个限定的值,这本身就是一种限流的设计。限流的目的防止恶意请求流量、恶意攻击,或者防止流量超过系统峰值。
Sentinel集成
第一步:Sentinel 应用于服务消费方(Consumer),在消费方添加依赖如下:
<dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-sentinel</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> </dependency>第二步:打开服务消费方配置文件application.yml,添加sentinel配置,代码如下:
spring: cloud: sentinel: transport: port: 8099 #跟sentinel控制台交流的端口,随意指定一个未使用的端口即可 dashboard: localhost:8180 # 指定sentinel控制台地址。第三步:启动服务提供者,服务消费者,然后在浏览器访问消费者url,如图所示:
第四步:刷新sentinel 控制台,检测服务列表,如图所示:
Sentinel的控制台其实就是一个SpringBoot编写的程序,我们需要将我们的服务注册到控制台上,即在微服务中指定控制台的地址,并且还要在消费端开启一个与sentinel控制台传递数据端的端口,控制台可以通过此端口调用微服务中的监控程序来获取各种信息。Sentinel限流快速入门
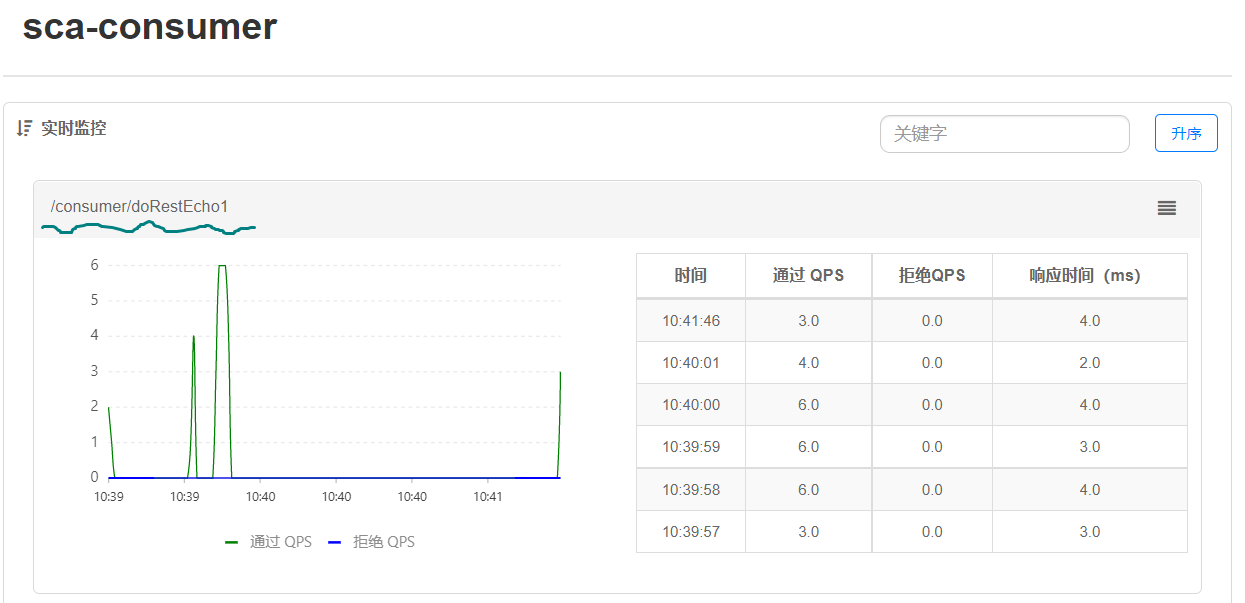
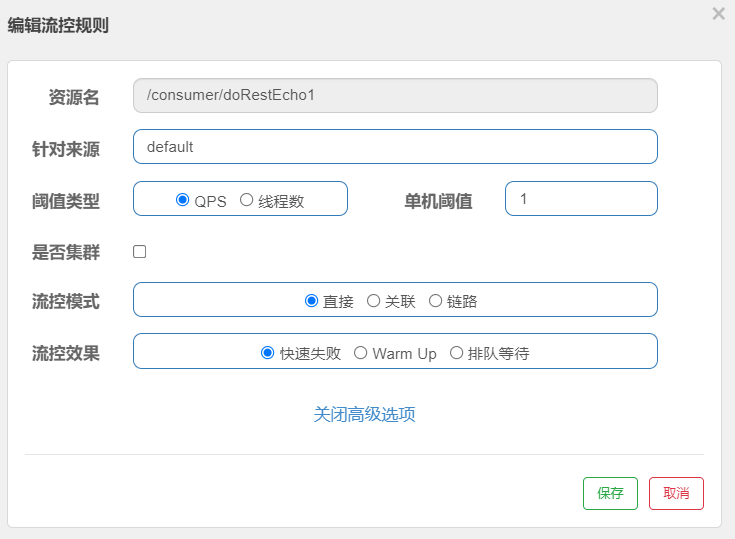
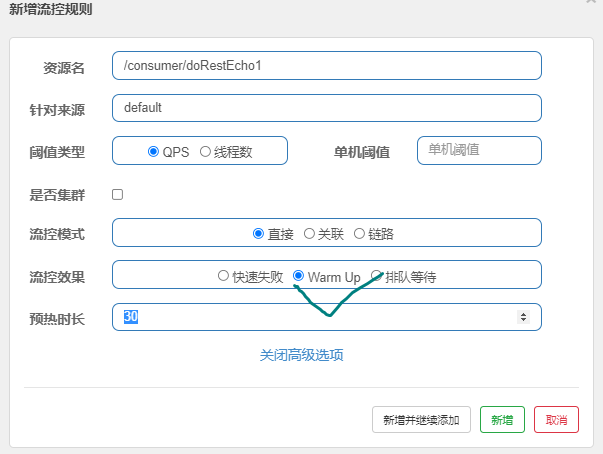
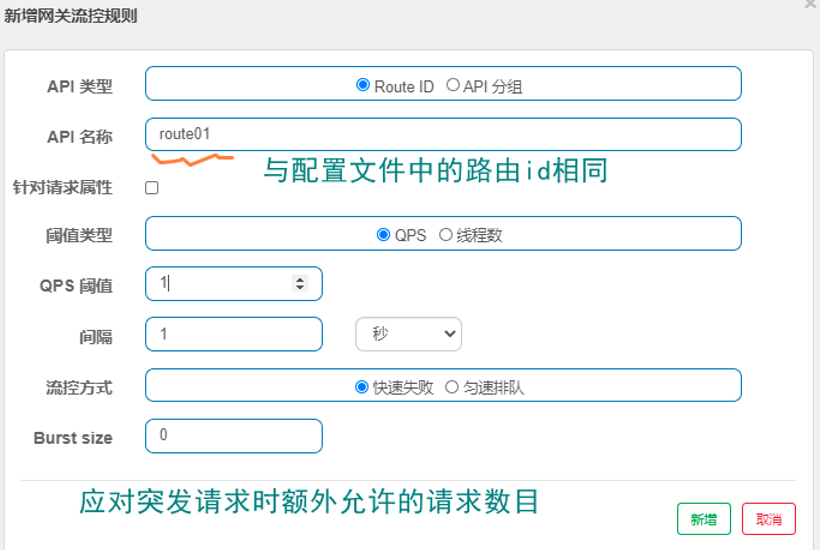
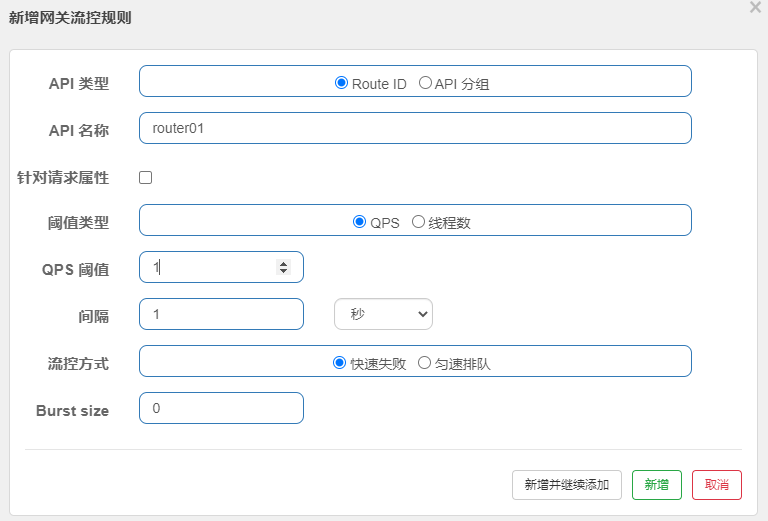
我们设置一下指定接口的流控(流量控制),QPS(每秒请求次数)单机阈值为1,代表每秒请求不能超出1次,要不然就做限流处理,处理方式直接调用失败。
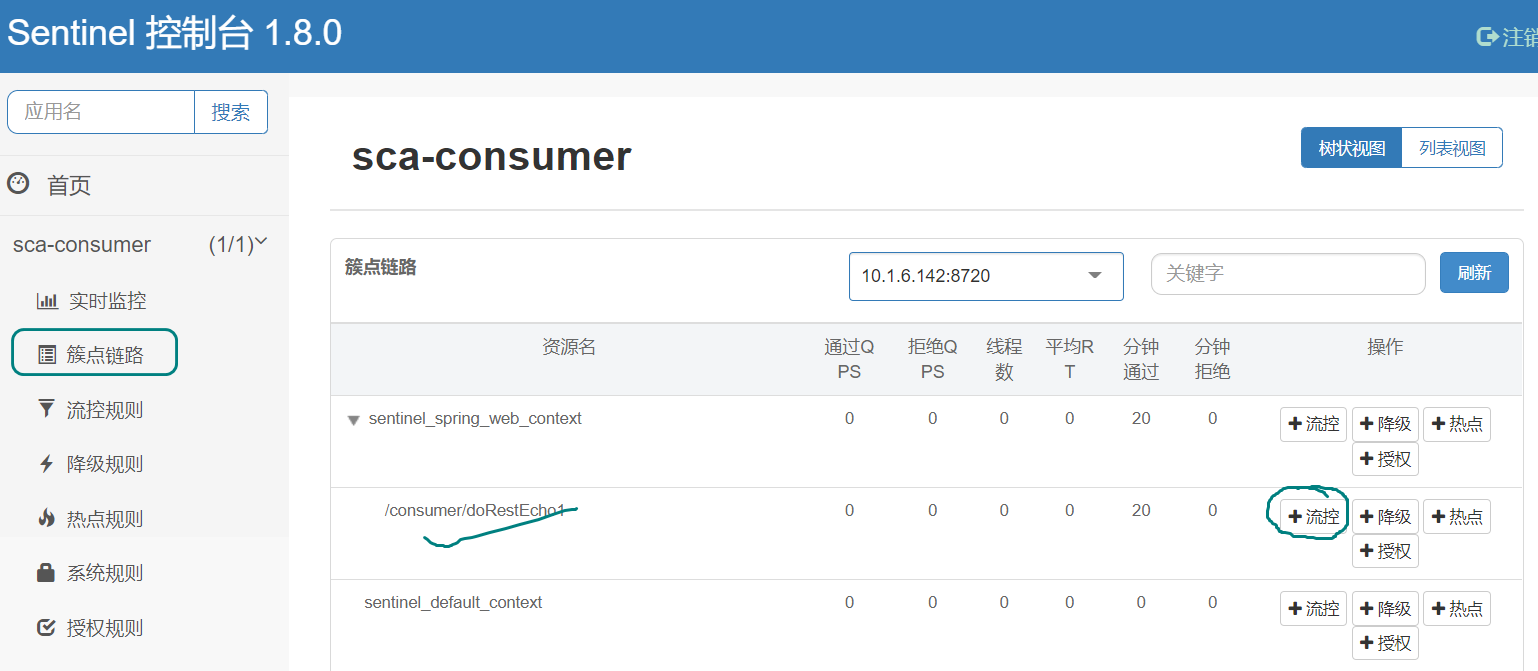
第一步:选择要限流的链路,如图所示:
第二步:设置限流策略,如图所示:
第三步:反复刷新访问消费端端服务,检测是否有限流信息输出,如图所示:
Sentinel流控规则分析
阈值类型分析
QPS(Queries Per Second):当调用相关url对应的资源时,QPS达到单机阈值时,就会限流。
线程数:当调用相关url对应的资源时,线程数达到单机阈值时,就会限流。
设置限流模式
Sentinel的流控模式代表的流控的方式,默认【直接】,还有关联,链路。
Sentinel默认的流控处理就是【直接->快速失败】。
当关联的资源达到阈值,就限流自己。例如设置了关联资源为/ur2时,假如关联资源/url2的qps阀值超过1时,就限流/url1接口(是不是感觉很霸道,关联资源达到阀值,是本资源接口被限流了)。这种关联模式有什么应用场景呢?我们举个例子,订单服务中会有2个重要的接口,一个是读取订单信息接口,一个是写入订单信息接口。在高并发业务场景中,两个接口都会占用资源,如果读取接口访问过大,就会影响写入接口的性能。业务中如果我们希望写入订单比较重要,要优先考虑写入订单接口。那就可以利用关联模式;在关联资源上面设置写入接口,资源名设置读取接口就行了;这样就起到了优先写入,一旦写入请求多,就限制读的请求。例如:
链路模式只记录指定链路入口的流量。也就是当多个服务对指定资源调用时,假如流量超出了指定阈值,则进行限流。被调用的方法用@SentinelResource进行注解,然后分别用不同业务方法对此业务进行调用,假如A业务设置了链路模式的限流,在B业务中是不受影响的。例如现在设计一个业务对象,代码如下(为了简单,可以直接写在启动类内部):
@Service public class ConsumerService{ @SentinelResource("doGetResource") public String doGetResource(){ return "doGetResource";接下来我们在/consumer/doRestEcho1对应的方法中对ConsumerService中的doGetResource方法进行调用(应用consumerService对象之前,要先在doRestEcho01方法所在的类中进行consumerService值的注入)。例如:
@GetMapping("/consumer/doRestEcho1") public String doRestEcho01() throws InterruptedException { consumerService.doGetResource(); //Thread.sleep(200); String url="http://localhost:8081/provider/echo/"+server; //远程过程调用-RPC return restTemplate.getForObject(url,String.class);//String.class调用服务响应数据类型其路由规则配置如下:
说明,流控模式为链路模式时,假如是sentinel 1.7.2以后版本,Sentinel Web过滤器默认会聚合所有URL的入口为sentinel_spring_web_context,因此单独对指定链路限流会不生效,需要在application.yml添加如下语句来关闭URL PATH聚合,例如:
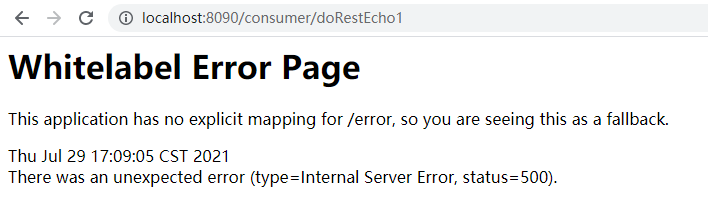
sentinel: web-context-unify: false修改配置以后,重新sentinel,并设置链路流控规则,然后再频繁对链路/consumer/doRestEcho1进行访问,检测是否会出现500异常。
设计限流效果(了解)
此模块做为课后了解内容,感兴趣自学即可.
流量达到指定阀值,直接返回报异常。(类似路前方坍塌,后面设定路标,让后面的车辆返回)
WarmUp (预热)
WarmUp也叫预热,根据codeFactor(默认3)的值,(阀值/codeFactor)为初始阈值,经过预热时长,才到达设置的QPS的阈值,假如单机阈值为100,系统初始化的阈为 100/3 ,即阈值为33,然后过了10秒,阈值才恢复到100。这个预热的应用场景,如:秒杀系统在开启的瞬间,会有很多流量上来,很有可能把系统打死,预热方式就是把为了保护系统,可慢慢的把流量放进来,慢慢的把阈值增长到设置的阈值。例如:
从字面上面就能够猜到,匀速排队,让请求以均匀的速度通过,阈值类型必须设成QPS,否则无效。比如有时候系统在某一个时刻会出现大流量,之后流量就恢复稳定,可以采用这种排队模式,大流量来时可以让流量请求先排队,等恢复了在慢慢进行处理,例如:
小节面试分析
- Sentinel是什么?(阿里推出一个流量控制平台,防卫兵)
- 类似Sentinel的产品你知道有什么?(hystrix-一代微服务产品)
- 你了解哪些限流算法?(计数器、令牌桶、漏斗算法,滑动窗口算法,…)
- Sentinel 默认的限流算法是什么?(滑动窗口算法)
- 你了解sentinel中的阈值应用类型吗?(两种-QPS,线程数)
