GAMA: Generative Adversarial Multi-Object Scene Attacks(NeurIPS 2022)
代码:https://github.com/abhishekaich27/GAMA-pytorch
大多数制作对抗攻击的方法都集中在具有单一主导对象的场景上(例如,来自ImageNet的图像)。另一方面,自然场景包括多个语义相关的主导对象。因此,探索设计攻击策略是至关重要的,这些策略不仅仅局限于学习单对象场景或攻击单对象受害者分类器。由于生成模型固有的扰动对未知模型的强可转移性,本文提出了第一个使用生成模型进行多目标场景对抗性攻击的方法。为了表示输入场景中不同对象之间的关系,我们利用了开源预训练的视觉-语言模型CLIP(对比语言-图像预训练),动机是利用语言空间和视觉空间中的编码语义。我们称这种攻击方法为生成对抗多目标攻击(GAMA)。GAMA演示了CLIP模型作为攻击者的工具的效用,为多目标场景训练强大的扰动生成器。使用联合图像-文本特征来训练生成器,我们表明GAMA可以制造有效的可转移扰动,以便在各种攻击设置中欺骗受害者分类器。例如,在攻击者的分类器架构和数据分布都与受害者不同的黑盒设置中,GAMA比最先进的生成方法多触发16%的错误分类率。
本文提出的GAMA攻击使用CLIP模型来利用文本特征中编码的自然语言语义以及视觉特征(由于其联合图像-文本对齐属性)。与之前的工作不同,GAMA利用CLIP模型从约4亿张图像中提取的知识,最大限度地提高了扰动图像
\(x_p\)
与干净图像
\(x_c\)
计算的两种不同类型特征的特征差异:(1)从代理模型计算的
\(x_c\)
特征,(2)从CLIP的图像编码器计算的
\(x_c\)
特征。此外,GAMA还通过一个对比损失函数,通过使用CLIP的文本编码器的特征,指导
\(x_p\)
包含与
\(x_c\)
不同的特征。例如,在图1中,考虑一个干净的图像
\(x_c\)
,对象为“沙发和瓶子”。使用CLIP的图像-文本对齐特性,我们估计在一些随机选择的候选(由虚线圈表示)中,$x_c
\((具有文本特征\)
_c
\()与文本提示“汽车和自行车”(文本特征\)
_p
\()最不相似。GAMA使用从上下文一致的类创建的\)
p
\(,在特征空间中将受扰动的\)
x_p
\(与\)
x_c
\(进行对比和移动。因为\)
G
()$被优化以创建来自两个不同图像特征的不同特征的扰动。这使得GAMA可以对看不见的受害者模型发起高度可转移的攻击。
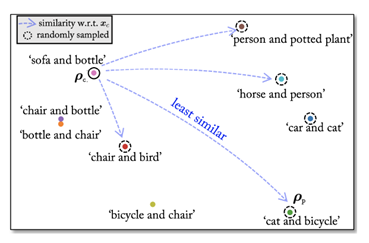 image-20230221101857994
image-20230221101857994
问题定义 从具有多个对象的图像训练分布训练一个模型
\(\mathcal{G}\left(\cdot\right)\)
,假设我们可以访问一个源数据集
\(\mathcal{D}\)
,它由来自
\(C\)
个类的
\(N\)
个训练样本组成,每个样本/图像可能由多个对象标签组成,即多标签图像。
\(\mathcal{D}\)
中的每个第
\(i\)
个样本表示为
\(x^{\left(i\right)}\in\mathbb{R}^{H\times W\times T}\)
(高H,宽W,通道T),包含标签
\(y^{\left(i\right)}=[y_1^{(i)},···,y_c^{(i)}]\in\mathcal{Y}⊆\{0,1\}^C\)
。更具体地说,如果样本
\(x^{\left(i\right)}\)
