业内第一个开源大语言模型 Dolly 2.0 发布,对此你有哪些期待?
关注者
73
被浏览
44,433
9 个回答

Dolly v1版本的时候我就在看了,其实本质上还是挺简单的
v1版本的时候databricks为了绕开Llama的只能非商用限制,把基础模型从Llama换成了GPT-J-6B,然后再用Alpaca的方法和数据重训。但是这样做并不能完全开源,因为Alpaca的数据是从ChatGPT来的,这个数据是遵循一个特殊的Data License的
v2版本做了两件事, 一是终于彻底摆脱了束缚,把Alpaca的数据集换成了他们自己的,并把这个数据集也开源了,这样一来Dolly正式成为完全开源的Alpaca替代品。 另一件是用Pythia替换掉了GPT-J。Pythia [1] 是做gpt-neo和gpt-neox的 EleutherAI 出的模型,其实2.7B的版本出了也有段时间了,理论上Pythia来说能力应该是比Llama要差一些的,我还没有做进一步的测试所以就先不锐评了。
Dolly一直有关注,因为它搞的这个全开源的思路我觉得是很对的,我在前两周的这篇 LokLok:开源ChatGPT替代模型项目整理 文章里也有提及(说起来应该去更新下进展了)。
Dolly v2出来当然也是开源社区的好事,难度虽然不是特别大,但还是有工作量的,还是需要有人出来做才行。我现在最期待的两个希望开源大佬能搞出来的事情是:
- 同参数量级下持平或者超越LLaMA的开源模型
- 寻找超越alpaca的训练范式(alpaca那套一看就有点拍脑袋“先整了再说”的嫌疑,我觉得有优化空间的可能还是很大的)
(关于Dolly v2是不是“第一个开源大语言模型”我觉得还是有待商榷哈,opechatkit这个项目也是用gpt-neo这一系的基础模型,后来也更新了基于pythia的版本,只是用的方法不是alpaca那一套,关注的人可能相对少点)
参考
- ^ Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling https://arxiv.org/abs/2304.01373

喜欢打篮球的人形代码输出装置
一个问题三个AI回答,这就是知乎吗?
昨天down下来试用了一下,中文应该是没有进行特殊的预训练,所以只能测试英文效果。整体效果要好于aplaca系列的LLaMa微调模型,但是应该没有达到gpt3.5的能力。
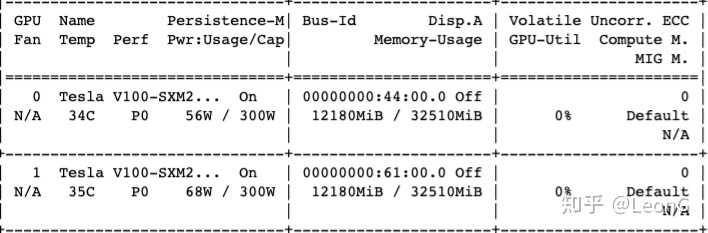
权重文件大小22G,加了自主多卡部署,大概占用两张V100各12G的显存

问答能力
先问问你是谁:


从美国洛杉矶到纽约怎么去,写一个简短的出行规划:


效果很一般,从回答上感觉默认的温度参数是比较高的,自由度很大,每次回复的差别很大。
代码能力
写一段打开文件并写入字符串的Python代码


简单的代码没有问题
增加一点难度
编写一个python代码,将一个字符串按照空格进行拆分,将拆分后的list写入到文件中。


依然是完成了任务,可能确实要求也比较简单
文案生成
为女装写一段200字的广告文案,要求贴近生活,符合大众需求,关键词是健康用料,性价比高


在过去的十年里,女性的服装经历了无数的变化,新一代女性越来越关注所使用材料的可持续性。这就是为什么Monki等阿姆斯特丹设计师与各种有机棉品牌合作,并在服装中使用可持续材料的原因。
公共数据的可用性为品牌提供了一个巨大的机会,可以展示他们的产品或服务如何适应客户的生活。因此,我们设计的牛仔裤不仅好看,而且在每个方向上都为我们的客户提供额外的英寸。这意味着我们的客户可以真正适合所有品牌的任何尺寸的牛仔裤。
最后,文本需要有吸引力和朗朗上口,使用能够吸引年轻一代的关键词。通过这种方式,我们将我们的品牌定位为可持续和健康服装的领导者,适应这些客户的日常生活。
文案生成能力和GPT是有一些差距的,生成文本的风格倒是和GPT区别很大,这也证明了Dolly2.0的训练数据来源不是通过self-instrution从chatGPT身上套过来的。
总结
这个模型的出现是一件好事,完全商用许可也给了很多公司去调优和部署的机会,虽然现在效果不及chatGPT,但是在此之上的研究肯定会越来越多,期待一个中文finetune的模型。