Speech recognition has been a trending topic for some time now. There are a multitude of use-cases for it and, the demand is rising. In this tutorial, I will show you how to create a React Speech Recognition App using AssemblyAI’s Speech-to-Text API and React Hooks.
Ingredients
React ^17.0.2
axios ^0.26.1
mic-recorder-to-mp3 ^2.2.2
react-loading-spinner ^6.0.0-0
Optional
to make things
🦄
tailwindcss ^3.0.23
daisyui ^2.8.0
What are We Building?
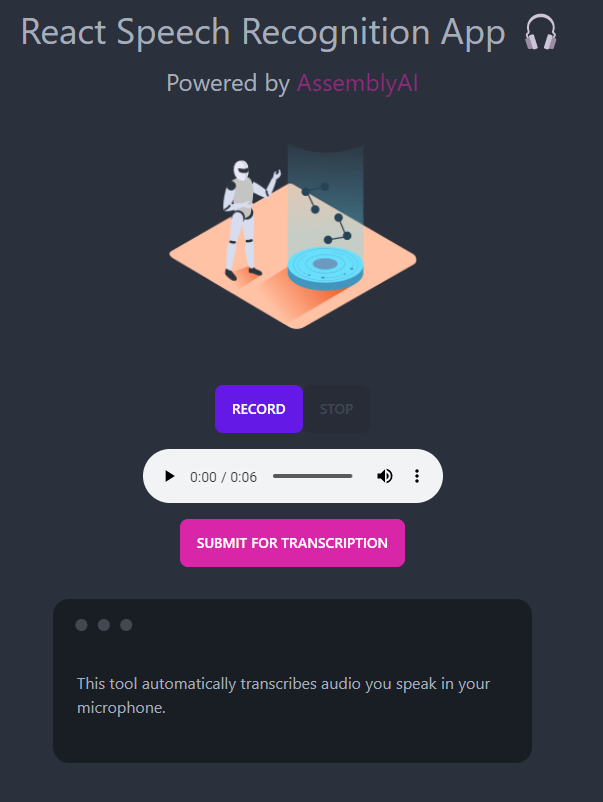
In this React Speech Recognition tutorial, we build an app that records the audio you speak into your microphone and it automatically transcribes the audio to text. The styling is completely optional, we will provide the full code with styling in our
Github Repository
for you.
We want to keep the main tutorial minimal, without confusing styles clogging up the code. Below is just an example of how it can look like if you add styling.
You can have a peek at what the finished app looks like
right here
.
Step 1 - Creating a New React App
The classic procedure you should be familiar with if you have used React before.
npx create-react-app@latest react-speech-recognition-app
cd react-speech-recognition-app
code .
Step 2 - Cleaning Up
Delete
App.css
,
App.test.js
,
logo.svg
,
reportWebVitals.js
and
setupTests.js
from
/src
Delete everything from
App.js
to look like this
function App() {
return <div></div>
export default App
Remove
reportWebVitals();
and its import from
index.js
Remove everything from
index.css
Step 3 - Installing Dependencies
Let’s get the installation part out of the way first. I will include styling dependencies - you can choose to leave them out.
To be able to create this whole React Speech Recognition app, we first need a way to record audio files. For that, we use the
mic-recorder-to-mp3
npm package that we have installed earlier.
Let’s start by importing a couple of things and adding some buttons and our audio player.
This is going to be a mouthful, but try to stay with me.
So first up, we are initiating a couple of state variables, which you should be familiar with if you have worked with
React Hooks
before.
Next up, we utilize
useEffect
to declare the recorder object and store it inside of the
useRef
function.
Why do we need to do this? Because
useRef
allows us to store a mutable value in its
.current
property. This means we are able to access this property even after a re-render of the DOM.
Then we declare the
startRecording
function, which asks us if we want to allow the app to
access our microphone
with a press of the
START
button. Then we set the
isRecording
state to
true
.
Finally, we initiate the
stopRecording
function, there are a bunch of things going on here.
With one press of the
STOP
button, we call a bunch of
mic-recorder-to-mp3
methods. The important part to note here is that we create a new
mp3 file
and store it in our
audioFile
state variable.
We also set the
blobUrl
, which allows us to play our recorded
audioFile
using our HTML player. I know this is a lot, but once you start to play around with it, it makes sense.
