

表格存储支持使用SQL查询功能快速查询数据。使用控制台创建映射关系后,您可以执行SELECT语句快速查询所需数据。
前提条件
-
如果要使用RAM用户进行操作,请确保已创建RAM用户,并为RAM用户授予所有SQL操作权限,即在自定义权限策略中配置
"Action": "ots:SQL*"。具体操作,请参见 通过RAM Policy为RAM用户授权 。 -
已创建数据表。
注意事项
目前支持使用SQL查询功能的地域有华东1(杭州)、华东2(上海)、华北2(北京)、华北3(张家口)、华北5(呼和浩特)、华北6(乌兰察布)、华南1(深圳)、西南1(成都)、中国香港、新加坡、印度尼西亚(雅加达)、德国(法兰克福) 、沙特(利雅得) 和美国(弗吉尼亚)。
步骤一:创建映射关系
-
登录 表格存储控制台 。
-
在页面上方,选择资源组和地域。
-
在 概览 页面,单击实例名称或在 操作 列单击 实例管理 。
-
在 SQL查询 页签,创建映射关系。
说明您也可以直接手动编写创建映射关系的SQL语句。更多信息,请参见 创建表的映射关系 和 创建多元索引的映射关系 。
-
单击
 图标。
说明
图标。
说明当不存在映射表时,单击 SQL查询 页签,系统会自动弹出 创建映射表 对话框。
-
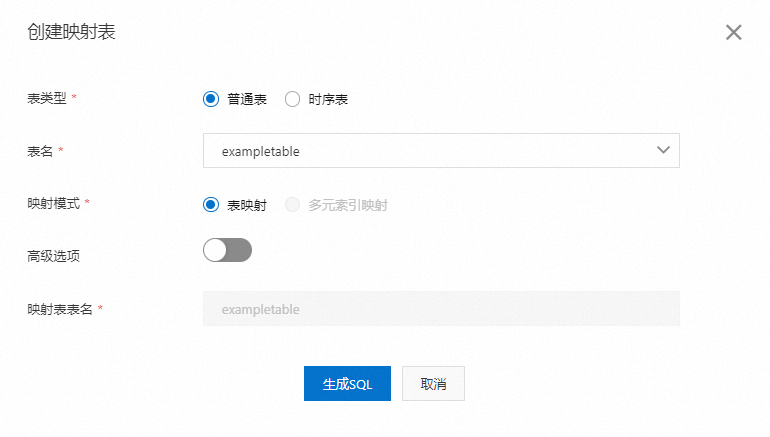
在 创建映射表 对话框中,根据下表说明配置参数。
参数
描述
表类型
表类型。取值范围如下:
-
普通表 (默认):在为数据表创建映射关系时,选择此项。
-
时序表 :在为时序表创建映射关系时,选择此项。
表名
表名称。
映射模式
创建映射关系的模式。只有当 表类型 选择为 普通表 时才能配置。取值范围如下:
-
表映射 (默认):为已存在的数据表创建映射关系。
-
多元索引映射 :为已存在的多元索引创建映射关系。
高级选项
用于配置映射表的一致性模式和是否使用不准确的聚合。打开 高级选项 开关,即可进行配置。只有当 映射模式 选择为 表映射 时才能进行配置。
一致性模式
执行引擎支持的一致性模式。只有打开了 高级选项 开关后才能配置。取值范围如下:
-
最终一致 (默认):执行的查询结果满足最终一致。此时新数据写入后会在几秒后影响到查询结果。
-
强一致性 :执行的查询结果满足强一致性。此时新数据写入后立刻影响到查询结果。
不准确的聚合
是否允许通过牺牲聚合操作的精准度提升查询性能。只有打开了 高级选项 开关后才能配置。取值范围如下:
-
是 (默认):允许通过牺牲聚合操作的精度来提升查询性能。
-
否 :不允许通过牺牲聚合操作的精度提升查询性能
多元索引表
映射表绑定的多元索引名称。只有当 映射模式 选择为 多元索引映射 时才能配置。
映射表表名
映射表名称。
-
