【实战前言】
(1)不管你是学生,还是已经工作了的小伙伴,可能你在过去、现在或者未来,会遇到这样的问题,公司/项目用的是
Oracle/DB2/MySQL
等关系型数据库,因公司发展需求,需要完成旧数据库数据安全迁移到新数据库的重要使命,新旧数据库可能是同一种类型的数据库,也可能是不同类型的数据库,相同类型数据库还好,比如都是MySQL数据库,那么你主要只需要考虑如何将数据安全、高效的完成迁移就好,而不同类型的数据库,比如从DB2迁移数据到MySQL,这种情况就需要在进行数据迁移之前,先按照新的数据库MySQL的建表规范,正确完成数据表的重建工作~
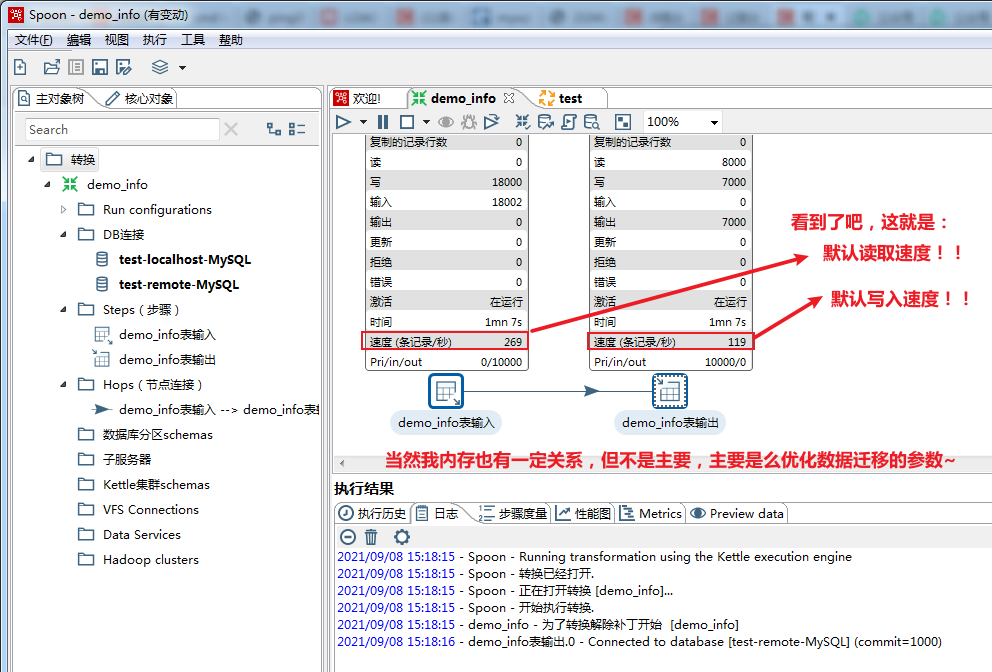
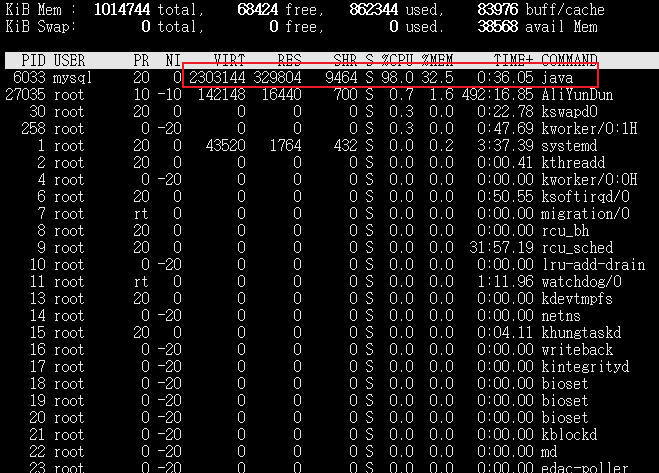
(2)本文主要分享我个人在实际工作当中,==如何使用Kettle这款基于纯Java实现(意味着扩平台特性,也就是Windows/Linux等操作系统通用)的开源ETL数据挖掘工具,经过性能优化(性能是默认效率的5 ~ 10倍以上)之后,实现新旧数据库之间数据的安全高效迁移~
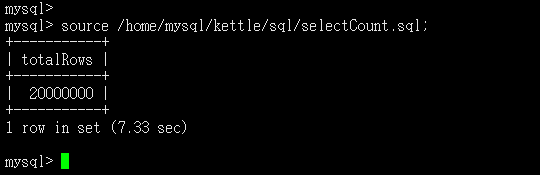