- Sentinel 限流规则中默认有哪些限流模式?(直连,关联,链路)
- Sentinel的限流效果有哪些?(快速失败,预热,排队)
- Sentinel 为什么可以对我们的业务进行限流,原理是什么?
我们在访问web应用时,在web应用内部会有一个拦截器,这个拦截器会对请求的url进行拦截,拦截到请求以后,读取sentinel 控制台的流控规则,基于流控规则对流量进行限流操作。Sentinel降级入门
除了流量控制以外,对调用链路中不稳定的资源进行熔断降级也是保障高可用的重要措施之一。由于调用关系的复杂性,如果调用链路中的某个资源不稳定,最终会导致请求发生堆积。
Sentinel 熔断降级会在调用链路中某个资源出现不稳定状态时(例如调用超时或异常比例升高),对这个资源的调用进行限制,让请求快速失败,避免影响到其它的资源而导致级联错误。当资源被降级后,在接下来的降级时间窗口之内,对该资源的调用都自动熔断(默认行为是抛出 DegradeException)。修改ConumserController 类中的doRestEcho01方法,假如没有创建即可,基于此方法演示慢调用过程下的限流,代码如下:
//AtomicLong 类支持线程安全的自增自减操作 private AtomicLong atomicLong=new AtomicLong(1); @GetMapping("/consumer/doRestEcho1") public String doRestEcho01() throws InterruptedException { //consumerService.doGetResource(); //获取自增对象的值,然后再加1 long num=atomicLong.getAndIncrement(); if(num%2==0){//模拟50%的慢调用比例 Thread.sleep(200); String url="http://localhost:8081/provider/echo/"+server; //远程过程调用-RPC return restTemplate.getForObject(url,String.class);//String.class调用服务响应数据类型Sentinel降级入门
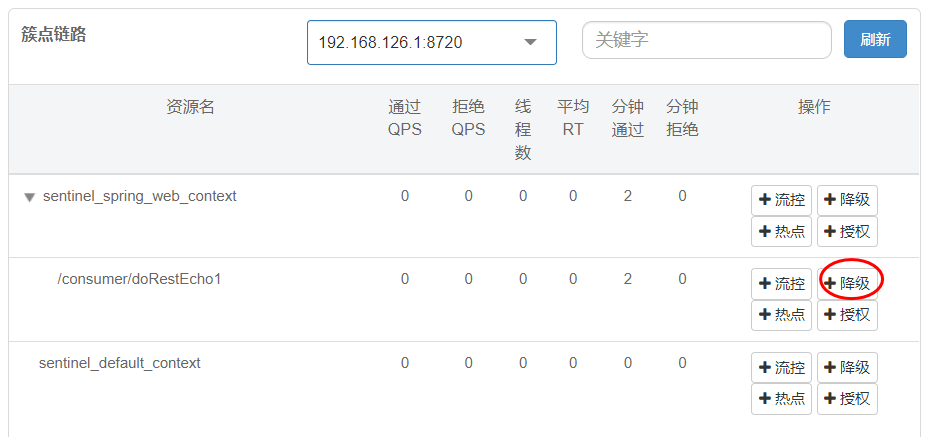
第一步:服务启动后,选择要降级的链路,如图所示:
第二步:选择要降级的链路,如图所示:
这里表示熔断策略为慢调用比例,表示链路请求数超过3时,假如平均响应时间假如超过200毫秒的有50%,则对请求进行熔断,熔断时长为10秒钟,10秒以后恢复正常。
第三步:对指定链路进行刷新,多次访问测试,假如出现了降级熔断,会出现如下结果:
我们也可以进行断点调试,在DefaultBlockExceptionHandler中的handle方法内部加断点,分析异常类型,假如异常类型DegradeException则为降级熔断。
Sentinel 异常处理
系统提供了默认的异常处理机制,假如默认处理机制不满足我们需求,我们可以自己进行定义。定义方式上可以直接或间接实现BlockExceptionHandler接口,并将对象交给spring管理。
@Component public class ServiceBlockExceptionHandler implements BlockExceptionHandler { @Override public void handle(HttpServletRequest request, HttpServletResponse response,BlockException e) throws Exception { //response.setStatus(601); //设置响应数据的编码 response.setCharacterEncoding("utf-8"); //告诉客户端要响应的数据类型以及客户端以什么编码呈现数据 response.setContentType("application/json;charset=utf-8"); PrintWriter pw=response.getWriter(); Map<String,Object> map=new HashMap<>(); if(e instanceof DegradeException){//降级、熔断 map.put("status",601); map.put("message", "服务被熔断了!"); }else if(e instanceof FlowException){ map.put("status",602); map.put("message", "服务被限流了!"); }else{ map.put("status",603); map.put("message", "Blocked by Sentinel (flow limiting)"); //将map对象转换为json格式字符串 String jsonStr=new ObjectMapper().writeValueAsString(map); pw.println(jsonStr); pw.flush();小节面试分析
- 何为降级熔断?(让外部应用停止对服务的访问,生活中跳闸,路障设置-此路不通)
- 为什么要进行熔断呢?(平均响应速度越来越慢或经常出现异常,这样可能会导致调用链堆积,最终系统崩溃)
- Sentinel中限流,降级的异常父类是谁?(BlockException)
- Sentinel 出现降级熔断时,系统底层抛出的异常是谁?(DegradeException)
- Sentinel中异常处理接口是谁?(BlockExceptionHandler)
- Sentinel中异常处理接口下默认的实现类为? (DefaultBlockExceptionHandler)
- 假如Sentinel中默认的异常处理规则不满足我们的需求怎么办?(自己定义)
- 我们如何自己定义Sentinel中异常处理呢?(直接或间接实现BlockExceptionHandler )
Sentinel降级策略分析(拓展)
Sentinel熔断降级支持慢调用比例、异常比例、异常数三种策略。
慢调用比例
慢调用指耗时大于阈值RT(Response Time)的请求称为慢调用,阈值RT由用户设置。其属性具体含义说明如下:
慢调用逻辑中的状态分析如下:
- 熔断(OPEN):请求数大于最小请求数并且慢调用的比率大于比例阈值则发生熔断,熔断时长为用户自定义设置。
- 探测(HALFOPEN):当熔断过了定义的熔断时长,状态由熔断(OPEN)变为探测(HALFOPEN)。
- 关闭(CLOSED):如果接下来的一个请求小于最大RT,说明慢调用已经恢复,结束熔断,状态由探测(HALF_OPEN)变更为关闭(CLOSED),如果接下来的一个请求大于最大RT,说明慢调用未恢复,继续熔断,熔断时长保持一致
注意:Sentinel默认统计的RT上限是4900ms,超出此阈值的都会算作4900ms,若需要变更此上限可以通过启动配置项-Dcsp.sentinel.statistic.max.rt=xxx来配置当资源的每秒请求数大于等于最小请求数,并且异常总数占通过量的比例超过比例阈值时,资源进入降级状态。其属性说明如下:
异常比例中的状态分析如下:
- 熔断(OPEN):当请求数大于最小请求并且异常比例大于设置的阈值时触发熔断,熔断时长由用户设置。