与类别
\(c\)
相关,
\(y_c^{\left(i\right)}\)
表示在
\(x^{\left(i\right)}\)
中存在一个来自类
\(c\)
的对象。此外,我们可以使用一个在
\(\mathcal{D}\)
上训练的代理多标签分类器,记为
\(f(·)\)
,用于优化扰动发生器
\(\mathcal{G}_\theta\left(\cdot\right)\)
的权值
\(\theta\)
。
在本文中一个预训练的CLIP被用作损失网络,使用CLIP的动机是利用其联合文本和图像匹配属性,并计算两种嵌入:从图像编码器中提取的干净图像嵌入和从文本编码器中提取的不同文本嵌入。目标是通过语言衍生来编码自然场景中多个对象之间的上下文关系。我们假设每张图像包含两个用于创建文本提示的共同出现类别,这主要是由于可用于多标签数据集的维
\(C\times C\)
的共现矩阵的计算而受到限制。正如我们稍后将看到的,共现矩阵允许我们丢弃在现实场景中不会出现的类对。
GAMA。在训练
\(\mathcal{G}_\theta\left(\cdot\right)\)
之前,我们首先使用CLIP文本编码器
\(\mathcal{T}\left(\cdot\right)\)
计算一个文本嵌入矩阵
\(A_{txt}=[ρ_1,ρ_2,···,ρ_N]∈R^{N×K}\)
,
\(ρ_N∈R^K\)
(后面会详细解释)。其中,
\(K\)
为
\(\mathcal{T}\left(\cdot\right)\)
输出的嵌入大小。在训练
\(\mathcal{G}_\theta\left(\cdot\right)\)
期间,我们首先将干净的图像
\(x\)
输入CLIP图像编码器
\(\mathcal{I}(\cdot)\)
,并计算图像嵌入
\(\rho_{img}=I\left(x\right)\in R^K\)
。接下来,从
\(A_{txt}\)
中提取一个与
\(\rho_{img}\)
相似度最小的特定向量
\(\rho_{txt}\in R^K\)
。然后,我们用扰动投影算子
\(\mathcal{P}(\cdot)\)
将x输入到
\(\mathcal{G}_\theta\left(\cdot\right)\)
,得到
\(x_\delta\)
,同时确保它在给定扰动
\(\ell_\infty\)
约束下。然后将这些干净的和扰动的图像输入代理分类器
\(f(·)\)
,在特定的第
\(k\)
层提取
\(k\)
维嵌入,分别用
\(f_k\left(x\right)\)
和
\(f_k\left(x_\delta\right)\)
表示。最后,使用上述四组嵌入(
\(\rho_{txt}\)
,
\(ρ_{img}\)
,
\(f_k(x)\)
,
\(f_k(x_δ)\)
)来计算基于对比学习的CLIP文本嵌入引导的损失
\(\mathcal{L}_{txt}(ρ_{txt},f_k(x),f_k(x_δ))\)
和基于回归学习的CLIP图像嵌入引导的损失
\(\mathcal{L}_{\mathcal{img}}\left(\rho_{img},f_k\left(x_\delta\right)\right)\)
来计算最终目标
\(\mathcal{L}\)
。我们还包括一个损失函数,进一步从替代分类器的角度最大化
\(f_k\left(x\right)\)
和
\(f_k\left(x_\delta\right)\)
之间的差异。这个损失
\(\mathcal{L}\)
被最小化,以更新生成器
\(\theta\)