(3)我个人也是工作用到,一开始完成UAT测试环境模拟迁移DB2数据库一千万左右数据量到MySQL数据库的过程,到最后在实际生产环境安全高效完成五千万数据量从DB2迁移到MySQL的方案落实,不过由于个人学习环境限制,就不装DB2数据库了,本文将以
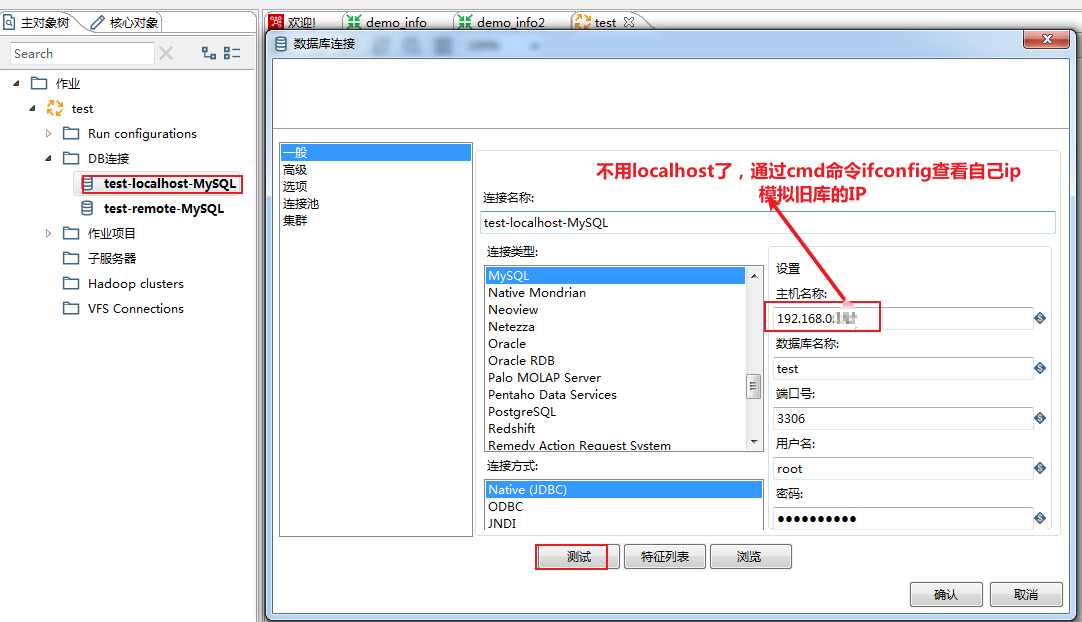
本地MySQL(模拟旧库)
迁移数据到
远程MySQL(模拟新库)
,进行实战演练,原理是一样的,要说区别主要在于数据库类型不同,在进行数据迁移之前,需要先按规范建立好新数据库的相关库表~
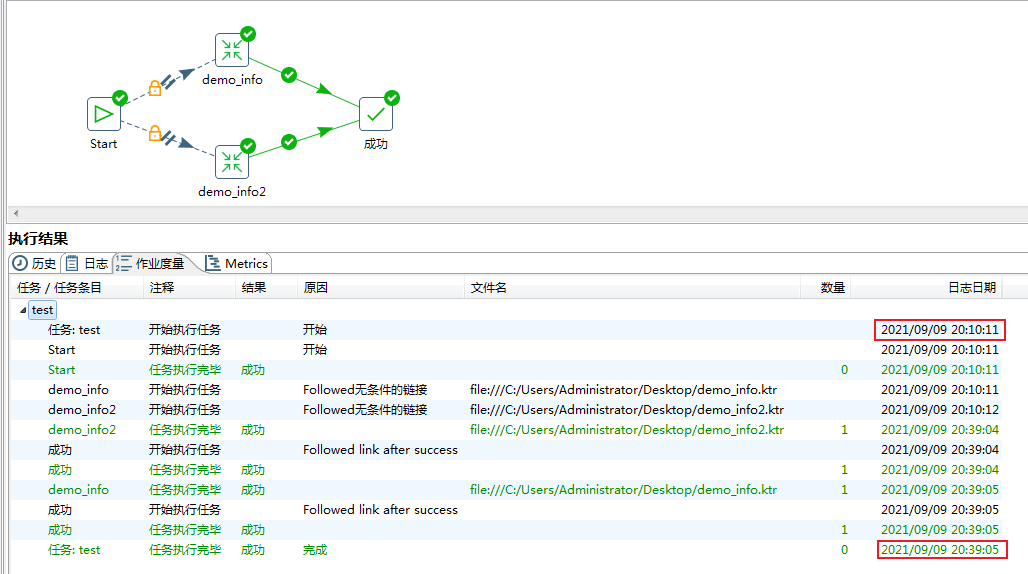
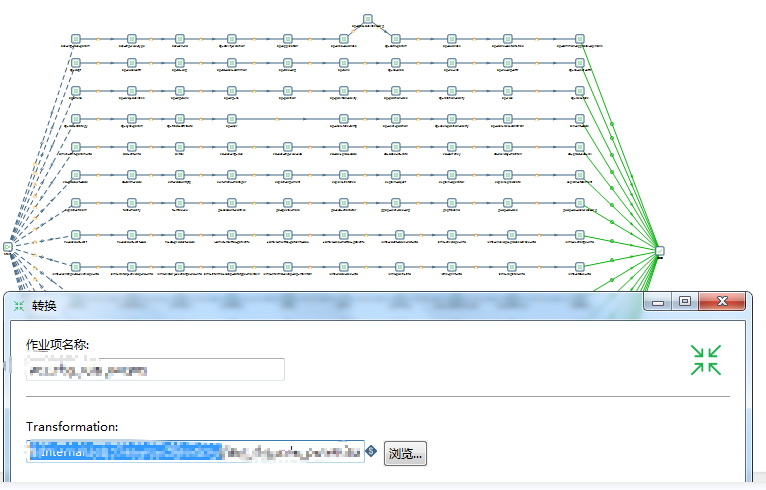
(4)Kettle脚本的制作、测试以及性能优化这部分的工作,主要在Windows下通过可视化界面来完成,实际的UAT测试环境以及生产环境数据库服务器大多都是在Linux的,因此Linux也需要搭建一套Kettle环境,并且将在Windows下性能优化好的Kettle脚本,放到Linux环境,同时如果数据量非常大的话(
亿级以上数据量
),还可以根据大表制作多个Shell脚本来执行准备好的Kettle作业脚本,利用更良好的CPU性能并发执行脚本,在单个脚本执行性能瓶颈的基础上再次成倍数提高数据迁移效率,更高效完成旧库数据迁移到新库,节省实际投产时的时间成本~