- 探测(HALFOPEN):当超过熔断时长时,由熔断(OPEN)转为探测(HALFOPEN)
- 关闭(CLOSED):如果接下来的一个请求未发生错误,说明应用恢复,结束熔断,状态由探测(HALF_OPEN)变更为关闭(CLOSED)。如果接下来的一个请求继续发生错误,说明应用未恢复,继续熔断,熔断时长保持一致。
当资源近1分钟的异常数目超过阈值(异常数)之后会进行服务降级。注意,由于统计时间窗口是分钟级别的,若熔断时长小于60s,则结束熔断状态后仍可能再次进入熔断状态。其属性说明如下:
基于异常数的状态分析如下:
- 熔断(OPEN):当请求数大于最小请求并且异常数量大于设置的阈值时触发熔断,熔断时长由用户设置。
- 探测(HALFOPEN):当超过熔断时长时,由熔断(OPEN)转为探测(HALFOPEN)
- 关闭(CLOSED):如果接下来的一个请求未发生错误,说明应用恢复,结束熔断,状态由探测(HALF_OPEN)变更为关闭(CLOSED)如果接下来的一个请求继续发生错误,说明应用未恢复,继续熔断,熔断时长保持一致。
小节面试分析
- Sentinel 降级熔断策略有哪些?(慢调用,异常比例,异常数)
- Sentinel 熔断处理逻辑中的有哪些状态?(Open,HalfOpen,Closed)
- Sentinel 对服务调用进行熔断以后处于什么状态?(熔断打开状态-Open)
- Sentinel 设置的熔断时长到期以后,Sentinel的熔断会处于什么状态?(探测-HalfOpen,假如再次访问时依旧响应时间比较长或依旧有异常,则继续熔断)
- Sentinel 中的熔断逻辑恢复正常调用以后,会出现什么状态?(熔断关闭-closed)
Sentinel热点规则分析(重点)
何为热点?热点即经常访问的数据。比如:
- 商品 ID 为参数,统计一段时间内最常购买的商品 ID 并进行限制。
- 用户 ID 为参数,针对一段时间内频繁访问的用户 ID 进行限制。
热点参数限流会统计传入参数中的热点数据,并根据配置的限流阈值与模式,对包含热点参数的资源调用进行限流。热点参数限流可以看做是一种特殊的流量控制,仅对包含热点参数的资源调用生效。其中,Sentinel会利用 LRU 策略统计最近最常访问的热点参数,结合令牌桶算法来进行参数级别的流控。
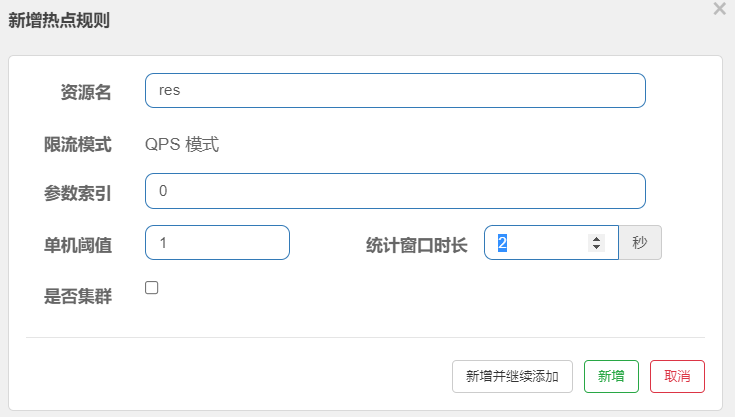
第一步:定义热点业务代码,如图所示:
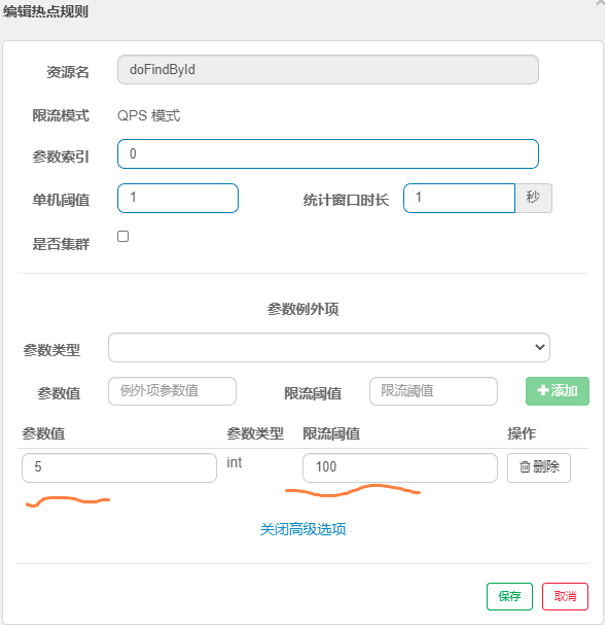
//http://ip:port/consumer/doFindById?id=10 @GetMapping("/consumer/findById") @SentinelResource("res") public String doFindById(@RequestParam("id") Integer id){ return "resource id is "+id;第二步:服务启动后,选择要限流的热点链路,如图所示:
第三步:设置要限流的热点,如图所示:
热点规则的限流模式只有QPS模式(这才叫热点)。参数索引为@SentinelResource注解的方法参数下标,0代表第一个参数,1代表第二个参数。单机阈值以及统计窗口时长表示在此窗口时间超过阈值就限流。
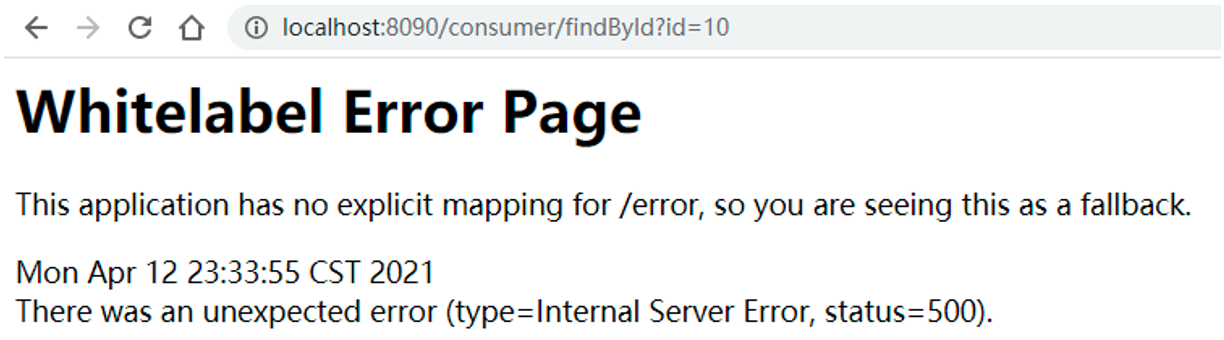
第四步:多次访问热点参数方法,前端会出现如下界面,如图所示:
然后,在后台出现如下异常表示限流成功。
com.alibaba.csp.sentinel.slots.block.flow.param.ParamFlowException: 2其中,热点参数其实说白了就是特殊的流控,流控设置是针对整个请求的;但是热点参数他可以设置到具体哪个参数,甚至参数针对的值,这样更灵活的进行流控管理。
一般应用在某些特殊资源的特殊处理,如:某些商品流量大,其他商品流量很正常,就可以利用热点参数限流的方案。特定参数设计
配置参数例外项,如图所示:
这里表示参数值为5时阈值为100,其它参数值阈值为1,例如当我们访问http://ip:port/consumer/doRestEcho1?id=5时的限流阈值为100。
小节面试分析
- 如何理解热点数据?(访问频度比较高的数据,某些商品、谋篇文章、某个视频)
- 热点数据的限流规则是怎样的?(主要是针对参数进行限流设计)
- 热点数据中的特殊参数如何理解?(热点限流中的某个参数值的阈值设计)
- 对于热点数据的访问出现限流以后底层异常是什么?(ParamFlowException)
Sentinel系统规则(了解)
系统在生产环境运行过程中,我们经常需要监控服务器的状态,看服务器CPU、内存、IO等的使用率;主要目的就是保证服务器正常的运行,不能被某些应用搞崩溃了;而且在保证稳定的前提下,保持系统的最大吞吐量。
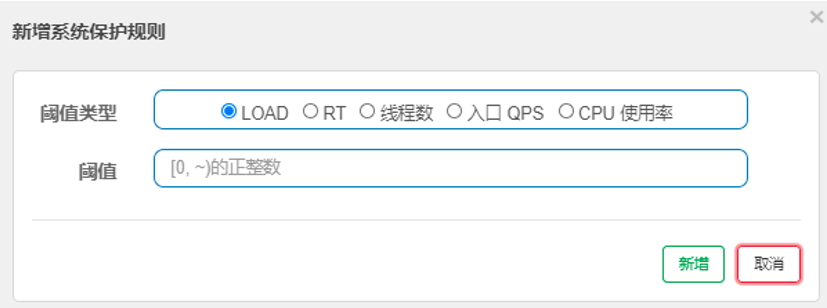
Sentinel的系统保护规则是从应用级别的入口流量进行控制,从单台机器的总体 Load(负载)、RT(响应时间)、入口 QPS 、线程数和CPU使用率五个维度监控应用数据,让系统尽可能跑在最大吞吐量的同时保证系统整体的稳定性。如图所示:
系统规则是一种全局设计规则,其中,
- Load(仅对 Linux/Unix-like 机器生效):当系统 load1 超过阈值,且系统当前的并发线程数超过系统容量时才会触发系统保护。系统容量由系统的 maxQps * minRt 计算得出。设定参考值一般是 CPU cores * 2.5。
- CPU使用率:当系统 CPU 使用率超过阈值即触发系统保护(取值范围 0.0-1.0)。
- RT:当单台机器上所有入口流量的平均 RT 达到阈值即触发系统保护,单位是毫秒。
- 线程数:当单台机器上所有入口流量的并发线程数达到阈值即触发系统保护。
- 入口 QPS:当单台机器上所有入口流量的 QPS 达到阈值即触发系统保护。
说明,系统保护规则是应用整体维度的,而不是资源维度的,并且仅对入口流量生效。入口流量指的是进入应用的流量(EntryType.IN),比如 Web 服务。
小节面试分析
- 如何理解sentinel中的系统规则?(是对所有链路的控制规则,是一种系统保护策略)
- Sentinel的常用系统规则有哪些?(RT,QPS,CPU,线程,Load-linux,unix)
- Sentinel系统保护规则被触发以后底层会抛出什么异常?(SystemBlockException)
Sentinel授权规则(重要)
很多时候,我们需要根据调用方来限制资源是否通过,这时候可以使用 Sentinel 的黑白名单控制的功能。黑白名单根据资源的请求来源(origin)限制资源是否通过,若配置白名单则只有请求来源位于白名单内时才可通过;若配置黑名单则请求来源位于黑名单时不通过,其余的请求通过。例如微信中的黑名单。
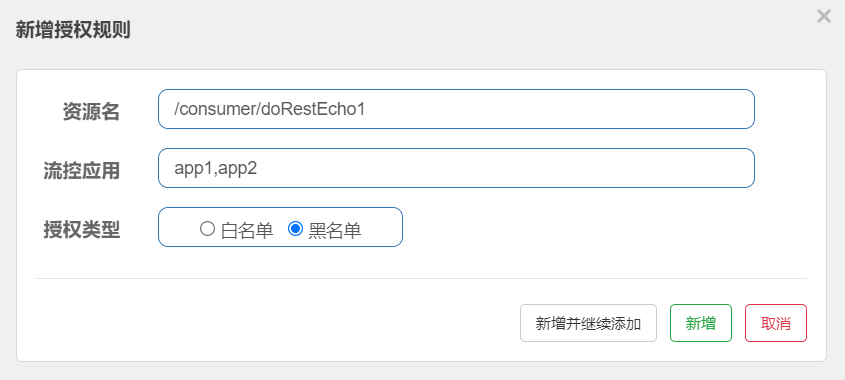
sentinel可以基于黑白名单方式进行授权规则设计,如图所示:
黑白名单规则(AuthorityRule)非常简单,主要有以下配置项:
- 资源名:即限流规则的作用对象
- 流控应用:对应的黑名单/白名单中设置的规则值,多个值用逗号隔开.