的权值。整个GAMA算法如图2所示,并在算法1中进行了总结。下面讨论损失目标
\(\mathcal{L}_{\mathcal{img}}\)
和
\(\mathcal{L}_{\mathcal{txt}}\)
(文本嵌入矩阵
\(A_{txt}\)
)的细节。
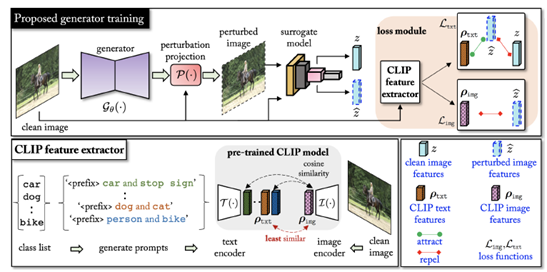 image-20230221103914078
image-20230221103914078
 image-20230221103925115
image-20230221103925115
CLIP 文本嵌入引导损失
\((\mathcal{L}_{\mathcal{t}xt})\)
。设
\(z=f_k\left(x\right)\quad\hat{z}=f_k\left(x_\delta\right)\)
。CLIP框架固有地通过对比学习机制学习文本和视觉嵌入关联,限制输入图像的特征嵌入与其对应的语言描述尽可能相似。与CLIP的图像嵌入
\(\rho_{img}\)
不同,CLIP的文本嵌入
\(\rho_{txt}\)
可以让我们超越基于像素的特征。更具体地说,CLIP的视觉和语言对齐能力允许我们利用文本特征来制作可转移的图像扰动。因此,我们可以优化
\(\mathcal{G}_\theta\left(\cdot\right)\)
来创建扰动图像
\(x_\delta\)
,这些图像不遵循与干净图像对应的
\(x\)
相同的文本嵌入对齐方式。为了引起这种文本错位,我们创建了一个嵌入的三重组,其中
\(x_\delta\)
被推离
\(z\)
,同时将其拉近与干净图像
\(x\)
关联最少或相似的文本嵌入
\(\rho_{txt}\)
。为了计算这个三重组,执行以下两个步骤。
训练之前计算
\(A_{txt}\)
。目标是创建一个文本嵌入的字典或矩阵,可以在优化
\(\mathcal{G}_\theta\left(\cdot\right)\)
时用于检索
\(\rho_{txt}\)
。首先,我们使用源分布类生成语言衍生物或文本提示。这意味着我们只需要知道
\(\mathcal{D}\)
中所有可用的类别
\(C\)
,而不需要知道它们与
\(x\)
的具体关联。其次,假设每个干净的图像
\(x\)
与两个类相关联,我们可以生成
\(C^2\)
文本提示,并创建一个大小为
\(C^2 \times k\)
的矩阵
\(A_{txt}\)
。例如,如果
\(\mathcal{D}\)
中存在类' cat ', ' dog ', ' person '和' boat ',然后可以创建文本提示,例如“一张照片描绘了猫和狗”或“一张照片描绘了人和船”(参见图1,从CLIP的“ViT-B/16”模型中使用Pascal-VOC的类提取了10个随机示例)。在这里,文本提示符下划线部分是所有文本提示符通用的推荐“前缀”。但是,这样的
\(A_{txt}\)
可以包含由现实生活中不存在的类生成的提示符的嵌入,为了避免这种情况,我们利用对象共现矩阵
\(\mathcal{O}\in R^{C\times C}\)
(二进制矩阵)来估计类之间的共现关系。从包含
\(C\)
类的训练数据集中计算,
\(\mathcal{O}\)
首先用只包含零的矩阵进行初始化。然后,如果
\(y_i\)
和
\(y_j\)
类的对象至少在一张图像中同时出现,则元
\(\mathcal{O}_{ij} (\mathcal{O}\)
的第
\(i\)
行和第
\(j\)
列)设为1。本文使用[1]提供的