前言废话有点多了,哈哈哈,进入正文吧~
@
TOC
csdn 下载1~
mpan 下载2~ 提取码:jj6l
说明:想学习和了解MySQL的load data infile导出数据的语法和使用技巧的话,可以先看下我的这篇文章学习下:
MySQL如何使用load data infile、into outfile高效导入导出数据…
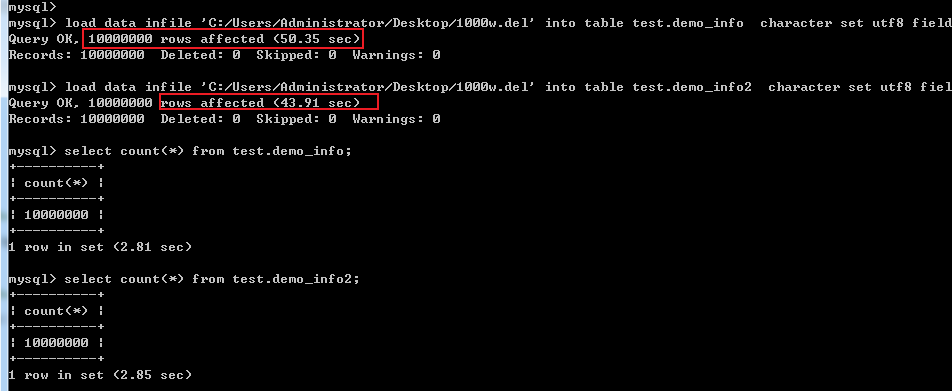
先执行这两行命令,导入10w条数据(性能优化前测试使用):
load data infile 'C:/Users/Administrator/Desktop/10w.del' into table test.demo_info character set utf8 fields terminated by 0x0f (name,sex,age);
load data infile 'C:/Users/Administrator/Desktop/10w.del' into table test.demo_info2 character set utf8 fields terminated by 0x0f (name,sex,age);