- 授权类型:白名单,黑名单(不允许访问).
案例实现:
定义请求解析器,用于对请求进行解析,并返回解析结果,sentinel底层 在拦截到用户请求以后,会对请求数据基于此对象进行解析,判定是否符合黑白名单规则
第一步:定义RequestOriginParser接口的实现类,基于业务在接口方法中解析请求数据并返回,底层会基于此返回值进行授权规则应用。
@Component public class DefaultRequestOriginParser implements RequestOriginParser { @Override public String parseOrigin(HttpServletRequest request) { String origin = request.getParameter("origin"); return origin;第二步:定义流控规则,如图所示:
第三步:执行资源访问,检测授权规则应用,当我们配置的流控应用值为app1时,假如规则为黑名单,则基于
http://ip:port/path?origin=app1的请求不可以通过,会出现如下结果:第四步:设计过程分析,如图所示:
拓展:尝试基于请求ip,请求头方式进行黑白名单的规则设计,例如:
@Component public class DefaultRequestOriginParser implements RequestOriginParser { //解析请求源数据 @Override public String parseOrigin(HttpServletRequest request) { //获取请求参数数据,参数名可以自己写,例如origin,然后基于参数值做黑白名单设计 // http://ip:port/path?origin=app1 return request.getParameter("origin"); //获取访问请求中的ip地址,基于ip地址进行黑白名单设计(例如在流控应用栏写ip地址) String ip= request.getRemoteAddr(); System.out.println("ip="+ip); return ip; //获取请求头中的数据,基于请求头中token值进行限流设计 (例如在监控应用栏写jack,tony) //String token=request.getHeader("token");//jack,tony //return token; }//授权规则中的黑白名单的值,来自此方法的返回值小节面试分析
- 如何理解Sentinel中的授权规则?(对指定资源的访问给出的一种简易的授权策略)
- Sentinel的授权规则是如何设计的?(白名单和黑名单)
- 如何理解Sentinel中的白名单?(允许访问的资源名单)
- 如何理解Sentinel中的黑名单?(不允许访问的资源名单)、
- Sentinel如何识别白名单和黑名单?(在拦截器中通过调用RequestOriginParser对象的方法检测具体的规则)
- 授权规则中RequestOriginParser类的做用是什么?(对流控应用值进行解析,检查服务访问时传入的值是否与RequestOriginParser的parseOrigin方法返回值是否相同。)
总结(Summary)
总之,Sentinel可为秒杀、抢购、抢票、拉票等高并发应用,提供API接口层面的流量限制,让突然暴涨而来的流量用户访问受到统一的管控,使用合理的流量放行规则使得用户都能正常得到服务。
重难点分析
- Sentinel诞生的背景?(计算机的数量是否有限,处理能力是否有限,并发比较大或突发流量比较大)
- 服务中Sentinel环境的集成,初始化?(添加依赖-两个,sentinel配置)
- Sentinel 的限流规则?(阈值类型-QPS&线程数,限流模式-直接,关联,链路)
- Sentinel 的降级(熔断)策略?(慢调用,异常比例,异常数)
- Sentinel 的热点规则设计(掌握)?
- Sentinel 系统规则设计?(了解,全局规则定义,针对所有请求有效)
- Sentinel 授权规则设计?(掌握,黑白名单)
FAQ分析
- 为什么要限流?
- 你了解的那些限流框架?(sentinel)
- 常用的限流算法有那些?(计数,令牌桶-电影票,漏桶-漏斗,滑动窗口)
- Sentinel有哪些限流规则?(QPS,线程数)
- Sentinel有哪些限流模式?(直接,关联-创建订单和查询订单,链路限流-北京六环外不限号,但是五环就限号)
- Sentinel 的降级(熔断)策略有哪些?(慢调用-响应时长,异常比例-异常占比,异常数)
- Sentinel 的热点规则中的热点数据?(热卖商品,微博大咖,新上映的电影)
- 如何理解Sentinel 授权规则中的黑白名单?
Bug分析
- 依赖下载失败 (maven-本地库,网络,镜像仓库)
- 单词错误(拼写错误)
07-网关Gateway 应用实践
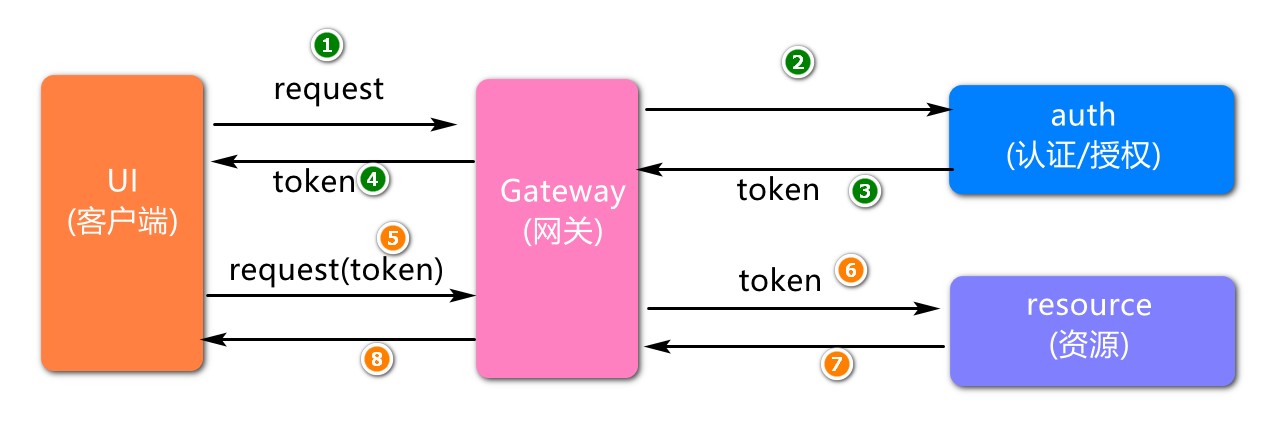
我们知道,一个大型系统在设计时,经常会被拆分为很多个微服务。那么作为客户端要如何去调用 这么多的微服务呢?客户端可以直接向微服务发送请求,每个微服务都有一个公开的URL,该URL可以直接映射到具体的微服务,如果没有网关的存在,我们只能在客户端记录每个微服务的地址,然后分别去调用。这样的架构,会存在着诸多的问题,例如,客户端请求不同的微服务可能会增加客户端代码或配置的复杂性。还有就是每个服务,在调用时都需要独立认证。并且存在跨域请求,也在一定程度上提高了代码的复杂度。基于微服务架构中的设计及实现上的问题,为了在项目中简化前端的调用逻辑,同时也简化内部服务之间互相调用的复杂度,更好保护内部服务,提出了网关的概念。
网关本质上要提供一个各种服务访问的入口,并提供服务接收并转发所有内外部的客户端调用,还有就是权限认证,限流控制等等。Spring Cloud Gateway是Spring公司基于Spring 5.0,Spring Boot 2.0 和 等技术开发的一个网关组件,它旨在为微服务架构提供一种简单有效的统一的 API入口,负责服务请求路由、组合及协议转换,并且基于 Filter 链的方式提供了权限认证,监控、限流等功能。
Spring Cloud Gateway优缺点分析:
- 性能强劲:是第一代网关Zuul的1.6倍。
- 功能强大:内置了很多实用的功能,例如转发、监控、限流等
- 设计优雅,容易扩展。
- 依赖Netty与WebFlux(Spring5.0),不是传统的Servlet编程模型(Spring MVC就是基于此模型实现),学习成本高。
- 需要Spring Boot 2.0及以上的版本,才支持
通过网关作为服务访问入口,对系统中的服务进行访问,例如通过网关服务去访问sca-provider服务.
入门业务实现
第一步:创建sca-gateway模块(假如已有则无须创建),其pom.xml文件如下:
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-gateway</artifactId> </dependency>第二步:创建application.yml(假如已有则无须创建),添加相关配置,代码如下:
server: port: 9000 spring: application: name: sca-gateway cloud: gateway: routes: #配置网关路由规则 - id: route01 #路由id,自己指定一个唯一值即可 uri: http://localhost:8081/ #网关帮我们转发的url predicates: ###断言(谓此):匹配请求规则 - Path=/nacos/provider/echo/** #请求路径定义,此路径对应uri中的资源 filters: ##网关过滤器,用于对谓词中的内容进行判断分析以及处理 - StripPrefix=1 #转发之前去掉path中第一层路径,例如nacos其中:路由(Route) 是 gateway 中最基本的组件之一,表示一个具体的路由信息载体。主要定义了下面的几个信息:
- id,路由标识符,区别于其他 Route。
- uri,路由指向的目的地 uri,即客户端请求最终被转发到的微服务。
- predicate,断言(谓词)的作用是进行条件判断,只有断言都返回真,才会执行路由。
- filter,过滤器用于修改请求和响应信息。
第三步:创建项目启动类,例如:
package com.cy; @SpringBootApplication public class GatewayApplication { public static void main(String[] args) { SpringApplication.run(GatewayApplication.class,args);第四步:启动项目进行访问测试,
依次启动sca-provider,sca-gateway服务,然后打开浏览器,进行访问测试,例如:
小节面试分析?
- 什么是网关?服务访问(流量)的一个入口,类似生活中的“海关“
- 为什么使用网关?(服务安全,统一服务入口管理,负载均衡,限流,鉴权)
- Spring Cloud Gateway 应用的初始构建过程(添加依赖,配置)
- Gateway 服务的启动底层是通过谁去实现的?(Netty网络编程框架-ServerSocket)
- Gateway 服务做请求转发时一定要在注册中心进行注册吗?(不一定,可以直接通过远端url进行服务访问)
负载均衡设计
为什么负载均衡?
网关才是服务访问的入口,所有服务都会在网关层面进行底层映射,所以在访问服务时,要基于服务serivce id(服务名)去查找对应的服务,让请求从网关层进行均衡转发,以平衡服务实例的处理能力。
Gateway中负载均衡实现?
第一步:项目中添加服务发现依赖,代码如下:
<dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId> </dependency>第二步:修改其配置文件,代码如下
server: port: 9000 spring: application: name: sca-gateway cloud: nacos: discovery: server-addr: localhost:8848 gateway: discovery: locator: enabled: true #开启通过服务注册中心的serviceId创建路由 routes: - id: route01 ##uri: http://localhost:8081/ uri: lb://sca-provider # lb为服务前缀(负载均衡单词的缩写),不能随意写 predicates: ###匹配规则 - Path=/nacos/provider/echo/** filters: - StripPrefix=1 #转发之前去掉path中第一层路径,例如nacos其中,lb指的是从nacos中按照名称获取微服务,并遵循负载均衡策略。同时建议开发阶段打开gateway日志,代码如下:
logging: level: org.springframework.cloud.gateway: debug
- 1
- 2
- 3
第三步:启动服务,进行访问测试,并反复刷新分析,如图所示:
执行流程分析(重要)
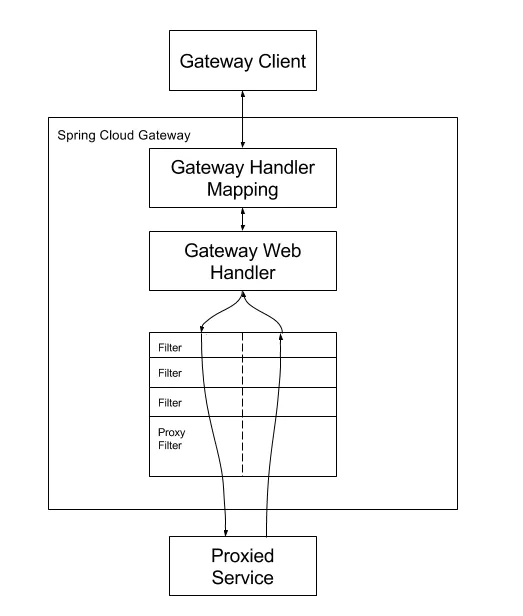
根据官方的说明,其Gateway具体工作流程,如图所示:
客户端向Spring Cloud Gateway发出请求。 如果Gateway Handler Mapping 通过断言predicates(predicates)的集合确定请求与路由(Routers)匹配,则将其发送到Gateway Web Handler。 Gateway Web Handler 通过确定的路由中所配置的过滤器集合链式调用过滤器(也就是所谓的责任链模式)。 Filter由虚线分隔的原因是, Filter可以在发送代理请求之前和之后运行逻辑。处理的逻辑是 在处理请求时 排在前面的过滤器先执行,而处理返回相应的时候,排在后面的过滤器先执行。
小节面试分析?
