一、背景:员工技能培训真的是浪费时间吗
假设你是一家大企业的老板,你希望知道员工技能培训对员工生产率的提升有多大帮助。已知参加培训的员工有500人,于是你又随机抽取了500个未参加培训的员工,观察两组之间生产率的差值(ATE),并打算以此作为培训对生产率提升的因果效应。结果发现,两组员工的生产率相差不大,于是你得出“员工培训都是浪费时间”的结论。
试问,这个老板得到的结论正确吗?我们且不说结论本身是否正确,但是可以确定老板得到结论的过程缺乏科学性(不满足CIA假设)。因为我们知道这两组员工本身生产能力可能就有差别,参加培训的员工往往都是技能水平不足想要提升的,而技能优秀的员工一般都不会参加培训。直接将两组生产率作差值忽略了两组员工本身技能水平的差异,这样计算得到的因果效应会偏小。那该怎么做才能得到正确的结论呢?
最理想的做法是说,让参加了培训的张三再倒退回参加培训前的时间点(回溯),然后不参加培训再过一遍人生,看看这两个人生的张三生产率有什么差异(ATT)。很明显,时光无法倒流,最真实的因果效应只停留在理论层面。但是可以退而求其次,尽最大努力去寻找一个没有参加培训的李四,他在各方面都和张三是一样的(替身),简直是张三的翻版。于是我们通过比较张三和李四生产率的差异,也能够得出比较准确的因果效应(ATT估计值)。那么该如何寻找李四呢?
二、PSM的原理及python实现
1、PSM的原理
这里倾向得分匹配(PSM,Propensity Score Matching)就要登场了。PSM通俗理解是说,首先计算每个人参加培训的倾向性,然后根据倾向性最相似的原则,为每个参加培训的人匹配未参加培训的人,最后计算两组人群的均值差异作为ATT的估计值(因果效应)。下面是PSM的详细步骤:
1.1 计算倾向性得分
关于PSM倾向性得分的计算方式,不能用简单的欧氏距离来计算是因为欧氏距离对每个协变量的权重是一样的,当协变量维度很高时会影响得分的计算效果。一般用LR来计算倾向性得分,因为LR能够赋予协变量不同的权重。还有很多方法比如用Propensity Tree来计算得分等等。
1.2 匹配对照组样本
倾向性得分计算完成后,还需要为实验组的每个样本,从对照组中采集合适的样本去做匹配。PSM匹配环节有以下几个要点:
1)采样方式
,有放回or无放回采样:从对照组抽取样本去匹配实验组样本时,被抽到的对照组样本是否允许放回。
2)匹配方式
,局部最优or全局最优:应当追求为实验组每个样本找到的替身都是最匹配的(局部最优),还是整体来看实验组找到的替身是最匹配的(全局最优)。
3)匹配数量
,一对一or一对多:一个实验组样本匹配一个对照组样本(一对一,偏差小,方差大),还是一个实验组用户匹配多个对照组用户(一对多,偏差大,方差小)。
4)匹配质量
,有卡尺or无卡尺:实验组和对照组做匹配时,他们之间相似度是否需要限制在一定范围内(有卡尺),还是只要当前对照组样本是最匹配的即可(无卡尺)。
1.3 平衡性检查
如何衡量PSM的匹配效果?或者说怎么判断PSM后实验组和对照组是否是同质的呢?下面介绍3种评估平衡性的方法:
1)观察法
:直接做协变量分布的直方图或QQ-Plot,观察实验组和对照组的协变量是否符合同一分布。
2)量化法
:计算每个混淆变量的标准化差值(stddiff),stddiff越小说明混淆变量在实验组和对照组间越均衡,因果效应的估计值也就越可靠。
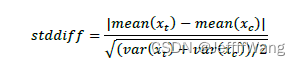
3)卡方检验
:每个协变量和treatment做卡方检验,若检验通过(p>0.05)则说明协变量和treatment是相互独立的,检验未通过(p<0.05)说明协变量对treatment是有影响的,因果效应中来自协变量的影响没有剔除干净。
目前为止,我们已经有一对接近同质的实验组和对照组了,接下来就可以估算实验的ATT了,最简单的做法是计算实验组和对照组均值的差值。
如果平衡性检查都通过了,说明已经得到了同质的实验组和对照组,下面就可以放心估计因果效应了。最简单的方法,是将两组样本均值直接做差,将差值作为因果效应的估计值。
1.4 敏感度分析
如何衡量我们估计的因果效应是不是可靠的呢?具体地说,混淆变量的主观选择会得到不一样的结论吗?当干预变量T不存在时,因果效应还会存在吗?下面介绍常用的评估方法,即反驳测试:
1)安慰剂数据法
:随机生成一列数据替代真实的treatment列,每个个体接收处理的事实已经不存在了,因此如果反驳测试中的因果效果大幅下降且接近0,说明了treatment对target具有一定的因果效应。
2)添加随机混淆变量法
:添加一列随机生成的混淆变量,若反驳测试的因果效应较真实因果效应估计值变化不大,则说明其因果效应的估计值是可靠的。
2、PSM的python实现
下面介绍一个用Python实现PSM的案例,即新建诊所是否能降低新生儿死亡率。
数据样例:
|
OPTUM_LAB_ID
|
CASE
|
infant_mortality
|
poverty_rate
|
per_capita_doctors
|
|
1
|
1
|
10
|
0.5
|
0.01
|
|
2
|
1
|
15
|
0.6
|
0.02
|
|
3
|
1
|
22
|
0.7
|
0.01
|
|
4
|
1
|
19
|
0.6
|
0.02
|
|
5
|
0
|
25
|
0.6
|
0.01
|
|
6
|
0
|
19
|
0.5
|
0.02
|
|
7
|
0
|
4
|
0.1
|
0.04
|
|
8
|
0
|
8
|
0.3
|
0.05
|
|
9
|
0
|
6
|
0.2
|
0.04
|
其中
OPTUM_LAB_ID
表示样本序号,
CASE(T)