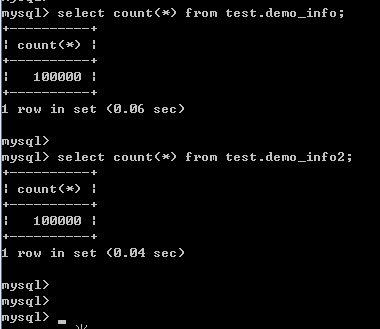
通过load data infile分别导入两张表的数据,还挺快的,单表不到1秒完成10w条数据导入~
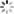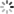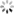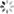
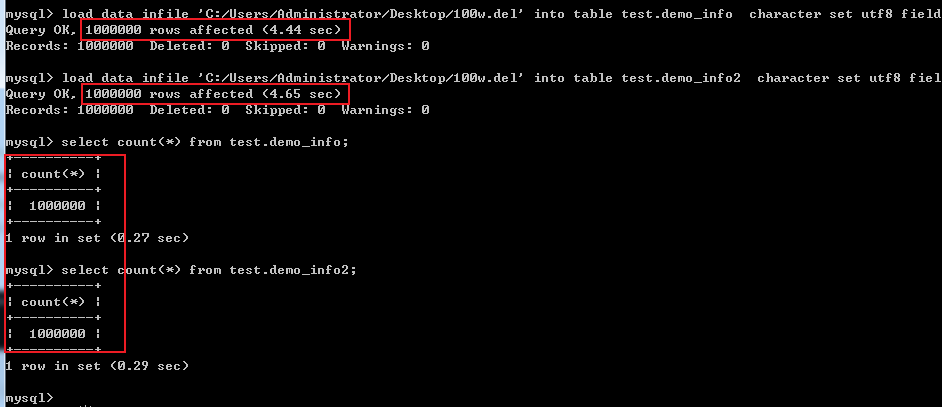
导入100w条数据(性能优化后测试再使用):
load data infile 'C:/Users/Administrator/Desktop/100w.del' into table test.demo_info character set utf8 fields terminated by 0x0f (name,sex,age);
load data infile 'C:/Users/Administrator/Desktop/100w.del' into table test.demo_info2 character set utf8 fields terminated by 0x0f (name,sex,age);