- 网关层面是如何实现负载均衡的?(通过服务名去查找具体的服务实例)
- 网关层面是如何通过服务名查找服务实例的?(Ribbon)
- 你了解Ribbon中的哪些负载均衡算法?(轮询,权重,hash,……可通过IRule接口进行查看分析)
- 网关进行请求转发的流程是怎样,有哪些关键对象?(XxxHandlerMapping,Handler,。。。)
- 网关层面服务的映射方式怎样的?(谓词-path,…,服务名/服务实例)
- 网关层如何记录服务的映射?(通过map,并要考虑读写锁的应用)
断言(Predicate)增强分析(了解)
Predicate 简介
Predicate(断言)又称谓词,用于条件判断,只有断言结果都为真,才会真正的执行路由。断言其本质就是定义路由转发的条件。
Predicate 内置工厂
SpringCloud Gateway包括一些内置的断言工厂(所有工厂都直接或间接的实现了RoutePredicateFactory接口),这些断言或谓词工程负责创建谓词对象,并通过这些谓词对象判断http请求的合法性,常见谓词工厂如下:
基于Datetime类型的断言工厂
此类型的断言根据时间做判断,主要有三个:
1) AfterRoutePredicateFactory:判断请求日期是否晚于指定日期
2) BeforeRoutePredicateFactory:判断请求日期是否早于指定日期
3) BetweenRoutePredicateFactory:判断请求日期是否在指定时间段内-After=2020-12-31T23:59:59.789+08:00[Asia/Shanghai]
当且仅当请求时的时间After配置的时间时,才转发该请求,若请求时的时间不是After配置的时间时,则会返回404 not found。时间值可通过ZonedDateTime.now()获取。
基于header的断言工厂HeaderRoutePredicateFactory
判断请求Header是否具有给定名称且值与正则表达式匹配。例如:
-Header=X-Request-Id, \d+
基于Method请求方法的断言工厂,
MethodRoutePredicateFactory接收一个参数,判断请求类型是否跟指定的类型匹配。例如:
-Method=GET
基于Query请求参数的断言工厂,QueryRoutePredicateFactory :
接收两个参数,请求param和正则表达式, 判断请求参数是否具 有给定名称且值与正则表达式匹配。例如:
-Query=pageSize,\d+
Predicate 应用案例实践
内置的路由断言工厂应用案例,例如:
server: port: 9000 spring: application: name: sca-gateway cloud: nacos: server-addr: localhost:8848 gateway: discovery: locator: enabled: true #开启通过服务中心的serviceId 创建路由的功能 routes: - id: bd-id ##uri: http://localhost:8081/ uri: lb://sca-provider predicates: ###匹配规则 - Path=/nacos/provider/echo/** - Before=2021-01-30T00:00:00.000+08:00 - Method=GET filters: - StripPrefix=1 # 转发之前去掉1层路径说明:当条件不满足时,则无法进行路由转发,会出现404异常。
小节面试分析
- 何为谓词?(网关中封装了判断逻辑的一个对象)
- 谓词逻辑的设计是怎样的?(谓词判断逻辑返回值为true则进行请求转发)
- 你了解哪些谓词逻辑?(path,请求参数,请求方式,请求头,….)
- 我们可以自己定义谓词工厂对象吗?(可以的)
过滤器(Filter)增强分析(了解)
过滤器(Filter)就是在请求传递过程中,对请求和响应做一个处理。Gateway 的Filter从作用范围可分为两种:GatewayFilter与GlobalFilter。其中:
- GatewayFilter:应用到单个路由或者一个分组的路由上。
- GlobalFilter:应用到所有的路由上。
局部过滤器设计及实现
在SpringCloud Gateway中内置了很多不同类型的网关路由过滤器。具体如下:
案例分析:基于AddRequestHeaderGatewayFilterFactory,为原始请求添加Header。
例如,为原始请求添加名为 X-Request-Foo ,值为 Bar 的请求头:
spring: cloud: gateway: routes: - id: add_request_header_route uri: https://example.org filters: - AddRequestHeader=X-Request-Foo, Bar基于AddRequestParameterGatewayFilterFactory,为原始请求添加请求参数及值,
例如,为原始请求添加名为foo,值为bar的参数,即:foo=bar。
spring: cloud: gateway: routes: - id: add_request_parameter_route uri: https://example.org filters: - AddRequestParameter=foo, bar基于PrefixPathGatewayFilterFactory,为原始的请求路径添加一个前缀路径
例如,该配置使访问${GATEWAY_URL}/hello 会转发到uri/mypath/hello。
spring: cloud: gateway: routes: - id: prefixpath_route uri: https://example.org filters: - PrefixPath=/mypath基于RequestSizeGatewayFilterFactory,设置允许接收最大请求包的大小
,配置示例:
spring: cloud: gateway: routes: - id: request_size_route uri: http://localhost:8080/upload predicates: - Path=/upload filters: - name: RequestSize args: # 单位为字节 maxSize: 5000000如果请求包大小超过设置的值,则会返回 413 Payload Too Large以及一个errorMessage
全局过滤器设计及实现
全局过滤器(GlobalFilter)作用于所有路由, 无需配置。在系统初始化时加载,并作用在每个路由上。通过全局过滤器可以实现对权限的统一校验,安全性验证等功能。一般内置的全局过滤器已经可以完成大部分的功能,但是对于企业开发的一些业务功能处理,还是需要我们 自己编写过滤器来实现的,那么我们一起通过代码的形式自定义一个过滤器,去完成统一的权限校验。 例如,当客户端第一次请求服务时,服务端对用户进行信息认证(登录), 认证通过,将用户信息进行加密形成token,返回给客户端,作为登录凭证 以后每次请求,客户端都携带认证的token 服务端对token进行解密,判断是否有效。学过spring中的webflux技术的同学可以对如下代码进行尝试实现(没学过的可以忽略).
package com.cy.filters; import org.springframework.cloud.gateway.filter.GatewayFilterChain; import org.springframework.cloud.gateway.filter.GlobalFilter; import org.springframework.core.Ordered; import org.springframework.http.HttpStatus; import org.springframework.stereotype.Component; import org.springframework.web.server.ServerWebExchange; import reactor.core.publisher.Mono; @Component public class AuthGlobalFilter implements GlobalFilter, Ordered { @Override public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) { String username=exchange.getRequest() .getQueryParams().getFirst("username"); if (!"admin".equals(username)) { System.out.println("认证失败"); exchange.getResponse().setStatusCode(HttpStatus.UNAUTHORIZED); return exchange.getResponse().setComplete(); //调用chain.filter继续向下游执行 return chain.filter(exchange); @Override public int getOrder() { return 0;启动Gateway服务,假如在访问的url中不带“user=admin”这个参数,可能会出现异常.
小节面试分析
- 网关过滤器的作用是什么?(对请求和响应数据做一个预处理)
- 网关过滤器的类型有哪些?(局部过滤器,全局过滤器)
- 如何理解局部过滤器?(针对具体链路的应用的过滤器,需要进行配置)
- 你了解哪些局部过滤器?
- 如何理解全局过滤器?(作用于所有请求链路)
- 如何自己定义全局过滤器?(直接或间接实现GlobalFilter接口)
- 假如现在让你进行平台的网关自研设计,你可以吗?(可以)
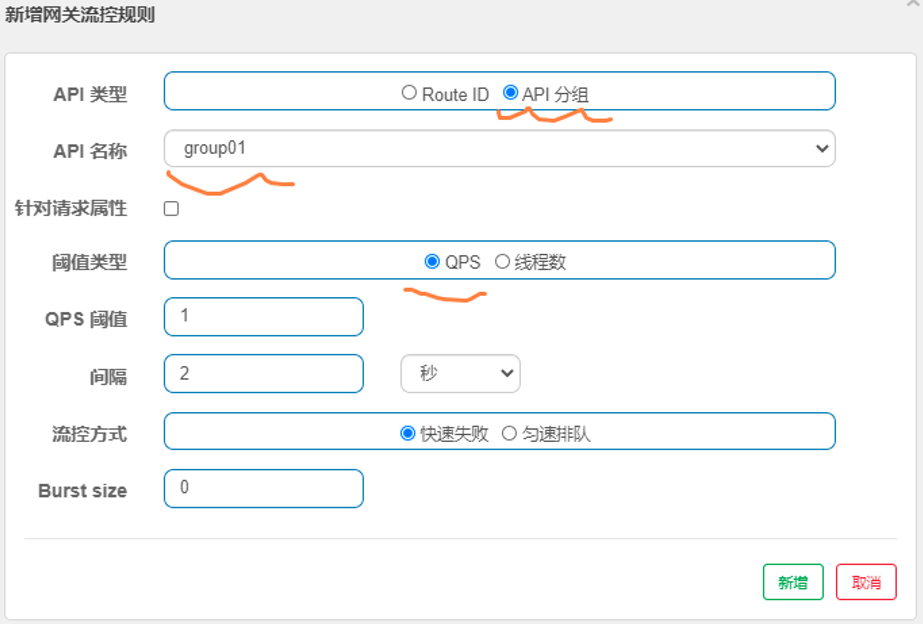
限流设计及实现
网关是所有外部请求的公共入口,所以可以在网关进行限流,而且限流的方式也很多,我们采用Sentinel组件来实现网关的限流。Sentinel支持对SpringCloud Gateway、Zuul等主流网关进行限流。参考网址如下:
https://github.com/alibaba/spring-cloud-alibaba/wiki/Sentinel限流快速入门
第一步:添加依赖
在原有spring-cloud-starter-gateway依赖的基础上再添加如下两个依赖,例如:<dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-sentinel</artifactId> </dependency> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-alibaba-sentinel-gateway</artifactId> </dependency>第二步:添加sentinel及路由规则(假如已有则无需设置)
routes: - id: route01 uri: lb://nacos-provider predicates: ###匹配规则 - Path=/provider/echo/**sentinel: transport: dashboard: localhost:8180 #Sentinel 控制台地址 port: 8719 #客户端监控API的端口 eager: true #取消Sentinel控制台懒加载,即项目启动即连接第三步:启动网关项目,检测sentinel控制台的网关菜单。
启动时,添加sentinel的jvm参数,通过此菜单可以让网关服务在sentinel控制台显示不一样的菜单,代码如下。-Dcsp.sentinel.app.type=1假如是在idea中,可以参考下面的图进行配置
Sentinel 控制台启动以后,界面如图所示:
说明,假如没有发现请求链路,API管理,关闭网关项目,关闭sentinel,然后重启sentinel,重启网关项目.第四步:在sentinel面板中设置限流策略,如图所示:
第五步:通过url进行访问检测是否实现了限流操作
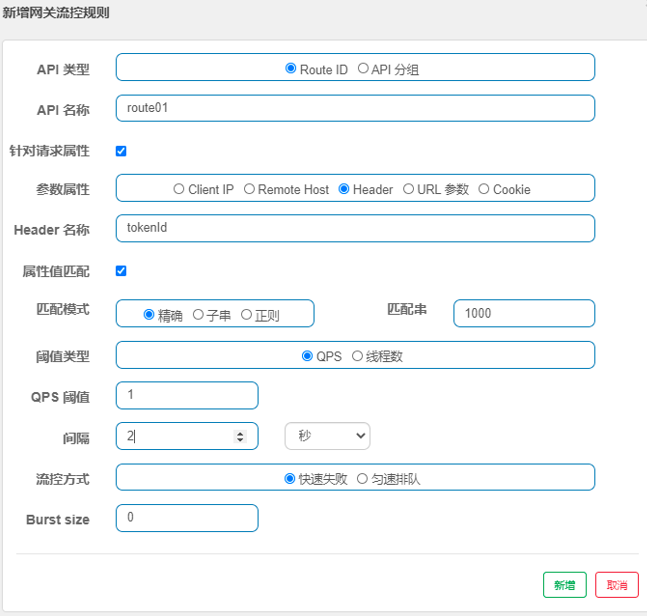
基于请求属性限流
定义指定routeId的基于属性的限流策略如图所示:
通过postman进行测试分析
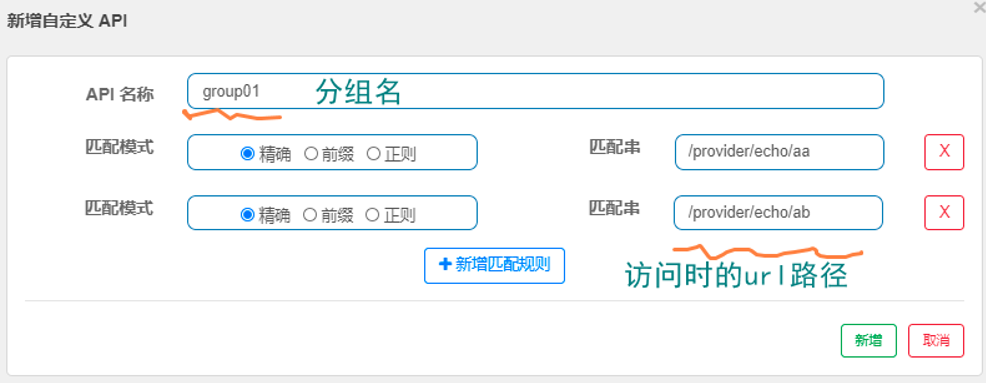
自定义API维度限流(重点)
自定义API分组,是一种更细粒度的限流规则定义,它允许我们利用sentinel提供的API,将请求路径进行分组,然后在组上设置限流规则即可。
第一步:新建API分组,如图所示:
第二步:新建分组流控规则,如图所示:
第三步:进行访问测试,如图所示
定制流控网关返回值
定义配置类,设计流控返回值,代码如下:
@Configuration public class GatewayConfig { public GatewayConfig(){ GatewayCallbackManager.setBlockHandler( new BlockRequestHandler() { @Override public Mono<ServerResponse> handleRequest(ServerWebExchange serverWebExchange, Throwable throwable) { Map<String,Object> map=new HashMap<>(); map.put("state",429); map.put("message","two many request"); String jsonStr=JSON.toJSONString(map); return ServerResponse.ok().body(Mono.just(jsonStr),String.class);其中,Mono 是一个发出(emit)0-1个元素的Publisher对象。
小节面试分析?
- 网关层面结合sentinel实现限流,其限流的类型有几种?(两种-route id,api)
- 网关层面可以自定义限流后的异常处理结果吗?(可以)
- 你知道Sentinel底层限流的算法有哪些?(滑动窗口,令牌桶,漏斗,。。。)
总结(Summay)
重难点分析
- 网关(Gateway)诞生的背景?(第一:统一微服务访问的入口,第二:对系统服务进行保护,第三进行统一的认证,授权,限流)
- 网关的选型?(Netifix Zuul,Spring Cloud Gateway,…)
- Spring Cloud Gateway的入门实现(添加依赖,路由配置,启动类)
- Spring Cloud Gateway中的负载均衡?(网关服务注册,服务的发现,基于uri:lb://服务id方式访问具体服务实例)
- Spring Cloud Gateway中的断言配置?(掌握常用几个就可,用时可以通过搜索引擎去查)
- Spring Cloud Gateway中的过滤器配置?(掌握过滤器中的两大类型-局部和全局)
- Spring Cloud Gateway中的限流设计?(Sentinel)
FAQ 分析
- Gateway在互联网架构中的位置?(nginx->gateway–>微服务–>微服务)
- Gateway底层负载均衡的实现?(Ribbon)
- Gateway应用过程中设计的主要概念?(路由id,路由uri,断言,过滤器)
- Gateway中你做过哪些断言配置?(after,header,path,cookie,…)
- Gateway中你用的过滤器有哪些?(添加前缀,去掉前缀,添加请求头,…,负载均衡,…)
BUG分析
- 503 异常?(服务不可用,检查你调用的服务是否启动ok,路由uri写的是否正确)
- 启动时解析.yml配置文件异常(格式没有对齐,单词写错)
08-微服务文件上传实战(总结与练习)
基于Spring Cloud Alibaba解决方案实现文件上传,例如
初始架构设计
本次项目实践,整体上基于前后端分离架构,服务设计上基于spring cloud alibaba解决方案进行实现,例如:
说明,为了降低学习难度,这里只做了初始架构设计,后续会逐步基于这个架构进行演进,例如我们会加上网关工程,认证工程等.工程创建及初始化
参考如下工程结构,进行项目创建,例如:
创建父工程
创建项目父工程用来管理项目依赖.
创建文件服务工程
创建用于处理文件上传业务的工程,例如:
创建客户端服务工程
创建一个客户端工程,在此工程中定义一些静态页面,例如文件上传页面.
父工程初始化
打开父工程的pom.xml文件,添加如下依赖:
<dependencyManagement> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-dependencies</artifactId> <version>2.3.2.RELEASE</version> <type>pom</type> <scope>import</scope> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-dependencies</artifactId> <version>Hoxton.SR9</version> <type>pom</type> <scope>import</scope> </dependency> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-alibaba-dependencies</artifactId> <version>2.2.6.RELEASE</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement> <dependencies> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <scope>provided</scope> </dependency> </dependencies>文件资源服务实现
添加项目依赖
在sca-resource工程中添加如下依赖:
<!--Spring Boot Web (服务-内置tomcat)--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!--Nacos Discovery (服务注册发现)--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId> </dependency> <!--Nacos Config (配置中心)--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId> </dependency> <!--Sentinel (流量防卫兵-限流和熔断)--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-sentinel</artifactId> </dependency> <!--Spring Boot 监控--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> </dependency>服务初始化配置
在项目的resources目录下创建bootstrap.yml配置文件(假如后续配置信息要写到配置中心配置文件名必须为bootstrap.yml),并添加如下内容:
server: port: 8881 spring: application: name: sca-resource servlet: multipart: max-file-size: 100MB #控制上传文件的大小 max-request-size: 110MB #请求数据大小 resources: #定义可以访问到上传资源的路径 static-locations: file:d:/uploads #静态资源路径(原先存储到resources/static目录下的资源可以存储到此目录中) cloud: nacos: discovery: server-addr: localhost:8848 config: server-addr: localhost:8848 jt: #这里的配置,后续会在一些相关类中通过@Value注解进行读取 resource: path: d:/uploads #设计上传文件存储的根目录(后续要写到配置文件) host: http://localhost:8881/ #定义上传文件对应的访问服务器构建项目启动类
在当前工程中,创建项目启动类,例如:
package com.jt; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; @SpringBootApplication public class FileApplication { public static void main(String[] args) { SpringApplication.run(FileApplication.class, args);类创建以后,启动当前项目,检测是否可以启动成功,是否有配置错误.
Controller逻辑实现
定义处理上传请求的Controller对象,例如:
package com.jt.resource.controller; import lombok.extern.slf4j.Slf4j; import org.springframework.beans.factory.annotation.Value; import org.springframework.web.bind.annotation.PostMapping; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController; import org.springframework.web.multipart.MultipartFile; import java.io.File; import java.io.IOException; import java.time.LocalDate; import java.time.format.DateTimeFormatter; import java.util.UUID; @Slf4j @RestController @RequestMapping("/resource/") public class ResourceController { //当了类的上面添加了@Slf4J就不用自己创建下面的日志对象了 // private static final Logger log= // LoggerFactory.getLogger(ResourceController.class); @Value("${jt.resource.path}") private String resourcePath;//="d:/uploads/"; @Value("${jt.resource.host}") private String resourceHost;//="http://localhost:8881/"; @PostMapping("/upload/") public String uploadFile(MultipartFile uploadFile) throws IOException { //1.创建文件存储目录(按时间创建-yyyy/MM/dd) //1.1获取当前时间的一个目录 String dateDir = DateTimeFormatter.ofPattern("yyyy/MM/dd") .format(LocalDate.now()); //1.2构建目录文件对象 File uploadFileDir=new File(resourcePath,dateDir); if(!uploadFileDir.exists())uploadFileDir.mkdirs(); //2.给文件起个名字(尽量不重复) //2.1获取原文件后缀 String originalFilename=uploadFile.getOriginalFilename(); String ext = originalFilename.substring( originalFilename.lastIndexOf(".")); //2.2构建新的文件名 String newFilePrefix=UUID.randomUUID().toString(); String newFileName=newFilePrefix+ext; //3.开始实现文件上传 //3.1构建新的文件对象,指向实际上传的文件最终地址 File file=new File(uploadFileDir,newFileName); //3.2上传文件(向指定服务位置写文件数据) uploadFile.transferTo(file); String fileRealPath=resourceHost+dateDir+"/"+newFileName; log.debug("fileRealPath {}",fileRealPath); //后续可以将上传的文件信息写入到数据库? return fileRealPath;跨域配置实现
我们在通过客户端工程,访问文件上传服务时,需要进行跨域配置,在服务端的跨域配置中有多种方案,最常见是在过滤器的层面进行跨域设计,例如:
package com.jt.files.config; * 跨域配置(基于过滤器方式进行配置,并且将过滤优先级设置高一些) @Configuration public class CorsFilterConfig { @Bean public FilterRegistrationBean<CorsFilter> filterFilterRegistrationBean(){ //1.对此过滤器进行配置(跨域设置-url,method) UrlBasedCorsConfigurationSource configSource=new UrlBasedCorsConfigurationSource(); CorsConfiguration config=new CorsConfiguration(); //允许哪种请求头跨域 config.addAllowedHeader("*"); //允许哪种方法类型跨域 get post delete put config.addAllowedMethod("*"); // 允许哪些请求源(ip:port)跨域 config.addAllowedOrigin("*"); //是否允许携带cookie跨域 config.setAllowCredentials(true); //2.注册过滤器并设置其优先级 configSource.registerCorsConfiguration("/**", config); FilterRegistrationBean<CorsFilter> fBean= new FilterRegistrationBean(new CorsFilter(configSource)); fBean.setOrder(Ordered.HIGHEST_PRECEDENCE); return fBean;客户端工程逻辑实现
本次项目我们的客户端工程基于springboot工程进行设计,项目上线时可以将其静态资源直接放到一个静态资源目录中.
在sca-resource-ui工程的pom文件中添加web依赖,例如:
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency>构建项目启动类
package com.jt; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; @SpringBootApplication public class ClientApplication { public static void main(String[] args) { SpringApplication.run(ClientApplication .class, args);创建文件上传页面
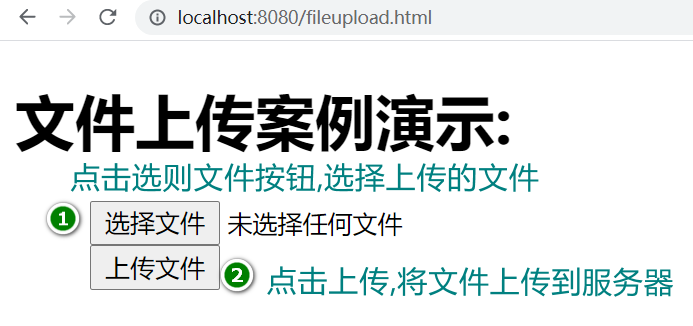
在工程的resources目录下创建static目录(假如这个目录已经存在则无需创建),然后在此目录创建fileupload.html静态页面,例如:
<!DOCTYPE html> <html lang="en"> <meta charset="UTF-8"> <title>文件上载演示</title> <script src="https://unpkg.com/axios/dist/axios.min.js"></script> </head> <form id="fileForm" method="post" enctype="multipart/form-data" onsubmit="return doUpload()"> <label>上传文件 <input id="uploadFile" type="file" name="uploadFile"> </label> <button type="submit">上传文件</button> </form> </body> <script> //jquery代码的表单提交事件 function doUpload(){ //获得用户选中的所有图片(获得数组) let files=document.getElementById("uploadFile").files; if(files.length>0){ //获得用户选中的唯一图片(从数组中取出) let file=files[0]; //开始上传这个图片 //由于上传代码比较多,不想和这里其它代码干扰,所以定义一个方法调用 upload(file); //阻止表单提交效果 return false; // 将file上传到服务器的方法 function upload(file){ //定义一个表单 let form=new FormData(); //将文件添加到表单中 form.append("uploadFile",file); //异步提交 let url="http://localhost:8881/resource/upload/"; axios.post(url,form) .then(function (response){ alert("upload ok") console.log(response.data); .catch(function (e){//失败时执行catch代码块 console.log(e); </script> </html>启动服务访问测试
第一步:启动nacos服务(在这里做服务的注册和配置管理)
第二步:启动sca-resource服务,此服务提供文件上传功能
第三步:启动sca-resource-ui服务,此服务为客户端工程,提供静态资源的访问.所有页面放到此工程中.
第四步:打开浏览器,访问sca-resource-ui工程下的文件上传页面,例如:
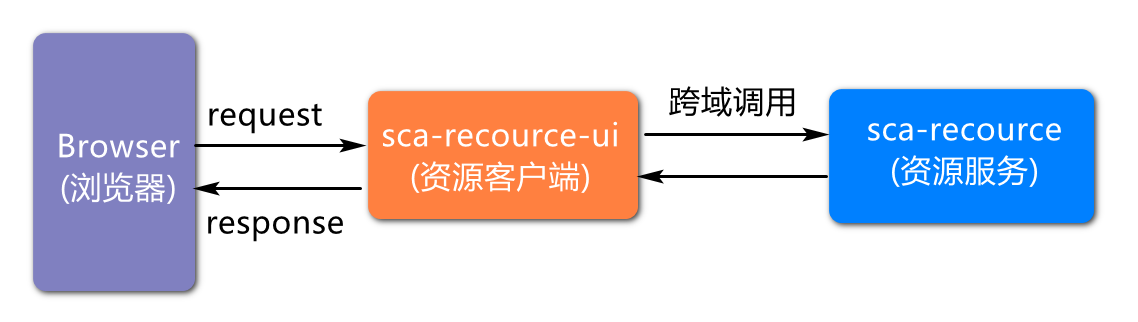
API网关(Gateway)工程实践
API 网关是外部资源对服务内部资源访问的入口,所以文件上传请求应该首先请求的是网关服务,然后由网关服务转发到具体的资源服务上。
服务调用架构
工程项目结构设计
创建网关工程及初始化
第一步:创建sca-resource-gateway工程,例如:
第二步:添加项目依赖,例如:<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-gateway</artifactId> </dependency> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId> </dependency> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId> </dependency>第三步:创建配置文件bootstrap.xml,然后进行初始配置,例如:
server: port: 9000 spring: application: name: sca-resource-gateway cloud: nacos: discovery: server-addr: localhost:8848 config: server-addr: localhost:8848 file-extension: yml gateway: discovery: locator: enabled: true routes: - id: router01 uri: lb://sca-resource predicates: - Path=/sca/resource/upload/** filters: - StripPrefix=1第四步:构建项目启动类,并进行服务启动,检测是否正确,例如:
package com.jt; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; @SpringBootApplication public class ResourceApplication { public static void main(String[] args) { SpringApplication.run(ResourceApplication.class,args);网关跨域配置
当我们基于Ajax技术访问网关时,需要在网关层面进行跨域设计,例如:
package com.jt.config; import org.springframework.context.annotation.Bean; import org.springframework.web.cors.CorsConfiguration; import org.springframework.web.cors.reactive.CorsWebFilter; import org.springframework.web.cors.reactive.UrlBasedCorsConfigurationSource; //@Configuration public class CorsFilterConfig { @Bean public CorsWebFilter corsWebFilter(){ //1.构建基于url方式的跨域配置 UrlBasedCorsConfigurationSource source= new UrlBasedCorsConfigurationSource(); //2.进行跨域配置 CorsConfiguration config=new CorsConfiguration(); //2.1允许所有ip:port进行跨域 config.addAllowedOrigin("*"); //2.2允许所有请求头跨域 config.addAllowedHeader("*"); //2.3允许所有请求方式跨域:get,post,.. config.addAllowedMethod("*"); //2.4允许携带有效cookie进行跨域 config.setAllowCredentials(true); source.registerCorsConfiguration("/**",config); return new CorsWebFilter(source);Spring Gateway工程中的跨域设计,除了可以在网关项目中以java代码方式进行跨域过滤器配置,还可以直接在配置文件进行跨域配置,例如:
spring: cloud: gateway: globalcors: #跨域配置 corsConfigurations: '[/**]': allowedOrigins: "*" allowedHeaders: "*" allowedMethods: "*" allowCredentials: true启动工程进行服务访问
首先打开网关(Gateway),资源服务器(Resource),客户端工程服务(UI),然后修改fileupload.html文件中访问资源服务端的url,例如
let url="http://localhost:9000/sca/resource/upload/";接下来进行访问测试,例如:
网关上对文件上传限流
第一步:在网关pom文件中添加依赖
<dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-sentinel</artifactId> </dependency> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-alibaba-sentinel-gateway</artifactId> </dependency>第二步:在网关配置文件中添加sentinel配置
sentinel: transport: dashboard: localhost:8180 eager: true第三步:在网关项目启动时,配置jvm启动参数,例如:
-Dcsp.sentinel.app.type=1第四步:先执行一次上传,然后对上传进行限流规则设计
第五步:修改文件上传页面js,对限流结果进行处理,例如:function upload(file){ //定义一个表单(axios中提供的表单对象) let form=new FormData(); //将文件添加到表单中 form.append("uploadFile",file); //异步提交(现在是提交到网关) //let url="http://localhost:8881/resource/upload/" let url="http://localhost:9000/sca/resource/upload/"; axios.post(url,form) .then(function (response){ alert("upload ok") console.log(response.data); .catch(function (e){//失败时执行catch代码块 //被限流后服务端返回的状态码为429 if(e.response.status==429){ alert("上传太频繁了"); console.log("error",e);第六步:启动服务进行文件上传测试,检测限流效果
AOP方式操作日志记录
在实现文件上传业务时,添加记录日志的操作.
添加项目依赖
在sca-resource工程中添加AOP依赖,例如:
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-aop</artifactId> </dependency>创建切入点注解
我们项目要为目标业务实现功能增强,锦上添花,但系统要指定谁是目标业务,这里我们定义一个注解,后续用此注解描述目标业务。
package com.jt.resource.annotation; import java.lang.annotation.ElementType; import java.lang.annotation.Retention; import java.lang.annotation.RetentionPolicy; import java.lang.annotation.Target; @Retention(RetentionPolicy.RUNTIME) @Target(ElementType.METHOD) public @interface RequiredLog { String value() default "";定义切入点方法
通过上面定义的注解RequiredLog,对sca-resources工程中的ResourceController文件上传方法进行描述,例如:
@RequiredLog("upload file") @PostMapping("/upload/") public String uploadFile(MultipartFile uploadFile) throws IOException {...}说明:通过@RequiredLog注解描述的方法可以认为锦上添花的“锦”,后续添花的行为可以放在切面的通知方法中。
定义日志操作切面
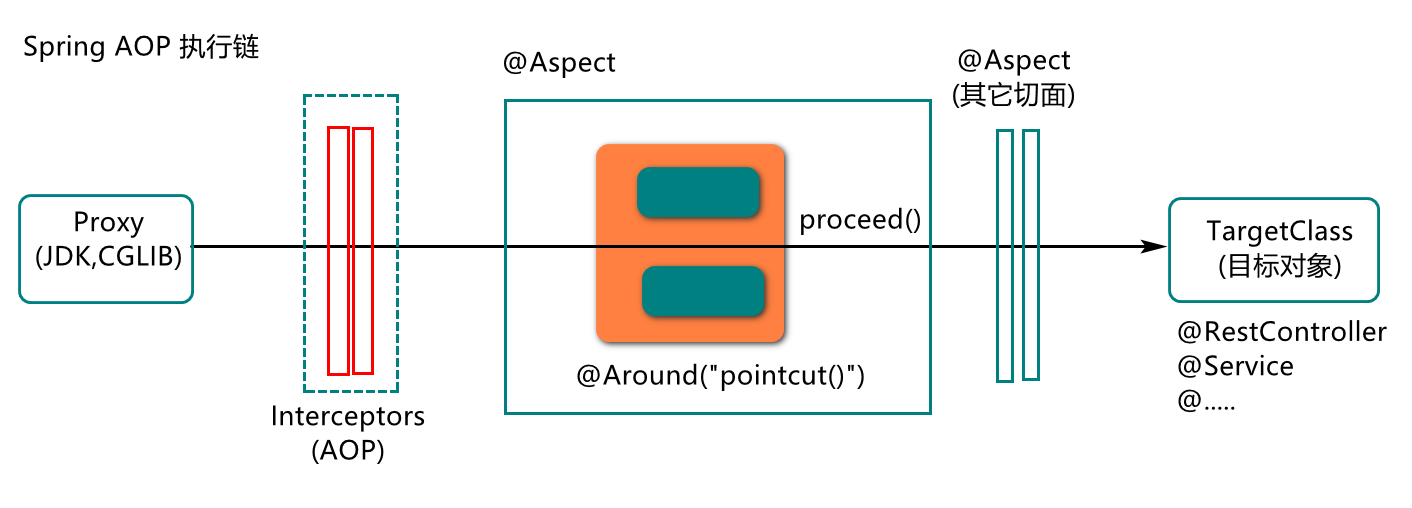
在AOP编程设计中,我们会通过切面封装切入点(Pointcut)和扩展业务逻辑(Around,…)的定义,例如:
package com.jt.resource.aspect; import lombok.extern.slf4j.Slf4j; import org.aspectj.lang.ProceedingJoinPoint; import org.aspectj.lang.annotation.Around; import org.aspectj.lang.annotation.Aspect; import org.aspectj.lang.annotation.Pointcut; import org.springframework.stereotype.Component; @Slf4j @Aspect @Component public class LogAspect { //定义切入点 @Pointcut("@annotation(com.jt.resource.annotation.RequiredLog)") public void doLog(){}//锦上添花的锦(注解描述的方法) //定义扩展业务逻辑 @Around("doLog()") //@Around("@annotation(com.jt.resource.annotation.RequiredLog)") public Object doAround(ProceedingJoinPoint joinPoint) throws Throwable { log.debug("Before {}",System.currentTimeMillis()); Object result=joinPoint.proceed();//执行执行链(其它切面,目标方法-锦) log.debug("After {}",System.currentTimeMillis()); return result;//目标方法(切入点方法)的执行结果AOP 方式日志记录原理分析
我们在基于AOP方式记录用户操作日志时,其底层工作流程如下:
说明:当我们在项目中定义了AOP切面以后,系统启动时,会对有@Aspect注解描述的类进行加载分析,基于切入点的描述为目标类型对象,创建代理对象,并在代理对象内部创建一个执行链,这个执行链中包含拦截器(封装了切入点信息),通知(Around,…),目标对象等,我们请求目标对象资源时,会直接按执行链的顺序对资源进行调用。总结(Summary)
本章节已经文件上传为例回顾和加强微服务基础知识的掌握和实践。
09-微服务版的单点登陆系统设计及实现
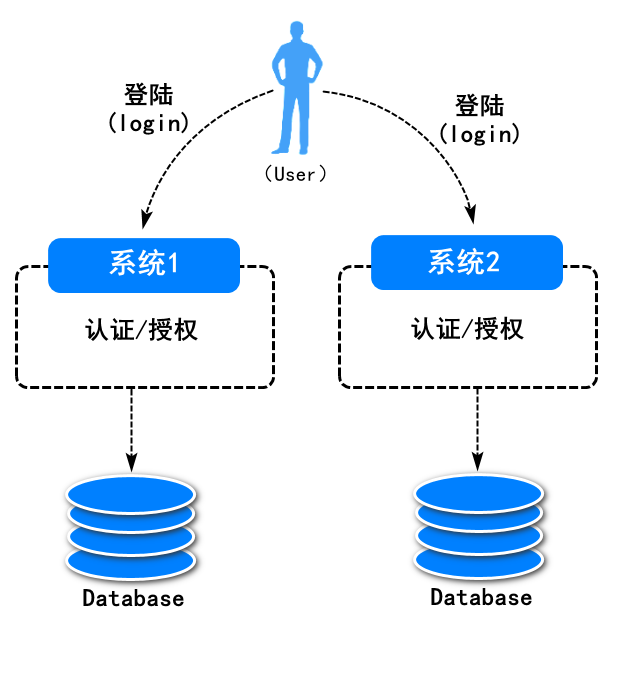
传统的登录系统中,每个站点都实现了自己的专用登录模块。各站点的登录状态相互不认可,各站点需要逐一手工登录。例如:
这样的系统,我们又称之为多点登陆系统。应用起来相对繁琐(每次访问资源服务都需要重新登陆认证和授权)。与此同时,系统代码的重复也比较高。由此单点登陆系统诞生。单点登陆系统
单点登录,英文是 Single Sign On(缩写为 SSO)。即多个站点共用一台认证授权服务器,用户在其中任何一个站点登录后,可以免登录访问其他所有站点。而且,各站点间可以通过该登录状态直接交互。例如:
快速入门实践
工程结构如下
基于资源服务工程添加单点登陆认证和授权服务,工程结构定义如下:
创建认证授权工程
添加项目依赖
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-oauth2</artifactId> </dependency> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId> </dependency> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId> </dependency>构建项目配置文件