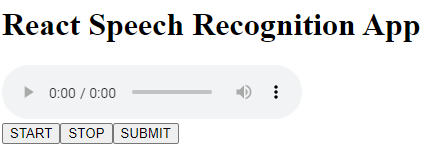
Step 5 - Microphone Check 🎤
Now let’s check if our code works so far! Hit the
START
button and give the app permission to use your microphone. Once done, sing your favorite song and hit
STOP
. You should now be able to re-play your wonderful song by pressing the ▶️ button on your audio player.
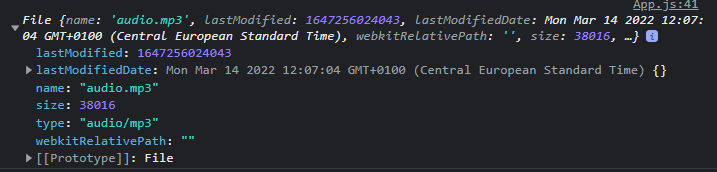
Let’s have a quick look at what the
audioFile
object actually looks like.
As you can see, there is a bunch of information in there.
This is the actual file that we are going to upload to AssemblyAI for transcription in a bit. Just understand that
blobURL
is a
reference to this file
so that we are able to play it using the HTML audio player, and
audioFile
is the
actual
audio.mp3 file.
Alright, now that we know how to record audio and we also know where our audio files are stored, we can start to set things up in terms of transcription.
Step 6 - Initiating AssemblyAI API Connection
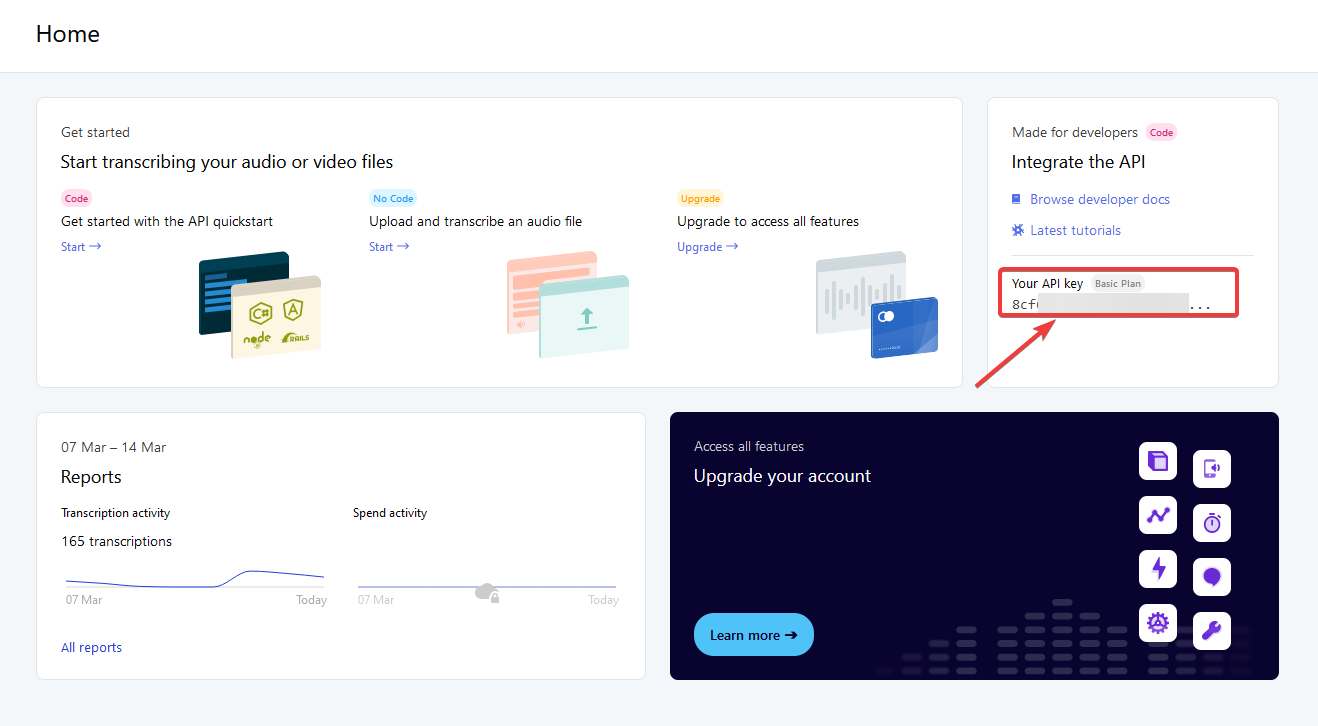
Next, we need to create an account with
AssemblyAI
. Once that is done, head over to your
dashboard
and grab your API key.