导入100w条数据(性能优化后测试再使用):
load data infile 'C:/Users/Administrator/Desktop/1000w.del' into table test.demo_info character set utf8 fields terminated by 0x0f (name,sex,age);
load data infile 'C:/Users/Administrator/Desktop/1000w.del' into table test.demo_info2 character set utf8 fields terminated by 0x0f (name,sex,age);
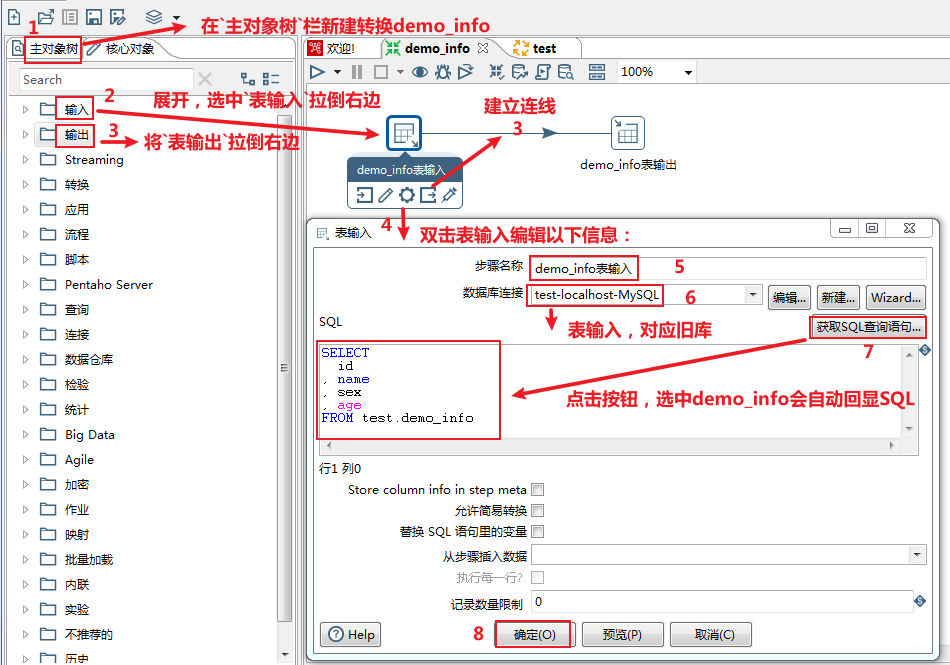
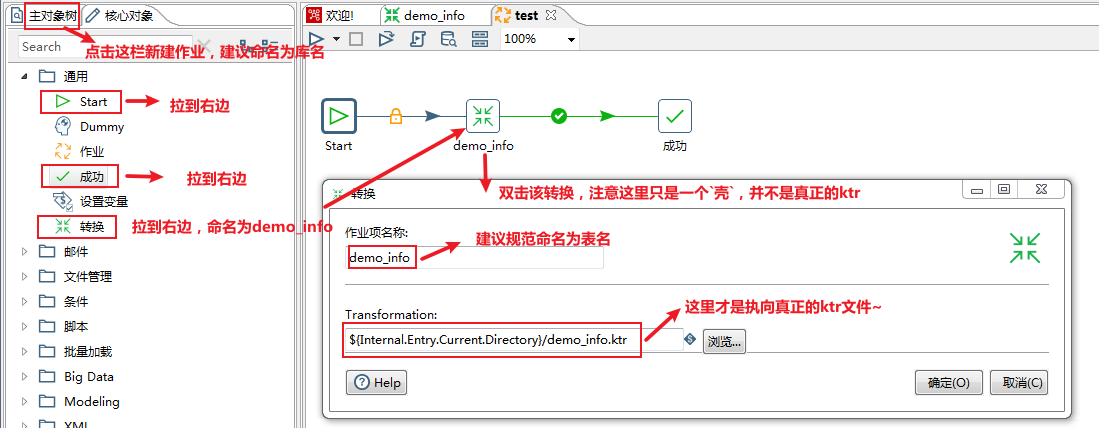
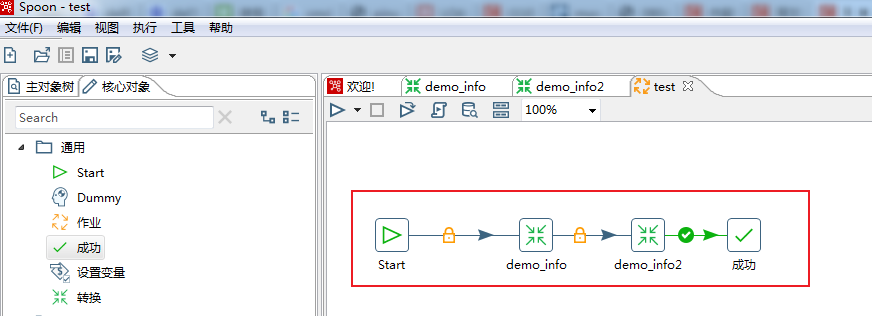
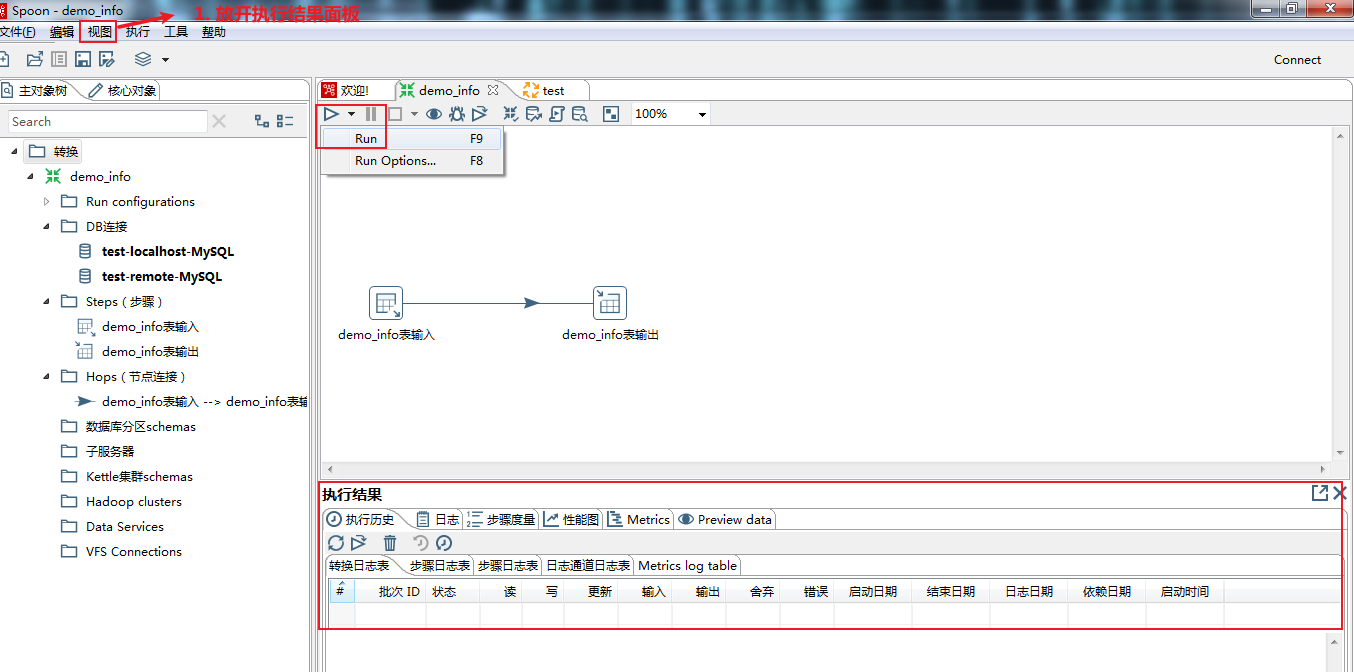
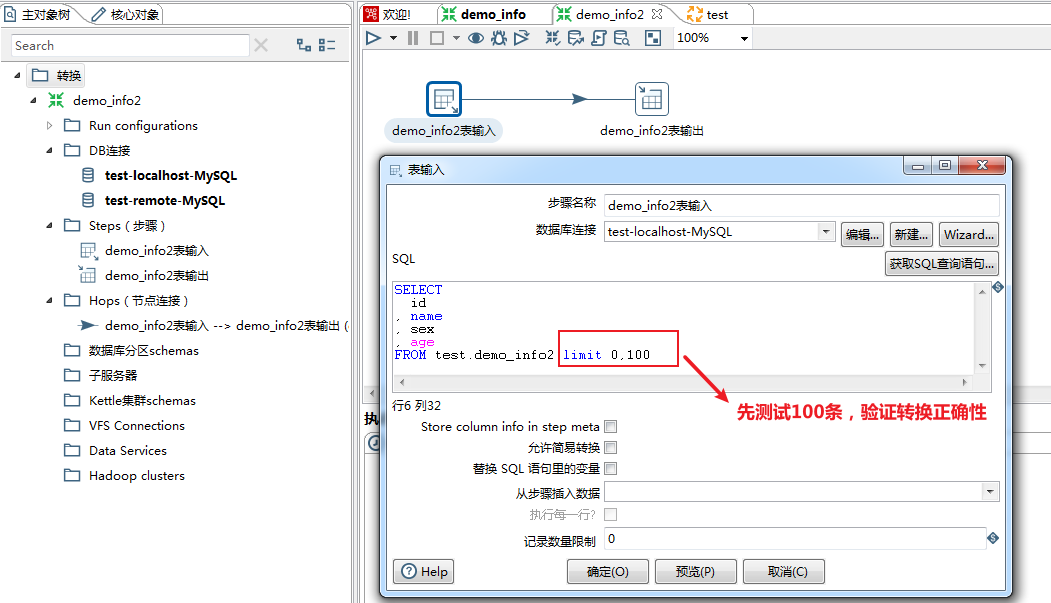