\(\mathcal{O}\)
。使用这样的共现矩阵,我们只从一对根据
\(\mathcal{O}\)
一起出现的类中创建文本提示。这得到了一个大小为
\(A_{txt}\)
的文本嵌入矩阵,大小为
\(\| O\|_0\times K\)
,其中
\(\| O\| _0\)
表示总非零元素。
训练中计算
\(\rho_{txt}\)
。CLIP的训练目标允许它将相关图像-文本对的嵌入与不匹配的图像-文本对相比推得更近。我们利用这个性质来计算最小相似的文本嵌入
\(\rho_{txt}\)
w.r.t图像嵌入
\(\rho_{img}\)
。在每个训练阶段,我们从
\(A_{txt}\)
中随机抽取B个候选值
\([ρ_1,ρ_2,····,ρ_B]\)
,并对
\(\rho_{txt}\)
进行如下估计:
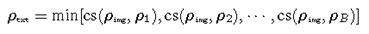 image-20230221104455104
image-20230221104455104
\(cs\left(\cdot\right)\)
代表余弦相似度,我们强制
\(\hat{z}\)
和
\(\rho_{txt}\)
对齐,和
\(z\)
远离。
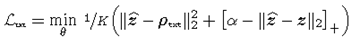 image-20230221104508674
image-20230221104508674
其中
\(\alpha>0,\left[v\right]_+=max\left(0,v\right)\)
CLIP 图像嵌入引导损失
\((\mathcal{L}_{img})\)
由于CLIP对来自不同类别的约4亿张互联网检索图像的学习,以及其在不同分布上的零样本图像识别性能,我们认为其图像编码器
\(\mathcal{I}(·)\)
输出的嵌入捕获了具有明显广义视觉特征的输入图像属性。GAMA利用这一点为我们的优势,并最大限度地提高了
\(\hat{z}\)
和CLIP的图像编码器对干净图像
\(\rho_{img}\)
的嵌入之间的差异。这样一个目标的目的是利用从
\(\mathcal{I}(·)\)
计算的广义特征来增加
\(\mathcal{G}_\theta\left(\cdot\right)\)
扰动的可转移度。用基于回归的的损失函数描述如下:
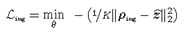 image-20230221105056309
image-20230221105056309
最终学习目标
\((\mathcal{L})\)
。
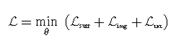 image-20230221105108607
image-20230221105108607
\(\mathcal{L}_{surr}\)
从替代模型
\(f\left(\cdot\right)\)
感知机最大化
\(x\)
和
\(x_\delta\)
,
\(\mathcal{L}_{img}\)
和
\(\mathcal{L}_{txt}\)
用CLIP提高迁移性。
将CILP引入对抗样本生成器的过程,从文本的角度编码多物体之间的关系。
[1] Zhao-Min Chen, Xiu-Shen Wei, Peng Wang, and Yanwen Guo. Multi-label image recognition with graph convolutional networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5177–5186, 2019.