Get your API key
IMPORTANT:
Never share this API key with anyone and don’t commit it to your Github account! (More on that later)
Authenticating with AssemblyAI
The first thing we need to do to be able to communicate with AssemblyAI using our React Speech Recognition app is to authenticate with AssemblyAI’s API. You can look this up in the
documentation
, several languages are covered.
To be able to talk to the AssemblyAI API, we need to make sure to
always include our API key inside of the request header
. Since we want to stick with the DRY principle, we simply create a variable for that instead of typing it out over and over again.
Make sure to
replace “YourAPIKey”
with your
actual API key
. Also, take note that we place this variable
outside
of our component. This has to do with how
useEffect()
works.
To test if the authentication works, we can simply test it by using this
example
. Just paste this code snippet right underneath the assembly variable we just created like so:
Now refresh the browser page (where your app is running) and check the developer console (F12). You should see a response much like this:
This response includes two important things we need in just a sec, the
id
and the
status
.
Good. Authentication works, you can go ahead and remove the testing code again.
Step 7 - Uploading the Audio File & Retrieving the Upload URL
Next, we need to get our audio file uploaded to the AssemblyAI API for transcription. Once it’s uploaded, we receive a response including an upload URL, we need to store this URL inside of a state variable.
Once we have this URL, we utilize
useEffect
to do a
POST request
to the API
once an audio file was created
. We
console.log
the result to see if it works.
...
// AssemblyAI API
// State variables
const [uploadURL, setUploadURL] = useState("")
// Upload the Audio File and retrieve the Upload URL
useEffect(() => {
if (audioFile) {
assembly
.post("/upload", audioFile)
.then((res) => setUploadURL(res.data.upload_url))
.catch((err) => console.error(err))
}, [audioFile])
console.log(uploadURL)
Once you have that code implemented,
refresh your page
, record a small audio file and look at the console to see what happens. A couple of seconds after hitting the
STOP
button, you should receive a response including your
upload URL
, which is now stored inside of
uploadURL
.
Got it? Cool. Let’s move on.
Install Note
The dependency array that includes [audioFile] inside of our useEffect hook ensures that the POST request is only made once the audioFile state changes (after the audio file was created).
Step 8 - Submitting the Audio File for Transcription
Now we need to send our
uploadURL
as a POST request to the API to start the transcription process. To do that, let’s add a simple button, for now, to handle this for us. We also need to create a bunch more state variables. Our whole code now looks like this.
import MicRecorder from "mic-recorder-to-mp3"
import { useEffect, useState, useRef } from "react"
import axios from "axios"
// Set AssemblyAI Axios Header
const assembly = axios.create({
baseURL: "https://api.assemblyai.com/v2",
headers: {
authorization: "YourAPIKey",
"content-type": "application/json",
"transfer-encoding": "chunked",
const App = () => {
// Mic-Recorder-To-MP3
const recorder = useRef(null) //Recorder
const audioPlayer = useRef(null) //Ref for the HTML Audio Tag
const [blobURL, setBlobUrl] = useState(null)
const [audioFile, setAudioFile] = useState(null)
const [isRecording, setIsRecording] = useState(null)
useEffect(() => {
//Declares the recorder object and stores it inside of ref
recorder.current = new MicRecorder({ bitRate: 128 })
}, [])
const startRecording = () => {
// Check if recording isn't blocked by browser
recorder.current.start().then(() => {
setIsRecording(true)
const stopRecording = () => {
recorder.current
.stop()
.getMp3()
.then(([buffer, blob]) => {
const file = new File(buffer, "audio.mp3", {
type: blob.type,
lastModified: Date.now(),
const newBlobUrl = URL.createObjectURL(blob)
setBlobUrl(newBlobUrl)
setIsRecording(false)
setAudioFile(file)
.catch((e) => console.log(e))
// AssemblyAI API
// State variables
const [uploadURL, setUploadURL] = useState("")
const [transcriptID, setTranscriptID] = useState("")
const [transcriptData, setTranscriptData] = useState("")
const [transcript, setTranscript] = useState("")
// Upload the Audio File and retrieve the Upload URL
useEffect(() => {
if (audioFile) {
assembly
.post("/upload", audioFile)
.then((res) => setUploadURL(res.data.upload_url))
.catch((err) => console.error(err))
}, [audioFile])
// Submit the Upload URL to AssemblyAI and retrieve the Transcript ID
const submitTranscriptionHandler = () => {
assembly
.post("/transcript", {
audio_url: uploadURL,
.then((res) => {
setTranscriptID(res.data.id)
.catch((err) => console.error(err))
console.log(transcriptID)
return (
<h1>React Speech Recognition App</h1>
<audio ref={audioPlayer} src={blobURL} controls='controls' />
<button disabled={isRecording} onClick={startRecording}>
START
</button>
<button disabled={!isRecording} onClick={stopRecording}>
</button>
<button onClick={submitTranscriptionHandler}>SUBMIT</button>
export default App
Alright, let’s give it a try. Refresh the page, record an audio file once again, and after pressing
STOP
, press the
SUBMIT
button. Once the submission is done, you should receive your
transcriptID
in the console.