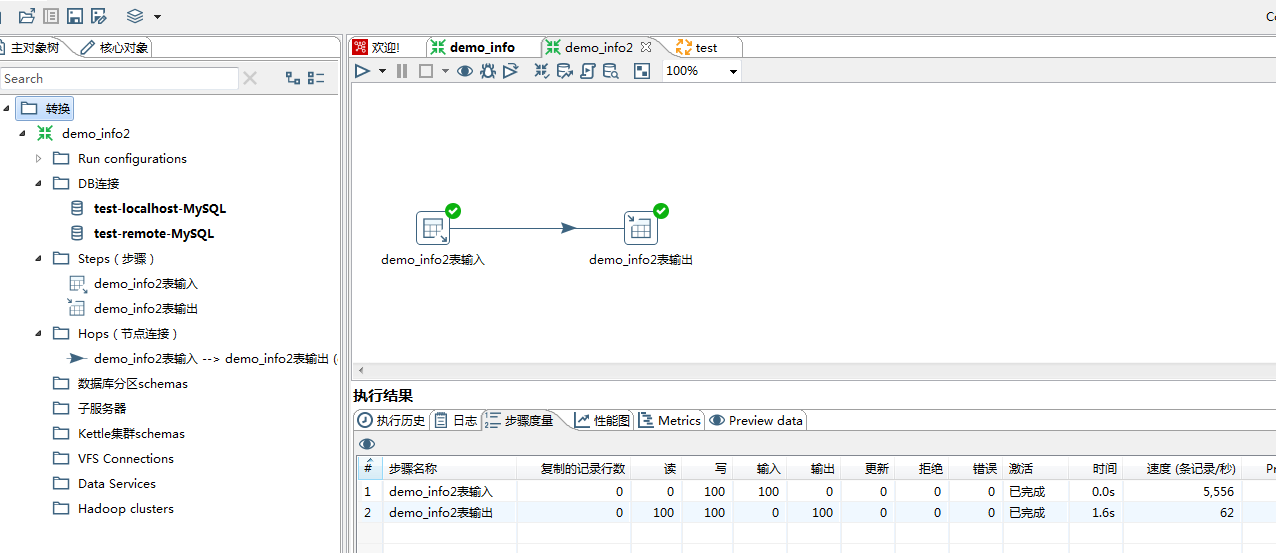
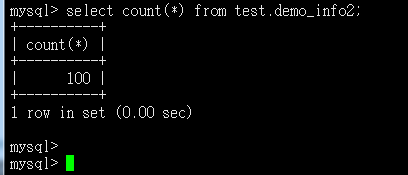
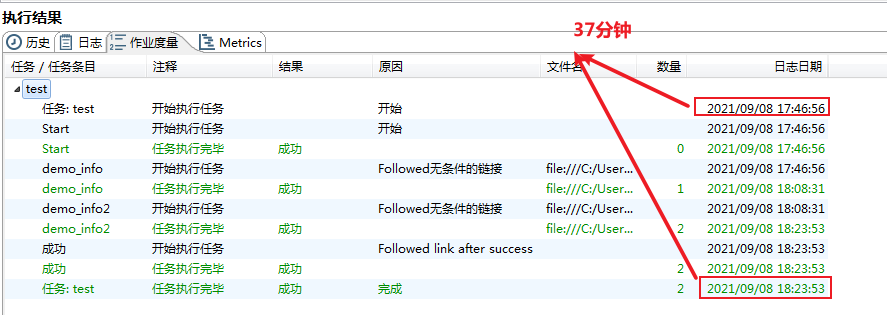
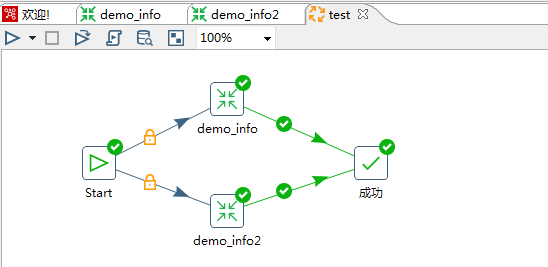
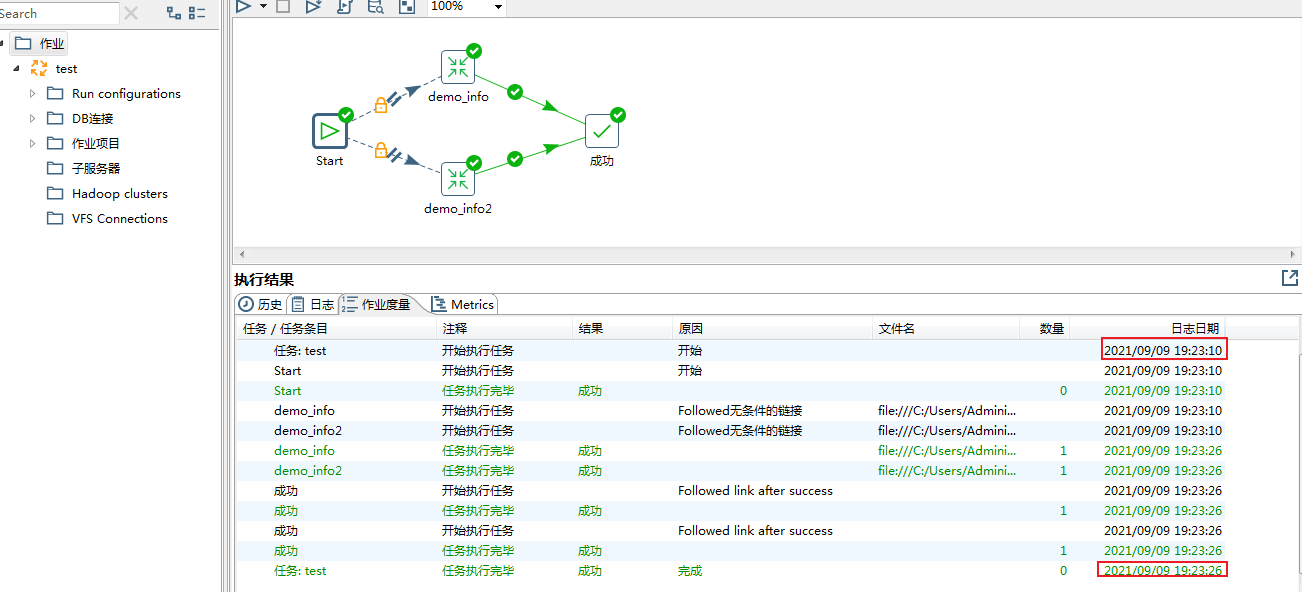
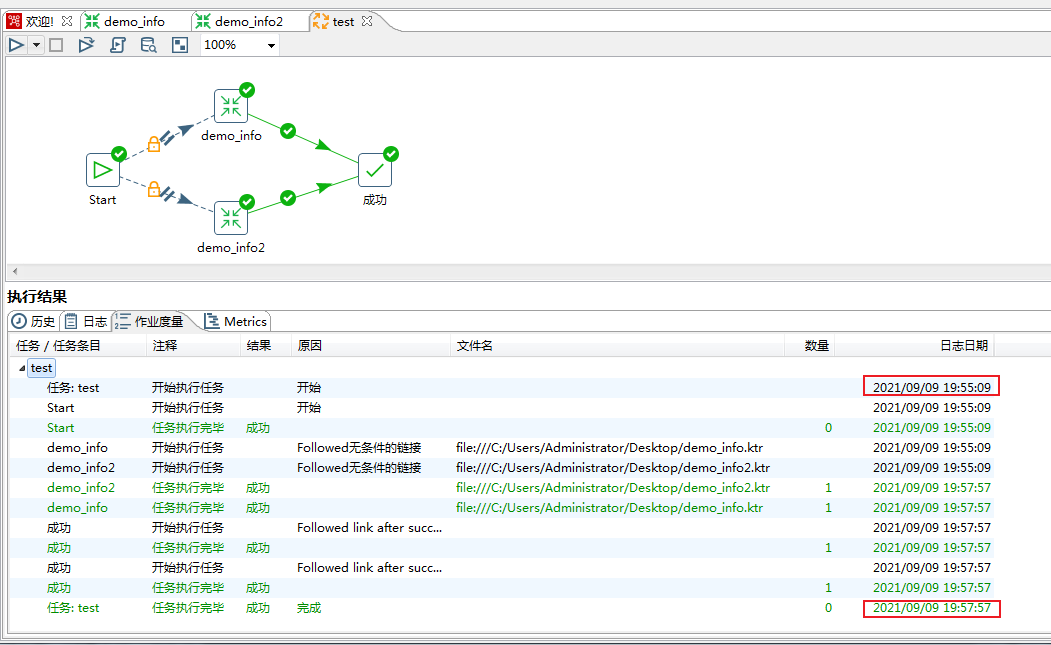
测试库表及数据构建完成,接下来进入正文学习如何制作Kettle脚本及性能优化的实战演练吧~
https://sourceforge.net/projects/pentaho/files/
我这里以最新版本pdi-ce-9.2.0.0-290.zip为例,直接下载zip压缩包后解压得到目录data-integration即可~
这里通过双击Spoon.bat即可~
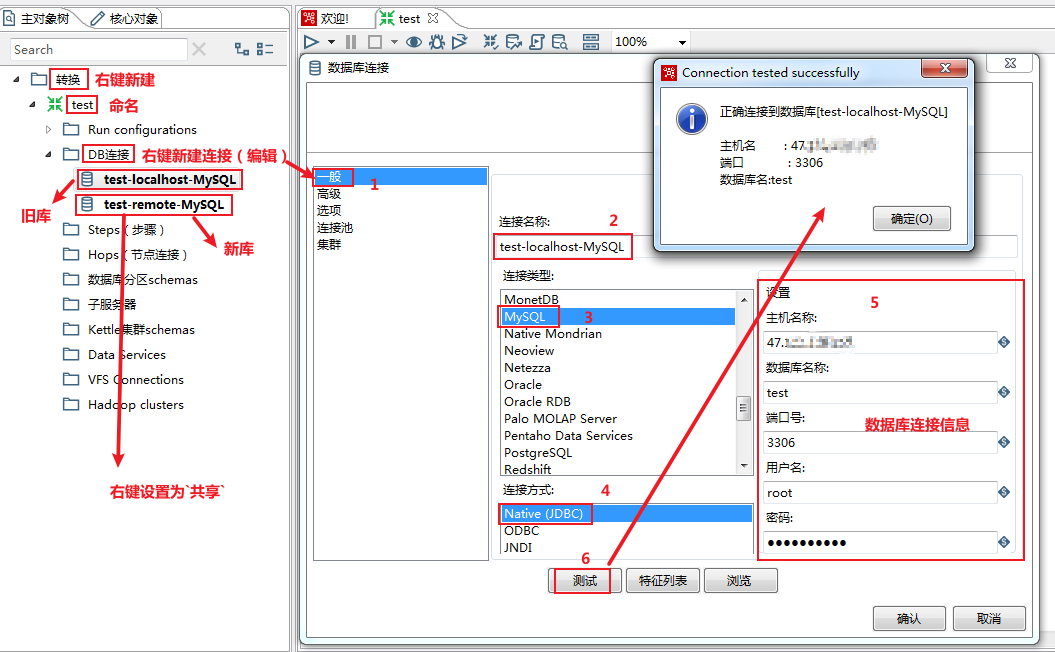
不过,在运行之前,还是要先装好相关相关数据库的连接驱动包,不然无法连接到数据库~
https://www.oracle.com/database/technologies/appdev/jdbc-downloads.html