表示“是否有诊所”,
infant_mortality(Y)
表示新生儿死亡率(百分比)。两个混淆变量,
poverty_rate
贫穷率和
per_capita_doctors
人均医生数量。
下面直接上完整的PSM代码,包括详细的注释:
import psmatching.match as psm
import numpy as np
# 数据集的地址,默认数据文件是csv格式,其他格式可能会报错
path=r'infant mortality.csv'
# 计算倾向性得分的模型格式,格式:Y~X1+X2+...+Xn,其中Y为treatment列,X为协变量列
model = "CASE ~ poverty_rate + per_capita_doctors"
# k每个实验组样本所匹配的对照组样本的数量
k = "1"
# 初始化PSMatch实例
m = psm.PSMatch(path, model, k)
# 计算倾向得分,为接下来的匹配准备数据
m.prepare_data()
# 根据倾向性得分做匹配,其中caliper代表是否有卡尺,replace代表是否是有放回采样
m.match(caliper = None, replace = True)
# 混淆变量与treatment做卡方检验,检验混淆变量和treatment是不是独立的
m.evaluate()
# 获取匹配后的样本
mdt = m.matched_data
# 计算实验的因果效应(ATT)
y_1=np.average(mdt[mdt.CASE==1]['infant_mortality'])
y_0=np.average(mdt[mdt.CASE==0]['infant_mortality'])
ATT=y_0-y_1
print(ATT)
最后计算得到的ATT为5.5,说明新建诊所能够降低约5.5%的新生儿死亡率。
本来想尝试下如果不使用运营商网络应用平台情况下,只是在服务商服务器上是否可以
实现
对终端完全控制,如果这样可行,那么物联网应用服务端更有灵活性。实际情况下,很难
实现
和运营商网络对等的处理,用
python
代码原型确实能够
实现
参数的变化(如
PSM
,eDXR等),但是终端分配的IP地址毕竟属于接入网部分,更近似一个局域网,如果采用其他方式访问(如IMSI、IMEI等),还是需要与运营商核心网进行配合。以下是尝试远程控制的
实现
方法。
主要
实现
功能
1、使用
python
pyserial模块通过串口发送AT命令给模组进行参数修改,参考<使用
python
pyserial模块串口通信>;
2、通过int
psm
-
python
脚本管理器
这是一个受pipsi启发并与pipsi类似的工具,但它只是一个独立的shell脚本,这意味着您无需在系统上安装pip或virtualenv或除普通
Python
3.4或更高版本以外的任何东西即可安装或使用它。
curl https://raw.githubusercontent.com/anlutro/
psm
/master/install-
psm
.bash | bash
...或者只是将
psm
.bash复制到$PATH您喜欢的目录中。
安装一个或多个pip软件包及其脚本:
psm
install b
python
streamlink
升级一个或多个现有软件包,或升级所有已安装的软件包:
psm
upgrade bpyton streamlink
psm
upgrade-all
卸载一个或多个软件包:
psm
uninstall strea
在交互式监视模式下启动测试运行器。 有关更多信息,请参见关于的部分。
yarn build
构建生产到应用程序build文件夹。 它在生产模式下正确捆绑了React,并优化了构建以获得最佳性能。
生成被最小化,并且文件名包括哈希值。 您的应用已准备好进行部署!
有关更多信息,请参见关于的部分。
yarn eject
注意:这是单向操作。 eject ,您将无法返回!
如果您对构建工具和配置选择不满意,则可以随时eject 。 此命令将从您的项目中删除单个生成依赖项。
相反,它将所有配置文件和传递依赖项(webpac
PSM
(Propensity Score Matching,倾向得分匹配)是一种常用的
因果
推断
方法,其主要思想是通过估计个体的倾向得分,将具有相似倾向得分的个体进行匹配,从而消除潜在的混淆因素,
实现
因果
推断
。
以下是使用
PSM
进行
因果
推断
的具体步骤:
1. 确定研究问题和研究对象,设计研究方案并收集相关数据。
2. 估计个体的倾向得分,即通过回归模型预测个体属于处理组的概率,常见的回归模型包括逻辑回归、Probit回归等。
3. 根据倾向得分进行匹配,常见的匹配方法有最近邻匹配、卡方匹配、贪心匹配等。
4. 检验匹配效果,即通过比较处理组和对照组在各个混淆因素上的均衡性来验证匹配的有效性。
5. 进行
因果
推断
,即通过比较处理组和对照组在研究结果上的差异,来估计处理效应,并进行统计检验。
需要注意的是,
PSM
虽然可以消除潜在的混淆因素,但仍然存在一些限制,例如倾向得分的估计可能存在误差,匹配过程可能会造成样本减少等,因此在使用
PSM
进行
因果
推断
时需要谨慎。
因果推断-【The MineThatData E-Mail Analytics And Data Mining Challenge】思路分析与Python实现代码
JeffffWang:
因果推断-【The MineThatData E-Mail Analytics And Data Mining Challenge】思路分析与Python实现代码
JeffffWang:

