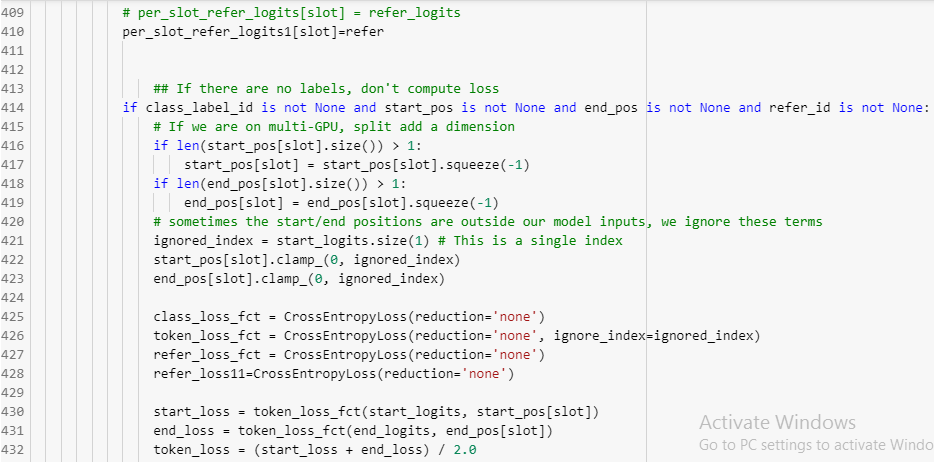
Hello. The following code snippet has a runtime error
Relevant error:
File “run_dst.py”, line 863, in
main()
File “run_dst.py”, line 848, in main
result = evaluate(args, model, tokenizer, processor, prefix=global_step)
File “run_dst.py”, line 296, in evaluate
outputs = model(**inputs)
File “/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py”, line 1102, in _call_impl
return forward_call(*input, **kwargs)
File “/content/drive/My Drive/graph_transformer/modeling_bert_dst.py”, line 430, in forward
start_loss = token_loss_fct(start_logits, start_pos[slot])
File “/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py”, line 1102, in _call_impl
return forward_call(*input, **kwargs)
File “/usr/local/lib/python3.7/dist-packages/torch/nn/modules/loss.py”, line 1152, in forward
label_smoothing=self.label_smoothing)
File “/usr/local/lib/python3.7/dist-packages/torch/nn/functional.py”, line 2846, in cross_entropy
return torch._C._nn.cross_entropy_loss(input, target, weight, _Reduction.get_enum(reduction), ignore_index, label_smoothing)
As can be seen in the relevant code snippet, the original author of the code tried to manage this error.
I got this error by changing other parts of the code that are not related to this part, I do not know what is the reason?
Could it be because of the version of Pytorch?
Because the version used by the author is 1.4.0 and I used version 1.10.0.
you should check the code on cpu and see what is the actual error.
but i guess it’s becuase of target dtype.
you can try
.long().cuda()
on all of the cross entroypy loss targets.
by the way you’re creating your loss functions in you the training loop.
it’s better to move it out
Yes, the number of class labels was not specified correctly.
I was confused just because the debugger did not pinpoint the error.
Thankful
I run into this error when training adversarial autoencoder network
for epoch in range(num_epochs):
# init mini batch counter
mini_batch_count = 0
# init epoch training losses
batch_reconstruction_losses = 0.0
batch_discriminator_losses = 0.0
batch_generator_losses = 0.0
# determine if GPU training is enabled
if (torch.backends.cudnn.version() != None) and (USE_CUDA == True):
# set all networks / models in GPU mode
encoder_train.cuda()
decoder_train.cuda()
discriminator_train.cuda()
# set networks in training mode (apply dropout when needed)
encoder_train.train()
decoder_train.train()
discriminator_train.train()
# start timer
start_time = datetime.now()
# iterate over epoch mini batches
for mini_batch_data in dataloader:
# increase mini batch counter
mini_batch_count += 1
# determine if GPU training is enabled
if (torch.backends.cudnn.version() != None) and (USE_CUDA == True):
# convert mini batch to torch variable
mini_batch_torch = torch.cuda.FloatTensor(mini_batch_data)
else:
# convert mini batch to torch variable
mini_batch_torch = torch.FloatTensor(mini_batch_data)
# reset the networks gradients
encoder_train.zero_grad()
decoder_train.zero_grad()
discriminator_train.zero_grad()
# =================== reconstruction phase =====================
# run autoencoder encoding - decoding
z_sample = encoder_train(mini_batch_torch)
mini_batch_reconstruction = decoder_train(z_sample)
# split input date to numerical and categorical part
batch_cat = mini_batch_torch[:, :ori_dataset_categ_transformed.shape[1]]
batch_num = mini_batch_torch[:, ori_dataset_categ_transformed.shape[1]:]
# split reconstruction to numerical and categorical part
rec_batch_cat = mini_batch_reconstruction[:, :ori_dataset_categ_transformed.shape[1]]
rec_batch_num = mini_batch_reconstruction[:, ori_dataset_categ_transformed.shape[1]:]
# backward pass + gradients update
rec_error_cat = reconstruction_criterion_categorical(input=rec_batch_cat, target=batch_cat) # one-hot attr error
rec_error_num = reconstruction_criterion_numeric(input=rec_batch_num, target=batch_num) # numeric attr error
# combine both reconstruction errors
reconstruction_loss = rec_error_cat + rec_error_num
# run backward pass - determine gradients
reconstruction_loss.backward()
# collect batch reconstruction loss
batch_reconstruction_losses += reconstruction_loss.item()
# update network parameter - decoder and encoder
decoder_optimizer.step()
encoder_optimizer.step()
# =================== regularization phase =====================
# =================== discriminator training ===================
# set discriminator in evaluation mode
discriminator_train.eval()
# generate target latent space data
z_target_batch = z_continous_samples_all[random.sample(range(0, z_continous_samples_all.shape[0]), mini_batch_size),:]
# convert to torch tensor
z_target_batch = torch.FloatTensor(z_target_batch)
if (torch.backends.cudnn.version() != None) and (USE_CUDA == True):
z_target_batch = z_target_batch.cuda()
# determine mini batch sample generated by the encoder -> fake gaussian sample
z_fake_gauss = encoder_train(mini_batch_torch)
# determine discriminator classification of both samples
d_real_gauss = discriminator_train(z_target_batch) # real sampled gaussian
d_fake_gauss = discriminator_train(z_fake_gauss) # fake created gaussian
# determine discriminator classification target variables
d_real_gauss_target = torch.FloatTensor(torch.ones(d_real_gauss.shape)) # real -> 1
d_fake_gauss_target = torch.FloatTensor(torch.zeros(d_fake_gauss.shape)) # fake -> 0
# determine if GPU training is enabled
if (torch.backends.cudnn.version() != None) and (USE_CUDA == True):
# push tensors to CUDA
d_real_gauss_target = d_real_gauss_target.cuda()
d_fake_gauss_target = d_fake_gauss_target.cuda()
# determine individual discrimination losses
discriminator_loss_real = discriminator_criterion(target=d_real_gauss_target, input=d_real_gauss) # real loss
discriminator_loss_fake = discriminator_criterion(target=d_fake_gauss_target, input=d_fake_gauss) # fake loss
# add real loss and fake loss
discriminator_loss = discriminator_loss_fake + discriminator_loss_real
# run backward through the discriminator network
discriminator_loss.backward()
# collect discriminator loss
batch_discriminator_losses += discriminator_loss.item()
# update network the discriminator network parameters
discriminator_optimizer.step()
# reset the networks gradients
encoder_train.zero_grad()
decoder_train.zero_grad()
discriminator_train.zero_grad()
# =================== regularization phase =====================
# =================== generator training =======================
# set encoder / generator in training mode
encoder_train.train()
# reset the encoder / generator networks gradients
encoder_train.zero_grad()
# determine fake gaussian sample generated by the encoder / generator
z_fake_gauss = encoder_train(mini_batch_torch)
# determine discriminator classification of fake gaussian sample
d_fake_gauss = discriminator_train(z_fake_gauss)
# determine discriminator classification target variables
d_fake_gauss_target = torch.FloatTensor(torch.ones(d_fake_gauss.shape)) # fake -> 1
# determine if GPU training is enabled
if (torch.backends.cudnn.version() != None) and (USE_CUDA == True):
# push tensors to CUDA
d_fake_gauss_target = d_fake_gauss_target.cuda()
# determine discrimination loss of fake gaussian sample
generator_loss = discriminator_criterion(target=d_fake_gauss_target, input=d_fake_gauss)
# collect generator loss
batch_generator_losses += generator_loss.item()
# run backward pass - determine gradients
generator_loss.backward()
# update network paramaters - encoder / generatorc
encoder_optimizer.step()
# reset the networks gradients
encoder_train.zero_grad()
decoder_train.zero_grad()
discriminator_train.zero_grad()
# collect epoch training losses - reconstruction loss
epoch_reconstruction_loss = batch_reconstruction_losses / mini_batch_count
epoch_reconstruction_losses.extend([epoch_reconstruction_loss])
# collect epoch training losses - discriminator loss
epoch_discriminator_loss = batch_discriminator_losses / mini_batch_count
epoch_discriminator_losses.extend([epoch_discriminator_loss])
# collect epoch training losses - generator loss
epoch_generator_loss = batch_generator_losses / mini_batch_count
epoch_generator_losses.extend([epoch_generator_loss])
# print epoch reconstruction loss
now = datetime.utcnow().strftime("%Y%m%d-%H:%M:%S")
print('[LOG TRAIN {}] epoch: {:04}/{:04}, reconstruction loss: {:.4f}'.format(now, epoch + 1, num_epochs, epoch_reconstruction_loss))
print('[LOG TRAIN {}] epoch: {:04}/{:04}, discriminator loss: {:.4f}'.format(now, epoch + 1, num_epochs, epoch_discriminator_loss))
print('[LOG TRAIN {}] epoch: {:04}/{:04}, generator loss: {:.4f}'.format(now, epoch + 1, num_epochs, epoch_generator_loss))
# =================== save model snapshots to disk ============================
# save trained encoder model file to disk
now = datetime.utcnow().strftime("%Y%m%d-%H_%M_%S")
encoder_model_name = "{}_ep_{}_encoder_model.pth".format(now, (epoch+1))
torch.save(encoder_train.state_dict(), os.path.join("./models", encoder_model_name))
# save trained decoder model file to disk
decoder_model_name = "{}_ep_{}_decoder_model.pth".format(now, (epoch+1))
torch.save(decoder_train.state_dict(), os.path.join("./models", decoder_model_name))
# save trained discriminator model file to disk
decoder_model_name = "{}_ep_{}_discriminator_model.pth".format(now, (epoch+1))
torch.save(discriminator_train.state_dict(), os.path.join("./models", decoder_model_name))
71 # run backward pass - determine gradients
—> 72 reconstruction_loss.backward()
74 # collect batch reconstruction loss
1 frames
/usr/local/lib/python3.9/dist-packages/torch/autograd/init.py in backward(tensors, grad_tensors, retain_graph, create_graph, grad_variables, inputs)
198 # some Python versions print out the first line of a multi-line function
199 # calls in the traceback and some print out the last line
→ 200 Variable.execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
201 tensors, grad_tensors, retain_graph, create_graph, inputs,
202 allow_unreachable=True, accumulate_grad=True) # Calls into the C++ engine to run the backward pass
RuntimeError: CUDA error: device-side assert triggered
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
Compile with TORCH_USE_CUDA_DSA to enable device-side assertions.