官方DB2 Java驱动包下载:https://www.ibm.com/support/pages/node/382667
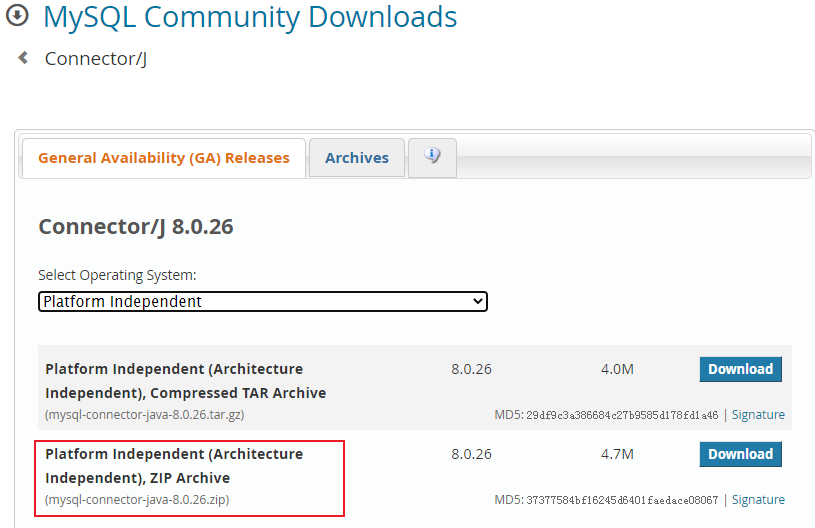
官方MySQL Java驱动包下载: https://dev.mysql.com/downloads/connector/j/
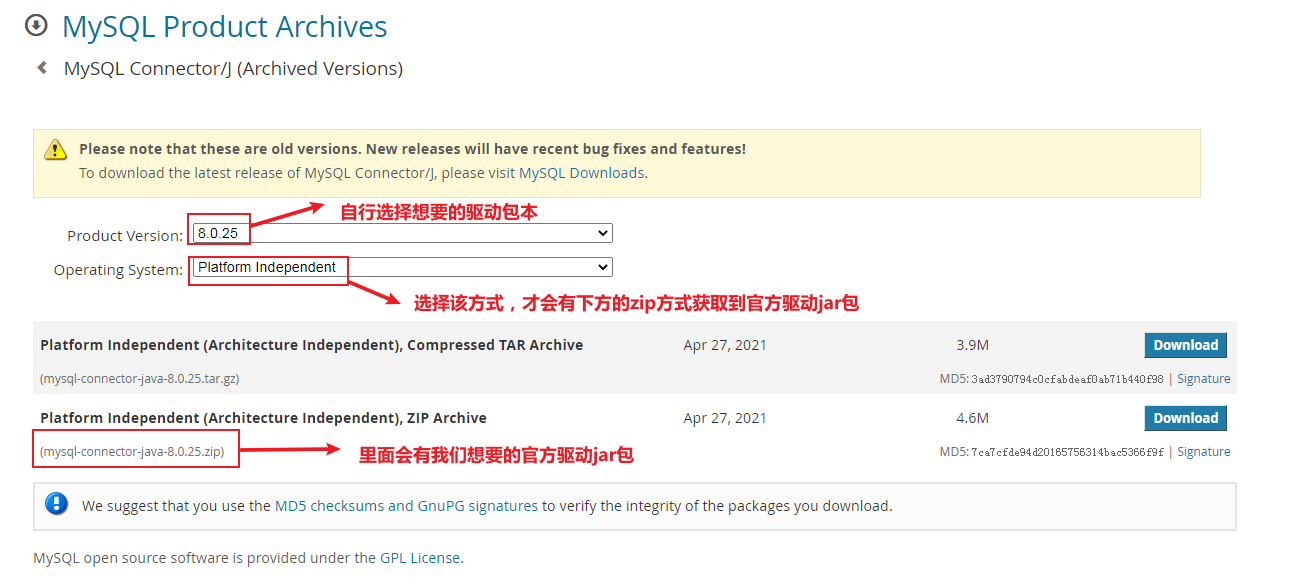
我这里下载MySQL的驱动包,选择哪个版本呢?~
Archives下载对应的5.1.+版本的驱动包即可~
解压下载得到的zip压缩包,得到官方MySQL连接驱动jar包~
https://dev.mysql.com/doc/connectors/en/connector-j-reference-configuration-properties.html
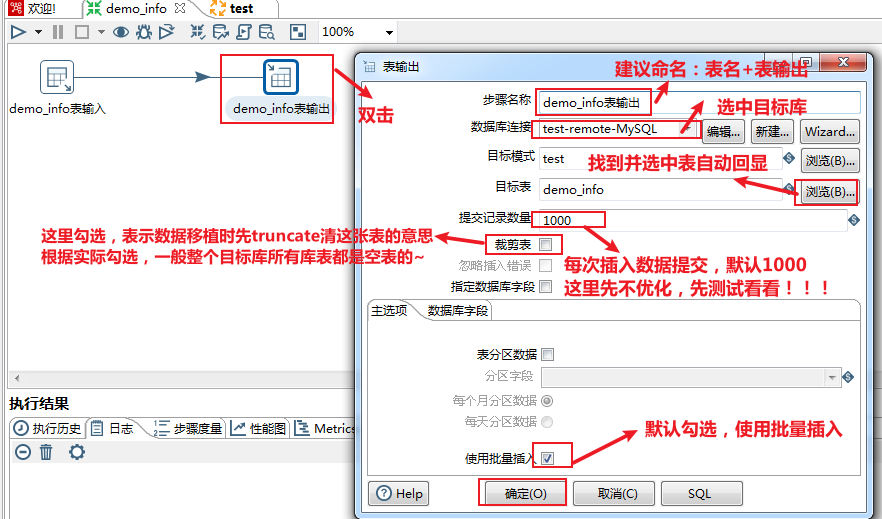
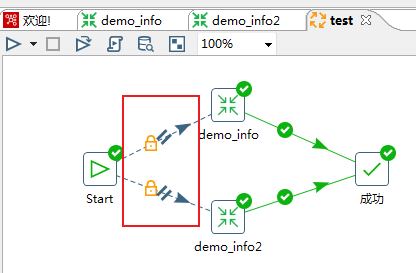
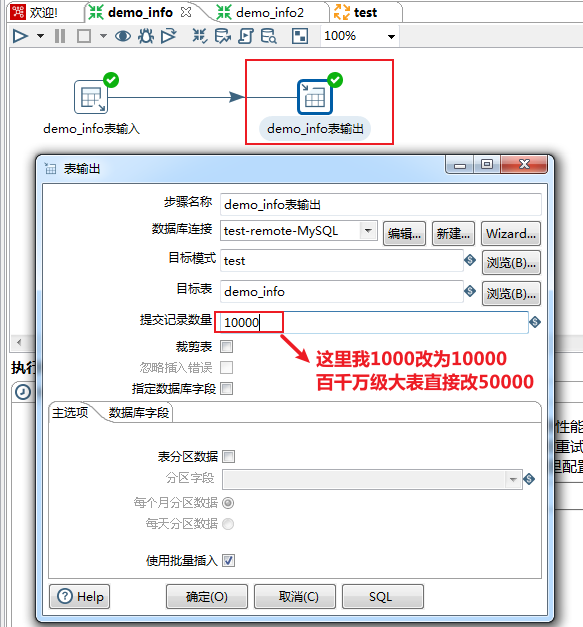
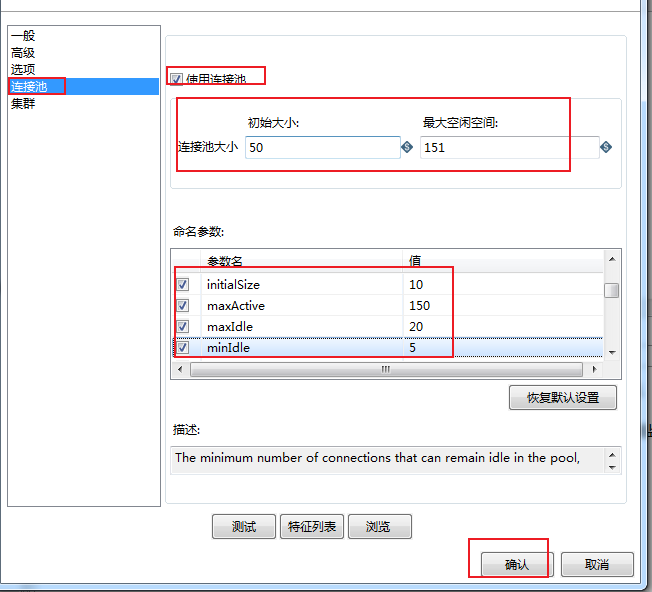