ILA-DA:Improving Transferability of Intermediate Level Attack with Data Augmentation (ICLR 2023)
代码:https://github.com/argenycw/ILA-DA
阅读全文 »
Yet Another Intermediate-Level Attack(ECCV 2020)
代码:https://github.com/qizhangli/ila-plus-plus
本篇也是利用网络中间层进行攻击,是[
1
]的延续。本文的主要思想是建立一个由中间层特征到对抗损失的映射
\(W\)
,生成具有最大预期对抗损失的像素级扰动。在本文中定的对抗扰动是交叉熵损失。作者认为映射
\(W\)
包含了baseline攻击方法的每一步的信息,比单独使用最后一次迭代的结果更具有引导作用。
阅读全文 »
代码链接:https://github.com/MetaMain/ViTRobust
本文研究了ViT鲁棒性,迁移安全性研究分为3点:
在白盒和黑盒攻击场景下测试 transformer 鲁棒性
对抗样本很难从 CNN 迁移到 transformer,基于这一发现分析 CNN 和 transformer 简单的集成防御的安全性。
提出一种 self-attention blended gradient attack(SAGA),简单集成防御模型对于白盒攻击时不安全的,在黑盒对抗攻击下,作者指出集成防御模型可以在不牺牲准确率的情况下,达到较好的鲁棒性。
攻击方法:测试6种不同的白盒攻击方法:FGSM,MIN,PGD,APGD(Auto Projected Gradient Descent[
1
]),C&W,当梯度masking或者梯度混淆出现时白盒攻击失败,Backward Pass Differentiable Approximation (BPDA)[
2
],解决上述问题。
分类模型:ViT-B-32,ViT-B-16,ViT-L-16,ViT-R50,B代表模型复杂度,B模型有12层,L模型有24层。Big Transfer Models:BiT-M-R50 和 BiT-M-R101x3,ResNet-56 和ResNet-164,对于CIFAR-10 和 CIFAR-100,攻击8个模型,ViT-B-32,ViT-B-16,ViT-L-16,ViT-R50,BiT-M-R50,BiT-M-R101x3,ResNet-56 和 ResNet-164,对于ImageNet,攻击7个模型:ViT-B-16,ViT-L-16(图片大小224),ViT-L-16 (图片大小512),BiT-M-R50,BiT-MR152x4,ResNet-50 和 ResNet-152。
实验结果:
ViT对白盒攻击没有鲁棒性,表中数值代表对抗样本分类准确率,Acc代表这个模型干净样本准确率。
ViT迁移性研究
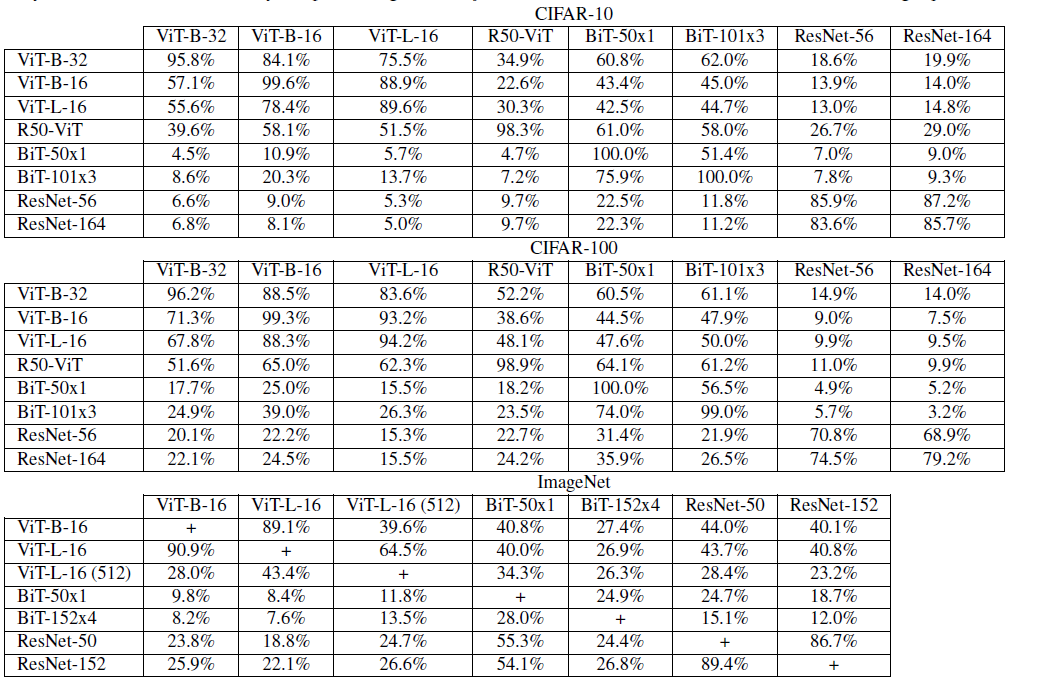 image-20220421205559121
image-20220421205559121
表中每个数据取几种攻击方法最高迁移率。
Instead of focusing completely on optimizing over one of the models, SAGA focuses on breaking multiple models at once.