Checking Transcription Status
To be able to see if our file is finished being transcribed, we can use one of two methods.
The first
is using
web hooks
, and the
second
is using a simple function. We do the latter in this tutorial since it helps us understand each step.
Add the
checkStatusHandler
async function below. Also, change the
console.log
to log
transcriptData
and add the
CHECK STATUS
button in your HTML code.
...
// Submit the Upload URL to AssemblyAI and retrieve the Transcript ID
const submitTranscriptionHandler = () => {
assembly
.post("/transcript", {
audio_url: uploadURL,
.then((res) => {
setTranscriptID(res.data.id)
.catch((err) => console.error(err))
// Check the status of the Transcript and retrieve the Transcript Data
const checkStatusHandler = async () => {
try {
await assembly.get(`/transcript/${transcriptID}`).then((res) => {
setTranscriptData(res.data)
setTranscript(transcriptData.text)
} catch (err) {
console.error(err)
console.log(transcriptData)
return (
<h1>React Speech Recognition App</h1>
<audio ref={audioPlayer} src={blobURL} controls='controls' />
<button disabled={isRecording} onClick={startRecording}>
START
</button>
<button disabled={!isRecording} onClick={stopRecording}>
</button>
<button onClick={submitTranscriptionHandler}>SUBMIT</button>
<button onClick={checkStatusHandler}>CHECK STATUS</button>
export default App
Alright, once again. Refresh, Record, hit
STOP
, hit
SUBMIT
, and then, hit
CHECK STATUS
.
You should receive the response, telling you that it is still processing.
Now how do we check if the status changes to “completed”? By clicking the
CHECK STATUS
button again. Don’t worry, we are going to automate this in a second.
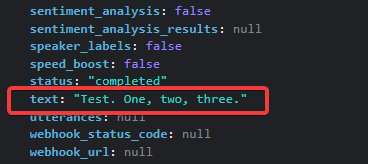
A couple of seconds later, the transcription is finished.
If you open up this object and scroll down until you find
text
, you will see the text you have spoken into your microphone.
Since we are storing this response inside of our
transcriptData
variable, we now have full access to it.
Displaying Transcript Data
Now you also see that we store the
transcriptData.text
inside of the
transcript
variable. That means the transcript variable will hold our transcribed text once it's finished. We are now able to display this text using a conditional render.
To get the final result
, we need to repeatedly press the
CHECK STATUS
button until
the audio file was done processing
. Gladly, there is a much easier way to do this.