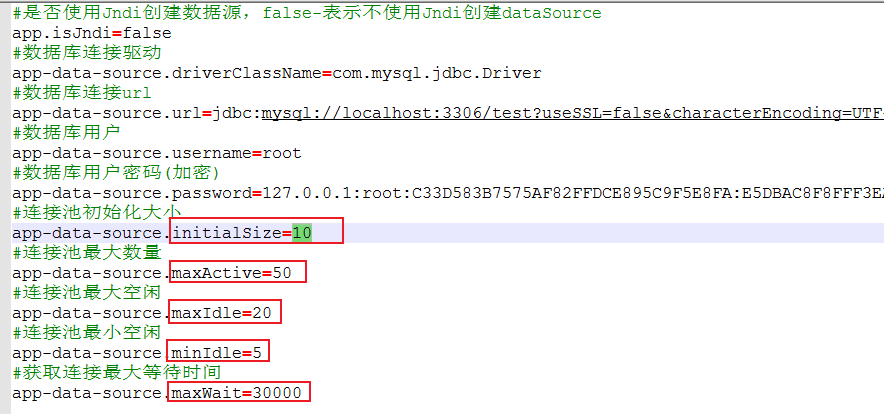
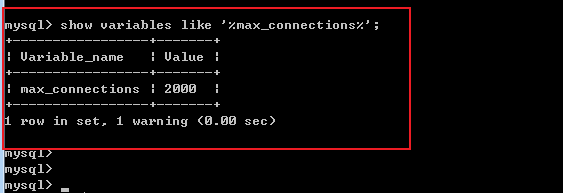
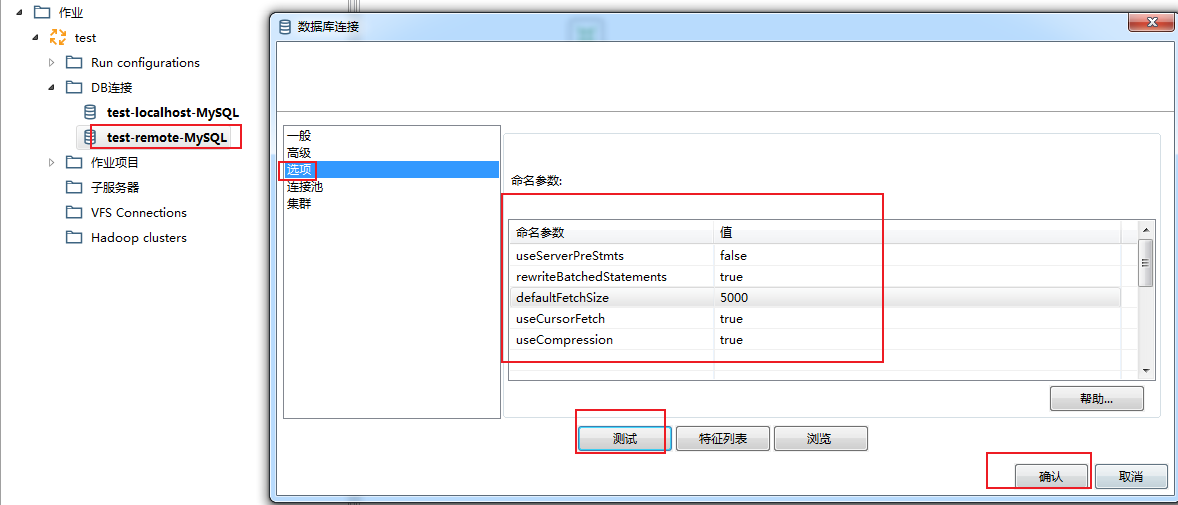
==-- 表输出(写)核心参数优化==
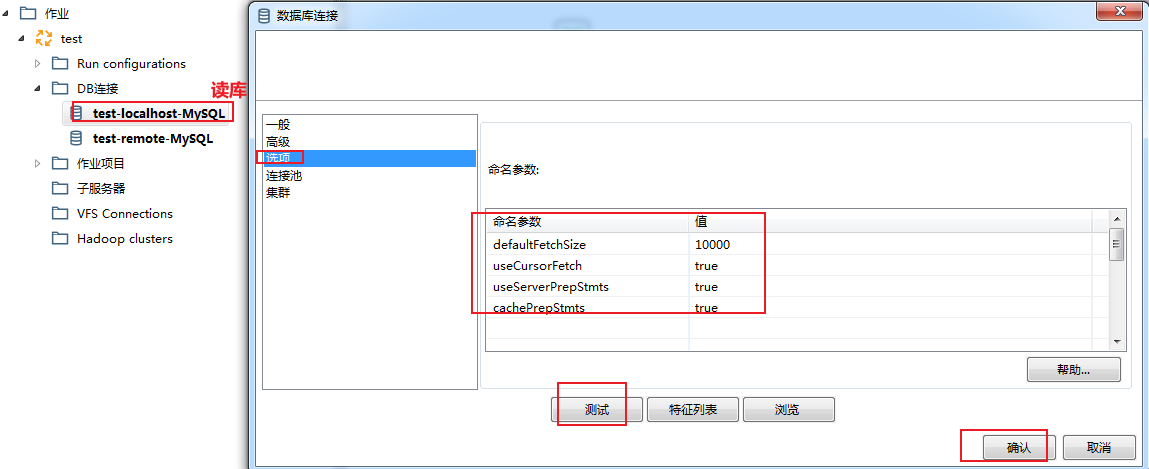
双击DB连接(写库),对选项下的相关参数进行配置:
- - 参数说明
参数及赋值
defaultFetchSize=5000
每次与数据库交互,从内存中读取多少条数据写入数据表,不设置默认把所有数据写入, ==rewriteBatchedStatements设置true,该参数会失效==
rewriteBatchedStatements=true
是否开启批量写入,true表示开启,原多条insert变成单条insert执行
useServerPreStmts=false
是否使用服务端预编译,设置为false,表示在客户端编译好
useCompression=true
是否使用压缩,使用压缩优化客户端与服务端传输效率
useCursorFetch=true
是否允许部分数据到客户端就进行处理,如果为false表示所有数据到达客户端后,才进行处理
[email protected]