在sca-auth工程中创建bootstrap.yml文件,例如:
server: port: 8071 spring: application: name: sca-auth cloud: nacos: discovery: server-addr: localhost:8848 config: server-addr: localhost:8848添加项目启动类
package com.jt; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; @SpringBootApplication public class ResourceAuthApplication { public static void main(String[] args) { SpringApplication.run(ResourceAuthApplication.class, args);启动并访问项目
项目启动时,系统会默认生成一个登陆密码,例如:
打开浏览器输入http://localhost:8071呈现登陆页面,例如:
其中,默认用户名为user,密码为系统启动时,在控制台呈现的密码。执行登陆测试,登陆成功进入如下界面(因为没有定义登陆页面,所以会出现404):自定义登陆逻辑
我们的单点登录系统最终会按照如下结构进行设计和实现,例如:
我们在实现登录时,会在UI工程中,定义登录页面(login.html),然后在页面中输入自己的登陆账号,登陆密码,将请求提交给网关,然后网关将请求转发到auth工程,登陆成功和失败要返回json数据,在这个章节我们会按这个业务逐步进行实现
定义安全配置类
修改SecurityConfig配置类,添加登录成功或失败的处理逻辑,例如:
package com.jt.auth.config; import org.codehaus.jackson.map.ObjectMapper; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.security.authentication.AuthenticationManager; import org.springframework.security.config.annotation.web.builders.HttpSecurity; import org.springframework.security.config.annotation.web.configuration.WebSecurityConfigurerAdapter; import org.springframework.security.core.Authentication; import org.springframework.security.core.AuthenticationException; import org.springframework.security.crypto.bcrypt.BCryptPasswordEncoder; import org.springframework.security.web.authentication.AuthenticationFailureHandler; import org.springframework.security.web.authentication.AuthenticationSuccessHandler; import javax.servlet.ServletException; import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletResponse; import java.io.IOException; import java.io.PrintWriter; import java.util.HashMap; import java.util.Map; * spring security 配置类,此类中要配置: * 1)加密对象 * 2)配置认证规则 * 当我们在执行登录操作时,底层逻辑(了解): * 1)Filter(过滤器) * 2)AuthenticationManager (认证管理器) * 3)AuthenticationProvider(认证服务处理器) * 4)UserDetailsService(负责用户信息的获取及封装) @Configuration public class SecurityConfig extends WebSecurityConfigurerAdapter { //初始化加密对象 //此对象提供了一种不可逆的加密方式,相对于md5方式会更加安全 @Bean public BCryptPasswordEncoder passwordEncoder(){ return new BCryptPasswordEncoder(); /**配置认证规则*/ @Override protected void configure(HttpSecurity http) throws Exception { //super.configure(http);//默认所有请求都要认证 //1.禁用跨域攻击(先这么写,不写会报403异常) http.csrf().disable(); //2.放行所有资源的访问(后续可以基于选择对资源进行认证和放行) http.authorizeRequests() .anyRequest().permitAll(); //3.自定义定义登录成功和失败以后的处理逻辑(可选) //假如没有如下设置登录成功会显示404 http.formLogin()//这句话会对外暴露一个登录路径/login .successHandler(successHandler()) .failureHandler(failureHandler()); //定义认证成功处理器 //登录成功以后返回json数据 @Bean public AuthenticationSuccessHandler successHandler(){ // return new AuthenticationSuccessHandler() { // @Override // public void onAuthenticationSuccess(HttpServletRequest httpServletRequest, HttpServletResponse httpServletResponse, Authentication authentication) throws IOException, ServletException { // } // }; //lambda return (request,response,authentication)->{ //构建map对象封装到要响应到客户端的数据 Map<String,Object> map=new HashMap<>(); map.put("state",200); map.put("message", "login ok"); //将map对象转换为json格式字符串并写到客户端 writeJsonToClient(response,map); //定义登录失败处理器 @Bean public AuthenticationFailureHandler failureHandler(){ return (request,response,exception)->{ //构建map对象封装到要响应到客户端的数据 Map<String,Object> map=new HashMap<>(); map.put("state",500); map.put("message", "login error"); //将map对象转换为json格式字符串并写到客户端 writeJsonToClient(response,map); private void writeJsonToClient( HttpServletResponse response, Map<String,Object> map) throws IOException { //将map对象,转换为json String json=new ObjectMapper().writeValueAsString(map); //设置响应数据的编码方式 response.setCharacterEncoding("utf-8"); //设置响应数据的类型 response.setContentType("application/json;charset=utf-8"); //将数据响应到客户端 PrintWriter out=response.getWriter(); out.println(json); out.flush();定义用户信息处理对象
在spring security应用中底层会借助UserDetailService对象获取数据库信息,并进行封装,最后返回给认证管理器,完成认证操作,例如:
package com.jt.auth.service; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.security.core.GrantedAuthority; import org.springframework.security.core.authority.AuthorityUtils; import org.springframework.security.core.userdetails.User; import org.springframework.security.core.userdetails.UserDetails; import org.springframework.security.core.userdetails.UserDetailsService; import org.springframework.security.core.userdetails.UsernameNotFoundException; import org.springframework.security.crypto.bcrypt.BCryptPasswordEncoder; import org.springframework.stereotype.Service; import java.util.List; * 登录时用户信息的获取和封装会在此对象进行实现, * 在页面上点击登录按钮时,会调用这个对象的loadUserByUsername方法, * 页面上输入的用户名会传给这个方法的参数 @Service public class UserDetailsServiceImpl implements UserDetailsService { @Autowired private BCryptPasswordEncoder passwordEncoder; //UserDetails用户封装用户信息(认证和权限信息) @Override public UserDetails loadUserByUsername(String username) throws UsernameNotFoundException { //1.基于用户名查询用户信息(用户名,用户状态,密码,....) //Userinfo userinfo=userMapper.selectUserByUsername(username); String encodedPassword=passwordEncoder.encode("123456"); //2.查询用户权限信息(后面会访问数据库) //这里先给几个假数据 List<GrantedAuthority> authorities = AuthorityUtils.createAuthorityList(//这里的权限信息先这么写,后面讲 "sys:res:create", "sys:res:retrieve"); //3.对用户信息进行封装 return new User(username,encodedPassword,authorities);网关中登陆路由配置
在网关配置文件中添加登录路由配置,例如
- id: router02 uri: lb://sca-auth #lb表示负载均衡,底层默认使用ribbon实现 predicates: #定义请求规则(请求需要按照此规则设计) - Path=/auth/login/** #请求路径设计 filters: - StripPrefix=1 #转发之前去掉path中第一层路径基于Postman进行访问测试
启动sca-gateway,sca-auth服务,然后基于postman访问网关,执行登录测试,例如:
自定义登陆页面
在sca-resource-ui工程的static目录中定义登陆页面,例如:
<!doctype html> <html lang="en"> <!-- Required meta tags --> <meta charset="utf-8"> <meta name="viewport" content="width=device-width, initial-scale=1"> <!-- Bootstrap CSS --> <link href="https://cdn.jsdelivr.net/npm/bootstrap@5.0.2/dist/css/bootstrap.min.css" rel="stylesheet" integrity="sha384-EVSTQN3/azprG1Anm3QDgpJLIm9Nao0Yz1ztcQTwFspd3yD65VohhpuuCOmLASjC" crossorigin="anonymous"> <title>login</title> </head> <div class="container"id="app"> <h3>Please Login</h3> <div class="mb-3"> <label for="usernameId" class="form-label">Username</label> <input type="text" v-model="username" class="form-control" id="usernameId" aria-describedby="emailHelp"> <div class="mb-3"> <label for="passwordId" class="form-label">Password</label> <input type="password" v-model="password" class="form-control" id="passwordId"> <button type="button" @click="doLogin()" class="btn btn-primary">Submit</button> </form> <script src="https://cdn.jsdelivr.net/npm/bootstrap@5.0.2/dist/js/bootstrap.bundle.min.js" integrity="sha384-MrcW6ZMFYlzcLA8Nl+NtUVF0sA7MsXsP1UyJoMp4YLEuNSfAP+JcXn/tWtIaxVXM" crossorigin="anonymous"></script> <script src="https://cdn.jsdelivr.net/npm/vue/dist/vue.js"></script> <script src="https://unpkg.com/axios/dist/axios.min.js"></script> <script> var vm=new Vue({ el:"#app",//定义监控点,vue底层会基于此监控点在内存中构建dom树 data:{ //此对象中定义页面上要操作的数据 username:"", password:"" methods: {//此位置定义所有业务事件处理函数 doLogin() { //1.定义url let url = "http://localhost:9000/auth/login" //2.定义参数 let params = new URLSearchParams() params.append('username',this.username); params.append('password',this.password); //3.发送异步请求 axios.post(url, params).then((response) => { debugger let result=response.data; console.log(result); if (result.state == 200) { alert("login ok"); } else { alert(result.message); </script> </body> </html>