Step 9 - Automating the Process
Now the code will change quite a bit, but in essence, it will stay the same. I explain to you what changed.
import MicRecorder from "mic-recorder-to-mp3"
import { useEffect, useState, useRef } from "react"
import axios from "axios"
// Set AssemblyAI Axios Header
const assembly = axios.create({
baseURL: "https://api.assemblyai.com/v2",
headers: {
authorization: "YourAPIKey",
"content-type": "application/json",
"transfer-encoding": "chunked",
const App = () => {
// Mic-Recorder-To-MP3
const recorder = useRef(null) //Recorder
const audioPlayer = useRef(null) //Ref for the HTML Audio Tag
const [blobURL, setBlobUrl] = useState(null)
const [audioFile, setAudioFile] = useState(null)
const [isRecording, setIsRecording] = useState(null)
useEffect(() => {
//Declares the recorder object and stores it inside of ref
recorder.current = new MicRecorder({ bitRate: 128 })
}, [])
const startRecording = () => {
// Check if recording isn't blocked by browser
recorder.current.start().then(() => {
setIsRecording(true)
const stopRecording = () => {
recorder.current
.stop()
.getMp3()
.then(([buffer, blob]) => {
const file = new File(buffer, "audio.mp3", {
type: blob.type,
lastModified: Date.now(),
const newBlobUrl = URL.createObjectURL(blob)
setBlobUrl(newBlobUrl)
setIsRecording(false)
setAudioFile(file)
.catch((e) => console.log(e))
// AssemblyAI API
// State variables
const [uploadURL, setUploadURL] = useState("")
const [transcriptID, setTranscriptID] = useState("")
const [transcriptData, setTranscriptData] = useState("")
const [transcript, setTranscript] = useState("")
const [isLoading, setIsLoading] = useState(false)
// Upload the Audio File and retrieve the Upload URL
useEffect(() => {
if (audioFile) {
assembly
.post("/upload", audioFile)
.then((res) => setUploadURL(res.data.upload_url))
.catch((err) => console.error(err))
}, [audioFile])
// Submit the Upload URL to AssemblyAI and retrieve the Transcript ID
const submitTranscriptionHandler = () => {
assembly
.post("/transcript", {
audio_url: uploadURL,
.then((res) => {
setTranscriptID(res.data.id)
checkStatusHandler()
.catch((err) => console.error(err))
// Check the status of the Transcript
const checkStatusHandler = async () => {
setIsLoading(true)
try {
await assembly.get(`/transcript/${transcriptID}`).then((res) => {
setTranscriptData(res.data)
} catch (err) {
console.error(err)
// Periodically check the status of the Transcript
useEffect(() => {
const interval = setInterval(() => {
if (transcriptData.status !== "completed" && isLoading) {
checkStatusHandler()
} else {
setIsLoading(false)
setTranscript(transcriptData.text)
clearInterval(interval)
}, 1000)
return () => clearInterval(interval)
return (
<h1>React Speech Recognition App</h1>
<audio ref={audioPlayer} src={blobURL} controls='controls' />
<button disabled={isRecording} onClick={startRecording}>
START
</button>
<button disabled={!isRecording} onClick={stopRecording}>
</button>
<button onClick={submitTranscriptionHandler}>SUBMIT</button>
{transcriptData.status === "completed" ? (
<p>{transcript}</p>
) : (
<p>{transcriptData.status}</p>
export default App
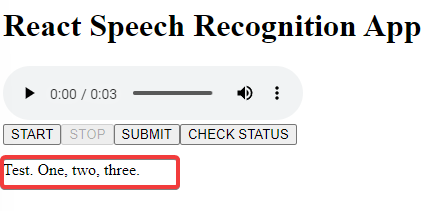
The first thing you should try now is to run the app again. You will see that you only need to hit
START
,
STOP
, and then
SUBMIT
. Now
processing...
appears on the screen. And after a short moment, our transcribed text appears. How did this magic happen?
Firstly, we have added an
isLoading
state variable to check if the status is
“processing”
or
“completed”
.
Then we have created a so-called interval to periodically run our
checkStatusHandler()
function to see if the status has changed to
“completed”
. Once the status has changed to “completed”, it sets
isLoading
to
false
, adds the transcribed text to our
transcript
variable, and ends the interval.
// Periodically check the status of the Transcript
useEffect(() => {
const interval = setInterval(() => {
if (transcriptData.status !== "completed" && isLoading) {
checkStatusHandler()
} else {
setIsLoading(false)
setTranscript(transcriptData.text)
clearInterval(interval)
}, 1000)
return () => clearInterval(interval)
And this is basically it. Again, this is completely un-styled for better visibility. In the final version, I have added a loading spinner while the status does not equal
“completed”
.
Conclusion
As you can see, React Speech Recognition can be confusing at first, but once you understand how it works under the hood, it’s a great tool to have in your repository.
There are a ton of project ideas that can utilize the power of speech recognition. Check out some of these videos for ideas!