攻击目标:Vision Transformers集合
\(V\)
,CNN集合
\(K\)
,在扰动
\(\epsilon\)
边界条件下使
\(V\)
和
\(K\)
所有成员都错分。
\[
x_{a d v}^{(i+1)}=x_{a d v}^{(i)}+\epsilon_{s} * \operatorname{sign}\left(G_{b l e n d}\left(x_{a d v}^{(i)}\right)\right)
G_{b l e n d}\left(x_{a d v}^{(i)}\right)=\sum_{k \in K} \alpha_{k} \frac{\partial L_{k}}{\partial x_{a d v}^{(i)}}+\sum_{v \in V} \alpha_{v} \phi_{v} \odot \frac{\partial L_{v}}{\partial x_{a d v}^{(i)}}
\(\phi_{v}\)
是
\(v^{th}\)
transformer 的自注意力图,用 attention rollout [
3
]计算如下
\[
\phi_{v}=\left(\prod_{l=1}^{n_{l}}\left[\sum_{i=1}^{n_{h}}\left(0.5 W_{l, i}^{(a t t)}+0.5 I\right)\right]\right)
\]
\(n_h\)
是每层attention heads个数,
\(n_l\)
是注意力层数,
\(W_{l,i}^{(att)}\)
是每个attention heads注意力权重矩阵,
\(I\)
是恒等矩阵,
\(x\)
是输入图像,这个公式考虑到注意力从transformer 每一层流动到下一层,包括跳跃链接的影响。平均来自同一层内不同attention heads的注意力值,注意力值在不同层之间递归地相乘。
实验结果:
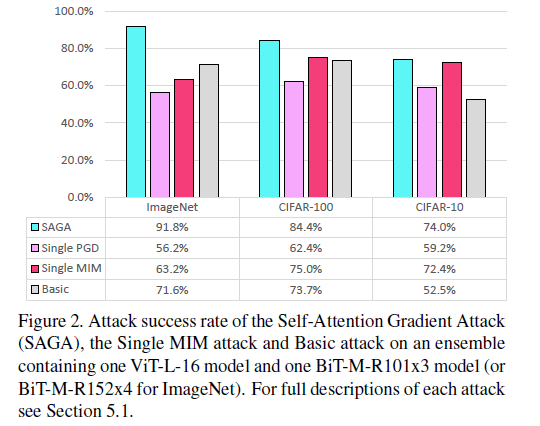 image-20220422223042259
image-20220422223042259
对Vision Transformers 和 Big Transfer Models简单集成的攻击,使用1000张正确分类的图片,
basic attack 是没有权重参数和自注意力的梯度的组合,SAGA攻击的贡献在于证明了Vision Transformers 和 Big Transfer Models简单集成对于白盒攻击是不安全的。SAGA攻击优于其他两种攻击。
黑盒安全性和迁移性
测试了 RayS attack[
4
] 和 Adaptive Black-Box Attack[
5
] 的安全性,最大查询次数10000,对于 Adaptive Black-Box Attack,攻击者可以获得全部训练数据,synthetic model 为 ViTB-32。Vision Transformer 和 Big Transfer model 的简单集成大幅提高了安全性。
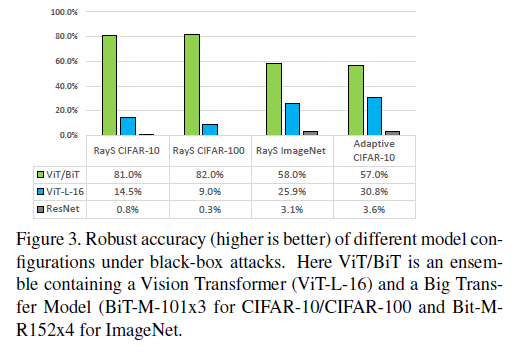 image-20220423185104889
image-20220423185104889
[1] Francesco Croce and Matthias Hein. Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks. In International Conference on Machine Learning, pages 2206–2216. PMLR, 2020.
[2] Anish Athalye, Nicholas Carlini, and David Wagner. Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples. In Proceedings of the 35th International Conference on Machine Learning, pages 274– 283, 2018.
[3] Samira Abnar and Willem Zuidema. Quantifying attention flow in transformers. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4190–4197, 2020.
[4] Jinghui Chen and Quanquan Gu. Rays: A ray searching method for hard-label adversarial attack. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 1739–1747, 2020.
[5] Kaleel Mahmood, Phuong Ha Nguyen, Lam M. Nguyen, Thanh Nguyen, and Marten van Dijk. Buzz: Buffer zones for defending adversarial examples in image classification, 2020.