如果 表类型 选择为 普通表 ,当 映射模式 选择为 表映射 时,映射表表名与数据表名称相同,不能更改;当 映射模式 选择为 多元索引映射 时,需要填写映射表名称。
-
如果 表类型 选择为 时序表 ,请根据实际填写映射表名称。时序表映射关系创建成功后,系统会自动在映射表名前添加
时序表名称::前缀。
-
-
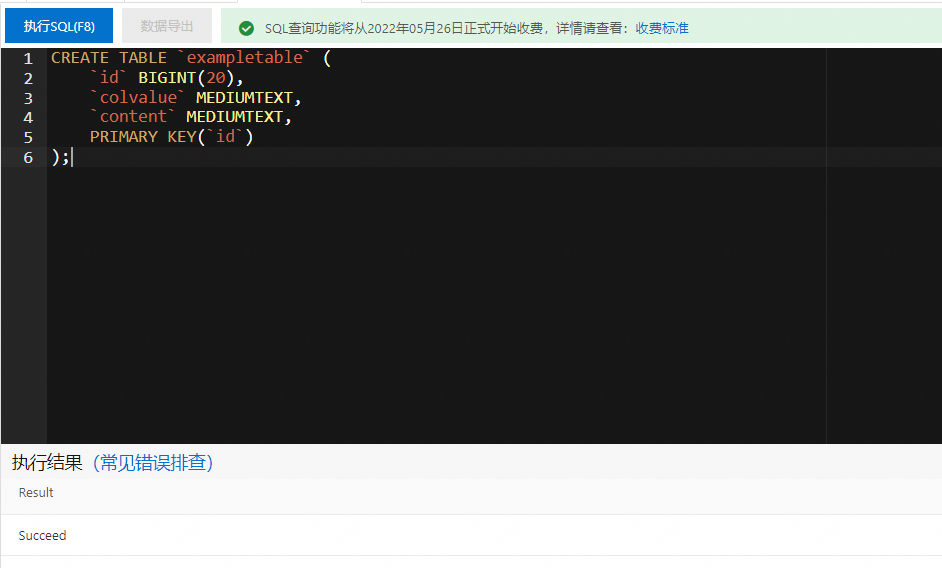
单击 生成SQL 。
系统会自动生成创建映射表的SQL语句。SQL示例如下:
CREATE TABLE `exampletable` ( `id` BIGINT(20), `colvalue` MEDIUMTEXT, `content` MEDIUMTEXT, PRIMARY KEY(`id`) );重要请确保映射关系中字段数据类型和数据表中字段数据类型相匹配。关于数据类型映射的更多信息,请参见 SQL数据类型映射 。
-
根据实际需要修改映射表的Schema后,按住鼠标左键拖动选中一条SQL语句并单击 执行SQL(F8) 。
执行成功后,在 执行结果 区域会显示执行结果。
重要-
创建映射表时设置的Schema中需要包括后续查询数据所需的列。
-
执行SQL语句时,请选中一条所需SQL语句,否则系统默认执行第一条SQL语句。
-
执行SQL语句时,一次只能选中一条SQL语句,否则系统会报错。
-
-
步骤二:查询数据
创建映射表后,在 SQL查询 页签,执行SELECT语句查询所需数据。更多信息,请参见 查询数据 。
查询到数据后,您可以单击 数据导出 ,导出最多2000条数据到本地文件(CSV格式)。
重要
通过数据导出功能最多只能导出2000条数据。如果需要导出的数据较多,请通过DataX、命令行工具等将表格存储数据下载到本地文件。更多信息,请参见 将表格存储数据下载到本地文件 。
常见问题
相关文档
-
您还可以通过命令行工具、SDK、JDBC或者Go语言驱动使用SQL查询数据。更多信息,请参见 通过SDK使用SQL查询 、 通过命令行工具使用SQL查询 、 通过JDBC使用SQL查询 、 通过Go语言驱动使用SQL查询数据 。
-
您还可以将Tablestore实例接入到DataWorks或DMS,然后使用SQL查询与分析Tablestore数据。更多信息,请参见 接入到DataWorks 和 接入到DMS 。
-
如果要加速SQL数据查询和计算,您可以通过创建二级索引或者多元索引实现。更多信息,请参见 索引选择策略 和 计算下推 。
-
您还可以通过MaxCompute、Spark、Hive或者HadoopMR、函数计算、Flink、PrestoDB等计算引擎实现表中数据的计算与分析。具体操作,请参见 计算与分析 。
-
如果要以图表等形式可视化展示数据,您可以通过对接Grafana实现。更多信息,请参见 对接Grafana 。